Embed Size (px)
Citation preview

Processing Difficulty and Structural Uncertainty in Relative Clauses across East Asian Languages
Zhong Chen and John HaleDepartment of Linguistics
Cornell University
Thursday, October 11, 2012

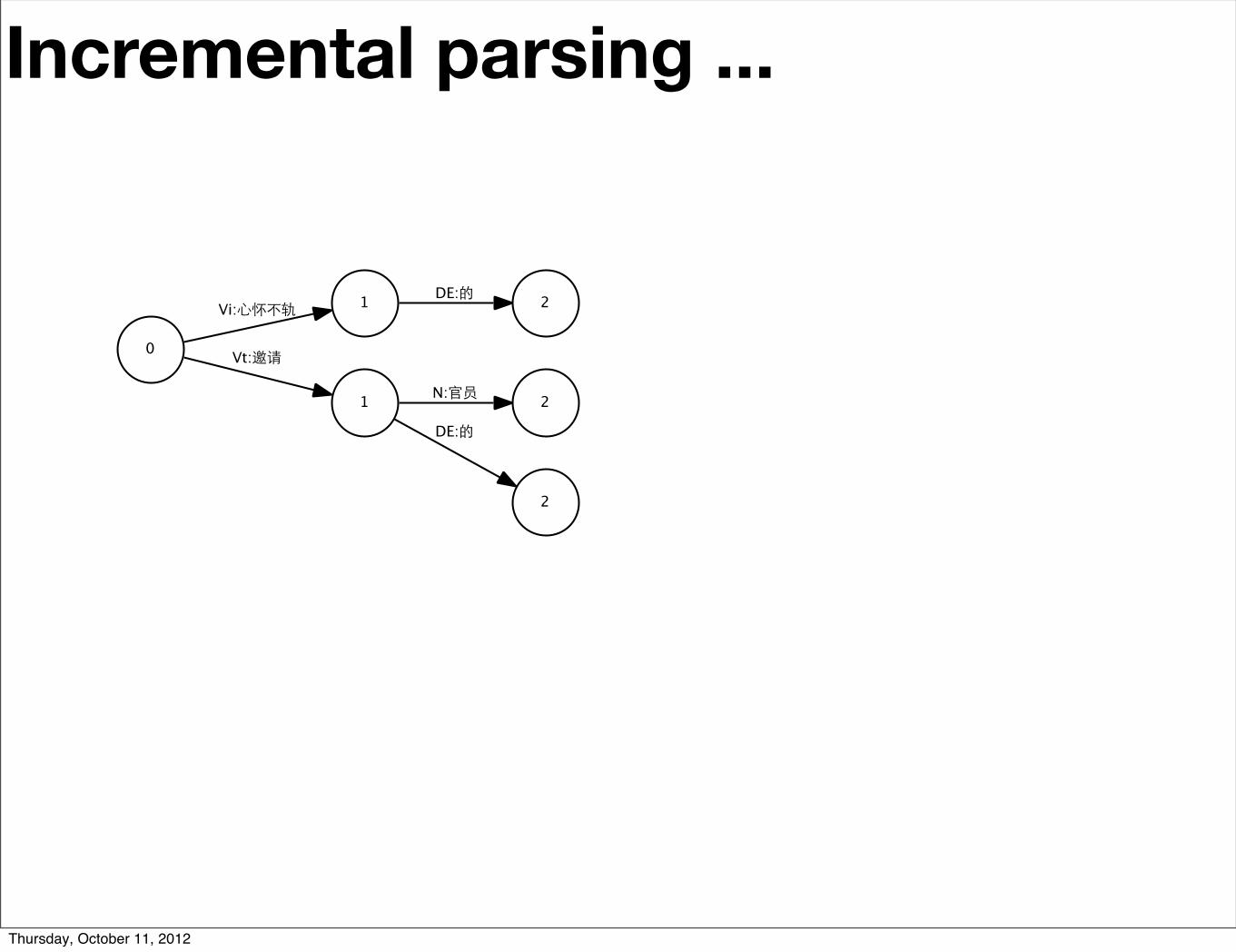
Incremental parsing ...
0
Thursday, October 11, 2012

0
1Vi:����
1
Vt:��
Incremental parsing ...
Thursday, October 11, 2012
0
1Vi:����
1
Vt:�
2DE:�
2N:��
2
DE:�
Incremental parsing ...
Thursday, October 11, 2012

0
1Vi:���
1
Vt:��
2DE:�
2N:��
2
DE:�
3N:��
3N:�
3DE:�
3N:��
3N:�
3
Vt:�
3
Vi:���
Incremental parsing ...
Thursday, October 11, 2012

0
1Vi:��
1
Vt:��
2DE:
2N:��
2
DE:
3N:��
3N:��
3DE:
3N:��
3N:��
3
Vt:��
3
Vi:��
4
N:��
4N:��
4N:��
4
Vt:��
4
Vi:��
Incremental parsing ...
Thursday, October 11, 2012

0
1Vi:��
1
Vt:��
2DE:
2N:��
2
DE:
3N:��
3N:��
3DE:
3N:��
3N:��
3
Vt:��
3
Vi:��
4
N:��
4N:��
4N:��
4
Vt:��
4
Vi:��
Incremental parsing ...
Thursday, October 11, 2012

0
1Vi:��
1
Vt:��
2DE:
2N:��
2
DE:
3N:��
3N:��
3DE:
3N:��
3N:��
3
Vt:��
3
Vi:��
4
N:��
4N:��
4N:��
4
Vt:��
4
Vi:��
Incremental parsing ...
Thursday, October 11, 2012

Expectations after the first wordProb Remainder
1. 0.678 ������ ��2. 0.083 ������ �� � ��3. 0.052 ������ �� � �� �� ��4. 0.039 ������ �� � �� ����5. 0.018 ������ �� � �� ��6. 0.015 ������ �� �� � ��7. 0.013 ������ �� � ����8. 0.011 ������ � �� �� ��9. 0.011 ������ � �� �� ��10. 0.010 ������ �� �� � ��11. 0.009 ������ � �� ����12. 0.009 ������ � �� ����13. 0.006 ������ �� � �� �� �� � ��14. 0.005 ������ �� �� �15. 0.004 ������ � �� ��16. 0.004 ������ � �� ��17. 0.003 ������ �� � ��18. 0.003 ������ �� � ��19. 0.003 ������ �� �� �20. 0.003 ������ � ����21. 0.003 ������ � ����22. 0.002 ������ �� � �� �� � ��23. 0.001 ������ � �� �� �� � ��24. 0.001 ������ � �� �� �� � ��25. 0.001 ������ �� � �� �� �� �� � ��26. 0.001 ������ �� �27. 0.001 ������ �� �
Thursday, October 11, 2012

Expectations after the first wordProb Remainder
1. 0.678 Vt N2. 0.083 Vt N de N3. 0.052 Vt N de N Vt N4. 0.039 Vt N de N Vi5. 0.018 Vt N de Vt N6. 0.015 Vt Vt N de N7. 0.013 Vt N de Vi8. 0.011 Vt de N Vt N9. 0.011 Vt de N Vt N10. 0.010 Vt N Vt de N11. 0.009 Vt de N Vi12. 0.009 Vt de N Vi13. 0.006 Vt N de N Vt N de N14. 0.005 Vt Vt N de15. 0.004 Vt de Vt N16. 0.004 Vt de Vt N17. 0.003 Vt Vt de N18. 0.003 Vt Vt de N19. 0.003 Vt N Vt de20. 0.003 Vt de Vi21. 0.003 Vt de Vi22. 0.002 Vt N de Vt N de N23. 0.001 Vt de N Vt N de N24. 0.001 Vt de N Vt N de N25. 0.001 Vt N de N Vt Vt N de N26. 0.001 Vt Vt de27. 0.001 Vt Vt de
(a) SRC prefix Vt
Prob Remainder1. 0.471 N Vt N2. 0.358 N Vi3. 0.057 N Vt N de N4. 0.026 N de N Vt N5. 0.017 N de N Vi6. 0.013 N Vt de N Vt N7. 0.010 N Vt Vt N de N8. 0.010 N Vt de N Vi9. 0.007 N Vt N Vt de N10. 0.004 N Vt de Vt N11. 0.004 N Vt Vt N de12. 0.003 N Vt de Vi13. 0.003 N de N Vt N de N14. 0.002 N Vt Vt de N15. 0.002 N Vt Vt de N16. 0.002 N Vt N Vt de17. 0.002 N Vt de N Vt N de N
(b) ORC prefix N
Thursday, October 11, 2012

V1(src)/N1(orc) N1(orc)/V1(src) DE N2(head)
600
800
1000
1200
1400
Read
ing
Tim
e (m
s)
S−SRS−ORO−SRO−OR
Observed: Chinese SRC < ORC
Lin & Bever 2006Thursday, October 11, 2012

Predicted: Chinese SRC < ORC0.
00.
20.
40.
60.
81.
01.
21.
4En
tropy
Red
uctio
n (b
it)
Vt(SR)/N(OR) N(SR)/Vt(OR) de N(head)
0.97
1.07
0.650.72
0 0
0.62
0.82
SRCORC
Thursday, October 11, 2012

Plan
1.Entropy reduction
2.Relative clausesa.Koreanb.Japanesec.Chinese
Thursday, October 11, 2012

Expectations after the first wordSRC: Vt... entropy = 2.157 bits
Prob Remainder1. 0.678 Vt N2. 0.083 Vt N de N3. 0.052 Vt N de N Vt N4. 0.039 Vt N de N Vi5. 0.018 Vt N de Vt N6. 0.015 Vt Vt N de N7. 0.013 Vt N de Vi8. 0.011 Vt de N Vt N9. 0.011 Vt de N Vt N10. 0.010 Vt N Vt de N11. 0.009 Vt de N Vi12. 0.009 Vt de N Vi13. 0.006 Vt N de N Vt N de N14. 0.005 Vt Vt N de15. 0.004 Vt de Vt N16. 0.004 Vt de Vt N17. 0.003 Vt Vt de N18. 0.003 Vt Vt de N19. 0.003 Vt N Vt de20. 0.003 Vt de Vi21. 0.003 Vt de Vi22. 0.002 Vt N de Vt N de N23. 0.001 Vt de N Vt N de N24. 0.001 Vt de N Vt N de N25. 0.001 Vt N de N Vt Vt N de N26. 0.001 Vt Vt de27. 0.001 Vt Vt de
ORC: N... entropy = 2.052 bits
Prob Remainder1. 0.471 N Vt N2. 0.358 N Vi3. 0.057 N Vt N de N4. 0.026 N de N Vt N5. 0.017 N de N Vi6. 0.013 N Vt de N Vt N7. 0.010 N Vt Vt N de N8. 0.010 N Vt de N Vi9. 0.007 N Vt N Vt de N10. 0.004 N Vt de Vt N11. 0.004 N Vt Vt N de12. 0.003 N Vt de Vi13. 0.003 N de N Vt N de N14. 0.002 N Vt Vt de N15. 0.002 N Vt Vt de N16. 0.002 N Vt N Vt de17. 0.002 N Vt de N Vt N de N
Thursday, October 11, 2012

Ingredients
Brown
corpus
1430 subject RC929 direct object167 indirect object41 oblique34 genitive subject4 genitive object
2. construction frequencies
1. formal grammar
e.g. Minimalist Grammars (Stabler 97)
CP
C’✭✭✭✭✭✭✭✭C
❤❤❤❤❤❤❤❤TP
DP(4)
D’✘✘✘✘✘D
the
RelP✥✥✥✥✥✥
DP(1)✧✧
NP(0)
N’
N
boy
❜❜D’
✚✚D
who
NumP
Num’✱✱
NumNP
t(0)
Rel’✘✘✘✘✘
Rel
TP✭✭✭✭✭✭✭
DP(3)
D’✚✚
D
the
NumP
Num’✱✱
Num❧❧NP
N’
N
sailor
❤❤❤❤❤❤❤T’✘✘✘✘✘
T✧✧
v✚✚
V
tell
v
❜❜T
-ed
vP✦✦✦
DP
t(3)
❛❛❛v’✏✏✏✏
v
t
����VP✏✏✏✏
DP(2)
D’✚✚
D
the
NumP
Num’✱✱
Num❧❧NP
N’
N
story
����V’✧✧
DP
t(2)
❜❜V’
✚✚V
t
p toP
p to’✏✏✏✏p to✚✚
Pto
to
p to
����PtoP✟✟✟
DP(1)
t(1)
❍❍❍Pto’✱✱
Pto
t
❧❧DP
t(1)
T’✦✦✦T
✱✱Be
be
❧❧T
-ed
❛❛❛BeP
Be’✧✧
Be
t
❜❜aP
✧✧DP
t(4)
❜❜a’
a AP
A’
A
interesting
1
Thursday, October 11, 2012

Entropy
H(X) = −�
x∈Xp(x) log2 p(x)
Thursday, October 11, 2012

Entropy example I# sides binary names entropy
4
00011011
2 bits
8
000001010011100101110111
3 bits
16
000000010010...
4 bits
7Thursday, October 11, 2012

Entropy example II
0.01
0.1
1
pro
ba
bili
ty
entropy = 2.1026594864876187
0.01
0.1
1
pro
ba
bili
ty
entropy = 2.765974425769394
Thursday, October 11, 2012

Entropy Reduction
expectations about as-yet-unheard words. As new words come in, given what one has already read, the probability of grammatical alternatives fluctuates. The idea of ER is that decreased uncertainty about the whole sentence, including probabilistic expectations, correlates with observed processing difficulty.1 Such processing difficulty reflects the amount of information that a word supplies about the overall disambiguation task in which the reader is engaged.
The average uncertainty of specified alternatives can be quantified using the fundamental information-theoretic notion, entropy, as formulated below in definition (1). In a language-processing scenario, the random variable X in (1) might take values that are derivations on a probabilistic grammar G. We could further specialize X to reflect derivations proceeding from various categories, e.g., NP, VP, S etc. Since rewriting grammars always have a start symbol, e.g. S, the expression HG(S) reflects the average uncertainty of guessing any derivation that G generates.
!
H(X) = " p(x)log2 p(x)x#X$ (1)
This entropy notation extends naturally to express conditioning events. If w1w2… wi
is an initial substring of a sentence generated by G, the conditional entropy HG(S|w1w2… wi) will be the uncertainty about just those derivations that have w1w2…wi as a prefix.2 By abbreviating HG(S|w1w2… wi) with Hi, the cognitive load ER(i) reflects the difference between conditional entropies before and after wi, a particular word in a particular position in a sentence.
!
ER(i) =Hi"1 "Hi when this difference is positive0 otherwise# $ % (2)
Formula (2) defines the ER complexity metric. It says that cognitive work is
predicted whenever uncertainty about the sentence’s structure, as generated by the grammar G, goes down after reading in a new word.
Intuitively, disambiguation occurs when the uncertainty about the rest of the sentence decreases. In such a situation, readers’ “beliefs” in various syntactic alternatives take on a more concentrated probability distribution (Jurafsky, 1996). The disambiguation work spent on this change is exactly the entropy reduction. By contrast when beliefs about syntactic alternatives become more disorganized, e.g. there exist many equiprobable syntactic expectations, then disambiguation work has not been done and the parser has gotten more confused. The background assumption of ER is that human sentence comprehension is making progress towards a peaked, disambiguated parser state and that the disambiguation efforts made during this process can be quantified by the reductions of structural uncertainty conveyed by words.
The ER proposal is not to be confused with another widely applied complexity metric, Surprisal (Hale, 2001; Levy, 2008), which is the conditional expectation of the log-ratio between forward probabilities of string prefixes before and after a word. 1 The ER is a generalization of Narayanan and Jurafsky’s (2002) idea of the “flipping the preferred interpretation”. Here the flip only counts if the reader moves towards a less-confused state of mind. 2 Conditional entropies can be calculated using standard techniques from computational linguistics such as chart parsing (Bar-Hillel, Perles & Shamir, 1964; Nederhof & Satta, 2008). See Chapter 13 of Jurafsky and Martin (2008) for more details.
Let w1w2…wi be a prefix of a sentence
generated by the grammar.
Thursday, October 11, 2012

Plan
1.Entropy reduction
2.Relative clausesa.Koreanb.Japanesec.Chinese
Thursday, October 11, 2012

RC processing principlesBroad Categories General Proposals
Memory
Burden
Linear Distance:Wanner and Maratsos (1978);Gibson (2000);Lewis and Vasishth (2005)
ORCs are harder than SRCsbecause they impose a greaterworking memory burden.
Structural Distance:O’Grady (1997); Hawkins (2004)
Structural
Frequency
Tuning Hypothesis:Mitchell et al (1995);Jurafsky (1996)
SRCs occur more frequently thanORCs and therefore are more ex-pected and easier to process.
Surprisal:Hale (2001); Levy (2008)
ORCs are more difficult becausethey require a low-probability rule.
Entropy Reduction:Hale (2006)
ORCs are harder because they forcethe comprehender through moreconfusing intermediate states.
Thursday, October 11, 2012

RC processing principlesBroad Categories General Proposals
Memory
Burden
Linear Distance:Wanner and Maratsos (1978);Gibson (2000);Lewis and Vasishth (2005)
ORCs are harder than SRCsbecause they impose a greaterworking memory burden.
Structural Distance:O’Grady (1997); Hawkins (2004)
Structural
Frequency
Tuning Hypothesis:Mitchell et al (1995);Jurafsky (1996)
SRCs occur more frequently thanORCs and therefore are more ex-pected and easier to process.
Surprisal:Hale (2001); Levy (2008)
ORCs are more difficult becausethey require a low-probability rule.
Entropy Reduction:Hale (2006)
ORCs are harder because they forcethe comprehender through moreconfusing intermediate states.
Thursday, October 11, 2012

e.g. Wanner, Maratsos & Kaplan’s HOLD hypothesis (1970s)or Gibson’s DLT (1990s) or Lewis & Vasishth ACT-R model (2000s)
Memory load in English RCs
a.�
The reporteri [ who ei attacked the senator ] disliked the editor.
b.�
The reporteri [ who the senator attacked ei ] disliked the editor.
Thursday, October 11, 2012

RC processing principlesBroad Categories General Proposals
Memory
Burden
Linear Distance:Wanner and Maratsos (1978);Gibson (2000);Lewis and Vasishth (2005)
ORCs are harder than SRCsbecause they impose a greaterworking memory burden.
Structural Distance:O’Grady (1997); Hawkins (2004)
Structural
Frequency
Tuning Hypothesis:Mitchell et al (1995);Jurafsky (1996)
SRCs occur more frequently thanORCs and therefore are more ex-pected and easier to process.
Surprisal:Hale (2001); Levy (2008)
ORCs are more difficult becausethey require a low-probability rule.
Entropy Reduction:Hale (2006)
ORCs are harder because they forcethe comprehender through moreconfusing intermediate states.
Thursday, October 11, 2012

RC processing principlesBroad Categories General Proposals
Memory
Burden
Linear Distance:Wanner and Maratsos (1978);Gibson (2000);Lewis and Vasishth (2005)
ORCs are harder than SRCsbecause they impose a greaterworking memory burden.
Structural Distance:O’Grady (1997); Hawkins (2004)
Structural
Frequency
Tuning Hypothesis:Mitchell et al (1995);Jurafsky (1996)
SRCs occur more frequently thanORCs and therefore are more ex-pected and easier to process.
Surprisal:Hale (2001); Levy (2008)
ORCs are more difficult becausethey require a low-probability rule.
Entropy Reduction:Hale (2006)
ORCs are harder because they forcethe comprehender through moreconfusing intermediate states.
Thursday, October 11, 2012

___ t senator-ACC criticize-REL reporter ‘the reporter who criticized the senator’
___
senator-NOM t criticize-REL reporter ‘the reporter whom the senator criticized’
Korean relative clauses
SRC
ORC
Thursday, October 11, 2012

!"
#!!"
$!!"
%!!"
&!!"
'!!!"
'#!!"
'$!!"
()*+,-"
.+/)01-234556789"
4:.;"
1<.12=:34>7"
/+<:,/2+?3789
"
-=<)2+?3455"
@,A01/0B"
1<-,02=:"
CD"
8D"
Observed: Korean SRC < ORC
Kwon et alLanguage 86(3) p546 2010
Thursday, October 11, 2012

Uncertainty and Prediction in Relativized Structures across East Asian LanguagesZhong Chen, Jiwon Yun, John Whitman, John Hale
Department of Linguistics, Cornell University
Korean Chinese Japanese
Our modeling derives an SR advantage at the head noun in line with structural frequencies (SR 55%/OR 45%). It also implicates headless RCs as a grammatical alternative whose exis-tence makes processing easier at the head noun in SRs. A corpus study reveals that 14% of SRs have a null head whereas 31% of ORs are headless. This asymmetry suggests that an overt head is more predictable in SRs and less work needs to be done.
Our modeling derives a pattern consistent with the empirical !nding in Kahraman et al. (2011) that at the “-no-wa” marked embedded verb, subject clefts are read more slowly than object clefts. Upon reaching the topic marker “-wa”, complement clauses with SBJ-pro are still in play in case of the SC pre!x, which causes more amount of uncertainties re-duced around that point. On the other hand, the OC pre!x is less ambiguous because complement clauses with object-pro are extremely rare.
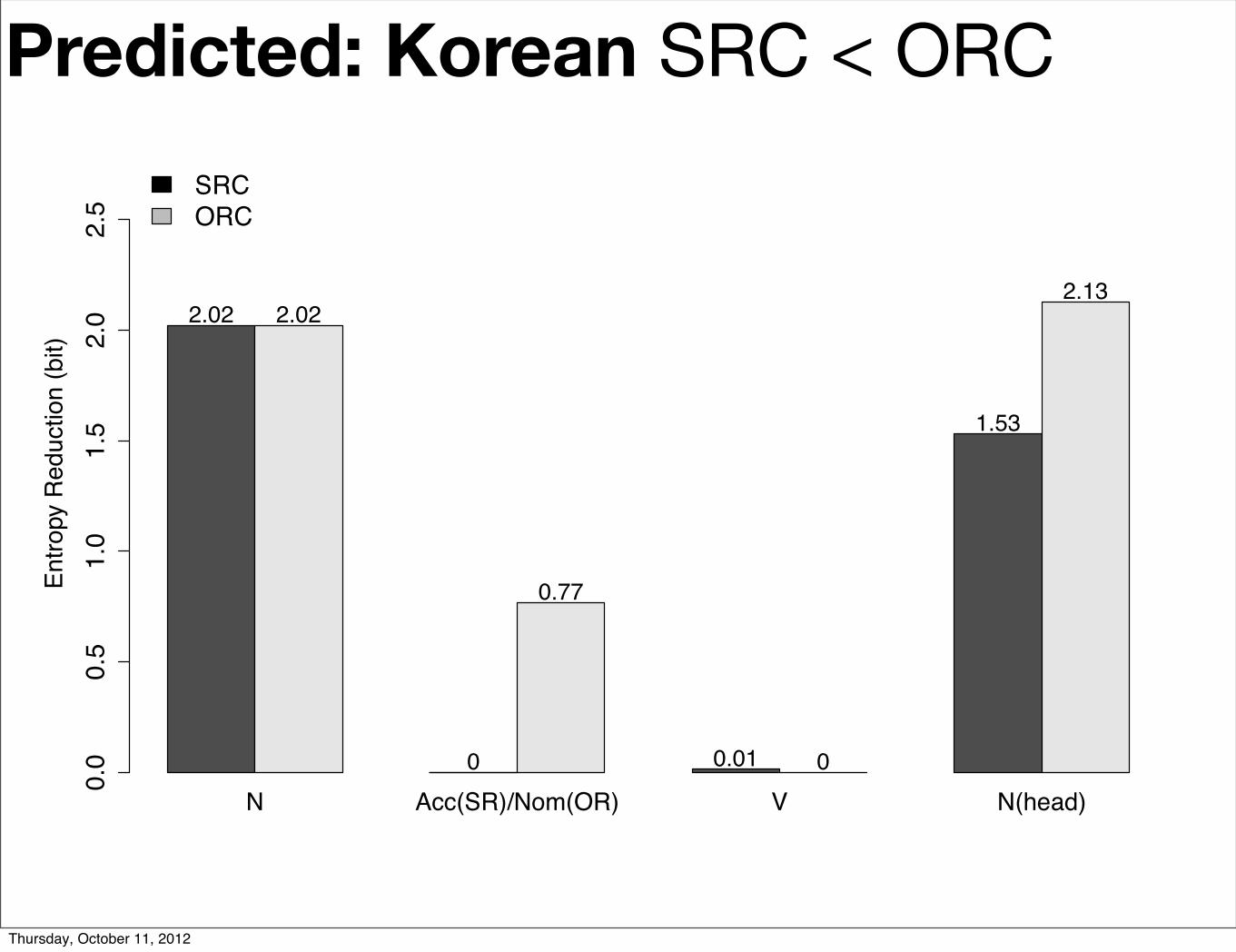
Our modeling con!rms the SR preference in Korean reported by Kwon et al. (2010) and fur-ther shows that this e"ect could emerge as early as the accusative/nominative marker. This re#ects, among other factors, a greater entropy reduction brought by sentence-initial nominative noun phrases.
Analysis
0.38 “Vt N de N” pro in matrix SBJ & Poss-OBJ0.25 “Vt N de N Vt N” SR in matrix SBJ0.19 “Vt N de N Vi” SR in matrix SBJ0.06 “Vt N de Vt N” headless SR in matrix SBJ0.05 “Vt N de Vi” headless SR in matrix SBJ
0.37 “Vt N de N”0.28 “Vt N de N Vt N”0.22 “Vt N de N Vi”SR
W3 “Vt N de” W4 “Vt N de N”
0.35 “N Vt de N Vt N” OR in matrix SBJ0.27 “N Vt de N Vi” OR in matrix SBJ0.17 “N Vt de Vt N” headless OR in matrix SBJ0.13 “N Vt de Vi” headless OR in matrix SBJ0.04 “N Vt de N Vt N de N” OR in matrix SBJ & Poss-OBJ
0.51 “N Vt de N Vt N”0.39 “N Vt de N Vi”0.06 “N Vt de N Vt N de N”OR
Subject Relatives (SR)
Object Relatives (OR)
0.51 “N Nom N Acc Vt” whole matrix C0.09 “N Acc Vt” pro in matrix SBJ0.05 “N Acc Vadj N Nom N Acc Vt” pro in adjunct SBJ0.03 “N Nom N Acc Vadn N Acc Vt” SR in matrix OBJ0.03 “N Acc Vadn N Nom N Acc Vt” SR in matrix SBJ
0.27 “N Acc Vt”0.17 “N Acc Vadj N Nom N Acc Vt”0.11 “N Acc Vadn N Nom N Acc Vt”SR
W1 “N” W2 “N Acc”
0.75 “N Nom N Acc Vt”0.05 “N Nom N Acc Vadn N Acc Vt”
OR
W4 “N Acc Vt no” W5 “N Acc Vt no wa”
Grammatical phenomena such as case-marking, head-omission, and object-drop create inferential problems that must be solved by any parsing mechanism. The Entropy Reductions brought about by "solving" these problems -- moving towards more concentrated distributions on derivations -- correspond with observed processing di$culty.
Hale, J. (2006). Uncertainty about the rest of the sentence. Cognitive Science, 30(4). Hsiao, F., & Gibson, E. (2003). Processing relative clauses in Chinese. Cognition, 90, 3–27.Kahraman, B., Sato, A., Ono, H. & Sakai, H. (2011). Incremental processing of gap-!ller dependencies: Evidence from the processing of subject and object clefts in Japanese. In
Proceedings of the 12th Tokyo Conference on Psycholinguistics.Kwon, N., Lee, Y., Gordon, P. C., Kluender, R., & Polinsky, M. (2010). Cognitive and linguistic factors a"ecting subject/object asymmetry: An eye-tracking study of pre-nominal relative
clauses in korean. Language, 86(3), 546–582.Lin, C.-J. C., & Bever, T. G. (2006). Subject preference in the processing of relative clauses in Chinese. In Proceedings of the 25th WCCFL (p. 254-260). Nederhof, M.-J. & Satta, G. (2008). Computation of distances for regular and context-free probabilistic languages. Theoretical Computer Science, 395, 235–254.Stabler, E. (1997). Derivational minimalism. In C. Retore (Ed.), Logical aspects of computational linguistics. Springer-Verlag.
Conclusion Selected References
0.51 “N Nom N Acc Vt” whole matrix C0.09 “N Acc Vt” SBJ-pro in matrix C0.05 “N Acc Vadj N Nom N Acc Vt” SBJ-pro in adjunct C0.03 “N Nom N Acc Vadn N Acc Vt” SR in matrix OBJ0.03 “N Acc Vadn N Nom N Acc Vt” SR in matrix SBJ
SC
OC
0.08 “N Acc Vt no Nom N Acc Vt” SR in matrix SBJ0.08 “N Acc Vt no wa N Acc Vt” SR in matrix Topic0.05 “N Acc Vt no Acc Vt” SR in matrix OBJ0.05 “N Acc Vt no Acc Vt” SBJ-pro in Comp C0.05 “N Acc Vt no Nom Vi” SR in matrix SBJ
0.15 “N Nom Vt no wa N Acc Vt” OR in matrix SBJ0.09 “N Nom Vt no Acc Vt” OR in matrix OBJ0.09 “N Nom Vt no wa Vi” OR in matrix Topic0.08 “N Nom Vt no Nom N Acc Vt” OR in matrix SBJ0.05 “N Nom Vt no Acc N Nom Vt” OR in matrix SBJ
0.39 “N Acc Vt no wa N Acc Vt”
0.39 “N Nom Vt no wa N Acc Vt”0.23 “N Nom Vt no wa Vi”
MinimalistGrammar
(Stabler, 1997)
WeightedContext-Free Grammar
‘Intersection’ Grammar conditioned on pre!xes(Nederhof & Satta, 2008)
Weighted, predictive syntactic analysisweighting constructions
with corpus counts
IntroductionEntropy Reduction (Hale, 2006) is a complexity metric that quanti!es the amount of information a word contributes towards reducing structural uncertainty. This certainty level depends on weighted, predictive syntactic analyses that are "still in play" at a given point. This poster uses Entropy Reduction to derive reported processing contrasts in Korean, Chinese and Japanese relativized structures.
Modeling procedure
Experimental Observation: SBJ Relatives > OBJ Relatives (Kwon et al., 2010)
Experimental Observations: SBJ Relatives > OBJ Relatives (Lin & Bever, 2006; Wu, 2009; Chen et al., 2012) SBJ Relatives < OBJ Relatives (Hsiao & Gibson, 2003; Gibson & Wu, in press)
Experimental Observation: Subject Clefts < Object Clefts (Kahraman et al., 2011)
ER Modeling:ER Modeling:Subject Relatives (SR)
Object Relatives (OR)
Analysis
Subject Clefts (SC)
Object Clefts (OC)
Analysis
Comprehension di"culty prediction
ER Modeling:
!"
#$
%&'()*+,-./012(3*'-453(6
7" 7# 7$ 7% 78 79
!:" !:"!:!
":;#
!:! !:!
!:%9!:$#
#:8#:9$
$:#;
$:8<=.>.
!"
#$
%&'()*+,-./012(3*'-453(6
7" 7# 7$ 7% 78 79 7:
!;!:!;!:
!;88
";:"
!;"%!;! !;! !;!
$;98
#;:9
!;8:!;8:
#;#%#;#%
<=>=
parse each pre!xin the sentence
Uncertainty at this word
set of derivations
derivation
!"# !$# !%# !&# !'# !(# !)#
e 祖母 を 介抱した の は 親戚 だ。 (SBJ) grandma ACC nursed NO WA relative COP ‘It was the relative who nursed the grandmother.’ #
!"# !$# !%# !&# !'# !(# !)#
祖母 が e 介抱した の は 親戚 だ。 grandma NOM (OBJ) nursed NO WA relative COP ‘It was the relative who the grandmother nursed.’ #
!"# !$# !%# !&# !'# !(#
e 邀 富豪 的 (官 ) 打了 者 SBJ invite tycoon DE official hit reporter ‘The official/Someone who invited the tycoon hit the reporter.’ #
!"# !$# !%# !&# !'# !(#
富豪 邀 e 的 (官 ) 打了 者 tycoon invite OBJ DE official hit reporter ‘The official/Someone who the tycoon invited hit the reporter.’ #
!"# !$# !%# !&# !'# !(#
e 기자 를 협박한 의원 이 유명해졌다. (SBJ) reporter ACC threaten-ADN senator NOM became famous ‘The senator who threatened the reporter became famous.’ #
!"# !$# !%# !&# !'# !(#
기자 가 e 협박한 의원 이 유명해졌다. reporter NOM (OBJ) threaten-ADN senator NOM became famous ‘The senator who the reporter threatened became famous.’ #
Comprehension di"culty predictionComprehension di"culty prediction
W1 “N” W2 “N Nom” W3 “N Vt de” W4 “N Vt de N” W4 “N Nom Vt no” W5 “N Nom Vt no wa”
!"!
!"#
$"!
$"#
%&'()*+,-./01'2)&,342'5
6$ 67 68 69 6# 6:
!";8
$"!<
!"#;
!"=
!"! !"!
!"99
!";$
$"8#
!"#;
!"8< !"8<
>-?-
The 25th Annual CUNY Conference on Human Sentence Processing, March 14-16, 2012 {zc77, jy249, jbw2, jthale}@cornell.edu
Korean
Thursday, October 11, 2012
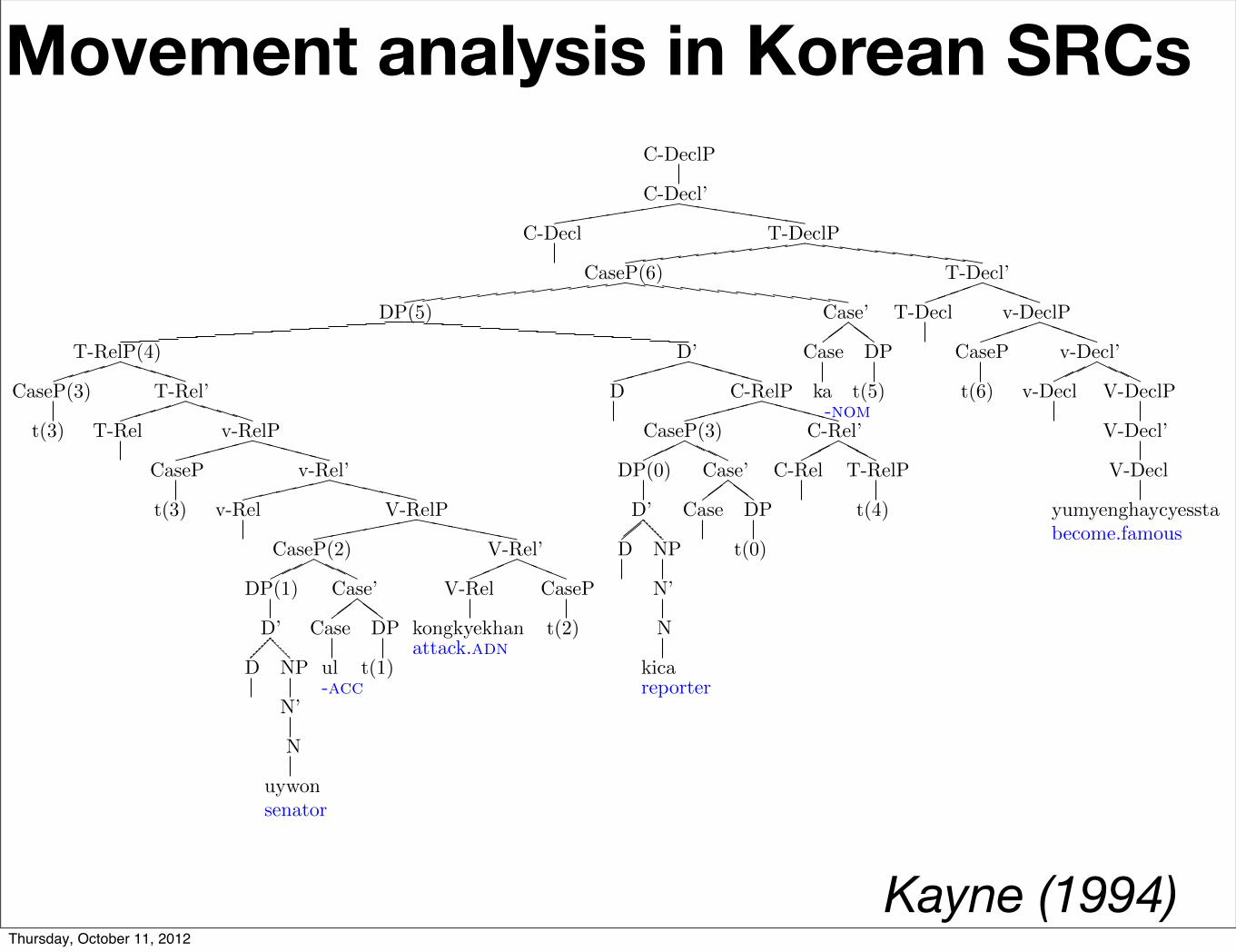
Movement analysis in Korean SRCs
Kayne (1994)
C-DeclP
C-Decl’✭✭✭✭✭✭✭C-Decl
❤❤❤❤❤❤❤T-DeclP✭✭✭✭✭✭✭✭✭✭
CaseP(6)✭✭✭✭✭✭✭✭✭✭✭✭DP(5)
T-RelP(4)✏✏✏✏CaseP(3)
t(3)
����T-Rel’✏✏✏✏
T-Rel
����v-RelP✘✘✘✘✘
CaseP
t(3)
v-Rel’✘✘✘✘✘
v-Rel
V-RelP✥✥✥✥✥✥
CaseP(2)✟✟✟
DP(1)
D’
D NP
N’
N
uywonsenator
❍❍❍Case’✚✚
Case
ul-acc
DP
t(1)
V-Rel’✦✦✦
V-Rel
kongkyekhanattack.adn
❛❛❛CaseP
t(2)
D’✘✘✘✘✘D
C-RelP✘✘✘✘✘
CaseP(3)✟✟✟
DP(0)
D’✱✱D NP
N’
N
kicareporter
❍❍❍Case’✚✚
CaseDP
t(0)
C-Rel’✟✟✟
C-Rel❍❍❍T-RelP
t(4)
❤❤❤❤❤❤❤❤❤❤❤❤Case’✚✚
Case
ka-nom
DP
t(5)
❤❤❤❤❤❤❤❤❤❤T-Decl’✏✏✏✏
T-Decl
����v-DeclP✏✏✏✏
CaseP
t(6)
����v-Decl’✟✟✟
v-Decl❍❍❍V-DeclP
V-Decl’
V-Decl
yumyenghaycyesstabecome.famous
Thursday, October 11, 2012

Uncertainty in processing relative clauses across East Asian languages 25
(1952), Attneave (1959) and Garner (1962). What differs in the present applicationof information theory is the use of generative grammars to specify the sentence-structural expectations that hearers have. The conditional probabilities in dia-grams like Figure 5 are calculated over grammatical alternatives, not just singlesuccessor words. In this regard our method integrates both information-processingpsychology and generative grammar.
This integration can be viewed also a defense of the view that all humansare bound by the same kinds of processing limitations. Namely, when faced witha flatter distribution on a greater number of grammatical alternatives, we shouldexpect slower reading times. Although such a limitation may perhaps reflect some-thing deep about cognition, something that constrains both humans and machines,the precise implications of this limit depend crucially on the grammar of particu-lar languages.
A Attestation counts
Attestation counts for selected construction types in three corpora are listed below.
Table 5 Attestation counts from Chinese Treebank 7.0
Count Construction Type4387 Simple sentence4206 Simple sentence with SBJ-pro366 Headed subject relatives123 Headless subject relatives203 Headed object relatives149 Headless object relatives
Table 6 Attestation counts from Korean Treebank 2.0
Count Construction Type511 Simple sentence96 Simple sentence with SBJ-pro2 Simple sentence with OBJ-pro631 Noun complement clause685 Noun complement clause with SBJ-pro6 Noun complement clause with OBJ-pro2854 Subject relative clause125 Object relative clause14 Relative clause with a pro
B A note on the infinity of possible remainders
Reference to the 100 most likely sentence-remainders in Figure 13, and listings of dozens ofpossible remainders consistent with various sentence prefixes, might prompt the question ofwhether our account assumes some degree of parallelism in the parsing process. It is true that,
Thursday, October 11, 2012

Morpheme level...
# simple transitive474 N Nom N Acc Vtd
# pro-drop264 N Acc Vtd
# relative clauses w/transitive verb543 N Acc Vtn N Nom N Acc Vtd125 N Nom Vtn N Nom N Acc Vtd
# noun complement clauses547 N Acc Vtn fact Nom N Acc Vtd6 N Nom Vtn fact Nom N Acc Vtd
...
Thursday, October 11, 2012

Predicted: Korean SRC < ORC0.
00.
51.
01.
52.
02.
5En
tropy
Red
uctio
n (b
it)
N Acc(SR)/Nom(OR) V N(head)
2.02 2.02
0
0.77
0.01 0
1.53
2.13
SRCORC
Thursday, October 11, 2012

Predicted: Korean SRC < ORC0.
00.
51.
01.
52.
02.
5En
tropy
Red
uctio
n (b
it)
N Acc(SR)/Nom(OR) V N(head)
2.02 2.02
0
0.77
0.01 0
1.53
2.13
SRCORC
Thursday, October 11, 2012

Uncertainty in processing relative clauses across East Asian languages 17
Probability Remainder Type
0.272 [e N Acc Vtn] fact Nom Vid NCC with Sbj-pro0.239 [e N Acc Vtn] N Nom Vid SRC
0.052 [e N Acc Vtn] [e Vin] N Nom Vid stacked SRCs
0.033 [e N Acc Vtn] fact Nom N Acc Vtd NCC with Sbj-pro0.032 e N Acc Vtd simple SOV sentence with Sbj-pro. . . . . . . . .
entropy = 5.930
(a) SRC prefix N Acc
Probability Remainder Type
0.764 N nom Vid simple SV sentence
0.094 N nom N Acc Vtd simple SOV sentence
0.021 [N nom Vin] fact Nom Vid NCC
0.020 N nom [eVin] N Acc Vtd SRC
0.014 [N nom N Acc Vtn] fact Nom Vid NCC
. . . . . . . . .
entropy = 2.072
(b) ORC prefix N Nom
Fig. 6 Possible remainders at the second word for Korean RCs
both SRC and ORC prefixes. The fact that one of the tables is much shorter than
the other makes clear, visually, that the cardinality of non-trivial remainders is
greater in the ORC prefix. This formalizes the idea of greater sentence-medial
ambiguity mentioned in the Introduction (section 1).
This explanation of the Subject Advantage at the head noun accords with that
given in Yun et al (2010). These authors attribute the ORC processing penalty
to additional possible remainders. The derivations numbered in 15, 16, and 17 in
Table 3 correspond to the additional structures for the ORC prefix presented in
Yun et al (2010).
(7) kica
reporter
ka
Nom
[e e kongkyekhan]
t pro attack.Adn
uywon
senator
ul
Acc
manassta.
meet.Decl
‘The reporter met the senator who attacked someone.’
(8) kica
reporter
ka
Nom
[e e kongkyekhan]
pro t attack.Adn
uywon
senator
ul
Acc
manassta.
meet.Decl
‘The reporter met the senator whom someone attacked.’
(9) kica
reporter
ka
Nom
[e e kongkyekhan]
pro pro attack.Adn
sasil
fact
ul
Acc
alkoissta.
know.Decl
‘The reporter knows the fact that someone attacked someone.’
5.2 Japanese
The Japanese processing difficulty predictions are shown in Figure 7. The pattern
here is very similar to the Korean difficulty predictions given in subsection 5.1
As shown in Figure 7, the Subject Advantage is observed at the same structural
position as in the Korean examples: at the second word (i.e. case marker) and at
the fourth word (i.e. head noun).
As in Korean, the the Subject Advantage at the case marker is attributable
to the lower entropy value associated with the ORC prefix N Nom, albeit the
Thursday, October 11, 2012

Uncertainty in processing relative clauses across East Asian languages 17
Probability Remainder Type
0.272 [e N Acc Vtn] fact Nom Vid NCC with Sbj-pro0.239 [e N Acc Vtn] N Nom Vid SRC
0.052 [e N Acc Vtn] [e Vin] N Nom Vid stacked SRCs
0.033 [e N Acc Vtn] fact Nom N Acc Vtd NCC with Sbj-pro0.032 e N Acc Vtd simple SOV sentence with Sbj-pro. . . . . . . . .
entropy = 5.930
(a) SRC prefix N Acc
Probability Remainder Type
0.764 N nom Vid simple SV sentence
0.094 N nom N Acc Vtd simple SOV sentence
0.021 [N nom Vin] fact Nom Vid NCC
0.020 N nom [eVin] N Acc Vtd SRC
0.014 [N nom N Acc Vtn] fact Nom Vid NCC
. . . . . . . . .
entropy = 2.072
(b) ORC prefix N Nom
Fig. 6 Possible remainders at the second word for Korean RCs
both SRC and ORC prefixes. The fact that one of the tables is much shorter than
the other makes clear, visually, that the cardinality of non-trivial remainders is
greater in the ORC prefix. This formalizes the idea of greater sentence-medial
ambiguity mentioned in the Introduction (section 1).
This explanation of the Subject Advantage at the head noun accords with that
given in Yun et al (2010). These authors attribute the ORC processing penalty
to additional possible remainders. The derivations numbered in 15, 16, and 17 in
Table 3 correspond to the additional structures for the ORC prefix presented in
Yun et al (2010).
(7) kica
reporter
ka
Nom
[e e kongkyekhan]
t pro attack.Adn
uywon
senator
ul
Acc
manassta.
meet.Decl
‘The reporter met the senator who attacked someone.’
(8) kica
reporter
ka
Nom
[e e kongkyekhan]
pro t attack.Adn
uywon
senator
ul
Acc
manassta.
meet.Decl
‘The reporter met the senator whom someone attacked.’
(9) kica
reporter
ka
Nom
[e e kongkyekhan]
pro pro attack.Adn
sasil
fact
ul
Acc
alkoissta.
know.Decl
‘The reporter knows the fact that someone attacked someone.’
5.2 Japanese
The Japanese processing difficulty predictions are shown in Figure 7. The pattern
here is very similar to the Korean difficulty predictions given in subsection 5.1
As shown in Figure 7, the Subject Advantage is observed at the same structural
position as in the Korean examples: at the second word (i.e. case marker) and at
the fourth word (i.e. head noun).
As in Korean, the the Subject Advantage at the case marker is attributable
to the lower entropy value associated with the ORC prefix N Nom, albeit the
Thursday, October 11, 2012

entropy = 4.862
0.483 N Nom Vid0.104 Vin N Nom Vid0.059 N Nom N Acc Vtd0.024 Vin fact Nom Vid0.022 Vin Vin N Nom Vid. . . . . .
entropy = 2.840
0.697 N Nom Vid0.086 N Nom N Acc Vtd0.024 N Acc Vtn fact Nom Vid0.021 N Acc Vtn N Nom Vid0.019 N Nom Vin fact Nom Vid. . . . . .
entropy = 2.840
0.697 N Nom Vid0.086 N Nom N Acc Vtd0.024 N Acc Vtn fact Nom Vid0.021 N Acc Vtn N Nom Vid0.019 N Nom Vin fact Nom Vid. . . . . .
entropy = 5.930
0.272 N Acc Vtn fact Nom Vid0.239 N Acc Vtn N Nom Vid0.052 N Acc Vtn Vin N Nom Vid0.033 N Acc Vtn fact Nom N Acc Vtd0.032 N Acc Vtd. . . . . .
entropy = 2.072
0.764 N Nom Vid0.094 N Nom N Acc Vtd0.021 N Nom Vin fact Nom Vid0.020 N Nom Vin N Acc Vtd0.014 N Nom N Acc Vtn fact Nom Vid. . . . . .
entropy = 5.915
0.281 N Acc Vtn fact Nom Vid0.247 N Acc Vtn N Nom Vid0.053 N Acc Vtn Vin N Nom Vid0.035 N Acc Vtn fact Nom N Acc Vtd0.030 N Acc Vtn N Nom N Acc Vtd. . . . . .
entropy = 6.813
0.367 N Nom Vtn N Nom Vid0.079 N Nom Vtn Vin N Nom Vid0.045 N Nom Vtn N Nom N Acc Vtd0.042 N Nom Vtn fact Nom Vid0.018 N Nom Vtn Vin fact Nom Vid. . . . . .
entropy = 4.384
0.588 N Acc Vtn N Nom Vid0.072 N Acc Vtn N Nom N Acc Vtd0.020 N Acc Vtn N Acc Vtn fact Nom Vid0.020 N Acc Vtn N Acc Vtn fact Nom Vid0.018 N Acc Vtn N Acc Vtn N Nom Vid. . . . . .
entropy = 4.686
0.562 N Nom Vtn N Nom Vid0.069 N Nom Vtn N Nom N Acc Vtd0.019 N Nom Vtn N Acc Vtn fact Nom Vid0.019 N Nom Vtn N Acc Vtn fact Nom Vid0.017 N Nom Vtn N Acc Vtn N Nom Vid. . . . . .
SRC ORC
w0
w1
w2
w3
w4
ER=2.02ER=2.02
ER=0 ER=0.77
ER=0.01 ER=0
ER=1.53 ER=2.13
Thursday, October 11, 2012

entropy = 4.862
0.483 N Nom Vid0.104 Vin N Nom Vid0.059 N Nom N Acc Vtd0.024 Vin fact Nom Vid0.022 Vin Vin N Nom Vid. . . . . .
entropy = 2.840
0.697 N Nom Vid0.086 N Nom N Acc Vtd0.024 N Acc Vtn fact Nom Vid0.021 N Acc Vtn N Nom Vid0.019 N Nom Vin fact Nom Vid. . . . . .
entropy = 2.840
0.697 N Nom Vid0.086 N Nom N Acc Vtd0.024 N Acc Vtn fact Nom Vid0.021 N Acc Vtn N Nom Vid0.019 N Nom Vin fact Nom Vid. . . . . .
entropy = 5.930
0.272 N Acc Vtn fact Nom Vid0.239 N Acc Vtn N Nom Vid0.052 N Acc Vtn Vin N Nom Vid0.033 N Acc Vtn fact Nom N Acc Vtd0.032 N Acc Vtd. . . . . .
entropy = 2.072
0.764 N Nom Vid0.094 N Nom N Acc Vtd0.021 N Nom Vin fact Nom Vid0.020 N Nom Vin N Acc Vtd0.014 N Nom N Acc Vtn fact Nom Vid. . . . . .
entropy = 5.915
0.281 N Acc Vtn fact Nom Vid0.247 N Acc Vtn N Nom Vid0.053 N Acc Vtn Vin N Nom Vid0.035 N Acc Vtn fact Nom N Acc Vtd0.030 N Acc Vtn N Nom N Acc Vtd. . . . . .
entropy = 6.813
0.367 N Nom Vtn N Nom Vid0.079 N Nom Vtn Vin N Nom Vid0.045 N Nom Vtn N Nom N Acc Vtd0.042 N Nom Vtn fact Nom Vid0.018 N Nom Vtn Vin fact Nom Vid. . . . . .
entropy = 4.384
0.588 N Acc Vtn N Nom Vid0.072 N Acc Vtn N Nom N Acc Vtd0.020 N Acc Vtn N Acc Vtn fact Nom Vid0.020 N Acc Vtn N Acc Vtn fact Nom Vid0.018 N Acc Vtn N Acc Vtn N Nom Vid. . . . . .
entropy = 4.686
0.562 N Nom Vtn N Nom Vid0.069 N Nom Vtn N Nom N Acc Vtd0.019 N Nom Vtn N Acc Vtn fact Nom Vid0.019 N Nom Vtn N Acc Vtn fact Nom Vid0.017 N Nom Vtn N Acc Vtn N Nom Vid. . . . . .
SRC ORC
w0
w1
w2
w3
w4
ER=2.02ER=2.02
ER=0 ER=0.77
ER=0.01 ER=0
ER=1.53 ER=2.13
Thursday, October 11, 2012
Predicted: Korean SRC < ORC0.
00.
51.
01.
52.
02.
5En
tropy
Red
uctio
n (b
it)
N Acc(SR)/Nom(OR) V N(head)
2.02 2.02
0
0.77
0.01 0
1.53
2.13
SRCORC
Thursday, October 11, 2012

Predicted: Korean SRC < ORC0.
00.
51.
01.
52.
02.
5En
tropy
Red
uctio
n (b
it)
N Acc(SR)/Nom(OR) V N(head)
2.02 2.02
0
0.77
0.01 0
1.53
2.13
SRCORC
Thursday, October 11, 2012

16 anonymized running head
entropy = 4.862
0.483 N Nom Vid0.104 Vin N Nom Vid0.059 N Nom N Acc Vtd0.024 Vin fact Nom Vid0.022 Vin Vin N Nom Vid. . . . . .
entropy = 2.840
0.697 N Nom Vid0.086 N Nom N Acc Vtd0.024 N Acc Vtn fact Nom Vid0.021 N Acc Vtn N Nom Vid0.019 N Nom Vin fact Nom Vid. . . . . .
entropy = 2.840
0.697 N Nom Vid0.086 N Nom N Acc Vtd0.024 N Acc Vtn fact Nom Vid0.021 N Acc Vtn N Nom Vid0.019 N Nom Vin fact Nom Vid. . . . . .
entropy = 5.930
0.272 N Acc Vtn fact Nom Vid0.239 N Acc Vtn N Nom Vid0.052 N Acc Vtn Vin N Nom Vid0.033 N Acc Vtn fact Nom N Acc Vtd0.032 N Acc Vtd. . . . . .
entropy = 2.072
0.764 N Nom Vid0.094 N Nom N Acc Vtd0.021 N Nom Vin fact Nom Vid0.020 N Nom Vin N Acc Vtd0.014 N Nom N Acc Vtn fact Nom Vid. . . . . .
entropy = 5.915
0.281 N Acc Vtn fact Nom Vid0.247 N Acc Vtn N Nom Vid0.053 N Acc Vtn Vin N Nom Vid0.035 N Acc Vtn fact Nom N Acc Vtd0.030 N Acc Vtn N Nom N Acc Vtd. . . . . .
entropy = 6.813
0.367 N Nom Vtn N Nom Vid0.079 N Nom Vtn Vin N Nom Vid0.045 N Nom Vtn N Nom N Acc Vtd0.042 N Nom Vtn fact Nom Vid0.018 N Nom Vtn Vin fact Nom Vid. . . . . .
entropy = 4.384
0.588 N Acc Vtn N Nom Vid0.072 N Acc Vtn N Nom N Acc Vtd0.020 N Acc Vtn N Acc Vtn fact Nom Vid0.020 N Acc Vtn N Acc Vtn fact Nom Vid0.018 N Acc Vtn N Acc Vtn N Nom Vid. . . . . .
entropy = 4.686
0.562 N Nom Vtn N Nom Vid0.069 N Nom Vtn N Nom N Acc Vtd0.019 N Nom Vtn N Acc Vtn fact Nom Vid0.019 N Nom Vtn N Acc Vtn fact Nom Vid0.017 N Nom Vtn N Acc Vtn N Nom Vid. . . . . .
SRC ORC
w0
w1
w2
w3
w4
ER=2.02 ER=2.02
ER=0 ER=0.77
ER=0.01 ER=0
ER=1.53 ER=2.13
Fig. 5 Likely derivations and their conditional probabilities in Korean RCs
As shown in Figure 5, the Subject Advantage at the head noun is mainly
because the ORC prefix before the head noun, N Nom Vtn, is associated with
higher entropy value (6.813 bits) than the corresponding SRC prefix N acc Vtn(5.915 bits); since the entropy at w4 is similar in both cases (4.38 and 4.67 bits), the
higher entropy at w3 in the ORC case corresponds to a greater reduction in entropy.
Since the difference at w3 is not big enough to be clearly reflected in the in the top
five parses, it is necessary to examine more derivations to characterize the source
of the difference. As mentioned in section 4, a higher entropy is associated with
a flatter distribution; for any given threshold, say 0.001, higher entropy therefore
corresponds to having a greater number of derivations whose probabilities are
above the threshold. Table 3 shows all parses with a probability over 0.001 for
Thursday, October 11, 2012

16 anonymized running head
entropy = 4.862
0.483 N Nom Vid0.104 Vin N Nom Vid0.059 N Nom N Acc Vtd0.024 Vin fact Nom Vid0.022 Vin Vin N Nom Vid. . . . . .
entropy = 2.840
0.697 N Nom Vid0.086 N Nom N Acc Vtd0.024 N Acc Vtn fact Nom Vid0.021 N Acc Vtn N Nom Vid0.019 N Nom Vin fact Nom Vid. . . . . .
entropy = 2.840
0.697 N Nom Vid0.086 N Nom N Acc Vtd0.024 N Acc Vtn fact Nom Vid0.021 N Acc Vtn N Nom Vid0.019 N Nom Vin fact Nom Vid. . . . . .
entropy = 5.930
0.272 N Acc Vtn fact Nom Vid0.239 N Acc Vtn N Nom Vid0.052 N Acc Vtn Vin N Nom Vid0.033 N Acc Vtn fact Nom N Acc Vtd0.032 N Acc Vtd. . . . . .
entropy = 2.072
0.764 N Nom Vid0.094 N Nom N Acc Vtd0.021 N Nom Vin fact Nom Vid0.020 N Nom Vin N Acc Vtd0.014 N Nom N Acc Vtn fact Nom Vid. . . . . .
entropy = 5.915
0.281 N Acc Vtn fact Nom Vid0.247 N Acc Vtn N Nom Vid0.053 N Acc Vtn Vin N Nom Vid0.035 N Acc Vtn fact Nom N Acc Vtd0.030 N Acc Vtn N Nom N Acc Vtd. . . . . .
entropy = 6.813
0.367 N Nom Vtn N Nom Vid0.079 N Nom Vtn Vin N Nom Vid0.045 N Nom Vtn N Nom N Acc Vtd0.042 N Nom Vtn fact Nom Vid0.018 N Nom Vtn Vin fact Nom Vid. . . . . .
entropy = 4.384
0.588 N Acc Vtn N Nom Vid0.072 N Acc Vtn N Nom N Acc Vtd0.020 N Acc Vtn N Acc Vtn fact Nom Vid0.020 N Acc Vtn N Acc Vtn fact Nom Vid0.018 N Acc Vtn N Acc Vtn N Nom Vid. . . . . .
entropy = 4.686
0.562 N Nom Vtn N Nom Vid0.069 N Nom Vtn N Nom N Acc Vtd0.019 N Nom Vtn N Acc Vtn fact Nom Vid0.019 N Nom Vtn N Acc Vtn fact Nom Vid0.017 N Nom Vtn N Acc Vtn N Nom Vid. . . . . .
SRC ORC
w0
w1
w2
w3
w4
ER=2.02 ER=2.02
ER=0 ER=0.77
ER=0.01 ER=0
ER=1.53 ER=2.13
Fig. 5 Likely derivations and their conditional probabilities in Korean RCs
As shown in Figure 5, the Subject Advantage at the head noun is mainly
because the ORC prefix before the head noun, N Nom Vtn, is associated with
higher entropy value (6.813 bits) than the corresponding SRC prefix N acc Vtn(5.915 bits); since the entropy at w4 is similar in both cases (4.38 and 4.67 bits), the
higher entropy at w3 in the ORC case corresponds to a greater reduction in entropy.
Since the difference at w3 is not big enough to be clearly reflected in the in the top
five parses, it is necessary to examine more derivations to characterize the source
of the difference. As mentioned in section 4, a higher entropy is associated with
a flatter distribution; for any given threshold, say 0.001, higher entropy therefore
corresponds to having a greater number of derivations whose probabilities are
above the threshold. Table 3 shows all parses with a probability over 0.001 for
Thursday, October 11, 2012

Japanese predictions0.
00.
20.
40.
60.
81.
01.
21.
4En
tropy
Red
uctio
n (b
it)
N Acc(SR)/Nom(OR) V N(head)
1.05 1.05
0.15
0.45
0 0 0
0.87
SRCORC
Thursday, October 11, 2012

Plan
1.Entropy reduction
2.Relative clausesa.Koreanb.Japanesec.Chinese
Thursday, October 11, 2012

Chinese relative clauses
SRC [[
eiei
��yaoqinginvite
��fuhaotycoon
�deDE
]]
(��i)guanyuaniofficial
��da-lehit
��jizhereporter
‘The official who invited the tycoon hit the reporter.’
ORC [
[
��fuhaotycoon
��yaoqinginvite
eiei
�deDE
]
]
(��i)guanyuaniofficial
��da-lehit
��jizhereporter
‘The official who the tycoon invited hit the reporter.’
Thursday, October 11, 2012

V1(src)/N1(orc) N1(orc)/V1(src) DE N2(head)
600
800
1000
1200
1400
Read
ing
Tim
e (m
s)
S−SRS−ORO−SRO−OR
Observed: Chinese SRC < ORC
Lin & Bever 2006Thursday, October 11, 2012

Predicted: Chinese SRC < ORC0.
00.
20.
40.
60.
81.
01.
21.
4En
tropy
Red
uctio
n (b
it)
Vt(SR)/N(OR) N(SR)/Vt(OR) de N(head)
0.97
1.07
0.650.72
0 0
0.62
0.82
SRCORC
Thursday, October 11, 2012

Why?entropy = 3.126
0.311 N Vt N0.237 N Vi0.179 Vt N0.073 Vi0.038 N Vt N de N. . . . . .
entropy = 2.157
0.678 Vt N0.083 Vt N de N0.052 Vt N de N Vt N0.039 Vt N de N Vi0.018 Vt N de Vt N. . . . . .
entropy = 2.052
0.471 N Vt N0.358 N Vi0.057 N Vt N de N0.026 N de N Vt N0.017 N de N Vi. . . . . .
entropy = 1.505
0.745 Vt N0.091 Vt N de N0.057 Vt N de N Vt N0.043 Vt N de N Vi0.019 Vt N de Vt N. . . . . .
entropy = 1.330
0.794 N Vt N0.097 N Vt N de N0.022 N Vt de N Vt N0.018 N Vt Vt N de N0.017 N Vt de N Vi. . . . . .
entropy = 2.460
0.377 Vt N de N0.237 Vt N de N Vt N0.180 Vt N de N Vi0.080 Vt N de Vt N0.061 Vt N de Vi. . . . . .
entropy = 2.342
0.384 N Vt de N Vt N0.292 N Vt de N Vi0.130 N Vt de Vt N0.099 N Vt de Vi0.047 N Vt de N Vt N de N. . . . . .
entropy = 1.841
0.449 Vt N de N0.283 Vt N de N Vt N0.215 Vt N de N Vi0.034 Vt N de N Vt N de N0.006 Vt N de N Vt Vt N de N. . . . . .
entropy = 1.526
0.514 N Vt de N Vt N0.391 N Vt de N Vi0.063 N Vt de N Vt N de N0.011 N Vt de N Vt Vt N de N0.007 N Vt de N Vt N Vt de N. . . . . .
SRC ORC
w0
w1
w2
w3
w4
ER=0.97ER=1.07
ER=0.65 ER=0.72
ER=0 ER=0
ER=0.62 ER=0.82
Thursday, October 11, 2012

Why?entropy = 3.126
0.311 N Vt N0.237 N Vi0.179 Vt N0.073 Vi0.038 N Vt N de N. . . . . .
entropy = 2.157
0.678 Vt N0.083 Vt N de N0.052 Vt N de N Vt N0.039 Vt N de N Vi0.018 Vt N de Vt N. . . . . .
entropy = 2.052
0.471 N Vt N0.358 N Vi0.057 N Vt N de N0.026 N de N Vt N0.017 N de N Vi. . . . . .
entropy = 1.505
0.745 Vt N0.091 Vt N de N0.057 Vt N de N Vt N0.043 Vt N de N Vi0.019 Vt N de Vt N. . . . . .
entropy = 1.330
0.794 N Vt N0.097 N Vt N de N0.022 N Vt de N Vt N0.018 N Vt Vt N de N0.017 N Vt de N Vi. . . . . .
entropy = 2.460
0.377 Vt N de N0.237 Vt N de N Vt N0.180 Vt N de N Vi0.080 Vt N de Vt N0.061 Vt N de Vi. . . . . .
entropy = 2.342
0.384 N Vt de N Vt N0.292 N Vt de N Vi0.130 N Vt de Vt N0.099 N Vt de Vi0.047 N Vt de N Vt N de N. . . . . .
entropy = 1.841
0.449 Vt N de N0.283 Vt N de N Vt N0.215 Vt N de N Vi0.034 Vt N de N Vt N de N0.006 Vt N de N Vt Vt N de N. . . . . .
entropy = 1.526
0.514 N Vt de N Vt N0.391 N Vt de N Vi0.063 N Vt de N Vt N de N0.011 N Vt de N Vt Vt N de N0.007 N Vt de N Vt N Vt de N. . . . . .
SRC ORC
w0
w1
w2
w3
w4
ER=0.97ER=1.07
ER=0.65 ER=0.72
ER=0 ER=0
ER=0.62 ER=0.82
Thursday, October 11, 2012

Expectations at a given prefixSRC: Vt... entropy = 2.157 bits
Prob Remainder1. 0.678 Vt N2. 0.083 Vt N de N3. 0.052 Vt N de N Vt N4. 0.039 Vt N de N Vi5. 0.018 Vt N de Vt N6. 0.015 Vt Vt N de N7. 0.013 Vt N de Vi8. 0.011 Vt de N Vt N9. 0.011 Vt de N Vt N10. 0.010 Vt N Vt de N11. 0.009 Vt de N Vi12. 0.009 Vt de N Vi13. 0.006 Vt N de N Vt N de N14. 0.005 Vt Vt N de15. 0.004 Vt de Vt N16. 0.004 Vt de Vt N17. 0.003 Vt Vt de N18. 0.003 Vt Vt de N19. 0.003 Vt N Vt de20. 0.003 Vt de Vi21. 0.003 Vt de Vi22. 0.002 Vt N de Vt N de N23. 0.001 Vt de N Vt N de N24. 0.001 Vt de N Vt N de N25. 0.001 Vt N de N Vt Vt N de N26. 0.001 Vt Vt de27. 0.001 Vt Vt de
ORC: N... entropy = 2.052 bits
Prob Remainder1. 0.471 N Vt N2. 0.358 N Vi3. 0.057 N Vt N de N4. 0.026 N de N Vt N5. 0.017 N de N Vi6. 0.013 N Vt de N Vt N7. 0.010 N Vt Vt N de N8. 0.010 N Vt de N Vi9. 0.007 N Vt N Vt de N10. 0.004 N Vt de Vt N11. 0.004 N Vt Vt N de12. 0.003 N Vt de Vi13. 0.003 N de N Vt N de N14. 0.002 N Vt Vt de N15. 0.002 N Vt Vt de N16. 0.002 N Vt N Vt de17. 0.002 N Vt de N Vt N de N
Thursday, October 11, 2012
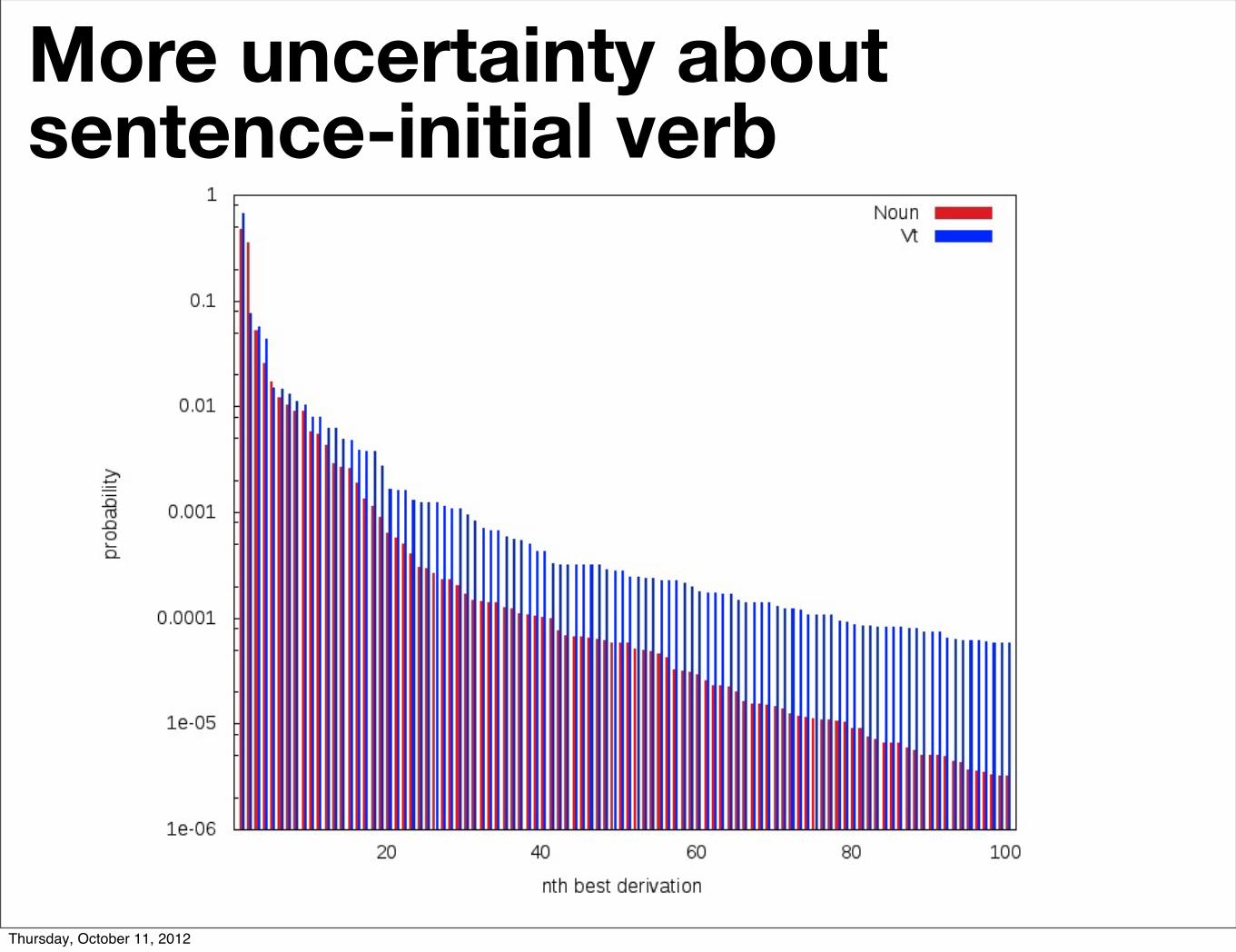
More uncertainty aboutsentence-initial verb
Thursday, October 11, 2012

Why? entropy = 3.126
0.311 N Vt N0.237 N Vi0.179 Vt N0.073 Vi0.038 N Vt N de N. . . . . .
entropy = 2.157
0.678 Vt N0.083 Vt N de N0.052 Vt N de N Vt N0.039 Vt N de N Vi0.018 Vt N de Vt N. . . . . .
entropy = 2.052
0.471 N Vt N0.358 N Vi0.057 N Vt N de N0.026 N de N Vt N0.017 N de N Vi. . . . . .
entropy = 1.505
0.745 Vt N0.091 Vt N de N0.057 Vt N de N Vt N0.043 Vt N de N Vi0.019 Vt N de Vt N. . . . . .
entropy = 1.330
0.794 N Vt N0.097 N Vt N de N0.022 N Vt de N Vt N0.018 N Vt Vt N de N0.017 N Vt de N Vi. . . . . .
entropy = 2.460
0.377 Vt N de N0.237 Vt N de N Vt N0.180 Vt N de N Vi0.080 Vt N de Vt N0.061 Vt N de Vi. . . . . .
entropy = 2.342
0.384 N Vt de N Vt N0.292 N Vt de N Vi0.130 N Vt de Vt N0.099 N Vt de Vi0.047 N Vt de N Vt N de N. . . . . .
entropy = 1.841
0.449 Vt N de N0.283 Vt N de N Vt N0.215 Vt N de N Vi0.034 Vt N de N Vt N de N0.006 Vt N de N Vt Vt N de N. . . . . .
entropy = 1.526
0.514 N Vt de N Vt N0.391 N Vt de N Vi0.063 N Vt de N Vt N de N0.011 N Vt de N Vt Vt N de N0.007 N Vt de N Vt N Vt de N. . . . . .
SRC ORC
w0
w1
w2
w3
w4
ER=0.97ER=1.07
ER=0.65 ER=0.72
ER=0 ER=0
ER=0.62 ER=0.82
Thursday, October 11, 2012

Why? entropy = 3.126
0.311 N Vt N0.237 N Vi0.179 Vt N0.073 Vi0.038 N Vt N de N. . . . . .
entropy = 2.157
0.678 Vt N0.083 Vt N de N0.052 Vt N de N Vt N0.039 Vt N de N Vi0.018 Vt N de Vt N. . . . . .
entropy = 2.052
0.471 N Vt N0.358 N Vi0.057 N Vt N de N0.026 N de N Vt N0.017 N de N Vi. . . . . .
entropy = 1.505
0.745 Vt N0.091 Vt N de N0.057 Vt N de N Vt N0.043 Vt N de N Vi0.019 Vt N de Vt N. . . . . .
entropy = 1.330
0.794 N Vt N0.097 N Vt N de N0.022 N Vt de N Vt N0.018 N Vt Vt N de N0.017 N Vt de N Vi. . . . . .
entropy = 2.460
0.377 Vt N de N0.237 Vt N de N Vt N0.180 Vt N de N Vi0.080 Vt N de Vt N0.061 Vt N de Vi. . . . . .
entropy = 2.342
0.384 N Vt de N Vt N0.292 N Vt de N Vi0.130 N Vt de Vt N0.099 N Vt de Vi0.047 N Vt de N Vt N de N. . . . . .
entropy = 1.841
0.449 Vt N de N0.283 Vt N de N Vt N0.215 Vt N de N Vi0.034 Vt N de N Vt N de N0.006 Vt N de N Vt Vt N de N. . . . . .
entropy = 1.526
0.514 N Vt de N Vt N0.391 N Vt de N Vi0.063 N Vt de N Vt N de N0.011 N Vt de N Vt Vt N de N0.007 N Vt de N Vt N Vt de N. . . . . .
SRC ORC
w0
w1
w2
w3
w4
ER=0.97ER=1.07
ER=0.65 ER=0.72
ER=0 ER=0
ER=0.62 ER=0.82
Thursday, October 11, 2012

at headnoun
entropy = 3.126
0.311 N Vt N0.237 N Vi0.179 Vt N0.073 Vi0.038 N Vt N de N. . . . . .
entropy = 2.157
0.678 Vt N0.083 Vt N de N0.052 Vt N de N Vt N0.039 Vt N de N Vi0.018 Vt N de Vt N. . . . . .
entropy = 2.052
0.471 N Vt N0.358 N Vi0.057 N Vt N de N0.026 N de N Vt N0.017 N de N Vi. . . . . .
entropy = 1.505
0.745 Vt N0.091 Vt N de N0.057 Vt N de N Vt N0.043 Vt N de N Vi0.019 Vt N de Vt N. . . . . .
entropy = 1.330
0.794 N Vt N0.097 N Vt N de N0.022 N Vt de N Vt N0.018 N Vt Vt N de N0.017 N Vt de N Vi. . . . . .
entropy = 2.460
0.377 Vt N de N0.237 Vt N de N Vt N0.180 Vt N de N Vi0.080 Vt N de Vt N0.061 Vt N de Vi. . . . . .
entropy = 2.342
0.384 N Vt de N Vt N0.292 N Vt de N Vi0.130 N Vt de Vt N0.099 N Vt de Vi0.047 N Vt de N Vt N de N. . . . . .
entropy = 1.841
0.449 Vt N de N0.283 Vt N de N Vt N0.215 Vt N de N Vi0.034 Vt N de N Vt N de N0.006 Vt N de N Vt Vt N de N. . . . . .
entropy = 1.526
0.514 N Vt de N Vt N0.391 N Vt de N Vi0.063 N Vt de N Vt N de N0.011 N Vt de N Vt Vt N de N0.007 N Vt de N Vt N Vt de N. . . . . .
SRC ORC
w0
w1
w2
w3
w4
ER=0.97ER=1.07
ER=0.65 ER=0.72
ER=0 ER=0
ER=0.62 ER=0.82
Thursday, October 11, 2012

at headnoun
c
entropy = 3.126
0.311 N Vt N0.237 N Vi0.179 Vt N0.073 Vi0.038 N Vt N de N. . . . . .
entropy = 2.157
0.678 Vt N0.083 Vt N de N0.052 Vt N de N Vt N0.039 Vt N de N Vi0.018 Vt N de Vt N. . . . . .
entropy = 2.052
0.471 N Vt N0.358 N Vi0.057 N Vt N de N0.026 N de N Vt N0.017 N de N Vi. . . . . .
entropy = 1.505
0.745 Vt N0.091 Vt N de N0.057 Vt N de N Vt N0.043 Vt N de N Vi0.019 Vt N de Vt N. . . . . .
entropy = 1.330
0.794 N Vt N0.097 N Vt N de N0.022 N Vt de N Vt N0.018 N Vt Vt N de N0.017 N Vt de N Vi. . . . . .
entropy = 2.460
0.377 Vt N de N0.237 Vt N de N Vt N0.180 Vt N de N Vi0.080 Vt N de Vt N0.061 Vt N de Vi. . . . . .
entropy = 2.342
0.384 N Vt de N Vt N0.292 N Vt de N Vi0.130 N Vt de Vt N0.099 N Vt de Vi0.047 N Vt de N Vt N de N. . . . . .
entropy = 1.841
0.449 Vt N de N0.283 Vt N de N Vt N0.215 Vt N de N Vi0.034 Vt N de N Vt N de N0.006 Vt N de N Vt Vt N de N. . . . . .
entropy = 1.526
0.514 N Vt de N Vt N0.391 N Vt de N Vi0.063 N Vt de N Vt N de N0.011 N Vt de N Vt Vt N de N0.007 N Vt de N Vt N Vt de N. . . . . .
SRC ORC
w0
w1
w2
w3
w4
ER=0.97ER=1.07
ER=0.65 ER=0.72
ER=0 ER=0
ER=0.62 ER=0.82
Thursday, October 11, 2012

Is it headless?
24 anonymized running head
0.00
0001
0.00
0100
0.01
0000
1.00
0000
0 20 40 60 80 100
nth best derivationPr
obab
ility
Vt ...Noun ...
Fig. 13 Probabilities of top 100 derivations at the first word in Chinese RCs
ture is easier in SRCs than in ORCs because less uncertainty about the overallstructure is eliminated.
Prob Remainder Type
0.377 Vt N de N Sbj-pro & Poss Obj
0.237 Vt N de N Vt N SRC & matrix Vt
0.180 Vt N de N Vi SRC & matrix Vi
0.080 Vt N de Vt N headless SRC & matrix Vt
0.061 Vt N de Vi headless SRC & matrix Vi
. . . . . . . . .
entropy = 2.460
Prob Remainder Type
0.449 Vt N de N Sbj-pro & Poss Obj
0.283 Vt N de N Vt N SRC & matrix Vt
0.215 Vt N de N Vi SRC & matrix Vi
0.034 Vt N de N Vt N de N SRC & Poss Obj
0.006 Vt N de N Vt Vt N de N Sbj SRC & Obj SRC
. . . . . . . . .
entropy = 1.841
Prob Remainder Type
0.384 N Vt de N Vt N ORC & matrix Vt
0.292 N Vt de N Vi ORC & matrix Vi
0.130 N Vt de Vt N headless ORC & matrix Vt
0.099 N Vt de Vi headless ORC & matrix Vi
0.047 N Vt de N Vt N de N ORC & Poss Obj
. . . . . . . . .
entropy = 2.342
Prob Remainder Type
0.514 N Vt de N Vt N ORC & matrix Vt
0.391 N Vt de N Vi ORC & matrix Vi
0.063 N Vt de N Vt N de N ORC & Poss Obj
0.011 N Vt de N Vt Vt N de N Sbj ORC & Obj SRC
0.007 N Vt de N Vt N Vt de N Sbj ORC & Obj ORC
. . . . . . . . .
entropy = 1.526
ER=0.62
ER=0.82
Fig. 14 ER at the head noun in Chinese RCs (zoomed in from Figure 11)
6 Conclusion
Asymmetries in processing difficulty across CJK relative clauses can be understoodas differential degrees of confusion about sentence structure. On the one hand, thisidea has a certain intuitive obviousness about it: a harder information-processingproblem ought to be associated with greater observable processing difficulty. Butit is not a foregone conclusion. It could have been the case that the sentence struc-tures motivated by generative syntax do not derive these “harder” vs “easier”information processing problems in just the cases where human readers seem tohave trouble. But in fact, as section 5 details, they do.
By suggesting that human listeners are information-processors subject to in-formation theory, this methodology revives the approach of psychologists like Hick
ORC
SRC
✓
✓
✓
Thursday, October 11, 2012

Reflects distributional facts
The Entropy Reduction complexity metric derives processing difficulty, in part, from probabilities. This means we need to weight the prepared MG grammar with help from language resources.
The methodology of the grammar weighting is to estimate probabilistic context-free rules of MG derivations by parsing a “mini-Treebank.” We obtain corpus counts8 for relevant structural types in the Chinese Treebank 7.0 (Xue et al., 2010) and treat these counts as attestation counts of certain construction in a mini-Treebank. For example, Table 3 lists corpus counts of four RC constructions. It suggests that SRs are more frequent than ORs when they modify matrix subjects. In addition, ORs tend to allow more covert heads than SRs. Through parsing each of these sentence types in the mini-Treebank, we estimate the weight of particular grammar rules by adding up the number of time such a rule is used in sentence construction while also considering how often each sentence type occurs in the mini-Treebank (Chi, 1999). However, for structurally stricter sentence types such as the RC with a determiner-classifier and a frequency phrase in (2), we could not get enough corpus counts from the Chinese Treebank. We then estimate their counts proportionally based on their counterparts in a simpler version such as regular RCs in (1).
Table 3. A fragment of the “Mini-Treebank” that includes corpus counts on Chinese RCs
Strings Construction Types Corpus Counts
Vt Noun de Noun Vt Noun Vt Noun de Vt Noun Noun Vt de Noun Vt Noun Noun Vt de Vt Noun
Subject-modifying SR with Vt Subject-modifying headless SR with Vt Subject-modifying OR with Vt Subject-modifying headless OR with Vt
366 123 203 149
3.3 Prefix Parsing as Intersection Grammars
The weighted grammar allows us to calculate the probability of constructing a complete sentence. But since we are more interested in predicting human comprehension difficulty word-by-word, it is necessary for us to determine the entropy of a prefix string.
Based on a weighted grammar G obtained after the training stage, we use chart parsing to recover probabilistic “intersection” grammars G’ conditioned on each prefix of the sentences of interest (Nederhof & Satta, 2008). An intersection grammar derives all and only the sentences in the language of G that are consistent with the initial prefix. It implicitly defines comprehenders’ expectations about how the sentence continues. Given the prefix string, the conditional entropy of the start symbol models a reader’s degree of confusion about which construction he or she is in at that point in the sentence. Comparing the conditional entropies before and after adding a new word, any decrease will quantify disambiguation work that, ideally, could have been done at that word.
Besides computing entropies, our system also samples syntactic alternatives from intersection grammars to get an intuitive picture of how uncertainties are reduced during parsing. These syntactic alternatives are discussed further in Section 3.4. 8 Corpus inquiries about construction types were done by using the pattern-matching tool Tregex (Levy & Andrew, 2006). For an example of Tregex queries for Chinese RCs, see Table 4 in Chen et al. In Press.
Thursday, October 11, 2012

Conclusions
Thursday, October 11, 2012

Conclusions
entropy reduction:derives processing consequencesfrom generative grammars
Thursday, October 11, 2012

Conclusions
entropy reduction:derives processing consequencesfrom generative grammars
providesa new account of the Subject Advantage
Thursday, October 11, 2012

Conclusions
entropy reduction:derives processing consequencesfrom generative grammars
key ideasentence-medial ambiguity levels
providesa new account of the Subject Advantage
Thursday, October 11, 2012

Write to us for the paper and the software:
Cornell Conditional Probability Calculator
Thursday, October 11, 2012

Joint work with
John Whitman
Tim Hunter
Jiwon Yun
Thursday, October 11, 2012