
Algorithms for Bioinformatics– Introductory lectureVELI MÄKINEN, AUTUMN 2019
HTTPS://COURSES.HELSINKI.FI/FI/LSI31001/130408680

Course formatVideo lecture -> Friday lecture -> Monday study group->Thursday exercises
◦ First week a special case: ◦ Thursday python crash course, introduction to Rosalind
◦ Friday (this lecture)
◦ Video lecture + other material
◦ Monday study group
Grading:◦ To pass, you need to attend all study groups:
◦ Check course moodle for compensatory assignments
◦ Exercises 12 points (30% ⇒ 1, 85% ⇒ 12)
◦ Exam 48 points (to take part, you need at least 1 point from exercises)
◦ Total points 30 ⇒ 1, ∼ 50 ⇒ 5
Lectures and study groups are given by Veli Mäkinen (parts 0-2), Leena Salmela (parts 3-4), and Jarkko Toivonen (part 5). Exercises are given by Jarkko Toivonen (parts 0-4) and Veli Mäkinen (part 5).

Course overviewIntroduction to algorithms in the context of molecular biology
Targeted for ◦ first year bioinformatics students
◦ biology and medicine students
◦ CS / Math / Statistics students thinking of specializing in bioinformatics
Some programming skills and high school level biology are sufficient background◦ We will use Python in this course (no advanced features)
◦ Central dogma of molecular biology will be covered in Monday study group
Not as systematic as other CS algorithm courses: emphasis is on learning some design principles and techniques with the biological realm as motivation

Algorithms for BioinformaticsState-of-the-art algorithms in bioinformatics are rather involved
Instead, we study toy problems motivated by biology (but not too far from reality) that have clean and introductory level algorithmic solutions
The goal is to arouse interest to study the real advanced algorithms in bioinformatics!
We mostly avoid statistical notions to give algorithmic concepts the priority
Continue to further bioinformatics courses to learn the practical realm

AlgorithmWell-defined problem Solution to problem
input output
Homework: Find out what the following algorithm running time notions mean:
Number of steps: f(size of input)
…

Algorithms in BioinformaticsWeakly defined problem Solution to problem
input output=input2 output2=… outputN
Reasons: Biological problems usually too complex to admit a simple algorithmic formulation
Problem modeling sometimes leads to statistical notions
Problematic for CS theory: Optimal solutions to subproblems do not necessarily lead to best global solution

Algorithms in BioinformaticsPlenty of important subproblems where algorithmic techniques have been vital:
◦ Fragment assembly⇒ human genome
◦ Design of microarrays⇒ gene expression measurements
◦ Sequence comparison⇒ comparative genomics
◦ Phylogenetic tree construction⇒ evolution modeling
◦ Genome rearrangements ⇒ comparative genomics, evolution
◦ Motif finding ⇒ gene regulatory mechanism
◦ Biomolecular secondary structure prediction ⇒ function
◦ Analysis of high-throughput sequencing data ⇒ genomic variations in populations

Course contentPart 0: Getting familiar with biological sequences using Python
Part 1: Exhaustive search and randomized algorithms for motif discovery
Part 2: Graph Algorithms for Genome Assembly
Part 3: Dynamic Programming and Sequence Alignment
Part 4: Combinatorial Algorithms and Genomic Rearrangements
Part 5: Combinatorial Pattern Matching
Exam: Friday 18.10
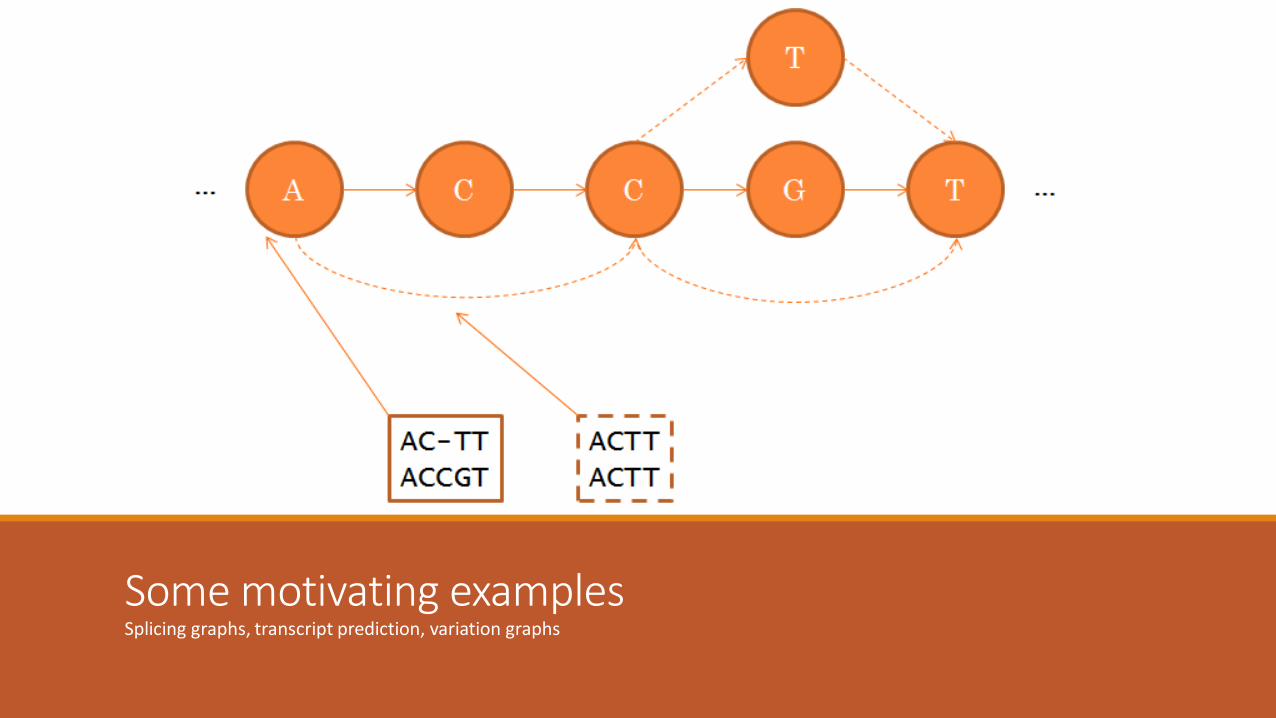
Some motivating examplesSplicing graphs, transcript prediction, variation graphs
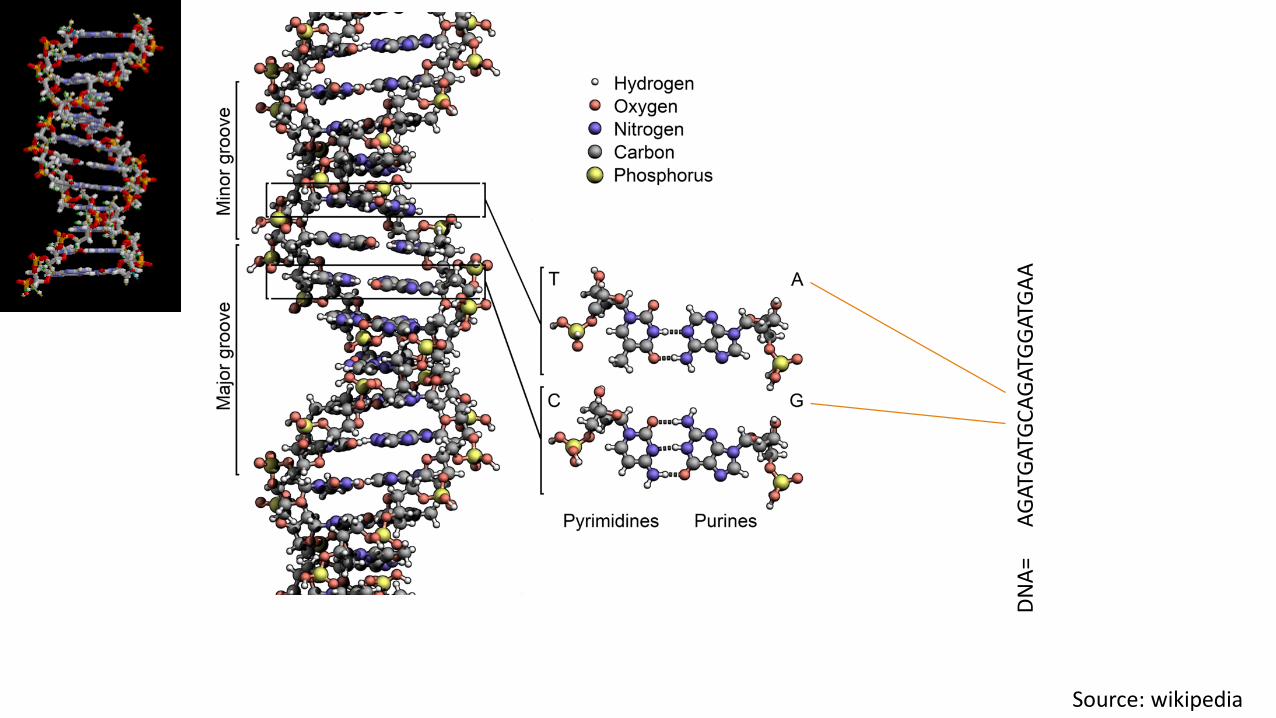
AG
ATG
ATG
CA
GAT
GG
ATG
AA
Source: wikipedia
DN
A=
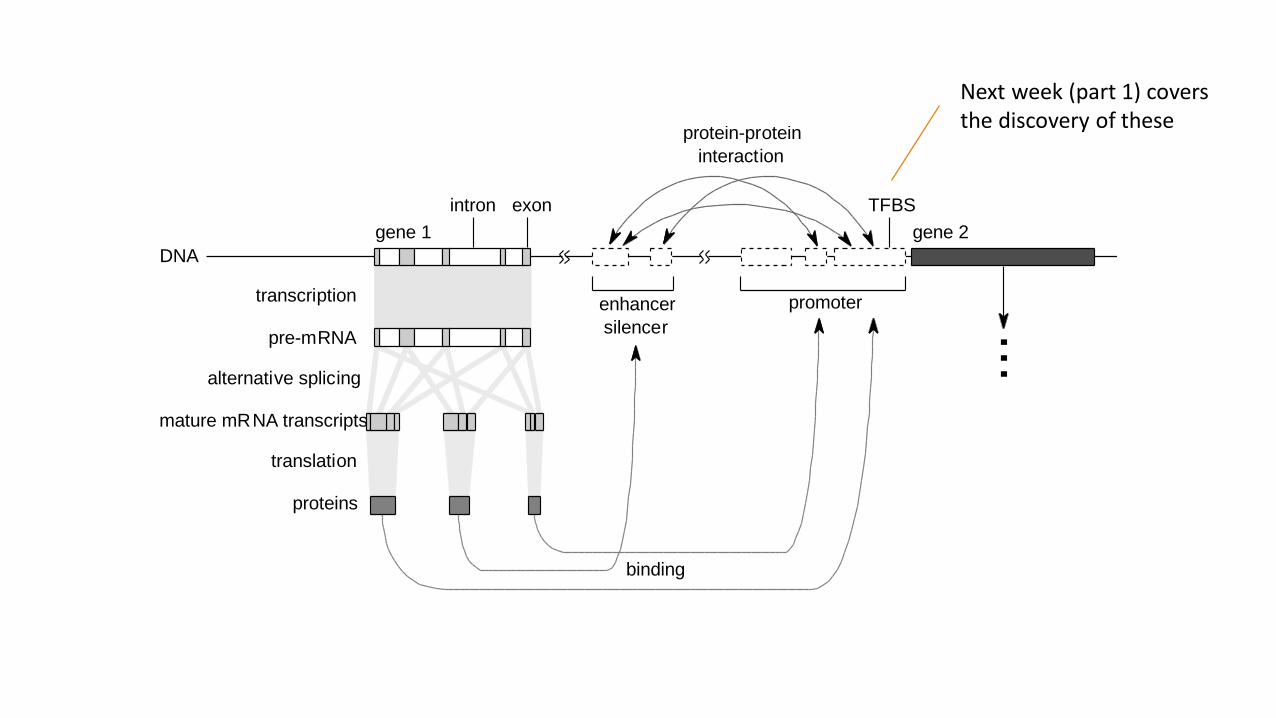
DNA
transcription
binding
promoterenhancer
silencer
protein-protein
interaction
gene 1
pre-mRNA
mature mRNA transcripts
intron exon
alternative splicing
translation
proteins
TFBS
gene 2
...
Next week (part 1) coversthe discovery of these

TranscriptomicsStudy of RNA biology
genome
Transcription, alternative splicing
1203x
gene
87x
234xHow to measure these?
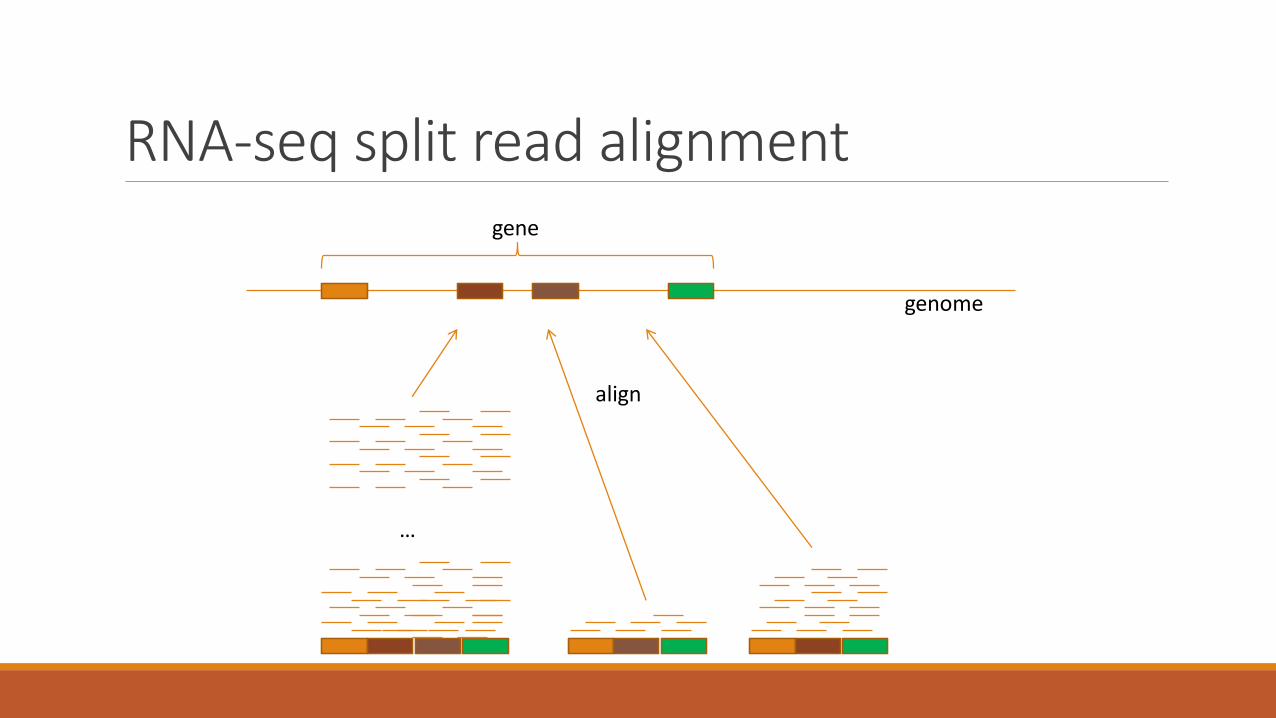
RNA-seq split read alignment
genome
…
align
gene
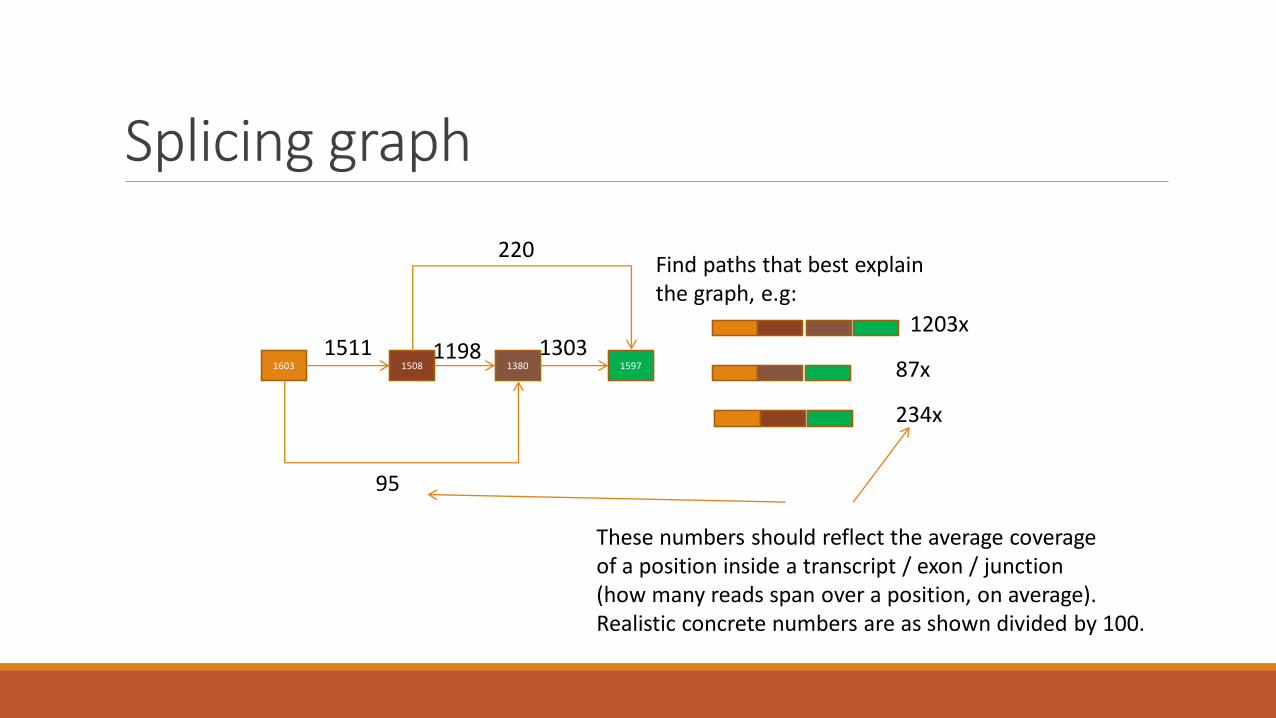
Splicing graph
1603 1508 1380 1597
95
1511
220
1198 13031203x
87x
234x
Find paths that best explainthe graph, e.g:
These numbers should reflect the average coverageof a position inside a transcript / exon / junction(how many reads span over a position, on average).Realistic concrete numbers are as shown divided by 100.

Annotated transcript expressionestimation
1603 1508 1380 1597
95
1511
220
1198 1303?x
?x
?x
Assume we know the possible transcriptsbut their relative abundancies are unknown
a
b
c
(1603-(a+b+c))2+(95-b) 2 +(1511-(a+c)) 2 +(1508-(a+c)) 2 +(220-c) 2 +(1198-a) 2 +(1380-(a+b)) 2 +(1303-(a+b)) 2 +(1597-(a+b+c)) 2
f(a,b,c)=Least squares problem:
Minimize

Least squares problemf(a,b,c) receives minimum when all partial derivates of f are zero.
f’a(a,b,c) = 2(a+b+c-1603)+ 2(a+c-1511) +2(a+c-1508) + 2(a-1198) + 2(a+b-1380) +2(a+b-1303) + 2(a+b+c-1597)
f’b(a,b,c) = 2(a+b+c-1603)+ 2(b-95) +2(a+b-1380) +2(a+b-1303) + 2(a+b+c-1597)
f’c(a,b,c) = 2(a+b+c-1603) + 2(a+c-1511) +2(a+c-1508) + 2(c-220) + 2(a+b+c-1597)
7a+4b+4c=101004a+5b+2c=59784a+2b+5c=6439 This system has a unique solution, which is
{ a = 21032/17, b = 5260/51, c = 13097/51 }.
Google: linear equations solver, click first link, copy-paste, click ”solve the system”, copy-paste the result

Solution
1603 1508 1380 1597
95
1511
220
1198 13031237 x
103 x
257 x
a
b
c

Splicing graphs and this courseWe need a way to align short DNA fragments on the genome, allowing splicing.
We will cover basic principles of such alignment algorithms (part 3) and take a look at data structures that enable fast pattern matching (part 5).
More on advanced alignment algorithms:◦ Biological Sequence Analysis, period III, Spring 2020.

What if there is no genome available?
…
align???
gene

One can exploit read overlaps (part 2)
…
align
gene

Genome rearrangements
1 2 3 4
1 234
Species A with 4 genes
Species B with 4 genes
During evolution, some chromosome level rearrangements happen
These can be modeled using signed permutations
We will cover some basic algorithms (part 4).
More on evolution related algorithms in the new course Elements of Bioinformatics, Autumn 2020.

Pan-genomics1000 Genomes Project and other high-throughput sequencing based projects have gathered a huge catalogue of human variation.
Such datasets can be represented as variation graphs
Alignment algorithms need to be revisited to work on graphs
More on this next Spring: Biological Sequence Analysis
Recommended

















