Embed Size (px)
Citation preview

Using a cluster analysis based case-mix solution to facilitate the evaluation and
development of adolescent substance abuse treatment programs.
Michael L. Dennis, Ph.D.Chestnut Health Systems, Bloomington, IL

Objectives
1. Identification of Clients with similar presenting pathology based on a cluster analysis of the GAIN’s core psychiatric and behavior scales.
2. Demonstration of how the “case-mix” of these subgroups impacts program averages.
3. Illustration of how psychiatric case mix groups can be used to aid program evaluation and planning within or across program evaluation.

Global Appraisal of Individual Needs (GAIN)
• A standardized bio-psycho-social that integrates clinical and research assessment for diagnosis, placement, treatment planning, process measures, outcome monitoring, and economic evaluation.
• Core sections include cognitive assessment, background/access, substance use, physical health, risk behaviors, mental health, environment, legal, vocational, staff ratings
• Over 100 scales/indices, with alpha over .9 on main scales and over .7 on subscales• Test retest data suggest reliability of items/scales over .7 • Self reported use consistent with urine, salvia, and collateral reports (Kappa of .81
or more)• Predicts blind diagnosis of co-occurring psychiatric disorders including ADHD
(kappa = 1.00), Mood Disorders (kappa = 0.85), Conduct Disorder or Oppositional Defiant Disorder (kappa = 0.82), Adjustment Disorder (kappa = 0.69), and No other diagnosis (kappa = 0.91)

Factor Structure and Cluster Analysis based on 2968 Clients from 61 Treatment Units
Adolescent Inpatient/Therapeutic CommunityAdolescent Outpatient/IOP
Adult Outpatient/IOP/OP Methadone TreatmentAdult Inpatient/Therapeutic Community
Oakland, CA
Shiprock, NMLos Angeles, CAPhoenix/Tempe, AZ
Tucson, AZ
Miami, FLSt. Petersburg, FL
Cantonsville, MDBaltimore, MD
New York, NYChicago, ILPeoria, IL
Maryville, IL
Philadelphia, PABloomington, IL
Farmington, CT

Hypothesized Structure of the GAIN’s Psychopathology Measures
* Main scales have alpha over .85, subscales over .7
S u b s ta n ce Issu e s In d exS u b s ta n ce A b u se In d exS u b s tan ce D e p e nd e n ce In d ex
S u b s ta nce U se S e ve rity
S o m atic S ym pto m In d exD e p re ss io n S ym p to m In d exH o m ic id a l/S u ic id a l T ho u g h t In d exA n x ie ty S ym p to m In d exT ra u m a tic D is tre ss In d ex
In te rn a l L ife D is tre ss
In a tten tiven e ss In d exH yp e ra c tiv ity -Im p lu s iv ity In d exC o n d u c t D iso rd e r In d ex
E x te rn a l L ife D is tre ss
G e n e ra l C o n flic t T a c tic S ca leP ro p e rty C rim e In d exIn te rp e rso n a l C rim e In d exD ru g C rim e In d ex
V io le n ce , D e lin q u e ncy & C rim e
G e n e ra l P a th o lo g ica l S e ve rity
Behavioral Complexity Crime and Violence
Internal Mental Distress
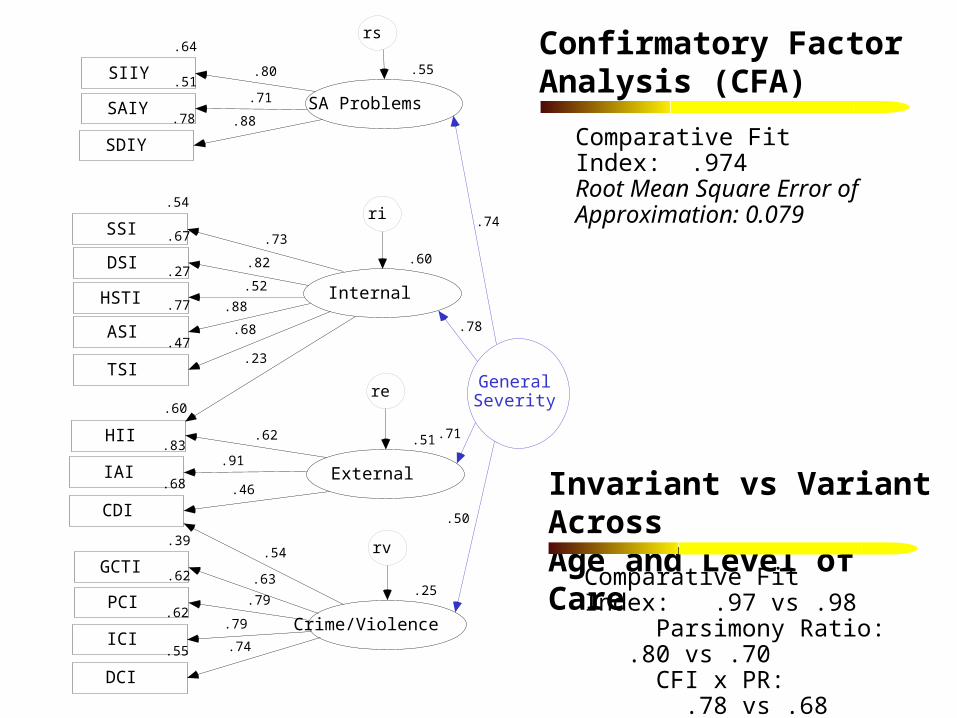
Confirmatory Factor Analysis (CFA)
Comparative Fit Index: .974 Root Mean Square Error of Approximation: 0.079
.60
Internal.27
HSTI
.67
DSI
.77
ASI.47
TSI
.51
External.68
CDI
.83
IAI
.60
HII
.25
Crime/Violence
.55
DCI
.62
ICI
.62
PCI
.39
GCTI
.55
SA Problems.78
SDIY
.51
SAIY
.64
SIIY
.54
SSI
.54
GeneralSeverity
.50
ri
re
rv
rs
.71
.78
.74
.68
.88
.52
.82
.73
.88
.71
.62
.91
.46
.23
.80
.74
.63
.79
.79
Comparative Fit Index: .97 vs .98 Parsimony Ratio: .80 vs .70 CFI x PR: .78 vs .68 Root Mean Square Error of Approximation: .04 vs .04
Invariant vs Variant AcrossAge and Level of Care

Creating Cluster Code Types
• The overall severity and four core dimensions were used to create 7 code types with Ward’s minimum distance cluster analysis.
• Total and four dimensional scores triaged into low, medium and high based on +/- .5 standard deviations from the mean
• Code types labeled most common group as: – High, medium or low overall severity on total score– Labeled in order from highest to lowest severity dimension– Lines // used to separate those in high/ medium/ low severity on each
each of four dimensions– Sample size
• Discriminate Function Analysis for Classifying New Cases (Kappa =.82)
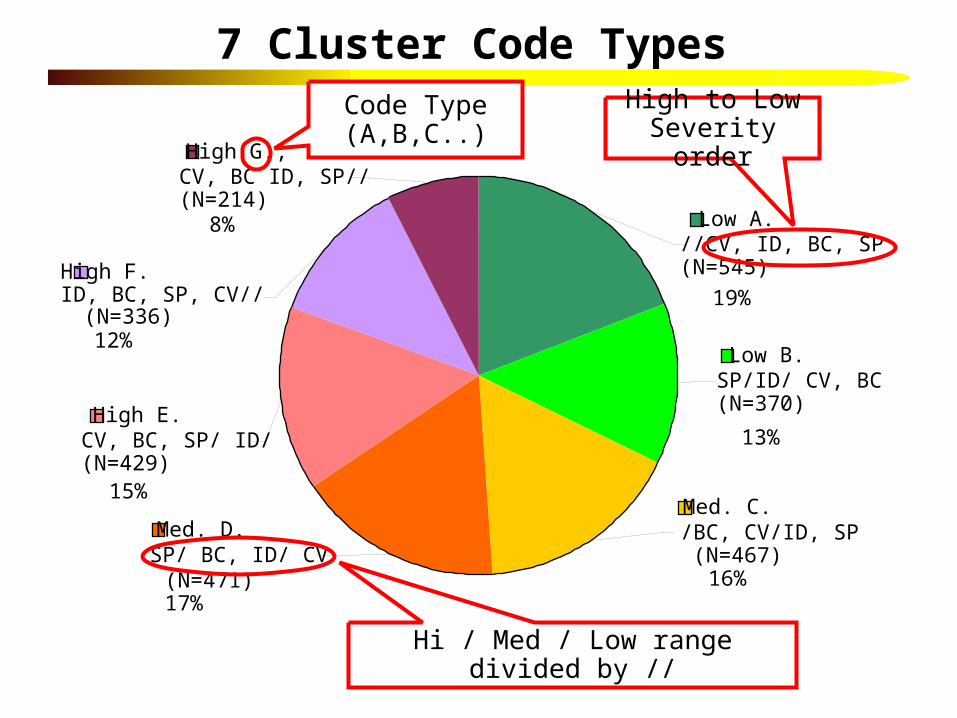
7 Cluster Code Types
High G., CV, BC ID, SP//(N=214)8%
High F. ID, BC, SP, CV// (N=336)12%
High E. CV, BC, SP/ ID/ (N=429)15%
Med. D. SP/ BC, ID/ CV(N=471)17%
Low A. //CV, ID, BC, SP (N=545)
19%
Low B. SP/ID/ CV, BC(N=370)
13%
Med. C. /BC, CV/ID, SP (N=467)16%
High to Low Severity order
Hi / Med / Low range divided by //
Code Type (A,B,C..)

General Severity by Code Type
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Low
A.
//CV
, ID
, BC
,S
P (N
=54
5)
Low
B.
SP
/ID
/ CV
,B
C (
N=
370)
Med
. C/B
C, C
V/ I
D,
SP
(N=
467)
Med
. DS
P/ B
C, I
D/
CV
(N
=47
1)
Hig
h E
CV
, BC
, SP
/ID
/ (N
=42
9)
Hig
h F.
ID, B
C, S
P,C
V//
(N=
336)
Hig
h G
.C
V, B
C, I
D,
SP
// (N
=21
4)
Tota
l(N
=28
32)
Low Severity Medium Severity High Severity Total

Substance Problem (SP) by Code Type
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Low
A.
//CV
, ID
, BC
,S
P (N
=54
5)
Low
B.
SP
/ID
/ CV
,B
C (
N=
370)
Med
. C/B
C, C
V/ I
D,
SP
(N=
467)
Med
. DS
P/ B
C, I
D/
CV
(N
=47
1)
Hig
h E
CV
, BC
, SP
/ID
/ (N
=42
9)
Hig
h F.
ID, B
C, S
P,C
V//
(N=
336)
Hig
h G
.C
V, B
C, I
D,
SP
// (N
=21
4)
Tota
l(N
=28
32)
Low Severity Medium Severity High Severity Total

Internal Distress (ID) by Code Type
Internal Distress (ID) Severity by Code Type
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Low
A.
//CV
, ID
, BC
,S
P (N
=54
5)
Low
B.
SP
/ID
/ CV
,B
C (
N=
370)
Med
. C/B
C, C
V/ I
D,
SP
(N=
467)
Med
. DS
P/ B
C, I
D/
CV
(N
=47
1)
Hig
h E
CV
, BC
, SP
/ID
/ (N
=42
9)
Hig
h F.
ID, B
C, S
P,C
V//
(N=
336)
Hig
h G
.C
V, B
C, I
D,
SP
// (N
=21
4)
Tota
l(N
=28
32)
Low Severity Medium Severity High Severity Total

Behavior Complexity (BC) by Code TypeBehavior Complexity (BC) Severity by Code Type
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Low
A.
//CV
, ID
, BC
,S
P (N
=54
5)
Low
B.
SP
/ID
/ CV
,B
C (
N=
370)
Med
. C/B
C, C
V/ I
D,
SP
(N=
467)
Med
. DS
P/ B
C, I
D/
CV
(N
=47
1)
Hig
h E
CV
, BC
, SP
/ID
/ (N
=42
9)
Hig
h F.
ID, B
C, S
P,C
V//
(N=
336)
Hig
h G
.C
V, B
C, I
D,
SP
// (N
=21
4)
Tota
l(N
=28
32)
Low Severity Medium Severity High Severity Total

Behavior Complexity (CV) by Code Type
Crime/Violence (CV) Severity by Code Type
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Low
A.
//CV
, ID
, BC
,S
P (N
=54
5)
Low
B.
SP
/ID
/ CV
,B
C (
N=
370)
Med
. C/B
C, C
V/ I
D,
SP
(N=
467)
Med
. DS
P/ B
C, I
D/
CV
(N
=47
1)
Hig
h E
CV
, BC
, SP
/ID
/ (N
=42
9)
Hig
h F.
ID, B
C, S
P,C
V//
(N=
336)
Hig
h G
.C
V, B
C, I
D,
SP
// (N
=21
4)
Tota
l(N
=28
32)
Low Severity Medium Severity High Severity Total
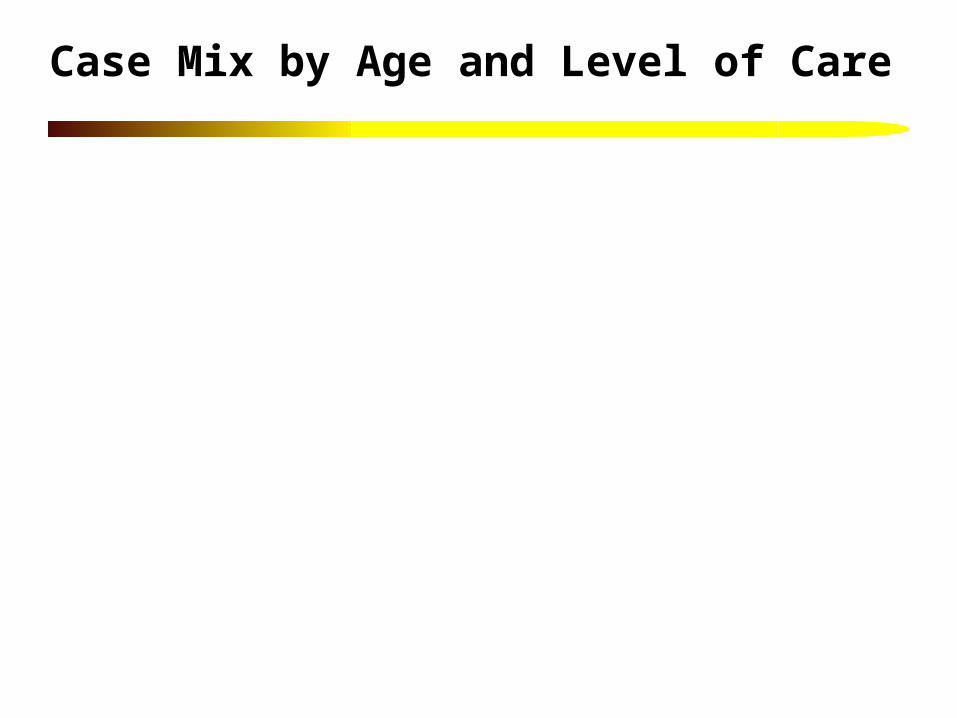
Case Mix by Age and Level of Care
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Adol. OP
Adol Residential
Adult OP
Adult Residential
Low A. //CV, ID, BC, SP (N=545) Low B. SP/ID/ CV, BC (N=370)Med. C. /BC, CV/ ID, SP (N=467) Med. D. SP/ BC, ID/ CV (N=471)High E. CV, BC, SP/ ID/ (N=429) High F. ID, BC, SP, CV// (N=336)High G. CV, BC, ID, SP// (N=214)

Sponsored By:Center for Substance Abuse Treatment (CSAT),Substance Abuse and Mental Health Services Administration (SAMHSA),U.S. Department of Health and Human Services (DHHS)
Adolescent Treatment Model Program SitesATM
1999
1998
Miami, FL
Bloomington, IL
Cantonsville, MD
Tempe, AZ
Shiprock, NM
Baltimore, MD
Los Angeles, CA
Oakland, CA
New York, NY
Tucson, AZ

ATM involved the full range of Code Types
A-Low //CV,ID,BC,S
P15%
B-Low /SP,ID/CV,BC
7%
D-Mod SP/BC,ID/CV
16%
C-Mod BC/CV,ID/SP
20%
E-High CV,BC,SP/ID/
18%
F-High ID,BC,SP/CV/-
-12%
G-High CV,BC,ID,SP/
/12%

Evaluating Cluster Code Types
• Severity should go up with level of care (LOC) – one of the most commonly used case mix variables.
• The cluster code type should do better than LOC in terms of: – Maximizing individual differences between
cluster subgroups– Minimizing individual indifference by LOC
within cluster subgroups• The cluster code types should help to predict
differential response patterns to treatment

Case Mix Severity Goes up With Level of Care
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Early Intervention OP/IOP LTR STR
G-HighCV,BC,ID,SP//
F-HighID,BC,SP/CV/--
E-HighCV,BC,SP/ID/
D-ModSP/BC,ID/CV
C-ModBC/CV,ID/SP
B-Low/SP,ID/CV,BC
A-Low//CV,ID,BC,SP
PCM Index Score
PCM Index Score (Weighted Average)

Level of Care Is Related to “Average” Severity
-4.0
-3.0
-2.0
-1.0
0.0
1.0
2.0
3.0
4.0
Tot
al S
core
(f=
0.4)
SP
. Sub
stan
ceP
robl
em(f
=0.
26)
ID.
Inte
rnal
Dis
tres
s(f
=0.
29)
BC
Beh
avio
rC
ompl
exit
y(f
=0.
28)
CV
.C
rim
e/V
iole
nce
(f=
0.14
)
Z-s
core
OP (n=553)
LTR (n=373)
STR (n=573)
Individual Differences explained by
LOC quantified
with Cohen’s effect size f

However Cluster Subgroups are More Distinct From Each Other
-4.0
-3.0
-2.0
-1.0
0.0
1.0
2.0
3.0
4.0
Tot
al S
core
(f=
1.75
)
SP
. Sub
stan
ceP
robl
em(f
=0.
48)
ID.
Inte
rnal
Dis
tres
s(f
=1.
19)
BC
Beh
avio
rC
ompl
exit
y(f
=1.
85)
CV
.Cri
me
Vio
lenc
e(f
=1.
19)
Z-s
core
A-Low//CV,ID,BC,SP(n=208)
B-Low/SP,ID/CV,BC(n=101)
C-ModBC/CV,ID/SP(n=286)
D-ModSP/BC,ID/CV(n=252)
E-HighCV,BC,SP/ID/(n=281)
F-HighID,BC,SP/CV/--(n=180)
G-HighCV,BC,ID,SP//(n=191)+338% +85% +310% +561% +750%
Cohen’s effect size f increased by 85% to 750%

-4.0
-3.0
-2.0
-1.0
0.0
1.0
2.0
3.0
4.0T
otal
Sco
re(f
=0.
05)
SP
. Sub
stan
ceP
robl
em(f
=0.
04)
ID.
Inte
rnal
Dis
tres
s(f
=0.
11)
BC
Beh
avio
rC
ompl
exit
y(f
=0.
16)
CV
.C
rim
e/V
iole
nce
(f=
0.04
)
Z-s
core
OP (n=114)
LTR (n=59)
STR (n=35)
A-Low //CV,ID,BC,SP
Once we account for subgroup,
LOC differences are
gone and Cohen’s effect
size f goes down
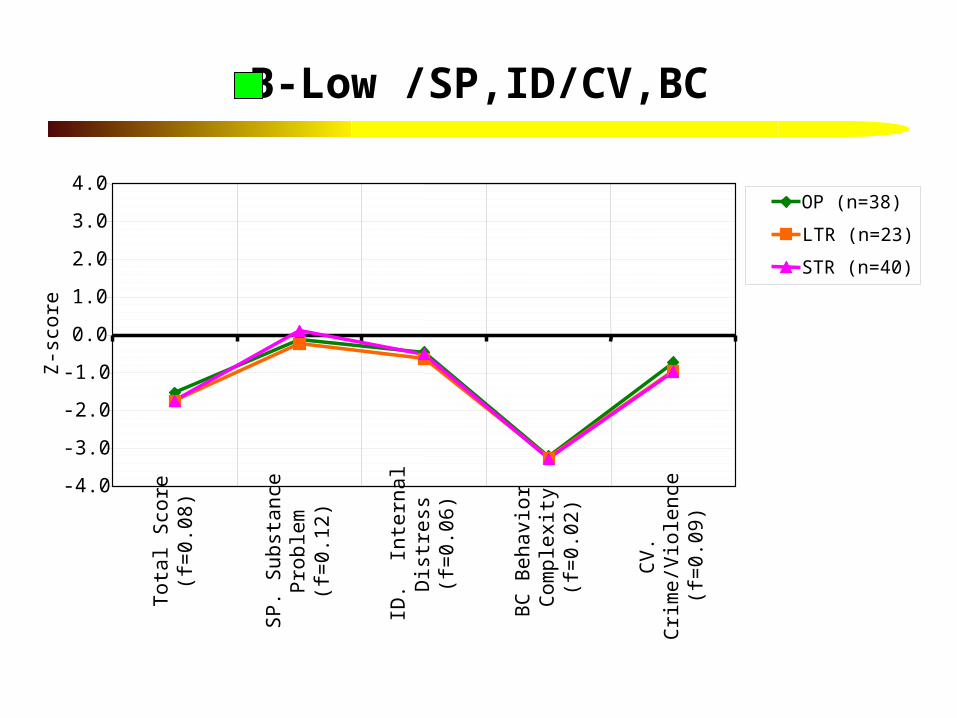
B-Low /SP,ID/CV,BC
-4.0
-3.0
-2.0
-1.0
0.0
1.0
2.0
3.0
4.0T
otal
Sco
re(f
=0.
08)
SP
. Sub
stan
ceP
robl
em(f
=0.
12)
ID.
Inte
rnal
Dis
tres
s(f
=0.
06)
BC
Beh
avio
rC
ompl
exit
y(f
=0.
02)
CV
.C
rim
e/V
iole
nce
(f=
0.09
)
Z-s
core
OP (n=38)
LTR (n=23)
STR (n=40)
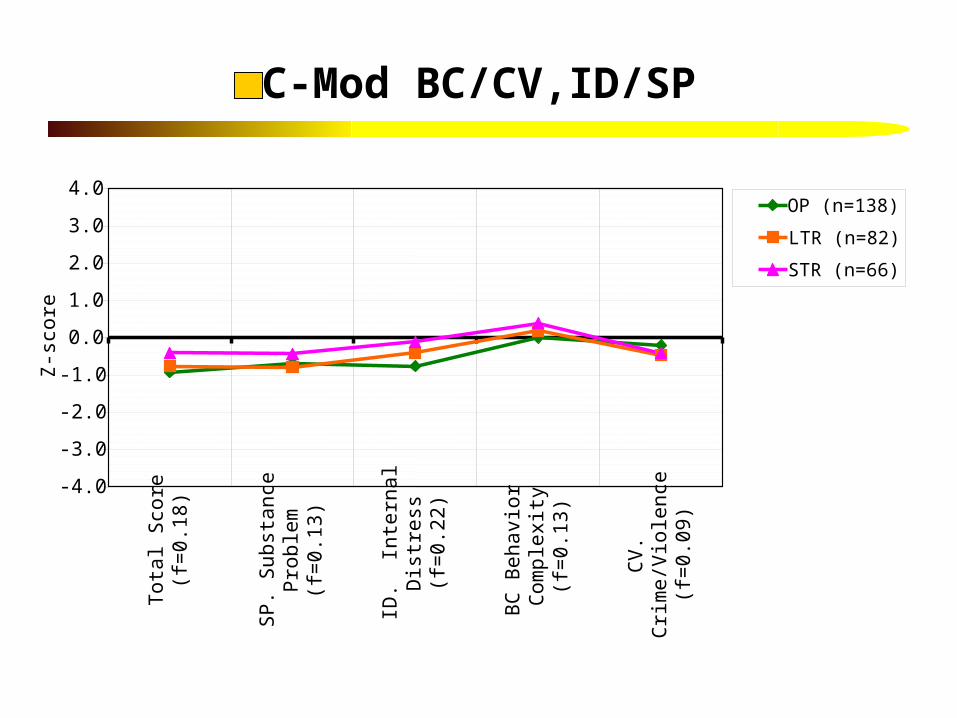
C-Mod BC/CV,ID/SP
-4.0
-3.0
-2.0
-1.0
0.0
1.0
2.0
3.0
4.0
Tot
al S
core
(f=
0.18
)
SP
. Sub
stan
ceP
robl
em(f
=0.
13)
ID.
Inte
rnal
Dis
tres
s(f
=0.
22)
BC
Beh
avio
rC
ompl
exit
y(f
=0.
13)
CV
.C
rim
e/V
iole
nce
(f=
0.09
)
Z-s
core
OP (n=138)
LTR (n=82)
STR (n=66)

D-Mod SP/BC,ID/CV
-4.0
-3.0
-2.0
-1.0
0.0
1.0
2.0
3.0
4.0T
otal
Sco
re(f
=0.
17)
SP
. Sub
stan
ceP
robl
em(f
=0.
18)
ID.
Inte
rnal
Dis
tres
s(f
=0.
14)
BC
Beh
avio
rC
ompl
exit
y(f
=0.
1)
CV
.C
rim
e/V
iole
nce
(f=
0.1)
Z-s
core
OP (n=78)
LTR (n=57)
STR (n=117)

E-High CV,BC,SP/ID/
-4.0
-3.0
-2.0
-1.0
0.0
1.0
2.0
3.0
4.0T
otal
Sco
re(f
=0.
13)
SP
. Sub
stan
ceP
robl
em(f
=0.
22)
ID.
Inte
rnal
Dis
tres
s(f
=0.
14)
BC
Beh
avio
rC
ompl
exit
y(f
=0.
08)
CV
.C
rim
e/V
iole
nce
(f=
0.08
)
Z-s
core
OP (n=103)
LTR (n=50)
STR (n=128)

F-High ID,BC,SP/CV/
-4.0
-3.0
-2.0
-1.0
0.0
1.0
2.0
3.0
4.0
Tot
al S
core
(f=
0.06
)
SP
. Sub
stan
ceP
robl
em(f
=0.
18)
ID.
Inte
rnal
Dis
tres
s(f
=0.
05)
BC
Beh
avio
rC
ompl
exit
y(f
=0.
06)
CV
.C
rim
e/V
iole
nce
(f=
0.08
)
Z-s
core
OP (n=43)
LTR (n=44)
STR (n=93)

G-High CV,BC,ID,SP//
-4.0
-3.0
-2.0
-1.0
0.0
1.0
2.0
3.0
4.0
Tot
al S
core
(f=
0.15
)
SP
. Sub
stan
ceP
robl
em(f
=0.
28)
ID.
Inte
rnal
Dis
tres
s (f
=0.
1)
BC
Beh
avio
rC
ompl
exit
y(f
=0.
13)
CV
.C
rim
e/V
iole
nce
(f=
0.06
)
Z-s
core
OP (n=39)
LTR (n=58)
STR (n=94)

Cluster Subgroups Significantly Reduces the Individual Differences Associated with Level of Care
-100.0%
-80.0%
-60.0%
-40.0%
-20.0%
0.0%
20.0%
40.0%
60.0%
80.0%
100.0%T
otal
Sco
re
SP
. Sub
stan
ceP
robl
em
ID.
Inte
rnal
Dis
tres
s
BC
Beh
avio
rC
ompl
exit
y
CV
.C
rim
e/V
iole
nce
Cha
nge
in L
OC
Eff
ect S
ize
f
A-Low//CV,ID,BC,SP(n=208)
B-Low /SP,ID/CV,BC(n=101)
C-Mod BC/CV,ID/SP(n=286)
D-Mod SP/BC,ID/CV(n=252)
E-High CV,BC,SP/ID/(n=281)
F-HighID,BC,SP/CV/--(n=180)
G-HighCV,BC,ID,SP//(n=191)

Outpatient by Cluster Types
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0 6 12
Months from Intake
Su
bst
ance
Fre
qu
ency
Sca
le
A-Low //CV,ID,BC,SP
B-Low /SP,ID/CV,BC
C-Mod BC/CV,ID/SP
D-Mod SP/BC,ID/CV
E-High CV,BC,SP/ID/
F-High ID,BC,SP/CV/--
G-High CV,BC,ID,SP//
Differentiates initial severity, and differences in response

Long Term Residential by Cluster Types
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0 6 12
Months from Intake
Su
bst
ance
Fre
qu
ency
Sca
le
A-Low //CV,ID,BC,SP
B-Low /SP,ID/CV,BC
C-Mod BC/CV,ID/SP
D-Mod SP/BC,ID/CV
E-High CV,BC,SP/ID/
F-High ID,BC,SP/CV/--
G-High CV,BC,ID,SP//
Can identify subgroups (E, B) that are a higher risk of relapse or having other problems
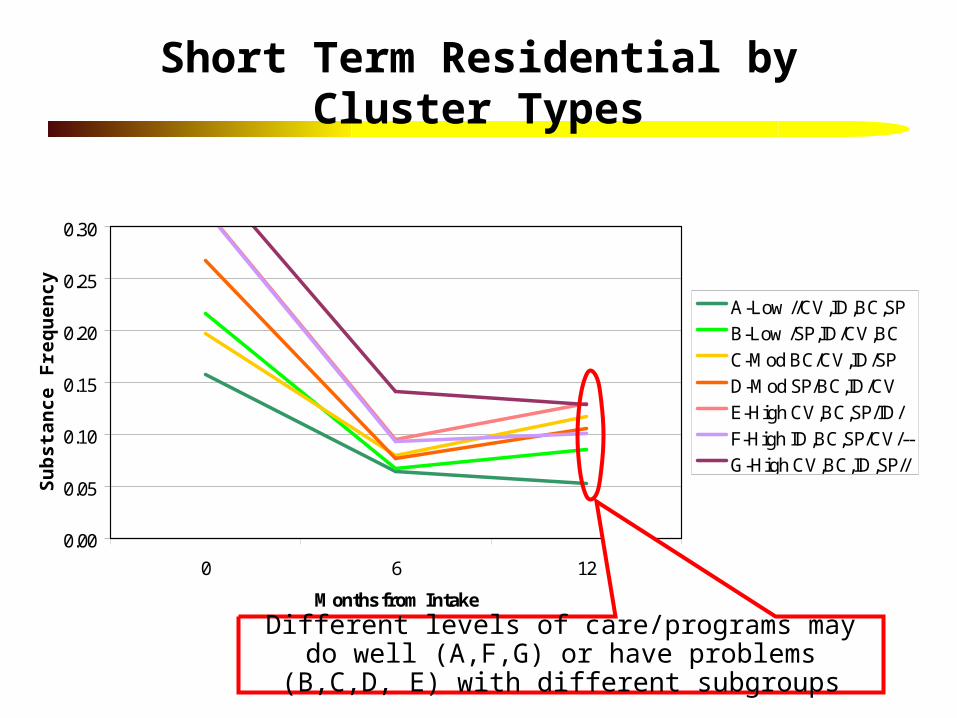
Short Term Residential by Cluster Types
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0 6 12
Months from Intake
Su
bst
ance
Fre
qu
ency
Sca
le
A-Low //CV,ID,BC,SP
B-Low /SP,ID/CV,BC
C-Mod BC/CV,ID/SP
D-Mod SP/BC,ID/CV
E-High CV,BC,SP/ID/
F-High ID,BC,SP/CV/--
G-High CV,BC,ID,SP//
Different levels of care/programs may do well (A,F,G) or have problems (B,C,D, E) with different subgroups

0.00
0.05
0.10
0.15
0.20
0.25
0.30
0 6 12
Months from Intake
Su
bst
ance
Fre
qu
ency
Sca
le
OP/IOP
LTR
STR
For a Given Subtype, it can identify when a particular level of care (or
program) appears to do better.
C-Mod BC/CV,ID/SP by LOC
However this is still quasi-experimental and the
adjustments are often imperfect

Conclusions
• Clustering people based on presenting problems appears to work better than level of care for describing initial case mix but is also correlated with it.
• Clinical subtype clusters can help to identify subgroups for which a program works well and/or where continuing care or other services may be needed.
• Within a clinical subtype, comparisons of level of care (programs, services etc) could be used to guide placement decisions and/or identify promising areas for experimentation.

Contact Information
Michael L. Dennis, Ph.D.
Lighthouse Institute, Chestnut Health Systems
720 West Chestnut, Bloomington, IL 61701
Phone: (309) 827-6026, Fax: (309) 829-4661
E-Mail: [email protected]
A copy of these slides will be posted at: www.chestnut.org/li/posters

Errata
The following additional slide was presented by the discussant, Dr. Mark Fishman, to show how case mix varied at the program level even within level of care.

Case Mix by Level of Care/ATM program
0%
20%
40%
60%
80%
100%
EI M
iam
i MD
FT
EI-
Mia
mi V
illag
e
OP-
Blo
omin
gton
OP-
Cat
onsv
ille
LTR
-LA
MH
Gro
up H
omes
OP-
Phoe
nix
AD
JC
STR
-Shi
proc
k
LTR
-LA
Pho
enix
Hou
se
OP-
Tucs
on 7
Cha
lleng
es
OP-
Tucs
on D
rug
Cou
rt
OP-
Phoe
nix
TSA
T
STR
-Oak
land
STR
-Tuc
son
La
Can
ada
LTR
-NY
Res
iden
tial
LTR
-Oak
land
STR
-Bal
timor
e
7-HighCV,BC,ID,SP//
6-HighID,BC,SP/CV/--
5-HighCV,BC,SP/ID/
4-ModSP/BC,ID/CV
3-ModBC/CV,ID/SP
2-Low/SP,ID/CV,BC
1-Low//CV,ID,BC,SP
PCM Index Score
Early Intervention at the low end
STR/LTR dominates high end
Also demonstrates that Level of Care is only a rough proxy of case mix





























