
Algorithms and Data Structures
Objectives: To review the fundamental algorithms and data structures that are commonly used in programs. To see how to use and implement these algorithms and data structures in different languages and to see what language and library support exists for them.

Topics
Arrays and VectorsListsLinear/Binary SearchQuicksortHash Tables - DictionariesC, C++, Java, Perl

Arrays
Sequence of itemsIndexable (can refer to any element immediately, by its index number)(Conceptually) contiguous chunks of memory
0 51 2 3 4 6

Arrays
Access: constant-time (θ(1))Searching: Sorted array - θ(lg(n)) Unsorted - θ(n)
Inserting/removing Unordered - θ(1)
(Add to end, or swap last guy w/deleted guy) Ordered - θ(n)
Need to make (or fill in) a hole, move n/2 elements (on average) to maintain relative order

Resizing Arrays
If the number of elements in an array is not known ahead of time it may be necessary to resize the array.Involves dynamic memory allocation and copyingTo minimize the cost it is best to resize in chunks (some factor of its current size)

Libraries - Arrays
Arrays (lists) in Perl, Bash, Python, Awk, resize automatically, as do C++ vectors, and the Array in JavaThis does not mean that it is free. Depending on the task, what goes on underneath the hood may be importantWe shall create our own machinery in C

Some C memory things…void* malloc(int n) – allocates n contiguous bytes from heap, returns address of first byte (NULL if it failed)free( void* p ) – returns memory addressed by p to the heap (does nothing to p itself)void* memmove( void* d, void* s, size_t n ) – moves n bytes from s to (possibly overlaping region at) dvoid* memcpy( void* d, void* s, size_t n ) – copies n bytes from s to (non-overlaping region at) dsizeof() – actually an operator, returns size, in bytes, of given object or typevoid* realloc( void* src, size_t n ) – attempts to resize array for you, and copy the stuff over. Returns ptr to new location (might be the same), NULL if it fails.

Growing Arrays in Cenum { INIT_SIZE=1, GROW_FACTOR=2 };
int curr_size = INIT_SIZE;
int nr_elems = 0; /* # of useful elements */
int *a = (int*)malloc( INIT_SIZE * sizeof( int ));
… /* some stuff here */
/* attempt to insert 24 */
if( nr_elems >= curr_size ) { /* need to grow */
int *t = realloc( a, curr_size*GROW_FACTOR*sizeof( int ))
if( t != NULL ) { /* success! */
curr_size *= GROW_FACTOR;
a = t;
a[nr_elems++] = 24;
}
else
/* FAILURE! */
}

Lists
A sequence of elementsNot indexable (immediately)Space is allocate for each new element and consecutive elements are linked together with a pointer.Note, though, that the middle can be modified in constant time.
data 1 data 2 data 3
NULL
data 4
head

Lists
Access (same as searching) – linear, θ(n)Modifying anywhere – constant time, θ(1)θ(1) time to insert at front, θ(n) to append unless pointer to last element kept

Lists in Python
The list-type in Python is really an array (I think. Somebody experiment? How would you?).We can make a linked-list in a very LISP way; build it out of simple pairs 1st element – the data at that node 2nd element – the rest of the list

Lists in PythonL = []
# add 24 to front
L = [ 24, L ]
print L
# add 3 to the front
L = [ 3, L ]
print L
Would output:[ 24, [] ]
[ 3, [ 24, [] ]]
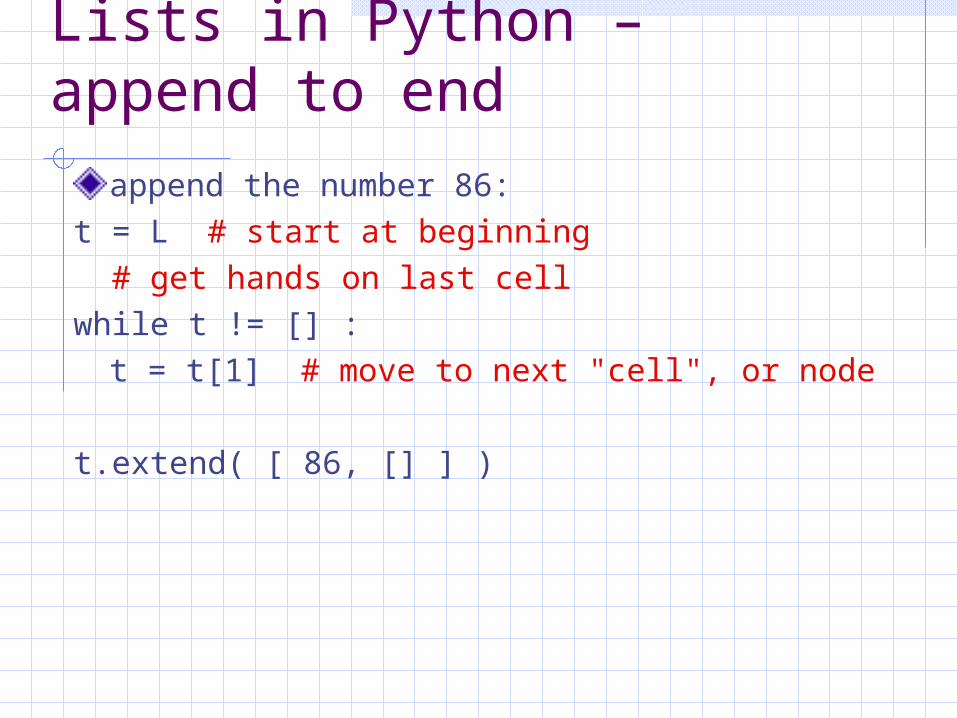
Lists in Python – append to end
append the number 86:t = L # start at beginning
# get hands on last cell
while t != [] :
t = t[1] # move to next "cell", or node
t.extend( [ 86, [] ] )

Lists in Python – searching
def search( L, t ) :
"""Return cell of L that contains t,
None if not found"""
while L != [] :
if L[0] == t :
return L
L = L[1] # move to next "cell"
return None # didn't find it

Apply function to elements
def apply( l, fn ) :
while l != [] :
fn( l )
l = l[1]
fn is any function that takes a single cell, does something

Lists in Python – apply
Print list:def printCell( cell ) :
print cell[0],
apply( L, printCell )
Add 2 to each element in list:def add2( cell ) :
cell[0] += 2
apply( L, add2 )

Lists in Ctypedef struct sNode sNode;struct sNode { /* a node (cell) in a singly-link list */
int data; /* the payload */sNode* next; /* next node in list */
};
/* newitem: create new item from name and value */sNode* newNode( int d ) {
sNode *newp;newp = (sNode*) malloc( sizeof( sNode ));if( newp != NULL ) {
newp->data = d;newp->next = NULL;
}return newp;
}

Lists in C/* addfront: add newp to front of listp *
* return ptr to new list */
sNode* addfront( sNode *listp, sNode *newp )
{
newp->next=listp;
return newp;
}
list = addfront( list, newitem( 13 ));

Append Element to Back of List/* append: add newp to end of listp * * return ptr to new list */sNode* addend( sNode *listp, sNode *newp ){ sNode *p; if( listp == NULL ) return newp; for( p=listp; p->next!=NULL; p=p->next ) ; p->next = newp; return listp;}

Lookup Element in List/* lookup: linear search for t in listp *
* return ptr to node containing t, or NULL */
sNode* lookup( sNode *listp, int t )
{
for( ; listp != NULL; listp = listp->next )
if( listp->data = t )
return listp;
return NULL; /* no match */
}

Apply Function to Elements in List/* apply: execute fn for each element of listp */void apply( sNode *listp, void (*fn)(sNode ),
void* arg ){
for ( ; listp != NULL; listp = listp->next)(*fn)( listp, arg ); /* call the function */
}
void (*fn)( sNode* ) is a pointer to a void function of one argument – the first argument is a pointer to a sNode and the second is a generic pointer.

Print Elements of a List/* printnv: print name and value using format in
arg */
void printnv( sNode *p, void *arg )
{
char *fmt;
fmt = (char*) arg;
printf( fmt, p->data );
}
apply( list, printnv, “%d ” );

Count Elements of a List/* inccounter: increment counter *arg */void incCounter( sNode *p, void *arg ){ int *ip; /* p is unused – we were called,
there's a node */ ip = (int *) arg; (*ip)++;}
int n = 0;/* n is an int, &n is its address (a ptr) */
apply( list, inccounter, &n );printf( “%d elements in list\n”, n );

Free Elements in List/* freeall: free all elements of listp */void freeall( sNode *listp ){
sNode *next;for ( ; listp != NULL; listp = next) {
next = listp->next;free(listp)
}}
? for ( ; listp != NULL; listp = listp->next)? free( listp );

Delete Element in List/* delitem: delete first t from listp */sNode *delitem( sNode *listp, int t ) {
sNode *p, *prev = NULL;for( p=listp; p!=NULL; p=p->next ) {
if( p->data == t ) {if( prev == NULL ) /* front of list */
listp = p->next;else
prev->next = p->next;free(p);break;
}prev = p;
}return listp;}

Linear Search
Just exhaustively examine each elementWorks on any list (sorted or unsorted)Only search for a linked-listExamine each element in the collection, until you find what you seek, or you've examined every element Note that order of examination doesn't
matter
Need θ(n), worst and average
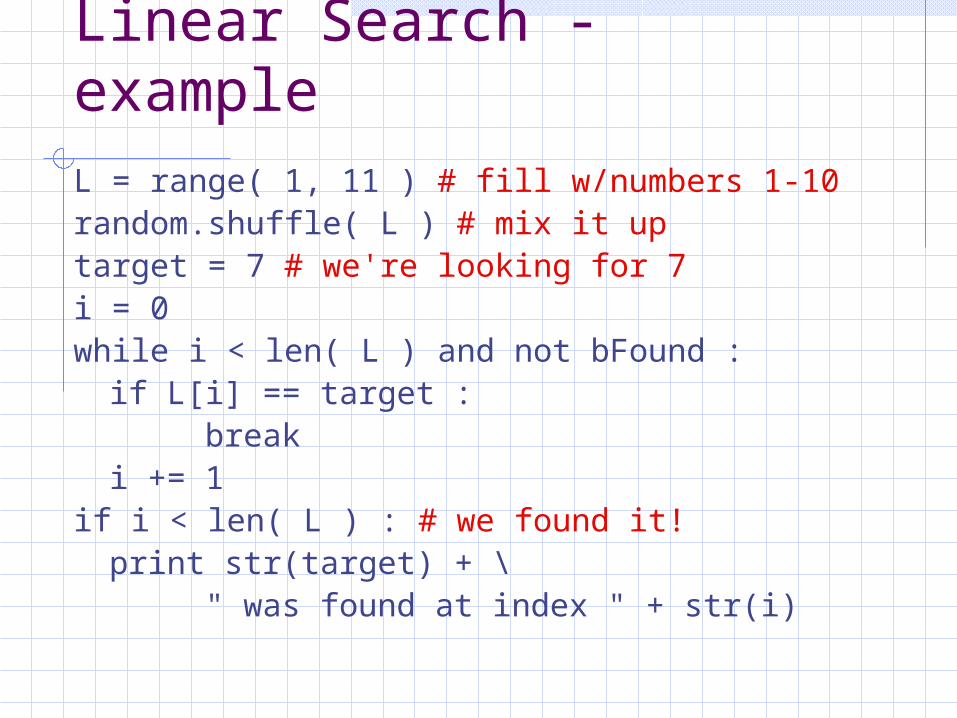
Linear Search - exampleL = range( 1, 11 ) # fill w/numbers 1-10random.shuffle( L ) # mix it uptarget = 7 # we're looking for 7i = 0while i < len( L ) and not bFound :if L[i] == target :
breaki += 1
if i < len( L ) : # we found it!print str(target) + \
" was found at index " + str(i)

Binary Search
Only works on sorted collectionsOnly works on indexed collections (arrays, vectors)Start in the middle: Find it?
Less than? Look in lower ½ Greater than? Look in upper ½
Cut search space in ½Need θ(lg(n)) time, worst (and avg.)

Binary Search# from previous exampleL.sort() # put into ordert = 7 # our targeti = -1l = 0 ; h = len(L)-1
while l<=h and i==-1 :m = (l+h)/2 # find middle elementif( L[m] == t ) : # found
i = melif t < L[m] : # look in left ½
h = m – 1else : # look in right ½
l = m + 1
if i != -1 :print "Found " + str(t) + " at " + str(i)

Quicksort
pick one element of the array (pivot)partition the other elements into two groups those less than the pivot those that are greater than or equal to
the pivot
Pivot is now in the right placerecursively sort each (strictly smaller) group

Partition
unexaminedp
last i e
unexamined< pp >= p
b b+1 last i e
< p p >= p
b last e

Quicksort – the recursive algorithmdef qsort( L, b, e ) :
# base caseif b >= e : # nothing to do - 0 or 1 element
return;# partition returns index of pivot element
piv = partition( L, b, e )# Note that the pivot is right where it
belongs# It does not get sent out in either call
qsort( L, b, piv-1 ) # elements in [ b, piv )qsort( L, piv+1, e ) # elements in ( piv, e ]

Quicksort – the Partitiondef partition( L, b, e ) :
"Return: index of pivot"
# move pivot element to L[0]swap( L, b, random.randint( b, e ))last = b
# Move <p to left side, marked by `last'for i in range( b+1, e+1 ) :
if L[i] < L[b] :last += 1swap( L, last, i )
swap( L, b, last ) # restore pivot
return last

Quicksort - Swap
def swap( l, i, j ) :
"swaps elements at indices i, j in list l"
tmp = l[i]
l[i] = l[j]
l[j] = tmp

Libraries - sort
C: qsort (in stdlib.h)C++: sort (algorithm library from STL)Java: java.util.collections.sort
Perl: sortPython: list.sort

qsort – standard C libraryqsort( void *a, int n, int s,int(*cmp)(void *a, void *b) );Sorts array a, which has n elementsEach element is s bytescmp is a function that you must provide compares 2 single elements, *a & *b
qsort must pass void pointers (addresses), since it doesn't know the type
cmp does, since you provide it for a given sort returns integer -1 if a<b, 0 if a==b, and 1 if a>b For sorting in descending order, return 1 if a < b

qsort (int)int arr[N];
qsort(arr, N, sizeof(arr[0]), icmp);
/* icmp: integer compare of *p1 and *p2 */int icmp( const void *p1, const void *p2 ) { int v1, v2; v1 = *((int*) p1); v2 = *((int*) p2); if( v1 < v2 ) return –1; else if( v1 == v2 ) return 0; else return 1;}

qsort (strings)char *str[N];
qsort(str, N, sizeof(str[0]), scmp);
/* scmp: string compare of *p1 and *p2 *//* p1 is a ptr to a string, or char*, so is a *//* ptr to a ptr, or a char** */int scmp(const void *p1, const void *p2) { char *v1, *v2;
v1 = *((char**) p1); v2 = *((char**) p2); return strcmp(v1, v2);}

Dictionary (Map)
Allows us to associate satellite data w/a key e.g., phone book, student record (given
a student ID as key), error string (given an error # as key), etc.
Operations: insert find remove

Dictionary
The key-value pairs may be stored in any aggregate type (list, struct, etc)Using an unordered list: constant-time insertion linear lookup
Ordered list linear insertion lg(n) lookup

Other dictionaries
Binary Search Tree lg(n) insertion, lookup (if balanced)
Hash table constant-time insertion, lookup (if done
well)

Trees
A binary tree is either NULL or contains a node with the key/value pair, and a left and right child which are themselves trees. In a binary search tree (BST) the keys in the left child are smaller than the keys at the node and the values in the right child are greater than the value at the node. (Recursively true through all subtrees.)O(log n) expected search and insertion timein-order traversal provides elements in sorted order.

Examples
In the following examples each node stores the key/value pair: name – a string value – a hex #, that represents the
character (MBCS)
As well as a reference (ptr) to each of the 2 subtrees

Trees in Python
We can use a list of 3 elements:0. The key/value pair1. The left subtree2. The right subtree
The following is a tree w/one node (empty subtrees)T = [ ["Smiley", 0x263A], [], [] ]

BST Lookup - Pythondef lookup( T, name ) :
"""lookup: look up name in tree T, return the cell, None if not found"""
if T == [] : # T is the empty treereturn None
if T[0][0] == name :return T
elif name < T[0][0] : # look in left subtreereturn lookup( T[1], name );
else : # look in right subtreereturn lookup( T[2], name );
}

BST in C
We will use a struct to hold the key, value, and pointers to the subtrees
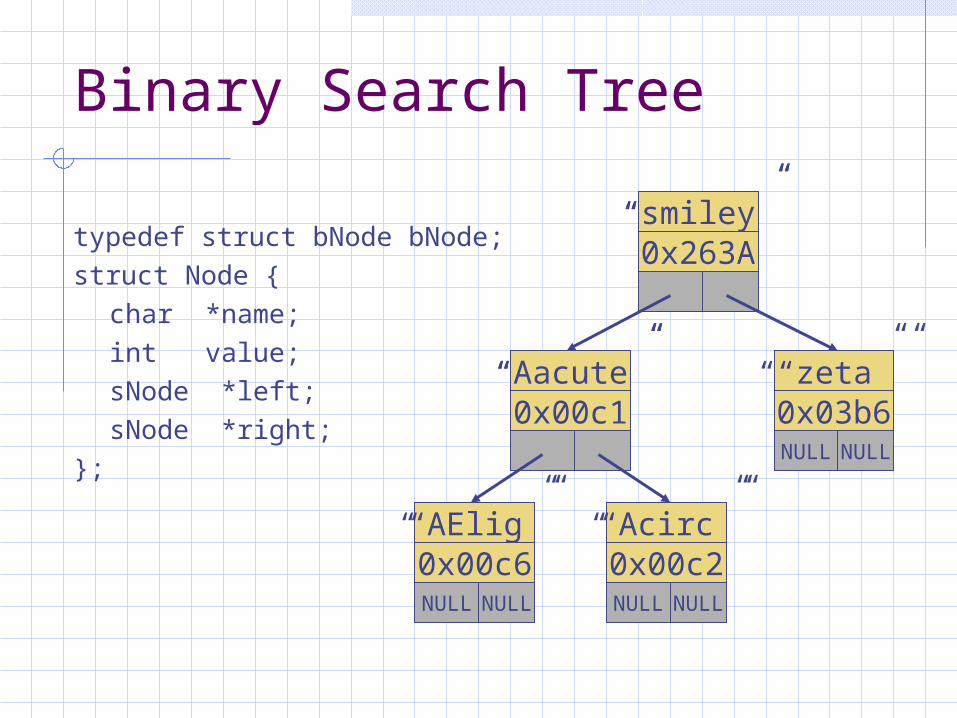
Binary Search Tree
typedef struct bNode bNode;
struct Node {
char *name;
int value;
sNode *left;
sNode *right;
};
“smiley”0x263A“zeta”0x03b6
NULL NULL
“smiley”0x263A“smiley”0x263A
“smiley”0x263A
“Aacute”0x00c1
“smiley”0x263A“Acirc”0x00c2
NULL NULL
“smiley”0x263A“AElig”0x00c6
NULL NULL

Binary Search Tree Lookup/* lookup: look up name in tree treep */sNode *lookup( sNode *treep, char *name ){
int cmp;
if( treep == NULL )return NULL;
cmp = strcmp(name, tree->name);if( cmp == 0 )
return treep;else if( cmp < 0 )
return lookup( treep->left, name );else
return lookup( treep->right, name );}

Hash Tables
Provides key lookup and insertion with constant expected costUsed to create lookup table (with m slots), where it is not usually possible to reserve a slot for each possible elementhash function maps key to index (should evenly distribute keys) H(k) -> [ 0, m-1 ]
duplicates stored in a chain (list) – other mechanisms are possible.

Dictionaries in Python
Python (as well as Perl and Awk) has a built-in dictionary (associative array)Type is dict
d = {} # empty dictionary
# initialise
nvList = { 'Smiley': 0x263A, 'Aacute': 0x00c1 }
print nvList[ 'Smiley' ]

Dictionaries - Python
Add an entry:nvList[ 'Zeta', 0x03b6 ]
Test for existence:if nvList.has_key( 'AElig' ) :
Remove an entry:nvList.pop( 'Smiley', None )
Iterate over keys:for i in nvList.keys() :
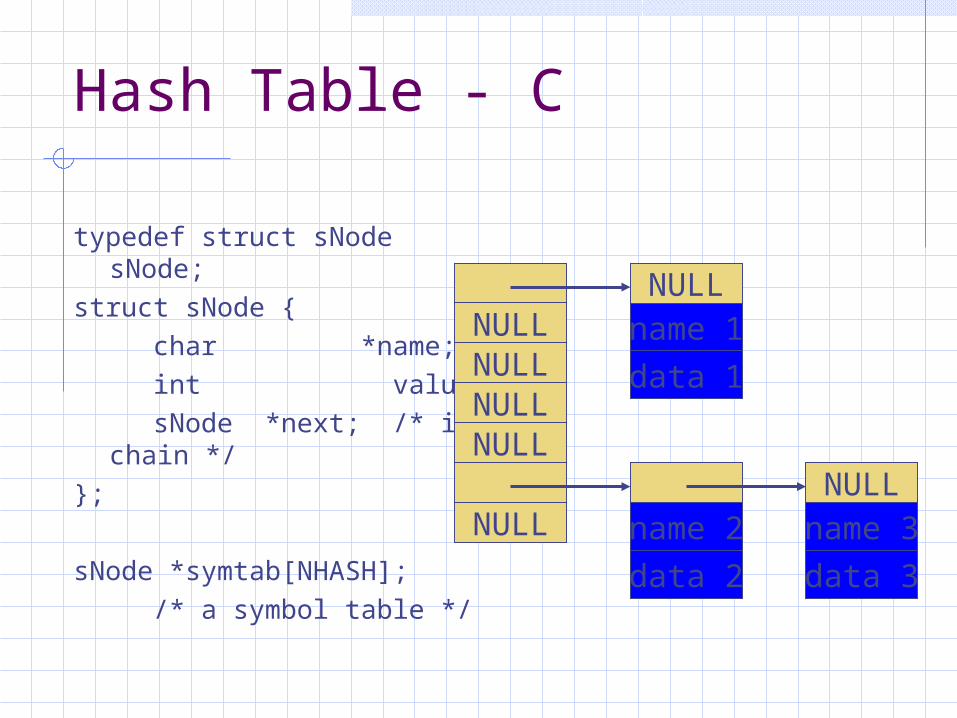
Hash Table - C
typedef struct sNode sNode;struct sNode { char *name; int value; sNode *next; /* in chain */};
sNode *symtab[NHASH]; /* a symbol table */
NULLNULLNULLNULL
NULL
NULLname 1
data 1
name 2
data 2
NULLname 3
data 3

Hash Table Lookup/* lookup: find name in symtab, with optional create */sNode *lookup(char *name, int create, int value){ int h; sNode *sym;
h = hash(name); for (sym = symtab[h]; sym != NULL; sym = sym->next) if (strcmp(name, sym->name) == 0) return sym; if (create) { sym = (sNode *) emalloc(sizeof(sNode)); sym->name = name; /* assumed allocated elsewhere */ sym->value = value; sym->next = symtab[h]; symtab[h] = sym; } return sym;}

Hash Functionenum { MULTIPLIER = 31};
/* hash: compute hash value of string */unsigned int hash(char* str){ unsigned int h; unsigned char *p; h = 0; for (p = (unsigned char *) str; *p != ‘\0’; p++) h = MULTIPLIER * h + *p; return h % NHASH;}
Recommended

















