Embed Size (px)
Citation preview

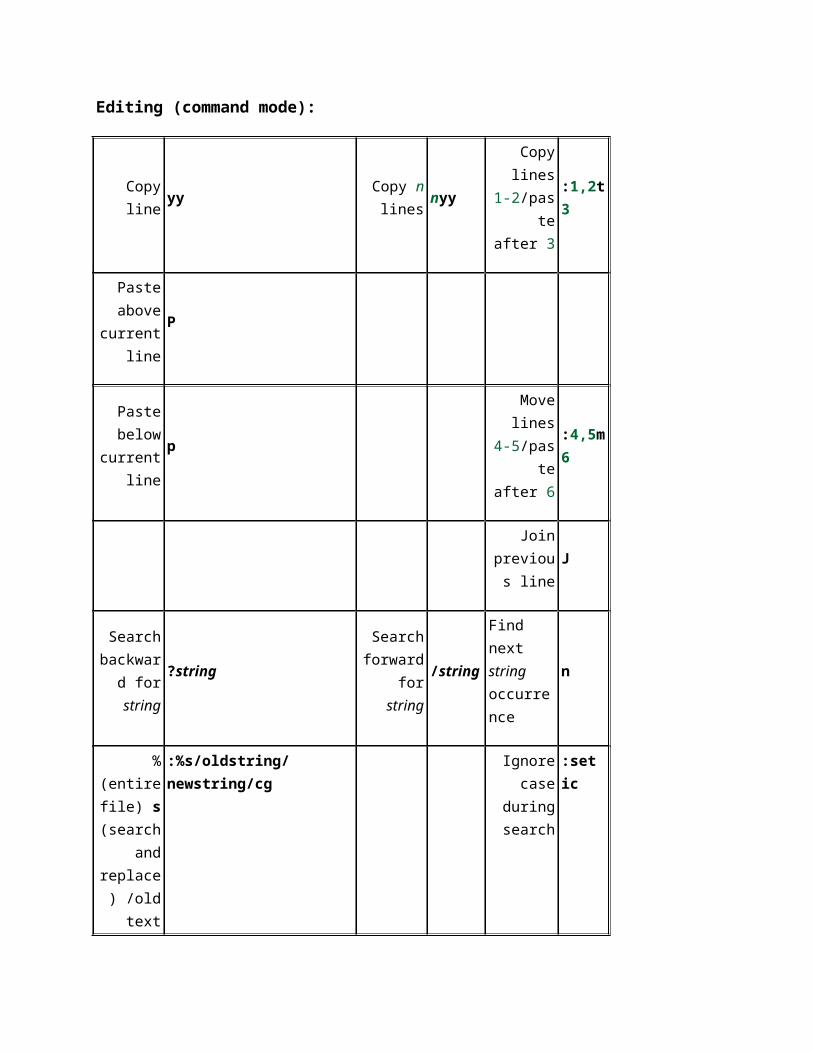
Basic VI Commands Summary
How to create Shared Disk “between” two Solaris Machine on VMWare
Step 1 Create first Machine
Create the windows folders to house the first virtual machines and the shared storage.
D:\>mkdir SUNOS-1
F:\>mkdir SHARED-STORAGE

Install Solaris virtual machine in SUNOS-1 Directory.
Step 2 Create virtual disks for storage usage, which is shared by Both Machine.
Down the virtual Machine
Go to VMware Server Console. Click on Edit virtual machine settings.
Virtual Machine Settings: Click on Add.
Add Hardware Wizard: Click on Next.
Hardware types: Select Hard Disk.
Select a Disk:
Disk: Select create a new virtual disk.
Select a Disk Type:
Virtual Disk Type: Select SCSI (Recommended).
Specify Disk Capacity:
Disk capacity: Enter “10GB.”
Select Allocate all disk space now.
Specify Disk File:
Disk file: Enter “F:\>SHARED-STORAGE\DISK1.vmdk.”
Click on Advanced
Add Hardware Wizard:
Virtual device node: Select IDE0.1.
Mode: Select Independent, Persistent for all shared disks.
Click on Finish.
Step 3 Modify virtual machine configuration file.
Additional parameters are required to enable disk sharing between the two virtual RAC nodes. Open
the configuration file, D:\>SUNOS-1\ Solaris 10.vmx.vmx and add the bold parameters listed below.
.
.

.
priority.grabbed = "normal"
priority.ungrabbed = "normal"
disk.locking = "FALSE"
diskLib.dataCacheMaxSize = "0"
ide0:1.sharedBus = "virtual"
ide0:0.redo = ""
ethernet0.addressType = "generated
-
-
-
-
-
ethernet0.connectionType = "hostonly"
ide0:1.present = "TRUE"
ide0:1.fileName = "E:\SHARED-DISK.vmdk"
ide0:1.redo = ""
checkpoint.vmState = ""
ide0:1.mode = "independent-persistent"
ide0:1.deviceType= "disk"

floppy0.present = "FALSE"
Step 4 Create and Configure the Second Virtual Machine
Create the windows folders to house the second virtual machines.
E:\>mkdir SUNOS-2
Shutdown the First Virtual Machine
Copy all the files from D:\SUNOS-1 to E:\SUNOS-2
Open your VMware Server Console, press CTRL-O to open the second virtual machine,
E:\SUNOS-2\Solaris 10.vmx.
Rename the second virtual machine name from SUN1 to SUN2.
Click on Start this virtual machine to start SUN2, leaving SUN1 powered off.
SUN2 – Virtual Machine: Select create a new identifier.
Log in as the root user and modify the network configuration.
Follow below step for modifying Host Name and IP
$ ifconfig <Ethernat> <new IP>
$ ifconfig <Ethernet> up
$ go to /etc/hosts file and change IP and host
$ go to /etc/nodenames file and change host anme
$ go to /etc/hostname.<Ethernet> and change host name
Restart the Second Virtual Machine.
Start the First virtual Machine
Verify all changes and Enjoy. Your Shared Storage is ready for fun.
If you want to add disk with Sun Solaris server. You just shut down the Machine and attached the
disk. Start the machine and execute the following command (#devfsadm). After executing this
command sun refresh the device list.
I am describing here example for adding disk on VM (SUN SOLARIS)

Step: 1 shut down the VM
Step: 2 go to the Vmware setting
Step: 3 add a new hard disk device
Step: 4 Start Virtual machine and execute one of the following Method:
Method: 1 Open terminal and type following command:
# devfsadm
Method: 2 open terminal and type following command:
# touch /reconfigure
# reboot
After adding the physical disk. You must format the disk, partition the disk, create file system and
mount the file system.
We will discuss How to Format the Disk? in next session.
How to Format Disk?
You have learned about adding disk in my previous update. What do you think, only after adding the
disk, you are able to store data on disk?. NO…….NO….Never……you can not store data on disk.
if you want to store data on disk. You must complete the following task: Format the Disk, create disk
partition, create slice, create file system and mount the file system.
I will discuss all topics separately on my blog.
Here we will discuss only about How to Format the Disk?
Step 1 Invoke the format utility. This will display a numbered of list of disks.
Step 2 Type the number of the disk (Newelly Added Disk) on which to create a Solaris fdisk partition।
Step 3 Select the fdisk menu।format> fdisk
Step 4 The fdisk menu that is displayed depends upon whether the disk has existing fdisk partitions...
Type Yes for making 100% Solaris disk partation।
Step 5 Label the disk
format> label

Ready to label disk, continue? yes
format> Quit
Step 6 After creating fdisk partition, Next we will create slices on the disk(I will discuss How to create
Disk slice and label in next session...please wait coming soon........)
How to Create Disk Partation / Slices and Label a Disk? Posted On Thursday, November 20, 2008 at at 9:12 AM by Anup Kumar Srivastav
How to Create Disk Partation / Slices and Label a Disk?
After adding and formating disk we should create Disk Partation/Slice and Label the Disk.
Step 1 Invoke the format utility. A numbered list of disks is displayed.
Step 2 Type the number of the disk that you want to repartition.where disk-number is the number of
the disk that you want to repartition.
Step 3 Select the partition menu.
format> partition
Step 4 Display the current partition (slice) table.
partition> print
Step 5 Start the modification process.
partition> modify
Step 6 Set the disk to all free hog.
Choose base (enter number) [0]? 1
Step 7 Create a new partition table by answering yes when prompted to continue.
Do you wish to continue creating a new partition table based on above table[yes]? yes

Step 8. Make the displayed partition table the current partition table by answering yes when prompted.
Okay to make this the current partition table[yes]? yes
If you don't want the current partition table and you want to change it, answer no.
Step 9. Name the partition table.
Enter table name (remember quotes): "partition-name"where partition-name is the name for the new
partition table.
Step 10. Label the disk with the new partition table after you have finished allocating slices on the new
disk.
Ready to label disk, continue? Yes
Step 11. Quit the partition menu.
Step 12 Verify the new disk label.
Step 13. Exit the format utility.
Step 14 After Labelind you can create file systems on the disk
How to Create File Systems?
How to Create File Systems?
After creating Disk Partition, we should create File System and Mount the file file system.

Step 1. Create a file system for each slice.
# newfs /dev/rdsk/cwtxdysz
where /dev/rdsk/cwtxdysz is the raw device for the file system to be created.
Step 2. Create a Directory
# mkdir
Step 3. Verify the new file system by mounting.
# mount /dev/dsk/cwtxdysz /
# ls
How to Add an Entry to the /etc/vfstab File?
How to Add an Entry to the /etc/vfstab File
Step 1 log in as a Root User
Step 2 Edit the /etc/vfstab file and add an entry.
Step 3 save the changes.
Solaris 10 OS Installation on VMWARE
Solaris 10 OS Installation on VMWARE
1. Open VMWARE Console and Click on New Virtual Machine and click next.
2. Select Virtual Machine Configurations: Typical
3. Select Gust Operation System: Sun Solaris and version solaris10
4. Type virtual Machine Name and Location.
5. Select Network Connection. Total 4 options.

User Bridge connection
Use network address translation (NAT)
Use host only network (Select Host Only Network)
Do not use a network
6. Specify Disk Capacities. (8 GB) and Click on Finish Button.
Now your virtual machine is ready to install Solaris 10 OS
7. Double Click on CD-ROM Devices
8. Select Use ISO image when you planning to install OS through ISO image otherwise Use physical
drive.
9. Click on Start the Virtual Machine.
10. Select Solaris Interactive (Default) installation
11. Configure keyboard Layout screen appear (press F2)
12 Select a language English
13 welcome screen appear (Click Next)
14 Select network connectivity and (Click Next).
15. DHCP Screen appears select No and (Click Next).
16 Type Host Nome and (Click Next)
17 Type IP Address and (Click Next)
18 Type netmask (Select default) and (Click Next)
19 Select No for Enable Ipv6 for pcn0 and (Click Next)
20 Select None for Default Route and (Click Next)

21 Select No for Enable Kerberos security and (Click Next)
22 Select None for Name Services and (Click Next)
23 NFSv4 Domain Name select Default and (Click Next)
24 Select Geographic Time Zones and (Click Next)
25 Continent and Country (INDIA) and (Click Next)
26 Accept the default date and time and (Click Next)
27 Enter ROOT password and (Click Next)
28 Select Yes for Enabling Remote Services and (Click Next)
29 Confirm Information and (Click Next)
30 Select default Install option and (Click Next)
After that the system is being analyzed. Please wait screen appear and select the Type of Installation
Now Installer Install to OS…
_________________________________________________________________________________
Fileystems
What is a file system?
Display all filesystems
We will start by issuing a df –k command to get a listing of all UNIX mounts points. This example is from the Solaris dislect of UNIX.
root> df -k
Filesystem kbytes used avail capacity Mounted on/dev/dsk/c0t0d0s0 4032504 104381 3887798 3% //dev/dsk/c0t0d0s4 4032504 992890 2999289 25% /usr

/proc 0 0 0 0% /procfd 0 0 0 0% /dev/fdmnttab 0 0 0 0% /etc/mnttab/dev/dsk/c0t0d0s3 4032504 657034 3335145 17% /varswap 4095176 8 4095168 1% /var/runswap 4095192 24 4095168 1% /tmp/dev/dsk/c0t0d0s5 1984564 195871 1729157 11% /opt/dev/dsk/c0t0d0s7 14843673 1619568 13075669 12% /helpdesk/dev/oradg/u02vol 12582912 8717924 3744252 70% /u02/dev/oradg/u01vol 8796160 5562586 3132548 64% /u01/dev/oradg/u04vol 10035200 1247888 8519534 13% /u04/dev/oradg/u03vol 12582912 2524060 9744542 21% /u03/dev/dsk/c0t0d0s6 1984564 931591 993437 49% /export/home/vol/c0t/orcl901_3 270364 270364 0 100% /cdrom/orcl901_3
Here we see the following display columns:
1 – Filesystem name
2 – The kbytes in the filesystem
3 – Kbytes used in the filesystem
4 – Kbytes available in the filesystem
5 – File system capacity
6 – The mount point associated with the filesystem
Our goal is to filter this output to see the available space for the Oracle file systems. We also see rows
in this server that are not associated with Oracle files.
Display Oracle filesystems
Our next step is to eliminate all file systems except the Oracle file systems. In this system, we are
using the Oracle Optimal Flexible Architecture (OFA), and all Oracle filesystems begin with /u0. Hence,
we can use the UNIX grep utility to eliminate all lines except for those containing the string /u0:
root> df -k|grep /u0
/dev/vx/dsk/oradg/u02vol 12582912 8717924 3744252 70% /u02
/dev/vx/dsk/oradg/u01vol 8796160 5563610 3131556 64% /u01
/dev/vx/dsk/oradg/u04vol 10035200 1247888 8519534 13% /u04
/dev/vx/dsk/oradg/u03vol 12582912 2524060 9744542 21% /u03

Extract the available space for each filesystem
Now that we have the Oracle file systems, we can use the UNIX awk utility to extract the fourth
column, which is the available space in the filesystem.
root> df -k|grep /u0|awk '{ print $4 }'
3744252
3132546
8519534
9744542
Create the script to check space in all file systems
Now that we see the command, we can place this command inside a loop to evaluate the free space
for each filesystem. Note that our command is placed inside the Korn shell for loop, and the command
is enclosed in back-ticks (the key immediately above the tab key).
check_filesystem_size.ksh
#!/bin/ksh
for i in `df -k|grep /u0|awk '{ print $4 }'`
do
# Convert the file size to a numeric value
filesize=`expr i`
# If any filesystem has less than 100k, issue an alert
if [ $filesize -lt 100 ]
then
mailx -s "Oracle filesystem $i has less than 100k free."\
fi
done
This simple script will check every file system on the server and e-mail us as soon as any file system
has less than 100k of free space.

Scheduling the file alert
I generally place this type of script in a crontab file, and execute it every three minutes as shown in
the UNIX crontab entry below.
#****************************************************************
# This is the every 5 min. trace file alert report for the DBAs
#****************************************************************
1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,
47,49,51,53,5,57,59 * * * * /home/oracle/check_filesystem_size.ksh >
dev/null >&1
How do I find out what the largest files are in a file system?? In other words, if I get the message that /tmp is 90% full and /tmp is not a raw slice but a file system, how do I find out what the 20 largest files are and their complete path??
Other people will probably be able to write some nice scripts for you, but I've found the best solution on Linux to be fsv. I don't know much about HP-UX, but I found what looks to be an HP-UX version of fsv.
Here's a one liner getting the 20 largest files in /tmp:
# all on one linefind /tmp -type f -print | xargs ls -l | sort -r -n -k 5,5 | head -20
You could also do the ls within the find command like this:
find /tmp -type f -exec ls -la {} \; | sort -r -n -k 5,5 | head -20
I tried your xargs command and that got me most of what I wanted...The problem is that I got the 20 largest files under /tmp, but I didn't get the 20 largest files in the /tmp "filesystem"...

When I ran it on the 2 largest files I got this:
-rw-r--r-- 1 oracle dba
714559 Aug 20 2002 /tmp/admin/export.dmp-rw-r----- 1 oracle dba 558828 May 16 2002 /tmp/files/dh_out.txt
If I go and do a "df -k ." from /tmp/admin and /tmp/files, I get two different filesystems (see below):
/tmp/admin (/dev/vg00/lvol1) : 8733 total allocated Kb1893621 free allocated Kb6840322 used allocated Kb78 % allocation used
/tmp/files (/dev/vg01/lvol1) : 4059 total allocated Kb2145 free allocated Kb3787 used allocated Kb47 % allocation used
Do you have any ideas or suggestions??
It should work. You must have links in your /tmp file system. I don't know about HP-UX, but the Solaris find has a -follow option which means "to follow the link". This might help:
find /tmp -type f -follow -print | xargs ls -l | sort -r -n -k 5,5 | head -20
Differences between shells in UNIXby admin in AIX
sh csh ksh bash tcsh zsh rc esJob control N Y Y Y Y Y N NAliases N Y Y Y Y Y N NShell functions Y(1) N Y Y N Y Y Y"Sensible" Input/Output redirection Y N Y Y N Y Y YDirectory stack N Y Y Y Y Y F FCommand history N Y Y Y Y Y L LCommand line editing N N Y Y Y Y L LVi Command line editing N N Y Y Y(3) Y L LEmacs Command line editing N N Y Y Y Y L LRebindable Command line editing N N N Y Y Y L LUser name look up N Y Y Y Y Y L L

Login/Logout watching N N N N Y Y F FFilename completion N Y(1) Y Y Y Y L LUsername completion N Y(2) Y Y Y Y L LHostname completion N Y(2) Y Y Y Y L LHistory completion N N N Y Y Y L LFully programmable Completion N N N N Y Y N NMh Mailbox completion N N N N(4) N(6) N(6) N NCo Processes N N Y N N Y N NBuiltin artithmetic evaluation N Y Y Y Y Y N NCan follow symbolic links invisibly N N Y Y Y Y N NPeriodic command execution N N N N Y Y N NCustom Prompt (easily) N N Y Y Y Y Y YSun Keyboard Hack N N N N N Y N NSpelling Correction N N N N Y Y N NProcess Substitution N N N Y(2) N Y Y YUnderlying Syntax sh csh sh sh csh sh rc rcFreely Available N N N(5) Y Y Y Y YChecks Mailbox N Y Y Y Y Y F FTty Sanity Checking N N N N Y Y N NCan cope with large argument lists Y N Y Y Y Y Y YHas non-interactive startup file N Y Y(7) Y(7) Y Y N NHas non-login startup file N Y Y(7) Y Y Y N NCan avoid user startup files N Y N Y N Y Y YCan specify startup file N N Y Y N N N NLow level command redefinition N N N N N N N YHas anonymous functions N N N N N N Y YList Variables N Y Y N Y Y Y YFull signal trap handling Y N Y Y N Y Y YFile no clobber ability N Y Y Y Y Y N FLocal variables N N Y Y N Y Y YLexically scoped variables N N N N N N N YExceptions N N N N N N N Y
Key to the table above.
Y Feature can be done using this shell.
N Feature is not present in the shell.
F Feature can only be done by using the shells function mechanism.
L The readline library must be linked into the shell to enable this Feature. Notes to the table above
1. This feature was not in the orginal version, but has since become almost standard.

2. This feature is fairly new and so is often not found on many versions of the shell, it is gradually making its way into standard distribution. 3. The Vi emulation of this shell is thought by many to be incomplete. 4. This feature is not standard but unoffical patches exist to perform this. 5. A version called 'pdksh' is freely available, but does not have the full functionality of the AT&T version. 6. This can be done via the shells programmable completion mechanism. 7. Only by specifing a file via the ENV environment variable.
Sudo (superuser do) allows a system administrator to work using his own account and switch to root or other user identity available on the system only for commands that need it. It also provide a better logging and "ticketing" system. Sudo is useful on all version and flavors of Unix, with possible exception of Solaris 10 and later because native OS mechanisms (RBAC) are superior. For a brief history of Sudo see history section
Main advantages
The simplification of delegation of root. In large enterprises one of the services Unix group provides is to set a temp root password on one or several boxes so that application administrator can perform some operations which require root access. Communication of temp root password creates a vulnerability due to which an intelligent person can access root account on some other systems that currently are converted for temp root. For example this is the case if temp password is created using some formula that contains as a part server name (for example prefix) and a random string (as a suffix). In case of sudo you can use automatic remote enrollment of user into particular group (wheel or sysadmin, depending on flavor of Unix used) and do not even need to communicate anything to the user other that he got the ability to become root from his account.
Ssh or Tivoli TCM permit mass changing group membership for the wheel group. In this case you need to execute just one command to enroll the person who need temporary root access to aq group of servers. What is important you can automatically provide deenrollement after the requested period is over: just schedule at command that remove the person from the group at the end of agreed period.

This way there is no possibility of forgetting to remove the privileges of the user for whom the specified term of root access is expired: Deletion is done automatically when the period expires by the at command scheduled beforehand. Otherwise this operation requires human action of resetting password back, the operation that more often then not is performed later then in due time.
Audit trail for all attempts to switch to root both successful and unsuccessful. That tremendously help in troubleshooting, especially as is typical for large enterprise environment when there are multiple cooks (aka sysadmins ;-) in the kitchen and the left hand does not know what right hand is doing.
Simplification of switching to root for administrators. Sudo can be configured in such a way that members of wheel group do not need additional authentication to became the root. That saves time and troubles of remembering multiple root passwords if you need to administer multiple systems (or a creation of a security vulnerability if such password are constructed using a pre-defined formula; intelligent users can soon get this "secret" and use it to their own advantage to cut red tape).
Ubuntu goes one step further here in the default sudo configuration. By default, the root account password is locked in Ubuntu. This means that you cannot login as root directly. However, since the root account physically exists it is still possible to sudo to root and to run programs with root-level privileges.
Prevention of costly mistakes. The main value of sudo for sysadmins is that it helps to prevent some really horrible things that often happen when you work as root and do something in a hurry as root. With sudo you can try to execute command as a regular user but it permissions are inadequate and command fails repeat it as root using shortcut sudo !!. And that's probably the best part of its usefulness. It permits to execute single command as root without authentication (if configured this way) by prefixing with sudo. In most cases that all administrator needs so long (and dangerous) sessions of using root account to trivial operations can be eliminated. If passwords for regular accounts are one time (e.g. reasonably secure as is the case if SecurID or similar one-time password system is used) this is a very attractive solution. Please remember that a lot of systems were destroyed by administrators using some badly though out command as root without proper testing. See Admin Horror Stories
Possibility to grant "read-only" access to certain files. From this point of view this capability of granting command access is most useful for providing a "read-only" and "re-write" assess to some root owned files by granting usage of explicit cat (or cp in case of re-write access) commands for selected files, or other simple commands with explicit arguments (not vi or other commands with the possibility escaping to command shell). But even this is dangerous and this privilege can be abused. If cp command granted, the wrapper can be provided which to modify the file the user needs first to save it in his own directory and then executes move to target destination command. With ACLs this capability is now less useful but still worth mentioning.
Possibility to grant only selected commands executed with extended privileges to certain users. Suse is definitely not RBAC, but some functionality similar to RBAC can be imitated by granting access to several command (for example the ability to start and stop particular application server). The command should be unable to escape to shell and be simple enough to exclude this possibility (it is a bad idea to grant the ability to execute find caommand as root for obvious reasons) Compete specification of arguments usually is required to prevent attempts to

use the command as a "universal root opener". While definitely useful for restarting daemons and some similar actions this is not a RBAC and you should keep such assignments simple. Excessive zeal here really hurts. The alternative is using one command accounts like shutdown and restart, where the logging with password executes the required command. This might be more convenient for operators.
Logging of each command, providing a clear audit trail of "who did what." When used in tandem with remote syslogd, sudo can log all commands to a central loghost (as well as on the local host). Please note the for AIX you need to enable syslog first.
"Time ticketing" system. When a user invokes sudo and enters their password, they are granted a ticket for 5 minutes (this timeout is configurable at compile-time). Each subsequent sudo command updates the ticket for another 5 minutes. This gives some level of protection in situation where there is a danger of accidentally leaving a root shell where others can physically get to your keyboard. While certainly annoying, this is a useful facility for critical boxes.
Sudo is distributed under a BSD-style license and currently maintained by Todd Miller. The current homepage is http://www.courtesan.com/sudo/
Conceptually sudo is a really simple package that unfortunately grow too complex with time. It consist of just three utilities (sudo, visudo and sudoreplay) and a single configuration file:
1. sudo(8) command: setuid root wrapper that users invoke to execute commands as root (or other privileged account).
2. /etc/sudoers. This is a configuration file which can also be located in /etc/sudo or /usr/local/etc directory. It is sudo's roles definition file specifying who may run what commands as which user. It is fully documented in sudoers(5). See also a good into in Gentoo Sudo(ers) Guide — Gentoo Linux Documentation
3. visudo(8) command allows administrators to edit the sudoers file without risking locking themselves out of the system.
4. Sudoreplay plays back or lists the session logs created by sudo. When replaying, sudoreplay can play the session back in real-time, or the playback speed may be adjusted (faster or slower) based on the command line options.
List sessions run by user millert:
sudoreplay -l user millert
List sessions run by user bob with a command containing the string vi:
sudoreplay -l user bob command vi
List sessions run by user jeff that match a regular expression:
sudoreplay -l user jeff command '/bin/[a-z]*sh'
List sessions run by jeff or bob on the console:

sudoreplay -l ( user jeff or user bob ) tty console
SUDO IN SOLARIS 10
Solaris 10 Role Based Access Control (RBAC)The problem with the traditional model is not just that root (superuser) is so powerful, but that a regular user accounts are not powerful enough to fix their own problems.
There were some limited attempts to address this problem in Unix in the past (wheel group and immutable file attributes in BSD, sudo, extended attributes (ACL), etc), but Role Based Access Control (RBAC) as implemented in Solaris 10 is probably the most constructive way to address this complex problem in its entirety.
RBAC is not a completely new thing. Previous versions of RBAC with more limited capabilities existed for more then ten years in previous versions of Solaris. It was introduced in Trusted Solaris and was later incorporated into the Solaris 8. In was improved and several additional predefined roles were introduced in Solaris 9. Still they generally fall short of expectations and only Solaris 10 implementation has the qualities necessary for enterprize adoption of this feature.
Among predefined roles that is several that are immediately useful and usable:
1. All Provides a role access to commands without security attributes: all commands that do not need root permission to run in a regular Solaris system (Solaris without RBAC implementation) :
2. Primary Administrator Administrator role that is equivalent to the root user.
3. System Administrator. Secondary administrators who can administer users (add, remove user accounts, etc). Has privileges solaris.admin.usermgr.read solaris.admin.usermgr.write that provides read/write access to users’ configuration files. Cannot change passwords.
4. Operator. Has few security related capabilities but still capable of mounting volumes. Also has solaris.admin.usermgr.read privilege that provides read access to users’ configuration files.
5. Basic Solaris User. Enables users to perform tasks that are not related to security.
6. Printer Management. Dedicated to printer administration.
But the original implementation has had severe limitation in defining new roles which blocked wide adoption of this feature: in practice most system commands that were needed for roles should be run as root. Still even the old implementation that exited till Solaris 9 has sudo-style capability of one time assumption of the command with specific (additional) privileges is

accomplished by pfexec command. If the user is assigned "Primary Administrator" profile then pfexec command became almost exact replica of the typical sudo usage.
Also if role has no password then switch of context does not require additional authentication (only authorized users can assume roles). That can be convenient for some application roles.
There were several problems with early RBAC implementations:
Limited flexibility in constructing new roles Hidden dangers of running selected commands with root privileges (that danger that is typified by
sudo). Fuzzy interaction of RBAC facility with the extended attributes facility (ACL). The four flat flat files that Solaris 8 implementation introduced suggested some questionable
quality of engineering.
All-in-all Solaris RBAC until version 10 has limited appeal to most organization and unless there was a stron push from the top was considered by most administrators too complex to be implemented properly. It also has some deficiencies even in comparison with sudo. The only "cheap and sure" application in the old RBAC implementation was conversion of root account to role and conversion of operators to operator roles. Conversion of application-related accounts like oracle into roles was also possible, but more problematic.
That changed with Solaris 10 when RBAC model was extended with Solaris privileges model. It extended the ability to create new custom roles by assigning very granular privileges to the roles. Previously such tricks needed heavy usage of ACLs, and as any ACL-based solution were both expensive and heavy maintenance solutions
There are three distinct properties of roles:
1. A role is not accessible for normal logins (root is a classic example of an account that should not be accessible by normal login; most application accounts fall into the same category)
2. Users can gain access to it only explicitly changing his identity via su command, the activity that is logged and can be checked for compliance.
3. Role account uses a special shell (pfksh or pfsh). Please note that bash is not on the list :-)
Each user can assume as many roles as is required for him to perform his responsibilities (one at a time) and switch to a particular role for performing a subset of operations that are provided for this role. Theoretically an administrator can map user responsibilities into a set of roles and then grant users the ability to "assume" only those roles that match their job responsibilities. And no user should beg for root access any longer :-) But the devil is in details: even with Solaris 10 power this easier said then done. Role engineering is a pretty tough subject in itself even if technical capabilities are here and it requires time and money to implement properly.
Still it looks like Solaris 10 was the first Unix that managed to breaks old Unix dichotomy of "root and everybody else". In this sense Solaris 10 is the first XXI century Unix. The privilege model that was incorporated in RBAC made it more flexible and useful, surpassing sudo in most

respects. One time execution of a command, for example vi, with additional privileges still remains the problem as the command can have a backdoor to shell.
Like its predecessor sudo, Solaris RBAC provides the ability selectively package superuser privileges for assignment to user accounts by assigning them packages of the appropriate privileges. For example, the need for root account can be diminished by dividing those capabilities into several packages and assigning them separately to individuals sharing administrative responsibilities (still root remains a very powerful account as it owns most important files).
It might be useful to distinguish between following notions:
Authorization - A right that is used to grant access to a restricted function Profile - A mechanism used for grouping authorizations and commands for subsequent
assignment to role or to a user. You can assign one or several profile to role. Role - A special type of user account that you cannot login directly, but can only su to it. It
intended for application accounts and sometimes is useful as a container for performing a set of administrative tasks
Role shell Special shell alias (for example pfksh, instead of ksh) that gives the shell capability to consult RBAC database before execution of the command. Please note that bash can't be used as role shell.
RBAC relies on a database that consist of four flat files (naming suggests that Microsoft agents penetrated Sun on large scale ;-), as the proper way to group related configuration files in Unix is to use common prefix, like rbas_user, rbac_prof, rbac_exec, rbac_auth, but Unix is flexible and you can create such links and forget about this problem):
/etc/user_attr (main RBAC file) /etc/security/prof_attr (right profile attributes/authorizations) /etc/security/exec_attr (profile execution attributes) /etc/security/auth_attr (authorization attributes).
As usual syntax is pretty wild and is a testimony that in Sun left hand does not know what right is doing. Essentially this is another mini-language in a family of approximately a hundred mini-languages that Sun boldly introduced for configuration files while naively expecting that administrators say with Solaris no matter what perverse syntax they are using in "yet another configuration file" (TM) :-). HEre are some details on those configuration files:
1. /etc/user_attr (main RBAC file, essentially the extension of /etc/passwd)
/etc/user_attr lists the accounts that are roles, associates regular users with roles. Consists of type of the account (type=) and authorizations list (auth= ) and profiles (profiles=, which is an indirect way to assign authorizations). If type is notmal then the account is a regular traditional Unix account for example:
root::::type=normal;auth=solaris.*,solaris.grant
If type is "role" then this is a new type of account -- role account. For example:

datesetter::::type=role;profile=Date Management
By default all Solaris users are granted Basic Solaris User profile. The default profile stored in /etc/security/policy.conf is applicable to all accounts that do not have an explicit assignment.
Effective profile for normal users can also be changed, for example for the user Joe Doers the profile can be changed to Log Management:
doerj::::type=normal;profile=Date Management
2. /etc/security/prof_attr (right profile attributes/authorizations) Associates names of right profiles (or simply profiles, although the tem is confusing) with the set of authorizations. Only authorizations listed in /etc/security/auth_attr are allowed.
This is a little bit problematic implementation as right profile is essentially a parameterless macro that is substituted into a predefined set of authorizations. But surprisingly the only form of this macro definition is plain vanilla list. There is no wildcard capabilities of regular expression capabilities in specifying them. Also there is no way to deny certain lower level authorization while granting a higher level authorizations. For example, I cannot specify expressions like (solaris.admin.usermgr.* - solaris.admin.usermgr.write). There is also no possibility to grant global access to a specific operation reading like solaris.*.*.read In general I see no any attempt to incorporate the access control logistics typical for TCP wrappers, firewalls and similar programs. That makes creation of a profile less flexible then it should be, but hopefully this is not that frequent operation anyway, and you can write Perl scripts that generate any combination of authorizations you want quote easily, so the damage is minor.
Like I mentioned in my lecture before there are several predefined right profiles (all of the them can be modified by sysadmin):
o All right profile that provides a role access to commands without security attributes. In a non-RBAC system, these commands would be all commands that do not need root permission to run.
o Primary Administrator right profile that is designed specifically for the Primary Administrator role. In a non-RBAC system, this role would be equivalent to the root user.
o System Administrator. right profile that is designed specifically for a junior level System Administrator role. The System Administrator rights profile uses discrete supplementary profiles to create a powerful role.
o Operator right profile Designed specifically for the Operator role. The Operator rights profile uses a few discrete supplementary profiles to create a basic role.
o Basic Solaris User right profile that enables users to perform tasks that are not related to security.
o Printer Management. right profile dedicated to the single area of printer administration.
Each profile consists of one or more authorizations, for example:
Basic Solaris User:::Automatically assigned rights:

auths=
solaris.profmgr.read,solaris.jobs.users, solaris.mail.mailq, solaris.admin.usermgr.read, solaris.admin.logsvc.read, solaris.admin.fsmgr.read, solaris.admin.serialmgr.read, solaris.admin.diskmgr.read, solaris.admin.procmgr.user, solaris.compsys.read, solaris.admin.printer.read, solaris.admin.prodreg.read, solaris.admin.dcmgr.read, solaris.snmp.read,solaris.project.read, solaris.admin.patchmgr.read, solaris.network.hosts.read, solaris.admin.volmgr.read;
profiles=All; help=RtDefault.html
Notes:
it uses mnemonic name for a privilege set, not dotted representation. There are many Sun-supplied profiles (30 in Solaris 9), for example:
o Primary Administrator (profile that permits performing all administrative tasks) o Basic Solaris User (Default profile assigned to the new accounts ) o Operator (Can perform simple administrative tasks).
3. /etc/security/exec_attr(profile execution attributes) - this is sudo style file that defines
the commands assigned to a profile and under which EUID and EGID. The fields in the /etc/security/exec_attr database are separated by colons:
name:policy:type:res1:res2:id:attr
o name The name of the profile. Profile names are case sensitive. o policy -- The security policy (priviledge) associated with this entry. In Solaris 9 the suser
(superuser policy model) is the only valid policy entry. o type The type of entity whose attributes are specified. The only valid type is cmd
(command). o res1,res2 Reserved for future use. Reserved for future use. o id A string identifying the entity. You can use the asterisk (*) wildcard. Commands
should have the full path or a path with a wildcard. To specify arguments, write a script with the arguments, and point the id to the script.
o attr An optional list of key-value pairs that describes the security attributes to apply to the entity when executed. You can specify zero or more keys. The list of valid key words depends on the policy being enforced. There are four valid keys: euid, uid, egid, and gid.
o euid and uid – Contain a single user name or a numeric user ID. Commands designated with euid run with the effective UID indicated, which is similar to setting the setuid bit on an executable file. Commands designated with uid run with both the real and effective UIDs set to the UID you specify.
o egid and gid – Contain a single group name or numeric group ID. Commands designated with egid run with the effective GID indicated, which is similar to setting the setgid bit on an executable file. Commands designated with gid run with both the real and effective GIDs set to the GID you specify.
For example

Date Management:suser:cmd:::/usr/bin/date:euid=0
Adds to the profile "Date Management" the ability to execute command "/usr/bin/date
4. /etc/security/auth_attr (authorization attributes)- This is a system generated static file that predefines a hierachical sets of privileges available on a particular system (92 in Solaris 9, 126 in Solaris 10). Privileges (authorizations) are structured like DNS with dots separating each constituent:
o Authorizations for the Solaris OE use solaris as a prefix.
o The suffix indicates what is being authorized, typically the functional area and operation. For example grant or delete or modify.
o When there is no suffix (that is, the authname consists of a prefix, a functional area, and ends with a period), the authname serves as a heading for use by applications in their GUI rather than as an authorization. The authname solaris.printmgr. is an example of a heading.
o When authname ends with the word grant, the authname serves as a grant authorization and lets the user delegate related authorizations (that is, authorizations with the same prefix and functional area) to other users. The authname solaris.printmgr.grant is an example of a grant authorization. It gives the user the right to delegate such authorizations as solaris.printmgr.admin and solaris.printmgr.nobanner to other users.
Only system programmers can add entries to this database. It also identifies the help file that explains a particular privilege set.
For example:
solaris.admin.usermgr.:::User Accounts::help=AuthUsermgrHeader.htmlsolaris.admin.usermgr.write:::Manage Users::help=AuthUsermgrWrite.htmlsolaris.admin.usermgr.read:::View Users and Roles::help=AuthUsermgrRead.htmlsolaris.admin.usermgr.pswd:::Change Password::help=AuthUserMgrPswd.html
5. In addition to those four file, /etc/security/policy.conf lets you grant specific rights profiles and authorizations to all users. Essentially provides system default authorizations for all users. Entries consist of key-value pairs, for example:
6. AUTHS_GRANTED=solaris.device.cdrw
PROFS_GRANTED=Basic Solaris User
The solaris.device.cdrw authorization provides access to the cdrw command.

# grep ’solaris.device.cdrw’ /etc/security/auth_attr solaris.device.cdrw:::CD-R/RW Recording Authorizations::help=DevCDRW.html
The Basic Solaris User profile grants users access to all listed authorizations.
Paradoxically RBAC can be more useful for application accounts then to "human" accounts. That means that for a large organization an optimal plan for conversion to RBAC is first to convert system and applications accounts to roles.
Among system roles are root and operator. Both roles can (and probably should ) be converted to role even in previous versions of Solaris.
By application accounts we mean the account used for structuring permissions and launching processes for a particular enterprise software like Oracle, Webshere, Apache, Sendmail, bind, etc) because privileges requirements for those accounts are static.
The main command line tools include:
roleadd – Adds a role account on the system. rolemod – Modifies a role’s login information. useradd – Adds a user account on the system.
Additional commands that you can use with RBAC operations.
auths Displays authorizations for a user. pam_roles Identifies the role account management module for the Password Authentication
Module (PAM). Checks for authorization to assume a role. pfexec Executes commands with the attributes specified in the exec_attr database. roles Displays roles granted to a user. roleadd Adds a role account to the system. roledel Deletes a role’s account from the system. rolemod Modifies a role’s account information in the system.
Command that has role relat4ed options:
useradd Adds a user account to the system. Use the -R option to assign a role to a user’s account. userdel Deletes a user’s login from the system. usermod Modifies a user’s account information in the system.
Related commands:
makedbm Makes a dbm file. nscd Identifies the name service cache daemon, which is useful for caching the user_attr,
prof_attr, and exec_attr databases
Useful Commands
Command Description

<esc><esc> or <esc>\ autocompletion
file * Show file types, such as "ascii".
find <path> -name <name> -print
Finds a file in the OS at the starting path on down
grep
groups <username> Shows groups for a user
kmtune Displays kernel tunable parameters
listusers -g <group> Lists the users in a group
ln -s <file or directory> <symbolic link>
Creates a symbolic link to a file or a directory
pr -o10 -l64 -F -h <HEADER> <file> | lp
prints using margins of 10, page length of 64, header on each page
rcp <source> remote_machine:<path>
remote copy
remsh <host> opens a remote command shell on the host machine
rlogin <host> remote login to host machine
sar
set_parms Change host name (/etc/set_parms)
tail -f <file> Looks at end of file and keeps it open to watch changes
top realtime display of processes
uname -a information about the system
print $(uname -i)16op|dc prints hex system id

who -u, who -Rm who is using the system
Process to recover from a lost/forgotten root password
1. Power off the server 2. Power on the server 3. Interupt the boot process during the 10 second interval (display will indicate this on the screen) 4. bo pri 5. Answer yes to interact with the ipl 6. At the prompt "hpux -is" for single user mode 7. cd /sbin 8. passwd root and follow prompts to put in new password 9. shutdown -r 0 to reboot to multiuser mode
Solaris tar command to backup data on tape deviceby nixcraft on March 22, 2005 · 17 comments
Tar name come from Tape ARchiver. It is both a file format and the name of the program used to handle such file. Tar archive files have names ending in ".tar". If an archive is compressed, the compression program adds its own suffix as usual, resulting in filename endings like ".tar.Z", ".tar.gz", and ".tar.bz2". Tar doesn't require any particular filename suffix in order to recognize a file as an archive. Tar was originally created for backups on magnetic tape, but it can be used to create tar files anywhere on a filesystem. Archives that have been created with tar are commonly referred to as tarballs.
Create a new set of backup
To create a Tar file, use tar command as follows:# tar cvf /dev/rmt/X file1 file2 dir1 dir2 file2 …Where
c – Create a new files on tape/archive

v – verbose i.e. show list of files while backing up f – tape device name or file
For example, backup /export/home/vivek/sprj directory to tape device /dev/rmt/0, enter# tar cvf /dev/rmt/0 /export/home/vivek/sprj/Remember c option should only use to create new set of backup.
Appending or backing up more files to same tape using tar
tar provides r option for appending files to tape. For example to backup /data2/tprj/alpha1 files to same tape i.e. appending files to a first tape device:# tar rvf /dev/rmt/0 /data2/tprj/alpha1/*Where
r – append files to the end of an archive/tape
List files on a tape using tar command
To display file listing of a first tape use tar as follows:# tar tvf /dev/rmt/0To listing the Contents of a Stored Directory (for example wwwroot directory):# tar tvf /dev/rmt/0 wwwrootWhere
t – list the contents of an archive/tape
Retrieve / restore tape backup taken with tar
1) Use tar command as follows to retrieve tape drive backup to current directory:(a) Change directory where you would like to restore files:# cd /path/to/restore# pwd(b) Now, do a restore from tape:# tar xvf /dev/rmt/0
To specify target directory use –C option
Restore everything to /data2 directory:# tar xvf /dev/rmt/0 –C /data2To retrieve directory or file use tar as follows:# tar xvf /dev/rmt/0 tprjNote that Solaris tar command is little different from GNU tar, if you wish to use gnu tar with Solaris use command gtar. Gnu tar accepts same command line options plus bunch of additional options :)
TAPE ERROR
I've backed up several files to tape using tar, and wish to list those that have backed up.

% tar cvf /dev/rmt/2un /s_1/oradata/pgpub/config.oraa /s_1/oradata/pgpub/config.ora 2 tape blocks
But when I go to list the files:
% tar tvf /dev/rmt/2untar: tape read error
What am I doing wrong? How can I verify that it was backed up?
Did you rewind the tape before giving the tar tvf command?
whoops, That was it! My mistake. Thanks a ton!
am not sure what the u means, but the n stands for NOrewind, so rewind your tape (mt -f /dev/rmt/2 rewind) and test it again. have a look at the mt man page
Question: How do I find out all the available file attributes. i.e I would like to know more about a file or directory than what the ls -l command displays.
Answer: Everything in Unix is treated as files. This includes devices, directories and sockets — all of these are files. Stat command displays file or filesystem status as explained in this article.
File Stat – Display Information About File
For example, to find out more information about 101hacks.txt file, execute the stat command as shown below.
$ stat 101hacks.txt File: `/home/sathiyamoorthy/101hacks.txt' Size: 854 Blocks: 8 IO Block: 4096 regular fileDevice: 801h/2049d Inode: 1058122 Links: 1Access: (0600/-rw-------) Uid: ( 1000/ sathiya) Gid: ( 1000/ sathiya)Access: 2009-06-28 19:29:57.000000000 +0530Modify: 2009-06-28 19:29:57.000000000 +0530Change: 2009-06-28 19:29:57.000000000 +0530
Details of Linux Stat Command Output
File: `/home/sathiyamoorthy/101hacks.txt’ – Absolute path name of the file. Size: 854 – File size in bytes. Blocks: 8 – Total number of blocks used by this file. IO Block: 4096 – IO block size for this file. regular file – Indicates the file type. This indicates that this is a regular file. Following are
available file types. o regular file. ( ex: all normal files ). o directory. ( ex: directories ). o socket. ( ex: sockets ). o symbolic link. ( ex: symbolic links. ) o block special file ( ex: hard disk ).

o character special file. ( ex: terminal device file ). Device: 801h/2049d – Device number in hex and device number in decimal Inode: 1058122 – Inode number is a unique number for each file which is used for the internal
maintenance by the file system. Links: 1 – Number of links to the file Access: (0600/-rw——-): Access specifier displayed in both octal and character format. Let us
see explanation about both the format. Uid: ( 1000/ sathiya) – File owner’s user id and user name are displayed. Gid: ( 1000/ sathiya) – File owner’s group id and group name are displayed. Access: 2009-06-28 19:29:57.000000000 +0530 – Last access time of the file. Modify: 2009-06-28 19:29:57.000000000 +0530 – Last modification time of the file. Change: 2009-06-28 19:29:57.000000000 +0530 – Last change time of the inode data of that
file.
Dir Stat – Display Information About Directory
You can use the same command to display the information about a directory as shown below.
$ stat /home/rameshFile: `/home/ramesh'Size: 4096 Blocks: 8 IO Block: 4096 directoryDevice: 803h/2051d Inode: 5521409 Links: 7Access: (0755/drwxr-xr-x) Uid: ( 401/ramesh) Gid: ( 401/ramesh)Access: 2009-01-01 12:17:42.000000000 -0800Modify: 2009-01-01 12:07:33.000000000 -0800Change: 2009-01-09 12:07:33.000000000 -0800
Details of File Permission:
File Permission In Octal Format
This information about the file is displayed in the Access field when you execute stat command. Following are the values for read, write and execute permission in Unix.
UNIX File Attributes & Access Permissions
Remember when we first looked at the listing from ls -la (Figure 12), and we skipped over most of the symbols in the first column? Well, "They're baaaack!" But that's OK, because we're ready for them now. Let's take a closer look at a single entry from that listing, and see if we can't demystify that first column.
-rw-r----- 1 picard STAFF 1397 May 28 12:50 mj.ultra
OK, let's isolate the part in question: the first column. We'll diagram it so you understand what each position means.
Figure 13. Diagram of UNIX File Attribute

After the first character, which identifies the entry type (Remember? d for a directory, and - for a regular file.), you will find exactly nine (9) other characters. In order to make sense of these, you have to break them up in your head, into three groups of three symbols each (3 times 3 = 9).
The first three symbols represent the access permissions/attributes which apply to the user who owns the file (usually you).
The second group of three symbols represents the access permissions/attributes which apply to the group associated with the file. In UNIX, every userid is a member of one or more groups, and separate permissions/attributes can be set for the group, as opposed to the owner. In the example we used in Figure 12 (Chapter 22), the group associated with this file is "STAFF."
The third and last group of three symbols represents the access permissions and attributes which apply to all other userids (other than the owning user and members of the owning group).
Now, let's look at the individual sets of attributes. Each of the three sets (User, Group, and Others) is identical, with respect to the meaning of the three characters of which it is composed. That is to say, each of the three positions in each set means the same thing from set to set.
Figure 14. UNIX File-Access Attributes
Changing File attributes with the chmod command
We'll just mention briefly the use of the chmod (change permission mode) command to change these attributes and permissions, as this is getting into advanced territory, beyond the scope of

this introductory manual. However, it is important that you are at least aware of these flags and their meanings so you can investigate this area further when and if the need arises.
The basic form of the chmod command is:
chmod who add-or-remove what_permissions filename
Note
there should not be any spaces between the "who", "add-or-remove", and "what_permissions" portions of the command, in a real chmod command. The spaces were included in the above diagram to make it more readable. See the following examples for samples of proper syntax.)
We'll break that diagram down a little further, and then give some examples.
Command "Breakdown": chmod.
chmod
This is the name of the command.
who
Any combination of u (for "user"), g (for "group"), or o (for "others"), or a (for "all"--that is, user, group, and others).
add-or-remove
Use + to add the attribute (set the flag), or - to remove the attribute (clear the flag).
what_permissions
Any combination of r (for Read), w (for Write), or x (for Execute).
filename
A file or directory name (or wildcard pattern) to which you wish to apply the listed permission changes.
Examples of Using chmod.
chmod a+r *
Makes all files in the current directory readable by anyone.
chmod u-w special.documentfilename

"Write-protects" special.document so that you, the user/owner, can't change it (without first issuing another chmod command to make the file writable).
chmod g+r group.stuff
Value Meaning 4 Read Permission 2 Write Permission 1 Execute Permission
File Permission In Character Format
This information about the file is displayed in the Access field when you execute stat command.
File Type: First bit of the field mentions the type of the file. User Permission: 2nd, 3rd and 4th character specifies the read, write and execute permission of
the user. Group Permission: 5th, 6th and 7th character specifies the read, write and execute permission
of the group. Others Permission: 8th, 9th and 10th character specifies the read, write and execute permission
of the others.
Display Information About File System
You can also use stat command to display the file system information as shown below.
$ stat -f / File: "/" ID: 0 Namelen: 255 Type: ext2/ext3Blocks: Total: 2579457 Free: 1991450 Available: 1860421 Size: 4096Inodes: Total: 1310720 Free: 1215875
What are Inodes?
Origin of term
The exact reason for designating these as "i" nodes is unknown. When asked, Unix pioneer Dennis Ritchie replied:[1]
In truth, I don't know either. It was just a term that we started to use. "Index" is my best guess, because of the slightly unusual file system structure that stored the access information of files as a flat array on the disk, with all the hierarchical directory information living aside from this. Thus the i-number is an index in this array, the i-node is the selected element of the array. (The "i-" notation was used in the 1st edition manual; its hyphen was gradually dropped.)

[edit] Details
An important part of a file system is the data structures that contain information about the files. Each file is associated with an inode (identified by an inode number, often referred to as an i-number or inode).
Inodes basically store information about files and folders, such as (user and group) ownership, access mode (read, write, execute permissions) and file type. On many types of file systems the number of inodes available is fixed at file system creation, limiting the maximum number of files the file system can hold. A typical space allocation for inodes in a file system is 1% of total size.
The inode number indexes a table of inodes in a known location on the device; from the inode number, the kernel can access the contents of the inode, including the location of the file allowing access to the file.
A file's inode number can be found using the ls -i command. The ls -l command displays some of the inode contents for each file.
Some Unix-style file systems such as ReiserFS omit an inode table, but must store equivalent data in order to provide equivalent capabilities. The data may be called stat data, in reference to the stat system call that provides the data to programs.
File names and directory implications:
Inodes do not contain file names, only file metadata. Unix directories are lists of "link" structures, each of which contains one filename and one inode
number. The kernel must search a directory looking for a particular filename and then convert the
filename to the correct corresponding inode number.
The kernel's in-memory representation of this data is called struct inode in Linux. Systems derived from BSD use the term vnode, with the v of vnode referring to the kernel's virtual file system layer.
[edit] POSIX inode description
The POSIX standard mandates filesystem behavior that is strongly influenced by traditional UNIX filesystems. Regular files must have the following attributes:
The size of the file in bytes. Device ID (this identifies the device containing the file). The User ID of the file's owner. The Group ID of the file. The file mode which determines the file type and how the file's owner, its group, and others can
access the file. Additional system and user flags to further protect the file (limit its use and modification).

Timestamps telling when the inode itself was last changed (ctime, changing time), the file content last modified (mtime, modification time), and last accessed (atime, access time).
A link count telling how many hard links point to the inode. Pointers to the disk blocks that store the file's contents (see inode pointer structure).
The stat system call retrieves a file's inode number and some of the information in the inode.
[edit] Implications
Files can have multiple names. If multiple names hard link to the same inode then the names are equivalent. I.e., the first to be created has no special status. This is unlike symbolic links, which depend on the original name, not the inode (number).
An inode may have no links. Unlinked files are removed from disk and its resources are freed for reallocation but deletion must wait until all processes that have opened it finish accessing it. This includes executable files which are implicitly held open by the processes executing them.
It is typically not possible to map from an open file to the filename that was used to open it. The operating system immediately converts the filename to an inode number then discards the filename. This means that the getcwd() and getwd() library functions search the parent directory to find a file with an inode matching the working directory, then search that directory's parent, and so on until reaching the root directory. SVR4 and Linux systems maintain extra information to make this possible.
Historically, it was possible to hard link directories. This made the directory structure into an arbitrary directed graph as opposed to a directed acyclic graph (DAG). It was even possible for a directory to be its own parent. Modern systems generally prohibit this confusing state, except that the parent of root is still defined as root.
A file's inode number stays the same when it is moved to another directory on the same device, or when the disk is defragmented which may change its physical location. This also implies that completely conforming inode behavior is impossible to implement with many non-Unix file systems, such as FAT and its descendants, which don't have a way of storing this lasting "sameness" when both a file's directory entry and its data are moved around.
Installation of new libraries is simple with inode filesystems. A running process can access a library file while another process replaces that file, creating a new inode, and an all new mapping will exist for the new file so that subsequent attempts to access the library get the new version. This facility eliminates the need to reboot to replace currently mapped libraries. For this reason, when updating programs, best practice is to delete the old executable first and create a new inode for the updated version, so that any processes executing the old version may proceed undisturbed.
[edit] Practical considerations
Many computer programs used by system administrators in UNIX operating systems often designate files with inode numbers. Examples include popular disk integrity checking utilities such as the fsck or pfiles. Thus, the need naturally arises to translate inode numbers to file pathnames and vice versa. This can be accomplished using the file finding utility find with the -inum option, or the ls command with the proper option (-i on POSIX compliant platforms).

It is possible to use up a device's set of inodes. When this happens, new files cannot be created on the device, even though there may be free space available. For example, a mail server may have many small files that don't fill up the disk, but use many inodes to point to the numerous files.
Filesystems (such as JFS, ext4, or XFS) escape this limitation via support extents and/or dynamic inode allocation, which can 'grow' the filesystem and/or increase the number of inodes.
Inode is a unique number given to a file in Unix OS. Every
file in Unix has a inode number. unix treats
directories/folders as a file so they are also having a
inode value.
When a file system is created, data structures that contain
information about files are created. Each file has an inode
and is identified by an inode number (often "i-number" or
even shorter, "ino") in the file system where it resides.
Inodes store information on files such as user and group
ownership, access mode (read, write, execute permissions)

and type of file. There is a fixed number of inodes, which
indicates the maximum number of files each filesystem can hold.
A file's inode number can be found using the ls -i command,
while the ls -l command will retrieve inode information.
This is description of inode information which it contain:
* The length of the file in bytes.
* Device ID (this identifies the device containing the
file).
* The User ID of the file's owner.
* The Group ID of the file.
* The file mode, which determines what users can read,
write, and execute the file.

* Timestamps telling when the inode itself was last
modified (ctime, change time), the file content last
modified (mtime, modification time), and last accessed
(atime, access time).
* A reference count telling how many hard links point to
the inode.
* Pointers to the disk blocks that store the file's content
Unix File System Nodes (inodes) Unix directories and files don't really have names. They are numbered, using node numbers called inodes, vnodes, or even gnodes (depending on the version of Unix). You won't find the name of a particular file or directory in or near the file or directory itself. All the name-to-number mappings of files and directories are stored in the parent directories. For each file or directory, a link count keeps track of how many parent directories contain a name-number mapping for each node. When a link count goes to zero, no directory points to the node and Unix is free to reclaim the disk space.
Unix permits all files to have many name-to-number mappings. So, a file may appear to have several different "names" (Unix calls them "links"); that is, several names that all map to the same node number (and thus to the same file). Or, the file may have the same "name"; but, that name may appear in different directories.
Anyone can create a link to any file to which they have access. They don't need to be able to read or write the file itself to make the link; they only need write permission on the directory in which the name-to-number map (the name, or "link") is being created.
Directories are not allowed to have many name-to-number mappings. Each directory name-to-number map is allowed to appear in exactly one parent directory and no more. This restriction means that every directory has only one "name". It prevents loops and cycles in the file system tree. (Many things are simpler if the tree has no cycles.)

Since a parent directory may have many sub-directories, and since the name ".." (dot dot) in every one of those sub-directories is a map to the node number of the parent directory, the link count of the parent directory is increased by one for every sub-directory the parent contains. Every directory also contains the name "." (dot), a map to the directory itself, so the smallest link count of any Unix directory is 2: one for the map in the parent directory that gives the directory its "name", and one for the dot map in the directory itself.
Example
Suppose the root directory has node number #2. Here is a small part of a Unix file system tree, showing hypothetical node numbers:
Node #2
. (dot) 2
.. (dot dot) 2
home 123
bin 555
usr 654
Node #555
. (dot) 555
.. (dot dot) 2
rm 546
ls 984
cp 333
ln 333
mv 333
Node #123
. (dot) 123
.. (dot dot) 2
ian 111
stud0002 755
stud0001 883
stud0003 221
Note how one directory (#555) has three name-to-number maps for the same node. All three names (cp, ln, mv) refer to the same node number, in this case a file containing an executable program. (This program looks at its name and behaves differently depending on which name you use to call it.)
Node #111
. (dot) 111
.. (dot dot) 123
.profile 334
.login 335
Node #333
Node #335

.logout 433
Disk blocks
for the
cp / ln / mv
file
(link count: 3)
Disk blocks
for the
.login
file
(link count: 1)
Example
Here are two shell programs that are linked into different directories under different names. The only way you can tell which names point to the same program files is by looking at the inode numbers using the "-i" option to ls:
# ls -i /sbin/sh /usr/bin/sh 136724 /sbin/sh 279208 /usr/bin/sh# ncheck -i 279208,136724/dev/dsk/c0t3d0s0:279208 /usr/lib/rsh136724 /sbin/jsh136724 /sbin/sh279208 /usr/bin/jsh279208 /usr/bin/sh
The ncheck command is usable only by the Super User. It finds all pathnames that lead to a particular inode.
Damage
When a Unix file system suffers damage, one or more nodes may become unreadable. If the damaged or lost nodes are file nodes, the file content pointed to by those nodes will be missing or incomplete. If any of the nodes are directory nodes, containing the names of files and sub-directories, the files and sub-directories that were once mapped by those nodes will lose their "names".
The Unix file-system checking program ("fsck") usually notices the existence of files and sub-directories that no longer have names, and it gives them false names and links them into a special directory named "lost+found" when the system reboots itself. The system admin must go into the directory and figure out what the files are, what their names are, and where they belong.
Many File Systems
A Unix file system is equivalent to a single disk partition. Each Unix file system has its own set of node numbers. Since the overall hierarchical tree on a Unix system may transparently include

pieces from several file systems, some items in the hierarchical tree will appear to have the same node numbers, but will actually be different files residing on different file systems.
A directory's name-to-number mapping applies only within a single Unix file system. It isn't possible for a directory to map to a node number in a different file system (i.e. in a different disk partition). A special "mount" command is used to splice together different file systems into one hierarchical tree.
Answer:
All UNIX files have its description stored in a structure called inode. The inode contains info about the file-size, its location, time of last access, time of last modification, permission and so on. Directories are also represented as files and have an associated inode. In addition to descriptions about the file, the inode contains pointers to the data blocks of the file. If the file is large, inode has indirect pointer to a block of pointers to additional data blocks (this further aggregates for larger files). A block is typically 8k.Inodeconsistsofthefollowingfields:FileowneridentifierFiletype
FileaccesspermissionsFileaccesstimesNumberoflinksFilesizeLocation of the file data
UNIX INODE STRUCTUREMode (file type and permissions)Link countOwner's UID numberOwner's GID numberFile size in bytesTime file was last accessedTime file was last modifiedTime inode was last changed12 direct block pointers(32/64 bits each)to reference up to 96KB1 single indirect block pointer(32/64 bits) to reference up to 16MB1 double indirect block pointer(32/64 bits) to reference up to 32GB1 triple indirect block pointer(32/64 bits) to reference up to 70TBCount of data blocks actually held1 data block(8KB)per pointer2048 direct pointers

1 data block(8KB)per pointer2048 indirect pointers2048 direct pointers1 data block(8KB)per pointerOther direct pointers1 data block(8KB)per pointer2048 indirect pointers 2048 indirect pointers 2048 direct pointersOther indirect pointers Other direct pointers© 2000 Integrated [email protected]: Drs.M.Waldorp-Bonkinode.sda 20000709
Inode status (flags)Optional: extra fields/reserved fieldsLegenda:- each (unix) file system has its own inode table; on disk eachcylinder group will hold a relevant part of that table- each inode is referenced by a "device + inode number" pair- each file is assigned an inode number which is unique withinthat file system; each directory structure will consist of a list of"filename + inode number" pairs; inodes won't hold filenames- reserved inode numbers: 0, 1, 20: deleted files/directories1: (fs dependent) file system creation time/bad blocks count/.....2: refers to the root directory of the file system- the "mode" field will always be the first field in the inode;the order of the other fields is file system dependent- timestamps: in seconds since 00:00:00 GMT 01-01-1970- access time: updated after each read/write of file- modification time: updated after each write to file- inode change time: updated after each modification of one ofthe fields in the inode (chmod, chown, chgrp, ln, ...)- triple indirect pointer: use is fs and max.file size dependent- status/flags like "compress file" or "do not update access time"or "do not extend file" are file system dependent- extra fields may hold: an inode generation number (for NFS)and/or ACL info (sometimes this field contains a "continuationinode number": a pointer to a special inode that holds ACL info)and/or a file type identification (for device files: major and minornumber; for directories: inode number of parent directory);
all extra/reserved fields are file system dependent!
The UNIX filesystem controls the way that information in files and directories is stored on disk and other forms of secondary storage. It controls which users can access what items and how. The filesystem is therefore one of the most basic tools for enforcing UNIX security on your system.

Information stored in the UNIX filesystem is arranged as a tree structure of directories and files. The tree is constructed from directories and subdirectories within a single directory, which is called the root . [1] Each directory, in turn, can contain other directories or entries such as files, pointers (symbolic links) to other parts of the filesystem, logical names that represent devices (such as /dev/tty ), and many other types.[2]
[1] This is where the "root" user (superuser) name originates: the owner of the root of the filesystem.
[2] For example, the UNIX "process" filesystem in System V contains entries that represent processes that are currently executing.
This chapter explains, from the user's point of view, how the filesystem represents and protects information.
5.1 Files
From the simplest perspective, everything visible to the user in a UNIX system can be represented as a "file" in the filesystem - including processes and network connections. Almost all of these items are represented as "files" each having at least one name, an owner, access rights, and other attributes. This information is actually stored in the filesystem in an inode (index node), the basic filesystem entry. An inode stores everything about a filesystem entry except its name; the names are stored in directories and are associated with pointers to inodes.
5.1.1 Directories
One special kind of entry in the filesystem is the directory . A directory is nothing more than a simple list of names and inode numbers. A name can consist of any string of any characters with the exception of a "/" character and the "null" character (usually a zero byte).[3] There is a limit to the length of these strings, but it is usually quite long: 1024 or longer on many modern versions of UNIX ; older AT&T versions limit names to 14 characters or less.
[3] Some versions of UNIX may further restrict the characters that can be used in filenames and directory names.
These strings are the names of files, directories, and the other objects stored in the filesystem. Each name can contain control characters, line feeds, and other characters. This can have some interesting implications for security, and we'll discuss those later in this and other chapters.
Associated with each name is a numeric pointer that is actually an index on disk for an inode. An inode contains information about an individual entry in the filesystem; these contents are described in the next section.
Nothing else is contained in the directory other than names and inode numbers. No protection information is stored there, nor owner names, nor data. The directory is a very simple relational database that maps names to inode numbers. No restriction on how many names can point to the

same inode exists, either. A directory may have 2, 5, or 50 names that each have the same inode number. In like manner, several directories may have names that associate to the same inode. These are known as links [4] to the file. There is no way of telling which link was the first created, nor is there any reason to know: all the names are equal in what they access. This is often a confusing idea for beginning users as they try to understand the "real name" for a file.
[4] These are hard links or direct links . Some systems support a different form of pointer, known as a symbolic link , that behaves in a different way.
This also means that you don't actually delete a file with commands such as rm. Instead, you unlink the name - you sever the connection between the filename in a directory and the inode number. If another link still exists, the file will continue to exist on disk. After the last link is removed, and the file is closed, the kernel will reclaim the storage because there is no longer a method for a user to access it.
Every normal directory has two names always present. One entry is for " . " (dot), and this is associated with the inode for the directory itself; it is self-referential. The second entry is for " .. " (dot-dot), which points to the "parent" of this directory - the directory next closest to the root in the tree-structured filesystem. The exception is the root directory itself, named "/". In the root directory, ".." is also a link to "/".
5.1.2 Inodes
For each object in the filesystem, UNIX stores administrative information in a structure known as an inode. Inodes reside on disk and do not have names. Instead, they have indices (numbers) indicating their positions in the array of inodes.
Each inode generally contains:
The location of the item's contents on the disk, if any The item's type (e.g., file, directory, symbolic link) The item's size, in bytes, if applicable The time the file's inode was last modified (the ctime ) The time the file's contents were last modified (the mtime ) The time the file was last accessed (the atime ) for read ( ) , exec ( ), etc A reference count: the number of names the file has The file's owner (a UID ) The file's group (a GID ) The file's mode bits (also called file permissions or permission bits )
The last three pieces of information, stored for each item, and coupled with UID/GID information about executing processes, are the fundamental data that UNIX uses for practically all operating system security.
Other information can also be stored in the inode, depending on the particular version of UNIX involved. Some systems may also have other nodes such as vnodes, cnodes, and so on. These are

simply extensions to the inode concept to support foreign files, RAID [5] disks, or other special kinds of filesystems. We'll confine our discussion to inodes, as that abstraction contains most of the information we need.
[5] RAID means Redundant Array of Inexpensive Disks. It is a technique for combining many low-cost hard disks into a single unit that offers improved performance and reliability.
Figure 5.1 shows how information is stored in an inode.
Figure 5.1: Files and inodes
Figure 5.1: Files and inodes
5.1.3 Current Directory and Paths
Every item in the filesystem with a name can be specified with a pathname . The word pathname is appropriate because a pathname represents the path to the entry from the root of the filesystem. By following this path, the system can find the inode of the referenced entry.
Pathnames can be absolute or relative. Absolute pathnames always start at the root, and thus always begin with a "/", representing the root directory. Thus, a pathname such as /homes/mortimer/bin/crashme represents a pathname to an item starting at the root directory.
A relative pathname always starts interpretation from the current directory of the process referencing the item. This concept implies that every process has associated with it a current directory . Each process inherits its current directory from a parent process after a fork (see Appendix C, UNIX Processes ). The current directory is initialized at login from the sixth field of the user record in the /etc/passwd file: the home directory . The current directory is then

updated every time the process performs a change-directory operation (chdir or cd). Relative pathnames also imply that the current directory is at the front of the given pathname. Thus, after executing the command cd /usr, the relative pathname lib/makekey would actually be referencing the pathname /usr/lib/makekey . Note that any pathname that doesn't start with a "/" must be relative.
5.1.4 Using the ls Command
You can use the ls command to list all of the files in a directory. For instance, to list all the files in your current directory, type:
% ls -a instructions letter notes invoice more-stuff stats %
You can get a more detailed listing by using the ls -lF command:
% ls -lF total 161 -rw-r--r-- 1 sian user 505 Feb 9 13:19 instructions -rw-r--r-- 1 sian user 3159 Feb 9 13:14 invoice -rw-r--r-- 1 sian user 6318 Feb 9 13:14 letter -rw------- 1 sian user 15897 Feb 9 13:20 more-stuff -rw-r----- 1 sian biochem 4320 Feb 9 13:20 notes -rwxr-xr-x 1 sian user 122880 Feb 9 13:26 stats* %
The first line of output generated by the ls command ("total 161" in the example above) indicates the number of kilobytes taken up by the files in the directory.[6] Each of the other lines of output contains the fields, from left to right, as described in Table 5.1 .
[6] Some older versions of UNIX reported this in 512-byte blocks rather than in kilobytes.
Table 5.1: ls Output
Field Contents Meaning- The file's type; for regular files, this field is always a dashrw-r--r-- The file's permissions1 The number of "hard" links to the file; the number of "names" for the filesian The name of the file's owneruser The name of the file's group505 The file's size, in bytesFeb 9 13:19 The file's modification timeinstructions The file's name
The ls -F option makes it easier for you to understand the listing by printing a special character after the filename to indicate what it is, as shown in Table 5.2 .

Table 5.2: ls -F Tag Meanings
Symbol Meaning(blank) Regular file or named pipe (FIFO[7])* Executable program or command file/ Directory= Socket@ Symbolic link
[7] A FIFO is a First-In, First-Out buffer, which is a special kind of named pipe.
Thus, in the directory shown earlier, the file stats is an executable program file; the rest of the files are regular text files.
The -g option to the ls command alters the output, depending on the version of UNIX being used.
If you are using the Berkeley-derived version of ls,[8] you must use the ls -g option to display the file's group in addition to the file's owner:
[8] On Solaris systems, this program is named /usr/ucb/ls .
% ls -lFg total 161 -rw-r--r-- 1 sian user 505 Feb 9 13:19 instructions -rw-r--r-- 1 sian user 3159 Feb 9 13:14 invoice -rw-r--r-- 1 sian user 6318 Feb 9 13:14 letter -rw------- 1 sian user 15897 Feb 9 13:20 more-stuff -rw-r----- 1 sian biochem 4320 Feb 9 13:20 notes -rwxr-xr-x 1 sian user 122880 Feb 9 13:26 stats* %
If you are using an AT&T -derived version of ls,[9] using the -g option causes the ls command to only display the file's group:
[9] On Solaris systems, this program is named /bin/ls .
% ls -lFg total 161 -rw-r--r-- 1 user 505 Feb 9 13:19 instructions -rw-r--r-- 1 user 3159 Feb 9 13:14 invoice -rw-r--r-- 1 user 6318 Feb 9 13:14 letter -rw------- 1 user 15897 Feb 9 13:20 more-stuff -rw-r----- 1 biochem 4320 Feb 9 13:20 notes -rwxr-xr-x 1 user 122880 Feb 9 13:26 stats* %
5.1.5 File Times
The times shown with the ls -l command are the modification times of the files ( mtime). You can obtain the time of last access (the atime) by providing the -u option (for example, by typing ls -lu ). Both of these time values can be changed with a call to a system library routine.[10]

Therefore, as the system administrator, you should be in the habit of checking the inode change time ( ctime) by providing the -c option; for example, ls -lc . You can't reset the ctime of a file under normal circumstances. It is updated by the operating system whenever any change is made to the inode for the file.
[10] utimes ( )
Because the inode changes when the file is modified, ctime reflects the time of last writing, protection change, or change of owner. An attacker may change the mtime or atime of a file, but the ctime will usually be correct.
Note that we said "usually." A clever attacker who gains superuser status can change the system clock and then touch the inode to force a misleading ctime on a file. Furthermore, an attacker can change the ctime by writing to the raw disk device and bypassing the operating system checks altogether. And if you are using Linux with the ext2 filesystem, an attacker can modify the inode contents directly using the debugfs command.
For this reason, if the superuser account on your system has been compromised, you should not assume that any of the three times stored with any file or directory are correct.
NOTE: Some programs will change the ctime on a file without actually changing the file itself. This can be misleading when you are looking for suspicious activity. The file command is one such offender. The discrepancy occurs because file opens the file for reading to determine its type, thus changing the atime on the file. By default, most versions of file then reset the atime to its original value, but in so doing change the ctime. Some security scanning programs use the file program within them (or employ similar functionality), and this may result in wide-scale changes in ctime unless they are run on a read-only version of the filesystem.
5.1.6 Understanding File Permissions
The file permissions on each line of the ls listing tell you what the file is and what kind of file access (that is, ability to read, write, or execute) is granted to various users on your system.
Here are two examples of file permissions:
-rw------- drwxr-xr-x
The first character of the file's mode field indicates the type of file described in Table 5.3 .
Table 5.3: File Types
Contents Meaning- Plain filed Directoryc Character device (tty or printer)b Block device (usually disk or CD-ROM)

Table 5.3: File Types
Contents Meaningl Symbolic link ( BSD or V.4)s Socket ( BSD or V.4)= or p FIFO (System V, Linux)
The next nine characters taken in groups of three indicate who on your computer can do what with the file. There are three kinds of permissions:
r
Permission to read
w
Permission to write
x
Permission to execute
Similarly, there are three classes of permissions:
owner
The file's owner
group
Users who are in the file's group
other
Everybody else on the system (except the superuser)
In the ls -l command, privileges are illustrated graphically (see Figure 5.2 ).

Figure 5.2: Basic permissions
5.1.7 File Permissions in Detail
The terms read , write , and execute have very specific meanings for files, as shown in Table 5.4 .
Table 5.4: File Permissions
Character Permission Meaningr READ Read access means exactly that: you can open a file with the open()
system call and you can read its contents with read.w WRITE Write access means that you can overwrite the file with a new one or
modify its contents. It also means that you can use write() to make the file longer or truncate() or ftruncate() to make the file shorter.
x EXECUTE Execute access makes sense only for programs. If a file has its execute bits set, you can run it by typing its pathname (or by running it with one of the family of exec() system calls). How the program gets executed depends on the first two bytes of the file.The first two bytes of an executable file are assumed to be a magic number indicating the nature of the file. Some numbers mean that the file is a certain kind of machine code file. The special two-byte sequence "#!" means that it is an executable script of some kind. Anything with an unknown value is assumed to be a shell script and is executed accordingly.
File permissions apply to devices, named sockets, and FIFOS exactly as they do for regular files. If you have write access, you can write information to the file or other object; if you have read access, you can read from it; and if you don't have either access, you're out of luck.
File permissions do not apply to symbolic links. Whether or not you can read the file pointed to by a symbolic link depends on the file's permissions, not the link's. In fact, symbolic links are almost always created with a file permission of "rwxrwxrwx" (or mode 0777, as explained later in this chapter) and are ignored by the operating system.[11]

[11] Apparently, some vendors have found a use for the mode bits inside a symbolic link's inode. HP-UX 10.0 uses the sticky bit of symbolic links to indicate "transition links" - portability links to ease the transition from previous releases to the new SVR4 filesystem layout.
Note the following facts about file permissions:
You can have execute access without having read access. In such a case, you can run a program without reading it. This ability is useful in case you wish to hide the function of a program. Another use is to allow people to execute a program without letting them make a copy of the program (see the note later in this section).
If you have read access but not execute access, you can then make a copy of the file and run it for yourself. The copy, however, will be different in two important ways: it will have a different absolute pathname; and it will be owned by you, rather than by the original program's owner.
On some versions of UNIX (including Linux), an executable command script must have both its read and execute bits set to allow people to run it.
Most people think that file permissions are pretty basic stuff. Nevertheless, many UNIX systems have had security breaches because their file permissions are not properly set.
NOTE: Sun's Network Filesystem ( NFS ) servers allow a client to read any file that has either the read or the execute permission set. They do so because there is no difference, from the NFS server's point of view, between a request to read the contents of a file by a user who is using the read() system call and a request to execute the file by a user who is using the exec() system call. In both cases, the contents of the file need to be transferred from the NFS server to the NFS client. (For a detailed description, see Chapter 20, NFS .)
Get a Grip on the Grep! – 15 Practical Grep Command Examples (this is for linux be generic for other flavours)First create the following demo_file that will be used in the examples below to demonstrate grep command.
$ cat demo_fileTHIS LINE IS THE 1ST UPPER CASE LINE IN THIS FILE.this line is the 1st lower case line in this file.

This Line Has All Its First Character Of The Word With Upper Case.
Two lines above this line is empty.And this is the last line.
1. Search for the given string in a single file
The basic usage of grep command is to search for a specific string in the specified file as shown below.
Syntax:grep "literal_string" filename$ grep "this" demo_filethis line is the 1st lower case line in this file.Two lines above this line is empty.
2. Checking for the given string in multiple files.Syntax:grep "string" FILE_PATTERN
This is also a basic usage of grep command. For this example, let us copy the demo_file to demo_file1. The grep output will also include the file name in front of the line that matched the specific pattern as shown below. When the Linux shell sees the meta character, it does the expansion and gives all the files as input to grep.
$ cp demo_file demo_file1
$ grep "this" demo_*demo_file:this line is the 1st lower case line in this file.demo_file:Two lines above this line is empty.demo_file:And this is the last line.demo_file1:this line is the 1st lower case line in this file.demo_file1:Two lines above this line is empty.demo_file1:And this is the last line.
3. Case insensitive search using grep -iSyntax:grep -i "string" FILE
This is also a basic usage of the grep. This searches for the given string/pattern case insensitively. So it matches all the words such as “the”, “THE” and “The” case insensitively as shown below.
$ grep -i "the" demo_fileTHIS LINE IS THE 1ST UPPER CASE LINE IN THIS FILE.this line is the 1st lower case line in this file.This Line Has All Its First Character Of The Word With Upper Case.And this is the last line.
4. Match regular expression in filesSyntax:grep "REGEX" filename

This is a very powerful feature, if you can use use regular expression effectively. In the following example, it searches for all the pattern that starts with “lines” and ends with “empty” with anything in-between. i.e To search “lines[anything in-between]empty” in the demo_file.
Determining a File's Type
To determine a file's type, specify the -l option to the ls. When this option is specified, ls lists the file type for the specified files. For example, the command
$ ls -l /home/ranga/.profile
produces the following output:
-rwxr-xr-x 1 ranga users 2368 Jul 11 15:57 .profile*
Here, you see that the very first character is a hyphen (-). This indicates that the file is a regular file. For special files, the first character will be one of the letters given in Table 5.1.
To obtain file type information about a directory, you must specify the -d option along with the -l option:
$ ls -ld /home/ranga
This produces the following output:
drwxr-xr-x 27 ranga users 2048 Jul 23 23:49 /home/ranga/
Table 5.1 Special Characters for Different File Types
Character File Type
- Regular file
l Symbolic link
c Character special
b Block special
p Named pipe
s Socket
d Directory file

I'll provide the actual descriptions of each of these file types in the following sections.
Regular Files
Regular files are the most common type of files you will encounter. These files store any kind of data. This data can be stored as plain text, an application- specific format, or a special binary format that the system can execute.
UNIX does not have to understand the data contained in a regular file. A regular file can store any form of raw data because UNIX does not interpret the data that is in the file.
Note - Often simply determining that a file is a regular file tells you very little about the file itself. Usually you need to know whether a particular file is a binary program, a shell script, or a library. In these instances, the file program is very useful.
It is invoked as follows:
file filename
Here, filename is the name of the file you want to examine. As an example, on my system, the command
$ file /sbin/sh
produces the following output:
/sbin/sh: ELF 32-bit MSB executable SPARC Version 1, statically linked, stripped
Here you see that the file, /sbin/sh, is an executable program. Try it out on a few files to get an idea of the kind of information that it can give you.
Symbolic Links
A symbolic link is a special file that points to another file on the system. When you access one of these files, it has a pathname stored inside it. Use this pathname to advance to the file or directory on the system represented by the pathname stored in the symbolic link.
For readers who are familiar with Windows or Mac OS, a symbolic link is similar to a shortcut or an alias.
You can use symbolic links to make a file appear as though it is located in many different places or has many different names in the file system. Symbolic links can point to any type of file or directory.
The ls -l output for a symbolic link looks like this:

lrwxrwxrwx 1 root root 9 Oct 23 13:58 /bin/ -> ./usr/bin/
The output indicates that the directory /bin is really a link to the directory ./usr/bin.
The relative path in the output is not relative to your current working directory: it is relative to the directory where the link resides. In this case, the link /bin resides in the / directory, thus ./usr/bin indicates that /bin is a link to the directory /usr/bin.
Creating Symbolic Links
Create symbolic links using the ln command with the -s option. The syntax is as follows:
ln -s source destination
Here, source is either the absolute or relative path to the original version of the file, and destination is the name you want the link to have.
For example, the following command
$ ln -s /home/httpd/html/users/ranga /home/ranga/public_html
creates a link in my home directory to my Web files. If you encounter an error while creating a link, ln will display an error message. Otherwise, it displays no output.
In this example, you used absolute paths. In practice, relative paths are preferred for the source and the destination. For example, the actual commands I used to create a link to my Web files are the following:
$ cd $ ln -s ../httpd/html/users/ranga ./public_html
You can see the relative path by using ls -l:
$ ls -l ./public_htmllrwxrwxrwx 1 ranga users 26 Nov 9 1997 public_html -> ../httpd/html/users/ranga
This output indicates that the file is a link and also shows the file or directory that the link points to.
Common Errors
The two most common errors encountered when creating symbolic links happen when
The destination already exists. The destination is a directory.
If the specified destination is a file, it does not create the requested link. For example, if the file .exrc exists in my home directory, the command
$ ln -s /etc/exrc .exrc
produces the following error message:

ln: cannot create .exrc: File exists
If the specified destination is a directory, ln creates a link in that directory with the same name as the source. For example, if the directory pub exists in the current directory, the following command
$ ln -s /home/ftp/pub/ranga pub
creates the link pub/ranga rather than complaining that the destination is a directory. I mention this behavior of ln as a common error because forgetting about that fact is a common shell script bug.
Device Files
You can access UNIX devices through reading and writing to device files. These device files are access points to the device within the file systems.
Usually, device files are located under the /dev directory. The two main types of device files are
Character special files Block special files
Character Special Files
Character special files provide a mechanism for communicating with a device one character at a time. Usually character devices represent a "raw" device. The output of ls on a character special file looks like the following:
crw------- 1 ranga users 4, 0 Feb 7 13:47 /dev/tty0
The first letter in the output is c, therefore you know that this particular file is a character special file, but you also see two extra numbers before the date. The first number is called the major number and the second number is called the minor number. UNIX uses these two numbers to identify the device driver that this file communicates with.
Block Special Files
Block special files also provide a mechanism for communicating with device drivers via the file system. These files are called block devices because they transfer large blocks of data at a time. This type of file typically represents hard drives and removable media.
Look at the ls -l output for a typical block device. For example, /dev/sda:
brw-rw---- 1 root disk 8, 0 Feb 7 13:47 /dev/sda
Here the first character is b, indicating that this file is a block special file. Just like the character special files, these files also have a major and a minor number.
Named Pipes
One of the greatest features of UNIX is that you can redirect the output of one program to the input of another program with very little work. For example, the command who | grep ranga takes the output of the who command and makes it the input to the grep command. This is called piping the output of one command into another. You will examine input and output redirection in great detail in Chapter 13, "Input/Output."

On the command line, temporary anonymous pipes are used, but sometimes more control is needed than the command line provides. For such instances, UNIX provides a way to create a named pipe, so that two or more process can communicate with each other via a file that acts like a pipe. Because these files allow process to communicate with one another, they are one of the most popular forms of interprocess communication (IPC for short) available under UNIX.
Sockets
Socket files are another form of interprocess communication, but sockets can pass data and information between two processes that are not running on the same machine. Socket files are created when communication to a process on another machine located on a network is required. Internet tools in use today, such as Web browsers, use sockets to make a connection to the Web server.
Solaris 10 Filesystems
<< PreviousNext >>
What Are Your Choices? May 26, 2008, Volume 123, Issue 4
Solaris 10 provides admins with more [storage] choices than any other operating system.
-- John Finigan
One of the most enthusiastic responses around to the various file system choices in the Solaris 10 Operating System (Solaris OS) can be found in the OSNews article by John Finigan, who says, "Solaris 10 provides admins with more [storage] choices than any other operating system. Right out of the box, it offers two filesystems, two volume managers, an iscsi target and initiator, and, naturally, an NFS server. Add a couple of Sun packages and you have volume replication, a cluster filesystem, and a hierarchical storage manager...in one well-tested package. Trust your data to the still-in-development features found in OpenSolaris, and you can have a fibre channel target and an in-kernel CIFS server, among other things." Quite a package!
Finigan discusses the four common on-disk filesystems for Solaris 10 OS, which are: UFS, ZFS, SAM and QFS, and VxFS. Of each in turn he writes:
UFS
Softw are

UFS is old technology but stable, fast filesystem whose code Sun has continuously tuned and improved over the last decade to the extent, probably, of having wrung the last bit of performance out of this particular type of filesystem. Solaris 10 OS can only boot from a UFS root filesystem, Finigan notes but, nevertheless, UFS remains a good choice for databases though it will likely be replaced by ZFS.
ZFS
No magic bullet, Finigan writes, this "first third-generation UNIX FS," which is both hybrid filesystem and volume manager. Integrating these two functionalities makes ZFS flexible but also the source of layering violation, which he sees as a minor impediment. A big plus with ZFS in Finigan's view is not having to worry about resizing a filesystem. He also likes the robustness of ZFS's error checking, which is validated on every read and write. Bad disks, bad controllers and bad fibre paths are protected against. Also finding favor with Finigan is the copy-on-write feature of ZFS, which makes for nearly free snapshot and clone functionality, as well as the solution's administrative features and self-healing capability. Eventually, he would like to see per-user-quota support but he still sees ZFS as the best filesystem option.
SAM and QFS
Though SAM and QFS are designed to work together (the former is a hierarchical storage manager, the latter a cluster filesystem), each may be used separately. Without the need for an extra LVM to do striping or concatenation, a QFS filesystem can span multiple disks, allowing data to be striped or round-robined. With QFS, metadata can be separated from data making it possible for a few disks to serve random metadata and the rest to serve a sequential data workload. As QFS cannot manage its own RAID if it is striping, users would need to employ a hardware controller, a traditional volume manager or a raw ZFS volume.
VxFS
Finigan characterizes VxFS as a fast, extent-based, journaled, clusterable filesystem. Using VxFS, he writes, "If you ever wanted to unmount a volume from your AIX box and mount it on Linux or Solaris, now you can." VxFS and its tightly integrated companion, VxVM, enable users to resize filesystems and their underlying volumes with little trouble. One reservation Finigan registers about these twins is that they are closed source solutions.
Other options in the Sun Open Storage line -- though not mentioned by Finigan -- that deserve attention include the following:
Squashfs
Squashfs is a compressed read-only file system optimized for memory-constrained systems. Project members have plans to write a complete driver that will enable the kernel to boot from a Squashfs file system, thus enabling Live-CD/DVDs to use it. This would also allow Solaris to access embedded devices using Squashfs, such as some Motorola phones.
JFS: Journaled File System
JFS provides users with a log-based, byte-level file system developed for transaction-oriented, high performance systems. JFS is scalable and robust and, with its quick restart capability, can restore a file system to a consistent state within seconds or minutes.

Ext3 File System Support
Recent achievements in this project have enabled the driver to mount and clearly unmount ext2 or ext3 filesystem; browse directories; read, write, remove or rename files, links and directories; check and set file's attributes or owner; create link, symlink, file and directory. In the works are improvements in performance and stability; enabling POSIX compliance; added support for both extended attributes and for SPARC-based machines.
Fuse on OpenSolaris
FUSE stands for 'File system in User Space'. It provides a simple interface to allow implementation of a fully functional file system in user-space. FUSE originates from the Linux community and is included in the Linux kernel (2.6.14+). The team is working on a port of FUSE to OpenSolaris using the FUSE implementation for FreeBSD as a reference with the implementation for OpenSolaris re-using much code from fuse4bsd. Documentation about the FreeBSD version of FUSE can be found at the fuse4bsd website.
ZFS on Disk Encryption Support
This project is working to provide on-disk encryption/decryption support for ZFS datasets. The project will cover the addition of encryption and decryption to the ZFS IO pipeline and the key management for ZFS datasets. Results will deliver in multiple phases to support different key management strategies, including one that provides support for secure deletion based on encrypted datasets. [...read more...]
A file system (often also written as filesystem) is a method of storing and organizing computer files and their data. Essentially, it organizes these files into a database for the storage, organization, manipulation, and retrieval by the computer's operating system.
File systems are used on data storage devices such as hard disks or CD-ROMs to maintain the physical location of the files. Beyond this, they might provide access to data on a file server by acting as clients for a network protocol (e.g., NFS, SMB, or 9P clients), or they may be virtual and exist only as an access method for virtual data (e.g., procfs). It is distinguished from a directory service and registry.
Aspects of file systems
Most file systems make use of an underlying data storage device that offers access to an array of fixed-size physical sectors, generally a power of 2 in size (512 bytes or 1, 2, or 4 KiB are most common). The file system is responsible for organizing these sectors into files and directories, and keeping track of which sectors belong to which file and which are not being used. Most file systems address data in fixed-sized units called "clusters" or "blocks" which contain a certain number of disk sectors (usually 1-64). This is the smallest amount of disk space that can be allocated to hold a file. However, file systems need not make use of a storage device at all. A file system can be used to organize and represent access to any data, whether it is stored or dynamically generated (e.g., procfs).
[edit] File names
A file name is a name assigned to a file in order to secure storage location in the computer memory. Whether the file system has an underlying storage device or not, file systems typically

have directories which associate file names with files, usually by connecting the file name to an index in a file allocation table of some sort, such as the FAT in a DOS file system, or an inode in a Unix-like file system. Directory structures may be flat, or allow hierarchies where directories may contain subdirectories. In some file systems, file names are structured, with special syntax for filename extensions and version numbers. In others, file names are simple strings, and per-file metadata is stored elsewhere.
[edit] Metadata
Other bookkeeping information is typically associated with each file within a file system. The length of the data contained in a file may be stored as the number of blocks allocated for the file or as an exact byte count. The time that the file was last modified may be stored as the file's timestamp. Some file systems also store the file creation time, the time it was last accessed, and the time that the file's meta-data was changed. (Note that many early PC operating systems did not keep track of file times.) Other information can include the file's device type (e.g., block, character, socket, subdirectory, etc.), its owner user-ID and group-ID, and its access permission settings (e.g., whether the file is read-only, executable, etc.).
Arbitrary attributes can be associated on advanced file systems, such as NTFS, XFS, ext2/ext3, some versions of UFS, and HFS+, using extended file attributes. This feature is implemented in the kernels of Linux, FreeBSD and Mac OS X operating systems, and allows metadata to be associated with the file at the file system level. This, for example, could be the author of a document, the character encoding of a plain-text document, or a checksum.
[edit] Hierarchical file systems
The hierarchical file system (not to be confused with Apple's HFS) was an early research interest of Dennis Ritchie of Unix fame; previous implementations were restricted to only a few levels, notably the IBM implementations, even of their early databases like IMS. After the success of Unix, Ritchie extended the file system concept to every object in his later operating system developments, such as Plan 9 and Inferno.
[edit] Facilities
Traditional file systems offer facilities to create, move and delete both files and directories. They lack facilities to create additional links to a directory (hard links in Unix), rename parent links (".." in Unix-like OS), and create bidirectional links to files.
Traditional file systems also offer facilities to truncate, append to, create, move, delete and in-place modify files. They do not offer facilities to prepend to or truncate from the beginning of a file, let alone arbitrary insertion into or deletion from a file. The operations provided are highly asymmetric and lack the generality to be useful in unexpected contexts. For example, interprocess pipes in Unix have to be implemented outside of the file system because the pipes concept does not offer truncation from the beginning of files.
[edit] Secure accessSee also: Secure computing

Secure access to basic file system operations can be based on a scheme of access control lists or capabilities. Research has shown access control lists to be difficult to secure properly, which is why research operating systems tend to use capabilities.[citation needed] Commercial file systems still use access control lists.
[edit] Types of file systems
File system types can be classified into disk file systems, network file systems and special purpose file systems.
[edit] Disk file systems
A disk file system is a file system designed for the storage of files on a data storage device, most commonly a disk drive, which might be directly or indirectly connected to the computer. Examples of disk file systems include FAT (FAT12, FAT16, FAT32, exFAT), NTFS, HFS and HFS+, HPFS, UFS, ext2, ext3, ext4, btrfs, ISO 9660, ODS-5, Veritas File System, VMFS ZFS, ReiserFS, Linux SWAP and UDF. Some disk file systems are journaling file systems or versioning file systems.
ISO 9660 and Universal Disk Format are the two most common formats that target Compact Discs and DVDs. Mount Rainier is a newer extension to UDF supported by Linux 2.6 series and Windows Vista that facilitates rewriting to DVDs in the same fashion as has been possible with floppy disks.
[edit] Flash file systemsMain article: Flash file system
A flash file system is a file system designed for storing files on flash memory devices. These are becoming more prevalent as the number of mobile devices is increasing, and the capacity of flash memories increase.
While a disk file system can be used on a flash device, this is suboptimal for several reasons:
Erasing blocks: Flash memory blocks have to be explicitly erased before they can be rewritten. The time taken to erase blocks can be significant, thus it is beneficial to erase unused blocks while the device is idle.
Random access: Disk file systems are optimized to avoid disk seeks whenever possible, due to the high cost of seeking. Flash memory devices impose no seek latency.
Wear levelling : Flash memory devices tend to wear out when a single block is repeatedly overwritten; flash file systems are designed to spread out writes evenly.
Log-structured file systems have many of the desirable properties for a flash file system. Such file systems include JFFS2 and YAFFS.

[edit] Tape file systems
A tape file system is a file system and tape format designed to store files on tape in a self-describing form. Magnetic tapes are sequential storage media, posing challenges to the creation and efficient management of a general-purpose file system. IBM has recently announced a new file system for tape called the Linear Tape File System. The IBM implementation of this file system has been released as the open-source IBM Long Term File System product.
[edit] Database file systems
A recent concept for file management is the idea of a database-based file system. Instead of, or in addition to, hierarchical structured management, files are identified by their characteristics, like type of file, topic, author, or similar metadata.
[edit] Transactional file systems
Some programs need to update multiple files "all at once." For example, a software installation may write program binaries, libraries, and configuration files. If the software installation fails, the program may be unusable. If the installation is upgrading a key system utility, such as the command shell, the entire system may be left in an unusable state.
Transaction processing introduces the isolation guarantee, which states that operations within a transaction are hidden from other threads on the system until the transaction commits, and that interfering operations on the system will be properly serialized with the transaction. Transactions also provide the atomicity guarantee, that operations inside of a transaction are either all committed, or the transaction can be aborted and the system discards all of its partial results. This means that if there is a crash or power failure, after recovery, the stored state will be consistent. Either the software will be completely installed or the failed installation will be completely rolled back, but an unusable partial install will not be left on the system.
Windows, beginning with Vista, added transaction support to NTFS, abbreviated TxF. TxF is the only commercial implementation of a transactional file system, as transactional file systems are difficult to implement correctly in practice. There are a number of research prototypes of transactional file systems for UNIX systems, including the Valor file system[1], Amino[2], LFS [3], and a transactional ext3 file system on the TxOS kernel[4], as well as transactional file systems targeting embedded systems, such as TFFS [5].
Ensuring consistency across multiple file system operations is difficult, if not impossible, without file system transactions. File locking can be used as a concurrency control mechanism for individual files, but it typically does not protect the directory structure or file metadata. For instance, file locking cannot prevent TOCTTOU race conditions on symbolic links. File locking also cannot automatically roll back a failed operation, such as a software upgrade; this requires atomicity.
Journaling file systems are one technique used to introduce transaction-level consistency to file system structures. Journal transactions are not exposed to programs as part of the OS API; they are only used internally to ensure consistency at the granularity of a single system call.

[edit] Network file systemsMain article: Distributed file system
A network file system is a file system that acts as a client for a remote file access protocol, providing access to files on a server. Examples of network file systems include clients for the NFS, AFS, SMB protocols, and file-system-like clients for FTP and WebDAV.
[edit] Shared disk file systemsMain article: Shared disk file system
A shared disk file system is one in which a number of machines (usually servers) all have access to the same external disk subsystem (usually a SAN). The file system arbitrates access to that subsystem, preventing write collisions. Examples include GFS from Red Hat, GPFS from IBM, and SFS from DataPlow.
[edit] Special purpose file systemsMain article: Special file system
A special purpose file system is basically any file system that is not a disk file system or network file system. This includes systems where the files are arranged dynamically by software, intended for such purposes as communication between computer processes or temporary file space.
Special purpose file systems are most commonly used by file-centric operating systems such as Unix. Examples include the procfs (/proc) file system used by some Unix variants, which grants access to information about processes and other operating system features.
Deep space science exploration craft, like Voyager I and II used digital tape-based special file systems. Most modern space exploration craft like Cassini-Huygens used Real-time operating system file systems or RTOS influenced file systems. The Mars Rovers are one such example of an RTOS file system, important in this case because they are implemented in flash memory.
[edit] File systems and operating systems
Most operating systems provide a file system, as a file system is an integral part of any modern operating system. Early microcomputer operating systems' only real task was file management — a fact reflected in their names (see DOS). Some early operating systems had a separate component for handling file systems which was called a disk operating system. On some microcomputers, the disk operating system was loaded separately from the rest of the operating system. On early operating systems, there was usually support for only one, native, unnamed file system; for example, CP/M supports only its own file system, which might be called "CP/M file system" if needed, but which didn't bear any official name at all.
Because of this, there needs to be an interface provided by the operating system software between the user and the file system. This interface can be textual (such as provided by a command line interface, such as the Unix shell, or OpenVMS DCL) or graphical (such as provided by a graphical user interface, such as file browsers). If graphical, the metaphor of the

folder, containing documents, other files, and nested folders is often used (see also: directory and folder).
[edit] Flat file systems
In a flat file system, there are no subdirectories—everything is stored at the same (root) level on the media, be it a hard disk, floppy disk, etc. While simple, this system rapidly becomes inefficient as the number of files grows, and makes it difficult for users to organize data into related groups.
Like many small systems before it, the original Apple Macintosh featured a flat file system, called Macintosh File System. Its version of Mac OS was unusual in that the file management software (Macintosh Finder) created the illusion of a partially hierarchical filing system on top of EMFS. This structure meant that every file on a disk had to have a unique name, even if it appeared to be in a separate folder. MFS was quickly replaced with Hierarchical File System, which supported real directories.
A recent addition to the flat file system family is Amazon's S3, a remote storage service, which is intentionally simplistic to allow users the ability to customize how their data is stored. The only constructs are buckets (imagine a disk drive of unlimited size) and objects (similar, but not identical to the standard concept of a file). Advanced file management is allowed by being able to use nearly any character (including '/') in the object's name, and the ability to select subsets of the bucket's content based on identical prefixes.
[edit] File systems under Unix-like operating systems
Unix-like operating systems create a virtual file system, which makes all the files on all the devices appear to exist in a single hierarchy. This means, in those systems, there is one root directory, and every file existing on the system is located under it somewhere. Unix-like systems can use a RAM disk or network shared resource as its root directory.
Unix-like systems assign a device name to each device, but this is not how the files on that device are accessed. Instead, to gain access to files on another device, the operating system must first be informed where in the directory tree those files should appear. This process is called mounting a file system. For example, to access the files on a CD-ROM, one must tell the operating system "Take the file system from this CD-ROM and make it appear under such-and-such directory". The directory given to the operating system is called the mount point – it might, for example, be /media. The /media directory exists on many Unix systems (as specified in the Filesystem Hierarchy Standard) and is intended specifically for use as a mount point for removable media such as CDs, DVDs, USB drives or floppy disks. It may be empty, or it may contain subdirectories for mounting individual devices. Generally, only the administrator (i.e. root user) may authorize the mounting of file systems.
Unix-like operating systems often include software and tools that assist in the mounting process and provide it new functionality. Some of these strategies have been coined "auto-mounting" as a reflection of their purpose.

1. In many situations, file systems other than the root need to be available as soon as the operating system has booted. All Unix-like systems therefore provide a facility for mounting file systems at boot time. System administrators define these file systems in the configuration file fstab or vfstab in Solaris Operating Environment, which also indicates options and mount points.
2. In some situations, there is no need to mount certain file systems at boot time, although their use may be desired thereafter. There are some utilities for Unix-like systems that allow the mounting of predefined file systems upon demand.
3. Removable media have become very common with microcomputer platforms. They allow programs and data to be transferred between machines without a physical connection. Common examples include USB flash drives, CD-ROMs, and DVDs. Utilities have therefore been developed to detect the presence and availability of a medium and then mount that medium without any user intervention.
4. Progressive Unix-like systems have also introduced a concept called supermounting; see, for example, the Linux supermount-ng project. For example, a floppy disk that has been supermounted can be physically removed from the system. Under normal circumstances, the disk should have been synchronized and then unmounted before its removal. Provided synchronization has occurred, a different disk can be inserted into the drive. The system automatically notices that the disk has changed and updates the mount point contents to reflect the new medium. Similar functionality is found on Windows machines.
5. A similar innovation preferred by some users is the use of autofs, a system that, like supermounting, eliminates the need for manual mounting commands. The difference from supermount, other than compatibility in an apparent greater range of applications such as access to file systems on network servers, is that devices are mounted transparently when requests to their file systems are made, as would be appropriate for file systems on network servers, rather than relying on events such as the insertion of media, as would be appropriate for removable media.
[edit] File systems under Linux
Linux supports many different file systems, but common choices for the system disk include the ext* family (such as ext2, ext3 and ext4), XFS, JFS, ReiserFS and btrfs.
[edit] File systems under Solaris
The Sun Microsystems Solaris operating system in earlier releases defaulted to (non-journaled or non-logging) UFS for bootable and supplementary file systems. Solaris defaulted to, supported, and extended UFS.
Support for other file systems and significant enhancements were added over time, including Veritas Software Corp. (Journaling) VxFS, Sun Microsystems (Clustering) QFS, Sun Microsystems (Journaling) UFS, and Sun Microsystems (open source, poolable, 128 bit compressible, and error-correcting) ZFS.
Kernel extensions were added to Solaris to allow for bootable Veritas VxFS operation. Logging or Journaling was added to UFS in Sun's Solaris 7. Releases of Solaris 10, Solaris Express, OpenSolaris, and other open source variants of the Solaris operating system later supported bootable ZFS.

Logical Volume Management allows for spanning a file system across multiple devices for the purpose of adding redundancy, capacity, and/or throughput. Legacy environments in Solaris may use Solaris Volume Manager (formerly known as Solstice DiskSuite.) Multiple operating systems (including Solaris) may use Veritas Volume Manager. Modern Solaris based operating systems eclipse the need for Volume Management through leveraging virtual storage pools in ZFS.
Purpose of storage
Many different forms of storage, based on various natural phenomena, have been invented. So far, no practical universal storage medium exists, and all forms of storage have some drawbacks. Therefore a computer system usually contains several kinds of storage, each with an individual purpose.
A digital computer represents data using the binary numeral system. Text, numbers, pictures, audio, and nearly any other form of information can be converted into a string of bits, or binary digits, each of which has a value of 1 or 0. The most common unit of storage is the byte, equal to 8 bits. A piece of information can be handled by any computer whose storage space is large enough to accommodate the binary representation of the piece of information, or simply data. For example, using eight million bits, or about one megabyte, a typical computer could store a short novel.
Traditionally the most important part of every computer is the central processing unit (CPU, or simply a processor), because it actually operates on data, performs any calculations, and controls all the other components.
Without a significant amount of memory, a computer would merely be able to perform fixed operations and immediately output the result. It would have to be reconfigured to change its behavior. This is acceptable for devices such as desk calculators or simple digital signal processors. Von Neumann machines differ in that they have a memory in which they store their operating instructions and data. Such computers are more versatile in that they do not need to have their hardware reconfigured for each new program, but can simply be reprogrammed with new in-memory instructions; they also tend to be simpler to design, in that a relatively simple processor may keep state between successive computations to build up complex procedural results. Most modern computers are von Neumann machines.
In practice, almost all computers use a variety of memory types, organized in a storage hierarchy around the CPU, as a trade-off between performance and cost. Generally, the lower a storage is in the hierarchy, the lesser its bandwidth and the greater its access latency is from the CPU. This traditional division of storage to primary, secondary, tertiary and off-line storage is also guided by cost per bit.

[edit] Hierarchy of storage
Various forms of storage, divided according to their distance from the central processing unit. The fundamental components of a general-purpose computer are arithmetic and logic unit, control circuitry, storage space, and input/output devices. Technology and capacity as in common home computers around 2005.
[edit] Primary storageDirect links to this section: Primary storage, Main memory, Internal Memory.
Primary storage (or main memory or internal memory), often referred to simply as memory, is the only one directly accessible to the CPU. The CPU continuously reads instructions stored there and executes them as required. Any data actively operated on is also stored there in uniform manner.
Historically, early computers used delay lines, Williams tubes, or rotating magnetic drums as primary storage. By 1954, those unreliable methods were mostly replaced by magnetic core

memory. Core memory remained dominant until the 1970s, when advances in integrated circuit technology allowed semiconductor memory to become economically competitive.
This led to modern random-access memory (RAM). It is small-sized, light, but quite expensive at the same time. (The particular types of RAM used for primary storage are also volatile, i.e. they lose the information when not powered).
As shown in the diagram, traditionally there are two more sub-layers of the primary storage, besides main large-capacity RAM:
Processor registers are located inside the processor. Each register typically holds a word of data (often 32 or 64 bits). CPU instructions instruct the arithmetic and logic unit to perform various calculations or other operations on this data (or with the help of it). Registers are the fastest of all forms of computer data storage.
Processor cache is an intermediate stage between ultra-fast registers and much slower main memory. It's introduced solely to increase performance of the computer. Most actively used information in the main memory is just duplicated in the cache memory, which is faster, but of much lesser capacity. On the other hand it is much slower, but much larger than processor registers. Multi-level hierarchical cache setup is also commonly used—primary cache being smallest, fastest and located inside the processor; secondary cache being somewhat larger and slower.
Main memory is directly or indirectly connected to the central processing unit via a memory bus. It is actually two buses (not on the diagram): an address bus and a data bus. The CPU firstly sends a number through an address bus, a number called memory address, that indicates the desired location of data. Then it reads or writes the data itself using the data bus. Additionally, a memory management unit (MMU) is a small device between CPU and RAM recalculating the actual memory address, for example to provide an abstraction of virtual memory or other tasks.
As the RAM types used for primary storage are volatile (cleared at start up), a computer containing only such storage would not have a source to read instructions from, in order to start the computer. Hence, non-volatile primary storage containing a small startup program (BIOS) is used to bootstrap the computer, that is, to read a larger program from non-volatile secondary storage to RAM and start to execute it. A non-volatile technology used for this purpose is called ROM, for read-only memory (the terminology may be somewhat confusing as most ROM types are also capable of random access).
Many types of "ROM" are not literally read only, as updates are possible; however it is slow and memory must be erased in large portions before it can be re-written. Some embedded systems run programs directly from ROM (or similar), because such programs are rarely changed. Standard computers do not store non-rudimentary programs in ROM, rather use large capacities of secondary storage, which is non-volatile as well, and not as costly.
Recently, primary storage and secondary storage in some uses refer to what was historically called, respectively, secondary storage and tertiary storage.[2]

[edit] Secondary storage
A hard disk drive with protective cover removed.
Secondary storage (also known as external memory or auxiliary storage), differs from primary storage in that it is not directly accessible by the CPU. The computer usually uses its input/output channels to access secondary storage and transfers the desired data using intermediate area in primary storage. Secondary storage does not lose the data when the device is powered down—it is non-volatile. Per unit, it is typically also two orders of magnitude less expensive than primary storage. Consequently, modern computer systems typically have two orders of magnitude more secondary storage than primary storage and data is kept for a longer time there.
In modern computers, hard disk drives are usually used as secondary storage. The time taken to access a given byte of information stored on a hard disk is typically a few thousandths of a second, or milliseconds. By contrast, the time taken to access a given byte of information stored in random access memory is measured in billionths of a second, or nanoseconds. This illustrates the significant access-time difference which distinguishes solid-state memory from rotating magnetic storage devices: hard disks are typically about a million times slower than memory. Rotating optical storage devices, such as CD and DVD drives, have even longer access times. With disk drives, once the disk read/write head reaches the proper placement and the data of interest rotates under it, subsequent data on the track are very fast to access. As a result, in order to hide the initial seek time and rotational latency, data are transferred to and from disks in large contiguous blocks.
When data reside on disk, block access to hide latency offers a ray of hope in designing efficient external memory algorithms. Sequential or block access on disks is orders of magnitude faster than random access, and many sophisticated paradigms have been developed to design efficient algorithms based upon sequential and block access . Another way to reduce the I/O bottleneck is to use multiple disks in parallel in order to increase the bandwidth between primary and secondary memory.[3]
Some other examples of secondary storage technologies are: flash memory (e.g. USB flash drives or keys), floppy disks, magnetic tape, paper tape, punched cards, standalone RAM disks, and Iomega Zip drives.
The secondary storage is often formatted according to a file system format, which provides the abstraction necessary to organize data into files and directories, providing also additional

information (called metadata) describing the owner of a certain file, the access time, the access permissions, and other information.
Most computer operating systems use the concept of virtual memory, allowing utilization of more primary storage capacity than is physically available in the system. As the primary memory fills up, the system moves the least-used chunks (pages) to secondary storage devices (to a swap file or page file), retrieving them later when they are needed. As more of these retrievals from slower secondary storage are necessary, the more the overall system performance is degraded.
[edit] Tertiary storage
Large tape library. Tape cartridges placed on shelves in the front, robotic arm moving in the back. Visible height of the library is about 180 cm.
Tertiary storage or tertiary memory,[4] provides a third level of storage. Typically it involves a robotic mechanism which will mount (insert) and dismount removable mass storage media into a storage device according to the system's demands; this data is often copied to secondary storage before use. It is primarily used for archival of rarely accessed information since it is much slower than secondary storage (e.g. 5–60 seconds vs. 1-10 milliseconds). This is primarily useful for extraordinarily large data stores, accessed without human operators. Typical examples include tape libraries and optical jukeboxes.
When a computer needs to read information from the tertiary storage, it will first consult a catalog database to determine which tape or disc contains the information. Next, the computer will instruct a robotic arm to fetch the medium and place it in a drive. When the computer has finished reading the information, the robotic arm will return the medium to its place in the library.

[edit] Off-line storage
Off-line storage is a computer data storage on a medium or a device that is not under the control of a processing unit.[5] The medium is recorded, usually in a secondary or tertiary storage device, and then physically removed or disconnected. It must be inserted or connected by a human operator before a computer can access it again. Unlike tertiary storage, it cannot be accessed without human interaction.
Off-line storage is used to transfer information, since the detached medium can be easily physically transported. Additionally, in case a disaster, for example a fire, destroys the original data, a medium in a remote location will probably be unaffected, enabling disaster recovery. Off-line storage increases general information security, since it is physically inaccessible from a computer, and data confidentiality or integrity cannot be affected by computer-based attack techniques. Also, if the information stored for archival purposes is accessed seldom or never, off-line storage is less expensive than tertiary storage.
In modern personal computers, most secondary and tertiary storage media are also used for off-line storage. Optical discs and flash memory devices are most popular, and to much lesser extent removable hard disk drives. In enterprise uses, magnetic tape is predominant. Older examples are floppy disks, Zip disks, or punched cards.
[edit] Characteristics of storage
A 1GB DDR RAM memory module (detail)
Storage technologies at all levels of the storage hierarchy can be differentiated by evaluating certain core characteristics as well as measuring characteristics specific to a particular implementation. These core characteristics are volatility, mutability, accessibility, and

addressibility. For any particular implementation of any storage technology, the characteristics worth measuring are capacity and performance.
[edit] VolatilityNon-volatile memory
Will retain the stored information even if it is not constantly supplied with electric power. It is suitable for long-term storage of information. Nowadays used for most of secondary, tertiary, and off-line storage. In 1950s and 1960s, it was also used for primary storage, in the form of magnetic core memory.
Volatile memory
Requires constant power to maintain the stored information. The fastest memory technologies of today are volatile ones (not a universal rule). Since primary storage is required to be very fast, it predominantly uses volatile memory.
[edit] DifferentiationDynamic random access memory
A form of volatile memory which also requires the stored information to be periodically re-read and re-written, or refreshed, otherwise it would vanish.
Static memory
A form of volatile memory similar to DRAM with the exception that it never needs to be refreshed as long as power is applied. (It loses its content if power is removed).
[edit] MutabilityRead/write storage or mutable storage
Allows information to be overwritten at any time. A computer without some amount of read/write storage for primary storage purposes would be useless for many tasks. Modern computers typically use read/write storage also for secondary storage.
Read only storage
Retains the information stored at the time of manufacture, and write once storage (Write Once Read Many) allows the information to be written only once at some point after manufacture. These are called immutable storage. Immutable storage is used for tertiary and off-line storage. Examples include CD-ROM and CD-R.
Slow write, fast read storage
Read/write storage which allows information to be overwritten multiple times, but with the write operation being much slower than the read operation. Examples include CD-RW and flash memory.

[edit] AccessibilityRandom access
Any location in storage can be accessed at any moment in approximately the same amount of time. Such characteristic is well suited for primary and secondary storage.
Sequential access
The accessing of pieces of information will be in a serial order, one after the other; therefore the time to access a particular piece of information depends upon which piece of information was last accessed. Such characteristic is typical of off-line storage.
[edit] AddressabilityLocation-addressable
Each individually accessible unit of information in storage is selected with its numerical memory address. In modern computers, location-addressable storage usually limits to primary storage, accessed internally by computer programs, since location-addressability is very efficient, but burdensome for humans.
File addressable
Information is divided into files of variable length, and a particular file is selected with human-readable directory and file names. The underlying device is still location-addressable, but the operating system of a computer provides the file system abstraction to make the operation more understandable. In modern computers, secondary, tertiary and off-line storage use file systems.
Content-addressable
Each individually accessible unit of information is selected based on the basis of (part of) the contents stored there. Content-addressable storage can be implemented using software (computer program) or hardware (computer device), with hardware being faster but more expensive option. Hardware content addressable memory is often used in a computer's CPU cache.
[edit] CapacityRaw capacity
The total amount of stored information that a storage device or medium can hold. It is expressed as a quantity of bits or bytes (e.g. 10.4 megabytes).
Memory storage density
The compactness of stored information. It is the storage capacity of a medium divided with a unit of length, area or volume (e.g. 1.2 megabytes per square inch).

[edit] PerformanceLatency
The time it takes to access a particular location in storage. The relevant unit of measurement is typically nanosecond for primary storage, millisecond for secondary storage, and second for tertiary storage. It may make sense to separate read latency and write latency, and in case of sequential access storage, minimum, maximum and average latency.
Throughput
The rate at which information can be read from or written to the storage. In computer data storage, throughput is usually expressed in terms of megabytes per second or MB/s, though bit rate may also be used. As with latency, read rate and write rate may need to be differentiated. Also accessing media sequentially, as opposed to randomly, typically yields maximum throughput.
[edit] Energy use
Storage devices that reduce fan usage, automatically shut-down during inactivity, and low power hard drives can reduce energy consumption 90 percent. [6]
2.5 inch hard disk drives often consume less power than larger ones.[7][8] Low capacity solid-state drives have no moving parts and consume less power than hard disks.[9][10][11] Also, memory may use more power than hard disks.[11]
[edit] Fundamental storage technologies
As of 2008, the most commonly used data storage technologies are semiconductor, magnetic, and optical, while paper still sees some limited usage. Some other fundamental storage technologies have also been used in the past or are proposed for development.
[edit] Semiconductor
Semiconductor memory uses semiconductor-based integrated circuits to store information. A semiconductor memory chip may contain millions of tiny transistors or capacitors. Both volatile and non-volatile forms of semiconductor memory exist. In modern computers, primary storage almost exclusively consists of dynamic volatile semiconductor memory or dynamic random access memory. Since the turn of the century, a type of non-volatile semiconductor memory known as flash memory has steadily gained share as off-line storage for home computers. Non-volatile semiconductor memory is also used for secondary storage in various advanced electronic devices and specialized computers.
[edit] Magnetic
show]
v • d • eMagnetic storage media

Magnetic storage uses different patterns of magnetization on a magnetically coated surface to store information. Magnetic storage is non-volatile. The information is accessed using one or more read/write heads which may contain one or more recording transducers. A read/write head only covers a part of the surface so that the head or medium or both must be moved relative to another in order to access data. In modern computers, magnetic storage will take these forms:
Magnetic disk o Floppy disk, used for off-line storage o Hard disk drive, used for secondary storage
Magnetic tape data storage, used for tertiary and off-line storage
In early computers, magnetic storage was also used for primary storage in a form of magnetic drum, or core memory, core rope memory, thin-film memory, twistor memory or bubble memory. Also unlike today, magnetic tape was often used for secondary storage.
[edit] Optical
[show]
v • d • e
Optical storage media
Optical storage, the typical optical disc, stores information in deformities on the surface of a circular disc and reads this information by illuminating the surface with a laser diode and observing the reflection. Optical disc storage is non-volatile. The deformities may be permanent (read only media ), formed once (write once media) or reversible (recordable or read/write media). The following forms are currently in common use:[12]
CD, CD-ROM, DVD, BD-ROM: Read only storage, used for mass distribution of digital information (music, video, computer programs)
CD-R, DVD-R, DVD+R, BD-R: Write once storage, used for tertiary and off-line storage CD-RW, DVD-RW, DVD+RW, DVD-RAM, BD-RE: Slow write, fast read storage, used for tertiary
and off-line storage Ultra Density Optical or UDO is similar in capacity to BD-R or BD-RE and is slow write, fast read
storage used for tertiary and off-line storage.
Magneto-optical disc storage is optical disc storage where the magnetic state on a ferromagnetic surface stores information. The information is read optically and written by combining magnetic and optical methods. Magneto-optical disc storage is non-volatile, sequential access, slow write, fast read storage used for tertiary and off-line storage.
3D optical data storage has also been proposed.
WHat is the difference between Veritas filesystem and veritas volume manager?

I had trouble with this in the beginning also.
Volume Manager has to do with managing the disks, raid, striping, plexes, etc....
Veritas Filesystem is just that. Anything that you need to do to manage the data on the disks. Such as mkfs, mount, online resizing and defragmenting. It also gives you control over I/O, caching, and allocation.
Remember:VM is managing the disks.
Veritas Filesystem is managing the data on the disks.
The Veritas filesystem is the filesystem used for specific partitions. It is controlled by the Veritas Volume Manager which is a gui software interface to create the different volumes being used (by Oracle, Sybase, and other applications). Normally UNIX OS does not need to be placed under Veritas but could (although failures in drives then creates more of a headache for the OS recovery.)
Logical Volume ManagersLogical volume management is a relatively new approach to UNIX disks and filesystems. Instead of dealing directly with physical disk partitions, the logical volume manager (abbreviated LVM) splits disk space up into logical partitions. The difference between an ordinary disk partition and a logical partition is analogous to the difference between a physical filesystem and the UNIX logical filesystem. A logical partition may span multiple physical disks, but is accessed transparently as if it were a single disk.
There are numerous advantages to using a logical volume manager:
They offer greater flexibility for disk partitioning. The size of logical volumes can be modified according to need, while the operating system is
running Logical volumes can span multiple disks. Disk mirroring is often supported, for greater data reliability
The simplest way to understand logical volume management is to look at the structure of the system from the bottom up:
Disks, Physical Volumes, and Volume GroupsThe lowest level is that of the physical disk itself. A physical disk is formatted into a physical volume for use by the LVM. Each physical volume is split up into discrete chunks, called physical partitions or physical extents. Note that this is not the same thing as an ordinary disk partition; physical partitions/extents are allocatable units of space, on the order of 4MB.
Physical volumes are combined into a volume group. A volume group is thus a collection of disks, treated as one large storage area. The physical volume is analogous to the physical disk

under the ordinary UNIX partitioning scheme -- it is a single storage area that can be split up into several independent filesystems.
Logical VolumesLogical volumes are the LVM's equivalent to the ordinary UNIX disk partition. A logical volume is made into a filesystem, or may be used as a swap device, a boot device, and so on. A logical volume consists of some number of physical partitions/extents, allocated from a single volume group. The allocation of physical partitions within a volume group is generally arbitrary, though some LVM's may allow a logical volume to be allocated from a specific physical volume. Logical volumes may be any size that is a multiple of the size of a physical partition within a given volume group.
VI Editor CommandsVi has two modes insertion mode and command mode. The editor begins in command mode, where cursor movement and copy/paste editing occur. Most commands execute as soon as typed except for "colon" commands which execute when you press the return key.
Switch to Text or Insert mode:
Open line
above cursor O
Insert text at beginning of line
I Insert text at
cursori
Insert text after cursor
aAppend text at
line endA
Open line
below cursoro
Switch to Command mode:
Switch to command mode
<ESC>
Cursor Movement (command mode):
Scroll Backward 1
screen<ctrl>b
Scroll Up 1/2 <ctrl>u

screen
Go to beginning of line
0 Go to line n nGGo to end of
line$
Scroll Down 1/2
screen<ctrl>d
Go to line number ##
:##
Scroll Forward 1
screen<ctrl>f
Go to last line G
Scroll by sentence f/b
( )
Scroll by word f/bw b
Move left, down, up, right
h j k l Left 6 chars 6h
Scroll by paragraph f/b
{ } Directional Movement
Arrow Keys
Go to line #6 6G
Deleting text (command mode):
Change word
cw Replace one character r
Delete word
dw Delete text at cursor xDelete entire line (to
buffer)dd
Delete (backspace) text at
cursorX
Delete 5 lines (to buffer)
5dd
Delete current to end of line
D Delete lines 5-10 :5,10d
Editing (command mode):
Copy line yy Copy n lines
nyy Copy lines 1-2/paste
:1,2t 3

after 3
Paste above
current line
P
Paste below
current line
p
Move lines 4-5/paste after 6
:4,5m 6
Join
previous line
J
Search backward for string
?stringSearch forward
for string/string
Find next string occurrence
n
% (entire file) s
(search and
replace) /old text
with new/ c
(confirm) g (global
- all)
:%s/oldstring/newstring/cg
Ignore case
during search
:set ic
Repeat last
command.
Undo previous
commandu
Undo all changes
to lineU
Save and Quit (command mode):
Save changes to buffer
:wSave changes and
quit vi:wq
Save file to new file
:w file

Quit without saving :q!Save lines to
new file:10,15w file
:syntax on Turn on syntax highlighting:syntax off Turn off syntax highlighting:set number Turn on Line numbering (shorthand :set nu) :set nonumber Turn off Line numbering (shorthand :set nonu)
:set ignorecase Ignore case sensitivity when searching:set noignorecase Restore case sensitivity (default)
:set autoindent Turn on Auto-indentation Use the command >> to indent and the << command to outdent :set shiftwidth=4 Set indentation to four spaces:set noautoindent Turn off Auto-indentation
What is vi?The default editor that comes with the UNIX operating system is called vi (visual editor). [Alternate editors for UNIX environments include pico and emacs, a product of GNU.]
The UNIX vi editor is a full screen editor and has two modes of operation:
1. Command mode commands which cause action to be taken on the file, and 2. Insert mode in which entered text is inserted into the file.
In the command mode, every character typed is a command that does something to the text file being edited; a character typed in the command mode may even cause the vi editor to enter the insert mode. In the insert mode, every character typed is added to the text in the file; pressing the <Esc> (Escape) key turns off the Insert mode. While there are a number of vi commands, just a handful of these is usually sufficient for beginning vi users. To assist such users, this Web page contains a sampling of basic vi commands. The most basic and useful commands are marked with an asterisk (* or star) in the tables below. With practice, these commands should become automatic.
NOTE: Both UNIX and vi are case-sensitive. Be sure not to use a capital letter in place of a lowercase letter; the results will not be what you expect.

To Get Into and Out Of vi
To Start viTo use vi on a file, type in vi filename. If the file named filename exists, then the first page (or screen) of the file will be displayed; if the file does not exist, then an empty file and screen are created into which you may enter text.
* vi filename edit filename starting at line 1
vi -r filename recover filename that was being edited when system crashed
To Exit viUsually the new or modified file is saved when you leave vi. However, it is also possible to quit vi without saving the file.
Note: The cursor moves to bottom of screen whenever a colon (:) is typed. This type of command is completed by hitting the <Return> (or <Enter>) key.
* :x<Return> quit vi, writing out modified file to file named in original invocation
:wq<Return> quit vi, writing out modified file to file named in original invocation
:q<Return> quit (or exit) vi
* :q!<Return> quit vi even though latest changes have not been saved for this vi call
Moving the CursorUnlike many of the PC and MacIntosh editors, the mouse does not move the cursor within the vi editor screen (or window). You must use the the key commands listed below. On some UNIX platforms, the arrow keys may be used as well; however, since vi was designed with the Qwerty keyboard (containing no arrow keys) in mind, the arrow keys sometimes produce strange effects in vi and should be avoided.
If you go back and forth between a PC environment and a UNIX environment, you may find that this dissimilarity in methods for cursor movement is the most frustrating difference between the two.
In the table below, the symbol ^ before a letter means that the <Ctrl> key should be held down while the letter key is pressed.
* j or <Return> move cursor down one line

[or down-arrow]
* k [or up-arrow] move cursor up one line
* h or <Backspace> [or left-arrow]
move cursor left one character
* l or <Space> [or right-arrow]
move cursor right one character
* 0 (zero) move cursor to start of current line (the one with the cursor)
* $ move cursor to end of current line
w move cursor to beginning of next word
b move cursor back to beginning of preceding word
:0<Return> or 1G move cursor to first line in file
:n<Return> or nG move cursor to line n
:$<Return> or G move cursor to last line in file
Screen ManipulationThe following commands allow the vi editor screen (or window) to move up or down several lines and to be refreshed.
^f move forward one screen
^b move backward one screen
^d move down (forward) one half screen
^u move up (back) one half screen
^l redraws the screen
^r redraws the screen, removing deleted lines

Adding, Changing, and Deleting TextUnlike PC editors, you cannot replace or delete text by highlighting it with the mouse. Instead use the commands in the following tables.
Perhaps the most important command is the one that allows you to back up and undo your last action. Unfortunately, this command acts like a toggle, undoing and redoing your most recent action. You cannot go back more than one step.
* u UNDO WHATEVER YOU JUST DID; a simple toggle
The main purpose of an editor is to create, add, or modify text for a file.
Inserting or Adding TextThe following commands allow you to insert and add text. Each of these commands puts the vi editor into insert mode; thus, the <Esc> key must be pressed to terminate the entry of text and to put the vi editor back into command mode.
* i insert text before cursor, until <Esc> hit
I insert text at beginning of current line, until <Esc> hit
* a append text after cursor, until <Esc> hit
A append text to end of current line, until <Esc> hit
* o open and put text in a new line below current line, until <Esc> hit
* O open and put text in a new line above current line, until <Esc> hit
Changing TextThe following commands allow you to modify text.
* r replace single character under cursor (no <Esc> needed)
R replace characters, starting with current cursor position, until <Esc> hit
cw change the current word with new text, starting with the character under cursor, until <Esc> hit
cNw change N words beginning with character under cursor, until <Esc> hit; e.g., c5w changes 5 words
C change (replace) the characters in the current line, until <Esc> hit

cc change (replace) the entire current line, stopping when <Esc> is hit
Ncc or cNc change (replace) the next N lines, starting with the current line,stopping when <Esc> is hit
Deleting TextThe following commands allow you to delete text.
* x delete single character under cursor
Nx delete N characters, starting with character under cursor
dw delete the single word beginning with character under cursor
dNw delete N words beginning with character under cursor; e.g., d5w deletes 5 words
D delete the remainder of the line, starting with current cursor position
* dd delete entire current line
Ndd or dNd delete N lines, beginning with the current line; e.g., 5dd deletes 5 lines
Cutting and Pasting TextThe following commands allow you to copy and paste text.
yy copy (yank, cut) the current line into the buffer
Nyy or yNy copy (yank, cut) the next N lines, including the current line, into the buffer
p put (paste) the line(s) in the buffer into the text after the current line
Other Commands
Searching TextA common occurrence in text editing is to replace one word or phase by another. To locate instances of particular sets of characters (or strings), use the following commands.
/string search forward for occurrence of string in text
?string search backward for occurrence of string in text

n move to next occurrence of search string
N move to next occurrence of search string in opposite direction
Determining Line NumbersBeing able to determine the line number of the current line or the total number of lines in the file being edited is sometimes useful.
:.= returns line number of current line at bottom of screen
:= returns the total number of lines at bottom of screen
^g provides the current line number, along with the total number of lines,in the file at the bottom of the screen
Saving and Reading Files
These commands permit you to input and output files other than the named file with which you are currently working.
:r filename<Return> read file named filename and insert after current line (the line with cursor)
:w<Return> write current contents to file named in original vi call
:w newfile<Return> write current contents to a new file named newfile
:12,35w smallfile<Return> write the contents of the lines numbered 12 through 35 to a new file named smallfile
:w! prevfile<Return> write current contents over a pre-existing file named prevfile
vi command summaryThe following tables contain all the basic vi commands.
Starting vi

Command Description
vi file start at line 1 of file
vi +n file start at line n of file
vi + file start at last line of file
vi +/pattern file start at pattern in file
vi -r file recover file after a system crash
Saving files and quitting vi
Command Description
:e file edit file (save current file with :w first)
:w save (write out) the file being edited
:w file save as file
:w! file save as an existing file
:q quit vi
:wq save the file and quit vi
:x save the file if it has changed and quit vi
:q! quit vi without saving changes
Moving the cursor
Keys pressed Effect
h left one character
l or <Space> right one character
k up one line
j or <Enter> down one line
b left one word
w right one word
( start of sentence
) end of sentence
{ start of paragraph
} end of paragraph
1G top of file
nG line n
G end of file
<Ctrl>W first character of insertion
<Ctrl>U up ½ screen
<Ctrl>D down ½ screen
<Ctrl>B up one screen

<Ctrl>F down one screen
Inserting text
Keys pressed Text inserted
a after the cursor
A after last character on the line
i before the cursor
I before first character on the line
o open line below current line
O open line above current line
Changing and replacing text
Keys pressed Text changed or replaced
cw word
3cw three words
cc current line
5cc five lines
r current character only
R current character and those to its right
s current character
S current line
~ switch between lowercase and uppercase
Deleting text
Keys pressed Text deleted
x character under cursor
12x 12 characters
X character to left of cursor
dw word
3dw three words
d0 to beginning of line
d$ to end of line
dd current line
5dd five lines
d{ to beginning of paragraph
d} to end of paragraph

:1,. d to beginning of file
:.,$ d to end of file
:1,$ d whole file
Using markers and buffers
Command Description
mf set marker named ``f''
`f go to marker ``f''
´f go to start of line containing marker ``f''
"s12yy copy 12 lines into buffer ``s''
"ty} copy text from cursor to end of paragraph into buffer ``t''
"ly1G copy text from cursor to top of file into buffer ``l''
"kd`f cut text from cursor up to marker ``f'' into buffer ``k''
"kp paste buffer ``k'' into text
Searching for text
Search Finds
/and next occurrence of ``and'', for example, ``and'', ``stand'', ``grand''
?and previous occurrence of ``and''
/^The next line that starts with ``The'', for example, ``The'', ``Then'', ``There''
/^The\> next line that starts with the word ``The''
/end$ next line that ends with ``end''
/[bB]ox next occurrence of ``box'' or ``Box''
n repeat the most recent search, in the same direction
N repeat the most recent search, in the opposite direction
Searching for and replacing text
Command Description
:s/pear/peach/g replace all occurrences of ``pear'' with ``peach'' on current line
:/orange/s//lemon/g change all occurrences of ``orange'' into ``lemon'' on next line containing ``orange''
:.,$/\<file/directory/g replace all words starting with ``file'' by ``directory'' on every line from current line onward, for example, ``filename'' becomes ``directoryname''
:g/one/s//1/g replace every occurrence of ``one'' with 1, for example, ``oneself'' becomes ``1self'', ``someone'' becomes ``some1''
Matching patterns of text

Expression Matches
. any single character
zero or more of the previous expression
. zero or more arbitrary characters
\< beginning of a word
\> end of a word
\ quote a special character
\ the character `` ''
^ beginning of a line
$ end of a line
[set] one character from a set of characters
[XYZ] one of the characters ``X'', ``Y'', or ``Z''
[[:upper:]][[:lower:]]* one uppercase character followed by any number of lowercase characters
[^set] one character not from a set of characters
[^XYZ[:digit:]] any character except ``X'', ``Y'', ``Z'', or a numeric digit
Options to the :set command
Option Effect
all list settings of all options
ignorecase ignore case in searches
list display <Tab> and end-of-line characters
mesg display messages sent to your terminal
nowrapscan prevent searches from wrapping round the end or beginning of a file
number display line numbers
report=5 warn if five or more lines are changed by command
term=ansi set terminal type to ``ansi''
terse shorten error messages
warn display ``[No write since last change]'' on shell escape if file has not been saved
Unix (officially trademarked as UNIX, sometimes also written as UNIX with small caps) is a computer operating system originally developed in 1969 by a group of AT&T employees at Bell Labs, including Ken Thompson, Dennis Ritchie, Brian Kernighan, Douglas McIlroy, and Joe Ossanna. Today's Unix systems are split into various branches, developed over time by AT&T as well as various commercial vendors and non-profit organizations.

The Open Group, an industry standards consortium, owns the “Unix” trademark. Only systems fully compliant with and certified according to the Single UNIX Specification are qualified to use the trademark; others might be called "Unix system-like" or "Unix-like" (though the Open Group disapproves of this term). However, the term "Unix" is often used informally to denote any operating system that closely resembles the trademarked system.
During the late 1970s and early 1980s, the influence of Unix in academic circles led to large-scale adoption of Unix (particularly of the BSD variant, originating from the University of California, Berkeley) by commercial startups, the most notable of which are Solaris, HP-UX and AIX. Today, in addition to certified Unix systems such as those already mentioned, Unix-like operating systems such as Linux and BSD descendants (FreeBSD, NetBSD, and OpenBSD) are commonly encountered. The term "traditional Unix" may be used to describe a Unix or an operating system that has the characteristics of either Version 7 Unix or UNIX System V.
Overview
Unix operating systems are widely used in servers, workstations, and mobile devices.[1] The Unix environment and the client–server program model were essential elements in the development of the Internet and the reshaping of computing as centered in networks rather than in individual computers.
Both Unix and the C programming language were developed by AT&T and distributed to government and academic institutions, which led to both being ported to a wider variety of machine families than any other operating system. As a result, Unix became synonymous with "open systems".
Unix was designed to be portable, multi-tasking and multi-user in a time-sharing configuration. Unix systems are characterized by various concepts: the use of plain text for storing data; a hierarchical file system; treating devices and certain types of inter-process communication (IPC) as files; and the use of a large number of software tools, small programs that can be strung together through a command line interpreter using pipes, as opposed to using a single monolithic program that includes all of the same functionality. These concepts are collectively known as the Unix philosophy.
Under Unix, the "operating system" consists of many of these utilities along with the master control program, the kernel. The kernel provides services to start and stop programs, handles the file system and other common "low level" tasks that most programs share, and, perhaps most importantly, schedules access to hardware to avoid conflicts if two programs try to access the same resource or device simultaneously. To mediate such access, the kernel was given special rights on the system, leading to the division between user-space and kernel-space.
The microkernel concept was introduced in an effort to reverse the trend towards larger kernels and return to a system in which most tasks were completed by smaller utilities. In an era when a "normal" computer consisted of a hard disk for storage and a data terminal for input and output (I/O), the Unix file model worked quite well as most I/O was "linear". However, modern systems include networking and other new devices. As graphical user interfaces developed, the file model

proved inadequate to the task of handling asynchronous events such as those generated by a mouse, and in the 1980s non-blocking I/O and the set of inter-process communication mechanisms was augmented (sockets, shared memory, message queues, semaphores), and functionalities such as network protocols were moved out of the kernel.
[edit] History
In the 1960s, Massachusetts Institute of Technology, AT&T Bell Labs, and General Electric developed an experimental operating system called Multics for the GE-645 mainframe.[2] Multics was highly innovative, but had many problems.
Bell Labs, frustrated by the size and complexity of Multics but not the aims, slowly pulled out of the project. Their last researchers to leave Multics, Ken Thompson, Dennis Ritchie, M. D. McIlroy, and J. F. Ossanna,[3] decided to redo the work on a much smaller scale. At the time, Ritchie says "What we wanted to preserve was not just a good environment in which to do programming, but a system around which a fellowship could form. We knew from experience that the essence of communal computing, as supplied by remote-access, time-shared machines, is not just to type programs into a terminal instead of a keypunch, but to encourage close communication."[3]
While Ken Thompson still had access to the Multics environment, he wrote simulations for the new file and paging system on it. He also programmed a game called Space Travel, but the game needed a more efficient and less expensive machine to run on, and eventually a little-used PDP-7 at Bell Labs fit the bill.[4] On this PDP7, a team of Bell Labs researchers led by Thompson and Ritchie, including Rudd Canaday, developed a hierarchical file system, the notions of computer processes and device files, a command-line interpreter, and some small utility programs.[3]
[edit] 1970s
In the 1970s Brian Kernighan coined the project name Unics as a play on Multics, (Multiplexing Information and Computer Services). Unics could eventually support multiple simultaneous users, and it was renamed Unix.
Up until this point there had been no financial support from Bell Labs. When the Computer Science Research Group wanted to use Unix on a much larger machine than the PDP-7, Thompson and Ritchie managed to trade the promise of adding text processing capabilities to Unix for a PDP-11/20 machine. This led to some financial support from Bell. For the first time in 1970, the Unix operating system was officially named and ran on the PDP-11/20. It added a text formatting program called roff and a text editor. All three were written in PDP-11/20 assembly language. Bell Labs used this initial "text processing system", made up of Unix, roff, and the editor, for text processing of patent applications. Roff soon evolved into troff, the first electronic publishing program with a full typesetting capability. The UNIX Programmer's Manual was published on November 3, 1971.
In 1972, Unix was rewritten in the C programming language, contrary to the general notion at the time "that something as complex as an operating system, which must deal with time-critical events, had to be written exclusively in assembly language".[5] The migration from assembly

language to the higher-level language C resulted in much more portable software, requiring only a relatively small amount of machine-dependent code to be replaced when porting Unix to other computing platforms.
Under a 1958 consent decree in settlement of an antitrust case, AT&T (the parent organization of Bell Labs) had been forbidden from entering the computer business. Unix could not, therefore, be turned into a product; indeed, under the terms of the consent decree, Bell Labs was required to license its nontelephone technology to anyone who asked. Ken Thompson quietly began answering requests by shipping out tapes and disk packs – each, according to legend, with a note signed “love, ken”.[6]
AT&T made Unix available to universities and commercial firms, as well as the United States government under licenses. The licenses included all source code including the machine-dependent parts of the kernel, which were written in PDP-11 assembly code. Copies of the annotated Unix kernel sources circulated widely in the late 1970s in the form of a much-copied book by John Lions of the University of New South Wales, the Lions' Commentary on UNIX 6th Edition, with Source Code, which led to considerable use of Unix as an educational example.
Versions of the Unix system were determined by editions of its user manuals. For example, "Fifth Edition UNIX" and "UNIX Version 5" have both been used to designate the same version. Development expanded, with Versions 4, 5, and 6 being released by 1975. These versions added the concept of pipes, which led to the development of a more modular code-base and quicker development cycles. Version 5 and especially Version 6 led to a plethora of different Unix versions both inside and outside Bell Labs, including PWB/UNIX and the first commercial Unix, IS/1. As more of Unix was rewritten in C, portability also increased. A group at the University of Wollongong ported Unix to the Interdata 7/32. Bell Labs developed several ports for research purposes and internal use at AT&T. Target machines included an Intel 8086-based computer (with custom-built MMU) and the UNIVAC 1100.[7]
In May 1975 ARPA documented the benefits of the Unix time-sharing system which "presents several interesting capabilities" as an arpa network mini-host in RFC 681.
In 1978, UNIX/32V was released for DEC's then new VAX system. By this time, over 600 machines were running Unix in some form. Version 7 Unix, the last version of Research Unix to be released widely, was released in 1979. Versions 8, 9 and 10 were developed through the 1980s but were only released to a few universities, though they did generate papers describing the new work. This research led to the development of Plan 9 from Bell Labs, a new portable distributed system.

[edit] 1980s
A Unix desktop running the X Window System graphical user interface. Shown are a number of client applications common to the MIT X Consortium's distribution, including Tom's Window Manager, an X Terminal, Xbiff, xload, and a graphical manual page browser.
AT&T licensed UNIX System III, based largely on Version 7, for commercial use, the first version launching in 1982. This also included support for the VAX. AT&T continued to issue licenses for older Unix versions. To end the confusion between all its differing internal versions, AT&T combined them into UNIX System V Release 1. This introduced a few features such as the vi editor and curses from the Berkeley Software Distribution of Unix developed at the University of California, Berkeley. This also included support for the Western Electric 3B series of machines.
In 1983, the U.S. Department of Justice settled its second antitrust case against AT&T and broke up the Bell System. This relieved AT&T from the 1956 consent decree that had prevented them from turning Unix into a product. AT&T promptly rushed to commercialize Unix System V, a move that nearly killed Unix.[6]
Since the newer commercial UNIX licensing terms were not as favorable for academic use as the older versions of Unix, the Berkeley researchers continued to develop BSD Unix as an alternative to UNIX System III and V, originally on the PDP-11 architecture (the 2.xBSD releases, ending with 2.11BSD) and later for the VAX-11 (the 4.x BSD releases). Many contributions to Unix first appeared on BSD releases, notably the C shell with job control (modelled on ITS). Perhaps the most important aspect of the BSD development effort was the addition of TCP/IP network code to the mainstream Unix kernel. The BSD effort produced several significant releases that contained network code: 4.1cBSD, 4.2BSD, 4.3BSD, 4.3BSD-Tahoe ("Tahoe" being the nickname of the Computer Consoles Inc. Power 6/32 architecture that was the first non-DEC release of the BSD kernel), Net/1, 4.3BSD-Reno (to match the "Tahoe" naming, and that the release was something of a gamble), Net/2, 4.4BSD, and 4.4BSD-lite. The network code found in these releases is the ancestor of much TCP/IP network code in use today, including code that was later released in AT&T System V UNIX and early versions of Microsoft

Windows. The accompanying Berkeley sockets API is a de facto standard for networking APIs and has been copied on many platforms.
Other companies began to offer commercial versions of the UNIX System for their own mini-computers and workstations. Most of these new Unix flavors were developed from the System V base under a license from AT&T; however, others were based on BSD instead. One of the leading developers of BSD, Bill Joy, went on to co-found Sun Microsystems in 1982 and created SunOS for their workstation computers. In 1980, Microsoft announced its first Unix for 16-bit microcomputers called Xenix, which the Santa Cruz Operation (SCO) ported to the Intel 8086 processor in 1983, and eventually branched Xenix into SCO UNIX in 1989.
For a few years during this period (before PC compatible computers with MS-DOS became dominant), industry observers expected that UNIX, with its portability and rich capabilities, was likely to become the industry standard operating system for microcomputers.[8] In 1984 several companies established the X/Open consortium with the goal of creating an open system specification based on UNIX. Despite early progress, the standardization effort collapsed into the "Unix wars", with various companies forming rival standardization groups. The most successful Unix-related standard turned out to be the IEEE's POSIX specification, designed as a compromise API readily implemented on both BSD and System V platforms, published in 1988 and soon mandated by the United States government for many of its own systems.
AT&T added various features into UNIX System V, such as file locking, system administration, STREAMS, new forms of IPC, the Remote File System and TLI. AT&T cooperated with Sun Microsystems and between 1987 and 1989 merged features from Xenix, BSD, SunOS, and System V into System V Release 4 (SVR4), independently of X/Open. This new release consolidated all the previous features into one package, and heralded the end of competing versions. It also increased licensing fees.
During this time a number of vendors including Digital Equipment, Sun, Addamax and others began building trusted versions of UNIX for high security applications, mostly designed for military and law enforcement applications.
[edit] 1990s
In 1990, the Open Software Foundation released OSF/1, their standard Unix implementation, based on Mach and BSD. The Foundation was started in 1988 and was funded by several Unix-related companies that wished to counteract the collaboration of AT&T and Sun on SVR4. Subsequently, AT&T and another group of licensees formed the group "UNIX International" in order to counteract OSF. This escalation of conflict between competing vendors gave rise again to the phrase "Unix wars".
In 1991, a group of BSD developers (Donn Seeley, Mike Karels, Bill Jolitz, and Trent Hein) left the University of California to found Berkeley Software Design, Inc (BSDI). BSDI produced a fully functional commercial version of BSD Unix for the inexpensive and ubiquitous Intel platform, which started a wave of interest in the use of inexpensive hardware for production

computing. Shortly after it was founded, Bill Jolitz left BSDI to pursue distribution of 386BSD, the free software ancestor of FreeBSD, OpenBSD, and NetBSD.
By 1993 most commercial vendors had changed their variants of Unix to be based on System V with many BSD features added on top. The creation of the COSE initiative that year by the major players in Unix marked the end of the most notorious phase of the Unix wars, and was followed by the merger of UI and OSF in 1994. The new combined entity, which retained the OSF name, stopped work on OSF/1 that year. By that time the only vendor using it was Digital, which continued its own development, rebranding their product Digital UNIX in early 1995.
Shortly after UNIX System V Release 4 was produced, AT&T sold all its rights to UNIX to Novell. (Dennis Ritchie likened this to the Biblical story of Esau selling his birthright for the proverbial "mess of pottage".[9]) Novell developed its own version, UnixWare, merging its NetWare with UNIX System V Release 4. Novell tried to use this to battle against Windows NT, but their core markets suffered considerably.
In 1993, Novell decided to transfer the UNIX trademark and certification rights to the X/Open Consortium.[10] In 1996, X/Open merged with OSF, creating the Open Group. Various standards by the Open Group now define what is and what is not a "UNIX" operating system, notably the post-1998 Single UNIX Specification.
In 1995, the business of administering and supporting the existing UNIX licenses, plus rights to further develop the System V code base, were sold by Novell to the Santa Cruz Operation.[11] Whether Novell also sold the copyrights is currently the subject of litigation (see below).
In 1997, Apple Computer sought out a new foundation for its Macintosh operating system and chose NEXTSTEP, an operating system developed by NeXT. The core operating system, which was based on BSD and the Mach kernel, was renamed Darwin after Apple acquired it. The deployment of Darwin in Mac OS X makes it, according to a statement made by an Apple employee at a USENIX conference, the most widely used Unix-based system in the desktop computer market.
[edit] 2000s
In 2000, SCO sold its entire UNIX business and assets to Caldera Systems, which later on changed its name to The SCO Group.
The dot-com bubble (2001–2003) led to significant consolidation of versions of Unix. Of the many commercial variants of Unix that were born in the 1980s, only Solaris, HP-UX, and AIX were still doing relatively well in the market, though SGI's IRIX persisted for quite some time. Of these, Solaris had the largest market share in 2005.[12]
In 2003, the SCO Group started legal action against various users and vendors of Linux. SCO had alleged that Linux contained copyrighted Unix code now owned by The SCO Group. Other allegations included trade-secret violations by IBM, or contract violations by former Santa Cruz customers who had since converted to Linux. However, Novell disputed the SCO Group's claim to hold copyright on the UNIX source base. According to Novell, SCO (and hence the SCO

Group) are effectively franchise operators for Novell, which also retained the core copyrights, veto rights over future licensing activities of SCO, and 95% of the licensing revenue. The SCO Group disagreed with this, and the dispute resulted in the SCO v. Novell lawsuit. On August 10, 2007, a major portion of the case was decided in Novell's favor (that Novell had the copyright to UNIX, and that the SCO Group had improperly kept money that was due to Novell). The court also ruled that "SCO is obligated to recognize Novell's waiver of SCO's claims against IBM and Sequent". After the ruling, Novell announced they have no interest in suing people over Unix and stated, "We don't believe there is Unix in Linux".[13][14][15] SCO successfully got the 10th Circuit Court of Appeals to partially overturn this decision on August 24, 2009 which sent the lawsuit back to the courts for a jury trial.[16][17][18]
On March 30, 2010, following a jury trial, Novell, and not The SCO Group, is "unanimously [found]" to be the owner of the UNIX and UnixWare copyrights.[19] The SCO Group, through bankruptcy trustee Edward Cahn, has decided to continue the lawsuit against IBM for causing a decline in SCO revenues.[20]
See also: SCO-Linux controversies
In 2005, Sun Microsystems released the bulk of its Solaris system code (based on UNIX System V Release 4) into an open source project called OpenSolaris. New Sun OS technologies, notably the ZFS file system, were first released as open source code via the OpenSolaris project. Soon afterwards, OpenSolaris spawned several non-Sun distributions. In 2010, after Oracle acquired Sun, OpenSolaris was officially discontinued, but the development of derivatives continued.
[edit] Standards
Beginning in the late 1980s, an open operating system standardization effort now known as POSIX provided a common baseline for all operating systems; IEEE based POSIX around the common structure of the major competing variants of the Unix system, publishing the first POSIX standard in 1988. In the early 1990s a separate but very similar effort was started by an industry consortium, the Common Open Software Environment (COSE) initiative, which eventually became the Single UNIX Specification administered by The Open Group. Starting in 1998 the Open Group and IEEE started the Austin Group, to provide a common definition of POSIX and the Single UNIX Specification.
In an effort towards compatibility, in 1999 several Unix system vendors agreed on SVR4's Executable and Linkable Format (ELF) as the standard for binary and object code files. The common format allows substantial binary compatibility among Unix systems operating on the same CPU architecture.
The Filesystem Hierarchy Standard was created to provide a reference directory layout for Unix-like operating systems, particularly Linux.
[edit] ComponentsSee also: List of Unix programs

The Unix system is composed of several components that are normally packed together. By including – in addition to the kernel of an operating system – the development environment, libraries, documents, and the portable, modifiable source-code for all of these components, Unix was a self-contained software system. This was one of the key reasons it emerged as an important teaching and learning tool and has had such a broad influence.
The inclusion of these components did not make the system large – the original V7 UNIX distribution, consisting of copies of all of the compiled binaries plus all of the source code and documentation occupied less than 10MB, and arrived on a single 9-track magnetic tape. The printed documentation, typeset from the on-line sources, was contained in two volumes.
The names and filesystem locations of the Unix components have changed substantially across the history of the system. Nonetheless, the V7 implementation is considered by many to have the canonical early structure:
Kernel – source code in /usr/sys, composed of several sub-components: o conf – configuration and machine-dependent parts, including boot code o dev – device drivers for control of hardware (and some pseudo-hardware) o sys – operating system "kernel", handling memory management, process scheduling,
system calls, etc. o h – header files, defining key structures within the system and important system-specific
invariables Development Environment – Early versions of Unix contained a development environment
sufficient to recreate the entire system from source code: o cc – C language compiler (first appeared in V3 Unix) o as – machine-language assembler for the machine o ld – linker, for combining object files o lib – object-code libraries (installed in /lib or /usr/lib) libc, the system library with C run-
time support, was the primary library, but there have always been additional libraries for such things as mathematical functions (libm) or database access. V7 Unix introduced the first version of the modern "Standard I/O" library stdio as part of the system library. Later implementations increased the number of libraries significantly.
o make – build manager (introduced in PWB/UNIX), for effectively automating the build process
o include – header files for software development, defining standard interfaces and system invariants
o Other languages – V7 Unix contained a Fortran-77 compiler, a programmable arbitrary-precision calculator (bc, dc), and the awk scripting language, and later versions and implementations contain many other language compilers and toolsets. Early BSD releases included Pascal tools, and many modern Unix systems also include the GNU Compiler Collection as well as or instead of a proprietary compiler system.
o Other tools – including an object-code archive manager (ar), symbol-table lister (nm), compiler-development tools (e.g. lex & yacc), and debugging tools.
Commands – Unix makes little distinction between commands (user-level programs) for system operation and maintenance (e.g. cron), commands of general utility (e.g. grep), and more general-purpose applications such as the text formatting and typesetting package. Nonetheless, some major categories are:

o sh – The "shell" programmable command line interpreter, the primary user interface on Unix before window systems appeared, and even afterward (within a "command window").
o Utilities – the core tool kit of the Unix command set, including cp, ls, grep, find and many others. Subcategories include:
System utilities – administrative tools such as mkfs, fsck, and many others. User utilities – environment management tools such as passwd, kill, and others.
o Document formatting – Unix systems were used from the outset for document preparation and typesetting systems, and included many related programs such as nroff, troff, tbl, eqn, refer, and pic. Some modern Unix systems also include packages such as TeX and Ghostscript.
o Graphics – The plot subsystem provided facilities for producing simple vector plots in a device-independent format, with device-specific interpreters to display such files. Modern Unix systems also generally include X11 as a standard windowing system and GUI, and many support OpenGL.
o Communications – Early Unix systems contained no inter-system communication, but did include the inter-user communication programs mail and write. V7 introduced the early inter-system communication system UUCP, and systems beginning with BSD release 4.1c included TCP/IP utilities.
Documentation – Unix was the first operating system to include all of its documentation online in machine-readable form. The documentation included:
o man – manual pages for each command, library component, system call, header file, etc. o doc – longer documents detailing major subsystems, such as the C language and troff
[edit] ImpactSee also: Unix-like
The Unix system had significant impact on other operating systems. It won its success by:
Direct interaction. Moving away from the total control of businesses like IBM and DEC. AT&T being willing to give the software away for free. Running on cheap hardware. Being easy to adopt and move to different machines.
It was written in high level language rather than assembly language (which had been thought necessary for systems implementation on early computers). Although this followed the lead of Multics and Burroughs, it was Unix that popularized the idea.
Unix had a drastically simplified file model compared to many contemporary operating systems, treating all kinds of files as simple byte arrays. The file system hierarchy contained machine services and devices (such as printers, terminals, or disk drives), providing a uniform interface, but at the expense of occasionally requiring additional mechanisms such as ioctl and mode flags to access features of the hardware that did not fit the simple "stream of bytes" model. The Plan 9 operating system pushed this model even further and eliminated the need for additional mechanisms.

Unix also popularized the hierarchical file system with arbitrarily nested subdirectories, originally introduced by Multics. Other common operating systems of the era had ways to divide a storage device into multiple directories or sections, but they had a fixed number of levels, often only one level. Several major proprietary operating systems eventually added recursive subdirectory capabilities also patterned after Multics. DEC's RSX-11M's "group, user" hierarchy evolved into VMS directories, CP/M's volumes evolved into MS-DOS 2.0+ subdirectories, and HP's MPE group.account hierarchy and IBM's SSP and OS/400 library systems were folded into broader POSIX file systems.
Making the command interpreter an ordinary user-level program, with additional commands provided as separate programs, was another Multics innovation popularized by Unix. The Unix shell used the same language for interactive commands as for scripting (shell scripts – there was no separate job control language like IBM's JCL). Since the shell and OS commands were "just another program", the user could choose (or even write) his own shell. New commands could be added without changing the shell itself. Unix's innovative command-line syntax for creating chains of producer-consumer processes (pipelines) made a powerful programming paradigm (coroutines) widely available. Many later command-line interpreters have been inspired by the Unix shell.
A fundamental simplifying assumption of Unix was its focus on ASCII text for nearly all file formats. There were no "binary" editors in the original version of Unix – the entire system was configured using textual shell command scripts. The common denominator in the I/O system was the byte – unlike "record-based" file systems. The focus on text for representing nearly everything made Unix pipes especially useful, and encouraged the development of simple, general tools that could be easily combined to perform more complicated ad hoc tasks. The focus on text and bytes made the system far more scalable and portable than other systems. Over time, text-based applications have also proven popular in application areas, such as printing languages (PostScript, ODF), and at the application layer of the Internet protocols, e.g., FTP, SMTP, HTTP, SOAP and SIP.
Unix popularized a syntax for regular expressions that found widespread use. The Unix programming interface became the basis for a widely implemented operating system interface standard (POSIX, see above).
The C programming language soon spread beyond Unix, and is now ubiquitous in systems and applications programming.
Early Unix developers were important in bringing the concepts of modularity and reusability into software engineering practice, spawning a "software tools" movement.
Unix provided the TCP/IP networking protocol on relatively inexpensive computers, which contributed to the Internet explosion of worldwide real-time connectivity, and which formed the basis for implementations on many other platforms. This also exposed numerous security holes in the networking implementations.

The Unix policy of extensive on-line documentation and (for many years) ready access to all system source code raised programmer expectations, and contributed to the 1983 launch of the free software movement.
Over time, the leading developers of Unix (and programs that ran on it) established a set of cultural norms for developing software, norms which became as important and influential as the technology of Unix itself; this has been termed the Unix philosophy.
[edit] Free Unix-like operating systems
In 1983, Richard Stallman announced the GNU project, an ambitious effort to create a free software Unix-like system; "free" in that everyone who received a copy would be free to use, study, modify, and redistribute it. The GNU project's own kernel development project, GNU Hurd, had not produced a working kernel, but in 1991 Linus Torvalds released the Linux kernel as free software under the GNU General Public License. In addition to their use in the GNU/Linux operating system, many GNU packages – such as the GNU Compiler Collection (and the rest of the GNU toolchain), the GNU C library and the GNU core utilities – have gone on to play central roles in other free Unix systems as well.
Linux distributions, comprising Linux and large collections of compatible software have become popular both with individual users and in business. Popular distributions include Red Hat Enterprise Linux, Fedora, SUSE Linux Enterprise, openSUSE, Debian GNU/Linux, Ubuntu, Mandriva Linux, Slackware Linux and Gentoo.
A free derivative of BSD Unix, 386BSD, was also released in 1992 and led to the NetBSD and FreeBSD projects. With the 1994 settlement of a lawsuit that UNIX Systems Laboratories brought against the University of California and Berkeley Software Design Inc. (USL v. BSDi), it was clarified that Berkeley had the right to distribute BSD Unix – for free, if it so desired. Since then, BSD Unix has been developed in several different directions, including OpenBSD and DragonFly BSD.
Linux and BSD are now rapidly occupying much of the market traditionally occupied by proprietary Unix operating systems, as well as expanding into new markets such as the consumer desktop and mobile and embedded devices. Due to the modularity of the Unix design, sharing bits and pieces is relatively common; consequently, most or all Unix and Unix-like systems include at least some BSD code, and modern systems also usually include some GNU utilities in their distributions.
OpenSolaris is a relatively recent addition to the list of operating systems based on free software licenses marked as such by FSF and OSI. It includes a number of derivatives that combines CDDL-licensed kernel and system tools and also GNU userland and is currently the only open source System V derivative available.
[edit] 2038Main article: Year 2038 problem

Unix stores system time values as the number of seconds from midnight January 1, 1970 (the "Unix Epoch") in variables of type time_t, historically defined as "signed long". On January 19, 2038 on 32 bit Unix systems, the current time will roll over from a zero followed by 31 ones (0x7FFFFFFF) to a one followed by 31 zeros (0x80000000), which will reset time to the year 1901 or 1970, depending on implementation, because that toggles the sign bit.
Since times before 1970 are rarely represented in Unix time, one possible solution that is compatible with existing binary formats would be to redefine time_t as "unsigned 32-bit integer". However, such a kludge merely postpones the problem to February 7, 2106, and could introduce bugs in software that computes time differences.
Some Unix versions have already addressed this. For example, in Solaris and Linux in 64-bit mode, time_t is 64 bits long, meaning that the OS itself and 64-bit applications will correctly handle dates for some 292 billion years. Existing 32-bit applications using a 32-bit time_t continue to work on 64-bit Solaris systems but are still prone to the 2038 problem. Some vendors have introduced an alternative 64-bit type and corresponding API, without addressing uses of the standard time_t.
[edit] ARPANET
In May 1975 ARPA documented in RFC 681 detailed very specifically why Unix is the operating system of choice for use as an ARPANET "mini-host". The evaluation process was also documented. Unix required a license that was very expensive with US$20,000 for non-university users and US$150 for an educational license. It was noted that for an "ARPA network wide license" Bell "were open to suggestions in that area".
Specific features found beneficial were:
Local processing facilities. Compilers. Editor. Document preparation system. Efficient file system and access control. Mountable and de-mountable volumes. Unified treatment of peripherals as special files. The network control program (NCP), is integrated within the Unix file system. Network connections treated as special files which can be accessed through standard Unix I/O
calls. The system closes all files on program exit. "desirable to minimize the amount of code added to the basic Unix kernel".
Development hardware used:
"The network software for Unix was developed on a PDP-11/50, with memory management, two RK05 disk packs, two nine track magtape drives, four dectape drives, 32k words of core, and three terminals. Presently this has been expanded to encompass a DH11 terminal multiplexor, an RP03 moving head disk, a twin platter RF11 fixed head disk, floating point, and 48k of core.

User files are stored on the RP03. the RF11 is used as a swap disk and for temporary file storage; one RK05 platter contains the system files, and the second contains login and accounting information. In the near future, the system will be expanded to 128k words of core memory with 10 dial in and 10 hard wired terminal lines"
"The base operating system occupies 24.5k words of memory. this system includes a large number of device drivers, and enjoys a generous amount of space for I/O buffers and system tables. A minimal system would require 40k words of hardware memory. It should be noted that Unix also requires the memory management"
As a comparison the "network control program" (NCP) in kernel code uses 3.5k and the swappable userspace is approx 8.5k.
"After telnet has proved itself reliable, the open system call will be expanded to include further parameterization .. ability to listen on a local socket"
"After those extensions, net mail, then network FTP and finally network RJE will be implemented. all will run as user programs so the kernel system size will not increase."
"Gary Grossman who participated in the design and wrote the NCP daemon" "Steve Bunch who was the third member of our design group and wrote the kernel message
software."
[edit] BrandingSee also: List of Unix systems
In October 1993, Novell, the company that owned the rights to the Unix System V source at the time, transferred the trademarks of Unix to the X/Open Company (now The Open Group),[10] and in 1995 sold the related business operations to Santa Cruz Operation.[11] Whether Novell also sold the copyrights to the actual software was the subject of a 2006 federal lawsuit, SCO v. Novell, which Novell won; the case is being appealed.[citation needed] Unix vendor SCO Group Inc. accused Novell of slander of title.
The present owner of the trademark UNIX is The Open Group, an industry standards consortium. Only systems fully compliant with and certified to the Single UNIX Specification qualify as "UNIX" (others are called "Unix system-like" or "Unix-like").
By decree of The Open Group, the term "UNIX" refers more to a class of operating systems than to a specific implementation of an operating system; those operating systems which meet The Open Group's Single UNIX Specification should be able to bear the UNIX 98 or UNIX 03 trademarks today, after the operating system's vendor pays a fee to The Open Group. Systems licensed to use the UNIX trademark include AIX, HP-UX, IRIX, Solaris, Tru64 (formerly "Digital UNIX"), A/UX, Mac OS X,[21][22] and a part of z/OS.
Sometimes a representation like "Un*x", "*NIX", or "*N?X" is used to indicate all operating systems similar to Unix. This comes from the use of the "*" and "?" characters as "wildcard" characters in many utilities. This notation is also used to describe other Unix-like systems, e.g. Linux, BSD, etc., that have not met the requirements for UNIX branding from the Open Group.

The Open Group requests that "UNIX" is always used as an adjective followed by a generic term such as "system" to help avoid the creation of a genericized trademark.
"Unix" was the original formatting, but the usage of "UNIX" remains widespread because, according to Dennis Ritchie, when presenting the original Unix paper to the third Operating Systems Symposium of the American Association for Computing Machinery, “we had a new typesetter and troff had just been invented and we were intoxicated by being able to produce small caps.”[23] Many of the operating system's predecessors and contemporaries used all-uppercase lettering, so many people wrote the name in upper case due to force of habit.
Several plural forms of Unix are used to refer to multiple brands of Unix and Unix-like systems. Most common is the conventional "Unixes", but "Unices" (treating Unix as a Latin noun of the third declension) is also popular. The Anglo-Saxon plural form "Unixen" is not common, although occasionally seen. Trademark names can be registered by different entities in different countries and trademark laws in some countries allow the same trademark name to be controlled by two different entities if each entity uses the trademark in easily distinguishable categories. The result is that Unix has been used as a brand name for various products including book shelves, ink pens, bottled glue, diapers, hair driers and food containers.[24]
[edit] See also
What is an Operating System
An operating system (OS) is a program that allows you to interact with the computer -- all of the software and hardware on your computer. How?
Basically, there are two ways.
With a command-line operating system (e.g., DOS), you type a text command and the computer responds according to that command.
With a graphical user interface (GUI) operating system (e.g., Windows), you interact with the computer through a graphical interface with pictures and buttons by using the mouse and keyboard.
With Unix you have in general the option of using either command-lines (more control and flexibility) or GUIs (easier).
Unix and Windows: Two Major Classes of Operating Systems
And they have a competitive history and future. Unix has been in use for more than three decades. Originally it rose from the ashes of a failed attempt in the early 1960s to develop a reliable timesharing operating system. A few survivors from Bell Labs did not give up and developed a system that provided a work environment described as "of unusual simplicity, power, and elegance".
Since the 1980's Unix's main competitor Windows has gained popularity due to the increasing power of micro-computers with Intel-compatible processors. Windows, at the time, was the only major OS designed for this type of processors. In recent years, however, a new version of Unix called Linux, also

specifically developed for micro-computers, has emerged. It can be obtained for free and is therefore a lucrative choice for individuals and businesses.
On the server front, Unix has been closing in on Microsoft’s market share. In 1999, Linux scooted past Novell's Netware to become the No. 2 server operating system behind Windows NT. In 2001 the market share for the Linux operating system was 25 percent; other Unix flavors 12 percent. On the client front, Microsoft is currently dominating the operating system market with over 90% market share.
Because of Microsoft’s aggressive marketing practices, millions of users who have no idea what an operating system is have been using Windows operating systems given to them when they purchased their PCs. Many others are not aware that there are operating systems other than Windows. But you are here reading an article about operating systems, which probably means that you are trying to make conscious OS decisions for home use or for your organizations. In that case, you should at least give Linux/Unix your consideration, especially if the following is relevant in your environment.
Advantages of Unix
- Unix is more flexible and can be installed on many different types of machines, including main-frame computers, supercomputers and micro-computers.
- Unix is more stable and does not go down as often as Windows does, therefore requires less administration and maintenance.
- Unix has greater built-in security and permissions features than Windows.
- Unix possesses much greater processing power than Windows.
- Unix is the leader in serving the Web. About 90% of the Internet relies on Unix operating systems running Apache, the world's most widely used Web server.
- Software upgrades from Microsoft often require the user to purchase new or more hardware or prerequisite software. That is not the case with Unix.
- The mostly free or inexpensive open-source operating systems, such as Linux and BSD, with their flexibility and control, are very attractive to (aspiring) computer wizards. Many of the smartest programmers are developing state-of-the-art software free of charge for the fast growing "open-source movement”.
- Unix also inspires novel approaches to software design, such as solving problems by interconnecting simpler tools instead of creating large monolithic application programs.
Remember, no one single type of operating system can offer universal answers to all your computing needs. It is about having choices and making educated decisions.