Embed Size (px)
Citation preview

What lies beneath? Building a semantic web-ready repository
for complex collections
Louise Corti UKDAAgostina Martinez, Patrick Carmichael, CARET, Cambridge
IASSIST 2009

The Ensemble Project• Semantic Technologies for the Enhancement of Case Based
Learning• 3 Year, £1.5 Million ESRC/EPSRC Project: Research,
Development and Implementation (2008-2011)• working with teachers and students in undergraduate and
postgraduate courses to explore both the nature and role of the cases around which learning is focused
• and the part that emerging semantic web technologies can play in supporting this learning
• a big, happy interdisciplinary andmulti-institutional extended family …
• website: http://www.ensemble.ac.uk
2

Pedagogy• examining teaching and learning in complex, politically or ethically
contentious, and rapidly-evolving fields where case-based learning is the pedagogical approach of choice
• how do teachers and learners design, develop, describe and reconstruct cases, and how do these processes contribute to academic and professional outcomes?
• the learning technologies need to be robust yet flexible enough to support teachers and learners as they grapple with complex situations and develop creative solutions
• and they need to be able to easily access, adapt and manage their case based learning……a pedagogical challenge!

The settings
• where reflective processes allows learners to achieve the higher levels of understanding and capability that characterise the ‘expert’ or the ‘virtuoso’
• advanced undergraduate, taught postgraduate and professional development courses (6 groups)
• teachers and learners are taking part in ‘case-building’ activities in which semantic web tools and digital repositories are used to support engagement with rich case data
• data differently structured and represented and in which alternative constructions of cases are possible

Technical aims• repurposing, reconfiguring and enhancing existing repositories
and other data sources
• aims to easily ‘translate’ research data in a Repository for integration into applications which use semantic or 'Web 3.0' technologies:
– federated searches– visualisation tools – collaborative working environments
• allow end-users to engage in flexible discovery, aggregation, representation and visualisation of data using:
– topic maps, tag clouds, timelines and maps – VLE's and wikis to share data, interpretation and analysis

One Semantic Web VisionTim Berners Lee’s 2001 ‘vision’ of the SW - personalisation of services through seamless integration of web based systems
“At the doctor's office, Lucy instructed her Semantic Web agent through her handheld Web browser. The agent promptly retrieved information about Mom's prescribed treatment from the doctor's agent, looked up several lists of providers, and checked for the ones in-plan for Mom's insurance within a 20-mile radius of her home and with a rating of excellent or very good on trusted rating services. It then began trying to find a match between available appointment times supplied by the agents …”
Berners-Lee et al, 2001
The general tone is not unlike that of upbeat 1950’s films about the promise of futuristic kitchens, full of labour saving devices and intelligent fridges
Source: Stellman & Greene

• Backend: archiving systems and tools for data management
– digital repositories and libraries, with data and/or metadata in differing formats
– Web services: lookups, converters, searches (i.e. external data providers)
• Middleware: data aggregation and semantic data management
– Triplestore: large data aggregators containing data, metadata, vocabularies, ontologies and sets of rules
– Endpoints and APIs to allow querying the Triplestore
• Frontend: presentation and visualization of data
– Web Interfaces, portals, visualization tools, personal information managers
7
Our semantic web application
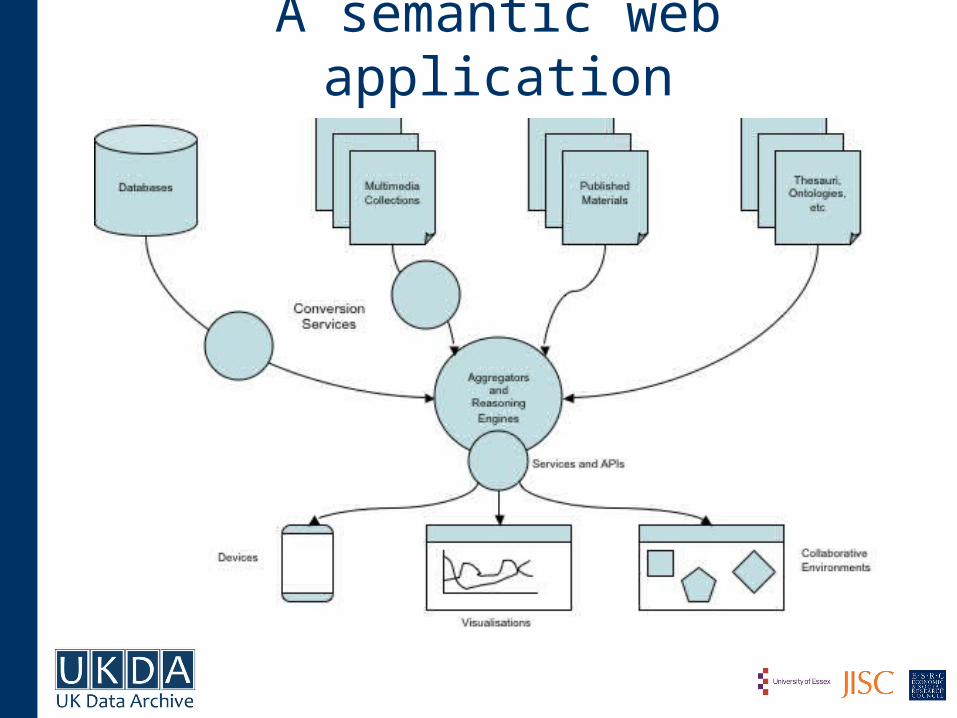
A semantic web application

The technologies we are using
Our back end repository: Fedora
• open source digital repository framework
• specifically oriented towards supporting semantic web applications (Fedora 3.0 represents a major upgrade)
• stores digital objects and manages external references
• enforces no specific collection structure and allows multiple metadata schemes to be used describe specific resources

Fedora’s SW potential
• also allows in-line RDF semantic data to be stored in a digital object
• these can be streamed directly to other applications
• can search across the repository using exposed metadata AND semantic information if present
• relationships among digital resources need to be defined to enable this e.g. just like DDI3 is doing

Data out• convert data to RDF/XML using a RDFizer
– Triplify or RDF123– Eg Excel to RDF, PDF to RDF and so on
• metadata record (in RDF/XML) accompanies data – with permanent address to dataset
• using the Fedora Resource Index module to index relationships among objects (contained in the inline RDF datastreams - RDF/XML)
• now available to aggregators, triplestores, reasoners
• we storing and syncronizing the metadata in every object into a Mulgara Triplestore
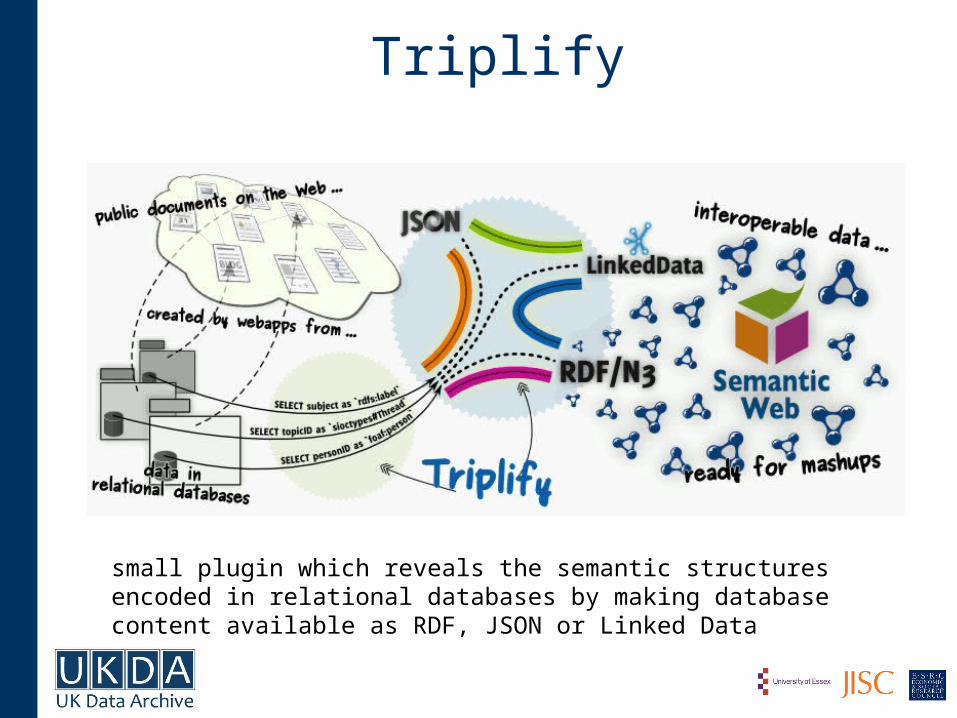
Triplify
small plugin which reveals the semantic structures encoded in relational databases by making database content available as RDF, JSON or Linked Data

Mulgara Semantic Triplestore• is a large database optimised for very rapid searching and pattern
matching
• It does this by rendering all data into ‘triples’ - a record of information in the form of subject - predicate – object
eg URL - property of the resource - value of that property
• can be used to describe connectedness of objects
• a single bibliographic record is represented by about 10-20 triples
• a Triplestore can contain hundreds of millions of triples
• N3 format (Notation3) is a compact and readable alternative to RDF's XML syntax

SPARQL endpoints• emerging W3C standard for semantic data management,
aggregation, selection and querying semantic triplestores
• exploration of SPARQL as a basis for user interaction with data sets and a means of exposing repository content for querying, reuse and repurposing
• we have implemented as a set of predefined queries running across the Triplestore
• results are formatted on the fly for the visualisation tools at hand
• with SPARQL, Web applications can be constructed without extensive additional templating or scripting - 'lowerins the bar'
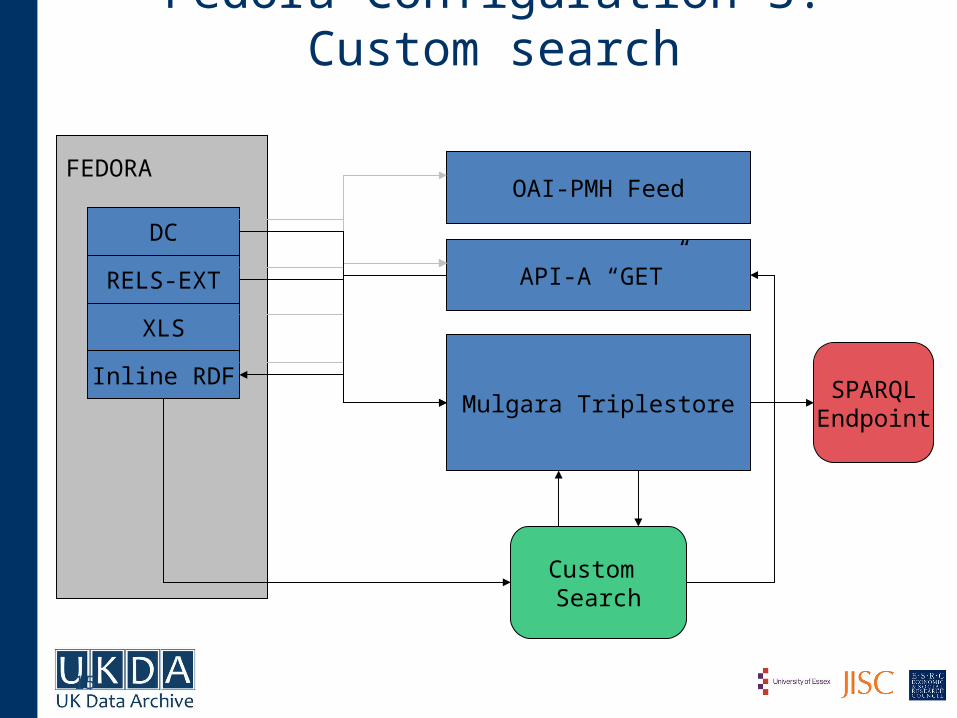
Fedora Configuration 3: Custom search
FEDORA
API-A “GET”
OAI-PMH Feed
DC
RELS-EXT
XLS
Inline RDFMulgara Triplestore
Custom Search
SPARQLEndpoint
15

Visualisation tools• Using SIMILE tooklit based at MIT and supported by
WWW3 and Hewlett-Packard labs
• SIMILE tools:
– customisable browser LONGWELL – aggregates RDF content from multiple sources and presents them through a faceted browser
– can then display through catalogues, maps, timelines, network views, eg using Web widgets such as SIMILE’s Exhibit geo representations and Timeline


What Kinds of Questions?
• What is the latin name for Aleppo Pine?• What does an Aleppo Pine look like?• How do Aleppo Pines reproduce?• Show me a map of their distribution?• Is this a picture of an Aleppo Pine? • Tell me about Aleppo Pines?• Show me examples of plants which frequently inhabit the
same environment as Aleppo Pines• What insect life do Aleppo Pines support?• What do people from Aleppo call Aleppo Pines?
Source: PlantWiki
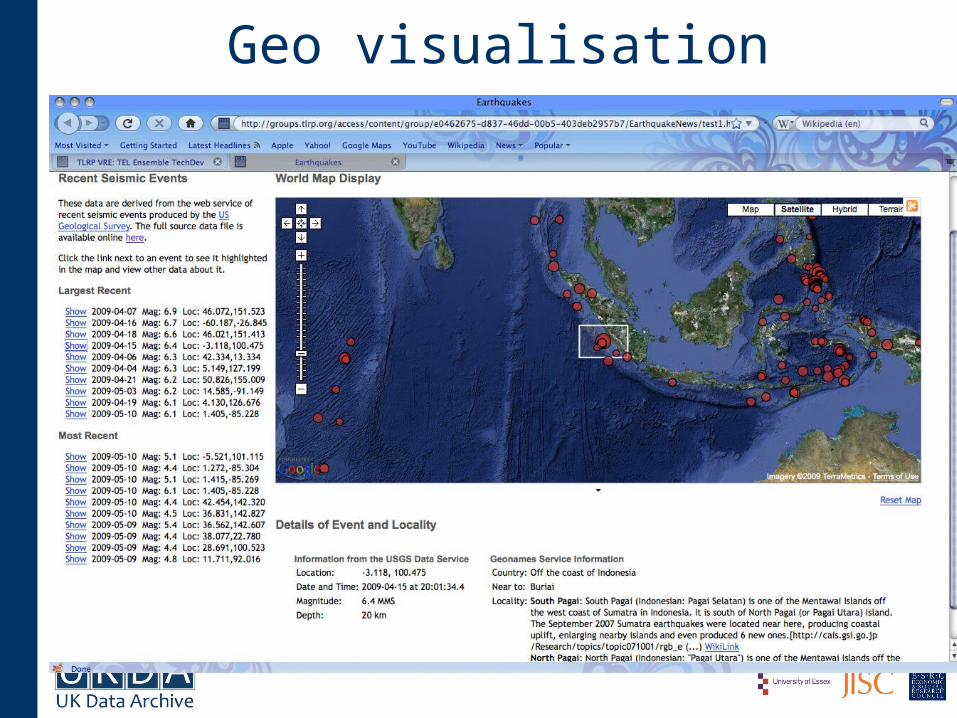
Geo visualisation

Exhibit faceted browsing

Interactivity and creativity• encourages students to experiment, construct
their own evidence-based cases
• appreciate new data sources, be more adventurous, have more fun!
• discuss findings with fellows using social networking tools and so on
• and give back newly constructed datasets

Summary• Fedora Digital Repository provides a framework to store
large and heterogeneous data– not only access to the metadata descriptions but access to
the data itself
• data structured and defined in semantic-ready format– triplestores like Mulgara enable to aggregate and reason
across different data sources
• visualization and presentation tools– process semantic-ready data and present the information in
different formats
22 The Ensemble Project. 2009

Implications for the likes of us?• access to generically applicable and well documented tools
& scripts, APIs in an open access Tools Library
• need help implementing such tools using the experience of existing implementers
• We need to know:
– what technical skills does one need and what will it cost? – how much manual data manipulation needs to be done– how easy is it to integrate these tools into existing systems and
platforms e.g. VREs and VLEs?– and so on








