Embed Size (px)
Citation preview

Centro de Investigacion y de Estudios Avanzadosdel Instituto Politecnico Nacional
Unidad Zacatenco
Departamento de Computacion
Paralelizacion heterogenea del algoritmo de Cuppen,
caso de estudio: problema regular de Sturm-Liouville
Tesis que presenta
Alberto Estrella Cruz
para obtener el grado de
Maestro en Ciencias en Computacion
Director de Tesis
Dr. Sergio Vıctor Chapa Vergara
Mexico, Distrito Federal Diciembre, 2014

ii

Resumen
El algoritmo de Cuppen (o algoritmo divide y venceras) es un algoritmo numericamenteestable y eficiente que calcula todos los valores y vectores propios de una matriz tridiagonalsimetrica. Los problemas regulares de Sturm-Liouville son ecuaciones diferenciales lineales desegundo orden que tienen una forma especial y cuyos valores en la frontera deben respetarciertas condiciones. El calculo numerico de los valores propios de este tipo de problemas es degran importancia, debido a las distintas areas de aplicacion que tienen, tales como: vibracionde cuerdas, propagacion de ondas, termodinamica, mecanica y quımica cuantica. Entre losmetodos numericos para resolver este problema se encuentran, el metodo de disparo y elmetodo de diagonalizacion de matrices.
Estos metodos tienen un alto costo computacional, por lo que, en esta tesis se desarrollaronimplementaciones paralelas de ellos para reducir su tiempo de ejecucion, y se utilizaron encasos especıficos del problema regular de valores propios de Sturm-Liouville. En este trabajose presenta, a nuestro conocimiento, la primera implementacion paralela heterogenea en uncluster con multiples GPUs y CPUs del algoritmo divide y venceras para valores propios. Unade las principales desventajas de implementar dicho algoritmo en GPUs es que el computoesta limitado por la cantidad de memoria del GPU. Para superar este problema nosotrosutilizamos multiples nodos con CPUs y GPUs para resolver subproblemas que encajan en lamemoria de un GPU en paralelo y reunimos sus resultados para obtener la solucion completa.Experimentos preliminares muestran resultados prometedores. Nuestro enfoque tiene mejordesempeno que el de librerıas actuales. Ademas, las soluciones obtenidas muestran un altogrado de exactitud con respecto a la ortogonalidad de los vectores propios y a la calidad delos eigenpares.
iii

iv

Abstract
Cuppen’s algorithm (or divide-and-conquer algorithm) is a numerically stable and efficientalgorithm that computes all eigenvalues and eigenvectors of a symmetric tridiagonal matrix.Regular Sturm-Liouville problems are second order differential equations with special formthose boundary values accomplish certain conditions. The considerable importance of thenumerical calculation of their eigenvalues laid on the many eigenvalue problems that arise inscientific and engineering applications such as: vibrating strings, propagation of waves, ther-modynamics, quantum mechanics and quantum chemistry. Among the variety of methods tosolve these problems are shooting methods and matrix diagonalization.
These methods have a high computational cost, for this reason in this thesis parallelimplementations of them were developed in order to reduce running times. Also, they wereapplied to specific cases of the regular Sturm-Liouville eigenvalue problem. In this work wepresent, to the best of our knowledge, the first heterogeneous parallel implementation on acluster with multiple GPUs and CPUs of the divide-and-conquer eigenvalue algorithm. Amajor drawback of implementing such algorithm on GPUs is that computation is limited bythe amount of GPU memory. We overcome the issue by using multiple nodes with CPUsand GPUs to solve subproblems, which fit on device memory in parallel, and merging thosesubproblems to get the whole result. Preliminary experiments show promising results. Ourapproach has better performance than state-of-the-art libraries. Furthermore, it exhibits ameaningful degree of accuracy with respect to orthogonality of eigenvectors and quality ofegeinpairs.
v

vi

Agradecimientos
A mi madre y a mi hermana por el apoyo incondicional que me han brindado y con el quesiempre podre contar
A mi director el Dr. Sergio Vıctor Chapa Vergara por aceptarme como su tesista
A mis sinodales el Dr. Oliver Steffen Schutze y el Dr. Amilcar Meneses Viveros por susvaliosos comentarios
Al Departamento de Computacion por las todas las experiencias y el aprendizaje que medejaron
Al Centro de Investigacion y Estudios Avanzados del Instituto Politecnico Nacional(CINVESTAV-IPN) por darme la oportunidad de ser parte de uno de sus posgrados de
maestrıa
Al Consejo Nacional de Ciencia y Tecnologıa (CONACYT) por el apoyo economico que mebrindo durante esta etapa
A los companeros y amigos que he conocido a lo largo de mi vida, en especial a Hugo yJorge por creer en mi
vii

viii

Indice general
Resumen III
Abstract V
Indice de figuras XIII
Indice de tablas XV
Indice de algoritmos XV
1. Introduccion 1
1.1. Antecedentes y motivacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2. Estado del arte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3. Planteamiento del problema . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.4. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.5. Contribuciones y resultados esperados . . . . . . . . . . . . . . . . . . . . . . 5
1.6. Organizacion de la tesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2. Marco teorico 7
2.1. Problema regular de Sturm-Liouville . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1. Ecuacion de Schrodinger . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.2. Ecuacion de Dirac . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2. Metodo de disparo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.1. Metodo de Runge-Kutta . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3. Metodo de diferencias finitas . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.4. Problema algebraico de valores propios . . . . . . . . . . . . . . . . . . . . . 12
2.4.1. Definicion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.4.2. Transformaciones similares . . . . . . . . . . . . . . . . . . . . . . . . 14
2.4.3. Diagonalizacion de matrices . . . . . . . . . . . . . . . . . . . . . . . 16
2.4.4. Algoritmo QR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.4.5. Metodo de Householder . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.4.6. Metodo de Givens . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.5. Programacion paralela . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.5.1. Hıbrida . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.5.2. Heterogenea . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.5.3. Tecnologıas para implementar algoritmos paralelos . . . . . . . . . . 23
ix

x INDICE GENERAL
3. Algoritmo divide y venceras 27
3.1. Idea general . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
3.2. Ecuacion secular . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.3. Ortogonalidad de los vectores propios . . . . . . . . . . . . . . . . . . . . . . 33
3.4. El problema de valores propios para D + vvT . . . . . . . . . . . . . . . . . 34
3.5. Deflacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.6. Matrices de permutacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.7. Algoritmo completo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4. Diseno e implementacion 39
4.1. Implementacion secuencial del metodo de disparo . . . . . . . . . . . . . . . 39
4.2. Implementacion secuencial del algoritmo divide y venceras . . . . . . . . . . 40
4.2.1. Almacenamiento de matrices . . . . . . . . . . . . . . . . . . . . . . . 41
4.2.2. Generacion de matrices y metodos de calculo de error . . . . . . . . . 41
4.2.3. Estructuras de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.2.4. Funciones principales . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.2.5. Escalamiento del problema original . . . . . . . . . . . . . . . . . . . 42
4.2.6. Consideraciones en la ecuacion secular . . . . . . . . . . . . . . . . . 44
4.2.7. Consideraciones en las rotaciones de Givens . . . . . . . . . . . . . . 45
4.2.8. Permutaciones compuestas . . . . . . . . . . . . . . . . . . . . . . . . 45
4.2.9. Ventajas practicas de la deflacion . . . . . . . . . . . . . . . . . . . . 45
4.3. Estrategias de paralelizacion . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.3.1. Descomposicion por datos . . . . . . . . . . . . . . . . . . . . . . . . 46
4.3.2. Descomposicion por tareas . . . . . . . . . . . . . . . . . . . . . . . . 46
4.4. Paralelizacion del metodo de disparo . . . . . . . . . . . . . . . . . . . . . . 46
4.5. Paralelizacion del algoritmo divide y venceras . . . . . . . . . . . . . . . . . 46
4.5.1. Paralelizacion de la ecuacion secular . . . . . . . . . . . . . . . . . . 48
4.5.2. Paralelizacion de la correccion de la ortogonalidad de los vectores propios 48
4.5.3. Paralelizacion del calculo de los vectores propios de la modificacion derango uno . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.5.4. Paralelizacion de la aplicacion de las rotaciones de Givens . . . . . . 48
4.5.5. Paralelizacion de las pertmutaciones . . . . . . . . . . . . . . . . . . 48
4.5.6. Paralelizacion de la multiplicacion de matrices . . . . . . . . . . . . . 49
4.5.7. Otras paralelizaciones . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5. Pruebas, resultados y discusion 51
5.1. Infraestructura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.1.1. Software . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.1.2. Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.2. Tiempo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.3. Error . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5.4. Schrodinger . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.5. Dirac . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
5.6. Discusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73

INDICE GENERAL xi
6. Conclusiones y trabajo a futuro 756.1. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 756.2. Trabajo futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
Bibliografıa 79

xii INDICE GENERAL

Indice de figuras
1.1. Arquitectura paralela heterogenea . . . . . . . . . . . . . . . . . . . . . . . . 2
4.1. Flujo del proceso . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.1. Tiempo Eigensistema Simetrico Tridiagonal . . . . . . . . . . . . . . . . . . 535.2. Tiempo Disparo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 545.3. Tiempo Diagonalizacion vs Disparo . . . . . . . . . . . . . . . . . . . . . . . 555.4. Soluciones pares Schrodinger - Diagonalizacion . . . . . . . . . . . . . . . . . 595.5. Soluciones impares Schrodinger - Diagonalizacion . . . . . . . . . . . . . . . 605.6. Soluciones Schrodinger - Diagonalizacion . . . . . . . . . . . . . . . . . . . . 605.7. Suma soluciones Schrodinger - Diagonalizacion . . . . . . . . . . . . . . . . . 615.8. Soluciones pares Schrodinger - Disparo (y = 0, z = 1) . . . . . . . . . . . . . 615.9. Soluciones impares Schrodinger - Disparo (y = 0, z = 1) . . . . . . . . . . . . 625.10. Soluciones Schrodinger - Disparo (y = 0, z = 1) . . . . . . . . . . . . . . . . 625.11. Suma Soluciones Shrodinger - Disparo (y = 0, z = 1) . . . . . . . . . . . . . . 635.12. Soluciones pares Schrodinger - Disparo (y = 0, z = −1) . . . . . . . . . . . . 635.13. Soluciones impares Schrodinger - Disparo (y = 0, z = −1) . . . . . . . . . . . 645.14. Soluciones Schrodinger - Disparo (y = 0, z = −1) . . . . . . . . . . . . . . . 645.15. Suma Soluciones Shrodinger - Disparo (y = 0, z = −1) . . . . . . . . . . . . 655.16. Soluciones pares Dirac - Disparo (y = 0, z = 1) . . . . . . . . . . . . . . . . . 685.17. Soluciones impares Dirac - Disparo (y = 0, z = 1) . . . . . . . . . . . . . . . 685.18. Soluciones Dirac - Disparo (y = 0, z = 1) . . . . . . . . . . . . . . . . . . . . 695.19. Suma Soluciones Dirac - Disparo (y = 0, z = 1) . . . . . . . . . . . . . . . . 695.20. Soluciones pares Dirac - Disparo (y = 0, z = −1) . . . . . . . . . . . . . . . . 705.21. Soluciones impares Dirac - Disparo (y = 0, z = −1) . . . . . . . . . . . . . . 705.22. Soluciones Dirac - Disparo (y = 0, z = −1) . . . . . . . . . . . . . . . . . . . 715.23. Suma Soluciones Dirac - Disparo (y = 0, z = −1) . . . . . . . . . . . . . . . 71
xiii

xiv INDICE DE FIGURAS

Indice de tablas
5.1. Tiempo - Diagonalizacion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 535.2. Tiempo - Disparo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 545.3. Tiempo - Digonalizacion vs Disparo . . . . . . . . . . . . . . . . . . . . . . . 555.4. Error Schrodinger - Disparo secuencial . . . . . . . . . . . . . . . . . . . . . 565.5. Error Schrodinger - Disparo paralelo . . . . . . . . . . . . . . . . . . . . . . 575.6. Error eigenpares ‖AQ−QΛ‖F - Diagonalizacion . . . . . . . . . . . . . . . . 585.7. Error ortogonalidad ‖QQT − I‖F - Diagonalizacion . . . . . . . . . . . . . . 585.8. Error Schrodinger - Diagonalizacion . . . . . . . . . . . . . . . . . . . . . . . 595.9. Solucion Schrodinger (y = 0, z = 1) - Disparo secuencial . . . . . . . . . . . . 665.10. Solucion Schrodinger (y = 0, z = 1) - Disparo paralelo . . . . . . . . . . . . . 675.11. Solucion Dirac (y = 0, z = 1) - Disparo paralelo . . . . . . . . . . . . . . . . 72
xv

xvi INDICE DE TABLAS

Indice de algoritmos
2.1. Disparo para el problema de Sturm-Liouville . . . . . . . . . . . . . . . . . . 102.2. Runge-Kutta de cuarto orden . . . . . . . . . . . . . . . . . . . . . . . . . . 102.3. Runge-Kutta para sistemas de ecuaciones . . . . . . . . . . . . . . . . . . . . 112.4. Metodo iterativo QR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.5. Obtencion del vector de Householder . . . . . . . . . . . . . . . . . . . . . . 182.6. Tridiagonalizacion de Householder . . . . . . . . . . . . . . . . . . . . . . . . 192.7. Obtencion de una rotacion de Givens . . . . . . . . . . . . . . . . . . . . . . 212.8. Aplicacion de una rotacion de Givens (pre-multiplicacion) . . . . . . . . . . . 212.9. Aplicacion de una rotacion de Givens (pos-multiplicacion) . . . . . . . . . . 223.1. Diagonalizacion de matrices tridiagonales simetricas . . . . . . . . . . . . . . 293.2. Encontrar la i-esima raız de la ecuacion secular . . . . . . . . . . . . . . . . 313.2. Encontrar la i-esima raız de la ecuacion secular . . . . . . . . . . . . . . . . 323.2. Encontrar la i-esima raız de la ecuacion secular . . . . . . . . . . . . . . . . 333.3. Solucion de la ecuacion secular . . . . . . . . . . . . . . . . . . . . . . . . . . 33
xvii

xviii INDICE DE ALGORITMOS

Capıtulo 1
Introduccion
1.1. Antecedentes y motivacion
El problema de valores propios regular de Sturm-Liouville tiene un gran numero de apli-caciones, debido a que todos aquellos problemas que puedan ser modelados con una ecuaciondiferencial que cumpla con las caracterısticas del problema de valores propios regular deSturm-Liouville, que se mencionan en el siguiente capıtulo, se pueden solucionar mediantelas tecnicas que se estudian en esta tesis.
Prueba de esto fue la conferencia que tuvo lugar en Suiza en 2003 en conmemoracion del200 aniversario del nacimiento de Charles Francois Sturm, el fundador de la teorıa de Sturm-Liouville, a la que asistieron mas de 60 participantes de 16 paıses. Como resultado de estecoloquio se publico una recopilacion de artıculos presentados en este evento [1], en los que semencionan las distintas areas de aplicacion que tiene el problema regular de Sturm-Liouvilleentre las que se encuentran: vibracion de cuerdas, propagacion de ondas, resonancias, termo-dinamica, mecanica cuantica, quımica cuantica.
Entre los metodos numericos utilizados para resolver el problema de valores propios regu-lar de Sturm-Liouville se encuentran, el metodo de disparo y el metodo de diagonalizacion dematrices simetricas, estos metodos tienen un costo computacional alto, por lo que, emplearprogramacion paralela para su implementacion, puede resultar en una mejora significativa enel tiempo de ejecucion.
La programacion paralela hasta hace algunos anos, se habıa realizado comunmente conuna gran cantidad de nodos con procesadores multinucleo, recientemente se han aprovechadoel poder de computo y el bajo consumo energetico de las unidades de procesamiento grafico(GPUs) para realizar computo de proposito general y no solo procesamiento de graficos. Sinembargo, ambos enfoques tienen ventajas y desventajas, por lo que, la tendencia actual esutilizar las fortalezas individuales de cada uno, en un enfoque hıbrido.
1

2 Capıtulo 1
GPU
CPU CPU
GPU GPU
GPU
CUDA CUDA
CUDA CUDA
MPI
OpenMP OpenMP
Figura 1.1: Arquitectura paralela heterogenea
Un punto que es importante mencionar es que la cantidad de memoria maxima con laque cuenta una GPU hoy en dıa es limitada, aproximadamente 8GB, por lo que el contar conuna implementacion que utilice varios nodos puede ayudar a disminuir esta restriccion.
En esta tesis se estudia cual es el beneficio obtenido al utilizar este enfoque hıbrido ycual metodo es mas conveniente, al resolver el problema de valores propios regular de Sturm-Liouville, en terminos de tiempo y exactitud.
1.2. Estado del arte
Entre las soluciones existentes para resolver el problema de valores propios destacan, lasbibliotecas LAPACK (Linear Algebra PACKage) [2] y MAGMA (Matrix Algebra on GPUand Multicore Architectures) [3].
LAPACK es una biblioteca secuencial que es la base para otras bibliotecas de algebralineal, de hecho practicamente todas las aplicaciones que requieren operaciones de algebralineal la utilizan. Existen version optimizadas de LAPACK, la que mejores tiempos reportaes la MKL de Intel, esta implementacion puede ejecutarse de forma secuencial o utilizar losdiferentes nucleos de un procesador.
MAGMA es la sucesora de LAPACK, el proposito de esta biblioteca es utilizar los proce-sadores multi-nucleo y las unidades de procesamiento grafico GPUs. Sin embargo, no utilizamultiples nodos, esto limita el tamano de las matrices que pueden resolverse en especial enaquellas funciones que utilizan una GPU, ya que estas tienen una memoria mas limitada quela que puede acceder un CPU. Por ejemplo una targeta de un GB de memoria puede resolverun problema de n = 9318, pero al aumentar una unidad este numero se presenta un errorpor memoria insuficiente.
1.3. Planteamiento del problema
El problema de valores propios regular de Sturm-Liouville tiene muchas aplicaciones, en-tre las cuales existen problemas para los que no se conoce un solucion analıtica, por lo tanto,se requieren metodos numericos.
Cinvestav Departamento de Computacion

Introduccion 3
Entre los metodos mas utilizados estan la diagonalizacion de matrices simetricas y elmetodo de disparo. A continuacion, se da una breve descripcion de los metodos numericosque se estudian en esta tesis.
Metodo de disparo
El metodo de disparo aplicado al problema de Sturm-Liouville, consiste en, tomar unrango de posibles valores propios, resolver la ecuacion diferencial correspondiente para cadauno de ellos y seleccionar aquellos valores para los cuales se cumplen las condiciones a lafrontera del problema.
Para obtener el conjunto de valores propios y las aproximaciones de la funciones soluciony de su derivada se siguen los siguientes pasos:
1. Se parte el intervalo en el cual se buscan las soluciones en N intervalos, usualmenteigualmente espaciados.
2. Se utiliza un algoritmo para resolver problemas de valores iniciales como Runge-Kuttapara generar las posibles funciones solucion y sus derivadas.
3. Se filtran las soluciones que cumplan las condiciones en la frontera y se agregan alconjunto de soluciones finales.
Una mejor explicacion de este metodo puede consultarse en [4].
Diagonalizacion de matrices tridiagonales simetricas
En este metodo matricial la ecuacion diferencial se ve como un operador diferencial (eloperador de Sturm-Liouville), y se representa con diferencias finitas en una forma matricial,Lx = λx. Con lo que se obtiene un problema de valores propios simetrico matricial que seresuelve mediante diagonalizacion de matrices. Es decir, encontrar una matriz diagonal D yuna matriz ortogonal P tal que L = PDP−1.
Para obtener los vectores y valores propios de una matriz tridiagonal T simetrica real sesiguen los siguientes tres pasos [5]:
1. Los subeigenproblemas T1 = Q1Λ1QT1 y T2 = Q2Λ2Q
T2 son resueltos para dos matrices
que son, salvo una modificacion de rango uno, los bloques diagonales de la matrizoriginal. Este paso puede hacerse utilizando cualquier metodo.
2. Usando los eigenpares de T1, T2 todos los valores propios de T son calculados mediantela solucion de la ecuacion secular.
0 = 1 + ρ
n∑i=1
v2i
di − λ
3. Una vez que los valores propios de T son conocidos, los vectores propios de T se calculanen dos fases, un escalamiento diagonal apropiado seguido de una multiplicacion dematriz por matriz.
Cinvestav Departamento de Computacion

4 Capıtulo 1
Una explicacion mas completa de este metodo puede encontrarse en [6]. Los principalesproblemas que se presentan al implementar este algoritmo son el calculo de la ecuacion se-cular [7] y el conservar la ortogonalidad de los vectores propios [8].
Las soluciones numericas tienen un error de aproximacion en la practica y son costosascomputacionalmente, sobre todo, la diagonalizacion de matrices, debido a esto se hace nece-sario el uso de programacion paralela para disminuir el tiempo de computo.
En esta tesis se estudia cual es el beneficio que se obtiene al implementar metodos parasolucionar el problema de valores propios regular de Sturm-Liouvile en arquitecturas parale-las hıbridas (GPUs + CPUs), en terminos de exactitud y tiempo.
En particular los metodos de disparo y diagonalizacion de matrices, ya que se quiere ave-riguar cual de ellos es el mas conveniente para resolver este problema y que tanto se puedenadecuar a un enfoque hıbrido.
No existe una implementacion del algoritmo de Cuppen [9, 6] para diagonalizar matricesque utilice multiples nodos con CPUs de multiples nucleos y multiples GPUs [10], por lo queno se sabe cual es el beneficio que se obtendra al utilizar varios nodos, ya que este beneficiopodrıa disminuir principalmente por el costo de comunicacion entre los nodos.
En esta tesis se pretende contestar las interrogantes antes mencionadas. Con el uso delas arquitecturas hıbridas se busca lograr acelerar la ejecucion de las implementaciones delos metodos para solucionar el problema de valores propios regular de Sturm-Liouville yaprovechar al maximo los recursos disponibles. El contar con tales implementaciones puedeayudar a resolver una gran cantidad de problemas en los que se utilizan problemas regularesde Sturm-Liouville. Ademas, la implementacion del algoritmo de Cuppen en multiples nodospuede disminuir las limitaciones de memoria que tienen las unidades de procesamiento grafico,a la vez que, su bajo consumo de energıa, reduce los costos de ejecucion.
1.4. Objetivos
Esta tesis tiene como objetivo general implementar el algoritmo para diagonalizar ma-trices simetricas tridiagonales conocido como algoritmo divide y venceras, de forma paralelaheterogenea (GPUs + CPUs), en multiples nodos y utilizarlo para solucionar el problemade valores propios regular de Sturm-Liouville, con el fin de, averiguar que tan adecuado esaplicar este metodo en este problema, en terminos de exactitud y tiempo.
Para paralelizar el algoritmo se utilizan unidades de procesamiento grafico empleando laplataforma CUDA de Nvidia, procesadores de multiples nucleos de Intel usando OpenMP, ymultiples nodos mediante paso de mensajes con MPI.
Para cumplir con el objetivo general se definieron los siguientes objetivos particulares:
Investigacion sobre las mejoras al algoritmo divide y venceras para diagonalizar matricessimetricas, en particular la solucion de la ecuacion secular.
Cinvestav Departamento de Computacion

Introduccion 5
Paralelizar el algoritmo de disparo para el problema de valores propios regular de Sturm-Liouville, de forma hıbrida (GPU + CPU) en un nodo.
Aumentar la escalabilidad y la independencia de la cantidad de memoria de la GPU,de la implementacion del algoritmo divide y venceras.
Reducir el tiempo de computo de la diagonalizacion de matrices simetricas tridiagona-les.
Mostrar la ventaja de aprovechar el poder de procesamiento de los GPUs y CPUs enconjunto, y de utilizar varios nodos a la vez, en este problema en particular.
Averiguar que metodo es mas conveniente para solucionar el problema de valores pro-pios regular de Sturm-Liouville, el metodo de disparo paralelo o el metodo de Cuppenparalelo, en terminos de exactitud y tiempo.
Resolver un problema de Sturm-Liouville del que no se conozca la solucion exacta.
Comparar los metodos implementados con los existentes, en terminos de tiempo yexactitud.
1.5. Contribuciones y resultados esperados
Las contribuciones y resultados que se esperan obtener de esta tesis son:
Tener un estudio de los metodos para solucionar el problema de valores propios regularde Sturm-Liouville en CUDA para multiples tarjetas.
Implementacion hıbrida escalable en clusters de GPUs del metodo divide y venceraspara diagonalizar matrices tridiagonales simetricas.
Calculo del error practico del problema de valores propios simetrico tridiagonal conmetodos matriciales.
1.6. Organizacion de la tesis
El resto del documento esta organizado en seis capıtulos, a continuacion se presenta unabreve descripcion de cada uno de ellos.
Capıtulo 2. Marco teorico: En este capıtulo se explican los conceptos y algoritmosque se utilizaran durante el documento, principalmente sobre el problema regular deSturm-Liouville, solucion de ecuaciones diferenciales de segundo grado, y diagonali-zacion de matrices. Tambien, se muestra los diferentes paradigmas de programacionparalela, la definicion de algoritmo hıbrido y heterogeneo, y se describen las tecnologıasque se utilizan para implementar los algoritmos.
Capıtulo 3. Algoritmo divide y venceras: En este capıtulo se describe el algoritmodivide y venceras para diagonalizar matrices tridiagonales simetricas, su justificacionteorica y los elementos que se deben tomar en cuenta para su correcta implementacion.
Cinvestav Departamento de Computacion

6 Capıtulo 1
Capıtulo 4. Diseno e implementacion: En este capıtulo se presentan las estra-tegias de paralelizacion, el diseno y la implementacion del algoritmo de disparo y dediagonalizacion de matrices simetricas tridiagonales en su version secuencial y paralela.
Capıtulo 5. Pruebas, resultados y discusion: En este capıtulo se describen loscasos de prueba y la arquitectura de computo sobre la que se trabaja, se presentanlos resultados obtenidos, se comparan con otras implementaciones, y se discute querelevancia tienen los resultados obtenidos.
Capıtulo 6. Conclusiones y trabajo a futuro: En este capıtulo se presentan lasprincipales conclusiones de esta tesis y se discuten algunos aspectos que nos gustarıamejorar en una investigacion futura.
Cinvestav Departamento de Computacion

Capıtulo 2
Marco teorico
En este capıtulo inicia en la seccion 2.1 con una revision formal del problema regular deSturm-Liouville, se describen dos problemas sobre mecanica cuantica, ya que los casos deprueba se basan en estos problemas, enseguida en las secciones 2.2 y 2.3 (en las pags. 10 y12) se explican los metodos de disparo y de diferencias finitas, despues en la seccion 2.4 (en lapag. 12) se define el problema algebraico de valores propios y se presentan algunos metodosque son utilizados comunmente en su resolucion. Por ultimo, en la seccion 2.5 (en la pag. 22)se describen brevemente las tecnologıas que utilizamos para implementar los algoritmos.
2.1. Problema regular de Sturm-Liouville
Un problema de valores a la frontera que consiste de la ecuacion diferencial lineal desegundo orden {
− d
dx
[p(x)
d
dx
]+ q(x)
}y(x) = λy(x) x ∈ [a, b]
y las condiciones en la frontera
α1y(a) + α2y′(a) = 0, α2
1 + α22 > 0,
β1y(b) + β2y′(b) = 0, β2
1 + β22 > 0
donde p(x) > 0, q(x) son funciones reales continuas en el intervalo (a, b)
Es llamado problema de Sturm-Liouville, se dice que un problema de Sturm-Liouville esregular si el intervalo [a, b] es finito y la funcion q(x) es integrable en este intervalo [11],resolver este problema significa encontrar los valores de λ, llamados valores propios, y lascorrespondientes soluciones no triviales yλ(x), conocidas como funciones propias. El conjuntode todos valores propios de un problema regular es llamado espectro [12].
Uno de los resultados importantes en la teorıa de Sturm-Liouville, es el teorema de osci-lacion, cuya demostracion se puede encontrar en [11]. Las soluciones numericas encontradasen esta tesis respetan este teorema, como podra verse mas adelante.
7

8 Capıtulo 2
Teorema 2.1 (Teorema de oscilacion) Existe una secuencia creciente indefinida de va-lores propios λ0, λ1, . . . , λn, . . . del problema regular de Sturm-Liouville, y la funcion propiacorrespondiente al valor propio λm, tiene precisamente m ceros en el intervalo (a, b).
Ejemplos de problemas de Sturm-Liouville son las ecuaciones de Schodinger y Dirac quese utilizan para describir sistemas de mecanica cuantica relativista y no relativista. La locali-zacion de una partıcula en estos sistemas esta determinada por la funcion ψ(x) en el sentidode que |ψ(x)|/||ψ||2 en una medida de su densidad de probabilidad en R [13].
2.1.1. Ecuacion de Schrodinger
Erwin Schrodinger publico esta ecuacion de onda en 1926 en [14], la cual se expresa de lasiguiente forma
i~∂
∂tψ(x, t) = − ~
2m∇2ψ(x, t) + V (x, t)ψ(x, t)
donde x ∈ Rn y n es la dimension del espacio de configuracion o espacio posicion [15]. Siconsideramos una dimension en el espacio de configuracion, la ecuacion anterior se escribecomo
i~d
dtψ(x, t) = − ~
2mψ(x, t) + V (x, t)ψ(x, t))
consideremos el caso en que el potencial V solo depende de x, la ecuacion se resuelve conrespecto a x tal que la solucion ψ(x, t) se puede escribir como
ψ(x, t) = e−iEt/~ψ(x, t0) = e−iEt/~φ(x)
que es conocida como la ecuacion para el caso estacionario, podemos escribirla en notacionde una matriz de dimension 2× 2, y si consideramos a la constante ~ como menos uno y a lamasa m de la partıcula como uno, obtenemos la siguiente representacion
dZ(x)
dx=
(0 E − V (x)1 0
)Z(x)
que es equivalente al par de ecuaciones diferenciales acopladas
dy(x)
dx= z(x),
dz(x)
dx= [E − V (x)] y(x)
El problema del pozo de potencial infinito es un problema clasico en mecanica cuantica,se asume que el potencial es infinito fuera de la region (−a, a) y cero en esta region. Estepotencial indica que las partıculas dentro de la region estan atrapadas y no pueden salir,ası que la probabilidad de encontrarlas en esta region es 1. Entonces, el potencial se describecomo
V (x) =
{0 x ∈ (−a, a)
∞ en otro caso
Cinvestav Departamento de Computacion

Marco teorico 9
Los valores propios de este problema estan dados por
λc = −2 + 2 cos
(cπ
n+ 1
), c = 1, · · · , n
2.1.2. Ecuacion de Dirac
La ecuacion de Dirac es una ecuacion de onda para la mecanica cuantica relativista. PaulDirac publico esta ecuacion de onda en 1928 [16]. A diferencia de la ecuacion de Schrodinger,la ecuacion de Dirac es un sistema de ecuaciones diferenciales acopladas. La ecuacion deDirac se escribe a partir del hamiltoniano
EΨ = HΨ,
H = iσ2d
dx+m0c
2σ3 + V (x)I,
Ψ =
(ψ1
ψ2
)donde E ∈ R y representa la energıa; H es el operador hamiltoniano (u operador de energıa);Ψ es el vector de las funciones de onda solucion del sistema, y se le llama espinor; I es lamatriz unitaria; y σ1, σ2, σ3 son las matrices de Dirac
σ1 =
(0 11 0
), σ2 =
(0 −ii 0
), σ3 =
(1 00 −1
)En una dimension, la ecuacion de Dirac para el caso estacionario donde el potencial es
independiente del tiempo, puede escribirse en forma matricial como
dΨ(x)
dx=
(0 m0 − [V (x)− E]
m0 + [V (x)− E] 0
)Ψ(x)
donde m0 es la masa en reposo y V (x) el potencial independiente del tiempo [15]. La ecuacionanterior es equivalente al par de ecuaciones diferenciales acopladas
dy(x)
dx= {m0 + [E − V (x)]} z(x),
dz(x)
dx= {m0 − [E − V (x)]} y(x)
Dentro de los enfoques con los que se cuenta para resolver el problema regular de Sturm-Liouville estan, el enfoque de problema de valores a la frontera y el de representacion comooperador matricial.
Cinvestav Departamento de Computacion

10 Capıtulo 2
2.2. Metodo de disparo
Este metodo de valores en la frontera consiste en transformar el problema en uno de valoresiniciales. En este metodo se seleccionan los valores de las variables dependientes en uno delos limites de la frontera, usualmente los valores iniciales, enseguida se integra la ecuaciondiferencial ordinaria, con metodos de valores iniciales (como Runge-Kutta), llegando hasta elotro limite tratando de satisfacer las condiciones en la frontera en el punto final. En generalse encuentran discrepancias con el valor deseado en el punto final, por lo que, se ajustanlos parametros iniciales hasta que ambas condiciones, las finales y las iniciales, se satisfacen.Esto es analogo a intentar varios disparos de integracion con condiciones iniciales tratandode atinar en las condiciones finales, por lo que, se le conoce como metodo de disparo.
Algoritmo 2.1 Disparo para el problema de Sturm-Liouville
Entrada: Puntos finales a, b; condiciones en la frontera α, β; rango de λ, [l, r]; numero desubintervalos N
Salida: Conjunto Λ de valores propios y S de aproximaciones wi de y(xi) y w′i de y′(xi)para cada i = 0, 1, ..., N
1: para los puntos λ que surgen de partir [l, r] en N intervalos hacer2: Usar un algoritmo de valores iniciales como Runge-Kutta para generar wi, w
′i
3: si wi, w′i cumplen con las condiciones en la frontera α, β entonces
4: Agregar wi, w′i a S y λ a Λ
5: devolver (Λ, S)
Una mejor explicacion de este metodo puede consultarse en [4].
2.2.1. Metodo de Runge-Kutta
Para aproximar la solucion al problema de valores iniciales
f ′ = F (x, f), a ≤ x ≤ b, F (a) = α0
en (N+1) numeros igualmente espaciados en el intervalo [a, b]; usamos el siguiente algoritmo
Algoritmo 2.2 Runge-Kutta de cuarto orden
Entrada: Puntos finales a, b; numero de subintervalos N ; condicion inicial α0
Salida: Aproximaciones fi de y(xi) para i = 0, 1, ..., N1: h← (b− a)/N2: x0 ← a3: f0 ← α0
4: para i = 0 a N hacer5: k1 ← F (xi, fi)6: k2 ← F (xi + 1
2h, fi + 1
2k1h)
7: k3 ← F (xi + 12h, fi + 1
2k2h)
8: k4 ← F (xi + h, fi + k3h)9: fi+1 ← fi + 1
6(k1 + 2k2 + 2k3 + k4)h
10: xi+1 ← a+ ih
11: devolver f
Cinvestav Departamento de Computacion

Marco teorico 11
Para aproximar la solucion al sistema de problemas de valores iniciales
y′ = z = F (x, y, z), a ≤ x ≤ b, F (a) = α0,
z′ = y′′ = G(x, y, z), a ≤ x ≤ b, G(a) = α1
en (N+1) numeros igualmente espaciados en el intervalo [a, b]; usamos el siguiente algoritmo
Algoritmo 2.3 Runge-Kutta para sistemas de ecuaciones
Entrada: Puntos finales a, b; numero de subintervalos N ; condiciones iniciales α0, α1
Salida: Aproximaciones yi de y(xi) y zi de y′(xi) para i = 0, 1, ..., N1: h← (b− a)/N2: x0 ← a3: y0 ← α0
4: z0 ← α1
5: para i = 0 a N hacer6: k1 ← F (xi, yi, zi)7: l1 ← G(xi, yi, zi)8: k2 ← F (xi + 1
2h, yi + 1
2k1h, zi + 1
2l1h)
9: l2 ← G(xi + 12h, yi + 1
2k1h, zi + 1
2l1h)
10: k3 ← F (xi + 12h, yi + 1
2k2h, zi + 1
2l2h)
11: l3 ← G(xi + 12h, yi + 1
2k2h, zi + 1
2l2h)
12: k4 ← F (xi + h, yi + k3h, zi + l3h)13: l4 ← G(xi + h, yi + k3h, zi + l3h)14: yi+1 ← yi + 1
6(k1 + 2k2 + 2k3 + k4)h
15: zi+1 ← zi + 16(l1 + 2l2 + 2l3 + l4)h
16: xi+1 ← a+ ih
17: devolver (y, z)
Por ejemplo, para utilizar el metodo de Runge-Kutta para el problema de Schrodinger Fy G estan definidos por
F (xi, yi, zi) = zi,
G(xi, yi, zi) = [E − V (xi)] yi
y para el problema de Dirac por
F (xi, yi, zi) = {m0 + [E − V (xi)]} zi,
G(xi, yi, zi) = {m0 − [E − V (xi)]} yi
Cinvestav Departamento de Computacion

12 Capıtulo 2
2.3. Metodo de diferencias finitas
Los metodos de diferencias finitas se basan en sustituir las derivadas en las ecuacionesdiferenciales por sus analogas discretas, las diferencias finitas. Por ejemplo, para resolver laecuacion de Schrodinger, sabemos que las diferencias finitas centradas para la derivada desegundo orden son
d2y
dx2≈ yi−1 − 2yi + yi+1
h2, h = ∆x
aplicando diferencias finitas a la ecuacion independiente del tiempo de Schrodinger
d2y
dx2= [E − V (x)] y
obtenemos la siguiente aproximacion
yi−1 − 2yi + yi+1
h2≈ [E − V (x)] yi
reacomodando los terminos obtenemos
1
h2
{yi−1 +
[h2V (xi)− 2
]yi + yi+1
}≈ Eyi
y finalmente con la expresion anterior podemos construir la siguiente matriz
1
h2
h2V (x0)− 2 1 0
1 h2V (x1)− 2 1. . . . . . . . .
1 h2V (xn−2)− 2 10 1 h2V (xn−1)− 2
y0
y1...
yn−2
yn−1
= E
y0
y1...
yn−2
yn−1
que representa un problema de valores propios.
2.4. Problema algebraico de valores propios
Los valores y vectores propios pertenecen a los temas de mayor utilidad del algebra lineal.Se usan en varias aereas de las matematicas, fısica, mecanica, ingenierıa electrica y nuclear,hidrodinamica y aerodinamica. De hecho es raro encontrar un una area de la ciencia aplicadadonde nunca se hayan usado.
La transformacion L : Rn → Rn definida por L(x) = Ax para x en Rn, es una trans-formacion lineal. Una cuestion de gran importancia en una gran variedad de problemas deaplicacion es la determinacion de vectores x, si los hay tales que x y Ax son paralelos. Talcuestion aparece en todas las aplicaciones relacionadas con las vibraciones [17]: en elasticidad,mecanica nuclear, ingenierıa quımica, biologıa, ecuaciones diferenciales, etc.
Existe un gran numero de problemas matematicos que no corresponden necesariamenteal campo del algebra lineal cuya representacion puede llevarse a un problema algebraico de
Cinvestav Departamento de Computacion

Marco teorico 13
valores propios, esto ocurre debido a que las soluciones de dichos problemas se llevan a cabomediante la utilizacion de operadores lineales. Un operador lineal puede representarse poruna matriz de transformacion, esta matriz puede ser utilizada para reducir el problema iniciala un problema de valores propios.
Por ejemplo, el problema general de valores propios puede referirse a ecuaciones diferen-ciales con coeficientes constantes. El conjunto general de ecuaciones homogeneas de primerorden con n incognitas y1, y2, . . . , yn puede ser escrito en la forma
Bd
dt(y) = Cy
suponiendo que B es no singular esta ecuacion puede ser escrita en la forma
d
dt(y) = Cy,
A = B−1C
asumiendo que la ecuacion tiene una solucion de la forma
y = xeλt
donde x es un vector independiente de t. Se debe tener
λxeλt = Axeλt
y por lo tanto
λx = Ax
se tiene una solucion si λ es un valor propio de A y x es el vector propio correspondiente.
2.4.1. Definicion
El problema fundamental de los valores propios es la determinacion de aquellos valoresde λ para los que el conjunto de n ecuaciones lineales homogeneas con n incognitas
Ax = λx (2.1)
tiene una solucion no trivial [18]. La ecuacion (2.1) puede ser escrita en la forma
(A− λI)x = 0 (2.2)
La teorıa general de ecuaciones algebraicas lineales simultaneas nos muestra que existeuna solucion no trivial si, y solo si, la matriz A− λx es singular, esto es
det(A− λx) = 0
El determinante en el lado izquierdo de la ecuacion anterior puede ser desarrollado paraobtener la ecuacion polinomio explıcita
Cinvestav Departamento de Computacion

14 Capıtulo 2
α0 + α1λ+ · · ·+ αn−1λn−1 + (−1)nλn = 0
La ecuacion anterior es llamada ecuacion caracterıstica de la ecuacion de la matriz A y elpolinomio en el lado izquierdo de la ecuacion es llamado el polinomio caracterıstico. Como elcoeficiente de λn no es cero y se asume que se trabaja en el campo de los numeros complejos,la ecuacion siempre tiene n raıces. En general, las raıces pueden ser complejas, incluso si lamatriz A es real, y puede haber raıces de cualquier multiplicidad hasta n. Las n raıces sonllamadas los valores propios de la matriz A.
Correspondiendo con cualquier valor propio λ, el conjunto de ecuaciones (2.2) tiene almenos una solucion no trivial x. Cada solucion es llamada un vector propio correspondientea este valor propio. Si la matriz A− λx es de rango menor que n− 1, entonces habra mas deun vector independiente que satisface la ecuacion (2.2). Es evidente que si x es una solucion,entonces kx tambien es una solucion para cualquier valor de k, de forma que incluso cuando(A− λx) es de rango n− 1, el vector propio correspondiente a λ es libre de usar un multipli-cador constante.
Es conveniente escoger este multiplicador de forma que el vector propio tenga algunaspropiedades numericas que sean deseables, dichos vectores son llamados vectores normaliza-dos.
2.4.2. Transformaciones similares
Las transformaciones de la forma H−1AH de la matriz A, donde H es no singular son defundamental importancia tanto para el punto de vista teorico como para el practico, y sonconocidas como transformaciones similares; mientras que A y H−1AH se dicen ser similareso semejantes. Obviamente H−1AH es tambien una transformacion similar de A. Cuando losvalores propios de A son distintos, entonces hay una transformacion similar que reduce A ala forma diagonal, es decir, A se puede diagonalizar, y la matriz de transformacion tiene suscolumnas iguales a los vectores propios de A.
Si se tiene
H−1AH = D
entonces
AH = HD
La ultima ecuacion implica que di son los valores propios de A en el mismo orden en que lai-esima columna de H es un vector propio correspondiente a di.
Los valores propios de una matriz son invariantes sobre una transformacion similar.
Porque si
Ax = λx
Cinvestav Departamento de Computacion

Marco teorico 15
entonces
H−1Ax = λH−1x
se obtiene
H−1A(HH−1)x = λH−1x
(H−1AH)H−1x = λH−1x
Los valores propios son por lo tanto preservados y los valores propios son multiplicados porH−1.
Una forma mas comun de demostrar que los valores propios de las matrices similares sepreservan es mostrando que tienen el mismo polinomio caracterıstico.
Si A es semejante a B
B = H−1AH
entonces
det = det(H−1AH − λI)
= det(H−1(A− λI)H)
= det(H−1)det(A− λI)det(H)
= det(A− λI)
ya que el polinomio caracterıstico de A y B es igual, tienen los mismos valores propios.
Muchos de los metodos numericos para encontrar los valores y vectores propios de unamatriz consisten esencialmente en la determinacion de una transformacion similar que redu-ce una matriz A de la forma general a una matriz B de una forma especial, para la que elproblema de valores y vectores propios puede ser resuelto de una forma mas simple.
La semejanza es una propiedad transitiva, porque si
B = H−11 AH1 C = H−1
2 AH2
entonces
C = H−12 H−1
1 AH1H2 = (H1H2)−1A(H1H2)
En general la reduccion de una matriz general a una forma diagonal se realizara medianteuna secuencia de transformaciones similares.
Cinvestav Departamento de Computacion

16 Capıtulo 2
2.4.3. Diagonalizacion de matrices
Como mencionamos anteriormente, para encontrar los valores y vectores propios de unamatriz, con frecuencia, se utilizan transformaciones similares para obtener una matriz simi-lar a la original para la que es mas facil encontrar los valores y vectores propios. Por lo quees logico preguntarnos cual es la matriz mas sencilla que podemos obtener en terminos decalcular sus valores y vectores propios, la respuesta es, la matriz diagonal.
Una matriz se dice ser diagonal si todos los elementos fuera de su diagonal principal soniguales a cero, y su valores propios son precisamente los valores en su diagonal principal, porlo que se pueden obtener por simple inspeccion.
Por lo mencionado en los dos parrafos anteriores al proceso de encontrar un transformacionsimilar de la forma
A = PDP−1
se le conoce como diagonalizacion.
Existen diversos tipos de algoritmos para calcular los valores y vectores propios de unamatriz, entre los que destacan aquellos que se basan en la diagonalizacion de una matriz apartir de sucesivas transformaciones similares. Para llegar a una matriz diagonal, es comunhacer una transformacion para llegar a una matriz tridiagonal y despues realizar otra parafinalmente obtener la matriz diagonal
Este escrito se centra en este enfoque, especialmente cuando se aplica a matrices simetri-cas. Un punto importante de mencionar, es que incluso para resolver problemas con valorescomplejos y problemas generales de valores propios, por lo general, se termina resolviendouna matriz tridiagonal simetrica. Que es el caso especifico que abordaremos en esta tesis.
A continuacion se mencionan de manera breve algunos algoritmos que son de gran utilidaden la determinacion de los valores y vectores propios de una matriz.
2.4.4. Algoritmo QR
Si A es una matriz cuadrada con columnas linealmente independientes, entonces A puedefactorizarse en la forma
A = QR
En la que Q es una matriz con columnas ortonormales y R es una matriz triangular superior.
Para encontrar estas matrices es comun utilizar el proceso de ortonormalizacion de Gram-Schmidt, no obstante, se pueden emplear otros algoritmos de factorizacion para este proposi-to. La descomposicion QR se puede utilizar para aproximar los valores propios de una matrizcuadrada, al algoritmo resultante se le llama algoritmo QR, este algoritmo determina todoslos valores propios de una matriz.
Cinvestav Departamento de Computacion

Marco teorico 17
La idea principal de este algoritmo es construir una secuencia de matrices similares,A1, A2, . . . , Ak,donde Ak converge a una matriz triangular superior semejante a la matrizA conforme k aumenta. Por consiguiente los elementos diagonales de dicha matriz son losvalores propios de A, ya que los valores propios de una matriz triangular son los elementosde su diagonal.
Se comienza calculando la factorizacion QR de A0 = Q0R0, y a continuacion se forma lamatriz A1 = R0Q0, se puede observar que A0 y A1 son semejantes, porque
A1 = R0Q0 = (Q−10 A0)Q0
Por lo tanto, tienen los mismos valores propios. Se continua con la factorizacion QR deA1 = Q1R1, y se forma la matriz A2 = R1Q1 que tiene los mismos valores propios de A.Como se habıa mencionado, se itera hasta obtener una matriz triangular superior.
Se puede ver que todas las matrices en la secuencia son similares, debido a que
Ak = Rk−1Qk−1 = (Q−1k−1Ak−1)Qk−1
Entonces, todas las matrices en la secuencia tienen los mismos valores propios, incluyendola matriz triangular resultante del proceso iterativo.
Una de las caracterısticas mas notables del algoritmo QR es que al ser aplicado a unamatriz simetrica produce una matriz diagonal, esto significa que el algoritmo QR nos permitediagonalizar una matriz simetrica.
El costo computacional del algoritmo QR es igual al numero de iteraciones necesariaspara obtener la matriz triangular por la complejidad del algoritmo utilizado para calcular lafactorizacion QR.
Los pasos del algoritmo pueden observarse de forma resumida en el siguiente algoritmo
Algoritmo 2.4 Metodo iterativo QR
Entrada: Matriz real simetrica A ∈ Rn×n
Salida: Matriz P ∈ Rn×n cuyas columnas son los vectores propios de A; Matriz Λ ∈ Rn×n
diagonal cuyos elementos son los valores propios de A1: Λ← A2: P ← I3: mientras Λ 6= diagonal hacer4: QR← Λ5: P ← PQ6: Λ← RQ
7: devolver (Λ, P )
2.4.5. Metodo de Householder
El metodo de Householder reduce una matriz simetrica arbitraria a una matriz tridiagonalsimetrica que es semejante a la matriz inicial. El algoritmo se basa en utilizar transformaciones
Cinvestav Departamento de Computacion

18 Capıtulo 2
de Householder, tambien conocidas como reflexiones elementales, que sirven para eliminar demanera selectiva bloques de elementos en una forma extremadamente estable con respecto alredondeo. El algoritmo de Householder utiliza n− 2 transformaciones para llevar una matrizsimetrica a una matriz tridiagonal. Para cada una de estas transformaciones se calcula unamatriz Pk de la forma
1 0 0 0 · · · 00 p p p · · · p0 p p p · · · p0 p p p · · · p...
......
.... . .
...0 p p p · · · p
k=1
,
1 0 0 0 · · · 00 1 0 0 · · · 00 0 p p · · · p0 0 p p · · · p...
......
.... . .
...0 0 p p · · · p
k=2
, · · · ,
1 0 0 · · · 0 00 1 0 · · · 0 00 0 1 · · · 0 0...
......
. . ....
...0 0 0 · · · p p0 0 0 · · · p p
k=n−2
mas formalmente Pk esta determinada por
Pk = I − βvvT , β =2
vTv
para calcular β y v se puede utilizar el siguiente algoritmo [19]
Algoritmo 2.5 Obtencion del vector de Householder
Entrada: Vector x ∈ Rn
Salida: Vector v ∈ Rn con v(1) = 1 y β ∈ R tal que P = In − βvvT es ortogonal yPx = ||x||2e1
1: σ ← x(2 : n)Tx(2 : n), v ←(
1x(2 : n)
)2: si σ = 0 y x(1) ≥ 0 entonces3: β ← 04: si no5: si σ = 0 y x(1) ≤ 0 entonces6: β ← −27: si no8: µ←
√x(1)2 + σ
9: si x(1) ≤ entonces10: v(1)← x(1)− µ11: si no12: v(1)← −σ/(x(1) + µ)
13: β ← 2v(1)2/(σ + v(1)2)14: v ← v/v(1)
15: devolver (v, β)
para cada iteracion k = 1, 2, · · · , n− 2 se calcula la nueva Ak+1 de la siguiente manera
Ak+1 = PkAkPk
para realizar estas iteraciones se pude utilizar el siguiente algoritmo [19]
Cinvestav Departamento de Computacion

Marco teorico 19
Algoritmo 2.6 Tridiagonalizacion de Householder
Entrada: Matriz simetrica A ∈ Rn×n
Salida: Matriz modificada A ∈ Rn×n con T = QTAQ, donde T es tridiagonal y Q =H1, H2, · · · , Hn−2 es el producto de transformaciones de Householder
1: para k = 1 a n− 2 hacer2: Utilizar el algoritmo 2.5 con A(k + 1 : n, k) como entrada y v, β como salida3: p← βA(k + 1 : n, k + 1 : n)v4: w ← p− (βpTv/2)v5: A(k + 1, k)← ‖A(k + 1 : n, k)‖2; A(k, k + 1)← A(k + 1, k)6: A(k + 1 : n, k + 1 : n)← A(k + 1 : n, k + 1 : n)− vwT − wvT
7: devolver A
Despues de realizar todas las iteraciones, se obtiene en An−1 una matriz tridiagonal ysimetrica. Ya que se tiene la matriz tridiagonal se suele utilizar un algoritmo como QRpara calcular los valores propios de la matriz. Una de las propiedades de mayor utilidadde las proyecciones de Householder es que al ser ortogonales y simetricas evitan realizarcalculos computacionales adicionales para obtener sus correspondientes matrices inversas ytranspuestas.
2.4.6. Metodo de Givens
El algoritmo de Givens es un caso especial del algoritmo de Jacobi. Al igual que el metodode Householder, este metodo anula ciertos elementos de una matriz, pero mediante la aplica-cion de rotaciones sucesivas de Givens. Estas transformaciones mantienen los mismos valorespropios que la matriz original.
Se puede utilizar una serie de rotaciones de Givens sobre una matriz cuadrada para anularsus entradas bajo su diagonal principal, transformando la matriz original en una matriztriangular superior, a este procedimiento se le llama reduccion de Givens.
a11 a12 a13 · · · a1n
a21 a22 a23 · · · a2n
a31 a32 a33 · · · a3n...
......
. . ....
a41 a42 a43 · · · ann
→a11 a12 a13 · · · a1n
a22 a23 · · · a2n
a33 · · · a3n
. . ....
0 ann
Para convertir una matriz densa en una matriz triangular superior, se deben anular todos
los elementos que se encuentran debajo de la diagonal principal de izquierda a derecha yde abajo hacia arriba. Cada una de las rotaciones que anulan los distintos elementos de lamatriz original solo altera la fila donde se encuentra el elemento a eliminar y la fila anteriora esta. (
u1 u2 u3 u4
v1 v2 v3 v4
)Para logar anular un elemento en particular, el primer paso es calcular la matriz de
rotacion de Givens esta se obtiene con las siguientes formulas.
Cinvestav Departamento de Computacion

20 Capıtulo 2
g =
(c s−s c
)donde
c =u1√u2
1 + v21
y s =v1√u2
1 + v21
(2.3)
el elemento que se desea anular es v1 y el elemento que se encuentra en la misma columnapero en la fila inmediatamente superior a v1, es decir arriba de el, es u1.
Una vez que se ha calculado esta matriz se multiplica por las filas que alteran esta rotacion,para obtener los nuevos elementos de la matriz rotada los cuales se denotan por R de lasiguiente manera.
R =
u1√u2
1 + v21
v1√u2
1 + v21
− v1√u2
1 + v21
u1√u2
1 + v21
(u1 u2 u3 u4
v1 v2 v3 v4
)=
(r11 r12 r13 r14
r21 r22 r23 r24
)
notese que al efectuar la multiplicacion el elemento r21 = 0, que es el objetivo que se planteabadesde un principio, esto ocurre debido a que
r21 = − v1u1√u2
1 + v21
+v1u1√u2
1 + v21
= 0
la matriz original despues de aplicar una rotacion de Givens para anular, por ejemplo, elelemento a41 es la siguiente:
a11 a12 a13 a14
a21 a22 a23 a24
r31 r32 r33 r34
0 r42 r43 r44
por la tanto, la reduccion de Givens permite determinar la matriz R del algoritmo QR.
Tal vez la distincion mas significativa entre el metodo de Givens y otros metodos, es queal utilizarlo en matrices simetricas, es altamente paralelizable.
Una matriz simetrica requiere n(n − 1)/2 rotaciones de Givens para convertirse en unamatriz triangular superior, mas aun, si la matriz es tambien tridiagonal solo se requieren n−1rotaciones. Tal vez esta es la diferencia de mayor importancia entre el metodo de Jacobi y elde Givens, ya que el metodo de Jacobi no especıfica un numero finito de pasos.
En la practica, hay mejores formas de calcular c y s que la ecuacion (2.3) (en la pag 20),por ejemplo, con el siguiente algoritmo [19].
Cinvestav Departamento de Computacion

Marco teorico 21
Algoritmo 2.7 Obtencion de una rotacion de Givens
Entrada: Escalares a, b ∈ RSalida: Escalares c = cos(θ), s = sin(θ) ∈ R tales que(
c s−s c
)T (ab
)=
(r0
)1: si b = 0 entonces2: c← 1; s← 03: si no4: si |b| > |a| entonces5: τ ← −a/b; s← 1/
√1 + τ 2; c← sτ
6: si no7: τ ← −b/a; c← 1/
√1 + τ 2; s← cτ
8: devolver (c, s)
Este algoritmo solo requiere cinco flops y una sola raız cuadrada, tampoco necesitan fun-ciones trigonometricas inversas.
Es importante aprovechar la estructura de la rotacion de Givens cuando la utilizamos enuna multiplicacion de matrices. Por ejemplo, si se multiplica una rotacion de Givens por unamatriz es conveniente utilizar el siguiente algoritmo [19].
Algoritmo 2.8 Aplicacion de una rotacion de Givens (pre-multiplicacion)
Entrada: Matriz A ∈ Rn×n, los escalares c = cos(θ), s = sin(θ) ∈ RSalida: Matriz A ∈ Rn×n, tal que la actualizacion A = G(i, k, θ)TA afecta solo dos filas
A([i, k], :) =
(c s−s c
)TA([i, k], :)
1: para j = 1 a n hacer2: τ1 ← A(i, j)3: τ2 ← A(k, j)4: A(i, j)← cτ1 − sτ2
5: A(k, j)← sτ1 − cτ2
6: devolver A
Y si se multiplica una matriz por una rotacion de Givens es conveniente utilizar el siguientealgoritmo [19].
Cinvestav Departamento de Computacion

22 Capıtulo 2
Algoritmo 2.9 Aplicacion de una rotacion de Givens (pos-multiplicacion)
Entrada: Matriz A ∈ Rn×n, los escalares c = cos(θ), s = sin(θ) ∈ RSalida: Matriz A ∈ Rn×n, tal que la actualizacion A = AG(i, k, θ) afecta solo dos columnas
A(:, [i, k]) = A(:, [i, k])
(c s−s c
)1: para j = 1 a n hacer2: τ1 ← A(j, i)3: τ2 ← A(j, k)4: A(j, i)← cτ1 − sτ2
5: A(j, k)← sτ1 − cτ2
6: devolver A
Estos algoritmos tienen complejidades lineales en vez de cubicas, como pasarıa en el casode una multiplicacion tıpica de matrices densas.
2.5. Programacion paralela
Los terminos computacion paralela, procesamiento paralelo, y programacion paralela sonusados de forma ambigua algunas veces, o no son claramente definidos y diferenciados [20].Computacion paralela es un termino que engloba todas las tecnologıas utilizadas en la eje-cucion simultanea de multiples tareas en multiples procesadores. El procesamiento paralelo,o paralelismo, es alcanzado dividiendo una sola tarea en multiples tareas mas pequenas e in-dependientes. Las tareas pueden ejecutarse simultaneamente cuando uno o mas procesadoresestan disponibles. Si solo un procesador esta disponible, las tareas se ejecutan secuencialmen-te. En un solo procesador moderno de alta velocidad, las tareas puden parecer ser ejecutadasal mismo tiempo, pero en realidad no pueden ser ejecutadas simultaneamente en un soloprocesador.
Programacion paralela es la metodologıa de software usada para implementar el procesa-miento paralelo. El programa debe incluir instrucciones para informar al sistema de ejecucionque partes de la aplicacion pueden ser ejecutadas simultaneamente. El programa entonces sedice estar paralelizado. La programacion paralela es una tecnica de optimizacion de desem-peno que intenta reducir el ”tiempo de reloj”de ejecucion de una aplicacion permitiendo alprograma manejar varias actividades simultaneamente. La programacion paralela puede serimplementada utilizando muchas diferentes interfaces de software, o modelos de programa-cion paralela.
El modelo de programacion paralela usado en cualquier aplicacion depende de la arquitec-tura de hardware del sistema sobre el cual se espera ejecutar. Especıficamente, el desarolladordebe distinguir entre un sistema de memoria compartida y un sistema de memoria distribui-da. En una arquitectura de memoria compartida, la aplicacion puede acceder de maneratransparente a cualquier localidad de memoria. Un procesador multinucleo es un ejemplo dede un sistema de memoria compartida. En un entorno de memoria distribuida, la aplicacionsolamente puede acceder transparentemente a la memoria de el nodo sobre el que se esta
Cinvestav Departamento de Computacion

Marco teorico 23
ejecutando. El acceso a la memoria en otro nodo tiene que ser explicitamente acordado conla aplicacion. Clusters y grids son ejemplos de sistemas de memoria distribuida.
2.5.1. Hıbrida
Un modelo hıbrido combina mas de un modelo de programacion paralela [20]. Con lallegada de los sistemas multinucleo, un creciente numero de clusters y grids son sistemas pa-ralelos con dos capas. Dentro de un solo nodo, la rapida comunicacion a traves de la memoriacompartida puede ser explotada, y un protocolo de red pude ser utilizado para comunicarsea traves de los nodos. Los programas puede tomar ventaja de ambos la memoria compartiday la memoria distribuida.
El modelo de MPI pude ser usado para ejecutar aplicaciones paralelas en clusters de sis-temas multinucleo. Las aplicaciones MPI pueden ejecutarse a traves de los nodos tambiencomo dentro de cada nodo, por lo que ambas capas de paralelizacion, compartida y distribui-da pueden ser utilizadas con MPI. En ciertas situaciones, sin embargo, la agregacion de laparalelizacion de grano fino ofrecida por un modelo de programacion de memoria compartidatal como Pthreads o OpenMP es mas eficiente. Tıpicamente, la ejecucion paralela sobre losnodos es alcanzada por medio de MPI. Dentro de un nodo, Pthreads o OpenMP es usado.Cuando dos modelos de programacion son usados en una aplicacion, la aplicacion se dice serparalelizada con un modelo de programacion hıbrido.
Actualmente, un ejemplo comun de modelo hıbrido es la combinacion de el modelo pasode mensajes (MPI) con el modelo de hilos (OpenMP). Los hilos realizan funciones compu-tacionalmente intensivas usando datos locales en un nodo. La comunicacion entre procesosen diferentes nodos ocurre sobre la red utilizando MPI. Otro ejemplo similar de un modelohıbrido con una creciente popularidad es el uso de MPI con programacion en GPU [21]. LasGPUs desarrollan funciones computacionales intensas usando datos locales sobre un nodo.La comunicacion entre procesos en diferentes nodos ocurre sobre la red utilizando MPI.
2.5.2. Heterogenea
El computo heterogeneo se refiere a sistemas que usan mas de una clase de procesador[22]. Estos son sistemas multinuclo que ganan desempeno no solo agregando nucleos, si no quetambien incorporan capacidades especiales de procesamiento para manejar tareas especiales(tıpicamente CPUs y GPUs) para brindar lo mejor de ambos mundos: el procesamiento enGPU puede realizar computaciones matematicamente intensivas sobre conjuntos muy grandesde datos, mientras que los CPUs pueden ejecutar el sistema operativo y desempenar tareasseriales tradicionales. La programacion paralela heterogenea se refiere a la programacion deeste tipo de sistemas para realizar operaciones que requieren grandes cantidades de computo.
2.5.3. Tecnologıas para implementar algoritmos paralelos
A continuacion se describen brevemente las tecnologıas que utilizamos para implementarlos algoritmos en esta tesis.
Cinvestav Departamento de Computacion

24 Capıtulo 2
CUDA
Es una arquitectura de calculo paralelo de NVIDIA que aprovecha la gran potencia de laGPU (unidad de procesamiento grafico) para proporcionar un incremento extraordinario delrendimiento del sistema [23]. Parte de CUDA es un una extension al lenguaje C que permiteal codigo de GPU ser escrito en C regular. El codigo es dirigido al procesador host (el CPU)o al procesador device (el GPU). El procesador host genera tareas multihilo (o kernels comoson conocidos en CUDA) en el GPU. El GPU tiene su propio planificador que entonces asig-nara los kernels a cualquiera hardware de GPU que este presente [24].
Un programa consiste de una o mas fases que son ejecutadas en el host o en el device.Las fases que exhiben poco o ningun paralelismo son implementadas en el codigo de host.Las fases que exhiben una gran cantidad de paralelismo son implementadas en el codigo deldevice. Las funciones kernels (o simplemente kernels) tıpicamente generan un gran numerode hilos para explotar el paralelismo [25]. Mas informacion sobre la programacion en CUDApuede encontrarse en los libros [26, 25, 24, 27]
OpenMP
Es una especificacion para un conjunto de directivas de compilacion, rutinas de biblioteca,y variables de entorno que pueden ser usadas para especificar paralelismo de alto nivel enprogramas Fortran y C/C++ [28]. OpenMP ofrece un modelo de mas alto nivel que el de loshilos POSIX y tambien provee funcionalidad adicional. En mucho casos, una implementaciones construida sobre un modelo nativo de hilos como POSIX threads.
Las directivas de compilador juegan un papel importante en OpenMP, mediante la in-sercion de directivas en el codigo fuente, el desarrollador especifica que partes del programapueden ser ejecutadas en paralelo. El compilador transforma estas partes especificadas de elprograma dentro de la infraestructura apropiada, tal como una llamada a una funcion deuna biblioteca multitarea. OpenMP tiene cuatro ventajas principales sobre otros modelos deprogramacion:
Potabilidad - Un programa que usa OpenMP es portable a otro compilador o entornoOpenMP
Facilidad de uso - El desarrollador no tiene que crear y manejar hilos al nivel de loshilos de POSIX, por ejemplo. La gestion de hilos es manejada por el compilador y lalibrerıa multitarea que utiliza.
La aplicacion puede ser paralelizada paso por paso - El desarrollador especifica lassecciones que pueden ser ejecutadas en paralelo, y pueden por lo tanto paralelizarincrementalmete la aplicacion como sea necesario.
La version secuencial de el programa es preservada - Si el programa no es compilado conla opcion de OpenMP, las directivas en el codigo son ignoradas. Este comportamientoefectivamente deshabilita la ejecucion para que el programa se ejecute secuencialmenteotra vez.
Una buena referencia para el aprendizaje de OpenMP es [29].
Cinvestav Departamento de Computacion

Marco teorico 25
MPI
Message-Passing Interface es una especificacion de una interfaz de una biblioteca de pasode mensajes [30]. MPI principalmente se enfoca en el modelo de programacion paralela depaso de mensajes: los datos son enviados de un espacio de direcciones de un proceso a otrade otro proceso a traves de operaciones cooperativas en cada proceso. El modelo de MPIes comunmente usado para paralelizar aplicaciones para un cluster de computadoras, o unagrid. Como OpenMP, esta interfaz es una capa de software adicional por encima de la fun-cionalidad basica del sistema operativo. MPI es construido por encima de una interfaz dered, tal como sockets, con un protocolo tal como TCP/IP. MPI provee un basto conjunto derutinas de comunicacion, y es ampliamente disponible.
Un programa MPI es un programa secuencial C, C++, o Fortran que se ejecuta sobre unsubconjunto de procesadores, o todos los procesadores en un cluster. El programador imple-menta la distribucion de tareas y la comunicacion entre ellas, y decide que trabajo es asignadoa los diferentes hilos. Para lograr este fin, el programa necesita ser aumentado con llamadasa funciones de la biblioteca de MPI, por ejemplo, enviar y recibir informacion de otros hilos(o nodos). MPI es un modelo de programacion muy explicito. Aunque alguna funcionalidadconveniente es proveıda, tal como una operacion global de broadcast, el desarrollador tieneque disenar especıficamente la aplicacion paralela para este modelo de programacion. Muchosdetalles de bajo nivel tambien tienen que ser manejados explicitamente.
La ventaja de MPI es que una aplicacion puede ejecutarse sobre cualquier tipo de clusterque tiene el software para soportar el modelo de programacion de MPI. Aunque originalmentelos programas de MPI se ejecutaron en clusters de un solo procesador, estaciones de trabajoo PCs, ejecutar una aplicacion MPI sobre uno o mas computadoras de memoria compartidaes ahora comun. Mas informacion sobre MPI puede consultarse en [31].
Cinvestav Departamento de Computacion

26 Capıtulo 2
Cinvestav Departamento de Computacion

Capıtulo 3
Algoritmo divide y venceras
En este capıtulo se describe cada una de las fases del algoritmo divide y venceras paradiagonalizar matrices tridiagonales simetricas; en las secciones 3.2 y 3.3 (en las pags. 30y 33) se presta especial atencion a la solucion de la ecuacion secular y a la ortogonalidad delos vectores propios, ya que son estos puntos en los que se presentan las mayores dificultadesal implementar el algoritmo; tambien, en la seccion 3.5 (en la pag. 34), se senalan algunospasos que son esenciales para una implementacion eficiente como es la deflacion, la cual tienedos propositos: reducir la complejidad del problema y evitar malas condiciones para resolverla ecuacion secular; finalmente, en la seccion 3.6 (en la pag. 36), se definen las matricesde permutacion que se utilizan para ordenar los valores propios de los subproblemas y parareducir el tamano del problema.
3.1. Idea general
Para utilizar esta estrategia se debe tener como matriz inicial una matriz tridiagonalsimetrica de la forma
T =
a1 b1 0b1 a2 b2
. . . . . . . . .
bn−2 an−1 bn−1
0 bn−1 an
que se puede separar de la siguiente manera [9]
T =
. . . . . .
. . . am−1 bm−1
bm−1 am ∓ bmam+1 ∓ bm bm+1
bm+1 am+2. . .
. . . . . .
+
bm ±bm±bm bm
,
m ≈ n
2
27

28 Capıtulo 3
con lo que se tienen dos matrices tridiagonales simetricas
T1 =
a1 b1 0b1 a2 b2
. . . . . . . . .
bm−2 am−1 bm−1
0 bm−1 am ∓ bm
y
T2 =
am+1 ∓ bm bm+1 0bm+1 am+2 bm+2
. . . . . . . . .
bn−2 an−1 bn−1
0 bn−1 an
por lo tanto, la matriz original esta dada por
T =
(T1 00 T2
)+ ρuuT
donde
u =
0...0
m→ 1m+ 1→ 1
0...0
y ρ = ±bm
de esta forma, se tienen dos problemas separados de diagonalizacion
T1 = Q1Λ1QT1 y T2 = Q2Λ2Q
T2
con
Λ1 =
λ1 0
λ2
. . .
0 λm
y Λ2 =
λm+1 0
λm+2
. . .
0 λn
y
D =
(Λ1 00 Λ2
)La matriz original se reescribe como
Cinvestav Departamento de Computacion

Algoritmo divide y venceras 29
T =
(Q1 00 Q2
){(λ1 00 λ2
)+ ρvvT
}(Q1 00 Q2
)Tcon
v =
(Q1 00 Q2
)Tu =
(±ultima columna de QT
1
primera columna de QT2
)La matriz M tiene los mismos valores propios que la matriz original T (es similar)
M ≡ D + ρvvT
Cuyos valores propios estan dados por la ecuacion secular
0 = 1 + ρn∑i=1
v2i
di − λ
Los vectores propios de M son
yi = (D − λiI)−1v (3.1)
Los vectores propios de la matriz original estan dados por
qi =
(Q1 00 Q2
)yi
El seguimiento de estos pasos lleva al siguiente algoritmo recursivo [32].
Algoritmo 3.1 Diagonalizacion de matrices tridiagonales simetricas
Entrada: Una matriz simetrica tridiagonal T ∈ Rn×n
Salida: La descomposicion espectral de T = QΛQT , donde la diagonal Λ es la matriz devalores propios y Q es la matriz de vectores propios y es ortogonal
1: si T es 1× 1 entonces2: devolver (Λ = T,Q = 1)3: si no
4: Separar la matriz en la forma T =
[T1 00 T2
]+ ρuuT
5: Usar este algoritmo con T1 como entrada y Q1, Λ1 como salida6: Usar este algoritmo con T2 como entrada y Q2, Λ2 como salida7: Formar D + ρvvT a partir de Λ1, Λ2, Q1, Q2
8: Calcular los valores propios Λ de D+ρvvT con la ecuacion secular 0 = 1+ρ∑n
i=1v2idi−λ
9: Calcular los vectores propios Q′ de D + ρvvT con q′i = (D − λiI)−1v
10: Formar Q =
[Q1 00 Q2
]·Q′ que son los vectores propios de T
11: devolver (Λ, Q)
Cinvestav Departamento de Computacion

30 Capıtulo 3
3.2. Ecuacion secular
El calculo de la ecuacion no es trivial. En [7] se propone una forma estable y eficientepara resolver esta ecuacion. El autor propone utilizar una variante de Newton-Raphson queutiliza una ecuacion no lineal para aproximar la funcion.
Considere el valor propio λi ∈ (di, di+1) donde 1 ≤ i ≤ n − 1; el caso para i = n esconsiderado despues. λi es la raız de la ecuacion secular
f(λ) ≡ 1 +n∑j=1
v2j
dj − λ= 0 (3.2)
Primero suponemos que λi ∈ (di,di+di+1
2). Sea δj = dj − di y sea
ψ(µ) ≡ 1 +i∑
j=1
v2j
δj − µy φ(µ) ≡ 1 +
n∑j=i+1
v2j
δj − µ
ya que
f(µ+ di) = 1 + ψ(µ) + φ(µ) ≡ g(µ),
nosotros buscamos la raız µi = λi − di ∈ (0, δi+1/2) de g(µ) = 0.
Una propiedad importante de g(µ) es que cada diferencia δj − µ puede ser evaluada conuna alta exactitud relativa para cualquier µ ∈ (0, δi+1/2). Debido a esta propiedad cadafraccion v2
j/(δj − µ) puede ser evaluada con una alta exactitud relativa.
Nosotros ahora suponemos que λi ∈ [di+di+1
2, di+1). Sea δj = dj − di+1 y sea
ψ(µ) ≡ 1 +i∑
j=1
v2j
δj − µy φ(µ) ≡ 1 +
n∑j=i+1
v2j
δj − µ
Nosotros buscamos la raız µi = λi − di+1 ∈ [δi/2, 0) de la ecuacion
g(µ) = f(µ+ di+1) = 1 + ψ(µ) + φ(µ) = 0.
Para cada µ ∈ [δi/2, 0), cada diferencia δj − µ y cada relacion v2j/(δj − µ) puede ser otra
vez computada con alta exactitud relativa.
Por ultimo, consideramos el caso i = n. Sea δj = dj − dn y sea
ψ(µ) ≡ 1 +n∑j=1
v2j
δj − µy φ(µ) ≡ 0
Nosotros buscamos la raız µn = λn − dn ∈ (0, ‖v‖) de la ecuacion
g(µ) = f(µ+ dn) = 1 + ψ(µ) + φ(µ) = 0.
Cinvestav Departamento de Computacion

Algoritmo divide y venceras 31
Para cada µ ∈ (0, ‖v‖), cada diferencia δj − µ y cada relacion v2j/(δj − µ) puede ser
computada con alta exactitud relativa como antes.
En el siguiente algoritmo, el valor de ρ es igual 1, ya que en nuestra implementacion seescala la matriz original de forma que siempre se obtenga ese valor. De la misma forma, lamatriz diagonal D, se representa con un vector d, porque al implementar el algoritmo estoreduce el uso de memoria. Los elementos del vector λ son calculados como (dk−dI)−(λi−dI)para tener una buena exactitud con los calculos en coma flotante.
Algoritmo 3.2 Encontrar la i-esima raız de la ecuacion secular
Entrada: Un vector d ∈ Rn cuyas entradas esten en orden ascendente, un vector v ∈ Rn
con ‖v‖2 = 1, el ındice i ∈ Z+ de la raız que se va a obtener, la precision de la maquinaε ∈ R
Salida: La i-esima raız de la ecuacion secular λi ∈ R, el vector dmlambda = [d1 − λi, d2 −λi, . . . , dn − λi]T ∈ Rn
1: di← di2: η ← 13: g(µi)← 14: si i < n entonces5: dip1← di+1
6: λi ← (di+ dip1)/27: f(λi)← 1 + φ(λi) + ψ(λi)8: si f(λi) > 0 entonces . El cero esta en la mitad izquierda del intervalo9: para j = 1 a n hacer . Trasladar el origen a di
10: δj ← dj − di11: µi ← λi − di12: dip1← dip1− di
13: mientras |g(µi)| > ε y
∣∣∣∣ ηµi∣∣∣∣ > 8ε hacer . Encontrar el cero
14: g(µi)← 1 + φ(µi) + ψ(µi)15: ∆i ← −µi . δi − µi, pero δi = di − di = 016: ∆i+1 ← dip1− µi . δi+1 − µi17: a← (∆i + ∆i+1)g(µi)−∆i∆i+1(ψ′(µi) + φ′(µi))18: b← ∆i∆i+1g(µi)19: c← g(µi)−∆iψ
′(µi)−∆i+1φ′(µi)
20: si a > 0 entonces
21: η ← 2b
a+√a2 − 4bc
22: si no
23: η ← a−√a2 − 4bc
2c24: µi ← µi + η25: si µi = 0 entonces . Prevenir division por cero26: µi ← ε
27: λi ← µi + di . Regresar el origen a cero
Cinvestav Departamento de Computacion

32 Capıtulo 3
Algoritmo 3.2 Encontrar la i-esima raız de la ecuacion secular
28: si no . El cero esta en la mitad derecha del intervalo29: para j = 1 a n hacer . Trasladar el origen a di+1
30: δj ← dj − dip131: µi ← λi − dip132: di← di− dip1
33: mientras |g(µi)| > ε y
∣∣∣∣ ηµi∣∣∣∣ > 8ε hacer . Encontrar el cero
34: g(µi)← 1 + φ(µi) + ψ(µi)35: ∆i ← di− µi . δi − µi36: ∆i+1 ← −µi . δi+1 − µi, pero δi+1 = di+1 − di+1 = 037: a← (∆i + ∆i+1)g(µi)−∆i∆i+1(ψ′(µi) + φ′(µi))38: b← ∆i∆i+1g(µi)39: c← g(µi)−∆iψ
′(µi)−∆i+1φ′(µi)
40: si a > 0 entonces
41: η ← 2b
a+√a2 − 4bc
42: si no
43: η ← a−√a2 − 4bc
2c44: µi ← µi + η45: si µi = 0 entonces . Prevenir division por cero46: µi ← −ε47: λi ← µi + dip1 . Regresar el origen a cero
48: si no . i = n49: dip1← dn + 1 . dn + ‖v‖2
50: λi ← dn + 0.5 . (dn + dn+1)/2 = (dn + dn + ‖v‖2)/251: f(λi)← 1 + φ(λi) + ψ(λi)52: si f(λi) > 0 entonces . El cero esta en la mitad izquierda del intervalo53: para j = 1 a n hacer . Trasladar el origen a dn54: δj ← dj − di55: µi ← λi − di
56: mientras |g(µi)| > ε y
∣∣∣∣ ηµi∣∣∣∣ > 8ε hacer . Encontrar el cero
57: g(µi)← 1 + φ(µi) + ψ(µi)58: ∆i ← −µi . δn − µi, pero δn = dn − dn = 059: ∆i−1 ← δi−1 − µi . dn−1 − λi = (dn−1 − dn)− (λi − dn)60: a← (∆i−1 + ∆i)g(µi)−∆i−1∆i(ψ
′(µi) + φ′(µi))61: b← ∆i−1∆ig(µi)62: c← g(µi)−∆i−1ψ
′(µi)−∆iφ′(µi)
63: si a < 0 entonces . Notese que cambia el operador relacional
64: η ← 2b
a−√a2 − 4bc
. Notese que cambia el signo de la raız
65: si no
66: η ← a+√a2 − 4bc
2c. Notese que cambia el signo de la raız
67: µi ← µi + η
Cinvestav Departamento de Computacion

Algoritmo divide y venceras 33
Algoritmo 3.2 Encontrar la i-esima raız de la ecuacion secular
68: si µi = 0 entonces . Prevenir division por cero69: µi ← ε
70: λi ← µi + di . Regresar el origen a cero71: si no . El cero esta en la mitad derecha del intervalo72: para j = 1 a n hacer . Trasladar el origen a dn+1 = dn + ‖v‖2
73: δj ← dj − dip174: µi ← λi − dip1
75: mientras |g(µi)| > ε y
∣∣∣∣ ηµi∣∣∣∣ > 8ε hacer . Encontrar el cero
76: g(µi)← 1 + φ(µi) + ψ(µi)77: ∆i ← δi − µi78: ∆i−1 ← δi−1 − µi79: a← (∆i−1 + ∆i)g(µi)−∆i−1∆i(ψ
′(µi) + φ′(µi))80: b← ∆i−1∆ig(µi)81: c← g(µi)−∆i−1ψ
′(µi)−∆iφ′(µi)
82: si a < 0 entonces . Notese que cambia el operador relacional
83: η ← 2b
a−√a2 − 4bc
. Notese que cambia el signo de la raız
84: si no
85: η ← a+√a2 − 4bc
2c. Notese que cambia el signo de la raız
86: µi ← µi + η87: si µi = 0 entonces . Prevenir division por cero88: µi ← −ε89: λi ← µi + dip1 . Regresar el origen a cero
90: para j = 1 a n hacer91: dlambdaj ← δj − µi . dj − λi = (dj − dI)− (λi − dI), I = i o i+ 1
Algoritmo 3.3 Solucion de la ecuacion secular
Entrada: Un vector d ∈ Rn cuyas entradas esten en orden ascendente sin valores repetidos,un vector v ∈ Rn con ‖v‖2 = 1, la precision de la maquina ε ∈ R
Salida: Las n raıces de la ecuacion secular en el vector λ ∈ Rn, una matriz dfmlc ∈ Rn×n
cuyo valor en la fila f y la columna c es df − λc1: para i = 1 a n hacer2: Usar el algoritmo 3.2 con d, v, i, ε como entrada y λi, la columna i de dfmlc como
salida
3.3. Ortogonalidad de los vectores propios
Si se utiliza la ecuacion 3.1 para calcular los vectores propios de D+vvT se puede perderla ortogonalidad de los vectores propios. Gu y Eisenstat [8] proponen las siguientes ecuacionespara evitar que esto ocurra:
Cinvestav Departamento de Computacion

34 Capıtulo 3
v′k = sign (vk)
√√√√ ∏k−1j=1 (dk − λj)
∏nj=k (λj − dk)∏k−1
j=1 (dk − dj)∏n
j=k+1 (dj − dk)(3.3)
qi =(D − λiI)−1v’
‖ (D − λiI)−1v’ ‖La solucion de Gu y Eisenstat es a la vez ingeniosa y simple, ademas, no depende de la
arquitectura de la maquina donde se implemente; basicamente proponen el siguiente proble-ma inverso de valores propios:
Dado D y valores λ1, λ2, . . . , λn que satisfacen la propiedad de entrelazado, encontrar unvector v’ = [v′1, v
′2, . . . , v
′n]T tal que la matriz D + vvT tiene los valores propios prescritos
λ1, λ2, . . . , λn. La solucion a este problema esta dada por la ecuacion 3.3.
Ellos observaron que v′k en la ecuacion 3.3 esta determinada por los valores di y λi conuna gran exactitud. Por lo tanto una vez que los valores propios son calculados con un buengrado de exactitud, un vector v′ puede calcularse, tal que los valores λi son los valores propiosexactos de D + vvT .
Antes de que se propusiera esta solucion, se habıa utilizado doble precision para los proble-mas de valores propios de precision sencilla y cuadruple precision (simulada en software) paralos problemas de precision doble, por lo que se tenıan implementaciones que eran totalmentedependientes de la maquina.
3.4. El problema de valores propios para D + vvT
Como se menciono anteriormente nosotros escalamos la matriz original T con el escalar1/(2ρ) por lo que el problema que resolvemos es D + vvT , en lugar de D + ρvvT ; ademasesto facilita tener un vector v con ‖v‖ = 1.
Con los puntos estudiados en las secciones anteriores, se puede observar que para resolvereste problema necesitamos resolver la ecuacion secular con el algoritmo 3.3 y la correccionpara restaurar la ortogonalidad de los vectores.
Este problema se conoce como modificacion de rango uno y todos los solucionadoresde valores propios basados en el algoritmo divide y venceras tienen que resolverlo, inclusoaquellos para solucionar problemas generales de valores propios, por lo que se considera unode los puntos claves de muchas implementaciones actuales.
3.5. Deflacion
La deflacion es un proceso mediante el que se reduce el tamano del problema de valo-res propios para D + vvT . Esta reduccion tambien es necesaria para cubrir las condicionesdel algoritmo 3.3 que utilizamos para resolver la ecuacion secular; no tener valores propiosrepetidos, ni elementos cero en el vector v. Existen dos tipos de deflacion. El primer tipo
Cinvestav Departamento de Computacion

Algoritmo divide y venceras 35
de deflacion se aplica cuando hay una elemento en v igual a cero. Si esto ocurre entoncestenemos que
(vi = 0 ⇐⇒ vTei = 0) =⇒ (D + vvT )ei = diei
Esta es una de ciertas soluciones que se pueden obtener inmediatamente, solo observandocuidadosamente la ecuacion. Por lo tanto, si un elemento de v se aproxima a cero podemostomar el valor propio directamente de la diagonal de D y el correspondiente vector propio esun vector coordenado.
El segundo tipo de deflacion se aplica cuando hay entradas identicas en la diagonal deD, es decir, di = dj, con i < j. Si esto ocurre nosotros podemos encontrar una rotacion deGivens G(i, j, ϕ) tal que esta introduce un cero en la j-esima posicion de v,
×...
i→√v2i + v2
j
...j → 0
...×
= G(i, j, ϕ)v = Gv
Notese que para cualquier ϕ,
G(i, j, ϕ)DG(i, j, ϕ)T = D, di = dj
Por lo tanto, si hay multiples valores propios en D podemos reducir todos. excepto uno,al introducir ceros en v y despues proceder como en el primer tipo de deflacion.
En nuestra implementacion aplicamos deflacion si
|vi| < 8.0εt o |(di − dj)cs| < 8.0εt con t = max (max(di),max(vi))
Utilizamos t como tolerancia por ser una aproximacion a ‖D + vvT‖ y ε es la precisionde la maquina.
Como se puede observar la aplicacion primeramente de la deflacion para todos los valoresvi iguales a cero y despues para todos valores propios repetidos de D nos permite cumplircon las condiciones necesarias para resolver la ecuacion secular de forma correcta.
La deflacion cambia el problema de valores propios para D + vvT por el de
G(D + vvT )GT = D +GvvTGT = D + (Gv)(Gv)T
Donde G es el producto de todas las rotaciones de Givens.
Sin embargo, tambien debemos cambiar todas las entradas igualadas a cero en v a laparte inferior del vector y guardar esta permutacion para poder: 1) utilizarla una vez que
Cinvestav Departamento de Computacion

36 Capıtulo 3
tengamos los valores propios de la ecuacion secular y 2) tener los valores correspondientes ensu orden original.
Con la permutacion el problema se transforma en
(Ddef1 + vdefv
Tdef 0
0 Ddef2
)= PdefG(D + vvT )GTP T
def =
(Q 00 I
)(Λ 00 Ddef2
)(Q 00 I
)TEs esta reduccion la que permite al algoritmo divide y venceras ser uno de los mas efi-
cientes, incluso en versiones secuenciales. Entre mayor sea la deflacion mas rapida sera laejecucion del algoritmo.
3.6. Matrices de permutacion
Una matriz de permutacion es una matriz P ∈ Rnxn que es una permutacion de filas (ocolumnas) de la matriz identidad [33]. Son una clase especial de matriz ortogonal que pormedio de multiplicaciones reordena las filas o las columnas de otra matriz. Por ejemplo,
P =
0 1 00 0 11 0 0
Si una matriz A ∈ Rnxm es premultiplicada por P , el resultado es que re-ordena las filas
de A: 0 1 00 0 11 0 0
1 2 34 5 67 8 9
=
4 5 67 8 91 2 3
Si una matriz B ∈ Rmxn es postmultiplicada por P , el resultado es que re-ordena las
columnas de B: 1 2 34 5 67 8 9
0 1 00 0 11 0 0
=
3 1 26 4 59 7 8
Podemos revertir la permutacion, multiplicando la matriz permutada por la inversa de la
matriz de permutacion que causo el cambio en primer lugar ası:
P TPA = A y APP T = A
Por ejemplo, retomando nuestro primer ejemplo:0 0 11 0 00 1 0
4 5 67 8 91 2 3
=
1 2 34 5 67 8 9
En la practica, el uso de matrices de permutacion requiere mucha memoria por lo que
se usan vectores de permutacion. Un vector de permutacion p ∈ Z+1×no ∈ Z+n×1
es una
Cinvestav Departamento de Computacion

Algoritmo divide y venceras 37
permutacion de enteros del 1 a n que se utiliza como ındice para colocar las filas o columnas enel ındice correcto. Para obtener el vector de permutacion a partir de la matriz de permutacion,solo se multiplica P por el vector que contiene los numeros del 1 a n, por ejemplo:
p =
0 1 00 0 11 0 0
123
=
231
3.7. Algoritmo completo
Despues de ver los detalles que deben ser tomados en cuenta para una correcta imple-mentacion, podemos ver que la descomposicion que buscamos tiene la forma
(Q1 00 Q2
)P TsortG
TP TdefPdefGPsort
{(λ1 00 λ2
)+ ρvvT
}P TsortG
TP TdefPdefGPsort
(Q1 00 Q2
)Tque equivale a
(Q1 00 Q2
)P TsortG
TP Tdef
((Qr1 00 I
)(Λr1 00 Ddef2
)(Qr1 00 I
)T)PdefGPsort
(Q1 00 Q2
)Tpor lo que los vectores propios de T son
Q =
(Q1 00 Q2
)P TsortG
TP Tdef
(Qr1 00 I
)y los valores propios son
Λ =
(Λr1 00 Ddef2
)es decir
T = QΛQT
Cinvestav Departamento de Computacion

38 Capıtulo 3
Cinvestav Departamento de Computacion

Capıtulo 4
Diseno e implementacion
Este capitulo describe el desarrollo principal de la tesis, los problemas que se encontraronal implementar los algoritmos y como se resolvieron.
Primero, se muestra en la seccion 4.1, la implementacion secuencial del metodo de dis-paro, y en la seccion 4.2 (en la pag. 40) la implementantacion secuencial del algoritmodivide y venceras. Enseguida, en la seccion 4.3 (en la pag. 45), se explican las estrate-gias de paralelizacion que se utilizaron y cual es mas adecuada para cada granularidad dedatos y herramienta de programacion. Despues, en la seccion 4.4 (en la pag. 46) se descri-be la implementacion paralela del metodo de disparo, finalmente, en la seccion 4.5 (en lapag. 46) se detalla la implementacion paralela del algoritmo divide y venceras, se muestracomo se sincronizaron el CPU con el GPU y los mensajes que se intercambian entre los nodos.
Se explica con detalle como se implemento cada uno de los pasos que conforman los al-goritmos de cada metodo.
4.1. Implementacion secuencial del metodo de disparo
La implementacion secuencial del metodo de disparo se realizo unicamente en lenguajeC, por que se conocıa mucho mejor la forma de implementarlo y no existıa la necesidad dehacer tantas pruebas.
Para la implementacion basicamente se desarrollaron las siguientes tareas:
Runge-Kutta de cuarto orden
Recorrido de intervalos
Contar el numero de cruces que realiza cada funcion que resulta de integrar usandoRunge-kutta, para saber a que valor propio corresponde
Filtrar resultados que si cumplen con las condiciones finales e iniciales de las ecuacionesdiferenciales
Comparar errores con respecto a soluciones analıticas, cuando estas existan
39

40 Capıtulo 4
Las estructuras de datos que se utilizaron fueron arreglos de longitud n× n que guardanen cada fila un discretizacion de las funciones de la ecuacion diferencial de segundo grado, entotal son dos matrices una para y = f y otra para z = f ′ que son las funciones desacopladasde la ecuacion diferencial.
Se utilizaron tres arreglos de longitud n, uno para guardar la discretizacion del intervalode x donde se buscan los valores propios, uno para guardar los valores de energıa E, y unopara guardar los cruces de cada disparo que se intento c.
4.2. Implementacion secuencial del algoritmo divide y
venceras
Se desarrollaron dos implementaciones secuenciales, una en matlab y otra en lenguaje C.La metodologıa que se siguio durante la tesis para implementar los algoritmos fue:
Primeramente, codificar en matlab con funciones de algebra lineal que ya incluye matlab,el objetivo de esta fase fue aprender y comprender los algoritmos utilizados, en especial elalgoritmo divide y venceras, porque era del que menor informacion se tenıa, gracias estaimplementacion se logro identificar varios errores que ocurrıan al seguir de forma estricta losalgoritmos utilizados en los artıculos en los que nos basamos. Al darnos cuenta de que senecesitaba investigar mas los detalles propios de la implementacion, hicimos pruebas sobrevarias versiones, hasta asegurarnos que la implementacion funcionaba en todos los casos, yno solo en ejemplos especıficos, esta fue la principal razon para desarrollar funciones genera-doras de matrices y funciones que median el error de las soluciones encontradas. Matlab nospermitio crear estas funciones de una forma muy rapida, ademas por el hecho de mantenerlas variables en el espacio de trabajo nos permitio hacer diferentes experimentos sobre losresultados de cada ejecucion.
Despues, fuimos modificando la version que utilizaba instrucciones vectorizadas y funcio-nes de matlab hasta llegar a una que encajara con el tipo de programacion del lenguaje c.Aunque eliminar las instrucciones vectorizadas produce una ejecucion mas lenta, nos pro-porciona otras ventajas. Estas modificaciones nos permitieron pensar como se paralelizarıacada parte del codigo, porque identificamos las estructuras de datos que utilizarıamos, losdatos que debıamos enviar entre los nodos, y el profiler de matlab nos permitio analizar lastareas que mas tiempo consumıan. Ademas, la implementacion de matlab con estructura dellenguaje C puede ayudar a otras personas interesadas en implementar el algoritmo divide yvenceras, por ejemplo, futuros estudiantes, al servirles como un buen punto de partida pararealizar sus propios desarrollos en otros lenguajes, porque la implemetacion esta desarrolladaa un bajo nivel, que permite ver los detalles de implementacion que son necesarios para ob-tener buenos resultados y permite hacer experimentos a futuras modificaciones de una formarapida.
Finalmente, se codifico una version secuencial en lenguaje C, basandonos en la versionde matlab, al implementar esta version pensamos en estructurarla de forma que fuera facilportarla a la version paralela, para hacer esto, tomamos en cuenta que los modelos de ejecu-cion paralela son operaciones de una y dos dimensiones, en los que cada elemento resultante
Cinvestav Departamento de Computacion

Diseno e implementacion 41
es calculado por un hilo de ejecucion, entonces generamos metodos de la forma <metodo>_r
para una dimension, y <metodo>_rc para dos dimensiones. Estos metodos normalmente seencuentran dentro de un ciclo for y contiene las operaciones que calculan el resultado delelemento en la fila r y columna c, ası imitamos el comportamiento de los kernels de CUDAo de los pragma de OpenMP. Sin embargo, imitar el comportamiento de MPI no se puedelograr de esta forma y es preferible limitarse a mantener estructuras de datos separadas enlo que se convertira en diferentes procesos sobre nodos distintos.
4.2.1. Almacenamiento de matrices
El metodo para almacenar matrices densas que utilizamos fue el colum-major order, quecomo su nombre lo indica consiste en almacenar los elementos de una columna en direccionescontinuas de memoria, esto difiere al formato tradicional del lenguaje C, pero nos permitepartir las matrices de una forma mas sencilla y tener compatibilidad con bibliotecas comocublas en la version paralela. Para tener un buen desempeno cuando recorremos las matricesrecorremos todas las filas de una columna y despues pasamos a la siguiente columna, porqueel acceder a elementos que son continuos en memoria es mas rapido.
4.2.2. Generacion de matrices y metodos de calculo de error
En todas las versiones del codigo se desarrollaron funciones de generacion de matrices, enespecifico:
Matrices tridiagonales T
Matrices de modificacion de rango uno D + vvT
Tambien en todas las versiones, se desarrollaron funciones para medir el error de lassoluciones encontradas, en particular:
‖AQ−QΛ‖F para medir la calidad de los eigenpares de una matriz tridiagonal
‖(D + vvT )Q−QΛ‖F para medir la calidad de los eigenpares de una modificacion derango uno
‖QQT − I‖F para medir la ortogonalidad de los vectores propios
4.2.3. Estructuras de datos
Las estructuras de datos que se emplearon utilizan la menor cantidad posible de memoria:
Matriz tridiagonal T utiliza dos arreglos; uno de longitud n para la diagonal principaly uno de longitud n− 1 para la subdiagonal
Matriz de modificacion de rango uno D + vvT utiliza dos arreglos de longitud n; unopara la diagonal principal de D y uno para los valores del vector v
Cinvestav Departamento de Computacion

42 Capıtulo 4
Matriz de rotaciones de givens G utiliza cuatro arreglos de longitud igual al maximonumero de rotaciones que se pueden aplicar n; dos arreglos con las posiciones i, j de lasrotaciones y dos arreglos con los valores s, c de las rotaciones
Matrices densas cuadradas utilizan un arreglo de longitud n× n
Para medir los tiempos de ejecucion se utiliza la funcion gettimeofday, porque utilizarotras funciones como time de c, solo miden el uso del CPU y no del GPU. Esta es la mismafuncion (enmascarada) que utiliza MAGMA para medir sus tiempos.
4.2.4. Funciones principales
A grandes rasgos, las funciones principales que se implementaron para la version secuencialson:
Merge
Deflacion
Modificacion de rango uno
• Solucion de la ecuacion secular
• Correccion de la ortogonalidad de los vectores propios
• Calcular vectores propios
Aplicar e invertir rotaciones de givens.
Aplicar permutaciones simples y compuestas.
4.2.5. Escalamiento del problema original
Durante la primera fase del codigo se escala la matriz tridiagonal original, esta opera-cion se realiza en todas las implementaciones que hemos observado, sin embargo, rara vezse comenta en los artıculos, ya que esta operacion esta directamente relacionada con noperder precision en las operaciones de coma flotante. El escalamiento no afecta el algoritmoque utilizamos de manera significativa, y en general ningun otro que se utilice por lo siguiente:
Sea A la matriz original y B la matriz escalada
B = αA
A =1
αB
si la descomposicion en valores propios de B es
B = QDQT
entonces
Cinvestav Departamento de Computacion

Diseno e implementacion 43
A =1
αQDQT
= Q1
αDQT
= QΛQT
por lo tanto, los valores propios de A son1
αD, y los vectores propios son los mismos que los
de B, es decir, Q.
El escalar α que utilizamos es1
2ρo, donde ρo es el valor bm de la matriz original; porque
nos permite llegar a una modificacion de rango uno del tipo D+ vvT en lugar de D+ ρvvT .La razon por la que esto sucede se describe a continuacion.
Primero, el algoritmo que utilizamos para resolver la ecuacion secular tiene como condicionprevia que ‖v‖ = 1 pero los subproblemas dan como resultado v1 y v2, que despues seconcatenan para formar v, ya que ‖v1‖ = 1 y ‖v2‖ = 1, tenemos que
‖v1‖ =
√√√√ m∑k=1
v2k = 1⇒
m∑k=1
v2k = 1,
‖v2‖ =
√√√√ n∑k=m+1
v2k = 1⇒
n∑k=m+1
v2k = 1
entonces
‖v‖ =
√√√√ n∑k=1
v2k =
√√√√ m∑k=1
v2k +
n∑k=m+1
v2k =√
1 + 1 =√
2
para lograr que la norma sea igual a 1 dividimos v1 y v2 (lo que equivale a dividir v) por√2, y multiplicamos ρo por 2 para no alterar la ecuacion, con lo que obtenemos
D + 2ρo
(1√2v
)(1√2v
)T= D + 2ρovvT
entonces, tenemos ρ = 2ρo y para tener un ρ = 1 necesitamos una matriz B con ρe =1
2, para
lograr esto multiplicamos la matriz original A por el escalar α =1
2bm=
1
2ρoy obtenemos
una matriz B con ρe =1
2y por lo tanto un a modificacion de rango uno de B con ρ = 1, es
decir
D + 2ρe
(1√2v
)(1√2v
)T= D + 2ρevvT = D + 2
1
2vvT = D + vvT
Cinvestav Departamento de Computacion

44 Capıtulo 4
que es lo que querıamos obtener.
Por ultimo, como habıamos observado antes, los valores propios de A son los valores pro-
pios de B multiplicados por1
α= 2ρo y los vectores propios son los mismos que los de la
matriz escalada B.
Podrıamos pensar que este escalamiento aplicado a la matriz A aumenta el tiempo decomputo de nuestra implementacion, pero esto no ocurre, ya que en otras implementacionesse escala utilizando como valor de α el maximo valor absoluto de las entradas de la matrizoriginal. Ademas, nosotros evitamos otro tipo de transformaciones que ocurren por tener unvalor de ρ 6= 1, por ejemplo, valores negativos.
4.2.6. Consideraciones en la ecuacion secular
La precision de la maquina la tomamos de la macro DBL EPSILON de la biblioteca float.h
del lenguaje C. Pero este valor es un parametro que se puede ajustar.
En la version secuencial utilizamos Lapack para calcular la multiplicacion de matrices.Tambien, utilizamos la funcion dstedc para calcular los subproblemas del algoritmo dividey venceras, aunque puede utilizarse cualquier otro metodo como el QR.
Nosotros utilizamos un criterio de parada para resolver la ecuacion secular distinto delartıculo de Li [7], el criterio que utilizamos es:
|g(µi)| > ε y
∣∣∣∣ ηµi∣∣∣∣ > 8ε
Este criterio mostro buenos resultados al realizar pruebas en matlab, el criterio de paro esdiferente porque usamos el metodo al que Li llama The Middle Way, y los criterios que usapara este metodo dependen del tamano del problema, ya que nosotros manejamos problemasde una gran magnitud, estos criterios se ven demasiado afectados, llevado a malos resultados.
Tambien, evitamos que existieran divisiones entre cero al resolver la ecuacion secular, Limenciona que esto puede ocurrir pero de forma poco frecuente, sin embargo, nosotros reali-zamos pruebas en matlab y este fenomeno se presentaba en muchos casos, debido al tamanode problema que nosotros estamos manejando.
Otro hecho del que nos percatamos al realizar pruebas en matlab fue que, aunque loscasos de la ecuacion secular que se toman en cuenta en la teorıa son tres en la practica soncuatro, dividendo el tercer caso en λn en dos uno para cada mitad del intervalo (0, ‖v‖) enel que se encuentra µn.
Cinvestav Departamento de Computacion

Diseno e implementacion 45
4.2.7. Consideraciones en las rotaciones de Givens
La transpuesta de G es igual a la multiplicacion en orden inverso de cada una de lasmatrices transpuestas de cada rotacion de givens
G−1 = GT = (Gnr . . . G2G1)T = GT1G
T2 . . . G
Tnr
Sin embargo, como se puede notar en las estructuras de datos que utilizamos nosotrosnunca tenemos almacenada en memoria la matriz G o GT , porque ocuparıan demasiado es-pacio, lo unico que hacemos es aplicar GT a cada columna que se requiera de Q utilizandolos indices i, j y los valores c, s que definen cada rotacion. De hecho G nunca se multiplicacon ninguna matriz completa, solo se aplica a entradas especificas del vector d y del vector vdurante la deflacion, y a columnas especificas de lo que sera la matriz de vectores propios.
4.2.8. Permutaciones compuestas
Un punto muy importante en la implementacion secuencial que nos trae ventajas en laversion paralela es la utilizacion los vectores de permutacion de forma compuesta, esto es,crear una nueva permutacion que tenga el mismo efecto que a dos o mas permutciones, deesta forma los movimientos de memoria se reducen y por lo tanto, se obtienen mejores tiem-pos de ejecucion.
Para obtener una nueva permutacion a partir de dos permutaciones se usa el valor de laposicion que resulta de la aplicacion de la primera permutacion como nuevo indice para lasiguiente permutacion, por ejemplo, nosotros utilizamos la siguiente composicion:
k ← pdef (psort(i))
Para invertir las permutaciones que usamos para, ordenar los valores propios, y reducirel problema utilizando deflacion.
4.2.9. Ventajas practicas de la deflacion
Debemos destacar que en las pruebas de matlab la deflacion reducıa el numero de colum-nas en la multiplicacion final del algoritmo, la que se realiza entre los vectores propios delos subproblemas y los vectores de la modificacion de rango uno, en un ochenta porcientoaproximadamente.
4.3. Estrategias de paralelizacion
Es importante mencionar que en cualquiera de las estrategias de paralelizacion que pue-dan utilizarse, las operaciones que se van a realizar deben ser lo suficientemente pesadas paracompensar el overhead (creacion de hilos, creacion de procesos, paso de mensajes).
Basicamente se usaron dos estrategias de paralelizacion las cuales se definen a continua-cion:
Cinvestav Departamento de Computacion

46 Capıtulo 4
4.3.1. Descomposicion por datos
En esta estrategia buscamos idealmente partir los datos asociados al problema. Si es po-sible, partimos los datos en partes iguales y se asignan hilos de procesamiento relacionadoscon cada dato.
La descomposicion por datos, generalmente, se realiza sobre los ciclos de las instruccionesde programacion, tipicamente, ciclos for.
Por lo que mencionamos anteriormente, CUDA y OpenMP son los mas aptos para estetipo de estrategia.
4.3.2. Descomposicion por tareas
La descomposicion por tareas se realiza generalmente sobre las funciones que conformanun metodo.
Se busca encontrar la dependencia de las funciones y realizar la mayor cantidad posiblede funciones independientes en paralelo. Si estas funciones necesitan informacion de otras,se requiere utilizar comunicacion; pero, en general, se trata de evitar esta comunicacion lomas que se pueda. En MPI esta comunicacion tiene que hacerse a mano, mientras que enOpenMP es practicamente automatica.
La granularidad que se utiliza es de grano grueso, para realizar una gran cantidad deoperaciones en una estructura de datos y evitar comunicacion. Por lo que MPI es mas aptopara este tipo estrategia.
4.4. Paralelizacion del metodo de disparo
Para paralelizar el metodo de disparo solo se utilizo CUDA en un solo nodo, debido aque este metodo no utiliza tanta memoria y es mas rapido que el divide y venceras, pero susresultados tienen errores mucho mas significativos, como veremos en la seccion de resultados,por lo que este metodo es recomendable si se quieren soluciones inexactas y rapidas.
Se paralelizo cada una de las integraciones de runge-kutta, es decir, recorremos todo losrangos de energıa posible y lanzamos un kernel de CUDA para cada integracion que tambiencuenta el numero de cruces en paralelo. Las partes restantes del metodo se hacen de formasecuencial.
4.5. Paralelizacion del algoritmo divide y venceras
Primeramente, describiremos el particionamiento general del problema, ası como los men-sajes que se intercambian, y despues nos centraremos en describir, las principales funcionesque se paralelizaron.
Cinvestav Departamento de Computacion

Diseno e implementacion 47
Como mencionamos anteriormente una de las razones principales para utilizar el algorit-mo divide y venceras es que podemos partir por datos la matriz en dos partes independientes,por lo que en la implementacion enviamos la mitad del vector que contiene la diagonal prin-cipal y la mitad del vector que contiene la subdiagonal de la matriz original a otro nodocon MPI, resolvemos cada uno de los subproblemas que se generan debido a este particona-miento usando la funcion dstedx de MAGMA, aplicando antes ciertas transformaciones quemencionamos anteriormente (escalamiento y restar ρ) usando CUDA y OpenMP. Despuesenviamos la solucion de regreso al nodo principal para poder aplicar la deflacion y calcular lamodificacion de rango uno, para poder finalmente unir las dos soluciones obtenidas y formarla solucion completa del problema original. Para realizar estos pasos se desarrollaron variasfunciones que emplean CUDA, CUBLAS y OpenMP. Las mas importantes se describen enlas siguientes subsecciones de este capitulo.
Antes de comenzar a describir cada funcion debemos senalar que es un error comun pen-sar que solo por el hecho de usar una mayor cantidad de procesadores tendremos un mejortiempo, proporcional al inverso del numero de procesadores empleados, lo cual es falso. Estoocurre debido a que, por una parte, se genera un overhead en la programacion paralela deri-vado de la creacion y destruccion de hilos, sincronizacion, y tiempos de comunicacion, entreotras cosas; y por otra parte, existen funciones que tienen una gran dependencia funcional,por lo tanto no pueden ser paralelizadas de forma eficiente. Ası, contrario al sentido comun,existen versiones paralelas que son mas lentas que las secuenciales.
Por la razon antes mencionada, hay funciones que no paralizamos, por ejemplo, la deflacionque es inherentemennte secuencial. En la siguiente figura se muestra las diferentes etapas dela implementacion paralela. Las secciones azules representan el CPU y las verdes la GPU.
Dividir problema
Escalar
Ordenar
Escalar
Deflación
Desrotar eigenvectores
Reortogonalización
Ecuación secular
Eigenvectores
Juntar eigenvectores
Dividir mul;plicación
Reescalar
Eigensistema completo
Mul;plicación de matrices
Resolver subproblema
Mod
ifica
ción
de
rang
o un
o
Resolver subproblema
Mul;plicación de matrices
Figura 4.1: Flujo del proceso
Cinvestav Departamento de Computacion

48 Capıtulo 4
4.5.1. Paralelizacion de la ecuacion secular
Para paralelizar la ecuacion secular, primero calculamos v2 en la GPU haciendo una pa-ralelizacion de una dimension, porque utilizaremos sus valores despues, para cada raız de laecuacion secular calculamos df −λc y λc, ejecutando un kernel de CUDA sobre los intervalosde la ecuacion secular. Como vamos a utilizar los resultados encontrados por esta funcion enGPU mantenemos los datos en la memoria de la GPU para evitar hacer copias de memoriainnecesarias y hacer mas rapida la ejecucion
En otras implementaciones esto siempre se hace de forma secuencial o con OpenMP.Ası que esta implementacion es una de las primeras que aplica este enfoque.
4.5.2. Paralelizacion de la correccion de la ortogonalidad de losvectores propios
Para paralelizar la correccion de la ortogonalidad de los valores propios utilizamos laecuacion 3.3 (en la pag 34). Empleamos los valores de df − λc que forman una matriz detamano n × n, aplicamos una paralelizacion de una dimension para calcular cada elementodel vector v′.
Otra vez, mantenemos los datos en la memoria de la GPU para evitar hacer copias dememoria innecesarias y hacer mas rapida la ejecucion.
4.5.3. Paralelizacion del calculo de los vectores propios de la mo-dificacion de rango uno
Con los valores corregidos de v′ hacemos una paralelizacion de una dimension para calcu-lar la norma con la que se divide cada vector columna de la matriz Qr1 de vectores propios,utilizamos un kernel de CUDA para lograr esto.
Luego utilizamos una paralelizacion de dos dimensiones para calcular cada elemento dela matriz Qr1 utilizando otro kernel de CUDA.
4.5.4. Paralelizacion de la aplicacion de las rotaciones de Givens
Para paralelizar la aplicacion de las rotaciones de Givens utilizamos un ciclo que recorrecada uno de las rotaciones de Givens y lanzamos varios hilos de OpenMP para que se apliquecada rotacion en la columna correspondiente de la matriz afectada por las rotaciones.
En un principio pensabamos utilizar CUDA pero el numero de rotaciones que observamosen los experimentos de matlab eran muy pocas y el tiempo de transferencia de las columnas,serıa mayor que el de aplicar la rotacion.
4.5.5. Paralelizacion de las pertmutaciones
Para paralelizar la aplicacion de las permutaciones usamos una paralelizacion de una di-mension utilizando OpenMP. Cada hilo calcula en nuevo ındice de la permutacion compuesta
Cinvestav Departamento de Computacion

Diseno e implementacion 49
y copia los elementos de una columna a la nueva ubicacion que le corresponde.
No utilizamos CUDA porque el tiempo de copiar las matrices a la GPU es mayor que elde permutar las columnas de la matriz.
4.5.6. Paralelizacion de la multiplicacion de matrices
La multiplicacion de matrices que se utiliza para producir los vectores propios de lamatriz escalada a partir de la multiplicacion de los vectores propios de los subproblemas y lamodificacion de rango uno se paralelizo utilizando CUBLAS ya que es la version mas eficienteque conocemos.
Ya que la multiplicacion de matrices es una de las operaciones que mayor tiempo requiere,en una version posterior, se utilizo MPI para partir el problema en dos, cada nodo calcula lamitad de las columnas del resultado final.
4.5.7. Otras paralelizaciones
Otras paralelizaciones que no son parte de las funciones principales del algoritmo, comoson los escalamientos y el calculo de errores, se paralelizaron identificando los ciclos en losque se podıa emplear OpenMP.
Cinvestav Departamento de Computacion

50 Capıtulo 4
Cinvestav Departamento de Computacion

Capıtulo 5
Pruebas, resultados y discusion
Este capıtulo inicia en la seccion 5.1 describiendo la infraestructura en la que se realizaronlas pruebas. Enseguida, se presentan en la seccion 5.2 (en la pag. 52) los resultados deltiempo y en la seccion 5.3 (en la pag. 55) del error que se obtuvieron y se comparan con lasimplementaciones existentes. Despues, en las secciones 5.4 (en la pag. 59) y 5.5 (en la pag. 68)se presentan los casos de estudio que se seleccionaron, los cuales son casos especıficos de laecuacion de Schrodinger y Dirac, especıficamente, el problema del pozo infinito. Se describe lametodologıa con la que se realizaron las pruebas, por ejemplo, tamano del problema, intervalode energıa, tolerancia de error. Y por ultimo, en la seccion 5.6 (en la pag. 73) se discute larelevancia de los resultados.
5.1. Infraestructura
Durante el desarrollo de este trabajo se emplearon dos equipos de computo, un servidor yuna laptop. En la laptop se escribio la mayorıa del codigo y se realizaron pequenas pruebas, sinembargo, todos los resultados presentados en este capitulo fueron ejecutados en el servidor.Cuando nos referimos a los resultados de una implmentacion que utiliza una sola tarjeta, nosreferimos a la Tesla 2070, y cuando nos referimos a los resultados de una implementacion queutiliza multiples tarjetas nos referimos a la Tesla 2070 y a la GeForce GTX 460.
5.1.1. Software
Para el desarrollo de esta tesis se requirio que los equipos de computo cumplan con losrequerimientos de software de:
CUDA
MPI
OpenMP
MKL
MAGMA (requiere CUDA, CPU BLAS, LAPACK)
51

52 Capıtulo 5
5.1.2. Hardware
En esta tesis se utilizaron equipos de computo que cuentan con tarjetas graficas quesoportan la tecnologıa CUDA de Nvidia y con procesadores que pueden utilizar la bibliotecaMKL de Intel. A continuacion se mencionan las caracterısticas de cada uno:
1. Servidor
Procesador doble zocalo Intel Xenon X5675 6 cores a 3.07 GHz con 12288kB decache
Memoria RAM 24GB
Tarjeta de vıdeo
• Nvidia Tesla 2070 6GB con 448 CUDA Cores a 1.15 GHz
• Nvidia GeForce GTX 460 1GB con 336 CUDA Cores a 1.35 GHz
2. Laptop
Procesador Intel Core i5 2 cores a 2.5 GHz con 3072kB de cache
Memoria RAM 4 GB
Tarjeta de vıdeo GeForce GT 630m 1GB con 96 CUDA cores a 800 MHz
5.2. Tiempo
Las pruebas de tiempo que se realizaron fueron: la comparacion entre las diferentes im-plementaciones del algoritmo divide y venceras, la comparacion entre la implementacionsecuencial y la paralela del metodo de disparo, y por ultimo, una comparacion entre las ver-siones paralelas de disparo y diagonalizacion que se desarrollaron en esta tesis.
En la figura 5.1 (en la pag. 53), las etiquetas se refieren a las siguientes implementaciones:
dstedc: Rutina divide y venceras secuencial de MAGMAcuppen seq : Implementacion secuencial desarrollada en esta tesisdstedx : Rutina divide y venceras paralela de MAGMA (12 hilos, 1 GPUs)cuppen hib: Implementacion paralela hıbrida desarrollada en esta tesis (2 nodos con 6 hilosy 1 GPU cada uno)
Se puede observar que la implementacion paralela hıbrida es la que tiene menor tiempode ejecucion a partir de un tamano de matriz de 8000 y que la diferencia con respecto a lasotras implementaciones se incrementa conforme el tamano de la matriz aumenta. Tambien, sepuede apreciar que, aunque pequena, existe una mejora de la version secuencial desarrolladadurante la tesis con respecto de la funcion equivalente de MAGMA. Las matrices para obtenerestos resultado se obtuvieron con la funcion dlarnv de LAPACK.
Cinvestav Departamento de Computacion

Pruebas, resultados y discusion 53
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 2000 4000 6000 8000 10000 12000 14000 16000 18000
tiem
po (m
s)
tamaño de matriz n
dstedccuppen sec
dstedxcuppen hib
Figura 5.1: Tiempo Eigensistema Simetrico Tridiagonal
n dstedc secuencial dstedx hıbrido1000 35.31166 37.33702 348.03122 438.654492000 102.14143 100.76133 402.26580 484.716023000 195.90396 190.97439 489.56982 510.666724000 309.85035 302.20978 598.61821 581.947855000 464.09548 454.94648 694.29419 637.957996000 641.83560 624.25859 819.95210 718.355307000 832.40324 804.41708 978.27698 840.650678000 1056.75981 1022.35738 1172.71708 931.074169000 1312.63305 1272.95771 1333.19804 1000.8430010000 1586.35967 1525.64633 1539.87303 1128.7240911000 1881.45098 1798.57443 1786.86850 1292.1625712000 2207.90081 2108.81810 2020.06893 1427.8547013000 2557.15771 2431.70690 2302.09985 1636.0401014000 2935.44659 2779.96399 2595.15100 1776.9972915000 3343.56440 3181.02741 2939.45126 1974.2107016000 3773.65241 3577.17584 3257.57760 2146.6282317000 4210.57625 3983.19193 3547.57581 2300.5737818000 4680.37327 4416.38142 3946.83685 2545.83336
Tabla 5.1: Tiempo (ms) - Diagonalizacion
Cinvestav Departamento de Computacion
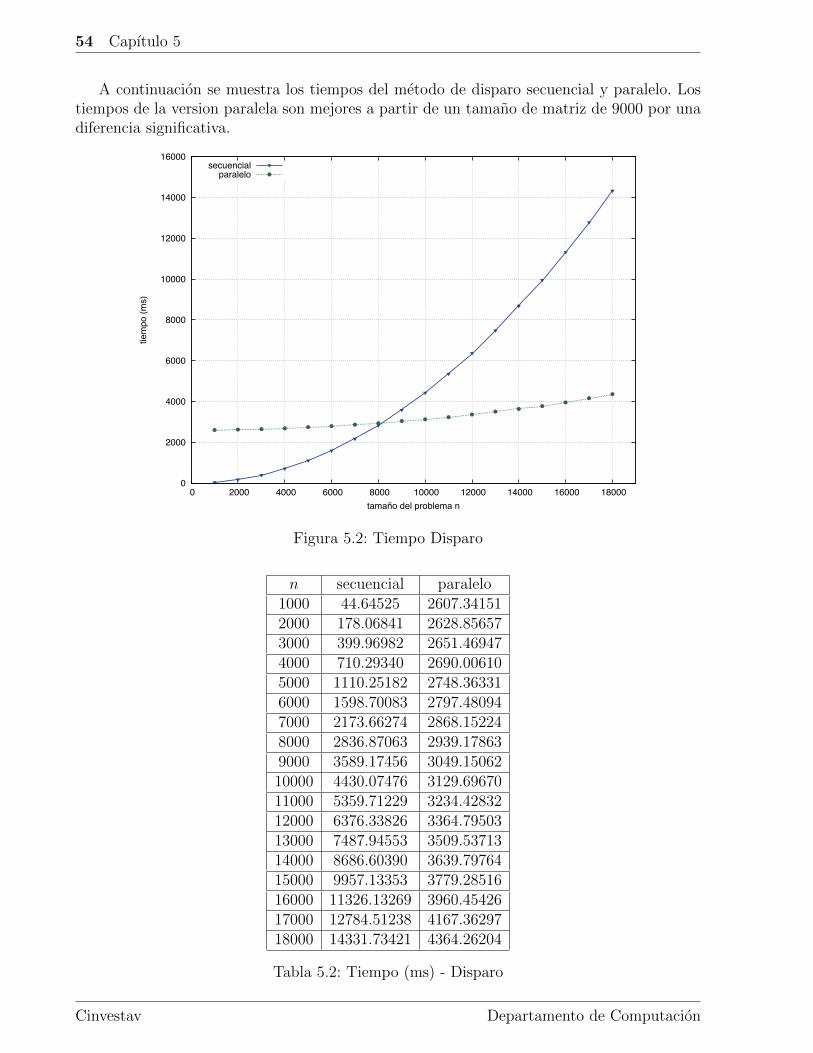
54 Capıtulo 5
A continuacion se muestra los tiempos del metodo de disparo secuencial y paralelo. Lostiempos de la version paralela son mejores a partir de un tamano de matriz de 9000 por unadiferencia significativa.
0
2000
4000
6000
8000
10000
12000
14000
16000
0 2000 4000 6000 8000 10000 12000 14000 16000 18000
tiem
po (m
s)
tamaño del problema n
secuencialparalelo
Figura 5.2: Tiempo Disparo
n secuencial paralelo1000 44.64525 2607.341512000 178.06841 2628.856573000 399.96982 2651.469474000 710.29340 2690.006105000 1110.25182 2748.363316000 1598.70083 2797.480947000 2173.66274 2868.152248000 2836.87063 2939.178639000 3589.17456 3049.1506210000 4430.07476 3129.6967011000 5359.71229 3234.4283212000 6376.33826 3364.7950313000 7487.94553 3509.5371314000 8686.60390 3639.7976415000 9957.13353 3779.2851616000 11326.13269 3960.4542617000 12784.51238 4167.3629718000 14331.73421 4364.26204
Tabla 5.2: Tiempo (ms) - Disparo
Cinvestav Departamento de Computacion

Pruebas, resultados y discusion 55
El metodo de disparo muestra un mejor tiempo que el de diagonalizacion en el problemade Schrodinger, sin embargo, presenta varios inconvenientes, como veremos mas adelante.
0
1000
2000
3000
4000
5000
6000
7000
8000
0 2000 4000 6000 8000 10000
tiem
po (m
s)
tamaño del problema n
DisparoDiagonalización
Figura 5.3: Tiempo Diagonalizacion vs Disparo
n diagonalizacion disparo1000 455.67820 2607.341512000 584.53394 2628.856573000 833.77009 2651.469474000 1148.19218 2690.006105000 1702.04420 2748.363316000 2700.62526 2797.480947000 3391.34500 2868.152248000 4539.96886 2939.178639000 6145.23960 3049.1506210000 7945.36903 3129.69670
Tabla 5.3: Tiempo (ms) - Digonalizacion vs Disparo
5.3. Error
El error respecto a la solucion analıtica en el metodo de disparo va aumentando conformese incrementa ındice del valor propio i en las tablas 5.4 y 5.5 (en las pags 56 y 57).
Cinvestav Departamento de Computacion

56 Capıtulo 5
i Edisparo Eanalıtica |Edisparo − Eanalıtica|0 2.500000000E-01 2.500000000E-01 1.665335000E-161 1.000000000E+00 1.000000000E+00 6.661338000E-162 2.250000000E+00 2.250000000E+00 1.367795000E-133 4.000000000E+00 4.000000000E+00 3.295142000E-134 6.250000000E+00 6.250000000E+00 4.218847000E-135 9.000000000E+00 9.000000000E+00 4.511946000E-136 1.225000000E+01 1.225000000E+01 1.350031000E-127 1.600000000E+01 1.600000000E+01 3.428369000E-128 2.025000000E+01 2.025000000E+01 1.765699000E-129 2.500000000E+01 2.500000000E+01 7.570833000E-1210 3.025000000E+01 3.025000000E+01 1.399769000E-1111 3.600000000E+01 3.600000000E+01 6.799894000E-1212 4.225000000E+01 4.225000000E+01 7.780443000E-1213 4.900000000E+01 4.900000000E+01 2.349765000E-1114 5.625000000E+01 5.625000000E+01 4.038014000E-1115 6.400050000E+01 6.400000000E+01 4.999999000E-0416 7.225000000E+01 7.225000000E+01 1.907097000E-1117 8.100000000E+01 8.100000000E+01 2.270895000E-1118 9.025050000E+01 9.025000000E+01 5.000001000E-0419 1.000005000E+02 1.000000000E+02 5.000001000E-0420 1.102510000E+02 1.102500000E+02 1.000000000E-0321 1.210005000E+02 1.210000000E+02 5.000002000E-0422 1.322510000E+02 1.322500000E+02 1.000000000E-0323 1.440010000E+02 1.440000000E+02 1.000000000E-0324 1.562515000E+02 1.562500000E+02 1.500000000E-0325 1.690020000E+02 1.690000000E+02 2.000000000E-0326 1.822525000E+02 1.822500000E+02 2.500001000E-0327 1.960030000E+02 1.960000000E+02 3.000001000E-0328 2.102540000E+02 2.102500000E+02 4.000001000E-0329 2.250045000E+02 2.250000000E+02 4.500001000E-0330 2.402560000E+02 2.402500000E+02 6.000001000E-0331 2.560070000E+02 2.560000000E+02 7.000001000E-0332 2.722580000E+02 2.722500000E+02 8.000000000E-0333 2.890100000E+02 2.890000000E+02 1.000000000E-0234 3.062615000E+02 3.062500000E+02 1.150000000E-0235 3.240140000E+02 3.240000000E+02 1.400000000E-0236 3.422665000E+02 3.422500000E+02 1.650000000E-0237 3.610190000E+02 3.610000000E+02 1.900000000E-0238 3.802725000E+02 3.802500000E+02 2.250000000E-0239 4.000260000E+02 4.000000000E+02 2.600000000E-0240 4.202800000E+02 4.202500000E+02 3.000000000E-0241 4.410345000E+02 4.410000000E+02 3.450000000E-0242 4.622900000E+02 4.622500000E+02 4.000000000E-0243 4.840460000E+02 4.840000000E+02 4.600000000E-02
Tabla 5.4: Error Schrodinger - Disparo secuencial
Cinvestav Departamento de Computacion

Pruebas, resultados y discusion 57
i Edisparo Eanalıtica |Edisparo − Eanalıtica|0 2.500000000E-01 2.500000000E-01 1.665335000E-161 1.000000000E+00 1.000000000E+00 6.661338000E-162 2.250000000E+00 2.250000000E+00 1.367795000E-133 4.000000000E+00 4.000000000E+00 3.295142000E-134 6.250000000E+00 6.250000000E+00 4.218847000E-135 9.000000000E+00 9.000000000E+00 4.511946000E-136 1.225000000E+01 1.225000000E+01 1.350031000E-127 1.600000000E+01 1.600000000E+01 3.428369000E-128 2.025000000E+01 2.025000000E+01 1.765699000E-129 2.500000000E+01 2.500000000E+01 7.570833000E-1210 3.025000000E+01 3.025000000E+01 1.399769000E-1111 3.600000000E+01 3.600000000E+01 6.799894000E-1212 4.225000000E+01 4.225000000E+01 7.780443000E-1213 4.900000000E+01 4.900000000E+01 2.349765000E-1114 5.625000000E+01 5.625000000E+01 4.038014000E-1115 6.400050000E+01 6.400000000E+01 4.999999000E-0416 7.225000000E+01 7.225000000E+01 1.907097000E-1117 8.100000000E+01 8.100000000E+01 2.270895000E-1118 9.025050000E+01 9.025000000E+01 5.000001000E-0419 1.000005000E+02 1.000000000E+02 5.000001000E-0420 1.102510000E+02 1.102500000E+02 1.000000000E-0321 1.210005000E+02 1.210000000E+02 5.000002000E-0422 1.322510000E+02 1.322500000E+02 1.000000000E-0323 1.440010000E+02 1.440000000E+02 1.000000000E-0324 1.562515000E+02 1.562500000E+02 1.500000000E-0325 1.690020000E+02 1.690000000E+02 2.000000000E-0326 1.822525000E+02 1.822500000E+02 2.500001000E-0327 1.960030000E+02 1.960000000E+02 3.000001000E-0328 2.102540000E+02 2.102500000E+02 4.000001000E-0329 2.250045000E+02 2.250000000E+02 4.500001000E-0330 2.402560000E+02 2.402500000E+02 6.000001000E-0331 2.560070000E+02 2.560000000E+02 7.000001000E-0332 2.722580000E+02 2.722500000E+02 8.000000000E-0333 2.890100000E+02 2.890000000E+02 1.000000000E-0234 3.062615000E+02 3.062500000E+02 1.150000000E-0235 3.240140000E+02 3.240000000E+02 1.400000000E-0236 3.422665000E+02 3.422500000E+02 1.650000000E-0237 3.610190000E+02 3.610000000E+02 1.900000000E-0238 3.802725000E+02 3.802500000E+02 2.250000000E-0239 4.000260000E+02 4.000000000E+02 2.600000000E-0240 4.202800000E+02 4.202500000E+02 3.000000000E-0241 4.410345000E+02 4.410000000E+02 3.450000000E-0242 4.622900000E+02 4.622500000E+02 4.000000000E-0243 4.840460000E+02 4.840000000E+02 4.600000000E-02
Tabla 5.5: Error Schrodinger - Disparo paralelo
Cinvestav Departamento de Computacion
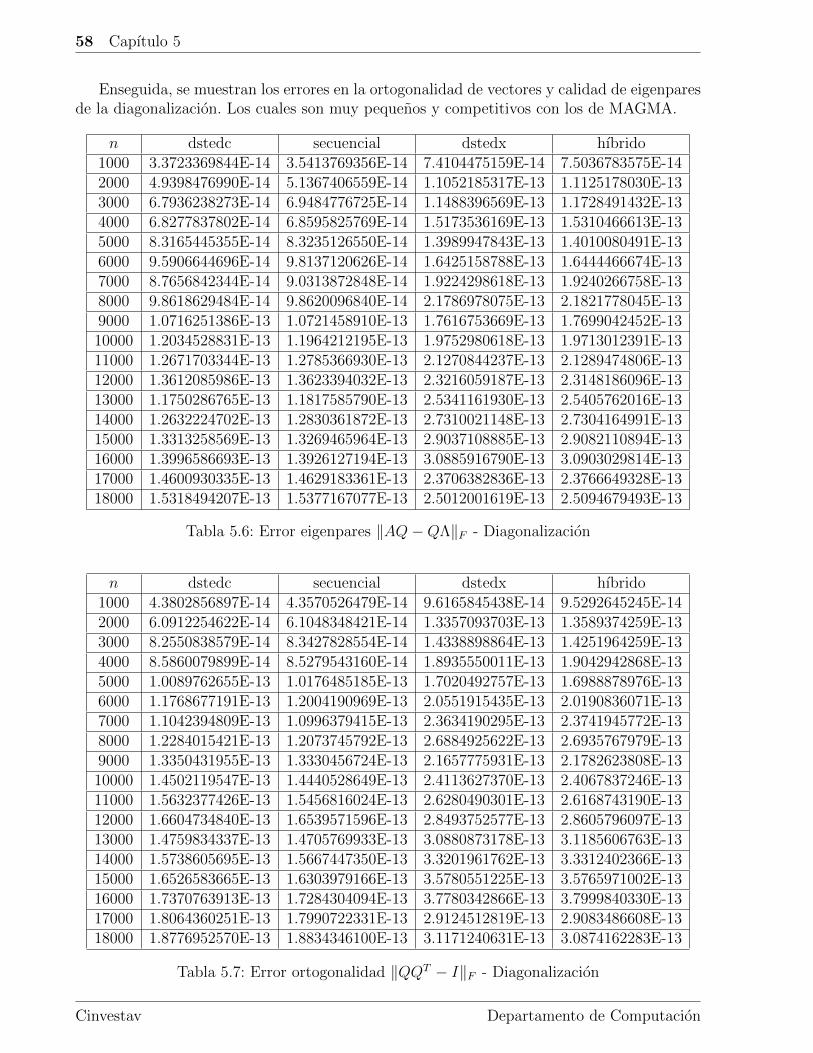
58 Capıtulo 5
Enseguida, se muestran los errores en la ortogonalidad de vectores y calidad de eigenparesde la diagonalizacion. Los cuales son muy pequenos y competitivos con los de MAGMA.
n dstedc secuencial dstedx hıbrido1000 3.3723369844E-14 3.5413769356E-14 7.4104475159E-14 7.5036783575E-142000 4.9398476990E-14 5.1367406559E-14 1.1052185317E-13 1.1125178030E-133000 6.7936238273E-14 6.9484776725E-14 1.1488396569E-13 1.1728491432E-134000 6.8277837802E-14 6.8595825769E-14 1.5173536169E-13 1.5310466613E-135000 8.3165445355E-14 8.3235126550E-14 1.3989947843E-13 1.4010080491E-136000 9.5906644696E-14 9.8137120626E-14 1.6425158788E-13 1.6444466674E-137000 8.7656842344E-14 9.0313872848E-14 1.9224298618E-13 1.9240266758E-138000 9.8618629484E-14 9.8620096840E-14 2.1786978075E-13 2.1821778045E-139000 1.0716251386E-13 1.0721458910E-13 1.7616753669E-13 1.7699042452E-1310000 1.2034528831E-13 1.1964212195E-13 1.9752980618E-13 1.9713012391E-1311000 1.2671703344E-13 1.2785366930E-13 2.1270844237E-13 2.1289474806E-1312000 1.3612085986E-13 1.3623394032E-13 2.3216059187E-13 2.3148186096E-1313000 1.1750286765E-13 1.1817585790E-13 2.5341161930E-13 2.5405762016E-1314000 1.2632224702E-13 1.2830361872E-13 2.7310021148E-13 2.7304164991E-1315000 1.3313258569E-13 1.3269465964E-13 2.9037108885E-13 2.9082110894E-1316000 1.3996586693E-13 1.3926127194E-13 3.0885916790E-13 3.0903029814E-1317000 1.4600930335E-13 1.4629183361E-13 2.3706382836E-13 2.3766649328E-1318000 1.5318494207E-13 1.5377167077E-13 2.5012001619E-13 2.5094679493E-13
Tabla 5.6: Error eigenpares ‖AQ−QΛ‖F - Diagonalizacion
n dstedc secuencial dstedx hıbrido1000 4.3802856897E-14 4.3570526479E-14 9.6165845438E-14 9.5292645245E-142000 6.0912254622E-14 6.1048348421E-14 1.3357093703E-13 1.3589374259E-133000 8.2550838579E-14 8.3427828554E-14 1.4338898864E-13 1.4251964259E-134000 8.5860079899E-14 8.5279543160E-14 1.8935550011E-13 1.9042942868E-135000 1.0089762655E-13 1.0176485185E-13 1.7020492757E-13 1.6988878976E-136000 1.1768677191E-13 1.2004190969E-13 2.0551915435E-13 2.0190836071E-137000 1.1042394809E-13 1.0996379415E-13 2.3634190295E-13 2.3741945772E-138000 1.2284015421E-13 1.2073745792E-13 2.6884925622E-13 2.6935767979E-139000 1.3350431955E-13 1.3330456724E-13 2.1657775931E-13 2.1782623808E-1310000 1.4502119547E-13 1.4440528649E-13 2.4113627370E-13 2.4067837246E-1311000 1.5632377426E-13 1.5456816024E-13 2.6280490301E-13 2.6168743190E-1312000 1.6604734840E-13 1.6539571596E-13 2.8493752577E-13 2.8605796097E-1313000 1.4759834337E-13 1.4705769933E-13 3.0880873178E-13 3.1185606763E-1314000 1.5738605695E-13 1.5667447350E-13 3.3201961762E-13 3.3312402366E-1315000 1.6526583665E-13 1.6303979166E-13 3.5780551225E-13 3.5765971002E-1316000 1.7370763913E-13 1.7284304094E-13 3.7780342866E-13 3.7999840330E-1317000 1.8064360251E-13 1.7990722331E-13 2.9124512819E-13 2.9083486608E-1318000 1.8776952570E-13 1.8834346100E-13 3.1171240631E-13 3.0874162283E-13
Tabla 5.7: Error ortogonalidad ‖QQT − I‖F - Diagonalizacion
Cinvestav Departamento de Computacion

Pruebas, resultados y discusion 59
A continuacion, se muestra la tabla con el error de la diagonalizacion hıbrida de matricescon respecto a la solucion analıtica para el problema de Schrodinger. El cual, es muy pequenoy mucho menor que el del metodo de disparo. Tambien se muestra el error de la ortogonalidadde vectores y calidad de eigenpares.
n ‖AQ−QΛ‖F ‖QQT − I‖F |Ediagonalizacion − Eanalıtica|1000 1.22645524043179E-13 1.17657912596398E-13 1.89045842511042E-152000 1.86785904435307E-13 2.02689701523453E-13 2.08486308500503E-153000 2.27668436012644E-13 2.92843251204076E-13 1.70298048316227E-154000 3.16896071971424E-13 3.76369181625732E-13 1.81455987084739E-155000 3.46510503075467E-13 4.68284011291394E-13 2.01528963843077E-156000 4.23242278834166E-13 5.59249282620112E-13 1.96988744779653E-157000 5.01955777605751E-13 6.57178492262681E-13 2.09725963790725E-158000 5.44568727373566E-13 7.22458636075449E-13 1.81238253262755E-159000 5.59048336561493E-13 8.16715994459751E-13 2.00809809519925E-1510000 6.17935928379211E-13 9.09085051267901E-13 1.99061966115400E-15
Tabla 5.8: Error Schrodinger - Diagonalizacion
5.4. Schrodinger
En las siguientes figuras se muestran los resultados de las primeras diez soluciones de ladiagonalizacion paralela del problema de Schrodinger.
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−0.05
−0.04
−0.03
−0.02
−0.01
0
0.01
0.02
0.03
0.04
0.05
x
Ψ(x)
Figura 5.4: Soluciones pares Schrodinger - Diagonalizacion
Cinvestav Departamento de Computacion

60 Capıtulo 5
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−0.05
−0.04
−0.03
−0.02
−0.01
0
0.01
0.02
0.03
0.04
0.05
x
Ψ(x)
Figura 5.5: Soluciones impares Schrodinger - Diagonalizacion
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−0.05
−0.04
−0.03
−0.02
−0.01
0
0.01
0.02
0.03
0.04
0.05
x
Ψ(x)
Figura 5.6: Soluciones Schrodinger - Diagonalizacion
Cinvestav Departamento de Computacion

Pruebas, resultados y discusion 61
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−0.25
−0.2
−0.15
−0.1
−0.05
0
0.05
0.1
0.15
0.2
x
Ψ(x)
Figura 5.7: Suma soluciones Schrodinger - Diagonalizacion
A continuacion, se presentan las diez primeras soluciones del metodo de disparo paralelopara el problema de Schrodinger con y = 0, z = 1. A partir de aquı y en lo que resta de estecapitulo y = Ψ0 y z = Ψ′0, es decir los valores de la funcion y la derivada de Ψ en el puntoinicial del metodo de disparo.
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−1
−0.5
0
0.5
1
1.5
2
x
Ψ(x)
Figura 5.8: Soluciones pares Schrodinger - Disparo (y = 0, z = 1)
Cinvestav Departamento de Computacion
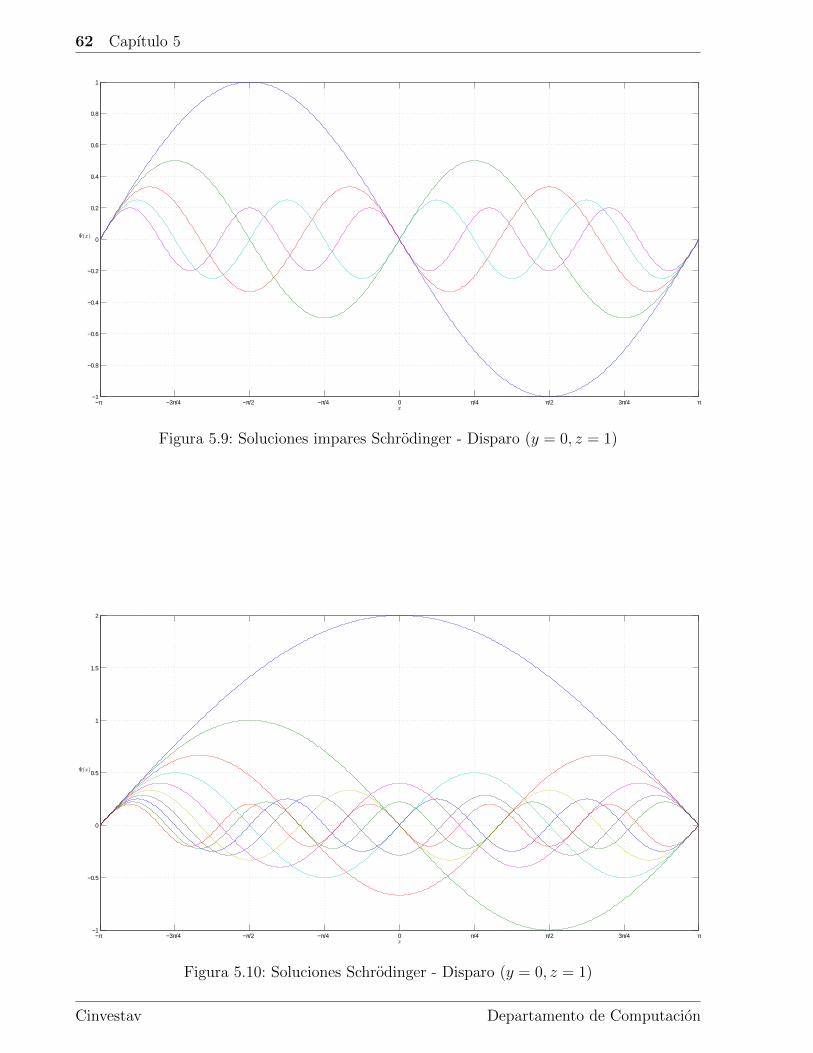
62 Capıtulo 5
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
Ψ(x)
Figura 5.9: Soluciones impares Schrodinger - Disparo (y = 0, z = 1)
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−1
−0.5
0
0.5
1
1.5
2
x
Ψ(x)
Figura 5.10: Soluciones Schrodinger - Disparo (y = 0, z = 1)
Cinvestav Departamento de Computacion
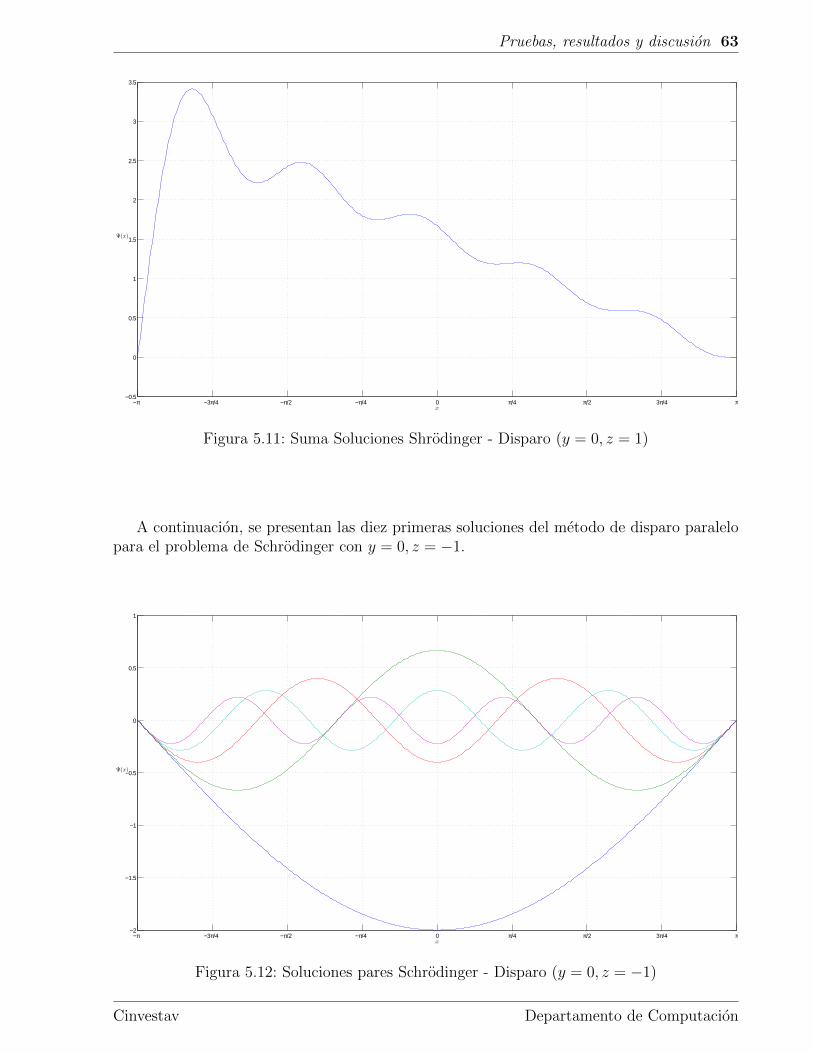
Pruebas, resultados y discusion 63
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−0.5
0
0.5
1
1.5
2
2.5
3
3.5
x
Ψ(x)
Figura 5.11: Suma Soluciones Shrodinger - Disparo (y = 0, z = 1)
A continuacion, se presentan las diez primeras soluciones del metodo de disparo paralelopara el problema de Schrodinger con y = 0, z = −1.
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−2
−1.5
−1
−0.5
0
0.5
1
x
Ψ(x)
Figura 5.12: Soluciones pares Schrodinger - Disparo (y = 0, z = −1)
Cinvestav Departamento de Computacion

64 Capıtulo 5
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
Ψ(x)
Figura 5.13: Soluciones impares Schrodinger - Disparo (y = 0, z = −1)
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−2
−1.5
−1
−0.5
0
0.5
1
x
Ψ(x)
Figura 5.14: Soluciones Schrodinger - Disparo (y = 0, z = −1)
Cinvestav Departamento de Computacion
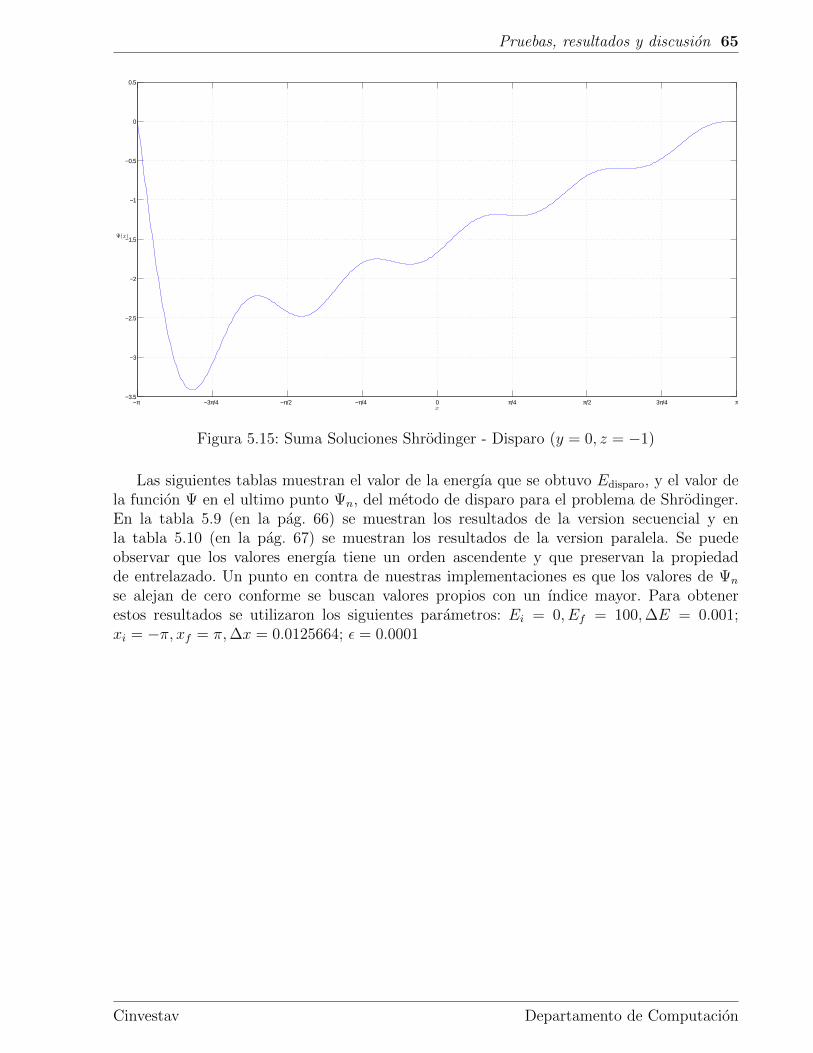
Pruebas, resultados y discusion 65
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−3.5
−3
−2.5
−2
−1.5
−1
−0.5
0
0.5
x
Ψ(x)
Figura 5.15: Suma Soluciones Shrodinger - Disparo (y = 0, z = −1)
Las siguientes tablas muestran el valor de la energıa que se obtuvo Edisparo, y el valor dela funcion Ψ en el ultimo punto Ψn, del metodo de disparo para el problema de Shrodinger.En la tabla 5.9 (en la pag. 66) se muestran los resultados de la version secuencial y enla tabla 5.10 (en la pag. 67) se muestran los resultados de la version paralela. Se puedeobservar que los valores energıa tiene un orden ascendente y que preservan la propiedadde entrelazado. Un punto en contra de nuestras implementaciones es que los valores de Ψn
se alejan de cero conforme se buscan valores propios con un ındice mayor. Para obtenerestos resultados se utilizaron los siguientes parametros: Ei = 0, Ef = 100,∆E = 0.001;xi = −π, xf = π,∆x = 0.0125664; ε = 0.0001
Cinvestav Departamento de Computacion

66 Capıtulo 5
i Ψn Edisparo
0 8.160331000E-11 2.500000000E-011 -1.305607000E-09 1.000000000E+002 6.609377000E-09 2.250000000E+003 -2.088649000E-08 4.000000000E+004 5.098509000E-08 6.250000000E+005 -1.057066000E-07 9.000000000E+006 1.957992000E-07 1.225000000E+017 -3.339542000E-07 1.600000000E+018 5.348004000E-07 2.025000000E+019 -8.149011000E-07 2.500000000E+0110 1.192743000E-06 3.025000000E+0111 -1.689942000E-06 3.600000000E+0112 2.326054000E-06 4.225000000E+0113 -3.126939000E-06 4.900000000E+0114 4.118656000E-06 5.625000000E+0115 1.921388000E-05 6.400050000E+0116 6.788868000E-06 7.225000000E+0117 -8.528146000E-06 8.100000000E+0118 -6.823048000E-06 9.025050000E+0119 2.723776000E-06 1.000005000E+0220 -1.272159000E-05 1.102510000E+0221 -6.005330000E-06 1.210005000E+0222 -1.087153000E-06 1.322510000E+0223 -5.039522000E-06 1.440010000E+0224 1.438843000E-06 1.562515000E+0225 2.397536000E-07 1.690020000E+0226 -1.686318000E-07 1.822525000E+0227 -1.522974000E-06 1.960030000E+0228 -2.729682000E-06 2.102540000E+0229 -2.435475000E-06 2.250045000E+0230 -4.105856000E-06 2.402560000E+0231 1.558231000E-06 2.560070000E+0232 2.988212000E-06 2.722580000E+0233 1.414212000E-06 2.890100000E+0234 2.392683000E-06 3.062615000E+0235 1.161219000E-06 3.240140000E+0236 -1.436178000E-06 3.422665000E+0237 -1.383529000E-06 3.610190000E+0238 -1.105241000E-06 3.802725000E+0239 -4.966827000E-08 4.000260000E+0240 9.331154000E-07 4.202800000E+0241 -1.924546000E-06 4.410345000E+0242 -3.346333000E-08 4.622900000E+0243 9.443011000E-07 4.840460000E+02
Tabla 5.9: Solucion Schrodinger (y = 0, z = 1) - Disparo secuencial
Cinvestav Departamento de Computacion

Pruebas, resultados y discusion 67
i Ψn Edisparo
0 8.160573000E-11 2.500000000E-011 -1.305610000E-09 1.000000000E+002 6.609186000E-09 2.250000000E+003 -2.088623000E-08 4.000000000E+004 5.098530000E-08 6.250000000E+005 -1.057067000E-07 9.000000000E+006 1.957988000E-07 1.225000000E+017 -3.339535000E-07 1.600000000E+018 5.348006000E-07 2.025000000E+019 -8.149020000E-07 2.500000000E+0110 1.192744000E-06 3.025000000E+0111 -1.689943000E-06 3.600000000E+0112 2.326054000E-06 4.225000000E+0113 -3.126937000E-06 4.900000000E+0114 4.118654000E-06 5.625000000E+0115 1.921389000E-05 6.400050000E+0116 6.788867000E-06 7.225000000E+0117 -8.528146000E-06 8.100000000E+0118 -6.823045000E-06 9.025050000E+0119 2.723772000E-06 1.000005000E+0220 -1.272158000E-05 1.102510000E+0221 -6.005335000E-06 1.210005000E+0222 -1.087147000E-06 1.322510000E+0223 -5.039529000E-06 1.440010000E+0224 1.438850000E-06 1.562515000E+0225 2.397454000E-07 1.690020000E+0226 -1.686231000E-07 1.822525000E+0227 -1.522983000E-06 1.960030000E+0228 -2.729672000E-06 2.102540000E+0229 -2.435485000E-06 2.250045000E+0230 -4.105846000E-06 2.402560000E+0231 1.558220000E-06 2.560070000E+0232 2.988218000E-06 2.722580000E+0233 1.414211000E-06 2.890100000E+0234 2.392679000E-06 3.062615000E+0235 1.161226000E-06 3.240140000E+0236 -1.436188000E-06 3.422665000E+0237 -1.383515000E-06 3.610190000E+0238 -1.105258000E-06 3.802725000E+0239 -4.964828000E-08 4.000260000E+0240 9.330928000E-07 4.202800000E+0241 -1.924521000E-06 4.410345000E+0242 -3.349060000E-08 4.622900000E+0243 9.443304000E-07 4.840460000E+02
Tabla 5.10: Solucion Schrodinger (y = 0, z = 1) - Disparo paralelo
Cinvestav Departamento de Computacion

68 Capıtulo 5
5.5. Dirac
A continuacion, se presentan las diez primeras soluciones del metodo de disparo paralelopara el problema de Dirac con y = 0, z = 1.
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
Ψ(x)
Figura 5.16: Soluciones pares Dirac - Disparo (y = 0, z = 1)
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
Ψ(x)
Figura 5.17: Soluciones impares Dirac - Disparo (y = 0, z = 1)
Cinvestav Departamento de Computacion

Pruebas, resultados y discusion 69
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
Ψ(x)
Figura 5.18: Soluciones Dirac - Disparo (y = 0, z = 1)
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−2
−1
0
1
2
3
4
5
6
x
Ψ(x)
Figura 5.19: Suma Soluciones Dirac - Disparo (y = 0, z = 1)
A continuacion, se presentan las diez primeras soluciones del metodo de disparo paralelopara el problema de Dirac con y = 0, z = −1.
Cinvestav Departamento de Computacion

70 Capıtulo 5
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
Ψ(x)
Figura 5.20: Soluciones pares Dirac - Disparo (y = 0, z = −1)
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
Ψ(x)
Figura 5.21: Soluciones impares Dirac - Disparo (y = 0, z = −1)
Cinvestav Departamento de Computacion

Pruebas, resultados y discusion 71
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−1
−0.8
−0.6
−0.4
−0.2
0
0.2
0.4
0.6
0.8
1
x
Ψ(x)
Figura 5.22: Soluciones Dirac - Disparo (y = 0, z = −1)
−π −3π/4 −π/2 −π/4 0 π/4 π/2 3π/4 π−6
−5
−4
−3
−2
−1
0
1
2
x
Ψ(x)
Figura 5.23: Suma Soluciones Dirac - Disparo (y = 0, z = −1)
La tabla 5.11 (en la pag. 72) muestra el valor de la energıa que se obtuvo Edisparo, yel valor de la funcion Ψ en el ultimo punto Ψn, del metodo de disparo para el problemade Dirac. Otra vez, se respeta la propiedad de entrelazado, pero los valores de Ψn se vanalejando de cero conforme se buscan valores propios con un ındice mayor. Para obtenerestos resultados se utilizaron los siguientes parametros: Ei = 0, Ef = 20,∆E = 0.0001;xi = −π, xf = π,∆x = 0.012566; ε = 0.001
Cinvestav Departamento de Computacion

72 Capıtulo 5
i Ψn Edisparo
0 3.574388000E-05 1.078700000E+001 4.979779000E-05 1.414200000E+002 9.861971000E-05 1.802800000E+003 7.784952000E-05 2.236050000E+004 8.084182000E-05 2.692600000E+005 1.318840000E-04 3.162250000E+006 -2.442342000E-05 3.640050000E+007 -2.238969000E-04 4.123150000E+008 -1.160660000E-04 4.609750000E+009 -1.575235000E-04 5.099050000E+0010 -1.109656000E-04 5.590150000E+0011 7.530727000E-05 6.082750000E+0012 -1.386229000E-04 6.576450000E+0013 1.159656000E-04 7.071050000E+0014 -1.533971000E-04 7.566350000E+0015 7.970880000E-05 8.062250000E+0016 1.110008000E-04 8.558650000E+0017 -1.680925000E-05 9.055400000E+0018 -1.270847000E-05 9.552500000E+0019 -2.339856000E-05 1.004990000E+0120 7.172086000E-05 1.054755000E+0121 -3.563066000E-05 1.104540000E+0122 7.289701000E-05 1.154345000E+0123 -2.692072000E-05 1.204165000E+0124 8.623182000E-06 1.254000000E+0125 -1.129107000E-04 1.303850000E+0126 1.288694000E-04 1.353710000E+0127 -1.248394000E-04 1.403580000E+0128 1.600655000E-04 1.453460000E+0129 8.421215000E-06 1.503345000E+0130 -4.231477000E-05 1.553240000E+0131 -9.781499000E-05 1.603145000E+0132 -1.457496000E-04 1.653050000E+0133 -1.442867000E-04 1.702970000E+0134 1.048962000E-04 1.752890000E+0135 -5.451473000E-05 1.802815000E+0136 1.273540000E-05 1.852745000E+0137 3.242446000E-06 1.902680000E+0138 2.165363000E-05 1.952620000E+01
Tabla 5.11: Solucion Dirac (y = 0, z = 1) - Disparo paralelo
Cinvestav Departamento de Computacion

Pruebas, resultados y discusion 73
5.6. Discusion
A lo largo de las pruebas realizadas durante esta tesis observamos que la implementacionparalela hıbrida obtuvo una mejora en tiempo respecto de MAGMA, sobre todo en la ver-sion paralela. Esta mejora en el tiempo de ejecucion no solo significa que pueden tratarseproblemas con mayor tamano en un menor tiempo, si no que tambien, en el caso de la im-plementacion hıbrida, es posible pasar la barrera del tamano de la matriz, impuesta por lacantidad de memoria de la GPU, utilizando varios nodos con multiples tarjetas y paso demensajes. Aunque se presentan resultados hasta un tamano de 18000 nuestra implementa-cion puede potencialmente resolver una matriz de 46000. En cuanto al metodo de disparo,tambien se obtuvo una mejora significativa en el tiempo de la version paralela respecto a lasecuencial. Sin embargo, no utiliza multiples nodos, porque para resolver los casos de estudiode esta tesis no se requiere memoria extra, esto no descarta la posibilidad de que existanproblemas que si la necesiten.
Una vez obtenido una mejora en los tiempos de ejecucion, la siguiente pregunta natural es¿que tan buenos son los resultados obtenidos con estos tiempos? Se debe destacar que en elmetodo de diagonalizacion nuestros resultados presentan una gran calidad en los eigenparesy en la ortogonalidad de los vectores propios. Siendo competitivos con los resultados de lasbibliotecas actuales como MAGMA y MKL. Pero es notorio que, en el metodo de disparo, sedebe realizar una investigacion mas extensa para obtener mejores resultados, ya que el errorse incrementa muy rapidamente conforme aumenta el ındice de los valores propios.
Tambien se debe mencionar que los resultados obtenidos muestran que se puede aplicarcon exito la diagonalizacion heterogenea a casos especıficos del problema regular de valorespropios de Sturm-Liouville, ya que, se compararon los resultados que obtuvimos con los dela solucion analıtica, cuando esta se conocıa, obteniendo errores muy pequenos.
Cinvestav Departamento de Computacion

74 Capıtulo 5
Cinvestav Departamento de Computacion

Capıtulo 6
Conclusiones y trabajo a futuro
En este capıtulo, en la seccion 6.1 se presentan las principales conclusiones y contribu-ciones de esta tesis, y en la seccion 6.2 (en la pag 76) se discuten algunos aspectos que nosgustarıa abordar en una investigacion futura.
6.1. Conclusiones
En este trabajo se implemento el algoritmo para diagonalizar matrices simetricas tridia-gonales conocido como algoritmo divide y venceras, de forma paralela hıbrida en multiplesnodos, utilizando tanto GPUs como CPUs. Esta implementacion resuelve el problema de larestriccion del tamano de la matriz que se puede utilizar con respecto a la cantidad de memo-ria que posee una GPU. Como mencionamos anteriormente, esta cantidad es muy pequenaen comparacion con la cantidad de memoria a la que puede acceder un CPU.
Utilizar el algoritmo de Cuppen en multiples nodos redujo el tiempo de computo de ladiagonalizacion de matrices simetricas tridiagonales con respecto tanto a la implementacionsecuencial que presentamos en este trabajo, como a la implementacion secuencial y paralelade bibliotecas actuales.
Las pruebas realizadas mostraron que las soluciones obtenidas por la implementacionparalela heterogenea tienen un alto grado de exactitud con respecto a la ortogonalidad devectores propios y la calidad de eigenpares.
Para conseguir una buena implementacion es importante considerar donde es mas apro-piado ejecutar cada fase del algoritmo, en el CPU, la GPU, o ambos, teniendo en cuentael tamano del problema y la granularidad de la tarea a realizarse. Otro factor relevante es,mantener al mınimo la comunicacion entre los nodos y realizar los calculos sobre estructurasde datos que ocupen la menor cantidad de memoria posible.
Utilizar la implementacion paralela heterogenea para resolver problemas regulares de va-lores propios de Sturm-Liouville es factible, esto fue verificado con un caso de estudio en elque se conoce la solucion analıtica.
Crear versiones paralelas de las rutinas que calculan el error en las soluciones obtenidas
75

76 Capıtulo 6
representa un gran beneficio ya que se puede avanzar en realizar nuevas versiones al detec-tar problemas de forma mas rapida. Las funciones de error que utilizamos en este trabajoson altamente paralelas y nos permitieron calcular los errores hasta diez veces mas rapidoahorrandonos dıas de trabajo.
La version paralela del metodo de disparo mejoro el tiempo con respecto a su versionsecuencial y fue aplicada tanto a un problema del que se conocıa su solucion analıtica comoa uno del que no. Sin embargo, la calidad de las soluciones obtenidas disminuye conforme sebuscan valores propios con un mayor ındice.
Las principales contribuciones de esta tesis son:
Implementacion paralela heterogenea (GPUs + CPUs) escalable del algoritmo dividey venceras para diagonalizar matrices tridiagonales simetricas. La primera de la quetenemos conocimiento.
Mayor escalabilidad en la implementacion del algoritmo divide y venceras y aumentoen la independencia de la cantidad de memoria de la GPU.
Mejora del tiempo de computo de la diagonalizacion de matrices tridiagonales simetri-cas.
Muestra del beneficio de utilizar multiples nodos tanto con GPUs como con CPUs enel problema de valores propios de matrices tridiagonales simetricas.
Implementacion paralela del metodo de disparo para el problema del pozo infinito deSchrodinger y Dirac, la cual puede extenderse con pocos cambios a otros casos.
Mejora del tiempo de computo del metodo de disparo.
Aplicacion exitosa de la implementacion paralela heterogenea del algoritmo divide yvenceras a un problema regular de valores propios de Sturm-Liouville. Para el problemadel pozo infinito de Schrodinger obtuvimos soluciones muy cercanas a las analıticas.
Se sabe que los solucionadores de valores propios de matrices tridiagonales simetricasson bloques constructores para resolver problemas mas generales, tales como, valores propiosgenerales. El enfoque divide y venceras, ademas, puede ser aplicado a solucionadores devalores singulares. La importancia de este trabajo recae en la gran cantidad de problemas devalores propios que surgen en aplicaciones cientıficas y de ingenierıa. Por lo tanto, nuestrotrabajo potencialmente puede llevar a nuevos descubrimientos cientıficos.
6.2. Trabajo futuro
Ciertamente, queda mucho trabajo por hacer. Quiza la extension mas importante serıatratar matrices densas simetricas. Para lograr esto, primeramente, se debe implementar unalgoritmo de tridiagonalizacion, por ejemplo, el metodo de Householder, lo ideal serıa im-plementar un version que utilice multiples nodos. Aunque durante esta tesis se desarrolloel marco principal de trabajo para la diagonaliacion de matrices tridiagonales simetricas, se
Cinvestav Departamento de Computacion

Conclusiones y trabajo a futuro 77
debe extender la implementacion de forma que utilice un numero arbitrario de nodos redu-ciendo al maximo la comunicacion entre ellos. Posiblemente, una forma de lograrlo es usaruna estructura de arbol binario. Otro punto de interes es utilizar otros metodos para resol-ver la ecuacion secular, con el fin de obtener mejores soluciones y ver que tanto afectan eltiempo total de computo. En cuanto al metodo de disparo, evidentemente, se debe realizaruna investigacion mas extensa para obtener mejores resultados, ya que el error se incrementamuy rapidamente conforme aumenta el ındice de los valores propios.
Tambien, como trabajo a futuro se pueden realizar pruebas adicionales con la implemen-tacion actual, por ejemplo: resolver otros problemas de Sturm-Liouville que se presentan enel mundo real, hacer comparaciones con otras bibliotecas actuales como CULA, y medir elconsumo energetico de cada implementacion.
En general, se pueden realizar mejoras a las implementaciones desarrolladas en este tra-bajo utilizando caracterısticas de CUDA como streams, memoria compartida y memoria uni-ficada. Ademas, serıa particularmente benefico utilizar el paralelismo dinamico de las nuevasversiones de CUDA en el metodo de disparo. Las tecnologıas que mas nos permitirıan reducirlos tiempos de computo son aquellas que transfieren datos directamente de una GPU a otra,como son, MVAPICH2-GDR 2.0 y OpenMPI 1.8.3, que utilizan GPUDirect.
Cinvestav Departamento de Computacion

78 Capıtulo 6
Cinvestav Departamento de Computacion

Bibliografıa
[1] Werner O. Amrein, Andreas M. Hinz, and David P. Pearson. Sturm-Liouville theory:past and present. Springer, Germany, 1st edition, 2005.
[2] E. Anderson, Z. Bai, C. Bischof, S. Blackford, J. Demmel, J. Dongarra, J. Du Croz,A. Greenbaum, S. Hammarling, A. McKenney, and D. Sorensen. LAPACK Users’ Guide.Society for Industrial and Applied Mathematics, Philadelphia, PA, 3rd edition, 1999.
[3] Innovative Computing Laboratory (ICL) Team. Matrix Algebra on GPU and MulticoreArchitectures (MAGMA) library, version 1.5.0. Web site: http://icl.cs.utk.edu/
magma/ [Last accessed: 31 November 2014].
[4] William H. Press, Saul A. Teukolsky, William T. Vetterling, and Brian P. Flannery.Numerical Recipes in C: The Art of Scientific Computing. Cambridge University Press,New York, NY, USA, 2nd edition, 1992.
[5] Christof Vomel, Stanimire Tomov, and Jack Dongarra. Divide and conquer on hybridGPU-accelerated multicore systems. SIAM Journal on Scientific Computing, 34(2):70–82, April 2012.
[6] James W. Demmel. Applied Numerical Linear Algebra. Society for Industrial and Ap-plied Mathematics, Philadelphia, PA, USA, 1st edition, 1997.
[7] Ren-Cang Li. Solving secular equations stably and efficiently. Technical ReportUCB/CSD-94-851, EECS Department, University of California, Berkeley, Berkeley, CA,USA, Dec 1994.
[8] Ming Gu and Stanley C. Eisenstat. A stable and efficient algorithm for the rank-onemodification of the symmetric eigenproblem. SIAM Journal on Matrix Analysis andApplications, 15(4):1266–1276, October 1994.
[9] J.J.M. Cuppen. A divide and conquer method for the symmetric tridiagonal eigenpro-blem. Numerische Mathematik, 36(2):177–195, March 1980.
[10] Azzam Haidar, Mark Gates, Stan Tomov, and Jack Dongarra. Toward a scalable multi-gpu eigensolver via compute-intensive kernels and efficient communication. In Allen DMalony, Mario Nemirovsky, and Sam Midkiff, editors, Proceedings of the 27th Interna-tional ACM Conference on International Conference on Supercomputing, ICS ’13, pages223–232, Eugene, Oregon, USA, 10–12 June 2013. ACM.
[11] Boris Moiseevich Levitan and Ischan S Sargsjan. Sturm—Liouville and Dirac Operators.Springer, 1991.
79

80
[12] Ravi P. Agarwal and Donal O’Regan. Ordinary and partial differential equations: withspecial functions, Fourier series, and boundary value problems. Springer, USA, 1st edi-tion, 2009.
[13] Mohammed Al-Gwaiz. Sturm-Liouville theory and its applications. Springer, 2007.
[14] Erwin Schrodinger. Quantisierung als eigenwertproblem. Annalen der physik,385(13):437–490, 1926.
[15] Amilcar Meneses Viveros. Simulacion de paquetes de onda y teorıa de Weyl. PhD thesis,Computer Science Department, CINVESTAV-IPN, 2009.
[16] Paul AM Dirac. The quantum theory of the electron. Proceedings of the Royal Society ofLondon. Series A, Containing Papers of a Mathematical and Physical Character, pages610–624, 1928.
[17] B. Kolman, D.R. Hill, and V.H.I. Mercado. Introductory Linear Algebra. Pearson Edu-cation, 2008.
[18] J.H. Wilkinson. The Algebraic Eigenvalue Problem. Monographs on numerical analysis.Clarendon Press, 1988.
[19] Gene H Golub and Charles F Van Loan. Matrix computations. JHU Press, 4th edition,2012.
[20] Susan Morgan. Making sense of parallel programming terms. In Solaris Studiodocumentation. Web site: http://www.oracle.com/technetwork/server-storage/
solarisstudio/documentation/parallel-terminology-362819.html [Last acces-sed: 31 November 2014].
[21] Blaise Barney. Introduction to Parallel Computing (Tutorial). Web site: https://
computing.llnl.gov/tutorials/parallel_comp [Last accessed: 31 November 2014].
[22] AMD. What is Heterogeneous Computing? Web site: http://developer.amd.com/resources/heterogeneous-computing/what-is-heterogeneous-computing/ [Lastaccessed: 31 November 2014].
[23] Nvidia. What is CUDA? Web site: http://www.nvidia.com/object/cuda_home_new.html [Last accessed: 31 November 2014].
[24] Shane Cook. CUDA programming: a developer’s guide to parallel computing with GPUs.Newnes, 2013.
[25] David B Kirk and W Hwu Wen-mei. Programming massively parallel processors: ahands-on approach. Newnes, 2012.
[26] Jason Sanders and Edward Kandrot. CUDA by example: an introduction to general-purpose GPU programming. Addison-Wesley Professional, 2010.
[27] Nicholas Wilt. The CUDA handbook: A comprehensive guide to GPU programming.Pearson Education, 2013.
Cinvestav Departamento de Computacion

Bibliografıa 81
[28] OpenMP Architecture Review Board. What is OpenMP? Web site: http://openmp.org/openmp-faq.html [Last accessed: 31 November 2014].
[29] Barbara Chapman, Gabriele Jost, and Ruud Van Der Pas. Using OpenMP: portableshared memory parallel programming. MIT press, 2008.
[30] Message Passing Interface Forum. MPI: A Message-Passing Interface Standard Version3.0. Web site: http://www.mpi-forum.org/docs/mpi-3.0/mpi30-report.pdf [Lastaccessed: 31 November 2014].
[31] William Gropp, Ewing Lusk, and Anthony Skjellum. Using MPI: portable parallel pro-gramming with the message-passing interface, volume 1. 1999.
[32] Peter Arbenz. Chapter 4 The Cuppen’s divide and conquer algorithm. In Lecture noteson solving large scale eigenvalue problems. Web site: http://people.inf.ethz.ch/arbenz/ewp/Lnotes/chapter4.pdf [Last accessed: 31 November 2014].
[33] StataCorp. Permutation. In Stata 13 Base Reference Manual. Web site: http://www.stata.com/manuals13/m-1permutation.pdf [Last accessed: 31 November 2014].
Cinvestav Departamento de Computacion





























