Embed Size (px)
Citation preview

Today’s Agenda
Exam post-mortem Should I drop? Search Engines: Details & Ramifications Future:
– 2 Presentations every Thursday– Project #2 is coming out next week (Website)– Lab: Switching to Javascript

Exam post-mortem
1. Communication substrates Ethernet USB Wireless Satellite Infrared

Exam post-mortem
2. Content & Services email (pop, imap, etc.) webpage (http) documents (ftp) peer-to-peer, chat, IM, etc video audio

Exam post-mortem
3. Two or more computers NetworkTwo or more networks Inter-network
A sub-network is actually part of a network.
WAN Wide Area Network implies long distance.
An inter-network can be in the same room.

Exam post-mortem
6. The Internet was a military project DARPANET until 1969/70.The Internet was a research project ARPANET
throughout the 70’s (Available only at National Labs and Universities)
Bulletin boards and email became available to the general public in the 80’s
However, 1990 is a reasonable answer.

Exam post-mortem
7. In 1946 computers didn’t really exist yet.In 1956 people had yet to even envision connecting
computers in different locations
8. Web browsing via hypertext was going on in the late 80’sBy 1995 e-commerce was already happening
Emerged to come forth from obscurity

Exam post-mortem
19. 200 million hosts in 2002
20. Did you notice that it multiplies by 4 every year.800,000,000 best answer
500 million to 1 billion was only -1
21. False, In 2010 will there be 100 billion people on the earth?

Exam post-mortem
23-28. 100 cable pro connections is betterCosts less
More bandwidth
The problem is that you’d have to manage 100 separate connections
Road Runner probably doesn’t have that many separate lines crossing one point.

Exam post-mortem
38. Perhaps I wasn’t clear but…Domain registration is a yearly costInternet access is required.
Was anyone thinking: At school or work internet access is free.
1. At school its not! Is your room free?
2. At work its not! Someone pays.
3. Netzero is free, right? Good luck.
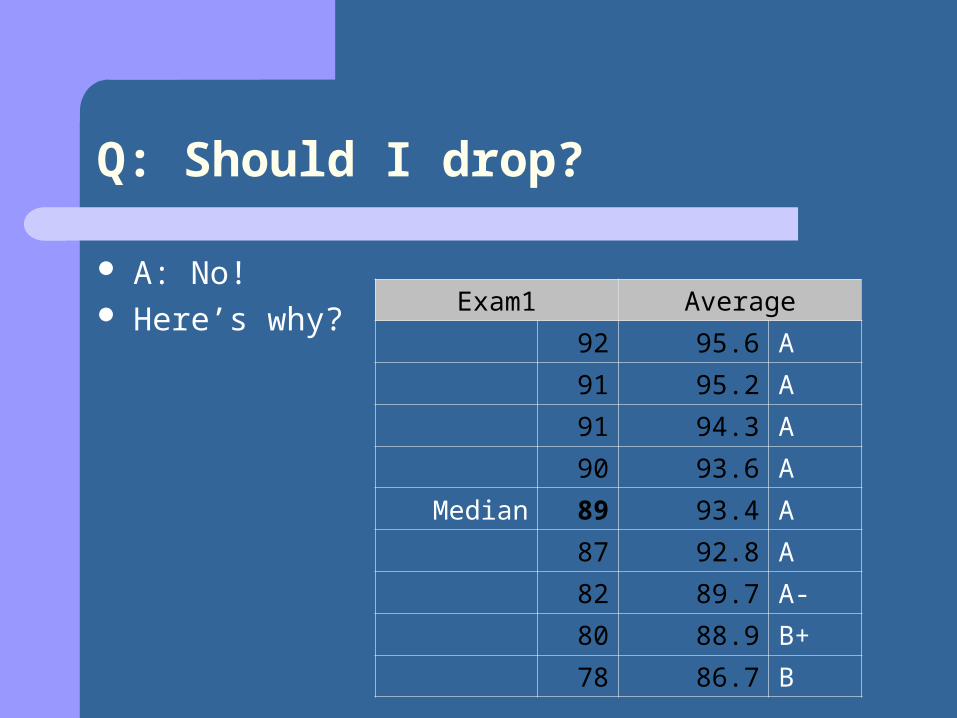
Q: Should I drop?
A: No! Here’s why?
Exam1 Average
92 95.6 A
91 95.2 A
91 94.3 A
90 93.6 A
Median 89 93.4 A
87 92.8 A
82 89.7 A-
80 88.9 B+
78 86.7 B

Today’s Agenda
Exam post-mortem Should I drop? Search Engines: How exactly they work. Future:
– 2 Presentations every Thursday– Project #2 is coming out next week (Website)– Lab: Switching to Javascript

Search Engines
Background In the early 90’s, people
still wore mullets, and finding info. on the
WWW was not easy. Links were important Hubs & Authorities
emerged.

Search Engines
Typical Academic Webpage
– Welcome to UCLA’s Neurosurgery Website
– Here are some academic publications
– Here are links to other Neurosurgery Websites
Typical Personal Webpage
– Hi my name is Rupert “I don’t have a life” McNerd
– Here are pictures of Heather Locklear
– Here are links to other people who have nerdy websites with pictures of Heather Locklear

Search Engines
Through – word of mouth– email– message boards
Hubs & Authorities emerged A hub is a website that links you to other important websites
– There are good hubs and bad hubs An authority is any website that has information, data, etc.
– There are good and bad authorities Some websites are both Authorities and Hubs

Search Engines
The Problem: People designed “homepages” with lots of links
– Not for the benefits of others but – to help themselves find stuff
The lists of links were not necessarily related, organized, or kept up to date
As a result, its hard for ordinary people to find or identify good hubs.
Example– http://alumni.umbc.edu/~efreem2/lynx.html

Search Engines
The Solution: Comprehensive Directories
– The first big one was Yahoo! Yahoo! began as a student hobby in February 1994
– David Filo and Jerry Yang, Ph.D. candidates in Electrical Engineering at Stanford University
They started their guide to keep track of their personal interests on the Internet.
Eventually, became too long and unwieldy, and they broke them out into categories.
When the categories became too full, they developed subcategories ...

Search Engines
Yahoo!– an acronym for "Yet Another Hierarchical Officious Oracle,“
Even though much of the process was automated, a lot of human care went into their directory.
Yahoo distinguished itself by using a combination of custom software and human care to make a well-organized and somewhat comprehensive directory of the WWW.
The had experts who would help organize categories They allowed people to submit web pages, locations,
and descriptions

Search Engines
Yahoo’s directory is stored in a database
ID Title URL Description Keywords Category Sub-category
1 ESPN www.espn.com A comprehensive site with scores, stories, stats…
NBA, NFL, MLB, games, scores, players
Entertainment Sports
2 Siena CS
www.cs.siena.edu The computer science department at Siena…
CS, siena, computer…
Education Colleges
…
1,234,041

Search Engines
Yahoo! Directory is created using
1. User submission
2. Staff, consultants, etc.
3. Robots/Spiders (programs that fetch pages automatically and add them to the directory)

Search Engines
Initially, Yahoo’s was not a search engine. It was a directory. While it was possible to search the directory
using keywords, Users were not searching the entire WWW Problem: If you were not in the directory,
your site would not be found by a Yahoo search.
Search Engines
Ways to get your site noticed by Yahoo
1. Fill out an online site submission form
2. Get lot of people to link their page with your page and hope that a Yahoo staff or robot finds it.
3. Add lots of meta tags that are consistent with your sites content.

Search Engines
Problem: Great websites pop us so quickly that Yahoo can’t find them all.
1. User submission (many people don’t submit their site)
2. Staff, consultants, etc. (you’d need an army)
3. Robots/Spiders(most effective way to build a directory)

Search Engines
Another Problem: Robots/Spiders aren’t good at automatically
determining– Description– Keywords– Category– even the title
Web pages are often poorly composed, and Down-right, misleading.

Search Engines
Example:
Click here to view your local weather (Actually this will bring you to a porn site and the makers of this web page
get 0.5 cents every time some idiot clicks this link)your local weather, your local weather, weather channel, current temp, local weather, your local
weather, your local weather, your local weather, your local weather, your local weather, weather channel, current temp, local weather, your local weather, your local weather, your local weather, your local weather, your local weather, weather channel, current temp, local weather, your local weather, your local weather, your local weather, your local weather, your local weather, weather channel, current temp, weather, your local weather, your local weather, your local weather, your local weather, weather channel, current temp, local weather, your local weather, your local weather, your local weather, weather channel, current temp, local local weather, your local weather, your local weather, your local weather, your local weather, weather channel, current temp, local, your local weather, your local weather, your local weather,

Search Engines
Even though these robots/spiders do a poor job of analyzing information
Search engines emerge with directories completely built from information gathered automatically.
As the WWW grows, – directories become more automated to the point where
there is little human care involved– search engines compete to try to index the entire WWW

Search Engines
Quantity becomes more important than quality and the Search Engine is born.
– (see the history of search engines) Q: What is the difference between a search engine
and a searchable directory? A: Nothing really.
– In fact, some search engines automatically generate a categorized directory from their index database.
If there is a difference… its the quality and correctness of the categories.

Search Engines
Recall the database behind Yahoo’s directory
ID Title URL Description Keywords Category Sub-category
1 ESPN www.espn.com A comprehensive site with scores, stories, stats…
NBA, NFL, MLB, games, scores, players
Entertainment Sports
2 Siena CS
www.cs.siena.edu The computer science department at Siena…
CS, siena, computer…
Education Colleges
…
1,234,041

Search Engines
Recall that robots/spiders do NOT do a good job of determining – Description– Keywords– Category– even the title
Q: So what is actually stored in the database of a search engine?

Search Engines
All you can store is the raw content (i.e., the words)
ID URL
1 www.espn.com Sports (35) NFL (42) ESPN (103) Scores (27) …
2 www.cs.siena.edu Siena (11) Computer (15) Science (22) Breimer (7) …
…
1,234,041

Search Engines
How to make a search engine.
1. Send robots out to collect websites
2. Build an index URL list of words.
3. Remove stop words
4. Invert the index Word list of URL’s
5. Design some formula or methodology for ranking URL’s

Search Engines
Despite the problems, search engines dramatically changed the WWW.
People had the notion that the WWW was itself a huge database of information that could be searched.
Most prominent Search Engines– Altavista, Lycos, Infoseek, AskJeeves, Looksmart, Hotbot,
Google. To survive ($$$) search engines became advertising
venues

Search Engines
The Big Problem Too Much Information. Even if most of the information retrieved by a search
engine was relevant to what the user wanted, users could easily get overwhelmed and give up if
the first two or three hits were not appropriate. The problem of dealing with too much information is
a problem that was never really a problem in the past.

Search Engines
Designing an effective search engine was an information management dilemma that had never been seen before.– The information was vastly distributed– Not uniform or consistent– Excessively redundant
– Massively large

Next Class
Two presentations





























