Embed Size (px)
Citation preview

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
“Metodos Estadısticos”
Carlos Valle [email protected]
Departamento de Informatica -Universidad Tecnica Federico Santa Marıa
Santiago, Abril 2009
1 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Temario
1 Regresion Lineal
2 Inferencia
3 Con base ortogonal
4 Salidas Multiples
5 Seleccion de subconjuntos
6 Regularizacion (shrinkage) de coeficientes
7 Metodos que generan entradas alternativas
8 Regresion no lineal y extensiones
2 / 51
“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Temario
1 Regresion Lineal
2 Inferencia
3 Con base ortogonal
4 Salidas Multiples
5 Seleccion de subconjuntos
6 Regularizacion (shrinkage) de coeficientes
7 Metodos que generan entradas alternativas
8 Regresion no lineal y extensiones
3 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Introduccion
Es uno de los metodos que aplican estadıstica masutilizados.
Se usa para describir la relacion entre el promedio(tendencia) de una variable y los valores tomados por otrasvariables V regresion
A veces tenemos varios modelos plausibles, y queremosseleccionar cual es el mas apropiado V Analisis de varianza
4 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Regresion lineal
yj = β0 +β1x1j +β2x2j + · · ·+βpxpj + εj, j = 1,2, . . . ,n (1)
{εj} i.i.d. N(0,σ2), n es el numero de datos.Los xi se conocen como regresores, o variablesindependientes o explicativas.y es la variable dependiente o de salida.Matricialmente el modelo queda
Y = Xβ+ ε (2)
El modelo se dice lineal porque el valor esperado de yj esuna funcion lineal de los regresores
E(yj) = β0 +n
∑i=1
βixij
5 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Regresion lineal (2)
Existe un gran numero de problemas de regresion quepueden ser convertidos a forma lineal general
Existen maneras de transformar la salida o las entradas paraque el modelo lineal nos entregue algun grado deinformacion.
Podemos hacer inferencia esa partir del modelo V Usar testde hipotesis para comparar los diferentes modelos y obtenerintervalos de confianza para las estimaciones de {β}
6 / 51
“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
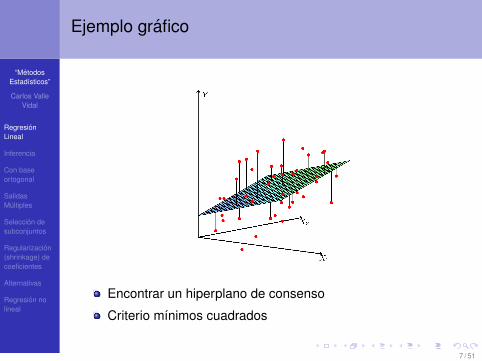
Ejemplo grafico
Encontrar un hiperplano de consenso
Criterio mınimos cuadrados
7 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Mınimos cuadrados residuales
Sea (x1,y1), . . .(xn,yn) la muestra de entrenamiento desde laque queremos estimar β = (β0,β1, . . . ,βP)T
Cada xi = (xi1,xi2, . . . ,xip)T un vector de caracterısticas parael i-esimo dato.
Usando mınimos cuadrados de los residuos
RSS(β) =n
∑i=1
(yi− f (xi))2
=n
∑i=1
(yi−β0−
p
∑j=1
xijβj
)2
8 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Mınimos cuadrados residuales (2)
Esto puede ser escrito como
RSS(β) = (y−Xβ)T(y−Xβ)
X es una matriz de Nx(p+1), donde cada fila es un vectorde entrada con un uno en la primera posicion
Es una forma cuadratica de p+1 parametros
Derivando respecto de β obtenemos
δRSSδβ
= −2XT(y−Xβ)
δ2RSSδβδβT = −2XTX
9 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Mınimos cuadrados residuales (3)
Asumiendo que X es no-singular (det(X) 6= 0) y que XTX esdefinida positiva, podemos igualar la derivada a cero
XT(y−Xβ) = 0
Obteniendo solucion unica
β = (XTX)−1XTy) (3)
f (x0) = (1 : xT0 )β
Los valores de salida del modelo para los datos deentrenamiento son
y = Xβ = X(XTX)−1XTy
yi = f (xi)10 / 51
“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
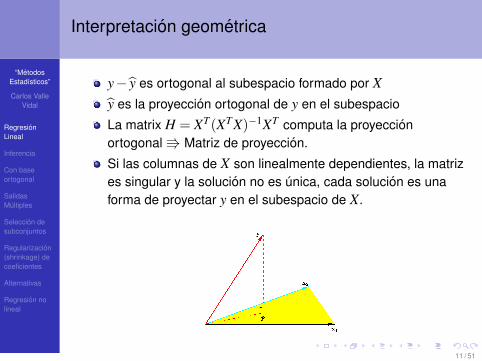
Interpretacion geometrica
y− y es ortogonal al subespacio formado por Xy es la proyeccion ortogonal de y en el subespacio
La matrix H = XT(XTX)−1XT computa la proyeccionortogonal V Matriz de proyeccion.
Si las columnas de X son linealmente dependientes, la matrizes singular y la solucion no es unica, cada solucion es unaforma de proyectar y en el subespacio de X.
11 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Propiedades distribucionales de β
Asumamos yi decorrelacionados conVar(yi) = σ2,∀i = 1, . . . ,n
xi se asumen fijos
De (3) podemos obtener la matriz de varianzas y covarianzaspara β
Var(β) = (XTX)−1σ
2
El estimador de la varianza σ2 es
σ2 =
1n−p−1
n
∑i=1
(yi− yi)2
El ajuste en el denominador es para que σ sea insesgadoE[σ2] = σ2
12 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Inferencia sobre β
Asumamos que el modelo (1) es cierto, E[Y|X1, . . . ,Xp] eslineal y los errores son gaussianos y aditivos. Es decir
Y = E[Y|X1, . . . ,Xp]+ ε
= β0 +p
∑j=1
Xjβj + ε
ε∼ N(0,σ2)
β∼ N(β,(XTX)−1σ
2)
Ademas(n−p−1)σ2 ∼ σ
2χ
2n−p−1
β y σ2 son estadısticamente independientes.
13 / 51
“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Temario
1 Regresion Lineal
2 Inferencia
3 Con base ortogonal
4 Salidas Multiples
5 Seleccion de subconjuntos
6 Regularizacion (shrinkage) de coeficientes
7 Metodos que generan entradas alternativas
8 Regresion no lineal y extensiones
14 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Intervalo de Confianza y Test de hipotesis para β
Para un coeficienteβj−β
σ√vj∼ tn−p−1
vj es el j-esimo elemento de la diagonal de (XTX)−1
Por lo tantoIC(1−α)% = βj± σ
√vj
El test de hipotesis sobre que un H0 : βj = 0 v/s H1 : βj 6= 0 lodetermina el coeficiente estandarizado
zj =βj
σ√vj∼ tn−p−1
si |zj|> tn−p−1(α/2)⇒ se rechaza H0
Para σ conocido zj puede ser una normal estandar
15 / 51
“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
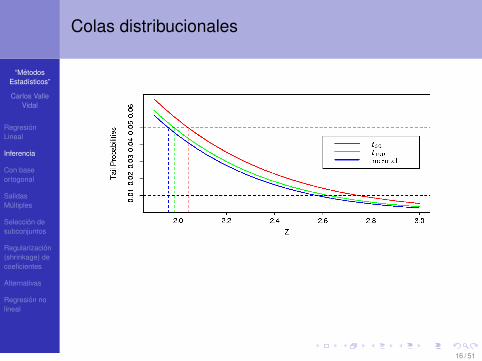
Colas distribucionales
16 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Intervalo de Confianza y Test de hipotesis para β (2)
Para un conjunto coeficientes
Encontrar los valores de β para los cuales la elipsoide
(β−β)T(XTX)(β−β)≤ FCσ2(p1−p0)
Donde Fp1−p0,n−p1−1 ≥ FC = α
H0 : βj = 0 v/s H1 : βj 6= 0; θ,θ ∈ Rk
F =(RSS0−RSS1)/(p1−p0)
RSS1/(n−p1−1)∼ Fp1−p0,n−p1−1
17 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Intervalo de Confianza y Test de hipotesis para β (3)
RSS1 es la suma de cuadrado de los residuos del modelomas grande (con todas las variables), con p1 +1 parametros
RSS0 es la suma de cuadrado de los residuos del modelomas chico (sin las variables que se desea eliminar), conp0 +1 parametros
Es decir hay p1−p0 parametros restringidos a cero
El estadıstico F mide el cambio residual de la suma decuadrados residuales al adicionar las nuevas variables
18 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Estimador de la varianza σ2
Sea e = Y− Y
S2R =
1n−p−1
n
∑i=1
e2i
S2R =
nn−p−1
σ2MV
Por lo tanto(n−p−1)S2
Rσ2 ∼ χ
2n−p−1
El I.C del 1−α% de confianza es
(n−p−1)S2R
χ2n−p−1(1−α/2)
≤ σ2 ≤ (n−p−1)S2
R
χ2n−p−1(α/2)
19 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Teorema Gauss-Markov
En la estimacion del modelo de regresion lineal (2) si lasperturbaciones εi estan decorrelacionadas, de igual varianzae independientes de las variables explicativas. Entonces losestimadores mınimo-cuadraticos son de mınima varianzadentro de la clase de los estimadores insesgados que sonfunciones lineales de las observaciones yi
MSE(θ) = E(θ−θ)2
= Var(θ)+ [E(θ)−θ]2
Puede existir un estimador sesgado con varianza menor, ypor lo tanto con menos MSE
20 / 51
“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Temario
1 Regresion Lineal
2 Inferencia
3 Con base ortogonal
4 Salidas Multiples
5 Seleccion de subconjuntos
6 Regularizacion (shrinkage) de coeficientes
7 Metodos que generan entradas alternativas
8 Regresion no lineal y extensiones
21 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Regresion multiple a partir de regresion univariada
Consideremos el caso p = 1
Y = Xβ+ ε
Mınimos cuadrados residuales
β = ∑ni=1 xiyi
∑ni=1 x2
i
ri = yi− xiβ
vectorialmente sea y = (y1, . . . ,yn)T ,x = (x1, . . . ,xn)T ,definamos
〈x,y〉 =n
∑i=1
xiy1
= xTy
Como el producto interno entre x e y22 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Regresion multiple a partir de regresion univariada(2)
Por lo tanto
β =〈x,y〉〈x,x〉
r = y− xβ
Para las siguientes columnas de X: x1, . . . ,xp (supongamosortogonalidad V 〈xj,xk〉= 0,∀j 6= k)
En regresion multiple. si las entradas son ortogonalesβ = 〈xj,y〉/〈xj,xj〉, es decir, entre los parametros a estimardel modelo no hay influencias.
La regresion de b sobre a significa hacer regresion univariadasin intercepto
Generando el coeficiente γ = 〈a,b〉/〈a,a〉 y el residuo b− γaSe dice que b es ortogonalizado respecto de a
23 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Regresion multiple a partir de regresion univariada(3)
1 Realicemos la regresion de x sobre 1 para producir el residuoz = x− x1
2 Realicemos la regresion de y sobre z para generar elcoeficiente β1
x = ∑i xi/n y 1 = x0, vector de n unos.
β1 =〈x− x1,y〉
〈x− x1,x− x1〉
24 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Regresion multiple a partir de regresion univariada(4)
Algoritmo 1 usando ortogonalizacion sucesiva
1: Inicializar z0 = x0 = 12: for j = 1 to p do3: Hacer la regresion de xj sobre z0,z1, . . . ,zj−1 para generar
los coeficientes γlj = 〈zj,xj〉/〈zl,zl〉, l = 0, . . . , j−1 y el vectorresidual zj = xj−∑
j−1k=0 γkjzk−1
4: end for5: Hacer la regresion de y sobre el zp residual para generar el
estimador βp
25 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Regresion multiple a partir de regresion univariada(5)
Reordenando xj cualquier vector columna podrıa estar en laultima posicion, por lo tanto, el j-esimo coeficiente es laregresion univariada de y sobre xj·012...(j−1)(j+1)...p
El coeficiente βj representa la contribucion adicional de xj
sobre y despues de que xj fuese ajustado porx0,x1, . . . ,xj−1,xj+1, . . . ,xp
Si xp esta correlacionado altamente con xk el vector residual
zp estara cercano a cero y βp sera muy inestable.
Var(βp) =σ2
〈zp,zp〉=
σ2
||zp||2
Depende del largo de zp y por ende, de que tan bienexplicado esta xp por los demas xk.
26 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Regresion multiple a partir de regresion univariada(6)
El paso 2 del Algoritmo (1) puede ser escrito en formamatricial
X = ZΓ
Z tienes las columas zj en orden , y Γ es la matriz diagonalsuperior con las entradas γkj
D es la matriz diagonal donde la j- esima entrada de ladiagonal djj = ||zj||
27 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Regresion multiple a partir de regresion univariada(6)
X = ZD−1DΓ
= QR
Esta se llama la descomposicion QR de X
Q es una matriz de n× (p+1) ortogonal V QTQ = I
R es una matriz triangular de (p+1)× (p+1)
β = R−1QTy
y = QQTy
28 / 51
“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Temario
1 Regresion Lineal
2 Inferencia
3 Con base ortogonal
4 Salidas Multiples
5 Seleccion de subconjuntos
6 Regularizacion (shrinkage) de coeficientes
7 Metodos que generan entradas alternativas
8 Regresion no lineal y extensiones
29 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Salidas multiples
Supongamos que tenemos multiples salidas Y1,Y2, . . . ,Yk
para que nuestras entradas X0,X1, . . . ,Xp las predigan
Asumamos un modelo lineal para cada salida
Yk = β0k +p
∑j=1
Xjβjk + εk
= fk(X)+ εk
Usando notacion matricial
Y = XB+E
Y es una matriz de n× k.X es la matriz de entrada den× (p+1) .B es la matriz de (p+1)× k. E es la matriz den× k de errores.
30 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Salidas multiples (2)
RSS(B) =K
∑k=1
n
∑i=1
(yik− fk(xi))2
= tr[(Y−XB)T(Y−XB)]
Los mınimos cuadrados estimados quedan de la mismaforma anterior
B = (XTX)−1XTY
Si los errores ε = (ε1, . . . ,εk) estan correlacionados pareceapropiado modificar la version multivariada (4) por
RSS(B;Σ) =n
∑i=1
(yi− f (xi))TΣ−1(yi− f (xi))
31 / 51
“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Temario
1 Regresion Lineal
2 Inferencia
3 Con base ortogonal
4 Salidas Multiples
5 Seleccion de subconjuntos
6 Regularizacion (shrinkage) de coeficientes
7 Metodos que generan entradas alternativas
8 Regresion no lineal y extensiones
32 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Razones para no elegir mınimos cuadrados
Cuando queremos calidad de la prediccion, ya que tiene bajosesgo pero alta varianza. Nos gustarıa usar tecnicas quesuban un poco el sesgo pero reduciendo la varianza
Interpretacion, cuando tenemos muchos predictores nosgustarıa reducir al mas pequeno subconjunto que nosexplique mejor el modelo.
33 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Seleccion de subconjunto
Nos quedaremos con un subconjunto de variables del modelo
El mejor subconjunto es el que nos permite obtener la sumade cuadrados residuales mas pequena
Una tecnica popular es Forward stepwise selection comienzacon el intercepto y agrega secuencialmente el mejor predictorque mejore el modelo de acuerdo al estadıstico
F =RSS(β)−RSS(β)
RSS(β)/(n− k−2)
Existen tambien Backward selection y estrategias hıbridas.
34 / 51
“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Temario
1 Regresion Lineal
2 Inferencia
3 Con base ortogonal
4 Salidas Multiples
5 Seleccion de subconjuntos
6 Regularizacion (shrinkage) de coeficientes
7 Metodos que generan entradas alternativas
8 Regresion no lineal y extensiones
35 / 51
“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
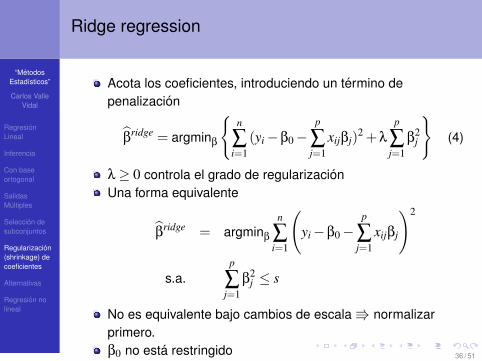
Ridge regression
Acota los coeficientes, introduciendo un termino depenalizacion
βridge = argminβ
{n
∑i=1
(yi−β0−p
∑j=1
xijβj)2 +λ
p
∑j=1
β2j
}(4)
λ≥ 0 controla el grado de regularizacionUna forma equivalente
βridge = argminβ
n
∑i=1
(yi−β0−
p
∑j=1
xijβj
)2
s.a.p
∑j=1
β2j ≤ s
No es equivalente bajo cambios de escala V normalizarprimero.β0 no esta restringido 36 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Ridge regression (2)
Podemos reparametrizar usando xij← (xij− xj)Estimamos β0 = y = ∑
ni yi/n
Ahora X tiene p columnas y se puede reescribir el criterio (4)de la forma
RSS(λ) = (y−Xβ)T(y−Xβ)+λβT
β
La solucion de esta ecuacion es
βridge = (XTX +λI)−1XTy
Esto transforma el problema en no-singular
En el caso de entradas ortogonales βridge = γβLS,0≤ γ≤ 1
37 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Ridge regression (3)
Podemos usar descomposicion por valores propios (SVD) dela matriz centrada X
S = UDVT
U y V son matrices ortogonales de n×p y p×p. D es unamatriz diagonal de p×p, con entradasd1 ≥ d2 ≥ ·· · ≥ dp ≥ 0 llamados valores propios de X
XβLS = X(XTX)−1XTy
= UUTy
Notar la similaridad con (4)
38 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Ridge regression (4)
Para las soluciones ridge tenemos
Xβridge = X(XTX +λI)−1XTy
= UD(D+λI)−1DUTy
=p
∑j=1
ujd2
j
d2j +λ
uTj y
uj son las columnas de U. Como λ≥ 0⇒ d2j /(d2
j +λ)
Si d2j es pequeno hay mas regularizacion del j-esimo vector
base
39 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Ridge regression (5)
La matriz de covarianza es S = XTX/n y tenemos que
XTX = VD2VT
Los vectores propios son llamados las componentesprincipales
z1 = Xv1 = u1d1 es la primera componente principal
zj tiene una varianza maxima de d2j /n
40 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Lasso
Se define el estimador lasso como
βlasso = argminβ
n
∑i=1
(yi−β0−
p
∑j=1
xijβj
)2
s.a.p
∑j=1|βj| ≤ s
Penalizacion L1
41 / 51
“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Temario
1 Regresion Lineal
2 Inferencia
3 Con base ortogonal
4 Salidas Multiples
5 Seleccion de subconjuntos
6 Regularizacion (shrinkage) de coeficientes
7 Metodos que generan entradas alternativas
8 Regresion no lineal y extensiones
42 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Regresion usando componentes principales
Haciendo zm = Xvm entonces hacer la regresion de y sobrez1,z2, . . . ,zm para algun m≤ p
ypcr = y+∑Mm=1 θmzm
Donde θm = 〈zm,y〉/〈zm,zm〉
βpcr(M) =
M
∑m=1
θmvm
Estandarizar las entradas
Ridge regression acota los componentes principales convalores propios mas pequenos.
43 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Mınimos cuadrados parciales (PLS)
Asumamos que y esta centrada y cada xj estandarizado conmedia 0 y varianza 1.
PLS calcula el coeficiente de regresion ϕ1j = 〈xj,y〉 de ysobre xj
Construyamos la entrada derivada z1 = ∑ϕ1jxj
Para construir cada zm las entradas son pesadas por elefecto que producen sobre y
Luego ortogonalizamos x1,x2, . . . ,xp respecto de z1
Si M = p tenemos mınimos cuadrados.
44 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Mınimos cuadrados parciales (PLS)(2)
Algoritmo 2 Partial Least Squares
1: Estandarizar cada xj a media 0 varianza 1. y(0) = 1y y x(0)j =
xj, j = 1, . . . ,p2: for m = 1 to p do3: zm = ∑
pj=1 ϕmjx
(m−1)j , donde ϕmj = 〈x(m−1)
j ,y〉4: θm = 〈zm,y〉/〈zm,zm〉5: y(m) = y(m−1) + θmzm
6: Ortogonalizar cada x(m−1)j respecto de zm : x(m)
j = x(m−1)j −
[〈zm,x(m−1)j 〉/〈zm,zm〉]zm, j = 1,2, . . . ,p
7: end for8: Salidas: la secuencia de vectores corregidos y(m),m = 1, . . . ,p.
Los coeficientes de los xj originales βplsj (m) = ∑
ml=1 ϕljθl
45 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
¿Que hacen?
La m-esima componente principal en la direccion vm resuelve
max||α||=1,vT
l sα=0,l=1,...,m−1Var(Xα)
Asegura la decorrelacion de zm = Xα con los anterioreszl = Xvl
La m-esima direccion PLS ϕm resuelve
max||α||=1,vT
l sα=0,l=1,...,m−1Corr2(y,Xα)Var(Xα)
46 / 51
“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Temario
1 Regresion Lineal
2 Inferencia
3 Con base ortogonal
4 Salidas Multiples
5 Seleccion de subconjuntos
6 Regularizacion (shrinkage) de coeficientes
7 Metodos que generan entradas alternativas
8 Regresion no lineal y extensiones
47 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Regresion no lineal
Difiere del modelo anterior en que la salida esperada no esuna suma con pesos de las entradas.
Modelo alometrico
yj = β0xβ1ij + εj, j = 1,2, . . . ,m
Para un modelo lineal el estimador de m.v. se reduce a lasolucion de los mınimos cuadrados.
48 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Modelos lineales generalizados
La generalizacion se produce en dos partes:1 La distribucion de la salida no es Normal, pero es de la familia
exponencial.2 La esperanza de la salida tiene la siguiente relacion
g(E(yj)) = β0 +n
∑i=1
βixij
Donde g es una funcion monotona y diferenciable.
49 / 51
“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
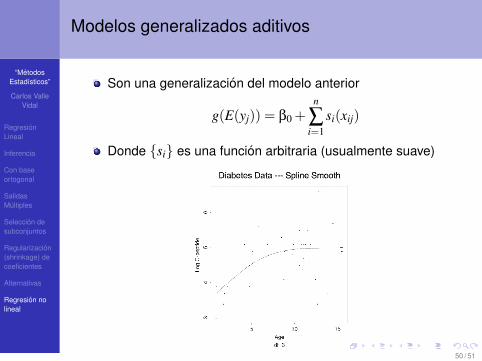
Modelos generalizados aditivos
Son una generalizacion del modelo anterior
g(E(yj)) = β0 +n
∑i=1
si(xij)
Donde {si} es una funcion arbitraria (usualmente suave)
50 / 51

“MetodosEstadısticos”
Carlos ValleVidal
RegresionLineal
Inferencia
Con baseortogonal
SalidasMultiples
Seleccion desubconjuntos
Regularizacion(shrinkage) decoeficientes
Alternativas
Regresion nolineal
Consultas y Comentarios
51 / 51





























