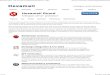
v=1v=–1 v=–1 v=–1
v=–1 v=1
v=–1
optimaalin
en peli
O O
O
XX
O O
O
XXX X
O O
OX
XX X
OO
O
X
XX X
O
O OX
XX
O
O
O
X
XXO
O
O
O
O
X
XX XO
XO
XO
OX
2) 3)
5) 6) 7) 8) 9)
12)
O
O O
OX
XX XO
11)
O O
O
OX
XXO
XO
13)
OO
I N T R O D U C T I O N T O A R T I F I C I A L I N T E L L I G E N C E
D A TA 1 5 0 0 1
E P I S O D E 5 : P R O B A B I L I S T I C I N F E R E N C E

1. B AY E S R U L E
2. N A I V E B AY E S C L A S S I F I E R
3. S PA M F I LT E R
T O D A Y ’ S M E N U

B AY E S R U L E ?
• P(state | obs) = P(state) P(obs | state) / P(obs)
• State ∈ {sick, healthy} // patient is healthy or sick
• Obs ∈ {pos,neg} // test is positive or negative
• P(sick) = 0.001 P(healthy) =__0.999_____P(pos | sick) = 0.9 P(pos | healthy) = 0.01P(neg | sick) = __0.1___ P(neg | healthy) = __0.99___
• P(pos) = __0.01089_____
• P(sick | pos) = __0.0826___
T H I N K : W H Y I S T H I S S M A L L E R T H A N ~ 9 0 % ?

H O W T O M A K E M O N E Y

H O W T O M A K E M O N E Y
FROM: "MARGARETTA NITA" <[email protected]>SUBJECT: SPECIAL OFFER : VIAGRA ON SALE AT $1.38 !!!X-BOGOSITY: YES, TESTS=BOGOFILTER, SPAMICITY=0.99993752, VERSION=2011-08-29DATE: MON, 26 SEP 2011 21:52:26 +0300X-CLASSIFICATION: JUNK - AD HOC SPAM DETECTED (CODE = 73)
SPECIAL OFFER : VIAGRA ON SALE AT $1.38 !!!
COMPARE THE BEST ONLINE PHARMACIES TO BUY VIAGRA. ORDER VIAGRA ONLINE WITH HUGE DISCOUNT.MULTIPLE BENEFITS INCLUDE FREE SHIPPING, REORDER DISCOUNTS, BONUS PILLSHTTP://RXPHARMACYCVS.RU

N A I V E B AY E S F O R S PA M F I LT E R I N G
CLASS
WORD1 WORD2 WORD3 WORD4 WORD6 WORD7
• General strategy: – estimate word probabilities in each class (spam/ham)
=> we'll return to this a bit later – use the estimates to compute the posterior probability
P(spam | message) where message is the contents (words) of a new message
– if P(spam | message) > 0.5, classify as spam
T H E S E M A N T I C S O F T H I S G R A P H : W O R D S A R E " C O N D I T I O N A L LY I N D E P E N D E N T O F E A C H O T H E R G I V E N T H E C L A S S "

N A I V E B AY E S
Random variables:– Class: spam/ham– Word1
– Word2
– ...
Distributions:– P(Class = spam) = 0.5– P(Wordi = 'viagra' | spam)=0.002– P(Wordi = 'viagra' | ham)=0.0001– P(Wordi = '$' | spam)=0.005– P(Wordi = '$' | ham)=0.0002– P(Wordi = 'is' | spam)=0.002– P(Wordi = 'is' | ham)=0.002– P(Wordi = 'algorithm' | spam)=0.0001– P(Wordi = 'algorithm' | ham)=0.002– ...

N A I V E B AY E S
Inference:
1. P(spam) = 0.5 P(spam) P(Word1= 'viagra'| spam)2. P(spam | Word1= 'viagra') = ––––––––––––––––––––––––––––––– P(Word1= 'viagra')
BAYES RULES!

N A I V E B AY E S
Inference:
1.P(spam) = 0.5 P(spam) P(Word1= 'viagra'| spam)2. P(spam | Word1= 'viagra') = ––––––––––––––––––––––––––––––– P(Word1= 'viagra') P(Word1= 'viagra') = P(spam) P(Word1= 'viagra'| spam) + P(ham) P(Word1= 'viagra'| ham)

N A I V E B AY E S
Inference:
1.P(spam) = 0.5 P(spam) P(Word1= 'viagra'| spam)2. P(spam | Word1= 'viagra') = ––––––––––––––––––––––––––––––– P(Word1= 'viagra')3. P(spam | Word1= 'viagra', Word2= 'is') = P(spam) P(Word1= 'viagra', Word2= 'is' | spam) ––––––––––––––––––––––––––––––––––––––––––– P(Word1= 'viagra', Word2= 'is')

N A I V E B AY E S
Inference:
1.P(spam) = 0.5 P(spam) P(Word1= 'viagra'| spam)2. P(spam | Word1= 'viagra') = ––––––––––––––––––––––––––––––– P(Word1= 'viagra')3. P(spam | Word1= 'viagra', Word2= 'is') = P(spam) P(Word1= 'viagra', Word2= 'is' | spam) ––––––––––––––––––––––––––––––––––––––––––– P(Word1= 'viagra', Word2= 'is')4. P(spam | Word1= 'viagra', Word2= 'is', Word3= 'algorithm') = P(spam) P(Word1= 'viagra', Word2= 'is', Word3= 'algorithm' | spam) –––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– P(Word1= 'viagra', Word2= 'is', Word3= 'algorithm')

N A I V E B AY E S
Avoiding the denominator:
P(spam | message) R = ––––––––––––––––––– ⇔ P(spam | message) = R / (1+R) P(ham | message)
P(spam) P(message | spam) / P(message) R = –––––––––––––––––––––––––––––––––––––– P(ham) P(message | ham) / P(message)

N A I V E B AY E S
Avoiding the denominator:
P(spam | message) R = ––––––––––––––––––– ⇔ P(spam | message) = R / (1+R) P(ham | message)
P(spam) P(message | spam) / P(message) P(spam) P(message | spam) R = –––––––––––––––––––––––––––––––––––––– = ––––––––––––––––––––––––– P(ham) P(message | ham) / P(message) P(ham) P(message | ham)
4. P(spam | Word1= 'viagra', Word2= 'is', Word3= 'algorithm') –––––––––––––––––––––––––––––––––––––––––––––––––––––– P(ham | Word1= 'viagra', Word2= 'is', Word3= 'algorithm') P(spam) P(Word1= 'viagra', Word2= 'is', Word3= 'algorithm' | spam) = –––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––– P(ham) P(Word1= 'viagra', Word2= 'is', Word3= 'algorithm' | ham)

N A I V E B AY E S
Factorization and the naive Bayes assumption:
P(Word1= 'viagra', Word2= 'is', Word3= 'algorithm' | spam)= P(Word1= 'viagra' | spam) P(Word2= 'is' | spam) ∙ P(Word3= 'algorithm' | spam)
• This is starting to look good because we can estimate terms like P(Word3= 'algorithm' | spam) can be estimated from a training data set...
• ...whereas estimating the probability of combinations of three or more words (n-grams) would require massive data sets

N A I V E B AY E S
Putting things together
P(spam |'viagra', 'is', 'algorithm') –––––––––––––––––––––––––––––– P(ham | 'viagra', 'is', 'algorithm') P(spam) P('viagra' | spam) P('is' | spam) P('algorithm' | spam) = ––––––––––––––––––––––––––––––––––––––––––––––––––––––– P(ham) P('viagra' | ham) P('is' | ham) P('algorithm' | ham) P(spam) P('viagra' | spam) P('is' | spam) P('algorithm' | spam) = –––––––– ∙ ––––––––––––––– ∙ ––––––––––– ∙ –––––––––––––––––– P(ham) P('viagra' | ham) P('is' | ham) P('algorithm' | ham)
• Here we use the fact that (ABC) / (DEF) = (A/D) (B/E) (C/F)
• A nice routine calculation that smoothly becomes a program

N A I V E B AY E S
Putting things together
spamicity(words, estimates):
1: R = estimates.prior_spam / estimates.prior_ham
2: for each w in words:
3: R = R * estimates.spam_prob(w) / estimates.ham_prob(w)
4: return R
• estimates.prior_spam = P(spam)estimates.prior_ham = P(ham) = 1 – P(spam)
• estimates.spam_prob(w) = P(Wordi= 'w'| spam)estimates.ham_prob(w) = P(Wordi = 'w' | ham)
• Recall that P(spam | message) = R / (1+R)

N A I V E B AY E S : I N T E R I M S U M M A R Y
• What we need to estimate from training data: – prior probabilities P(spam) and P(ham) – conditional probabilities for words P(Wordi= 'w'| spam) and
P(Wordi= 'w'| ham)
• The conditional independence assumption, aka. "naive Bayes assumption", implies that P(Wordi= 'w', Wordj= 'v'| spam) = P(Wordi= 'w' | spam) P(Wordi= 'v'| spam)
• The essential quantity is the ratio P(Wordi= 'w'| spam) / P(Wordi = 'w' | ham)

N A I V E B AY E S : I N T E R I M S U M M A R Y
• The cost function is asymmetric: – worse to misclassify ham as spam than vice versa – the decision to classify should be made only if
P(spam | message) > a, for some a > 0.5
• Under- and overflows: – a product with many terms tends to become either very
large or very small (close to zero) – can be solved by computing log(R) instead of R – log(AB) = log(A) + log(B), log(A/B) = log(A) – log(B) – at the end, get R by exp(log(R)) = R
Additional remarks

N A I V E B AY E S : E S T I M AT I O N
Estimating the word probabilities from training data:
1 MONEY...5 VIAGRA...10 IS...19 REPLICA20 EMAIL20 YOU21 DATABASE25 EMAILS26 OF31 TO43 AND48 THETOTAL 2386
21 ALGORITHM...62 MONEY...2199 FOR2492 THAT2990 YOU3141 IN3160 I3218 AND3283 IS3472 OF3874 A5442 TO9196 THETOTAL 283736
spam ham0.04 %
0.21 %
0.42 %
0.80 %0.84 %0.84 %0.88 %1.05 %1.09 %1.30 %1.80 %2.01 %
0.01 %
0.02 %
0.78 %0.88 %1.05 %1.11 %1.11 %1.13 %1.16 %1.22 %1.37 %1.92 %3.24 %

N A I V E B AY E S : E S T I M AT I O N
Estimating the word probabilities from training data:
1 MONEY...5 VIAGRA...10 IS...19 REPLICA20 EMAIL20 YOU21 DATABASE25 EMAILS26 OF31 TO43 AND48 THETOTAL 2386
21 ALGORITHM...62 MONEY...2199 FOR2492 THAT2990 YOU3141 IN3160 I3218 AND3283 IS3472 OF3874 A5442 TO9196 THETOTAL 283736
spam ham0.04 %
0.21 %
0.42 %
0.80 %0.84 %0.84 %0.88 %1.05 %1.09 %1.30 %1.80 %2.01 %
0.01 %
0.02 %
0.78 %0.88 %1.05 %1.11 %1.11 %1.13 %1.16 %1.22 %1.37 %1.92 %3.24 %
P(Wordi='money' | spam) 0.0004 –––––––––––––––––––––––– = –––––– = 1.918 > 1 P(Wordi='money' | ham) 0.0002

N A I V E B AY E S : E S T I M AT I O N
Estimating the word probabilities from training data:
1 MONEY...5 VIAGRA...10 IS...19 REPLICA20 EMAIL20 YOU21 DATABASE25 EMAILS26 OF31 TO43 AND48 THETOTAL 2386
21 ALGORITHM...62 MONEY...2199 FOR2492 THAT2990 YOU3141 IN3160 I3218 AND3283 IS3472 OF3874 A5442 TO9196 THETOTAL 283736
spam ham0.04 %
0.21 %
0.42 %
0.80 %0.84 %0.84 %0.88 %1.05 %1.09 %1.30 %1.80 %2.01 %
0.01 %
0.02 %
0.78 %0.88 %1.05 %1.11 %1.11 %1.13 %1.16 %1.22 %1.37 %1.92 %3.24 %
P(Wordi='money' | spam) 0.0004 –––––––––––––––––––––––– = –––––– = 1.918 > 1 P(Wordi='money' | ham) 0.0002
P(Wordi='is' | spam) 0.0042 ––––––––––––––––––– = ––––––– = 0.3622 < 1 P(Wordi='is' | ham) 0.0116

N A I V E B AY E S : E S T I M AT I O N
Estimating the word probabilities from training data:
1 MONEY...5 VIAGRA...10 IS...19 REPLICA20 EMAIL20 YOU21 DATABASE25 EMAILS26 OF31 TO43 AND48 THETOTAL 2386
21 ALGORITHM...62 MONEY...2199 FOR2492 THAT2990 YOU3141 IN3160 I3218 AND3283 IS3472 OF3874 A5442 TO9196 THETOTAL 283736
spam ham0.04 %
0.21 %
0.42 %
0.80 %0.84 %0.84 %0.88 %1.05 %1.09 %1.30 %1.80 %2.01 %
0.01 %
0.02 %
0.78 %0.88 %1.05 %1.11 %1.11 %1.13 %1.16 %1.22 %1.37 %1.92 %3.24 %
P ( ' a l g o r i t h m ' | s p a m ) = 0 . 0 ? M a y l e a d t o a s i t u a t i o n w h e r e w e r a t i o i s 0 / 0 ! S o l u t i o n : R e p l a c e 0 b y, e . g . , 0 . 0 0 0 0 0 1 .
Recommended













![[Potential spam]](https://img.pdfslide.us/doc/110x75/589e2ad01a28ab5c128b53b1/potential-spam.jpg)