Embed Size (px)
Citation preview

What about the trees ofWhat about the trees of the Mississippi? the Mississippi?
Suffix Trees explained in an algorithm Suffix Trees explained in an algorithm for indexing large biological sequencesfor indexing large biological sequences
Jacob Kleerekoper & Marjolijn ElsingaJacob Kleerekoper & Marjolijn Elsinga

Overview
Suffix Suffix array Suffix tree Suffix links tree Demo

Suffix
Suffices of mississippi:1 mississippi 11 i2 ississippi 8 ippi3 ssissippi 5 issippi4 sissippi 2 ississippi5 issippi sort alphabetically 1 mississippi6 ssippi 10 pi7 sippi 9 ppi8 ippi 7 sippi9 ppi 4 sissippi10 pi 6 ssippi11 i 3 ssissippi

Suffix array
m i s s i s s i p p i
5 2 1 10 9 7 411 8 36
2 3 4 5 6 7 80 1 109
Suffix
Index

Search in suffix array
Idea: two binary searches- search for leftmost position of X- search for rightmost position of X
In between are all suffices that begin with X

5 2 1 10 9 7 411 8 36
2 3 4 5 6 7 80 1 109
Suffix
Index
Search in suffix arraySearch for leftmost occurrence of is
m i s s i s s i p p i
more occurrences of is left of this one possible!
piissippiippiFound leftmost

5 2 1 10 9 7 411 8 36
2 3 4 5 6 7 80 1 109
Suffix
Index
Search for rightmost occurrence of is
m i s s i s s i p p i
more occurrences of is right of this one possible!
Search in suffix array
issippi piFound rightmostississippi mississippi

Result search in suffix array
Leftmost occurrence of is: 5 at index 2
Rightmost occurrence of is: 2 at index 3
is can be found at [2..3] in the suffix array

Tree & Trie
Suffix tree is a compressed digital (suffix) trie

Suffix tree definition
A suffix tree is a rooted directed tree with m leaves, where m is the length S (the database string)
For any leaf i, the concatenation of the edge-labels on the path from the root to leaf i exactly spells out the suffix of S that starts at position i
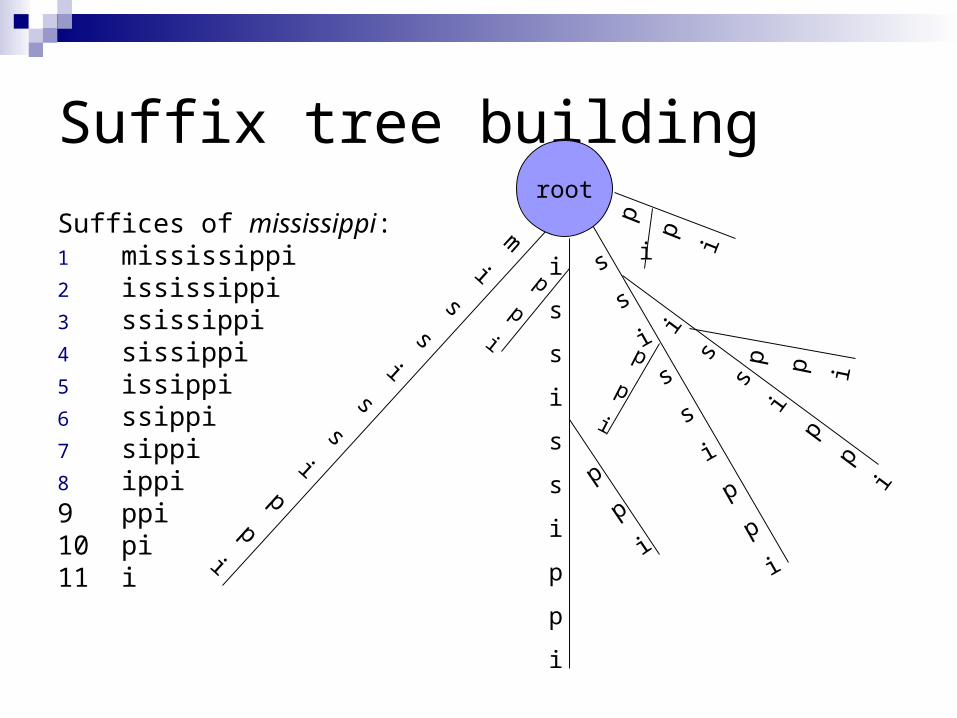
Suffices of mississippi:1 mississippi2 ississippi3 ssissippi4 sissippi5 issippi6 ssippi7 sippi8 ippi9 ppi10 pi11 i
Suffix tree building
mi
ss
is
si
pp
i
i
s
s
i
s
s
i
p
p
i
s
s
i
s
s
i
p
p
i
root
i
s
s
i
p
p
ip
p
i
p
p
i
p p i
p
p
i
p
p
ii
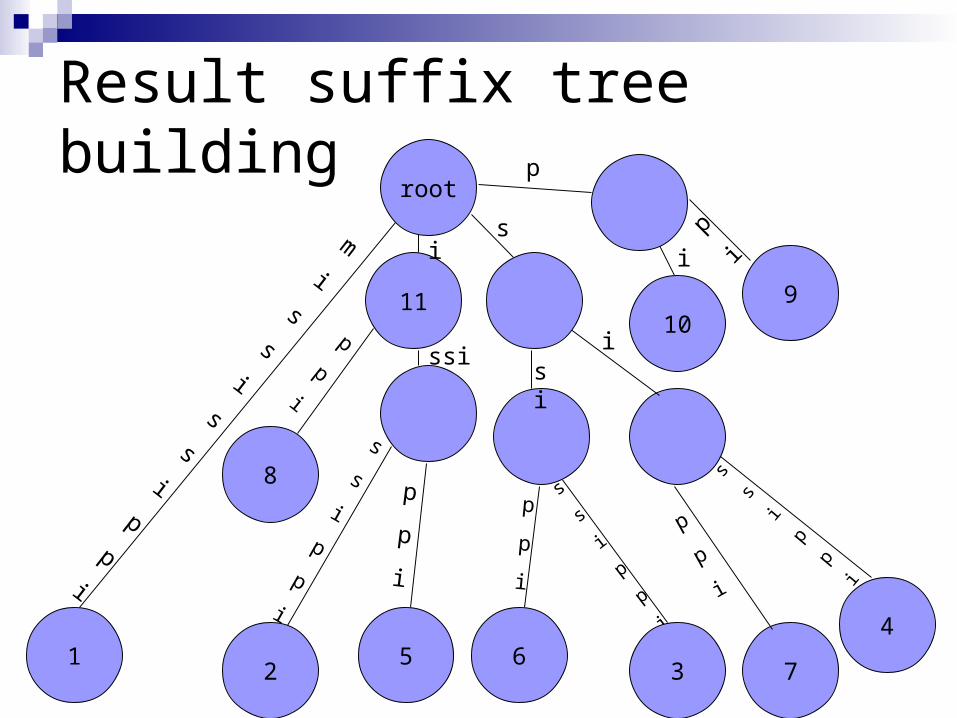
Result suffix tree building
m
i
s
s
i
s
s
i
p
p
i
s
s
i
p
p
i
s
s
i
p
p
i
p
p
i
p
p
i
p
p
i
pii
1
11
root
8
25
109
63
i
4
7
s
s
i
p
p
i
p
p
i
s
si
p
issi

Questions
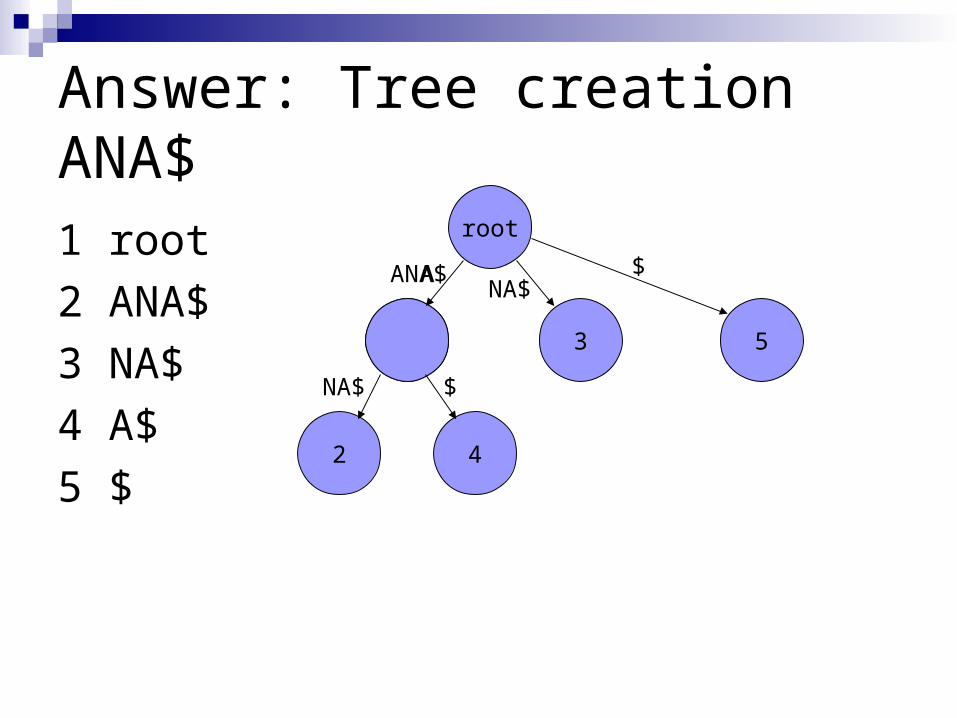
Adriano: How is the tree created for ANA$?
2
Answer: Tree creation ANA$
1 root
2 ANA$
3 NA$
4 A$
5 $
root
3
2 4
5
ANA$NA$
NA$ $
$A

Implicit vs. explicit
Trees in which a special end symbol is used are called explicit
Searching in this trees can only be stopped at this end symbol, which is always in a leaf
A search in a implicit tree can stop at any internal or external node, at the last matching symbol

Question
Peter: How does this method search for homologous sequences as is done in BLAST and CAFE?
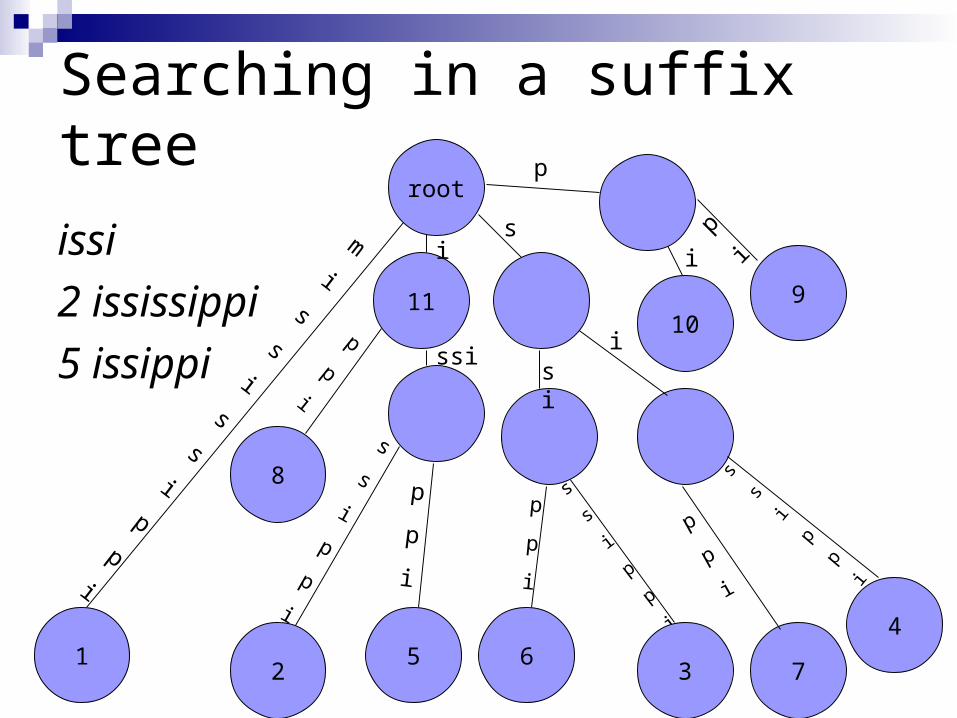
Searching in a suffix tree
issi
2 ississippi
5 issippi
m
i
s
s
i
s
s
i
p
p
i
s
s
i
p
p
i
s
s
i
p
p
i
p
p
i
p
p
i
p
p
i
pii
1
11
root
8
25
109
63
i
4
7
s
s
i
p
p
i
p
p
i
s
si
p
issi

Time analysis of suffix tree
Building a suffix tree can be done in O(k) where k is the length of the database string
Searching a suffix tree can be done in O(n) where n is the length of the query string
(Note: only in Ukkonen’s implementation)

Question
Laurence: Can you explain the suffix links tree?

Suffix links
A necessary implementation trick to achieve a linear time and space bound during building the tree
A suffix link is: a pointer from an internal node xS to another internal node S where x is a arbitrary character and S is a possibly empty substring
xS S
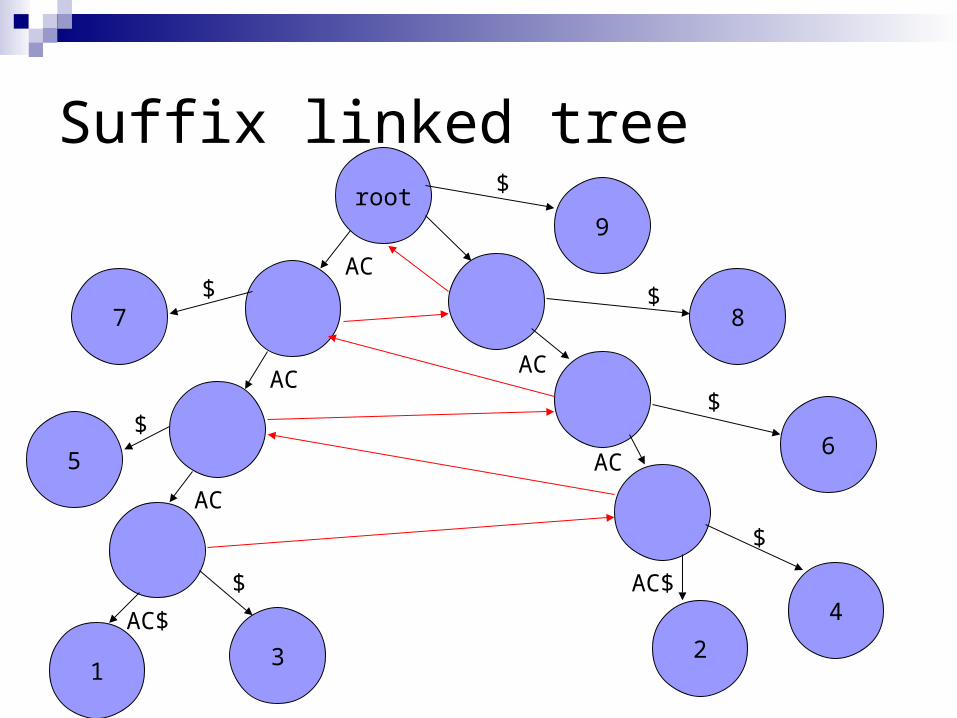
Suffix linked treeroot
2
4
6
8
9
13
5
7
AC
AC
AC
AC$
AC
AC
AC$
$
$
$
$
$
$
$

Question
Ingmar: Why is the memory bottleneck a problem, and how is it solved with the use of suffix links?
Answer: we interpreted the article in such way that the suffix links cause the memory bottleneck and not the other way around

Question
Lee: How can suffix links cause the memory bottleneck and why is its reliance on virtual memory impractical?
Answer: Suffix links are designed to take you from one region of the tree to another. It could be possible, because of the size of the tree, that the region pointed to is not in memory available. The same holds for virtual memory.

Question
Bram: Why do we need random access of the memory?
Answer: a tree is based on pointers, these are not sequentially inserted into the memory, so random access is necessary

Question
Bogdan: How does this index cope with partial matches, gapped alignments and so forth, or is it just used for exact matches, which usually don’t help a lot?
Answer: Your intuition is correct here. Suffix trees as described in the article can only be used for exact (local) matches

Question
Lee: Can this method be used for protein data as well / can this method also be used for similar matches?
Answer: Suffix trees probably can be used for protein data, but it is not possible to implement wildcards or the fact that amino acids are evolutionary related, but do not match exactly in some cases.

Question
Peter: Why is it a problem that DNA cannot be broken into words, and why doesn’t it use the overlapping intervals as in CAFE?
Answer: the begin and end of a base string cannot be determined. Suffices are a special kind of overlapping intervals.

Question
Bogdan: Why do we have to change the index for each search instead of building the index once and update it when the database is changed?
Answer: the index mentioned is the BLAST index and in BLAST the index has to be updated for every search. It has not much to do with suffix trees.

Question
Adriano: What is the meaning of "cold store" and "warm store"?
Answer: We think that cold store means that not the entire database is available in the memory and in the case of warm store the used part of the database is in the physical memory. This can be concluded from the fact that in warm store only short queries are run.

Question
Bogdan: What is the checkpointing which is done?
Answer: “Checkpointing is the process of associating a resource with one or more registry keys so that when the resource is moved to a new node, the required keys are propagated to the local registry on the new node.”
We think that the checkpointing is used to first build a portion of the tree in the memory and then put the finished (checkpointed) portion onto the disk

DemoUkkonen’s linear time suffix tree algorithm (on-line available at:
http://www.i.kyushu-u.ac.jp/~takeda/PM/SuffixTree/STreeDemo.html)





























