Embed Size (px)
Citation preview

Page 1 sur 13 LCA 7
LCA 7, Pr N.Meyer Laura Luhmann et Lauriane Stenger
20/12/12 de 16h à 17h
Méthodologie de la recherche clinique
BIAIS ET GRAPHIQUES Plan du cours : I – Introduction II – Quelques exemples de base III – Critères de jugement IV – Présenter et interpréter les résultats V – Biais les plus courants VI – Graphiques
V. Biais les plus courants (suite) 1) Notion de biais : biais dans les essais thérapeutiques
• Évolution naturelle de la maladie aggravation ou rémission spontanée possible de la maladie : une maladie n’est pas
figée
d’où l’intérêt des groupes références pour pallier ce biais
• effet placebo (un placebo n’est pas une substance inactive comme on a tendance à le croire.
Il a une action thérapeutique sans action pharmacologique connue.)
• régression à la moyenne
dans tout échantillon, les mesures sont soumises à un aléa. Ex. : si on mesure la tension artérielle dans un groupe pour un essai sur un
traitement anti HTA, on va choisir des patients hypertendus. Certains auront une
valeur élevée constante (180/110), d’autres auront une valeur ponctuellement élevée (qu’importe la cause) qui régresse d’elle-‐même. Si on ne fait pas attention, on va donc inclure des sujets qui vont être hypertendus de manière erronée (personnes
qui ont des valeurs de TA hautes ponctuellement) (biais de sélection) Le groupe sera constitué de vrais hypertendus et de faux hypertendus. Si on
laisse ce groupe évoluer dans le temps, on aboutit à une normalisation de la
moyenne de la TA : c’est l’effet de régression à la moyenne. L’effet du traitement étudié sera alors dans ce cas mal quantifié.
L’étude de l’HTA doit se faire sur plusieurs mois. Dans certains essais, on fait
des périodes de RUN-‐IN : on mesure la TA à plusieurs reprises à intervalles de temps différents (par exemple 3 mesures lors de 4 consultations différentes). On fait ensuite une moyenne des TA qui sera plus significative
qu’une seule mesure (ponctuelle) pour inclure les sujets à l’étude.
• effet des traitements concomitants

Page 2 sur 13 LCA 7
d’où l’intérêt de la randomisation. Grâce au tirage au sort, toutes les caractéristiques
biologiques connues et inconnues des sujets tendent à être égalisées.
2) Les analyses d’études (= prise en compte des résultats) Objectif : diminuer les biais
a) Analyse en intention de traiter C’est une notion assez récente. Lors de l’analyse des résultats, on prend en compte tous les sujets,
même si : Erreur de randomisation Erreur ou arrêt de traitement
Erreur d’inclusion (non respect des critères d’inclusion) Ecart protocolaire Perdu de vue, sortie d’étude, etc…
Conséquence : l’analyse est non biaisée alors que si l’on avait retiré les sujets de l’analyse, on aurait créé un biais car mauvais échantillonnage.
Avantages :
On limite les biais
On a une vision concrète de la réalité (Dans la vie de tous les jours, on observe souvent une mauvaise observance des patients pour un traitement)
b) Comparaison des 3 types d’analyse : en intention de traiter, per protocole, traitement reçu
Explication :

Page 3 sur 13 LCA 7
Lorsqu’on donne au groupe A le traitement A, il peut y avoir des erreurs, et certains
peuvent recevoir le traitement B. Il en est de même pour le groupe B. En intention de traiter : On considère ce qu’à reçu le patient, donc on prend en compte
l’erreur, mais le patient reste dans son groupe établi lors du protocole !
En per protocole : On applique le protocole au moment de l’analyse, on considère que tous ceux du groupe A ont reçu A, même si ce n’est pas le cas !
En traitement reçu : On analyse les résultats tel qu’a été la réalité. Si un patient du
groupe A a reçu le traitement B, il fait désormais parti du traitement B modification du nombre de personnes par groupe, alors qu’en intention de traiter ce n’est pas le cas. L’analyse en traitement reçu permet de comparer des groupes qui ne sont pas biaisés.
Dans un essai thérapeutique, il faut analyser en intention de traiter.
L’analyse en intention de traiter est utilisée quand on fait un essai de supériorité (lorsque l’on veut montrer qu’un médicament est plus efficace qu’un autre). Quand on veut montrer que 2 traitements ont la même efficacité (par exemple une molécule
princeps et le placebo, ou une gélule et un comprimé), c’est un essai d’équivalence. On utilise ici une analyse en per protocole qui a tendance à exagérer la différence entre 2 traitements. Si malgré cette exagération, on arrive quand même à conclure qu’il y a une équivalence entre les 2 traitements, on
est relativement confiant sur notre conclusion.
3) Plans expérimentaux : répartition des sujets de façon organisée en groupe
On distingue plusieurs types de plans expérimentaux dont les 3 principaux sont les suivants : groupes parallèles, plan factoriel, essai croisé (cross-‐over)
a) Groupes parallèles : -‐Deux groupes de sujets randomisés :
On donne traitement A au 1er groupe
On donne traitement B au 2nd groupe -‐Puis on suit les gens dans le temps et on recueille les résultats à la fin. Il n’y a pas de
croisement entre les groupes (un sujet d’un 1er groupe n’ira jamais dans le second)
b) Plan factoriel
-‐On va tester simultanément deux traitements, soit constitution de 4 groupes : 1er : traitement A et B 2nd : traitement A et placebo
3ème : placebo et traitement B 4ème : placebo et placebo
B+ B-‐ A+ Groupe 1 Groupe 2 A-‐ Groupe 3 Groupe 4
-‐Ce plan est utilisé quand on teste par exemple des bithérapies (traitement anti-‐HTA par
ex). Il est possible de rajouter un traitement C, mais les données seront plus difficiles à analyser.

Page 4 sur 13 LCA 7
c) Croisé (chassé croisé ou Cross over) -‐C’est un essai dans lequel le sujet est son propre témoin, ce qui permet d’éliminer la variabilité interindividuelle. On va comparer 2 groupes de sujets, chaque groupe
prendra les 2 traitements 1er groupe : d’abord A puis B 2ème groupe : d’abord B puis A
-‐Intérêt : comparaison plus efficace si on prend un même sujet à qui on administre un traitement, puis un autre, il s’agit alors du même échantillon. -‐Indication : maladies chroniques, incurables (SEP, asthme, PR)
-‐Limites : risque d’effet du 1er traitement sur le 2ème car il est encore efficace, encore présent dans le sang.
-‐Notion de WASH-‐OUT : la période entre la prise de A et de B doit être suffisamment grande pour que l’effet de A ait disparu lors de l’introduction de B.
IV. Explications Graphiques
1. Généralités Les graphiques sont devenus indispensables dans un article. Ce qui est intéressant, c’est souvent ce qui n’y est pas (et non ce qui y est). Une représentation
imagée est toujours orientée. Un bon graphique doit comporter : a un titre, des axes
annotations : quels groupes sont comparés échelle, unités, quantification de l’échelle effectif
nom du test statistique et la valeur de « p » doit être autonome : on doit le comprendre sans avoir lu l’article
Ex : Graphique qui étudie la valeur des lactates chez des sujets en réanimation.

Page 5 sur 13 LCA 7
Etude lactate et sepsis/choc septique En regardant l’aspect global du graphique, on a l’impression qu’il y a autant de décès que de survivants. Or quand on regarde l’axe des ordonnées, on se rend compte qu’il s’agit de la fréquence et non d’un effectif ! Il faut toujours prendre le temps de décortiquer l’article !
Différents types de graphiques :
Histogramme = diagramme à bâtons Nuage de points (régression) Boite à moustaches = box-‐spot
Diagramme à points Courbes de survies (Kaplan-‐Meier) Nombreux autres types de représentations
2. Histogramme / diagramme à bâtons
On fait souvent la confusion entre histogramme et diagramme à bâtons. Dans l’histogramme : c’est la surface du rectangle qui compte (et non pas juste la hauteur). Cette surface est proportionnelle au nombre de sujet représentés. Cependant, pour des raisons de
simplicité la largeur du rectangle est quasi toujours la même, pour que la lecture soit uniquement sur l’axe y (hauteur du bâton)
Dans le diagramme à bâtons : c’est seulement la hauteur qui véhicule l’information. Ces 2 représentations graphiques permettent de faire des comparaisons rapides exemples :

Page 6 sur 13 LCA 7
Histogramme avec comparaison
La valeur du « p » indique si c’est statistiquement significatif ou non. L’axe des ordonnées est un axe logarithmique, les écarts ne sont pas de 1 mais sont beaucoup plus grands ! Dans certains cas, l’axe des Y peut être rompu, ce qui permet de dilater artificiellement l’écart entre les groupes.
3. Nuage de points
Permet de mettre en relation deux variables quantitatives (âge et cholestérol ici) Si l’on regarde de manière brève cette représentation, on peut penser qu’il y a une relation de
proportionnalité. A partir de 70 ans, tous les points sont au-‐dessus d’une certaine limite (à 5 environ). Avant 70 ans, il y a bien une relation de proportionnalité.
Attention : sachez que le cerveau est construit pour voir des formes, il ne voit que ce qu’il veut voir à analysez dans son ensemble et ne pas sauter sur l’occasion d’une relation en fait non
significative.
4. Boîte à moustaches

Page 7 sur 13 LCA 7
N’est pas uniforme. Permet de synthétiser l’information. On y retrouve la médiane, le Q1 et le Q3.
On peut y ajouter en plus des données habituelles la moyenne représentée par un point La médiane est représentée par un trait épais
Les données extrêmes La moustache (entre Q3 et la barre du haut) vaut 1,5x(Q3-‐Q1) : moustache= 1,5 fois l’écart interquartile .
Il est possible de représenter 2 boites à moustaches côte à côte pour faire la comparaison NB : ** indiquent que c’est réalisé à un niveau assez significatif ( p<0,01)
5. Diagramme à points On représente sur ce diagramme l’ensemble
des valeurs individuelles (Pour faire simple, on met tout les résultats : chaque valeur est représentée explicitement
par un point) Ici : l’importance de différence entre
hydroxyzine et placebo est due aux 2 points du haut seulement !
Ex : Un auteur analyse le lien entre le nombre d’heures de TD de LCA et la note à l’examen. Il réalise une régression linéaire et donne les résultats suivants :
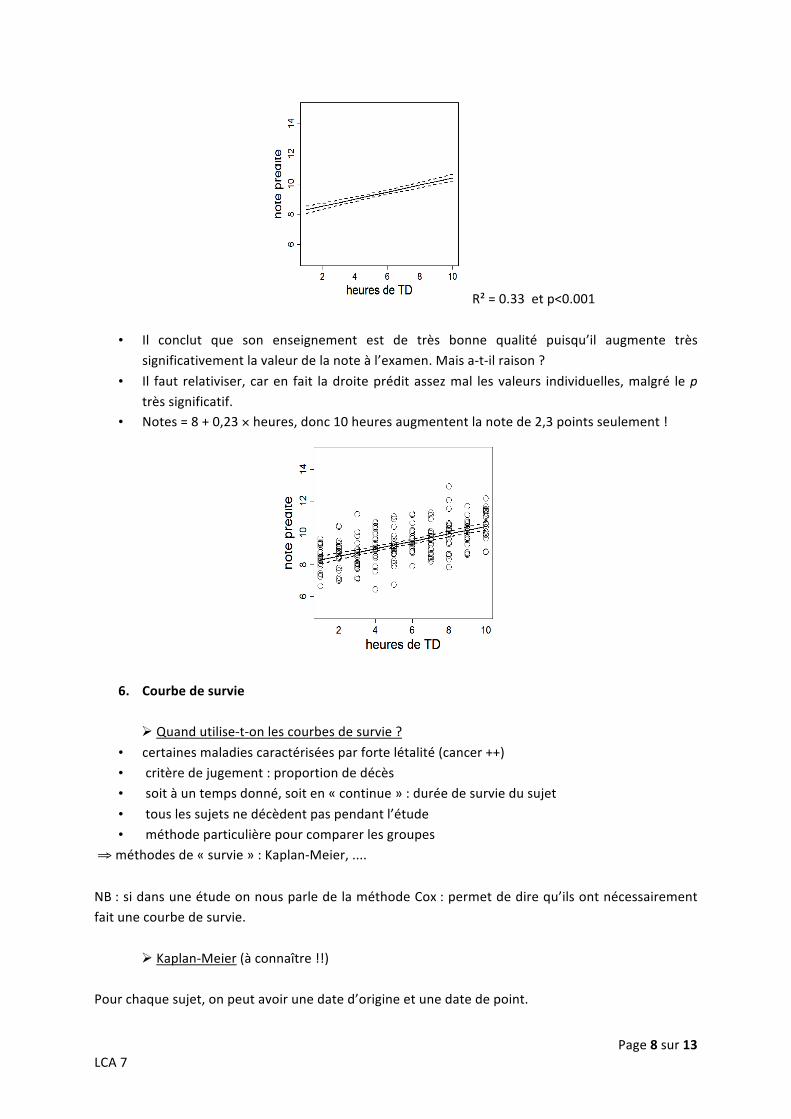
Page 8 sur 13 LCA 7
R² = 0.33 et p<0.001
• Il conclut que son enseignement est de très bonne qualité puisqu’il augmente très significativement la valeur de la note à l’examen. Mais a-‐t-‐il raison ?
• Il faut relativiser, car en fait la droite prédit assez mal les valeurs individuelles, malgré le p très significatif.
• Notes = 8 + 0,23 × heures, donc 10 heures augmentent la note de 2,3 points seulement !
6. Courbe de survie
Quand utilise-‐t-‐on les courbes de survie ?
• certaines maladies caractérisées par forte létalité (cancer ++) • critère de jugement : proportion de décès • soit à un temps donné, soit en « continue » : durée de survie du sujet
• tous les sujets ne décèdent pas pendant l’étude • méthode particulière pour comparer les groupes
⇒ méthodes de « survie » : Kaplan-‐Meier, ....
NB : si dans une étude on nous parle de la méthode Cox : permet de dire qu’ils ont nécessairement fait une courbe de survie.
Kaplan-‐Meier (à connaître !!) Pour chaque sujet, on peut avoir une date d’origine et une date de point.
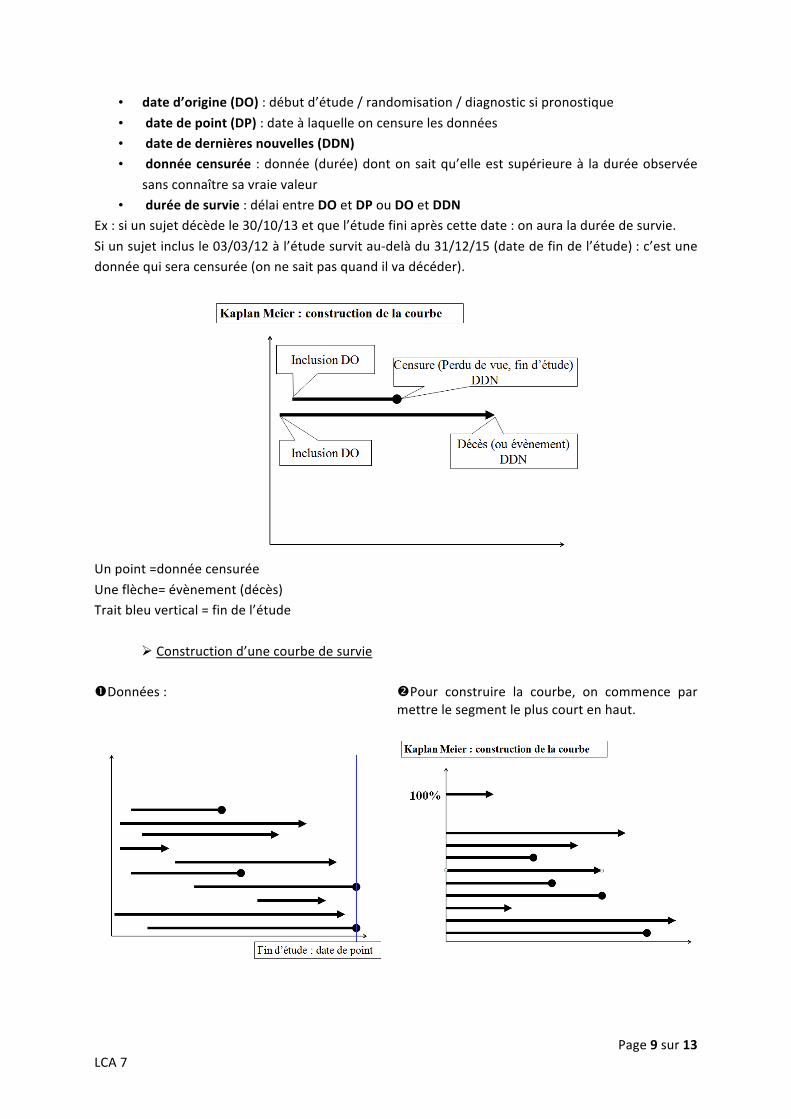
Page 9 sur 13 LCA 7
• date d’origine (DO) : début d’étude / randomisation / diagnostic si pronostique
• date de point (DP) : date à laquelle on censure les données • date de dernières nouvelles (DDN) • donnée censurée : donnée (durée) dont on sait qu’elle est supérieure à la durée observée
sans connaître sa vraie valeur • durée de survie : délai entre DO et DP ou DO et DDN
Ex : si un sujet décède le 30/10/13 et que l’étude fini après cette date : on aura la durée de survie.
Si un sujet inclus le 03/03/12 à l’étude survit au-‐delà du 31/12/15 (date de fin de l’étude) : c’est une donnée qui sera censurée (on ne sait pas quand il va décéder).
Un point =donnée censurée
Une flèche= évènement (décès) Trait bleu vertical = fin de l’étude
Construction d’une courbe de survie Données :
Pour construire la courbe, on commence par mettre le segment le plus court en haut.
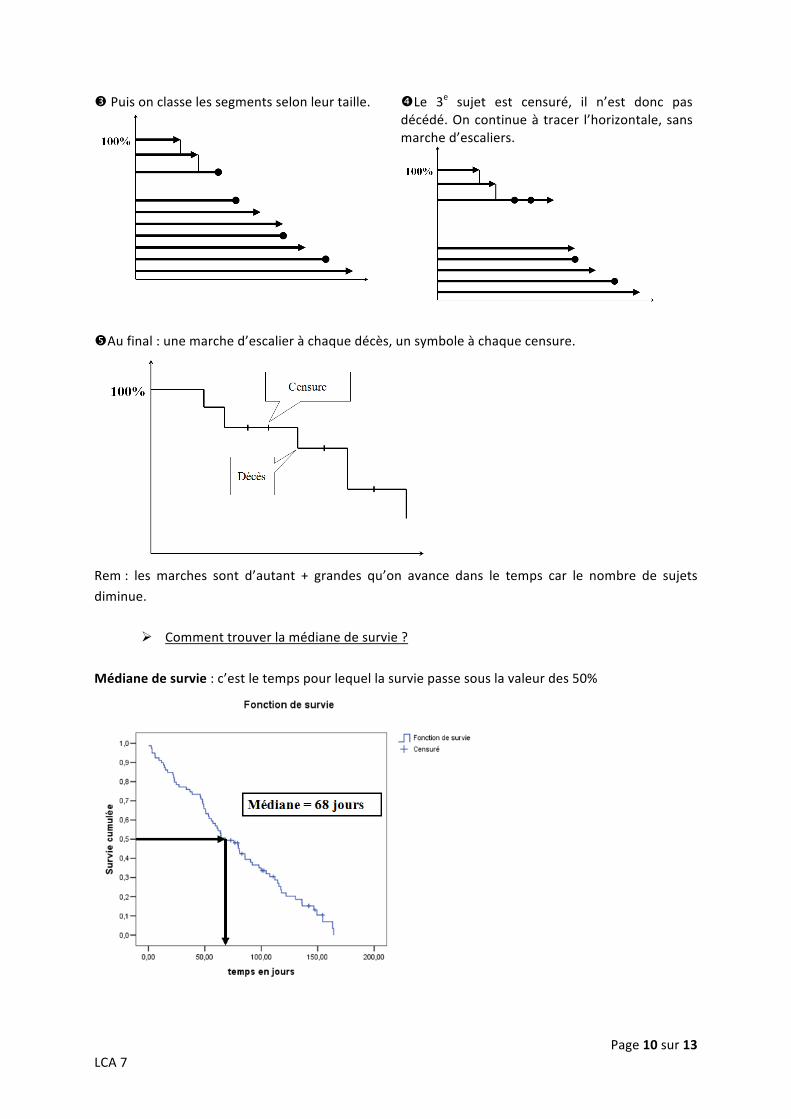
Page 10 sur 13 LCA 7
Puis on classe les segments selon leur taille.
Le 3e sujet est censuré, il n’est donc pas décédé. On continue à tracer l’horizontale, sans marche d’escaliers.
Au final : une marche d’escalier à chaque décès, un symbole à chaque censure.
Rem : les marches sont d’autant + grandes qu’on avance dans le temps car le nombre de sujets
diminue.
Comment trouver la médiane de survie ?
Médiane de survie : c’est le temps pour lequel la survie passe sous la valeur des 50%
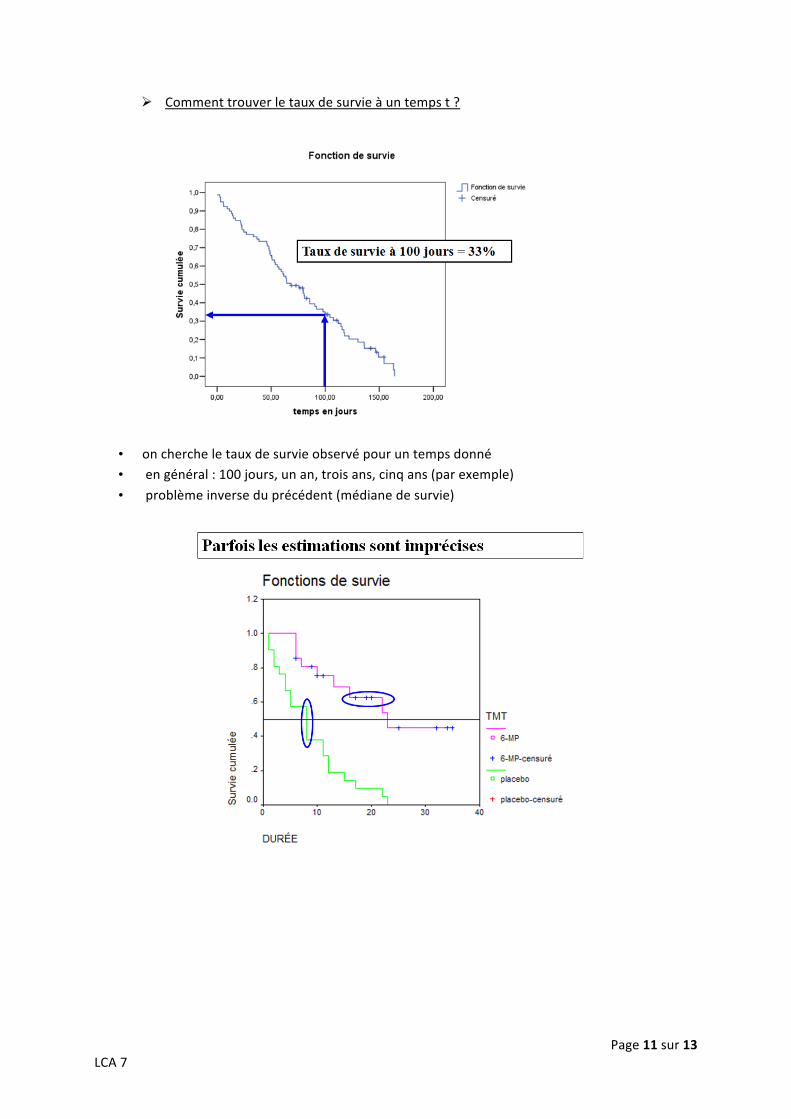
Page 11 sur 13 LCA 7
Comment trouver le taux de survie à un temps t ?
• on cherche le taux de survie observé pour un temps donné • en général : 100 jours, un an, trois ans, cinq ans (par exemple)
• problème inverse du précédent (médiane de survie)

Page 12 sur 13 LCA 7
Attention aux échelles ! Sur la figure ci-‐dessus, on pourrait croire à une importante différence alors qu’en fait on a dilaté l’axe des ordonnées.
NB : test du Log-‐rank : inutile de savoir le faire, ça doit simplement nous mettre la puce à l’oreille (courbe de survie)
Parfois, on inverse la courbe de survie donnant ainsi l’incidence de la survenue d’événements (la mort ici en l’occurrence)
Plus logique car on a jamais 0% de survie
• Autre présentation de la survie : proportion de patients ayant rempli le critère de
jugement
Plusieurs courbes sont sur le graphique on n’utilise pas nécessairement la méthode Kaplan-‐ Meier. Sur le graphique : il n’y a pas la valeur de p : c’est insuffisant.
Page 13 sur 13 LCA 7
7. Forest Plot
Il s’agit d’une « forêt de graphique ». On y trouve les représentations des données et des résultats.
Cette représentation permet de montrer les différences entre les groupes. Quand l’intervalle de confiance franchi la barrière du 1, c’est qu’il n’y a pas de différence entre les groupes.
8. Représentation de données répétées
NB : on remarque que le nombre de sujets utilisés à chaque analyse diminue.





![M11782 A Decathlon Trekking Poles IS · 2014-05-30 · [FR] NOTICE D’UTILISATION BÂTONS DE RANDONNÉE Tous les bâtons Black Diamond sont équipés de nos systèmes de réglage](https://img.pdfslide.us/doc/110x75/5e952a923276421de0368fe3/m11782-a-decathlon-trekking-poles-is-2014-05-30-fr-notice-dautilisation-btons.jpg)























