Embed Size (px)
Citation preview

Sistemas Inteligentes
y Redes Neuronales
(WOIA)
MSc. Ing. José C. Benítez P.
Sesión: 6
Adaline y Backpropagation

2
Sesión 6. Adaline y Backpropagation
� Características de Adaline.
� Regla de Aprendizaje (LMS). Regla Delta
� Aplicaciones de Adaline.
� Regla del Perceptron.
� Backpropagation.

3
Adaline: Características
� En 1960, en la Universidad de Stanford, Bernard
Widrow y Marcian Hoff, introdujeron la red ADALINE
(ADAptive LInear Neuron – ADAptive LINear Element) y
una regla de aprendizaje que llamaron LMS (Least
mean square).
� La adaline es similar al perceptron, sólo que su función
de transferencia es lineal, en lugar del escalón.
� Igual que el perceptrón, sólo puede resolver
problemas linealmente separables.
� MADALINE: Multiple ADALINE

4
Adaline: Características
Objetivo:
� Aplicar los principios de aprendizaje del rendimiento a redes
lineales de una sola capa.
� El aprendizaje Widrow-Hoff es una aproximación del
algoritmo del Descenso por gradiente, en el cual el índice de
rendimiento es el error cuadrático medio.
Importancia del algoritmo:
� Se usa ampliamente en aplicaciones de procesamiento de
señales.
� Es el precursor del algoritmo Backpropagation para redes
multicapas.

5
Adaline: CaracterísticasAlgoritmo LMS:
� Es más poderoso que la regla de aprendizaje del
perceptron.
� La regla de aprendizaje del perceptron garantiza
convergencia a una solución que clasifica correctamente
los patrones de entrenamiento. Esa red es sensible al
ruido, debido a que los patrones con frecuencia están muy
cerca de las fronteras de decisión.
� El algoritmo LMS minimiza el error cuadrático medio,
desplaza las fronteras de decisión lejos de los patrones de
entrenamiento.
� El algoritmo LMS tiene más aplicaciones prácticas que la
regla de aprendizaje del perceptron, especialmente en el
procesamiento digital de señales, como por ejemplo, para
cancelar echo en líneas telefónicas de larga distancia.

6
Adaline: Características
Algoritmo LMS:
� La aplicación de este algoritmo a redes multicapas no
prosperó por lo que Widrow se dedicó a trabajar en el
campo del procesamiento digital adaptativo, y en 1980
comenzó su investigación con la aplicación de las Redes
al control adaptativo, usando backpropagation temporal,
descendiente del LMS.

7
Adaline: Características
• Tipo de aprendizaje: Supervisado (OFF Line).
• Tipo de aprendizaje: por corrección de error.
• Algoritmo de aprendizaje: Regla del Mínimo Error
Cuadrático Medio (LMS), o regla Delta, o regla de
Widrow-Hoff
• Función de transferencia: lineal (purelin).
• Procesamiento de información analógica, tanto de
entrada como de salida, utilizando una función de
Activación Lineal o Sigmoidal.
• También puede resolver problemas LS.
8
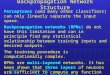
Adaline: Características
� Es aplicada a estructuras Lineales:
Idea:
Modificación de Pesos para tratar de reducir la diferencia entre la
salida deseada y la actual (para cada patrón).
� Se denomina LMS (Least mean squares): Minimo Error
Cuadrático Medio sobre todos los patrones de entrenamiento.

9
Adaline: CaracterísticasCálculo de Pesos ÓptimosSea el conjunto de entrenamiento:
(X,D): Patrones de entrada y salidas deseadas.
X : Conjunto de L vectores de dimensión n.
D: Salida Deseada.
Conjunto de L vectores de dimensión m (en este caso m=1).
Y: Salida Obtenida
Conjunto de L vectores de dimensión m ( en este caso m=1).
Se trata de minimizar: Sea Yk la salida obtenida para el patrón k.

10
Adaline: Características

11
Adaline: Características

12
Adaline: Características
Cálculo de W*: Método de Gradiente Descendente.
Diferentes Métodos:
� Buscar por todo el espacio de pesos hasta
encontrar los que hiciesen el error mínimo.
� Realizar una búsqueda aleatoria.
� Realizar una búsqueda Dirigida.
Método:
� Se inicializan los pesos aleatoriamente (pto. de
partida).
� Se determina, la dirección de la pendiente más
pronunciada en dirección hacia abajo.
� Se modifican los pesos para encontrarnos un
poco más abajo en la superficie.

13
Adaline: Características

14
Adaline: Características

15
Adaline: Algoritmo de Aprendizaje
1. Inicialización de pesos.
2. Se aplica un patrón de entrada (entradas y salida deseada).
3. Se computa la salida lineal que se obtiene de la red.
4. Se calcula el error cometido para dicho patrón.
5. Se actualizan las conexiones mediante la ecuación obtenida anteriormente.
6. Se repiten los pasos del 2 al 5 para todos los patrones de entrenamiento.
7. Si el error cuadrático medio es un valor reducido aceptable, termina el proceso. Sino se vuelve al paso 2.
16
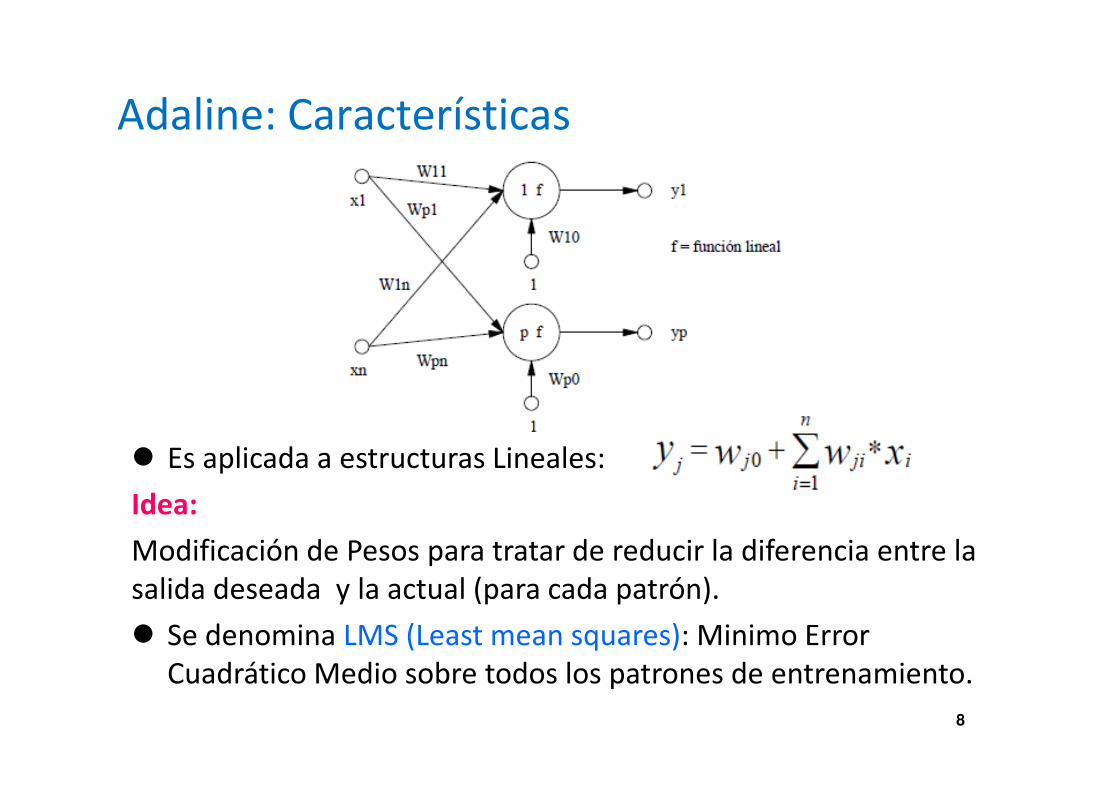
Adaline: Aplicaciones
� La principal aplicación de las redes tipo Adaline se encuentra
en el campo de procesamiento de señales. Concretamente
en el diseño de filtros capaces de eliminar ruido en señales
portadoras de información.
� Otra aplicación es la de los filtros adaptativos: Predecir el
valor futuro de una señal a partir de su valor actual.

17
Adaline: Conclusiones
� Una simple capa de PE lineales pueden realizar
aproximaciones a funciones lineales o asociación de
patrones.
� Una simple capa de PE lineales puede ser entrenada
con algoritmo LMS.
� Relaciones No Lineales entre entradas y salidas no
pueden ser representadas exactamente por redes
lineales. Dichas redes harán aproximaciones lineales.
Otro tipo de redes abordarán la resolución de
problemas no lineales.

18
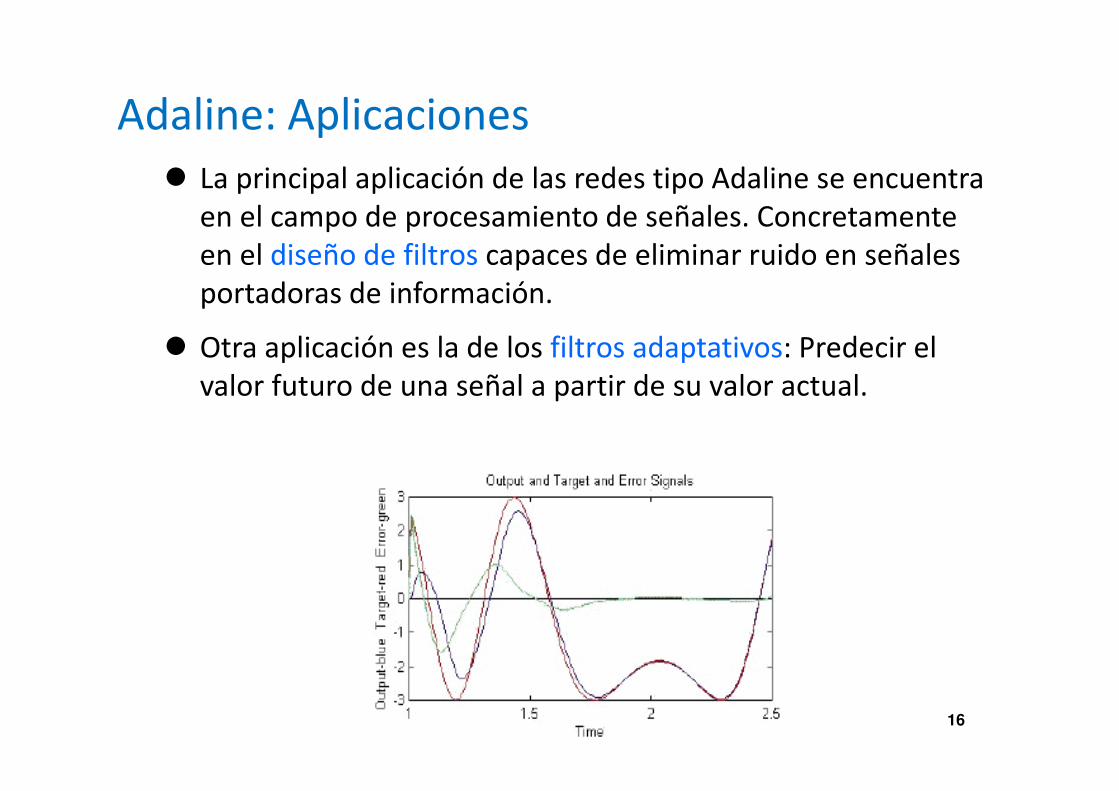
Regla del Perceptron (Rosenblatt)
� Supongamos un PE con una función de transferencia del tipo Hardlimiter y en donde las entradas son binarias o bipolares (mismo que Adaline pero con esas restricciones).
� La regla que rige el cambio de pesos es:
� Wi(t+1) = Wi(t) Si la salida es correcta.
� Wi(t+1) = Wi(t) + Xi(t) Si la salida = -1 y debería de ser 1.
� Wi(t+1) = Wi(t) - Xi(t) Si la salida = 1 y debería de ser -1.
� Sobre la regla anterior se han realizado diferentes modificaciones:

19
Regla del Perceptron (Rosenblatt)
� A)
� Wi(t+1) = Wi(t) Si la salida es correcta.
� Wi(t+1) = Wi(t) + µXi(t) Si la salida = -1 y debería de ser 1.
� Wi(t+1) = Wi(t) - µXi(t) Si la salida = 1 y debería de ser -1.
Con µ [0,1], término de control de ganancia y velocidad de aprendizaje.
� B) Otra de las modificaciones propuestas fue sugerida por Widrow and Hoff. Ellos propusieron una regla basada en la regla Delta. (Es la más utilizada).
Tomando las entradas y salidas como bipolares tenemos que el cambio en los pesos se produce de la manera siguiente:

20
Regla del Perceptron (Rosenblatt)
21
Regla del Perceptron (Rosenblatt)

22
Red Backpropagation
• Fue primeramente propuesto por Paul Werbos en los
70s en una Tesis doctoral.
• Sin embargo, este algoritmo no fue conocido sino hasta
1980 año en que fue re-descubierto por David
Rumelhart, Geoffrey Hinton y Ronald William, también
David Parker y Yan Le Cun.
• Fue publicado “Procesos Distribuidos en Paralelo” por
David Rumelhart y Mc Clelland, y ampliamente
publicitado y usado el algoritmo Backpropagation.
• El perceptron multicapa entrenado por el algoritmo de
retro propagación es la red mas ampliamente usada.

23
Red Backpropagation
• En muchas situaciones del mundo real, nos
enfrentamos con información incompleta o con ruido, y
también es importante ser capaz de realizar
predicciones razonables sobre casos nuevos de
información disponible.
• La red de retro propagación adapta sus pesos, para
adquirir un entrenamiento a partir de un conjunto de
pares de patrones entrada/salida
• Después que la red ha aprendido ha esta se le puede
aplicar un conjunto de patrones de prueba, para ver
como esta generaliza a patrones no proporcionados.

24
Red Backpropagation
• Red feedforward, completamente conectada.
• El flujo de información fluye de la capa de entrada a la
de salida a través de la capa oculta.
• Cada unidad de procesamiento en la capa se conecta a
todas las de la siguiente capa.
• El nivel de activación en la capa de salida determina la
salida de la red.
• Las unidades producen valores reales basados en una
función sigmoide.

25
Red Backpropagation
• Si n=0 a=0.5, conforme n se incrementa la
salida se aproxima a 1, conforme n
disminuye, a se aproxima a 0.
• Funciones de transferencia (diferenciables)
• Sigmoidales,
• Lineales
ne
a−
+=
1
1

26
Red Backpropagation
• La función de error define una superficie en el espacio de
pesos, y estos son modificados sobre el gradiente de la
superficie
• Un mínimo local puede existir en la superficie de decisión:
esto significa que no hay teorema de convergencia para la
retropropagación (el espacio de pesos es lo
suficientemente grande que esto rara ves sucede)
• Las redes toman un periodo grande de entrenamiento y
muchos ejemplos.
• Además mientras la red generaliza, el sobre entrenamiento
puede generar un problema.

27
Red Backpropagation: Arquitectura
R – S1 – S2 – S3 Network

28
Red BP: Algoritmo de Aprendizaje
• Los pesos se ajustan después de ver los pares entrada/salida
del conjunto de entrenamiento.
• En el sentido directo la red permite un flujo de activación en
las capas.
• En la retropropagación, la salida actual es comparada con la
salida deseada, entonces se calcula el error para las unidades
de salida
• Entonces los pesos en la salida son ajustados para reducir el
error, esto da un error estimado para las neuronas ocultas y
así sucesivamente.
• Una época se define como el ajuste de los pesos para todos los
pares de entrenamientos, usualmente la red requiere muchas
épocas para su entrenamiento.

29
Red BP: Algoritmo de Aprendizaje
1. Inicialice los pesos de la red con valores pequeños aleatorios.
2. Presentar un patrón de entrada y especificar la salida
deseada.
3. Calcule los valores de ajuste de las unidades de salida en base
al error observado.
4. Empezando por el nivel de salida, repita lo siguiente por cada
nivel de la red, hasta llegar al primero de los niveles ocultos:
• Propague los valores de ajuste de regreso al nivel anterior
• Actualice los pesos que hay entre los dos niveles.
5. El proceso se repite hasta que el error resulta
aceptablemente pequeño para cada uno de los patrones
aprendidos.

30
Red BP: Algoritmo de Aprendizaje
Gradiente Descendente:
Después que se calcula el error, cada peso se ajusta en
proporción al gradiente del error, retropropagado de la
salidas a las entradas.
El cambio en los pesos reduce el error total.
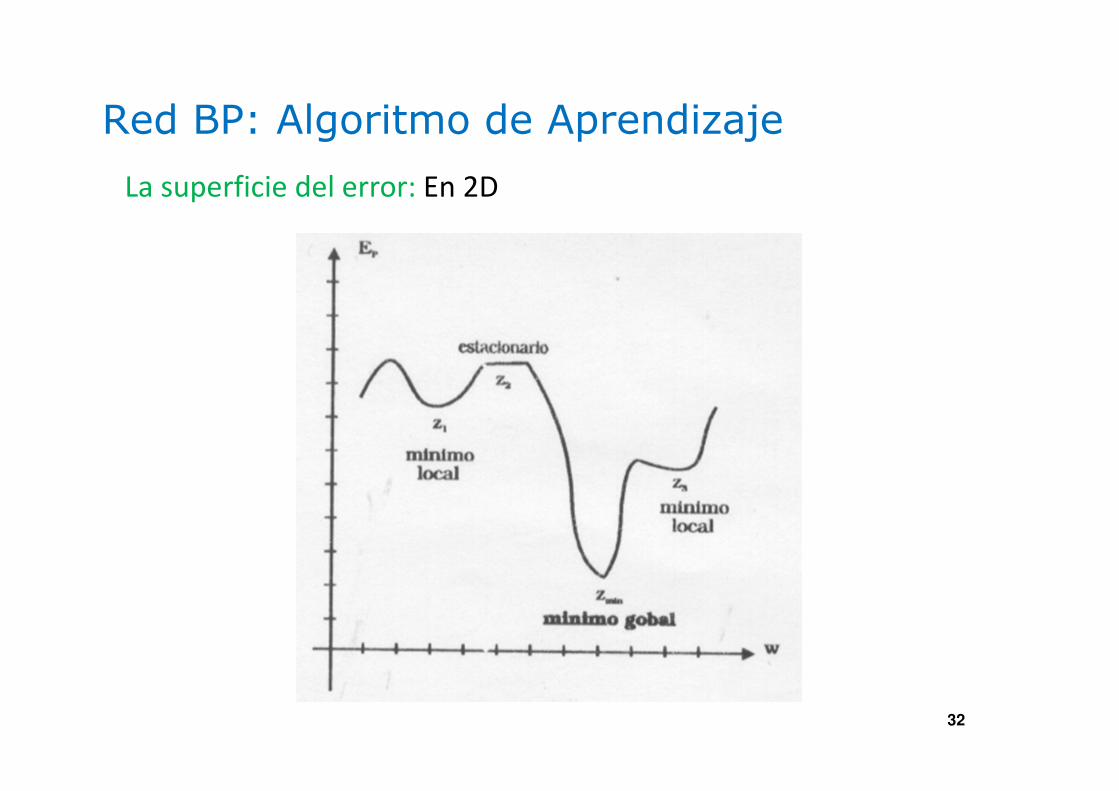
Mínimo Local:
Entre mas unidades ocultas se tengan en red, menor es
la probabilidad de encontrar un mínimo local.

31
Red BP: Algoritmo de Aprendizaje
La superficie del error:
32
Red BP: Algoritmo de Aprendizaje
La superficie del error: En 2D

33
Red BP: Algoritmo de Aprendizaje
La superficie del error: En 3D

34
Red BP: Algoritmo de Aprendizaje
Selección de los Wij iniciales:
• El error retro propagado a través de la red es proporcional
al valor de los pesos.
• Si todos los pesos son iguales, entonces el error retro
propagado será igual, y todos los pesos serán actualizados
en la misma cantidad
• Si la solución al problema requiere que la red aprenda con
pesos diferentes, entonces el tener pesos iguales al inicio
previene a la red de aprender.
• Es también recomendable tener valores pequeños de
activación (umbral) en las unidades de procesamiento.

35
Red Backpropagation: Aplicaciones
Determinar si un hongo es venenoso
• Considera 8124 variedades de hongo
• Cada hongo es descrito usando 21 características.
36
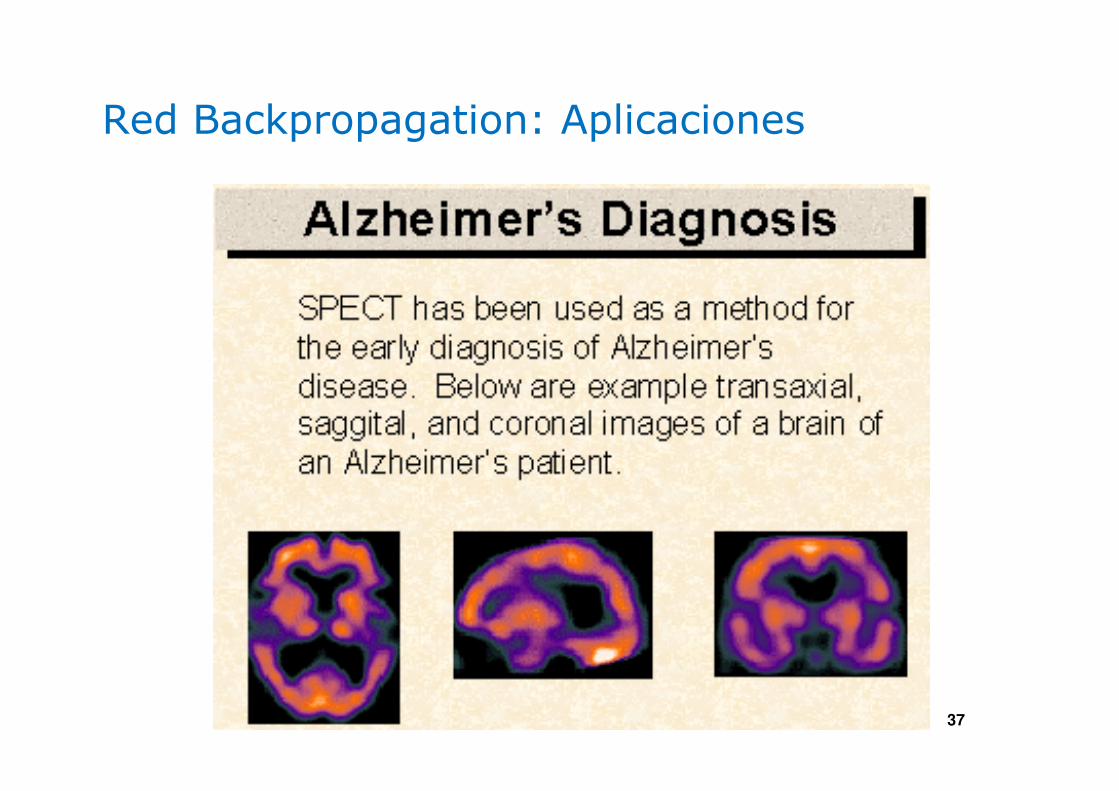
Red Backpropagation: Aplicaciones
Diagnostico Medico
• Basado en Visión
por computadora.
• Los síntomas son las
entradas.
• Los síntomas son
trasladadas a un
punto en el espacio
de los patrones.
37
Red Backpropagation: Aplicaciones
38
Red Backpropagation: Ejemplo XOR
011
14
110
13
111
02
010
01
=
=
=
=
=
=
=
=
TP
TP
TP
TP
Diseñe una red de retropropagación que
solucione el problema de la OR-exclusiva
usando el algoritmo de retropropación
(regla delta generalizada)
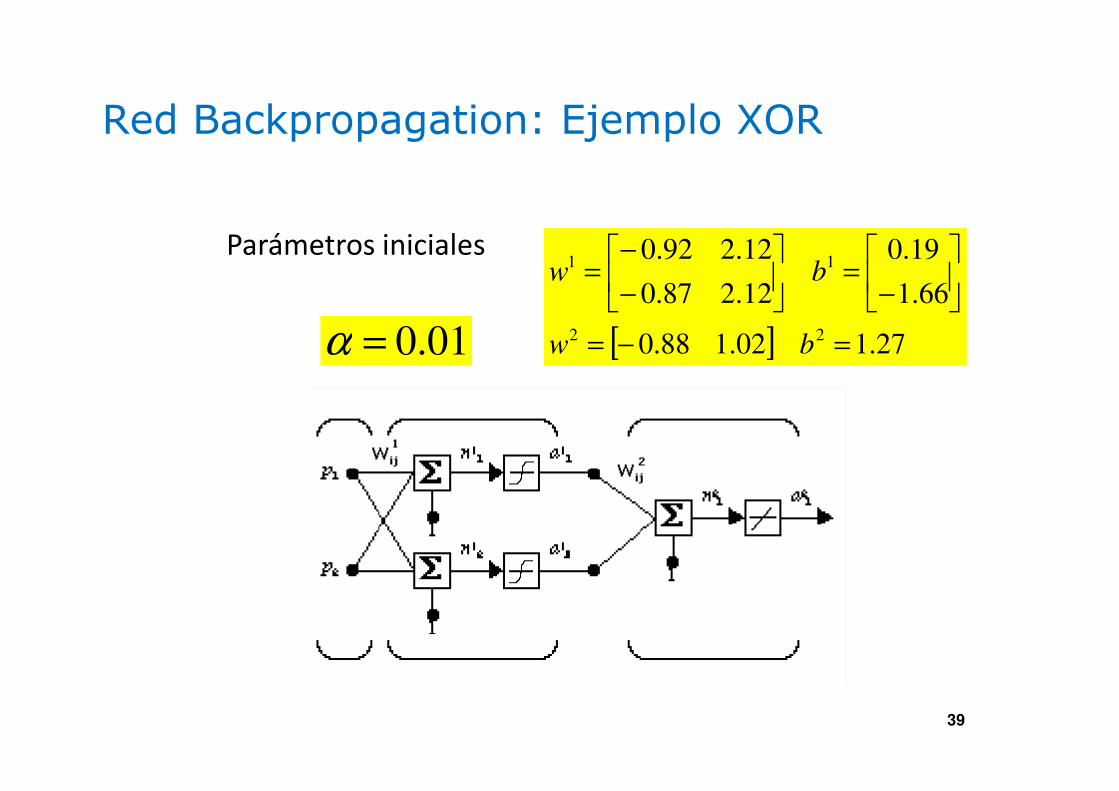
39
Red Backpropagation: Ejemplo XOR
[ ] 27.102.188.0
66.1
19.0
12.287.0
12.292.0
22
11
=−=
−=
−
−=
bw
bw
01.0=α
Parámetros iniciales

Resumen
Las Tareas que no cumplan las
indicaciones no serán consideradospor el profesor.
40
� Realizar un resumen mediante mapas conceptuales (CMapTools)
de esta diapositiva.
� Serán mejor consideradas los resúmenes que tengan información
extra a esta diapositiva.
� Las fuentes adicionales utilizadas en el resumen se presentarán
en su carpeta personal del Dropbox y deben conservar el nombre
original y agregar al final _S6.
� Las fuentes y los archivos *.cmap deben colocarse dentro de su
carpeta personal del Dropbox, dentro de una carpeta de nombre:
SIRN_PaternoM_S6

Preguntas
El resumen con mapas conceptuales solicitado de la Sesión al
menos debe responder las siguientes preguntas:
1. ¿Cuáles son las características de la red Adaline?
2. Describir el algoritmo de aprendizaje de la red Adaline.
3. Comparar las características del Perceptron y de Adaline.
4. Comparar la regla de aprendizaje del Perceptron y de Adaline.
5. Listar cinco aplicaciones de las redes Adaline/Madaline.
6. ¿Cuáles son las características de la red Backpropagation?
7. Describir el algoritmo de aprendizaje de la red BP.
8. Comparar las características del Perceptron y de Adaline.
9. Comparar la regla de aprendizaje de Adaline y BP.
10. Listar cinco aplicaciones de las redes BP.
41

42
Sesión 6. Adaline y Backpropagation
Sistemas Inteligentes y Redes Neuronales
http://utpsirn.blogspot.com