Embed Size (px)
Citation preview

Computer Networks 46 (2004) 555–574
www.elsevier.com/locate/comnet
Using the small-world model to improveFreenet performance q
Hui Zhang a,*,1, Ashish Goel b,2, Ramesh Govindan a,1
a Department of Computer Science, University of Southern California, 2642 Ellendale place #207, 941 W. 37th Place,
Los Angeles, CA 90007, USAb Departments of Management Science and Engineering and (by courtesy) Computer Science, Stanford University, CA 94305, USA
Received 11 August 2003; received in revised form 5 April 2004; accepted 18 May 2004
Available online 8 July 2004
Responsible Editor: S. Lam
Abstract
Efficient data retrieval in an unstructured peer-to-peer system like Freenet is a challenging problem. In this paper, we
study the impact of workload on the performance of Freenet. We find that there is a steep reduction in the hit ratio of
document requests with increasing load in Freenet. We show that a slight modification of Freenet�s routing table cachereplacement scheme (from LRU to a replacement scheme that enforces clustering in the key space) can significantly
improve performance. Our modification is based on intuition from the small-world models and theoretical results by
Kleinberg; our replacement scheme forces the routing tables to resemble neighbor relationships in a small-world
acquaintance graph––clustering with light randomness. Our simulations show that this new scheme improves the re-
quest hit ratio dramatically while keeping the small average hops per successful request comparable to LRU. A simple,
highly idealized model of Freenet under clustering with light randomness proves that the expected message delivery time
in Freenet is O(logn) if the routing tables satisfy the small-world model and have the size h(log2n).� 2004 Elsevier B.V. All rights reserved.
Keywords: Peer-to-peer; Algorithms; Freenet; Small-world; Cache replacement
1389-1286/$ - see front matter � 2004 Elsevier B.V. All rights reserved.
doi:10.1016/j.comnet.2004.05.004
q This is an extended version of the paper appearing in the proceedings of the IEEE Infocom, 2002.* Corresponding author. Tel.: +1 323 766 9537; fax: +1 213 740 7108.
E-mail address: [email protected] (H. Zhang).1 This research was supported in part by NSF grant CCR0126347.2 This research was done while the author was at the University of Southern California, and was supported in part by NSF grant
CCR0126347 and NSF Career grant No. 0133968.

556 H. Zhang et al. / Computer Networks 46 (2004) 555–574
1. Introduction
A peer-to-peer networked system is a collabo-
rating group of Internet nodes which overlay their
own special-purpose network on top of the Inter-net. Such a system performs application-level rout-
ing on top of IP routing. These systems share some
of the same characteristics as the Internet: they can
grow to be quite large, may need to utilize distrib-
uted control and configuration, usually employ a
naming scheme that allows them to address a node
without knowing its exact whereabouts, and pos-
sess a routing mechanism that allows each nodeto meaningfully communicate with the rest of the
system. Typically a peer-to-peer network performs
a very specific function such as distributed data
storage, cache replication, multicasting, and uses
normal Internet functionality for all other pur-
poses. These systems are diverse enough that it
would not be desirable to make modifications to
the IP routing/naming protocols to support eachinstance of such a system.
Peer-to-peer systems such as Napster [20] and
Gnutella [21] have received a fair amount of atten-
tion in the non-technical literature. In a parallel
development, several research groups have de-
signed a variety of peer-to-peer systems: systems
that provide infrastructure for flexibly evolving
the Internet [13,16], and systems for large-scalenetwork storage [10], anonymous publishing [3],
and application-level multicast [2,5,6].
At the core of many of these systems [3,10,13,16]
lie innovative and novel distributed algorithms for
disseminating content. These systems can be mode-
led as distributed hash–tables; they essentially dis-
tribute Ækey,dataæ tuples across various nodes in alarge network in a manner that facilitates scalableaccess to these tuples using the key. We taxonomize
these systems into two categories: structured sys-
tems where the assignment of a key to the node
on which its corresponding data is stored is deter-
mined by the structure of the key space, and
unstructured systems where no such assignment ex-
ists. Systems like CAN [13], Chord [16], and Tapes-
try [19] are examples of the former, and Freenet [3]is an instance of the latter.
Such systems can have interesting and unantici-
pated properties. In this paper, we study the per-
formance of an unstructured system, Freenet. We
find that the hit ratio (the likelihood of finding
the datum associated with a key within a fixed num-
ber of network hops) in Freenet is crucially depend-
ent on the local policy used to manage the cache ofdata (called datastore in Freenet) and the routing
table. A standard LRU-like cache replacement pol-
icy can result in significantly low hit ratio under
heavy load (i.e., when the number of files stored
in the network is high). This is an important find-
ing. While memory is cheap these days, Freenet-
like peer-to-peer systems will always have limits
on cache sizes. Thus, examining the performancedegradation of such systems under heavy load be-
comes important, especially, for example, in the
context of understanding the immunity of these
systems to denial-of-service attacks. Moreover, this
is not merely an academic exercise; heavy routing
loads and the resulting poor performance have
been observed in the Freenet network [22] recently,
caused by users splitting large files (e.g., operatingsystem images) into hundreds of smaller files to
enable faster, parallel, downloads.
At low loads, Freenet performs well because
each node ‘‘specializes’’ in a part of the key space
[3], resulting in routing tables at nodes that are
clustered around a small number of values. At
higher loads, however, frequent replacement of
routing table entries using LRU breaks up the clus-tering in the routing table. Our solution to this per-
formance degradation relies on two observations.
First, we observe that the routing tables can be
shaped by changing the cache replacement policy
at each node; this need not include any changes
to the Freenet routing protocol and is therefore
incrementally deployable. Second, we use intuition
from the small world model [8,17,18] which saysthat the routing distance in a graph is small if each
node has pointers to its geographical neighbors
(causing clustering) as well as some randomly cho-
sen far away nodes. This intuition leads us to pro-
pose a simple clustered cache replacement scheme
with a small amount of randomization.
We then perform a simulation study to compare
the two schemes under heavy loads. Our proposedcache replacement scheme results in a significantly
higher hit ratio compared to LRU, and also a
significantly smaller number of average hops per

Fig. 1. An example of a search in a Freenet network. Node A
searches for key 8 and finally finds it in E.
H. Zhang et al. / Computer Networks 46 (2004) 555–574 557
request. The proposed scheme and LRU result in
similar values for the average number of hops
per successful request. It is interesting that such a
small change in the system can lead to a significant
improvement.To understand this, we also develop an ideal-
ized model of Freenet under our cache replace-
ment scheme. We prove that the expected
message delivery time in this idealized model is
O(logn), provided we have h(log2n) amount ofmemory per node. Here n is the number of nodes
in the system. By comparison, more structured sys-
tems such as Chord [16], Pastry [15], Tapestry [19]achieve a delivery time of O(logn) with h(logn)memory. It is surprising that an unstructured sys-
tem such as Freenet can come so close to the struc-
tured systems, even in a highly idealized model.
The paper is organized as follows: in Section 2
we give a brief description of Freenet and the
small-world model. Section 3 presents the prelimi-
nary simulation results for the original Freenetprotocol. In Section 4 a simple enhanced-clustering
cache replacement scheme is proposed and the sim-
ulation results show that the enhanced-clustering
caching outperformed both LRU caching and the
strict enhanced-clustering caching without random
shortcuts. Section 5 presents our analytical results
and Section 6 concludes the paper.
2. Freenet and the small-world model
This section provides some background on the
design of Freenet and on the properties of small-
world graphs.
2.1. Freenet
Freenet [3] is a distributed anonymous informa-
tion storage and retrieval system. In Freenet, files
are identified by binary file keys obtained by
applying a hash function to a string that describes
the contents of the file. For this reason, we use the
words key, file, and data interchangeably in this
paper. Each node maintains a routing table whichis a set of Ækey,pointeræ pairs, where pointer pointsto a node that has a copy of the file associated with
key. A steepest-ascent hill-climbing search with
backtracking is used to locate a document. Loop
detection and aHopsToLive (Freenet�s TTL) coun-ter are added to this basic scheme to avoid request
looping and exhaustive searching.
Freenet�s routing algorithm is best described
using an example. Fig. 1 shows how a request mes-
sage is routed in Freenet. A request for key 8 is ini-
tiated at node A. Node A forwards the request to
node B, which forwards it to node C since in B�srouting table C is the node who has the closestkey to key 8. Node C is unable to contact any
other nodes and returns a backtracking ‘‘request
failed’’ message to B. Node B then tries its second
choice, D. Node D finds key 8 in its routing table
and forwards the request to the corresponding
node––E. The data is returned from E via D and
B back to A, which ends this request sequence.
The data is cached on D, B and A. An entry forkey 8 is also created in the routing tables of D, B
and A. Data inserts follow a similar strategy to re-
quests [3].
In this algorithm, there is no global consensus
on where a document should be stored. Freenet
chose an unstructured key space architecture in or-
der to achieve anonymity and deniability. How-
ever, the request routing, data insertion, anddata caching algorithms in Freenet are designed
so that, over time, the key space becomes increas-
ingly structured and the routing tables converge to
a state where most of the queries are answered suc-
cessfully and quickly.
In addition to appropriately structuring theFree-
net routing tables, essential to system performance

3 The simulator can be downloaded from http://net-
web.usc.edu/~huizhang/freenet.html
558 H. Zhang et al. / Computer Networks 46 (2004) 555–574
in Freenet is its datastore. As described in Freenet
protocol [3], when a file is ultimately returned (for-
warded) for a successful retrieval (insertion), the
node caches the file in its datastore, passes the data
to the upstream (downstream) requester, and cre-ates a new entry in its routing table associating
the actual data source with the requested key.
When a new file arrives (from either a new insert
or a successful request) which would cause the
datastore to exceed the designated size, the least
recently used (LRU) files are evicted in order until
there is room. Routing table entries are also even-
tually replaced using an LRU policy as the tablefills up. Note that the size of the routing table is
chosen with the intention that the entry for a file
will be retained longer than the file itself.
2.2. Small-world model
The small-world phenomenon is pervasive in
networks arising from society, nature, and tech-nology. In many such networks, empirical obser-
vations suggest that any two individuals in the
network are likely to be connected through a short
sequence of intermediate acquaintances [9,17]. One
network construction that gives rise to small-world
behavior is where each node in the network knows
its physical neighbors, as well as a small number of
randomly chosen distant nodes. The latter repre-sent shortcuts in the network. It has been shown
that this construction leads to graphs with small
diameter, leading to a small routing distance be-
tween any two individuals [17,18]. Kleinberg [9]
defined an infinite family of network models that
naturally generalized the model in [18] and then
proved that there is exactly one model within this
family for which a decentralized algorithm existsto find short paths with high probability. In this
model, the probability of a random shortcut being
a distance x away from the source is proportional
to 1/x in one dimension, proportional to 1/x2 in
two dimensions, and so on.
2.3. Freenet and the small-world phenomenon
Freenet�s routing mechanisms were designed toevolve the network into a state with low average
path lengths and high hit ratios. In particular, in
[7] it is shown that the median path length in a
Freenet network scales logarithmically with the
size of the network and its clustering coefficient
is high, both defining characteristics of small-
world networks. However, those simulations wereconducted under low load. In their 1000-node sim-
ulation, the average number of files inserted into
the network by one node is only 2.5. We were able
to reproduce the logarithmic relationship observed
in [7] at these low loads using our simulator.
However, in this paper, we focus on the behav-
ior of Freenet under heavy loads. We show that, in
this regime, Freenet�s performance degrades con-siderably. Then, we use intuition from the small-
world model to design a cache replacement scheme
that attempts to preserve Freenet�s performanceeven under heavy loads.
3. Simulating Freenet performance under heavy load
Freenet�s design focus on anonymity makes ithard to measure the global network directly, a fact
already observed by the designers of Freenet [3].
For this reason, we resort to simulation to study
the performance of Freenet. We implemented a
stand-alone simulator 3 that mimics document
generation, storage, routing, and retrieval in Free-
net. In this section, we state the assumptions madein our simulation, define the metrics that we use in
our evaluation of Freenet and present our simula-
tion results.
Much of this paper is devoted to the study of
Freenet under heavy ‘‘loads’’. Our measure of load
is the average number of files inserted by a node
into the system, since we are interested in investi-
gating the impact of cache replacement strategies.
3.1. Simulation assumptions
Lacking data about actual file insertion work-
loads, we assume that all nodes generate data files
and send requests at the same rate. Furthermore,
we assume that all nodes have the same size of

0
0.2
0.4
0.6
0.8
1
5 10 15 20 25
Req
uest
Hit
Rat
io
# of keys generated per node
RING TOPOLOGY (300 nodes, cache size =60)
LRU
Fig. 2. The curve of hit ratio vs. load for Freenet with LRU
scheme.
H. Zhang et al. / Computer Networks 46 (2004) 555–574 559
datastore and routing table. While these assump-
tions are somewhat unrealistic, they enable us to
understand the impact of cache limits more easily.
We also examine how deviations from these
assumptions impact our conclusion.In our simulations, we do not model the impact
of node failures. Node failures are somewhat or-
thogonal to the impact of cache limits, and we
do not expect that they will alter our basic find-
ings. Node failures can impact the convergence
time of the Freenet system to a ‘‘good’’ state, how-
ever.
3.2. Performance metrics
Intuitively, the performance of a routing system
such as Freenet is well captured by the average
path length required to access a data item. In prac-
tice, Freenet imposes a HopsToLive on data ac-
cesses. Therefore, the performance of the system
is better represented by two metrics: request hit ra-tio and average hops per request.
The former is defined as the ratio of the number
of successful requests to the total number of re-
quests made. For reasons that will become later,
we define two variants of the latter metric. Average
hops per request is the ratio of the total number of
hops incurred across all requests to the number of
all requests. When a request fails, it is deemed tohave incurred HopsToLive number of hops. Aver-
age hops per successful request is defined similarly,
but only for requests that are successful.
3.3. Freenet performance under varying loads
In this section, we illustrate the performance of
Freenet under heavy load using a simple simula-tion. The duration of the simulation was 30,000
time steps, and the network had 300 nodes. All
files are of the same size (we call it uniform size dis-
tribution). Each node had a datastore limit of 60
files, a routing table limit of 110 files. The initial
topology of the system is a ring: each node has
pointer to two neighbors. This initial topology is
imposed by Freenet routing tables, and need nothave any relation to the underlying physical Inter-
net topology. Each request is limited to 40 hops.
Each node randomly generates and inserts a key
(i.e., a file) with probability K per time step in
the first 200 time steps (K varies in the range
[0.005,0.13]). All insertions are stopped after time
200. Each node generates a request for a random
key with probability R=0.002 per time stepthroughout the whole simulation. The document
popularity has an uniform distribution, i.e., all files
have the same probability to be requested.
The simulation result in Fig. 2 shows that re-
quest hit ratio decreases significantly with an in-
crease in the loads in the network. To check
whether this behavior was primarily due to cache
or routing table size limits, we repeated the abovesimulation but increased the datastore size to 180
and the routing table size to 230, or kept the data-
store size as 60 but increased the routing table size
to 240. The simulation results in Fig. 3 shows two
curves with the same shape. In addition, we did the
same simulation with the document popularity as
Zipf distribution and the document size as Zipf
distribution (the Zipf parameter a=1), and stillgot the qualitatively same curves as shown in
Fig. 4.
In an attempt to understand this rapid degrada-
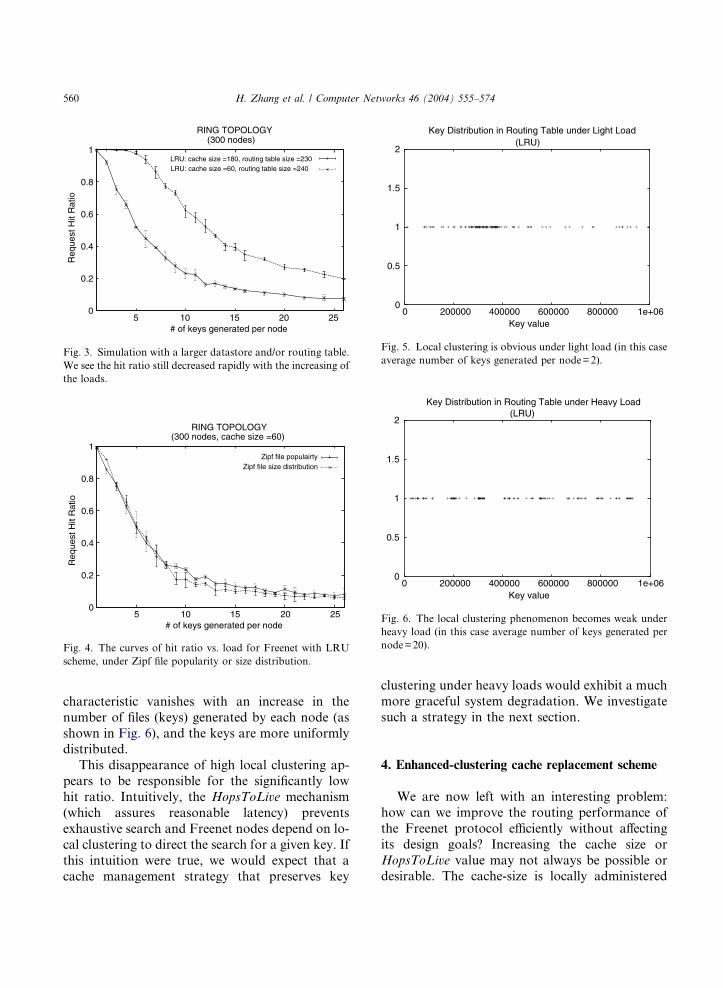
tion with loads, we plot the key distribution (at the
end of the simulation) of an arbitrarily chosen
Freenet node�s routing table under light and heavyloads. Fig. 5 shows that under light loads, the keys
at this node tend to be clustered close to key num-ber 350,000 (approximately). But this clustering
0
0.5
1
1.5
2
0 200000 400000 600000 800000 1e+06Key value
Key Distribution in Routing Table under Heavy Load (LRU)
Fig. 6. The local clustering phenomenon becomes weak under
heavy load (in this case average number of keys generated per
node=20).
0
0.2
0.4
0.6
0.8
1
5 10 15 20 25
Req
uest
Hit
Rat
io
# of keys generated per node
RING TOPOLOGY (300 nodes)
LRU: cache size =180, routing table size =230LRU: cache size =60, routing table size =240
Fig. 3. Simulation with a larger datastore and/or routing table.
We see the hit ratio still decreased rapidly with the increasing of
the loads.
0
0.2
0.4
0.6
0.8
1
5 10 15 20 25
Req
uest
Hit
Rat
io
# of keys generated per node
RING TOPOLOGY (300 nodes, cache size =60)
Zipf file populairtyZipf file size distribution
Fig. 4. The curves of hit ratio vs. load for Freenet with LRU
scheme, under Zipf file popularity or size distribution.
0
0.5
1
1.5
2
0 200000 400000 600000 800000 1e+06Key value
Key Distribution in Routing Table under Light Load (LRU)
Fig. 5. Local clustering is obvious under light load (in this case
average number of keys generated per node=2).
560 H. Zhang et al. / Computer Networks 46 (2004) 555–574
characteristic vanishes with an increase in the
number of files (keys) generated by each node (as
shown in Fig. 6), and the keys are more uniformlydistributed.
This disappearance of high local clustering ap-
pears to be responsible for the significantly low
hit ratio. Intuitively, the HopsToLive mechanism
(which assures reasonable latency) prevents
exhaustive search and Freenet nodes depend on lo-
cal clustering to direct the search for a given key. If
this intuition were true, we would expect that acache management strategy that preserves key
clustering under heavy loads would exhibit a much
more graceful system degradation. We investigate
such a strategy in the next section.
4. Enhanced-clustering cache replacement scheme
We are now left with an interesting problem:
how can we improve the routing performance of
the Freenet protocol efficiently without affecting
its design goals? Increasing the cache size or
HopsToLive value may not always be possible ordesirable. The cache-size is locally administered

Random key(shortcut)
s (x)
Clustered keys
Key Space
Fig. 7. For the routing table at node x to conform to the small-
world model, we need a set of key entries clustered around some
key s(x) and one or more randomly chosen shortcut keys.
H. Zhang et al. / Computer Networks 46 (2004) 555–574 561
since it depends on individual system resources.Increasing the HopsToLive value could increase
the hit ratio, but at the expense of significantly in-
creased access latency. From Fig. 7, the crucial
observation is that we can achieve our perform-
ance goals by preserving key clustering in the
cache and this can be done passively by changing
the cache replacement policy without changing
the Freenet routing protocol or sacrificing ano-nymity and deniability. Recall that when a data-
store is full at a node, the node discards the least
recently used files and creates a new Ækey,pointerætuple in the routing table for the new file to be ca-
ched. In order to shape the routing table, we use
the following enhanced-clustering cache replace-
ment scheme instead of LRU (note that LRU is
still used for routing table replacement).
4.1. Enhanced-clustering cache replacement scheme
The enhanced-clustering cache replacement
scheme consists of two parts:
1. Each node x chooses a seed s(x) 4 randomly
from the key space S when it joins the system.2. When the datastore at a node x is full and a new
file with the tuple ÆKey u,DataSource dæ arrivesdue to either a new insertion or a successful re-
quest, the node finds out in the current data-
store the file with key v farthest from the seed
in terms of the distance in the key space S.
4 s(x) can be the globally unique identifier assigned to x in
original Freenet protocol.
Distanceðv; sðxÞÞ¼ maxw2Datastore
Distanceðw; sðxÞÞ:
(a) If Distance(u, s(x))>Distance(v, s(x)), with
the probability p (randomness) x caches the
new file, creates one entry Æu,dæ for it in therouting table, and evicts the old file associ-
ated with key v. This has the effect of creat-
ing a few random shortcuts.
(b) If Distance(u, s(x)) 6 Distance(v, s(x)), withthe probability 1�p x caches the new file,
creates one entry Æu,dæ for it in the routingtable, and evicts the old file associated with
key v. This has the effect of clustering the
keys in the routing table around the seed
of the node.
(c) Otherwise, the file is not locally cached and
no routing table entry is created for it.
4.2. Comparison of three cache replacement
schemes
We now investigate whether this simple replace-
ment scheme performs well under heavy load. To
calibrate its performance, we compare it with the
LRU cache replacement scheme. In addition, toseparately understand the contribution to per-
formance of clustering and random shortcuts, we
evaluate a third alternative that we call strict en-
hanced-clustering. Strict enhanced-clustering uses
the algorithm defined above, but with p set to 0:
this disables random shortcuts and effectively
shapes the routing table to make the network a
regular graph.In our evaluations, enhanced-clustering uses
p=0.03 and keeps small number of random short-
cuts in the routing table. Intuitively, this scheme
should make Freenet look more like a small-world
network. The probability p=0.03 was chosen in
order to achieve a combination of high hit ratio
and low average hops per request for the range
0 6 p 6 1 in simulations. It remains an interestingopen problem to determine the best value of p as a
function of the network and load characteristics.
4.2.1. Performance under heavy load
We repeated the simulation in Section 3 with
uniform file size and popularity distributions.
Fig. 8 shows the availability of the system (i.e.,
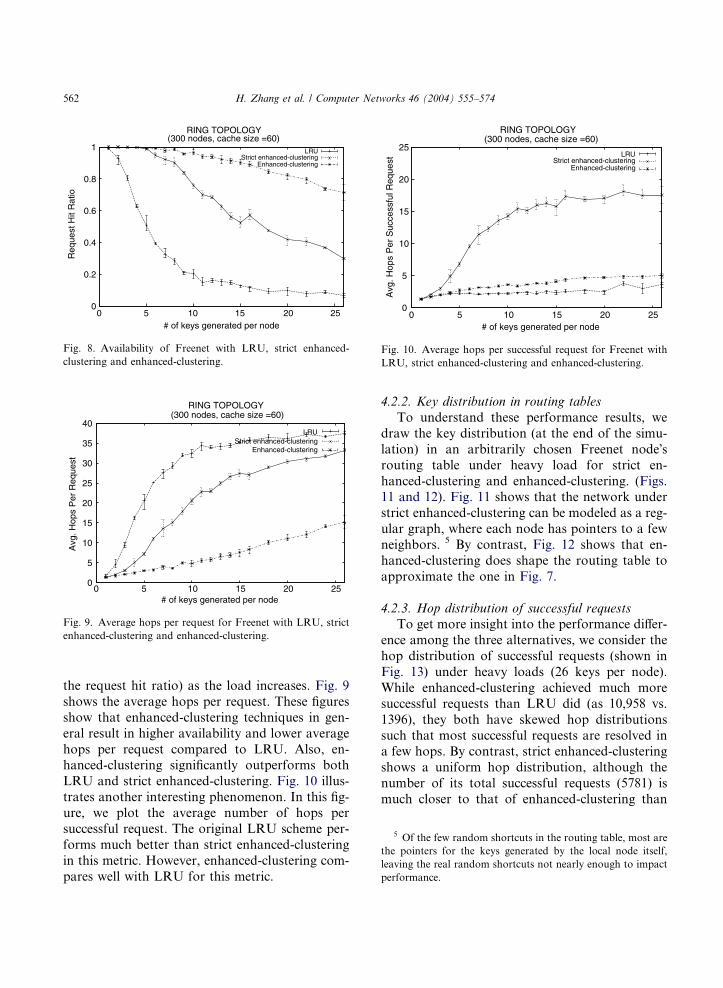
0
5
10
15
20
25
30
35
40
0 5 10 15 20 25
Avg
. Hop
s P
er R
eque
st
# of keys generated per node
RING TOPOLOGY (300 nodes, cache size =60)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 9. Average hops per request for Freenet with LRU, strict
enhanced-clustering and enhanced-clustering.
0
5
10
15
20
25
0 5 10 15 20 25
Avg
. Hop
s P
er S
ucce
ssfu
l Req
uest
# of keys generated per node
RING TOPOLOGY (300 nodes, cache size =60)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 10. Average hops per successful request for Freenet with
LRU, strict enhanced-clustering and enhanced-clustering.
5 Of the few random shortcuts in the routing table, most are
the pointers for the keys generated by the local node itself,
leaving the real random shortcuts not nearly enough to impact
performance.
0
0.2
0.4
0.6
0.8
1
0 5 10 15 20 25
Req
uest
Hit
Rat
io
# of keys generated per node
RING TOPOLOGY (300 nodes, cache size =60)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 8. Availability of Freenet with LRU, strict enhanced-
clustering and enhanced-clustering.
562 H. Zhang et al. / Computer Networks 46 (2004) 555–574
the request hit ratio) as the load increases. Fig. 9
shows the average hops per request. These figures
show that enhanced-clustering techniques in gen-
eral result in higher availability and lower average
hops per request compared to LRU. Also, en-hanced-clustering significantly outperforms both
LRU and strict enhanced-clustering. Fig. 10 illus-
trates another interesting phenomenon. In this fig-
ure, we plot the average number of hops per
successful request. The original LRU scheme per-
forms much better than strict enhanced-clustering
in this metric. However, enhanced-clustering com-
pares well with LRU for this metric.
4.2.2. Key distribution in routing tables
To understand these performance results, we
draw the key distribution (at the end of the simu-
lation) in an arbitrarily chosen Freenet node�srouting table under heavy load for strict en-
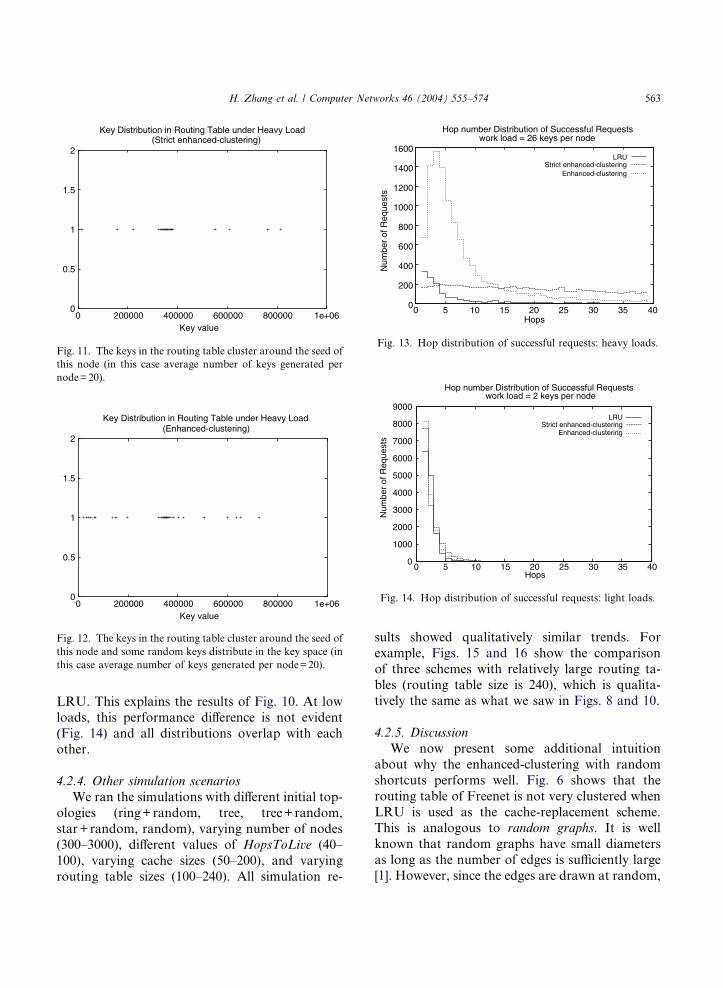
hanced-clustering and enhanced-clustering. (Figs.11 and 12). Fig. 11 shows that the network under
strict enhanced-clustering can be modeled as a reg-
ular graph, where each node has pointers to a few
neighbors. 5 By contrast, Fig. 12 shows that en-
hanced-clustering does shape the routing table to
approximate the one in Fig. 7.
4.2.3. Hop distribution of successful requests
To get more insight into the performance differ-
ence among the three alternatives, we consider the
hop distribution of successful requests (shown in
Fig. 13) under heavy loads (26 keys per node).
While enhanced-clustering achieved much more
successful requests than LRU did (as 10,958 vs.
1396), they both have skewed hop distributions
such that most successful requests are resolved ina few hops. By contrast, strict enhanced-clustering
shows a uniform hop distribution, although the
number of its total successful requests (5781) is
much closer to that of enhanced-clustering than
0
0.5
1
1.5
2
0 200000 400000 600000 800000 1e+06Key value
Key Distribution in Routing Table under Heavy Load (Enhanced-clustering)
Fig. 12. The keys in the routing table cluster around the seed of
this node and some random keys distribute in the key space (in
this case average number of keys generated per node=20).
0
200
400
600
800
1000
1200
1400
1600
0 5 10 15 20 25 30 35 40
Num
ber
of R
eque
sts
Hops
Hop number Distribution of Successful Requests work load = 26 keys per node
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 13. Hop distribution of successful requests: heavy loads.
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
0 5 10 15 20 25 30 35 40
Num
ber
of R
eque
sts
Hops
Hop number Distribution of Successful Requests work load = 2 keys per node
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 14. Hop distribution of successful requests: light loads.
0
0.5
1
1.5
2
0 200000 400000 600000 800000 1e+06Key value
Key Distribution in Routing Table under Heavy Load (Strict enhanced-clustering)
Fig. 11. The keys in the routing table cluster around the seed of
this node (in this case average number of keys generated per
node=20).
H. Zhang et al. / Computer Networks 46 (2004) 555–574 563
LRU. This explains the results of Fig. 10. At low
loads, this performance difference is not evident
(Fig. 14) and all distributions overlap with each
other.
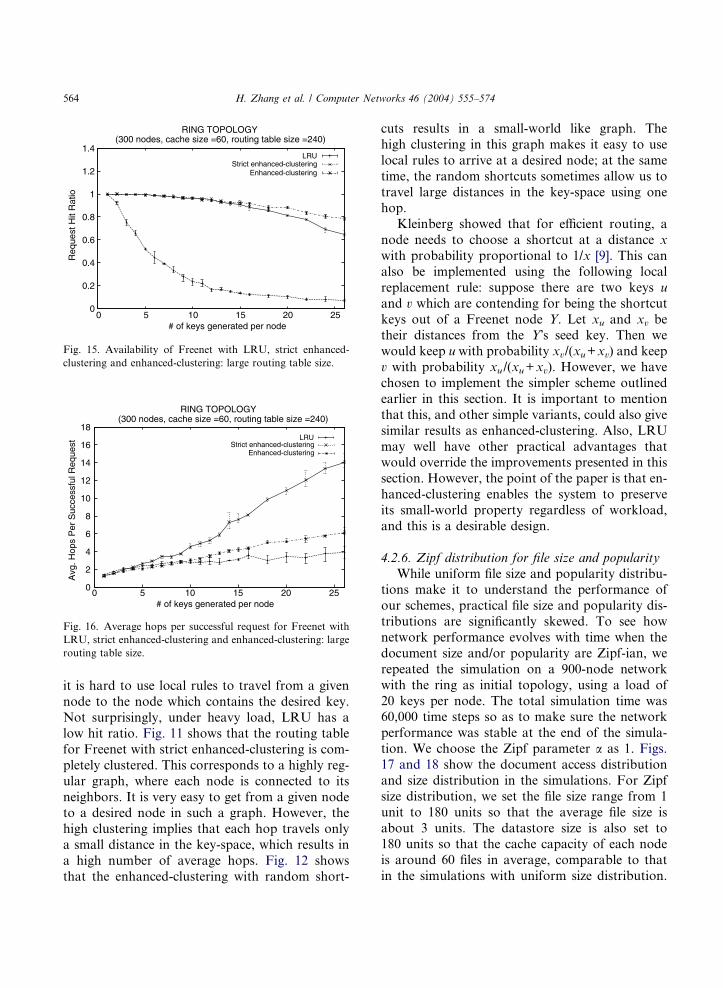
4.2.4. Other simulation scenarios
We ran the simulations with different initial top-
ologies (ring+random, tree, tree+random,
star+random, random), varying number of nodes
(300–3000), different values of HopsToLive (40–
100), varying cache sizes (50–200), and varying
routing table sizes (100–240). All simulation re-
sults showed qualitatively similar trends. For
example, Figs. 15 and 16 show the comparison
of three schemes with relatively large routing ta-
bles (routing table size is 240), which is qualita-tively the same as what we saw in Figs. 8 and 10.
4.2.5. Discussion
We now present some additional intuition
about why the enhanced-clustering with random
shortcuts performs well. Fig. 6 shows that the
routing table of Freenet is not very clustered when
LRU is used as the cache-replacement scheme.This is analogous to random graphs. It is well
known that random graphs have small diameters
as long as the number of edges is sufficiently large
[1]. However, since the edges are drawn at random,
0
2
4
6
8
10
12
14
16
18
0 5 10 15 20 25
Avg
. Hop
s P
er S
ucce
ssfu
l Req
uest
# of keys generated per node
RING TOPOLOGY (300 nodes, cache size =60, routing table size =240)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 16. Average hops per successful request for Freenet with
LRU, strict enhanced-clustering and enhanced-clustering: large
routing table size.
0
0.2
0.4
0.6
0.8
1
1.2
1.4
0 5 10 15 20 25
Req
uest
Hit
Rat
io
# of keys generated per node
RING TOPOLOGY (300 nodes, cache size =60, routing table size =240)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 15. Availability of Freenet with LRU, strict enhanced-
clustering and enhanced-clustering: large routing table size.
564 H. Zhang et al. / Computer Networks 46 (2004) 555–574
it is hard to use local rules to travel from a given
node to the node which contains the desired key.
Not surprisingly, under heavy load, LRU has a
low hit ratio. Fig. 11 shows that the routing table
for Freenet with strict enhanced-clustering is com-
pletely clustered. This corresponds to a highly reg-
ular graph, where each node is connected to its
neighbors. It is very easy to get from a given nodeto a desired node in such a graph. However, the
high clustering implies that each hop travels only
a small distance in the key-space, which results in
a high number of average hops. Fig. 12 shows
that the enhanced-clustering with random short-
cuts results in a small-world like graph. The
high clustering in this graph makes it easy to use
local rules to arrive at a desired node; at the same
time, the random shortcuts sometimes allow us to
travel large distances in the key-space using onehop.
Kleinberg showed that for efficient routing, a
node needs to choose a shortcut at a distance x
with probability proportional to 1/x [9]. This can
also be implemented using the following local
replacement rule: suppose there are two keys u
and v which are contending for being the shortcut
keys out of a Freenet node Y. Let xu and xv betheir distances from the Y�s seed key. Then wewould keep u with probability xv/(xu+xv) and keep
v with probability xu /(xu+xv). However, we have
chosen to implement the simpler scheme outlined
earlier in this section. It is important to mention
that this, and other simple variants, could also give
similar results as enhanced-clustering. Also, LRU
may well have other practical advantages thatwould override the improvements presented in this
section. However, the point of the paper is that en-
hanced-clustering enables the system to preserve
its small-world property regardless of workload,
and this is a desirable design.
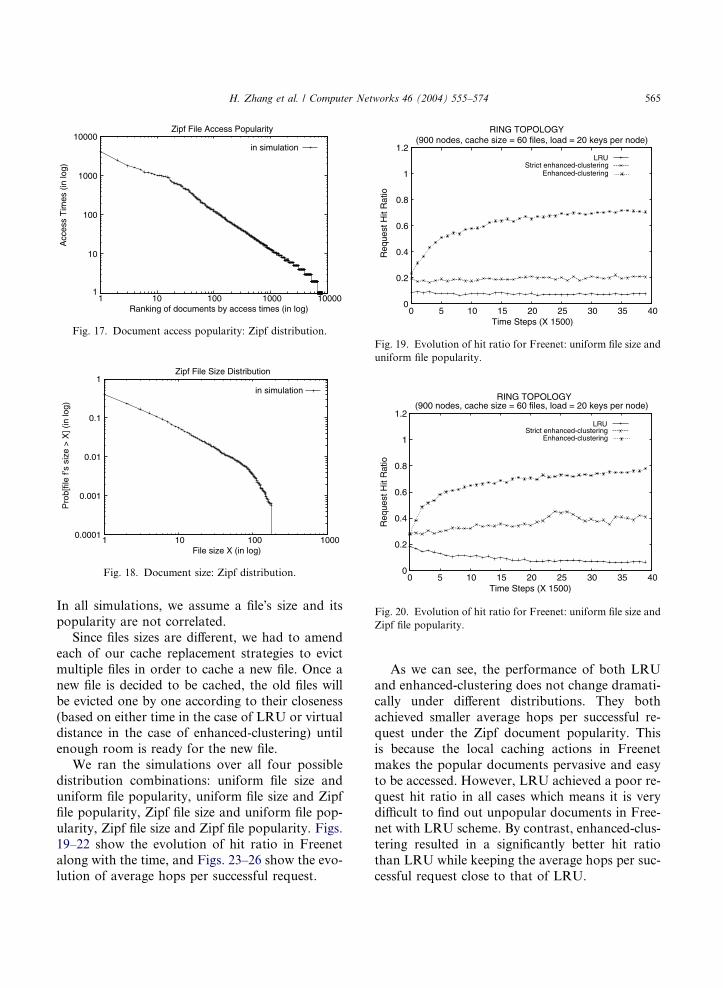
4.2.6. Zipf distribution for file size and popularity
While uniform file size and popularity distribu-tions make it to understand the performance of
our schemes, practical file size and popularity dis-
tributions are significantly skewed. To see how
network performance evolves with time when the
document size and/or popularity are Zipf-ian, we
repeated the simulation on a 900-node network
with the ring as initial topology, using a load of
20 keys per node. The total simulation time was60,000 time steps so as to make sure the network
performance was stable at the end of the simula-
tion. We choose the Zipf parameter a as 1. Figs.17 and 18 show the document access distribution
and size distribution in the simulations. For Zipf
size distribution, we set the file size range from 1
unit to 180 units so that the average file size is
about 3 units. The datastore size is also set to180 units so that the cache capacity of each node
is around 60 files in average, comparable to that
in the simulations with uniform size distribution.
0
0.2
0.4
0.6
0.8
1
1.2
0 5 10 15 20 25 30 35 40
Req
uest
Hit
Rat
io
Time Steps (X 1500)
RING TOPOLOGY (900 nodes, cache size = 60 files, load = 20 keys per node)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 19. Evolution of hit ratio for Freenet: uniform file size and
uniform file popularity.
0
0.2
0.4
0.6
0.8
1
1.2
0 5 10 15 20 25 30 35 40
Req
uest
Hit
Rat
io
Time Steps (X 1500)
RING TOPOLOGY (900 nodes, cache size = 60 files, load = 20 keys per node)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 20. Evolution of hit ratio for Freenet: uniform file size and
Zipf file popularity.
1
10
100
1000
10000
1 10 100 1000 10000
Acc
ess
Tim
es (
in lo
g)
Ranking of documents by access times (in log)
Zipf File Access Popularity
in simulation
Fig. 17. Document access popularity: Zipf distribution.
0.0001
0.001
0.01
0.1
1
1 10 100 1000
Pro
b[fil
e f’s
siz
e >
X] (
in lo
g)
File size X (in log)
Zipf File Size Distribution
in simulation
Fig. 18. Document size: Zipf distribution.
H. Zhang et al. / Computer Networks 46 (2004) 555–574 565
In all simulations, we assume a file�s size and itspopularity are not correlated.
Since files sizes are different, we had to amend
each of our cache replacement strategies to evict
multiple files in order to cache a new file. Once a
new file is decided to be cached, the old files will
be evicted one by one according to their closeness
(based on either time in the case of LRU or virtualdistance in the case of enhanced-clustering) until
enough room is ready for the new file.
We ran the simulations over all four possible
distribution combinations: uniform file size and
uniform file popularity, uniform file size and Zipf
file popularity, Zipf file size and uniform file pop-
ularity, Zipf file size and Zipf file popularity. Figs.
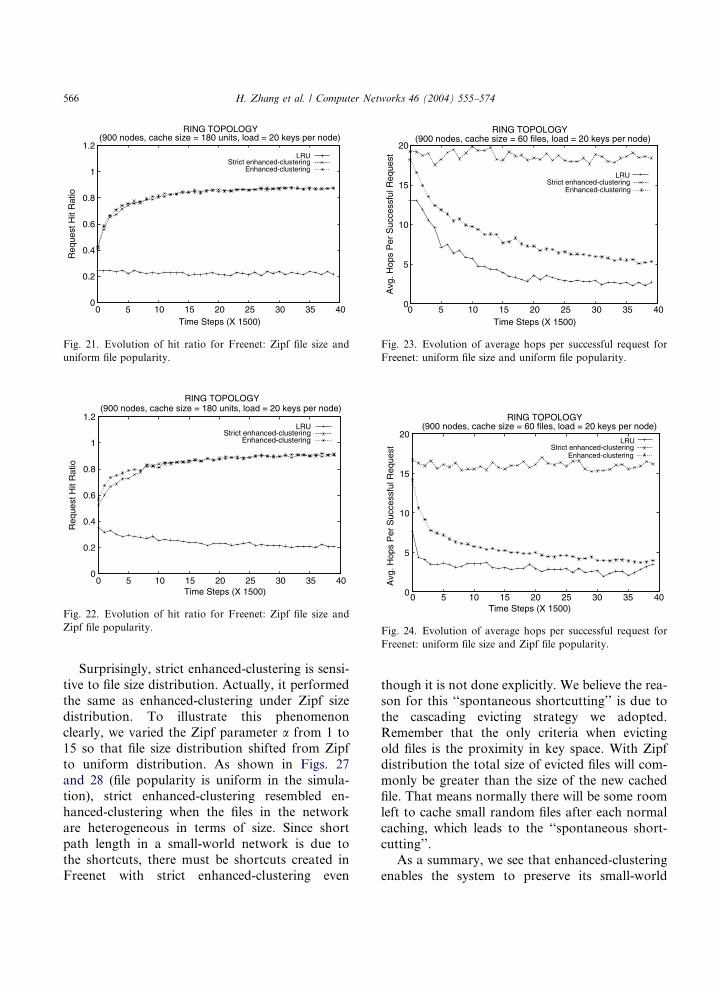
19–22 show the evolution of hit ratio in Freenetalong with the time, and Figs. 23–26 show the evo-
lution of average hops per successful request.
As we can see, the performance of both LRUand enhanced-clustering does not change dramati-
cally under different distributions. They both
achieved smaller average hops per successful re-
quest under the Zipf document popularity. This
is because the local caching actions in Freenet
makes the popular documents pervasive and easy
to be accessed. However, LRU achieved a poor re-
quest hit ratio in all cases which means it is verydifficult to find out unpopular documents in Free-
net with LRU scheme. By contrast, enhanced-clus-
tering resulted in a significantly better hit ratio
than LRU while keeping the average hops per suc-
cessful request close to that of LRU.
0
0.2
0.4
0.6
0.8
1
1.2
0 5 10 15 20 25 30 35 40
Req
uest
Hit
Rat
io
Time Steps (X 1500)
RING TOPOLOGY (900 nodes, cache size = 180 units, load = 20 keys per node)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 22. Evolution of hit ratio for Freenet: Zipf file size and
Zipf file popularity.
0
0.2
0.4
0.6
0.8
1
1.2
0 5 10 15 20 25 30 35 40
Req
uest
Hit
Rat
io
Time Steps (X 1500)
RING TOPOLOGY (900 nodes, cache size = 180 units, load = 20 keys per node)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 21. Evolution of hit ratio for Freenet: Zipf file size and
uniform file popularity.
0
5
10
15
20
0 5 10 15 20 25 30 35 40
Avg
. Hop
s P
er S
ucce
ssfu
l Req
uest
Time Steps (X 1500)
RING TOPOLOGY (900 nodes, cache size = 60 files, load = 20 keys per node)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 23. Evolution of average hops per successful request for
Freenet: uniform file size and uniform file popularity.
0
5
10
15
20
0 5 10 15 20 25 30 35 40
Avg
. Hop
s P
er S
ucce
ssfu
l Req
uest
Time Steps (X 1500)
RING TOPOLOGY (900 nodes, cache size = 60 files, load = 20 keys per node)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 24. Evolution of average hops per successful request for
Freenet: uniform file size and Zipf file popularity.
566 H. Zhang et al. / Computer Networks 46 (2004) 555–574
Surprisingly, strict enhanced-clustering is sensi-
tive to file size distribution. Actually, it performed
the same as enhanced-clustering under Zipf size
distribution. To illustrate this phenomenon
clearly, we varied the Zipf parameter a from 1 to
15 so that file size distribution shifted from Zipf
to uniform distribution. As shown in Figs. 27
and 28 (file popularity is uniform in the simula-tion), strict enhanced-clustering resembled en-
hanced-clustering when the files in the network
are heterogeneous in terms of size. Since short
path length in a small-world network is due to
the shortcuts, there must be shortcuts created in
Freenet with strict enhanced-clustering even
though it is not done explicitly. We believe the rea-
son for this ‘‘spontaneous shortcutting’’ is due to
the cascading evicting strategy we adopted.
Remember that the only criteria when evicting
old files is the proximity in key space. With Zipfdistribution the total size of evicted files will com-
monly be greater than the size of the new cached
file. That means normally there will be some room
left to cache small random files after each normal
caching, which leads to the ‘‘spontaneous short-
cutting’’.
As a summary, we see that enhanced-clustering
enables the system to preserve its small-world
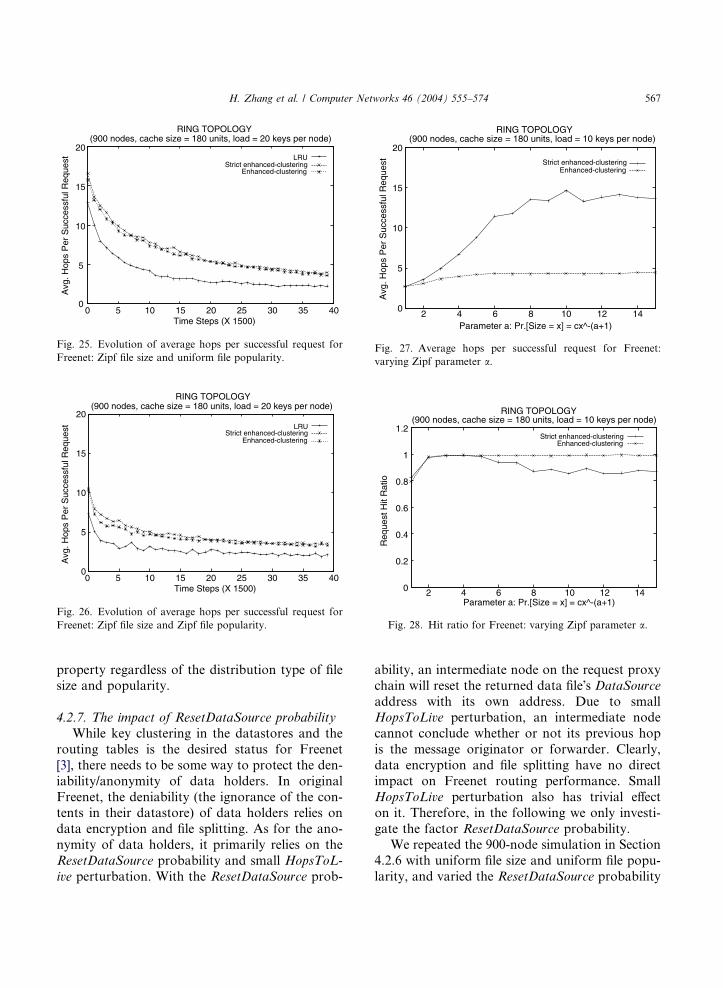
0
5
10
15
20
2 4 6 8 10 12 14
Avg
. Hop
s P
er S
ucce
ssfu
l Req
uest
Parameter a: Pr.[Size = x] = cx^-(a+1)
RING TOPOLOGY (900 nodes, cache size = 180 units, load = 10 keys per node)
Strict enhanced-clusteringEnhanced-clustering
Fig. 27. Average hops per successful request for Freenet:
varying Zipf parameter a.
0
5
10
15
20
0 5 10 15 20 25 30 35 40
Avg
. Hop
s P
er S
ucce
ssfu
l Req
uest
Time Steps (X 1500)
RING TOPOLOGY (900 nodes, cache size = 180 units, load = 20 keys per node)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 26. Evolution of average hops per successful request for
Freenet: Zipf file size and Zipf file popularity.
0
0.2
0.4
0.6
0.8
1
1.2
2 4 6 8 10 12 14
Req
uest
Hit
Rat
io
Parameter a: Pr.[Size = x] = cx^-(a+1)
RING TOPOLOGY (900 nodes, cache size = 180 units, load = 10 keys per node)
Strict enhanced-clusteringEnhanced-clustering
Fig. 28. Hit ratio for Freenet: varying Zipf parameter a.
0
5
10
15
20
0 5 10 15 20 25 30 35 40
Avg
. Hop
s P
er S
ucce
ssfu
l Req
uest
Time Steps (X 1500)
RING TOPOLOGY (900 nodes, cache size = 180 units, load = 20 keys per node)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 25. Evolution of average hops per successful request for
Freenet: Zipf file size and uniform file popularity.
H. Zhang et al. / Computer Networks 46 (2004) 555–574 567
property regardless of the distribution type of filesize and popularity.
4.2.7. The impact of ResetDataSource probability
While key clustering in the datastores and the
routing tables is the desired status for Freenet
[3], there needs to be some way to protect the den-
iability/anonymity of data holders. In original
Freenet, the deniability (the ignorance of the con-tents in their datastore) of data holders relies on
data encryption and file splitting. As for the ano-
nymity of data holders, it primarily relies on the
ResetDataSource probability and small HopsToL-
ive perturbation. With the ResetDataSource prob-
ability, an intermediate node on the request proxy
chain will reset the returned data file�s DataSource
address with its own address. Due to smallHopsToLive perturbation, an intermediate node
cannot conclude whether or not its previous hop
is the message originator or forwarder. Clearly,
data encryption and file splitting have no direct
impact on Freenet routing performance. Small
HopsToLive perturbation also has trivial effect
on it. Therefore, in the following we only investi-
gate the factor ResetDataSource probability.We repeated the 900-node simulation in Section
4.2.6 with uniform file size and uniform file popu-
larity, and varied the ResetDataSource probability
0
0.2
0.4
0.6
0.8
1
0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5
Req
uest
Hit
Rat
io
ResetSource probability
RING TOPOLOGY (900 nodes, cache size =60, load = 20 keys per node)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 29. Hit ratio for Freenet: varying ResetDataSource prob-
ability.
0
5
10
15
20
25
0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5
Avg
. Hop
s P
er S
ucce
ssfu
l Req
uest
ResetSource probability
RING TOPOLOGY (900 nodes, cache size =60, load = 20 keys per node)
LRUStrict enhanced-clustering
Enhanced-clustering
Fig. 30. Average hops per successful request for Freenet:
varying ResetDataSource probability.
0
0.2
0.4
0.6
0.8
1
1.2
0 0.2 0.4 0.6 0.8 1
Req
uest
Hit
Rat
io
Precentage of Freenet Nodes using enhanced-clustering scheme
2000 nodes, cache size = 60 files, load = 12 keys per node
Zipf file popularity
Fig. 31. Hit ratio vs. percentage of enhanced-clustering-ena-
bled nodes.
568 H. Zhang et al. / Computer Networks 46 (2004) 555–574
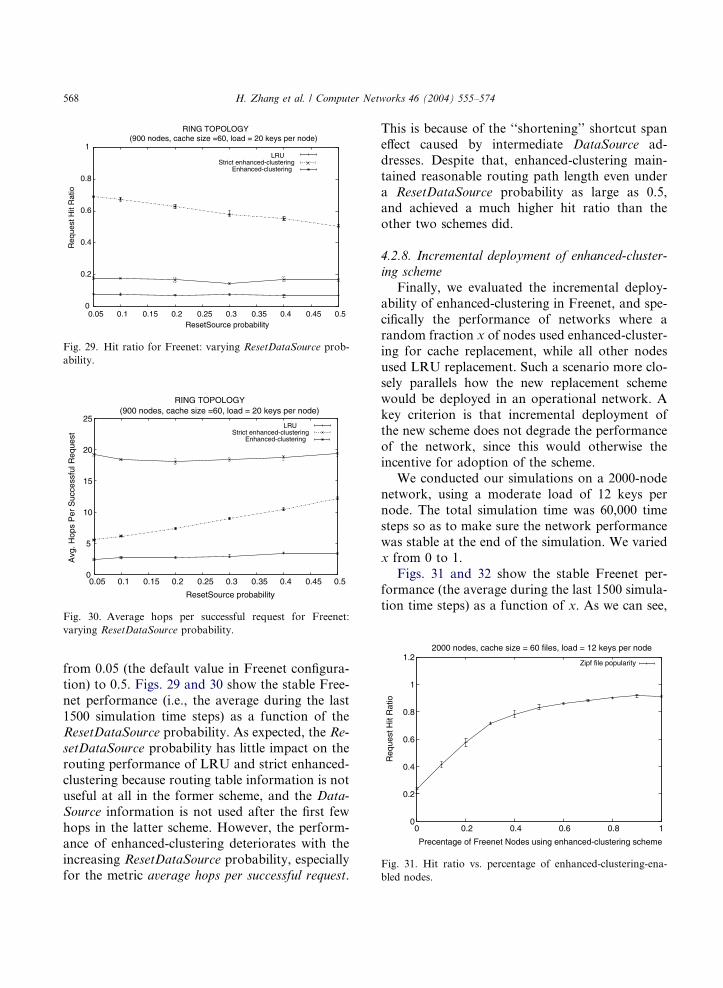
from 0.05 (the default value in Freenet configura-
tion) to 0.5. Figs. 29 and 30 show the stable Free-
net performance (i.e., the average during the last
1500 simulation time steps) as a function of the
ResetDataSource probability. As expected, the Re-
setDataSource probability has little impact on the
routing performance of LRU and strict enhanced-
clustering because routing table information is notuseful at all in the former scheme, and the Data-
Source information is not used after the first few
hops in the latter scheme. However, the perform-
ance of enhanced-clustering deteriorates with the
increasing ResetDataSource probability, especially
for the metric average hops per successful request.
This is because of the ‘‘shortening’’ shortcut span
effect caused by intermediate DataSource ad-
dresses. Despite that, enhanced-clustering main-
tained reasonable routing path length even under
a ResetDataSource probability as large as 0.5,and achieved a much higher hit ratio than the
other two schemes did.
4.2.8. Incremental deployment of enhanced-cluster-
ing scheme
Finally, we evaluated the incremental deploy-
ability of enhanced-clustering in Freenet, and spe-
cifically the performance of networks where arandom fraction x of nodes used enhanced-cluster-
ing for cache replacement, while all other nodes
used LRU replacement. Such a scenario more clo-
sely parallels how the new replacement scheme
would be deployed in an operational network. A
key criterion is that incremental deployment of
the new scheme does not degrade the performance
of the network, since this would otherwise theincentive for adoption of the scheme.
We conducted our simulations on a 2000-node
network, using a moderate load of 12 keys per
node. The total simulation time was 60,000 time
steps so as to make sure the network performance
was stable at the end of the simulation. We varied
x from 0 to 1.
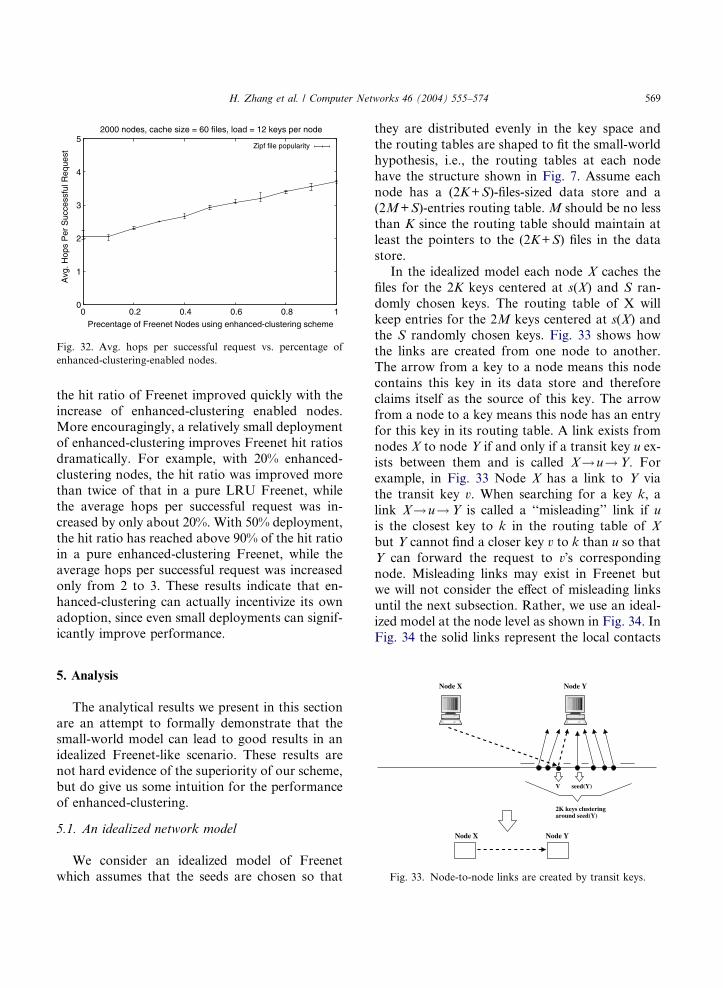
Figs. 31 and 32 show the stable Freenet per-formance (the average during the last 1500 simula-
tion time steps) as a function of x. As we can see,
0
1
2
3
4
5
0 0.2 0.4 0.6 0.8 1
Avg
. Hop
s P
er S
ucce
ssfu
l Req
uest
Precentage of Freenet Nodes using enhanced-clustering scheme
2000 nodes, cache size = 60 files, load = 12 keys per node
Zipf file popularity
Fig. 32. Avg. hops per successful request vs. percentage of
enhanced-clustering-enabled nodes.
H. Zhang et al. / Computer Networks 46 (2004) 555–574 569
the hit ratio of Freenet improved quickly with the
increase of enhanced-clustering enabled nodes.More encouragingly, a relatively small deployment
of enhanced-clustering improves Freenet hit ratios
dramatically. For example, with 20% enhanced-
clustering nodes, the hit ratio was improved more
than twice of that in a pure LRU Freenet, while
the average hops per successful request was in-
creased by only about 20%. With 50% deployment,
the hit ratio has reached above 90% of the hit ratioin a pure enhanced-clustering Freenet, while the
average hops per successful request was increased
only from 2 to 3. These results indicate that en-
hanced-clustering can actually incentivize its own
adoption, since even small deployments can signif-
icantly improve performance.
Node X Node Y
V seed(Y)
2K keys clustering around seed(Y)
Node X Node Y
Fig. 33. Node-to-node links are created by transit keys.
5. Analysis
The analytical results we present in this section
are an attempt to formally demonstrate that thesmall-world model can lead to good results in an
idealized Freenet-like scenario. These results are
not hard evidence of the superiority of our scheme,
but do give us some intuition for the performance
of enhanced-clustering.
5.1. An idealized network model
We consider an idealized model of Freenet
which assumes that the seeds are chosen so that
they are distributed evenly in the key space and
the routing tables are shaped to fit the small-world
hypothesis, i.e., the routing tables at each node
have the structure shown in Fig. 7. Assume each
node has a (2K+S)-files-sized data store and a(2M+S)-entries routing table.M should be no less
than K since the routing table should maintain at
least the pointers to the (2K+S) files in the data
store.
In the idealized model each node X caches the
files for the 2K keys centered at s(X) and S ran-
domly chosen keys. The routing table of X will
keep entries for the 2M keys centered at s(X) andthe S randomly chosen keys. Fig. 33 shows how
the links are created from one node to another.
The arrow from a key to a node means this node
contains this key in its data store and therefore
claims itself as the source of this key. The arrow
from a node to a key means this node has an entry
for this key in its routing table. A link exists from
nodes X to node Y if and only if a transit key u ex-ists between them and is called X!u!Y. For
example, in Fig. 33 Node X has a link to Y via
the transit key v. When searching for a key k, a
link X!u!Y is called a ‘‘misleading’’ link if u
is the closest key to k in the routing table of X
but Y cannot find a closer key v to k than u so that
Y can forward the request to v�s correspondingnode. Misleading links may exist in Freenet butwe will not consider the effect of misleading links
until the next subsection. Rather, we use an ideal-
ized model at the node level as shown in Fig. 34. In
Fig. 34 the solid links represent the local contacts

Node 1 Node i 1 Node i Node i+1 Node N
N nodes in the network
Fig. 34. An idealized model of Freenet from the node level. The
dotted edges correspond to shortcut connections.
570 H. Zhang et al. / Computer Networks 46 (2004) 555–574
between each pair of neighbors via their over-
lapped routing tables and the dotted links depictthe random shortcuts the nodes choose. Each node
has two pointers to its two neighbors and a link
pointing to a node randomly chosen in the net-
work. We assume that all nodes lose information
about the initial inserters of the files eventually.
The source of any file (key) is known to everyone
as the current holder of this file.
Theorem 1. In the idealized network model, if each
node x has S= logn random shortcuts, and x chooses
its random shortcuts so that any random shortcut
has an endpoint y with probability proportional to
1/dxy where dxy = js(x)� s(y)j, then the expectednumber of hops required to find a document in this
idealized system is O(logn) using Freenet�s search
algorithm. Here n is the number of nodes in the
system.
Proof. Analogous to the proof in [9], we start
by calculating the probability that node v is cho-
sen by node u for its random shortcut i (1 6 i 6logn):
d�1uvP
x6¼ud�1ux
Pd�1uvPn=2
i¼12i�1
P1
2 lnð3nÞduv:
Now, we say that the execution of the searching
for the target k is in phase j when the distance of
the current node to k is greater than 2j and at most
2j+1. Therefore, the initial value of j is at most
log(n/2). Suppose we are now in phase j,
log(logn) 6 j 6 logn�1, and the current node
holding the request is u, how long will it take to
end the search in phase j and enter the next phase?This requires the request to enter the set Bj of
nodes within distance 2j of the target k. There are
1þX2ji¼12 > 2jþ1
nodes in Bj, each is within the distance
2j+1+2j<2j+2 of u, and therefore each has a prob-
ability of at least logn/(2 ln (3n)2j+2) of being one
shortcut of u. Thus the probability that u can find
a node in Bj to forward the request to is at least
2jþ1 log n
2 lnð3nÞ2jþ2> 1
8ðwhen n � 1Þ:
Let Xj denote total number of steps spent in phase
j, log(logn) 6 j 6 logn�1. We have
E½X j ¼X1i¼1
Pr½X j P i 6X1i¼1
1� 18
� �i�1 ¼ 8:
Finally, if 0 6 j 6 log(logn), E[Xj] is still O(1) with
the analogous analysis. Now we use X to denote
the total number of steps spent during the whole
search. By definition,
X ¼Xlog n�1j¼0
X j:
By the linearity of expectation, we have
E½X ¼Xlog n�1j¼0
E½X j ¼ Oðlog nÞ: �
5.2. Idealized model with misleading links
Theorem 1 holds only if the distance from the
request to target k decreases strictly in each step
during the search. However, this condition may
not exist when there are misleading links in Free-net. In this subsection, we will consider the possi-
bility that a misleading link may be chosen at
some step of a search in Freenet. We assume that
while searching for key k, some node X forwarded
the request to Y. The node X must have had an en-
try of the form Æk 0,Yæ in its routing table, while k 0
must be one of the keys in Y�s data store. Let usassume that k 0 can be any of the (2K+S) keyswhich are present in the data store of Y with equal
probability. Clearly, Y will now find a tuple Æk*,Væ

searching direction
searching direction
seed(Y)
2K keys clustering around seed(Y)
Node X Node Y
seed(Y)
2K keys clustering around seed(Y)
Node X Node Y
(a)
(b)
Fig. 35. Two cases in which the request is forwarded through a
misleading link. (a) A request is passed from X to Y through a
key far away from seed. (b) A request is passed from X to Y
through the rightmost key of Y.
H. Zhang et al. / Computer Networks 46 (2004) 555–574 571
in its routing table such that k* is closest to k, and
then forward the request to node V. But there are
two cases in which Y cannot find such a node V:
� Key k 0 is one of the S shortcuts of Y. In thiscase all other keys may be far away from the
target key k (shown in Fig. 35a);
� Key k 0 is the closest key to k in Y�s 2K clusteredkeys (shown in Fig. 35b).
Then, the possibility that a misleading link is
chosen is equal to (S+1)/(2K+S). Next we will
prove that Freenet�s performance (logarithmicnumber of hops) in Theorem 1 can be maintained
even under the effect of misleading links as long as
a polylogarithmic-sized routing table/datastore is
provided in each node.
Theorem 2. In the idealized network model
considering the effect of misleading links, if K P32 log2(n) and each node x chooses its logn random
shortcuts so that any random shortcut has an
endpoint y with probability proportional to 1/d
where dxy = js(x)� s(y)j, then the expected number
of hops required to find a document in this idealized
system is O(logn) using Freenet�s search algorithm.
Here n is the number of nodes in the system.
Proof. From Theorem 1 we know a search will end
in at most 8 logn steps on the average when there isno effect of misleading links. We count 16 logn
steps as one run. If no misleading links are encoun-
tered during a run, then using Theorem 1 and
Markov�s inequality [11], we know that the proba-bility of finding the key in that run is at least 1/2.
Let q be the probability of encountering nomislead-
ing link during a run, and let p be the probability
that that run is successful under the effect of mis-leading links. Then p P q/2. Also, the possibility
that a misleading link is chosen at one step is equal
to (S+1)/(2K+S)<1/(32 log n), which leads to
qP 1� 1
32 log n
� �16 log n¼
ffiffiffi1
e
rðwhen n � 10Þ:
Therefore, p P 0.303. Let X denotes the total
number of runs to find a document. We have
E½X ¼X1i¼1
Pr½X P i 6X1i¼1
ð1� pÞi�1 ¼ 1p� 3:3:
The expected number of hops to find a document
is at most 3.3· (16 logn)=O(logn). h
Theorems 1 and 2 state that, our replacement
policy motivated by the small-world model gives
a logarithmic number of hops on the average in
our idealized model, both with and without mis-
leading links. Here there is a requirement that
the random shortcut be chosen from a specific dis-
tribution (called inverse rth-power distribution in[9]). It is possible to satisfy this requirement in
our scheme by using different values of p depend-
ing on the distance of the candidate shortcut key
from the seed key. The datastore (and routing ta-
ble size) required is also polylogarithmic in the size
of the Freenet system. Of course the size of the
data store should be at least large enough to make
sure that every key has a copy in some node.
5.3. Idealized Freenet model vs. skip-list based
architecture
A skip-list based architecture is one of the gen-
eral architectures adopted by many structured

572 H. Zhang et al. / Computer Networks 46 (2004) 555–574
peer-to-peer systems including Chord [16], Pastry
[15] and Tapestry [19]. In skip-list based architec-
tures, the key space S is linear, and a hierarchical
routing structure is constructed on top of this
space in a distributed fashion. The hierarchicalstructure resembles a skip-list. Each node is
responsible for a continuous range of values in
the key-space. Each node stores a pointer to a
node that is its neighbor in the key-space, to an-
other node that is roughly a distance two away,
another node that is roughly a distance 4 away,
and so on. Thus an arbitrary node stores roughly
logn pointers where n is the number of nodes inthe peer-to-peer system, and routing to a node
takes roughly logn steps. This is an elegant and
practical design.
To discover the relation between skip-list
based architecture and the idealized model, we
calculate the cumulative probability Pr(D/2, D)
of the inverse-distance probability used in the ide-
alized model, i.e., the probability that the short-cut x falls in the distance range [D/2, D]. Now,
we have
PrD2;D
� �¼ 1
c log n
XDx¼D=2
1
x� 1
c0 log nðD � 1Þ:
That means for a node i, when we divide the
remaining nodes into log(n/d) groups A0;A1; . . . ;Ai; . . . ;Alognd�1, where Ai consists of all nodes thedistance of whose seeds to s(i) is between 2id and
2i+1d, i will have a shortcut from each group with
the same probability. When the number of short-
cuts is h(logn), the routing table in the nodesresembles exactly that in the skip-list based archi-
tecture in a probabilistic way.
To summarize, in this idealized model, a care-
fully configured unstructured system gives thesame ballpark performance (i.e. polylogarithmic)
in terms of the size of the data store/routing table
and the average number of hops as the structured
schemes. If Theorem 2 continues to hold in more
realistic settings, then it would be an important
consideration in the design of peer-to-peer net-
worked systems. In order to have a less-idealized
and more realistic model, we need to analyze Free-net dynamics in more. This is an important open
problem.
6. Conclusions
In this paper we sketched some preliminary
work we did toward improving the performance
of unstructured systems such as Freenet by usingintuition from the small-world model. We first
gave a brief description of the Freenet protocol.
We then sketched the main idea behind the
small-world model and explained how we could
use intuition gained from this model to influence
Freenet performance. We presented a new but sim-
ple cache replacement scheme: enhanced-cluster-
ing. Our simulations showed a significantincrease in availability and a significant decrease
in average number of hops per request when we
used the enhanced-clustering caching rather than
LRU or strict enhanced-clustering caching. It is
important to note that this change did not involve
any modifications to the Freenet protocol, just to
local user behavior when the datastore gets filled.
Finally, we analyzed the latency of Freenet (withthe modified cache replacement scheme) in an ide-
alized model and proved that the average time to
find a key in such a model is just O(logn) where
n is the number of nodes in the system. In addition
to being interesting in their own right, the results
sketched in this paper also illustrate how theoreti-
cal techniques and insights can improve the per-
formance of peer-to-peer systems.It would be interesting to do a more complete
analysis of Freenet as a stochastic system as op-
posed to our simple idealized model. More gener-
ally, there is a need to take a principled look at the
properties of various algorithms proposed in the
peer-to-peer literature. Peer-to-peer networks have
a rich theoretical structure, and sophisticated algo-
rithmic techniques have been employed in the sys-tems currently under development [10,13,16].
Some of the rich structure of this problem was
exemplified by the pioneering work of Plaxton
et al. [12], where they give an elegant scheme to
achieve optimum latency in networks which fol-
low power-law expansion [4]. This has recently
been extended to all graphs, but with weaker per-
formance guarantees [14]. Some of the specificquestions that need to be addressed are under-
standing the fundamental bounds on the perform-
ance of peer-to-peer systems, designing algorithms

H. Zhang et al. / Computer Networks 46 (2004) 555–574 573
that allow these systems to perform at peak avail-
ability and minimum latency, and understanding
the role that the small-world model might play in
improving the performance of the peer-to-peer sys-
tems.
Acknowledgment
We would like to thank the anonymous referees
for their insightful comments that improved the
presentation of this paper.
References
[1] B. Bollobas, Random Graphs, Academic Press, London,
1985.
[2] Y. Chu, S. Rao, H. Zhang, A case for end-system
multicast, in: ACM Sigmetrics, 2000.
[3] I. Clarke, O. Sandberg, B. Wiley, T.W. Hong, Freenet: A
distributed anonymous information storage and retrieval
system, Freenet White Paper, http://freenetproject.org/
freenet.pdf, 1999.
[4] M. Faloutsos, P. Faloutsos, C. Faloutsos, On power-law
relationships of the Internet topology, in: ACM SIG-
COMM, 1999.
[5] P. Francis, Yallcast: Extending the Internet multicast
infrastructure, Unrefereed Report, http://www.yallcast.
com/docs/index.html, 1999.
[6] A. Goel, K. Munagala, Extending greedy multicast routing
to delay sensitive applications, in: ACM Symposium on
Discrete Algorithms (short abstract), July 1999, Also, to
appear as an invited paper in the special issue of Algorith-
mica on Internet Algorithms.
[7] T. Hong, Performance, in: A. Oram (Ed.), Peer-to-Peer:
Harnessing the Power of Disruptive Technologies, O�Re-illy, Sebastopol, CA, 2001.
[8] J. Kleinberg, Navigation in a small-world, Nature 406
(2000).
[9] J. Kleinberg, The small-world phenomenon: an algorithmic
perspective, Cornell Computer Science Technical Report
99-1776, 2000.
[10] J. Kubiatowicz, D. Bindel, Y. Chen, S. Czerwinski, P.
Eaton, D. Geels, R. Gummadi, S. Rhea, H. Weatherspoon,
W. Weimer, C. Wells, B. Zhao, Oceanstore: An architec-
ture for global-scale persistent storage, in: Ninth Interna-
tional Conference on Architectural Support for
Programming Languages and Operating Systems (ASP-
LOS 2000), November 2000.
[11] R. Motwani, P. Raghavan, Randomized Algorithms,
Cambridge University Press, Cambridge, 1995.
[12] C.G. Plaxton, R. Rajaraman, A.W. Richa, Accessing
nearby copies of replicated objects in a distributed
environment, in: 9th Annual ACM Symposium on Parallel
Algorithms and Architectures, Newport, RI, June 1997,
pp. 311–320.
[13] S. Ratnasamy, P. Francis, M. Handley, R. Karp, S.
Shenker, A scalable content addressable network, in: ACM
SIGCOMM, 2001.
[14] R. Rajaraman, A.W. Richa, B. Vocking, G. Vuppuluri, A
data tracking scheme for general networks, in: Thirteen
ACM Symposium on Parallel Algorithms and Architec-
tures, 2001.
[15] A. Rowstron, P. Druschel, Pastry: Scalable, distributed
object location and routing for large-scale peer-to-peer
systems, in: International Conference on Distributed Sys-
tems Platforms (Middleware), November 2001.
[16] I. Stoica, R. Morris, D. Karger, F. Kaashoek, H. Balak-
rishnan, Chord: A peer-to-peer lookup service for Internet
applications, in: ACM SIGCOMM, 2001.
[17] D.J. Watts, Small-Worlds: The Dynamics of Networks
Between Order and Randomness, Princeton University
Press, Princeton, NJ, 1999.
[18] D.J. Watts, S.H. Strogatz, Collective dynamics of �small-world� networks, Nature 393 (1998) 440–442.
[19] B.Y. Zhao, J.D. Kubiatowicz, A.D. Joseph, Tapestry: an
infrastructure for fault-tolerant wide-area location and
routing, Technical Report UCB/CSD-01-1141, UC Berke-
ley, April 2001.
[20] Napster, http://www.napster.com.
[21] Gnutella, http://www.gnutella.wego.com.
[22] I. Clarke, Private communication, April 2003.
Hui Zhang received his B.Eng. degreefrom Hunan University, and hisM.Eng. degree from Institute of Auto-mation, Chinese Academy of Sciences.He is now pursuing his Ph.D. degree inthe Computer Science Department atthe University of Southern California.His research interests include peer-to-peer and overlay routing, and rand-omized algorithms.
Ashish Goel is an Assistant Professor ofManagement Science and Engineeringand (by courtesy) Computer Science atStanford University. He received hisPh.D. in Computer Science from Stan-ford in 1999, and was an AssistantProfessor of Computer Science at theUniversity of Southern California from1999 to 2002.His research interests lie inanalysis of algorithms, with computernetworks and molecular self-assemblybeing two important application do-mains. He is a recipient of an Alfred P.
Sloan faculty fellowship (2004–2006), a Terman faculty fellow-
ship from Stanford, and an NSF Career Award (2002–2007).
574 H. Zhang et al. / Computer Networks 46 (2004) 555–574
Ramesh Govindan received his B.Tech.degree from the Indian Institute ofTechnology at Madras, and his M.S.and Ph.D. degrees from the Universityof California at Berkeley. He is anAssociate Professor in the ComputerScience Department at the Universityof Southern California. His researchinterests include Internet routing andtopology, and wireless sensor net-works.