Embed Size (px)
Citation preview

Web mining
• Web mining deals with mining of patterns from web and e-commerce data.
• Web data– Web pages– Web structures– Web logs– E-commerce sites– E-mail messages– Customer profiles– Telephone calls
• The aim is to create an intelligent enterprise.
E-commerce Business Objectives
• E-commerce business objectives
[PPS 03]
[BL 97]
[MMPH 03][BM 98]
[LPSHG 01]
[SM 00][FCJ 01][MPT 99]

Objectives
• Web mining is the hottest areas in computer science because of its direct applications in e-commerce, information retrieval and filtering, and web information systems.
• Web mining.– Web usage mining.– Web content mining– Web structure mining.
• And applications to e-commerce and business intelligence.• Data mining, text mining, information retrieval, Machine
learning techniques will be covered for business intelligence, site management, personalization and user profiling.
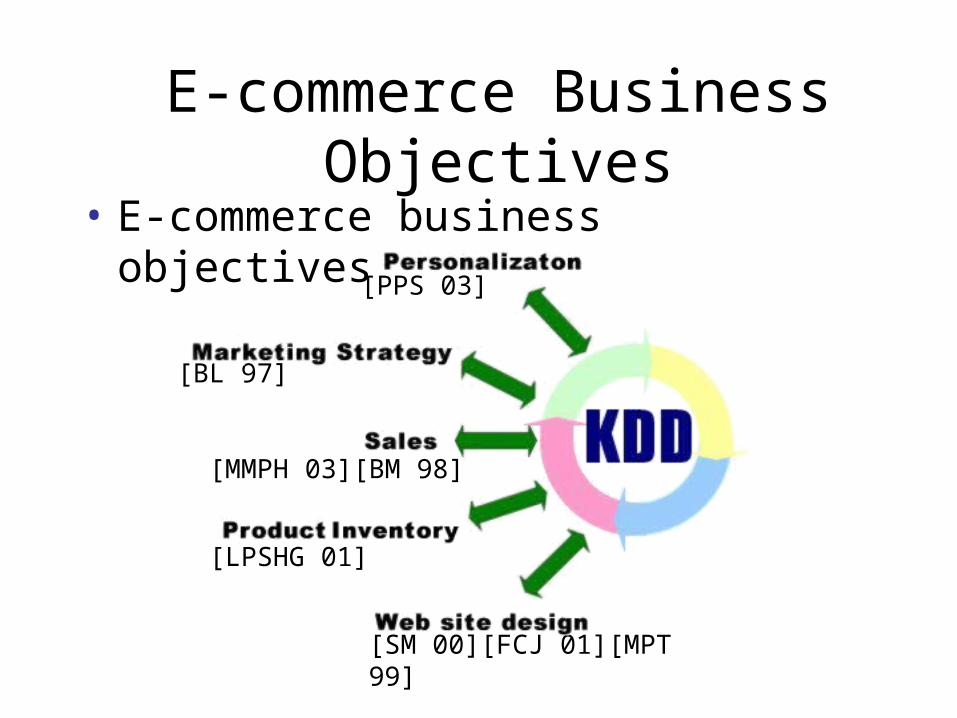
Web Mining Taxonomy
• Web structure mining• Web content mining• Web usage mining
– Mining the usage data– User’s behaviour
• Click the link• Browsing time• Transaction
Web MiningWeb Mining
Web Structure
Mining
Web Structure
Mining
WebUsage Mining
WebUsage Mining
Web Content Mining
Web Content Mining
The taxonomy of web mining [CMS 97]

Topics
• Overview of data mining and E-business analytics– Data preprocessing, association rules, classification, clustering.
• Web structure mining– Link based search algorithms
• Web content/text mining– Information retrieval
• Web usage mining: E-metrics and E-commerce data analysis.– Web log mining
• Web personalization and recommendation systems
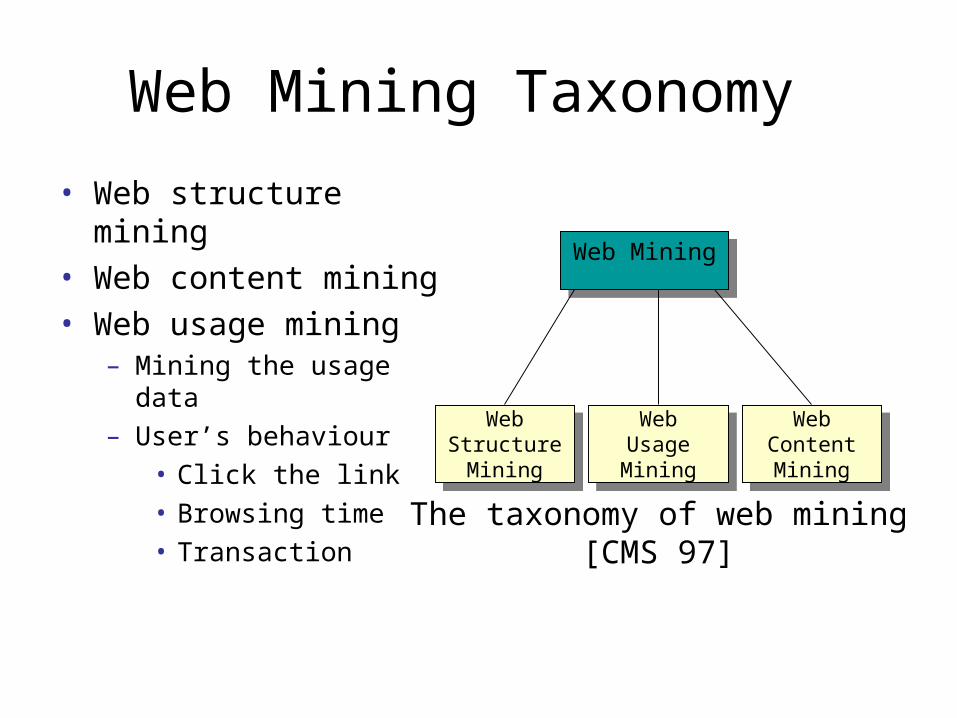
The web miner system
Site files Access Log Referrer Log Agent Log Registration orRemote agent data
Data cleaningPath completion
Session identificationUser Identification
Site CrawlerClassification
algorithm
Page classification Site topology User session file
TransactionIdentification
Transaction file
Site Filter
AssociationRule mining
Clustering
Standard StatisticsPackageSequential
Patternmining
Sequential patternsPage clusters
Association rules
Usage statistics
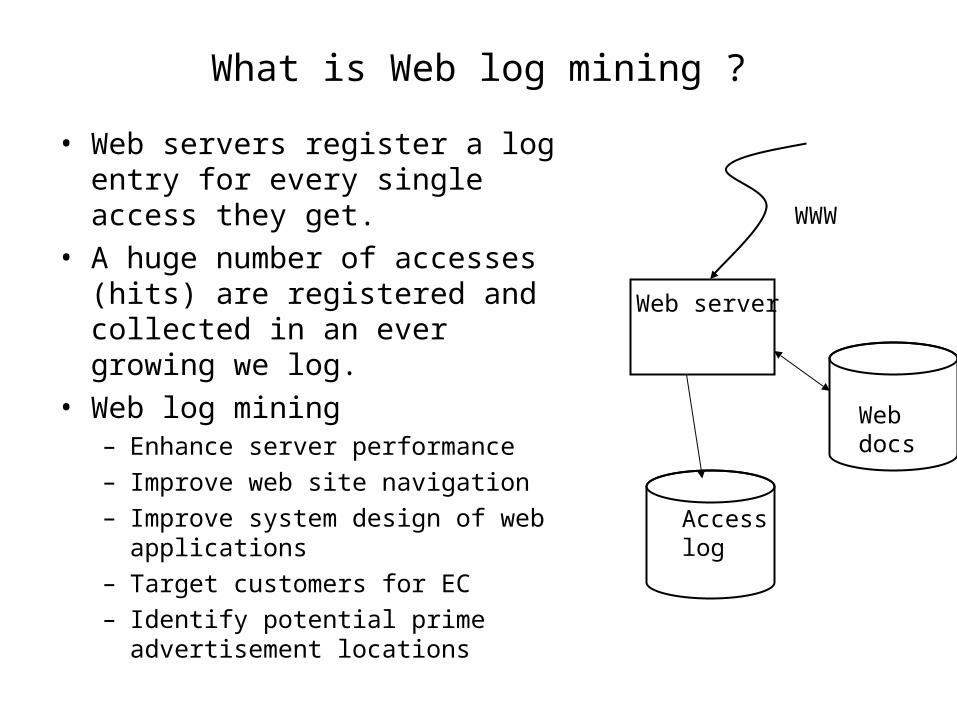
What is Web log mining ?
• Web servers register a log entry for every single access they get.
• A huge number of accesses (hits) are registered and collected in an ever growing we log.
• Web log mining– Enhance server performance– Improve web site navigation– Improve system design of web
applications– Target customers for EC– Identify potential prime
advertisement locations
Web server
Webdocs
Accesslog
WWW

Existing Web Log Analysis Tools• Many products are available
– Slow and make assumptions to reduce the size of the log file to analyze.
• Frequently used, predefined reports– Summary report of hits and bytes transferred.– List of top requested URLs– List of referrers.– List of most common browsers.– Hits per hour/day/week/month reports.– Hits per Internet domain– Error report– Directory tree report etc.
• Tools are limited in their performance, comprehensiveness, and depth of analysis.

client’s IP address, the date and time the request is received, the time zone where the server is located, the request command, the URL (Uniform Resource Locator) of the requested page, the protocol of the request, the
return code of server, and the size of the page.
mac04cville.wam.umd.edu - - [01/Apr/1997:00:00:00 -0600]
"GET /~ka/graphics/mel/melting_glass.html HTTP/1.0" 200 11880
mac04cville.wam.umd.edu - - [01/Apr/1997:00:00:20 -0600]
"GET /~ka/graphics/mel/glass.html HTTP/1.0" 200 11880

Web Server log file entries
IP address User ID Timestamp Method URL/path status size Reference agent cookie
dd23-125.compuserve.com-rhuia[01/Apr/1997:00:03:25-0800]”GET/SFU/cgi-bin/rg/vg-dspmsg.cgi?ci=40154&mi=49 HTTP/1.0”200417
129.128.4.241-[15/Aug/1999:10:45:32-0800] ”GET/source/pages/chapter.html”200618 /source/pages/index.html Mozilla/3.04 (win95)

Diversity of web log mining
• Weblog provides rich information about web dynamics• Multidimensional web log analysis
– Disclose potential customers, users, markets, etc
• Plan mining (mining general web accessing regularities)– Web linkage adjustment, performance improvements.
• Web accessing association/sequential pattern analysis– Web caching, pre-fetching
• Trend analysis– Dynamics of the web: what has been changing ?
• Customized to individual users.

More on web log mining
• Information NOT contained in the log files.– Use of browser functions, e.g. backtracking within-page
navigation, e.g., scrolling up and down.– Requests of pages stored in the cache– Requests of pages stored in cache server.– Etc.
• Special problems with dynamic pages– Different user actions call same cgi script– Same user action at different times may call different cgi scripts.– One user using more than one browser at a time.– Etc.

Use of log files
• Basic summarization– Get frequency of individual actions by user, domain and session.– Group actions into activities, e.g., reading messages in a
conference.– Get frequency of different errors.
• Questions answerable by such summary– Which components or features are the most/least used ?– Which events are most frequent ?– What is the user distribution over the domain areas ?– Are there, and what are the differences in access from different
domain areas or geographic areas ?

In-depth analysis of log files• In-depth analysis
– Pattern analysis e.g between users, over different courses, instructional design and materials.
– Trend analysis: e.g user behaviour change over time, network traffic change over time.
• Questions can be answered by in-depth analysis– In what contexts, the components or features used ?– What are the typical event sequences ? – What are the differences in usage and access patterns among
users ?– What are the overall patterns of use of a given environment ?– What user behaviours change over time ?– How usage patterns change over quality of service (slow/fast)?– What is the distribution of network traffic over time ?
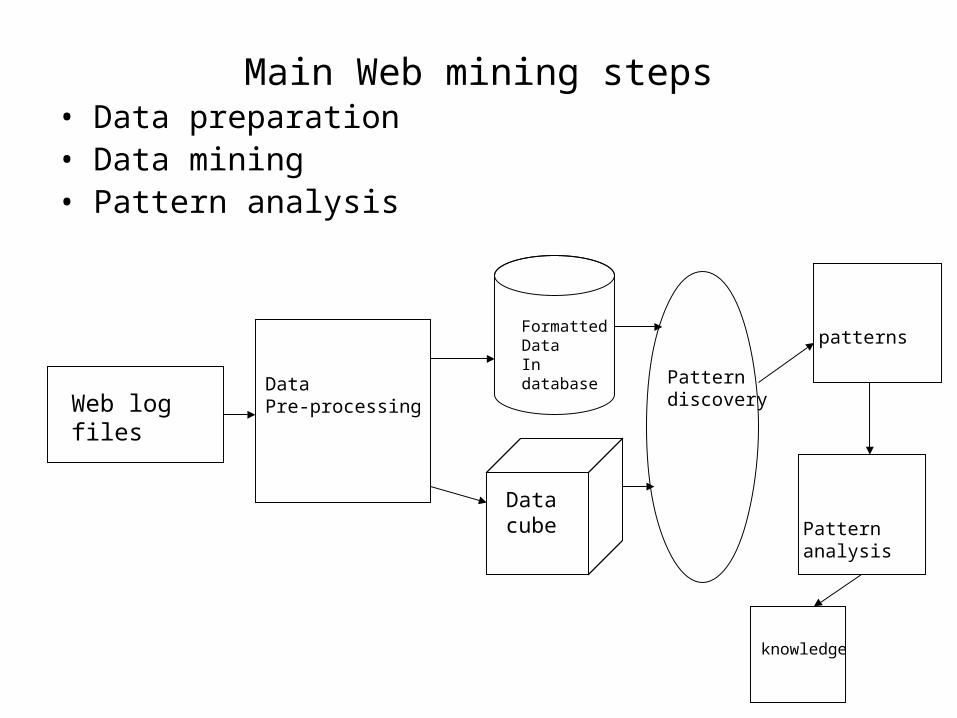
Main Web mining steps• Data preparation• Data mining• Pattern analysis
Web log files
Data Pre-processing
FormattedDataIn database
Data cube
Patterndiscovery
patterns
Patternanalysis
knowledge

Data preprocessing
• Problems– Identifying types of pages: content page of navigation page– Identify visitor (user)– Identify session, transaction, sequence, action,…– Inferring cached pages
• Identifying visitors– Login/cookies/combination: IP addresses, agent, path followed
• Identification of session (division of click stream)– We do not know when a visitor leaves Use a timeout (usually
30 minutes)
• Identification of user actions– Parameters and path analysis.

Preprocessing• Inputs to pre-processing
– Server logs, site files, usage statistics
• Outputs– User session file, transaction file, site topology, and page
classifications
• Impediments: browser and proxy caching.• Methods used to collect information about cached
references– Cookies
• Can be deleted by user
– Cache busting: forcing a browser to download a page from browser.
• Defeats the advantage of caching
– Registration• Privacy concerns

Data cleaning• Data cleaning steps
– Eliminate irrelevant items
• HTTP protocol requires separate connection for every request.
• Graphics is automatically downloaded.• Only log entry of HTML request should be kept.• All the log entries with file name suffixes such as gif,
jpeg, GIF, JPEG, jpg, JPG are removed.• WEBMINER uses default list of suffixes to remove files.• Main intent of web usage mining
– Knowing the intent of the user.

User Identification• Unique users must be identified• This task is complicated by the existence of local
caches, corporate firewalls, and proxy servers.• Heuristic can be applied
– If IP address is same and agent is different, the user is different– If referrer is different then users are different

Session Identification• Users will visit server more than once.• Goal of session identification
– Divide the page accesses of each user into individual sessions.
• Simplest method– Use timeout. Many commercial products use 30 minutes.
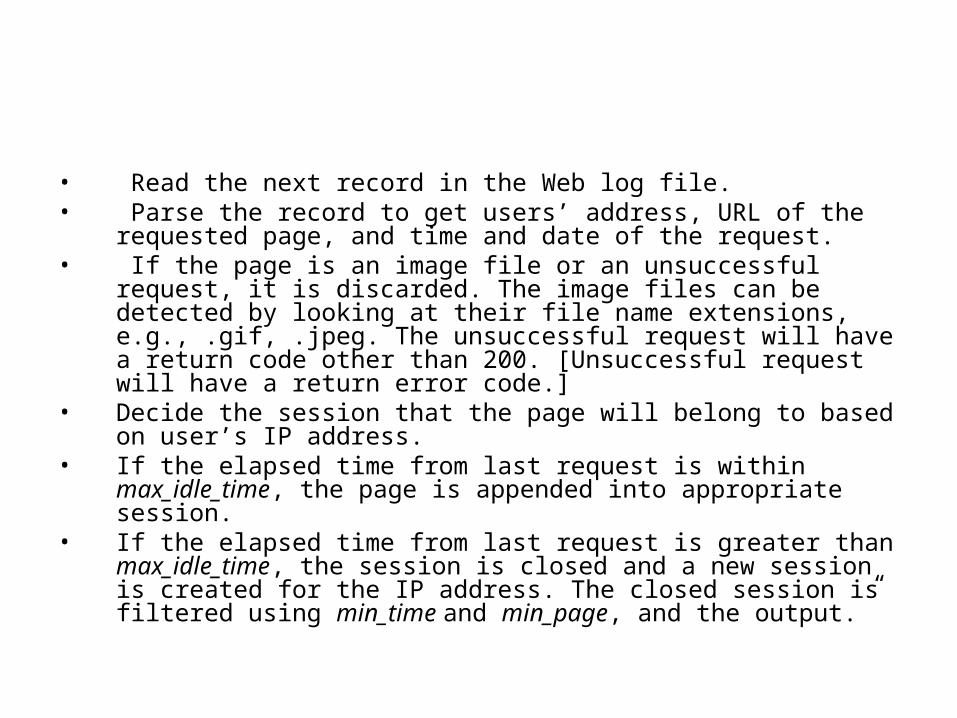
• Read the next record in the Web log file.• Parse the record to get users’ address, URL of the requested
page, and time and date of the request.• If the page is an image file or an unsuccessful request, it is
discarded. The image files can be detected by looking at their file name extensions, e.g., .gif, .jpeg. The unsuccessful request will have a return code other than 200. [Unsuccessful request will have a return error code.]
• Decide the session that the page will belong to based on user’s IP address.
• If the elapsed time from last request is within max_idle_time, the page is appended into appropriate session.
• If the elapsed time from last request is greater than max_idle_time, the session is closed and a new session is created for the IP address. The closed session is filtered using min_time and min_page, and the output.”

User Access Patterns
• Due to cache function in client-side machine, the server log file doesn’t store every request from client.
• How to find user access pattern between two consecutive pages in a session?

User Access Patterns
• Assumption: Users always follow the shortest path for navigation.
• Principles:– Once a click through happens, no back is
allowed. Otherwise, it is not a shortest path.– Whenever there is ambiguity of click through
or back, we choose back. This will make future "back" streams shorter

User Access Patterns
• CT -> click through.
CB -> click back.
• 1. CT1 -> …->CTx where x >= 1
• 2. CB1 -> …->CBy ->CT0->…->CTz
where y >=1, z >= 0
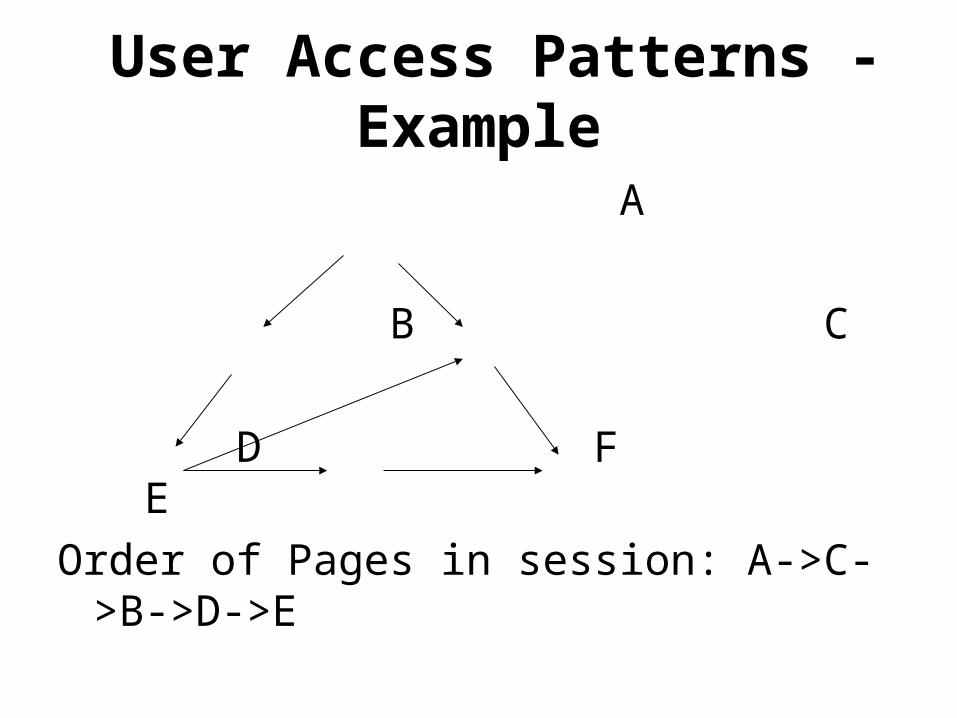
User Access Patterns -Example
A
B C
D F E
Order of Pages in session: A->C->B->D->E

User Access Patterns -Example
• 1. A 2. A -> C
Step: CT
Cache: A Cache: AC
Path: A Path: AC
3. C -> B 4. B->D
Step: CB->CT Step:CT
Cache:ACB Cache:ACBD
Path: AB Path: ABD

User Access Patterns -Example
5. D ->E
possible Path: 1. D->F->E
2. D->C->E
3. D->B->A->C->E
Step: CT->CT
Cache: ACBDE
Path: ABDCE

Path Completion• Path completion: Finding out important accesses that are
not recorded in the log.• If a page request is made which is not directly linked to
last page, the referrer log has to be checked.• Missing page references are inferred and added to the
user session file.

Example
A
DCB E
O
F G H I J K L M
O
T
P R S
N
X Content page
X
J
Auxiliary page
Multiple PurposePage
Session identification: A-B-F-O-G, A-D, A-B-C-J, L-R
Path completion: A-B-F-O-F-B-G, A-D, A-B-A-C-J, L-R

Summary of Sample Log Pre-processing Results
•A-B-F-O-G•A-D•A-B-C-J•L-R
Task Result
Clean Log •A-B-L-F-A-B-R-C-O-J-G-A-D
User Identification •A-B-F-O-G-A-D•A-B-C-J•L-R
Session Identification
Path Completion •A-B-F-O-F-B-G•A-D•A-B-AC-J•L-R

Transaction Identification• Goal of transaction identification: create meaningful
clusters of references for each user.• Input to transaction identification process
– All of page references for a given user session. Let L is a user session file
• General transaction model– t=<ipt,uidt, {(lt1.url, lt1.time),…., (ltm.url,ltm.time)}>
– Apply divide approach to generate transactions.
• Three methods to identify transactions.– Reference length– Maximal forward reference– Time window

Transaction Identification by reference length• Transaction Identification by Reference Length
– The amount of time the user spends on a page correlates to whether the page should be classified as a auxiliary or content page for that user.
• Approximate to cut-off for auxiliary and content reference length can be calculated.
• The definition of a transaction within the reference length approach is a quadruple with the reference length is addded for each page.– t=<ipt,uidt, {(lt1.url, lt1.time, lt1.length),…., (ltm.url, ltm.time, ltm.length)}>
• The length of each reference is calculated by taking the difference between the time of the references.
• After determining the cut-off – Auxiliary content transaction: for 1<= k <= (m-1): ltk.length <C and k=m:
ltk.length >C
– Content –only transaction: for 1 <=k<=m: lk.length >C

Use of content and structure in data cleaning
• Structure– The structure of a web site is needed to analyze session and
transactions– Hyper-tree of links between pages
• Content– Contents of web pages visited can give hints for data cleaning
and selection• Eg. Grouping web transactions by terminal page content.
– Content of web pages gives a clue on type of page: navigation or content.
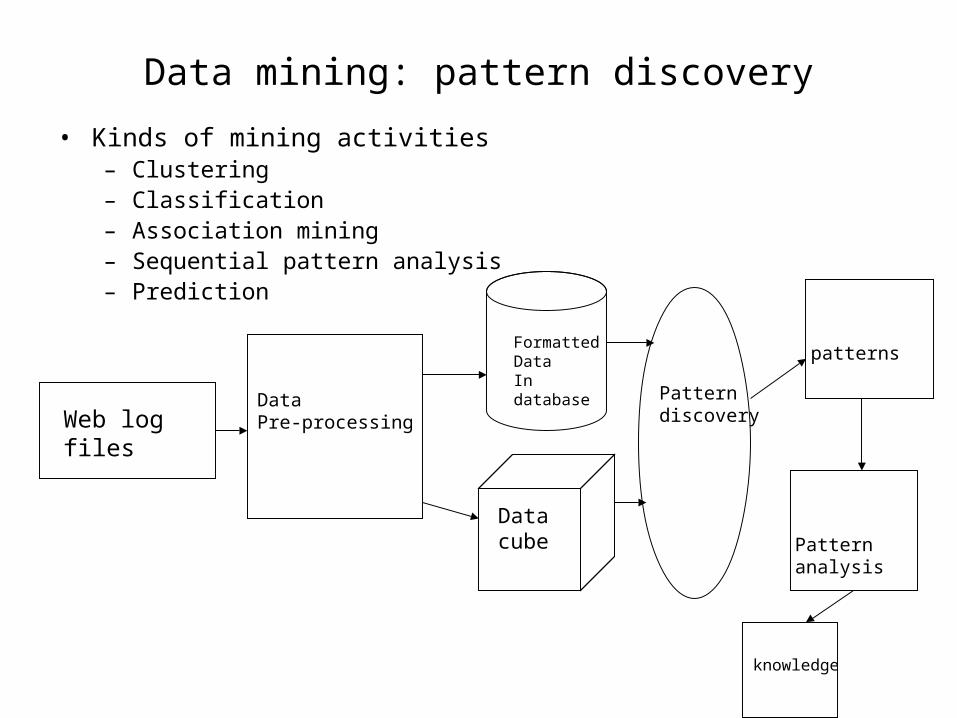
Data mining: pattern discovery
• Kinds of mining activities– Clustering– Classification– Association mining– Sequential pattern analysis– Prediction
Web log files
Data Pre-processing
FormattedDataIn database
Data cube
Patterndiscovery
patterns
Patternanalysis
knowledge

Clustering
• Grouping together objects that have similar characteristics– Clustering of transactions
• Grouping same behaviours regardless of visitor or content.
– Clustering of pages and paths• Grouping same pages visited based on content and visits
– Clustering of visitors• Grouping of visitors with some behaviour.

Classification
• Classification of visitors• Categorizing or profiling visitors by selecting features
that best describe the properties of their behaviour.– 25 % of visitors who buy fiction books come from Ontario are
aged between 18 and 35 and visit after 5.00 PM.
• The behaviour (i.e., class) of a visitor may change in time.

Association mining
• Association of frequently visited pages• Pages visited in the same session constitute a
transaction. – Relating pages that are often referenced together regardless of
the order in which they are accessed (may not be hyper-linked)
• Inter-session or intra-session association

Sequential Pattern Aalysis
• Sequential patterns are inter-session ordered sequences of page visits. Pages in a session are time-ordered sets of episodes by the same visitor.– (<A,B,C>, <A,B,C,E,F>, B, <A,B,C,E,F>)– (<A,B,C>, <E,F>, B, <A,*,F>),…

Pattern Analysis
• Set of rules can be discovered can be very large• Pattern analysis reduces the set of rules by filtering out
uninteresting rules and directly pinpointing interesting rules.– SQL analysis– OLAP from data cube
• Viewing data at different levels
– visualization

Web usage mining systems
• General web usage mining:– WebLogMiner (Zaiane et al. 1998)– WUM (Spiliopoulou et al 1998)– WebSIFT (Cooley et al. 1999)
• Adaptive web sites (Perkowitz et al. 1998)• Personalization and recommendation
– WebWatcher (Joachims et al 1997)– Clustering of users (Mobhasher et al 1999)
• Traffic and caching improvement– (Cochen et al 1998)
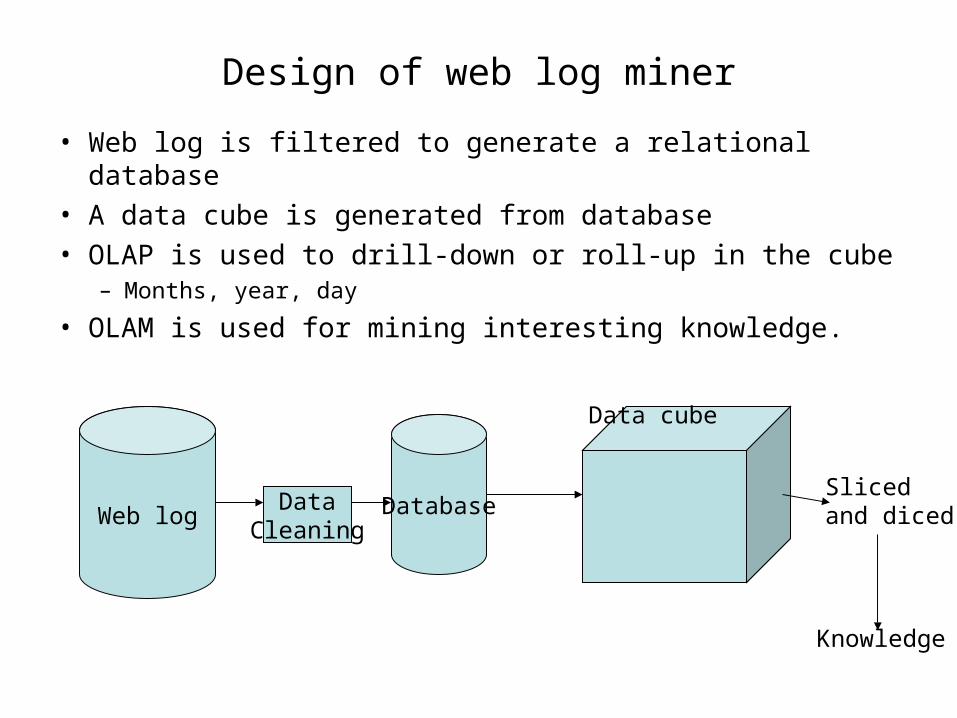
Design of web log miner
• Web log is filtered to generate a relational database• A data cube is generated from database• OLAP is used to drill-down or roll-up in the cube
– Months, year, day
• OLAM is used for mining interesting knowledge.
Web logData
CleaningDatabase
Data cube
Sliced and diced
Knowledge
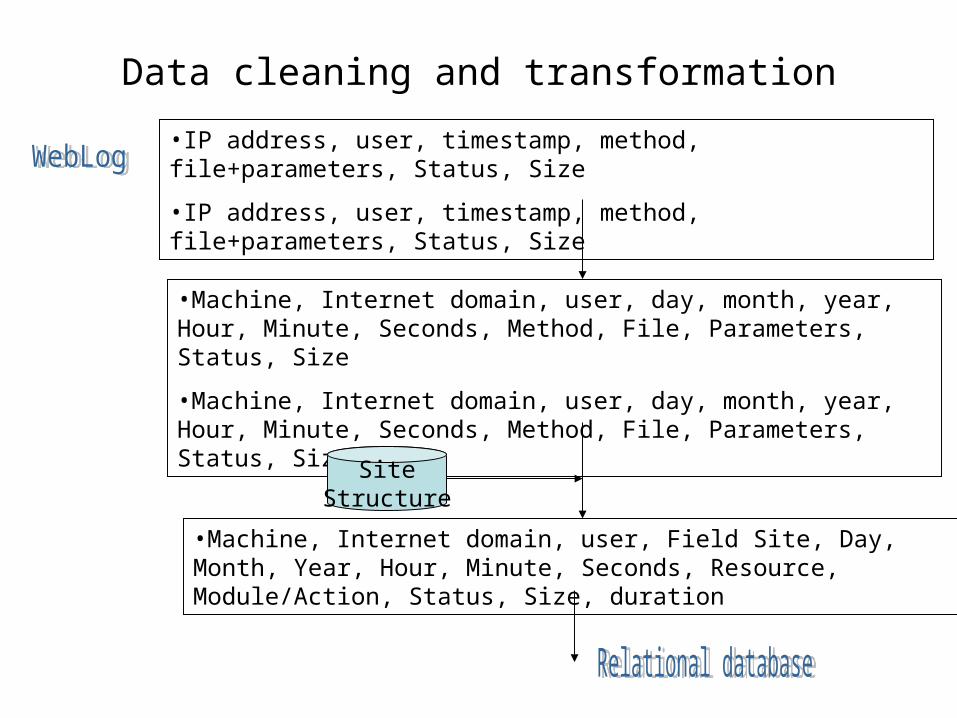
Data cleaning and transformation
•IP address, user, timestamp, method, file+parameters, Status, Size
•IP address, user, timestamp, method, file+parameters, Status, Size
•Machine, Internet domain, user, day, month, year, Hour, Minute, Seconds, Method, File, Parameters, Status, Size
•Machine, Internet domain, user, day, month, year, Hour, Minute, Seconds, Method, File, Parameters, Status, Size
•Machine, Internet domain, user, Field Site, Day, Month, Year, Hour, Minute, Seconds, Resource, Module/Action, Status, Size, duration
SiteStructure

Typical summaries
• Request summary:– Request statistics for all modules/pages/files
• Domain summary: – Request statistics from different domains
• Event summary:– statistics of the occurring of all events /actions
• Session summary: – statistics of sessions
• Bandwidth summary: – statistics of generated network traffic
• Error summary: – statistics of all error messages
• Referring organization summary: – statistics of where the users were from
• Agent summary: – statistics of the use of different browsers, etc

From OLAP to Mining
• OLAP can answer questions such as:– Which components or features are the most/least used ?– What is the distribution of network traffic over time (hour of the
day, day of the week, month of the year etc)– What is the user distribution over different domain areas ?– Are there and what are the differences in access for users from
different geographic areas ?
• Some questions need further analysis: mining– In what context are the components or the features used ?– What are the typical event sequences ?– Are there any general behaviour patterns across all users, and
what are they ?– What are the differences in usage and behaviour for different
user population ?– Whether user behaviours change over time and How ?

Web Log Data Mining
• Data characterization• Class comparison• Association• Prediction• Classification• Time-series analysis• Web traffic analysis
– Typical event sequence and user behaviour pattern analysis– Transition analysis– Trend analysis

Discussion
• Analyzing the web access logs can help understand the user behavior and web structure, there by improving the design of web collections and web applications, targeting e-commerce potential customers, etc.
• Web log entries do not collect enough information.• Data cleaning and transformation is crucial and often
requires site structure knowledge (MetaData)• OLAP provides data views from different perspectives
and at different conceptual levels.• Web Log data mining provides in depth reports like time
series analysis, associations, classification, etc.