Embed Size (px)
Citation preview

Toward Grounding Knowledge in Prediction
orToward a Computational
Theory of Artificial Intelligence
Rich SuttonAT&T Labswith thanks to
Satinder Singh and Doina Precup

It’s Hard to Build Large AI Systems
• Brittleness• Unforeseen interactions• Scaling
• Requires too much manual complexity management– people must understand, intervene, patch and tune– like programming
• Need more autonomy– learning, verification– internal coherence of knowledge and experience

Marr’s Three Levels of Understanding
• Marr proposed three levels at which any information-processing machine must be understood– Computational Theory Level
• What is computed and why
– Representation and Algorithm Level– Hardware Implementation Level
• We have little computational theory for Intelligence– Many methods for knowledge representation, but no
theory of knowledge– No clear problem definition– Logic

Reinforcement Learning provides a little Computational
Theory• Policies (controllers): States Pr(Actions)
• Value Functions
V (s) =E γ t−1rewardt
t=1
∞
∑ start ins0 , follow
V : States → ℜ
• 1-Step Models
P st+1 st ,at E rt+1 st ,at

Outline of Talk
• Experience
• Knowledge Prediction
• Macro-Predictions
• Mental Simulation
offering a coherent candidate computational theory of intelligence
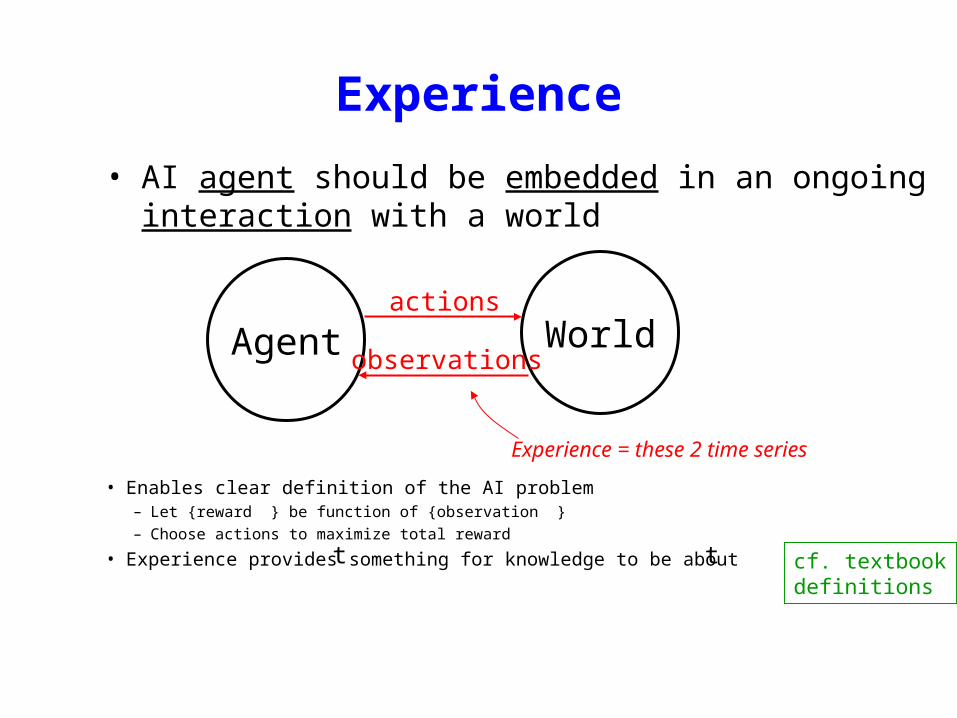
Experience
• AI agent should be embedded in an ongoing interaction with a world
Agent Worldactions
observations
Experience = these 2 time series
• Enables clear definition of the AI problem– Let {reward } be function of {observation }– Choose actions to maximize total reward
• Experience provides something for knowledge to be about tt cf. textbookdefinitions

What is Knowledge?
What is Knowledge?
Deny the physical world Deny existence of objects, people, space… Deny all non-answers, correspondence
theories
All we really know about is our experienceKnowledge must be in terms of experience

Grounded Knowledge
A is always followed by B A,B observations
if = A then = B
if A( ) then B( ) A,B predicates
if A( ) then B( )
Action conditioning:
if A( ) and C( ) then B( )
All of these are predictions
ot ot+1
ot ot+1
ht ht+1 ht =ot ,at−1,ot−1,at−2 ,ot−2 ,K
ht at ht+1

• The world is a black box, known only by its I/O behavior (observations in response to actions)
• Therefore, all meaningful statements about the world are statements about the observations it generates
• The only observations worth talking about are future ones
The only meaningful things to say about the world are predictions
World Knowledge Predictions
Therefore:

Non-predictive “Knowledge”• Mathematical knowledge, theorems and proofs
– always true, but tell us nothing about the world– not world knowledge
• Uninterpretted signals, e.g., useful representations– real and useful, but not by themselves world
knowledge, only an aid to acquiring it
• Knowledge of the past• Policies
– could be viewed as predictions of value– but by themselves are more like uninterpretted
signals
Predictions capture “regular”, descriptive world knowledge

Grounded Knowledge
A is always followed by B A,B observations
if = A then = B
if A( ) then B( ) A,B predicates
if A( ) then B( )
Action conditioning:
if A( ) and C( ) then B( )
1-steppreds.
ot ot+1
ot ot+1
ht ht+1 ht =ot ,at−1,ot−1,at−2 ,ot−2 ,K
ht at ht+1
Still a pretty limited kind of knowledge.Can’t say anything beyond one step!

Grounded Knowledge
A is always followed by B A,B observations
if = A then = B
if A( ) then B( ) A,B predicates
if A( ) then B( )
Action conditioning:
if A( ) and C( ) then B( )
if A( ) and <arbitrary experiment> then B(<outcome>)
many steps later
prior grounding
many steps long
1-steppreds.
macro-pred.
posterior grounding
ot ot+1
ot ot+1
ht
ht
ht+1 ht =ot ,at−1,ot−1,at−2 ,ot−2 ,K
ht at ht+1

Both Prior and Posterior Grounding are Needed
• “Classical” AI systems omit prior grounding– e.g., “Tweety is a bird”, “John loves Mary”– sometimes called the “symbol grounding problem”
• Modern AI sytems tend to skimp the posterior– supervised learning, Bayes nets, robotics…
• It is not OK to leave posterior grounding to external, human observers– the information is just not in the machine– we don’t understand it; we haven’t done our job!
• Yet this is such an appealing shortcut that we have almost always done it

Outline of Talk
• Experience
• Knowledge Prediction
• Macro-Predictions
• Mental Simulation
offering a coherent candidate computational theory of intelligence

Macro-Predictions (Options)a la Sutton, Precup & Singh, 1999 et al.
Let : States Pr(Actions) be an arbitrary policyLet : States Pr({0,1}) be a termination condition
Then < > is a kind of experiment – do until =1 – measure something about the resulting experienceSuppose we measure the outcome: – the state at the end of the experiment – the total reward during the experimentThen the macro-prediction for < > would predict Pr(end-state), E{total reward} given start-state
This is a very general, expressive form of prediction
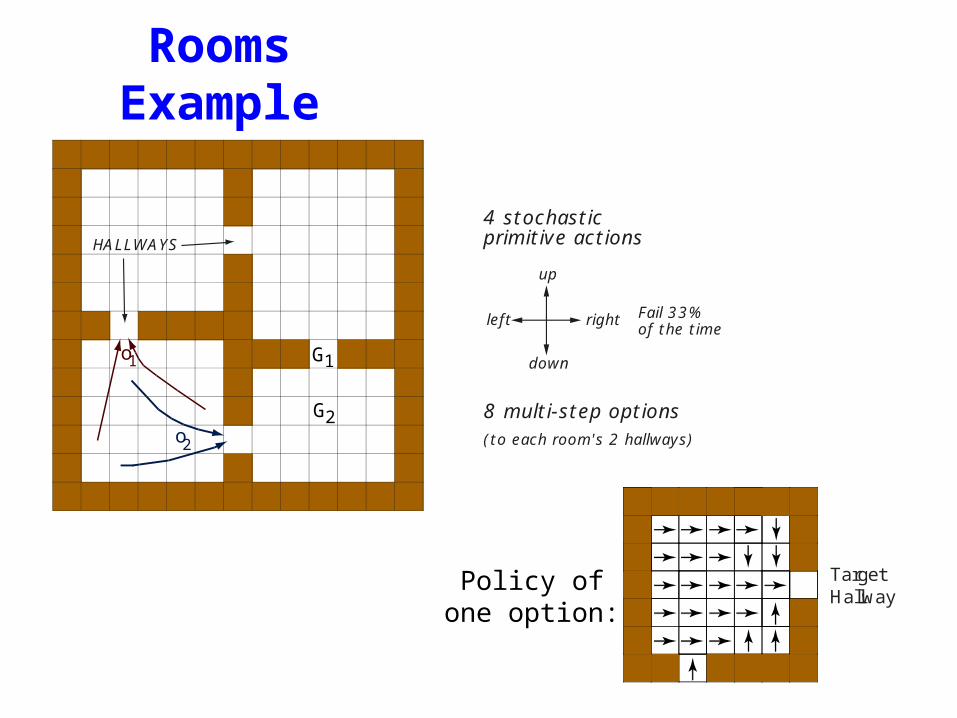
Rooms Example
o2
HALLWAYS
o1
8 multi-step options
up
down
rightleft
(to each room's 2 hallways)
G2
4 stochastic primitive actions
Fail 33% of the time
G1
TargetHallway
Policy of one option:
Sutton, Precup,& Singh, 1999
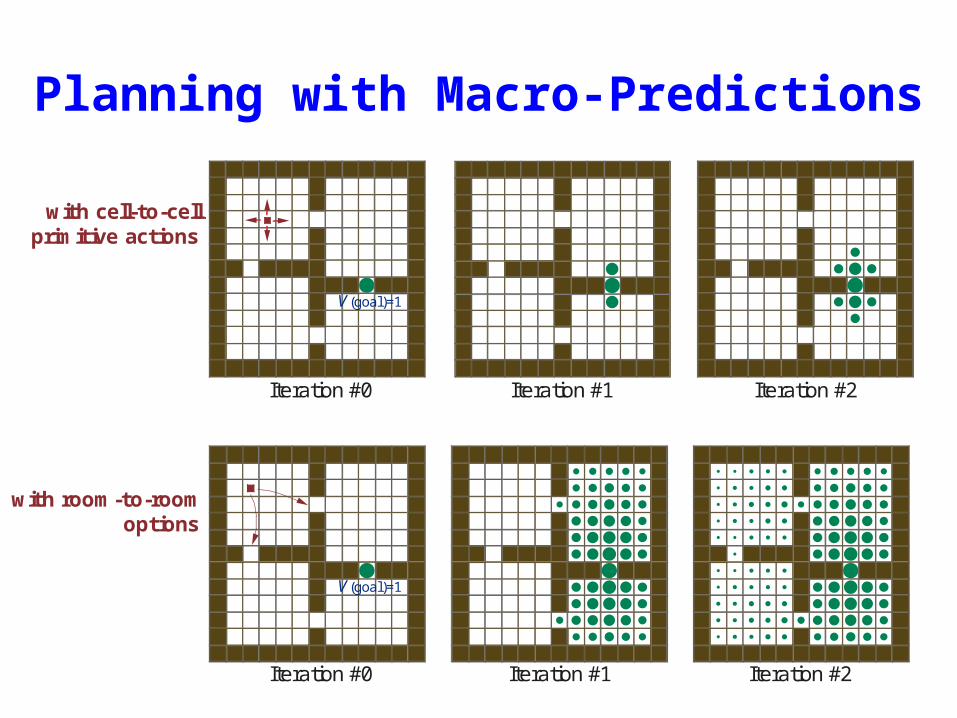
Planning with Macro-Predictions
Iteration #0 Iteration #1 Iteration #2
with cell-to-cellprimitive actions
Iteration #0 Iteration #1 Iteration #2
with room-to-roomoptions
V(goa l)=1
V (goa l)=1
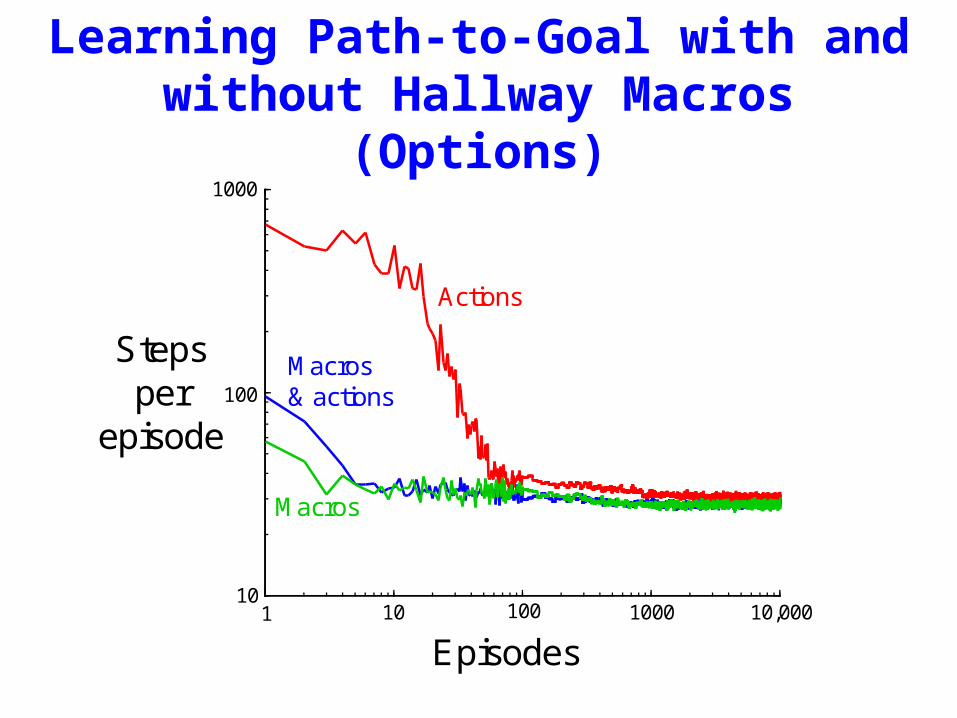
Learning Path-to-Goal with and without Hallway Macros
(Options)
Episodes
Stepsper
episode
1 10 100 1000 10,00010
100
1000
Actions
Macros
Macros& actions

Mental Simulation
• Knowledge can be gained from experience– by actually performing experiments
• But knowledge can also be gained without overt experience– we call this thinking, reasoning, planning, cognition…
• This can be done through “thought experiments”– internal simulation of experience– generated from predictive knowledge– subject to learning methods as before
• Much thought can be achieved this way...
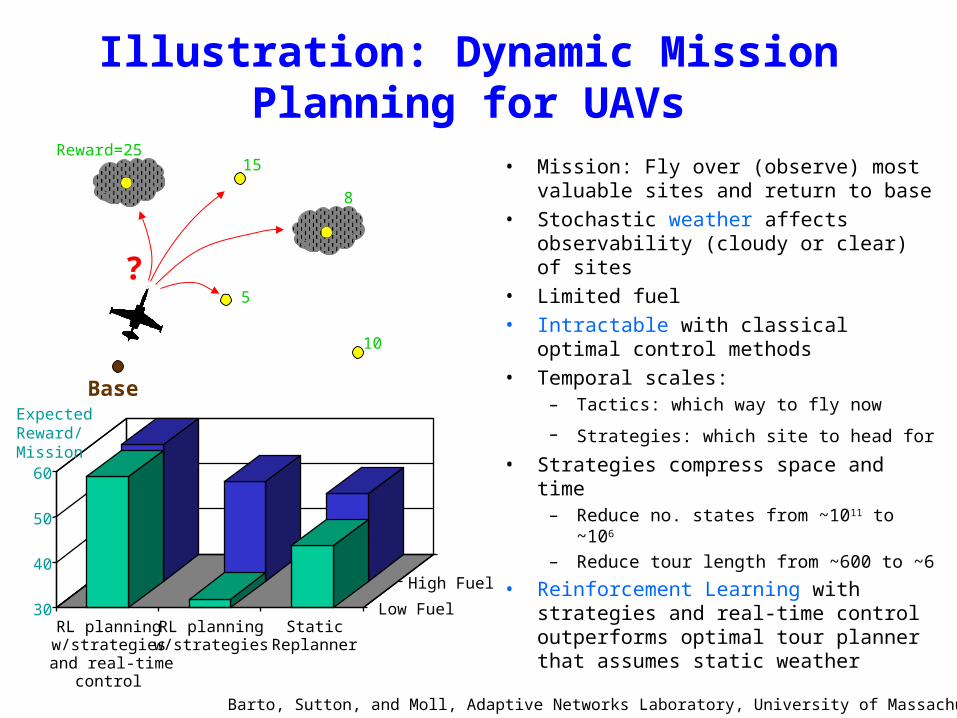
Illustration: Dynamic Mission Planning for UAVs
30
40
50
60
StaticReplanner
RL planningw/strategies
RL planningw/strategiesand real-time
control
Low Fuel
High Fuel
• Mission: Fly over (observe) most valuable sites and return to base
• Stochastic weather affects observability (cloudy or clear) of sites
• Limited fuel• Intractable with classical optimal
control methods• Temporal scales:
– Tactics: which way to fly now
– Strategies: which site to head for • Strategies compress space and time
– Reduce no. states from ~1011 to ~106
– Reduce tour length from ~600 to ~6
• Reinforcement Learning with strategies and real-time control outperforms optimal tour plannerthat assumes static weather
?
Reward=2515
8
10
5
Barto, Sutton, and Moll, Adaptive Networks Laboratory, University of Massachusetts
ExpectedReward/Mission
Base
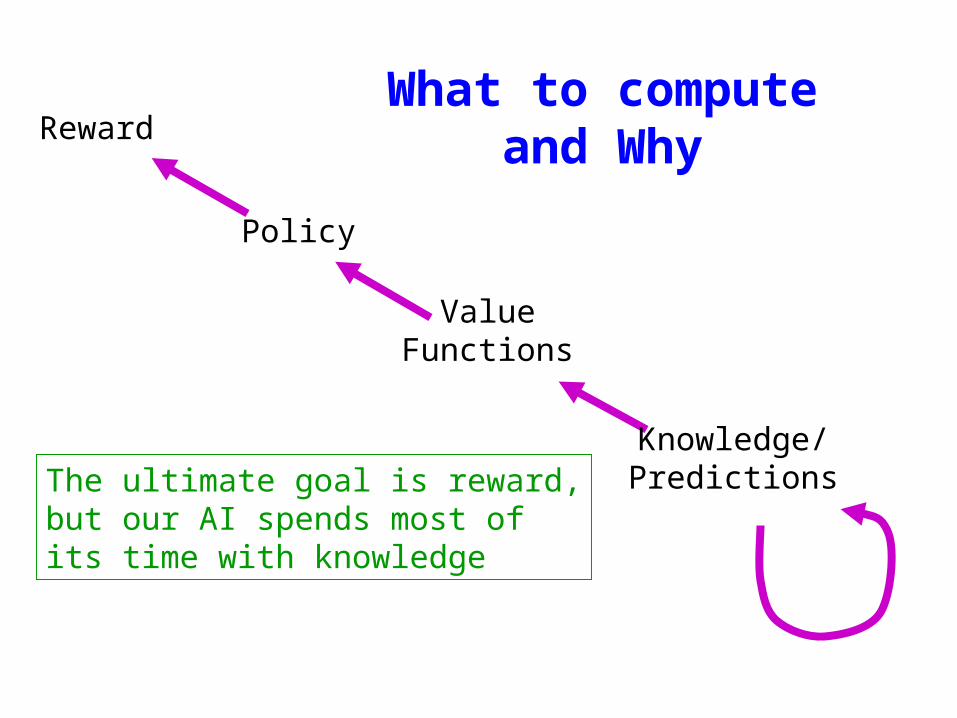
What to compute and
WhyReward
ValueFunctions
Knowledge/Predictions
Policy
The ultimate goal is reward,but our AI spends most ofits time with knowledge

A Candidate Computational Theory
of Artificial Intelligence• AI Agent should be focused on finding general
macro-predictions of experience• Especially seeking predictions that enable rapid
computation of values and optimal actions• Predictions and their associated experiments are
the coin of the realm– they have a clear semantics, can be tested & learned– can be combined to produce other predictions, e.g.
values
• Mental Simulation (plus learning)– makes new predictions from old– start of a computational theory of knowledge use

Conclusions
• World knowledge must be expressed in terms of the data
• Such posterior grounding is challenging,– lose expressiveness in the short term– lose external (human) coherence, explainability
• But can be done step by step, • And brings palpable benefits
– autonomous learning/verification/extension of knowledge– autonomous complexity management due to internal
coherence – knowledge suited to general reasoning process – mental
simulation
• We must provide this grounding!





























