Embed Size (px)
Citation preview

Using String Similarity Metrics for Terminology RecognitionJonathan ButtersMarch 2008LREC 2008 – Marrakech, Morocco

Introduction - Terms• Objects are discrete, the terms people use to
describe objects are usually not!
• Different groups of people tend to use different terms to refer to identical objects – Sublanguage (Harris, 1968)
• Terms can differ due to: orthographical differences, abbreviations, acronyms and synonyms
Football
Foot-ball
Soccerball
Footy
Icosahedron
Design
PersonnelMaintenanc
eOther Countries!

Introduction – Relating Terms• There are many applications where the ability to
relate the different terms would be useful
• String similarity metrics can be used to relate terms• String similarity metrics inherently take into
consideration aspects such as:• Word Order• Acronyms• Abbreviations
Predictive text suggestions
Matching component concepts Reducing lists of options

An Example Application
• We have a list of locations
• Some are similar• Most are dissimilar
(irrelevant)
• How do we choose the most similar?• Top 10? Top 100? Top 1000?
Top 10%?

Introduction – Selecting Terms• Background In Aerospace Engineering
• Specialising in Avionics
• Electronic noise is a problem• But can be filtered!
• Can dissimilar string matches be identified as noise?• Can this noise be removed?...
Automatically

String Similarity Metrics

Introduction – Similarity Metrics• String metrics automatically calculate
how similar (or dissimilar) two strings are:• Two strings are identical if they have the
same characters in the same order• Each similarity measure assigns a
numeric value based upon the relative similarity between the two strings
• Vector based• Cost based

Metric Selection - Examples• Query String = “language resources and evaluation conference 2008”
• String A = “language resources and evaluation conference 2009”
• String B = “lrec 2008”
Metric Name String A score
String B score
Levenshtein 1.0 40.0
Monge Elkan 0.9583333 0.46666667
Jaro Winkler 0.99455786 0.1
Euclidean Distance 1.4142135 2.4494898
Jaccard Similarity 0.71428573 0.14285715
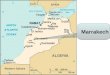
Metric Selection - SimMetrics• SimMetrics – Java library of 23 string similarity metrics
• Developed at the University of Sheffield (Chapman, 2004)• Outputs a normalised similarity score!
Metric Name String A score
String B score
Levenshtein 0.97959185 0.18367344
Monge Elkan 0.9583333 0.46666667
Jaro Winkler 0.99455786 0.1
Euclidean Distance 0.8333333 0.61270165
Jaccard Similarity 0.71428573 0.14285715

Metric Selection

Metric Selection - Investigation• Investigation focused on Aerospace domain terms
• Reduce list of components presented to user
• 298 automatically extracted sublanguage engine component terms
• 513 official component terms• The similarity of each combination of 298 terms
was calculated... 298C2 = 44253 comparisons• Carried out for each of the 23 metrics in
SimMetrics

Metric Selection - Investigation• For each metric - each string pair (and score) was
ordered by decreasing similarity• Few string pairs scored high results - wide similarity
band• Vast majority scored low scores
• Bands of similarity score were made, the number of strings that scored within those bands were totalled
• Distribution graphs were Gaussian or Dirac• Depending on the scoring mechanism of the similarity
metric
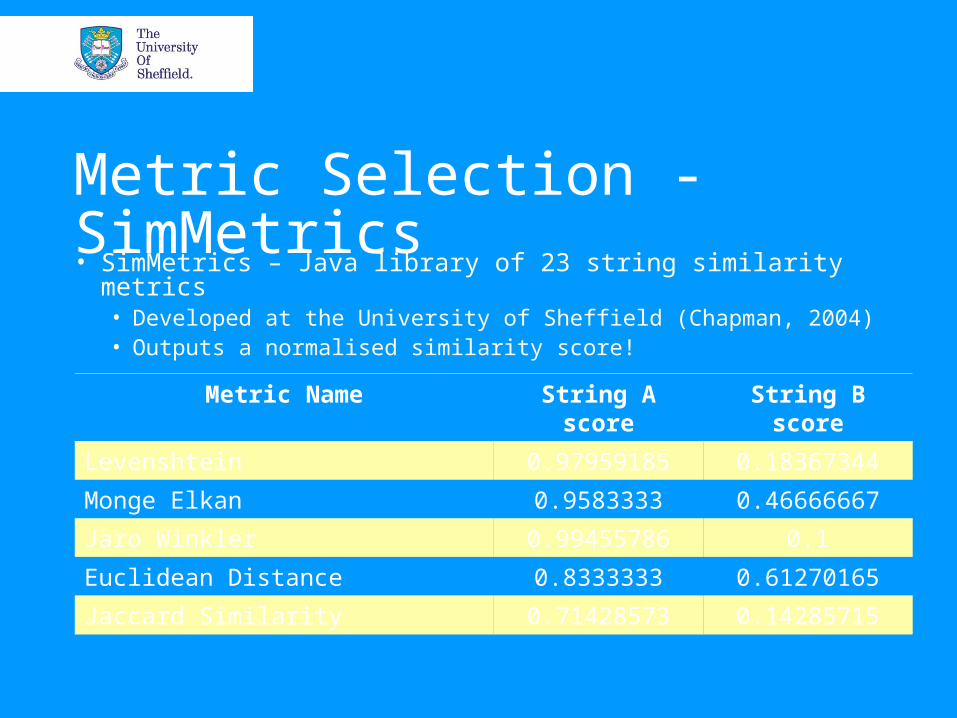
Metric Selection - Results• Dirac distributions
• Gaussian distributions

Metric Selection - Levenshtein
Because:• Jaro-Winkler gave consistently relatively
high scores to unrelated strings
• Levenshtein grouped dissimilar strings further towards the lower end of the scale - More similar strings over a wider range
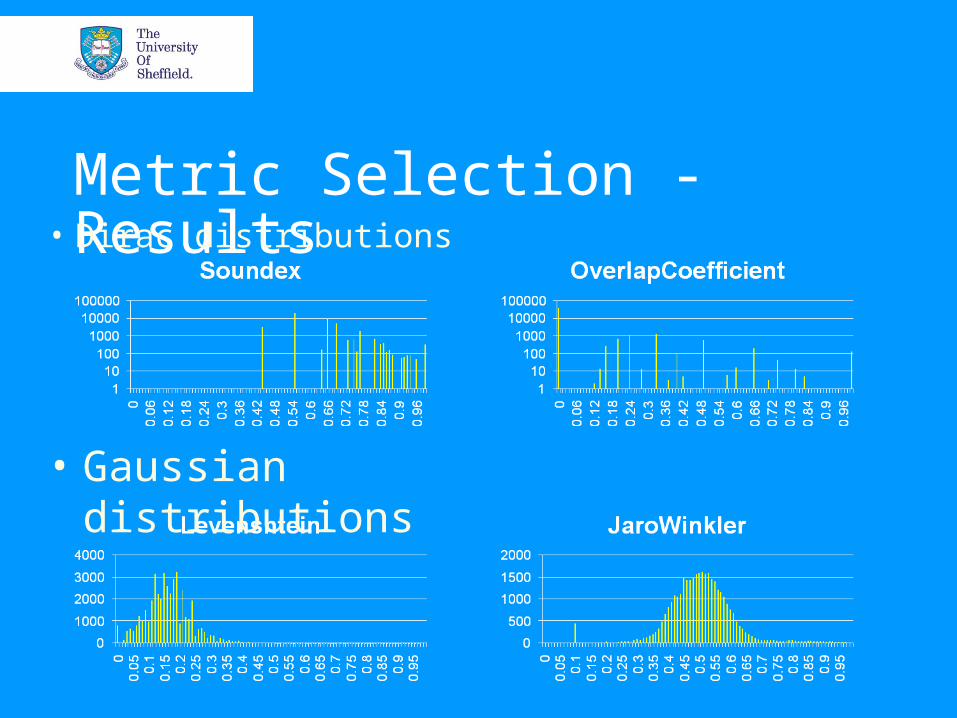
Metric Selection - Example
“Air Oil Heat Exchanger” & “Air/Oil Heat Exchanger”
“Starter Valve” & “Tail Bearing Oil Feed Tube ASSY.”

Noise Detection & Removal• The peak is formed by the strings that are dissimilar
• If two random strings are compared, they will have a random similarity score
• As there are many randomly similar string pairs their scores form a Gaussian noise pattern...
• Approximately 100% of a randomly distributed variable falls below approximately four standard deviations above the mean

Noise Detection & Removal• Strings that scored outside the randomly distributed scores
were... by definition, not randomly distributed!
• Strings that were not randomly distributed tended to include terms that were relevant to one another!...
• The noise peak can be located and isolated by disregarding all similarities below four standard deviations above the mean:
n
x
n
xx2
4Similarity Cutoff Automatic
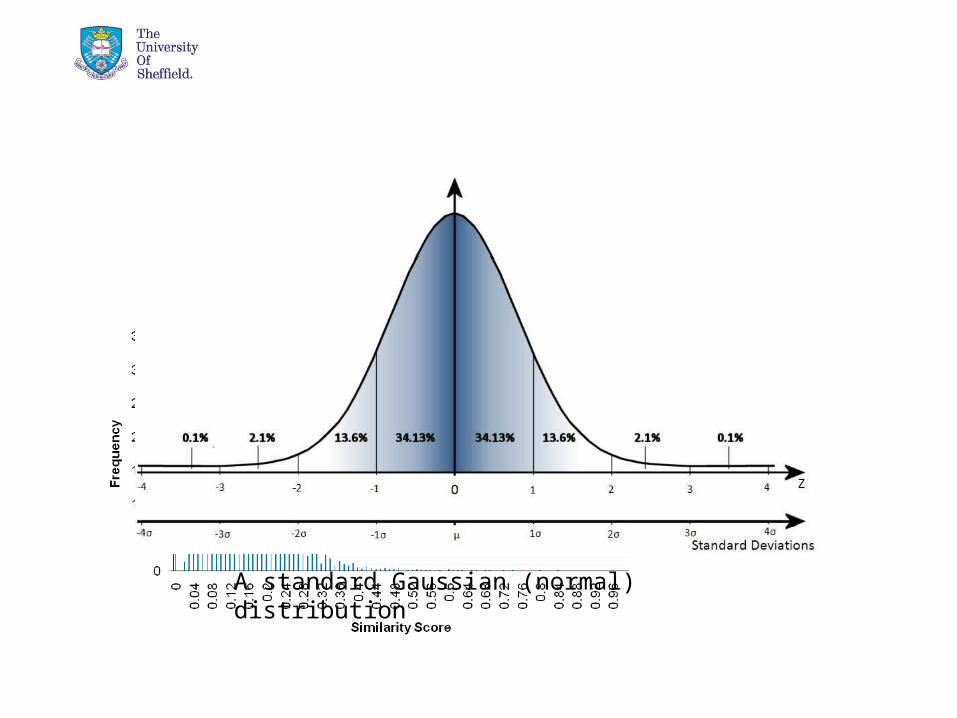
Noise Detection & Removal
A standard Gaussian (normal) distribution

Shorter Terms• Although the dataset used contained mostly long
strings, noise removal method remains effective for shorter strings within the dataset
• Shorter terms constitute a small, random match of longer and more typical strings• longer strings are now randomly distributed!
• The mean similarity tends to be lower, and hence, the cut-off similarity automatically reduces, now similar shorter strings fall above the automatic cut off

Noise Detection & Removal• Advantages of this automatic method:
1. Scales with source data size
2. Selecting top 10 may include or exclude relevant results!
3. Can be used to pick out strings that are more similar than, or stand out from the rest of the strings

Results• The 298 extracted terms were compared against each of
the 513 official terms.• After noise was automatically removed, in some cases more
than one relevant result suggested, in this case, the first n results were considered as follows:
n Recall at n Precision at n
1 86.84% 86.84%
2 90.13% 88.83%
3 92.67% 89.04%
4 98.67% 91.56%
5 99.40% 92.08%
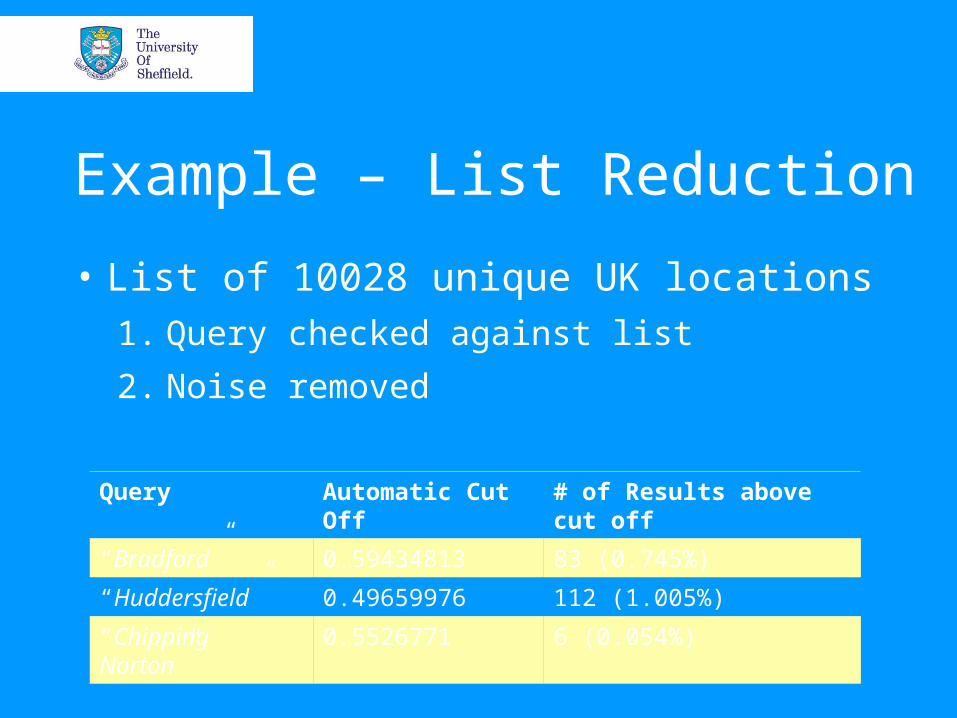
Example – List Reduction
• List of 10028 unique UK locations1. Query checked against list
2. Noise removed
Query Automatic Cut Off
# of Results above cut off
“Bradford” 0.59434813 83 (0.745%)
“Huddersfield” 0.49659976 112 (1.005%)
“Chipping Norton”
0.5526771 6 (0.054%)

Conclusions• Dissimilar string matches can be modelled as a noise pattern
• The noise pattern can be removed!
• Methodology is applicable to any set of strings• Not only for Aerospace domain terms!• Method is scalable
• Can be used to automatically remove obviously incorrect matches• Provides users with fewer options – faster selection!
• Can be used to extract strings that are more similar than, or stand out from the rest

Future Work
• Integrate approach into many apps• Form Filling
• Improved similarity metrics• Domain specific datasets (Aerospace)
• Stop words, mutually exclusive words
• Combine metrics to break ties

Thank you

Refs• Butters, Jonathan (2007) - A Terminology
Recognizer for the Aerospace Domain. Masters’ Thesis, The University of Sheffield• http://www.dcs.shef.ac.uk/~jdb/papers.html
• Harris, Z. (1968). Mathematical Structures of Language.• John Wiley & Sons, New York.
• Sam Chapman – SimMetrics• http://www.dcs.shef.ac.uk/~sam/simmetrics.html