Embed Size (px)
Citation preview

Zoom to Learn, Learn to ZoomSupplementary Material
Xuaner ZhangUC Berkeley
Qifeng ChenHKUST
Ren NgUC Berkeley
Vladlen KoltunIntel Labs
A. SR-RAW training patch examples
SR-RAW is a diverse dataset that covers indoor and out-door scenes under different illuminations. During train-ing, we randomly cropped 64 × 64 patches from a full-resolution Bayer mosaic as input for training. Exampletraining patches are shown in Figure 1.
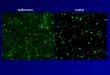
B. Visual Analysis of CoBi
Figure 2: Number of unique feature matches increases astraining progresses, indicating a more diverse nearest neigh-bor feature field and thus potentially closer feature matchingto ground truth.
As detailed in Section 4, we analyze the percentage offeatures that are matched uniquely (i.e., bijectively) in near-est feature search when applying directly contextual loss totraining. The percentage of target features matched witha unique source feature is only 43.7%, much less than theideal percentage of 100%. By using the proposed contex-tual bilateral loss (CoBi), in Figure 2, we plot the numberof unique feature matches with training step. On the x-axis, training step 0 denotes the starting point of the modeltrained with only the contextual loss. The number of uniquefeature matches for our model trained with CoBi increasesfrom 43.7% to 93.9%. A high percentage of unique fea-ture matches implies a more diverse nearest neighbor fea-ture field and being closer to the optimal feature matching.
C. Additional Qualitative 4X Results
Comparison with Baselines More results on 4X baselinecomparisons are shown in Figure 5. We compare againstLapSRN [4] that demonstrates SR models with a differentnetwork architecture; a model by Johnson et al. [3] thatadopts perceptual losses for SR, and finally ESRGAN [5],the winner of the most recent Perceptual SR ChallengePIRM [1]. This extends Figure 4 in the main paper.Comparison with Our Model Variants More results ofcontrolled experiments with our model are shown in Fig-ure 5. We compare our model trained on real sensor datawith “Ours-png” – our model trained on processed RGBimages, and “Ours-syn-raw” – our model trained on syn-thetic sensor data. We adopt the standard sensor synthesismodel described in [2] to generate synthetic Bayer mosaicsfrom 8-bit RGB images. This extends Figure 5 in the mainpaper.
Additional inference results (without ground truth) areshown in Figure 6.
D. Qualitative 8X Results
This extends Figure 6 in the main paper.
E. Generalization to Smartphone Sensor
Data Capture To obtain ground truth zoomed images fora smartphone that has limited optical zoom power, we usea DSLR with a zoom lens to obtain ground truth high-resolution images. As shown in Figure 3 A, the smartphoneis stably mounted on top of a DSLR. For calibration, wecapture a pair of images using the smartphone and DSLRwith the same focal length, call them SP-Low and DSLR-Low, and then use the DSLR to take a zoomed image, callit DSLR-High by adjusting the focal length to the desiredratio.Data Pre-processing We align the pair of images taken bythe smartphone and DSLR using SP-Low and DSLR-Low.Additional Qualitative Results This extends Figure 7 inthe main paper.
1

Figure 1: Example training patch pairs of Bayer mosaic (Left) and ground truth RGB image (Right). Bayer mosaics, afterpacking, are 64 × 64 randomly cropped from a full-resolution sensor data in SR-RAW, and RGB images are corresponding256× 256 ground truth patch.
2

(A) Data Capture Setup (B) Example Smartphone Input (C) Example DSLR Target
Figure 3: Smartphone-DSLR data capture and example data pair.
References[1] Y. Blau, R. Mechrez, R. Timofte, T. Michaeli, and L. Zelnik-
Manor. The 2018 PIRM challenge on perceptual image super-resolution. In ECCV Workshops, 2018. 1
[2] M. Gharbi, G. Chaurasia, S. Paris, and F. Durand. Deepjoint demosaicking and denoising. ACM Trans. on Graphics(TOG), 2016. 1
[3] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses forreal-time style transfer and super-resolution. In ECCV, 2016.1
[4] W.-S. Lai, J.-B. Huang, N. Ahuja, and M.-H. Yang. DeepLaplacian pyramid networks for fast and accurate super-resolution. In CVPR, 2017. 1
[5] X. Wang, K. Yu, S. Wu, J. Gu, Y. Liu, C. Dong, C. C. Loy,Y. Qiao, and X. Tang. ESRGAN: Enhanced super-resolutiongenerative adversarial networks. In ECCV, 2018. 1
3

Input GT for Red Patch GT for Blue Patch
ESRGAN Johnson et al. LapSRN Ours
Input GT for Red Patch GT for Blue Patch
ESRGAN Johnson et al. LapSRN Ours
Figure 4: Our 4X zoom results show better perceptual performance in super-resolving distant objects against baseline methodsthat are trained under a synthetic setting and applied to processed RGB images.
4

Input GT for Red Patch GT for Blue Patch
ESRGAN Johnson et al. LapSRN Ours
Input GT for Red Patch GT for Blue Patch
ESRGAN Johnson et al. LapSRN Ours
Figure 4 (Cont.): .5

Input GT for Red Patch GT for Blue Patch
ESRGAN Johnson et al. LapSRN Ours
Input GT for Red Patch GT for Blue Patch
ESRGAN Johnson et al. LapSRN Ours
Figure 4 (Cont.): .
6

Input GT for Red Patch GT for Blue Patch
ESRGAN Johnson et al. LapSRN Ours
Input GT for Red Patch GT for Blue Patch
ESRGAN Johnson et al. LapSRN Ours
Figure 5: Our model trained on real sensor data produces clean and high quality zoomed images than “Ours-png”, our modeltrained on processed 8-bit RGB images and “Ours-syn-raw”, our model trained on synthetic sensor data.
7

Input Ours-png Ours-syn-raw
Ours GT
Input Ours-png Ours-syn-raw
Ours GT
Figure 5: .
8

Input Ours-png Ours-syn-raw
Ours GT
Input Ours-png Ours-syn-raw
Ours GT
Figure 5 (Cont.): .
9

Input Ours-png Ours-syn-raw Ours
Figure 6: More inference results on 4X compared against “Ours-png” and “Ours-syn-raw”.10

Smartphone Input Bicubic Ours
Figure 7: Our model fine-tuned on a much smaller dataset can adapt to a Bayer mosaic variant from an iPhone X sensor.
11


![Zoom to Learn, Learn to Zoom - cqf · deep neural network for joint demosaicing and denoising. Zhou et al. [35] address joint demosaicing, denoising, and super-resolution. These methods](https://img.pdfslide.us/doc/110x75/5eb672e6dcf8565d963f6c7d/zoom-to-learn-learn-to-zoom-cqf-deep-neural-network-for-joint-demosaicing-and.jpg)