Embed Size (px)
Citation preview

(This is a sample cover image for this issue. The actual cover is not yet available at this time.)
This article appeared in a journal published by Elsevier. The attachedcopy is furnished to the author for internal non-commercial researchand education use, including for instruction at the authors institution
and sharing with colleagues.
Other uses, including reproduction and distribution, or selling orlicensing copies, or posting to personal, institutional or third party
websites are prohibited.
In most cases authors are permitted to post their version of thearticle (e.g. in Word or Tex form) to their personal website orinstitutional repository. Authors requiring further information
regarding Elsevier’s archiving and manuscript policies areencouraged to visit:
http://www.elsevier.com/copyright

Author's personal copy
Using SAX representation for human action recognition
Imran N. Junejo ⇑, Zaher Al AghbariUniversity of Sharjah, P.O. Box 27272, Sharjah, United Arab Emirates
a r t i c l e i n f o
Article history:Received 13 December 2011Accepted 27 April 2012Available online 11 May 2012
Keywords:Action recognitionComputer visionPattern recognitionImage understandingSAX representationData miningIntelligent systemsVideo surveillance
a b s t r a c t
Human action recognition is an important problem in Computer Vision. Although most of the existingsolutions provide good accuracy results, the methods are often overly complex and computationallyexpensive, hindering practical application. In this regard, we introduce Symbolic Aggregate approxima-tion (SAX) to address the problem of human action recognition. Given motion trajectories of referencepoints on an actor, SAX efficiently converts this time-series data to a symbolic representation. Moreover,the distance between two time series is approximated by the distance between their SAX representation,which is straight-forward and very simple. Requiring only trajectories of reference points, our methodrequires neither structure recovery nor silhouette extraction. The proposed method is validated on twopublic datasets. It has an accuracy comparable to related works and it performs well even in varying con-ditions, in addition to being faster compared to the existing methods.
� 2012 Elsevier Inc. All rights reserved.
1. Introduction
Visual recognition and understanding of human actions has at-tracted much attention over the past three decades [1,2] and re-mains an active research area of Computer Vision. A goodsolution to the problem holds a yet unexplored potential for manyapplications such as the searching and the structuring of largevideo archives, video surveillance, human–computer interaction,gesture recognition and video editing. The difficulty associatedwith this problem has to do with the large variation of humanaction data due to the individual variations of people in expression,posture, motion and clothing; perspective effects and cameramotions; illumination variations; occlusions and disocclusions;and distracting effects of scenes surroundings. As a consequence,current methods often resort to complex solutions, which mightprovide a good accuracy, but render the solutions impractical.
Various approaches using different constructs have been pro-posed over the years for action recognition. These approachescan be roughly categorized on the basis of representation usedby the authors. Time evolution of human silhouettes was fre-quently used as an action descriptor. For example, [3] proposedto capture the history of shape changes using temporal templatesand [4] extends these 2D templates to 3D action templates. Simi-larly, the notions of action cylinders [5], and space–time shapes[6–8] have been introduced based on silhouettes. Recently,
space–time approaches analyzing the structure of local 3D patchesin the video have shown promising [9–13]. Almost all of the men-tioned works above rely mostly on an effective feature extractiontechnique, which is then combined with machine learning or pat-tern recognition techniques. These feature extraction methods canbe roughly categorized into: motion-based [14,15], appearancebased [8], space–time volume based [6–8], and space–time interestpoints or local features based [9–13,16]. Motion-based methodsgenerally compute the optical-flow from a given action sequence,followed by appropriate feature extraction. However, optical-flowbased methods are known to be very susceptible to noise and areeasily led to inaccuracies. Appearance based methods are proneto differences in appearance between the already seen sequences(i.e. the training dataset) and the new sequences (i.e. the testingsequence). Volume or shape based methods require highly detailedsilhouette extraction, which may not be possible in a given real-world noisy video datasets. In comparison to these approaches,the space–time interest point (STIP) based methods [9,11,12] havereceived considerable attention and thus are extremely popular.STIP-based methods are more robust to noise and camera move-ment and also seem to work quite well with low resolution inputs.However, these methods rely solely on the discriminative power ofindividual local space–time descriptors. Information related to theglobal spatio-temporal distribution is ignored. Thus due to the lackof this temporal information, smooth motions cannot be capturedusing STIP methods. In addition, issues like optimal space–timedescriptor selection and codebook clustering algorithm selectionhave to be addressed, with fine-tuning various parameters, whichis highly data dependent [17].
1047-3203/$ - see front matter � 2012 Elsevier Inc. All rights reserved.http://dx.doi.org/10.1016/j.jvcir.2012.05.001
⇑ Corresponding author.E-mail addresses: [email protected] (I.N. Junejo), [email protected]
(Z.A. Aghbari).
J. Vis. Commun. Image R. 23 (2012) 853–861
Contents lists available at SciVerse ScienceDirect
J. Vis. Commun. Image R.
journal homepage: www.elsevier .com/ locate/ jvc i
Author's personal copy
Most of above mentioned techniques perform reasonably wellfor standard action recognition. However, for large-scale actionrecognition, where the dataset consists of thousands of labeledaction videos, such a scheme requires a tremendous amount oftime for (i) computing the image/video descriptors, and (ii) com-puting the (dis) similarities between the sequences – thus the com-plexity increases dramatically. Dimensionality reduction helpssomewhat, but at the cost of reduced accuracy. In this regards, asimple and an efficient method is desired that scales well to largedatasets, and yet provides comparable or better accuracy thanexisting methods.
In this work, while using trajectories of tracked body-joints,we use a new time series representation: Symbolic AggregateapproXimation (SAX) [18–20] in order to effectively address theaction recognition problem. SAX tremendously reduces thedimensionality of time series that represents an action sequence.Other symbolic representations, such as Discrete Fourier Trans-form (DCT) [21], and Discrete Wavelet Transform (DWT) [22],may be used to reduce the memory space required to store thetime series but the intrinsic dimensionality of the symbolic rep-resentation is not reduced [20]. Another desirable feature of SAXis its lower bounding property. That is, the Euclidean distancebetween two time series in the SAX space is guaranteed to beless than or equal to the distance between them in the originalspace [20]. Due to the above two features, SAX symbolic repre-sentation is used in this paper to efficiently and effectively rec-ognize human actions from large sequences of video. Thus
using this method, in contrast to the geometry-based methods[5,23–25] (to be discussed in Section 2), we do not requireestimation of corresponding points between video sequences.Differently to the prevailing methods, we do not extract any fea-tures from SAX representation and rely solely on the Euclideandistance; thus we are able to avoid resorting to expensive ma-chine learning techniques. We believe that this is the key to afast and an efficient solution: avoiding complex computationsand achieving good and comparable action recognition accuracy.
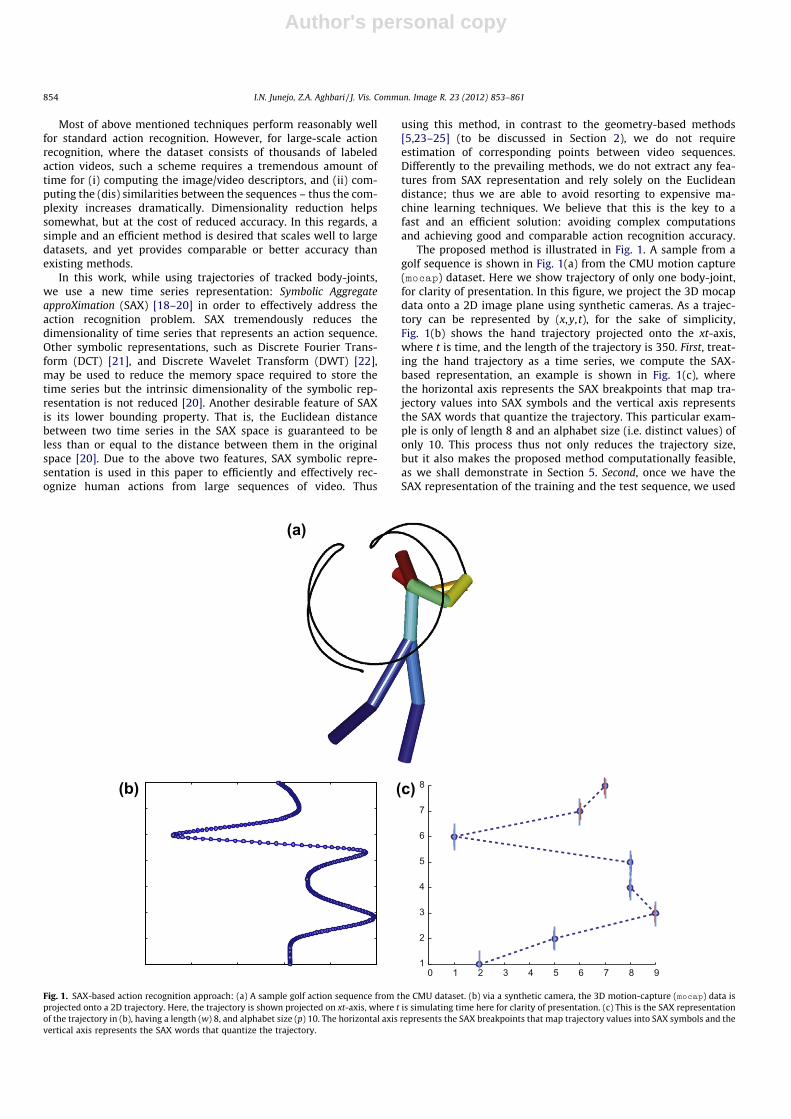
The proposed method is illustrated in Fig. 1. A sample from agolf sequence is shown in Fig. 1(a) from the CMU motion capture(mocap) dataset. Here we show trajectory of only one body-joint,for clarity of presentation. In this figure, we project the 3D mocapdata onto a 2D image plane using synthetic cameras. As a trajec-tory can be represented by (x,y, t), for the sake of simplicity,Fig. 1(b) shows the hand trajectory projected onto the xt-axis,where t is time, and the length of the trajectory is 350. First, treat-ing the hand trajectory as a time series, we compute the SAX-based representation, an example is shown in Fig. 1(c), wherethe horizontal axis represents the SAX breakpoints that map tra-jectory values into SAX symbols and the vertical axis representsthe SAX words that quantize the trajectory. This particular exam-ple is only of length 8 and an alphabet size (i.e. distinct values) ofonly 10. This process thus not only reduces the trajectory size,but it also makes the proposed method computationally feasible,as we shall demonstrate in Section 5. Second, once we have theSAX representation of the training and the test sequence, we used
(a)
−0.15 −0.1 −0.05 0 0.05 0.1
0
200
400
600
800
1000
1200
1400
0 1 2 3 4 5 6 7 8 91
2
3
4
5
6
7
8(c)(b)
Fig. 1. SAX-based action recognition approach: (a) A sample golf action sequence from the CMU dataset. (b) via a synthetic camera, the 3D motion-capture (mocap) data isprojected onto a 2D trajectory. Here, the trajectory is shown projected on xt-axis, where t is simulating time here for clarity of presentation. (c) This is the SAX representationof the trajectory in (b), having a length (w) 8, and alphabet size (p) 10. The horizontal axis represents the SAX breakpoints that map trajectory values into SAX symbols and thevertical axis represents the SAX words that quantize the trajectory.
854 I.N. Junejo, Z.A. Aghbari / J. Vis. Commun. Image R. 23 (2012) 853–861

Author's personal copy
the distance measure defined in Section 4 to compare corre-sponding tracked joints and perform the Nearest Neighbor (NN)classification. Although the method does require known corre-spondences between joints but time correspondences are not re-quired. We show recognition results comparable to the state ofthe art methods, and additionally the method is shown to be veryfast as well.
The paper is organized as follows: Section 2 reviews some of thework relevant to the action recognition and the time series repre-sentation. We introduce the SAX representation of human actionrecognition in Section 3. We describe our action recognitionscheme in Section 4, along with distance measure used to comparedifferent SAX representations. Finally, we test the proposed meth-od on two public datasets and demonstrate strong results in Sec-tion 5, followed by conclusion.
2. Related work
This paper addresses action recognition, a topic which has re-ceived a considerable attention from researchers recently. The in-put to our method is the tracked position of body joints of anactor performing a particular action sequence – we will also callthese as the reference points. This is an input to various existingtechniques as well, especially view-independent action recognitionmethods using epipolar geometry as in [5,23–27]. In [5,23,24]point correspondences between actions are assumed to be knownfor imposing fundamental matrix constraints and performingview-invariant action recognition. Rao et al. [25] show that themaxima in space–time curvature of a 3D trajectory are preservedin 2D image trajectories, and are also view-invariant. Parameswa-ran and Chellappa [27] proposed a quasi view-invariant approach,requiring at least 5 body points lying on a 3D plane or that thelimbs trace a planar area during the course of an action. Recently[26] showed that for a moving plane the fundamental ratios, i.e.the ratios among the elements in the upper left 2 � 2 submatrixof the fundamental matrix, are invariant to the camera parametersas well as its orientation and can be used for action recognition.Such methods, however, rely either on existing point correspon-dences between image sequences or/and on many videos repre-senting actions in multiple views. Both of these assumptions, arelimiting in practice due to (i) the difficulty of estimating non-rigidcorrespondences in videos and (ii) the difficulty of obtaining suffi-cient video data spanning view variations for many action classes.Thus, obtaining automatic and reliable point correspondencesacross videos for natural human actions is a very challenging andcurrently unsolved problem, which limits the application of abovementioned methods in practice. Given an action sequence andsome low-level features, [28] compute distances between ex-tracted features for all pairs of time frames and store results in aSelf-Similarity Matrix (SSM). The authors claim SSM to be stableacross view changes. Histograms of gradient orientations are accu-mulated at local patches in regions around the diagonal of theseSSMs, which have a log-polar structure. Finally Nearest Neighborclassifiers or the SVMs are used for the final classification.Although we do not claim our SAX representation to be view-inde-pendent, but we shall demonstrate experimentally that the perfor-mance decreases gracefully under 3D view changes, whichindicates the robustness of the proposed method.
Treating motion trajectory of reference points on an actor astime-series data has a close relation to the works [29–32] (a full re-view of all the related work is beyond the scope of the currentwork). Using velocity history of (KLT) tracked points, [30] presenta generative mixture model for the video sequences. A log-polaruniform quantization is performed on these tracks, with eight binsfor direction, and five for magnitude. Activity classes are modeled
as weighted mixture of bags of augmented trajectory sequences,where each mixture component models a velocity history featurewith a Markov Chain. The model is trained by using the EM algo-rithm. In addition, to choose the best parameters for quantization,depending on the number of mixture components, the approachcan be computationally expensive. Employing a probabilisticframework, [29] present a method for augmenting local featureswith spatio-temporal relationships. Using STIP-HOG based and tra-jectory-based features, probabilities are accumulated in a Naive-Bayes like fashion into a reduced number of bins, and SVMs areused to perform the final classification. Using concepts from thetheory of chaotic systems [31], the trajectories of reference pointsare treated as non-linear dynamical system that are generating anaction. Using delay-embedding scheme, each such reference trajec-tory is used to construct a phase space of appropriate dimension.Final representation of each action is a feature vector, containingdynamical and metric invariants of the constructed phase space,namely Lyapunov exponent, correlation integral and correlationdimension. Along the same lines, based on extracted silhouettes,[32] introduces a manifold embedding method, called Local Spa-tio-Temporal Discriminant Embedding (LSTDE), that projectspoints lying in a local neighborhood into the embedding space.The idea is that the points of the same class are close together inthis space and the data points of different classes are far apart.The authors aim to find an optimal embedding by maximizingthe principal angles between temporal subspaces associated withdata points of different classes. However, the embedding is a costlyaffair, often relying on fine-tuning of many parameters such anembedding dimension. In this work, we show recognition resultscomparable to [31] and a significant improvement over [32], inaddition to proposing a simple and computationally less complexsolution that is very efficient.
Typically, since the size of time series is too large to fit in mainmemory, reducing the size of time series using an appropriate rep-resentation emerged as an issue of interest in the data mining com-munity. Many representation techniques have been proposed inthe literature, but we will address in this section the most com-monly used ones. Faloutsos et al. introduced Discrete FourierTransform, DFT, [21] to reduce the dimensionality of subsequenceswhich are then indexed using the reduced representation. Theindexing was then improved in [22] by using the Discrete WaveletTransform, DWT, to reduce the dimensionality of time series; how-ever, DWT is effective for time series of lengths that are an integerpower of two. The authors of [33] used the Piecewise AggregateApproximation, PAA, in efficient data mining techniques. Then,the Singular Value Decomposition, SVD, was proposed by [34] toimprove the accuracy of time series mining however at the ex-pense of the computational cost. In contrast to the above men-tioned techniques, the SAX representation uniquely has bothdesirable properties [20]: dimensionality reduction of time seriesand lower bounding of Euclidean distance between time series inthe original space.
Recently, although a different approach altogether, [16] intro-duces Prototype Trees to solve action recognition. We thus com-pare results of the proposed method with the Prototype Treesapproach and demonstrate the effectiveness and efficiency of ourtool.
3. SAX – time series representation
We briefly review the SAX (Symbolic Aggregate approXimation)representation of a time series as presented in [20]. Although thereare many representations for time series in the literature, SAX isthe only one that reduces the dimensionality and lower boundsthe Lp norms (distance functions) [35], which guarantees that
I.N. Junejo, Z.A. Aghbari / J. Vis. Commun. Image R. 23 (2012) 853–861 855

Author's personal copy
the distance between any two vectors in the SAX representation issmaller than, or equal to, the distance between these two vectorsin the original space. Table 1 explains the symbols used in thispaper.
We begin by a formal definition of time series:
Definition. A time series T = {t1, t2, t3, . . . , tn}, tn is an ordered set ofn real-valued variables.
Before dealing with time series, we have to remove the distor-tions, namely the offset translation and the amplitude scaling, thatcould greatly affect the results of the action recognition tasks. Thus,we normalize each time series to have a mean of zero and a stan-dard deviation of one, since it is well understood that it is mean-ingless to compare two time series with different offsets andamplitudes. Eq. (1) is used to normalize the time series.
T ¼ To �meanðToÞstdðToÞ
ð1Þ
where To is the original time series, mean(To) is the mean value oftime series variables, and std(To) is the standard deviation of thetime series variable.
3.1. Converting time series to SAX representation
After normalizing the time series, it is converted to a PiecewiseAggregate Approximation (PAA) amd then to the symbolic repre-sentation SAX (see Fig. 2).
The conversion process is performed by the time series to SAXrepresentation algorithm, which takes as input the time series, T,its length, n, the number of PAA segments, w, and the number ofalphabets used to represent the time series, p.
The details of the time series to SAX representation algorithm areexplained below:
Algorithm. Time series to SAX representation
Input: T, n, w, pOutput: SAX representation
(1) Normalize T using Eq. (1).
(2) Set the number of PAA segments i.e. w.
(3) Transform T into PAA coefficients using Eq. (2).
(4) Convert the PAA coefficients into SAX symbols
� An input time series T of length n is normalized using Eq. (1).� Choose an appropriate value for w.� Transform T into segments using PAA by dividing the length n of
T into w equal-sized ‘‘frames’’. The mean value of the data fall-ing within a frame is calculated using Eq. (2) and a vector ofthese values (PAA coefficients) becomes the data-reducedrepresentation.
xi ¼wn
Xnwi
j¼nwði�1Þþ1
xj ð2Þ
� Since normalized time series follow the Gaussian distribution[19,20], breakpoints are determined so that they produceequal-sized areas under the Gaussian curve. The Gaussian curveused to compute the breakpoints has been defined to representthe distribution of the normalized time series and thus it has amean of zero and standard deviation of one. Breakpoints are asorted list of numbers B = {b1,b2, . . . ,bp�1} such that the areaunder a Gaussian curve from bi to bi+1 = 1/p(b0 and bp aredefined as �1 and +1, respectively), see Fig. 2. These break-points can be taken from a breakpoint lookup table [19,20]and they divide the amplitude values of the time series into pequi-probable regions as follows:– Depending on the value of p, the breakpoints are
determined.– All the PAA coefficients that are below the smallest break-
point are mapped to the first symbol, say a all coefficientsgreater than or equal to the smallest breakpoint and lessthan the second smallest breakpoint are mapped to the sec-ond symbol, say b, and so on.
� After mapping all PAA coefficients to their corresponding sym-bols, we get a SAX representation of the input time series. Forexample, in Fig. 2 the SAX representation of the time series Ti
is bbcbaacb.
4. SAX-based action recognition
For Computer Vision applications, we look for a representationthat is general enough to work with trajectories of differentlengths, is easy to compute and does not introduce computationaloverhead. In addition, Computer Vision also applications requires arepresentation with fewer parameters to optimize. This is wherethe SAX representation shines considerably. Based on extensiveexperiments, the authors of [20,35] show that the parametersalphabet size, p, and word size, w, are not too critical and a wordsize in the range of 5–8 and an alphabet size of 3–10 seem reason-able for the task at hand. However, the appropriate value of w andp depends on the data. That is, smaller values of w are more suit-able for relatively smooth and slowly varying trajectories and onthe other hand larger value of w are appropriate for fast varyingtrajectories. Also, smaller values of p would result in clustering
Table 1Symbols used in the paper.
Symbol Meaning
T Time seriesQ Query time seriesn Length of time seriesw Number of PAA segmentsp Number of alphabets used to represent the time seriesbi A breakpoint under a Gaussian curve that divides the curve
into p equi-probable regions.
Fig. 2. A time series Ti (smooth curve) is converted to PAA segments and then usingthe pre-determined breakpoints the PAA coefficients are mapped into symbols (SAXrepresentation).
856 I.N. Junejo, Z.A. Aghbari / J. Vis. Commun. Image R. 23 (2012) 853–861
Author's personal copy
trajectory values in few alphabets and larger values of p worksagainst the SAX goal to reduce the dimensionality of trajectories.
4.1. Features
We aim to match action sequences with similar characteristics.Therefore, in addition to the reference point trajectories, which werefer to as traj feature, we also you explore three additionalfeatures:
4.1.1. Motion characteristics:The action trajectory whose velocity is similar to the velocity
characteristics of another action trajectory should be consideredsimilar. Velocity for a trajectory T(xi,yi, ti), i = 0,1,N � 1, is calcu-lated as:
v0i ¼xiþ1 � xi
tiþ1 � ti
yiþ1 � yi
tiþ1 � ti
� �; i ¼ 0;1; . . . ;N � 1 ð3Þ
where v0i is velocity information of the action trajectory. In addition,we also extract the acceleration from the action trajectory. We con-vert the velocity and the acceleration to the SAX representation,which we denote as vel and acc, respectively.
4.1.2. Spatio-temporal curvature feature:We would like to capture the discontinuity in the velocity,
acceleration and position of an action trajectory. This allows usto discriminate between a straight arm motion and a motioninvolving elbow bending etc. The curvature is defined as:
j ¼
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiy00ðtÞ2 þ x00ðtÞ2 þ ðx0ðtÞy00ðtÞ � x00ðtÞyðtÞÞ2
qðffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffix0ðtÞ2 þ y0ðtÞ2 þ 1
qÞ3
ð4Þ
where x0 and y0 are the velocity components in x and y direction, andx00 and y00 are the acceleration components in x and y direction,
(a)
(b)
Fig. 3. SAX-based action recognition on CMU mocap data. (a) Accuracy obtained for different camera view with their corresponding parameters. (b) For cam5, and usingtraj + acc + curv features, we test with different parameters and plot the accuracy obtained. The figure shows that different combinations of w and p does not greatly affectthe overall accuracy.
I.N. Junejo, Z.A. Aghbari / J. Vis. Commun. Image R. 23 (2012) 853–861 857
Author's personal copy
respectively. We convert the curvature characteristics of the actiontrajectory to the SAX representation, denoted by curv.
4.2. SAX distance
Once trajectories of reference points are converted into SAXrepresentation, the distance between two trajectories is approxi-mated by the distance between their SAX representations. Giventwo SAX representations: a query trajectory, Q, and a test trajec-tory, T, the following formula returns the minimum distance be-tween them:
DðQ ; TÞ ¼ffiffiffiffinw
r ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiXw
i¼1
ðdistðqi; tiÞÞ2vuut ð5Þ
The distance between two SAX representations of trajectories re-quires looking up the corresponding breakpoints in the breakpointlookup table between each pair of SAX symbols, squaring them,summing them, taking the square root and finally multiplying bythe square root of the compression rate n
w.The distance, dist(r,c) values, between two SAX symbol values
r and c is calculated by the following expression:
distðr;cÞ ¼0 if jr� cj 6 1bmaxðr;cÞ�1 � bminðr;cÞ otherwise
(ð6Þ
where b(r,c) is the breaking point value [35]. The first case of Eq.(6) simply says that if the two symbols r and c fall in same region,or two consecutive regions, under the Gaussian curve then the dis-tance between these two symbols will be zero. That is the distancebetween neighboring SAX symbols is zero. In the second case of Eq.(6), what bmin(r,c) means, for example, is the breakpoint correspond-ing to the minimum of the two symbols r and c. For example, if werefer to Fig. 2, the distance between symbol a and c would bebmax(r,c)�1 � bmin(r,c) = bb � ba = �0.43 � (�0.43) = 0.86. For two ac-tion sequences, denoted by Hð�Þ where m body joint trajectoriesare available, the total SAX distance between the two sequencesis defined as:
MINDISTðHðIÞ;HðJ ÞÞ ¼Xm
j¼1
D HjðIÞ;HjðJ Þ� �
ð7Þ
which is the sum of the distances between each corresponding pairof body parts.
5. Experiments and results
In this section we evaluate the SAX-based trajectory representa-tion for the task of human action recognition. The input to themethod is the location of the reference points throughout an actionsequence, given in the form of xy-trajectories. For this purpose, weuse trajectories of only 13 joints on the human body. We alsoexperiments with the vel, acc, and curv features, as describedabove.
In the following we consider the Nearest Neighbor Classifier(NNC). We simply assign to test sequence HðIÞ the action labelof the training sequence I� which minimizes distanceMINDISTðHðIÞ;HðI�ÞÞ over all training sequences. The distanceMINDIST is as defined in (7).
We evaluate SAX-based action recognition on two public data-sets. For all recognition experiments we report results for n-foldcross-validation and make sure the actions of the same persondo not appear in the training and in the test sets simultaneously.In Section 5.1 we validate the approach in controlled multi-viewsettings using motion capture data. In Section 5.2 we demonstrateand compare the discriminative power of our method on a stan-dard action dataset [7]. We compare our results with the state ofthe art methods using the same dataset.
5.1. Experiments with CMU MoCap dataset
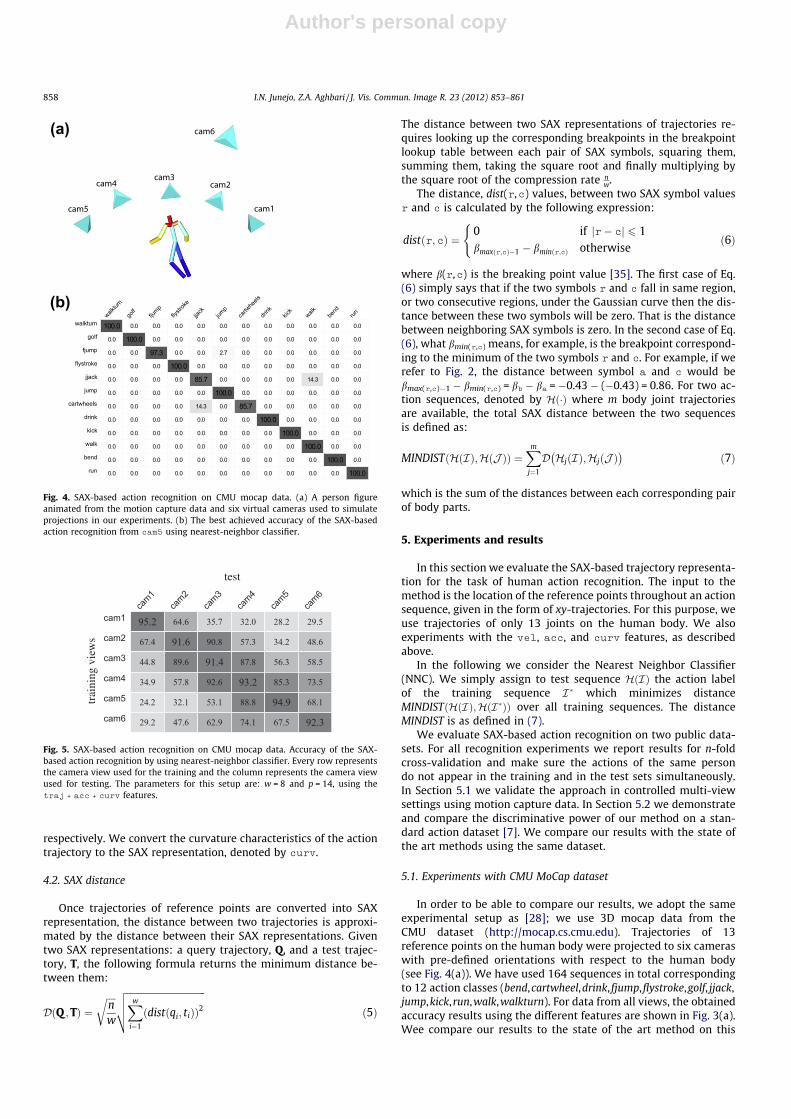
In order to be able to compare our results, we adopt the sameexperimental setup as [28]; we use 3D mocap data from theCMU dataset (http://mocap.cs.cmu.edu). Trajectories of 13reference points on the human body were projected to six cameraswith pre-defined orientations with respect to the human body(see Fig. 4(a)). We have used 164 sequences in total correspondingto 12 action classes (bend,cartwheel,drink, fjump,flystroke,golf, jjack,jump,kick,run,walk,walkturn). For data from all views, the obtainedaccuracy results using the different features are shown in Fig. 3(a).Wee compare our results to the state of the art method on this
(a)
(b)
Fig. 4. SAX-based action recognition on CMU mocap data. (a) A person figureanimated from the motion capture data and six virtual cameras used to simulateprojections in our experiments. (b) The best achieved accuracy of the SAX-basedaction recognition from cam5 using nearest-neighbor classifier.
Fig. 5. SAX-based action recognition on CMU mocap data. Accuracy of the SAX-based action recognition by using nearest-neighbor classifier. Every row representsthe camera view used for the training and the column represents the camera viewused for testing. The parameters for this setup are: w = 8 and p = 14, using thetraj + acc + curv features.
858 I.N. Junejo, Z.A. Aghbari / J. Vis. Commun. Image R. 23 (2012) 853–861
Author's personal copy
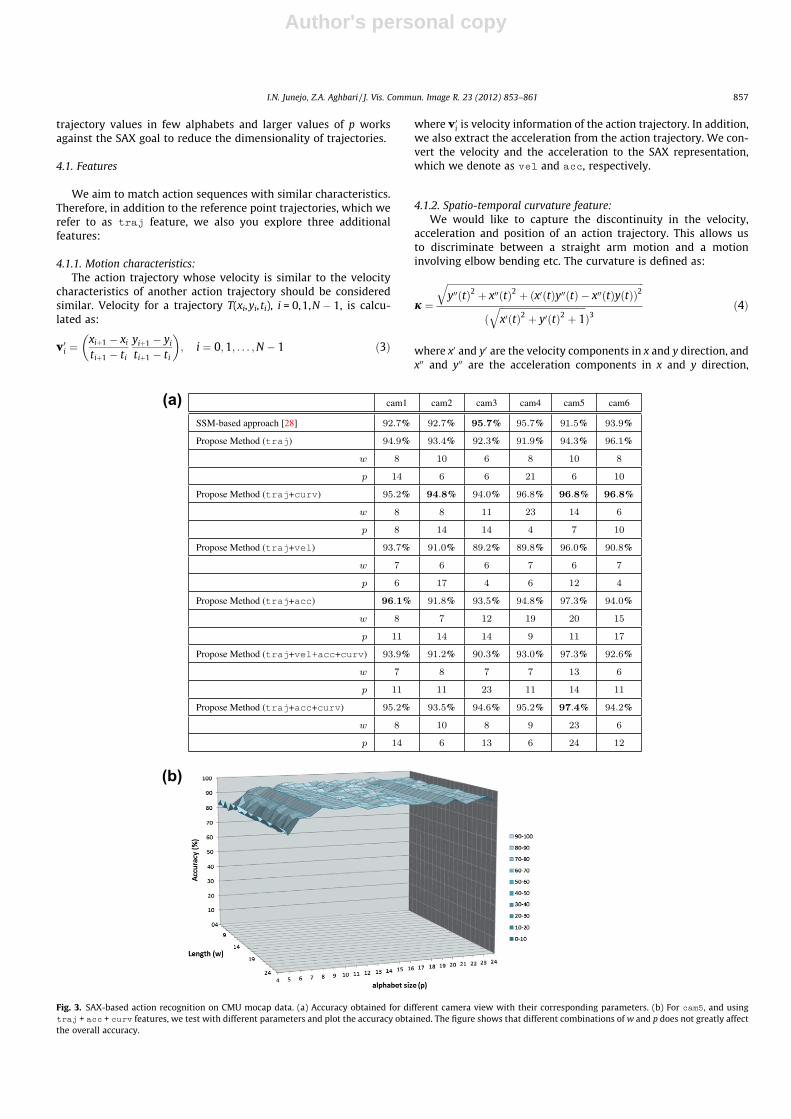
dataset [28]. The second row shows the results obtained by [28],and the subsequent rows show the accuracy obtained by our meth-od using the traj, traj + curv, traj + vel, traj + acc, traj + -vel + acc + curv, and traj + acc + curv, respectively. We haveput the highest accuracy for each column in bold typeset. As thefigure shows, we outperform [28] in four of the six views whileusing only traj, and five of the six view using the traj + curv
feature, and have comparable accuracy in the remaining views.From this figure, we observe the vel feature does not contributetowards a higher accuracy, and the best overall results are obtainedusing just the traj + curv feature.
As discussed above in Section 1, the parameters w and p do notgreatly affect the accuracy results. This can be seen in Fig. 3(b),which shows the recognition accuracy for different combinations
Fig. 6. Weizman dataset: The top row shows instances from the nine different action sequences. The bottom row depicts recognition results. The dataset contains ninety-three action sequences videos of varying lengths, each having a resolution of 180 � 144. The nine difference action are: bending down, jumping back, jumping, jumpingin place, galloping sideways, running, walking, waving one hand and waving two hands.
Fig. 7. Time Comparisons: The curves above show the time taken, in seconds, for the leave-on-out cross validation when performed on the different sizes of the same dataset.
I.N. Junejo, Z.A. Aghbari / J. Vis. Commun. Image R. 23 (2012) 853–861 859

Author's personal copy
of w and p, ranging from 4 to 24 each. The average accuracy acrossthis entire range is 92.7%. Thus, the recognition rate is fairly stableacross different values of w and p.
Fig. 4(b) demonstrates the best action recognition results, ob-tained from cam5. The average accuracy here is 97.4%, comparedto 93.9% obtained by [28]. The parameters for this setup are:w = 23 and p = 24, and the running time for the entire trainingand testing is approximately 24 s implemented on MATLAB. Theaction of jjack is confused with walk, and cartwheel withjjack, which is understandable as the actions are greatly similar.
Although we make no claims that the SAX-based representationis view-invariant, Fig. 5 demonstrates results of action recognitionwhen training and testing on different views. For this setup, theparameters were set to w = 8 and p = 14, while using the tra-
j + acc + curv features. As observed from the diagonal of the con-fusion matrix, the recognition accuracy is highest when trainingand testing on the same views while the best accuracy 95.2% isachieved for cam1. Interestingly, the recognition accuracy degradesgracefully, i.e. the regions near the diagonal still show good accu-racy results, which indicates the method is somewhat robust to an-gle changes.
5.2. Experiments with Weizman action dataset
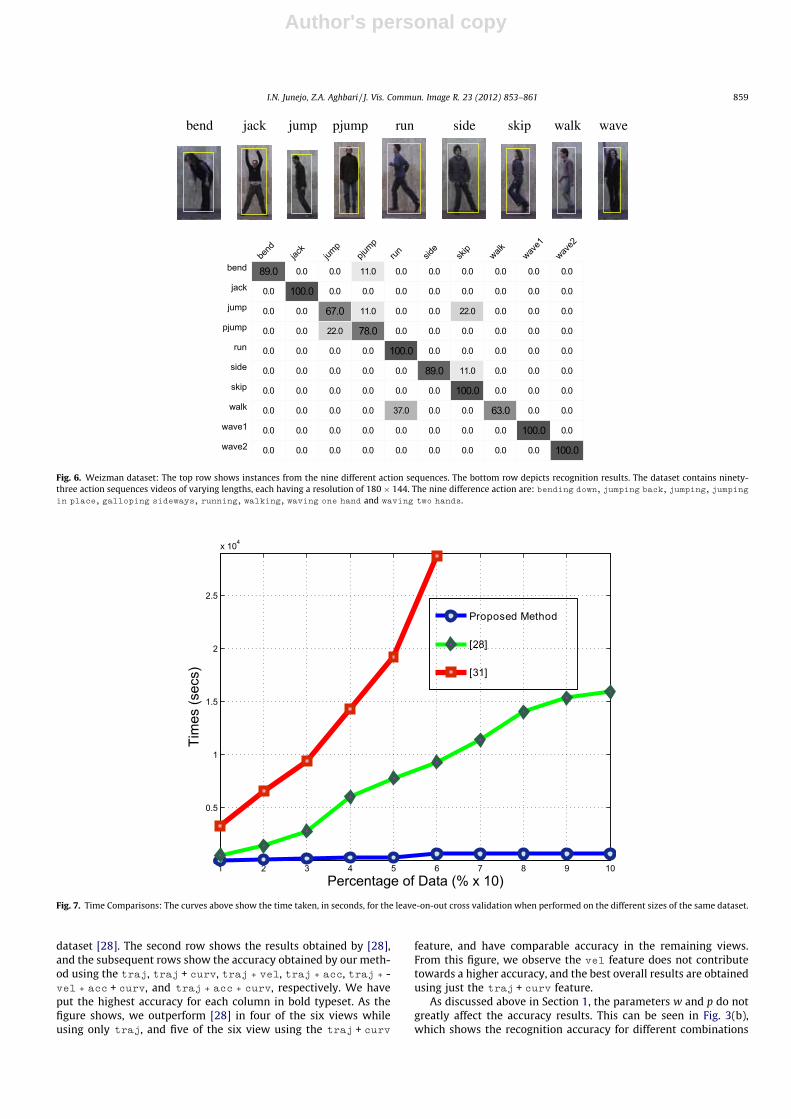
To assess the discriminative power of our method on real videosequences, we apply it to a standard single-view video dataset withnine classes of human actions performed by nine subjects [7](seeFig. 6(top)). The dataset contains ninety-three action sequencesof varying lengths, each having a resolution of 180 � 144. The ninedifferent actions classes are: bending down, jumping back, jumping,jumping in place, galloping sideways, running, walking, waving onehand and waving two hands. Given the low resolution of image se-quences in this dataset, the trajectories were acquired by [31] viasemi-automatic tracking of 13 body joints.
By using the NNC classifier, the best average recognition accu-racy achieved by our method is 88.6% using the traj feature alone.The corresponding confusion matrices are illustrated in Fig. 6(bot-tom). Some errors occur when jump action is confused with theskip action, or when the walk is confused with the running ac-tion. Although the obtained accuracy is not state of the art on thisdataset, it is comparable, if not better, than the methods that treattrajectory data as time series, i.e. 89.7% for [31], and 80% for [32].Similarly, [16] recently introduced prototype trees to solve actionrecognition and reports an accuracy of 88.89% (when using motioninformation only). However, these methods are computationallyexpensive. Whereas higher recognition rates on this dataset havebeen reported, e.g., in [36], the main strength of our method isthe fast and the simple solution: where the entire process of crossvalidation takes less than 50 s on MATLAB. Such an efficient re-sponse time and comparable accuracy makes our method suitablefor various action recognition applications.
5.3. Time comparison
We compare speed of the proposed method with that of [28] and[31]. Since we are only interested in comparing the running times,in order to simulate conditions of working with a large dataset, wetake the CMU dataset ( 164 sequences), and duplicate it uniformlyuntil it reaches to 1312 files (i.e. 800% of the original size). Wechoose to compare with [28,31], for availability of code and easeof use, and because [28] is the only method, to our knowledge, thatis using the particular CMU dataset for action recognition, thus en-abling us to make a fair comparison.
The three methods are implemented on MATLAB (althoughsome parts of [31] are coded in C), using an Intel Core2 2.4 GHzCPU. The final comparison results are shown in Fig. 7. To make a
fair comparison, we start the three methods with input features al-ready computed, so the figure compares only the classification (orthe training/testing) phases of the two methods, while ignoring thefeature extraction costs. We then perform leave-one-out cross val-idation for the different data sizes, as shown in the figure. For thecase when all 1312 sequences are used, the time taken for method[28] is >15,000 s (250 min), compared to the 654.23 s(10.9 min) forour method, which is a considerable improvement.
6. Conclusion
In conclusion, we have proposed an effective and an efficientmethod to address the human action recognition problem byemploying the SAX representation. The SAX representation tre-mendously reduces the dimensionality of the time-series data,thus reducing the strain on the memory space and computationalpower required. The conversion is simple and straight-forward,and the distance to compare two SAX representations is shownto be fast as well. We believe the proposed method is very practicaland considering the existing solutions, is very suitable for variousaction recognition applications. We test on two public datasetsand report encouraging results. In addition to its simplicity andlow computational costs, we have shown that the results obtainedare comparable, if not better, to the existing methods.
References
[1] T. Moeslund, A. Hilton, V. Krüger, A survey of advances in vision-based humanmotion capture and analysis, CVIU 103 (2–3) (2006) 90–126.
[2] L. Wang, W. Hu, T. Tan, Recent developments in human motion analysis,Pattern Recogn. 36 (3) (2003) 585–601.
[3] A. Bobick, J. Davis, The recognition of human movement using temporaltemplates, PAMI 23 (3) (2001) 257–267.
[4] D. Weinland, R. Ronfard, E. Boyer, Free viewpoint action recognition usingmotion history volumes, CVIU 103 (2–3) (2006) 249–257.
[5] T. Syeda-Mahmood, M. Vasilescu, S. Sethi, Recognizing action events frommultiple viewpoints, in: Proc. EventVideo, 2001, pp. 64–72.
[6] A. Yilmaz, M. Shah, Actions sketch: a novel action representation, in: Proc.CVPR, 2005, pp. I:984–I:989.
[7] L. Gorelick, M. Blank, E. Shechtman, M. Irani, R. Basri, Actions as space–timeshapes, PAMI 29 (12) (2007) 2247–2253.
[8] M. Grundmann, F. Meier, I. Essa, 3d shape context and distance transform foraction recognition, in: Proc. ICPR, 2008, pp. 1–4.
[9] I. Laptev, On space–time interest points, IJCV 64 (2/3) (2005) 107–123.[10] E. Shechtman, M. Irani, Space–time behavior based correlation, in: Proc. CVPR,
2005, pp. I:405–412.[11] P. Dollár, V. Rabaud, G. Cottrell, S. Belongie, Behavior recognition via sparse
spatio-temporal features, in: VS-PETS, 2005, pp. 65–72.[12] J. Niebles, H. Wang, F. Li, Unsupervised learning of human action categories
using spatial-temporal words, in: Proc. BMVC, 2006.[13] A. Gilbert, J. Illingworth, R. Bowden, Scale invariant action recognition using
compound features mined from dense spatio-temporal corners, in: Proc. ECCV,2008, pp. I: 222–233.
[14] A.A. Efros, A.C. Berg, E.C. Berg, G. Mori, J. Malik, Recognizing action at adistance, in: ICCV, 2003, pp. 726–733.
[15] L.-P. Morency, A. Quattoni, T. Darrell, Latent-dynamic discriminative modelsfor continuous gesture recognition, in: Proc. CVPR, 2007.
[16] Z. Lin, Z. Jiang, L.S. Davis, Recognizing actions by shape-motion prototype trees,in: Proc. ICCV, 2009.
[17] M. Bregonzio, S. Gong, T. Xiang, Recognising action as clouds of space–timeinterest points, in: Proc. CVPR, 2009, pp. 1948–1955.
[18] E.J. Keogh, M.J. Pazzani, Scaling up dynamic time warping for data miningapplications, Knowl. Discov. Data Min. (2000) 285–289.
[19] J. Lin, E.J. Keogh, L. Wei, S. Lonardi, Experiencing sax: a novel symbolicrepresentation of time series, Data Min. Knowl. Discov. 15 (2) (2007) 107–144.
[20] J. Lin, E.J. Keogh, S. Lonardi, B.Y. chi Chiu, A symbolic representation of timeseries, with implications for streaming algorithms, in: 8th ACM SIGMODWorkshop on Research Issues in Data Mining and Knowledge Discovery, 2003,pp. 2–11.
[21] C. Faloutsos, M. Ranganathan, Y. Manolopoulos, Fast subsequence matching intime-series databases, in: R.T. Snodgrass, M. Winslett (Eds.), Proceedings ofthe 1994 ACM SIGMOD International Conference on Management of Data,ACM Press, New York, 1994, pp. 419–429.
[22] K.-P. Chan, W.-C. Fu, Efficient time series matching by wavelets, in: Proc. ofInternational conference on Data Engineering (ICDE), Sydney, Australia, 1999,pp. 126–133.
[23] A. Yilmaz, M. Shah, Recognizing human actions in videos acquired byuncalibrated moving cameras, in: Proc. ICCV, 2005, pp. I:150–I:157.
860 I.N. Junejo, Z.A. Aghbari / J. Vis. Commun. Image R. 23 (2012) 853–861

Author's personal copy
[24] S. Carlsson, Recognizing walking people, Int. J. Robotic Res. 22 (6) (2003) 359–370.
[25] C. Rao, A. Yilmaz, M. Shah, View-invariant representation and recognition ofactions, IJCV 50 (2) (2002) 203–226.
[26] Y. Shen, H. Foroosh, View-invariant action recognition from point triplets, IEEETrans. Pattern Anal. Mach. Intell. 31 (2009) 1898–1905.
[27] V. Parameswaran, R. Chellappa, View invariance for human action recognition,IJCV 66 (1) (2006) 83–101.
[28] I.N. Junejo, E. Dexter, I. Laptev, P. PTrez, View-independent action recognitionfrom temporal self-similarities., IEEE Trans. Pattern Anal. Mach. Intell. (2011)172–185.
[29] P. Matikainen, M. Hebert, R. Sukthankar, Representing pairwise spatialand temporal relations for action recognition, in: N.P.K. Daniilidis, P.Maragos (Ed.), European Conference on Computer Vision 2010 (ECCV 2010),2010.
[30] R. Messing, C. Pal, H. Kautz, Activity recognition using the velocity histories oftracked keypoints, 2009, pp. 104–111.
[31] S. Ali, A. Basharat, M. Shah, Chaotic invariants for human action recognition, in:Proc. ICCV, 2007.
[32] R. Li, T. Tian, S. Sclaroff, Simultaneous learning of nonlinear manifold anddynamical models for high-dimensional time series, in: Proc. ICCV, 2007.
[33] E. Keogh, S. Chu, D. Hart, M. Pazzani, An online algorithm for segmenting timeseries, in: ICDM, 2001, pp. 289–296.
[34] I. Popivanov, Similarity search over time series data using wavelets, in: ICDE,2002, pp. 212–221.
[35] E.J. Keogh, J. Lin, A.W.-C. Fu, Hot sax: efficiently finding the most unusual timeseries subsequence, in: IEEE International Conf. on Data Mining (ICDM), 2005,pp. 226–233.
[36] N. Ikizler, P. Duygulu, Human action recognition using distribution of orientedrectangular patches, in: Workshop on Human Motion, 2007, pp. 271–284.
I.N. Junejo, Z.A. Aghbari / J. Vis. Commun. Image R. 23 (2012) 853–861 861
























![SCORE IN C - Amos Elkana [Composer]Sop. Sax. Alto Sax. Ten. Sax. Bari. Sax. Mar. Vln. 85 Sop. Sax. Alto Sax. Ten. Sax. Bari. Sax. Mar. Pno. Vln. 88 pp pp &, , &, ,?, ,?, , & & > >](https://img.pdfslide.us/doc/110x75/60a8fffc38c9f319c0407756/score-in-c-amos-elkana-composer-sop-sax-alto-sax-ten-sax-bari-sax-mar.jpg)

![Quebec [big band] - Free- · PDF filesax a.1 Intro sax a.2 sax t.1 sax t.2 sax b. trp 1](https://img.pdfslide.us/doc/110x75/5ab15ee27f8b9a1d168c8278/quebec-big-band-free-a1-intro-sax-a2-sax-t1-sax-t2-sax-b-trp-1.jpg)
