Anatomy of Data Frame API
A deep dive into the Spark Data Frame API
https://github.com/phatak-dev/anatomy_of_spark_dataframe_api

● Madhukara Phatak
● Big data consultant and trainer at datamantra.io
● Consult in Hadoop, Spark and Scala
● www.madhukaraphatak.com

Agenda
● Spark SQL library● Dataframe abstraction● Pig/Hive pipleline vs SparkSQL● Logical plan● Optimizer● Different steps in Query analysis

Spark SQL library● Data source API
Universal API for Loading/ Saving structured data● DataFrame API
Higher level representation for structured data● SQL interpreter and optimizer
Express data transformation in SQL● SQL service
Hive thrift server

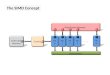
Architecture of Spark SQL
CSV JSON JDBC
Data Source API
Data Frame API
Spark SQL and HQLDataframe DSL

DataFrame API● Single abstraction for representing structured data in
Spark● DataFrame = RDD + Schema (aka SchemaRDD)● All data source API’s return DataFrame● Introduced in 1.3● Inspired from R and Python panda● .rdd to convert to RDD representation resulting in RDD
[Row]● Support for DataFrame DSL in Spark

Need for new abstraction● Single abstraction for structured data
○ Ability to combine data from multiple sources○ Uniform access from all different language API’s○ Ability to support multiple DSL’s
● Familiar interface to Data scientists○ Same API as R/ Panda○ Easy to convert from R local data frame to Spark○ New 1.4 SparkR is built around it

Data Structure of structured world● Data Frame is a data structure to represent structured
data, whereas RDD is a data structure for unstructured data
● Having single data structure allows to build multiple DSL’s targeting different developers
● All DSL’s will be using same optimizer and code generator underneath
● Compare with Hadoop Pig and Hive

Pig and Hive pipeline
HiveQL
Hive parser
Optimizer
Executor
Hive queries
Logical Plan
Optimized Logical Plan(M/R plan)
Physical Plan
Pig latin
Pig parser
Optimizer
Executor
Pig latin script
Logical Plan
Optimized Logical Plan(M/R plan)
Physical Plan

Issue with Pig and Hive flow● Pig and hive shares a lot similar steps but independent
of each other● Each project implements it’s own optimizer and
executor which prevents benefiting from each other’s work
● There is no common data structure on which we can build both Pig and Hive dialects
● Optimizer is not flexible to accommodate multiple DSL’s● Lot of duplicate effort and poor interoperability

Spark SQL pipeline HiveQL
Hive parser
Hive queries
SparkQL
SparkSQL Parser
Spark SQL queries
Dataframe DSL
DataFrame
Catalyst
Spark RDD code

Spark SQL flow● Multiple DSL’s share same optimizer and executor● All DSL’s ultimately generate Dataframes● Catalyst is a new optimizer built from ground up for
Spark which is rule based framework● Catalyst allows developers to plug custom rules specific
to their DSL● You can plug your own DSL too!!

What is a data frame?● Data frame is a container for Logical Plan● Logical Plan is a tree which represents data and
schema ● Every transformation is represented as tree
manipulation● These trees are manipulated and optimized by catalyst
rules● Logical plan will be converted to physical plan for
execution

Explain Command● Explain command on dataframe allows us look at these
plans● There are three types of logical plans
○ Parsed logical plan○ Analysed Logical Plan○ Optimized logical Plan
● Explain also shows Physical plan● DataFrameExample.scala

Filter example● In last example, all plans looked same as there were no
dataframe operations● In this example, we are going to apply two filters on the
data frame● Observe generated optimized plan● Example : FilterExampleTree.scala

Optimized Plan● Optimized plan normally allows spark to plug in set of
optimization rules ● In our example, When multiple filters are added, spark
&& them for better performance● Even developer can plug in his/her own rules to
optimizer

Accessing Plan trees● Every dataframe is attached with queryExecution object
which allows us to access these plans individually.● We can access plans as follows
○ parsed plan - queryExecution.logical○ Analysed - queryExecution.analyzed○ Optimized - queryExecution.optimizedPlan
● numberedTreeString on the plan allows us to see the hierarchy
● Example : FilterExampleTree.scala

Filter tree representation
02 LogicalRDD [c1#0,c2#1,c3#2,c4#3]
01 Filter NOT (CAST(c1#0, DoubleType) = CAST(0, DoubleType))
00 Filter NOT (CAST(c2#0, DoubleType) = CAST(0, DoubleType))
02 LogicalRDD [c1#0,c2#1,c3#2,c4#3]
Filter (NOT (CAST(c1#0, DoubleType) = 0.0) && NOT (CAST(c2#1, DoubleType) = 0.0))

Manipulating Trees● Every optimization in spark-sql is implemented as a tree
or logical transformation● Series of these transformation allows for modular
optimizer● All tree manipulations are done using scala case class● As developer we can write these manipulations too● Let’s create an OR filter rather than and● OrFilter.scala

Understanding steps in plan ● Logical plan goes through series of rules to resolve and
optimize plan● Each plan is a Tree manipulation we seen before● We can apply series of rules to see how a given plan
evolves over time● This understanding allows us to understand how to
tweak given query for better performance● Ex : StepsInQueryPlanning.scala

Query
select a.customerId from ( select customerId , amountPaid as amount from sales where 1 = '1') a where amount=500.0

Parsed Plan● This is plan generated after parsing the DSL● Normally these plans generated by the specific parsers
like HiveQL parser, Dataframe DSL parser etc● Usually they recognize the different transformations and
represent them in the tree nodes● It’s a straightforward translation without much tweaking ● This will be fed to analyser to generate analysed plan

Parsed Logical Plan
UnResolvedRelationSales
`Filter(1 = 1)
`Projection'customerId,'amountPaid
`SubQuerya
`Filter(amount = 500)
`Projecta.customerId

Analyzed plan● We use sqlContext.analyser access the rules to
generate analyzed plan● These rules has to be run in sequence to resolve
different entities in the logical plan● Different entities to be resolved is
○ Relations ( aka Table)○ References Ex : Subquery, aliases etc○ Data type casting

ResolveRelations Rule● This rule resolves all the relations ( tables) specified in
the plan
● Whenever it finds a new unresolved relation, it consults catalyst aka registerTempTable list
● Once it finds the relation, it resolves that with actual relationship

Resolved Relation Logical Plan
JsonRelation Sales[amountPaid..]
Filter(1 = 1)
`Projection'customerId,'amountPaid
`SubQuerya
`Filter(amount = 500)
`Projecta.customerId
SubQuery - salesUnResolvedRelation
Sales
`Filter(1 = 1)
`Projection'customerId,'amountPaid
`SubQuerya
`Filter(amount = 500)
`Projecta.customerId

ResolveReferences● This rule resolves all the references in the Plan
● All aliases and column names get a unique number which allows parser to locate them irrespective of their position
● This unique numbering allows subqueries to removed for better optimization

Resolved References Plan
JsonRelation Sales[amountPaid#0..]
`Filter(1 = 1)
ProjectioncustomerId#1L,amountPaid#0
SubQuerya
Filter(amount#4 = 500)
ProjectcustomerId#1L
SubQuery - sales
JsonRelation Sales[amountPaid..]
`Filter(1 = 1)
`Projection'customerId,'amountPaid
`SubQuerya
`Filter(amount = 500)
`Projecta.customerId
SubQuery - sales

PromoteString● This rule allows analyser to promote string to right data
types
● In our query, Filter( 1=’1’) we are comparing a double with string
● This rule puts a cast from string to double to have the right semantics

Promote String Plan
JsonRelation Sales[amountPaid#0..]
`Filter(1 = CAST(1, DoubleType))
ProjectioncustomerId#1L,amountPaid#0
SubQuerya
Filter(amount#4 = 500)
ProjectcustomerId#1L
SubQuery - sales
JsonRelation Sales[amountPaid#0..]
`Filter(1 = 1)
ProjectioncustomerId#1L,amountPaid#0
SubQuerya
Filter(amount#4 = 500)
ProjectcustomerId#1L
SubQuery - sales

Optimize

Eliminate Subqueries● This rule allows analyser to eliminate superfluous sub
queries
● This is possible as we have unique identifier for each of the references
● Removal of sub queries allows us to do advanced optimization in subsequent steps

Eliminate subqueries
JsonRelation Sales[amountPaid#0..]
`Filter(1 = CAST(1, DoubleType))
ProjectioncustomerId#1L,amountPaid#0
Filter(amount#4 = 500)
ProjectcustomerId#1L
JsonRelation Sales[amountPaid#0..]
`Filter(1 = CAST(1, DoubleType))
ProjectioncustomerId#1L,amountPaid#0
SubQuerya
Filter(amount#4 = 500)
ProjectcustomerId#1L
SubQuery - sales

Constant Folding● Simplifies expressions which result in constant values
● In our plan, Filter(1=1) always results in true
● So constant folding replaces it in true

ConstantFoldingPlan
JsonRelation Sales[amountPaid#0..]
`FilterTrue
ProjectioncustomerId#1L,amountPaid#0
Filter(amount#4 = 500)
ProjectcustomerId#1L
JsonRelation Sales[amountPaid#0..]
`Filter(1 = CAST(1, DoubleType))
ProjectioncustomerId#1L,amountPaid#0
Filter(amount#4 = 500)
ProjectcustomerId#1L

Simplify Filters● This rule simplifies filters by
○ Removes always true filters○ Removes entire plan subtree if filter is false
● In our query, the true Filter will be removed
● By simplifying filters, we can avoid multiple iterations on data

Simplify Filter Plan
JsonRelation Sales[amountPaid#0..]
ProjectioncustomerId#1L,amountPaid#0
Filter(amount#4 = 500)
ProjectcustomerId#1L
JsonRelation Sales[amountPaid#0..]
`FilterTrue
ProjectioncustomerId#1L,amountPaid#0
Filter(amount#4 = 500)
ProjectcustomerId#1L

PushPredicateThroughFilter● It’s always good to have filters near to the data source for better optimizations ● This rules pushes the filters near to the JsonRelation● When we rearrange the tree nodes, we need to make
sure we rewrite the rule match the aliases● In our example, the filter rule is rewritten to use alias
amountPaid rather than amount

PushPredicateThroughFilter Plan
JsonRelation Sales[amountPaid#0..]
Filter(amountPaid#0 = 500)
ProjectioncustomerId#1L,amountPaid#0
ProjectcustomerId#1L
JsonRelation Sales[amountPaid#0..]
ProjectioncustomerId#1L,amountPaid#0
Filter(amount#4 = 500)
ProjectcustomerId#1L

Project Collapsing● Removes unnecessary projects from the plan● In our plan , we don’t need second projection, i.e
customerId, amount Paid as we only require one projection i.e customerId
● So we can get rid of the second projection● This gives us most optimized plan

Project Collapsing Plan
JsonRelation Sales[amountPaid#0..]
Filter(amountPaid#0 = 500)
ProjectioncustomerId#1L,amountPaid#0
ProjectcustomerId#1L
JsonRelation Sales[amountPaid#0..]
Filter(amountPaid#0 = 500)
ProjectcustomerId#1L

Generating Physical Plan● Catalyser can take a logical plan and turn into a
physical plan or Spark plan● On queryExecutor, we have a plan called executedPlan
which gives us physical plan● On physical plan, we can call executeCollect or
executeTake to start evaluating the plan

References● https://www.youtube.com/watch?v=GQSNJAzxOr8
● https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html
● http://spark.apache.org/sql/
Recommended