Embed Size (px)
Citation preview

Toward Exploring End-to-End Learning Algorithms for Autonomous AerialMachines
Srivatsan Krishnandagger Behzad BoroujerdianDagger Aleksandra Faust∓ and Vijay Janapa Reddidagger
dagger Harvard University DaggerThe University of Texas at Austin ∓ Robotics at Googlehttpbitly2WhhWYz
Abstractmdash We develop AirLearning a tool suite for end-to-end closed-loop UAV analysis equipped with a customizedyet randomized environment generator in order to exposethe UAV with a diverse set of challenges We take Deep Qnetworks (DQN) as an example deep reinforcement learningalgorithm and use curriculum learning to train a point topoint obstacle avoidance policy While we determine the bestpolicy based on the success rate we evaluate it under strictresource constraints on an embedded platform such as Ras-Pi 3 Using hardware in the loop methodology we quantifythe policyrsquos performance with quality of flight metrics suchas energy consumed endurance and the average length ofthe trajectory We find that the trajectories produced on theembedded platform are very different from those predictedon the desktop resulting in up to 2643 longer trajectoriesQuality of flight metrics with hardware in the loop characterizesthose differences in simulation thereby exposing how the choiceof onboard compute contributes to shortening or widening oflsquoSim2Realrsquo gap
I INTRODUCTION
Unmanned Aerial Vehicles (UAVs) have shown greatpromises in various robotics applications such as searchand rescue [1] package delivery [2] [3] construction in-spection [4] and others Among these UAVs rotor basedplatforms have been exceedingly deployed due to theirrobust mechanical design and favorable flight characteristicssuch as vertical take-offlanding and the high degree ofagilitymaneuverability [5]
To fully explore and exploit such UAVs there is a needto increase their level of autonomy speed and agility Inthe context of autonomous navigation end-to-end learningthat includes deep reinforcement learning (DRL) is show-ing promising results in sensory-motor control in cars [6]indoor robots [7] as well as UAVs [8] [9] Deep RLrsquosability to adapt and learn with minimum apriori knowledgemakes them attractive for use as a controller in complexsystems [10] At the heart of these algorithms is a policy thatis approximated by a neural network Simply put a policytakes sensor data (RGBIMU) as input and predicts controlactions as an output
Despite the promises offered by reinforcement learningthere are several challenges in adopting reinforcement learn-ing for UAV control The challenge is that deep reinforce-ment learning algorithms are hungry for data Collectinglarge amounts of data on real UAVs has logistical issues Forinstance most of the commercial and off the shelf (COTS)UAVs can only operate for less than 30 mins and collectinghundreds of millions of images takes about 1850 fights1Also for effective learning there is a need to include negativescenarios such as collisions which significantly increases the
1Assuming flight time between recharge is 30 mins and camera through-put is 30fps
cost of collecting real data from UAVs [9] In such scenariossimulation provides a scalable and cost-effective approachfor generating data for reinforcement learning
The second challenge stems from the limited onboardenergy compute capability and power budget Since UAVsare mobile machines they need to be able to accomplishtheir tasks with the limited amount of energy on boardThis problem exacerbates as the size decreases reducing thetotal energy onboard while the same level of intelligence isrequired For example a nano-UAV such as a CrazyFlie [11]must have the same autonomous navigation capabilitiescomparing to its mini counterpart eg DJI-Mavic Pro [12]while its onboard energy is 1
15 th Hence onboard compute isa scarce resource and reinforcement learning policies needto be carefully co-designed with underlying hardware so thatit meets the real-time requirements under fixed power budget
The third challenge is the metrics that are used for theevaluation of deep reinforcement learning algorithms incontext of UAVs Since reinforcement learning policies arecomputationally intensive evaluation metrics of the DRL al-gorithms need to be expanded beyond the traditional metricsused in OpenAI gym and arcade games For instance sinceenergy is severely constrained in real time a policy can onlybe evaluated as long as there is enough battery Hence theDRL algorithm designed for UAVs needs to include metricssuch as energy and flight time to denote the quality of flight
To address these challenges we develop the AirLearningsuite which consists of a configurable environment generatorwith a wide range of knobs in order to enable variousdifficulty levels These knobs tune the number of static anddynamic obstacles their speed (if relevant) their texture andcolor and etc For quantifying the real-time performanceof different reinforcement learning policies on resource-constrained compute platforms we use the hardware-in-the-loop methodology where a policy is evaluated on embeddedcompute platforms that might potentially be the onboardcompute of the UAVs The tool suite also has metrics suchas energy consumed the average length of the trajectory andendurance so that different reinforcement learning policiescan be evaluated on these metrics that quantify the qualityof flight The primary contributions of the AirLearningbenchmarking suite are as follows
bull To assist in the dataset generation and generalization oflearning algorithms for navigation tasks in Aerial robotswe develop a configurable environment generator withparameters to vary the number of static obstacles arenasize type of objects in the environment textures ofthe objects the color of objects number of dynamicobstacles and their velocity
bull Using closed loop Hardware-in-the-Loop methodologywe characterize the performance of policies on real em-
GeneratedEnvironment
Game Configuration
Autonomous Navigation
TaskReinforcement
Learning
Discrete Actions
Polices
MultirotorControl
DQN DDQN
Task - AlgorithmExploration
Algorithm - PolicyExploration
Policy - HardwareExploration
EnvironmentGenerator
Accelerators Embedded CPUs
Flight Control
Machine Learning Tools
Task Definition and EnvironmentGeneration
Algorithm Exploration Policy Design Exploration
Hardware Exploration
AirSim
KerasTensorFlowAirSim Server
AirSim
AirSim Client
Quality of
Flight Metrics
Fig 1 Air Learning infrastructure and benchmarking suite for end-to-end learning in aerial autonomous machines
bedded devices that are resource and power constrainedbull We provide quality of flight metrics such as energy
consumed endurance and average length of trajectoryin the evaluation of learning algorithms specificallydesigned for aerial robots
Using our tool we show that the extent of lsquoSim2Realrsquo gapis not just limited to the fidelity of simulation environmentsbut also extends to the choice of onboard compute platformfor UAVs For instance the best performing algorithm andits policy are often evaluated on high-end desktops butwhen ported to onboard compute platform the real-timeperformance of the policy are different thus widening thelsquoSim2Realrsquo gap [13] [14] Hence having an end-to-endclosed-loop analysis tool suite such as AirLearning we candevelop policies characterize the real-time performance ofsaid policies identify critical bottlenecks possibly co-designalgorithms and hardware to bridge the lsquoSim2Realrsquo gap
II AIR LEARNING
AirLearning consist of four keys components the envi-ronment generator algorithm exploration closed loop realtime hardware in the loop setup and quality of flight metricsthat is cognizant of the resource constraints of the UAV Byusing all these components in unison AirLearning allows tocarefully fine tune algorithms for the underlying hardwareFigure 1 illustrates the AirLearing infrastructureA Environment Generator
Environment generator is creates high fidelity photo-realistic environments for the UAVrsquos to fly in It is built ontop of UE4 and uses AirSim UE4 [15] plugin for the UAVmodel and flight physics
The Environment generator uses a game configuration fileto generate the required configuration tailored for the taskHere a task corresponds to navigating from one point toanother while avoiding obstacles Game configuration file isthe interface between Unreal and the reinforcement learningalgorithms The runtime program writes a set of parametersinto the game configuration file that the Unreal engineparses before starting the game The Arena size numberof staticdynamic obstacles and their velocity (if relevant)minimum distance between obstacles obstacle types colorstexture and the destination of the UAV are some of theparameters that are configurable
B Algorithm exploration and Policy ExplorationWe seed the AirLearning algorithm suite with Deep
Q Network (DQN) [16] a commonly used reinforcementlearning algorithm DQN falls into the discrete action algo-rithms where the control commands are high-level commands(lsquomove forwardrsquo lsquomove leftrsquo etc) For DQN Agent weuse the keras-RL framework To make it more amenable todevelop other reinforcement learning algorithms we improveupon the work of AirGym [17] which provides the capabilityof interfacing with OpenAI gym We extend the originalimplementation of AirGym by providing an array of newcapabilities such as support for curriculum learning trainingmulti-modal policies with inputs such as depthRGBIMUmeasurements These extrasensory data are exposed as partof the environment in OpenAI gym and used for developinga new class of RL algorithms and its associated policiesC Hardware Exploration
Once the Algorithm and policy are finalized AirLearningallows for characterizing the performance of the differenttype of hardware platforms Often aerial roboticists port thealgorithm on real UAVs to validate the functionality of thealgorithm These UAVs might be a custom built[18] or off theshelf UAVs [19] [20] Using our framework we can explorethe performance of different on-board off-the-shelf computeplatforms or even examine the possibilities of designingcustom processors (hardware accelerators)
To seed the framework we use Ras Pi 3 as hardware plat-forms to evaluate the DQN algorithms We use an establishedhardware-in-the-loop (HIL) methodology [21] to characterizethe performance of various algorithms and policies OurHIL methodology enables accurate performance and energybenchmarking of the computation kernelsD Quality of Flight Metrics
Algorithms and policies need to be evaluated on themetrics that describe the quality of flight such as missiontime distance flown etc We consider the following metrics
Success rate (Sr) The percentage of the times the UAVreaches the goal state without collisions or running out ofbattery Ideally we expect this number to be close to 100as it reflects the algorithmsrsquo navigation efficiency
Time to Completion (Tc) The total time UAV spendsfinishing a mission within the simulated world
Energy (E) consumed Total energy spent while carryingthe mission Limited battery on-board constrains the missiontime Hence monitoring energy is of utmost importance andcan be a measure of policyrsquos efficiency
Distance Traveled (Dt) Total distance flown while car-rying out the mission This metric is the average length ofthe trajectory This metric can be used to measure the pathplanning intelligence of a particular policy
III EVALUATION METHODOLOGY
This section discusses our trainingtesting methodologyand DQN results DQN policy generates high-level discreteactions (eg move forward) and these are mapped to low-level controls by the flight controller
Environments For the autonomous navigation task wecreate an environment with varying levels of static obstaclesThe environment size is 50 m x 50 m The number ofobstacles varies from 5 to 10 and it is changed every4 episodes The obstacles start and goal positions are placedin random locations in every episode to ensure that the policydoes not overfit to the environment
Training Methodology We train the DQN agent on theenvironment described above To speed up the learningwe employ the curriculum learning [22] approach wherethe goal position is progressively moved farther away fromthe starting point of the agent To implement this wedivide the entire arena into multiple zones namely Zone 1Zone 2 and Zone 3 as shown in Figure 2 Here Zone 1corresponds to the region that is within 16 m from the UAVstarting position and Zone 2 and Zone 3 are within 32 mand what is this number respectively Initially the positionof goal for the UAV is chosen randomly such that the goalposition lies within zone 1 Once the UAV agent achieves50 success over a rolling window of past 1000 episodesthe position of the goal expands to zone 2 and so forthTo make sure that the agent does not forget learning inthe previous zone the goal position in the next zone isinclusive of previous zones We train the agent to progressuntil zone 3 and upon achieving 50 success rate in thatzone we terminate the training We checkpoint the policy atevery zone so it can be evaluated on how well it has learnedto navigate across all three environments To compare theeffectiveness of curriculum learning we also train using non-curriculum learning where we train for 250000 steps in theentire arena the same number of steps where the curriculumlearning reached zone 3
Testing For testing of curriculum learning policies weevaluate the checkpoints saved at each zone For testingthe non-curriculum learning counterpart we evaluate thecheckpoints saved at fixed intervals of 50000 steps Toensure the policy does not overfit to the environment weevaluate the policy on the unknown zone (zone 3) whichwas not used during training We also randomly change theposition of the goal and obstacles
IV ALGORITHM EVALUATION
In this section we compare the results of curriculumlearning approach with the non-curriculum learning approachon the environment described in Section III The primarymetric is the success rate The policy is evaluated on 100 tra-jectories
Figure 3a and Figure 3c show success rate of policy trainedusing curriculum learning and non-curriculum learning re-spectively Here chkpt1 chkpt2 chkpt3 corresponds
Zone 3
Zone 2
Zone1
UAV
Obstacles
Fig 2 Top view of the Arena An Arena is divided into logicalpartition called Zones The UAV is first trained into Zone0 and thegoals are assigned within this region The zone gets incrementedwhen the UAV agent has met 50 success in the previous zone
to the checkpoints of policy saved in Zone1 Zone2 andZone3 respectively The confusion matrix represents thesuccess rate of a particular checkpoint in each zone HereZone3 represents a region where the agent was not trainedbefore In Figure 3b and Figure 3d shows the number ofsteps it took for the agent to transition from one zoneto the other for curriculum learning and non-curriculumlearning respectively Recall that in curriculum learning thecriteria for transitioning from one zone to another is to finishthe goal 50 of the time over a rolling window of 1000episodes For non-curriculum learning the interval is fixedsince we checkpoint at a fixed interval of 50000 steps Inthis evaluation we use the policy checkpointed at 150000steps 200000 steps and 250000 steps respectively Forcurriculum learning we see that the transition from Zone0to Zone1 happens at 140000 steps and from Zone2 toZone3 happens at 200000 steps Contrasting the successrate of curriculum learning and non-curriculum learningwe find that across different checkpoints and zones policytrained using curriculum learning generally performs betterthan non-curriculum learning with a fewer number of stepsAlso chkpt3 policy of curriculum learning is the best policycompared to other policies trained using both approaches
In summary we use the curriculum learning technique todetermine the best performing policy We use this policy toevaluate the policy performance on a resource constrainedRas-pi 3 platform (Section V)
V SYSTEM EVALUATION
This section evaluates the best policy obtained in theSection IV on real embedded platforms such as Ras Pi 3 [23]using the hardware-in-the-loop (HIL) methodology In HILmethodology the state information is fed from the simulatorrunning on a high end desktop and policy is evaluated onthe Ras Pi 3 The actions determined by the policy on RasPi 3 are relayed back to the simulator
The quality of flight metrics in system evaluation is timeto completion (Tc) distance traveled (Dt) and energy left atthe end of the mission (E) Using HIL evaluation and QOFmetrics we show two things First the choice of onboardcompute affects the quality of flight metrics Second theevaluation on a high-end machine does not accurately reflectthe real-time performance on the onboard compute availableon UAVs thus contributing to a new type of lsquoSim2Realrsquo gap
Table I shows the comparison of performance of thepolicy a high end desktop and Ras pi 3 averaged over 100trajectories on Zone 3 the region not used during thetraining For the policy with 44 Million parameters the
Zone 0
Zone1
Zone2
Zone3
chkpt 1
chkpt 2
chkpt 3
03 02 02 01
04 04 02 02
07 06 03 03
(a) Curriculum learning on staticobstacles
Zone 1
Zone 2Zone 3
Che
ckpo
int
0
1
2
3
Steps0 1times105 2times105
(b) Zone transition steps countfor Curriculum learning
Zone 0
Zone1
Zone2
Zone3
chkpt1
chkpt 2
chkpt 3
01 01 01 01
01 01 0 0
02 01 0 0
(c) Non-Curriculum learning
Zone 2Zone 3
Zone 1
Che
ckpo
int
0
1
2
3
Steps0 2times105
(d) Non-Curriculum learning
Fig 3 Comparison of Curriculum learning and non-curriculumlearning Figure 3a shows the confusion matrix of success rate forcurriculum learning Figure 3b shows the zone transition intervalfor curriculum learning Figure 3c shows the success rate for non-curriculum learning and Figure 3d shows the zone transition intervalfor non-curriculum learning
Metric Intel core i7 Ras Pi 3 Performance Gap ()Inference latency (ms) 300 6800 216666Success rate () 3000 2500 500QOF metricsFlight time (s) 6443 8886 3790Distance Flown (m) 3492 4416 2643Energy (kJ) 4235672 5455736 2877
TABLE I Inference time success rate and quality of flight metricscomparison between Intel core i7 desktop and Ras-Pi 3 in Zone3level The policy under evaluation is the best policy obtained fromAlgorithmic evaluation
inference time on Ras-Pi 3 is 68ms while on the desktopequipped with GTX 1080 Ti GPU and Intel core I7 CPU is3ms more than 20 times faster The policy running on thedesktop is 5 more successful While some degradation inperformance is expected the magnitude of the degradation isan order of magnitude more severe for the other QoF metrics
The trajectories on the embedded platform are longerslower and less energy efficient The flight time needed toreach the goal on the high-end desktop on an average is644 s whereas on Ras-pi 3 is 8886 s yielding a performancegap of around 38 The Distance flown for the same policyon the high-end desktop has a trajectory is 349 m whereason Ras-pi 3 is 4416 m thereby contributing to a differenceof 2643 Lastly the high-end desktop consumes on anaverage of 42 kJ of energy while Ras-pi 3 platform consumeson an average of 54 kJ 287 more energy
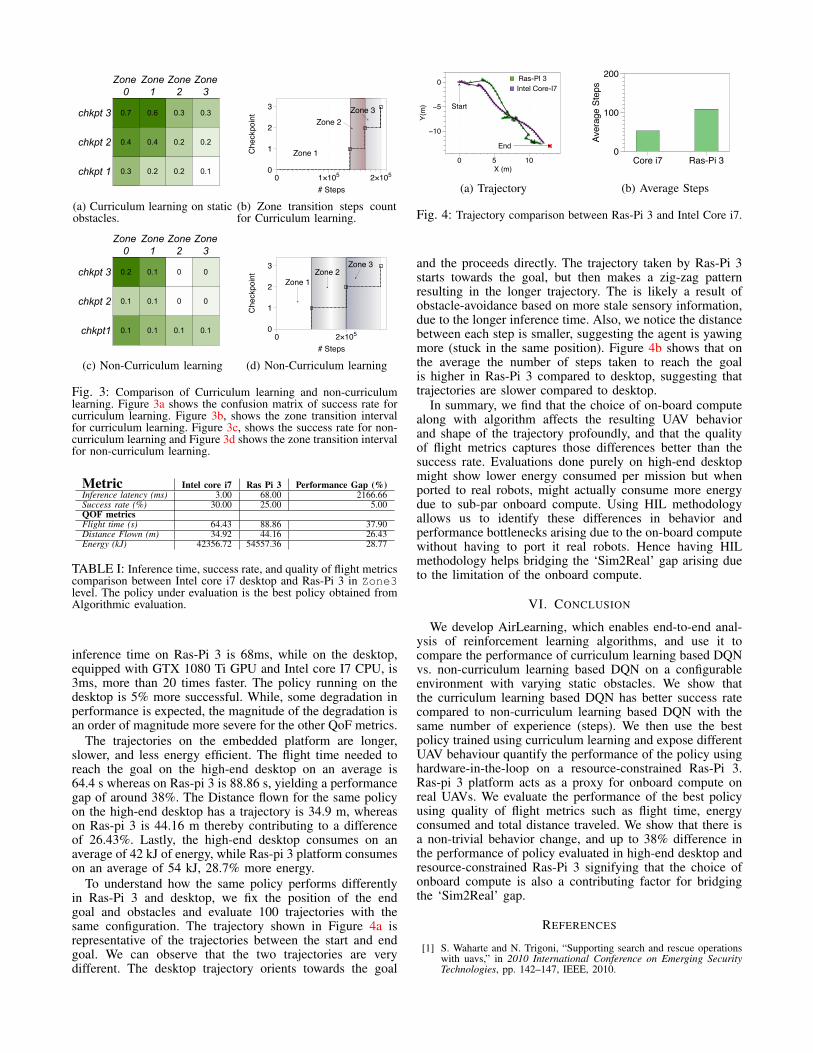
To understand how the same policy performs differentlyin Ras-Pi 3 and desktop we fix the position of the endgoal and obstacles and evaluate 100 trajectories with thesame configuration The trajectory shown in Figure 4a isrepresentative of the trajectories between the start and endgoal We can observe that the two trajectories are verydifferent The desktop trajectory orients towards the goal
Start
End
Y(m
)
minus10
minus5
0
X (m)0 5 10
Ras-PI 3Intel Core-I7
(a) Trajectory
Aver
age
Step
s
0
100
200
Core i7 Ras-Pi 3
(b) Average Steps
Fig 4 Trajectory comparison between Ras-Pi 3 and Intel Core i7
and the proceeds directly The trajectory taken by Ras-Pi 3starts towards the goal but then makes a zig-zag patternresulting in the longer trajectory The is likely a result ofobstacle-avoidance based on more stale sensory informationdue to the longer inference time Also we notice the distancebetween each step is smaller suggesting the agent is yawingmore (stuck in the same position) Figure 4b shows that onthe average the number of steps taken to reach the goalis higher in Ras-Pi 3 compared to desktop suggesting thattrajectories are slower compared to desktop
In summary we find that the choice of on-board computealong with algorithm affects the resulting UAV behaviorand shape of the trajectory profoundly and that the qualityof flight metrics captures those differences better than thesuccess rate Evaluations done purely on high-end desktopmight show lower energy consumed per mission but whenported to real robots might actually consume more energydue to sub-par onboard compute Using HIL methodologyallows us to identify these differences in behavior andperformance bottlenecks arising due to the on-board computewithout having to port it real robots Hence having HILmethodology helps bridging the lsquoSim2Realrsquo gap arising dueto the limitation of the onboard compute
VI CONCLUSION
We develop AirLearning which enables end-to-end anal-ysis of reinforcement learning algorithms and use it tocompare the performance of curriculum learning based DQNvs non-curriculum learning based DQN on a configurableenvironment with varying static obstacles We show thatthe curriculum learning based DQN has better success ratecompared to non-curriculum learning based DQN with thesame number of experience (steps) We then use the bestpolicy trained using curriculum learning and expose differentUAV behaviour quantify the performance of the policy usinghardware-in-the-loop on a resource-constrained Ras-Pi 3Ras-pi 3 platform acts as a proxy for onboard compute onreal UAVs We evaluate the performance of the best policyusing quality of flight metrics such as flight time energyconsumed and total distance traveled We show that there isa non-trivial behavior change and up to 38 difference inthe performance of policy evaluated in high-end desktop andresource-constrained Ras-Pi 3 signifying that the choice ofonboard compute is also a contributing factor for bridgingthe lsquoSim2Realrsquo gap
REFERENCES
[1] S Waharte and N Trigoni ldquoSupporting search and rescue operationswith uavsrdquo in 2010 International Conference on Emerging SecurityTechnologies pp 142ndash147 IEEE 2010
[2] A Goodchild and J Toy ldquoDelivery by drone An evaluation ofunmanned aerial vehicle technology in reducing co2 emissions in thedelivery service industryrdquo Transportation Research Part D Transportand Environment vol 61 pp 58ndash67 2018
[3] A Faust I Palunko P Cruz R Fierro and L Tapia ldquoAutomatedaerial suspended cargo delivery through reinforcement learningrdquo Ar-tificial Intelligence vol 247 pp 381 ndash 398 2017 Special Issue onAI and Robotics
[4] K Peng L Feng Y Hsieh T Yang S Hsiung Y Tsai and C KuoldquoUnmanned aerial vehicle for infrastructure inspection with imageprocessing for quantification of measurement and formation of facademaprdquo in 2017 International Conference on Applied System Innovation(ICASI) pp 1969ndash1972 IEEE 2017
[5] M Fassler Quadrotor Control for Accurate Agile Flight PhD thesisUniversitat Zurich 2018
[6] M Bojarski D D Testa D Dworakowski B Firner B FleppP Goyal L D Jackel M Monfort U Muller J Zhang X ZhangJ Zhao and K Zieba ldquoEnd to end learning for self-driving carsrdquoCoRR vol abs160407316 2016
[7] H L Chiang A Faust M Fiser and A Francis ldquoLearning navigationbehaviors end-to-end with autorlrdquo IEEE Robotics and AutomationLetters vol 4 pp 2007ndash2014 April 2019
[8] F Sadeghi and S Levine ldquo(cad)$ˆ2$rl Real single-image flightwithout a single real imagerdquo CoRR vol abs161104201 2016
[9] D Gandhi L Pinto and A Gupta ldquoLearning to fly by crashingrdquoCoRR vol abs170405588 2017
[10] R M Kretchmar A synthesis of reinforcement learning and robustcontrol theory Colorado State University Fort Collins CO 2000
[11] Crazyflie ldquoCrazyflie 20rdquo httpswwwbitcrazeiocrazyflie-2 2018
[12] DJI ldquoDji-mavic prordquo httpswwwdjicommavic 2018[13] S Koos J-B Mouret and S Doncieux ldquoCrossing the reality gap in
evolutionary robotics by promoting transferable controllersrdquo in Pro-ceedings of the 12th annual conference on Genetic and evolutionarycomputation pp 119ndash126 ACM 2010
[14] A Boeing and T Braunl ldquoLeveraging multiple simulators for crossingthe reality gaprdquo in 2012 12th International Conference on ControlAutomation Robotics amp Vision (ICARCV) pp 1113ndash1119 IEEE 2012
[15] S Shah D Dey C Lovett and A Kapoor ldquoAirSim High-fidelityvisual and physical simulation for autonomous vehiclesrdquo CoRRvol abs170505065 2017
[16] V Mnih K Kavukcuoglu D Silver A Graves I AntonoglouD Wierstra and M Riedmiller ldquoPlaying atari with deep reinforcementlearningrdquo arXiv preprint arXiv13125602 2013
[17] K Kjell ldquoProject titlerdquo httpshttpsgithubcomKjell-KAirGym 2018
[18] Nvidia-Ai-Iot ldquoNvidia-ai-iotredtailrdquo[19] A Hummingbird ldquoAsctec hummingbirdrdquo httpshttp
wwwasctecdeenuav-uas-drones-rpas-roavasctec-hummingbird 2018
[20] Intel ldquoIntel aero ready to fly dronerdquo httpshttpswwwintelcomcontentwwwusenproductsdronesaero-ready-to-flyhtml 2018
[21] W Adiprawita A S Ahmad and J Semibiring ldquoHardware inthe loop simulator in UAV rapid development life cyclerdquo CoRRvol abs08043874 2008
[22] Y Bengio J Louradour R Collobert and J Weston ldquoCurriculumlearningrdquo in Proceedings of the 26th annual international conferenceon machine learning pp 41ndash48 ACM 2009
[23] R pi 3 ldquoRaspberry pi 3rdquo httpswwwraspberrypiorgproductsraspberry-pi-3-model-b 2018

GeneratedEnvironment
Game Configuration
Autonomous Navigation
TaskReinforcement
Learning
Discrete Actions
Polices
MultirotorControl
DQN DDQN
Task - AlgorithmExploration
Algorithm - PolicyExploration
Policy - HardwareExploration
EnvironmentGenerator
Accelerators Embedded CPUs
Flight Control
Machine Learning Tools
Task Definition and EnvironmentGeneration
Algorithm Exploration Policy Design Exploration
Hardware Exploration
AirSim
KerasTensorFlowAirSim Server
AirSim
AirSim Client
Quality of
Flight Metrics
Fig 1 Air Learning infrastructure and benchmarking suite for end-to-end learning in aerial autonomous machines
bedded devices that are resource and power constrainedbull We provide quality of flight metrics such as energy
consumed endurance and average length of trajectoryin the evaluation of learning algorithms specificallydesigned for aerial robots
Using our tool we show that the extent of lsquoSim2Realrsquo gapis not just limited to the fidelity of simulation environmentsbut also extends to the choice of onboard compute platformfor UAVs For instance the best performing algorithm andits policy are often evaluated on high-end desktops butwhen ported to onboard compute platform the real-timeperformance of the policy are different thus widening thelsquoSim2Realrsquo gap [13] [14] Hence having an end-to-endclosed-loop analysis tool suite such as AirLearning we candevelop policies characterize the real-time performance ofsaid policies identify critical bottlenecks possibly co-designalgorithms and hardware to bridge the lsquoSim2Realrsquo gap
II AIR LEARNING
AirLearning consist of four keys components the envi-ronment generator algorithm exploration closed loop realtime hardware in the loop setup and quality of flight metricsthat is cognizant of the resource constraints of the UAV Byusing all these components in unison AirLearning allows tocarefully fine tune algorithms for the underlying hardwareFigure 1 illustrates the AirLearing infrastructureA Environment Generator
Environment generator is creates high fidelity photo-realistic environments for the UAVrsquos to fly in It is built ontop of UE4 and uses AirSim UE4 [15] plugin for the UAVmodel and flight physics
The Environment generator uses a game configuration fileto generate the required configuration tailored for the taskHere a task corresponds to navigating from one point toanother while avoiding obstacles Game configuration file isthe interface between Unreal and the reinforcement learningalgorithms The runtime program writes a set of parametersinto the game configuration file that the Unreal engineparses before starting the game The Arena size numberof staticdynamic obstacles and their velocity (if relevant)minimum distance between obstacles obstacle types colorstexture and the destination of the UAV are some of theparameters that are configurable
B Algorithm exploration and Policy ExplorationWe seed the AirLearning algorithm suite with Deep
Q Network (DQN) [16] a commonly used reinforcementlearning algorithm DQN falls into the discrete action algo-rithms where the control commands are high-level commands(lsquomove forwardrsquo lsquomove leftrsquo etc) For DQN Agent weuse the keras-RL framework To make it more amenable todevelop other reinforcement learning algorithms we improveupon the work of AirGym [17] which provides the capabilityof interfacing with OpenAI gym We extend the originalimplementation of AirGym by providing an array of newcapabilities such as support for curriculum learning trainingmulti-modal policies with inputs such as depthRGBIMUmeasurements These extrasensory data are exposed as partof the environment in OpenAI gym and used for developinga new class of RL algorithms and its associated policiesC Hardware Exploration
Once the Algorithm and policy are finalized AirLearningallows for characterizing the performance of the differenttype of hardware platforms Often aerial roboticists port thealgorithm on real UAVs to validate the functionality of thealgorithm These UAVs might be a custom built[18] or off theshelf UAVs [19] [20] Using our framework we can explorethe performance of different on-board off-the-shelf computeplatforms or even examine the possibilities of designingcustom processors (hardware accelerators)
To seed the framework we use Ras Pi 3 as hardware plat-forms to evaluate the DQN algorithms We use an establishedhardware-in-the-loop (HIL) methodology [21] to characterizethe performance of various algorithms and policies OurHIL methodology enables accurate performance and energybenchmarking of the computation kernelsD Quality of Flight Metrics
Algorithms and policies need to be evaluated on themetrics that describe the quality of flight such as missiontime distance flown etc We consider the following metrics
Success rate (Sr) The percentage of the times the UAVreaches the goal state without collisions or running out ofbattery Ideally we expect this number to be close to 100as it reflects the algorithmsrsquo navigation efficiency
Time to Completion (Tc) The total time UAV spendsfinishing a mission within the simulated world
Energy (E) consumed Total energy spent while carryingthe mission Limited battery on-board constrains the missiontime Hence monitoring energy is of utmost importance andcan be a measure of policyrsquos efficiency
Distance Traveled (Dt) Total distance flown while car-rying out the mission This metric is the average length ofthe trajectory This metric can be used to measure the pathplanning intelligence of a particular policy
III EVALUATION METHODOLOGY
This section discusses our trainingtesting methodologyand DQN results DQN policy generates high-level discreteactions (eg move forward) and these are mapped to low-level controls by the flight controller
Environments For the autonomous navigation task wecreate an environment with varying levels of static obstaclesThe environment size is 50 m x 50 m The number ofobstacles varies from 5 to 10 and it is changed every4 episodes The obstacles start and goal positions are placedin random locations in every episode to ensure that the policydoes not overfit to the environment
Training Methodology We train the DQN agent on theenvironment described above To speed up the learningwe employ the curriculum learning [22] approach wherethe goal position is progressively moved farther away fromthe starting point of the agent To implement this wedivide the entire arena into multiple zones namely Zone 1Zone 2 and Zone 3 as shown in Figure 2 Here Zone 1corresponds to the region that is within 16 m from the UAVstarting position and Zone 2 and Zone 3 are within 32 mand what is this number respectively Initially the positionof goal for the UAV is chosen randomly such that the goalposition lies within zone 1 Once the UAV agent achieves50 success over a rolling window of past 1000 episodesthe position of the goal expands to zone 2 and so forthTo make sure that the agent does not forget learning inthe previous zone the goal position in the next zone isinclusive of previous zones We train the agent to progressuntil zone 3 and upon achieving 50 success rate in thatzone we terminate the training We checkpoint the policy atevery zone so it can be evaluated on how well it has learnedto navigate across all three environments To compare theeffectiveness of curriculum learning we also train using non-curriculum learning where we train for 250000 steps in theentire arena the same number of steps where the curriculumlearning reached zone 3
Testing For testing of curriculum learning policies weevaluate the checkpoints saved at each zone For testingthe non-curriculum learning counterpart we evaluate thecheckpoints saved at fixed intervals of 50000 steps Toensure the policy does not overfit to the environment weevaluate the policy on the unknown zone (zone 3) whichwas not used during training We also randomly change theposition of the goal and obstacles
IV ALGORITHM EVALUATION
In this section we compare the results of curriculumlearning approach with the non-curriculum learning approachon the environment described in Section III The primarymetric is the success rate The policy is evaluated on 100 tra-jectories
Figure 3a and Figure 3c show success rate of policy trainedusing curriculum learning and non-curriculum learning re-spectively Here chkpt1 chkpt2 chkpt3 corresponds
Zone 3
Zone 2
Zone1
UAV
Obstacles
Fig 2 Top view of the Arena An Arena is divided into logicalpartition called Zones The UAV is first trained into Zone0 and thegoals are assigned within this region The zone gets incrementedwhen the UAV agent has met 50 success in the previous zone
to the checkpoints of policy saved in Zone1 Zone2 andZone3 respectively The confusion matrix represents thesuccess rate of a particular checkpoint in each zone HereZone3 represents a region where the agent was not trainedbefore In Figure 3b and Figure 3d shows the number ofsteps it took for the agent to transition from one zoneto the other for curriculum learning and non-curriculumlearning respectively Recall that in curriculum learning thecriteria for transitioning from one zone to another is to finishthe goal 50 of the time over a rolling window of 1000episodes For non-curriculum learning the interval is fixedsince we checkpoint at a fixed interval of 50000 steps Inthis evaluation we use the policy checkpointed at 150000steps 200000 steps and 250000 steps respectively Forcurriculum learning we see that the transition from Zone0to Zone1 happens at 140000 steps and from Zone2 toZone3 happens at 200000 steps Contrasting the successrate of curriculum learning and non-curriculum learningwe find that across different checkpoints and zones policytrained using curriculum learning generally performs betterthan non-curriculum learning with a fewer number of stepsAlso chkpt3 policy of curriculum learning is the best policycompared to other policies trained using both approaches
In summary we use the curriculum learning technique todetermine the best performing policy We use this policy toevaluate the policy performance on a resource constrainedRas-pi 3 platform (Section V)
V SYSTEM EVALUATION
This section evaluates the best policy obtained in theSection IV on real embedded platforms such as Ras Pi 3 [23]using the hardware-in-the-loop (HIL) methodology In HILmethodology the state information is fed from the simulatorrunning on a high end desktop and policy is evaluated onthe Ras Pi 3 The actions determined by the policy on RasPi 3 are relayed back to the simulator
The quality of flight metrics in system evaluation is timeto completion (Tc) distance traveled (Dt) and energy left atthe end of the mission (E) Using HIL evaluation and QOFmetrics we show two things First the choice of onboardcompute affects the quality of flight metrics Second theevaluation on a high-end machine does not accurately reflectthe real-time performance on the onboard compute availableon UAVs thus contributing to a new type of lsquoSim2Realrsquo gap
Table I shows the comparison of performance of thepolicy a high end desktop and Ras pi 3 averaged over 100trajectories on Zone 3 the region not used during thetraining For the policy with 44 Million parameters the
Zone 0
Zone1
Zone2
Zone3
chkpt 1
chkpt 2
chkpt 3
03 02 02 01
04 04 02 02
07 06 03 03
(a) Curriculum learning on staticobstacles
Zone 1
Zone 2Zone 3
Che
ckpo
int
0
1
2
3
Steps0 1times105 2times105
(b) Zone transition steps countfor Curriculum learning
Zone 0
Zone1
Zone2
Zone3
chkpt1
chkpt 2
chkpt 3
01 01 01 01
01 01 0 0
02 01 0 0
(c) Non-Curriculum learning
Zone 2Zone 3
Zone 1
Che
ckpo
int
0
1
2
3
Steps0 2times105
(d) Non-Curriculum learning
Fig 3 Comparison of Curriculum learning and non-curriculumlearning Figure 3a shows the confusion matrix of success rate forcurriculum learning Figure 3b shows the zone transition intervalfor curriculum learning Figure 3c shows the success rate for non-curriculum learning and Figure 3d shows the zone transition intervalfor non-curriculum learning
Metric Intel core i7 Ras Pi 3 Performance Gap ()Inference latency (ms) 300 6800 216666Success rate () 3000 2500 500QOF metricsFlight time (s) 6443 8886 3790Distance Flown (m) 3492 4416 2643Energy (kJ) 4235672 5455736 2877
TABLE I Inference time success rate and quality of flight metricscomparison between Intel core i7 desktop and Ras-Pi 3 in Zone3level The policy under evaluation is the best policy obtained fromAlgorithmic evaluation
inference time on Ras-Pi 3 is 68ms while on the desktopequipped with GTX 1080 Ti GPU and Intel core I7 CPU is3ms more than 20 times faster The policy running on thedesktop is 5 more successful While some degradation inperformance is expected the magnitude of the degradation isan order of magnitude more severe for the other QoF metrics
The trajectories on the embedded platform are longerslower and less energy efficient The flight time needed toreach the goal on the high-end desktop on an average is644 s whereas on Ras-pi 3 is 8886 s yielding a performancegap of around 38 The Distance flown for the same policyon the high-end desktop has a trajectory is 349 m whereason Ras-pi 3 is 4416 m thereby contributing to a differenceof 2643 Lastly the high-end desktop consumes on anaverage of 42 kJ of energy while Ras-pi 3 platform consumeson an average of 54 kJ 287 more energy
To understand how the same policy performs differentlyin Ras-Pi 3 and desktop we fix the position of the endgoal and obstacles and evaluate 100 trajectories with thesame configuration The trajectory shown in Figure 4a isrepresentative of the trajectories between the start and endgoal We can observe that the two trajectories are verydifferent The desktop trajectory orients towards the goal
Start
End
Y(m
)
minus10
minus5
0
X (m)0 5 10
Ras-PI 3Intel Core-I7
(a) Trajectory
Aver
age
Step
s
0
100
200
Core i7 Ras-Pi 3
(b) Average Steps
Fig 4 Trajectory comparison between Ras-Pi 3 and Intel Core i7
and the proceeds directly The trajectory taken by Ras-Pi 3starts towards the goal but then makes a zig-zag patternresulting in the longer trajectory The is likely a result ofobstacle-avoidance based on more stale sensory informationdue to the longer inference time Also we notice the distancebetween each step is smaller suggesting the agent is yawingmore (stuck in the same position) Figure 4b shows that onthe average the number of steps taken to reach the goalis higher in Ras-Pi 3 compared to desktop suggesting thattrajectories are slower compared to desktop
In summary we find that the choice of on-board computealong with algorithm affects the resulting UAV behaviorand shape of the trajectory profoundly and that the qualityof flight metrics captures those differences better than thesuccess rate Evaluations done purely on high-end desktopmight show lower energy consumed per mission but whenported to real robots might actually consume more energydue to sub-par onboard compute Using HIL methodologyallows us to identify these differences in behavior andperformance bottlenecks arising due to the on-board computewithout having to port it real robots Hence having HILmethodology helps bridging the lsquoSim2Realrsquo gap arising dueto the limitation of the onboard compute
VI CONCLUSION
We develop AirLearning which enables end-to-end anal-ysis of reinforcement learning algorithms and use it tocompare the performance of curriculum learning based DQNvs non-curriculum learning based DQN on a configurableenvironment with varying static obstacles We show thatthe curriculum learning based DQN has better success ratecompared to non-curriculum learning based DQN with thesame number of experience (steps) We then use the bestpolicy trained using curriculum learning and expose differentUAV behaviour quantify the performance of the policy usinghardware-in-the-loop on a resource-constrained Ras-Pi 3Ras-pi 3 platform acts as a proxy for onboard compute onreal UAVs We evaluate the performance of the best policyusing quality of flight metrics such as flight time energyconsumed and total distance traveled We show that there isa non-trivial behavior change and up to 38 difference inthe performance of policy evaluated in high-end desktop andresource-constrained Ras-Pi 3 signifying that the choice ofonboard compute is also a contributing factor for bridgingthe lsquoSim2Realrsquo gap
REFERENCES
[1] S Waharte and N Trigoni ldquoSupporting search and rescue operationswith uavsrdquo in 2010 International Conference on Emerging SecurityTechnologies pp 142ndash147 IEEE 2010
[2] A Goodchild and J Toy ldquoDelivery by drone An evaluation ofunmanned aerial vehicle technology in reducing co2 emissions in thedelivery service industryrdquo Transportation Research Part D Transportand Environment vol 61 pp 58ndash67 2018
[3] A Faust I Palunko P Cruz R Fierro and L Tapia ldquoAutomatedaerial suspended cargo delivery through reinforcement learningrdquo Ar-tificial Intelligence vol 247 pp 381 ndash 398 2017 Special Issue onAI and Robotics
[4] K Peng L Feng Y Hsieh T Yang S Hsiung Y Tsai and C KuoldquoUnmanned aerial vehicle for infrastructure inspection with imageprocessing for quantification of measurement and formation of facademaprdquo in 2017 International Conference on Applied System Innovation(ICASI) pp 1969ndash1972 IEEE 2017
[5] M Fassler Quadrotor Control for Accurate Agile Flight PhD thesisUniversitat Zurich 2018
[6] M Bojarski D D Testa D Dworakowski B Firner B FleppP Goyal L D Jackel M Monfort U Muller J Zhang X ZhangJ Zhao and K Zieba ldquoEnd to end learning for self-driving carsrdquoCoRR vol abs160407316 2016
[7] H L Chiang A Faust M Fiser and A Francis ldquoLearning navigationbehaviors end-to-end with autorlrdquo IEEE Robotics and AutomationLetters vol 4 pp 2007ndash2014 April 2019
[8] F Sadeghi and S Levine ldquo(cad)$ˆ2$rl Real single-image flightwithout a single real imagerdquo CoRR vol abs161104201 2016
[9] D Gandhi L Pinto and A Gupta ldquoLearning to fly by crashingrdquoCoRR vol abs170405588 2017
[10] R M Kretchmar A synthesis of reinforcement learning and robustcontrol theory Colorado State University Fort Collins CO 2000
[11] Crazyflie ldquoCrazyflie 20rdquo httpswwwbitcrazeiocrazyflie-2 2018
[12] DJI ldquoDji-mavic prordquo httpswwwdjicommavic 2018[13] S Koos J-B Mouret and S Doncieux ldquoCrossing the reality gap in
evolutionary robotics by promoting transferable controllersrdquo in Pro-ceedings of the 12th annual conference on Genetic and evolutionarycomputation pp 119ndash126 ACM 2010
[14] A Boeing and T Braunl ldquoLeveraging multiple simulators for crossingthe reality gaprdquo in 2012 12th International Conference on ControlAutomation Robotics amp Vision (ICARCV) pp 1113ndash1119 IEEE 2012
[15] S Shah D Dey C Lovett and A Kapoor ldquoAirSim High-fidelityvisual and physical simulation for autonomous vehiclesrdquo CoRRvol abs170505065 2017
[16] V Mnih K Kavukcuoglu D Silver A Graves I AntonoglouD Wierstra and M Riedmiller ldquoPlaying atari with deep reinforcementlearningrdquo arXiv preprint arXiv13125602 2013
[17] K Kjell ldquoProject titlerdquo httpshttpsgithubcomKjell-KAirGym 2018
[18] Nvidia-Ai-Iot ldquoNvidia-ai-iotredtailrdquo[19] A Hummingbird ldquoAsctec hummingbirdrdquo httpshttp
wwwasctecdeenuav-uas-drones-rpas-roavasctec-hummingbird 2018
[20] Intel ldquoIntel aero ready to fly dronerdquo httpshttpswwwintelcomcontentwwwusenproductsdronesaero-ready-to-flyhtml 2018
[21] W Adiprawita A S Ahmad and J Semibiring ldquoHardware inthe loop simulator in UAV rapid development life cyclerdquo CoRRvol abs08043874 2008
[22] Y Bengio J Louradour R Collobert and J Weston ldquoCurriculumlearningrdquo in Proceedings of the 26th annual international conferenceon machine learning pp 41ndash48 ACM 2009
[23] R pi 3 ldquoRaspberry pi 3rdquo httpswwwraspberrypiorgproductsraspberry-pi-3-model-b 2018

Energy (E) consumed Total energy spent while carryingthe mission Limited battery on-board constrains the missiontime Hence monitoring energy is of utmost importance andcan be a measure of policyrsquos efficiency
Distance Traveled (Dt) Total distance flown while car-rying out the mission This metric is the average length ofthe trajectory This metric can be used to measure the pathplanning intelligence of a particular policy
III EVALUATION METHODOLOGY
This section discusses our trainingtesting methodologyand DQN results DQN policy generates high-level discreteactions (eg move forward) and these are mapped to low-level controls by the flight controller
Environments For the autonomous navigation task wecreate an environment with varying levels of static obstaclesThe environment size is 50 m x 50 m The number ofobstacles varies from 5 to 10 and it is changed every4 episodes The obstacles start and goal positions are placedin random locations in every episode to ensure that the policydoes not overfit to the environment
Training Methodology We train the DQN agent on theenvironment described above To speed up the learningwe employ the curriculum learning [22] approach wherethe goal position is progressively moved farther away fromthe starting point of the agent To implement this wedivide the entire arena into multiple zones namely Zone 1Zone 2 and Zone 3 as shown in Figure 2 Here Zone 1corresponds to the region that is within 16 m from the UAVstarting position and Zone 2 and Zone 3 are within 32 mand what is this number respectively Initially the positionof goal for the UAV is chosen randomly such that the goalposition lies within zone 1 Once the UAV agent achieves50 success over a rolling window of past 1000 episodesthe position of the goal expands to zone 2 and so forthTo make sure that the agent does not forget learning inthe previous zone the goal position in the next zone isinclusive of previous zones We train the agent to progressuntil zone 3 and upon achieving 50 success rate in thatzone we terminate the training We checkpoint the policy atevery zone so it can be evaluated on how well it has learnedto navigate across all three environments To compare theeffectiveness of curriculum learning we also train using non-curriculum learning where we train for 250000 steps in theentire arena the same number of steps where the curriculumlearning reached zone 3
Testing For testing of curriculum learning policies weevaluate the checkpoints saved at each zone For testingthe non-curriculum learning counterpart we evaluate thecheckpoints saved at fixed intervals of 50000 steps Toensure the policy does not overfit to the environment weevaluate the policy on the unknown zone (zone 3) whichwas not used during training We also randomly change theposition of the goal and obstacles
IV ALGORITHM EVALUATION
In this section we compare the results of curriculumlearning approach with the non-curriculum learning approachon the environment described in Section III The primarymetric is the success rate The policy is evaluated on 100 tra-jectories
Figure 3a and Figure 3c show success rate of policy trainedusing curriculum learning and non-curriculum learning re-spectively Here chkpt1 chkpt2 chkpt3 corresponds
Zone 3
Zone 2
Zone1
UAV
Obstacles
Fig 2 Top view of the Arena An Arena is divided into logicalpartition called Zones The UAV is first trained into Zone0 and thegoals are assigned within this region The zone gets incrementedwhen the UAV agent has met 50 success in the previous zone
to the checkpoints of policy saved in Zone1 Zone2 andZone3 respectively The confusion matrix represents thesuccess rate of a particular checkpoint in each zone HereZone3 represents a region where the agent was not trainedbefore In Figure 3b and Figure 3d shows the number ofsteps it took for the agent to transition from one zoneto the other for curriculum learning and non-curriculumlearning respectively Recall that in curriculum learning thecriteria for transitioning from one zone to another is to finishthe goal 50 of the time over a rolling window of 1000episodes For non-curriculum learning the interval is fixedsince we checkpoint at a fixed interval of 50000 steps Inthis evaluation we use the policy checkpointed at 150000steps 200000 steps and 250000 steps respectively Forcurriculum learning we see that the transition from Zone0to Zone1 happens at 140000 steps and from Zone2 toZone3 happens at 200000 steps Contrasting the successrate of curriculum learning and non-curriculum learningwe find that across different checkpoints and zones policytrained using curriculum learning generally performs betterthan non-curriculum learning with a fewer number of stepsAlso chkpt3 policy of curriculum learning is the best policycompared to other policies trained using both approaches
In summary we use the curriculum learning technique todetermine the best performing policy We use this policy toevaluate the policy performance on a resource constrainedRas-pi 3 platform (Section V)
V SYSTEM EVALUATION
This section evaluates the best policy obtained in theSection IV on real embedded platforms such as Ras Pi 3 [23]using the hardware-in-the-loop (HIL) methodology In HILmethodology the state information is fed from the simulatorrunning on a high end desktop and policy is evaluated onthe Ras Pi 3 The actions determined by the policy on RasPi 3 are relayed back to the simulator
The quality of flight metrics in system evaluation is timeto completion (Tc) distance traveled (Dt) and energy left atthe end of the mission (E) Using HIL evaluation and QOFmetrics we show two things First the choice of onboardcompute affects the quality of flight metrics Second theevaluation on a high-end machine does not accurately reflectthe real-time performance on the onboard compute availableon UAVs thus contributing to a new type of lsquoSim2Realrsquo gap
Table I shows the comparison of performance of thepolicy a high end desktop and Ras pi 3 averaged over 100trajectories on Zone 3 the region not used during thetraining For the policy with 44 Million parameters the
Zone 0
Zone1
Zone2
Zone3
chkpt 1
chkpt 2
chkpt 3
03 02 02 01
04 04 02 02
07 06 03 03
(a) Curriculum learning on staticobstacles
Zone 1
Zone 2Zone 3
Che
ckpo
int
0
1
2
3
Steps0 1times105 2times105
(b) Zone transition steps countfor Curriculum learning
Zone 0
Zone1
Zone2
Zone3
chkpt1
chkpt 2
chkpt 3
01 01 01 01
01 01 0 0
02 01 0 0
(c) Non-Curriculum learning
Zone 2Zone 3
Zone 1
Che
ckpo
int
0
1
2
3
Steps0 2times105
(d) Non-Curriculum learning
Fig 3 Comparison of Curriculum learning and non-curriculumlearning Figure 3a shows the confusion matrix of success rate forcurriculum learning Figure 3b shows the zone transition intervalfor curriculum learning Figure 3c shows the success rate for non-curriculum learning and Figure 3d shows the zone transition intervalfor non-curriculum learning
Metric Intel core i7 Ras Pi 3 Performance Gap ()Inference latency (ms) 300 6800 216666Success rate () 3000 2500 500QOF metricsFlight time (s) 6443 8886 3790Distance Flown (m) 3492 4416 2643Energy (kJ) 4235672 5455736 2877
TABLE I Inference time success rate and quality of flight metricscomparison between Intel core i7 desktop and Ras-Pi 3 in Zone3level The policy under evaluation is the best policy obtained fromAlgorithmic evaluation
inference time on Ras-Pi 3 is 68ms while on the desktopequipped with GTX 1080 Ti GPU and Intel core I7 CPU is3ms more than 20 times faster The policy running on thedesktop is 5 more successful While some degradation inperformance is expected the magnitude of the degradation isan order of magnitude more severe for the other QoF metrics
The trajectories on the embedded platform are longerslower and less energy efficient The flight time needed toreach the goal on the high-end desktop on an average is644 s whereas on Ras-pi 3 is 8886 s yielding a performancegap of around 38 The Distance flown for the same policyon the high-end desktop has a trajectory is 349 m whereason Ras-pi 3 is 4416 m thereby contributing to a differenceof 2643 Lastly the high-end desktop consumes on anaverage of 42 kJ of energy while Ras-pi 3 platform consumeson an average of 54 kJ 287 more energy
To understand how the same policy performs differentlyin Ras-Pi 3 and desktop we fix the position of the endgoal and obstacles and evaluate 100 trajectories with thesame configuration The trajectory shown in Figure 4a isrepresentative of the trajectories between the start and endgoal We can observe that the two trajectories are verydifferent The desktop trajectory orients towards the goal
Start
End
Y(m
)
minus10
minus5
0
X (m)0 5 10
Ras-PI 3Intel Core-I7
(a) Trajectory
Aver
age
Step
s
0
100
200
Core i7 Ras-Pi 3
(b) Average Steps
Fig 4 Trajectory comparison between Ras-Pi 3 and Intel Core i7
and the proceeds directly The trajectory taken by Ras-Pi 3starts towards the goal but then makes a zig-zag patternresulting in the longer trajectory The is likely a result ofobstacle-avoidance based on more stale sensory informationdue to the longer inference time Also we notice the distancebetween each step is smaller suggesting the agent is yawingmore (stuck in the same position) Figure 4b shows that onthe average the number of steps taken to reach the goalis higher in Ras-Pi 3 compared to desktop suggesting thattrajectories are slower compared to desktop
In summary we find that the choice of on-board computealong with algorithm affects the resulting UAV behaviorand shape of the trajectory profoundly and that the qualityof flight metrics captures those differences better than thesuccess rate Evaluations done purely on high-end desktopmight show lower energy consumed per mission but whenported to real robots might actually consume more energydue to sub-par onboard compute Using HIL methodologyallows us to identify these differences in behavior andperformance bottlenecks arising due to the on-board computewithout having to port it real robots Hence having HILmethodology helps bridging the lsquoSim2Realrsquo gap arising dueto the limitation of the onboard compute
VI CONCLUSION
We develop AirLearning which enables end-to-end anal-ysis of reinforcement learning algorithms and use it tocompare the performance of curriculum learning based DQNvs non-curriculum learning based DQN on a configurableenvironment with varying static obstacles We show thatthe curriculum learning based DQN has better success ratecompared to non-curriculum learning based DQN with thesame number of experience (steps) We then use the bestpolicy trained using curriculum learning and expose differentUAV behaviour quantify the performance of the policy usinghardware-in-the-loop on a resource-constrained Ras-Pi 3Ras-pi 3 platform acts as a proxy for onboard compute onreal UAVs We evaluate the performance of the best policyusing quality of flight metrics such as flight time energyconsumed and total distance traveled We show that there isa non-trivial behavior change and up to 38 difference inthe performance of policy evaluated in high-end desktop andresource-constrained Ras-Pi 3 signifying that the choice ofonboard compute is also a contributing factor for bridgingthe lsquoSim2Realrsquo gap
REFERENCES
[1] S Waharte and N Trigoni ldquoSupporting search and rescue operationswith uavsrdquo in 2010 International Conference on Emerging SecurityTechnologies pp 142ndash147 IEEE 2010
[2] A Goodchild and J Toy ldquoDelivery by drone An evaluation ofunmanned aerial vehicle technology in reducing co2 emissions in thedelivery service industryrdquo Transportation Research Part D Transportand Environment vol 61 pp 58ndash67 2018
[3] A Faust I Palunko P Cruz R Fierro and L Tapia ldquoAutomatedaerial suspended cargo delivery through reinforcement learningrdquo Ar-tificial Intelligence vol 247 pp 381 ndash 398 2017 Special Issue onAI and Robotics
[4] K Peng L Feng Y Hsieh T Yang S Hsiung Y Tsai and C KuoldquoUnmanned aerial vehicle for infrastructure inspection with imageprocessing for quantification of measurement and formation of facademaprdquo in 2017 International Conference on Applied System Innovation(ICASI) pp 1969ndash1972 IEEE 2017
[5] M Fassler Quadrotor Control for Accurate Agile Flight PhD thesisUniversitat Zurich 2018
[6] M Bojarski D D Testa D Dworakowski B Firner B FleppP Goyal L D Jackel M Monfort U Muller J Zhang X ZhangJ Zhao and K Zieba ldquoEnd to end learning for self-driving carsrdquoCoRR vol abs160407316 2016
[7] H L Chiang A Faust M Fiser and A Francis ldquoLearning navigationbehaviors end-to-end with autorlrdquo IEEE Robotics and AutomationLetters vol 4 pp 2007ndash2014 April 2019
[8] F Sadeghi and S Levine ldquo(cad)$ˆ2$rl Real single-image flightwithout a single real imagerdquo CoRR vol abs161104201 2016
[9] D Gandhi L Pinto and A Gupta ldquoLearning to fly by crashingrdquoCoRR vol abs170405588 2017
[10] R M Kretchmar A synthesis of reinforcement learning and robustcontrol theory Colorado State University Fort Collins CO 2000
[11] Crazyflie ldquoCrazyflie 20rdquo httpswwwbitcrazeiocrazyflie-2 2018
[12] DJI ldquoDji-mavic prordquo httpswwwdjicommavic 2018[13] S Koos J-B Mouret and S Doncieux ldquoCrossing the reality gap in
evolutionary robotics by promoting transferable controllersrdquo in Pro-ceedings of the 12th annual conference on Genetic and evolutionarycomputation pp 119ndash126 ACM 2010
[14] A Boeing and T Braunl ldquoLeveraging multiple simulators for crossingthe reality gaprdquo in 2012 12th International Conference on ControlAutomation Robotics amp Vision (ICARCV) pp 1113ndash1119 IEEE 2012
[15] S Shah D Dey C Lovett and A Kapoor ldquoAirSim High-fidelityvisual and physical simulation for autonomous vehiclesrdquo CoRRvol abs170505065 2017
[16] V Mnih K Kavukcuoglu D Silver A Graves I AntonoglouD Wierstra and M Riedmiller ldquoPlaying atari with deep reinforcementlearningrdquo arXiv preprint arXiv13125602 2013
[17] K Kjell ldquoProject titlerdquo httpshttpsgithubcomKjell-KAirGym 2018
[18] Nvidia-Ai-Iot ldquoNvidia-ai-iotredtailrdquo[19] A Hummingbird ldquoAsctec hummingbirdrdquo httpshttp
wwwasctecdeenuav-uas-drones-rpas-roavasctec-hummingbird 2018
[20] Intel ldquoIntel aero ready to fly dronerdquo httpshttpswwwintelcomcontentwwwusenproductsdronesaero-ready-to-flyhtml 2018
[21] W Adiprawita A S Ahmad and J Semibiring ldquoHardware inthe loop simulator in UAV rapid development life cyclerdquo CoRRvol abs08043874 2008
[22] Y Bengio J Louradour R Collobert and J Weston ldquoCurriculumlearningrdquo in Proceedings of the 26th annual international conferenceon machine learning pp 41ndash48 ACM 2009
[23] R pi 3 ldquoRaspberry pi 3rdquo httpswwwraspberrypiorgproductsraspberry-pi-3-model-b 2018
Zone 0
Zone1
Zone2
Zone3
chkpt 1
chkpt 2
chkpt 3
03 02 02 01
04 04 02 02
07 06 03 03
(a) Curriculum learning on staticobstacles
Zone 1
Zone 2Zone 3
Che
ckpo
int
0
1
2
3
Steps0 1times105 2times105
(b) Zone transition steps countfor Curriculum learning
Zone 0
Zone1
Zone2
Zone3
chkpt1
chkpt 2
chkpt 3
01 01 01 01
01 01 0 0
02 01 0 0
(c) Non-Curriculum learning
Zone 2Zone 3
Zone 1
Che
ckpo
int
0
1
2
3
Steps0 2times105
(d) Non-Curriculum learning
Fig 3 Comparison of Curriculum learning and non-curriculumlearning Figure 3a shows the confusion matrix of success rate forcurriculum learning Figure 3b shows the zone transition intervalfor curriculum learning Figure 3c shows the success rate for non-curriculum learning and Figure 3d shows the zone transition intervalfor non-curriculum learning
Metric Intel core i7 Ras Pi 3 Performance Gap ()Inference latency (ms) 300 6800 216666Success rate () 3000 2500 500QOF metricsFlight time (s) 6443 8886 3790Distance Flown (m) 3492 4416 2643Energy (kJ) 4235672 5455736 2877
TABLE I Inference time success rate and quality of flight metricscomparison between Intel core i7 desktop and Ras-Pi 3 in Zone3level The policy under evaluation is the best policy obtained fromAlgorithmic evaluation
inference time on Ras-Pi 3 is 68ms while on the desktopequipped with GTX 1080 Ti GPU and Intel core I7 CPU is3ms more than 20 times faster The policy running on thedesktop is 5 more successful While some degradation inperformance is expected the magnitude of the degradation isan order of magnitude more severe for the other QoF metrics
The trajectories on the embedded platform are longerslower and less energy efficient The flight time needed toreach the goal on the high-end desktop on an average is644 s whereas on Ras-pi 3 is 8886 s yielding a performancegap of around 38 The Distance flown for the same policyon the high-end desktop has a trajectory is 349 m whereason Ras-pi 3 is 4416 m thereby contributing to a differenceof 2643 Lastly the high-end desktop consumes on anaverage of 42 kJ of energy while Ras-pi 3 platform consumeson an average of 54 kJ 287 more energy
To understand how the same policy performs differentlyin Ras-Pi 3 and desktop we fix the position of the endgoal and obstacles and evaluate 100 trajectories with thesame configuration The trajectory shown in Figure 4a isrepresentative of the trajectories between the start and endgoal We can observe that the two trajectories are verydifferent The desktop trajectory orients towards the goal
Start
End
Y(m
)
minus10
minus5
0
X (m)0 5 10
Ras-PI 3Intel Core-I7
(a) Trajectory
Aver
age
Step
s
0
100
200
Core i7 Ras-Pi 3
(b) Average Steps
Fig 4 Trajectory comparison between Ras-Pi 3 and Intel Core i7
and the proceeds directly The trajectory taken by Ras-Pi 3starts towards the goal but then makes a zig-zag patternresulting in the longer trajectory The is likely a result ofobstacle-avoidance based on more stale sensory informationdue to the longer inference time Also we notice the distancebetween each step is smaller suggesting the agent is yawingmore (stuck in the same position) Figure 4b shows that onthe average the number of steps taken to reach the goalis higher in Ras-Pi 3 compared to desktop suggesting thattrajectories are slower compared to desktop
In summary we find that the choice of on-board computealong with algorithm affects the resulting UAV behaviorand shape of the trajectory profoundly and that the qualityof flight metrics captures those differences better than thesuccess rate Evaluations done purely on high-end desktopmight show lower energy consumed per mission but whenported to real robots might actually consume more energydue to sub-par onboard compute Using HIL methodologyallows us to identify these differences in behavior andperformance bottlenecks arising due to the on-board computewithout having to port it real robots Hence having HILmethodology helps bridging the lsquoSim2Realrsquo gap arising dueto the limitation of the onboard compute
VI CONCLUSION
We develop AirLearning which enables end-to-end anal-ysis of reinforcement learning algorithms and use it tocompare the performance of curriculum learning based DQNvs non-curriculum learning based DQN on a configurableenvironment with varying static obstacles We show thatthe curriculum learning based DQN has better success ratecompared to non-curriculum learning based DQN with thesame number of experience (steps) We then use the bestpolicy trained using curriculum learning and expose differentUAV behaviour quantify the performance of the policy usinghardware-in-the-loop on a resource-constrained Ras-Pi 3Ras-pi 3 platform acts as a proxy for onboard compute onreal UAVs We evaluate the performance of the best policyusing quality of flight metrics such as flight time energyconsumed and total distance traveled We show that there isa non-trivial behavior change and up to 38 difference inthe performance of policy evaluated in high-end desktop andresource-constrained Ras-Pi 3 signifying that the choice ofonboard compute is also a contributing factor for bridgingthe lsquoSim2Realrsquo gap
REFERENCES
[1] S Waharte and N Trigoni ldquoSupporting search and rescue operationswith uavsrdquo in 2010 International Conference on Emerging SecurityTechnologies pp 142ndash147 IEEE 2010
[2] A Goodchild and J Toy ldquoDelivery by drone An evaluation ofunmanned aerial vehicle technology in reducing co2 emissions in thedelivery service industryrdquo Transportation Research Part D Transportand Environment vol 61 pp 58ndash67 2018
[3] A Faust I Palunko P Cruz R Fierro and L Tapia ldquoAutomatedaerial suspended cargo delivery through reinforcement learningrdquo Ar-tificial Intelligence vol 247 pp 381 ndash 398 2017 Special Issue onAI and Robotics
[4] K Peng L Feng Y Hsieh T Yang S Hsiung Y Tsai and C KuoldquoUnmanned aerial vehicle for infrastructure inspection with imageprocessing for quantification of measurement and formation of facademaprdquo in 2017 International Conference on Applied System Innovation(ICASI) pp 1969ndash1972 IEEE 2017
[5] M Fassler Quadrotor Control for Accurate Agile Flight PhD thesisUniversitat Zurich 2018
[6] M Bojarski D D Testa D Dworakowski B Firner B FleppP Goyal L D Jackel M Monfort U Muller J Zhang X ZhangJ Zhao and K Zieba ldquoEnd to end learning for self-driving carsrdquoCoRR vol abs160407316 2016
[7] H L Chiang A Faust M Fiser and A Francis ldquoLearning navigationbehaviors end-to-end with autorlrdquo IEEE Robotics and AutomationLetters vol 4 pp 2007ndash2014 April 2019
[8] F Sadeghi and S Levine ldquo(cad)$ˆ2$rl Real single-image flightwithout a single real imagerdquo CoRR vol abs161104201 2016
[9] D Gandhi L Pinto and A Gupta ldquoLearning to fly by crashingrdquoCoRR vol abs170405588 2017
[10] R M Kretchmar A synthesis of reinforcement learning and robustcontrol theory Colorado State University Fort Collins CO 2000
[11] Crazyflie ldquoCrazyflie 20rdquo httpswwwbitcrazeiocrazyflie-2 2018
[12] DJI ldquoDji-mavic prordquo httpswwwdjicommavic 2018[13] S Koos J-B Mouret and S Doncieux ldquoCrossing the reality gap in
evolutionary robotics by promoting transferable controllersrdquo in Pro-ceedings of the 12th annual conference on Genetic and evolutionarycomputation pp 119ndash126 ACM 2010
[14] A Boeing and T Braunl ldquoLeveraging multiple simulators for crossingthe reality gaprdquo in 2012 12th International Conference on ControlAutomation Robotics amp Vision (ICARCV) pp 1113ndash1119 IEEE 2012
[15] S Shah D Dey C Lovett and A Kapoor ldquoAirSim High-fidelityvisual and physical simulation for autonomous vehiclesrdquo CoRRvol abs170505065 2017
[16] V Mnih K Kavukcuoglu D Silver A Graves I AntonoglouD Wierstra and M Riedmiller ldquoPlaying atari with deep reinforcementlearningrdquo arXiv preprint arXiv13125602 2013
[17] K Kjell ldquoProject titlerdquo httpshttpsgithubcomKjell-KAirGym 2018
[18] Nvidia-Ai-Iot ldquoNvidia-ai-iotredtailrdquo[19] A Hummingbird ldquoAsctec hummingbirdrdquo httpshttp
wwwasctecdeenuav-uas-drones-rpas-roavasctec-hummingbird 2018
[20] Intel ldquoIntel aero ready to fly dronerdquo httpshttpswwwintelcomcontentwwwusenproductsdronesaero-ready-to-flyhtml 2018
[21] W Adiprawita A S Ahmad and J Semibiring ldquoHardware inthe loop simulator in UAV rapid development life cyclerdquo CoRRvol abs08043874 2008
[22] Y Bengio J Louradour R Collobert and J Weston ldquoCurriculumlearningrdquo in Proceedings of the 26th annual international conferenceon machine learning pp 41ndash48 ACM 2009
[23] R pi 3 ldquoRaspberry pi 3rdquo httpswwwraspberrypiorgproductsraspberry-pi-3-model-b 2018

[2] A Goodchild and J Toy ldquoDelivery by drone An evaluation ofunmanned aerial vehicle technology in reducing co2 emissions in thedelivery service industryrdquo Transportation Research Part D Transportand Environment vol 61 pp 58ndash67 2018
[3] A Faust I Palunko P Cruz R Fierro and L Tapia ldquoAutomatedaerial suspended cargo delivery through reinforcement learningrdquo Ar-tificial Intelligence vol 247 pp 381 ndash 398 2017 Special Issue onAI and Robotics
[4] K Peng L Feng Y Hsieh T Yang S Hsiung Y Tsai and C KuoldquoUnmanned aerial vehicle for infrastructure inspection with imageprocessing for quantification of measurement and formation of facademaprdquo in 2017 International Conference on Applied System Innovation(ICASI) pp 1969ndash1972 IEEE 2017
[5] M Fassler Quadrotor Control for Accurate Agile Flight PhD thesisUniversitat Zurich 2018
[6] M Bojarski D D Testa D Dworakowski B Firner B FleppP Goyal L D Jackel M Monfort U Muller J Zhang X ZhangJ Zhao and K Zieba ldquoEnd to end learning for self-driving carsrdquoCoRR vol abs160407316 2016
[7] H L Chiang A Faust M Fiser and A Francis ldquoLearning navigationbehaviors end-to-end with autorlrdquo IEEE Robotics and AutomationLetters vol 4 pp 2007ndash2014 April 2019
[8] F Sadeghi and S Levine ldquo(cad)$ˆ2$rl Real single-image flightwithout a single real imagerdquo CoRR vol abs161104201 2016
[9] D Gandhi L Pinto and A Gupta ldquoLearning to fly by crashingrdquoCoRR vol abs170405588 2017
[10] R M Kretchmar A synthesis of reinforcement learning and robustcontrol theory Colorado State University Fort Collins CO 2000
[11] Crazyflie ldquoCrazyflie 20rdquo httpswwwbitcrazeiocrazyflie-2 2018
[12] DJI ldquoDji-mavic prordquo httpswwwdjicommavic 2018[13] S Koos J-B Mouret and S Doncieux ldquoCrossing the reality gap in
evolutionary robotics by promoting transferable controllersrdquo in Pro-ceedings of the 12th annual conference on Genetic and evolutionarycomputation pp 119ndash126 ACM 2010
[14] A Boeing and T Braunl ldquoLeveraging multiple simulators for crossingthe reality gaprdquo in 2012 12th International Conference on ControlAutomation Robotics amp Vision (ICARCV) pp 1113ndash1119 IEEE 2012
[15] S Shah D Dey C Lovett and A Kapoor ldquoAirSim High-fidelityvisual and physical simulation for autonomous vehiclesrdquo CoRRvol abs170505065 2017
[16] V Mnih K Kavukcuoglu D Silver A Graves I AntonoglouD Wierstra and M Riedmiller ldquoPlaying atari with deep reinforcementlearningrdquo arXiv preprint arXiv13125602 2013
[17] K Kjell ldquoProject titlerdquo httpshttpsgithubcomKjell-KAirGym 2018
[18] Nvidia-Ai-Iot ldquoNvidia-ai-iotredtailrdquo[19] A Hummingbird ldquoAsctec hummingbirdrdquo httpshttp
wwwasctecdeenuav-uas-drones-rpas-roavasctec-hummingbird 2018
[20] Intel ldquoIntel aero ready to fly dronerdquo httpshttpswwwintelcomcontentwwwusenproductsdronesaero-ready-to-flyhtml 2018
[21] W Adiprawita A S Ahmad and J Semibiring ldquoHardware inthe loop simulator in UAV rapid development life cyclerdquo CoRRvol abs08043874 2008
[22] Y Bengio J Louradour R Collobert and J Weston ldquoCurriculumlearningrdquo in Proceedings of the 26th annual international conferenceon machine learning pp 41ndash48 ACM 2009
[23] R pi 3 ldquoRaspberry pi 3rdquo httpswwwraspberrypiorgproductsraspberry-pi-3-model-b 2018

![Algorithms for Social Good: Kidney Exchange · Parts of this work also appeared in AAAI 2016 and EC 2016. ... Toward this end, kidney exchange [Rapaport 1986; Roth et al. 2004] is](https://img.pdfslide.us/doc/110x75/5f051d8d7e708231d411577c/algorithms-for-social-good-kidney-exchange-parts-of-this-work-also-appeared-in.jpg)



























