Embed Size (px)
Citation preview

arX
iv:2
002.
0415
6v3
[cs
.LG
] 2
0 Fe
b 20
211
Turbo-Aggregate: Breaking the QuadraticAggregation Barrier in Secure Federated Learning
Jinhyun So, Basak Güler, Member, IEEE and A. Salman Avestimehr, Fellow, IEEE
Abstract—Federated learning is a distributed framework fortraining machine learning models over the data residing atmobile devices, while protecting the privacy of individual users.A major bottleneck in scaling federated learning to a largenumber of users is the overhead of secure model aggregationacross many users. In particular, the overhead of the state-of-the-art protocols for secure model aggregation grows quadraticallywith the number of users. In this paper, we propose the firstsecure aggregation framework, named Turbo-Aggregate, that ina network with # users achieves a secure aggregation overhead of
$ (# log #), as opposed to $ (#2), while tolerating up to a userdropout rate of 50%. Turbo-Aggregate employs a multi-groupcircular strategy for efficient model aggregation, and leveragesadditive secret sharing and novel coding techniques for injectingaggregation redundancy in order to handle user dropouts whileguaranteeing user privacy. We experimentally demonstrate thatTurbo-Aggregate achieves a total running time that grows almostlinear in the number of users, and provides up to 40× speedupover the state-of-the-art protocols with up to # = 200 users. Ourexperiments also demonstrate the impact of bandwidth on theperformance of Turbo-Aggregate.
Index Terms—Federated learning, privacy-preserving machinelearning, secure aggregation.
I. INTRODUCTION
Federated learning is an emerging approach that enablesmodel training over a large volume of decentralized dataresiding in mobile devices, while protecting the privacy ofthe individual users [2]–[5]. This is achieved by two keydesign principles. First, the training data is kept on the userdevice rather than sending it to a central server, and userslocally perform model updates using their individual data.Second, local models are aggregated in a privacy-preservingframework, either at a central server (or in a distributed manneracross the users) to update the global model. The global modelis then pushed back to the mobile devices for inference. Thisprocess is demonstrated in Figure 1.
The privacy of individual models in federated learning isprotected through what is known as a secure aggregation
protocol [3], [4]. In this protocol, each user locally masksits own model using pairwise random masks and sends themasked model to the server. The pairwise masks have a uniqueproperty that once the masked models from all users are
Jinhyun So is with the Department of Electrical and Computer Engineering,University of Southern California, Los Angeles, CA, 90089 USA (e-mail:[email protected]). Basak Güler is with the Department of Electrical andComputer Engineering, University of California, Riverside, CA, 92521 USA(email: [email protected]). A. Salman Avestimehr is with the Departmentof Electrical and Computer Engineering, University of Southern California,Los Angeles, CA, 90089 USA (e-mail: [email protected]).
This work is published in IEEE Journal on Selected Areas in InformationTheory [1].
local updates
x1(t) x2(t) xN (t)
user 1 user Nuser 2
x(t+ 1)N∑
i=1
xi(t)server
updated global model
x(t) x(t) x(t)
· · ·
secure aggregation
Fig. 1. Federated learning framework. At iteration C , the central server sendsthe current version of the global model, x(C), to the mobile users. User 8 ∈[# ] updates the global model using its local data, and computes a localmodel x8 (C). The local models are then aggregated in a privacy-preservingmanner. Using the aggregated models, the central server updates the globalmodel x(C + 1) for the next round, and pushes it back to the mobile users.
summed up at the server, the pairwise masks cancel out. Asa result, the server learns the aggregate of all models, but noindividual model is revealed to the server during the process.This is a key property for ensuring user privacy in securefederated learning. In contrast, conventional distributed train-ing setups that do not employ secure aggregation may revealextensive information about the private datasets of the users,which has been recently shown in [6]–[8]. To prevent suchinformation leakage, secure aggregation protocols ensure thatthe individual update of each user is kept private, both fromother users and the central server [3], [4]. A recent promisingimplementation of federated learning, as well as its applicationto Google keyboard query suggestions is demonstrated in [9].Several other works have also demonstrated that leveragingthe information that is distributed over many mobile users canincrease the training performance dramatically, while ensuringdata privacy and locality [10]–[12].
The overhead of secure model aggregation, however, createsa major bottleneck in scaling secure federated learning to alarge number of users. More specifically, in a network with# users, the state-of-the-art protocols for secure aggregationrequire pairwise random masks to be generated between eachpair of users (for hiding the local model updates), and thereforethe overhead of secure aggregation grows quadratically in thenumber of users (i.e., $ (#2)) [3], [4]. This quadratic growthof secure aggregation overhead limits its practical applicationsto hundreds of users while the scale of current mobile systemsis in the order of tens of millions [11].
Another key challenge in model aggregation is the dropoutor unavailability of the users. Device availability and con-nection quality in mobile networks change rapidly, and usersmay drop from federated learning systems at any time due to

2
various reasons, such as poor connectivity, making a phonecall, low battery, etc. The design protocol hence needs tobe robust to operate in such environments, where users candrop at any stage of the protocol execution. Furthermore,dropped or delayed users can lead to privacy breaches [4], andprivacy guarantees should hold even in the case when usersare dropped or delayed.
In this paper, we introduce a novel secure aggregationframework for federated learning, named Turbo-Aggregate,with four salient features:
1) Turbo-Aggregate reduces the overhead of secure aggre-gation to $ (# log#) from $ (#2);
2) Turbo-Aggregate has provable robustness guaranteesagainst up to a user dropout rate of 50%;
3) Turbo-Aggregate protects the privacy of the localmodel updates of each individual user, in the stronginformation-theoretic sense;
4) Turbo-Aggregate experimentally achieves a total runningtime that grows almost linear in the number of users,and provides up to 40× speedup over the state-of-the-art with # = 200 users, in distributed implementationover Amazon EC2 cloud.
At a high level, Turbo-Aggregate is composed of three maincomponents. First, Turbo-Aggregate employs a multi-groupcircular strategy for model aggregation. In particular, the usersare partitioned into several groups, and at each aggregationstage, the users in one group pass the aggregated modelsof all the users in the previous groups and current group tousers in the next group. We show that this structure enablesthe reduction of aggregation overhead to $ (# log#) (from$ (#2)). However, there are two key challenges that need tobe addressed in the proposed multi-group circular strategy formodel aggregation. The first one is to protect the privacy of theindividual user, i.e., the aggregation protocol should not allowthe identification of individual model updates. The second oneis handling the user dropouts. For instance, a user dropped ata higher group of the protocol may lead to the loss of theaggregated model information from all the previous groups,and collecting this information again from the lower groupsmay incur a large communication overhead.
The second key component is to leverage additive secretsharing [13], [14] to enable privacy and security of the users.In particular, additive sharing masks each local model byadding randomness in a way that can be cancelled out once themodels are aggregated. Finally, the third component is to addaggregation redundancy via Lagrange coding [15] to enablerobustness against delayed or dropped users. In particular,Turbo-Aggregate injects redundancy via Lagrange polynomialso that the added redundancy can be exploited to reconstructthe aggregated model amidst potential dropouts.
Turbo-Aggregate allows the use of both centralized anddecentralized communication architectures. The centralizedarchitecture refers to the communication model used in theconventional federated learning setup where all communica-tion goes through a central server, i.e., the server acts as anaccess point [2], [4], [5]. The decentralized architecture, on theother hand, refers to the setup where mobile devices commu-nicate directly with each other via an underlay communication
network (e.g., a peer-to-peer network) [16], [17] withoutrequiring a central server for secure model aggregation. Turbo-Aggregate also allows additional parallelization opportunitiesfor communication, such as broadcasting and multi-casting.
We theoretically analyze the performance guarantees ofTurbo-Aggregate in terms of the aggregation overhead, privacyprotection, and robustness to dropped or delayed users. In par-ticular, we show that Turbo-Aggregate achieves an aggregationoverhead of $ (# log#) and can tolerate a user dropout rate of50%. We then quantify the privacy guarantees of our system.An important implication of dropped or delayed users is thatthey may lead to privacy breaches [3]. Accordingly, we showthat the privacy-protection of our algorithm is preserved insuch scenarios, i.e., when users are dropped or delayed.
We also provide extensive experiments to numerically eval-uate the performance of Turbo-Aggregate. To do so, we im-plement Turbo-Aggregate for up to 200 users on the AmazonEC2 cloud, and compare its performance with the state-of-the-art secure aggregation protocol from [4]. We demonstratethat Turbo-Aggregate can achieve an overall execution timethat grows almost linear in the number of users, and providesup to 40× speedup over the state-of-the-art with 200 users.Furthermore, the overall execution time of Turbo-Aggregateremains stable as the user dropout rate increases, while for thebenchmark protocol, the overall execution time significantlyincreases as the user dropout rate increases. We further studythe impact of communication bandwidth on the performanceof Turbo-Aggregate, by measuring the total running timewith various bandwidth constraints. Our experimental resultsdemonstrate that Turbo-Aggregate still provides substantialgain in environments with more severe bandwidth constraints.
II. RELATED WORK
A potential solution for secure aggregation is to leveragecryptographic approaches, such as multiparty computation(MPC), homomorphic encryption, or differential privacy. MPC-based techniques mainly utilize Yao’s garbled circuits or secretsharing (e.g., [18]–[21]). Their main bottleneck is the highcommunication cost, and communication-efficient implementa-tions require an extensive offline computation part [20], [21]. Anotable recent work is [22], which focuses on optimizing MPCprotocols for network security and monitoring. Homomorphicencryption is a cryptographic secure computation schemethat allows aggregations to be performed on encrypted data[23]–[25]. However, the privacy guarantees of homomorphicencryption depends on the size of the encrypted data (moreprivacy requires a larger encypted data size), and performingcomputations in the encrypted domain is computationallyexpensive [26], [27]. Differential privacy is a a noisy releasemechanism that preserves the privacy of personally identifiableinformation, in that the removal of any single element from thedataset does not affect the computation outcomes significantly.As such, the computation outcomes cannot be used to infermuch about any single individual element [28]. In the contextof federated learning, differential privacy is mainly used toensure that individual data points from the local datasetscannot be identified from the local updates sent to the server,

3
by adding artificial noise to the local updates at the clients’side [10], [29], [30]. This approach entails a trade-off betweenconvergence performance and privacy protection, i.e., strongerprivacy guarantees lead to a degradation in the convergenceperformance. On the other hand, our focus is on ensuring thatthe server or a group of colluding users can learn nothingbeyond the aggregate of all local updates, while preservingthe accuracy of the model. This approach, also known assecure aggregation [3], [4], does not sacrifice the convergenceperformance.
A recent line of work has focused on secure aggregationby additive masking [31], [4]. In [31], users agree on pairwisesecret keys using a Diffie-Hellman type key exchange protocoland then each user sends the server a masked version oftheir data, which contains the pairwise masks as well as anindividual mask. The server can then sum up the maskeddata received from the users to obtain the aggregated value,as the summation of additive masks cancel out. If a userfails and drops out, the server asks the remaining users tosend the sum of their pairwise keys with the dropped usersadded to their individual masks, and subtracts them from theaggregated value. The main limitation of this protocol is thecommunication overhead of this recovery phase, as it requiresthe entire sum of the missing masks to be sent to the server.Moreover, the protocol terminates if additional users dropduring this phase.
A novel technique is proposed in [4] to ensure that theprotocol is robust if additional users drop during the recoveryphase. It also ensures that the additional information sent to theserver does not breach privacy. To do so, the protocol utilizespairwise random masks between users to hide the individualmodels. The cost of reconstructing these masks, which takesthe majority of execution time, scales with respect to $ (#2),with # corresponding to the number of users. The executiontime of [4] increases as more users are dropped, as the protocolrequires additional information corresponding to the droppedusers. The recovery phase of our protocol does not require anyadditional information to be shared between the users, which isachieved by a coding technique applied to the additively secretshared data. Hence, the execution time of our algorithm staysalmost the same as more and more users are dropped, the onlyoverhead comes from the decoding phase whose contributionis very small compared to the overall communication cost.
Notable approaches to reduce the communication cost infederated learning include reducing the model size via quanti-zation, or learning in a smaller parameter space [32]. In [33],a framework has been proposed for autotuning the parame-ters in secure federated learning, to achieve communication-efficiency. Another line of work has focused on approachesbased on decentralized learning [34], [35] or edge-assistedhierarchical physical layer topologies [36]. Specifically, [36]utilizes edge servers to act as an intermediate aggregatorfor the local updates from edge devices. The global modelis then computed at the central server by aggregating theintermediate computations available at the edge servers. Thesesetups perform the aggregation using the clear (unmasked)model updates, i.e., the aggregation is not required to preservethe privacy of individual model updates. Our focus is different,
as we study the secure aggregation problem which requiresthe server to learn no information about an individual updatebeyond the aggregated values. Finally, approaches that aim atalleviating the aggregation overhead by reducing the modelsize (e.g., quantization [32]) can also be leveraged in Turbo-Aggregate, which can be an interesting future direction.
Circular communication and training architectures havebeen considered previously in the context of distributedstochastic gradient descent on clear (unmasked) gradient up-dates, to reduce communication load [37] or to model data-heterogeneity [38]. Different from these setups, our key chal-lenge in this work is handling user dropouts while ensuringuser privacy, i.e., secure aggregation. Conventional federatedlearning frameworks consider a centralized communicationarchitecture in which all communication between the mobiledevices goes through a central server [2], [4], [5]. Morerecently, decentralized federated learning architectures withouta central server have been considered for peer-to-peer learningon graph topologies [16] and in the context of social networks[17]. Model poisoning attacks on federated learning architec-tures have been analyzed in [39], [40]. Differentially-privatefederated learning frameworks have been studied in [29], [41].A multi-task learning framework for federated learning hasbeen proposed in [42], for learning several models simultane-ously. [43], [44] have explored federated learning frameworksto address fairness challenges and to avoid biasing the trainedmodel towards certain users. Convergence properties of trainedmodels are studied in [45].
III. SYSTEM MODEL
In this section, we first discuss the basic federated learningmodel. Next, we introduce the secure aggregation protocolfor federated learning and discuss the key parameters forperformance evaluation. Finally, we present the state-of-the-art for secure aggregation.
A. Basic Federated Learning Model
Federated learning is a distributed learning framework thatallows training machine learning models directly on the dataheld at distributed devices, such as mobile phones. The goalis to learn a single global model x with dimension 3, usingdata that is generated, stored, and processed locally at millionsof remote devices. This can be represented by minimizing aglobal objective function,
minx!(x) such that !(x) =
#∑
8=1
F8!8 (x), (1)
where # is the total number of mobile users, !8 is the localobjective function of user 8, and F8 ≥ 0 is a weight parameterassigned to user 8 to specify the relative impact of eachuser such that
∑8 F8 = 1. One natural setting of the weight
parameter is F8 =<8
<where <8 is the number of samples of
user 8 and < =
∑#8=1 <8
1.
1For simplicity, we assume that all users have equal-sized datasets i.e., aweight parameter assigned to user 8 satisfies F8 =
1# for all 8 ∈ [# ].

4
To solve (1), conventional federated learning architecturesconsider a centralized communication topology in which allcommunication between the individual devices goes througha central server [2], [4], [5], and no direct links are allowedbetween the mobile users. The learning setup is as demon-strated in Figure 1. At iteration C, the central server sharesthe current version of the global model, x(C), with the mobileusers. Each user then updates the model using its local data.User 8 ∈ [#] then computes a local model x8 (C). To increasecommunication efficiency, each user can update the localmodel over multiple local epochs before sending it to theserver [2]. The local models of the # users are sent to theserver and then aggregated by the server. Using the aggregatedmodels, the server updates the global model x(C + 1) for thenext iteration. This update equation is given by
x(C + 1) =∑
8∈U(C)
x8 (C), (2)
where U(C) denotes the set of participating users at iterationC. Then, the server pushes the updated global model x(C + 1)
to the mobile users.
B. Secure Aggregation Protocol for Federated Learning and
Key Parameters
The basic federated learning model from Section III-A aimsat addressing the privacy concerns over transmitting raw datato the server, by letting the training data remain on the userdevice and instead requiring only the local models to besent to the server. However, as the local models still carryextensive information about the local datasets stored at theusers, the server can reconstruct the private data from thelocal models by using a model inversion attack, which hasbeen recently demonstrated in [6]–[8]. Secure aggregation hasbeen introduced in [4] to address such privacy leakage fromthe local models. A secure aggregation protocol enables thecomputation of the aggregation operation in (2) while ensuringthat the server learns no information about the local modelsx8 (C) beyond their aggregated value
∑#8=1 x8 (C). In this paper,
our focus is on the aggregation phase in (2) and how to makethis aggregation phase secure and efficient. In particular, ourgoal is to evaluate the aggregate of the local models
z =
∑
8∈U
x8 , (3)
where we omit the iteration index C for simplicity. As wediscuss in Section III-C and Appendix A in detail, secureaggregation protocols build on cryptographic primitives thatrequire all operations to be carried out over a finite field.Accordingly, similar to prior works [3], [4], we assume thatthe elements of x
(;)8
and z are from a finite field F@ for somefield size @.
We evaluate the performance of a secure aggregation proto-col for federated learning through the following key parame-ters.
1) Robustness guarantee: We consider a network modelin which each user can drop from the network with aprobability ? ∈ [0, 1], called the user dropout rate. In a
real world setting, the dropout rate varies between 0.06
and 0.1 [11]. The robustness guarantee quantifies themaximum user dropout rate that a protocol can toleratewith a probability approaching to 1 as # → ∞ tocorrectly evaluate the aggregate of the surviving usermodels.
2) Privacy guarantee: We consider a security model wherethe users and the server are honest but curious. Weassume that up to ) users can collude with each otheras well as with the server for learning the models ofother users. The privacy guarantee quantifies the maxi-mum number of colluding entities that the protocol cantolerate for the individual user models to keep private.
3) Aggregation overhead: The aggregation overhead, de-noted by �, quantifies the asymptotic time complexity(i.e., runtime) with respect to the number of mobileusers, # , for aggregating the models of all users in thenetwork. Note that this includes both the computationand communication time complexities.
C. State-of-the-art for Secure Aggregation
The state-of-the-art for secure aggregation in federatedlearning is the protocol proposed in [4]. In this protocol, eachmobile user locally trains a model. By using pairwise randommasking, the local models are securely aggregated through acentral server, who then updates the global model. We presentthe details of the state-of-the-art in Appendix A. This protocolachieves robustness guarantee to user dropout rate of up to? = 0.5, while providing privacy guarantee to up to ) =
#2
colluding users. However, its aggregation overhead is quadraticwith the number of users (i.e., � = $ (#2)). This quadraticaggregation overhead severely limits the network size for real-world applications [11].
Our goal in this paper is to develop a secure aggregationprotocol that can provide comparable robustness and privacyguarantees as the state-of-the-art, while achieving a signifi-cantly lower (almost linear) aggregation overhead.
IV. THE TURBO-AGGREGATE PROTOCOL
We now introduce the Turbo-Aggregate protocol for securefederated learning that can simultaneously achieve robustnessguarantee to a user dropout rate of up to ? = 0.5, privacyguarantee to up to ) =
#2
colluding users, and aggregationoverhead of � = $ (# log#). Turbo-Aggregate is composed ofthree main components. First, it creates a multi-group circularaggregation structure for fast model aggregation. Second, itleverages additive secret sharing by adding randomness in away that can be cancelled out once the models are aggregated,in order to guarantee the privacy of the users. Third, it addsaggregation redundancy via Lagrange polynomial in the modelupdates that are passed from one group to the next, so thatthe added redundancy can be exploited to reconstruct theaggregated model amidst potential user dropouts. We nowdescribe each of these components in detail. An illustrativeexample is also presented in Appendix B to demonstrate theexecution of Turbo-Aggregate.

5
server
· · ·
Group 1
Group L
Group 2
Nl users
Group l
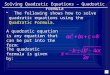
Fig. 2. Network topology with # users partitioned to ! groups, with #;
users in group ; ∈ [!].
A. Multi-group circular aggregation
Turbo-Aggregate computes the aggregate of the individualuser models by utilizing a circular aggregation strategy. Givena mobile network with # users, this is done by first partitioningthe users into ! groups as shown in Figure 2, with #; usersin group ; ∈ [!], such that
∑;∈[! ] #; = # . We consider a
random partitioning strategy in which each user is assignedto one of the available groups uniformly at random, by usinga bias-resistant public randomness generation protocol suchas in [46]. We use U; ⊆ [#;] to represent the set of usersthat complete their part in the protocol (surviving users), andD; = [#;]\U; to denote the set of dropped users2. We use x
(;)8
to denote the local model of user 8 in group ; ∈ [!], whichis a vector of dimension 3 that corresponds to the parametersof their locally trained model. Then, we can rewrite (3) as
z =
∑
;∈[! ]
∑
8∈U;
x(;)8. (4)
The elements of x(;)8
and z are from a finite field F@ for somefield size @. All operations are carried out over the finite fieldand we omit the modulo @ operation for simplicity.
The dashed links in Figure 2 represent the communicationlinks between the server and mobile users. In our generaldescription, we assume that all communication takes placethrough a central server, via creating pairwise secure keys us-ing a Diffie-Hellman type key exchange protocol [47] as in [4].Turbo-Aggregate can also use decentralized communicationarchitectures with direct links between devices, such as peer-to-peer communication, where users can communicate directlythrough an underlay communication network [16], [17]. Then,the aggregation steps are the same as the centralized settingexcept that messages are now communicated via direct linksbetween the users, and a random election algorithm should becarried out to select one user (or multiple users, depending onthe application) to aggregate the final sum at the final stage
2For modeling the user dropouts, we focus on the worst-case scenario,which is the case when a user drops during the execution of the correspondinggroup, i.e., when a user receives messages from the previous group but failsto propagate it to the next group.
instead of the server. The detailed process of the final stagewill be explained in Section IV-D.
Turbo-Aggregate consists of ! execution stages performedsequentially. At stage ; ∈ [!], users in group ; encodetheir inputs, including their trained models and the partialsummation of the models from lower stages, and send themto users in group ; + 1. Next, users in group ; + 1 recover(decode) the missing information due to potentially droppedusers, and then aggregate the received messages. At the end ofthe protocol, models of all surviving users will be aggregated.
The proposed coding and aggregation mechanism guaran-tees that no party (mobile users or the server) can learn anindividual model, or a partial aggregate of a subset of models.The server learns nothing but the final aggregated model of allsurviving users. This is achieved by leveraging additive secretsharing to mask the individual models, which we describe inthe following.
B. Masking with additive secret sharing
Turbo-Aggregate hides the individual user models usingadditive masks to protect their privacy against potential col-lusions between the interacting parties. This is done by a two-step procedure. In the first step, the server sends a randommask to each user, denoted by a random vector u
(;)8 for user
8 ∈ [#;] at group ; ∈ [!]. Each user then masks its localmodel x
(;)8
as x(;)8
+ u(;)8
. Since this random mask is knownonly by the server and the corresponding user, it protectsthe privacy of each user against potential collusions betweenany subset of the remaining users, as long as the server ishonest. On the other hand, privacy may be breached if theserver is adversarial and colludes with a subset of users. Thesecond step of Turbo-Aggregate aims at protecting user privacyagainst such scenarios. In this second step, users generateadditive secret sharing of the individual models for privacyprotection against potential collusions between the server andthe users. To do so, user 8 in group ; sends a masked versionof its local model to each user 9 in group ; + 1, given by
x(;)8, 9 = x
(;)8 + u
(;)8 + r
(;)8, 9 , (5)
for 9 ∈ [#;+1], where r(;)8, 9
is a random vector such that∑9∈[#;+1 ] r
(;)8, 9
= 0 for all 8 ∈ [#;]. The role of additive secretsharing is not only to mask the model to provide privacyagainst collusions between the server and the users, but alsoto maintain the accuracy of aggregation by making the sumof the received data over the users in each group equal to theoriginal data, as the vectors r
(;)8, 9 cancel out.
In addition, each user holds a variable corresponding tothe aggregated masked models from the previous group. Foruser 8 in group ;, this variable is represented by s
(;)8 . At each
stage of Turbo-Aggregate, users in the active group updateand propagate these variables to the next group. Aggregationof these masked models is defined via the recursive relation,
s(;)8
=
1
#;−1
∑
9∈[#;−1 ]
s(;−1)9
+∑
9∈U;−1
x(;−1)9 ,8
(6)
at user 8 in group ; > 1, whereas the initial aggregation atgroup ; = 1 is set as s
(1)8 = 0, for 8 ∈ [#1]. While computing

6
(6), any missing values in {s(;−1)9
} 9∈[#;−1 ] (due to the usersdropped in group ; − 1) is reconstructed via the recoverytechnique presented in Section IV-C.
User 8 in group ; then sends the aggregated value in (6) toeach user in group ; +1. The average of the aggregated valuesfrom the users in group ; consists of the models of the usersup to group ; − 1, masked by the randomness sent from theserver. This can be observed by defining the following partialsummation, which can be computed by each user in group; + 1,
s(;+1)=
1
#;
∑
8∈[#; ]
s(;)8
=
1
#;−1
∑
9∈[#;−1 ]
s(;−1)9
+∑
9∈U;−1
x(;−1)9
+∑
9∈U;−1
u(;−1)9
(7)
= s(;) +∑
9∈U;−1
x(;−1)9
+∑
9∈U;−1
u(;−1)9
, (8)
where (7) follows from∑9∈[#;−1 ]
r(;−1)8, 9
= 0. With the initial
partial summation s(2) =1#1
∑8∈[#1 ] s
(1)8 = 0, one can show
that s(;+1) is equal to the aggregation of the models of allsurviving users in up to group ;−1, masked by the randomnesssent from the server,
s(;+1)=
∑
<∈[;−1]
∑
9∈U<
x(<)9
+∑
<∈[;−1]
∑
9∈U<
u(<)9. (9)
At the final stage, the server obtains the final aggregate valuefrom (9) and removes the random masks
∑<∈[! ]
∑9∈U<
u(<)9
.This approach works well if no user drops out during theexecution of the protocol. On the other hand, if any user ingroup ; +1 drops out, the random vectors masking the modelsof the ;-th group in the summation (7) cannot be cancelledout. In the following, we propose a recovery technique thatis robust to dropped or delayed users, based on coding theoryprinciples.
C. Adding redundancies to recover the data of dropped or
delayed users
The main intuition behind our recovery strategy is to encodethe additive secret shares (masked models) in a way that guar-antees secure aggregation when users are dropped or delayed.To do so, we leverage Lagrange coding [15], which has beenapplied to other problems such as offloading or collaborativemachine learning in the privacy-preserving manner [48], [49].The primary benefits of Lagrange coding over alternative codesthat may also be used for introducing redundancy, such asother error-correcting codes, is that Lagrange coding enablesus to perform the aggregation operation on the encodedmodels, and that the final result can be decoded from thecomputations performed on the encoded models. This is notnecessarily true for other error-correcting codes, as they do notguarantee the recovery of the original computation results (i.e.,the computations performed on the true values of the modelparameters) from the computations performed on the encodedmodels. It encodes a given set of vectors (v1, . . . , v )
by using a Lagrange interpolation polynomial. One can viewthis as embedding a given set of vectors on a Lagrangepolynomial, such that each encoded value represents a point on
the polynomial. The resulting encoding enables a set of usersto compute a given polynomial function ℎ on the encoded datain a way that any individual computation {ℎ(v8)}8∈[ ] can bereconstructed using any subset of 346(ℎ) ( − 1) + 1 othercomputations. The reconstruction is done through polynomialinterpolation. Therefore, one can reconstruct any missing valueas long as a sufficient number of other computations areavailable, i.e., enough number of points are available to inter-polate the polynomial. In our problem of gradient aggregation,the function of interest, ℎ, would be linear and accordinglyhave degree 1, since it corresponds to the summation of allindividual gradient vectors.
Turbo-Aggregate utilizes Lagrange coding for recoveryagainst user dropouts, via a novel strategy that encodes thesecret shared values to compute secure aggregation. Morespecifically, in Turbo-Aggregate, the encoding is performedas follows. Initially, user 8 in group ; forms a Lagrangeinterpolation polynomial 5 (;)
8: F@ → F
3@ of degree #;+1 − 1
such that 5 (;)8 (U(;+1)9 ) = x
(;)8, 9 for 9 ∈ [#;+1], where U (;+1)
9 isan evaluation point allocated to user 9 in group ; + 1. This isaccomplished by letting
5(;)8
(I) =∑
9∈[#;+1 ]
x(;)8, 9
·∏
:∈[#;+1 ]\{ 9 }
I − U(;+1)
:
U(;+1)9
− U(;+1)
:
.
Then, another set of #;+1 distinct evaluation points{V
(;+1)9
} 9∈[#;+1 ] are allocated from F@ such that
{V(;+1)9 } 9∈[#;+1 ] ∩ {U
(;+1)9 } 9∈[#;+1 ] = ∅. Next, user 8 ∈ [#;] in
group ; generates the encoded model,
x(;)8, 9
= 5(;)8
(V(;+1)9
), (10)
and sends x(;)8, 9
to user 9 in group (; + 1). In addition, user 8 ∈
[#;] in group ; aggregates the encoded models {x(;−1)9 ,8 } 9∈U;−1
received from the previous stage, with the partial summations(;) from (7) as
s(;)8 = s(;) +
∑
9∈U;−1
x(;−1)9 ,8 . (11)
The summation of the masked models in (6) and the summa-tion of the coded models in (11) can be viewed as evaluationsof a polynomial 6 (;) such that
s(;)8 = 6 (;) (U
(;)8 ), (12)
s(;)8 = 6 (;) (V
(;)8 ), (13)
for 8 ∈ [#;], where 6 (;) (I) = s(;) +∑9∈U;−1
5(;−1)9
(I) is apolynomial function with degree at most #; − 1. Then, user8 ∈ [#;] sends the set of messages {x
(;)8, 9, x
(;)8, 9, s
(;)8, s
(;)8} to user
9 in group ; + 1.Upon receiving the messages, user 9 in group ; + 1 recon-
structs the missing terms in {s(;)8}8∈[#; ] (caused by the dropped
users in group ;), computes the partial sum s(;+1) from (7), andupdates the terms {s
(;+1)9
, s(;+1)9
} as in (6) and (11). Users in
group ; + 1 can reconstruct each term in {s(;)8}8∈[#; ] as long
as they receive at least #; evaluations out of 2#; evaluationsfrom the users in group ;. This is because {s
(;)8 , s
(;)8 }8∈[#; ] are
evaluation points of the polynomial 6 (;) whose degree is at

7
most #; − 1. As a result, the model can be aggregated at eachstage as long as at least half of the users at that stage are notdropped. As we will demonstrate in the proof of Theorem 1, aslong as the drop rate of the users is below 50%, the fractionof dropped users at all stages will be below half with highprobability, hence Turbo-Aggregate can proceed with modelaggregation at each stage.
D. Final aggregation and the overall Turbo-Aggregate proto-
col
For the final aggregation, we need a dummy stage tosecurely compute the aggregation of all user models, especiallyfor the privacy of the local models of users in group !. To doso, we arbitrarily select a set of users who will receive andaggregate the models sent from the users in group !. Theycan be any surviving user who has participated in the protocol,and will be called user 9 ∈ [# 5 8=0;] in the final stage, where# 5 8=0; is the number of users selected.
During this phase, users in group ! mask their own modelwith additive secret sharing by using (5), generate the encodeddata by using (10), and aggregate the models received fromthe users in group (! − 1) by using (6) and (11). Then, user8 from group ! sends {x
(!)8, 9 , x
(!)8, 9 , s
(!)8 , s
(!)8 } to user 9 in the
final stage.Upon receiving the set of messages, user 9 ∈ [# 5 8=0;] in
the final stage recovers the missing terms in {s(!)8 }8∈[#! ] , and
aggregates them with the masked models,
s( 5 8=0;)
9=
1
#!
∑
8∈[#! ]
s(!)8
+∑
8∈U!
x(!)8, 9, (14)
s( 5 8=0;)9 =
1
#!
∑
8∈[#! ]
s(!)8 +
∑
8∈U!
x(!)8, 9 , (15)
and sends the resulting {s( 5 8=0;)
9, s
( 5 8=0;)
9} to the server.
The server then recovers the summations{s
( 5 8=0;)
9} 9∈[# 5 8=0; ] , by reconstructing any missing terms
in (14) using the set of received values (14) and (15). Finally,the server computes the average of the summations from (14)and removes the random masks
∑<∈[! ]
∑9∈U<
u(<)9
from theaggregate, which, as can be observed from (7)-(9), is equal tothe aggregate of the individual models of all surviving users,
1
# 5 8=0;
∑
9∈[# 5 8=0; ]
s( 5 8=0;)9 −
∑
<∈[! ]
∑
9∈U<
u(<)9 =
∑
<∈[! ]
∑
9∈U<
x(<)9 .
(16)Having all above steps, the overall Turbo-Aggregate protocolis presented in Algorithm 1.
V. THEORETICAL GUARANTEES OF TURBO-AGGREGATE
In this section, we formally state our main theoretical result.
Theorem 1. Turbo-Aggregate can simultaneously achieve:
1) robustness guarantee to any user dropout rate ? < 0.5,
with probability approaching to 1 as the number of users
# → ∞,
2) privacy guarantee against up to ) = (0.5−n)# colluding
users, with probability approaching to 1 as the number
of users # → ∞, and for any n > 0,
Algorithm 1 Turbo-Aggregate
input Local models x(;)8
of users 8 ∈ [#;] in group ; ∈ [!].
output Aggregated model∑;∈[! ]
∑8∈U;
x(;)8
.
1: for group ; = 1, . . . , ! do
2: for user 8 = 1, . . . , #; do
3: Compute the masked model {x(;)8, 9
};∈[#;+1 ] from (5).
4: Generate the encoded model {x(;)8, 9
} 9∈[#;+1 ] from (10).
5: if ; = 1 then6: Initialize s
(1)8
= s(1)8
= 0.7: else8: Reconstruct the missing values in {s
(;−1)
:}:∈[#;−1 ] due to
the dropped users in group ; − 1.9: Update the aggregate value s
(;)8
from (6).
10: Compute the coded aggregate value s(;)8
from (11).
11: Send {x(;)8, 9, x
(;)8, 9, s
(;)8, s
(;)8
} to user 9 ∈ [#;+1] in group ; + 1
( 9 ∈ [# 5 8=0; ] if ; = !).
12: for user 8 = 1, . . . , # 5 8=0; do
13: Reconstruct the missing values in {s(!):
}:∈[#! ] due to thedropped users in group !.
14: Compute s( 5 8=0;)8
from (14) and s( 5 8=0;)8
from (15).
15: Send {s( 5 8=0;)8
, s( 5 8=0;)8
} to the server.16: Server computes the final aggregated model from (16).
3) aggregation overhead of � = $ (# log#).
Remark 1. Theorem 1 states that Turbo-Aggregate can tol-erate up to 50% user dropout rate and #
2collusions between
the users, simultaneously. Turbo-Aggregate can guarantee ro-bustness against an even higher number of user dropouts bysacrificing the privacy guarantee as a trade-off. Specifically,when we generate and communicate : set of evaluationpoints during Lagrange coding, we can recover the partialaggregations by decoding the polynomial in (12) as long aseach user receives #; evaluations, i.e., (1+ :) (#; − ?#;) ≥ #; .As a result, Turbo-Aggregate can tolerate up to a ? < :
1+:
user dropout rate. On the other hand, the individual modelswill be revealed whenever ) (: + 1) ≥ # . In this case, one canguarantee privacy against up to ( 1
:+1− n)# colluding users for
any n > 0. This demonstrates a trade-off between robustnessand privacy guarantees achieved by Turbo-Aggregate, that is,one can increase the robustness guarantee by reducing theprivacy guarantee and vice versa.
Proof. The proof of Theorem 1 is presented in Appendix C.
As we showed in the proof of Theorem 1, Turbo-Aggregateachieves its robustness and privacy guarantees by choosinga group size of #; =
12
log# for all ; ∈ [!] where2 , min{� (0.5| |?), � (0.5| | )
#)} and � (0 | |1) is the Kullback-
Leibler (KL) distance between two Bernoulli distributions withparameter 0 and 1 [50]. We can further reduce the aggregationoverhead if we choose a smaller group size #;. However, wecannot further reduce the group size beyond $ (log#) becausewhen 0 < � (0.5| |?) < 1 ( 1
2> 1) and #; = log# , the
probability that Turbo-Aggregate guarantees the accuracy offull model aggregation goes to 0 with sufficiently large numberof users, which is stated in Theorem 2.

8
Theorem 2. (Converse) When 0 < � (0.5| |?) < 1 and #; =
log# for all ; ∈ [!], the probability that Turbo-Aggregate
achieves the robustness guarantee to any user dropout rate
? < 0.5 goes to 0 as the number of users # → ∞.
Proof. The proof of Theorem 2 is presented in Appendix D.
A. Generalized Turbo-Aggregate
Theorem 1 states that the privacy of each individual model
is guaranteed against any collusion between the server and upto #
2users. On the other hand, a collusion between the server
and a subset of users can reveal the partial aggregation of agroup of honest users. For instance, a collusion between theserver and a user in group ; can reveal the partial aggregationof the models of all users up to group ; − 2, as the colludingserver can remove the random masks in (9). However, theprivacy protection can be strengthened to guarantee the privacyof any partial aggregation, i.e., the aggregate of any subset ofuser models, with a simple modification.
The modified protocol follows the same steps in Algorithm 1except that the random mask u
(;)8
in (5) is generated byeach user individually, instead of being generated by theserver. At the end of the aggregation phase, the server learns∑<∈[! ]
∑9∈U<
(x(<)9
+u(<)9
). Simultaneously, the protocol ex-ecutes an additional random partitioning strategy to aggregatethe random masks u
(<)9
, at the end of which the server ob-
tains∑<∈[! ]
∑9∈U<
u(<)9
and recovers∑<∈[! ]
∑9∈U<
x(<)9
.In this second partitioning, # users are randomly allocatedinto ! groups with a group size of #; . User 8 in group; ′ ∈ [!] then secret shares u
(;′)8 with the users in group
; ′ + 1, by generating and sending a secret share denoted by[u
(;′)8
] 9 to user 9 in group ; ′ + 1. For secret sharing, weutilize Shamir’s #;
2-out-of-#; secret sharing protocol [19]. Let
U′
;′denote the surviving users in group ; ′ in the second
partitioning. User 8 in group ; ′ then aggregates the receivedsecret shares
∑9∈U
′
;′−1
[u(;′−1)
9
]8, which in turn is a secret
share of∑9∈U
′
;′−1
u(;′−1)9
, and sends the sum to the server.
Finally, the server reconstructs∑9∈U
′
;′u(;′)9
for all ; ′ ∈ [!]
and recovers the aggregate of the individual models of allsurviving users by subtracting
{ ∑9∈U
′
;′u(;′)9
};′∈[! ]
from the
aggregate∑<∈[! ]
∑9∈U<
(x(<)9
+ u(<)9
).In this generalized version of Turbo-Aggregate, the privacy
of any partial aggregation, i.e., the aggregate of any subset ofuser models, can be protected as long as a collusion betweenthe server and the users does not reveal the aggregation ofthe random masks,
∑9∈U;
u(;)9 in (9) for any ; ∈ [!]. Since
there are at least #2
unknown random masks generated byhonest users and the server only knows ! =
##;
equations,
i.e.,{∑
9∈U′
;u(;)9
};∈[! ]
, the server cannot calculate∑9∈U;
u(;)9
for any ; ∈ [!]. Therefore, a collusion between the server andusers cannot reveal the partial aggregate as they cannot removethe random masks in (9). We now formally state the privacyguarantee, robustness guarantee, and aggregation overhead ofthe generalized Turbo-Aggregate protocol in Theorem 3.
TABLE ISUMMARY OF SIMULATION PARAMETERS.
Variable Definition Value
N number of users 4 ∼ 200d model size (32 bit entries) 100000p dropout rate 10%, 30%, 50%q field size 232 − 5
maximum bandwidth constraint 100Mbps ∼ 1Gbps
Theorem 3. Generalized Turbo-Aggregate simultaneously
achieves 1), 2), and 3) from Theorem 1. In addition, it provides
privacy guarantee for the partial aggregate of any subset of
user models, against any collusion between the server and
up to ) = (0.5 − n)# users for any n > 0, with probability
approaching to 1 as the number of users # → ∞.
Proof. The proof of Theorem 3 is presented in Appendix E.
VI. EXPERIMENTS
In this section, we evaluate the performance of Turbo-Aggregate by experiments over up to # = 200 users for varioususer dropout rates and bandwidth conditions.
A. Experiment setup
Platform. In our experiments, we implement Turbo-Aggregateon a distributed platform by using FedML library [51], andexamine its total running time with respect to the state-of-the-art [4]. Computation is performed in a distributed network overthe Amazon EC2 cloud using m3.medium machine instances.Communication is implemented using the MPI4Py [52] mes-sage passing interface on Python. The default setting forthe maximum bandwidth constraint of m3.medium machineinstances is 1�1?B. The model size, 3, is fixed to 100,000
with 32 bit entries, and the field size, @, is set as the largestprime within 32 bits. We summarize the simulation parametersin Table I.Modeling user dropouts. To model the dropped users inTurbo-Aggregate, we randomly select ?#; users out of #;users in group ; ∈ [!] where ? is the dropout rate. We considerthe worst case scenario where the selected users drop afterreceiving the messages sent from the previous group (usersin group ; − 1) and do not send their messages to users ingroup ; + 1. To model the dropped users in the benchmarkprotocol, we follow the scenario in [4]. We randomly select?# users out of # users, which artificially drop after sendingtheir masked models. In this case, the server has to reconstructthe pairwise seeds of the dropped users and execute a pseudorandom generator using the reconstructed seeds to remove therandom masks (the details are provided in Appendix A).Implemented Schemes. We implement the following schemesfor performance evaluation. For the schemes with Turbo-Aggregate, we use #; = log# .
1) Turbo-Aggregate: For our first implementation, wedirectly implement Turbo-Aggregate as described in

9
(a) Turbo-Aggregate. Each arrow is carried out sequentially.Turbo-Aggregate requires 7 stages.
(b) Turbo-Aggregate+. Arrows for the same execution stage arecarried out simultaneously. Turbo-Aggregate+ requires only 3stages.
Fig. 3. Example networks with # = 24, #; = 3 and ! = 8. An arrowrepresents that users in one group generate and send messages to the users inthe next group.
Fig. 4. Total running time of Turbo-Aggregate versus the benchmark protocol[4] as the number of users increases, for various user dropout rates.
Section IV, where the ! execution stages are performedsequentially.
2) Turbo-Aggregate+: We can speed up Turbo-Aggregateby parallelizing the ! execution stages. To do so, weagain utilize the circular aggregation topology but lever-age a tree structure for flooding the information betweendifferent groups across the network, which reduces therequired number of execution stages from !−1 to log !.We refer to this implementation as Turbo-Aggregate+.Figure 3 demonstrates the difference between Turbo-Aggregate+ and Turbo-Aggregate through an examplenetwork of # = 24 users and ! = 8 groups. Turbo-Aggregate+ requires only 3 stages to complete the pro-tocol while Turbo-Aggregate carries out each executionstage sequentially and requires 7 stages.
3) Benchmark: We implement the benchmark protocol [4]
where a server mediates the communication betweenusers to exchange the information required for keyagreements (rounds of advertising and sharing keys) andusers send their masked models to the server (maskedinput collection). One can also speed up the roundsof advertising and sharing keys by allowing users tocommunicate in parallel. However, this has minimaleffect on the total running time of the protocol, as thetotal running time is dominated by the overhead whenthe server generates the pairwise masks [4].
B. Performance evaluation
For performance analysis, we measure the total running timefor a single round of secure aggregation with each protocolwhile increasing the number of users # gradually for differentuser dropout rates. We use synthesized vectors for locallytrained models and do not include the local training timein the total running time. One can also consider the entirelearning process and since all other steps remain the samefor the three schemes, we expect the same speedup in theaggregation phase. Our results are demonstrated in Figure 4.We make the following key observations.
• Total running time of Turbo-Aggregate and Turbo-Aggregate+ are almost linear in the number of users,while for the benchmark protocol, the total running timeis quadratic in the number of users.
• Turbo-Aggregate and Turbo-Aggregate+ provide a stabletotal running time as the user dropout rate increases.This is because the encoding and decoding time ofTurbo-Aggregate do not change significantly when thedropout rate increases, and we do not require additionalinformation to be transmitted from the remaining userswhen some users are dropped or delayed. On the otherhand, for the benchmark protocol, the running time sig-nificantly increases as the dropout rate increases. Thisis because the total running time is dominated by thereconstruction of pairwise masks at the server, whichsubstantially increases as the number of dropped usersincreases.
• Turbo-Aggregate and Turbo-Aggregate+ provide aspeedup of up to 5.8× and 40× over the benchmark,respectively, for a user dropout rate of up to 50% with# = 200 users. This gain is expected to increase furtheras the number of users increases.
To illustrate the impact of user dropouts, we present thebreakdown of the total running time of the three schemes andthe corresponding observations in Appendix F1. We furtherstudy the impact of the bandwidth, by measuring the totalrunning time with various communication bandwidth con-straints. Turbo-Aggregate provides substantial gain over thestate-of-the-art in environments with more severe bandwidthconstraints. The details of these additional experiments arepresented in Appendix F2.
In this section, we have primarily focused on the aggre-gation phase and measured a single round of the secureaggregation phase with synthesized vectors for the locallytrained models. This is due to the fact that these vectors can

10
be replaced with any trained model using the real world fed-erated learning setups. We further investigate the performanceof Turbo-Aggregate in real world federated learning setupsby implementing both training phase and aggregation phase.Turbo-Aggregate still provides substantial speedup over thebenchmark, which is detailed in Appendix F3.
VII. CONCLUSION
This paper presents the first secure aggregation frame-work that theoretically achieves an aggregation overhead of$ (# log#) in a network with # users, as opposed to the prior$ (#2) overhead, while tolerating up to a user dropout rate of50%. Furthermore, via experiments over Amazon EC2, wedemonstrated that Turbo-Aggregate achieves a total runningtime that grows almost linearly in the number of users, andprovides up to 40× speedup over the state-of-the-art schemewith # = 200 users.
Turbo-Aggregate is particularly suitable for wireless topolo-gies, in which network conditions and user availability canvary rapidly, as Turbo-Aggregate can provide a resilient frame-work to handle such unreliable network conditions. Specifi-cally, if some users cause unexpected delays due to unstableconnection, Turbo-Aggregate can simply treat them as userdropouts and can reconstruct the information of dropped ordelayed users in the previous groups as long as half of the usersremain. One may also leverage the geographic heterogeneityof wireless networks to better form the communication groupsin Turbo-Aggregate. An interesting future direction would beto explore how to optimize the multi-group communicationstructure of Turbo-Aggregate based on the specific topologyof the users, as well as the network conditions.
In this work, we have focused on protecting the privacy ofindividual models against an honest-but-curious server and upto ) colluding users so that no information is revealed aboutthe individual models beyond their aggregated value. If onewould like to further limit the information that may be revealedfrom the aggregated model, differential privacy can be utilizedto ensure that the individual data points cannot be identifiedfrom the aggregated model. All the benefits of differentialprivacy could be applied to our approach by adding noise to thelocal models before the aggregation phase in Turbo-Aggregate.Combining these two techniques is another interesting futuredirection.
Finally, the implementation of Turbo-Aggregate in a real-world large-scale distributed system would be another inter-esting future direction. This would require addressing thefollowing three challenges. First, the computation complexityof implementing the random grouping strategy may increaseas the number of users increases. Second, Turbo-Aggregatecurrently focuses on protecting the privacy against honest-but-curious adversaries. In settings with malicious (Byzantine)adversaries who wish to manipulate the global model bypoisoning their local datasets, one may require additionalstrategies to protect the resilience of the trained model. Oneapproach is combining secure aggregation with an outlierdetection algorithm as proposed in [53], which has a com-munication cost of $ (#2) that limits its scalability to large
federated learning systems. It would be an interesting directionto leverage Turbo-Aggregate to address this challenge, i.e.,develop a communication-efficient secure aggregation strategyagainst Byzantine adversaries. Third, communication may stillbe a bottleneck in severely resource-constrained systems sinceusers need to exchange the masked models with each other,whose size is as large as the size of the global model. To over-come this bottleneck, one may leverage model compressiontechniques or group knowledge transfer [54].
REFERENCES
[1] J. So, B. Güler, and A. S. Avestimehr, “Turbo-aggregate: Breaking thequadratic aggregation barrier in secure federated learning,” IEEE Journal
on Selected Areas in Information Theory, 2021.[2] H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas,
“Communication-efficient learning of deep networks from decentralizeddata,” in Int. Conf. on Artificial Int. and Stat. (AISTATS), 2017, pp. 1273–1282.
[3] K. Bonawitz, V. Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan,S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggre-gation for federated learning on user-held data,” Conference on Neural
Information Processing Systems, 2016.[4] ——, “Practical secure aggregation for privacy-preserving machine
learning,” in Proceedings of the 2017 ACM SIGSAC Conference on
Computer and Communications Security, 2017, pp. 1175–1191.[5] P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N.
Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings et al.,“Advances and open problems in federated learning,” arXiv preprint
arXiv:1912.04977, 2019.[6] L. Zhu, Z. Liu, and S. Han, “Deep leakage from gradients,” in Advances
in Neural Information Processing Systems 32, 2019, pp. 14 774–14 784.[7] Z. Wang, M. Song, Z. Zhang, Y. Song, Q. Wang, and H. Qi, “Beyond
inferring class representatives: User-level privacy leakage from federatedlearning,” in IEEE INFOCOM 2019 - IEEE Conference on Computer
Communications, 2019, pp. 2512–2520.[8] J. Geiping, H. Bauermeister, H. Dröge, and M. Moeller, “Inverting
gradients – how easy is it to break privacy in federated learning?” arXiv
preprint arXiv:2003.14053, 2020.[9] T. Yang, G. Andrew, H. Eichner, H. Sun, W. Li, N. Kong, D. Ram-
age, and F. Beaufays, “Applied federated learning: Improving googlekeyboard query suggestions,” arXiv preprint arXiv:1812.02903, 2018.
[10] H. B. McMahan, D. Ramage, K. Talwar, and L. Zhang, “Learningdifferentially private recurrent language models,” Int. Conf. on Learning
Representations (ICLR), 2018.[11] K. Bonawitz, H. Eichner, W. Grieskamp, D. Huba, A. Ingerman,
V. Ivanov, C. Kiddon, J. Konecny, S. Mazzocchi, H. B. McMahan et al.,“Towards federated learning at scale: System design,” in 2nd SysML
Conf., 2019.[12] T. Li, A. K. Sahu, A. Talwalkar, and V. Smith, “Federated learning:
Challenges, methods, and future directions,” IEEE Signal Processing
Magazine, vol. 37, no. 3, pp. 50–60, 2020.[13] A. Beimel, “Secret-sharing schemes: a survey,” in Int. Conf. on Coding
and Cryptology. Springer, 2011, pp. 11–46.[14] D. Evans, V. Kolesnikov, M. Rosulek et al., “A pragmatic introduction
to secure multi-party computation,” Foundations and Trends in Priv. and
Sec., vol. 2, no. 2-3, pp. 70–246, 2018.[15] Q. Yu, S. Li, N. Raviv, S. M. M. Kalan, M. Soltanolkotabi, and A. S.
Avestimehr, “Lagrange coded computing: Optimal design for resiliency,security and privacy,” in Int. Conf. on Artificial Int. and Stat. (AISTATS),2019.
[16] A. Lalitha, O. C. Kilinc, T. Javidi, and F. Koushanfar, “Peer-to-peerfederated learning on graphs,” arXiv preprint arXiv:1901.11173, 2019.
[17] C. He, C. Tan, H. Tang, S. Qiu, and J. Liu, “Central server free fed-erated learning over single-sided trust social networks,” arXiv preprint
arXiv:1910.04956, 2019.[18] A. C. Yao, “Protocols for secure computations,” in IEEE Ann. Symp. on
Foundations of Comp. Sci., 1982, pp. 160–164.[19] A. Shamir, “How to share a secret,” Communications of the ACM,
vol. 22, no. 11, pp. 612–613, 1979.[20] M. Ben-Or, S. Goldwasser, and A. Wigderson, “Completeness theorems
for non-cryptographic fault-tolerant distributed computation,” in ACM
Symposium on Theory of Computing. ACM, 1988, pp. 1–10.

11
[21] Z. Beerliová-Trubíniová and M. Hirt, “Perfectly-secure MPC with linearcommunication complexity,” in Theory of Cryptography Conference.Springer, 2008, pp. 213–230.
[22] M. Burkhart, M. Strasser, D. Many, and X. Dimitropoulos, “Sepia:Privacy-preserving aggregation of multi-domain network events andstatistics,” Network, vol. 1, no. 101101, 2010.
[23] I. Leontiadis, K. Elkhiyaoui, and R. Molva, “Private and dynamictime-series data aggregation with trust relaxation,” in International
Conference on Cryptology and Network Security. Springer, 2014, pp.305–320.
[24] V. Rastogi and S. Nath, “Differentially private aggregation of distributedtime-series with transformation and encryption,” in ACM SIGMOD Int.
Conf. on Management of data, 2010, pp. 735–746.[25] S. Halevi, Y. Lindell, and B. Pinkas, “Secure computation on the web:
Computing without simultaneous interaction,” in Annual Cryptology
Conf. Springer, 2011, pp. 132–150.[26] C. Gentry and D. Boneh, A fully homomorphic encryption scheme.
Stanford University, Stanford, 2009, vol. 20, no. 09.[27] I. Damgård, V. Pastro, N. Smart, and S. Zakarias, “Multiparty compu-
tation from somewhat homomorphic encryption,” in Annual Cryptology
Conf. Springer, 2012, pp. 643–662.[28] C. Dwork, F. McSherry, K. Nissim, and A. Smith, “Calibrating noise to
sensitivity in private data analysis,” in Theory of Crypto. Conf. Springer,2006, pp. 265–284.
[29] R. C. Geyer, T. Klein, and M. Nabi, “Differentially private federatedlearning: A client level perspective,” arXiv preprint arXiv:1712.07557,2017.
[30] K. Wei, J. Li, M. Ding, C. Ma, H. H. Yang, F. Farokhi, S. Jin, T. Q. Quek,and H. V. Poor, “Federated learning with differential privacy: Algorithmsand performance analysis,” IEEE Transactions on Information Forensics
and Security, 2020.[31] G. Ács and C. Castelluccia, “I have a dream! (differentially private smart
metering),” in International Workshop on Information Hiding. Springer,2011, pp. 118–132.
[32] J. Konecný, H. B. McMahan, F. X. Yu, P. Richtarik, A. T. Suresh, andD. Bacon, “Federated learning: Strategies for improving communicationefficiency,” in Conference on Neural Information Processing Systems:
Workshop on Private Multi-Party Machine Learning, 2016.[33] K. Bonawitz, F. Salehi, J. Konecny, B. McMahan, and M. Gruteser,
“Federated learning with autotuned communication-efficient secure ag-gregation,” arXiv preprint arXiv:1912.00131, 2019.
[34] L. He, A. Bian, and M. Jaggi, “Cola: Decentralized linear learning,” inAdvances in Neural Information Processing Systems, 2018, pp. 4536–4546.
[35] X. Lian, C. Zhang, H. Zhang, C.-J. Hsieh, W. Zhang, and J. Liu,“Can decentralized algorithms outperform centralized algorithms? A casestudy for decentralized parallel stochastic gradient descent,” in Advances
in Neural Information Processing Systems, 2017, pp. 5330–5340.[36] L. Liu, J. Zhang, S. Song, and K. B. Letaief, “Edge-assisted hierarchical
federated learning with non-iid data,” arXiv preprint arXiv:1905.06641,2019.
[37] Y. Li, M. Yu, S. Li, S. Avestimehr, N. S. Kim, and A. Schwing, “Pipe-sgd: A decentralized pipelined sgd framework for distributed deep nettraining,” in Advances in Neural Information Processing Systems, 2018,pp. 8045–8056.
[38] H. Eichner, T. Koren, H. B. McMahan, N. Srebro, and K. Talwar, “Semi-cyclic stochastic gradient descent,” arXiv preprint arXiv:1904.10120,2019.
[39] A. N. Bhagoji, S. Chakraborty, P. Mittal, and S. Calo, “Analyz-ing federated learning through an adversarial lens,” arXiv preprint
arXiv:1811.12470, 2018.[40] M. Fang, X. Cao, J. Jia, and N. Z. Gong, “Local model poison-
ing attacks to byzantine-robust federated learning,” arXiv preprint
arXiv:1911.11815, 2019.[41] Z. Sun, P. Kairouz, A. T. Suresh, and H. B. McMahan, “Can you really
backdoor federated learning?” arXiv preprint arXiv:1911.07963, 2019.[42] V. Smith, C.-K. Chiang, M. Sanjabi, and A. S. Talwalkar, “Federated
multi-task learning,” in Advances in Neural Information Processing
Systems, 2017, pp. 4424–4434.[43] M. Mohri, G. Sivek, and A. T. Suresh, “Agnostic federated learning,”
arXiv preprint arXiv:1902.00146, 2019.[44] T. Li, M. Sanjabi, and V. Smith, “Fair resource allocation in federated
learning,” arXiv preprint arXiv:1905.10497, 2019.[45] X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the convergence
of fedavg on non-iid data,” arXiv preprint arXiv:1907.02189, 2019.
[46] E. Syta, P. Jovanovic, E. K. Kogias, N. Gailly, L. Gasser, I. Khoffi, M. J.Fischer, and B. Ford, “Scalable bias-resistant distributed randomness,” in2017 IEEE Symposium on Security and Privacy (SP), 2017, pp. 444–460.
[47] W. Diffie and M. Hellman, “New directions in cryptography,” IEEE
Trans. on Inf. Theory, vol. 22, no. 6, pp. 644–654, 1976.[48] J. So, B. Guler, A. S. Avestimehr, and P. Mohassel, “Codedprivateml: A
fast and privacy-preserving framework for distributed machine learning,”arXiv preprint arXiv:1902.00641, 2019.
[49] J. So, B. Guler, and A. S. Avestimehr, “A scalable approach for privacy-preserving collaborative machine learning,” in Advances in Neural
Information Processing Systems, 2020.[50] T. M. Cover and J. A. Thomas, Elements of Information Theory (Wiley
Series in Telecommunications and Signal Processing). USA: Wiley-Interscience, 2006.
[51] C. He, S. Li, J. So, M. Zhang, H. Wang, X. Wang, P. Vepakomma,A. Singh, H. Qiu, L. Shen et al., “Fedml: A research library and bench-mark for federated machine learning,” arXiv preprint arXiv:2007.13518,2020.
[52] L. Dalcín, R. Paz, and M. Storti, “MPI for Python,” Journal of Parallel
and Dist. Comp., vol. 65, no. 9, pp. 1108–1115, 2005.[53] J. So, B. Güler, and A. S. Avestimehr, “Byzantine-resilient secure
federated learning,” IEEE Journal on Selected Areas in Communications,2020.
[54] C. He, S. Avestimehr, and M. Annavaram, “Group knowledge transfer:Collaborative training of large cnns on the edge,” Advances in Neural
Information Processing Systems, 2020.[55] W. Hoeffding, “Probability inequalities for sums of bounded random
variables,” Journal of the American Statistical Association, vol. 58, no.301, pp. 13–30, 1963.
[56] K. S. Kedlaya and C. Umans, “Fast polynomial factorization andmodular composition,” SIAM Journal on Computing, vol. 40, no. 6, pp.1767–1802, 2011.

12
APPENDIX
A. State-of-the-Art of Secure Aggregation
A centralized secure aggregation protocol for federated learning has been proposed by [3], where each mobile user locallytrains a model. The local models are securely aggregated through a central server, who then updates the global model. Forsecure aggregation, users create pairwise keys through a key exchange protocol, such as [46], then utilize them to communicatemessages securely with other users, while all communication is forwarded through the server. Privacy of individual models isprovided by pairwise random masking. Specifically, each pair of users D, E ∈ [#] first agree on a pairwise random seed BD,E .In addition, user D creates a private random seed 1D . The role of 1D is to prevent the privacy breaches that may occur if userD is only delayed instead of dropped (or declared as dropped by a malicious server), in which case the pairwise masks aloneare not sufficient for privacy protection. User D ∈ [#] then masks its model xD ,
yD =xD + PRG(1D) +∑
E:D<E
PRG(BD,E ) −∑
E:D>E
PRG(BE,D) (17)
where PRG is a pseudo random generator, and sends it to the server. Finally, user D secret shares 1D as well as {BD,E }E∈[# ]
with the other users, via Shamir’s secret sharing3 [18]. From a subset of users who survived the previous stage, the servercollects either the shares of the pairwise seeds belonging to a dropped user, or the shares of the private seed belonging to asurviving user (but not both). Using the collected shares, the server reconstructs the private seed of each surviving user, andthe pairwise seeds of each dropped user, to be removed from the aggregate of the masked models. The server then computesthe aggregated model,
z =
∑
D∈U
(yD − PRG(1D)
)−
∑
D∈D
( ∑
E:D<E
PRG(BD,E) −∑
E:D>E
PRG(BE,D))=
∑
D∈U
xD (18)
where U and D represent the set of surviving and dropped users, respectively.A major bottleneck in scaling secure aggregation to a large number of users is the aggregation overhead, which is quadratic
in the number of users (i.e., $ (#2)). This quadratic aggregation overhead results from the fact that the server has to reconstructand remove the pairwise random masks corresponding to dropped users. In order to recover the random masks of dropped users,the server has to execute a pseudo random generator based on the recovered seeds BD,E , which has a quadratic computationoverhead as the number of pairwise masks is quadratic in the number of users, which dominates the overall time consumed inthe protocol. This quadratic aggregation overhead severely limits the network size for real-world applications [10].
B. An Illustrative Example
We next demonstrate the execution of Turbo-Aggregate through an illustrative example. Consider the network in Figure 5with # = 9 users partitioned into ! = 3 groups with #; = 3 (; ∈ [3]) users per group, and assume that user 3 in group 2 dropsduring protocol execution.
In the first stage, user 8 ∈ [3] in group 1 masks its model x(1)8
using additive masking as in (5) and computes {x(1)8, 9
} 9∈[3] .
Then, the user generates the encoded models, {x(1)8, 9
} 9∈[3] , by using the Lagrange polynomial from (10). Finally, the user
initializes s(1)8
= s(1)8
= 0, and sends {x(1)8, 9, x
(1)8, 9, s
(1)8, s
(1)8
} to user 9 ∈ [3] in group 2. Figure 6 demonstrates this stage for oneuser.
In the second stage, user 9 ∈ [3] in group 2 generates the masked models {x(2)
9 ,:}:∈[3] , and the coded models {x
(2)
9 ,:}:∈[3] ,
by using (5) and (10), respectively. Next, the user aggregates the messages received from group 1, by computing, s(2)9
=
13
∑8∈[3] s
(1)8
+∑8∈[3] x
(1)8, 9
and s(2)9
=13
∑8∈[3] s
(1)8
+∑8∈[3] x
(1)8, 9
. Figure 7 shows this aggregation phase for one user. Finally,
user 9 sends {x(2)
9 ,:, x
(2)
9 ,:, s
(2)9, s
(2)9} to user : ∈ [3] in group 3. However, user 3 (in group 2) drops out during the execution of
this stage and fails to complete its part.In the third stage, user : ∈ [3] in group 3 generates the masked models {x
(3)
:,C}C ∈[3] and the coded models {x
(3)
:,C}C ∈[3] . Then,
the user runs a recovery phase due to the dropped user in group 2. This is facilitated by the Lagrange coding technique.Specifically, user : can decode the missing value s
(2)
3= 6 (2) (U
(2)
3) due to the dropped user, by using the four evaluations
{s(2)
1, s
(2)
1, s
(2)
2, s
(2)
2} = {6 (2) (U
(2)
1), 6 (2) (V
(2)
1), 6 (2) (U
(2)
2), 6 (2) (V
(2)
2)} received from the remaining users in group 2. Then, user
: aggregates the received and reconstructed values by computing s(3)
:=
13
∑9∈[3] s
(2)9
+∑9∈[2] x
(2)
9 ,:and s
(3)
:=
13
∑9∈[3] s
(2)9
+∑9∈[2] x
(2)
9 ,:.
In the final stage, Turbo-Aggregate selects a set of surviving users to aggregate the models of group 3. Without loss ofgenerality, we assume these are the users in group 1. Next, user : ∈ [3] from group 3 sends {x
(3)
:,C, x
(3)
:,C, s
(3)
:, s
(3)
:} to user
3The state-of-the art protocol utilizes Shamir’s secret sharing to provide the robustness guarantee and privacy guarantee. It can achieve robustness guaranteeto user dropout rate of up to ? = 0.5 while providing privacy guarantee against up to ) =
#2
colluding users by setting the parameter C = #2+ 1 in Shamir’s
C-out-of-# secret sharing protocol. This allows each user to split its own random seeds into # shares such that any C shares can be used to reconstruct theseeds, but any set of at most C − 1 shares reveals no information about the seeds.

13
x(1)1
x(2)1
x(3)1
x(1)2
x(1)3
x(2)2
x(2)3
x(3)2
x(3)3
server
Group 1 Group 2
Group 3
Fig. 5. Example with # = 9 users and ! = 3 groups, with 3 users per group. User 3 in group 2 drops during protocol execution.
x(1)1
x(2)1
x(3)1
x(1)2
x(1)3
x(2)2
x(2)3
x(3)2
x(3)3
server
Group 1 Group 2
Group 3
{x(1)1,j}j∈[3]
{x(1)1,j}j∈[3]
s(1)1
s(1)1
Fig. 6. Illustration of the computations performed by user 1 in group 1, who then sends {x(1)
1, 9, x
(1)
1, 9, s
(1)
1, s
(1)
1} to user 9 ∈ [3] in group 2 (using pairwise
keys through the server).
C ∈ [3] in the final group. Then, user C computes the aggregation, s( 5 8=0;)C =
13
∑:∈[3] s
(3)
:+∑:∈[3] x
(3)
:,Cand s
( 5 8=0;)C =
13
∑:∈[3] s
(3)
:+∑:∈[3] x
(3)
:,C, and sends {s
( 5 8=0;)C , s
( 5 8=0;)C } to the server.
Finally, the server computes the average of the summations received from the final group and removes the added randomness,which is equal to the aggregate of the original models of the surviving users.
1
3
∑
C ∈[3]
s( 5 8=0;)C −
∑
8∈[3]
u(3)8
−∑
9∈[2]
u(2)9
−∑
:∈[3]
u(3)
:=
∑
8∈[3]
x(1)8
+∑
9∈[2]
x(2)9
+∑
:∈[3]
x(3)
:.
C. Proof of Theorem 1
As described in Section IV-A, Turbo-Aggregate first employs an unbiased random partitioning strategy to allocate the #users into ! =
##;
groups with a group size of #; for all ; ∈ [!]. To prove the theorem, we choose #; = 12
log# where2 , min{� (0.5| |?), � (0.5| | )
#)} and � (0 | |1) is the Kullback-Leibler (KL) distance between two Bernoulli distributions with
parameter 0 and 1 (see e.g., page 19 of [49]). We now prove each part of the theorem separately.(Robustness guarantee) In order to compute the aggregate of the user models, Turbo-Aggregate requires the partial summation
in (8) to be recovered by the users in group ; ∈ [!]. This requires users in each group ; ∈ [!] to be able to reconstruct theterm s
(;−1)8
of all the dropped users in group ; − 1. This is facilitated by our encoding procedure as follows. At stage ;, eachuser in group ; + 1 receives 2(#; − �;) evaluations of the polynomial 6 (;) , where �; is the number of users dropped in group;. Since the degree of 6 (;) is at most #; − 1, one can reconstruct s
(;)8 for all 8 ∈ [#;] using polynomial interpolation, as long as

14
x(1)1
x(2)1
x(3)1
x(1)2
x(1)3
x(2)2
x(2)3
x(3)2
x(3)3
server
Group 1
Group 2
Group 3
{x(1)i,1 }i∈[3]
{s(1)i }i∈[3]
{s(1)i }i∈[3]
{x(1)i,1 }i∈[3]
s(2)1 =
1
3
∑
i∈[3]
s(1)i +
∑
i∈[3]
x(1)i1
s(2)1 =
1
3
∑
i∈[3]
s(1)i +
∑
i∈[3]
x(1)i1
Fig. 7. The aggregation phase for user 1 in group 2. After receiving the set of messages{x(1)
8,1, x
(1)
8,1, s
(1)8, s
(1)8
}8∈[3]
from the previous stage, the user computes
the aggregated values s(2)1
and s(2)1
(note that this is an aggregation of the masked values).
2(#;−�;) ≥ #;. If the condition of 2(#;−�;) ≥ #; is satisfied for all ; ∈ [!], Turbo-Aggregate can compute the aggregate ofthe user models. Therefore, the probability that Turbo-Aggregate provides robustness guarantee against user dropouts is givenby
P[robustness] = P[ ⋂
;∈[! ]
{�; ≤#;
2}]= 1 − P
[ ⋃
;∈[! ]
{�; ≥ ⌊#;
2⌋ + 1}
]. (19)
Now, we show that this probability goes to 1 as # → ∞. �; follows a binomial distribution with parameters #; and ?.When ? < 0.5, its tail probability is bounded as
P[�; ≥ ⌊#;
2⌋ + 1] ≤ exp
(− 2?#;), (20)
where 2? = � (⌊#;2⌋+1
#;| |?) [54]. When #; is sufficiently large, 2? ≈ � (0.5| |?). Note that 2? > 0 is a positive constant for any
? < 0.5, since by definition the KL distance is non-negative and equal to 0 if and only if ? = 0.5 (Theorem 2.6.3 of [49]).Then, using a union bound, the probability of failure can be bounded by
P[failure] = P[ ⋃
;∈[! ]
{�; ≥ ⌊#;
2⌋ + 1}
]≤
∑
;∈[! ]
P[�; ≥ ⌊#;
2⌋ + 1]
≤#
#;exp(−2?#;) (21)
, �failure, (22)
where (21) follows from (20). Asymptotic behavior of this upper bound is given by
lim#→∞
�failure = exp{
lim#→∞
log �failure
}
= exp{
lim#→∞
(log# − log#; − 2?#;
)}
= exp (−∞) (23)
= 0, (24)
where (23) holds because #; = 12
log# ≥ 12?
log# . From (22) and (24), lim#→∞ P[failure] = 0.(Privacy guarantee) Let �; be an event that a collusion between users and the server can reveal the local model of any
honest user in group ; − 1, and -; be a random variable corresponding to the number of colluding users in group ; ∈ [!].First, note that the colluding users in groups ; ′ ≤ ; − 1 cannot learn any information about a user in group ; − 1 becausecommunication in Turbo-Aggregate is directed from users in lower groups to users in upper groups. Moreover, colluding usersin groups ; ′ ≥ ; +1 can learn nothing beyond the partial summation, s(;
′) . Hence, information breach of a local model in group; − 1 occurs only when the number of colluding users in group ; is greater than or equal to half of the number of users ingroup ;. In this case, colluding users can obtain a sufficient number of evaluation points to recover all of the masked models

15
belonging to a certain user, i.e., x(;−1)8, 9
in (5) for all 9 ∈ #;. Then, they can recover the original model x(;−1)8
by adding all
of the masked models and removing the randomness u(;−1)8
. Therefore, P[�;] = P[-; ≥#;
2]. To calculate P[�;], we again
consider the random partitioning strategy described in Section IV-A which allocates # users to ! =##;
groups whose size is#; for all groups, while ) out of # users are colluding users. Then, -; follows a hypergeometric distribution with parameters(#,), #;) and its tail probability is bounded as
P[-; ≥#;
2] ≤ exp
(− 2) #;), (25)
where 2) = � (0.5| | )#) [54]. Note that 2) > 0 is a positive constant when ) ≤ (0.5− n)# for any n > 0. Then the probability
of privacy leakage of any individual model is given by
P[privacy leakage] = P[⋃
;∈[! ]
�;] ≤∑
;∈[! ]
P[�;] (26)
≤#
#;exp(−2) #;) (27)
, �privacy ,
where (26) follows from a union bound and (27) follows from (25). Note that (27) can be bounded similarly to (21) by replacing2? with 2) , from which we find that lim#→∞ �privacy = 0. As a result, lim#→∞ P[privacy leakage] = 0.
(Aggregation overhead) As described in Section III, aggregation overhead consists of two main components, computationand communication. The computation overhead quantifies the processing time for: 1) masking the models with additive secretsharing, 2) adding redundancies to the models through Lagrange coding, and 3) reconstruction of the missing information due touser dropouts. First, masking the model with additive secret sharing has a computation overhead of $ (log#). Second, encodingthe masked models with Lagrange coding has a computation overhead of $ (log# log2 log# log log log#), because evaluating apolynomial of degree 8 at any 9 points has a computation overhead of $ ( 9 log2 8 log log 8) [55], and both 8 and 9 are log# for theencoding operation. Third, the decoding operation to recover the missing information due to dropped users has a computationoverhead of $ (? log# log2 log# log log log#), because it requires evaluating a polynomial of degree log# at ? log# points.Within each execution stage, the computations are carried out in parallel by the users. Therefore, computations per executionstage has a computation overhead of $
(log# log2 log# log log log#
), which is the same as the computation overhead of a
single user. Since there are ! =2#
log #execution stages, overall the computation overhead is $
(# log2 log# log log log#
).
Communication overhead is evaluated by measuring the total amount of communication over the entire network, to quantifythe communication time in the worst-case communication architecture, which corresponds to the centralized communicationarchitecture where all communication goes through a central server. At execution stage ; ∈ [!], each of the #; users in group; sends a message to each of the #;+1 users in group ; + 1, which has a communication overhead of $ (log2 #). Since thereare ! =
2#log#
stages, overall the communication overhead is $ (# log#).As the aggregation overhead consists of the overheads incurred by communication and computation, the aggregation overhead
of Turbo-Aggregate is � = $ (# log#).
D. Proof of Theorem 2
We first note that �; , the number of users dropped in group ;, follows a binomial distribution with parameters #; and ?.The probability that the information of the users in group ; cannot be reconstructed is given by P
[�; ≥ ⌊
#;
2⌋ + 1
]. From [49],
this probability can be bounded as
P[�; ≥ ⌊
#;
2⌋ + 1
]≥
1
#; + 1exp (−2′#;), (28)
where 2′ = � (0.5| |?).The probability that Turbo-Aggregate can provide robustness against user dropouts is given by
P[robustness] = P[ ⋂
;∈[! ]
{�; ≤#;
2}]
= P[{�; ≤
#;
2}]!
(29)
=
(1 − P
[�; ≥ ⌊
#;
2⌋ + 1
])!
≤(1 −
1
#; + 1exp (−2′#;)
)!(30)
=
(1 −
1
log# + 1exp (−2′ log#)
) #log #
=
(1 −
#−2′
log# + 1
) #log #
, �robustness, (31)

16
where (29) holds since the events are independent over the groups and (30) follows from (28). The asymptotic behavior of theupper bound is then given by
lim#→∞
�robustness = exp{
lim#→∞
log �}
= exp{
lim#→∞
log(1 − # −2′
log #+1
)
log #
#
}
= exp{
lim#→∞
2′# −2′−1 (1+log # )+# −2−1
(1+log# ) (1+log #−# −2′ )
1−log #
# 2
}(32)
= exp{
lim#→∞
2′#1−2′ log# + #1−2′ (1 + 2′)
(1 − log2 #) (1 + log# − #−2′)
}
= exp{
lim#→∞
2′#1−2′ log# + #1−2′ (1 + 2′)
− log3 # − log2 # + log#
}(33)
= exp{
lim#→∞
2′(1 − 2′)#1−2′ log# + #1−2′ (1 + 2′ − 2′2)
−3 log2 # − 2 log# + 1
}(34)
= exp{
lim#→∞
2′(1 − 2′)2#1−2′ log# + #1−2′ (1 − 2′) (1 + 22′ − 2′2)
−6 log# − 2
}(35)
= exp{
lim#→∞
2(1 − 2′)3#1−2′ log# + #1−2′ (1 − 2′)2(1 + 32′ − 2′2)
−6
}(36)
= exp (−∞) (37)
= 0, (38)
where (32), (34), (35), and (36) follow the L’Hospital’s rule, (33) removes the terms which do not go to infinity as # goes toinfinity, and (37) holds since #1−2′ goes to infinity when 0 < 2′ = � (0.5| |?) < 1.
From (31) and (38), lim#→∞ P[robustness] = 0, which completes the proof.
E. Proof of Theorem 3
The generalized version of Turbo-Aggregate creates two independent random partitionings of the users, where eachpartitioning randomly assigns # users into ! groups with a group size of #; for all ; ∈ [!]. To prove the theorem, wechoose #; = $ (log#) as in the proof of Theorem 1 for both the first and second partitioning. We now prove the privacyguarantee for each individual model as well as any aggregate of a subset of models, robustness guarantee, and the aggregationoverhead.
(Privacy guarantee) As the generalized protocol follows Algorithm 1, the privacy guarantee of individual models followsfrom the proof of the privacy guarantee in Theorem 1. We now prove the privacy guarantee of any partial aggregation, i.e.,aggregate of the models from any subset of users. A collusion between the server and users can reveal a partial aggregationin two events: 1) for any ;, ; ′ ∈ [!], U; and U
′
;′are exactly the same where U; and U
′
;′denote the set of surviving users
in group ; of the first partitioning and group ; ′ of the second partitioning, respectively, or 2) the number of colluding usersin group ; ′ of the second partitioning is larger than half of the group size, and the number of such groups is large enoughthat colluding users can reconstruct the individual random masks {u
(;)9} 9∈U;
in (5) for some group ; of the first partitioning.
In the first event, the server can reconstruct the aggregate of the random masks,∑9∈U;
u(;)9
, and then if the server colludes
with any user in group ; + 1 and any user in group ; + 2, they can reveal the partial aggregation∑9∈U;
x(;)9
by subtracting
s(;+1) +∑9∈U;
u(;)9
from s(;+2) in (9). The probability that a given group from the second partitioning is the same as any group; ∈ [!] from the first partitioning is #
#;
1
( ##;)
. As there are ! =##;
groups in the second partitioning, the probability of the first
event is bounded by # 2
# 2;
1
( ##;)
from a union bound, which goes to zero as # → ∞ when #; = $ (log#). In the second event,
the colluding users in group ; ′ where the number of colluding users is larger than half of the group size can reconstruct theindividual random masks of all users in group ; ′ − 1. If these colluding users can reconstruct the individual random masks ofall users in group ; for any ; ∈ [!] and collude with any user in group ; + 1 and any user in group ; + 2, they can reveal thepartial aggregation
∑9∈U;
x(;)9
. As the second event requires that the number of colluding users is larger than half of the groupsize in multiple groups, the probability of the second event is less than the probability in (25), which goes to zero as # → ∞.Therefore, as the upper bounds on these two events go to zero, generalized Turbo-Aggregate can provide privacy guaranteefor any partial aggregation, i.e., aggregate of any subset of user models, with probability approaching to 1 as # → ∞.
(Robustness guarantee) Generalized Turbo-Aggregate can provide the same level of robustness guarantee as Theorem 1. Thisis because the probability that all groups in the first partitioning have enough numbers of surviving users for the protocol to

17
TABLE IIBREAKDOWN OF THE RUNNING TIME (MS) OF TURBO-AGGREGATE WITH # = 200 USERS.
Drop rate Encoding Decoding Communication Total
10% 2070 2333 22422 2682530% 2047 2572 22484 2710350% 2051 3073 22406 27530
correctly compute the aggregate∑9∈U;
(x(;)9
+ u(;)9
)is the same as the probability in (19), and the probability that all groups
in the second partitioning have enough numbers of surviving users is also the same as the probability in (19). Therefore, froma union bound, the upper bound on the failure probability of generalized Turbo-Aggregate is twice that of the bound in (22),which goes to zero as # → ∞.
(Aggregation overhead) Generalized Turbo-Aggregate follows Algorithm 1 which achieves an aggregation overhead of$ (# log#), and additional operations to secret share the individual random masks u
(;)8
and decode the aggregate of therandom masks also have an aggregation overhead of $ (# log#). The aggregation overhead of the additional operationsconsists of four parts: 1) user 8 in group ; generates the secret shares of u
(;)8
via Shamir’s secret sharing with a polynomialdegree #;
2, 2) user 8 in group ; sends the secret shares to the #; users in group ; + 1, 3) user 8 in group ; aggregates the
received secret shares,∑9∈U
′
;−1
[u(;−1)9
]8, and sends the sum to the server, and 4) server reconstructs the secret
∑9∈U
′
;u(;)9
for
all ; ∈ [!]. The computation overhead of Shamir’s secret sharing is $ (#2;) [18], and these computations are carried out in
parallel by the users in one group. As there are ! =##;
groups and #; = $ (log#), the computation overhead of the first part is$ (# log#). The communication overhead of the second part is $ (# log#) as the total number of secret shares is $ (# log#).The communication overhead of the third part is $ (#) as each user sends a single message to the server. The computationoverhead of the last part is $ (# log#) as the computation overhead of decoding the secret from the #; = $ (log#) secretshares is $ (log2 #) [18], and the server must decode ! = $ ( #
log #) secrets. Therefore, generalized Turbo-Aggregate also
achieves an aggregation overhead of $ (# log#).
F. Additional Experiments
In this section, we provide further numerical evaluations on the performance of Turbo-Aggregate.
1) Breakdown of the total running time: To illustrate the impact of user dropouts, we present the breakdown of the totalrunning time of Turbo-Aggregate, Turbo-Aggregate+, and the benchmark protocol in Tables II, III and IV, respectively, for thecase of # = 200 users. Tables II and III demonstrate that, for Turbo-Aggregate and Turbo-Aggregate+, the encoding time staysconstant with respect to the user dropout rate, and decoding time is linear in the number of dropout users, which takes onlya small portion of the total running time. Table IV shows that, for the benchmark protocol, total running time is dominatedby the reconstruction of pairwise masks (using a pseudo random generator) at the server, which has a computation overheadof $
((# − �) + � (# − �)
)where � is the number of dropout users [3]. This leads to an increased running time as the
number of user dropouts increases. The running time of two Turbo-Aggregate schemes, on the other hand, is relatively stableagainst varying user dropout rates, as the communication time is independent from the user dropout rate and the only additionaloverhead comes from the decoding phase, whose overall contribution is minimal. Table III shows that the encoding time ofTurbo-Aggregate+ is reduced to an !-th of the encoding time of original Turbo-Aggregate because encoding is performed inparallel across all groups. Turbo-Aggregate+ also speeds up the decoding and communication phases by reducing the numberof execution stages from ! − 1 to log !.
It is also useful to comment on the selection of a user dropout rate of up to ? = 0.5. From a practical perspective, our selectionof ? = 0.5 is to demonstrate our results with the same parameter setting as the state-of-the-art [3]. From a privacy perspective,as most secure systems, e.g., Blockchain systems, are designed to tolerate at most 50% adversaries, Turbo-Aggregate is alsodesigned to achieve a privacy guarantee against up to ) = #/2 where # is total number of users, which limits the maximumvalue of ? to 0.5, as Turbo-Aggregate provides a trade-off between the maximum user dropout rate ? and the privacy guarantee) , as detailed in Remark 1.
2) Impact of bandwidth and stragglers: In this following, we further study the impact of the bandwidth and stragglerson the performance of our protocol, by measuring the total running time with various communication bandwidth constraints.Our results are demonstrated in Figure 8, from which we observe that Turbo-Aggregate still provides substantial gain inenvironments with more severe bandwidth constraints.
Bandwidth. For simulating various bandwidth conditions in mobile network environments, we measure the total running timewhile decreasing the maximum bandwidth constraint for the communication links between the Amazon EC2 machine instances

18
TABLE IIIBREAKDOWN OF THE RUNNING TIME (MS) OF TURBO-AGGREGATE+ WITH # = 200 USERS.
Drop rate Encoding Decoding Communication Total
10% 93 356 3353 380230% 94 460 3282 383650% 94 559 3355 4009
TABLE IVBREAKDOWN OF THE RUNNING TIME (MS) OF THE BENCHMARK PROTOCOL [3] WITH # = 200 USERS.
Drop rate Communication of Reconstruction Other Totalthe models at server
10% 8670 53781 832 6328430% 8470 101256 742 11046850% 8332 151183 800 160315
from 1�1?B to 100"1?B. In Figure 8, we observe that the gain of Turbo-Aggregate and Turbo-Aggregate+ over the benchmarkdecrease as the maximum bandwidth constraint decreases. This is because for the benchmark, the major bottleneck is the runningtime for the reconstruction of pairwise masks, which remains constant over various bandwidth conditions. On the other hand,for Turbo-Aggregate, the total running time is dominated by the communication time which is a reciprocal proportion to thebandwidth. This leads to a significantly decreased gain of Turbo-Aggregate over the benchmark, 1.9× with the maximumbandwidth constraint of 100"1?B. However, total running time of Turbo-Aggregate+ increases moderately as the maximumbandwidth constraint decreases because communication time of Turbo-Aggregate+ is even less than the communication timeof the benchmark. Turbo-Aggregate+ still provides a speedup of 12.1× over the benchmark with the maximum bandwidthconstraint of 100"1?B. In real-world settings, this gain is expected to increase further as the number of users increases.
Stragglers or delayed users. Beyond user dropouts, in a federated learning environment, stragglers or slow users can alsosignificantly impact the total running time. Turbo-Aggregate can effectively handle these straggling users by simply treatingthem as user dropouts. At each stage of the aggregation, if some users send their messages later than a certain threshold,users at the higher group can start to decode those messages without waiting for stragglers. This has negligible impact on thetotal running time because Turbo-Aggregate provides a stable total running time as the number of dropout users increases. Forthe benchmark, however, stragglers can significantly delay the total running time even though it can also handle stragglers asdropout users. This is because the running time for the reconstruction of pairwise masks corresponding to the dropout users,which is the dominant time consuming part of the benchmark protocol, significantly increases as the number of dropout usersincreases.
Fig. 8. Total running time of Turbo-Aggregate versus the benchmark protocol from [3] as the maximum bandwidth increases, for various user dropout rates.The number of users is fixed to # = 200.

19
Fig. 9. Running time of Turbo-Aggregate versus the benchmark protocol from [3]. Both protocols are applied to the aggregation phase in FedAvg withCIFAR-10 dataset and CNN architecture [1]. We measure the running time of training phase and aggregation phase to achieve a test accuracy of 80% with# = 100, � = 5 (number of local epochs), and � = 50 (mini-batch size).
3) Additional experiments with the federated averaging scheme (FedAvg) [1]: In Section VI, we have primarily focused onthe aggregation phase and measured a single round of the secure aggregation phase with synthesized vectors for the locallytrained models. This is due to the fact that these vectors can be replaced with any trained model using the real world federatedlearning setups.
To further investigate the performance of Turbo-Aggregate in real world federated learning setups, we implement the FedAvg
scheme from [1] with a convolutional neural network (CNN) architecture on the CIFAR-10 dataset as considered in [1], andapply two secure aggregation protocols, Turbo-Aggregate and the benchmark protocol from [3], in the aggregation phase. Thisarchitecture has 100,000 parameters, and with the setting of # = 100, � = 5 (number of local epochs), and � = 50 (mini-batchsize), it requires 280 rounds to achieve a test accuracy of 80% [1]. Figure 9 shows the local training time, aggregation time, andtotal running time of Turbo-Aggregate and the benchmark protocol [3], from which we have observed that Turbo-Aggregateprovides 10.8× speedup over the benchmark to achieve 80% test accuracy. We note that this gain can be much larger (almost40×) when the number of users is larger (# = 200).