Embed Size (px)
Citation preview

IBM
Transcription with Content Platform Engine
Configuring Transcription and Building Transcription Handlers
1

Table of ContentsIntroduction......................................................................................................................................4Overview..........................................................................................................................................5
Main Components.......................................................................................................................5Overall Flow................................................................................................................................6
Configuring and Administering Transcription.................................................................................8Installing the Rich Media Transcription Extensions Add-on......................................................8Installing a Transcription Handler...............................................................................................9Creating a Document Class for Rich Media...............................................................................9Establishing Document Classes to Transcribe..........................................................................10Validating Transcription............................................................................................................10Establishing Text Indexing Preprocessor for Transcript Annotations.......................................11Validating Text Indexing of Videos with Transcription............................................................11Additional Configuration..........................................................................................................12
Temporary File Location for Transcription Handlers...........................................................12Configuring a Transcription Handler...................................................................................12Configuration to Transcribe Existing Documents................................................................13Configuring the Transcription Queue Sweep.......................................................................13
Developing a Transcription Handler..............................................................................................15Preparing for Implementation...................................................................................................15
Synchronous vs Asynchronous.............................................................................................15Files versus Streams.............................................................................................................15Additional Servers................................................................................................................15
Implementing the Transcription Handler..................................................................................16ContentConversionHandler Interface...................................................................................16ContentConversionResult Interface......................................................................................16CmContentConversionAction..............................................................................................17CmContentConversionSettings............................................................................................18HandlerCallContext..............................................................................................................19Requirements on the Transcription Handler.........................................................................19
Creating an Installer for the Transcription Handler..................................................................20Creating a Code Module.......................................................................................................20Creating a Subclass of CmContentConversionAction.........................................................21Creating an Instance of the CmContentConversionAction Subclass...................................24Example Install Program......................................................................................................24
Monitoring and Troubleshooting...................................................................................................25Monitoring with the Administration Console...........................................................................25
Transcription Processing......................................................................................................25Indexing................................................................................................................................25
Monitoring with System Dashboard.........................................................................................25Transcription Sweep.............................................................................................................25Content Conversion..............................................................................................................26Index Preprocessing.............................................................................................................27
Possible Issues...........................................................................................................................29Imported videos do not get queued to the transcription sweep............................................29Transcription requests do not execute..................................................................................29Transcription never completes..............................................................................................29Transcription fails due to networking or HTTP errors.........................................................29Documents transcribed incorrectly.......................................................................................30Transcription takes too long.................................................................................................30

Transcribed documents not indexed.....................................................................................30Multiple index requests for one video..................................................................................30
Exceptions.................................................................................................................................31Tracing......................................................................................................................................31
Transcription Sweep.............................................................................................................32Conversion Subsystem.........................................................................................................32Index Preprocessing.............................................................................................................32
Conclusion.....................................................................................................................................33References......................................................................................................................................33Notices...........................................................................................................................................34Trademarks.....................................................................................................................................35
3

Introduction
FileNet® P8 V5.2.1 contains a technology preview feature for managing the automatic transcription of video documents. This feature, in combination with an appropriate transcription handler server plug-in, allows for the transcribing of rich media and indexing for full-text search. This paper describes the overall design of the transcription capability, how to configure it as an administrator, and how to troubleshoot possible issues. It also contains information on how to develop a transcription handler plug-in.

Overview
The implementation of transcription in FileNet P8 builds upon existing server features and introduces several new capabilities, which ultimately go beyond the basic requirements that are necessary for transcription. This complexity can make it difficult to understand how transcription is set up and performed. In this overview, it will be broken down to make it easier to understand.
Transcriptions are stored in FileNet P8 as Timed Text Markup Language (TTML) files. TTML is an XML standard for representing captions. After transcription, a single TTML annotation will be added to the video document.
The following table lists the new and existing server capabilities that are used.
Add-on The Rich Media Transcription Add-on allows all of the server definitions that are needed for transcription to be optionally included. It can be added to new or existing object stores.
Queue Sweep This existing feature is used by transcription to queue transcription requests and to manage that queue until the transcriptions have completed.
Content Conversion This is a new capability in V5.2.1, which is a pluggable framework for providing content conversion in the server. It is used only by transcription for conversions from video to TTML.
Code Module This existing capability is used by transcription to allow a vendor-supplied transcription handler to be plugged in.
Text Index Preprocessor This is a new capability in V5.2.1, which allows an extension of the text extraction for full-text search. Transcription provides a built-in preprocessor that extracts the text from TTML transcriptions.
Main Components
There are several key components of the transcription processing. Although some components are part of the FileNet P8 server, they are mentioned separately to help you understand the overall flow.
Transcription Request Handler and Request Sweep
This component handles requests for trancription; after it initially queues the requests, it then removes them from the queue and processes them through transcription conversion.
Content Conversion Subsystem
This new subsystem provides a pluggable framework for content conversion in the server.
Transcription Handler A transcription handler provides the actual conversion from video to TTML. It plugs into the Content Conversion subsystem via a code module. This component is vendor-supplied.
Content-based retrieval Indexing Support
This component provides support that is contained within the FileNet P8 server to perform content-based retrieval (CBR). A new enhancement to CBR indexing provides for the extension of the extraction of text from documents via Text Index Preprocessors.
5
Transcription Annotation Preprocessor
The transcription annotation preprocessor is a text index preprocessor that extracts text from TTML annotations that are created for transcribed documents.
IBM Content Search Services To complete the picture, IBM Content Search Services provides the final full-text index for the transcribed documents.
Overall Flow
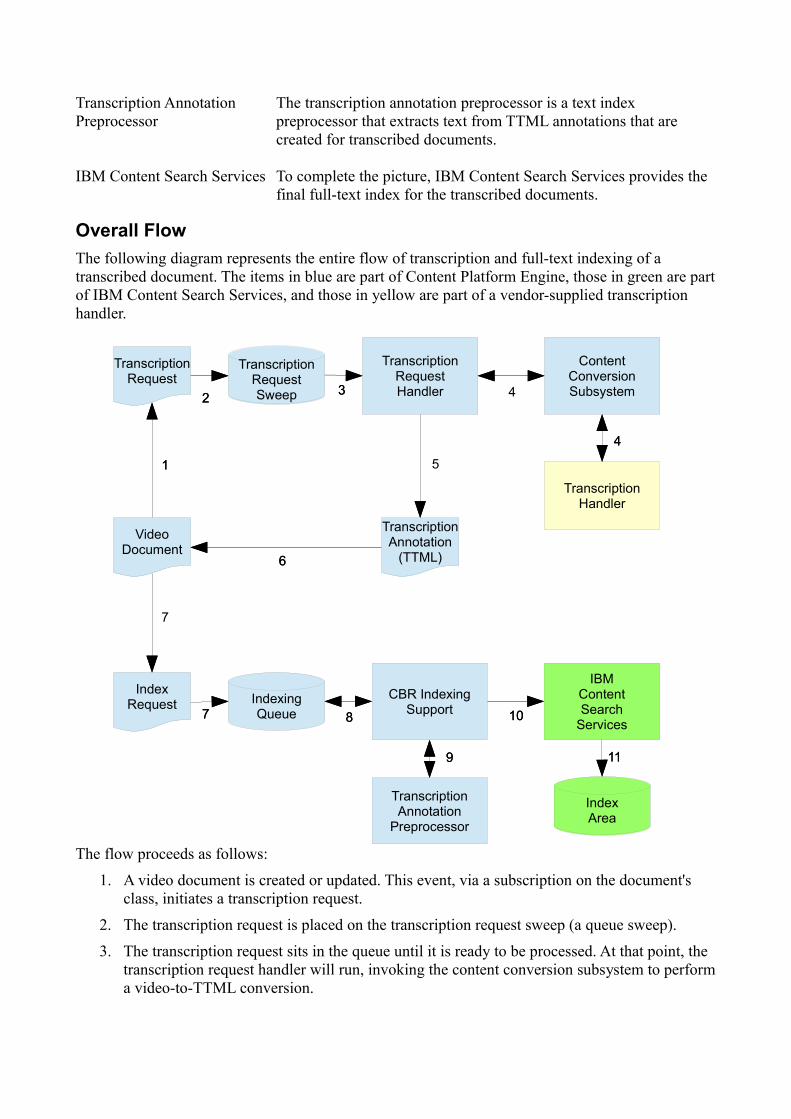
The following diagram represents the entire flow of transcription and full-text indexing of a transcribed document. The items in blue are part of Content Platform Engine, those in green are part of IBM Content Search Services, and those in yellow are part of a vendor-supplied transcription handler.
The flow proceeds as follows:
1. A video document is created or updated. This event, via a subscription on the document's class, initiates a transcription request.
2. The transcription request is placed on the transcription request sweep (a queue sweep).
3. The transcription request sits in the queue until it is ready to be processed. At that point, the transcription request handler will run, invoking the content conversion subsystem to perform a video-to-TTML conversion.
TranscriptionRequestHandler
ContentConversionSubsystem
TranscriptionHandler
VideoDocument
TranscriptionRequest
TranscriptionAnnotation
(TTML)
IndexRequest
CBR IndexingSupport
TranscriptionAnnotation
Preprocessor
IndexingQueue
IndexArea
IBMContentSearch
Services
1
23 4
4
5
7 8
9
10
11
6
TranscriptionRequestSweep
TranscriptionRequestHandler
ContentConversionSubsystem
TranscriptionHandler
VideoDocument
TranscriptionRequest
TranscriptionAnnotation
(TTML)
IndexRequest
CBR IndexingSupport
TranscriptionAnnotation
Preprocessor
IndexingQueue
IndexArea
IBMContentSearch
Services
1
23
4
7 8
9
10
11
6
TranscriptionRequestSweep
7

4. The content conversion subsystem examines all registered content conversion handlers and chooses the appropriate handler for transcription.
5. The transcription handler extracts the audio from the video and transcribes the audio, creating a TTML file for the transcription.
6. The TTML file is returned to the transcription request handler, which then creates an annotation for the TTML and attaches it to the original video document.
At this point, the document has been transcribed and the transcription is stored in an annotation on the document.
7. The creation of an annotation on the video document triggers an index request to be created and placed on the indexing queue.
8. The index request sits in the queue until it is ready to be processed. At that point, the CBR indexing support code in FileNet P8 will prepare the document for sending to IBM Content Search Services. As part of that preparation, it will invoke the transcription annotation preprocessor.
9. The transcription annotation preprocessor extracts the transcript text from the TTML file.
10. The index processor sends the extracted text to IBM Content Search Services.
11. IBM Content Search Services full-text indexes the document, updating the index area.
At this point, the video document is indexed within the full-text index and can be searched for words within the transcription for the video.
7
Configuring and Administering Transcription
This section discusses the configuration steps necessary to enable transcription on an object store by using the administration console.
Installing the Rich Media Transcription Extensions Add-on
The first step in configuring an object store for transcription is to install the Rich Media Transcription Extensions add-on, which adds IBM FileNet extensions required for generating text transcripts from video streams. It also defines the transcription annotation preprocessor, which is necessary for full-text indexing of videos with annotations.
For a new object store:
• Using the administration console, right-click the Object Stores node for the domain tree and select New Object Store.
• On the Select Add-ons step, select 5.2.1 Rich Media Transcription Extensions.
• Select other Add-ons and enter information for the other steps as needed to create the object store and install the add-on.
For an existing object store:
• Using the administration console, right-click the object store node in the domain tree and select Install Add-on Features.
• Scroll down the list of add-ons and select the 5.2.1 Rich Media Transcription Extensions add-on.
• Click OK to install the add-on.
The following classes are defined by the add-on:
Class Description
RmsTranscriptAnnotation A subclass of Annotation, used for storing transcriptions.
RmsTranscriptionRequestSubscription Represents a subscription used to trigger the automatic generation of a transcription.
RmsTranscriptionSettings A Content Conversion Settings class that defines the desired conversion with both input and output properties.
RmsTranscriptionRequestSweep An object controlling the processing of transcription requests.
RmsTranscriptionJob A custom sweep job for generating transcription requests for existing documents.
RmsTranscriptionRequest A subclass of Abstract Queue Entry with additional properties for transcription sweep.
The following object instances are created:
Object Name Class Description
Transcription Request Event Action
Event Action Event action to support automatic transcription of video files.
Transcription Request Sweep
Queue Sweep A Queue Sweep class to support sweep-based conversion of video to transcript text.
Transcription Sweep Action Sweep Action A Sweep Action class to support transcription.
Transcription Annotation Preprocessor
Text Indexing Preprocessor Action
Defines a text indexing preprocessor handler. This is a built-in handler, with a Prog ID of com.filenet.engine.transcription.TranscriptionAnnotationPreprocessor.
Installing a Transcription Handler
The second step in preparing for transcription is to obtain and install a transcription handler, which is provided by a vendor. Details on developing a transcription handler are discussed in the Developing a Transcription Handler section. For this section, it is assumed that the handler already exists.
The transcription handler should have been provided with an install program or packaged as a add-on. Run the install program or install the add-on according to the vendor instructions. At a minimum, the transcription handler installer or add-on should create:
• A content conversion action. This action will be an instance of the CmContentConversionAction class or an instance of a subclass of CmContentConversionAction.
• A code module containing the logic for the conversion action. This code performs the transcription.
Additional installation, including establishing separate servers and configuring communications with them, is provided by the vendor of the transcription handler.
Creating a Document Class for Rich Media
Although this step is not required, it is a recommended best practice to create a separate document class for rich media. This step will not only allow for a separate storage location for these large documents but it will likely result in a significant performance improvement for indexing because it will limit the execution of the annotation preprocessor to only rich media documents. To create a Document class, follow these steps:
• Using the administration console, open the object store.
• Navigate to Data Design / Classes in the tree, right-click on the Document class, and select New Class.
• Enter a display name and symbolic name for the class. Click Next, then Finish to create the class.
• If the default storage area is Database, open the class definition and change the default storage area to a file-based storage area. Because videos are large documents, it is much
9

more efficient to store them as files rather than in the database.
Change the RmsTranscriptAnnotation class so that it uses file-based storage.
Establishing Document Classes to Transcribe
In order to perform transcription automatically when videos are added or updated, a subscription needs to be added to the rich media document class to create transcription requests.
To create a subscription:
• Using the administration console, open the rich media class definition.
• Click on Actions and choose New Subscription.
• Enter a meaningful name for the subscription, such as "Transcription Subscription", and click Next.
• Select the Create a video transcription check box and click Next.
• For the triggers, choose Checkin Event and click Next.
• For transcription settings, choose Default Transcription Settings, unless the vendor of the transcription handler indicates that settings other than the default are required. Click Next.
• For additional options, consider selecting the check box for including subclasses if you plan to create subclasses of the rich media class. Edit the filter expression to include all of the content types used for rich media, or remove the ContentElementsPresent clause from the filter to include all content types.
Note: Consider clearing the filter only if a Document subclass is being used for rich media and all media is to be transcribed. Otherwise, every document added to the class will be queued for transcription.
• Click Next, then Finish to create the subscription.
At this point, video documents that are imported into the rich media class should be automatically scheduled for transcription and transcribed. Additional configuration of the transcription queue sweep is covered in Configuring the Transcription Queue Sweep.
Validating Transcription
You can test that the transcription is working by importing a video into the rich media class:
• Using the administration console, navigate to an appropriate folder for importing in the object store by using the tree, select Browse / Root Folder and navigate to an appropriate subfolder. Then, right-click and choose New Document.
• Enter an appropriate name and choose the rich media class. Click Next.
• Add the video as a content element and click Next. Choose a small video that has audio for testing. Note: If the video is an mp4 format, ensure that its content type is video/mp4 and not audio/mp4.
• Click Next. change any other options as needed, then click Finish to create the document.
At this point, you should be able to validate that a transcription request is created and queued in the Transcription Queue Sweep:

• Using the administration console, navigate in the tree on the object store to Sweep Management / Queue Sweeps and click Transcription Queue Sweep.
• Click Queue Entries. You should see the request for transcription appear. It should then be processed and completed, disappearing from the queue. If you don't see an entry in the queue, it either ran too quickly for you to see it or there was a problem in the subscription such that it was not queued. Check the filter expression on the subscription and the content type of the document and content element to make sure they are correct and are specifying a supported content type for the transcription handler. See the Possible Issues section for more tips on resolving issues.
• Depending on the length of the video and the speed of the transcription handling, it can take a long time for the transcription to complete, especially if the video is large.
When the transcription completes, a new annotation will be created on the document. This annotation will be of class RmsTranscriptAnnotation and will contain a content element with the TTML transcript of the video. To view the annotation, follow this procedure:
• Using the administration console, navigate to the document and open it.
• Click on the Annotations tab and select the annotation to open it.
• On the annotation, click the Content Elements tab. Select the content element, click the Content Element button, and select View/Download.
• Choose an application to read the TTML document and view the generated TTML.
Establishing Text Indexing Preprocessor for Transcript Annotations
To make videos searchable by the text of the transcription of the video, you must CBR-enable the rich media class and associate the transcription annotation preprocessor with the rich media class:
• Using the administration console, open the rich media class definition.
• Select the CBR-enabled check box on the General tab.
• Select the Text Indexing Preprocessor Definitions tab and click New.
• Enter a name for the subscription, select the Enabled check box, and select Transcription Annotation Preprocessor for the action.
Important: It is not necessary to CBR-enable the RmsTranscriptAnnotation class. Because the Annotated Object property of the RmsTrancriptAnnotation class has the CBR Propagation Type property set to 1 (push), a text indexing request on the annotated document will occur when the annotation is added or changed. This is the desired behavior, because you you will probably want to search for videos in the rich media class rather than for annotations in the annotation class.
Validating Text Indexing of Videos with Transcription
To verify that videos that are transcribed are also text indexed, follow this procedure:
• Using the administration console, perform an import of a video into the rich media class as described in Validating Transcription.
• Monitor the transcription progress in the Transcription Queue Sweep, waiting until the transcription has completed.
• Open the indexing queue (Administrative / Indexing Queue) and monitor the indexing
11

requests that are queued for the video document. There are two indexing requests: one request for when the video was first imported and another request for after the transcription annotation was created. Wait for both requests to complete.
• Once the text indexing has completed, run a search to validate that the video document's transcription has been indexed as the "text" of the video document. This can be done in the administration console as follows:
◦ Select Search in the object store navigation tree.
◦ Click New Object Store Search.
◦ Select the SQL View tab.
◦ Replace the default SQL statement with a statement similar to:
SELECT d.Id, cs.ContentSummary FROM <videoDocClass> d INNER JOIN ContentSearch cs ON d.This = cs.QueriedObject " + "WHERE CONTAINS(d.*, '<word>')
In this statement, <word> is a word in the transcript. Verify that this word is in the transcript. You may need to check the generated TTML to verify that the transcription handler has transcribed the word correctly.
◦ Run the search by clicking the Run toolbar button.
Additional Configuration
There are additional configuration options for you to consider.
Temporary File Location for Transcription Handlers
If the transcription handler requires files, the directory to use for these files can be specified on the domain. Review the vendor documentation for the transcription handler to determine if temporary files are required. To select the temporary file location in the administration console:
• On the domain tab, select the Content Conversion Subsystem tab.
• In the Temporary directory path field, enter the path to the directory to use.
If the field is empty, the default is the directory ConvTemp\<handler-id> under the application server's current directory. For example, for WAS on Windows this directory is AppServer\profiles\<profile>\FileNet\<server>\ConvTemp\<handler-id>, where <handler-id> is the ID of the transcription handler action.
It is a best practice to relocate the default temporary folders from the application server directory to a faster read/write storage area. Consider using a faster disk such as a RAID disk array or a RAM disk to improve transcription speeds. In general, the performance of a RAM disk is faster than other forms of storage media.
Configuring a Transcription Handler
Configuring a transcription handler is normally performed by changing the properties on the conversion action that is associated with the handler. There are several general properties on the action that you can use to control the conversion handler:

• Is Enabled: If True, the handler will be used by conversion services.
• Priority: In cases where there are multiple conversion actions, actions with higher priority will be chosen first.
There might be other properties on the action that are defined by the vendor of the transcription handler. Some possible properties are:
• URL to a transcription server.
• Credential for authentication with a transcription server.
Configuration to Transcribe Existing Documents
In order to transcribe existing documents, a custom sweep job can be created to find the documents and queue them for transcription:
• Using the administration console, navigate to the object store / Sweep Management / Job Sweeps / Custom Jobs. Right-click and select New Custom Job.
• Select a name for the job, such as “Transcription Sweep Job”.
• For the Custom sweep subclass, choose Transcription Job.
• For the Sweep mode, choose Normal.
• Check the Enabled check box and click Next.
• For the target class, choose the rich media class. (See earlier discussion on the importance of a subclass of Document for rich media.)
• Modify the filter expression to add other content types that are to be transcribed.
• Optionally, check Include subclasses or Record failures, and click Next.
• Enter start and end dates, click Next, then Finish.
You can open the job created and view its status with the General tab and results on the Sweep Results tab. If the job didn't process the documents you expected, you can clone the job, modify it and rerun it.
Configuring the Transcription Queue Sweep
Additional options exist on the transcription queue sweep. You can find these options by accessing the Transcription Queue Sweep in the administration console:
• Maximum Failures: This setting controls how many times a failed transcription will be retried. Failures can occur due to problems with transcription server connectivity. The default is zero, which will cause failed transcriptions to be retried indefinitely. You can change the default to a specific number to limit the number of retries.
• Schedule: This setting defines how often and when the transcription queue sweep will run and dispatch transcription requests to the transcription handler. By default, the queue sweep will run continuously. Change this setting to run at certain times if the server performing transcription is slow or network access to the server is slow or only available at certain times.
• Maximum Sweep Workers: The number of threads that will run to dispatch transcription requests. If the transcription request is synchronous, this setting will define the total number
13

of transcriptions that can occur simultaneously. The default, 2, is sufficient for asynchronous transcription.
• Sweep Retry Wait Interval: The time in seconds between retry attempts if a transcription fails (but can be retried).
• Sweep Batch Size: The maximum number of requests that will be processed in a batch. This setting has an impact primarily on synchronous transcription handling as it can limit the number of simultaneous transcriptions so that the videos in the batch are transcribed one at a time. For asynchronous transcription, this setting has little impact.

Developing a Transcription Handler
This section is intended for those who develop transcription handlers.
Preparing for Implementation
There are two components that should be built for any transcription handler:
1. The transcription handler, which is a Java™ class implementing the ContentConversionHandler interface (described below).
2. A Java program, or alternatively a FileNet P8 add-on, to install the transcription handler and set up the definitions within FileNet P8 that are necessary to define the handler as a conversion action.
The interfaces required for both components are defined within Jace.jar, the FileNet P8 Java API JAR file supplied with FileNet P8.
You should also provide documentation for installing and configuring the transcription handler.
For information about Content Engine server extensions, see http:// www-01.ibm.com/support/knowledgecenter/SSNW2F_5.2.1/com.ibm.p8.ce.dev.ce.doc/server_extensions.htm.
Synchronous vs Asynchronous
The transcription handler interface supports either synchronous or asynchronous conversion. The choice of which mode to use depends on the speed of the conversion. However, because transcription normally takes a considerable period of time, asynchronous conversion is the best mode to use for most transcription.
Files versus Streams
The transcription handler interface also supports the passing of files for either content or streaming. In general, it is more efficient to use the stream interface. However, if a transcription uses files directly for the content, the file interface will be more natural to use and will allow the administrator to configure the temporary directory to contain the files.
Note that document content placed in temporary storage is not encrypted or compressed, which means that it can use additional space and can cause security concerns for some customers.
Additional Servers
Because transcription processing can take a long time and use considerable machine resources, it is likely that additional servers that are separate from the FileNet P8 server will be used to perform the transcription. There are several considerations to keep in mind:
1. Because the FileNet P8 server is normally deployed as a cluster of server instances, any additional transcription servers supporting asynchronous transcription should run sessionlessly and not operate under the assumption that the FileNet P8 server instance that requests transcription is the same FileNet P8 server instance that requests the results of the transcription.
2. For scalability, any additional transcription servers should also be able to be deployed on a server cluster. This means that the temporary results storage will need to be able to be shared
15

across the transcription assist server instances in the cluster.
Implementing the Transcription Handler
FileNet P8 V5.2.1 contains a content conversion framework that is used by transcription for managing and launching transcription handlers. In a sense, transcription is considered by FileNet P8 to be a content conversion, from video or audio to TTML.
Note: The content conversion framework provides a general capability that may be used for other purposes in the future, but for the 5.2.1 release its only use is for transcription.
ContentConversionHandler Interface
As a content conversion handler, the transcription handler must implement the following interface:
interface ContentConversionHandler {
boolean requiresFile(String outputConversionClassName);
boolean isSynchronous(String outputConversionClassName);
void convertStream(CmContentConversionAction action, InputStream source,String sourceContentType, String retrievalName,CmContentConversionSettings outputSettings,ContentConversionResult result);
void convertFile(CmContentConversionAction action, String sourceFile,String sourceContentType, String retrievalName,CmContentConversionSettings outputSettings,ContentConversionResult result);
void resumeConversion(CmContentConversionAction action,byte[] deferralData, CmContentConversionSettings outputSettings,ContentConversionResult result);
};
This interface has two Boolean methods to determine the requirements of the handler and three other methods to perform the actual conversion:
requiresFile: Allows the conversion handler to indicate its preference for either a file or a input stream for the source content. The parameter outputConversionClassName holds the name of the FileNet P8 server object model subclass of CmContentConversionSettings. For transcription, this will be the FileNet P8 class RmsTranscriptionSettings.
IsSynchronous: Allows the conversion handler to describe if conversion will be performed synchronously or asynchronously. A synchronous conversion will complete during the time of the call to the conversion handler. An asynchronous conversion will not and will require polling from the FileNet P8 server (to resumeConversion) to obtain the results of the conversion in an asynchronous fashion.
ConvertStream: Called to launch conversion if the requiresFile returned false for the conversion class of the content.
ConvertFile: Called to launch conversion if the requiresFile returned true for the conversion class of the content.
ResumeConversion: If the conversion is asynchronous (isSynchronous returns false for the conversion class of the content), then this method will be called to obtain the results of the conversion.
ContentConversionResult Interface
The results from each of the conversion methods are represented with an instance of the ContentConversionResult interface. This code for this interface looks similar to the following:

interface ContentConversionResult {enum ResultType {
STREAM, DEFERRED, UNABLE, ABANDONED};
ResultType getResultType();
void setStreamResult(InputStream s);
InputStream getStreamResult();
void setDeferral(byte[] deferralData, int deferralSeconds);
byte[] getDeferralData();
int getDeferralDelay();
void setAbandonedResult();
void setUnableResult();};
The transcription handler invokes only one of the setter methods on this object as follows: setStreamResult: Sets an input stream that can be used to access the results of the
conversion. setDeferral: Indicates that the result is not available (asynchronous). The deferralData can be
any byte-array value requested by the conversion handler and is intended to be a “continuation cookie”, such as a job ID. deferralSeconds indicates an estimate of the time at which results will be available. The FileNet P8 server will invoke the conversion handler again (using resumeConversion) after this amount of time has transpired to obtain the results (or be instructed to defer the results again).
setAbandonedResult: Indicates, in asynchronous situations, that the conversion handler has abandoned the conversion and will not return a result. However, if it is retried, the conversion handler may be able to return a result on the same content in the future.
setUnableResult: Indicates that the conversion handler is unable to convert the content. That is, a retry will not successfully convert the content.
For more information about the proper return of transcription results, see Requirements on the Transcription Handler .
CmContentConversionAction
An instance of CmContentConversionAction is passed on the convert and resumeConversion calls to the transcription handler. This class corresponds to a FileNet P8 server object that was originally defined by the transcription conversion handler installation program. The interface to this object is as follows:
public interface CmContentConversionAction extends com.filenet.api.core.RepositoryObject, com.filenet.api.events.Action{
public Boolean get_IsEnabled();public void set_IsEnabled(Boolean value);
public CmConversionSettingsClassDefinition get_CmOutputConversion();public void set_CmOutputConversion(CmConversionSettingsClassDefinition value);
public StringList get_CmSupportedInputContentTypes();public void set_CmSupportedInputContentTypes(StringList value);
public StringList get_CmUnsupportedInputContentTypes();
17

public void set_CmUnsupportedInputContentTypes(StringList value);
public Integer get_Priority();public void set_Priority(Integer value);
}
Only the getter methods should be used by the transcription handler. (Setter methods are used by the transcription handler installer and the administration console when creating or updating the action.) They return properties of the object that have the following meanings:
• get_IsEnabled: Returns true if the transcription handler is enabled for new transcriptions.• get_CmOutputConversion: Returns the FileNet P8 server class definition for the
CmContentConversionSettings instance, which is either the class definition for RmsTranscriptionSettings or a subclass of it.
• get_CmSupportedInputContentTypes: Returns a list of the content types supported by the transcription handler. This will normally be video and audio types.
• get_CmUnsupportedInputContentTypes: Returns a list of content types that are not supported by the transcription handler. This list contains more qualified versions of the supported content types.
• get_Priority: Returns the priority of this transcription handler relative to other transcription handlers.
Although these properties can be used within the transcription handler, it is more likely that you will add new properties to contain the configuration of the handler and then refer to these properties using logic like the following:
String propertyValue = action.getProperties().getStringValue("<PropertyName>");
where <PropertyName> is the name of a property defined on a subclass of CmContentConversionAction. See Creating an Installer for the Transcription Handler for more details on the CmContentConversionAction class and creating an instance of it during handler installation.
CmContentConversionSettings
An instance of CmContentConversionSettings is passed to the transcription handler on the convert and resumeConversion method calls. This is a FileNet P8 server object provided by the requester of the conversion. It has the following unique property:
• CmOutputContentType: The MIME content type to be returned. For transcription, this should always be “application/ttml+xml”.
In the case of transcription, CmContentConversionSettings is actually an instance of RmsTranscriptionSettings, which provides one additional property:
• TranscriptionLocale: A local string (for example, “en-us”) that can be used as a hint for the language in which transcription is desired.
Similar to CmContentConversionAction, a subclass of RmsTranscriptionSettings can be created to add additional properties that can be inspected by the handler. The advantage of adding additional properties on the settings object rather than the action object is that there can be multiple settings objects with different property values that are used with the same transcription handler. The added properties can define information related to the quality of transcription desired. The administrator can choose the instance of settings to use when establishing document classes to transcribe.

HandlerCallContext
As with other FileNet P8 server handlers, a HandlerCallContext instance is available for use within a transcription handler. This object contains methods that are useful for a variety of purposes. It is accessed as in the following example:
HandlerCallContext.getInstance().traceModerate("Conversion started");
Here are some useful methods on HandlerCallContext:• getReadProtectedProperty: Reads a property that is encrypted in the FileNet P8 server. This
might be useful if a password needs to be stored as a property of the action for the handler.• getTemporaryFilesDirectory: Obtains a directory to place temporary files.• logError, logWarning, isSummaryTraceEnabled, isModerateTraceEnabled,
isDetailTraceEnabled, traceSummary, traceModerate, traceDetail: Used for trace/logging. Using these methods allows the log information to be embedded with in the FileNet P8 server log.
• isShuttingDown: Detects if the server is shutting down. For synchronous transcription, any current transcription process occurring should be terminated.
Requirements on the Transcription Handler
The previous section outlines the basic programming interfaces. In addition, some other requirements are implied by the FileNet P8 server:
The convert methods return an input stream that delivers the content in the target format. A handler should either return null or an exception if it cannot carry out the conversion. If null is returned, the framework will try other lower priority handlers, if available. In the case of an exception, it will be returned to the caller instead of trying another lower priority handler.
If the stream result returned is over a temporary file that is created by the handler, the handler is responsible for overloading the close() method of the InputStream returned in order to delete that temporary file.
If source content is required in the form of a file, then the requiresFile method returns true. In that case, the framework will call the convertFile method.
The convertFile method must treat the source file as read-only. A Content Conversion Settings instance will be passed in if there is one available for the
requested target type. A handler can update this instance with output metadata, but it must not attempt to save the object.
A handler should not assume that a stream result will be consumed in the calling thread; therefore, implementation cannot rely on thread local storage.
A handler should not consume unbounded amounts of memory, especially when content is quite large when using ByteArrayInputStream or the equivalent.
Asynchronous operation is based on a polling model. The handler initially returns an opaque “continuation cookie” in the form of a blob (deferral data), along with an estimate of the number of seconds that will elapse before the operation is complete. This is accomplished by calling the setDeferredResult() method on the interface passed as the result parameter of the convert() method. The consumer of the conversion will then call the resumeConversion() method, passing back the deferral data along with a conversion settings instance in an identical state to that passed originally (although not necessarily the same Java object). The resumeConversion() method may then either deliver the final stream result (via setStreamResult), subject to the same rules as given previously, or may continue to defer by making another call to setDeferredResult (with a refined completion
19

time estimate).
The following additional requirements apply to asynchronous operation: If the handler is unable to perform the requested conversion, it must indicate this in the same
manner as the synchronous case by calling setUnableResult() within the convert() method. It must not defer conversion and then later (in response to resumeConversion) indicate its inability to produce the requested output.
The handler must completely consume the source content (stream or file) within the convert() method. The stream/file will be unavailable once the convert() method returns.
The handler must allow the resumeConversion() method to be called by a different Content Engine instance than that which made the original convert() call. That is, the deferral data must be call location-independent.
The handler must be prepared to deal with the possibility that resumeConversion is never called (it is impossible to guarantee the Content Engine server will never lose track of an in-progress conversion). Hence, there must be a way for the handler and its underpinnings to detect and clean up conversion results that have been “abandoned”. This will clearly require some kind of timeout mechanism and it is recommended that this timeout be (a) at least an order of magnitude longer than the completion time estimate given in the deferral response, and (b) no less than a number of hours.
As a consequence of the preceding point, the handler must also be able to deal with a resumption call specifying deferral data that is no longer valid; for example, if the call has been unavoidably delayed (for example, by Content Engine server down time) for longer than the abandonment timeout. The setAbandonedResult() method on the result interface is used specifically for this case and should not be used in any other circumstance.
Creating an Installer for the Transcription Handler
For a transcription handler to be usable, it must be installed and configured into the FileNet P8 server. This requires the development of an installation program, typically written in Java for portability, that invokes the Content Engine APIs. In this program, the following must be performed:
1. A Java archive file (JAR) containing the transcription handler needs to be imported into FileNet P8 as a Code Module.
2. In the FileNet P8 server, a subclass and instance of the CmContentConversionAction class needs to be created. This server object will point to the transcription conversion handler code module. It will also provide properties that are needed by the conversion framework to know when to invoke the conversion handler, such as the content types that are supported by the conversion handler, as well as properties needed by the conversion handler itself, such as the URI and credentials to a transcription server.
In lieu of a complete sample installer, the following code examples demonstrate some of the tasks of the installer.
Creating a Code Module
The following code example demonstrates how to install a JAR as a Code Module:
public CodeModule createCodeModule(String jarFileName)throws FileNotFoundException {
FileInputStream fileIS = new FileInputStream(jarFileName);
// Get object for existing folder where JAR will be stored in object// store

Folder folder = Factory.Folder.fetchInstance(objectStore,"/CodeModules", null);
// Create ContentTransfer object from JAR contentContentElementList contentList = Factory.ContentElement.createList();ContentTransfer ctNew;ctNew = Factory.ContentTransfer.createInstance();ctNew.setCaptureSource(fileIS);ctNew.set_ContentType("application/java-archive");
// Add content element to list, which will be added to CodeModule object// (below)ddcontentList.add(ctNew);
// Create CodeModule objectCodeModule newCM = Factory.CodeModule.createInstance(objectStore,
"CodeModule");// Set DocumentTitle propertynewCM.getProperties().putValue("DocumentTitle",
"ContentConversionHandlerJar_" + vendorName);// Add content element to CodeModule objectnewCM.set_ContentElements(contentList);
// Check in CodeModule objectnewCM.checkin(AutoClassify.DO_NOT_AUTO_CLASSIFY,
CheckinType.MAJOR_VERSION);newCM.save(RefreshMode.REFRESH);
// File CodeModule object and saveDynamicReferentialContainmentRelationship drcr = (DynamicReferentialContainmentRelationship)
folder.file(newCM,
AutoUniqueName.AUTO_UNIQUE,"ContentConversionHandlerJar_" + vendorName,DefineSecurityParentage.DO_NOT_DEFINE_SECURITY_PARENTAGE);
drcr.save(RefreshMode.NO_REFRESH);
return newCM;}
Creating a Subclass of CmContentConversionAction
The following code example demonstrates how to create a FileNet P8 object model subclass of the CmContentConversionAction and introduces the userId and password properties for the conversion service URI:
// Create subclass of CmContentConversionActionpublic ClassDefinition createCCASubClass() {
ClassDefinition cdCCA = Factory.ClassDefinition.fetchInstance(objectStore, ClassNames.CM_CONTENT_CONVERSION_ACTION, null);
String className = "ContentConversionAction_" + vendorName;Id classId = Id.createId();ClassDefinition cdSubCCA = createNewClassDefinition(cdCCA, className,
classId);
PropertyTemplateString ptStringURI = createPropertyTemplateString("ConversionServiceURI_" + vendorName, Cardinality.SINGLE,new Integer(256), null, false);
PropertyTemplateString ptStringUser = createPropertyTemplateString("ConversionServiceUser_" + vendorName, Cardinality.SINGLE,new Integer(32), null, false);
PropertyTemplateBinary ptBinaryPass = createPropertyTemplateBinary("ConversionServicePassword_" + vendorName, null);
addPropertyDefinitionString(cdSubCCA, ptStringURI, null, null);addPropertyDefinitionString(cdSubCCA, ptStringUser, null, null);addPropertyDefinitionBinary(cdSubCCA, ptBinaryPass, null);
cdSubCCA.save(RefreshMode.REFRESH);
21

return cdSubCCA;}
public ClassDefinition createNewClassDefinition(ClassDefinition superClass,String name, Id classId) {
ClassDefinition p = superClass.createSubclass(classId);
// set the localized nameLocalizedStringList lsl = Factory.LocalizedString.createList();lsl.add(getLocalizedStringEntry(name));p.set_DisplayNames(lsl);p.getProperties().putValue(PropertyNames.SYMBOLIC_NAME, name);p.save(RefreshMode.REFRESH);return p;
}
public PropertyTemplateString createPropertyTemplateString(String name,Cardinality card, Integer maxLength, String defaultStr,boolean useLongColumn) {
PropertyTemplateString pts = Factory.PropertyTemplateString.createInstance(objectStore);
if (maxLength != null)pts.set_MaximumLengthString(maxLength);
if (card.equals(Cardinality.SINGLE) && defaultStr != null)pts.set_PropertyDefaultString(defaultStr);
if (useLongColumn)pts.set_UsesLongColumn(Boolean.TRUE);
setTemplateSystemProps(pts, name, card);return pts;
}
public PropertyTemplateBinary createPropertyTemplateBinary(String name,byte[] defaultBinary) {
PropertyTemplateBinary ptb = Factory.PropertyTemplateBinary.createInstance(objectStore);
if (defaultBinary != null)ptb.set_PropertyDefaultBinary(defaultBinary);
setTemplateSystemProps(ptb, name, Cardinality.SINGLE);return ptb;
}
public PropertyDefinitionString addPropertyDefinitionString(ClassDefinition p, PropertyTemplateString pts, String defaultStr,Id aliasId) {
PropertyDefinitionString pds = null;Iterator iterPDefn = p.get_PropertyDefinitions().iterator();while (iterPDefn.hasNext()) {
PropertyDefinition pDefn = (PropertyDefinition) iterPDefn.next();
String pDefSymbolicName = null;if (pDefn.getProperties().isPropertyPresent(
PropertyNames.SYMBOLIC_NAME)) {pDefSymbolicName = pDefn.get_SymbolicName();
} else {pDefSymbolicName = pDefn.get_PropertyTemplate()
.get_SymbolicName();}
if (pDefSymbolicName.equals(pts.get_SymbolicName())) {pds = (PropertyDefinitionString) pDefn;break;
}}
if (pds == null) {pds = (PropertyDefinitionString) pts.createClassProperty();if (defaultStr != null)
pds.set_PropertyDefaultString(defaultStr);if (aliasId != null) {
IdList idlist = Factory.IdList.createList();idlist.add(aliasId);pds.set_AliasIds(idlist);

}p.get_PropertyDefinitions().add(pds);p.save(RefreshMode.REFRESH);
}
return pds;}
public PropertyDefinitionBinary addPropertyDefinitionBinary(ClassDefinition p, PropertyTemplateBinary ptb, byte[] defaultBinary) {
PropertyDefinitionBinary pdb = (PropertyDefinitionBinary) ptb.createClassProperty();
if (defaultBinary != null)pdb.set_PropertyDefaultBinary(defaultBinary);
p.get_PropertyDefinitions().add(pdb);return pdb;
}
private void setTemplateSystemProps(PropertyTemplate pt, String name,Cardinality card) {
// set the localized nameLocalizedStringList lsl = Factory.LocalizedString.createList();lsl.add(getLocalizedStringEntry(name));pt.set_DisplayNames(lsl);
LocalizedStringList lsl2 = Factory.LocalizedString.createList();lsl2.add(getLocalizedStringEntry(name
+ " Property Template Description"));pt.set_DescriptiveTexts(lsl2);
pt.set_Cardinality(card);PropertyPersistence pp = PropertyPersistence.OWN_COLUMN;
if (pt instanceof PropertyTemplateString&& card.equals(Cardinality.LIST)) {
if (pt.getProperties().isPropertyPresent(PropertyNames.USES_LONG_COLUMN)&& ((PropertyTemplateString) pt).get_UsesLongColumn()) {
pp = PropertyPersistence.OWN_TABLE;}
}pt.set_PersistenceType(pp);pt.save(RefreshMode.REFRESH);
}
/** * Sets up a localized string based on the user's locale information. */public LocalizedString getLocalizedStringEntry(String text) {
UserContext uc = UserContext.get();return getLocalizedStringEntry(text, uc.getLocale().getLanguage(), uc
.getLocale().getCountry());}
/** * Sets up a localized string based on the locale parameters. */public LocalizedString getLocalizedStringEntry(String text,
String lang, String country) {if (lang == null || lang.length() == 0)
lang = "en";
if (country == null || country.length() == 0)country = "US";
String localeName = lang + "-" + country;
// set the localized nameLocalizedString ls = Factory.LocalizedString.createInstance();ls.set_LocalizedText(text);ls.set_LocaleName(localeName);return ls;
}
23

Creating an Instance of the CmContentConversionAction Subclass
The following code example demonstrates how to create an instance of the new subclass:
public CmContentConversionAction createCCA(String name, String actionClass,CodeModule cm, String progId, String script,String targetContentType, StringList supportedSourceContentTypes,StringList unSupportedContentTypes, String conversionServiceURI,String conversionServiceUser, String conversionServicePass) {
CmContentConversionAction cca = Factory.CmContentConversionAction.createInstance(objectStore, actionClass);
cca.set_DisplayName(name);cca.set_ProgId(progId);cca.set_CodeModule(cm);cca.set_ScriptText(script);cca.set_IsEnabled(Boolean.TRUE);cca.set_CmSupportedInputContentTypes(supportedSourceContentTypes);cca.set_CmUnsupportedInputContentTypes(unSupportedContentTypes);cca.getProperties().putValue("ConversionServiceURI_" + vendorName,
conversionServiceURI);cca.getProperties().putValue("ConversionServiceUser_" + vendorName,
conversionServiceUser);cca.getProperties().putValue("ConversionServicePassword_" + vendorName,
conversionServicePass.getBytes());
cca.save(RefreshMode.REFRESH);
return cca;}
Example Install Program
The following code example demonstrates how to use a vendor install program for a video transcription conversion handler:
public void install(String ceUri, String domainName,String objectStoreName, String codeModuleJarFileName,String conversionServiceURI, String conversionServiceUser,String conversionServicePass) throws Exception {
// ===== Create session objectdomain = Factory.Domain.fetchInstance(
Factory.Connection.getConnection(ceUri), domainName, null);
objectStore = Factory.ObjectStore.fetchInstance(domain,objectStoreName, null);
CodeModule cm = createCodeModule(codeModuleJarFileName);
ClassDefinition ccaSubClass = createCCASubClass();
String targetContentType = "txt/plain";StringList supportedTypes = Factory.StringList.createList();supportedTypes.add("audio/mpeg");supportedTypes.add("audio/wav");StringList unsupportedTypes = Factory.StringList.createList();unsupportedTypes.add("audio/wma");unsupportedTypes.add("audio/alac");
CmContentConversionAction cca = createCCA("AudioToTextConverter_"+ vendorName, ccaSubClass.get_Id().toString(), cm, "com."+ vendorName.toLowerCase() + ".TranscriptionConversionHandler",null, targetContentType, supportedTypes, unsupportedTypes,conversionServiceURI, conversionServiceUser,conversionServicePass);
}

Monitoring and Troubleshooting
Monitoring with the Administration Console
Transcription Processing
To monitor transcription processing, examine the Transcription Request Sweep:
• In the administration console, navigate to the object store / Sweep Management / Queue Sweeps / Transcription Request Sweep.
• On the general tab, examine the fields for Examined object count, Processed object count, and Failed object count. The contents of these fields will change as videos are processed.
If failures appear, examine individual requests:
• Click the Queue Entries tab.
• Examine the Reason for Last Failure column for information about why the transcription failed.
Indexing
The indexing of transcribed videos can be monitored in the administration console by using the Indexing Queue view:
• In the administration console, navigate to the object store / Administrative / Indexing Queue.
• Examine the list of all the documents queued for indexing. This list includes transcribed videos as well as other documents.
• You can use the Filter field in the upper right to narrow on certain aspects, such as recent requests, or failing requests if the queue is large.
Monitoring with System Dashboard
The IBM System Dashboard for Enterprise Content Management can be used to monitor the performance of transcription. This section describes the existing and new counters added for the System Dashboard.
Transcription Sweep
For the transcription request sweep queue, there are many counters for monitoring sweep queues. No new counters have been added for V5.2.1. The following screen shot shows the counters for the transcription request sweep:
25

The following table describes some of the counters as they are used for transcription:
Objects Failed The number of object that failed during processing.
Objects Obtained The number of objects that are obtained from the base table.
Objects Processed The number of objects that are successfully processed.
Sweep Active Workers The current number of active sweep worker threads.
Sweep Workers Started The number of SweepWorker tasks that were started.
Sweep Workers Ended The number of SweepWorker tasks that have ended.
Sweeps Started The number of sweeps that have started and the time spent to start the sweep.
Sweeps Ended The number of sweeps that have ended and the time spent to end the sweep.
For more information about the counters, see the Sweep Framework Counters section in the IBM Knowledge Center documentation for IBM FileNet P8.
Content Conversion
The content conversion subsystem provides several new counters, which can be used in combination with the transcription request sweep to understand where time is spent and how to tune

performance. The following screen shot shows the counters in the dashboard:
The following table describes the new counters:
Content Conversion Cache HitsContent Conversion Cache Misses
For each conversion, either an existing, cached conversion handler is used or a new handler is loaded. These counters count each of those cases.
Content Copy Duration ms When content must be copied to a temporary file, this counter measures the copy duration.
Content Retrieval Duration ms Measures the duration required to retrieve the content.
Conversion Duration Counts the total time that is spent in conversion handlers. Note that this time is not the same as conversion time because conversion can occur asynchronously.
Conversions Executed Displays a moving average of the number of conversions executed over the last 15 minutes.
Index Preprocessing
The queue processing for indexing changes as it relates to video transcription is as follows:
Preprocessing queue: Multiple threads manage execution on all of the indexing preprocessors.
The following text extraction types are processed:
1. Outside In 2. PDF Box3. DGN4. HTML
27

Each queue maintains PCH counters under the “Server Based Counters/CSS/<Queue-Name>” location in System Dashboard:
For each queue, the following counters/structure is provided:
Execution A measurement of the PCH Event, which represents the processing of requests that the worker queue performs. The worker queue extracts elements from the queue and performs the work. In the case of text extraction, this work is done in batches, meaning each worker thread extracts multiple entries from the queue. For pre-processing, each worker thread extracts a single entry from the queue at a time.
Execution Duration A measurement of the Execution Event, which is the amount of time the worker thread takes to process the request.
Execution Size A measurement of the execution event, which is the number of entries the worker thread extracted from the queue for the execution of work. This counter providesis a single entry for preprocessing and multiple entries for text extraction.
In Progress The number of queue entries that are currently being executed.
Pending in Queue The number of queue entries that are waiting to be processed by a worker thread.
Requests Per-Minute The number of queue entries that are processed per minute for the last 15 minutes.

Possible Issues
Imported videos do not get queued to the transcription sweep
There are several possible causes of this issue, mostly related to setup:
• If you are using a separate class for rich media, verify that the video is imported into the rich media class.
• Review the subscription on the rich media class that is creating the transcription requests. Verify that the filter expression includes the imported video; in particular, verify that any content type filtering includes the content type of the imported video.
• Verify that the transcription request sweep is enabled.
• Verify that the transcription handler is properly installed and that the action is enabled. If it is properly installed, turn on errorlogging and look for a message similar to the following:
Transcription Request was not created for document <object id> , content element sequence number 0, content type <contentType>". No content conversion handler available. Verify that the content conversion handler is configured for <contentType> and enabled on the object store.
If this message is present, there is an issue with the transcription handler identifying the document.
• Check the examined object count to see if it increases. It is possible that the video has been examined but determined not to be convertible, most likely due to having the wrong content type.
Transcription requests do not execute
If requests remain in the Transcription Request Sweep and are not processed:
• Verify that the transcription sweep queue is enabled.
• If there is a schedule on the Transcription Request Sweep, verify that it is scheduled to run.
• Verify that the Maximum Sweep Workers count on the Transcription Request Sweep is greater than zero.
• Check the failed object count for the sweep or the failure count on the queued entries to verify that they are not increasing. The requests might be constantly failing after execution.
Transcription never completes
If asynchronous transcription is being used and transcriptions do not complete, there might be network addressability issues. Requests might reach the transcription server but callbacks from the server might not reach the FileNet P8 server domain:
• Examine any vendor specific properties on the transcription handler's action, especially any callback URLs, to verify that they are correct and accessible.
• Examine firewall access to the callback URL to verify that it is addressable, even if the transcription server is outside of a firewall.
Transcription fails due to networking or HTTP errors
This is likely due to either a misconfigured transcription handler or the transcription servers that are
29

invoked by the handler being inaccessible or unavailable:
• Examine any URLs in the configuration settings on the transcription handler action's settings to make sure they are correct and accessible.
• Test the availability of any transcription servers. If it is based on REST services, you can test it by sending a request to the server via a browser.
Documents transcribed incorrectly
Transcription is not always perfect. However, if it is very incorrect, there are probably issues either with the quality of the audio being transcribed or with improper settings on the transcription handler or backing servers:
• Work with the transcription handler vendor to improve the quality of the transcription.
• If the accuracy does not meet your needs, consider performing the transcription manually for all or a portion of the problem videos. This service may even be provided by the vendor.
Transcription takes too long
The time it takes to perform transcription can be related to many things, including:• Audio length and bit rate• Load on the transcription service• Quality and nature of the transcription being performed
It is not unusual for the transcription handler to take twice as long (or longer) as the video play length transcribe a video. Compared to that time, the time for the FileNet P8 server itself to launch the transcription and process the results is likely negligable. Therefore, you should work with the transcription handler vendor to improve the speed of transcription.
Transcribed documents not indexed
This indicates a problem with setup or some other issues with CBR:
• Examine the setup instructions and verify that the text indexing preprocessor for transcript annotations is property established.
• Verify that CBR is enabled for the rich media document class, not the annotation class.
• The transcript annotation preprocessor is sensitive to both the annotation class and the MIME content type of the annotation content object. It will ignore any annotation that is not of the right class and content type. The annotation must be of class RmsTranscriptAnnotation or a subclass and the content type must be application/ttml+xml.
Multiple index requests for one video
Because transcriptions are stored as annotations, there are always two index requests created for a single video document: one request on the import of the video and another request after the transcript annotation has been created. If there are more than two requests, it may be a sign that something is wrong:
• Verify that the RmsTranscriptAnnotation class itself is not CBR enabled. It is not required to have the annotation class be CBR enabled. The index preprocessor for the rich media document class will process the transcript annotations due to CBR propagation.

• Verify that there are no other subscriptions that could be generating duplication transcription requests or indexing requests. You can determine if there are duplicate transcription requests by looking at the counts on the transcription sweep queue.
It is important to note that additional index requests can normally occur if any property changes are made to a transcript annotation or if the document class has any CBR-enabled properties that are updated.
Exceptions
The following new or existing exceptions related to transcription can be thrown by the APIs as EngineRuntimeException or appear in the FileNet P8 error log.
FNRCN0001 An exception occurred in the content conversion handler.
This code is used for any exception that occurs within a transcription handler. The contained exception will have more detail on the original cause of the exception.
FNRCN0002 Content conversion handler capable of converting content from {0} to {1} could not be found.
There is no transcription handler installed that can handle the content. The content might be of the wrong content type or there might be a problem with the installation of the transcription handler.
FNRCN0003 An RmsTranscriptionSettings property must be set on a Transcription Sweep Job, sweep job {0} does not have an RmsTranscriptionSettings property.
The default instance of RmsTranscriptionSettings can be overridden on the transcription subscription. If it is overridden with null, this error will occur.
FNRCN0004 The Content Platform Engine server cannot resume the content conversion operation, the content conversion settings class is {0}.
This exception could occur if the transcription handler were uninstalled during the processing of an asynchronous conversion request, such that the request had started but there was no handler to resume the handling of the request.
FNRCE0015E Transcripts can only be generated for classes of Document. Class '{0}' is not a Document class.
Transcription is supported only on server objects of the Document content class or one of its subclasses. To avoid unneccessary processing through the transcription request handler, a subclass should be used.
FNRCE0082E TranscriptionRequestHandler is terminating prematurely because the server is shutting down.
This exception is thrown by the TranscriptionRequestHandler worker threads when the server is shutting down.
Tracing
Although tracing is primarily for IBM support purposes, it can also be useful for developing server
31

extensions such as the transcription handler.
Transcription Sweep
Enabling trace within the transcription sweep is done by enabling the Handlers subsystem. The Sweep subsystem can also be enabled for general sweep trace logging.
Conversion Subsystem
The content conversion subsystem has its own entry in the tracing subsystem's list and can be separately controlled at the summary, moderate, or detail trace levels. Some interesting trace messages:
• Before each conversion handler call, the following message is logged at the detail trace level:
FNRCE0000D - DEBUG Calling convertStream on handler <action name> with inputContentType: <content type> outputSettings: <settings class name> retrievalName: <retrieval name> tempFileDir: <temp dir>
or
FNRCE0000D - DEBUG Calling convertFile on handler <action name> with filename: <file name> inputContentType: <content type> outputSettings: <settings class name> retrievalName: <retrieval name> tempFileDir: <temp dir>
• After each successful conversion, the following message is logged at the summary trace level:
FNRCE0000D - DEBUG Conversion completed for object <object id> ElementSequenceNumber <num> RetrievalName <retrieval name> InputContentType <content type> OutputContentType application/ttml+xml TotalConversionDuration <num> ms ContentRetrievalDuration <num> ms
or
FNRCE0000D - DEBUG Conversion completed for object <object id> ElementSequenceNumber <num> RetrievalName <retrieval name> InputContentType <content type> OutputContentType application/ttml+xml TotalConversionDuration <num> ms ContentRetrievalDuration <num> ms ContentCopyDuration <num> ms
Index Preprocessing
Tracing for index preprocessing is enabled by selecting flags for the CBR subsystem in the trace subsystem settings in the administration console. Some interesting trace messages:
• The following messages are written at the moderate trace level before and after a call to the transcription annotation preprocessor:
FNRCE0000D - DEBUG Invoking TextIndexingPreprocessor.process for action <action> via class <class name> ... Source Object <object id>
FNRCE0000D - DEBUG TextIndexingPreprocessor.preprocess returned: <return code> SourceObject <object id>
• CBR echoes several values being pushed to PCH at the detail trace level:
FNRCE0000D - DEBUG Queue <pch name> inprogress being set to <num>FNRCE0000D - DEBUG Queue <pch name> execution size <num> executionDurationMS <num>FNRCE0000D - DEBUG Queue <pch name> setting number in queue to <num>

Conclusion
FileNet P8 V5.2.1, in combination with an appropriate transcription handler server plug-in, allows for the automatic transcription and text indexing of rich media documents. This document has described how to configure, administer and troubleshoot transcription. It has also described how to develop a transcription handler, including the interfaces and code examples to help you get started.
References
FileNet P8 V5.2.1 documentation in the IBM Knowledge Center:http://www.ibm.com/support/knowledgecenter/SSNW2F_5.2.1
Specification for Timed Text Markup Language (TTML): http://www.w3.org/TR/ttaf1-dfxp/
33

Notices
This information was developed for products and services offered in the U.S.A.
IBM® may not offer the products, services, or features discussed in this document in other countries. Consult your local IBM representative for information on the products and services currently available in your area. Any reference to an IBM product, program, or service is not intended to state or imply that only that IBM product, program, or service may be used. Any functionally equivalent product, program, or service that does not infringe any IBM intellectual property right may be used instead. However, it is the user's responsibility to evaluate and verify the operation of any non-IBM product, program, or service.
IBM may have patents or pending patent applications covering subject matter described in this document. The furnishing of this document does not grant you any license to these patents. You can send license inquiries, in writing, to:
IBM Director of LicensingIBM CorporationNorth Castle DriveArmonk, NY 10504-1785U.S.A.
For license inquiries regarding double-byte (DBCS) information, contact the IBM Intellectual Property Department in your country or send inquiries, in writing, to:
Intellectual Property LicensingLegal and Intellectual Property LawIBM Japan Ltd.19-21, Nihonbashi-Hakozakicho, Chuo-kuTokyo 103-8510, Japan
The following paragraph does not apply to the United Kingdom or any other country where such provisions are inconsistent with local law: INTERNATIONAL BUSINESS MACHINES CORPORATION PROVIDES THIS PUBLICATION "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Some states do not allow disclaimer of express or implied warranties in certain transactions, therefore, this statement may not apply to you.
This information could include technical inaccuracies or typographical errors. Changes are periodically made to the information herein; these changes will be incorporated in new editions of the publication. IBM may make improvements and/or changes in the product(s) and/or the program(s) described in this publication at any time without notice.
Any references in this information to non-IBM Web sites are provided for convenience only and do not in any manner serve as an endorsement of those Web sites. The materials at those Web sites are not part of the materials for this IBM product and use of those Web sites is at your own risk.
IBM may use or distribute any of the information you supply in any way it believes appropriate without incurring any obligation to you.
Licensees of this program who wish to have information about it for the purpose of enabling: (i) the exchange of information between independently created programs and other programs (including this one) and (ii) the mutual use of the information which has been exchanged, should contact:
IBM Corporation

J46A/G4555 Bailey AvenueSan Jose, CA 95141-1003U.S.A.
Such information may be available, subject to appropriate terms and conditions, including in some cases, payment of a fee.
The licensed program described in this document and all licensed material available for it are provided by IBM under terms of the IBM Customer Agreement, IBM International Program License Agreement or any equivalent agreement between us.
Any performance data contained herein was determined in a controlled environment. Therefore, the results obtained in other operating environments may vary significantly. Some measurements may have been made on development-level systems and there is no guarantee that these measurements will be the same on generally available systems. Furthermore, some measurements may have been estimated through extrapolation. Actual results may vary. Users of this document should verify the applicable data for their specific environment.
Information concerning non-IBM products was obtained from the suppliers of those products, their published announcements or other publicly available sources. IBM has not tested those products and cannot confirm the accuracy of performance, compatibility or any other claims related to non-IBM products. Questions on the capabilities of non-IBM products should be addressed to the suppliers of those products.
All statements regarding IBM's future direction or intent are subject to change or withdrawal without notice, and represent goals and objectives only.
All IBM prices shown are IBM's suggested retail prices, are current and are subject to change without notice. Dealer prices may vary.
This information is for planning purposes only. The information herein is subject to change before the products described become available.
This information contains examples of data and reports used in daily business operations. To illustrate them as completely as possible, the examples include the names of individuals, companies, brands, and products. All of these names are fictitious and any similarity to the names and addresses used by an actual business enterprise is entirely coincidental.
COPYRIGHT LICENSE:
This information contains sample application programs in source language, which illustrate programming techniques on various operating platforms. You may copy, modify, and distribute these sample programs in any form without payment to IBM, for the purposes of developing, using, marketing or distributing application programs conforming to the application programming interface for the operating platform for which the sample programs are written. These examples have not been thoroughly tested under all conditions. IBM, therefore, cannot guarantee or imply reliability, serviceability, or function of these programs. The sample programs are provided "AS IS", without warranty of any kind. IBM shall not be liable for any damages arising out of your use of the sample programs.
Trademarks
IBM, the IBM logo, and ibm.com are trademarks or registered trademarks of International Business Machines Corp., registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on
35

the Web at "Copyright and trademark information" at http://www.ibm.com/legal/copytrade.shtml
Adobe, the Adobe logo, PostScript, and the PostScript logo are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States, and/or other countries.
Linux is a registered trademark of Linus Torvalds in the United States, other countries, or both.
Microsoft, Windows, Windows NT, and the Windows logo are trademarks of Microsoft Corporation in the United States, other countries, or both.
Java™ and all Java-based trademarks and logos are trademarks or registered trademarks of Oracle and/or its affiliates.
UNIX is a registered trademark of The Open Group in the United States and other countries.
Other company, product, and service names may be trademarks or service marks of others.





























