Embed Size (px)
Citation preview

Tutorial on
Deep Generative ModelsShakir Mohamed and Danilo Rezende
UAI 2017 Australia
@shakir_za @deepspiker

Abstract
This tutorial will be a review of recent advances in deep generative models. Generative models have a long history at UAI and recent methods have combined the generality of probabilistic reasoning with the scalability of deep learning to develop learning algorithms that have been applied to a wide variety of problems giving state-of-the-art results in image generation, text-to-speech synthesis, and image captioning, amongst many others. Advances in deep generative models are at the forefront of deep learning research because of the promise they offer for allowing data-efficient learning, and for model-based reinforcement learning. At the end of this tutorial, audience member will have a full understanding of the latest advances in generative modelling covering three of the active types of models: Markov models, latent variable models and implicit models, and how these models can be scaled to high-dimensional data. The tutorial will expose many questions that remain in this area, and for which there remains a great deal of opportunity from members of the UAI community.
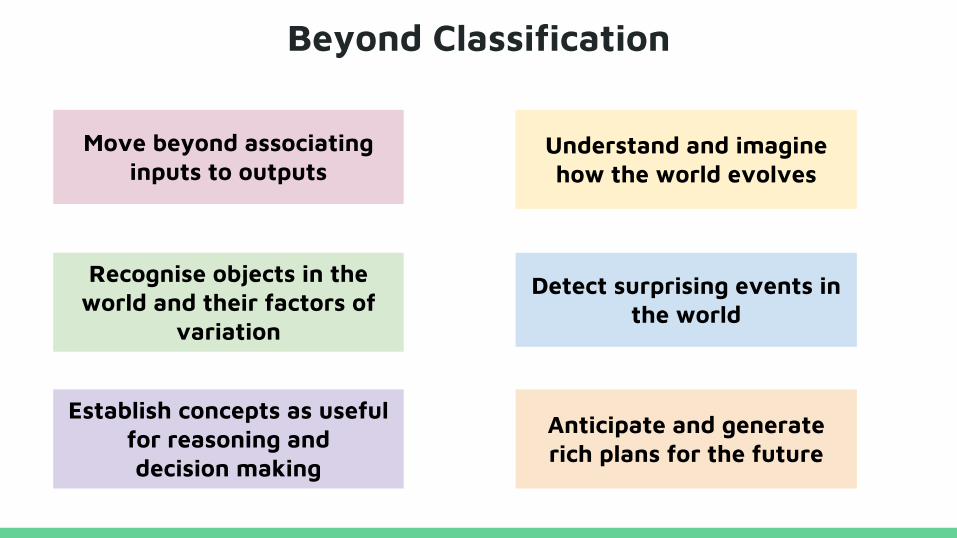
Beyond Classification
Move beyond associating inputs to outputs
Understand and imagine how the world evolves
Recognise objects in the world and their factors of
variation
Detect surprising events in the world
Establish concepts as useful for reasoning and decision making
Anticipate and generate rich plans for the future

What is a Generative Model?
Characteristics are:
- Probabilistic models of data that allow
for uncertainty to be captured.
- Data distribution p(x) is targeted.
- High-dimensional outputs.
A model that allows us to learn a
simulator of data
Models that allow for (conditional) density
estimation
Approaches for unsupervised learning
of data

Why Generative Models?
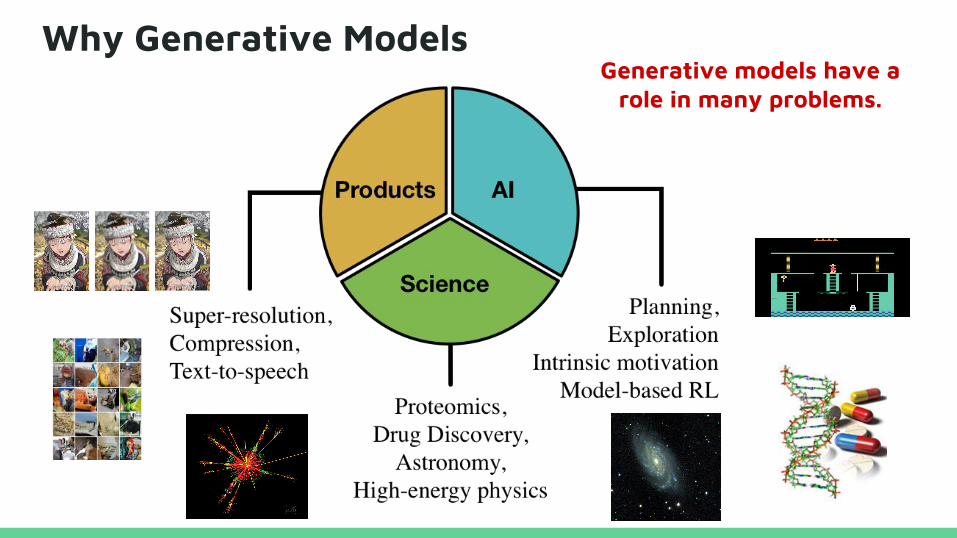
Why Generative ModelsGenerative models have a
role in many problems.
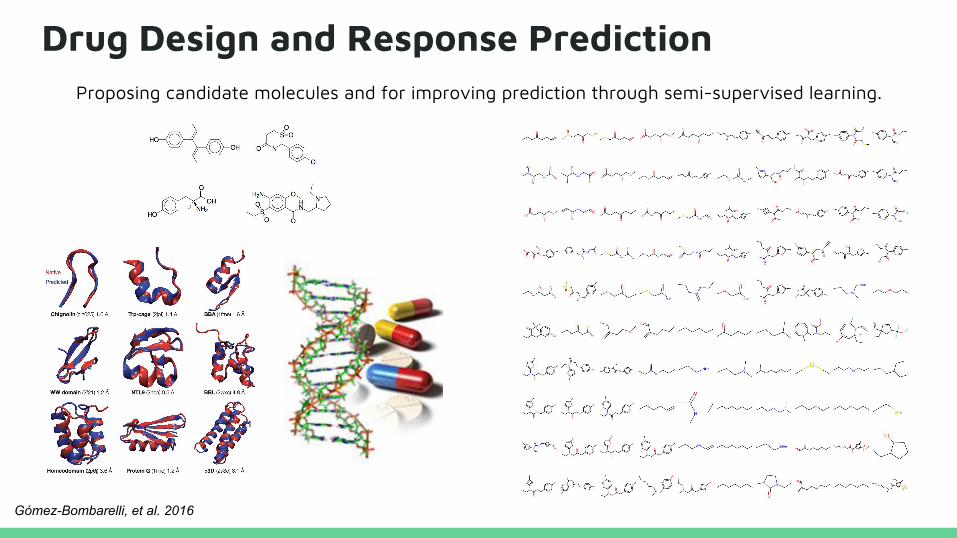
Drug Design and Response PredictionProposing candidate molecules and for improving prediction through semi-supervised learning.
Gómez-Bombarelli, et al. 2016

Locating Celestial BodiesGenerative models for applications in astronomy and high-energy physics.
Regier et al., 2015

Image super-resolutionPhoto-realistic single image super-resolution
Ledig et al., 2016
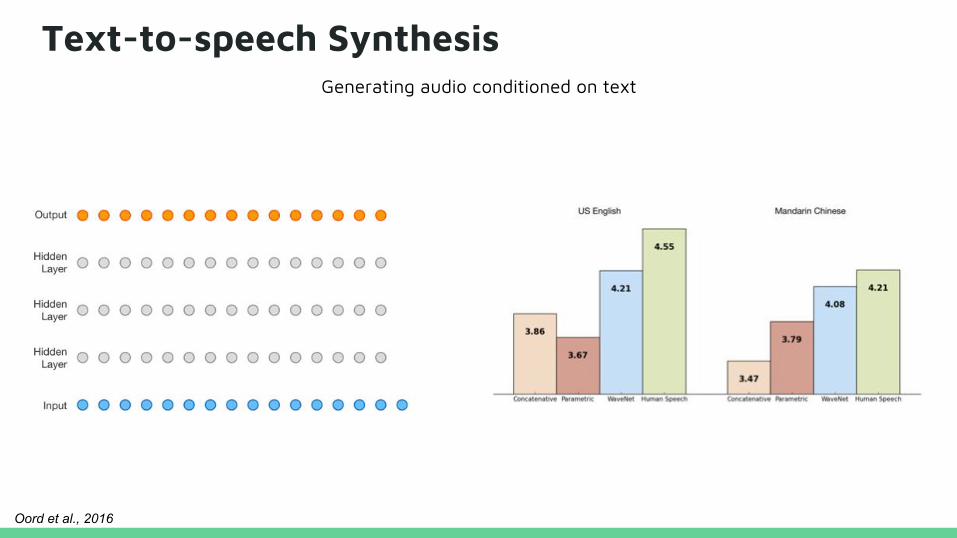
Text-to-speech SynthesisGenerating audio conditioned on text
Oord et al., 2016

Image and Content Generation
DRAW Pixel RNN
Generating images and video content.
ALIGregor et al., 2015, Oord et al., 2016, Dumoulin et al., 2016

Communication and Compression
Original images
JPEG-2000
JPEG
RVAE v1
Compression rate: 0.2bits/dimension
RVAE v2
Hierarchical compression of images and other data.
Gregor et al., 2016

One-shot GeneralisationRapid generalisation of novel concepts
Rezende et al., 2016
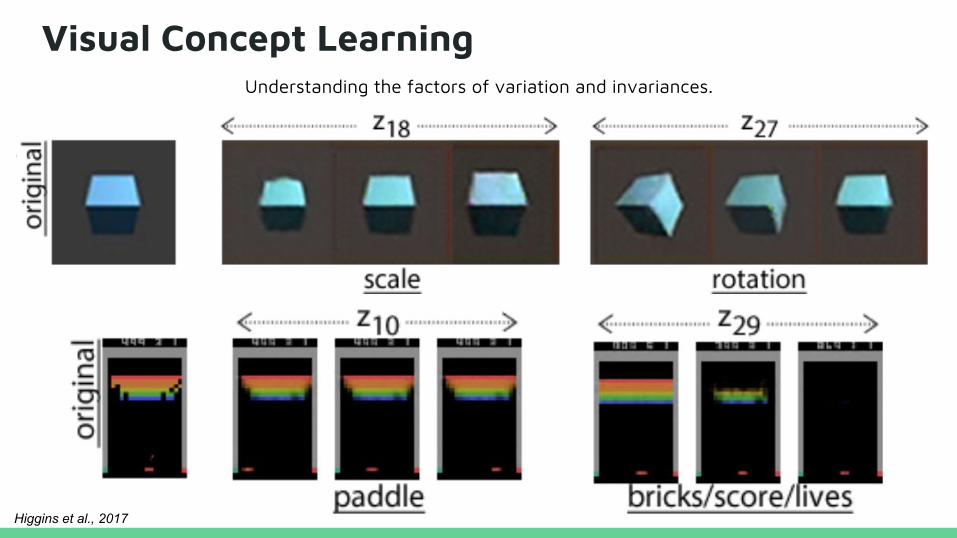
Visual Concept LearningUnderstanding the factors of variation and invariances.
Higgins et al., 2017

Future Simulation
Robot arm simulationAtari simulation
Simulate future trajectories of environments based on actions for planning
Chiappa et al, 2017, Kalchbrenner et al., 2017
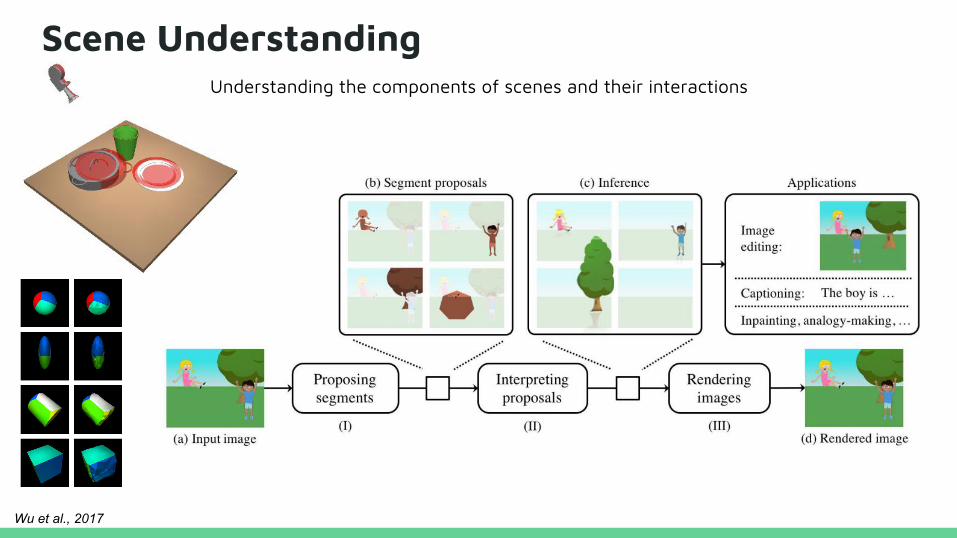
Scene UnderstandingUnderstanding the components of scenes and their interactions
Wu et al., 2017

Probabilistic Deep Learning
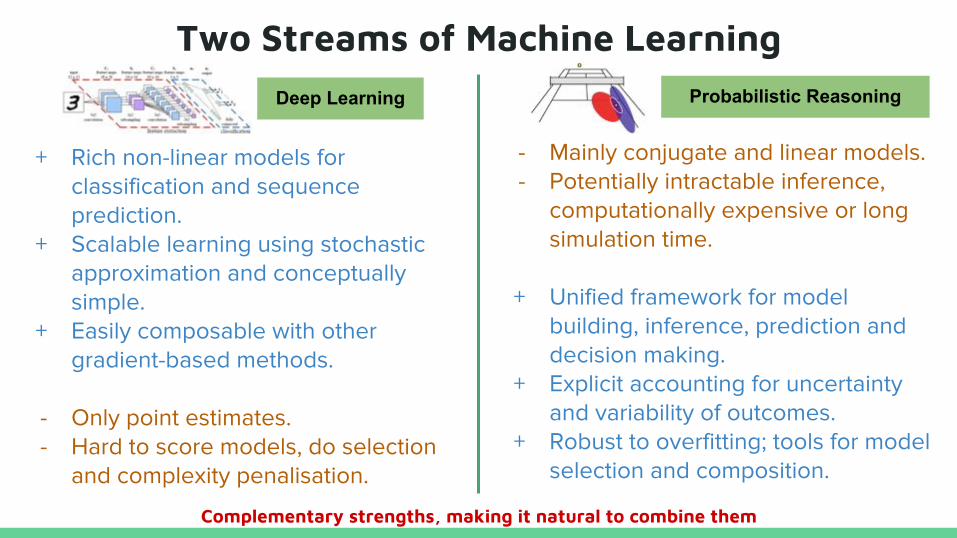
Two Streams of Machine Learning
+ Rich non-linear models for classification and sequence prediction.
+ Scalable learning using stochastic approximation and conceptually simple.
+ Easily composable with other gradient-based methods.
- Only point estimates.- Hard to score models, do selection
and complexity penalisation.
- Mainly conjugate and linear models.- Potentially intractable inference,
computationally expensive or long simulation time.
+ Unified framework for model building, inference, prediction and decision making.
+ Explicit accounting for uncertainty and variability of outcomes.
+ Robust to overfitting; tools for model selection and composition.
Deep Learning Probabilistic Reasoning
Complementary strengths, making it natural to combine them

Thinking about Machine Learning
1. Models 2. Learning Principles
3. Algorithms
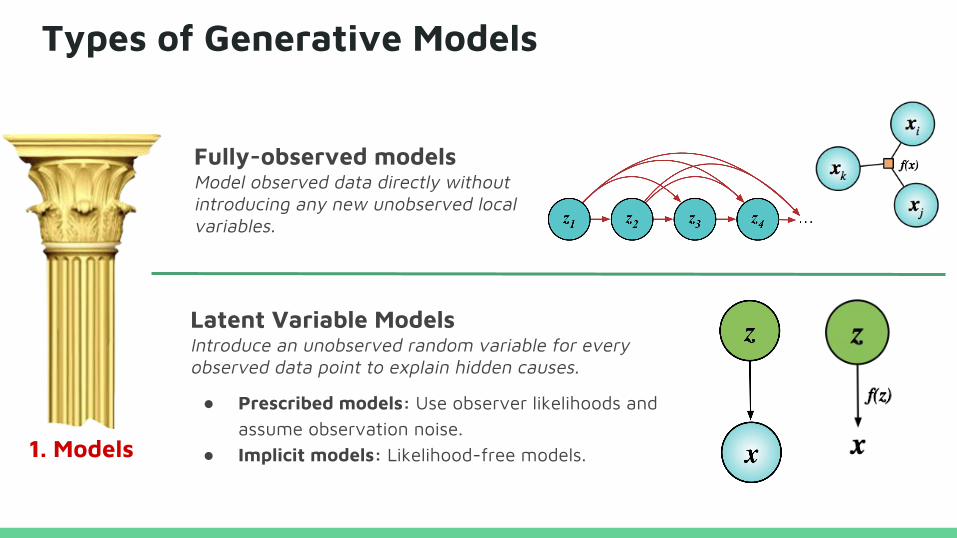
Types of Generative Models
Fully-observed modelsModel observed data directly without introducing any new unobserved local variables.
Latent Variable ModelsIntroduce an unobserved random variable for every observed data point to explain hidden causes.
● Prescribed models: Use observer likelihoods and assume observation noise.
● Implicit models: Likelihood-free models.1. Models
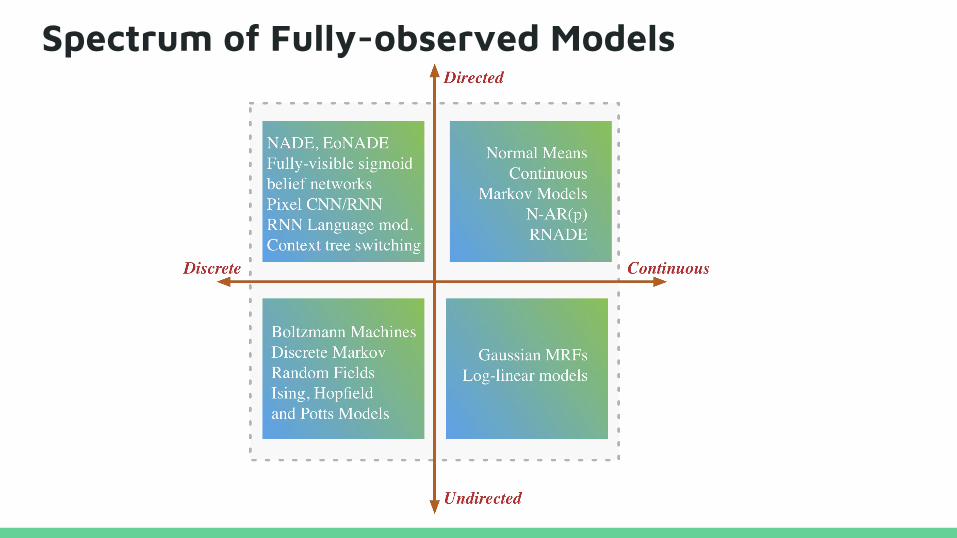
Spectrum of Fully-observed Models
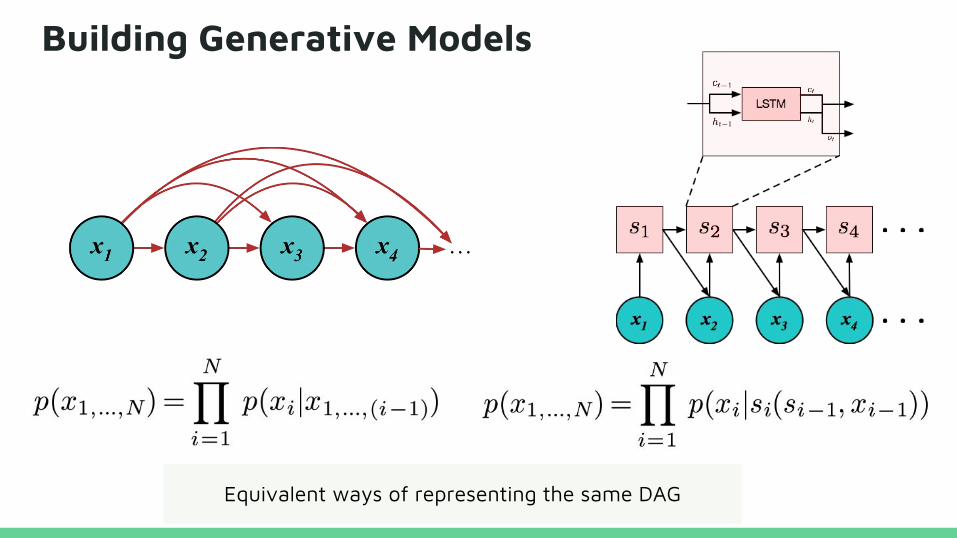
Building Generative Models
Equivalent ways of representing the same DAG
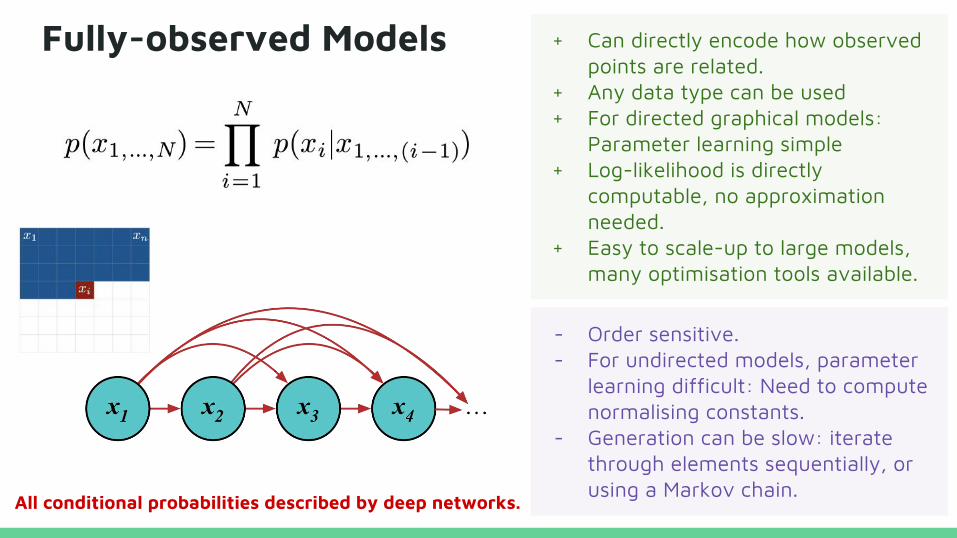
Fully-observed Models + Can directly encode how observed points are related.
+ Any data type can be used+ For directed graphical models:
Parameter learning simple+ Log-likelihood is directly
computable, no approximation needed.
+ Easy to scale-up to large models, many optimisation tools available.
- Order sensitive.- For undirected models, parameter
learning difficult: Need to compute normalising constants.
- Generation can be slow: iterate through elements sequentially, or using a Markov chain.
All conditional probabilities described by deep networks.
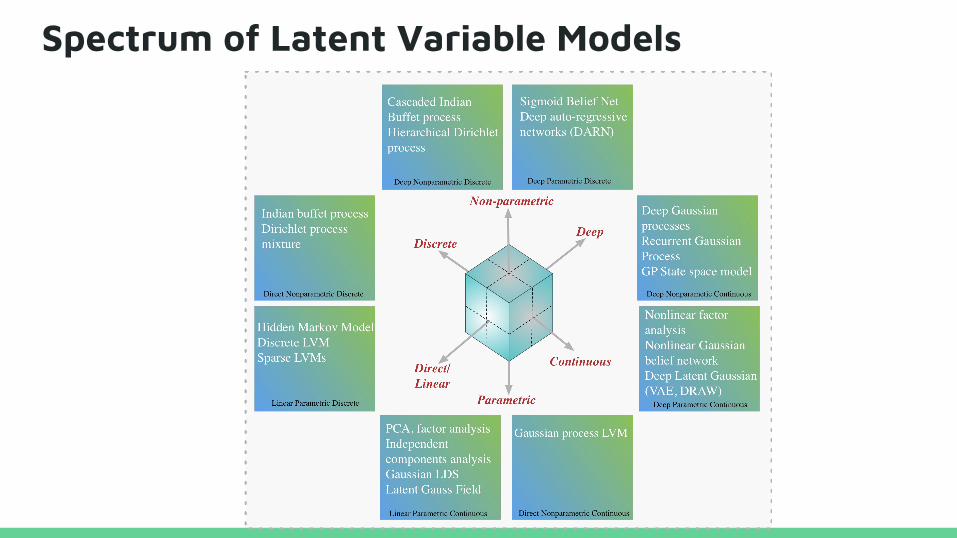
Spectrum of Latent Variable Models

Building Generative Models

Building Generative ModelsGraphical Models + Computational Graphs (aka NNets)

Latent Variable Models + Easy sampling. + Easy way to include
hierarchy and depth.+ Easy to encode structure + Avoids order dependency
assumptions: marginalisation induces dependencies.
+ Provide compression and representation.
+ Scoring, model comparison and selection possible using the marginalised likelihood.
- Inversion process to determine latents corresponding to a input is difficult in general
- Difficult to compute marginalised likelihood requiring approximations.
- Not easy to specify rich approximations for latent posterior distribution.
Introduce an unobserved local random variables that represents
hidden causes.

Choice of Learning Principles
2. Learning Principles
For a given model, there are many competing inference methods.
● Exact methods (conjugacy, enumeration)● Numerical integration (Quadrature)● Generalised method of moments● Maximum likelihood (ML)● Maximum a posteriori (MAP)● Laplace approximation● Integrated nested Laplace approximations (INLA)● Expectation Maximisation (EM)● Monte Carlo methods (MCMC, SMC, ABC)● Contrastive estimation (NCE)● Cavity Methods (EP)● Variational methods
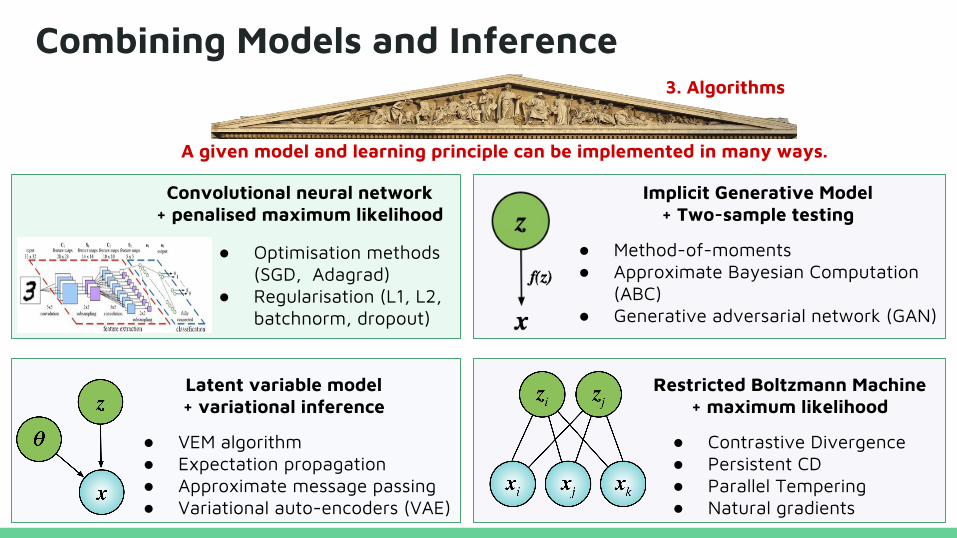
Combining Models and Inference
A given model and learning principle can be implemented in many ways.
● Optimisation methods (SGD, Adagrad)
● Regularisation (L1, L2, batchnorm, dropout)
Convolutional neural network + penalised maximum likelihood
Latent variable model + variational inference
Restricted Boltzmann Machine + maximum likelihood
● VEM algorithm● Expectation propagation● Approximate message passing● Variational auto-encoders (VAE)
● Contrastive Divergence● Persistent CD● Parallel Tempering● Natural gradients
Implicit Generative Model + Two-sample testing
● Method-of-moments● Approximate Bayesian Computation
(ABC)● Generative adversarial network (GAN)
3. Algorithms

Objective Quantity of Interest
Prediction
Planning
Parameter estimation
Experimental Design
Hypothesis testing
Inference Questions?

Approximate Inference

Latent Variable Models

Methods for Approximate Inference
● Laplace approximations
● Importance sampling
● Variational approximations
● Perturbative corrections
● Other methods: MCMC, Langevin, HMC, Adaptive MCMC
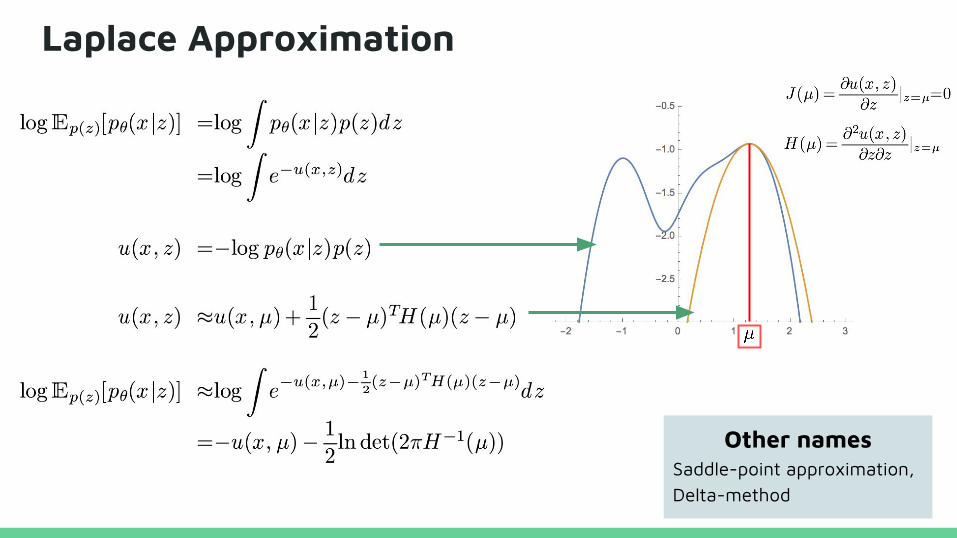
Laplace Approximation
Other namesSaddle-point approximation, Delta-method

Importance Sampling
Importance weights
Monte-Carlo
Important property
Pointwise Free-energy
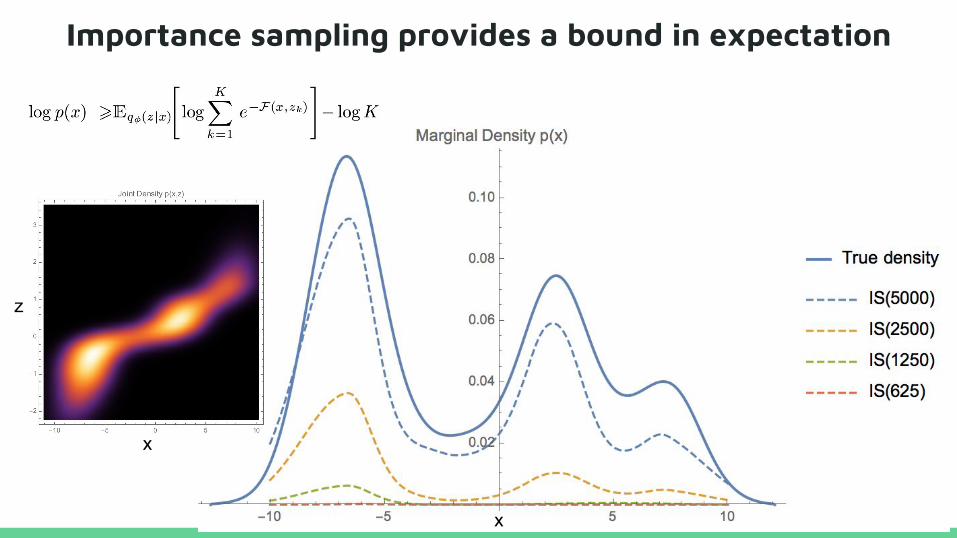
Importance sampling provides a bound in expectation
x
x
z

Variational Inference

Variational Inference
Reconstruction Regularizer

Perturbative Corrections
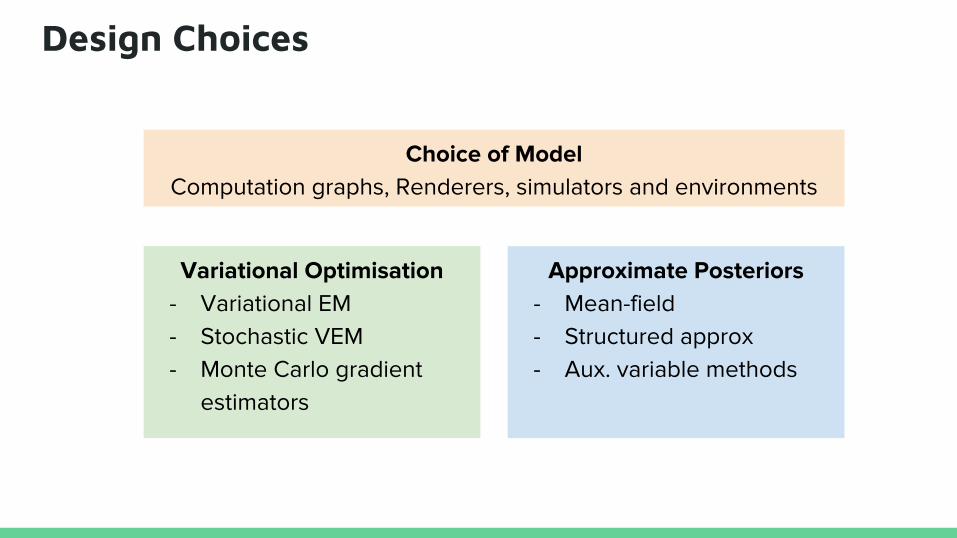
Design Choices
Choice of ModelComputation graphs, Renderers, simulators and environments
Approximate Posteriors- Mean-field- Structured approx- Aux. variable methods
Variational Optimisation- Variational EM- Stochastic VEM- Monte Carlo gradient
estimators
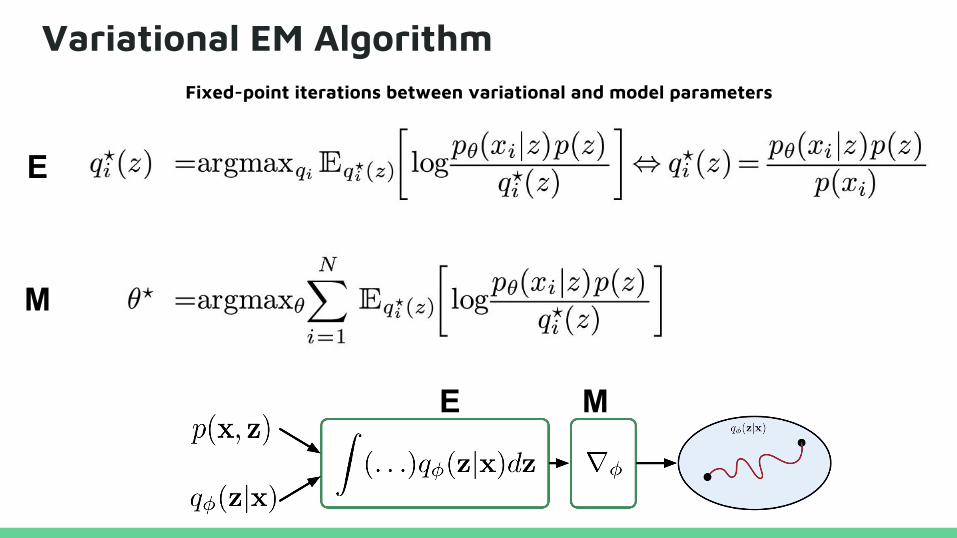
Variational EM Algorithm
E
M
Fixed-point iterations between variational and model parameters
E M

Amortised Inference
Introduce a parametric family of conditional densities
Rezende et al., 2015
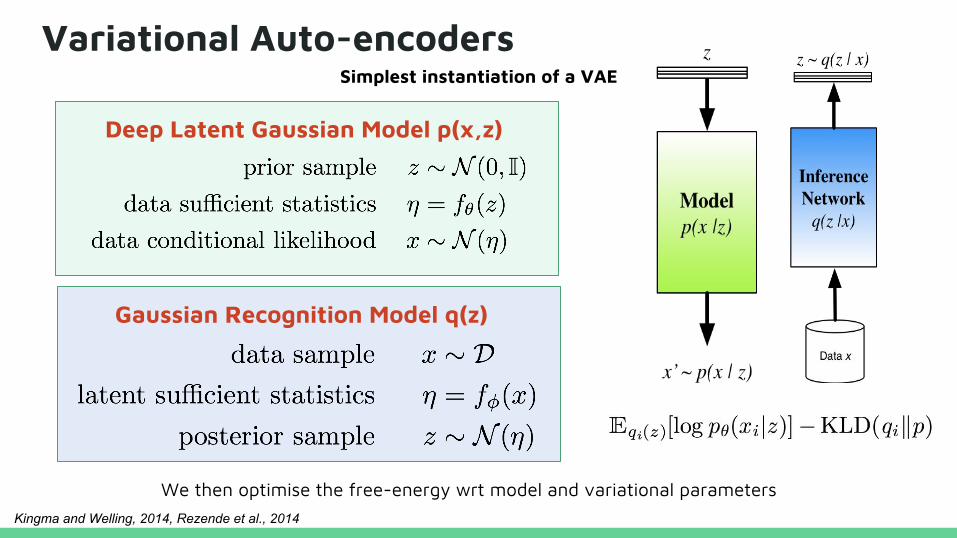
Variational Auto-encoders
Deep Latent Gaussian Model p(x,z)
Gaussian Recognition Model q(z)
Simplest instantiation of a VAE
We then optimise the free-energy wrt model and variational parametersKingma and Welling, 2014, Rezende et al., 2014
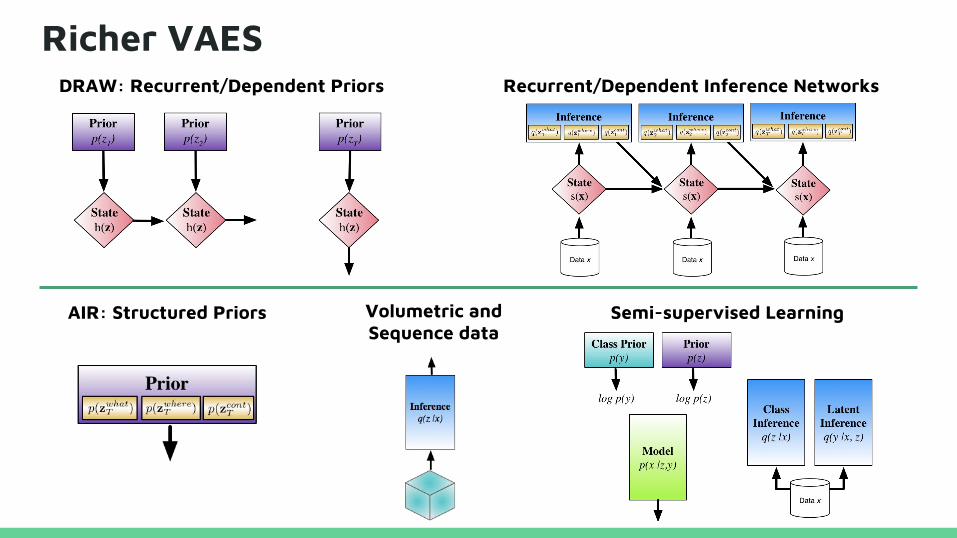
Richer VAESDRAW: Recurrent/Dependent Priors Recurrent/Dependent Inference Networks
Volumetric and Sequence data
AIR: Structured Priors Semi-supervised Learning
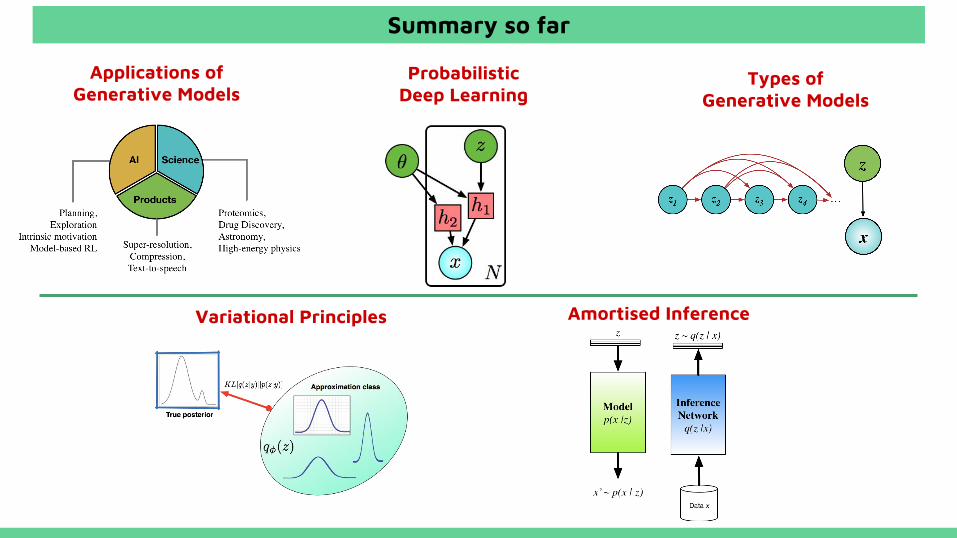
Applications of Generative Models
Types of Generative Models
Amortised InferenceVariational Principles
Probabilistic Deep Learning
Summary so far

END OF FIRST HALF

Stochastic Optimisation
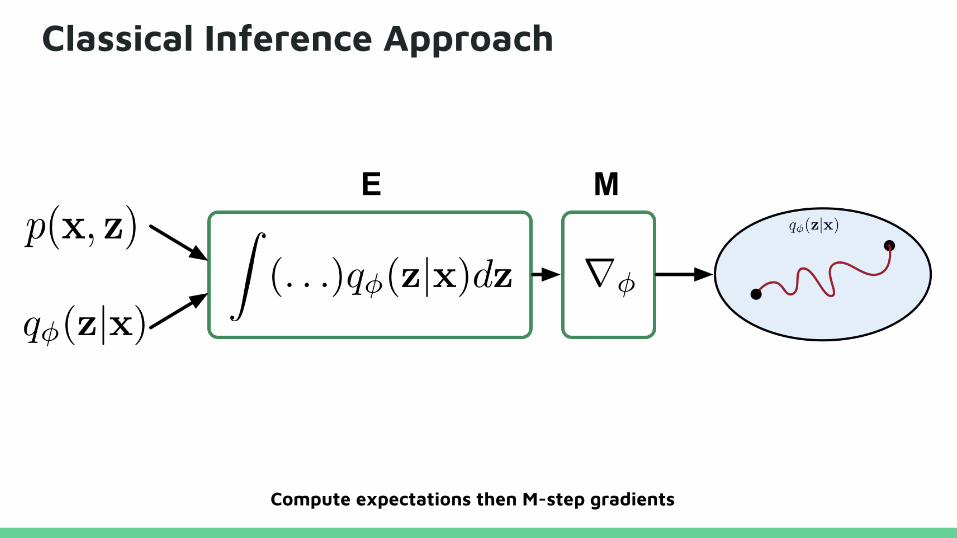
Classical Inference Approach
E M
Compute expectations then M-step gradients
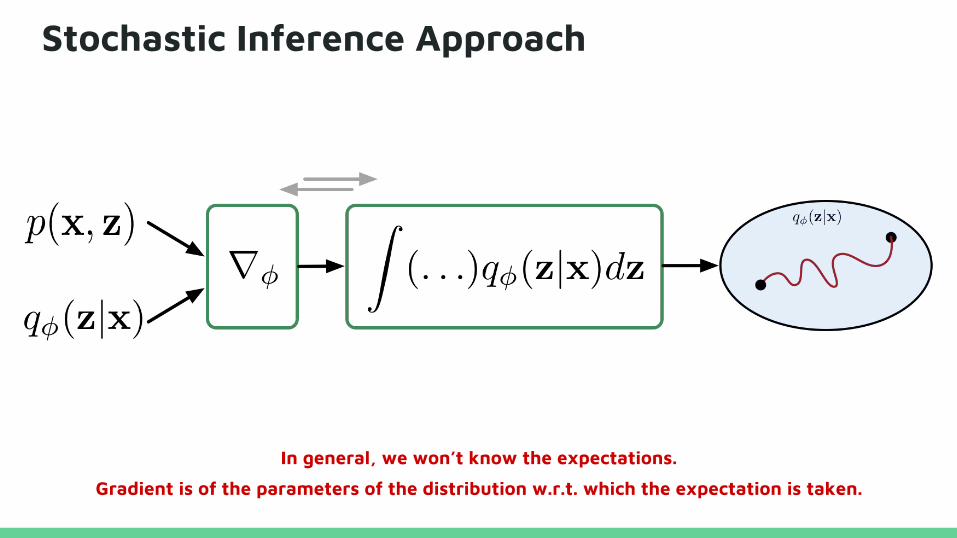
Stochastic Inference Approach
Gradient is of the parameters of the distribution w.r.t. which the expectation is taken.
In general, we won’t know the expectations.
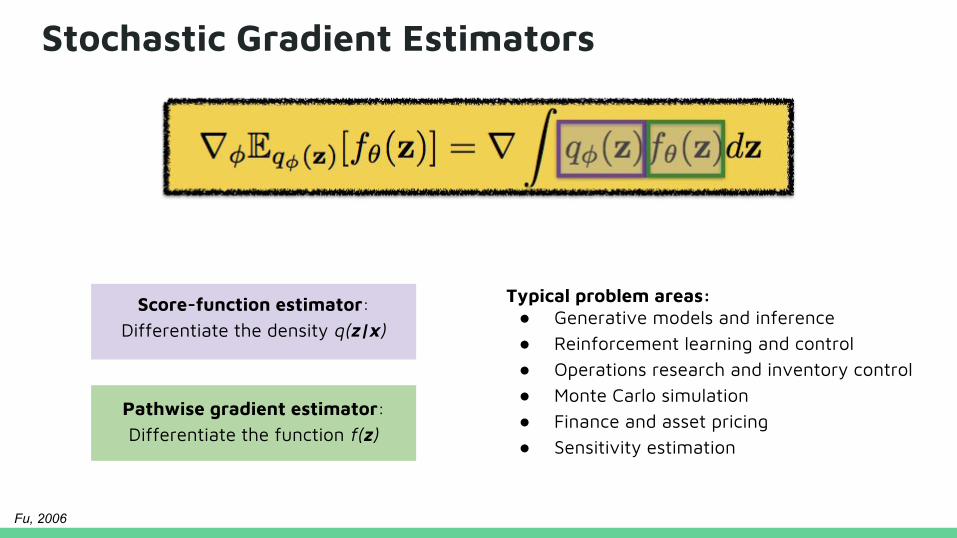
Stochastic Gradient Estimators
Score-function estimator: Differentiate the density q(z|x)
Typical problem areas:● Generative models and inference● Reinforcement learning and control● Operations research and inventory control● Monte Carlo simulation● Finance and asset pricing● Sensitivity estimation
Pathwise gradient estimator: Differentiate the function f(z)
Fu, 2006

Score Function Estimators
Other names:● Likelihood-ratio trick● Radon-Nikodym derivative● REINFORCE and policy
gradients● Automated inference● Black-box inference
When to use:● Function is not differentiable.● Distribution q is easy to sample
from.● Density q is known and
differentiable.
Gradient reweighted by the value of the function

Reparameterisation
Find an invertible function g(.) that expresses z as a transformation of a base distribution .
Kingma and Welling, 2014, Rezende et al., 2014
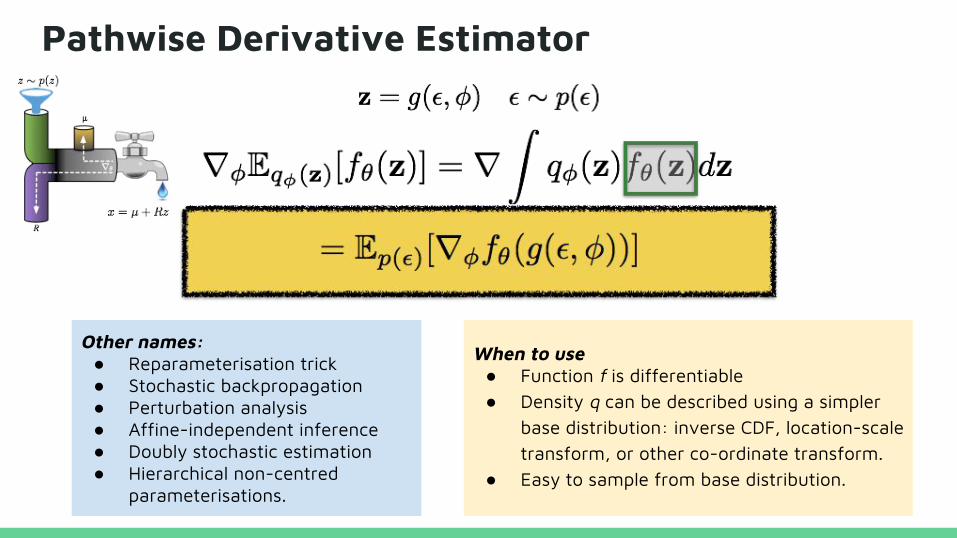
Pathwise Derivative Estimator
Other names:● Reparameterisation trick● Stochastic backpropagation● Perturbation analysis● Affine-independent inference● Doubly stochastic estimation● Hierarchical non-centred
parameterisations.
When to use● Function f is differentiable● Density q can be described using a simpler
base distribution: inverse CDF, location-scale transform, or other co-ordinate transform.
● Easy to sample from base distribution.

Gaussian Stochastic Gradients
First-order Gradient
Second-order Gradient
We can develop low-variance estimators by exploiting knowledge of the distributions involved when we know them
Rezende et al., 2014

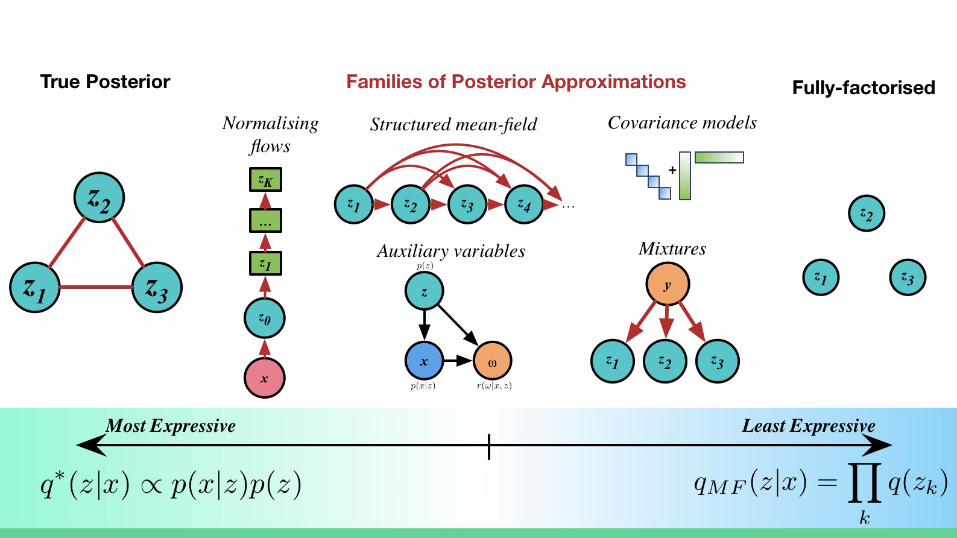
Beyond the Mean Field
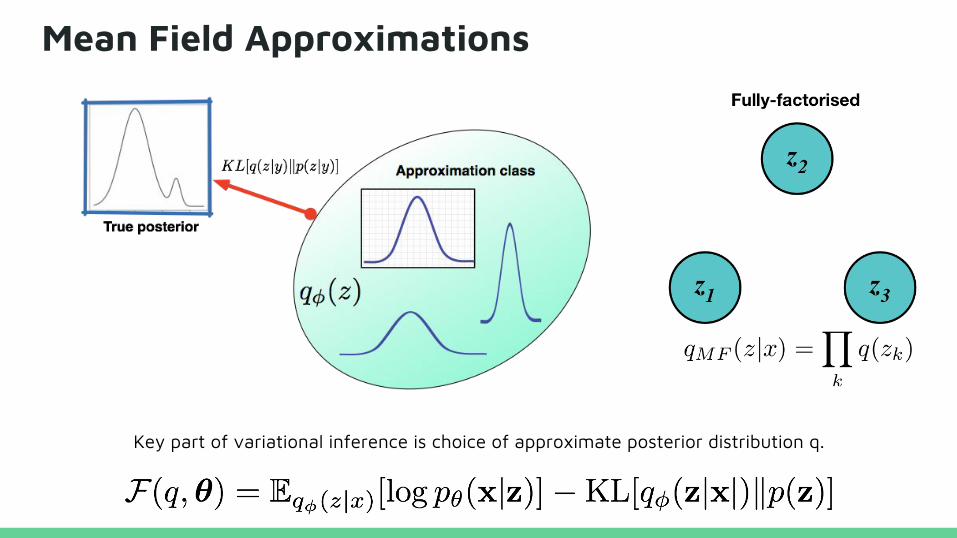
Mean Field Approximations
Key part of variational inference is choice of approximate posterior distribution q.
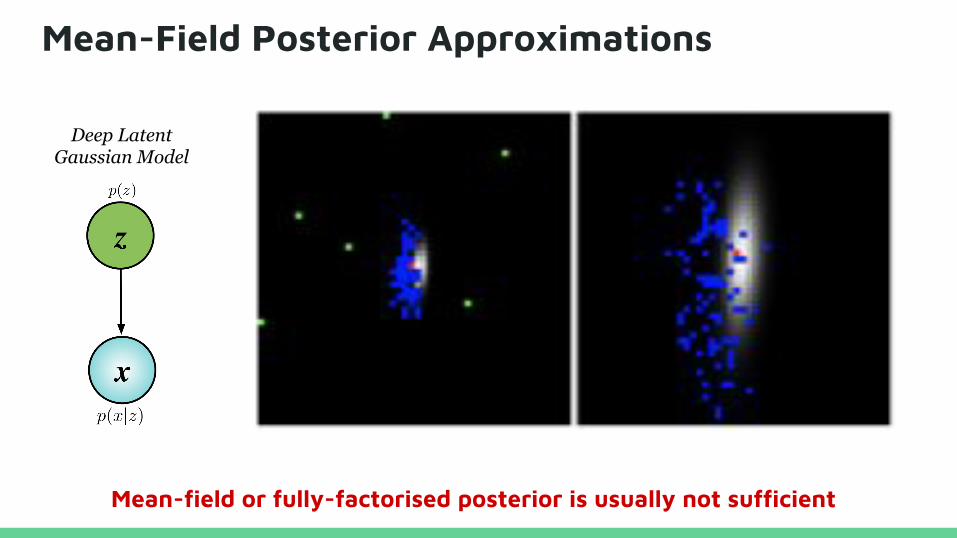
Mean-Field Posterior Approximations
Mean-field or fully-factorised posterior is usually not sufficient
Deep Latent Gaussian Model
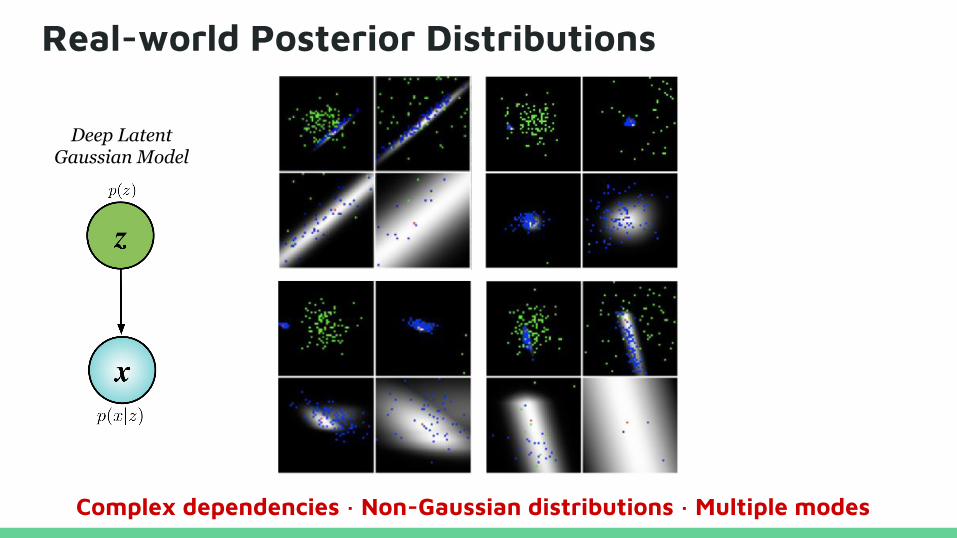
Real-world Posterior Distributions
Complex dependencies · Non-Gaussian distributions · Multiple modes
Deep Latent Gaussian Model
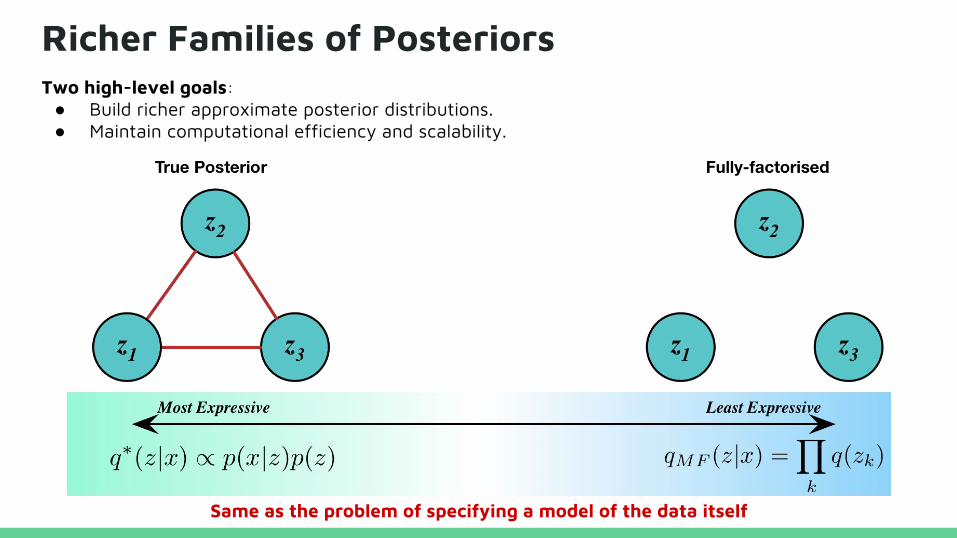
Richer Families of Posteriors
Same as the problem of specifying a model of the data itself
Two high-level goals: ● Build richer approximate posterior distributions.● Maintain computational efficiency and scalability.
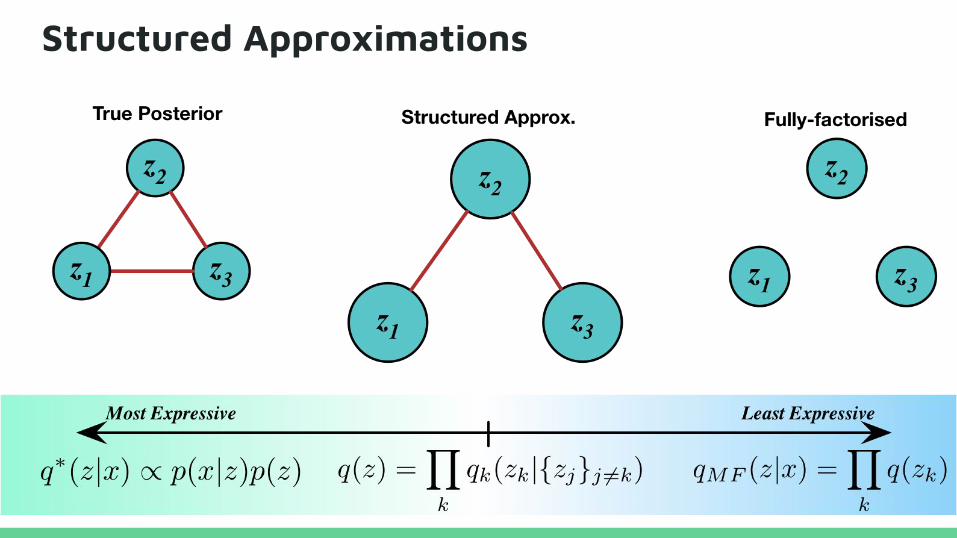
Structured Approximations
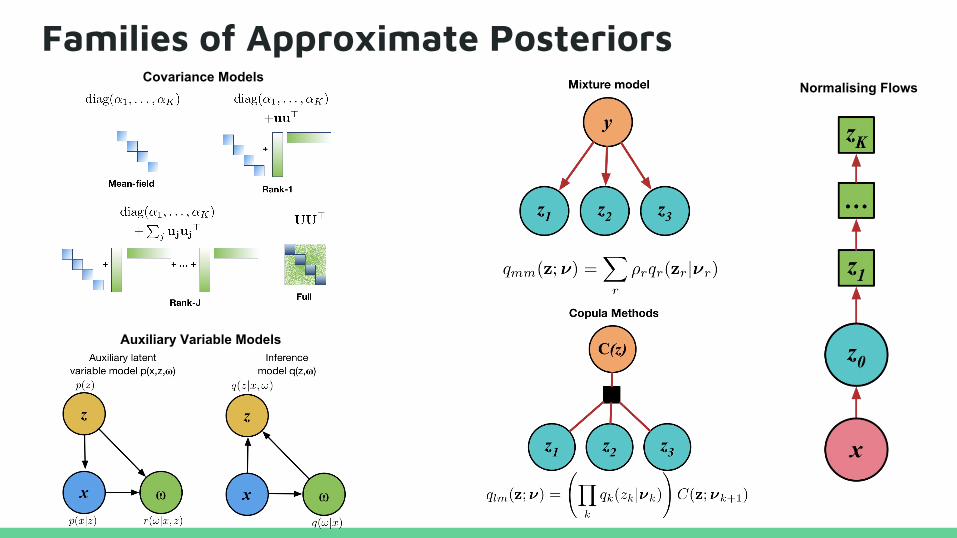
Families of Approximate PosteriorsNormalising Flows
Covariance Models
Auxiliary Variable Models
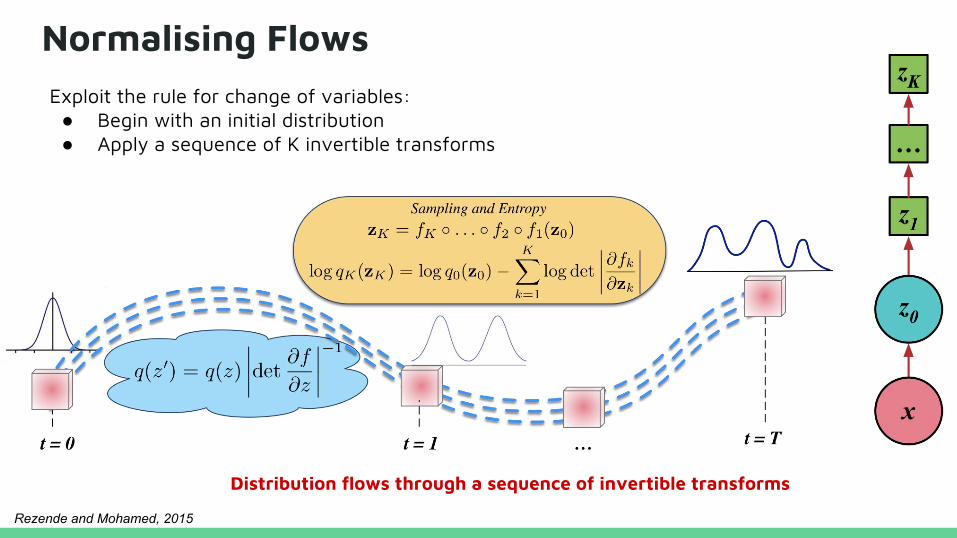
Normalising Flows
Distribution flows through a sequence of invertible transforms
Exploit the rule for change of variables:● Begin with an initial distribution ● Apply a sequence of K invertible transforms
Rezende and Mohamed, 2015
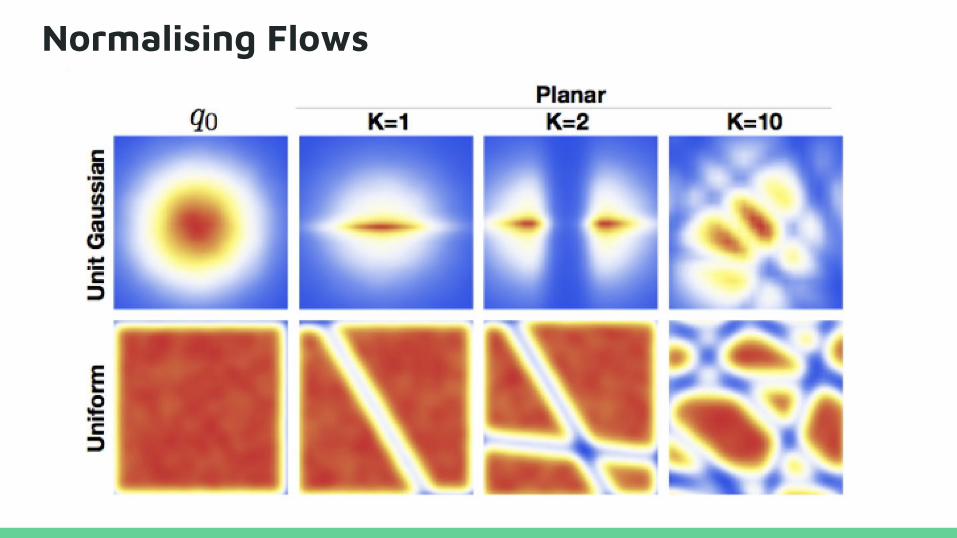
Normalising Flows
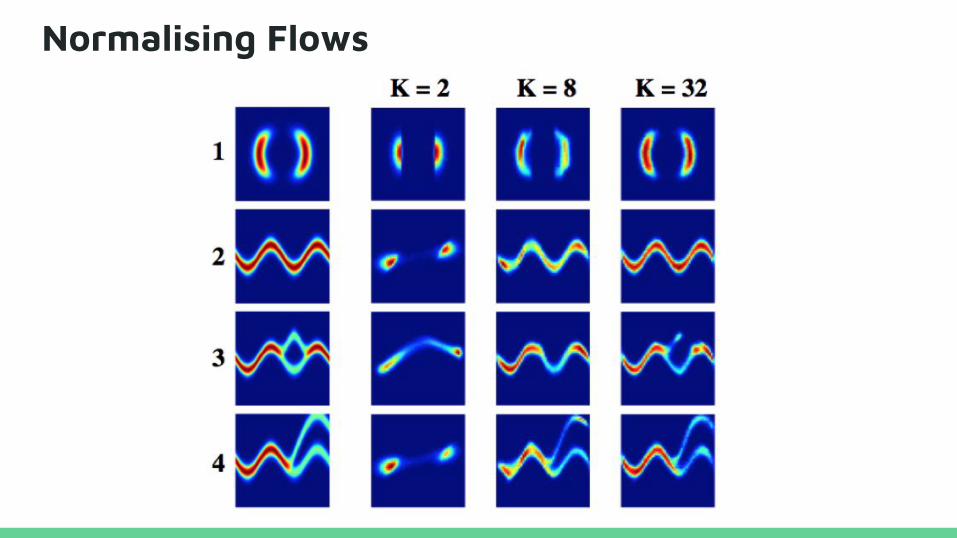
Normalising Flows
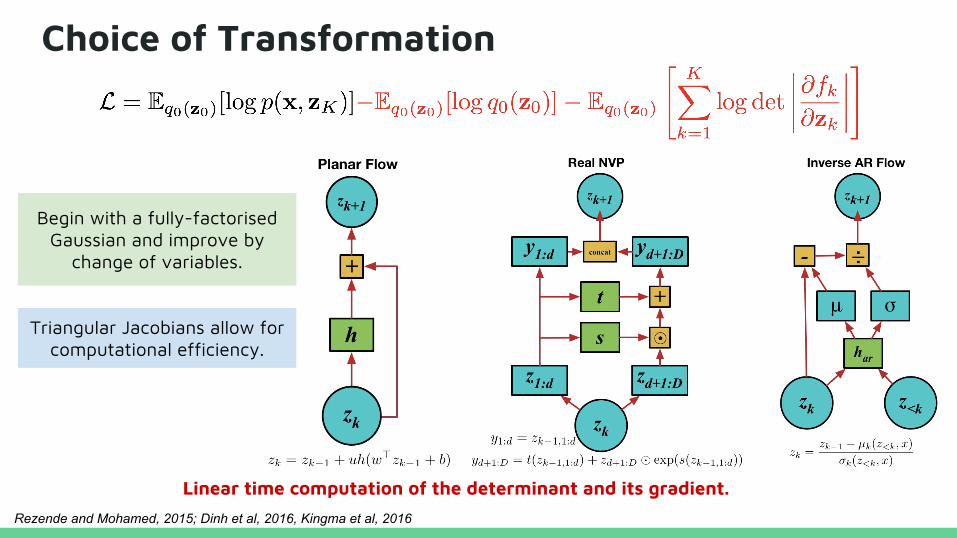
Choice of Transformation
Triangular Jacobians allow for computational efficiency.
Linear time computation of the determinant and its gradient.
Begin with a fully-factorised Gaussian and improve by
change of variables.
Rezende and Mohamed, 2015; Dinh et al, 2016, Kingma et al, 2016
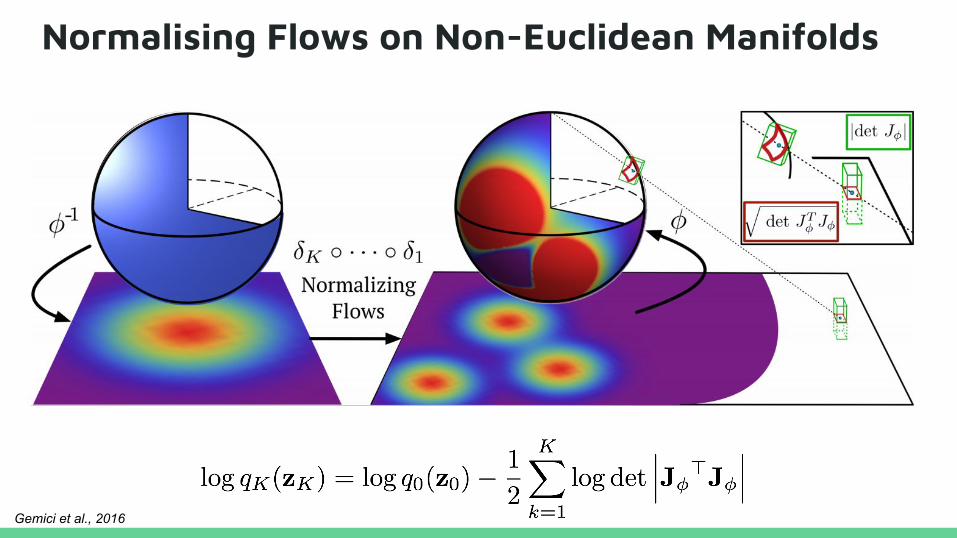
Normalising Flows on Non-Euclidean Manifolds
Gemici et al., 2016

Normalising Flows on non-Euclidean Manifolds

Learning in Implicit Generative Models
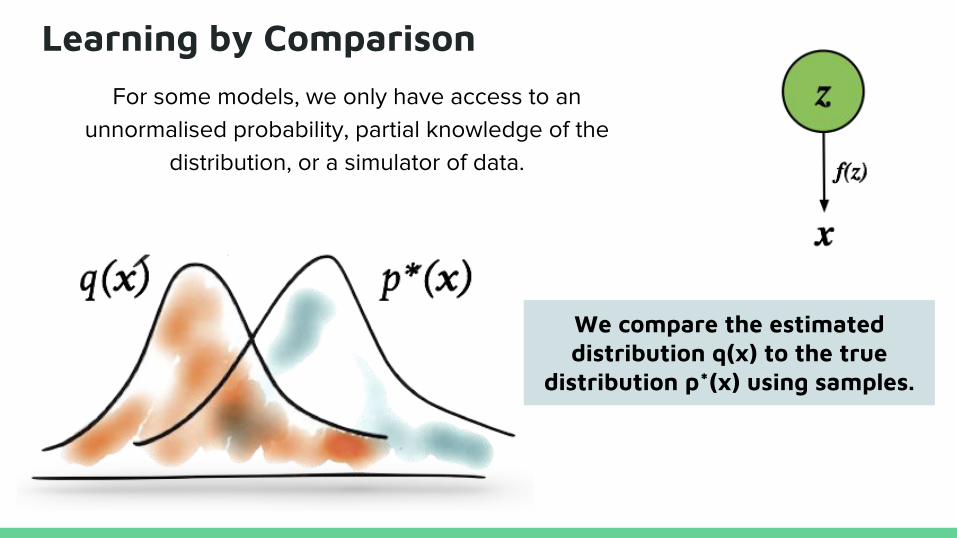
Learning by ComparisonFor some models, we only have access to an
unnormalised probability, partial knowledge of the distribution, or a simulator of data.
We compare the estimated distribution q(x) to the true
distribution p*(x) using samples.
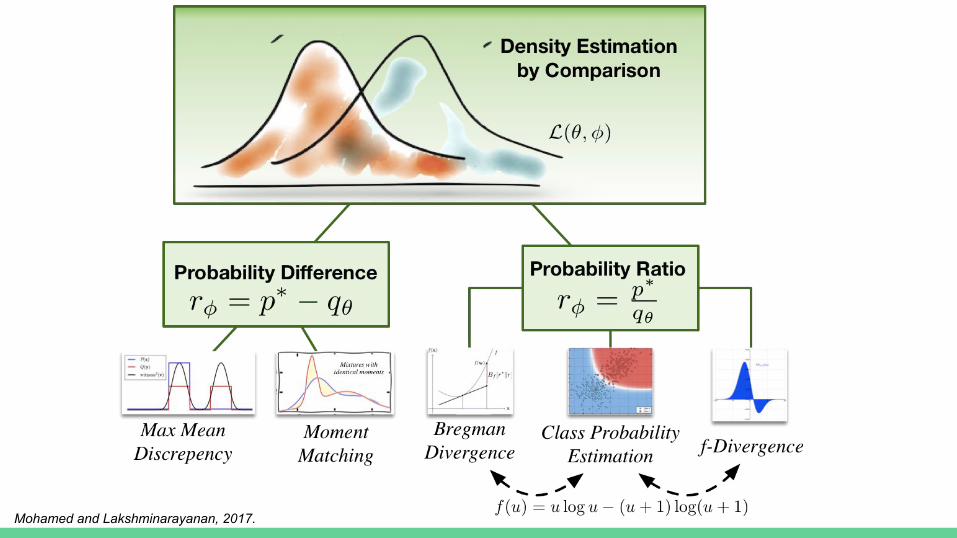
Mohamed and Lakshminarayanan, 2017.
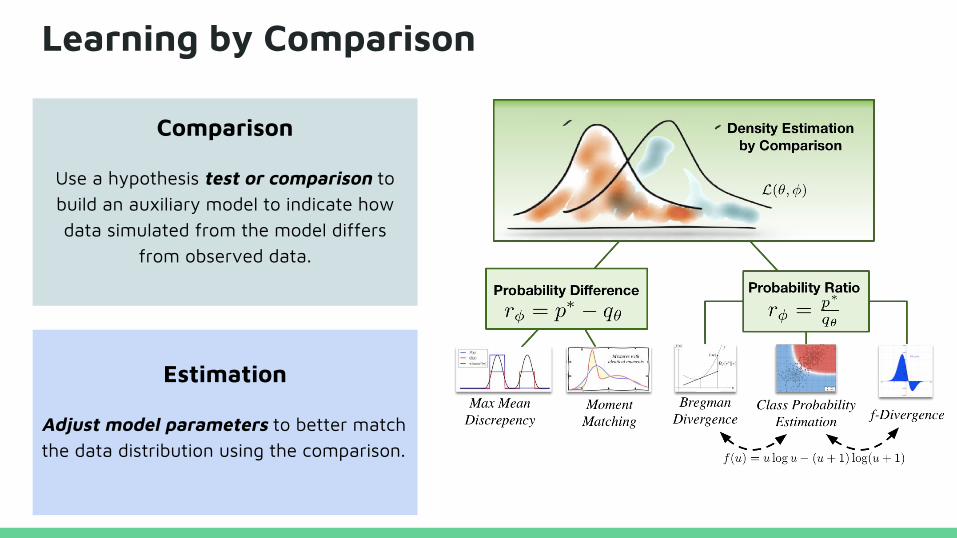
Learning by Comparison
Comparison
Use a hypothesis test or comparison to build an auxiliary model to indicate how data simulated from the model differs
from observed data.
Estimation
Adjust model parameters to better match the data distribution using the comparison.

Density Ratios and Classification
Combine data
Assign labels
Equivalence
Density Ratio
Bayes’ Rule
Real Data Simulated Data
Sugiyama et al, 2012

Density Ratios and Classification
Computing a density ratio is equivalent to class probability estimation.
Conditional
Bayes’ substitution
Class probability

Unsupervised-as-Supervised Learning
Scoring Function
Bernoulli Loss
Alternating optimisation
Other names and places:● Unsupervised and supervised learning● Continuously updating inference● Classifier ABC● Generative Adversarial Networks
● Use when we have differentiable simulators and models
● Can form the loss using any proper scoring rule.
Friedman et al. 2001

Generative Adversarial Networks
Comparison loss
Alternating optimisation
(Alt) Generative loss
Goodfellow et al. 2014
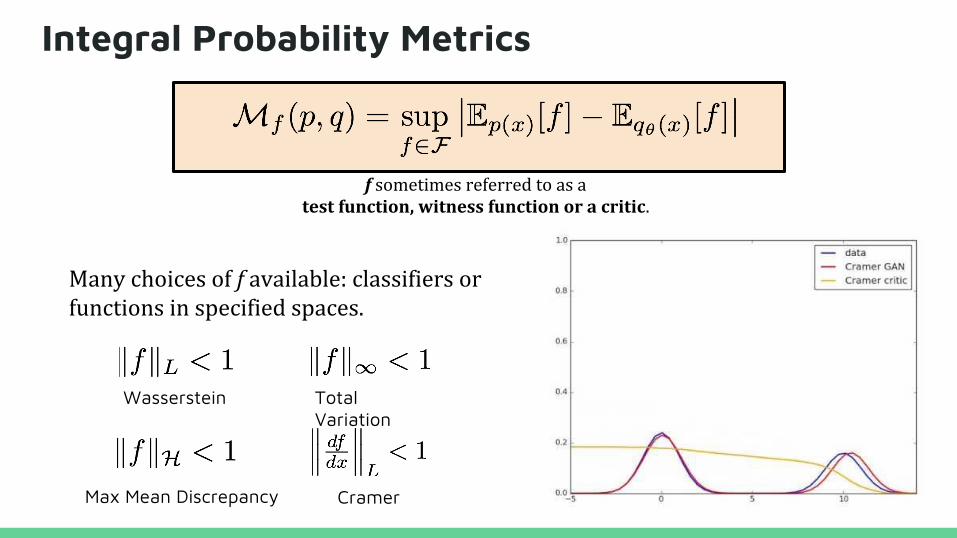
Integral Probability Metrics
Many choices of f available: classifiers or functions in specified spaces.
Wasserstein Total Variation
Max Mean Discrepancy Cramer
f sometimes referred to as a test function, witness function or a critic.

Generative Models and RL

Other names and instantiations:● Planning-as-inference ● Variational MDPs● Path-integral control
Probabilistic Policy Learning
Policy gradient update:● Uniform prior on actions● Score-function gradient estimator (aka Reinforce)
Other algorithms:● Relative entropy policy search● Generative adversarial imitation learning● Reinforced variational inference

The Future
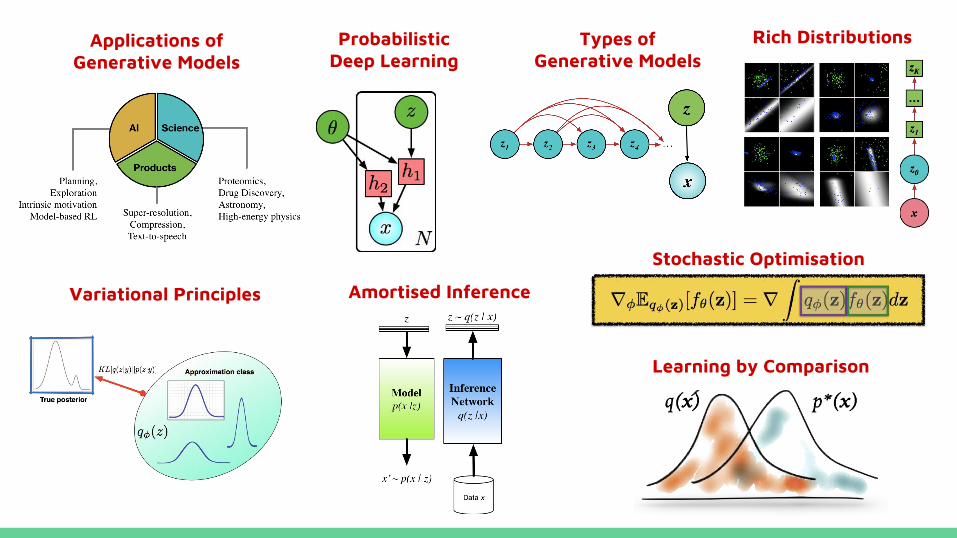
Applications of Generative Models
Types of Generative Models
Amortised Inference
Learning by Comparison
Stochastic Optimisation
Variational Principles
Probabilistic Deep Learning
Rich Distributions

Challenges● Scalability to large images, videos, multiple data modalities.● Evaluation of generative models.● Robust conditional models.● Discrete latent variables.● Support-coverage in models, mode-collapse.● Calibration.● Parameter uncertainty.● Principles of likelihood-free inference.

Tutorial on
Deep Generative ModelsShakir Mohamed and Danilo Rezende
UAI 2017 Australia
@shakir_za @deepspiker

References: Applications● Frey, Brendan J., and Geoffrey E. Hinton. "Variational learning in nonlinear Gaussian belief networks." Neural Computation 11, no. 1
(1999): 193-213. � ● Eslami, S. M., Heess, N., Weber, T., Tassa, Y., Kavukcuoglu, K., and Hinton, G. E. Attend, Infer, Repeat: Fast Scene Understanding
with Generative Models. NIPS (2016). � ● Rezende, Danilo Jimenez, Shakir Mohamed, Ivo Danihelka, Karol Gregor, and Daan Wierstra. "One-Shot Generalization in Deep
Generative Models." ICML (2016). � ● Kingma, Diederik P., Shakir Mohamed, Danilo Jimenez Rezende, and Max Welling. "Semi-supervised learning with deep
generative models." In Advances in Neural Information Processing Systems, pp. 3581-3589. 2014.● Higgins, Irina, Loic Matthey, Xavier Glorot, Arka Pal, Benigno Uria, Charles Blundell, Shakir Mohamed, and Alexander Lerchner.
"Early Visual Concept Learning with Unsupervised Deep Learning." arXiv preprint arXiv:1606.05579 (2016).● Bellemare, Marc G., Sriram Srinivasan, Georg Ostrovski, Tom Schaul, David Saxton, and Remi Munos. "Unifying Count-Based
Exploration and Intrinsic Motivation." arXiv preprint arXiv:1606.01868 (2016).● Odena, Augustus. "Semi-Supervised Learning with Generative Adversarial Networks." arXiv preprint arXiv:1606.01583 (2016).● Springenberg, Jost Tobias. "Unsupervised and Semi-supervised Learning with Categorical Generative Adversarial Networks."
arXiv preprint arXiv:1511.06390 (2015).● Alexander (Sasha) Vezhnevets, Mnih, Volodymyr, John Agapiou, Simon Osindero, Alex Graves, Oriol Vinyals, and Koray
Kavukcuoglu. "Strategic Attentive Writer for Learning Macro-Actions." arXiv preprint arXiv:1606.04695 (2016).● Gregor, Karol, Ivo Danihelka, Alex Graves, Danilo Jimenez Rezende, and Daan Wierstra. "DRAW: A recurrent neural network for
image generation." arXiv preprint arXiv:1502.04623 (2015).

References: Applications● Gómez-Bombarelli R, Duvenaud D, Hernández-Lobato JM, Aguilera-Iparraguirre J, Hirzel TD, Adams RP, Aspuru-Guzik A.
Automatic chemical design using a data-driven continuous representation of molecules. arXiv preprint arXiv:1610.02415. 2016.● Rampasek L, Goldenberg A. Dr. VAE: Drug Response Variational Autoencoder. arXiv preprint arXiv:1706.08203. 2017 Jun 26.● Regier J, Miller A, McAuliffe J, Adams R, Hoffman M, Lang D, Schlegel D, Prabhat M. Celeste: Variational inference for a
generative model of astronomical images. In International Conference on Machine Learning 2015 Jun 1 (pp. 2095-2103).● Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, Aitken A, Tejani A, Totz J, Wang Z, Shi W. Photo-realistic single
image super-resolution using a generative adversarial network. arXiv preprint arXiv:1609.04802. 2016 Sep 15.● Oord AV, Dieleman S, Zen H, Simonyan K, Vinyals O, Graves A, Kalchbrenner N, Senior A, Kavukcuoglu K. Wavenet: A generative
model for raw audio. arXiv preprint arXiv:1609.03499. 2016 Sep 12.● Dumoulin V, Belghazi I, Poole B, Lamb A, Arjovsky M, Mastropietro O, Courville A. Adversarially learned inference. arXiv preprint
arXiv:1606.00704. 2016 Jun 2.● Gregor K, Besse F, Rezende DJ, Danihelka I, Wierstra D. Towards conceptual compression. In Advances In Neural Information
Processing Systems 2016 (pp. 3549-3557).● Higgins I, Matthey L, Glorot X, Pal A, Uria B, Blundell C, Mohamed S, Lerchner A. Early visual concept learning with unsupervised
deep learning. arXiv preprint arXiv:1606.05579. 2016 Jun 17.● Chiappa S, Racaniere S, Wierstra D, Mohamed S. Recurrent Environment Simulators. arXiv preprint arXiv:1704.02254. 2017 Apr 7.● Kalchbrenner N, Oord AV, Simonyan K, Danihelka I, Vinyals O, Graves A, Kavukcuoglu K. Video pixel networks. arXiv preprint
arXiv:1610.00527. 2016 Oct 3.● Wu J, Tenenbaum JB, Kohli P. Neural Scene De-rendering., CVPR 2017

References: Fully-observed Models● Oord, Aaron van den, Nal Kalchbrenner, and Koray Kavukcuoglu. "Pixel recurrent neural networks." arXiv preprint
arXiv:1601.06759 (2016).● Larochelle, Hugo, and Iain Murray. "The Neural Autoregressive Distribution Estimator." In AISTATS, vol. 1, p. 2. 2011.● Uria, Benigno, Iain Murray, and Hugo Larochelle. "A Deep and Tractable Density Estimator." In ICML, pp. 467-475. 2014.● Veness, Joel, Kee Siong Ng, Marcus Hutter, and Michael Bowling. "Context tree switching." In 2012 Data Compression
Conference, pp. 327-336. IEEE, 2012.● Rue, Havard, and Leonhard Held. Gaussian Markov random fields: theory and applications. CRC Press, 2005.● Wainwright, Martin J., and Michael I. Jordan. "Graphical models, exponential families, and variational inference." Foundations and
Trends® in Machine Learning 1, no. 1-2 (2008): 1-305.

References: Latent Variable Models● Hyvärinen, A., Karhunen, J., & Oja, E. (2004). Independent component analysis (Vol. 46). John Wiley & Sons.● Gregor, Karol, Ivo Danihelka, Andriy Mnih, Charles Blundell, and Daan Wierstra. "Deep autoregressive networks." arXiv preprint
arXiv:1310.8499 (2013).● Ghahramani, Zoubin, and Thomas L. Griffiths. "Infinite latent feature models and the Indian buffet process." In Advances in neural
information processing systems, pp. 475-482. 2005.● Teh, Yee Whye, Michael I. Jordan, Matthew J. Beal, and David M. Blei. "Hierarchical dirichlet processes." Journal of the american
statistical association (2012).● Adams, Ryan Prescott, Hanna M. Wallach, and Zoubin Ghahramani. "Learning the Structure of Deep Sparse Graphical Models." In
AISTATS, pp. 1-8. 2010.● Lawrence, Neil D. "Gaussian process latent variable models for visualisation of high dimensional data." Advances in neural
information processing systems 16.3 (2004): 329-336.● Damianou, Andreas C., and Neil D. Lawrence. "Deep Gaussian Processes." In AISTATS, pp. 207-215. 2013.● Mattos, César Lincoln C., Zhenwen Dai, Andreas Damianou, Jeremy Forth, Guilherme A. Barreto, and Neil D. Lawrence.
"Recurrent Gaussian Processes." arXiv preprint arXiv:1511.06644 (2015).● Salakhutdinov, Ruslan, Andriy Mnih, and Geoffrey Hinton. "Restricted Boltzmann machines for collaborative filtering." In
Proceedings of the 24th international conference on Machine learning, pp. 791-798. ACM, 2007.● Saul, Lawrence K., Tommi Jaakkola, and Michael I. Jordan. "Mean field theory for sigmoid belief networks." Journal of artificial
intelligence research 4, no. 1 (1996): 61-76.● Frey, Brendan J., and Geoffrey E. Hinton. "Variational learning in nonlinear Gaussian belief networks." Neural Computation 11, no. 1
(1999): 193-213.● Durk Kingma and Max Welling. "Auto-encoding Variational Bayes." ICLR (2014). � ● Burda Y, Grosse R, Salakhutdinov R. Importance weighted autoencoders. arXiv preprint arXiv:1509.00519. 2015 Sep 1.

References: Latent Variable Models (cont)● Ranganath, Rajesh, Sean Gerrish, and David M. Blei. "Black Box Variational Inference." In AISTATS, pp. 814-822. 2014.● Mnih, Andriy, and Karol Gregor. "Neural variational inference and learning in belief networks." arXiv preprint arXiv:1402.0030
(2014).● Lázaro-Gredilla, Miguel. "Doubly stochastic variational Bayes for non-conjugate inference." (2014).● Wingate, David, and Theophane Weber. "Automated variational inference in probabilistic programming." arXiv preprint
arXiv:1301.1299 (2013).● Paisley, John, David Blei, and Michael Jordan. "Variational Bayesian inference with stochastic search." arXiv preprint
arXiv:1206.6430 (2012).● Barber D, de van Laar P. Variational cumulant expansions for intractable distributions. Journal of Artificial Intelligence Research.
1999;10:435-55.

References: Stochastic Gradients● Pierre L’Ecuyer, Note: On the interchange of derivative and expectation for likelihood ratio derivative estimators, Management
Science, 1995 � ● Peter W Glynn, Likelihood ratio gradient estimation for stochastic systems, Communications of the ACM, 1990 � ● Michael C Fu, Gradient estimation, Handbooks in operations research and management science, 2006 � ● Ronald J Williams, Simple statistical gradient-following algorithms for connectionist reinforcement learning, Machine learning, 1992 � ● Paul Glasserman, Monte Carlo methods in financial engineering, 2003 � ● Omiros Papaspiliopoulos, Gareth O Roberts, Martin Skold, A general framework for the parametrization of hierarchical models,
Statistical Science, 2007 � ● Michael C Fu, Gradient estimation, Handbooks in operations research and management science, 2006 � ● Rajesh Ranganath, Sean Gerrish, and David M. Blei. "Black Box Variational Inference." In AISTATS, pp. 814-822. 2014. � ● Andriy Mnih, and Karol Gregor. "Neural variational inference and learning in belief networks." arXiv preprint arXiv:1402.0030 (2014).● Michalis Titsias and Miguel Lázaro-Gredilla. "Doubly stochastic variational Bayes for non-conjugate inference." (2014). � ● David Wingate and Theophane Weber. "Automated variational inference in probabilistic programming." arXiv preprint arXiv:1301.1299
(2013). � ● John Paisley, David Blei, and Michael Jordan. "Variational Bayesian inference with stochastic search." arXiv preprint arXiv:1206.6430
(2012). � ● Durk Kingma and Max Welling. "Auto-encoding Variational Bayes." ICLR (2014). � ● Danilo Jimenez Rezende, Shakir Mohamed, Daan Wierstra. "Stochastic Backpropagation and Approximate Inference in Deep
Generative Models." ICML (2014).● Papaspiliopoulos O, Roberts GO, Sköld M. A general framework for the parametrization of hierarchical models. Statistical Science.
2007 Feb 1:59-73.● Fan K, Wang Z, Beck J, Kwok J, Heller KA. Fast second order stochastic backpropagation for variational inference. InAdvances in
Neural Information Processing Systems 2015 (pp. 1387-1395).

References: Amortised Inference● Dayan, Peter, Geoffrey E. Hinton, Radford M. Neal, and Richard S. Zemel. "The helmholtz machine." Neural computation 7, no. 5
(1995): 889-904. � ● Gershman, Samuel J., and Noah D. Goodman. "Amortized inference in probabilistic reasoning." In Proceedings of the 36th Annual
Conference of the Cognitive Science Society. 2014. � ● Danilo Jimenez Rezende, Shakir Mohamed, Daan Wierstra. "Stochastic Backpropagation and Approximate Inference in Deep
Generative Models." ICML (2014).● Durk Kingma and Max Welling. "Auto-encoding Variational Bayes." ICLR (2014). � \● Heess, Nicolas, Daniel Tarlow, and John Winn. "Learning to pass expectation propagation messages." In Advances in Neural
Information Processing Systems, pp. 3219-3227. 2013. � ● Jitkrittum, Wittawat, Arthur Gretton, Nicolas Heess, S. M. Eslami, Balaji Lakshminarayanan, Dino Sejdinovic, and Zoltà ˛an Szabøs.
"Kernel-based just-in-time learning for passing expectation propagation messages." arXiv preprint arXiv:1503.02551 (2015). � ● Korattikara, Anoop, Vivek Rathod, Kevin Murphy, and Max Welling. "Bayesian dark knowledge." arXiv preprint arXiv:1506.04416
(2015).

References: Structured Mean Field ● Jaakkola, T. S., and Jordan, M. I. (1998). Improving the mean field approximation via the use of mixture distributions. In Learning in
graphical models (pp. 163-173). Springer Netherlands. � ● Saul, L.K. and Jordan, M.I., 1996. Exploiting tractable substructures in intractable networks. Advances in neural information
processing systems, pp.486-492. � ● Gregor, Karol, Ivo Danihelka, Alex Graves, Danilo Jimenez Rezende, and Daan Wierstra. "DRAW: A recurrent neural network for
image generation." ICML (2015). � ● Gershman, S., Hoffman, M. and Blei, D., 2012. Nonparametric variational inference. arXiv preprint arXiv:1206.4665.● Felix V. Agakov, and David Barber. "An auxiliary variational method." NIPS (2004). � Rajesh Ranganath, Dustin Tran, and David M.
Blei. "Hierarchical Variational Models." ICML (2016). � Lars Maaløe et al. "Auxiliary Deep Generative Models." ICML (2016). � Tim Salimans, Durk Kingma, Max Welling. "Markov chain Monte Carlo and variational inference: Bridging the gap. In International Conference on Machine Learning." ICML (2015).
● Maaløe L, Sønderby CK, Sønderby SK, Winther O. Auxiliary deep generative models. arXiv preprint arXiv:1602.05473. 2016 Feb 17.

References: Normalising Flows● Tabak, E. G., and Cristina V. Turner. "A family of nonparametric density estimation algorithms." Communications on Pure and
Applied Mathematics 66, no. 2 (2013): 145-164. � ● Rezende, Danilo Jimenez, and Shakir Mohamed. "Variational inference with normalizing flows." ICML (2015). � ● Kingma, D.P., Salimans, T. and Welling, M., 2016. Improving variational inference with inverse autoregressive flow. arXiv preprint
arXiv:1606.04934. � ● Dinh, L., Sohl-Dickstein, J. and Bengio, S., 2016. Density estimation using Real NVP. arXiv preprint arXiv:1605.08803.

References: Other Variational Objectives● Yuri Burda, Roger Grosse, Ruslan Salakhutidinov. "Importance weighted autoencoders." ICLR (2015). � ● Yingzhen Li, Richard E. Turner. "Rényi divergence variational inference." NIPS (2016). � ● Guillaume and Balaji Lakshminarayanan. "Approximate Inference with the Variational Holder Bound." ArXiv (2015). � ● José Miguel Hernández-Lobato, Yingzhen Li, Daniel Hernández-Lobato, Thang Bui, and Richard E. Turner. Black-box
α-divergence Minimization. ICML (2016). � ● Rajesh Ranganath, Jaan Altosaar, Dustin Tran, David M. Blei. Operator Variational Inference. NIPS (2016).

References: Discrete Latent Variable Models● �Radford Neal. "Learning stochastic feedforward networks." Tech. Rep. CRG-TR-90-7: Department of Computer Science,
University of Toronto (1990). � ● Lawrence K. Saul, Tommi Jaakkola, and Michael I. Jordan. "Mean field theory for sigmoid belief networks." Journal of artificial
intelligence research 4, no. 1 (1996): 61-76. � ● Karol Gregor, Ivo Danihelka, Andriy Mnih, Charles Blundell, and Daan Wierstra. "Deep autoregressive networks." ICML (2014). � ● Rajesh Ranganath, Linpeng Tang, Laurent Charlin, and David M. Blei. "Deep Exponential Families." AISTATS (2015). � ● Rajesh Ranganath, Dustin Tran, and David M. Blei. "Hierarchical Variational Models." ICML (2016).

References: Implicit Generative Models● Borgwardt, Karsten M., and Zoubin Ghahramani. "Bayesian two-sample tests." arXiv preprint arXiv:0906.4032 (2009).● Gutmann, Michael, and Aapo Hyvärinen. "Noise-contrastive estimation: A new estimation principle for unnormalized statistical
models." AISTATS. Vol. 1. No. 2. 2010.● Tsuboi, Yuta, Hisashi Kashima, Shohei Hido, Steffen Bickel, and Masashi Sugiyama. "Direct Density Ratio Estimation for
Large-scale Covariate Shift Adaptation." Information and Media Technologies 4, no. 2 (2009): 529-546.● Sugiyama, Masashi, Taiji Suzuki, and Takafumi Kanamori. Density ratio estimation in machine learning. Cambridge University
Press, 2012.● Goodfellow, Ian, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua
Bengio. "Generative adversarial nets." In Advances in Neural Information Processing Systems, pp. 2672-2680. 2014.● Verrelst, Herman, Johan Suykens, Joos Vandewalle, and Bart De Moor. "Bayesian learning and the Fokker-Planck machine." In
Proceedings of the International Workshop on Advanced Black-box Techniques for Nonlinear Modeling, Leuven, Belgium, pp. 55-61. 1998.
● Devroye, Luc. "Random variate generation in one line of code." In Proceedings of the 28th conference on Winter simulation, pp. 265-272. IEEE Computer Society, 1996.
● Mohamed S, Lakshminarayanan B. Learning in implicit generative models. arXiv preprint arXiv:1610.03483. 2016 Oct 11.● Gutmann MU, Dutta R, Kaski S, Corander J. Likelihood-free inference via classification. Statistics and Computing. 2017 Mar 13:1-5.● Beaumont MA, Zhang W, Balding DJ. Approximate Bayesian computation in population genetics. Genetics. 2002 Dec
1;162(4):2025-35.● Arjovsky M, Chintala S, Bottou L. Wasserstein gan. ICML 2017.● Nowozin S, Cseke B, Tomioka R. f-gan: Training generative neural samplers using variational divergence minimization. In
Advances in Neural Information Processing Systems 2016 (pp. 271-279).● Bellemare MG, Danihelka I, Dabney W, Mohamed S, Lakshminarayanan B, Hoyer S, Munos R. The Cramer Distance as a Solution
to Biased Wasserstein Gradients. arXiv preprint arXiv:1705.10743. 2017 May 30.● Dumoulin V, Belghazi I, Poole B, Lamb A, Arjovsky M, Mastropietro O, Courville A. Adversarially learned inference.● Friedman J, Hastie T, Tibshirani R. The elements of statistical learning. New York: Springer series in statistics; 2001.

References: Prob. Reinforcement Learning● Kappen HJ. Path integrals and symmetry breaking for optimal control theory. Journal of statistical mechanics: theory and
experiment. 2005 Nov 30;2005(11):P11011.● Rawlik K, Toussaint M, Vijayakumar S. Approximate inference and stochastic optimal control. arXiv preprint arXiv:1009.3958. 2010
Sep 20.● Toussaint M. Robot trajectory optimization using approximate inference. InProceedings of the 26th annual international
conference on machine learning 2009 Jun 14 (pp. 1049-1056). ACM.● Weber T, Heess N, Eslami A, Schulman J, Wingate D, Silver D. Reinforced variational inference. In Advances in Neural Information
Processing Systems (NIPS) Workshops 2015.● Rajeswaran A, Lowrey K, Todorov E, Kakade S. Towards Generalization and Simplicity in Continuous Control.● Peters J, Mülling K, Altun Y. Relative Entropy Policy Search. In AAAI 2010 Jul 11 (pp. 1607-1612).● Furmston T, Barber D. Variational methods for reinforcement learning. In Proceedings of the Thirteenth International Conference
on Artificial Intelligence and Statistics 2010 Mar 31 (pp. 241-248).● Ho J, Ermon S. Generative adversarial imitation learning. In Advances in Neural Information Processing Systems 2016 (pp.
4565-4573





























