16/05/15
1
A BigData Tour – HDFS, Ceph and MapReduce
These slides are possible thanks to these sources – Jonathan Drusi - SCInet Toronto – Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing – SICS; Yahoo! Developer Network MapReduce Tutorial
Data Management and Processing
• Data intensive computing • Concerns with the production, manipulation and analysis of data in the
range of hundreds of megabytes (MB) to petabytes (PB) and beyond • A range of supporting parallel and distributed computing technologies to
deal with the challenges of data representation, reliable shared storage, efficient algorithms and scalable infrastructure to perform analysis
16/05/15
2
Challenges Ahead
• Challenges with data intensive computing • Scalable algorithms that can search and process massive datasets • New metadata management technologies that can scale to handle
complex, heterogeneous and distributed data sources • Support for accessing in-memory multi-terabyte data structures • High performance, highly reliable petascale distributed file system • Techniques for data reduction and rapid processing • Software mobility to move computation where data is located • Hybrid interconnect with support for multi-gigabyte data streams • Flexible and high performance software integration technique
• Hadoop • A family of related project, best known for MapReduce and Hadoop
Distributed File System (HDFS)
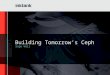
• Data volumes increasing massively!
• Clusters, storage capacity increasing massively!
• Disk speeds are not keeping pace.!
• Seek speeds even worse than read/write
Mahout!data mining
Dis
k (M
B/s)
, CPU
(M
IPS) 1000x!
Data Intensive Computing

16/05/15
3
Scale-Out
• Disk streaming speed ~ 50MB/s!
• 3TB =17.5 hrs!
• 1PB = 8 months!
• Scale-out (weak scaling) - filesystem distributes data on ingest
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
Scale-Out• Seeking too slow!
• ~10ms for a seek!
• Enough time to read half a megabyte!
• Batch processing!
• Go through entire data set in one (or small number) of passes
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

16/05/15
4
Combining results
• Each node pre-processes its local data!
• Shuffles its data to a small number of other nodes!
• Final processing, output is done there
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
Fault Tolerance
• Data also replicated upon ingest!
• Runtime watches for dead tasks, restarts them on live nodes!
• Re-replicates
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

16/05/15
5
Why Hadoop
• Drivers • 500M+ unique users per month • Billions of interesting events per day • Data analysis is key
• Need massive scalability • PB’s of storage, millions of files, 1000’s of nodes
• Need to do this cost effectively • Use commodity hardware • Share resources among multiple projects • Provide scale when needed
• Need reliable infrastructure • Must be able to deal with failures – hardware, software, networking • Failure is expected rather than exceptional • Transparent to applications • very expensive to build reliability into each application
• The Hadoop infrastructure provides these capabilities
Introduction to Hadoop
• Apache Hadoop • Based on 2004 Google MapReduce Paper • Originally composed of HDFS (distributed F/S), a core-runtime and
an implementation of Map-Reduce • Open Source – Apache Foundation project • Yahoo! is Apache Platinum Sponsor
• History • Started in 2005 by Doug Cutting • Yahoo! became the primary contributor in 2006 • Yahoo! scaled it from 20 node clusters to 4000 node clusters today
• Portable • Written in Java • Runs on commodity hardware • Linux, Mac OS/X, Windows, and Solaris

16/05/15
6
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
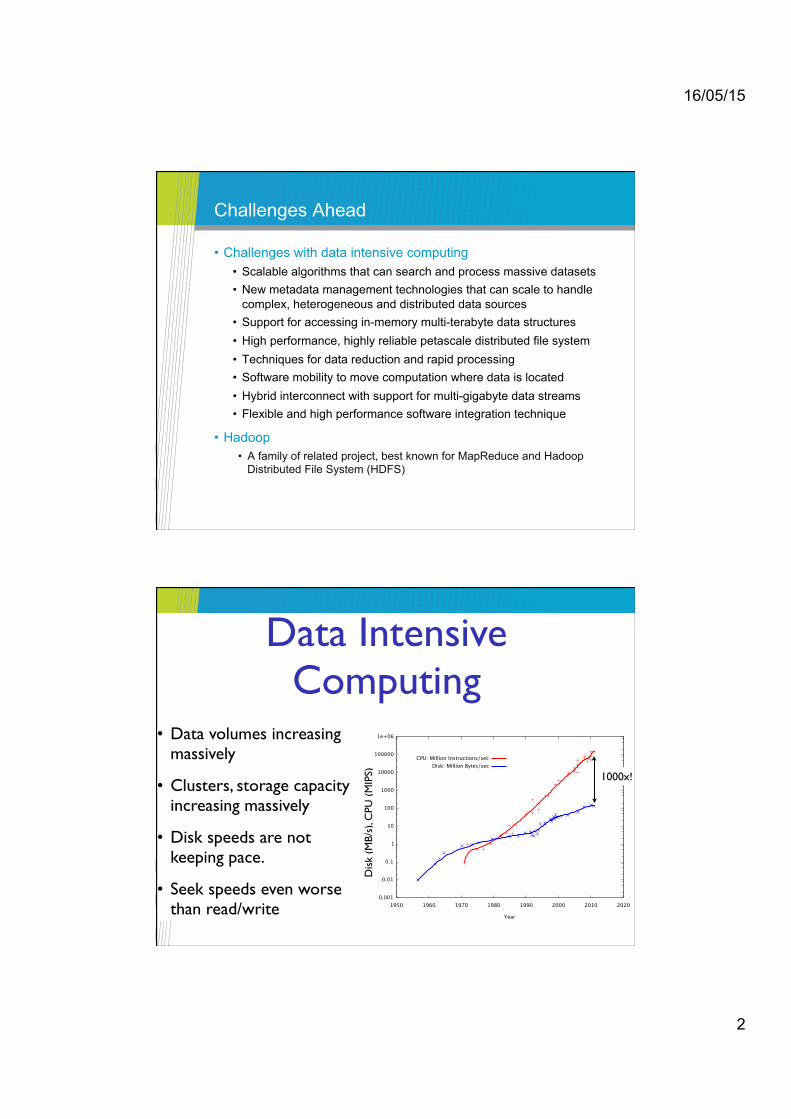
HPC vs Hadoop
• HPC attitude – “The problem of disk-limited, loosely-coupled data analysis was solved by throwing more disks and using weak scaling”
• Flip-side: A single novice developer can write real, scalable, 1000+ node data-processing tasks in Hadoop-family tools in an afternoon
• MPI... less so
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
16/05/15
7
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

16/05/15
8
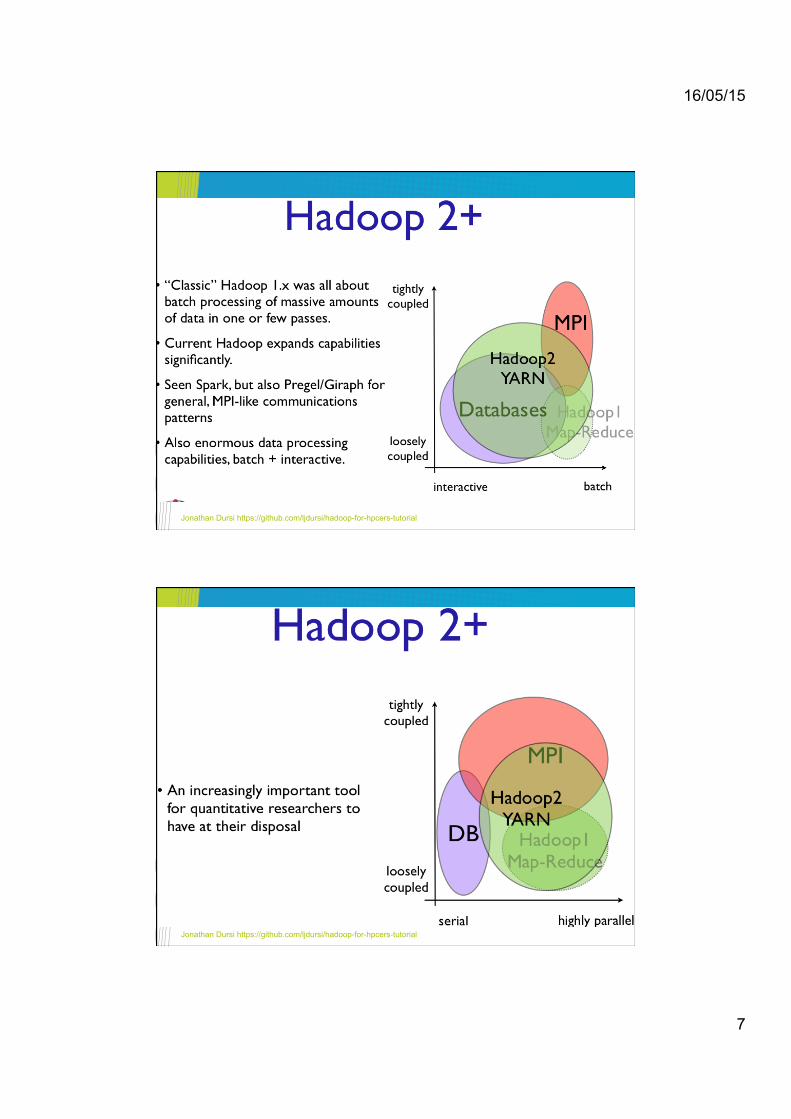
Data Distribution: Disk
• Hadoop and similar architectures handle the hardest part of parallelism for you - data distribution.!
• On disk: HDFS distributes, replicates data as it comes in!
• Keeps track; computations local to data
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
Data Distribution: Network
• On network: Map Reduce (eg) works in terms of key-value pairs.!
• Preprocessing (map) phase ingests data, emits (k,v) pairs!
• Shuffle phase assigns reducers, gets all pairs with same key onto that reducer.!
• Programmer does not have to design communication patterns
(key1,83) (key2, 9)(key1,99) (key2, 12)(key1,17) (key5, 23)
(key1,[17,99]) (key5,[23,83]) (key2,[12,9])
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
16/05/15
9
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
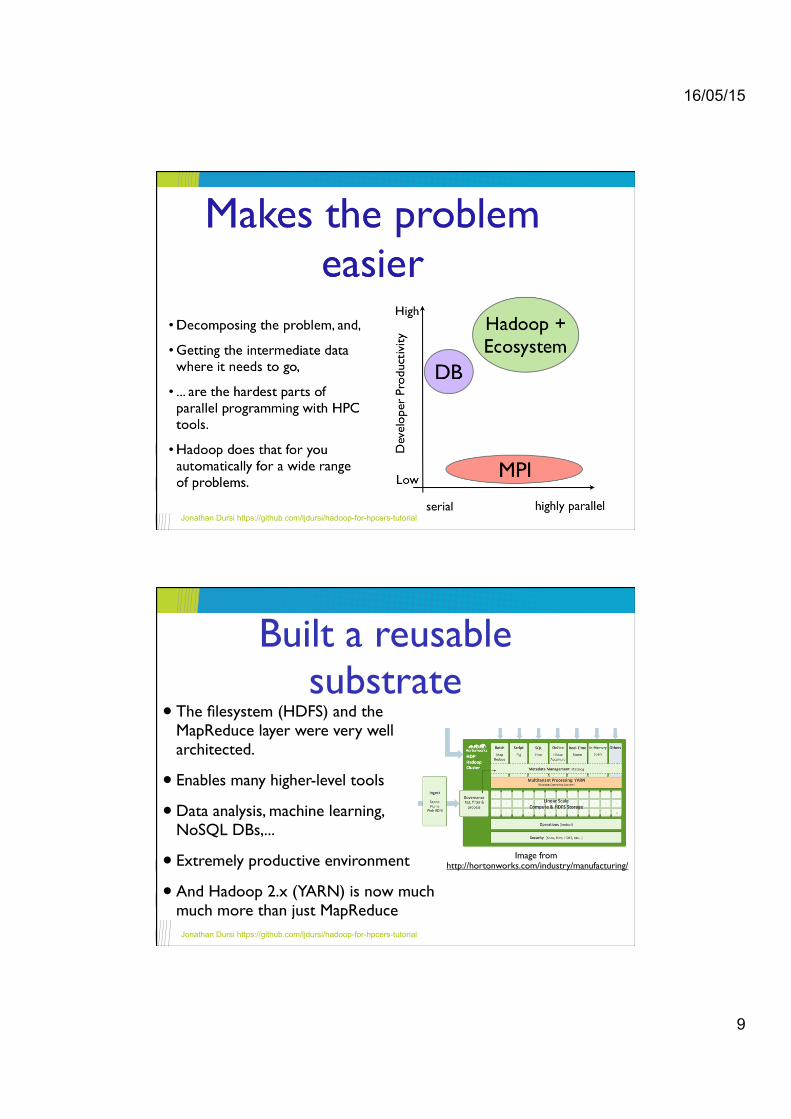
Built a reusable substrate
• The filesystem (HDFS) and the MapReduce layer were very well architected.!
• Enables many higher-level tools!
• Data analysis, machine learning, NoSQL DBs,...!
• Extremely productive environment!
• And Hadoop 2.x (YARN) is now much much more than just MapReduce
Image from http://hortonworks.com/industry/manufacturing/
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

16/05/15
10
• Not either-or anyway!
• Use HPC to generate big / many simulations, Hadoop to analyze results!
• Use Hadoop to preprocess huge input data sets (ETL), and HPC to do the tightly coupled computation afterwards.!
• Besides, ...
Hadoop vs HPCand
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
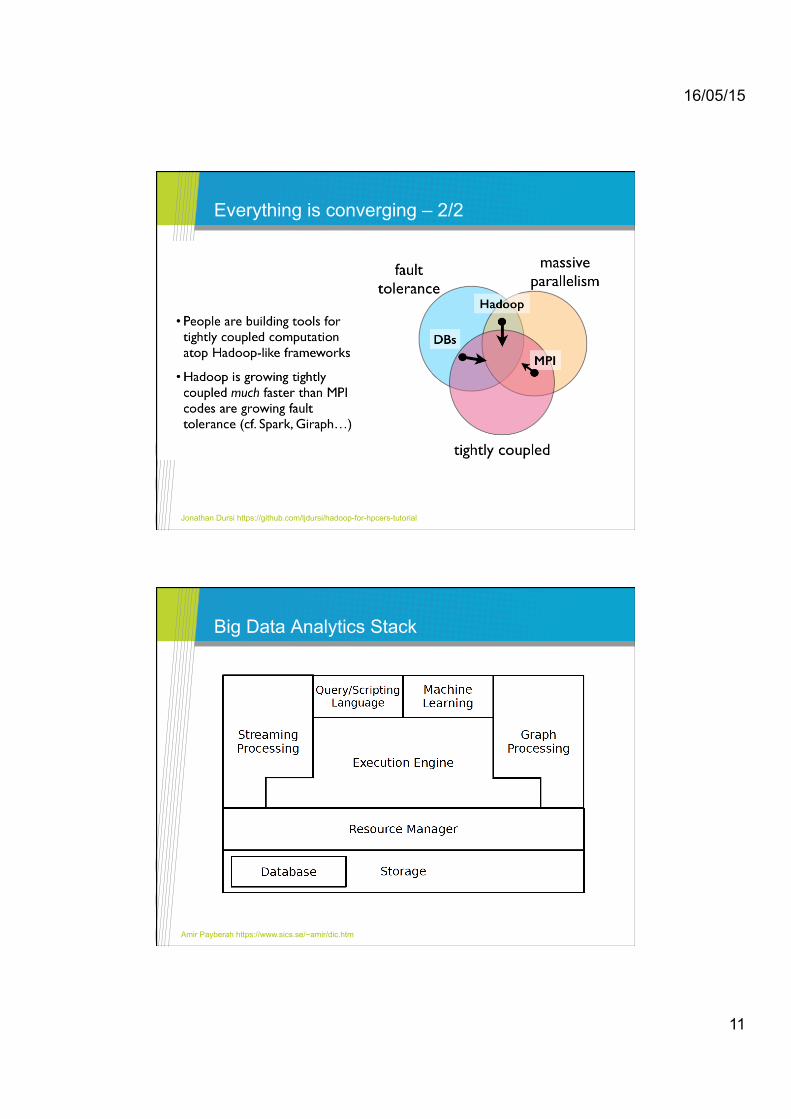
Everything is converging – 1/2
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
16/05/15
11
Everything is converging – 2/2
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
Big Data Analytics Stack
Big Data Analytics Stack
Amir H. Payberah (SICS) Introduction April 8, 2014 23 / 36
Amir Payberah https://www.sics.se/~amir/dic.htm

16/05/15
12
Big Data – Storage (sans POSIX) Big Data - Storage (Filesystem)
I Traditional filesystems are not well-designed for large-scale dataprocessing systems.
I E�ciency has a higher priority than other features, e.g., directoryservice.
I Massive size of data tends to store it across multiple machines in adistributed way.
I HDFS, Amazon S3, ...
Amir H. Payberah (SICS) Introduction April 8, 2014 24 / 36
Big Data - Storage (Filesystem)
I Traditional filesystems are not well-designed for large-scale dataprocessing systems.
I E�ciency has a higher priority than other features, e.g., directoryservice.
I Massive size of data tends to store it across multiple machines in adistributed way.
I HDFS, Amazon S3, ...
Amir H. Payberah (SICS) Introduction April 8, 2014 24 / 36
Amir Payberah https://www.sics.se/~amir/dic.htm
Big Data - Databases Big Data - Database
I Relational Databases Management Systems (RDMS) were not de-signed to be distributed.
I NoSQL databases relax one or more of the ACID properties: BASE
I Di↵erent data models: key/value, column-family, graph, document.
I Dynamo, Scalaris, BigTable, Hbase, Cassandra, MongoDB, Volde-mort, Riak, Neo4J, ...
Amir H. Payberah (SICS) Introduction April 8, 2014 25 / 36
Big Data - Database
I Relational Databases Management Systems (RDMS) were not de-signed to be distributed.
I NoSQL databases relax one or more of the ACID properties: BASE
I Di↵erent data models: key/value, column-family, graph, document.
I Dynamo, Scalaris, BigTable, Hbase, Cassandra, MongoDB, Volde-mort, Riak, Neo4J, ...
Amir H. Payberah (SICS) Introduction April 8, 2014 25 / 36
Amir Payberah https://www.sics.se/~amir/dic.htm

16/05/15
13
Big Data – Resource Management Big Data - Resource Management
I Di↵erent frameworks require di↵erent computing resources.
I Large organizations need the ability to share data and resourcesbetween multiple frameworks.
I Resource management share resources in a cluster between multipleframeworks while providing resource isolation.
I Mesos, YARN, Quincy, ...
Amir H. Payberah (SICS) Introduction April 8, 2014 26 / 36
Big Data - Resource Management
I Di↵erent frameworks require di↵erent computing resources.
I Large organizations need the ability to share data and resourcesbetween multiple frameworks.
I Resource management share resources in a cluster between multipleframeworks while providing resource isolation.
I Mesos, YARN, Quincy, ...
Amir H. Payberah (SICS) Introduction April 8, 2014 26 / 36
Amir Payberah https://www.sics.se/~amir/dic.htm
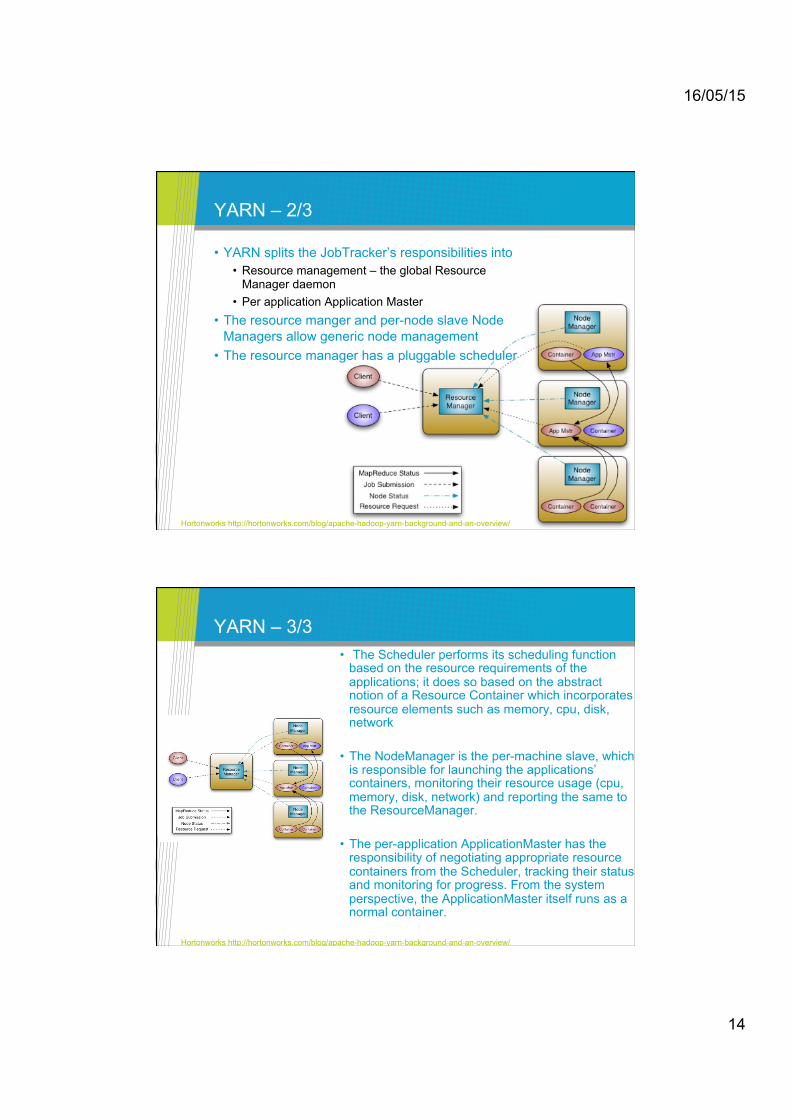
YARN – 1/3
• To address Hadoop v1 deficiencies with scalability, memory usage and synchronization, the Yet Another Resource Negotiator (YARN) Apache sub-project was started
• Previously a JobTracker service ran on each node. Its roles were then split into separate daemons for
• Resource management • Job scheduling/monitoring
Hortonworks http://hortonworks.com/blog/apache-hadoop-yarn-background-and-an-overview/
16/05/15
14
YARN – 2/3
• YARN splits the JobTracker’s responsibilities into • Resource management – the global Resource
Manager daemon • Per application Application Master
• The resource manger and per-node slave Node Managers allow generic node management
• The resource manager has a pluggable scheduler
Hortonworks http://hortonworks.com/blog/apache-hadoop-yarn-background-and-an-overview/
YARN – 3/3 • The Scheduler performs its scheduling function
based on the resource requirements of the applications; it does so based on the abstract notion of a Resource Container which incorporates resource elements such as memory, cpu, disk, network
• The NodeManager is the per-machine slave, which is responsible for launching the applications’ containers, monitoring their resource usage (cpu, memory, disk, network) and reporting the same to the ResourceManager.
• The per-application ApplicationMaster has the responsibility of negotiating appropriate resource containers from the Scheduler, tracking their status and monitoring for progress. From the system perspective, the ApplicationMaster itself runs as a normal container.
Hortonworks http://hortonworks.com/blog/apache-hadoop-yarn-background-and-an-overview/

16/05/15
15
Big Data – Execution Engine Big Data - Execution Engine
I Scalable and fault tolerance parallel data processing on clusters ofunreliable machines.
I Data-parallel programming model for clusters of commodity ma-chines.
I MapReduce, Spark, Stratosphere, Dryad, Hyracks, ...
Amir H. Payberah (SICS) Introduction April 8, 2014 27 / 36
Big Data - Execution Engine
I Scalable and fault tolerance parallel data processing on clusters ofunreliable machines.
I Data-parallel programming model for clusters of commodity ma-chines.
I MapReduce, Spark, Stratosphere, Dryad, Hyracks, ...
Amir H. Payberah (SICS) Introduction April 8, 2014 27 / 36
Amir Payberah https://www.sics.se/~amir/dic.htm
Big Data – Query/Scripting Languages
Big Data - Query/Scripting Language
I Low-level programming of execution engines, e.g., MapReduce, isnot easy for end users.
I Need high-level language to improve the query capabilities of exe-cution engines.
I It translates user-defined functions to low-level API of the executionengines.
I Pig, Hive, Shark, Meteor, DryadLINQ, SCOPE, ...
Amir H. Payberah (SICS) Introduction April 8, 2014 28 / 36
Big Data - Query/Scripting Language
I Low-level programming of execution engines, e.g., MapReduce, isnot easy for end users.
I Need high-level language to improve the query capabilities of exe-cution engines.
I It translates user-defined functions to low-level API of the executionengines.
I Pig, Hive, Shark, Meteor, DryadLINQ, SCOPE, ...
Amir H. Payberah (SICS) Introduction April 8, 2014 28 / 36Amir Payberah https://www.sics.se/~amir/dic.htm
16/05/15
16
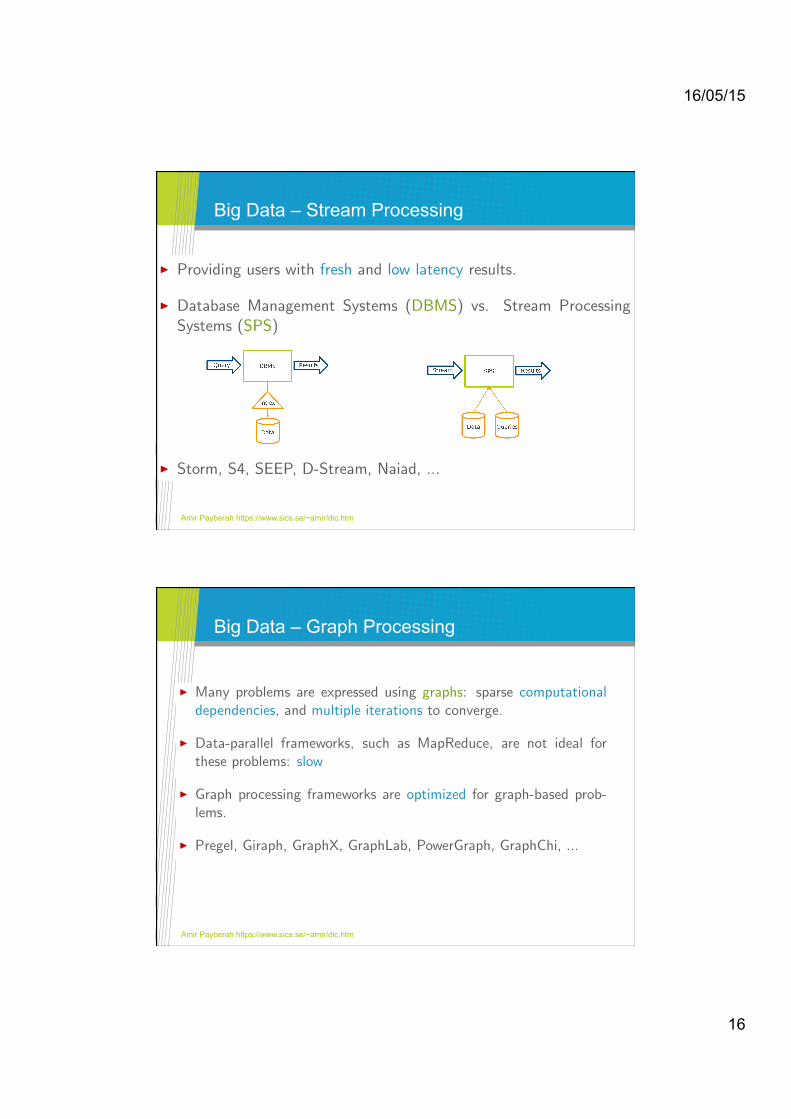
Big Data – Stream Processing Big Data - Stream Processing
I Providing users with fresh and low latency results.
I Database Management Systems (DBMS) vs. Stream ProcessingSystems (SPS)
I Storm, S4, SEEP, D-Stream, Naiad, ...
Amir H. Payberah (SICS) Introduction April 8, 2014 29 / 36
Amir Payberah https://www.sics.se/~amir/dic.htm
Big Data – Graph Processing Big Data - Graph Processing
I Many problems are expressed using graphs: sparse computationaldependencies, and multiple iterations to converge.
I Data-parallel frameworks, such as MapReduce, are not ideal forthese problems: slow
I Graph processing frameworks are optimized for graph-based prob-lems.
I Pregel, Giraph, GraphX, GraphLab, PowerGraph, GraphChi, ...
Amir H. Payberah (SICS) Introduction April 8, 2014 30 / 36
Amir Payberah https://www.sics.se/~amir/dic.htm

16/05/15
17
Big Data – Machine Learning
Big Data - Machine Learning
I Implementing and consuming machine learning techniques at scaleare di�cult tasks for developers and end users.
I There exist platforms that address it by providing scalable machine-learning and data mining libraries.
I Mahout, MLBase, SystemML, Ricardo, Presto, ...
Amir H. Payberah (SICS) Introduction April 8, 2014 31 / 36
Amir Payberah https://www.sics.se/~amir/dic.htm
Hadoop Big Data Analytics Stack
Hadoop Big Data Analytics Stack
Amir H. Payberah (SICS) Introduction April 8, 2014 32 / 36
Amir Payberah https://www.sics.se/~amir/dic.htm

16/05/15
18
Spark Big Data Analytics Stack Spark Big Data Analytics Stack
Amir H. Payberah (SICS) Introduction April 8, 2014 34 / 36
Amir Payberah https://www.sics.se/~amir/dic.htm
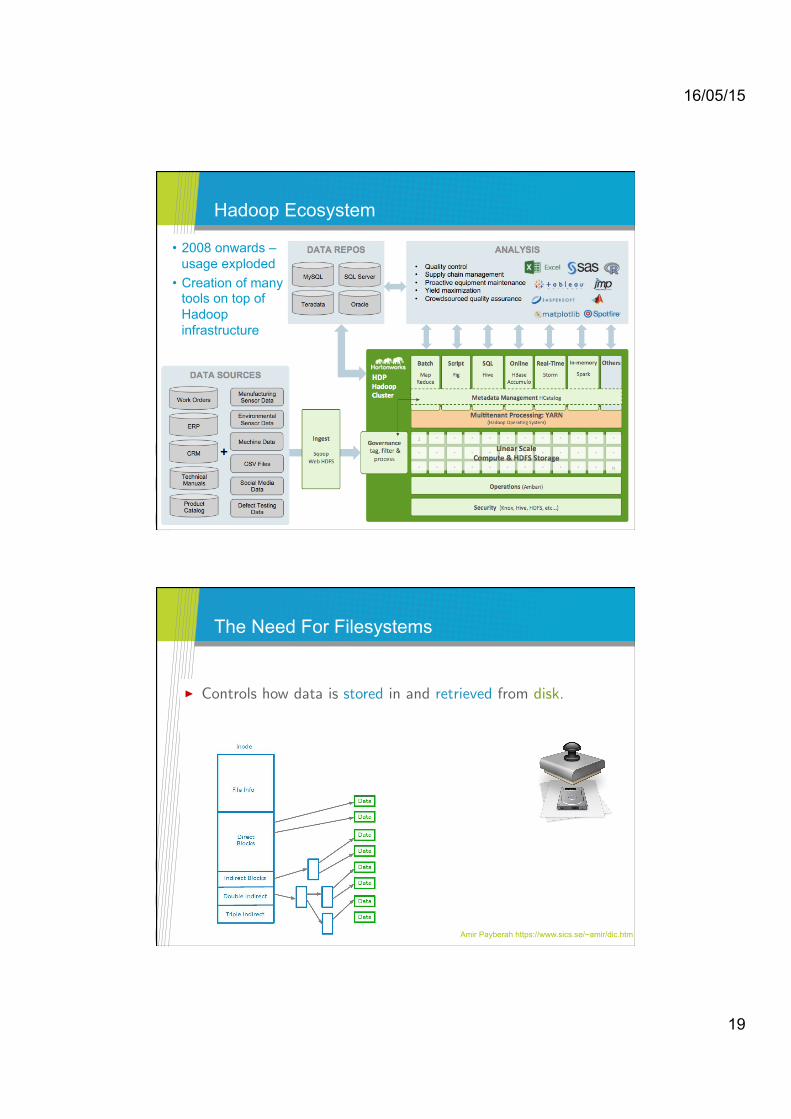
Hadoop Ecosystem Hortonworks http://hortonworks.com/industry/manufacturing/
16/05/15
19
Hadoop Ecosystem
• 2008 onwards – usage exploded
• Creation of many tools on top of Hadoop infrastructure
The Need For Filesystems
What is Filesystem?
I Controls how data is stored in and retrieved from disk.
Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 2 / 32
What is Filesystem?
I Controls how data is stored in and retrieved from disk.
Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 2 / 32
Amir Payberah https://www.sics.se/~amir/dic.htm

16/05/15
20
Distributed Filesystems Distributed Filesystems
I When data outgrows the storage capacity of a single machine: par-tition it across a number of separate machines.
I Distributed filesystems: manage the storage across a network ofmachines.
Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 3 / 32
Amir Payberah https://www.sics.se/~amir/dic.htm
Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 4 / 32

16/05/15
21
Hadoop Distributed File System (HDFS)
• A distributed file system designed to run on commodity hardware
• HDFS was originally built as infrastructure for the Apache Nutch web search engine project, with the aim to achieve fault tolerance, ability to run on low-cost hardware and handle large datasets
• It is now an Apache Hadoop subproject • Share similarities with existing distributed file systems and supports
traditional hierarchical file organization • Reliable data replication and accessible via Web interface and Shell
commands • Benefits: Fault tolerant, high throughput, streaming data access,
robustness and handling of large data sets • HDFS is not a general purpose F/S
Assumptions and Goals
• Hardware failures • Detection of faults, quick and automatic recovery
• Streaming data access • Designed for batch processing rather than interactive use by users
• Large data sets • Applications that run on HDFS have large data sets, typically in
gigabytes to terabytes in size • Optimized for batch reads rather than random reads
• Simple coherency model • Applications need a write-once, read-many times access model for files
• Computation migration • Computation is moved closer to where data is located
• Portability • Easily portable between heterogeneous hardware and software
platforms

16/05/15
22
What HDFS is not good for HDFS is Not Good for ...
I Low-latency reads• High-throughput rather than low latency for small chunks of data.• HBase addresses this issue.
I Large amount of small files• Better for millions of large files instead of billions of small files.
I Multiple writers• Single writer per file.• Writes only at the end of file, no-support for arbitrary o↵set.
Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 7 / 32
Amir Payberah https://www.sics.se/~amir/dic.htm
HDFS Architecture
• The Hadoop Distributed File System (HDFS)
• Offers a way to store large files across multiple machines, rather than requiring a single machine to have disk capacity equal to/greater than the summed total size of the files
• HDFS is designed to be fault-tolerant
• Using data replication and distribution of data
• When a file is loaded into HDFS, it is replicated and broken up into "blocks" of data
• These blocks are stored across the cluster nodes designated for storage, a.k.a. DataNodes.
http://www.revelytix.com/?q=content/hadoop-ecosystem

16/05/15
23
Files and Blocks – 1/3 Files and Blocks (1/3)
I Files are split into blocks.
I Blocks• Single unit of storage: a contiguous piece of information on a disk.• Transparent to user.• Managed by Namenode, stored by Datanode.• Blocks are traditionally either 64MB or 128MB: default is 64MB.
Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 10 / 32Amir Payberah https://www.sics.se/~amir/dic.htm
Files and Blocks – 2/3 Files and Blocks (2/3)
I Why is a block in HDFS so large?• To minimize the cost of seeks.
I Time to read a block = seek time + transfer time
I Keeping the ratio seektimetransfertime small: we are reading data from the
disk almost as fast as the physical limit imposed by the disk.
I Example: if seek time is 10ms and the transfer rate is 100MB/s, tomake the seek time 1% of the transfer time, we need to make theblock size around 100MB.
Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 11 / 32
Amir Payberah https://www.sics.se/~amir/dic.htm

16/05/15
24
Files and Blocks – 3/3 Files and Blocks (3/3)
I Same block is replicated on multiple machines: default is 3• Replica placements are rack aware.• 1st replica on the local rack.• 2nd replica on the local rack but di↵erent machine.• 3rd replica on the di↵erent rack.
I Namenode determines replica placement.
Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 12 / 32
Amir Payberah https://www.sics.se/~amir/dic.htm
HDFS Daemons (2/2)
Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 9 / 32
HDFS Daemons
• HDFS cluster is manager by three types of processes
• Namenode • Manages the filesystem, e.g., namespace, meta-data, and file
blocks • Metadata is stored in memory
• Datanode • Stores and retrieves data blocks • Reports to Namenode • Runs on many machines
• Secondary Namenode • Only for checkpointing. • Not a backup for Namenode
Amir Payberah https://www.sics.se/~amir/dic.htm

16/05/15
25
Hadoop Server Roles
http://www.revelytix.com/?q=content/hadoop-ecosystem
NameNode – 1/3
• The HDFS namespace is a hierarchy of files and directories • These are represented in the NameNode using inodes • Inodes record attributes
• permissions, modification and access times; • namespace and disk space quotas.
• The file content is split into large blocks (typically 128 megabytes, but user selectable file-by-file), and each block of the file is independently replicated at multiple DataNodes (typically three, but user selectable file-by-file)
• The NameNode maintains the namespace tree and the mapping of blocks to DataNodes
• A Hadoop cluster can have thousands of DataNodes and tens of thousands of HDFS clients per cluster, as each DataNode may execute multiple application tasks concurrently
http://www.revelytix.com/?q=content/hadoop-ecosystem

16/05/15
26
NameNode – 2/3
• The inodes and the list of blocks that define the metadata of the name system are called the image (FsImage above)
• NameNode keeps the entire namespace image in RAM
• Each client-initiated transaction is recorded in the journal, and the journal file is flushed and synced before the acknowledgment is sent to the client
• The NameNode is a multithreaded system and processes requests simultaneously from multiple clients.
http://www.revelytix.com/?q=content/hadoop-ecosystem
NameNode – 3/3
• HDFS requires • A NameNode process to run on one node in the cluster • All other nodes run the DataNode service to run on each "slave"
node that will be processing data. • When data is loaded into HDFS
• Data is replicated and split into blocks that are distributed across the DataNodes
• The NameNode is responsible for storage and management of metadata, so that when MapReduce or another execution framework calls for the data, the NameNode informs it where the needed data resides.
http://www.revelytix.com/?q=content/hadoop-ecosystem

16/05/15
27
Where to Replicate?• Tradeoff to choosing replication
locations!
• Close: faster updates, less network bandwidth!
• Further: better failure tolerance!
• Default strategy: first copy on different location on same node, second on different “rack”(switch), third on same rack location, different node.!
• Strategy configurable.!
• Need to configure Hadoop file system to know location of nodes
rack1 rack2
switch 1 switch 2
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
DataNode – 1/3
• Each block replica on a DataNode is represented by two files in the local native filesystem. The first file contains the data itself and the second file records the block's metadata including checksums for the data and the generation stamp.
• At startup each DataNode connects to a NameNode and preforms a handshake. The handshake verifies that the DataNode is part of the NameNode and runs the same version of software
• A DataNode identifies block replicas in its possession to the NameNode by sending a block report.
• A block report contains the block ID, the generation stamp and the length for each block replica the server hosts
• The first block report is sent immediately after the DataNode registration
• Subsequent block reports are sent every hour and provide the NameNode with an up-to-date view of where block replicas are located on the cluster.
http://www.aosabook.org/en/hdfs.html

16/05/15
28
DataNode – 2/3
• During normal operation DataNodes send heartbeats to the NameNode to confirm that the DataNode is operating and the block replicas it hosts are available
• If the NameNode does not receive a heartbeat from a DataNode in ten minutes, it considers the DataNode to be out of service and the block replicas hosted by that DataNode to be unavailable
• The NameNode then schedules creation of new replicas of those blocks on other DataNodes.
• Heartbeats from a DataNode also carry information about total storage capacity, fraction of storage in use, and the number of data transfers currently in progress. These statistics are used for the NameNode's block allocation and load balancing decisions.
http://www.aosabook.org/en/hdfs.html
DataNode – 3/3
• The NameNode does not directly send requests to DataNodes. It uses replies to heartbeats to send instructions to the DataNodes
• The instructions include commands to replicate blocks to other
nodes, remove local block replicas, re-register and send an immediate block report, and shut down the node
• These commands are important for maintaining the overall system integrity and therefore it is critical to keep heartbeats frequent even on big clusters. The NameNode can process thousands of heartbeats per second without affecting other NameNode operations.
http://www.aosabook.org/en/hdfs.html

16/05/15
29
HDFS Client – 1/3
• User applications access the filesystem using the HDFS client, a library that exports the HDFS filesystem interface
• User is oblivious to backend implementation details eg # of replicas and which servers have appropriate blocks
http://www.aosabook.org/en/hdfs.html
HDFS Client – 2/3
• When an application reads a file, the HDFS client first asks the NameNode for the list of DataNodes that host replicas of the blocks of the file
• The list is sorted by the network topology distance from the client
• The client contacts a DataNode directly and requests the transfer of the desired block.
http://www.aosabook.org/en/hdfs.html
16/05/15
30
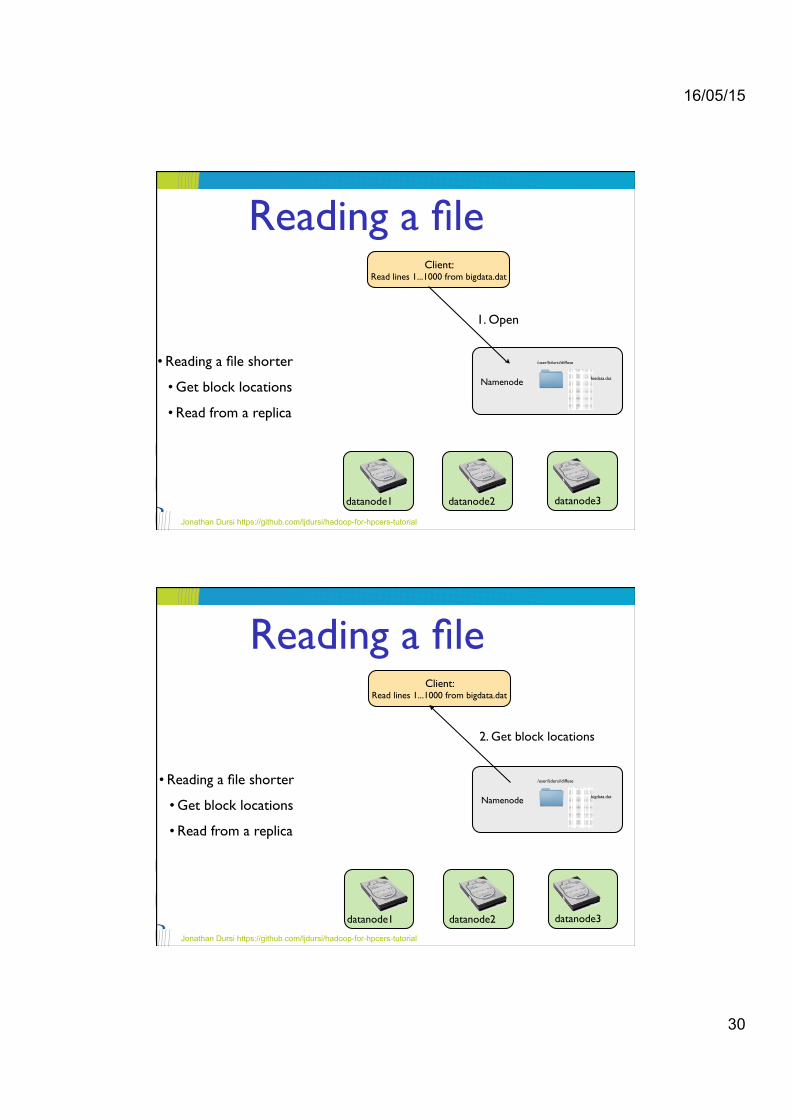
Reading a file
• Reading a file shorter !
• Get block locations!
• Read from a replica
Namenode
/user/ljdursi/diffuse
bigdata.dat
datanode1 datanode2 datanode3
Client: !Read lines 1...1000 from bigdata.dat
1. Open
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
Reading a file
• Reading a file shorter !
• Get block locations!
• Read from a replica
Namenode
/user/ljdursi/diffuse
bigdata.dat
datanode1 datanode2 datanode3
Client: !Read lines 1...1000 from bigdata.dat
2. Get block locations
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
16/05/15
31
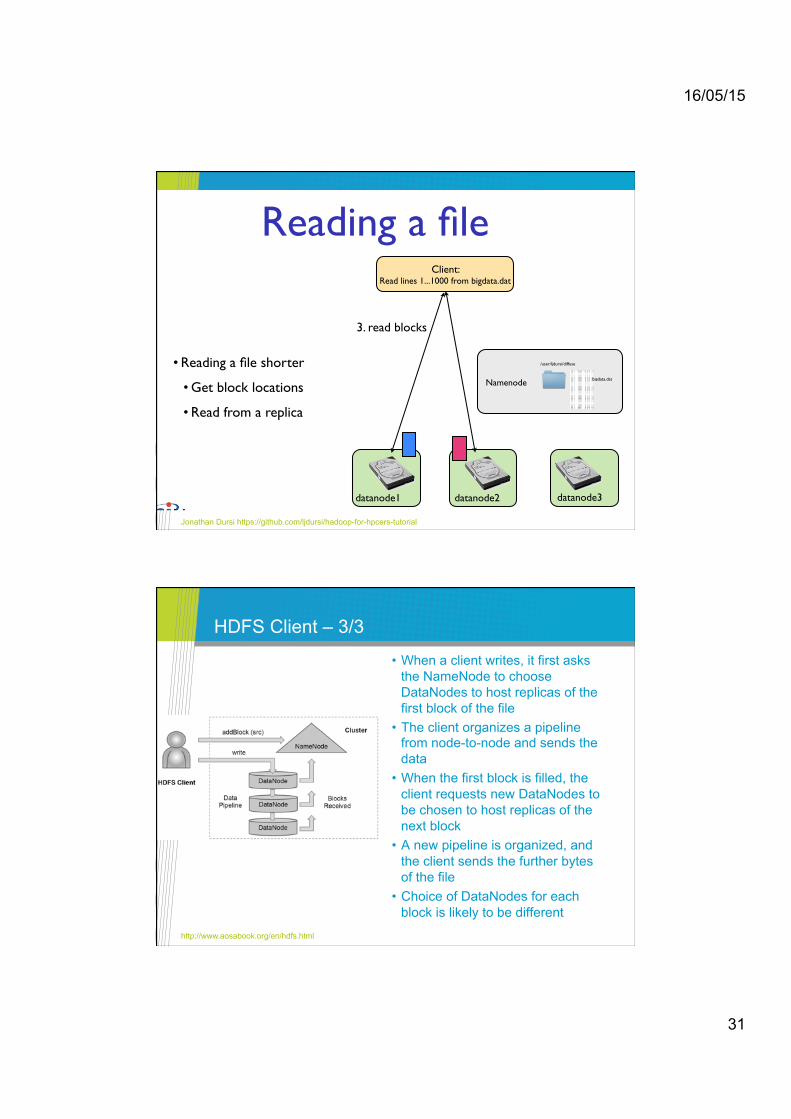
Reading a file
• Reading a file shorter !
• Get block locations!
• Read from a replica
Namenode
/user/ljdursi/diffuse
bigdata.dat
datanode1 datanode2 datanode3
Client: !Read lines 1...1000 from bigdata.dat
3. read blocks
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
HDFS Client – 3/3
• When a client writes, it first asks the NameNode to choose DataNodes to host replicas of the first block of the file
• The client organizes a pipeline from node-to-node and sends the data
• When the first block is filled, the client requests new DataNodes to be chosen to host replicas of the next block
• A new pipeline is organized, and the client sends the further bytes of the file
• Choice of DataNodes for each block is likely to be different
http://www.aosabook.org/en/hdfs.html

16/05/15
32
Writing a file
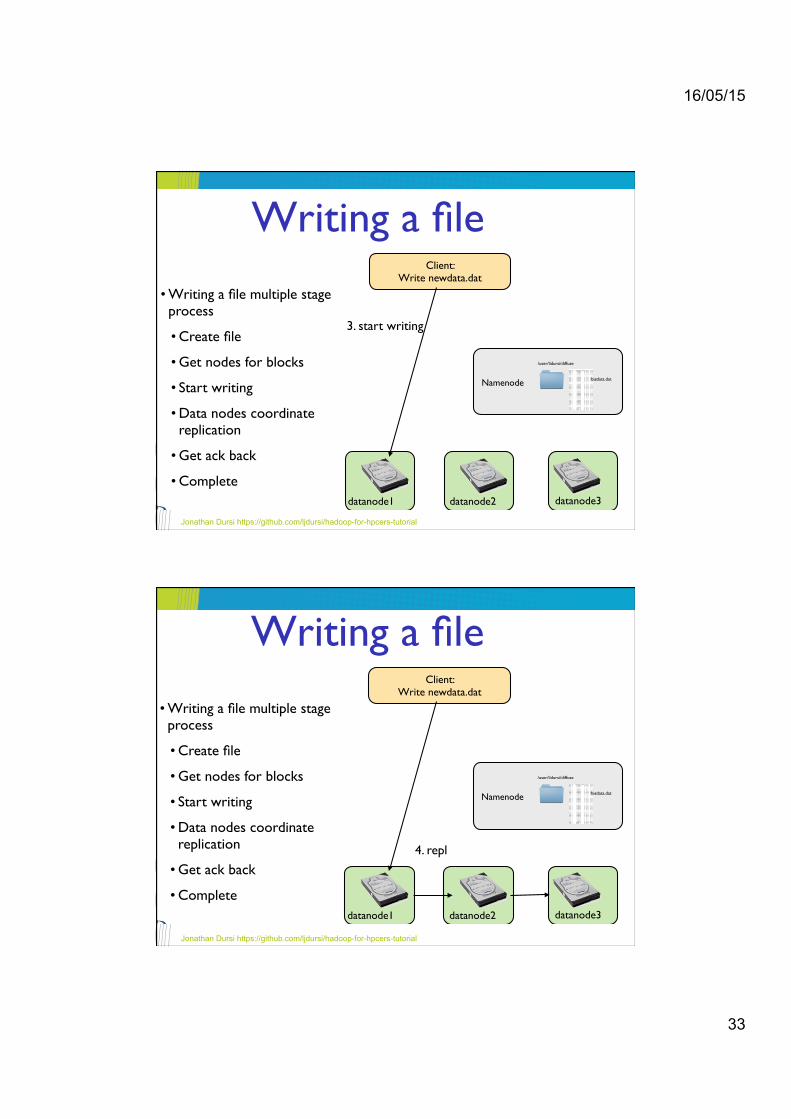
• Writing a file multiple stage process!
• Create file!
• Get nodes for blocks!
• Start writing!
• Data nodes coordinate replication!
• Get ack back !
• Complete
Namenode
/user/ljdursi/diffuse
bigdata.dat
datanode1 datanode2 datanode3
Client: !Write newdata.dat
1. create
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
Writing a file
• Writing a file multiple stage process!
• Create file!
• Get nodes for blocks!
• Start writing!
• Data nodes coordinate replication!
• Get ack back !
• Complete
Namenode
/user/ljdursi/diffuse
bigdata.dat
datanode1 datanode2 datanode3
Client: !Write newdata.dat
2. get nodes
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
16/05/15
33
Writing a file
• Writing a file multiple stage process!
• Create file!
• Get nodes for blocks!
• Start writing!
• Data nodes coordinate replication!
• Get ack back !
• Complete
Namenode
/user/ljdursi/diffuse
bigdata.dat
datanode1 datanode2 datanode3
Client: !Write newdata.dat
3. start writing
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
Writing a file
• Writing a file multiple stage process!
• Create file!
• Get nodes for blocks!
• Start writing!
• Data nodes coordinate replication!
• Get ack back !
• Complete
Namenode
/user/ljdursi/diffuse
bigdata.dat
datanode1 datanode2 datanode3
Client: !Write newdata.dat
4. repl
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
16/05/15
34
Writing a file
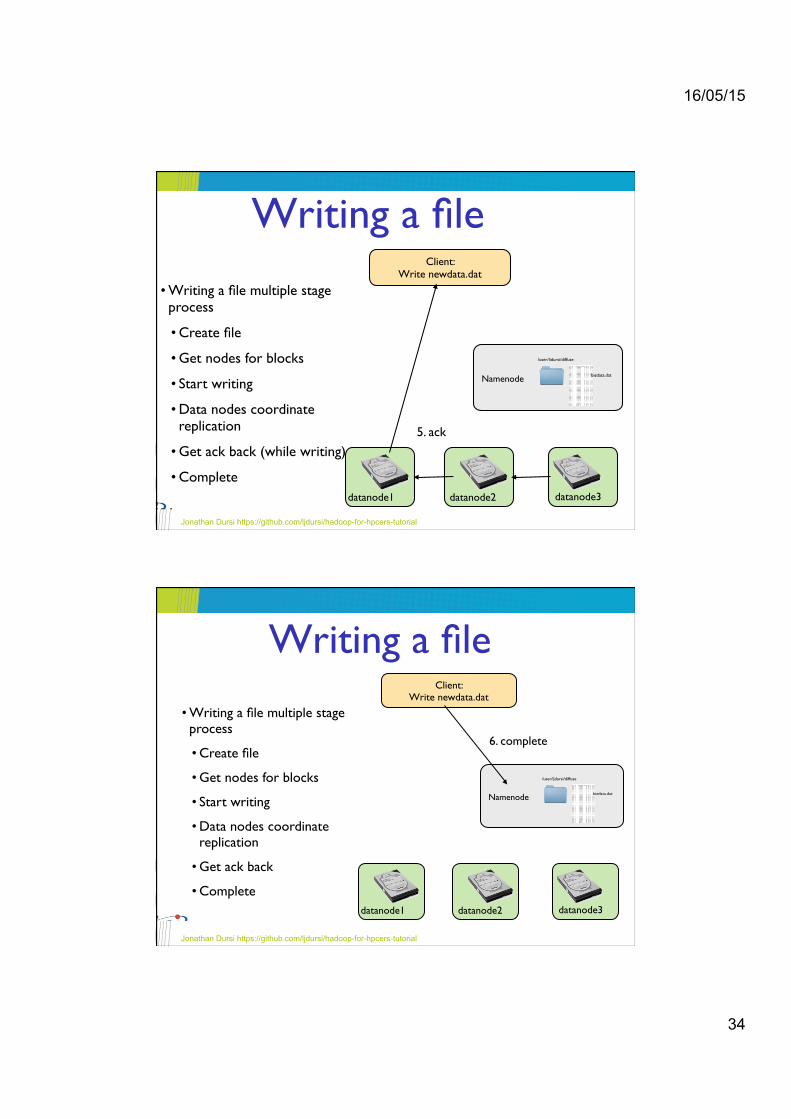
• Writing a file multiple stage process!
• Create file!
• Get nodes for blocks!
• Start writing!
• Data nodes coordinate replication!
• Get ack back (while writing)!
• Complete
Namenode
/user/ljdursi/diffuse
bigdata.dat
datanode1 datanode2 datanode3
Client: !Write newdata.dat
5. ack
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial
Writing a file
• Writing a file multiple stage process!
• Create file!
• Get nodes for blocks!
• Start writing!
• Data nodes coordinate replication!
• Get ack back !
• Complete
Namenode
/user/ljdursi/diffuse
bigdata.dat
datanode1 datanode2 datanode3
Client: !Write newdata.dat
6. complete
Jonathan Dursi https://github.com/ljdursi/hadoop-for-hpcers-tutorial

16/05/15
35
HDFS Federation HDFS Federation
I Hadoop 2+
I Each Namenode will host part of the blocks.
I A Block Pool is a set of blocks that belong to a single namespace.
I Support for 1000+ machine clusters.
Amir H. Payberah (SICS) Distributed Filesystems April 8, 2014 17 / 32
Amir Payberah https://www.sics.se/~amir/dic.htm
File I/O and Leases in HDFS
• An application • Adds data to HDFS by creating a new file and writing data to it • On closing the file, new data can only be appended • HDFS implements a single-writer, multiple-reader model
• Leases are granted by the NameNode to HDFS clients • Writer clients need to periodically renew the lease via a heartbeat
to the NameNode • On file close, the lease is revoked • There are soft and hard limits for leases (the hard limit being an
hour) • A write lease does not prevent multiple readers from reading the
file

16/05/15
36
Data Pipelining for Writing Blocks – 1/2
• An HDFS file consists of blocks
• When there is a need for a new block, the NameNode allocates a block with a unique block ID and determines a list of DataNodes to host replicas of the block
• The DataNodes form a pipeline, the order of which minimizes the total network distance from the client to the last DataNode
http://www.aosabook.org/en/hdfs.html
Data Pipelining for Writing Blocks – 2/2
• Bytes are pushed to the pipeline as a sequence of packets. The bytes that an application writes first buffer at the client side
• After a packet buffer is filled (typically 64 KB), the data are pushed to the pipeline
• The next packet can be pushed to the pipeline before receiving the acknowledgment for the previous packets
• The number of outstanding packets is
limited by the outstanding packets window size of the client.
http://www.aosabook.org/en/hdfs.html

16/05/15
37
HDFS Interfaces
• There are many interfaces to interact with HDFS
• Simplest way of interacting with HDFS in command-line
• Two properties are set in HDFS configuration
• Default Hadoop filesystem fs.default.name: hdfs://localhost/ • Used to determine the host (localhost) and port (8020) for the
HDFS NameNode
• Replication factor dfs.replication • Default is 3, disable replication by setting it to 1 (single datanode)
• Other HDFS interfaces • HTTP: a read only interface for retrieving directory listings and data
over HTTP • FTP: permits the use of the FTP protocol to interact with HDFS
Replication in HDFS
• Replica placement • Critical to improve data reliability, availability and network bandwidth
utilization • Rack-aware policy as rack failure is far less than node failure • With the default replication factor (3), one replica is put on one node in
the local rack, another on a node in a different (remote) rack, and the last on a different node in the same remote rack
• One third of replication are on one node; two-third of replicas are on one rack, and the other third are evenly distributed across racks
• Benefits is to reduce inter-rack write traffic
• Replica selection • A read request is satisfied from a replica that is nearby to the
application • Minimizes global bandwidth consumption and read latency • If HDFS spans multiple data center, replica in the local data center is
preferred over any remote replica

16/05/15
38
Communication Protocol
• All HDFS communication protocols are layered on top of the TCP/IP protocol
• A client establishes a connection to a configurable TCP port on the NameNode machine and uses ClientProtocol
• DataNodes talk to the NameNode using DataNode protocol
• A Remote Procedure Call (RPC) abstraction wraps both the ClientProtocol and DataNode protocol
• NameNode never initiates a RPC, instead it only responds to RPC requests issued by DataNodes or clients
Robustness
• Primary objective of HDFS is to store data reliably even during failures
• Three common types of failures: NameNode, DataNode and network partitions
• Data disk failure • Heartbeat messages to track the health of DataNodes • NameNodes performs necessary re-replication on DataNode
unavailability, replica corruption or disk fault
• Cluster rebalancing • Automatically move data between DataNodes, if the free space on a
DataNode falls below a threshold or during sudden high demand
• Data integrity • Checksum checking on HDFS files, during file creation and retrieval
• Metadata disk failure • Manual intervention – no auto recovery, restart or failover
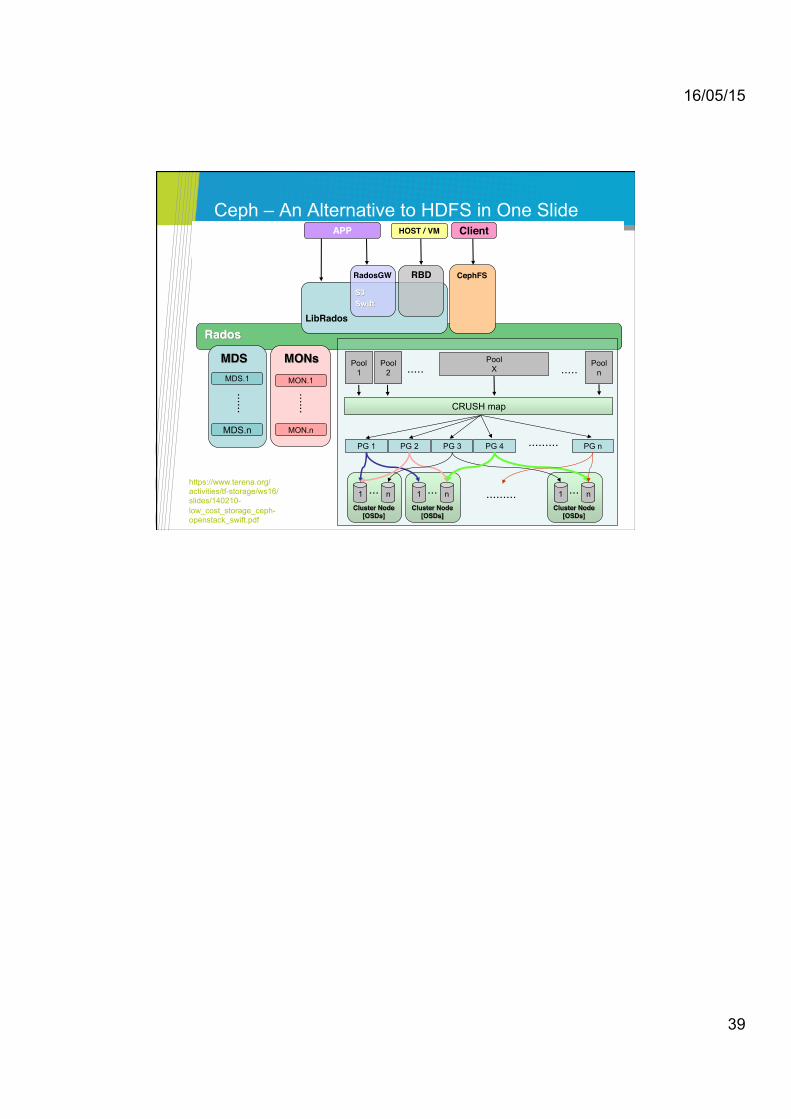
16/05/15
39
Ceph – An Alternative to HDFS in One Slide Software: Ceph
Rados
MDS MDS.1
MDS.n
......
MONs
MON.1
MON.n
......
Pool 1
Pool 2
Pool n ..... .....
Pool X
CRUSH map
PG 1 PG 2 PG 3 PG 4 PG n .........
1 n
Cluster Node [OSDs]
... 1 n
Cluster Node [OSDs]
... 1 n
Cluster Node [OSDs]
... .........
LibRados
RadosGW RBD CephFS
APP HOST / VM Client
S3 Swift
https://www.terena.org/activities/tf-storage/ws16/slides/140210-low_cost_storage_ceph-openstack_swift.pdf
Recommended