Embed Size (px)
Citation preview

1
111Equation Chapter 1 Section
1Equation Chapter 1 Section 1
Trabajo Fin de Grado
Grado en Ingeniería en las Tecnologías
Industriales
Simulación Multi-Agente: Aplicación de Anylogic
para el estudio de la cadena de suministro
Autor: Pablo Antonio Osuna Pando
Tutor: Víctor Fernández-Viagas Escudero
Co-tutor: Salvatore Cannella
Co-tutor: Roberto Domínguez Cañizares
Dep. Organización Industrial y Gestión de Empresas I
Escuela Técnica Superior de Ingeniería
Universidad de Sevilla
Sevilla, 2016

2
Trabajo Fin de Grado
Grado en Ingeniería de las Tecnologías Industriales

3
Simulación Multi-Agente: Aplicación de Anylogic
para el estudio de la cadena de suministro
Autor:
Pablo Antonio Osuna Pando
Tutor:
Víctor Fernández-Viagas Escudero
Profesor titular
Dep. Organización Industrial y Gestión de Empresas I
Escuela Técnica Superior de Ingeniería
Universidad de Sevilla
Sevilla, 2016

4

5
Trabajo de Fin de Grado: Simulación Multi-Agente: Aplicación de Anylogic para el estudio de la cadena de
suministro
Autor: Pablo Antonio Osuna Pando
Tutor: Víctor Fernández-Viagas Escudero
El tribunal nombrado para juzgar el Trabajo arriba indicado, compuesto por los siguientes miembros:
Presidente:
Vocales:
Secretario:
Acuerdan otorgarle la calificación de:
Sevilla, 2016
El Secretario del Tribunal

6

7
A mi familia y a mis amigos
A todos mis maestros, sin excepción
alguna

8

9
Agradecimientos
Después de muchas horas de estudio y constancia, este trabajo sirve como colofón a cuatro años de carrera llenos
de vivencias y aprendizaje. Llegados a este punto, solo puedo agradecer a mis padres, a mis compañeros y a todos
los profesores que me han ayudado y guiado desde mis primeros años de colegio hasta el día de hoy, pasando especialmente por los primeros días en esta universidad.

10

11
Resumen
En este trabajo se presenta en primer lugar una breve introducción a la simulación multi-agente para el estudio de
las dinámicas de la cadena de suministro, sus ventajas y las principales diferencias con respecto a los métodos de
simulación más tradicionales. La primera parte del proyecto vendrá acompañada también de una introducción al
software Anylogic y sus principales características, junto con una explicación de las mismas y lo que pueden
aportar a nuestros modelos de simulación.
Posteriormente, se introduce la cadena de suministro y sus principales criticidades, haciendo especial hincapié en
el efecto látigo, sus causas y su medida.
Finalmente, se construye un modelo de una cadena de suministro en Anylogic utilizando el método Multi-Agente
y comparemos dos métodos de gestión de inventario. Los resultados serán analizados en términos de variabilidad
de los pedidos.
De este modo, se presenta al software Anylogic y a la simulación multi-agente, como métodos disponibles hoy día
para muchos investigadores, e igualmente potentes que los más usados hoy día.

12

13
Abstract
In this project will be firstly and briefly introduced the Multi-Agent Based Simulation method, focused on the
supply chain dynamics, its benefits and differences with traditional modelling methods. This first part of the
research will be completed with an introduction on the software Anylogic and his main characteristics, with an
explanation of how they work and how can help us to build our models.
Afterwards, supply chain and his main critical points are explained, especially bullwhip effect, causes and
measurement.
Finally, a simulation model is built using multi-agent based simulation and comparing two differents stock
policies. The results will be analysed in terms of orders variablity.
By this way, Anylogic and Multi-Agent Based Simulation are presenteed, as available methods nowadays for
many researchers, and as useful as the most popular and used.

14

15
Índice
Agradecimientos 9
Resumen 11
Abstract 13
Índice 15
Índice de Tablas 17
Índice de Figuras 19
Notación 21
1 Simulación Multi-Agente 23
2 Anylogic 25 2.1. Primeros pasos 25 2.2. Creación de los agentes 26 2.3. Palette 26
2.3.1 General 26 2.2.2 Actionchart 27 2.2.3 Analysis 28 2.2.4 Otros 29
2.4. Simulación 29
3 La cadena de suministro 31 3.1. Los costes logísticos 31 3.2. El efecto látigo 31
3.2.1. Causas 32 3.2.2. Medida 33
4 Modelo 35 4.1. Agentes 35 4.2. Generación de la demanda 35 4.3. Comunicación con el minorista 36 4.4. Variables y parámetros comunes 36 4.5. Aprovisionamiento 37
4.5.1. Ajuste exponencial 37 4.5.2. Punto de pedido 39
4.6. Envío pedidos 39 4.7. Fabricación 43 4.8. Estadísticas 44 4.9. Gráficas 44 4.10. Simulación 45 4.11. Resultados 47
4.11.1. Modelo I 47 4.11.2. Modelo II 53
Referencias 61

16

17
ÍNDICE DE TABLAS
Tabla 4–1. Resultados del Modelo I. 59
Tabla 4–2. Resultados del Modelo II. 59

18

19
ÍNDICE DE FIGURAS
Figura 1. Página principal de Anylogic. 25
Figura 2. Palette. 26
Figura 3. Menú Actionchart 28
Figura 4. Menú Simulación. 29
Figura 5. Generación de la demanda. 35
Figura 6. Previsión de la demanda con ajuste exponencial 38
Figura 7. Previsión de la demanda con punto de pedido. 39
Figura 8. Previsión de la demanda con punto de pedido. Actionchart. 39
Figura 9. Recepción de pedidos. 40
Figura 10. Gestión de inventario. 41
Figura 11. Envío de pedidos. 42
Figura 12. Envío de pedidos. Evento dinámico. 42
Figura 13. Fabricación. 43
Figura 14. Estadísticas. 44
Figura 15. Gráficas temporales. 45
Figura 16. Simulación. 45
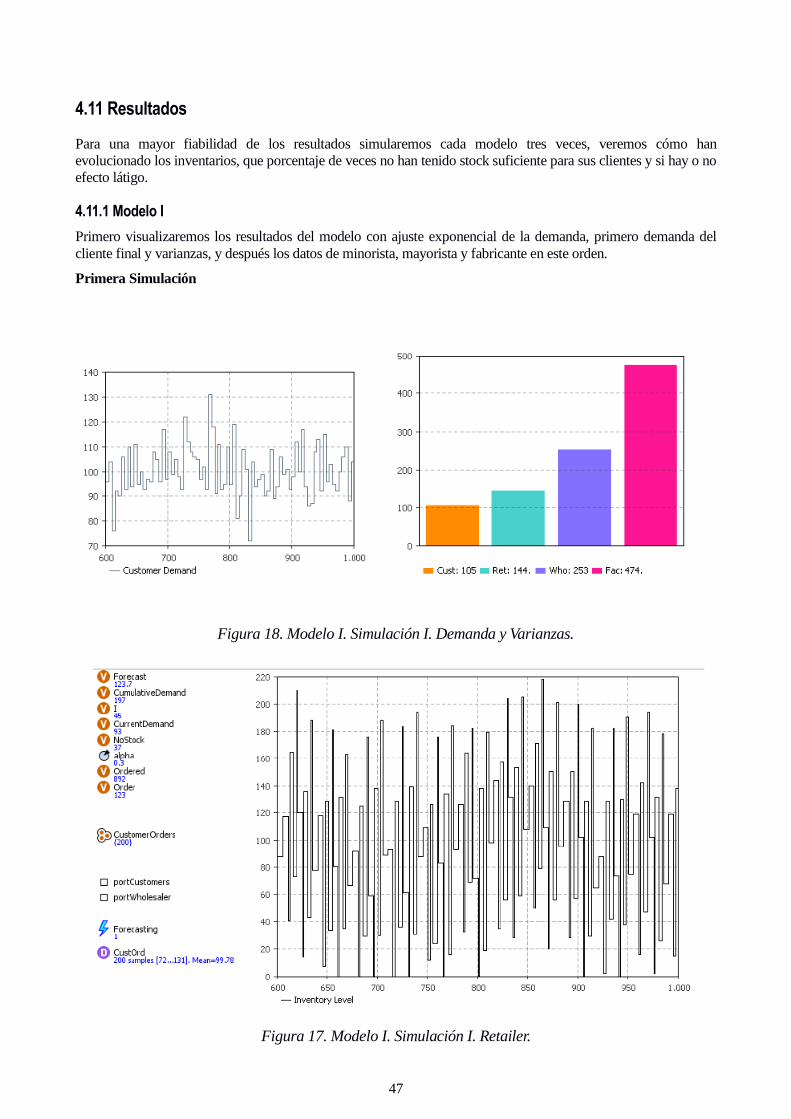
Figura 17. Modelo I. Simulación I. Retailer. 47
Figura 18. Modelo I. Simulación I. Demanda y Varianzas. 47
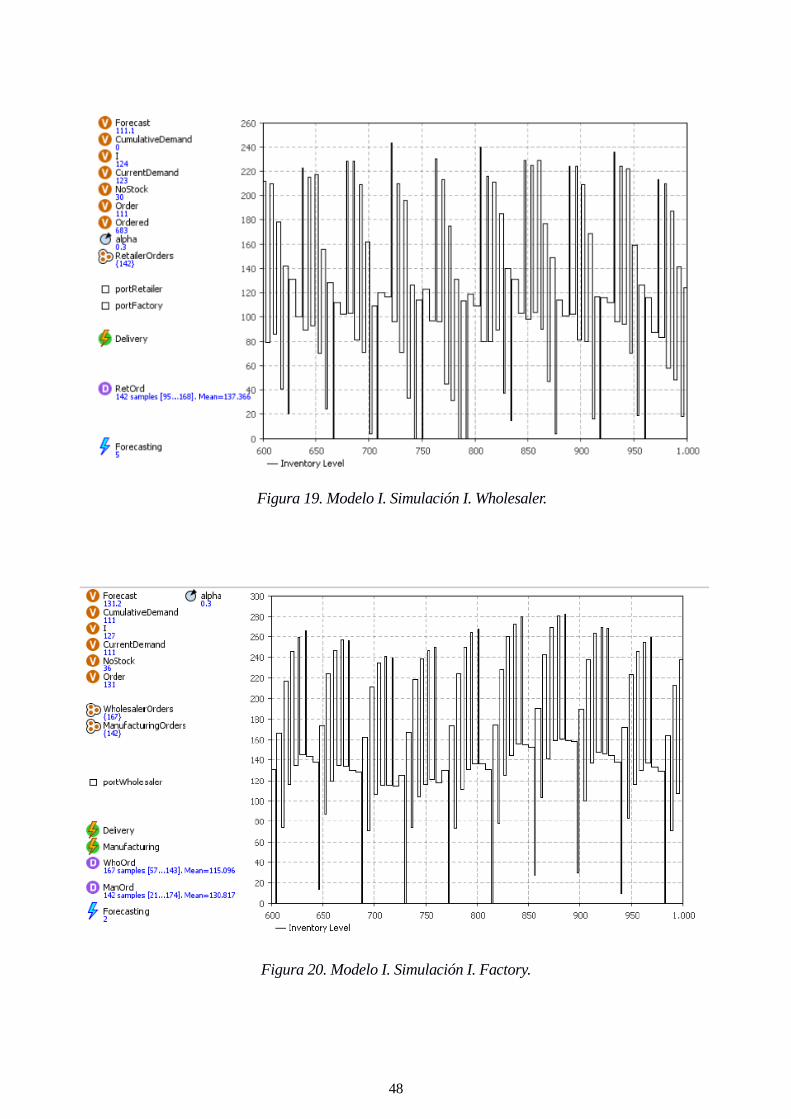
Figura 19. Modelo I. Simulación I. Wholesaler. 48
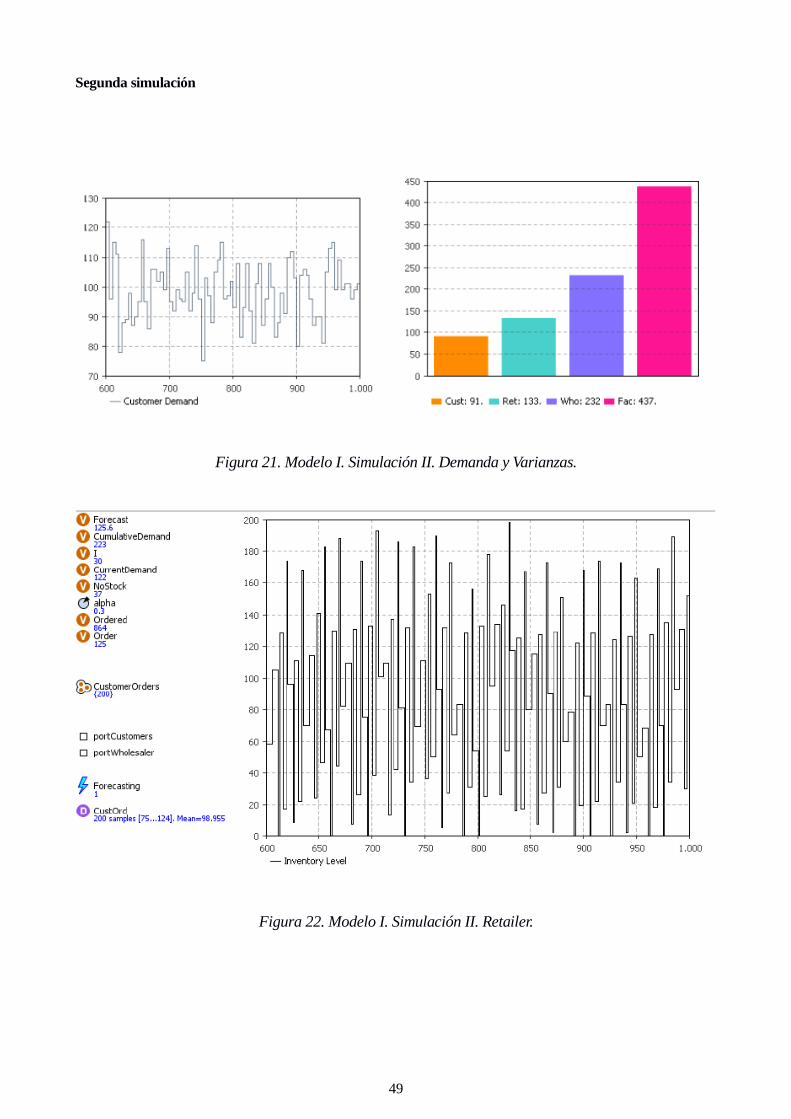
Figura 20. Modelo I. Simulación I. Factory. 48
Figura 21. Modelo I. Simulación II. Demanda y Varianzas. 49
Figura 22. Modelo I. Simulación II. Retailer. 49
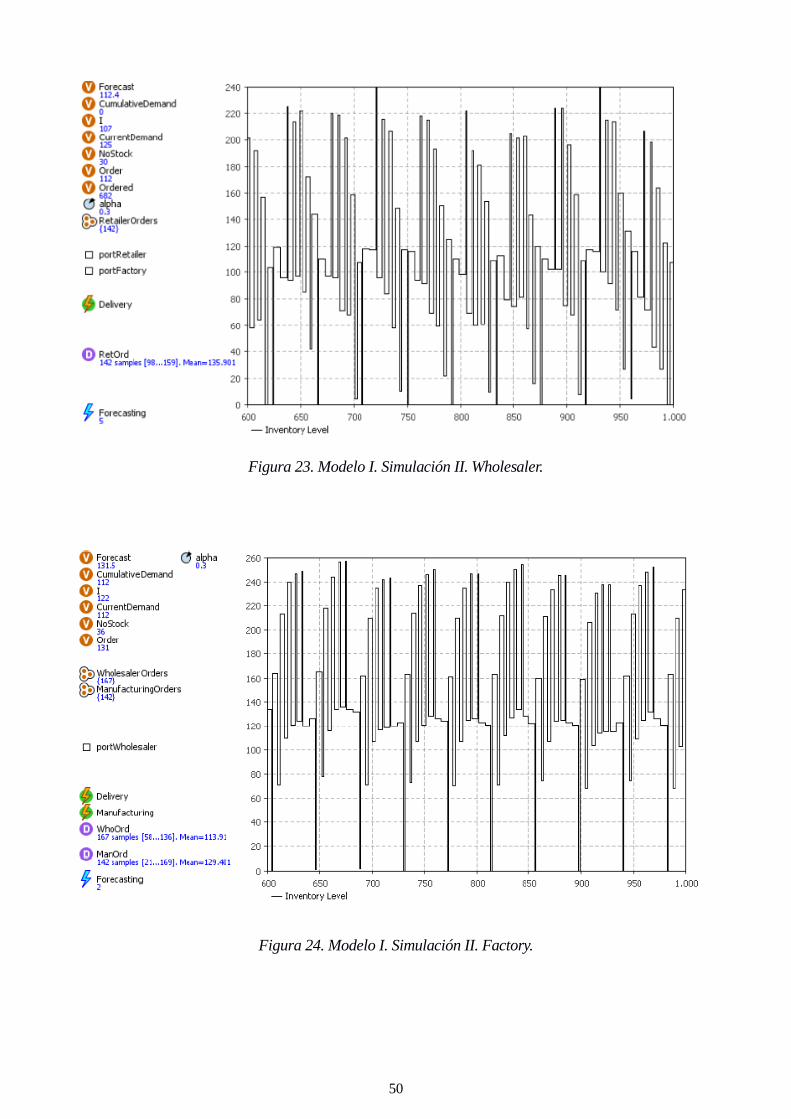
Figura 23. Modelo I. Simulación II. Wholesaler. 50
Figura 24. Modelo I. Simulación II. Factory. 50
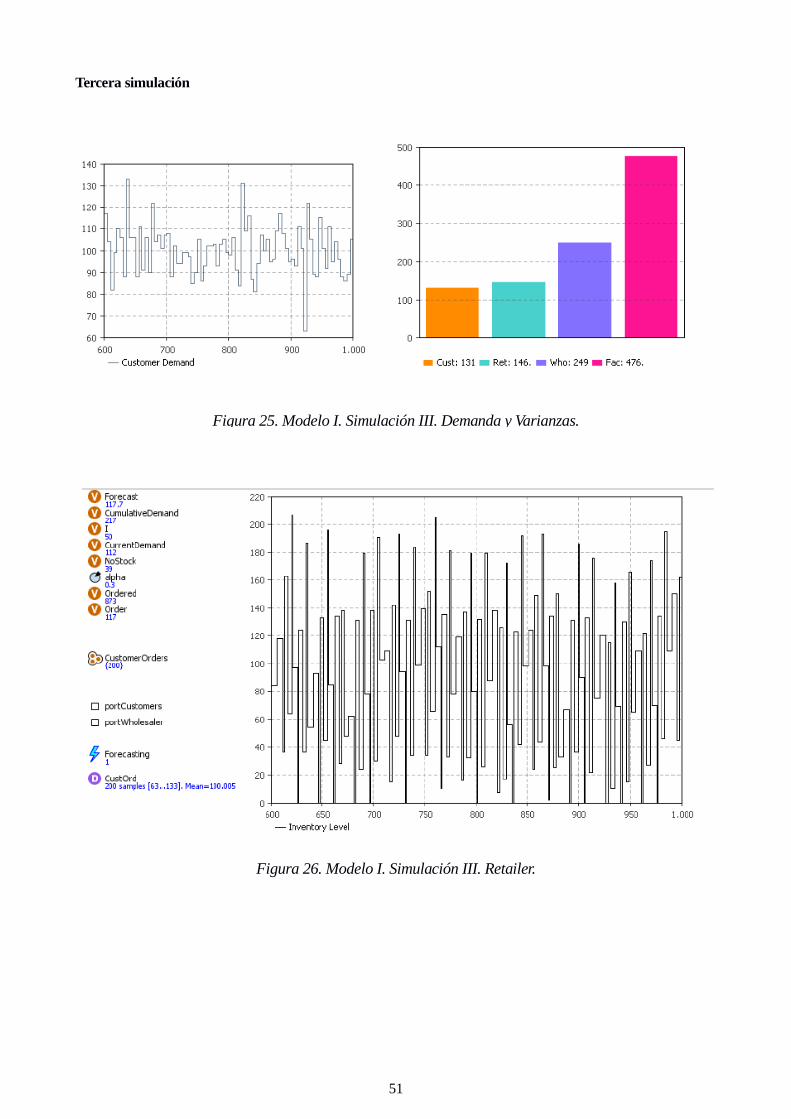
Figura 25. Modelo I. Simulación III. Demanda y Varianzas. 51
Figura 26. Modelo I. Simulación III. Retailer. 51
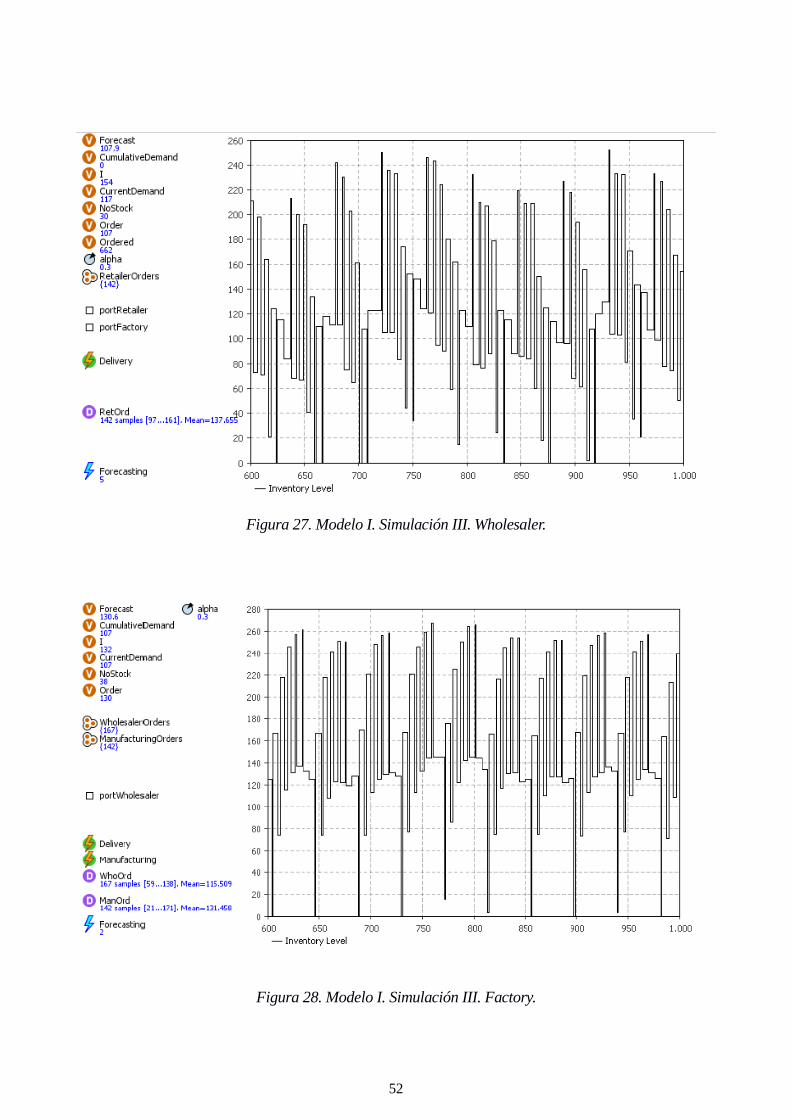
Figura 27. Modelo I. Simulación III. Wholesaler. 52
Figura 28. Modelo I. Simulación III. Factory. 52
Figura 29. Modelo II. Simulación I. Demanda y Varianzas. 53
Figura 30. Modelo II. Simulación I. Retailer. 53
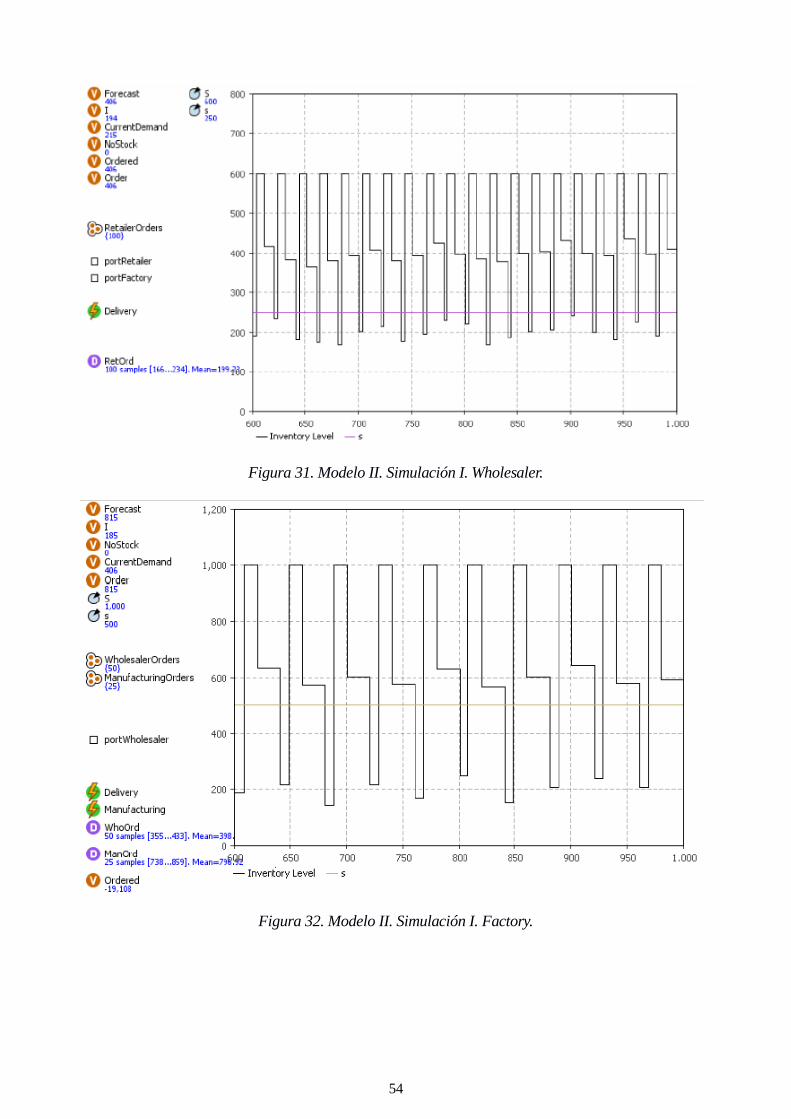
Figura 31. Modelo II. Simulación I. Wholesaler. 54
Figura 32. Modelo II. Simulación I. Factory. 54
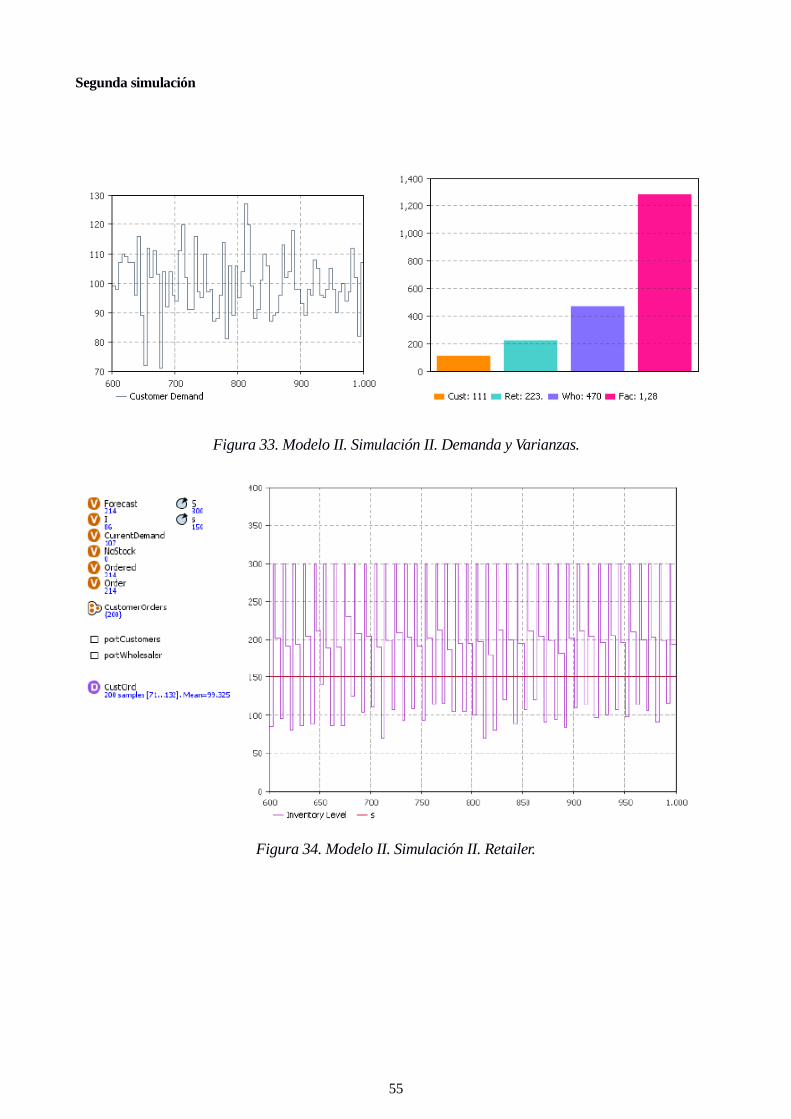
Figura 33. Modelo II. Simulación II. Demanda y Varianzas. 55
Figura 34. Modelo II. Simulación II. Retailer. 55
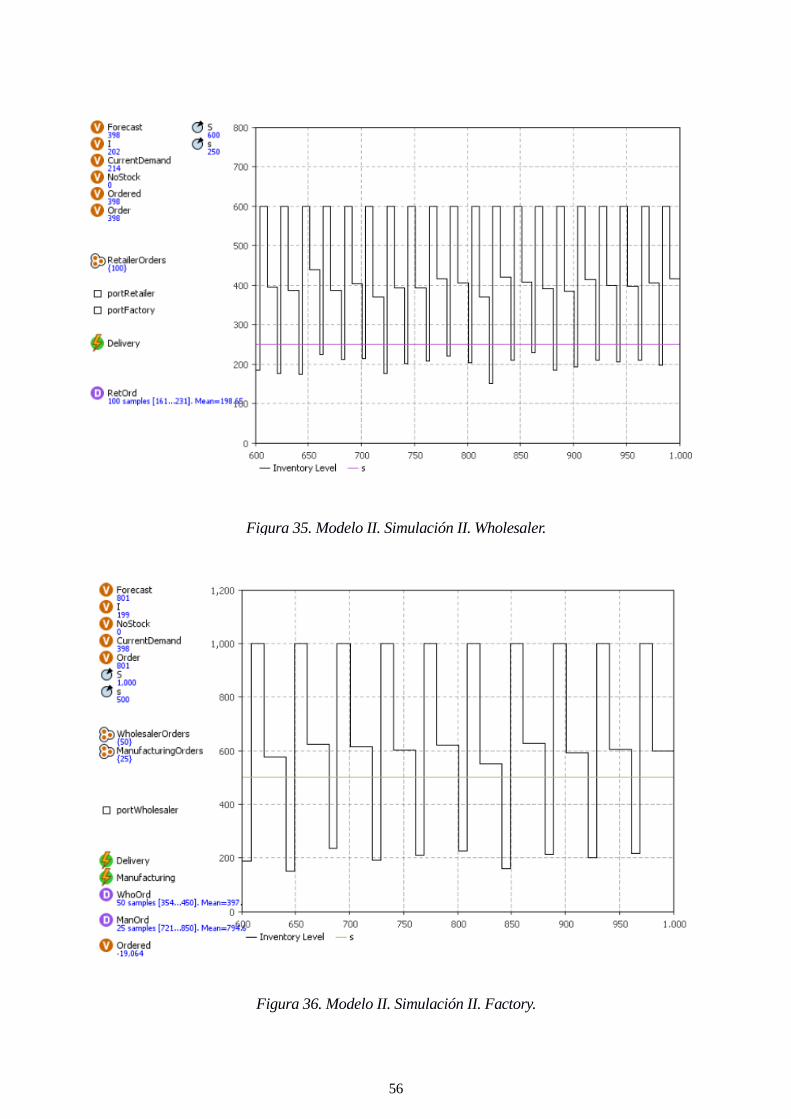
Figura 35. Modelo II. Simulación II. Wholesaler. 56
Figura 36. Modelo II. Simulación II. Factory. 56
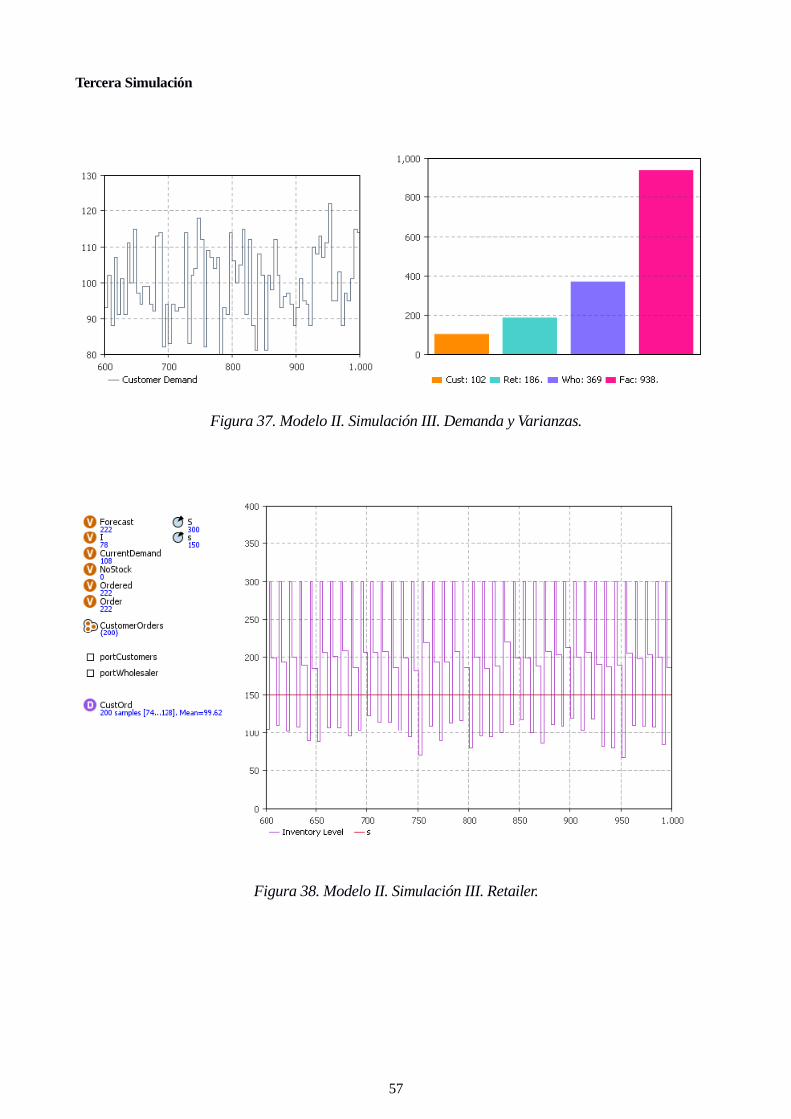
Figura 37. Modelo II. Simulación III. Demanda y Varianzas. 57

20
Figura 38. Modelo II. Simulación III. Retailer. 57
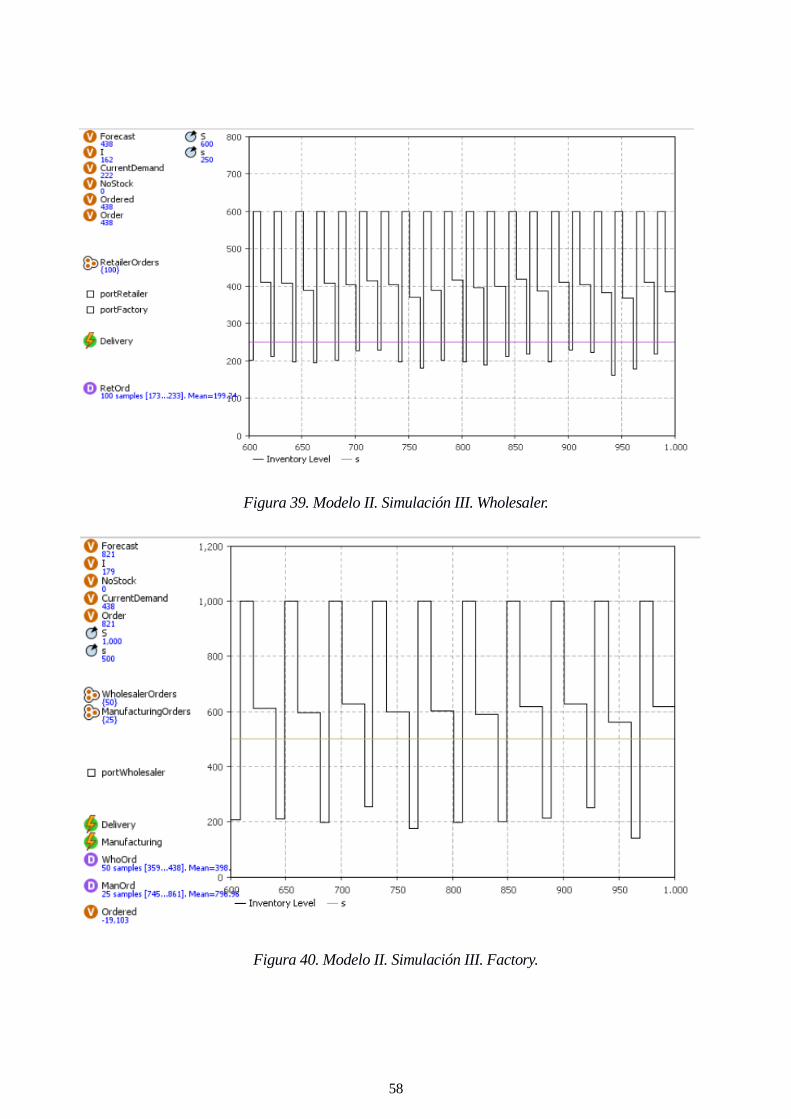
Figura 39. Modelo II. Simulación III. Wholesaler. 58
Figura 40. Modelo II. Simulación III. Factory. 58

21
Notación
BW BullWhip (efecto látigo)
σ Desviación típica
Max(a,b) Función máximo entre a y b
Normal(σ,μ) Función normal de media μ y desviación típica σ
Ft Previsión de la demanda en el periodo t
α Parámetro del ajuste exponencial
Dt Demanda en el periodo t
BW(n) Efecto látigo en la simulación n

22

23
1 SIMULACIÓN MULTI-AGENTE
Aunque podemos encontrar numerosas definiciones de Agent Based Simulation en la literatura, en la práctica
podemos definir el modelado basado en agentes como una aproximación descentralizada al diseño de nuestro
modelo, y que se centra en los individuos que lo componen. Durante el diseño de un modelo de simulación
multiagente, se identifican las entidades activas, es decir los agentes del modelo.
Los agentes del modelo pueden ser personas, empresas, productos, vehículos, ciudades, barcos o cualquier otra
entidad que participe de manera activa en nuestro estudio. Estos agentes son colocados en un entorno que se
asemeje a la realidad, se establecen las conexiones entre ellos y se realiza la simulación. De este modo, el
comportamiento global del modelo surge como resultado de las interacciones de todos los comportamientos
individuales.
Esta es una de las principales ventajas que nos ofrece este tipo de simulación, no es necesario conocer una gran
variedad de datos de nuestro caso de estudio, tan solo es necesario identificar los principales agentes, sus
características más relevantes y sus interacciones con otros agentes.
En el modelado tradicional, es usual tratar a los empleados, productos, proyectos y clientes de una empresa como
cantidades promediadas, entidades pasivas o recursos del proceso. Por ejemplo, en modelos de dinámica de
sistemas podemos encontrar suposiciones como “tenemos 200 empleados, capaces de producir 30 unidades a la
semana”, o “contamos con una flota de 1000 vehículos capaces de transportar 2 toneladas de producto al mes”.
Por otro lado, en la simulación de eventos discretos, se hace una visión de la empresa como un número de
procesos, es decir: “el producto llega a la estación de trabajo número 2 cada 5 minutos, donde un trabajador del
tipo C tarda una media de 10 segundos en procesarlo, el 2% del producto final de esta estación requiere de un
reprocesado”.
Este tipo de aproximaciones son realmente más poderosas que la que ocupa nuestro estudio, sin embargo, dichas
simulaciones obvian el hecho de que cada una de estas personas, productos, piezas o activos poseen sus propias
historias, intenciones, deseos, propiedades individuales y complejas interrelaciones. Por ejemplo, las personas
pueden tener distintas expectativas en función de sus ingresos y carrera dentro de la empresa, o es posible que su
productividad varíe significativamente dependiendo del día de la semana, turno o equipo de trabajo.
Los proyectos dentro de una misma empresa pueden interactuar entre ellos, en una fábrica de coches, si durante el
proceso de fabricación de un coche de tipo A ocurre un fallo que entorpece la fabricación del mismo, los
trabajadores centrados en la producción de coches tipo B se verán obligados a centrarse en los primeros.
También es posible que la decisión de un cliente final de nuestro producto se vea influenciada por otros
consumidores de su mismo nivel, o incluso por miembros de su familia. La simulación basada en agentes es capaz
de lidiar con todas estas limitaciones, y sugiere que el modelo sea creado centrándose en las individualidades que
están dentro y alrededor de nuestra empresa, sus comportamientos y sus conexiones. Estos nuevos modelos nos
permiten dar un paso adelante en el estudio y la comprensión de los modelos de negocio, principalmente en
aquellos que poseen un gran factor humano.
Llegados a este punto es interesante estudiar en qué campos es interesante aplicar la simulación multiagente. Los
mercados de las telecomunicaciones, seguros, salud y alquileres son mercados complejos y dinámicos donde los
clientes toman decisiones basándose en sus propias características y en otros factores que son fácilmente
modelables con nuestros modelos basados en comportamientos individuales, como puede ser la aceptación de un
producto por parte de otros consumidores.
El estudio de las epidemias es otro campo que encaja a la perfección con los modelos basados en agentes. En estos
modelos epidemiológicos las personas pueden ser susceptibles a contraer la enfermedad, infectados, recuperados o
inmunes a la misma. El modelo nos permite crear una imagen de la sociedad para la simulación, relacionando los
agentes de los diferentes tipos, así como sus interconexiones y sus cambios de estado, lo que nos permite una
mayor y más precisa previsión de la propagación de la enfermedad.
Sin embargo, no debemos encasillar a estos modelos únicamente en casos que incluyan a una elevada población.
Existen problemas de logística, fabricación, cadenas de suministro y otros procesos donde la simulación basada en
agentes funciona mejor que cualquier otra. Por ejemplo, en una cadena de suministros, los diferentes participantes
(fabricantes, mayoristas, minoristas, distribuidores, clientes finales) poseen sus propios objetivos y reglas y es
factibles representarlos como agentes.

24

25
2 ANYLOGIC
Anylogic es una herramienta de simulación que nos permite desarrollar nuestros modelos como Discrete Events,
System Dynamics, Agent-Based Simulation o una mezcla de ellos. De esta manera se convierte en un útil y
completo programa que nos permite representar la realidad de la mejor manera posible. Anylogic nos proporciona,
además, un catálogo de ejemplos que incluyen los tres tipos de modelos y diferentes ámbitos de negocio como
logística, salud o fabricación.
El programa incluye también una extensa guía con ejemplos ilustrados y con una explicación detallada de todo lo
que contiene y sus aplicaciones. Esta guía, junto con los anteriormente mencionados ejemplos, nos ha servido
como base para el desarrollo de nuestros modelos, haciendo más fácil el entendimiento del programa ya que la
literatura y ejemplos externos al programa son escasos, especialmente sobre Agent-Based Simulation.
2.1 Primeros pasos
Cuando decidimos crear un nuevo modelo, después de nombrarlo y elegir el directorio donde guardarlo, Anylogic
nos permite la opción de empezarlo desde cero, o de usar una plantilla ya existente. En nuestro caso será más
sencillo comenzar desde cero, controlando desde el principio todo el contenido de nuestro estudio.
La pantalla principal nos muestra a la izquierda un resumen esquematizado de nuestro proyecto y sus elementos,
en el centro visualización y propiedades del elemento seleccionado, y a la derecha el Palette donde están incluidos
todos los elementos que se pueden añadir a nuestro modelo organizados por categoría. Nuestro modelo creado
desde cero tan solo incluye un elemento llamado Main. Main será para nosotros el entorno donde incluiremos
todos los agentes y sus relaciones.
Como podemos observar Anylogic se presenta de una manera sencilla y limpia, y con una manera intuitiva de
añadir elementos nuevos al modelo mediante el Palette, el cual explicaremos más adelante.
Figura 1. Página principal de Anylogic.
26
2.2 Creación de los agentes
Este es un paso primordial, por lo que antes de hacerlo es conveniente conocer bien nuestro problema e identificar
correctamente los participantes del mismo. En un modelo de cadena de suministros, a priori, los agentes parecen
claros. Por ejemplo, si queremos modelar la rapidez con la que se expande una enfermedad entre la población,
tendríamos dos agentes. Un agente sería “Población Sana”, y el otro “Población Infectada”. Marcaríamos los
parámetros de infección, cura y densidad de cada una de las poblaciones y simularíamos.
Para crear un agente hay que hacer click con el botón derecho en el nombre del proyecto, y en el menú desplegado
New>Active Object Class. Los últimos detalles de la creación del nuevo agente, son darle un nombre y una
descripción. La descripción es opcional, pero es recomendable en modelos con gran cantidad de agentes o en
modelos con agentes de origen similar.
Una vez creados nuestros agentes es hora de definirlos y darle las propiedades adecuadas para el correcto
funcionamiento del modelo. Para ello utilizaremos el Palette, que nos permitirá de manera sencilla atribuir
eventos, características y variables a nuestros agentes, entre otras funcionalidades.
2.3 Palette
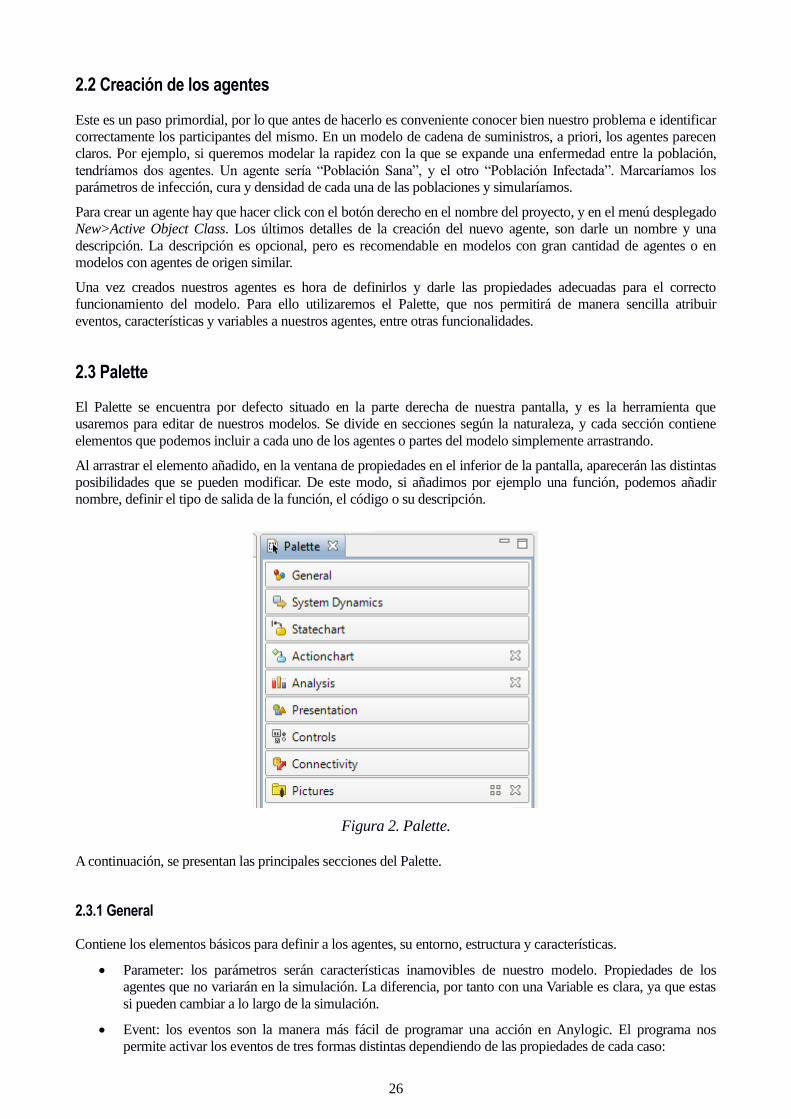
El Palette se encuentra por defecto situado en la parte derecha de nuestra pantalla, y es la herramienta que
usaremos para editar de nuestros modelos. Se divide en secciones según la naturaleza, y cada sección contiene
elementos que podemos incluir a cada uno de los agentes o partes del modelo simplemente arrastrando.
Al arrastrar el elemento añadido, en la ventana de propiedades en el inferior de la pantalla, aparecerán las distintas
posibilidades que se pueden modificar. De este modo, si añadimos por ejemplo una función, podemos añadir
nombre, definir el tipo de salida de la función, el código o su descripción.
A continuación, se presentan las principales secciones del Palette.
2.3.1 General
Contiene los elementos básicos para definir a los agentes, su entorno, estructura y características.
Parameter: los parámetros serán características inamovibles de nuestro modelo. Propiedades de los
agentes que no variarán en la simulación. La diferencia, por tanto con una Variable es clara, ya que estas
si pueden cambiar a lo largo de la simulación.
Event: los eventos son la manera más fácil de programar una acción en Anylogic. El programa nos
permite activar los eventos de tres formas distintas dependiendo de las propiedades de cada caso:
Figura 2. Palette.

27
◦ Timeout triggered event: el evento ocurre cuando un contador llega a su fin, nos permite que un
evento suceda en el momento concreto deseado. También podemos especificar si el evento es cíclico
o puntual.
◦ Condition triggered event: especificamos una condición en las propiedades del evento, y este se
ejecuta cuando se cumple la condición.
◦ Rate triggered event: suele usarse para programar una serie de sucesos independientes, ya que siguen
una distribución de Poisson.
Dynamic Event: los eventos dinámicos siguen la misma base que los eventos previamente explicados,
pero nos ofrecen la ventaja de que el mismo evento dinámico puede estar desarrollándose más de una vez
en el mismo instante de tiempo.
Plain variable: utilizaremos las variables para aquellos datos del modelo que sí que cambiarán con el
tiempo. Por ejemplo, el inventario o la cantidad de producto terminado.
Collection variable: las colecciones de variables nos permiten almacenar datos de aquellas variables
cuyos datos históricos son de interés o serán utilizados en el futuro, como puede ser la demanda de los
clientes.
Function: mediante las funciones, Anylogic nos permite definir nuestras propias funciones y operar así
con los datos obtenidos en el programa.
Table function: este comando nos permite, además, definir las funciones en forma de tabla.
Port: los puertos nos permiten conectar varios agentes del modelo entre ellos y el envío de mensajes entre
ellos. Serán esenciales en los modelos que explicaremos más adelante.
Connector: los conectores son las herramientas que nos permitirán unir los Ports de los diferentes agentes.
Environment: el programa nos permite definir un entorno específico en el que desarrollar nuestro modelo.
No es estrictamente necesario, aunque puede resultar bastante útil para aquellos entornos con propiedades
especiales.
Con la ayuda de estos elementos seremos capaces de definir cada uno de los agentes de nuestro modelo, sus
relaciones y algunas de las acciones propias de los mismos agentes o del sistema. Sin embargo, necesitaremos de
más herramientas de Anylogic si queremos una mayor complejidad y riqueza en nuestro problema.
2.3.2 Actionchart
Los Actioncharts son herramientas gráficas, intuitivas y fáciles de incluir en el modelo que nos permitirán
implementar diagramas de flujo.
Action Chart: para generar un nuevo actionchart basta con arrastrar el icono desde el Palette al agente. En
las propiedades generales, además de características visuales como color o nombre, es posible definir el
tipo de salida que devuelven los cálculos al final del diagrama.
Code: un bloque Code inserta una acción que será ejecutada cuando el diagrama llegue al mismo.
Decision: será necesario insertar este bloque cuando el diagrama deba dividirse en dos opciones, según si
la condición para la toma de decisión se cumple o no. Dicha decisión será definida en las propiedades
generales del bloque.
Local variable: si utilizamos el diagrama para representar un algoritmo con varios cálculos intermedios,
puede ser necesario utilizar este bloque para el almacenaje de resultados.
While Loop: dentro de un While Loop se define una acción o serie de acciones que serán ejecutadas
mientras la condición de entrada al bucle sea verdadera.
Do While Loop: funciona del mismo modo que el While Loop, con la diferencia de que el Do While
Loop se ejecuta al menos una vez, aunque la condición de entrada no se cumpla.
For Loop: se ejecutan las acciones definidas en su interior tantas veces como se especifique en la
condición. Tanto en este bucle como en los dos anteriores, la condición a cumplir se define en las
propiedades generales.

28
Return: especifica el valor que devuelve el diagrama cuando llega a este bloque.
Break: si el diagrama llega a este bloque, se detiene la iteración en curso.
2.3.3 Analysis
La pestaña de Analysis nos permitirá ahondar en el estudio de nuestro modelo y representar gráficamente
resultados y variables del sistema. Las herramientas de análisis son la parte más compleja de Anylogic, pero a su
vez, son la que nos permiten explotar al máximo el software.
Data set: permite almacenar datos de tipo entero. Actualiza los valores máximos y mínimos, sin embargo,
la memoria es limitada y solo almacena un número determinado de los últimos.
Statistics: calcula valores estadísticos como la media de una serie de datos de tipo entero. Hay que hacer
distinción entre datos continuos en el tiempo o discretos. Para datos continuos y persistentes en el tiempo
de manera, por ejemplo, diaria, para calcular la media se tendrán en cuenta los datos de todos los días,
incluso si son nulos. Para eventos discretos, que solo ocurren de manera aislada, el cálculo de la media
será la suma total partido el número de muestras.
Histogram data: calcula los indicadores estadísticos más típicos de los datos dados, construye un PDF con
distribución de probabilidad o función de densidad.
Histogram 2D data: colecta información a partir de una serie de histogramas.
Bar chart: gráfico comparativo entre variables en forma de barras.
Stack chart: gráfico de barras similar al anterior, pero en el que las variables aparecen apiladas en una
misma barra.
Pie chart: muestra la distribución de una seria de valores a través de la división por sectores de un círculo.
Muy útil para representar porcentajes.
Plot: comparación gráfica entre valores de dos variables con un eje X y un eje Y.
Time plot: en este caso el eje X es el tiempo, y en el eje Y se representan los datos temporales de la
variable deseada.
Time color chart: muestra la tendencia de una serie de datos en forma de barra con divisiones
horizontales.
Histogram: representa los datos recogidos por un Histogram Data.
Figura 3. Menú Actionchart

29
Histogram 2D: mismo caso que el anterior, pero con Histogram 2D Data.
2.3.4 Otros
Además de estos, existen más utilidades dentro del Palette. Algunas tienen un carácter meramente gráfico y
estético como las pertenecientes a la pestaña Presentation, que nos permitirá añadir complementos como texto o
imágenes, o la pestaña Pictures, que incorpora una serie de gráficos típicos como una fábrica o un almacén.
También hay otras pestañas que no usaremos al no aplicar al objetivo de nuestro estudio, como la de System
Dynamics.
2.4 Simulación
Para la simulación, Anylogic genera de manera automática una pestaña dentro del modelo donde se pueden
personalizar características tales como el tiempo de simulación, uso de CPU o ventanas de presentación de la
simulación. Esto último hace referencia a que al hacer una simulación, emerge una ventana con un título y un
texto, más un botón de correr la simulación.
Esta ventana es totalmente modificable, a nivel de texto, imágenes y botones. Especialmente interesante las
posibilidades que ofrece los botones, pues con los conocimientos suficientes, el tiempo y los medios se pueden
construir modelos complejos pero fácilmente simulables, donde cada botón redireccione a unas simulación, texto
o imagen.
Figura 4. Menú Simulación.

30

31
3 LA CADENA DE SUMINISTRO
El eje central de nuestro estudio será la cadena de suministro. La cadena de suministro, en mayor o menor escala
está presente en todos los procesos industriales, y mediante ella se conectan los distintos escalones del mercado.
Estos escalones trabajan por y para el correcto funcionamiento de la cadena, con el objetivo principal de satisfacer
al siguiente escalón, y al escalón final.
Un cliente satisfecho que recibe la cantidad deseada de producto, en el tiempo acordado, y sin costes adicionales
será un cliente potencial en el futuro. Alcanzar estos niveles para una empresa no es fácil, ya que depende de
factores internos y externos que no siempre pueden controlarse. La previsión de la demanda, el factor humano, la
competencia, o la maquinaria son algunos de estos factores.
Si a estos factores le añadimos, además, que la empresa forma parte de un engranaje y que es un eslabón más
dentro de una cadena, donde cada una de las partes tiene estos mismos inconvenientes, la tarea de tener al cliente
siempre satisfecho es todavía más compleja. Debido a esto, la colaboración dentro de la cadena es fundamental a
la hora de alcanzar un mejor servicio con los clientes.
Podemos pensar que una cadena de suministro tipo cuenta con una empresa fuente de materias primas, que
suministra a una fábrica que convierte dicha materia en producto y le añade valor. Esta fábrica a su vez, puede
suministrar a un mayorista, que almacena en producto en grandes cantidades para venderlo al minorista, que es el
último paso antes del cliente final. Todo esto sin contar otros intermediarios como empresas de transporte
especializadas en la distribución de mercancía.
Las grandes multinacionales, pueden tener capacidad económica suficiente para realizar varias tareas dentro de la
cadena, desempeñando varios papeles a la vez. Esto permite, por ejemplo, a las principales compañías de
refrescos o cerveza poder ser fabricantes, mayoristas y distribuidores al mismo tiempo, por lo que en la cadena de
suministro del producto que ellos mismo venden únicamente tienen relación con el proveedor de materias primas
y con el minorista.
Esto puede ser de vital importancia a la hora de coordinar una cadena, ya que una misma empresa controla varias
etapas de la misma. Si en una cadena, cada una de las empresas busca únicamente su beneficio propio, olvidando
al resto de componentes de la cadena, los resultados serán presumiblemente peores que si existe una actitud
colaborativa entre todos los escalones. Por este motivo, para un correcto análisis es importante considerar a la
cadena de suministro como el conjunto, y no como cada empresa por separado.
3.1 Los costes logísticos
La importancia de que la cadena de suministro funcione de manera eficaz y fluida, es la cantidad de costes
asociados que tiene para las empresas. Costes de gestión de compras, de almacenamiento, inventario o la
distribución de los productos ya terminados a los clientes, todo esto unido al personal involucrado en todas las
operaciones mencionadas.
¿Cómo repercute una mala gestión de la logística a una empresa? Imaginemos a una empresa que casi nunca tiene
inventario para servir, perdería a todos los clientes. O a una empresa que los costes de transporte de sus productos
son mayores que su precio de venta, iría a la bancarrota. Por esto, las empresas deben invertir para tener personal
de calidad y cualificado encargado de las tareas logística y prevenir los problemas, como el efecto látigo.
3.2 El efecto látigo
Ya en 1961, el inventor de la Dinámica de Sistemas Jay Forrester, mostró en sus estudios la posibilidad de que se
producía un aumento de la demanda de un componente de la cadena a su proveedor a medida que subimos en la
cadena.
El efecto látigo es un indicador claro de ineficiencia de una cadena de suministro, y conlleva consigo una serie de
errores muy costosos para las empresas, como el exceso de inventario o la rotura de stock. Hay cadenas más
propensas que otras a sufrir las consecuencias del efecto látigo, ya que la variabilidad de la demanda es uno de los
mayores causantes del mismo.

32
3.2.1 Causas
Lee et al [1], señalaban cuatro principales causas del efecto látigo: los métodos utilizados para el pronóstico de la
demanda, la formación de los lotes de compra, variaciones en los precios de los productos y la realización de
pedidos de cantidad excesiva a los proveedores con la intención de evitar la rotura de stock.
Previsión de la demanda
Todas las compañías de la cadena cuentan con una previsión de la demanda, necesaria para un correcto
funcionamiento interno. Normalmente, la previsión de la demanda está basada en el histórico de los pedidos
recibidos por los el siguiente escalón aguas abajo de la cadena. Cuando se recibe un pedido del cliente, los datos
recibidos proporcionan información sobre pedidos futuros y el responsable de previsión de la demanda de la
empresa actualizará sus previsiones.
Pongamos por ejemplo al mayorista de la cadena, que usa para prever su demanda el método del ajuste
exponencial, cuando este recibe un nuevo pedido actualiza sus previsiones sobre qué cantidades tendrá que pedir
en el futuro a su distribuidor. Estas previsiones incluyen el nivel de stock considerado necesario para satisfacer la
demanda y una cantidad de stock de seguridad, cuya magnitud dependerá de la política de la empresa y las
fluctuaciones del mercado.
En un entorno con tiempos significativos de entrega en los pedidos, podemos encontrarnos grandes cantidades en
concepto de stock de seguridad, ante el riesgo de no poder satisfacer la demanda, y el resultado es que la
fluctuación de las cantidades que pide el mayorista a lo largo del tiempo es mucho mayor que la reflejada en la
demanda que recibe.
Por otro lado, el distribuidor, recibe una demanda ya ajustada por el mayorista, con las ya mencionadas
fluctuaciones. Cuando el distribuidor realice la previsión de su demanda estará tratando datos que ya han sido
previamente tratados, aumentado más las fluctuaciones. Por tanto, a medida que pasa el tiempo y se avanza en la
cadena, las variaciones en los pedidos serán más significativas.
Formación de los lotes
A la hora de realizar los pedidos aguas arriba de la cadena de suministro, las empresas no lo hacen
inmediatamente cuando su inventario decrece. Se acumula cierta demanda y se preparan determinados lotes de
pedidos. Existen dos políticas de pedidos, periódica o push.
En vez de lanzar pedidos constantemente, las empresas optan por pedidos semanales, quincenales, etc. Uno de los
principales motivos son los costes asociados a la formalización de un pedido, que pueden ser muy elevados en
función de medio de transporte, tipo de producto o distancia. Esto hace que las empresas esperen a tener un
tamaño de pedido notable antes de lanzarlo, optimizando el precio del transporte por unidad de producto.
Sin embargo, cuanto mayor sean los periodos entre pedidos, mayor será la variabilidad de los mismos. Si una
empresa lanza a su distribuidor pedidos mensuales, y se produce un pico de demanda concentrado en un par de
días del mes, y el resto del mes la demanda es muy baja, la variabilidad será mejor que si se trabajara con pedidos
quincenales o semanales. Por tanto, los componentes de la cadena deberán buscar el equilibrio entre el coste y la
variabilidad de los pedidos.
Aquellas empresas que funcionan con una política de pedidos push también sufren fluctuaciones en su demanda y
por tanto en sus pedidos en forma de oleadas. Este hecho se retrata fácilmente en empresas donde se mide
regularmente a los empleados o en las que se realizan periodos de evaluación, ya que la productividad del
personal de venta se ve aumentada, lo que provoca picos de venta concretados en momentos puntuales.
Fluctuaciones de precios
Muchas de las compras entre componentes de la cadena de suministro se producen de manera adelantada. Es
decir, se compra producto antes de necesitarlo en stock. Esto puede ser debido a descuentos por parte del
suministrador, fluctuaciones a la baja de los precios o si por ejemplo el coste de almacenamiento es menor que el
coste de pedido.
El resultado de que comprar con antelación se convierta en una norma la cadena, es que cuando haya precios
bajos, se harán grandes pedidos, y cuando haya precios altos, los niveles de inventario serán lo suficientemente
altos y no habrá pedidos o serán de poca cantidad. Por lo tanto, los pedidos serán muy variables.

33
Rotura de stock
Uno de los mayores problemas a los que se puede enfrentar una empresa es la rotura de stock, la escasez de
inventario. No tener producto suficiente para dar servicio a un cliente, puede significar la pérdida de compradores
y beneficio económico. Una buena previsión de la demanda y conocimiento de tus clientes puede ayudar a las
empresas a comprender como fluctuará la misma, cuando habrá picos de demanda o épocas donde las ventas
disminuyan y con esta información actuar en consecuencia, tratando siempre de tener el nivel de inventario
adecuado.
Sin embargo, en ocasiones las empresas no disponen de esta clase de información, o la que disponen no es de
calidad, o simplemente se encuentran en un mercado donde la demanda es muy variable. Ante este escenario, hay
compañías que toman la decisión de realizar pedidos muy por encima de su demanda real para evitar la escasez de
inventario, y cuentan con un stock de seguridad desproporcionado. Esto conlleva también unos costes asociados, y
al final para tratar de solucionar un problema se está incurriendo en otro.
A esto hay que sumarle, que cuando las empresas saben que no van a tener el nivel de inventario suficiente para
satisfacer completamente la demanda de todos sus clientes, tienden a racionalizar el servicio. Esto provoca una
reacción en los clientes, que sabiendo que no recibirán la totalidad de lo que pidan, exageran su demanda. Una vez
que la empresa dispone ya del stock suficiente para satisfacer el resto de la demanda no servido previamente, se
encuentra con que la supuesta demanda de los clientes ha desaparecido o con cancelaciones de pedidos.
3.2.2 Medida
Viendo la repercusión que puede tener en el correcto funcionamiento de una cadena y de una empresa el efecto
látigo, parece primordial disponer de alguna herramienta de medida que nos permita cuantificar el problema. El
método clásico para medir el efecto látigo en un escalón de la cadena, es el cociente entre la varianza de los
pedidos realizados y los pedidos recibidos:
Si el resultado de este cociente es mayor que 1, hay efecto látigo. En este trabajo señalábamos anteriormente la
importancia de considerar la cadena de suministro como un conjunto global y no como individuales, por lo que
sería necesario poder medir el efecto látigo de la cadena entera. Como los pedidos emitidos por un eslabón de la
cena, son los recibidos por el eslabón siguiente, el efecto látigo de la cadena al completo sería el productorio de los
efectos látigos de cada uno de los componentes.

34
35
4 MODELO
4.1 Agentes
El primer paso a la hora de trabajar con este tipo de simulación es la definición de los agentes. Para una correcta
definición de los mismos, es necesario conocer el sistema que vamos a modelar. Es nuestro caso, trabajaremos en
un entorno en serie, es decir, una cadena en la que solo hay un representante de cada escalón. El fabricante sirve al
minorista, que vende al minorista, y este último al cliente final.
Para la creación de los agentes seguiremos los pasos especificados previamente en este mismo trabajo. Podríamos
pensar que tendremos cuatro agentes, sin embargo, no será necesario definir un agente para el cliente final. Esto se
puede explicar debido a que la única intervención dentro de la cadena del consumidor final es pedir producto al
minorista, y esta función es fácilmente modelable sin necesidad de definir un agente exclusivamente para esto.
En definitiva, los agentes de la cadena serán identificados como Retailer (Minorista), Wholesaler (Mayorista) y
Factory (Fabricante). Estos agentes necesitan de unas características y funciones que permitan un funcionamiento
correcto del modelo, así como las interrelaciones correspondientes.
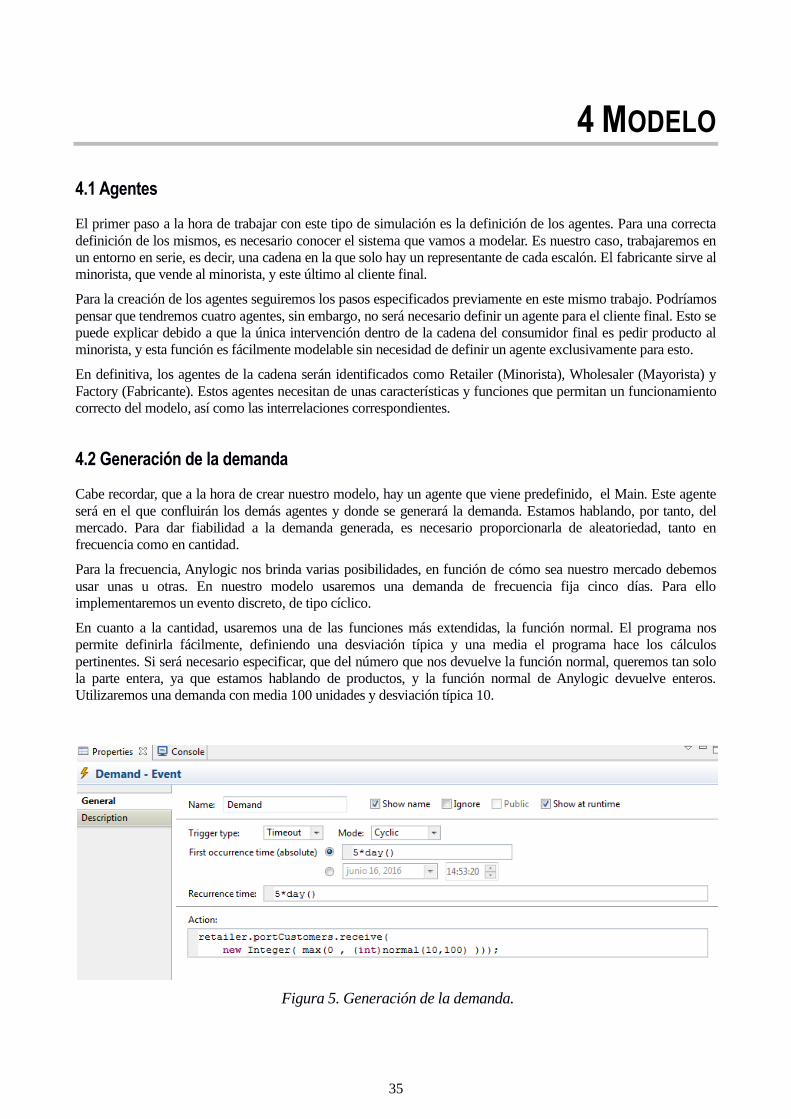
4.2 Generación de la demanda
Cabe recordar, que a la hora de crear nuestro modelo, hay un agente que viene predefinido, el Main. Este agente
será en el que confluirán los demás agentes y donde se generará la demanda. Estamos hablando, por tanto, del
mercado. Para dar fiabilidad a la demanda generada, es necesario proporcionarla de aleatoriedad, tanto en
frecuencia como en cantidad.
Para la frecuencia, Anylogic nos brinda varias posibilidades, en función de cómo sea nuestro mercado debemos
usar unas u otras. En nuestro modelo usaremos una demanda de frecuencia fija cinco días. Para ello
implementaremos un evento discreto, de tipo cíclico.
En cuanto a la cantidad, usaremos una de las funciones más extendidas, la función normal. El programa nos
permite definirla fácilmente, definiendo una desviación típica y una media el programa hace los cálculos
pertinentes. Si será necesario especificar, que del número que nos devuelve la función normal, queremos tan solo
la parte entera, ya que estamos hablando de productos, y la función normal de Anylogic devuelve enteros.
Utilizaremos una demanda con media 100 unidades y desviación típica 10.
Figura 5. Generación de la demanda.

36
4.3 Comunicación con el minorista
Ya hemos visto como se genera la demanda por parte del cliente pero, ¿cómo la recibe el minorista? Bien, una de
las partes clave de la cadena de suministro es la interrelación, ya que el flujo tanto de información como de
producto es constante, y para ello es necesario definir los Ports. Cada uno de los agentes tendrá unos ports u otros
dependiendo de aquellos agentes con los que tenga relación.
Por lo que el minorista tiene un PortCustomer, que lo une al consumidor final, y un PortWholesaler, que define la
conexión con el mayorista. El mayorista por su parte, tiene un PortRetailer, que es el que hace el camino inverso
entre minorista y el mayorista, y un PortFactory que lo conecta con el fabricante. Por último, el fabricante solo
cuenta con un PortWholesaler ya que únicamente tiene trato con el mayorista.
Para que estas conexiones sean efectivas, es necesario incluir los agentes en el agente donde hemos decidido que
se relacionan, el Main. Y una vez ahí conectar los puertos correspondientes para que el flujo de información y de
producto sea efectivo.
De esta manera, es como en la figura anterior, vemos que en la acción que se ejecuta en el evento de la generación
de la demanda, directamente indicamos que el minorista recibe esa cantidad de demanda en el puerto que lo une
con el cliente final. Para que el programa no de errores de compilación, es necesario definir en los puertos que es
lo que se recibe y que es lo que se manda, es nuestro caso siempre serán datos de tipo entero.
Dentro del agente Retailer, hay que definir qué uso va a dar el minorista de esta información. Cómo se ve afectado
su inventario, que uso hace de esta información, como recopila los datos, etc.
4.4 Variables y parámetros comunes
Es obvio, que aunque cada agente tiene su propio comportamiento, existen una serie de características que son
comunes a todos ellos, y son las que explicaremos en este apartado. Por ejemplo, aunque cada uno de los
componentes de la cadena tenga un nivel distinto, o una manera diferente a los demás de gestionarlo, todos tienen
inventario. Por tanto, será necesario definir para todos ellos una variable inventario.
Para definir estas variables, como explicamos anteriormente, basta con arrastrar el icono correspondiente desde el
Palette hasta el marco del agente en cuestión que le aplica esta variable. Podríamos pensar, que al tener tres
inventarios distintos, uno para cada agente, tendremos que dotar a cada uno de ellos con un nombre específico,
como por ejemplo, RetailerStock o FactoryStock. Pero al estar definiendo la variable dentro de cada agente, esto
no es necesario, pues es una variable exclusiva de cada uno.
En definitiva, llamaremos a las tres variables de la misma manera, I, uno dentro del Retailer, otro en el Wholesaler
y el último en el agente Factory. De esta manera, si llamamos a dicha variable dentro de cada uno de los agentes
para actualizar el inventario, bastará con usar la denominación establecida. Esto será muy útil, pues ayudará a
estandarizar ecuaciones que serán válidas y extensibles a todos los agentes. Esta variable inventario I, será de tipo
entero.
Explicado esto, queda claro como referenciar el nivel de stock del minorista, dentro del campo del minorista, pero
también es posible hacerlo en otros campos donde este agente esta incluido. Si queremos comparar o representar
los niveles de inventario en el agente Main, que es el que estamos usando como mercado y donde hemos incluidos
todos los agentes, será necesario especificar antes de la variable, a que agente pertenece. De este modo, el
inventario del minorista sería retailer.I, diferenciándolo así de los otros dos.
Otras variables comunes a los tres agentes serán Forecast, CumulativeDemand, CurrentDemand, Order, Ordered y
NoStock. Las variables Forecast y Order serán de tipo real y entero respectivamente, y en estas variables
guardaremos las previsiones de la demanda, cuyo cálculo y procedimiento será explicado más adelante.
También será útil para la previsión de las demandas de los periodos venideros la variable CumulativeDemand, y
en ella será donde iremos sumando la demanda acumulado donde los intervalos de tiempos que se estimen
oportunos. Al ser otra variable que también trabaje con cantidades de producto, igualmente será de tipo entero.
Por otro lado, las variables CurrentDemand y NoStock, tendrán que ver con el nivel de servicio que está prestando
la empresa a sus clientes y con la gestión del inventario. También serán de tipo entero.

37
Existe otra variable que es común en uso a todos los agentes, pero que por claridad no lo es en nombre. Se trata de
una variable del tipo Collection Variable que almacene a modo de lista de variables enteras los pedidos recibidos
por el cliente. CustomerOrders es el nombre que recibe esta variable en el minorista, y en ella se almacenarán
todos los pedidos históricos del consumidor final. RetailerOrders, para el mayorista y WholesalerOrders para el
fabricante.
El fabricante por su parte tiene otras dos variables muy similares a las anteriores y que servirán para el cálculo de
las órdenes de fabricación. La primera, Order, de tipo entero y donde se almacenará la orden de fabricación
correspondiente al siguiente periodo. La segunda, de tipo Collection Variable, será ManufacturingOrders, de tipo
lista de variables enteras y se usará para guardar los datos históricos de las órdenes de fabricación.
Además de estas variables también tendremos parámetros, que no variarán en ningún momento de la simulación
su valor. Estos parámetros y su uso vendrán definidos en función de la política de pedidos que tenga la empresa y
son:
Alpha: constante que utilizaremos para el cálculo de la demanda futura en el alisado exponencial.
S: máximo stock, inventario objetivo.
s: nivel mínimo de inventario admisible, punto de pedido.
4.5 Aprovisionamiento
En este trabajo para no limitarnos a un único tipo de simulación, aprovecharemos las facilidades de Anylogic e
implementaremos dos políticas de pedido distintas.
4.5.1 Ajuste Exponencial
Este método es fácil de implementar y práctico para aquellos escenarios con demanda aleatoria. Tan solo serán
necesarios tres datos para calcular la previsión de la demanda del siguiente periodo: los datos de demanda del
periodo actual, la previsión de la demanda que se hizo para el periodo actual y el coeficiente de alisado.
11 *-1* ttt Fα+Dα=F
Donde F representa la previsión, D la demanda real y α el coeficiente de alisado. ¿Cómo trasladar esto a nuestro
modelo? Vamos a considerar que las empresas realizan pedidos semanales, y calculando la cantidad a pedir con el
método anteriormente descrito.
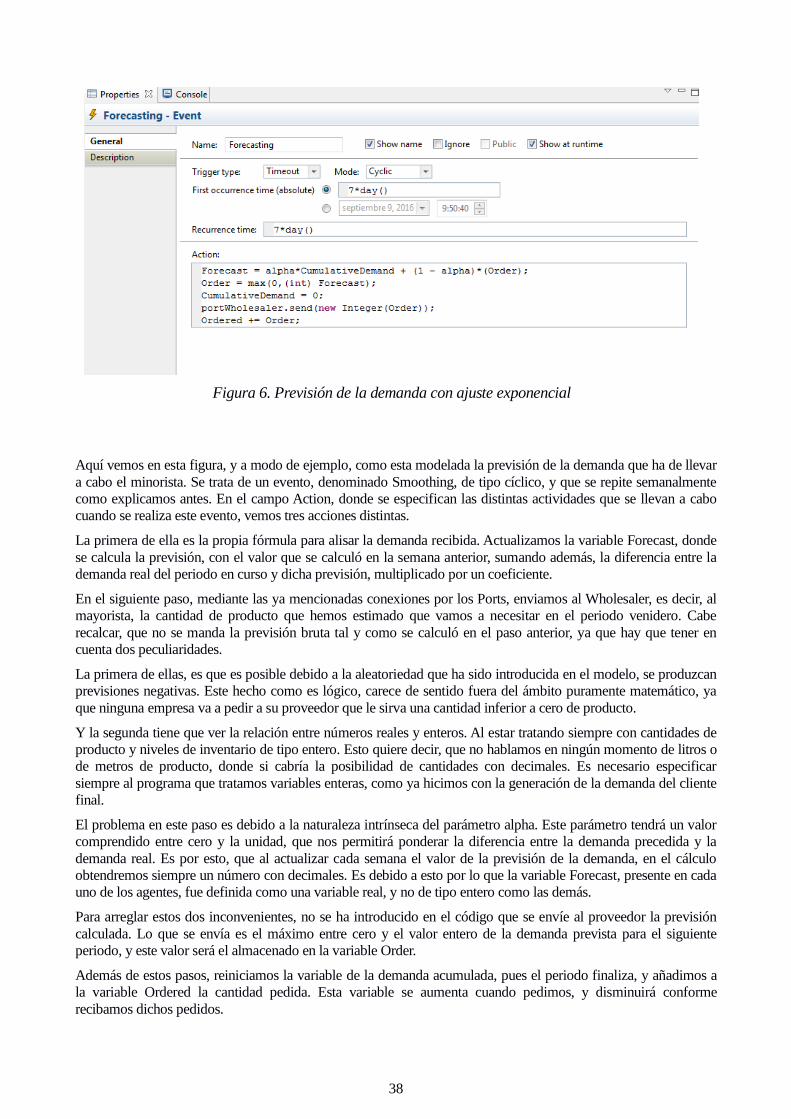
Al ser una acción que se repetirá cíclicamente cada 7 días, lo ideal es modelar estos cálculos con evento. Dicho
evento será de tipo Cyclic, y esto nos permitiría también variar fácilmente si queremos simular pedidos
quincenales o mensuales, cambiando el tiempo de recurrencia.
38
Aquí vemos en esta figura, y a modo de ejemplo, como esta modelada la previsión de la demanda que ha de llevar
a cabo el minorista. Se trata de un evento, denominado Smoothing, de tipo cíclico, y que se repite semanalmente
como explicamos antes. En el campo Action, donde se especifican las distintas actividades que se llevan a cabo
cuando se realiza este evento, vemos tres acciones distintas.
La primera de ella es la propia fórmula para alisar la demanda recibida. Actualizamos la variable Forecast, donde
se calcula la previsión, con el valor que se calculó en la semana anterior, sumando además, la diferencia entre la
demanda real del periodo en curso y dicha previsión, multiplicado por un coeficiente.
En el siguiente paso, mediante las ya mencionadas conexiones por los Ports, enviamos al Wholesaler, es decir, al
mayorista, la cantidad de producto que hemos estimado que vamos a necesitar en el periodo venidero. Cabe
recalcar, que no se manda la previsión bruta tal y como se calculó en el paso anterior, ya que hay que tener en
cuenta dos peculiaridades.
La primera de ellas, es que es posible debido a la aleatoriedad que ha sido introducida en el modelo, se produzcan
previsiones negativas. Este hecho como es lógico, carece de sentido fuera del ámbito puramente matemático, ya
que ninguna empresa va a pedir a su proveedor que le sirva una cantidad inferior a cero de producto.
Y la segunda tiene que ver la relación entre números reales y enteros. Al estar tratando siempre con cantidades de
producto y niveles de inventario de tipo entero. Esto quiere decir, que no hablamos en ningún momento de litros o
de metros de producto, donde si cabría la posibilidad de cantidades con decimales. Es necesario especificar
siempre al programa que tratamos variables enteras, como ya hicimos con la generación de la demanda del cliente
final.
El problema en este paso es debido a la naturaleza intrínseca del parámetro alpha. Este parámetro tendrá un valor
comprendido entre cero y la unidad, que nos permitirá ponderar la diferencia entre la demanda precedida y la
demanda real. Es por esto, que al actualizar cada semana el valor de la previsión de la demanda, en el cálculo
obtendremos siempre un número con decimales. Es debido a esto por lo que la variable Forecast, presente en cada
uno de los agentes, fue definida como una variable real, y no de tipo entero como las demás.
Para arreglar estos dos inconvenientes, no se ha introducido en el código que se envíe al proveedor la previsión
calculada. Lo que se envía es el máximo entre cero y el valor entero de la demanda prevista para el siguiente
periodo, y este valor será el almacenado en la variable Order.
Además de estos pasos, reiniciamos la variable de la demanda acumulada, pues el periodo finaliza, y añadimos a
la variable Ordered la cantidad pedida. Esta variable se aumenta cuando pedimos, y disminuirá conforme
recibamos dichos pedidos.
Figura 6. Previsión de la demanda con ajuste exponencial

39
4.5.2 Punto de pedido
Este método para la gestión del inventario es también sencillo de entender y de implantar en el modelo. Se basa en
que cada vez que se alcance un nivel de inventario inferior a la cantidad de producto que marquemos como límite,
se lanza un nuevo pedido al proveedor. El tamaño de este pedido, será el suficiente hasta alcanzar el punto
deseado de stock.
Para la implementación de este método no utilizaremos un Event como en el ajuste exponencial, sino un
Actionchart muy sencillo, pero con los pasos necesarios. Primero comprobar que si el nivel de inventario está por
debajo del mínimo, y si es así, lanzar el pedido.
La idea es que el inventario se revise cada vez que nuestro inventario disminuye, por eso introduciremos un
comando para actualizar este Actionchart en la parte de procesamiento de pedidos, que será explicado a
continuación.
4.6 Envío de pedidos
Acabamos de explicar cómo calculan las empresas de la cadena la cantidad a pedir o fabricar, el siguiente paso es
procesar estos pedidos. Es necesario explicar cómo se transmite la información y los productos en Anylogic, pues
las relaciones entre agentes de la cadena es uno de los motivos principales de este trabajo, y una buena o mala
comunicación en la cadena de suministro condicionan el funcionamiento de la misma.
Como se ha mencionado en pasos anteriores, los Ports son la clave de la comunicación, y los que permiten enviar
y recibir mensajes entre agentes. Para que eso sea efectivo en la simulación, es necesario no solo que los agentes
tengan estos puertos, también tienen que estar incluidos en un agente común, y que los puertos que tengan
relación entre sí, estén unidos mediante los denominados Connectors.
En nuestro ejemplo, el agente donde confluyen los demás, es el Main, y al introducir en este agente los demás,
Anylogic inserta directamente los Ports de cada uno de ellos. Ahora hay que conectarlos correctamente y según las
Figura 7. Previsión de la demanda con punto de pedido.
Figura 8. Previsión de la demanda con punto
de pedido. Actionchart.

40
relaciones que sean necesarias. Por ejemplo, no resultaría práctico unir ningún puerto del minorista con otro del
fabricante, pues en el modelo que estamos estudiando no tienen relación alguna.
Las relaciones en nuestro modelo son las siguientes:
El PortWholesaler del Retailer, se une con el PortRetailer del Wholesaler, representando la conexión entre
minorista y mayorista.
El PortFactory del Wholesaler se conecta con el PortWholesaler del Factory, haciendo posible la unión
entre mayorista y fabricante.
Para un correcto funcionamiento de esta funcionalidad, es muy importante que tengamos claro, y así lo
declaremos en Anylogic, de que tipo es el mensaje que se manda y se recibe. Es decir, no podemos declarar que el
PortWholesaler del minorista, envía un mensaje de tipo entero, y que el PortRetailer del mayorista, que es el que
recibe este mensaje, reciba uno de tipo real. En nuestro caso, una vez más, al hablar siempre de productos, todos
los mensajes que se envíen o reciban en los puertos serán de tipo entero. Aunque algunos de ellos serán pedidos y
otros serán productos.
Para una comprensión más fácil de todo lo que representan los Ports, y todas las acciones que se llevan a cabo
cuando se recibe un mensaje, veamos como ejemplo el PortRetailer del mayorista:
Como podemos ver, el programa denomina a la información recibida “msg”, independientemente del nombre que
tuviera en su origen cuando fue enviado. Y con este mensaje se hacen múltiples acciones. Las dos primeras son de
una utilidad clara e inevitable si queremos hacer un modelo consistente y que se asemeje lo máximo posible a la
realidad. Primero se actualiza el valor de una variable, CurrentDemand, que se iguala al pedido recibido, y luego
se ejecuta un ActionChart denominado “stock”. Todo esto sirve para gestionar los pedidos recibidos en función del
nivel de inventario, y será explicado más adelante.
La variable RetailerOrders, junto con sus homólogas en los otros agentes, servirá para almacenar los datos
históricos en forma de lista, lo que resultará útil en el futuro. Mediante la orden RetailerOrders.add, estamos
añadiendo el mensaje recibido, es decir la demanda, en la última posición de la lista. Además de este comando,
existen otros más que pueden servir de ayuda en otros casos, como añadir en primera posición, eliminar elementos
o coger uno de una posición determinada.
En la siguiente acción nos encontramos con una variable que ya habíamos visto en el paso anterior cuando
explicábamos el cálculo de la previsión de la demanda. Esta variable CumulativeDemand, irá añadiendo a su valor
actual la demanda entrante, si bien será reiniciada al final de cada periodo como ya explicamos, pues solo nos
interesa la demanda acumulada por periodo.
Una de las posibilidades más interesantes que presenta Anylogic es la estadística. De igual manera que con el
comando stock(), mandamos ejecutar el ActionChart correspondiente, con la orden RetOrd.update(), estamos
mandando actualizar esta variable estadística. Esto será explicado con más detalle en puntos posteriores.
Hemos visto que cada vez que un agente recibe un pedido nuevo, ejecuta un ActionChart denominado stock. Este
ActionChart realiza una función inherente en las empresas, antes de servir al cliente, hay que conocer cómo está el
nivel del inventario.
Figura 9. Recepción de pedidos.

41
Podemos resumir las posibilidades a tres:
Tenemos stock suficiente en el almacén para suplir el pedido de nuestro cliente en su totalidad.
Almacenado hay una cantidad de producto insuficiente para abastecer el total del pedido del cliente.
No hay inventario alguno.
De estos tres escenarios, es evidente que exclusivamente el primero es positivo para la empresa, ya que los otros
dos repercutirían en la imagen de la empresa, mostraría un bajo nivel de servicio y propiciaría la pérdida de
clientes.
Todo esto se podría modelar en Anylogic de múltiples maneras, pero la manera más sencilla es utilizar el modelo
secuencial y lógico que nos ofrece un ActionChart, donde mediante decisiones sencillas en función del estado del
inventario se tomarán unas decisiones u otras.
Siguiendo con el ejemplo del Wholesaler, este es el aspecto que tiene su ActionChart:
Como se puede observar, el resultado es un diagrama sencillo, corto y lógico, que aglutina las tres posibilidades
previamente descritas. Lo primero es tomar una decisión en función de si nuestro inventario es positivo o
inexistente. Esto se consigue mediante el primer bloque de decisión, se impone la condición de que el inventario
sea estrictamente mayor que cero y en función de si esto es verdadero o falso avanzaremos por un lado u otro del
diagrama.
Si el inventario es nulo, avanzamos a un bloque denominado “breakage”. Esto indica que en este momento no
tenemos producto alguno a nuestra disposición, la única acción tomada será aumentar en una unidad la variable
NoStock, que servirá para contabilizar el número de veces que no podemos satisfacer por completo las
necesidades de producto del cliente.
En caso de si disponer de inventario, avanzamos a otro bloque de decisión. La condición esta vez dependerá de si
la demanda recibida, almacenada previamente en la variable CurrentDemand, es mayor o no que el inventario del
que disponemos.
En caso de que esta condición no se cumpla, y nuestro producto disponible supere en cantidad al deseado por el
consumidor, avanzamos a un bloque denominado “Update Stock”. En este bloque se realizan las siguientes
acciones:
Figura 10. Gestión de inventario.
42
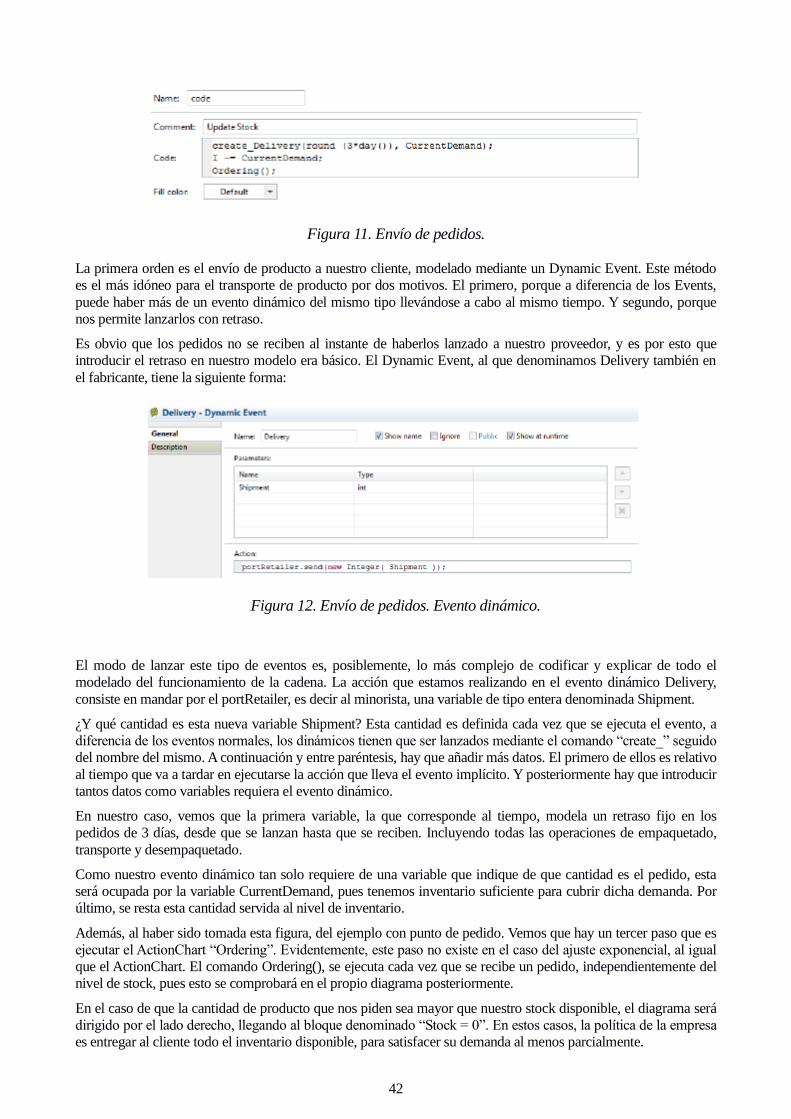
La primera orden es el envío de producto a nuestro cliente, modelado mediante un Dynamic Event. Este método
es el más idóneo para el transporte de producto por dos motivos. El primero, porque a diferencia de los Events,
puede haber más de un evento dinámico del mismo tipo llevándose a cabo al mismo tiempo. Y segundo, porque
nos permite lanzarlos con retraso.
Es obvio que los pedidos no se reciben al instante de haberlos lanzado a nuestro proveedor, y es por esto que
introducir el retraso en nuestro modelo era básico. El Dynamic Event, al que denominamos Delivery también en
el fabricante, tiene la siguiente forma:
El modo de lanzar este tipo de eventos es, posiblemente, lo más complejo de codificar y explicar de todo el
modelado del funcionamiento de la cadena. La acción que estamos realizando en el evento dinámico Delivery,
consiste en mandar por el portRetailer, es decir al minorista, una variable de tipo entera denominada Shipment.
¿Y qué cantidad es esta nueva variable Shipment? Esta cantidad es definida cada vez que se ejecuta el evento, a
diferencia de los eventos normales, los dinámicos tienen que ser lanzados mediante el comando “create_” seguido
del nombre del mismo. A continuación y entre paréntesis, hay que añadir más datos. El primero de ellos es relativo
al tiempo que va a tardar en ejecutarse la acción que lleva el evento implícito. Y posteriormente hay que introducir
tantos datos como variables requiera el evento dinámico.
En nuestro caso, vemos que la primera variable, la que corresponde al tiempo, modela un retraso fijo en los
pedidos de 3 días, desde que se lanzan hasta que se reciben. Incluyendo todas las operaciones de empaquetado,
transporte y desempaquetado.
Como nuestro evento dinámico tan solo requiere de una variable que indique de que cantidad es el pedido, esta
será ocupada por la variable CurrentDemand, pues tenemos inventario suficiente para cubrir dicha demanda. Por
último, se resta esta cantidad servida al nivel de inventario.
Además, al haber sido tomada esta figura, del ejemplo con punto de pedido. Vemos que hay un tercer paso que es
ejecutar el ActionChart “Ordering”. Evidentemente, este paso no existe en el caso del ajuste exponencial, al igual
que el ActionChart. El comando Ordering(), se ejecuta cada vez que se recibe un pedido, independientemente del
nivel de stock, pues esto se comprobará en el propio diagrama posteriormente.
En el caso de que la cantidad de producto que nos piden sea mayor que nuestro stock disponible, el diagrama será
dirigido por el lado derecho, llegando al bloque denominado “Stock = 0”. En estos casos, la política de la empresa
es entregar al cliente todo el inventario disponible, para satisfacer su demanda al menos parcialmente.
Figura 11. Envío de pedidos.
Figura 12. Envío de pedidos. Evento dinámico.

43
Los códigos internos de este bloque son iguales que en el caso de que la empresa sí tuviera inventario suficiente,
pero sirviendo al cliente la variable I, es decir, el inventario disponible en vez de lo que realmente pide. Y
reduciendo también el stock a cero.
4.7 Fabricación
Aunque modelada de manera similar a los pedidos, mención especial merece el proceso de fabricación llevado a
cabo por el agente Factory, debido a una serie de variables exclusivas ya mencionadas anteriormente. Como ya
vimos el cálculo de las cantidades a fabricar en cada periodo por parte del fabricante se llevaba a cabo del mismo
modo que el cálculo de que unidades pedir por parte del minorista y el mayorista.
Al igual que los otros agentes, tendremos implementados los dos modelos, o bien cada siete días se realiza una
previsión de que cantidades fabricar o se establece un nivel mínimo y máximo de inventario. Pero además de esto,
hay que fabricarlo. Al igual que el envío de producto, la mejor manera de modelar la fabricación es con un evento
dinámico de la siguiente manera:
Tomaremos como ejemplo el ajuste exponencial. Las dos primeras acciones son del mismo tipo que las que
utilizan los otros agentas para lanzar sus pedidos. Primero se realiza un alisado de los datos, y después se manda
fabricar el valor mayor entre cero y el entero del número previamente calculado.
Posteriormente se lanza el evento dinámico Manufacturing, que fabricará la cantidad estimada anteriormente, y
tardará en fabricarlo la cantidad a producir multiplicado por cinco minutos y por tres. Este cálculo es debido a que
se estima que se tardan cinco minutos en terminar un producto entero, pero de las 24 horas que tiene el día la
fábrica solo está operativa 8 horas, es decir, un tercio del día. De esta manera es modelada la capacidad de
producción de la fábrica.
En el evento dinámico Manufacturing tan solo se añaden estas cantidades fabricadas al inventario. Con la orden
ManufacturingOrders.add(Order), añadimos la cantidad producida al registro de históricos y la última orden es
para actualizar las estadísticas.
Figura 13. Fabricación.
44
4.8 Estadísticas
Para conseguir que el estudio tenga profundidad y no se quede únicamente en un modelo que represente a la vida
real y que funcione, es necesario que seamos capaces de valorar los resultados, calcular estadísticas, y en
definitiva estudiar cual ha sido el comportamiento de los agentes durante la simulación. En definitiva, este es el
fin último de toda simulación. Simular con las herramientas disponibles, y que nos ofrece la tecnología de hoy en
día, de la manera más aproximada cómo funciona la realidad, y estudiar qué es mejorable en la actualidad, o en
qué puntos puede haber problemas en el futuro.
Nuestro objetivo es el estudio de la cadena de suministro en general, y del efecto látigo, sus causas y sus
consecuencias en particular. Con el fin de investigar este aspecto en concreto, es necesario obtener los datos
relativos a los pedidos que han ido realizando cada uno de los agentes de nuestro modelo a sus proveedores.
Hemos visto que cada vez que se recibe un pedido, ordenábamos ejecutar y actualizar una variable estadística
relativa a estos pedidos. Esta variable varía de nombre según el agente, para mayor claridad. En el caso del
minorista se denomina CustOrd, como abreviatura de pedidos del cliente, y para mayorista y fabricante se
denominan RetOrd y WhoOrd respectivamente. En el fabricante además, también es necesario conocer los datos
de las órdenes de fabricación en el fabricante, mediante la variable ManOrd.
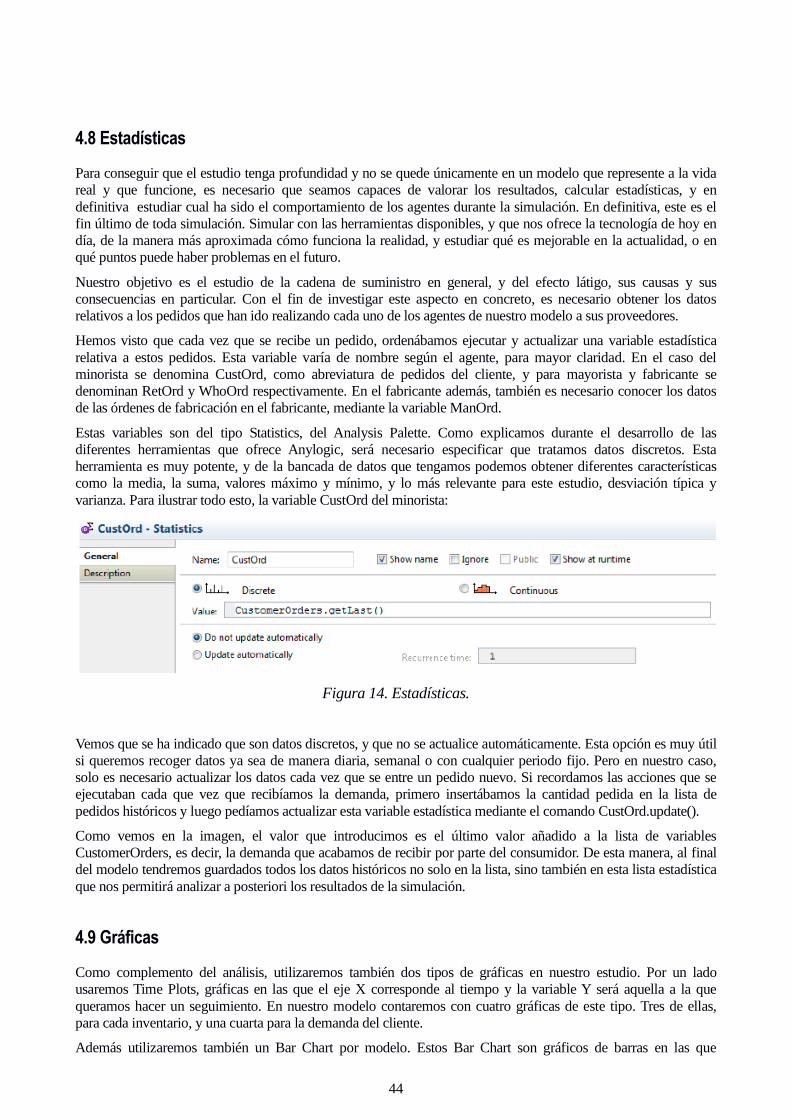
Estas variables son del tipo Statistics, del Analysis Palette. Como explicamos durante el desarrollo de las
diferentes herramientas que ofrece Anylogic, será necesario especificar que tratamos datos discretos. Esta
herramienta es muy potente, y de la bancada de datos que tengamos podemos obtener diferentes características
como la media, la suma, valores máximo y mínimo, y lo más relevante para este estudio, desviación típica y
varianza. Para ilustrar todo esto, la variable CustOrd del minorista:
Figura 14. Estadísticas.
Vemos que se ha indicado que son datos discretos, y que no se actualice automáticamente. Esta opción es muy útil
si queremos recoger datos ya sea de manera diaria, semanal o con cualquier periodo fijo. Pero en nuestro caso,
solo es necesario actualizar los datos cada vez que se entre un pedido nuevo. Si recordamos las acciones que se
ejecutaban cada que vez que recibíamos la demanda, primero insertábamos la cantidad pedida en la lista de
pedidos históricos y luego pedíamos actualizar esta variable estadística mediante el comando CustOrd.update().
Como vemos en la imagen, el valor que introducimos es el último valor añadido a la lista de variables
CustomerOrders, es decir, la demanda que acabamos de recibir por parte del consumidor. De esta manera, al final
del modelo tendremos guardados todos los datos históricos no solo en la lista, sino también en esta lista estadística
que nos permitirá analizar a posteriori los resultados de la simulación.
4.9 Gráficas
Como complemento del análisis, utilizaremos también dos tipos de gráficas en nuestro estudio. Por un lado
usaremos Time Plots, gráficas en las que el eje X corresponde al tiempo y la variable Y será aquella a la que
queramos hacer un seguimiento. En nuestro modelo contaremos con cuatro gráficas de este tipo. Tres de ellas,
para cada inventario, y una cuarta para la demanda del cliente.
Además utilizaremos también un Bar Chart por modelo. Estos Bar Chart son gráficos de barras en las que

45
veremos visualmente representados y comparados entre si distintas variables. La utilidad de este tipo de gráficos
será la de representar las varianzas de los pedidos de cada uno de los agentes.
Este tipo de gráficas son además muy útiles a la hora de construir el modelo, pues si algo dentro del modelo está
fallando o ha sido modelado de manera errónea, es fácilmente identificable. Como muestra el modelado del
inventario del fabricante:
4.10 Simulación
Una vez implementado todo lo anterior, es hora de comprobar los resultados. Pero antes de lanzarnos a simular,
conviene asegurarse de que todo está correcto y fijar algún que otro parámetro final. Anylogic antes de lanzar una
simulación, siempre avisa si detecta algún error. Esta funcionalidad, aunque no detecte errores conceptuales, sirve
de gran ayuda para corregir paréntesis que faltan o comas.
Con todo listo y corregido, al simular, Anylogic nos mostrará la siguiente pantalla:
Figura 16. Simulación.
Figura 15. Gráficas temporales.
Figura 4-11. Gráficas temporales.

46
Cumpliendo con una de las mejores características de Anylogic, todo lo presente en este texto es modificable,
desde el texto hasta el botón. Cuando queramos ejecutar la simulación, pulsamos en el botón de correr el modelo.
En nuestro modelo, hemos elegido simular 1000 días, para de esta forma tener un número representativo de
pruebas. Teniendo en cuenta esto, es preferible acelerar la simulación e ir visualizando los cambios de manera
progresiva, o saltar directamente al final de la simulación y ver los resultados finales.
Dentro de la simulación tendremos a cada uno de los agentes, la pantalla principal será el Main, pero podemos ir
al minorista, mayorista y fabricante. En el Main tendremos el Bar Chart con las varianzas de los pedidos y una
gráfica temporal con la evolución de la demanda del cliente final. En cada agente podremos visualizar un gráfico
con la evolución del inventario en los 400 últimos días de simulación. Además, en el modelo en el que
implementaremos un punto de pedido, también vendrá representado dicho punto.
47
4.11 Resultados
Para una mayor fiabilidad de los resultados simularemos cada modelo tres veces, veremos cómo han
evolucionado los inventarios, que porcentaje de veces no han tenido stock suficiente para sus clientes y si hay o no
efecto látigo.
4.11.1 Modelo I
Primero visualizaremos los resultados del modelo con ajuste exponencial de la demanda, primero demanda del
cliente final y varianzas, y después los datos de minorista, mayorista y fabricante en este orden.
Primera Simulación
Figura 18. Modelo I. Simulación I. Demanda y Varianzas.
Figura 17. Modelo I. Simulación I. Retailer.
48
Figura 19. Modelo I. Simulación I. Wholesaler.
Figura 4-15. Modelo I. Simulación I. Wholesaler.
Figura 20. Modelo I. Simulación I. Factory.
49
Segunda simulación
Figura 21. Modelo I. Simulación II. Demanda y Varianzas.
Figura 22. Modelo I. Simulación II. Retailer.
50
Figura 23. Modelo I. Simulación II. Wholesaler.
Figura 24. Modelo I. Simulación II. Factory.
51
Tercera simulación
Figura 25. Modelo I. Simulación III. Demanda y Varianzas.
Figura 26. Modelo I. Simulación III. Retailer.
52
Figura 27. Modelo I. Simulación III. Wholesaler.
Figura 28. Modelo I. Simulación III. Factory.

53
4.11.2 Modelo II
A continuación las tres simulaciones del modelo con punto de pedido:
Primera simulación
Figura 4-24. Modelo II. Simulación I. Demanda y Varianzas.
Figura 29. Modelo II. Simulación I. Demanda y Varianzas.
Figura 30. Modelo II. Simulación I. Retailer.
54
Figura 31. Modelo II. Simulación I. Wholesaler.
Figura 32. Modelo II. Simulación I. Factory.
55
Segunda simulación
Figura 34. Modelo II. Simulación II. Retailer.
Figura 33. Modelo II. Simulación II. Demanda y Varianzas.
Figura 4-29. Modelo II. Simulación II. Retailer.
56
Figura 4-30. Modelo II. Simulación II. Wholesaler.
Figura 35. Modelo II. Simulación II. Wholesaler.
Figura 36. Modelo II. Simulación II. Factory.
57
Tercera Simulación
Figura 37. Modelo II. Simulación III. Demanda y Varianzas.
Figura 38. Modelo II. Simulación III. Retailer.
58
Figura 40. Modelo II. Simulación III. Factory.
Figura 39. Modelo II. Simulación III. Wholesaler.

59
Veamos cuáles han sido los resultados obtenidos en ambas simulaciones:
Modelo I
Tabla 1. Resultados del Modelo I.
Modelo II
Tabla 2. Resultados del Modelo II.
Conclusiones
Como podemos observar en las tablas y en las gráficas obtenidas a raíz de las simulaciones, Anylogic no solo se
presenta como una herramienta amplia y sencilla, sino que además devuelve resultados lógicos y fiables.
Confirmando la teoría de que es una herramienta aplicable y que, como en todas las herramientas, requiere de un
periodo de aprendizaje y adaptación, permite crear modelos en poco tiempo.
Observamos, por ejemplo, que en ambos modelo existe efecto látigo, y que este aumenta a lo largo de la cadena.
También observamos que el flujo de los inventarios sigue una secuencia que se puede asumir cercana a la realidad
en ambos casos. La demanda comprobamos que también oscila siempre entre las cien unidades como modelamos
en ambos casos, y que los pedidos no llegan tal y como se piden.
Comparando ambos modelos, vemos que el efecto látigo y las varianzas en los pedidos cuando trabajamos con
punto de pedido, son mucho mayores que cuando ajustamos exponencialmente la demanda. Por el contrario, al
usar el ajuste exponencial vemos que todos los agentes de la cadena tienen problemas de servicio, pues todos
ellos, una de cada cinco veces aproximadamente, no tienen inventario suficiente para satisfacer la demanda total
de su cliente.
Sería por tanto decisión de la empresa valorar qué escenario le conviene más, uno con mayor incertidumbre pero
con mejor nivel de servicio u otro con menor varianza y peor calidad en el servicio.

60

61
REFERENCIAS
[1] Lee, H. L., Padmanabhan, V., & Whang, S. (1997). The bullwhip effect in supply chains. MIT Sloan
Management Review, 38(3), 93.





























