Embed Size (px)
DESCRIPTION
ABout vnx
Citation preview

Follow us on the web!
Search the VNX Series page for “Uptime Bulletin” here:
https://support.emc.com/products/12781
VOLUME 6 September 2013 Understanding how pool LUN ownership and tres-
passed LUNs can impact performance as well as uptime The following article applies to the VNX 05.31.x.x.x and 05.32.x.x.x. families of code only.
The introduction of Pool LUNs provided users with many benefits not possible with traditional LUNs. Pools support Thin LUNs, and Thin LUNs offer customers more flexibility when configuring and allocating storage since Thin LUNs allocate their space from the pool “on demand,” and can be over-provisioned. Over-provisioning allows a system administrator to present more potential storage space to users than is actually available in the pool. Since the space is allocated and consumed “on demand,” the users enjoy more flexibility in their planning and allocating of storage space. Pools can be easily expanded on an as needed basis.
Along with the increased flexibility and simplicity offered by Pools comes some underlying changes in the ar-chitecture that have very real implications on design and performance that not everyone is familiar with. This article will discuss the impact of trespassed Pool LUNs, one of the most common configuration problems asso-ciated with Pool LUNs, and will provide tips on how to avoid unexpected performance problems.
Pools allow for the creation and deployment of Thin LUNs. Thin LUNs differ from traditional LUNs in several key ways. When a traditional LUN is created, all of its configured space is carved out and allocated up front. The traditional LUN is assigned a default owner, and a current owner. Initially, these are both set to the same storage processor (SP). During the life of a traditional LUN, circumstances may cause the LUN to trespass over to the peer SP. When this happens, the LUN’s current owner will change. When a traditional LUN re-sides on its non-default SP, there is no significant performance impact other than the increased load on the peer SP associated with the extra LUN or LUNs that it now owns.
When a Pool is created, a large number of private FLARE LUNs are bound on all the Pool drives, and these drives are divided up between SP-A and SP-B. When a Pool LUN is created, it uses a new category of LUN ownership called the allocation owner to determine which SP’s private LUNs should be used to store the Pool LUN slices. For example, a Pool LUN created with SP-A as its allocation owner will be allocating its space from private FLARE LUNs owned by SP-A.
When a Pool LUN is created, its allocation owner is the same as its default and current owner. A Pool LUN’s default owner should never be changed from its allocation owner. If a Pool LUN’s current owner differs from its allocation owner, I/O to that LUN will have to pass over the CMI bus between SPs in order to reach the under-lying Pool private FLARE LUNs. This is inefficient and may introduce performance problems.
When Pool LUN ownerships (default, allocation, and current) do not match, it creates a potentially sizeable performance bottleneck. If enough LUNs have inconsistent ownerships, performance can bottleneck to the point where host I/Os can timeout and even result in data unavailability in extreme cases. Every effort should be made to maintain consistent ownership of Pool LUNs. EMC recommends avoiding prolonged peri-ods of having trespassed Pool LUNs.
For more information about Pool LUN ownership settings, see knowledge-base article 88169: Setting the Pool LUN default and allocation owner correctly. For information about several other performance related concerns specific to Pool LUNs, see knowledge-base article 15782: How to fix Pool performance issues.
WE’D LIKE TO HEAR YOUR
COMMENTS ABOUT THE UP-TIME BULLETIN. SEND US
YOUR IDEAS FOR FUTURE
ISSUES AT :
Customer Documenta-tion
https://mydocs.emc.com/VNX
http://emc.com/vnxesupport
Pool LUN owner-
ship concerns. 1
248 Day reboot
issue reminder. 2
Vault drive replace-ment procedure
tips.
2
Array power down
tips. 2
Target code revi-
sions and key fixes. 3
Storage pool re-served space re-quirements by soft-
ware revision.
4
VNX Block OE
32.207 key fixes. 4
For VNX/VNXe

How do I subscribe to EMC Technical Advisories?
Within EMC Online Support, users can sub-scribe to advisories for individual products from the Support by Product pages. Under Adviso-ries on the left side of a given product page, click Get Advisory Alerts to subscribe. You can also view and manage subscriptions for multiple
products within Preferences > Subscriptions &
Alerts > Product Advisories.
More VNX Storage Systems Approach 248 Day Reboot The following article applies to VNX Block OE code family 05.31.x.x.x only.
More VNX Storage Systems running VNX Block OE versions earlier than 05.31.000.5.720 are approaching 248 consecutive days of uptime; this makes them vulnerable to a known Storage Processor (SP) reboot issue that may occur on systems run-ning iSCSI.
VNX systems with iSCSI-attached hosts may have a single or dual storage processor (SP) reboot after 248 days of uptime. This is a concern for systems running VNX Block OE versions earlier than 05.31.000.5.720. It is possible that these reboots could occur at the same time. If this happens, vulnerable storage systems are at risk of a brief data unavailability (DU) or even a cache dirty/data loss situation.
This known issue is one of the most important reasons to ensure that your storage system is running newer code. The current target VNX Block OE code is 05.31.000.5.726. Any code that is 05.31.000.5.720 or later contains a fix for this issue.
References
Refer to ETA emc291837: VNX: Single or dual storage processor (SP) reboots on VNX systems after 248 days of runtime for detailed infor-mation on this issue, or when contacting support.
Vault drive replacement procedure tips and best practices. On the VNX series storage platform, the first 4 drives in enclosure 0 (slots 0, 1, 2, and 3) are considered the vault drives. In addition to po-
tentially holding user data, these drives also hold the VNX OE software. Replacing all of your vault drives should not be undertaken lightly, and the complete swapping of vault drives should only be performed by EMC personnel. It is always a good idea to generate a full set of spcollects before and after the entire procedure has been attempted. In the unlikely event that anything should ever go wrong with the procedure, having full sets of spcollects from immediately before and after the attempted procedure can be the key to successfully recover-
ing data. Note that you cannot swap NL-SAS drives in the vault with SAS drives. Mixed drive types in the vault are not supported.
There are many other specific steps and restrictions spelled out by the official EMC procedures for swapping out vault drives. Among them
is the order in which the drives are replaced. While this order is no longer as critical as it once was in past storage system generations, it should still be followed. The amount of time you delay between removing a drive and inserting the new replacement drive continues to be a very important factor, however. You should always ensure that you wait at least 30 seconds before inserting the replacement disk. This allows the VNX OE enough time to fully realize that the drive has been removed and replaced with a new disk. If a replacement drive is in-
serted too quickly after removing the old drive, DU/DL could occur. This delay between removing a drive and inserting a new one is impor-tant when proactively swapping out any drive that has not yet failed.
Common mistakes and serious ramifications of incorrect or unplanned power downs of VNX storage systems. Past VNX Uptime Bulletins have shared details of many bug fixes or best practices which can help avoid
outages and improve uptime statistics on your VNX storage system. It may surprise you to learn that the most common, ongoing cause of outages on the VNX platform is the improper shutdown of the VNX storage system. Never power down your system simply by pulling cables. Pulling cables to achieve a power down of your system can bypass the system’s ability to protect its cache.
Detailed VNX storage array power down procedures can be found here: https://mydocus.emc.com/VNX/requestMyDoc.jsp.
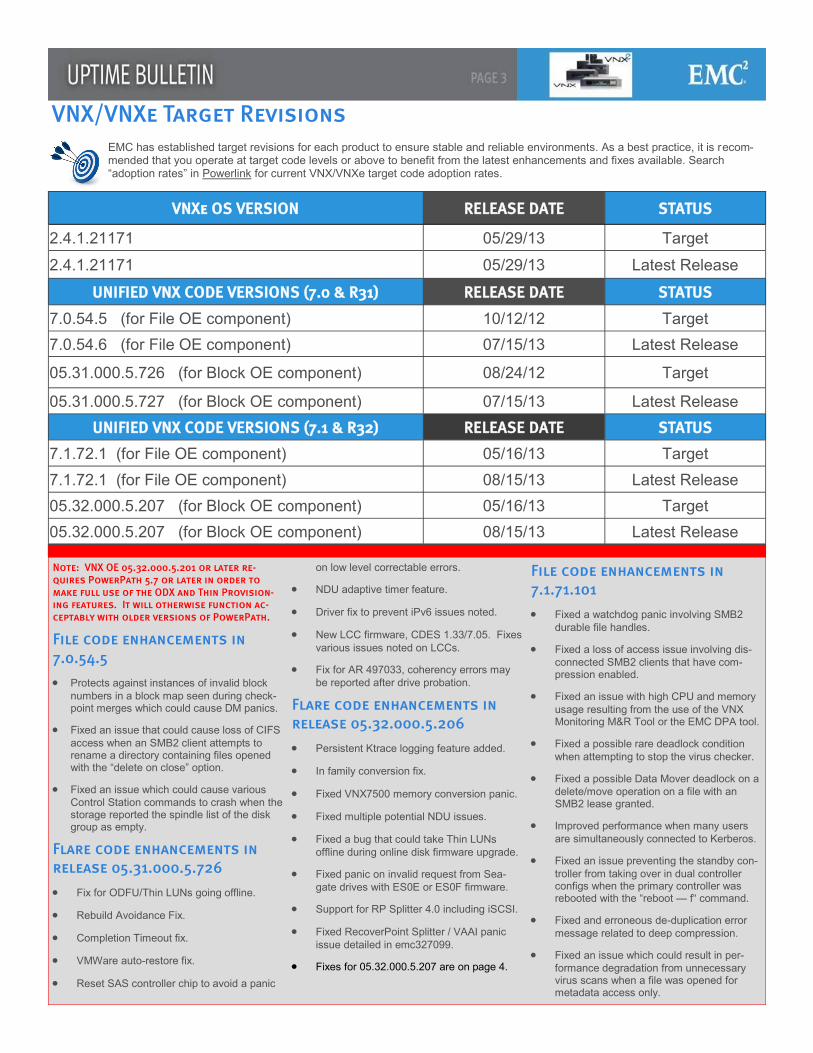
VNX/VNXe Target Revisions EMC has established target revisions for each product to ensure stable and reliable environments. As a best practice, it is recom-mended that you operate at target code levels or above to benefit from the latest enhancements and fixes available. Search “adoption rates” in Powerlink for current VNX/VNXe target code adoption rates.
VNXe OS VERSION RELEASE DATE STATUS
2.4.1.21171 05/29/13 Target
2.4.1.21171 05/29/13 Latest Release
UNIFIED VNX CODE VERSIONS (7.0 & R31) RELEASE DATE STATUS
7.0.54.5 (for File OE component) 10/12/12 Target
7.0.54.6 (for File OE component) 07/15/13 Latest Release
05.31.000.5.726 (for Block OE component) 08/24/12 Target
05.31.000.5.727 (for Block OE component) 07/15/13 Latest Release
UNIFIED VNX CODE VERSIONS (7.1 & R32) RELEASE DATE STATUS
7.1.72.1 (for File OE component) 05/16/13 Target
7.1.72.1 (for File OE component) 08/15/13 Latest Release
05.32.000.5.207 (for Block OE component) 05/16/13 Target
05.32.000.5.207 (for Block OE component) 08/15/13 Latest Release
Note: VNX OE 05.32.000.5.201 or later re-quires PowerPath 5.7 or later in order to make full use of the ODX and Thin Provision-ing features. It will otherwise function ac-ceptably with older versions of PowerPath.
File code enhancements in 7.0.54.5
Protects against instances of invalid block
numbers in a block map seen during check-point merges which could cause DM panics.
Fixed an issue that could cause loss of CIFS
access when an SMB2 client attempts to rename a directory containing files opened with the “delete on close” option.
Fixed an issue which could cause various
Control Station commands to crash when the storage reported the spindle list of the disk group as empty.
Flare code enhancements in release 05.31.000.5.726
Fix for ODFU/Thin LUNs going offline.
Rebuild Avoidance Fix.
Completion Timeout fix.
VMWare auto-restore fix.
Reset SAS controller chip to avoid a panic
on low level correctable errors.
NDU adaptive timer feature.
Driver fix to prevent iPv6 issues noted.
New LCC firmware, CDES 1.33/7.05. Fixes
various issues noted on LCCs.
Fix for AR 497033, coherency errors may
be reported after drive probation.
Flare code enhancements in release 05.32.000.5.206
Persistent Ktrace logging feature added.
In family conversion fix.
Fixed VNX7500 memory conversion panic.
Fixed multiple potential NDU issues.
Fixed a bug that could take Thin LUNs
offline during online disk firmware upgrade.
Fixed panic on invalid request from Sea-
gate drives with ES0E or ES0F firmware.
Support for RP Splitter 4.0 including iSCSI.
Fixed RecoverPoint Splitter / VAAI panic
issue detailed in emc327099.
Fixes for 05.32.000.5.207 are on page 4.
File code enhancements in 7.1.71.101
Fixed a watchdog panic involving SMB2
durable file handles.
Fixed a loss of access issue involving dis-
connected SMB2 clients that have com-pression enabled.
Fixed an issue with high CPU and memory
usage resulting from the use of the VNX Monitoring M&R Tool or the EMC DPA tool.
Fixed a possible rare deadlock condition
when attempting to stop the virus checker.
Fixed a possible Data Mover deadlock on a
delete/move operation on a file with an SMB2 lease granted.
Improved performance when many users
are simultaneously connected to Kerberos.
Fixed an issue preventing the standby con-
troller from taking over in dual controller configs when the primary controller was rebooted with the “reboot — f“ command.
Fixed and erroneous de-duplication error
message related to deep compression.
Fixed an issue which could result in per-
formance degradation from unnecessary virus scans when a file was opened for metadata access only.

EMC believes the information in this publication is accurate as of its publication date. The information is subject to change without notice.
THE INFORMATION IN THIS PUBLICATION IS PROVIDED “AS IS.” EMC CORPORATION MAKES NO REPRESENTATIONS OR WARRANTIES OF ANY KIND W ITH RESPECT TO THE INFORMA-
TION IN THIS PUBLICATION, AND SPECIFICALLY DISCLAIMS IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE.
Use, copying, and distribution of any EMC software described in this publication requires an applicable software license.EMC2, EMC, E-Lab, Powerlink, VNX, VNXe, Unisphere, RecoverPoint, and the
EMC logo are registered trademarks or trademarks of EMC Corporation in the United States and other countries. All other trademarks used herein are the property of their respective owners. Copyright
© 2013 EMC Corporation. All rights reserved. Published in the USA, September, 2013.
Upgrading to R31.727 as an in-terim step prior to upgrading from R31 to R32 can avoid a small risk of an outage: The latest VNX OE release for the R31 family, 05.31.000.5.727, has a fix for an uncommon bug which could impact a very small percent-age of NDU upgrades from the R31 family into the R32 family. The bug can cause a storage processor (SP) to panic at some
point during the upgrade. It is estimated that the bug has impacted less than 1% of upgrades.
Should this panic occur during the NDU, it may or may not cause a “data unavailable” event, depending on the timing of the panic. If the panic occurs on one SP while its peer is rebooting to install software, then it can cause a brief “data unavailable” situation to any attached hosts.
VNX OE 05.31.000.5.727 fixes this issue and prevents it from causing a panic during any NDU. Sometimes the RCM team or other EMC personnel may recommend multi-step NDUs that involve passing through 05.31.000.5.727 as an interim step when upgrading from R31 to R32.
Note that EMC has not made this interim NDU step mandatory at this time because of the very low rate of occurrence of the problem.
VNX Block OE 05.32.000.5.207 contains 3 key fixes. VNX Block OE 05.32.000.5.207, released on 8/15/2013, contains the following three fixes mentioned in the “futures” section of last quar-
ter’s Uptime Bulletin:
1. A fix for a performance degradation issue introduced in R32.201, related to running VDI applications on the VNX storage system.
2. A fix for a connectivity issue whereby Thin LUNs could “disconnect” from hosts when connected to the VNX using the FCoE protocol.
3. A fix for an extremely rare, hardware induced, simultaneous dual storage processor reboot.
Why is it important to leave some free space in a storage pool, and how does the recommended amount of free space vary by software revision? While a storage pool can operate at 100% consumed space, it is best practice to leave some space available as free overhead. The amount
of recommended space left free varies by VNX OE software revision. In VNX OE releases in the R31 family, we recommend leaving 10% free space, so that a storage pool is no more than 90% full. In VNX OE releases in the R32 family, some changes were made to pre-allocate some space in the background, so best practice dictates that you only need to leave 5% free space.
Two specific areas of functionality can be negatively impacted if pools do not leave enough free space. The FAST VP feature requires free space in the pool in order to perform its slice relocations. When there are not enough free slices remaining in the pool, it could limit the amount of relocations that can run at once. This can impact pool LUN performance, or can cause slice relocations and auto-tiering migra-
tions to fail. Although it is not common, LUNs in a storage pool with 0% free space can become offline to a host.
If Pool LUNs are taken offline for any reason such that they require EMC to run a “recovery” on them using EMC’s recovery tools, those re-
covery tools also use the free space remaining in a pool. If there is not enough free space for recovery tools to run efficiently, a pool may need to be expanded in order to give it more free space. However, expanding a pool is a time consuming option and can prolong the dura-tion of an outage.
Pools can be configured to warn the user as they approach various thresholds of available space consumption. For more information about the free space requirements for FAST VP, see knowledge base solution 00078223: Storage Pool does not have enough free space for FAST VP to relocate slices.





























