Embed Size (px)
Citation preview

Big Data Training for Translational Omics Research
Simple Association Test
Unit4,Session1

Big Data Training for Translational Omics Research
PLINK• PLINKisafree,open-sourcewholegenomeassociationanalysistoolset
• Designedtoperformarangeofbasic,large-scaleanalysesinacomputationallyefficientmanner,seehttp://pngu.mgh.harvard.edu/~purcell/plink/.

Big Data Training for Translational Omics Research
PLINK Input Files•PEDfile:5SNPs.ped•MAPfile:5SNPs.map•Alternatephenotypefile:conty.txt/biny.txt•Optionalcovariatefile:covariate0.txt

Big Data Training for Translational Omics Research
PLINK Input Files•PEDfile
Col1:FamilyIDCol2:IndividualIDCol3:PaternalIDCol4:MaternalIDCol5:Sex(1=male;2=female;other character=unknown)Col6:Phenotype(Themissingphenotypevalueforquantitativetraitsis,bydefault,-9)Col7:Genotypes(Themissinggenotypevalueisdenotedas0,bydefault)
•Example:FAM00110013.4AA GG ACC CFAM00120012.5AA A G00AC

Big Data Training for Translational Omics Research
PLINK Input Files•MAPfile
Col1:Chromosome(1-22,X,Yor0ifunplaced)Col2:rs#orSNPidentifierCol3:Geneticdistance(morgans)Col4:Base-pairposition(bp units)
•Example:1rs123456012345551rs234567012377931rs2245340-12376971rs23355601337456

Big Data Training for Translational Omics Research
PLINK Input Files• Tospecifyanalternatephenotypeforanalysis,i.e.otherthantheoneinthe*.ped file,usetheoption--pheno.
•AlternatephenotypefileCol1:FamilyIDCol2:IndividualIDCol3:Phenotype
•ExampleF111102.322.222F2220234.1218.231

Big Data Training for Translational Omics Research
PLINK Input Files• The phenotype can be either a quantitative trait or an
affection status • PLINK will automatically detect which type (i.e. based
on whether a value other than 0, 1, 2 or the missing genotype code is observed).

Big Data Training for Translational Omics Research
Quantitative Trait Association Test (Continuous Trait ~ 5 SNPs)
•Genotypedata:5SNPs.ped&5SNPs.map

Big Data Training for Translational Omics Research
Quantitative Trait Association Test (Continuous Trait ~ 5 SNPs)
•Alternatephenotypedata:conty.txt

Big Data Training for Translational Omics Research
Quantitative Trait Association Test(Continuous Trait ~ 5 SNPs)
• PLINKcommands:plink--noweb --file5SNPs--assoc --pheno conty.txt--outyounameit
• Usage--filespecifies.ped and.mapfiles,--assoc performscase/controlorQTLassociation,--pheno specifiesalternatephenotype,--outspecifiesoutputfilename
• Thiswillgeneratethefilesyounameit.qassoc withfieldsasfollows:CHRChromosomenumberSNPSNP identifierBPPhysicalposition(base-pair)NMISS Numberofnon-missinggenotypesBETARegressioncoefficientSE StandarderrorR2 Regressionr-squaredT Waldtest(basedont-distribution)P Waldtestasymptoticp-value
Big Data Training for Translational Omics Research
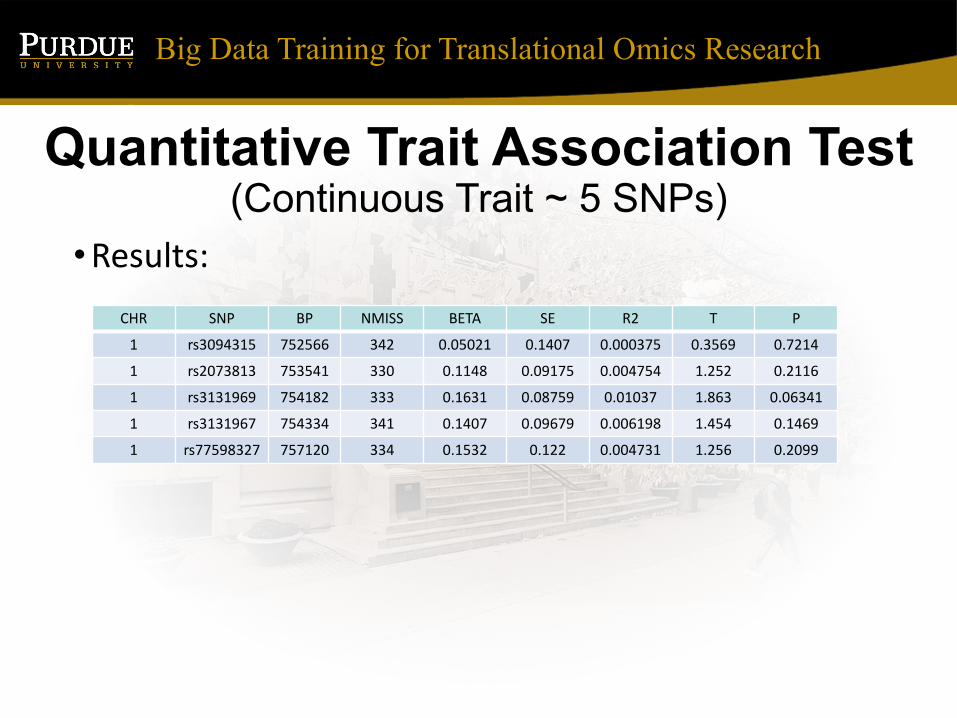
Quantitative Trait Association Test (Continuous Trait ~ 5 SNPs)
•Results:CHR SNP BP NMISS BETA SE R2 T P
1 rs3094315 752566 342 0.05021 0.1407 0.000375 0.3569 0.7214
1 rs2073813 753541 330 0.1148 0.09175 0.004754 1.252 0.2116
1 rs3131969 754182 333 0.1631 0.08759 0.01037 1.863 0.06341
1 rs3131967 754334 341 0.1407 0.09679 0.006198 1.454 0.1469
1 rs77598327 757120 334 0.1532 0.122 0.004731 1.256 0.2099

Big Data Training for Translational Omics Research
Case/Control Association Test (Binary Trait ~ 5 SNPs)
•Genotypedata:5SNPs.ped&5SNPs.map•Alternatephenotypedata:biny.txt

Big Data Training for Translational Omics Research
Case/Control Association Test (Binary Trait ~ 5 SNPs)
•PLINKcommands:plink--noweb --file5SNPs--assoc --pheno biny.txt--outyounameit
• Thiswillgeneratethefilesyounameit.assoc withfieldsasfollows:CHR ChromosomeSNP SNPIDBP Physicalposition(base-pair)A1 Minorallelename(basedonwholesample)F_A FrequencyofthisalleleincasesF_U FrequencyofthisalleleincontrolsA2 MajorallelenameCHISQ Basicallelictestchi-square(1df)P Asymptoticp-valueforthistestOR Estimatedoddsratio(forA1,i.e.A2isreference)
Big Data Training for Translational Omics Research
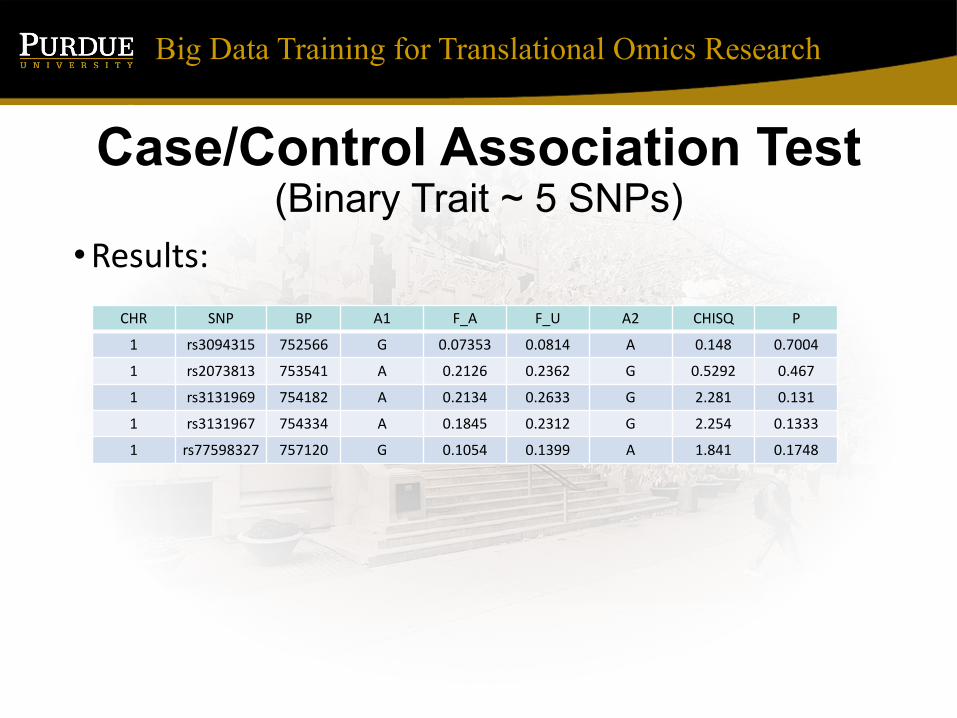
Case/Control Association Test (Binary Trait ~ 5 SNPs)
•Results:CHR SNP BP A1 F_A F_U A2 CHISQ P
1 rs3094315 752566 G 0.07353 0.0814 A 0.148 0.7004
1 rs2073813 753541 A 0.2126 0.2362 G 0.5292 0.467
1 rs3131969 754182 A 0.2134 0.2633 G 2.281 0.131
1 rs3131967 754334 A 0.1845 0.2312 G 2.254 0.1333
1 rs77598327 757120 G 0.1054 0.1399 A 1.841 0.1748

Big Data Training for Translational Omics Research
Quantitative Trait Association Test (Continuous Trait ~ 5 SNPs + 3 Covariates)
•Genotypedata:5SNPs.ped&5SNPs.map•Phenotypedata:conty0.txt•Covariates:covariates0.txt (age,gender,bmi)

Big Data Training for Translational Omics Research
Quantitative Trait Association Test (Continuous Trait ~ 5 SNPs + 3 Covariates)
• Covariatesadjustments(usingR):pheno=read.table("conty0.txt")covar=read.table("covariates0.txt")pheno=as.matrix(pheno)covar=as.matrix(covar)n=dim(pheno)[1]p=dim(pheno)[2]
fit=list()residpheno=matrix(0,n,p)for(i in1:p){fit[[i]]=lm(pheno[,i]~covar)residpheno[,i]=resid(fit[[i]])
}write.table(residpheno,"resid_phenotype0.txt",row.names=F,col.names=F,quote=F,sep="")

Big Data Training for Translational Omics Research
Quantitative Trait Association Test (Continuous Trait ~ 5 SNPs + 3 Covariates)
•Residualphenotype(alternate)dataaftercovariatesadjustments:resid_phenotype.txt

Big Data Training for Translational Omics Research
Quantitative Trait Association Test (Continuous Trait ~ 5 SNPs + 3 Covariates)
•PLINKcommands:plink--noweb --file5SNPs--assoc --pheno resid_phenotype.txt--outyounameit
• Thiswillgeneratethefilesyounameit.qassoc withfieldsasfollows:CHRChromosomenumberSNPSNP identifierBPPhysicalposition(base-pair)NMISSNumberofnon-missinggenotypesBETARegressioncoefficientSEStandarderrorR2Regressionr-squaredTWaldtest(basedont-distribtion)PWaldtestasymptoticp-value
Big Data Training for Translational Omics Research
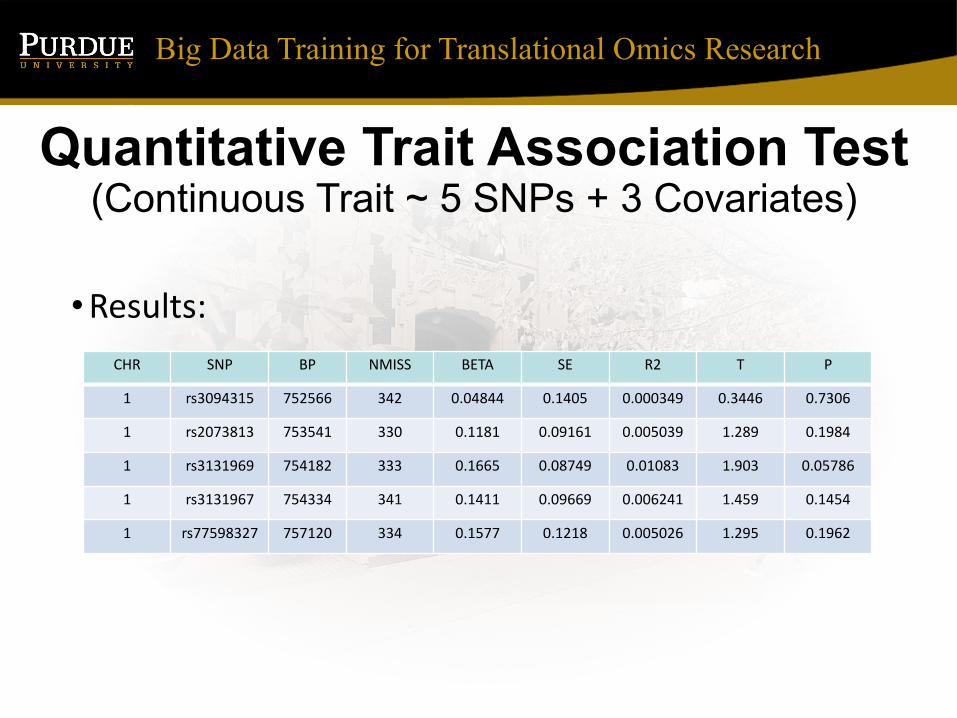
Quantitative Trait Association Test (Continuous Trait ~ 5 SNPs + 3 Covariates)
•Results:CHR SNP BP NMISS BETA SE R2 T P
1 rs3094315 752566 342 0.04844 0.1405 0.000349 0.3446 0.7306
1 rs2073813 753541 330 0.1181 0.09161 0.005039 1.289 0.1984
1 rs3131969 754182 333 0.1665 0.08749 0.01083 1.903 0.05786
1 rs3131967 754334 341 0.1411 0.09669 0.006241 1.459 0.1454
1 rs77598327 757120 334 0.1577 0.1218 0.005026 1.295 0.1962

Big Data Training for Translational Omics Research
Quality Control Using PLINK

Big Data Training for Translational Omics Research
PLINK Input Files•PEDfile
Col1:FamilyIDCol2:IndividualIDCol3:PaternalIDCol4:MaternalIDCol5:Sex(1=male;2=female;othercharacter=unknown)Col6:Phenotype(Themissingphenotypevalueforquantitativetraitsis,bydefault,-9)Col7:Genotypes(Themissinggenotypevalueisdenotedas0,bydefault)
•Example:FAM00110013.4AA GG ACC CFAM00120012.5AA A G00AC

Big Data Training for Translational Omics Research
PLINK Input Files•MAPfile
Col1:Chromosome(1-22,X,Yor0ifunplaced)Col2:rs#orSNPidentifierCol3:Geneticdistance(morgans)Col4:Base-pairposition(bp units)
•Example:1rs123456012345551rs234567012377931rs2245340-12376971rs23355601337456

Big Data Training for Translational Omics Research
Inclusion Thresholds• CommonoptionsthatcanbeusedtofilteroutindividualsorSNPsonthebasisofthesummarystatisticmeasures:
• Reference:http://pngu.mgh.harvard.edu/~purcell/plink/thresh.shtml
Featureinclusioncriteria Assummarystatistic AsinclusioncriteriaMissingnessperindividual --missing --mindNMissingnesspermarker --missing --genoNAllelefrequency --freq --mafNHardy-Weinbergequilibrium --hardy --hwe N

Big Data Training for Translational Omics Research
PLINK Output Files•Option1:Wecouldoutputintofilesthatlooklikeourinput(--recode),whichisusefulifwewanttouseMACHafterwards.
•Outputs:*.ped &*.mapFAM00110012AAGGFAM00120012AAAG
1rs123456012345551rs23456701237793

Big Data Training for Translational Omics Research
PLINK Output Files•Option2:Wecouldoutputintoformatsthatarereadyforassociationstudy(--recodeA),whichisusefulifwewouldliketorunassociationstudyafterwards.
•Outputs:*.rawFAM0011001200FAM0012001201

Big Data Training for Translational Omics Research
Example - Summary Statistic• Inputfiles:5SNPs.ped5SNPs.map
•PLINKcommands:plink--noweb --file5SNPs--missing--outyounameit

Big Data Training for Translational Omics Research
Example - Summary Statistic• This option creates two files:
plink.imissplink.lmiss
which detail missingness by individual and by SNP (locus).

Big Data Training for Translational Omics Research
Example - Summary Statistic•PLINKcommands:plink--noweb --file5SNPs--freq --outyounameit
� Thisoptioncreateafileyounameit.frq withfivecolumns:CHRChromosomeSNPSNP identifierA1Allele1code(minorallele)A2Allele2code(majorallele)MAFMinorallelefrequencyNCHROBSNon-missingallelecount

Big Data Training for Translational Omics Research
Example - Summary Statistic•PLINKcommands:plink--noweb --file5SNPs--hardy--outyounameit
� Thisoptioncreateafileyounameit.hwe withthefollowingformat:SNPSNP identifierTESTCodeindicatingsampleA1MinorallelecodeA2MajorallelecodeGENOGenotypecounts:11/12/22O(HET)ObservedheterozygosityE(HET)ExpectedheterozygosityPH-Wp-value

Big Data Training for Translational Omics Research
Example - Inclusion Thresholds• Inputfiles:5SNPs.ped5SNPs.map
•PLINKcommands:plink--noweb --file5SNPs--mind0.1--geno 0.1--maf 0.05--hwe 0.001--recode--outyounameit

Big Data Training for Translational Omics Research
Example of the Log File5(of5)markerstobeincludedfrom[5SNPs.map]344individualsreadfrom[5SNPs.ped]Beforefrequencyandgenotypingpruning,thereare5SNPs344foundersand0non-foundersfound32of344individualsremovedforlowgenotyping(MIND>0.1)0markerstobeexcludedbasedonHWEtest(p<=0.001)
0markersfailedHWEtestincases0markersfailedHWEtestincontrols
Totalgenotypingrateinremainingindividualsis10SNPsfailedmissingness test(GENO>0.1)0SNPsfailedfrequencytest(MAF<0.05)Afterfrequencyandgenotypingpruning,thereare5SNPsAfterfiltering,thereare312individualsWritingrecodedped fileto[younameit.ped ]Writingnewmapfileto[younameit.map ]

Big Data Training for Translational Omics Research
Remove Closely Related Individuals• Inputfiles:5SNPs.ped5SNPs.map
•PLINKcommands:plink--noweb --file5SNPs--genome--outyounameit

Big Data Training for Translational Omics Research
Remove Closely Related Individuals• Thiswillcreatethefileyounameit.genome whichhasthefollowingfields:
FID1FamilyIDforfirstindividualIID1IndividualIDforfirstindividualFID2FamilyIDforsecondindividualIID2IndividualIDforsecondindividualRTRelationshiptypegivenPEDfileEZExpectedIBDsharinggivenPEDfileZ0P(IBD=0)Z1P(IBD=1)Z2P(IBD=2)PI_HATP(IBD=2)+0.5*P(IBD=1)(proportionIBD)PHEPairwisephenotypiccode(1,0,-1=AA,AUandUUpairs)DSTIBSdistance(IBS2+0.5*IBS1)/(NSNPpairs)PPCIBSbinomialtestRATIOOfHETHET:IBS0SNPs(expectedvalueis2)

Big Data Training for Translational Omics Research
Remove Closely Related Individuals• Scantheyounameit.genome fileforanyindividualswithhighPIHATvalues(e.g.greaterthan0.05).Optionally,removeonememberofthepairifyoufindcloserelatives.
• Reference:http://pngu.mgh.harvard.edu/~purcell/plink/ibdibs.shtml