Embed Size (px)
Citation preview

Y. Chenevoy [email protected] 1
© A. Belaïd [email protected]
Constraint Propagation vs Syntactical Analysis for the Logical Structure of Library References
A. BelaïdLORIA-CNRS Nancy France
Y. ChenevoyCRID Univ. Bourgogne Dijon, France
Outline• Structure Modeling
• Syntactical Analysis
• Constraint Propagation
• Results & Conclusion

Y. Chenevoy [email protected] 3
© A. Belaïd [email protected]
Model: Attribute Grammar
Object ::= Constructor {subordinate objects [qualifier]}sequence, required,aggregate, optional,choice repetitive
Separator : space, graphic line / punctuation
Attributes : Physical Logical Typographical position lexicon typeface…
Weights : Attributes Sub-objects Imp / Reco. Imp / Hyp. Ambig.
Y. Chenevoy [email protected] 4
© A. Belaïd [email protected]
• Top-down: Model driven
• Bottom-up: Data driven
• Mixed:
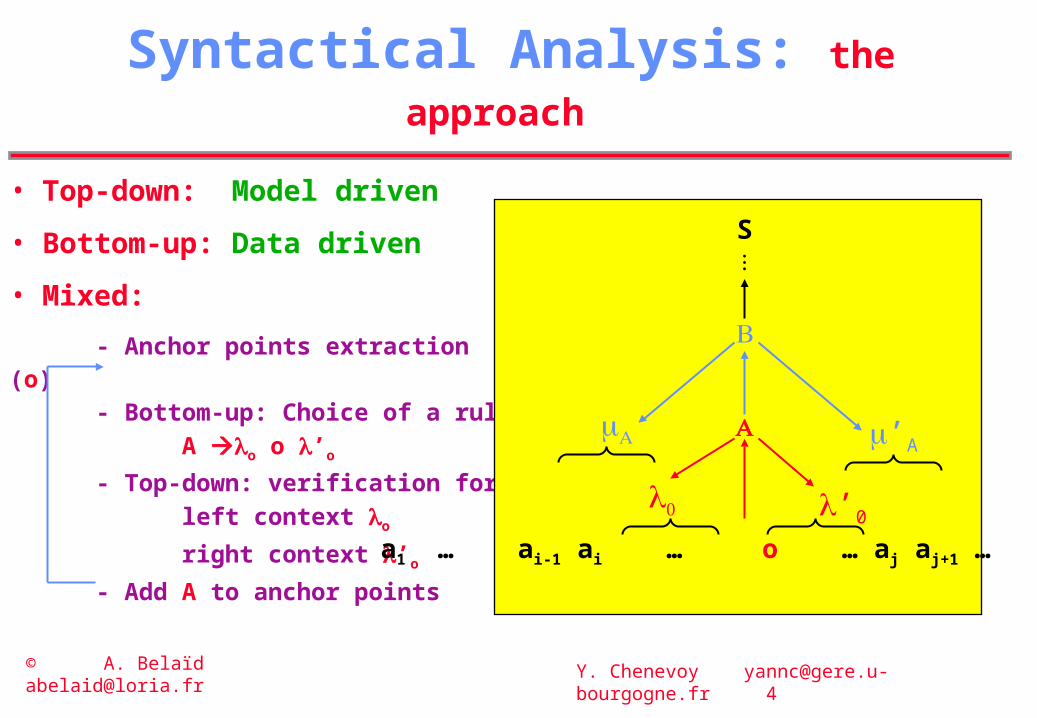
- Anchor points extraction (o)- Bottom-up: Choice of a rule
A o o ’o
- Top-down: verification for
left context o
right context ’o
- Add A to anchor points
Syntactical Analysis: the approach
’0
a1 … ai-1 ai … o … aj aj+1 … an
S
’A

Y. Chenevoy [email protected] 5
© A. Belaïd [email protected]
Syntactical Analysis: Left context verification

Y. Chenevoy [email protected] 6
© A. Belaïd [email protected]
Initials & Finals
Finals
O ::= Cho A B C F(O) = {A, B, C}O ::= Seq A B C F(O) = {C}O ::= Seq A B C? F(O) = {B, C}
O Vt , F*(O) = O
O Vn , F*(O) = F(O) (iF(O) F*(i))
Initials
O ::= Cho A B C I(O) = {A, B, C}O ::= Seq A B C I(O) = {A}O ::= Seq A? B C I(O) = {A, B}
O Vt , I*(O) = O
O Vn , I*(O) = I(O) (iI(O) I*(i))
Model : G = (Vn, Vt, P, S)

Y. Chenevoy [email protected] 7
© A. Belaïd [email protected]
Indices Extraction: without OCR
Specific problems
4.7%
76.7%
37.5%
55.5%
37.5% 61%
31.5%
91.0%
43.3%
16.1%
Corr. with Corr. with

Y. Chenevoy [email protected] 8
© A. Belaïd [email protected]
Indices Extraction: the approaches
Masks
Profile Projection
Bounding Box& Baseline
Sound Lines
- Projection- Spacing- Bounding Box
Bounding Box& Baseline
_-
. , ; :
Particular words
Text style (Bold Italic Underlined) ( spaced text) (Small text)
( ) {} []
Y. Chenevoy [email protected] 11
© A. Belaïd [email protected]
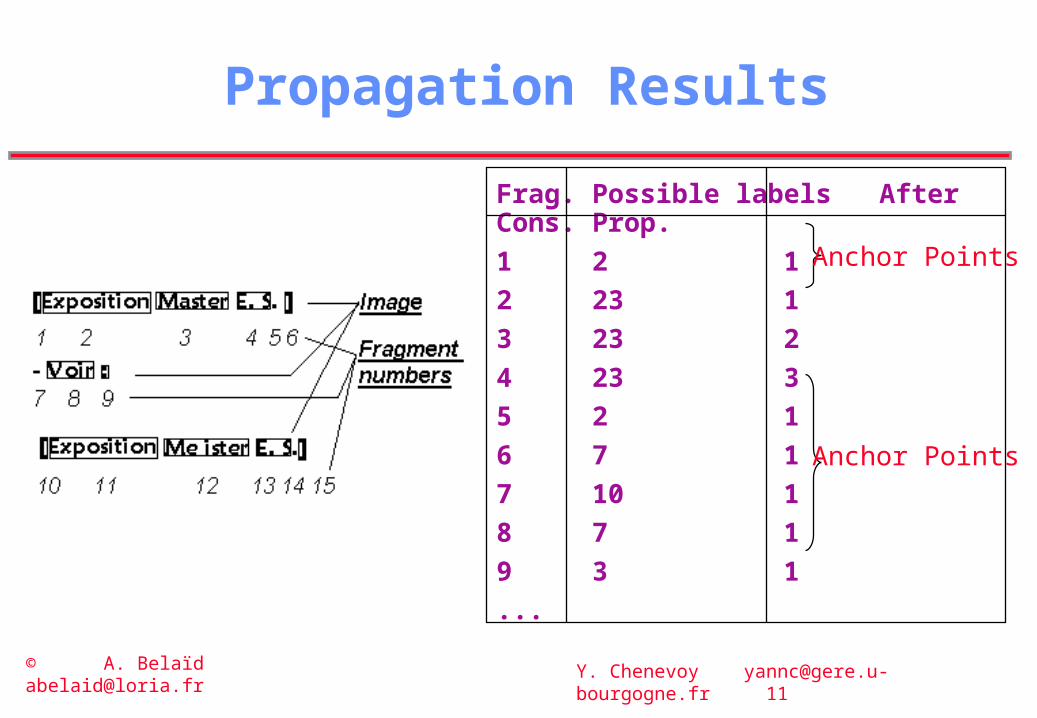
Propagation Results
Frag. Possible labels After Cons. Prop.
1 2 1
2 23 1
3 23 2
4 23 3
5 2 1
6 7 1
7 10 1
8 7 1
9 3 1
...
Anchor Points
Anchor Points

Y. Chenevoy [email protected] 12
© A. Belaïd [email protected]
Model Compilation
• Pre-processing of the model
• Find initials, finals and neighbors
let LNa,p = the set of possible neighbors at the left of a in the rule :
p a (Vt Vn)* ((Vt Vn)* - {a})if a then LNa,p = F else LNa,p = F LNa
by extension ln*a,p = lLNa,p F*l
and LN*a = pPa ln*
a,p the left neighborhood of a in the model
A is left compatible with B if B LN*A or A RN*
B or(A B) PA PA and PB PB / PA PB

Y. Chenevoy [email protected] 13
© A. Belaïd [email protected]
Results
Group Vedette:
Area Title:Principal Title:
End of the title:
Area Address / Date:
Address:Date:
Area Collection:
Group Cote:
Crossing Title:
Cros. Formulae:
Crossing Title:
200 references75%
Y. Chenevoy [email protected] 14
© A. Belaïd [email protected]
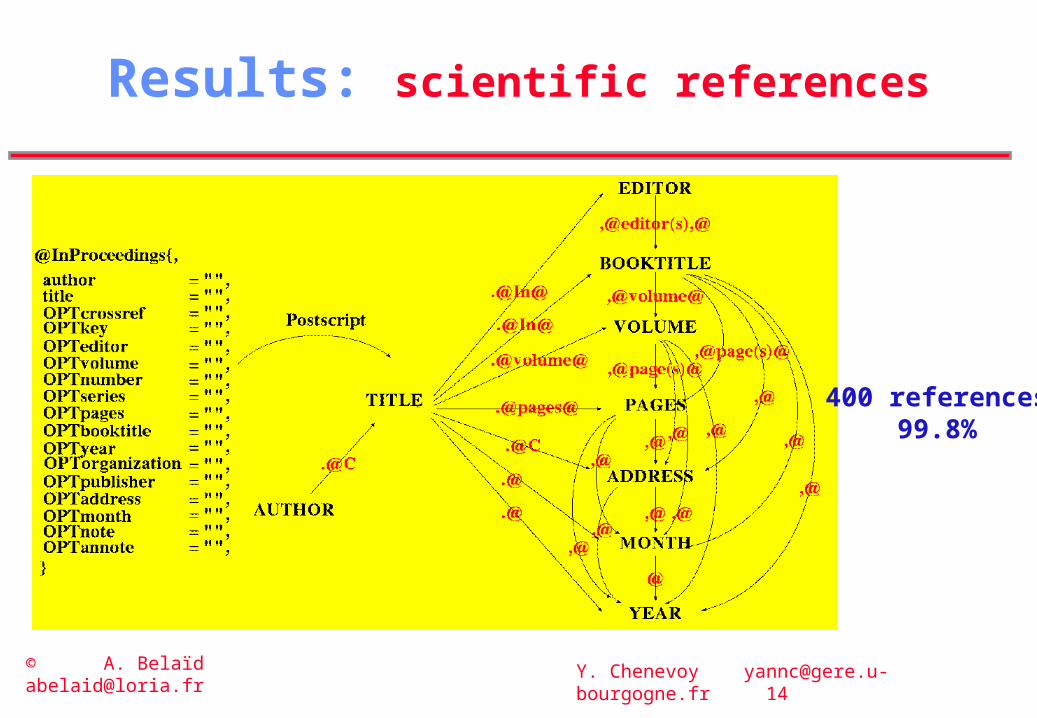
Results: scientific references
400 references99.8%

Y. Chenevoy [email protected] 15
© A. Belaïd [email protected]
Results
[Yua 95] J. Juan, Y. Y. Tang, and C. Y. Suen. Four Directional Adjacency Graphs (fdag) and their Application in Locating \34elds in Forms. In Third International Conference on Document Analysisand Recognition (ICDAR’95), pages 752\25 755. IEEE Computer Society Press, Aug. 1995.
Author(3) : J. Juan, Y. Y. Tang, and C. Y. SuenTitle : Four Directional Adjacency Graphs (fdag) and their Application in Locating fields in FormsEditor (0) :Month : AugYear : 1995Volume : Number : Publisher : IEEE Computer Society PressADDRESS : PA--GES : 752-755Organization: Booktitle : Third International Conference on Document Analysis and Recognition (ICDAR’95)Series :Note :

Y. Chenevoy [email protected] 16
© A. Belaïd [email protected]
Conclusion
Weak points
• 25 % lead to inconsistant chain
• Feasability study without OCR
• Weakness of indices extractio algo.
• Local context handling
Strong points or improvements
• Fast analysis
• Structure well recognized for the others
• The method can be applied with OCR with better results
• Global context can be applied (path consistency) at the cost of CPU time
• Good for ambiguous models
• Limit the number of hypotheses during the analysis
• Limit the number of backtracking
![arXiv:1903.06035v1 [quant-ph] 13 Mar 2019 · e-mailaddress: simon.perdrix@loria.fr Universit´e de Lorraine, CNRS, Inria, LORIA, F 54000 Nancy, France e-mailaddress: renaud.vilmart@loria.fr](https://img.pdfslide.us/doc/110x75/5f533a34e762445a8c79da78/arxiv190306035v1-quant-ph-13-mar-2019-e-mailaddress-simonperdrixloriafr.jpg)


















![PSPACE-decidability of Japaridze's Polymodal Logicaiml08.loria.fr/talks/shapirovsky.pdf · 2008. 9. 10. · Japaridze’s Polymodal Logic [Beklemishev, 2007] Hereditary orders. Main](https://img.pdfslide.us/doc/110x75/5fdeba11d0a9a62b6730b7e3/pspace-decidability-of-japaridzes-polymodal-2008-9-10-japaridzeas-polymodal.jpg)











