Embed Size (px)
Citation preview

TMpro:Transmembrane Helix Prediction using Amino Acid Properties and Latent Semantic Analysis
Madhavi Ganapathiraju, N. Balakrishnan, Raj Reddy and Judith Klein-Seetharaman
Carnegie Mellon University
6th International Conference on Bioinformatics, Hong Kong, PR China,August 29th, 2007

2
Outline
Introduction Membrane proteins Transmembrane helix prediction
Previous methods Drawbacks
Amino acid properties Approach
Algorithm Features and models Evaluations
Web server
Introduction Properties Approach Algorithm Web ServerPrevious Methods
3
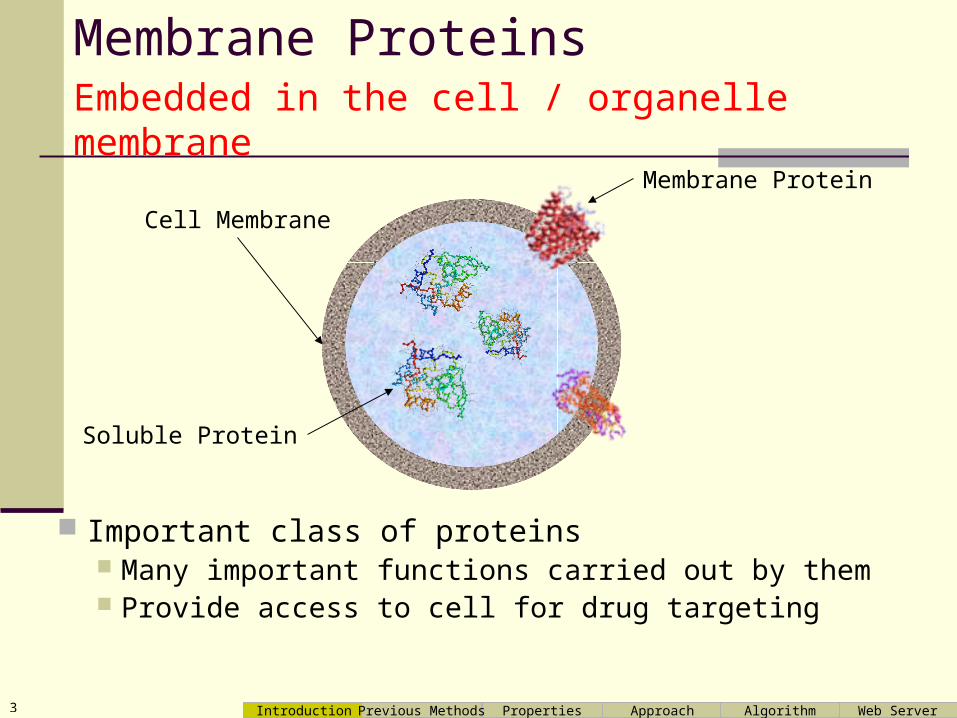
Membrane Proteins
Important class of proteins Many important functions carried out by them Provide access to cell for drug targeting
Embedded in the cell / organelle membrane
Cell Membrane
Membrane Protein
Soluble Protein
Introduction Properties Approach Web ServerPrevious Methods Algorithm

4
Transmembrane Segment Characteristics
Cytoplasm(Aqueous medium)
Transmembrane 30Å hydrophobic coreA helix has to be 19 residues long to go from one side to the other
Extracellular(Aqueous medium)
Side view
Questions to be addressed by prediction algorithm How many transmembrane segments are there? Where are the transmembrane locations in primary
sequence?
Introduction Properties Approach Web ServerPrevious Methods Algorithm

5
Transmembrane Helix Prediction
Important protein family structure and function regions accessible from extracellular side
Challenges Little available training data Overtraining Difficulty in discovery of novel architectures
Introduction Properties Approach Web ServerPrevious Methods Algorithm
6
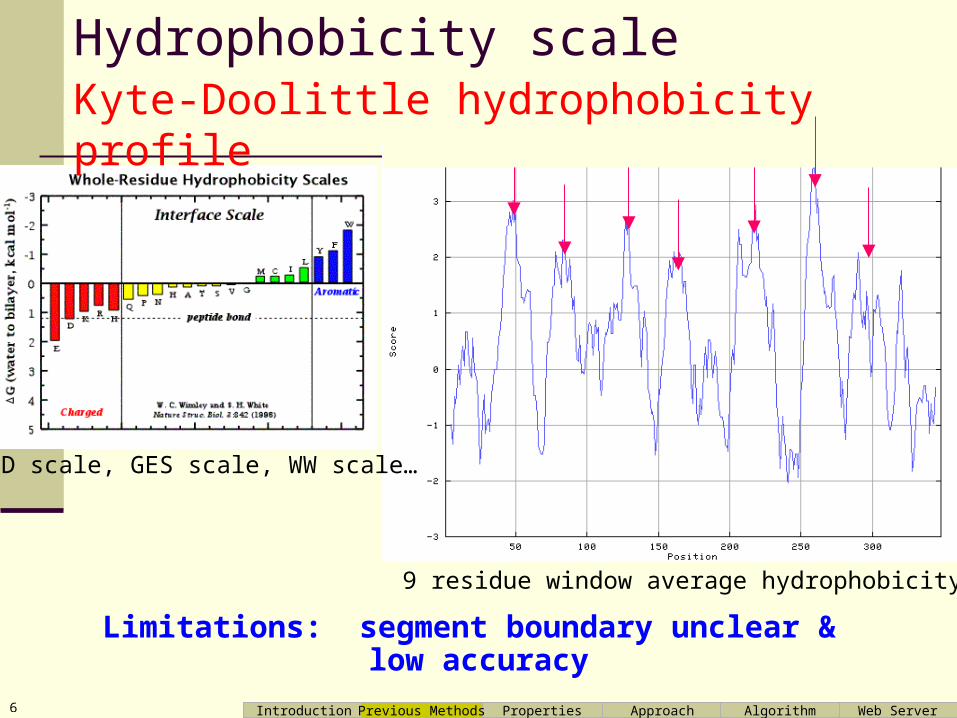
Hydrophobicity scale
9 residue window average hydrophobicity
Limitations: segment boundary unclear & low accuracy
KD scale, GES scale, WW scale…
Introduction Properties Approach Web ServerPrevious Methods Algorithm
Kyte-Doolittle hydrophobicity profile
7
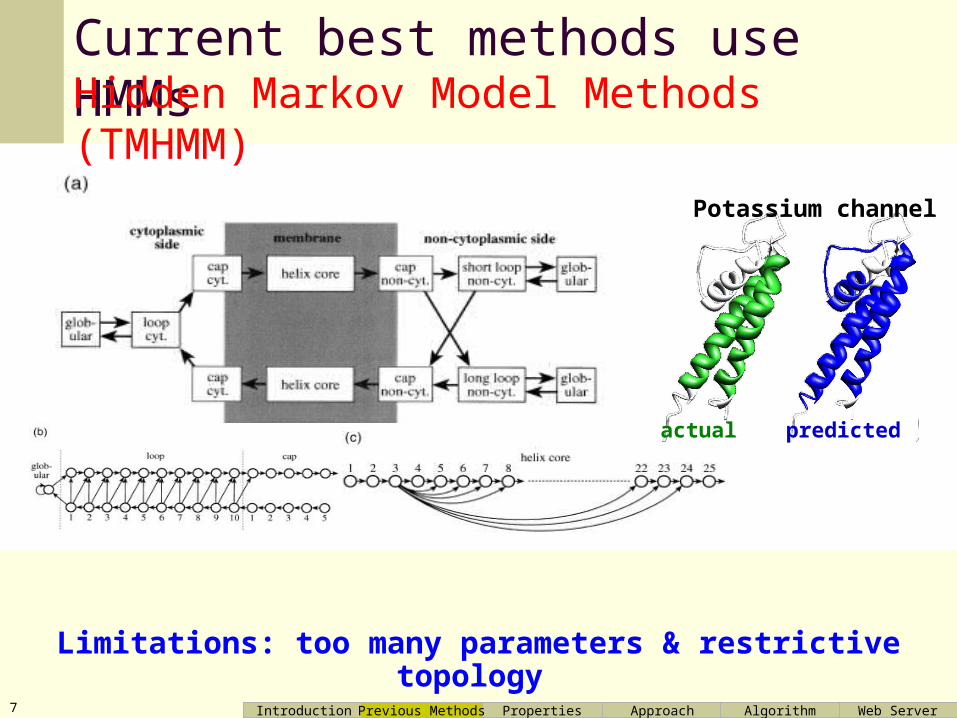
Current best methods use HMMs
Limitations: too many parameters & restrictive topology
Hidden Markov Model Methods (TMHMM)
Introduction Properties Approach Web ServerPrevious Methods Algorithm
actual predicted
Potassium channel

TMpro: TMpro:
property based algorithm for property based algorithm for
transmembrane helix transmembrane helix
predictionprediction

9
Opportunities for Improvement
Previous methods: Do not employ all possible property distributions Find average occurrences of amino acids
Nonpolar residues
Charged Residues
Introduction Properties Approach Web ServerPrevious Methods Algorithm
Aromatic Residues
Amino acid properties
10
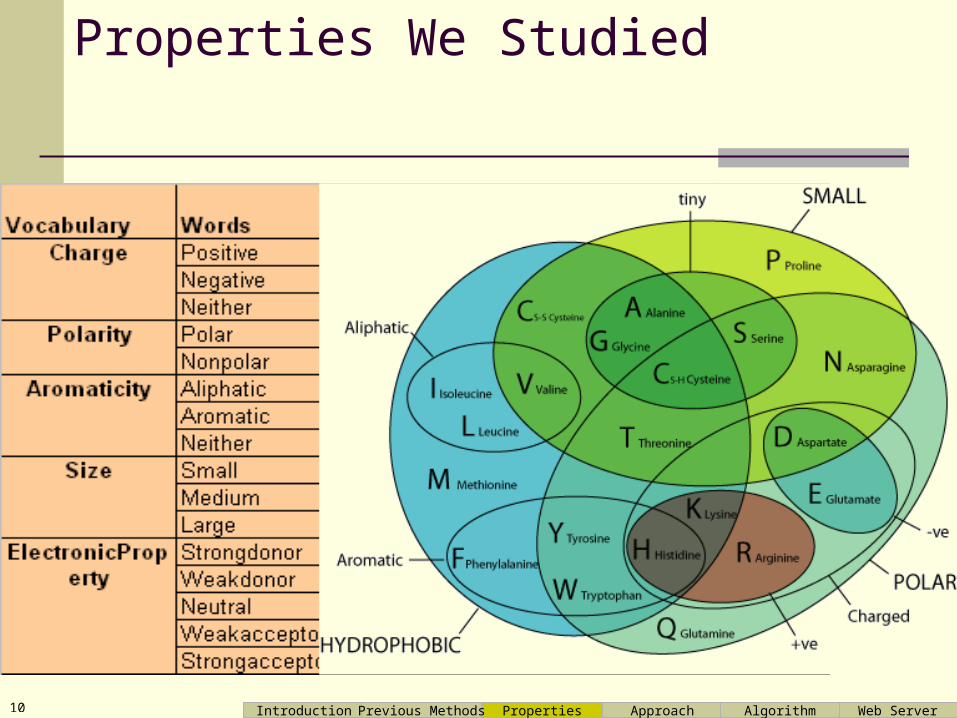
Properties We Studied
Introduction Properties Approach Web ServerPrevious Methods Algorithm

11
Modified Representation of Primary Sequence
Amino Acid Property Sequences
Charge
PolarityAromaticity
Size
Electronicproperties
Introduction Properties Approach Web ServerPrevious Methods Algorithm

12
Predictive Capability of Each Property Adjust parameters of TMHMM (v 1.0):
To make it emit one of the property values Properties considered
Polarity : polar, non-polar Aromaticity: aromatic, aliphatic, neutral Electronic properties: strong donor, weak donor,
neutral, weak acceptor, strong acceptor
Sequence representation
Number of symbols
Segment F-score
Segment F-score as % of that with amino acid representation
Q2 Q2 score as % of that with amino
acid representation
Amino acids 20 92 - 81 - Polarity 2 59 64 % 65 80 % Aromaticity 3 84 91 % 74 91 % Electronic property 5 85 92 % 76 94 %
3-valued property observations achieve 91% accuracy of that of 20-valued amino acid observation
Introduction Properties Approach Web ServerPrevious Methods Algorithm
13
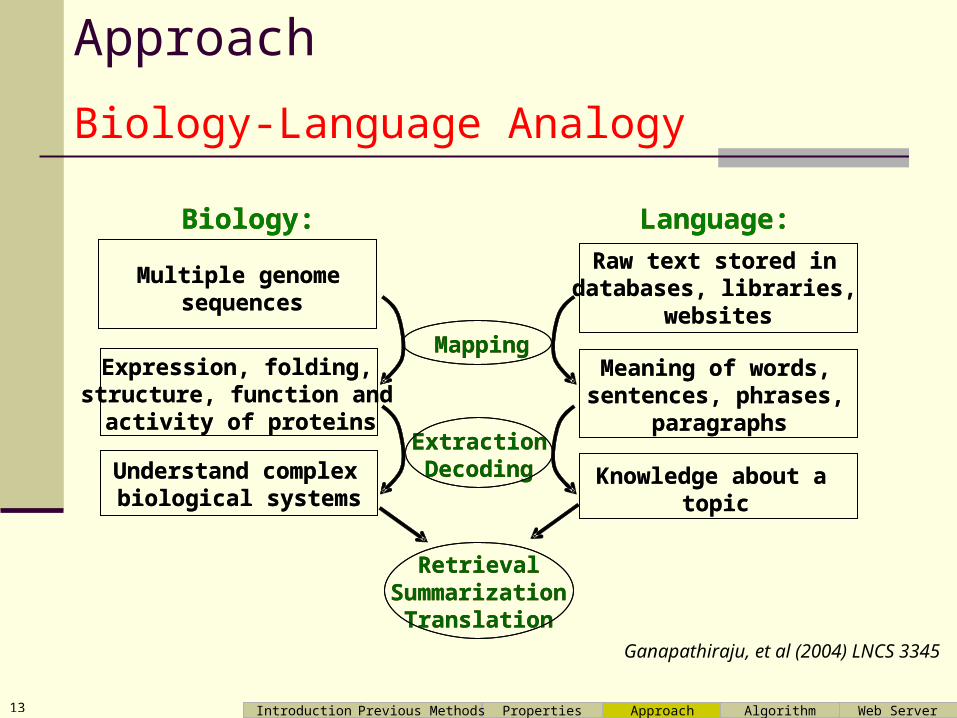
Approach
Biology-Language Analogy
Mapping
Biology:
Knowledge about a topic
Language:
Multiple genome sequences
Raw text stored in databases, libraries,
websites
Expression, folding, structure, function and
activity of proteins
Meaning of words, sentences, phrases,
paragraphs
Understand complex biological systems
RetrievalSummarization
Translation
ExtractionDecoding
Mapping
Biology:
Knowledge about a topic
Language:
Multiple genome sequences
Raw text stored in databases, libraries,
websites
Expression, folding, structure, function and
activity of proteins
Meaning of words, sentences, phrases,
paragraphs
Understand complex biological systems
RetrievalSummarization
Translation
ExtractionDecoding
Introduction Properties Approach Web ServerPrevious Methods Algorithm
Ganapathiraju, et al (2004) LNCS 3345
14
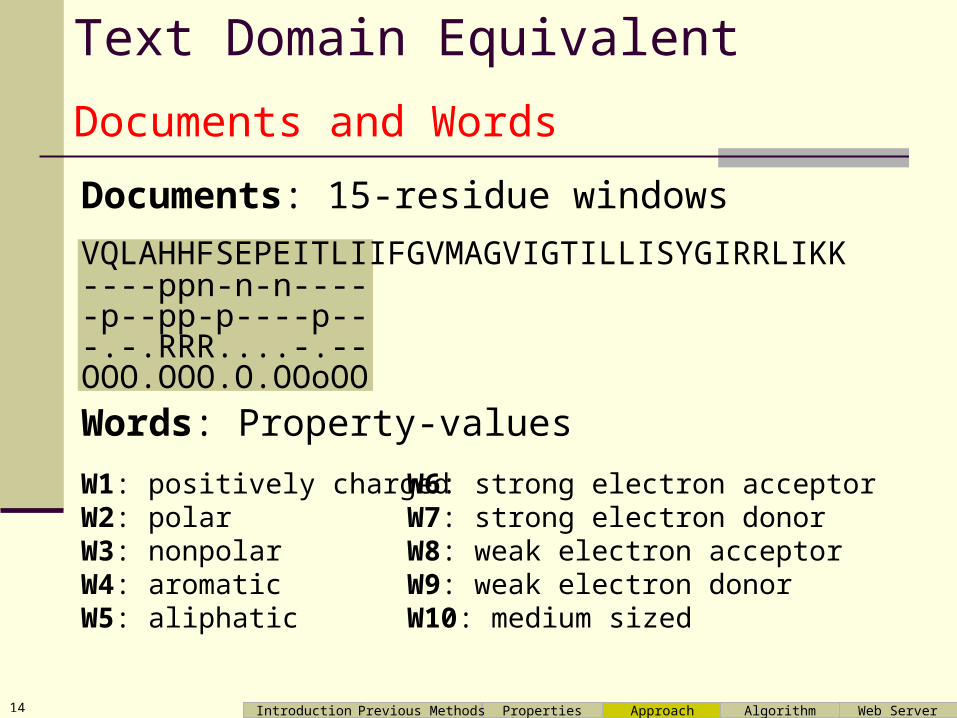
Text Domain Equivalent
Words: Property-values
VQLAHHFSEPEITLIIFGVMAGVIGTILLISYGIRRLIKK----ppn-n-n-----p--pp-p----p---.-.RRR....-.--OOO.OOO.O.OOoOO
W1: positively chargedW2: polarW3: nonpolarW4: aromaticW5: aliphatic
W6: strong electron acceptorW7: strong electron donorW8: weak electron acceptorW9: weak electron donorW10: medium sized
Documents and Words
Documents: 15-residue windows
Introduction Properties Approach Web ServerPrevious Methods Algorithm

15
Latent Semantic Analysis
Words
Documents
Build Word-Document Matrix
Introduction Properties Approach Web ServerPrevious Methods Algorithm
Dimension 1D
imen
sion
2
Distinct features of TM and nonTM achieved
W = USVT
For classification feature vectors SVT can be used
Reduced dimensions: 4

16
Different Classifiers/Models
Support vector machines Neural networks Linear classifier
Hidden Markov modeling
Decision trees
Neural network with LSA features is called TMpro
Method Qok Segment F Score
Segment Recall
Segment Precision
Q2 # of TM proteins misclassified as soluble proteins
High resolution proteins (36 TM proteins) 1a TMHMM 71 90 90 90 80 3 1b TMpro LC 61 94 94 94 76 0 1c TMpro HMM 66 95 97 92 77 0 1d TMpro NN 83 96 95 96 75 0
Without SVD 1f TMpro NN
without SVD 69 94 95 93 73 0
Introduction Properties Approach Web ServerPrevious Methods Algorithm
17
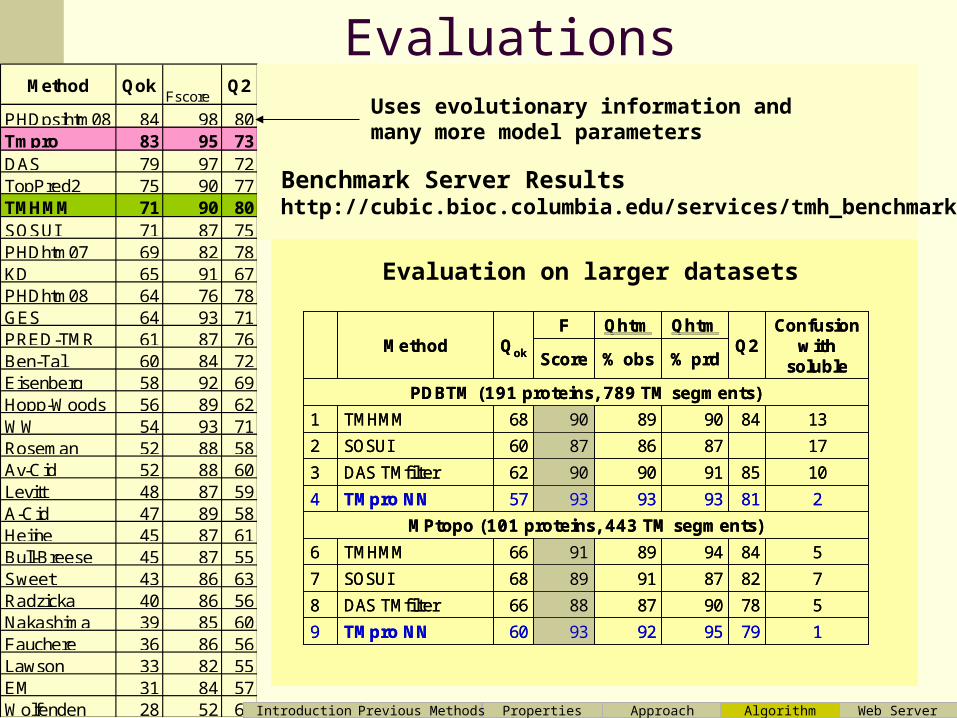
EvaluationsPHDpsihtm08 84 98 80Tmpro 83 95 73DAS 79 97 72TopPred2 75 90 77TMHMM 71 90 80SOSUI 71 87 75PHDhtm07 69 82 78KD 65 91 67PHDhtm08 64 76 78GES 64 93 71PRED-TMR 61 87 76Ben-Tal 60 84 72Eisenberg 58 92 69Hopp-Woods 56 89 62WW 54 93 71Roseman 52 88 58Av-Cid 52 88 60Levitt 48 87 59A-Cid 47 89 58Heijne 45 87 61Bull-Breese 45 87 55Sweet 43 86 63Radzicka 40 86 56Nakashima 39 85 60Fauchere 36 86 56Lawson 33 82 55EM 31 84 57Wolfenden 28 52 62
Method Qok Q2 Fscore
Uses evolutionary information and many more model parameters
Introduction Properties Approach Web ServerPrevious Methods Algorithm
Benchmark Server Resultshttp://cubic.bioc.columbia.edu/services/tmh_benchmark/
17995929360TMpro NN9
57890878866DAS TMfilter8
78287918968SOSUI7
58494899166TMHMM6
MPtopo (101 proteins, 443 TM segments)
28193939357TMpro NN 4
108591909062DAS TMfilter3
1787868760SOSUI2
138490899068TMHMM1
PDBTM (191 proteins, 789 TM segments)
% prd% obsScore
Confusion with
solubleQ2
QhtmQhtmFQokMethod
17995929360TMpro NN9
57890878866DAS TMfilter8
78287918968SOSUI7
58494899166TMHMM6
MPtopo (101 proteins, 443 TM segments)
28193939357TMpro NN 4
108591909062DAS TMfilter3
1787868760SOSUI2
138490899068TMHMM1
PDBTM (191 proteins, 789 TM segments)
% prd% obsScore
Confusion with
solubleQ2
QhtmQhtmFQokMethod
Evaluation on larger datasets
18
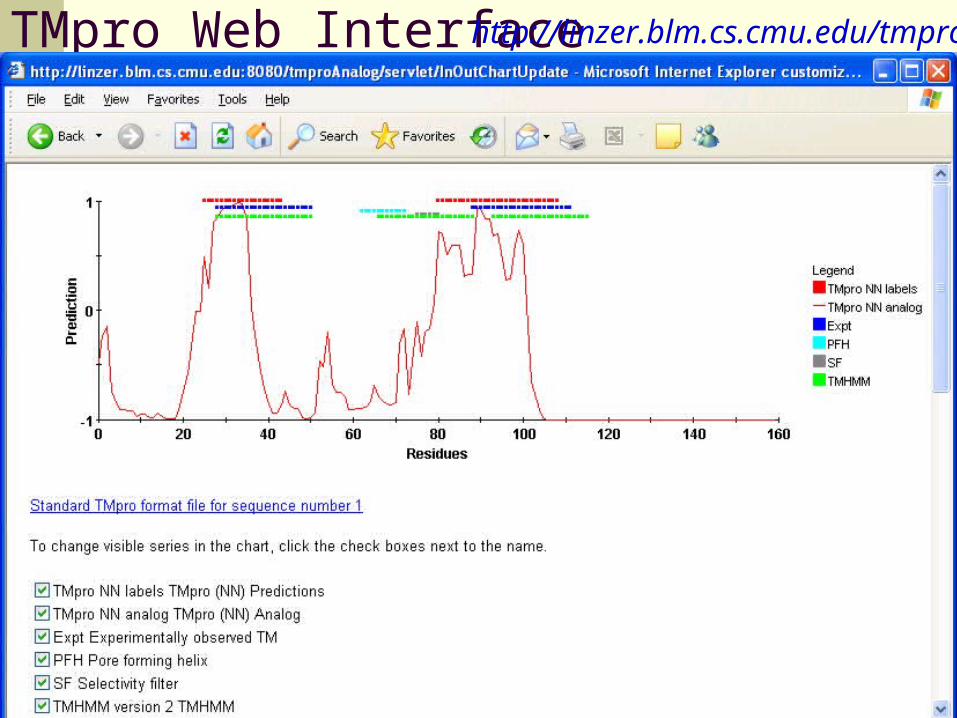
TMpro Web Interface
Novel featuresfor manual annotation
http://linzer.blm.cs.cmu.edu/tmpro/
Introduction Properties Approach Web ServerPrevious Methods Algorithm

19
Acknowledgements
Co-authors:Judith Klein-SeetharamanRaj ReddyN. Balakrishnan
Web-site Development:Christopher Jon JursaHassan A. Karimi
Introduction Properties Approach Web ServerPrevious Methods Algorithm

Thank you!

21
Larger training data does not improve TMHMM
60708090
100
F-score %Membraneproteinspredicted
Q2 Recall Precision
TMpro STMHMM TMHMM
STMHMM is TMHMM trained with recent 145 TM proteins
Introduction Properties Approach Web ServerPrevious Methods Algorithm
22
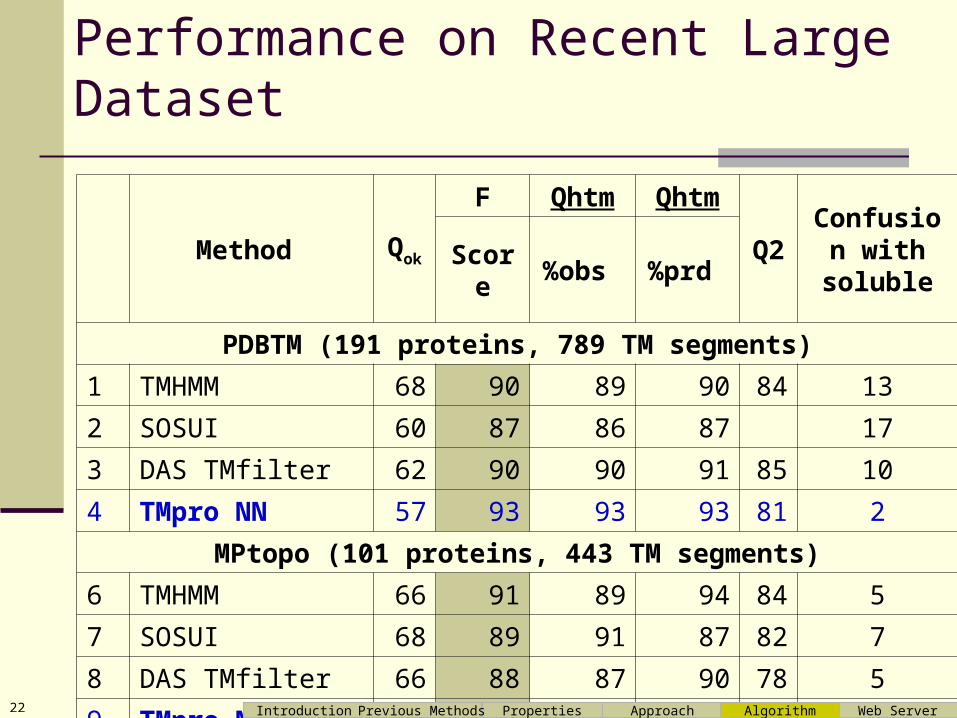
Performance on Recent Large Dataset
Method Qo
k
F Qhtm QhtmQ2
Confusion with soluble
Score
%obs %prd
PDBTM (191 proteins, 789 TM segments)
1 TMHMM 68 90 89 90 84 13
2 SOSUI 60 87 86 87 17
3 DAS TMfilter 62 90 90 91 85 10
4 TMpro NN 57 93 93 93 81 2
MPtopo (101 proteins, 443 TM segments)
6 TMHMM 66 91 89 94 84 5
7 SOSUI 68 89 91 87 82 7
8 DAS TMfilter 66 88 87 90 78 5
9 TMpro NN 60 93 92 95 79 1Introduction Properties Approach Web ServerPrevious Methods Algorithm





























