Embed Size (px)
Citation preview

Xrootd Present & Future The Drama Continues
Andrew HanushevskyStanford Linear Accelerator Center
Stanford UniversityHEPiX
13-October-05http://xrootd.slac.stanford.edu

13-October-05 2: http://xrootd.slac.stanford.edu
Outline
The state of performanceSingle serverClustered servers
The SRM Debate
The Next Big Thing
Conclusion

13-October-05 3: http://xrootd.slac.stanford.edu
Application Design Point
Complex embarrassingly parallel analysis Determine particle decay products 1000’s of parallel clients hitting the same data
Small block sparse random access Median size < 3K Uniform seek across whole file (mean 650MB)
Only about 22% of the file read (mean 140MB)

13-October-05 4: http://xrootd.slac.stanford.edu
Performance Measurements
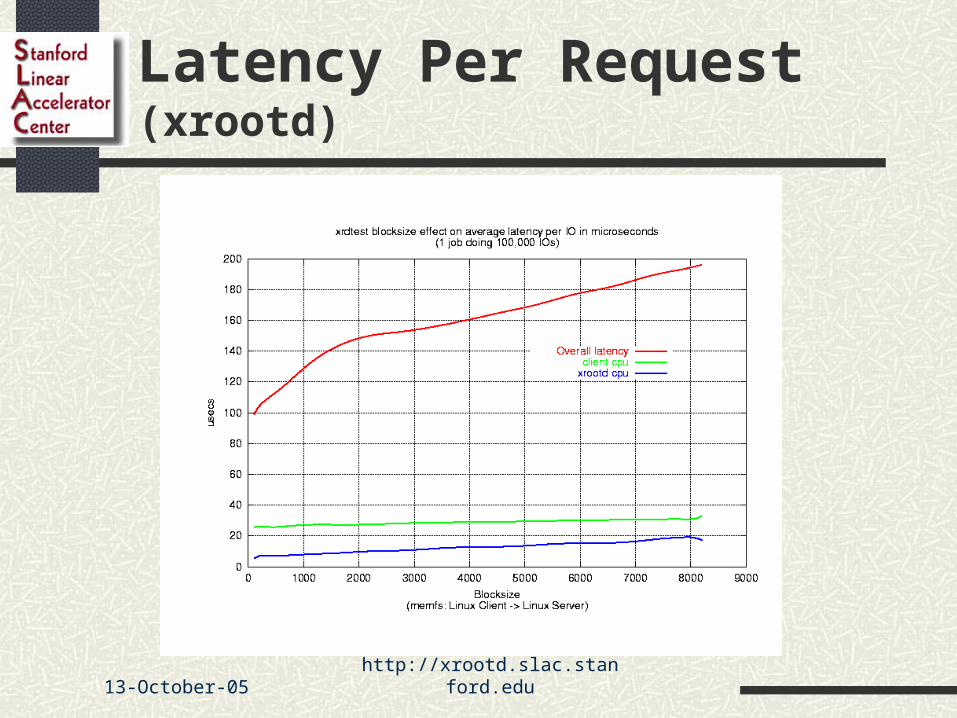
Goals Very low latency Handle many parallel clients
Test setup Sun V20z 1.86MHz dual Opteron, 2GB RAM 1Gb on board Broadcom NIC (same subnet) Solaris 10 x86 Linux RHEL3 2.4.21-2.7.8.ELsmp Client running BetaMiniApp with analysis removed
13-October-05 5: http://xrootd.slac.stanford.edu
Latency Per Request (xrootd)

13-October-05 6: http://xrootd.slac.stanford.edu
Capacity vs Load (xrootd)

13-October-05 7: http://xrootd.slac.stanford.edu
xrootd Server Scaling
Linear scaling relative to load Allows deterministic sizing of server
Disk NIC CPU Memory
Performance tied directly to hardware cost Competitive to best-in-class commercial file servers
13-October-05 8: http://xrootd.slac.stanford.edu
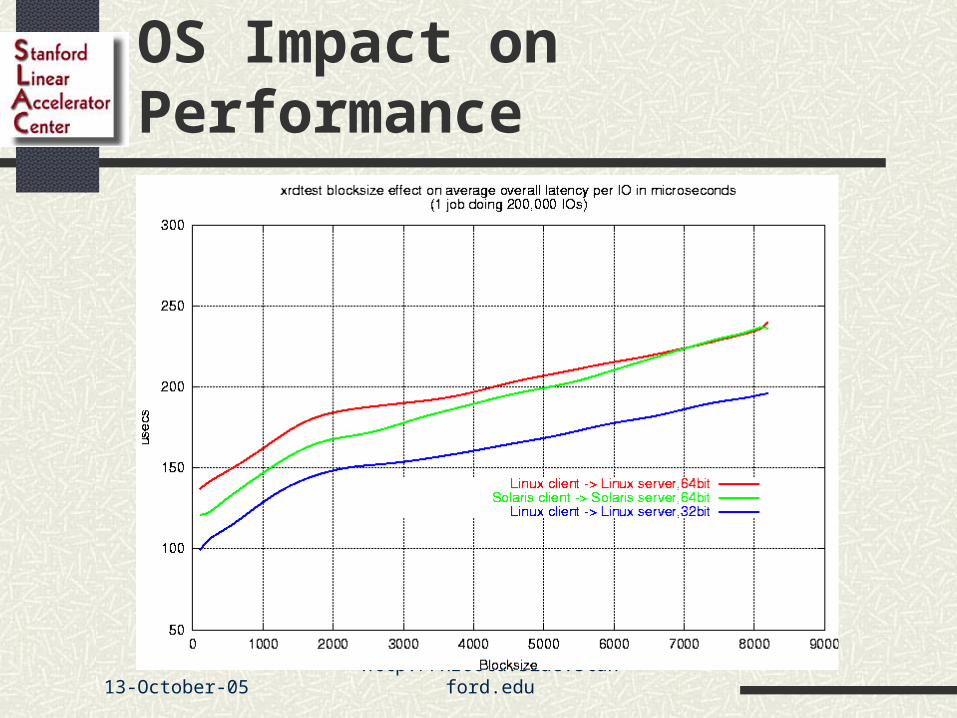
OS Impact on Performance
13-October-05 9: http://xrootd.slac.stanford.edu
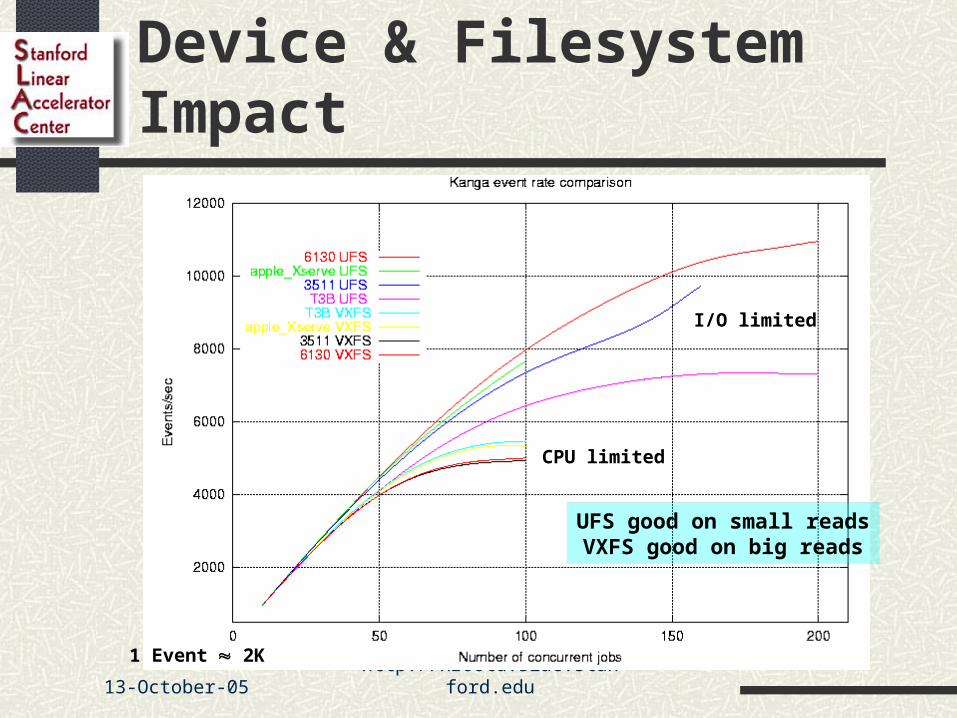
Device & Filesystem Impact
CPU limited
I/O limited
1 Event 2K
UFS good on small readsVXFS good on big reads
13-October-05 10: http://xrootd.slac.stanford.edu
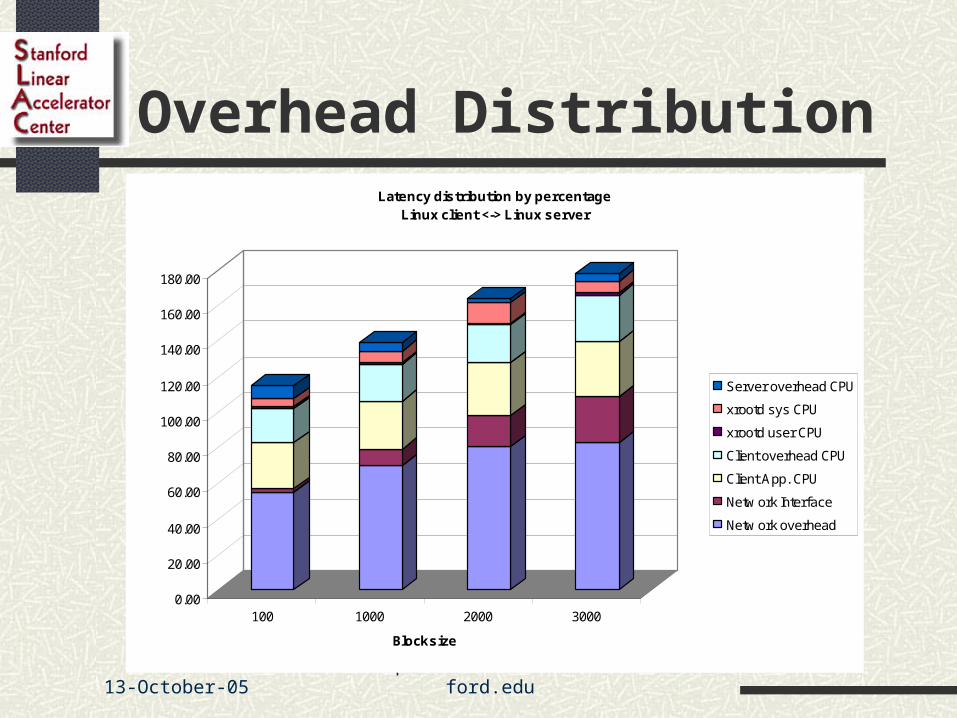
Overhead Distribution
0.00
20.00
40.00
60.00
80.00
100.00
120.00
140.00
160.00
180.00
100 1000 2000 3000
Blocksize
Latency distribution by percentageLinux client <-> Linux server
Server overhead CPU
xrootd sys CPU
xrootd user CPU
Client overhead CPU
Client App. CPU
Netw ork Interface
Netw ork overhead
13-October-05 11: http://xrootd.slac.stanford.edu
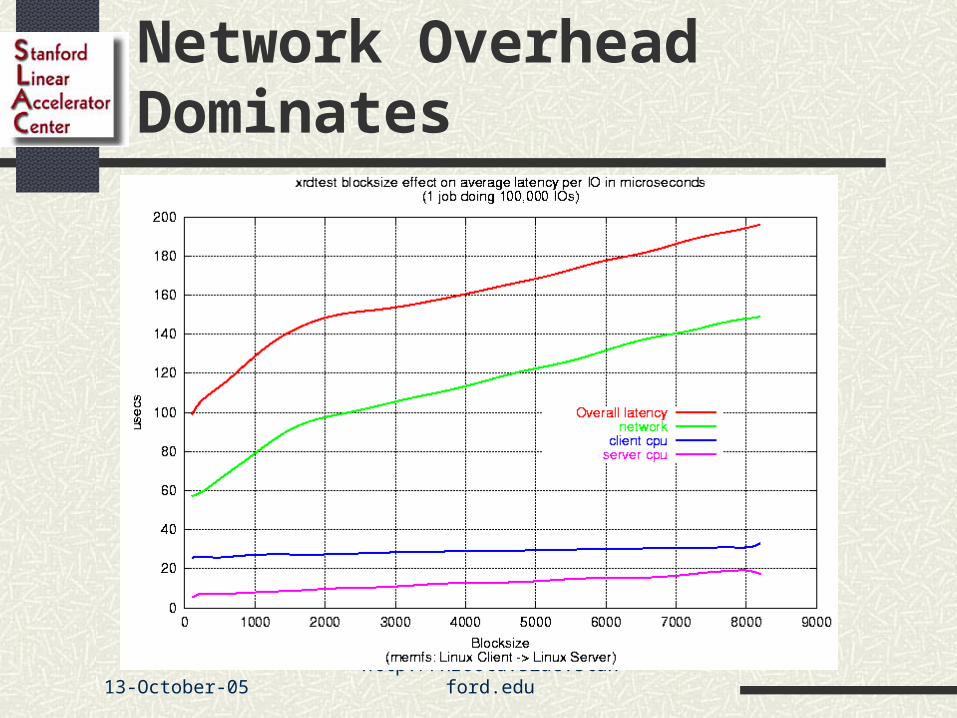
Network Overhead Dominates
13-October-05 12: http://xrootd.slac.stanford.edu
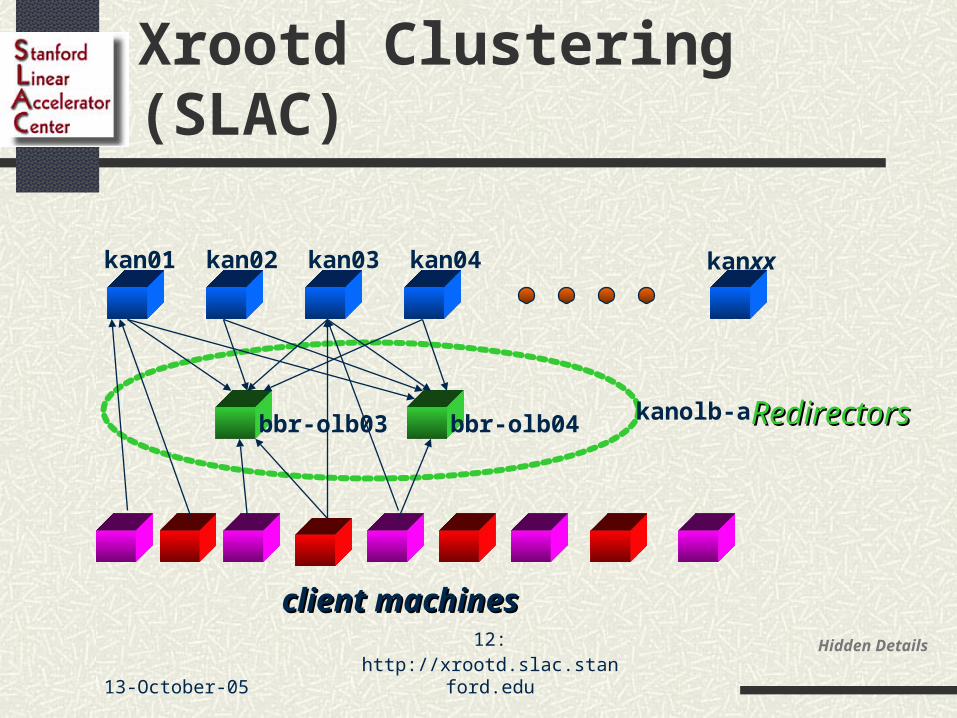
Xrootd Clustering (SLAC)
client machinesclient machines
kan01 kan02 kan03 kan04 kanxx
bbr-olb03 bbr-olb04 kanolb-a
Hidden Details
RedirectorsRedirectors

13-October-05 13: http://xrootd.slac.stanford.edu
Clustering Performance
Design can scale to at least 256,000 servers SLAC runs a 1,000 node test server cluster BNL runs a 350 node production server cluster
Self-regulating (via minimal spanning tree algorithm) 280 nodes self-cluster in about 7 seconds 890 nodes self-cluster in about 56 seconds
Client overhead is extremely low Overhead added to meta-data requests (e.g., open)
~200us * log64(number of servers) / 2
Zero overhead for I/O

13-October-05 15: http://xrootd.slac.stanford.edu
Current MSS SupportLightweight agnostic interfaces provided oss.mssgwcmd command
Invoked for each create, dirlist, mv, rm, stat oss.stagecmd |command
Long running command, request stream protocol Used to populate disk cache (i.e., “stage-in”)
xrootd(oss layer)
mssgwcmd
MSSstagecmd

13-October-05 16: http://xrootd.slac.stanford.edu
Future Leaf Node SRM
MSS Interface ideal spot for SRM hook Use existing hooks or new long running hook
mssgwcmd & stagecmd oss.srm |command
Processes external disk cache management requests Should scale quite well
xrootd(oss layer)
srm
MSS
Grid
13-October-05 17: http://xrootd.slac.stanford.edu
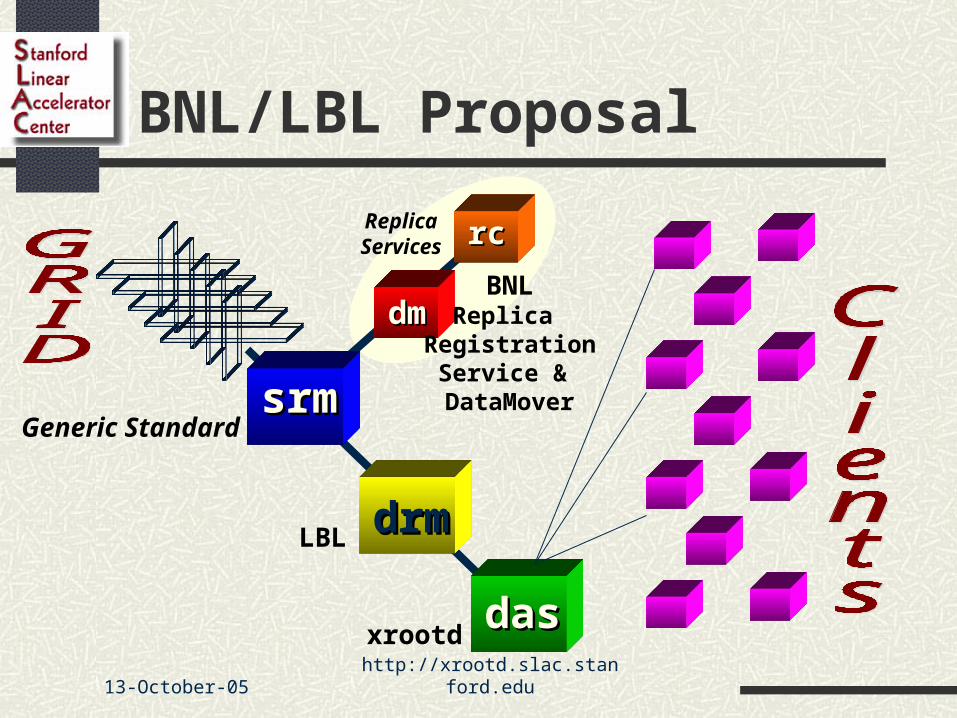
BNL/LBL Proposal
srmsrm
drmdrm
dasdas
Generic Standard
LBL
xrootd
dmdm
rcrcReplicaServices
BNLReplica
RegistrationService & DataMover

13-October-05 18: http://xrootd.slac.stanford.edu
Alternative Root Node SRMTeam olbd with SRM File management & discovery Tight management control
Several issues need to be considered Introduces many new failure modes Will not generally scale
olbd(root node)
srm
MSS
Grid

13-October-05 19: http://xrootd.slac.stanford.edu
SRM Integration Status
Unfortunately, SRM interface in flux Heavy vs light protocol
Working with LBL team Working towards OSG sanctioned future proposal
Trying to use the Fermilab SRM Artem Turnov at IN2P3 exploring issues

13-October-05 20: http://xrootd.slac.stanford.edu
The Next Big Thing
High Performance Data Access ServersHigh Performance Data Access Serversplusplus
Efficient large scale clusteringEfficient large scale clusteringAllowsAllows
Novel cost-effective super-fast massive storageNovel cost-effective super-fast massive storageOptimized for sparse random accessOptimized for sparse random access
Imagine 30TB of DRAMImagine 30TB of DRAMAt commodity pricesAt commodity prices
13-October-05 21: http://xrootd.slac.stanford.edu
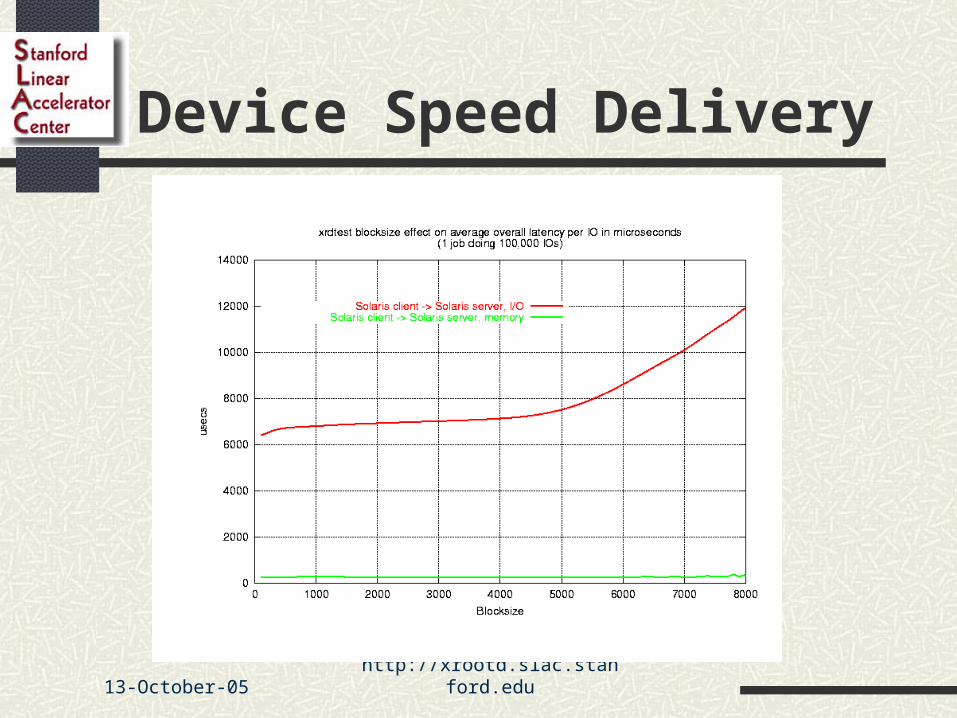
Device Speed Delivery
13-October-05 22: http://xrootd.slac.stanford.edu
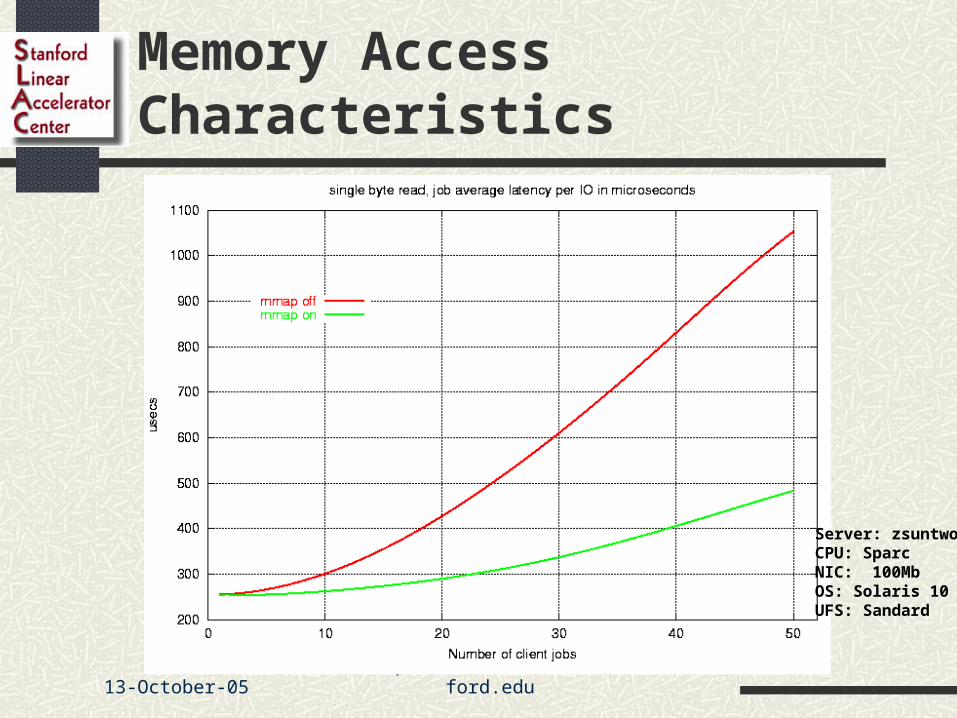
Memory Access Characteristics
Server: zsuntwoCPU: SparcNIC: 100MbOS: Solaris 10UFS: Sandard

13-October-05 23: http://xrootd.slac.stanford.edu
The Peta-Cache
Cost-effect memory access impacts science Nature of all random access analysis
Not restricted to just High Energy Physics Enables faster and more detailed analysis
Opens new analytical frontiers
Have a 64-node test cluster V20z each with 16GB RAM
1TB “toy” machine

13-October-05 24: http://xrootd.slac.stanford.edu
Conclusion
High performance data access systems achievable The devil is in the details
Must understand processing domain and deployment infrastructure Comprehensive repeatable measurement strategy
High performance and clustering are synergetic Allows unique performance, usability, scalability, and
recoverability characteristicsSuch systems produce novel software architectures Challenges
Creating application algorithms that can make use of such systems Opportunities
Fast low cost access to huge amounts of data to speed discovery

13-October-05 25: http://xrootd.slac.stanford.edu
Acknowledgements
Fabrizio Furano, INFN Padova Client-side design & development
Bill Weeks Performance measurement guru
100’s of measurements repeated 100’s of times
US Department of Energy Contract DE-AC02-76SF00515 with Stanford University
And our next mystery guest!





























