Embed Size (px)
Citation preview

Trials Units Information Systems – Functions and Modules
Data and Information Systems Project
The DIMS Project Team

Trials Units IS ‐ Functions and Modules
Contents
Aims and Introduction .................................................................................................................. 1
Scope............................................................................................................................................. 2
The Advantages of Modularity...................................................................................................... 4
Problems of a Single System Approach ........................................................................................ 6
Linkage and Standards .................................................................................................................. 8
Modules I ‐ Setup and Design Components................................................................................ 11 Trial Setup .............................................................................................................................................. 11 Schedule Specification............................................................................................................................ 12 Data Items Specification ........................................................................................................................ 13 CRF / eCRF Production ........................................................................................................................... 14 Database Generation............................................................................................................................. 15 Centre Setup........................................................................................................................................... 16 Actor Setup ............................................................................................................................................ 17 Randomisation Setup............................................................................................................................. 18
Modules II ‐ Clinical Data Management Components ................................................................ 19 Randomisation....................................................................................................................................... 19 Data Capture at Centre.......................................................................................................................... 19 Data Input to DB .................................................................................................................................... 21 Discrepancy management ..................................................................................................................... 22 Data Coding ........................................................................................................................................... 23
Modules III ‐ Trial Management Components ............................................................................ 24 Tracking Data Receipt............................................................................................................................ 24 Contacts Management .......................................................................................................................... 24 Pharmacovigilance................................................................................................................................. 25 Research Governance Monitoring ......................................................................................................... 27 Quality of Life Management .................................................................................................................. 28 Drug Management ................................................................................................................................ 29 Budget and Payment Management....................................................................................................... 30 Sample Tracking..................................................................................................................................... 31
Modules IV ‐ Data Extraction and Analysis Components............................................................ 32 Correspondence Generation .................................................................................................................. 32 Accrual Monitoring ................................................................................................................................ 33 Report generation ‐ Inspection and Monitoring .................................................................................... 33 Metadata Exports .................................................................................................................................. 35 Transformed Data Exports ..................................................................................................................... 36 Analysis Datasets ................................................................................................................................... 37 Long‐term Curation................................................................................................................................ 38

Trials Units IS – Functions and Modules
Page | 1
Aims and Introduction
1 The aims of this document are
a) To describe the different functions IT systems can provide, actually and potentially, within Clinical Trials Units.
b) To encourage a more granular, modular based view of Clinical Trial (CT) IT systems, as a prelude to further debates about specifying, developing and procuring those systems.
c) To explain why future IT systems in clinical trials units should be based upon distinct and clearly specified modules, linked together by appropriate data standards.
d) To explore how such future systems could be specified, by examining each of the identified functional components in turn.
2 The document is one of four white papers supporting the main deliverable of the NIHR / UKCRC’s DIMS Project: ‘Trials Units Information Systems – General Proposals’. (The other three papers deal with the Consultation Results, Data Standards and System Standards respectively). It should be read in conjunction with the other DIMS documents.
3 As the next section on ‘Scope’ makes clear, the paper covers a wide range of potential IT functions. This is partly to counter the tendency of debates about IT in trials units to focus only on the relative merits of clinical data systems (paper versus eRDC, Macro versus Medidata, etc.), partly because many of the current and future developments in NHS IT are, in the short term, more likely to impact trial administration systems than those dealing with clinical data.
4 The following section, the ‘Advantages of Modularity’, advances the central tenet of this paper, that a more modular approach to specifying, developing and procuring CT IT would give greater flexibility and choice, be safer commercially and in the long term more efficient, allow faster response to change, let trials units (especially their IT staff) retain their autonomy, and still leave room for innovation.
5 An alternative approach to developing greater consistency and inter‐operability between trials units would simply be to mandate the use of a single system throughout the UK, but this strategy was explicitly rejected by the DIMS project team. The reasons why are discussed in ‘Problems of a Single System Approach’
6 Any modular approach is dependent on effective communication between the different components. That means as a minimum adherence to basic data standards and, implicitly or explicitly, sharing core data models. This is discussed further in ‘Linkage and Standards’.
7 The next four sections then take each of the 28 identified functions in turn and describe them in a little more detail. Each component is considered largely as a ‘black box’, with inputs, outputs and the relevant data stores depicted on a sketch, together with some commentary. Possible future developments and / or interactions with other systems are indicated where relevant. The descriptions provided are basic, but could be worked up to provide more detailed, specific requirements specifications if necessary.
Trials Units IS – Functions and Modules
Page | 2
Scope
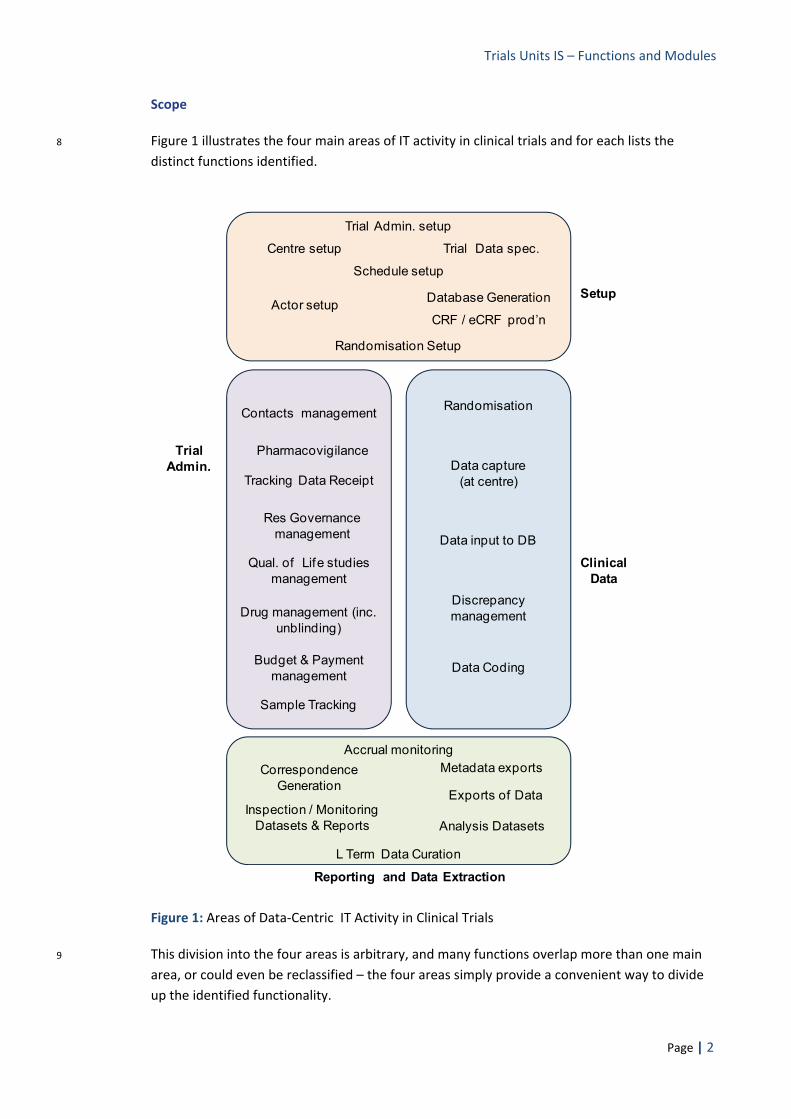
8 Figure 1 illustrates the four main areas of IT activity in clinical trials and for each lists the distinct functions identified.
Setup
Randomisation Setup
Trial Admin.
Reporting and Data Extraction
Clinical Data
Res Governance management
Pharmacovigilance
Trial Data spec.
Database Generation
Tracking Data Receipt
Accrual monitoring
Drug management (inc. unblinding)
Centre setup
Actor setup
Budget & Payment management
CRF / eCRF prod’n
Schedule setup
Trial Admin. setup
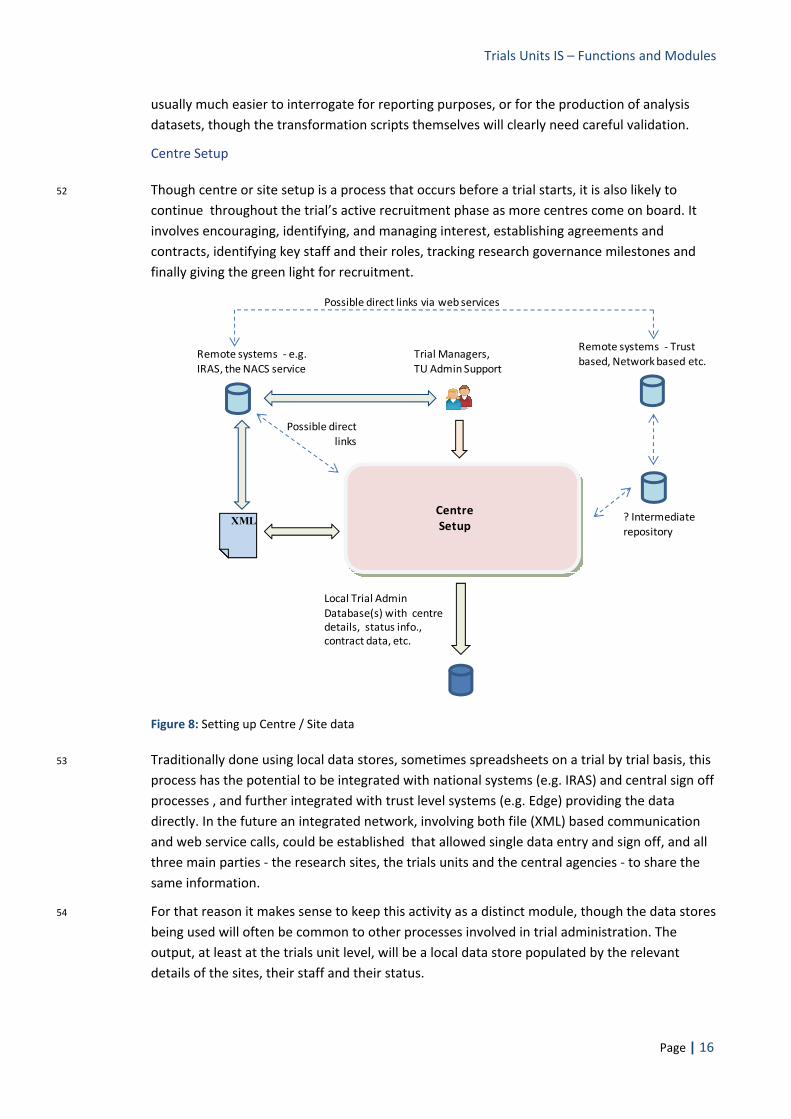
Sample Tracking
Randomisation
Data capture (at centre)
Data input to DB
Discrepancy management
Analysis Datasets
L Term Data Curation
Inspection / Monitoring Datasets & Reports
Exports of Data
Data Coding
Contacts management
Correspondence Generation
Qual. of Life studies management
Metadata exports
Figure 1: Areas of Data‐Centric IT Activity in Clinical Trials
9 This division into the four areas is arbitrary, and many functions overlap more than one main area, or could even be reclassified – the four areas simply provide a convenient way to divide up the identified functionality.

Trials Units IS – Functions and Modules
Page | 3
10 The functions listed are all ‘data‐centric’, i.e. they involve databases. Whilst IT systems are obviously also used to support document production and management, functions that are document centric are not considered. Protocol development, composing patient information sheets, completing applications for funding, formulating contracts, writing papers, building reference lists, etc. are therefore all excluded.
11 It is recognised, however, that in the future many protocols may become more structured and include computable sections, e.g. end points and inclusion / exclusion criteria expressed using XML and SNOMED terms. This is reflected in current work on structured protocols within the BRIDG project, as well as in the functionality of products like Medidata’s (formerly Fast Track’s) Designer software. An additional function, and therefore module, dealing with the structured protocol design process will therefore probably need to be specified in the future.
12 Specialist statistical software is excluded from consideration, which is why the analysis function per se (as opposed to generating datasets for analysis) is missing. In any case statistical software already provides a model of modular deployment, given the range of general packages (Stata, SPSS, SAS etc.) and the range of specialist packages and add‐ons (e.g. nQuery, PEST, EAST for powering analysis) that are available. Individual trials units, indeed individual statisticians, are able to select the software that best suits them and the task in hand.
13 The diagram depicts rather more functions in the trial administration section than it does in clinical data management, despite the fact that the acquisition and storage of the clinical data has been the traditional remit of most existing clinical trial systems and that, up to now, IT systems for trial administration have often been piecemeal and relatively basic, e.g. written in MS Excel or Access.
14 In fact it is quite possible that, notwithstanding the central scientific importance of the trial’s clinical data and the absolute need to store it securely and process it accurately, the biggest improvements in trial management, and potentially the biggest cost savings, can be gained from developing improved IT systems for trial administration.

Trials Units IS – Functions and Modules
Page | 4
The Advantages of Modularity
15 The assertion that a planned, standards based, modular approach is the best way of implementing Clinical Trials IT in the future is based on the following series of observations:
a) No single system will ever do it all – The range of IT functionality required in a clinical trials unit, including database design, clinical data capture, randomising new subjects, CRF tracking, discrepancy management, generating analysis datasets (etc., etc.), together with the range of research goals, methodologies and subjects to be found in different units, some requiring specific and unique system support, is always going to be too wide for any single system, or any single vendor, to be able to cover easily or responsively.
b) Planned modularity is far better than ad hoc assembly – The debate is therefore less about the need for a modular approach as it is about the availability, scope, granularity and inter‐operability of what is inevitably a range of different system components, and the choices available when procuring them. Taking a deliberate, planned approach to modularity allows component functionality and interfaces to be clearly specified. This should lead, in turn, to systems that could inter‐connect more efficiently, and that could support national standards and initiatives (e.g. the NHS RCP), in a way in which the current and various ad hoc collections of systems will never be able to do.
c) Modularity allows more flexible purchase and / or development. A mosaic of modules can be purchased and / or developed, and then upgraded / replaced, independently of each other (as long as they use standard interfaces). In addition there is nothing to stop a variety of suppliers, whether commercial or community based, developing each module (again as long as it uses standard interfaces). This would allow far more flexible system procurement, whether built or bought, than is usually the case now. It should introduce effective, continual competition to the procurement process (where as now a unit is often locked into a system and supplier, from a single purchase / development decision, for many years). Critically, it allows individual units to add or upgrade detailed functionality as their requirements change and resources allow.
d) Modules can put the users in the driving seat – Particularly with regard to clinical database systems, commercial systems, often more attuned to the needs and budgets of pharmaceutical companies rather than academic units, are the ‘givens’ in the marketplace. Purchasers must compare and select between them or run the risks and expense of developing their own system. Specifying modules and the standards to link them, making it clear to system vendors (and local developers) that we are interested in standards compliant modules covering distinct functional areas, breaking up the procurement process and maintaining a wider pool of potential suppliers, as described above, all offer an opportunity for a user‐driven procurement process rather than the current vendor dominated one.
e) Increased modularity of procurement reduces vulnerability – Dependence on a single system and / or vendor for a large proportion of CT IT functionality does make a trials unit very vulnerable to the supplying company disappearing or, for a larger corporation, simply

Trials Units IS – Functions and Modules
Page | 5
deciding to discontinue support for that product line, or, for systems developed in‐house, to the developers leaving or changing role. The more modular a Unit’s IT system, the more it can spread the risk across different commercial and academic suppliers.
f) More discrete components means more room for innovation – Many of those working in CT IT have a very high level of technical skills as well as extensive knowledge of their specialist area. Consequently there are a number of exciting projects happening in different trials units – SharePoint based systems, web services, Ruby on Rails sites, metadata repositories, minimisation systems, pharmacovigilance systems etc., etc. The more modular the general approach the more easily these new components can be evaluated and, if appropriate, integrated with other systems.
There is a caveat relating to innovation in isolated TUs. Innovation risks being lost if the responsible individual moves on or the group involved is disbanded. Systems based upon it can become obscure ‘legacy’ systems that few understand. A mechanism is therefore needed to monitor such work and – where it has proved particularly effective – to elevate its status to a centrally promoted and maintained component. The centre, and the ISWG, can also take an active role in forging sensible collaborations between CT IT staff working on similar or complementary projects, so that innovation does not occur in isolation.
Of course innovation is not confined to the UK’s academic trials units. Modularity also gives more room to buy in / co‐develop tools with the pharmaceutical industry and trials units abroad, as well as making easier to incorporate the developments in IT systems within Trusts and Research Networks (e.g. Edge).
g) Increased modularity allows faster software development – Small systems with more tightly defined requirements are usually quicker to modify and test than larger complex systems. Increased modularity allows quicker responses to both challenges and opportunities (e.g. if a pharmacovigilance system is ‘factored out’ as a separate component, than a change in European regulations can much more easily be applied to just that component, leaving other systems unchanged).
h) Modularity allows easier uniformity when it is deemed desirable – There are certain situations where uniformity is seen as potentially a good idea: for example it is often advanced that the full benefits of eRDC will only be realised in the UK when local research staff only have to use a single log‐in system, and a single or very similar interface when entering data. It would be much easier to introduce convergence into a particular component if it is only that component needs to change, with the interface(s) to other components remaining the same.
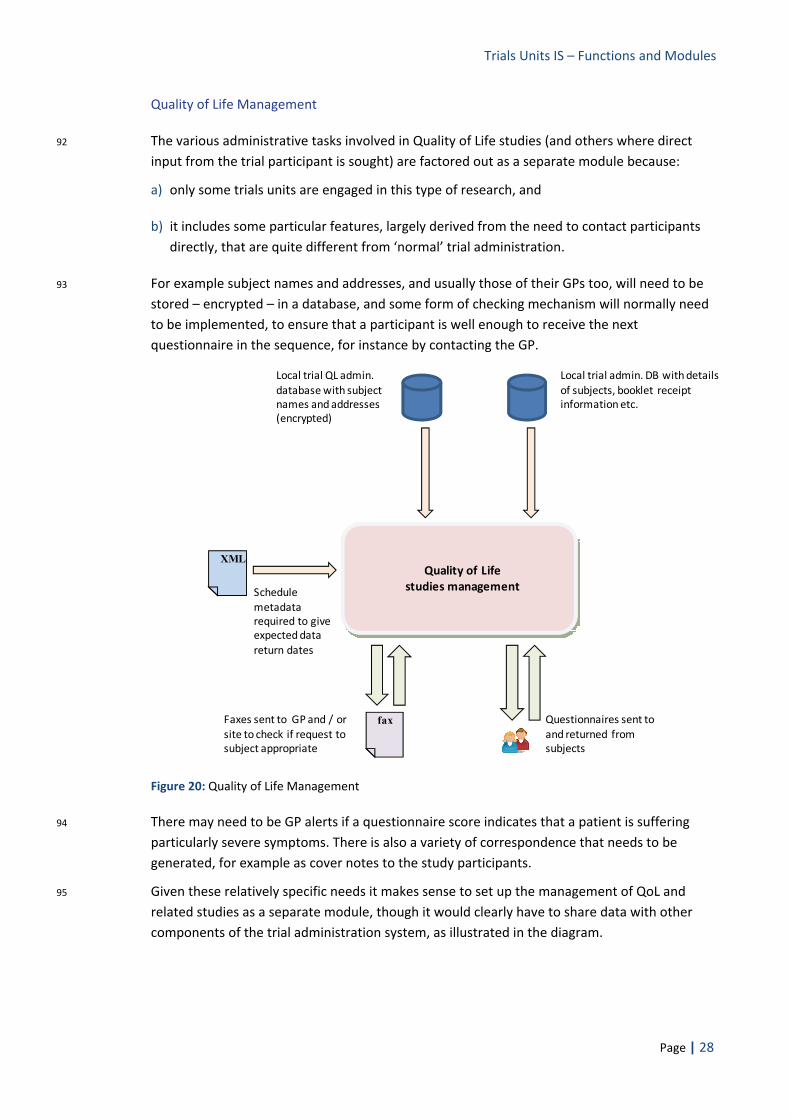
i) Modularity offers the least impractical way to manage / convert older systems – The issue of existing systems and data, that might become ‘legacy systems’ in the context of a radically different future for IT in clinical trials, is probably the biggest single problem facing any attempt to improve and rationalise current systems. Trial data systems, especially when used for long term trials and follow up, e.g. in cancer and mental health studies, can be used for decades. Changing data systems for existing studies may not

Trials Units IS – Functions and Modules
Page | 6
always be cost effective. In other words, whatever is finally proposed, it is very likely that we will have to live with a mix of systems for several years. If changing systems is required, however, trying to do it on a modular basis is much more achievable than a full changeover, allowing different functionality in the old system(s) to be ‘switched off’ and replaced by the new on a module by module basis. This would allow, for instance, metadata descriptions and long term curation of old trials to conform to new standards and use new tools, even if the basic data collection process remained in the old system.
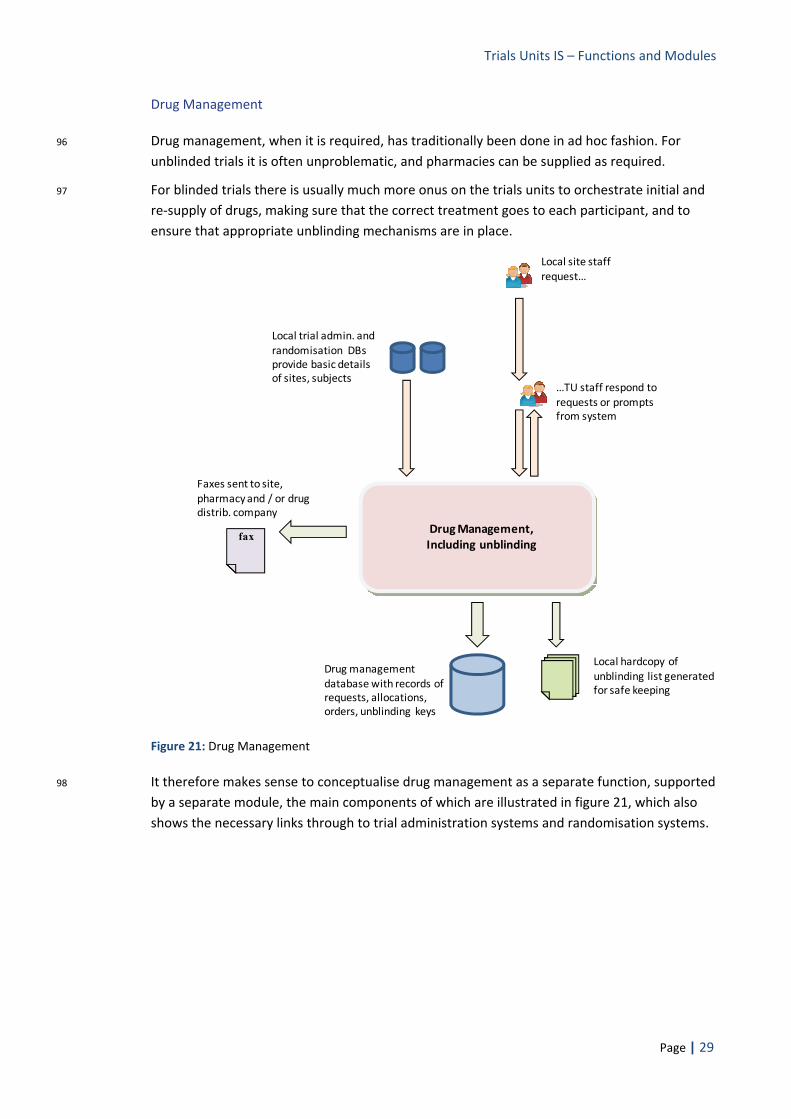
Problems of a Single System Approach
16 If the goals of greater data sharing, quicker trial set up and more rational system development are to be realised, the only alternative to a modular / standards based approach would be for all UK registered trial units to be forced to use the same system, or possibly one of two ‘approved’ systems. Given the time, resources and organisation that would be required to develop a suitable system within the public sector, the system(s) involved would, in the short term, almost certainly have to be purchased from commercial vendors.
17 This would be a simple and superficially attractive strategy, and the DIMS team considered it very seriously. In the particular context of UK academic clinical trials units, however, it was felt that such a strategy would bring with it more problems than it would solve. The following specific difficulties were identified with the ‘single system’ approach:
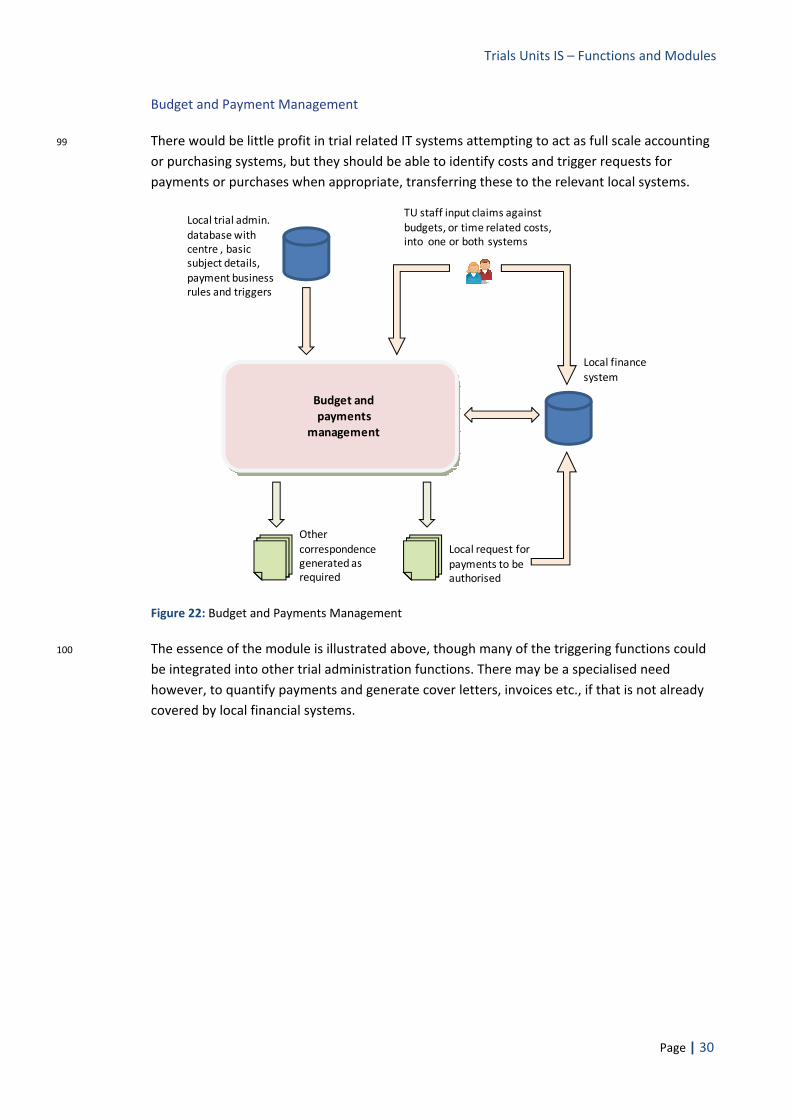
a) Restricted Scope: Any advantages would be restricted only to the management of the
clinical data, because that is the focus of existing commercial systems. Many of the outstanding IS issues and problems, however, are outside clinical data management (e.g. they are concerned with trial administration or description) and a single system approach would therefore offer little direct benefit in these areas.
b) Diverse requirements: The heterogeneity of existing systems (as confirmed by the responses from the DIMS consultation exercise) only confirms the fact that trials units often feel they have specific needs. It would be difficult to find a system flexible enough to meet all those needs, and probably impossible to persuade all trials units that it could be tailored for their specific requirements.
c) Staff training and support costs: The existing heterogeneity has also led to a great variation in experience and expertise amongst IT and other staff. Any rapid move to a new system would demand expensive training and support costs for large numbers of staff.
d) Constraints on purchasing decisions: Some units lack freedom of action with regard to purchase / use of systems (e.g. parent institutions may insist on one particular product or, conversely, refuse to countenance another).
e) Dependence on vendors: Commercial dependencies and vulnerabilities would be built into the system if only one or two commercial products were used. A small company could

Trials Units IS – Functions and Modules
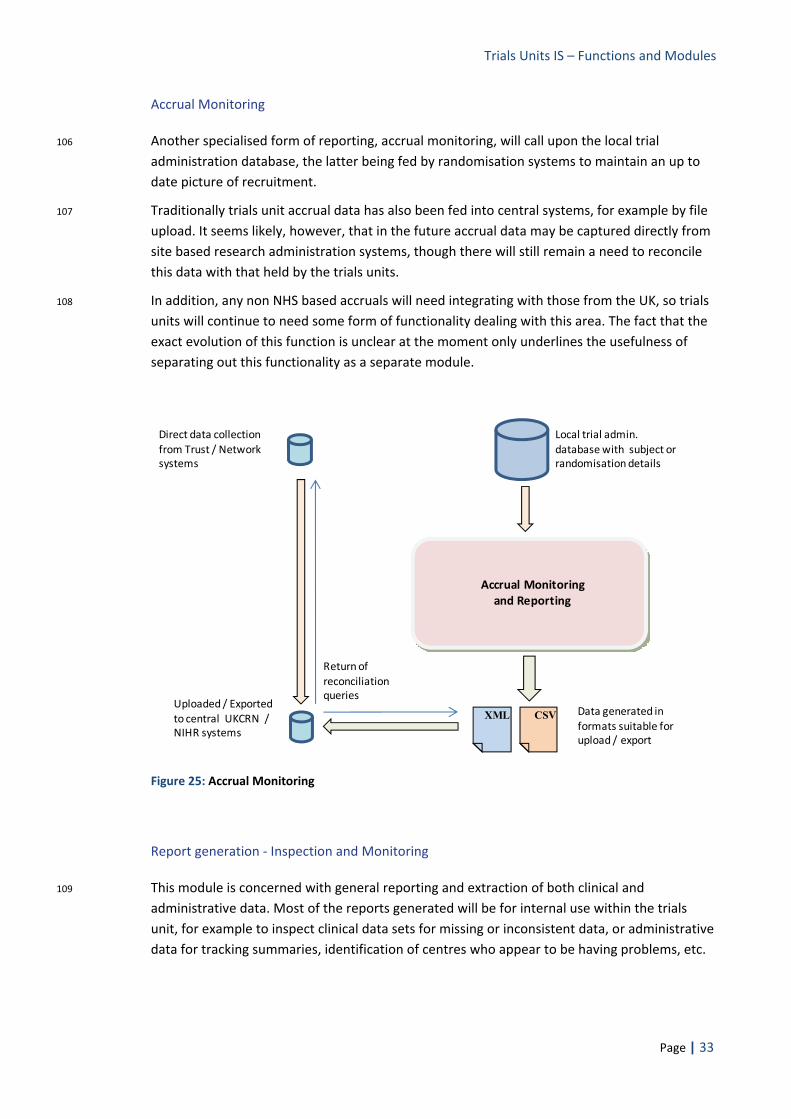
Page | 7
fold or be acquired by a larger; a large company could discontinue the product, or take it in a direction that was not well matched to our particular needs, e.g. under the pressure of US rather than European legislation.
f) Lack of consensus on which system: Very strong and divergent views currently exist about the relative merits of different systems. Though a great deal of debate has been generated around this approach in recent years, no general consensus has ever been reached as to how it should be implemented or which system(s) should be used.
g) Resentment and resistance: Given the large amount of time and money units have invested in their own systems, any coercion towards a particular system would be highly resented by many people and could generate considerable resistance, enough to drastically slow the uptake of the proposed system. For the same reason some experienced and valuable staff could leave the sector altogether.
h) The need to run multiple systems: Huge amounts of data in existing and legacy systems would still need managing for many years, if not decades, alongside any new imposed ‘solution’. Most units would therefore have to manage at least two different systems, potentially for decades. This is hardly likely to improve costs or the ability of systems to better support research – if anything they will, overall, become less effective.
i) Problems of this approach in other contexts: The ‘use one of a few prescribed systems’ approach has been tried elsewhere, for instance in the context of the NHS’s Connecting for Health programme. In general there has now been a retreat from such an approach, because of a range of practical and organisational difficulties, with the focus instead now on standards compliance and inter‐operability of modules, as it is in the DIMS proposals.
j) Problems of this approach in clinical trials: Previous, smaller scale efforts to travel down this route (e.g. the NCRN attempt to introduce MediData’s Rave system for nine accredited Cancer trials units, or the Periscope project to create a shared system for the Scottish units) have so far been unsuccessful. Given this, there appears to be no great appetite to go through another large scale procurement exercise.
k) It offers little specific support for better data sharing: Even if all trials used the same system to host their data, if that data is not organised and labelled in the same way little would be gained with regard to the more fundamental issues facing trials unit IS, particularly the need to better support research by making data easier to identify, share, and merge. There is a sense therefore in which debates about which software system to use ‘miss the point’.
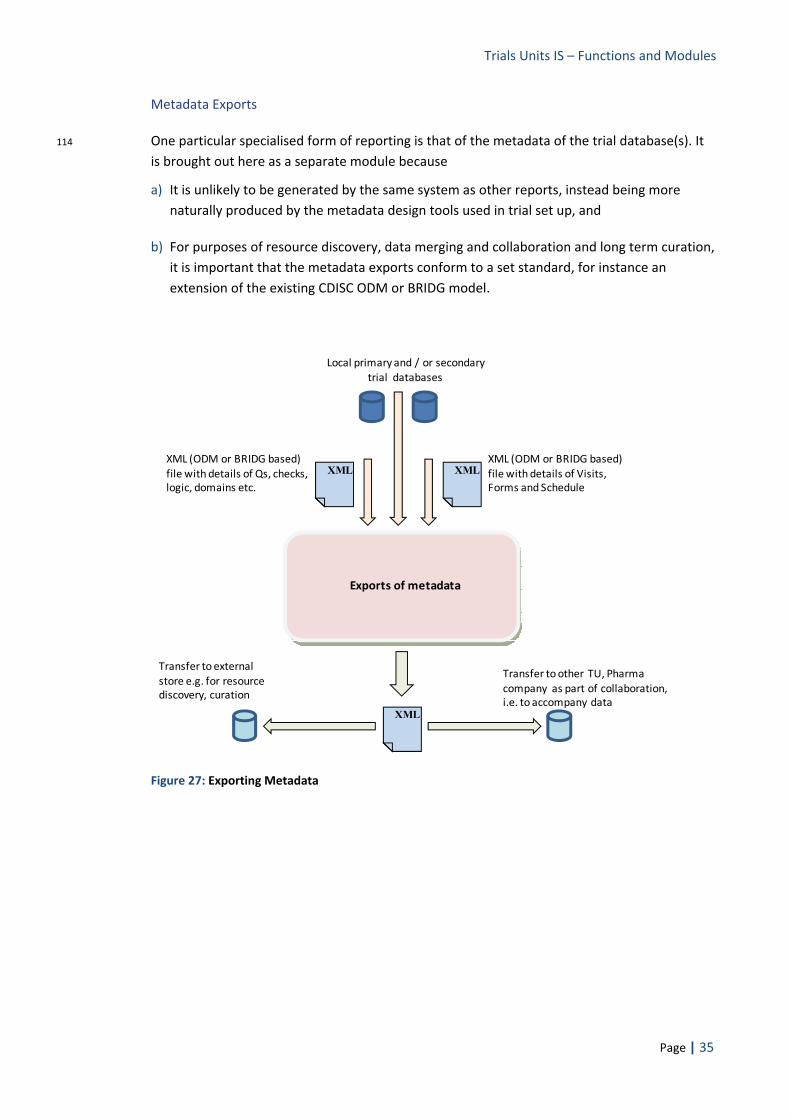
18 The single system proposition therefore seems unworkable, both practically and politically. Instead, thinking about CT IT systems in terms of the discrete functions they provide, evolving a pattern of implementation that provides that functionality on a module by module basis, requiring and reflecting a standards based approach to data and the interfaces between modules, retaining flexibility and local control but guided by developments in the wider IT and

Trials Units IS – Functions and Modules
Page | 8
clinical trials communities, including the gradual implementation of quality standards for system functionality, seems to be the only practical way to proceed.
19 Taking such a deliberately modular approach to trials unit IT is a relatively radical departure from current practice. The DIMS project, however, represents a rare opportunity to set out a national strategy for IT systems in trials units for the next decade or more, and in that context a fundamental re‐examination of our requirements, practices and systems is not out of place.
Linkage and Standards
20 Discrete components are only productive if they can communicate effectively with each other: successful modularity therefore depends upon effective linkage. The linkage can be of two types (illustrated schematically in Figure 2).
a) Loose Coupling , where systems are linked by the import and export of data, usually as XML packets, possibly as discrete files, either directly in response to electronic requests, e.g. via web services, or indirectly through the actions of people or other systems.
b) Data Coupling, where systems share access to the same databases, and interact indirectly via the changes they make in that data.
21 In neither case is one system interacting directly with another, for instance by calling procedures in an API. If that were the case the modules would essentially be component parts of the same system. Instead both loose and data coupling allow modules to remain independent, ignorant of the specific mechanisms and operations of the other – communication is merely via agnostic, standard protocols like WSDL and SOAP, or through access to the same data.
22 Loose coupling is particularly well suited to geographically distributed systems, allowing communication through firewalls (and thus between different organisations), for instance a trials unit system requesting and receiving a treatment group allocation from a remote randomisation server.
23 The processing of clinical trial data also lends itself to loose coupling. There is a well defined sequence of processing steps: request > capture > transfer > storage > reporting > analysis, more evident perhaps with manual systems than those involving eRDC, because the latter can obscure the chain by locking data into proprietary carriers – i.e. eCRFs and the databases to which they are tightly bound. With XML or file based exchange between the steps, however, suitably secured, encrypted and managed, the whole process opens up, allowing each stage to be developed, modified, extended, tested, or swapped independently.
24 Data Coupling, on the other hand, is more useful within a firewall (unless remote access is orchestrated via Citrix or VPN), and where a relatively static repository of data is used as a resource by various systems. Critically, it allows data to be entered and stored once, to be updated efficiently, by whichever module receives the relevant information first, and to be available as widely as required. Trial administration data is well suited to data coupling – using common pools of trial, contact and centre data, updated by different users in the contexts of different tasks, using different systems.

Trials Units IS – Functions and Modules
Page | 9
25 Within clinical trials there are opportunities to combine both approaches – with an integrated pool of local data repositories communicating with remote ‘master’ systems using periodic loose coupling. For instance a database of contact information could download updated data from a centrally maintained source, but also put forward people new to the system, entered locally, for validation and inclusion in the master store.
CENTRAL SYSTEMS AND DATA
CENTRE OR SITE
TRIALS UNIT
Trust based research databases
Linked Admin databases
Data Queries
Initial Data Capture
Data import
Data transforms
Analysis
Exports
Primary Clinical Database
Secondary Database(s)
Reports
Figure 2: Loose and Data Coupling in a trials unit ‐ A purely illustrative schematic. The flow of clinical
data is shown in green. Different modules and processes ( ) orchestrate this flow, and also connect to a linked trial administration data repository. Some of the admin. databases are loosely coupled to external databases, both central and trust based.
26 The same is true of data item repositories, which can be maintained centrally as a source of downloadable items for designing trials. For any particular study the items will almost certainly need to be supplemented locally, but those additions, if properly documented, can in turn be returned as candidates for the central system.
27 Both types of coupling depend on well managed data standards. With data coupling the standards are implicit – it is the same data structure – but the client systems must each ‘understand’ that structure and be able to work with it. With loose coupling, the modules must not only use the same technical (TCP/IP) and protocol (XML) standards to transfer data, they must each understand the schema which organises that data. That schema will itself be derived from the underlying data model of the domain.
28 Standard based systems are rather like telephone systems, interesting but pointless if there is only one user, progressively more useful as the population of adopters increases. Thus, the

Trials Units IS – Functions and Modules
Page | 10
more data standards are developed, published, and used, the greater the opportunities for modular development and the wider the choice for trials units. To achieve widespread adoption, however, central encouragement, funding and leadership (but not dictat) will also be required.
29 Without these linkage components – standards, shared data models and adequately resourced central support to co‐ordinate them – a modular approach will be limited. Trials units will inevitably be tempted to buy in a single product to cater for most of their clinical data needs, with all the vulnerability that can imply, and potentially huge costs in the long term, or they will attempt to develop their own systems, which may or may not withstand the tests of regulatory requirements and staff movement. Administration systems will tend to remain proprietary, piecemeal and bolted on to the clinical data systems.
30 With well developed standards, however, there is a real opportunity to develop a mixed economy of Clinical Trial IT systems, some commercially produced and some produced within the community itself. We do not need a fixed ‘road map’ or huge, binding purchase decisions to move forward; we can instead evolve systems and functions in a flexible way, retaining a greater degree of local control, and at a pace commensurate with the resources available.

Trials Units IS – Functions and Modules
Page | 11
Modules I ‐ Setup and Design Components
Trial Setup
31 This module is concerned with the initial entry into systems of the trial’s details – its names and numbers, target and type, sponsors and personnel etc. (but not the details of individual sites and their governance and staff details). It is a process that needs to be integrated with, perhaps ultimately driven by, the central application process supported by IRAS.
XML
Local Trial Admin Database(s) with trial details and identifiers
Trial ManagersRemote systems ‐ IRAS, EudraCT etc.
Trial Administration
Setup
Possible direct links
Figure 3: Setting up a Trial
32 As the diagram illustrates the process is seen as some combination of data entry into local and central systems, with links – mediated by XML – between the systems. The exact nature and timing of data entry into each system and the subsequent data flows will partly depend upon how the central systems evolve in the future. In fact this whole area is likely to be subject to considerable development – a good reason to maintain it as a separate module, both conceptually and technologically.
33 The main input to the process will be data from the trial protocol, as input and structured by the trial managers, increasingly as part of an on‐line application process. The main outputs are seen as a representation of that trial in both central systems (e.g. as an instance of the NIHR’s longitudinal research record, LRR) and in local administration systems, (e.g. as a set of database records). As the BRIDG model of trials develops, particularly with regard to structured protocols (for instance with coded inclusion and exclusion criteria) and registration data sets, then there may be profit in defining this trial information in terms of the BRIDG model, or a comprehensive XML schema derived from it, and then drawing information from that as required – for the LRR, registration, etc.

Trials Units IS – Functions and Modules
Page | 12
Schedule Specification
34 This process also starts with the protocol, and maps out the pattern of ‘visits’ (or ‘study events’, i.e. the data capture time points) and ‘forms’ (the data capture structures) for trial participants.
XML
Protocol
XML (ODM or BRIDG based) file with details of Visits, Forms and Schedule
Trial Managers, IT staff
Trial Schedule Specification
Figure 4: Establishing the Trial Schedule
35 For simple trials this may be a trivial exercise ‐ all subjects may experience the same data capture routine, as a series of visits dated from randomisation. For many trials, however, this process can be complex, for instance for cross over designs, or when different groups of visits are dated from different subject milestones (date of surgery, end of radiotherapy, key results obtained etc). In addition different visit schedules and forms may apply to for different subjects, e.g. depending on their treatment group, or, if the schedule is revised mid‐way, when they entered the trial.
36 Carefully mapping out the trial schedule(s) is vital as an initial step in designing the data capture instruments and database, and they will also be used to structure future workflow and identify which CRFs are late arriving. It is quite distinct from the more detailed work need on individual data items, has its own well defined output and data model, and is therefore best considered as a separate module.
37 The BRIDG model (or an XML schema derived from it) provides an existing data model for trial structure, and the obvious output from the module would therefore be a BRIDG based XML file. This may need extending to include ‐ for each visit ‐ not just a description of the information required but also the forms, form sections and / or repeating question groups needed to capture the data. The trial schedules therefore provide a broad brush picture of the data that will be sought, as well as the timetable of its collection.

Trials Units IS – Functions and Modules
Page | 13
Data Items Specification
38 Once the type of data that is required has been identified, and in broad terms its structure (as part of the schedule definition process described above) it can be combined with other information in the protocol to identify the individual data items that will be collected, and to generate a full metadata description of the trial‘s primary database.
39 This process is seen, ideally, as a collaboration between statistician, trial managers and IT staff, working with the protocol and schedule definition(s) to identify each data item, the validation logic that will need to be applied, the skips through the data collection, and any key derived variables that will be required. It also offers the statistician, at this early stage, the opportunity to identify the data items that they will need, and indicate how they would like them organised.
XML
Protocol
XML (ODM or BRIDG based) file with details of Qs, checks, logic, domains etc.
Library of ‘tagged’, fully defined questions
Statisticians, Trial Managers, IT staff
Remote repository of common questions
Data Items Specification
Figure 5: Generating Data Items
40 Critically, this process can also call on libraries of existing questions, either used and stored locally or belonging to a centrally managed store of defined data items, especially as the latter develops over time. This has three huge advantages:
a) It allows questions to be quickly selected, already defined, coded, and labelled, and used ‘off the shelf’, rather than being laboriously re‐invented each time. The most appropriate logic and range checks, often selected from a library as well, could be added as part of the process.
b) Those questions, especially if drawn from a centrally managed store rather than locally, can be pre‐linked to various coding schemes (e.g. SNOMED).
c) It leads to greater standardisation between trials and, when making use of a centrally managed store, between trials units.
41 The end result will be a detailed description of the trial data base’s structure and metadata , using an XML schema (most obviously one based on the CDISC ODM schema). Note that the production of this file is distinct from the generation of the database itself, and / or the CRFs

Trials Units IS – Functions and Modules
Page | 14
that are used to collect the data. The module is a self contained trial metadata definition process, making use of a local repository of data items, itself supplemented by download from a central store of such items, and / or a central store directly, e.g. by consuming a web service.
CRF / eCRF Production
42 This is an entirely different process from database specification, even though traditionally they have usually been linked within a single design phase, inside a particular product. The inputs are the two specifications previously developed for the trial schedule and data items, the outputs will normally be either a set of electronic CRFs, i.e. screens representing the data collection forms, or the forms themselves, typically in PDF format, or both.
XML
Paper CRFs
XML (ODM or BRIDG based) file with details of Qs, checks, logic, domains etc.
XML (ODM or BRIDG based) file with details of Visits, Forms and Schedule
XML
eCRFs
CRF / eCRF Generation
‐‐‐‐ Trial managers to polish results as necessary
Metadata refinement
Figure 6: Generating (e)CRFs
43 The combination will be required when some centres in a trial cannot or do not wish to use eRDC, or to support the common practice, even in centres happy to use eRDC, of collecting the data first on paper and then transferring it to a computer screen later.
44 The electronic / paper CRF may be the most common output of this process but it is not necessarily the only one. In quality of life studies the output may be a booklet, more or less modelled on a standard instrument. In the future the output may be screens in Lorenzo or a similar eHCR system, so that clinical staff can enter data during normal working practice.
45 The flexibility required in generating data collection instruments is one reason for separating out this process as a distinct module. Another is to allow the design process to be taken over by specialist staff who are familiar with the instruments available, the rules to be followed, the headers, footers and logos to be added etc.
46 A third is the need to sometimes add derived, echoing and check data fields to the specification, to help ensure users are on the correct subject when they enter data. These can

Trials Units IS – Functions and Modules
Page | 15
include, for instance, a field that echoes back the subject’s initials and site, or a special trial ID field that really only functions as a check against that put in on the initial page. In this way this module can provide a final refinement of the trial’s detailed structure and metadata, and a revision of the relevant specification file.
47 As the diagram illustrates this module is unlikely ever to be completely automatic. The outputs will often need manual improvement and rearrangement of the design (but not the structure) of the data collection instruments.
Database Generation
48 Once the schedule and the data items have been defined, and any additional fields constructed to support CRF design, the trial primary database can be constructed. This module is therefore about translating the specifications into the necessary data tables.
XML
XML (ODM or BRIDG based) file with details of Qs, checks, logic, domains etc.
XML (ODM or BRIDG based) file with details of Visits, Forms and Schedule
XML
Primary database for holding raw data, including audit trail
Database Generation
Possible secondary database for holding (?transformed) data for reporting etc.
Figure 7: Generating the Database(s)
49 It is a distinct module to allow the specification and construction phases to be clearly separated so that, for instance, the database supplier can be changed without affecting the design module, or vice versa, and so that reliance on a particular product or supplier is reduced.
50 The main output of this process is the primary clinical database, i.e. the one that first receives the clinical data from the CRFs, and which normally contains all the audit data required for GCP.
51 There may also be a secondary database produced as part of this process ‐ one where data will be transformed into a more normalised form, perhaps reflecting the original form / CRF structure, perhaps reflecting the data split into CDISC domain tables. Data in this form is
Trials Units IS – Functions and Modules
Page | 16
usually much easier to interrogate for reporting purposes, or for the production of analysis datasets, though the transformation scripts themselves will clearly need careful validation.
Centre Setup
52 Though centre or site setup is a process that occurs before a trial starts, it is also likely to continue throughout the trial’s active recruitment phase as more centres come on board. It involves encouraging, identifying, and managing interest, establishing agreements and contracts, identifying key staff and their roles, tracking research governance milestones and finally giving the green light for recruitment.
XML
Local Trial Admin Database(s) with centre details, status info., contract data, etc.
Trial Managers, TU Admin Support
Remote systems ‐ e.g. IRAS, the NACS service
Centre Setup
Possible direct links via web services
Possible direct links
Remote systems ‐ Trust based, Network based etc.
? Intermediate repository
Figure 8: Setting up Centre / Site data
53 Traditionally done using local data stores, sometimes spreadsheets on a trial by trial basis, this process has the potential to be integrated with national systems (e.g. IRAS) and central sign off processes , and further integrated with trust level systems (e.g. Edge) providing the data directly. In the future an integrated network, involving both file (XML) based communication and web service calls, could be established that allowed single data entry and sign off, and all three main parties ‐ the research sites, the trials units and the central agencies ‐ to share the same information.
54 For that reason it makes sense to keep this activity as a distinct module, though the data stores being used will often be common to other processes involved in trial administration. The output, at least at the trials unit level, will be a local data store populated by the relevant details of the sites, their staff and their status.

Trials Units IS – Functions and Modules
Page | 17
Actor Setup
55 Establishing the main personnel involved in a trial and their associated data (roles, titles, addresses, links, in some cases CVs and training, etc.) is a key component of the site set up function described above, though there will be people ‐ DMEC members, associated pathologists and laboratory scientists, some members of a Trial Management Group, etc. who will not be part of any site.
XML
Local Trial Admin Database(s) with participant details, contact info, etc.
Trial Managers, TU Admin Support
Remote systems ‐ IRAS, NIHR identity m’ment etc.
Actor Setup
Possible direct links via web services
Possible direct links
Remote systems ‐ Trust based, Network based etc.
Local Contacts Database
Remote central managed repository of Contact details
? Intermediate repository
Figure 9: Setting up trial actors
56 Like site management, contact management would also benefit hugely from linking through to central, managed repositories of contact data, enabling a single identity to be established and used throughout the system. In this case the most useful central database is likely to be that behind the NIHR’s identity management programme, which will provide the single sign on for users of the NIHR’s various services.
57 Local stores of contact data could download identifiers and people from the identity management system. If someone did not exist on that central system they would need to be added locally, but then proffered as a potential candidate for inclusion in the central database. After the necessary checks, e.g. to avoid duplication of people within the system, they would augment an increasingly comprehensive database of relevant contacts. Again, direct or indirect links with trust based systems could also be usefully incorporated into an integrated system, enabling people related data to be updated once ’at source’ and for the changes to be propagated through the system.

Trials Units IS – Functions and Modules
Page | 18
58 Because of this potential for development and integration it makes sense for this function to be conceptualised as a separate module. The underlying data may be integrated, at both local and national levels, with other aspects of trial administration, but the linking functionality, the various user interfaces, etc. is better developed and maintained as a separate entity.
Randomisation Setup
59 The exact nature of this process will depend upon the randomisation method to be used (e.g. blocks versus minimisation), whether or not the trial is blinded, and the trial design (e.g. number of randomisations). There may even need to be separate modules to support the different types of randomisation planned.
Possible export to remote randomisation system
XML
Local trial admin. database with centre details
RandomisationSetup
Local randomisation database with lists generated, minimisation mechanisms in place
Statisticians, Trial Managers with randomisation requirements, e.g. stratifications, minimisation, trial ID format etc.
Figure 10: Setting up randomisations
60 In general there will be a need to identify the treatment groups, either explicitly or by labels for blinded trials, the stratifications to be used, the numbers of list sets needed (e.g. per site or groups of sites) and the type of randomisation required. For block based randomisation the block size(s) need to be identified; for minimisation the degree of permitted randomness has to be specified. For unblinded trials the way in which the trial ID is constructed, e.g. to reflect stratification, may need to be considered; for blinded trials there may have to be a link between box numbers and a randomisation list.
61 All these factors and more need to be fed into a separate module so that lists (etc.) can be constructed. For minimisation it probably makes sense for the module to be closely linked to the randomisation system itself, but if the outputs are randomisation lists, whether on paper or electronically, then the randomisation setup can be separate from its application (in particular one or both could be performed remotely). For that reason it is best considered a separate module.

Trials Units IS – Functions and Modules
Page | 19
Modules II ‐ Clinical Data Management Components
Randomisation
62 Though randomisation is the initial step in the data capture process, and may well share many of the components of the generic process it is distinct enough to be considered as a separate module, not least because it involves initial processing and subject assignment before any data is captured for the primary database.
Faxes returned to site, pharmacy with confirmation
fax
Randomisation database with lists and / or minimisation parameters
Randomisation(includes registration)
Basic details into trial admin. database for immediate record of randomisation
Site staff using web interface, or TU staff with local system, input relevant details
Basic details into clinical data database to create new patient
Details of randomisation instance stored in randomisation DB itself
?? Immediate reporting to central accrual database
?? Immediate feedback of details to Trust R&D systems
Figure 11: The randomisation process(es)
63 Some of the data may also be transferred to trial administration systems, to establish the new subject within the system and set up future workflow for them. In general, as illustrated in Figure 11, the details of the randomisation process itself will also be stored in the relevant specialist database.
64 Randomisation could be done remotely, or at the site via a web link or even centrally (the latter suggesting one easy way to monitor accrual in different trials). The method could be web based, automatic using telephony, or manually over the telephone. These variations, the various ways the data could be used, and the potential for considerable system and technological development in this area, all underlie the need for randomisation to be considered as a distinct function and where possible constructed as a separate module.
Data Capture at Centre
65 For paper based systems this is straightforward ‐ the CRFs are completed and then sent via a postal / courier service back to the trials unit. For eRDC based systems this module involves the entry of the data on to an electronic screen and then, once validation checks have fired and been dealt with, the capture of the data, with associated audit information, into a particular format (e.g. a snippet of XML).

Trials Units IS – Functions and Modules
Page | 20
Data Capture at Centre
eCRFs submitted to server with data and audit metadata, e.g. readable as XML
Local research staff complete paper CRFs
Local research staff return CRFs in post
eCRFs presented as requested or required by workflow
‐‐‐‐
CRFs sent as booklet or downloaded
Local research staff
? In the future, direct use of eHCR, other Trust systems
? In the future, direct use of SUS, NCIN etc. via the RCP
Single Sign‐on
Figure 12: Initial Data Capture
66 The data collection instrument therefore acts as an information carrier, and can be submitted as a web page submission (or returned in some other way) immediately or at a later time point, to the next stage of the process.
67 There is an important related module in this context, not explicitly identified in the Figure 1 ‘map’: initial user log‐in. Experience with eRDC so far indicates that one of the most common problems is the difficulty staff have with different log‐in systems, and remembering passwords for all the different systems they have to deal with, some of them only infrequently.
68 Extracting out the log‐in to a separate module, that meant staff had to only log‐in into one system, would make the process much simpler and therefore cheaper to support. The log‐in system would then have to offer the user the choice of moving to the particular trial they were working on, and thence whatever data capture system that trial was using. One way of implementing such a system might be to combine it with the NIHR log‐in for the relevant users.

Trials Units IS – Functions and Modules
Page | 21
Data Input to DB
69 Again for paper based systems this is straightforward ‐ the CRFs are received and entered onto the clinical database system, audit information being added at the point of data entry. For eRDC based systems the data package on the eCRF is extracted and processed so that it is stored appropriately.
Data potentially drawn from other systems in the sites, e.g. eHCRs, or centrally
Data Entry into the Database
Local primary clinical data database
Data managers enter data manually from paper CRFs
eCRFs submitted to server, carrying XML data packets
XML
‐‐‐‐
Excel
Data potentially drawn from lab and other spreadsheets
Figure 13: Data Transfer, to the Primary Clinical Database
70 It would be a mistake to assume a direct connection between data capture and data input and storage, even though web based commercial systems tend to do this, binding database fields to source controls on screen.
71 Making the link indirect, via XML, allows the data to be captured more easily from a variety of different systems ‐ e.g. from eCRFs completed manually, by extracting data from a pathology system automatically, by importing a spreadsheet from a laboratory (or for instance a radiotherapy machine) in a semi‐automatic process, or ‐ in the future perhaps ‐ from the hospital episode data in the clinical system. In short modularity is essential here to give the flexibility and functionality required.
72 It also means that the XML schema that should be used, which would also act as a common ‘batch data entry’ specification, ought to be based on the HL7 Clinical Document Architecture (CDA), or a simplified version of it, as this is the basis of most electronic Health Care records

Trials Units IS – Functions and Modules
Page | 22
Discrepancy management
73 Apparently missing and extreme, inconsistent or unexpected values require queries to be raised with the sites and the data cleaned or commented as appropriate. In many modern systems this functionality is embedded in the clinical trials database, so that when validation logic fires warnings or rejections a query can be automatically generated.
Local Contacts Database
Discrepancy Management
Local primary clinical data database, with corrected data
Primary clinical data database, with raised discrepanciesResults of analysis of
inspection datasets
Queries raised and / or filtered manually by Data Managers
Local research staff respond to queries
Electronic and / or paper queries
Figure 14: Discrepancy Management
74 Though that works in many instances, there are various reasons why considering and constructing discrepancy management as a distinct module, as illustrated in figure 14, is more flexible and productive. These include…
a) Clinical database systems can come and go, and a trials unit may have several in use at any one time. Keeping query management in a single independent system is easier than trying to manage a similar system for each clinical DBMS, especially when those products can change with successive versions.
b) Access to the underlying data is not always possible, e.g. when managing data for another trials unit, who may not give remote access for discrepancy management .
c) Query management under the unit’s own control allows a more flexible and rapid response to user requests for system modification, including (for instance) combining queries with correspondence generation (using a linked contacts database) so that a complete query ‘package’ can be generated for each site when required.

Trials Units IS – Functions and Modules
Page | 23
d) Users appreciate the opportunity to manually manage the process, deciding themselves for instance which warnings should be sent and which can be safely ignored, and which might need greater explanation of the underlying issue.
e) Resending, sending reference queries (i.e. those sent for information and which do not seek a response) and withdrawing queries are easier with an independent system.
f) Some types of queries, e.g. those regarding forms that are missing entirely, are difficult to generate in a system embedded in the clinical DBMS.
g) As the diagram illustrates, queries can also be raised by statisticians and trial co‐ordinators after examining bulk data sets, as well as on data entry.
Data Coding
Local and / or central policies on coding practice
Local and / or remote coding databases
Local secondary databases for clinical data, containing codes, Or specialist coding databases
Trial Managers and coding specialists
Data Coding
Figure 15: Data Coding
75 Coding may involve several modules (because more than one type of coding may be required) and refers to any system that supports the translation of returned values ‐ especially those in ‘free text’ – to a standardised coding system. MedDRA for adverse events and WHO DRUG for medicines are, currently, probably the most common coding systems used.
76 The coding databases may be local or central (or some combination of both). An important input are the policies (again these may be local or central) which determine exactly how any coding scheme is applied.

Trials Units IS – Functions and Modules
Page | 24
77 The results of coding are envisaged as being stored in trial secondary databases, rather than back in the primary clinical database, and / or specialised databases that hold a record of all the coding done (against a particular system).
Modules III ‐ Trial Management Components
Tracking Data Receipt
78 Knowing what CRFs have arrived (for paper based systems) or have been completed / submitted (for eCRFs), and then providing the necessary ‘chasing’ messages and reports, is a standard task within trial administration.
79 Like discrepancy management, and for several of the same reasons, it is much more flexible to have this functionality factored out as a separate module rather than embedded in a particular system. The main components of such a module are illustrated below.
For eCRFs receipt data is an automatic by‐product of data collection process
Tracking Data Receipt
Local Trial Administration Database with records of missing CRFs, journey times etc.
For paper CRFs, receipt recorded manually
Pre‐coded CRFs could be scanned in some circumstances
XML
Schedule metadata required to give expected data return dates
Local research staff respond to requests
Electronic and / or paper messaging
Figure 16: Tracking Data Receipt
Contacts Management
80 During a trial contacts management is an extension of the ‘contacts setup’ discussed earlier, with a local data store linked to a central managed database.
81 The local store can be used by several different applications, ranging from a desk top widget that provides simple Cardex type information, through integration with correspondence and report generation systems, to local person and organisation management screens, where details can be inserted and edited.

Trials Units IS – Functions and Modules
Page | 25
82 The centrally managed facility is key in providing and maintaining unique identifiers for people (and places) in the system, and would almost certainly have to be integrated with the identity management systems of the NIHR. To be useful in a trials context, however, it would also have to include details of many overseas personnel and organisations.
Remote central managed contacts system
Contacts Management
Local Contacts database, with name, role and links information for people, places and organisations
TU IT staff manage periodic submission of new names / receipt of amended data / download of bulk datasets etc.
Local trial management staff browse and amend local contacts DB
Figure 17: Contact Management
83 If the central store can also be linked to trust based research administration systems (such as Edge), then it should also be possible to have contact data updated by those dealing most directly with it, in many cases by the individuals themselves. The greater the number of users therefore, the greater the potential usefulness of the system.
84 The system described here is predicated on the legal (e.g. DPA) aspects of this data sharing being clarified to the satisfaction of all concerned. In some cases restrictions may have to be placed on the distribution of the data.
Pharmacovigilance
85 A full pharmacovigilance (PV) module would ideally contain both local and web based central components, the latter being particularly useful for the rapid evaluation of SAEs by the relevant clinicians.
86 The scheme illustrated, which is only one of the many possible, has a local PV system that receives SAE data from sites, either via a specialised eRDC system, a web based interface, or via fax. The data required in any trial will consist of a core set of PV data, plus that specific to the trial, for instance previous treatment details. (It is envisaged that the specific requirements will be defined beforehand, e.g. as XML).

Trials Units IS – Functions and Modules
Page | 26
87 Once received details are separated a copy, including trial specific data, is pushed to the primary clinical database, where it can be reported on, and reconciled with, other AE data as part of the clinical dataset.
Local primary data database for core and trial specific data
Pharmacovigilance
Local pharmacovigilance databaseFor core and tracking data
Trial Managers input details of SAEs…
? in the future, centre research staff input details of SAEs locally
having determined the extra trial specific data required
Export of core data to central store
Coding and EudraVigilance reporting
For core data: standardised data structure for storage, reporting, tracking
XML
Figure 18: Pharmacovigilance
88 The core PV dataset is transferred to a web based central system, available (possibly) through the NIHR portal, and alerts are generated and set to the clinician(s) responsible for evaluation. Once that evaluation has been given, the system requests and records the relevant information flows.
89 Having a central system for the core SAE data allows PV reports to be available both to the local sites and the centre much more easily, could support both centralised and site based coding, and could streamline the reporting of PV data to both national and international agencies such as EUDRAVigilance.

Trials Units IS – Functions and Modules
Page | 27
Research Governance Monitoring
90 Just as centres need to be set up before and during the trial, so ongoing changes in site status and roles needs to be monitored and reported upon. This may include, for instance, ensuring relevant documentation and systems have been updated after a change in the site’s Principal Investigator, and that the delegation logs – the list of who carries out what function on each site, are maintained accurately.
Local trial admin. database with centre details, SSA, CTA data, delegation log data etc.
Managing Research Governance
TU staff input data in receipt from sites
? Intermediate repository
XML
Remote systems ‐IRAS, etc.
Possible direct links via web services
Possible direct links
Remote systems ‐ Trust based, Network based etc.
responses
messaging
Figure 19: Research Governance
91 The components involved in such a module, which are similar to those involved in site setup, are illustrated in the diagram above. The more site based research administration systems can be integrated with those of trials units, either directly or indirectly via a central hub, then the more such data can be managed by single point data entry followed by a ‘ripple‐through’ to the rest of the system. Similarly, because a subset of this data is required to be held centrally, it would make sense to loosely couple local modules with central systems.
Trials Units IS – Functions and Modules
Page | 28
Quality of Life Management
92 The various administrative tasks involved in Quality of Life studies (and others where direct input from the trial participant is sought) are factored out as a separate module because:
a) only some trials units are engaged in this type of research, and
b) it includes some particular features, largely derived from the need to contact participants directly, that are quite different from ‘normal’ trial administration.
93 For example subject names and addresses, and usually those of their GPs too, will need to be stored – encrypted – in a database, and some form of checking mechanism will normally need to be implemented, to ensure that a participant is well enough to receive the next questionnaire in the sequence, for instance by contacting the GP.
Local trial QL admin. database with subject names and addresses (encrypted)
Quality of Life studies management
Local trial admin. DB with details of subjects, booklet receipt information etc.
XML
Schedule metadata required to give expected data return dates
Faxes sent to GP and / or site to check if request to subject appropriate
fax Questionnaires sent to and returned from subjects
Figure 20: Quality of Life Management
94 There may need to be GP alerts if a questionnaire score indicates that a patient is suffering particularly severe symptoms. There is also a variety of correspondence that needs to be generated, for example as cover notes to the study participants.
95 Given these relatively specific needs it makes sense to set up the management of QoL and related studies as a separate module, though it would clearly have to share data with other components of the trial administration system, as illustrated in the diagram.
Trials Units IS – Functions and Modules
Page | 29
Drug Management
96 Drug management, when it is required, has traditionally been done in ad hoc fashion. For unblinded trials it is often unproblematic, and pharmacies can be supplied as required.
97 For blinded trials there is usually much more onus on the trials units to orchestrate initial and re‐supply of drugs, making sure that the correct treatment goes to each participant, and to ensure that appropriate unblinding mechanisms are in place.
Local trial admin. and randomisation DBs provide basic detailsof sites, subjects
Drug Management, Including unblinding
Drug management database with records of requests, allocations, orders, unblinding keys
Local site staff request…
…TU staff respond to requests or prompts from system
Local hardcopy of unblinding list generated for safe keeping
Faxes sent to site, pharmacy and / or drug distrib. company
fax
Figure 21: Drug Management
98 It therefore makes sense to conceptualise drug management as a separate function, supported by a separate module, the main components of which are illustrated in figure 21, which also shows the necessary links through to trial administration systems and randomisation systems.
Trials Units IS – Functions and Modules
Page | 30
Budget and Payment Management
99 There would be little profit in trial related IT systems attempting to act as full scale accounting or purchasing systems, but they should be able to identify costs and trigger requests for payments or purchases when appropriate, transferring these to the relevant local systems.
Local trial admin. database with centre , basic subject details, payment business rules and triggers
Budget and payments
management
Local finance system
TU staff input claims against budgets, or time related costs, into one or both systems
Local request for payments to be authorised
Other correspondence generated as required
Figure 22: Budget and Payments Management
100 The essence of the module is illustrated above, though many of the triggering functions could be integrated into other trial administration functions. There may be a specialised need however, to quantify payments and generate cover letters, invoices etc., if that is not already covered by local financial systems.

Trials Units IS – Functions and Modules
Page | 31
Sample Tracking
101 The need to anticipate, request, manage and track blood and tissue samples is an increasing requirement in many trials units, as the number of translational studies and sub studies increases.
102 A separate module is required, one linked to general trial administration (so that relevant subjects and the details of their consents can be identified), but which focuses on the samples, the associated biological tests, and the results of those tests.
Local site / path. Lab staff
Local trial admin. database with subject, consent details
Sample Tracking (and results collection)
Local samples database with sample acquisition, tracking, consent data + laboratory results
Laboratory staff, with direct web or other remote access
Receive & respond to requests
Inform of receipt, generation
Insert / upload resultsTU staff for
local data entry
Collection of Linked Modules
Figure 23: Sample Management
103 To call such a system a ‘module’ would normally be a considerable understatement – often a full system will be required, with its own security management, web based data entry of sample generation and combination, test details, test results etc. Several distinct modules are therefore likely to be needed, all linked to a central samples database, as illustrated above.

Trials Units IS – Functions and Modules
Page | 32
Modules IV ‐ Data Extraction and Analysis Components
Correspondence Generation
104 This is a ‘module’ in the sense that within various other systems there is a need to generate letters, faxes, cover notes, requests etc., which share many features such as recipient’s address, sender’s name, designation and contact details and, very often, letterheads and other graphics. It makes sense therefore to factor out this function as a separate module.
Correspondence Generation
‘Reports’ embedded in relevant applications
XML
Correspondence definitions
Access control, scheduling policies, etc.
running
containing
Report Server
Local contacts database
Requests from applications (e.g. query m’ment, QL m’ment, RG m’ment)
Figure 24: Correspondence Generation
105 Correspondence generation will be linked to the local contacts database, and also to more general report generation systems. As with other reports, it is envisaged that correspondence will sometimes be generated directly from a report server or other stand alone system, and sometimes will be requested from other applications, as an embedded component, often linked (e.g. acting as a cover sheet) to more traditional reports.
Trials Units IS – Functions and Modules
Page | 33
Accrual Monitoring
106 Another specialised form of reporting, accrual monitoring, will call upon the local trial administration database, the latter being fed by randomisation systems to maintain an up to date picture of recruitment.
107 Traditionally trials unit accrual data has also been fed into central systems, for example by file upload. It seems likely, however, that in the future accrual data may be captured directly from site based research administration systems, though there will still remain a need to reconcile this data with that held by the trials units.
108 In addition, any non NHS based accruals will need integrating with those from the UK, so trials units will continue to need some form of functionality dealing with this area. The fact that the exact evolution of this function is unclear at the moment only underlines the usefulness of separating out this functionality as a separate module.
Uploaded / Exported to central UKCRN / NIHR systems
XML
Local trial admin. database with subject or randomisation details
Accrual Monitoring and Reporting
Data generated in formats suitable for upload / export
CSV
Direct data collection from Trust / Network systems
Return of reconciliation queries
Figure 25: Accrual Monitoring
Report generation ‐ Inspection and Monitoring
109 This module is concerned with general reporting and extraction of both clinical and administrative data. Most of the reports generated will be for internal use within the trials unit, for example to inspect clinical data sets for missing or inconsistent data, or administrative data for tracking summaries, identification of centres who appear to be having problems, etc.

Trials Units IS – Functions and Modules
Page | 34
110 Many of the reports will be linked to, and their generation embedded within, some of the other modules described in this document. Some reports are likely to be available ‘standalone’ from a report server, or published on a fixed schedule by that server to designated recipients.
Report generation for inspection / monitoring
metadata
XML
Secondary files or database for holding (transformed) data etc.
XML
Primary database for clinical data
This intermediate stage may not be necessary for smaller datasets.
XML
Report definitions
Access control, scheduling policies, etc.
running
containing
Report Server
Reports embedded in applications
Reports available independently from web site, SharePoint site
Figure 26: generating datasets and reports for inspection and monitoring
111 It is envisaged that report definitions would be stored as standalone documents in a standardised format, e.g. an XML schema, as used by SQL Server Reporting Services (SSRS) or Crystal. The integration of SSRS with Share Point would appear to make it a particularly useful tool for report design and management.
112 For large trials the primary database can be very large and the records very difficult to query efficiently and re‐arrange for a report. In such circumstances the use of a secondary database, with data in a more traditional table or domain based form, may be a useful component in the system.
113 In either case transferring data to XML first, rather than using a more proprietary data base format, and merging that with the XML definition of a report, i.e. using a XSLT transform, offers a way of increasing the portability of report generation.
Trials Units IS – Functions and Modules
Page | 35
Metadata Exports
114 One particular specialised form of reporting is that of the metadata of the trial database(s). It is brought out here as a separate module because
a) It is unlikely to be generated by the same system as other reports, instead being more naturally produced by the metadata design tools used in trial set up, and
b) For purposes of resource discovery, data merging and collaboration and long term curation, it is important that the metadata exports conform to a set standard, for instance an extension of the existing CDISC ODM or BRIDG model.
Transfer to external store e.g. for resource discovery, curation
Local primary and / or secondary trial databases
Exports of metadata
Transfer to other TU, Pharma company as part of collaboration, i.e. to accompany data
XML
XMLXML (ODM or BRIDG based) file with details of Qs, checks, logic, domains etc.
XML (ODM or BRIDG based) file with details of Visits, Forms and Schedule
XML
Figure 27: Exporting Metadata

Trials Units IS – Functions and Modules
Page | 36
Transformed Data Exports
115 Exporting clinical data, for instance, in metadata analysis or data exchange with collaborators, normally requires that data to be in a pre‐specified format. Ideally that format will be based on a standardised scheme, for instance the CDISC SDTM structure, or HL7 / BRIDG based classes. It will also have to include or be associated with an adequate metadata definition.
Export of transformed data
Specific requests from recipients about table structure
metadata
XML
Secondary files or database for holding (transformed) data etc.
XML
Primary database for clinical data
This intermediate stage may not be necessary for smaller datasets.
Library of relevant transforms
XML
Data in standardised format (e.g. ODM or Bridg based)
Figure 28: Exporting Transformed Data
116 It therefore behoves trials units to possess systems to generate the data sets in the required formats. Again the use of XML files to characterize the format details, coupled with transforms working on XML source data, provides a way of liberating these processes from proprietary systems and procedures.

Trials Units IS – Functions and Modules
Page | 37
Analysis Datasets
117 Analysis datasets are those supplied to statisticians. They may exclude some variables as being irrelevant to the analysis, include others derived as useful supplementary data, and may be organised in a very different way from the primary data. In particular, perhaps as a function of statistical tools and training, analysis data sets often use a one record / subject structure, and include very wide tables spanning multiple time points, as opposed to the more vertical structures of normalised data and the primary database.
Specific requests from statisticians about table structure
XML
Database created via XSL transforms and / or directly via scripts
Production of analysis datasets
Read only snapshot database for export for analysis
metadata
XML
Secondary files or database for holding (transformed) data etc.
XML
Primary database for clinical data
This intermediate stage may not be necessary for smaller datasets.
Library of relevant transforms and scripts
Possible aggregation with laboratory derived data
Figure 29: Production of Analysis datasets
118 A distinct set of functions, best grouped as a separate module, are therefore required by trials units. Though few standards currently exist for analysis datasets, despite the work of CDISC on the proposed ‘ADAM’ standards, specialist scripts and transforms will be required to meet this need. Such scripts and structures could also power data viewing and extraction tools, made available to statisticians and others so that they can pull in their own data as required (rather than relying on snapshots being prepared for them), as long as proper record keeping of such data use was maintained.

Trials Units IS – Functions and Modules
Page | 38
Long‐term Curation
119 The final module required is that needed for long term curation of clinical data. For security, this will have to make use of non proprietary, self describing and simple data formats, which effectively means an XML schema.
Data transformed to standard curation format (e.g. ODM based)
XML
Long term data curation
All files transferred to a remote curation store
XMLXML
Associated metadata
XMLXMLAssociated metadata
XML
Primary database for clinical data
This intermediate stage may not be necessary for smaller datasets.
Figure 30: Long term curation of Data
120 As the diagram above illustrates, curation will require systems that can transform trial documents, metadata (and also, eventually, structured protocols) and the data itself into standardised, and well documented, XML schemas.

Trials Units IS – Functions and Modules
Page | 39
Document History
Version Date Issued
Brief Summary of Change Owner’s Name/Signature
0.1 00/02/2009 Initial version, distributed for comments
Steve Canham
0.2 10/02/2009 Comments added. Will Crocombe
0.3 24/02/2009 Will’s comments incorporated. Reformatted to conform to that of other white papers
Steve Canham
0.4 14/03/2009 Changed the title; rewrote the reasons for modularity section; minor corrections and revisions elsewhere
Steve Canham
0.5 01/04/2009 Repasted PowerPoint graphics as enhanced metafiles for greater clarity; minor corrections and revisions
Steve Canham
0.6 23/05/2009 Expanded reasons for not using single system approach into separate section; other minor changes accordingly. Structured protocols mentioned as a possible future development
Steve Canham, following DIMS board meeting, UKCRC CTU OG
This is an NIHR controlled document. On receipt of a new version, please destroy all previous versions.













![Embedded Systems[All Units]](https://img.pdfslide.us/doc/110x75/577cc3b31a28aba71196ea25/embedded-systemsall-units.jpg)














