Embed Size (px)
Citation preview

UNDER REVIEW 1
A Reinforcement Learning Approach forTransient Control of Liquid Rocket Engines
Gunther Waxenegger-Wilfing∗, Kai Dresia∗, Jan Deeken, and Michael Oschwald
Abstract— Nowadays, liquid rocket engines use closed-loop control at most near steady operating conditions. Thecontrol of the transient phases is traditionally performedin open-loop due to highly nonlinear system dynamics.This situation is unsatisfactory, in particular for reusableengines. The open-loop control system cannot provide op-timal engine performance due to external disturbances orthe degeneration of engine components over time. In thispaper, we study a deep reinforcement learning approachfor optimal control of a generic gas-generator engine’s con-tinuous start-up phase. It is shown that the learned policycan reach different steady-state operating points and con-vincingly adapt to changing system parameters. A quantita-tive comparison with carefully tuned open-loop sequencesand PID controllers is included. The deep reinforcementlearning controller achieves the highest performance andrequires only minimal computational effort to calculate thecontrol action, which is a big advantage over approachesthat require online optimization, such as model predictivecontrol.
Index Terms— Liquid rocket engines, intelligent control,reinforcement learning, simulation-based optimization
I. INTRODUCTION
THE demands on the control system of liquid rocketengines have significantly increased in recent years [1], in
particular for reusable engines. Advanced mission scenarios,e.g. in-orbit maneuvers or propulsive landings, require deepthrottling and re-start capabilities. The aging of reusable en-gines also requires a robust control system as the performanceof engine components might degrade over time, e.g. due tosoot depositions [2]–[4], increased leakage mass flows causedby seal aging [5], or turbine blade erosions [6]. The cost-efficient operation of a reusable launch vehicle is only possibleif the engines possess a long service life without expensivemaintenance.
Nowadays, most liquid rocket engines use predefined valvesequences to drive the system from the start signal to a desiredsteady-state and to shut down the engine safely. These control
∗ Both authors contributed equally to this work.The authors are with the Department of Rocket Propulsion, German
Aerospace Center (DLR) Institute of Space Propulsion, Hardthausenam Kocher, Germany (e-mail: [email protected],[email protected], [email protected], [email protected]).
©2020 IEEE. Personal use of this material is permitted. Permissionfrom IEEE must be obtained for all other uses, in any current or futuremedia, including reprinting/republishing this material for advertising orpromotional purposes, creating new collective works, for resale orredistribution to servers or lists, or reuse of any copyrighted componentof this work in other works.
sequences are usually determined during costly ground tests.Closed-loop control is at most used near steady operatingconditions to maintain a desired combustion chamber pressureand mixture ratio [7]. The resulting lower deviations of thecontrolled variables decrease the amount of extra propellantto be carried, which in turn increases the payload capacityof the launch vehicle. Although the importance of closed-loopcontrol has been evident for many years, the majority of rocketengines still employ valves which are operated with pneumaticactuators, too inefficient for a sophisticated closed-loop controlsystem. The development of an all-electric control systemstarted in the late 90s in Europe [8]. The future EuropeanPrometheus engine will have such a system [9]. Other coun-tries are also well advanced in the research and developmentof electrically operated flow control valves [10]. Due to theelectrification of the actuators and the grown demands, theinterest in closed-loop solutions increased recently and willfurther rise in the future.
Furthermore, optimal control of the engine operation, in-cluding the transient phases, is the only way to realize highperforming systems, which also comply with the aforemen-tioned demands on the control system of future liquid rocketengines [11]. One way to solve optimal control problems isto use reinforcement learning (RL). Although the applicationof such modern methods of artificial intelligence seems un-orthodox in this setting, it offers certain advantages. First,given a suitable simulation environment, RL algorithms canautomatically generate optimal transient sequences. Second,the trained RL controller features a minimal computationaleffort to calculate the control action, so it can easily be used forclosed-loop control of the demanding transient phases. Third,RL is perfectly suited for complex control tasks, includingmultiple objectives and multiple regimes [12]. Optimal controlusing RL [13] has been studied in many different areas,from robotics [14], [15] and medical science [16] to flightcontrol [17], [18] and process control [19]. Furthermore, thebenefits of an intelligent engine control system, where artificialintelligence techniques are used for control reconfiguration andcondition monitoring, have already been investigated in thespace shuttle area [20], [21].
The objective of our work is analogous to the investigationof Perez-Roca et al. [22], where a model predictive control(MPC) approach to control the start-up transient of a liquidrocket engine was studied. After the derivation of a suitablestate-space model [23], a linear MPC controller was synthe-sized. The controller completes the start-up and can track
arX
iv:2
006.
1110
8v1
[cs
.LG
] 1
9 Ju
n 20
20

2 UNDER REVIEW
the end-state references with sufficient accuracy. MPC andRL have specific advantages and disadvantages. The workpresented here aims to evaluate the capabilities and limitationsof RL for liquid rocket engine control.Our main contributions are the following:• formulation of optimal start-up control as a RL problem• training and evaluation of the RL controller for multiple
operating conditions and degrading turbine efficiencies• quantitative comparison with carefully tuned open-loop
sequences and PID controllersThe remainder of this paper is structured as follows: SectionII describes the basics of RL and presents pseudocode ofthe used RL algorithm. The simulation environment and itscoupling with the RL algorithms are outlined in section III.Section IV discusses the test case. Section V reports theresults, including the comparison with the performance of PIDcontrollers. Finally, section VI provides concluding remarks.
II. REINFORCEMENT LEARNING
In this section, we review basic RL concepts [24]. RLalgorithms can be used to solve optimal control problemsstated as Markov decision processes (MDPs) [25]. MDPsprovide a mathematical framework for modeling decisionmaking in situations where the system changes possibly ina stochastic manner. Standard MDPs work in discrete time:at each time step, the controller (usually called the agent inRL) receives information on the state of the system and takesan action in response. The decision rule is called a policyin RL. The action changes the state of the system, and thelatest transition is evaluated via a reward function. The optimalcontrol objective is to maximize the (expected) cumulativereward from each initial state. Formally, an MDP consists ofthe state-space X of the system, the action (input) space U ,the transition function (dynamics) f of the system, and thereward function ρ (negative costs). Due to the origins of thefield in artificial intelligence, the usual notation would be Sfor the state-space, A for the action space, P for the dynamics,and R for the reward function. In this paper, notation inspiredby control theory is used. As a result of the action uk appliedin state xk at discrete time step k, the state changes to xk+1
and a scalar reward rk+1 = ρ(xk, uk, xk+1) is received. Thegoal is to find a policy π, so that uk = π(xk), that maximizesthe cumulative reward, typically the expected discounted sumover the infinite horizon:
Exk+1∼f(xk,π(xk),·)
{ ∞∑k=0
γkρ(xk, π(xk), xk+1)
}, (1)
where γ ∈ (0, 1] is the discount factor. The mapping from astate x0 to the value of the cumulative reward for a policy πis called the (state) value function V π(x0):
V π(x0) = Exk+1∼f(xk,π(xk),·)
{ ∞∑k=0
γkρ(xk, π(xk), xk+1)
}.
(2)The control objective is to find an optimal policy π∗ that leadsto the maximal value function, for all x0:
V ∗(x0) := maxπ
V π(x0),∀x0 (3)
Although state-values functions suffice to define optimality, itis useful to define action-value functions, called Q-functions.The action-value function gives the expected reward if onestarts in state x, takes an arbitrary action u (which maynot have come from the policy), and then forever after actsaccording to policy π:
Qπ(x, u) = Ex′∼f(x,u,·){ρ(x, u, x′) + γV π(x′)}, (4)
where the prime notation indicates quantities at the nextdiscrete time step. The optimal Q-function Q∗ is defined usingV ∗. Once an optimal Q-function Q∗ is available, an optimalpolicy π∗ can be computed by
π∗(x) ∈ argmaxu
Q∗(x, u), (5)
while the formula to compute π∗ from V ∗ is more compli-cated. As a consequence of the definitions, the Q-functionsQπ and Q∗ fulfill the Bellman equations:
Qπ(x, u) = Ex′∼f(x,u,·){ρ(x, u, x′) + γQπ(x′, π(x′))} (6)
and
Q∗(x, u) = Ex′∼f(x,u,·){ρ(x, u, x′) + γmaxu′
Q∗(x′, u′)},(7)
which are of central importance in RL. The crucial advantageof RL algorithms is that they do not require a model of thesystem dynamics. Instead, an optimal policy can be found bylearning from samples of transitions and rewards. The problemformulation with MDPs and the associated solution techniquesalso handle nonlinear, stochastic dynamics, and nonquadraticreward functions. Perhaps the most popular RL algorithm isQ-learning. In Q-learning, one starts from an arbitrary initialQ-function Q0 and updates it using observed state transitionsand rewards. The update rule is of the following form:
Qk+1(xk, uk) = Qk(xk, uk)
+ αk[rk+1 + γmaxu′
Qk(xk+1, u′)−Qk(xk, uk)], (8)
where αk ∈ (0, 1] is the learning rate. The term inside thesquare bracket is nothing else than the difference betweenthe updated estimate of the optimal Q-value of (xk, uk)and the current estimate Qk(xk, uk). Under mild assump-tions on the learning rate and that a suitable exploratorypolicy is used to obtain samples, i.e. data tuples of the form(xk, uk, xk+a, rk+1), Q-learning asymptotically converges toQ∗, which satisfies the Bellman optimality equation. Thereader is referred to [26] for a description of similar RLalgorithms. Q-learning and its many variants require that Q-functions and policies are exactly represented, e.g. as a tableindexed by the discrete states and actions. Especially forthe control of physical systems, the states and actions arecontinuous; moreover, exact representations are in generalimpossible. Normal Q-learning does not work in this setting.Fortunately, methods like Q-learning can be combined withfunction approximation. We denote approximate versions ofthe Q-function and the policy by Q(x, u; θ) and π(x;w),where θ and w are the parameters of parametric approximators.There are many different function approximators to choosefrom.

WAXENEGGER-WILFING et al.: A REINFORCEMENT LEARNING APPROACH FOR TRANSIENT CONTROL OF LIQUID ROCKET ENGINES 3
The combination of RL with deep neural networks (DNNs)as function approximators leads to the field of deep RL. Inthe last years, deep RL algorithms have achieved impressiveresults, such as reaching super-human performance in thegame of Go. Besides the sensational results in board gamesor video games, those algorithms are successfully used inareas like robotics. In deep Q-learning, one uses a neuralnetwork to approximate the Q-function. Neural networks canrepresent any smooth function arbitrarily well given enoughparameters, and therefore they can learn complex Q-functions.Loss functions and gradient descent optimization are used to fitthe parameters of the models. Gradient estimates are usuallyaveraged over individual gradients computed for a batch ofexperiences.
Nevertheless, the simple training procedure is unstable,because sequential observations are correlated, and techniqueslike experience replay have to be used. Correlated experiencesare saved into a replay buffer. When batches of experiences areneeded for training, these batches are generated by samplingfrom the replay buffer in a randomized order. A furtherreason for the simple training procedure’s instability is thatthe target values depend on the parameters one wants tooptimize. The solution is to use a so-called target network,Q(x, u; θ−), with target parameters θ−, which slowly trackthe online parameters. While deep Q-learning solves problemswith continuous state-spaces, it can only handle discrete andlow-dimensional action spaces. The reason for that is thefollowing: (deep) Q-learning requires fast maximization ofQ-functions over actions. When there are a finite number ofdiscrete actions, this poses no problem. However, when theaction space is continuous, this is highly non-trivial (and wouldbe a very computational expensive subroutine).
The deep deterministic policy gradient (DDPG) [27] algo-rithm is specially adapted for environments with continuousaction spaces. It uses neural networks to approximate boththe Q-function and a deterministic policy, i.e. the policynetwork deterministically maps a state to a specific action. Forexploration, one adds noise sampled from a stochastic processN to the actions of the deterministic policy and updates it by agradient-based learning rule. As in deep Q-learning, the DDPGalgorithm uses a replay buffer and target networks to improvestability during neural network training. Further details of theDDPG algorithm and its performance on different simulatedphysics tasks are given by Lillicrap et al. [27].
Although the DDPG algorithm is quite powerful, it hasa direct successor, the Twin Delayed DDPG (TD3) [28]algorithm, which further improves the stability by employingthree critical tricks. The first trick addresses a particular failuremode of the DDPG algorithm: if the Q-function approximatordevelops an incorrect sharp peak for some actions, the policywill quickly exploit that peak and then have brittle or incorrectbehavior. This failure mode can be averted by smoothing outthe Q-function over similar actions. For this, one computesthe action that is used to form the Q-learning target in thefollowing way:
u′(x′) = clip(π(x′;w−) + clip(ε,−c, c), xLow, xHigh), (9)
where ε ∼ N (0, σ) is noise sampled from a Gaussian process
Algorithm 1 Twin Delayed DDPG (TD3)1: Input: initial policy parameters w, Q-function parametersθ1, θ2, empty replay buffer D
2: Set target parameters equal to main parametersw− ← w, θ−1 ← θ1, θ−2 ← θ2
3: repeat4: Observe state x and select action
u = clip(π(x;w) + ε, xLow, xHigh), where ε ∼ N5: Execute u in the environment6: Observe next state x′, reward r, and done signal d to
indicate whether x′ is terminal7: Store (x, u, r, x′, d) in replay buffer D8: If x′ is terminal, reset environment state9: if it is time to update then
10: for j in range(however many updates) do11: Randomly sample a batch of transitions
B = {(x, u, r, x′, d)} from D12: Compute target actions
u′(x′) = clip(π(x′;w−) + clip(ε,−c, c),xLow, xHigh), ε ∼ N (0, σ)
13: Compute targets
q(r, x′, d) = r + γ(1− d) mini=1,2
Q(x′, u′(x′); θ−i )
14: Update Q-functions by one step of gradient descent
∇θi1
|B|∑
(x,u,r,x′,d)∈B
(Q(x, u; θi)− q(r, x′, d))2,
for i = 1, 215: if j mod policy delay = 0 then16: Update policy by one step of gradient ascent
∇w1
|B|∑x∈B
Q(x, π(x;w); θ1)
17: Update target networks
θ−i ← (1− τ)θ−i + τθi, for i = 1, 2
w− ← (1− τ)w− + τw
18: end if19: end for20: end if21: until convergence
(target policy noise). The action is based on the target policy,but with clipped noise added (target noise clip c). After addingthe noise, the target action is also clipped to lie in the validaction range (xLow, xHigh). The second trick is to learn twoQ-functions Q(x, u; θi), for i = 1, 2, instead of one anduse the smaller of the two Q-values to form the target. Thisimprovement reduces overestimation in the Q-function.
q(r, x′, d) = r + γ(1− d) mini=1,2
Q(x′, u′(x′); θ−i ) (10)

4 UNDER REVIEW
The third trick is to update the policy less frequently than theQ-functions (policy delay) to damp the volatility that arises inthe DDPG algorithm. Algorithm 1 shows the full pseudocodeof the TD3 algorithm. The done signal d is equal to one whenx′ is the terminal state and otherwise equal to zero. The donesignal guarantees that the agent gets no additional rewardsafter the current state at the end of an episode.
In addition to enhancements that improve the stability ofthe training process, research is also carried out to speedup the learning process of RL agents [29]. Besides DDPG,TD3, or SAC [30], which are so-called off-policy algorithms,there are also state-of-the-art on-policy algorithms like TRPO[31] or PPO [32]. Nevertheless, on-policy methods are muchmore sample inefficient and have longer training time toachieve equivalent performances. From a control perspective,reinforcement learning converts the system identificationproblem and the optimal control problem to machine learningproblems. Similar to explicit model predictive control italso addresses the problem of removing one of the maindrawbacks of model predictive control, namely the need tosolve a complex optimization problem online to compute thecontrol action.
The main advantages of RL for control:• no derivation of a suitable state-space model, model order
reduction or linearization needed• direct use of a nonlinear simulation model• ideal for highly dynamic situations (no complex online
optimization needed)• complex reward functions enable complicated goals
The main disadvantage of RL for control:• stability of the controller is in general not guaranteed
Concerning the last point (stability), we would like to make aremark. The controller’s output can always be tested using thesimulation environment, and there has been promising recentwork on certifying stability of RL policies [33].
III. SIMULATION ENVIRONMENT AND RLIMPLEMENTATION
A suitable simulation environment for our intended useis given by EcosimPro [34]. EcosimPro is a modeling andsimulation tool for 0D or 1D multidisciplinary continuous anddiscrete systems. The system description is based on dierential-algebraic equations and discrete events. Within a graphicaluser interface, one can combine dierent components, whichare arranged in several libraries. Of particular interest arethe European Space Propulsion System Simulation (ESPSS)libraries, which are commissioned by the European SpaceAgency (ESA). These EcosimPro libraries are suited for thesimulation of liquid rocket engines and have continuously beenupgraded in recent years.
We use the TD3 implementation of Stable-Baselines [35].Stable-Baselines is a set of improved implementations of RLalgorithms based on OpenAI Baselines. It features a commoninterface for many modern RL algorithms and additionalwrappers for preprocessing, monitoring, and multiprocessing.
LOX
GG
IGN
NE
CC
IGN
LH2
Turbine Starter
VGO VGH
VGC
VCO
TurboPump
TurboPump
VCH
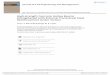
Fig. 1. Flow plan of the considered engine architecture. Some ofthe propellants are burned in an additional combustion chamber, thegas-generator (GG), and the resulting hot-gas is used as the workingmedium of the turbines which power the engine’s pumps. The gas isthen exhausted. The engine architecture features five valves, but onlythree valves (VGH, VGO, VGC) are used for closed-loop control.
We encapsulate our simulation environment into a customOpenAI Gym environment using an interface between Ecosim-Pro and Python. Hence, we can directly use Stable-Baselinesfor training and testing. A big advantage of the RL approachis that it works regardless of whether one uses a lumpedparameter model, continuous state-space models, surrogatemodels employing artificial neural networks [36], [37], or acombination of the above.
IV. TEST CASE
The engine architecture considered to study the suitabilityof an RL approach for the control of the transient start-upis shown in Fig. 1. It is similar to the architecture of theEuropean Vulcain 1 engine [38], which powered the cryogeniccore stage of Ariane 5 launch vehicle before it got replaced by

WAXENEGGER-WILFING et al.: A REINFORCEMENT LEARNING APPROACH FOR TRANSIENT CONTROL OF LIQUID ROCKET ENGINES 5
0 1 2 3 4 50.0
0.2
0.4
0.6
0.8
1.0
Valv
eP
osi
tion
(-)
VGO VGH VGC VCO VCH
0 1 2 3 4 5
−8
−6
−4
−2
0
Cum
ula
tive
Rew
ard
(-)
total sp GG valve
0 1 2 3 4 5
Time (s)
0
25
50
75
100
125
Pre
ssure
(bar)
CC GG ref
0 1 2 3 4 5
Time (s)
0
2
4
6
8
Mix
ture
Rati
o(-
)
PI GG ref
Fig. 2. 100bar nominal open-loop start-up sequence. The main combustion chamber pressure settles at 100bar, while the gas-generator pressurereaches 75bar. The reference mixture ratios are given by 5.2 and 0.9. The engine reaches steady-state conditions after approximately 4 s.
the upgraded Vulcain 2 engine. It is fed with cryogenic liquidoxygen (LOX) at a temperature of 92K and liquid hydrogen(LH2) at 22K. The engine generates approximately 1MN ofthrust at a main combustion chamber (CC) pressure of 100 barand a chamber mixture ratio of 5.6, i.e. the chamber massflow of the oxidizer divided by the chamber mass flow of thefuel equals 5.6. The engine cycle is an open gas-generatorcycle, where a small amount of the propellants is burned in asmall combustion chamber, the gas-generator (GG). The gas-generator is operated at a fuel-rich mixture ratio of 0.9. Theproduced hot-gas is used to drive the turbines before it isexhausted. The turbines power the pumps which force thepropellants into the combustion chambers. LH2 is used tocool the nozzle and main combustion chamber before it getsburned. A convergent-divergent nozzle, which usually includesan uncooled nozzle extension (NE), accelerates the combustiongases to generate thrust.
The actuators are given by five flow control valves (VCO,VCH, VGO, VGH, VGC). VCO and VCH are the maincombustion chamber valves that regulate the propellant flowto the combustion chamber. VGO and VGH, the gas-generatorvalves, are used to control the gas-generator pressure andmixture ratio. The turbine valve, VGC, is located downstreamof the gas-generator and is used to determine the hot-gas flowratio between the LOX and LH2 turbines. Thus, this valvemainly influences the global mixture ratio (PI, pump-inlet).Further actuators are the ignition systems (IGN) for the maincombustion chamber and the gas-generator, as well as a turbine
starter. The turbine starter produces hot-gas for a short periodto spin up the turbines during the start-up.
To start the engine and reach steady-state conditions, asuccession of discrete events, including valve openings andchamber ignitions are necessary. The start-up sequence ofan engine, i.e. the chronological order of oxidizer and fuelvalve openings, as well as the precise ignition timings, deter-mines the engine’s thermodynamic conditions and mechanicalstresses during start-up. A non-ideal start-up sequence candamage the engine, e.g. by excessive temperatures. These hightemperatures can substantially damage the turbine blades orat least reduce their live expectancy [39]. An optimal start-up sequence leads to a smooth ignition of the combustionchamber and gas-generator with low thermal and mechanicalstresses. An open-loop start-up sequence (OLS) for a steady-state chamber pressure of 100 bar is shown in Fig. 2. Thesequence does not correspond exactly to the Vulcain 1 start-upsequence, but it is realistic for such an engine cycle. The flowcontrol valves are opened monotonically until the end positionsare reached. First the VCH valve starts to open at t = 0.1 s,followed by VCO at t = 0.6 s. A fuel-lead transient is usuallyused for a smooth ignition of the combustion chamber, whichtakes place at t = 1.0 s. At this point, the main combustionchamber is burning at low pressure, only fed by the tankpressurization. At t = 1.1 s, the turbine starter activates tospin up the turbopumps, which start to build up the pressure inthe main combustion chamber and at the gas-generator valvesVGO, VGH. At t = 1.4 s and t = 1.5 s, the gas-generator

6 UNDER REVIEW
valves VGH and VGO open and the gas-generator is ignited.The VGC valve is set to a fixed position during the entire start-up sequence. At t = 2.6 s, the turbine starter is burned out andthe engine reaches steady-state conditions after approximately4 s. The valve positions in Fig. 2 are tuned to reach a maincombustion chamber pressure pcc of 100 bar, a global mixtureratio MRPI of 5.2 and a gas-generator mixture ratio MRGG of0.9.
Although RL can solve discrete or hybrid control problems,there are controllability and observability issues during the firstphase of discrete events due to very low mass flows [21]. Thuswe focus on the fully continuous phase starting at t = 1.5s.The goal of the controller (agent) is to drive the engine asfast as possible towards the desired reference by adjusting theflow control valve positions. In our multi-input multi-output(MIMO) control tasks, only three flow control valves, VGO,VGH, and VGC, are used for active control of the combustionchamber pressure, and the mixture ratio of the gas-generatoras well as the global mixture ratio. The valve actuators aremodeled as a first-order transfer function with a time constantof τ = 0.05 s and a linear valve characteristic. The minimumvalve position is set to 0.25 for VGH and VGO and 0.20 forVGC, respectively. The maximum valve position is 1.0 for allvalves.
We study different reference values for the combustionchamber pressure, namely 80 and 100 bar. The reference mix-ture ratios remain the same, 5.2 for the global mixture ratio and0.9 for the mixture ratio of the gas-generator. For a combustionchamber pressure of 80 bar, the valve timings are the same,but the final valve positions were adjusted accordingly (seeFig. 9). Furthermore, we study the effect of degrading turbineefficiencies on the start-up transient. This scenario has practi-cal relevance for future reusable engines. The use of cryogenicpropellants leads to significant thermostructural challenges inthe operation of turbopumps. Since thermal stresses dependon the temperature gradient, they can cause significant loadson the metal parts that have to react to these stresses. Theresulting fatigue deformation [39] affects the performanceof the turbines. Furthermore, the aging of seals can causeincreased leakage mass flows, which in turn decreases theturbine efficiency [5]. Additional reasons are turbine bladeerosions [6] and soot depositions on the turbine nozzles byfuel-rich gases when using hydrocarbons as fuel. These sootdepositions can decrease the effective nozzle area up to 20%[2], thus reducing the turbopump performance. Furthermore,soot depositions are a main shortcoming for reusable enginesdue to the unpredictable impacts for engine re-start [40].To study the effect of degrading turbine efficiencies for ourgeneric test case, we simulate and evaluate the performanceof the open-loop start-up sequence, a family of PID controllers,and our RL-agent for 16 different combinations of LOXand LH2 turbine efficiencies. For each turbine, 4 differentefficiencies are considered ranging from 100% to 85% of thenominal value.
The reward, which is used to evaluate a start-up sequenceand to train the RL agent consists of 3 different terms:
r = rsp + rGG + rvalve. (11)
The first term
rsp = −∑xi
clip
(∣∣∣∣xi − xi,refxi,ref
∣∣∣∣ , 0.2) (12)
for xi ∈ [pCC, MRGG, MRPI] penalizes deviations from thedesired set-point for all controlled variables. Each rewardcomponent in this term is clipped to a maximum value of0.2 to improve training and to balance the accumulated rewardduring start-up and steady-state. The second term of the reward
rGG = −
MRGG −MRGG,ref
MRGG,ref, if
MRGG
MRGG,ref> 1
0, otherwise(13)
additionally penalizes high mixture ratios in the gas-generator.High mixture ratios are dangerous because they result inincreased temperatures and thus possible damaging conditionsto the turbines. The last reward component
rvalve = −|sVGH|+ |sVGO|+ |sVGC|
3, (14)
where s is the change in valve position between two time steps,penalizes excessive valve motion. By adding this component,we encourage the agent to move the valves as little aspossible to avoid valve wear, valve oscillations, and valvejittering. All together, this reward allows the agent to tradeoff between reaching the desired reference point as fast aspossible, avoiding steady-state errors, minimizing overshoots,and reducing valve motion as much as possible. Fig. 2 showsall 3 components of the cumulative reward for the nominalOLS for 100 bar. Since the valves are only moved once in theOLS, the contribution of rvalve to the total reward is low. Asthe overshoot in the gas-generator mixture ratio is also small(small rGG), the total reward is mainly composed of the setpoint error rsp.
To train and use a RL agent, one needs to define the obser-vation and action space of the agent. The observation space,i.e. the variables the agent receives from the environment ateach time step, should at least contain sufficient informationto unambiguously define the state of the system. In our set-up,the observation space
X = [pcc,ref , εcc, εPI, εGG, PosVGO, PosVGH, PosVGC,
ωLOX, ωLH2] (15)
contains 9 variables, where εi = xi−xi,ref is the absolute errorfor each controlled variable, PosVGO, PosVGH, and PosVGC
are the positions of all control valves, and ωLOX and ωLH2 arethe rotational speeds of the turbopumps. The observation spaceis normalized with the reference steady-state values. All vari-ables in our observation state are measurable in real engines.Thus our approach is not limited to simulation environments,where one could possibly use variables that are impossible tomeasure directly in real engines (e.g. the turbine efficiencies).The agent’s action space U consists of all 3 gas-generatorvalve positions
U = [PosVGO, PosVGH, PosVGC]. (16)
At each time step, the RL agent receives observations fromthe environment and sends control signals to the flow control

WAXENEGGER-WILFING et al.: A REINFORCEMENT LEARNING APPROACH FOR TRANSIENT CONTROL OF LIQUID ROCKET ENGINES 7
1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
Time (s)
0.0
0.2
0.4
0.6
0.8
1.0
Valv
eP
osi
tion
(-)
VGO VGH VGC
Fig. 3. Manipulated valve positions by the PID controllers for the100bar nominal start-up. VGO is used to control the mixture ratio ofthe gas-generator, while VHG and VGC control the pressure of the maincombustion chamber and the global mixture ratio respectively.
1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
Time (s)
0.0
0.2
0.4
0.6
0.8
1.0
Valv
eP
osi
tion
(-)
VGO VGH VGC
Fig. 4. Manipulated valve positions by the RL agent for the 100barnominal start-up. The action clearly changes at t = 2.6 s, which is thetime when the firing of turbine starter stops.
valves of the engine. The frequency of interaction betweenthe controller (RL-agent and PID) and the environment is setto 25Hz.
V. RESULTS
In this section, we assess the performance of our RLcontroller. For this we use the approximation of the integratedabsolute error over one entire episode for each controlledvariable:
(IAE)i =∫|εi| dt ≈
∑tj
|εi(tj)| , (17)
where tj are the discrete time steps. Furthermore, we evaluatethe average steady-state values of the controlled variables fromt = 3.5 s to t = 5.0 s and the value of the cumulative reward.
Before we turn to the performance of closed-loop control,let us record the downsides of open-loop sequences (OLS).The first column in Fig. 5 shows the resulting engine start-up
for the nominal OLS and degrading turbine efficiencies. Forthe latter, the steady-state values deviate strongly from thereference values. The minimum steady-state value of the maincombustion chamber pressure is 92 bar. The steady-state of theglobal mixture ratio varies between 4.9 and 6.0. To preventfuel or oxidizer from running out during a mission in the eventof a persisting mixing ratio deviation, the loaded propellantsmust be increased, which reduces the payload capacity of thelaunch vehicle. A further negative effect is that the temperaturein the combustion chamber can rise significantly due to a shiftin the mixing ratio, which could reduce the engine’s servicelife. Additionally, the steady-state value of the mixture ratioof the gas-generator changes too. The temperature in the gas-generator is sensitive to the mixture ratio, and an increasedtemperature can also damage the turbines. These damagingconditions are especially problematic for reusable engines,which must possess a long service life. The same implicationsapply to the 80 bar case as Fig. 8 shows.
Those unfavorable effects can be counteracted with aclosed-loop control system. First, we tune a family of PIDcontrollers to achieve the start-up. The process of controllingthe chamber pressure of the main combustion chamber, themixture ratio of the gas-generator, and the global mixtureratio by manipulating VGO, VGH, and VGC is coupled.E.g. changing VGO does affect not only the mixture ratioof the gas-generator but also the other two controlled vari-ables. Nevertheless, for rocket engine control near steady-state conditions, the standard approach is to use separatePID controllers and tune the control loops at different speedsto avoid oscillations [7]. Hence, we also use three separatecontrollers.
The first controller manipulates VGO to control the mixtureratio of the gas-generator, the second controller manipulatesVGH to control the chamber pressure of the main combustionchamber, and the third controller manipulates VGC to controlthe global mixture ratio. Starting far away from the referencepoint can be problematic for a simple PID controller becausethe integrator begins to accumulate a significant error duringthe rise. Consequently, a large overshoot may occur. ModernPID controllers use different methods to address this problemof integrator-windup. We use a simple feedback loop, wherethe difference between the actual and the commanded actuatorposition is fed back to the integrator, to avoid the effects ofsaturation. If there is no saturation, our anti-windup schemehas no effect. The ratio between the time constant for the anti-windup and the integration time is 0.1 for all PID controllers.
For PID parameter tuning, we directly use the simulationmodel coupled with a genetic algorithm [41] of the DistributedEvolutionary Algorithms in Python (DEAP) framework [42].To guarantee a fair comparison, we use the reward function tocalculate the fitness value of a certain parameter combination.Table IV presents the optimal PID parameters, which maxi-mize the reward function. The genetic algorithm uses a popu-lation of 5000 valid individuals and evolves the population for20 generations. Fig. 3 show that the best PID controllers openthe valves in a nonmonotonic way, which leads to a fasterstart-up. Furthermore, the PID controllers fulfill their maintask: the feedback loops lead to an adjustment of the valve

8 UNDER REVIEW
2 3 4 580
90
100
110
CC
Pre
ssu
re(b
ar)
OLS
nom ref degr
2 3 4 580
90
100
110
PID
nom ref degr
2 3 4 580
90
100
110
RL
nom ref degr
2 3 4 54
5
6
7
PI
Mix
ture
Rati
o(-
)
2 3 4 54
5
6
7
2 3 4 54
5
6
7
2 3 4 50.6
0.8
1.0
1.2
GG
Mix
ture
Rati
o(-
)
2 3 4 50.6
0.8
1.0
1.2
2 3 4 50.6
0.8
1.0
1.2
2 3 4 5
Time (s)
−30
−20
−10
0
Cum
ula
tive
Rew
ard
(-)
2 3 4 5
Time (s)
−30
−20
−10
0
2 3 4 5
Time (s)
−30
−20
−10
0
Fig. 5. Comparison of the controlled variables for the 100 bar start-up. Shaded area marks the range of the controlled variable for different degradedefficiencies. At different turbine efficiencies the standard open-loop sequence provides significantly different steady-state values for the chamberpressure and the mixture ratios.

WAXENEGGER-WILFING et al.: A REINFORCEMENT LEARNING APPROACH FOR TRANSIENT CONTROL OF LIQUID ROCKET ENGINES 9
TABLE ICONTROLLER PERFORMANCE FOR NOMINAL TURBINE EFFICIENCIES
Target Algo. Reward Steady-State Values IAE
pCC cum. pCC MRGG MRPI pCC MRGG MRPI
(bar) (–) (bar) (–) (–) (bar) (–) (–)
100 OLS -7.9 100.0 0.90 5.18 591 4.7 27PID -6.5 98.9 0.90 5.17 632 4.0 19RL -4.2 99.9 0.90 5.18 519 2.8 13
80 OLS -7.0 79.7 0.90 5.20 576 6.0 15PID -5.2 79.9 0.90 5.20 433 3.8 9RL -4.4 80.8 0.90 5.18 366 2.9 8
positions at lower turbine efficiencies and significantly reducethe deviations from the reference values of the controlledvariables. Due to the structure of PID controllers, with theirproportional, integral, and derivative terms, the shape of thecontrol input is restricted and does not provide optimal control.
Fig. 5 shows that the optimized PID controllers lead tocertain overshoots of the main combustion chamber pressureand the global mixture ratio. It is possible to eliminate theovershoots by changing the PID parameters, but this wouldsignificantly increase the settling time. For our parameters,there is still an error in combustion chamber pressure after 4 seven for nominal efficiencies. The settling time is not the onlyreason for a large error in the combustion chamber pressure inthe case of lower turbine efficiencies. For the lowest turbineefficiencies, a combustion chamber pressure of 100 bar isphysically no longer possible while maintaining the otherconstraints (especially the desired gas-generator mixture ratio).A specific disadvantage of PID controllers is that degeneratingefficiencies or other system parameters cannot be considereddirectly as further input variables. Fig. 6 shows that for the80 bar start-up VGC oscillates a little. It is challenging totune a single family of PID controllers for different referencecombustion chamber pressures. For even lower combustionchamber pressures (deep throttling), it becomes more andmore difficult to achieve a convincing performance for alloperating conditions. The prevention of oscillations leads toan increased settling time for all reference values. All inall, the performance of the PID controllers is not perfect butsatisfactory for the case of 100 and 80 bar and fixed mixtureratios.
Now we examine the performance of our RL approach.The comparison of Fig. 3 and Fig. 4 shows that at firstglance the RL agent’s behavior shows strong similarities tothe PID controllers. The flow control valves are opened in anonmonotonic way. Nevertheless, the agent can guarantee aneven faster start-up, as presented in Fig. 5. The RL controllercan better control the combustion chamber pressure and theglobal mixing ratio. The control of the gas-generator mixtureratio is comparatively good. Furthermore, the RL agent candirectly take the firing of the turbine starter into account.The action changes at t = 2.6 s, which is the time when thefiring of turbine starter stops. Similar to the PID controllers,the RL agent can handle degrading turbine efficiencies to a
certain extent. It can detect deviating efficiencies because therelationship between valve positions and controlled variableschanges, and adjusts the start-up. A prerequisite for this is thatthe valve positions are also included in the observation space,and that experiences with different efficiencies were generatedduring the training.
Table I compares the rewards, steady-state values, and IAEsof the studied approaches for nominal turbine efficienciesand both main combustion chamber pressures of 100 bar and80 bar. The open-loop sequences are satisfying for the nominalstart-ups. Nevertheless, both IAEs and rewards show thatimprovement is possible. One can start up faster if the valvesare opened nonmonotonously. Why is this not done for realisticstart-up sequences? As already mentioned, it is commonpractice to determine the control sequences employing testson test benches, which is expensive and time-consuming. Withnon-reusable engines, the demands on the control system arenot so dramatic, and one can accept good but not optimalsequences as long as a large amount of development costs issaved. Another reason is that, as a rule, disturbances influencethe start-up anyway and cancel out the advantages of optimizedsequences. The advantages can only be realized by closingthe control loop. The tuned PID controllers are better than theopen-loop sequences concerning the value of the reward. TheRL agent is even better. The RL agent and the PID controllersalso achieve decent steady-state values.
Table II compares the rewards, steady-state values, and IAEsof the studied approaches for degrading turbine efficiencies.We present the mean and standard deviation of the measuresinstead of giving all values for the 16 different combinations ofturbine efficiencies. For the steady-state values, the minimumand maximum values are also listed in Table II. As alreadyseen in Figure 5, the OLS results in large deviations fordegrading turbine efficiencies. For 100 bar, the steady-statemain combustion chamber pressure ranges between 92 bar to100 bar. Furthermore, degrading turbine efficiencies stronglyinfluence the overall mixture ratio MRPI. Large deviationsin MRPI (here from 4.9 to 6.0) poses two major problems.First, the fuel and oxidizer tank volumes are designed forthe nominal mixture ratio. Deviations in MRPI result in anon-ideal utilization of the propellants, thus lowering thelauncher’s performance. Second, the mixture ratio in the maincombustion chamber is directly affected by the overall mixtureratio, potentially resulting in more damaging conditions forthe main combustion chamber. The cumulative reward for theOLS increases to a mean value of −14.9 with a large standarddeviation of 5.2.
The controller performances of both closed-loop controllershighlight the benefits of closed-loop control for degradingturbine efficiencies. The mean and standard deviations of thecumulative rewards are much smaller for the PID controllersand the RL agent. The additional reduction for the RL agentis mainly due to an even faster start-up. The mean steady-state value of pCC is given by 96.0 bar for the agent, whichis a little bit closer to 100.0 bar than the value of PIDcontrollers and much closer than the value of the open-loopsequence. Furthermore, the maximum deviation is the smallest.The advantages of closed-loop control and especially the RL

10 UNDER REVIEW
TABLE IICONTROLLER PERFORMANCE FOR 16 DIFFERENT COMBINATIONS OF DEGRADED TURBINE EFFICIENCIES
Target Algo. Reward Steady-State Values Integral Absolute Error IAE
pCC (bar) cumulative (–) pCC (bar) MRGG (–) MRPI (–) pCC (bar) MRGG (–) MRPI (–)mean sd min max mean sd min max mean sd min max mean sd mean std mean std mean std
100 OLS -14.9 5.2 92.0 100.0 96.1 2.3 0.87 0.96 0.91 0.03 4.9 6.0 5.4 0.3 1841 151 5.8 1.0 45 18PID -7.6 0.7 95.5 98.9 97.7 1.0 0.89 0.90 0.89 0.01 5.0 5.2 5.2 0.1 758 98 4.1 0.1 25 4RL -5.5 0.9 96.0 100.7 98.8 1.4 0.89 0.90 0.90 0.02 5.1 5.3 5.2 0.0 636 91 2.9 0.1 29 6
80 OLS -15.4 5.8 71.1 79.7 75.5 2.4 0.86 0.96 0.91 0.03 4.8 6.2 5.5 0.4 815 149 7.0 0.9 36 21PID -5.7 0.6 79.5 79.9 79.7 0.1 0.90 0.90 0.90 0.00 5.2 5.5 5.2 0.1 459 18 3.9 0.1 12 6RL -4.4 0.8 79.6 82.1 80.3 0.6 0.89 0.90 0.90 0.00 5.2 5.4 5.2 0.0 366 30 3.3 0.1 10 5
For each turbine, 4 different efficiencies are considered ranging from 100% to 85% of the nominal value.
approach are also reflected in the mixture ratios, which aremuch closer to their nominal values compared to the OLS.The IAEs also show that the RL agent performs better thanthe PID controllers.
VI. CONCLUSION AND OUTLOOK
In this work, we presented a RL approach for the optimalcontrol of the fully continuous phase of the start-up of agas-generator cycle liquid rocket engine. Using a suitableengine simulator, we employed the TD3 algorithm to learnan optimal policy. The policy achieves the best performancecompared with carefully tuned open-loop sequences and PIDcontrollers for different reference states and varying turbineefficiencies. Furthermore, the prediction of the control actiontakes only 0.7ms, which allows a high interaction frequency,and in comparison to MPC enables the real-time use of RLalgorithms for closed-loop control. The modest computationalrequirements should be met by the current generation of enginecontrol units. A potential drawback of the RL approach is thelack of stability guarantees. Nevertheless, the control systemcan be tested using a high fidelity simulation model, and thereis ongoing work on certifying stability of RL policies [33].
The present work can be improved in many directions.It is necessary to carefully examine the performance of thecontroller when various disturbances occur. Disturbance rejec-tion, integration of filtering, and observer design will be thefocus of future work. Furthermore, even the most sophisticatedmodels usually have prediction errors due to not includedeffects or model miss-specifications. Therefore, it is essentialto ensure that controllers trained in a simulation environmentare robust enough to be used in real applications. There are RLapproaches that explicitly consider modeling errors. Domainrandomization [43] can produce agents that generalize wellto a wide range of environments. Another issue with RLis implementing hard state constraints. Using the exampleof liquid rocket engine control, one would like to imposehard constraints to limit the maximum rotational speed of theturbopumps and maximum temperatures to prevent damage tothe engine. It is possible to approximate hard state constraintsby carefully tuning the reward function, e.g. one can give theagent a sizeable negative reward upon constraint violation andpossibly terminate the training episode. Besides, there has been
recent work on implementing hard constraints in RL usingconstrained policy optimization [44].
We would like to conclude this publication with an outlookon the potential advantages of this approach for rocket enginecontrol. Controllers trained with RL can depend on many inputvariables, can be used for very different operating conditions,and can include multiple objectives. The thrust control ofrocket engines is crucial for improving the performance ofthe launch vehicle, but it is particularly critical when usingrocket engines for the soft landing of returning rocket stages.Deep throttling domains of an engine, i.e. 25-100% range ofnominal thrust, are not supposed to pose a problem for RLcontrollers. Regarding multiple objectives, one can modify thereward function to optimize both the system’s performanceand damage mitigation [45]. The coupling of sophisticatedhealth monitoring systems, possibly based on machine learningtechniques, with suitable policies trained by RL, can increasethe reliability of launch systems further. Given a suitablesimulation environment, end-to-end RL may even enable thetraining of integrated flight and engine control systems. Over-all, it is hoped that the current work will serve as a basis forfuture studies regarding the application of RL in the field ofrocket engine control.
ACKNOWLEDGMENT
The authors would like to thank Wolfgang Kitsche, RobsonDos Santos Hahn, and Michael Borner for valuable discussionsconcerning the start-up of a gas-generator cycle liquid rocketengine.

WAXENEGGER-WILFING et al.: A REINFORCEMENT LEARNING APPROACH FOR TRANSIENT CONTROL OF LIQUID ROCKET ENGINES 11
APPENDIX IIMPLEMENTATION AND TRAINING DETAILS
The agent is trained for 100 000 time steps, which is equalto approximately 1.5 hours of simulation time. The agents’hyperparameters are tuned with Optuna [46] and are presentedin Table III. For exploration we use action noise sampledfrom an Ornstein-Uhlenbeck process [47]. Table IV shows theparameters of all three PID controllers and the correspondingcontrolled variable and control valve.
TABLE IIITD3 HYPERPARAMETERS
Parameter Value
number of hidden units per layer [400, 300]number of hidden layer 2activation function ReLU
optimizer Adamnumber of samples per minibatch 256learning rate 0.001soft update coefficient (τ ) 0.005train frequency 10gradient steps 10discount rate (γ) 0.90warm-up steps 5000
total training steps 100 000
size of the replay buffer 25 000
target policy noise 0.01target noise clip 0.02policy delay 2action noise type Ornstein-Uhlenbeckaction noise std (σ) 0.05rate of mean reversion (θ) 0.25
TABLE IVPID PARAMETERS
Valve Controlled Variable Parameter Value
VGO MRGG (−) Kp 98.5Ti 36.3Td 3.56× 10−4
VGH pcc (Pa) Kp 2.59× 10−7
Ti 1.22Td 6.82× 10−3
VGC MRPI (−) Kp 0.786Ti 1.06Td 2.12× 10−2
APPENDIX IIPLOTS FOR 80 BAR CASE
Fig. 9 shows the nominal OLS for a main combustionchamber pressure of 80 bar. The manipulated valve positionsby the PID and RL agent for 80 bar are shown in Fig. 6 andFig. 7. Finally, Fig. 8 compares controller performances fordifferent degraded turbine efficiencies.
1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
Time (s)
0.0
0.2
0.4
0.6
0.8
1.0
Valv
eP
osi
tion
(-)
VGO VGH VGC
Fig. 6. Manipulated valve positions by the PID controllers for the80bar nominal start-up. VGO is used to control the mixture ratio of thegas-generator, while VHG and VGC control the pressure of the maincombustion chamber and the global mixture ratio respectively.
1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
Time (s)
0.0
0.2
0.4
0.6
0.8
1.0
Valv
eP
osi
tion
(-)
VGO VGH VGC
Fig. 7. Manipulated valve positions by the RL agent for the 80barnominal start-up. The action clearly changes at t = 2.6 s, which is thetime when the firing of turbine starter stops.

12 UNDER REVIEW
2 3 4 560
70
80
90
CC
Pre
ssu
re(b
ar)
OLS
nom ref degr
2 3 4 560
70
80
90
PID
nom ref degr
2 3 4 560
70
80
90
RL
nom ref degr
2 3 4 54
5
6
7
PI
Mix
ture
Rati
o(-
)
2 3 4 54
5
6
7
2 3 4 54
5
6
7
2 3 4 50.6
0.8
1.0
1.2
GG
Mix
ture
Rati
o(-
)
2 3 4 50.6
0.8
1.0
1.2
2 3 4 50.6
0.8
1.0
1.2
2 3 4 5
Time (s)
−30
−20
−10
0
Cum
ula
tive
Rew
ard
(-)
2 3 4 5
Time (s)
−30
−20
−10
0
2 3 4 5
Time (s)
−30
−20
−10
0
Fig. 8. Comparison of the controlled variables for the 80bar start-up. Shaded area marks the range of the controlled variable for different degradedefficiencies. At different turbine efficiencies the standard open-loop sequence provides significantly different steady-state values for the chamberpressure and the mixture ratios.

WAXENEGGER-WILFING et al.: A REINFORCEMENT LEARNING APPROACH FOR TRANSIENT CONTROL OF LIQUID ROCKET ENGINES 13
0 1 2 3 4 50.0
0.2
0.4
0.6
0.8
1.0
Valv
eP
osi
tion
(-)
VGO VGH VGC VCO VCH
0 1 2 3 4 5
−8
−6
−4
−2
0
Cum
ula
tive
Rew
ard
(-)
total sp GG valve
0 1 2 3 4 5
Time (s)
0
25
50
75
100
125
Pre
ssure
(bar)
CC GG ref
0 1 2 3 4 5
Time (s)
0
2
4
6
8
Mix
ture
Rati
o(-
)
PI GG ref
Fig. 9. 80bar nominal start-up sequence. The main combustion chamber pressure settles at 80bar, while the gas-generator pressure reaches45bar. The reference mixture ratios are given by 5.2 and 0.9. The engine reaches steady-state operating conditions after approximately 4 s. Thecumulative reward for the OLS is dominated by the set-point error rsp.
REFERENCES
[1] S. Colas, S. L. Gonidec, P. Saunois, M. Ganet, A. Remy, and V. Leboeuf,“A point of view about the control of a reusable engine cluster,” inProceedings of the 8th European Conference for Aeronautics and SpaceSciences, Madrid, Spain, 2019.
[2] L. Meland and F. Thompson, “History of the Titan liquid rocketengines,” in 25th Joint Propulsion Conference. Sacramento, CA:American Institute of Aeronautics and Astronautics, 1989.
[3] M. Lausten, D. Rousar, and S. Buccella, “Carbon deposition withLOX/RP-1 propellants,” in 21st Joint Propulsion Conference. Mon-terey,CA: American Institute of Aeronautics and Astronautics, Jul. 1985.
[4] J. A. B. Bossard, “Effect of Propellant Flowrate and Purity on CarbonDeposition in LO2/Methane Gas Generators,” May 1989.
[5] R. J. Roelke, “Miscellaneous losses. [tip clearance and disk friction],”NASA Technical Report, Jan. 1973.
[6] M. E. B. Hampson, “Reusable rocket engine turbopump conditionmonitoring,” in Space Systems Technology, Long Beach, CA, 1984.
[7] C. F. Lorenzo and J. L. Musgrave, “Overview of rocket engine control,”in AIP Conference Proceedings, Albuquerque, NM, 1992.
[8] J.-N. Chopinet, F. Lassoudiere, G. Roz, O. Faye, S. Le Gonidec,P. Alliot, and G. Sylvain, “Progress of the development of an all-electriccontrol system of a rocket engine,” in 48th AIAA/ASME/SAE/ASEE JointPropulsion Conference & Exhibit, Atlanta, Georgia, Jul. 2012.
[9] A. Iannetti, “Prometheus, a LOX/LCH4 reusable rocket engine,” inProceedings of the 7th European Conference for Aeronautics and SpaceSciences, Milano, Italy, Jul. 2017.
[10] H. Asakawa, M. Tanaka, T. Takaki, and K. Higashi, “Component tests ofa LOX/methane full-expander cycle rocket engine: Electrically actuatedvalve,” in Proceedings of the 8th European Conference for Aeronauticsand Space Sciences, 2019.
[11] S. Perez-Roca, J. Marzat, H. Piet-Lahanier, N. Langlois, F. Farago,M. Galeotta, and S. Le Gonidec, “A survey of automatic control methodsfor liquid-propellant rocket engines,” Progress in Aerospace Sciences,May 2019.
[12] V. G. Lopez and F. L. Lewis, “Dynamic Multiobjective Control forContinuous-Time Systems Using Reinforcement Learning,” IEEE Trans-actions on Automatic Control, Jul. 2019.
[13] B. Kiumarsi, K. G. Vamvoudakis, H. Modares, and F. L. Lewis, “Optimaland Autonomous Control Using Reinforcement Learning: A Survey,”IEEE Transactions on Neural Networks and Learning Systems, vol. 29,no. 6, pp. 2042–2062, Jun. 2018.
[14] S. Gu, E. Holly, T. Lillicrap, and S. Levine, “Deep Reinforcement Learn-ing for Robotic Manipulation with Asynchronous Off-Policy Updates,”arXiv:1610.00633 [cs], Nov. 2016.
[15] Z. Yang, K. Merrick, L. Jin, and H. A. Abbass, “Hierarchical DeepReinforcement Learning for Continuous Action Control,” IEEE Trans-actions on Neural Networks and Learning Systems, vol. 29, no. 11, pp.5174–5184, Nov. 2018.
[16] M. Mahmud, M. S. Kaiser, A. Hussain, and S. Vassanelli, “Applicationsof Deep Learning and Reinforcement Learning to Biological Data,”IEEE Transactions on Neural Networks and Learning Systems, vol. 29,no. 6, pp. 2063–2079, Jun. 2018.
[17] S. Heyer, D. Kroezen, and E.-J. Van Kampen, “Online Adaptive In-cremental Reinforcement Learning Flight Control for a CS-25 ClassAircraft,” in AIAA Scitech 2020 Forum, Orlando, FL, Jan. 2020.
[18] B. Gaudet, R. Linares, and R. Furfaro, “Deep reinforcement learning forsix degree-of-freedom planetary landing,” Advances in Space Research,vol. 65, no. 7, pp. 1723–1741, Apr. 2020.
[19] S. Spielberg, R. Gopaluni, and P. Loewen, “Deep reinforcement learningapproaches for process control,” in 2017 6th International Symposium onAdvanced Control of Industrial Processes (AdCONIP). Taipei, Taiwan:IEEE, May 2017, pp. 201–206.
[20] J. L. Musgrave and D. E. Paxson, “A demonstration of an intelligentcontrol system for a reusable rocket engine,” NASA Technical Memo-randum 105794, Jun. 1992.
[21] E. Nemeth, “Reusable rocket engine intelligent control system frame-work design, phase 2,” NASA Contractor Report 187213, Sep. 1991.
[22] S. Perez-Roca, J. Marzat, E. Flayac, H. Piet-Lahanier, N. Langlois,F. Farago, M. Galeotta, and S. L. Gonidec, “An MPC Approach

14 UNDER REVIEW
to Transient Control of Liquid-Propellant Rocket Engines,” IFAC-PapersOnLine, vol. 52, no. 12, pp. 268–273, 2019.
[23] S. Perez-Roca, N. Langlois, J. Marzat, H. Piet-Lahanier, M. Galeotta,F. Farago, and S. L. Gonidec, “Derivation and Analysis of a State-SpaceModel for Transient Control of Liquid-Propellant Rocket Engines,”in 2018 9th International Conference on Mechanical and AerospaceEngineering (ICMAE), Budapest, Jul. 2018.
[24] R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction,ser. Adaptive Computation and Machine Learning Series. Cambridge,MA: The MIT Press, 2018.
[25] D. P. Bertsekas, Reinforcement Learning and Optimal Control. AthenaScientific, 2019.
[26] L. Busoniu, T. de Bruin, D. Tolic, J. Kober, and I. Palunko, “Reinforce-ment learning for control: Performance, stability, and deep approxima-tors,” Annual Reviews in Control, vol. 46, pp. 8–28, 2018.
[27] T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa,D. Silver, and D. Wierstra, “Continuous control with deep reinforcementlearning,” arXiv:1509.02971 [cs, stat], Jul. 2019.
[28] S. Fujimoto, H. van Hoof, and D. Meger, “Addressing Function Approx-imation Error in Actor-Critic Methods,” arXiv:1802.09477, Oct. 2018.
[29] X. Wang, Y. Gu, Y. Cheng, A. Liu, and C. L. P. Chen, “ApproximatePolicy-Based Accelerated Deep Reinforcement Learning,” IEEE Trans-actions on Neural Networks and Learning Systems, vol. 31, no. 6, pp.1820–1830, Jun. 2020.
[30] T. Haarnoja, H. Tang, P. Abbeel, and S. Levine, “Reinforcement Learn-ing with Deep Energy-Based Policies,” arXiv:1702.08165, Jul. 2017.
[31] J. Schulman, S. Levine, P. Moritz, M. I. Jordan, and P. Abbeel, “TrustRegion Policy Optimization,” arXiv:1502.05477 [cs], Apr. 2017.
[32] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov,“Proximal Policy Optimization Algorithms,” arXiv:1707.06347 [cs],Aug. 2017.
[33] M. Jin and J. Lavaei, “Stability-certified reinforcement learning: Acontrol-theoretic perspective,” arXiv:1810.11505 [cs], Oct. 2018.
[34] J. Vila, J. Moral, V. Fernandez-Villace, and J. Steelant, “An Overviewof the ESPSS Libraries: Latest Developments and Future,” in SpacePropulsion, Seville, Spain, 2018.
[35] A. Hill, A. Raffin, M. Ernestus, A. Gleave, A. Kanervisto, R. Traore,P. Dhariwal, C. Hesse, O. Klimov, A. Nichol, M. Plappert, A. Radford,J. Schulman, S. Sidor, and Y. Wu, “Stable baselines,” GitHub repository,2018.
[36] G. Waxenegger-Wilfing, K. Dresia, J. C. Deeken, and M. Oschwald,“Heat Transfer Prediction for Methane in Regenerative Cooling Chan-nels with Neural Networks,” Journal of Thermophysics and Heat Trans-fer, vol. 34, no. 2, pp. 347–357, Apr. 2020.
[37] K. Dresia, G. Waxenegger-Wilfing, J. Riccius, J. Deeken, and M. Os-chwald, “Numerically Efficient Fatigue Life Prediction of Rocket Com-bustion Chambers using Artificial Neural Networks,” in Proceedingsof the 8th European Conference for Aeronautics and Space Sciences.Madrid, Spain: Proceedings of the 8th European Conference for Aero-nautics and Space Sciences. Madrid, Spain, 2019.
[38] A. Iffly and M. Brixhe, “Performance model of the Vulcain Ariane 5main engine,” in 35th Joint Propulsion Conference and Exhibit. LosAngeles,CA: American Institute of Aeronautics and Astronautics, Jun.1999.
[39] R. Ryan and L. Gross, “Effects of geometry and materials on low cyclefatigue life of turbine blades in LOX/hydrogen rocket engines,” in 22ndJoint Propulsion Conference. American Institute of Aeronautics andAstronautics, 1986.
[40] P. Pempie, T. Froehlich, and H. Vernin, “LOX/methane andLOX/kerosene high thrust engine trade-off,” in 37th Joint PropulsionConference and Exhibit. Salt Lake City,UT: American Institute ofAeronautics and Astronautics, Jul. 2001.
[41] P. Cominos and N. Munro, “PID controllers: Recent tuning methodsand design to specification,” IEE Proceedings - Control Theory andApplications, vol. 149, no. 1, pp. 46–53, Jan. 2002.
[42] F.-A. Fortin, F.-M. De Rainville, M.-A. Gardner, M. Parizeau, andChristian Gagne, “DEAP: Evolutionary algorithms made easy,” Journalof Machine Learning Research, vol. 13, pp. 2171–2175, Jul. 2012.
[43] J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel,“Domain randomization for transferring deep neural networks from sim-ulation to the real world,” in 2017 IEEE/RSJ International Conferenceon Intelligent Robots and Systems (IROS), Sep. 2017, pp. 23–30.
[44] J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained PolicyOptimization,” arXiv:1705.10528 [cs], May 2017.
[45] A. Ray, X. Dai, M.-K. Wu, M. Carpino, and C. F. Lorenzo, “Damage-mitigating control of a reusable rocket engine,” Journal of Propulsionand Power, vol. 10, no. 2, pp. 225–234, Mar. 1994.
[46] T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, “Optuna: A next-generation hyperparameter optimization framework,” in Proceedingsof the 25rd ACM SIGKDD International Conference on KnowledgeDiscovery and Data Mining, 2019.
[47] G. E. Uhlenbeck and L. S. Ornstein, “On the Theory of the BrownianMotion,” Physical Review, vol. 36, no. 5, pp. 823–841, Sep. 1930.
Gunther Waxenegger-Wilfing received hisPh.D. degree in theoretical physics from theUniversity of Vienna. He is a senior researchscientist for intelligent engine control at theGerman Aerospace Center (DLR) Institute ofSpace Propulsion and a lecturer at the Univer-sity of Wurzburg. As part of the DLR projectAMADEUS, he manages the investigation of theuse of artificial intelligence in space transporta-tion. He previously was the lead quantitative an-alyst of Nova Portfolio VermogensManagement,
where he focused on applied machine learning, time series analy-sis, and forecasting. Gunther Waxenegger-Wilfings research interestsinclude deep learning for control and condition monitoring, optimalcontrol, model-free as well as model-based reinforcement learning, andapplications in autonomous launch vehicles and landers.
Kai Dresia received his Masters degree inaerospace engineering from RWTH Aachen Uni-versity. In his master thesis, he investigated theapplication of artificial neural networks for heattransfer modeling into supercritical methaneflowing in cooling channels of a regenerativelycooled combustion chamber. He is currently aPh.D. candidate at the German Aerospace Cen-ter (DLR) Institute of Space Propulsion, wherehis work focuses on combining machine learningwith physics-based modeling for rocket engine
control and condition monitoring.
Jan Deeken received his Ph.D. in aerospaceengineering from the university of Stuttgart forhis work on a novel injection concept for gas-liquid injection in high pressure rocket combus-tion chambers. He is currently head of the rocketengine system analysis group within the depart-ment of rocket propulsion at the DLR Instituteof Space Propulsion in Lampoldshausen, Ger-many. He is also managing the DLR LUMENproject, which aims at developing and operatinga LOX/LNG expander-bleed engine testbed in
the 25kN thrust class.
Michael Oschwald is a professor for SpacePropulsion of the RWTH Aachen University andat the same time head of the Department ofRocket Propulsion at the Institute of SpacePropulsion at the German Aerospace Center(DLR). His fields of activity cover all aspects ofrocket engine design and operation with a spe-cific focus on cryogenic propulsion. His depart-ment at DLR has a long heritage in experimentalinvestigations of high-pressure combustion, heattransfer, combustion instabilities, and expansion
nozzles. In parallel to the experimental work, numerical tools are devel-oped in his department to predict the behavior of rocket engines andtheir components.