Embed Size (px)
Citation preview

UKOLN is supported by:
Enhancing access to research data:
the e-Science project eBank UK
www.bath.ac.uk
A centre of expertise in digital information management
2005-09-01 www.ukoln.ac.uk

Enhancing access to research data: overview
• E-Science: impact of digital technologies on research process
• Scholarly knowledge cycle and publication bottleneck
• eBank project: applying digital library techniques to support data curation in crystallography
• Services, metadata, issues; phase 3

Changes in research process
• Increasing data volumes from eScience / Grid-enabled / cyber-infrastructure applications, “big science”, data-driven science
• Changing research methods: high througput technologies, automation, ‘smart labs’
• Potential for re-use of data, new inter-disciplinary research
• Different types of data: observational data, experimental data, computational data: different stewardship and long-term access requirements

Diversity of data collections• Very large, relatively homogeneous: Large-scale Hadron
Collider (LHC) outputs from CERN• Smaller, heterogeneous and richer collections: World Data Centre for
Solar-terrestrial Physics CCLRC• Small-scale laboratory results: “jumping robots” project
at the University of Bath• Population survey data: UK Biobank
• Highly sensitive, personal data: patient care records

Taxonomy of data collections• Research collections:
jumping robots • Community collections:
Flybase at Indiana (with UC Berkeley )
• Reference collections: Protein Data Bank
Source: NSF Long-Lived Digital Data Collections Draft report March 2005
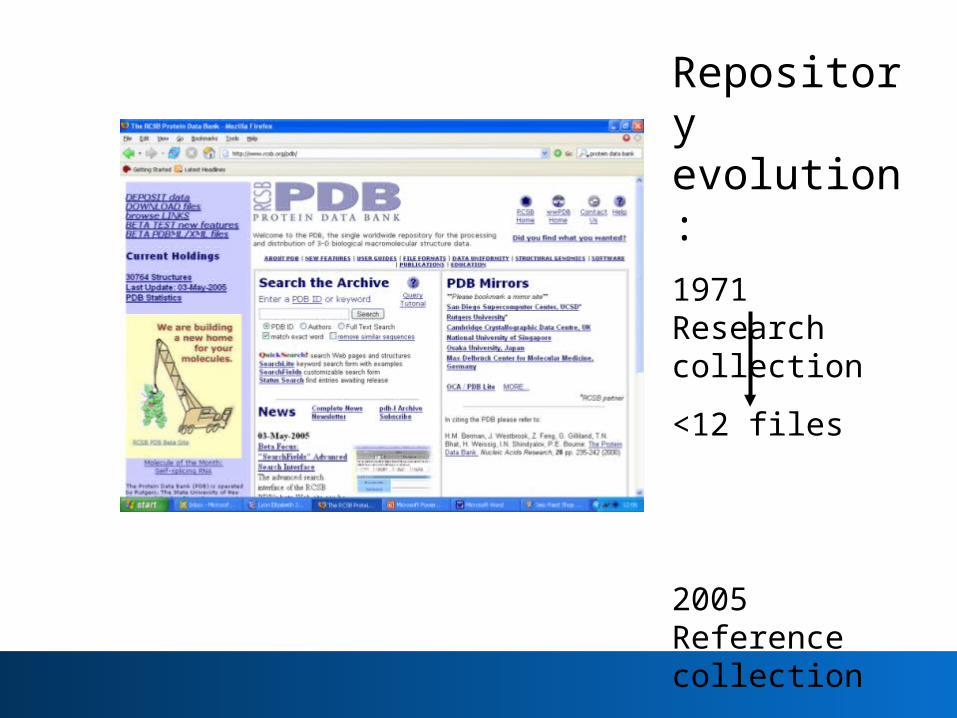
Repository evolution:
1971 Research collection
<12 files
2005 Reference collection
>2700 structures deposited in 6 months

1. Issues: research data as content
• Sharing or not; Open Access to data?• Data diversity
– Homo- or heterogeneous– Raw and derived / processed – Sensitivity– Fast or slow growth in volume
• Repository evolution: – Likelihood to scale up (from bytes to petabytes)– Quality assurance (from the start)– Community-based standards development – Relationship between institutional and subject r’s– Build robust services
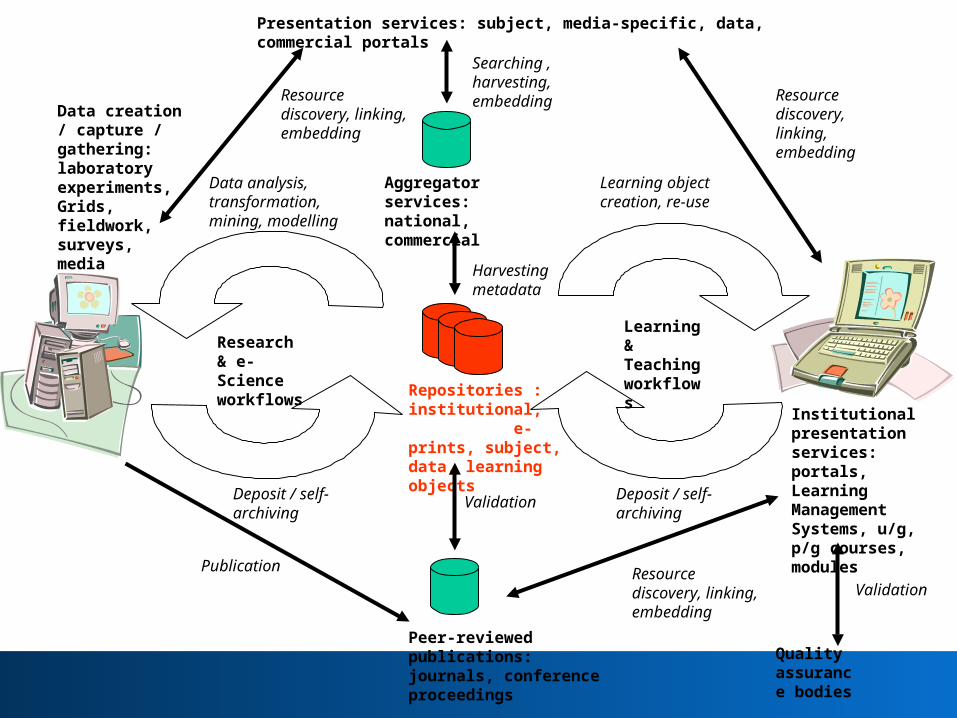
Learning & Teaching workflows
Research & e-Science workflows
Aggregator services: national, commercial
Repositories : institutional, e-prints, subject, data, learning objects
Institutional presentation services: portals, Learning Management Systems, u/g, p/g courses, modules
Harvestingmetadata
Data creation / capture / gathering: laboratory experiments, Grids, fieldwork, surveys, media
Resource discovery, linking, embedding
Deposit / self-archiving
Peer-reviewed publications: journals, conference proceedings
Publication
Validation
Data analysis, transformation, mining, modelling
Resource discovery, linking, embedding
Deposit / self-archiving
Learning object creation, re-use
Searching , harvesting, embedding
Quality assurance bodies
Validation
Presentation services: subject, media-specific, data, commercial portals
Resource discovery, linking, embedding
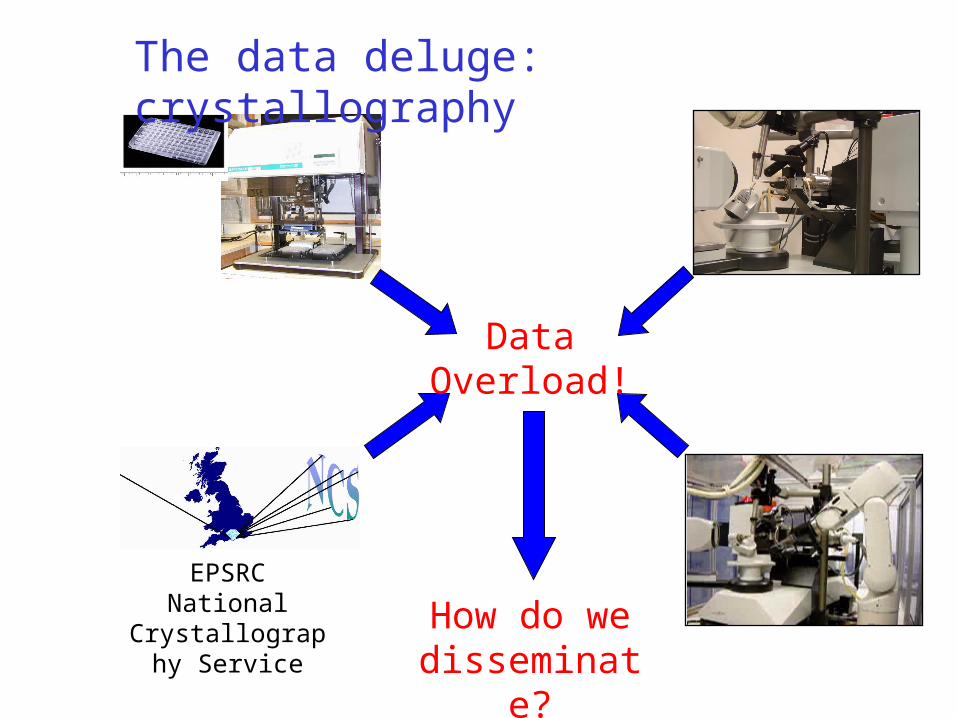
Data Overload!
How do we disseminate?
EPSRC National Crystallography
Service
The data deluge: crystallography
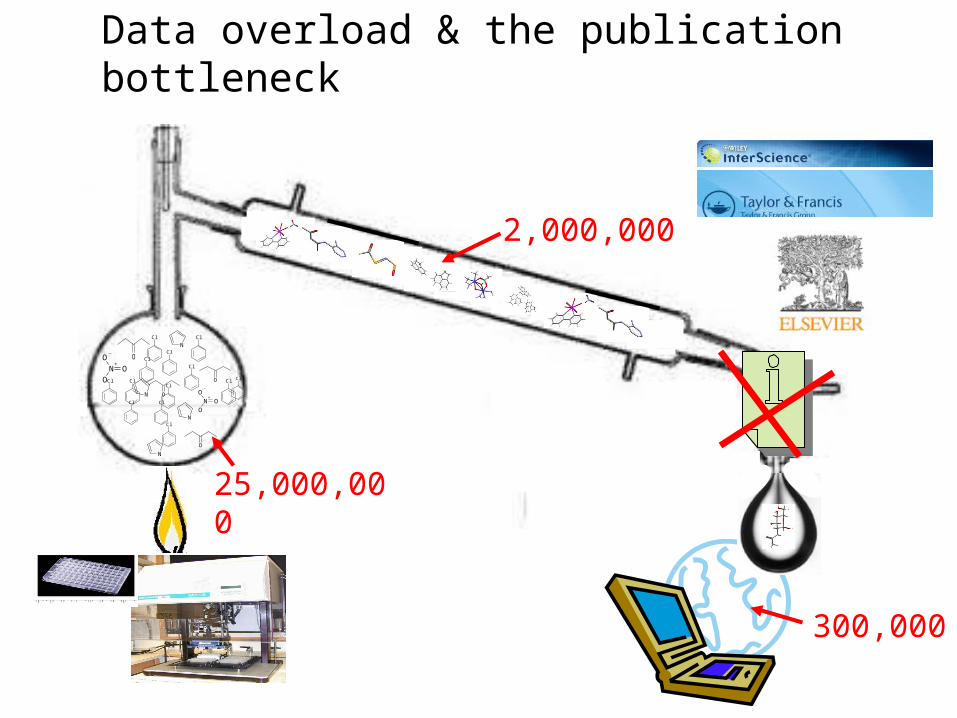
Data overload & the publication bottleneck
Cl
Cl
Cl
Cl
Cl
Cl
ClCl Cl
Cl
Cl
ClCl
O
O
O
O
N
N
N
N
N+
O
O
O
N+
O
O
O
25,000,000
2,000,000
300,000

Current Publishing Process• Journal articles: aims, ideas, context, conclusions – only most significant data
• Raw & underlying data required by peers not readily available

Context: existing data repositories• National data archives:
– UK Data Archive, Arts and Humanities Data Service, US National Archives and Records Administration (NARA), Atlas Datastore
• Discipline specific archives: – GenBank, Protein Data Bank
• Crystallography archives– Cambridge Crystallographic Data Centre (Cambridge
Structural Database) , Indiana University Molecular Structure Center (Crystal Data Server, Reciprocal Net), FIZ Karlsruhe (Inorganic crystals), Toth Information Systems (CHRYSTMET)
• Journals require deposit of data to support articles– Typically deposit of summary data…. partial coverage

eBank UK project overview
• JISC funded in 2003, now in Phase 2 to 2006• Joint effort between crystallographers, computer
scientists, digital library researchers• Investigating contribution of existing digital library
technologies to enable ‘publication at source’• Partners have interest in dissemination of
chemistry research data, open access, OAI, institutional repositories http://www.ukoln.ac.uk/projects/ebank-uk/

eBank project team
University of Bath, UKOLN (lead)• Monica Duke, Rachel Heery, Traugott Koch, Liz
Lyon, University of Southampton, School of Chemistry• Simon Coles, Jeremy Frey, Mike HursthouseUniversity of Southampton, School of Electronics
and Computer Science• Leslie Carr, Chris GutteridgeUniversity of Manchester, PSIgate (physical
sciences portal in RDN)• John Blunden-Ellis

eBank phase one: achievements• Gathered requirements from crystallographers • Established pilot institutional repository for
crystallography data at Southampton with web interface
• Developed a demonstrator aggregator service at UKOLN (CCDC exploring aggregation service)
• Developed appropriate schema • Demonstrated a search interface as an embedded
service at PSIgate portal• Demonstrated an added value service linking
research data to papers (one-off)

Institutional repositories…publication at source
• Institution establishes repository(s)• Institution pro-actively supports deposit
process• OAI provides basis for interoperability • Potential for added value services
• And/Or ….international subject based archives?

Crystallography good fit….
• Crystallography has well defined data creation workflow
• Tradition of sharing using standard file format
• Crystallography Information File (CIF)
• What about other chemistry sub-disciplines? other scientific disciplines?

eBank: UK e-Science testbed ‘Combechem’
– Grid-enabled combinatorial chemistry– Crystallography, laser and surface chemistry
examples– Development of an e-Lab using pervasive
computing technology– National Crystallography Service at
Southampton
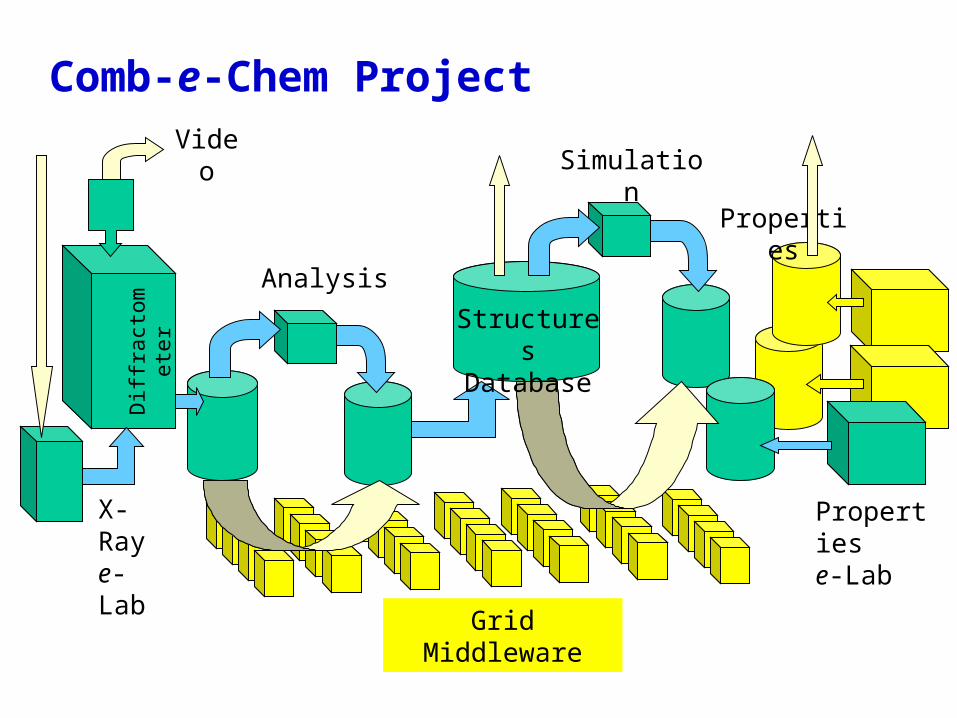
Comb-e-Chem Project
X-Raye-Lab
Analysis
Properties
Propertiese-Lab
SimulationVideo
Diff
ract
omet
er
Grid Middleware
StructuresDatabase

Crystallography workflowRAW DATA DERIVED DATA RESULTS DATA
• Initialisation: mount new sample on diffractometer & set up data collection
• Collection: collect data• Processing: process and correct images• Solution: solve structures• Refinement: refine structure• CIF: produce CIF (Crystallographic Information File)• Validation: chemical & crystallographic checks
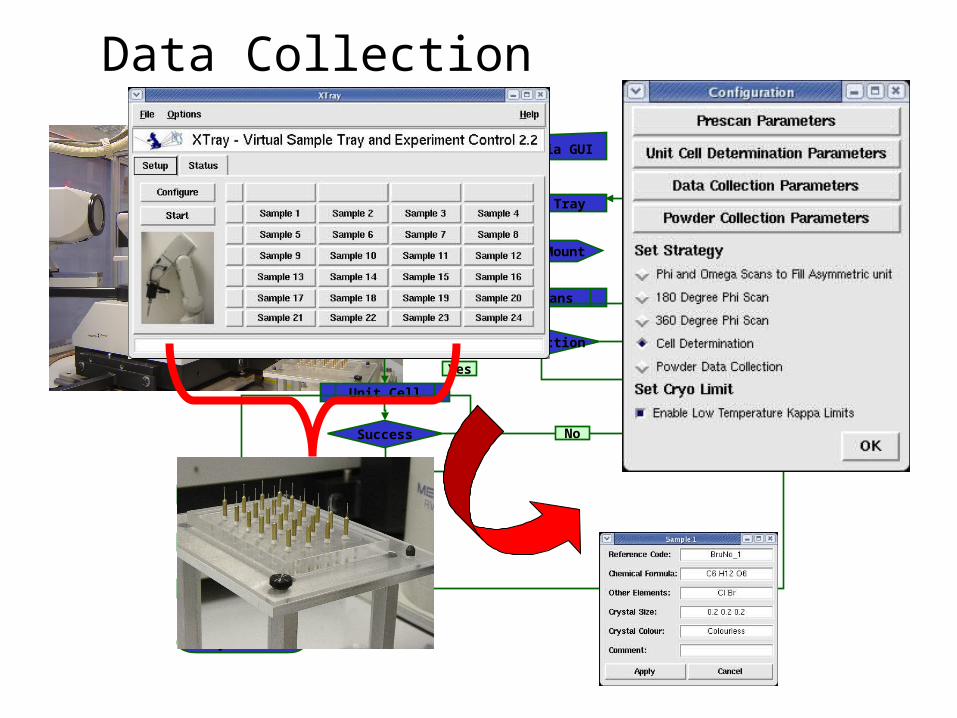
Data Collection
Diffraction
Unit Cell
Success
Strategy
Data Collection
Data Process
System Y
PreScans
Yes
Yes
BruNo Mount
BruNo Unmount
Setup via GUI
Sample Tray
No
No
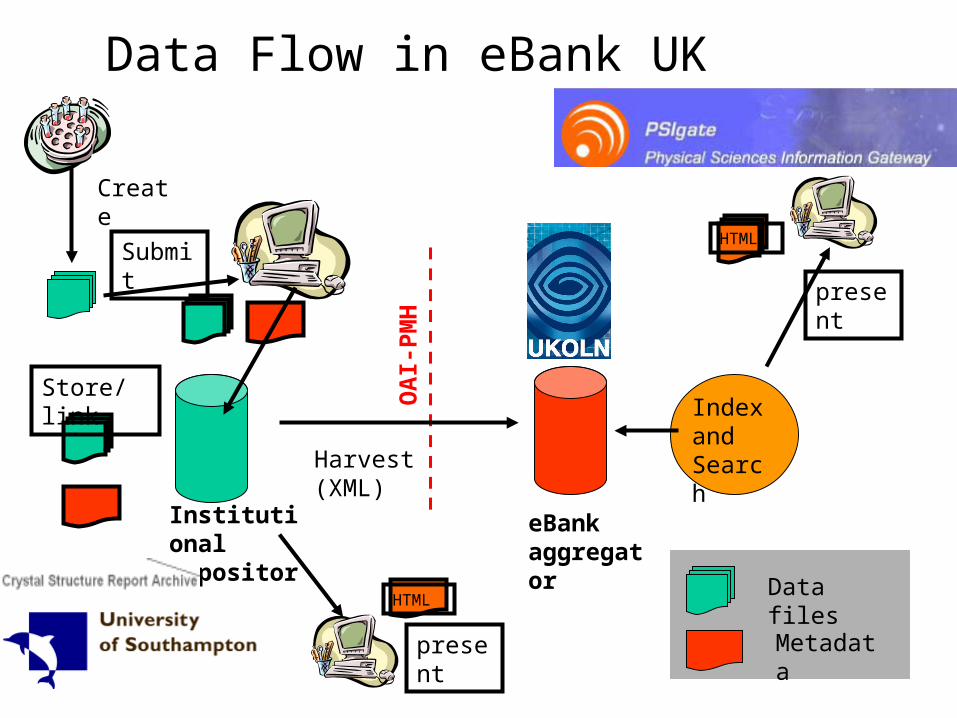
Data Flow in eBank UK
OA
I-P
MH
Submit
Store/link
Harvest (XML)
Index and Search
Data files
Metadatapresent
HTML
present
HTML
Institutional repository
eBank aggregator
Create
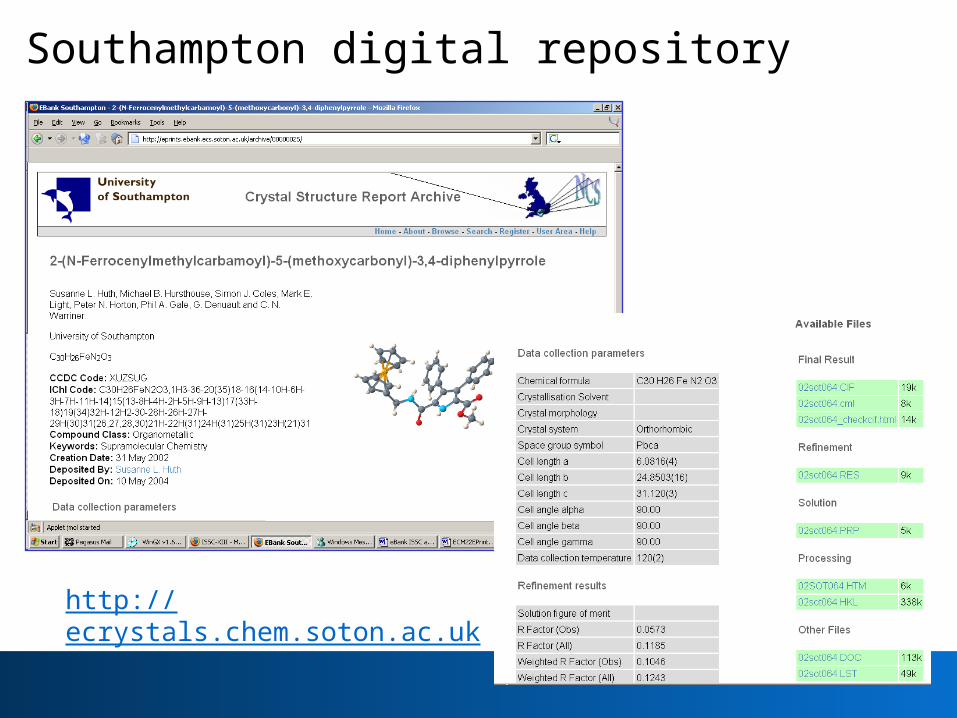
Southampton digital repository
http://ecrystals.chem.soton.ac.uk
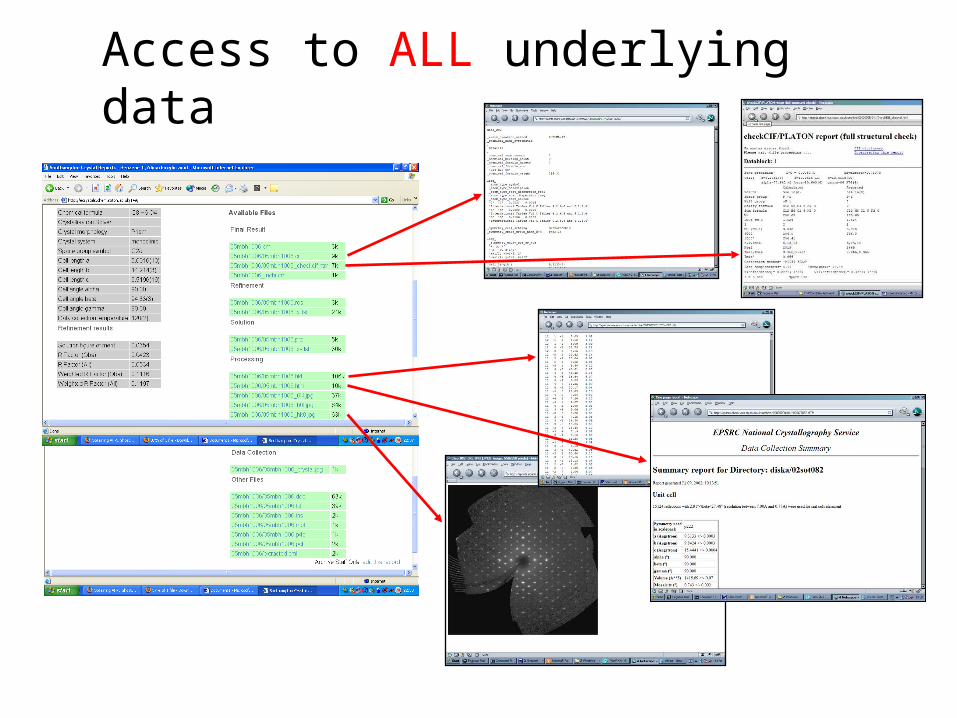
Access to ALL underlying data
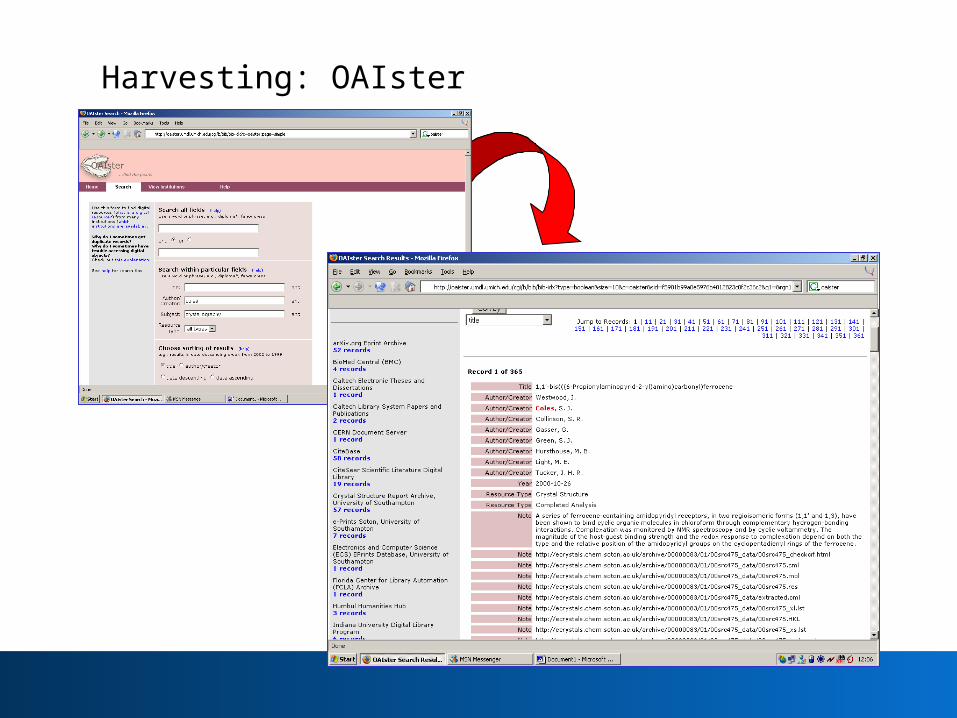
Harvesting: OAIster
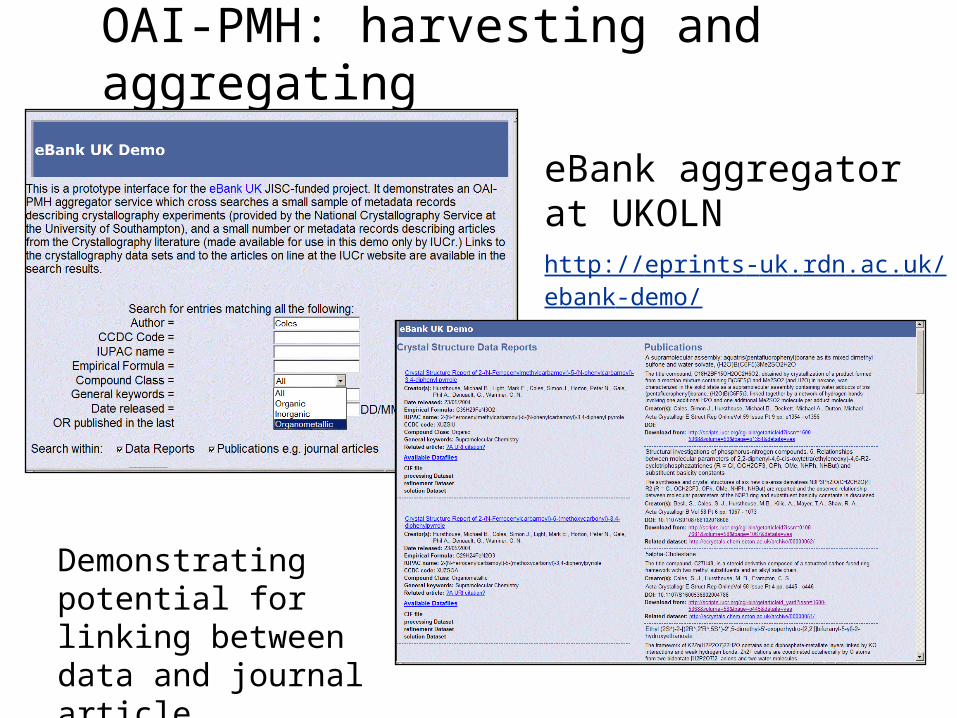
OAI-PMH: harvesting and aggregating
eBank aggregator at UKOLNhttp://eprints-uk.rdn.ac.uk/ebank-demo/
Demonstrating potential for linking between data and journal article
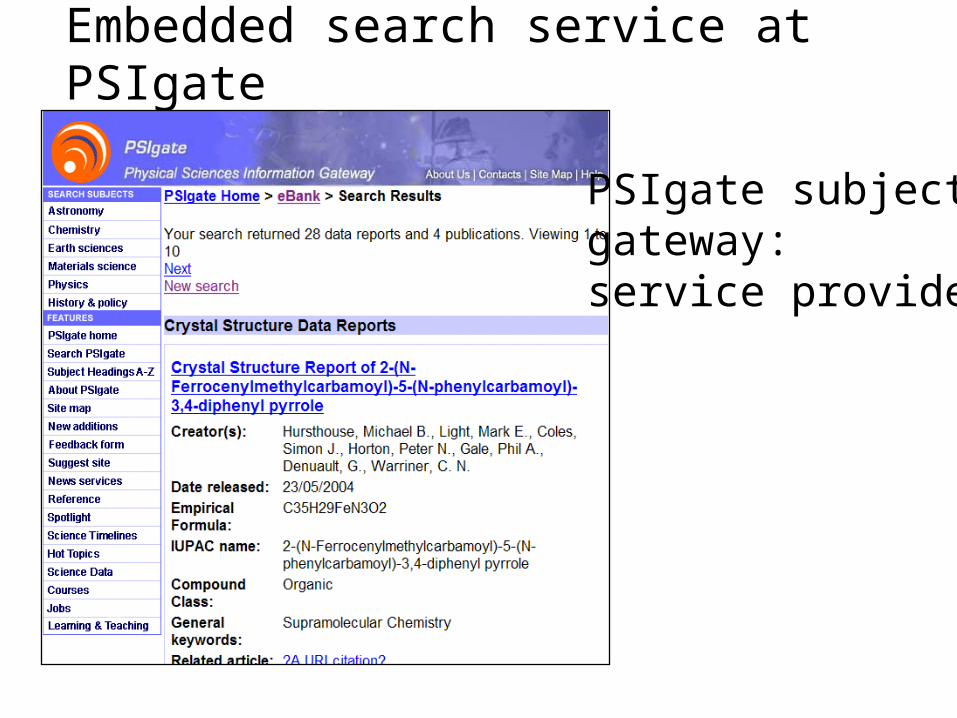
Embedded search service at PSIgate
PSIgate subject gateway:service provider

Schema for records made available for harvesting• Data holding (collection of files associated with
experiment)• Qualified Dublin Core data elements plus additional chemical
properties – Chemical formula– International Chemical Identifier (InChI)– Compound Class
• Individual data files• Separate records for stage status of each file
• Description set wrapped into one XML record using METS
• Research metadata/data as a complex object
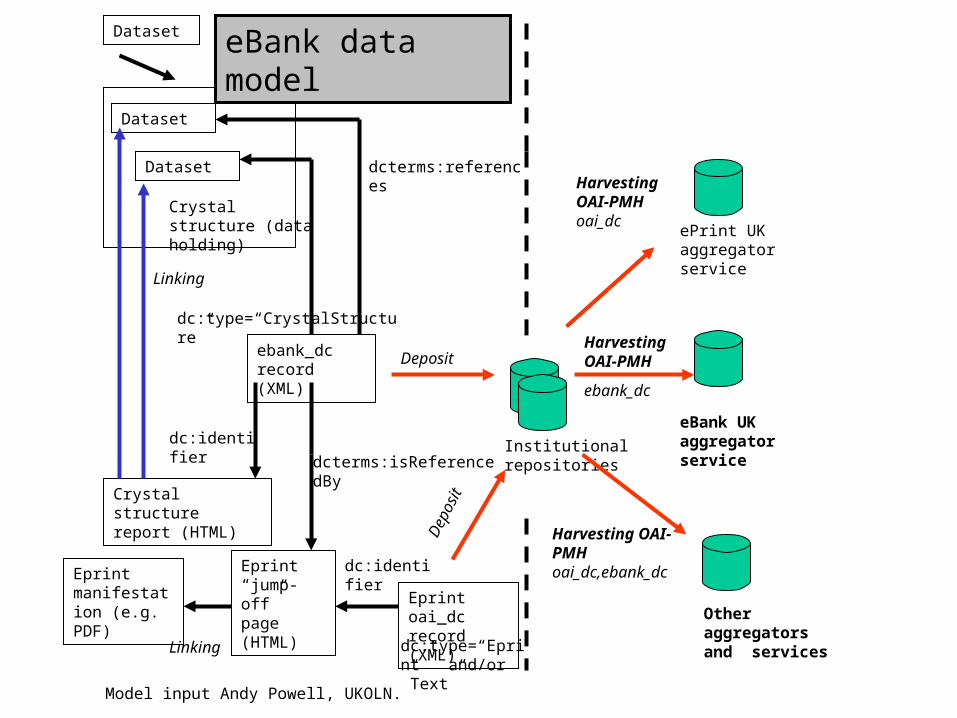
ebank_dc record (XML)
Crystal structure (data holding)
Crystal structure report (HTML)
Dataset
Dataset
Institutional repositories
eBank UK aggregator service
ePrint UK aggregator service
Other aggregators and services
DepositHarvesting OAI-PMH
ebank_dc
Harvesting OAI-PMH oai_dc,ebank_dc
Harvesting OAI-PMH oai_dc
Dataset
dc:identifier
dcterms:references
Linking
dc:type=“CrystalStructure”
Model input Andy Powell, UKOLN.
Eprint oai_dc record (XML)
dcterms:isReferencedBy
dc:type=“Eprint” and/or ”Text”
eBank data model
Eprint “jump-off” page (HTML)
dc:identifierEprint manifestation (e.g. PDF)
Linking
Dep
osit

Creating the metadata
• Potential to embed ‘deposit and disseminate’ into workflow of chemist in automated way

eBank phase two work areas
• Sub-disciplines of chemistry, earth sciences, engineering
• Pursue generic data model• Use of identifiers for citing datasets• Subject approach to discovering research
data (keywords, classification, ontology)• Access to research data in teaching and
learning context• Liaise with other digital repository initiatives

Related UK projects
• National e-Science Centre NESC• NERC Data Grid (Athmospheric and Oceanographic Data
Centres)• JISC Digital Repositories Programme: - Spectra (experim. chemistry, high volume
ingestion) - R4L (lab equipment, metadata generation)
- CLADDIER (citation, identifiers, linking) - StORe (data and publ. repository links) - GRADE (reuse of geospatial data)

2. Issues: generic data models, metadata schema & terminology
• Validation against generic schema– CCLRC Scientific Data Model Vs 2
• Complex digital objects and packaging options – METS– MPEG 21 DIDL
• Terminologies– Domain: crystallography– Inter-disciplinary e.g. biomaterials– Metadata enhancement: subject keyword additions to
datasets based on related publications – Meaningful resource discovery?

3. Issues: linking
• Links to individual datasets within an experiment• Links to all datasets associated with an experiment or a data
collection• Links to derived eprints and published literature • Context sensitive linking: find me
– Datasets by this author / creator– Datasets related to this subject– Learning objects by this author / creator– Learning objects related to this subject
• Identifiers and persistence– “generic” – domain: International Chemical Identifier (InChI code)
• Resource discovery : Google Scholar?• Provenance: authenticity, authority, integrity?

4. Issues: identifiers
• Identifiers and persistence– “generic”: DOI, PURL, Handle, ARK – domain: International Chemical Identifier (InChI)– Resolution; lookup
• Resource discovery : Google Scholar?• Granularity (metadata, linking)?• Provenance: authenticity, authority, integrity?

5. Issues: embedding and workflow
• Into the crystallographic publishing community International Union of Crystallography
• Into the chemistry research workflow– SMART TEA Digital Lab Book e-synthesis Lab– Other analytical techniques and instrumentation
• Into the curriculum and e-Learning workflows– MChem course – Undergraduate Chemical Informatics courses

For the future…
• Who provides added value services?– Authority files, automated subject indexing,
annotation, data mining, visualisation
• What are the preservation issues?– UK Digital Curation Centre http://www.dcc.ac.uk
– National Science Board Draft report on long-lived data collections http://www.nsf.gov/nsb/meetings/2005/LLDDC_draftreport.pdf
• How to manage complex objects descriptions within OAI ?
• Digital curation of research data presents new roles for scientists, computer scientists, data managers….

For later use? In use now (and the future)?
Repositories and digital curation
Data preservation Data curation
Static Dynamic
“maintaining and adding value to a trusted body of digital information for current and future use”

Provide value-added services
Annotation
• e-Lab books (Smart Tea Project in chemistry)
• Gene and protein sequences

Enable “post-processing” and knowledge extraction
The acquisition of newly-derived information and knowledge from repository content
• Run complex algorithms over primary datasets
• Mining (data, text, structures)
• Modelling (economic, climate, mathematical, biological)
• Analysis (statistical, lexical, pattern matching, gene)
• Presentation (visualisation, rendering)

6. Issues: “knowledge services”
• Layered over repositories– Annotation– Mining, modelling, analysis– Visualisation
• Across multiple repositories– Grid enabled applications– Highly distributed, dynamic and collaborative
• Associated with curatorial responsibility– UK Digital Curation Centre
http://www.dcc.ac.uk

Issues summary1. Research data is diverse, increasing rapidly in
volume and complexity2. Repository collections are dynamic and evolve3. Technical challenges associated with
interoperability, persistence, provenance, resource discovery and infrastructure provision
4. Embedding in workflow is critical: scholarly communications, research practice, learning
5. Knowledge extraction tools will generate new discoveries based on repository content
6. Repository solutions must scale: M2M processing will become the norm

Project homepage:http://www.ukoln.ac.uk/projects/ebank-uk/
Duke, M. et al: Enhancing access to research data: the challenge of crystallography. JCDL 2005.http://www.ukoln.ac.uk/projects/ebank-uk/dissemination/jcdl2005/preprint.pdf
Acknowledgement to all project partners for their contributions to this presentation.




























