Embed Size (px)
Citation preview

1
© Sudhakar Yalamanchili, Georgia Institute of Technology
Revisiting ParallelismRevisiting Parallelism
ECE 4100/6100 (2)
Where Are We Headed?
0.01
0.1
1
10
100
1000
10000
100000
1000000
1970 1980 1990 2000 2010
MIP
S
Speculative, OOO
Era of Era of Instruction Instruction
LevelLevelParallelismParallelism
Super Scalar
486386
2868086 Era of Era of
PipelinedPipelinedArchitectureArchitecture
Multi ThreadedEra of Era of
Thread &Thread &ProcessorProcessor
LevelLevelParallelismParallelism
Special Special Purpose HWPurpose HW
Multi-Threaded, Multi-Core
Source: Shekhar Borkar, Intel Corp.

2
ECE 4100/6100 (3)
Beyond ILP
• Performance is limited by the serial fraction parallelizable
1CPU 2CPUs 3CPUs 4CPUs
• Coarse grain parallelism in the post ILP era– Thread, process and data parallelism
• Learn from the lessons of the parallel processing community– Revisit the classifications and architectural techniques
ECE 4100/6100 (4)
Flynn’s Model*
• Flynn’s Classification– Single instruction stream, single data stream (SISD)
– The conventional, word-sequential architecture including pipelined computers
– Single instruction stream, multiple data stream (SIMD)– The multiple ALU-type architectures (e.g., array processor)
– Multiple instruction stream, single data stream (MISD)– Not very common
– Multiple instruction stream, multiple data stream (MIMD)– The traditional multiprocessor system
*M.J. Flynn, “Very high speed computing systems,” Proc. IEEE, vol. 54(12), pp. 1901–1909, 1966.
Data Level Parallelism
(DLP)
Thread Level Parallelism
(TLP)

3
ECE 4100/6100 (5)
ILP Challenges
• As machine ILP capabilities increase, i.e., ILP width and depth, so do challenges– OOO execution cores
– Key data structure sizes increase – ROB, ILP window, etc. – Dependency tracking logic increases quadratically
– VLIW/EPIC– Hardware interlocks, ports, recovery logic (speculation)
increases quadratically
• Circuit complexity increases with number of inflightinstructions
Data ParallelismData Parallelism
ECE 4100/6100 (6)
Example: Itanium 2
• Note the percentage of the die devoted to control
• And this is a statically scheduled processor!

4
ECE 4100/6100 (7)
Data Parallel Alternatives
• Single Instruction Stream Multiple Data Stream Cores– Co-processors exposed through the ISA– Co-processors exposed as a distinct processor
• Vector Processing– Over 5 decades of development
ECE 4100/6100 (8)
The SIMD Model
• Single instruction stream broadcast to all processors– Processors execute in lock step on local data– Efficient in use of silicon area - less resources devoted to
control– Distributed memory model vs. shared memory model
• Distributed memory– Each processor has local memory– Data routing network whose operation is under centralized
control. – Processor masking for data dependent operations
• Shared memory– Access to memory modules through an alignment network
• Instruction classes: computation, routing, masking

5
ECE 4100/6100 (9)
Two Issues
• Conditional Execution
• Data alignment
© Sudhakar Yalamanchili, Georgia Institute of Technology
Vector CoresVector Cores
6
ECE 4100/6100 (11)
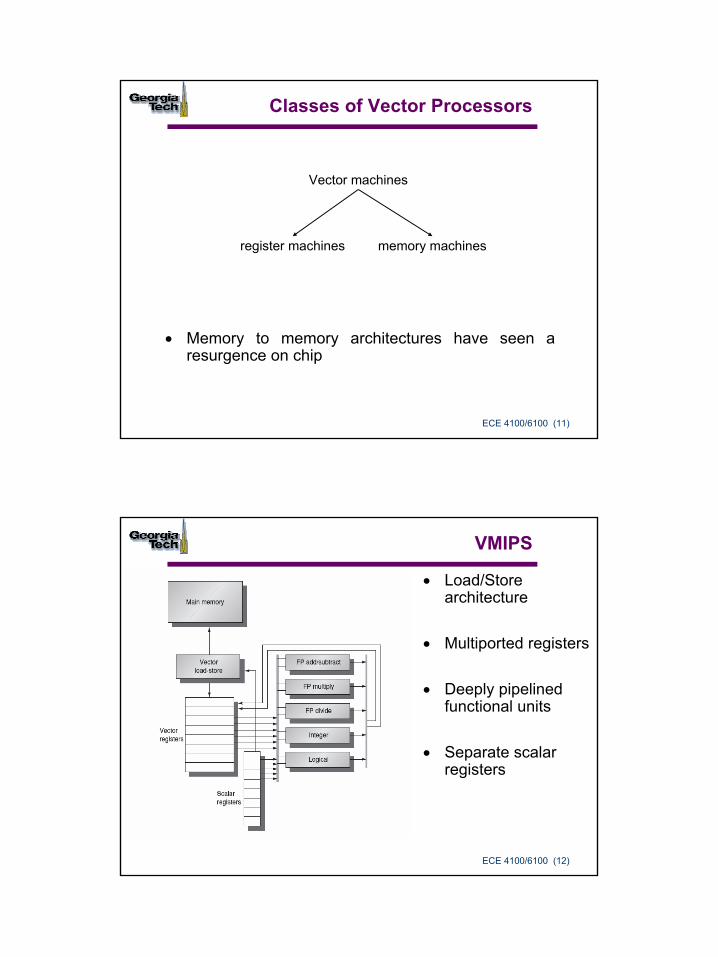
Classes of Vector Processors
• Memory to memory architectures have seen a resurgence on chip
Vector machines
register machines memory machines
ECE 4100/6100 (12)
VMIPS
• Load/Store architecture
• Multiported registers
• Deeply pipelined functional units
• Separate scalar registers

7
ECE 4100/6100 (13)
Cray Family Architecture
• Stream oriented
• Recall data skewing and concurrent memory accesses!
• The first load/store ISA design Cray 1 (1976)
ECE 4100/6100 (14)
Features of Vector Processors
• Significantly less dependency checking logic– Order of complexity of scalar comparisons with a
significantly smaller number
• Vector data sets – Hazard free operation on deep pipelines– Conciseness of representation leads to low instruction
issue rate– Reduction in normal control hazards– Vector operations vs. a sequence of scalar operations
• Concurrency in operation, memory access and address generation– Often statically known
8
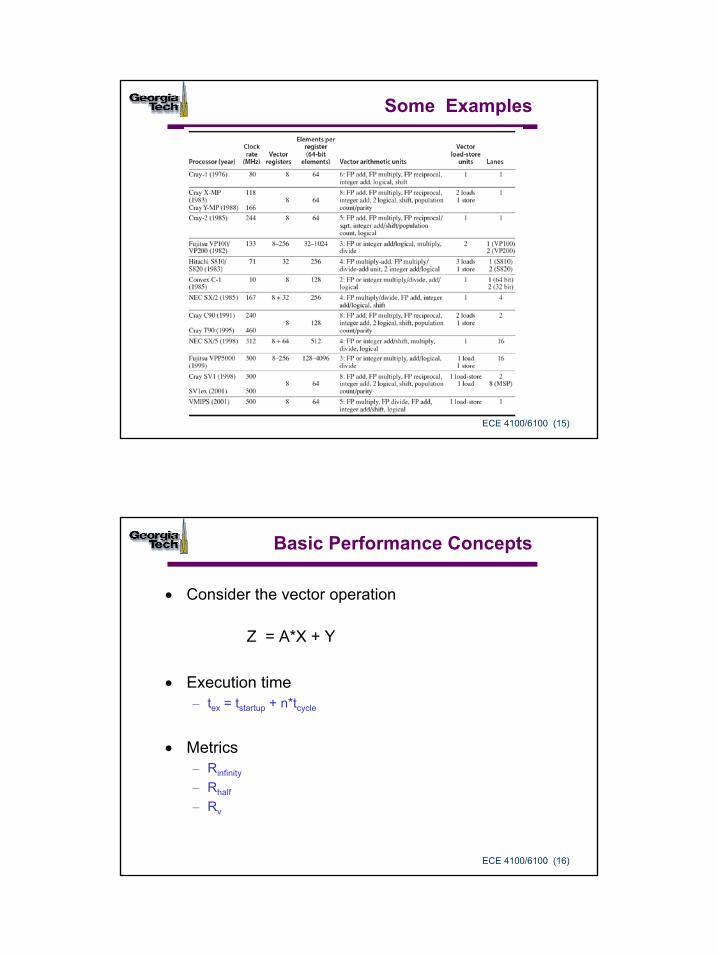
ECE 4100/6100 (15)
Some Examples
ECE 4100/6100 (16)
Basic Performance Concepts
• Consider the vector operation
Z = A*X + Y
• Execution time– tex = tstartup + n*tcycle
• Metrics– Rinfinity
– Rhalf
– Rv

9
ECE 4100/6100 (17)
Optimizations for Vector Machines
• ChainingMULT.V V1, V2. V3ADD.V V4, V1, V5
– Fine grained forwarding of elements if a vector– Need additional ports on a vector register
– Effectively creates a deeper pipeline
• Conditional operations and vector masks• Scatter/gather operations• Vector lanes
– Each lane is coupled to a portion of the vector register file– Lanes are transparent to the code and are like caches in
the family of machines concept
© Sudhakar Yalamanchili, Georgia Institute of Technology
The IBM Cell ProcessorThe IBM Cell Processor

10
ECE 4100/6100 (19)
Cell Overview
• IBM/Toshiba/Sony joint project - 4-5 years, 400 designers– 234 million transistors, 4+ Ghz– 256 Gflops (billions of floating pointer operations per second)– 26 Gflops (double precision)– Area 221 mm2
– Technology 90nm SOI
PPU
SPU
SPU
SPU
SPU
SPU
SPU
SPU
SPU
MIC
RRAC
BIC
MIB
ECE 4100/6100 (20)
Cell Overview (cont.)
• One 64-bit PowerPC processor– 4+ Ghz, dual issue, two threads– 512 kB of second-level cache
• Eight Synergistic Processor Elements– Or “Streaming Processor Elements”– Co-processors with dedicated 256kB of memory (not cache)
• EIB data ring for internal communication– Four 16 byte data rings, supporting multiple transfers– 96B/cycle peak bandwidth– Over 100 outstanding requests
• Dual Rambus XDR memory controllers (on chip)– 25.6 GB/sec of memory bandwidth
• 76.8 GB/s chip-to-chip bandwidth (to off-chip GPU)

11
ECE 4100/6100 (21)
Cell Features
• Security– SPE dynamically reconfigurable as secure co-processor
• Networking– SPEs might off-load networking overheads (TCP/IP)
• Virtualization– Run multiple OSs at the same time– Linux is primary development OS for Cell
• Broadband– SPE is RISC architecture with SIMD organization and
Local Store– 128+ concurrent transactions to memory per processor
ECE 4100/6100 (22)
PPE Block Diagram
• PPE handles operating system and control tasks– 64-bit Power ArchitectureTM with VMX– In-order, 2-way hardware Multi-threading– Coherent Load/Store with 32KB I & D L1 and 512KB L2

12
ECE 4100/6100 (23)
PPE Pipeline
ECE 4100/6100 (24)
SPE Organization and Pipeline
IBM Cell SPE pipeline diagram
IBM Cell SPE Organization

13
ECE 4100/6100 (25)
Cell Temperature Graph
Source: IEEE ISSCC, 2005• Power and heat are key constrains – Cell is ~80 watts at 4+ Ghz– Cell has 10 temperature sensors
ECE 4100/6100 (26)
SPE
• User-mode architecture– No translation/protection within SPU– DMA is full Power Arch protect/x-late
• Direct programmer control– DMA/DMA-list– Branch hint
• VMX-like SIMD dataflow– Broad set of operations– Graphics SP-Float– IEEE DP-Float (BlueGene-like)
• Unified register file– 128 entry x 128 bit
• 256kB Local Store– Combined I & D– 16B/cycle L/S bandwidth– 128B/cycle DMA bandwidth

14
ECE 4100/6100 (27)
Cell I/O
• XDR is new high-speed memory from Rambus– Dual XDRTM controller (25.6GB/s @ 3.2Gbps)– Two configurable interfaces (76.8GB/s @6.4Gbps)– Flexible Bandwidth between interfaces– Allows for multiple system configurations
• Pros:– Fast - dual controllers give 25GB/sed
– Current AMD Opteron is only 6.4GB/s – Small pin count– Only need a few chips for high bandwidth
• Cons:– Expensive ($ per bit)
ECE 4100/6100 (28)
Multiple system support
• Game console systems• Workstations (CPBW)• HDTV• Home media servers• Supercomputers
15
ECE 4100/6100 (29)
Programming Cell
• 10 virtual processors– 2 threads of PowerPC– 8 co-processor SPEs
• Communicating with SPEs– 256kB “local storage” is NOT a cache
– Must explicitly move data in and out of local store– Use DMA engine (supports scatter/gather)
ECE 4100/6100 (30)
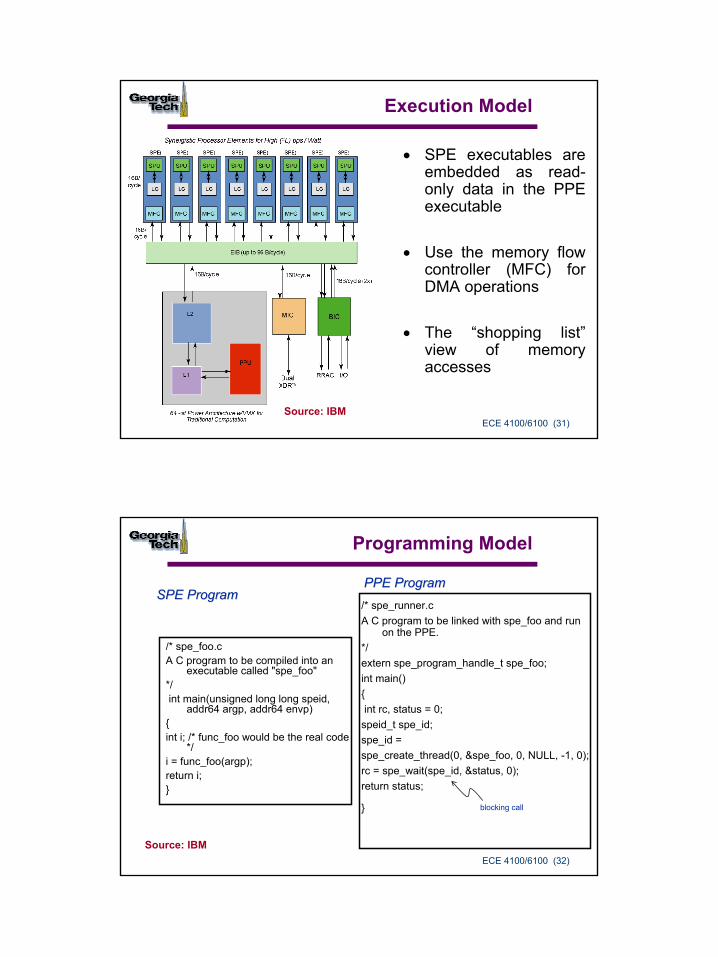
Programming Cell
Multiple-ISA hand tuned programs
Explicit SIMD coding
Explicit parallelization with local memories
Automatic tuning for each ISA
Automatic SIMDization
Automatic parallelization
Highest performance with help from programmers
Highest Productivity with fully automatic compiler technology
SIMD alignment directives
Shared memory, single program abstraction
16
ECE 4100/6100 (31)
Execution Model
• SPE executables are embedded as read-only data in the PPE executable
• Use the memory flow controller (MFC) for DMA operations
• The “shopping list”view of memory accesses
Source: IBM
ECE 4100/6100 (32)
Programming Model
/* spe_foo.cA C program to be compiled into an
executable called "spe_foo" */int main(unsigned long long speid,
addr64 argp, addr64 envp) { int i; /* func_foo would be the real code
*/ i = func_foo(argp); return i; }
/* spe_runner.cA C program to be linked with spe_foo and run
on the PPE. */ extern spe_program_handle_t spe_foo; int main() {int rc, status = 0;
speid_t spe_id; spe_id = spe_create_thread(0, &spe_foo, 0, NULL, -1, 0); rc = spe_wait(spe_id, &status, 0); return status;
}
SPE ProgramSPE ProgramPPE ProgramPPE Program
Source: IBM
blocking call
17
ECE 4100/6100 (33)
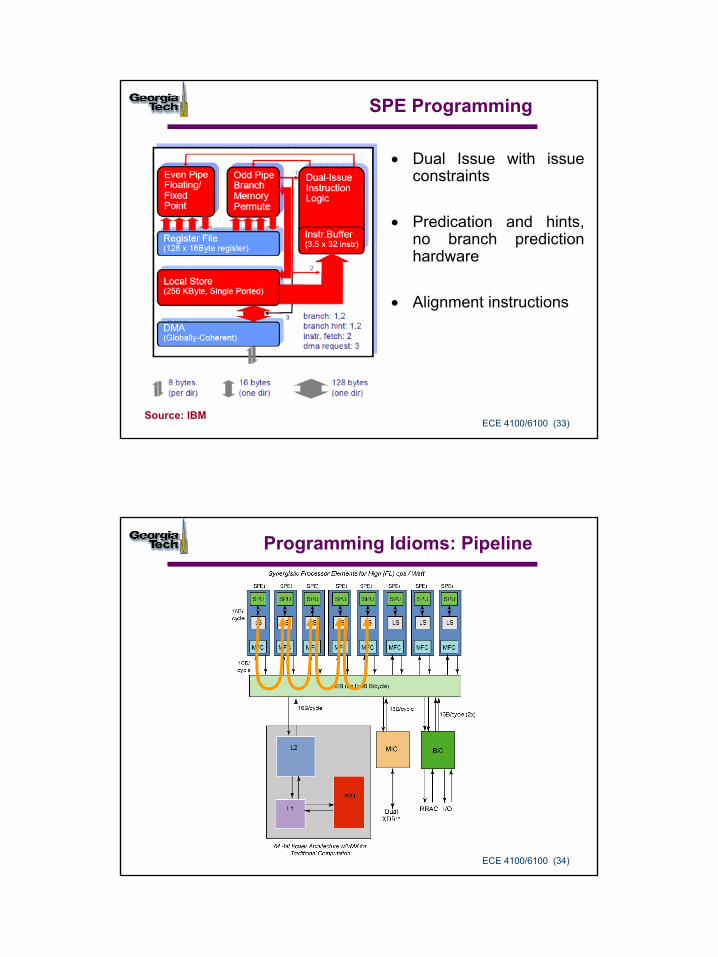
SPE Programming
• Dual Issue with issue constraints
• Predication and hints, no branch prediction hardware
• Alignment instructions
Source: IBM
ECE 4100/6100 (34)
Programming Idioms: Pipeline
18
ECE 4100/6100 (35)
Programming Idioms: Work Queue Model
work queue
• Pull data off of a shared queue
• Self scheduled
ECE 4100/6100 (36)
SPMD & MIMD Accelerators
Executing same (SPMD) or different (MPMD) programs

19
ECE 4100/6100 (37)
Cell Processor Application Areas
• Digital content creation (games and movies)• Game playing and game serving• Distribution of (dynamic, media rich) content• Imaging and image processing• Image analysis (e.g. video surveillance)• Next-generation physics-based visualization• Video conferencing (3D)• Streaming applications (codecs etc.)• Physical simulation & science
ECE 4100/6100 (38)
Some References and Links
• http://researchweb.watson.ibm.com/journal/rd/494/kahle.html
• http://en.wikipedia.org/wiki/Cell_(microprocessor)• http://www.research.ibm.com/cell/home.html• http://www.research.ibm.com/cellcompiler/slides/pa
ct05.pdf• http://www.hpcaconf.org/hpca11/slides/Cell_Public_
Hofstee.pdf• http://www.hpcaconf.org/hpca11/papers/25_hofstee
-cellprocessor_final.pdf• http://www.research.ibm.com/cellcompiler/papers/p
ham-ISSCC05.pdf
20
© Sudhakar Yalamanchili, Georgia Institute of Technology
IRAM CoresIRAM Cores
ECE 4100/6100 (40)
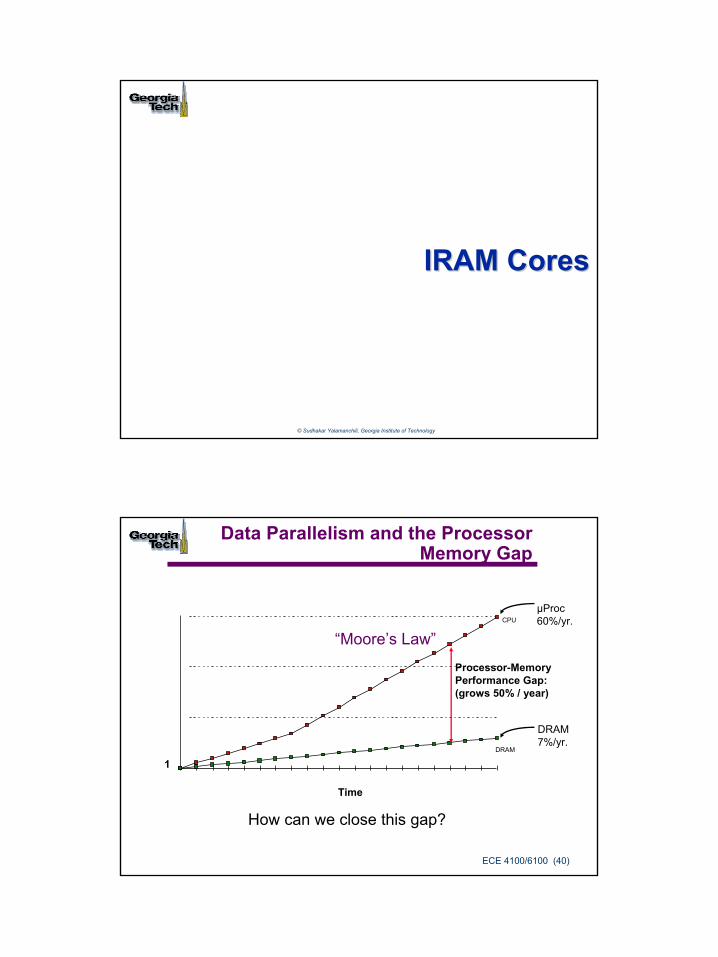
Data Parallelism and the Processor Memory Gap
µProc60%/yr.
DRAM7%/yr.
1DRAM
CPU
Processor-MemoryPerformance Gap:(grows 50% / year)
Time
“Moore’s Law”
How can we close this gap?

21
ECE 4100/6100 (41)
The Effects of the Processor-Memory Gap
• Tolerate gap with deeper cache memories increasing worst case performance
• System level impact: Alpha 21164– I & D cache access: 2 clocks– L2 cache: 6 clocks– L3 cache: 8 clocks– Memory: 76 clocks– DRAM component access: 18 clocks
• How much time is spent in the memory hierarchy? – SpecInt92: 22%– Specfp92: 32%– Database: 77%– Sparse matrix: 73%
ECE 4100/6100 (42)
Where do the Transistors Go?
• Caches have no inherent value, they simply recover bandwidth?
Processor % Area %Transistors (-cost) (-power)
• Alpha 21164 37% 77%• StrongArm SA110 61% 94%• Pentium Pro 64% 88%

22
ECE 4100/6100 (43)
Impact of DRAM Capacity
• Increasing capacity creates a quandary– Continual four fold increase in density increases minimum
memory increment for a given width– How do we match the memory bus width?– Cost/bit issues for wider DRAM chips
– die size, testing, package costs
• Number of DRAM chips decrease decrease in concurrency
ECE 4100/6100 (44)
Merge Logic and DRAM!
• Bring the processors to memoryTremendous on-chip bandwidth for predictable application reference patterns
• Enough memory to hold complete programs and data
feasible
• More applications are limited by memory speedBetter memory latency for applications with irregular
access patterns
• Synchronous DRAMs to integrate with the higher speed logic
compatible

23
ECE 4100/6100 (45)
Potential: IRAM for Lower Latency
• DRAM Latency– Dominant delay = RC of the word lines – Keep wire length short & block sizes small?
• 10-30 ns for 64b-256b IRAM “RAS/CAS”?
ECE 4100/6100 (46)
Potential for IRAM Bandwidth
• 1024 1Mbit modules(1Gb), each 256b wide– 20% @ 20 ns RAS/CAS = 320 GBytes/sec
• If cross bar switch delivers 1/3 to 2/3 of BW of 20% of modules⇒ 100 - 200 GBytes/sec
• FYI: AlphaServer 8400 = 1.2 GBytes/sec – 75 MHz, 256-bit memory bus, 4 banks
24
ECE 4100/6100 (47)
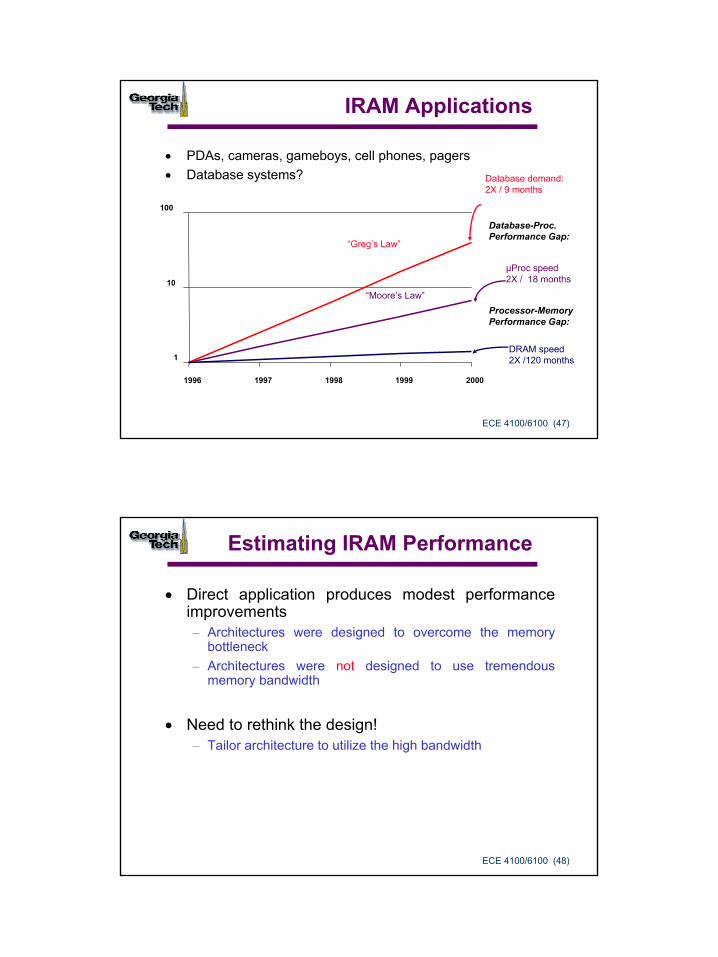
IRAM Applications
• PDAs, cameras, gameboys, cell phones, pagers• Database systems?
µProc speed2X / 18 months
Processor-MemoryPerformance Gap:
Database demand:2X / 9 months
DRAM speed2X /120 months
Database-Proc.Performance Gap:
“Greg’s Law”
“Moore’s Law”
1
10
100
1996 1997 1998 1999 2000
ECE 4100/6100 (48)
Estimating IRAM Performance
• Direct application produces modest performance improvements– Architectures were designed to overcome the memory
bottleneck– Architectures were not designed to use tremendous
memory bandwidth
• Need to rethink the design!– Tailor architecture to utilize the high bandwidth

25
ECE 4100/6100 (49)
Emerging Embedded Applications and Characteristics
• Fastest growing application domain– Video processing, speech recognition, 3D Graphics– Set top boxes, game consoles, PDAs
• Data parallel– Typically low temporal locality– Size, weight and power constraints– Highest speed not necessarily the best processor
–What about the role of ILP processors here?
• Real Time constraints– Right data at the right time
ECE 4100/6100 (50)
SIMD/Vector Architectures
• VIRAM - Vector IRAM– Logic is slow in DRAM process– Put a vector unit in a DRAM and provide a port between a traditional
processor and the vector IRAM instead of a whole processor in DRAM
Source: Berkeley Vector IRAM

26
ECE 4100/6100 (51)
ISA
• LD/SD vector ISA defined as a co-processor to the MIPS 64 ISA
• Vector register file with 32 entries– Each can be configured as 64b, 32b, or 16b– Integer or FP elements
• Two scalar register files– Memory and exception handling, base addresses and
stride information– Scalar operands
• Flag registers• Special
– Limited scope instructions to permute contents of vector registers
– Integer instructions for saturated arithmetic
ECE 4100/6100 (52)
MIMD Machines
• Parallel processing has catalyzed the development of a several generations of parallel processing machines
• Unique features include the interconnection network, support for system wide synchronization, and programming languages/compilers
P + C
Dir
Memory
P + C
Dir
Memory
P + C
Dir
Memory
P + C
Dir
Memory
Interconnection Network

27
ECE 4100/6100 (53)
Basic Models for Parallel Programs
• Shared Memory– Coherency/consistency are driving concerns– Programming model is simplified at the expense of system
complexity
• Message Passing– Typically implemented on distributed memory machines– System complexity is simplified at the expense of
increased effort by the programmer
ECE 4100/6100 (54)
Shared Memory Vs. Message Passing
• Shared memory– Simplifies software development– Increases complexity of hardware
– Power directories, coherency enforcement logic– More recently transactional memory
• Message passing doesn’t need centralized bus– Simplifies hardware
– Scalable memory and interconnect bandwidth– Increases complexity of software development
– Increases the burden on the developer
28
ECE 4100/6100 (55)
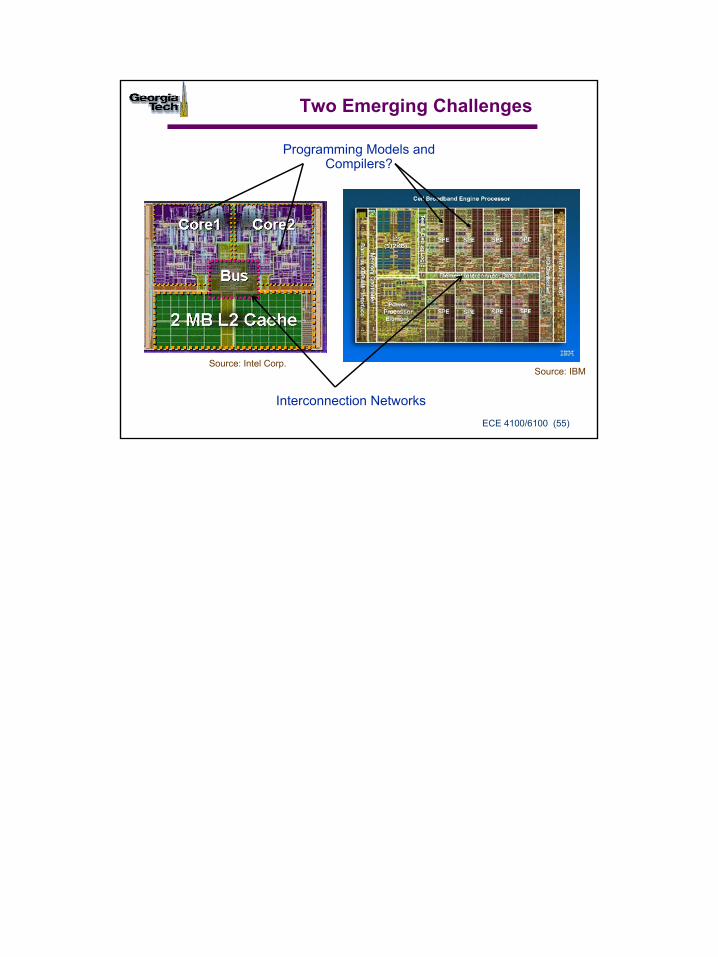
Two Emerging Challenges
Programming Models and Compilers?
Interconnection Networks
Source: IBMSource: Intel Corp.





























