Embed Size (px)
Citation preview

TWITTER SENTIMENT ANALYSISAND VISUALIZATION USING
APACHE SPARK ANDELASTICSEARCH
Maragatham G1, ShobanaDevi A2
1Research Supervisor, 2Research Scholar,Department of Information & Technology,
SRM University, Chennai, [email protected]
July 25, 2018
Abstract
Sentiment analysis on Twitter data has paying more at-tention recently. The systems key feature, is the immediatecommunication with other users in an easy, fast way anduser-friendly too. Sentiment analysis is the process of iden-tifying and classifying opinions or sentiments expressed insource text. There is a huge volume of data present in theweb for internet users and a lot of data is generated per sec-ond due to the growth and advancement of web technology.Nowadays, Internet has become best platform to share ev-eryone’s opinion, to exchange ideas and to learn online. Peo-ple are using social network sites like facebook, twitter and ithas gained more popularity among them to share their viewsand pass messages about some topics around the world. Inthe form of tweets, status updates and blog posts, the socialmedia is generating a vast amount of sentiment rich data.This user generated sentiment analysis data is very useful inknowing the opinion of the people crowd. When compared
1
International Journal of Pure and Applied MathematicsVolume 120 No. 6 2018, 10335-10356ISSN: 1314-3395 (on-line version)url: http://www.acadpubl.eu/hub/Special Issue http://www.acadpubl.eu/hub/
10335

to general sentiment analysis the twitter sentiment analysisis much difficult due to its slang words and misspellings.Twitter allows 140 as the maximum limit of characters permessage. The two strategies that are mainly used for textanalysis is knowledge base approach and machine learningapproach. In this paper, we analyzed the twitter generatedposts using Machine Learning approach. Performing senti-ment analysis in a specific domain, is to identify the effectof domain information in sentiment classification. we clas-sified the tweets as positive, negative and extract differentpeoples’ information about that particular domain. In thispaper, we developed a novel method for sentiment learningusing the Spark coreNLP framework. Our method exploitsthe hashtags and emoticons inside a tweet, as sentiment la-bels, and proceeds to a classification procedure of diversesentiment types in a parallel and distributed manner.
1 Introduction
Nowadays, people be likely to disseminate information, using short140-character messages called ”tweets”, for various aspects on Twit-ter. Additionally, they follow other users in sequence to receivetheir status updates on tweets. In nature, Twitter has a wide dis-tribution instant messaging platform and people are using that toget informed about world news, current scientific advancements,etc. Unavoidably, a variety of view clusters that includes a wealthysentiment information is formed. Sentiment is termed as ”A wayof expressing one’s thought, view, or attitude, particularly basedmainly on emotion instead of reason” and it also describes some-one’s mood or critic towards a particular entity or domain[3, 5].
The information about overall sentiment tendency towards aspecific topic may be used enormously in certain cases. For repre-sentation, assume a mechanical organization would be intrigued tothink about their client’s perspectives about the most recent item,with a specific end goal to get accommodating criticism that willuse in the creation of the next device[6, 7].
In this way, clearly a comprehensive feeling examination for aday and age after the arrival of the new item is required. In addi-tion [4, 6], client produced content that catches opinion data has
2
International Journal of Pure and Applied Mathematics Special Issue
10336

turned out to be important among numerous web applications anddata frameworks, for example, web crawlers or proposal systems.In the setting of this work, we use hash tags and emojis as sup-position marks to perform characterization of different slant writes[23]. Hash tags are a tradition for including extra setting and meta-data and are widely used in tweets. Their use is twofold: they givearrangement of a message as well as feature of a point and they en-hance the seeking of tweets that allude to a typical subject. A hashtag is made by prefixing a word with a hash symbol (e.g. love).Emoji alludes to a computerized symbol or an arrangement of con-sole images that serves to speak to an outward appearance, as :-( for a pitiful face. Both, hashtags and emojis, give a fine-grainedsupposition learning at tweet level which makes them reasonable tobe utilized for assessment mining.
The issue of opinion investigation has been contemplated widelyamid late years. The greater part of existing arrangements is lim-ited in brought together conditions and base on characteristic di-alect handling strategies and machine learning approaches. Be thatas it may, this sort of strategies are tedious and computationallyserious [16, 22]. Thus, it is restrictive to process in excess of a cou-ple of thousand tweets without surpassing the abilities of a solitaryserver. Unexpectedly, a large number of tweets are distributed dayby day on Twitter. Subsequently, underline arrangements are nei-ther adequate nor appropriate for conclusion mining, since thereis an enormous bungle between their preparing abilities and theexponential development of accessible information [16]. It is morethan clear that there is a basic need to swing to high adaptable ar-rangements. Distributed computing innovations give instrumentsand foundation to make such arrangements and deal with the in-formation distributed among various servers. The most conspicuousand strikingly effective instrument is the MapReduce programmingmodel [7], created by Google, for handling extensive scale informa-tion. [13, 21]
3
International Journal of Pure and Applied Mathematics Special Issue
10337

2 Preliminaries
2.1 Previous Work
In spite of the fact that the idea of notion examination, or suppo-sition mining, is generally new, the exploration around this area isvery broad. Early examinations center around report level suppo-sition investigation concerning motion picture or item audits [11,30] and posts distributed on site pages or online journals [29]. Be-cause of the multifaceted nature of record level supposition mining,numerous endeavors have been made towards the sentence levelsentiment analysis. The arrangements exhibited in inspect expres-sions and dole out to every last one of them a conclusion extremity(positive, negative, nonpartisan) [25, 26, 28]. A less researchedzone is the theme based assessment examination [15, 17] becauseof the trouble to give a satisfactory meaning of point and how toconsolidate the slant factor into the conclusion mining undertak-ing. The most widely recognized ways to deal with go up againstthe issue of sentiment examination incorporate machine learning aswell as characteristic dialect preparing procedures. In, the creatorsutilize [20] Naive Bayes, Maximum Entropy and Support VectorMachines to characterize film audits as positive or negative, andperform a correlation between the techniques as far as order exe-cution. Then again, Nasukawa and Yi [18] endeavor to distinguishsemantic connections between the estimation articulations and thesubject. Together with a syntactic parser and an opinion vocab-ulary their approach figures out how to expand the precision ofassumption investigation within web pages and online articles. Be-sides, Ding and Liu [8] characterize an arrangement of semanticprinciples together with another conclusion total capacity to dis-tinguish slant introductions in online item surveys. Amid the mostrecent five years, Twitter has gotten much consideration for as-sumption investigation. In [2], the creators continue to a 2-steporder process. In the initial step, they isolate messages as sub-jective and objective and in the second step they recognize thesubjective tweets as positive or negative. Davidov et al. [6] as-sess the commitment of various highlights (e.g. n-grams) togetherwith a kNN classifier. They exploit the hashtags and smileys intweets to characterize assumption classes and to keep away from
4
International Journal of Pure and Applied Mathematics Special Issue
10338

manual explanation. In this paper, we embrace this approach andincredibly extend it to help the investigation of substantial scaleTwitter information. Agarwal et al. [1] examine the utilization of atree piece model for distinguishing opinion introduction in tweets.A three-advance classifier is proposed in [12] that takes after anobjective ward estimation order system. Besides, a diagram basedmodel is proposed in [23] to perform assessment mining in Twit-ter information from a point based viewpoint. A later approach[27], fabricates a supposition and emoji vocabulary to help multidimensional slant investigation of Twitter information. A vast scalearrangement is introduced in [14] where the creators assemble anopinion vocabulary and characterize tweets utilizing a MapReducecalculation and a disseminated database show. In spite of the factthat the precision of the technique is great, it experiences the te-dious development of the supposition vocabulary. Our approach issubstantially less complex and completely misuses the abilities ofSpark system. To our best learning, we are the first to introducea Spark-based extensive scale approach for conclusion mining onTwitter information without the need of building an assumptionvocabulary or continuing to any manual information explanation.
2.2 Spark Framework
Apache Spark [13, 21] is a quick and general motor for extensivescale information handling. Basically, it is the advancement ofHadoop [10, 24] structure. Hadoop is the open source execution ofthe MapReduce demonstrate and is broadly utilized for conveyedpreparing among various servers. It is perfect for cluster based pro-cedures when we have to experience all information. Be that as itmay, its execution drops quickly for certain issue writes (e.g. whenwe need to manage iterative or chart based calculations). Spark is abrought together pile of different firmly coordinated segments andconquers the issues of Hadoop. It has a Directed Acyclic Graph(DAG) execution motor that backings cyclic information streamand in-memory registering. Subsequently, it can run programs upto 100x quicker than Hadoop in memory, or 10x speedier on plate.Start incorporates a heap of libraries that consolidate SQL, gushing,machine learning and diagram handling in a solitary motor. Startoffers some abnormal state systems, for example, reserving and
5
International Journal of Pure and Applied Mathematics Special Issue
10339

makes simple to construct circulated applications in Java, Python,Scala and R. The applications are converted into MapReduce em-ployments and keep running in parallel. Besides, Spark can get tovarious information sources, for example, HDFS or HBase [30].
3 Sentiment Analysis Framework
3.1 Spark CoreNLP
Our pipeline system was initially designed for internal use. Previ-ously, when combining multiple natural language analysis compo-nents, each with their own ad hoc APIs, we had tied them togetherwith custom glue code. The resulting Annotation, containing allthe analysis information added by the Annotators, can be outputin XML or plain text forms.annotation pipeline was developed in2006 in order to replace this jumble with something better. A uni-form interface was provided for an Annotator that adds some kindof analysis information to some text. An Annotator does this bytaking in an Annotation object to which it can add extra informa-tion. An Annotation is stored as a type safe heterogeneous map,following the ideas for this data type presented by Bloch (2008).This basic architecture has proven quite successful, and is still thebasis of the system described here.
The inspirations were:
• To have the capacity to rapidly and effortlessly get semanticcomments for a content.
• To shroud varieties crosswise over segments behind a typicalAPI.
• To have a negligible theoretical impression, so the frameworkis anything but difficult to learn.
• To give a lightweight system, utilizing plain Java objects (asopposed to something of heavier weight, for example, XMLor UIMA’s CommonAnalysis System (CAS) objects).
In 2009, at first as a feature of a multi-site grant project, theframework was stretched out to be all the more effortlessly usable
6
International Journal of Pure and Applied Mathematics Special Issue
10340

by a more extensive scope of clients. We provided a commandline interface and the capacity to write out an Annotation in dif-ferent arrangements, including XML. Additionally work promptedthe framework being released as free open source programming in2010. From one perspective, from a compositional point of view,Stanford CoreNLP does not endeavor to do everything. It is simplya straight forward pipeline engineering. It gives just a Java API.1Itdoes not endeavor to give various machine scale-out (however itprovides multi-threaded processing on a solitary machine). It givesa simple concrete API. In any case, these prerequisites satisfy asubstantial level of potential clients, and the resulting simplicitymakes it less demanding for clients to get started with the system.That is, the essential preferred standpoint of Stanford CoreNLPover bigger systems like UIMA (Ferrucci and Lally, 2004) or GATE(Cunningham et al., 2002) is that clients do not need to learn UIMAor GATE before they can get began; they just need to know a littleJava [25, 28].
By and by, this is an extensive and essential differentiator. Ifmore mind boggling situations are required, for example, variousmachine scale-out, they can regularly be accomplished by runningthe investigation pipeline inside a framework that spotlights on ap-propriated workflows(such as Hadoop or Spark). Different frame-works endeavor to give all the more, for example, the UIUC Cura-tor(Clarke et al., 2012), which incorporates bury machine customerserver correspondence for preparing and the storing of normal di-alect examinations. Yet, this usefulness includes some significantdownfalls. The framework is unpredictable to introduce and com-plex to get it. In addition, by and by, an association may wellbe focused on a scale-out arrangement which is not the same asthat gave by the characteristic dialect examination toolbox. For in-stance, they might utilize Kryo [30] or Google’s proto yet for doubleserialization as opposed to Apache Thrift which underlies Curator.For this situation, the client is ideally serviced by a genuinely littleand independent common dialect examination framework, insteadof something which accompanies a great deal of things for a widerange of purposes, the greater part of which they are not utilizing.
Then again, most clients advantage enormously from the ar-rangement of an arrangement of steady, powerful, high. All thingsconsidered, it can call an investigation segment written in different
7
International Journal of Pure and Applied Mathematics Special Issue
10341

dialects through a fitting wrapper Annotator, and thus, it has beenwrapped by numerous individuals to give Stanford CoreNLP tiesto different dialects. Quality semantic investigation parts, whichcan be effortlessly summoned for normal situations. While the de-veloper of a bigger framework may have settled on general plandecisions, for example, how to deal with scale out, they are prob-ably not going to be a NLP master, and are henceforth searchingfor NLP segments that simply work. This is a colossal preferredstandpoint that Stanford CoreNLP and GATE have over the va-cant tool compartment of an Apache UIMA download, somethingtended to some extent by the advancement of all around incorpo-rated part bundles for UIMA, for example, ClearTK (Bethard et al.,2014) [29], DKPro Core(Gurevych et al., 2007), and JCoRe (Hahnet al.,2008). In any case, the arrangement gave by these bundlesstays harder to learn, more intricate and heavier weight for clientsthan the pipeline portrayed here.
Practically speaking, this is a huge and essential differentia-tor. In the event that more unpredictable situations are required,for example, different machine scale-out, they can ordinarily be ac-complished by running the examination pipeline inside a frameworkthat spotlights on dispersed workflows(such as Hadoop or Spark).Different frameworks endeavor to give all the more, for example, theUIUC Curator(Clarke et al., 2012), which incorporates bury ma-chine customer server correspondence for preparing and the storingof characteristic dialect examinations. In any case, this usefulnessincludes some major disadvantages. The framework is perplexingto introduce and complex to get it. In addition, practically speak-ing, an association may well be focused on a scale-out arrangementwhich is unique in relation to that gave by the normal dialect in-vestigation toolbox. For instance [9, 10], they might utilize Kryoor Google’s proto yet for paired serialization as opposed to ApacheThrift which underlies Curator.
For this situation, the client is ideally serviced by a genuinelylittle and independent regular dialect investigation framework, in-stead of something which accompanies a considerable measure ofstuff for a wide range of purposes, the greater part of which they arenot utilizing. Then again, most clients advantage extraordinarilyfrom the arrangement of an arrangement of steady, powerful, high.In any case, it can call an examination part written in different di-
8
International Journal of Pure and Applied Mathematics Special Issue
10342

alects by means of a suitable wrapper Annotator, and thusly, it hasbeen wrapped by numerous individuals to give Stanford CoreNLPties to different dialects. Quality semantic investigation segments,which can be effortlessly conjured for regular situations. While themanufacturer of a bigger framework may have settled on generaloutline decisions, for example, how to deal with scale out, theyare probably not going to be a NLP master, and are consequentlysearching for NLP segments that simply work. This is an enormousfavorable position that Stanford CoreNLP and GATE have over thevoid tool compartment of an Apache UIMA download, somethingtended to a limited extent by the advancement of all around incor-porated part bundles for UIMA, for example, ClearTK (Bethard etal., 2014), DKPro Core(Gurevych et al., 2007) [21, 23], and JCoRe(Hahn et al.,2008). Be that as it may, the arrangement gave bythese bundles stays harder to learn, more unpredictable and heavierweight for clients than the pipeline portrayed here. The frameworkcomes bundled with models for English. Isolate display bundlesoffer help for Chinese and for the case-obtuse handling of English.Support for different dialects is less total, yet a considerable lot ofthe Annotators likewise bolster models for French, German, andArabic (see supplement B), and building models for facilitating di-alects is conceivable utilizing the hidden instruments. In this area,we plot the gave annotators, concentrating on the English variants.It ought to be noticed that a portion of the model’s basic annota-tors are prepared from explained corpora utilizing directed machinelearning, while others are lead-based parts, which all things consid-ered frequently require some dialect assets of their own. tokenize[2, 15] Tokenizes the content into an arrangement of tokens. TheEnglish segment gives a PTB style tokenizer, stretched out to sen-sibly deal with boisterous and web content. The relating segmentsfor Chinese and Arabic give word what’s more, clitic division. Thetokenizer spares the character balances of every token in the infor-mation content. Clean XML Removes most or all XML labels fromthe records split Splits a grouping of tokens into sentences genuinecase Determines the imaginable genuine instance of tokens in con-tent (that is, their conceivable case in very much altered content),where this data was lost, e.g., for all capitalized content. This is ac-tualized with a discriminative model utilizing a CRF arrangementtagger (Finkel et al., 2005) [19, 22].
9
International Journal of Pure and Applied Mathematics Special Issue
10343

3.2 Elasticsearch
Elasticsearch is an Apache Lucene-based hunt server. It was createdby Shay Banon and distributed in 2010. It is currently kept up byElasticsearch BV. Its most recent variant is 2.1.0. Elasticsearch is acontinuous conveyed and open source full-content hunt and exam-ination motor. It is available from RESTful web benefit interfaceand utilizations pattern less JSON (JavaScript Object Notation)reports to store information. It is based on Java programming di-alect, which empowers Elasticsearch to keep running on variousstages. It empowers clients to investigate extensive measure of in-formation at rapid. The general highlights of Elasticsearch will be,Elasticsearch is versatile up to petabytes of organized and unstruc-tured information. Elasticsearch can be utilized as a substitutionof archive stores like MongoDB and RavenDB. Elasticsearch uti-lizes denormalization to enhance the hunt execution. Elasticsearchis one of the well known endeavor web crawlers, which is presentlybeing utilized by numerous enormous associations like Wikipedia,The Guardian, Stack Overflow, GitHub and so on. Elasticsearch isopen source and accessible under the Apache permit version 2.0.
3.2.1 Elasticsearch Key Concepts
The key ideas of Elasticsearch are as per the following:
• Node: It alludes to a solitary running occurrence of Elastic-search. Single physical and virtual server obliges various hubsrelying on the abilities of their physical assets like RAM, Stackand processing power.
• Cluster: It is an accumulation of at least one hubs. Clustergives aggregate ordering what’s more, look capacities overevery one of the hubs for whole information.
• Index: It is an accumulation of various kind of reports andrecord properties. File additionally utilizes the idea of shardsto enhance the execution. For instance, a set of report con-tains information of a person to person communication appli-cation.
• Type/Mapping: It is an accumulation of records sharing anarrangement of normal fields introduce in a similar record.
10
International Journal of Pure and Applied Mathematics Special Issue
10344

For instance, an Index contains information of a social or-ganizing application, and afterward there can be a particularkind for client profile information, another write for informinginformation and another for remarks information.
• Document: It is an accumulation of fields in a particular waycharacterized in JSON design. Each record has a place witha sort and lives inside a file. Each archive is related with aremarkable identifier, called the UID.
• Shard: Indexes are evenly subdivided into shards. This im-plies every shard contains every one of the properties of record,yet contains less number of JSON objects than list. The flatpartition makes shard an autonomous hub, which can be storein any hub. Essential shard is the first even piece of a list andafter that these essential shards are recreated into reproduc-tion shards.
• Replicas: Elasticsearch enables a client to make copies of theirlists and shards. Replication not just aides in expanding theaccessibility of information if there should be an occurrenceof disappointment, yet additionally enhances the executionof seeking via completing a parallel hunt activity in thesereproductions.
3.2.2 Elasticsearch Advantages
• Elasticsearch is created on Java, which makes it good on rel-atively every stage.
• Elasticsearch is ongoing, as it were following one moment theadditional archive is accessible in this motor.
• Elasticsearch is appropriated, which makes it simple to scaleand incorporate in any enormous association.
• Creating full reinforcements are simple by utilizing the ideaof the entryway, which is available in flexible hunt.
• Handling multi-tenure is simple in Elasticsearch when con-trasted with Apache Solr.
11
International Journal of Pure and Applied Mathematics Special Issue
10345

• Elasticsearch utilizes JSON questions as reactions, which makesit conceivable to summon the versatile hunt server with count-less programming dialects.
• Elasticsearch underpins relatively every report write with theexception of those that don’t bolster content rendering.
4 Proposed framework
In the first place, we got the labels from the tweets, check how oftenit (a tag) shows up and sort them by the tally. From that pointforward, we hold on the outcome to point Splunk (or some otherapparatus for this issue) to it. We could fabricate some intriguingdashboards utilizing this data so we can track the most slantinghashtags. In view of this data my associate could make battlesand utilize these prominent labels to draw in a greater group ofonlookers. In the wake of trying different things with various appli-cations to process spilling information like Spark streaming, flume,kafka, storm and so on gives now a chance to take a gander at howassumption scores can be created for tweets using Spark stanfordCoreNLP and assemble representation dashboards on this informa-tion utilizing elasticsearch and kibana.
Figure 1. The Proposed Framework of Sentiment Analysis
12
International Journal of Pure and Applied Mathematics Special Issue
10346

5 Implementation
This work is implemented using ApachSpark, First the tweets arecollected from the twitter’s official website. Once we register intwitter site, the latest tweets of about size 1GB can be downloaded.The twitter site will generate security keys and oAuth tokens forevery user, It is used mainly for coding in Spark.
Next step is to create a scala maven project and the corre-sponding pom.xml file is updated with the dependencies that arerequired for this work. A scala object file was created, to receivethe streaming data that are collected from the twitter. Using thetwitter data, the sentiment scores are detected on each tweet byimporting the package stanford coreNLP library. Once the analysishas been done, the output can be visualized by creating an indexin elasticsearch and the ouput is written in that index. The indexcreated in this paper is named as twitter 092517/tweet. Elastic-search basically requires index content that can be translated intoa document. Before storing the content in the created index (twit-ter 092517/tweet), each RDD in Spark is transformed to a Mapobject. The stanford university provided a useful natural languageprocessing library coreNLP in Spark, to parse and detect the sen-timents of each tweet data.
Stanford coreNLP gives a device pipeline as far as annotatorsutilizing which distinctive phonetic investigation instruments mightbe connected on content. Following annotators are incorporatedinto this case:
• tokenize - Divides content into an arrangement of words
• - Split the content into sentence. Distinguish fullstop, outcryand so forth and split sentences
• POS- Reads message and appoints parts of discourse to eachword, for example, thing, verb, descriptive word, and so on.Ex. ”This is a basic sentence” will be labeled as ”This/DTis/VBZ a/DT test/NN sentence/NN”
• lemma - Group together types of a word so they can be ex-amined as a solitary thing.
• parse - Provides syntactic investigation
13
International Journal of Pure and Applied Mathematics Special Issue
10347

• sentiment - Provides show for assumption investigation. Joinsa binarized tree of the sentence. The hubs of the tree atthat point contain the comments from RNNCoreAnnotationsshowing the anticipated class and scores for that subtree. Theslant estimations of the individual words are accumulated atthe base of the binarized tree.
Sentiment score is then found the middle value of in view oflength of each sentence as longer sentence must convey more weightin the general opinion of the content.
6 Results and Discussion
Once the implementation is done, the results can be viewed visuallyby using Elastic search and Kibana. Using the index created twit-ter 092517/tweet before, the contents of output are transformed toElasticSearch. From the total number of 4,315 tweets data, theSpark calculates sentiment score for each tweet data and based onthe score it is classified as either positive, negative neutral, not un-derstanding and very negative categories. In this given tweet data4,315 tweets are classified into 3,249 of negative, 138 of positive, 847of neutral, 75 of not understood and 8 of very negative categories.
Figure 2. Elastic search view of results based on the created indextwitter 092517
The results are displayed below with total counts of tweet datafor analysis and the list of classified tweets based one sentimentsand the quarter hourly analysis of classified tweets and the piechart view of classified tweets and the trending Hash tags list andthe graphical view of text based sentiment classification. Thus this
14
International Journal of Pure and Applied Mathematics Special Issue
10348
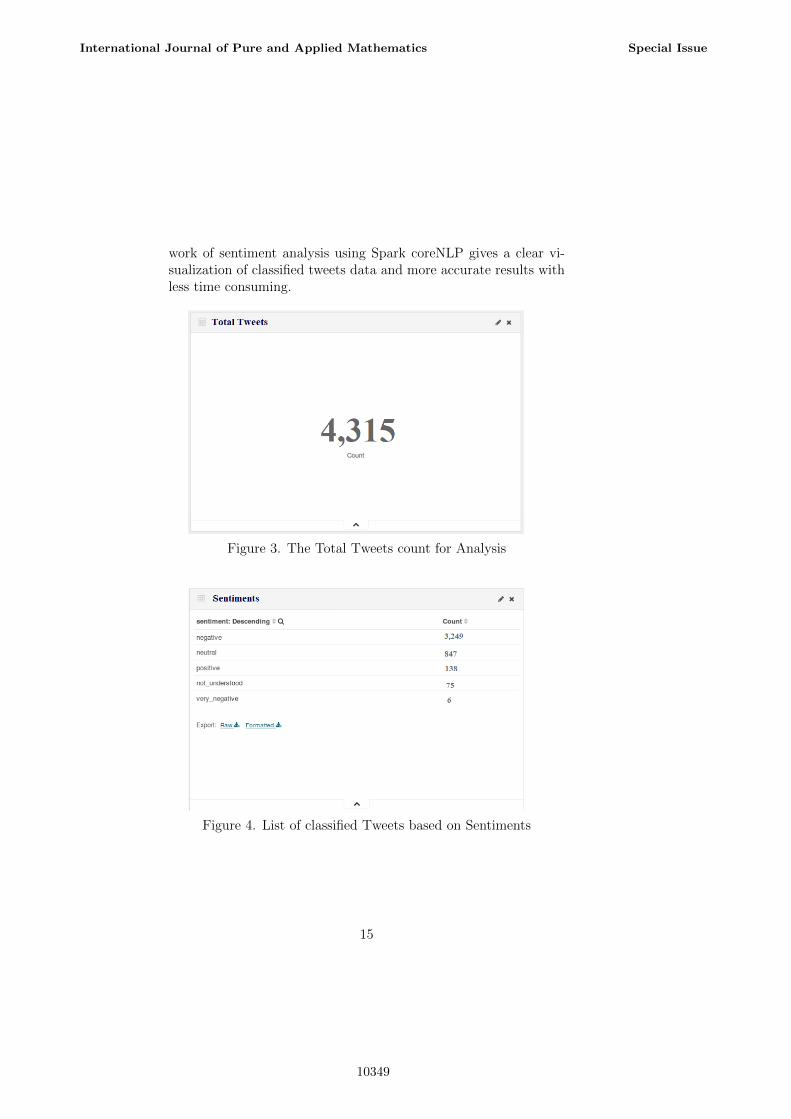
work of sentiment analysis using Spark coreNLP gives a clear vi-sualization of classified tweets data and more accurate results withless time consuming.
Figure 3. The Total Tweets count for Analysis
Figure 4. List of classified Tweets based on Sentiments
15
International Journal of Pure and Applied Mathematics Special Issue
10349
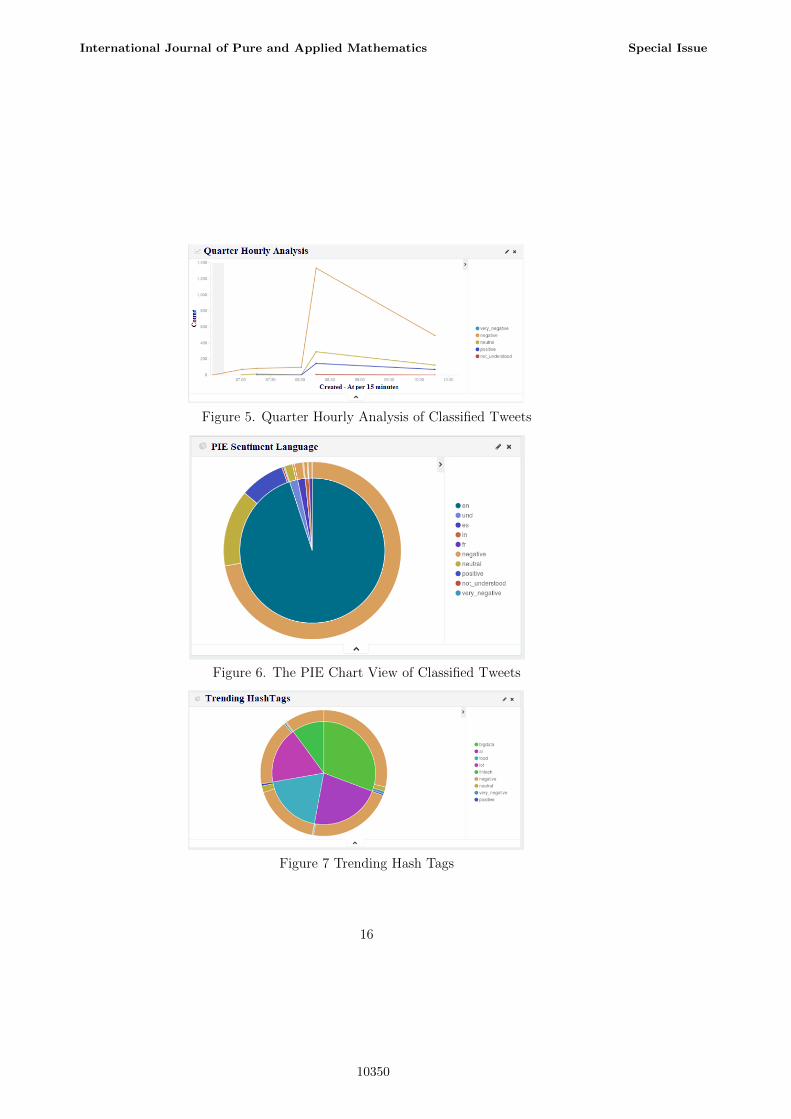
Figure 5. Quarter Hourly Analysis of Classified Tweets
Figure 6. The PIE Chart View of Classified Tweets
Figure 7 Trending Hash Tags
16
International Journal of Pure and Applied Mathematics Special Issue
10350
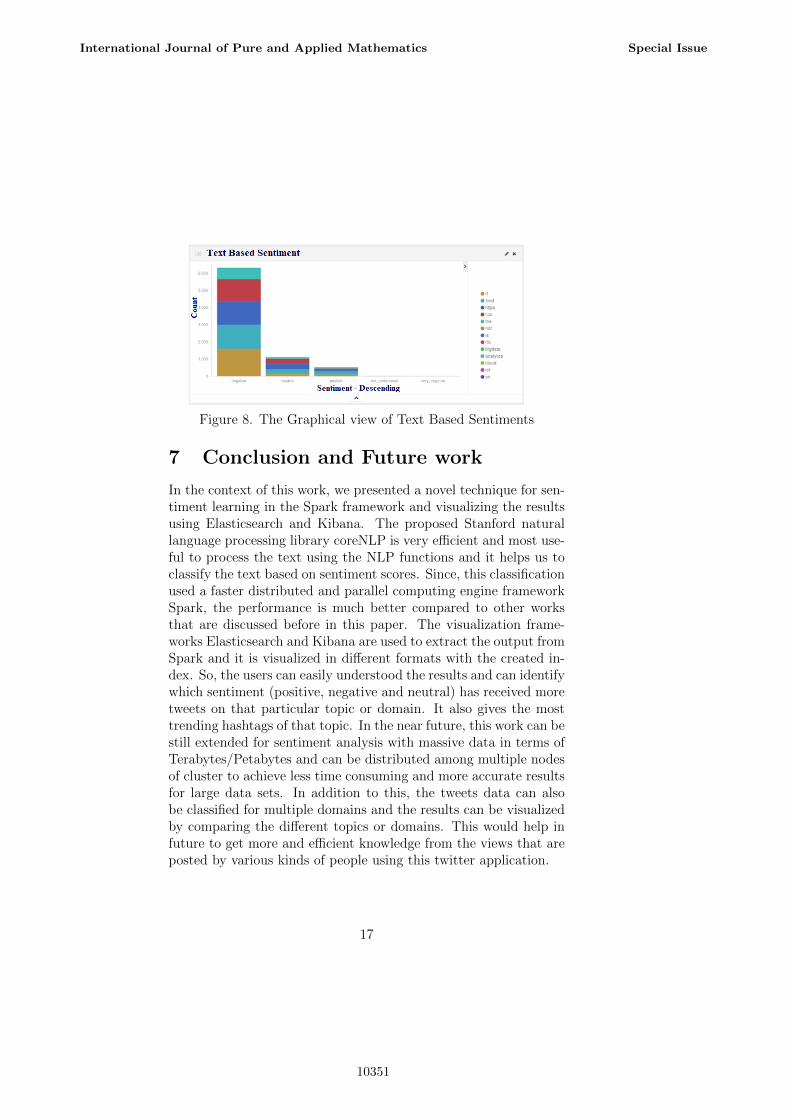
Figure 8. The Graphical view of Text Based Sentiments
7 Conclusion and Future work
In the context of this work, we presented a novel technique for sen-timent learning in the Spark framework and visualizing the resultsusing Elasticsearch and Kibana. The proposed Stanford naturallanguage processing library coreNLP is very efficient and most use-ful to process the text using the NLP functions and it helps us toclassify the text based on sentiment scores. Since, this classificationused a faster distributed and parallel computing engine frameworkSpark, the performance is much better compared to other worksthat are discussed before in this paper. The visualization frame-works Elasticsearch and Kibana are used to extract the output fromSpark and it is visualized in different formats with the created in-dex. So, the users can easily understood the results and can identifywhich sentiment (positive, negative and neutral) has received moretweets on that particular topic or domain. It also gives the mosttrending hashtags of that topic. In the near future, this work can bestill extended for sentiment analysis with massive data in terms ofTerabytes/Petabytes and can be distributed among multiple nodesof cluster to achieve less time consuming and more accurate resultsfor large data sets. In addition to this, the tweets data can alsobe classified for multiple domains and the results can be visualizedby comparing the different topics or domains. This would help infuture to get more and efficient knowledge from the views that areposted by various kinds of people using this twitter application.
17
International Journal of Pure and Applied Mathematics Special Issue
10351

References
[1] Agarwal, B. Xie, I. Vovsha, O. Rambow, and R. Passonneau.Sentiment analysis of twitter data. In Proceedings of the Work-shop on Languages in Social Media, pages 30{38}, 2011.
[2] L. Barbosa and J. Feng. Robust sentiment detection on twitterfrom biased and noisy data. In Proceedings of the 23rd Inter-national Conference on Computational Linguistics: Posters,pages 36{44, 2010.
[3] H. Bloom. Space/time trade-o s in hash coding with allowableerrors. Commun. ACM, 13(7):422{426, 1970.
[4] Z. Cheng, J. Caverlee, and K. Lee. You are where you tweet: Acontent-based approach to geo-locating twitter users. In Pro-ceedings of the 19th ACM International Conference on Infor-mation and Knowledge Management, pages 759{768, 2010.
[5] Davidov and A. Rappoport. E cient unsupervised discovery ofword categories using symmetric patterns and high frequencywords. In Proceedings of the 21st International Conference onComputational Linguistics and the 44th Annual Meeting ofthe Association for Computational Linguistics, pages 297{304,2006.
[6] D. Davidov, O. Tsur, and A. Rappoport. Enhanced sentimentlearning using twitter hashtags and smileys. In Proceedings ofthe 23rd International Conference on Computational Linguis-tics: Posters, pages 241{249, 2010.
[7] J. Dean and S. Ghemawat. Mapreduce: Simpli ed data pro-cessing on large clusters. In Proceedings of the 6th Sympo-sium on Operating Systems Design and Implementation, pages137{150, 2004.
[8] X. Ding and B. Liu. The utility of linguistic rules in opinionmining. In Proceedings of the 30th Annual International ACMSIGIR Conference on Research and Development in Informa-tion Retrieval, pages 811{812, 2007.
18
International Journal of Pure and Applied Mathematics Special Issue
10352

[9] Hadoop. The apache software foundation: Hadoop home-page. http://hadoop.apache.org/, 2015. [Online; accessed 20-September-2015].
[10] M. Hu and B. Liu. Mining and summarizing customer re-views. In Proceedings of the Tenth ACM SIGKDD Interna-tional Conference on Knowledge Discovery and Data Mining,pages 168{177, 2004.
[11] L. Jiang, M. Yu, M. Zhou, X. Liu, and T. Zhao.Target-dependent twitter sentiment classi cation. In Proceedings ofthe 49th Annual Meeting of the Association for ComputationalLinguistics: Human Language Technologies - Volume 1, pages151{160, 2011.
[12] H. Karau, A. Konwinski, P. Wendell, and M. Zaharia. Learn-ing Spark: Lightning-Fast Big Data Analysis. O’Reilly Media,2015.
[13] V. N. Khuc, C. Shivade, R. Ramnath, and J. Ramanathan.Towards building large-scale distributed systems for twittersentiment analysis. In Proceedings of the 27th Annual ACMSymposium on Applied Computing, pages 59{464, 2012.
[14] C. Lin and Y. He. Joint sentiment/topic model for sentimentanalysis. In Proceedings of the 18th ACM Conference on In-formation and Knowledge Management, pages 375{384, 2009.
[15] J. Lin and C. Dyer. Data-Intensive Text Processing withMapReduce. Morgan and Claypool Publishers, 2010.
[16] Q. Mei, X. Ling, M. Wondra, H. Su, and C. Zhai. Topic sen-timent mixture: Modeling facets and opinions in weblogs. InProceedings of the 16th International Conference on WorldWide Web, pages 171{180, 2007.
[17] T. Nasukawa and J. Yi. Sentiment analysis: Capturing favora-bility using natural language processing. In Proceedings of the2Nd International Conference on Knowledge Capture, pages70{77, 2003.
19
International Journal of Pure and Applied Mathematics Special Issue
10353

[18] N. Nodarakis, E. Pitoura, S. Sioutas, A. K. Tsakaidis, D.Tsoumakos, and G. Tzimas. kdann+: A rapid aknn classi erfor big data. T. Large-Scale Data- and Knowledge-CenteredSystems, 23:139{168, 2016.
[19] B. Pang, L. Lee, and S. Vaithyanathan. Thumbs up?: Senti-ment classi cation using machine learning techniques. In Pro-ceedings of the ACL-02 Conference on Empirical Methods inNatural Language Processing - Volume 10, pages 79{86, 2002.
[20] Spark. The apache software foundation: Spark home-page. http://spark.apache.org/, 2015. [Online; accessed 27-December-2015].
[21] M. van Banerveld, N. Le-Khac, and M. T. Kechadi. Perfor-mance evaluation of a natural language processing approachapplied in white collar crime investigation. In Future Data andSecurity Engineering - First International Conference, FDSE2014, Ho Chi Minh City, Vietnam, November 19-21, 2014, Pro-ceedings, pages 29{43, 2014.
[22] X. Wang, F. Wei, X. Liu, M. Zhou, and M. Zhang. Topic sen-timent analysis in twitter: A graph-based hashtag sentimentclassi cation approach. In Proceedings of the 20th ACM Inter-national Conference on Information and Knowledge Manage-ment, pages 1031{1040, 2011.
[23] T. White. Hadoop: The De nitive Guide, 3rd Edition. O’ReillyMedia / Yahoo Press, 2012.
[24] T. Wilson, J. Wiebe, and P. Ho mann. Recognizing contextualpolarity in phrase-level sentiment analysis. In Proceedings ofthe Conference on Human Language Technology and Empiri-cal Methods in Natural Language Processing, pages 347{354,2005.
[25] T. Wilson, J. Wiebe, and P. Ho mann. Recognizing contextualpolarity: An exploration of features for phrase-level sentimentanalysis. Comput. Linguist., 35(3):399{433, Sept. 2009.
[26] Y. Yamamoto, T. Kumamoto, and A. Nadamoto. Role ofemoticons for multidimensional sentiment analysis of twitter.
20
International Journal of Pure and Applied Mathematics Special Issue
10354

In Proceedings of the 16th International Conference on Infor-mation Integration and Web-based Applications 38; Services,pages 107{115, 2014.
[27] H. Yu and V. Hatzivassiloglou. Towards answering opinionquestions: Separating facts from opinions and identifying thepolarity of opinion sentences. In Proceedings of the 2003 Con-ference on Empirical Methods in Natural Language Processing,pages 129{136, 2003.
[28] W. Zhang, C. Yu, and W. Meng. Opinion retrieval from blogs.In Proceedings of the Sixteenth ACM Conference on Con-ference on Information and Knowledge Management, pages831{840, 2007.
[29] L. Zhuang, F. Jing, and X.-Y. Zhu. Movie review miningand summarization. In Proceedings of the 15th ACM Inter-national Conference on Information and Knowledge Manage-ment, pages 43{50, 2006.
[30] S.V.Manikanthan and T.Padmapriya Recent Trends In M2mCommunications In 4g Networks And Evolution Towards 5g,International Journal of Pure and Applied Mathematics, ISSNNO: 1314-3395, Vol-115, Issue -8, Sep 2017.
[31] S.V. Manikanthan, T. Padmapriya An enhanced distributedevolved node-b architecture in 5G tele-communications net-work International Journal of Engineering Technology (UAE),Vol 7 Issues No (2.8) (2018) 248-254.March2018.
[32] S.V. Manikanthan, T. Padmapriya, Relay Based ArchitectureFor Energy Perceptive For Mobile Adhoc Networks, Advancesand Applications in Mathematical Sciences, Volume 17, Issue1, November 2017, Pages 165-179
21
International Journal of Pure and Applied Mathematics Special Issue
10355

10356





























