Unicode Normalization Mark Davis www.macchiato.com Slide 2
Normalization Uniqueness two equivalent strings have precisely the
same normalized form Fast binary comparison, accurate digital
signatures Recommended for XML, JavaScript and other standards
Slide 3 Canonical Equivalence Fundamental equivalence
Indistinguishable to users, when correctly rendered Includes
Combining sequences Hangul Singletons C Slide 4 Compatibility
Equivalence Formatting differences Font variants ( ) Breaking
differences (-) Cursive forms ( ) Circled ( ) Width, size, rotated
( ) Super/subscripts ( ) Squared characters ( ) Fractions ( )
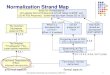
Others ( ) fi kg Slide 5 UTR #15: Unicode Normalization Forms Form
DCanonical Decomposition Form KDCompatibility Decomposition Form C
Form D + Canonical Composition Form KC Form KD + Canonical
Composition Slide 6 Normalization Requirement Uniqueness: two
equivalent strings will have precisely the same normalized form If
two strings x and y are canonical equivalents, then C(x) = C(y)
D(x) = D(y) If two strings are compatibility equivalents, then
KC(x) = KC(y) KD(x) = KD(y) Slide 7 Affected Characters None of the
forms affect text with only ASCII characters (U+0000 to U+007F)
None of the forms generate compability characters that were not in
the source text. Both KD and KC replace compatibility characters.
Both D and C maintain compatibility characters. Slide 8 Cautions:
Decomposition Requires decomposition mappings from the Unicode
Character Database Those decomposition mappings must be applied
recursively The string must be put into canonical order Either
Canonical or Compatibility Slide 9 Cautions: Composition
Decomposition required first! Then canonical composition
Composition data: fixed at Unicode 3.0.0 Some characters are
excluded from composition Form C and Form KC can still have
combining characters! Required for Indic, Arabic, Hebrew, &c.
Slide 10 Caution: Both C & D All normalization forms are not
closed under string concatenation. Example: NFC/D "a " + " " Not
Norm. "a " NFC " " NFD "a " Exceptions easy to test for Slide 11
Composition Process 1. Decompose (D or KD) 2. Combine unblocked
characters with the previous starter, if possible* Slide 12
Composition Exclusions Script Specifics + Futures: G + G
Singletons* Non-starter sequences* + Slide 13 Legacy Encoding
Legacy text is normalized if it maps 1:1 to normalized Unicode text
Legacy sets: Prenormalized: e.g. ISO 8859-1 Normalizable: e.g. ISO
2022 (ISO 5426/ISO 8859-1/) Unnormalizable: e.g. ISO 5426 Slide 14
Programming Identifiers Closed under all Normalization Forms, if
minor changes incorporated Modified syntax: identifier := start (
start | extend )* start := [{Lu}{Ll}{Lt}{Lm}{Lo}{Nl}] - irregulars
combining_like extend := [{Mn}{Mc}{Nd}{Pc}{Cf}] - irregulars +
combining_like + mid_dot (Almost) closed under Case Mappings see
SpecialCasing.txt Slide 15 Resources Reference version on Unicode
Site Production Version http://oss.software.ibm.com/icu ICU: C/C++
and Java Versions Open Source, with IBM Public License Free
commercial use and distribution: Not Viral! Panel Later today Other
companies also providing: ask! Slide 16 Normalization Uniqueness:
two equivalent strings have precisely the same normalized form Fast
binary comparison, accurate digital signatures Recommended for XML,
JavaScript and other standards Slide 17 Q & A Slide 18 Backup
Slides Slide 19 Definition: Starter S is a starter = Canonical
class of zero in the Unicode Character Database Can start a
composition Examples: Starters: Spacing marks, some non-spacing a,
Non-starters: most non-spacing marks , Slide 20 Definition: Blocked
C is blocked from S There is some character B between S and C, and
either B is a starter or B has the same canonical class as C
Examples ABC B blocks C from A A blocks from A A doesnt block from
A Slide 21 Testing Conformance: Canonical For all Unicode
characters X C(X) = C(D(X) D(X), C(X) in canonical order CDMNo CDM
X = D(X) X = C(X) X D(X) No characters in D(X) have CDM X
Exclusions X C(D(X)X = C(D(X) Slide 22 Unicode Normalization
Introduction Normalization forms Design goals Specification
Excluded characters Versions Legacy encodings Applications Slide 23
Characters and Encoding Forms A C5 AbstractEncoded 212B F0000 6130A
Serialized 00 212B DB80DC00 61030A C5 UTF-16BE UTF-8 C3 E284 F3B080
61CC8A 85 AB