

BIOMEDICAL DATA ANALYSIS ON
HETEROGENEOUS PLATFORM
Dong Ping Zhang
Heterogeneous System Architecture
AMD

3 | Biomedical data analysis on heterogeneous platform | June, 2012
VASCULATURE ENHANCEMENT

4 | Biomedical data analysis on heterogeneous platform | June, 2012
EXAMPLE: COMPUTED TOMOGRAPHY IMAGE
Before enhancement After enhancement with
bone structure

5 | Biomedical data analysis on heterogeneous platform | June, 2012
EXAMPLE: MAGNETIC RESONANCE ANGIOGRAM
Before enhancement After enhancement

6 | Biomedical data analysis on heterogeneous platform | June, 2012
VASCULATURE ENHANCEMENT
Before enhancement After enhancement ?

7 | Biomedical data analysis on heterogeneous platform | June, 2012
Gaussian convolution
(three 1D kernels instead of one 3D kernel)
Hessian matrix computation and analysis
Eigen decomposition
Eigenvector + eigenvalue sorting
VASCULATURE ENHANCEMENT | ALGORITHM

8 | Biomedical data analysis on heterogeneous platform | June, 2012
Shape space for Hessian matrix in 3D[1]
[1]: Q. Lin. PhD thesis, 2003, Enhancement, Extraction, and Visualization of 3D Volume Dataset
ALGORITHM: FIRST THREE COMPONENTS
Analyse the main modes of 2nd-order variation in image intensity to determine the type of local structure

9 | Biomedical data analysis on heterogeneous platform | June, 2012
zz
L
yz
L
xz
L
zy
L
yy
L
xy
L
yx
L
yx
L
xx
L
222
222
222
H
e3
e1
e2
Compute Hessian matrix of
)()()( zGyGxGIL
Vessel segment representation at voxel
x
ALGORITHM: FIRST THREE COMPONENTS
x
Table: List of geometric patterns in 2D and 3D, depending
on the sign and magnitude of the eigenvalues.
H: high value; L: low value; +/-: the sign of the eigenvalue.

10 | Biomedical data analysis on heterogeneous platform | June, 2012
Gaussian convolution
(three 1D kernels instead of one 3D kernel)
Hessian matrix computation and analysis
Eigen decomposition
Eigenvector + eigenvalue sorting
Vesselness computation
(calculating how likely a voxel being part of vascular network)
ALGORITHM

11 | Biomedical data analysis on heterogeneous platform | June, 2012
otherwise11
0or 0 if0
2
2
2
2
2
2
222
32
SRR
eeeV
BA
RA 23
RB 1
23
S i2
i
V max min max
V
where
ALGORITHM: VESSELNESS
Compute single scale vesselness response from a scale :
Tensor voting to bridge the gaps
Compute maximal vesselness response from multiple scales:

12 | Biomedical data analysis on heterogeneous platform | June, 2012
Experiment setting:
Input CTA image: 256 x 256 x 200 voxel, voxel size 0.62 x 0.62 x 0.5 mm
Application parameters: 7 scales distributed in range 0.5-4mm
Hardware: AMD PhenomTM II X6 1090T, RadeonTM HD 6970
Comparison:
10.3
83
275.27
396.2
0 50 100 150 200 250 300 350 400 450
OpenCL(conv+h+eigen+v)
OpenCL(conv+hmatrix+v),TBB(eigen)
OpenCL(conv+hmatrix+v), eigen
TBB(conv), hmatrix, eigen, v
Execution time (s)
PERFORMANCE | CPU + “CAYMAN” GPU

13 | Biomedical data analysis on heterogeneous platform | June, 2012
APP Profiling Windows of scenario 4:
Projection (HSA Simulator):
Kernel execution: 35.1%
Data transfer (read & write) + launch latency (kernel launch, read launch and write launch): 41.7%
Execution time is reduced to 3.8s by eliminating data transfer, launch latency and unaccounted activities.
PERFORMANCE | CPU + “CAYMAN” GPU
Kernel execution
35.1%
Data transfer
32.7%
Launch
latency 9%
unaccounted
activities

14 | Biomedical data analysis on heterogeneous platform | June, 2012
Per-kernel execution time (% of sum) and ISA statistics
PERFORMANCE | “LLANO”

15 | Biomedical data analysis on heterogeneous platform | June, 2012
Breakdown of command durations and projected APU performance
Per-size/direction data transfer time (% of sum)
PERFORMANCE | “LLANO”

16 | Biomedical data analysis on heterogeneous platform | June, 2012
7.4
81.8
265.64
396.2
0 50 100 150 200 250 300 350 400 450
OpenCL(conv+h+eigen+v)
OpenCL(conv+hmatrix+v),TBB(eigen)
OpenCL(conv+hmatrix+v), eigen
TBB(conv), hmatrix, eigen, v
Execution time (s)
Experiment: CTA image: 256 x 256 x 200 voxel, voxel size 0.62 x 0.62 x 0.5 mm
Application parameters: 7 scales distributed in range 0.5-4mm
Hardware: AMD PhenomTM II X6 1090T + RadeonTM HD 7950
PERFORMANCE | CPU + “TAHITI” GPU

17 | Biomedical data analysis on heterogeneous platform | June, 2012
Experiment: CTA image: 256 x 256 x 200 voxel, voxel size 0.62 x 0.62 x 0.5 mm
Application parameters: 7 scales distributed in range 0.5-4mm
Hardware: AMD PhenomTM II X6 1090T + RadeonTM HD 6970
AMD PhenomTM II X6 1090T + RadeonTM HD 7950
Architecture Overview:
PERFORMANCE COMPARISON | “CAYMAN” AND “TAHITI”

18 | Biomedical data analysis on heterogeneous platform | June, 2012
7.4
81.8
265.64
396.2
10.304
83
275.272
396.2
0 50 100 150 200 250 300 350 400 450
OpenCL(conv+h+eigen+v)
OpenCL(conv+hmatrix+v),TBB(eigen)
OpenCL(conv+hmatrix+v), eigen
TBB(conv), hmatrix, eigen, v
Execution time comparison
28%
Experiment: CTA image: 256 x 256 x 200 voxel, voxel size 0.62 x 0.62 x 0.5 mm
Application parameters: 7 scales distributed in range 0.5-4mm
Hardware: AMD PhenomTM II X6 1090T + RadeonTM HD 6970
AMD PhenomTM II X6 1090T + RadeonTM HD 7950
PhenomTM II X6 + “Tahiti” PhenomTM II X6 + “Cayman”
seconds
PERFORMANCE COMPARISON | “CAYMAN” AND “TAHITI”

19 | Biomedical data analysis on heterogeneous platform | June, 2012
Per-kernel execution time (% of sum) and ISA statistics
PERFORMANCE | “TRINITY”

20 | Biomedical data analysis on heterogeneous platform | June, 2012
Breakdown of command durations and projected APU performance
Per-size/direction data transfer time (% of sum)
PERFORMANCE | “TRINITY”

21 | Biomedical data analysis on heterogeneous platform | June, 2012
VASCULATURE SEGMENTATION

22 | Biomedical data analysis on heterogeneous platform | June, 2012
Ridge points satisfy:
Ridgeness function:
VASCULATURE EXTRACTION | RIDGE TRAVERSAL

23 | Biomedical data analysis on heterogeneous platform | June, 2012
VASCULATURE EXTRACTION | RIDGE TRAVERSAL

24 | Biomedical data analysis on heterogeneous platform | June, 2012
Using A* graph search to find minimal cost path from start to end nodes:
VASCULATURE EXTRACTION | GRAPH SEARCH

25 | Biomedical data analysis on heterogeneous platform | June, 2012
VASCULATURE EXTRACTION | GRAPH SEARCH RESULTS
26 | Biomedical data analysis on heterogeneous platform | June, 2012
26
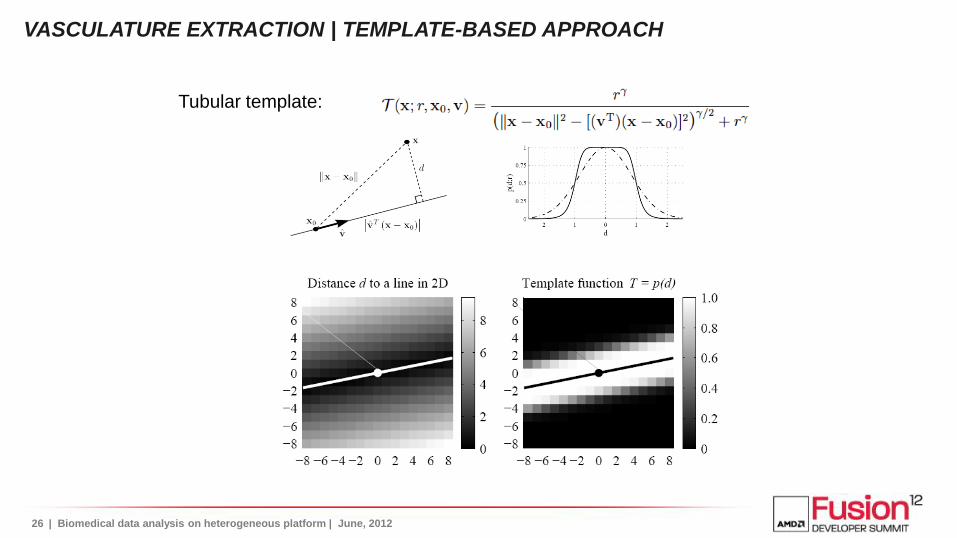
Tubular template:
VASCULATURE EXTRACTION | TEMPLATE-BASED APPROACH
27 | Biomedical data analysis on heterogeneous platform | June, 2012
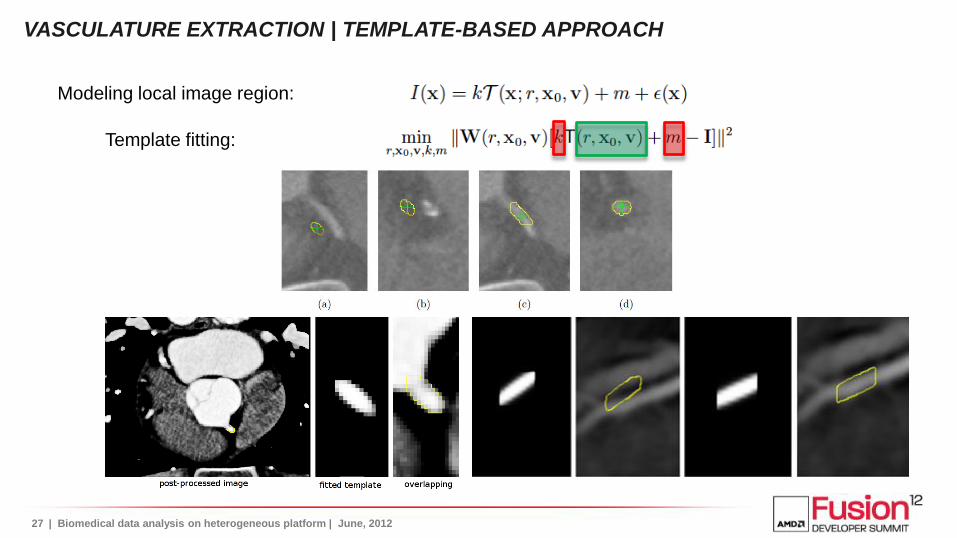
Template fitting:
Modeling local image region:
VASCULATURE EXTRACTION | TEMPLATE-BASED APPROACH

28 | Biomedical data analysis on heterogeneous platform | June, 2012
964
490
244
49
264.5
136.7
67.2
13.3
0 100 200 300 400 500 600 700 800 900 1000
240
120
60
12
3D Vessel Template Match
multi-threaded single-threaded
PERFORMANCE
Experiment setting:
Input CTA image: 256 x 256 x 200 voxel, voxel size 0.62 x 0.62 x 0.5 mm
Template size: 17 x 17 x 17 voxels, voxel size 0.62 x 0.62 x 0.5 mm
Hardware: AMD PhenomTM II X6 1090T, RadeonTM HD 7970
regions
seconds
PERFORMANCE | TEMPLATE-BASED APPROACH

29 | Biomedical data analysis on heterogeneous platform | June, 2012
Input is a vasculature image I, output are the vascular trees in that image.
Step 1: Parallel_for_each voxel x in the input image I { compute the vesselness value v(x) representing how likely a voxel is part of the vessel structure. }
Step2: Compute cost image from input image I, using vesselness image V from previous step
Step 4: Parallel_for_each (voxels in the vascular tree) { do template-fitting at local region of input image. }
VESSEL SEGMENTATION FRAMEWORK
Step3: Select starting and ending nodes, do A* graph search to compute the minimal cost path; Bifurcation are dealt with here semi-automatically. Output: vascular tree.

30 | Biomedical data analysis on heterogeneous platform | June, 2012
VASCULAR SEGMENTATION FRAMEWORK | BIFURCATION

31 | Biomedical data analysis on heterogeneous platform | June, 2012
Nested enqueue?
Input is a vasculature image I, output are the vascular trees in that image.
Step 1: Parallel_for_each voxel x in the image I { compute the vesselness value v(x) representing how likely a voxel is part of the vessel structure. }
Step2: Sort all voxels based on v(x) value;
Step 3: Parallel_for_each (voxels with a high probability of being part of the vascular system) { A: Extract the vascular branch from that voxel (noted as parent voxel) by template-match algorithm; If (Bifurcation is detected) { Parallel_for_each(children voxels) { B: same as A; } } }
VESSEL SEGMENTATION FRAMEWORK

32 | Biomedical data analysis on heterogeneous platform | June, 2012
Big data-parallel single-layer dispatch is not necessarily the appropriate abstraction for representing the
programmer’s problem.
Key component in vessel lumen segmentation is template match:
foreach block:
while(found closest match):
foreach element in comparison
Serial code mixed in with two levels of parallel code
– So what if instead of trying to do a single flat dispatch we explicitly layer the task launches?
VESSEL SEGMENTATION FRAMEWORK

33 | Biomedical data analysis on heterogeneous platform | June, 2012
parallelFor(int numThreads [](int index){ // “scalar” functor
// do scalar stuff
// for example, to do a template match we might do
X’.Initialize();
sumSq = FLOAT_MAX;
while( sumSq still being minimized ){
X = estimating new position from X’
Accumulator<float> acc;
localParallelFor(template size, [=X](int3 index) {
auto diff = templateData(X + index) - imageData(X + index);
acc += diff*diff;
}); // end localParallelFor
If sumSq > acc // See if it’s small enough or continue search using heuristic
X’ = X}});
A parallel thread launch:
One wavefront/workgroup
launched for each index.
One launched for each block in
the data set.
A serial loop that searches for the
best match. This is best written as
a serial loop and is clean scalar
code. Extracting this from the
parallel context can feel messy.
Parallel loop:
Covers each pixel in the block
being compared. Easily
vectorisable and with no launch
overhead.
VESSEL SEGMENTATION FRAMEWORK | LAYERED DISPATCH

34 | Biomedical data analysis on heterogeneous platform | June, 2012
BOLT: A C++ Template Library for HSA, Ben Sander, 5:15 PM, Wednesday 13th June
Bolt Bolt::Parallel_for_each (voxel x in the image I) { compute how likely a voxel is part of the vessel structure: v(x); construct vesselness image V } Bolt::Sort (voxels of image V ) Create initial list “L” of N voxels with highest probability of being part of vessel structure. Bolt::parallel_do (L) { Implement template match process with bolt::parallel_for_each; If bifurcation is detected, enqueue new voxel to L };
VESSEL EXTRACTION FRAMEWORK | FUTURE

35 | Biomedical data analysis on heterogeneous platform | June, 2012
Channel
VESSEL EXTRACTION FRAMEWORK | FUTURE
Can GPGPU programming be liberated from the data-parallel bottleneck?
1:15 PM, Tuesday 12th June
HSA memory and execution model, HSA runtime
3:15 PM, Wednesday 13th June
Lee Howes

36 | Biomedical data analysis on heterogeneous platform | June, 2012
Trademark Attribution
AMD, the AMD Arrow logo, PhenomTM, RadeonTM and combinations thereof are trademarks of Advanced Micro Devices, Inc.
in the United States and/or other jurisdictions. Other names used in this presentation are for identification purposes only and
may be trademarks of their respective owners.
©2012 Advanced Micro Devices, Inc. All rights reserved.
ACKNOWLEDGEMENT
Lee Howes, Jay Cornwall
Heterogeneous System Architecture, AMD
Daniel Rueckert
Imperial College London

37 | Biomedical data analysis on heterogeneous platform | June, 2012
Disclaimer & Attribution The information presented in this document is for informational purposes only and may contain technical inaccuracies, omissions
and typographical errors.
The information contained herein is subject to change and may be rendered inaccurate for many reasons, including but not limited
to product and roadmap changes, component and motherboard version changes, new model and/or product releases, product
differences between differing manufacturers, software changes, BIOS flashes, firmware upgrades, or the like. There is no
obligation to update or otherwise correct or revise this information. However, we reserve the right to revise this information and to
make changes from time to time to the content hereof without obligation to notify any person of such revisions or changes.
NO REPRESENTATIONS OR WARRANTIES ARE MADE WITH RESPECT TO THE CONTENTS HEREOF AND NO
RESPONSIBILITY IS ASSUMED FOR ANY INACCURACIES, ERRORS OR OMISSIONS THAT MAY APPEAR IN THIS
INFORMATION.
ALL IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR ANY PARTICULAR PURPOSE ARE EXPRESSLY
DISCLAIMED. IN NO EVENT WILL ANY LIABILITY TO ANY PERSON BE INCURRED FOR ANY DIRECT, INDIRECT, SPECIAL
OR OTHER CONSEQUENTIAL DAMAGES ARISING FROM THE USE OF ANY INFORMATION CONTAINED HEREIN, EVEN IF
EXPRESSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
AMD, the AMD arrow logo, and combinations thereof are trademarks of Advanced Micro Devices, Inc. All other names used in
this presentation are for informational purposes only and may be trademarks of their respective owners.
© 2012 Advanced Micro Devices, Inc.
Recommended

















