
Big Data and Veracity ChallengesText Mining Workshop, ISI Kolkata
L V k t S b iL. Venkata SubramaniamIBM Research India
Jan 8, 20141
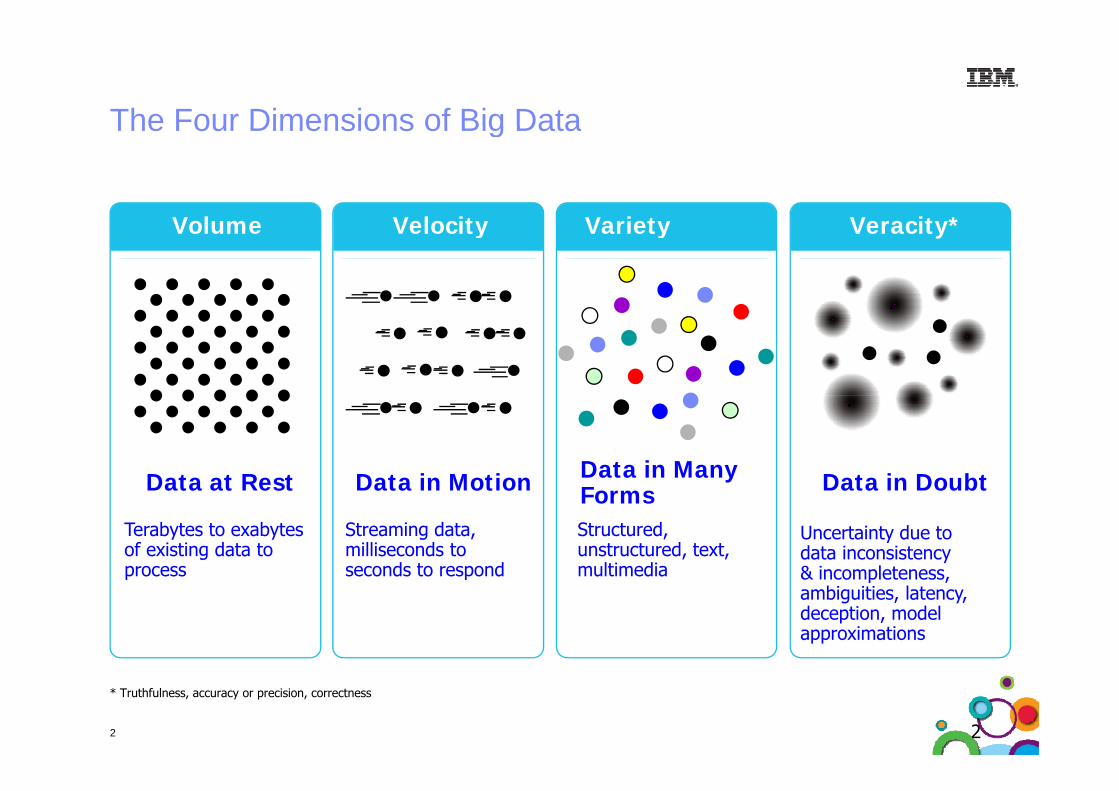
The Four Dimensions of Big DataThe Four Dimensions of Big Data
l l i i *iVolume Velocity Veracity*Variety
Data at Rest Data in Motion Data in Many Data in DoubtData at Rest
Terabytes to exabytes of existing data to process
Data in Motion
Streaming data, milliseconds to seconds to respond
FormsStructured, unstructured, text, multimedia
Data in Doubt
Uncertainty due to data inconsistency& incompletenessprocess seconds to respond multimedia & incompleteness, ambiguities, latency, deception, model approximations
2
* Truthfulness, accuracy or precision, correctness
2

In order to realize new opportunities, you need to thinkWe’ve Moved into a New Era of opportunities, you need to think beyond traditional sources of dataComputing !
The term Big Data applies to information that can’t be processed or analyzed using traditional processes or tools
Transactional & Application
Data
Machine Data
Social Data Enterprise Content
of Tweets
12+ terabytestrade eventsper second.
5+million
Volume
eetscreated daily.
Velocity
• Volume
Str ct red
• Velocity
Semi
• Variety
Highl
• Variety
Highl
Varietyof different100’s Veracity
decision makersOnly 1 in 3
• Structured
• Throughput
• Semi-structured
• Ingestion
• Highly unstructured
• Veracity
• Highly unstructured
• Volume
of different typesof data.
decision makers trust their information.
3
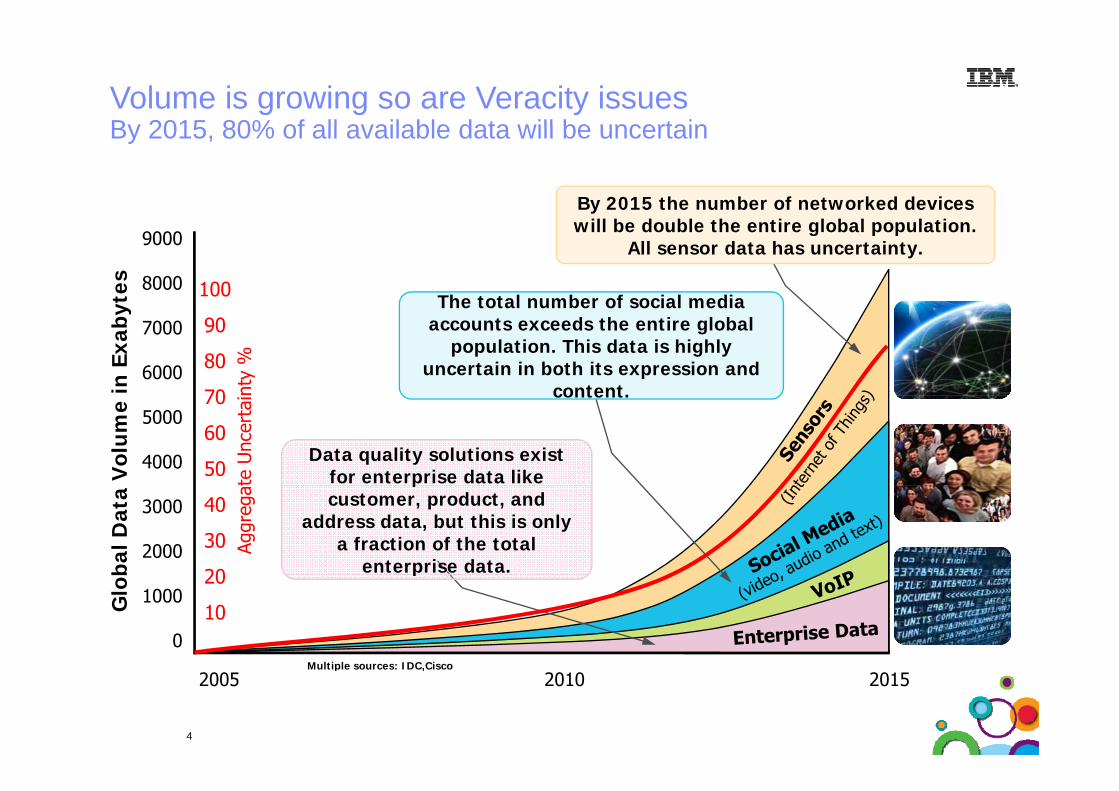
Volume is growing so are Veracity issuesBy 2015 80% of all available data will be uncertainBy 2015, 80% of all available data will be uncertain
By 2015 the number of networked devices
ytes 100
9000
8000
will be double the entire global population. All sensor data has uncertainty.
The total number of social media
in E
xaby 90
80
70 nty
%
7000
6000
The total number of social media accounts exceeds the entire global
population. This data is highly uncertain in both its expression and
content.
Vol
um
e 70
60
50 te U
ncer
tai
5000
4000 Data quality solutions exist for enterprise data like
content.
bal D
ata 40
30
20
Aggr
egat
3000
2000
pcustomer, product, and
address data, but this is only a fraction of the total
enterprise data.
Glo
b
Multiple sources: IDC Cisco
20
101000
0
p
4
Multiple sources: IDC,Cisco2005 2010 2015
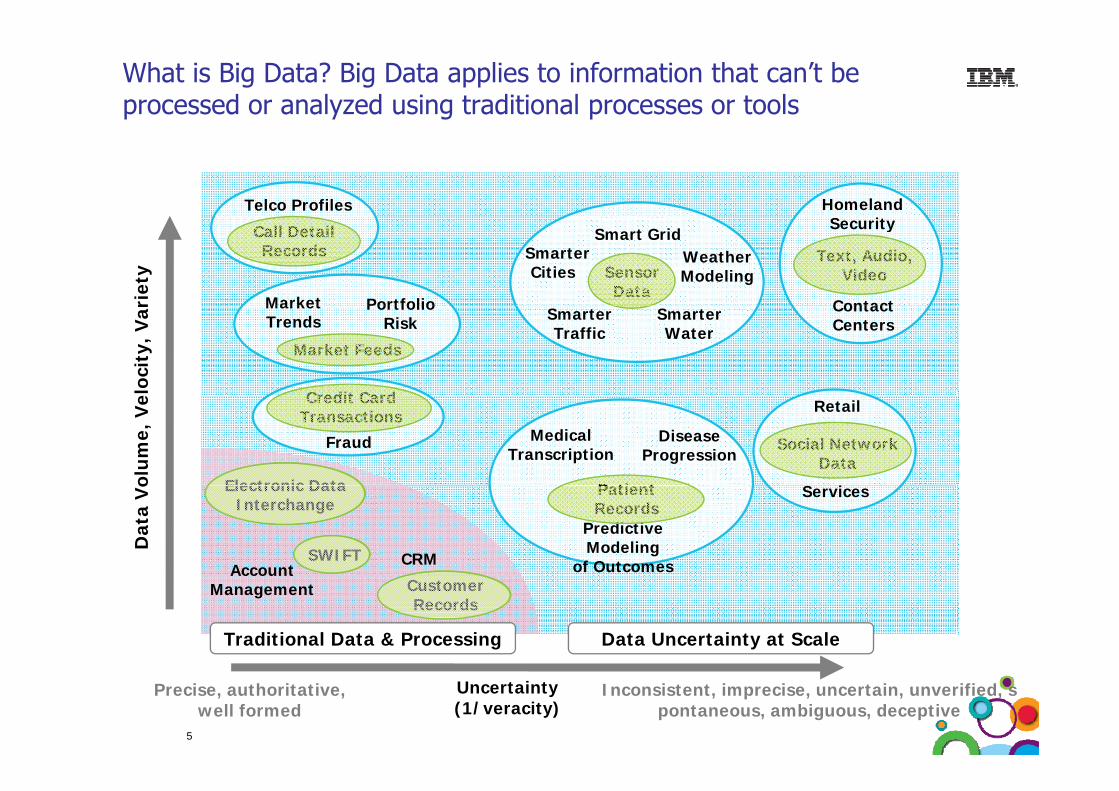
What is Big Data? Big Data applies to information that can’t be processed or analyzed using traditional processes or tools
Homeland Telco Profiles
riet
y
SmarterCities
WeatherModeling
Contact
Security
Market Portfolio
Smart Grid
SensorData
Text, Audio, Video
Call DetailRecords
eloc
ity,
Var Smarter
TrafficSmarterWater
ContactCenters
MarketTrends
PortfolioRisk
Credit Card
Market Feeds
olum
e, V
e Retail
S i
MedicalTranscription
Disease Progression
Fraud Social NetworkData
P ti t
Credit Card Transactions
Electronic Data
Dat
a V
o Services
Predictive Modeling
of Outcomes
Patient Records
Electronic Data Interchange
SWIFTAccount
CRM
Traditional Data & Processing Data Uncertainty at Scale
AccountManagement Customer
Records
5
Inconsistent, imprecise, uncertain, unverified, spontaneous, ambiguous, deceptive
Uncertainty(1/veracity)
Precise, authoritative, well formed
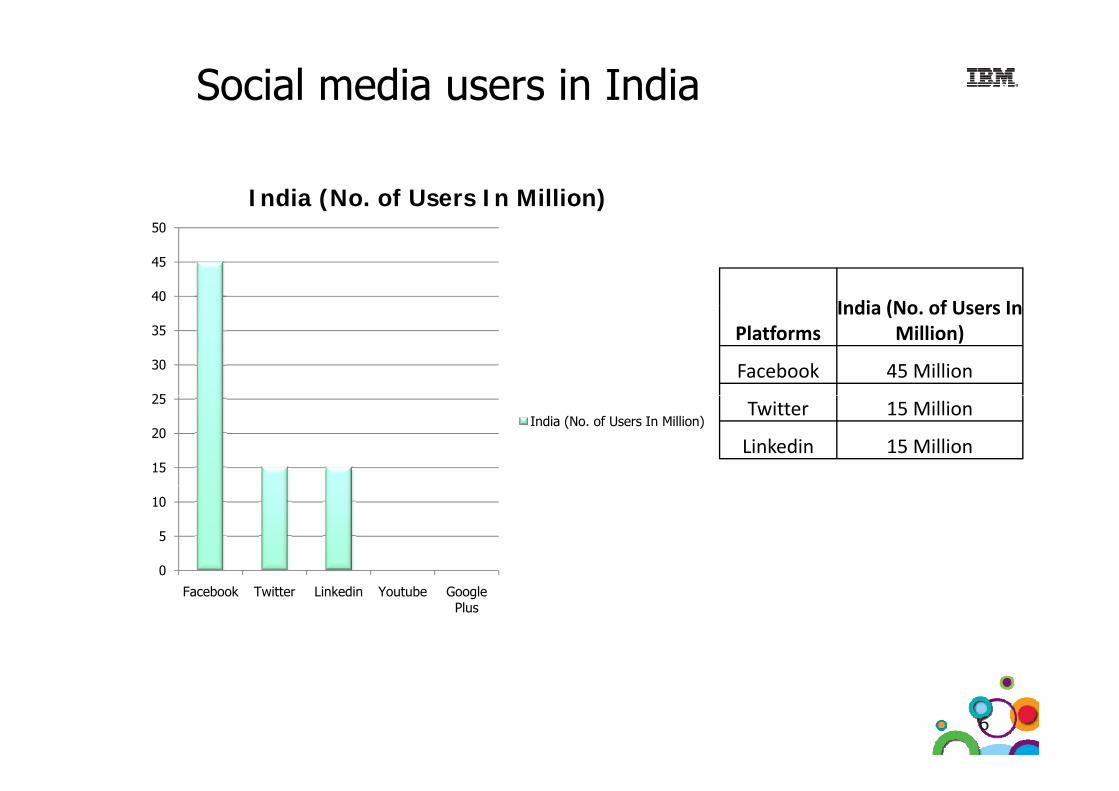
Social media users in India
India (No. of Users In Million)
India (No of Users In40
45
50
PlatformsIndia (No. of Users In
Million)
Facebook 45 Million25
30
35
Twitter 15 Million
Linkedin 15 Million15
20
25
India (No. of Users In Million)
0
5
10
0
Facebook Twitter Linkedin Youtube Google Plus
6

Veracity issues arise due to:
Model UncertaintyAll modeling is approximate
Process UncertaintyProcesses contain
“ d ”
Data UncertaintyData input is uncertain
“randomness”
Intended Spelling Text Entry
Actual Spellingp g y
??
?Fitting a curve to data
Uncertain travel times GPS Uncertainty?
? ?
Ambiguity{Paris Airport}Testimony
? ? ?
Forecasting a hurricane( )
Semiconductor yieldContaminated?
{John Smith, Dallas}{John Smith, Kansas}
g y
7
(www.noaa.gov)Rumors
Contaminated?Conflicting Data
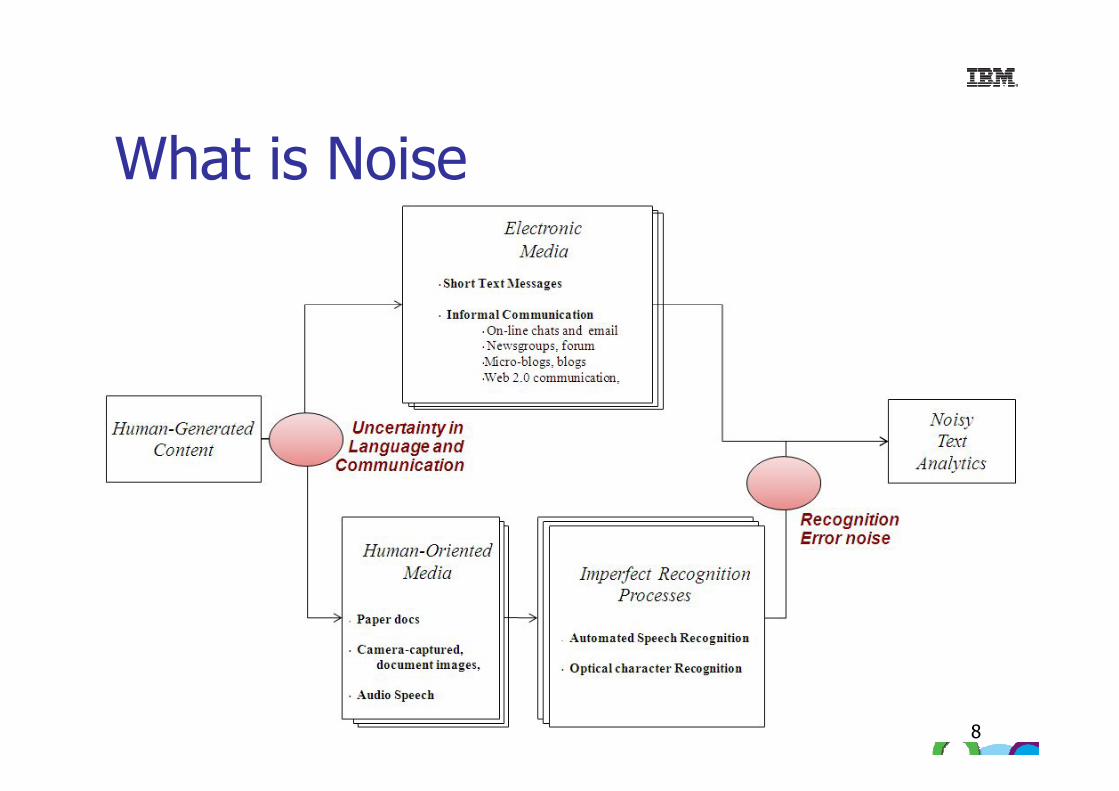
What is Noise
8
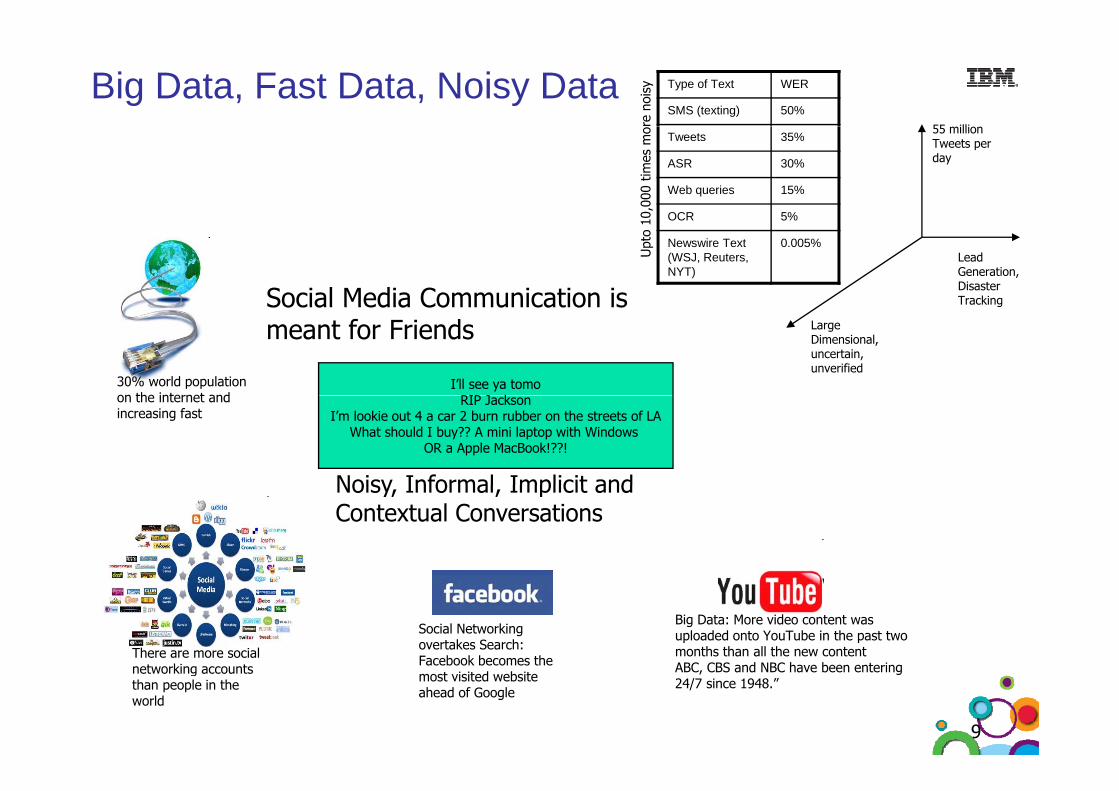
Big Data, Fast Data, Noisy Data Type of Text WER
SMS (texting) 50%
re n
oisy
55 illiTweets 35%
ASR 30%
Web queries 15%
OCR 5%0,00
0 tim
es m
o 55 million Tweets per day
Social Media Communication is
OCR 5%
Newswire Text (WSJ, Reuters, NYT)
0.005%
Upt
o 10
Lead Generation, Disaster Tracking
30% world population on the internet and
I’ll see ya tomoRIP J k
Social Media Communication is meant for Friends
g
Large Dimensional, uncertain, unverified
on the internet and increasing fast
RIP JacksonI’m lookie out 4 a car 2 burn rubber on the streets of LA
What should I buy?? A mini laptop with Windows OR a Apple MacBook!??!
Noisy Informal Implicit andNoisy, Informal, Implicit and Contextual Conversations
There are more social t ki t
Social Networking overtakes Search: Facebook becomes the
Big Data: More video content was uploaded onto YouTube in the past two months than all the new content ABC CBS and NBC have been enteringnetworking accounts
than people in the world
Facebook becomes the most visited website ahead of Google
ABC, CBS and NBC have been entering 24/7 since 1948.”
9

SMSSMS0 there – there 1 aint are not
Texting Language: Over 50% of the words are written in non standard ways
1 aint – are not2 no – no3 doubt – doubt 4 there – there 5 hon – honey
Spontaneous Language: Use of slang, ungrammatical, no punctuations, no case information
6 im – I am7 gonna – going 8 be – be 9 takin – taking10 it – it
information
Mixing of Languages: Many SMS contain text in a mix of two or more languages10 it it
11 4 – for12 life – life 13 u – You14 wont – wont15 b be
mix of two or more languages
Type of Noise %15 b – be16 rida – rid of17 me – me 18 lol – laugh out loud19 Ray – (NAME)
Deletion of Characters
48%
Phonetic Substitution
33%101 SMSes
Substitution
Abbreviations 5%
Dialectical Usage
4%
52% wordswere non standard
Usage
Deletion of Words
1.2% (Contractor et al., 2010)
10

Speech RecognitionSpeech RecognitionSPEAKER 1: windows thanks for calling and you can
learn yes i don't mind it so then i went to
SPEAKER 2: well and ok bring the machine front
Recognition Errors: 10-40% Word Error Rates
end loaded with a standard um and that's um it's
a desktop machine and i did that everything was
working wonderfully um I went ahead connected
into my my network um so i i changed my network
Word Error Rates
Spontaneous Language: Use of slang use of fillerssettings to um to my home network so i i can you
know it's showing me for my workroom um and then
it is said it had to reboot in order for changes
to take effect so i rebooted and now it's asking
Use of slang, use of fillers like um and ah, ungrammatical, false starts no punctuations nome for a password which i never i never said
anything up
SPEAKER 1: ok just press the escape key i can
doesn't do anything can you pull up so that i mean
starts, no punctuations, no case information
Mi i f LMixing of Languages: Contain words from two or more languages
11

Historical TextNon Standard Spellings: No notion of the importance of having a single spelling for each word. Letters would be added or removed to ease line justification.
New words: New words, words that are variants of present vocabulary words
Different Language Style: Different grammar, language g g y g , g gmodel.
OCR: Character substitution errors, missed punctuations.
Baron et al 2009Baron et al. 2009
12

Emails, Blogs, Tweets, Online Chat,……
Chat Logsg[12:51:13 PM] Geetha: alrite
[12:52:01 PM] Richa: id has valid pw not expired
[12:52:49 PM] Geetha: can't get to theh site[12:52:49 PM] Geetha: can t get to theh site
[12:53:04 PM] Richa: network connection may be slow
[12:54:39 PM] Geetha: ok Im able to now
[12:54:53 PM] Richa: should I reset the password
13

What is Noisy Text?Any kind of difference in the surface form of an electronic text from the intended, correct or original text (Knoblock et al., 2007)2007)
Noise can be at the lexical level {b4 before befour}Noise can be at the lexical level {b4, before, befour}Resulting in substitution, insertion, deletion, transposition, run-on, and split.
Noise can be at morphological, syntactic, discourse level {I can hear u, I can hear you, I can here you}hear u, I can hear you, I can here you}
Resulting in substitution, insertion, deletion, transposition of words and the introduction of out of vocabulary
dwords.
14

Classifying NoiseLexical Errors (Subramaniam et
al., 2009)
Syntactical Errors (Kukich, 1992; Foster et al., 2007)Missing Word {What are the
Missing characters {before > bef}Extra characters {raster >
Missing Word {What are the subjects? > What the subjects?}Extra word {Was that in the summer? >Was that in the summerraaster}
Phonetic substitution {before > b4, late > l8}
summer? >Was that in the summer it?}Real word spelling errors {She could not comprehend > She could no, }
Abbreviations {laugh out loud> lol, United Nations > UN}
not comprehend. > She could no comprehend.}Agreement {She steered Melissa round a corner > She steeredround a corner. > She steered Melissa round a corners.}Dialectical usage {I’m going to be th I’ b th }there > I’m gonna be there}
15

Techniques for Automatically Detecting Lexical Errors (Kukich 92)
Efficient methods to detect strings that do not appear in a given word list, dictionary or lexicon
N d d t tiNonword error detection
Two approachesN-gram
Look up each n-gram in an input string in a precompiled table to ascertain either its existence or its frequency. Nonexistent or infrequent
( hj i ) id tifi d ibl i llin-grams (shj, iqn) are identified as possible misspellings.Good for identifying errors made by OCR devicesBut unusual/foreign language valid words will be marked and nice-looking mistakes ill be ma ked alidlooking mistakes will be marked valid
Dictionary basedf fInput string appears in a dictionary? If not, the string is flagged as a
misspelled word.But nearly two-thirds of the words in a dictionary did not appear in an eight million word corpus of New York Times text and conversely twoeight million word corpus of New York Times text, and, conversely two-thirds of the words in the text were not in the dictionary (1986 study)
16

Techniques for automatically Detecting Incorrect (Syntax)Techniques for automatically Detecting Incorrect (Syntax) Grammar (Foster et al., 2007)
Effi i h d d d h d fEfficient methods to detect word sequences that do not form a grammatical sentence
Three ApproachesN-gram
Classifies a sentence as ungrammatical if it contains an unusual part of speech sequence
Precision-grammarClassifies a sentence using a parser and a broad-coverage hand-written grammar
Probabilistic parsingProbabilistic-parsingFinds sentences with parsing error
17

Quantifying Noise (Subramaniam et al., 2009)
Quantifying Lexical Errors {Before, b4, befour, befor, bfore}Edi DiEdit Distance
Good for measuring surface level deviation from originalPerplexity e p e ty
Good for measuring deviation from underlying language structure at character level
Quantifying Semantic Errors {I came to LA yesterday. I am still jet lagged., Came la yester day still jetlagged, Came 2 LA ystrday stil jetl8d}jetl8d}
WERGood for measuring real word errors (speech recognition errors)
Perplexity Good for measuring deviation from “proper”
BLEUBLEUGood for comparing a candidate translation against multiple reference translations 18

Spelling Correction (Kukich, 1992)
Isolated Word CorrectionMinimum edit distance techniquesSimilarity key techniquesProbabilistic techniquesN gram based techniquesN-gram-based techniquesRule-based techniquesWill not catch typos resulting in correctly spelled words {form, from}yp g y p { , }Estimates put real word errors at 30% of all word errors
Context-Dependent Word CorrectionParsingLanguage modelsCan errors be ignored and still meaningful interpretation be done? {ICan errors be ignored and still meaningful interpretation be done? {I am coming with you, I comes with you}
19

dis is n eg 4 txtin lang
SMS Text Normalizationdis is n eg 4 txtin lang
This is an example for Texting language
Extreme corruption of words and sentences
Models for SMS language are lacking
Tomorrow never dies!!!Models for SMS language are lacking
Tomorrow never dies!!!2moro (9) tomm (1)( )tomoz (25) tomoro (12) tomrw (5)
( )tomo (3)tomorow (3)2mro (2)
tom (2)tomra (2)tomorrow (24)
( )
morrow (1)tomor (2)tmorro (1)
( )tomora (4) moro (1)Occurrence in a 1000 sms corpus
20

Finding Canonical Sets (Acharyya, 2009)
Learn mappingscostmer, castumar, kustamar, customer
How can we do it in an unsupervised way ?
costmer, castumar, kustamar,
coustomber
customer
How can we do it in an unsupervised way ?
Find some invariant, that does not change in spite of corruptions
Buckets of context seem invariant!<..Back Bucket....> sceam <..Front Bucket...>
(2) (5) h (4) t l id (2) b t(3)sceam : sms(2) new(5) recharge(4) tel-provider(2) about(3)
<..Back Bucket...> scheme <..Front Bucket...>scheme : sms(4) new(2) activate(3) tel-provider(2) about(1) recharge(1)
21
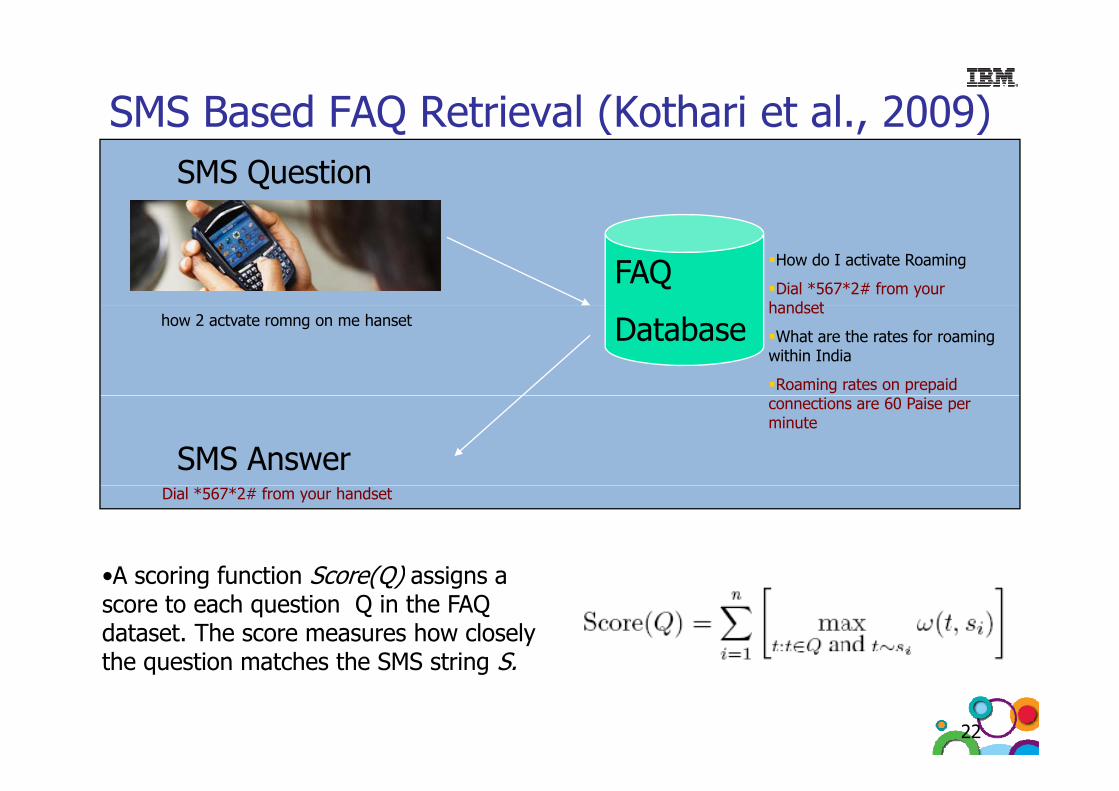
SMS Based FAQ Retrieval (Kothari et al., 2009)SMS Based FAQ Retrieval (Kothari et al., 2009)SMS Question
FAQ How do I activate Roaming
Dial *567*2# from your handset
Databasehandset
What are the rates for roaming within India
Roaming rates on prepaid
how 2 actvate romng on me hanset
SMS Answer
connections are 60 Paise per minute
Goal is to find the Question Q* that best matches the SMS S
Dial *567*2# from your handset
•A scoring function Score(Q) assigns a•A scoring function Score(Q) assigns a score to each question Q in the FAQ dataset. The score measures how closely the question matches the SMS string Sthe question matches the SMS string S.
22

FAQ Retrieval Problem FormulationSMS is treated as a sequence of tokens S=s1,s2,…,sn
Let Θ denote the questions in the FAQ corpus where each question Q ∈ Θ is treated as a set of tokens
Goal is to find the question Q* that best matches the SMS S
23

M th dMethodF h t k li t L i ti f ll t f th di tiFor each token si , a list Li consisting of all terms from the dictionary that are variants of si are constructed. Variants are sorted in the descending order of their weight
This space is searched to find the closest matching FAQ question.
24

Extracting Dialog Models (Negi et al 2009)Extracting Dialog Models (Negi et al., 2009)
Huge number of repetitive calls at contact centers
B ildi t k i t d di l tBuilding task oriented dialog systemsTask specific information – concepts, subtasks Task structure - manual encodinggUsing large amounts of human to human conversation data
E t ti di l d l i h t h tiExtracting dialogue models using human-to-human conversations
25

Example Conversation: Car Rental Domain
26
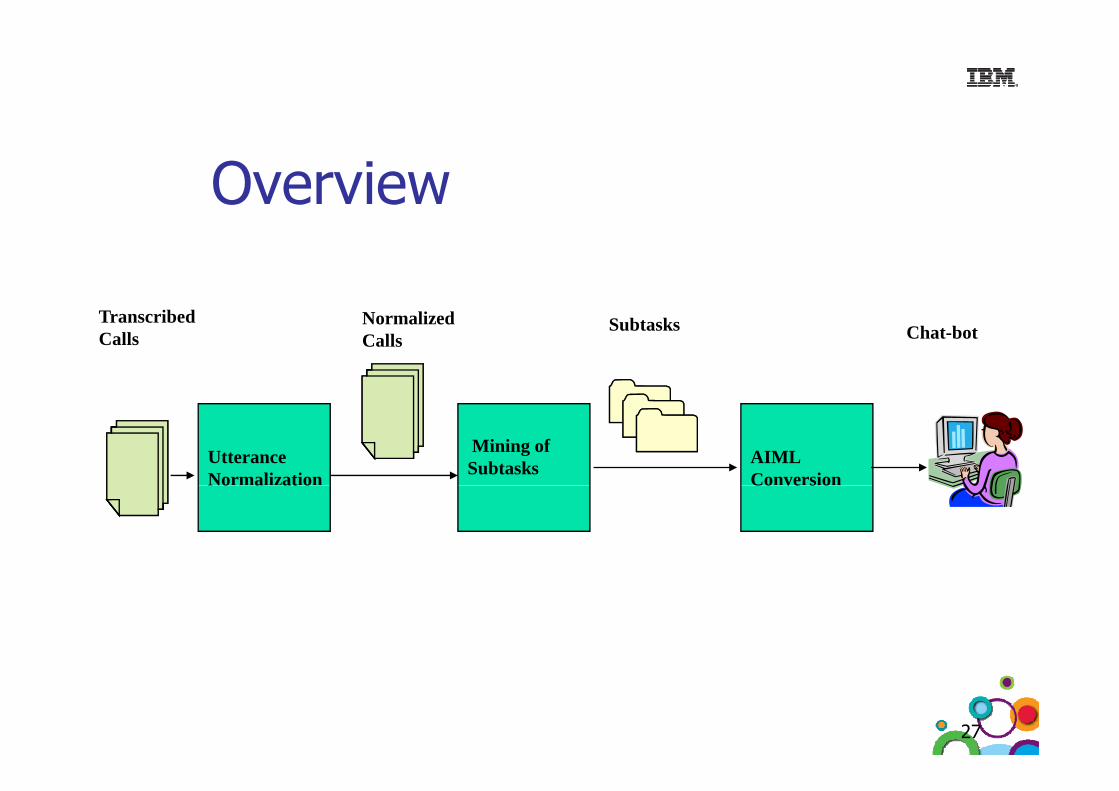
Overview
TranscribedCalls
NormalizedCalls
Subtasks Chat-bot
UtteranceNormalization
Mining of Subtasks AIML
ConversionNo a at o Co ve s o
27

Finding Patterns with GapsFinding Patterns with GapsN d f i i i i iNeed for patterns capturing variations in expressions
Have you rented a car from us beforeHave you rented a car from us before
Have you rented a car before
Have you rented a car from <Rent Agency> before
Mining regular expression patterns over tokens or entity typesE h tt t d t k
Have you rented a car from <Rent_Agency> before
Each pattern represented as a token sequence[rented car before]
Token sequences mined efficiently using extension of apriori algorithmToken sequences mined efficiently using extension of apriori algorithm
28
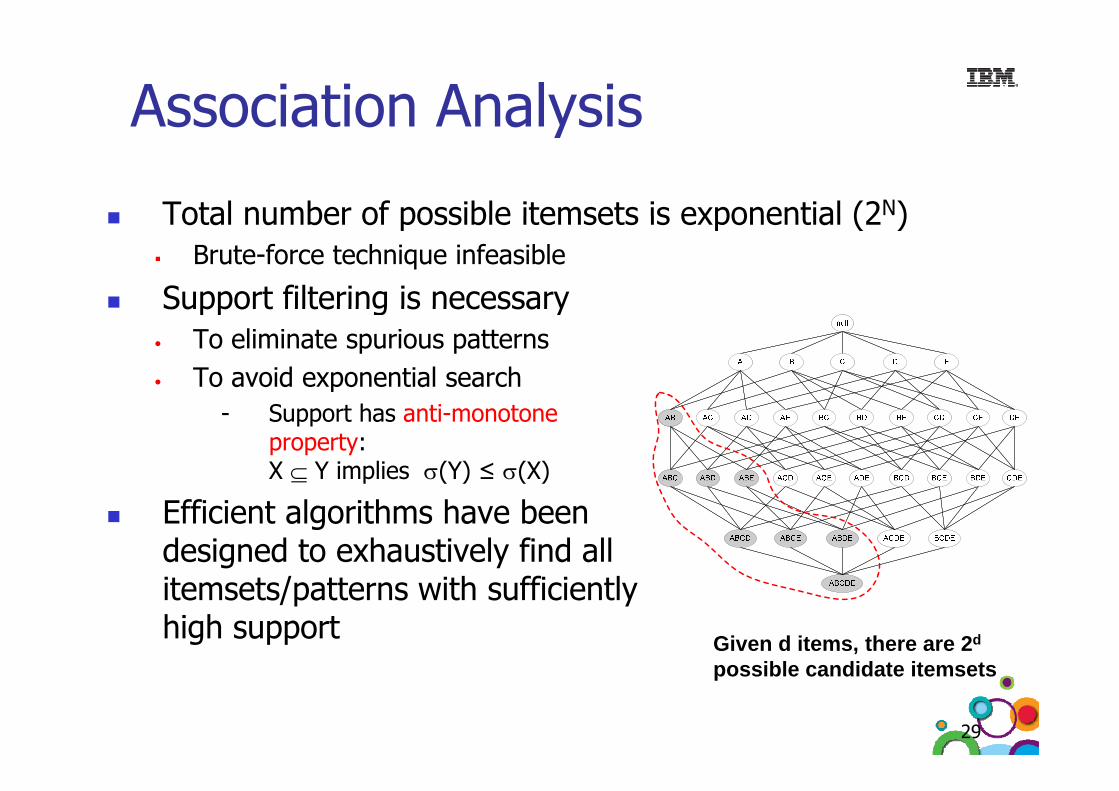
Association Analysis
Total number of possible itemsets is exponential (2N)
Association Analysis
Total number of possible itemsets is exponential (2 )Brute-force technique infeasible
Support filtering is necessarySupport filtering is necessary • To eliminate spurious patterns• To avoid exponential search
- Support has anti-monotone property: X ⊆ Y implies σ(Y) ≤ σ(X)
Efficient algorithms have been designed to exhaustively find all itemsets/patterns with sufficiently high support Given d items, there are 2d
ibl did t it tpossible candidate itemsets
29

Utterance NormalizationUtterance NormalizationIdentify conceptsIdentify concepts
Named Entity AnnotationRule based annotator for annotations such as location, date, car model and amountmodel, and amount
“I want to pick it up from <location> on <date>”
Grouping of utterancesFind patterns with gaps and represent each utterance by them along with unigrams and bi-gramsAgent and customer utterances are clustered separately using an off-g p y gthe shelf clustering algorithm
30
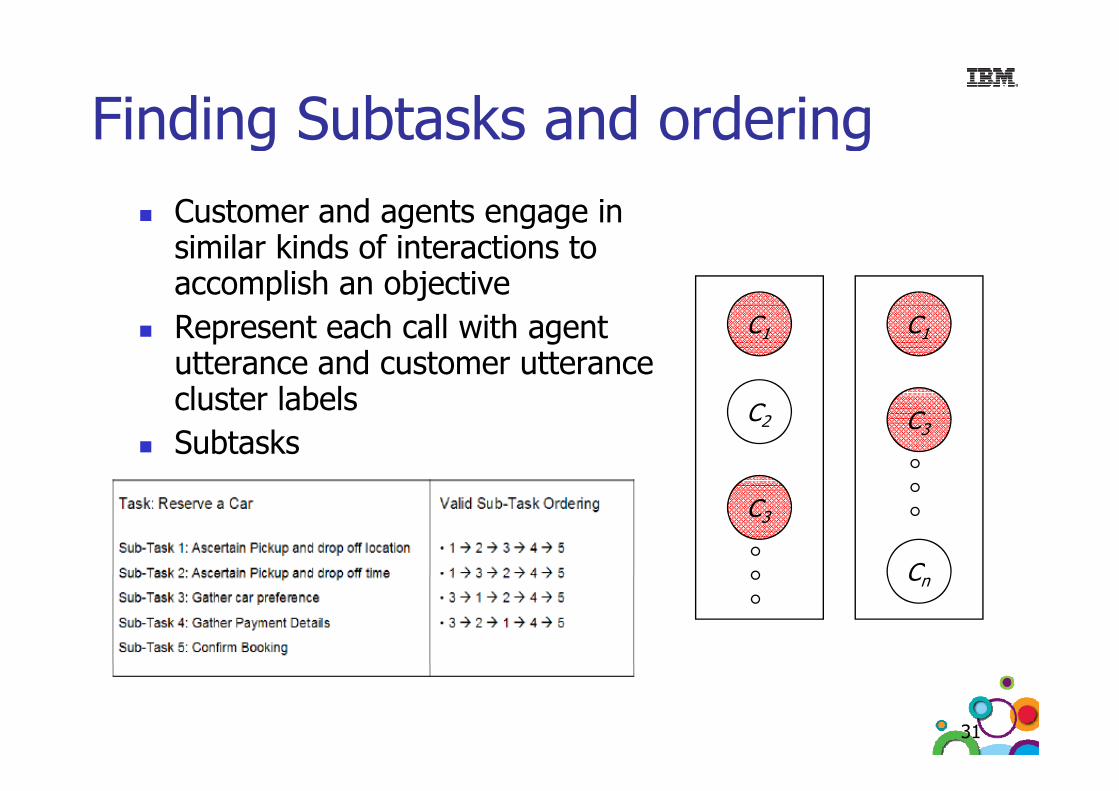
Finding Subtasks and orderingFinding Subtasks and orderingCustomer and agents engage inCustomer and agents engage in similar kinds of interactions to accomplish an objectiveRepresent each call with agent utterance and customer utterance cluster labels
C1 C1
cluster labelsSubtasks
Patterns of cluster labels
C2 C3
Patterns of cluster labels (agents) with possible gapsLot of variability in customer
C3
CLot of variability in customer utterances
Vertical pattern mining
Cn
31

Subtask PreconditionsSubtask Preconditions
U di iUtterance pre-conditionsCustomer utterances that indicate start of a subtask
“please make this booking” for “make payment” subtaskplease make this booking for make payment subtaskFrequent features from customer utterances
Flow pre-conditionsOnly logical orders of subtasks are allowed
“ k t” bt k t b t d l “ th“make payment” subtask cannot be executed unless “gather pick-up information” subtask has been executed.Collection of all the subtasks that precede the subtaskp
32

Finding Subtasks
33

Data FusionProblem
Given multiple data points about an entity, create a single p p y, gobject representation while resolving conflicting data values
DifficultiesNull values: Subsumption and complementationNull values: Subsumption and complementationContradictions in data valuesUncertainty & truth: Discover the true value and model uncertainty in this processu ce ta ty t s p ocessMetadata: Preferences, recency, correctnessLineage: Keep original values and their originImplementation in DBMS: SQL extended SQL UDFs etcImplementation in DBMS: SQL, extended SQL, UDFs, etc.
34
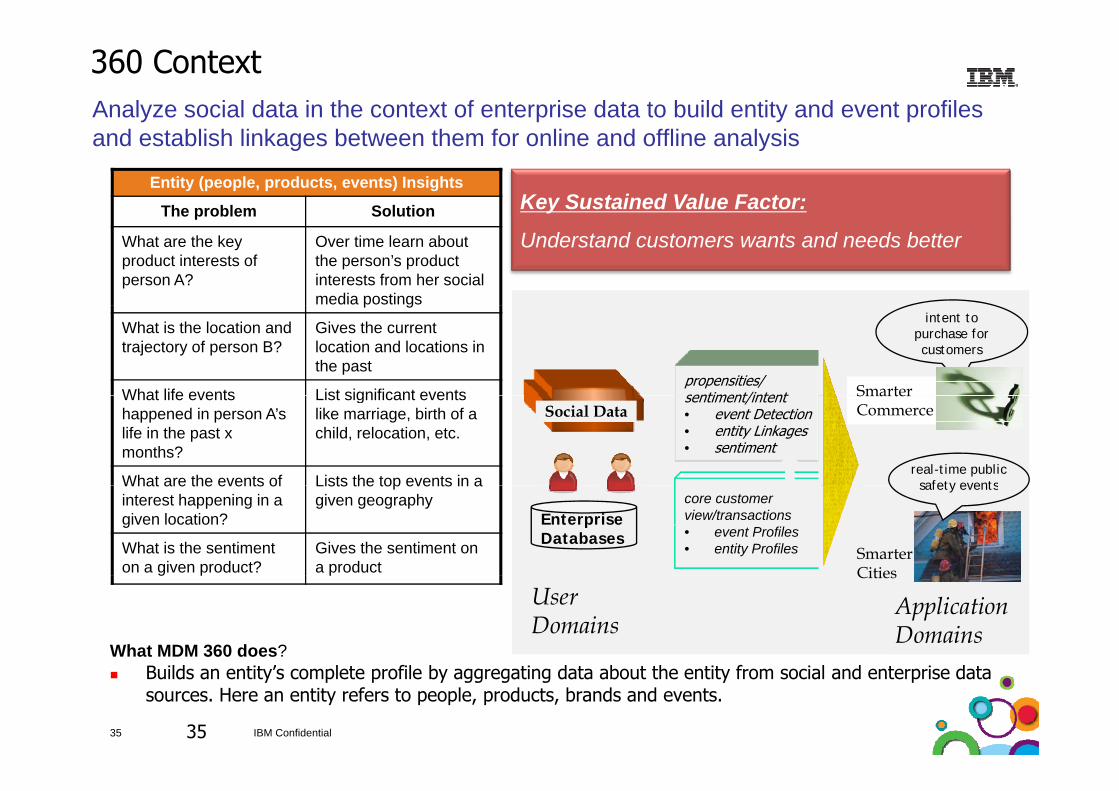
Analyze social data in the context of enterprise data to build entity and event profiles
360 Context
Entity (people, products, events) Insights
The problem Solution Key Sustained Value Factor:
and establish linkages between them for online and offline analysis
The problem Solution
What are the key product interests of person A?
Over time learn about the person’s product interests from her social media postings
Understand customers wants and needs better
p g
What is the location and trajectory of person B?
Gives the current location and locations in the past
What life events List significant events
intent to purchase for customers
propensities/sentiment/intent Smarter What life events
happened in person A’s life in the past x months?
List significant events like marriage, birth of a child, relocation, etc.
What are the events of Lists the top events in a
Social Datasentiment/intent • event Detection• entity Linkages • sentiment
Smarter Commerce
real-time public safety eventsWhat are the events of
interest happening in a given location?
Lists the top events in a given geography
What is the sentiment on a given product?
Gives the sentiment on a product
Enterprise Databases
core customer view/transactions• event Profiles• entity Profiles
core customer view/transactions• event Profiles• entity Profiles Smarter
Cities
safety events
g p p
What MDM 360 does?ld ’ l f l b d b h f l d d
Application Domains
User Domains
Cities
3535 IBM Confidential
Builds an entity’s complete profile by aggregating data about the entity from social and enterprise data sources. Here an entity refers to people, products, brands and events.
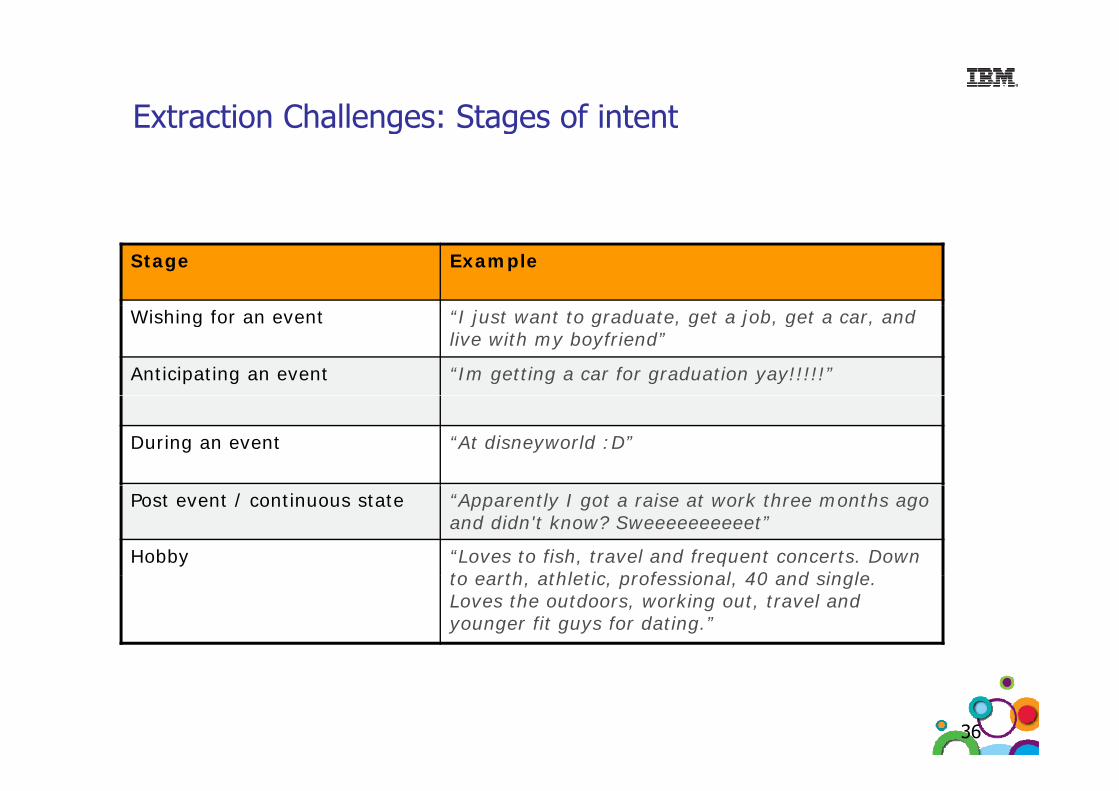
Extraction Challenges: Stages of intentExtraction Challenges: Stages of intent
Stage Example
Wishing for an event “I just want to graduate, get a job, get a car, and live with my boyfriend”
Anticipating an event “Im getting a car for graduation yay!!!!!”
During an event “At disneyworld :D”
Post event / continuous state “Apparently I got a raise at work three months ago and didn't know? Sweeeeeeeeeet”
Hobby “Loves to fish, travel and frequent concerts. Down to earth athletic professional 40 and single to earth, athletic, professional, 40 and single. Loves the outdoors, working out, travel and younger fit guys for dating.”
36
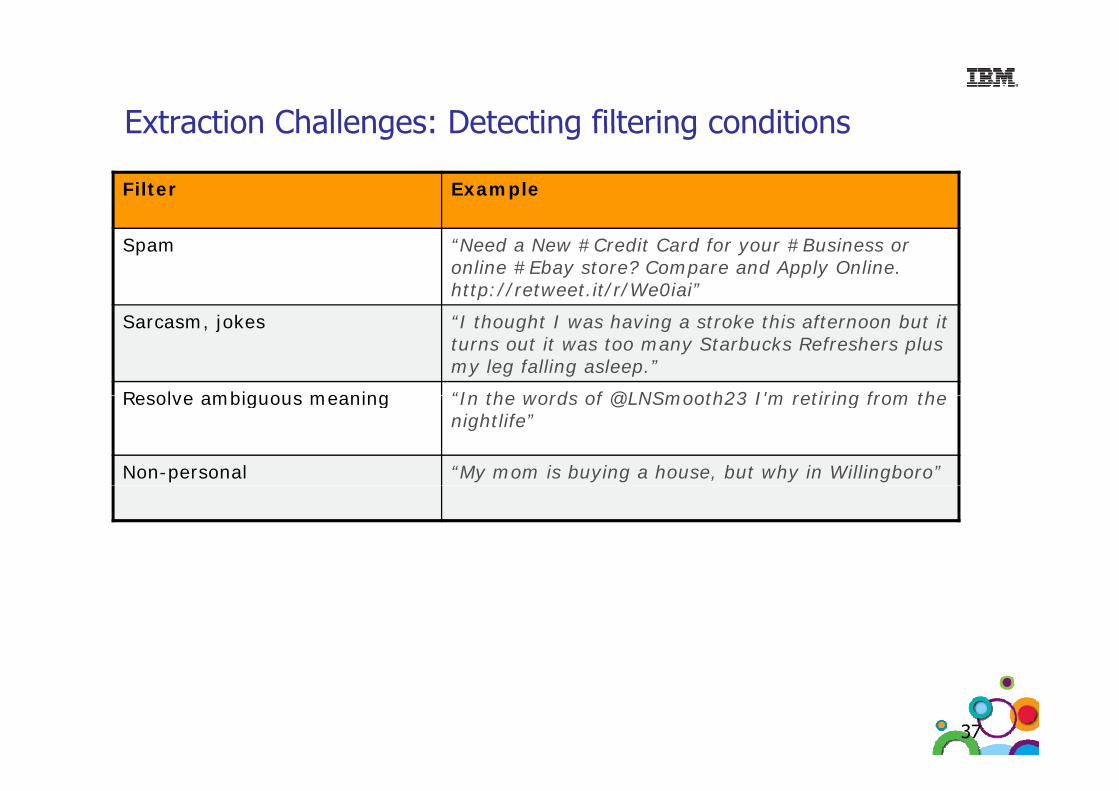
Extraction Challenges: Detecting filtering conditionsExtraction Challenges: Detecting filtering conditions
Filter Example
Spam “Need a New #Credit Card for your #Business or online #Ebay store? Compare and Apply Online. http://retweet.it/r/We0iai”
Sarcasm, jokes “I thought I was having a stroke this afternoon but it turns out it was too many Starbucks Refreshers plus my leg falling asleep.”
Resolve ambiguous meaning “In the words of @LNSmooth23 I'm retiring from the Resolve ambiguous meaning “In the words of @LNSmooth23 I'm retiring from the nightlife”
Non-personal “My mom is buying a house, but why in Willingboro”
37
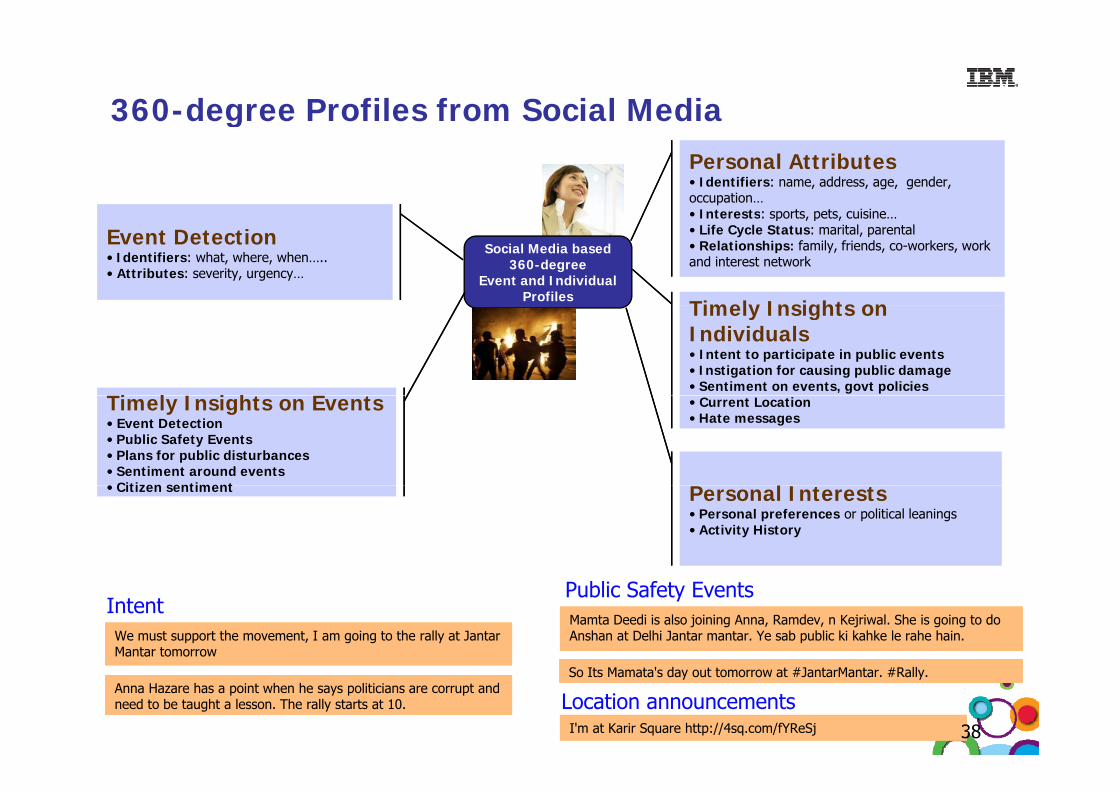
360-degree Profiles from Social MediagPersonal Attributes• Identifiers: name, address, age, gender, occupation…• Interests: sports pets cuisine
Event Detection• Identifiers: what, where, when…..• Attributes: severity, urgency…
Social Media based 360-degree
Event and Individual Profiles
Timely Insights on
• Interests: sports, pets, cuisine…• Life Cycle Status: marital, parental• Relationships: family, friends, co-workers, work and interest network
Ti l I i ht E t
Timely Insights on Individuals• Intent to participate in public events• Instigation for causing public damage• Sentiment on events, govt policies
P l I
Timely Insights on Events• Event Detection• Public Safety Events• Plans for public disturbances• Sentiment around events• Citizen sentiment
• Current Location• Hate messages
Personal Interests• Personal preferences or political leanings• Activity History
• Citizen sentiment
IntentPublic Safety EventsMamta Deedi is also joining Anna, Ramdev, n Kejriwal. She is going to do Anshan at Delhi Jantar mantar. Ye sab public ki kahke le rahe hain. Mamta Deedi is also joining Anna, Ramdev, n Kejriwal. She is going to do Anshan at Delhi Jantar mantar. Ye sab public ki kahke le rahe hain. We must support the movement, I am going to the rally at Jantar
Mantar tomorrowWe must support the movement, I am going to the rally at JantarMantar tomorrow
Location announcementsSo Its Mamata's day out tomorrow at #JantarMantar. #Rally. So Its Mamata's day out tomorrow at #JantarMantar. #Rally.
I'm at Karir Square http://4sq.com/fYReSjI'm at Karir Square http://4sq.com/fYReSj
Anna Hazare has a point when he says politicians are corrupt and need to be taught a lesson. The rally starts at 10.Anna Hazare has a point when he says politicians are corrupt and need to be taught a lesson. The rally starts at 10.
38
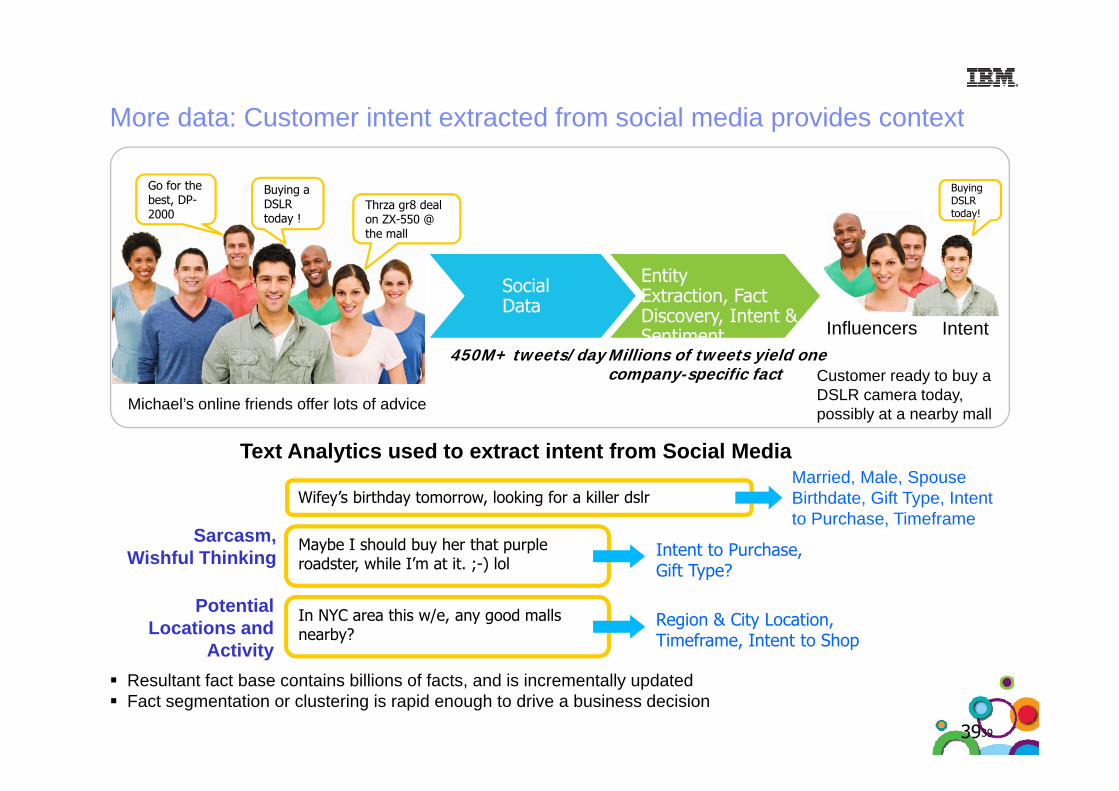
More data: Customer intent extracted from social media provides context
Buying a DSLR today !
Thrza gr8 deal ZX 550 @
Go for the best, DP-2000
More data: Customer intent extracted from social media provides context
Buying DSLR today!
Prior Business Transactions
today ! on ZX-550 @ the mall
2000
Entity Extraction, Fact Social
Data
today!
Customer ready to buy a DSLR camera today
Discovery, Intent & Sentiment
Data
450M+ tweets/day Millions of tweets yield one company-specific fact
Influencers Intent
DSLR camera today, possibly at a nearby mallMichael’s online friends offer lots of advice
Text Analytics used to extract intent from Social MediaMarried, Male, Spouse
Wifey’s birthday tomorrow, looking for a killer dslr
Sarcasm,Wishful Thinking
Maybe I should buy her that purple roadster, while I’m at it. ;-) lol
, , pBirthdate, Gift Type, Intent to Purchase, Timeframe
Intent to Purchase,Gift Type?Gift Type?
PotentialLocations and
Activity
In NYC area this w/e, any good malls nearby?
Region & City Location, Timeframe, Intent to Shop
39
Resultant fact base contains billions of facts, and is incrementally updatedFact segmentation or clustering is rapid enough to drive a business decision
39
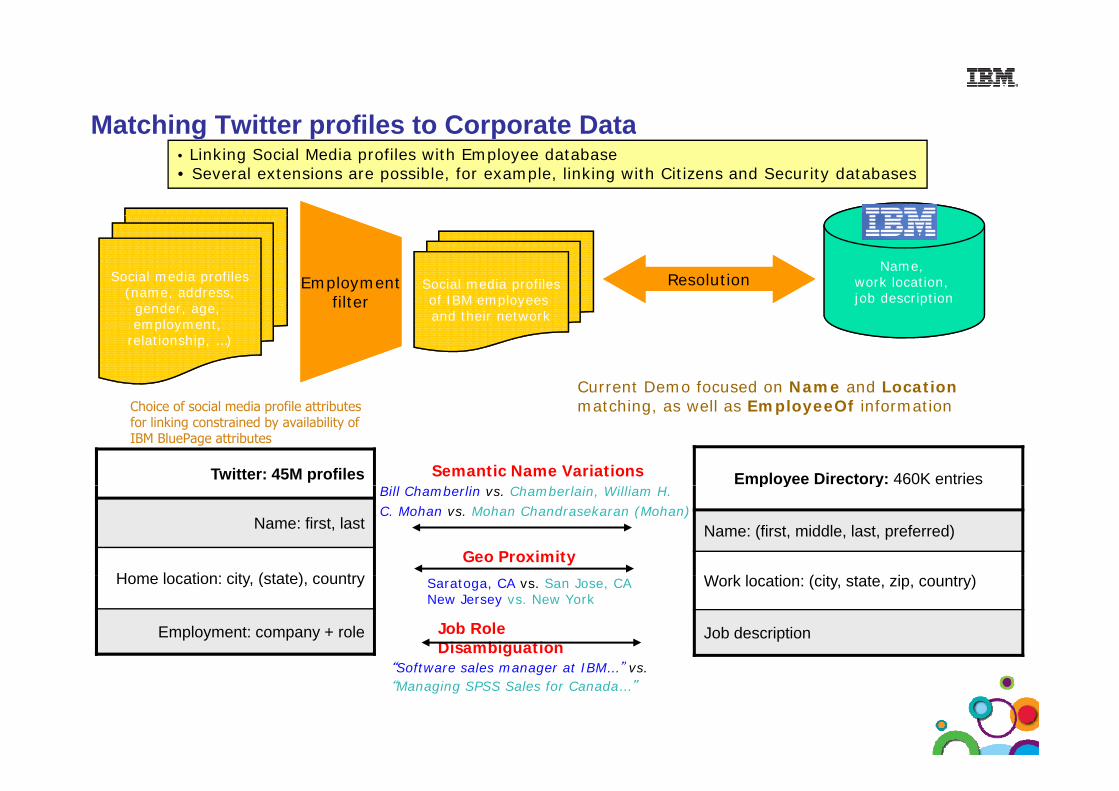
Matching Twitter profiles to Corporate DataMatching Twitter profiles to Corporate Data• Linking Social Media profiles with Employee database• Several extensions are possible, for example, linking with Citizens and Security databases
Name, work location, job description
Employmentfilter
Social media profiles(name, address,
gender age
Social media profilesof IBM employees
Resolutionfiltergender, age,
employment, relationship, …)
p yand their network
Current Demo focused on Name and Location
Twitter: 45M profiles Employee Directory: 460K entries
Choice of social media profile attributes for linking constrained by availability of IBM BluePage attributes
Semantic Name Variations
matching, as well as EmployeeOf information
Name: first, last
H l ti it ( t t ) t
p y y
Name: (first, middle, last, preferred)
W k l i ( i i )
Bill Chamberlin vs. Chamberlain, William H.C. Mohan vs. Mohan Chandrasekaran (Mohan)
Geo ProximityHome location: city, (state), country
Employment: company + role
Work location: (city, state, zip, country)
Job description
Saratoga, CA vs. San Jose, CANew Jersey vs. New York
Job Role Disambiguation
“Soft a e sales manage at IBM ” s
40
Software sales manager at IBM… vs. “Managing SPSS Sales for Canada…”

Example ResultExample Result
• Semantic name variations: Twitter name is a close variation of the IBM names
• Geo Proximity: Work locations are within 25mi of the Twitter location
41
• Geo Proximity: Work locations are within 25mi of the Twitter location
• Job Role Disambiguation : description in Twitter profile matches HR role

C D t P blCommon Data Problems
• Lack of information t d d
Ashok Kumar 416 Anand Niketan, New Delhi, India 110021
A Kumar Four sixteen Street 8 Anand Niketan Delhistandards• Different formats & structures across
different systems
A Kumar Four sixteen Street 8, Anand Niketan, Delhi
110021
Mr. Ashok Kr #416 Anand Niketan, N Delhi, 21
Data surprises in individual fields
Email Tax ID Telephone
91,,,, 228-02-1975 6173380300i i@ h i 025 37 1888 415 392 2000fields
• Data misplaced in the database
• Special characters in the data
[email protected] 025-37-1888 415-392-2000,[email protected] 34-2671434 3380321HP 15 State St. 508-466-1200 Orlando
90328574 IBM 187 N.Pk. Str. Salem NH 01456
• The redundancy nightmare• Duplicate records with a lack of
90328575 I.B.M. Inc. 187 N.Pk. St. Salem NH 0145690238495 Int. Bus. Machines 187 No. Park St Salem NH 0415690233479 International Bus. M. 187 Park Ave Salem NH 0415690233489 Inter-Nation Consults 15 Main Street Andover MA 0234190345672 I B Manufacturing Park Blvd Bostno MA 04106• Duplicate records with a lack of
standards90345672 I.B. Manufacturing Park Blvd. Bostno MA 04106
42

Address VariationsAddress Variations…
• Spelling variations, hyphenation, abbreviations• I 344 | Sarojini Nagar | N Delhi | 23• I-344 | Sarojini Nagar | N Delhi | 23• 344 Block J | Sarojni Ngr | New Delhi | 110023• 344 Block I | Sarojni Ngr | New Delhi | 110023
• Multiple Ways of writing the same field• 13B | Link Road | Versova | Mumbai• 18 Block M | Bandra Versova Link Rd | Versova | Mumbai• 18 Block M | Bandra Versova Link Rd. | Versova | Mumbai
• Missing Address Fields• 4 Block C | ISID Campus I I V Kunj I New Delhi | 110070• 4, Block C | ISID Campus I I V. Kunj I New Delhi | 110070• 4C I ISID Campus | Institutional Area| V. Kunj | New Delhi | 110070
• Errors• 4C I ISID Campus | Institutional Area| V. Kunj, New Delhi | 110007
43

Regional variations in Addresses across IndiaIndia
Addresses in different regions contain words of the local language even when the addresses are written in Englishaddresses are written in English
Ex : The commonly used word to describe a street type is “Gali” in Northern India whereas “Beedhi/Veedhi” is the commonly used term in Southern India
Street Intersections and Street Information containing multiple Street Type Identifiers like Cross and Main are extensively found in the Southern Indian regions
Ex : “3rd Main, 4th B Cross”,
Sector and Pocket Information are found primarily in North Indian Addresses
Ex : “Sector 5, Pocket 2A 2nd Block”
Regional differences in writing addresses necessitate bifurcation of standardization rules based on regions.
44

Investigating the Datag gTake the Example: 123 St. Virginia St.
Parsing:Separates multi-valued fields into individual pieces 123 St. Virginia St.
L i l A l iNumber Street Alpha Street
Type TypeLexical Analysis:Determines business significance of individual pieces
Type Type
123 St. Virginia St.
Context Sensitive:Number Street Name Street
TypeContext Sensitive:Identifies various data structures and content 123 St. Virginia St.
45
“The instructions for handling the data are inherent within the data itself.”
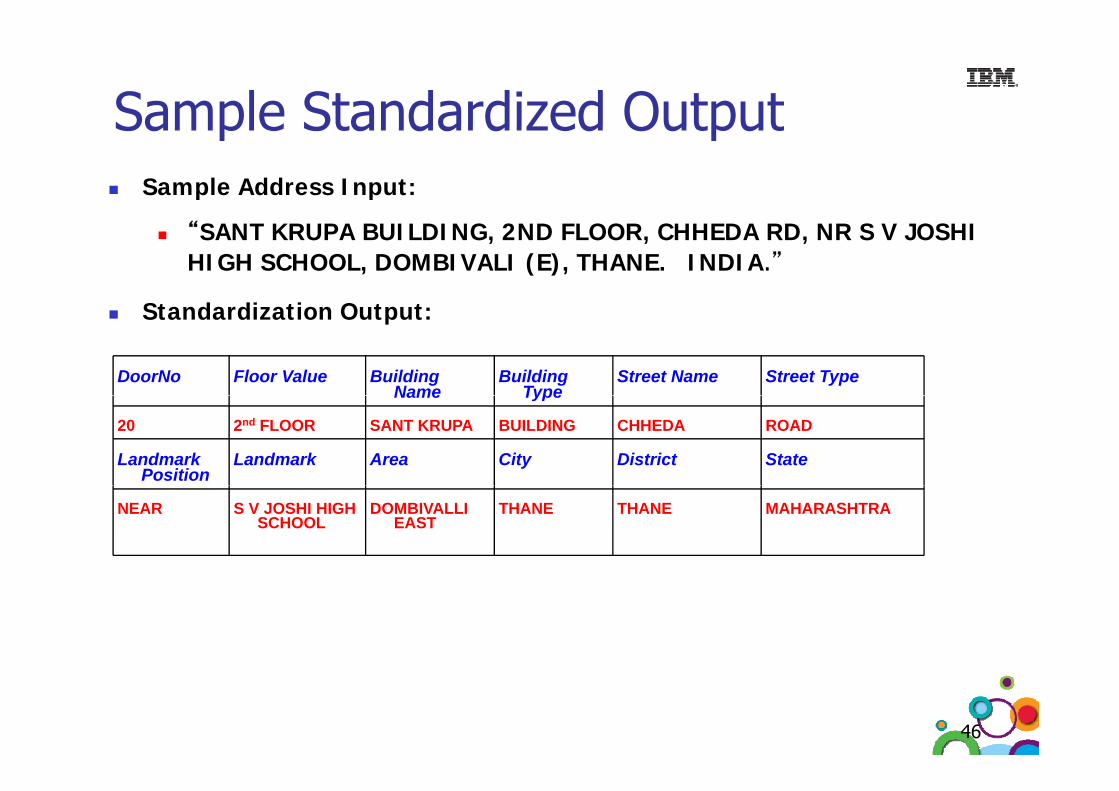
Sample Standardized OutputSample Standardized OutputSample Address Input:
“SANT KRUPA BUILDING, 2ND FLOOR, CHHEDA RD, NR S V JOSHI HIGH SCHOOL, DOMBIVALI (E), THANE. INDIA.”
St d di ti O t tStandardization Output:
DoorNo Floor Value Building Name
Building Type
Street Name Street TypeName Type
20 2nd FLOOR SANT KRUPA BUILDING CHHEDA ROAD
Landmark Position
Landmark Area City District State
NEAR S V JOSHI HIGH SCHOOL
DOMBIVALLI EAST
THANE THANE MAHARASHTRA
46
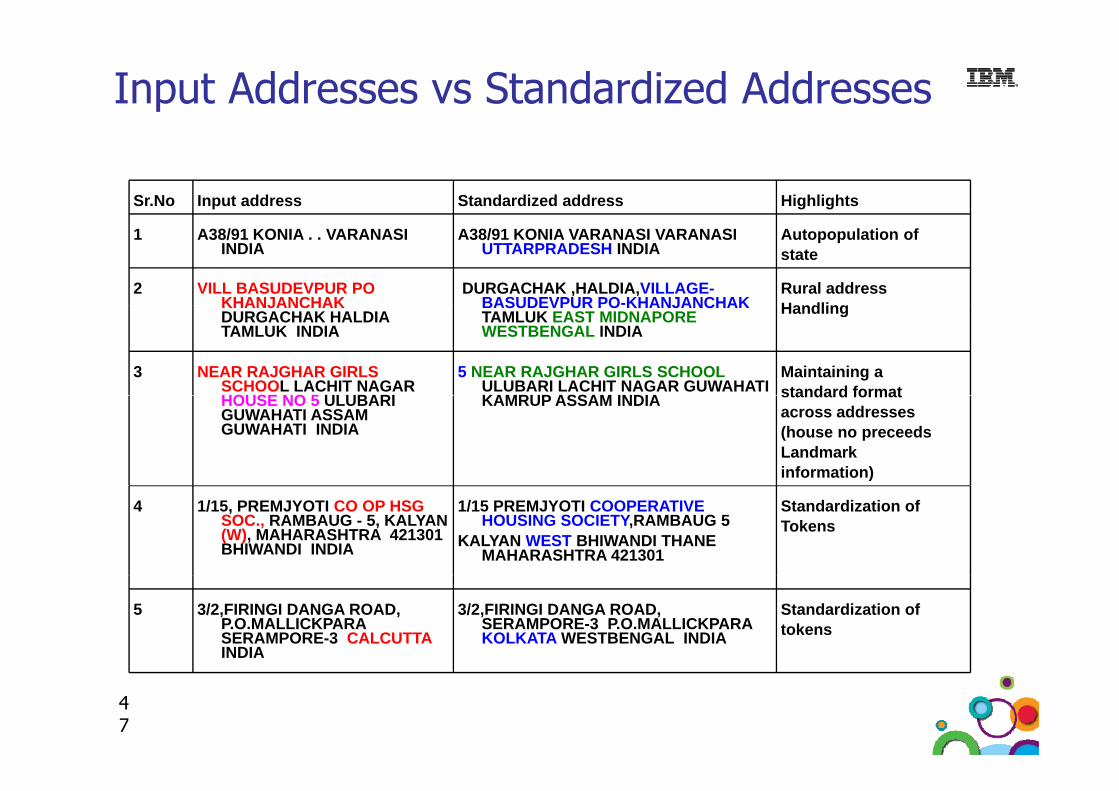
Input Addresses vs Standardized Addresses
Sr.No Input address Standardized address Highlights
1 A38/91 KONIA . . VARANASI INDIA
A38/91 KONIA VARANASI VARANASI UTTARPRADESH INDIA
Autopopulation ofstate
2 VILL BASUDEVPUR PO KHANJANCHAK
DURGACHAK ,HALDIA,VILLAGE-BASUDEVPUR PO-KHANJANCHAK
Rural addressHandlingKHANJANCHAK
DURGACHAK HALDIA TAMLUK INDIA
BASUDEVPUR PO KHANJANCHAKTAMLUK EAST MIDNAPORE WESTBENGAL INDIA
Handling
3 NEAR RAJGHAR GIRLS SCHOOL LACHIT NAGAR HOUSE NO 5 ULUBARI
5 NEAR RAJGHAR GIRLS SCHOOLULUBARI LACHIT NAGAR GUWAHATI KAMRUP ASSAM INDIA
Maintaining astandard formatHOUSE NO 5 ULUBARI
GUWAHATI ASSAM GUWAHATI INDIA
KAMRUP ASSAM INDIA standard formatacross addresses(house no preceedsLandmarkinformation)
4 1/15, PREMJYOTI CO OP HSG SOC., RAMBAUG - 5, KALYAN(W), MAHARASHTRA 421301 BHIWANDI INDIA
1/15 PREMJYOTI COOPERATIVE HOUSING SOCIETY,RAMBAUG 5
KALYAN WEST BHIWANDI THANE MAHARASHTRA 421301
Standardization ofTokens
5 3/2,FIRINGI DANGA ROAD, P.O.MALLICKPARA SERAMPORE-3 CALCUTTA INDIA
3/2,FIRINGI DANGA ROAD, SERAMPORE-3 P.O.MALLICKPARA KOLKATA WESTBENGAL INDIA
Standardization oftokens
47

Two Methods to Decide a MatchAre these two records a match?
Two Methods to Decide a Match
RHITU K KAZANGIAN 128 MAIN ST 02111 12/8/62
RITU KUMAR KAZANGIAN 128 MAINE RD 02110 12/8/62/ /B B A A B D B A = BBAABDBA
+5 +2 +20 +3 +4 -1 +7 +9 = +49
Deterministic Decisions Tables:• Fields are compared• Letter grade assignedg g• Combined letter grades are compared to a vendor delivered file• Result: Match; Fail; Suspect
Probabilistic Record Linkage:• Fields are evaluated for degree-of-match• Weight assigned: represents the “information content” by value• Weights are summed to derived a total score
Result: Statistical probability of a match
48
• Result: Statistical probability of a match
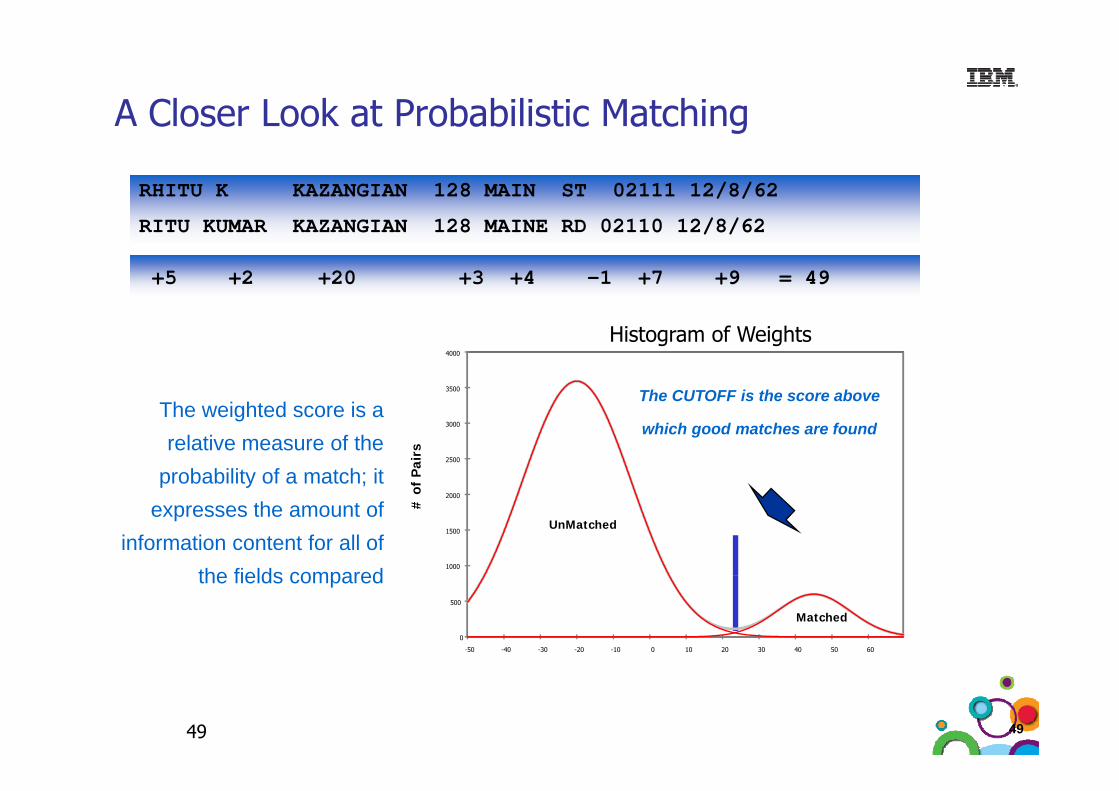
A Closer Look at Probabilistic Matching
RHITU K KAZANGIAN 128 MAIN ST 02111 12/8/62
C ose oo at obab st c atc g
RITU KUMAR KAZANGIAN 128 MAINE RD 02110 12/8/62
+5 +2 +20 +3 +4 -1 +7 +9 = 49
The CUTOFF is the score above
Histogram of Weights
3500
4000
The weighted score is a relative measure of the
probability of a match; it
The CUTOFF is the score above
which good matches are found
2500
3000f
Pai
rs
p y ;expresses the amount of
information content for all of the fields compared
1000
1500
2000
# o
f
UnMatched
the fields compared
0
500
-50 -40 -30 -20 -10 0 10 20 30 40 50 60
Matched
49 49

The Value of Information Content
Information Content is measured both at the field and at the field value level and is calculated automaticallyDiscriminating Value represents the significance of one field versus another inDiscriminating Value represents the significance of one field versus another in contributing to a match
For example a Gender Code contributes less information than a Tax-Id NumberFrequency represents the significance of one value in a field over another valueq y p g
For example in a Last-Name Field, “SMITH” contributes less information than “ROUTZAHN”
Probabilistic Matching uses the automatically generated measures of Information C h h h h h bl l f ll f blContent to achieve the highest match rates possible utilizing a scientifically-justifiable methodology
50
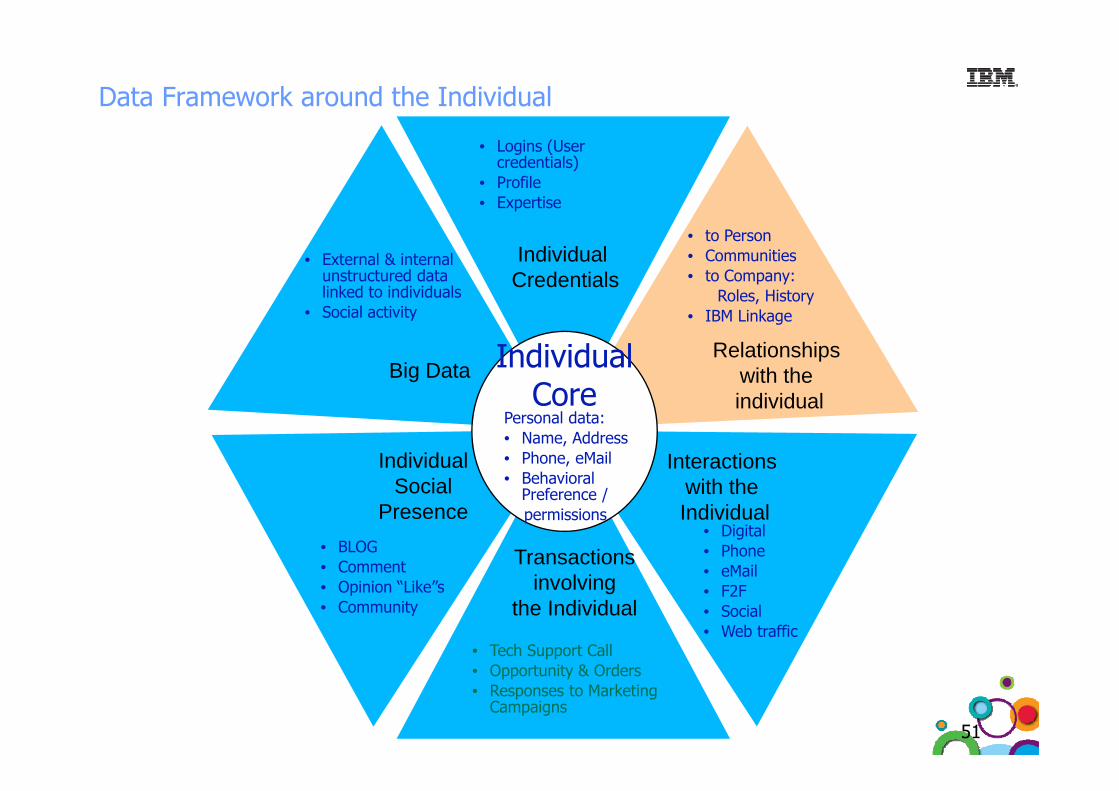
Data Framework around the Individual
• Logins (User credentials)
• Profile• Expertise
IndividualCredentials
• to Person • Communities• to Company:
Roles, History
• External & internal unstructured data linked to individualsS l
Relationships with the i di id l
• IBM Linkage
IndividualCore
Big Data
• Social activity
individual
Interactions with the
CorePersonal data:• Name, Address• Phone, eMail• Behavioral
IndividualSocial with the
Individual
Transactions i l i
• Digital• Phone• eMail
Preference / permissions
SocialPresence
• BLOG• Comment
involving the Individual
eMail• F2F• Social• Web traffic
• Opinion “Like”s• Community
• Tech Support CallO t it & O d• Opportunity & Orders
• Responses to Marketing Campaigns
51
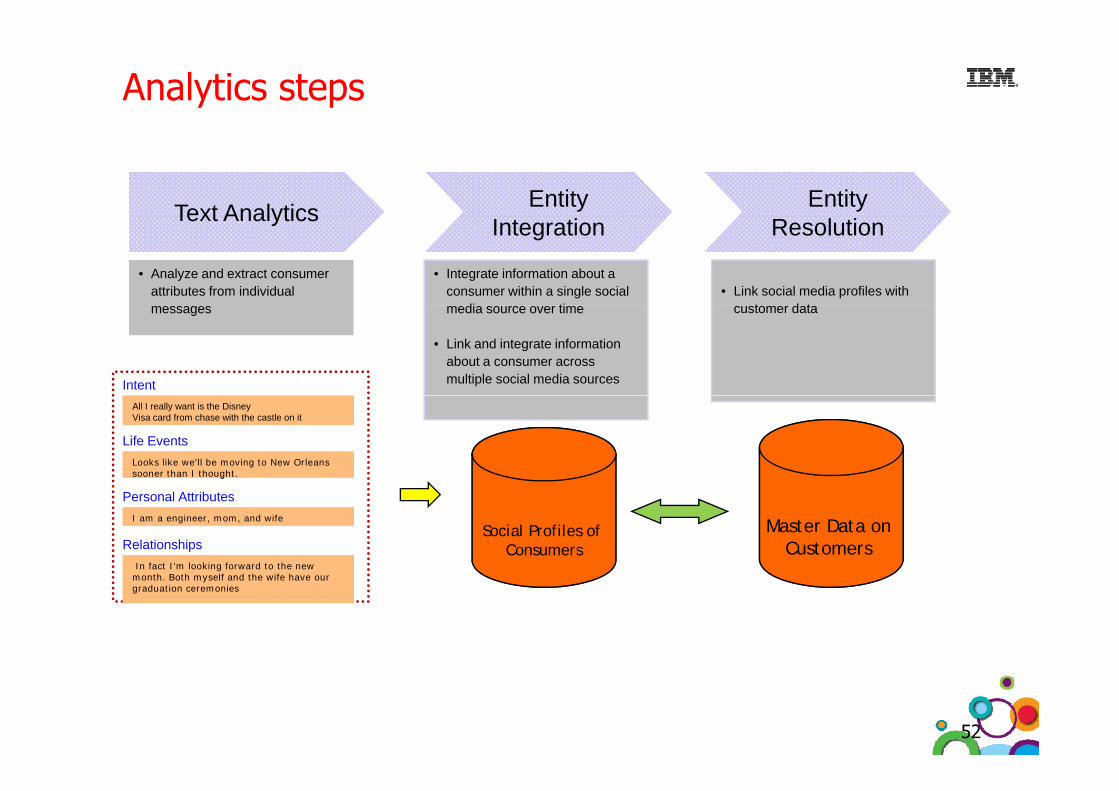
Analytics steps
Text Analytics Entity Entity Text Analytics
• Analyze and extract consumer attributes from individual
Integration
• Integrate information about a consumer within a single social
di ti
Resolution
• Link social media profiles with t d tmessages
Intent
media source over time
• Link and integrate information about a consumer across multiple social media sources
customer data
All I really want is the Disney Visa card from chase with the castle on itAll I really want is the Disney Visa card from chase with the castle on it
Life EventsLooks like we'll be moving to New Orleans sooner than I thought.Looks like we'll be moving to New Orleans sooner than I thought.
Personal AttributesI am a engineer, mom, and wifeI am a engineer, mom, and wife
RelationshipsIn fact I'm looking forward to the new
th B th lf d th if h In fact I'm looking forward to the new
th B th lf d th if h
Social Profiles of Consumers
Master Data on Customers
month. Both myself and the wife have our graduation ceremoniesmonth. Both myself and the wife have our graduation ceremonies
52
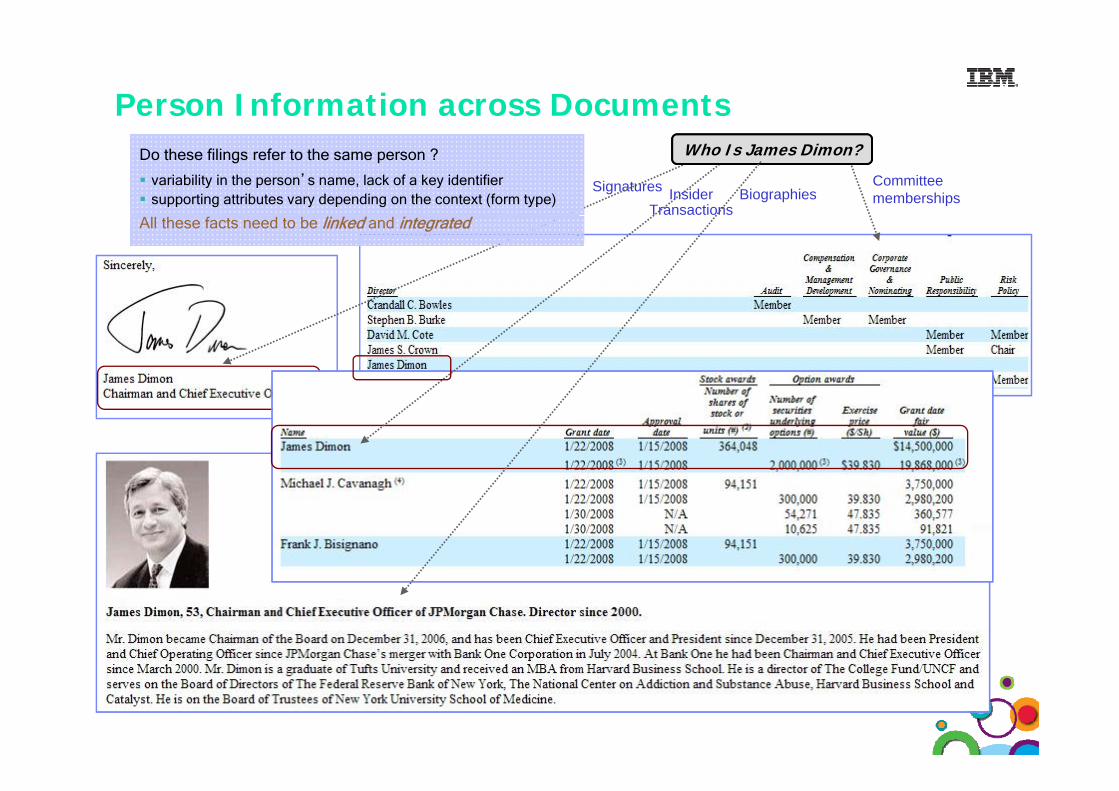
Person Information across Documents
Signatures BiographiesCommittee memberships
Who Is James Dimon?Do these filings refer to the same person ?
variability in the person’s name, lack of a key identifiersupporting attributes vary depending on the context (form type) Insider
TransactionsAll these facts need to be linked and integrated
5353
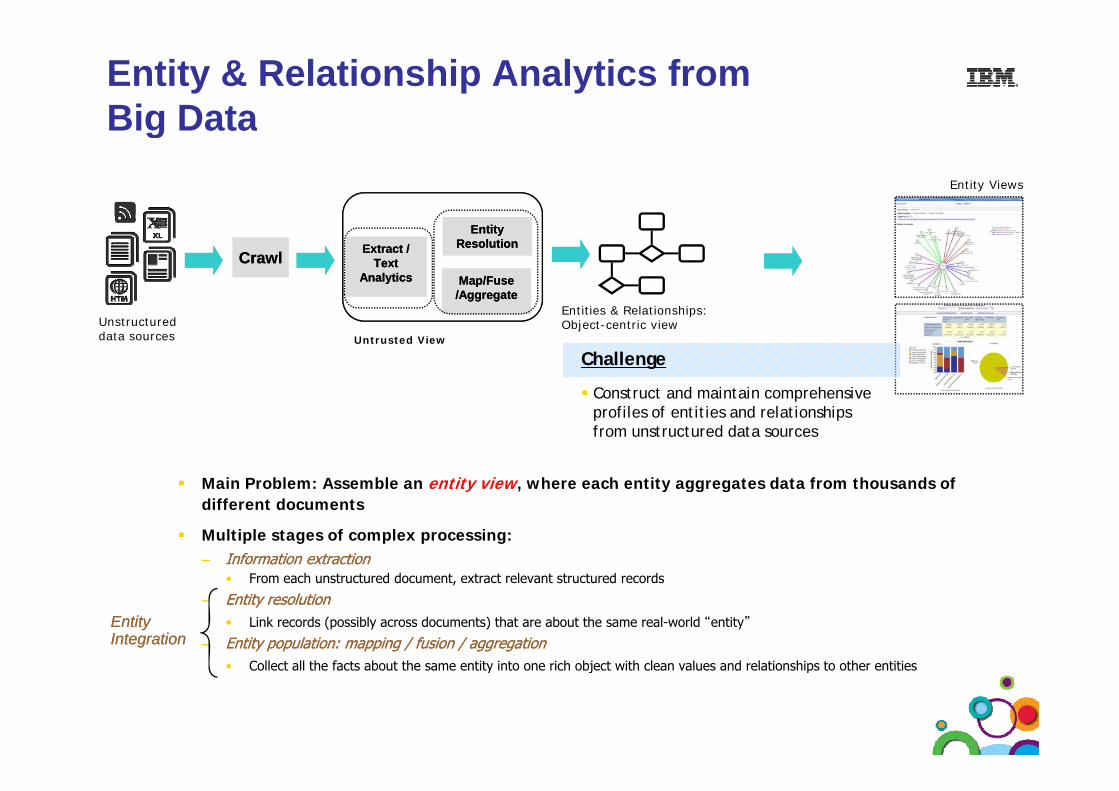
Entity & Relationship Analytics from Big DataBig Data
Entity Views
CrawlCrawlCrawlCrawl
Entity Entity ResolutionResolution
Map/FuseMap/Fuse/Aggregate/Aggregate
Extract /Extract /Text Text
AnalyticsAnalytics
E i i & R l i hi Unstructured data sources
Entities & Relationships: Object-centric view
Untrusted View
Challenge
Construct and maintain comprehensive Construct and maintain comprehensive profiles of entities and relationships from unstructured data sources
Main Problem: Assemble an entity view where each entity aggregates data from thousands ofMain Problem: Assemble an entity view, where each entity aggregates data from thousands of different documents
Multiple stages of complex processing:–– Information extractionInformation extraction
F h t t d d t t t l t t t d d• From each unstructured document, extract relevant structured records
–– Entity resolutionEntity resolution• Link records (possibly across documents) that are about the same real-world “entity”
–– Entity population: mapping / fusion / aggregationEntity population: mapping / fusion / aggregation• Collect all the facts about the same entity into one rich object with clean values and relationships to other entities
Entity Entity IntegrationIntegration
54
• Collect all the facts about the same entity into one rich object with clean values and relationships to other entities
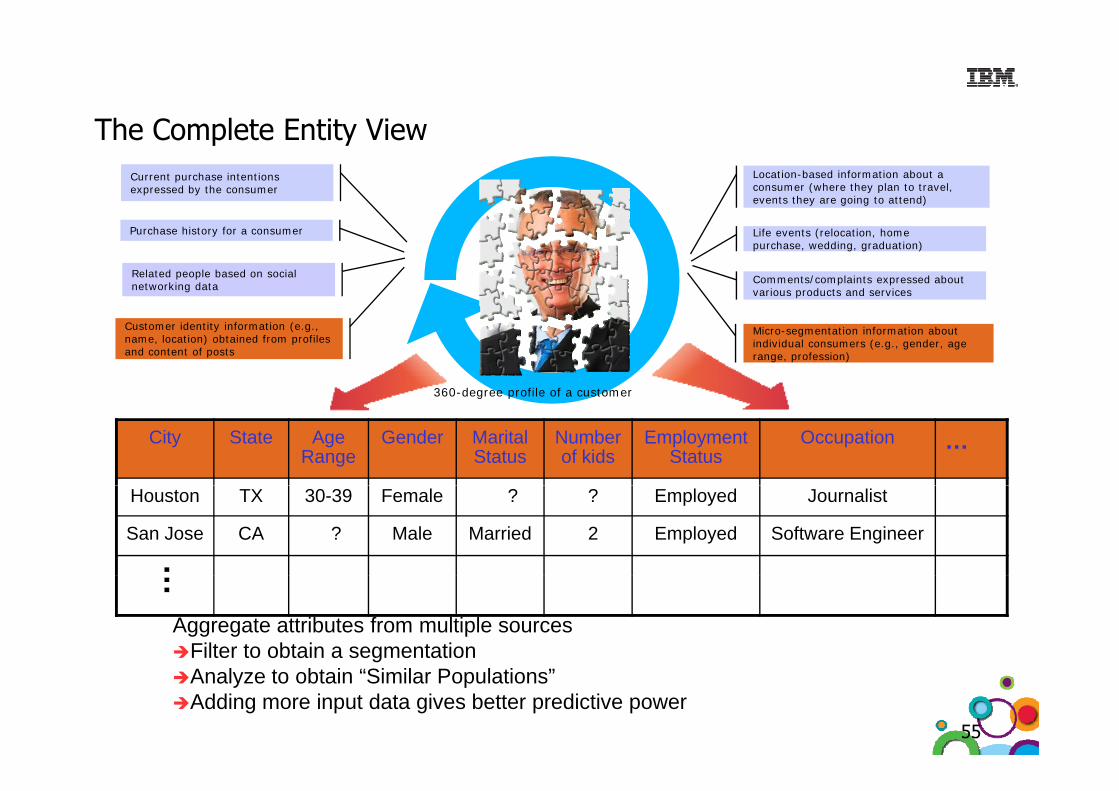
The Complete Entity ViewThe Complete Entity ViewCurrent purchase intentions expressed by the consumer
Location-based information about a consumer (where they plan to travel, events they are going to attend)
Related people based on social networking data
Purchase history for a consumer Life events (relocation, home purchase, wedding, graduation)
Comments/complaints expressed about various products and services
Micro-segmentation information about individual consumers (e.g., gender, age range, profession)
Customer identity information (e.g., name, location) obtained from profiles and content of posts
360-degree profile of a customer
City State AgeRange
Gender MaritalStatus
Number of kids
Employment Status
Occupation …
360 degree profile of a customer
Houston TX 30-39 Female ? ? Employed Journalist
San Jose CA ? Male Married 2 Employed Software Engineer
……
Aggregate attributes from multiple sourcesFilter to obtain a segmentationAnalyze to obtain “Similar Populations”Adding more input data gives better predictive power
55

Attribute fusion example: Inferring location from multiple cluesScreen name : @tracyguida
Social Media ProfileScreen name : @tracyguidaLocation: Tampa, FLName: Tracy Guida
Name: Tracy GuidaScreen name: @tracyguida
Metadata
Disambiguation, fusion of partial information
Sc ee a e @ acygu daLocation: TampaDescription: just a Nor-Cal gal trying to fall in love with Florida
Fusion libraries:• Confidence:
metadata vs. content
Permanent location
Messages Gotta love Florida football #hot #humid http://instagr.am/p/QOHPqhKdYt/ Gotta love Florida football #hot #humid http://instagr.am/p/QOHPqhKdYt/
h k bl b f dh k bl b f d Temporary locationTextual clues
I'm at Tracy's Seat At Micah's (Tampa, FL) http //4sq com/SZ4 jjI'm at Tracy's Seat At Micah's (Tampa, FL) http //4sq com/SZ4 jj
Check out my blog about #food in #TampaBay http://www.myothercitybythebay.comCheck out my blog about #food in #TampaBay http://www.myothercitybythebay.com
Temporary location
http://4sq.com/SZ4yjj http://4sq.com/SZ4yjj
I'm at S.o.G (Tampa, Florida) http://4sq.com/UDweM5 I'm at S.o.G (Tampa, Florida) http://4sq.com/UDweM5
Fusion libraries:• Confidence: place mentions vs. geo-codes
Check-ins
G l d
I'm at Eats American Grill (Tampa, FL) http://4sq.com/O1a1JmI'm at Eats American Grill (Tampa, FL) http://4sq.com/O1a1Jm
Wh ' hi h # id i l #d b i h ?Wh ' hi h # id i l #d b i h ?
g• Analysis of location time-series
Geo-located documents
Who's watching the #presidential #debate tonight?(from 27.97989014,-82.54825406)Who's watching the #presidential #debate tonight?(from 27.97989014,-82.54825406)
56
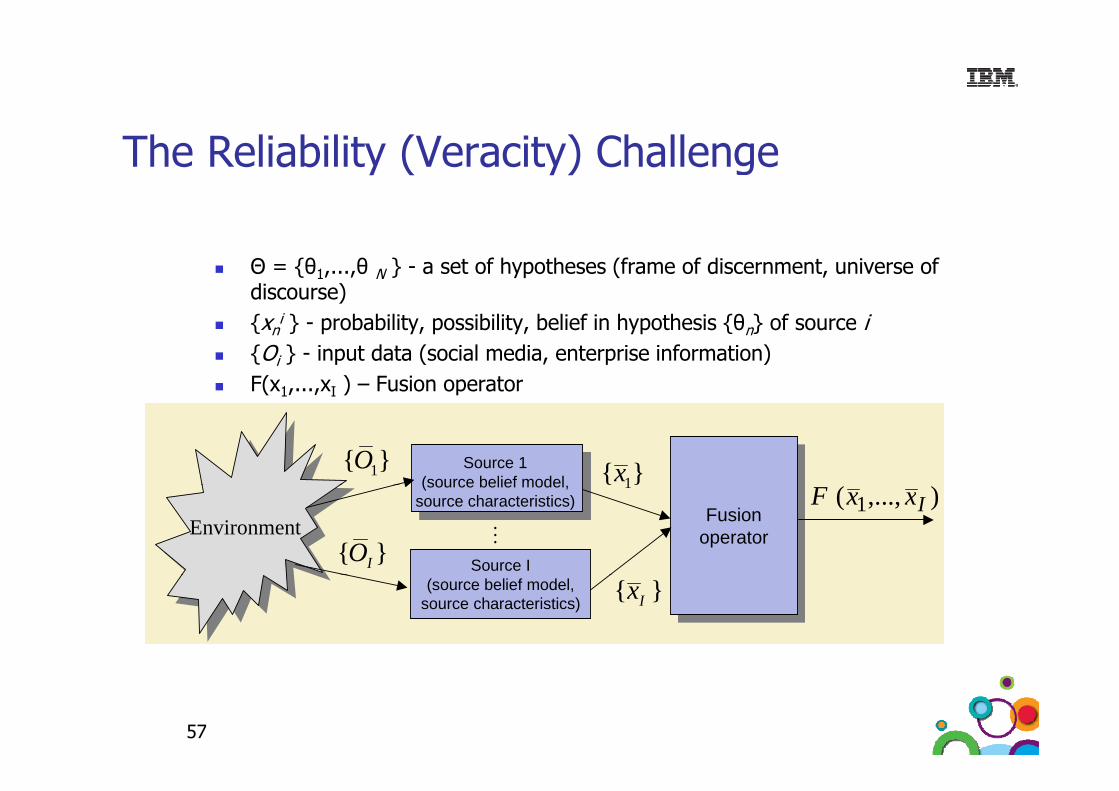
The Reliability (Veracity) Challenge
Θ = {θ1,...,θ N } - a set of hypotheses (frame of discernment, universe of discourse) {xn
i } - probability, possibility, belief in hypothesis {θn} of source i {Oi } - input data (social media, enterprise information)F(x1,...,xI ) – Fusion operator1 I
1{ }x1{ }O Source 1(source belief model
EnvironmentEnvironment FusionoperatorFusion
operator
1{ }),...,( 1 IxxF
{ }IO
(source belief model,source characteristics)
Source I
{ }Ix(source belief model,source characteristics)
57

Typical Reliability Settings
It is possible to assign a numerical degree of reliability to each sourceA subset of sources is reliable but we do not know which oneA subset of sources is reliable but we do not know which oneReliabilities of the sources can be ordered but no precise reliability values are known
Reliability dependent on context tooReliability dependent on context tooDuring Mumbai Mantralaya fire a few tens of tweets on this event on TwitterSame day there is a match and there are several thousand tweets “MiamiSame day there is a match and there are several thousand tweets Miami on Fire”
58

Strategies for Utilizing Reliability
Strategies explicitly utilizing reliability of sources Reliability is used to modify beliefs of each model before fusion andReliability is used to modify beliefs of each model before fusion and then use transformed beliefs (separable case)Strategies for modifying the fusion process to account for the reliability of the sources (non separable case)reliability of the sources (non-separable case).
Strategies identifying reliability of data input to fusion processes and eliminating the sources of poor reliabilityCombination of strategies mentioned above
F(x1,...,xI ) FR (x1,...,xI )F i t t d d t t hi h d d thFR - is a context dependent operator, which depends on the
strategy selected and defined within the framework used for uncertainty representation
59

Reliability CoefficientsReliability coefficients represent trust in each belief model. They introduce the second level of uncertainty and represent a measure of y pthe adequacy of the model used, the reality of the environment, and source characteristics
Ri = Ri (Mi, γ ,Υ) - reliability of source i (reliability of source i and ( i, γ , ) y ( yhypothesis j : Ri
j) Mi - model of source iγ parameters characterizing external environment (context)γ parameters characterizing external environment (context) Υ -parameters characterizing the internal environment of source I (tuning parameters)Rel ti e eli bilit ∑ IR 1Relative reliability : ∑i
IRi =1May be replaced with max Ri = 1
i
60

Bayesian FusionIn the Bayesian framework the degrees of belief are represented by a priori conditional and a posteriorirepresented by a priori, conditional, and a posteriori probabilities.
Usually, decisions are made on a posteriori probabilities P(θn | yi ), h i th i t i f Iwhere yi is the input coming from source I,
xi = P(θn | yi ) represents statistics of each source to be combined (data, outputs of classifiers).
F i i f d b th B i l hi h d thFusion is performed by the Bayesian rule, which under the condition of source independence is reduced to a product:
Fn(x1,...,xI)|y =Fn(P)|yi =P(θn)∏[P(θn |yi)/P(θn)], n
This fusion operator is conjunctive and assumes total reliability of the sources
61

Weighted AverageIf the sources are not totally reliable, several fusion rules within the framework of the probability theory have been proposed inthe framework of the probability theory have been proposed in the literatureA majority of the weighted average methods are based on
th hi h i l l d fconsensus theory, which involves general procedures of combining single source probability distributions while decisions are based on Bayesian decision theory
Fn(x1,...,xI,R1,...,RI)|yi =Fn(P,R)|yi =∑iP(θn |yi) Ri
where Ri is reliability associated with the sources in the global membership function expressing quantitatively the goodness of membership function expressing quantitatively the goodness of each source
62

Incorporation of ContextualIncorporation of Contextual Information
This method integrates contextual informationTh th d i b d th f t th t i i t tThe method is based on the fact that, in a given context, only a subset J of a set N of all sources to be combined is valid or reliable (i.e. their belief model adequately represents reality)Fn ( x1 ,..., x I , R1 ,..., R I ) | y = ∑P(θ |y1,...,yn,AJ ) P(AJ )where P(A ) is the probability of validity of the subset J ofwhere P(AJ) is the probability of validity of the subset J of inputs. This probability is calculated thanks to the reliability Ri of the individual inputs
63

Biographical and Biometric fusion for Person Identification
Many modern data repositories record both biographical and biometric information
Motor Vehicle Licensing Authority, Passport, Identify cards etcUnique Identification number (www.uidai.gov.in)
Fusing information from multiple sources bring value in Data integration: Creating single view of citizen, person, customerIdentification of the person using Biometric information and biographical information
Scaling person identification for large number of customer records– Biographical data is abundant, easy to match, scales to millions of records but can be noisy and uncertain. – Biometric data is noise free and gives high precision for identification but does not scale to large number of records– Both stream contain complimentary information which can be exploited by fusing together
Fusion for Person Identification can be done at two levels– Decision fusion: Each matcher provides the decision which are then fused to produce the final decision.
64
– Score fusion: Each matcher provides score which is used for producing a score for decision making.

Score Fusion using Biometric and Biographical matcher
Consider M matchers operating on a database containing N records which have both biographical and biometric information.
Th b lti l bi t i ll bi hi l
For query q if all the records are equally likely for the identifier than the posterior of the score given records is given by
There can be multiple biometric as well as biographical matchersEach query q will generate N x M scores i.e. M dimensional scores for N records
We model the scores as being generated from a b bilit di t ib ti
Imposter match score density
Genuine matchscore density
probability distribution.Score is fused using a joint distribution from different sources
The probability distribution under reasonable assumption is the posterior distribution of scores given a query
The posterior distribution is modeled as a Gaussian mixture
The genuine and imposter match scores are assumed to be identically distributed
score densityscore density
The posterior distribution is modeled as a Gaussian mixture model.The model is built for both genuine match distribution and imposter distribution
Models are learnt from training data.
The algorithms is
The query is assigned an identity of n0 only if
The algorithms is
Which simplifies to
65

ResultsResults
DataSetsBiometrics: NIST Dataset consisting of match scores of right and left index fingerand left index fingerBiographical : Electoral records of citizens in an emerging economy
Consists of Names and AddressTotal of 6000 people were associated with the biometrics and the biographical data.Here M = 4, 2: Biometric, 2: Biographical (Name & Address)
Experimental SetupHalf of the dataset was used for training the probability
Accuracy for different modalities
densities for both the imposter and genuine match score distribution was estimatedThe number of Gaussians components was 5The remaining records was used for testing.
E i t l R ltExperimental Results.Score is fused using a joint distribution from these four different sourcesThe name modality has the lowest accuracy where the biometric modality has high accuracy
Identification accuracy for fusion of modalitiesbiometric modality has high accuracyThe fused accuracy is much higher than the individual localitiesThe accuracy increases when all the modalities are combined thus validating the usefulness of fusion
66

Social listening for monitoring the Philippine general elections 2013
• Online and offline analysis of social media messages around election debates and election chatter for ABS‐CBN TV Channel
• Analysis of English and Filipino chatter to determine buzz and reaction on candidates, campaigns, parties, topics and eventscampaigns, parties, topics and events
• Analysis of over 6 million election related Twitter and Facebook posts
• Comparison with Pulse Asia Election Survey Mar 13Real time and offline monitoring of social
POE, GRACE
35%40%45%50%
gmedia conversations about parties and candidates
VILLANUEVA, BRO.EDDIE (BP)VILLAR,CYNTHIA HANEPBUHAY (NP)
ZUBIRI, MIGZ (UNA)
Positive and negative sentiments for candidates
0%5%
10%15%20%25%30%35%
LEGARDA, LOREN (NPC)LLASOS, MARWIL (KPTRAN)
MACEDA, MANONG ERNIE (UNA)MADRIGAL, JAMBY (LP)
MAGSAYSAY, MITOS (UNA)MAGSAYSAY, RAMON JR. (LP)
PENSON, RICARDOPOE, GRACE
SEÑERES, CHRISTIAN (DPP)TRILLANES, ANTONIO IV (NP)
0% Mar 08 Mar 09 Mar 10 Mar 11 Mar 12 Mar 13 Mar 14
Grace Poe released her TV ad which drew flak from viewers. This was also the time that 3 candidates (Legarda Poe Escudero) of the
COJUANGCO, TINGTING (UNA)DAVID, LITO (KPTRAN)
DELOS REYES,JC (KPTRAN)EJERCITO ESTRADA, JV (UNA)ENRILE, JUAN PONCE JR.(NPC)
ESCUDERO, CHIZFALCONE, BAL (DPP)
HAGEDORN, EDHONASAN, GRINGO (UNA)
HONTIVEROS, RISA (AKBAYAN)( )candidates (Legarda, Poe, Escudero) of the
Liberal Party who were also "guest" candidates of UNA were dropped by UNA as the President forbade them to attend UNA's soirees. Escudero felt really, really bad about being dropped by UNA (l d b f id E d ) G
0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% 70.00% 80.00% 90.00% 100.00%
ALCANTARA, SAMSON (SJS)ANGARA, EDGARDO (LDP)
AQUINO, BENIGNO BAM (LP)BELGICA, GRECO (DPP)
BINAY, NANCY (UNA)CASIÑO, TEDDY
CAYETANO, ALAN PETER (NP), ( )
UNA (led by former president Estrada). Grace Poe offered to mediate between Escudero and Estrada.
67
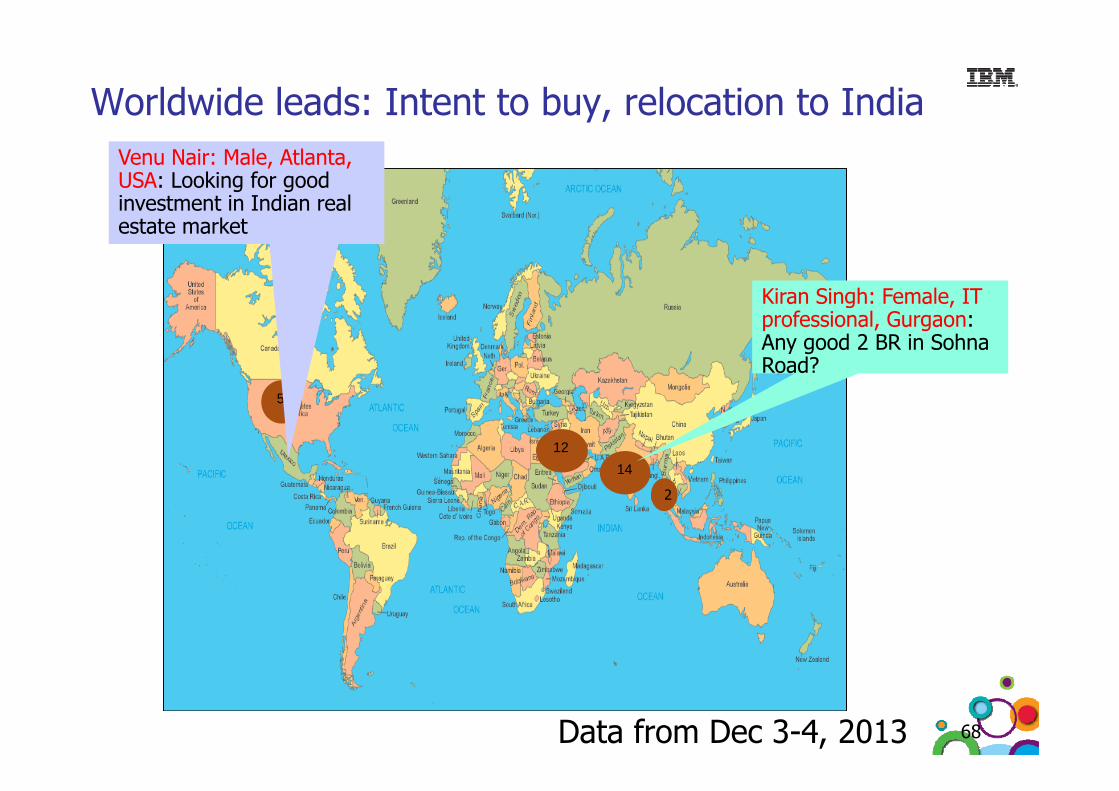
Worldwide leads: Intent to buy, relocation to IndiaVenu Nair: Male, Atlanta, USA: Looking for good investment in Indian real
Kiran Singh: Female, IT
estate market
5
g ,professional, Gurgaon: Any good 2 BR in SohnaRoad?
14
5
12
2
Data from Dec 3-4, 2013 68
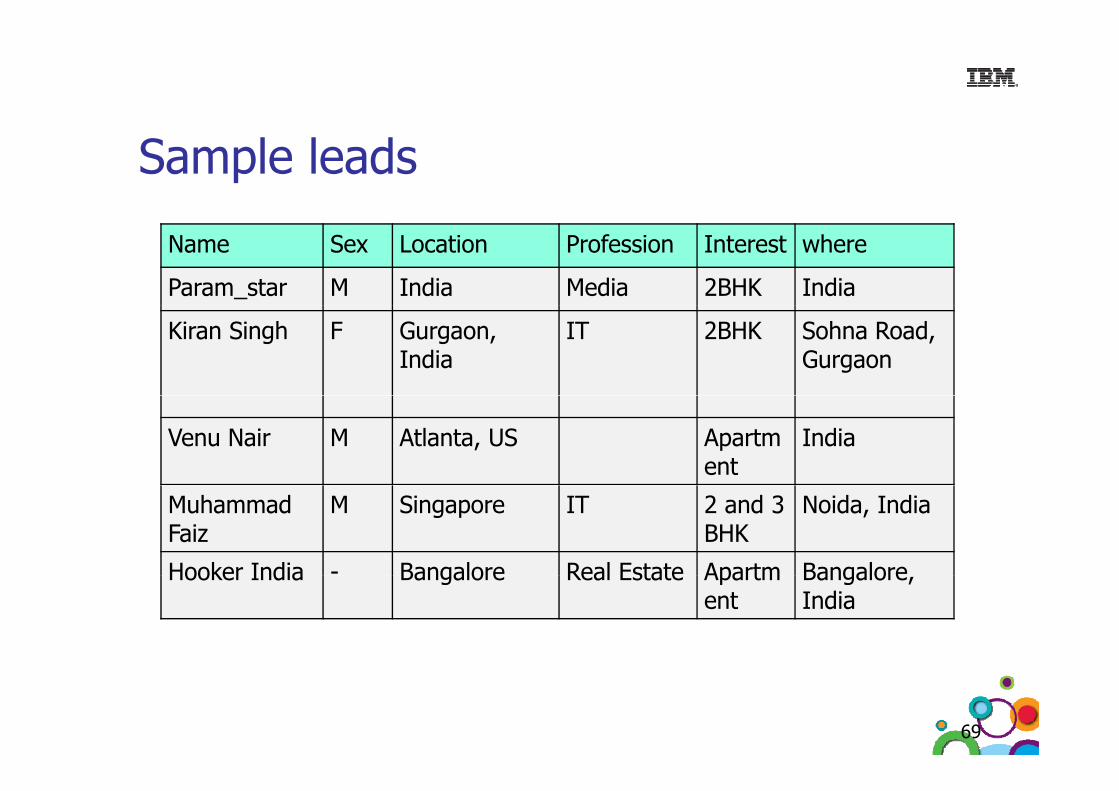
Sample leads
Name Sex Location Profession Interest where
Param_star M India Media 2BHK India
Kiran Singh F Gurgaon,India
IT 2BHK Sohna Road, Gurgaon
Venu Nair M Atlanta, US Apartment
India
Muhammad Faiz
M Singapore IT 2 and 3 BHK
Noida, India
Hooker India - Bangalore Real Estate Apartm BangaloreHooker India Bangalore Real Estate Apartment
Bangalore, India
69
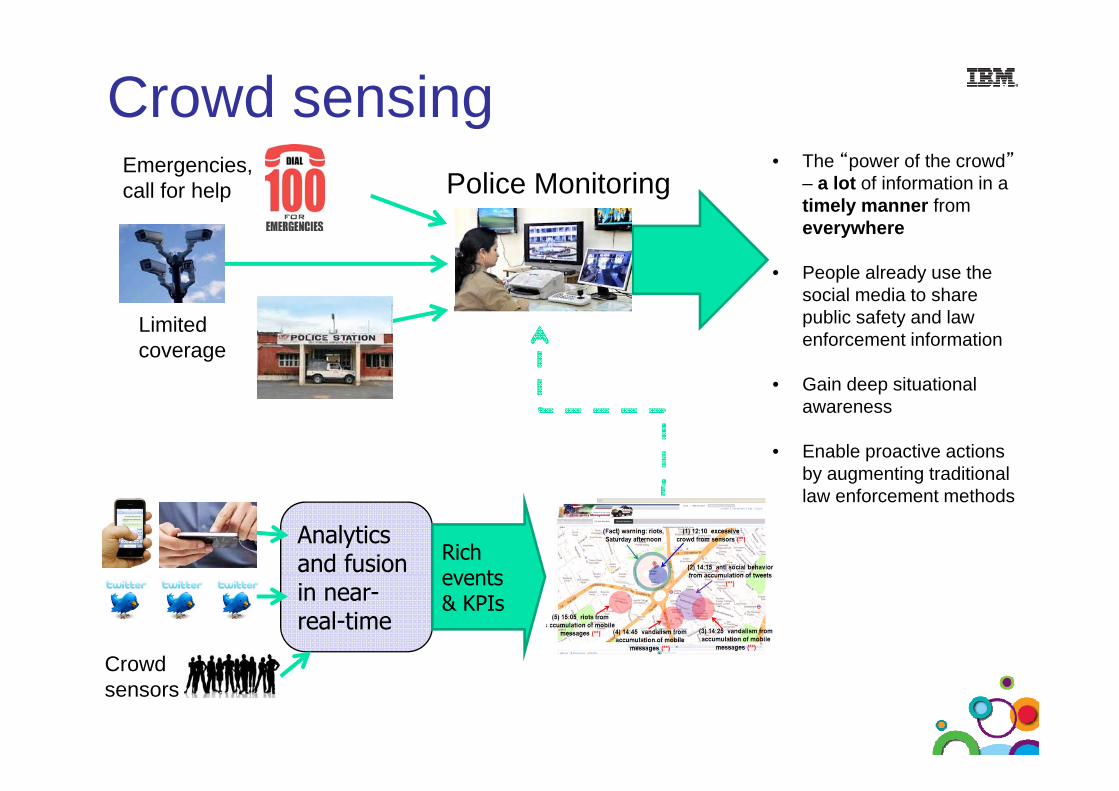
Crowd sensinggPolice Monitoring
Emergencies, call for help
• The “power of the crowd”– a lot of information in a timely manner from everywhere
• People already use the social media to share
Limited coverage
public safety and law enforcement information
• Gain deep situational awareness
• Enable proactive actions by augmenting traditional
Analytics and fusion Rich
events
law enforcement methods
in near-real-time
events & KPIs
Crowd70
Crowd sensors

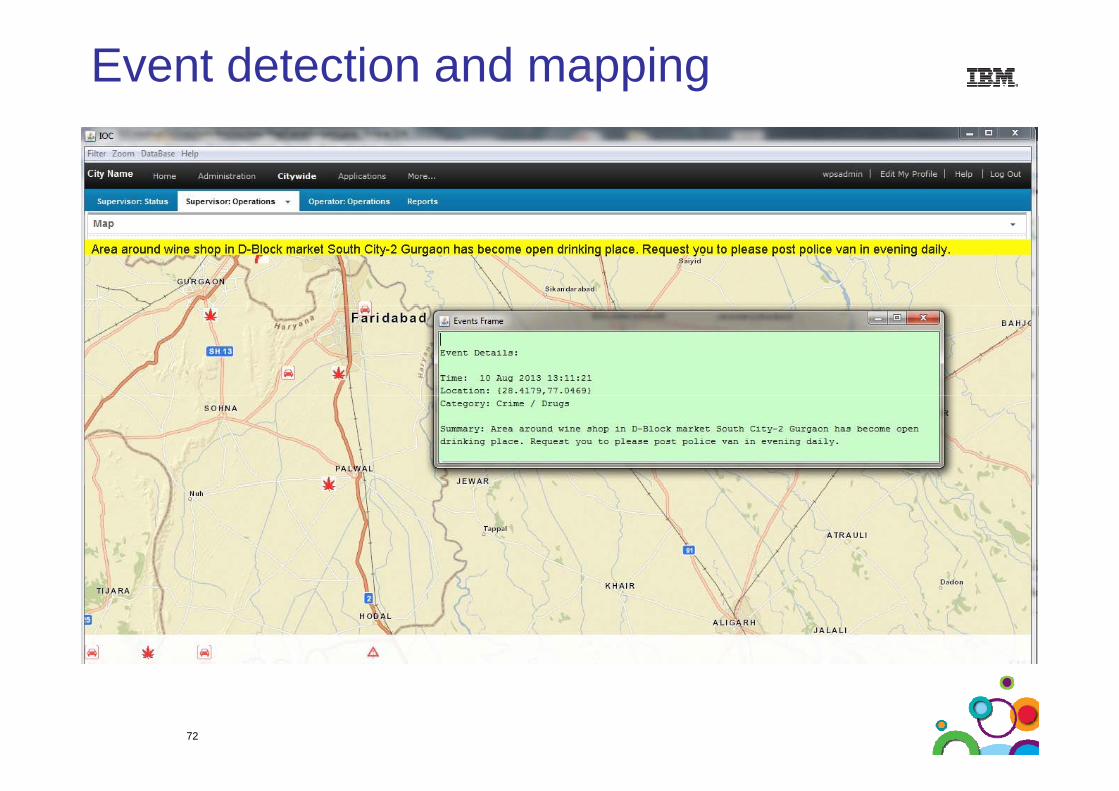
Drinking in the OpenDrinking in the OpenCome to South City 2, in evening, its a regular scene there since last 4 years, people drink in open and food is served by restaurants in their carscarskhandsa road per sunrise hospital se aage tekho ke pass rehari waalesharab pilaate hai, jinki wajah se waha aane jaane wale log pareshaanho rahe hai even shaam ko to PCR ka bhi unhe darr ni hai kirpaho rahe hai, even shaam ko to PCR ka bhi unhe darr ni hai, kirpakarke inhe waha se hataiya Gurgaon PoliceI also have a complaint to register. We have an alcohal drinking menace in front of our commercial complex anand ganga comlex atmenace in front of our commercial complex, anand ganga comlex, at sohna chowk, on the main road.
Police HarassmentThese two Constables (Davinder Singh & his Colleague) were at their worst behaviour...when they found all documents ok in the Car. I couldn't understand the reason for harrasment...opp
Wrong Parkingthis is the main way from sadar bazar to bhuteshwar mandir. I dntthink y this road exist. It is the best place to park vehicles both the way y p p yare used to park vehicles no action have been taken from years. I think HUDA or MCG is not serious abt matter.
71
Event detection and mapping
72

ConclusionsNoise is an unavoidable fact of real life communication
C i ti t f h ti bCommunication meant for human consumption can be noisy for computers and vice versa
Due to ubiquitous sensors (GPS, Accelerometer), easy of use apps (Facebook, Twitter, YouTube), and higher internet connectivity, the key characteristics of raw data is changing.
This new data can be characterized by 4Vs Volume,This new data can be characterized by 4Vs Volume, Velocity, Variety and Veracity
For example, during a Football match, some people will Tweet about Goals Penalties etc while in addition there may be otherabout Goals, Penalties, etc. while in addition there may be other reports in news channels. The data describes the same event
Fusion should create a single object representationDifferent sources may have different reliability and it is necessary to account for this fact to avoid decreasing in performance of fusion results
73
pReliability and context should be taken into account during fusion

Conclusions
Noise can be defined as any kind of difference in the surfaceNoise can be defined as any kind of difference in the surface form of an electronic text from the intended, correct or original text
N i b i h f f i i f i iNoise can be in the form of errors arising from uncertainty in language and communication and recognition errors
74
Recommended


















