Embed Size (px)
Citation preview

Product Version
Document Organization
Getting Help
Table of Contents
FASTFIND LINKS
MK-99ARC023-04
Hitachi Content PlatformUsing a Namespace

Copyright © 2009–2011 Hitachi Data Systems Corporation, ALL RIGHTS RESERVED
No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying and recording, or stored in a database or retrieval system for any purpose without the express written permission of Hitachi Data Systems Corporation (hereinafter referred to as “Hitachi Data Systems”).
Hitachi Data Systems reserves the right to make changes to this document at any time without notice and assumes no responsibility for its use. This document contains the most current information available at the time of publication. When new and/or revised information becomes available, this entire document will be updated and distributed to all registered users.
Some of the features described in this document may not be currently available. Refer to the most recent product announcement or contact your local Hitachi Data Systems sales office for information about feature and product availability.
Notice: Hitachi Data Systems products and services can be ordered only under the terms and conditions of the applicable Hitachi Data Systems agreement(s). The use of Hitachi Data Systems products is governed by the terms of your agreement(s) with Hitachi Data Systems.
By using this software, you agree that you are responsible for:
a) Acquiring the relevant consents as may be required under local privacy laws or otherwise from employees and other individuals to access relevant data; and
b) Ensuring that data continues to be held, retrieved, deleted, or otherwise processed in accordance with relevant laws.
Hitachi is a registered trademark of Hitachi, Ltd. in the United States and other countries. Hitachi Data Systems is a registered trademark and service mark of Hitachi, Ltd. in the United States and other countries.
All other trademarks, service marks, and company names are properties of their respective owners.

Contents
Preface........................................................................................................ ixIntended audience . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .ixProduct version . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ixDocument organization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xSyntax notation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .xiRelated documents. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .xiGetting help. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xivComments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xiv
1 Introduction to Hitachi Content Platform.............................................1-1About Hitachi Content Platform . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-2
Object-based storage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-2Namespaces and tenants . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-2Namespace access . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-3
REST interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-3Metadata query API . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-4Namespace Browser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-4Search Console. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-5HCP Data Migrator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-6HCP client tools . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-6
Transmitting data in compressed format . . . . . . . . . . . . . . . . . . . . . . . . . 1-7Data access permissions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-8Replication. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-9
Operations. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-9Operation restrictions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1-9Supported operations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1-10Prohibited operations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1-11
2 Understanding objects........................................................................2-1Object naming considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-2
Contents iii
Using a Namespace

Cryptographic hash value . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-2Object ingest time and change time . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-3Data protection level. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-3Retention . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-3
Object retention settings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-5Deleting objects and versions under retention . . . . . . . . . . . . . . . . . . . . . 2-5Holding objects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-6Retention classes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-6Returned retention information . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-8Specifying retention settings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2-8
Specifying a date and time . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-10Specifying an offset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-11Specifying a retention class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-13
Shredding . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-13Versioning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-14
Creating versions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-14Retrieving and listing versions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-15Deleting objects with versioning enabled . . . . . . . . . . . . . . . . . . . . . . . .2-16Purging objects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-16
Indexing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-17Custom metadata. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .2-17
3 Accessing a namespace.....................................................................3-1URLs for HTTP access to the namespace . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-2
URL formats. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-2Enabling URLs with hostnames . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-4Using an IP address in the URL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-5URL considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-6
Authenticating namespace access . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3-8
4 Working with objects and versions .....................................................4-1Adding an object or version of an object. . . . . . . . . . . . . . . . . . . . . . . . . . . . 4-2Checking the existence of an object or version . . . . . . . . . . . . . . . . . . . . . . .4-12Listing object versions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4-16Retrieving an object or version of an object . . . . . . . . . . . . . . . . . . . . . . . . .4-22Deleting an object and using privileged delete. . . . . . . . . . . . . . . . . . . . . . . .4-38Purging an object and using privileged purge . . . . . . . . . . . . . . . . . . . . . . . .4-43
5 Working with directories .....................................................................5-1Creating an empty directory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-2Checking the existence of a directory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-3Listing directory contents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5-5Deleting an empty directory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .5-10
iv Contents
Using a Namespace

6 Working with system metadata...........................................................6-1Specifying metadata on object creation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-2Modifying object metadata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6-5
7 Working with custom metadata ..........................................................7-1Storing custom metadata . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7-2Checking the existence of custom metadata . . . . . . . . . . . . . . . . . . . . . . . . . 7-6Retrieving custom metadata for objects and versions. . . . . . . . . . . . . . . . . . . 7-8Deleting custom metadata. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .7-11
8 Using the HCP metadata query API ...................................................8-1About the metadata query API. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-2
Operation records. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-3Paged queries . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-4
Request URL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-4Connecting using a DNS name. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-5Connecting using an IP address . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-5
Request considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-6Request format . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-6
Request HTTP elements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-6Request body. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-8
XML request body. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-8JSON request body . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8-9Request body contents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8-10
Response format . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8-14Request-specific return codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8-14Request-specific response headers . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8-16Response body. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8-16
XML response body. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8-16JSON response body . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8-17Response body contents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8-17
Examples. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8-21Example 1: Retrieving detailed metadata for indexable objects in a directory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .8-22
Example 2: Retrieving metadata for changed objects . . . . . . . . . . . . . . .8-25Example 3: Using a paged query to retrieve a large number of records. . .8-26
9 Retrieving namespace information .....................................................9-1Listing accessible namespaces . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9-2Listing retention classes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9-5Listing namespace and user permissions. . . . . . . . . . . . . . . . . . . . . . . . . . . . 9-8Listing namespace statistics. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .9-12
Contents v
Using a Namespace

10 Using the Namespace Browser ........................................................10-1About the Namespace Browser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-2
Logging in . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-2Common elements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-3
Changing your password. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-3Working with namespace contents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-4
Listing directory contents . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-5Directory listing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-5Showing and hiding deleted objects and directories . . . . . . . . . . . . . . .10-7
Listing object versions. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-7Viewing and retrieving object and version content . . . . . . . . . . . . . . . . . .10-9Adding objects and versions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-10Deleting objects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-10Creating directories. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-10
Viewing namespace information. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-11Viewing accessible namespaces . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-11Viewing retention classes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-12Viewing permissions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-13Viewing namespace statistics. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10-13
11 General usage considerations..........................................................11-1Namespace access by IP address . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11-2Directory structures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11-2Shredding considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11-3Storing zero-sized files . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11-3Data chunking with write operations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11-4Failed write operations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11-4Objects open for write . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11-5Non-WORM objects . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11-6Deleting objects under repair. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11-6Persistent connections . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11-6Connection failure handling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11-7Multithreading . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .11-7
A HTTP reference................................................................................. A-1HTTP methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-2HTTP return codes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-9HCP-specific HTTP response headers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-13Response body formats. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . A-16
vi Contents
Using a Namespace

B Java classes for examples ................................................................ B-1GZIPCompressedInputStream class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-2WholeIOInputStream class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-8WholeIOOutputStream class . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . B-9
Glossary
Index
Contents vii
Using a Namespace

viii Contents
Using a Namespace

Preface
This book is your guide to working with Hitachi Content Platform (HCP) namespaces. It introduces HCP concepts and describes how HCP represents content using familiar data structures. It includes instructions for accessing a namespace and explains how to store, view, retrieve, and delete objects in a namespace, as well as how to change object metadata such as retention and shred settings. It also contains usage considerations to help you work more effectively with namespaces.
This book does not discuss using the default namespace. For information on that namespace, see Using the Default Namespace.
Intended audience
This book is intended for people who need to know how to store, retrieve, and otherwise manipulate data and metadata in an HCP namespace. It addresses both those who are writing applications to access one or more namespaces and those who are accessing a namespace directly through a command-line interface or GUI (such as Windows Explorer).
If you are writing applications, this book assumes you have programming experience.
Product version
This book applies to release 4.1 of HCP.
Note: Throughout this book, the word Unix is used to represent all UNIX-like operating systems (such as UNIX itself or Linux).
Preface ix
Using a Namespace
Document organization
Document organization
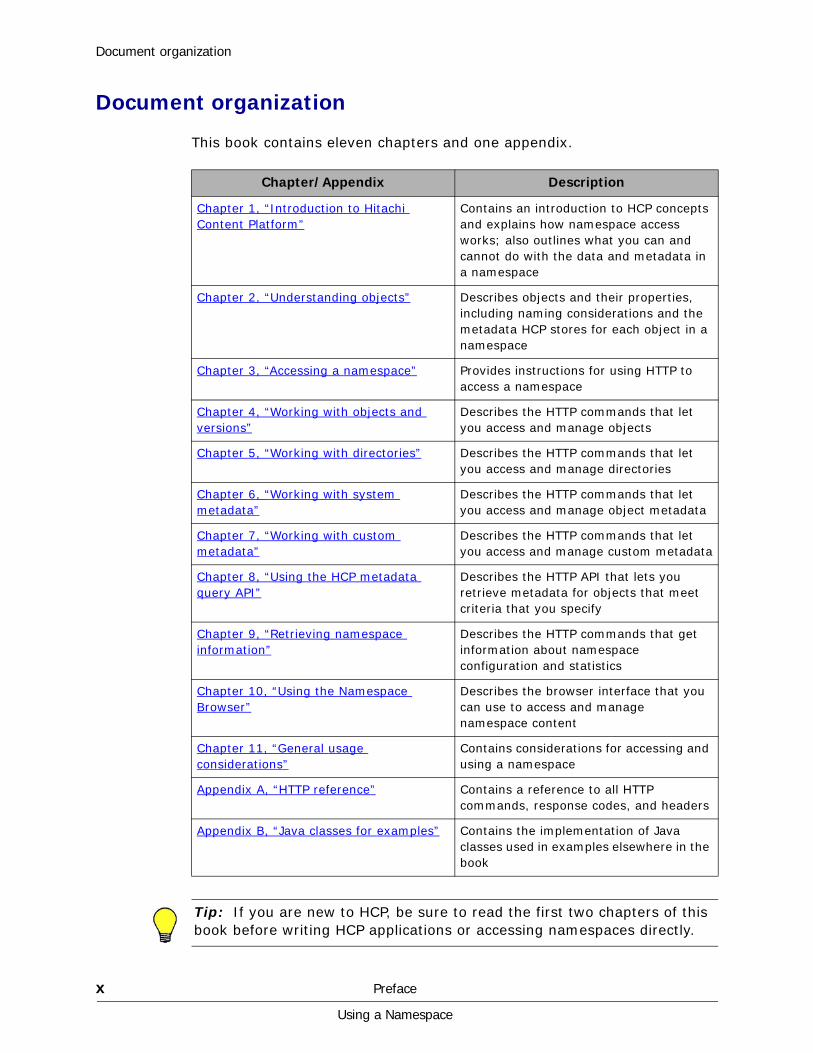
This book contains eleven chapters and one appendix.
Chapter/Appendix Description
Chapter 1, “Introduction to Hitachi Content Platform”
Contains an introduction to HCP concepts and explains how namespace access works; also outlines what you can and cannot do with the data and metadata in a namespace
Chapter 2, “Understanding objects” Describes objects and their properties, including naming considerations and the metadata HCP stores for each object in a namespace
Chapter 3, “Accessing a namespace” Provides instructions for using HTTP to access a namespace
Chapter 4, “Working with objects and versions”
Describes the HTTP commands that let you access and manage objects
Chapter 5, “Working with directories” Describes the HTTP commands that let you access and manage directories
Chapter 6, “Working with system metadata”
Describes the HTTP commands that let you access and manage object metadata
Chapter 7, “Working with custom metadata”
Describes the HTTP commands that let you access and manage custom metadata
Chapter 8, “Using the HCP metadata query API”
Describes the HTTP API that lets you retrieve metadata for objects that meet criteria that you specify
Chapter 9, “Retrieving namespace information”
Describes the HTTP commands that get information about namespace configuration and statistics
Chapter 10, “Using the Namespace Browser”
Describes the browser interface that you can use to access and manage namespace content
Chapter 11, “General usage considerations”
Contains considerations for accessing and using a namespace
Appendix A, “HTTP reference” Contains a reference to all HTTP commands, response codes, and headers
Appendix B, “Java classes for examples” Contains the implementation of Java classes used in examples elsewhere in the book
Tip: If you are new to HCP, be sure to read the first two chapters of this book before writing HCP applications or accessing namespaces directly.
x Preface
Using a Namespace
Syntax notation
Syntax notation
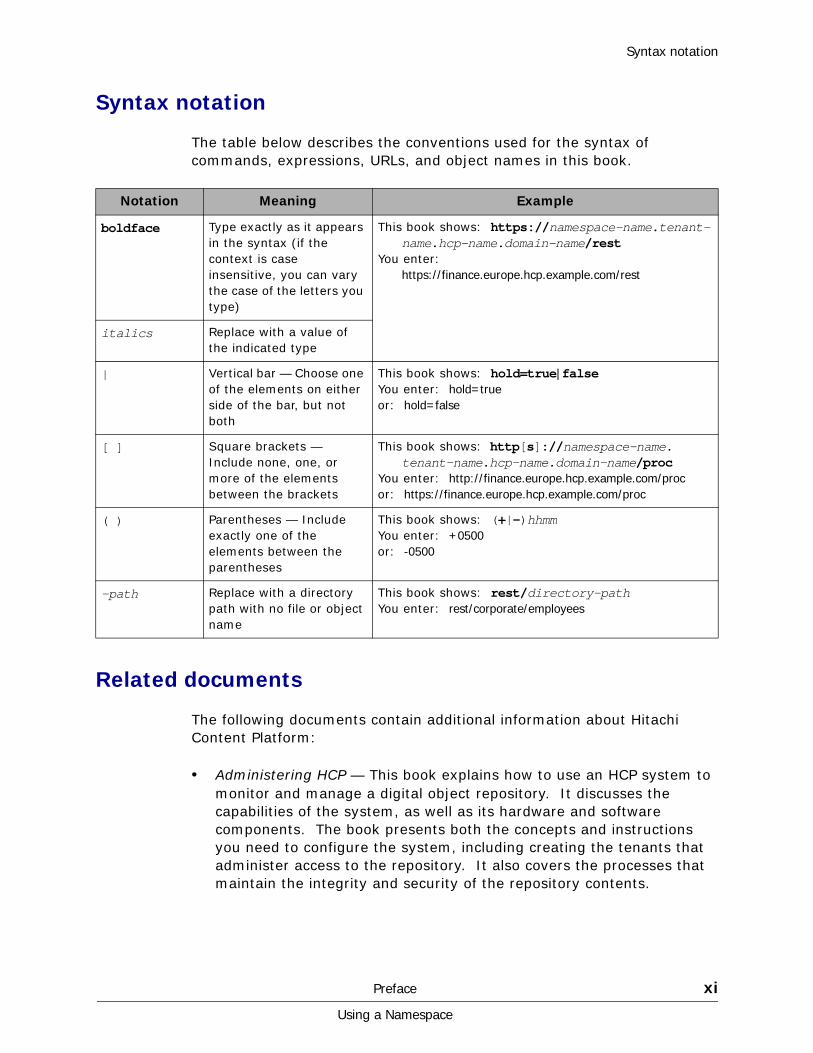
The table below describes the conventions used for the syntax of commands, expressions, URLs, and object names in this book.
Related documents
The following documents contain additional information about Hitachi Content Platform:
• Administering HCP — This book explains how to use an HCP system to monitor and manage a digital object repository. It discusses the capabilities of the system, as well as its hardware and software components. The book presents both the concepts and instructions you need to configure the system, including creating the tenants that administer access to the repository. It also covers the processes that maintain the integrity and security of the repository contents.
Notation Meaning Example
boldface Type exactly as it appears in the syntax (if the context is case insensitive, you can vary the case of the letters you type)
This book shows: https://namespace-name.tenant-name.hcp-name.domain-name/rest
You enter: https://finance.europe.hcp.example.com/rest
italics Replace with a value of the indicated type
| Vertical bar — Choose one of the elements on either side of the bar, but not both
This book shows: hold=true|falseYou enter: hold=trueor: hold=false
[ ] Square brackets — Include none, one, or more of the elements between the brackets
This book shows: http[s]://namespace-name.tenant-name.hcp-name.domain-name/proc
You enter: http://finance.europe.hcp.example.com/procor: https://finance.europe.hcp.example.com/proc
( ) Parentheses — Include exactly one of the elements between the parentheses
This book shows: (+|-)hhmmYou enter: +0500or: -0500
-path Replace with a directory path with no file or object name
This book shows: rest/directory-pathYou enter: rest/corporate/employees
Preface xi
Using a Namespace

Related documents
• Managing a Tenant and Its Namespaces — This book contains complete information for managing the HCP tenants and namespaces created in an HCP system. It provides instructions for setting up both administrative user accounts and data access accounts, configuring the HTTP protocol, which allows access to namespaces, managing search, and downloading installation files for HCP Data Migrator and the HCP client tools. It also explains how to work with retention classes and the privileged delete functionality.
• Managing the Default Tenant and Namespace — This book contains complete information for managing the default tenant and namespace in an HCP system. It provides instructions for changing tenant and namespace settings, configuring the protocols that allow access to the namespace, managing search, and downloading installation files for HCP Data Migrator and the HCP client tools. It also explains how to work with retention classes and the privileged delete functionality.
• Replicating Tenants and Namespaces — This book covers all aspects of tenant and namespace replication. Replication is the process of copying tenants and namespaces from one HCP system to another to ensure data availability and enable disaster recovery. The book describes how replication works, contains instructions for working with replication links, and explains how to monitor the replication process.
• HCP Management API Reference — This book contains the information you need to use the HCP management API. This REST API enables you to create and manage tenants and namespaces programmatically. The book explains how to use the API to access an HCP system, specify resources, and update and retrieve resource properties.
• Using the Default Namespace — This book describes the file system HCP uses to present the contents of the default namespace. It provides instructions for accessing the namespace by using the HCP-supported protocols for the purpose of storing, retrieving, and deleting objects, as well as changing object metadata such as retention and permissions.
• Searching Namespaces — This book describes the HCP Search Console. It explains how to search namespaces for objects that satisfy criteria you specify. It also explains how to manage and manipulate queries and search results. The book contains many examples, which you can use as models for your own searches.
xii Preface
Using a Namespace

Related documents
• Using HCP Data Migrator — This book contains the information you need to install and use the HCP Data Migrator (HCP-DM) utility distributed with HCP. This utility enables you to copy data between local file systems, HCP namespaces, and earlier HCAP archives. It also supports bulk delete operations. The book describes both the interactive window-based interface and the set of command-line tools included in HCP-DM.
• Using the HCP Client Tools — This book contains the information you need to install and use the set of client command-line tools distributed with HCP. These tools enable you to find files and to copy and move files to and from namespaces. The book contains many examples that show command-line details and the overall workflow.
• Installing an HCP System — This book provides the information you need to install the software for a new HCP system. It explains what you need to know to successfully configure the system and contains step-by-step instructions for the installation procedure.
• Third-Party Licenses and Copyrights — This book contains copyright and license information for third-party software distributed with or embedded in HCP.
• HCP-DM Third-Party Licenses and Copyrights — This book contains copyright and license information for third-party software distributed with or embedded in HCP Data Migrator.
• Installing an HCP 500 System — Final On-site Setup — This book contains instructions for deploying an assembled and configured HCP 500 system at a customer site. It explains how to make the necessary physical connections and reconfigure the system for the customer computing environment.
• Installing an HCP 300 System — Final On-site Setup — This book contains instructions for deploying an assembled and configured HCP 300 system at a customer site. It explains how to make the necessary physical connections and reconfigure the system for the customer computing environment.
Note: For most purposes, the HCP client tools have been superseded by HCP Data Migrator. However, they have some features, such as finding files, that are not available in HCP-DM.
Preface xiii
Using a Namespace

Getting help
Getting help
The Hitachi Data Systems® customer support staff is available 24 hours a day, seven days a week. If you need technical support, please call:
• United States: (800) 446-0744
• Outside the United States: (858) 547-4526
Comments
Please send us your comments on this document:
Include the document title, number, and revision, and refer to specific sections and paragraphs whenever possible.
Thank you! (All comments become the property of Hitachi Data Systems.)
Note: If you purchased HCP from a third party, please contact your authorized service provider.
xiv Preface
Using a Namespace

1
Introduction to Hitachi ContentPlatform
Hitachi Content Platform (HCP) is a distributed storage system designed to support large, growing repositories of fixed-content data. HCP stores objects that include both data and metadata that describes the data. It distributes these objects across the storage space but still presents them as files in a standard directory structure.
HCP provides access to stored objects through the HTTP protocol, as well as through user interfaces such as the Namespace Browser and Search Console.
This chapter introduces basic HCP concepts and includes information on what you can do with an HCP namespace.
Introduction to Hitachi Content Platform 1–1
Using a Namespace

About Hitachi Content Platform
About Hitachi Content Platform
HCP is a combination of hardware and software that provides an object-based data storage environment. An HCP repository stores all types of data, from simple text files to medical images to multigigabyte database images. HCP provides easy access to the repository for adding, retrieving, and deleting the stored data. HCP uses write-once, read-many (WORM) storage technology and a variety of policies and internal processes to ensure the integrity of the stored data and the efficient use of storage capacity.
Object-based storage
HCP stores objects in the repository. Each object permanently associates data HCP receives (for example, a file, an image, or a database) with information about that data, called metadata.
An object encapsulates:
• Fixed-content data — An exact digital reproduction of data as it existed before it was stored. Once it’s in the repository, this fixed-content data cannot be modified.
• System metadata — System-managed properties that describe the fixed-content data (for example, its size and creation date). System metadata includes settings, such as retention and data protection level, that influence how transactions and internal processes affect the object.
• Custom metadata — Metadata that a user or application provides to further describe an object. Custom metadata is typically specified as XML.
You can use custom metadata to create self-describing objects. Future users and applications can use this metadata to understand and repurpose the object content.
Namespaces and tenants
An HCP repository is partitioned into namespaces. A namespace is a logical grouping of objects such that the objects in one namespace are not visible in any other namespace. To the user of a namespace, the namespace is the repository.
1–2 Introduction to Hitachi Content Platform
Using a Namespace

About Hitachi Content Platform
Namespaces provide a mechanism for separating the data stored for different applications, business units, or customers. For example, you could have one namespace for accounts receivable and another for accounts payable.
Namespaces also enable operations to work against selected subsets of repository objects. For example, you could perform a query that targets the accounts receivable and accounts payable namespaces but not the employees namespace.
Namespaces are owned and managed by administrative entities called tenants. A tenant typically corresponds to an actual organization such as a company or a division or department within a company. A tenant can also correspond to an individual person.
Namespace access
HCP provides several techniques for accessing and managing data in the namespace. These include:
• REST interface
• Metadata query API
• Namespace Browser
• Search Console
• HCP Data Migrator
• HCP client tools
REST interface
Clients use an HTTP-based REST interface to access the namespace. Using this interface, you can perform actions such as adding objects to the namespace, viewing and retrieving objects, changing object metadata, and deleting objects. You can access the namespace programmatically with applications, interactively with a command-line tool, or through a GUI interface.
Introduction to Hitachi Content Platform 1–3
Using a Namespace

About Hitachi Content Platform
The figure below shows the relationship between original data, objects in a namespace, and the HTTP access protocol.
Metadata query API
HCP allows clients to use HTTP requests to find objects that meet specific criteria, including object change time, index setting, operations on the object, and the object location. If the client has the appropriate permissions, it can query multiple namespaces, and a single request can query multiple HCP namespaces and the default namespace.
When you submit a query, HCP returns a set of records containing metadata that describes the matching objects. If a query matches a large number of objects, you can use multiple requests to page sequentially through the records and retrieve only a specific number of records in response to each request.
Namespace Browser
The HCP Namespace Browser lets you manage namespace content and view information about namespaces. With the Browser, you can:
• List, view, and retrieve objects and versions of objects
• Create empty directories
• Store and delete objects
• Display namespace information, including:
– The namespaces that you can access
Original data
Namespace
Object
Fixedcontent
Systemmetadata Custom
metadata
HTT
P
Client
1–4 Introduction to Hitachi Content Platform
Using a Namespace

About Hitachi Content Platform
– Retention classes that you can use in a namespace
– Permissions for namespace access
– Statistics about a namespace
Search Console
The HCP Search Console is an easy-to-use web application that lets you search for and manage objects based on specified criteria. For example, you can search for objects stored before a certain date or larger than a specified size and then delete them or prevent them from being deleted.
The Search Console works with either of two implementations, which must be enabled at the HCP system level:
• The HDDS search facility — This facility interacts with Hitachi Data Discovery Suite (HDDS), which performs searches and returns results to the HCP Search Console. HDDS is a separate product from HCP.
• The HCP search facility — This facility is integrated with HCP and works internally to perform searches and return results to the Search Console.
Only one of the search facilities can be enable at any given time. If neither one is enabled, HCP does not support using the Search Console to search namespaces. The system associated with the enabled search facility is called the active search system.
The active search system (that is, HDDS or HCP) maintains an index of data objects in each search-enabled namespace. The index is based on object content and metadata. The active search system uses the index for fast retrieval of search results. When objects are added to or removed from the namespace or when object metadata changes, the active search system automatically updates the index to keep it current.
For information on using the Search Console, see Searching Namespaces.
Note: Not all namespaces support search. To find out whether a namespace is search enabled, see your namespace administrator.
Introduction to Hitachi Content Platform 1–5
Using a Namespace

About Hitachi Content Platform
HCP Data Migrator
HCP Data Migrator (HCP-DM) is a high-performance, multithreaded client-side utility for viewing, copying, and deleting data. With HCP-DM, you can:
• Copy objects, files, and directories between local file systems, HCP namespaces, and earlier HCAP archives
• Delete objects, files, and directories, including performing bulk delete operations
• View the content of objects and files, including the content of old versions of objects
• Rename files and directories on the local file system
• View object, file, and directory properties
• Create empty directories
• Add, replace, or delete custom metadata for objects
HCP-DM has both a graphical user interface (GUI) and a command-line interface (CLI).
For information on using HCP-DM, see Using HCP Data Migrator.
HCP client tools
HCP comes with a set of command-line tools that let you copy or move data between a client and an HCP system. They let you search for the files you want to work with based on criteria you specify. Additionally, they let you create empty directories in a local or remote file system or HCP system.
The client tools support multiple namespace access protocols and multiple client platforms. The command syntax is the same for all supported configurations.
For information on installing and using the client tools, see Using the HCP Client Tools.
Note: For most purposes, the HCP client tools have been superseded by HCP Data Migrator. However, they have some features, such as finding files, that are not available in HCP-DM.
1–6 Introduction to Hitachi Content Platform
Using a Namespace

About Hitachi Content Platform
Transmitting data in compressed format
To save bandwidth, you can compress object data or custom metadata in gzip format before sending it to HCP. In the PUT request, you tell HCP that data is compressed so that HCP knows to decompress the data before storing it.
Similarly, in a GET request, you can tell HCP to return object data or custom metadata in compressed format. In this case, you need to decompress the returned data yourself.
HCP supports only the gzip algorithm for compressed data transmission.
You tell HCP that the request body is compressed by including a Content-Encoding header with the value gzip. In this case, HCP uses the gzip algorithm to decompress the received data.
You tell HCP to send a compressed response by specifying an Accept-Encoding header. If the header specifies gzip, a list of compression algorithms that includes gzip, or *, HCP uses the gzip algorithm to compress the data before sending it.
For examples of sending and receiving objects in compressed format, see Chapter 4, “Working with objects and versions.”
Notes:
• You can also have HCP compress and decompress metadata query API requests and responses. For more information on this, see “Request HTTP elements” on page 5-5.
• HCP normally compresses object data and custom metadata that it stores, so you do not need to explicitly compress objects for storage. However, if you do need to store gzip-compressed objects or custom metadata, do not use a Content-Encoding header. To retrieve stored gzip-compressed data, do not use an Accept-Encoding header.
Introduction to Hitachi Content Platform 1–7
Using a Namespace

About Hitachi Content Platform
Data access permissions
All namespace access clients must have permission to access and perform actions on data. The table below describes the permissions and the operations they allow.
Some operations require multiple permissions. For example, to place an object on hold, you need to have both write and privileged permissions. Similarly, to perform a privileged purge, you need delete, privileged, and purge permissions.
Permissions are set at two levels:
• Namespace-level permissions — Specify the maximum permissions for any user that accesses the namespace.
• Data access account — Specifies permissions for an individual user. To access a namespace, you need a data access account with a username and password. The account specifies which namespaces you can access and what you can do in each one.
For you to perform an operation, the required permissions must be enabled in both the namespace-level permissions and your data access account.
Permission Operations
Read • Retrieve objects and system metadata.
• Check for object existence.
• Check for and retrieve custom metadata.
Write • Add objects.
• Create directories.
• Set and change system and custom metadata.
Delete • Delete objects, empty directories, and custom metadata.
Purge • Delete objects and their historical versions.
Privileged • Delete or purge objects regardless of retention.
• Place objects on hold.
Search • Search for objects. For information on this, see Searching Namespaces and Chapter 8, “Using the HCP metadata query API”.
1–8 Introduction to Hitachi Content Platform
Using a Namespace

Operations
Replication
Replication is the process of keeping selected tenants and namespaces in two HCP systems in sync with each other. Basically, this entails copying object creations, deletions, and metadata changes from one system to the other. HCP also replicates the tenant and namespace configuration, data access accounts, and retention classes.
The HCP system in which the objects are initially created is called the primary system. The second system is called the replica.
Replication has several purposes, including:
• If the primary system becomes unavailable (for example, due to network issues), the replica can provide continued data availability.
• If the primary system suffers irreparable damage, the replica can serve as a source for disaster recovery.
• If an object cannot be read from the primary system (for example, because a server is unavailable), HCP can try to read it from the replica.
Operations
You use familiar commands and tools to perform operations on a namespace. Some operations relate to specific types of metadata. For more information on this metadata, see Chapter 2, “Understanding objects.”
Operations that store or retrieve data can optionally transmit the data in gzip-compressed format. For more information on this, see the individual commands used for those operations.
Operation restrictions
The operations you can perform are subject to these restrictions:
• The HTTP request headers must include valid user information.
Note: Replication is an add-on feature to HCP. Not all systems include it.
Introduction to Hitachi Content Platform 1–9
Using a Namespace

Operations
• The namespace must be configured to allow HTTP or HTTPS access from your client IP address.
• The namespace configuration and user permissions must allow the operation.
For information on user permissions, see “Namespace Browser” on page 1-4.
Supported operations
You can perform these operations on a namespace:
• Write data to the namespace
• If versioning is enabled, store new versions of existing objects
• Override default metadata when storing an object
• Create an empty directory in the namespace
• Check for object existence
• View the content of an object
• View object metadata
• Delete an object
• Delete an empty directory
• Set retention for an object that has none
• Extend the retention period for an object
• Set or change a retention class for an object
• Hold or release an object
• Enable shredding an object
• Change the index setting for an object
• Add, replace, or delete custom metadata for an object
1–10 Introduction to Hitachi Content Platform
Using a Namespace

Operations
• Add or retrieve object data and custom metadata in a single operation
• Check for and read custom metadata
• List retention classes available in the namespace
• List namespace permissions for the user
• List the namespace statistics
• List the namespaces accessible to you
• Use the HCP metadata query API to get information about objects that meet specified criteria in one or more namespaces
Prohibited operations
HCP never lets you:
• Rename an object or directory.
• Overwrite a successfully stored object. However, if versioning is enabled, you can write new versions of an object.
• Modify the fixed-content portion of an object.
• Delete an object that’s under retention if you do not have the privileged permission or if the namespace is configured to prevent this operation.
• Delete a directory that contains one or more objects.
• Shorten an explicitly set retention period.
Introduction to Hitachi Content Platform 1–11
Using a Namespace

Operations
1–12 Introduction to Hitachi Content Platform
Using a Namespace

2
Understanding objectsObjects in a namespace have a variety of properties, such as a retention period and an index setting. These properties are defined for each object by the object metadata. You can view all the metadata for objects in a namespace and modify some of it.
A namespace can be configured to allow objects to have multiple versions. Each version is an independent copy of the object that includes both data and metadata. A new version is created each time you save the object, but not when you modify metadata or custom metadata. A version can also be a special entity that represents a deleted object.
Several namespace properties affect objects. For example, the namespace can be configured to automatically delete objects after their retention periods expire. The namespace configuration also specifies defaults for several metadata values. When you add an object to the namespace, the object inherits these values unless you override them.
This chapter provides detailed information about objects and their properties, including object names, metadata you can change, custom metadata, and object versions.
For a complete list of object metadata, see “Checking the existence of an object or version” on page 4-12.
Understanding objects 2–1
Using a Namespace

Object naming considerations
Object naming considerations
When naming objects and directories, keep these considerations in mind:
• The name of each object must conform to the POSIX standard. In particular:
– Object names are case sensitive.
– Names can include nonprinting characters, such as spaces and line breaks.
– All characters are valid except the NULL character (ASCII 0 (zero)) and the forward slash (ASCII 47 (/), which is the separator character in directory paths).
• The maximum length for the combined directory path and name of an object, including separators, is 4,095 bytes.
• Some character-set encoding schemes, such as UTF-8, can require more than one byte to encode a single character. As a result, such encoding can invisibly increase the length of a full object specification (directory path and object name) causing it to exceed the HCP limit of 4,095 bytes.
• When searching namespaces, HDDS and HCP rely on UTF-8 encoding conventions to find objects by name. If the name of an object is not UTF-8 encoded, searches for the object by name may return unexpected results.
• When HCP indexes an object with a name that includes certain characters that cannot be UTF-8 encoded, it percent-encodes those characters. As a result, searches for those objects by name must explicitly include the percent-encoded characters in the name.
Cryptographic hash value
The cryptographic hash value for an object is a form of fingerprint. HCP calculates this value from the object data and uses it to check that object data remains unchanged.
You can view this value, but you cannot change it.
2–2 Understanding objects
Using a Namespace

Object ingest time and change time
Object ingest time and change time
Objects in a namespace have both an ingest time and a change time. The ingest time is the time when the object or version of the object was first added to the namespace. The change time is the most recent of these events:
• The object was closed after being added to the namespace.
• Any metadata, including custom metadata, was changed.
• The object was recovered from a replica.
• The HCP search facility tried but could not index the object. When this happens, the facility sets the change time for the object to two weeks in the future, at which time it tries again to index it.
If an object has not changed since ingestion, the ingest time and change time may not be identical. This is because, the ingest time is set when HCP opens the object for write and the change time is set when HCP closes the object after ingestion is complete.
Data protection level
The data protection level (DPL) for an object is the number of copies of the object HCP must maintain in the repository to ensure the integrity and availability of the object. Regardless of the DPL, you see each object as a single entity.
The DPL is determined by the namespace configuration. You can view the DPL for an object, but you cannot change it. However, namespace configuration changes can cause the DPL to change.
Retention
Objects have a retention property, which determines how long the object must remain in the namespace. This can range from allowing the object to be deleted at any time to preventing the object from ever being deleted. While an object cannot be deleted due to retention, it is said to be under retention.
Understanding objects 2–3
Using a Namespace

Retention
Retention settingsEach object in a namespace has a retention setting. The namespace is configured with a default retention setting. When you add an object to the namespace, the object inherits the namespace retention setting unless you explicitly override it. You can change the retention setting for an existing object at a later time.
Retention periodsThe retention period for an object is the length of time the object must remain in the namespace. A retention period can be a specific length of time, infinite time, or no time, in which case the object can be deleted at any time.
When the retention period for an object expires, the object becomes deletable.
Normally, if you try to delete an object that’s under retention, HCP prevents you from doing so. For the exception, see “Deleting objects and versions under retention” on page 2-5.
Retention classesA retention class is a named retention setting. Retention classes let you manage object retention consistently. For more information on retention classes, see “Retention classes” on page 2-6.
Automatic deletionA namespace can be configured to automatically delete objects after their retention periods expire. For an object to be deleted automatically:
• A specified retention period must expire. Objects with 0 (Deletion Allowed) or -2 (Initial Unspecified) retention settings are not automatically deleted.
• If the object is in a retention class, the class must have automatic deletion enabled.
Note: If the default retention setting is in the past, new objects that would otherwise get that setting are added with a setting of Deletion Allowed (0). For information on this setting, see “Object retention settings” on page 2-5.
2–4 Understanding objects
Using a Namespace
Retention
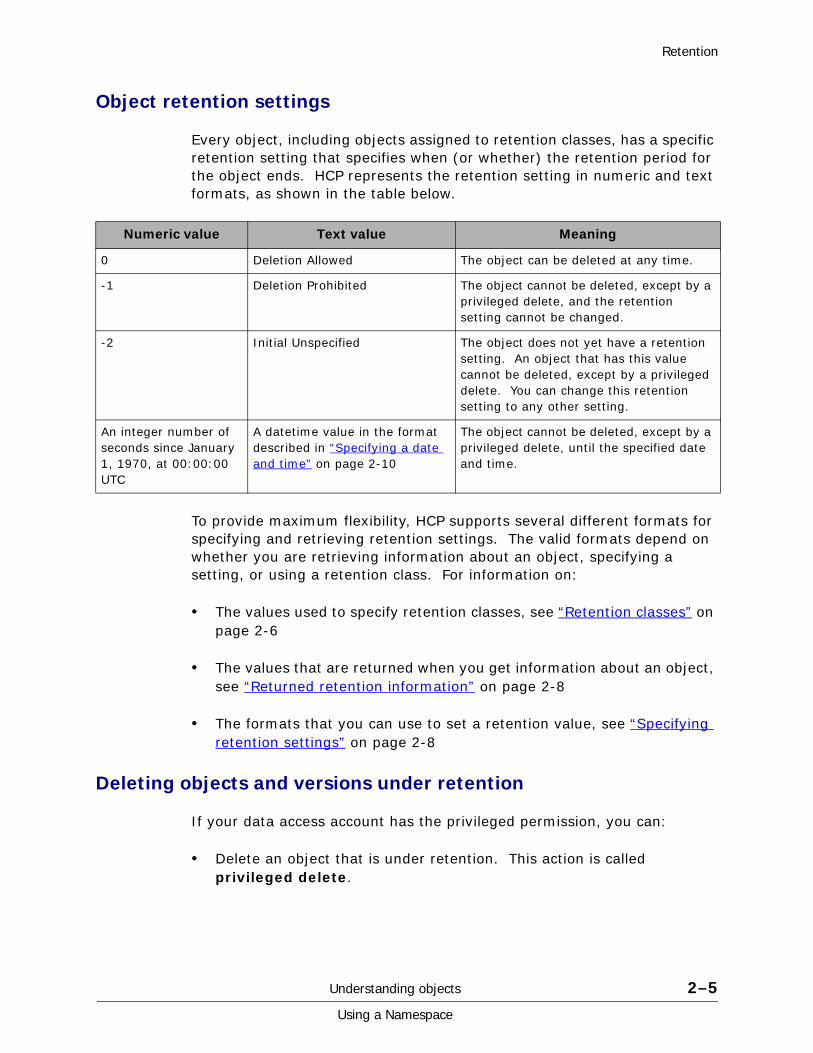
Object retention settings
Every object, including objects assigned to retention classes, has a specific retention setting that specifies when (or whether) the retention period for the object ends. HCP represents the retention setting in numeric and text formats, as shown in the table below.
To provide maximum flexibility, HCP supports several different formats for specifying and retrieving retention settings. The valid formats depend on whether you are retrieving information about an object, specifying a setting, or using a retention class. For information on:
• The values used to specify retention classes, see “Retention classes” on page 2-6
• The values that are returned when you get information about an object, see “Returned retention information” on page 2-8
• The formats that you can use to set a retention value, see “Specifying retention settings” on page 2-8
Deleting objects and versions under retention
If your data access account has the privileged permission, you can:
• Delete an object that is under retention. This action is called privileged delete.
Numeric value Text value Meaning
0 Deletion Allowed The object can be deleted at any time.
-1 Deletion Prohibited The object cannot be deleted, except by a privileged delete, and the retention setting cannot be changed.
-2 Initial Unspecified The object does not yet have a retention setting. An object that has this value cannot be deleted, except by a privileged delete. You can change this retention setting to any other setting.
An integer number of seconds since January 1, 1970, at 00:00:00 UTC
A datetime value in the format described in “Specifying a date and time” on page 2-10
The object cannot be deleted, except by a privileged delete, until the specified date and time.
Understanding objects 2–5
Using a Namespace

Retention
• If versioning is enabled and your data access account has purge permission, purge all versions of an object that is under retention. This action is called privileged purge.
For more information on permissions, see “Data access permissions” on page 1-8
Holding objects
If your data access account has the privileged permission, you can place an object on hold. An object that is on hold cannot be deleted, even by a privileged delete operation. Also, you cannot store new versions of an object that is on hold. Holding objects is particularly useful when the objects are needed for legal discovery.
While an object is on hold, you cannot change its retention setting. You can, however, change its shred setting. If the namespace is configured to allow changes to custom metadata for objects under retention, you can also change its custom metadata.
For information on permissions, see “Data access permissions” on page 1-8
Retention classes
A retention class is a named retention setting. For example, a retention class named HlthReg-107 could have a duration of 21 years. All objects assigned to that class could then not be deleted for 21 years after they’re added to the namespace.
A retention class can specify:
• A duration after object creation
• 0 (Deletion Allowed)
• -1 (Deletion Prohibited)
• -2 (Initial Unspecified)
Tip: You can use the HCP Search Console to place multiple objects on hold at the same time.
2–6 Understanding objects
Using a Namespace

Retention
Retention class duration values use this format:
+yearsy+monthsM+daysd
The format can omit parts with zero values. For example, this value specifies a 21 year retention period:
+21y
You can use retention classes to consistently manage data that must conform to a specific retention rule. For example, if local law requires that medical records be kept for a specific number of years, you can use a retention class to enforce that requirement.
Namespace administrators create retention classes. Each namespace has its own independent set of retention classes. When creating a class, the administrator specifies the class name, the retention setting, and whether HCP can automatically delete objects in the class when the retention period expires.
A namespace can be configured to allow administrative users to increase or decrease class retention times and delete classes. Otherwise, the retention time for a class can only be increased and classes cannot be deleted. In all cases, any change to a retention class affects the retention period of objects that have been assigned to that class.
You can assign a retention class to an object when you save the object or at a later time. For detailed information on the rules for assigning retention classes, see “Specifying retention settings” on page 2-8.
For information on getting an XML listing of retention classes, see “Listing retention classes” on page 9-5. For information on viewing the retention class list in the Namespace Browser, see “Viewing retention classes” on page 10-12.
Note: Automatic deletion must be enabled for the namespace for objects under retention to be automatically deleted. For more information on automatic deletion, see “Automatic deletion” on page 2-4.
Understanding objects 2–7
Using a Namespace

Retention
Returned retention information
When you retrieve metadata for an object, the returned HTTP header information includes four retention-related values, as shown in the table below.
Specifying retention settings
You can specify a retention setting when you add an object to the namespace. You can also change the retention setting for an existing object. The following information describes the retention settings you can specify. For information on specifying these settings, see Chapter 6, “Working with system metadata.”
Header Value
X-HCP-Retention One of:
• The retention setting expressed as a number of seconds since January 1, 1970, at 00:00:00 UTC
• One of the special values 0, -1, or -2
X-HCP-RetentionString One of:
• The retention period end time expressed as a datetime value in the format described in “Specifying a date and time” on page 2-10
• One of the special values Deletion Allowed, Deletion Prohibited, or Initial Unspecified
X-HCP-RetentionClass The retention class of the object or an empty string if the object is not assigned to a retention class. The information is returned in this format:
(retention-class-name, retention-class-duration)
If the retention class is deleted, the retention-class-duration value is undefined.
X-HCP-RetentionHold A value of true or false specifying whether the object is on hold.
Note: If a class is deleted, the retention periods for objects that were assigned to the class do not change, and the objects are retained until the time specified in the X-HCP-Retention and X-HCP-RetentionString values.
2–8 Understanding objects
Using a Namespace
Retention
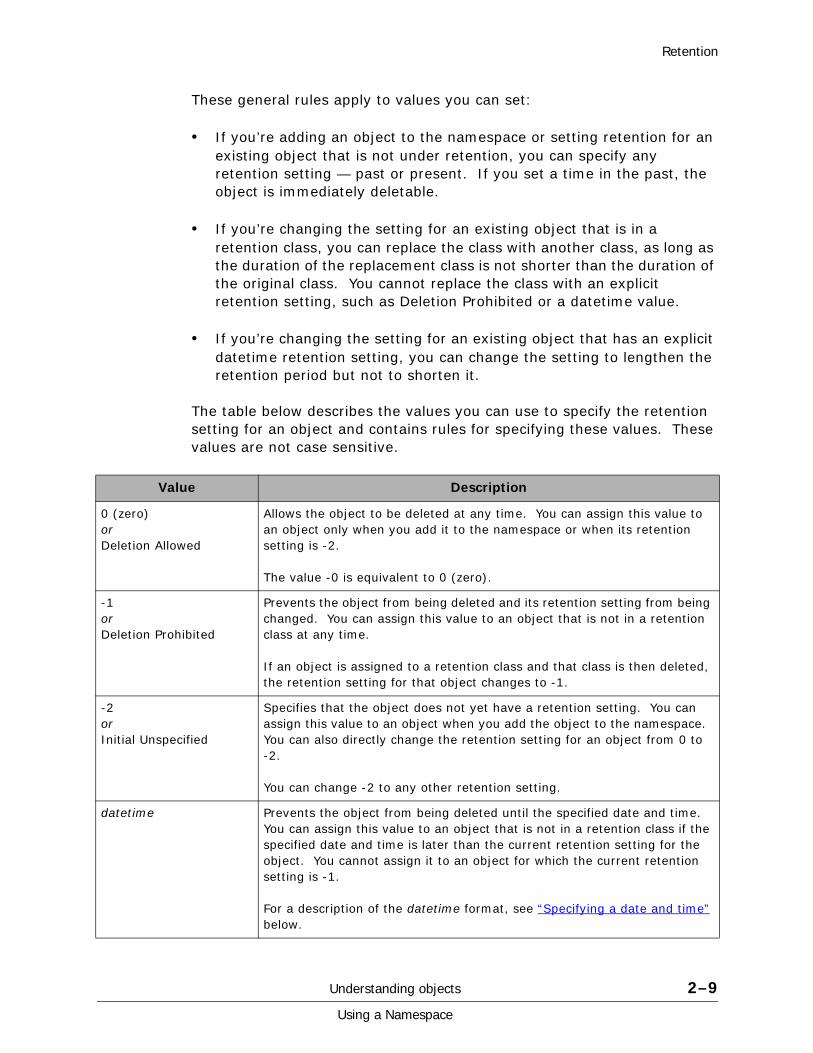
These general rules apply to values you can set:
• If you’re adding an object to the namespace or setting retention for an existing object that is not under retention, you can specify any retention setting — past or present. If you set a time in the past, the object is immediately deletable.
• If you’re changing the setting for an existing object that is in a retention class, you can replace the class with another class, as long as the duration of the replacement class is not shorter than the duration of the original class. You cannot replace the class with an explicit retention setting, such as Deletion Prohibited or a datetime value.
• If you’re changing the setting for an existing object that has an explicit datetime retention setting, you can change the setting to lengthen the retention period but not to shorten it.
The table below describes the values you can use to specify the retention setting for an object and contains rules for specifying these values. These values are not case sensitive.
Value Description
0 (zero)orDeletion Allowed
Allows the object to be deleted at any time. You can assign this value to an object only when you add it to the namespace or when its retention setting is -2.
The value -0 is equivalent to 0 (zero).
-1orDeletion Prohibited
Prevents the object from being deleted and its retention setting from being changed. You can assign this value to an object that is not in a retention class at any time.
If an object is assigned to a retention class and that class is then deleted, the retention setting for that object changes to -1.
-2orInitial Unspecified
Specifies that the object does not yet have a retention setting. You can assign this value to an object when you add the object to the namespace. You can also directly change the retention setting for an object from 0 to -2.
You can change -2 to any other retention setting.
datetime Prevents the object from being deleted until the specified date and time. You can assign this value to an object that is not in a retention class if the specified date and time is later than the current retention setting for the object. You cannot assign it to an object for which the current retention setting is -1.
For a description of the datetime format, see “Specifying a date and time” below.
Understanding objects 2–9
Using a Namespace

Retention
For more information on the retention settings listed in the first four rows of this table, see “Object retention settings” on page 2-5.
Specifying a date and time
You can set retention by specifying a date and time in either of these formats:
• Time in seconds since January 1, 1970, at 00:00:00 UTC. For example:
1450137600
The calendar date that corresponds to 1450137600 is Tuesday, December 15, 2015, at 00:00:00 EST.
• Date and time in this ISO 8601 format:
yyyy-MM-ddThh:mm:ssZ
offset Specifies a period for which to retain the object. You can assign this value to an object that is not in a retention class at any time, except when its current retention setting is -1.
HCP determines the retention setting date and time from the offset and the time the object was added to the namespace, the current retention setting, or the current time. For a description of the offset format, see “Specifying an offset” on page 2-11.
C+retention_class_name Assigns the object to a retention class. You can assign this value to an object if any one of these is true:
• The original retention period for the object has expired.
• The original retention period for the object has not expired, and the class results in a retention period that is longer than the current retention period.
• The retention setting for the object is 0 or -2.
• The retention setting for the object is -1, and the class has a retention setting of -1.
• The object is in a retention class, and the duration of the new class is not shorter than the duration of the original class.
For more information on retention classes, see “Retention classes” on page 2-6.
(Continued)
Value Description
2–10 Understanding objects
Using a Namespace

Retention
Z represents the offset from UTC and is specified as:
(+|-)hhmm
For example, 2015-11-16T14:27:20-0500 represents the start of the 20th second into 2:27 PM, November 16, 2015, EST.
If you specify certain forms of invalid dates, HCP automatically adjusts the retention setting to make a real date. For example, if you specify 2010-11-33, which is three days past the end of November, HCP changes it to 2010-12-03.
Specifying an offset
You can set retention by specifying an offset from:
• The current time
• The time at which the object was added to the namespace
• The current retention setting for the object
Because you can only extend a retention period, the offset must be a positive value.
Offset syntaxTo use an offset as a retention setting, specify a standard expression that conforms to this syntax:
^([RAN])?([+-]\d+y)?([+-]\d+M)?([+-]\d+w)?([+-]\d+d)?([+-]\d+h)?([+-]\d+m)?([+-]\d+s)?
The table below explains this syntax.
Character Description
^ Start of the expression.
( ) Sequence of terms treated as a single term
? Indicator that the preceding term is optional
[ ] Group of alternatives, exactly one of which must be used
+ Plus
- Minus
R* The current retention setting for the object
A* The time at which the object was added to the namespace
Understanding objects 2–11
Using a Namespace

Retention
The time measurements included in an expression must go from the largest unit to the smallest (that is, in the order in which they appear in the syntax).
Offset examplesHere are some examples of using an offset to extend a retention period:
• This value sets the retention value to 100 years past the time when the object was stored:
A+100y
• This value sets the end of the retention period to 20 days minus five hours past the current date and time:
N+20d-5h
• This value extends the current retention period by two years and one day:
R+2y+1d
N* The current time
\d+ An integer in the range 0 (zero) through 9,999
y Years
M Months
w Weeks
d Days
h Hours
m Minutes
s Seconds
* R, A, and N are mutually exclusive. If you don’t include any of them, the default is R.
(Continued)
Character Description
Tip: When you add an object to the namespace, R, A, and N are equivalent; that is, they all represent the current date and time. Because A and N are more intuitively meaningful, you should use either one of them instead of R for these purposes.
2–12 Understanding objects
Using a Namespace

Shredding
Specifying a retention class
You can set retention by specifying a retention class in this format:
C+retention-class-name
For example:
C+SEC17a
The retention class must already be defined for the namespace.
Shredding
Shredding, also called secure deletion, is the process of deleting an object and overwriting the places where its copies were stored in such a way that none of its data or metadata can be reconstructed.
Every object has a shred setting that determines whether it will be shredded when it’s deleted.
The shred setting values are:
• false — Don’t shred.
• true — Shred following deletion.
Overriding default shred settingsThe namespace is configured with a default shred setting. When you add an object to the namespace, the object inherits the namespace shred setting unless you explicitly override it. For more information on overriding default shred settings, see “Specifying metadata on object creation” on page 6-2.
Changing shred settingsYou can change the shred setting for an existing object from false to true but not from true to false. For more information on changing shred settings, see “Modifying object metadata” on page 6-5.
Tip: As a general rule, multiple objects with the same content should all have the same shred setting.
Tip: As a general rule, if you mark an object for shredding, you should also mark all other objects with the same content for shredding.
Understanding objects 2–13
Using a Namespace

Versioning
Versioning
Versioning is the capability of the namespace to store multiple versions of objects. If the namespace supports versioning, you can save a new version of an object, and the previous version will be kept.
All objects, including those created when versioning is not enabled, have version IDs. Version IDs are integers. Each time a new version of an existing object is created, it is assigned an ID that is greater than the previous version of the object, but the numbers may not be consecutive.
Directories do not normally have versions. One exception exists: if a directory contains or contained one or more versions of an object and also contained, at some time, a subdirectory with the same name as the object, the deleted subdirectory has a version ID. For more information on this, see “Listing object versions” on page 4-16.
If versioning is enabled for the namespace, pruning may also be enabled. Pruning is the automatic deletion of old versions after a specific length of time. HCP does not prune versions of objects that are on hold.
Retention settings apply to individual object versions. If you specify a retention value for an object by using an offset or retention class, the retention period is relative to the time the current version was stored, not when the first version was stored.
Hold settings apply to all versions of an object; if you put an object on hold, all historic versions are also put on hold.
Each version of an object has its own retention, shred, and index settings and its own custom metadata. While the index settings of historic versions can vary, only the current version is returned by a search.
Administrators can enable, disable, and reenable versioning without losing version information. However, while versioning is disabled, you cannot list or access historic versions. If versioning is later reenabled, you can again list, retrieve, and purge any preexisting versions (until HCP prunes them because of their age).
Creating versions
If versioning is enabled, you can store new versions of an existing object by storing the object using the same URL you used to create the object originally. HCP retains the previous version until it is automatically deleted or you explicitly purge the object.
2–14 Understanding objects
Using a Namespace

Versioning
Updates to the system metadata or custom metadata for an object do not create a new version of the object.
When HCP creates a new version of an object, the previous version becomes a historic version.
The historic version:
• Includes the object data, system metadata, and custom metadata. This information, except the hold setting, is locked and treated as historic data; it cannot be changed.
• Can be accessed by using the version ID that was assigned when you first stored it.
The new version:
• Gets a version ID that is greater than the ID of the previous version
• Inherits the system and custom metadata from the previous version, unless you specify new metadata when you add the new version to the namespace
For more information about creating versions, see “Adding an object or version of an object” on page 4-2.
Retrieving and listing versions
When you retrieve an object from a namespace that supports versioning, you get the current version by default. You can retrieve an older version of the object by specifying a version ID. To determine the ID to use, you can retrieve an XML listing of the available versions of the object. For more information on retrieving versions, see “Retrieving an object or version of an object” on page 4-22. For more information on listing versions, see “Listing object versions” on page 4-16.
When you list versions, the list includes the system metadata values for each version. You can retrieve the system metadata or custom metadata for an individual version by specifying the version ID in the command that checks for object existence or retrieves custom metadata. For information on retrieving system metadata, see “Checking the existence of an object or version” on page 4-12. For information on retrieving custom metadata, see “Retrieving custom metadata for objects and versions” on page 7-8.
Note: You cannot create new versions of an object that is under retention or on hold or that has a retention setting of -2 (Initial Unspecified).
Understanding objects 2–15
Using a Namespace

Versioning
Deleting objects with versioning enabled
If you delete an object while versioning is enabled, HCP:
• Retains a copy of the deleted object as a historic version.
• Creates a special version, called a deleted version, as the current version to indicate that the object has been deleted. This version has a version ID but does not include any object data or metadata.
After you delete an object, any attempt to get the object without specifying the version ID of a historic version results in a 404 (Not Found) error.
HCP keeps all historic versions of a deleted object until they are pruned or the object is purged. If shredding is enabled on a version, HCP shreds the version when it is automatically deleted.
Because HCP keeps deleted objects as historic versions, you can retrieve an accidentally deleted object if HCP has not yet pruned it. To do so, request the object, specifying the version ID of the version you want. You can restore the deleted object by storing the retrieved version using the original URL.
When you list the versions of an object that has been deleted and restored, the returned XML for the deleted version identifies the version state as deleted, contains the date and time the object was deleted, and contains the version ID for the deleted version. The remaining XML contains information about the object that you deleted.
For an example of a version list that includes a deleted version, see “Example: Listing the versions of an object” on page 4-19. For more information on deleting objects, see “Deleting an object and using privileged delete” on page 4-38.
Purging objects
You cannot delete specific historic versions of an object, but if your data access account has the purge permission, you can purge the object to delete all its versions.
If the current version of an object is under retention, you cannot purge the object. However, if your data access account has both the purge and privileged permissions, you can perform a privileged purge to delete all versions of the object. For more information on purge and privileged purge operations, see “Purging an object and using privileged purge” on page 4-43.
2–16 Understanding objects
Using a Namespace

Indexing
Indexing
Each object has an index setting that is either true or false. The setting is present regardless of how HCP and the namespace are configured.
When building the search index, HCP uses this setting to determine whether to include the object in the index. Additionally, metadata query API requests can use this setting as a search criterion, and third-party applications can use this setting for their own purposes.
Overriding default index settingsThe namespace is configured with a default index setting. When you add an object to the namespace, the object inherits the namespace index setting unless you explicitly override it. For more information on overriding default index settings, see “Specifying metadata on object creation” on page 6-2.
Changing index settingsYou can enable or disable indexing for an existing object. When you disable indexing, HCP removes the object from the search index, so searches do not find the object. When you enable indexing, HCP adds the object to the index. For more information on changing index settings, see “Modifying object metadata” on page 6-5.
Custom metadata
Custom metadata is user-supplied descriptive information about an object. Custom metadata is stored as a unit. You can add, replace, or delete it in its entirety. You cannot modify it in place.
Custom metadata is typically specified using XML, but this is not required. The namespace configuration determines whether HCP checks that custom metadata is well-formed XML. While checking is enabled, if you try to store custom metadata that is not well-formed XML, HCP rejects it.
You can use a single HTTP request to store or retrieve object data and custom metadata together.
The namespace configuration determines what you can do with custom metadata for objects that are under retention. The namespace can be set to:
• Allow all custom metadata operations for objects under retention
Understanding objects 2–17
Using a Namespace

Custom metadata
• Allow only the addition of new custom metadata for objects under retention and disallow replacement or deletion of existing custom metadata
• Disallow all custom metadata operations for objects under retention
For an example of:
• Storing custom metadata, see “Storing custom metadata” on page 7-2
• Using a single request to store object data and custom metadata, see “Example 4: Storing object or version data with custom metadata (Unix)” on page 4-9
• Using a single request to retrieve object data and custom metadata together, see “Example 6: Retrieving object data and custom metadata together (Java)” on page 4-36
2–18 Understanding objects
Using a Namespace

3
Accessing a namespaceYou use the HTTP protocol to access a namespace. The namespace configuration determines whether you need to use HTTP with SSL (HTTPS). To access a namespace, you can write applications that use any standard HTTP client library, or you can use a command-line tool, such as cURL, that supports HTTP. You can also use a web browser to access the namespace.
Using the HTTP protocol, you can store, view, retrieve, and delete objects. You can specify certain metadata when you store new objects. You can also change the metadata for existing objects. You can add, replace, and delete custom metadata and get information about the namespace. Additionally, you can get information on objects that match query criteria in one or more namespaces.
HCP is compliant with HTTP/1.1, as specified by RFC 2616.
This chapter provides general information on using HTTP to access HCP namespaces and describes how to access an individual namespace. For information on URLs for the metadata query API, which can retrieve information about the contents of multiple namespaces, see “Request URL” on page 8-4.
The examples in this book use cURL and Python with PycURL, a Python interface that uses the libcurl library. cURL and PycURL are both freely available open-source software. You can download them from http://curl.haxx.se.
For a condensed reference of the HTTP methods you use and responses you get when accessing a namespace, see Appendix A, “HTTP reference.”
Note: As of version 7.12.1 of PycURL, the PUT method has been deprecated and replaced with UPLOAD. The Python examples in this book show PUT but work equally well with UPLOAD.
Accessing a namespace 3–1
Using a Namespace

URLs for HTTP access to the namespace
URLs for HTTP access to the namespace
Depending on the HTTP method you’re using and what you want it to do, a URL can identify any of:
• A namespace
• A directory in a namespace
• An object in a namespace
• Information about a namespace
URL formats
The following sections show the URL formats you can use for namespace access. These formats all use the hostname to identify the HCP system and namespace. As an alternative, you can use an IP address for the system, as described in “Using an IP address in the URL” on page 3-5.
Namespace URLThe URL that identifies a namespace has this format:
https://namespace-name.tenant-name.hcp-name.domain-name
For example:
https://finance.europe.hcp.example.com
In this example:
• finance is the namespace.
• europe is the tenant.
Notes:
• The URL formats and examples that follow show https. If the namespace configuration does not require SSL security for the HTTP protocol, you can specify http instead of https in your URLs.
• If you use HTTPS, check with your namespace administrator as to whether you need to disable SSL certificate verification. For example, with cURL you may need to use the -k or --insecure option.
3–2 Accessing a namespace
Using a Namespace

URLs for HTTP access to the namespace
• hcp is the HCP system name.
• example.com is the domain name.
The URL for a namespace is not case sensitive.
URLs for accessing objects in the namespaceTo access the top level of the namespace directory tree, append rest, in all lowercase letters, to the namespace URL, as in this example:
https://finance.europe.hcp.example.com/rest
To access a specific object or directory in the namespace, append the directory or object path to the namespace URL and the interface identifier rest. The format for this is:
https://namespace-name.tenant-name.hcp-name.domain-name/rest/directory-path[/object-name]
Here’s a sample URL that identifies a directory:
https://finance.europe.hcp.example.com/rest/Corporate/Employees
Here’s a sample URL that identifies an object:
https://finance.europe.hcp.example.com/rest/Corporate/Employees/23_John_Doe.xls
Directory and object names are case sensitive. You cannot tell from a URL whether it identifies an object or a directory.
URLs for namespace informationYou may have access to multiple namespaces owned by a given tenant. To retrieve information about these namespaces, use this format for the URL:
https://namespace-name.tenant-name.hcp-name.domain-name/proc
In the URL, proc must be all-lowercase.
A URL used to retrieve information about multiple namespaces owned by a tenant must start with the name of one of the namespaces. The response contains information about all the namespaces you can access, not just the one specified in the URL.
Here’s a URL that can be used to list all accessible namespaces owned by the europe tenant, including the finance namespace:
https://finance.europe.hcp.example.com/proc
Accessing a namespace 3–3
Using a Namespace

URLs for HTTP access to the namespace
To retrieve information about a specific namespace, use this format:
https://namespace-name.tenant-name.hcp-name.domain-name/proc/list-type
list-type must be one of these all-lowercase values:
• statistics
• permissions
• retentionClasses
Here’s the URL used to retrieve information about the retention classes defined for the finance namespace:
https://finance.europe.hcp.example.com/proc/finance/retentionClasses
For more information on retrieving namespace information, see Chapter 9, “Retrieving namespace information.”
Enabling URLs with hostnames
To access a namespace by hostname, one of these must be true:
• The HCP system is configured for DNS. Check with your namespace administrator as to whether this is true.
• The client hosts file contains mappings from the hostname identifiers for each namespace to HCP system IP addresses.
Using a hosts fileAll operating systems have hosts files that contain mappings from hostnames to IP addresses. If your HCP configuration does not support DNS, you can use this file to enable access to the namespace by hostname.
The location of the hosts file differs among operating systems.:
• On Windows, by default: c:\windows\system32\drivers\etc\hosts
• On Unix: /etc/hosts
Note: For information on considerations for using hostnames and IP addresses, see “Namespace access by IP address” on page 11-2.
3–4 Accessing a namespace
Using a Namespace

URLs for HTTP access to the namespace
• On Mac OS X: /private/etc/host
The hosts file contains lines consisting of an IP address and one or more hostnames, separated by white space. One entry can map multiple hostnames to an IP address, or each mapping can have a separate entry. Each line can have a trailing comment, or comments can be put on separate lines. Comments start with a number sign (#). Blank lines are ignored.
The hosts file must map each hostname that you use to an HCP system IP address. The hostnames must be fully qualified. For example, if you need to access the contents of two namespaces owned by the tenant named europe, you need to have two hostname entries, one for each namespace.
Hostname mapping considerationsAn HCP system has multiple IP addresses. You can map each hostname to more than one of these IP addresses in the hosts file. The way multiple mappings are used depends on the client platform. For information on how your client handles multiple mappings in a hosts file, see your client documentation.
Sample hosts file entriesThe following lines show the portion of a hosts file that maps the hostnames for two namespaces, which are owned by a single tenant, to two IP addresses, 192.168.130.13 and 192.168.14. The example has only a single hostname per entry to make the file contents easier to read.
# europe tenant data access192.168.130.13 finance.europe.hcp.example.com# finance namespace192.168.130.14 finance.europe.hcp.example.com# finance namespace192.168.130.13 support.europe.hcp.example.com# support namespace192.168.130.14 support.europe.hcp.example.com# support namespace
Using an IP address in the URL
Because you need to provide a hostname that includes the tenant and namespace names in all HTTP requests, using the hostname is the simplest way to access a namespace. In some applications, however, using IP addresses may be more efficient than using the hostname. For information on when to use an IP address, see “Namespace access by IP address” on page 11-2.
Note: If any of the HCP system IP addresses are unavailable, timeouts may occur when using a hosts file for system access.
Accessing a namespace 3–5
Using a Namespace

URLs for HTTP access to the namespace
If you use an IP address in the URL, you provide the hostname in an HTTP Host header.
In curl commands, you use the -H option and specify a Host header with the namespace, tenant, HCP system, and domain names, in this format:
-H "Host: namespace-name.tenant-name.hcp-name.domain-name"
This example shows a complete curl command that uses an IP address:
curl -iT wind.jpg -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d-H "Host: finance.europe.hcp.example.com" "https://192.168.130.14/rest/images/wind.jpg"
In Python with PycURL, you specify an HTTPHEADER option, in this format:
curl.setopt(pycurl.HTTPHEADER, ["Host: namespace-name.tenant-name.cluster-domain-suffix"])
In the preceding syntax, the left and right brackets ([]) and parentheses (()) are required and do not indicate an optional component.
This example shows a Python script that uses an IP address:
import pycurlimport osfilehandle = open("wind.jpg", 'rb')curl = pycurl.Curl()curl.setopt(pycurl.URL, "https://192.168.125.125/rest/images/wind.jpg")curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.HTTPHEADER, ["Host: finance.europe.hcp.example.com"])curl.setopt(pycurl.PUT, 1)curl.setopt(pycurl.INFILESIZE, os.path.getsize("wind.jpg"))curl.setopt(pycurl.READFUNCTION, filehandle.read)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()filehandle.close()
URL considerations
The following considerations apply to specifying URLs in HTTP requests against a namespace. For considerations that apply specifically to naming new objects, see “Object naming considerations” on page 2-2.
3–6 Accessing a namespace
Using a Namespace

URLs for HTTP access to the namespace
URL lengthFor all HTTP methods except POST, the portion of a URL after rest, excluding any appended parameters, is limited to 4,095 bytes. If an HTTP request includes a URL that violates that limit, HCP returns a status code of 414.
URL character caseAll elements except for the hostname are case sensitive.
Object names with non-ASCII, nonprintable charactersWhen you store an object with non-ASCII, nonprintable characters in its name, those characters in the name are percent-encoded in the name displayed back.
Regardless of how the name is displayed, the object is stored with its original name, and you can access it either by its original name or by the name with the percent-encoded characters.
Non-UTF-8-encoded characters in directory listingsWhen you view a directory listing in a web browser, non-UTF-8-encoded characters in object names are percent-encoded.
Percent-encoding for special charactersSome characters have special meaning when used in a URL and may be interpreted incorrectly when used for other purposes. To avoid ambiguity, percent-encode the special characters listed in the table below.
Percent-encoded values are not case sensitive.
Character Percent-encoded value
Space %20
Tab %09
New line %0A
Carriage return %0D
+ %2B
% %25
# %23
? %3F
& %26
Note: Do not percent-encode metadata parameters appended to URLs. For information on these parameters, see “Specifying metadata on object creation” on page 6-2.
Accessing a namespace 3–7
Using a Namespace

Authenticating namespace access
Quotation marks with URLs in command linesWhen using a command-line tool to access the namespace through HTTP, you work in a Unix, Mac OS X, or Windows shell. Some characters in the commands you enter may have special meaning to the shell. For example, the ampersand (&) used in URLs to join multiple metadata parameters also often indicates that a process should be put in the background.
To avoid the possibility of the Unix, Mac OS X, or Windows shell misinterpreting special characters in a URL, always enclose the entire URL in double quotation marks.
Authenticating namespace access
Only authenticated clients can access a namespace. As a result, you need to pass a username and password in every HTTP request. The username must identify a data access account that has the permissions needed to perform the requested operation. For more information on permissions, see “Namespace Browser” on page 1-4
You specify the username and password in an hcp-ns-auth cookie. The cookie consists of the username in Base64-encoded format and the password hashed using the MD5 (Message-Digest algorithm 5) algorithm, in this format:
hcp-ns-auth=base64-encoded-username:md5-hashed-password
If you do not provide valid credentials, HCP responds with a 302 (Found) error message and Location header with a URL. If you get this error, do not use the URL. Instead, use correct credentials in the hcp-ns-auth cookie
The user authentication cookie for a data access account named myuser and a password value of p2Ss#0rd looks like this:
hcp-ns-auth=bXl1c2Vy:6ecaf581f6879c9a14ca6b76ff2a6b15
The GNU core utilities provide base64 and md5sum commands that can generate the required values. With these commands, a line such as this can create the required cookie:
echo hcp-ns-auth=`echo -n user-name | base64`:`echo -n password |md5sum` | awk '{print $1}'
Note: HCP does not require passwords to be hashed. For security reasons, never use a clear-text password unless you are using HTTP with SSL.
3–8 Accessing a namespace
Using a Namespace

Authenticating namespace access
The character before echo, before and after the colon, and following md5sum is a backtick (or grave accent). The echo command -n option prevents the command from appending a newline to its output. This is required to ensure correct Base64 and MD5 values.
For more information about the GNU core utilities, see http://www.gnu.org/software/coreutils/.
Other tools to generate Base64-encoded text and MD5 hash values are available for download on the web. For security reasons, do not use interactive public web-based tools to generate these values.
Accessing a namespace 3–9
Using a Namespace

Authenticating namespace access
3–10 Accessing a namespace
Using a Namespace
4
Working with objects andversions
HCP lets you perform operations on individual objects. Also, if the namespace you’re using is configured to allow versioning, HCP can store multiple versions of an object. You can use this technique, for example, to preserve multiple states of a file that changes over time.
You can perform these operations on objects and object versions:
• Add an object or version (with or without custom metadata) to the namespace
• Check whether an object or version exists
• List the versions of an object
• Retrieve all or part of an object or version (with or without custom metadata)
• Delete an object or the current version of an object
• Purge all versions of an object
This chapter describes how to perform these operations, including how to delete and purge objects that are under retention.
You can also manage the metadata and custom metadata for an object. For more information on this, see Chapter 6, “Working with system metadata,” and Chapter 7, “Working with custom metadata.”
Note: In this chapter, the term object refers to an object that does not have versions or to the current version of an object with multiple versions. The term historic version refers to any version of an object except the current one.
Working with objects and versions 4–1
Using a Namespace

Adding an object or version of an object
Adding an object or version of an object
You use the HTTP PUT method to add an object or new version of an existing object to the namespace. You can optionally use this method to store the object or version data and custom metadata in a single operation. To add versions, the namespace must be configured to allow versioning. When versioning is enabled, adding an object with the same name as an existing object creates a new version of the object.
By default, a new object inherits several metadata values from namespace configuration settings. A new version of an object inherits the metadata values of the previous version of the object. However, you can override this default metadata when you add the object or version. For more information on this, see “Specifying metadata on object creation” on page 6-2.
Request contents — adding object data onlyThe PUT request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• A URL specifying the location in which to store the object
• A body containing the fixed-content data to be stored in the namespace
Request contents — sending data in compressed formatYou can send object data in compressed format and have HCP decompress it before storing it. To do this, in addition to specifying the request elements listed above:
• Use gzip to compress the content before sending it.
• Include a Content-Encoding request header with a value of gzip.
• Use a chunked transfer encoding.
Note: You cannot add new versions of an object that is under retention or on hold.
4–2 Working with objects and versions
Using a Namespace

Adding an object or version of an object
Request contents — adding object data and custom metadata togetherIf you’re using a single request to add object data and custom metadata, the PUT request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• An X-HCP-Size header specifying the size, in bytes, of the data object
• A URL specifying the location in which to store the object
• A type URL query parameter with a value of whole-object
• A body containing the fixed-content data to be stored, followed by the custom metadata, with no delimiter between them
When you store an object with its custom metadata in a single operation, the object data must always precede the custom metadata. This differs from the behavior when you retrieve an object and its custom metadata, where you can tell HCP to return the results in either order.
You can send the body in gzip-compressed format and have HCP decompress the data before storing it. To do this, make sure that the request includes the elements described in “Request contents — sending data in compressed format” on page 4-2.
Access permissionTo add an object or version of an object to the namespace, you need write permission for the namespace.
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Code Meaning Description
201 Created HCP successfully stored the object. If versioning is enabled and an object with the same name already exists, HCP created a new version of the object.
Working with objects and versions 4–3
Using a Namespace
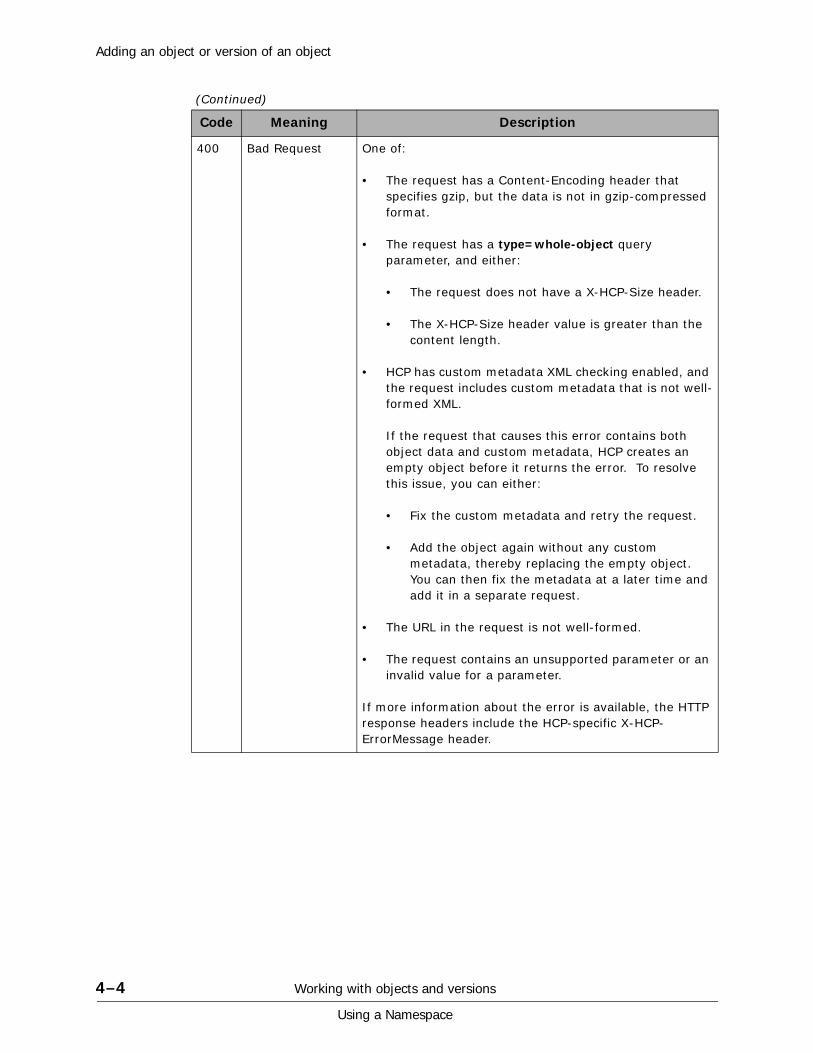
Adding an object or version of an object
400 Bad Request One of:
• The request has a Content-Encoding header that specifies gzip, but the data is not in gzip-compressed format.
• The request has a type=whole-object query parameter, and either:
• The request does not have a X-HCP-Size header.
• The X-HCP-Size header value is greater than the content length.
• HCP has custom metadata XML checking enabled, and the request includes custom metadata that is not well-formed XML.
If the request that causes this error contains both object data and custom metadata, HCP creates an empty object before it returns the error. To resolve this issue, you can either:
• Fix the custom metadata and retry the request.
• Add the object again without any custom metadata, thereby replacing the empty object. You can then fix the metadata at a later time and add it in a separate request.
• The URL in the request is not well-formed.
• The request contains an unsupported parameter or an invalid value for a parameter.
If more information about the error is available, the HTTP response headers include the HCP-specific X-HCP-ErrorMessage header.
(Continued)
Code Meaning Description
4–4 Working with objects and versions
Using a Namespace
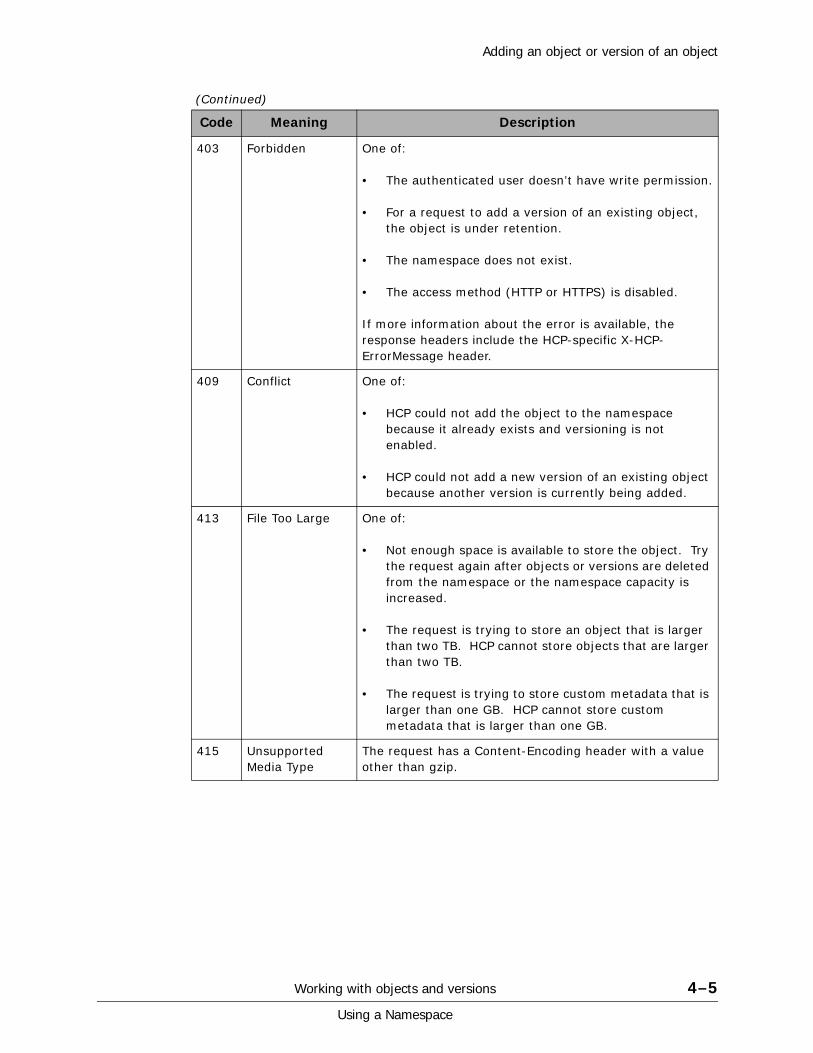
Adding an object or version of an object
403 Forbidden One of:
• The authenticated user doesn’t have write permission.
• For a request to add a version of an existing object, the object is under retention.
• The namespace does not exist.
• The access method (HTTP or HTTPS) is disabled.
If more information about the error is available, the response headers include the HCP-specific X-HCP-ErrorMessage header.
409 Conflict One of:
• HCP could not add the object to the namespace because it already exists and versioning is not enabled.
• HCP could not add a new version of an existing object because another version is currently being added.
413 File Too Large One of:
• Not enough space is available to store the object. Try the request again after objects or versions are deleted from the namespace or the namespace capacity is increased.
• The request is trying to store an object that is larger than two TB. HCP cannot store objects that are larger than two TB.
• The request is trying to store custom metadata that is larger than one GB. HCP cannot store custom metadata that is larger than one GB.
415 Unsupported Media Type
The request has a Content-Encoding header with a value other than gzip.
(Continued)
Code Meaning Description
Working with objects and versions 4–5
Using a Namespace
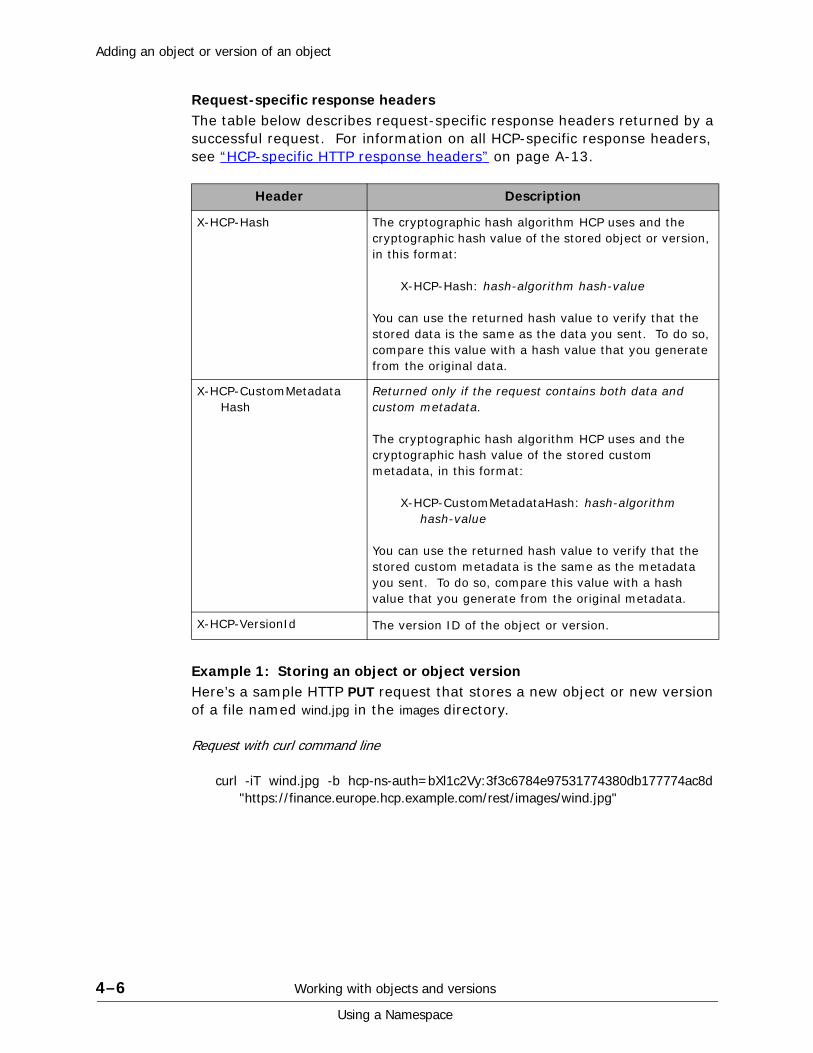
Adding an object or version of an object
Request-specific response headersThe table below describes request-specific response headers returned by a successful request. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Example 1: Storing an object or object versionHere’s a sample HTTP PUT request that stores a new object or new version of a file named wind.jpg in the images directory.
Request with curl command line
curl -iT wind.jpg -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images/wind.jpg"
Header Description
X-HCP-Hash The cryptographic hash algorithm HCP uses and the cryptographic hash value of the stored object or version, in this format:
X-HCP-Hash: hash-algorithm hash-value
You can use the returned hash value to verify that the stored data is the same as the data you sent. To do so, compare this value with a hash value that you generate from the original data.
X-HCP-CustomMetadataHash
Returned only if the request contains both data and custom metadata.
The cryptographic hash algorithm HCP uses and the cryptographic hash value of the stored custom metadata, in this format:
X-HCP-CustomMetadataHash: hash-algorithm hash-value
You can use the returned hash value to verify that the stored custom metadata is the same as the metadata you sent. To do so, compare this value with a hash value that you generate from the original metadata.
X-HCP-VersionId The version ID of the object or version.
4–6 Working with objects and versions
Using a Namespace

Adding an object or version of an object
Request in Python using PycURL
import pycurlimport osfilehandle = open("wind.jpg", 'rb')curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/wind.jpg")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.PUT, 1)curl.setopt(pycurl.INFILESIZE, os.path.getsize("wind.jpg"))curl.setopt(pycurl.READFUNCTION, filehandle.read)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()filehandle.close()
Request headers
PUT /rest/images/wind2.jpg HTTP/1.1Host: /finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8dContent-Length: 238985
Response headers
HTTP/1.1 201 CreatedLocation: /rest/images/wind2.jpgX-HCP-VersionId: 79885459513089X-HCP-Hash: SHA-256 E830B86212A66A792A79D58BB185EE63A4FADA76BB8A1...X-HCP-Time: 1259584200Content-Length: 0
Example 2: Sending object data in compressed format (Unix)Here’s a Unix command line that uses the gzip utility to compress the wind.jpg file and then pipes the compressed output to a curl command. The curl command makes an HTTP PUT request that sends the data and informs HCP that the data is compressed.
Request with gzip and curl commands
gzip -c wind.jpg | curl -T – -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d "https://finance.europe.hcp.example.com/rest/images/wind.jpg" -H "Content-Encoding: gzip"
Working with objects and versions 4–7
Using a Namespace

Adding an object or version of an object
Request headers
PUT /rest/images/wind.jpg HTTP/1.1Host: /finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8dContent-Length: 124863Transfer-Encoding: chunkedContent-Encoding: gzipExpect: 100-continue
Response headers
HTTP/1.1 100 ContinueHTTP/1.1 201 CreatedLocation: /rest/images/wind.jpgX-HCP-VersionId: 79885459513089X-HCP-Hash: SHA-256 E830B86212A66A792A79D58BB185EE63A4FADA76BB8A1...X-HCP-Time: 1259584200Content-Length: 0
Example 3: Sending object data in compressed format (Java)Here’s the partial implementation of a Java class named HTTPCompression. The implementation shows the WriteToHCP method, which stores an object (or version) in an HCP namespace. The method compresses the data before sending it and uses the Content-Encoding header to tell HCP that the data is compressed.
The WriteToHCP method uses the GZIPCompressedInputStream helper class. For an implementation of this class, see “GZIPCompressedInputStream class” on page B-2.
import org.apache.http.client.methods.HttpPut;import org.apache.http.HttpResponse;import com.hds.hcp.examples.GZIPCompressedInputStream;
class HTTPCompression { . . .void WriteToHCP() throws Exception {
/* * Set up the PUT request. * * This method assumes that the HTTP client has already been * initialized. */ HttpPut httpRequest = new HttpPut(sHCPFilePath);
4–8 Working with objects and versions
Using a Namespace

Adding an object or version of an object
// Indicate that the content encoding is gzip. httpRequest.setHeader("Content-Encoding", "gzip");
// Open an input stream to the file that will be sent to HCP. // This file will be processed by the GZIPCompressedInputStream to // produce gzip-compressed content when read by the Apache HTTP client. GZIPCompressedInputStream compressedInputFile = new GZIPCompressedInputStream(new FileInputStream( sBaseFileName + ".toHCP"));
// Point the HttpRequest to the input stream. httpRequest.setEntity(new InputStreamEntity(compressedInputFile, -1));
// Create the HCP authentication cookie and put in cookie store. httpRequest.setHeader("Cookie", NS_AUTH_TOKEN + "=" + sEncodedUserName + ":" + sEncodedPassword);
/* * Now execute the PUT request. */ HttpResponse httpResponse = mHttpClient.execute(httpRequest);
/* * Process the HTTP response. */ // If the return code is anything but in the 200 range indicating // success, throw an exception. if (2 != (int)(httpResponse.getStatusLine().getStatusCode() / 100)) { throw new Exception("Unexpected HTTP status code: " + httpResponse.getStatusLine().getStatusCode() + " (" + httpResponse.getStatusLine().getReasonPhrase() + ")"); }} . . .}
Example 4: Storing object or version data with custom metadata (Unix)Here’s a Unix command line that uses an HTTP PUT request to store the object data and custom metadata for a file named wind.jpg. The request stores the object in the images directory.
The cat command appends the contents of the wind-custom-metadata.xml file to the contents of the wind.jpg file. The result is piped to a curl command that sends the data to HCP.
Working with objects and versions 4–9
Using a Namespace

Adding an object or version of an object
Unix command line
cat wind.jpg wind-custom-metadata.xml | curl -iT – -H "X-HCP-Size: `stat -c %s wind.jpg`"-b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images/wind.jpg?type=whole-object"
Request headers
PUT /rest/images/wind2.jpg HTTP/1.1Host: /finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8dX-HCP-Size: 237423Content-Length: 238985
Response headers
HTTP/1.1 201 CreatedLocation: /rest/images/wind2.jpgX-HCP-VersionId: 79885459513089X-HCP-Hash: SHA-256 E830B86212A66A792A79D58BB185EE63A4FADA76BB8A1...X-HCP-CustomMetadataHash: SHA-256 86212A6692A79D5B185EE63A4DA76BBC...X-HCP-Time: 1259584200Content-Length: 0
Example 5: Storing object or version data with custom metadata (Java)Here’s the partial implementation of a Java class named WholeIO. The implementation shows the WholeWriteToHCP method, which uses a single HTTP PUT request to store data and custom metadata for an object (or version).
The WholeWriteToHCP method uses the WholeIOInputStream helper class. For an implementation of this class, see “WholeIOInputStream class” on page B-8.
import org.apache.http.client.methods.HttpPut;import org.apache.http.HttpResponse;import com.hds.hcp.examples.WholeIOInputStream;
class WholeIO { . . .void WholeWriteToHCP() throws Exception {
4–10 Working with objects and versions
Using a Namespace

Adding an object or version of an object
/* * Set up the PUT request to store both object data and custom * metadata. * * This method assumes that the HTTP client has already been * initialized. */ HttpPut httpRequest = new HttpPut(sHCPFilePath + "?type=whole-object");
FileInputStream dataFile = new FileInputStream(sBaseFileName);
// Put the size of the object data into the X-HCP-Size header. httpRequest.setHeader("X-HCP-Size", String.valueOf(dataFile.available()));
// Point the HttpRequest to the input stream with the object data // followed by the custom metadata. httpRequest.setEntity( new InputStreamEntity( new WholeIOInputStream( new FileInputStream(sBaseFileName), new FileInputStream(sBaseFileName + ".cm")), -1));
// Create an HCP authentication cookie and put in the cookie store. httpRequest.setHeader("Cookie", NS_AUTH_TOKEN + "=" + sEncodedUserName + ":" + sEncodedPassword);
/* * Now execute the PUT request. */ HttpResponse httpResponse = mHttpClient.execute(httpRequest);
// If the return code is anything but in the 200 range indicating // success, throw an exception. if (2 != (int)(httpResponse.getStatusLine().getStatusCode() / 100)) { throw new Exception("Unexpected HTTP status code: " + httpResponse.getStatusLine().getStatusCode() + " (" + httpResponse.getStatusLine().getReasonPhrase() + ")"); }} . . .}
Working with objects and versions 4–11
Using a Namespace

Checking the existence of an object or version
Checking the existence of an object or version
You use the HTTP HEAD method to check whether an object or specific version exists in a namespace. A 200 (OK) return code indicates that the requested object or version exists. A 404 (Not Found) return code indicates that the specified URL does not identify an existing object or version. Even if versioning is currently disabled, the method returns a 200 code and metadata if the requested version exists.
This request also retrieves the metadata for the object without retrieving the object data. The metadata is returned in HTTP response headers.
Request contentsThe HEAD request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• The URL of the object
To check the existence of a specific version of an object and retrieve its metadata, specify the version URL query parameter with the ID of the version you want.
Access permissionTo check object existence, you need read permission for the namespace.
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Code Meaning Description
200 OK HCP found the specified object or version and returned its metadata. This code is also returned if the URL specified a directory, not an object.
204 No Content The requested version is a historic deleted version.
404 Not Found HCP could not find an object, version, or directory at the specified URL. The specified object or version does not exist, or the HEAD request specified the current version of an object that has been deleted.
4–12 Working with objects and versions
Using a Namespace
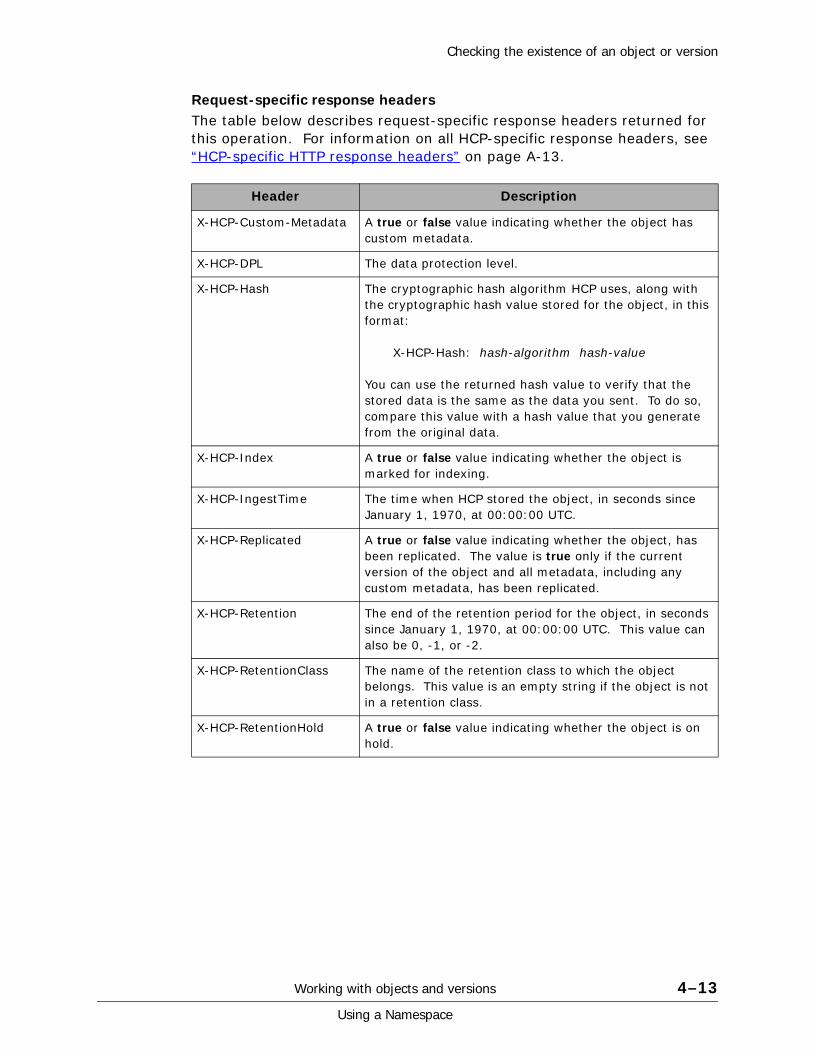
Checking the existence of an object or version
Request-specific response headersThe table below describes request-specific response headers returned for this operation. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Header Description
X-HCP-Custom-Metadata A true or false value indicating whether the object has custom metadata.
X-HCP-DPL The data protection level.
X-HCP-Hash The cryptographic hash algorithm HCP uses, along with the cryptographic hash value stored for the object, in this format:
X-HCP-Hash: hash-algorithm hash-value
You can use the returned hash value to verify that the stored data is the same as the data you sent. To do so, compare this value with a hash value that you generate from the original data.
X-HCP-Index A true or false value indicating whether the object is marked for indexing.
X-HCP-IngestTime The time when HCP stored the object, in seconds since January 1, 1970, at 00:00:00 UTC.
X-HCP-Replicated A true or false value indicating whether the object, has been replicated. The value is true only if the current version of the object and all metadata, including any custom metadata, has been replicated.
X-HCP-Retention The end of the retention period for the object, in seconds since January 1, 1970, at 00:00:00 UTC. This value can also be 0, -1, or -2.
X-HCP-RetentionClass The name of the retention class to which the object belongs. This value is an empty string if the object is not in a retention class.
X-HCP-RetentionHold A true or false value indicating whether the object is on hold.
Working with objects and versions 4–13
Using a Namespace
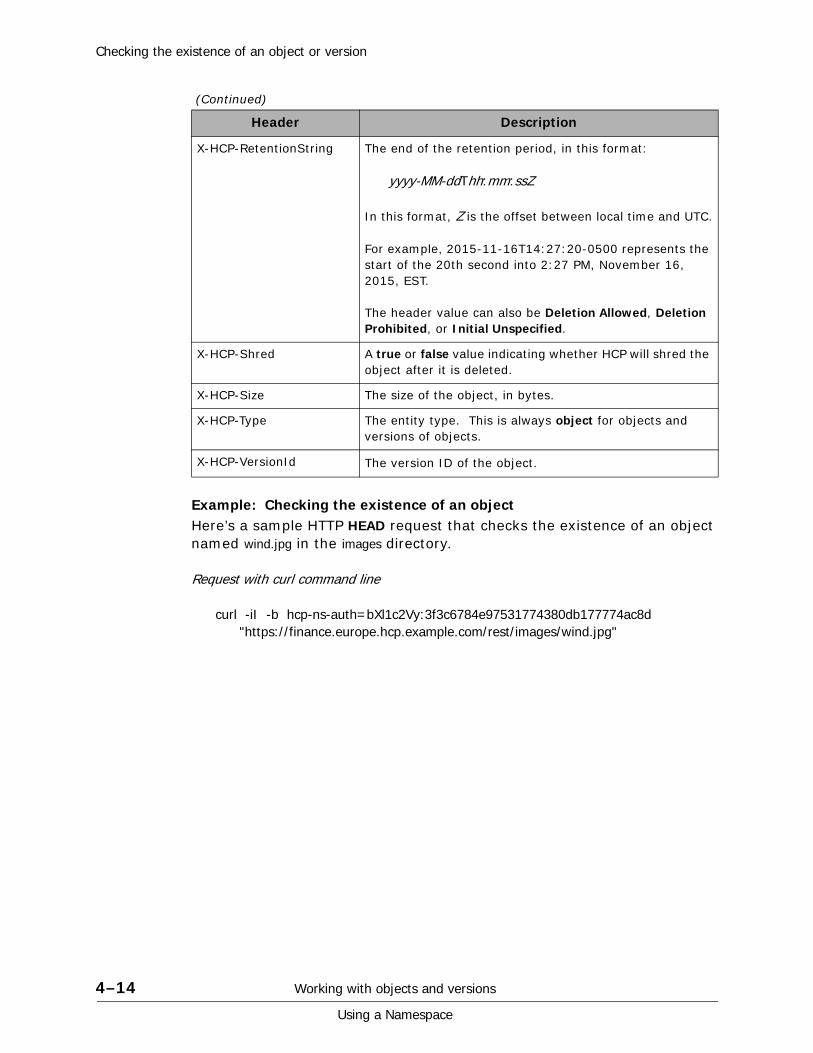
Checking the existence of an object or version
Example: Checking the existence of an objectHere’s a sample HTTP HEAD request that checks the existence of an object named wind.jpg in the images directory.
Request with curl command line
curl -iI -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images/wind.jpg"
X-HCP-RetentionString The end of the retention period, in this format:
yyyy-MM-ddThh:mm:ssZ
In this format, Z is the offset between local time and UTC.
For example, 2015-11-16T14:27:20-0500 represents the start of the 20th second into 2:27 PM, November 16, 2015, EST.
The header value can also be Deletion Allowed, Deletion Prohibited, or Initial Unspecified.
X-HCP-Shred A true or false value indicating whether HCP will shred the object after it is deleted.
X-HCP-Size The size of the object, in bytes.
X-HCP-Type The entity type. This is always object for objects and versions of objects.
X-HCP-VersionId The version ID of the object.
(Continued)
Header Description
4–14 Working with objects and versions
Using a Namespace

Checking the existence of an object or version
Request in Python using PycURL
import pycurlimport StringIOcin = StringIO.StringIO()curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/wind.jpg")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.HEADER, 1)curl.setopt(pycurl.NOBODY, 1)curl.setopt(pycurl.WRITEFUNCTION, cin.write)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)print cin.getvalue()curl.close()
Request headers
HEAD /rest/images/wind.jpg HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1259584200X-HCP-SoftwareVersion: 4.1.0.123Content-Type: image/jpegContent-Length: 238985X-HCP-Type: objectX-HCP-Size: 238985X-HCP-Hash: SHA-256 36728BA190BC4C377FE4C1A57AEF9B6AFDA98720422960...X-HCP-VersionId: 80111794065921X-HCP-IngestTime: 1251746782X-HCP-RetentionClass: (SEC17a, A+7y)X-HCP-RetentionString: 2016-08-31T15:26:22-0400X-HCP-Retention: 1472671582X-HCP-RetentionHold: falseX-HCP-Shred: falseX-HCP-DPL: 1X-HCP-Index: falseX-HCP-Custom-Metadata: falseX-HCP-Replicated: false
Working with objects and versions 4–15
Using a Namespace

Listing object versions
Listing object versions
When versioning is enabled, you use the HTTP GET method to list the versions of an object. By default, the response body contains an XML listing of historic object versions (that is, versions that you have saved and that have not been pruned) and their metadata. You can also choose to include deleted versions (markers that indicate that a version was deleted) in the list.
If versioning is disabled, even if it was enabled in the past, HCP returns a 400 (Invalid Request) error in response to a request to list object versions. However, if versioning is then reenabled, HCP returns information about all historic versions that have not been pruned.
Request contentsThe GET request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie.
• The URL of the object.
• The version=list URL query parameter. This parameter is not case sensitive.
Request contents — requesting deleted versionsBy default, the list does not include deleted versions (that is, the marker versions that indicate when an object was deleted); it shows only versions that were ingested and have not been pruned. To get a listing that includes deleted versions, specify this query parameter:
deleted=true
You can also specify deleted=false, which results in the default behavior.
Access permissionTo list object versions you need read permission for the namespace.
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Code Meaning Description
200 OK HCP successfully returned the version list.
404 Not Found HCP could not find the specified object.
4–16 Working with objects and versions
Using a Namespace

Listing object versions
Request-specific response headersThis operation does not return any request-specific response headers. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Response bodyThe body of the HTTP response to a GET request to list object versions contains an XML document listing the versions, in this format:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="/static/xsl/ns-versions.xsl"?><versions xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="/static/xsd/ns-versions.xsd"path="object-path"utf8Path="object-path"parentDir="parent-directory-path"utf8ParentDir="parent-directory-path"deleted="true|false"showDeleted="true|false"namespaceName="namespace-name"utf8NamespaceName="utf-8-encoded-namespace-name">
<entry urlname="object-name"utf8Name="object-name"type="object"size="size-in-bytes" hashScheme="hash-algorithm" hash="hash-value"retention="retention-seconds-after-1/1/1970"retentionString="retention-datetime-value"retentionClass="retention-class-name"hold="true|false"shred="true|false"dpl="dpl"index="true|false"customMetadata="true|false"replicated="true|false"state="created|deleted"version="version-id" ingestTime="ingested-seconds-after-1/1/1970"ingestTimeString="ingested-datetime"changeTimeMilliseconds="change-milliseconds-after-1/1/1970.unique-
integer"changeTimeString="yyyy-MM-ddThh:mm:ssZ"
/>...
</versions>
Working with objects and versions 4–17
Using a Namespace

Listing object versions
The deleted attribute of the versions element indicates whether the object is currently deleted. The value of the showDeleted attribute indicates whether the list includes deleted versions (true) or only the versions that were ingested (false).
The state attribute of the entry for each individual version specifies whether the version contains data or is a marker indicating that the object was deleted (that is, a deleted version).
The XML entry for a deleted version differs from the entry created when the deleted object was ingested in these ways:
• The state value is deleted.
• The version value is different.
• The ingestTime and changeTimeMilliseconds values are the date and time the object was deleted.
If the directory that contains the object contained at some time a subdirectory with the same name as the object, the results of a version list request that includes deleted versions shows deleted versions for both the object and the directory.
For example, assume you do the following:
1. Create a maintenance subdirectory of the departments directory.
2. Delete the maintenance directory.
3. Save a maintenance object in the departments directory.
In this case, a version listing for the maintenance entry that includes deleted versions shows these items:
• An entry, with a version ID, for the deleted maintenance directory
• Entries for all versions of the maintenance object, including any deleted version entries for the object
4–18 Working with objects and versions
Using a Namespace

Listing object versions
Version list entries for deleted directories look like this:
<entry urlname="object-name"utf8Name="object-name"type="directory"state="deleted"version=version-id" ingestTime="ingested-seconds-after-1/1/1970"ingestTimeString="ingested-datetime"changeTimeMilliseconds="change-millseconds-after-1/1/1970.unique-integerchangeTimeString="yyyy-MM-ddThh:mm:ssZ"
/>
Example: Listing the versions of an objectHere’s a sample HTTP GET request that saves an XML listing of the versions of an object named earth.jpg located in the images directory. The object has three versions: the original version that was ingested, a deleted version, and a version that was ingested after the original version was deleted. The request asks for all versions, including deleted versions.
Request with curl command line
curl -i -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d "https://finance.europe.hcp.example.com/rest/images/earth.jpg?version=list&deleted=true" > earth-versions.xml
Request in Python using PycURL
import pycurlfilehandle = open("earth-versions.xml", 'wb')curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/earth.jpg?version=list&deleted=true")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.WRITEFUNCTION, filehand.write)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)filehandle.close()curl.close()
Request headers
GET /rest/images/earth.jpg?version=list HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Working with objects and versions 4–19
Using a Namespace

Listing object versions
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1259584200X-HCP-SoftwareVersion: 4.1.0.123Content-Type: text/xmlContent-Length: 2080
Response body
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="/static/xsl/ns-versions.xsl"?><versions xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="/static/xsd/ns-versions.xsd"path="/rest/images/obsolete/earth.jpg"utf8path="/rest/images/obsolete/earth.jpg"parentDir="/rest/images/obsolete">utf8ParentDir="/rest/images/obsolete">deleted="false"showDeleted="true"namespaceName="finance"utf8NamespaceName="finance">
<entry urlName="earth.jpg"utf8Name="earth.jpg"type="object"size="1204765"hashScheme="SHA-256"hash="42C605FBFFCD7CEAC36BE62F294374F94503D1DC1793736EF..."retention="0"retentionString="Deletion Allowed"retentionClass=""hold="false"shred="false"dpl="2"index="true"customMetadata="false"state="created"version="80232488492929"replicated="false"ingestTime="1258469462"ingestTimeString="11/17/2009 9:51AM"changeTimeMilliseconds="1258469513362.00"changeTimeString="2009-11-17T09:51:53-0400"
/><entry urlName="earth.jpg"
utf8Name="earth.jpg"type="object"size="1200857"hashScheme="SHA-256"
4–20 Working with objects and versions
Using a Namespace

Listing object versions
hash="36728BA190BC4C377FE4C1A57AEF9B6AFDA98720422960B19..."retention="0"retentionString="Deletion Allowed"retentionClass=""hold="false"shred="false"dpl="2"index="true"customMetadata="false"replicated="false"state="deleted"version="80232488876481"ingestTime="1258405200"ingestTimeString="11/16/2009 4:00PM"changeTimeMilliseconds="1258405200259.00"changeTimeString="2009-11-16T:16:00-0400"
/><entry urlName="earth.jpg"
utf8Name="earth.jpg"type="object"size="1200857"hashScheme="SHA-256"hash="36728BA190BC4C377FE4C1A57AEF9B6AFDA98720422960B19..."retention="0"retentionString="Deletion Allowed"retentionClass=""replicated="false"hold="false"shred="false"dpl="2"index="true"customMetadata="false"replicated="false"state="created"version="80232489767169"ingestTime="1258392981"ingestTimeString="11/16/2009 12:36PM"changeTimeMilliseconds="1258392981147.00"changeTimeString="2009-11-16T:12:16-0400"
/></versions>
Working with objects and versions 4–21
Using a Namespace

Retrieving an object or version of an object
Retrieving an object or version of an object
You use the HTTP GET method to retrieve an object or a version of an object from a namespace. When retrieving an object or version, you can request all the object data or part of the data.
You can also use a single GET request to retrieve all the object data and custom metadata together. You cannot retrieve part of the object data together with the custom metadata in a single request.
To request only part of the object or version data, you specify the range of bytes you want in the HTTP GET request URL. By specifying a byte range, you can limit the amount of data returned, even when you don’t know the size of the object.
Request contentsTo retrieve an object, the GET request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• The URL of the object
Request contents — requesting data in compressed formatTo request that HCP return the object or version in gzip-compressed format, use an Accept-Encoding header containing the value gzip or *. The header can specify additional compression algorithms, but HCP uses gzip only.
Request contents — requesting a historic versionTo retrieve a historic version of an object, specify a version URL query parameter with the ID of the version you want. You can omit this parameter to retrieve the current version of an object. You can find the ID of the version you want by listing the versions of the object, as described in “Listing object versions” on page 4-16.
Request contents — retrieving object data and custom metadata togetherTo retrieve an object or version and its custom metadata with a single request, in addition to the elements described above, specify these elements:
• A type URL query parameter with a value of whole-object
Note: Any attempt to retrieve the current version of a deleted object results in a 404 error code. However, if versioning is enabled, you can retrieve the version you deleted by specifying its version ID.
4–22 Working with objects and versions
Using a Namespace

Retrieving an object or version of an object
• Optionally, an X-HCP-CustomMetadataFirst header specifying the order of the parts, as follows:
– true — The custom metadata should precede the object data.
– false — The object data should precede the custom metadata.
The default is false.
You can also retrieve the data in gzip-compressed format by specifying an Accept-Encoding header containing the value gzip or *. The header can specify additional compression algorithms, but HCP uses gzip only.
Request contents — requesting a partial objectTo retrieve only part of the object or version data, in addition to the elements described in “Request contents” and, optionally, “Request contents — requesting data in compressed format” on page 4-22, specify an HTTP Range request header with the range of bytes of the object data to retrieve. The first byte of the data is in position 0 (zero), so a range of 1-5 specifies the second through sixth bytes of the object, not the first through fifth.
These rules apply to the Range header:
• If you omit the Range header, HCP returns the complete object data.
• If you specify a valid range, HCP returns the requested amount of data with a status code of 206.
• If you specify an invalid range, HCP ignores it and returns the complete object data, with a status code of 416.
• You cannot request partial object data and custom metadata in the same request. If the request includes a Range header and a type=whole-object query parameter, HCP returns an HTTP 400 error response.
Working with objects and versions 4–23
Using a Namespace
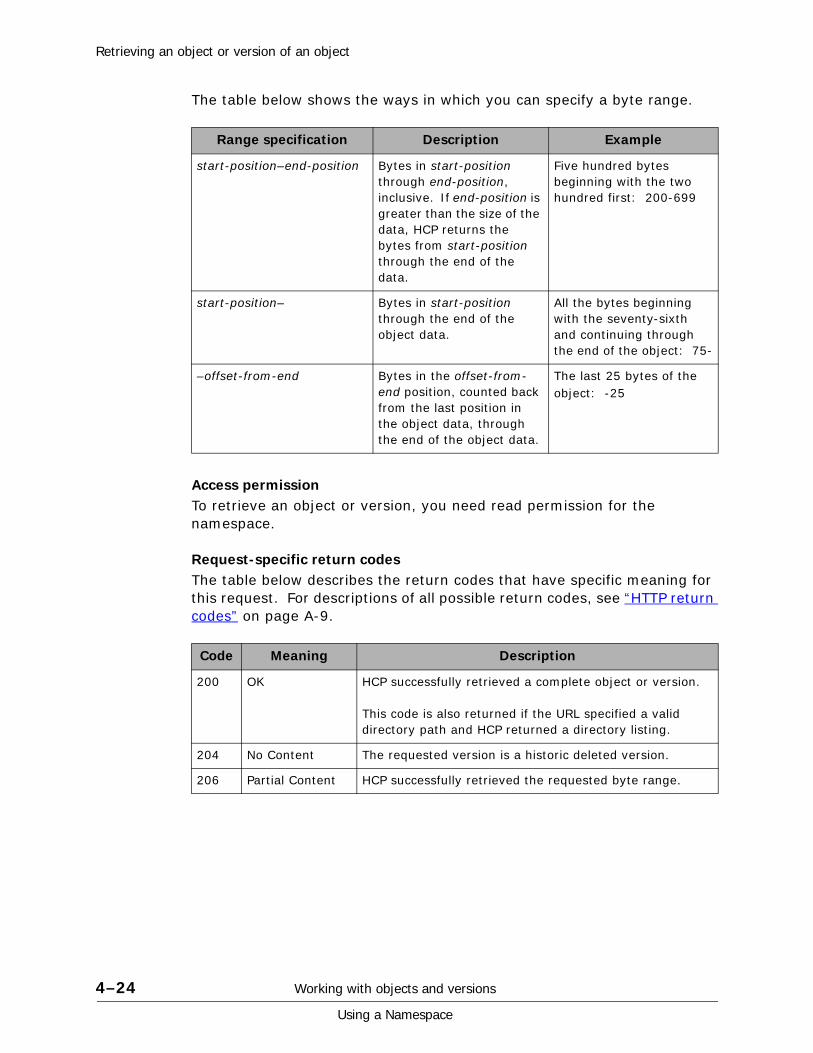
Retrieving an object or version of an object
The table below shows the ways in which you can specify a byte range.
Access permissionTo retrieve an object or version, you need read permission for the namespace.
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Range specification Description Example
start-position–end-position Bytes in start-position through end-position, inclusive. If end-position is greater than the size of the data, HCP returns the bytes from start-position through the end of the data.
Five hundred bytes beginning with the two hundred first: 200-699
start-position– Bytes in start-position through the end of the object data.
All the bytes beginning with the seventy-sixth and continuing through the end of the object: 75-
–offset-from-end Bytes in the offset-from-end position, counted back from the last position in the object data, through the end of the object data.
The last 25 bytes of the object: -25
Code Meaning Description
200 OK HCP successfully retrieved a complete object or version.
This code is also returned if the URL specified a valid directory path and HCP returned a directory listing.
204 No Content The requested version is a historic deleted version.
206 Partial Content HCP successfully retrieved the requested byte range.
4–24 Working with objects and versions
Using a Namespace
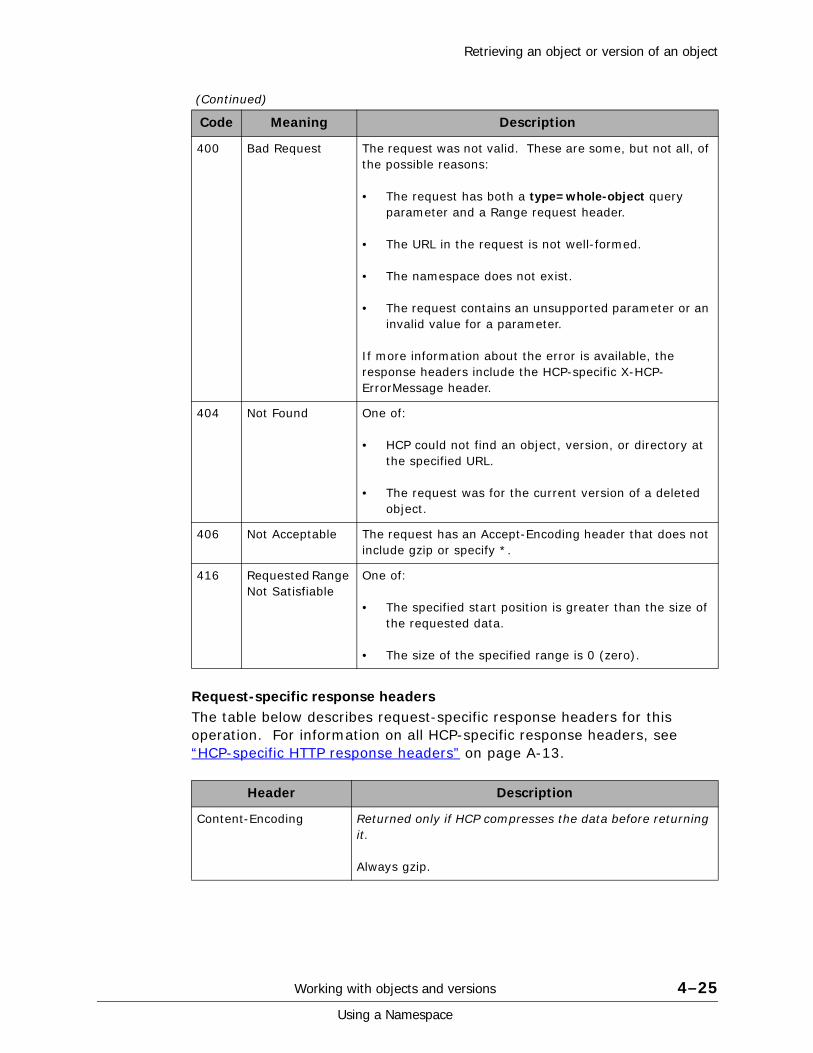
Retrieving an object or version of an object
Request-specific response headersThe table below describes request-specific response headers for this operation. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
400 Bad Request The request was not valid. These are some, but not all, of the possible reasons:
• The request has both a type=whole-object query parameter and a Range request header.
• The URL in the request is not well-formed.
• The namespace does not exist.
• The request contains an unsupported parameter or an invalid value for a parameter.
If more information about the error is available, the response headers include the HCP-specific X-HCP-ErrorMessage header.
404 Not Found One of:
• HCP could not find an object, version, or directory at the specified URL.
• The request was for the current version of a deleted object.
406 Not Acceptable The request has an Accept-Encoding header that does not include gzip or specify *.
416 Requested Range Not Satisfiable
One of:
• The specified start position is greater than the size of the requested data.
• The size of the specified range is 0 (zero).
Header Description
Content-Encoding Returned only if HCP compresses the data before returning it.
Always gzip.
(Continued)
Code Meaning Description
Working with objects and versions 4–25
Using a Namespace
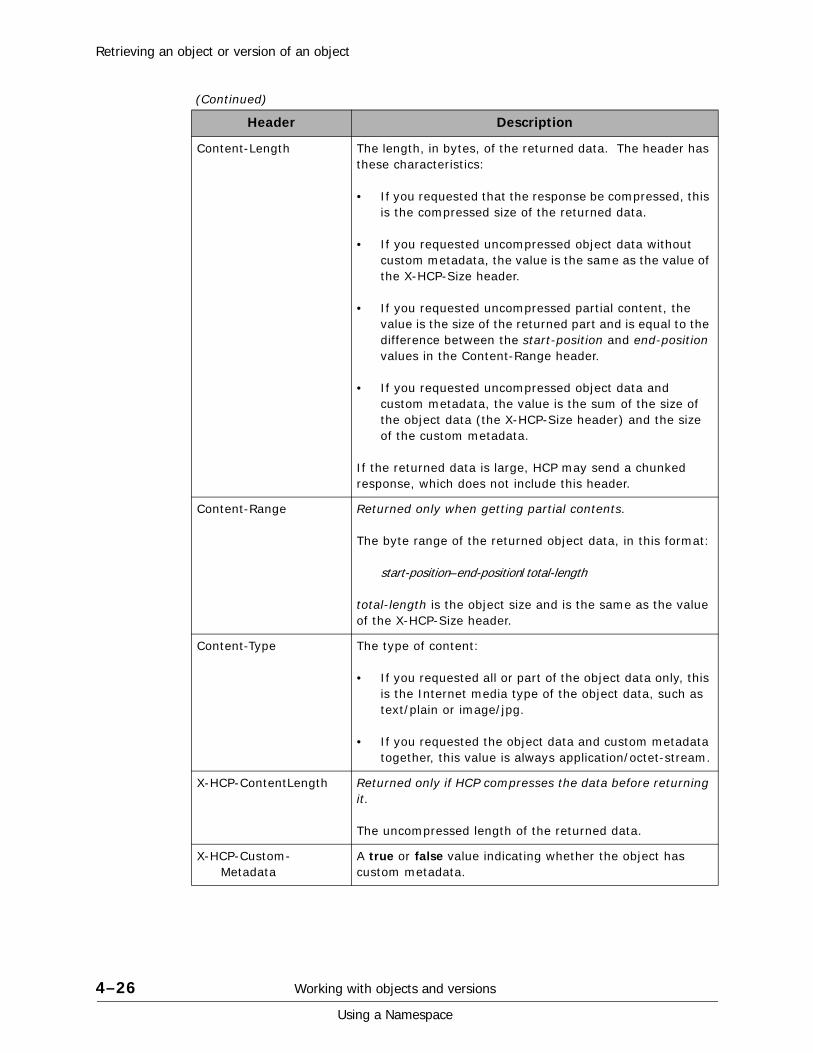
Retrieving an object or version of an object
Content-Length The length, in bytes, of the returned data. The header has these characteristics:
• If you requested that the response be compressed, this is the compressed size of the returned data.
• If you requested uncompressed object data without custom metadata, the value is the same as the value of the X-HCP-Size header.
• If you requested uncompressed partial content, the value is the size of the returned part and is equal to the difference between the start-position and end-position values in the Content-Range header.
• If you requested uncompressed object data and custom metadata, the value is the sum of the size of the object data (the X-HCP-Size header) and the size of the custom metadata.
If the returned data is large, HCP may send a chunked response, which does not include this header.
Content-Range Returned only when getting partial contents.
The byte range of the returned object data, in this format:
start-position–end-position/total-length
total-length is the object size and is the same as the value of the X-HCP-Size header.
Content-Type The type of content:
• If you requested all or part of the object data only, this is the Internet media type of the object data, such as text/plain or image/jpg.
• If you requested the object data and custom metadata together, this value is always application/octet-stream.
X-HCP-ContentLength Returned only if HCP compresses the data before returning it.
The uncompressed length of the returned data.
X-HCP-Custom-Metadata
A true or false value indicating whether the object has custom metadata.
(Continued)
Header Description
4–26 Working with objects and versions
Using a Namespace
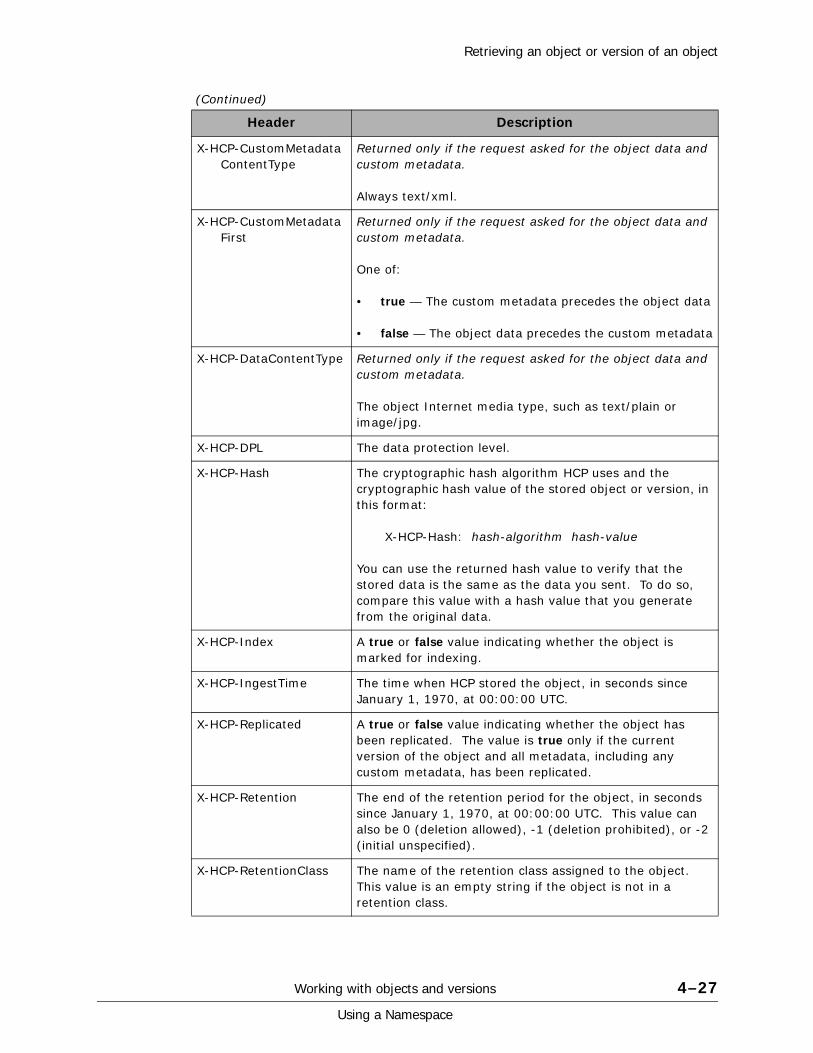
Retrieving an object or version of an object
X-HCP-CustomMetadataContentType
Returned only if the request asked for the object data and custom metadata.
Always text/xml.
X-HCP-CustomMetadataFirst
Returned only if the request asked for the object data and custom metadata.
One of:
• true — The custom metadata precedes the object data
• false — The object data precedes the custom metadata
X-HCP-DataContentType Returned only if the request asked for the object data and custom metadata.
The object Internet media type, such as text/plain or image/jpg.
X-HCP-DPL The data protection level.
X-HCP-Hash The cryptographic hash algorithm HCP uses and the cryptographic hash value of the stored object or version, in this format:
X-HCP-Hash: hash-algorithm hash-value
You can use the returned hash value to verify that the stored data is the same as the data you sent. To do so, compare this value with a hash value that you generate from the original data.
X-HCP-Index A true or false value indicating whether the object is marked for indexing.
X-HCP-IngestTime The time when HCP stored the object, in seconds since January 1, 1970, at 00:00:00 UTC.
X-HCP-Replicated A true or false value indicating whether the object has been replicated. The value is true only if the current version of the object and all metadata, including any custom metadata, has been replicated.
X-HCP-Retention The end of the retention period for the object, in seconds since January 1, 1970, at 00:00:00 UTC. This value can also be 0 (deletion allowed), -1 (deletion prohibited), or -2 (initial unspecified).
X-HCP-RetentionClass The name of the retention class assigned to the object. This value is an empty string if the object is not in a retention class.
(Continued)
Header Description
Working with objects and versions 4–27
Using a Namespace
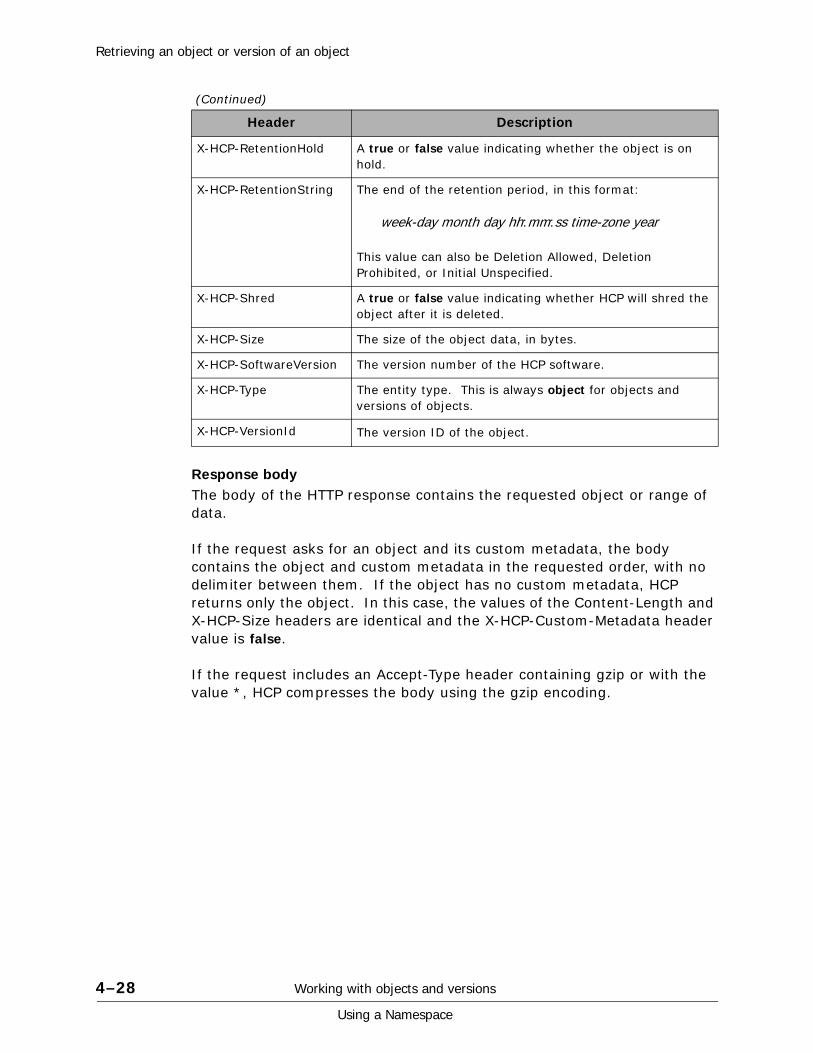
Retrieving an object or version of an object
Response bodyThe body of the HTTP response contains the requested object or range of data.
If the request asks for an object and its custom metadata, the body contains the object and custom metadata in the requested order, with no delimiter between them. If the object has no custom metadata, HCP returns only the object. In this case, the values of the Content-Length and X-HCP-Size headers are identical and the X-HCP-Custom-Metadata header value is false.
If the request includes an Accept-Type header containing gzip or with the value *, HCP compresses the body using the gzip encoding.
X-HCP-RetentionHold A true or false value indicating whether the object is on hold.
X-HCP-RetentionString The end of the retention period, in this format:
week-day month day hh:mm:ss time-zone year
This value can also be Deletion Allowed, Deletion Prohibited, or Initial Unspecified.
X-HCP-Shred A true or false value indicating whether HCP will shred the object after it is deleted.
X-HCP-Size The size of the object data, in bytes.
X-HCP-SoftwareVersion The version number of the HCP software.
X-HCP-Type The entity type. This is always object for objects and versions of objects.
X-HCP-VersionId The version ID of the object.
(Continued)
Header Description
4–28 Working with objects and versions
Using a Namespace

Retrieving an object or version of an object
Example 1: Retrieving all object dataHere’s a sample HTTP GET request that retrieves an object named wind.jpg in the images directory.
Request with curl command line
curl -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images/wind.jpg" > wind.jpg
Request in Python using PycURL
import pycurlfilehandle = open("wind.jpg", 'wb')curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/wind.jpg")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.WRITEFUNCTION, filehandle.write)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()filehandle.close()
Request headers
GET /rest/images/wind.jpg HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Tip: If a GET request unexpectedly returns a zero-length file, use the -i parameter with curl to return the response headers in the target file. These headers may provide helpful information for diagnosing the problem.
Working with objects and versions 4–29
Using a Namespace

Retrieving an object or version of an object
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1259584200X-HCP-SoftwareVersion: 4.1.0.123Content-Type: image/jpegContent-Length: 2938985X-HCP-Type: objectX-HCP-Size: 238985X-HCP-Hash: SHA-256 36728BA190BC4C377FE4C1A57AEF9B6AFDA98720422960...X-HCP-VersionId: 80205544854849X-HCP-IngestTime: 1258469614X-HCP-RetentionClass: X-HCP-RetentionString: Deletion AllowedX-HCP-Retention: 0X-HCP-RetentionHold: falseX-HCP-Shred: falseX-HCP-DPL: 2X-HCP-Index: falseX-HCP-Custom-Metadata: falseX-HCP-Replicated: false
Response body
The contents of the wind.jpg object
Example 2: Retrieving partial object dataHere’s a sample HTTP GET request that retrieves the first 10,000 bytes of an object named status27.txt in the status directory.
Request with curl command line
curl -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d -r 0-9999"https://finance.europe.hcp.example.com/rest/status/status27.txt"> status27a.txt
4–30 Working with objects and versions
Using a Namespace

Retrieving an object or version of an object
Request in Python using PycURL
import pycurlfilehandle = open("status27a.txt", 'wb')curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.RANGE, "0-9999"curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/status27.txt")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.WRITEFUNCTION, filehandle.write)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()filehandle.close()
Request headers
GET /rest/status/status27.txt HTTP/1.1Range: bytes=0-9999Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Response headers
HTTP/1.1 206 Partial ContentX-HCP-Time: 1259584200X-HCP-SoftwareVersion: 4.1.0.123Content-Type: text/plainContent-Range: bytes 0-9999/38985Content-Length: 10000X-HCP-Type: objectX-HCP-Size: 38985X-HCP-Hash: SHA-256 36728BA190BC4C377FE4C1A57AEF9B6AFDA98720422960...X-HCP-VersionId: 80232488876481X-HCP-IngestTime: 1258469462X-HCP-RetentionClass: X-HCP-RetentionString: Deletion AllowedX-HCP-Retention: 0X-HCP-RetentionHold: falseX-HCP-Shred: falseX-HCP-DPL: 2X-HCP-Index: falseX-HCP-Custom-Metadata: falseX-HCP-Replicated: false
Working with objects and versions 4–31
Using a Namespace

Retrieving an object or version of an object
Response body
The first 10,000 bytes of the contents of status27.txt
Example 3: Retrieving a historic version of an objectHere’s a sample HTTP GET request that retrieves version 80232998058817 of an object named wind.jpg in the images directory.
Request with curl command line
curl -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images/wind.jpg?version=80232998058817" > wind.jpg
Request in Python using PycURL
import pycurlfilehandle = open("wind.jpg", 'wb')curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/wind.jpg?version=80232998058817")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.WRITEFUNCTION, filehandle.write)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()filehandle.close()
Request headers
GET /rest/images/wind.jpg?version=80232998058817 HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
4–32 Working with objects and versions
Using a Namespace

Retrieving an object or version of an object
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1259584200X-HCP-SoftwareVersion: 4.1.0.123Content-Type: image/jpegContent-Length: 238985X-HCP-Type: objectX-HCP-Size: 238985X-HCP-Hash: SHA-256 36728BA190BC4C377FE4C1A57AEF9B6AFDA98720422960...X-HCP-VersionId: 80232998058817X-HCP-IngestTime: 1258469614X-HCP-RetentionClass: X-HCP-RetentionString: Deletion AllowedX-HCP-Retention: 0X-HCP-RetentionHold: falseX-HCP-Shred: falseX-HCP-DPL: 2X-HCP-Index: falseX-HCP-Custom-Metadata: falseX-HCP-Replicated: false
Response body
The contents of the requested version of the object.
Example 4: Retrieving object data in compressed format (command line)Here’s a sample curl command that tells HCP to compress the wind.jpg object before sending it to the client and then decompresses the returned content.
Request with curl command line
curl --compressed -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images/wind.jpg" > wind.jpg
Working with objects and versions 4–33
Using a Namespace

Retrieving an object or version of an object
Request in Python using PycURL
import pycurlfilehandle = open("wind.jpg", 'wb')curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/wind.jpg")
curl.setopt(pycurl.ENCODING, 'gzip')curl.setopt(pycurl.WRITEFUNCTION, filehandle.write)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()filehandle.close()
Request headers
GET /rest/images/wind.jpg HTTP/1.1Host: finance.europe.hcp.example.comAccept-Encoding: deflate, gzipCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Response headers
HTTP/1.1 200 OK X-HCP-Time: 1259584200X-HCP-SoftwareVersion: 4.1.0.123Content-Encoding: gzipContent-Type: image/jpegX-HCP-Type: objectX-HCP-Size: 238985X-HCP-Hash: SHA-256 36728BA190BC4C377FE4C1A57AEF9B6AFDA98720422960...X-HCP-VersionId: 80205544854849X-HCP-IngestTime: 1258469614X-HCP-RetentionClass: X-HCP-RetentionString: Deletion AllowedX-HCP-Retention: 0X-HCP-RetentionHold: falseX-HCP-Shred: falseX-HCP-DPL: 2X-HCP-Index: falseX-HCP-Custom-Metadata: falseX-HCP-Replicated: false
Response body
The contents of the wind.jpg object in gzip-compressed format.
4–34 Working with objects and versions
Using a Namespace

Retrieving an object or version of an object
Example 5: Retrieving object data in compressed format (Java)Here’s the partial implementation of a Java class named HTTPCompression. The implementation shows the ReadFromHCP method, which retrieves an object from an HCP namespace. It uses the Accept-Encoding header to tell HCP to compress the object before returning it and then decompresses the results.
import org.apache.http.client.methods.HttpGet;import org.apache.http.HttpResponse;import java.util.zip.GZIPInputStream;
class HTTPCompression { . . .void ReadFromHCP() throws Exception {
/* * Set up the GET request. * * This method assumes that the HTTP client has already been * initialized. */ HttpGet httpRequest = new HttpGet(sHCPFilePath);
// Indicate that you want HCP to compress the returned data with gzip. httpRequest.setHeader("Accept-Encoding", "gzip");
// Create Authentication Cookie and put in Cookie Store. httpRequest.setHeader("Cookie", NS_AUTH_TOKEN + "=" + sEncodedUserName + ":" + sEncodedPassword);
/* * Now execute the GET request. */ HttpResponse httpResponse = mHttpClient.execute(httpRequest);
/* * Process the HTTP Response. */ // If the return code is anything but in the 200 range indicating // success, throw an exception. if (2 != (int)(httpResponse.getStatusLine().getStatusCode() / 100)) { throw new Exception("Unexpected HTTP status code: " + httpResponse.getStatusLine().getStatusCode() + " (" + httpResponse.getStatusLine().getReasonPhrase() + ")"); }
Working with objects and versions 4–35
Using a Namespace

Retrieving an object or version of an object
/* * Write the decompressed file to disk. */ FileOutputStream outputFile = new FileOutputStream( sBaseFileName + ".fromHCP");
// Build the string that contains the response body for return to the // caller. GZIPInputStream bodyISR = new GZIPInputStream(httpResponse.getEntity().getContent()); byte partialRead[] = new byte[1024]; int readSize = 0; while (-1 != (readSize = bodyISR.read(partialRead))) { outputFile.write(partialRead, 0, readSize); }} . . .}
Example 6: Retrieving object data and custom metadata together (Java)Here’s the partial implementation of a Java class named WholeIO. The implementation shows the WholeReadFromHCP method, which retrieves an object and its custom metadata in a single data stream, splits the object from the custom metadata, and stores each in a separate file.
The WholeReadFromHCP method uses the WholeIOOutputStream helper class. For an implementation of this class, see “WholeIOOutputStream class” on page B-9.
import org.apache.http.client.methods.HttpGet;import org.apache.http.HttpResponse;import com.hds.hcp.examples.WholeIOOutputStream;
class WholeIO { . . .void WholeReadFromHCP() throws Exception {
/* * Set up the GET request and specifying the whole-object I/O. * * This method assumes that the HTTP client has already been * initialized. */ HttpGet httpRequest = new HttpGet(sHCPFilePath + "?type=whole-object");
4–36 Working with objects and versions
Using a Namespace

Retrieving an object or version of an object
// Create Authentication Cookie and put in Cookie Store. httpRequest.setHeader("Cookie", NS_AUTH_TOKEN + "=" + sEncodedUserName + ":" + sEncodedPassword);
// Request the custom metadata before the object data. // This can be useful if the application examines the custom metadata // to set the context for the data that will follow. httpRequest.setHeader("X-HCP-CustomMetadataFirst", "true");
/* * Now execute the GET request. */ HttpResponse httpResponse = mHttpClient.execute(httpRequest);
// If the return code is anything but in the 200 range indicating // success, throw an exception. if (2 != (int)(httpResponse.getStatusLine().getStatusCode() / 100)) { throw new Exception("Unexpected HTTP status code: " + httpResponse.getStatusLine().getStatusCode() + " (" + httpResponse.getStatusLine().getReasonPhrase() + ")"); }
/* * Determine whether data or custom metadata is first. */ Boolean cmFirst = new Boolean(httpResponse.getFirstHeader( "X-HCP-CustomMetadataFirst").getValue());
/* * Determine the size of the first part based on whether the object * data or custom metadata is first. */ // Assume object data is first. int firstPartSize = Integer.valueOf(httpResponse.getFirstHeader("X-HCP-Size").getValue());
// If custom metadata is first, do the math. if (cmFirst) { // subtract the data size from the content length returned. firstPartSize = Integer.valueOf( httpResponse.getFirstHeader("Content-Length").getValue()) - firstPartSize; } /* * Split and write the file to disk. */ WholeIOOutputStream outputCreator= new WholeIOOutputStream( new FileOutputStream(sBaseFileName + ".fromHCP"), new FileOutputStream(sBaseFileName + ".fromHCP.cm"), cmFirst);
Working with objects and versions 4–37
Using a Namespace

Deleting an object and using privileged delete
outputCreator.copy(httpResponse.getEntity().getContent(), firstPartSize);
outputCreator.close(); // Files should be created.} . . .}
Deleting an object and using privileged delete
You use the HTTP DELETE method to delete the current version of an object. You cannot delete individual historic versions of an object. For information on deleting all versions of an object, see “Purging an object and using privileged purge” on page 4-43.
If you delete an object and versioning is not enabled for the namespace, HTTP deletes the object. If you delete an object and versioning is enabled for the namespace, HTTP creates a special deleted version of the object and retains the previous version as a historic version. The deleted version is a marker that indicates that the object has been deleted and has no data.
You can delete an object that is under retention only if the namespace is configured to allow privileged operations and you have the necessary permissions. Privileged operations require you to provide a reason.
Request contentsThe DELETE request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• The URL of the object
Tip: If an object is not under retention, you can use a privileged delete operation to specify a reason for the deletion. Although the object is not under retention, the namespace must still support privileged operations, and you need the privileged permission.
4–38 Working with objects and versions
Using a Namespace

Deleting an object and using privileged delete
Request – using privileged deleteTo perform a privileged delete, the request must specify both of these parameters:
privileged=truereason=reason-text
reason-text must be from one through 1,024 characters long and can contain any valid UTF-8 characters, including white space.
You can specify the parameters in either of these ways:
• As query parameters at the end of the URL, in this format:
?privileged=true&reason=reason-text
• As form-encoded data (application/x-www-form-urlencoded content type) in the request. For example, in cURL, you can use the -d option to specify form-encoded data in a DELETE request.
You cannot combine query parameters and form-encoded data in a single request.
Access permissionTo delete an object, you need delete permission for the namespace.
To perform a privileged delete, even if the object is not under retention, you also need the privileged permission for the namespace.
Note: If you use query parameters, you need to percent-encode characters in the reason parameter that have special meanings in URLs. For more information on percent-encoding, see “Percent-encoding for special characters” on page 3-7.
If you use form-encoded data, you need to percent-encode only ampersand (&) characters in the reason parameter. This prevents HCP from interpreting these characters as starting a new URL parameter.
Working with objects and versions 4–39
Using a Namespace
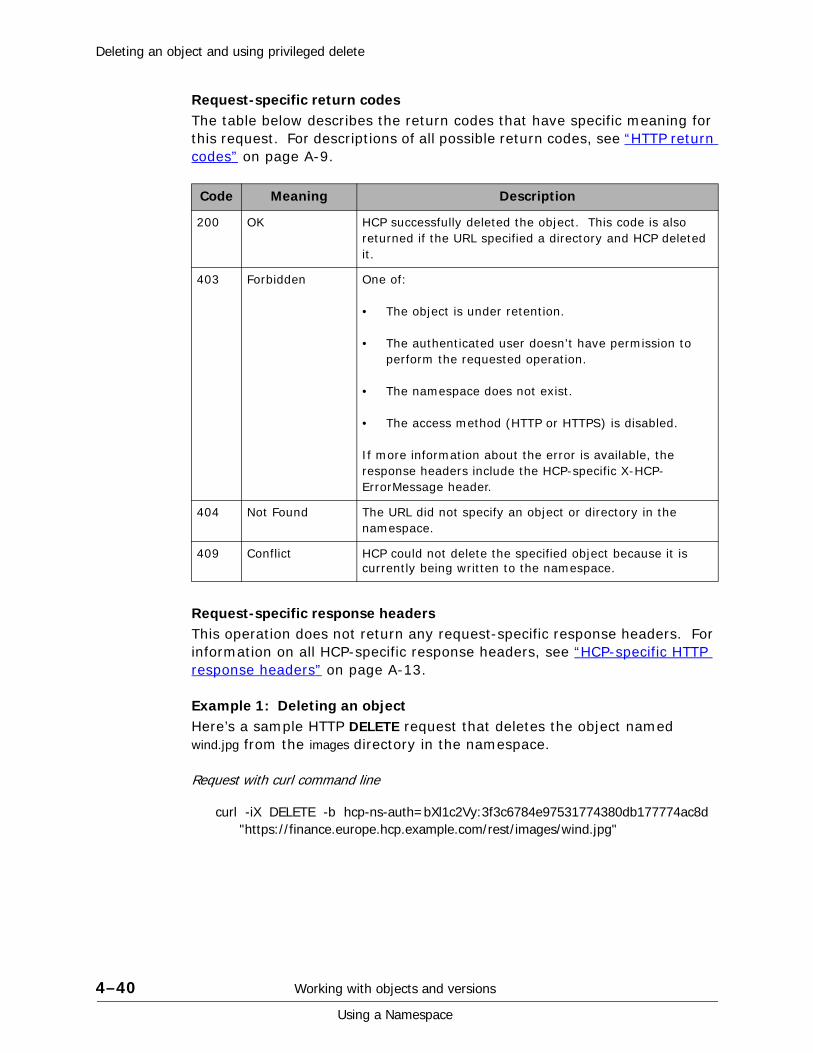
Deleting an object and using privileged delete
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headersThis operation does not return any request-specific response headers. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Example 1: Deleting an objectHere’s a sample HTTP DELETE request that deletes the object named wind.jpg from the images directory in the namespace.
Request with curl command line
curl -iX DELETE -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images/wind.jpg"
Code Meaning Description
200 OK HCP successfully deleted the object. This code is also returned if the URL specified a directory and HCP deleted it.
403 Forbidden One of:
• The object is under retention.
• The authenticated user doesn’t have permission to perform the requested operation.
• The namespace does not exist.
• The access method (HTTP or HTTPS) is disabled.
If more information about the error is available, the response headers include the HCP-specific X-HCP-ErrorMessage header.
404 Not Found The URL did not specify an object or directory in the namespace.
409 Conflict HCP could not delete the specified object because it is currently being written to the namespace.
4–40 Working with objects and versions
Using a Namespace

Deleting an object and using privileged delete
Request in Python using PycURL
import pycurlcurl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/wind.jpg")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.CUSTOMREQUEST, "DELETE")curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()
Request headers
DELETE /rest/images/wind.jpg HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1259584200Content-Length: 0
Example 2: Performing a privileged deleteHere’s a sample HTTP DELETE request that deletes the object named wind.jpg, which is under retention, from the images directory in the namespace.
Request with curl command line
curl -iX DELETE -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d-d "privileged=true" -d "reason=Deleted per Compliance Order 12323.""https://finance.europe.hcp.example.com/rest/images/wind.jpg"
Working with objects and versions 4–41
Using a Namespace

Deleting an object and using privileged delete
Request in Python using PycURL
import pycurlcurl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "http://finance.europe.hcp.example.com/rest/images/wind.jpg")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.CUSTOMREQUEST, "DELETE")
args = {'privileged':'true', 'reason':'Deleted per Compliance Order 12323.'}
args = urllib.urlencode(args)curl.setopt(pycurl.POSTFIELDS, args)
curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()
Request headers
DELETE /rest/images/wind.jpg HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8dContent-Length: 65Content-Type: application/x-www-form-urlencoded
Request body
Contains the privileged and reason parameters as form-encoded data.
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1258469462X-HCP-SoftwareVersion: 4.1.0.123Content-Length: 0
4–42 Working with objects and versions
Using a Namespace

Purging an object and using privileged purge
Purging an object and using privileged purge
You can use the HTTP DELETE method to purge all versions of an object from a namespace. You can also use the DELETE method to purge an object that is under retention (privileged purge) if the namespace is configured to allow privileged operations and you have the necessary permissions.
If versioning has never been enabled for the namespace, a purge request deletes the object. If versioning was enabled in the past but is no longer enabled, the purge request deletes all existing versions of the object.
Purging is the only way to explicitly delete historic versions. You cannot delete an individual historic version.
Request contentsThe DELETE request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• The URL of the object or directory
• A purge=true parameter
Request – using privileged purgeTo perform a privileged purge, the request must specify these additional parameters:
privileged=truereason=reason-text
reason-text must be from one through 1,024 characters long and can contain any valid UTF-8 characters, including white space.
You can specify the parameters in either of these ways:
• As query parameters at the end of the URL, in this format:
?purge=true&privileged=true&reason=reason-text
Tip: If an object is not under retention, you can use a privileged purge operation to specify a reason for the purge. Although the object is not under retention, the namespace must still support privileged operations, and you need the privileged permission.
Working with objects and versions 4–43
Using a Namespace

Purging an object and using privileged purge
• As form-encoded data (application/x-www-form-urlencoded content type) in the request. For example, in cURL, you can use the -d option to specify each parameter in a DELETE request.
You cannot combine query parameters and form-encoded data in a single request.
Access permissionTo purge objects you need both delete and purge permission for the namespace.
To perform a privileged purge operation, even if the object is not under retention, you also need the privileged permission.
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Note: If you use query parameters, you need to percent-encode characters in the reason parameter that have special meanings in URLs. For more information on percent-encoding, see “Percent-encoding for special characters” on page 3-7 If you use form-encoded data, you need to percent-encode only ampersand (&) characters in the reason parameter. This prevents HCP from interpreting these characters as starting a new URL parameter.
Code Meaning Description
200 OK HCP successfully purged all versions of the object.
403 Forbidden One of:
• The object is under retention and you do not have the privileged permission.
• You don’t have permission to perform the requested operation.
• The namespace does not exist.
• The access method (HTTP or HTTPS) is disabled.
If more information about the error is available, the response headers include the HCP-specific X-HCP-ErrorMessage header.
4–44 Working with objects and versions
Using a Namespace

Purging an object and using privileged purge
Request-specific response headersThis operation does not return any request-specific response headers. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Example 1: Purging an objectHere’s a sample HTTP DELETE request that purges all versions of the object named wind.jpg from the images directory. This example uses a URL query string to pass the operation parameters.
Request with curl command line
curl -iX DELETE -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images/wind.jpg?purge=true"
Request in Python using PycURL
import pycurlcurl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/wind.jpg?purge=true")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.CUSTOMREQUEST, "DELETE")curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()
Request headers
DELETE /rest/images/WindVersion.jpg?purge=true HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1258469462Content-Length: 0
404 Not Found HCP could not find the specified object.
409 Conflict HCP could not purge the specified object because it is currently being written to the namespace.
(Continued)
Code Meaning Description
Working with objects and versions 4–45
Using a Namespace

Purging an object and using privileged purge
Example 2: Performing a privileged purgeHere’s a sample HTTP DELETE request that purges the object named wind.jpg, which is under retention, from the images directory. This example uses form-encoded data to pass the operation parameters and percent-encodes the reason because it contains an ampersand.
Request with curl command line
curl -iX DELETE -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d-d "purge=true" -d "privileged=true" -d "reason=Purged%20per%20Compliance%20Dept.%20order%20AD%26943""https://finance.europe.hcp.example.com/rest/images/wind.jpg"
Request in Python using PycURL
import pycurlcurl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.example.hcp.com/rest/images/wind.jpg")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.CUSTOMREQUEST, "DELETE")
args = {'privileged':'true', 'purge':'true', 'reason':'Purged per Compliance Dept. order AD&943'}
params = urllib.urlencode(args)curl.setopt(pycurl.POSTFIELDS, params)
curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()
Request headers
DELETE /rest/images/wind.jpg HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8dContent-Length: 90Content-Type: application/x-www-form-urlencoded
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1258469462Content-Length: 0
4–46 Working with objects and versions
Using a Namespace
5
Working with directoriesHCP lets you perform these operations on directories:
• Create an empty directory
• Check the existence of a directory
• List the contents of a directory
• Delete an empty directory
This chapter describes these procedures.
Working with directories 5–1
Using a Namespace

Creating an empty directory
Creating an empty directory
You use the HTTP PUT method to create empty directories in a namespace. If any other directories in the path you specify for a new directory do not already exist, HCP creates them.
Request contentsThe PUT request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• A URL specifying the location in which to put the object
• A type URL query parameter with a value of directory.
Access permissionTo add a directory to a namespace, you need write permission for the namespace.
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headersThe directory creation operation does not return any request-specific response headers. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Example: Adding a directoryHere’s a sample HTTP PUT request that creates a new obsolete directory in the images directory.
Request with curl command line
curl -iX PUT -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images/obsolete?type=directory"
Code Meaning Description
201 Created HCP successfully created the directory.
409 Conflict HCP could not create the directory in the namespace because it already exists.
5–2 Working with directories
Using a Namespace

Checking the existence of a directory
Request in Python using PycURL
import pycurlcurl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/obsolete?type=directory")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.CUSTOMREQUEST, "PUT")curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()
Request headers
PUT /rest/images/obsolete?type=directory HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Response headers
HTTP/1.1 201 CreatedLocation: /rest/images/obsoleteContent-Length: 0
Checking the existence of a directory
You use the HTTP HEAD method to check whether a directory exists in a namespace.
Request contentsThe HEAD request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• URL of the directory
Access permissionTo check for directory existence, you need read permission for the namespace.
Working with directories 5–3
Using a Namespace

Checking the existence of a directory
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headersThe table below describes the request-specific response header for this operation. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Example: Checking the existence of a directoryHere’s a sample HTTP HEAD request that checks the existence of a directory named images.
Request with curl command line
curl -I b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images"
Code Meaning Description
200 OK HCP found a directory or object at the specified URL.
404 Not Found HCP could not find a directory or object at the specified URL.
Header Description
X-HCP-Type The type of the entity. This is always directory for directories. A value of object indicates that the requested entity is an object.
5–4 Working with directories
Using a Namespace

Listing directory contents
Request in Python using PycURL
import pycurlimportStringIOcin = StringIO.StringIO()curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.HEADER, 1)curl.setopt(pycurl.NOBODY, 1)curl.setopt(pycurl.WRITEFUNCTION, cin.write)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)print cin.getvalue()curl.close()
Request headers
HEAD /rest/images HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1259584200X-HCP-SoftwareVersion: 4.1.0.123X-HCP-Type: directoryContent-Length: 0
Listing directory contents
You use the HTTP GET method to list the contents of a directory.
Request contentsThe GET request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• URL of the directory
Working with directories 5–5
Using a Namespace

Listing directory contents
Request contents – listing deleted directories and objectsBy default, the returned list does not include deleted directories or objects. If the namespace supports versioning you can include deleted objects and directories in the list. To do this, add the following query parameter to the URL:
deleted=true
You can also specify deleted=false, which results in the default behavior.
Also specify the deleted=true parameter to list the contents of a deleted directory (which can contain only deleted objects and directories).
Access permissionTo list the contents of a directory, you need read permission for the namespace.
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headersThe table below describes the request-specific response header for this operation. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Response bodyThe body of the HTTP response consists of XML that lists the contents of the requested directory, including metadata for the objects the directory contains. It lists only the immediate directory contents, not the contents of any subdirectories.
Code Meaning Description
200 OK HCP retrieved the directory listing. This code is also returned if the URL specified an object and HCP retrieved it.
404 Not Found HCP could not find a directory or object at the specified URL.
Header Description
X-HCP-Type The type of the entity.
The header value is always directory for directories.
5–6 Working with directories
Using a Namespace

Listing directory contents
The XML for the list has this format:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="/static/xsl/directory.xsl"?><directory xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="/static/xsd/directory.xsd"path="directory-path" utf8Path="utf-8-encoded-directory-path" parentDir="directory-path" utf8ParentDir="utf-8-encoded-directory-path"dirDeleted="true|false"showDeleted="true|false"namespaceName="namespace-name"utf8NamespaceName="utf-8-encoded-namespace-name">
<!-- Format for a subdirectory --><entry urlName="directory-name"
utf8Name="utf-8-encoded-directory-name"type="directory"state="created|deleted"
/>
<!-- Format for an object --><entry urlName="object-name"
utf8Name="utf-8-encoded-object-name"type="object"size="object-size-in-bytes" hashScheme="hash-algorithm" hash="hash-value"retention="retention-seconds-after-1/1/1970"retentionString="retention-datetime-value"retentionClass="retention-class-name"ingestTime="ingest-seconds-after-1/1/1970"ingestTimeString="ingest-datetime-string"hold="true|false"shred="true|false"dpl="data-protection-level"index="true|false"customMetadata="true|false"version="version-number"replicated="true|false"changeTimeMilliseconds="change-milliseconds-after-1/1/1970.unique-integerchangeTimeString="yyyy-MM-ddThh:mm:ssZ"state="created|deleted"
/>
</directory>
Working with directories 5–7
Using a Namespace

Listing directory contents
Example: Listing a directory that includes deleted objectsHere’s a sample HTTP GET request that lists all the contents, including any deleted objects or subdirectories, of a directory named images in a namespace that supports versioning.
Request with curl command line
curl -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images?deleted=true" > images.xml
Request in Python using PycURL
import pycurlfilehandle = open("images.xml", 'wb')curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images?deleted=true")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.WRITEFUNCTION, filehandle.write)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()filehandle.close()
Request headers
GET /rest/images HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Notes:
• The ingestTimeString and retentionString values are in the time zone of the HCP system. Therefore, if the repository is in Boston, Massachusetts, and the ingestTime is 1259166212 (which corresponds to 11/25/2009 16:23:32 UTC), the ingestTimeString value is 11/25/2009 11:23AM.
• The changeTimeString value uses a different format from the others. It is in ISO 8601 format, which is in the time zone of the HCP system and ends with the hour and minute offset between local time and UTC. For more information on changeTimeMilliseconds and changeTimeString, see “object entry” on page 8-18.
5–8 Working with directories
Using a Namespace

Listing directory contents
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1259584200X-HCP-SoftwareVersion: 4.1.0.123X-HCP-Type: directoryContent-Type: text/xmlContent-Length: 577
Response body
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="/static/xsl/ns-directory.xsl"?><directory xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="/static/xsd/ns-directory.xsd"path="/rest/images"utf8Path="/rest/images"parentDir="/rest">utf8ParentDir="/rest"dirDeleted="false"showDeleted="true"namespaceName="finance"utf8NamespaceName="finance">
<entry urlName="fire.jpg"utf8Name="fire.jpg"type="object"size="19461"hashScheme="SHA-256"hash="42C605FBFFCD7CEAC36BE62F294374F94503D1DC1793736EF367..."retention="0"retentionString="Deletion Allowed"retentionClass=""ingestTime="1284580187"ingestTimeString="9/15/2010 3:49PM"hold="false"shred="false"dpl="2"index="true"customMetadata="false"version="80238375537921"replicated="false"changeTimeMilliseconds="1284580187533.00"changeTimeString="2010-09-15T15:49:47-0400" state="created"
/><entry urlName="obsolete"
utf8Name="obsolete"type="directory"
Working with directories 5–9
Using a Namespace

Deleting an empty directory
state="deleted"/><entry urlName="wind.jpg"
utf8Name="wind.jpg"type="object"size="238985"hashScheme="SHA-256"hash="E830B86212A66A792A79D58BB185EE63A4FADA76BB8A1C257C01..."retention="0"retentionString="Deletion Allowed"retentionClass=""ingestTime="1258469462"ingestTimeString="11/17/2009 9:51AM"hold="false"shred="false"dpl="2"index="true"customMetadata="false"version="80238376132993"replicated="false"changeTimeMilliseconds="1258469462598.00"changeTimeString="2009-11-17T09:51:57-0400" state="created"
/></directory>
Note that the obsolete directory was deleted. It does not appear in a directory listing if the URL does not include the deleted=true parameter.
Deleting an empty directory
You use the HTTP DELETE method to delete an empty directory from a namespace. You cannot delete a directory that contains objects or subdirectories.
Request contentsThe DELETE request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• URL of the directory
Access permissionTo delete a directory you need delete permission for the namespace.
5–10 Working with directories
Using a Namespace

Deleting an empty directory
Request-specific return codesThe table below describes the return codes that have specific meanings for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headersThis operation does not return any request-specific response headers. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Example: Deleting a directoryHere’s a sample HTTP DELETE request that deletes the directory named obsolete from the images directory in the namespace.
Request with curl command line
curl -iX DELETE -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images/obsolete”
Code Meaning Description
200 OK HCP successfully deleted the directory.
403 Forbidden One of:
• The directory specified for deletion is not empty.
• The authenticated user doesn’t have permission to perform the requested operation.
• The namespace does not exist.
• The access method (HTTP or HTTPS) is disabled.
If more information about the error is available, the response headers include the HCP-specific X-HCP-ErrorMessage header.
404 Not Found HCP could not find the specified directory.
409 Conflict HCP could not delete the specified directory because it is currently being written to the namespace.
Working with directories 5–11
Using a Namespace

Deleting an empty directory
Request in Python using PycURL
import pycurlcurl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/obsolete")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.CUSTOMREQUEST, "DELETE")curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()
Request headers
DELETE /rest/images/obsolete HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1259584200Content-Length: 00
5–12 Working with directories
Using a Namespace

6
Working with system metadataYou can perform these operations on the system metadata associated with objects:
• Specify metadata when you create an object
• Modify the metadata for an existing object
• List the metadata for an object
This chapter describes how to specify and modify system metadata. For information on listing the metadata for an object, see “Checking the existence of an object or version” on page 4-12. For more information on metadata, see Chapter 2, “Understanding objects.”
Note: When converting legacy applications to use the HTTP REST interface to access to an HCP namespace, be aware that the values used to specify certain metadata settings differ from those used for metadata settings in the default namespace and HCAP 2.x archives. For information on the default namespace, see Using the Default Namespace.
Working with system metadata 6–1
Using a Namespace

Specifying metadata on object creation
Specifying metadata on object creation
You use the HTTP PUT method to add objects to the namespace. When adding an object, you can specify these metadata values by including HCP-specific parameters in the request URL:
• Hold
• Index setting
• Retention setting
• Shred setting
The metadata values you specify override the default values for the namespace.
Request contentsThe PUT request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• A URL specifying the location in which to put the object
• A body containing the object to be put in the namespace
• Any combination of zero or more of the URL query parameters described in the table below
Parameter Valid values Description
hold true or false Places an object on hold or specifies that it’s not on hold
index true or false Specifies whether the object should be indexed for search
retention Any valid retention expression, as described in “Specifying retention settings” on page 2-8
Specifies the retention setting for the object
shred true or false Specifies whether to shred the object after it is deleted
Note: Each object has index metadata setting regardless of whether a search facility is enabled at the system level.
6–2 Working with system metadata
Using a Namespace
Specifying metadata on object creation
Access permissionTo add objects and versions to the namespace, you need write permission for the namespace.
To specify the hold parameter, you also need the privileged permission.
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headerThe table below describes the request-specific HTTP response header. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Code Meaning Description
201 Created The request successfully added the specified object.
409 Conflict HCP could not add the object to the namespace because it already exists and versioning is not enabled.
413 File Too Large One of:
• Not enough space is available to store the object. Try the request again after objects or versions are deleted from the namespace or the namespace capacity is increased.
• The request is trying to store an object that is larger than two TB. HCP cannot store objects larger than two TB.
Header Description
X-HCP-Hash The cryptographic hash algorithm HCP uses and the cryptographic hash value of the stored object, in this format:
X-HCP-Hash: hash-algorithm hash-value
You can use the returned hash value to verify that the stored data is the same as the data you sent. To do so, compare this value with a hash value that you generate from the original data.
Working with system metadata 6–3
Using a Namespace

Specifying metadata on object creation
Example: Storing a file and setting the retention valueHere’s a sample HTTP PUT request that stores a file named wind.jpg in the images directory and sets the retention value to the HlthReg-107 class.
Request with curl command line
curl -iT wind.jpg -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d "https://finance.europe.hcp.example.com/rest/images/wind.jpg?retention=C+HlthReg-107"
Request in Python using PycURL
import pycurlimport osfilehandle = open("wind.jpg", 'rb')curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/wind.jpg?retention=C+HlthReg-107"
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.PUT, 1)curl.setopt(pycurl.INFILESIZE, os.path.getsize("wind.jpg"))curl.setopt(pycurl.READFUNCTION, filehandle.read)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()filehandle.close()
Request headers
PUT /rest/images/wind.jpg?retention=C+HlthReg-107 HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8dContent-Length: 238985
Response headers
HTTP/1.1 201 CreatedLocation: /rest/images/wind.jpgX-HCP-VersionId: 80238663473089X-HCP-Hash: SHA-256 E830B86212A66A792A79D58BB185EE63A4FADA76BB8A1C...X-HCP-Time: 1258392981Content-Length: 0
6–4 Working with system metadata
Using a Namespace

Modifying object metadata
Modifying object metadata
You use the HTTP POST method to change the metadata for existing objects in the namespace. The request changes only the metadata that it explicitly specifies. All other metadata remains unchanged.
You can modify metadata only for the current object. You cannot modify it for a historic version.
Request contentsThe POST request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie.
• A URL specifying the object for which you are changing the metadata.
• A body containing form-encoded metadata (application/x-www-form-urlencoded content type). The content can consist of any combination of the parameters described in the table below.
Request limitationsThese limitations affect the valid requests and their results:
• You cannot change the hold and retention settings in the same request.
• You cannot change the shred setting from true to false.
Access permissionTo modify object metadata, you need write permission for the namespace.
To specify a hold parameter, you also need the privileged permission.
Parameter Valid values Description
hold true or false Places an object on hold or specifies that it’s not on hold
index true or false Specifies whether the object should be indexed for search
retention Any valid retention expression, as described in “Specifying retention settings” on page 2-8
Specifies the retention setting for the object
shred true or false Specifies whether to shred the object after it is deleted
Working with system metadata 6–5
Using a Namespace
Modifying object metadata
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headersThis operation does not return any request-specific response headers. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Example: Changing multiple metadata values for an existing objectHere’s a sample HTTP POST request that makes these changes to the metadata for the wind.jpg file:
• Increases retention by one year from the current value
• Turns on shredding on delete
• Turns off indexing
Code Meaning Description
200 OK The request successfully updated the metadata.
400 Bad Request One of:
• The request is trying to change the retention setting from a retention class to an explicit setting, such as a datetime value.
• The request is trying to change the retention setting and the retention hold setting at the same time.
• The request is trying to change the retention setting for an object on hold.
• The request is trying to change the shred value from true to false.
• The URL in the request is not well-formed.
• The request contains an unsupported parameter or an invalid value for a parameter.
If more information about the error is available, the response headers include the HCP-specific X-HCP-ErrorMessage header.
404 Not Found HCP could not find the specified object.
6–6 Working with system metadata
Using a Namespace

Modifying object metadata
Request with curl command line
curl -i -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d-d "retention=R+1y" -d "shred=true" -d "index=false"https://finance.europe.hcp.example.com/rest/images/wind.jpg
Request in Python using PycURL
import pycurlcurl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/wind.jpg"
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.POST, 1)theFields = "retention=R+1y&shred=true&index=false"theHeader = ["Transfer-Encoding: chunked"]curl.setopt(pycurl.HTTPHEADER, theHeader) curl.setopt(pycurl.POSTFIELDS, theFields
curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()
Request headers
POST /rest/images/wind.jpg HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8dContent-Length: 37Content-Type: application/x-www-form-urlencoded
Response headers
HTTP/1.1 200 OKContent-Length: 0
Working with system metadata 6–7
Using a Namespace

Modifying object metadata
6–8 Working with system metadata
Using a Namespace
7
Working with custom metadataYou can perform these operations on custom metadata:
• Store or replace the custom metadata for an object
• Check the existence of custom metadata for an object or version
• Retrieve the custom metadata for an object or version
• Delete the custom metadata for an object
This chapter describes the procedures for the operations listed above.
Working with custom metadata 7–1
Using a Namespace

Storing custom metadata
Storing custom metadata
You use the HTTP PUT method to store or replace custom metadata for an existing object. Some namespaces are configured to require custom metadata to be well-formed XML. In this case, HCP rejects custom metadata that is not well-formed XML and returns a 400 error code.
Custom metadata is stored as a single unit. You can add it or replace it in its entirely, but you cannot add to or change existing custom metadata. If you store custom metadata for an object that already has custom metadata, the new metadata replaces the existing metadata.
In addition to storing custom metadata for an existing object, you can use a single request to store object data and custom metadata at the same time. For more information on this, see “Adding an object or version of an object” on page 4-2.
Request contentsThe PUT request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• A URL specifying the object for which you are setting the custom metadata
• A type=custom-metadata URL query parameter
• A body consisting of the custom metadata
Request contents — sending data in compressed formatYou can send custom metadata in compressed format and have HCP decompress the data before storing it. To do this, in addition to specifying the request elements listed above:
• Use gzip to compress the content before sending it.
• Include a Content-Encoding request header with a value of gzip.
• Use a chunked transfer encoding.
Access permissionTo store custom metadata, you need write permission for the namespace.
7–2 Working with custom metadata
Using a Namespace
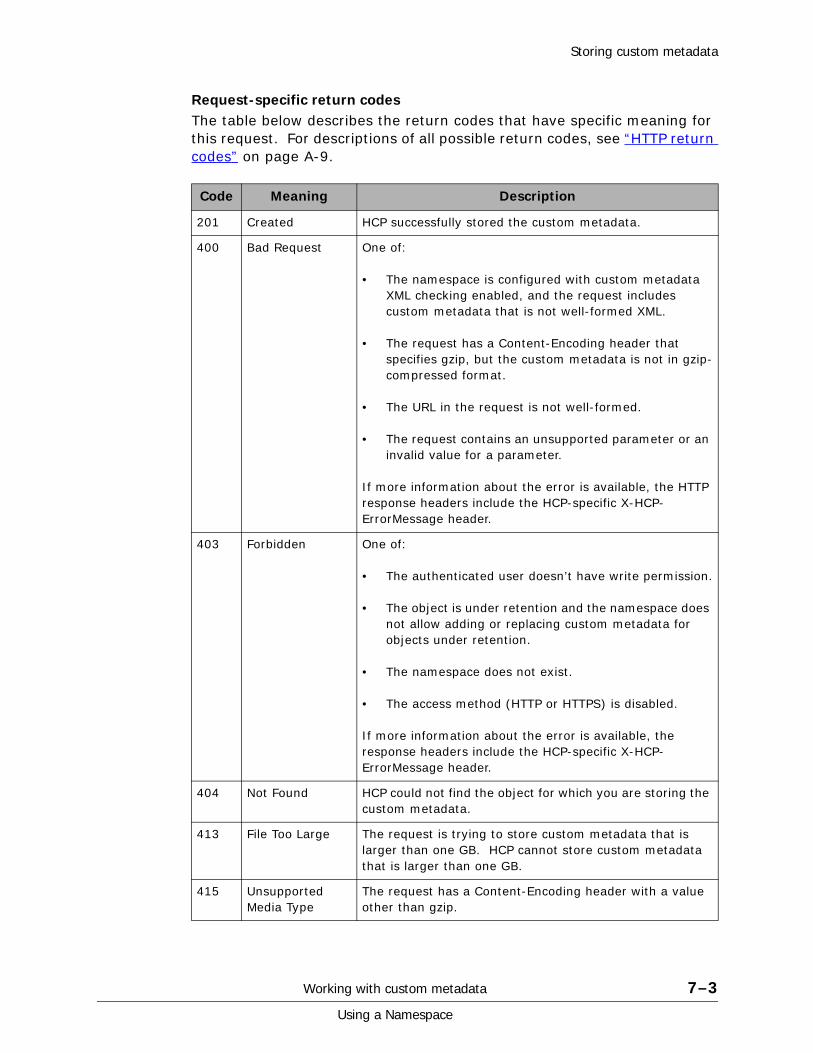
Storing custom metadata
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Code Meaning Description
201 Created HCP successfully stored the custom metadata.
400 Bad Request One of:
• The namespace is configured with custom metadata XML checking enabled, and the request includes custom metadata that is not well-formed XML.
• The request has a Content-Encoding header that specifies gzip, but the custom metadata is not in gzip-compressed format.
• The URL in the request is not well-formed.
• The request contains an unsupported parameter or an invalid value for a parameter.
If more information about the error is available, the HTTP response headers include the HCP-specific X-HCP-ErrorMessage header.
403 Forbidden One of:
• The authenticated user doesn’t have write permission.
• The object is under retention and the namespace does not allow adding or replacing custom metadata for objects under retention.
• The namespace does not exist.
• The access method (HTTP or HTTPS) is disabled.
If more information about the error is available, the response headers include the HCP-specific X-HCP-ErrorMessage header.
404 Not Found HCP could not find the object for which you are storing the custom metadata.
413 File Too Large The request is trying to store custom metadata that is larger than one GB. HCP cannot store custom metadata that is larger than one GB.
415 Unsupported Media Type
The request has a Content-Encoding header with a value other than gzip.
Working with custom metadata 7–3
Using a Namespace

Storing custom metadata
Request-specific response headersThe table below describes the request-specific response header for this operation. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Usage considerationThe PUT of custom metadata may fail with a 400 (Bad Request) error in either of these cases:
• The XML has a large number of different elements and attributes.
In this case, try restructuring the XML to have fewer different elements and attributes. For example, try concatenating multiple element values, such as the different parts of an address, to create a new value for a single element.
If you cannot restructure the XML to prevent failures, ask your namespace administrator about reconfiguring the namespace to prevent HCP from validating custom metadata XML.
• A number of clients try to store custom metadata for multiple objects at the same time.
In this case, limit the number of concurrent requests from clients to the namespace.
Header Description
X-HCP-Hash The cryptographic hash algorithm HCP uses and the cryptographic hash value of the stored custom metadata, in this format:
X-HCP-Hash: hash-algorithm hash-value
You can use the returned hash value to verify that the stored data is the same as the data you sent. To do so, compare this value with a hash value that you generate from the original data.
7–4 Working with custom metadata
Using a Namespace

Storing custom metadata
Example: Storing custom metadata for an objectHere’s a sample HTTP PUT request that stores the custom metadata defined in the wind.custom-metadata.xml file in for an existing object named wind.jpg.
Request with curl command line
curl -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d-iT wind.custom-metadata.xml "https://finance.europe.hcp.example.com/rest/images/wind.jpg?type=custom-metadata"
Request in Python using PycURL
import pycurlimport osfilehandle = open("wind.custom-metadata.xml", 'rb')curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/wind.jpg?type=custom-metadata")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.PUT, 1)curl.setopt(pycurl.INFILESIZE, os.path.getsize("wind.custom-metadata.xml"))
curl.setopt(pycurl.READFUNCTION, filehandle.read)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()filehandle.close()
Request headers
PUT /rest/images/wind.jpg?type=custom-metadata HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8dContent-Length: 317
Response headers
HTTP/1.1 201 CreatedX-HCP-Hash: SHA-256 20BA1FDC958D8519D11A4CC2D6D65EC64DD12466E456...Location: /rest/images/wind.jpgX-HCP-Time: 1259584200Content-Length: 0
Working with custom metadata 7–5
Using a Namespace

Checking the existence of custom metadata
Checking the existence of custom metadata
You use the HTTP HEAD method to check whether an object or a version of an object has custom metadata.
Request contentsThe HEAD request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• The URL of the object
• The type=custom-metadata URL query parameter
If an object has multiple versions, specify this optional URL query parameter to check whether a specific version of the object has metadata:
version=version-id
If you omit the version parameter, HCP checks the current version of the object.
Access permissionTo check for the existence of custom metadata, you need read permission for the namespace.
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headersIf HCP finds custom metadata for the specified object:
• The Content-Type response header value is txt/xml.
• The Content-Length response header value is the length of the custom metadata XML.
Code Meaning Description
200 OK The specified object has custom metadata.
204 No Content The specified object does not have custom metadata.
404 Not Found HCP could not find the specified object.
7–6 Working with custom metadata
Using a Namespace

Checking the existence of custom metadata
The HCP-specific response headers contain the same object metadata as the response to a HEAD request that checks the existence of an object. For example, the X-HCP-Hash header contains the hash value for the object, not the custom metadata. For details on these headers, see “Checking the existence of an object or version” on page 4-12. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Example: Checking the existence of custom metadataHere’s a sample HTTP HEAD request that checks the existence of custom metadata for an object named wind.jpg in the images directory.
Request with curl command line
curl -iI -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images/wind.jpg?type=custom-metadata"
Request in Python using PycURL
import pycurlimport StringIOcin = StringIO.StringIO()curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/wind.jpg?type=custom-metadata")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.HEADER, 1)curl.setopt(pycurl.NOBODY, 1)curl.setopt(pycurl.WRITEFUNCTION, cin.write)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)print cin.getvalue()curl.close()
Request headers
HEAD /rest/images/wind.jpg?type=custom-metadata HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Working with custom metadata 7–7
Using a Namespace

Retrieving custom metadata for objects and versions
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1258469462X-HCP-SoftwareVersion: 4.1.0.123Content-Type: text/xmlContent-Length: 317X-HCP-Type: objectX-HCP-Size: 19461X-HCP-Hash: SHA-256 42C605FBFFCD7CEAC36BE62F294374F94503D1DC1793736...X-HCP-VersionId: 80205544854849X-HCP-IngestTime: 1258372270X-HCP-RetentionClass:X-HCP-RetentionString: Deletion AllowedX-HCP-Retention: 0X-HCP-RetentionHold: falseX-HCP-Shred: falseX-HCP-DPL: 2X-HCP-Index: trueX-HCP-Custom-Metadata: trueX-HCP-Replicated: false
Retrieving custom metadata for objects and versions
You use the HTTP GET method to retrieve the custom metadata for an object or a version of an object. Custom metadata is returned in the format it had before it was stored.
You can also use a single request to retrieve object or version data and custom metadata together. For more information, see “Retrieving an object or version of an object” on page 4-22.
Request contentsThe GET request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• The URL of the object
• The type=custom-metadata URL query parameter
7–8 Working with custom metadata
Using a Namespace

Retrieving custom metadata for objects and versions
Request contents – retrieving custom metadata for a specific versionIf an object has multiple versions, specify this optional URL query parameter to retrieve the custom metadata for a specific version of the object:
version=version-ID
If you omit the version parameter, HCP retrieves the custom metadata for the current version of the object.
Request contents – retrieving data in compressed formatTo request that HCP return custom metadata in gzip-compressed format, use an Accept-Encoding header containing the value gzip or *. The header can specify additional compression algorithms, but HCP uses gzip only.
Access permissionTo retrieve custom metadata, you need read permission for the namespace.
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headersThe HCP-specific response headers contain the same object metadata as the response to a HEAD request that checks the existence of an object. For example, the X-HCP-Hash header contains the hash value for the object, not the custom metadata. For details on these headers, see “Checking the existence of an object or version” on page 4-12. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Code Meaning Description
200 OK HCP successfully retrieved the custom metadata.
204 No Content The specified object does not have custom metadata.
404 Not Found HCP could not find the specified object.
406 Not Acceptable The request has an Accept-Encoding header that does not include gzip or specify *.
Working with custom metadata 7–9
Using a Namespace

Retrieving custom metadata for objects and versions
If the request specifies a gzip-compressed response, the response headers have these characteristics:
• HCP returns a Content-Encoding header with a value of gzip.
• HCP returns a X-HCP-ContentLength header with the length of the returned custom metadata before it was compressed.
If HCP can provide information about an invalid request, the response has an X-HCP-ErrorMessage header describing the error.
Response bodyThe body of the HTTP response contains the custom metadata.
Example: Retrieving custom metadata for an objectHere’s a sample HTTP GET request that retrieves the custom metadata for an object named wind.jpg in the images directory.
Request with curl command line
curl -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images/wind.jpg?type=custom-metadata" > wind.jpg.custom-metadata.xml
Request in Python using PycURL
import pycurlfilehandle = open("wind.jpg.custom-metadata.xml", 'wb')curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/wind.jpg?type=custom-metadata")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.WRITEFUNCTION, filehandle.write)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()filehandle.close()
Request headers
GET /rest/images/wind.jpg?type=custom-metadata HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
7–10 Working with custom metadata
Using a Namespace

Deleting custom metadata
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1258469462X-HCP-SoftwareVersion: 4.1.0.123Content-Type: text/xmlContent-Length: 317X-HCP-Type: objectX-HCP-Size: 19461X-HCP-Hash: SHA-256 42C605FBFFCD7CEAC36BE62F294374F94503D1DC1793736...X-HCP-VersionId: 80205544854849X-HCP-IngestTime: 1258372270X-HCP-RetentionClass:X-HCP-RetentionString: Deletion AllowedX-HCP-Retention: 0X-HCP-RetentionHold: falseX-HCP-Shred: falseX-HCP-DPL: 2X-HCP-Index: trueX-HCP-Custom-Metadata: trueX-HCP-Replicated: false
Response body
<?xml version="1.0" ?><weather>
<location>Massachusetts</location><date>20091130</date><duration_secs>180</duration_secs><temp_F>
<temp_high>31</temp_high><temp_low>31</temp_low>
</temp_F><velocity_mph>
<velocity_high>22</velocity_high><velocity_low>17</velocity_low>
</velocity_mph></weather>
Deleting custom metadata
You use the HTTP DELETE request to delete the custom metadata from an object in a namespace. You cannot delete custom metadata from historic versions of an object.
Working with custom metadata 7–11
Using a Namespace

Deleting custom metadata
Request contentsThe DELETE request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• The URL of the object
• The type=custom-metadata parameter
Access permissionTo delete custom metadata, you need delete permission for the namespace.
Request-specific return codesThe table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headersThis operation does not return any request-specific response headers. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Code Meaning Description
200 OK HCP successfully deleted the custom metadata.
204 No Content The specified object does not have custom metadata.
403 Forbidden One of:
• The authenticated user doesn’t have the delete permission.
• The object is under retention and the namespace does not allow deleting custom metadata for objects under retention.
• The access method (HTTP or HTTPS) is disabled.
If more information about the error is available, the response headers include the HCP-specific X-HCP-ErrorMessage header.
404 Not Found HCP could not find the specified object.
409 Conflict HCP could not delete the custom metadata because it is currently being written to the namespace.
7–12 Working with custom metadata
Using a Namespace

Deleting custom metadata
Example: Deleting custom metadata of an objectHere’s a sample HTTP DELETE request that deletes the custom metadata for an object named wind.jpg located in the images directory.
Request with curl command line
curl -iX DELETE -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/rest/images/wind.jpg?type=custom-metadata"
Request in Python using PycURL
import pycurlcurl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/rest/images/wind.jpg?type=custom-metadata")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.CUSTOMREQUEST, "DELETE")curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()
Request headers
DELETE /rest/images/wind.jpg?type=custom-metadata HTTP/1.1Host: finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Response headers
HTTP/1.1 200 OKX-RequestId: E62EFD408DBB7B8FX-HCP-Time: 1259584200Content-Length: 0
Working with custom metadata 7–13
Using a Namespace

Deleting custom metadata
7–14 Working with custom metadata
Using a Namespace

8
Using the HCP metadata queryAPI
The HCP metadata query API lets you search HCP for objects that meet specific criteria and get back metadata for the matching objects. With this API, you can search not only for objects and versions currently in the repository but also for information about deleted or purged objects. This API is particularly useful for applications that need to track changes to namespaces.
This chapter describes how to use the metadata query API to retrieve information about objects.
Using the HCP metadata query API 8–1
Using a Namespace

About the metadata query API
About the metadata query API
The metadata query API is an HTTP interface that lets you query HCP for object metadata using any combination of these criteria:
• Namespace in which the object is stored
• Object change time
• Operations on the object
• Object index setting
• Directory that contains the object
A query can specify multiple namespaces and directories, a range of change times, and any combination of create, delete, and purge operations.
The API accepts query entries in XML or JavaScript Object Notation (JSON) format and can return results in either format. For example, you could use XML to specify the entries and request that the response be in JSON.
When you use the query API, HCP returns a set of operation records each of which identifies an object and an operation on the object and contains additional metadata for the object and operation. For more information on operation records, see “Operation records” below.
Because a large number of matching objects can result in a very large response, HCP lets you limit the number of operation records returned for a single request. You can retrieve data for all the matching objects by using multiple requests. This process is called using a paged query. For more information on paged queries, see “Paged queries” on page 8-4.
Note: This chapter uses entry to refer to an XML element and the equivalent JSON object and property for an XML attribute or the equivalent JSON name/value pair.
8–2 Using the HCP metadata query API
Using a Namespace

About the metadata query API
Operation records
HCP maintains records of object creation, deletion, and purge operations (also referred to as transactions). Deletion and purge information is helpful for applications, such as search applications, that must track changes to namespace contents. The HCP system configuration determines how long HCP keeps deletion or purge records.
By default, HCP returns only basic information about the object and operation, including the operation type, object identification information, and the change time. For creation records, the change time is the time the object was last modified. For deletion and purge records, the change time identifies the time of the operation.
If you specify a verbose entry with a value of true in a query, HCP returns complete system metadata for the object and operation, as listed in “object entry” on page 8-18.
Records returned while versioning is enabledIf versioning is enabled for a namespace, these rules determine which operation records HCP returns:
• HCP returns creation records for historic versions of an object until these versions are pruned.
• HCP returns creation records for versions of deleted objects until these versions are pruned.
• HCP returns deletion records until it removes them from the system, as determined by the system.
• HCP returns a single purge record for each purge operation. It does not return any records for the individual purged objects. HCP returns purge records until it removes them from the system.
Records returned while versioning is disabledIf you create and then delete an object while versioning is not enabled, HCP does not return the creation record. It returns the deletion record until HCP removes that record from the system.
If versioning was enabled at an earlier time but is no longer enabled, HCP continues to return records of all operations performed during that time according to the rules listed in “Records returned while versioning is enabled” above. If you delete any object while versioning is disabled, HCP does not return any creation records, regardless of when the object was created.
Using the HCP metadata query API 8–3
Using a Namespace

Request URL
Paged queries
In some cases, a query can result in a very large number of operation records, which can overload or reduce the efficiency of the client. You can prevent this by using paged queries, where you issue multiple requests that each retrieve a limited number of operation records. The client can process the records from each response before requesting additional data.
To use a paged query:
• Optionally, specify a count entry in each request except the last. By default, HCP returns 10,000 records per request.
• For each request after the first, specify a lastResult entry containing the values of the urlName, changeTimeMilliseconds, and version properties in the last record returned in response to the previous request.
• Determine whether the response contains the final record of the query result set by checking the value of the code property of the response status entry:
– If the value is INCOMPLETE, more records remain. Request another page.
– If the value is COMPLETE, all records have been retrieved.
For an example of using a paged query, see “Example 3: Using a paged query to retrieve a large number of records” on page 8-26.
Request URL
The URL format in a metadata query API request depends on whether you use a DNS name or IP address to connect to the HCP system and on the namespace or namespaces you want to access.
8–4 Using the HCP metadata query API
Using a Namespace

Request URL
Connecting using a DNS name
The URL format you use to connect to HCP depends on the type of account you’re using for namespace access. To use a data access account to query one or more namespaces owned by a tenant, specify the tenant and hostname in the URL in this format:
http[s]://tenant-name.hcp-name.domain-name/query
Unlike with requests to the /rest interface, do not specify a namespace in this URL.
If the tenant has granted system-level users administrative access to itself, you can use a system-level user account for your query. In this case, use a URL with this format:
https://admin.hcp-name.domain-name/query
In this case, the request can include any namespaces owned by any tenants to which system-level users have administrative access. A query that does not specify any namespace returns information about all namespaces in all such tenants, including the default namespace.
For this URL format, you need to use HTTP with SSL security (HTTPS).
Connecting using an IP address
To connect to a specific server, specify an IP address for the HCP system:
https://server-ip-address/query
The request Host header must specify the applicable hostname for either DNS name format; for example, europe.hcp.example.com or admin.hcp.example.com.
For this URL format, you need to use HTTP with SSL security.
Using the HCP metadata query API 8–5
Using a Namespace

Request considerations
Request considerations
The following considerations apply to metadata query API requests:
• If the metadata query uses HTTP with SSL security and the HCP system uses a self-signed SSL server certificate, the request must include an instruction not to perform SSL certificate verification. With cURL, you do this by including the -k option in the request command line. In Python with PycURL, you do this by setting the SSL_VERIFYPEER option to false.
• The request must specify query, in all lowercase, as the first element following the hostname or IP address in the URL path.
• HCP caches each query for a period of time on the server that receives the request. If you use an IP address in the URL in each request, you access the cached query and avoid having to recreate the query with each request. This can significantly improve the performance of paged queries that get large amounts of data.
Some HTTP libraries cache HTTP connections. Programs using these libraries may automatically reconnect to the same server for paged queries. In this case, using a DNS name to establish the connection provides the same performance benefit as using an IP address.
For more information on the relative advantages of DNS names and IP addresses, see “Namespace access by IP address” on page 11-2.
Request format
You use the HTTP POST method to send a metadata query API request to HCP.
Request HTTP elements
The POST request has these HTTP elements:
• If the URL starts with an IP address and the request specifies any namespaces, a Host header with the tenant name.
8–6 Using the HCP metadata query API
Using a Namespace

Request format
• An hcp-ns-auth authorization cookie.
The authorization cookie must specify the username and password for one of these:
– If the URL hostname or Host header starts with a tenant name, a data access account with read and search permission for the namespaces to be queried.
– If the URL hostname or Host header starts with admin, a system-level user account with the search role. In this case, the request can query all namespaces for all tenants to which system-level users have administrative access.
For information on the authorization cookie format, see “Authenticating namespace access” on page 3-8.
• An HTTP Content-Type header with one of these values:
– If the request body is XML, application/xml
– If the request body is JSON, application/json
• An HTTP Accept header that specifies the response format: application/xml or application/json.
• Optionally, to send the query in gzip-compressed format:
– A Content-Encoding header with a value of gzip
– A chunked transfer encoding
• Optionally, to request that HCP return the response in gzip-compressed format, an Accept-Encoding header containing the value gzip or *. The header can specify additional compression algorithms, but HCP uses only gzip.
• A request body containing the query parameters in the specified format.
Using the HCP metadata query API 8–7
Using a Namespace

Request format
Request body
The body of the HTTP request consists of entries in XML or JSON format.
XML request body
An XML request body must contain a top-level queryRequest element. All other elements are optional. For example, an XML body that requests all available information contains only this line:
<queryRequest/>
The XML request body has the format shown below. Elements at each hierarchical level can be in any order.
<queryRequest><count>return-record-count</count><lastResult><urlName>object-url</urlName><changeTimeMilliseconds>change-time-in-milliseconds.index</changeTimeMilliseconds><version>version-id</version>
</lastResult><systemMetadata><changeTime><start>start-time-in-milliseconds</start><end>end-time-in-milliseconds</end>
</changeTime><directories><directory>directory-path</directory>...
</directories><indexable>true|false</indexable><namespaces><namespace>namespace-name.tenant-name</namespace>...
</namespaces><transactions>Any combination of the following<transaction>create</transaction><transaction>delete</transaction><transaction>purge</transaction>
</transactions></systemMetadata><verbose>true|false</verbose>
</queryRequest>
8–8 Using the HCP metadata query API
Using a Namespace

Request format
JSON request body
A JSON request body must contain a top-level container object. All other objects are optional. For example, a JSON body that requests all available information contains only this line:
{}
The JSON request body has the format shown below. Objects at each hierarchical level can be in any order.
{"count":"return-record-count","lastResult": {"urlName":"object-url","changeTimeMilliseconds":"change-time-in-milliseconds.index","version":version-id
},"systemMetadata": {"changeTime": {"start":start-time-in-milliseconds,"end":end-time-in-milliseconds
},"directories": {"directory":["directory-path",...]
},"indexable":"true|false","namespaces": {"namespace":["namespace-name.tenant-name",...]
},"transactions": {"transaction":[Any combination of "create","delete",
"purge"]}
},"verbose":"true|false"
}
Using the HCP metadata query API 8–9
Using a Namespace
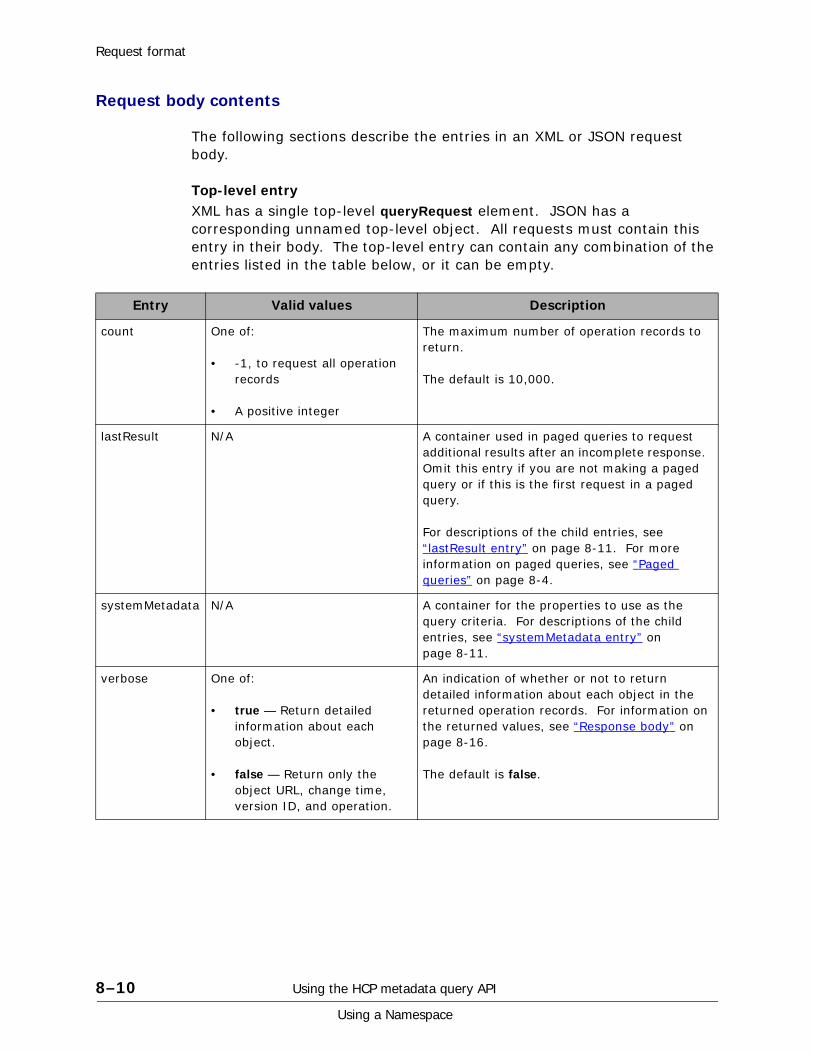
Request format
Request body contents
The following sections describe the entries in an XML or JSON request body.
Top-level entryXML has a single top-level queryRequest element. JSON has a corresponding unnamed top-level object. All requests must contain this entry in their body. The top-level entry can contain any combination of the entries listed in the table below, or it can be empty.
Entry Valid values Description
count One of:
• -1, to request all operation records
• A positive integer
The maximum number of operation records to return.
The default is 10,000.
lastResult N/A A container used in paged queries to request additional results after an incomplete response. Omit this entry if you are not making a paged query or if this is the first request in a paged query.
For descriptions of the child entries, see “lastResult entry” on page 8-11. For more information on paged queries, see “Paged queries” on page 8-4.
systemMetadata N/A A container for the properties to use as the query criteria. For descriptions of the child entries, see “systemMetadata entry” on page 8-11.
verbose One of:
• true — Return detailed information about each object.
• false — Return only the object URL, change time, version ID, and operation.
An indication of whether or not to return detailed information about each object in the returned operation records. For information on the returned values, see “Response body” on page 8-16.
The default is false.
8–10 Using the HCP metadata query API
Using a Namespace
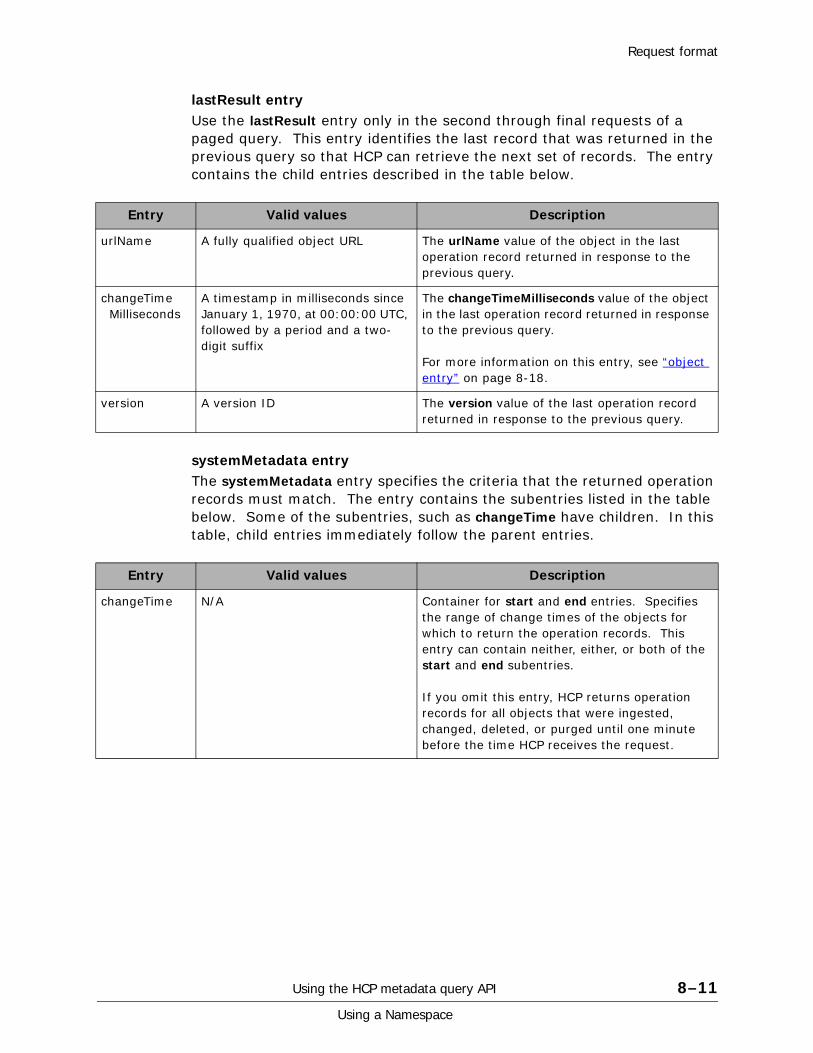
Request format
lastResult entryUse the lastResult entry only in the second through final requests of a paged query. This entry identifies the last record that was returned in the previous query so that HCP can retrieve the next set of records. The entry contains the child entries described in the table below.
systemMetadata entryThe systemMetadata entry specifies the criteria that the returned operation records must match. The entry contains the subentries listed in the table below. Some of the subentries, such as changeTime have children. In this table, child entries immediately follow the parent entries.
Entry Valid values Description
urlName A fully qualified object URL The urlName value of the object in the last operation record returned in response to the previous query.
changeTimeMilliseconds
A timestamp in milliseconds since January 1, 1970, at 00:00:00 UTC, followed by a period and a two-digit suffix
The changeTimeMilliseconds value of the object in the last operation record returned in response to the previous query.
For more information on this entry, see “object entry” on page 8-18.
version A version ID The version value of the last operation record returned in response to the previous query.
Entry Valid values Description
changeTime N/A Container for start and end entries. Specifies the range of change times of the objects for which to return the operation records. This entry can contain neither, either, or both of the start and end subentries.
If you omit this entry, HCP returns operation records for all objects that were ingested, changed, deleted, or purged until one minute before the time HCP receives the request.
Using the HCP metadata query API 8–11
Using a Namespace
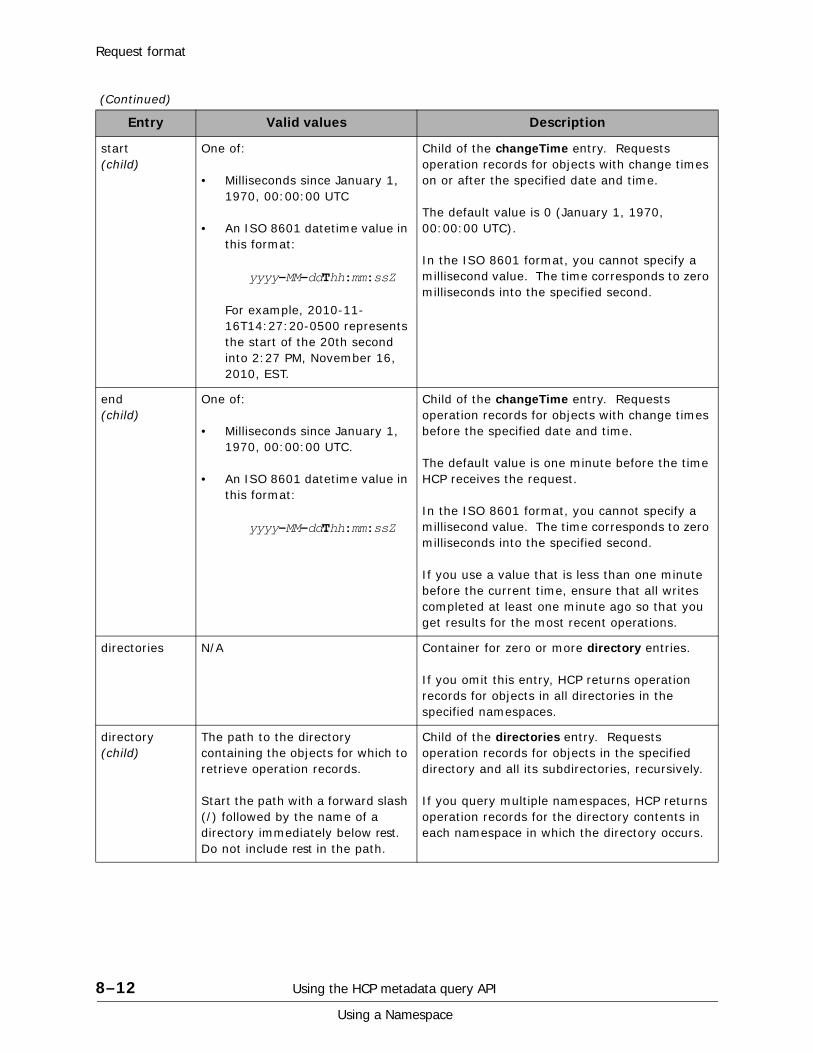
Request format
start(child)
One of:
• Milliseconds since January 1, 1970, 00:00:00 UTC
• An ISO 8601 datetime value in this format:
yyyy-MM-ddThh:mm:ssZ
For example, 2010-11-16T14:27:20-0500 represents the start of the 20th second into 2:27 PM, November 16, 2010, EST.
Child of the changeTime entry. Requests operation records for objects with change times on or after the specified date and time.
The default value is 0 (January 1, 1970, 00:00:00 UTC).
In the ISO 8601 format, you cannot specify a millisecond value. The time corresponds to zero milliseconds into the specified second.
end(child)
One of:
• Milliseconds since January 1, 1970, 00:00:00 UTC.
• An ISO 8601 datetime value in this format:
yyyy-MM-ddThh:mm:ssZ
Child of the changeTime entry. Requests operation records for objects with change times before the specified date and time.
The default value is one minute before the time HCP receives the request.
In the ISO 8601 format, you cannot specify a millisecond value. The time corresponds to zero milliseconds into the specified second.
If you use a value that is less than one minute before the current time, ensure that all writes completed at least one minute ago so that you get results for the most recent operations.
directories N/A Container for zero or more directory entries.
If you omit this entry, HCP returns operation records for objects in all directories in the specified namespaces.
directory(child)
The path to the directory containing the objects for which to retrieve operation records.
Start the path with a forward slash (/) followed by the name of a directory immediately below rest. Do not include rest in the path.
Child of the directories entry. Requests operation records for objects in the specified directory and all its subdirectories, recursively.
If you query multiple namespaces, HCP returns operation records for the directory contents in each namespace in which the directory occurs.
(Continued)
Entry Valid values Description
8–12 Using the HCP metadata query API
Using a Namespace
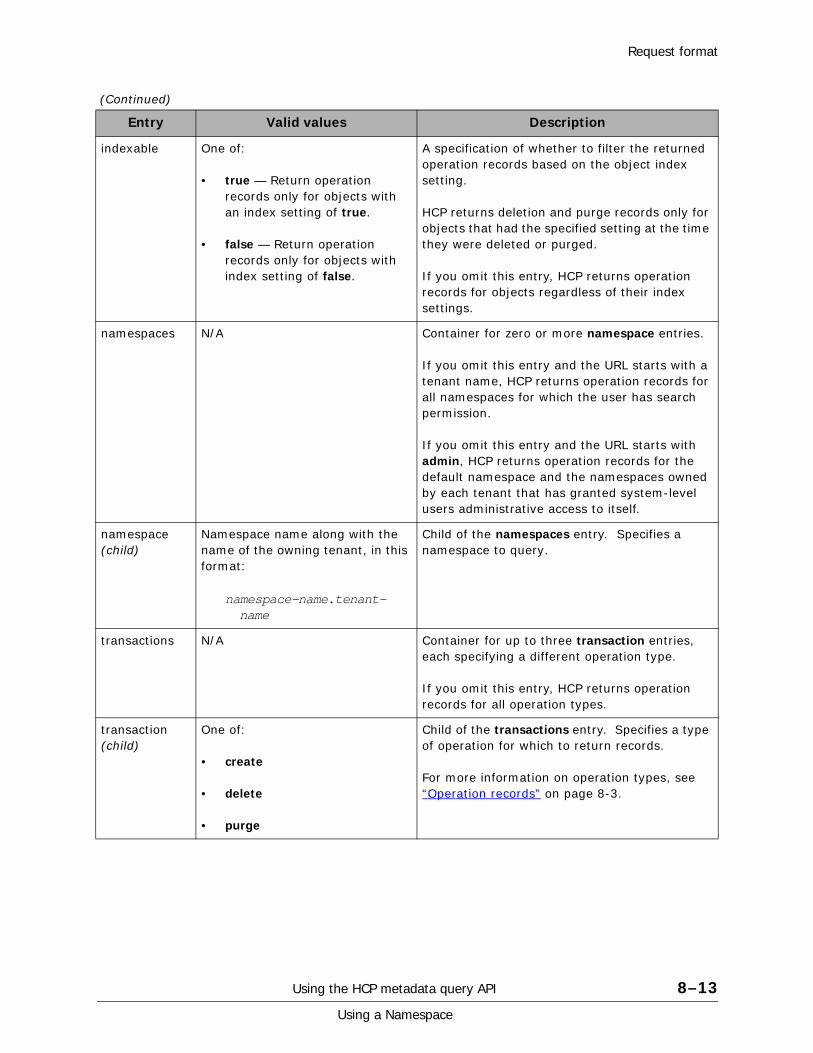
Request format
indexable One of:
• true — Return operation records only for objects with an index setting of true.
• false — Return operation records only for objects with index setting of false.
A specification of whether to filter the returned operation records based on the object index setting.
HCP returns deletion and purge records only for objects that had the specified setting at the time they were deleted or purged.
If you omit this entry, HCP returns operation records for objects regardless of their index settings.
namespaces N/A Container for zero or more namespace entries.
If you omit this entry and the URL starts with a tenant name, HCP returns operation records for all namespaces for which the user has search permission.
If you omit this entry and the URL starts with admin, HCP returns operation records for the default namespace and the namespaces owned by each tenant that has granted system-level users administrative access to itself.
namespace(child)
Namespace name along with the name of the owning tenant, in this format:
namespace-name.tenant-name
Child of the namespaces entry. Specifies a namespace to query.
transactions N/A Container for up to three transaction entries, each specifying a different operation type.
If you omit this entry, HCP returns operation records for all operation types.
transaction(child)
One of:
• create
• delete
• purge
Child of the transactions entry. Specifies a type of operation for which to return records.
For more information on operation types, see “Operation records” on page 8-3.
(Continued)
Entry Valid values Description
Using the HCP metadata query API 8–13
Using a Namespace

Response format
Response format
The response to a query API request returns the results as XML or JSON, depending on the value of the Accept request header. The returned results are sorted in this order:
• Namespace. The namespaces are not sorted alphabetically, but all entries for a single namespace are contiguous.
• changeTimeMilliseconds value, with the oldest records first.
• Path within the namespace.
• Version ID of the operation record.
Request-specific return codes
The table below describes the return codes that have specific meaning for this request. For descriptions of all possible return codes, see “HTTP return codes” on page A-7.
Code Meaning Description
200 OK HCP successfully ran the query and returned the results.
302 Found One of:
• The hcp-ns-auth cookie does not provide a valid username and password for a data access account with search permission or for a system-level user account with the search role.
• The tenant specified in the URL does not exist.
8–14 Using the HCP metadata query API
Using a Namespace
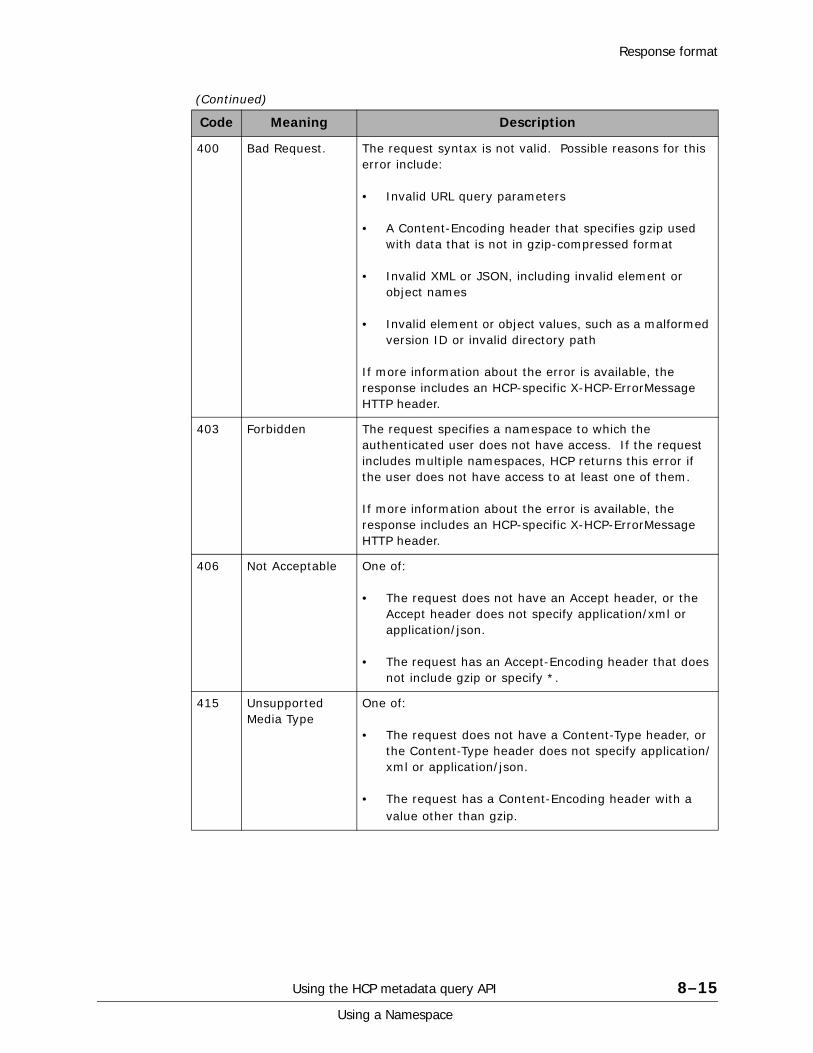
Response format
400 Bad Request. The request syntax is not valid. Possible reasons for this error include:
• Invalid URL query parameters
• A Content-Encoding header that specifies gzip used with data that is not in gzip-compressed format
• Invalid XML or JSON, including invalid element or object names
• Invalid element or object values, such as a malformed version ID or invalid directory path
If more information about the error is available, the response includes an HCP-specific X-HCP-ErrorMessage HTTP header.
403 Forbidden The request specifies a namespace to which the authenticated user does not have access. If the request includes multiple namespaces, HCP returns this error if the user does not have access to at least one of them.
If more information about the error is available, the response includes an HCP-specific X-HCP-ErrorMessage HTTP header.
406 Not Acceptable One of:
• The request does not have an Accept header, or the Accept header does not specify application/xml or application/json.
• The request has an Accept-Encoding header that does not include gzip or specify *.
415 Unsupported Media Type
One of:
• The request does not have a Content-Type header, or the Content-Type header does not specify application/xml or application/json.
• The request has a Content-Encoding header with a value other than gzip.
(Continued)
Code Meaning Description
Using the HCP metadata query API 8–15
Using a Namespace

Response format
Request-specific response headers
The response for a valid request includes a Transfer-Encoding header with a value of chunked.
If the request specifies a gzip-compressed response, the response includes these headers:
• Content-Encoding header with a value of gzip
• X-HCP-ContentLength header with the length of the returned data before it was compressed
If HCP can provide information about an invalid request, the response has an X-HCP-ErrorMessage header describing the error.
Response body
The body of the HTTP response contains XML or JSON that lists the operation records that match the query.
The order of entries in the response body may vary from one request to another. However, all entries in a response have the same order.
XML response body
An XML response has this format:
<?xml version='1.0' encoding='UTF-8'?><queryResult xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="/static/xsd/query-result.xsd"><query start="start-time-in-milliseconds"
end="end-time-in-milliseconds" /><resultSet>
<object Additional attributes if the verbose entry specified truechangeTimeMilliseconds="change-time-in-milliseconds.index"version=version-idurlName="object-url" operation="operation-type"
/>Additional object elements
</resultSet><status results=returned-record-count, message="message-text",
code="COMPLETE|INCOMPLETE" /></queryResult>
8–16 Using the HCP metadata query API
Using a Namespace

Response format
JSON response body
A JSON response has this format:
{"queryResult":{
"query":{"end":end-time-in-milliseconds,"start":start-time-in-milliseconds
},"resultSet":{[
{Additional name/value pairs if the verbose entry specified true"urlName":"object-url","operation":"operation-type", "changeTimeMilliseconds":"change-time-in-milliseconds.index","version":version-id,
},Additional object entries
] },"status":{
"results":returned-record-count,"message":"message-text","code":"COMPLETE|INCOMPLETE"
}}
}
Response body contents
XML and JSON have a single top-level queryResult entry. The queryResult entry contains one each of the entries listed in the table below.
Entry Description
query The time period that this query covers. The results include only operation records for objects with change times during this period. For more information, see “query entry” below.
resultSet A set of object entries representing the operation records that match the query. For more information, see “resultSet entry” on page 8-18.
status Information about the response, including the number of returned records and whether the response completes the query results. For more information, see “status entry” on page 8-21.
Using the HCP metadata query API 8–17
Using a Namespace

Response format
query entryThe query entry has the properties described in the table below.
resultSet entryThe resultSet entry has one child object entry for each operation record that matches the query.
object entryIn XML, the object entries are child object elements of the resultSet element. In JSON, the object entries are unnamed objects in the resultSet entry.
Each object entry provides information about an individual create, delete, or purge operation and the object affected by the operation. The properties the entry contains depend on the value of the verbose request entry. The object entry has the properties listed in the table below.
Property Description
start The value of the request start entry in milliseconds since January 1, 1970, at 00:00:00 UTC. If you omitted the entry, the value is 0 (zero).
end The value of the request end entry, in milliseconds since January 1, 1970, at 00:00:00 UTC.
If you omitted an end entry in the request, the value is one minute before the time HCP received the request.
Note: The metadata query API does not return records for open objects (that is, objects that are still being written or never finished being written).
Property Description
Returned in all responses
changeTimeMilliseconds For creation records, the time when the object or version was last changed. For deletion and purge records, the time when the object was deleted or purged.
The value is the time in milliseconds since January 1, 1970, at 00:00:00 UTC, followed by a period and a two-digit suffix. The suffix ensures that the change time values for versions of an object are unique.
8–18 Using the HCP metadata query API
Using a Namespace
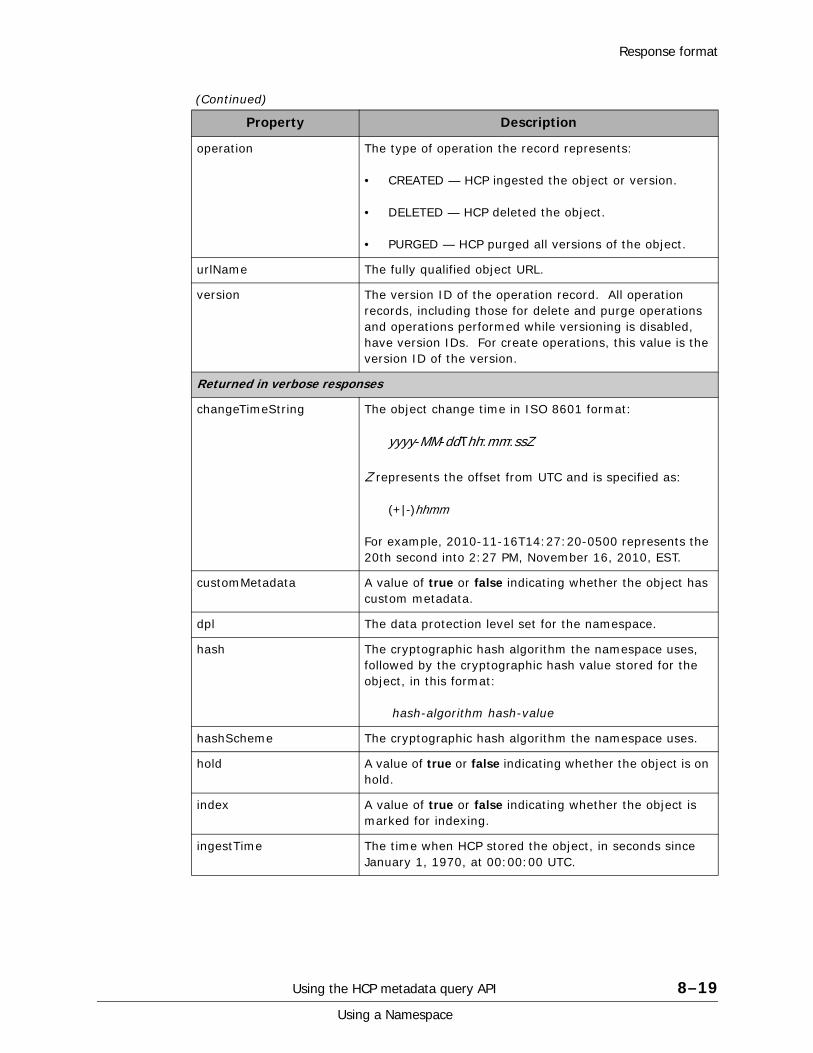
Response format
operation The type of operation the record represents:
• CREATED — HCP ingested the object or version.
• DELETED — HCP deleted the object.
• PURGED — HCP purged all versions of the object.
urlName The fully qualified object URL.
version The version ID of the operation record. All operation records, including those for delete and purge operations and operations performed while versioning is disabled, have version IDs. For create operations, this value is the version ID of the version.
Returned in verbose responses
changeTimeString The object change time in ISO 8601 format:
yyyy-MM-ddThh:mm:ssZ
Z represents the offset from UTC and is specified as:
(+|-)hhmm
For example, 2010-11-16T14:27:20-0500 represents the 20th second into 2:27 PM, November 16, 2010, EST.
customMetadata A value of true or false indicating whether the object has custom metadata.
dpl The data protection level set for the namespace.
hash The cryptographic hash algorithm the namespace uses, followed by the cryptographic hash value stored for the object, in this format:
hash-algorithm hash-value
hashScheme The cryptographic hash algorithm the namespace uses.
hold A value of true or false indicating whether the object is on hold.
index A value of true or false indicating whether the object is marked for indexing.
ingestTime The time when HCP stored the object, in seconds since January 1, 1970, at 00:00:00 UTC.
(Continued)
Property Description
Using the HCP metadata query API 8–19
Using a Namespace
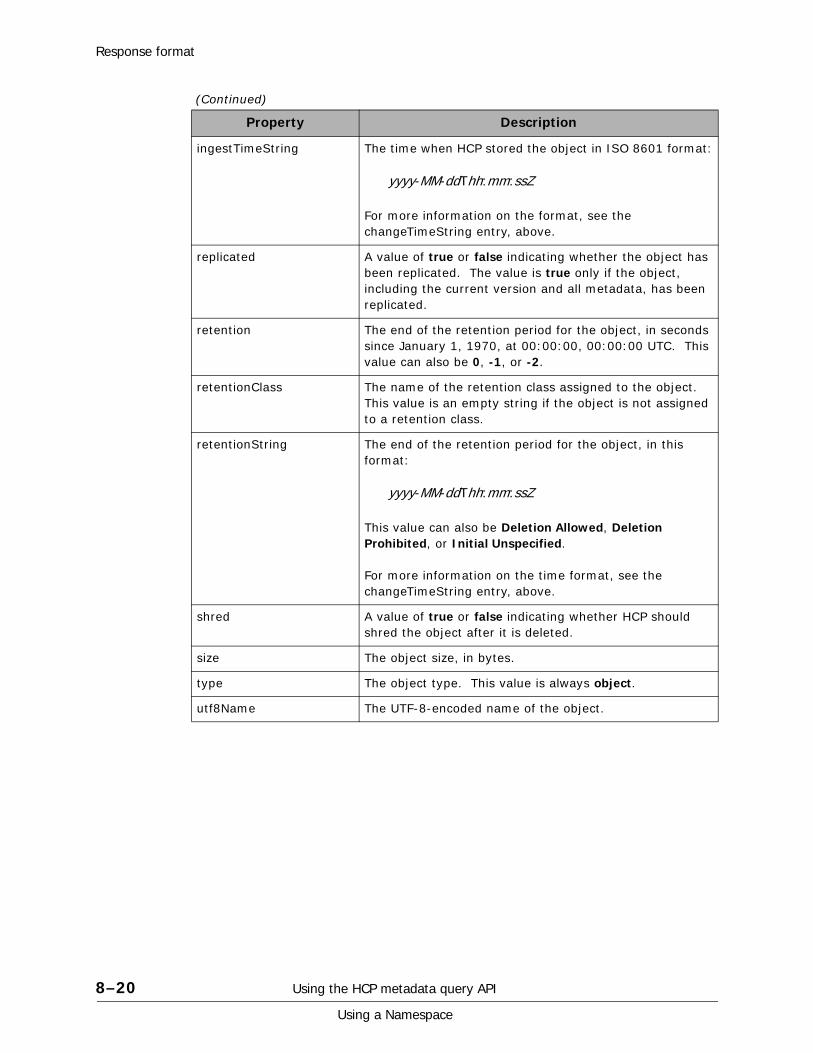
Response format
ingestTimeString The time when HCP stored the object in ISO 8601 format:
yyyy-MM-ddThh:mm:ssZ
For more information on the format, see the changeTimeString entry, above.
replicated A value of true or false indicating whether the object has been replicated. The value is true only if the object, including the current version and all metadata, has been replicated.
retention The end of the retention period for the object, in seconds since January 1, 1970, at 00:00:00, 00:00:00 UTC. This value can also be 0, -1, or -2.
retentionClass The name of the retention class assigned to the object. This value is an empty string if the object is not assigned to a retention class.
retentionString The end of the retention period for the object, in this format:
yyyy-MM-ddThh:mm:ssZ
This value can also be Deletion Allowed, Deletion Prohibited, or Initial Unspecified.
For more information on the time format, see the changeTimeString entry, above.
shred A value of true or false indicating whether HCP should shred the object after it is deleted.
size The object size, in bytes.
type The object type. This value is always object.
utf8Name The UTF-8-encoded name of the object.
(Continued)
Property Description
8–20 Using the HCP metadata query API
Using a Namespace

Examples
status entryThe status entry has the properties listed in the table below.
Examples
The following examples show some of the ways you can use the query API to get information. They show how to:
• Get detailed metadata for all indexable objects in a specific directory in a namespace
• Get metadata for objects that changed during a specific time span
• Use a paged query to get a large number of operation records
Property Description
code An indication of whether all matching records have been returned:
• COMPLETE — All matching records have been returned. This value is returned if the response includes all matching records or if the response includes the last record in a set of partial responses in a paged query.
• INCOMPLETE — Not all matching records have been returned. This value is returned if the request count entry is smaller than the number of records that meet the query criteria or if the response is incomplete due to an error encountered in executing the query.
You can get additional results by resubmitting the request with a lastResult entry identifying the last record in the returned response. For more information on this technique, see “Paged queries” on page 8-4.
message Normally, an empty string. If HCP encounters an error, such as a server being unavailable while processing the request, this entry describes the error.
results The number of operation records returned.
Using the HCP metadata query API 8–21
Using a Namespace

Examples
Example 1: Retrieving detailed metadata for indexable objects in a directory
Here’s a sample HTTP POST request that retrieves operation records for all objects in the /customers/widgetco/orders directory in the finance.europe namespace. The query uses an XML body and retrieves detailed metadata as JSON.
The response contains up to 10,000 detailed records for all versions of the objects in the specified directory and its subdirectories and includes records for all operations.
Request body in the XML file myRequst.xml
<queryRequest><count>-1</count><systemMetadata>
<directories><directory>/customers/widgetco/orders</directory>
</directories><namespaces>
<namespace>finance.europe</namespace></namespaces>
</systemMetadata><verbose>true</verbose>
</queryRequest>
Request with curl command line
curl -i -k -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d-H "Content-Type: application/xml" -H "Accept: application/json"-d @myRequest.xml "https://europe.hcp.example.com/query"
8–22 Using the HCP metadata query API
Using a Namespace

Examples
Request in Python using PycURL
import pycurlcurl = pycurl.Curl()
# Set the HTTP cookie, URL, command, and headerscurl.setopt(pycurl.COOKIE,
"hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")curl.setopt(pycurl.URL, "https://europe.hcp.example.com/query")curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.POST, 1)theHeaders = ["Content-Type: application/xml",
"Accept: application/json"]curl.setopt(pycurl.HTTPHEADER, theHeaders)
# Set the request body from an XML filefilehandle = open("myRequest.xml", 'rb')theFields = filehandle.read()curl.setopt(pycurl.POSTFIELDS, theFields)filehandle.close()
curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()
Request headers
POST /query HTTP/1.1Host: europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8dContent-Type: application/xmlAccept: application/jsonContent-Length: 258
Response headers
HTTP/1.1 200 OKTransfer-Encoding: chunked
Using the HCP metadata query API 8–23
Using a Namespace

Examples
JSON Response body
To limit the example size, the JSON below contains only one of the object entries included in the response.
{"queryResult":{"query":{"end":1277926250658,"start":0},
"resultSet":[{"retentionClass":"",
"hashScheme":"SHA-256","customMetadata":false,"hash":"SHA-256 C67EF26C0E5EDB102A2DEF74EF02A8DF5A4F16BF4D...","retention":"0","dpl":2,"utf8Name":"C346527","retentionString":"Deletion Allowed","ingestTime":1277924133,"ingestTimeString":"Wed Jun 30 14:55:33 EDT 2010","hold":false,"shred":false,"replicated":false,"type":"object","size":4500,"index":true,"operation":"CREATED","urlName":"https://finance.europe.hcp.example.com/rest/
customers/widgetco/orders/C346527","changeTimeMilliseconds":"1277924133948.00","changeTimeString":"2010-06-30T18:55:33-0400","version":81787144560449},
.
.
.],
"status":{"results":7,"message":"","code":"COMPLETE"}}
}
8–24 Using the HCP metadata query API
Using a Namespace

Examples
Example 2: Retrieving metadata for changed objects
Here’s a sample HTTP POST request that uses a JSON body specified directly in the code and retrieves up to 10,000 operation records for objects that:
• Are in any namespace accessible by the data access account
• Changed during 2010
The start entry specifies 12:00:00.00 a.m. on January 1, 2010, and the end entry specifies 12:00:00.00 a.m. on January 1, 2011.
The response, which is in XML, includes records for all operations and object versions. The information returned for each operation record that meets the query criteria consists of the change time, version, operation, and URL.
Request with curl command line
curl -k -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d-H "Content-type: application/json" -H "Accept: application/xml"-d '{"systemMetadata":{"changeTime":{"start":1262304000000,"end":1293840000000}}}' "https://europe.hcp.example.com/query"
Request in Python using PycURL
import pycurlcurl = pycurl.Curl()
# Set the HTTP cookie, URL, command, and headerscurl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://europe.hcp.example.com/query")curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.POST, 1)theHeaders = ["Content-Type: application/json",
"Accept: application/xml"]curl.setopt(pycurl.HTTPHEADER, theHeaders)
# Set the request bodytheFields = '{"systemMetadata":{"changeTime":\
{"start":1262304000000,"end":1293840000000}}}'curl.setopt(pycurl.POSTFIELDS, theFields)
curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()
Using the HCP metadata query API 8–25
Using a Namespace

Examples
Request headers
POST /query HTTP/1.1Host: europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8dContent-Type: application/jsonAccept: application/xmlContent-Length: 81
Response headers
HTTP/1.1 200 OKTransfer-Encoding: chunked
Response body
To limit the example size, the XML below contains only two of the object elements of the response.
<?xml version='1.0' encoding='UTF-8'?><queryResult xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="/static/xsd/query-result.xsd"><query start="1262304000000" end="1293840000000"/><resultSet>
<object changeTimeMilliseconds="1277923464679.00"version="81787101672577"urlName="https://finance.europe.hcp.example.com/rest/test2.txt" operation="CREATED"/>
<object changeTimeMilliseconds="1277923478677.00" version="81787102472129" url="https://finance.europe.hcp.example.com/rest/test2.bak" operation="CREATED"/>
.
.
.</resultSet><status results="11" message="" code="COMPLETE"/>
</queryResult>
Example 3: Using a paged query to retrieve a large number of records
The Python example below implements a paged query that uses multiple requests to retrieve a large number of records in small batches.
8–26 Using the HCP metadata query API
Using a Namespace

Examples
This example requires two methods, fromDict and toDict, that are not part of the Python or PycURL distribution. These methods convert between XML text and Python dict structures. In this example, they are imported from the XML module of the arc.parser.xml_parser module. To use this example, you need to provide these or equivalent methods.
#!/usr/bin/env python# encoding: utf-8
import pycurlimport StringIO# Import XML - dict conversion methods.from arc.parser.xml_parser import XML
# The request class represents a query and executes the request.class Request(Exception): """The request class used in the queries.""" def __init__(self): Exception.__init__(self) self.header=None self.cookie=None self.urlName="" self.namespace=None self.directory=None self.count=None self.body=None self.verbose=None # The query dictionary, a container for the request # body entries. self.queryDict={'queryRequest':{}}
def queryRequest(self, data, namespace, systemName): """Make a request to HCP.""" # Define the pycurl parameters. headers = {pycurl.HTTPHEADER :["Accept: application/xml", "Content-Type: application/xml", "Host: europe.%s" %(systemName)]} self.lastHeader = StringIO.StringIO() self.curl=pycurl.Curl() self.curl.setopt(pycurl.FAILONERROR, 1) self.curl.setopt(pycurl.COOKIE, self.cookie) self.curl.setopt(pycurl.HTTPHEADER, headers[pycurl.HTTPHEADER]) self.curl.setopt(pycurl.URL, self.urlName) cout=StringIO.StringIO() self.curl.setopt(pycurl.WRITEFUNCTION, cout.write) cin=StringIO.StringIO(data) fileSize=len(data) self.curl.setopt(pycurl.INFILESIZE, fileSize) self.curl.setopt(pycurl.READFUNCTION, cin.read)
Using the HCP metadata query API 8–27
Using a Namespace

Examples
self.curl.setopt(pycurl.PUT, 1) self.curl.setopt(pycurl.CUSTOMREQUEST, 'POST') self.curl.setopt(pycurl.SSL_VERIFYPEER, 0) self.curl.setopt(pycurl.SSL_VERIFYHOST, 0) self.curl.setopt(pycurl.VERBOSE, 0) for header, value in headers.iteritems(): self.curl.setopt(header, value) self.curl.perform() output=cout.getvalue() response=self.curl.getinfo(pycurl.RESPONSE_CODE) self.curl.close # Return the XML response and the HTTP response code. return output, response
# Initialize the query dictionary - called by the class initializer. def makeQueryDict(self): """ Add the system metadata to the query dictionary.""" self.queryDict['queryRequest'].update({'systemMetadata':{}}) self.queryDict['queryRequest']['systemMetadata'].update \ ({'namespaces':{'namespace':[]}}) self.queryDict['queryRequest']['systemMetadata']['namespaces']\ ['namespace'].append(self.namespace) self.queryDict['queryRequest']['count']=self.count self.queryDict['queryRequest']['verbose']=self.verbose self.queryDict['queryRequest']['systemMetadata'].update \ ({'directories':{'directory':[]}}) self.queryDict['queryRequest']['systemMetadata']['directories']\ ['directory'].append("/%s" % self.directory)
# Utility methods used by main.def getRecords(resultsDict): """ Returns a list of operation records from the query, plus the / result count.""" recordList = {} resultsCount=0 currResultCount = int(resultsDict['status']['results']) if currResultCount: resultsCount += currResultCount if resultsDict['resultSet']: recordList = resultsDict['resultSet']['object'] if isinstance(recordList, dict): recordList = [recordList] print "Got " + str(resultsCount) + " records." # Return the operation records as a list, number of results \ # received to date. return recordList, resultsCount
8–28 Using the HCP metadata query API
Using a Namespace

Examples
def getResults(currRecordList): """ Returns a results iterator. """ while currRecordList != None and len(currRecordList) > 0: obj = {} for obj in currRecordList: yield obj currRecordList = list()
# Executed when you run python query_test.py.def main(): """Run a query using the Request class""" # Create a query request and set the request entries. testQuery=Request() testQuery.namespace="finance.europe" systemName="hds.example.com" testQuery.directory="" testQuery.count=3 testQuery.verbose=True testQuery.cookie="hcp-ns-auth=YWxscm9sZXM=:04EC9F614D89FF5C7126D..." testQuery.urlName="https://europe.%s/query" % systemName testQuery.makeQueryDict() # Make the first request to HCP. data, response=testQuery.queryRequest(XML.fromDict (testQuery.queryDict), testQuery.namespace, systemName) # If the response is invalid, raise an exception. if response!=200: raise Exception("Error. Response code is: %d" % response) # The response is valid. Convert XML to python dict. resultsDict=XML.toDict(data)['queryResult'][1] # Call getRecords to get the operation records and results count. recordList, resultCount = getRecords(resultsDict) # Show the operation records list on the command line. # Open a file in which to put the operation records. outRecords=open("recordList.txt", 'wb') try: # Write the first set of operation records to the file. outRecords.write("%s" % recordList) # Loop to make the requests and add the results to the file. # Executed until HCP returns a result with a COMPLETE status. while resultsDict['status']['code']!='COMPLETE': # Get the last result record in the response. for rowDict in getResults(recordList): continue # Add results to the queryDict for the next request. testQuery.queryDict['queryRequest']['lastResult']= {} testQuery.queryDict['queryRequest']['lastResult']\ ['urlName']=rowDict['urlName']
Using the HCP metadata query API 8–29
Using a Namespace

Examples
testQuery.queryDict['queryRequest']['lastResult']\ ['changeTimeMilliseconds']=rowDict\ ['changeTimeMilliseconds'] testQuery.queryDict['queryRequest']['lastResult']\ ['version']=rowDict['version'] # Make the new request and get the results. data, response=testQuery.queryRequest(XML.fromDict (testQuery.queryDict), testQuery.namespace, systemName) resultsDict=XML.toDict(data)['queryResult'][1] recordList, resultCount = getRecords(resultsDict) # If the HTTP response was not 200, raise an exception. if response!=200: raise Exception("Error. Response code is: %d" % response) # Add the results to the file. outRecords.write("%s" % recordList) # Close the file in all cases. finally: outRecords.close()
if __name__== '__main__': main()
8–30 Using the HCP metadata query API
Using a Namespace

9
Retrieving namespaceinformation
You can use HTTP GET requests to retrieve information about the namespaces you can access with your data access account. You can retrieve this information:
• Namespaces you can access
• Retention classes supported by a namespace
• Permissions that apply to a namespace
• Statistics for a namespace
This chapter describes the procedures for getting this information and the format of the returned information.
Retrieving namespace information 9–1
Using a Namespace

Listing accessible namespaces
Listing accessible namespaces
You use the HTTP GET method to list the namespaces that you can access. The list contains the namespaces owned by the specified tenant for which your data access account has any permissions.
The GET request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• A URL in the following format:
http[s]://namespace-name.tenant-name.hcp-name.domain-name/proc
The URL must include a namespace. You can use the name of any namespace owned by the tenant, even if your data access account doesn’t include any permissions for that namespace.
Request-specific return codesThis operation does not have any request-specific return codes. For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headersThis operation does not return any request-specific response headers. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
9–2 Retrieving namespace information
Using a Namespace

Listing accessible namespaces
Response bodyThe HTTP response body consists of XML that lists the namespaces you can access, along with their settings. The XML has this format:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="/static/xsl/proc-namespaces.xsl"?><namespaces xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="/static/xsd/proc-namespaces.xsd"tenantHostName="tenant-name.hcp-name.domain-name"httpScheme="http"><namespace name="namespace-name"
nameIDNA="namespace-url-name"versioningEnabled="true|false"searchEnabled="true|false"retentionMode="compliance|enterprise"defaultShredValue="true|false"defaultIndexValue="true|false"defaultRetentionValue="retention-setting"hashScheme="hash-algorithm"dpl="data-protection-level"><description><![CDATA[
namespace-description]]></description>
</namespace>...</namespaces>
Example: Listing accessible namespacesHere’s a sample HTTP GET request that returns information about the namespaces owned by the europe tenant in the hcp.example.com system.
Request with curl command line
curl -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d "https://finance.europe.hcp.example.com/proc"
Request in Python using PycURL
import pycurlcurl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/proc")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()
Retrieving namespace information 9–3
Using a Namespace

Listing accessible namespaces
Request headers
GET /proc HTTP/1.1Host: /finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1259584200Content-Length: 1275
Response body
<namespaces xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:noNamespaceSchemaLocation="/static/xsd/proc-namespaces.xsd"tenantHostName="europe.hcp.example.com"httpScheme="https"><namespace name="finance"
nameIDNA="finance" versioningEnabled="true" searchEnabled="true" retentionMode="enterprise" defaultShredValue="false" defaultIndexValue="true" defaultRetentionValue="0" hashScheme="SHA-256" dpl="2" ><description><![CDATA[
Finance department]]></description>
</namespace><namespace name="support"
nameIDNA="support" versioningEnabled="true" searchEnabled="true" retentionMode="enterprise" defaultShredValue="false" defaultIndexValue="true" defaultRetentionValue="0" hashScheme="SHA-256" dpl="2" ><description><![CDATA[
Technical Support department]]></description>
</namespace></namespaces>
9–4 Retrieving namespace information
Using a Namespace

Listing retention classes
Listing retention classes
You use the HTTP GET method to list the retention classes defined for a namespace.
The GET request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• A URL in the following format:
http[s]://namespace-name.tenant-name.hcp-name.domain-name/proc/retentionClasses
Request-specific return codeIf you request information about a namespace to which you do not have access, HCP returns 401 (Unauthorized).
For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headersThis operation does not return any request-specific response headers. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Response bodyThe body of the HTTP response consists of XML that lists the retention classes defined for the namespace. The XML has this format:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="/static/xsl/proc-retention-classes.xsl"?><retentionClasses xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="/static/xsd/proc-retention-classes.xsd"namespaceName="namespace-name">
<retentionClassname="class-name"value="retention-value">autoDelete="true|false"<description><![CDATA[
class-description]]></description>
</retentionClass>...</retentionClasses>
Retrieving namespace information 9–5
Using a Namespace

Listing retention classes
Example: Listing retention classes for a namespaceHere’s a sample HTTP GET request that retrieves XML describing the retention classes defined for the finance namespace owned by the europe tenant in the hcp.example.com system. The example saves the results in a file named finance.europe.retentionclasses.xml.
Request with curl command line
curl -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d "https://finance.europe.hcp.example.com/proc/retentionClasses" > finance.europe.retentionclasses.xml
Request in Python using PycURL
import pycurlfilehandle = open("finance.europe.retentionclasses.xml", 'wb')curl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/proc/retentionClasses")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.setopt(pycurl.WRITEFUNCTION, filehandle.write)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()filehandle.close()
Request headers
GET /proc/retentionClasses HTTP/1.1Host: /finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1259584200Content-Length: 1186
9–6 Retrieving namespace information
Using a Namespace

Listing retention classes
Response body
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="/static/xsl/proc-retention-classes.xsl"?><retentionClasses xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="/static/xsd/proc-retention-classes.xsd"namespaceName="support">
<retentionClassname="deletable"value="-1"autoDelete="false"><description><![CDATA[
Can be deleted at any time.]]></description>
</retentionClass><retentionClass
name="undeletable"value="-1"autoDelete="false"><description><![CDATA[
Deletion is permanently disallowed.]]></description>
</retentionClass><retentionClass
name="HlthReg-107"value="A+21y"autoDelete="true"><description><![CDATA[
Meets health information rule 107 for retention of 21 years.]]></description>
</retentionClass><retentionClass
name="sevenYears"value="A+7y"autoDelete="true"><description><![CDATA[
Object can be deleted after seven years.]]></description>
</retentionClass></retentionClasses>
Retrieving namespace information 9–7
Using a Namespace

Listing namespace and user permissions
Listing namespace and user permissions
You use the HTTP GET method to list the permissions for the namespace.
The GET request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• A URL in the following format:
http[s]://namespace-name.tenant-name.hcp-name.domain-name/proc/permissions
Request-specific return codeIf you request information about a namespace to which you do not have access, HCP returns 401 (Unauthorized).
For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headersThis operation does not return any request-specific response headers. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Response bodyThe body of the HTTP response consists of XML that lists the permissions for the namespace and user. The table below describes the XML elements.
Element Description
namespacePermissions The permissions specified for the namespace.
namespaceEffectivePermissions The permissions that are in effect for the namespace. This is the logical AND of the permissions specified at the system, tenant, and namespace levels.
userPermissions The permissions included in the user’s data access account.
userEffectivePermissions The permissions that are in effect for the current user in the namespace. This is the logical AND of the permissions specified for the system, tenant, namespace, and user’s data access account.
9–8 Retrieving namespace information
Using a Namespace

Listing namespace and user permissions
The XML has this format:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="/static/xsl/proc-permissions.xsl"?><permissions xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="/static/xsd/proc-permissions.xsd"
namespaceName="namespace-name"><namespacePermissions
read="true|false"write="true|false"delete="true|false"privileged="true|false"purge="true|false"search="true|false"/>
<namespaceEffectivePermissionsread="true|false"write="true|false"delete="true|false"privileged="true|false"purge="true|false"search="true|false"/>
<userPermissionsread="true|false"write="true|false"delete="true|false"privileged="true|false"purge="true|false"search="true|false"/>
<userEffectivePermissionsread="true|false"write="true|false"delete="true|false"privileged="true|false"purge="true|false"search="true|false"/>
</permissions>
Example: Listing permissions for a namespace and userHere’s a sample HTTP GET request that retrieves namespace and user permissions for:
• The finance namespace owned by the europe tenant in the hcp.example.com system.
• The myuser data access account. (The account is identified by the hcp-ns-auth cookie).
Retrieving namespace information 9–9
Using a Namespace

Listing namespace and user permissions
Request with curl command line
curl -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/proc/permissions"
Request in Python using PycURL
import pycurlcurl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/proc/permissions")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()
Request headers
GET /proc/permissions HTTP/1.1Host: /finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8dContent-Length: 1286
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1259584200Content-Length: 880
9–10 Retrieving namespace information
Using a Namespace

Listing namespace and user permissions
Response body
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="/static/xsl/proc-permissions.xsl"?><permissions xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="/static/xsd/proc-permissions.xsd"namespaceName="finance">
<namespacePermissionsread="true"write="true"delete="true"privileged="true"purge="true"search="false"/>
<namespaceEffectivePermissionsread="true"write="true"delete="true"privileged="false"purge="false"search="false"/>
<userPermissionsread="true"write="true"delete="true"privileged="true"purge="true"search="false"/>
<userEffectivePermissionsread="true"write="true"delete="true"privileged="false"purge="false"search="false"/>
</permissions>
Retrieving namespace information 9–11
Using a Namespace

Listing namespace statistics
Listing namespace statistics
You use the HTTP GET method to list statistics for a namespace. The values returned include information such as the total and used capacity of the namespace and the number of objects with custom metadata. For a description of the statistics returned, see “Response body” below.
The GET request must specify these HTTP elements:
• An hcp-ns-auth authorization cookie
• A URL in the following format:
http[s]://namespace-name.tenant-name.hcp-name.domain-name/proc/statistics
Request-specific return codeIf you request information about a namespace to which you do not have access, HCP returns 401 (Unauthorized).
For descriptions of all possible return codes, see “HTTP return codes” on page A-9.
Request-specific response headersThis operation does not return any request-specific response headers. For information on all HCP-specific response headers, see “HCP-specific HTTP response headers” on page A-13.
Response bodyThe body of the HTTP response consists of XML that lists the namespace statistics. The table below describes the XML elements.
Element Description
namespaceName The namespace name.
totalCapacityBytes The number of bytes of storage allocated to the namespace. This is the total space available for all data stored in the namespace, including object data, metadata, and the redundant data required to satisfy the namespace DPL.
usedCapacityBytes The number of bytes currently occupied by all data stored in the namespace, including object data, metadata, and any redundant data required to satisfy the namespace DPL.
softQuotaPercent The percent of the totalCapacityBytes value at which HCP notifies the tenant that free storage space for the namespace is running low.
9–12 Retrieving namespace information
Using a Namespace

Listing namespace statistics
The XML has this format:
<?xml-stylesheet type="text/xsl" href="/static/xsl/proc-statistics.xsl"?><statistics xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="/static/xsd/proc-statistics.xsd" namespaceName=namespace-name" totalCapacityBytes="total-capacity-bytes" usedCapacityBytes="used-capacity-bytes" softQuotaPercent="soft-quota-percent" objectCount="number-of-objects" shredObjectCount="number-of-objects-to-be-shredded" shredObjectBytes="bytes-to-be-shredded" customMetadataObjectCount="number-of-objects-with-custom-metadata" customMetadataObjectBytes="bytes-of-custom-metadata"
/>
Example: Listing statistics for a namespaceHere’s a sample HTTP GET request that retrieves the statistics for the finance namespace owned by the europe tenant of the hcp.example.com system.
Request with curl command line
curl -b hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d"https://finance.europe.hcp.example.com/proc/statistics"
objectCount The number of objects and versions stored in the namespace.
The object count includes individual versions of objects, including the versions of deleted objects, but not deleted versions. For example, if you create an object, add a version, delete the object, and then add a new version of the object, the object count increases by three.
shredObjectCount The number of objects and versions that have been deleted and are waiting to be shredded.
shredObjectBytes The number of bytes occupied by the objects and versions that are waiting to be shredded.
customMetadataObjectCount
The number of objects and versions that have custom metadata.
customMetadataObjectBytes
The number of bytes occupied by custom metadata.
(Continued)
Element Description
Retrieving namespace information 9–13
Using a Namespace

Listing namespace statistics
Request in Python using PycURL
import pycurlcurl = pycurl.Curl()curl.setopt(pycurl.COOKIE, "hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8d")
curl.setopt(pycurl.URL, "https://finance.europe.hcp.example.com/proc/statistics")
curl.setopt(pycurl.SSL_VERIFYPEER, 0)curl.setopt(pycurl.SSL_VERIFYHOST, 0)curl.perform()print curl.getinfo(pycurl.RESPONSE_CODE)curl.close()
Request headers
GET /proc/statistics HTTP/1.1Host: /finance.europe.hcp.example.comCookie: hcp-ns-auth=bXl1c2Vy:3f3c6784e97531774380db177774ac8dContent-Length: 1286
Response headers
HTTP/1.1 200 OKX-HCP-Time: 1259584200Content-Length: 565
Response body
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="/static/xsl/proc-statistics.xsl"?><statistics xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="/static/xsd/proc-statistics.xsd"namespaceName="finance"totalCapacity="10737418240"usedCapacity="932454739"softQuota="85"objectCount="43230"shredObjectCount="0"shredObjectBytes="0"customMetadataObjectCount="6754"customMetadataObjectBytes="894893"
/>
9–14 Retrieving namespace information
Using a Namespace

10
Using the Namespace BrowserThe HCP Namespace Browser lets you manage namespace content and view information about namespaces. This chapter describes the Browser interface and how to use it.
Using the Namespace Browser 10–1
Using a Namespace

About the Namespace Browser
About the Namespace Browser
The Namespace Browser is an easy-to-use web application that lets you:
• Navigate and manage namespace content
• View information about namespaces
When you work with namespace content, you can list directories and view or retrieve objects. You can also manage namespace content by adding directories and by adding and deleting objects. If versioning is enabled, you can list, view, and retrieve historical versions and view deleted objects.
When you view information about namespaces, the Browser can display the namespaces that you can access, retention classes that you can use in a namespace, permissions for namespace access, and statistics about a namespace.
To use the Namespace Browser, you need a data access account. The account defines your username, password, and what you have permission to do in the Browser. The information you see and actions you can perform in the Namespace Browser depend on your permissions.
Logging in
To log into the Namespace Browser:
1. Open a web browser window.
2. In the address field, enter the URL for the namespace for which you want information. For example, to use HTTPS to browse the finance.europe.hcp.example.com namespace, enter:
https://finance.europe.hcp.example.com
The Namespace Browser login page appears.
3. In the Username field, type your data access account username.
4. In the Password field, type your case-sensitive password.
Note: You cannot use an IP address in the URL to access the Namespace Browser.
10–2 Using the Namespace Browser
Using a Namespace

Changing your password
5. Click on the Log In button.
The Namespace Browser opens showing the rest directory for the namespace.
You can log out at any time by clicking on the Log Out link in the Browser menu bar.
Common elements
All Namespace Browser pages have these options in the menu bar at the top of the page:
• Content — Displays the top-level directories in the current namespace.
• Namespace — Displays the list of namespaces you can access and provides access to information about these namespaces.
• Search HCP — Opens the HCP Search Console. For more information on using this Console, see Searching Namespaces. This option appears only if search is enabled for the namespace.
• Log Out — Logs you out and displays the login page.
• Password — Displays the Change Password page. For more information on the Change Password page, see “Changing your password” below.
Changing your password
You can use the Namespace Browser to change the password for your data access account. Doing this changes the login password for your username for the Namespace Browser, HTTP namespace access, and the Search Console.
Passwords:
• Are case sensitive.
• Can contain any valid UTF-8 characters, including white space.
• Must include at least one character from two of these three groups: alphabetic, numeric, and other.
• Have a minimum length that’s typically six or eight characters. To find out the minimum password length, see your namespace administrator.
Using the Namespace Browser 10–3
Using a Namespace

Working with namespace contents
To change your password:
1. Click on Password in the Browser menu bar.
2. On the Change Password page:
– In the Existing Password field, type your current password.
– In the New Password field, type your new password.
– In the Confirm New Password field, type your new password again.
3. Click on the Update Password button.
After you change the password, the Change Password page continues to be displayed. To continue using the Namespace Browser, navigate to another page.
Working with namespace contents
The Namespace Browser lets you perform these operations on the contents of a namespace:
• Browse the namespace to list directories and their contents. If versioning is enabled for the namespace, you can optionally include deleted objects in the lists.
• If versioning is enabled for the namespace, list versions of an object.
• View or retrieve the content of objects and, if versioning is enabled for the namespace, the content of specific versions of objects.
• Add and delete objects.
• Create directories.
All directory and version listing pages have a parent directory icon ( ) in the upper left next to the directory path or, for version lists, next to the object path. Click on this icon to display the parent directory or the directory that contains the object whose versions are listed.
10–4 Using the Namespace Browser
Using a Namespace

Working with namespace contents
Listing directory contents
To list the contents of a directory in a namespace, navigate to the directory you want. Each directory name is a link that lists the directory contents.
The upper right of the directory listing page has two controls that add directories and objects to the directory. The table below describes these controls.
Directory listing
The directory listing displays information about the objects in a directory and provides access to subdirectories and object versions.
These controls appear in a bar immediately above the directory listing:
• If versioning is enabled for the namespace, the left side has a link that alternately says Show deleted objects or Hide deleted objects. Click on the link to show or hide deleted objects and directories.
• The right side has two buttons: Previous and Next. The Namespace Browser displays up to 100 entries at a time. If a directory has more than 100 entries, these buttons are active and you can use them to page through the directory to see all its contents.
Click on any column heading to sort the listing by the column values. Clicking on a heading alternately sorts in ascending and descending order.
Control Description
Create Directory Click on this tab to add a new directory.
For more information how to add a directory, see “Creating directories” on page 10-10.
Upload Object Click on this tab to add an object to the namespace.
For more information on how to add an object, see “Adding objects and versions” on page 10-10.
Using the Namespace Browser 10–5
Using a Namespace
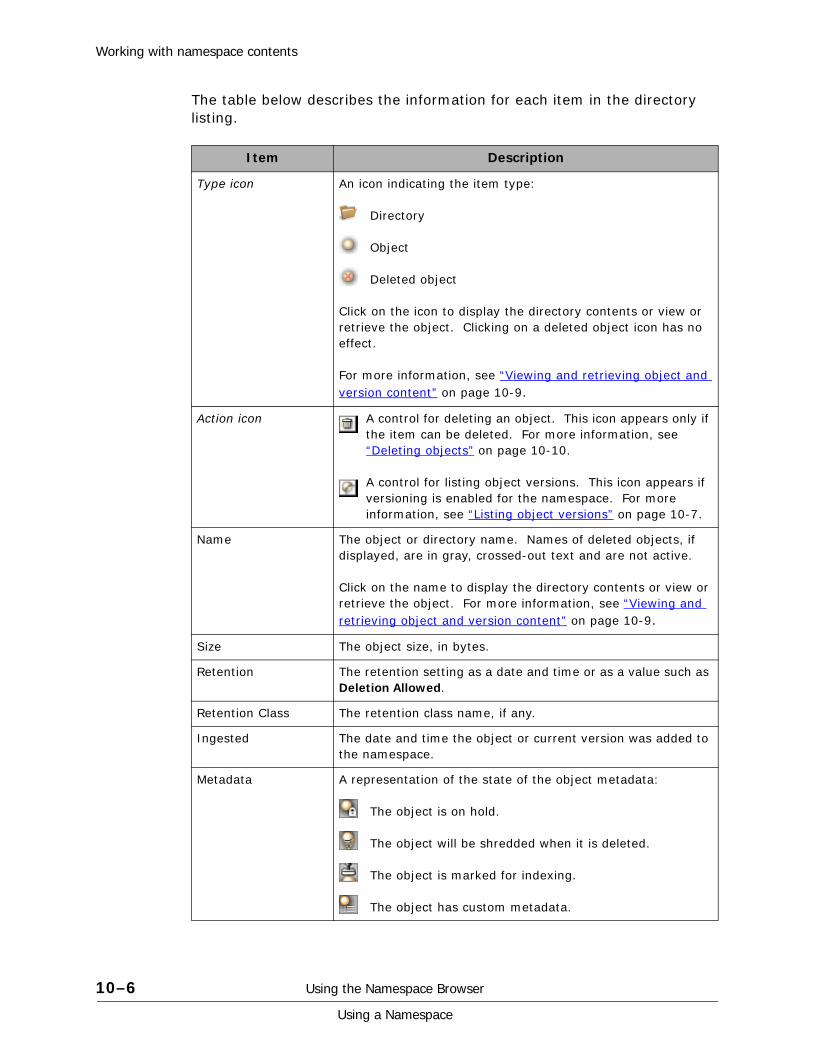
Working with namespace contents
The table below describes the information for each item in the directory listing.
Item Description
Type icon An icon indicating the item type:
Directory
Object
Deleted object
Click on the icon to display the directory contents or view or retrieve the object. Clicking on a deleted object icon has no effect.
For more information, see “Viewing and retrieving object and version content” on page 10-9.
Action icon A control for deleting an object. This icon appears only if the item can be deleted. For more information, see “Deleting objects” on page 10-10.
A control for listing object versions. This icon appears if versioning is enabled for the namespace. For more information, see “Listing object versions” on page 10-7.
Name The object or directory name. Names of deleted objects, if displayed, are in gray, crossed-out text and are not active.
Click on the name to display the directory contents or view or retrieve the object. For more information, see “Viewing and retrieving object and version content” on page 10-9.
Size The object size, in bytes.
Retention The retention setting as a date and time or as a value such as Deletion Allowed.
Retention Class The retention class name, if any.
Ingested The date and time the object or current version was added to the namespace.
Metadata A representation of the state of the object metadata:
The object is on hold.
The object will be shredded when it is deleted.
The object is marked for indexing.
The object has custom metadata.
10–6 Using the Namespace Browser
Using a Namespace

Working with namespace contents
Showing and hiding deleted objects and directories
By default, the directory listing does not include deleted objects and directories. If the namespace has versioning enabled, you can show or hide deleted objects and directories by clicking on the link that says Show deleted objects (if deleted objects are not being shown) or Hide deleted objects (if they are being shown).
When you show deleted objects and directories, you can click on a deleted directory to view the list of objects that it had contained. All objects and subdirectories in a deleted directory are also deleted.
Listing object versions
To view a list of the versions of an object, browse to the directory that contains the object and click on the version icon ( ) for the object. If show deleted objects is selected, you can list the versions of the deleted objects.
Version history listThe version history list shows all versions of an object that remain in the namespace.
The Namespace Browser displays up to 100 entries at a time. If an object has more than 100 versions, you can use the Previous and Next buttons to page through all the versions.
If the list displays deleted versions, they appear in gray text. The entry for a deleted version contains the metadata for the version that was deleted. Only the type icon, version ID, and ingested time contain information about the deleted version (that is, the deletion record) instead of the version that was deleted.
DPL The data protection level.
Hash (algorithm-name)
Hash information for the object. Move the mouse over the View Hash link to view the hash value. You can then highlight and copy it to the clipboard.
(Continued)
Item Description
Tip: You can use the view-source option in the web browser to see the XML for the Namespace Browser page. For information on this XML, see “Listing directory contents” on page 5-5.
Using the Namespace Browser 10–7
Using a Namespace
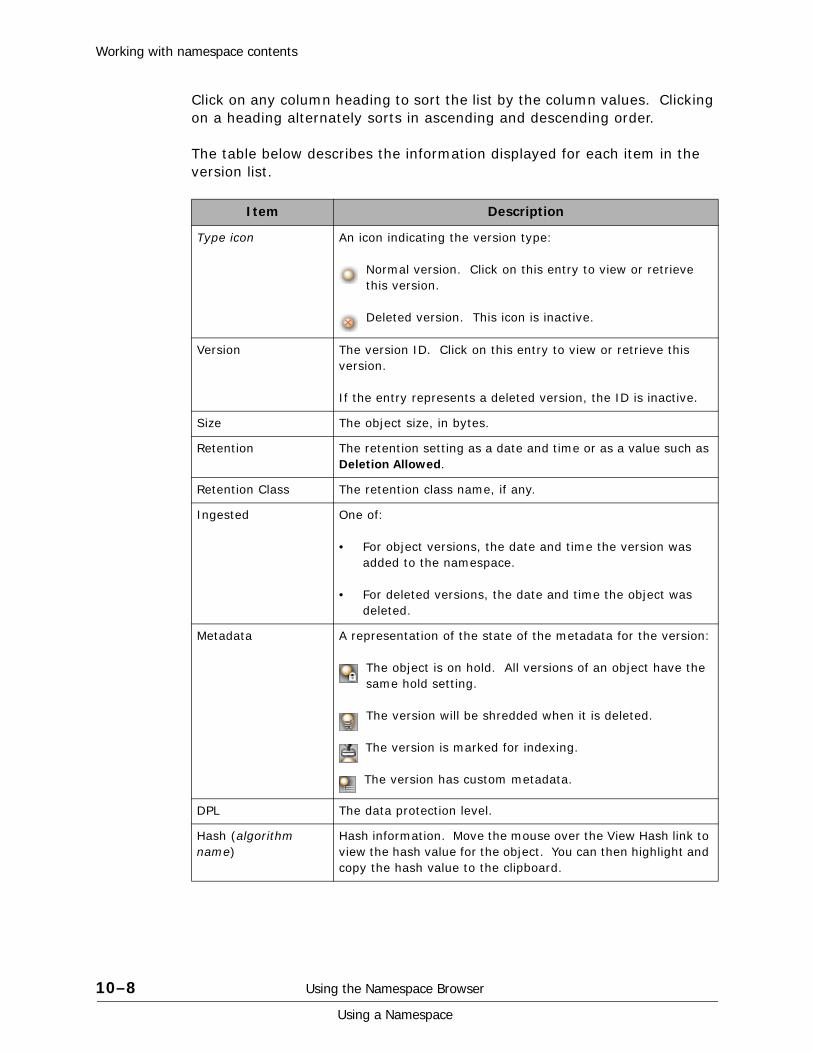
Working with namespace contents
Click on any column heading to sort the list by the column values. Clicking on a heading alternately sorts in ascending and descending order.
The table below describes the information displayed for each item in the version list.
Item Description
Type icon An icon indicating the version type:
Normal version. Click on this entry to view or retrieve this version.
Deleted version. This icon is inactive.
Version The version ID. Click on this entry to view or retrieve this version.
If the entry represents a deleted version, the ID is inactive.
Size The object size, in bytes.
Retention The retention setting as a date and time or as a value such as Deletion Allowed.
Retention Class The retention class name, if any.
Ingested One of:
• For object versions, the date and time the version was added to the namespace.
• For deleted versions, the date and time the object was deleted.
Metadata A representation of the state of the metadata for the version:
The object is on hold. All versions of an object have the same hold setting.
The version will be shredded when it is deleted.
The version is marked for indexing.
The version has custom metadata.
DPL The data protection level.
Hash (algorithm name)
Hash information. Move the mouse over the View Hash link to view the hash value for the object. You can then highlight and copy the hash value to the clipboard.
10–8 Using the Namespace Browser
Using a Namespace

Working with namespace contents
Listing versions of deleted objects and directories with the same nameA directory listing in the Namespace Browser can include only one item with a specific name, but a version listing for a deleted object can include entries for both the object and a deleted directory with the same name. The following example shows how this can happen:
1. Create a test1 directory.
2. In the test1 directory, create and delete a subdirectory named test2.
3. In the test1 directory, save and delete an object with the name test2.
4. List the contents of the test1 directory and select Show deleted objects.
The test1 directory listing includes the deleted test2 object but not the deleted test2 directory.
5. List the versions of the test2 object and select Show deleted objects.
The version list includes the deleted test2 directory.
Viewing and retrieving object and version content
You can view objects or historic versions of objects and retrieve their content.
Accessing objectsTo view or retrieve an object, navigate to the directory that contains the object and click on the object name or the type icon to the left of the object name. The browser downloads the object data and either opens it in the default application for the content type or prompts to open or save it.
Accessing historic versions of an objectTo view or retrieve a historic version of an object:
1. Navigate to the directory that contains the object.
Note: If you create and delete the test2 object before you create the test2 directory (whether you delete the test2 directory or not), you cannot list versions of test2 in the Namespace Browser, and you cannot see the deleted object versions. You can however, use direct HTTP requests (for example, with curl) to get this information.
Using the Namespace Browser 10–9
Using a Namespace

Working with namespace contents
2. Click on the version icon ( ) to display a list of the versions of the object.
3. In the version list, click on the version ID or type icon for the version you want.
Adding objects and versions
To add an object or new version of an object to the namespace:
1. Navigate to the directory to which you want to add the object or version.
2. Click on the Upload Object tab.
3. Click on the Browse button. Then select the file you want.
4. Click on the Upload button.
The new object is added with the default metadata values for the namespace.
Deleting objects
To delete an object from the namespace:
1. Navigate to the directory that contains the object.
2. Click on the delete icon ( ) for the object you want to delete.
3. In response to the confirming message, click on the OK button.
The object disappears from the list. For information on displaying deleted objects, see “Listing directory contents” on page 10-5.
Creating directories
To create a directory:
1. Navigate to the parent directory.
2. If the create directory interface is not active, click on the Create Directory tab.
3. Enter the name of the new directory in the entry field below the tab.
10–10 Using the Namespace Browser
Using a Namespace

Viewing namespace information
4. Click on the Create button.
Viewing namespace information
The Namespace Browser can display this information about namespaces:
• Namespaces you can access
• Retention classes defined for a namespace
• Permissions for accessing a namespace
• Namespace statistics
Viewing accessible namespaces
Your data access account gives you access to one or more namespaces owned by a tenant. You can use the Namespace Browser to view a list of the namespaces to which you have access. When you view accessible namespaces, the list shows all namespaces owned by the specified tenant for which your data access account has at least one permission.
To view the namespaces that you can access, click on Namespaces in the Namespace Browser menu bar.
For each namespace, the Browser shows:
• Namespace name. Click on the name to browse the directories and objects in the namespace. For more information on browsing namespaces, see “Working with namespace contents” on page 10-4.
• Hash algorithm.
• Data protection level.
• Whether versioning is enabled.
• Whether search is enabled.
• Retention mode. This mode affects whether privileged operations are allowed on objects. A namespace can be in either of two retention modes: compliance or enterprise. In compliance mode, privileged operations are allowed. In enterprise mode, they are not allowed.
• Default shred setting for objects added to the namespace.
Using the Namespace Browser 10–11
Using a Namespace

Viewing namespace information
• Default index setting for objects added to the namespace.
• Default retention setting for objects added to the namespace.
• Statistics — A link that displays the namespace statistics. For more information, see “Viewing namespace statistics” on page 10-13.
• Permissions — A link that displays the permissions for the namespace and current user. For more information, see “Viewing permissions” on page 10-13.
• Retention Classes — A link that displays the retention classes defined for the namespace. For more information, see “Viewing retention classes” below.
• Namespace description.
Viewing retention classes
To view the retention classes defined for a namespace:
1. In the Namespace Browser menu bar, click on Namespaces to open the list of accessible namespaces.
2. Click on the Retention Classes link for the namespace you want.
For each retention class, the Namespace Browser shows:
• Retention class name
• Retention setting
• Whether to automatically delete objects in the class after their retention periods expire
• Retention class description
For more information on retention classes, see “Retention classes” on page 2-6.
10–12 Using the Namespace Browser
Using a Namespace

Viewing namespace information
Viewing permissions
To view the data access permissions that apply to a namespace and your data access account:
1. In the Namespace Browser menu bar, click on Namespaces to open the list of accessible namespaces.
2. Click on the Permissions link for the namespace you want.
The table below describes the information shown about permissions.
For more information on permissions, see “Namespace Browser” on page 1-4.
Viewing namespace statistics
To view the statistics for a namespace:
1. In the Namespace Browser menu bar, click on Namespaces to open the list of accessible namespaces.
2. Click on the Statistics link for the namespace you want.
The table below describes the namespace statistics.
Item Description
Namespace permissions The permissions specified for the namespace.
Namespace effective permissions
The permissions that are in effect for the namespace. This is the logical AND of the permissions specified for the system, tenant, and namespace.
Data access account username permissions
The permissions included in your data access account.
Data access account username effective permissions
The permissions that are in effect for the combination of your user account and the namespace. This is the logical AND of the permissions specified for the system, tenant, namespace, and user’s data access account.
Statistic Description
Total Capacity (Bytes)
The number of bytes of storage allocated to the namespace. This is the total space available for all data stored in the namespace, including object data, metadata, and the redundant data required to satisfy the namespace DPL.
Using the Namespace Browser 10–13
Using a Namespace
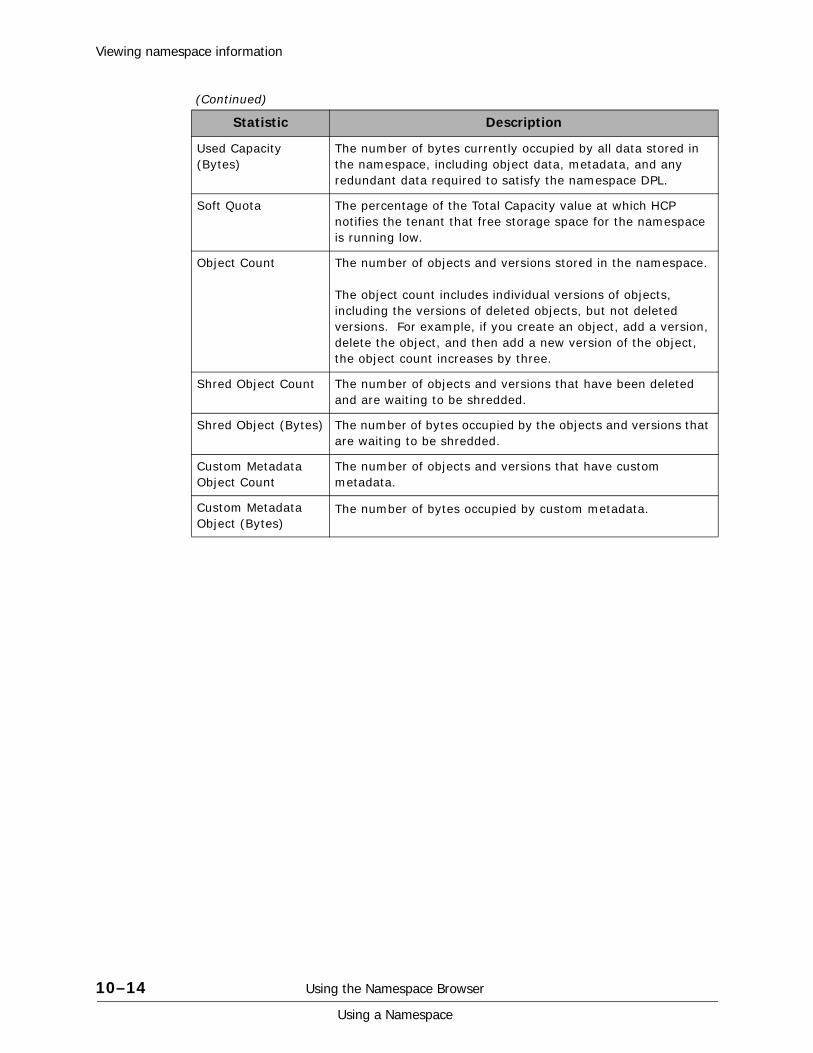
Viewing namespace information
Used Capacity (Bytes)
The number of bytes currently occupied by all data stored in the namespace, including object data, metadata, and any redundant data required to satisfy the namespace DPL.
Soft Quota The percentage of the Total Capacity value at which HCP notifies the tenant that free storage space for the namespace is running low.
Object Count The number of objects and versions stored in the namespace.
The object count includes individual versions of objects, including the versions of deleted objects, but not deleted versions. For example, if you create an object, add a version, delete the object, and then add a new version of the object, the object count increases by three.
Shred Object Count The number of objects and versions that have been deleted and are waiting to be shredded.
Shred Object (Bytes) The number of bytes occupied by the objects and versions that are waiting to be shredded.
Custom Metadata Object Count
The number of objects and versions that have custom metadata.
Custom Metadata Object (Bytes)
The number of bytes occupied by custom metadata.
(Continued)
Statistic Description
10–14 Using the Namespace Browser
Using a Namespace

11
General usage considerationsThis appendix contains usage considerations that affect namespace access in general.
General usage considerations 11–1
Using a Namespace

Namespace access by IP address
Namespace access by IP address
You can access a namespace by specifying either the namespace hostname or an IP address. If your HCP system supports DNS and you specify the hostname, HCP selects the IP address for you from the currently available servers. HCP uses a round-robin method to ensure that it doesn’t always select the same address.
When you specify IP addresses, your application must take responsibility for balancing the load among servers. Also, you risk trying to connect (or reconnect) to a server that is not available. However, in several cases using explicit IP addresses to connect to specific servers can have advantages over using hostnames.
These considerations apply when deciding which technique to use:
• If your client uses a hosts file to map HCP host names to IP addresses, the client system has full responsibility for converting any hostnames to IP addresses. Therefore, HCP cannot spread the load or prevent attempts to connect to an unavailable server. For more information on using a hosts file, see “Enabling URLs with hostnames” on page 3-4.
• If your client caches DNS information, connecting by hostname may result in the same server being used repeatedly.
• When you access the HCP system by hostname, HCP ensures that requests are distributed among servers, but it does not ensure that the resulting loads on the servers are evenly balanced.
• When multiple applications access the HCP system by hostname concurrently, HCP is less likely to spread the load evenly across the servers than with a single application.
For detailed information on using an IP address to access a namespace, see “Using an IP address in the URL” on page 3-5.
Directory structures
Because of the way HCP stores objects, the directory structures you create and the way you store objects in them can have an impact on performance. Here are some guidelines for creating effective directory structures:
• Plan your directory structures before storing objects. Make sure all namespace users are aware of these plans.
11–2 General usage considerations
Using a Namespace

Shredding considerations
• Avoid structures that result in a single directory getting a large amount of traffic in a short time. For example, if you ingest objects rapidly, use structures that do not store objects by date and time.
• If you do store objects by date and time, consider the number of objects ingested during a given period of time when planning the directory structure. For example, if you ingest several hundred files per second, you might use a directory structure such as year/month/day/hour/minute/second. If you ingest just a few files per second, a less fine-grained structure would be better.
• Follow these guidelines on directory depth and size:
– Try to balance the namespace directory tree width and depth.
– Do not create directory structures that are more than 20 levels deep. Instead, create flatter directory structures.
– Avoid placing a large number of objects (greater than 100,000) in a single directory. Instead, create multiple directories and evenly distribute the objects among them.
Shredding considerations
Multiple objects with the same content should all have the same shred setting. If they don't and you delete the objects:
• Each object is shredded or not according to its shred setting.
• If the last object deleted is marked for shredding, HCP shreds the storage used for that object and for all the other objects that were not marked for shredding. As a result, none of the content remains on the system storage in any form.
• If the last object deleted is not marked for shredding, HCP does not shred the storage used for that object or any of the other objects that were not marked for shredding. As a result, the unshredded content remains on the system storage until the storage is reused.
Storing zero-sized files
When you store a zero-sized file, you get an empty object in the namespace. Because HTTP causes a flush and a close even when no data is present, this object is WORM and is treated like any other object in the namespace.
General usage considerations 11–3
Using a Namespace

Data chunking with write operations
Data chunking with write operations
In some cases, the size of a file to be sent cannot be known at the start of an HTTP PUT request. For example, the size is unknown if data is dynamically generated and the PUT request starts before all data is available. This scenario would occur if you do not have enough memory or disk space to stage dynamically generated data locally, so the application streams the PUT request as the data is generated.
In such cases, you can send the data using the chunked HTTP transfer coding. Each chunk is sent with a known size, except for the last chunk, which is sent with a size of 0 (zero).
If possible, you should avoid chunking data because it increases the overhead required for the PUT operation.
Failed write operations
A write operation is considered to have failed if either of these is true:
• The target server failed while the object was open for write.
• The TCP connection broke while the object was open for write (for example, due to a network failure or the abnormal termination of the client application).
Also, in some circumstances, a write operation is considered to have failed if system hardware failed while the object was open for write.
HTTP causes a flush only at the end of a write operation, so an object left by a failed write:
• Remains open
• Is empty
• Is not WORM
• Has no cryptographic hash value
• Is not subject to retention
• Cannot have custom metadata
• Is not indexed
11–4 General usage considerations
Using a Namespace

Objects open for write
• Is not replicated
An object like this can be deleted or overwritten.
If versioning is enabled and you delete an object following a failed write:
• The open empty object from the failed write is removed, and no version of the empty instance of the object is retained.
• A deleted version of the object is created, even if the object did not exist prior to the failed write.
Objects open for write
These considerations apply to objects that are open for write:
• While an object is open for write through one IP address, you cannot open it for write through any other IP address.
• While an object is open for write, you can read it from any IP address, even though the object data may be incomplete. If the read is against the server hosting the write, it may return more data than reads against other servers.
• While an object is open for write, you cannot delete it.
• While an object that’s open for write has no data:
– It is not WORM
– It may or may not have a cryptographic hash value
– It is not subject to retention
– It cannot have custom metadata
Tip: If a write operations fails, retry the request.
Note: Depending on the timing, the delete request may result in a busy error. In that case, wait one or two seconds and then try the request again
General usage considerations 11–5
Using a Namespace

Non-WORM objects
– It is not indexed
– It is not replicated
Non-WORM objects
The namespace can contain objects that are not WORM:
• Objects that are open for write and have no data are not WORM.
• Objects left by certain failed write operations are not WORM.
Objects that are not WORM are not subject to retention. You can delete these objects or overwrite them without first deleting them.
Deleting objects under repair
If you try to delete an object while HCP is repairing it, HCP returns a 409 (Conflict) error code, and the object is not deleted. In this case, wait a few minutes and then try the request again.
Persistent connections
HCP supports HTTP persistent connections. Following a request for an operation, HCP keeps the connection open for 60 seconds so a subsequent request can use the same connection.
Persistent connections enhance performance because they avoid the overhead of opening and closing multiple connections. In conjunction with persistent connections, using multiple threads so that operations can run concurrently provides still better performance.
If the persistent connection timeout period is too short, tell your namespace administrator.
Note: With persistent connections, if a single IP address has more than 254 concurrent open connections, those above the first 254 may have to wait as long as ten minutes to be serviced. This includes connections where the request explicitly targeted the IP address, as well as connections where the HCP hostname resolved to the target IP address.
To avoid this issue, either don’t use persistent connections or ensure that no more than 254 threads are working against a single server at any time.
11–6 General usage considerations
Using a Namespace

Connection failure handling
Connection failure handling
You should retry an HTTP request if either of these happens:
• You (or an application) cannot establish an HTTP connection to the HCP system.
• The connection breaks while HCP is processing a request. In this case, the most likely cause is that the server processing the request became unavailable.
When retrying the request:
• If the original request used the hostname of the HCP system in the URL, repeat the request in the same way.
• If the original request used an IP address, retry the request using either a different IP address or the hostname of the system.
If the connection breaks while HCP is processing a GET request, you may not know whether the returned data is all or only some of the object data. In this case, you can check the number of returned bytes against the content length returned in the HTTP Content-Length response header. If the numbers match, the returned data is complete.
Multithreading
HCP lets multiple threads access the namespace simultaneously. Using multiple threads can enhance performance, especially when accessing many small files across multiple directories.
Here are some guidelines for the effective use of multithreading:
• Concurrent threads, both reads and writes, should be directed against different directories. If that’s not possible, multiple threads working against a single directory is still better than a single thread.
• To the extent possible, concurrent threads should work against different IP addresses. If that’s not possible, multiple threads working against a single IP address is still better than a single thread.
• Only one client can write to a given object at one time. Similarly, a multithreaded client can write to multiple objects at the same time but cannot have multiple threads writing to the same object simultaneously.
General usage considerations 11–7
Using a Namespace

Multithreading
• Multiple clients can read the same object concurrently. Similarly, a multithreaded client can use multiple threads to read a single object. However, because the reads can occur out of order, you generally get better performance by using one thread per object.
• HCP has a limit of 255 concurrent HTTP connections per server, with another 20 queued.
Tip: For better performance, consider limiting the number of concurrent read threads per server to 200 and concurrent write threads per server to 50 for small objects. For large objects, consider using fewer threads.
11–8 General usage considerations
Using a Namespace
A
HTTP referenceThis appendix contains a reference of HTTP requests and responses for accessing a namespace and for using the metadata query API.
For detailed information on using HTTP, see Chapters 4 through 7. For detailed information on using the metadata query API, see Chapter 8, “Using the HCP metadata query API.”
HTTP reference A–1
Using a Namespace
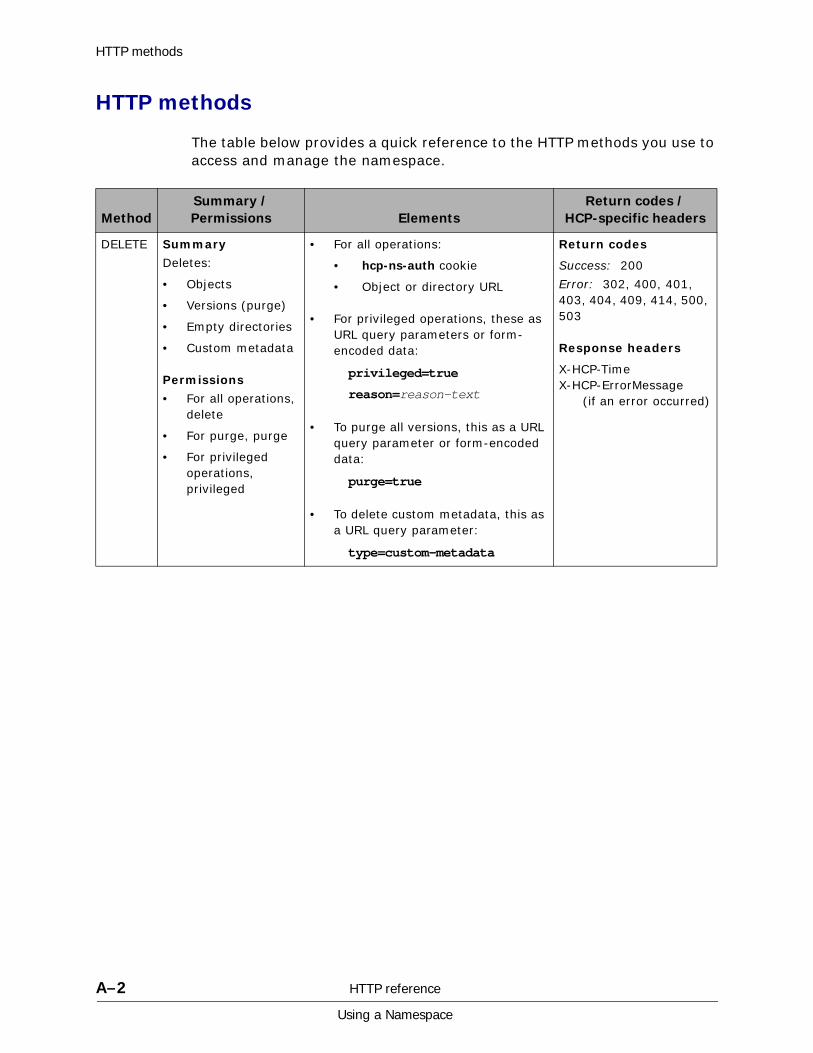
HTTP methods
HTTP methods
The table below provides a quick reference to the HTTP methods you use to access and manage the namespace.
MethodSummary /Permissions Elements
Return codes / HCP-specific headers
DELETE Summary
Deletes:
• Objects
• Versions (purge)
• Empty directories
• Custom metadata
Permissions
• For all operations, delete
• For purge, purge
• For privileged operations, privileged
• For all operations:
• hcp-ns-auth cookie
• Object or directory URL
• For privileged operations, these as URL query parameters or form-encoded data:
privileged=true
reason=reason-text
• To purge all versions, this as a URL query parameter or form-encoded data:
purge=true
• To delete custom metadata, this as a URL query parameter:
type=custom-metadata
Return codes
Success: 200
Error: 302, 400, 401, 403, 404, 409, 414, 500, 503
Response headers
X-HCP-TimeX-HCP-ErrorMessage
(if an error occurred)
A–2 HTTP reference
Using a Namespace
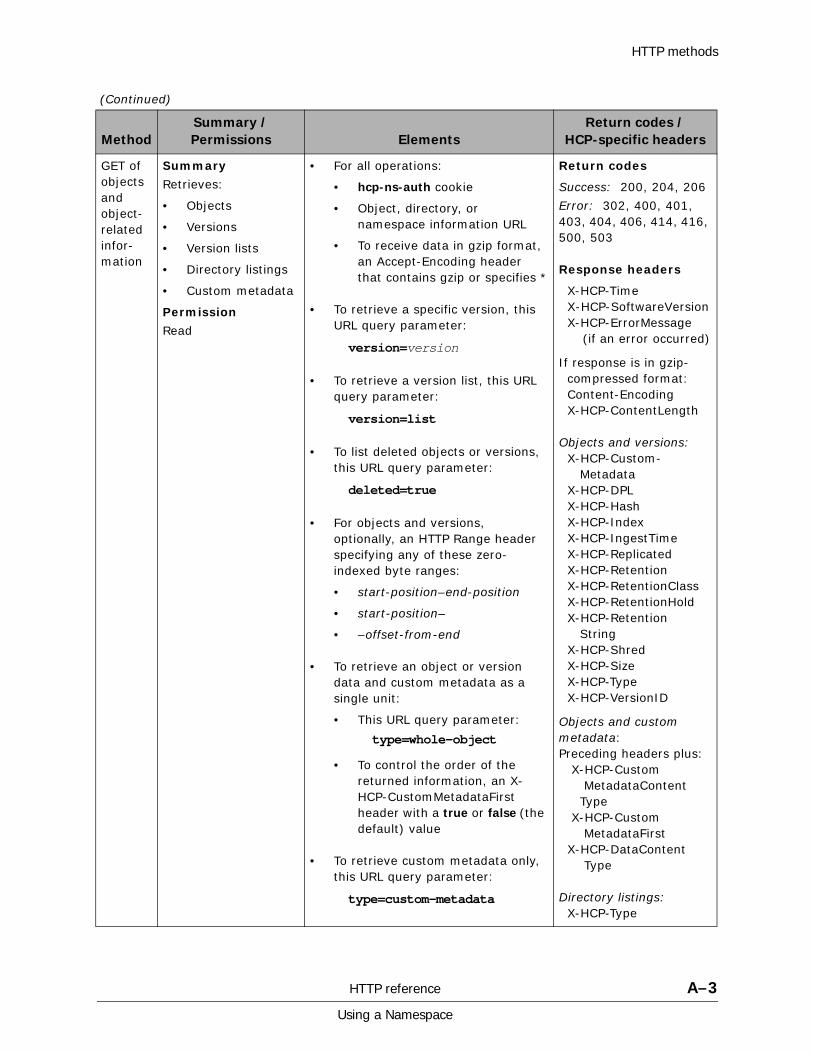
HTTP methods
GET of objects and object-related infor-mation
Summary
Retrieves:
• Objects
• Versions
• Version lists
• Directory listings
• Custom metadata
Permission
Read
• For all operations:
• hcp-ns-auth cookie
• Object, directory, or namespace information URL
• To receive data in gzip format, an Accept-Encoding header that contains gzip or specifies *
• To retrieve a specific version, this URL query parameter:
version=version
• To retrieve a version list, this URL query parameter:
version=list
• To list deleted objects or versions, this URL query parameter:
deleted=true
• For objects and versions, optionally, an HTTP Range header specifying any of these zero-indexed byte ranges:
• start-position–end-position
• start-position–
• –offset-from-end
• To retrieve an object or version data and custom metadata as a single unit:
• This URL query parameter:
type=whole-object
• To control the order of the returned information, an X-HCP-CustomMetadataFirst header with a true or false (the default) value
• To retrieve custom metadata only, this URL query parameter:
type=custom-metadata
Return codes
Success: 200, 204, 206
Error: 302, 400, 401, 403, 404, 406, 414, 416, 500, 503
Response headers
X-HCP-TimeX-HCP-SoftwareVersionX-HCP-ErrorMessage
(if an error occurred)
If response is in gzip-compressed format: Content-EncodingX-HCP-ContentLength
Objects and versions:X-HCP-Custom-
MetadataX-HCP-DPLX-HCP-HashX-HCP-IndexX-HCP-IngestTimeX-HCP-ReplicatedX-HCP-RetentionX-HCP-RetentionClassX-HCP-RetentionHoldX-HCP-Retention
StringX-HCP-ShredX-HCP-SizeX-HCP-TypeX-HCP-VersionID
Objects and custom metadata:Preceding headers plus:
X-HCP-CustomMetadataContentType
X-HCP-CustomMetadataFirst
X-HCP-DataContentType
Directory listings:X-HCP-Type
(Continued)
MethodSummary /Permissions Elements
Return codes / HCP-specific headers
HTTP reference A–3
Using a Namespace
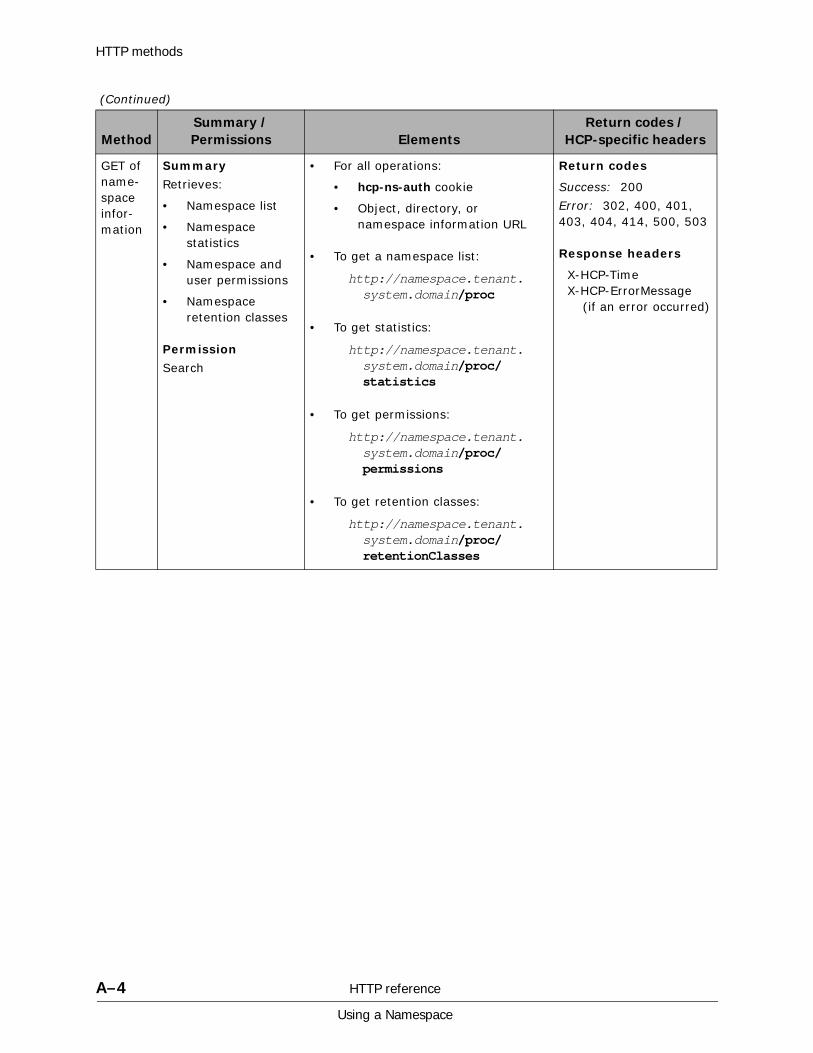
HTTP methods
GET of name-space infor-mation
Summary
Retrieves:
• Namespace list
• Namespace statistics
• Namespace and user permissions
• Namespace retention classes
Permission
Search
• For all operations:
• hcp-ns-auth cookie
• Object, directory, or namespace information URL
• To get a namespace list:
http://namespace.tenant.system.domain/proc
• To get statistics:
http://namespace.tenant.system.domain/proc/statistics
• To get permissions:
http://namespace.tenant.system.domain/proc/permissions
• To get retention classes:
http://namespace.tenant.system.domain/proc/retentionClasses
Return codes
Success: 200
Error: 302, 400, 401, 403, 404, 414, 500, 503
Response headers
X-HCP-TimeX-HCP-ErrorMessage
(if an error occurred)
(Continued)
MethodSummary /Permissions Elements
Return codes / HCP-specific headers
A–4 HTTP reference
Using a Namespace
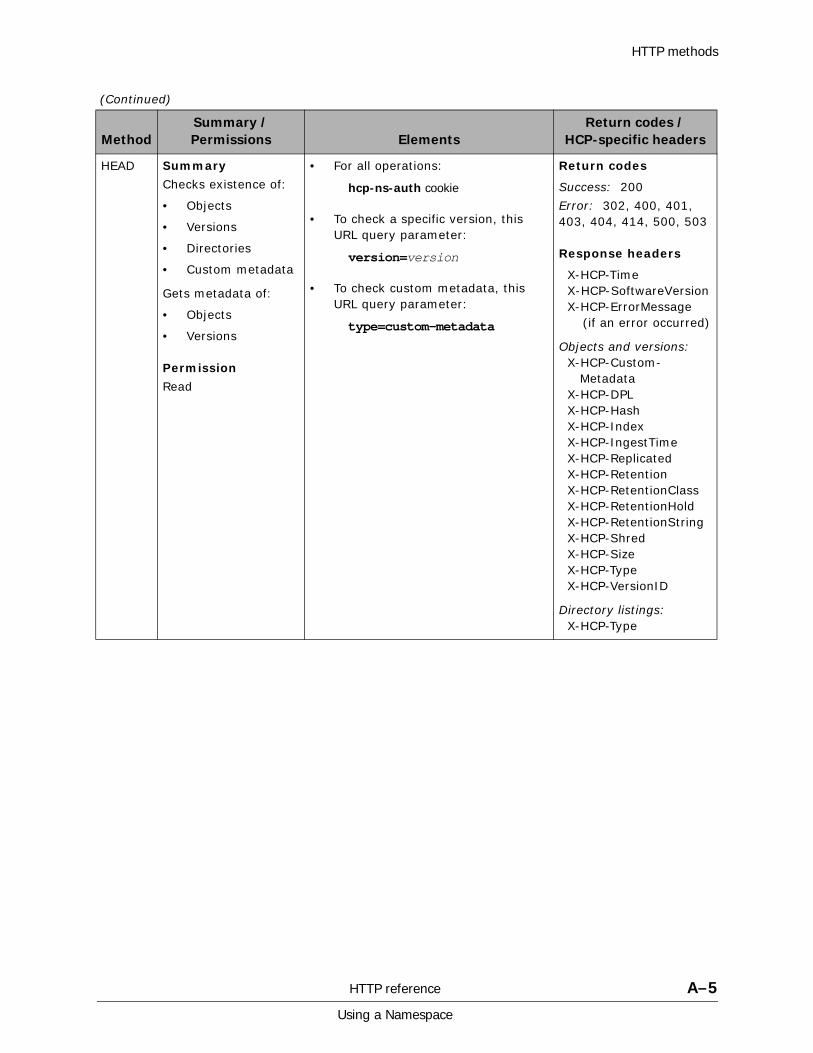
HTTP methods
HEAD Summary
Checks existence of:
• Objects
• Versions
• Directories
• Custom metadata
Gets metadata of:
• Objects
• Versions
Permission
Read
• For all operations:
hcp-ns-auth cookie
• To check a specific version, this URL query parameter:
version=version
• To check custom metadata, this URL query parameter:
type=custom-metadata
Return codes
Success: 200
Error: 302, 400, 401, 403, 404, 414, 500, 503
Response headers
X-HCP-TimeX-HCP-SoftwareVersionX-HCP-ErrorMessage
(if an error occurred)
Objects and versions:X-HCP-Custom-
MetadataX-HCP-DPLX-HCP-HashX-HCP-IndexX-HCP-IngestTimeX-HCP-ReplicatedX-HCP-RetentionX-HCP-RetentionClassX-HCP-RetentionHoldX-HCP-RetentionStringX-HCP-ShredX-HCP-SizeX-HCP-TypeX-HCP-VersionID
Directory listings:X-HCP-Type
(Continued)
MethodSummary /Permissions Elements
Return codes / HCP-specific headers
HTTP reference A–5
Using a Namespace
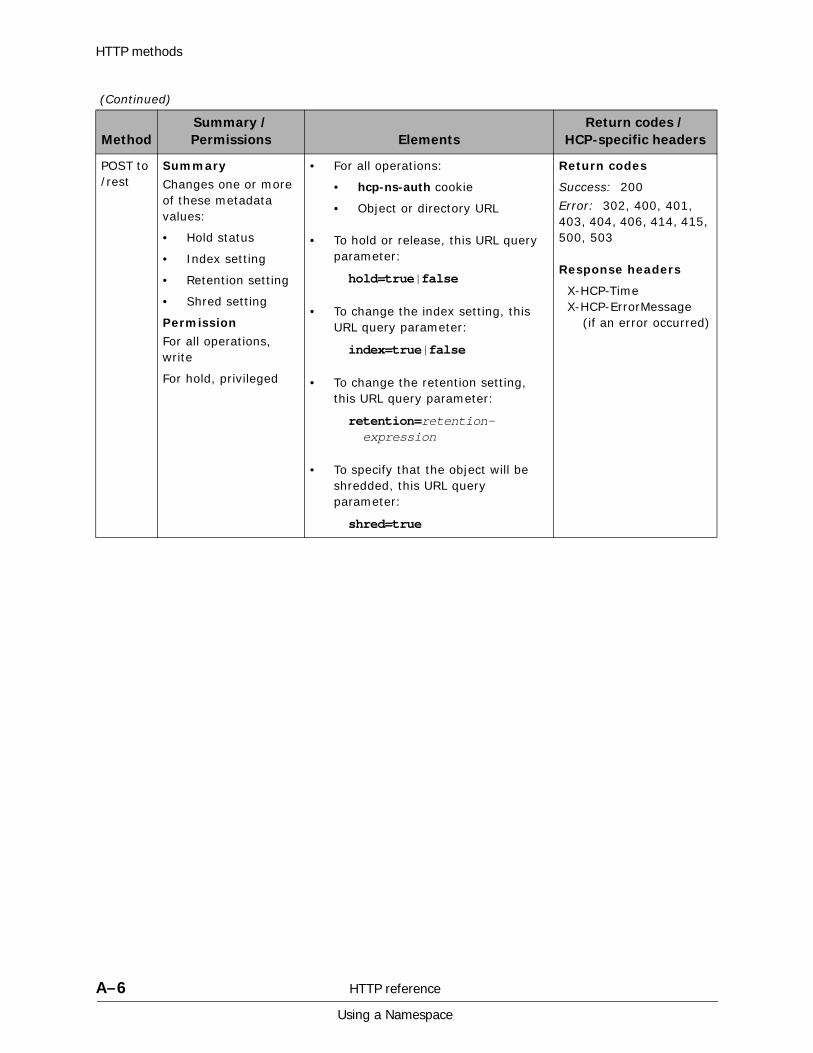
HTTP methods
POST to /rest
Summary
Changes one or more of these metadata values:
• Hold status
• Index setting
• Retention setting
• Shred setting
Permission
For all operations, write
For hold, privileged
• For all operations:
• hcp-ns-auth cookie
• Object or directory URL
• To hold or release, this URL query parameter:
hold=true|false
• To change the index setting, this URL query parameter:
index=true|false
• To change the retention setting, this URL query parameter:
retention=retention-expression
• To specify that the object will be shredded, this URL query parameter:
shred=true
Return codes
Success: 200
Error: 302, 400, 401, 403, 404, 406, 414, 415, 500, 503
Response headers
X-HCP-TimeX-HCP-ErrorMessage
(if an error occurred)
(Continued)
MethodSummary /Permissions Elements
Return codes / HCP-specific headers
A–6 HTTP reference
Using a Namespace
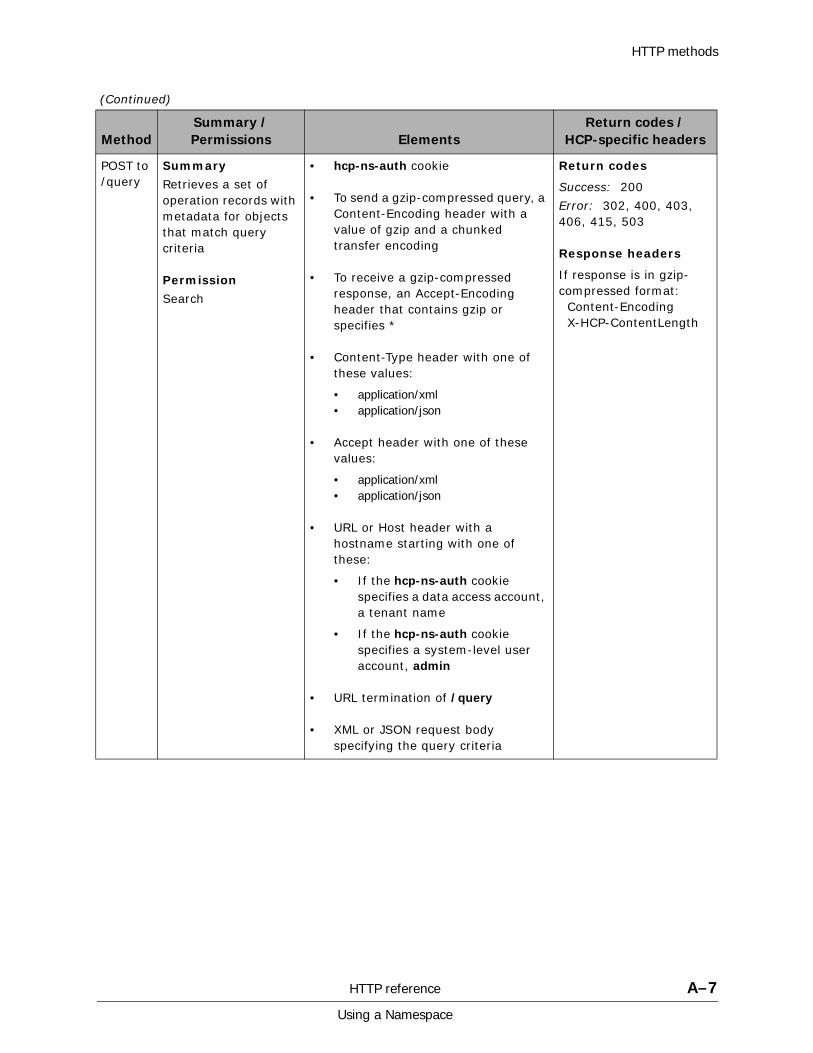
HTTP methods
POST to /query
Summary
Retrieves a set of operation records with metadata for objects that match query criteria
Permission
Search
• hcp-ns-auth cookie
• To send a gzip-compressed query, a Content-Encoding header with a value of gzip and a chunked transfer encoding
• To receive a gzip-compressed response, an Accept-Encoding header that contains gzip or specifies *
• Content-Type header with one of these values:
• application/xml• application/json
• Accept header with one of these values:
• application/xml• application/json
• URL or Host header with a hostname starting with one of these:
• If the hcp-ns-auth cookie specifies a data access account, a tenant name
• If the hcp-ns-auth cookie specifies a system-level user account, admin
• URL termination of /query
• XML or JSON request body specifying the query criteria
Return codes
Success: 200
Error: 302, 400, 403, 406, 415, 503
Response headers
If response is in gzip-compressed format:
Content-EncodingX-HCP-ContentLength
(Continued)
MethodSummary /Permissions Elements
Return codes / HCP-specific headers
HTTP reference A–7
Using a Namespace
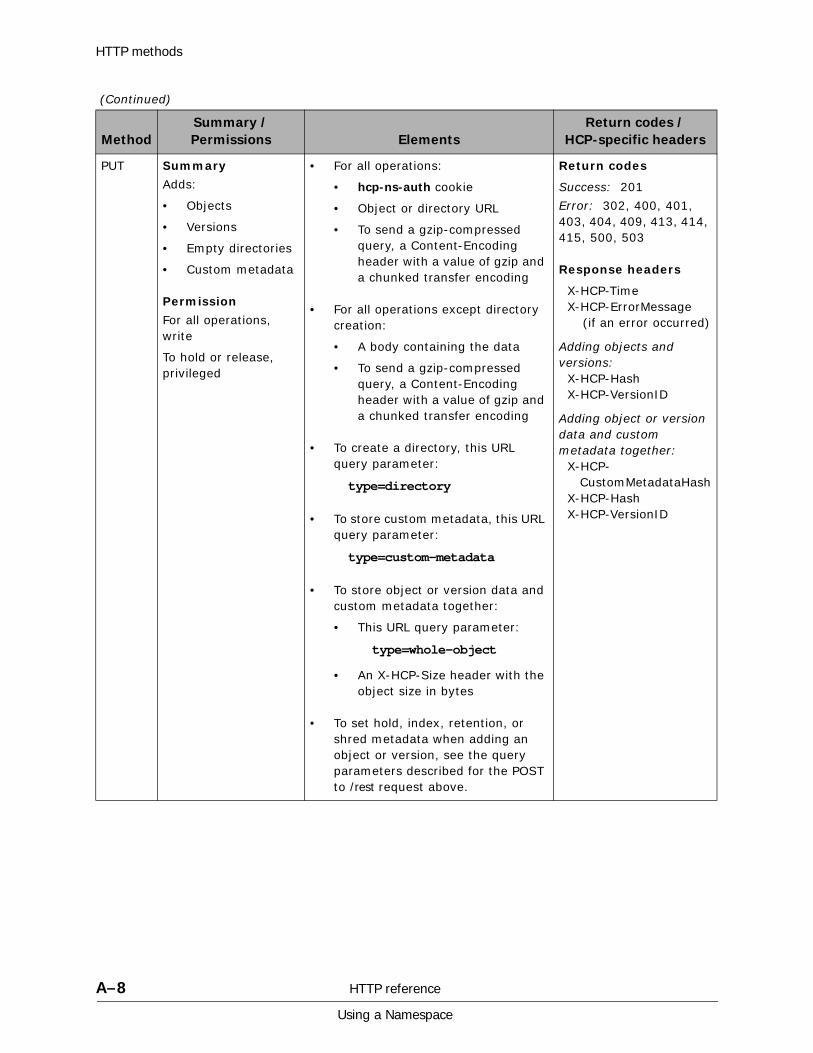
HTTP methods
PUT Summary
Adds:
• Objects
• Versions
• Empty directories
• Custom metadata
Permission
For all operations, write
To hold or release, privileged
• For all operations:
• hcp-ns-auth cookie
• Object or directory URL
• To send a gzip-compressed query, a Content-Encoding header with a value of gzip and a chunked transfer encoding
• For all operations except directory creation:
• A body containing the data
• To send a gzip-compressed query, a Content-Encoding header with a value of gzip and a chunked transfer encoding
• To create a directory, this URL query parameter:
type=directory
• To store custom metadata, this URL query parameter:
type=custom-metadata
• To store object or version data and custom metadata together:
• This URL query parameter:
type=whole-object
• An X-HCP-Size header with the object size in bytes
• To set hold, index, retention, or shred metadata when adding an object or version, see the query parameters described for the POST to /rest request above.
Return codes
Success: 201
Error: 302, 400, 401, 403, 404, 409, 413, 414, 415, 500, 503
Response headers
X-HCP-TimeX-HCP-ErrorMessage
(if an error occurred)
Adding objects and versions:
X-HCP-HashX-HCP-VersionID
Adding object or version data and custom metadata together:
X-HCP-CustomMetadataHash
X-HCP-HashX-HCP-VersionID
(Continued)
MethodSummary /Permissions Elements
Return codes / HCP-specific headers
A–8 HTTP reference
Using a Namespace
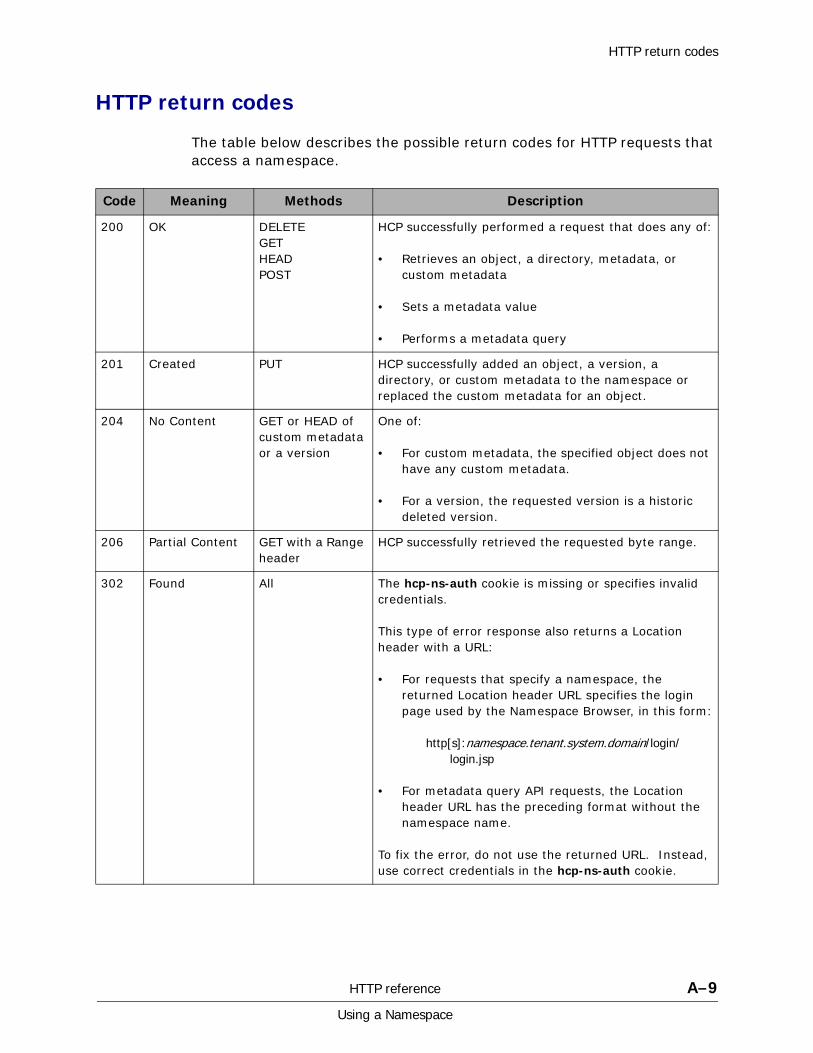
HTTP return codes
HTTP return codes
The table below describes the possible return codes for HTTP requests that access a namespace.
Code Meaning Methods Description
200 OK DELETEGETHEADPOST
HCP successfully performed a request that does any of:
• Retrieves an object, a directory, metadata, or custom metadata
• Sets a metadata value
• Performs a metadata query
201 Created PUT HCP successfully added an object, a version, a directory, or custom metadata to the namespace or replaced the custom metadata for an object.
204 No Content GET or HEAD of custom metadata or a version
One of:
• For custom metadata, the specified object does not have any custom metadata.
• For a version, the requested version is a historic deleted version.
206 Partial Content GET with a Range header
HCP successfully retrieved the requested byte range.
302 Found All The hcp-ns-auth cookie is missing or specifies invalid credentials.
This type of error response also returns a Location header with a URL:
• For requests that specify a namespace, the returned Location header URL specifies the login page used by the Namespace Browser, in this form:
http[s]:namespace.tenant.system.domain/login/login.jsp
• For metadata query API requests, the Location header URL has the preceding format without the namespace name.
To fix the error, do not use the returned URL. Instead, use correct credentials in the hcp-ns-auth cookie.
HTTP reference A–9
Using a Namespace
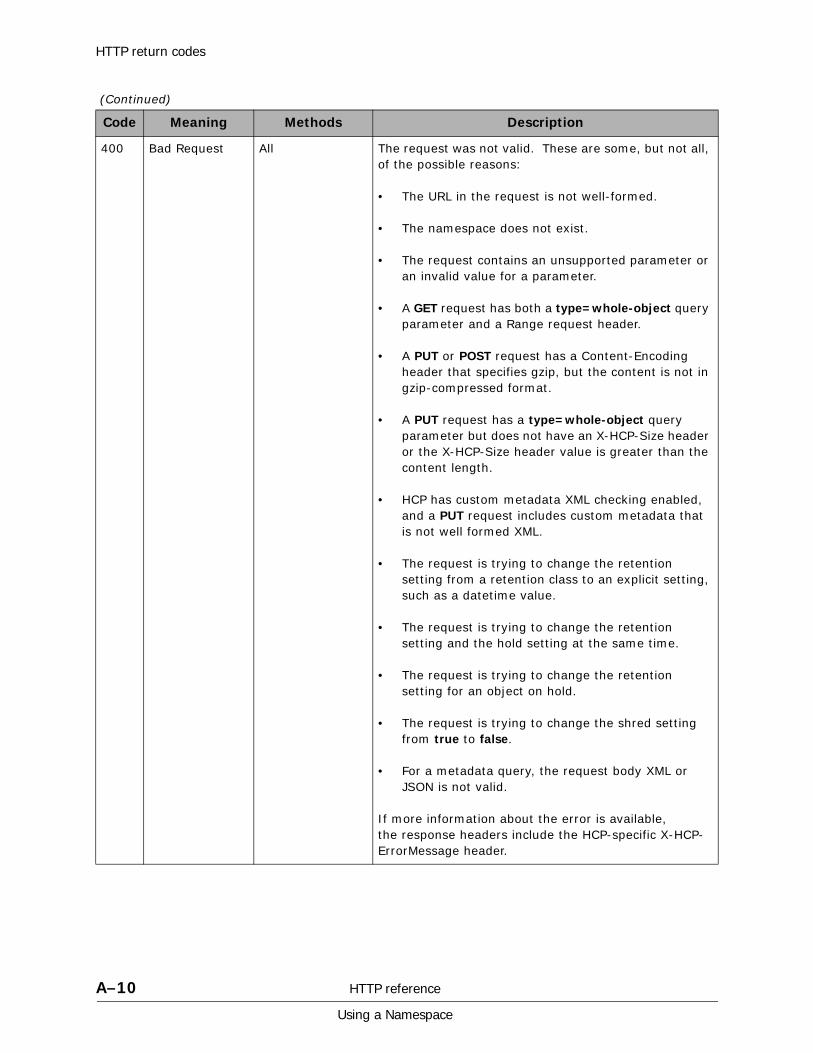
HTTP return codes
400 Bad Request All The request was not valid. These are some, but not all, of the possible reasons:
• The URL in the request is not well-formed.
• The namespace does not exist.
• The request contains an unsupported parameter or an invalid value for a parameter.
• A GET request has both a type=whole-object query parameter and a Range request header.
• A PUT or POST request has a Content-Encoding header that specifies gzip, but the content is not in gzip-compressed format.
• A PUT request has a type=whole-object query parameter but does not have an X-HCP-Size header or the X-HCP-Size header value is greater than the content length.
• HCP has custom metadata XML checking enabled, and a PUT request includes custom metadata that is not well formed XML.
• The request is trying to change the retention setting from a retention class to an explicit setting, such as a datetime value.
• The request is trying to change the retention setting and the hold setting at the same time.
• The request is trying to change the retention setting for an object on hold.
• The request is trying to change the shred setting from true to false.
• For a metadata query, the request body XML or JSON is not valid.
If more information about the error is available, the response headers include the HCP-specific X-HCP-ErrorMessage header.
(Continued)
Code Meaning Methods Description
A–10 HTTP reference
Using a Namespace
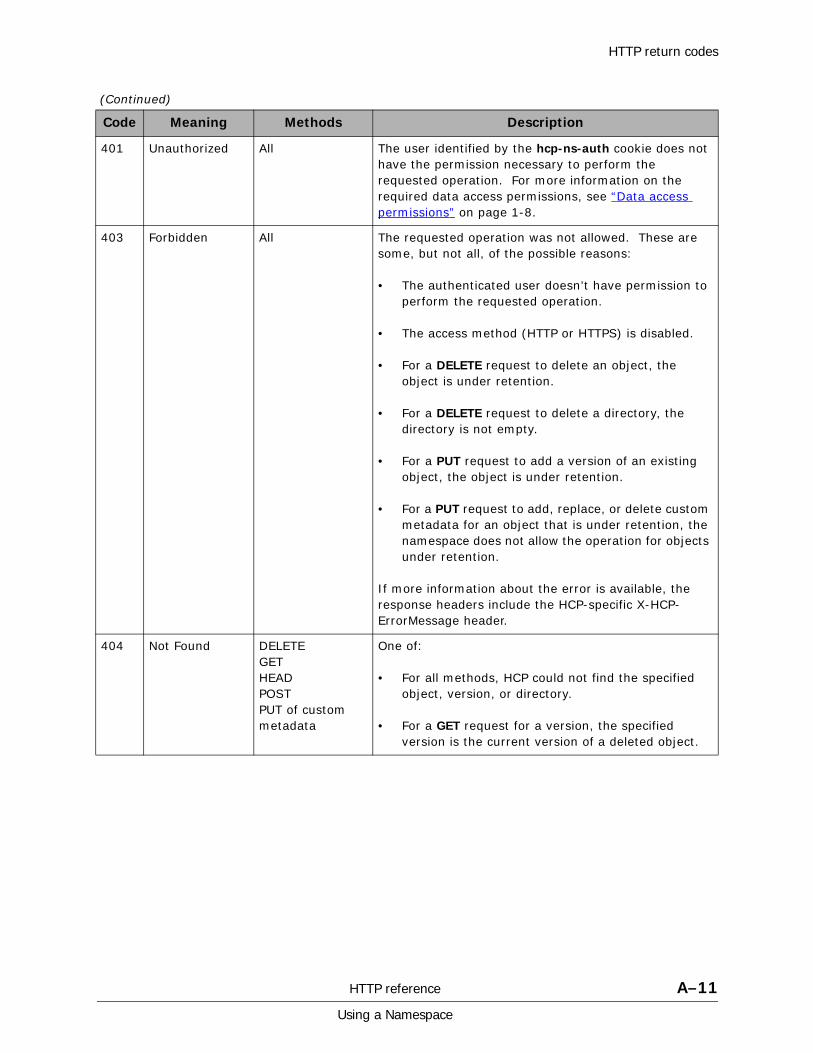
HTTP return codes
401 Unauthorized All The user identified by the hcp-ns-auth cookie does not have the permission necessary to perform the requested operation. For more information on the required data access permissions, see “Data access permissions” on page 1-8.
403 Forbidden All The requested operation was not allowed. These are some, but not all, of the possible reasons:
• The authenticated user doesn’t have permission to perform the requested operation.
• The access method (HTTP or HTTPS) is disabled.
• For a DELETE request to delete an object, the object is under retention.
• For a DELETE request to delete a directory, the directory is not empty.
• For a PUT request to add a version of an existing object, the object is under retention.
• For a PUT request to add, replace, or delete custom metadata for an object that is under retention, the namespace does not allow the operation for objects under retention.
If more information about the error is available, the response headers include the HCP-specific X-HCP-ErrorMessage header.
404 Not Found DELETEGETHEADPOSTPUT of custom metadata
One of:
• For all methods, HCP could not find the specified object, version, or directory.
• For a GET request for a version, the specified version is the current version of a deleted object.
(Continued)
Code Meaning Methods Description
HTTP reference A–11
Using a Namespace
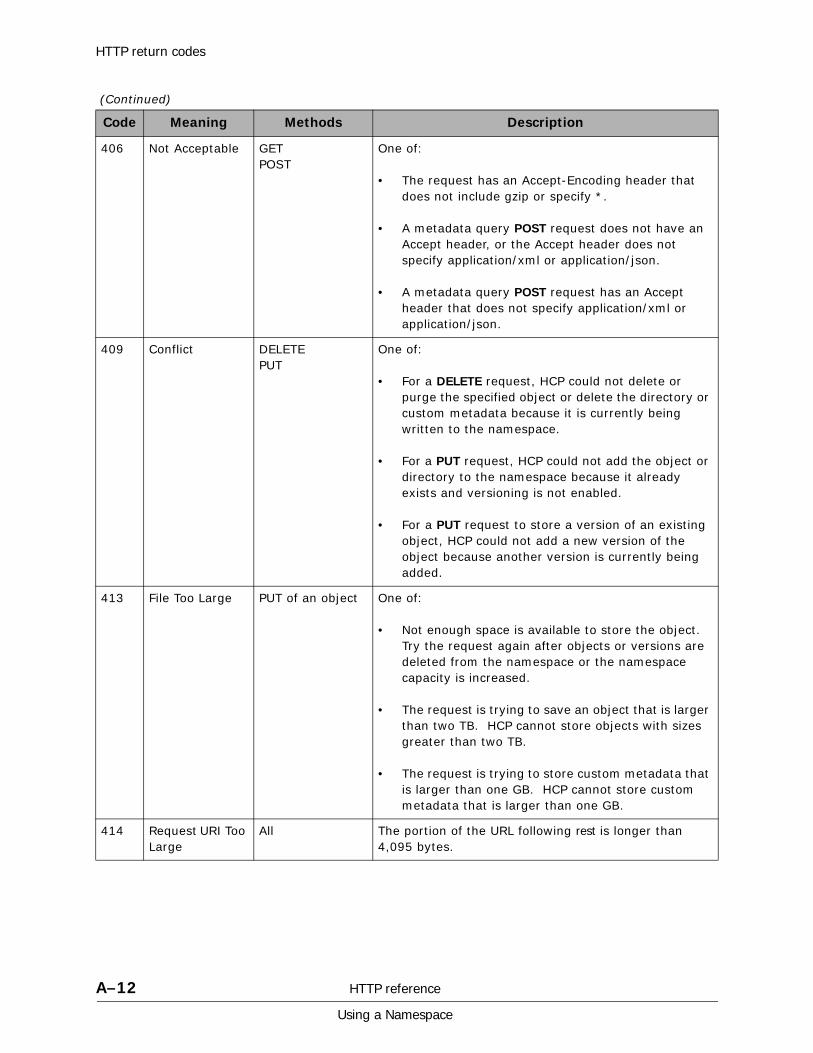
HTTP return codes
406 Not Acceptable GETPOST
One of:
• The request has an Accept-Encoding header that does not include gzip or specify *.
• A metadata query POST request does not have an Accept header, or the Accept header does not specify application/xml or application/json.
• A metadata query POST request has an Accept header that does not specify application/xml or application/json.
409 Conflict DELETEPUT
One of:
• For a DELETE request, HCP could not delete or purge the specified object or delete the directory or custom metadata because it is currently being written to the namespace.
• For a PUT request, HCP could not add the object or directory to the namespace because it already exists and versioning is not enabled.
• For a PUT request to store a version of an existing object, HCP could not add a new version of the object because another version is currently being added.
413 File Too Large PUT of an object One of:
• Not enough space is available to store the object. Try the request again after objects or versions are deleted from the namespace or the namespace capacity is increased.
• The request is trying to save an object that is larger than two TB. HCP cannot store objects with sizes greater than two TB.
• The request is trying to store custom metadata that is larger than one GB. HCP cannot store custom metadata that is larger than one GB.
414 Request URI Too Large
All The portion of the URL following rest is longer than 4,095 bytes.
(Continued)
Code Meaning Methods Description
A–12 HTTP reference
Using a Namespace
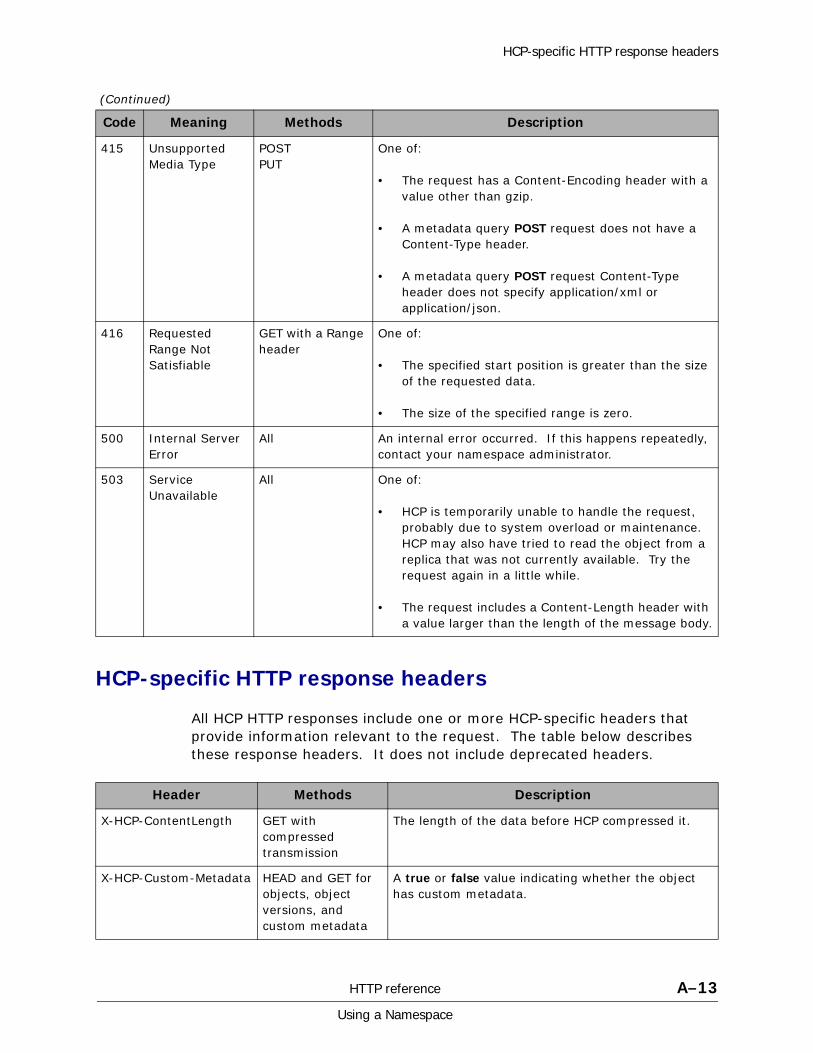
HCP-specific HTTP response headers
HCP-specific HTTP response headers
All HCP HTTP responses include one or more HCP-specific headers that provide information relevant to the request. The table below describes these response headers. It does not include deprecated headers.
415 Unsupported Media Type
POSTPUT
One of:
• The request has a Content-Encoding header with a value other than gzip.
• A metadata query POST request does not have a Content-Type header.
• A metadata query POST request Content-Type header does not specify application/xml or application/json.
416 Requested Range Not Satisfiable
GET with a Range header
One of:
• The specified start position is greater than the size of the requested data.
• The size of the specified range is zero.
500 Internal Server Error
All An internal error occurred. If this happens repeatedly, contact your namespace administrator.
503 Service Unavailable
All One of:
• HCP is temporarily unable to handle the request, probably due to system overload or maintenance. HCP may also have tried to read the object from a replica that was not currently available. Try the request again in a little while.
• The request includes a Content-Length header with a value larger than the length of the message body.
(Continued)
Code Meaning Methods Description
Header Methods Description
X-HCP-ContentLength GET with compressed transmission
The length of the data before HCP compressed it.
X-HCP-Custom-Metadata HEAD and GET for objects, object versions, and custom metadata
A true or false value indicating whether the object has custom metadata.
HTTP reference A–13
Using a Namespace
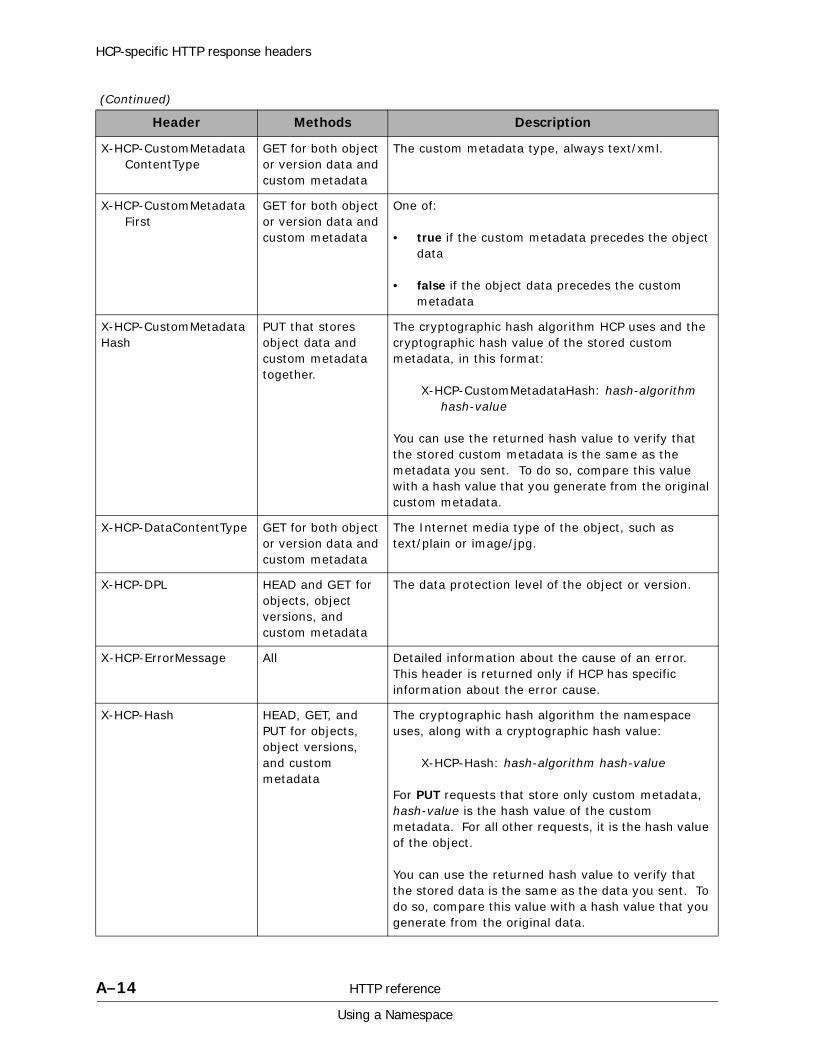
HCP-specific HTTP response headers
X-HCP-CustomMetadataContentType
GET for both object or version data and custom metadata
The custom metadata type, always text/xml.
X-HCP-CustomMetadataFirst
GET for both object or version data and custom metadata
One of:
• true if the custom metadata precedes the object data
• false if the object data precedes the custom metadata
X-HCP-CustomMetadataHash
PUT that stores object data and custom metadata together.
The cryptographic hash algorithm HCP uses and the cryptographic hash value of the stored custom metadata, in this format:
X-HCP-CustomMetadataHash: hash-algorithm hash-value
You can use the returned hash value to verify that the stored custom metadata is the same as the metadata you sent. To do so, compare this value with a hash value that you generate from the original custom metadata.
X-HCP-DataContentType GET for both object or version data and custom metadata
The Internet media type of the object, such as text/plain or image/jpg.
X-HCP-DPL HEAD and GET for objects, object versions, and custom metadata
The data protection level of the object or version.
X-HCP-ErrorMessage All Detailed information about the cause of an error. This header is returned only if HCP has specific information about the error cause.
X-HCP-Hash HEAD, GET, and PUT for objects, object versions, and custom metadata
The cryptographic hash algorithm the namespace uses, along with a cryptographic hash value:
X-HCP-Hash: hash-algorithm hash-value
For PUT requests that store only custom metadata, hash-value is the hash value of the custom metadata. For all other requests, it is the hash value of the object.
You can use the returned hash value to verify that the stored data is the same as the data you sent. To do so, compare this value with a hash value that you generate from the original data.
(Continued)
Header Methods Description
A–14 HTTP reference
Using a Namespace
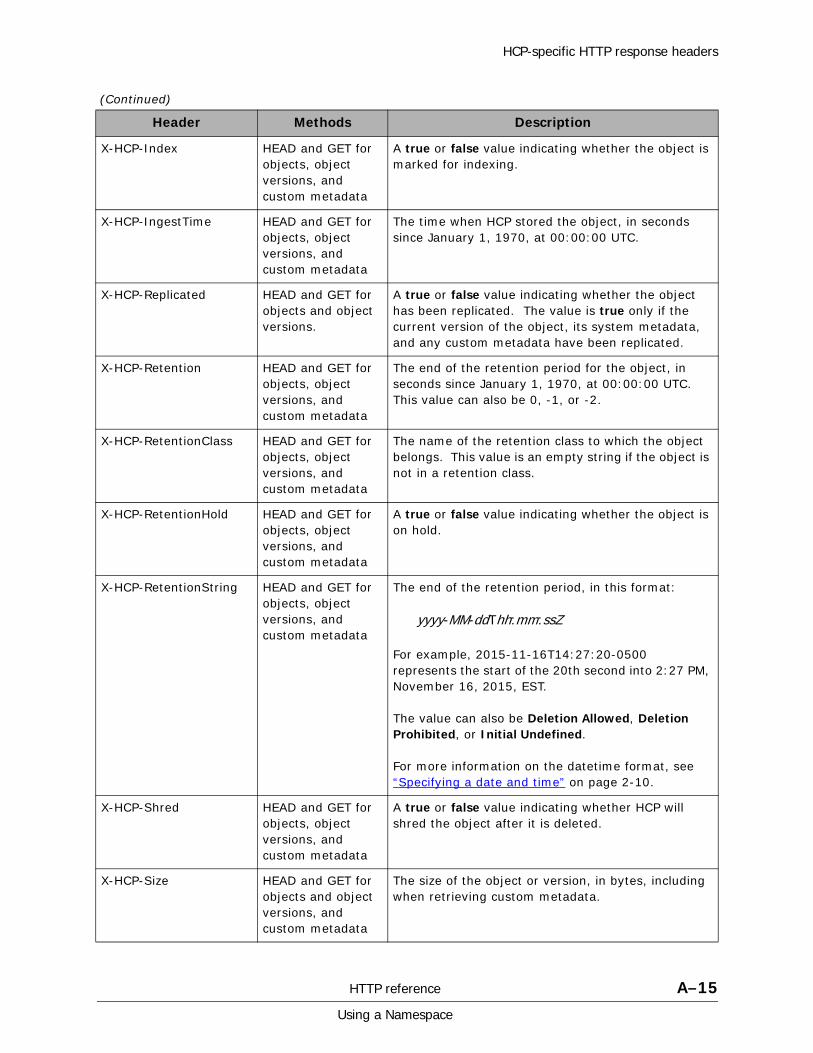
HCP-specific HTTP response headers
X-HCP-Index HEAD and GET for objects, object versions, and custom metadata
A true or false value indicating whether the object is marked for indexing.
X-HCP-IngestTime HEAD and GET for objects, object versions, and custom metadata
The time when HCP stored the object, in seconds since January 1, 1970, at 00:00:00 UTC.
X-HCP-Replicated HEAD and GET for objects and object versions.
A true or false value indicating whether the object has been replicated. The value is true only if the current version of the object, its system metadata, and any custom metadata have been replicated.
X-HCP-Retention HEAD and GET for objects, object versions, and custom metadata
The end of the retention period for the object, in seconds since January 1, 1970, at 00:00:00 UTC. This value can also be 0, -1, or -2.
X-HCP-RetentionClass HEAD and GET for objects, object versions, and custom metadata
The name of the retention class to which the object belongs. This value is an empty string if the object is not in a retention class.
X-HCP-RetentionHold HEAD and GET for objects, object versions, and custom metadata
A true or false value indicating whether the object is on hold.
X-HCP-RetentionString HEAD and GET for objects, object versions, and custom metadata
The end of the retention period, in this format:
yyyy-MM-ddThh:mm:ssZ
For example, 2015-11-16T14:27:20-0500 represents the start of the 20th second into 2:27 PM, November 16, 2015, EST.
The value can also be Deletion Allowed, Deletion Prohibited, or Initial Undefined.
For more information on the datetime format, see “Specifying a date and time” on page 2-10.
X-HCP-Shred HEAD and GET for objects, object versions, and custom metadata
A true or false value indicating whether HCP will shred the object after it is deleted.
X-HCP-Size HEAD and GET for objects and object versions, and custom metadata
The size of the object or version, in bytes, including when retrieving custom metadata.
(Continued)
Header Methods Description
HTTP reference A–15
Using a Namespace

Response body formats
Response body formats
GET requests and metadata query API POST requests return the requested information in the response body. GET requests return information as XML. Metadata query API requests return information as XML or JSON. For the structure of the returned information, see:
• “Listing object versions” on page 4-16
• “Listing directory contents” on page 5-5
• “Response format” on page 8-14 for the XML and JSON returned in response to a metadata query API request
• “Listing accessible namespaces” on page 9-2
• “Listing retention classes” on page 9-5
• “Listing namespace and user permissions” on page 9-8
• “Listing namespace statistics” on page 9-12
X-HCP-SoftwareVersion HEAD and GET for objects, object versions, and directories
The version number of the HCP software.
X-HCP-Time All except POST The time at which HCP sent the response to the request, in seconds since January 1, 1970, at 00:00:00 UTC.
X-HCP-Type HEAD and GET for objects, object versions, and directories
The entity type. The value is either directory or object.
X-HCP-VersionId HEAD, GET, and PUT for objects and object versions
The version ID of the object.
(Continued)
Header Methods Description
A–16 HTTP reference
Using a Namespace

B
Java classes for examplesThis appendix contains the implementation of these Java classes that are used in examples in this book:
• GZIPCompressedInputStream — This class is used by the WriteToHCP method of the HTTPCompression class. This method is defined in “Example 3: Sending object data in compressed format (Java)” on page 4-15.
• WholeIOInputStream — This class is used by the WholeWriteToHCP method of the WholeIO class. This method is defined in “Example 5: Storing object data with custom metadata (Java)” on page 4-17.
• WholeIOOutputStream — This class is used by the WholeReadFromHCP method of the WholeIO class. This method is defined in “Example 6: Retrieving object data and custom metadata together (Java)” on page 4-31.
Java classes for examples B–1
Using a Namespace

GZIPCompressedInputStream class
GZIPCompressedInputStream class
package com.hds.hcp.examples;
import java.io.IOException;import java.io.InputStream;import java.util.zip.CRC32;import java.util.zip.Deflater;import java.util.zip.DeflaterInputStream;
public class GZIPCompressedInputStream extends DeflaterInputStream {
/** * This static class is used to hijack the InputStream * read(b, off, len) function to be able to compute the CRC32 * checksum of the content as it is read. */ static private class CRCWrappedInputStream extends InputStream { private InputStream inputStream;
/** * CRC-32 of uncompressed data. */ protected CRC32 crc = new CRC32();
/** * Construct the object with the InputStream provided. * @param pInputStream - Any class derived from InputStream class. */ public CRCWrappedInputStream(InputStream pInputStream) { inputStream = pInputStream; crc.reset(); // Reset the CRC value. }
/** * This group of methods are the InputStream equivalent methods * that just call the method on the InputStream provided during * construction. */ public int available() throws IOException { return inputStream.available(); }; public void close() throws IOException { inputStream.close(); }; public void mark(int readlimit) { inputStream.mark(readlimit); }; public boolean markSupported() { return inputStream.markSupported(); }; public int read() throws IOException { return inputStream.read(); }; public int read(byte[] b) throws IOException { return inputStream.read(b); }; public void reset() throws IOException { inputStream.reset(); }; public long skip(long n) throws IOException { return inputStream.skip(n); };
B–2 Java classes for examples
Using a Namespace

GZIPCompressedInputStream class
/* * This function intercepts all read requests in order to * calculate the CRC value that is stored in this object. */ public int read(byte b[], int off, int len) throws IOException { // Do the actual read from the input stream. int retval = inputStream.read(b, off, len);
// If we successfully read something, compute the CRC value // of it. if (0 <= retval) { crc.update(b, off, retval); } // All done with the intercept. Return the value. return retval; }; /* * Function to retrieve the CRC value computed thus far while the * stream was processed. */ public long getCRCValue() { return crc.getValue(); }; } // End class CRCWrappedInputStream.
/** * Creates a new input stream with the default buffer size of * 512 bytes. * @param pInputStream - Input Stream to read content for * compression. * @throws IOException if an I/O error has occurred. */ public GZIPCompressedInputStream(InputStream pInputStream) throws IOException { this(pInputStream, 512); } /** * Creates a new input stream with the specified buffer size. * @param pInputStream - Input Stream to read content for * compression. * @param size the output buffer size * @exception IOException If an I/O error has occurred. */ public GZIPCompressedInputStream(InputStream pInputStream, int size) throws IOException { super(new CRCWrappedInputStream(pInputStream), new Deflater(Deflater.DEFAULT_COMPRESSION, true), size);
mCRCInputStream = (CRCWrappedInputStream) super.in; }
Java classes for examples B–3
Using a Namespace

GZIPCompressedInputStream class
// Indicator for if EOF has been reached for this stream. private boolean mReachedEOF = false;
// Holder for the hi-jacked InputStream that computes the // CRC-32 value. private CRCWrappedInputStream mCRCInputStream; /* * GZIP Header structure and positional variable. */ private final static int GZIP_MAGIC = 0x8b1f;
private final static byte[] mHeader = { (byte) GZIP_MAGIC, // Magic number (short) (byte)(GZIP_MAGIC >> 8), // Magic number (short) Deflater.DEFLATED, // Compression method (CM) 0, // Flags (FLG) 0, // Modification time MTIME (int) 0, // Modification time MTIME (int) 0, // Modification time MTIME (int) 0, // Modification time MTIME (int) 0, // Extra flags (XFLG) 0 // Operating system (OS) FYI. UNIX/Linux OS is 3 };
private int mHeaderPos = 0; // Keeps track of how much of the // header has already been read. /* * GZIP trailer structure and positional indicator. * * Trailer consists of 2 integers: CRC-32 value and original file * size. */ private final static int TRAILER_SIZE = 8; private byte mTrailer[] = null; private int mTrailerPos = 0;
/*** * Overridden functions against the DeflatorInputStream */
/* * Function to indicate whether there is any content available to * read. It is overridden because there are the GZIP header and * trailer to think about. */ public int available() throws IOException { return (mReachedEOF ? 0 : 1); }
B–4 Java classes for examples
Using a Namespace

GZIPCompressedInputStream class
/* * This read function is the meat of the class. It handles passing * back the GZIP header, GZIP content, and GZIP trailer in that * order to the caller. */ public int read(byte[] outBuffer, int offset, int maxLength) throws IOException, IndexOutOfBoundsException {
int retval = 0; // Contains the number of bytes read into // outBuffer and will be the return value of // the function. int bIndex = offset; // Used as current index into outBuffer. int dataBytesCount = 0; // Used to indicate how many data bytes // are in the outBuffer array.
// Make sure we have a buffer. if (null == outBuffer) { throw new NullPointerException("Null buffer for read"); } // Make sure offset is valid. if (0 > offset || offset >= outBuffer.length) { throw new IndexOutOfBoundsException( "Invalid offset parameter value passed into function"); }
// Make sure the maxLength is valid. if (0 > maxLength || outBuffer.length - offset < maxLength) throw new IndexOutOfBoundsException( "Invalid maxLength parameter value passed into function");
// Asked for nothing; you get nothing. if (0 == maxLength) return retval;
/** * Put any GZIP header in the buffer if we haven't already returned * it from previous calls. */ if (mHeaderPos < mHeader.length) { // Get how much will fit. retval = Math.min(mHeader.length - mHeaderPos, maxLength);
// Put it there. for (int i = retval; i > 0; i--) { outBuffer[bIndex++] = mHeader[mHeaderPos++]; }
Java classes for examples B–5
Using a Namespace

GZIPCompressedInputStream class
// Return the number of bytes copied if we exhausted the // maxLength specified. // NOTE: Should never be >, but... if (retval >= maxLength) { return retval; } }
/** * At this point, the header has all been read or put into the * buffer. * * Time to add some GZIP compressed data, if there is some still * left. */ if (0 != super.available()) {
// Get some data bytes from the DeflaterInputStream. dataBytesCount = super.read(outBuffer, offset+retval, maxLength-retval);
// As long as we didn't get EOF (-1) update the buffer index and // retval. if (0 <= dataBytesCount) { bIndex += dataBytesCount; retval += dataBytesCount; }
// Return the number of bytes copied during this call, if we // exhausted the maxLength requested. // NOTE: Should never be >, but... if (retval == maxLength) { return retval; }
// If we got here, we should have read all that can be read from // the input stream, so make sure the input stream is at EOF just // in case someone tries to read it outside this class. byte[] junk = new byte[1]; if (-1 != super.read(junk, 0, junk.length)) { // Should never happen. But you know how that goes. throw new IOException( "Unexpected content read from input stream when EOF expected"); } }
/** * Got this far; time to write out the GZIP trailer. */
// Have we already set up the GZIP trailer in a previous // invocation? if (null == mTrailer) {
B–6 Java classes for examples
Using a Namespace

GZIPCompressedInputStream class
// Time to prepare the trailer. mTrailer = new byte[TRAILER_SIZE];
// Put the content in it. writeTrailer(mTrailer, 0); }
// If there are still GZIP trailer bytes to be returned to the // caller, do as much as will fit in the outBuffer. if (mTrailerPos < mTrailer.length) {
// Get the number of bytes that will fit in the outBuffer. int trailerSize = Math.min(mTrailer.length - mTrailerPos, maxLength - bIndex);
// Move them in. for (int i = trailerSize; i > 0; i--) { outBuffer[bIndex++] = mTrailer[mTrailerPos++]; }
// Return the total amount of bytes written during this call. return retval + trailerSize; }
/** * If we got this far, we have already been asked to read * all content that is available. * * So we are at EOF. */ mReachedEOF = true; return -1; }
/*** * Helper functions to construct the trailer. */
/* * Writes GZIP member trailer to a byte array, starting at a given * offset. */ private void writeTrailer(byte[] buf, int offset) throws IOException { writeInt((int)mCRCInputStream.getCRCValue(), buf, offset); // CRC-32 of uncompr. data writeInt(def.getTotalIn(), buf, offset + 4); // Number of uncompr. bytes }
Java classes for examples B–7
Using a Namespace

WholeIOInputStream class
/* * Writes integer in Intel byte order to a byte array, starting at * a given offset. */ private void writeInt(int i, byte[] buf, int offset) throws IOException { writeShort(i & 0xffff, buf, offset); writeShort((i >> 16) & 0xffff, buf, offset + 2); }
/* * Writes short integer in Intel byte order to a byte array, * starting at a given offset */ private void writeShort(int s, byte[] buf, int offset) throws IOException { buf[offset] = (byte)(s & 0xff); buf[offset + 1] = (byte)((s >> 8) & 0xff); }}
WholeIOInputStream class
package com.hds.hcp.examples;import java.io.IOException;import java.io.InputStream;import java.io.OutputStream;
/** * This class defines an InputStream that is composed of both a data * file and a custom metadata file. * * The class is used to provide a single stream of data and custom * metadata to be transmitted over HTTP for type=whole-object PUT * operations. */public class WholeIOInputStream extends InputStream {
/* * Constructor. Passed in an InputStream for the data file and the * custom metadata file. */ WholeIOInputStream( InputStream inDataFile, InputStream inCustomMetadataFile) { mDataFile = inDataFile; mCustomMetadataFile = inCustomMetadataFile; bFinishedDataFile = false; }
B–8 Java classes for examples
Using a Namespace

WholeIOOutputStream class
// Private member variables. private Boolean bFinishedDataFile; // Indicates when all data file // content has been read. private InputStream mDataFile, mCustomMetadataFile; /* * Base InputStream read function that reads from either the data * file or custom metadata, depending on how much has been read so * far. */ public int read() throws IOException { int retval = 0; // Assume nothing read. // Do we still need to read from the data file? if (! bFinishedDataFile ) { // Read from the data file. retval = mDataFile.read();
// If reached the end of the stream, indicate it is time to read // from the custom metadata file. if (-1 == retval) { bFinishedDataFile = true; } }
// This should not be coded as an "else" because it may need to be // run after data file has reached EOF. if ( bFinishedDataFile ) { // Read from the custom metadata file. retval = mCustomMetadataFile.read(); } return retval; }}
WholeIOOutputStream class
package com.hds.hcp.examples;import java.io.IOException;import java.io.InputStream;import java.io.OutputStream;
/** * This class defines an OutputStream that will create both the data * file and the custom metadata file for an object. The copy() method * is used to read an InputStream and create the two output files based * on the indicated size of the data file portion of the stream. * * The class is used to split and create content retrieved over HTTP as * a single stream for type=whole-object GET operations. */
Java classes for examples B–9
Using a Namespace

WholeIOOutputStream class
public class WholeIOOutputStream extends OutputStream { // Constructor. Passed output streams for the data file and the // custom metadata file. Allows specification of whether the custom // metadata comes before the data. WholeIOOutputStream(OutputStream inDataFile, OutputStream inCustomMetadataFile, Boolean inCustomMetadataFirst) {
bCustomMetadataFirst = inCustomMetadataFirst; // Set up first and second file Output Streams based on whether // custom metadata is first in the stream. if (bCustomMetadataFirst) { mFirstFile = inCustomMetadataFile; mSecondFile = inDataFile; } else { mFirstFile = inDataFile; mSecondFile = inCustomMetadataFile; } bFinishedFirstPart = false; } // Member variables. private Boolean bFinishedFirstPart; private Boolean bCustomMetadataFirst; private OutputStream mFirstFile, mSecondFile; /** * This routine copies content in an InputStream and to this * output stream. The first inDataSize number of bytes are written * to the data file output stream. * * @param inStream - InputStream to copy content from. * @param inFirstPartSize - number of bytes of inStream that should * be written to the first output stream. * @throws IOException */ public void copy(InputStream inStream, Integer inFirstPartSize) throws IOException { int streamPos = 0; int readValue = 0; // Keep reading bytes until EOF has been reached. while (-1 != (readValue = inStream.read())) { // Have we read all the bytes for the data file? if (streamPos == inFirstPartSize) { // Yes. bFinishedFirstPart = true; }
B–10 Java classes for examples
Using a Namespace

WholeIOOutputStream class
// Write the bytes read. write(readValue); streamPos++; } } /** * This is the core write function for the InputStream implementation. * It either writes to the data file stream or the custom metadata * stream. */ public void write(int b) throws IOException { // Write to first or second file depending on where we are in the // stream. if (! bFinishedFirstPart ) { mFirstFile.write(b); } else { mSecondFile.write(b); } }
/** * flush() method to flush all files involved. */ public void flush() throws IOException { mFirstFile.flush(); mSecondFile.flush(); super.flush(); } /** * close() method to first close the data file and custom metadata * files. Then close itself. */ public void close() throws IOException { mFirstFile.close(); mSecondFile.close(); super.close(); }}
Java classes for examples B–11
Using a Namespace

WholeIOOutputStream class
B–12 Java classes for examples
Using a Namespace

Glossary
A
access protocol
See namespace access protocol.
active search system
The system that works with the enabled search facility to perform searches and return results to the HCP Search Console. The active search system also maintains an index of objects in searchable namespaces, which it uses for fast retrieval of search results.
authentication
See namespace access authentication
C
compliance mode
The retention mode in which objects under retention cannot be deleted through any mechanism. This is the more restrictive retention mode.
cryptographic hash value
A system-generated metadata value calculated by a cryptographic hash algorithm from object data. This value is used to verify that the content of an object has not changed.
custom metadata
One or more user-defined properties that provide descriptive information about an object. Custom metadata, which is normally specified as XML, enables future users and applications to understand and repurpose object content.
Glossary–1
Using a Namespace

data access account
D
data access account
A set of credentials that give a user or application access to one or more HCP namespaces. For each namespace, the account specifies which operations the user or application can perform.
data access permission mask
A set of permissions that determine which of these operations are allowed in a namespace: read, write, delete, purge, privileged delete, and search.
data protection level (DPL)
The number of copies of an object HCP must maintain in the repository. Each namespace has its own DPL setting that applies to all objects in that namespace.
E
effective permissions
For a namespace, the permissions that are included in all three of the system-level, tenant-level, and namespace-level permission masks.
For a user or application accessing a given namespace, the permissions that are included in both the data access account in use and the effective permission mask for the namespace.
enterprise mode
The retention mode in which these operations are allowed:
• Privileged delete
• Changing the retention class of an object to one with a shorter duration
• Reducing retention class duration
• Deleting retention classes
expired object
An object that is no longer under retention.
Glossary–2
Using a Namespace

Hitachi Content Platform (HCP)
F
fixed-content data
A digital asset ingested into HCP and preserved in its original form as the core part of an object. Once stored, fixed-content data cannot be modified.
H
hash value
See cryptographic hash value.
HCP
See Hitachi Content Platform (HCP).
HCP metadata query API
See metadata query API.
HCP namespace
A namespace that requires user authentication for data access. An HCP system can have multiple HCP namespaces.
HCP search facility
The search facility that interacts with HCP.
HDDS
See Hitachi Data Discovery Suite (HDDS).
HDDS search facility
The search facility that interacts with Hitachi Data Discovery Suite.
Hitachi Content Platform (HCP)
A distributed object-based storage system designed to support large, growing repositories of fixed-content data. HCP provides a single scalable environment that can be used for archiving, business continuity, content depots, disaster recovery, e-discovery, and other services. With its support for multitenancy, HCP securely segregates data among various constituents in a shared infrastructure. Clients can use an HTTP REST interface and various HCP-specific interfaces to access and manipulate objects in an HCP repository.
Glossary–3
Using a Namespace

Hitachi Data Discovery Suite (HDDS)
Hitachi Data Discovery Suite (HDDS)
A Hitachi product that enables federated searches across multiple HCP systems and other supported systems.
hold
A condition that prevents an object from being deleted by any means and from having its metadata modified, regardless of its retention setting, until it is explicitly released.
HTTP
Hypertext Transfer Protocol. The protocol HCP uses to provide access to the contents of a namespace.
HTTPS
HTTP with SSL security. See HTTP and SSL.
I
index
See search index.
index setting
The property that specifies whether an object should be indexed.
M
metadata
System-generated and user-supplied information about an object. Metadata is stored as an integral part of the object it describes, thereby making the object self-describing.
metadata query API
An HTTP REST interface that lets you search HCP for objects that meet specified metadata-based criteria. With this API, you can search not only for objects currently in the repository but also for information about objects that have been deleted or purged.
Glossary–4
Using a Namespace

permission
N
namespace
A logical partition of the objects stored in an HCP system. A namespace consists of a grouping of objects such that the objects in one namespace are not visible in any other namespace. Namespaces are configured independently of each other and, therefore, can have different properties.
namespace access authentication
The process of checking the credentials presented by users and applications when they try to access a namespace.
namespace access protocol
A protocol that can be used to transfer data to and from namespaces in an HCP system. HCP supports the HTTP protocol for access to HCP namespaces.
O
object
An exact digital representation of data as it existed before it was ingested into HCP, together with the system and custom metadata that describes that data. An object is handled as a single unit by all transactions and internal processes, including shredding, indexing, versioning, and replication.
operation record
A record of a create, delete, or purge operation. The record identifies the object involved, the type of operation, and the time at which the operation occurred and also contains system metadata for the object HCP updates the applicable creation record when object metadata changes.
P
permission
One of these:
• In a data access permission mask, the condition of allowing a specific type of operation to be performed in a namespace.
Glossary–5
Using a Namespace

permission mask
• In a data access account, the granted ability to perform a specific type of operation in a given namespace.
permission mask
See data access permission mask.
policy
One or more settings that influence how transactions and internal processes work on objects. Such a setting can be a property of an object, such as retention, or a property of a namespace, such as versioning.
POSIX
Portable Operating System Interface for UNIX. A set of standards that define an application programming interface (API) for software designed to run under heterogeneous operating systems.
privileged delete
A delete operation that works on objects regardless of their retention settings, except for objects on hold. This operation is available only to users and applications with explicit permission to perform it.
privileged purge
The operation that deletes all versions of an object regardless of whether the object is under retention, except if the object is on hold. This operation is available only to users and applications with explicit permission to perform it.
Privileged purge operations work only in namespaces in enterprise mode.
protocol
See namespace access protocol.
purge
The operation that deletes all versions of an object.
Q
query
A request submitted to HCP to return operation records
Glossary–6
Using a Namespace

retention period
query API
See metadata query API.
R
replication
The process of keeping selected tenants and namespaces in two HCP systems in sync with each other. This entails copying object creations, deletions, and metadata changes from one system to the other.
repository
The aggregate of the namespaces defined for an HCP system.
REST
Representational State Transfer. A software architectural style that defines a set of rules (called constraints) for client/server communication. In a REST architecture:
• Resources (where a resource can be any coherent and meaningful concept) must be uniquely addressable.
• Representations of resources (for example, as XML) are transferred between clients and servers. Each representation communicates the current or intended state of a resource.
• Clients communicate with servers through a uniform interface (that is, a set of methods that resources respond to) such as HTTP.
retention class
A named retention setting. The value of a retention class can be a duration, Deletion Allowed, Deletion Prohibited, or Initial Unspecified.
retention hold
See hold.
retention mode
A namespace property that affects which operations are allowed on objects under retention. A namespace can be in either of two retention modes: compliance or enterprise.
retention period
The period of time during which an object cannot be deleted (except by means of a privileged delete).
Glossary–7
Using a Namespace

retention setting
retention setting
The property that determines the retention period for an object.
S
Search Console
The web application that provides interactive access to the search functionality of the active search system.
search facility
An interface between the search functionality provided by a system such as HDDS or HCP and the HCP Search Console. Only one search facility can be enabled at any given time.
search index
An index of the metadata and key terms in namespace objects. The active search system builds, maintains, and stores this index.
shred setting
The property that determines whether a data object will be shredded or simply removed when it’s deleted from HCP.
shredding
The process of deleting a data object and overwriting the locations where its bytes were stored in such a way that none of its data or metadata can be reconstructed. Also called secure deletion.
SSL
Secure Sockets Layer. A key-based Internet protocol for transmitting documents through an encrypted link.
system metadata
System-managed properties that describe the content of an object. System metadata includes policies, such as retention and data protection level, that influence how transactions and internal processes affect the object.
Glossary–8
Using a Namespace

WORM
T
tenant
An administrative entity created for the purpose of owning and managing namespaces and data access accounts. Tenants typically correspond to customers, business units, or individuals.
U
Unix
Any UNIX-like operating system (such as UNIX itself or Linux).
user account
A set of credentials that gives an HCP system administrator access to the metadata query API.
V
versioning
A feature that allows the creation and management of multiple versions of an object.
W
WORM
Write once, read many. A data storage property that protects the stored data from being modified or overwritten.
Glossary–9
Using a Namespace

WORM
Glossary–10
Using a Namespace

Index
Numbers0 (retention setting) 2-5, 2-9-1 (retention setting) 2-5, 2-9-2 (retention setting) 2-5, 2-9
AAccept HTTP header 8-7Accept-Encoding HTTP header 1-7access, authenticating 3-8–3-9active search system 1-5adding
See storing; creatingassigning objects to retention classes 2-10authenticating namespace access 3-8–3-9authorization
See hcp-ns-auth cookie
BBase64 username encoding 3-8–3-9browsing the namespace 10-1–10-14byte range, retrieving
about 4-22–4-24example 4-30–4-32
Cchange time
about 2-3in metadata query request 8-11–8-12in metadata query response 8-18, 8-19selector for metadata query API 8-2
changingindex settings 2-17passwords 10-3–10-4retention settings 6-5shred settings 2-13system metadata 6-5–6-7
checkingcustom metadata existence 7-6–7-8directory existence 5-3–5-5object existence 4-12–4-15
chunking data 11-4clear-text passwords 3-8client tools 1-6compressed data
See gzipcompressing data for transmission 1-7connections
handling failed 11-7persistent 11-6
Content-Encoding HTTP header 1-7Content-Type HTTP header 8-7create operations, records for 8-3creating
See also storingdirectories 5-2–5-3directories in the Namespace
Browser 10-10–10-11cryptographic hash values 2-2cURL 3-1custom metadata
about 1-2, 2-17–2-18allowed operations 2-17checking existence 7-6–7-8deleting 7-11–7-13with objects under retention 2-17–2-18receiving in compressed format 7-9retrieving 7-8–7-11retrieving together with object data 4-22–
4-23, 4-36–4-38sending in compressed format 7-2storing 7-2–7-5storing in compressed format 1-7storing together with object data 4-3, 4-9–
4-11transmitting in compressed format 1-7
Index–1
Using a Namespace

data access
Ddata access 1-3–1-6data access account 1-8data access permission mask 1-8data access permissions
about 1-8listing 9-8–9-11privileged 2-5–2-6viewing in the Namespace Browser 10-13XML listing format 9-8–9-9
data chunking with HTTP 11-4data compression
See gzipdata protection level 2-3date and time, specifying for retention
setting 2-9, 2-10–2-11delete operations, records for 8-3delete permission 1-8deleted objects and directories
listing 5-6listing in the Namespace Browser 10-7listing versions 4-16, 4-18–4-19listing versions in the Namespace
Browser 10-9deleted versions 2-16, 4-38deleting
all versions of an object 4-43–4-46custom metadata 7-11–7-13directories 5-10–5-12objects 2-16, 4-38–4-42objects automatically 2-4objects in the Namespace Browser 10-10objects under repair 11-6objects under retention 4-38–4-39
Deletion Allowed 2-9Deletion Prohibited 2-9directories
checking existence of 5-3–5-5creating 5-2–5-3creating in the Namespace Browser 10-5,
10-10–10-11deleting 5-10–5-12listing contents 5-5–5-10listing contents in the Namespace
Browser 10-5–10-7listing deleted 5-6listing deleted in the Namespace
Browser 10-7, 10-9listing deleted versions 4-18–4-19selector for metadata query API 8-2specifying in metadata API query
requests 8-12structuring 11-2–11-3
version IDs for deleted 2-14XML listing format 5-6–5-8
DNS names, namespace access by 11-2
Eeffective permissions, user and
namespace 10-13error codes
See return codesexamples
changing object metadata 6-6–6-7checking custom metadata existence 7-7–
7-8checking directory existence 5-4–5-5checking object existence 4-14–4-15creating directories 5-2–5-3deleting custom metadata 7-13deleting directories 5-11–5-12deleting objects 4-40–4-42listing accessible namespaces 9-3–9-4listing directory contents 5-8–5-10listing namespace statistics 9-13–9-14listing object versions 4-19–4-21listing permissions 9-9–9-11listing retention classes 9-6–9-7metadata query API 8-21–8-30paged queries 8-26–8-30privileged delete 4-41–4-42privileged purge 4-46purging objects 4-45–4-46querying namespaces 8-21–8-30retrieving custom metadata 7-10–7-11retrieving historic versions 4-32–4-33retrieving metadata for changed
objects 8-25–8-26retrieving metadata for indexable
objects 8-22–8-24retrieving object data and custom metadata
together 4-36–4-38retrieving objects and versions 4-29–4-38retrieving objects in compressed
format 4-33–4-36retrieving partial objects 4-30–4-32sending object data in compressed
format 4-7–4-9specifying metadata on object creation 6-4storing custom metadata 7-5storing objects 4-6–4-11
Ffailed write operations 11-4–11-5fixed-content data 1-2
Index–2
Using a Namespace

HTTP GET
Ggzip
compressing custom metadata data for retrieval 7-9
compressing custom metadata data for submission 7-2
compressing data for transmission 1-7compressing metadata queries and
responses 8-7compressing object data and custom
metadata for retrieval 4-23compressing object data and custom
metadata for submission 4-3compressing object data for retrieval 4-22,
4-33–4-36compressing object data for submission 4-2,
4-7–4-9encoding data for operations 1-9storing compressed data in HCP 1-7
Hhash values
See cryptographic hash valuesHCP 1-1HCP client tools 1-6HCP Data Migrator 1-6HCP search facility 1-5hcp-ns-auth cookie
format 3-8generating 3-8–3-9metadata query API 8-7
HDDS search facility 1-5historic versions
See versionsHitachi Content Platform 1-1hold HTTP metadata parameter 6-2, 6-5hold settings, for versions 2-14holding objects 2-6hostnames
enabling use in URLs 3-4–3-5namespace access by 11-2
hosts file 3-4–3-5HTTP
See also individual HTTP methodsabout 1-3–1-4checking existence of directories 5-3–5-5checking existence of objects and
versions 4-12–4-15compliance level 3-1connection failure handling 11-7creating directories 5-2–5-3data chunking 11-4
deleting directories 5-10–5-12deleting objects 4-38–4-42failed write operations 11-4–11-5HCP-specific response header
summary A-13–A-16listing accessible namespaces 9-2–9-4listing directory contents 5-5–5-10listing namespace statistics 9-12–9-14listing object versions 4-16–4-21listing permissions 9-8–9-11listing retention classes 9-5–9-7method summary A-2–A-8namespace access by IP address 11-2purging objects 4-43–4-46retrieving objects and versions 4-22–4-38return code summary A-9–A-13storing objects 4-2–4-11transferring data in compressed format 1-7URLs for metadata query API 8-4–8-6URLs for namespace access 3-2–3-8using self-signed server certificates 8-6
HTTP DELETESee also HTTPdeleting custom metadata 7-11–7-13deleting directories 5-10–5-12deleting objects 4-38–4-42examples 4-40–4-42, 4-45–4-46, 5-11–
5-12, 7-13method summary A-2purging objects 4-43–4-46
HTTP GETSee also HTTPbyte-range requests 4-22–4-24connection failure 11-7examples 4-19–4-21, 4-29–4-38, 5-8–5-10,
7-10–7-11, 9-3–9-4, 9-6–9-7, 9-9–9-11, 9-13–9-14
listing accessible namespaces 9-2–9-4listing directory contents 5-5–5-10listing namespace statistics 9-12–9-14listing object versions 4-16–4-21listing permissions 9-8–9-11listing retention classes 9-5–9-7method summary A-3, A-4Range request header 4-23–4-24response headers 4-25–4-28retrieving custom metadata 7-8–7-11retrieving custom metadata in compressed
format 7-9retrieving data in compressed format 1-7retrieving object data and custom metadata
in compressed format 4-23
Index–3
Using a Namespace

HTTP GET, retrieving object data and custom metadata together
retrieving object data and custom metadata together 4-22–4-23
retrieving object data in compressed format 4-22
retrieving objects and versions 4-22–4-38HTTP HEAD
See also HTTPchecking existence of custom metadata 7-6–
7-8checking existence of directories 5-3–5-5checking existence of objects 4-12–4-15examples 4-14–4-15, 5-4–5-5, 7-7–7-8method summary A-5response headers 4-13–4-14
HTTP Host header 3-6HTTP method summary A-2–A-8HTTP POST
See also HTTPchanging system metadata 6-5–6-7examples, changing object metadata 6-6–
6-7examples, metadata query API 8-21–8-30metadata query API 8-6–8-21method summary A-6–A-7
HTTP PUTSee also HTTPcreating directories 5-2–5-3examples 4-6–4-11, 5-2–5-3, 6-4, 7-5method summary A-8overriding default metadata 6-2–6-4response headers 4-6sending custom metadata in compressed
format 7-2sending data in compressed format 1-7sending object data in compressed
format 4-2storing custom metadata 7-2–7-5storing object data and custom metadata
together 4-3, 4-9–4-11storing objects 4-2–4-11
HTTP response headersHCP-specific A-13–A-16object metadata 4-13–4-14, 4-25–4-28storing objects 4-6
HTTP return codes A-9–A-13
Iindex HTTP metadata parameter 6-2, 6-5index settings
changing 2-17, 6-5overriding default 2-17, 6-2selector for metadata query API 8-2specifying in metadata query request 8-13
valid values 2-17for versions 2-14
indexing 2-17ingest time, compared to change time 2-3Initial Unspecified 2-9IP addresses
for metadata queries 8-5–8-6namespace access by 3-5–3-6, 11-2
JJSON
metadata query API request body format 8-9metadata query API response body
format 8-17specifying as metadata query request body
format 8-7specifying as metadata query response body
format 8-7
Llibcurl 3-1listing
accessible namespaces 9-2–9-4deleted objects and directories 5-6directory contents 5-5–5-10namespace statistics 9-12–9-14object versions 4-16–4-21, 10-7–10-8permissions 9-8–9-11retention classes 9-5–9-7
Location header A-9logging into Namespace Browser 10-2–10-3
MMac OS X hosts file 3-5MD5 password hashing 3-8–3-9metadata
about 2-1changing 6-5–6-7custom 1-2HTTP parameters A-6retrieving 4-12–4-15specifying on object creation 6-2–6-4system 1-2for versions 2-14
metadata query APISee also queriesabout 1-4, 8-2examples 8-21–8-30request body contents 8-10–8-13request body formats 8-8–8-9request format 8-6–8-13request specific return codes 8-14–8-15
Index–4
Using a Namespace

objects
response body contents 8-17–8-21response body formats 8-16–8-17response format 8-14–8-21specifying request body format 8-7specifying response body format 8-7transmitting queries and responses in
compressed format 8-7methods, HTTP A-2–A-8multithreading 11-7–11-8
NNamespace Browser
about 1-4–1-5, 10-2accessing object versions 10-9–10-10accessing objects 10-9adding objects and versions 10-10common elements 10-3creating directories 10-10–10-11deleting objects 10-10listing deleted objects and directories 10-7listing directory contents 10-5–10-7listing object versions 10-7–10-8listing versions of deleted objects and
directories 10-9logging in 10-2–10-3viewing accessible namespaces 10-11–10-12viewing permissions 10-13viewing retention classes 10-12viewing statistics 10-13–10-14
namespacesabout 1-2–1-3accessible 9-2accessible, XML listing format 9-3accessing 1-3–1-6, 3-1–3-9accessing by DNS name 11-2accessing by hostname 11-2accessing by IP address 3-5–3-6, 11-2authenticating access to 3-8–3-9browsing 10-1–10-14listing accessible 9-2–9-4listing permissions 9-8–9-11listing statistics 9-12–9-14operations 1-9–1-11querying 8-2replicated 1-9retrieving information 9-1–9-14specifying in metadata query request 8-13viewing data access permissions 10-13viewing in the Namespace Browser 10-11–
10-12viewing permissions in the Namespace
Browser 10-13
viewing retention classes in the Namespace Browser 10-12
viewing statistics in the Namespace Browser 10-13–10-14
XML listing format 9-3XML statistics listing format 9-12–9-13
naming objects 2-2, 3-7non-ASCII, nonprintable characters 3-7non-WORM objects 11-6
Oobjects
See also versionsabout 1-2adding in the Namespace Browser 10-10assigning retention classes to 2-10change time 2-3changing system metadata 6-5–6-7checking existence 4-12–4-15deleted versions 4-38deleting 2-16, 4-38–4-42deleting automatically 2-4deleting in the Namespace Browser 10-10deleting while under retention 4-38–4-39holding 2-6indexing 2-17ingest time 2-3listing deleted 5-6listing deleted in the Namespace
Browser 10-7, 10-9listing deleted versions 4-16, 4-18listing versions 4-16–4-21, 10-7–10-8names with non-ASCII, nonprintable
characters 3-7naming 2-2non-WORM 11-6open 11-5–11-6overriding default metadata 6-2–6-4properties of 2-1purging 2-16, 4-43–4-46replicated 1-9retention 2-3–2-13retention setting formats 2-5, 2-8–2-13retrieving 4-22–4-38retrieving in compressed format 4-22, 4-33–
4-36retrieving in the Namespace Browser 10-9retrieving object data and custom metadata
together 4-22–4-23, 4-36–4-38sending in compressed format 4-2, 4-7–4-9shredding 2-13storing 1-2, 4-2–4-11storing in compressed format 1-7
Index–5
Using a Namespace

objects, storing object data and custom metadata together
storing object data and custom metadata together 4-3, 4-9–4-11
transmitting in compressed format 1-7uploading in the Namespace Browser 10-5viewing in the Namespace Browser 10-9
offset, specifying for retention setting 2-10, 2-11–2-12
open objects 11-5–11-6operation records
about 8-3with versioning disabled 8-3with versioning enabled 8-3
operationsabout 8-3privileged 2-5–2-6prohibited 1-11query response values 8-19restrictions 1-9–1-10selector for metadata query API 8-2specifying types in metadata query
requests 8-13supported 1-10–1-11types of 8-3using compressed data 1-9
overridingdefault index settings 2-17, 6-2default metadata 6-2–6-4default retention settings 2-4, 6-2default shred settings 2-13, 6-2
Ppaged queries
about 8-2example 8-26–8-30lastResult request parameter 8-10, 8-11using 8-4
partial objects, retrievingabout 4-22–4-24example 4-30–4-32
passwordschanging 10-3–10-4clear-text 3-8hashing 3-8–3-9
percent-encodingreturned object names 3-7in URLs 3-7
permissionsSee data access permissions
persistent connections 11-6primary system, replication 1-9privileged delete
about 2-5, 4-38–4-39examples 4-41–4-42
privileged operations 2-5–2-6privileged permission 1-8, 2-5–2-6privileged purge
about 2-6, 4-43–4-46examples 4-46
/proc 3-3–3-4, 9-2prohibited operations 1-11pruning 2-14purge operations, records for 8-3purge permission 1-8purging objects 2-16, 4-43–4-46
Qqueries
See also metadata query APIcaching of 8-6compressed format 1-7examples of 8-21–8-30hcp-ns-auth cookie 8-7paged, using 8-4response status 8-21selection criteria 8-2specifying operation types 8-13URLs for 8-4–8-6
/query 8-6, A-7query API
See queries; metadata query APIquotation marks with URLs 3-8
Rread from replica 1-9read permission 1-8replica 1-9replicated, in metadata query API response 8-20replication
about 1-9metadata query API status entry 8-20X-HCP-Replicated response header A-15
response headersSee HTTP response headers
/rest 3-3, A-6REST interface 1-3–1-4restrictions on operations 1-9–1-10retention
See also retention classes; retention settingsabout 2-3changing hold setting 6-5deleting objects under 4-38–4-39hold 2-6HTTP metadata parameter 6-2, 6-5periods 2-4purging objects under 4-43–4-46specifying hold setting 6-2
Index–6
Using a Namespace

versions
retention classesSee also retention; retention settingsabout 2-4, 2-6–2-7assigning to objects 2-10listing 9-5–9-7specifying 2-13valid values 2-6–2-7XML listing format 9-5
retention settingsSee also retention; retention classeschanging 6-5default 2-4HTTP response headers for 2-8overriding default 2-4, 6-2representation formats 2-5specifying 2-8–2-13specifying a date and time 2-9, 2-10–2-11specifying a retention class 2-13specifying an offset 2-10, 2-11–2-12for versions 2-14
retrievingcustom metadata 7-8–7-11historic versions 4-22, 4-32–4-33object data and custom metadata
together 4-22–4-23, 4-36–4-38objects and versions 4-22–4-38objects in the Namespace Browser 10-9part of an object 4-22–4-24, 4-30–4-32versions in the Namespace Browser 10-9–
10-10return codes, HTTP A-9–A-13
SSearch Console
about 1-5holding objects 2-6
search facilities 1-5search permission 1-8search, object naming considerations 2-2secure deletion 2-13self-signed server certificates, using 8-6shred HTTP metadata parameter 6-2, 6-5shred settings
about 2-13changing 2-13, 6-5overriding default 2-13, 6-2for versions 2-14
shredding 2-13SSL, using self signed server certificates 8-6statistics
listing for namespaces 9-12–9-14viewing in the Namespace Browser 10-13–
10-14
status codesSee return codes
storingSee also creatingcustom metadata 7-2–7-5object data and custom metadata
together 4-3, 4-9–4-11objects 1-2, 4-2–4-11objects and versions using the Namespace
Browser 10-10zero-sized files 11-3
structuring directories 11-2–11-3supported operations 1-10–1-11system metadata 1-2
Ttenants 1-3transactions
See operations
UUnix hosts file 3-4URLs
enabling use of hostnames 3-4–3-5formats for 3-2–3-4HTTP access to the namespace 3-2–3-8maximum length 3-7percent-encoding 3-7for metadata query API 8-4–8-6
usage considerations 11-1–11-8user permissions
See data access permissionsusername encoding 3-8–3-9users, listing permissions 9-8–9-11UTF-8 encoding 2-2, 3-7
Vversion
See also versionsin metadata query requests 8-11in operation records 8-19
version IDsSee also versionsabout 2-14for deleted versions 2-16for new versions 2-15using to retrieve versions and version
metadata 2-15versioning, effect on operation records 8-3versions
See also objectsabout 2-1, 2-14
Index–7
Using a Namespace

versions, adding in the Namespace Browser
adding in the Namespace Browser 10-10checking existence 4-12–4-15checking existence of custom metadata 7-6–
7-8creating 2-14–2-15deleted 2-16, 4-38deleted directories 2-14deleting objects with 2-16historic 2-15listing 4-16–4-21listing for deleted objects and
directories 4-16, 4-18–4-19listing for deleted objects and directories in
the Namespace Browser 10-9listing in the Namespace Browser 10-7–10-8listing, about 2-15metadata for 2-14operation records for 8-3pruning 2-14purging 2-16, 4-43–4-46retrieving 4-22, 4-32–4-38retrieving custom metadata 7-8–7-11retrieving in the Namespace Browser 10-9–
10-10retrieving, about 2-15viewing in the Namespace Browser 10-9–
10-10XML listing format 4-17
viewingaccessible namespaces in the Namespace
Browser 10-11–10-12namespace statistics in the Namespace
Browser 10-13–10-14objects in the Namespace Browser 10-9permissions in the Namespace
Browser 10-13retention classes in the Namespace
Browser 10-12versions in the Namespace Browser 10-9–
10-10
Wwhole-object URL query parameter 4-3Windows hosts file 3-4WORM 1-2write operations, failed 11-4–11-5write permission 1-8
XX-HCP-Custom-Metadata response header A-13X-HCP-CustomMetadataContentType response
header A-14
X-HCP-CustomMetadataFirst response header A-14
X-HCP-CustomMetadataHash response header A-14
X-HCP-DataContentType response header A-14X-HCP-DPL response header A-14X-HCP-ErrorMessage response header A-14X-HCP-Hash response header A-14X-HCP-Index response header A-15X-HCP-IngestTime response header A-15X-HCP-Replicated response header A-15X-HCP-Retention response header A-15X-HCP-RetentionClass response header A-15X-HCP-RetentionHold response header A-15X-HCP-RetentionString response header A-15X-HCP-Shred response header A-15X-HCP-Size response header A-15X-HCP-SoftwareVersion response header A-16X-HCP-Time response header A-16X-HCP-Type response header A-16X-HCP-UncompresseLength response
header A-13X-HCP-VersionID response header A-16XML
custom metadata format checking 2-17directory listing format 5-6–5-8metadata query API request format 8-8metadata query API response format 8-16namespace listing format 9-3namespace statistics listing format 9-12–
9-13permissions format 9-8–9-9retention class listing format 9-5specifying as metadata query response body
format 8-7version listing format 4-17
Zzero-sized files, storing 11-3
Index–8
Using a Namespace

Using a Namespace

MK-99ARC023-04
Hitachi Data Systems
Corporate Headquarters750 Central ExpresswaySanta Clara, California 95050-2627U.S.A.Phone: 1 408 970 [email protected]
Asia Pacific and Americas750 Central ExpresswaySanta Clara, California 95050-2627U.S.A.Phone: 1 408 970 [email protected]
Europe HeadquartersSefton ParkStoke PogesBuckinghamshire SL2 4HDUnited KingdomPhone: + 44 (0)1753 [email protected]


























![International Space University [venue] [date] [name] [title] [organization]](https://img.pdfslide.us/doc/110x75/56649d425503460f94a1d7ba/international-space-university-venue-date-name-title-organization.jpg)


