Embed Size (px)
Citation preview

VirtuaLatin - Agent Based
Percussive Accompaniment
David Murray-Rust
Master of Science
School of Informatics
University of Edinburgh
2003

Abstract
This project details the construction and analysis of a percussive agent, able to
add timbales accompaniment to pre-recorded salsa music. We propose, imple-
ment and test a novel representational structure specific to latin music, inspired
by Lerdahl and Jackendoff’s General Theory of Tonal Music, and incorporating
specific domain knowledge. This is found to capture the relevant information but
lack some flexibility.
We develop a music listening designed to build up these high level representa-
tions using harmonic and rhythmic aspects along with parallelism, but find that
it lacks the information necessary to create full representations. We develop a
generative system which uses expert knowledge and high level representations to
combine and alter templates in a musically sensitive manner. We implement and
test an agent based platform for the composition of music, which is found to con-
vey the necessary information and perform fast enough that real time operation
should be possible. Overall, we find that the agent is capable of creating accom-
paniment which is indistinguishable from human playing to the general public,
and difficult for domain experts to identify.
i

Acknowledgements
Thanks to everyone who has helped and supported me through this project, in
particular, Alan Smaill and Manuel Contreras my supervisor and co-supervisor,
and everyone who took the Salsa Challenge.
ii

Declaration
I declare that this thesis was composed by myself, that the work contained herein
is my own except where explicitly stated otherwise in the text, and that this work
has not been submitted for any other degree or professional qualification except
as specified.
(David Murray-Rust)
iii

Table of Contents
1 Introduction 1
1.1 The use of agent systems for musical activities . . . . . . . . . . . 1
1.2 Customised representations for latin music . . . . . . . . . . . . . 2
1.3 Output Generation . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.4 Musical analysis of latin music . . . . . . . . . . . . . . . . . . . . 3
1.5 Aims . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Background 5
2.1 Music Representations . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1 Audio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.2 Common Practice Notation . . . . . . . . . . . . . . . . . 5
2.1.3 MIDI - Overview . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Literature Review . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2.1 Music Representations and Analyses . . . . . . . . . . . . 7
2.2.2 Mechanical Analysis of Music . . . . . . . . . . . . . . . . 8
2.2.3 Computer Generated Music . . . . . . . . . . . . . . . . . 8
2.2.4 Agents and Music . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.5 Interactive Systems . . . . . . . . . . . . . . . . . . . . . . 11
2.2.6 Distributed Architectures . . . . . . . . . . . . . . . . . . 11
2.3 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Design 14
3.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.2 Higher Level Representations . . . . . . . . . . . . . . . . . . . . 14
iv

3.2.1 The GTTM and its Application to Latin Music . . . . . . 15
3.2.2 Desired Results . . . . . . . . . . . . . . . . . . . . . . . . 16
3.2.3 Design Philosophy . . . . . . . . . . . . . . . . . . . . . . 17
3.2.4 Well-Formedness Rules . . . . . . . . . . . . . . . . . . . 19
3.2.5 Preference Rules . . . . . . . . . . . . . . . . . . . . . . . 20
3.3 Agent System . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.4 Generative Methods . . . . . . . . . . . . . . . . . . . . . . . . . 25
3.4.1 Basic Rhythm Selection . . . . . . . . . . . . . . . . . . . 26
3.4.2 Phrasing . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.4.3 Fills . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.4.4 Chatter . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3.5 Design Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4 System Architecture 30
4.1 Agent Architecture . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.1.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.1.2 Class Hierarchy and Roles . . . . . . . . . . . . . . . . . 31
4.1.3 Information Flow . . . . . . . . . . . . . . . . . . . . . . 34
4.2 High Level Representations . . . . . . . . . . . . . . . . . . . . . 38
4.2.1 Representation Classes . . . . . . . . . . . . . . . . . . . . 38
4.2.2 Human Readability . . . . . . . . . . . . . . . . . . . . . . 41
4.2.3 Identities . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.2.4 Representations By Hand . . . . . . . . . . . . . . . . . . 44
4.3 Low Level Music Representation . . . . . . . . . . . . . . . . . . . 45
4.4 Architecture Summary . . . . . . . . . . . . . . . . . . . . . . . . 45
5 Music Listening 46
5.1 The Annotation Class . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2 Feature Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.2.1 Harmonic Analysis . . . . . . . . . . . . . . . . . . . . . . 48
5.2.2 Pattern Analysis . . . . . . . . . . . . . . . . . . . . . . . 51
5.3 Rhythmic Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . 52
v

5.4 Dissection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.5 Music Listening Summary . . . . . . . . . . . . . . . . . . . . . . 54
6 Generative Methods 56
6.1 Basic Rhythm Selection . . . . . . . . . . . . . . . . . . . . . . . 56
6.2 Ornamentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6.2.1 Phrasing . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
6.2.2 Fills . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
6.2.3 Chatter . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
6.2.4 Transformations . . . . . . . . . . . . . . . . . . . . . . . . 60
6.3 Modularity and Division of Labour . . . . . . . . . . . . . . . . . 61
6.3.1 Memory . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
6.4 Generative Methods Summary . . . . . . . . . . . . . . . . . . . . 62
7 Results and Discussion 63
7.1 Music Listening . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
7.1.1 Chordal Analysis . . . . . . . . . . . . . . . . . . . . . . . 64
7.1.2 Chord Pattern Analysis . . . . . . . . . . . . . . . . . . . 65
7.1.3 Phrasing Extraction . . . . . . . . . . . . . . . . . . . . . 66
7.1.4 Final Dissection . . . . . . . . . . . . . . . . . . . . . . . . 67
7.2 Listening Tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
7.3 Representations . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
7.3.1 Structural Assumptions . . . . . . . . . . . . . . . . . . . 70
7.4 Infrastructure . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
8 Future Work 74
8.1 Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
8.1.1 Chord Recognition . . . . . . . . . . . . . . . . . . . . . . 74
8.1.2 Pattern Analysis . . . . . . . . . . . . . . . . . . . . . . . 75
8.2 Generation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
8.2.1 Ornament Selection . . . . . . . . . . . . . . . . . . . . . . 76
8.2.2 Groove and Feel . . . . . . . . . . . . . . . . . . . . . . . . 77
8.2.3 Soloing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
vi

8.3 Representations . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
8.4 Agent Environment . . . . . . . . . . . . . . . . . . . . . . . . . . 79
8.5 Long Term Improvements . . . . . . . . . . . . . . . . . . . . . . 79
9 Conclusions 83
A Musical Background 85
A.1 History and Use of the Timbales . . . . . . . . . . . . . . . . . . . 85
A.2 The Structure of Salsa Music . . . . . . . . . . . . . . . . . . . . 89
A.3 The Role of the Timbalero . . . . . . . . . . . . . . . . . . . . . . 90
A.4 Knowledge Elicitation . . . . . . . . . . . . . . . . . . . . . . . . 91
B MIDI Details 92
B.1 MIDI Streams . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
B.2 MIDI Files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
C jMusic 95
C.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 95
C.2 Alterations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
C.3 jMusic Issues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
D Listening Assessment Test 99
E Example Output 101
Bibliography 108
vii

List of Figures
3.1 Representation Structure . . . . . . . . . . . . . . . . . . . . . . . 18
3.2 Example section: the montuno from Mi Tierra (Gloria Estefan),
leading up to the timbales solo . . . . . . . . . . . . . . . . . . . . 18
3.3 Possible Network Structures . . . . . . . . . . . . . . . . . . . . . 22
3.4 Possible Distributed Network Structure . . . . . . . . . . . . . . . 23
3.5 Music Messages Timeline . . . . . . . . . . . . . . . . . . . . . . . 24
3.6 Final Agent Architecture . . . . . . . . . . . . . . . . . . . . . . . 25
4.1 Overview of System Structure . . . . . . . . . . . . . . . . . . . . 31
4.2 Class Hierarchy . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.3 Message Flow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4.4 Example jMusic XML File . . . . . . . . . . . . . . . . . . . . . . 36
4.5 SequentialRequester and CyclicResponseCollector flow diagrams . 37
4.6 Different sets of notes which would be classified as as C major . . 40
4.7 Ambiguous Chords . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.8 Example fragment of Section textual output . . . . . . . . . . . . 43
5.1 Analysis Operations . . . . . . . . . . . . . . . . . . . . . . . . . 47
6.1 Generative Structure . . . . . . . . . . . . . . . . . . . . . . . . . 57
6.2 Rhythm Selection Logic . . . . . . . . . . . . . . . . . . . . . . . 58
7.1 Guitar part for bars 22-25 of Mi Tierra, exhibiting split bar chords 65
7.2 Phrasing under the solos (bars 153-176) . . . . . . . . . . . . . . . 66
8.1 Chunk Latency for the Agent System . . . . . . . . . . . . . . . . 80
viii

A.1 Example Timbales setup (overhead view) . . . . . . . . . . . . . . 86
A.2 Scoring Timbale Sounds . . . . . . . . . . . . . . . . . . . . . . . 88
A.3 Standard Son Claves . . . . . . . . . . . . . . . . . . . . . . . . . 88
A.4 Basic Cascara pattern, with a backbeat on the hembra . . . . . . 89
C.1 jMusic Part, Phrase and Note Structure . . . . . . . . . . . . . . 96
ix

Chapter 1
Introduction
This report details the construction of VirtuaLatin, a software agent which is
capable of taking the place of a human timbalero (drummer) in a salsa band.
There are several “real world” reasons to do this, as well as research interest:
• As a practice tool for musicians, so that band rehearsals are possible when
the drummer is ill
• As a learning tool, to give illustrations of how and why timbales should be
played in the absence of a human teacher
• a first step on the road toward allowing hybrid ensembles of human and
mechanical performers
This is a large and complex task, so we identify four main areas of interest.
1.1 The use of agent systems for musical activities
The use of autonomous software agents is becoming increasingly widespread, and
as with many other technological advances, it is highly applicable to music. The
agent paradigm allows an opportunity to analyse the interaction between mu-
sicians, as well as each individual’s mental processes; we feel that this is a key
aspect of understanding how music is created. Ultimately, it is a step towards
a distributable heterogeneous environment in which musicians can play together
1

Chapter 1. Introduction 2
regardless of physical location or mental substrate. We describe an implementa-
tion of an agent infrastructure for musical activities, and analyse its use for both
the project at hand and future work.
1.2 Customised representations for latin music
Music exists in many forms; from the abstract forms in a composer or listeners
mind, through increasingly concrete formal representations such as musical scores
and MIDI data to physical measurements of the sound waves produced when the
music is played[8]. Each level of representation has its own characteristic virtues
and failings, and correct choice or design of representation is crucial to the success
of musical projects. We explore very different levels of musical representation here
- low level representations which allow the basic musical “facts” to be commu-
nicated between agents, and high level representations which seek to understand
the music being played.
When human musicians compose, play or listen to music, high level represen-
tations of the music are created, which enable a deeper understanding of musical
structure[18]. We therefore develop a novel high level symbolic representation of
latin music which captures all the important features of a piece in such a way as
to enable our agent to play in a highly musical manner.
1.3 Output Generation
The ultimate aspiration of the work presented here is to create high quality music;
as such, we need a subsystem which can work over the representations given to
perform in a musical manner. We use a combination of a rule based expert system
which can select and combine templates, and alter them to fit specific situations,
with domain knowledge and high level representations to provide playing which
supports and enhances the musical structure of the piece.

Chapter 1. Introduction 3
1.4 Musical analysis of latin music
In order to provide musically sensitive accompaniment to previously unheard
pieces, our agent needs to be capable of extracting the salient features from mu-
sic it is listening to, and using these to build up the higher level representations
it is going to work with. We combine modified versions of existing methods with
domain knowledge and bespoke algorithms to create a comprehensive analysis of
music heard, inspired by the structure of the GTTM [18]. We give a domain spe-
cific treatment of harmonic, rhythmic and structural features, including a search
for musical parallelism, and investigate whether this is capable of creating the
representations we need. We do not, however, integrate this with the generative
system.
1.5 Aims
The overall aim of the project is:
To create a process which is capable of providing a timbales accom-paniment to prerecorded salsa music, in an agent based environment,which is of sufficient quality to be indistinguishable from human play-ing.
This can be divided into four main aims:
1. construction of an agent environment suitable for the production of music
2. creation of representations which are suitably rich to inform the agent’s
playing
3. implementation of a generative system which can produce high quality out-
put
4. implementation of a music listening subsystem which can build the neces-
sary representations
The dissertation is structured as follows:

Chapter 1. Introduction 4
• some background on the general area, and a look at related work
• an explanation of the design concepts behind the system
• a look at the overall system architecture, including the agent platform and
the music representations used
• description of the music listening sections of the project
• detail of the generative methods used
• analysis of results and discussion
• ideas for further work
• some conclusions and final thoughts

Chapter 2
Background
This chapter gives some background to the project as a whole. A detailed dis-
cussion of latin music and the role of the timbalero in a latin ensemble is given
in Appendix A.
2.1 Music Representations
There are many different ways to represent music, with varying levels of com-
plexity and expression. An overview is given in [8], but here we briefly detail the
three standard representations which are most relevant to this project.
2.1.1 Audio
Audio data is the most basic representation of music, and consists of a direct
recording of the sound produced when it is played. In the digital domain this
consists of a series of samples which represent the waveform of a sound. It can be
used to represent any sound, but is very low level - it does not delineate pitches,
notes, beats or bars.
2.1.2 Common Practice Notation
Common Practice Notation (CPN) is the name given to standard “Western”
scores. It contains information on what notes are to be played at particular times
5

Chapter 2. Background 6
by each instrument. This information is then subject to interpretation - the exact
rendition is up to the players; parameters such as timing, dynamics and timbre
are to some extent encoded encoded in the score, but will generally be played
differently by different players, and are not trivially reproducible mechanically
(work relating to this is discussed below).
2.1.3 MIDI - Overview
MIDI stands somewhere in between Audio and CPN in terms of representational
levels. A MIDI file encodes:
• The start and end times, pitches and velocities of all notes
• Information regarding other parameters of each part (such as volume and
possible timbre changes)
• Information regarding what sounds should be used for each part
To some extent, this captures all of the information about a particular per-
formance - a MIDI recording of a pianist playing a certain piece will generally
be recognisable as the same performance. A MIDI file will be played back by a
sequencer, which in turn triggers a synthesiser to play sounds. It is in this stage
that interpretation is possible; the MIDI sequencer has no idea what sounds it
is triggering - it has simply asked for a sound by number (for example, sound
01 corresponds to a grand piano in the standard mapping). It is possible that
the synthesiser in question does not support all of the parameters encoded in
the MIDI file, or that the sounds are set up unexpectedly. Finally, different
synthesisers will produce sounds of varying quality and realism.
However, due in large part to conventions such as the General MIDI standard,
one can be fairly sure that playing a MIDI file on compatible equipment will sound
close to the authors intention. Thus we have a representational standard with
close to the realism of Audio, with many of the high level features present in
CPN. There exist many packages which can (with varying degrees of success)
turn MIDI data into CPN scores.

Chapter 2. Background 7
2.2 Literature Review
2.2.1 Music Representations and Analyses
A broad overview of the issues surrounding music representation is given by Dan-
nenburg [8]. He explores the problems in musical representation in several areas,
the most relevant of which being hierarchy and structure, timing, timbre and
notation.
One of the most cited works in reference to musical representation is the
Generative Theory of Tonal Music, by Lerdahl and Jackendoff [18]. This outlines
a manner in which to hierarchically segment music into structurally significant
groups, which it is argued is an essential step in developing an understanding of
the music. As presented, it has two main obstructions to implementation; firstly it
is incomplete1, and secondly it is not a full formal specification. Many of the rules
given are intentionally ambiguous - they indicate preferences, and often two rules
will indicate opposing decisions with no decision procedure being defined. Despite
these acknowledged issues, it provides a comprehensive framework on which music
listening applications can be built, and there are many partial implementations
which exhibit some degree of success.
A different aspect of musical representation is covered by the MusES system[24],
developed by Francois Pachet. A novel aspect of this system is the full treatment
of enharmonic spelling - that is, considering C# and Db to be different pitch
classes, despite the fact that they sound the same.2 This is a distinction which
may often be necessary to analysis. The design of the system leans towards sup-
port for analysis, but is intended to be able to support any development - it relies
on the idea that there is “some common sense layer of musical knowledge which
may be made explicit”[25].
MusES was originally developed in Smalltalk, but subsequently ported to
Java. Through conversations with F. Pachet, I was able to obtain a partial copy
1there are features such as parallelism which are relied on but no method for determining
them is given2in some tuning systems, when played on some instruments they may in fact be different.
On a piano keyboard, however, C# and Db are the same key

Chapter 2. Background 8
of the MusES library, and it would have made an ideal development platform.
Unfortunately, due to portions of the code being copyrighted, I was unable to
obtain a complete system.
[13] describes a highly detailed formal representation of music, capable of
representing a wide range of musical styles. An example is given of representing
a minimalist piece which does not have explicitly heard notes; rather, a continuous
set of sine waves is played, the amplitudes of which tend towards the idealised
spectrum of the implied note at any given time, with the frequencies of the tones
close to harmonics tending towards the ideal harmonics. The representation
allows for many different levels of hierarchy and grouping, and is specifically
designed for automated analysis tasks.
2.2.2 Mechanical Analysis of Music
There is a key distinction which lies at the heart of much musical analysis, and
in many ways is more deeply entrenched than in other disciplines: the divide
between symbolic and numeric analysis. This dichotomy is explored in [23], and
synthetic approaches suggested. Harmonic reasoning based in the MusES system
is compared with numeric harmonic analysis by NUSO, which performs statistical
analysis on tonal music. It is suggested that symbolic analysis performs well if
there are recognisable structures specific to a domain, and that numeric analysis
is likely to perform better on “arbitrary sequences of notes”.
2.2.3 Computer Generated Music
In order to create generative musical systems in a scientific manner, it is necessary
to have a specific goal in mind; this often includes tasks such as recreating a par-
ticular style of playing (imitative)3, creating music which has a specific function
(intentional), or testing a particular technique with respect to the generation of
music (technical).
Intentional music is particularly interesting due to it’s broad usage. Every day
3definitions are my own, intended to aid discussion not create a rigorous framework

Chapter 2. Background 9
we hear many pieces of music designed to have specific effects on us, rather than be
pleasurable to listen to. Film soundtracks, and the music in computer games are
two common examples. The creators of GhostWriter [27] (a virtual environment
used to aid children in creative writing in the horror genre) use music as a tool to
build and relieve tension — to support the surprise and suspense which are the
basic tools of the horror narrative. The tool proposed is a generative system which
takes as input a desired level of “scariness” (tension). This is then converted into
a set of parameters which control a high level form generator, a rhythmic section
and a harmonic section. The harmonic section is based on the musical work of
Herrman (who wrote scores for many of Hitchcock’s films, most notably Psycho)
and the theoretical work of Schoenberg. Although the system is not tested in
[27], tests to be performed are outlined.
Zimmeremann [30] uses complex models of musical structure to create music
designed to enhance presentations — the music is used to guide the audience’s
attention and motivation. One contention of this paper is that there is a missing
middle level in the theories of musical structure as applied to this domain -
while they are good at modelling high level structure (e.g. sonata form) and
low level forms (such as cadences and beats) a layer in between is needed, which
is called the music-rhetorical level. A structure of the presentation is created,
which defines series of important points, such as the announcement of an event,
or the introduction of an object, associated with a mood, function and a time.
This structure is then used to guide music-rhetorical operations. The system as
described is a partial implementation, and no analysis is given.
This leads us on to PACTs - Possible ACTions, introduced by Pachet as
strategies, and expanded in [26]. PACTs provide variable levels of description
for musical actions, from low level operations (play “C E G”, play loud, play
a certain rhythm) to high level concepts (play bluesy, play in a major scale).
These are clearly useful tools for intention based composition; they also allow
a different formulation of the the problem of producing musical output - rather
than starting with an empty bar and the problem being how to fill it, we can
start with a general impression of what to play, and the problem is to turn this

Chapter 2. Background 10
into a single concrete performance.
Even if the exact notes and rhythms are known (to the level of a musical
score), this is not generally sufficient to produce quality output. Hence there
are ongoing efforts to both understand how human players interpret scores, and
use this information to enhance the realism of mechanical performance. The
SaxEx system [7] has been designed to take as input sound file of a phrase played
inexpressively, some MIDI data describing the notes and an indication of the
desired output. Case Based Reasoning is then applied, and a new sound file is
created. It was found that this generated pleasing, natural output. The system
has also been extended [2] to include affect driven labels on three axes (tender-
aggressive, sad-joyful, calm-restless) for more control over output.
2.2.4 Agents and Music
There are several ways in which agents could be used for music. A natural
breakdown is to model each player in an ensemble as an agent. This is the
approach taken in the current project. A alternative would be to model a single
musician as a collection of agents, as in Minsky’s Society of Agents model of
cognition.
A middle path between these ideas is taken by Pachet in his investigations into
evolving rhythms [15]. Here, each percussive sound (e.g. kick drum, snare drum)
is assigned to an agent. The agents then work together to evolve a rhythm. They
are given a starting point, and a set of rules (expressed in the MusES system) and
play a loop continuously, with every agent listening to the output of all the others.
Typical rules are: emphasise strong/weak beats, move notes towards/away from
other notes and adding syncopation or double beats. From the interaction of
simple rules, it was found that some standard rhythms could be evolved, and the
interesting versions of existing rhythms could be produced.
The use of multiple agents for beat tracking is described in [11]. This system
creates several agents with different hypotheses about where the beat is, and
assigns greater weight to the agents which correctly predict many new beats. The
system is shown to be both computationally inexpensive and robust with respect

Chapter 2. Background 11
to different styles of music; in all test cases it correctly divined the tempo, the
only error being the phase (it sometimes tracked off-beats rather than on-beats).
2.2.5 Interactive Systems
Antoni Camurri has carried out a lot of work into interactive systems, and is
director of the Laboratorio di Informatica Musicale. 4. In [1] and [6], he looks
at analysis of human gestures and movement. In [4], he develops an architecture
for environmental agents, which alter an environment according to the actions of
people within it. He breaks these agents down in to input and output sections,
then a rational, emotional and reactive component. He finds the architecture
to be flexible, and has used it in performances. The architecture is extended in
[5] to give a fuller treatment of emotion, developing concepts such as happiness,
depression, vanity, apathy and anger.
Rowe [28] has developed the Cypher system, which can be used as an inter-
active compositional or performance tool. It does not use any stored scores, but
will play along with a human performer with “a distinctive style and a voice quite
recognizably different from the music presented at its input”. It offers a general
architecture on which the user can build many different types of system.
Another section of interest is auto accompaniment - creating mechanical sys-
tems which can “play along” with human performers. Raphael [9] creates a system
where the computer plays a prerecorded accompaniment in time to a soloist. It
uses a Hidden Markov model to model the soloist’s note onset times, a phase
vocoder to allow for variable speed playback, and a Bayesian network to link
the two. Training sessions (analogous to rehearsals) are used to train the belief
network.
2.2.6 Distributed Architectures
Since one of the great benefits of agent based approaches is that agents may
be distributed and of unknown origin (as long as they conform to a common
4http://musart.dist.unige.it/sito inglese/laboratorio/description.html

Chapter 2. Background 12
specification), a logical direction is the distributed composition or performance
of music. [16] describes some of the issues in distributed music applications. Two
of the key barriers are defined - latency (the average delay in information being
received after it has been transmitted) and jitter (the variability of this delay).
It is stated that one can generally compensate for jitter by increasing latency,
and that there is a problem with the current infrastructure in that there is no
provision made for Quality of Service specification or allocation. The issues of
representations and data transfer rate are discussed: audio represents a complete
description of the music played, while MIDI only specifies pitches and onsets.
This means that audio will be a more faithful reproduction, but that MIDI has
far lower data transfer rates (typically 0.1 5kbps against 256kbps for high quality
MP3 audio). It is concluded that it is currently impossible to perform music in
a fully distributed fashion, but that all of the problems have technical solutions
on the horizon - except the latencies due to the speed of light.
There are many constraints associated with real time programming; in re-
sponse to this, there have been attempts to set out agent systems designed to
handle real time operation. [12] discusses the difference between reactive and
cognitive agents, and gives a possible hybrid architecture which couples an outer
layer of behaviours (which may be reactive or cognitive) with a central supervisor
(based on an Augmented Transition Network). This ensures that hard goals are
met by reactive processes, but more complex cognitive functions can be performed
when the constraints are relaxed. [10] presents an agent language which allows
the specification of real time constraints, and a CORBA layer which enforces
this. Finally, [14] presents a real-time agent architecture which can take account
of temporal, structural and resource constraints, goal resolution and unexpected
results. This architecture is designed to be implemented by individual agents to
allow them to function in a time and resource limited environment.

Chapter 2. Background 13
2.3 Conclusions
Several pieces of work have been particularly inspiring for this project; the the-
oretical work of Lerdahl and Jackendoff suggets a very useful model for musical
analysis, and also helps support claims about musical structure. Pachet’s work on
the MusES system has been useful, as it has given a complete (working) frame-
work to examing, as well as the concept of PACTs. It is encouraging to see that
not much work has been done on interacting musical agents, so we are covering
new territory. Finally, the work of Rowe has demonstrated the possibilities of
interactive music, and given many concrete examples of how certain subsystems
may be implemented.

Chapter 3
Design
3.1 Overview
From the overall problem domain, we have selected several areas of interest:
• High level representations specific to latin music which are sufficient to
adequately inform the playing of a timbalero.
• Generative methods working over high level representations which are ca-
pable of creating realistic timbale playing.
• Music listening algorithms which are capable of generating the necessary
high level representations from raw musical data.
• Construction of an Agent based environment for musical processes.
The desired end result is a system which can combine these components to
generate high quality timbales parts to prerecorded salsa music.
3.2 Higher Level Representations
The musical representations discussed so far are designed to encode enough data
about a piece of music to enable its reproduction in some manner. A musician
either hearing or playing the music encoded in this form would need to have some
14

Chapter 3. Design 15
higher level understanding of the music in order to either play or hear the piece
correctly. It is these representations which we now consider.
In our specific case, we are attempting to create a representation which will:
• be internal to a particular agent
• aid the agent in generating its output
The goal is not a full formal analysis - this is both difficult and unnecessary.
The agent needs, at this stage:
• An idea of where it is in the piece
• An idea of what to play at this point in time
• Some idea as to what will happen next
3.2.1 The GTTM and its Application to Latin Music
There can be no doubt that the GTTM has played a massive role in the current
state of computational analysis of music - it appears in the bibliography of almost
every paper on the subject. It is the theoretical framework around which the
higher level representations used in this project have been built
To recap, the GTTM consists of four levels:
Grouping Structure segments the piece into a tree of units, with no overlap1.
Metrical Structure Divides the piece up by placing strong and weak beats at
a number of levels
Time-span Reduction calculates an importance for the pitches in a piece based
on grouping and metre
Prolongational Reduction calculates the harmonic and melodic importance
of pitches
1except for the case of elisions, where the last note of one group may also be the first note
of the next

Chapter 3. Design 16
At each of these levels there are a set of well formedness rules, and a set of
preference rules. The idea behind this is that there will often be many valid
interpretations of a section, so we should try and calculate which one is most
likely or preferred.
The GTTM is a very general theory, and in this case we are focusing on a
specific style of music; what extra information does this give us?
Latin music always has an repetitive rhythm going on. Although this may change
for different sections, there will always be a basic ‘groove’ happening. In
almost all cases, this will be based on a clave, a repeating two bar pattern
(see discussion elsewhere).
There are clearly defined hyper-measure structures - mambos, verses, montunos
and more - which provide the large structural elements from which a piece
is built. The actions of a player can generally be described using a single
sentence for each section ( “the horns play in the second mambo, and then
all the percussion stops except the clave in the bridge” )
3.2.2 Desired Results
In general, the smallest structural unit in latin music is the bar; phrases may be
played which cross bars, or which take up less than a single bar, but the structure
is defined in terms of bars. Further, the clave will continue throughout, and will
be implied even when not played. It follows that the necessary tasks are:
quantization of the incoming data, according to an isochronous pulse2
metricization of the quantized data into beats and bars
segmentation of the resulting bars into sections
2Quantization in this sense is different to standard usage in sequencers. In this case we mean
“determining the most appropriate isochronous pulse and notating the incoming events relative
to this”, rather than shifting incoming notes to be exact multiples of some chosen rhythmic
value.

Chapter 3. Design 17
Here we are assume that we are dealing with music which is described in terms
of beats and bars (i.e. metricised and quantized), we are only left with the task
of segmenting these bars and extracting relevant features from them - a process
described in Section 5.
3.2.3 Design Philosophy
The structures under consideration do not represent the music itself, but only its
higher level structure and features.
There are also some assumptions which are used to simplify matters:
Structural Assumption 1 There are high level sections of music with distinct
structural roles
Structural Assumption 2 The smallest structural unit in latin music is the
bar; phrases may be played which cross bars, or which take up less than a single
bar, but the structure is defined in terms of bars.
Structural Assumption 3 A bar contains one and only one chord
Structural Assumption 4 A segment contains one and only one groove
Grouping in the GTTM is completely hierarchical: each group contains other
groups down to the note level and is contained within a larger group up to the
group containing the entire piece; the number of grouping levels is unspecified.
A fully recursive structure is highly expressive, but may cause difficulty with
implementation and makes dealing with the resulting representation more com-
plex. It is clear that more than two levels of grouping would provide a richer
representation: a tune may have a repeated section which is composed of eight
bars of a steady rumba groove, followed by six bars of phrasing. It would make
sense to have this represented as one large group which contained two smaller
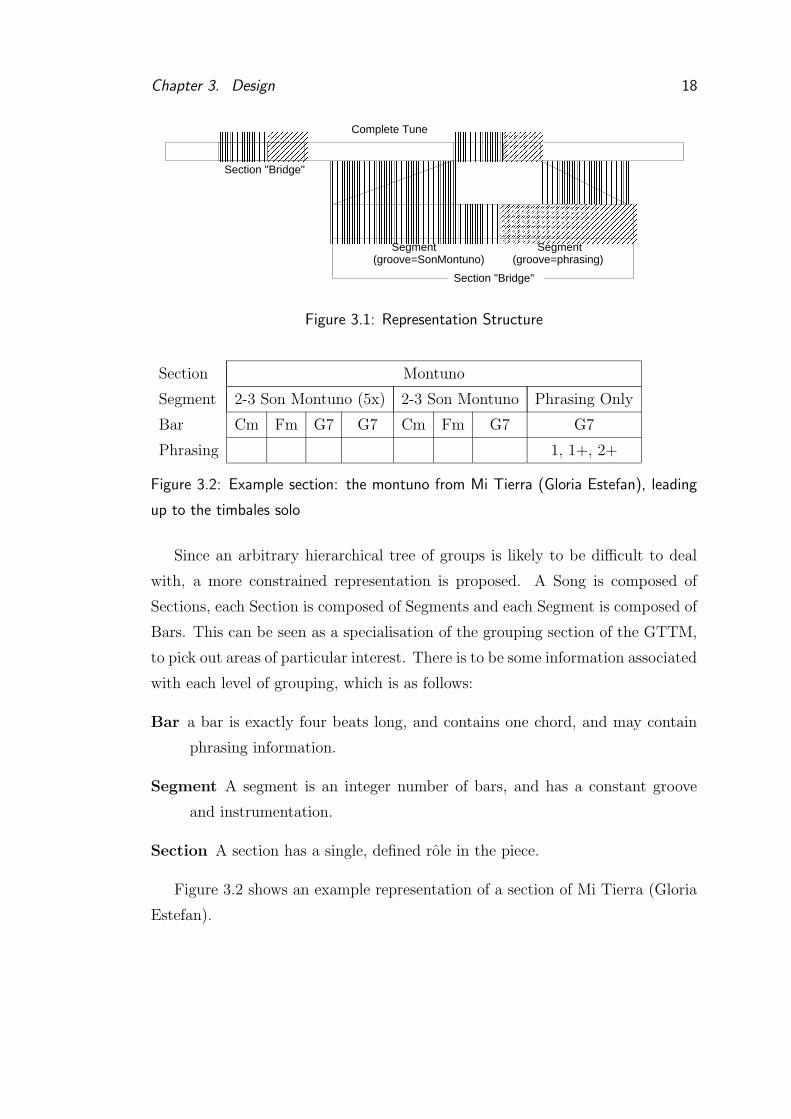
groups (see Figure 3.1) . This representation is more complex to manage than
one which considers only sections which are made up of sets of bars, but is ulti-
mately richer, and allows for specification of groove at the section level, which is
more appropriate than the bar level.
Chapter 3. Design 18
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
�������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
���������������������������������������������������������������
���������������������������������������������������������
���������������������
���������
������������������������������
���������������������������������������������������������
���������������������
� � � � � � � � �
������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������
Section "Bridge"
Complete Tune
Segment(groove=phrasing)
Segment
Section "Bridge"
(groove=SonMontuno)
Figure 3.1: Representation Structure
Section Montuno
Segment 2-3 Son Montuno (5x) 2-3 Son Montuno Phrasing Only
Bar Cm Fm G7 G7 Cm Fm G7 G7
Phrasing 1, 1+, 2+
Figure 3.2: Example section: the montuno from Mi Tierra (Gloria Estefan), leading
up to the timbales solo
Since an arbitrary hierarchical tree of groups is likely to be difficult to deal
with, a more constrained representation is proposed. A Song is composed of
Sections, each Section is composed of Segments and each Segment is composed of
Bars. This can be seen as a specialisation of the grouping section of the GTTM,
to pick out areas of particular interest. There is to be some information associated
with each level of grouping, which is as follows:
Bar a bar is exactly four beats long, and contains one chord, and may contain
phrasing information.
Segment A segment is an integer number of bars, and has a constant groove
and instrumentation.
Section A section has a single, defined role in the piece.
Figure 3.2 shows an example representation of a section of Mi Tierra (Gloria
Estefan).

Chapter 3. Design 19
In a similar manner to the GTTM, we specify a set of Well Formedness and
Preference rules with which to perform the analyses. Some of these rules are
derived from the structure of the representations, and some are heuristics based
on musical knowledge.
3.2.4 Well-Formedness Rules
The well formedness rules here come from the design of the representation - there
is no psychological basis a la the GTTM, rather it is proposed as a beneficial
representation for the style of music in question.
The rules for a valid segment are:
SGWF 1 A Segment must contain an integer number of bars (Structural As-
sumption 2)
SGWF 2 A Segment must have one and only one groove associated with it
SGWF 3 A Segment must have only one set of instrumentation levels associated
with it
And for valid sections:
SCWF 1 A Section must have an integer number of Segments within it
SCWF 2 A Section must have a single role associated with it (Structural As-
sumption 1)
There are some implicit boundary conditions on these:
• The start of a piece is the start of a Section and Segment
• The end of a piece is the end of a Section and Segment

Chapter 3. Design 20
3.2.5 Preference Rules
The rules for preferences are more difficult. It is quite possible that different
musicians would group certain pieces differently, and there may be no “best”
analysis. The general goals are:
Preference Criterion 1 Maximise reusability - the more often a Section or Seg-
ment can be reused with minimal alterations, the better descriptor of the music it
is.
This supports the “chunking” often done by musicians (and visible on written
parts) which allows for easy specification of structure, such as “two verses then
a chorus”.
Preference Criterion 2 Avoid overly short units, which will complicate the
analysis and not reflect the perceived structure of the music
Preference Criterion 3 Capture as accurately as possible those structural ele-
ments which inform the playing of a timbalero.
There are some rules which are common to both Sections and Segments, and
come partially from personal experience, and partially from the goals given above:
UP 1 Prefer units which are similar or identical to other units, and hence reusable
(Preference Criterion 1)
UP 2 Prefer units with constant features
i.e. if given a choice of two places to make a break, choose the one which max-
imises the constancy of attributes on each side of the break.
UP 3 Prefer larger units (Preference Criterion 2)
UP 4 Prefer units whose size is a multiple of 4 bars, with extra preference given
for multiples of 8 and 16

Chapter 3. Design 21
This is a parallel to the specification in the GTTM of alternating strong beats at
each level.
Some rules are specific to this particular style of music, and also to Section or
Segments:
UP 5 Prefer units which either start or end with phrasing or fills.
Since phrasing and fills are used in part to support the structure of a piece, it
makes sense to use them to help with the dissection.
SGP 1 Prefer segments which have distinct instrumentation to surrounding seg-
ments
SCP 1 Prefer Sections which centre around a key and describe a tonal arc.
There is presently little to describe the method of creating Sections; a proper
treatment of this subject would require the analysis of a large amount of music,
which is outside the scope of this project.
In short, this representation builds on the hierarchical model set out in the
GTTM, but chooses to make certain levels of grouping special; these levels have
extra information attached to them, and are the only levels of grouping allowed.
3.3 Agent System
The Agent System used is designed to emulate an entire set of interactive agents
(be they human or mechanical) cooperating to create music together. Since only
one agent is being created here, this cannot be fully realised. To provide the
agent context, we use “Dumb Regurgitators” - agents which merely repeat the
music they have been given. Although this removes much of the interest relating
to agent systems, it is a necessary step on the way.
A group of musicians playing together could well be modelled as a set of
agents, each of which is communicating with all of the others3. A conductor
3there are other possibilities: [? ] describes a real-time Blackboard system where each agent
reads and writes data to a central blackboard

Chapter 3. Design 22
Fully InterconnectedNetwork
Central Conductor
Figure 3.3: Possible Network Structures
could be added to provide synchronisation, and potentially an audience could be
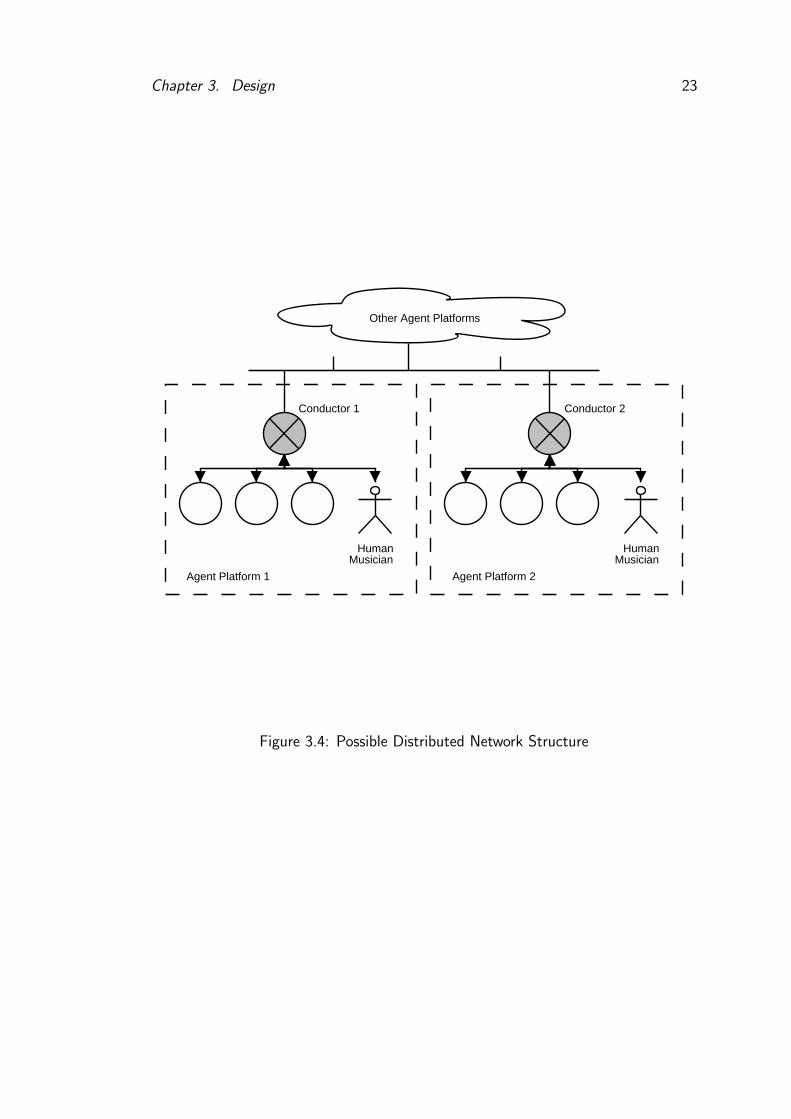
added. This has O(n2) complexity with the number of musicians, so we propose a
simpler design (see Figure 3.3) where each musician communicates only with the
central conductor. This would also allow better support for highly distributed
heterogeneous ensembles (see Figure 3.4) , as each platform could have a single
Conductor which handled synchronisation issues and gave any human players the
necessary framework to play within.
Ideally, the system would support these distributed heterogeneous ensembles,
but in reality this is likely to be a very complex problem. Almost any kind
of network based system will have sufficient latency to render fully real time
interaction with human players difficult at best[16], not to mention the time
taken for the virtual musicians to respond to events. Even having a synchronised
click would cause problems, as a musician on one platform would hear the other
musicians performances as being offset from the click. With a fully agent based
system, it is a slightly different story. Even if the system is to run as a real-
time system, it is not necessary that every part runs in real-time, and there is
the possibility for parts to run delayed with respect to others4. The system as
4something that not many human musicians are capable of doing intentionally!
Chapter 3. Design 23
Other Agent Platforms
Agent Platform 1 Agent Platform 2
Conductor 1 Conductor 2
HumanMusician
HumanMusician
Figure 3.4: Possible Distributed Network Structure

Chapter 3. Design 24
Segment starts playing
Segment sent out to all agents
Segment received by agent
Agent sends next segment
Conductor receives next segment
Next segment starts playing
Network Latency
Time allowed forchunk construction
Network Latency
Time
Figure 3.5: Music Messages Timeline
proposed addresses this issue by working with chunks of output. The central
conductor obtains one chunk of output from all of the musicians involved, starts
outputting this, and then delivers copies of the collated chunks to all the musicians
(see Figure 3.5) . This means that:
• every agent only has knowledge up to the end of the previously distributed
chunk. This appears to be reasonable, as it will always take a human some
time to process sounds which are heard, and decisions have to be made as to
what to play before it is played (and hence before you know what everyone
else will play)
• the only constraint necessary for real time operation is that all of the agents
produce their next output chunks before the current chunk has finished
playing.
For this project, bars are going to be used as the chunk size, as this feels
natural. The final proposed architecture is shown in Figure 3.6
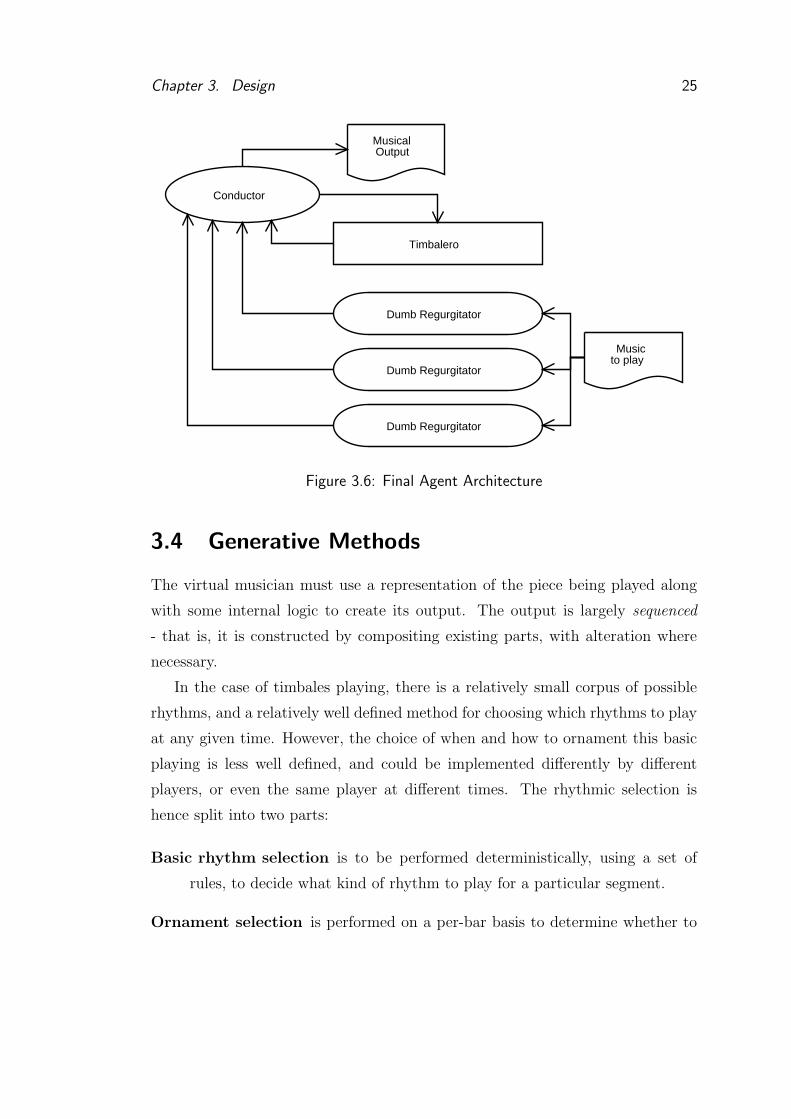
Chapter 3. Design 25
Conductor
Dumb Regurgitator
Dumb Regurgitator
Dumb Regurgitator
Timbalero
Musicto play
MusicalOutput
Figure 3.6: Final Agent Architecture
3.4 Generative Methods
The virtual musician must use a representation of the piece being played along
with some internal logic to create its output. The output is largely sequenced
- that is, it is constructed by compositing existing parts, with alteration where
necessary.
In the case of timbales playing, there is a relatively small corpus of possible
rhythms, and a relatively well defined method for choosing which rhythms to play
at any given time. However, the choice of when and how to ornament this basic
playing is less well defined, and could be implemented differently by different
players, or even the same player at different times. The rhythmic selection is
hence split into two parts:
Basic rhythm selection is to be performed deterministically, using a set of
rules, to decide what kind of rhythm to play for a particular segment.
Ornament selection is performed on a per-bar basis to determine whether to

Chapter 3. Design 26
add ornamentation, and if so, what.
Ornament selection is further divided into three distinct categories:
Phrasing involves the entire band, picking out a set of notes in a certain bar.
The timbalero will typically use cymbals and/or the loud open notes of the
timbales to accent these notes. Depending on the surrounding structure
and the spacing of the accented notes, the timbalero has three options:
• Continue playing as much of the basic rhythm as possible, while adding
emphasis to the specified notes
• Play only the specified notes
• Play the specified notes with small fills or ornaments in between.
Fills are the most well known ornament. When a player plays a fill, the basic
rhythm is stopped for the duration of the fill. Fills are generally technically
impressive, dynamically exciting and can provide a more complex rhythmic
counterpoint than the standard rhythm. Fills also often accent a particular
beat - normally the end of the fill, and often the downbeat of the bar after
the one in which the fill starts (although the last beat of the fill bar and
the second beat of the post fill bar are also common in latin music).
Chatter is a term derived from jazz music, to describe non-repeating patterns
played on the snare drum with the left hand (which is typically not used in
the basic rhythm, or may provide a simple backbeat) while the basic rhythm
continues in full. This is used to create tension, add rhythmic complexity
and generally avoid monotony.
3.4.1 Basic Rhythm Selection
Timbales playing is interesting in the degree of orthogonality between the patterns
in each hand. Apart from some patterns where left and right hands are used
together, it is generally possible to fit many left handed variations to a single
right hand part. The factors which affect these choices are:

Chapter 3. Design 27
Right Hand Left Hand
Cascara Clave (on block)
Doble Pailas
Hembra Backbeat
tacet
Mambo Bell Hembra Backbeat
Clave (on block)
Campana Pattern
Table 3.1: Instrumentation by Hand
• The style of the piece
• The current instrumentation
• The structural role of the current section
• The current dynamic
Table 3.1 gives common combinations of sounds played by each hand (see
Appendix A for details). For each combination, different specific rhythms may
be used - there are a variety of cascara patterns in common use, the clave will
change depending on the style of the piece etc.
The system should be designed to analyse the current surroundings and select
the appropriate basic rhythm. From the analysis of Salsa music earlier, we have
the following information to use:
• A salsa tune will consist of a beginning section in traditional Son style and a
second section in a more upbeat Montuno style. The start of the Montuno
is the high point of the piece, and after this the intensity does not drop
much until the end, although there may be a small coda at the end which
is a re-statement of the introduction.
• The Mambo bell is used from the Montuno onwards. While it is being
played, if there is no bongo player playing the Campana part, the timbalero

Chapter 3. Design 28
will do this; otherwise, the left hand plays a back beat on the Hembra.
• In the Son sections, the right hand is always playing cascara. The left hand
can fill in the gaps to play Doble Pailas in the louder sections, add in the
clave if no-one else is playing it in the quiet sections, or do nothing.
3.4.2 Phrasing
Phrasing is a key way to make a performance sound more dynamic and cohesive.
At present, Phrasing information is present only as a set of points within the bar
where the accenting should occur; this is in keeping with the musical practice of
identifying phrasing by accent marks, but does not encode all the information
a musician would use (for example, if the notes played by the rest of the band
have a downwards trend, a timbalero might add phrasing that moved from higher
towards lower pitched sounds)
There are two common modes of phrasing. Sometimes the bar is played as
normal, but the whole band will pick out certain notes to accent. Alternatively,
there may be some bars where everything stops except the phrasing;
3.4.3 Fills
As well as relieving monotony, fills are also used to highlight structural features,
such as changing from a one section to another. Also, fills are more likely to occur
in metrically strong bars.
The Timbalero uses a set of weighted rules to determine when to play a fill.
The rules are:
Fill Placement 1 Prefer fills on the last bar of an eight bar group (starting from
the start of a Section)
Fill Placement 2 Prefer fills on the last bar of a Section
Fill Placement 3 Prefer fills on the last bar of a Segment
Fill Placement 4 If Rule 3 is in force, Prefer fills when the next Segment has
a higher intensity than the current Segment

Chapter 3. Design 29
3.4.4 Chatter
Chatter is less structurally significant than fills are, and can be more widely
applied. A similar set of rules are used to determine when to add chatter:
Chatter Placement 1 Prefer chatter in loud/intense sections
Chatter Placement 2 Prefer chatter in Mambo sections
Chatter Placement 3 Prefer chatter towards the end of a section
Chatter Placement 4 Prefer chatter in the fourth bar of a four bar block (from
the beginning of the Section)
Chatter Placement 5 Prefer chatter in the fourth bar of an eight bar block
(from the beginning of the Section)
Chatter Placement 6 Avoid chatter on the first bar of a section
Chatter Placement 7 Prefer chatter if we played chatter in the previous bar
and it has a followOn
Chatter Placement 8 Avoid chatter if we have played a lot recently
Chatter Placement 9 Avoid chatter straight after a fill
3.5 Design Summary
Several assumptions have been made, based on expert knowledge, about the
structure of latin music. A high level representation system has been proposed,
following the general structure of the GTTM, but adapted to latin music by
means of the assumptions described. We have broken down timbales playing into
the selection of a basic rhythm and the addition of ornaments, and outlined the
principles used to select the basic rhythm. We have divided ornamentation into
three categories - phrasing, fills and chatter - and set out preference rules for
deciding when to add ornamentation of each type.

Chapter 4
System Architecture
In this section we discuss the infrastructure implementation, covering first the
agent platform, it’s protocols and interactions, then the high level representations
derived from the structural discussion in the previous section and finally the low
level musical representations which form the foundations of the system.
The following platform decisions have been made:
• The project is implemented in Java, due to personal familiarity, portability
and the availability of necessary libraries.
• The system will be able to read and write standard MIDI files, to allow
access to music stored in that format and enable usage of the wealth of
tools for turning MIDI into listenable music
• Agent functionality will be provided by the JADE libraries, which are Free,
stable and FIPA compliant
• Low level musical functionality will be provided by the jMusic library1,
which is also Free software.
The project aims to meet all of the objectives set out at the start of the Design
section.
1http://jmusic.ci.qut.edu.au/
30
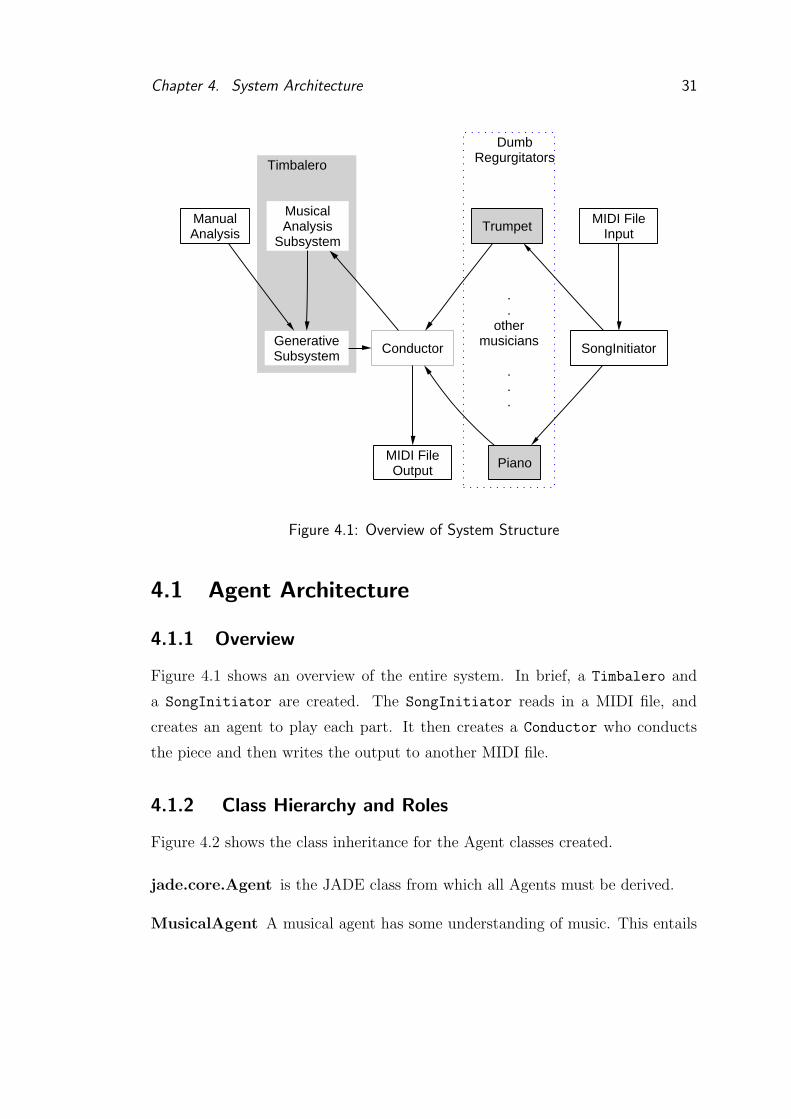
Chapter 4. System Architecture 31
Timbalero
DumbRegurgitators
ManualAnalysis
GenerativeSubsystem
MusicalAnalysis
Subsystem
Conductor
MIDI FileInput
SongInitiator
Trumpet
Piano
.
.other
musicians
.
.
.
MIDI FileOutput
Figure 4.1: Overview of System Structure
4.1 Agent Architecture
4.1.1 Overview
Figure 4.1 shows an overview of the entire system. In brief, a Timbalero and
a SongInitiator are created. The SongInitiator reads in a MIDI file, and
creates an agent to play each part. It then creates a Conductor who conducts
the piece and then writes the output to another MIDI file.
4.1.2 Class Hierarchy and Roles
Figure 4.2 shows the class inheritance for the Agent classes created.
jade.core.Agent is the JADE class from which all Agents must be derived.
MusicalAgent A musical agent has some understanding of music. This entails
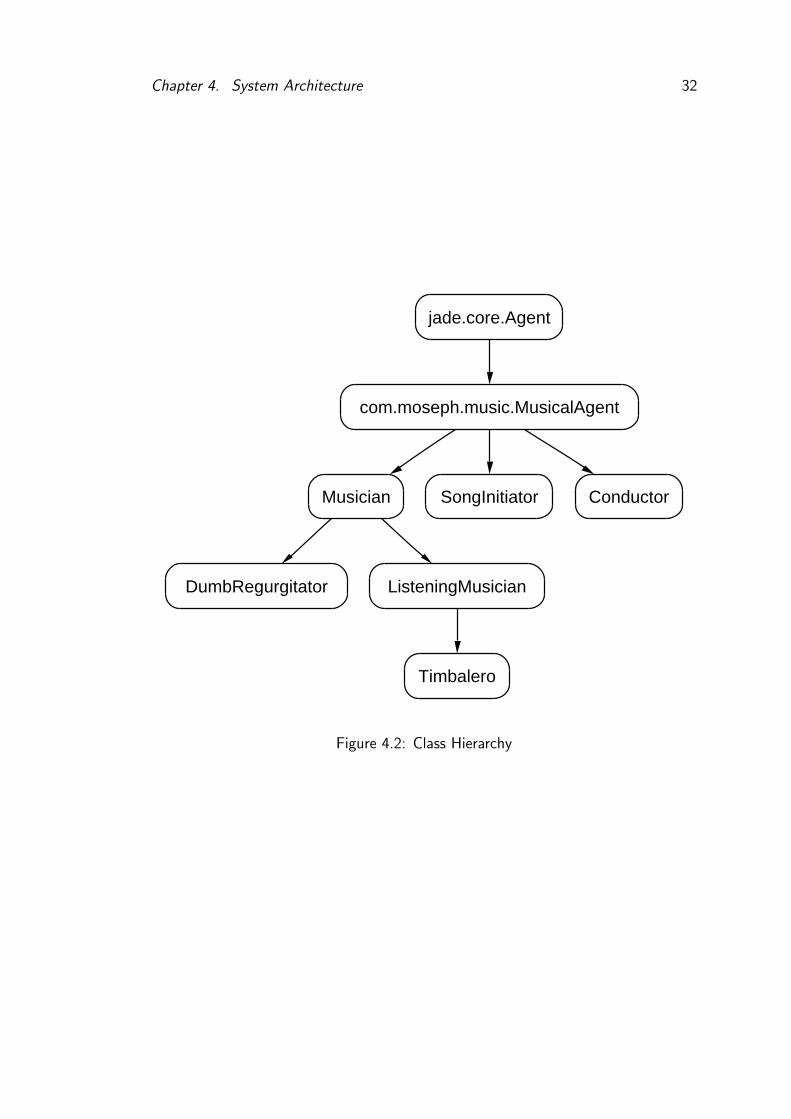
Chapter 4. System Architecture 32
jade.core.Agent
com.moseph.music.MusicalAgent
Musician SongInitiator Conductor
DumbRegurgitator ListeningMusician
Timbalero
Figure 4.2: Class Hierarchy

Chapter 4. System Architecture 33
being able to transmit and receive music in messages, and find out about
other musicians.
Musician A musician produces music. It has an identity, and provides the
service MusicalAgent.musicProducer. It can respond for requests to play
a bar of music, send it’s identity and restart the current song. The basic
musician class will respond with null to every request for a bar, as it has
no idea what to play.
SongInitiator The SongInitiator starts a song. It takes a filename as an
argument, and opens the specified MIDI file. It reads the file into Parts for
each musician, then creates a DumbRegurgitator to play each part. Finally,
it creates a Conductor to oversee playing the whole song, and finishes.
Conductor The conductor sits in the middle of the whole ensemble, and per-
forms several important tasks:
• Gathering information about the surrounding musicians.
• Requesting output from all the musicians, collating it and relaying the
combined information to all the ListeningMusicians.
• Recording all the playing so far and writing it to a MIDI file at the
end of the piece.
DumbRegurgitator To simulate other agents, the DumbRegurgitator takes
one Part of a tune, and returns the bars of it sequentially every time it is
asked for the next bar of music.
ListeningMusician A ListeningMusician adds the ability to receive music to
the basic Musician class. It provides the service MusicalAgent.musicListener,
and the Conductor sends collated output to all Agents providing this ser-
vice.
Timbalero The Timbalero adds the mechanics necessary to play the timbales to
a ListeningMusician - a Representation, Generator and an Annotation.
Chapter 4. System Architecture 34
Player
Conductor
ID Collection
Main SongLoop
Key: Message Structure
Listener
Send ID
INFORMIdentity String
Generatenext Bar
Sendnext Bar
INFORMXML Serialised
jMusic Part
REQUESTString:
BAR_REQUEST
CollateBars
REQUESTString:
IDENTITY_REQUEST
StoreIdentities
RequestIdentities
RequestBar
INFORMSerialised Java
Map of Identity Strings
SendBars
INFORMSerialised Java
Map of XMLSerialised
jMusic Parts
Receive Bar
Receive IDs
FIPA PerformativeContent
Description
Figure 4.3: Message Flow
ChordTranscriber A simple test harness for the chord recognition/key induc-
tion algorithm.
4.1.3 Information Flow
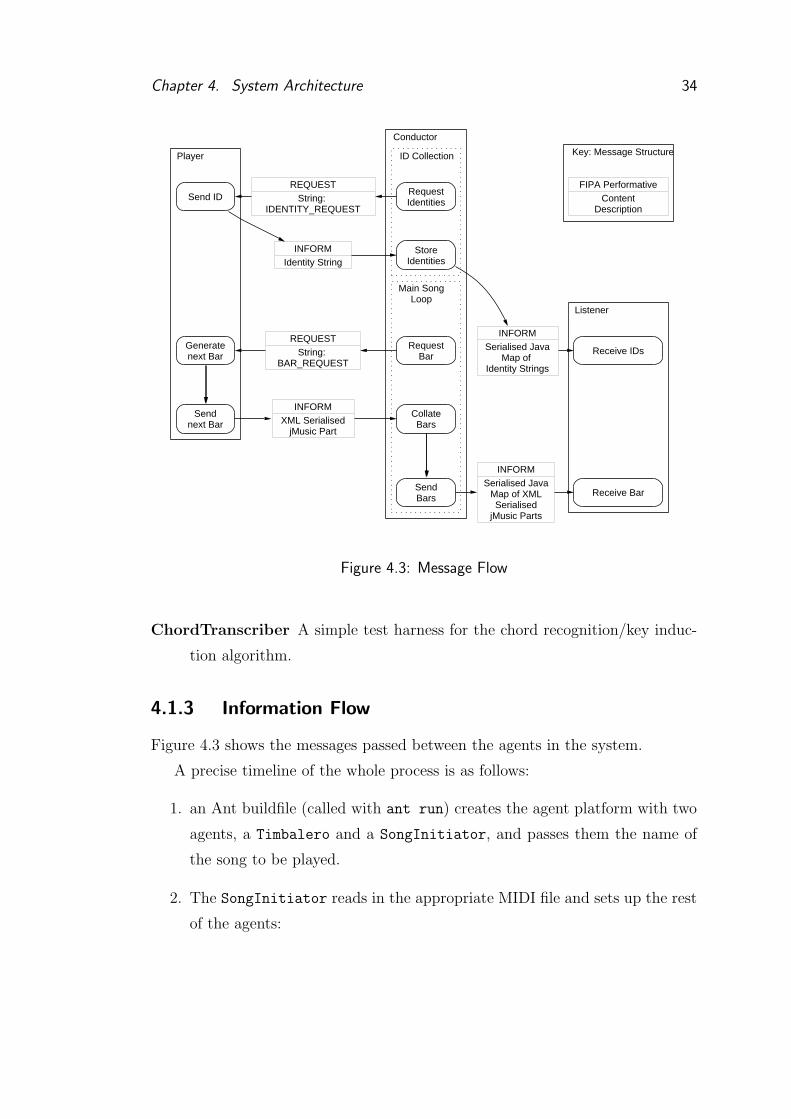
Figure 4.3 shows the messages passed between the agents in the system.
A precise timeline of the whole process is as follows:
1. an Ant buildfile (called with ant run) creates the agent platform with two
agents, a Timbalero and a SongInitiator, and passes them the name of
the song to be played.
2. The SongInitiator reads in the appropriate MIDI file and sets up the rest
of the agents:

Chapter 4. System Architecture 35
• a DumbRegurgitator is created for each part, and is passed an Identity
and a jMusic Part.
• a Conductor is created, and passed the name of the song, the length
to play for and the tempo of the song.
The SongInitiator then deletes itself
3. The Conductor requests the Identity of all the players present. Once they
reply, it sends all of the identities to each listener.
4. The Conductor now starts the main song loop. Each bar, the conductor:
(a) Requests a bar from each music producer
(b) Waits until it has received a bar from everyone
(c) Collates the bars, stores them, and sends a copy to all music listeners
5. Once the required number of bars have been played, the Conductor writes
the collected output to a file.
6. If the representation building abilities of the Timbalero are being tested,
the conductor sends out a request to restart the current song. The main loop
is then repeated to give the Timbalero a chance to use the representation
it has built up on the first iteration of the song.
4.1.3.1 Messages
While attempts have been made to use re-usable protocols for communication,
in some cases platform specific messages have been used; the system is amenable
to being made portable, but more work needs to be done.
Messages are sent as ACLMessages, as provided by the JADE framework.
FIPA performatives are used to distinguish different types of message, along with
a user defined parameters to further specify the communication. Where possible,
messages contain simple strings in the content: field, although in some cases
serialised Java objects are sent. In general, the conversation specifications are

Chapter 4. System Architecture 36
<?xml version="1.0" encoding="utf-8"?>
<Score tempo="180.0">
<Part title="Strings">
<Phrase tempo="-1.0">
<Note pitch="36" dynamic="80" rhythmValue="2.0" duration="1.91" />
<Note pitch="43" dynamic="80" rhythmValue="2.0" duration="1.91" />
</Phrase>
</Part>
</Score>
Figure 4.4: Example jMusic XML File
honoured, so messages will contain the correct :reply-to values, and Behaviours
expecting replies will only consider the correct messages.
Single parts of music are sent as XML fragments, using the jMusic serialisation
methods. This would allow other XML fluent applications access to the data, and
is a relatively simple language while encoding most of the necessary information
(see Figure 4.4). When parts are collated, they are sent as serialised Java hashes,
containing the XML strings indexed by agent ID.
Identities are sent as the stringified form the the Identity class. This is
simply a comma separated list of all the attributes, so it should be readily parsed
by other applications.
4.1.3.2 Behaviours
Although JADE defines several Behaviour classes, these were not really sufficient
for the task at hand so some new behaviours were defined. At least some of these
rely on the SendingState class, which allows messages to be sent to several agents
and keeps track of who has replied and who has not, and can be shared between
multiple behaviours.
These behaviours operate as SequentialRequester and
CyclicResponseCollector pairs. The requester will request a response
from a certain class of agents, and the collector will catch all the responses and
notify the requester when they are all in. The requester will then request the
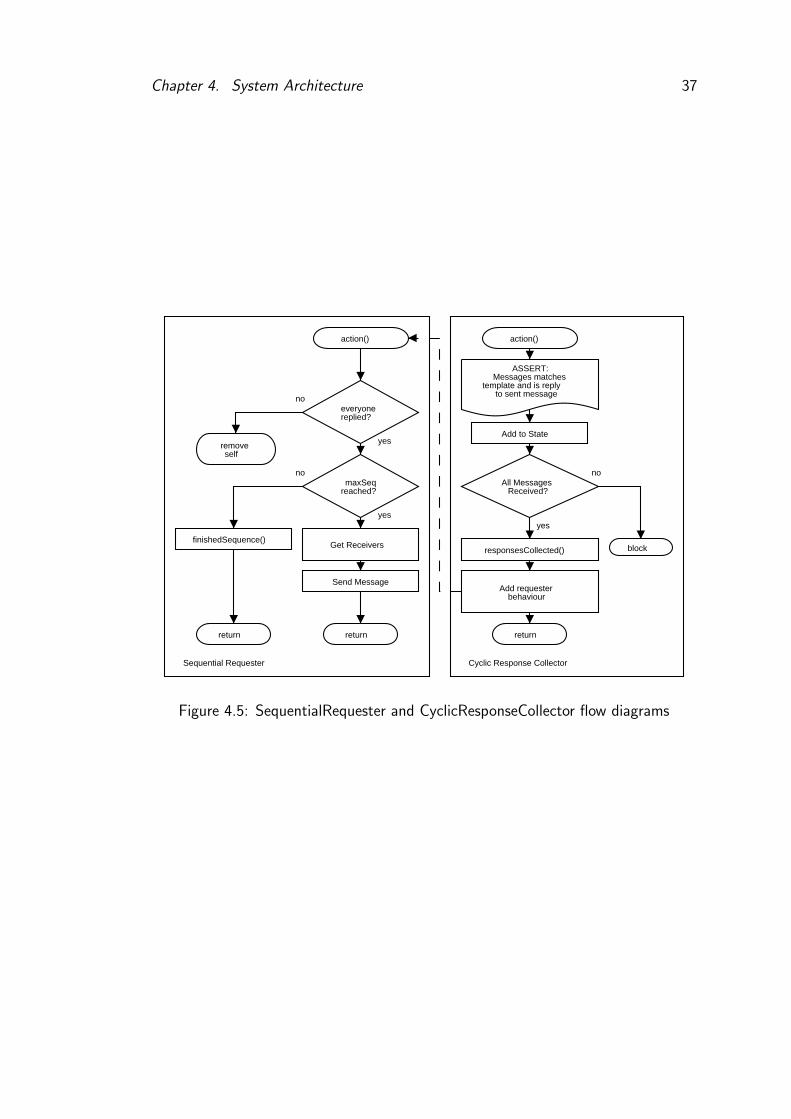
Chapter 4. System Architecture 37
Get Receivers
Send Message
Add to State
finishedSequence()
Add requesterbehaviour
All MessagesReceived?
maxSeqreached?
action()
everyonereplied?
removeself
action()
block
ASSERT:Messages matches
template and is reply to sent message
responsesCollected()
returnreturnreturn
yes
yesyes
no
nono
Sequential Requester Cyclic Response Collector
Figure 4.5: SequentialRequester and CyclicResponseCollector flow diagrams

Chapter 4. System Architecture 38
next message (see Figure 4.5). These are used by the Conductor for identity
collection at the start of the run, the main song loop, and requesting that the
song be restarted.
The musicians use a far simpler model. They wait for a request, whether it is
for a bar, their identity or to restart, and respond appropriately when they get
one.
4.2 High Level Representations
4.2.1 Representation Classes
The higher level classes are designed to directly model the high level represen-
tations discussed in the previous chapter. We have a Java class for each of the
main structures, plus some supporting classes.
4.2.1.1 Bar
A Bar represents a single bar of music. As per Assumption 3 above, each bar may
only have a single chord associated with it. A Bar hence has only two parameters:
Chord The chord played in the bar.
Accents Any notes within the bar which are especially accented by other musi-
cians. This covers both accents within bars of normal groove and the special
accents within areas of phrasing (see Section 6.3)
A bar knows nothing about who is playing in it or what groove is being played;
bars are designed to be a simplistic as possible.
4.2.1.2 Segment
A Segment represents a group of several bars where a certain set of features are
(reasonably) constant. The parameters of a Segment are:
Style This is a string specifying a particular style. The style may be a rhythmic
style (e.g. Bomba or Rumba) or one of the special styles (e.g. PhrasingOnly

Chapter 4. System Architecture 39
or TimabalesSolo). This is the name of the Java class which will provide the
output for the bars in this Segment (See Section 6.3 for a full description
of how Styles are used)
Clave The clave will always be “3-2” or “2-3”, except in certain Styles (such as
PhrasingOnly) where it may be omitted. If a Segment has an odd number
of bars, the following Segment will generally have the opposite clave.
Bars are contained in a Vector
Instrumentation A hash of player names along with a floating point value
representing their contribution.
Intensity is a single floating point number which provides a general measure-
ment of how intense the playing is at that point (number of instruments,
how loudly they are playing etc.).
Intensity Change takes a value depending on whether the intensity is increas-
ing, decreasing or remaining constant over the course of the Segment.
4.2.1.3 Section
Sections are the highest level structural elements. They contain Segments, and
the only restriction is that a Section has only one structural role.
Name is the working name of the Section, and is used solely to aid human
comprehension, as it is nice to see “VerseA”, ”Instrumental Chorus” etc.
rather than anonymous blocks of Segments.
Segments are stored in a Vector
Role defines the structural role of the section. This is one of the roles laid out
in the discussions on the structure of Salsa music (see Section ?)

Chapter 4. System Architecture 40
���
�
�
�
�
���
�
�
��
Figure 4.6: Different sets of notes which would be classified as as C major
Dm7
����
F6
��
��
Figure 4.7: Ambiguous Chords: conventionally, the first chord is written as Dm7,
while the second would be F6
4.2.1.4 Chord
The representation of chords is a relatively complex problem; Chords are typically
presented as a root note followed by a string denoting the “extension” of the chord
(e.g. ‘Abm’ ‘E7’). There are often different sets of notes which would be given the
same name (Figure 4.6), and there are different ways of writing the same chord -
a chord containing the notes D, F, A and C could be written as Dmin7, or as F6
(see [29], pages 50,51). In some cases the voicing helps, as shown in Figure 4.7.
To avoid problems, the Chord class has been made as flexible as possible. Chords
are represented as a root note (an integer between 0 and 11) and an extension,
which is an array of 7 integer values. These values represent the presence of notes
in a sequence of thirds starting from the root, taking the values given in Table
4.1. Table 4.2 gives some examples.
This allows multiple representations of the same data: in a C chord, the note
Eb would be written as “x -1 x x x x x”, but D# would be “x x x x 2 x x”, yet
they are the same note. In practice this is useful, as a chord speller/recogniser
will make its own choice about which representation is correct.
The Chord class contains many types of chord. Each type of chord can have

Chapter 4. System Architecture 41
0 Note not present
1 Note present in normal form
-1 Note present in diminished/minor form
2 Note present int augmented form
Table 4.1: Meanings of extension values
Chord Root Extension Notes Present
C major C [1, 1,1,0,0,0,0] C,E,G
C minor C [1,-1,1,0,0,0,0] C,Eb,G
D minor D [1,-1,1,0,0,0,0] D,F,A
unknown C [1, 1,1,1,1,1,1] C,E,G,B,D,F,A
Table 4.2: Example Chords
several extension vectors (for example, [1,1,1,0,0,0,0], [1,1,0,0,0,0,0] and
[1,0,1,0,0,0,0] are all considered to be major chords), and several ways of
being written (for example, ’C’, ’C maj’ and ’C major’ all represent a C major
chord).
4.2.2 Human Readability
In order to increase the usability of these classes, a lot of work has been put
into making sure that these objects are easy to create and visualise - this allows
for easy debugging as well as clear and maintainable coding. In all cases the
toString() method has been overridden to output something human readable,
and methods are available to create objects from easily understood strings.
Some examples are:
Chords can be created from a chord string detailing the root note of the chord
and an extension, for example ’Eb’, ’C minor’, ’Ddom7’. 2
2The exact specification is the regex ^([A-G][b#]?)\s?(.*)$

Chapter 4. System Architecture 42
Bars can be created from a chord string, as this is the only necessary information.
They output accents according to the informal counting convention used by
drummers 3. A Bar in D major with accents on the second beat and halfway
through the third beat would become "D ‘2 ‘3+".
Segments are defined by a Style, a clave and a list of Bars. The list of bars
can be specified by a set of Chord specifiers surrounded by ’|’ symbols,
for example new Segment( "SonMontuno", "3-2", "|C|C|D|G|" ).
Sections wrap the output from their component Segments and add role and
name information. Example section output is given in Figure 4.8.
Rhythms can be input using a simple specification language based on a grid
on which notes may or may not be played. The characters X x o . rep-
resent decreasingly loud strikes, with everything else representing a rest.
The following code will return a basic cascara/clave pattern (as shown in
Appendix A:
String[] basicRhythm = new String[] {
"CASCARA_RIGHT |X X xX xX xX x x|",
"BLOCK | x x x x x |" };
return UtilityMethods.stringToRhythm( basicRhythm, 16, QUAVER );
Although this might seem like a trivial detail, the ability to quickly and
intuitively add rhythmic fragments (not to mention their subsequent main-
tainability) is a large factor in the quality of the final output.
4.2.3 Identities
Identities are used for two reasons:
• Real musicians have identities, and it may be useful to remember people
you have played with previously.
3A bar full of semiquavers is counted as as “one ee and uh, two ee and uh, three . . . ” (here
represented as "1 ee + uh 2 ee + uh ...", and a note which starts one quaver after the
beginning of the bar is said to be “on the and of one”.

Chapter 4. System Architecture 43
--------
Section: Instrumental Chorus (Mambo)
8 bars of 2-3 SonMontuno: |Cm|Cm|G|G|Fm|G|G7|Cm ‘1+ ‘2+ ‘3+ ‘4|
Instrumentation:- : Trumpet->0.5
Intensity: 0.8, 0
8 bars of 2-3 SonMontuno: |Cm|Cm|G|G|Fm|G|G7|Cm ‘1+ ‘2+ ‘3+ ‘4|
Instrumentation:- :
Intensity: 0.8, 0
--------
--------
Section: Bridge (Son)
4 bars of PhrasingOnly: |Cm|Cm ‘2+ ‘3 ‘4|Cm|Cm ‘2+ ‘3 ‘4|
Instrumentation:- :
Intensity: 0.6, 0
--------
Figure 4.8: Example fragment of Section textual output
• We need a way to keep track of the MIDI instrument settings so that the
file can be reconstructed at the end.
MIDI files will specify an instrument number for each part, along with a
textual description of the part. This means that there might be a “Piano Solo”
part as well as a “Piano” part. There are also many different instrument numbers
for a single instrument, for example, here are the first few entries in the GM spec:
PC# Instrument
001 Acoustic Grand Piano
002 Bright Acoustic Piano
003 Electric Grand Piano
004 Honky-tonk Piano
A piano part could have any one of these instrument numbers (and more).
The agents in the system do not want to deal with either of these directly -
they simply want to know what instrument someone is playing. Hence, when the
SongInitiator starts the song, it will turn this information into a canonicalInstrument.
This will return a single string which is the internal representation of the instru-
ment played by that agent, and examples are “piano”, “bass”, “vocals”. Since

Chapter 4. System Architecture 44
this process is not foolproof, some MIDI files must be hand edited to set up the
correct names.
The Identity class encodes
• A name for each musician (these currently serve no purpose other than to
make debugging more interesting and illustrate how they could be used,
but could be used to learn the styles of certain musicians)
• A canonical instrument string
• A GM instrument number
• A MIDI channel specification
At present, there are two ways in which Identitys are used:
• the Conductor uses the MIDI channel and instrument number to write the
finished MIDI file
• some of the musical analysis modules will only look at certain instruments
(for example, the chordal analysis sections only consider bass, piano and
guitar.
4.2.4 Representations By Hand
It was necessary to create high level representations by hand in order to test
the generative subsystem without the availability of a finished analysis system.
Annotations for each piece were made using the relevant MIDI file and a recording
of the piece (as played by human musicians). Chordal analysis was carried out
by examining the notes on the score, while structural features were often more
readily derivable from the recorded version. At this stage it was also verified that
the MIDI files were true and accurate representations of the piece in question.

Chapter 4. System Architecture 45
4.3 Low Level Music Representation
Three methods of music representation have been discussed so far: Audio, MIDI
and CPN. Unfortunately, none of these are quite correct for the task at hand;
MIDI is slightly too low level, while CPN does not contain enough information.
Some of the deficiencies of MIDI are:
• The timestamps in ticks are not friendly to work with
• The length of a note is not known until it finishes
• The concept of beats and bars is derivable, but not given
• It is not always clear what instrument is playing each track.
Originally, a new low level music representation was designed and imple-
mented for this project, complete with MIDI file I/O and XML serialisation.
Development was subsequently switched to the jMusic libraries, as they offered
a more complete implementation (most notably in the presence of constants for
many musical values and display of music as scores and as piano roll notation).
A general description of the jMusic framework is given in Appendix C
4.4 Architecture Summary
In this section we have given specific implementations of the high level represen-
tational elements discussed in Section 3.2. An agent system has been defined in
terms of messages and behaviours: a Conductor agent requests each bar sequen-
tially from all available musicians, which are then collated and disseminated to
all interested musicians. A low level representation of music has been specified.
This gives a complete agent based infrastructure for musical activities.

Chapter 5
Music Listening
In this section, we explore the musical analyses which we hope to use to build up
high level representations by looking at ways to extract the features necessary for
the grouping and well-formedness rules discussed in Chapter 3.
The Timbalero attempts to analyse the structure of the music it plays along
with, in the hopes of building up a representation which is accurate enough to
produce high quality output. The structural rules rules given in Sections 3.2.4 and
3.2.5 are used to produce a set of break points which mark the transitions from
segment to segment and section to section. The features necessary to populate
this representation are then extracted from the relevant sections of the music
heard (see Figure 5.1)
5.1 The Annotation Class
The Annotation class is derived from the Memory class (described in Section
6.3.1) and is used by the agent to keep track of all the features extracted from a
piece of music. It consists of a set of strands, each of which stores a particular
class of object, and is referenced by name. Features and Rules both use the
Annotation to store their findings so that they are available to all. At the end
of the piece, the Timbalero can instruct the Annotation to segment itself, and
that way get a Representation of the music heard.
46
Chapter 5. Music Listening 47
FeatureExtraction
Complex FeatureExtraction
PreferenceRules
Well FormednessRules
Music Heard
NecessaryBreak Points
PreferredBreak Points
Dissection
Representation
AttributeExtraction
Figure 5.1: Analysis Operations

Chapter 5. Music Listening 48
5.2 Feature Extraction
There are two kinds of feature extraction considered - simple and complex. Sim-
ple feature extraction works directly on the music itself, while complex feature
extraction uses the results of previous feature extraction. In principle there is
little to distinguish the two methods other than the assertion that all simple
features must be extracted before the complex features are begun. Key Features
include the current instrumentation, the number of players, the bar to bar change
of both of these, harmonic information and phrasing information. Each Feature
creates and uses a strand in the Timbalero’s Annotation (see Section 5.1).
5.2.1 Harmonic Analysis
The basic level of harmonic analysis is performed using a modified version of
the Parncutt chord recogniser given in [29] in combination with a key finding
algorithm due to Longuet-Higgins[19], again as described in [29]. Several small
modifications of this were tried to give a simple adaption to the polyphonic envi-
ronment. The basic Parncutt algorithm looks at the presence of notes only; often,
due to the many voices involved in latin music, this would result in a severely
overloaded harmonic structure. Some attempts were hence made to look at the
weighting of pitch classes1, so notes held for more time would have more effect on
the final decision. The algorithm used is as follows (more formally in Figure 1):
• Construct a single jMusic Part containing all the notes to be analysed.
Presently, the system only looks at piano, bass and guitar parts.
• A strength is calculated for each of the 12 pitch classes . The algorithm
iterates over the notes given, and adds the duration of each note to the
relevant pitch class.
• The set of n significant notes is calculated. From the notes over a certain
threshold (currently 1.0), the strongest are chosen, up to a maximum of n.
1pitch classes represent the 12 notes of the scale, numbered from zero to 11

Chapter 5. Music Listening 49
• The presence array is calculated which contains the value 1.0 for each sig-
nificant pitch class, and 0 for the rest.
• For each possible chord root, a score is calculated, by multiplying the pres-
ence array by the Parncutt root support vector rotated2 by the integer value
of the potential root.
• The scores are normalised so that the average score is 10
• A vector of biases is now added. This can be one or both of:
– The Krummhansl and Kessler stability profiles
– An extra weighting for the lowest note in the given note set
• The pitch class with the highest score is chosen as the best root.
Once the best root has been found, the extension of the chord is calculated.
The getSignificant() function is used to extract the (up to) four most salient
notes played in the bar. These are then translated into entries is the sequence of
thirds above the root, by the Chord class.
The pitch finding algorithm uses the Krummhansl and Kessler stability pro-
files [17] which are a set of weights that indicate the compatibility of the possible
root with the current key centre. In order to do this we need to know what the
current key centre is, and to know that we have to know what chords are being
used. To avoid this deadlock, the most likely current chord is first calculated
without the contextual information. This is then used to update the weights for
the different key centres, so that the current key centre can be computed. The
best root can now be computed again, using the new contextual information.
To calculate the current key centre, a vector of key centre weights is main-
tained. This has 24 entries - one for each pitch class in major and minor flavours.
Each time a new chord is encountered, a fixed compatibility vector is rotated
according to the new chord’s root and flavour and added to the current vector of
2we use rotated here to mean moving each element in the vector right by n places, and
reinserti theng any that “fall off the end” on the left

Chapter 5. Music Listening 50
Algorithm 1 Calculation of best root from note data
N is set of notes
S is strength vector (length 12, initially 0.0)
W is root support weighting vector: [10, 0, 1, 3, 0, 0, 5, 0, 0, 2, 0]
R is support for each candidate root
p is presence vector
B is bias vector
for all n ∈ N do
pc = pitchClass(n)
Spc ⇐ Spc + duration(n)
end for
p⇐ getSignificant(S, numSignificant)
for i = 0 to 11 do
Ri ⇐ S · rotate(W, i)
end for
normalise(R)
for i = 0 to 11 do
Ri ⇐ Ri +Bi
end for
return argmaxi
(Ri)

Chapter 5. Music Listening 51
weights (subject to a maximum threshold)3. The pitch class and flavour with the
highest score is then taken to be the current key centre.
5.2.2 Pattern Analysis
The reason for performing the harmonic analysis detailed above is that is gives a
lot of information about the structure of the piece. To avoid a complex musical
analysis, and to support the rules which prefer reusable fragments, we look at
pattern. The guiding principle is that patterns which occur frequently are likely
to be structural units at some level.
Pattern search is performed using a PatternTree. Once the chord sequence
of the piece has been approximated, a tree is built of all the patterns contained
within this sequence as follows:
1. For each bar, a sequence of chords up the the maximum length to be con-
sidered, starting at that bar is extracted.
2. The pattern tree runs down the sequence in order, starting from a blank
root node, and for every element
• if the current element of the sequence is a child of the current node of
the tree4, then the child’s visit count is increased and it becomes the
new current node
• otherwise, a new child is added, with a visit count of 1, which then
becomes the current root.
Once this has been created, it is easy to see how many times a particular
sequence occurs by walking the tree and reading the visit count in the final node.
The support for the sequence is then the number of occurrences of the sequence
divided by the number of sequences of that length.
3The compatibility vector sums to less than zero; each weight is limited to being between
0 and 60. This means that only the compatible keys have weight at any given time, and
incompatible chords will quickly change the perceived key4Chords are compared by their stringified form, to make the system more accommodating
to insignificant changes in extension

Chapter 5. Music Listening 52
5.3 Rhythmic Analysis
Rhythmic analysis is performed by two separate but similar algorithms. The
general idea is measure the “agreement” of playing within the bar - how many of
the notes are played by everyone, and how many are played by some people and
not others. The idea is to pick out bars which should be classified as phrased,
either as only phrasing, or as a normal bar with some accents.
Both algorithms divide the bar into small segments and the quantize each
note onset to the nearest segment boundary.
The first algorithm (Algorithm 2) then goes through each subdivisions and
counts the number of beats on which almost everyone plays, on which some people
play, and on which (almost) no-one plays. The result is the ration of beats where
everyone played to the number of beats where anyone played.
The second algorithm (Algorithm 3) calculates the disagreement on each sub-
division. Each musician can either play or not play; if everyone or no-one plays,
that is maximum agreement, while if half the musicians play, that is maximum
disagreement. The disagreement is calculated for each subdivision, normalised by
the number of parts, and then the average disagreement for the bar is calculated.
This is then converted to an agreement, on the scale 0 to 1.
Algorithm 2 First Phrasing algorithm
for all subdivision do
if proportion playing > phrase threshold then
phrasedBeats++
else if proportion playing > rest threshold then
unphrasedBeats++
else
//it’s a rest
end if
end for
result = phrasedBeatsphrasedBeats+unphrasedBeats
The results of these algorithms are stored in a PhrasingAnalysis object,

Chapter 5. Music Listening 53
Algorithm 3 Second Phrasing algorithm
for all subdivision do
disagreement ⇐ numPlayers − abs( numPlaying - numNotPlaying )
totalDisagreement + = disagreement / numPlayers
end for
averageDisagreement = totalDisagreement / numSubdivisions
result = (0.5− averageDisagreement)× 2
which also decides5 whether to classify the bar as being normal, normal with
accents, phrasing only or tacet.
5.4 Dissection
The Preference and Well Formedness rules are run after all of the features have
been run. On AnnotationStrand is created for each of these: Well Formedness
rules store boolean values, while Preference rules store floating point numbers.
Each Well Formedness rule has the chance to specify that a particular bar must
be a break point, must not be a break point, or it may leave it in it’s current
state (the default state being a don’t care). Each Preference rule will add (or
subtract) an amount from the score for a particular bar. Breaks are then made
• where the Well Formedness rules force a break
• where the combined score of the Preference rules exceeds a certain threshold.
The current PreferenceRules are:
InstrumentationChange The instrumentation change rule works on the data
produced by the InstrumentationChange feature, which in turn relies on
the Instrumentation feature, which calculates an activity level for each
player. The InstrumentationChange feature then sums the absolute dif-
ferences between each instrument’s activity levels to get a value for the
overall instrumentation change. This is then used as the basis for a score
5by comparing each value to a threshold

Chapter 5. Music Listening 54
PatternAnalysis Works over the scores created by the ChordPattern feature,
and looks for high values and local peaks or jumps.
PlayerChange Similar to the InstrumentationChange rule, except that it looks
at the changes in who is playing, not what they are playing.
TotalInstrumentation Looks at the change in total activity, and adds scores
for changes relative to surrounding bars.
Most of these rules only work over the previous bar (or the next bar), so they
have a very tight window. The PatternAnalysis rule looks at the next but one
bar as well, but this is still not a large amount of data to work on.
The current set of Well Formedness rules is quite limited:
Groove There are no real groove identification tools in place, so the only grooves
which are considered are the transitions between PhrasingOnly and every-
thing else (partial implementation of Segment WF Rule 2).
Once the dissection has been calculated, a new Section or Segment is created
at each of the relevant break points. A set of Attribute rules are then run to fill
in the necessary attributes of each object - for example, a Segment needs to have
the style, intensity, the clave and any phrasing added. Attribute rules are given
a range of bars corresponding to their object, and calculate a value for that set
of bars. For example, the IntensityAttribute calculates the average intensity
over the Segment, and the IntensityChangeAttribute performs a regression fit
between the intensity of each bar and time (relative to the start of the section) to
determine whether the intensity is increasing or not. This results in the finished
Representation.
5.5 Music Listening Summary
In this chapter we have implemented the extraction of several basic musical fea-
tures and some more complex features. We have implemented rules which cor-
respond to some of the grouping rules we are attempting to realise, and show

Chapter 5. Music Listening 55
how a complete dissection may be created, but we are currently unable to realise
this. We have used novel algorithms for detection of phrasing, and have adapted
existing algorithms for key and pitch tracking to our specific purpose.

Chapter 6
Generative Methods
In this chapter we look at everything pertaining to the final output of the tim-
balero - the manner in which we use our high level representations to create a
musically sensitive accompaniment.
In keeping with the overall design, we split the generative subsection into
two main parts: basic rhythm selection and ornamentation. (see Figure 6.1 for
details)
6.1 Basic Rhythm Selection
Using the information given in the Design section, a set of rules has been produced
from a knowledge elicitation interview (Appendix A.4); Figure 6.2 gives pseudo-
code.
The Timbalero goes through three stages in generating the basic rhythm for
the current bar:
1. Select the patterns according to the rules given above. This results in a
pair of two bar Phrases, one each for the left and right hands
2. Adjust the Phrases for the current clave. All of the rhythms are stored
in 2-3 clave form. In 3-2 sections of the piece, the bars must be swapped
around to fit with the clave.
56
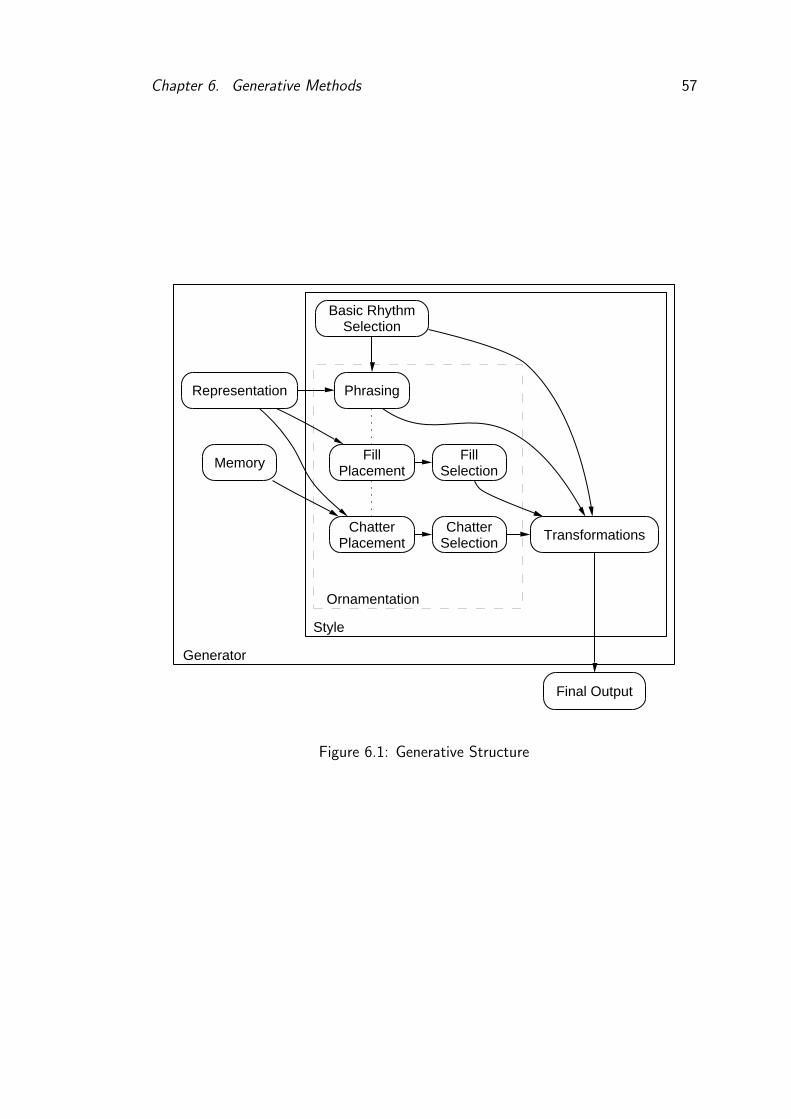
Chapter 6. Generative Methods 57
Generator
Style
Ornamentation
Representation
Memory
Phrasing
FillPlacement
ChatterPlacement
Basic RhythmSelection
Transformations
FillSelection
ChatterSelection
Final Output
Figure 6.1: Generative Structure

Chapter 6. Generative Methods 58
if ( not moved_to_bell ||
( current_section is "Coda" &&
current_style is "SonMontuno" ) )
{
right hand plays cascara;
if( very loud ) left hand plays Doble Pailas;
else if( needs a clave ) left hand plays clave;
else left hand plays nothing;
}
else
{
moved_to_bell = true;
right hand plays mambo bell
if( needs_campana ) left hand plays campana;
else left hand plays Hembra;
}
Figure 6.2: Rhythm Selection Logic
3. Select the correct bar. On even bar numbers (zero indexed) the first bar is
selected, and the second on odd bars.
It would be possible to combine the second and third operations, but this is
felt to be more transparent and analogous to how a musician would think.
6.2 Ornamentation
These ornaments are considered in the specified order:
if( has phrasing ) add phrasing;
else if ( should fill ) do fill;
else if ( should chatter ) add chatter;
end
6.2.1 Phrasing
Phrasing is generally performed with a loud open note on one of the timbales,
often augmented with a cymbal crash. The Timbalero in this case always uses

Chapter 6. Generative Methods 59
either the rim of the macho, or the rim of the hembra combined with the cym-
bal. This decision is made based on the proximity of other accents - if there is
another accent within a threshold distance (default 1.25 beats), then no cymbal
will be used. Without this, long runs of phrasing were very hard on the ear, and
unrealistic.
The area around the phrasing is also cleared of notes. Both the right and
left hand parts are cleared, which both simulates moving the hands to play the
accents and leaving some space around them so they stand out more.
For phrasing where play continues as normal, nothing need be done. For
Segments where only phrased notes are played, the PhrasingOnly Style must be
used (see Section 6.3). below.
6.2.2 Fills
The Fill subsection of the Timbalero performs two tasks:
• Fill placement
• Fill selection
The rules detailed in Section 3.4.3 for fill placement have been implemented.
Each rule produces a score for the current bar; the scores of all the rules are
summed, and then a small amount of noise is added. This value is then compared
to a threshold value set in the Generator (Section 6.3). If it is higher than the
threshold, a fill is played.
Fills are selected randomly from a pool, provided by the Style. The exception
to this is the Tacet Style, which is most likely to play an abanico on the lead in
to the next section.
Fills are stored as a single jMusic Phrase. The basic rhythm up until the start
of the Phrase is left in, and the rest is cleared. The fill is then added to the basic
Part. Many fills require an accent to be played on the downbeat of the bar after
the fill. However, due to this representation, each fill must stop before the bar
line. Fills hence have a requiresDownBeatAccent() method; if this returns true,

Chapter 6. Generative Methods 60
then the ornamentation system will add an accent to the beginning of the next
bar.
6.2.3 Chatter
Chatter is added according to the rules set out in Section 3.4.4. Similar to Fills,
Chatter is represented as a single jMusic Phrase, and this has a similar limitation:
in some cases, chatter should span several bars, particularly for chatter based on
displacements1. Since the current representations only allow for single bar chatter,
the Chatter class has been extended to allow a followOn to be added. If Chatter
is to be played and the previous bar contained a Chatter with a followOn, then
the previous Chatter’s followOn will always be used. Rule 7 also increases the
chance of chatter if the previous bar contained a Chatter with a followOn.
6.2.4 Transformations
The transformation section is designed to further enhance realism. Provision is
made to apply transformations which will
• Alter dynamic levels; this covers functions such as playing quietly in quiet
sections and increasing or decreasing dynamics throughout sections.
• Alter the feel or groove of the playing. This would cover both applying
preset grooves to the output and emulating the groove of the other players.
At present, no transformations are implemented - the dynamic changes are
generally implemented by the voicing/rhythms used, and much of the input is
quantized, and hence non-groovy.
1A displacement is a rhythm made up of repeating units whose length is not a power of two
multiple of the bar length, so the positioning of accents in the chatter rotates with respect to
the bar

Chapter 6. Generative Methods 61
6.3 Modularity and Division of Labour
The Timbalero uses a Generator and a Representation to produce the output.
The Representation holds the high level representation of a song and keeps
track of the current position within it. The Generator holds a Memory (see
Section 6.3.1) and loads a Style as apropriate for each Segement
The great majority of the work is done by the Style class; this allows for easy
expansion to other styles. While a range of Styles are possible, there are a few
key styles, whose operation may be illuminating:
Style The basic Style class provides SonMontuno playing, and rhythm and or-
nament selection for Salsa music.
SonMontuno implements nothing at all, and is provided so that Segments can
have a ”SonMontuno” style.
Tacet always returns empty basic parts for both hands, and is used for sections
where the Timbalero does not play. It is very likely to use an abanico as a
fill if a fill is performed, and will only perform a fill if it is the last bar of
the Segment and the next Segment is not Tacet.
PhrasingOnly refuses to play any fills or chatter, and returns empty parts for
the basic bar, so that only phrasing is played
TimbalesSolo Returns empty parts for the basic bars, plays a Fill in almost
every bar and adds Chatter when not playing a fill.
Rumba and Bomba are examples of adding new Styles. The Rumba style
only overrides the getClave() method, to return a rumba clave, while the
Bomba style overrides the default cascara pattern
All of the domain specific knowledge is encoded in the Style class2, from logic
which chooses rhythms down to the actual fragments used. This allows for the
2all the generative knowledge, that is - there is additional knowledge used to build up the
representations used which is stored elsewhere

Chapter 6. Generative Methods 62
easy addition of new styles; with some work, it would allow for expansion to other
genres of music. As noted before, each Segment has a set Style. Each Section,
however, has a structural role. This means that it is possible to have the Son
section of the piece contain a mixture of different rhythmic styles.
6.3.1 Memory
When a real player plays, current actions are often based on previous actions - if
some chatter is started two bars before the end of a section, it will probably be
continued and maybe intensified - until the end of the section. In general, we need
a memory of what decisions have been made previously. A general Memory class
is used for this, which holds a set of MemoryStrands, indexed by name. Each
MemoryStrand contains a list of a certain type of object, and has a set length.
Each time a new value is added to a full strand, the oldest value drops off the
end. This can then be queried to support rules such as ”if I played a really big
fill at the previous section change, I won’t play one here”.
In the current implementation, each bar, the Fill and Chatter played (or null
if none was used) are added to strands called ”Fill” and ”Chatter” respectively.
These are used to support Chatter Preference Rules 7, 8 and 9, the use of Chatter
followOn , and the downbeat accents after certain fills.
6.4 Generative Methods Summary
We have broken down the creation of output into the selection of a basic rhythm
and subsequent ornamentation. We have described how basic rhythm selection is
performed in the context of a salsa tune, and given procedures which implement
the design rules for structural use of ornamentation. We have described the
need for a memory of what has been played and its implementation. Finally,
we have described how a modular architecture is used to support the creation
of appropriate output, and concentrate all of the essential logic in a single place
amenable to extension.

Chapter 7
Results and Discussion
There were two major outputs from the finished system: an analysis of the music
heard, and an accompaniment based on a hand crafted representation. Analyses
of the representations used and the agent system are also given.
Much of the testing has been performed using a version of Mi Tierra, by Gloria
Estefan. The original MIDI file is of unknown origin, but has been compared to
the original recording and found to be a faithful representation of the piece. The
file was quantized, for two reasons:
• it makes life easier for the analysis systems (although the rhythmic analysis
should be relatively robust, there are representational issues1)
• the timbalero does not follow the feel of the other players, so it would be
likely to sound wrong and slightly out of time in some sections.
63

Chapter 7. Results and Discussion 64
By hand context free current key with context
Cm Cm C min Cm
Cm G1020010 C min Cm
G Gdom7 C min Gdom7
G Gdom7 C min Gdom7
Fm G110-1010 C min C1011010
G Gdom7 C min Gdom7
G G1020010 C min Cm
Cm Cm C min Cm
Table 7.1: Output of chord recognition against hand crafted representation for bars
41-48 of Mi Tierra (see text for details)
7.1 Music Listening
7.1.1 Chordal Analysis
Figure 7.1 shows the output of the chord recognition subsystem for a fragment
of music, with hand analysis for comparison. The “context free” output is the
result of running the simple chord recogniser. As noted before, this is fed into
the key induction algorithm to generate the current key (3rd column) and this
context is used to give a “contextual chord” (4th column).
In this section of music, most of the chord changes happen on the fourth beat
of the previous bar (see Section 7.1.1.1), which causes problems for the chord
recogniser. The second bar is originally recognised as a rather strange extension
for G - decoding this we come up with the notes G,Eb,C - quite clearly a C
minor chord. Somehow, possibly due to the extra weighting given to the lowest
note played, this is being misclassified. Looking at the fifth bar, we see another
strange extension to a G chord. This decodes to G,B,F,C, which would indeed be
1Due to the very simple segmentation techniques used, if a note occurs slightly before the
first beat of the bar, it will be considered as part of the previous bar, and the bar in question
will be missing a downbeat

Chapter 7. Results and Discussion 65
44
��
��� �
�
��� �
�
��� �
�
��� �
�
��� �
�
��� �
��
� � ��� �� �
��
�
Figure 7.1: Guitar part for bars 22-25 of Mi Tierra, exhibiting split bar chords
a strange chord, if it were not a superposition of G and F (minor) - a classic case
of a split bar chord. In this section, context seems to help - the chords in bars
2 and 7 are correctly classified with context. However, if we look at bar 55, it
has caused a serious error, where the notes G B F (classified correctly as Gdom7
originally) are classified as a strange rootless C chord - C0011010.
7.1.1.1 Split Bar Chords
Figure 7.1 shows and excerpt of the guitar part in Mi Tierra exhibiting split
bar chords. Using additional musical context2, it is possible to see that the
most appropriate chord sequence at this point in time is |Cm|Cm|Cm|G|, but it is
transcribed as |Cm|Cm|Gsus4|G|
7.1.2 Chord Pattern Analysis
The original version of the chord pattern finding algorithm performed quite
poorly. This was due to the chord recognition being quite sensitive, and classify-
ing broadly similar chords with different extensions. Observing the solo section
(bars 153-176) which consists of repeating the chords |Cm7|F|Ab|G|, we see sev-
eral different versions of the same sequence (compare bars 153-176 to 169-172).
The version given in the appendix (and discussed here) uses a more forgiving
version of the chord pattern rule, where only the root of the chord is considered.
We can see this giving very nice peaks with a period of four bars (the length of
the repetitive sequence), which is what is hoped for. If we look at the Montuno
2Mostly from observing other similar sections and listening to where it feels like the chord
changes

Chapter 7. Results and Discussion 66
44
� �� �
�� �
�� �
�� �
���� �
� �� �
�� �
�� �
��
Figure 7.2: Phrasing under the solos (bars 153-176)
(particularly 125-140) we can see that although the sequences are being found,
the peaks are out of phase with the desired boundaries. This can probably be
attributed to the quite ambiguous two chords at the beginning; this means that
the first repetitive sequence starts on bar 123, rather than bar 121.
7.1.3 Phrasing Extraction
There are many cases where the phrasing extraction algorithms perform as de-
sired. Both algorithms are used in the analysis, although it was found through
experimentation that the second phrasing rule (Algorithm 3) provided a better
discriminator - it was very hard to find a threshold for the first algorithm which
would label an appropriate proportion of bars. There are two aspects to examine
here: the classification of bars, and the identification of correct accents within
bars.
The algorithm has to classify a bar as being normal, phrasing only, normal
with accents or tacet. Almost all of the bars classified as being phrasing only
actually are. Some sections represent particular problems; the timbales solo and
subsequent playing in bars 153 to 176 has a constant set of accents in every bar
(see Figure 7.2), which should be considered as phrasing as everyone is hitting
the same notes except the people playing the solos. However, the fact of people
playing solos over the top confuses the analysis; the first bar, which contains many
accents is identified as phrasing for the first four cycles, after which it is obscured
by the solos. The second bar, which contains the last note of the first group of
accents and nothing else is harder to spot, and is not correctly identified. The
final two bars which contain a few notes of phrasing each are sometimes identified,

Chapter 7. Results and Discussion 67
but mostly missed. This exposes a limitation in the algorithm; if it had a sense
of parallelism, then the repeated rhythmic motifs would become clear.
It is also apparent that the distinction between the different types of bars is
not as clear as one might hope; it is difficult to detect tacet bars - at present a
bar is considered to be tacet if only one person is playing in it, which is clearly an
overly strong assumption (but it allows recognition of the conversation between
vocals and the band in the bridges (bars 17-20, 73-76)).
Where phrasing is correctly identified as being present, no examples have yet
been found where the wrong accents are identified. No results are shown here,
but the phrasing in the bridges is notated correctly, similarly the end of the verse
(bars 39-40) and the bar before the piano break (112).
As it stands, this algorithm has a disproportionate amount of work to do.
Classification of bars and extraction of accents should be split into two sections,
so that the classification section can use more information - for example, if all
the accent patterns were calculated before classification, there would be an op-
portunity to look for repeated motifs.
7.1.4 Final Dissection
As it stands, the final dissection is not really in a usable form. Many Segment
breaks are in the correct places: bars 41, 49, 57 and 65 are ideal examples of rules
combining to clearly specify break points. Indeed, most points where a break
is desired have a break point within one bar of them. The main issue seems to
be with extra breaks being added, which fall into two main categories: plausible
breaks, and implausible breaks. There are several breaks which are shown four
or eight bars from the beginning of a section (bars 69, 85, 91 and 109 are good
examples). A great many of these can be attributed to the chord pattern rule,
but there is often some support from the other rules. These breaks represent an
alternative, but fully plausible decomposition; although they are not structurally
significant points, it would not be ludicrous to (for example) divide the chorus into
smaller Segments. The musical knowledge necessary to avoid these could well be
hard to formulate, although it may be possible to tweak some of the rules slightly

Chapter 7. Results and Discussion 68
and clean this up. The implausible breaks are generally due to the well-formedness
rule stating that there must be a section break when the groove changes, and an
extra rule stating that no breaks were allowed in contiguous sections of phrasing
only playing3. If we look at bars 72 to 76, we can see that the last bar of the
chorus has been grouped with the bridge, which seems structurally wrong. We
can conclude that the rules we have put in place are not quite correct, or should
at least be relaxed.
There are also several sections missing entirely from the music listening sub-
system, as they would require a large scale investigation. No rules at all concern
themselves with inducing Section breaks. There is a reason for this - none are
apparent. Although it may well be clear to a listener what is a verse and what
is a chorus, it is not easy to formalise. Similarly, no work has been done on
classifying the role of Sections; there is information regarding what differentiates
one section from another (for instance, the montuno starts when the lead vocalist
starts improvising) but not enough to make a sufficient ruleset. The style of a
section is also only classified according to whether it is phrasing, normal playing
or tacet - some kind of stylistic analysis would need to be implemented.
7.2 Listening Tests
The listening tests were designed to test the generative subsystem of the tim-
balero; unfortunately, the analysis mechanisms could not be integrated in time,
so the complete system could not be analysed. Appendix D is a copy of the ques-
tionnaire. Two groups of listeners were tested: the general public, and a set of
domain experts (comprising Cambiando, the salsa band in which I used to play
timbales, and my co-supervisor Manuel Contreras who plays congas in another
salsa band).
Two versions of Mi Tierra were recorded, one using the virtual timbalero and
a hand crafted representation, the other played by myself, using a MIDI drum kit
3This was added because these sections typically have high values for many rules, and would
otherwise be highly fragmented

Chapter 7. Results and Discussion 69
Tested Correct Preferred Computer
Expert Listeners 6 83% 33%
General Public 10 60% 50%
Table 7.2: Results of Listening Tests
rearranged to approximate timbales. The use of a MIDI kit allowed completely
identical sounds to be used - a recording of timbales would be relatively easy
to distinguish from one composed of triggered sounds. The human playing was
quantized, and obvious mistakes were edited. The final recordings should hence
be a fair comparison of the two musicians, and should not give any obvious cues
as to which is which other than the actual music produced.
The timbales sounds were produced by recording a set of LP Tito Puente
Timbales, along with an appropriate selection of cowbells. Each possible timbale
sound was produced, then the recording was cleaned up and segmented into
individual files for each sound. The finished files were loaded into a Yamaha
A3000 sampler and mapped to notes corresponding to the MIDI notes sent out
by the electric drum kit. The rest of the sounds in the piece were produced using
the GM synthesiser module built into the drum kit. The level of the timbales was
set artificially high in the mix, to make it obvious exactly what they were doing
- the sound balance was designed to approximate that heard by the timbalero
while playing with a group. The final recordings were normalised, compressed
slightly to remove any possible dynamic inconsistencies and burned to CDs for
the tests. Each participant was given a copy of the questionnaire, a copy of the
CD and some means of listening to the CD (generally headphones) and asked
to read the instructions before listening to the music. Table 7.2 summarises the
results of the tests.
A a χ2 test is as follows:
H1 The general public can identify the virtual timbalero more accurately than
random guessing.
H0 The general public can not do better than random.

Chapter 7. Results and Discussion 70
We calculate a χ2 value of 0.4 (with 9 degrees of freedom), which is not signifi-
cant at any level, so we conclude that the general public are unable to differentiate
between mechanical and human playing. Unfortunately, there are explanations
other than the quality of the generated output for this: from speaking to the
subjects, it was clear that many of them were not quite sure what to look for,
and the general unfamiliarity with the genre made analysis difficult for them.
The domain experts were a different story; almost every expert tested was
able to discriminate between the recordings. We get a χ2 score of 2.67 (5 DOF),
which gives us support at the 95% level for the hypothesis that experts can tell
which is the human and which is the machine. Cited features that gave away the
virtual player include similarity of fills, sounding too polished and following the
marked phrasing too closely.
All subjects indicated a degree of uncertainty. Interestingly, the experts gen-
erally expressed more uncertainty than the general public, and the only person
who was certain which was which was also wrong.
From this we conclude that the generative system is of high quality. Many of
the criticisms could be solved by
• adding more ornamentation fragments to the library
• allowing more freedom over when to perform ornamentation
Some points, such as incoherent soloing, would require more work. It should
also be noted that exact timing information (groove or feel) was removed from
the human performance; this is one area where it is expected that the mechanical
player would have difficulties. However, no comments were made about a lack of
feel in either performance.
7.3 Representations
7.3.1 Structural Assumptions
There were several structural assumptions given in Section 3.2.3; we are interested
in how well they have held up:

Chapter 7. Results and Discussion 71
Structural Assumption 1 There are high level sections of music with distinct
structural roles
This was derived from the structural description of salsa music. It has proved to
be useful in the creation of realistic playing, and informs much of the generative
system. Unfortunately, nothing has so far been implemented which can detect
and label the top level structures (Sections), so empirical support is somewhat
limited. It is by no means inconceivable that these structures can be reliably
extracted - the work here presented would be a solid foundation for this, it simply
needs more work to be done.
Structural Assumption 2 The smallest structural unit in latin music is the
bar; phrases may be played which cross bars, or which take up less than a single
bar, but the structure is defined in terms of bars.
This was found to be generally true, but similarly to the problem with split-
bar chords, it is common that changes happen outside the first or last bar of
a particular Segment - a common example being a lead in. The representation
needs some way to specify or allow for the blurring of boundaries here.
Structural Assumption 3 A bar contains one and only one chord
It was seen from the harmonic analysis that although there is generally one chord
per bar, the chord and the bar do not always share the same boundary - a common
example being when a new chord starts on the last beat of the current bar, rather
than the first beat of the next (see Figure 7.1, and Section 7.1.1.1 for a discussion).
Some possible alternatives are:
• Allow bars to contain several chords - possibly one per beat.
• Allow chords to occur on a continuous timeline, and not be structurally
contained within bars
• Allow the scope of a bar to become somewhat fuzzy, so that chordal changes
near the beginning or end of the bar are absorbed into the appropriate bar
Chapter 7. Results and Discussion 72
With Timbalero (s) Without Timbalero (s)
34.46 26.51
35.09 26.65
35.06 26.67
Mean 34.87 26.61
Std Dev 0.3554 0.0872
Table 7.3: Run times for Mi Tierra with and without the Timbalero (tune length is
273 seconds)
Of these it is felt that the last possibility is most analogous to human per-
ception; Looking again at Figure 7.1 it would more commonly be transcribed
as |Cm|Cm|Cm|G| than |Cm|Cm|Cm/G|G| or similar. It might even be said that
the chord does not change until the next bar, but the notes used anticipate the
change.
We conclude that the assumption is roughly correct, but that account needs
to be taken of this anticipation of changes.
Structural Assumption 5 A segment contains one and only one groove
This assumption is valid, but has been slightly overstretched. There is a need for
a distinction between the current groove and playing instructions. To illustrate,
many segments have a final bar with phrasing in; for this to be played as phrasing
only, it needs to be classified as a new segment. However, it is still quite clearly
part of the previous segment. One possibility would be to allow specification of
playing directives at the bar level. This would allow segments where the general
groove was normal playing, but last bar was to be played phrasing only. It would
also support segments which were entirely comprised of phrasing, and even allow
for a slightly different treatment of these.

Chapter 7. Results and Discussion 73
7.4 Infrastructure
No problems were found with the JADE environment. Average runtimes were
calculated over three runs, with and without the Timbalero being created. 4 The
averages are shown in Table 7.3.
It can be seen that the infrastructure runs approximately ten times faster
than real-time, or alternatively, the infrastructure consumes 9.7% of the available
computing power in a real time situation. A run with the Timbalero playing takes
12.8% of the available CPU time. This indicates that real-time performance is
definitely feasible - especially considering that none of the code has been optimised
at all. The standard deviation of run times is small compared to the actual time;
although this does not directly imply that jitter will not be a problem, it gives
an indication that performance should be relatively dependable.
4the Timbalero is running the full output generation system, and performing basic feature
extraction. The machine is 1.6GHz Intel with 256MB RAM

Chapter 8
Future Work
8.1 Analysis
8.1.1 Chord Recognition
The chord recognition section is quite a key feature of the system, and has several
limitations. An improvement to the current algorithm woule be to use more musi-
cal knowledge in chord generation. For example, if two roots have similar scores,
but one root would give a rootless chord, then the other root would generally be
preferable (see the discussion of rootless chords in the previous section). Simi-
larly, if there is one root which would provide a known extension and one which
wouldn’t, then the first is preferable (e.g. prefer to classify a chord as Cm than
G1020010. While this should generally be inherent in the Parncutt algorithm, it
does not appear to be.
Another possibility is to use an alternative algorithm. [29] gives another chord
classifier based on simple lookup, which would probably be easier to code and
faster, and might prove to be more robust.
A problem with both of the algorithms as presented is that they do not appear
to be designed for continuous data; each measures only the presence or absence
of certain notes, which is not really appropriate for this kind of music. It is
not uncommon for melodies to have many passing notes which have little to do
with the underlying chord of a bar, and which should not necessarily be included
74

Chapter 8. Future Work 75
in analysis. It might also be appropriate to use alternative weighting vectors
designed for this style of music. It would be useful to have an algorithm which
ran continuously (rather than analysing discrete block of data) so that it could
specify chord boundaries, to aid with the problem of split chords.
Finally, at present the algorithm only looks at a defined set of instruments
(piano, bass and guitar). This has been chosen to fit the current set of examples.
It would be more useful if it had some way to both:
• decide which instruments in a tune were likely to be useful, possibly with
some order of preference
• select a subset of these based on who is playing at the moment and what
they are playing. This would allow for the piano to be ignored while it
is soloing, and for only listening to the most significant instruments when
many people are playing.
8.1.2 Pattern Analysis
There are two obvious methods for development here. Firstly, since the perfor-
mance of this algorithm is directly dependent on the output of the chord recog-
nition, improving the accuracy or robustness of the chord classifier will enhance
pattern finding ability. The second possibility is to enhance the chord pattern
algorithm, in a variety of ways:
• The use of a mismatch kernel, to allow for the odd misclassified chord.
• The addition of some domain knowledge specifying how similar different
chords are, so that a sequence could get a partial score from several similar
sequences. An advantage of this is that it would add robustness with respect
to the data provided by the chord recogniser, as a misclassified chord is likely
to be similar to it’s true classification, so that it retains a high score for a
match.

Chapter 8. Future Work 76
8.2 Generation
8.2.1 Ornament Selection
The ornament selection performed by the generative subsection is particularly
weak; Although it works reasonably well, much of it’s power comes from having
hand tuned snippets to work with, and the fact that drummers have a lot of
license over which fills are played when. The current random selection model is
clearly lacking in any kind of musical knowledge, but it would require a significant
amount of work to produce a good selection method. To treat ornament selection
properly using a similar approach to the rest of the project, we would need to:
• have some idea of which fills were appropriate for a particular piece
• make more strategic use of ornaments - using especially large fills for big
changes etc
• Tailor existing ornamentation fragments to fit the particular usage
• Be able to maintain some kind of thematic continuity between ornaments,
while not using the same ones all the time
Also, the ornament fragments need to be expertly tuned to produce the correct
sound; an ornamentation system with some musical knowledge should be able to
take care of at least some of this.
These are clearly large goals, and could easily take up a project on their own.
A quick boost to realism could be given by
• At present, ornamentation is created from strings, and in the creation pro-
cess a small amount of noise is added to the velocities of all the notes, to
simulate human imperfections. Unfortunately, this is done only when the
ornament is created, so every subsequent use will be completely identical.
Adding a bit of variation here would probably help
• Using the indications of ornament strength to guide the choice of ornaments.

Chapter 8. Future Work 77
8.2.2 Groove and Feel
Current output is completely quantized; each note is exactly on it’s chosen di-
vision. Latin music is famous for it’s feel more than anything else, so quantized
output is likely to be strongly sub-optimal. Two possible techniques to improve
the feel are:
• Creating a set of groove templates which describe offsets to be applied to
the placement of notes on each division in the bar. This could be done by
speaking to expert timbaleros, and analysing their playing.
• Analysing the playing of other musicians, to see where their notes are rela-
tive to the nominal pulse, and using the average displacements as a groove
template.
It would be possible to combine the two, so that the output could be smoothly
varied between using the predefined templates and the dynamic templates. Both
techniques are useful, because while dynamic templates allow the timbalero to
respond to the playing of the other musicians, a timbalero may well not always
place their notes the same as the other musicians.
8.2.3 Soloing
The soloing algorithm as implemented uses no musical knowledge at all. It will
play a random fill for about 3 out of four bars, and for every other bar it will
play the basic rhythm with some chatter. A good drum solo (like most good
improvised instrumental solos) should set out some kind of theme and explore it,
or at the very least be in some way musically coherent. As with the ornamentation
above, it could easily become a complete project, and similar future possibilities
apply. This is one area where the use of a probabilistic grammar would seem
highly appropriate[3].

Chapter 8. Future Work 78
8.3 Representations
Representations need to become more flexible. Some milestones in order of in-
creasing freedom from specification are:
• Allowing for the conductor to call for repeats of certain sections
• Having sections which can repeat indefinitely, such as solos1
• Being able to play a tune where the order of sections needs to be learnt, or
is completely fluid.
Although all of these depend heavily on other parts of the system than the rep-
resentational sections, the representations used would need to be able to support
certain operations and structures before they become possible.
The need for chord boundaries to become detached from bar boundaries has
been discussed previously. There is a case for extending this relaxation to other
features; Consider the case of a one and a half beat lead in into a new section.
It would make sense to consider the lead in as being part of the section to which
it leads in. At present, there are only two choices: either the lead in is part of
the previous section (which is the route taken by the hand analyses), or the last
bar of the previous section is absorbed by the new section (which does not seem
appropriate). Allowing segment boundaries to be placed at any point within
the bar would go some way towards solving this, but it is still not a perfect
representation of the structure. A more accurate breakdown would be to have
the boundary on the bar line, but allow the lead in part to be considered part of
the section it leads into. This could be done by allowing different boundaries for
each instrument: no instrument would be allowed to be playing more than one
section at once, but for small periods they could be playing different sections.
This would have the disadvantage of making representations more complex, but
analysing each individual instrument for boundaries would allow a treatment
closer to GTTM [18].
1where the backing repeats until some event takes place; it could be a nod from the soloist,
it could be a special phrase that they play, or it could simply be a general consensus among
the rest of the band

Chapter 8. Future Work 79
8.4 Agent Environment
There are a few issues with the agent environment which were not a problem with
this project, but would need to be addressed for the project to be scaled up:
• The messages passed round currently include serialised Java objects. This
is clearly poor from an interoperability standpoint, and should not be nec-
essary. It should be trivially possible to alter the collated messages to be
sent contained in a jMusic Score, rather than a hash of Parts. Similarly,
identities should be sent in some open format.
• With a few tweaks, the system could be made to work in some kind of real
time, although it is not quite clear what this would be. For this to work well,
there would have to be a mechanism in place to change the “chunk size” of
messages passed round: since a musician’s chunk only becomes available at
the end of a chunk period, there is effectively a two chunk latency for the
musicians to react(see Figure 8.1)
The communications protocol as a whole is slightly inelegant; it should be
possible for musicians to come and go as they please, and provision should be
made for musicians not producing output. A lot more flexibility would need to be
built in in general if the system is to perform in real time; it might be necessary
for each musician to construct parts in several passes, so that they will always
have something available in time. Similarly, they would have to become adept
at working with incomplete information - for example if a link on the network is
dropped or becomes congested and the other musician’s parts are not available
in time.
8.5 Long Term Improvements
The main direction of improvement should be towards more flexibility, generality
and robustness. At present there are many hard coded parameters, which should
be dynamically determinable for a given piece. Many of the rules are vague
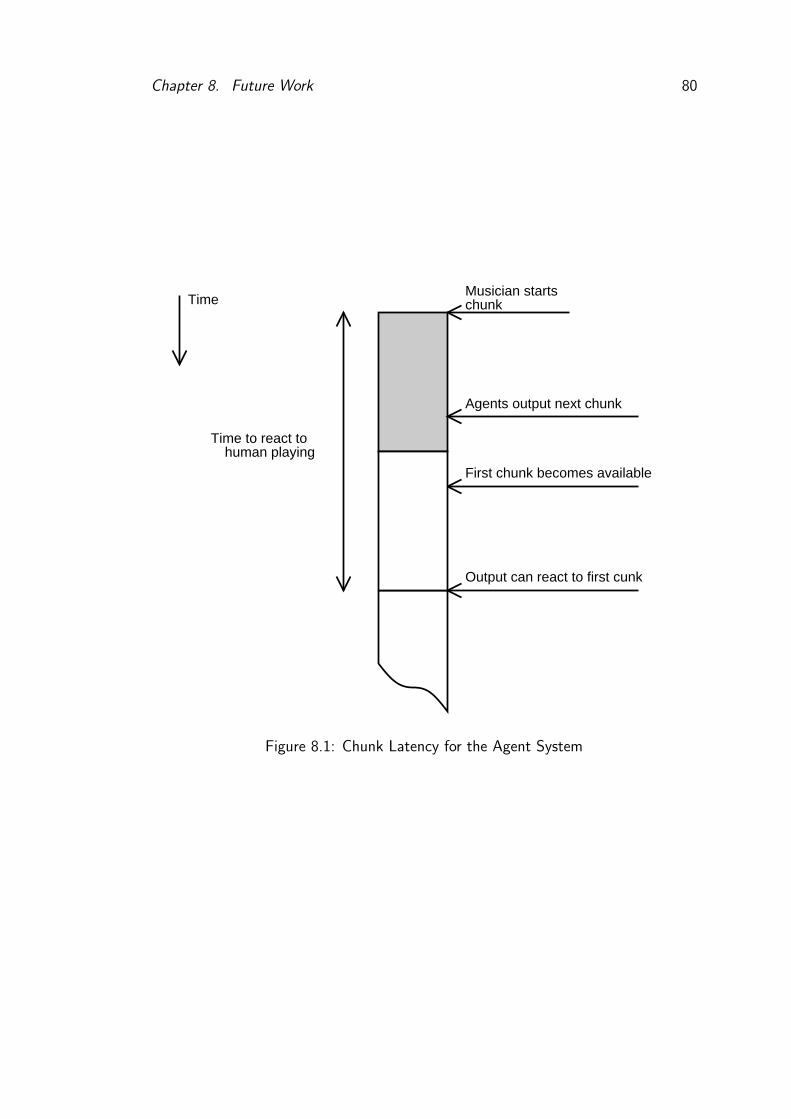
Chapter 8. Future Work 80
First chunk becomes available
Output can react to first cunk
TimeMusician startschunk
Agents output next chunk
Time to react to human playing
Figure 8.1: Chunk Latency for the Agent System

Chapter 8. Future Work 81
heuristics, which should be thoroughly researched and optimised. There is a
definite need for more reaction to what the other musicians are playing - at
present, only quite high level features are analysed. It would be quite possible to
have two very different tunes which had almost identical representations, which
indicates that there is more about a tune which could be captured.
There is also the possibility of expansion to both other percussion instruments
and other styles. Due to the modular design of the generative section, all of the
rules which govern rhythm and ornament selection are in the Style class. This
means that a lot of variation is possible simply by adding new styles. To take the
part of another percussionist in the same style would only require changing the
rhythmic fragments, and possibly altering the rhythm selection rules - an entirely
feasible task.
To play percussion in a different style would require that representations be
built up for that particular style. On the generative side, this would only require
that a Style was created with rules relevant to the particular style. It is easy to
imagine extension to latin jazz, and even funk or rock, so long as
• adequate representations can be built up
• playing can be broken down into selection of a basic rhythm followed by
addition of ornamentation.
• Templates are available for the various rhythms and ornaments
For this it would be useful if all of the necessary domain knowledge could be
encoded in a single place; at present, knowledge used to generate output is stored
in the Style class, but the knowledge used to build representations is elsewhere.
It would be useful if the JavaStyle class could also absorb this knowledge as well
- for example, it could define structural sections of music by specifying a set of
rules (selected from a common pool) which indicated that a particular part of the
piece played that role.
It would also be interesting to add automatic style selection, so that the agent
could hear a piece and determine what style to play in. This would be a large
step towards a generalised drummer. Ultimately, it would be desirable to add

Chapter 8. Future Work 82
learning capabilities, so that it could be “taught” new styles, and develop it’s
own rules for determining the structures of novel pieces.

Chapter 9
Conclusions
We will now summarise our findings about how well we have met the design aims,
and offer some final thoughts for the future.
• High level representations sufficient to adequately inform the playing of a
timbalero
The representations were found to be generally usable, and can be extended
without much difficulty. There were several cases where the representation
is essentially accurate, but needs to be slightly more relaxed1
• Generative methods capable of creating realistic timbale playing
The final output produced was able to fool the general public, but domain
experts were able to distinguish it from human playing (albeit without much
confidence). It is also expected that with a little more work, it could provide
much higher quality output, as most of the features which listeners have
used to discriminate between human and machine playing can be relatively
easily compensated for. The work provides a solid foundation on which to
build more involved systems which can deal with aspects such as groove (or
feel) and musical continuity.
1e.g. the assertion that there is one chord per bar, which is generally true, but the chord
boundaries and the bar boundaries do not always line up perfectly
83

Chapter 9. Conclusions 84
• Algorithms which are capable of generating the necessary high level repre-
sentations
The basic features of music are well extracted. More complex features (such
as chords and key) are extracted, but could benefit from more work. Musical
parallelism needs to be more fully investigated, and there are many cases
where the reasoning needs to be more forgiving and musically sensitive.
Some level of structure is discerned, which is close to the desired result in
many places, but it is not a complete and usable technique.
• Construction of an Agent based environment for musical processes
The agent environment seems to be robust, fast enough and can deal with
an acceptable number of musicians, although it has not been put to exten-
sive stress testing. The information encodings used convey all necessary
information adequately, but should be made less platform specific. It ap-
pears that the system is also fast enough to work in real-time, although
some work would need to be done to ensure responsiveness.
Overall, the project’s aim - to create an agent which can produce high quality
timbale accompaniment to salsa music - has been well met. We believe that it is
an extensible platform, and could be adapted to other instruments, other styles
and real-time operation.

Appendix A
Musical Background
A.1 History and Use of the Timbales
Much of the historical information in this section is paraphrased from {TODO:
add ref to Changuito}, and presented in a highly condensed form.
Timbales are commonly thought to be descendants of European timpani
(which are sometimes called timbal in Spanish). Timbales are also sometimes
called pailas Cubanas ; the paila is a hemispherical metal shell used in sugar cane
factories, and formed the body of the first Cuban timpani. In the early part of
the twentieth century, large timbales became unfeasible (for economic reasons)
and smaller versions were developed, which eventually came to be wooden, and
mounted on a single tripod between the players legs. It is not quite clear how
the modern form developed from here, but it is suspected that is has something
to do with the influence of jazz music and the more standard drum kit set up.
Timbales as we see them today consist of two cylindrical shells of metal, each
with a single skin (single skinned pitched membranophones in the Hornbostel-
Sachs scheme). They are mounted on a stand, with an assortment of bells and
woodblocks on a post in the middle, and there is the possibility of adding cymbals
and a kick drum (see Figure A.1) . Each instrument has its own characteristic
sounds and role:
Cascara Cascara (which means shell in Spanish) is produced by striking the
85
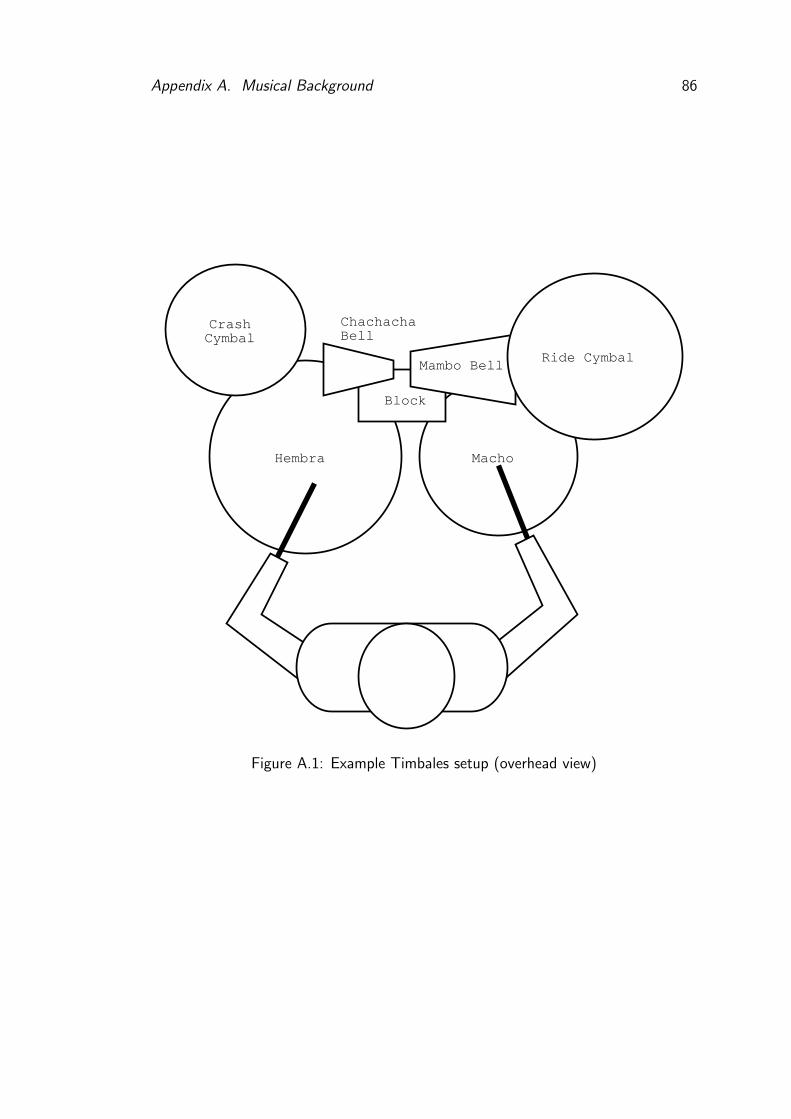
Appendix A. Musical Background 86
Hembra Macho
CrashCymbal
Ride CymbalMambo Bell
Block
ChachachaBell
Figure A.1: Example Timbales setup (overhead view)

Appendix A. Musical Background 87
metal shells of the drum with the stick. This forms the basis of many of the
rhythms. Often the right hand will play cascara while the left hand plays
another rhythm, but sometimes both hands play cascara, in which case it
is termed doble pailas . Here the right hand will play it’s standard pattern,
and the left hand will play in all the gaps left by the right.
Macho Themacho is the smaller of the two drums, and is considered to represent
the male role in playing1. It is played with the sticks, and can be played
open or as a rim shot, where the rim of the drum and the skin are struck
simultaneously to give a very piercing tone.
Hembra The hembra is the larger drum, and is often tuned either a fourth or
a fifth lower than the macho. As well as being played with the sticks for
fills and accents, it is often played with the left hand as part of the basic
rhythm. There are two sounds made with the hand - an open tone where
the fingers stroke the skin and bounce off, and a closed tone where the
fingers remain on the skin and mute the tone.
Block Traditionally, blocks were made out of wood, but nowadays can be made
out of acoustic plastic for a louder sound. the produce a single sound when
struck, and are often used to play the clave pattern.
Mambo Bell The larger of the two cowbells, the mambo bell is used in the
loud sections of pieces to create a powerful, driving rhythm. There are two
sounds, one produced by striking the body of the bell, and one by striking
across the mouth of the bell.
Chachacha Bell The chachacha bell is used for a lighter sound, and can make
two sounds in a similar manner to the mambo bell. The two bells can be
used together the play highly intricate rhythms.
Crash Cymbal Crash cymbals are used to add powerful accents to music. The
stick strikes the edge of the cymbal to produce a loud crash sound.
1many drums of African origin are sexualised. In this case, the bright forceful tones of the
macho make it seen to be more male, compared to the deep mellow tones of the hembra

Appendix A. Musical Background 88
� �cascara �block
�������������
Macho
open
� �
rim
���������������������
open
Hembra
sobado
muted body
�
mouth
�Mambo bell���������� �
body
���������� �Chacha bell�
mouth
�
Figure A.2: Scoring Timbale Sounds
3-2 Clave
2-3 Clave
44
44
� � ��
�
�� �
�
�
�� �
�
� � ��
��
Figure A.3: Standard Son Claves
Ride Cymbal More often used in latin jazz than salsa, ride cymbals are struck
on the bell, or with the tip of the stick on the surface. They create a
sound with a short, dynamic attack and a long sustain, that is often used
to provide a rhythmic framework, similar to the cascara. Some cymbals are
produced which can be used both as a crash and a ride.
Figure A.2 is a musical score showing the various sounds that the timbalero
can play. Figure A.3 shows the standard Son clave in 2-3 and 3-2 versions, and
Figure A.4 shows the basic Cascara pattern in 2-3 time.

Appendix A. Musical Background 89
Clave
� 44
44
��
�� �
�� �
� � � �
�� �
�� � � �
� � �� � �
Figure A.4: Basic Cascara pattern, with a backbeat on the hembra
A.2 The Structure of Salsa Music
The knowledge in this section comes from a knowledge elictation interview, de-
tailed in Section A.4.
There are many types of latin music. The first broad distinction is between
salsa and latin jazz, where latin jazz is a more modern style, and disregards
the traditional instrumentation of Cuban music. We are going to concentrate
on Salsa music, although can have many different stylistic variations (rumba,
danzon, bomba, mambo etc).
A typical piece of salsa music will be in a son montuno style. This is a
combination of the traditional son style with the more modern montuno sections.
Montuno The montuno2 is the high point of almost all salsa tunes. It is a
repeated section with an improvised lead vocal doing “call and response”
against a repeated phrase sung by the coros. Playing is generally upbeat,
but with a solid groove. The coros may start their repeated phrases before
the start of the montuno proper - the montuno is considered to start when
the lead vocals begins improvising. Once a piece hits the montuno, it will
generally stay at that level, with the possible exception of a short coda at
the end. More modern pieces tend to reach the montuno level earlier, and
2montuno can also be used to refer to repeated figures, generally played by the piano. This
would be referred to as e.g. a ”2-bar piano montuno” to keep it distinct from the usage as a
section of the piece

Appendix A. Musical Background 90
stay there longer for a more upbeat dynamic overall.
Son The section of the tune before the montuno will be in the more traditional
son style - hence the name son montuno. There are a variety of structural
forms used here; this is where the verses of the song appear, and there is
often an alternation of sections, but it is common for this to have quite an
intricate or unclear structure.
Mambo Mambos are similar to the montuno section, but replace the improvised
vocals with coordinated brass phrases. The feel is still upbeat, but there is
a lot more freedom for improvisation, ornamentation and “looseness”.
Intro Many songs have an instrumental introduction before any vocals come in.
Coda Some songs also have a coda at the end when the montuno has finished.
This commonly either contains a lot of phrasing for a punchy, upbeat end-
ing, or is a re-iteration of the introduction.
Solos The piano is by far the commonest soloing instrument in salsa. These
solos are backed by a lower level of playing from the rest of the band than
the montuno.
So a typical salsa tune might go: Intro, Son-A, Son-B, Son-A, Son-B, Montuno
(variable length), Mambos, Montuno, Coda.
A.3 The Role of the Timbalero
There are fairly standard combinations of parts which the timbalero would play
in most of these sections. As with most latin music (and most music in general)
none of the rules are hard and fast, but they do represent a general trend.
Montuno The right hand plays on the mambo bell. The left hand can play the
hembra on 2 and 4, the clave or some part of the campana pattern.

Appendix A. Musical Background 91
Verses Cascara in the right hand. The left hand can play clave on the block
if no-one else is playing the clave, or can fill in the gaps in the right for a
doble pailas pattern.
Mambo As montuno, but with more fills
Intro The intro is typically instrumental, and of a low intensity. The timbale
player will often tacet, but may play clave, or a gentle cascara depending
on the piece.
Coda If the coda is a repeat of the intro, then the coda is often played as cascara.
If the piece is ending on a high note, then the coda will be played as the
preceding section only more so.
A.4 Knowledge Elicitation
An interview was conducted with Hamish Orr, who is a latin percussion teacher
living in London. He was selected as a domain expert due to his experience
both as a teacher and a performer of the style in question. The interview was
conducted telephonically, and based on the “laddered grid” methodology. The
aim of the interview was to establish whether there were high level strucures
common to salsa music, what they were, and how a timbalero would behave
while playing them. Initial questions were asked to determine whether there
were such structures, and the expert was quickly able to specify several. Follow
up questions were used to determine the similarities and differences with a view
to automatic recognition. Finally, questions were asked to try and determine a
methodology for basic rhythm selection.

Appendix B
MIDI Details
The MIDI standard is an important part of this project, so we present a more
thorough discussion. Further information can be found at [20], [22] and [21].
Each MIDI device is referred to as a port, and each port has sixteen channels.
A channel refers to a particular instrument on the target synthesiser. The device
sending the MIDI information does not know what kind of sound will be produced
by the synthesiser, however - it only knows that it has asked it to use instrument
31 - but there are some standard mappings of instrument numbers to instruments.
There are two substrates on which MIDI exists: streams and files.
B.1 MIDI Streams
MIDI streams were originally transmitted over 11kHz serial links - this was the
original reason for MIDI: to allow keyboard players control over several synthe-
sisers (it replaced control voltage (CV) where a single analogue voltage was set
which could control the frequency of the oscillator in a synthesiser, and was lim-
ited to a single note of polyphony). MIDI gave the ability to control polyphonic
synthesisers (ones capable of playing more than one note at once) as well as giving
more control over different aspects of the sound (the force with which the keys on
the keyboard were struck, control over various parameters of the sound). MIDI
messages are sequences of bytes, with the first byte being a ”status byte” which
determines the type of the message. There are two types of MIDI messages seen
92

Appendix B. MIDI Details 93
in streams:
Short Messages Short messages are the bread and butter of MIDI. The two
most important being Note On and Note Off messages. All short messages
are three bytes long - one status byte and two data bytes. In the case of Note
On and Off messages, the status byte indicates the type of message and the
channel to which it refers, the first data byte gives the note number, and the
second byte gives the ”velocity” (how hard the key has been struck). Once
a sequence receives a Note On message, it will immediately start sounding
the note in question, and continue until it receives a Note Off for the same
note. The other common short messages are controller messages, which can
be used to tell the synthesiser to select a different instrument to play, or
alter parameters of the currently active instrument.
Sysex System Exclusive messages are used to add vendor specific extensions
to the protocol. These generally give very fine control of all aspects of a
synthesiser’s functionality - most of what a user can accomplish by using
the front panel of the instrument can be done via Sysex. Sysex messages
can be any length - this is specified by the the message.
B.2 MIDI Files
MIDI files are used by sequencers to store MIDI data. These contain a sequence
of MIDI messages, with appropriate timestamps (these are referred to as MIDI
Events, indicating a message and a time). There is a further type of MIDI mes-
sage found in MIDI files - meta messages give information about the sequence
contained the the file, such as tempo, time and key signatures and textual infor-
mation describing individual tracks or the file as a whole. These meta messages
consist of a status byte of F followed by a byte indicating the type of message,
and a variable number of bytes relevant to the message itself.
The timestamps of MIDI events are given in ”ticks”. A sequencer has an
internal resolution, measured in Pulses Per Quarter Note1 (PPQN or PPQ), and
1There are alternative timing specifications involving SMPTE, but they are not discussed

Appendix B. MIDI Details 94
each tick represents one of these pulses.
There are two types of standard MIDI Files (SMF): Type 0 and Type 1 (SMF-
0 and SMF-1). SMF-0 files simply contain a list of MIDI Events, each of which
is responsible for defining it’s output channel. SMF-1 files divide the data into
“tracks”. These are separate streams of events, which would typically be sent to
different instruments, each of which has a name and a channel (as well as other
parameters). There is no hard mapping from tracks to instruments, though, as
many tracks can be set to use the same channel. All MIDI files considered in this
project are SMF-1, as this is both the most prevalent and useful standard.
here

Appendix C
jMusic
C.1 Overview
After construction of the original low level classes, an Open Source library jMusic
was found 1 which could provide the required functionality, so development was
switched to these libraries. Among the benefits were:
• XML Serialisation support
• Display in Common Practice Notation.
• Many constants, for note durations, note names, GM specs etc.
• Support for reading and writing MIDI files
jMusic uses Scores, Parts, Phrases and Notes to represent music (see Figure
C.1 for a graphical explanation)
Note The smallest unit is a Note, which has
• pitch
• velocity
• rhythm value
1http://jmusic.ci.qut.edu.au/
95

Appendix C. jMusic 96
��������������������������������������������������
������������������������������������������������������
������������������
������������������������������
Start Time
Duration
Rhythmic Value
Pitch
Phrase (Staccato)
Phrase (Legato)Part
Figure C.1: jMusic Part, Phrase and Note Structure
• duration
Rests are indicated by Notes with a particular pitch value (jmusic.JMC.REST).
Phrase A Phrase is a list of Notes, with each Note added occurring after the
previous note has finished - that is, a note’s onset time is determined by
the sum of the rhythmic values of the previous notes in the phrase. The
duration of Notes allows construction of legato or staccato passages (a series
of notes with smaller durations than rhythmic values will be staccato - see
Figure C.1). Phrases have optional start times (relative to the start of the
Part which contains them). A Phrase containing a musical phrase which
started on the second beat of the piece could be represented either by a
Phrase with a start time of 1.0 (start times start from 0.0) or by a Phrase
where the first note is a one beat rest (and sometimes this distinction is
important).
CPhrases A CPhrase collects Phrases together, and allows them to overlap.
They are not used in this project
Part A Part represents everything that a musician would play in a piece. It is a

Appendix C. jMusic 97
collection of Phrases, along with useful information such as
• a title
• MIDI channel and instrument number
• time signature
• key signature
Score A Score contains the playing of all musicians for an entire piece. It also
has time and key signatures, a tempo and a title.
The limitations here are that Notes depend on the previous notes for their
timing - to move a note backwards in time, one has to shorten previous notes
and lengthen the note in question. A possible workround for this is to construct
a CPhrase made of several single note Phrases, the beginning points of which
can then be set individually. Fortunately, this was not necessary for this project.
Similarly, to play a chord, one has to either create a second Phrase, or add Notes
with a rhythmic value of zero (but the correct duration) so that they all start
at the same time. jMusic Phrases have basic support for this, but it has been
tweaked for flexibility.
C.2 Alterations
A few changes were needed to the stock jMusic distribution in order to make full
use of it. These are documented here.
XML Serialisation While jMusic has support for XML serialisation, this is
currently only applicable to complete scores. A wrapper class was added to
expose the necessary methods. The jMusic XML parser is very brittle, and
will only read it’s own XML.2
2There several undocumented constraints, including: no whitespace at all is allowed between
elements, attributes must be in the correct order. So while it produces valid XML it cannot
read all valid XML.

Appendix C. jMusic 98
Track Names jMusic as it stands cannot extract the track names from MIDI
files. This functionality has been added.
Better Chord Support Adding chords to Phrases in jMusic is an inelegant
operation - all except one of the notes are added with a rhythm value of
0, and they all have a default dynamic. A dynamic for each note is now
supported, and the algorithm will now not add unnecessary rests.
C.3 jMusic Issues
Towards a the end of development a bug was discovered in jMusic which meant
that MIDI files containing certain messages3 were dealt with incorrectly, and
caused the timing of parts to be drastically altered, rendering the music un-
recognisable. The MidiFileAnalyser class was repurposed to strip all offending
content from MIDI files to provide jMusic-safe versions.
3specifically pitch bend

Appendix D
Listening Assessment Test
As part of my MSc, I have been creating a musical agent which can play alongwith pre-recorded MIDI files in the way that a real player would. Specifically, itis being a timbalero in a salsa band.
The purpose of this assessment is to determine whether the virtual timbalero isdistinguishable from a human player, and also to determine which is preferable.
The enclosed CD contains three tracks:
1 A brief demo of the sounds and some of the rhythms which the timbalero will play
2,3 Two versions of ”Mi Tierra” by Gloria Estefan. One of these is played by thevirtual timbalero, and one by myself.
The recordings are made from a timbalero’s point of view - that is, the timbalesparts are louder than normal, to make it easier to hear what is happening. The liveversion was played on an electric drum kit (so that the same sounds are used); it hasbeen quantized and obvious mistakes have been fixed.
You will find the questionnaire on the back of this sheet - make sure you read itbefore listening so you know what to listen for. Please fill in the form before discussingthis with anyone. Any thoughts that come out of a group discussion should be addedin the comments section.
Finally, don’t spare my feelings! If you think that the virtual player sounds betterthan me, then that makes me just as happy as hearing that my playing is OK!
Thanks very much for your time,Dave
99
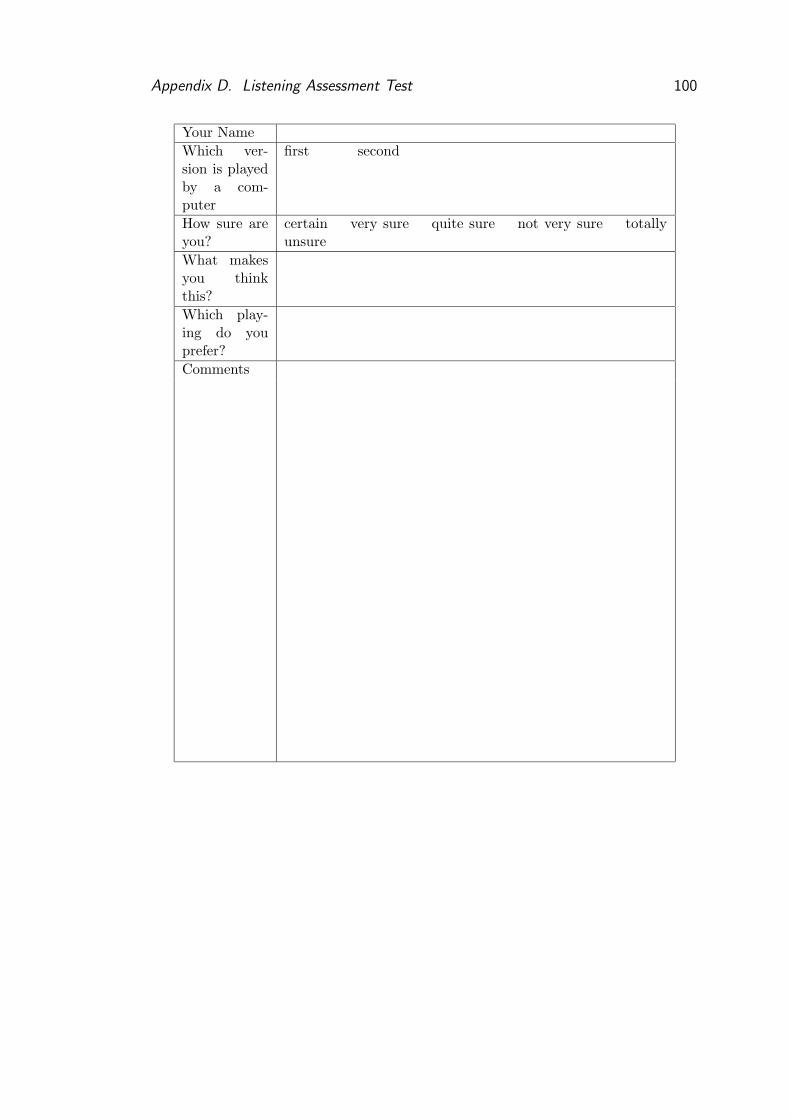
Appendix D. Listening Assessment Test 100
Your Name
Which ver-sion is playedby a com-puter
first second
How sure areyou?
certain very sure quite sure not very sure totallyunsure
What makesyou thinkthis?
Which play-ing do youprefer?
Comments

Appendix E
Example Output
Table E.1 shows the annotation of Mi Tierra produced by the timbalero.
The section headings are as follows:
Bar The bar number. (Note: bar numbers in actual output are zero indexed. Here
they have been converted to start at 1 to match musical convention. All references
in the text are to 1 indexed bar numbers)
Chord Context Free classification of the current chord
Key The current key
RKey The current key, calculated in reverse bar order
ContChord A contextual classification of the current chord
δii
Normalised change in instrumentation, calculated by adding up the absolute differ-
ences in activity of all instruments, and dividing by the average of the activity
levels for this bar and the previous bar.
i Instrumentation level - the sum of the durations of all the notes played by everyone
in this bar.
p Number of people playing (who have an activity level of more than 0.5)
δP The change in players (+1 for each instrument which enters and each instrument
which drops out)
Phrasing The results of the phrasing analysis; the scores from the two methods are
given. If it is preceded by as ’+’, then the bar is considered PhrasingOnly. A ’.’
means that the bar is considered to have phrasing
ChPat Results of the chord pattern feature
Pref The final score for segment preference
101

Appendix E. Example Output 102
WF Any indications of well formedness; ⊕ means there must be a break, 5 means
there must not be a break.
Break ⊗ means that there was a break.
For comparison to the hand analysis, Segment breaks are shown by single horizontal
rules, and Sections have the section name and role in a box at the top.
Some points to note:
• The output is from a run where the Timbalero did not play; the timbalero’s
playing can confuse some of the features (notably the phrasing analysis)
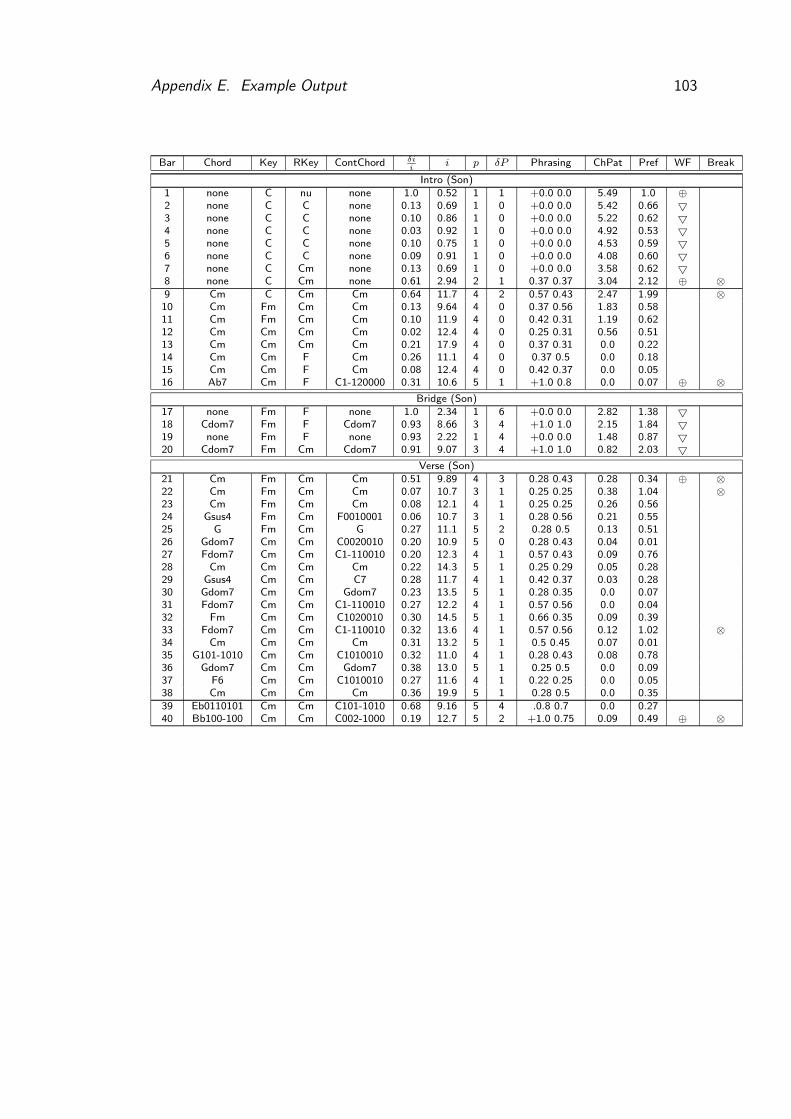
Appendix E. Example Output 103
Bar Chord Key RKey ContChord δi
ii p δP Phrasing ChPat Pref WF Break
Intro (Son)1 none C nu none 1.0 0.52 1 1 +0.0 0.0 5.49 1.0 ⊕
2 none C C none 0.13 0.69 1 0 +0.0 0.0 5.42 0.66 5
3 none C C none 0.10 0.86 1 0 +0.0 0.0 5.22 0.62 5
4 none C C none 0.03 0.92 1 0 +0.0 0.0 4.92 0.53 5
5 none C C none 0.10 0.75 1 0 +0.0 0.0 4.53 0.59 5
6 none C C none 0.09 0.91 1 0 +0.0 0.0 4.08 0.60 5
7 none C Cm none 0.13 0.69 1 0 +0.0 0.0 3.58 0.62 5
8 none C Cm none 0.61 2.94 2 1 0.37 0.37 3.04 2.12 ⊕ ⊗
9 Cm C Cm Cm 0.64 11.7 4 2 0.57 0.43 2.47 1.99 ⊗
10 Cm Fm Cm Cm 0.13 9.64 4 0 0.37 0.56 1.83 0.5811 Cm Fm Cm Cm 0.10 11.9 4 0 0.42 0.31 1.19 0.6212 Cm Cm Cm Cm 0.02 12.4 4 0 0.25 0.31 0.56 0.5113 Cm Cm Cm Cm 0.21 17.9 4 0 0.37 0.31 0.0 0.2214 Cm Cm F Cm 0.26 11.1 4 0 0.37 0.5 0.0 0.1815 Cm Cm F Cm 0.08 12.4 4 0 0.42 0.37 0.0 0.0516 Ab7 Cm F C1-120000 0.31 10.6 5 1 +1.0 0.8 0.0 0.07 ⊕ ⊗
Bridge (Son)17 none Fm F none 1.0 2.34 1 6 +0.0 0.0 2.82 1.38 5
18 Cdom7 Fm F Cdom7 0.93 8.66 3 4 +1.0 1.0 2.15 1.84 5
19 none Fm F none 0.93 2.22 1 4 +0.0 0.0 1.48 0.87 5
20 Cdom7 Fm Cm Cdom7 0.91 9.07 3 4 +1.0 1.0 0.82 2.03 5
Verse (Son)21 Cm Fm Cm Cm 0.51 9.89 4 3 0.28 0.43 0.28 0.34 ⊕ ⊗
22 Cm Fm Cm Cm 0.07 10.7 3 1 0.25 0.25 0.38 1.04 ⊗
23 Cm Fm Cm Cm 0.08 12.1 4 1 0.25 0.25 0.26 0.5624 Gsus4 Fm Cm F0010001 0.06 10.7 3 1 0.28 0.56 0.21 0.5525 G Fm Cm G 0.27 11.1 5 2 0.28 0.5 0.13 0.5126 Gdom7 Cm Cm C0020010 0.20 10.9 5 0 0.28 0.43 0.04 0.0127 Fdom7 Cm Cm C1-110010 0.20 12.3 4 1 0.57 0.43 0.09 0.7628 Cm Cm Cm Cm 0.22 14.3 5 1 0.25 0.29 0.05 0.2829 Gsus4 Cm Cm C7 0.28 11.7 4 1 0.42 0.37 0.03 0.2830 Gdom7 Cm Cm Gdom7 0.23 13.5 5 1 0.28 0.35 0.0 0.0731 Fdom7 Cm Cm C1-110010 0.27 12.2 4 1 0.57 0.56 0.0 0.0432 Fm Cm Cm C1020010 0.30 14.5 5 1 0.66 0.35 0.09 0.3933 Fdom7 Cm Cm C1-110010 0.32 13.6 4 1 0.57 0.56 0.12 1.02 ⊗
34 Cm Cm Cm Cm 0.31 13.2 5 1 0.5 0.45 0.07 0.0135 G101-1010 Cm Cm C1010010 0.32 11.0 4 1 0.28 0.43 0.08 0.7836 Gdom7 Cm Cm Gdom7 0.38 13.0 5 1 0.25 0.5 0.0 0.0937 F6 Cm Cm C1010010 0.27 11.6 4 1 0.22 0.25 0.0 0.0538 Cm Cm Cm Cm 0.36 19.9 5 1 0.28 0.5 0.0 0.3539 Eb0110101 Cm Cm C101-1010 0.68 9.16 5 4 .0.8 0.7 0.0 0.2740 Bb100-100 Cm Cm C002-1000 0.19 12.7 5 2 +1.0 0.75 0.09 0.49 ⊕ ⊗
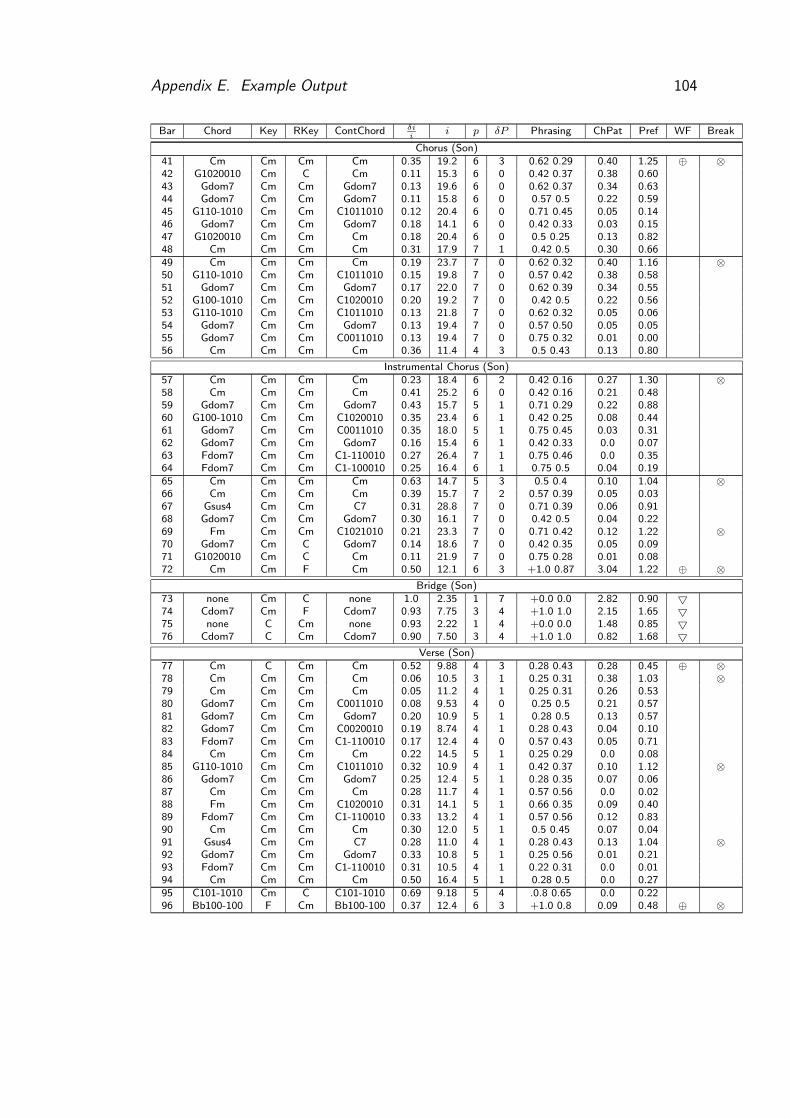
Appendix E. Example Output 104
Bar Chord Key RKey ContChord δi
ii p δP Phrasing ChPat Pref WF Break
Chorus (Son)41 Cm Cm Cm Cm 0.35 19.2 6 3 0.62 0.29 0.40 1.25 ⊕ ⊗
42 G1020010 Cm C Cm 0.11 15.3 6 0 0.42 0.37 0.38 0.6043 Gdom7 Cm Cm Gdom7 0.13 19.6 6 0 0.62 0.37 0.34 0.6344 Gdom7 Cm Cm Gdom7 0.11 15.8 6 0 0.57 0.5 0.22 0.5945 G110-1010 Cm Cm C1011010 0.12 20.4 6 0 0.71 0.45 0.05 0.1446 Gdom7 Cm Cm Gdom7 0.18 14.1 6 0 0.42 0.33 0.03 0.1547 G1020010 Cm Cm Cm 0.18 20.4 6 0 0.5 0.25 0.13 0.8248 Cm Cm Cm Cm 0.31 17.9 7 1 0.42 0.5 0.30 0.6649 Cm Cm Cm Cm 0.19 23.7 7 0 0.62 0.32 0.40 1.16 ⊗
50 G110-1010 Cm Cm C1011010 0.15 19.8 7 0 0.57 0.42 0.38 0.5851 Gdom7 Cm Cm Gdom7 0.17 22.0 7 0 0.62 0.39 0.34 0.5552 G100-1010 Cm Cm C1020010 0.20 19.2 7 0 0.42 0.5 0.22 0.5653 G110-1010 Cm Cm C1011010 0.13 21.8 7 0 0.62 0.32 0.05 0.0654 Gdom7 Cm Cm Gdom7 0.13 19.4 7 0 0.57 0.50 0.05 0.0555 Gdom7 Cm Cm C0011010 0.13 19.4 7 0 0.75 0.32 0.01 0.0056 Cm Cm Cm Cm 0.36 11.4 4 3 0.5 0.43 0.13 0.80
Instrumental Chorus (Son)57 Cm Cm Cm Cm 0.23 18.4 6 2 0.42 0.16 0.27 1.30 ⊗
58 Cm Cm Cm Cm 0.41 25.2 6 0 0.42 0.16 0.21 0.4859 Gdom7 Cm Cm Gdom7 0.43 15.7 5 1 0.71 0.29 0.22 0.8860 G100-1010 Cm Cm C1020010 0.35 23.4 6 1 0.42 0.25 0.08 0.4461 Gdom7 Cm Cm C0011010 0.35 18.0 5 1 0.75 0.45 0.03 0.3162 Gdom7 Cm Cm Gdom7 0.16 15.4 6 1 0.42 0.33 0.0 0.0763 Fdom7 Cm Cm C1-110010 0.27 26.4 7 1 0.75 0.46 0.0 0.3564 Fdom7 Cm Cm C1-100010 0.25 16.4 6 1 0.75 0.5 0.04 0.1965 Cm Cm Cm Cm 0.63 14.7 5 3 0.5 0.4 0.10 1.04 ⊗
66 Cm Cm Cm Cm 0.39 15.7 7 2 0.57 0.39 0.05 0.0367 Gsus4 Cm Cm C7 0.31 28.8 7 0 0.71 0.39 0.06 0.9168 Gdom7 Cm Cm Gdom7 0.30 16.1 7 0 0.42 0.5 0.04 0.2269 Fm Cm Cm C1021010 0.21 23.3 7 0 0.71 0.42 0.12 1.22 ⊗
70 Gdom7 Cm C Gdom7 0.14 18.6 7 0 0.42 0.35 0.05 0.0971 G1020010 Cm C Cm 0.11 21.9 7 0 0.75 0.28 0.01 0.0872 Cm Cm F Cm 0.50 12.1 6 3 +1.0 0.87 3.04 1.22 ⊕ ⊗
Bridge (Son)73 none Cm C none 1.0 2.35 1 7 +0.0 0.0 2.82 0.90 5
74 Cdom7 Cm F Cdom7 0.93 7.75 3 4 +1.0 1.0 2.15 1.65 5
75 none C Cm none 0.93 2.22 1 4 +0.0 0.0 1.48 0.85 5
76 Cdom7 C Cm Cdom7 0.90 7.50 3 4 +1.0 1.0 0.82 1.68 5
Verse (Son)77 Cm C Cm Cm 0.52 9.88 4 3 0.28 0.43 0.28 0.45 ⊕ ⊗
78 Cm Cm Cm Cm 0.06 10.5 3 1 0.25 0.31 0.38 1.03 ⊗
79 Cm Cm Cm Cm 0.05 11.2 4 1 0.25 0.31 0.26 0.5380 Gdom7 Cm Cm C0011010 0.08 9.53 4 0 0.25 0.5 0.21 0.5781 Gdom7 Cm Cm Gdom7 0.20 10.9 5 1 0.28 0.5 0.13 0.5782 Gdom7 Cm Cm C0020010 0.19 8.74 4 1 0.28 0.43 0.04 0.1083 Fdom7 Cm Cm C1-110010 0.17 12.4 4 0 0.57 0.43 0.05 0.7184 Cm Cm Cm Cm 0.22 14.5 5 1 0.25 0.29 0.0 0.0885 G110-1010 Cm Cm C1011010 0.32 10.9 4 1 0.42 0.37 0.10 1.12 ⊗
86 Gdom7 Cm Cm Gdom7 0.25 12.4 5 1 0.28 0.35 0.07 0.0687 Cm Cm Cm Cm 0.28 11.7 4 1 0.57 0.56 0.0 0.0288 Fm Cm Cm C1020010 0.31 14.1 5 1 0.66 0.35 0.09 0.4089 Fdom7 Cm Cm C1-110010 0.33 13.2 4 1 0.57 0.56 0.12 0.8390 Cm Cm Cm Cm 0.30 12.0 5 1 0.5 0.45 0.07 0.0491 Gsus4 Cm Cm C7 0.28 11.0 4 1 0.28 0.43 0.13 1.04 ⊗
92 Gdom7 Cm Cm Gdom7 0.33 10.8 5 1 0.25 0.56 0.01 0.2193 Fdom7 Cm Cm C1-110010 0.31 10.5 4 1 0.22 0.31 0.0 0.0194 Cm Cm Cm Cm 0.50 16.4 5 1 0.28 0.5 0.0 0.2795 C101-1010 Cm C C101-1010 0.69 9.18 5 4 .0.8 0.65 0.0 0.2296 Bb100-100 F Cm Bb100-100 0.37 12.4 6 3 +1.0 0.8 0.09 0.48 ⊕ ⊗
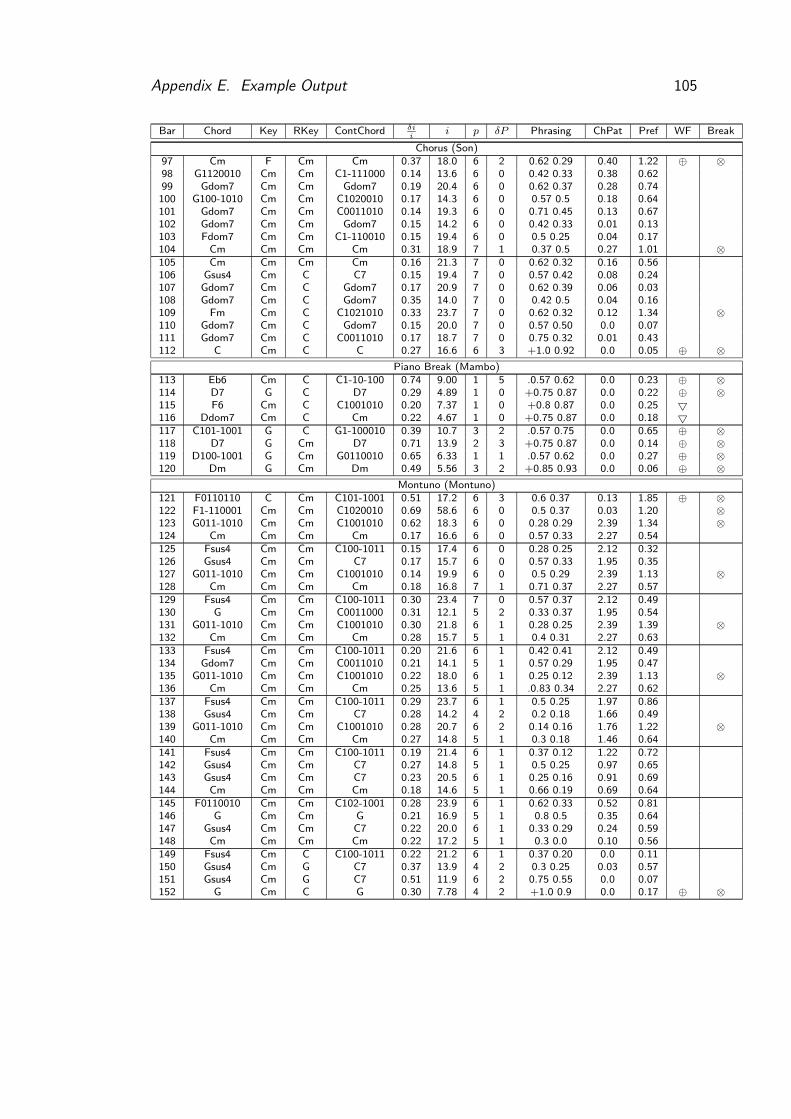
Appendix E. Example Output 105
Bar Chord Key RKey ContChord δi
ii p δP Phrasing ChPat Pref WF Break
Chorus (Son)97 Cm F Cm Cm 0.37 18.0 6 2 0.62 0.29 0.40 1.22 ⊕ ⊗
98 G1120010 Cm Cm C1-111000 0.14 13.6 6 0 0.42 0.33 0.38 0.6299 Gdom7 Cm Cm Gdom7 0.19 20.4 6 0 0.62 0.37 0.28 0.74100 G100-1010 Cm Cm C1020010 0.17 14.3 6 0 0.57 0.5 0.18 0.64101 Gdom7 Cm Cm C0011010 0.14 19.3 6 0 0.71 0.45 0.13 0.67102 Gdom7 Cm Cm Gdom7 0.15 14.2 6 0 0.42 0.33 0.01 0.13103 Fdom7 Cm Cm C1-110010 0.15 19.4 6 0 0.5 0.25 0.04 0.17104 Cm Cm Cm Cm 0.31 18.9 7 1 0.37 0.5 0.27 1.01 ⊗
105 Cm Cm Cm Cm 0.16 21.3 7 0 0.62 0.32 0.16 0.56106 Gsus4 Cm C C7 0.15 19.4 7 0 0.57 0.42 0.08 0.24107 Gdom7 Cm C Gdom7 0.17 20.9 7 0 0.62 0.39 0.06 0.03108 Gdom7 Cm C Gdom7 0.35 14.0 7 0 0.42 0.5 0.04 0.16109 Fm Cm C C1021010 0.33 23.7 7 0 0.62 0.32 0.12 1.34 ⊗
110 Gdom7 Cm C Gdom7 0.15 20.0 7 0 0.57 0.50 0.0 0.07111 Gdom7 Cm C C0011010 0.17 18.7 7 0 0.75 0.32 0.01 0.43112 C Cm C C 0.27 16.6 6 3 +1.0 0.92 0.0 0.05 ⊕ ⊗
Piano Break (Mambo)113 Eb6 Cm C C1-10-100 0.74 9.00 1 5 .0.57 0.62 0.0 0.23 ⊕ ⊗
114 D7 G C D7 0.29 4.89 1 0 +0.75 0.87 0.0 0.22 ⊕ ⊗
115 F6 Cm C C1001010 0.20 7.37 1 0 +0.8 0.87 0.0 0.25 5
116 Ddom7 Cm C Cm 0.22 4.67 1 0 +0.75 0.87 0.0 0.18 5
117 C101-1001 G C G1-100010 0.39 10.7 3 2 .0.57 0.75 0.0 0.65 ⊕ ⊗
118 D7 G Cm D7 0.71 13.9 2 3 +0.75 0.87 0.0 0.14 ⊕ ⊗
119 D100-1001 G Cm G0110010 0.65 6.33 1 1 .0.57 0.62 0.0 0.27 ⊕ ⊗
120 Dm G Cm Dm 0.49 5.56 3 2 +0.85 0.93 0.0 0.06 ⊕ ⊗
Montuno (Montuno)121 F0110110 C Cm C101-1001 0.51 17.2 6 3 0.6 0.37 0.13 1.85 ⊕ ⊗
122 F1-110001 Cm Cm C1020010 0.69 58.6 6 0 0.5 0.37 0.03 1.20 ⊗
123 G011-1010 Cm Cm C1001010 0.62 18.3 6 0 0.28 0.29 2.39 1.34 ⊗
124 Cm Cm Cm Cm 0.17 16.6 6 0 0.57 0.33 2.27 0.54125 Fsus4 Cm Cm C100-1011 0.15 17.4 6 0 0.28 0.25 2.12 0.32126 Gsus4 Cm Cm C7 0.17 15.7 6 0 0.57 0.33 1.95 0.35127 G011-1010 Cm Cm C1001010 0.14 19.9 6 0 0.5 0.29 2.39 1.13 ⊗
128 Cm Cm Cm Cm 0.18 16.8 7 1 0.71 0.37 2.27 0.57129 Fsus4 Cm Cm C100-1011 0.30 23.4 7 0 0.57 0.37 2.12 0.49130 G Cm Cm C0011000 0.31 12.1 5 2 0.33 0.37 1.95 0.54131 G011-1010 Cm Cm C1001010 0.30 21.8 6 1 0.28 0.25 2.39 1.39 ⊗
132 Cm Cm Cm Cm 0.28 15.7 5 1 0.4 0.31 2.27 0.63133 Fsus4 Cm Cm C100-1011 0.20 21.6 6 1 0.42 0.41 2.12 0.49134 Gdom7 Cm Cm C0011010 0.21 14.1 5 1 0.57 0.29 1.95 0.47135 G011-1010 Cm Cm C1001010 0.22 18.0 6 1 0.25 0.12 2.39 1.13 ⊗
136 Cm Cm Cm Cm 0.25 13.6 5 1 .0.83 0.34 2.27 0.62137 Fsus4 Cm Cm C100-1011 0.29 23.7 6 1 0.5 0.25 1.97 0.86138 Gsus4 Cm Cm C7 0.28 14.2 4 2 0.2 0.18 1.66 0.49139 G011-1010 Cm Cm C1001010 0.28 20.7 6 2 0.14 0.16 1.76 1.22 ⊗
140 Cm Cm Cm Cm 0.27 14.8 5 1 0.3 0.18 1.46 0.64141 Fsus4 Cm Cm C100-1011 0.19 21.4 6 1 0.37 0.12 1.22 0.72142 Gsus4 Cm Cm C7 0.27 14.8 5 1 0.5 0.25 0.97 0.65143 Gsus4 Cm Cm C7 0.23 20.5 6 1 0.25 0.16 0.91 0.69144 Cm Cm Cm Cm 0.18 14.6 5 1 0.66 0.19 0.69 0.64145 F0110010 Cm Cm C102-1001 0.28 23.9 6 1 0.62 0.33 0.52 0.81146 G Cm Cm G 0.21 16.9 5 1 0.8 0.5 0.35 0.64147 Gsus4 Cm Cm C7 0.22 20.0 6 1 0.33 0.29 0.24 0.59148 Cm Cm Cm Cm 0.22 17.2 5 1 0.3 0.0 0.10 0.56149 Fsus4 Cm C C100-1011 0.22 21.2 6 1 0.37 0.20 0.0 0.11150 Gsus4 Cm G C7 0.37 13.9 4 2 0.3 0.25 0.03 0.57151 Gsus4 Cm G C7 0.51 11.9 6 2 0.75 0.55 0.0 0.07152 G Cm C G 0.30 7.78 4 2 +1.0 0.9 0.0 0.17 ⊕ ⊗
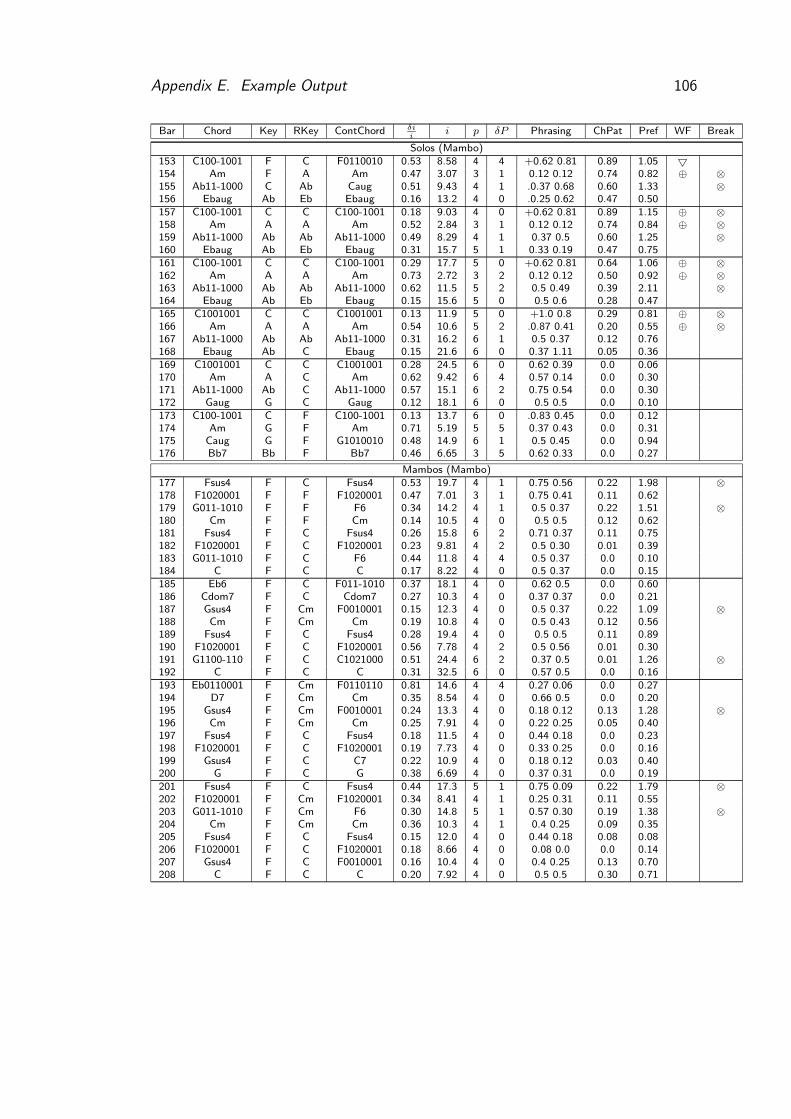
Appendix E. Example Output 106
Bar Chord Key RKey ContChord δi
ii p δP Phrasing ChPat Pref WF Break
Solos (Mambo)153 C100-1001 F C F0110010 0.53 8.58 4 4 +0.62 0.81 0.89 1.05 5
154 Am F A Am 0.47 3.07 3 1 0.12 0.12 0.74 0.82 ⊕ ⊗
155 Ab11-1000 C Ab Caug 0.51 9.43 4 1 .0.37 0.68 0.60 1.33 ⊗
156 Ebaug Ab Eb Ebaug 0.16 13.2 4 0 .0.25 0.62 0.47 0.50157 C100-1001 C C C100-1001 0.18 9.03 4 0 +0.62 0.81 0.89 1.15 ⊕ ⊗
158 Am A A Am 0.52 2.84 3 1 0.12 0.12 0.74 0.84 ⊕ ⊗
159 Ab11-1000 Ab Ab Ab11-1000 0.49 8.29 4 1 0.37 0.5 0.60 1.25 ⊗
160 Ebaug Ab Eb Ebaug 0.31 15.7 5 1 0.33 0.19 0.47 0.75161 C100-1001 C C C100-1001 0.29 17.7 5 0 +0.62 0.81 0.64 1.06 ⊕ ⊗
162 Am A A Am 0.73 2.72 3 2 0.12 0.12 0.50 0.92 ⊕ ⊗
163 Ab11-1000 Ab Ab Ab11-1000 0.62 11.5 5 2 0.5 0.49 0.39 2.11 ⊗
164 Ebaug Ab Eb Ebaug 0.15 15.6 5 0 0.5 0.6 0.28 0.47165 C1001001 C C C1001001 0.13 11.9 5 0 +1.0 0.8 0.29 0.81 ⊕ ⊗
166 Am A A Am 0.54 10.6 5 2 .0.87 0.41 0.20 0.55 ⊕ ⊗
167 Ab11-1000 Ab Ab Ab11-1000 0.31 16.2 6 1 0.5 0.37 0.12 0.76168 Ebaug Ab C Ebaug 0.15 21.6 6 0 0.37 1.11 0.05 0.36169 C1001001 C C C1001001 0.28 24.5 6 0 0.62 0.39 0.0 0.06170 Am A C Am 0.62 9.42 6 4 0.57 0.14 0.0 0.30171 Ab11-1000 Ab C Ab11-1000 0.57 15.1 6 2 0.75 0.54 0.0 0.30172 Gaug G C Gaug 0.12 18.1 6 0 0.5 0.5 0.0 0.10173 C100-1001 C F C100-1001 0.13 13.7 6 0 .0.83 0.45 0.0 0.12174 Am G F Am 0.71 5.19 5 5 0.37 0.43 0.0 0.31175 Caug G F G1010010 0.48 14.9 6 1 0.5 0.45 0.0 0.94176 Bb7 Bb F Bb7 0.46 6.65 3 5 0.62 0.33 0.0 0.27
Mambos (Mambo)177 Fsus4 F C Fsus4 0.53 19.7 4 1 0.75 0.56 0.22 1.98 ⊗
178 F1020001 F F F1020001 0.47 7.01 3 1 0.75 0.41 0.11 0.62179 G011-1010 F F F6 0.34 14.2 4 1 0.5 0.37 0.22 1.51 ⊗
180 Cm F F Cm 0.14 10.5 4 0 0.5 0.5 0.12 0.62181 Fsus4 F C Fsus4 0.26 15.8 6 2 0.71 0.37 0.11 0.75182 F1020001 F C F1020001 0.23 9.81 4 2 0.5 0.30 0.01 0.39183 G011-1010 F C F6 0.44 11.8 4 4 0.5 0.37 0.0 0.10184 C F C C 0.17 8.22 4 0 0.5 0.37 0.0 0.15185 Eb6 F C F011-1010 0.37 18.1 4 0 0.62 0.5 0.0 0.60186 Cdom7 F C Cdom7 0.27 10.3 4 0 0.37 0.37 0.0 0.21187 Gsus4 F Cm F0010001 0.15 12.3 4 0 0.5 0.37 0.22 1.09 ⊗
188 Cm F Cm Cm 0.19 10.8 4 0 0.5 0.43 0.12 0.56189 Fsus4 F C Fsus4 0.28 19.4 4 0 0.5 0.5 0.11 0.89190 F1020001 F C F1020001 0.56 7.78 4 2 0.5 0.56 0.01 0.30191 G1100-110 F C C1021000 0.51 24.4 6 2 0.37 0.5 0.01 1.26 ⊗
192 C F C C 0.31 32.5 6 0 0.57 0.5 0.0 0.16193 Eb0110001 F Cm F0110110 0.81 14.6 4 4 0.27 0.06 0.0 0.27194 D7 F Cm Cm 0.35 8.54 4 0 0.66 0.5 0.0 0.20195 Gsus4 F Cm F0010001 0.24 13.3 4 0 0.18 0.12 0.13 1.28 ⊗
196 Cm F Cm Cm 0.25 7.91 4 0 0.22 0.25 0.05 0.40197 Fsus4 F C Fsus4 0.18 11.5 4 0 0.44 0.18 0.0 0.23198 F1020001 F C F1020001 0.19 7.73 4 0 0.33 0.25 0.0 0.16199 Gsus4 F C C7 0.22 10.9 4 0 0.18 0.12 0.03 0.40200 G F C G 0.38 6.69 4 0 0.37 0.31 0.0 0.19201 Fsus4 F C Fsus4 0.44 17.3 5 1 0.75 0.09 0.22 1.79 ⊗
202 F1020001 F Cm F1020001 0.34 8.41 4 1 0.25 0.31 0.11 0.55203 G011-1010 F Cm F6 0.30 14.8 5 1 0.57 0.30 0.19 1.38 ⊗
204 Cm F Cm Cm 0.36 10.3 4 1 0.4 0.25 0.09 0.35205 Fsus4 F C Fsus4 0.15 12.0 4 0 0.44 0.18 0.08 0.08206 F1020001 F C F1020001 0.18 8.66 4 0 0.08 0.0 0.0 0.14207 Gsus4 F C F0010001 0.16 10.4 4 0 0.4 0.25 0.13 0.70208 C F C C 0.20 7.92 4 0 0.5 0.5 0.30 0.71
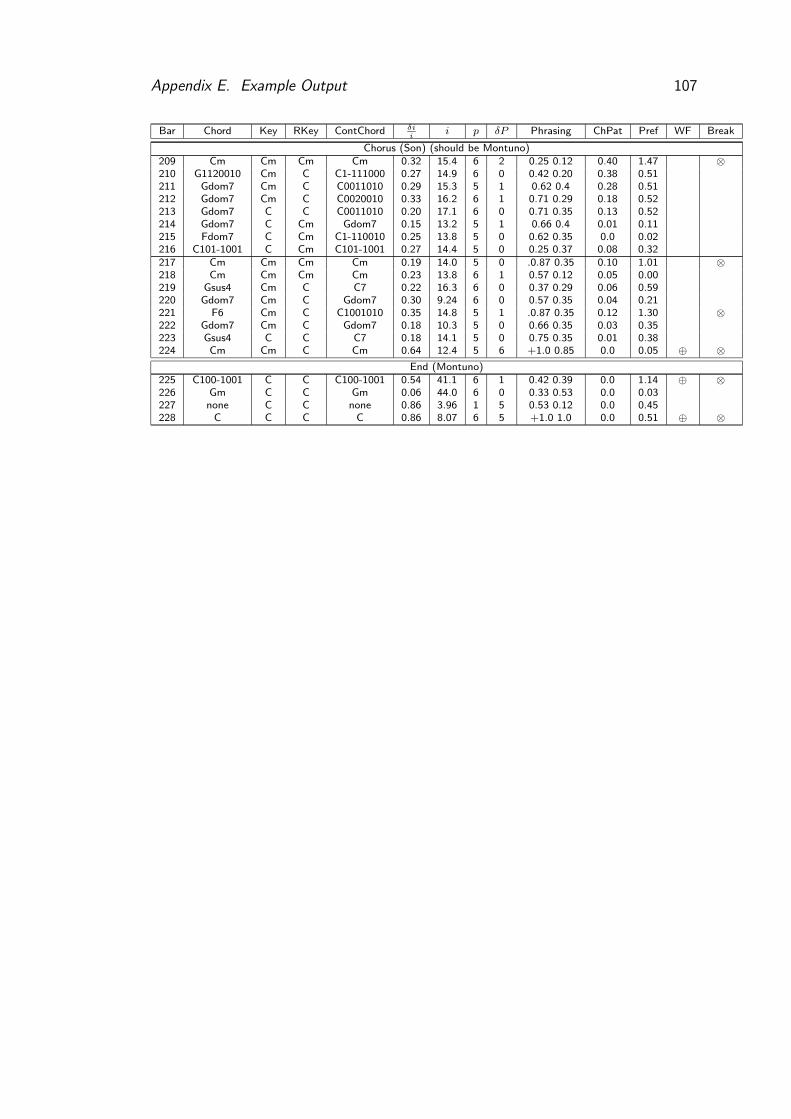
Appendix E. Example Output 107
Bar Chord Key RKey ContChord δi
ii p δP Phrasing ChPat Pref WF Break
Chorus (Son) (should be Montuno)209 Cm Cm Cm Cm 0.32 15.4 6 2 0.25 0.12 0.40 1.47 ⊗
210 G1120010 Cm C C1-111000 0.27 14.9 6 0 0.42 0.20 0.38 0.51211 Gdom7 Cm C C0011010 0.29 15.3 5 1 0.62 0.4 0.28 0.51212 Gdom7 Cm C C0020010 0.33 16.2 6 1 0.71 0.29 0.18 0.52213 Gdom7 C C C0011010 0.20 17.1 6 0 0.71 0.35 0.13 0.52214 Gdom7 C Cm Gdom7 0.15 13.2 5 1 0.66 0.4 0.01 0.11215 Fdom7 C Cm C1-110010 0.25 13.8 5 0 0.62 0.35 0.0 0.02216 C101-1001 C Cm C101-1001 0.27 14.4 5 0 0.25 0.37 0.08 0.32217 Cm Cm Cm Cm 0.19 14.0 5 0 .0.87 0.35 0.10 1.01 ⊗
218 Cm Cm Cm Cm 0.23 13.8 6 1 0.57 0.12 0.05 0.00219 Gsus4 Cm C C7 0.22 16.3 6 0 0.37 0.29 0.06 0.59220 Gdom7 Cm C Gdom7 0.30 9.24 6 0 0.57 0.35 0.04 0.21221 F6 Cm C C1001010 0.35 14.8 5 1 .0.87 0.35 0.12 1.30 ⊗
222 Gdom7 Cm C Gdom7 0.18 10.3 5 0 0.66 0.35 0.03 0.35223 Gsus4 C C C7 0.18 14.1 5 0 0.75 0.35 0.01 0.38224 Cm Cm C Cm 0.64 12.4 5 6 +1.0 0.85 0.0 0.05 ⊕ ⊗
End (Montuno)225 C100-1001 C C C100-1001 0.54 41.1 6 1 0.42 0.39 0.0 1.14 ⊕ ⊗
226 Gm C C Gm 0.06 44.0 6 0 0.33 0.53 0.0 0.03227 none C C none 0.86 3.96 1 5 0.53 0.12 0.0 0.45228 C C C C 0.86 8.07 6 5 +1.0 1.0 0.0 0.51 ⊕ ⊗

Bibliography
[1] Kansei-Based Approach Antonio. Interactive systems design:.
[2] J. Arcos, D. Canamero, and R. Lopez. Affect-driven generation of expressivemusical performances, 1998.
[3] Bernard Bel. http://www.lpl.univ-aix.fr/∼belbernard/music/bp2intro.htm.
[4] A. Camurri. An architecture for multimodal environment agents, 1997.
[5] Antonio Camurri and Alessandro Coglio. An architecture for emotionalagents. IEEE MultiMedia, 5(4):24–33, – 1998.
[6] Antonio Camurri, Barbara Mazzarino, and et al. Real-time analysis of ex-pressive cues in human movement.
[7] Dolores Canamero, Josep Lluıs Arcos, and Ramon Lopez de Mantaras. Im-itating human performances to automatically generate expressive jazz bal-lads.
[8] Roger B Dannenberg. A brief survey of music representation issues, tech-niques, and systems, 1994.
[9] Christopher Raphael Department. Orchestra in a box: A system for real-timemusical accompaniment.
[10] Lisa Cingiser DiPippo, Ethan Hodys, and Bhavani Thuraisingham. Towardsa real-time agent architecture - a whitepaper.
[11] Simon Dixon. A lightweight multi-agent musical beat tracking system. InPacific Rim International Conference on Artificial Intelligence, pages 778–788, 2000.
[12] Zahia Guessoum and M. Dojat. A real-time agent model in an asynchronous-object environment. In Rudy van Hoe, editor, Seventh European Workshopon Modelling Autonomous Agents in a Multi-Agent World, Eindhoven, TheNetherlands, 1996.
108

Bibliography 109
[13] M. Harris, A. Smaill, and G. Wiggins. Representing music symbolically,1991.
[14] B. Horling, V. Lesser, R. Vincent, and T. Wagner. The soft real-timeagent control architecture. Technical Report TR02 -14, University of Mas-sachusetts at Amherst, April 2002.
[15] ICMC. Rhythms as Emerging Structures, 2000.
[16] Fabio Kon and Fernando Iazzetta. Internet music: Dream or (virtual) real-ity?
[17] C. Krummhansl and E. Kessler. Tracing the dynamic changes in perceivedtonal organization in a spatial representation of musical keys. PsychologicalReview, (89):334–368, 1982.
[18] Fred Lerdahl and Ray Jackendoff. A Generative Theory of Tonal Music.MIT Press, 1983.
[19] H. C. Longuet-Higgins. Letter to a musical friend. The musical review,23:244–8,271–80, 1962.
[20] Midi specifications. http://www.midi.org/about-midi/specshome.shtml.
[21] The midi specification. http://www.borg.com/∼jglatt/tech/midispec.htm.
[22] Midi specification. http://www.sfu.ca/sca/Manuals/247/midi/MIDISpec.html.
[23] Remy Mouton and Francois Pachet. The symbolic vs. numeric controversyin automatic analysis of music.
[24] F. Pachet. The MusES system: An environment for experimenting withknowledge representation techniques in tonal harmony. In Proceedings ofthe 1st Brazilian Symposium on Computer Music, Caxambu, Minas Gerais,Brazil, pages 195–201, 1994.
[25] F. Pachet, G. Ramalho, and J. Carrive. Representing temporal musicalobjects and reasoning in the MusES system. Journal of New Music Research,5(3):252–275, 1996.
[26] Geber Ramalho and Jean-Gabriel Ganascia. Simulating creativity in jazzperformance. In National Conference on Artificial Intelligence, pages 108–113, 1994.
[27] Judy Robertson, Andrew de Quincey, Tom Stapleford, and Geraint Wiggins.Real-time music generation for a virtual environment.

Bibliography 110
[28] Robert Rowe. Interactive Music Systems - Machine Listening and Compos-ing. MIT Press, 1993.
[29] Robert Rowe. Machine Musicianship. MIT Press, 2001.
[30] D. Zimmermann. Exploiting models of musical structure for automaticintention-based composition of background music, 1995.





























