Embed Size (px)
Citation preview

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
2
UNIVERSITY OF SCIENCE AND TECHNOLOGY
AGH Faculty of Electrical Engineering, Automatics,
Computer Science and Electronics
DEPARTMENT OF COMPUTER SCIENCE
Anwendung von Multi-agentensystemen im
E-Learning
MAESTRO Multiagenten-Architektur für E-Learning Systeme
Diplomarbeit
Autor: Andrzej Kononowicz
Unter wissenschaftlicher Betreuung von: TU Clausthal Prof. Dr. Michael Kolonko AGH Kraków Dr. Małgorzata Żabińska Dipl. Ing. Witold Rakoczy
Clausthal-Zellerfeld/Kraków 2004

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
3
Diese Arbeit entstand im Rahmen der Kooperation zwischen der Technischen Universität Clausthal
und der University of Science and Technology AGH Kraków
Ich möchte mich sehr herzlich bei den wissenschaftlichen Betreuern meiner Diplomarbeit: Prof. Dr. Michael Kolonko, Dr. Małgorzata Żabińska und Dipl. Ing. Witold Rakoczy,
für die geleistete Hilfe bedanken.
Ich danke auch PD Dr. Ekhard Hultsch und Dr. Renate Hultsch für die große Unterstützung während meines Aufenthaltes in Deutschland und für die jahrelange Freundschaft.
Ich widme die Arbeit meinen Eltern.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
4
Inhaltsverzeichnis
1. Einleitung __________________________________________________________________________ 7 1.1. Ursprung der Arbeit____________________________________________________________7 1.2. Ziel der Arbeit_________________________________________________________________8 1.3. Struktur der Arbeit ____________________________________________________________9 1.4. Bemerkungen zur Sprache ______________________________________________________9
2. Einführung in die Multiagententechnologie______________________________________________ 11 2.1. Die Definition des Agent________________________________________________________11 2.1.1. Der allgemeine Begriff________________________________________________________11 2.1.2. Agent in der Künstlichen Intelligenz_____________________________________________12 2.1.3. Definition des Agenten nach Demazeau und Müller ________________________________12 2.1.4. Definition des Agenten nach Jennings und Wooldridge _____________________________13 2.1.5. Definition des Agenten nach Feber______________________________________________13 2.1.6. Weitere Klassifizierung der Agenten _____________________________________________14
2.1.6.1. Reflexive und kognitive Agenten 14 2.1.6.2. Kollaborative Agenten 15 2.1.6.3. BDI-Agenten 15 2.1.6.4. M-Agent 15 2.1.6.5. Software Agenten 15 2.1.6.6. Mobile Agenten 15
2.2. Der Begriff der Multiagentensysteme_____________________________________________16 2.3. Standards für Agenten_________________________________________________________16 2.3.1. FIPA ______________________________________________________________________16 2.3.2. MASIF ____________________________________________________________________18
2.4. Beispiele von Agentenplattformen _______________________________________________19 2.4.1. IBM Aglets Workbench _______________________________________________________19 2.4.2. MadKit ____________________________________________________________________20 2.4.3. JADE _____________________________________________________________________21
2.5. Übersicht der Anwendungsgebiete für Multiagentensysteme _________________________22 2.5.1. Verteiltes Lösen von Problemen ________________________________________________22 2.5.2. Simulationen _______________________________________________________________23 2.5.3. Robotik ____________________________________________________________________25 2.5.4. Internet ____________________________________________________________________25 2.5.5. Intelligente Softwarearchitekturen ______________________________________________27 2.5.6. Andere Agentenanwendungen und Zukunftsperspektiven des Einsatzes von Agenten. _____27
3. Charakteristik des E-Learning ________________________________________________________ 29 3.1. Einführung __________________________________________________________________29 3.2. Grundlagen des Lernens _______________________________________________________30 3.3. Lernparadigmen______________________________________________________________31 3.3.1. Behaviourismus _____________________________________________________________31 3.3.2. Kognitivismus_______________________________________________________________32 3.3.3. Konstruktivismus ____________________________________________________________32
3.4. E-Learning im Detail __________________________________________________________32 3.4.1. St. Galler E-Learning-Referenzmodell ___________________________________________33
3.5. Technologien des E-Learnings___________________________________________________35 3.5.1. Diskussionsforum____________________________________________________________36 3.5.2. Virtuelles Klassenzimmer______________________________________________________36
3.6. E-Learning-Plattformen _______________________________________________________37 3.6.1. WebCT ____________________________________________________________________38
3.7. Ausgewählte Beispiele von E-Learning-Aktivitäten _________________________________39 3.7.1. ELAN Niedersachsen_________________________________________________________40 3.7.2. Fernuniversität Hagen________________________________________________________40 3.7.3. Polski Uniwersytet Wirtualny __________________________________________________41

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
5
3.7.4. Zusammenfassung der gebrachten Beispiele ______________________________________41 3.8. Warum E-Learning? __________________________________________________________41 3.9. Nachteile des E-Learning_______________________________________________________43 3.10. Zusammenfassung ____________________________________________________________43
4. Grundlagen des Semantic Web ________________________________________________________ 44 4.1. Einführung __________________________________________________________________44 4.2. Schichten des Semantic Web ____________________________________________________45 4.3. Sprachen des Semantic Web ____________________________________________________46 4.3.1. RDF ______________________________________________________________________46 4.3.2. RDF Schema _______________________________________________________________47 4.3.3. OWL ______________________________________________________________________47
4.4. Übersicht der Werkzeuge zum Bau des Semantic Web ______________________________48 4.4.1. Semantic Web-Editoren _______________________________________________________48 4.4.2. RDF Datastores _____________________________________________________________48 4.4.3. APIs für Semantic Web _______________________________________________________48
4.5. Beispiele von Anwendungen des Semantic Web ____________________________________49 4.5.1. Data Mining ________________________________________________________________49 4.5.2. Verbinden von Zeitplänen _____________________________________________________49 4.5.3. Semantic Web im E-Learning __________________________________________________49
4.6. Kritik des Semantic Web _______________________________________________________50 4.7. Zusammenfassung ____________________________________________________________51
5. Übersicht der Möglichkeiten der Anwendung von Softwareagenten im E-Learning_____________ 52 5.1. Gründe der Verwendung der Agententechnologie im E-Learning _____________________52 5.2. Definition des pädagogischen Agenten ____________________________________________52 5.3. Beispiele von Agentenarchitekturen für Multiagentensysteme ________________________53 5.3.1. Multiagenten-Architektur für Intelligente Bildungssysteme __________________________53 5.3.2. Federated Architecture for Agent Communications_________________________________55 5.3.3. ADE-Architektur ____________________________________________________________56
5.4. Beispiele für realisierte Agenten-Systeme im E-Learning ____________________________57 5.4.1. Multiagentensystem zur Durchführung von Examen________________________________58 5.4.2. Agentenbasiertes E-Learning-System für Medizinstudenten __________________________58 5.4.3. Extempo Expert Characters____________________________________________________59
5.5. Zusammenfassung ____________________________________________________________61
6. MAESTRO-Architektur _____________________________________________________________ 62 6.1. Gründe für die Entstehung der MAESTRO-Architektur_____________________________63 6.2. Bemerkungen zur angewandten Notation _________________________________________63 6.3. Analyse der gebrauchten Funktionalität __________________________________________64 6.3.1. Der Lernende _______________________________________________________________65 6.3.2. Der Lehrende _______________________________________________________________66 6.3.3. Der Systemadministrator ______________________________________________________67
6.4. Architektur des System ________________________________________________________69 6.5. Lerneinheits-Knoten___________________________________________________________72 6.6. Benutzerdaten-Knoten_________________________________________________________74 6.7. MAESTRO-Agenten __________________________________________________________74 6.8. Beschreibung der Lerninhalte___________________________________________________78
7. MAT-MAESTRO ___________________________________________________________________ 82 7.1. Einschränkungen gegenüber der vollständigen MAESTRO-Architektur _______________82 7.2. Realisation der Funktionen des Lernenden ________________________________________83 7.2.1. Einloggen in das System ______________________________________________________85 7.2.2. Eröffnung eines neuen Lernmoduls _____________________________________________85 7.2.3. Wiedereröffnung eines Moduls _________________________________________________88 7.2.4. Anzeigen der gewünschten Seite mit Lerninhalten__________________________________88 7.2.5. Realisation der Hilfestellung ___________________________________________________89 7.2.6. Ausloggen aus dem System ____________________________________________________90
7.3. Beschreibung der Aktivitäten einzelner Agenten ___________________________________91 7.4. Realisation der Hilfestellung ____________________________________________________91

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
6
7.4.1. Algorithmus des Bezugs von Informationen aus dem semantischen Netz. _______________92 7.5. Realisation der Funktionen des Lehrenden und des Systemadministrators ______________94 7.6. Statische Struktur des Systems __________________________________________________95 7.7. Datenbanken im MAT-MAESTRO-System________________________________________96 7.7.1. Bemerkung zur Notationsform der Datenbankstruktur ______________________________96 7.7.2. Lerneinheits-Datenbanken ____________________________________________________96 7.7.3. Benutzerdaten-Datenbank _____________________________________________________97
7.8. Physische Struktur des Systems _________________________________________________99 7.8.1. MAESTRO-Plattform-Server__________________________________________________100 7.8.2. Lerneinheits-Knoten-Server___________________________________________________101 7.8.3. Benutzerdaten-Knoten-Server _________________________________________________103 7.8.4. Rechner des Lernenden ______________________________________________________104
8. Beschreibung der Implementation ____________________________________________________ 105 8.1. Beschreibung aus der Sicht des Programmierers __________________________________105 8.1.1. Prototypisch implementierte Elemente des MAT-MAESTRO ________________________105
8.2. Beschreibung aus der Sicht des Benutzers ________________________________________106 8.2.1. Prototyp des Learner UI______________________________________________________106
8.2.1.1. Das Einloggen in das System 106 8.2.1.2. Die Auswahl des Lernmoduls 107 8.2.1.3. Aufteilung der Steuerungs-Komponenten 107 8.2.1.4. Beschreibung des Menüs 108 8.2.1.5. Leistung der Hilfestellung 109
8.2.2. Prototyp des lmAdmins_______________________________________________________111 8.3. Beschreibung aus der Sicht des Systeminstallateurs ________________________________111 8.3.1. Installation des MAESTRO-Plattform-Servers____________________________________112 8.3.2. Installation des Lerneinheits-Knoten-Servers_____________________________________112 8.3.3. Installation des Benutzerdaten-Knoten-Servers ___________________________________112 8.3.4. Installationen auf dem Rechner des Lernenden ___________________________________112
9. Tests und Eindrücke aus der Implementierung des Prototyps______________________________ 113 9.1. Effizienz des Lerneinheits-Knotens______________________________________________113 9.1.1. Beschreibung des Tests ______________________________________________________113 9.1.2. Ergebnisse der Effizienzuntersuchung für die Einrichtung eines semantischen Netzes____114 9.1.3. Ergebnisse der Effizienzuntersuchung für Abfragen des semantischen Netzes __________115 9.1.4. Bewertung des Tests_________________________________________________________116
9.2. Eindrücke aus der Implementierung des Learner GUI _____________________________116
10. Zusammenfassung _________________________________________________________________ 118
A. Beschreibung des Inhalts der beigelegten CD _____________________________________________ 120
B. Literatur ___________________________________________________________________________ 121
C. Verzeichnis der wichtigsten Begriffe ____________________________________________________ 127
D. Abbildungs – und Tabellenverzeichnis___________________________________________________ 128

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
7
1. Einleitung
1.1. Ursprung der Arbeit
Die Welt ändert sich immer schneller. Die Wissenschaft bringt täglich neue Errungenschaften.
Das treibt die Technologie voran. Dementsprechend verändert sich auch der Arbeitsmarkt. Neue
Berufe entstehen, einige der alten werden nicht mehr gebraucht. Sehr breites Wissen ist seit langem
eine Grundvoraussetzung für einen gelungenen Start in die Karriere. Aber auch das reicht oft nicht für
das ganze Leben. Ohne Weiterbildung kann man leicht der Arbeitslosigkeit zum Opfer fallen. Die
Weiterbildung des Personals in Unternehmen wurde zum Alltag. Der Bedarf an verschiedenen Arten
von Bildungskursen wächst.
Weil die Zeit zu einer immer wertvolleren Ressource wird, versucht man den Bildungsprozess
mit Hilfe der neuen Technologien effizienter zu gestalten. Zeit und Ort des Lernens sollen dabei keine
Rolle spielen. Die neuen Trends fasst man unter dem Namen E-Learning (→ Kapitel 3) zusammen. Zu
einem sehr wichtigen Medium wurde dabei das Internet. Es bietet dem Lernenden eine nahezu
unerschöpfliche Quelle an neuem Wissen, die jederzeit und relativ einfach erreichbar ist. Kein
Buchverlag kann mit dem globalen Netz auf dem Gebiet der Geschwindigkeit oder Kosten der
Publikation konkurrieren. Leider ist das Internet als Wissensquelle bei weitem noch nicht ideal. Zwar
ist der Bestand des im Internet verfügbaren Wissens sehr groß, aber die Qualität der auf dieser Weise
zugänglichen Materialien lässt oft viel zu wünschen übrig. Einige sprechen sogar von einer Flut des
Unwissens oder der Desinformation. Um in der Menge der im Internet verfügbaren Daten die
gesuchten zu finden, entstanden spezielle Suchdienste wie z.B. Google [56] [97], Lycos oder Yahoo.
Obwohl man zu diesen Zwecken auch einige Technologien der Künstlichen Intelligenz verwendet ( →
2.5.4) sind die Ergebnisse der Internet-Recherche oft enttäuschend. Als Ergebnis der Suche
bekommen wir viele Verweise zu Informationen, die wir nicht gefordert haben, die uns nicht
interessieren oder die für uns zu schwer oder zu leicht sind. Oft finden wir die gesuchten Daten nicht,
obwohl sie irgendwo im Internet verfügbar sind. Grund dafür ist die Tatsache, dass die Suchverfahren
hauptsächlich auf dem mechanischen Vergleich von Zeichenketten basieren und nicht in der Lage
sind, die genannten Probleme selbstständig zu lösen. Was den Verfahren fehlt, ist ein elementares
Verständnis für die Bedeutung der gesuchten Information.
Eine Lösung für diese Probleme kann das Semantic Web sein [8] [120] (→ Kapitel 4). Dieses
Projekt ist keine utopische Vision einer Technologie, die den Maschinen das menschliche Denken
beibringen soll. Es ist nur ein Konzept, wie man die im Internet verfügbaren Ressourcen zusätzlich
beschreibt, um den maschinellen Verfahren die Möglichkeit zu geben, über die Semantik und die
Zusammenhänge der im Netz publizierten Materialien Schlüsse zu ziehen. Immerhin ist das aber ein
recht ehrgeiziges Ziel. Die Forschung auf diesem Gebiet dauert immer noch an, und die Einführung

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
8
eines globalen semantischen Netzes ist weiterhin in ferner Zukunft. Zu den wichtigsten Hindernissen
auf dem Weg zur Verbreitung der Technologie gehören: die ständigen Veränderungen der Standards,
Mangel an guten Werkzeugen, Fehlen an effizienten Inferenzmechanismen in großen Datenbeständen
und erheblicher Zeitbedarf zur Erstellung von gut beschriebenen Dokumenten. Dennoch werden schon
Versuche gemacht, das Konzept des semantischen Netzes in kleinen, abgegrenzten Wissensgebieten
einzuführen (→ 4.5).
Eng mit dem Semantic Web sind spezielle Verfahren verbunden, die semantische
Informationen automatisch verarbeiten können. Unter anderem befasst sich das Wissensgebiet der
Verteilten Künstlichen Intelligenz auch mit dieser Problemstellung. Die Kerntechnologie dazu sind
Multiagentensysteme (→ Kapitel 2). Agenten können autonom und gleichzeitig an verschiedenen
Orten das Wissen aus dem semantischen Netz beziehen, es mit Hilfe logischer Verfahren umbilden
und mit anderen Agenten austauschen, um so an die gesuchte Information heranzukommen. Dadurch
wird z.B. ermöglichlicht, Lernbestände aus mehreren Bildungszentren automatisch und transparent für
den Benutzer in einem E-Learning-System zu verbinden. Die „Intelligenz“-Eigenschaft erlaubt den
Agenten zusätzlich einige der Funktionen des Lehrenden zu übernehmen, wie z.B. die, an den
Lernenden angepasste Auswahl von didaktischen Inhalten (pädagogische Agenten → 5.2).
Die Idee des Semantischen Webs, verbunden mit der Multiagententechnologie kann viele neue
Möglichkeiten für die webbasierten Bildungssysteme mit sich bringen (z.B. [64]). Um jedoch das
technische Potential vollständig ausnutzen zu können, muss noch viel Arbeit geleistet werden. Was
noch fehlt, sind allgemein anerkannte Standards für dieses Gebiet der Anwendung der
Multiagentensysteme. Wichtig dabei ist, dass die Arbeiten sich nicht nur auf theoretische
Überlegungen beschränken, sondern dass versucht wird, die Konzepte auch praktisch zu realisieren.
Auf diese Weise kann man am besten die Korrektheit und den praktischen Nutzen der Ideen
überprüfen.
1.2. Ziel der Arbeit
Ziel meiner Arbeit ist, eine möglichst universelle Multiagenten-Architektur für E-Learning-
Systeme vorzuschlagen. Die Architektur soll den Aufbau großer und qualitativ guter E-Learning-
Systeme fördern. Dieses Ziel versuche ich durch die Entwicklung von Mechanismen zur
„intelligenten“ Beschreibung der didaktischen Inhalte und Wiederverwendung der existierenden
Wissensbestände zu erreichen. Mein Konzept wird auf den schon existierenden Lösungen aufbauen,
aber auch einige neue Ideen erhalten (wie z.B. Überlegungen zu der Wissensrepräsentation der
Lerninhalte). Ich werde untersuchen, in welcher Hinsicht Softwareagenten für Bildungszwecke
geeignet sind. Eine wichtige Frage ist, in welcher Form man Lernmaterialien effektiv und für
maschinelle Verfahren verständlich aufbewahren kann. Dabei werde ich den aktuellen Stand der
Wissenschaft beachten, wie auch die verfügbaren Technologien. In meiner Arbeit werde ich auch ein
kleines E-Learning-System entwerfen, das auf der von mir vorgeschlagenen Architektur aufbaut.
Einige der Elemente des Systems werde ich prototypisch implementieren. Das System soll in der

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
9
Mathematik (Spezialgebiet Statistik) angewandt werden. Der Lehrinhalt des E-Learning-Systems wird
u.a. ein Kapitel aus dem – im Rahmen des ELAN-Anstat-Projektes – auf der TU Clausthal
entstandenen Skriptums Statistik für Ingenieure von Michael Kolonko [43] sein.
1.3. Struktur der Arbeit
Meine Arbeit ist in 10 Kapitel und einen Anhang aufgeteilt. Der Anhang beinhaltet für das
Projekt wichtige Informationen, die aber aus Platzgründen nicht in die Arbeit mit aufgenommen
werden konnten. Kapitel 1 stellt die Thematik und die Ziele der Arbeit fest. Kapitel 2 ist eine
allgemeine Einführung in die Agententechnologie. Ich stelle einige Definitionen des Agenten und des
Multiagentensystems vor, charakterisiere kurz die allgemein anerkannten Standards für
Agentensysteme (FIPA, OMG), zeige Beispiele von Agentenumgebungen, und zum Schluss des
Kapitels widme ich mich den praktischen Anwendungen von Multiagentensystemen. Im Kapitel 3
befasse ich mich mit dem Begriff des E-Learining, einigen Lernparadigmen, Technologien für E-
Learning, sowie Beispielen schon realisierter Systeme aus diesem Bereich. Kapitel 4 gibt dem Leser
einen Einblick in das Semantic Web-Projekt. Kapitel 5 zeigt die Möglichkeiten der Synthese der E-
Learning-Systeme mit der Agententechnologie. Es werden vorhandene agentenbasierte Architekturen
für E-Learning vorgestellt, wie auch fertige Systeme, die Softwareagenten verwenden. Kapitel 6 ist
meinem Konzept einer Multiagenten-Architektur für E-Learning-Systeme gewidmet (die Architektur
habe ich MAESTRO genannt). Kapitel 7 umfasst einen formalen Entwurf eines Systems, der auf der
im Kapitel 6 vorgeschlagenen Architektur basiert. Das System werde ich MAT–MAESTRO nennen.
Das System wird nur einge Elemente der vollständigen MAESTRO-Architektur beinhalten. Ein
Prototyp des Systems wird im Rahmen dieser Diplomarbeit realisiert. Kapitel 8 ist eine Beschreibung
des implementierten Teils des MAT–MAESTRO-Systems. Die Beschreibung erfolgt aus drei Sichten:
des Programmierers, des Systemverwalters und des Benutzers. Die Beschreibung aus der Sicht des
Programmierers wird hauptsächlich mit Hilfe der UML Modellierungssprache (UML → 6.2)
dargestellt. Einige Teile der Beschreibung, die aus Platzgründen nicht in die Arbeit eingenommen
werden konnten, werden in den Anhang übergetragen. Kapitel 9 beinhaltet einen Bericht aus der
Testphase des prototypisch realisierten Systems. Kapitel 10 ist eine Zusammenfassung der Arbeit.
Ich habe mein Projekt MAESTRO genannt, weil das Wort der Abkürzung MAES
(Multiagenten-Architektur für E-Learning-Systeme) recht nahe liegt. Maestro bedeutet im
Italienischen Meister. Besonders gute Lehrer werden manchmal auch Meister genannt. So hat die
Wahl des Namens Maestro eine zusätzliche Begründung, da meine Arbeit sich mit modernen und
hoffentlich erfolgreichen Methoden der Lehre befassen wird.
1.4. Bemerkungen zur Sprache
Die vorliegende Diplomarbeit ist in der neuen deutschen Rechtschreibung geschrieben. Zitate aus
Texten in der alten Schreibung werden nicht in die neue transformiert. Englische Zitate werden stets
im Original belassen und nicht übersetzt.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
10
Zugunsten einer flüssigen und leicht lesbaren Sprache wurde darauf verzichtet, zusätzlich
weibliche Formen zu bilden (z.B. Benutzerin, Studentin, Lehrerin). Weibliche Personen sind bei den
Formulierungen aber stets mit eingeschlossen, es sei denn, es ist explizit das männliche Geschlecht
gemeint.
Eine gewisse Schwierigkeit war für mich in einigen Fällen die Wahl zwischen den Präfixen Lern-
und Lehr-. Obwohl der Unterschied zwischen Lernen und Lehren selbstverständlich ist1, war die
Trennung z.B. bei den Begriffen Lerneinheit und Lehreinheit nicht mehr so eindeutig. Die
Bezeichnung hängt von der Sicht des Betrachters ab. Der Lehrende spricht über Lehreinheiten, der
Lernende über Lerneinheiten. Gemeint wird aber immer dieselbe Information. Weil ich in der Arbeit
sowohl den Blickwickel des Lernenden wie auch den des Lehrenden präsentiere, werden die Begriffe
in der Arbeit abwechselnd benutzt.
In der Arbeit werden die englischen Fachausdrücke (z.B. des Semantic Web, des Pedagogical
Agent) übernommen und deshalb nicht nach den deutschen Regeln dekliniert.
1 Lernen als Aneignung des Wissens, Lehren als Übermittlung des Wissens. Das eine impliziert nicht unbedingt das andre.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
11
2. Einführung in die Multiagententechnologie
2.1. Die Definition des Agent
2.1.1. Der allgemeine Begriff
Den Begriff „Agent“ kennt wahrscheinlich jeder aus dem alltäglichen Leben. Das Wort kommt
von dem lateinischen Verb agere was wirken, handeln, zugleich aber auch vortäuschen bedeutet. Die
älteste von mir gefundene deutschsprachige Definition des Agenten kommt aus dem Jahre 1732 [68]2:
„Agenten, sind eigentlich zu reden, Leute, welche die Stande bey ihrem Oberhaupte halten, derer
Ansehen wol3 nicht gar sonderlich, ihre Function aber darinnen bestehet, daß sie Supplicationes4
machen, Bescheide sollicitiren5, und Relationes6 an die, von welchen sie ihre Bestallungen haben,
verfertigen. Sie müssen demnach etwas mit aus der Schule gebracht, oder durch die Prarin7 in denen
Dingen, so sie verwalten sollen, Erfahrung erlanget haben (…)“
Heutzutage hat der Begriff viele Bedeutungen. Zuerst: Agent als Spion, Mitarbeiter eines
Geheimdienstes. Eindeutig negativ gingen Stasi-Agenten in die deutsche Geschichte ein. Agenten
wurden aber auch zu Kinohelden wie z.B. James Bond – Agent im Dienste der britischen Krone.
Künstler haben auch ihre Agenten. In diesem Sinne sind das Personen, die Engagements der Artisten
vermitteln. Im Österreichischem (sonst veraltet) Önennt man auch Handelsvertreter Agenten. Im
angelsächsischen Bereich spricht man zusätzlich z.B. vom estate agent, was auf Deutsch
Grundstücksmakler bedeutet oder travel agent – Vertreter einer Reiseagentur.
Alle diese Bedeutungen – scheinbar so verschieden – weisen einige gemeinsame Merkmale auf.
Agenten sind immer Personen, die im Dienste anderer wirken (sei es der Staat, ein Artist oder ein
Reisebüro). Agenten sind in ihren Handlungen leistungsfähig und verfügen über eine gewisse
Autonomie (die Agenten wissen manchmal besser als ihre Auftraggeber deren Interessen zu vertreten
– z.B. Agenten der Künstler oder estate agents). Agenten arbeiten oft an vielen verschiedenen Orten
(deshalb sollten sie mobil sein) in fremder Umgebung (die Fähigkeit der Anpassung ist hier sehr
wichtig). In Namen ihres Mandanten verhandeln sie mit anderen Menschen, deshalb sollten sie
2 Zitiert in der altdeutschen Originalversion 3 wol [veraltet deutsch] - wohl 4 supplicatio [lat.] – Buß und Betfest im unglücklichen Zeiten, in diesem Fall kommt es aber wahrscheinlich von
„supplizieren“ – veraltetet für Bittgesuch einreichen 5 sollizitieren [veraltet deutsch] - nachsuchen 6 relatio [lat.] - Bericht 7 vermutlich - Praxis

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
12
kooperationsbereit sein. Aus den gesammelten Erfahrungen zieht ein guter Agent Schlüsse für
weiteres Handeln, deshalb sollte er auch lernfähig sein.
2.1.2. Agent in der Künstlichen Intelligenz
In der derzeitigen wissenschaftlichen Literatur findet man sehr viele unterschiedliche
Definitionen des Begriffs Agent. Zum größten Teil beziehen sich die Erläuterungen auf Merkmale des
allgemeinen Agenten. Verschiedene Aspekte des Begriffs werden aber unterschiedlich stark betont,
einige neue anwendungsspezifische Eigenschaften nimmt man in die Definition mit hinein8. In meiner
Arbeit präsentiere ich drei Definitionen des Agenten, verfasst von Autoritäten auf dem Gebiet der
Agententechnologie.
2.1.3. Definition des Agenten nach Demazeau und Müller
Ein Agent ist laut Demazeau und Müller ein intelligentes Wesen, das rational und absichtlich in
Hinsicht auf sein Ziel und momentanes Wissen handelt [23]. In seinem Lebenszyklus befasst sich der
Agent mit zahlreichen, oft unsicheren oder gar widersprüchlichen Informationen und befolgt die
häufig in Konflikt stehenden Ziele. In seiner Handlung muss der Agent die Unvollständigkeit seines
Wissens, wie auch seine fehlerbehaftete Wahrnehmung und eingeschränkte Wirkungskraft auf die
Umgebung berücksichtigen.
Um die Eigenschaften des Agenten besser beschreiben zu können, führen Demazeau und Müller
das Modell des generischen Agenten ein (Abbildung 2-1).
Kommunikation Wissen
Möglichkeiten
Ziele
Wahl
PerzeptionSchlussfolgerungs-
fähigkeitenEntscheidungs-fähigkeiten
Abbildung 2-1 Das Modell des generischen Agenten [23]
Ein Agent hat nach diesem Modell eine innere Repräsentation der Umgebung, in der er sich bewegt,
oder des Problems, das er zu lösen versucht. Diese Repräsentation nennt man das Wissen des Agenten.
Das Wissen bezieht er durch den Perzeptionsmechanismus und durch Kommunikation mit anderen
Agenten. Ein Agent hat ein Ziel, das er anstrebt. Anhand des gesammelten Wissens mit
Berücksichtigung der Ziele stellt der Agent eine Reihe der möglichen Schritte auf, die er ausführen
8 Der Grund, weshalb die Terminologie noch nicht klar begrenzt ist, ist wahrscheinlich die Tatschache, dass auf dem Wissensgebiet noch sehr aktiv geforscht wird.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
13
kann (Möglichkeiten). Aus dieser Menge wählt der Agent mit Hilfe eines Entscheidungsmechanismus’
einen Schritt zur Ausführung (Wahl), der in der gegebenen Situation der richtige ist.
Ein selbstständiger Agent (autonomous agent) ist nach Demazeau und Müller [23] ein Agent,
dessen Existenz nicht durch die Existenz anderer Agenten bedingt ist.
2.1.4. Definition des Agenten nach Jennings und Wooldridge
Ein Agent ist nach Jennings und Wooldridge ein Computersystem, das sich in einer bestimmten
Umgebung befindet und in der Lage ist, selbstständig in der Umgebung zu handeln, um die Ziele, für
die es entworfen wurde, zu erfüllen [36]. Der Unterschied zwischen einem Objekt und einem Agenten
ist der, dass der letztere nicht nur die Kontrolle über seinen inneren Zustand hat (Merkmal von
Objekten), sondern zusätzlich noch Kontrolle über sein Verhalten besitzt. Agenten sind nach Jennings
und Wooldridge auch Computerprogramme wie Systemdämone in den Betriebssystemen (wie z.B. der
Maildämon) oder auch Prozessleitsysteme (wie z.B. der Thermostat). Die Autoren nennen diese
Systeme nicht-intelligente Agenten. Im Gegensatz dazu sind die intelligenten Agenten zusätzlich
flexibel. Unter dem Begriff flexibel sind hier drei Eigenschaften gemeint: die Agenten sollen
reagieren, handeln und sozial sein. Reagieren bedeutet, dass sie zeitgemäß auf die Veränderungen in
ihrer Umgebung antworten sollen, handeln, dass sie nicht nur passiv antworten sollen, sondern
selbstständig die Initiative zur Erreichung des Zieles ergreifen sollen, und sozial sein, dass sie zu
gewollten Zeitpunkten mit anderen Agenten oder Menschen kommunizieren können, um eigene
Probleme zu lösen oder um den Anderen bei ihren Tätigkeiten zu helfen [36].
2.1.5. Definition des Agenten nach Feber
Eine sehr ausführliche Definition des Agenten stellt Ferber in seiner Monografie über
Multiagentensysteme vor [28]:
Ein Agent ist eine physische oder virtuelle Entität
1. die selbstständig in einer Umwelt agieren kann
2. die direkt mit anderen Agenten kommunizieren kann
3. die durch eine Menge von Absichten angetrieben wird (…)
4. die eigene Ressourcen besitzt
5. die fähig ist, ihre Umwelt wahrzunehmen (…)
6. die nur einen partielle Repräsentation ihrer Umwelt besitzt
7. die bestimmte Fähigkeiten besitzt und Dienste offerieren kann
8. die sich ggf. selbst reproduzierten kann
9. deren Verhalten darauf ausgerichtet ist, ihre Ziele unter Berücksichtigung der ihr zu Verfügung
stehenden Ressourcen und Fähigkeiten zu befriedigen und die dabei auf ihre Wahrnehmung, ihre
internen Modelle und ihre Kommunikation mit anderen Agenten (oder Menschen) angewiesen ist.
Diese Definition zeigt, dass Agenten nicht nur virtuelle Computerprogramme sein können, sondern
auch physische Entitäten wie z.B. Roboter. Neu in der Definition im Vergleich zu den oben genannten

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
14
ist auch, dass die Agenten eigene Ressourcen besitzen und sich gegebenenfalls bei Bedarf vermehren
können9.
2.1.6. Weitere Klassifizierung der Agenten
Agenten unterscheiden sich stark voneinander in ihren Fähigkeiten. Um die Eigenschaften
verschiedener Agenten gut zu vergleichen, kann man sie als Punkte in einem dreidimensionalen
Koordinatensystem darstellen [72]. Die Achsen (oder Dimensionen) zeigen den Grad der Autonomie,
Mobilität und Intelligenz des Agenten (Abbildung 2-2).
Intelligenz
Mobilität
Autonomie
Agent
Abbildung 2-2 Bewertung von Fähigkeiten von Softwareagenten
Kleine Werte auf der Autonomie-Achse bedeuten Agenten, die sehr stark mit dem Benutzer verbunden
sind (solche Agenten nennt man manchmal auch Assistenten), große Werte eine Entität, die sehr
eigenständig ist. Mobilität ist ein Maß für die Beweglichkeit des Agenten und zeigt, ob der Agent nur
an eine Stelle gebunden ist oder ob er ich sich frei zwischen den Agentenumgebungen bewegen kann
(Mobile Agenten → 2.1.6.6). „Wenig intelligente“ Agenten benutzen in ihrer Handlung nur einfache
Regeln, wobei die „intelligenteren“ komplexere Methoden der Künstlichen Intelligenz verwenden wie
unüberwachtes Lernen oder fortgeschrittene Methoden der logischen Folgerung.
Es gibt sehr viele diskrete Unterkategorien, in die man Agenten einteilen kann. In dem weiterem
Teil des Kapitels kommen einige der Kategorien vor.
2.1.6.1. Reflexive und kognitive Agenten
Einer der wichtigsten Unterscheidungsfaktoren der Agenten ist die Aufteilung aufgrund der
Verarbeitungsstrategie der Informationen aus der Umgebung. Man stellt die reaktiven (reflexiven)
Agenten 10 den kognitiven gegenüber [11]. Die reaktiven Agenten funktionieren nach dem Prinzip
Ereignis-Bedingung-Aktion. Sie beinhalten keine innere Darstellung der Außenwelt. Solche Agenten
begrenzen sich ausschließlich auf Reaktionen auf äußere Reize11 und sensorische Daten niedrigeren
9 Gilt natürlich nicht für physische Entitäten 10 Nach Feber [28] sind reaktive Agenten und reflexive Agenten verschiedne Klassen. Agenten können, müssen aber nicht
gleichzeitig reflexiv und reaktiv sein. Reflexive und zugleich reaktive Agenten nennt Faber tropistische Agenten 11 Das Prinzip ähnelt dem von neuronalen Netzwerken

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
15
Niveaus12, die sie aus der Umgebung wahrnehmen. Kognitive13 Agenten dagegen verfügen über eine
symbolische Wissensrepräsentation der Umgebung. Die Entscheidungen über weiteres Handeln treffen
sie auf Grund rationaler Analyse der verfügbaren Daten höheren Niveaus. Auf diese Weise lassen sich
komplexe Strategien einplanen.
2.1.6.2. Kollaborative Agenten
Kollaborative Agenten sind Individuen, die zwar autonom sind, aber alleine nicht das benötigte
Wissen und Können besitzen, um ein gegebenes Problem selbstständig zu lösen. Das angestrebte Ziel
erlangt man aufgrund der Zusammenwirkung von mehreren kollaborativen Agenten.
2.1.6.3. BDI-Agenten
Der BDI-Agent [17] ist ein sehr wichtiger Begriff auf dem Gebiet der Agentensysteme. Um
diese Definition entstanden ganze formelle Theorien [59] [60]. Die Abkürzung BDI steht für B-Beliefs
(Überzeugungen), D-Desires (Wünsche), I-Intensions (Absichten). Bei dem Konzept des BDI-Agenten
geht man davon aus, dass der Agent niemals über das gesamte Wissen über seine Umgebung verfügt.
Er besitzt ausschließlich Überzeugungen über die Sachverhalte, die aber schon nach der Definition mit
gewisser Unsicherheit behaftet sind. Der BDI-Agent hat eine Vision des Zielzustandes, den er
anstrebt. Wünsche sind Anforderungen an den Idealzustand. Wenn der Agent seine Wünsche mit den
Überzeugungen konfrontiert, entstehen Schritte, die man ausführen muss, um den Idealzustand zu
erreichen. Diese zielführenden Schritte bezeichnet man als Absichten. Die Realisation eines
kompletten BDI-Agenten ist recht anspruchsvoll, deshalb verwendet man oft einfachere Modelle.
2.1.6.4. M-Agent
Das an der AGH Krakau entwickelte Konzept des M-Agenten [18] [20] [69] leitet sich von der
BDI-Architektur ab. Der M-Agent unternimmt Entscheidungen aufgrund der Verarbeitung von
Außenwelt-Modellen in seinem „Bewusstsein“. Ein M-Agent führt zwei Tätigkeitsarten aus:
Tätigkeiten, für die der Agent erzeugt wurde, um das gestellte Problem zu lösen (engl. intellectual
profile), und Tätigkeiten, die die Existenz des Agenten in der Umgebung sichern und die
Überlebenschance erhöhen (engl. energetic profile).
2.1.6.5. Software Agenten
Software Agenten sind rein virtuelle Entitäten, die über keine physische Gestalt verfügen.
2.1.6.6. Mobile Agenten
Der Begriff Mobiler Agent ist eine Verbindung der Konzepte: Softwareagent und Mobiler
Code. Der Mobile Code findet seine Anwendung vor allem in Internet und Intranets. Man verlässt das
Dogma, dass der Programmcode in verteilten Anwendungen stationär sein muss und die Problemdaten
von einem Rechner zum anderen übertragen werden. Dank der Beweglichkeit der Applikationslogik
verringert sich zum großen Teil der Übertragungsaufwand der Daten.
12 Ein Beispiel von Daten niedrigeren Niveaus ist z.B. die Stärke eines Signalimpulses. 13 Auch deliberativ oder zielgerichtet genannt

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
16
Ein mobiler Agent ist ein Prozess, der die Fähigkeit besitzt, sich selbstständig – mit all seinen
wichtigen Bestandteilen und mit Erhaltung seines internen Zustandes – während der Ausführungszeit
innerhalb eines heterogenen Netzwerkes zu bewegen [57]. Einen nicht-mobilen Agenten nennt man
stationärer Agent.
Den Prozess der Übertragung des Programmcodes nennt man Migration. Obwohl in praktischen
Anwendungen die Übertragung der globalen Daten während der Migration keine Schwierigkeiten
bereiten, ist die Übergabe des Ausführungskontextes eher problematisch.
2.2. Der Begriff der Multiagentensysteme
Multiagentensysteme dienen als Plattform für die Zusammenarbeit von mehreren Agenten. Ein
Multiagentensystem ist laut Ferber [28] ein System, das über einen bestimmten Raum verfügt. In
diesem Raum ist eine Menge von Objekten situiert. Die Menge der Agenten ist eine Teilmenge der
Menge der Objekte. Objekte sind durch unterschiedliche Beziehungen verbunden. Agenten verfügen
über eine Menge von Operatoren, mit denen sie auf andere Objekte einwirken können. Eine weniger
formale, dafür aber mehr an den gewöhnlichen Gebrauch des Begriffs angepasste Definition lautet
[52]: Ein [Multi]agenten-System ist eine Plattform, die Agenten erzeugen, interpretieren, ausführen,
übertragen und beenden kann.
2.3. Standards für Agenten
Damit die Agententechnologien im breiten Bereich eingesetzt werden können, braucht man
allgemein anerkannte Standards. Eine Normierung der Softwareagenteninfrastruktur ermöglicht eine
Zusammenarbeit von Agenten und Agentenplattformen, die von verschiedenen Herstellern entworfen
sind. Ein bewährter Standard verkürzt und vereinfacht die Entstehung neuer agentenbasierter Systeme.
Zurzeit existieren zwei nennenswerte Organisationen, die sich mit der Standardisierung der
Agentenebene befassen: FIPA und MASIF.
2.3.1. FIPA
FIPA [96] (Foundation of Physical Intelligent Agents) ist eine gemeinnützige Organisation,
gegründet 1996 in Genf. FIPA wird durch Forschungsinstitute (u.A. University of Calgary, West
Florida) und durch Computer- und Telekommunikationsgesellschaften (u.A. British
Telecommunications, Motorola, Siemens) geleitet. Die Tätigkeiten der Organisation konzentrieren
sich auf Standards für Verwaltung von Agenten, Kommunikation zwischen Agenten und die
Integration von Agentensoftware, wobei der Schwerpunkt auf die Erforschung der
Kommunikationsmechanismen gelegt wurde. Es wurden bislang drei Reihen von Standards publiziert
FIPA97, FIPA98, FIPA2000 work.
Die FIPA 98 Agent Management Specification W[44] stellt die Standardkomponenten einer FIPA-
konformen Agentenplattform dar(Abbildung 2-1):

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
17
• Agent Managment System (AMS) – ist ein spezieller Agent, der den Zugang und das Nutzen
der Agentenplattform kontrolliert. AMS ist zuständig für die Verwaltung von Agentennamen und die
Regelung des Lebenszyklus’ der Agenten. Im Rahmen einer Agentenplattform gibt es nur einen AMS.
• Directory Facilitator (DF) – ist ein Agent, der einen Suchdienst ähnlich den Gelben Seiten
gewährleistet. DF verfügt über eine Liste der Dienste, die Agenten der Agentenplattform anbieten.
Agenten können sich selbst in einem DF registrieren oder DF um Auskunft bitten.
• Agent Communication Channel (ACC) – ist die standardmäßige Kommunikationsmethode
zwischen Agenten auf verschiedener Plattformen.
• Internal Platform Message Transport (IPMT) – ist eine Kommunikationsmethode innerhalb
der Plattform. Die Einzelheiten dieses Protokolls werden von dem FIPA Standard nicht festgelegt.
Software
Agent
Agent Platform
AgentManagement
System
Agent
Communication
Channel
DirectoryFacilitator
Internal Platform Message Transport
Agent
Communication
Channel
Abbildung 2-3 FIPA98-Referenzmodell zur Agentenverwaltung [89]
Agenten werden in Domänen gruppiert. Jede Domänen verfügt über eine DF-Instanz (nur eine pro
Domäne), die sie beschreibt. Eine Agentenplattform kann über mehrere Domänen verfügen. Ein Agent
kann Bestandteil mehrerer Domänen sein.
Die neuesten Arbeiten der FIPA (Standard FIPA2000) gehen in Richtung einer noch größeren
Abstrahierung der Agentensystemarchitektur. Die FIPA Abstract Architecture [91] schreibt nur
allgemein vor, was eine konkrete Architektur beinhalten soll (z.B. Mechanismen zum
Agentenregistrierung, Agentensuche und Kommunikation zwischen Agenten). Wie aber konkret diese
Funktionen realisiert werden, ist dem Projektanten der Agentenplattform übergelassen. Zum Beispiel
kann der Agent-Directory-Service durch eine einfache Text-Datei implementiert werden, ein LDAP
System oder einen Directory Facilitator –Agenten wie in dem Standard FIPA98.
Eine Nachricht in einem Agentensystem ist laut FIPA [91] ein Tupel, zusammengesetzt aus
Attribut-Wert-Paaren, geschrieben in einer Agentenkommunikationssprache wie z.B. FIPA ACL [92]
oder KQML. Der Inhalt einer Nachricht ist durch eine Inhaltssprache, wie z.B. KIF oder SL [94],
formuliert. Der Inhalt der Nachricht basiert auf Begriffen aus Ontologien. Verweise zu den benutzten
Ontologien sollen sich auch im Inhalt der Nachricht befinden.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
18
Die FIPA standardisierte auch die Menge der zugelassenen Kommunikationsakten in Form der
FIPA Communicative Act Library (CAL) [93]. Diese Sammlung von Redewendungen ermöglicht
einen „intelligenten“ Informationsaustausch zwischen Agenten verschiedener Hersteller. Die
Bibliothek enthält 22 grundlegende Kommunikationsakten die man zu komplexeren Aussagen
komponieren kann. Die FIPA-Agenten sind nicht verpflichtet zur Implementierung der CAL mit
Ausnahme des non-understood-Kommunikationsaktes, der besagt, dass der Empfänger die zuletzt
erhaltene Nachricht nicht verstanden hat. Andere Beispiele von Elementen der CAL-Bibliothek sind
cfp (Call for Proposal) – mit dieser Nachricht ruft der Agent andere Agenten auf, ihm Angebote zur
Leistung eines von ihm geforderten Dienstes zu schicken, oder request-when – mit diesem
Kommunikationsakt bittet ein Agent einen anderen um einen Dienst, falls eine Bedingung erfüllt ist.
Die Realisation der CAL ist nicht obligatorisch, wenn man jedoch einen Kommunikationsakt aus der
Bibliothek implementiert, so muss das gemäß dem Standard geschehen.
2.3.2. MASIF
MASIF (Mobile Agent System Interoperability Facility) [52] ist ein Standard für Agentensysteme
der Organisation OMG (Object Management Group) [106], die schon durch Spezifikationen wie
CORBA oder UML bekannt wurde. Die MASIF Normen beruhen auf den Erfahrungen, die man
während der Implementierung solcher Multiagentensysteme wie IBM Aglets Workbench (→ 2.4.1),
AgentTcl oder Grasshopper gemacht hat. Im Unterschied zu dem FIPA-Standards werden in MASIF
vor allem Aspekte, die mit der Mobilität des Agenten verbunden sind, betrachtet. Die Problematik der
Agentensprachen wird dagegen absichtlich außer Acht gelassen. Die MASIF Spezifikation befasst sich
des Weiteren mit solchen Fragen wie die Verwaltung, Agentenübertragung, Namensgebung,
Lokalisierung und Sicherheit der Agenten.
Der MASIF-Standard basiert stark auf CORBA, der Spezifikation für die Erstellung, Verbreitung
und Verwaltung verteilter Objekte in einem Computernetz. MASIF ist eine Kollektion von
Definitionen und Schnittstellen. Der Standard legt zwei neue Schnittstellen fest: MAFAgentSystem
(zur Agentenübertragung und Verwaltung) sowie MAFFinder (zur Namensgebung und Lokalisierung
von Agenten).
Wie schon gesagt, befasst sich MASIF auch mit dem wichtigen Aspekt der Sicherheit der
Agentensysteme14. Die Spezifikation beinhaltet Methoden, die die Agentenplattform und die Agenten
vor solchen Gefahren schützen sollen wie: Denial of Service-Attacken, Vortäuschung, unautorisierte
Modifikationen oder Belauschen des Datenstromes. Um die Sicherheit zu gewährleisten, müssen die
Agenten durch das System identifiziert und auf die entsprechenden Zugriffsrechte überprüft werden.
Weil die Agenten aus Sicherheitsgründen keine privaten Kodierungsschlüssel übertragen können,
führt der MASIF-Standard den Begriff des Authenticators ein. Ein Authenticator ist ein Algorithmus,
14 FIPA hat nach einem gescheiterten Versuch [90] aufgegeben, den Sicherheitsbereich der Agentensysteme zu
standardisieren. Laut [91] sind die Sicherheitsmaßnamen ungeeignet, um sie allgemein zu behandeln, und sollten daher
immer an den Einzelfall angepasst werden.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
19
der die Authentizität des Agenten überprüft anhand solcher Informationen wie z.B. Authentizität des
Agentenssystems, aus dem der Agent gekommen ist. Authenticators teilt man in zwei Gruppen auf:
one-hop und multi-hop Authenticators. One-hop bedeutet hier, dass der Agent direkt von seiner
Quellplattform gekommen ist, multi-hop dagegen, dass der Agent einen längeren Weg hinter sich
gebracht hat. Die MASIF-Spezifikation behandelt nur die One-hop Authenticators.
Sicherheitsvorkehrungen sind Regeln, die die Aktivitäten der Agenten und Agentenplattformen aus
Sicherheitsgründen einschränken. Sowohl Agenten als auch Agentenplattformen können viele
Sicherheitsvorkehrungen besitzen. Wenn ein Agent ein für den Dienst gefordertes Sicherheitsniveau
nicht gewährleisten kann, so muss er die Ausführung eines solchen Dienstes verweigern15.
2.4. Beispiele von Agentenplattformen
Es wurden bislang mehr als hundert Agentenplattformen realisiert. Die meisten davon wurden in
der Programmiersprache Java implementiert, die zum Standard der Agentenplattformen geworden ist.
Ausnahmen davon sind z.B. Systeme, die mit der Tcl/tk-Technik realisiert worden sind (z.B. AgentTcl
oder Ara). Die Technologie Tcl spielt aber zurzeit keine große Rolle in der Entwicklung von
Agentenplattformen. Die meisten Agentenplattformen haben ihren Ursprung als akademische Projekte
(z.B. MadKit, Ara), es gibt aber auch Projekte, gestartet durch die Softwareindustrie (z.B. IBM Aglets
Workbench). Um den Aufbau und die Möglichkeiten der Agentenplattformen zu schildern, möchte ich
drei Beispiele vorstellen. Die Exempel wurden repräsentativ ausgewählt. Mit Ausnahme der Plattform
IBM Aglets Workbench sind das Projekte, an denen zurzeit intensiv gearbeitet wird und die schon ihre
praktischen Anwendungen haben.
2.4.1. IBM Aglets Workbench
Obwohl die IBM Aglets Workbench (AWB) Plattform [39] seit ein paar Jahren nicht mehr weiter
entwickelt wird, hat sie zu ihrer Zeit so große Bedeutung gehabt, dass ich sie hier trotzdem kurz
erwähnen möchte.
Die AWB Plattform wurde entwickelt in der Forschungsabteilung der Firma IBM in Tokio.
Agenten in der AWB nennt man Aglets. Aglets sind Java-Threads, die zwischen verschiedenen
Agentenplattformen migrieren können. Ein Kontext ist der Arbeitsplatz eines Aglets. Es ist ein
stationäres Objekt, ausgestattet mit Mechanismen zur Wartung und Verwaltung der AWB-Agenten.
Ein Aglet wird von einem Proxy repräsentiert. Es dient zum Schutz vor dem direkten Aufruf der
öffentlichen Methoden des Aglets und verbirgt seine wirkliche Lokalisierung.
Zur Entwicklung eigener Aglets stellte die Firma IBM eine Programmierschnittstelle zur
Verfügung – A-API (Aglet API). Die Bibliothek besteht aus zwei Hauptklassen: Aglet und
AgletProxy. Die abstrakte Aglet – Klasse (leitet sich nicht direkt von der Object-Klasse ab)
beinhaltet Methoden zur Kontrolle des Lebens-Zyklus des Aglets (Methoden zur Nachbildung,
15 Ein ausführlicher Bericht von dem aktuellen Stand der Forschung auf dem Feld der Agentensicherheit ist in [14]
beschrieben.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
20
Entsendung, Deaktivierung und Löschen von Aglets). Aus dieser Klasse leiten sich die
anwendungsspezifischen Aglets ab. Die AgletProxy-Klasse dient als Vermittler in den Interaktionen
zwischen dem Aglet und den Entitäten, die mit ihm kommunizieren möchten. Die AgletContext-
Schnittstelle liefert Informationen über die Umgebung des Aglets und ermöglicht die
Kontaktaufnahme mit anderen Aglets, die sich innerhalb des Kontexts befinden.
Nennenswert ist auch das Sicherheitsmodell der AWB-Plattform. Das Modell teilt die Benutzer
des Multiagentensystems in Klassen ein. Die Klassen sind: Aglet, Agletshersteller, Agletsbesitzer,
Kontext, Kontexthersteller, Kontextmeister, Domäne (Domänen sind Gruppen von Kontexten) und
Domänenbehörde (verwaltet eine Domäne). Jede dieser Klassen von Benutzern (genannt Prinicpals)
kann ihre eigenen Sicherheitsregeln aufstellen. Die sich widersprechenden Regeln werden nach der
Relevanz des Principals entschieden, wobei die Domänenbehörden die mächtigsten Befugnisse haben,
die Aglets selbst die schwächsten. Die Sicherheitsregeln werden in einer speziellen, durch IBM
entwickelten Sprache formuliert. Auf diese Weise kann man den Zugang zu unterschiedlichen
Dateien, Ordnern, Internetschnittstellen, Bibliotheken oder Systemressourcen verweigern oder
gewährleisten.
2.4.2. MadKit
MadKit [104] ist eine in Java geschriebe Agentenplattform, die an der Universität Montpellier
entstanden ist. MadKit baut auf einem abstrakten Modell – Aalaadin – auf. Dieses Modell ist aus drei
Bausteinen zusammengesetzt: Agent, Gruppe und Rolle. Gruppen aggregieren Agenten. Rollen stellen
abstrakte Formen der Agentenfunktionen dar. Agenten sind aktive kommunizierende Entitäten, die
Rollen innerhalb Gruppen spielen. Zu den Merkmalen der MadKit Plattform zählen zusätzlich [29]:
eine Mikro-Kern-Architektur, Agentifizierung der Dienste und ein grafisches Komponentenmodell.
Der Kern des MadKits ist sehr klein (40Kb) und beinhaltet nur die wichtigsten Funktionen:
Kontrolle von lokalen Gruppen und Rollen, Verwaltung des Agenten-Lebenszyklus’ und die lokale
Übertragung der Nachrichten. Der ganze Kern ist in einem speziellen KernelAgent integriert und
kann beliebig durch so genannte Kern-Anschlüsse erweitert werden. Die Anschlüsse werden durch
andere Agenten realisiert, die zu der System-Gruppe gehören und die ihre Dienste bei dem Kern-
Agenten angemeldet haben. Sobald eine Kernoperation ausgeführt worden ist, leitet der Kern-Agent
die Information an alle Anschlüsse weiter. Man unterscheidet zwei Sorten von Kern-Anschlüssen:
Monitors und Interceptors. Die Monitore werden über alle Kern-Operationen informier,t für die sie
sich angemeldet haben. Ein Interceptor dagegen fängt die ganze Kern-Operation nur für sich auf.
Daher kann es nur einen registrierten Interceptor für jede Kern-Operation geben.
Man spricht von einer Agentifizierung der Dienste im MadKit, weil viele wichtige Funktionen
der Agentenplattform vollständig von den Agenten realisiert werden. So verwendet MadKit Agenten
zur verteilten Nachrichtenübertragung, dynamischer Sicherheitsgewährleistung und Übertragung der
Steuerung. Diese Lösung hat den Vorteil, dass sie sehr flexibel ist. Man kann die Realisation eines

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
21
Plattformendienstes wechseln, in dem man den Agenten, der diesen Dienst ausführt, durch einen
anderen ersetzt.
Das grafische Komponentenmodell von MadKit basiert auf Java Beans-Komponenten. Jeder
Agent verfügt über eine eigene graphische Oberfläche. Durch die Anwendung der Java Beans-
Technologie kann man mit der Maus (drag-and-drop Methode) Agenten zu einem einfachen, aber
funktionsfähigen Agentensystem komponieren, ohne dabei eine Zeile Programmcode schreiben zu
müssen. Das graphische Interface eines Agenten kann entweder ein einfaches Kennzeichen sein oder
eine ganze Reihe von Fenstern beinhalten. Bei komplexeren Aufgaben kann man immer noch auf die
traditionelle Programmiermethode zurückgreifen.
2.4.3. JADE
JADE (Java Agent DEvelopment Framework) [7] ist eine FIPA-kompatible Agentenplattform,
entwickelt durch TILAB (Telecom Italia LAB). Die Plattform ist frei zugänglich [99] unter der LGPL-
Lizenz. JADE wurde vollständig in Java implementiert und funktioniert auch in der J2ME-Umgebung.
Gemäß der FIPA-Spezifikation (→2.3.1) enthält die Plattform solche Dienste wie AMS, DL,
ACC und unterstütz, die FIPA-ACL-Sprache und FIPA-Kommunikationsakte. Um die
Kommunikation zwischen den Agenten noch mehr zu erleichtern, bietet JADE spezielle abstrakte
Klassen, die ganze komplexe Gespräche implementieren (wie z.B. Verhandlungen, Versteigerungen
oder Auftragweitergabe).
JADE unterstützt den Prozess der automatischen Konvertierung zwischen verschiedenen
Formaten der Wissensrepräsentation wie XML und RDF. Man kann JADE mit Ontologieeditoren
verknüpfen z.B. mit Protégé. Es besteht auch die Möglichkeit, JADE um externe
Inferenzmechanismen wie JESS oder Prolog zu erweitern.
JADE verfügt auch über eine ganze Reihe graphischer Werkzeuge, die den Prozess der
Erzeugung von Agentensystemen erleichtern. Der Remote Management Agent (RMA) funktioniert als
eine graphische Oberfläche für die Plattformverwaltung. Von RMA kann man alle anderen JADE-
Werkzeuge aufrufen. Der Dummy Agent ermöglicht das Testen von anderen Agenten, indem er eine
graphische Oberfläche anbietet, durch die man ACL-Nachrichten an andere Agenten verschicken und
die Antworten ablesen kann. Der Sniffer belauscht die Kommunikation zwischen den Agenten und
stellt sie graphisch in Form eines UML Sequenz-Diagrams dar. Der Introspector Agent überwacht den
ganzen Lebenszyklus der Agenten. Der SocketProxyAgent dient als Pforte zwischen der JADE-
Plattform und einer gewöhnlicher TCP/IP-Verbindung. Schließlich ist der DF GUI eine graphische
Oberfläche für den DF-Dienst.
JADE kann auch auf sehr kleinen Geräten, wie z.B. Handys mit integrierter Java VM, ausgeführt
werden. Dank der modularen Architektur von JADE kann man die Plattform den speziellen
Anforderungen der mobilen Geräte anpassen. So spaltet z.B. das Modul LEAP, das speziell für
drahtlose Netze konstruiert wurde, die JADE-Plattform in zwei Teile: das Front-End das auf dem
mobilen Gerät ausgeführt wird, und das Back-End, das im Festnetz ausgeführt wird. Diese Architektur
minimiert den Datenaustausch zwischen dem mobilen Gerät und dem Festnetz, weil das Back-End den

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
22
Großteil der Kommunikation mit anderen Agenten und der Agentenplattform übernimmt. Bei
unterbrochener Verbindung zum mobilen Gerät (was oft vorkommen kann) speichert das Back-End
die für das Front-End bestimmten Informationen und übermittelt sie weiter, sobald das Gerät sich dem
Netz wieder angeschlossen hat.
2.5. Übersicht der Anwendungsgebiete für Multiagentensysteme
In jahrelanger Forschung auf dem Gebiet der Agentensysteme wurden zahlreiche Versuche
gemacht, diese Technologie in diversen Bereichen anzuwenden. Die große Menge der so entstandenen
Applikationen wird auf verschiedene Weise klassifiziert. Die von mir aufgestellte Gliederung basiert
auf den Klassifikationen von Jennings und Wooldridge [36], Ferber [28] und Luck et al. [48].
2.5.1. Verteiltes Lösen von Problemen
Bei den verteilten Lösungsverfahren wird angenommen, dass eine Aufgabe durch eine Reihe
von autonomen Softwareagenten bearbeitet wird.
Ein gutes Beispiel für den Einsatz sehr vieler gleicher Agenten sind die Swarm Intelligence-
Verfahren16 [13]. Ihren Ursprung haben diese Methoden in der Beobachtung von sozialen Insekten wie
Ameisen, Bienen oder Termiten. Diese recht primitiven Lebewesen können in der Gruppe komplexe
Aufgaben bewältigen und das ohne jeglicher zentrale Aufsicht. Die Organisation beruht nur auf dem
Informationsaustausch zwischen Individuen. Eine Methode der Swarm Intelligence, die Ant Colony
Optimization (ACO) [24] [76], nahm sich die Funktionsweise einer Ameisen-Kolonie zum Vorbild.
Auf dem Weg von der Nahrungsquelle zum Bau zerstreuen die Ameisen eine chemische Substanz, die
Pheromon genannt wird. Die Ameisen bevorzugen den Pfad, der mit einer stärkeren Pheromonspur
versehen ist. Weil die Ameisen, die den kürzeren Weg nehmen, ihn öfter machen können, hinterlassen
sie auf diesem Pfad ein stärkeres Pheromon-Signal. Auf diese Weise wählen immer mehr Ameisen die
kürzere Strecke. Das ACO-Verfahren wird z.B. zur Lösung des Handelsreisendenproblems [25] oder
zur Optimierung des Routings in Computernetzen genutzt [62].
Ein anderes Beispiel der Dezentralisierung einer Aufgabe mit Hilfe von Methoden der
Verteilten Künstlichen Intelligenz kommt aus dem Bereich der industriellen Prozesskontrolle. Man hat
mit Erfolg Agenten zur Lösung des Flavors-Paint-Shop-Problems eingesetzt [53]. Bei diesem Problem
gibt es eine Reihe von Maschinen, die nach Wunsch des Kunden Kraftfahrzeuge mit bestimmten
Farbtönen lackieren. Die Anzahl der Lackierungsstationen ist kleiner als die Zahl der möglichen
Farbtöne. Aus diesem Grund werden in den Maschinen von Zeit zu Zeit die Farben gewechselt. Leider
ist der Austausch ein recht zeitaufwendiger und teurer Prozess, deshalb versucht man die Zahl der
Farbwechsel zu minimieren. Früher wurde zur Lösung dieses Problems ein zentrales
Steuerungsprogramm benutzt, das sehr fehleranfällig war. Das System wurde modernisiert, indem man
das zentrale Steuerungssystem durch ein Multiagentensystem ersetzte. Jeder Maschine wurde ein
Agent zugewiesen, der nach Bedarf zu entscheiden hhatte, ob in der Lackierungsstation die Farbe
16 Swarm Intelligence (eng.) – Intelligenz des Schwarms

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
23
gewechselt werden sollte oder nicht. Obwohl das System recht einfach ist, konnte man die Anzahl der
Farbwechsel im Durchschnitt um 50% reduzieren, was eine Einsparung von mehr als einer Million
Dollar pro Jahr brachte.
In den verteilten Lösungsverfahren können Agenten identische (wie im Fall der Ameisen im
ACO-Verfahren) oder auch komplementäre Fähigkeiten zur Lösung des Problems besitzen. Die zweite
Alternative wird auch „Kooperation zwischen Spezialisten“ [28] genannt und wird vor allem zur
Bearbeitung komplexerer Aufgaben angewandt. Wie z.B. in dem durch NASA, Ohio University und
der TU Clausthal entwickeltem HART-System (Hierarchical Agent-based Real-time Technologie) zur
Steuerung von Satelliten [26] gibt es eine ganze Reihe von unterschiedlich spezialisierten Agenten
(wie z.B. Data Management Agent - zum Verwalten von Daten, die durch den Satelliten gesammelt
wurde, Compression Agent - Agent zur Steuerung der Kompressionsrate der durch den Satelliten
gemachten abhängig von den Wetterverhältnissen auf der Erde, Health and Safety Data kontrolliert die
Sicherheitsmechanismen des Satelliten)
OASIS (Optimal Aircraft Sequencing using Intelligent Scheduling) ist ein agentenbasiertes
System zur Koordination des Flugzeugverkehrs [47]. Ähnlich wie im HART-System werden auch hier
verschiedene Sorten von Agenten benutzt. Im Allgemeinen gibt es in OASIS zwei Klassen von
Agenten: Aircraft Agents und Global Agents. Jedes Flugzeug, das den Flugraum fliegt, wird mit
einem Aircraft-Agenten repräsentiert. Dieser Agent besitzt Informationen über die Ziele (z.B.
Landung in Sydney), Fähigkeiten (ein Leistungsmodell) und den Zustand des Flugzeuges (z.B. Steigen
oder Sinken). Es gibt fünf Arten von Global Agents: Coordinator Agent – der die Arbeit aller Agenten
koordiniert, Sequencer Agent ordnet die Aircraft Agents so zur Landung ein, dass die Wartezeiten
möglichst gering sind, der Trajectory CheckerAgent kontrolliert, ob die geplanten Trajektorien der
Flugzeuge nicht zu dicht beieinander liegen, Wind Model Agent sammelt die Daten über
Wetterverhältnisse und schätzt die Windstärke bei der Landung ein, der User Interface Agent ist für
die Interaktion mit dem menschlichen Aufseher des Systems im Kontrollturm verantwortlich. Das
OASIS-System wurde erfolgreich auf dem Flughafen von Sydney getestet [37].
Andere Beispiele der Anwendung von Agenten zur verteilten Lösung von Problemen sind
Erkennung von Umrissen oder der natürlichen Sprache, Fehlersuche in Telekommunikations-
Netzwerken.
2.5.2. Simulationen
Ein sehr populäres Anwendungsgebiet von Multiagentensystemen sind Simulationen. In den
Simulationen werden Agenten zur Modellierung von Fragmenten der realen Welt benutzt. Auf diese
Weise können Experimente durchgeführt werden, die unter normalen Bedingungen oft unmöglich oder
sehr schwer zu realisieren wären.
Multiagenten Simulatoren werden oft zur Darstellung von Ecosystemen genutzt. Populationen
biologischer Lebewesen sind aus vielen Individuen zusammengesetzt, die aufgrund ihrer genetischen
Eigenschaften und den lokal unterschiedlichen Interaktionen einmalig sind. Solche Gruppen werden
oft besser durch Multiagentensysteme als allgemeine Modelle simuliert [84]. Solche Forschungen

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
24
tragen unter anderem dazu bei, dass die gefährdeten Naturregionen gezielter geschützt werden können.
Das an der University of Tennessee entwickelte ATLSS17 System [74] simuliert das Ecosystem der
Sumpfgebiete im Süden Floridas. Agenten modellieren einzelne Individuen der Tierpopulationen
(Hirsche und Panther, Alligatoren, usw.) wie auch Naturphänomene wie z.B. Waldbrände,
Regenschauer oder Wirbelstürme.
Eine oft in Simulationen modellierte Population sind Fische als Beispiel einer erneuerbaren
Ressource [44]. Durch solche Experimente kann man die Auswirkung verschiedener Strategien der
Nutzung dieser Bestände erforschen. In dem Simdelta-System wird die Fischerei im Niger-Delta in
Mali modelliert [17]. Dieses System beinhaltet drei Arten von Agenten: Biotope als Bestandteile der
Umwelt, Fische mit reaktivem Verhalten und Fischer als kognitive Agenten [28]. Mit Hilfe dieses
Modells konnte man die Größen-Veränderung der Fischpopulation untersuchen. Eine andere
Versuchsreihe hat das Verhalten der Fischer gezeigt, die sich bei ihren Entscheidungen an der Größe
des Fischbestandes orientieren. Diese Studie präsentierte die Wichtigkeit der Mechanismen zur
Entscheidungsfindung im Zusammenhang mit der Entwicklung erneuerbarer Ressourcen. Es wurde
bewiesen dass eine rein ökonomische Ausbeutung der Bestände auf längere Sicht weniger lohnend ist,
als eine Strategie, die auch den Lebenszyklus und die aktuelle Populationsgröße der Fische
berücksichtigt [17].
Multiagenten werden oft in den Sozialwissenschaften angewandt, unter anderem zur
Simulation von großen Menschenmenge (Crowd Simulations). Auf diese Weise kann man
Kommunikationsnetze planen [65] oder Evakuierungspläne großer Veranstaltungen für den Fall von
Ausnahmezuständen (wie z.B. Feuer, Terroranschlag oder Panikausbruch) bearbeiten [54]. Ein für die
Fußball WM 2006 in Deutschland erarbeitetes System errechnet die benötigte Zeit zur Evakuierung
von mehreren tausend Zuschauern aus einem Stadion aus [71]. Jeder der Zuschauer wird durch einen
Agenten modelliert, der mit solchen Eigenschaften wie Laufgeschwindigkeit, Geduld, Orientierung
oder Reaktionszeit charakterisiert ist. Weil Gefühle wie Angst, Verzweiflung, Panik, Hoffnung die
menschlichen Fähigkeiten stark beeinträchtigen können, versucht man, die Simulation noch realer zu
gestalten, Agenten mit Mechanismen zur Simulation von Emotionen auszustatten (z.B. die PSI-
Theorie [3]).
Simulationen werden auch in der Lehre benutzt. Die Medizinstudenten haben Dank des Adele-
Systems die Möglichkeit, bei einer virtuellen Behandlung eines Patienten auf der Intensivstation
teilzunehmen [75] (→ 5.4.2). Das Extempo-System [85] (→ 5.4.3) simulieren zu Bildungszwecken
unter anderem Gespräche eines Personalabteilungsleiters mit seinen Untergeordneten. Zahlreihe
Schulungssimulationen werden im Militär eingesetzt, wo, z.B. die Kampflugzeugpiloten die
Möglichkeit haben, zuerst rein virtuell Probe zu fliegen.
Die Unterhaltungsbranche wird von der Wissenschaft oft nicht ernst genommen. Dabei sind
die Umsätze dieser Industrie wirklich riesig und die bei der Erstellung solcher Systeme gelösten
Probleme oft nicht trivial [36]. Die Agenten werden in der Unterhaltung sowohl für Computerspiele
17 ATLSS = Across Trophic Level System Simulation

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
25
genutzt, wie auch zur Darstellung von Spezialeffekten in der Filmbranche. Ein Beispiel aus der
neusten Geschichte ist die sehr erfolgreiche Filmreihe Der Herr der Ringe. Zur Darstellung von
Schlachtszenen wurde ein spezielles Agentensystem mit dem Namen Massiv konstruiert [51], der den
Kampf von mehreren Tausenden Kreaturen simuliert.
2.5.3. Robotik
Die Anwendung von Agenten in der Robotik unterscheidet sich von den anderen
Anwendungen dadurch, dass die Agenten in der realen Welt agieren können. Die Robotik-Agenten
werden zur Steuerung separater Teile eines Roboters benutzt (Zellulare Robotik) oder zur Lenkung
von ganzen Roboter-Kollektiven (Modale Robotik) [28].
Beispiel einer Agenten-Anwendung in der Zellularen Robotik ist die Steuerung eines
Roboterarmes. Jeder Agent steuert ein anderes Segment des Armes und besitzt das Wissen über die
möglichen Bewegungen seines Segmentes. Der Kopf-Agent hat das Ziel, einen Gegenstand zu fassen.
Wenn das dem Kopf-Agenten nicht gelingt, so wendet er sich an andere Agenten mit der Bitte, eine
Bewegung auszuführen, die das Ziel näher bringt. Auf diese Weise kann man sogar sehr komplexe
Operationen mit wenig Rechenaufwand durchführen.
Die Veranstalter des RoboCups [118] haben sich zum Ziel gesetzt, bis zum Jahre 2050 ein
autonomes Team von menschenähnlichen Roboter zu entwickeln, das gegen ein menschliches
Weltmeister-Team im Fußball gewinnen kann. Um dieses Ziel zu verwirklichen, organisiert man
jährlich ein RoboCup Turnier18, in dem Roboter gegeneinander Fußball spielen. Die Regeln des
Spieles sind – so weit möglich – identisch mit den FIFA-Regeln. Es gibt zahlreiche Kategorien, in
denen gespielt wird (z.B. menschenähnliche Roboter, Sony AIBO Robots [77] oder reine
Softwaresysteme). Die künstlichen Fußball Spieler werden durch unterschiedliche
Multiagentensysteme gesteuert. Unter den zahlreichen Beispielen solcher Systeme sind auch das ABC
Team [1], ORAP [55] oder CS Freiburg [66].
2.5.4. Internet
Das sich ständig ausbreitende globale Netz bietet dank seiner großen Dezentralisierung und
Selbstständigkeit eine hervorragende Möglichkeit, um Softwareagenten einzusetzen. Assistent-
Agenten sind Agenten, die im Namen der Benutzer im Internet Informationen finden und
Transaktionen abschließen [48]. Die Benutzer sind nicht unbedingt Menschen, es können auch Web-
Dienste wie Suchmaschinen sein [127]. Search Engine Spiders (Searchbots) sind Agenten, die das
Internet auf Befehl der Suchmaschinen nach interessanten Webseiten absuchen. Die derzeit wohl
populärste Internet Suchmaschine – Google – benutzt zur Erstellung des Ranking von Seiten ein
Verfahren, das PageRank genannt wurde. Diese durch Page und Brin [56] an der Stanford University
erforschte Methode bewertet die Seiten aufgrund der Zahl der zu ihnen führenden Verweise. Die
Verweise, wie auch neue Seiten, werden von Googlebot, einem Search-Engine-Spider-Agenten,
18 Die Idee ist inzwischen so populär geworden, dass außer dem Welt RoboCup Turnier auch lokale RoboCup Turniere
organisiert werden. (z.B. German Open oder Japan Open)

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
26
gefunden. Code Validators sind Agenten, die dem Entwickler eines großen Internet Service helfen,
indem sie nach syntaktischen Fehlern in HTML-Seiten suchen.
Das Internet wurde zum Gerüst eines neuen Wirtschaftszweigs, das E-Commerce genannt
wurde. Darunter versteht man alle kommerziellen Aktivitäten, die mit Hilfe elektronischer Mittel zu
Stande kommen. Laut dem Bericht von PriceWaterhouseCoopers gab es Anfang 2001 [73] ca. 1000
frei zugängliche elektronische Märkte. Zurzeit ist die Zahl voraussichtlich viel größer. E-Commerce
Geschäfte finden in zwei Dimensionen statt: B2C (Business-to-Customer: Transaktionen zwischen
Anbieter und Verkäufer) und B2B (Business-to-Business: Transaktionen zwischen Verkäufern).
Assistenten-Agenten werden in beiden Bereichen benutzt. Sie ermöglichen, in kurzer Zeit das günstige
Angebot im Internet zu findet. Die elektronischen Assistenten vergleichen viele Angebote, nehmen an
Versteigerungen teil und verhandeln Preise mit anderen Agenten. Je nach Bedarf passen die Anbieter-
Agenten dynamisch das Angebot an den Kunden an. Das endgültige Angebot ist ein Ergebnis von
mehreren Verhandlungen zwischen Käufer/Verkäufer-Agenten. Auf diese Weise könnte die
Wirtschaft auf eine bislang unerreichte Ebene der Produktivität und der Rentabilität steigen [46].
Agenten können auch in der Realisation der E-commerce-Dienstleistung behilflich sein. In den
Quality-On-Demand-Diensten (z.B. Verkauf einer bestimmten Bildqualität bei Internet-Übertragungen
von verschiedenen Veranstaltungen) koordiniert ein Agentensystem das Routing der Daten auf solche
Weise, dass die vereinbarte Qualität immer gewährleistete ist.
Es werden Ansätze gemacht, die Agenten zum Vertrieb von Software (allgemeiner gesagt
Informationen) im Internet zu nutzen [58]. Auf diese Weise kann man die großen Shareware, Freeware
und Open Source-Kollektionen (wie z.B Tucows, FreshMeat) effektiv verwalten. Weil die
Speicherkapazität der Vertriebshäuser begrenzt ist, möchten die Software-Anbieter auf ihren Servern
nur die populärsten Programme in den neusten Versionen haben, eventuell auch die weniger
populären, für die der Produzent extra bezahlen möchte. Im agentenbasierten Konzept sind für die
Verbreitung von Versionen der Software in Internet spezielle mobile Agenten verantwortlich, die in
die vertriebene Software beinhalten. Am Anfang verfügt jeder Agent über eine Menge an virtuellen
Währungsmitteln, die beim Gebrauch des Servers abgezogen wird. Der Agent kann das elektronische
Geld auf zweierlei Art verdienen: erstens beim Zugriff auf die von ihm vertriebene Software durch
Kunden und zweitens durch zusätzliche Währungsmittel-Überweisungen vom Hersteller der Software,
der die virtuellen Punkte für richtiges Geld kaufen kann. Die Agenten könnten sich reproduzieren, um
neue Bereiche des Internets zu erobern (das virtuelle Geld wird dann auf die Agenten aufgeteilt). Die
Agenten verfügen über die Möglichkeit sicherzustellen, wo sich ihre eigenen Klone schon befinden,
um denselben Server nicht doppelt anzusiedeln.
Im Internet gibt es leider auch eine ganze Reihe von böswilligen Agenten mit dem Ziel, die
Arbeit anderer zu zerstören, auf illegale Weise auszuspionieren oder mit verschiedenen Methoden die
Arbeit zu erschweren. Computer-Viren sind auch eine Art von Agenten. Die Troian Horses sind
feindliche Agenten, die sich als nützliche Programme tarnen, um in das System des Benutzers
einzudringen, um von dort unautorisierte Operationen auszuführen. E-mail Collectors sind Agenten,

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
27
die im Internet nach E-Mail-Adressen suchen. Diese Art von Agenten wird vor allem dazu genutzt, um
den Benutzern (meist unerwünschte) Werbe-Mails zu verschicken. Es gibt auch Agenten, die
Sicherheitslücken in Systemen suchen und so gezielte feindliche Systemeinbrüche ermöglichen.
2.5.5. Intelligente Softwarearchitekturen
Intelligente Softwarearchitekturen sollen dazu beitragen, dass die Computersysteme sich selbst
reparieren oder entwickeln können. Die Softwarekomponenten werden zu Agenten erweitert und
können durch Interaktionen mit anderen intelligenten Komponenten und der selbstständigen
Anpassung an neue Bedingungen, ein viel flexibleres und robusteres System ergeben [28] [36]. Diese
Softwaredesign-Methode ermöglicht eine effektive Integration von alten und neuen Systemen. Den
Prozess der Transformation alter Applikationen zu Agenten nennt man auch Agentification [36].
Ein oft zitiertes Beispiel einer intelligenten Softwarearchitektur ist die Archon-Plattform
(Architecture for Cooperating Heterogenous On-Line Systems). Die Basis für die Plattform bildet ein
allgemeines Multiagentensystem [61] Die Archon-Agenten bestehen aus zwei Segmenten: dem Kopf
und dem Körper. Im Kopf befinden sich die Planungs- und Kommunikationskomponenten, wie auch
das Modell von den eigenen wie auch fremden Fähigkeiten. Im Körper wird eine Komponente aus
dem vorhandenen System mit dem Agenten integriert. Die Archon-Plattform wurde mehrmals
erfolgreich eingesetzt, u.a. zur Überwachung von Elektrizitätsnetzen im Norden Spaniens und zur
Kontrolle eines Partikelbeschleunigers.
Die Firma IBM, die auf dem Gebiet der Agententechnologie schon mit ihrer Aglets-
Technologie [39] aktiv wurde, baut jetzt eine neue Vision von Softwarearchitektur auf, in der Agenten
eine fundamentale Rolle spielen werden. Das Konzept heißt Autonomic Computing und soll eine
Lösung für die ständig wachsende Komplexität der Installation, Konfiguration und Verwaltung von
modernen Softwaresystemen sein [41]. Autonomic Computing bedeutet in der Praxis ein System, das
sich selbst konfigurieren, optimalisieren, reparieren und schützen kann. Der menschliche
Administrator wird dem System nur allgemeine Ziele geben, das System selbst wird sich um die
Details kümmern, wie z.B. die Erkennung und Integration mit schon installierter Systeme und Prüfung
der Richtigkeit der Installation. Möglich wird das dadurch, dass die neuen Systeme Sammlungen von
so genannten Autonomic elements sind, die durch Softwareagenten realisiert werden. Aufgaben dieser
intelligenten Komponenten sind z.B. die Suche nach neusten Versionen von Paketen mit
Fehlerkorrekturen oder Verhandlungen mit verschiedenen Anbietern eines Web Services. Der
menschliche Aufseher wird nur in kritischen Situationen benachrichtigt.
2.5.6. Andere Agentenanwendungen und Zukunftsperspektiven des Einsatzes
von Agenten.
Die oben genannten Kategorien decken noch nicht das ganze Spektrum der Anwendungen von
Agenten ab. Nicht besprochen wurde z.B. die Anwendung von Agenten in der Medizin [36].

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
28
Zu den Zukunftsanwendungen gehört unter anderem der Einsatz Agenten in der Ambient
Intelligence (AmI). Diese Richtung der Künstlichen Intelligenz befasst sich mit einer Vision der Welt,
in der Menschen durch Tausende von eingebetteten oder mobilen Geräten umgeben sind, die
miteinander kommunizieren, um die Ziele ihrer Benutzer zu realisieren [48].
Eine höchst interessante und viel versprechende Idee ist die Anwendung der
Agententechnologie in der Bioinformatik, z.B. in der Analyse des Genoms [48]. Bei der Dekodierung
des Genoms gewann man enorme Mengen an Informationen, die auf intelligente Weise analysiert
werden sollten. Des Weiteren könnte man anhand des schon dekodierten Genoms einer Gattung den
Dekodierungs-Prozess eines Genoms einer ähnlichen Gattung durch den Einsatz von Agenten
beschleunigen. GeneWeaver [16] ist ein Beispiel für ein inzwischen laufendes Projekt auf dem Gebiet
der Analyse des Genoms.
Die Vielfalt der gezeigten Agentenanwendungen zeigt ausdrücklich, welch großes Potential
sich hinter der Multiagenten-Technologie verbirgt. Die vielen erfolgreichen (auch aus finanziellee
Sicht) Einsätze dieser Systeme zeigen, wie bedeutsam Agenten für die Gesellschaft geworden sind.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
29
3. Charakteristik des E-Learning
Non scholae, sed vitae discimus
("nicht für die Schule, sondern für das Leben lernen wir")
Seneca, Epistulae 106, 12
3.1. Einführung
Der Begriff E-Learnig zählt zu der neuen, heutzutage sehr gerne benutzten Familie der E-
Ausdrücke. Das bekannteste Beispiel aus dieser Wortgruppe ist ohne Zweifel E-Mail. Man spricht
auch von E-Business, E-Commerce, E-Collaboration, E-Marketing, E-Money, E-Procurement, E-
Recruitment, E-Security und vielen Anderen E-Begriffen. Obwohl die Ausdrücke aus dem Englischen
stammen, werden sie oft (und das sowohl im Deutschen wie auch Polnischen) nicht übersetzt.
Die E-Wörter gliedern sich immer in zwei Teile auf: den Buchstaben E, der für electronic steht (und
nach etwas Neuem und Innovativem klingen soll) und einen zweites Glied, das inzwischen ein gut
eingebürgerter Begriff ist. Diese Namensgebung soll hervorheben, dass der beschriebene Begriff eine
Neuauflage eines alten Konzeptes ist, das mit Hilfe elektronischer Mittel realisiert wurde.
Der Begriff E-Learning taucht in der wissenschaftlichen Literatur erst seit kurzem auf, was aber
nicht bedeutet, dass das Konzept des Lernens, unterstützt durch elektronische Medien, erst jetzt
entstanden ist. Die früheren Ansätze benutzten u.a. die Namen virtuelles Lernen oder multimediale
Lernumgebungen. Auf der Suche nach der Definition des Terms E-Learning analysierte ich die
Arbeiten [5] [8] [40] [50]. Der Kern der Begriffserläuterungen ist immer der Selbe und lässt sich am
Besten mit der Definition aus [50] zusammenfassen: „Unter E-Learning versteht man das Lernen mit
Hilfe elektronischer Medien“. Zweck des E-Learnings ist die „Überwindung von räumlichen und
zeitlichen Distanzen zwischen Lehrenden, Lernenden und Gruppen von Lernenden (…)“ [45].
Manchmal wird unterstrichen, dass diese Lernform an die Lernenden nach dem Abitur gerichtet ist
[40]. Einige Forscher verstehen den Begriff recht eng, nämlich einzig als die Veröffentlichung von
Lernmaterialien mittels elektronischer Medien. Meiner Ansicht nach, wie auch der von vielen
Wissenschaftlern, ist dies eine viel zu starke Eingrenzung: „(…) we are disappointed when we hear
people in conferences or public speeches say that e-learning is as simple as publishing a presentation
on-line“ [49]. Zu einem erfolgreichen E-Learning gehört auch die Entwicklung einer an den Lernstoff,
die Lernenden und die benutzen Technologien angepassten Lehrstrategie. Wichtig sind auch die
Technologien des Wissensmanagement [49].
E-Learning wurde gezielt nicht E-Teaching genannt. Der Term sollte möglichst breit gesehen
werden. Das Lernen muss man klar vom Lehren unterscheiden. Lernen ist ein individueller Prozess –
niemand kann für uns selbst lernen. Das Lehren ist natürlich auf Lernen gerichtet, aber ist nicht dessen
Voraussetzung, denn man kann sehr wohl auch ohne Lehrer lernen. E-Learning ist daher mehr ein

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
30
Oberbegriff für E-Teaching, denn es befasst sich sowohl mit elektronisch gestützten Methoden des
Lehrens wie auch des individuellen Lernens.
Ein Fehler, der oft durch die Entwickler von E-Learnig-Systemen begangen wird, ist eine viel zu
große Konzentration auf die benutzten Technologien im Vergleich zu der Zeit, bestimmt für das
didaktische Design. Das vernachlässigte Lehrkonzept wird durch ein Spektakel aus multimedialen
Effekten ersetzt. Die Folge solcher Softwareentwicklung sind Systeme, die zwar im ersten Moment
beeindrucken, aber danach sehr schnell ermüden, langweilen oder frustrieren und sich im Endeffekt als
unnützlich erweisen. Aus diesem Grund möchte ich, bevor ich auf die technischen Details des E-
Learning eingehe, die grundlegende Frage stellen: was verstehen wir unter Lernen?
3.2. Grundlagen des Lernens
Unter Lernen versteht man den Erwerb vom Wissen. Der Erwerb vom Wissen geschieht durch die
Wahrnehmung von Informationen, die wiederum aus geordneten Daten zusammengesetzt sind.
Abhängig von der Art der Information unterscheiden wir verschiedene Wissensarten [45]:
• Affektives Wissen – Gefühle und Einstellungen betreffend
• Kognitives Wissen – Gegenstand intellektueller Reflextion
• Psychomotorisches Wissen – Bewegungsabläufe und körperliche Geschicklichkeit betreffend.
E-Learning konzentriert sich vor allem auf die Förderung des kognitiven Wissens. Andere
Wissensarten kann man schlecht mit Hilfe elektronischer Medien übermitteln. Das kognitive Wissen
gliedert sich weiter in Unterbegriffe. Die zwei wichtigsten sind [45]:
• Deklaratives Wissen – Wissen über Fakten, Ereignisse und Objekte
• Prozedurales Wissen – Die Fähigkeit zur Anwendung, Assoziation und darüber hinaus auch
Erzeugung von deklarativem Wissen.
In der Regel wird das prozedurale Wissen höher geschätzt als das deklarative. Ein gutes Beispiel sind
dafür die Gebiete der Mathematik oder Physik, wo man die vergessene Formel oft leicht aus anderen
Formeln ausrechnen kann. Daher ist die richtige Anwendung des Wissens (Verständnis der
Sachverhalte) viel wichtiger. Man sollte jedoch die Wichtigkeit des deklarativen Wissens nicht
unterschätzen. Zu den Wissensgebieten, die viel deklaratives Wissen benötigen, zählen z.B.
Linguistik, Jura oder Medizin. Ob deklaratives oder prozedurales Wissen von den Menschen besser
angenommen wird, hängt vom Einzelfall ab. Es gibt Leute, die meinen, sie hätten kein Gedächtnis für
Zahlen oder Daten (bevorzugen daher das prozedurale Wissen), andere wiederum lernen gerne
auswendig (Prädisposition für deklaratives Wissen).
Im negativen Kontext spricht man über träges Wissen. Es ist ein Wissen, das in einer Situation
theoretisch gelernt wurde, in einer Anwendungssituation jedoch nicht genutzt werden kann [50].
Anders gesagt: in dem Fall wurde das deklarative Wissen ohne das zugehörige prozedurale Wissen
gelernt. Daher sollte ein gutes Bildungsprogramm immer Methoden enthalten, die das prozedurale
Wissen fordern, wie z.B. Fallstudien und Übungsaufgaben. Der Lernende sollte auch möglichst oft
über die Anwendungsmöglichkeiten des gelernten Wissens informiert werden.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
31
Wir beschreiben drei grundlegende Lernformen: formelles, entdeckendes und beiläufiges Lernen.
Formelles Lernen findet in Situation statt, wo der Lernprozess gezielt geplant und gestaltet wird (z.B.
das Lernen im Klassenzimmer während einer Übungsstunde). Entdeckendes Lernen (engl. exploratory
learning) wird durch den Lernenden selbst gesteuert. Statt alle relevanten Informationen fertig
strukturiert zu bekommen, muss der Lernende wichtige Informationen selbst finden und neu ordnen,
bevor er daraus Regeln ableiten und Probleme lösen kann [12]. Beiläufiges Lernen (engl. learning by
doing) findet (oft unbemerkt) in alltäglichen Situationen des Lebens statt, ganz nebenbei während der
gewöhnlichen Tätigkeiten.
3.3. Lernparadigmen
Im Laufe – der Jahrhunderte währende – Anwendung der Didaktik entstanden zahlreiche
Methoden des Lernens. Die ersten bedeutenden Ansätzte führen sogar bis zum Zeitalter der Griechen
in der Antike und den Erkenntnissen solcher großen Philosophen wie Sokrates, Plato oder Aristoteles.
Wir sprechen z.B. von der sokratischen Methode, die Wissen durch intensive Fragestellung fördert.
Die gegenwärtige Erziehungswissenschaft unterscheidet drei grundlegende lerntheoretische
Paradigmen: Behaviourismus, Kognitivismus und Konstruktivismus [35] [45]. Jedem dieser Ansätze
ist eine Reihe von Theorien zugeordnet.
3.3.1. Behaviourismus
Das behaviouristische Konzept besagt, dass das Lernen durch Anpassung an äußere Reize
geschieht (Reiz-Reaktions-Modell19). Man betrachtet nicht die Prozesse, die in der Kognition des
Lernenden stattfinden, sondern lediglich die Endreaktion des Lernenden auf vorgegebene
Informationen20. Die möglichst schnelle Bestätigung der korrekten Antwort (oder Bestrafung der
falschen) verstärkt die richtige Reaktion des Lernenden. Das Lernziel ist nur das Erreichen der
richtigen Reaktion, nicht das Verständnis des gelernten Lernstoffs. Das zu Lernende teilt man in
möglichst kleine Informationsportionen, die man schnell abfragen kann. Die Rolle des Lehrenden
besteht vor allem in der Beurteilung der Korrektheit der Antworten des Lernenden. Das
behaviouristische Konzept eignet sich gut zum Einüben von automatischen Vorgängen
(psychomotorisches Wissen oder z.B. das Erlernen von Vokabeln einer Fremdsprache) [45]. Ein
Bespiel für die praktische Realisation der Ansätze des Behaviourismus ist die Callan-Methode des
Englischunterrichts [80]. Ein Callan-Lehrbuch besteht ausschließlich aus Fragen und Antworten auf
diese Fragen. Während des Unterrichts liest der Lehrende die in dem Buch stehenden Fragen vor, und
19 Grundlagen für dieses Lernparadigma waren u.a. die Arbeiten von I.P. Pawlow (berüchtigte Pawlows Hunde). Einer der
Einflussreichsten der behaviouristischen Schule war der Psychologe B.F. Skinner in den Fünfzigerjahren des vergangenen
Jahrhunderts. 20 Sowohl Behaviourismus wie auch Kognitivismus basieren übereinstimmend mit der objektivistischen Sichtweise.
Objektivismus besagt, dass es bloß eine einzige korrekte, vollständige, extern und objektiv existierende Form der Wahrheit
gibt. Konstruktivismus dagegen geht von der Annahme aus, es gäbe keine objektive Wahrnehmung von Realität.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
32
der Lernende muss so schnell wie möglich eine grammatisch korrekte21 Antwort geben. Der wichtigste
Kritikpunkt an der behaviouristischen Sichtweite des Lernens ist, dass man komplexe Fähigkeiten
nicht übermitteln kann, ohne einen Einblick in die Denkweise des Lernenden zu haben [45]. Des
Weiteren werden die individuellen Eigenschaften des Lernenden während des Lehrprozesses nicht
berücksichtigt. Trotz dieser Kritikpunkte ist die Mehrzahl der heutzutage verfügbaren Lernprogramme
überwiegend nach behaviouristischen Prinzipien gestaltet [12].
3.3.2. Kognitivismus
Im Kognitivismus22 spielen die Denk- und Verstehensprozesse des Lernenden eine zentrale Rolle.
Bildung wird als Internalisierung des Wissens, z.B. durch den Aufbau mentaler Modelle, verstanden
[12]. Im Gegensatz zum Behaviourismus wird der Lernende nicht nur durch einfache, vorgefertigte
Information gesteuert, sondern muss die aufgenommenen Informationen selbst strukturieren, mit
vorhandenem Wissen vergleichen und es entsprechend in neues Wissen umwandeln. Der Lehrende
soll dem Lernenden bei der richtigen Auswahl der wichtigen Informationen helfen, indem er die
Lehrmaterialien an den Lernenden (dessen Denkweise und Vorwissen) anpasst. Genauso wie im
behaviouristischen Ansatz gehört zu den Pflichten des Lehrenden auch die Verifikation und Korrektur
des Wissens des Lernenden.
3.3.3. Konstruktivismus
Der Konstruktivismus23 verwirft das Konzept der Existenz einer objektiven Wahrheit, die der
Lehrer während des Lernprozesses dem Lernenden übermitteln kann. Das Wissen erzeugt der
Lernende selbst durch interne subjektive Konstruktionen von Ideen [12]. Externe Informationen
dienen nur als Anregung zur Bildung der eigenen Anschauung [45]. Anders als in den vorigen
Ansätzen kann die Formulierung der Problemstellung schon selbst Ziel des Lernprozesses sein. Im
Konstruktivismus verliert der Lehrende die autoritäre Rolle. Seine Aufgabe wird vielmehr als die eines
Trainers gesehen, der dem Lernenden nur eine motivierende Umgebung zur selbstständigen Suche
nach Wissen bereitstellt. Diese Lernmethode eignet sich gut zur Auffassung von komplizierten und
bislang nicht gründlich erforschten Wissensgebieten.
3.4. E-Learning im Detail
Den Zusammenhang des E-Learnings mit anderen gängigen Begriffen aus den modernen
Bildungstechnologien zeigt die Abbildung 3-1. Technology-based Training, das in mancher Hinsicht
als Oberbegriff für E-Learning gesehen werden kann, bezeichnet alle Lerntechnologien, die auf
irgendwelche Weise moderne Informations- und Kommunikations-Geräte [4] benutzen. Der
Unterschied zu E-Learning ist, dass man mit dem Namen Technology-based Training auch
traditionelle Präsenzveranstaltungen bezeichnet, für die man z.B. Beamer oder Smartboards benutzt.
21 Es muss nicht unbedingt die Antwort sein, die in dem Buch steht 22 Der führende Vertreter des Kognitivismus ist J.Piaget 23 Einer der Gründer des Konstruktivismus war der italienische Philosoph Giambattista Vico

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
33
Blended Learning ist eine hybride Lernform, die eine Kombination aus Präsenzveranstaltungen und E-
Learning-Szenarios ist [50].
BlendedLearning
Technology-based Training
E-Learning
Distance Learning
WBTCBT
Abbildung 3-1 Begriffslandkarte, in Anlehnung anI [4]
Distance Learning ist ein recht alter24 Begriff und bedeutet Lernen in Situationen, wo den
Lernenden und den Lehrenden weite Entfernungen voneinander trennen. Die traditionelle
Kommunikationsmethode des Distance Learning (Briefe) wird heutzutage weitgehend modernisiert
und durch solche Technologien wie E-Mails, Chats, Whiteboards, Videokonferenzen und virtuelle
Klassenzimmer ersetzt. Distance Learning kann man, meiner Meinung nach, nicht als Unterbegriff für
E-Learning halten, denn die Verwendung von elektronischen Mitteln ist für diese Lehrform nicht
notwendig.
WBT (Web-Based-Training) bedeutet das Lernen über Netzumgebungen wie Internet oder
Intranet. CBT (Computer-Based-Training) sind computerbasierte Lernmethoden (z.B. Multimediale
Lernprogramme auf CD-ROM), die offline stattfinden. CBT kann nur statische Inhalte anbieten
(gebrannt auf CD-ROM oder DVD), im Gegensatz dazu können die WBT Materialien ständig
aktualisiert und ergänzt werden. Sowohl WBT wie auch CBT können interaktive Elemente beinhalten,
wobei nur WBT direkte Kommunikationsmöglichkeiten unter den Lernenden und zwischen dem
Lernenden und Lehrenden ermöglicht. Der Vorteil des CBT sind keine Einschränkungen aufgrund der
begrenzten Bandbreite der Übertragung von Daten. CBT Systeme können daher deutlich mehr
multimediale Materialien (wie Videofilme) beinhalten25.
3.4.1. St. Galler E-Learning-Referenzmodell
Das St. Galler E-Learning-Referenzmodell (Abbildung 3-2) wurde als Versuch der Ordnung und
Strukturierung der Begriffe des E-Learning entwickelt.
24 Die Geschichte des Distance Learning (von manchen auch D-Learning bezeichnet) begann in der zweiten Hälfte des
19.Jahrundert, zeitgleich mit der Industriellen Revolution. Die Erfindung der Bahn ermöglichte einen schnellen Transport der
Lehrmaterialien auf weite Entfernungen [40] 25 Man muss aber anmerken, dass bei den wachsenden Übertragungsgeschwindigkeiten der modernen Netze dieser
Unterschied immer mehr verwischt.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
34
E-Learning-Strategie
Prozesse und Methoden
Technologien und Systeme
E-Learning-Systeme
Lerntechnologien
Basistechnologien
Lernarchitektur
Lernraum
Lernprozesse
Management derVeränderung
Abbildung 3-2 St. Galler E-Learning-Referenzmodell, in Anlehnung an [4]
Das Modell gliedert sich in vier Ebenen auf [8]:
• Technologien und Systeme
• Prozesse und Methoden
• E-Learning-Strategie
• Management der Veränderungen
Die Ebene der Technologien und Systeme bezieht sich auf Beschaffung, Integration und Betrieb
von Basistechnologien, Lerntechnologien und E-Learning-Lernsystemen.
Unter Basistechnologien verstehen wir einfache Informations- und Kommunikationstechnologien,
die im E-Learning angewandt werden können, aber von E-Learning grundsätzlich unabhängig sind.
Dazu zählen wir z.B. E-Mail, Chat, Diskussionsforen, Suchmaschinen, Hypermediasysteme,
Technologien des Semantic Webs.
Bei den Lerntechnologien handelt es sich um Technologien, die speziell für den E-Learning-
Lernbereich entwickelt wurden. Beispiele von Lerntechnologien sind: Virtuelles Klassenzimmer,
Interaktives Whiteboard, Business TV.
E-Learning-Systeme bezeichnen eine konkrete Problemlösung im Lernbereich, die außer der
Technologie zusätzlich noch Lernstoff und didaktische Methoden und Konzepte zur Übermittlung des
Wissens beinhaltet. E-Learning-Systeme werden aus Basis- und Lerntechnologien zusammengesetzt
und ergänzt durch Konzepte aus den drei anderen Ebenen des St. Galler Referenzmodells. Komplexe
E-Learning-Systeme können selbst einfachere E-Learning-Systeme beinhalten. Beispiele von E-
Learning-Systemen sind konkrete CBT- oder WBT-Applikationen, wie z.B. (ADE → 5.4.1).

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
35
Die Ebene der Prozesse und Methoden definiert die Lernmaßnahmen des E-Learnings. Die
Ebene gliedert sich in drei Unterebenen auf: Lernprozesse, Lernraum und Lernarchitektur.
Lernprozesse bilden die unterste Gestaltungsebene der Lernmaßnahmen und beinhalten
Methoden, aus denen komplexere Lernszenarien entwickelt werden. Beispiele von Lernprozessen sind
E-Training26 (wo es um individuelle Vermittlung von Wissen geht), E-Collaboration (wo der
Wissensaustausch in der Gruppe im Vordergrund steht) und JIT-E-Learning27 (wo der Lernende bei
Ad-hoc-Lernbedarf direkt am Arbeitsplatz mit Informationen versorgt wird) [8].
Ein Lernraum umfasst alle Lernmaßnahmen in Bezug auf spezielle Zielgruppen oder eine
bestimmte Thematik. Ein Lernraum verschachtelt mehrere Lernprozesse. Beispiele zur Gestaltung von
Lernräumen sind nach [4]: kompetenzorientiertes Lernen (Lernen gerichtet auf den Erwerb und die
Anwendung einer bestimmten Kompetenz), supportorientiertes Lernen (Lernen, bei dem die
Unterstützung des Lernenden durch einen Lehrer als sehr wichtig gesehen wird),
mitgestaltungsorientiertes Lernen (wo der Lernende viele Parameter des Lernprozesses selbst
bestimmen kann) und anwendungs- und arbeitsplatzorientiertes Lernen (Ausrichtung des Lernraumes
auf konkrete Probleme und Bedürfnisse des Arbeitsalltags).
Die Lernarchitektur vernetzt Lernräume untereinander und orientiert sich an der E-Learning-
Strategie. Die Lernarchitektur wird nur für große Bildungssysteme aufgestellt.
Die E-Learning-Strategie-Ebene definiert die E-Learning-Politik in der Organisation, in der das
E-Learning-Programm eingesetzt wird. In Unternehmen ist es wichtig, die E-Learning-Strategie mit
anderen Strategien der Organisation (wie z.B. der Personalstrategie) abzugleichen. In der Strategie
werden sowohl aktuelle wie auch zukünftige Entwicklungen des E-Learnings berücksichtigt.
Die Ebene des Managements der Veränderung umfasst Elemente des Projektmanagements, die
mit der Weiterentwicklung des Systems in Zusammenhang stehen.
3.5. Technologien des E-Learnings
Im folgenden Unterkapitel werden einige der Basis- und Lerntechnologien kurz vorgestellt. Aus
Platzgründen ist es nicht möglich, im Rahmen meiner Diplomarbeit, alle möglichen Technologien des
E-Learnings zu beschreiben. Daher wurde willkürlich aus den im Punkt 3.4.1 genannten Beispielen je
ein Repräsentant für Basistechnologie (Diskussionsforum) und Lerntechnologie (Virtuelles
Klassenzimmer) charakterisiert. Die zwei gezeigten Begriffe unterscheiden sich voneinander auch
dadurch, dass die erste Technologie eine asynchrone und die zweite eine synchrone
Kommunikationstechnologie ist.
Die Prinzipien der Semantic Web-Basistechnologie wurden wegen der Relevanz dieses
Ansatzes für die MAESTRO-Architektur in einem getrennten Kapitel besprochen (→ Kapitel 4).
26 E-Training gliedert sich nach [4] in folgende Unterarten auf: E-Tutorials, E-Assignments, E-Discussions und E-
Simulations 27 JIT-E-Learning = Just-in-time-E-Learning

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
36
3.5.1. Diskussionsforum
Ein Diskussionsforum ist laut Internetlexikon Wikipedia [131] ”eine Kommunikations-Plattform
und ein Platz zum Austausch von Gedanken und Erfahrungen” Die Kommunikation in einem
Diskussionsforum findet asynchron, das heißt, nicht in Echtzeit, statt. Die Foren sind meistens einem
bestimmten Thema bewidmet (z.B. Mountainbiking oder Technologien verbunden mit der Java-
Programmiersprache) und können sich auf weitere Unterforen (Kanäle) gliedern. Um die Beiträge der
Teilnehmer der Foren zu ordnen, werden mehrere Aussagen zum selben Thema zu einem Thread
(Faden) oder Topic (Thema) zusammengefasst. Häufige Beispiele von Foren sind so genannte
Hilfsforen, in denen sich Benutzer einander bei verschiedenen technischen Problemen helfen. Die
meisten Foren sind frei zugänglich, es gibt jedoch auch eine Gruppe von kommerziellen Systemen
(z.B. Hilfeforen der Softwarehersteller zu ihren jeweiligen Produkten). Viele Foren unterscheiden
zwischen verschiedenen Benutzerrollen, zum Beispiel gewöhnlichen Forennutzern und
Administratoren, die die Diskussion moderieren können. Es gibt verschiedene Arten von
Diskussionsforen: WebForen, BBS, Usenet, Mailinglisten28.
Wenn man das Diskussionsforum im St.Gallen Referenzmodell betrachtet, so kann man sagen,
dass es ein klassisches Beispiel von einer Basistechnologie zur Gestaltung von E-Collaboration-
Lernprozessen ist. Die Primäranwendung von Diskussionsforen ist allgemein und nicht unbedingt mit
Lernen verbunden. Man kann sich jedoch leicht spezielle Foren vorstellen, in denen die Lernenden
gegenseitig ihre Erfahrungen in dem gelernten Wissensgebiet austauschen und sich gegenseitig bei
Problemen Hilfe leisten können. Der Lehrende kann auch Teilnehmer der Diskussionen werden, was
für die Lernenden eine zusätzliche Hilfe sein kann. Der Lehrende kann vom Einsatz der
Diskussionsforen auch profitieren, denn die einfachen Fragen können die Studenten unter sich klären,
was zur Entlastung der Sprechstunden führen kann. Möglich sind auch Foren, in denen eine Gruppe
Studenten zu didaktischen Zwecken kollaborativ ein Problem löst.
3.5.2. Virtuelles Klassenzimmer
Das Virtuelle Klassenzimmer ist eine synchrone E-Learning-Technologie der Übertragung des
Unterrichts in der Situation, wo die Lernenden vom Lehrenden durch eine bedeutende räumliche
Entfernung getrennt sind. Zur Ausstattung eines virtuellen Klassenzimmers gehören Webcams und
Mikrophone zur Übertragung vom Bild und Ton aus den Standorten, wo der Unterricht stattfindet.
Bestandteil von vielen virtuellen Klassenzimmern ist das interaktive Whiteboard. Das interaktive
Whiteboard (auch Smartboard genannt) ist eine Lerntechnologie der synchronen Übertragung von
Zeichenflächen zu mehren Orten gleichzeitig [33]. Es gibt verschiedene Varianten von Whiteboards.
Die einfachste Version ermöglicht, ähnlich wie eine traditionale Tafel, das Schreiben, Zeichnen von
einfachen Bildern und Löschen der virtuell beschriebenen Fläche. Komplexere Lösungen ermöglichen
zusätzlich z.B. das Anzeigen von derselben Power Point-Präsentation in verschiedenen Standorten
zugleich.
28 Details zu den einzelnen asynchronen Kommunikationsmechanismen des Internets findet der Benutzer u.a. in [131]

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
37
Abbildung 3-3 Multimedia-Hörsaal an der TU Clausthal
Die Abbildung 3-3 zeigt ein virtuelles Klassenzimmer an der TU-Clausthal. Dank der
Zusammenarbeit im Rahmen des ELAN-Projektes können die Studenten aus Clausthal virtuell an
manchen Vorlesungen der Universität Göttingen (und vice versa) teilnehmen.
3.6. E-Learning-Plattformen
Eine E-Learning-Plattform ist ein System, das es ermöglicht, innerhalb einer Organisation
(Unternehmen, Hochschule) ein virtuelles Bildungszentrum aufzubauen. Zu den Kernfunktionen einer
E-Leraning-Plattform gehören (laut [50]):
• Verwaltung von E-Learning-Angeboten
• Verwaltung von jeglicher Art von Lernmedien
• Verwaltung von Anwendern
Viele Lernplattformen bieten darüber hinaus unterschiedliche Kommunikationsmethoden und
Suchfunktionen, wie auch separate Arbeitspeicher für jeden Lernenden. Man kann sagen, dass eine E-
Learning-Plattform einen schnellen Aufbau der Ebene der Technologien und Systeme des St. Galler
Referenzmodells (→3.4.1) ermöglicht. Zu den bekanntesten E-Learning-Plattformen gehören: WebCT
[129], Blackboard [79], TopClass e-Learning Suite [125] sowie IBM Lotus Learning Management
System29 [98]. Einen detaillierten Vergleich der Funktionen der populären E-Learning-Plattformen
findet der Leser unter [83] [85] [130]. Im folgenden Punkt möchte ich kurz eine der Plattformen
vorstellen. Meine Wahl fiel auf WebCT, weil diese Plattform oft an den Universitäten eingesetzt wird
(z.B. [34]).
29 IBM Lotus Learning Management System ist Nachfolger der Lotus LearningSpace E-Learning-Plattform
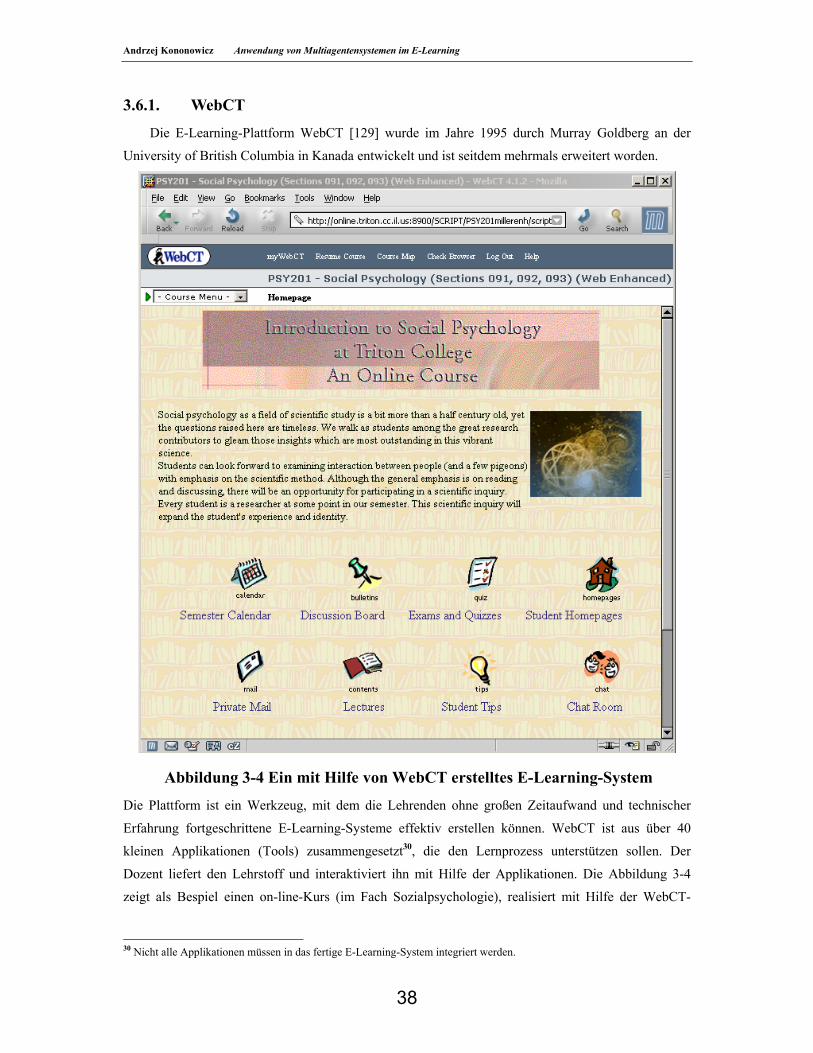
Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
38
3.6.1. WebCT
Die E-Learning-Plattform WebCT [129] wurde im Jahre 1995 durch Murray Goldberg an der
University of British Columbia in Kanada entwickelt und ist seitdem mehrmals erweitert worden.
Abbildung 3-4 Ein mit Hilfe von WebCT erstelltes E-Learning-System
Die Plattform ist ein Werkzeug, mit dem die Lehrenden ohne großen Zeitaufwand und technischer
Erfahrung fortgeschrittene E-Learning-Systeme effektiv erstellen können. WebCT ist aus über 40
kleinen Applikationen (Tools) zusammengesetzt30, die den Lernprozess unterstützen sollen. Der
Dozent liefert den Lehrstoff und interaktiviert ihn mit Hilfe der Applikationen. Die Abbildung 3-4
zeigt als Bespiel einen on-line-Kurs (im Fach Sozialpsychologie), realisiert mit Hilfe der WebCT-
30 Nicht alle Applikationen müssen in das fertige E-Learning-System integriert werden.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
39
Technologie. Die auf dem Bild sichtbaren Ikonen sind Verweise auf die oben erwähnten
Applikationen. In der Tabelle 3-1 sind einige der verfügbaren WebCT-Tools beschrieben [95].
Name der Applikation Beschreibung Discussion Board Implementation eines Diskussionsforums (→3.5.1), das sich mit
Themen verbunden mit der Lerneinheit befasst.
Student Tips Erlaubt den Kursleitern, spezielle Tipps für die Studenten im Kurs zu
schreiben.
Progress Beinhaltet Informationen über die Benutzung des Kurses durch den
Studierenden. Hier kann man sich informieren, welche Seiten man
schon gesehen hat und welcher Teil des Kurses schon absolviert wurde.
Compile Bietet den Studenten die Möglichkeit, mehrere oder alle Seiten des
Kursmaterials in ein langes Dokument zusammenzufassen (z.B. für den
Ausdruck).
Exams and Quizzes Erlaubt die Durchführung von Examen und Tests im Internet. Diese
Option beinhaltet auch die Ergebnisse und Statistiken der
durchgeführten Examen und Tests. Bei Mathematikaufgaben steht dem
Lernenden ein spezieller, in Java geschriebener Editor zur Verfügung,
womit der Lernende Formeln eingeben kann. Es existiert auch eine
separate WebCT-Tools-Applikation, die das Durchführen von Self-
Tests ermöglicht, das heißt Test, deren Ergebnisse dem Lehrenden nicht
zur Bewertung geschickt werden.
CD-ROM Ermöglicht dem Lehrenden bei besonders speicherbedürftigen
Lernmaterialien, sie auf CDs zu brennen, die man später unter den
Studenten aufteilt. Der Inhalt der CD wird auf dem Rechner des
Studenten mit dem on-line-Kurs integriert.
Tabelle 3-1 Einige der WebCT Tools
Außer den allgemein zugänglichen Applikationen gibt es auch eine Reihe von Authoring-Tools für die
Kursleiter, die die Vorbereitung der Lernmateriallien unterstützen sollen (z.B. File Manager, Student
Manager, Course Backup Tool).
3.7. Ausgewählte Beispiele von E-Learning-Aktivitäten
Die Bildungsministerien fast aller Staaten, Hochschulleiter, wie auch die Führungskräfte
zahlreicher Unternehmen haben das Potenzial des E-Learnings erkannt und entsprechende Programme
zur Förderung dieser Lernform gebildet. Über das Ausmaß des Trends zeugt die Tatsache, dass schon
im Jahre 2000 75% der amerikanischen Universitäten unterschiedliche Lernkurse durch Internet
anboten [109]. Aus der großen Menge der E-Learning-Unternehmen habe ich nur die Aktivitäten in

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
40
Deutschland und in meinem Heimatland Polen betrachtet und daraus repräsentativ drei Beispiele kurz
charakterisiert.
3.7.1. ELAN Niedersachsen
ELAN-Niedersachsen (E-Learning Academic Network) [86] ist ein von dem Ministerium für
Wissenschaft und Kultur des Landes Niedersachsen gefördertes Programm zur Unterstützung des
Einsatzes von neuen (multimedialen) Technologien in Lehre, Studium und Weiterbildung. Dieses Ziel
soll durch den Ausbau eines E-Learning-Netzwerkes in Niedersachsen geschehen. Die Teilnehmer des
Programms werden in drei Kategorien eingeteilt:
• Netz-Piloten, die die Rahmenbedingungen und Infrastrukturen für das Netzwerk festlegen und
dafür vom Land finanziell besonders gefördert sind,
• Netz-Träger, die das Netzwerk nach Absprache mit den „Netz-Piloten“ ausbauen
• Netz-Partnern, die die Leistungen des Netzwerkes nutzen und gegebenenfalls bei Lücken, in
den durch den „Netz-Piloten“ und „Netz-Träger“ abgedeckten Bereichen, eigene Leistungen
in das Netzwerk einbringen.
Grund für die Entstehung des Netzwerkes ist die Integration von Lernangeboten aus
verschiedenen Hochschulen. Der Studierende soll durch die Verbindung mit dem ELAN-Netz zeit-
und ortsunabhängig lernen können. Dank eines Systems von Kreditpunkten werden dem Studierenden
Leistungen, die er auf einer anderen Hochschule des ELAN-Projektes vollbracht hat, an dem
Studienort anerkannt.
Das Land Niedersachsen hat drei „ELAN-Piloten“ gewählt: Uni Oldenburg/Osnabrück, Uni und
MH Hannover/TU Braunschweig und Uni Göttingen/TU Clausthal. Ein Schwerpunkt des „ELAN-
Piloten“ Uni Göttingen/TU Clausthal ist der Aufbau eines „Lehrverbundes Informatik“. In Rahmen
dieser Zusammenarbeit können die Studierenden aus Clausthal und Göttingen mit Hilfe eines
virtuellen Klassenzimmers (Abbildung 3-3, →3.5.2) an manchen Vorlesungen der Partneruniversität
virtuell teilnehmen. Die Vorlesungen werden aufgezeichnet und stehen dem Studierenden beliebig zur
Verfügung.
3.7.2. Fernuniversität Hagen
Die Fernuniversität Hagen (gegründet 1974) ist eine der ersten deutschen Universitäten, für das
s.g. Fernstudium. Die Hochschule bietet Diplom-, Bachelor- und Master-Studiengänge in 6
Fachbereichen (Elektrotechnik, Informatik, Kultur- und Sozialwissenschaften, Mathematik,
Rechtswissenschaft und Wirtschaftswissenschaft) an. Das Fachwissen wird durch Studienbriefe,
Übungsaufgaben, interaktive CD-ROMs, Audio- und Videokassetten und immer häufiger auch über
das Netz erworben. An der FU Hagen sind zurzeit 55000 Studierende immatrikuliert, die durch 77
Professoren und 395 wissenschaftliche Mitarbeiter betreut werden. Das Durchschnittsalter der
Studenten ist 29 Jahre. Die meisten davon (80%) sind berufstätig, 40% haben bereits ein Studium an
einer anderen Hochschule erfolgreich abgeschlossen. An der FU Hagen werden auch

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
41
wissenschaftliche Arbeiten durchgeführt. Der Schwerpunkt der Forschung liegt im Bereich der
Anwendung „Neue Medien“.
3.7.3. Polski Uniwersytet Wirtualny
Polski Uniwersytet Wirtualny31 (PUW) [109] ist eine gemeinsame Initiative der Maria Curie-
Skłodowska Universität in Lublin und der Hochschule für Humanistik und Ökonomie in Łódź. An
dieser virtuellen Hochschule kann man in einer von vier Fakultäten (Verwaltung und Marketing,
Informatik, Politologie und Krankenpflege) studieren. Das Studium dauert 6-7 Semester. Jedes der
Semester besteht aus zwei Halbsemestern. In jedem Halbsemester muss der Student 3
Lehrveranstaltungen absolvieren. Die Studenten der PUW sind in Gruppen von 20 Personen aufgeteilt,
die wiederum in 4 Personen große Arbeitsgruppen gegliedert sind. Der Student bekommt Aufgaben,
die in der Arbeitsgruppe zu lösen sind, und auch individuelle Fragen und Aufgaben zur
selbstständigen Ausarbeitung. Die Basistechnologie für die PUW bildet die E-Learning-Plattform R5
Generation. Die Studenten benutzen bei ihrer Arbeit u.a. Diskussionsforen, Chats, Whiteboards, wie
auch spezielle elektronische Verzeichnisse, wo sie ihre fertigen Arbeiten abgeben können. Der
Lehrende bewertet die Arbeit der Lernenden anhand der abgegebenen Materialien, der Aktivität des
Lernenden in Diskussionsforen und auch eines Abschlusstests. Examen und Klausuren werden
traditionell (so wie in der Präsenzlehre) durchgeführt.
3.7.4. Zusammenfassung der gebrachten Beispiele
Aus der großen Anzahl der Lernenden in den virtuellen Studiengängen (z.B. FU Hagen) kann
man schließen, dass ein großer Bedarf an E-Learning-Diensten besteht. Die Vielfalt der Lernmethoden
(z.B. Polski Uniwersytet Wirtualny), unterstützt durch Förderungen der für die Bildung zuständigen
Behörden (z.B. ELAN Niedersachen), lässt vermuten, dass sich das Konzept des Einsatzes neuer
Technologien in der Bildung weiterhin positiv entwickeln wird.
3.8. Warum E-Learning?
Lernen wird oft zu Unrecht ausschließlich mit dem Schulalter verbunden. Tatsächlich lernt man
sein Leben lang. Einer der Gründe, weshalb man besondere Achtung auf die persönliche
Weiterbildung legen sollte, ist der Alterungsprozess des Wissens. Wie man in der Abbildung 3-5
sehen kann, wird nach 20 Jahren 50% unseres Schulwissens veraltet sein. Bei Hochschulwissen,
beruflichem Fachwissen und technischem Wissen geschieht der Prozess noch schneller. Ein
Extremfall ist hier das EDV-Wissen – nach fünf Jahren ohne Weiterbildung ist das Wissen praktisch
nutzlos.
Aus dem oben genannten Grund organisieren Unternehmen Schulungen, die die Angestellten auf
den neusten Stand des Wissens bringen sollen. Das Präsenzstudium bringt jedoch für den Arbeitgeber
Nachteile, vor allem das Fehlen des Personals am Arbeitplatz. Eine gute Lösung bietet hier E-
31 Polski Uniwersytet Wirtualny (pol.) – Polnische Virtuelle Universität

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
42
Learning. Wie die durch Harhoff und Küpper durchgeführte Befragung [30] zeigt, ist die
Verfügbarkeit des Personal der größte erhoffte Vorteil bei der Einführung des E-Learning gegenüber
Präsenzveranstaltungen. Die Anwendung der E-Learning-Technologie spart Zeit und fördert das
Selbstlernen. Früher galt die Kosteneinsparung als wichtiges Argument für E-Learnig (in [30] auf
vierter Stelle gesetzt). Die neuesten Umfragen bezüglich der praktischen Realisation des E-Learning in
Unternehmen haben jedoch gezeigt, dass dies nicht unbedingt der Fall ist32. Die anderen potenziellen
Vorteile des E-Learning (die aber in der Studie [30] nicht gut bewertet wurden) sind die schnellere
Aktualisierbarkeit der Lernmaterialien und erhöhte Qualität des Lernens.
Unternehmen sind nicht die einzigen Nutzer des E-Learning-Angebots. Die zeitliche und
räumliche Freiheit („überall und zu jeder Zeit“), die das E-Learning mit sich bringt, bietet eine Chance
für Menschen, die bislang wenige Möglichkeiten zur Weiterbildung hatten. Zu dieser Gruppe gehören
schwer Kranke und Behinderte, Eltern auf Erziehungsurlaub, Arbeitslose, Rentner und Berufstätige,
deren Arbeitgeber keine entsprechenden Schulungen ermöglichen.
Abbildung 3-5 Alterung von Wissen [45]
E-Learning kann auch bedeutende Vorteile für die traditionellen Hochschulen bringen [42]. Viele
Lehrveranstaltungen an den Universitäten sind überfüllt, und daher ist die Möglichkeit, die
Veranstaltung interaktiv zu gestalten, sehr begrenzt. Die verschiedenen interaktiven Technologien des
E-Learning, gedacht als Ergänzung zum Präsenzstudium, erlauben, diese Mängel zu minimieren. Die
Studierenden beginnen die Lehrveranstaltungen mit unterschiedlichen Vorkenntnissen. Die Dozenten
konzentrieren sich während der Vorlesungen lieber auf neue und komplexe Sachverhalte, als die Zeit
für Wiederholungen zu vergeuden. Durch E-Learning können die Studenten das fehlende Wissen
schnell selbstständig nachholen. In den heutigen Zeiten, wo der Haushalt für die Hochschulen ständig
gekürzt wird, könnten gut realisierte E-Learning-Systeme zusätzliche Einnahmequellen für die
Hochschulen bedeuten.
32 Das Wegfallen dieses Argumentes war einer der wichtigsten Gründe für die Ernüchterung nach der anfänglichen Euphorie
auf dem Markt der E-Learningsysteme.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
43
3.9. Nachteile des E-Learning
Nach dem anfänglichen Boom bei der Einführung des Konzeptes des E-Learnings, kam die
Ernüchterungsphase. Die hohen (oft überschätzten) Kosten der Realisation der E-Learning-Systeme,
die Überdosis an ablenkenden Multimedia und fehlende Lehrkonzepte haben viele zu der Ansicht
gebracht, dass E-Learning nur eine Zeitverschwendung ist.
Zu den Nachteilen des E-Learning gehört auch die begrenzte Auswahl an Themen der realisierten
Systeme [50]. Nicht alle Wissensbereiche lassen sich gut „computerisieren“. Die E-Learning-
Methoden setzen einen immer höheren Grad an interner Motivation des Lernenden zum Eigenstudium
voraus, was nicht immer der Fall ist. Nicht alle Lernenden verfügen über eine unbeschränkte
Netzverbindung. Der freien Zugänglichkeit und dadurch großen Vielfalt der E-Learning-Angebote
stehen die Urheberrecht-Fragestellungen im Wege. Die besten Bildungszentren wollen aus
Konkurrenzgründen ihre Lehrangebote nicht freigeben (das gilt auch für öffentliche Hochschulen)
[42].
Aus den oben genannten Gründen stießen die E-Learning-Ansätze immer wieder auf mangelnde
Akzeptanz bei den auszubildenden Angestellten und Führungskräften in Unternehmen, wie auch
relativ geringe Interessen bei den Studenten. Die zusätzlich andauernde Tiefkonjunktur in der IT-
Branche und finanzielle Probleme der Hochschulen führten dazu, dass in vielen Betrieben und
manchen Hochschulen die Arbeiten an E-Learning-Systemen eingestellt wurden.
3.10. Zusammenfassung
In diesem Kapitel habe ich mich mit dem Begriff E-Learning auseinandergesetzt. Ich habe
festgestellt, dass man damit die Methoden der Lehre mit Hilfe elektronischer Medien bezeichnet. Ich
habe betont, dass E-Learning nicht nur computerunterstützte Übertragung der Lernmaterialien ist,
sondern auch didaktische Methoden und Konzepte beinhalten muss. Um dem Leser einen Einblick in
die Lernmethoden zu geben, habe ich die klassischen Ansätze der Didaktik vorgestellt. Weitere
wichtige Aspekte des E-Learning sind Strategien der Weiterentwicklung der E-Learning-Systeme
sowie Methoden zur Verwaltung der Veränderungen. Alle diese Aspekte ordnet der das vorgestellte
St. Galler Referenz Modell. Im weiteren Verlauf des Kapitels charakterisierte ich kurz ausgewählte E-
Learning-Technologien und beschrieb einige E-Learning-Aktivitäten an deutschen und polnischen
Hochschulen. Zum Schluss des Kapitels fasste ich die wichtigsten Vor- und Nachteile des E-Learnings
zusammen.
Zu den größten Stärken der neuen Lernform gehört, meiner Ansicht nach, die Ermöglichung der
Lehre zu jeder Zeit an (fast) jedem Ort. Diese Technologie hat das Potential, das Konzept des
lebenslangen Lernens effektiv und zielgerichtet zu gestalten. Zu den bedeutendsten Schwächen des E-
Learnings würde ich dagegen den erheblichen Zeit- und Kostenaufwand der Vorbereitung von
hochwertigem Lernmaterial zählen. Die Unterschätzung dieses Aufwandes ist die wichtigste Ursache
der Misserfolge vieler E-Learning-Systeme.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
44
4. Grundlagen des Semantic Web
Wie ich schon im Abschnitt 3.5 kurz angedeutet habe, können die Technologien des Semantic
Web zur Realisation von E-Learning-Systemen angewandt werden. Dieses Kapitel schildert die
Grundrisse des Semantic Web Projekts.
4.1. Einführung
Die Menge der im Internet gesammelten Daten hat schon lange alle anfänglichen Erwartungen
übertroffen. Um in dieser Flut von Informationen die gesuchten Daten zu finden, entwickelte man
spezielle Internet-Suchmachinen (wie z.B. Google, Yahoo, AltaVista). Trotz großer Popularität haben
diese Dienste wesentliche Nachteile. Zu den wichtigsten Mängeln zählt die relativ geringe Qualität der
gelieferten Ergebnisse. Außer der geforderten Information erhalten wir sehr viele Verweise zu
Internet-Beständen, die uns überhaupt nicht interessieren. Dieser Effekt lässt sich leicht damit
erklären, dass die Suchmaschinen in ihren Recherchen nur auf dem einfachen Vergleich von
Zeichenketten basieren, ohne auf die Bedeutung der Begriffe schließen zu können.
Das oben genannte Problem soll das Semantic Web Projekt lösen [67]. Das Konzept wurde von
Tim Berners-Lee [10], dem Erfinder des WWW, vorgeschlagen und wird von dem W3C-Konsortium
[128] gefordert. Das Semantic Web soll die Nützlichkeit des Internets steigern. Der Benutzer wird
weniger Zeit gebrauchen, um wichtige Informationen vom unbrauchbaren Material zu trennen. Das
gegenwärtige Web kann man sich als großes Buch vorstellen. Nach der globalen Einführung des
Semantic Web wird es mehr einer globalen Datenbank ähneln. Dieses Ziel soll durch ein einheitliches
System der Beschreibung von Beständen (Metadaten) des Internets erreicht werden. Web-Entwickler,
die mit dem Semantic Web-Standard arbeiten, definieren ihr eigenes Vokabular oder benutzen
vorgefertigte Sammlungen von Begriffen (auch Ontologien genannt) womit sie Internetseiten (oder
nur ihre Abschnitte), wie auch andere im Web publizierte Bestände erläutern können. Die
Beschreibung kann automatisch von den Computern (z.B. durch Softwareagenten) bearbeitet werden.
Dies ist wiederum der Ausgangspunkt für viele potentielle Einsätze des Semantic Webs (→ Abschnitt
4.5).
Der große Vorteil des Semantic Web, das die Einführung des Konzeptes deutlich beschleunigen
soll, ist, dass das Projekt auf der existierenden Netz-Infrastruktur aufbauen wird. Die mit Semantic
Web beschriebenen Seiten werden weiterhin in HTML (XHTML) formatiert, durch den WWW-Dienst
vertrieben und können ohne Probleme neben traditionellen Internetseiten existieren (der
durchschnittliche Benutzer wird wahrscheinlich überhaupt nicht merken, dass es sich um eine Seite
aus dem Semantic Web handelt).

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
45
4.2. Schichten des Semantic Web
Das Semanitc Web besteht aus Schichten (→Abbildung 4-1). Unicode ist der Codierungsstandard
für Zeichen des Semantic Web. URI identifiziert die beschriebenen Bestände. Die XML Schicht
repräsentiert nur die Syntax der Daten. Über die Bedeutung der Tags lässt sich automatisch nicht
schließen33. Die Schicht des RDF (→ 4.3.1) und des RDF Schema (→ 4.3.2) liefert Mittel zur
Ergänzung der Dokumente mit semantischer Beschreibung. RDF erlaubt die Kodierung, den
Austausch und Wiederverwendung von strukturierten Metadaten [64] Die Schicht der Ontologie34
repräsentiert eine formale Vereinbarung über die Bedeutung der Daten.
Abbildung 4-1 Schichten des Semantic Web
Ontologie ist die logische Beschreibung eines Abschnittes der realen Welt. Sie beinhaltet eine
strukturierte Menge von Begriffen, die miteinander durch verschiedene Relationen verbunden sind.
Die Darstellung der Wirklichkeit muss nicht genau sein (häufig ist das wegen der Komplexität der
realen Welt auch nicht möglich), sondern man benutzt ein vereinfachtes Modell, das sich nur auf die
für den Betrachter interessanten Objekte der Wirklichkeit konzentriert. Zwei Ontologien kann man
vereinen durch die Kennzeichnung von semantisch äquivalenten und verwandten Begriffen aus beiden
Ontologien. Die aktuelle Sprache zur Definition von Ontologien ist OWL (→4.3.3) Die nächste
Schicht ist die Sicht der Logik, in der man über die Bestände logische Aussagen machen kann. Es
sollen Mechanismen entwickelt werden, die Aussagen beweisen können, wie auch neue Aussagen aus
den bestehenden folgern. Es besteht auch Bedarf an Anfragesprachen, die bestimmte Informationen in
den Beschreibungen effektiv aufsuchen können. Zum Schluss soll das Semantic Web-Projekt das
33 Wir können die Bedeutung des Tags nur intuitiv vermuten, die maschinellen Verfahren können es nicht. 34 Die Ontologie in der Informatik ist nicht gleich dem philosophischen Begriff der Ontologie, der eine Lehre vom Sein und
vom Seienden bedeutet.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
46
Problem der Sicherheit untersuchen. Die Aussagen sollen digital signiert sein, was dem Benutzer die
Möglichkeit gibt, Schlüsse über die Glaubwürdigkeit der Aussagen zu ziehen.
4.3. Sprachen des Semantic Web
Im folgendem Abschnitt stelle ich die drei Basissprachen des Semantic Web vor: RDF, RDF
Schema und OWL. Die RDF Schema-Sprache ist eine Ergänzung der RDF Sprache. OWL wiederum
baut auf RDF und RDF-Schema auf.
4.3.1. RDF
RDF [117] (engl. Resource Description Framework) ist eine Sprache zur Repräsentation von
Metadaten. Das RDF-Modell (RDFMS) besteht aus vier Klassen von Elementen:
• Ressourcen (engl. Resources)
• Literale (engl. Literals)
• Eigenschaften (engl. Properties)
• Aussagen (engl. Statements)
Ressourcen sind alle Objekte einer gegebenen Domäne, die mit Hilfe von RDF beschrieben werden.
Jede Ressource muss durch eine URI (engl. Uniform Resource Identifier) identifizierbar sein. Literale
sind einfache Zeichenketten. Eigenschaften beschreiben die Merkmale, Attribute und Relationen einer
Ressource. Die Menge der Eigenschaften ist eine Untermenge der Menge aller Ressourcen. Aussagen
sind Tripel der Form: {predicat, subject, object}. Subject ist eine Ressource, Predicat eine Eigenschaft
der Ressource und Object (der Wert der Eigenschaft einer Ressource) ist entweder eine andere
Ressource oder ein Literal. Aussagen kann man in Form gerichteter Graphen darstellen, in denen man
zwei Arten von Knoten unterscheiden kann: Knoten der Ressourcen (dargestellt in Form von Ellipsen)
und Knoten der Literale (dargestellt in Form eines Rechtecks). Die Kanten bedeuten die
Eigenschaften.
Als Beispiel betrachten wir die Aussage: Das Dokument http://www.kowalski.pl/cv.pdf wurde
erstellt durch Jan Kowalski (die Abbildung 4-2 zeigt den Graph für diese Aussage). Die beschriebene
Ressource ist hier das Dokument http://www.kowalski.pl/cv.pdf (wie man hier sieht, muss das nicht
unbedingt eine HTML Seite sein), die Ressource hat die Eigenschaft author (definiert unter der URI
http://www.propertyTypes/types#author) mit dem Wert (Literal): „Jan Kowalski“.
http://
www.kowalski.pl/
cv.pdf
Jan Kowalski
http://www.propertyTypes /types#author
Abbildung 4-2 Beispiel einer graphischen Darstellung einer RDF-Aussage

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
47
Die Syntax der RDF ist normalerweise35 ein XML-Dialekt. Die in der Abbildung 4-2 gezeigte
Aufgabe würde als RDF-Code folgende Form haben:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:books="http://www.propertyTypes/types#">
<rdf:RDF>
<rdf:Description rdf:about="http://www.kowalski.pdf">
<books:author>Jan Kowalski</books:author >
</rdf:RDF>
4.3.2. RDF Schema
Die RDF Schema-Sprache [114] ist eine Erweiterung von RDF. Das RDF Schema führt Konzepte
aus der Objektorientierten Programmierung (OOP) in das RDF ein. Jede Ressource kann jetzt
Vertreter einer oder mehrer Klassen sein. Die Klassen können durch die Relation der Vererbung
verbunden sein. Mit Hilfe des RDF Schema kann man den Eigenschaften Nebenbedingungen setzten
(engl. Constraints). Diese Nebenbedingungen definieren die Klassen der Ressourcen, die diese
Eigenschaft besitzen können, wie auch Klassen der möglichen Werte der Eigenschaft.
4.3.3. OWL
OWL [107] [108] (engl. Web Ontology Language) ergänzt die RDF und RDF Schema-Sprachen
um logische Operationen. Wie der Name der Sprache schon andeutet dient OWL hauptsächlich zur
Erstellung von Ontologien.
Es existieren drei Varianten von OWL: OWL Lite, OWL DL und OWL Full, die sich durch den
Komplexitätsgrad unterscheiden. Die OWL Full Variante bietet die größte Aussagekraft, aber die
Inferenz-Algorithmen in Beständen, beschrieben mit OWL Full, garantieren keine Berechenbarkeit.
Die einfachste Variante des OWL ist OWL Lite.
Klassen können in OWL als Schnittmenge, Vereinigung oder Komplement von anderen Klassen
definiert werden. Die Eigenschaften können zusätzlich durch maximale und minimale Kardinalität der
Ausprägungen der Eigenschaft in einer Instanz einer Klasse begrenzt sein. Die Eigenschaften selbst
können genauer bestimmt sein (z.B. durch die Transitivität oder Symmetrie - Eigenschaft). Schließlich
beinhaltet OWL Mechanismen zur Abbildung von Ontologien aufeinander (Relationen zur
Kennzeichnung von äquivalenten Klassen und äquivalenten Instanzen von Klassen in verschiedenen
Ontologien).
35 Es gibt auch eine RDF-Syntax Variante, die nicht XML konform ist.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
48
4.4. Übersicht der Werkzeuge zum Bau des Semantic Web
Um das Semantic Web entstanden viele Tools, die das Konzept erweitern oder dessen Realisation
vereinfachen. Eine genaue Beschreibung aller Werkzeuge würde bei weitem den Umfang dieser Arbeit
sprengen. Aus diesem Grund möchte ich nur kurz einige (meiner Ansicht nach) wichtige Kategorien
der Semantic Web-Tools besprechen. Dazu zählen Semantic Web-Editoren, RDF Datastores, APIs36
für das Semantic Web.
4.4.1. Semantic Web-Editoren
Das manuelle Eintippen von Semantic Web-Beschreibungen wäre ein sehr mühsamer Prozess.
Daher existiert eine ganze Reihe von RDF, RDF Schema und OWL-Editoren. Mit Hilfe dieser
Applikationen ist es möglich, die Internetbestände semantisch zu beschreiben. Diese Tools können
meistens auch neue Klassen von Ressourcen oder Eigenschaften erstellen oder aus existierenden
Ontologien, auf Befehl des Benutzers, Klassen importieren. Zu den wohl bekanntesten Editoren aus
dieser Gruppe gehört Protégé 2000 [111]. Diese Anwendung wurde auf der Universität in Standfort
entwickelt. Protégé 2000 wurde vollständig in der Java-Technologie geschrieben. Dank einer offenen
und modularen Architektur, gewährleistet durch ein System von Plug-Ins, entwickelte sich Protégé zu
einem sehr universellen Werkzeug zum Bau des Semantic Web.
4.4.2. RDF Datastores
Die semantischen Beschreibungen kann man in manchen Fällen direkt in die beschriebenen
Bestände integrieren. Die Suche nach bestimmten Informationen in einer Sammlung von vielen auf
diese Weise beschriebenen Ressourcen ist aber uneffektiv. Daher entstanden spezielle Anwendungen
zur Aufbewahrung und Verwaltung von semantischen Beschreibungen, genannt RDF Datastores (RDF
Webstores, RDF Servers). Zu dieser Gruppe zählen solche Applikationen wie Sesame [122], RDF
Gateway [113], Joseki [102]. Intern werden die RDF/OWL-Daten normalerweise in relationalen
Datenbanken gespeichert. Mit Hilfe spezieller (SQL-ähnlichen) Anfragesprachen (wie z.B. RQL
[119], RDQL [115], RDFQL [116], SquishQL [124]) kann der Klient dem RDF Datastore Fragen
bezüglich der gespeicherten Beschreibungen stellen. Die Sprachen unterscheiden sich in der
Komplexität der möglichen Anfragen. Manche suchen nur nach explizit eingegebenen Informationen
(z.B. RDQL, SquishQL), andere wiederum versuchen, zusätzliche Aussagen aus den gegebenen
Informationen zu folgern37 (z.B. RQL).
4.4.3. APIs für Semantic Web
Es entstand eine ganze Reihe von Bibliotheken (hauptsächlich für die Java-Programmiersprache)
zur Entwicklung von Semantic Web-Applikationen. Dazu gehören u.a. Jena [100], Sergey Melnik's
36 API – engl. Application Programming Interface 37 Für Semantic Web gibt es auch spezielle Inference Engines, die der Schlussfolgerung in den semantischen Beschreibungen
gewidmet sind (wie z.B. JESS [101] , Cerebra [82])

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
49
RDF API [121] oder JRDF [103]. Als Beispiel möchte ich hier kurz die Jena-Bibliothek
charakterisieren38:
Jena ist ein offenes Projekt, gestartet durch die firm HP. Das Jena-Paket beinhaltet Klassen zur
Verarbeitung (erzeugen, ändern, löschen) von RDF- und OWL-Dokumenten. Man kann mit Hilfe der
Jena-Bibliothek die RDF- und OWL-Daten in Dateien oder relationalen Datenbanken speichern und
aus ihnen wieder Daten laden. Jena beinhaltet auch eine Schnittstelle für die RDQL-Sprache. Es
existieren spezielle Klassen zur Formulierung von RDQL-Anfragen und zur Bearbeitung der
Antworten auf Anfragen.
4.5. Beispiele von Anwendungen des Semantic Web
4.5.1. Data Mining
Die Semantic Web-Technologie kann die automatische Suche nach Informationen in großen
Datenbeständen erleichtern. Man kann sich z.B. vorstellen, das Semantic Web in der Medizin zur
Ermittlung der Ursachen von seltenen Krankheiten zu verwenden. Die interessanten statistischen
Daten befinden sich auf getrennten Rechnern vieler Krankenhäuser. Durch die Beschreibung der
Daten mit Hilfe Semantic Web-Technologien können Softwareagenten die Daten automatisch
analysieren und den Benutzer über interessante Zusammenhänge informieren. Nach ähnlichem
Schema könnte man Informationen für wirtschaftliche Zwecke finden (z.B. durch die Analyse der auf
WWW publizierten Verkaufsdaten).
4.5.2. Verbinden von Zeitplänen
Eine weitere Anwendungsmöglichkeit für Semantic Web ist die automatische Erstellung von
verschiedenen Zeitplänen [112], die z.B. zusätzlich geographische Einschränkungen berücksichtigen
können. Durch eine SemanticWeb-Suchmaschine können wir (zurzeit immer noch hypothetisch) z.B.
den Befehl geben: „Finde für mich einen interessanten Film im Kino, den ich noch heute sehen könnte
und dass ich vor 22:00 wieder zu Hause bin“. Das Verfahren sucht erstmals die nahe gelegenen Kinos,
die Verbindungen vom Wohnort des Benutzers zu den Kinos und filtert danach die Filme in den
gefundenen Kinos in dem ermittelten Zeitfenster gemäß den Vorlieben des Benutzers. Das fertige
Ergebnis wird dem Benutzer präsentiert. Dieses Szenario ist nur dann möglich, wenn die WWW-
Server von Kinos und Transportfirmen ihre Dokumente nicht nur in der menschenlesbaren Form
präsentieren, zusätzlich sondern sie zusätzlich mit semantischer Beschreibung ergänzen.
4.5.3. Semantic Web im E-Learning
Die Anwendung, auf die ich mich in dieser Arbeit konzentriere, ist der Einsatz von Sematic Web
im Bildungsbereich.
38 Unter anderem aus dem Grund, dass ich diese Bibliothek später in dem MAT-MAESTRO (Kapitel 7 und ff.) System
verwende.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
50
E-Learning setzt Selbstständigkeit beim Lernprozess voraus. Nach dem Prinzip „überall und zur
jeden Zeit“ (→ 3.8) sucht der Lernende selbst Lerninhalte aus. Dank der Beschreibung von
didaktischen Seiten kann der Benutzer leichter die Suche seinen Bedürfnisse anpassen. Stojanovic,
Staab und Studer [64] unterscheiden in ihrer Arbeit drei potentielle Einsatzgebiete von Metadata in E-
Learning: Metadata zur Beschreibung des Inhaltes, des Kontextes und der Struktur.
Die Beschreibung des Inhalts lässt uns die Möglichkeit, äquivalente Begriffe aus verschiedenen
Wissensbeständen zu verbinden, was die Qualität der Suche erhöht. Durch allgemeine Angaben über
den Inhalt kann der Benutzer (oder dessen Agent) noch vor dem Öffnen der Seite entscheiden, ob
diese für den Lernenden interessant ist oder nicht. Ein Beispiel einer persönlichen Einstellung der
Suche nach Lerninhalten kann die Bestimmung des Schwierigkeitsgrads der gezeigten Dokumente
sein. So werden z.B. einem kleinen Kind vor allem Seiten angeboten, die die Sachverhalte ohne
komplizierte Fachausdrücke erklären, wobei für einen Erwachsenen kindliche Beschreibungen eher
uninteressant sind. Weitere Einstellungsmöglichkeiten der Suche könnten die Interessen des
Lernenden berücksichtigen: die benutzte Hardwareplattform, die beherrschten Sprachen, usw.
Die Beschreibung des Kontextes kann die Irrtümer in der Suche beschränken, die aus der
Gleichnamigkeit der Begriffe hervorgehen. Die Suche könnte auch den Kontext der Anfrage erkennen.
So würden jemandem, der gerade Seiten über Vögel ansieht und nach dem Adler sucht, Seiten über die
Vogelart Adler angeboten und nicht Seiten z.B. über das Modehaus „Adler“ oder den Einshockeyklub
„Adler Mannheim“. Ein weiterer Vorteil der Beschreibung des Kontextes in Hinsicht auf den
Lernprozess ist die Suche nach unbestimmten Begriffen (deren Name der Lernende noch nicht kennt),
die aber mit einem anderen Begriff semantisch verbunden sind. So kann der Benutzer in einer
entdeckungsreichen Weise lernen (exploratory learning → 3.2).
Die E-Learning-Lerninhalte sind normalerweise in kleine Portionen geteilt. Somit wird dem
Lernenden die Gelegenheit geboten, den Lernprozess möglichst gut an seine Bedürfnisse anzupassen.
Um aber Unordnung in dieser Datenmenge zu vermeiden, kann man parallel zur semantischen
Verknüpfung der Inhalte, noch eine chronologische Struktur aufstellen. Dazu dient die letzte Gruppe
der Struktur-Metadaten (wie z.B. die Felder next, prev oder isPartOf).
In diesem Abschnitt habe ich nur sehr kurz und allgemein angedeutet, welchen Nutzen die
Semantic Web-Technologie für E-Learning-Systeme haben kann. Im Kapitel 6 und den folgenden
findet der Leser eine detaillierte Beschreibung einer von mir entworfenen Architektur für
Bildungssysteme, die ein gutes Beispiel der Anwendung von Semantic Web im E-Learning bildet.
4.6. Kritik des Semantic Web
Einige Forscher sehen das Semantic Web-Projekt zwar als interessantes Konzept, das aber vom
Aufwand her unrealisierbar ist. Sie behandeln es daher mehr als utopische Vision als ein ernsthaftes
Projekt. Als Beweis dieser These wird angeführt, dass trotz jahrlanger Arbeit bei der Entwicklung des
Semanitc Web, immer noch Beispiele von erfolgreichen Einsätzen der Technologie in der Praxis
fehlen. Auf den Punkt brachte es Elliotte Rusty Harold auf der Konferenz WWW2004 [132] in New

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
51
York: „I feel like I'm a mechanical engineer in 1904 listening to a bunch of other engineers talking
about airplanes, but nobody's willing to show me how they actually expect to get their flying machines
into the air. Maybe they can do it, but I won't believe it until I see a plane in the air (…)” [133].
4.7. Zusammenfassung
Trotz der im vorigen Abschnitt gebrachten Kritik, sehe ich die Zukunft des Semantic Web
weiterhin positiv. Obwohl die Einführung eines globalen Semantic Web in vorhersehbarer Zeit eher
unrealistisch erscheint, kann meiner Ansicht nach das Konzept in abgegrenzten Gebieten erfolgreich
eingesetzt werden. Die vorgestellten Sprachen zur Beschreibung der Semantik wurden inzwischen zu
sehr ausgereiften Standards, die weltweit anerkannt sind. Zu RDF existieren zusätzlich sehr viele
Werkzeuge, die die Arbeit mit der Technologie beschleunigen. Die OWL-Technologie wird wegen
ihrer Innovation und Komplexität noch nicht in solchem Ausmaß unterstützt wie RDF, aber die
Situation von OWL verbessert sind ständig. Die gebrachten Anwendungsbeispiele zeigen große
Perspektiven für das Semantic Web. Als Fazit kann man sagen, dass die wirkliche Stärke von
Semantic Web sich erst in ein paar Jahren zeigen wird, wenn sich im Internet viele im Semantic Web
beschriebene Daten befinden werden.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
52
5. Übersicht der Möglichkeiten der Anwendung von Softwareagenten im E-Learning
Im Kapitel 2 habe ich allgemein das Konzept der Multiagentensysteme vorgestellt. Das Kapitel 3
beinhaltet eine Einführung in die Thematik des E-Learning. Im folgenden Kapitel untersuche ich die
Möglichkeiten der Synthese dieser zwei Forschungsgebiete und zeige einige Beispiele der Anwendung
von Agenten im E-Learning.
5.1. Gründe der Verwendung der Agententechnologie im E-Learning
Die Konsequenz der großen Flexibilität des E-Learning ist, dass der Lernende meistens auf einen
direkten Kontakt mit dem menschlichen Lehrer verzichten muss. Um diesen Nachteil gewissermaßen
auszugleichen, versucht man die modernen Bildungssysteme möglichst „menschenähnlich“ zu
gestalten. Dazu gehört vor allem die intelligente, an den Lernenden angepasste Gestaltung des
Lernprozesses. Agenten, als autonome, intelligente Prozesse (→Kapitel 2), können diese Aufgabe gut
übernehmen. Durch die Beobachtung des Verhaltens des Benutzers im Umgang mit dem System kann
der Agent selbstständig Schlüsse ziehen über die effektivsten Lernmethoden für den Benutzer.
Wie schon gesagt ist (→ 4.5.3), werden die Lerninhalte für intelligente Bildungssysteme meistens
in kleine Abschnitte geteilt. Ein Lernender, der über den Lernstoff noch wenig weiß, kann hier leicht
die Übersicht verlieren. Bei einer agentenverständlichen Beschreibung des didaktischen Materials (→
Kapitel 4) kann der Agent den Lernenden auf intelligente Weise von einem Thema zum anderen
führen. Er kann den Lernenden beim Prozess der Wissensaneignung begleiten und ihm im passenden
Moment mit adäquaten Ratschlägen (Bedienung des Systems, Lernmethoden, usw.) helfen oder ihn
motivieren.
Die Agenten können sich auch beim Anordnen der Lerninhalte als sehr nützlich erweisen. Die
didaktischen Seiten müssen nicht mehr zentral verwaltet sein, sondern können von mehreren Personen
zur gleichen Zeit in verschiedenen Bildungseinheiten erstellt werden. Dank der Intelligenz-, Mobilität-
und Autonomieeigenschaften können die Agenten verteilte Bestände, transparent für den Benutzer, in
einem System verbinden.
5.2. Definition des pädagogischen Agenten
Agenten, die die oben genannten Aufgaben realisieren, bezeichnet man als pädagogische Agenten
(manchmal auch als Guidebots). In der wissenschaftlichen Literatur findet man viele Definitionen
dieses Agententyps. So definiert Fenton-Kerr den Begriff z.B. folgendermaßen: „A pedagogical
software agent is an autonomous software process, which occupies the space between human learners
and a task to be learned. The agent‘s task is likely to involve offering some kind of proactive,
intelligent assistance [...] to aid task completion.“ [27]. Die Definition von Bendel stimmt mit der von

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
53
Fenton-Kerr weitgehend überein: „Pädagogische Agenten sind Agenten, die Lernende in virtuellen
Lernwelten oder in anderen elektronischen Umgebungen anleiten und begleiten. Sie dienen dazu,
Lern- und Wissensprozesse zu unterstützen und gegebenenfalls zu transformieren, z.B. in eine neue
Richtung zu lenken und damit auch zu optimieren.“ [9]
Für unerfahrene Benutzer, die oft Angst vor Computersystemen haben, wie auch für Kinder, die
herkömmliche Benutzerschnittstellen leicht langweilen, versucht man die Illusion der
„Menschlichkeit“ der Maschine zusätzlich mit graphischen Darstellungen der pädagogischen Agenten
zu verstärken. Solche Gestalten nennt man Avatars39. Einige Wissenschaftler setzten so eine
graphische Gestalt als wichtiges Merkmal der pädagogischen Agenten voraus: „Bei vielen Aufgaben
der pädagogischen Agenten ist ihre Sichtbarkeit unverzichtbar, und oft sind sie anthropomorph, also
menschenähnlich gestaltet“ [5]. Meine persönliche Erfahrung auf diesem Gebiet hat mich aber zu der
Ansicht gebracht, dass für bestimmte Benutzergruppen die Avatars der pädagogischen Agenten eher
störend als hilfreich erscheinen und mit einer Verflachung des betrachteten Themas verbunden
werden.
5.3. Beispiele von Agentenarchitekturen für Multiagentensysteme
Im Laufe der Forschung auf dem Gebiet der Multiagentensysteme entstanden viele Arbeiten, die
sich mit den Architekturen dieser Systeme befassen. Unter den zahlreichen Konzepten interessierten
mich vor allem die Lösungen, die explizit für Bildungssysteme entworfen sind. In meiner Arbeit
möchte ich einige der Architekturen kurz vorstellen.
5.3.1. Multiagenten-Architektur für Intelligente Bildungssysteme
Chen und Mizoguchi [21] stellen in ihrer Arbeit die Ergebnisse der zwanzigjährigen Forschung
auf dem Gebiet der Intelligenten Bildungssysteme (IES – engl. Intelligent Educational Systems) dar.
Sie definieren eine Liste der wichtigsten Agenten, die im allgemeinen IES gebraucht werden:
• Learning Material Agent – Verwahrt das fachspezifische Wissen (sowohl den Inhalt als auch die
Struktur) und antwortet auf Fragen von anderen Agenten, die das fachspezifische Wissen für die
Realisierung ihrer Ziele brauchen
• Learning Support Agent – Ist für die Planung des Lernprozesses verantwortlich. Entscheidet über
die optimale Lernstrategie für den Lernenden. Bekommt das fachspezifische Wissen von dem
Learning Material Agenten
• Learner Modeling Agent – Konstruiert ein abstraktes Modell des Lernenden. Die zur Herstellung
des Modells nötigen Informationen bezieht er aus der Beobachtung der Interaktion zwischen dem
Benutzer und dem Bildungssystem
39 Der Begriff Avatar kommt im ursprünglichen aus dem Sanskrit und bedeutet göttliche Herkunft, Verkörperung einer
Gottheit auf Erden. In der Informatik bezeichnet man mit dem Namen eine künstliche Person oder den virtuellen
Stellvertreter einer Person in der virtuellen Realität [131].

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
54
• Learner Model Agent – Antwortet auf von externen Agenten gestellte Fragen bezüglich des
Lernenden. Beinhaltet Hypothesen über das verfügbare Wissen und den mentalen Zustand des
Lernenden. Dieser Agent soll die Informationen des Lernenden vertraulich behandeln und entscheiden,
welche Daten man an welche Agenten weitergeben darf.
• Interface Agent – Ist direkt für die Interaktion mit dem Benutzer verantwortlich. Überwacht die
Tätigkeiten des Lernenden und leitet die Information an die anderen Agenten weiter.
Interface Agent
Learning Support Agent
Learner Modeling Agent
Learning Material Agent
Learner Model Agent
External AgentsLearner
Abbildung 5-1 Multiagenten-Architektur für Intelligente Bildungssysteme (nach [21])
Die von Chen und Mizoguchi vorgestellte Architektur war für mich ein direkter Impuls zum
Entwurf der MAESTRO-Architektur (→ Kapitel 6). Ich habe versucht, diese Architektur kritisch zu
betrachten. Meiner Ansicht nach überdecken sich die Funktionen des Learner Modeling Agent und des
Learner Model Agent. Der zusätzliche Aufwand der Implementierung von zwei statt einem Agenten
wie auch die Zeitkosten der (intensiven) Kommunikation zwischen den beiden Agenten haben, meiner
Ansicht nach, keine Begründung40. Des Weiteren ist für mich unklar, wie die Learning Support-
Agenten das fachspezifische Wissen aufbewahren wollen. Das Speichern des ganzen Wissens im einen
Agent scheint mir (wegen des Umfangs des Wissens) eine schlechte Idee zu sein. Meiner Ansicht nach
ist die Verwendung von speziellen Servern, die das fachspezifische Wissen effektiv verwalten können,
angebrachter41. Die Learning Support Agents könnten dann aus solchen Datenbanken nur einen
gewissen Teil des Wissens beziehen, das der Agent zur Bearbeitung des aktuellen Zustandes des
Systems benötig. Diese Lösung muss nicht eine erneute Zentralisierung des Systems bedeuten, weil
die Agenten das Wissen aus mehreren derartigen Servern schöpfen können. In der Chen und
40 Diese zwei Agententypen wurden in der MAESTRO-Architektur zu einem Pedagogical Agent vereinigt 41 Die MAESTRO-Architektur benutzt dazu spezielle Lerneinheits-Knoten

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
55
Mizoguchi-Architektur fehlen, meiner Ansicht nach, noch zusätzliche Agententypen, die den
Lehrenden und den Systemadministrator in einem E-Learning-System vertreten.
Zum Schluss kann man noch anmerken (nicht unbedingt kritisierend), dass sich trotz der
scheinbaren Schlichtheit des Modells ein enormer Aufwand der Implementierung hinter diesem
Konzept verbirgt. Zum Beispiel ist die Erstellung eines glaubwürdigen Modells des Zustandes eines
Lernenden ein sehr schwieriges Problem, mit dem sich Pädagogen und Psychologen seit
Jahrhunderten (oft vergeblich) auseinandersetzen.
5.3.2. Federated Architecture for Agent Communications
Ein anderes Konzept einer agentenbasierenden Architektur für Bildungssysteme stellt Cheikes
[17] vor. Das Modell wird Federated Architecture For Agent Communications (FAAC) genannt und
kann in der allgemeinen Form auch für andere Systeme (außer dem Gebiet des E-Learnings)
angewandt werden.
Standalone Executive
Kernel Agent Community Interface Agent Community
Facilitator
Abbildung 5-2 Federated Architecture for Agent Communications - Standalone Configuration (nach [17])
In der FAAC-Architektur bezeichnen wir als Facilitator einen (oder mehrere) auserwählte
Agenten, die die Arbeit der anderen Agenten koordinieren. Die „non-Facilitator“-Agenten werden in
Agent Communities (Agentengemeinden) aufgeteilt. Die Agent Communities gliedern sich weiter in
Kernel Agent Communities und Interface Agent Communities auf. Die Kernel Agents sind für das
logische Schließen und die Verarbeitung der Informationen zuständig. Diese Informationen werden
wiederum aufgrund der Beobachtungen des Benutzers durch die Interface Agents gesammelt. Die
Kernel Agents können sich beliebig weiter spezialisieren (z.B. Curriculum Manager, Training
Administrator, Activity Manager, Student Model, Coaching Planner). Auch die Interface Agents
nehmen verschiedene Funktionen auf (Argument Palette Agent, Database Browser Agent, usw.).
Man unterscheidet zwischen zwei Varianten der FAAC-Architektur: Standalone Configuration
und Networked Configuration. In der Standalone Configuration-Architektur (Abbildung 5-2) wird eine
Kernel Agent Community und eine Interface Agent Community durch einen einzigen Standalone
Executive Agents bedient (der die Rolle des Facilitators übernimmt).

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
56
In der Networked Configuration-Architektur (Abbildung 5-3) kommuniziert eine Kernel Agent
Community gleichzeitig mit einer oder mehreren Interface Agent Communities. Ein Kernel Executive
Agent und Screen Managers spielen die Rolle des Facilitator.
Screen Manager
Interface Agent Community Interface Agent Community
Facilitator
Screen Manager
Facilitator
Kernel Agent Community
Screen Manager
Facilitator
...
Abbildung 5-3 Federated Architecture for Agent Communications Networked
Configuration (nach [17])
Das FAAC-Modell eignet sich für Systeme, in denen man viele Benutzer mit Hilfe eines
zentralen Schlussfolgerungssystems bedienen möchte. Ein zentrales Schlussfolgerungssystem ist
einerseits günstig, weil es ausgereifte Inferenz-Mechanismen anwenden kann, anderseits kann es bei
großer Belastung des Systems zu einem Engpass werden oder sogar beim Ausfall das ganze System
lahm legen. Dasselbe gilt auch für Facilitator Agents, die möglichst gut gegen Ausfälle geschützt sein
sollten. Meiner Ansicht nach ist die Architektur in der gezeigten Form noch zu allgemein und bedarf
weiterer Forschung.
5.3.3. ADE-Architektur
ADE (Advanced Distance Education) ist ein Projekt, geführt von der CARTE-Gruppe (Center for
Advanced Research in Technology for Education) an der Universität Southern California [74]. Die
Forschungsgruppe arbeitet neben ADE auch an zahlreichen anderen Projekten im Bereich
agentenbasiertes E-Learning [81].
In Rahmen des ADE-Projektes erstand eine E-Learning-Architektur (Abbildung 5-4) [63], in
deren Mittelpunkt sich der pädagogische Agenten – Adele (Agent for Distance Education – Light

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
57
Edition) befindet. Die Architektur ist nach dem Server-Client-Modell gestaltet. Auf dem Server
befinden sich die Lernmaterialien und auch die gespeicherten Daten der einzelnen Studenten. ADE ist
für Netzverbindungen mit geringer Bandbreite angepasst, deshalb wird aus Effizienzgründen
(Kommunikationseinsparung) der ganze Agent in Form eines Java-Applets auf den Rechner des
Lernenden geladen. Außer dem Agenten befinden sich auf der Seite des Klienten auch Mechanismen
zur Durchführung von Simulationen (darüber später → 5.4.2), Transformation von Text in Sprache,
Planung der Aufgaben und die Benutzeroberfläche. Der Adele-Agent selbst ist aus einem
Schlussfolgerungsmodul (reasoning engine) und einer animierten Gestalt des Agenten (Avatar → 5.2)
zusammengesetzt.
Abbildung 5-4 ADE Architektur [63]
Die Adele-Architektur unterscheidet sich von den soeben vorgestellten Architekturen (→ 5.3.1,
→5.3.2) insofern, dass hier ein einziger Agent die ganze Funkion, die in anderen Beispielen auf
mehrere Agenten aufgeteilt wurde, übernimmt. Ich bin aber der Meinung, dass diese Architekur viele
Einschränkungen in Hinblick auf eine potentielle Erweiterung des Systems hat und die Möglichkeiten,
die die Agententechnologie bietet, nicht voll ausnutzt. Der Vorteil dieser Architektur ist die Reduktion
des Kommunikationsaufwandes zwischen Benutzer und Server.
Im Punkt 5.4.2 stelle ich ein auf der ADE-Architektur basierendes E-Learning-System vor, das
an Medizinstudenten gerichtet ist.
5.4. Beispiele für realisierte Agenten-Systeme im E-Learning
In den vergangenen Jahren entstanden zahlreiche Anwendungen, in denen Agenten-Technologien
zu Bildungszwecken verwendet worden sind. Bei den Anwendungen handelt sich um kommerzielle
Produkte und um wissenschaftliche Forschungsprojekte. Die meisten Systeme befinden sich immer
noch in der Testphase. Aus der Gruppe agentenbasierter E-Learning-Anwendungen habe ich
repräsentativ drei Beispiele ausgewählt, die ich jetzt kurz vorstellen möchte.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
58
5.4.1. Multiagentensystem zur Durchführung von Examen
Ein interessantes Beispiel der Anwendung von Agenten im E-Learning entstand an der AGH
Krakau. Es basiert auf dem Konzept von Test-Bäumen (engl. test tree, T-tree) [69]. Dem Lernenden
werden Testfragen gestellt. Die vollständige Antwort auf eine Frage verhindert weitere Fragen,
während eine unvollständige Antwort eine ganze Reihe von weiteren detaillierten Fragen aus dem
gegebenen Gebiet auslöst. Ein T-Tree spiegelt die Sequenz von Fragen wider, die gestellt werden, um
die kleinstmögliche Einheit des Wissens zu identifizieren, die dem Lernenden zur korrekten
Beantwortung der Frage fehlt. Die Fragen, die auf das mangelhafte Wissen des Lernenden hindeuten,
ergeben einen Baum der Unwissenheit (engl. ignorance tree, N-tree). Diese Art der Durchführung von
Tests soll dem realen Stil des Ablaufs von mündlichen Prüfungen ähnlicher sein als in herkömmlichen
Computertests.
Die Durchführung der soeben beschriebenen Tests wird durch eine Reihe von Softwareagenten
realisiert [70]. Der Advertiser Agent stellt dem Lernenden eine Prüfung vor, der sich der Lernende
unterziehen kann. Dieser Agent spielt eine rein informative Rolle. Der Examiner Agent führt die
Prüfung durch (zählt die gesammelten Punkte, überwacht den Stand der Prüfung und setzt die
endgültige Note fest). Ein ganzes Team von Test Agents ist verantwortlich für das Stellen von
Testfragen und die vorläufige Bewertung der Antworten des Lernenden. Wenn die Antwort auf eine
Frage durch den Test Agent als nicht ausreichend bewertet ist, erzeugt der Agent einen weiteren Test
Agent, der eine Frage repräsentiert, die tiefer in der Struktur des T-Baumes lokalisiert ist.
Außer den Agenten zur Durchführung von Prüfungen beinhaltet das realisierte Prüfungssystem
Agenten zur Realisation von Anfragen an die Datenbank, zur Durchführung des Einloggens,
Registrierung von Benutzern, Administrationsagenten und Agenten, die die Daten der Studenten
repräsentieren. Die Agenten können sich in zwei Umgebungsarten befinden: in Prüfungszentren (engl.
Examination Center, XC) und lokal auf dem Rechner des Benutzers. XC sind Server, auf denen die
momentan nicht gebrauchten Agenten gespeichert werden und auf denen die Testfragen deponiert
sind. Der Lernende kann sich mit mehreren XC in Verbindung setzen. Die Realisation des
vorgestellten Projektes war Gegenstand zweier Diplomarbeiten [22] [38].
5.4.2. Agentenbasiertes E-Learning-System für Medizinstudenten
Obwohl die E-Learning-ADE-Architektur (→ 5.3.3) nicht nur auf ein einziges Wissensgebiet
gerichtet sein soll, verwendet man den Adele Agent zurzeit hauptsächlich zur Bildung im
Medizinbereich.
Der Lernende wird in die Rolle eines Arztes versetzt und muss eine Reihe von Aufgaben
selbstständig (oder in Zusammenarbeit mit anderen Studenten42) lösen. Eine typische Aufgabe ist die
Diagnose eines Patienten (Abbildung 5-5). Der Student kann Fragen über die Krankheitsgeschichte
des Patienten stellen, ärztliche Untersuchungen ausführen oder zusätzliche Labortests anfordern.
42 Multiuser-Modus

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
59
Abbildung 5-5 Untersuchung eines Patienten im ADE-System
Zu den Funktionen von Adele zählen die klassischen Eigenschaften eines pädagogischen
Agenten: Präsentation von Lernmaterialien, Überwachung des Lernprozesses des Studenten, Abfragen
des Lernenden, Leistung von zusätzlicher Hilfe in Form von Hinweisen und Erklärungen. Das System
ermöglicht auch die Teilnahme an Simulationen, in denen die Zeit eine sehr wichtige Rolle spielt. Ein
Beispiel dafür ist die Behandlung eines Traumapatienten. Das Fehlen einer schnellen und korrekten
Reaktion des Lernenden auf z.B einen abrupt fallenden Herzschlag des Patienten wird negativ
bewertet.
Die Lernmaterialien werden im einem gewöhnlichen Java-unterstützenden Web-Browser
präsentiert. Der Agent wird in einem separaten Fenster angezeigt. Adele „beobachtet“ den Lernprozess
des Studenten und je nach dem Verhalten des Studenten versucht er, behilflich zu sein. Fordert der
Student z.B. einen unnötigen Labor-Test an, so liefert der Agent eine Begründung, weshalb dieser
Schritt in der Situation nicht zielführend gewesen ist. Darüber hinaus kann der Student den Agenten
immer um Tipps zum bearbeitenden Thema bitten. Auf manche Übungen kann ohne das Bestehen
eines Wissenstests nicht zugegriffen werden. In dem Exam-Modus darf der Student die Hilfe des
Agenten nicht nutzen, und am Ende der Übung wird sein Verhalten zusammengefasst und bewertet.
5.4.3. Extempo Expert Characters
Die Firma Extempo bietet eine ganze Reihe von pädagogischen Softwareagenten (genannt Expert
Characters) an [85]. Die Agenten verfügen über ein menschenähnliches graphisches Interface. Sie
können mit dem Benutzer in einer (fast) natürlichen Sprache kommunizieren. Das System wurde

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
60
hauptsächlich für Schulungen in großen Unternehmen realisiert. Es werden drei Arten der Expert
Characters unterschieden: Expert Coaches, Expert Role Players, Expert Guides.
Abbildung 5-6 Expert Coach Agent [87]
Expert Coaches Agents begleiten den Benutzer beim Lernen eines ausgewählten Lernmoduls.
Zu den angewandten Lernmethoden gehören das Anzeigen von Schulungsmaterialien, Durchführung
von Interaktiven Übungen, Quiz oder Simulationen (z.B. Simulation eines Gespräches mit einem
Kunden). Agenten dieser Art verwenden von dem Hersteller gelieferte Lernmaterialien, sind aber auch
offen für externe Daten. Um den Lernenden besser zu motivieren und den Bildungsprozess effektiver
zu gestalten, verwenden die Agenten Benutzerprofile. Diese Profile beinhalten solche Informationen
wie: eine Liste der bisher absolvierten Kurse, Aufzeichnungen der erbrachten Leistung und der
Lernfortschritte, Bemerkungen und Präferenzen des Benutzers.
Das Ziel der Expert Role Player Agents ist die Übung der interpersonellen Kontakte mit dem
Lernenden (z.B. Kontakte mit Kunden, Angestellten, Patienten). Der Lernerde führt ein Gespräch in
natürlicher Sprache mit dem Agenten, der verschiedene Rollen spielt. Der Benutzer bekommt
verschiedene Aufgaben (z.B. Abmahnung eines Angestellten), und der Agent simuliert verschiedene
mögliche Verläufe des Gesprächs.
Die Funktion des Expert Guides Agent besteht darin, den Lernenden bei der Wahl eines neuen
Kurses zu helfen.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
61
Abbildung 5-7 Expert Role Player Agent [87]
Das System der Firma Extempo ist ein kommerzielles Produkt, daher wurden die
Implementierungsdetails nicht veröffentlicht. Auf der Homepage des Produzenten [87] fehlen jegliche
Angaben über die Architektur des Systems und Informationen zu Methoden der Zusammenarbeit von
den Extempo Agents.
5.5. Zusammenfassung
In diesem Kapitel habe ich versucht, die wichtigsten Punkte der möglichen Zusammenarbeit von
Agenten und E-Learning-Systemen aufzuzählen. Zusammenfassend kann man sagen, dass die Agenten
eine Anpassung des Lernprozesses an den Lernenden ermöglichen und verteilte Lerninhalte gut
bedienen können.
Keine der gezeigten Architekturen von Agentensystemen für den Bildungsbereich konnte sich als
Standard durchsetzen. Gründe dafür gibt es meiner Ansicht nach mehrere. Einerseits sind einige der
Architekturen zu allgemein und lassen sehr viele schwierige Probleme offen (→ 5.3.1, → 5.3.2), oder
zu detailliert, dafür aber begrentzt einsatzfähig (→ 5.3.3). Die Lösung liegt wahrscheinlich in einem
Kompromiss zwischen diesen zwei Tendenzen.
Sehr wichtig ist die Durchführung von praktischen Experimenten mit Realisierung der
vorgeschlagenen Architekturen. Beispiele von realisierten E-Learning-Systemen, in denen man
Agenten verwendet, wurden am Schluss des Kapitels gezeigt. Diese Beispiele zeigen, dass die
Realisation von agentenbasierten Bildungssystemen möglich ist, aber die Applikationen schöpfen,
meiner Ansicht, nach noch nicht alle potentiellen Möglichkeiten der Agententechnologie aus.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
62
6. MAESTRO-Architektur
Dieses Kapitel führt das Konzept der MAESTRO-Architektur ein. Wegen der Komplexität des
Entwurfs einer agentenbasierenden Architektur für Bildungssysteme betrachte ich die Problemstellung
in Schichten (→ Abbildung 6-1).
MAESTRO
MAT-MAESTRO
Prototyp
Abbildung 6-1 Schichten in der Entwicklung der MAESTRO-Architektur
Die oberste Schicht ist recht abstrakt, umfasst aber ein großes Gebiet. Sie beinhaltet eine
allgemeine Beschreibung der von mir vorgeschlagenen, MAESTRO-Architektur. Eine detaillierte
Charakteristik der Architektur würde bei weitem den Umfang einer Diplomarbeit überschreiten. Aus
diesem Grund wähle ich einige Aspekte der Architektur aus und betrachte sie genauer während des
Designs des MAT-MAESTRO-Systems (→ Kapitel 7 und Anhang). Ich möchte hier betonen, dass
MAT-MAESTRO in sich keine Architektur mehr ist, sondern ein praktisches Computersystem, das
ausgewählte Elemente der MAESTRO-Architektur realisiert. Um einen Eindruck von den praktischen
Aspekten der Implementierung solcher Computersysteme zu gewinnen, habe ich mich entschlossen,
einige Teile des Systems in Form eines Prototypen zu programmieren (→ Kapitel 8 und Anhang).
Weitere Arbeiten auf diesem Gebiet können sich auf andere Aspekte der MAESTRO-Architektur
konzentrieren, die Architektur auf ähnliche Weise zu dekomponieren, wie ich es in dieser Arbeit
mache. Erfahrungen aus der praktischen Realisation der Systeme werden zu Verbesserungen der
allgemeinen Architektur führen. Ich bin der Meinung, dass solch ein zyklischer top-down- und
bottom-up-Entwicklungsprozess die besten Ergebnisse bei der Entwicklung der Architektur geben
kann.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
63
6.1. Gründe für die Entstehung der MAESTRO-Architektur
Die im Abschnitt 5.3 gezeigten Architekturen beweisen, dass das Konzept des Entwurfs eines
Gerüsts für agentenbasierende Systeme im Bildungsbereich nicht neu ist43. Wie ich aber auch gezeigt
habe, gibt es zurzeit keine optimale Lösung für diesen Bereich. Die von mir vorgeschlagene
Architektur vereinigt, vertieft und erweitert – meiner Ansicht nach – die besten Ideen aus den
bestehenden Ansetzten. Im Gegensatz zu den bestehenden Architekturen werden einige Funktionen
der Agenten, wie z.B. Leistung der Hilfestellung, detailliert betrachtet, und konkrete Methoden der
Realisierung dieser Aufgaben werden vorgestellt.
Innovativ in meiner Architektur sind vor allem Überlegungen zu der Wissensrepräsentation der
Lerninhalte. Ich führe in die Architektur spezielle Datenbank-Knoten ein, die Quelle des Wissens für
die Agenten sind. Eine wichtige Rolle spielt hier das Konzept des Semantic Web. Ich verwende es als
universelle Beschreibungsmethode für die Lernbestände.
Neu in meiner Architektur (obwohl nicht näher betrachtet) ist auch die Berücksichtigung
spezieller Agententypen zum Schutz der Sicherheit des Systems und auch zur Erfüllung der
Funktionen des Lehrenden und des Systemadministrators.
6.2. Bemerkungen zur angewandten Notation
Im weiteren Verlauf der Arbeit benutzte ich zur Darstellung einiger Konzepte die UML Notation
(engl. Unified Modeling Language) [126]. UML ist seit langem ein anerkannter Standard im Entwurf
objektorientierter Systeme. Die Version 1.5 der UML-Notation unterstützt neun verschiedene
Diagrammtypen, aufgeteilt in drei Gruppen:
• Statische Diagramme – beschreiben die logische Struktur des Systems –
(Anwendungsfalldiagramm (use case diagram), Klassendiagramm (class diagram),
Objektdiagramm (object diagram)),
• Verhaltensdiagramme – beschreiben die Dynamik des Systems – (Zustandsdiagramm
(statechart diagram), Aktivitätsdiagramm (activity diagram), Sequenzdiagramm (sequence
diagram), Kollaborationsdiagramm (collaboration diagram))
• Implementierungsdiagramme – beschreiben die physische Struktur des Systems
(Komponentdiagramm (component diagram) Verteilungsdiagramm (deployment
diagram)).
Die UML Diagramme-beinhalten einige Redundanzen. Z.B. kann man das Kollaborationsdiagramm
automatisch aus dem Sequenzdiagramm generieren. Aus diesem Grund werden in dieser Arbeit nicht
alle Diagrammtypen gezeigt.
Das Anwendungsfalldiagramm eines auf der MAESTRO-Architektur basierenden Systems wird im
Abschnitt 6.3 präsentiert. Die Klassen-, Aktivitäts- und Sequenz- und Implementierungsdiagramme
für das MAT-MAESTRO-System und sein Prototypen werden im Kapitel 7 und im Anhang gezeigt.
43 Gründe, weshalb man überhaupt Agenten im E-Learning benutzt, werden im Abschnitt 5.1 gebracht.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
64
6.3. Analyse der gebrauchten Funktionalität
Der erste Schritt auf dem Entwicklungsweg der MAESTRO-Architektur war die Analyse der
Funktionalität, die die mit ihr konformen Systeme zeigen sollen. Das Ziel erreiche ich durch die
Erstellung von UML-Anwendungsfalldiagrammen. Diese Diagramme werden zur Beschreibung eines
externen Systemverhaltens aus der Sicht der Benutzer verwendet.
Ich habe drei Klassen von Benutzern eines auf der MAESTRO-Architektur gründenden Systems
unterschieden (Abbildung 6-2). Es sind: die Lernenden, die Lehrenden und die Systemadministratoren.
Lehrender
Benutzer
Lernender
System-
administrator
Abbildung 6-2 Benutzer in der MAESTRO-Architektur
Alle Benutzer sollen die Möglichkeit haben, in das System eingefügt und aus ihm wieder
gelöscht zu werden44,45. Ein registrierter Benutzer soll die Möglichkeit haben, sich im System
anzumelden (einloggen) und sich aus ihm wieder abzumelden (ausloggen) (Abbildung 6-3).
Einloggen Ausloggen
Benutzer
Abbildung 6-3 Use-Case Diagram für den Benutzer
44 Mindestens ein Systemadministrator muss immer im System registriert sein 45 Die Einfügung der neuen Benutzer in das System und das Löschen der Benutzer aus dem System ist eine Funktion des
Systemadministrators.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
65
6.3.1. Der Lernende
Das Ziel des Lernenden (Studierenden oder an Weiterbildung interessierten Externen) während
der Arbeit mit dem System ist das Erlangen des Wissens auf möglichst effiziente und angenehme
Weise. Der Lernprozess soll möglichst nach dem Prinzip des Lernens durch Erforschen konzipiert
sein. Der Lernende kann sich in verschiedene Lerneinheiten einschreiben. Nicht alle Lerneinheiten
müssen für den Lernenden zugänglich sein. Einige Kurse können bestimmte Vorkenntnisse oder die
Einzahlung eines bestimmten Geldbetrags erfordern. Nach der Einschreibung hat der Benutzer die
Möglichkeit, die Materialien der Lehreinheit zu nutzen.
An-/Abmeldung zur Lerneinheit
Zugriff auf didaktische Seiten
Nutzung der "intelligenten" Hilfe
Bewertung der Hilfe
Persönliche Einstellungen des
Lernprozesses
Zahlung für die Nutzung der
Bestände
Diskussion über Lerninhalte
Lernender
Abbildung 6-4 Use-Case Diagram für den Lernenden
Während des Lernprozesses treten voraussichtlich Schwierigkeiten mit dem Verständnis des
Lehrstoffes auf. In solchen Fällen kann der Benutzer das System um Hilfe bitten. Die Hilfe soll
möglichst gut an den Benutzer angepasst werden. Anhand der Geschichte des bisherigen
Lernprozesses und der Erfahrungen aus der bisherigen Arbeit mit den Lernenden soll das System
schätzen, welche Materialien hilfreich sein können.
Die Hilfe, die der Benutzer von dem System erwartet, kann sehr unterschiedlich sein. Es können
sowohl Antworten auf sehr detaillierte Fragen sein (z.B. „Was bedeutet Kombinatorik?“46) und auch
Ratschläge auf sehr allgemein gestellte Probleme (z.B. „Finde etwas Interessantes, was ich noch
lernen könnte, was zusammenhängt mit dem was ich schon gelernt habe.“). Die letzte Anfrage stellt
46 Im praktischen Teil der Arbeit möchte ich nicht auf die sehr komplizierten Aspekte der Interpretation der natürlichen
Sprache eingehen – der Student soll nur stichwortartig die Begriffe nennen, die ihm Schwierigkeiten bereiten.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
66
eine spezielle Kategorie der Hilfestellung dar. Der Lernende versteht das Gelernte, aber aus Interesse
zum Thema möchte er sein Wissen auf diesem Gebiet erweitern. Diese Art der Hilfestellung bezeichne
ich im weiteren Verlauf der Arbeit als Vertiefungsfunktion. Als Antwort auf die Anfrage liefert das
System eine Liste der möglichen Hilfsverweise zu anderen Materialien. Die Liste sollte nach den
Wahrscheinlichkeiten des Zutreffens geordnet sein. Nur die n-besten Ergebnisse sollen angezeigt
werden. Der Studierende sollte auch die Möglichkeit haben, das System um Übungen zum aktuellen
Lernstoff zu bitten. Die Korrektur solcher Übungen überschreitet oft die Möglichkeiten der
gegenwärtigen Computer, aber dem Lernenden werden zumindest Antworten oder Musterlösungen der
Aufgaben angeboten. Der Benutzer kann die ihm angebotenen Lerninhalte und Hilfestellung bewerten,
um dem System die Möglichkeit zu geben, die Vorlieben des Lernenden kennen zu lernen. Der
Lernende kann die Parameter des Lernprozesses auch explizit festlegen. Der Lernende soll die
Möglichkeit haben, die Lehrmaterialien für den Lehrenden oder die Mitlernenden zu kommentieren
oder in Hinsicht auf Verständlichkeit und Nutzen zu bewerten.
Befinden sich im System Lerneinheiten, für deren Gebrauch eine Bezahlung vorgesehen ist, so
kann der Lernende wirkliches Geld in virtuelles Zahlungsmittel umwandeln (z.B. durch eine
elektronische Banküberweisung)47.
Die Architektur sollte auch das Recht auf persönlichen Datenschutz des Lernenden
berücksichtigen. Die mit der MAESTRO-Architektur realisierten Systeme dürfen einige der
gesammelten Daten überhaupt nicht oder nur anonymisiert an andere Benutzer (auch an Lehrende)
oder Agenten weitergeben. Die Funktionen der Architektur sollten auf keinen Fall zu aufdringlich sein
und auf diese Weise den Lernenden bei der Arbeit stören.
Abbildung 6-4 zeigt eine Zusammenfassung der Funktionen des System aus der Sicht des
Lernenden in Form eines UML Use-Case Diagram.
6.3.2. Der Lehrende
Der Lehrende publiziert seine Lehrmaterialien im MAESTRO-System. Die Materialien werden
vom Lehrenden derart beschrieben, das eine automatische Verarbeitung des Wissens ermöglich ist
(semantische Netze z.B. in der RDF [117] /RDF Schema [114] oder OWL- Sprache [107] [108],
Sprachen des Semantic Web → 4.3)48. Die Materialien können durch den Lehrenden modifiziert oder
gelöscht werden. Die Materialien werden in Lerneinheiten-Knoten gruppiert. Das MAESTRO-System
bietet dem Lehrenden die Möglichkeit, die für ihn bestimmten Kommentare des Lehrmaterials zu
lesen und zu beantworten. Der Lehrende kann sich über einige Statistiken des Lernprozesses
47 Die Problematik des Umgangs mit wirklichen Zahlungsmitteln in elektronischen Umgebungen ist so komplex, dass ich sie
in meiner Arbeit aus Platzgründen nur sehr allgemein (hypothetisch) betrachten werde. Die Implementierung dieses
Fragmentes der MAESTRO-Architektur wird in meiner Arbeit nicht realisiert. 48 Diese Sprachen sind in erster Linie den Maschinen und nicht den Menschen verständlich. Der Lehrende wird
voraussichtlich selten den RDF-Code selbst erstellen. Dafür sind in der MAESTRO-Architektur spezielle Werkzeuge
vorgesehen, die den Lehrenden auf angenehme Weise erlauben sollen, die semantischen Beschreibungen der Lerninhalte
anzufertigen.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
67
informieren (z.B. welche Übungen wurden besonders gerne gewählt, bei welchen Begriffen sind am
häufigsten Probleme entstanden, usw.). Aufgrund dieser Daten kann der Lehrende Schlüsse für die
weitere Entwicklung der Lehrveranstaltungen ziehen. Bei manchen Ergebnissen der Statistiken soll die
Anonymität der Daten zum Schutz der Lernenden gewährleistet sein. Der Lehrende soll über neue
Wissensmodule im MAESTRO-System informiert werden. Wenn sie semantisch ähnlich sind, soll er
die Möglichkeit haben, sie als Ergänzungsmaterial für seine Lehreinheit vorzuschlagen. Nicht alle
Lehreinheiten müssen frei zugänglich sein. Der Lehrende kann entscheiden, welchen Benutzern
(Gruppen von Benutzern) unter welchen Bedingungen der Zugriff auf die Daten ermöglicht wird. Die
Bedingungen können z.B. die Einzahlung eines gewissen Geldbetrages oder ein Nachweis der
Vorkenntnisse sein.
Erstellung der Lerninhalte
Erstellung des semantischen
Netzes
Lesen und Antworten auf
Kommentare der Lernenden
Zugriff auf Statistiken der
Lernprozesse
Erstellung von Verweisen zu
anderen Lerneinheiten
Lehrender
Abbildung 6-5 Use-Case Diagram für den Lehrenden
Abbildung 6-5 fasst die Funktionen des Systems aus der Sicht des Lehrenden, in Form eines UML
Use-Case Diagram zusammen.
6.3.3. Der Systemadministrator
Der Systemadministrator fügt neue Benutzer in das System ein. Dabei verifiziert er die Identität
des Benutzers, fügt die Daten des Benutzers in das System ein, erzeugt die für den Benutzer
vorgesehenen Agenten und übergibt dem Benutzer die Daten, die zur automatischen Autorisation im
System notwendig sind. Zu den Pflichten des Administrators gehört auch das Löschen der Benutzer
aus dem System, entweder auf Wunsch des Benutzers, nach Ablauf der Zeit, in der der Benutzer das
System nutzen konnte, oder nachdem der Benutzer die Regeln der Arbeit im System gebrochen hat.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
68
Hinzufügen von Benutzern
Kontrolle über die Befolgung der
Regeln durch die Benutzer
Kontrolle der Sicherheit des
SystemsKontrolle der Speicherbestände
Löschen von Benutzern
Erstellung von Zugriffsregeln für
Lernende
Erstellung und Löschen der
Lerneinheits-Knoten
System-
administrator
Abbildung 6-6 Use-Case Diagram für den Systemadministrator
Der Systemadministrator soll die Befolgung der Regeln der Arbeit mit dem System kontrollieren
und – wenn nötig – entsprechend handeln. Dazu gehört z.B. die Suche nach unsachlichen oder
vulgären Kommentaren. Der Systemadministrator verwaltet auch die Mechanismen zum Schutz des
Systems von außen wie von innen (z.B. Denial of Service-Attacks). Diese Sprachen sind in erster
Linie den Maschinen und nicht den Menschen verständlich. Der Lehrende wird voraussichtlich selten
den RDF-Code persönlich erstellen. Dafür sind in der MAESTRO-Architektur spezielle Werkzeuge
vorgesehen, die den Lehrenden auf angenehme Weise erlauben sollen, die semantischen
Beschreibungen der Lerninhalte anzufertigen. Wichtig ist auch die Kontrolle, ob die Speicherbestände
des Systems sich nicht den Grenzen nähern. Dabei sollte der Systemadministrator im richtigen
Moment entsprechend handeln (entweder die Ressourcen vergrößern oder den Selbstreinigungsprozess
des Systems starten). Der Systemadministrator sollte auch das Recht haben, ungenutzte Lerneinheits-
Knoten zu löschen (z.B. in dem Fall, wenn der Eigentümer dieser Einheit nicht mehr Benutzer des
Systems ist).
Die Abbildung 6-6 ist eine Zusammenfassung der Funktionalität des Systemadministrators in
Form eines UML Use-Case Diagrams.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
69
6.4. Architektur des System
Die MAESTRO-Architektur ist vor allem für große Bildungsprojekte wie z.B. das ELAN
Niedersachsen-Projekt (eLearning Academic Network Niedersachsen → 3.7.1 [86]) vorgesehen. In
diesen Projekten werden die Lernmaterialien verschiedener Bildungszentren verbunden und zur
gemeinsamen Nutzung freigesetzt.
ELAN
TU Clausthal Uni GöttingenUni
Oldenburg
MAESTRO-Plattform
Mathematik Informatik Mathematik
MAESTRO-PlattformMAESTRO-Plattform
MAESTRO-Plattform
Mobiler Agent
Stationärer Agent
Mathematik
Abbildung 6-7 Verbindungen von MAESTRO-Plattformen (Beispiel: ELAN Projekt)
Die MAESTRO-Architektur ist ein Netz von miteinander verbundenen MAESTRO-
Plattformen. Eine MAESTRO-Plattform ist eine Agentenplattform mit festgelegten Klassen von
Agenten, erweitert um zusätzliche Komponenten. Jedes Bildungszentrum kann eine oder mehrere (z.B.
eine pro Fakultät oder eine pro Bildungszentrum) MAESTRO-Plattformen besitzen (Abbildung 6-7).
Die Funktion einer einzelnen MAESTRO-Plattform ist die Verwaltung gewisser Mengen von
Lerninhalten und Benutzerdaten. Die mobilen Agenten verknüpfen Bestände aus mehreren
MAESTRO-Plattformen. So kann ein Benutzer aus einem Bildungszentrum auch die Ressourcen
anderer Bildungszentren nutzen.
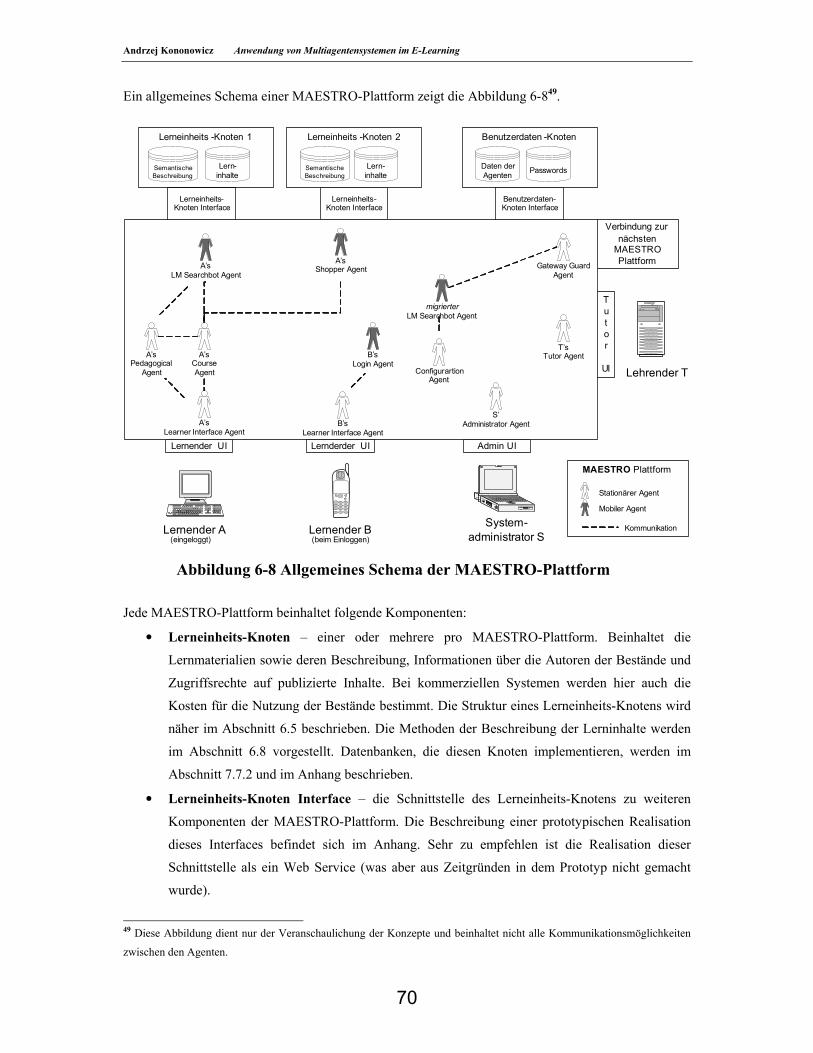
Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
70
Ein allgemeines Schema einer MAESTRO-Plattform zeigt die Abbildung 6-849.
Lernender UI Lernderder UI Admin UI
Semantische
Beschreibung
Lerneinheits-Knoten Interface
Lern-
inhalte
Lerneinheits -Knoten 1
Lern-
inhalte
Lerneinheits -Knoten 2
Lernender BLernender ASystem-
administrator S
A’sPedagogical
Agent
S’
Administrator Agent
Lehrender T
T’sTutor Agent
A’s
LM Searchbot Agent
T
u
t
o
r
UI
(eingeloggt) (beim Einloggen)
Passwords
Benutzerdaten -Knoten
Verbindung zur
nächstenMAESTRO
PlattformGateway Guard
Agent
A’s
Learner Interface Agent
Semantische
Beschreibung
A’sShopper Agent
Daten der
Agenten
Lerneinheits-Knoten Interface
Benutzerdaten-Knoten Interface
migrierter
LM Searchbot Agent
MAESTRO Plattform
Mobiler Agent
Stationärer Agent
Kommunikation
B’s
Login Agent
A’sCourse
Agent Configurartion Agent
B’s
Learner Interface Agent
Abbildung 6-8 Allgemeines Schema der MAESTRO-Plattform
Jede MAESTRO-Plattform beinhaltet folgende Komponenten:
• Lerneinheits-Knoten – einer oder mehrere pro MAESTRO-Plattform. Beinhaltet die
Lernmaterialien sowie deren Beschreibung, Informationen über die Autoren der Bestände und
Zugriffsrechte auf publizierte Inhalte. Bei kommerziellen Systemen werden hier auch die
Kosten für die Nutzung der Bestände bestimmt. Die Struktur eines Lerneinheits-Knotens wird
näher im Abschnitt 6.5 beschrieben. Die Methoden der Beschreibung der Lerninhalte werden
im Abschnitt 6.8 vorgestellt. Datenbanken, die diesen Knoten implementieren, werden im
Abschnitt 7.7.2 und im Anhang beschrieben.
• Lerneinheits-Knoten Interface – die Schnittstelle des Lerneinheits-Knotens zu weiteren
Komponenten der MAESTRO-Plattform. Die Beschreibung einer prototypischen Realisation
dieses Interfaces befindet sich im Anhang. Sehr zu empfehlen ist die Realisation dieser
Schnittstelle als ein Web Service (was aber aus Zeitgründen in dem Prototyp nicht gemacht
wurde).
49 Diese Abbildung dient nur der Veranschaulichung der Konzepte und beinhaltet nicht alle Kommunikationsmöglichkeiten
zwischen den Agenten.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
71
• Benutzerdaten-Knoten – nur ein Knoten pro MAESTRO-Plattform. Wie der Name des
Knotens andeutet, beinhaltet diese Einheit Daten über die Benutzer des Systems. Diese Daten
werden durch die Agenten gesammelt. Abschnitt 6.6 beschreibt diesen Knoten genauer. Eine
Datenbank, die diesen Knoten im MAT-MAESTRO-System implementiert, wird im Abschnitt
7.7.3 und im Anhang präsentiert.
• Benutzerdaten-Knoten Interface – die Schnittstelle des Benutzerdaten-Knotens zu weiteren
Komponenten der MAESTRO-Plattform. Die Beschreibung einer prototypischen Realisation
dieses Interfaces befindet sich im Anhang. Sehr zu empfehlen ist die Realisation dieser
Schnittstelle als Web Service (was aber aus Zeitgründen in dem Prototyp nicht gemacht
wurde).
• MAESTRO-Agenten – eine Reihe spezialisierter Agenten mit unterschiedlichen Funktionen.
Eine allgemeine Charakteristik der Agenten wird im Abschnitt 6.7 gezeigt. Die
Zusammenarbeit der Agenten zur Realisation der Systemfunktionen im MAT-MAESTRO-
System beschreibt Abschnitt 7.2. Einen detaillierten Einblick in die Dynamik der einzelnen
Agenten geben die Aktivitätsdiagramme, die in den Anhang aufgenommen wurden.
• Learner UI50 (Benutzerschnittstellen für den Lernenden) – Diese Schnittstelle bietet dem
Lernenden die Möglichkeit zur Ausführung seiner Funktionen im System (→ 6.3.1). Ein
Prototyp einer Web-Anwendung, der einige dieser Funktionen realisiert, wird im Abschnitt
8.2 und im Anhang gezeigt.
• Tutor UI (Benutzerschnittstellen für den Lehrenden) – Diese Schnittstelle bietet dem
Lehrenden die Möglichkeit zur Ausführung seiner Funktionen im System (→ 6.3.2). Ein
Werkzeug, das die Lernmodule mit dem semantischen Netz im RDF-Format einrichtet (→
6.8), ist Teil des MAT-MAESTRO. Die Beschreibung dazu befindet sich in den Abschnitten
7.5, 8.2 und im Anhang.
• Admin UI (Benutzerschnittstellen für Systemadministratoren) – Diese Schnittstelle bietet dem
Systemadministratoren die Möglichkeit der Ausführung seiner Funktionen im System (→
6.3.3). In Rahmen dieser Diplomarbeit wird kein explizites Werkzeug für den Administrator
entworfen oder implementiert.
• Verbindungen zu anderen Agentenplattformen – die Verknüpfung erfolgt durch eine
spezielle überwachte Pforte. Die Sicherheitsmechanismen zum Schutz gegen Gefahren
außerhalb der MAESTRO-Plattform werden aus Zeitgründen, trotz ihrer Relevanz, in dieser
Arbeit nicht näher betrachtet.
50 UI – (engl. User Interface) – Benutzerschnittstelle

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
72
6.5. Lerneinheits-Knoten
Die Lerneinheits-Knoten werden durch Lehrende für die Ordnung der Lerninhalte erzeugt. Die
Daten werden auch semantisch beschrieben, um ihre Weiterverarbeitung durch Agenten zu erlauben.
MAESTRO-Plattform
Lerneinheits-Knoten
Lernmodul
Seite
Semantische
Beschreibung des
Lernmoduls
Zugriffsrechte der
Benutzer
Informationen über den /die
Autor/-en
des Lernmoduls
Allgemeine Beschreibung
des Lernmoduls
Kommentare
Verknüpfungen
mit anderen Lernmodulen
0..n
1
1
0..n1
1..n
1
0..n 1
1..n
1
1..n
1..n1
0..n
1
1
0..n
Strukturelle
Beschreibung des
Lernmoduls
1..n
1
Abbildung 6-9 Lerneinheits-Knoten im Detail
Die Abbildung 6-9 zeigt das Schema eines Lerneinheits-Knoten. Ein Lerneinheits-Knoten
beinhaltet folgende Daten:
• Allgemeine Beschreibung – Eine Beschreibung der gebotenen Lerneinheit in natürlicher
Sprache. Diese Charakteristik dient nur als Information für andere Benutzer (vor allem
Lernende, aber auch andere Lehrende) und wird vom System nicht automatisch verarbeitetet
(dazu dient die semantische Beschreibung). Diese allgemeine Beschreibung kann als
Motivation für den Lernenden und zur Einschreibung für die Lehreinheit funktionieren. Sie
kann neben einem Überblick des präsentierten Lehrstoffes auch Anwendungsbeispiele des
vorgetragenen Wissens beinhalten. Nützlich sind Information über für die Lerneinheit
erforderliche Vorkenntnisse, wie auch mit dieser Lerneinheit verbundene Veranstaltungen im
Präsenzstudium. Das Format der Beschreibung kann eine einfache Textdatei sein oder
Webseiten im HTML/XHTML-Format.
• Lernmodule – Zusammenfassung inhaltlich verwandter didaktischer Seiten.
• Seiten – HTML/XML Dokumenten und auch mit ihnen verknüpfte Bilder, Applets usw., die
den Lernstoff bilden.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
73
• Semantische Beschreibung – Eine formale Beschreibung der Materialien der Lehreinheit. Die
Beschreibung wird im RDF-Format [117] (RDF Scheme [114] oder OWL [107] [108])
gespeichert. Zur Erstellung der Beschreibung kann man verschiedene Anwendungsprogramme
des Semantic Web benutzen wie z.B. Protégé 2000 [109], SMORE [123] oder spezielle
Werkzeuge, die für die MAESTRO-Architektur entwickelt wurden (→ 8.2.2). Die
Beschreibungen werden in speziellen RDF-orientieren Datenbanken aufbewahrt (RDF
Datastores → 4.4.2). Der Zugriff auf die Daten wird durch spezielle semantische
Anfragesprachen realisiert – z.B. RDFQL oder RQL [119].
• Zugriffsrechte der Benutzer – beinhaltet Informationen, welche Gruppen von Benutzern unter
welchen Bedingungen der Zugriff auf die Lerninhalte ermöglicht wird. Es können
Bedingungen kommerzieller Art sein (Zugriff nach Bezahlung) oder bedingt durch die
erbrachte Vorleistung (z.B. nur für Studenten im Hauptdiplom). Lernenden können in
verschiedene Gruppen eingeteilt werden (z.B. nach dem Bildungszentrum der Registrierung).
Gruppen können ihre eigenen Zugriffsrechte haben. Wenn sich verschiedene Zugriffsregeln
widersprechen, wird zu Gunsten des Lernenden entschieden. Je nach Menge der Regeln
können die Daten in einer einfachen Textdatei oder in einer Relationsdatenbank aufbewahrt
werden. Diese Daten werden nicht außerhalb des Lerninheits-Knotens in einem zentralen
Benutzerdaten-Knoten aufbewahrt, um die Dezentralisierung zu fördern und dadurch mehr
Flexibilität zu gewinnen.
• Autor des Lernmoduls – Information über den Autor der Lerneinheit. Identifikationsnummer
des Lehrenden, der die Materialien der Lehreinheit modifizieren oder löschen darf. Diese
Person oder deren Agenten haben auch Zugriff auf die Kommentare zu den Materialien der
Lerneinheit. Bei Bedarf kann der Lerneinheits-Knoten auch detaillierte Informationen über
den Lehrenden beinhalten: z.B. E-Mail-Adresse, Telefonnummer, Anschrift, Termine der
Sprechstunden, Foto oder Verweis auf die persönliche Homepage des Lehrenden oder auf
andere durch den Lehrenden geführte Lerneinheits-Knoten.
• Kommentare – Kommentare zu den Materialien der Lerneinheit die für andere Lernende oder
Lehrende bestimmt sind. Die Kommentare können in einfachem ASCII-Textformat, HTML
oder XML gespeichert sein. Jeder Kommentar beinhaltet zusätzlich den Namen des Autors
sowie den Zeitpunkt der Entstehung des Kommentars. Die Kommentare können auch andere
Kommentare betreffen. Auf diese Weise kann eine on-line Diskussion geführt werden. Der
Lehrende darf auch an öffentlichen Diskussionen teilnehmen. Die Identität des
kommentierenden Lernenden kann vor dem Lehrenden verborgen werden (aber nicht vor dem
Systemadministrator – aus Sicherheitsgründen).
• Verknüpfungen – Verknüpfungen zu anderen ähnlichen Lerneinheits-Knoten. Diese Verweise
werden von dem Lehrenden erzeugt, um den Agenten die Suche nach semantisch ähnlichen

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
74
Inhalten zu ermöglichen (es können sogar Verweise auf Bestände des öffentlichen Internets
sein, die nicht die Anforderungen der MAESTRO-Architektur erfüllen51).
6.6. Benutzerdaten-Knoten
In einem Benutzerdaten-Knoten werden Daten der Lernenden und Daten für alle
Benutzergruppen gemeinsam gespeichert. Diese Daten werden von unterschiedlichen Agenten52
verwendet.
Zu den Daten, die jeden Benutzer beschreiben, zählen u.a. der vollständige Name des
Benutzers, die Rolle des Benutzers im System (Lernender, Lehrender, Administrator) sowie das
Kennwort des Benutzers. Die allgemeinen Benutzerdaten werden vor allem durch die Login Agents
zwecks Autorisation genutzt.
Zu den Daten des Lernenden zählen die persönlichen Einstellungen des Lernprozesses (wie z.B.
Informationen über den Lernstil des Lernenden, das zulässige Format der Lerninhalte, interessante
Schlüsselwörter) und die Geschichte des Lernprozesses (die Liste der geöffneten Lernmodule und der
gesehenen Seiten). Diese Daten werden durch zwei Sorten von Agenten genutzt: Course Agents (vor
allem für die Geschichte der Lernprozesse) und Pedagogical Agents (vor allem für die persönlichen
Einstellungen des Lernprozesses). Die Daten werden von diesen Agenten beim Einloggen aus dem
Benutzerdaten-Knoten bezogen, während der Arbeit mit dem Lernenden verwendet und entsprechend
der Situation geändert und nach dem Ausloggen des Benutzers wieder in dem Benutzerdaten-Knoten
gespeichert.
6.7. MAESTRO-Agenten
Tabelle 6-1 beinhaltet eine kurze Charakteristik der MAESTRO-Agenten. Die erste Spalte
beinhaltet neben dem Namen des Agenten die Information, ob der Agent stationär oder mobil ist53. Die
weiteren Spalten beschreiben die Ziele, Aufgaben zur Realisation der Ziele und den Lebenszyklus des
Agenten. Eine detallierte Beschreibung der Funktion ausgewählter Agenten im MAT-MAESTRO-
System befindet sich im Abschnitt 7.2 und im Anhang.
51 Für diese Dokumente werden die Möglichkeiten der MAESTRO-Architektur selbstverständlich eingeschränkt. 52 Die Agenten werden im Abschnitt 6.7 charakterisiert. 53 Der Unterschied zwischen den Agententypen wird in Abschnitt 2.1.6.6 erklärt

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
75
Name des Agenten Ziel Aufgaben Lebenszyklus Login Agent (mobil)
Verifiziert die Identität des Benutzers − Übernimmt den Namen und das Kennwort des Benutzers von dem Interface Agent
− Findet den Benutzerdaten-Knoten − Verifiziert die Identität des Benutzers − Informiert den Learner Interface Agent
über das Ergebnis der Autorisation
� Erzeugt (durch den Learner Interface Agent, Tutor Agent oder Administrator Agent) bei jedem Versuch des Einloggens.
� Beseitigt nach der Übermittlung der Information über das Ergebnis der Autorisation
Course Agent (stationär)
Verwaltet für den Lernenden Informationen über eine bestimmte Lerneinheit
− Sammelt Information welche Materialien der Lerneinheit der Lernende schon gesehen hat (wie oft) und wie er sie bewertet hat
− Bei der Leistung der Hilfestellung schickt der Agent LM Searchbot Agents aus, auf der Suche nach zusätzlichen Informationen über den Inhalt des Lernmoduls
− Arbeitet mit dem Pedagogical Agent bei der Aufstellung einer, an den Lernenden angepassten Hilfestellungen zusammen
− Koordiniert die Bestellungen des Lernenden auf didaktische Materialien (schickt Shopper Agenten aus, empfängt die gekauften Ressourcen und leitet sie an den Learning Material Agent weiter)
� Erzeugt zum ersten Mal nach Anmeldung des Lernenden zu einer neuen Lerneinheit
� Beim Ausloggen des Lernenden speichert der Agent seine Daten in dem Benutzerdaten-Knoten ab. Der Agent selbst wird danach gelöscht.
� Beim nächsten Einloggen des Lernenden wird der Agent erneut erstellt. Er bezieht seine Daten aus dem Benutzerdaten-Knoten.
Pedagogical Agent (stationär)
Entscheidet über die für den Lernenden geeignete Lernstrategie
− Übernimmt von dem Learner Interface Agent die Informationen über das Verhalten des Benutzers und speichert sie
− Zieht anhand der gesammelten Daten Schlüsse über Charakter und Vorlieben des Lernenden
− Speichert die persönlichen Lernprozess-Einstellungen des Benutzers ab
− Auf Wunsch des Benutzers, eine neue Lerneinheit zu beginnen, schickt der Pedagogical Agent LM Searchbot Agents aus um nach neuen Modulen aus, verschiedenen Lerneinheits-Knoten zu suchen, filtert die Ergebnisse (unter Berücksichtigung der Informationen über
� Erzeugt zum ersten Mal nach dem ersten Einloggen des Lernenden in das System.
� Beim Ausloggen des Lernenden speichert der Agent seine Daten in dem Benutzerdaten-Knoten ab. Der Agent selbst wird danach gelöscht.
� Beim nächsten Einloggen des Lernenden wird der Agent erneut erstellt. Er bezieht seine Daten aus dem Benutzerdaten-Knoten.
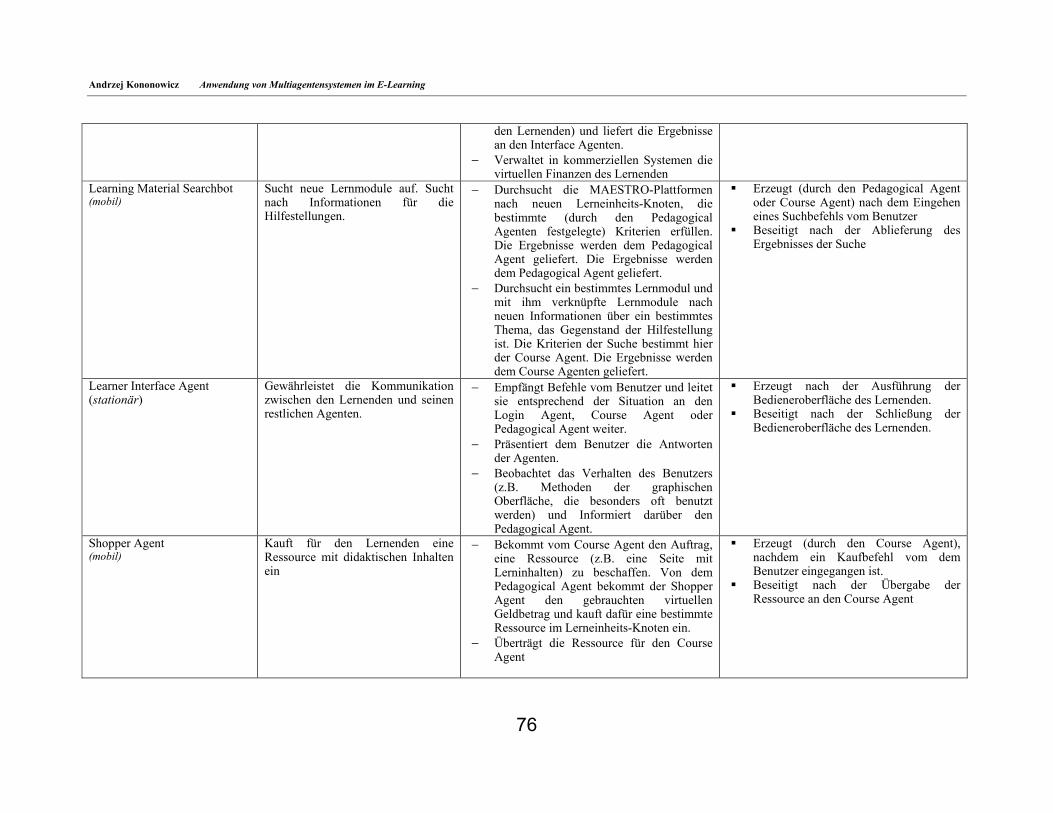
Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
76
den Lernenden) und liefert die Ergebnisse an den Interface Agenten.
− Verwaltet in kommerziellen Systemen die virtuellen Finanzen des Lernenden
Learning Material Searchbot (mobil)
Sucht neue Lernmodule auf. Sucht nach Informationen für die Hilfestellungen.
− Durchsucht die MAESTRO-Plattformen nach neuen Lerneinheits-Knoten, die bestimmte (durch den Pedagogical Agenten festgelegte) Kriterien erfüllen. Die Ergebnisse werden dem Pedagogical Agent geliefert. Die Ergebnisse werden dem Pedagogical Agent geliefert.
− Durchsucht ein bestimmtes Lernmodul und mit ihm verknüpfte Lernmodule nach neuen Informationen über ein bestimmtes Thema, das Gegenstand der Hilfestellung ist. Die Kriterien der Suche bestimmt hier der Course Agent. Die Ergebnisse werden dem Course Agenten geliefert.
� Erzeugt (durch den Pedagogical Agent oder Course Agent) nach dem Eingehen eines Suchbefehls vom Benutzer
� Beseitigt nach der Ablieferung des Ergebnisses der Suche
Learner Interface Agent (stationär)
Gewährleistet die Kommunikation zwischen den Lernenden und seinen restlichen Agenten.
− Empfängt Befehle vom Benutzer und leitet sie entsprechend der Situation an den Login Agent, Course Agent oder Pedagogical Agent weiter.
− Präsentiert dem Benutzer die Antworten der Agenten.
− Beobachtet das Verhalten des Benutzers (z.B. Methoden der graphischen Oberfläche, die besonders oft benutzt werden) und Informiert darüber den Pedagogical Agent.
� Erzeugt nach der Ausführung der Bedieneroberfläche des Lernenden.
� Beseitigt nach der Schließung der Bedieneroberfläche des Lernenden.
Shopper Agent (mobil)
Kauft für den Lernenden eine Ressource mit didaktischen Inhalten ein
− Bekommt vom Course Agent den Auftrag, eine Ressource (z.B. eine Seite mit Lerninhalten) zu beschaffen. Von dem Pedagogical Agent bekommt der Shopper Agent den gebrauchten virtuellen Geldbetrag und kauft dafür eine bestimmte Ressource im Lerneinheits-Knoten ein.
− Überträgt die Ressource für den Course Agent
� Erzeugt (durch den Course Agent), nachdem ein Kaufbefehl vom dem Benutzer eingegangen ist.
� Beseitigt nach der Übergabe der Ressource an den Course Agent
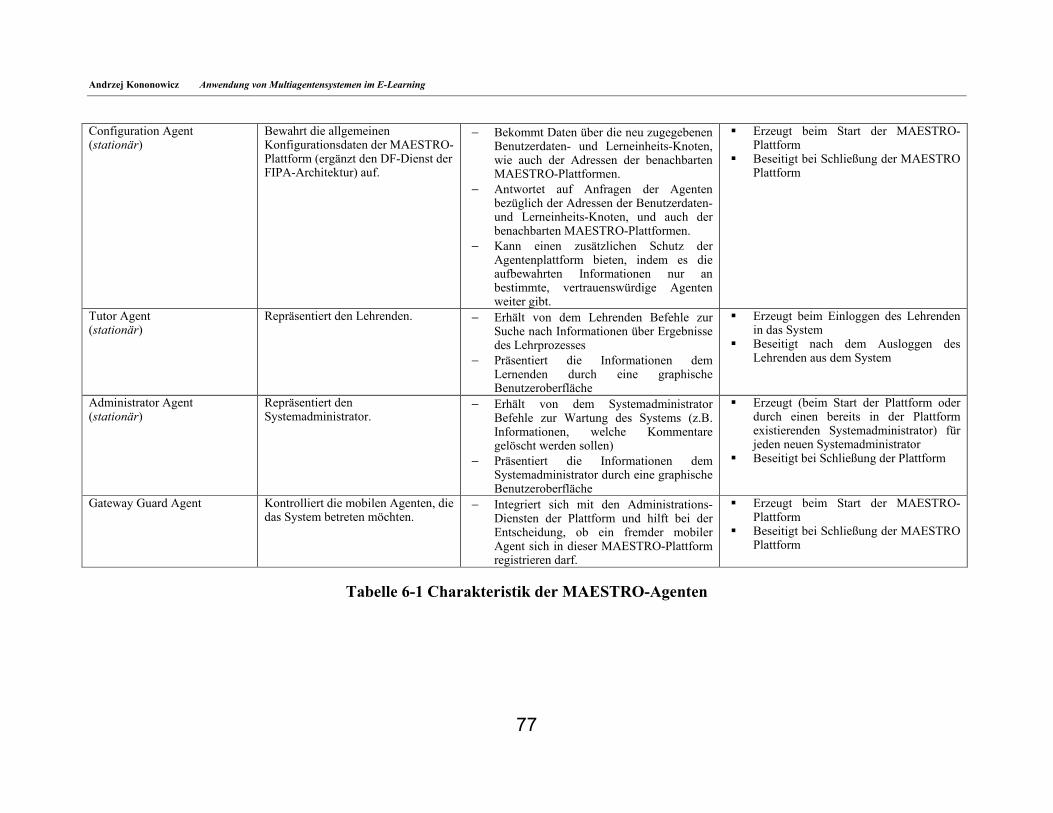
Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
77
Configuration Agent (stationär)
Bewahrt die allgemeinen Konfigurationsdaten der MAESTRO-Plattform (ergänzt den DF-Dienst der FIPA-Architektur) auf.
− Bekommt Daten über die neu zugegebenen Benutzerdaten- und Lerneinheits-Knoten, wie auch der Adressen der benachbarten MAESTRO-Plattformen.
− Antwortet auf Anfragen der Agenten bezüglich der Adressen der Benutzerdaten- und Lerneinheits-Knoten, und auch der benachbarten MAESTRO-Plattformen.
− Kann einen zusätzlichen Schutz der Agentenplattform bieten, indem es die aufbewahrten Informationen nur an bestimmte, vertrauenswürdige Agenten weiter gibt.
� Erzeugt beim Start der MAESTRO-Plattform
� Beseitigt bei Schließung der MAESTRO Plattform
Tutor Agent (stationär)
Repräsentiert den Lehrenden. − Erhält von dem Lehrenden Befehle zur Suche nach Informationen über Ergebnisse des Lehrprozesses
− Präsentiert die Informationen dem Lernenden durch eine graphische Benutzeroberfläche
� Erzeugt beim Einloggen des Lehrenden in das System
� Beseitigt nach dem Ausloggen des Lehrenden aus dem System
Administrator Agent (stationär)
Repräsentiert den Systemadministrator.
− Erhält von dem Systemadministrator Befehle zur Wartung des Systems (z.B. Informationen, welche Kommentare gelöscht werden sollen)
− Präsentiert die Informationen dem Systemadministrator durch eine graphische Benutzeroberfläche
� Erzeugt (beim Start der Plattform oder durch einen bereits in der Plattform existierenden Systemadministrator) für jeden neuen Systemadministrator
� Beseitigt bei Schließung der Plattform
Gateway Guard Agent Kontrolliert die mobilen Agenten, die das System betreten möchten.
− Integriert sich mit den Administrations-Diensten der Plattform und hilft bei der Entscheidung, ob ein fremder mobiler Agent sich in dieser MAESTRO-Plattform registrieren darf.
� Erzeugt beim Start der MAESTRO-Plattform
� Beseitigt bei Schließung der MAESTRO Plattform
Tabelle 6-1 Charakteristik der MAESTRO-Agenten

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
78
6.8. Beschreibung der Lerninhalte
Die Lerninhalte werden in der MAESTRO-Architektur mit Hilfe semantischer Netze beschrieben54.
Jedes Lernmodul besitzt sein eigenes Netz. Der Name „semantische Netze“ ist hier ein wenig irreführend55,
denn diese Strukturen beschreiben nicht nur die semantischen, sondern auch die strukturellen
Zusammenhänge von Konzepten aus den Lernmodulen. Diese Beschreibung wird in den Lerninhalts-Knoten
der MAESTRO-Plattform gespeichert.
Die MAESTRO-semantischen Netze bestehen aus drei Sorten von Knoten56:
• Term-Knoten, die Begriffe aus dem Lernbereich repräsentieren (Beispiele: Stichprobe57, DNA,
Schwerkraft, NP-Problem)
• Page-Knoten, die didaktische Seiten repräsentieren (Beispiele: Satz 2.258., Definition 2.5, Bemerkung
2.7)
• Structure-Knoten, die die Struktur des Lernmoduls repräsentieren (Beispiele: Kapitel 1, Abschnitt
1.2.3)
Abbildung 6-10 und Abbildung 6-11 zeigen beispielhafte semantische Netze für einen Abschnitt eines
Statistik-Lernmoduls (Quelle des Lerninhaltes ist [43]). Die weißen Knoten bedeuten Term-Knoten, die
rosafarbigen Page-Knoten, die bläulichen Structure-Knoten.
Die Knoten in den semantischen Netzen werden durch Relationen verknüpft. Relationen zur
Beschreibung der semantischen Zusammenhänge im Lernmodul zeigt die Tabelle 6-2. Die Liste der
Relationen ist nicht vollständig. Zu den möglichen weiteren Relationen gehören u.a. die Relationen (partOf,
related). Die Liste wird aber in der ersten Version der Architektur aus Komplexitätsgründen auf die vier in
der Tabelle 6-2 genannten Relationen beschränkt.
54 Die Netze werden in der RDF-Sprache (→ 4.3.1) implementiert 55 Das Problem kennt man schon von dem Begriff Semantic Web 56 Diese Knoten entsprechen in der RDF-Terminologie den Ressourcen 57 Die Ressourcen werden in RDF durch URI identifiziert. Das bedeutet, dass z.B. der Knoten Stichprobe durch den URI
http://maestro.org/clausthalMat1/AngwStatistik#stichprobe repräsentiert wird. Die landesspezifischen Zeichen werden auf
internationale Zeichen transformiert. Die Leerzeichen werden ausgelassen. Für eine bessere Lesbarkeit wird in diesem Kapitel auf die
URI-Bezeichnungen verzichtet. 58 Genauer gesagt, werden die Page-Knoten durch Dateinamen identifiziert. Die präsentierte Form dient lediglich der besseren
Lesbarkeit.
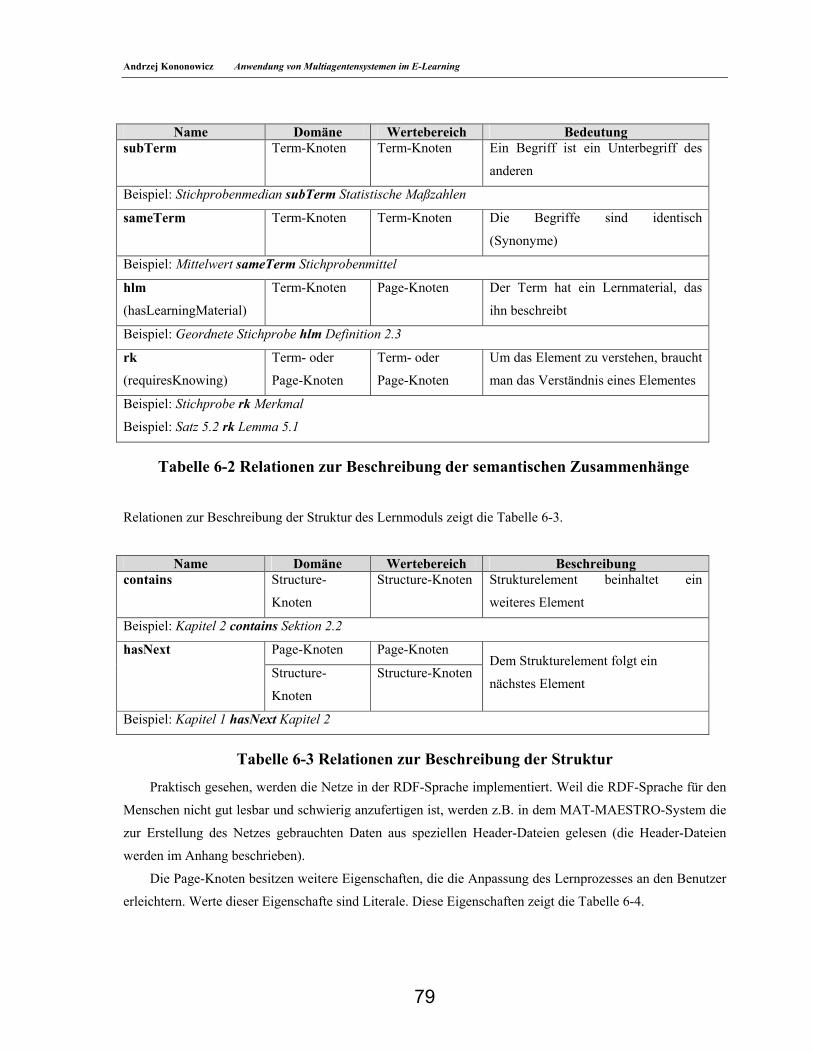
Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
79
Name Domäne Wertebereich Bedeutung subTerm Term-Knoten Term-Knoten Ein Begriff ist ein Unterbegriff des
anderen
Beispiel: Stichprobenmedian subTerm Statistische Maßzahlen
sameTerm Term-Knoten Term-Knoten Die Begriffe sind identisch
(Synonyme)
Beispiel: Mittelwert sameTerm Stichprobenmittel
hlm
(hasLearningMaterial)
Term-Knoten Page-Knoten Der Term hat ein Lernmaterial, das
ihn beschreibt
Beispiel: Geordnete Stichprobe hlm Definition 2.3
rk
(requiresKnowing)
Term- oder
Page-Knoten
Term- oder
Page-Knoten
Um das Element zu verstehen, braucht
man das Verständnis eines Elementes
Beispiel: Stichprobe rk Merkmal
Beispiel: Satz 5.2 rk Lemma 5.1
Tabelle 6-2 Relationen zur Beschreibung der semantischen Zusammenhänge
Relationen zur Beschreibung der Struktur des Lernmoduls zeigt die Tabelle 6-3.
Name Domäne Wertebereich Beschreibung contains Structure-
Knoten
Structure-Knoten Strukturelement beinhaltet ein
weiteres Element
Beispiel: Kapitel 2 contains Sektion 2.2
Page-Knoten Page-Knoten hasNext
Structure-
Knoten
Structure-Knoten Dem Strukturelement folgt ein
nächstes Element
Beispiel: Kapitel 1 hasNext Kapitel 2
Tabelle 6-3 Relationen zur Beschreibung der Struktur
Praktisch gesehen, werden die Netze in der RDF-Sprache implementiert. Weil die RDF-Sprache für den
Menschen nicht gut lesbar und schwierig anzufertigen ist, werden z.B. in dem MAT-MAESTRO-System die
zur Erstellung des Netzes gebrauchten Daten aus speziellen Header-Dateien gelesen (die Header-Dateien
werden im Anhang beschrieben).
Die Page-Knoten besitzen weitere Eigenschaften, die die Anpassung des Lernprozesses an den Benutzer
erleichtern. Werte dieser Eigenschafte sind Literale. Diese Eigenschaften zeigt die Tabelle 6-4.
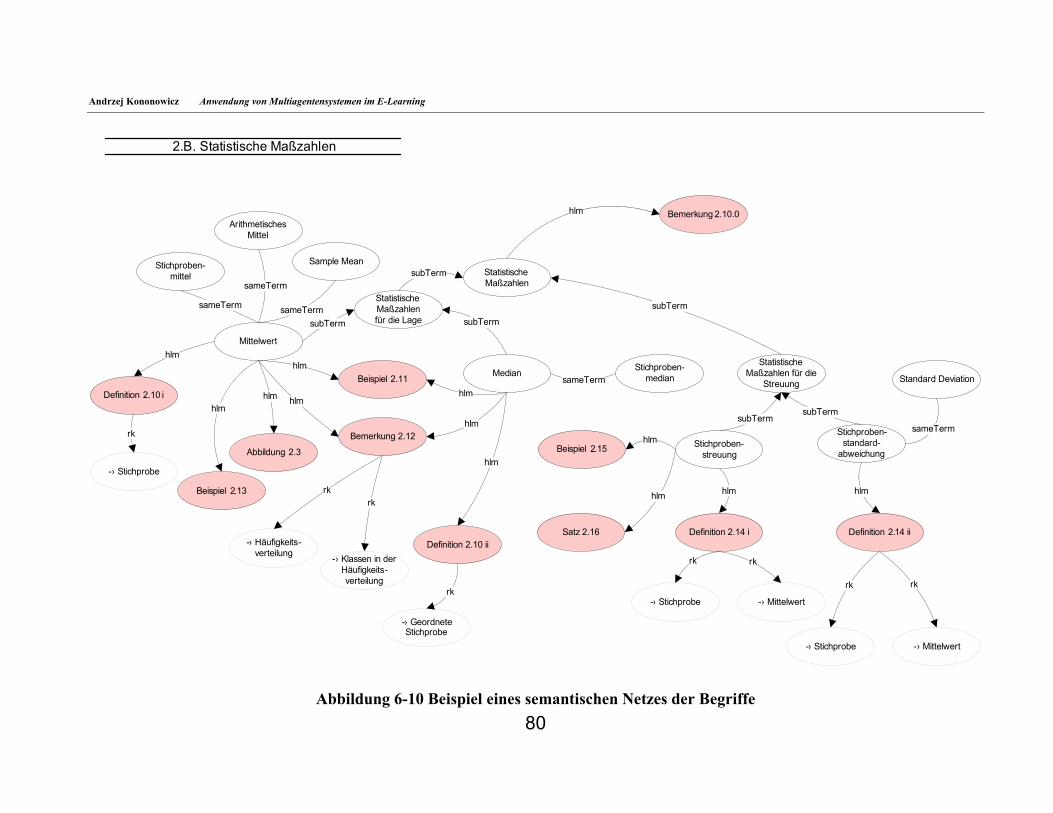
Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
80
2.B. Statistische Maßzahlen
Definition 2.10 i
hlm
subTerm
Mittelwert
-› Stichprobe
rk
Abbildung 2.3
hlm
Stichproben-
mittel
Arithmetisches
Mittel
Sample Mean
sameTerm
sameTerm
sameTerm
Statistische
Maßzahlen
Beispiel 2.11
Bemerkung 2.12
Median
Definition 2.10 ii
-› GeordneteStichprobe
Stichproben-
median
Bemerkung 2.10.0
Statistische
Maßzahlen für die
Streuung
Stichproben-
streuung
Stichproben-
standard-
abweichung
Standard Deviation
Beispiel 2.15
Satz 2.16 Definition 2.14 i Definition 2.14 ii
-› Stichprobe -› Mittelwert
-› Stichprobe -› Mittelwert
subTerm
subTerm
hlm
hlmhlm
hlm
hlm
rk
sameTerm
hlm
sameTermsubTerm
subTerm
hlm
hlmhlm
rk rk
rk rk
hlmBeispiel 2.13
hlm
-› Häufigkeits-
verteilung-› Klassen in der
Häufigkeits-
verteilung
rk
rk
Statistische
Maßzahlen
für die Lage
subTerm
Abbildung 6-10 Beispiel eines semantischen Netzes der Begriffe

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
81
Name der Eigenschaft Beschreibung Difficulty Beschreibt den Schwierigkeitsgrad des Lerninhaltes. Beispielwerte59 sind
very easy, easy, moderate, hard, very hard.
Stage Beschreibt das Niveau des Lerninhaltes. Beispielwerte: pre-primary,
primary, secondary, post-secondary.
lmType Beschreibt den Typ des Lerninhaltes. Beispielwerte: definition, static
example, interactive example, static static example, interactive example,
static exercise, interactive exercise, remark, theorem.
lmFormatType Gibt Formate der Ressourcen, die den Page-Knoten bilden. Beispielwerte:
pdf ,java applet ,png, gif ,jpeg , macromedia flash. (html ,xhtml, muss durch
den Benutzer akzeptiert werden)
hasAddFiles Gibt den Namen einer anderen Ressource, die mit der aktuellen Ressource
unzertrennlich zusammenhängt. Z.B. hängen mit einer Web-Seite
normalerweise zusätzliche Bilddateien zusammen. Die zusätzlichen
Ressourcen bilden in sich keinen selbstständigen Page-Knoten.
Tabelle 6-4 Eigenschaften der Page-Knoten
Die semantische Beschreibung wird u.a. zu zweierlei Anfragen verwendet: Hilfe bei einem nicht
verstandenen Begriff (oder alle Themen auf einer bestimmten Seite) und zur Realisation der Vertiefungs-
Funktion, bei dem der Lernende mehr Informationen über einen ihn interessierenden Begriff (oder alle
Themen auf einer bestimmten Seite) bekommen möchte. Details dieses Vorgangs werden im
Abschnitt 7.4 näher erklärt.
Kapitel 1
Einleitung
Teil I.
Beschreibende Statistik
Kapitel 2Beschr.Statistik bei
einem Merkmal
Abschnitt 2A
Stichprobe und
Häufigkeitsverteilung
Definition 2.3Beispiel 2.1 Satz 2.2
contains
contains
containscontains
contains
hasNext
hasNext hasNext
Abbildung 6-11 Beispiel eines strukturellen Netzes des Lernmoduls
59 Die Relationen, Eigenschaften und Beispielwerte der Eigenschaften könnten in der Zukunft eine formelle Ontologie bilden.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
82
7. MAT-MAESTRO
Wie schon in der Einführung zum Kapitel 6 gesagt wurde, ist die vollständige Entwicklung der
MAESTRO-Architektur ein sehr aufwendiger Prozess, der den Rahmen einer Diplomarbeit sprengen würde.
Aus diesem Grund konzentriere ich mich im Folgenden auf ausgewählte Aspekte der vorgeschlagenen
Architektur. Dieses Kapitel beinhaltet einen Teil des detaillierten Entwurfs des prototypischen MAT-
MAESTRO-Systems (hauptsächlich in der UML Notation → Kapitel 6). Dieses System kann für die
Mathematiklehre (Spezialgebiet Statistik) angewandt werden. Die Lerninhalte für den Prototyp sind aus den
ersten Kapiteln des Skripts Angewandte Statistik von Michael Kolonko [43] entnommen worden.
7.1. Einschränkungen gegenüber der vollständigen MAESTRO-Architektur
Das MAT-MAESTRO-System wird sich vor allem auf die Funktionen für den Lernenden konzentrieren.
Es werden Einloggen/Ausloggen in das/aus dem System, Eröffnung eines neuen Lernmoduls,
Wiedereröffnung eines Lernmoduls, Zugriff auf didaktische Seiten, Persönliche Einstellungen des
Lernprozesses und Realisation der Hilfestellung/Vertiefung – Funktionen entworfen. Das entsprechenden
Use-Case Diagram stellt die Abbildung 7-1dar.
Einloggen/Ausslogen
Eröffnung eines neuen Lernmoduls
Zugriff auf didaktische Seiten
Wiedereröffnung eines Lernmoduls
Realisation der
Hilfestellung/Vertiefungsfunktion
Persönliche Einstellungen des
Lernprozesses
Lernender
Abbildung 7-1 Funktionen des MAT-MAESTRO-System aus der Sicht des Lernenden

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
83
Im Vergleich zu den Use-Case Diagrams für die MAESTRO-Architektur (Abbildung 6-4) wurde die
Realisation der Funktionen zur kommerziellen Nutzung von Wissensbeständen, die Evaluation der
Hilfebestände sowie Möglichkeit zur Diskussion über Lerninhalte ausgelassen. Die Funktion An-/Abmeldung
zur Lerneinheit wurde in die Eröffnung eines neuen Lernmoduls und Wiedereröffnung eines Lernmoduls
gegliedert. Die Nutzung der „intelligenten“ Hilfe wurde auf Realisation der Hilfestellung/Vertiefung –
Funktionen präzisiert.
Es werden auch rudimentär einige Funktionen des Lehrenden (Erstellung des semantischen Netzes,
Erstellung von Verweisen auf andere Lerneinheiten) und des System-Administrators (Erstellung von
Lerneinheits-Knoten) in dem Prototyp des MAT-MAESTRO-Systems implementiert (Abbildung 7-2). Die
anderen Funktionen dieser zwei Benutzergruppen aus der MAESTRO-Architektur (→ Abbildung 6-4 und
Abbildung 6-5) wurden in dem Projekt ausgelassen.
Erstellung des semantischen
Netzes
Erstellung von Verweisen auf
andere Lerneinheiten
LehrenderErstellung von Lerneinheits-Knoten
System-
administrator
Abbildung 7-2 Funktionen des MAT-MAESTRO-System aus der Sicht des Lehrenden und des Lernenden
7.2. Realisation der Funktionen des Lernenden
Im Abschnitt 7.1 habe ich die Anwendungsfälle des MAT-MAESTRO-Systems für den Lernenden
vorgestellt. In diesem Abschnitt möchte ich die Realisation der Funktionalität des Systems für den
Lernenden mit Hilfe von Sequenzdiagrammen illustieren.
Ein UML-Sequenzdiagramm zeigt einzelne Abläufe der Realisation einer Systemfunktion in ihrer
genauen Reihenfolge. Dieses Diagramm stellt einen Weg durch den Entscheidungsbaum innerhalb eines
Systemablaufes dar [131]. Die UML-Sequenzdiagramme können auch durch UML-
Kollaborationsdiagramme ersetzt werden, die dieselben Informationen in einer anderen Notation
präsentieren. Um alle Entscheidungsmöglichkeiten des Ablaufes einer Systemfunktion zu zeigen, können die
UML-Aktivitätsdiagramme benutzt werden.
Ich habe die UML-Notation der genutzten Objekte ergänzt. Die weißen Rechtecke stellen den Benutzer
des Systems dar, der mit Hilfe eines Internet Browsers und Servlets mit dem System kommuniziert, die
bläulichen Rechtecke zeigen die MAESTRO-Agenten an, die rosafarbigen Kästchen dagegen bedeuten
entweder den Lerneinheits-Knoten, den Benutzerdaten-Knoten oder den DF-Dienst (also die Elemente der

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
84
Plattform, die nicht als Agenten realisiert sind60). Eine genaue Beschreibung der Nachrichten-Klassen
befindet sich im Anhang
Im folgenden Teil des Abschnittes präsentiere ich Sequenzdiagramme
• das Einloggen in das System
• die Wiedereröffnung einen Moduls
• die Eröffnung eines neuen Moduls
• das Anzeigen der gewünschten Seite mit Lerninhalten
• die Realisation der Hilfestellung
• das Ausloggen aus dem System
Die Vertiefungsfunktion wird nach identischem Schema, wie die Hilfestellung realisiert, daher wird sie
aus Platzgründen nicht dargestellt. Die Persönliche Einstellungen des Lernprozesses-Funktion wird in die
Eröffnung eines neuen Moduls und Realisation der Hilfestellung-Funktionen mit einbezogen (die gefundenen
Informationen werden an den Lernenden angepasst). Die Kommunikation der Agenten mit dem Directory
Facilitator (→2.3.1) zwecks Registrierung und Deregistrierung der Dienste, wie auch das Aufsuchen der
Agenten mit Hilfe des DF, wurde wegen der besseren Übersicht der Diagramme und auch der
Offensichtlichkeit dieses Prozesses ausgelassen. Für eine bessere Lesbarkeit der Diagrame wurde der Name
Learner Interface Agent auf Interface Agent gekürzt.
Eine gewisse Schwierigkeit stellen die Adressen der Lerneinheits- und Benutzerdatens-Knoten dar. Die
Knoten sind keine Agenten, daher sind sie auch nicht in dem DF zu finden. Das Aufsuchen dieser Adressen
erfolgt durch den Configuration Agent, der die globalen (nicht agentenspezifischen) Daten aufbewahrt.
Diesen Prozess zeigt die Abbildung 7-3, auf der ein unbestimmter MAESTRO-Agent die Adresse des
Benutzerdaten-Knoten ermittelt.
: Generic MAESTRO Agent : DF : Configuration Agent
findConfigurationAgent()
configurationAgentAID
GetUserNodeAddressMsg
UserNodeAddressMsg
Abbildung 7-3 Sequenzendiagramm - Aufsuchen von Adressen mit Hilfe des Configuration Agent
60 Laut der neusten FIPA Spezifikation [91] muss der DF nicht mehr als Agent realisiert sein.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
85
7.2.1. Einloggen in das System
Beim Einloggen in das System-Sequenzdiagramm (Abbildung 7-4) öffnet der Benutzer die Startseite des
MAT-MAESTRO-Systems und führt seinen Benutzernamen und sein Kennwort zwecks Autorisation ein.
Die Daten werden dem Learner Interface Agent durch das HTTP-Protokoll übergeben. Dieser Agent erzeugt
daraufhin einen Login Agent, der die Aufgabe erhält, den Benutzerdaten-Knoten zu finden, um die ihm als
Initialisierungsparameter übergebenen Daten des Benutzers zu prüfen. Der Knoten wird dank des
Configuration Agent gefunden (→ Abbildung 7-3). In unserem Beispiel erweisen sich die Autorisationsdaten
als korrekt, und der Benutzerdaten-Knoten stellt anhand der gespeicherten Daten den Pedagogical Agent
wieder her. Der Login Agent bekommt als Ergebnis einer erfolgreichen loginUser()-Methode allgemeine
Informationen über den Benutzer (z.B. dessen Vornamen, Nachnamen, Datum der letzten Sitzung). Diese
Daten werden an den Learner Interface Agent weitergeleitet und dienen der Erstellung der Anfangsseite.
Nach Übermittlung dieser Information beendet der Login Agent seine Tätigkeit. Der Learner Interface Agent
erzeugt für die Session des Benutzers ein Verzeichnis, speichert den Verzeichnis-Pfad in einer
entsprechenden Sessions-Variablen und zeigt dem Benutzer die Startseite des Systems an. Der Benutzer wird
nach dem Einloggen im Allgemeinen ein neues oder bereits gelesenes Lernmodul öffnen wollen. Der Prozess
der Öffnung eines neuen Moduls wird im nächsten Abschnitt (→7.2.3) detailliert beschrieben, die
Wiedereröffnung im übernächsten Abschnitt (→7.2.3).
: Pedagogical Agent
: Benutzerdaten-Knoten : Learner : Interface Agent
: Login Agent
LoginResponseMsg
UserDscrShort
LoginMsg
LoginResponseMsg
role=LEARNER
loginUser(userName,pass,role,interfaceAID)
<<create>> (interfaceAID,username,pass)
<<create>> (interfaceAID,PedagogicalAgentData)
Abbildung 7-4 Sequenzdiagramm - Einloggen
7.2.2. Eröffnung eines neuen Lernmoduls
Das Eröffnung eines neuen Lernmoduls-Sequenzdiagramm wird in Abbildung 7-5 präsentiert. Der
Befehl des Benutzers, ein neues Lernmodul zu eröffnen, geht in erster Linie an den Learner Interface Agent.
Der Learner Interface Agent leitet ihn an den Pedagogical Agent weiter. Der Pedagogical Agent verfügt über
Informationen, welche Lernmodule der Lernende schon gesehen hat und für welche
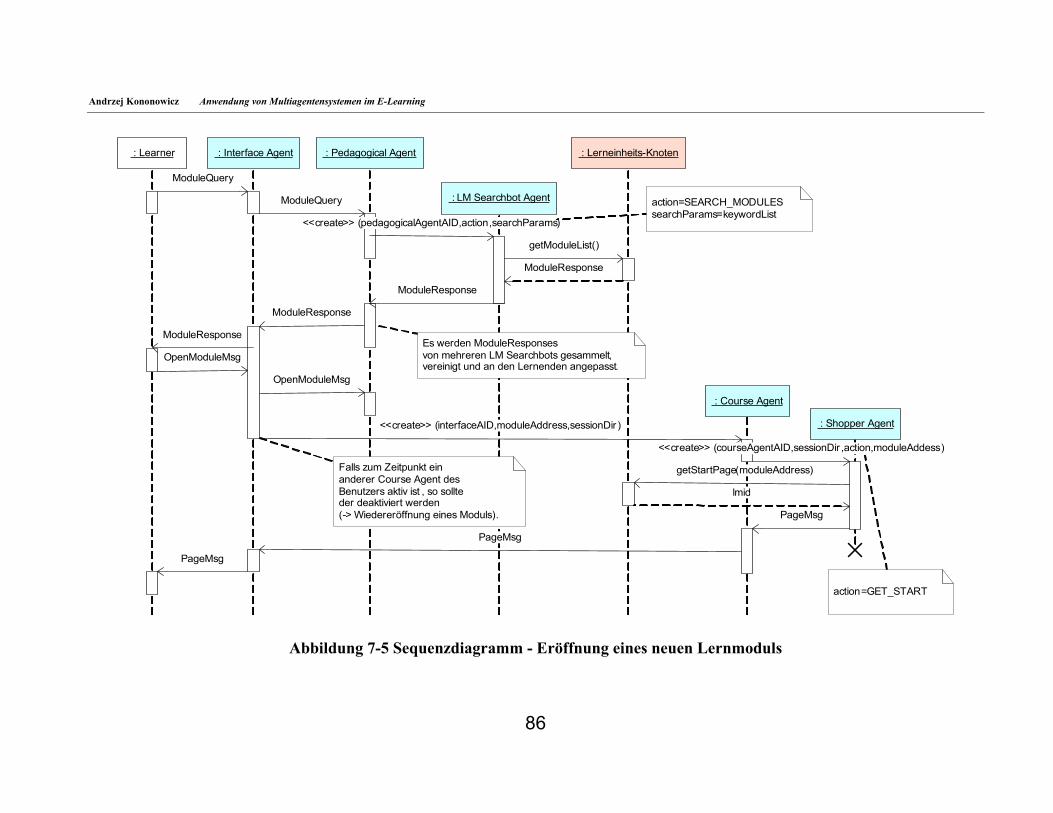
Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
86
: Learner : Interface Agent : Pedagogical Agent
: LM Searchbot Agent
: Lerneinheits-Knoten
: Course Agent
: Shopper Agent
getStartPage(moduleAddress)Falls zum Zeitpunkt ein
anderer Course Agent des
Benutzers aktiv ist , so sollte der deaktiviert werden
(-> Wiedereröffnung eines Moduls).
action=GET_START
ModuleQuery
ModuleQuery
<<create>> (pedagogicalAgentAID,action,searchParams)
ModuleResponse
ModuleResponse
ModuleResponse
OpenModuleMsg
<<create>> (interfaceAID,moduleAddress,sessionDir )
<<create>> (courseAgentAID,sessionDir ,action,moduleAddess)
lmid
PageMsg
ModuleResponse
action=SEARCH_MODULES
searchParams=keywordList
getModuleList()
Es werden ModuleResponses
von mehreren LM Searchbots gesammelt,vereinigt und an den Lernenden angepasst.
OpenModuleMsg
PageMsg
PageMsg
Abbildung 7-5 Sequenzdiagramm - Eröffnung eines neuen Lernmoduls

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
87
er sich eventuell interessieren könnte61. Diese Informationen bilden die Einschränkungen der Suche nach
neuen Lernmodulen. Der Pedagogical Agent erzeugt eine Reihe von LM Searchbot Agents, die den Auftrag
bekommen, in verschiedenen Lerneinheits-Knoten und MAESTRO-Plattformen nach verfügbaren
Lernmodulen zu suchen. Die Ziel-Plattform, auf der die Suche durch den gegebenen LM Searchbot Agent
durchgeführt werden soll, wird von dem Pedagogical Agent bestimmt (die Adressen der benachbarten
MAESTRO-Plattformen bekommt der Pedagogical Agent von dem Configurations-Agent, → analog wie auf
der Abbildung 7-3). Zu einer benachbarten MAESTRO-Plattform wird jeweils ein LM Searchbot Agent
geschickt, der sich dort gegebenenfalls klonieren kann, um weitere MAESTRO-Plattformen zu erreichen, die
nicht direkt mit der ursprünglichen MAESTRO-Plattform verbunden sind. Die max. Hop-Zahl bestimmt die
maximale Zahl der durch einen LM Searchbot Agent besuchten MAESTRO-Plattformen. Ein LM Searchbot
Agent kann eine Plattform (mit Ausnahme der Ursprungsplattform) nicht mehr als einmal besuchen. Der
klonierte Agent übernimmt von seinem Vorfahren die Liste der besuchten MAESTRO-Plattformen (das
beugt dem Kreisen von LM Searchbot Agents vor).
Die Listen der verfügbaren Lernmodule, die der LM Searchbot Agent von den jeweiligen Lerneinheits-
Knoten erhalten hat, werden gemäß den Suchparametern gefiltert und nach Abschluß der Suche an den
Pedagogical Agent zurückgegeben. Der Pedagogical Agent sammelt alle Suchergebnisse, löscht Duplikate in
der Liste und ordnet die Liste nach gewissen Kriterien (alphabetisch, nach Wissensgebieten, nach
Lerneinheiten, Bewertungen62, usw.). Die fertige Liste wird dem Learner Interface Agent übergeben, der sie
entsprechend formatiert und dem Benutzer anzeigt.
Der Benutzer wählt ein Lernmodul aus. Diese Nachricht wird durch den Learner Interface Agent
empfangen. Der Learner Interface Agent informiert den Pedagogical Agent über die Wahl des Benutzers und
erzeugt für den Benutzer einen neuen Course Agent. Falls zu diesem Zeitpunkt ein anderer Course Agent des
Benutzers aktiv ist, sollte er (wie in 7.2.3 gezeigt wird) in dem Benutzerdaten-Knoten gespeichert und
deaktiviert werden. Der neue Course Agent erzeugt einen Shopper Agent, der in dessen Auftrag die Startseite
des Lernmoduls aus dem Lerneinheits-Knoten übeträgt. Nachdem der Shopper Agent die bestellte Seite in
das Sessions-Verzeichnis kopiert hat, gibt er den Verweis zu der Seite an den Course Agent weiter und löst
sich auf. Der Course Agent schickt die erhaltenen Daten dem Learner Interface Agent, der die Seite dem
Benutzer anzeigt.
61 Die Information, für welche Themen sich der Lernende interessiert, kann durch den Lernenden explizit festgelegt werden oder
durch den Pedagogical Agent auf Grund der Beobachtungen des Verhaltens des Benutzers gefolgert werden. Diese Funktionen
werden in dem Prototyp nicht realisiert. 62 Die Bewertungen von Lerninhalten werden in dem Prototyp nicht betrachtet

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
88
7.2.3. Wiedereröffnung eines Moduls
Die Abbildung 7-6 zeigt das Sequenzdiagramm für die Wiedereröffnung eines Lernmoduls. Die Liste
aller bereits durch den Benutzer geöffneten Module wird auf Befehl des Benutzers durch den Learner
Interface Agent, vom Pedagogical Agent entnommen. Für jedes Lernmodul, das bereits durch den Benutzer
geöffnet worden ist, existiert in dem Benutzerdaten-Knoten ein gespeicherter Course Agent mit dem
aktuellen Stand des Lernprozesses (zu den gespeicherten Informationen gehören z.B. die Namen der
besuchten Seiten). Nach der Wahl eines bestimmten Lernmoduls zur Wiedereröffnung wird dem aktuellen
Course Agent von dem Learner Interface Agent der Befehl geschickt, sich in dem Benutzerdaten-Knoten zu
speichern und sich dann selbst zu löschen. Danach führt der Learner Interface Agent die Methode des
Benutzerdaten-Knotens zur Wiedererstellung des Course Agent des neu geöffneten Lernmoduls aus. Der
wiedererstellte Course Agent erzeugt einen Shopper Agent für die Übertragung der Startseite seines
Lernmoduls. Dieser Vorgang wurde bereits auf der Abbildung 7-5 gezeigt.
: Learner : Interface Agent old : Course Agent
new : Course Agent
: Benutzerdaten-Knoten : Pedagogical Agent
: Shopper Agent
Der weitere Ablauf so wie in
dem "Erstellung eines neuen
Modulus"-Sequenzdiagramm.
action=GET_START
GetModuleListMsg
ModuleResponse
OpenModuleMsg
GetModuleListMsg
SuspendMsg
storeCourseAgent(CourseAgentData)
true
restoreCourseAgent(interfaceAID,userName,pass,courseName,sessionDir )
<<create>> (interfaceAID,CourseAgentData,sessionDir)
<<create>> (courseAgent,sessionDir ,action,moduleAddress)
SuspendOKMsg
ModuleResponse
Abbildung 7-6 Sequenzdiagramm - Wiedereröffnung eines Moduls
7.2.4. Anzeigen der gewünschten Seite mit Lerninhalten
Das Anzeigen der gewünschten Seite mit Lerninhalten-Sequenzdiagramm wird in der Abbildung 7-7
präsentiert. Nachdem der Benutzer eine Seite mit Lerninhalten angefordert hat, wird diese Bestellung an den
dem Lernmodul zugehörigen Course Agent weitergeleitet. Dieser überprüft, ob sich diese Seite bereits in
dem Sessions-Verzeichnis befindet. Sollte das nicht der Fall sein, erzeugt der Course Agent einen Shopper
Agent und beauftragt ihn mit der Aufgabe, die gewünschte Seite aus dem geeigneten Lerneinheits-Knoten zu

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
89
entnehmen und in das Sessions-Verzeichnis zu kopieren. Der lmid-Parameter in der Abbildung 7-7 bedeutet
den vollständigen Identifikator der didaktischen Seite (d.h. Lerneinheits-Knoten-Name, Lernmodul-Name,
Seitenname). Der Course Agent erhält den Pfad zur kopierten Seite. Danach aktualisiert der Course Agent
die Statistiken über die besuchten Seiten und bittet den Learner Interface Agent, die Seite dem Benutzer zu
zeigen.
In kommerziellen Systemen63 kann zusätzlich für das Herunterladen der Seite aus dem Learneinheits-
Knoten ein virtueller Geldbetrag gefordert werden. In solchen Fällen wird der Benutzer, noch vor der
Bestellung, über den Preis informiert. Die Finanzen des Benutzers verwaltet der Pedagogical Agent. Von
ihm entnimmt der Shopper Agent den abgezählten Geldbetrag und kauft dafür die gewünschte Seite. Seiten,
die bereits vom Benutzer gekauft, aber nach dem Ausloggen zusammen mit dem Sessions-Verzeichnis
gelöscht worden sind, könnten von dem Lerneinheits-Knoten kostenlos heruntergeladen werden.
: Learner : Interface Agent : Course Agent
: Shopper Agent
: Lerneinheits-Knoten
GetPageMsg
GetPageMsg
page
getPage(lmid)
action=GET_PAGE
<<create>> (courseAgentAID,sessionDir ,action,lmid)
PageMsg
PageMsg
PageMsg
Aktualisiert Statistiken über die Seite
Abbildung 7-7 Sequenzdiagramm - Anzeigen von gewünschten Seiten
7.2.5. Realisation der Hilfestellung
Die Abbildung 7-8 stellt das Realisation der Hilfestellung-Sequenzdiagramm dar. Hilfestellung kann für
ganze Seiten wie auch für einzelne Begriffe geleistet werden. Die Leistung der Hilfe für eine ganze Seite
beinhaltet die Hilfe für alle mit der Seite verbundenen Begriffe. Die Frage nach einem bestimmten Begriff
wird dem für diese Lerneinheit verantwortlichen Course Agent von dem Learner Interface Agent übermittelt.
Dieser baut einen Baum der Begriffe auf, die mit dem aktuell gesuchten Begriff verbunden sind (eine
detaillierte Beschreibung des angewandten Algorithmus befindet sich in → 7.4). Die Daten für diesen Baum
entnimmt der Course Agent den Daten, die ihm seine LM Serachbot Agents liefern. Der Course Agent
sammelt die Antworten seiner LM Searchbot Agents und fügt sie in den Hilfestellungsbaum ein. Der Baum
wird durch den Pedagogical Agent an den Lernenden angepasst. Die Ergebnisse der Suche nach
63 Auf die finanziellen Aspekte der Verwaltung von Lerninhalten wird im Rahmen dieser Arbeit nicht eingegangen

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
90
Hilfestellungsseiten werden dem Benutzer vorgestellt, der selbst entscheidet, welche der ihm
vorgeschlagenen Seiten er sehen möchte. Das Herunterladen und Anzeigen von Seiten geschieht nach dem
im vorigen Abschnitt (→ 7.2.5) beschriebenen Schema.
: LM Searchbot Agent
: Learner : Interface Agent : Course Agent : Lerneinheits-Knoten : Pedagogical Agent
action=SEARCH_RELATED_NODES
searchParams={moduleName,subjectName,subjectType}
HelpRequest
<<create>> (courseAgentAID,action,searchParams)
findRelatedSubject(moduleName,subject)
relatedSubjects_rdf
PartModelMsg
HelpResponse
HelpResponse
HelpResponse
HelpRequest
Es werden PartModels von mehreren
LMSearchbot Agents gesammelt und vereinigt. Danach wird das Netz in die
HelpResponse-Klasse transformiert.
Passt die Hilfestelllung
an den Lernenden an.
Abbildung 7-8 Sequenzdiagramm - Realisation der Hilfestellung
Die Realisation der Vertiefungs-Funktion, die dem Lernenden ermöglichen soll, bestimmte Aspekte des
Lernstoffs zu erweitern, entspricht auf der Ebene des Sequenzdiagramms genau der Realisation der
Hilfestellung. Der Unterschied zwischen den zwei Funktionen wird erst auf der Ebene des semantischen
Netzes sichtbar, wo die Hilfestellungsbäume auf eine andere Weise konstruiert werden (→ 7.4.1).
In weiteren Stadien der Entwicklung des MAESTRO-Systems wird der Pedagogical Agent die
Hilfestellung mit zusätzlichen allgemeinen Tipps zum Lernprozess bereichern können. Möglich wäre auch,
dass der Agent bei dieser Gelegenheit Informationen über Veranstaltungen im Präsenzstudium, verbunden
mit dem vorgestellten Lernstoff, übermitteln würde (z.B. Zeiten der Sprechstunden, Termine der Übungen
im Präsenzstudium, Relevanz des Kurses für das weitere Studium, usw.).
7.2.6. Ausloggen aus dem System
Die Abbildung 7-9 zeigt das Sequenzdiagramm des Ausloggen aus dem System. Nachdem der Benutzer
auf den Ausloggen-Knopf gedrückt hat, befiehlt der Learner Interface-Agent dem aktuellen Course Agent
und dem Pedagogical Agent, ihre Daten auf Benutzerdaten-Knoten zu speichern und die Tätigkeit zu
beenden. Danach löscht der Learner Interface Agent das Sessions-Verzeichnis und zeigt dem Benutzer die
Logout-Seite. Der Ausloggen-Prozess ist damit beendet.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
91
: Learner : Interface Agent : Pedagogical Agent : Course Agent : Benutzerdaten-Knoten
SuspendMsg
LogoutMsg
SuspendMsg
storeCourseAgent(CourseAgentData)
true
LogoutResponse
true
storePedagogicalAgent(PedagogicalAgentData)
SuspendOKMsg
SuspendOKMsg
Abbildung 7-9 Sequenzdiagramm - Ausloggen
7.3. Beschreibung der Aktivitäten einzelner Agenten
Die Funktionsweise der MAESTRO-Agenten wird mit Hilfe der Aktivitätsdiagramme dargestellt. Das
UML-Aktivitätsdiagramm (engl. Activity Diagram) zeigt einzelne Abläufe der Realisation einer
Systemfunktion. Im Gegensatz zu Aktivitätsdiagrammen spielen hier die Zeitbeziehungen keine große Rolle
mehr, dafür werden aber alle Entscheidungsmöglichkeiten der Abläufe betrachtet. Ein Aktivitätsdiagramm
besitzt einen oder mehrere Start- und Endpunkte. Zwischen diesen Punkten befinden sich Teilaktivitäten.
In den von mir angefertigten Diagrammen sieht man, welch wichtige Rolle die Übertragung der
Nachrichten, für den inneren Zustand der Agenten hat. Diese Diagramme werden wegen Platzmangels im
Anhang aufgeführt.
7.4. Realisation der Hilfestellung
In diesem Abschnitt wird das allgemeine Schema der Hilfestellung64 in der MAESTRO-Architektur
vorgestellt. Dabei wird gezeigt, wie das im Abschnitt 6.8 vorgestellte semantische Netz praktisch genutzt
wird.
Der Benutzer wählt die Hilfestellungsfunktion durch die graphische Oberfläche aus. Er gibt dazu den
gewählten Begriff (oder die ganze Seite) an, den die Hilfestellung betreffen soll. Der Learner Interface Agent
64 Zwecks flüssigerer Beschreibung verwende ich in diesem Abschnitt den Begriff Hilfestellung (wenn das aus dem Kontext nicht
anders hervorgeht) auch für die Vertiefungsfunktion.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
92
erhält die Anfrage und leitet sie an den für das Lernmodul zuständigen Course Agent weiter. Dieser sendet
einen LM Searchbot Agent zu dem aktuellen Lernmodul (und bei Anfragen, die nicht die ganze Seite
betreffen, auch weitere LM Searchbot Agents zu den semantisch verwandten Lernmodulen). Die LM
Searchbot Agents beziehen aus dem semantischen Netz des jeweiligen Lernmoduls einen Ausschnitt, in
dessen Mittelpunkt sich der gesuchte Term- oder Page-Knoten befindet. Der Algorithmus des Bezugs des
Teilgraphen aus dem semantischen Netz wird in dem Abschnitt 7.4.1 vorgestellt. Die Ausschnitte aus den
Netzen werden dem Course Agent geliefert. Dieser vereinigt die Teilgraphen (die Verknüpfungsstelle ist der
gesuchte Term- oder Page-Knoten). Danach wird der gerichtete Graph zu einem Baum reduziert (dessen
Wurzel der gesuchte Term- oder Page-Knoten bildet) und mit Informationen versehen, wie oft der jeweilige
Page-Knoten aus dem Baum vom Lernenden aufgesucht wurde. Der Hilfestellungsbaum wird dem
Pedagogical Agent übermittelt, der dann die Reihenfolge der Knoten auf einem Niveau an den Benutzer
anpasst. Zum Beispiel werden – je nach Einstellung des Benutzers – die Page-Knoten, die der Lernende noch
nicht gesehen hat, vor (oder hinter) die anderen Knoten gestellt. Je nach dem Lernstil des Benutzers werden
Page-Knoten mit praktischen oder theoretischen Informationen bevorzugt. Die Page-Knoten, die Ressourcen
in – durch den Lernenden – nicht gewünschten Formaten beinhalten, werden aus dem Baum entfernt. Das
Schwierigkeitsniveau wird berücksichtigt. Die Reihenfolge der Knoten auf einem Niveau ist besonders in
großen Hilfsbäumen von Bedeutung, in denen aus Platzgründen nicht alle Informationen auf einmal gezeigt
werden können. Die angepassten Hilfestellungsbäume werden dem Interface Agent übermittelt, der sie für
den Benutzer visualisiert. Der Benutzer kann weitere Informationen über bestimmte Hilfestellungspunkte
anfordern. Die Informationen werden auf identische Weise gesammelt mit dem Unterschied, dass der
bisherige Teilgraph, der durch den Course Agent aufbewahrt wird, nicht gelöscht, sondern ergänzt wird (die
Verknüpfungsstelle ist der neu gesuchte Term- oder Page-Knoten, der aber nicht Wurzel des
Hilfestellungsbaumes ist). Der Teilgraph wird bei dem Befehl der Suche nach einem neuen Begriff gelöscht.
7.4.1. Algorithmus des Bezugs von Informationen aus dem semantischen Netz.
Algorithmus des Bezugs von Informationen bei der Hilfestellungs- oder Vertiefungsfunktion für einen
einzelnen Begriff:
1. Überprüfe, ob der gesuchte Begriff (Term-Knoten) im semantischen Netz vorhanden ist. Wenn nicht,
beende die Funktion mit einem leeren Ergebnis.
2. Finde Synonyme für den gesuchten Begriff. Zu diesem Zweck suche rekurent nach Aussagen der
Form65:
Subjekt Prädikat Objekt
* sameTerm gesuchter Begriff oder sein
Synonym gesuchter Begriff oder sein
Synonym sameTerm *
65 * - bedeutet alle möglichen Knoten
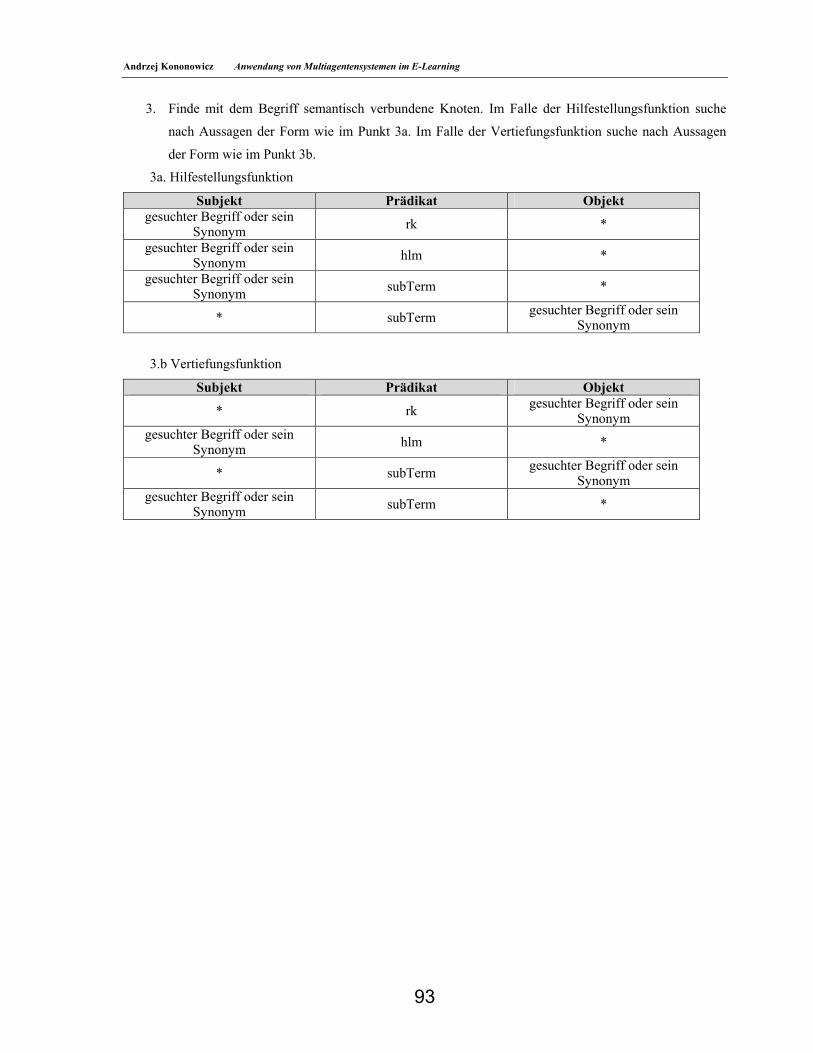
Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
93
3. Finde mit dem Begriff semantisch verbundene Knoten. Im Falle der Hilfestellungsfunktion suche
nach Aussagen der Form wie im Punkt 3a. Im Falle der Vertiefungsfunktion suche nach Aussagen
der Form wie im Punkt 3b.
3a. Hilfestellungsfunktion
Subjekt Prädikat Objekt gesuchter Begriff oder sein
Synonym rk *
gesuchter Begriff oder sein Synonym
hlm *
gesuchter Begriff oder sein Synonym
subTerm *
* subTerm gesuchter Begriff oder sein
Synonym
3.b Vertiefungsfunktion
Subjekt Prädikat Objekt
* rk gesuchter Begriff oder sein
Synonym gesuchter Begriff oder sein
Synonym hlm *
* subTerm gesuchter Begriff oder sein
Synonym gesuchter Begriff oder sein
Synonym subTerm *

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
94
7.5. Realisation der Funktionen des Lehrenden und des Systemadministrators
Die Vorbereitung der Materialien für E-Learning ist ein sehr zeitaufwendiger Prozess. Deshalb sieht die
MAESTRO-Architektur spezielle Hilfswerkzeuge für den Lehrenden und den Administrator vor (Tutor UI,
Admin UI → 6.4). Ein Prototyp eines solchen Tools, genannt lmAdmin, wurde für den Gebrauch des MAT-
MAESTRO entwickelt. Es erzeugt, aus speziellen Header-Dateien, ein Lernmodul im Lerneinheits-Knoten.
Die Header-Dateien werden von dem Lehrenden verfasst. Sie beschreiben das Lernmodul, das
veröffentlicht werden soll. Die Header-Dateien sind im XML-Format geschrieben und sollen möglichst
leicht für den Lernenden zu erstellen sein.
Es werden drei Arten von Header-Dateien unterschieden:
• !module.info.xml – diese Datei beinhaltet eine allgemeine Lernmodul-Beschreibung. Es existiert
nur eine Datei für das ganze Lernmodul. Die Datei befindet sich im Hauptverzeichnis des
Lernmoduls. Sie beinhaltet Daten wie den Namen des Lernmoduls, die Daten des Autors des
Lernmoduls, Schwierigkeitsgrad, Schlüsselwörter für das ganze Lernmodul und allgemeine
Bemerkungen zum Lerninhalt. Eine beispielhafte !module.info.xml-Datei und weitere Details
über diese Header-Dateien werden im Anhang präsentiert.
• [PageName].dscr.xml – beschreibt jede didaktische Seite. Für jede Seite im Modul existiert eine
solche Datei. Der Name der Datei ist identisch mit dem Namen der Seite, hat aber noch zusätzlich
den Suffix .dscr.xml. Diese Konfigurations-Datei ist in zwei Teile gegliedert. Im ersten Teil
werden allgemeine Daten zu der Seite angegeben (wie der vollständige Name der Seite,
Schwierigkeitsgrad der Seite, Typ des Lerninhaltes, Namen zusätzlicher Dateien, die mit dieser Seite
verbunden sind und Formate der Ressourcen, die auf der Seite oder in den verbundenen Ressourcen
verwendet werden). Im zweiten Teil der Datei werden die semantischen Zusammenhänge des Page-
Knotens (der Seite) mit Term-Knoten aus dem semantischen Netz beschrieben. Dabei müssen die
Term-Knoten nicht vorher definiert sein. Jeder zum ersten Mal angewandte Name des Term-Knotens
erzeugt automatisch einen neuen Term-Knoten im semantischen Netz. Die Zusammenhänge
entsprechen den Relationen in Tabelle 6-2. Eine beispielhafte [PageName].dscr.xml-Datei und
weitere Details über diese Header-Dateien werden im Anhang präsentiert.
• !module.struct.xml – beschreibt die strukturellen Zusammenhänge im Lernmodul. Es existiert
nur eine solche Datei für das ganze Modul. Diese Datei befindet sich im Hauptverzeichnis des
Moduls. Sie beschreibt die Reihenfolge der Lernseiten, auf eine Weise wie man sie aus klassischen
Inhaltsverzeichnissen kennt. Dabei werden Relationen aus der Tabelle 6-3 verwendet.
Ein im lmAdmin enthaltener Parser liest die Header-Dateien, erzeugt ein semantisches Netz im RDF-Format
und fügt Einträge in die Lerneinheits-Datenbanken ein (die Struktur dieser Datenbank wird im Abschnitt 7.7
beschrieben).

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
95
7.6. Statische Struktur des Systems
Das MAT-MAESTRO-System ist in sechs Pakete aufgeteilt (Abbildung 7-10).
learnerGUI
maestro
lmAdmin
agents
lmWebService
userWebService
comOntology test
Abbildung 7-10 Pakete des MAT-MAESTRO-Systems
Die Tabelle 7-1 beinhaltet eine kurze Beschreibung der Pakete.
Name des Pakets Beschreibung maestro Das Oberpaket. Beinhaltet die restlichen Pakete und Klassen, die allgemein
gebraucht werden oder in keines der anderen Pakete passen.
agents Beinhaltet Klassen der MAESTRO-Agenten.
comOntology Beinhaltet die Kommunikations-Ontologie der MAESTRO-Agenten.
learnerGUI Beinhaltet Klassen der graphischen Benutzeroberfläche des Lernenden (→ 8.2.1).
lmAdmin Beinhaltet Klassen des lmAdmin-Werkzeuges (→ 7.5) zur Erzeugung des
Lerneinheits-Knotens.
lmWebService Beinhaltet Klassen der Web-Anwendung, die den Zugriff auf die Funktionen des
Lerneinheits-Knotens gewährleisten.
test Beinhaltet Tests des Systems.
userWebService Beinhaltet Klassen der Web-Anwendung, die den Zugriff auf die Funktionen des
Benutzer-Knotens gewährleisten.
Tabelle 7-1 Beschreibung der MAT-MAESTRO Pakete
Eine detaillierte Beschreibung der Pakete wird aus Platzgründen im Anhang aufgeführt. Diese
Beschreibung beinhaltet Klassendiagramme der einzelnen Pakete. Ein UML-Klassendiagramm zeigt die
Objekt-Klassen, die zulässige Operationen auf Klassen, die Attribute der Klassen und die Beziehungen
zwischen den Klassen von Objekten.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
96
7.7. Datenbanken im MAT-MAESTRO-System
Die im Abschnitt 6.5 und 6.6 beschriebenen Lerneinheits- und Benutzerdaten-Knoten werden im MAT-
MAESTRO als relationale Datenbanken realisiert. Dieser Abschnitt beinhaltet eine Beschreibung der
Struktur dieser Datenbanken.
7.7.1. Bemerkung zur Notationsform der Datenbankstruktur
Obwohl das Design des Systems in dieser Arbeit überwiegend in der UML-Notation dargestellt wird
(→ 6.2), möchte ich hier eine Ausnahme machen und das Entity-Relationship-Diagram (ERD) der
Datenbanken, zwecks besserer Anschaulichkeit, in der alten Krähenfuss-Notation verfassen.
7.7.2. Lerneinheits-Datenbanken
Der Lerneinheits-Knoten (→ 6.5) wird durch zwei Datenbanken realisiert. Die erste, genannt
lmModuleDB, beinhaltet eine allgemeine Beschreibung der Lernmodule, die zweite Datenbank – rdfDB –
beinhaltet das semantische Netz für das Lernmodul.
Die Abbildung 7-11 zeigt die Struktur der lmModuleDB-Datenbank.
LmNodeInfo
Author
LMModule
Keyword
RelationType
RelatedModule
Difficulty
Level
StageOf
Education
LmAuthor
Abbildung 7-11 Struktur der lmModuleDB-Datenbank
Die Tabelle 7-2 charakterisiert die Tabellen der lmModuleDB-Datenbank
Name der Tabelle Beschreibung LmNodeInfo Beinhaltet die allgemeine Beschreibung des ganzen Lerneinheits-
Knotens66. Neben den vollständigen Namen des Knotens befindet sich in
dieser Tabelle auch die Beschreibung des Bildungszentrums, das für diesen
Knoten zuständig ist.
LmModule Beinhaltet die Beschreibung des Lernmoduls. In dieser Tabelle werden
66 Wie man hier sieht, kann eine Lerneinheits-Datenbank mehrere Lerneinheits-Knoten implementieren (obwohl das in der Praxis
wahrscheinlich wenige Vorteile hat).
Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
97
folgende Daten gespeichert: der vollständige Name des Lernmoduls, das
Hauptverzeichnis der didaktischen Inhalte, der Name des semantischen
Netzes in der rdfDB-Datenbank oder der Name der Start-Seite des Moduls.
Author Beinhaltet Daten über den Autor der Lerneinheit.
LmAuthor Implementiert die Relation N:M zwischen der Autoren- und der
LMModule-Tabelle.
RelatedModule Beinhaltet Adressen der Module, die mit dem aktuellen Modul semantisch
verbunden sind.
RelationType Definiert die zulässigen Typen der Verknüpfungen für die mit dem
aktuellen Knoten verbundenen Module. Beispiele aus dieser Tabelle sind:
Similar Module, Next Level Module, Prerequisite Module.
Keyword Beinhaltet allgemeine Stichwörter für das ganze Modul. Diese Stichwörter
sind nicht gleich der semantischen Beschreibung (die in der rdfDB-
Datenbank gespeichert ist).
Difficulty Level Definiert die zulässigen Werte für die Schwierigkeit des Moduls. Beispiele
sind easy, moderate, hard.
Stage of Education Definiert die zulässigen Namen der Etappen im Bildungsprozess der
Zielgruppen des Lernmoduls. Beispiele sind Pre-Primary, Primary,
Secondary, Post Secondary.
Tabelle 7-2 Tabellen der lmModuleDB-Datenbank
Die einzelnen Felder der Tabellen kann man im Initialisierungs-Skript lmnode.sql sehen, der im Anhang
dargestellt ist.
Die rdfDB spielt die Rolle eines RDF-Datastores ab. Im MAT-MAESTRO-System wird sie mit Hilfe
des Jena-Frameworks (→ 4.4.3) realisiert. Eine detaillierte Beschreibung des Jena-APIs findet man unter
[100].
7.7.3. Benutzerdaten-Datenbank
Der Benutzerdaten-Knoten (→ 6.6) wird durch eine relationale Datenbank realisiert. Diese Datenbank
wurde userDB genannt. Die Abbildung 7-12 zeigt die Struktur der userDB.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
98
LearnerData User
UserRole
MaestroRole
VisitedModule
VisitedPage
IntSubject
UserLearnStyle AcceptedFormat
LearnStyle LmFormat
Difficulty
Level
StageOf
EducationModuleKeyword
LmType
Abbildung 7-12 Struktur der userDB-Datenbank
Die Tabelle 7-3 charakterisiert die Tabellen der userDB-Datenbank
Name der Tabelle Beschreibung User Beinhaltet das Login, den vollständigen Vor- und Nachnamen, den Titel,
Geschlecht, Alter und das persönliche Kennwort des Benutzers. In dieser
Tabelle werden auch die Zeitpunkte des ersten und letzten Einloggens des
Benutzers in das System gespeichert.
MaestroRole Beinhaltet die Namen der möglichen Rollen, die der Benutzer in dem
System ausüben kann. Die vorgesehenen Werte sind: learner, tutor, admin.
Wie man sieht, kann ein Benutzer sowohl als Lernender als auch Lehrender
und Administrator im System auftreten.
UserRole Verbindet die Benutzer mit den Rollen.
LearnerData Beinhaltet allgemeine Daten über den Lernenden: Bildungszentrum, zu
dem der Lernende gehört, Etappe im Bildungsprozess, auf der sich der
Lernende befindet, die Studienrichtung und Fakultät (für Studenten) und
bevorzugtes Schwierigkeitsniveau der Lerninhalte.
StageOfEducation Definiert die zulässigen Werte für die Etappen im Bildungsprozess der
Zielgruppe des Moduls. Beispiele sind Pre-Primary, Primary, Secondary,
Post Secondary.
IntSubject Beinhaltet Schlüsselwörter, für die sich der Lernende interessiert.
AcceptedFormat Verknüpft den Lernenden mit den Ressource-Formaten, die er akzeptiert.
LmFormat Beinhaltet Werte der möglichen Formate von Lernressourcen. Beispiele
sind pdf, java applet, png, gif, jpeg, macromedia-flash.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
99
UserLearnStyle Verknüpft den Lernenden mit den entsprechenden Lernstilen.
LearnStyle Beinhaltet mögliche Werte für den Lernstil. Beispiele sind: example-driven,
theory-driven oder interactive-driven.
VisitedModule Speichert Informationen über die von dem Lernenden besuchten
Lernmodule. Aufbewahrt werden der Name des Moduls, der Name des
Lerneinheits-Knotens, der das Modul beinhaltet, die Zahl der Zugriffe auf
das Modul und Daten des ersten und letzten Zugriffes auf das Modul.
ModuleKeyword Beinhaltet Stichwörter, die mit dem Modul verbunden sind.
VisitedPage Enthält Daten über vom Lernenden besuchte Seiten. Gespeichert werden
der Name der Seite, der Lerninhaltstyp, Anzahl der Zugriffe auf die Seite
und Daten des ersten und letzten Zugriffes auf die Seite.
LmType Beinhaltet Namen der zulässigen Lerninhaltstypen der didaktischen Seiten.
Beispiele sind: Definition, Static Example, Interactive Example, Static
Exercise, Interactive Exercise, Remark, Theorem.
Tabelle 7-3 Tabellen der userDB-Datenbank
Die Attribute der Tabellen befinden sich im Initialisierungs-Skript user.sql im Anhang.
7.8. Physische Struktur des Systems
Die Physische Struktur des Systems beschreiben die UML Einsatz- und Komponentendiagramme. Das
Einsatzdiagramm (engl. Deployment Diagram) zeigt einen statischen Einblick in die Hardware-
Konfiguration der Knoten67 des Systems und die Abhängigkeiten der Knoten und informiert, welche
Komponenten auf welche Knoten verteilt und welche Protokolle für die Kommunikation der Elemente
gebraucht werden. Komponentendiagramme zeigen eine Menge physischer und austauschbarer Teile eines
Systems, dem Menge von Schnittstellenspezifikationen genügt und das diese realisiert.
In diesem Abschnitt konzentriere ich mich vor allem auf der Beschreibung der Einsatzdiagramme für
das MAT-MAESTRO-System. Die Komponentendiagramme werden in diesem Abschnitt nur gelegentlich
gezeigt, weil man sie in MAT-MAESTRO meistens aus den Klassen-Diagrammen ableiten kann, und
enthalten daher nicht viele Informationen (Klassen-Diagramme werden im Anhang beschrieben).
Abbildung 7-13 zeigt das allgemeine Einsatzdiagramm von MAT-MAESTRO. Im Folgenden werden
die einzelnen physischen Knoten genauer beschrieben.
67 Hier ensteht ein kleiner Namensgebungkonsflikt, denn in der MAESTRO-Architektur habe ich für zwei logische (nicht unbedingt
physische) Elemente der Architekur auch den Namen Knoten verwendet (Benutzerdaten-Knoten, Lerneinheits-Knoten). Ein Rechner,
der die physische Realisation dieser Elemente beinhaltet, sollte also konsequent z.B. Benutzerdaten-Knoten-Knoten genannt werden.
Ich benutze dafür den Namen Benutzerdaten-Knoten-Server und Lerneinheits-Knoten-Sever.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
100
Benutzerdaten-Knoten-Server
MAESTRO-Plattform-
Server
Rechner
des Lernenden
Nächster
MAESTRO-
Plattform-Server
HTTP
Lerneinheits-Knoten-
Server
Abbildung 7-13 Allgemeines Einsatzdiagramm von MAT-MAESTRO
7.8.1. MAESTRO-Plattform-Server
Ein MAESTRO-Plattform-Server ist ein zentraler Punkt des MAT-MAESTRO-Systems. Wie im
Kapitel 6 beschrieben, können mehrere MAESTRO-Plattform-Server miteinander verknüpft werden. Das
Einsatzdiagramm eines MAESTRO-Plattform-Servers zeigt Abbildung 7-14. In diesem physischen Knoten
werden folgende Komponenten installiert:
• Jade-Agenten-Plattform – Jade ist eine klassische FIPA-konforme Multiagentenplattform
(→2.4.3), die in vielen Projekten erfolgreich eingesetzt wurde. Diese Plattform bildet die
Ausführungsumgebung für die MAESTRO-Agenten. In dem Prototyp von MAT-MAESTRO wurde
die Version 3.1 der Jade-Bibliothek genutzt.
• maestro::agents.jar – das maestro.agents-Paket beinhaltet Klassen von MAESTRO-Agenten.
Die Komponenten aus diesem Paket greifen oft auf die Jade Bibliothek zurück.
• axis.jar – Axis ist ein Framework zum Bau von Web-Services. Einige der MAESTRO-Agenten
implementieren mit Hilfe dieser Bibliothek den Klienten-Teil des Web-Service. Die aktuelle Version
von Axis ist 1.2
• jena.jar – Jena ist ein API, mit dem man Semantic Web Applikationen implementieren kann (→
4.4.3). Diese Bibliothek wird auf dem MAESTRO-Plattform-Server von den MAESTRO-Agenten
(Course Agents) für die Verarbeitung von semantischen Netzen im RDF-Format benutzt. Im MAT-
MAESTRO wird die Version 2.1 der Bibliothek verwendet.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
101
MAESTRO-Plattform-
Server
Apache Tomcat (Servlet Container)Jade Agenten Plattform
maestro::agents.jarmaestro::learnerGUI.war
jena.jar axis.jar
Abbildung 7-14 Einsatzdiagramm des MAESTRO-Plattform-Servers
• Apache Tomcat – Tomcat ist ein Servlet-Container, entwickelt innerhalb des Apache-Projektes.
Diese Komponente verbindet den ganzen MAESTRO-Plattform-Server mit dem Rechner des
Benutzers. In dem Prototyp wird die Version 5.0.25 von Tomcat verwendet.
• maestro::learnerGUI.war – Diese Komponent beinhaltet Klassen des maestro.learnerGUI
Pakets, die den Prototyp der Learner GUI realisieren. Diese Web-Applikation verwendet Java
Servlets zur Kommunikation mit dem Benutzer durch das HTTP-Protokoll.
7.8.2. Lerneinheits-Knoten-Server
Es können mehrere Lerneinheits-Knoten-Server mit einem MAESTRO-Plattform-Server verbunden
werden. Es ist auch zulässig, dass sich der Lerneinheits-Knoten-Server auf demselben physischen Knoten
wie der MAESTRO-Plattform-Server befindet. Das Einsatzdiagramm für den Lerneinheits-Knoten-Server
zeigt Abbildung 7-15. Der Server beinhaltet folgende Komponenten:
• axis.jar – Auf dem Lerneinheits-Knoten-Server wird diese Bibliothek zur Implementierung des
Server-Teils des lmWebService verwendet.
• Apache Tomcat – Dieser Applikationsserver veröffentlicht den lmWebService
• maestro::lmWebService.jar – beinhaltet Klassen des maestro.lmWebService-Pakets, die die
Schnittstelle zum Lerneinheits-Knoten und einige Funktionen des Lerneinheits-Knotens
implementieren.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
102
Lerneinheits-Knoten-
Server
mySQL
maestro::lmWebService.jar
jena.jar
axis.jarApache Tomcat (Servlet Container)
rdfDB lmModuleDBmaestro::lmAdmin.jar
Abbildung 7-15 Einsatzdiagramm für den Lerneinheits-Knoten-Server
• mySQL ist ein effizienter, relationaler Datenbankserver. Der Lerneinheits-Knoten-Server beinhaltet
zwei Datenbanken – rdfDB und lmModuleDB (diese Datenbanken wurden im Abschnitt 7.7.2
beschrieben). Im MAT-MAESTRO-Prototyp wird die Version 7.2.1 des Servers benutzt.
• jena.jar – diese Bibliothek wird im Lerneinheits-Knoten-Server zum Verwalten der rdfDB
Datenbank verwendet. Sie ermöglicht, semantische Netze (z.B. im RDF-Format) in einer
relationalen Datenbank abzuspeichern.
• maestro.lmAdmin.jar – beinhaltet Klassen des maestro.lmAdmin-Pakets. Das Werkzeug
lmAdmin wurde bereits im Abschnitt 7.5 beschrieben. In Abbildung 7-16 wird zusätzlich das
Komponenten-Diagramm für dieses Werkzeug gezeigt. Wie man sieht, werden drei Typen von
Header-Dateien durch die LMParser-Komponente gelesen. LMAdminMain speichert die gelesenen
Daten durch das mySQL-Interface in die rdfDB- und lmModuleDB-Datenbanken.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
103
LMParser.class
!module
.info
.xml
{page
Name}
.dscr
.xml
{pageName}
.xml
!module
.struct
.xml
LMAdminMain.class
mySQLrdfDB
lmModuleDB
Abbildung 7-16 Komponentendiagramm des lmAdmin-Pakets
7.8.3. Benutzerdaten-Knoten-Server
Es darf nur ein Benutzerdaten-Knoten-Server mit einem MAESTRO-Plattform-Server verbunden
werden. Es ist zulässig, dass sich der Benutzerdaten -Knoten-Server auf demselben physischen Knoten wie
der MAESTRO-Plattform-Server befindet. Das Einsatzdiagramm für den Benutzerdaten-Knoten-Server zeigt
Abbildung 7-17. Der Server beinhaltet folgende Komponenten:
• axis.jar – Auf dem Benutzerdaten-Knoten-Server wird diese Bibliothek zur Implementierung des
Server-Teils des userWebService verwendet.
• Apache Tomcat – Dieser Applikationsserver veröffentlicht den userWebService
• maestro::userWebService.jar – beinhaltet Klassen des maestro.userWebService-Pakets, die
die Schnittstelle zum Benutzerdaten-Knoten und einige Funktionen des Benutzerdaten-Knoten
implementiert.
• mySQL – Auf dem Benutzerdaten-Knoten-Server beinhaltet dieser rationale Datenbankserver die
userDB Datenbank (diese Datenbank wurde im Abschnitt 7.7.3 beschrieben).

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
104
Benutzerdaten-Knoten-Server
mySQL
maestro::userWebService.jar
axis.jar
Apache Tomcat (Servlet Container)
userDB
Abbildung 7-17 Einsatzdiagramm für den Benutzerdaten-Knoten-Server
7.8.4. Rechner des Lernenden
Die einzige Software-Komponente, die der Lernende auf seiner Maschine installieren muss, um das
MAT-MAESTRO-System zu nutzen, ist ein Web-Browser (→Abbildung 7-18). Empfohlen wird der
Mozilla-Browser (z.B. die Version 1.7.2), da er ohne zusätzliche Plug-Ins68 das MathML-Format anzeigen
kann, das oft in dem Test-Lernmodul des MAT-MAESTRO-Prototyps auftritt.
Rechner des
Lernenden
Web Browser (Mozilla)
Abbildung 7-18 Einsatzdiagramm für den Rechner des Lernenden
Selbstverständlich können mehrere Rechner der Lernenden gleichzeitig mit dem MAESTRO-Plattform-
Server verbunden sein.
68 Es müssen gelegentlich spezielle Schriftarten (kostenlos) installiert werden.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
105
8. Beschreibung der Implementation
Einen eingeschränkten Teil der Funktionalität des MAT-MAESTRO-Systems habe ich in Form eines
Prototyps implementiert. Das Hauptziel des Prototyps ist die Untersuchung der Realisierbarkeit und
Effizienz der Grundfunktionen der MAESTRO-Architektur. Aufgrund der Ergebnisse kann man Schlüsse
über die Weiterentwicklung des Konzeptes ziehen.
Bei der Beschreibung der Implementierung hat sich eingebürgert, dass man die Dokumentation in drei
Teile gliedert:
• Handbuch für den Programmierer (→ 8.1) – der technische Details der Implementierung beinhaltet
• Handbuch für des Benutzer – der nur die Beschreibungen der äußersten Schnittstellen ohne
technische Details enthält (→ 8.2)
• Dokumentation für den Systeminstallateur (engl. Deployer) – der die Komponenten des Systems in
den physischen Knoten montiert (→ 8.3)
8.1. Beschreibung aus der Sicht des Programmierers
Der Prototyp wurde in der Java-Programmiersprache implementiert. Ich habe diese Sprache gewählt,
weil sie sehr gut für Internet-Anwendungen geeigent ist. Die weitere Beschreibung aus der Sicht des
Programmierers bilden das ganze Kapitel 7 und der Anhang. Im nächsten Unterabschnitt möchte ich nur kurz
aufzählen, welcher Teil des MAT-MAESTRO-Systementwurfes tatsächlich prototypisch implementiert
wurde.
8.1.1. Prototypisch implementierte Elemente des MAT-MAESTRO
• Die lmAdmin-Anwendung zum Erzeugen von Lernmodulen und der dazugehörigen semantischen
Netze aus Header-Dateien (ohne !module.struct.xml-Dateien)
• Die Funktionen des lmWebService (ohne diese Methoden in Form eines Web-Service darzustellen).
Aufwendig war vor allem die Realisation der Funktion findRelatedSubjects(), die aus dem
semantischen Netz, gespeichert in der rdfDB-Datenbank, einen Teilgraphen ausscheidet, der die
Umgebung des gesuchten Begriffs beinhaltet. Der Algorithmus dazu wurde im Abschnitt 7.4.1
beschrieben. Die Methode findRelatedSubjects() gibt den Teilgraphen als Zeichenkette (im
RDF-Format) zurück.
• Elemente des Learner GUI: Öffnen eines Moduls, Anzeigen einer didaktischen Seite, Anzeigen der
Hilfestellung (die Hilfestellung und die Modulliste werden im Prototyp noch nicht an den Lernenden
angepasst). Die graphische Oberfläche der Benutzerschnittstelle wird im Abschnitt 8.2 beschrieben.
• Elemente des Course Agent. Der Course Agent schickt keine LM Searchbot Agents aus, sondern
sucht selbst nach Informationen für die Hilfestellung in einem einzigen Lerneinheits-Knoten. Die

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
106
Adresse des Knotens ist festgelegt. In dem Lerneinheits-Knoten befindet sich nur ein einfaches
Lernmodul. Der Pedagogical Agent wird nicht implementiert. Die Daten werden direkt dem Learner
Interface Agent übermittelt. Die Informationen über die besuchten Seiten werden nicht gespeichert.
Der Course Agent kann sich nicht in dem Benutzerdaten-Knoten archivieren. Die bestellten Seiten
werden nicht in ein temporäres Verzeichnis kopiert, sondern direkt aus dem Server entnommen
(statische Verweise).
• Elemente des Learner Interface Agent: Hauptsächlich Kommunikation mit dem Course Agent.
8.2. Beschreibung aus der Sicht des Benutzers
8.2.1. Prototyp des Learner UI
Der Learner UI ist eine Web-Applikation. Sie kann durch einen beliebigen Browser aufgerufen
werden69. Die Arbeit mit dem Systems verläuft gewöhnlicher Weise nach folgendem Schema ab: der
Lernende loggt sich in das System ein, wählt ein Lernmodul aus, in dem Inhaltsverzeichnis wählt eine
gewünschte Seite aus, sieht sich die angezeigten Daten an, bei Bedarf ruft die Hilfestellungs-Funktion auf,
die ihm neue Seiten liefert, nach dem Lernprozess loggt sich der Benutzer wieder aus dem System aus.
8.2.1.1. Das Einloggen in das System
Der erste Schritt nach dem Aufruf der Internet-Adresse der Learner UI Web-Applikation ist das
Einloggen. Der Benutzer führt den Benutzernamen und das Kennwort in die entsprechenden Felder ein und
drückt auf den Login-Knopf (Abbildung 8-1).
Abbildung 8-1 Learner UI / Einloggen in das System
69 Gemeint sind die akutellen Versionen der populären Browser Internet Explorer, Mozilla, Netscape Navigator, Konqueror oder
Opera. Für unsere Ziele empfehle ich Mozilla, denn dieser Browser hat (neben vielen anderen Vorteilen) momentan die beste
Unterstützung für das MathML-Format

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
107
Sind die Autorisations-Daten nicht korrekt, wird dem Benutzer eine Fehlermeldung (unter dem Login-
Knopf) angezeigt. Dann kann der Benutzer nochmals versuchen die Daten einzugeben. Sind Benutzername
und Passwort korrekt, kann der Benutzer ein Lernmodul wählen.
8.2.1.2. Die Auswahl des Lernmoduls
Die Liste der im aktuellen Lerneinheits-Knoten zur Verfügung stehenden Module, wird im unteren Teil
des Browser-Fensters angezeigt (Abbildung 8-2). In der vollständigen Version von MAT-MAESTRO wird
der Benutzer noch zusätzlich die Möglichkeit haben, Suchkriterien für neue Lernmodule zu setzen. Im
Gegensatz zu dem Prototyp werden im fertigen System die Bestände anderer Lerneinheits-Knoten dem
Benutzer zur Verfügung gestellt. Es wird auch eine zusätzliche Liste der durch den Benutzer bereits
geöffneten Module gezeigt.
Abbildung 8-2 Learner UI / Wahl eines Moduls
Der Lernende wählt das gewünschte Modul durch einen Mausklick auf den Namen des Moduls. Dem
Lernenden wird die Start-Seite des Lernmoduls gezeigt (Abbildung 8-3).
8.2.1.3. Aufteilung der Steuerungs-Komponenten
An dieser Stelle möchte ich die Aufteilung der Steuerungs-Elemente in einem geöffneten Lernmodul
erläutern. Der Bildschirm wird horizontal in drei Teile gegliedert (Abbildung 8-3)70:
• Titelbalken-Frame – In der Mitte des Frame steht der Name der aktuellen Seite. Links und rechts
von dieser Beschriftung sind zwei Pfeile platziert, die die nächste oder vorhergehende didaktische
Seite in der strukturellen Ordnung des Lernmoduls aufrufen (das Navigieren zwischen den Seiten
mit Hilfe von Pfeilen wurde im Prototyp nicht implementiert).
• Aktuelle-Seite-Frame – In diesem Bildschirmabschnitt werden die Inhalte der didaktischen Seiten
gezeigt.
70 Beschrieben in der Reihenfolge von oben nach unten.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
108
• Menü-Frame – Das Verhältnis der Größe dieses Frame im Vergleich zu den anderen Frames kann
man durch Ziehen der Frame-Kante mit dem Mausanzeiger verändern. Die Beschreibung des Menüs
erfolg im Abschnitt 8.2.1.4.
Abbildung 8-3 Learner UI / Startseite eines Moduls
8.2.1.4. Beschreibung des Menüs
Der Menü-Frame beinhaltet sechs Funktions-Knöpfe und einen freien Platz für die Einstellungen der
einzelnen Funktionen.
Die Funktionsknöpfe sind:
• Hilfe – Durch diesen Funktionsknopf kann der Benutzer, Hilfestellung zu der aktuellen Seite oder
einem nicht verstandenen Begriff anfordern. Diese Funktion wird im Abschnitt 8.2.1.5 genauer
beschrieben.
• Vertiefung – Diese Funktion ermöglicht dem Benutzer, mehr Informationen über Themen,
verbunden mit der aktuellen Seite oder mit einem ausgewählten Begriff, zu erhalten. Die graphische
Oberfläche für diese Funktion ist identisch mit der für die Hilfe-Funktion. Aus diesem Grund wird
sie hier nicht extra beschrieben.
• Inhaltsverzeichnis – Dieser Funktionsknopf ruft das Inhaltsverzeichnis des aktuellen Lernmoduls
auf (Abbildung 8-4). Durch Anklicken auf die Namen kann der Lernende die gewählte Seite
anzeigen lassen.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
109
Abbildung 8-4 Learner UI / Inhaltsverzeichnis des Moduls
• Wechsle Modul – Diese Funktion meldet den Benutzer aus der aktuellen Lerneinheit ab. Es wird
erneut das Fenster zur Wahl des Moduls angezeigt (Abbildung 8-2).
• Einstellungen – Gibt dem Lernenden die Möglichkeit, seine persönlichen Einstellungen des
Lernprozesses zu ändern (Abbildung 8-5). Im Prototyp wurde diese Funktion nicht realisiert.
Abbildung 8-5 Learner UI / Persönliche Einstellungen des Lernprozesses
• Ausloggen – Durch diese Funktion verlässt der Benutzer das MAT-MAESTRO-System. Nach der
Durchführung dieser Operation zeigt der Browser erneut die Login-Seite (Abbildung 8-1)
8.2.1.5. Leistung der Hilfestellung
Bei Problemen mit dem Verständnis des Lerninhalts kann der Lernende Hilfe von dem System
beziehen. Dazu klickt man auf den Hilfe-Knopf im Menü. Der Benutzer kann jetzt entweder Hilfestellung zu
allen Begriffen, verbunden mit dieser Seite, oder zu einem bestimmten Begriff anfordern. Im ersten Fall

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
110
klickt er auf die Überschrift Hilfe allgemein zum Thema der Seite, bei der zweiten Möglichkeit führt er den
Begriff mit der Tastatur in das Feld Hilfe zum Begriff und klickt auf die Überschrift. Die Ergebnisse der
Hilfestellungs-Suche werden unter dem Menü angezeigt (Abbildung 8-6).
Abbildung 8-6 Learner UI / Hilfestellung
Das erste Ergebnis der Hilfestellung liefert nur Seitennamen oder Begriffe, die semantisch direkt mit dem
gesuchten Begriff verbunden sind.
Namen der gefundenen Begriffe werden auf weißem Hintergrund in Fettschrift angezeigt. Synonyme
des Begriffs werden in Normalschrift in runden Klammern nach dem Namen des Begriffs angezeigt. Falls
der Begriff ein Unterbegriff eines oberhalb von ihm gelegenes Begriffs ist (was das bedeutet, wird im
weiteren Verlauf des Abschnittes klar), wird die Anmerkung subTerm: vor dem Namen des Begriffs
hinzugefügt.
Namen der gefundenen Seiten werden auf farbigem (nicht-weißem) Hintergrund gezeigt. Die Farbe des
Hintergrundes hängt vom Typ des Lerninhaltes ab. So werden z.B. Seiten mit Definitionen auf gelbem
Hintergrund gezeigt, Seiten mit statischen Beispielen auf grünem und Seiten mit interaktiven Aufgaben auf
blauem. Den Namen der Seite (Fettschrift, unterstrichen) kann man anklicken, um den Inhalt der Seite
anzuzeigen. Außer dem Namen der Seite werden auch der Schwierigkeitsgrad und der Name des
Ursprungsmoduls der Seite dargestellt.
Vor jedem Begriff- und Seiten- Namen befindet sich ein blaues Dreieck. Dieses Symbol kann entweder
senkrecht ( – geschlossen) oder wagerecht ( – offen) orientiert sein. Jede Zeile in der Hilfestellung hat
ursprünglich das Symbol in der senkrechten Lage. Nachdem der Benutzer ein solches Symbol mit dem
Mausanzeiger angeklickt hat, sucht das System nach Begriffen oder Seiten, verbunden mit dem Begriff oder
der Seite aus der Zeile, zu der das Symbol gehört (nach gleichem Schema wie bei der ursprünglichen
Hilfestellung). Das Symbol ändert nach dem Anklicken die Lage. Die Ergebnisse der Suche werden
unterhalb der angeklickten Zeile (mit einem zusätzlichen Rand) platziert (Abbildung 8-6). Nach dem

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
111
erneuten Klick auf das soeben geklickte Symbol wechselt das Symbol wieder in die ursprüngliche senkrechte
Lage, und die von der angeklickten Zeile abhängigen Begriffe- und Seite-Namen werden wieder verborgen71.
8.2.2. Prototyp des lmAdmins
Die Funktionsweise des lmAdmin-Tools wurde bereits im Abschnitt 7.5 beschrieben. Im Vergleich zu
dem Entwurf werden in dem Prototyp nicht die !module.info.xml-Header-Dateien beschrieben. Im
weiteren Teil dieses Abschnittes wird kurz die Bedienung des Prototyps erklärt.
Der Prototyp besitzt eine bescheidene Mensch-Maschine-Schnittstelle. Das ganze Werkzeug wird durch
eine Java-Property-Datei gesteuert. Name und Pfad zu dieser Datei werden als Initialisierungs-Parameter bei
der Ausführung der Anwendung angegeben.
Die Property-Datei hat folgende Felder, die vor der Ausführung des lmAdmin mit Werten gefüllt sein
sollten:
• RDF_DB_URL – Beinhaltet die Adresse der rdfDB Datenbank (z.B.
jdbc:postgresql://localhost/rdfDB)
• RDF_DB_USER – Beinhaltet den Namen des Benutzers in der rdfDB-Datenbank
• RDF_DB_PASSWD – Beinhaltet das Kennwort zu der rdfDB-Datenbank
• Die Felder LM_DB_URL, LM_DB_USER und LM_DB_PASSWD haben analoge Bedeutung zu
den drei oben beschriebenen Feldern mit dem Unterschied, dass sie nicht den Zugriff auf die rdfDB
sonder auf die lmModuleDB Datenbank konfigurieren.
• fileRootDir – Gibt den Pfad zum Verzeichnis mit den Header-Dateien an (im Prototyp muss er
gleich dem Verzeichnis der Lernmodul-Ressourcen sein)
• lmNodeName – Enthält den Namen des neu angelegten Lernmoduls
lmAdmin wird mit dem Befehl:
java LmAdminMain [lmNode.prop] [dirName]
ausgeführt, wobei [lmNode.prop] Name und Pfad zu der Property-Datei und [dirName] Name des
Hauptverzeichnisses den Lernmoduls bedeutet. Im Classpath von Java sollte sich die Jena-Bibliothek
befinden.
8.3. Beschreibung aus der Sicht des Systeminstallateurs
Die folgenden Abschnitte beinhalten eine Beschreibung der Installation der Software des MAT-
MAESTRO-Prototyps. Sie beinhaltet Instruktionen zur Aufstellung der implementierten Teile des Systems
(daher zum Beispiel keine Anweisungen zur Installation des MAT-MAESTRO-Web Service). Die benötigte
Software befindet sich auf der Projekt-CD, die der Diplomarbeit beiliegt.
71 Technische Bemerkung: Die beschriebene Visualisierungsart ist eine Abbildung des an den Lernenden angepassten
Hilfestellungsbaumes (→7.4) in einer kompakteren Form.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
112
8.3.1. Installation des MAESTRO-Plattform-Servers
1. Installiere den Apache Tomcat gemäß den Anweisungen des Herstellers [78].
2. Kopiere das learnerGUI.war-Paket in das Servlet-Verzeichnis
3. Kopiere die Jena-, Jade- und maestro::agents.jar-Pakete in die Classpath von
learnerGUI.war
8.3.2. Installation des Lerneinheits-Knoten-Servers
1. Installiere den mySQL gemäß den Anweisungen des Herstellers [105]
2. Erzeuge im mySQL eine leere Datenbank für rdfDB
3. Erzeuge im mySQL eine leere Datenbank für lmNodeDB
4. Initialisiere die lmNodeDB Datenbank mit dem lmnode.sql Skript
5. Kopiere das maestro::lmadmin.jar-Paket auf die Festplatte des Servers
8.3.3. Installation des Benutzerdaten-Knoten-Servers
1. Installiere den mySQL gemäß den Anweisungen des Herstellers [105]
2. Erzeuge im mySQL eine leere Datenbank für userDB
3. Initialisiere die userDB Datenbank mit dem lmnode.sql-Skript
8.3.4. Installationen auf dem Rechner des Lernenden
1. Installiere den Mozilla-Browser (oder einen anderen) gemäß den Anweisungen des Herstellers
2. Bei Verwendung von Mozilla installiere zusätzlich die MathML-Schriftarten für Mozilla (die Datei
mathml-fonts-1.0-fc1.exe befindet sich auf der CD)

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
113
9. Tests und Eindrücke aus der Implementierung des Prototyps
In diesem Kapitel beschreibe ich einige Beobachtungen aus der Implementierungs-Phase der Arbeit.
Wie ich schon erklärt habe, ist die vollständige Realisation des Systems aus zeitlichen Gründen nicht
möglich, daher konzentrierte ich mich nur auf einige – meiner Ansicht nach interessante – Aspekte der
Implementierung. Dazu gehören: Aufbewahrung des semantischen Netzes der Beschreibungen im
Lerneinheits-Knoten (→ 9.1) und Verknüpfung der Benutzeroberfläche für den Lernenden mit den
MAESTRO-Agenten (→ 9.2).
9.1. Effizienz des Lerneinheits-Knotens
Ein wichtiger Aspekt für die Effizienz des gesamten MAT-MAESTRO-Systems ist eine korrekte Wahl
der Datenbank für die Lerneinheits-Knoten. Jena-API, die für die Speicherung der semantischen
Beschreibung in der der Datenbank verantwortlich ist, arbeitet mit drei Typen von RDBMS-Servern
zusammen: PostgreSQL, mySQL und Oracle. Die ersten zwei Technologien sind open-source-Datenbaken,
die dritte ist ein kommerzielles Produkt. Um die Kosten des Systems nicht unnötig zu erhöhen, habe ich
Oracle nicht weiter berücksichtigt. Die durchgeführten Tests untersuchen die Antwortszeiten bei der
Ausführung der Funktionen zum Aufbau – aus Daten aus Header-Dateien – eines semantischen Netzes in
einer Datenbank (lmAdmin → 9.1.2) und die Antwortszeiten bei der Suche im Lerneinheits-Knoten nach
semantisch verwandten Begriffen (lmAdmin → 9.1.3 ).
9.1.1. Beschreibung des Tests
Es wurden Test-Header Dateien mit Beschreibungen von Seiten generiert (*.dscr.xml). Jede der
Beschreibungen beinhaltet ein semantisches Netz mit der Topologie eines gerichteten vollständigen
Graphen. In einem vollständigen Graphen ist jeder Knoten mit jedem anderen Knoten durch eine Kante
verbunden. Gerichtet bedeutet hier, dass zwischen jedem Paar-Knoten sich zwei – in gegenseitige
Richtungen orientierte – Kanten befinden. Die Anzahl der Kanten in einem vollständigen Graphen mit n
Knoten beträgt
2
n. Im gerichteten vollständigen Graphen beträgt die Anzahl der Kanten
( )12
2 −⋅=
⋅ nnn
. Jede Kante entspricht einer RDF-Aussage. Als Typ für die Kanten wurde die rk-
Relation (→ Tabelle 6-2) benutzt. Es wurden Testdaten für Graphen mit 0,10,25,50,100 und 200 Kanten
generiert. Die Testprozedur wurde für jeden Graphen getrennt durchgeführt. Die Daten wurden mit Hilfe des

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
114
lmAdmin zu semantischen Netzen konvertiert und in der rdfDB-Datenbank gespeichert72. Die
Bearbeitungszeit dieses Prozesses wurde gemessen. Beim Durchlauf der Testprozedur wurde anschließend
eine Hilfestellung für einen bestimmten Knoten im rdfDB mit Hilfe der findRelatedSubject()-Methode
aus der LmNodeWSImpl (lmNodeWebService) gesucht73. Die Zeit dieses Vorgangs wurde auch gemessen.
Zum Schluss wurde das im rdfDB erzeugte Modell gelöscht. Dieser Vorgang wurde für jeden Graphen 10-
mal wiederholt und der Mittelwert der Ergebnisse berechnet. Die Postgres- und mySQL-Datenbanken
wurden abwechselnd getestet. Der erste Test wurde nicht mitgezählt, weil die Prozesse, verbunden mit der
Erstausführung des Testprogramms, die Ergebnisse stark beeinflusst haben.
Die Tests wurden auf einem Rechner mit Intel Celeron 2600 MHz, 512 DDR RAM und Linux Red Hat
9.074 durchgeführt. Es wurden die Datenbanken PostgreSQL 7.4.5 (JDBC3 Driver Build 215) und mySQL
4.0.20 (Connector/J 3.0) getestet. Zum Speichern der Modelle der semantischen Netze in der Datenbank
wurde die Version 2.1 des Jena-API benutzt.
Die durchgeführten Test-Prozeduren sind lediglich eine Einführung in die eigentliche Effizienz-
Untersuchung. Es fehlen Test der Antwortzeiten bei einem belasteten Server und gleichzeitigem Zugriff
mehrer Agenten. Die getesteten Datenbestände könnten noch größer sein. Es ist wichtig die Effizienz bei
unterschiedlichen Hardware-Architekturen zu testen. Die Durchführung einer vollständigen Studie würde
aber den Rahmen dieser Arbeit überschreiten.
9.1.2. Ergebnisse der Effizienzuntersuchung für die Einrichtung eines semantischen Netzes
Die Ergebnisse der Effizienzuntersuchung der Einrichtung von semantischen Netzen zeigen Abbildung
9-1 und Abbildung 9-2.
Eindeutiger Testsieger ist – ein wenig unerwartet – mySQL 4.075. Der Unterschied wird besonders bei
größeren Modellen (Abbildung 9-2, z.B. bei n=100 → 9900 Aussagen) sichtbar, in denen mySQL 4.0 mehr
als zweimal schneller als PostgreSQL ist.
72 Zu Testzwecken wurden die auf die lmNodeDB zugreifende Methoden zur Einrichtung der allgemeinen Beschreibung in
ausgelassen, 73 Weil das semantische Netz in dem Testbeispiel ein vollständiger Graph ist, beinhaltet die Antwort auf die Anfrage n-1 Knoten. 74 Es wurden auch Tests unter Windows XP und mySQL 3.23/ PostgreSQL 7.2 durchgeführt. Die Ergebnisse werden aber nicht
dargestellt, weil PostgreSQL 7.x unter Windows nur mit Hilfe eines Unix-Emulators (cygwin) funktionieren kann, der aber die
Geschwindigkeit der Datenbank enorm beeinträchtigt. In manchen Tests unter Windows war mySQL c.a. 10-mal schneller als
PostgreSQL (cygwin). 75 In der ersten Version des MAT-MAESTRO-System-Entwurfes habe ich (vor allem wegen ihres guten Rufes) PostgreSQL als
Datenbank für die Lerneinheits-Knoten vorgeschlagen. Nach der Durchführung der Tests habe ich den Entwurf geändert.
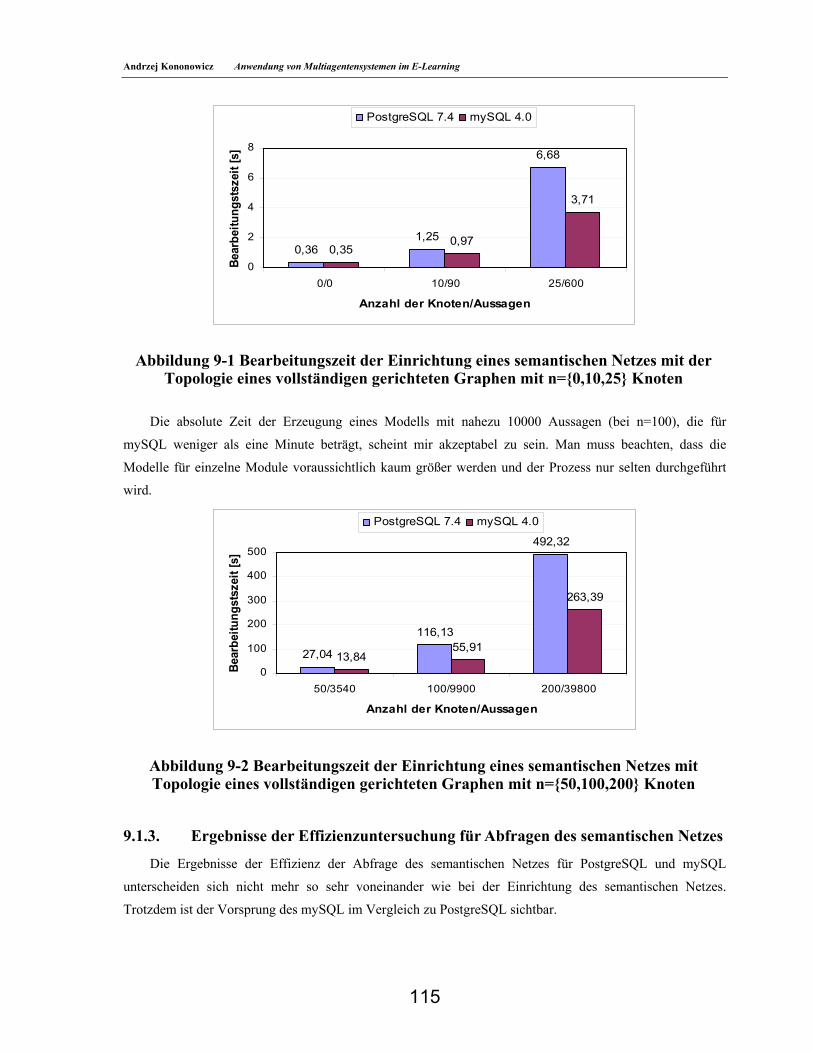
Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
115
0,361,25
6,68
0,350,97
3,71
0
2
4
6
8
0/0 10/90 25/600
Anzahl der Knoten/Aussagen
Bearbeitungstszeit [s]
PostgreSQL 7.4 mySQL 4.0
Abbildung 9-1 Bearbeitungszeit der Einrichtung eines semantischen Netzes mit der Topologie eines vollständigen gerichteten Graphen mit n={0,10,25} Knoten
Die absolute Zeit der Erzeugung eines Modells mit nahezu 10000 Aussagen (bei n=100), die für
mySQL weniger als eine Minute beträgt, scheint mir akzeptabel zu sein. Man muss beachten, dass die
Modelle für einzelne Module voraussichtlich kaum größer werden und der Prozess nur selten durchgeführt
wird.
27,04
116,13
492,32
13,8455,91
263,39
0
100
200
300
400
500
50/3540 100/9900 200/39800
Anzahl der Knoten/Aussagen
Bearbeitungstszeit [s]
PostgreSQL 7.4 mySQL 4.0
Abbildung 9-2 Bearbeitungszeit der Einrichtung eines semantischen Netzes mit Topologie eines vollständigen gerichteten Graphen mit n={50,100,200} Knoten
9.1.3. Ergebnisse der Effizienzuntersuchung für Abfragen des semantischen Netzes
Die Ergebnisse der Effizienz der Abfrage des semantischen Netzes für PostgreSQL und mySQL
unterscheiden sich nicht mehr so sehr voneinander wie bei der Einrichtung des semantischen Netzes.
Trotzdem ist der Vorsprung des mySQL im Vergleich zu PostgreSQL sichtbar.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
116
0,08 0,20 0,26 0,52
1,35
4,65
0,05 0,11 0,17 0,381,00
4,39
0
1
2
3
4
5
6
0/0 10/90 25/600 50/3540 100/9900 200/39800
Anzahl der Knoten/Aussagen
Antwortszeit [s]
PostgreSQL 7.4 mySQL 4.0
Abbildung 9-3 Antwortszeiten bei der Hilfestellungs-Funktion
Die Antwortszeiten liegen bei einem Modell mit 100 Knoten (9900 Aussagen) bei 1 Sekunde, was
wenig erscheint; man muss aber berücksichtigen, dass die Tests bei einem nicht belasteten Server
durchgeführt wurden und die Migrations-Zeiten der Agenten, die Zeit für die Anpassung der Ergebnisse an
den Lernenden und die graphische Darstellung der Ergebnisse nicht berücksichtigt wurden. Man sollte daher
im weiteren Verlauf der Arbeiten an Reduktionsmöglichkeiten der Wartezeiten auf die Hilfestellung
forschen.
9.1.4. Bewertung des Tests
Aus den durchgeführten Tests darf man keine allgemeinen Schlüsse für die Effizienz von PostgreSQL
und mySQL ziehen. Das Ergebnis hängt stark von der Effizienz der JDBC-Treiber und der internen
Anpassung des Jena-Framework an die einzelnen Datenbanken ab. Untersucht wurde nur die Performance
der Zusammenarbeit des MAT-MAESTRO-Prototyps mit den Datenbanken in Hinsicht auf ausgewählte
Funktionen des Lerneinheits-Knoten. Wie diese Studie zeigt, scheint sich zurzeit mySQL besser als
PostgreSQL für diese Anwendung zu eignen. Um die Tests zu vollständigen, sollten weitere Untersuchungen
durchgeführt werden, die zeigen, wie sich die Datenbanken im Falle mehrerer gleichzeitiger Anfragen
verhalten. Die Effizienz der Erstellung von semantischen Netzen in den Lerneinheits-Knoten scheint mir
zum jetzigen Zeitpunkt ausreichend zu sein. Die Performance der Anfragen ist zu diesem Zeitpunkt auch
akzeptabel, man sollte aber beachten, dass dieser Aspekt sehr kritisch in Hinsicht auf die Zufriedenstellung
des Lernenden ist.
9.2. Eindrücke aus der Implementierung des Learner GUI
Während der Implementierung des Learner GUI bin ich auf gewisse Schwierigkeiten bei der
Zusammenarbeit der Jade-Agentenplattform und Apache Tomcat gestoßen. Trotz vieler Versuche ist mir
nicht gelungen, die Jade-Agentenplattform (in der Version 3.1 und 3.2) mit Apache Tomcat 5.0 zu

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
117
verbinden. Die Fehlerursache sind wahrscheinlich neue Sicherheitsmaßnahmen des Tomcat-Applikations-
Servers. Die Verbindung Jade mit Apache Tomcat 4.1 klappte ohne Probleme.
Die prototypische Implementierung zeigte, dass die im Abschnitt 8.2 präsentierte graphische
Benutzeroberfläche mit Hilfe von Java Script und Java Server Pages leicht zu realisieren ist.
Es ist noch zu früh, um die Learner GUI –Schnittstelle objektiv zu testen. Es fehlt an umfangreichen
Lernmodulen, die an die MAESTRO-Architektur angepasst sind. Die Bewertung der Ergebnisse der
Hilfestellung sollten die an der Lerneinheit interessierten Lernenden und nicht die Programmierer oder
Autoren des zum Lernmodul gehörenden semantischen Netzes durchführen.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
118
10. Zusammenfassung
Das Hauptziel meiner Diplomarbeit war der Entwurf einer möglichst universellen Multiagenten-
Architektur für E-Learning-Systeme. Die durchgeführte Literaturrecherche gab mir Informationen über die
vorhandenen Lösungen in diesem Bereich, aber auch deren Mängel. Die daraufhin von mir vorgeschlagene
MAESTRO-Architektur vereinigt drei auf den ersten Blick getrennte Konzepte: Multiagentensysteme, E-
Learning und Semantic Web. Ein Einblick in die aktuellen Forschungsarbeiten auf diesen Gebieten gab mir
neue Ideen für die geplante Architektur.
Mein Konzept zeigt, wie Lerninhalte mit Hilfe der RDF-Sprache (der Basistechnologie für das
Semantic Web) beschrieben werden können. Des Weiteren zeigt, es wie die Materialien in getrennten
Knoten aufbewahrt und zur gegebenen Zeit zusammengeführt werden. Die Verteilung der didaktischen
Bestände gibt der Plattform eine gute Skalierbarkeit und Robustheit gegen potentielle Ausfälle. Ein weiterer
Knotentyp dient der Aufbewahrung der Daten von Lernenden. Diese Daten werden zur Anpassung des
Lernprozesses an den Benutzer genutzt. Mein Konzept der beiden Knotentypen ist eine Art hybride Lösung
aus traditionellen Datenbanken- und der Semantic Web-Technologie. Die Anwendung von Web Services als
Schnittstelle für diese Knoten ist zukunftsorientiert und flexibel.
Für das Verbinden der Lerninhalte ist eine Reihe von mir entworfenen Agenten zuständig. Es gibt
Agenten, die für das Aufsuchen und den Transport von Lerninhalten zuständig sind. Weitere Agenten führen
die gesammelten Daten zusammen und versuchen, die Ergebnisse der Suche für den Benutzer anzupassen.
Jeder Lernende in der MAESTRO-Architektur hat einen Agenten, der direkt für die Kommunikation mit ihm
verantwortlich ist und einen, der die Aufgaben des Einloggens für den Lernenden übernimmt.
Der Lehrende und der Systemadministrator bekommen in der MAESTRO-Architektur einige
Werkzeuge, die den Erstellungs- und Verwaltungsprozess des Systems erleichtern sollen.
Im praktischen Teil der Arbeit realisierte ich einen Prototyp eines Systems mit der MAESTRO-
Architektur (genannt MAT-MAESTRO). Die durchgeführten Tests beweisen die Nützlichkeit des Systems
und auch die Realisierbarkeit der ganzen Architektur. Während der Arbeit an der Implementierung hatte ich
Gelegenheit, viele Technologien unterschiedlicher Hersteller (Jade, Jena, Axis, Apache Tomcat) kennen zu
lernen und die Möglichkeiten ihrer Zusammenarbeit (auch mit anderen Technologien wie Java Servlets, Java
Server Pages, PostgreSQL) zu testen. Viele der Technologien befinden sich immer noch in einer intensiven
Entwicklungsphase (wie z.B. Jena), was meine Aufgabe erschwerte.
Meine Versuche raffiniertere Technologien des Semantic Web als RDF (z.B. OWL) anzuwenden,
sind vorerst gescheitert. Der Grund dafür war der enorme Zeitaufwand dieses Prozesses (bei der heutigen
Technologie) im Vergleich zu dem relativ niedrig erhofften Nutzen. Die RDF-Technologie reichte für die
aktuellen Bedürfnisse völlig aus. Ich will aber nicht ausschließen, dass in Zukunft die Einführung von OWL-
Ontologien für die MAESTRO-Architektur eine gute Lösung sein könnte. Man muss auch anmerken, dass
trotz meiner Bemühungen und gewisser Erfolge auf diesem Feld der Zeitaufwand für die Erstellung eines E-

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
119
Learning-Lernmoduls für den Lehrenden relativ groß ist. Meiner Ansicht nach werden viele Elemente des
Lehrprozesses noch lange Zeit (oder vielleicht für immer) nicht automatisierbar sein.
Die MAESTRO-Architektur ist ein sehr breit angelegtes Konzept. Nicht alle Aspekte der Architektur
konnten genau betrachtet werden. Zum Beispiel wurden Agenten für den Lehrenden und den
Systemadministrator in der Architektur berücksichtigt, aber aus Zeitgründen nicht entworfen. Gründlichere
Tests der Effizienz der Architektur sollten durchgeführt werden. Die Probleme der Zahlung für die Nutzung
der Bestände und der Sicherheit dieser Operationen wurden nicht gelöst. Dies könnte der Ausgangspunkt für
weitere Arbeiten an der MAESTRO-Architektur sein. Viele Elemente der Architektur und des MAT-
MAESTRO Systems warten noch auf eine prototypische Implementierung.
Zusammenfassend möchte ich feststellen, dass nach meiner Ansicht die MAESTRO-Architektur
(und das MAT-MAESTRO-System) einen guten Einblick in die Möglichkeiten der heutigen Technik gibt.
Sie zeigt, wie Multiagentensysteme, Semantic Web-Technologie und E-Learning sich gegenseitig ergänzen
können mit dem Ziel, den Lernprozess für den Menschen effektiver und angenehmer zu gestalten.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
120
A. Beschreibung des Inhalts der beigelegten CD
Die Tabelle 0-1 beinhaltet eine Beschreibung des Inhalts der Projekt-CD, die der Diplomarbeit beiliegt.
Name des Verzeichnisses Beschreibung des Inhaltes des Verzeichnisses
\diplomarbeit In diesem Verzeichnis befindet sich die Texte der Diplomarbeit
(Maestro_Diplomarbeit_Krakow_final.doc) und des
Anhangs (Maestro_Anhang_Krakow_final.doc).
\diplomarbeit\abbildungen Beinhaltet Abbildungen aus der Diplomarbeit im Microsoft Visio-
und IBM Rational Rose-Format.
\diplomarbeit\praesentation Beinhaltet Power Point-Präsentationen zu der Diplomarbeit.
\implementierung Beinhaltet den im praktischen Teil der Arbeit geschriebenen
Programmcode.
\implementierung\LearnerGUI Ein JBuilder76-Projekt des Prototyps des LearnerGUI.
\implementierung\lmNode Ein Beispiel eines kleinen Lerneinheits-Knotens zum Thema Statistik.
Die Lerninhalte sind im MathML- und XHTML-Format geschrieben.
Im Verzeichnis befinden sich außer den Lerninhalten Beispiele von
Header-Dateien.
\implementierung\
LMNodeAdminConsole
Ein JBuilder-Projekt des Prototyps des lmAdmin, des lmWebService
und der Methoden zum Testen der Effizienz der rdfDB-Datenbank.
\implementierung\sql SQL-Skripten zur Einrichtung der lmNodeDB- und userDB-
Datenbank.
\implementierung\TestGraph Ein JBuilder-Projekt eines Generators zum Erzeugen von Test-
Header-Dateien.
\implementierung\webapps\
maestro
Beinhaltet die LearnerGUI Web-Applikation, die in einem Servlet-
Container platziert sein kein.
\literatur Einige Literaturquellen, die in der Arbeit verwendet wurden
(hauptsächlich im Adobe PDF-Format).
\software Installationspakete einiger Programme, die in der Arbeit genutzt
werden (Windows-Versionen): Apache Tomcat 4.1, Jade 3.2, Jena
API 2.1, Mozilla 1.7.2 (mit MathML Fonts), mySQL 4.0.
\tests Testdateien, sowie Ergebnisse der Tests im Microsoft Excel Format.
Tabelle 0-1 Beschreibung des Inhalts der Projekt-CD
76 Borland JBuilder ist eine Java-Entwicklungsumgebung. Bei der Implementierung wurde die Version X des JBuilders genutzt.

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
121
B. Literatur
[1] Aiken M., Benzacar E., Cocosco C. A.: ABC - An Intelligent Robocup Agent , 1998, http://citeseer.nj.nec.com/aiken98abc.html
[2] Anderson R. et al.: XML professionell, MITP-Verlag, Bonn, 2000
[3] Bach J.: Enhancing Perception and Planning of Software Agents with Emotion and Acquired Hierarchical Categories, in: Proceedings of MASHO 02, German Conference on AI KI 2002, Karlsruhe, 2002, http://www.informatik.hu-berlin.de/~bach/publication/BachMasho2002.pdf
[4] Back A., Bendel O., Stoller-Schai D.: E-Learning im Unternehmen: Grundlagen - Strategien - Methoden – Technologien, Zürich, 2001
[5] Back A., Bendel O., Stoller-Schai D.: E-Learning - Ein Wörterbuch: Über 100 Begriffe - schnell nachgeschlagen, Kappelrodeck, 2002
[6] Baer W. S.: E-Learning: A Catalyst for Competition in Higher Education, in: iMP Information Impacts Magazine, 1999
[7] Bellifemine F., Caire G., Poggi A., Rimassa G.: JADE - A White Paper, in: exp – In Search of Innovation, Telecom Italia, Turin, vol.3, no.3, pp. 42-51, 2003
[8] Bendel O.: Pädagogische Agenten im Corporate E-Learning, Ph.D Thesis, Univeristy of St. Gallen, 2003, http://verdi.unisg.ch/org/iwi/iwi_pub.nsf/wwwPublAuthorGer/05535D23A73EF464C1256D0A003572E5/$file/Paedagogische_Agenten.pdf
[9] Bendel O.: Pädagogische Agenten im Corporate E-Learning, in: Neumann R., Nacke R., Ross A. (Ed.), Corporate E-Learning: Strategien, Märkte, Anwendungen, Wiesbaden, pp. 97-106, 2002.
[10] Berners-Lee T.: Semantic Web Road map, http://www.w3.org/DesignIssues/Semantic
[11] Bigus J, Bigus J.: Intelligente Agenten mit Java programmieren - eCommerce und Informationsrecherche automatisieren, Addison-Wesley, München 2001
[12] Blumstengel A.: Entwicklung hypermedialer Lernsysteme, Ph.D. Thesis, University of Paderborn, 1998
[13] Bonabeau E.,Théraulaz G.: Swarm smarts, in: Scientific American, pp. 72-79, 2000
[14] Borselius N.: Mobile agent security, in: Electronics & Communication Engineering Journal, IEE, vol.14, no. 5, pp. 211-218, 2002
[15] Bratman M. E.: Intentions, Plans, and Practical Reason, Harvard University Press, Cambridge, MA, 1987
[16] Bryson K., Luck M., Joy M., Jones D.T.: Applying Agents to Bioinformatics in GeneWeaver, in: Proceedings of the 4th International Workshop on Collaborative Information Agents IV, LNAI 1860, pp. 60-71, 2000
[17] Cambier C.: Simdelta: un systme multi-agents pour simuler la pche sur le Delta Central du Niger. PhD thesis, Universit de Paris, 1994
[18] Cetnarowicz K., Nawarecki E., Żabińska M.: M-Agent Architecture and its Application to the Agent Oriented Technology of Decentralized Systems, in: Proceedings of the Int. Workshop “Distributed Artificial Intelligence and Multi-Agent Systems” DAIMAS’97, St Petersburg, pp. 88-94, 1997
[19] Cetnarowicz K., Żabińska M., Cetnarowicz E.: An Application of th M-Agent Architecture to Learning Process, in: Proceedings of 4th International Conference, “Computer Aided Engineering Education CAEE’97”, Kraków, pp. II/7-II/14,1997

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
122
[20] Cheikes B.: GIA: An Agent-Based Architecture for Intelligent Tutoring Systems, in: Proceedings of the CIKM’95 Workshop on Intelligent Information Agents, 1995
[21] Chen W., Mizoguchi R.: Communication Content Ontology for Learner Model Agent in Multi-agent Architecture, in: Proceedings of the 7th International Conference on Computers in Education, ICCE99, pp. 95-102, 1999
[22] Cieszkowski M., Gołębiewski G.: Zastosowanie technologii agentów do realizacji procesu egzaminowania, Master Thesis, Supervisors: Żabińska M., Rakoczy W., Institute of Computer Science, University of Science and Technology (AGH), Kraków, 2000
[23] Demazeau Y., Müller J.P.: Decentralized artificial intelligence, in: Decentralized A.I., Elsevier North Holland, Amsterdam, pp. 3-13., 1990
[24] Dorigo M., Di Caro G.: The Ant Colony Optimization Meta-Heuristic. in: Corne D., Dorigo M., Glover F. (Ed.), New Ideas in Optimization, McGraw-Hill, pp. 11-32, 1999
[25] Dorigo M., Gambardella L.M.: Ant Colonies for the Traveling Salesman Problem, BioSystems, vol. 43, pp. 73-81., 1997
[26] Ecker K., et al., An Optimization Framework for Dynamic, Distributed Real-Time Systems, in: Proceedings of the International Parallel and Distributed Processing Symposium, Workshop on Parallel and Distributed Real-Time Systems, IEEE Computer Society, 2003
[27] Fenton-Kerr T.: GAIA: An Experimental Pedagogical Agent for Exploring Multimodal Interaction, in: Nehaniv Ch. (Ed.), Computation for Metaphors, Analogy, and Agents. Lecture Notes in Computer Science, Berlin, vol. 1562, pp. 154-164, 1999
[28] Ferber J.: Multiagentensysteme: eine Einführung in die Verteilte Künstliche Intelligenz, Addison-Wesley, München 2001
[29] Gutknecht O., Ferber J.: The MADKIT Agent Platform Architecture, in: Agents Workshop on Infrastructure for Multi-Agent Systems, pp.48-55, 2000
[30] Harhoff D, Küpper C.: Verbreitung und Akzeptanz von eLearning. Ergebnisse aus zwei Befragungen, in: Dowling M., Eberspächer J., Picot A (Ed.), eLearning in Unternehmen: neue Wege für Training und Weiterbildung ; Fachkonferenz -eLearning in Unternehmen: Neue Wege für Training und Weiterbildung, Springer, Berlin, 2003
[31] He M., Jennings N., Ho-Fung L.: The Agent-mediated Electronic Commerce http://citeseer.nj.nec.com/567141.html
[32] He, M., Jennings N., Leung H.: On agent-mediated electronic commerce, IEEE Trans. Knowledge Data Eng., vol. 15, pp. 985-1003, 2003
[33] Hoffman B.: The Encyclopedia of Educational Technology, San Diego State University, Department of Educational Technology, 1994-2004, http://coe.sdsu.edu/eet/
[34] Holm Ch.: The use of WebCT as the E-Learning Platform at the Universities of Applied Sciences Aargau and Solothurn, A project report FHA-01-03-015, Universities of Applied Sciences Aargau and Solothurn, 2001, http://www.edol.ch/Dozenten_Anlass2/chandra.pdf
[35] Issing, L.: Von der Mediendidaktik zur Multimedia-Didaktik, in: Unterrichtswissenschaft 22, pp. 267-284, 1994
[36] Jennings N., Wooldridge J.: Applications of Intelligent Agents, in: Agent Technology: Foundations, Applications, and Markets, Springer-Verlag: Heidelberg, pp. 3-28,1998, http://citeseer.nj.nec.com/jennings98applications.html
[37] Jennings N., Sycara K., Wooldridge M.: A Roadmap of Agent Research and Development, in: Journal of Autonomous Agents and Multi-Agent Systems, vol.1, no.1, pp. 7-38, 1998 http://citeseer.nj.nec.com/jennings98roadmap.html

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
123
[38] Kaczmarek W., Małecki B.: Agentowy system do egzaminowania, Rozszerzenie koncepcji "drzewa niewiedzy" i implementacji systemu OCET, Master Thesis, Supervisors: Żabińska M., Rakoczy W., Institute of Computer Science, University of Science and Technology (AGH), Kraków, 2002
[39] Karjoth G., Lange D.B, Oshima M.: A Security Model for Aglets, in: IEEE Internet Computing, vol.1, no. 4, pp. 68-77, 1997, http://citeseer.ist.psu.edu/karjoth97security.html
[40] Keegan D.: The future of learning: From elearning to mlearning, ZIFF-Papiere 119, Zentrales Inst. für Fernstudienforschung, Fernuniv. Hagen, 2002
[41] Kephart J., Chess D.: The Vision of Autonomic Computing, in: IEEE Computer, vol. 36(1), pp. 41-50, 2003
[42] zu Knyphausen-Aufseß D.: Die Rolle der Hochschule in der Weiterbildung durch E-Learning. E-Learning in Deutschland und den USA: ein Überblick, in: Dowling M., Eberspächer J., Picot A (Ed.) eLearning in Unternehmen : neue Wege für Training und Weiterbildung, Fachkonferenz "eLearning in Unternehmen: Neue Wege für Training und Weiterbildung", Berlin, Springer, 2003
[43] Kolonko M.: Angewandte Statistik, Vorlesungsskript, Technical University of Clausthal, 2003
[44] Koźlak J., Demazeau Y., Bousquet F.: Multi-agent system to model the FishBanks game process, in: The First International Workshop of Central and Eastern Europe on Multi-agent Systems (CEEMAS'99), St. Petersburg, pp. 154-162, 1999
[45] König M.: E-learning und Management von technischem Wissen in einer webbasierten Informationsumgebung, Ph.D Thesis, University of Dortmund, 2001
[46] Liu J., Ye Y. E-Commerce Agents- Marketplace Solutions, Security Issues, and Supply and Demand, Springer-Verlag, Heidelberg, 1998
[47] Ljungberg M., Lucas A.: The OASIS air-traffic management system, in: Proceedings of the Second Pacific Rim International Conference on Artificial Intelligence PRICAI '92, Seoul, 1992, http://citeseer.nj.nec.com/ljungberg92oasis.html
[48] Luck. M., McBurney, P., Preist, C.: Agent Technology: Enabling Next Generation Computing (A Roadmap for Agent Based Computing), AgentLink, 2003, http://www.agentlink.org/admin/docs/2003/2003-48.pdf
[49] Lytras M. D., Pouloudi A.: E-learning: Just a waste of time, in: Strong D., Straub D., DeGross J., (Ed.), 7th Americas Conference on Information Systems (AMCIS 2001), pp. 216-222, 2001.
[50] Mandl H., Winkler K.: Auf dem Weg zu einer neuen Weiterbildungskultur. Der Beitrag von eLearning in Unternehmen, in: Dowling M., Eberspächer J., Picot A (Ed.), eLearning in Unternehmen : neue Wege für Training und Weiterbildung, Fachkonferenz "eLearning in Unternehmen: Neue Wege für Training und Weiterbildung",Springer, Berlin, 2003
[51] Merrill M.: Where's massive? Past, present and future for the Lord of the Rings' crowd software, Metro Magazine, 2004, http://www.findarticles.com/p/articles/mi_m0PAM/is_139/ai_112861526
[52] Milojicic D., et. al. MASIF – The OMG Mobile Agent System Interoperability Facility, in: Proceedings of the Second International Workshop on Mobile Agents (MA ’98), Lecture Notes in Computer Science, Springer Verlag, Berlin, Heidelberg, vol. 1477, pp. 50–67, 1998
[53] Morley R.E., Schelberg C.: An Analysis of a Plant-Specific Dynamic Scheduler, in: Proceedings of the NSF, Workshop on Dynamic Scheduling, Cocoa Beach, FL, 1993
[54] Murakami Y., Minami K., Kawasoe T., Ishida T.: Multi-Agent Simulation for Crisis Management, IEEE International Workshop on Knowledge Media Networking (KMN-02), pp.135-139, 2002, http://www.lab7.kuis.kyoto-u.ac.jp/publications/02/yohei-kmn2002.pdf
[55] Nie A. G., et. al.: The Osnabrueck RoboCup Agents Project, 2001, http://citeseer.nj.nec.com/nie01orca.html
[56] Page L., Brin S., Motwani R., Winograd T.: The PageRank Citation Ranking: Bringing Order to the Web, 1998, http://citeseer.nj.nec.com/page98pagerank.html

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
124
[57] Peine H.: Run-Time Support for Mobile Code, Ph.D Thesis, University of Kaiserslautern, 2002
[58] Rakoczy W., Żabińska M.: Cyberprzestrzeń jako środowisko życia mobilnych agentów programowych, Automatyka, Uczelniane Wydawnictwa Naukowo-Dydaktyczne AGH, Kraków, vol. 7 (1/2) pp.245-250, 2003
[59] Rao A., Georgeff M.: Modeling Rational Agents within a {BDI}-Architecture, in: Proceedings of the 2nd International Conference on Principles of Knowledge Representation and Reasoning, Morgan Kaufmann publishers Inc., San Mateo, CA, 1991
[60] Rao A., Georgeff M.: {BDI}-agents: from theory to practice, in: Proceedings of the First Intl. Conference on Multiagent Systems San Francisco, 1995
[61] Roda C., Jennings N.R., Mamdani E.H.,: ARCHON: A Cooperation Framework for Industrial Process Control, in: Proceedings of workshop on Cooperating Knowledge Based Systems, Deen S. M. (Ed.), Springer, pp. 95-112, 1991
[62] Schoonderwoerd R., Holland O., Bruten J., Rothkrantz L.: Ant-based Load Balancing in Telecommunications Networks, Adaptive Behavior, 5(2), pp. 169-207, 1997
[63] Shaw E., Johnson, W., Ganeshan, R.: Pedagogical Agents on the Web, in: Proceedings of the 3th International Conference on Autonomous Agents, pp. 283-290, 1999
[64] Stojanovic L., Staab S., Studer R., Elearning based on the semantic web, in: WebNet2001-World Conference on the WWW and Internet, Orlando, FL, 2001, http://citeseer.nj.nec.com/stojanovic01elearning.html
[65] Wahle J., Bazzan A., Klügl F., Schreckenberg M.: Anticipatory Traffic Forecast Using Multi-Agent Techniques in: Traffic and Granular Flow '99, Springer, Heidelberg, pp. 87-92, 2000
[66] Weigel T., et al.: CS Freiburg: Doing the Right Thing in a Group, in: Stone P., Kraetzschmar G., Balch T., (Ed.), RoboCup-2000: Robot Soccer World Cup IV, Springer, Berlin, Heidelberg, New York, 2001, pp. 52-63, 2000, http://citeseer.nj.nec.com/article/weigel00cs.html
[67] Williamson B., Miller L.: The semantic web - A touch of intelligence for the internet?, Education.Guardian.co.uk, 2003, http://education.guardian.co.uk/elearning/story/0,10577,981948,00.html
[68] Zedler J. H., et al.: Grosses vollständiges Universal-Lexicon Aller Wissenschafften und Künste, J. H. Zedler Verlag, Halle, Leipzig, 1732
[69] Żabinska M., Ambroszkiewicz S., Cetnarowicz K.: The application of m-agent technology to dynamic resource distribution, in: Borzemski L., Grzech A., Molasy M., Wilimowska Z., (Ed.), Proceedings of the 20th International Scietific School: Information Systems Architecture and Technology ISAT'98, Oficyna Politechniki Wrocławskiej, Wrocław, pp. 201-208, 1998
[70] Żabinska M., Rakoczy W., Cieszkowski M., Gołębiewski G.: The Multi-Agent System for Examination – A Practical Realization of Ignorance Tree Concept, in: Štefan J. (Ed.), Proceedings of XXIInd International Colloquium ASIS 2000, Sv. Hostyn, MARQ, Ostrava, pp. 117-124, 2000
[71] Die Welt wird eins am Mittelkreis, Das Triaton Magazin, http://www.triaton.com/evolution/02_03/technologie/2002-03_1_1.php
[72] Intelligent Agent Resource Manager, Open Blueprint, G325-6592-0
[73] E-Markets: realism, not pessimism, PriceWaterhouseCoopers, 2001, http://www.pwcglobal.com/gx/eng/ins-sol/survey-rep/etrust/pwc_emarkets.pdf

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
125
Internetquellen
[74] Across Trophic Level System Simulation, http://atlss.org/ (16.02.2004)
[75] Advanced Distance Education, http://www.isi.edu/isd/ADE/ade.html (11.01.2004)
[76] Ant Colony Optimization, http://iridia.ulb.ac.be/~mdorigo/ACO/ACO.html (12.04.2004)
[77] AIBO, http://www.sony.net/Products/aibo/ (20.02.2004)
[78] Apache Tomcat, http://jakarta.apache.org/tomcat/ (20.08.2004)
[79] Blackboard, http://www.blackboard.com/ (22.05.2004)
[80] Callan Method, http://www.callan.co.uk (24.05.2004)
[81] Center for Advanced Research in Technology for Education, http://www.isi.edu/isd/carte/ (11.01.2004)
[82] Cerebra Server, http://www.networkinference.com/Products/Index.html (29.07.2004)
[83] Comparison of Online Course Delivery Software Products, http://www.marshall.edu/it/cit/webct/compare/comparison.html (30.05.2004)
[84] Cormas – Natural Resources and agent-based simulations, http://cormas.cirad.fr/en/demarch/sma.htm (16.02.2004)
[85] EduTech – Evaluation of Learning Management Systems, http://www.edutech.ch/lms/ev2.php (30.05.2004)
[86] ELAN E-Learning Academic Network Niedersachsen, http://www.elan-niedersachsen.de (30.05.2004)
[87] Extempo, http://www.extempo.com/index.html (11.01.2004)
[88] FernUniversität Hagen, http://www.fernuni-hagen.de (31.05.2004)
[89] FIPA 98 Part 1 Version 1.0: Agent Management Specification, http://www.fipa.org/specs/fipa00002/ (27.03.2004)
[90] FIPA 98 Part 10 Version 1.0: Agent Security Management Specification, http://www.fipa.org/specs/fipa00020/ (27.03.2004)
[91] FIPA Abstract Architecture Specification, http://www.fipa.org/specs/fipa00001/ (27.03.2004)
[92] FIPA ACL Message Structure Specification, http://www.fipa.org/specs/fipa00061/ (27.03.2004)
[93] FIPA Communicative Act Library Specification, http://www.fipa.org/specs/fipa00037/ (27.03.2004)
[94] FIPA SL Content Language Specification, http://www.fipa.org/specs/fipa00008/ (27.03.2004)
[95] FNL – Was kann WebCT, http://www.fnl.ch/webct/deutsch/indexD_MO.html (30.05.2004)
[96] Foundation of Physical Inteligent Agents, http://www.fipa.org/ (27.03.2004)
[97] Google, http://www.google.com (20.02.2004)
[98] IBM Lotus Learning Management System, http://www.lotus.com/lotus/offering6.nsf/wdocs/homepage (30.05.2004)
[99] JADE, http://sharon.cselt.it/projects/jade/ (31.03.2004)
[100] Jena, http://jena.sourceforge.net/ (29.07.2004)
[101] JESS, http://herzberg.ca.sandia.gov/jess/index.shtml (29.07.2004)
[102] Joseki, http://www.joseki.org/ (28.07.2004)
[103] JRDF, http://jrdf.sourceforge.net/ (29.07.2004)

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
126
[104] MadKit, http://www.madkit.org/ (30.03.2004)
[105] MySQL, http://www.mysql.com/ (04.09.2004)
[106] Object Management Group, http://www.omg.org (28.03.2004)
[107] OWL Web Ontology Language Overview, http://www.w3.org/TR/2004/REC-owl-features-20040210/ (20.02.2004)
[108] OWL Web Ontology Language Guide, http://www.w3.org/TR/2003/PR-owl-guide-20031215/ (20.02.2004)
[109] Polski Uniwersytet Wirtualny, http://www.puw.pl (30.05.2004)
[110] PostgreSQL, http://www.postgresql.org/ (20.08.2004)
[111] Protégé 2000, http://protege.stanford.edu/index.html (30.03.2004)
[112] RDF Calendar Taskforce, http://www.ilrt.bris.ac.uk/discovery/2001/04/calendar/ (28.07.2004)
[113] RDF Gateway, http://www.intellidimension.com/default.rsp?topic=/pages/site/products/rdfgateway.rsp (30.03.2004)
[114] RDF Vocabulary Description Language 1.0: RDF Schema, W3C, http://www.w3.org/TR/rdf-schema (20.02.2004)
[115] RDQL, http://www.w3.org/Submission/2004/SUBM-RDQL-20040109/ (29.07.2004)
[116] RDFQL, http://www.intellidimension.com/default.rsp?topic=/pages/rdfgateway/reference/db/default.rsp (29.07.2004)
[117] Resource Description Framework (RDF), W3C http://www.w3.org/RDF (20.02.2004)
[118] Robo Cup, http://www.robocup.org (16.02.2004)
[119] RQL, http://139.91.183.30:9090/RDF/RQL/ (30.03.2004)
[120] Semantic Web Activity Statement, http://www.w3.org/2001/sw/Activity (20.02.2004)
[121] Sergey Melnik's RDF API http://www-db.stanford.edu/%7Emelnik/rdf/api.html#overview (30.06.2004)
[122] Sesame, http://www.openrdf.org/ (30.03.2004)
[123] SMORE, http://www.mindswap.org/ (30.03.2004)
[124] SquishQL, http://www.w3.org/Submission/2004/SUBM-RDQL-20040109/ (29.07.2004)
[125] TopClass e-Learning Suite, http://www.wbtsystems.com/products (30.05.2004)
[126] UML Resource Page, http://www.uml.org/ (15.04.2004)
[127] User Agents, http://www.siteware.ch/webresources/useragents/ (20.02.2004)
[128] W3C – World Wide Web Consortium, http://www.w3.org/ (28.07.2004)
[129] WebCT, http://www.webct.com/ (30.05.2004)
[130] WebED Tools/Reviews & Comparison, http://www.osc.edu/education/webed/Tools/review.shtml (30.05.2004)
[131] Wikipedia, http://de.wikipedia.org (29.05.2004)
[132] WWW2004, 13th International World Wide Web Conference 2004, New York, http://www2004.org/ (29.07.2004)
[133] WWW2004 Semantic Web Roundup, http://www.xml.com/pub/a/2004/05/26/www2004.html (29.07.2004)

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
127
C. Verzeichnis der wichtigsten Begriffe
Agent ...................................................... 11, 12, 13 Agenten im E-Learning ......................................52 Agenteninhaltssprache........................................17 Agentenkommunikationssprache .......................17 Agentenplattform ...............................................19 Ant Colony Optimization ...................................22 Anwendungsgebiete für Multiagentensysteme...22 Apache Tomcat ................................................ 101 BDI-Agent ..........................................................15 Behaviourismus ..................................................31 Benutzerdaten-Datenbanken ..............................97 Benutzerdaten-Knoten.................................. 71, 74 Benutzerdaten-Knoten-Server .......................... 103 Computer-Based-Training..................................33 Directory Facilitator, DF ....................................17 Diskussionsforum...............................................36 Distance Learning ..............................................33 ELAN-Niedersachsen.........................................40 E-Learning.......................................... 7, 29, 41, 43 E-Learning-Plattform .........................................37 FIPA ...................................................................16 Header-Dateien...................................................94 hlm-Relation.......................................................79 IBM Aglets Workbench .....................................19 Intelligente Softwarearchitekturen .....................27 JADE ..................................................................21 Jena.....................................................................48 Kognitiver Agent................................................14 Kognitivismus ....................................................32 Kollaborativer Agent..........................................15 Konstruktivismus ...............................................32 Learner UI ..........................................................71 Lerneinheits-Datenbanken..................................96 Lerneinheits-Knoten..................................... 70, 72 Lerneinheits-Knoten-Server ............................. 101
Lernmodul ..........................................................72 MadKit................................................................20 MAESTRO.....................................................9, 62 MAESTRO-Agenten ..............................71, 74, 91 MAESTRO-Plattform-Server ...........................100 M-Agent .............................................................15 MASIF................................................................18 MAT-MAESTRO...................................62, 82, 95 MAT-MAESTRO-Prototyp........................62, 105 Mobiler Agent ....................................................15 Multiagenten-Architektur für Intelligente
Bildungssysteme ............................................53 Multiagentensystem........................................8, 16 mySQL .............................................................102 Ontologie ............................................................47 OWL...................................................................47 Pädagogischer Agent ..........................................52 Protégé................................................................48 RDF ....................................................................46 RDF Datastores ..................................................48 Reflexiver Agent ................................................14 rk-Relation..........................................................79 Schema ...............................................................47 Semantic Web.....................................7, 44, 45, 50 Semantic Web im E-Learning ............................49 Semantische Beschreibung ...........................73, 78 Simulationen.......................................................23 Software Agent ...................................................15 St. Galler E-Learning-Referenzmodell ...............33 Stationärer Agent................................................16 Swarm Intelligence .............................................22 UML ...................................................................63 Virtuelle Klassenzimmer ....................................36 Web-Based-Training ..........................................33 WebCT ...............................................................38

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
128
D. Abbildungs – und Tabellenverzeichnis
A b b i l d u n g e n Abbildung 2-1 Das Modell des generischen Agenten [21] ..............................................................................12 Abbildung 2-2 Bewertung von Fähigkeiten von Softwareagenten ..................................................................14 Abbildung 2-3 FIPA98-Referenzmodell zur Agentenverwaltung [87]............................................................17 Abbildung 3-1 Begriffslandkarte, in Anlehnung anW [4] ...................................................................................33 Abbildung 3-2 St. Galler E-Learning-Referenzmodell, in Anlehnung an [4] ..................................................34 Abbildung 3-3 Multimedia-Hörsaal an der TU Clausthal ................................................................................37 Abbildung 3-4 Ein mit Hilfe von WebCT erstelltes E-Learning-System.........................................................38 Abbildung 3-5 Alterung von Wissen [43] ........................................................................................................42 Abbildung 4-1 Schichten des Semantic Web ...................................................................................................45 Abbildung 4-2 Beispiel einer graphischen Darstellung einer RDF-Aussage ...................................................46 Abbildung 5-1 Multiagenten-Architektur für Intelligente Bildungssysteme (nach [19]).................................54 Abbildung 5-2 Federated Architecture for Agent Communications - Standalone Configuration (nach [17]) .55 Abbildung 5-3 Federated Architecture for Agent Communications Networked Configuration (nach [17]) ...56 Abbildung 5-4 ADE Architektur [61] ..............................................................................................................57 Abbildung 5-5 Untersuchung eines Patienten im ADE-System.......................................................................59 Abbildung 5-6 Expert Coach Agent [85] .........................................................................................................60 Abbildung 5-7 Expert Role Player Agent [85].................................................................................................61 Abbildung 6-1 Schichten in der Entwicklung der MAESTRO-Architektur ....................................................62 Abbildung 6-2 Benutzer in der MAESTRO-Architektur .................................................................................64 Abbildung 6-3 Use-Case Diagram für den Benutzer .......................................................................................64 Abbildung 6-4 Use-Case Diagram für den Lernenden.....................................................................................65 Abbildung 6-5 Use-Case Diagram für den Lehrenden.....................................................................................67 Abbildung 6-6 Use-Case Diagram für den Systemadministrator .....................................................................68 Abbildung 6-7 Verbindungen von MAESTRO-Plattformen (Beispiel: ELAN Projekt)..................................69 Abbildung 6-8 Allgemeines Schema der MAESTRO-Plattform .....................................................................70 Abbildung 6-9 Lerneinheits-Knoten im Detail.................................................................................................72 Abbildung 6-10 Beispiel eines semantischen Netzes der Begriffe...................................................................80 Abbildung 6-11 Beispiel eines strukturellen Netzes des Lernmoduls..............................................................81 Abbildung 7-1 Funktionen des MAT-MAESTRO-System aus der Sicht des Lernenden................................82 Abbildung 7-2 Funktionen des MAT-MAESTRO-System aus der Sicht des Lehrenden und des Lernenden 83 Abbildung 7-3 Sequenzendiagramm - Aufsuchen von Adressen mit Hilfe des Configuration Agent.............84 Abbildung 7-4 Sequenzdiagramm - Einloggen ................................................................................................85 Abbildung 7-5 Sequenzdiagramm - Eröffnung eines neuen Lernmoduls ........................................................86 Abbildung 7-6 Sequenzdiagramm - Wiedereröffnung eines Moduls...............................................................88 Abbildung 7-7 Sequenzdiagramm - Anzeigen von gewünschten Seiten .........................................................89 Abbildung 7-8 Sequenzdiagramm - Realisation der Hilfestellung...................................................................90 Abbildung 7-9 Sequenzdiagramm - Ausloggen ...............................................................................................91 Abbildung 7-10 Pakete des MAT-MAESTRO-Systems..................................................................................95 Abbildung 7-11 Struktur der lmModuleDB-Datenbank...................................................................................96 Abbildung 7-12 Struktur der userDB-Datenbank.............................................................................................98 Abbildung 7-13 Allgemeines Einsatzdiagramm von MAT-MAESTRO .......................................................100 Abbildung 7-14 Einsatzdiagramm des MAESTRO-Plattform-Servers..........................................................101 Abbildung 7-15 Einsatzdiagramm für den Lerneinheits-Knoten-Server .......................................................102 Abbildung 7-16 Komponentendiagramm des lmAdmin-Pakets ....................................................................103 Abbildung 7-17 Einsatzdiagramm für den Benutzerdaten-Knoten-Server ....................................................104 Abbildung 7-18 Einsatzdiagramm für den Rechner des Lernenden...............................................................104 Abbildung 8-1 Learner UI / Einloggen in das System ...................................................................................106

Andrzej Kononowicz Anwendung von Multiagentensystemen im E-Learning
129
Abbildung 8-2 Learner UI / Wahl eines Moduls............................................................................................107 Abbildung 8-3 Learner UI / Startseite eines Moduls......................................................................................108 Abbildung 8-4 Learner UI / Inhaltsverzeichnis des Moduls ..........................................................................109 Abbildung 8-5 Learner UI / Persönliche Einstellungen des Lernprozesses ...................................................109 Abbildung 8-6 Learner UI / Hilfestellung ......................................................................................................110 Abbildung 9-1 Bearbeitungszeit der Einrichtung eines semantischen Netzes mit der Topologie eines
vollständigen gerichteten Graphen mit n={0,10,25} Knoten ................................................................115 Abbildung 9-2 Bearbeitungszeit der Einrichtung eines semantischen Netzes mit Topologie eines
vollständigen gerichteten Graphen mit n={50,100,200} Knoten ..........................................................115 Abbildung 9-3 Antwortszeiten bei der Hilfestellungs-Funktion ....................................................................116
T a b e l l e n Tabelle 3-1 Einige der WebCT Tools ..............................................................................................................39 Tabelle 6-1 Charakteristik der MAESTRO-Agenten .......................................................................................77 Tabelle 6-2 Relationen zur Beschreibung der semantischen Zusammenhänge................................................79 Tabelle 6-3 Relationen zur Beschreibung der Struktur ....................................................................................79 Tabelle 6-4 Eigenschaften der Page-Knoten ....................................................................................................81 Tabelle 7-1 Beschreibung der MAT-MAESTRO Pakete.................................................................................95 Tabelle 7-2 Tabellen der lmModuleDB-Datenbank.........................................................................................97 Tabelle 7-3 Tabellen der userDB-Datenbank...................................................................................................99 Tabelle 0-1 Beschreibung des Inhalts der Projekt-CD ...................................................................................120





















