Embed Size (px)
Citation preview

U.S. Department of the InteriorU.S. Geological Survey
David V. Hill, Information Dynamics, David V. Hill, Information Dynamics, Contractor to USGS/EROSContractor to USGS/EROS12/08/201112/08/2011
Satellite Image Processing And Satellite Image Processing And Production With Apache HadoopProduction With Apache Hadoop

Overview Apache HadoopApache Hadoop Applications, Environment and Use CaseApplications, Environment and Use Case Log Processing ExampleLog Processing Example EROS Science Processing Architecture (ESPA) and EROS Science Processing Architecture (ESPA) and
HadoopHadoop ESPA Processing ExampleESPA Processing Example ESPA Implementation StrategyESPA Implementation Strategy Performance ResultsPerformance Results Thoughts, Notes and TakeawayThoughts, Notes and Takeaway QuestionsQuestions

Apache Hadoop – What is it?
Open source distributed processing systemOpen source distributed processing system Designed to run on commodity hardwareDesigned to run on commodity hardware Widely used for solving “Big Data” challengesWidely used for solving “Big Data” challenges Has been deployed in clusters with thousands of Has been deployed in clusters with thousands of
machines and petabytes of storagemachines and petabytes of storage Two primary subsystems: Hadoop Distributed File Two primary subsystems: Hadoop Distributed File
System (HDFS) and the MapReduce engineSystem (HDFS) and the MapReduce engine

Hadoop’s Applications
Web content indexingWeb content indexing Data miningData mining Machine learningMachine learning Statistical analysis and modelingStatistical analysis and modeling Trend analysisTrend analysis Search optimizationSearch optimization … … and of course, satellite image processing!and of course, satellite image processing!

Hadoop’s Environment
Linux and UnixLinux and Unix Java based but relies on ssh for job distribution Java based but relies on ssh for job distribution Jobs written in any language executable from shell Jobs written in any language executable from shell
promptprompt Java, C/C++, Perl, Python, Ruby, R, Bash, et. al.Java, C/C++, Perl, Python, Ruby, R, Bash, et. al.

Hadoop’s Use Case
Cluster of machines is configured into a Hadoop Cluster of machines is configured into a Hadoop clustercluster
Each contributes:Each contributes: Local compute resources to MapReduce Local storage resources to HDFS
Files are stored in HDFSFiles are stored in HDFS File size is typically measured in gigabytes and terabytes
Job is run against an input file in HDFSJob is run against an input file in HDFS Target input file is specified Code to run against input also specified

Hadoop’s Use Case
Unlike traditional systems which move data to the Unlike traditional systems which move data to the code, Hadoop flips this and moves code to the data code, Hadoop flips this and moves code to the data
Two software functions comprise a MapReduce jobTwo software functions comprise a MapReduce job Map operation Reduce operation
Upon execution:Upon execution: Hadoop identifies input file chunk locations, moves the algorithms
and executes the code The “Map”
Sorts the Map results and aggregates final answer (single thread) The “Reduce”
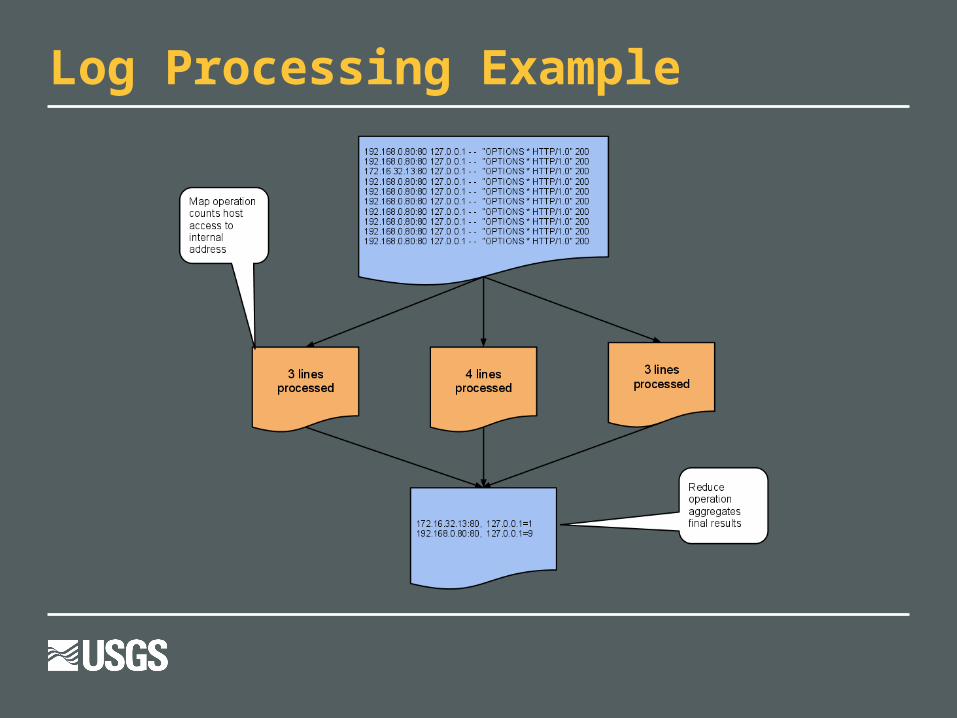
Log Processing Example

ESPA and Hadoop
Hadoop map code runs parallel on the input (log file)Hadoop map code runs parallel on the input (log file) Processes a single input file as quickly as possible
Reduce code runs on mapper outputReduce code runs on mapper output ESPA processes satellite images, not textESPA processes satellite images, not text
Algorithms cannot run parallel within an image Cannot use satellite images as the input
Solution: Use a text file with the image location as Solution: Use a text file with the image location as input. Skip the reduce stepinput. Skip the reduce step
Rather than parallelize within an image, ESPA Rather than parallelize within an image, ESPA handles many images at oncehandles many images at once
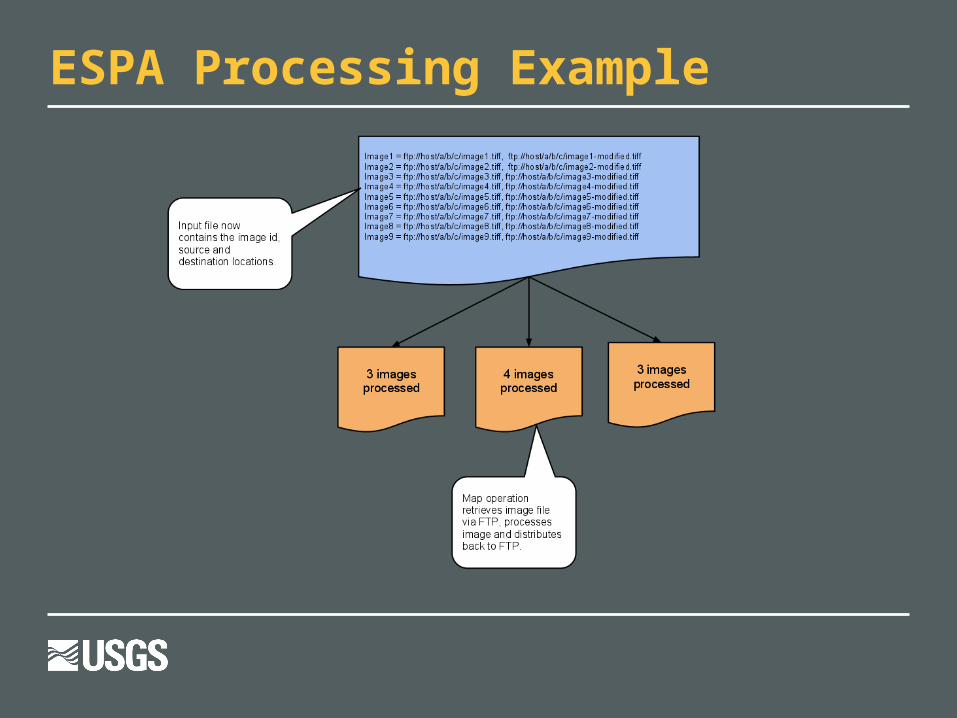
ESPA Processing Example

Implementation Strategy
LSRD is budget constrained for hardwareLSRD is budget constrained for hardware Other projects regularly excess old hardware Other projects regularly excess old hardware
upon warranty expirationupon warranty expiration Take ownership of these systems… if they fail, Take ownership of these systems… if they fail,
they failthey fail Also ‘borrow’ compute and storage from other Also ‘borrow’ compute and storage from other
projectsprojects Only network connectivity is necessary
Current cluster is 102 cores, minimal expenseCurrent cluster is 102 cores, minimal expense Cables, switches, etc

Performance Results
Original throughput requirement was 455 Original throughput requirement was 455 atmospherically corrected Landsat scenes per dayatmospherically corrected Landsat scenes per day
Currently able to process ~ 4800!Currently able to process ~ 4800! Biggest bottleneck is local machine storage Biggest bottleneck is local machine storage
input/outputinput/output Due to implementation of ftp’ing files instead of using HDFS as
intended
Attempted to solve this with ram disk, not enough Attempted to solve this with ram disk, not enough memorymemory
Currently evaluating solid state diskCurrently evaluating solid state disk

Thoughts and Notes
Number of splits on input file can be Number of splits on input file can be controlled via the dfs.block.size parametercontrolled via the dfs.block.size parameter Therefore control number of jobs run against an input
file
ESPA-like implementation does not require ESPA-like implementation does not require massive storage unlike other Hadoop massive storage unlike other Hadoop instancesinstances Input files are very small
Robust internal job monitoring mechanisms Robust internal job monitoring mechanisms are usually custom-builtare usually custom-built

Thoughts and Notes
Jobs written for Hadoop Streaming may be Jobs written for Hadoop Streaming may be tested and run without Hadooptested and run without Hadoop cat inputfile.txt | mapper.py | sort | reducer.py > out.txt
Projects can share resourcesProjects can share resources Hadoop is tunable to restrict resource utilization on a
per machine basis
Provides instant productivity gains versus Provides instant productivity gains versus internal developmentinternal development LSRD is all about science and science algorithms Minimal time and budget for building internal systems

Takeaways
Hadoop is proven and testedHadoop is proven and tested Massively scalable out of the boxMassively scalable out of the box Cloud based instances available from Amazon and Cloud based instances available from Amazon and
othersothers Shortest path to processing massive amounts of dataShortest path to processing massive amounts of data Extremely hardware failure tolerantExtremely hardware failure tolerant No specialized hardware or software neededNo specialized hardware or software needed Flexible job API allows existing software skills to be Flexible job API allows existing software skills to be
leveragedleveraged Industry adoption means support skills availableIndustry adoption means support skills available

Questions





























