Embed Size (px)
DESCRIPTION
WEB BAR 2004 Advanced Retrieval and Web Mining. Lecture 13. Clustering II: Topics. Some loose ends Evaluation Link-based clustering Dimension reduction. Some Loose Ends. Term vs. document space clustering Multi-lingual docs Feature selection Labeling. Term vs. document space. - PowerPoint PPT Presentation
Citation preview

WEB BAR 2004 Advanced Retrieval and Web Mining
Lecture 13

Clustering II: Topics
Some loose ends Evaluation Link-based clustering Dimension reduction

Some Loose Ends
Term vs. document space clustering Multi-lingual docs Feature selection Labeling

Term vs. document space So far, we clustered docs based on their
similarities in term space For some applications, e.g., topic analysis
for inducing navigation structures, can “dualize”: use docs as axes represent (some) terms as vectors proximity based on co-occurrence of terms
in docs now clustering terms, not docs
Diagonally symmetric problems

Term vs. document space
Cosine computation Constant for docs in term space Grows linearly with corpus size for terms in
doc space Cluster labeling
clusters have clean descriptions in terms of noun phrase co-occurrence
Easier labeling? Application of term clusters
Sometimes we want term clusters (example?)
If we need doc clusters, left with problem of binding docs to these clusters

Multi-lingual docs
E.g., Canadian government docs. Every doc in English and equivalent
French. Must cluster by concepts rather than
language Simplest: pad docs in one language with
dictionary equivalents in the other thus each doc has a representation in both
languages Axes are terms in both languages

Feature selection
Which terms to use as axes for vector space?
Large body of (ongoing) research IDF is a form of feature selection
can exaggerate noise e.g., mis-spellings Pseudo-linguistic heuristics, e.g.,
drop stop-words stemming/lemmatization use only nouns/noun phrases
Good clustering should “figure out” some of these

Major issue - labeling
After clustering algorithm finds clusters - how can they be useful to the end user?
Need pithy label for each cluster In search results, say “Animal” or “Car” in
the jaguar example. In topic trees (Yahoo), need navigational
cues. Often done by hand, a posteriori.

How to Label Clusters
Show titles of typical documents Titles are easy to scan Authors create them for quick scanning! But you can only show a few titles which
may not fully represent cluster Show words/phrases prominent in cluster
More likely to fully represent cluster Use distinguishing words/phrases
Differential labeling But harder to scan

Labeling
Common heuristics - list 5-10 most frequent terms in the centroid vector. Drop stop-words; stem.
Differential labeling by frequent terms Within a collection “Computers”, clusters all
have the word computer as frequent term. Discriminant analysis of centroids.

Evaluation of clustering Perhaps the most substantive issue in data
mining in general: how do you measure goodness?
Most measures focus on computational efficiency Time and space
For application of clustering to search: Measure retrieval effectiveness

Approaches to evaluating
Anecdotal User inspection Ground “truth” comparison
Cluster retrieval Purely quantitative measures
Probability of generating clusters found Average distance between cluster members
Microeconomic / utility

Anecdotal evaluation
Probably the commonest (and surely the easiest) “I wrote this clustering algorithm and look
what it found!” No benchmarks, no comparison possible Any clustering algorithm will pick up the
easy stuff like partition by languages Generally, unclear scientific value.

User inspection
Induce a set of clusters or a navigation tree Have subject matter experts evaluate the
results and score them some degree of subjectivity
Often combined with search results clustering
Not clear how reproducible across tests. Expensive / time-consuming

Ground “truth” comparison
Take a union of docs from a taxonomy & cluster Yahoo!, ODP, newspaper sections …
Compare clustering results to baseline e.g., 80% of the clusters found map “cleanly”
to taxonomy nodes How would we measure this?
But is it the “right” answer? There can be several equally right answers
For the docs given, the static prior taxonomy may be incomplete/wrong in places the clustering algorithm may have gotten right
things not in the static taxonomy
“Subjective”

Ground truth comparison
Divergent goals Static taxonomy designed to be the “right”
navigation structure somewhat independent of corpus at hand
Clusters found have to do with vagaries of corpus
Also, docs put in a taxonomy node may not be the most representative ones for that topic cf Yahoo!

Microeconomic viewpoint
Anything - including clustering - is only as good as the economic utility it provides
For clustering: net economic gain produced by an approach (vs. another approach)
Strive for a concrete optimization problem Examples
recommendation systems clock time for interactive search
expensive

Evaluation example: Cluster retrieval
Ad-hoc retrieval Cluster docs in returned set Identify best cluster & only retrieve docs
from it How do various clustering methods affect
the quality of what’s retrieved? Concrete measure of quality:
Precision as measured by user judgements for these queries
Done with TREC queries

Evaluation
Compare two IR algorithms 1. send query, present ranked results 2. send query, cluster results, present
clusters Experiment was simulated (no users)
Results were clustered into 5 clusters Clusters were ranked according to
percentage relevant documents Documents within clusters were ranked
according to similarity to query
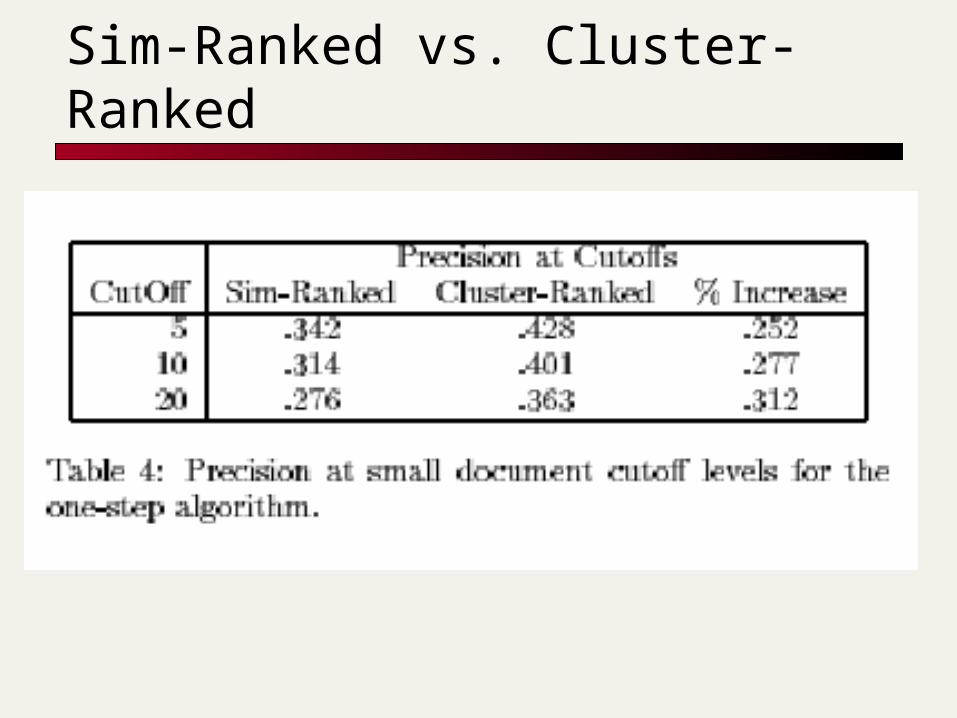
Sim-Ranked vs. Cluster-Ranked
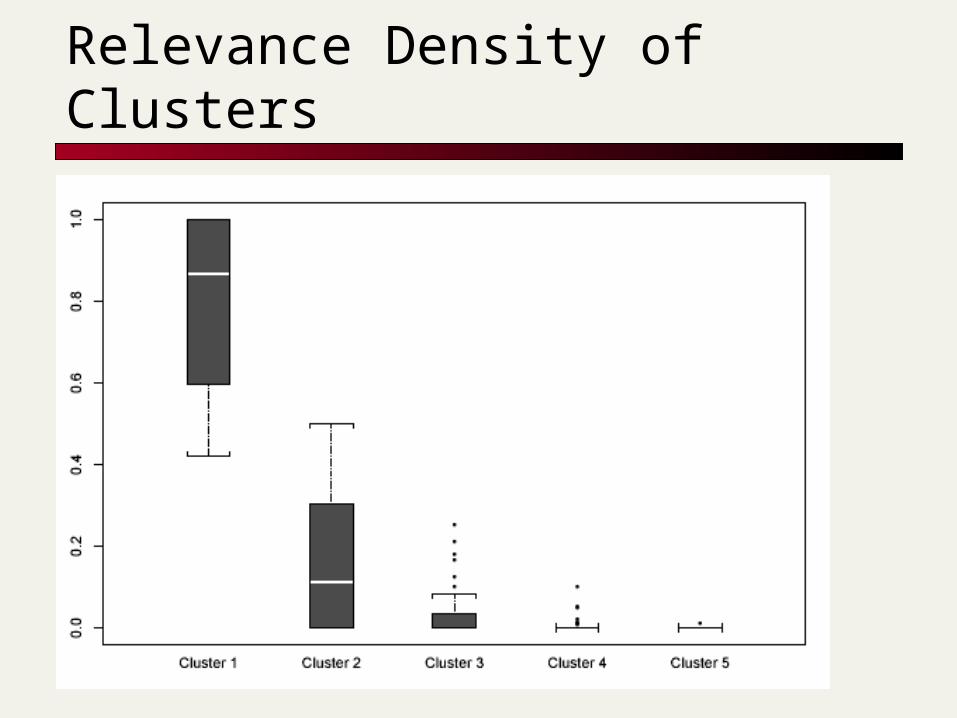
Relevance Density of Clusters

Objective evaluation?

Link-based clustering
Given docs in hypertext, cluster into k groups.
Back to vector spaces! Set up as a vector space, with axes for
terms and for in- and out-neighbors.
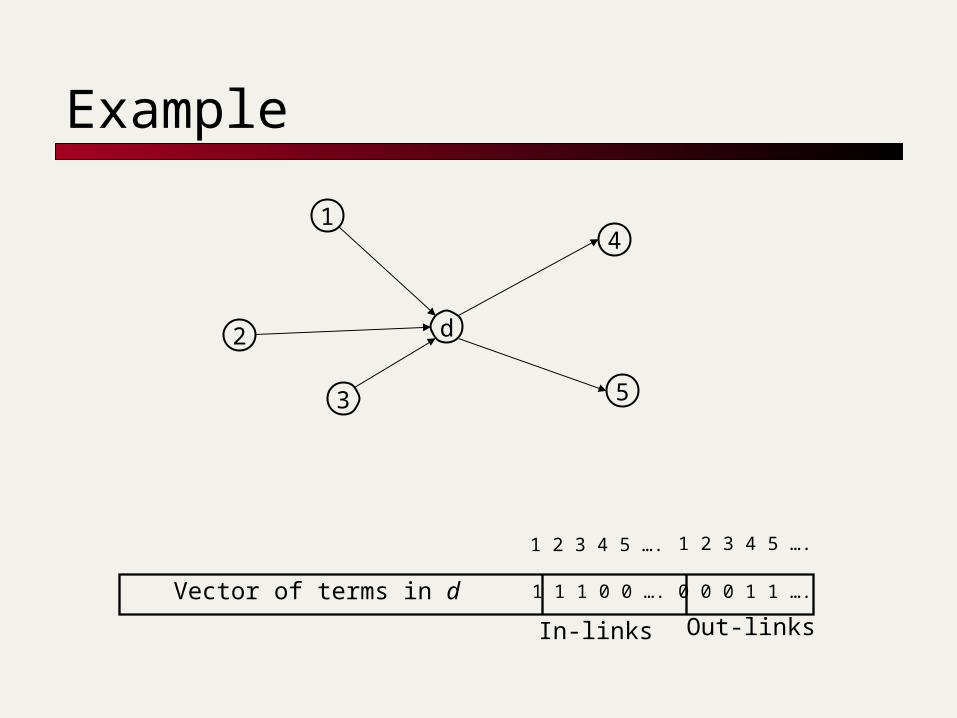
Example
4
2
1
3 5
d
Vector of terms in d
1 2 3 4 5 …. 1 2 3 4 5 ….
1 1 1 0 0 …. 0 0 0 1 1 ….
In-links Out-links

Link-based Clustering
Given vector space representation, run any of the previous clustering algorithms
Studies done on web search results, patents, citation structures - some basic cues on which features help.

Trawling
In clustering, we partition input docs into clusters.
In trawling, we’ll enumerate subsets of the corpus that “look related” each subset a topically-focused community will discard lots of docs
Can we use purely link-based cues to decide whether docs are related?

Trawling/enumerative clustering
In hyperlinked corpora - here, the web Look for all occurrences of a linkage pattern Slightly different notion of cluster
AT&T Alice
SprintBob MCI
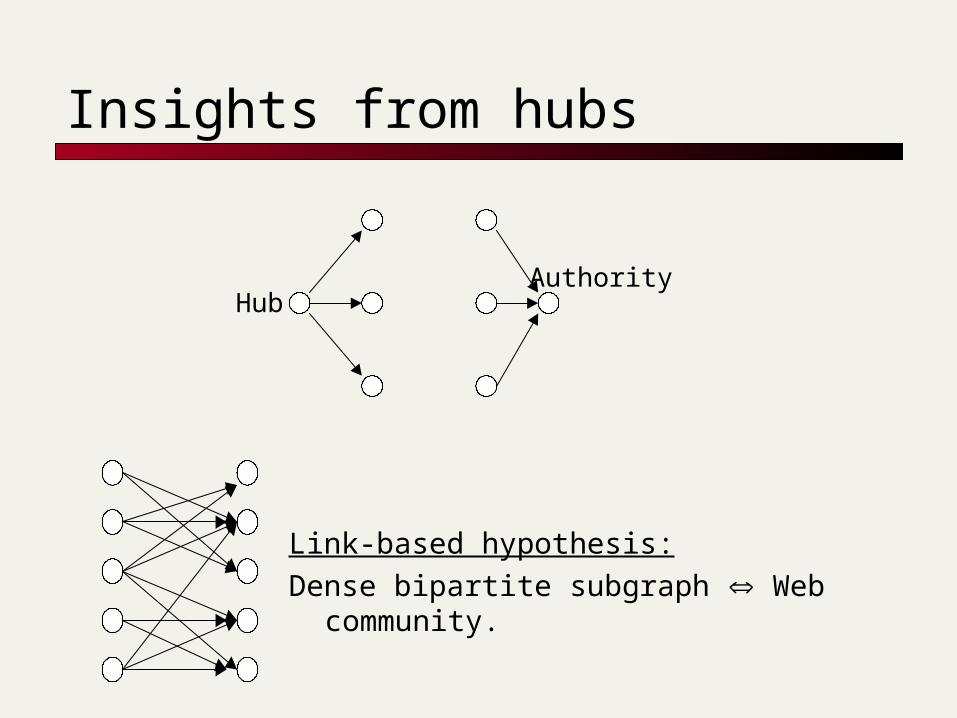
Insights from hubs
Link-based hypothesis:Dense bipartite subgraph Web
community.
HubAuthority

Communities from links
Based on this hypothesis, we want to identify web communities using trawling
Issues Size of the web is huge - not the stuff clustering algorithms
are made for What is a “dense subgraph”?
Define (i,j)-core: complete bipartite subgraph with i nodes all of which point to each of j others.
Fans Centers
(2,3) core

Random graphs inspiration
Why cores rather than dense subgraphs? hard to get your hands on dense subgraphs
Every large enough dense bipartite graph almost surely has “non-trivial” core, e.g.,: large: i=3 and j=10 dense: 50% edges almost surely: 90% chance non-trivial: i=3 and j=3.

Approach
Find all (i,j)-cores currently feasible ranges: 3 i,j 20.
Expand each core into its full community. Main memory conservation Few disk passes over data

Finding cores
“SQL” solution: find all triples of pages such that intersection of their outlinks is at least 3? Too expensive.
Iterative pruning techniques work in practice.

Initial data & preprocessing
Eliminate mirrors Represent URLs by 232 = 64-bit hash Can sort URL’s by either source or
destination using disk-run sorting

Pruning overview
Simple iterative pruning eliminates obvious non-participants no cores output
Elimination-generation pruning eliminates some pages generates some cores
Finish off with “standard data mining” algorithms

Simple iterative pruning
Discard all pages of in-degree < i or out-degree < j.
Repeat Reduces to a sequence of sorting
operations on the edge list Why?
Why?
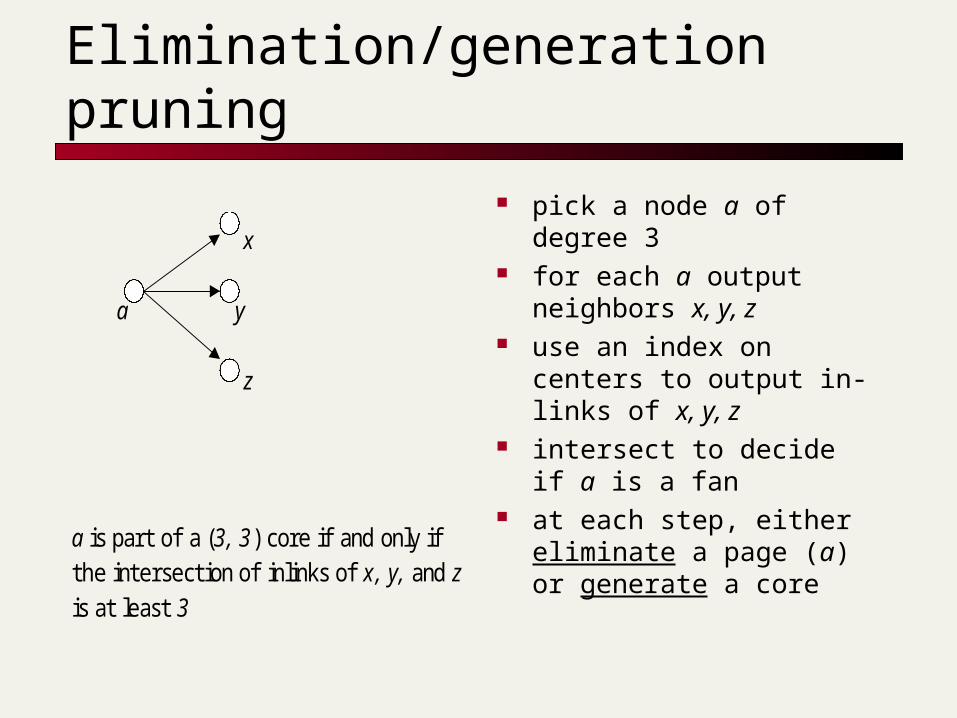
Elimination/generation pruning
pick a node a of degree 3 for each a output
neighbors x, y, z use an index on centers
to output in-links of x, y, z
intersect to decide if a is a fan
at each step, either eliminate a page (a) or generate a core
x
a y
z
a is part of a (3, 3) core if and only ifthe intersection of inlinks of x, y, and zis at least 3

Exercise
Work through the details of maintaining the index on centers to speed up elimination-generation pruning.

Results after pruning
Typical numbers from late 1990’s web: Elimination/generation pruning yields >100K non-
overlapping cores for i,j between 3 and 20. Left with a few (5-10) million unpruned edges
small enough for postprocessing by a priori algorithm build (i+1, j) cores from (i, j) cores. What’s
this?

Exercise
Adapt the a priori algorithm to enumerating bipartite cores.

Trawling results
3 5 7 90
20
40
60
80
100
Th
ou
san
ds i=3
4
5
6
Number of cores found by Elimination/Generation
3 5 7 90
20
40
60
80
Th
ou
san
ds i=3
4
Number of cores found during postprocessing

Sample cores
hotels in Costa Rica clipart Turkish student associations oil spills off the coast of Japan Australian fire brigades aviation/aircraft vendors guitar manufacturers

From cores to communities
Want to go from bipartite core to “dense bipartite graph” surrounding it
Augment core with all pages pointed to by any fan
all pages pointing into these all pages pointing into any center
all pages pointed to by any of these
Use induced graph as the base set in the hubs/authorities algorithm.
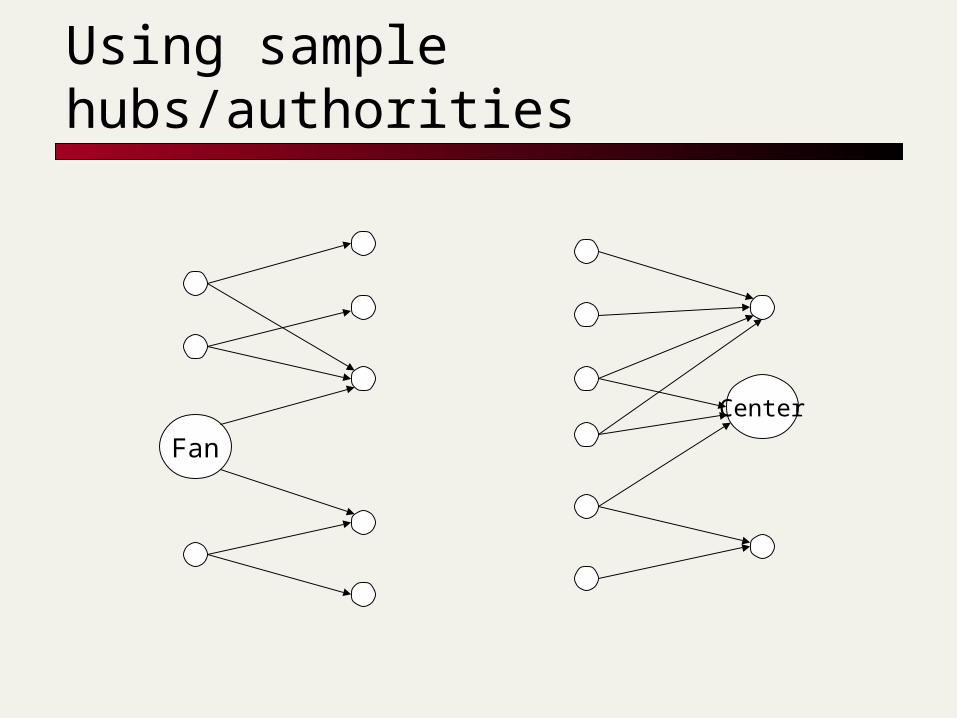
Using sample hubs/authorities
Fan
Center

Costa Rican hotels and travel The Costa Rica Inte...ion on arts, busi... Informatica Interna...rvices in Costa Rica Cocos Island Research Center Aero Costa Rica Hotel Tilawa - Home Page COSTA RICA BY INTER@MERICA tamarindo.com Costa Rica New Page 5 The Costa Rica Internet Directory. Costa Rica, Zarpe Travel and Casa Maria Si Como No Resort Hotels & Villas Apartotel El Sesteo... de San José, Cos... Spanish Abroad, Inc. Home Page Costa Rica's Pura V...ry - Reservation ... YELLOW\RESPALDO\HOTELES\Orquide1 Costa Rica - Summary Profile COST RICA, MANUEL A...EPOS: VILLA
Hotels and Travel in Costa Rica Nosara Hotels & Res...els & Restaurants... Costa Rica Travel, Tourism & Resorts Association Civica de Nosara Untitled: http://www...ca/hotels/mimos.html Costa Rica, Healthy...t Pura Vida Domestic & International Airline HOTELES / HOTELS - COSTA RICA tourgems Hotel Tilawa - Links Costa Rica Hotels T...On line Reservations Yellow pages Costa ...Rica Export INFOHUB Costa Rica Travel Guide Hotel Parador, Manuel Antonio, Costa Rica Destinations

Dimension Reduction
Text mining / information retrieval is hard because “term space” is high-dimensional.
Does it help to reduce the dimensionality of term space?
Best known dimension reduction technique: Principal Component Analysis (PCA)
Most commonly used for text: LSI / SVD Clustering is a form of data compression
the given data is recast as consisting of a “small” number of clusters
each cluster typified by its representative “centroid”

Simplistic example
Clustering may suggest that a corpus consists of two clusters one dominated by terms like quark, energy,
particle, and accelerator the other by valence, molecule, and
reaction Dimension reduction likely to find linear
combinations of these as principal axes (See work by Azar et al. on resources slides)
In this example, clustering and dimension reduction are doing similar work.

Dimension Reduction vs. Clustering
Common use of dimension reduction: Find “better” representation of data
Supporting more accurate retrieval Supporting more efficient retrieval
We are still using all points, but in a new representational space
Common use of clustering Summarize data or reduce data to fewer
objects Clusters are often first-class citizens,
directly used in the UI or as part of retrieval algorithm

Latent semantic indexing (LSI)
Technique for dimension reduction Data-dependent and deterministic
Eliminate redundant axes Pull together “related” axes – hopefully
car and automobile

Notions from linear algebra
Matrix, vector Matrix transpose and product Rank Eigenvalues and eigenvectors.

Recap: Why cluster documents?
For improving recall in search applications For speeding up vector space retrieval Navigation Presentation of search results

Recap: Two flavors of clustering
1. Given n docs and a positive integer k, partition docs into k (disjoint) subsets.
2. Given docs, partition into an “appropriate” number of subsets. E.g., for query results - ideal value of k not
known up front - though UI may impose limits.
Can usually take an algorithm for one flavor and convert to the other.

Recap: Agglomerative clustering
Given target number of clusters k. Initially, each doc viewed as a cluster
start with n clusters; Repeat:
while there are > k clusters, find the “closest pair” of clusters and merge them.
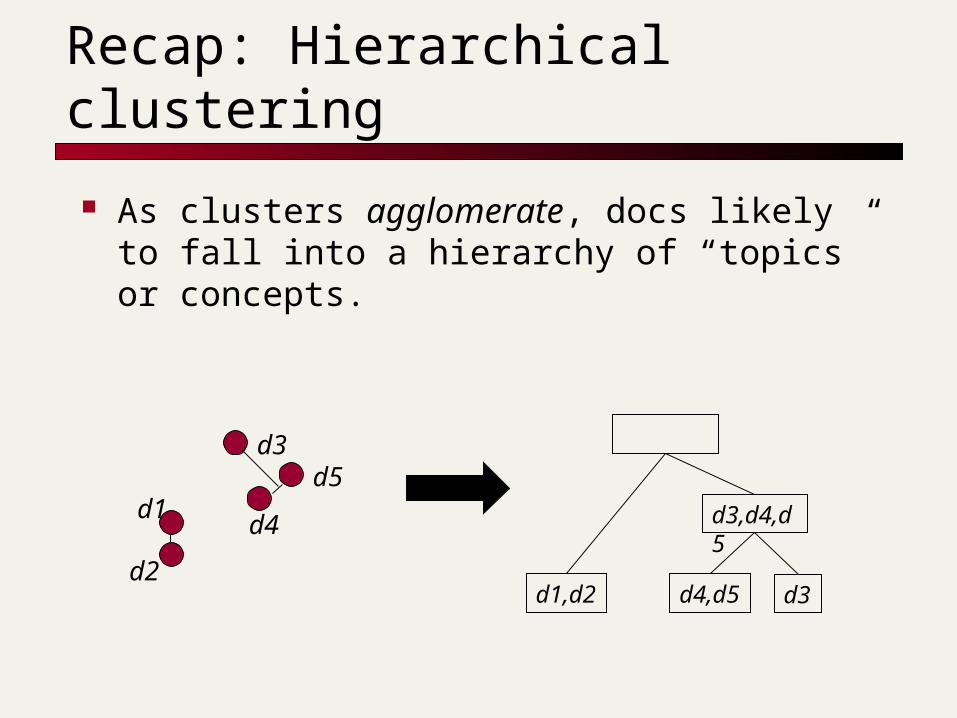
Recap: Hierarchical clustering
As clusters agglomerate, docs likely to fall into a hierarchy of “topics” or concepts.
d1
d2
d3
d4
d5
d1,d2
d4,d5
d3
d3,d4,d5

Recap: k-means basic iteration
At the start of the iteration, we have k centroids.
Each doc assigned to the nearest centroid. All docs assigned to the same centroid are
averaged to compute a new centroid; thus have k new centroids.

Recap: issues/applications
Term vs. document space clustering Multi-lingual docs Feature selection Building navigation structures
“Automatic taxonomy induction” Labeling Other applications
Speed up query/document scoring Document summarization

Resources A priori algorithm:
Mining Association Rules between Sets of Items in Large Databases: Agrawal, Imielinski, Swami. http://citeseer.nj.nec.com/agrawal93mining.html
R. Agrawal, R. Srikant. Fast algorithms for mining association rules.
http://citeseer.nj.nec.com/agrawal94fast.html Spectral Analysis of Data (2000): Y. Azar, A. Fiat, A. Karlin, F.
McSherry, J. Saia. http://citeseer.nj.nec.com/azar00spectral.html
Hypertext clustering: D.S. Modha, W.S. Spangler. Clustering hypertext with applications to web searching.http://citeseer.nj.nec.com/272770.html
Trawling: S. Ravi Kumar, P. Raghavan, S. Rajagopalan and A. Tomkins. Trawling emerging cyber-communities automatically.http://citeseer.nj.nec.com/context/843212/0
H. Schütze, C. Silverstein. Projections for Efficient Document
Clustering (1997). http://citeseer.nj.nec.com/76529.html

Resources
Scatter/Gather: A Cluster-based Approach to Browsing Large Document Collections (1992)
Cutting/Karger/Pedersen/Tukey http://citeseer.nj.nec.com/
cutting92scattergather.html
Data Clustering: A Review (1999) Jain/Murty/Flynn http://citeseer.nj.nec.com/jain99data.html

Resources
Initialization of iterative refinement clustering algorithms. (1998)
Fayyad, Reina, and Bradley http://citeseer.nj.nec.com/fayyad98initialization.html
Scaling Clustering Algorithms to Large Databases (1998)
Bradley, Fayyad, and Reina http://citeseer.nj.nec.com/bradley98scaling.html





























