Embed Size (px)
Citation preview

Theoretische Konzepte der
Zeitreihenanalyse und Anwendungen
auf die Signalklassifikation in
technischen Systemen
Dissertationzur Erlangung des Doktorgrades
der Fakultat der Naturwissenschaften (Dr. rer. nat.)
der Bergischen Universitat Gesamthochschule Wuppertal
vorgelegt von
Stefan Guttler
aus Konstanz
Juni 1999
WUB–DIS 99–7


Abstract
Subject of this work is the development and application of some concepts of time seriesanalysis to technical systems. Our interest in technical systems arises from the ideato study applications of nonlinear time series analysis to fully realistic problems of“intermediate complexity“, i.e. to systems which have a limited number of (effective)degrees of freedom and limited nonstationarity. Two problems are treated here: Theinduction motor failure detection using stator current monitoring and the automaticquality control of sliding sunroofs by classifying structure-born sound signals.
The first part of this work is theoretical and contains some background materi-al for the more applied second part. We give an overview over linear and quadratictime-frequency representations, which turn out to be a suitable starting point for bothtreated problems. From the viewpoint of signal analysis we focus on the propertiesof windowed Fourier- and wavelet transforms, especially the time-frequency resolu-tion characteristics. Subsequently the relation between the continuous and discreteversion of these transforms are thoroughly discussed, for which Shannon’s samplingtheorem provides the connection. For the classification of feature vectors calculatedfrom experimental time series we finally introduce estimators for the Bayes error, i.e.the smallest error which can be achieved in a classification statistics.
We present a new method for on-line induction motor failure detection, where theconcept of geometrical signal separation in feature space is introduced: A set of ob-servations from a single phase of the stator current is transformed into feature vectorsin a feature space. After establishing a metric in the feature space close neighboursof the present vector are searched for in a data basis representing the allowed statesof the motor. In their absence the present state is a novelty, which is considered as afailure if it persists for a certain time. Varying environmental conditions turn out tobe the main problem during fault sensing. The geometric method offers a solution forthat by combining the information of two feature spaces. This correction allows forour data the statistically significant separation of unknown environmental conditionsand motor failures.
We next introduce a feature vector for automatic acoustic quality control. For thispurpose the sliding noise of electric sunroofs was recorded. We do not explicitely searchfor the features of the time series which distinguish good from defective products, buttake advantage of the fact that the information being relevant for failure detectioncan be resolved by the human ear, i.e. by experts. We approximate the time-frequencyresolution of the ear by a wavelet transform and define a generalized class of wavelettransforms, which can be averaged in the time domain without loosing the time-resolved information. By this averaging process statistical fluctuations and noise arereduced sufficiently to reveal the features of the signals for the aimed classification.Wefirst study the properties of the feature vectors using artifical signals. The subsequentapplication to the sliding sunroof data confirms (qualitatively) these results.
i


Inhaltsverzeichnis
1 Einleitung und Problemstellung 1
2 Darstellung und Klassifikation von Signalen 72.1 Zeit-Frequenz Darstellungen . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.1 Quadratische ZFDs: Die Cohen Klasse und die affine Klasse . . 92.1.2 Gefensterte Fourier- und Wavelettransformationen . . . . . . . 112.1.3 Die Zeit-Frequenz Auflosungscharakteristik . . . . . . . . . . . 15
2.2 Diskrete Signaldarstellungen . . . . . . . . . . . . . . . . . . . . . . . . 182.2.1 Das Shannonsche Samplingtheorem . . . . . . . . . . . . . . . . 182.2.2 Diskrete gefensterte Fouriertransformationen . . . . . . . . . . 212.2.3 Diskrete Wavelettransformationen . . . . . . . . . . . . . . . . 24
2.3 Statistische Merkmalsklassifikation . . . . . . . . . . . . . . . . . . . . 302.3.1 Der Bayesche Klassifikator des kleinsten Fehlers . . . . . . . . . 302.3.2 Schatzen des Bayeschen Fehlers . . . . . . . . . . . . . . . . . . 332.3.3 Schranken des Bayeschen Fehlers: Die L- und die R- Statistik . 35
3 Fehlerfruherkennung bei Induktionsmotoren 393.1 Fehlererkennung durch Analyse des Statorstromes . . . . . . . . . . . 403.2 Geometrische Signaltrennung . . . . . . . . . . . . . . . . . . . . . . . 44
3.2.1 Vorprozessierung der Zeitreihen . . . . . . . . . . . . . . . . . . 453.2.2 Auswahl und Clusterung der Merkmalsvektoren . . . . . . . . . 463.2.3 Die Struktur der Merkmalsraume . . . . . . . . . . . . . . . . . 493.2.4 Berechnung von Umweltkorrekturen . . . . . . . . . . . . . . . 52
3.3 Anwendungen und Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . 543.3.1 Signalklassifikation mit Umweltkorrekturen . . . . . . . . . . . 563.3.2 Signalklassifikation ohne Umweltkorrekturen . . . . . . . . . . 593.3.3 Weitere Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . 61
4 Ein Merkmalsvektor zur akustischen Guteprufung 634.1 Darstellung und Klassifikation von Schallsignalen . . . . . . . . . . . . 644.2 Merkmale aus Wavelet- Restklassen . . . . . . . . . . . . . . . . . . . 67
4.2.1 Wavelettransformation der Zeitreihen . . . . . . . . . . . . . . 68
iii

iv INHALTSVERZEICHNIS
4.2.2 Definition der Wavelet- Restklassen . . . . . . . . . . . . . . . 694.2.3 Konstruktion der Merkmalsvektoren . . . . . . . . . . . . . . . 704.2.4 Eigenschaften der Merkmalsvektoren . . . . . . . . . . . . . . . 71
4.3 Akustische Qualitatskontrolle von Schiebedachern . . . . . . . . . . . . 764.3.1 Klassifikation der Merkmalsvektoren . . . . . . . . . . . . . . . 764.3.2 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78
Zusammenfassung 83
Literaturverzeichnis 87

Kapitel 1
Einleitung und Problemstellung
Obwohl das Interesse an nichtlinearen dynamischen Systemen nicht neu ist und sei-nen Ursprung in den (nichtintegrablen) Mehrkoperproblemen der Himmelsmechanikim 19. Jahrhundert findet, hat die nichtlineare Dynamik in den letzten 30 Jahreneine immense Enwicklung erfahren, die mit dem Begriff des deterministischen Chaosverbunden ist. Zunachst kamen die Hauptimpulse hierzu aus der Mathematik, z.B.Smale, [39], jedoch zeigte sich bald, daß auch das irregulare Verhalten von vielen phy-sikalischen Systeme durch eine niedrigdimensionale chaotische Dynamik beschriebenwerden kann. Obwohl sich die Zeitreihe einer Variablen solcher Systeme zunachst nichtvon einer stochastischen Zeitreihe (etwa eines autoregressiven Modells) unterscheidet,hat doch die zugrundeliegende Dynamik die verborgene Struktur eines deterministi-schen Systems mit nur wenigen Freiheitsgraden.
Die Verbindung zwischen mathematischen Modellen und der ”realen Welt“, alsophysikalischen Systemen, bilden Experimente und Beobachtungen, d.h. experimen-telle Zeitreihen. An dieser Stelle beginnt die Zeitreihenanalyse. Ihre Aufgabe ist,allgemein formuliert, Methoden zur qualitativen und quantitativen Charakterisie-rung gemessener Zeitreihen zu entwickeln, um einerseits die Identifikation und dasVerstandnis der zugrundeliegenden physikalischen Systeme zu ermoglichen, wie auchandererseits um weitergehende Fragestellungen zu beantworten, wie z.B. allgemeindie Vorhersage und Klassifikation von Zeitreihen.
Ausgangspunkt der Entwicklung der nichtlinearen Zeitreihenanalyse [22] ist dasEinbettungstheorem von Takens [34], welches es erlaubt, aus einer skalaren Zeitrei-he, die von einer Variablen eines dynamischen System gemessen wird, durch Bildungvon Zeitversatz-Vektoren eine Trajektorie zu rekonstruieren, welche diffeomorph zumursprunglichen, diskret abgetasteten Fluß des dynamischen Systems ist. Die hieraufbasierenden Phasenraummethoden ermoglichen die Zeitreihenanalyse aus dem Blick-winkel des deterministischen Chaos. Hier entsteht die Aufgabe, die mogliche determi-nistische Struktur eines Systems anhand von gemessenen Zeitreihen zu erkennen undzu charakterisieren sowie eine solche (verborgene) Dynamik, die nur von wenigen (ef-fektiven) Freiheitsgraden abhangt, fur weitere Fragestellungen der Zeitreihenanalyse
1

2 KAPITEL 1. EINLEITUNG UND PROBLEMSTELLUNG
auszunutzen. Nachdem fur die Entwicklung der Methoden der nichtlinearen Zeitrei-henanalyse zunachst einfache numerische Modelle intensiv studiert wurden, wendetsich das Interesse heute immer mehr praktischen Anwendungsmoglichkeiten zu.
Motivation und Ausgangangspunkt dieser Arbeit ist die Idee, neuere Entwick-lungen im Bereich der nichtlinearen Zeitreihenanalyse auf praxisorientierte Problemeanzuwenden. Wesentlicher Teil der Aufgabenstellung ist, daß die Fragestellungen vonaußen aus einem praxisbezogenen Umfeld an uns herangetragen werden, um die Ver-suchung zu umgehen, nur fur bereits vorhandene theoretische Losungsmodelle nacheinem passenden Problem zu suchen, dem es dann haufig an Praxisrelevanz mangelt.
Ein wichtiges Auswahlkriterium an ”reale“ Probleme muß naturlich die realisti-sche Einschatzung sein, mit dem derzeitigen Wissensstand einen Losungbeitrag brin-gen zu konnen. Dies leitet uns, den Blick auf Systeme von ”mittlerer Komplexitat“zu lenken, d.h. auf Systeme, die in ihren Eigenschaften komplizierter als numerische
”Spielmodelle“ sind, jedoch nur eine begrenzte Anzahl von Freiheitsgraden und einebegrenzte Nichtstationaritat aufweisen. Systeme sehr hoher Komplexitat, wie einer-seits physiologische Systeme (im Extremfall das Gehirn) und andererseits Volkswirt-schaften (z.B. Aktien-, Options- und Devisenmarkte) sind in ihren Zusammenhangenbis heute nicht (ausreichend) verstanden. Zeitreihen solcher Systeme zeigen haufig einnichtstationares, stochastisches Verhalten, das nur sehr schwer einen Zugang erlaubt,insbesondere da diese Systeme in vielen Fallen nichtautonom sind, d.h. von außerenunvorhersehbaren Ereignissen (z.B. politischen Entscheidungen) wesentlich beeinflußtwerden. Obwohl in diesen Bereichen bereits viel Forschungsarbeit geleistet wurde undeine große Zahl interessanter und relevanter Fragestellungen bestehen, scheint eineLosung vieler praxisbezogener Probleme, wie z.B. die zuverlassige Vorhersage derKursentwicklung an Aktienmarkten (auch ohne drastische außere Einflusse) oder dieVorhersage epilleptischer Anfalle aus EEG- Ableitungen, (noch) nicht in Reichweite.Solche Systeme eignen sich daher fur die von uns betrachtete Fragestellung kaum.
Als geeignete Systeme von ”mittlerer Komplexitat“ erweisen sich hingegen eineVielzahl technischer Systeme. Die Problemstellungen sind hierbei haufig die Auto-matisierung von Kontroll- oder Uberwachungsvorgangen fur Maschinen und Ferti-gungsprozesse verschiedenster Art. Als wichtige Problemkreise treten zum einen diePrazisionssteuerung von Anlagen (z.B. Roboter) und zum anderen die Fruherken-nung von Defekten auf, da ein unerwarteter verschleiß- oder fehlerbedingter Ausfalleinzelner Anlagenteile leicht ganze Fertigungsstraßen zum Erliegen bringt. Bei derVielzahl moglicher Fehlerquellen und der relativen Zuverlassigkeit der einzelnen Sys-temkomponenten muß jedoch der Uberwachungsaufwand fur jede einzelne Maschinegering gehalten werden. Hier entsteht die Idee, die aufwendige Diagnostik technischerAnlagen mittels einer Reihe spezifischer Meßinstrumente hin zu einer Uberwachungdurch einfache Sensoren und einer dafur komplexen Signalverarbeitung zu verlagern,die aber auf den heutigen Rechnern relativ billig durchgefuhrt werden kann.
Als einem weiteren Problemfeld kommt der Automatisierung von Qualitatskon-

KAPITEL 1. EINLEITUNG UND PROBLEMSTELLUNG 3
trollen eine immer großere Bedeutung zu. Die Forderung der Kunden nach gunstigenund zuverlassigen Produkten erfordert einerseits die sichere Einhaltung von Qualitats-standards wie auch aus Kostengrunden einen moglichst kleinen Produktionsausschuß.Hieraus entsteht der Wunsch nach der Automatisierung von Guteprufungen nicht nurzur Kostenersparnis, sondern wesentlich auch, um Qualitatstandards objektivieren zukonnen, da menschliche Bewertungen haufig nicht reproduzierbar sind und großerenSchwankungen unterliegen konnen. Dieses Problem wird auch bei der Verifikationunserer Ergebnisse in Kap. 4 auftreten.
Beide Fragestellungen konnen auf ein Grundproblem der Zeitreihenanalyse, dieKlassifikation von Signalen zuruckgefuhrt werden. Da diese Probleme aus dem Bereichder Ingenieurwissenschaften nicht neu sind, ist uber die Darstellung und Klassifika-tion technischer Signale schon viel Forschungsarbeit geleistet worden. So erwieß sichdie Entwicklung der linearen und quadratischen Zeit-Frequenz Darstellungen [18] seitBeginn der 60er Jahren als fruchtbar fur viele Probleme der Signalerkennung und-klassifikation. Die spater einsetzende Entwicklung der nichtlinearen Zeitreihenanaly-se verlief zunachst weitgehend unabhangig; erst in den letzten Jahren hat sich hierein reger Austausch entwickelt.
Heute existieren eine Reihe von Kooperationsprojekten zwischen dem Fachge-biet nichtlineare Dynamik und Zeitreihenanalyse der Physik und einerseits den In-genieurwissenschaften, insbesondere den Bereichen Maschinenbau und Elektrotech-nik, wie auch andererseits verschiedenen Industriepartnern1. Durch Kontakte zu denUnternehmen Siemens Corporate Research, Princeton, USA und Carl Schenck AG,Darmstadt ergaben sich fur uns zwei konkrete Projekte, die Fehlerfruherkennung beiInduktionsmotoren durch Analyse das Statorstroms sowie die automatische Qualitats-kontrolle von elektrischen Schiebedachern durch Klassifikation von Korperschallsigna-len. Beide Probleme, die Gegenstand der Kapitel 3 und 4 dieser Arbeit sind, stehenzunachst getrennt nebeneinander.
Wie kann die Aufgabenstellung aus einem Blickwinkel der Physik hierbei ausse-hen? Ein technisches System mit wenigen effektiven Freiheitsgraden laßt sich als einniedrigdimensionales dynamisches System betrachten, das an außere stochastischeEinflusse (schwach) gekoppelt ist. Im Fall zu vieler aktiver Freiheitsgrade ist aller-dings die Beschreibung durch ein stochastisches Modell meist besser geeignet, da sichdann in den gemessenen Zeitreihen im allgemeinen kein deterministischer Anteil mehrfinden laßt. Die Idee dieses Ansatzes ist, die Anderung der beobachteten Dynamikmit der Variation weniger Parameter zu identifizieren um somit die Instationaritatder gemessenen Zeitreihen durch entweder die kontrollierte Anderung eines Steuerpa-rameters oder durch zufallige Parameterdrifts, welche durch Umwelteinflusse bedingtsind, zu beschreiben. Die Parameter des Modells mussen sich hierbei aus den Zeitrei-hen schatzen lassen. Diese Vorgehehensweise ist prinzipiell physikalisch, auch wenndas betrachtete System, wie hier, ein technisches ist.
1Diese Arbeit entstand teilweise im Rahmen eines vom BMBF geforderten Kooperationsprojekts.

4 KAPITEL 1. EINLEITUNG UND PROBLEMSTELLUNG
Etwas allgemeiner betrachtet konnen wir unsere Aufgabe darin sehen, zur Losungtechnischer Problemstellungen alternative Vorgehensweisen zu jenen in ingenieurwis-senschaftlichen Arbeiten zu untersuchen, welche in unserem Fall durch die nichtlineareZeitreihenanalyse motiviert sind. Allerdings sollen die bekannten Forschungsergebnis-se Bezugspunkte (benchmarks) fur unsere Arbeit bilden, an denen wir uns orientierenwollen. Somit bieten sich die Alternativen eines eher problemorientierten und einesmehr wissenschaftlich orientierten Ansatzes. Im ersten Fall steht die Absicht im Vor-dergrund, mit einem neuen Zugang auch eine bessere Losung des Problems zu finden,als sie bereits veroffentlichte Arbeiten bieten. Dies stellt naturlich eine Einschrankungan die Auswahl der Methoden dar, da auch die Weiterentwicklung von Verfahren, dieauf ein gegebenes Problem zwar anwendbar sind, aber keine optimale Losung ermogli-chen, von wissenschaftlichem Interesse sein kann. So laßt sich zur Fehlerfruherkennungbei Induktionsmotoren auch die intrinsisch nichtlineare Methode der Kreuzfehlervor-hersagen anwenden, welche vom wissenschaftlichen Standpunkt interessant ist, jedochim Sinn der praktischen Fragestellung zu keinem optimalen Ergebnis fuhrt [43].
Wir haben uns hier fur die mehr problemorientierte Sichtweise entschieden, wasim Hinblick auf die Motivation der Arbeit auch konsequent ist. Unsere Losungsansatzeweichen von denen in ingenieurwissenschaftlichen Arbeiten ab und bilden eine opti-male Kombination aus linearen Verfahren und geometrischen Methoden im Merk-malsraum, die den Konzepten der nichtlinearen Analyse entlehnt sind. Sie konnendaher als ein alternativer, physikalisch motivierter Zugang angesehen werden.
Unser Vorgehen gliedert sich prinzipiell in zwei Teilschritte: Der erste und zu-meist schwierigere ist die Extraktion von geeigneten Merkmalen aus den Zeitreihen,welche die Kriterien moglichst gut reprasentieren sollen, nach denen die Klassifikationerfolgt. Hierzu werden die Zeitreihen oder Teilstucke davon in Merkmalsvektoren v ineinem Merkmalsraum V transformiert. Die Komponenten von v konnen beliebige sta-tistische Schatzgroßen sein, die im Hinblick auf die Aufgabenstellung sinnvoll gewahltsind. Dafur gibt es keine allgemeingultigen Kriterien. Im zweiten Schritt werden dieMerkmalsvektoren klassifiziert. Hierzu wird ein Klassifikationsalgorithmus konstruiertund mit Beispieldaten trainiert, der die Wahrscheinlichkeit fur Fehlklassifiktionen vonMerkmalsvektoren, d.h. den Bayeschen Fehler der Klassifikationsstatistik, minimiert.Die dafur benotigten Konzepte werden in Kap. 2 einfuhrt.
Die Schwerpunkte der beiden Projekte sind unterschiedlich. Aufgrund der Quasi-periodizitat des Statorstroms von Induktionsmotoren sowie theoretischer Uberlegun-gen ist es sinnvoll, gefensterte Fourierspektren des Statorstroms als Ausgangspunktzur Konstruktion von Merkmalsvektoren zu verwenden. Der Schwerpunkt unsererArbeit liegt in der Entwicklung einer neuen Methode zur Auswahl geeigneter Spek-tralkomponenten, die sensitiv auf Fehler reagieren, sowie der Unterscheidung von un-bekannten Umwelteinflussen und Defekten, welches sich als das eigentliche Problemherausstellen wird.
Im Unterschied dazu sind geeignete Merkmale fur die Klassifikation von Schall-

KAPITEL 1. EINLEITUNG UND PROBLEMSTELLUNG 5
signalen in akustischen Guteprufungen nicht bereits aus der Struktur der Zeitreihenerkennbar. Wir lassen uns hier von der Eigenschaft leiten, daß die fur die Fehlererken-nung relevanten Informationen der Schallsignale vommenschlichen Ohrs, d.h. von Ex-perten aufgelost werden konnen. Wir versuchen daher die Zeit-Frequenz Auflosungs-charakteristik des Gehor nachzuahmen. Dies ist fur Frequenzen & 500Hz in guterNaherung durch eine Wavelettransformation moglich.
Damit zeigt sich, daß fur beide Probleme Zeit-Frequenz Darstellungen einen ge-eigneten Ausgangspunkt bilden; im ersten Fall die gefensterten Fouriertransforma-tionen, welche eine konstante Auflosungscharakteristik in der Zeit-Frequenz Ebenehaben, sowie im zweiten Fall die Wavelettransformationen mit der Eigenschaft ei-ner hyperbolischen Zeit-Frequenz Auflosung. Die Zusammenhange werden in Kap. 2ausfuhrlich behandelt.
An dieser Stelle wollen wir zwei prinzipielle Vorgehensweisen in der Zeitreihen-analyse unterscheiden: Modellbasierte und modellfreie Ansatze. Im ersten Fall wirdversucht, ein mikroskopisches oder in den meisten Fallen phanomenologisches Modellzu entwickeln, welches das untersuchte System hinreichend gut beschreibt und dessenParameter sich durch Anfitten von gemessenen Zeitreihen schatzen lassen. Sind dieModellannahmen gut, so ist es moglich, einen wesentlichen Teil der Informationen zurekonstruieren, die durch das Messen einer skalaren Zeitreihe aus einem dynamischenSystem herausprojeziert werden. Ist das Modell zudem physikalisch motiviert, so laßtsich ein weitergehenderes Verstandnis des Systems gewinnen, als es nur die Informa-tionen erlauben, welche die Zeitreihen enthalten. Die meisten Arbeiten zur Fehler-erkennung bei Induktionsmotoren durch Analyse des Statorstroms basieren z.B. aufdem Modell einer idealen Induktionsmaschine.
Jedoch steht und fallt diese Vorgehensweise mit der Realitatsnahe des verwende-ten Modells. Sind die gemachten Idealisierungen, wie z.B. die Vernachlassigung vonUmwelteinflussen und Produktionstoleranzen, keine guten Naherungen, so wird derAnsatz zu keiner praxisgerechten Losung fuhren. In diesem Fall ist es sinnvoller, mo-dellfrei zu arbeiten. Hierfur stehen nur die Informationen zur Verfugung, welche diegemessenen Zeitreihen enthalten. Wir werden fur die beiden in dieser Arbeit unter-suchten Probleme im wesentlichen modellfreie Methoden vorstellen. Im Fall der In-duktionsmotoren zeigt es sich, daß Umweltbedingungen und Produktionstoleranzenerheblichen Einfluß auf den Statorstromhaben und sich nicht realitatsnahmodellierenlassen. Bei der Konstruktion von Merkmalsvektoren zur akustischen Qualitatskontrol-le fuhren einfache Modellannahmen fur die Schallsignale (autoregressive Modelle) zukeinem guten Ergebnis und eine genauere Kenntnis der Schallquellen existiert nicht.
Ein weiterer wichtiger Punkt in dieser Hinsicht sind Stationaritatsannahmen vongemessenen Zeitreihen. Hiermit ist die (Modell-) Annahme verbunden, daß der deter-ministische Anteil der Zeitreihe periodisch ist und sich der stochastische Signalanteildurch einen stationaren stochastischen Prozeß, d.h. meist ein autoregressives Modell(AR- Modell) beschreiben laßt. Jedoch sind gerade reale Systeme aufgrund außerer

6 KAPITEL 1. EINLEITUNG UND PROBLEMSTELLUNG
Einflusse haufig nichtstationar. Wir verzichten daher auf solche Annahmen, sofern wirkeine konkreten Hinweise darauf haben. Um das Spektrum eines Signals aus einemZeitreihenabschnitt zu schatzen, gehen wir nicht von der Stationaritat der Zeitreiheaus, um damit z.B. das Spektrum eines an diese Zeitreihe angefitteten AR- Modellszu verwenden, sondern approximieren eine kontinuierliche gefensterte Fouriertrans-formation des Signals durch eine entsprechende diskrete Transformation. Bei einemFenster mit kompaktem Trager muß hierzu nur ein endlicher Signalausschnitt bekanntsein. Diese Konzepte werden in Kap. 2 diskutiert.
Die Arbeit gliedert sich wie folgt: In Kap. 2 fuhren wir die theoretischen Grund-lagen und Konzepte ein, die den Ausgangspunkt fur den angewandten Teil der Arbeitbilden. Daruber hinaus wird der konzeptionelle und mathematische Rahmen des Ge-bietes der Signalanalyse vorgestellt, in das sich die speziellen, hier untersuchten Fra-gestellungen einordnen lassen. Wir beginnen dazu mit einem Uberblick uber die rechtallgemeinen linearen und quadratischen Zeit-Frequenz Darstellungen, die sich als ge-eigneter Ausgangspunkt fur unsere Arbeit erweisen. Dabei werden im Hinblick auf dieSignalanalyse die Eigenschaften von gefensterten Fourier- und Wavelettransformatio-nen, insbesondere die Zeit-Frequenz Auflosungscharakteristik dieser Abbildungen vonInteresse sein. Im Anschluß diskutieren wir die genauen Zusammenhange zwischenkontinuierlichen und diskreten gefensterten Fourier- und Wavelettransformationen.Unser Ziel ist es, fur kontinuierliche Zeit-Frequenz Darstellungen dieses Typs miteiner hohen Informationsauflosung moglichst gute diskrete Approximationen zu fin-den. Die Methoden der statistischen Merkmalsklassifikation, die wir zur Klassifiktionder aus experimentellen Zeitreihen berechneten Merkmalsvektoren benotigen, werdenschließlich im letzten Abschnitt eingefuhrt.
In Kap. 3 stellen wir einen neuen Losungsansatz fur das Problem der Fehlerfruher-kennung bei Induktionsmotoren durch Analyse des Statorstromes vor, wozu die Me-thode der geometrischen Signaltrennung im Merkmalsraum eingefuhrt wird. In Kap. 4wird das Konzept eines Merkmalsvektors ausWavelet- Restklassen zur automatischenKlassifikation von Schallsignalen vorgestellt, das wir auf die Qualitatsendkontrolle vonelektrischen Schiebedachern anwenden. Der erste Abschnitt dieser Kapitel gibt jeweilseine Einfuhrung in die technischen Problemstellungen.

Kapitel 2
Darstellung und Klassifikation
von Signalen
In diesem Kapitel wollen wir einen Uberblick uber einige Methoden zur Darstellungund Klassifikation von kontinuierlichen Signalen und Zeitreihen geben, auf die wir inden folgenden Kapiteln zuruckgreifen werden. Daruber hinaus wird der konzeptionelleund mathematische Rahmen des Gebietes der Signalanalyse vorgestellt, in das sich derangewandte Teil unserer Arbeit einordnen laßt und von wo er seinen Ausgang nimmt.Der erste Teil der Arbeit enthalt eine Darstellung dieser theoretischen Grundlagenund Konzepte.
Wir beginnen hierzu mit einem Uberblick uber die recht allgemeinen linearen undquadratischen Zeit-Frequenz Darstellungen, um von dort aus die von uns gewahltenAnsatze zu motivieren. Dabei werden im Hinblick auf die Signalanalyse insbesonderedie Eigenschaften von gefensterten Fourier- und Wavelettransformationen von Inter-esse sein, da sich diese Zeit-Frequenz Darstellungen als geeignete Ausgangspunkte furdie in Kap. 3 und 4 untersuchten technischen Problemstellungen erweisen.
Im Anschluß diskutieren wir die genauen Zusammenhange der kontinuierlichenund diskreten Version von gefensterten Fourier- und Wavelettransformationen, dadie mathematischen Konzepte der Signaldarstellung vorwiegend in der Sprache derFunktionalanalysis formuliert sind, wir bei allen Anwendungen jedoch nur endliche,diskret abgetastete Zeitreihen zur Verfugung haben. Den Verknupfungspunkt bildethierfur das Shannonsche Samplingtheorem, das wir zu Beginn des zweiten Abschnittsdiskutieren.
Die Klassifikation experimenteller Daten anhand von extrahierten Merkmalen er-fordert insbesondere wegen des haufig recht begrenzten Datenumfangs leistungsfahigestatistische Methoden. Die hierfur benotigten Konzepte der statistischen Merkmals-klassifikation werden schließlich im letzten Abschnitt eingefuhrt. Mathematisch for-muliert, wird der Bayesche Fehler einer Klassifikationsstatistik, d.h. der minimalegesamte Klassifikationsfehler, der erzielt werden kann, geschatzt.
7

8 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
2.1 Zeit-Frequenz Darstellungen
Als Zeit-Frequenz Darstellung (ZFD) eines skalaren Signals x(t) bezeichnet man dieTransformation von x(t) in eine skalare Funktion Φx(t, f), die von den Variablen Zeitund Frequenz abhangt. Die Grundidee hierbei ist, eine Art ”zeitabhangiges Spektrum“zu definieren, um gleichzeitig Informationen des Signals im Zeit- und im Frequenz-raum (im Rahmen der Zeit-Frequenz Unscharfe) auflosen zu konnen. Anschaulichmotiviert ist dieses Konzept durch musikalische Noten, welche eine zeitliche Abfolgevon Frequenzen oder genauer, von Wellenpaketen mit Grundschwingungen definierterFrequenz, beschreiben.
Man unterscheidet zwischen Zeit-Frequenz Darstellungen, welche Linearformen,quadratische Formen oder allgemein nichtlineare Funktionale des Signals x(t) sind;die quadratischen ZFDs haben hierunter die großte Bedeutung. Ein Ubersichtsartikeluber Zeit-Frequenz Darstellungen ist z.B. [18]. Wir wollen hier naher auf zwei wichti-ge ZFDs eingehen, die gefensterten (oder Kurzzeit-) Fouriertransformationen und dieWavelettransformationen. Ihre Betragsquadrate, das Spektrogramm bzw. das Skalo-gramm, sind Spezialfalle von zwei wichtigen Klassen quadratischer ZFDs, der CohenKlasse sowie der affinen Klasse, die wir in Abschnitt 2.1.1 einfuhren, um den ma-thematischen Rahmen der allgemeinen quadratischen Zeit-Frequenz Darstellungenherzustellen.
Die wohl wichtigste Transformation in der Signalverarbeitung (und von großerBedeutung allgemein in Physik) ist die Fouriertransformation, da sie durch Abbil-dung eines Signals vom Zeit- in den Frequenzraum das Konzept der Schwingung aufnaturliche Weise reprasentiert. Sei x(t) ∈ L2(R); dann existiert die Fouriertransfor-mierte
x(f) =∫tx(t)e−i2πftdt =
⟨x(t) , ei2πft
⟩,
und es gilt x(f) ∈ L2(R), siehe [2].⟨· , ·
⟩bezeichnet hierbei das gewohnliche Skalar-
produkt im L2–Raum. Damit existiert auch die inverse Transformation
x(t) =∫fx(f)ei2πftdf , (2.1)
welche als Entwicklung von x(t) in der kontinuierlichen (uberabzahlbaren) Orthonor-malbasis ei2πft; f ∈ R aufgefaßt werden kann. Betrachtet man die formale Ent-wicklung von x(t) in der (uneigentlichen) Orthonormalbasis von Deltadistributionen
x(t) =∫τ
x(τ)δ(τ − t)dτ , (2.2)
so geht (2.1) aus (2.2) durch Transformation der Zeitbasis δ(τ − t); τ ∈ R in dieharmonische Basis ei2πft; f ∈ R hervor. Bemerkenswert hierbei ist, daß die Ent-wicklungskoeffizienten der Vektoren δ(τ − t) bezuglich der Basis ei2πft; f ∈ R,⟨
δ(τ − t) , ei2πft⟩
= e−i2πfτ ,

2.1. ZEIT-FREQUENZ DARSTELLUNGEN 9
alle den Betrag 1 haben, d.h. jeder Vektor der Zeitbasis entsteht durch Superposi-tion von allen Vektoren der harmonischen Basis mit gleicher Gewichtung [14]. DieseEigenschaft bestimmt die Fouriertransformation eindeutig und begrundet ihr wohl-bekanntes Verhalten, im Zeitraum gut lokalisierte Darstellungen von Funktionen aufentsprechend schlecht lokalisierte Darstellungen im Frequenzraum abzubilden undumgekehrt. Die quantitative Formulierung dieser Eigenschaft ist die Zeit-FrequenzUnscharfe, auf die wir in Abschnitt 2.1.3 zuruckkommen.
Wir wollen allgemein das Transformationspaar (x(t), x(f)) als zwei Darstellungeneiner Funktion betrachten, welche viele mogliche Zeit-Frequenz Darstellungen besitzt.In der Sprache der Quantenmechanik wurde man von der Projektion eines Vektorsx ∈ H in den Zeit- oder Frequenzraum sprechen.
Aus der Orthonormalitat der Basen in (2.1) und (2.2) folgt, daß die Fouriertrans-formation unitar ist, d.h. das Skalarprodukt wird erhalten:⟨
x(t) , y(t)⟩=
⟨x(f) , y(f)
⟩. (2.3)
Gleichung (2.3) wird auch als Parsevalsches Theorem bezeichnet.
2.1.1 Quadratische ZFDs: Die Cohen Klasse und die affine Klasse
Die Zeit-Frequenz Darstellung Φx(t, f) eines Signals x(t) ist eine Abbildung des Si-gnals vom Zeitraum in die Zeit-Frequenz Ebene. Die geforderten Eigenschaften dieserAbbildung sind vom spezifischen Signal und den Informationen, die daraus extrahiertwerden sollen, abhangig. Fur eine gute Interpretierbarkeit von ZFDs ist allgemein dieForderung naturlich, daß sie reell sind. Weiterhin ist es sinnvoll, die Eigenschaft derTranslationsinvarianz im Zeitraum zu fordern, d.h.
x(t) = x(t− t0) ⇐⇒ Φx(t, f) = Φx(t− t0, f) , (2.4)
da somit die Zeit-Frequenz Darstellung eines periodischen Signals ebenfalls periodischist. Entsprechend kann auch die Eigenschaft der Translationsinvarianz im Frequenz-raum gefordert werden, d.h.
x(t) = x(t)ei2πf0t ⇐⇒ x(f) = x(f − f0) ⇐⇒ Φx(t, f) = Φx(t, f − f0) . (2.5)
Erfullt eine ZFD die Eigenschaften (2.4) und (2.5), so wird damit ihre Auflosungs-charakteristik in der Zeit-Frequenz Ebene festgelegt; wir gehen in Abschnitt 2.1.3hierauf genauer ein. Eine weitere interessante Eigenschaft in dieser Hinsicht ist dieSkalierungsinvarianz, d.h.
x(t) =√
|a0| x(a0t) ⇐⇒ Φx(t, f) = Φx
(a0t,
f
a0
). (2.6)
Der Faktor√
|a0| dient hierbei der Erhaltung der L2–Norm des skalierten Signals.

10 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
Eine reelle, quadratische Zeit-Frequenz Darstellung, welche die Eigenschaften(2.4)–(2.6) erfullt, ist die Wigner (oder Wigner-Ville) Verteilung1
Wx(t, f) =∫τx(t+
τ
2)x(t− τ
2)e−i2πfτdτ , (2.7)
wobei · die komplexe Konjugation bezeichnet. Die Wigner-Ville Verteilung besitzteine Vielzahl interessanter Eigenschaften [18], die bis heute zu vielfaltigen Anwendun-gen dieser Transformation in der Quantenmechanik, Optik, Signalverarbeitung undanderen Bereichen von Physik und Ingenieurwissenschaften gefuhrt haben [11, 28, 29].
Interessant in unserem Zusammenhang ist, daß die Darstellung (2.7) eine hoheInformationsauflosung des Signals x(t) in der Zeit-Frequenz Ebene ermoglicht, welchenur durch die Zeit-Frequenz Unscharfe begrenzt wird. Der Preis dafur ist das Auf-treten von Interferenztermen: Seien x und y zwei Signale, die an den Stellen (t1, f1),bzw. (t2, f2) in der Zeit-Frequenz Ebene lokalisiert sind. Aus (2.7) folgt unmittelbar:W(x+y)(t, f) =Wx(t, f)+Wy(t, f)+Wx,y(t, f)+Wy,x(t, f), wobei der InterferenztermWx,y(t, f) =W y,x(t, f) durch
Wx,y(t, f) =∫τx(t+
τ
2)y(t− τ
2)e−i2πfτdτ ,
definiert ist. Die Funktion Wx,y(t, f) oszilliert in der Zeit-Frequenz Ebene, wobei derFrequenzvektor der Grundschwingung durch (ν1,2, τ1,2) = (f1 − f2, t1 − t2) gegebenist. Die zweidimensionale Fouriertransformation von Wx,y(t, f), Wx,y(ν, τ), ist in derν-τ Ebene um so weiter vom Ursprung entfernt lokalisiert, je großer ‖(ν1,2, τ1,2)‖2
ist. Hierauf beruht die Idee, die Interferenzterme der Wigner-Ville Verteilung durchTiefpaßfiltern im ν-τ Raum oder entsprechend durch Falten im t-f Raum zu dampfen.
Die Faltung von (2.7)mit einer Kernfunktion Π(t, f) ist im allgemeinen nicht mehrskalierungsinvariant. Es laßt sich jedoch zeigen, daß alle quadratischen Zeit-FrequenzDarstellungen, welche die Bedingungen (2.4) und (2.5) erfullen, durch Faltung von(2.7) mit einer Kernfunktion erzeugt werden konnen [14, 17]:
Cx(t, f) =∫τ
∫νWx(τ, ν)Π(τ − t, ν − f)dτdν . (2.8)
Die in der Zeit-Frequenz Ebene translationsinvarianten ZFDs (2.8) bilden die CohenKlasse2. Entsprechend kann gezeigt werden, daß sich die Menge aller quadratischenZFDs, die den Gleichungen (2.4) und (2.6) genugen, aus der Wigner-Ville Verteilungdurch affine Faltung mit einer Kernfunktion Π(t, f) erzeugen laßt [33]:
Ωx(t, f) =∫τ
∫νWx(τ, ν)Π
(f
f0(τ − t),
f0
fν
)dτdν . (2.9)
1Wigner fand diese Verteilung 1932 im Zusammenhang mit der Quantenmechanik [45], wahrend
sie Ville 1948 zum ersten Mal in der Signalanalyse anwendete [44], offensichtlich ohne die Arbeit
Wigners zu kennen.2Die Klasse translationsinvarianter ZFDs wurde zuerst von Cohen 1966 im Rahmen quantenme-
chanischer Uberlegungen gefunden [3].

2.1. ZEIT-FREQUENZ DARSTELLUNGEN 11
Die Menge (2.9) wird entsprechend als affine Klasse bezeichnet. In der Literatur wirddie Abbildung Ωx auch haufig als Funktion des Skalierungsparameters a = f0/f de-finiert. Da die Konstante f0 > 0 willkurlich ist, scheint a die naturliche unabhangigeVariable von skalierungsinvarianten Abbildungen zu sein. Jedoch ist hier die Interpre-tation von Ωx als einer Abbildung in die Zeit-Frequenz Ebene erwunscht und somitihre explizite Abhangigkeit von f sinnvoll.
Interessanterweise besteht die Schnittmenge von affiner und Cohen Klasse nichtnur aus der Wigner-Ville Verteilung selber, sondern aus allen Abbildungen, die durchFaltung von (2.7) mit Kernfunktionen der Form Π(t, f) = Π(t·f) erzeugt werden [19].Das wichtigste Beispiel dieser sogenannten shift-scale class bilden Signaldarstellungenmit der Wahl Π(t, f) ∼ e−(t2f2/σ). Diese Kernfunktion wird haufig als Choi-WilliamsKern bezeichnet.
2.1.2 Gefensterte Fourier- und Wavelettransformationen
Im Vergleich zu den quadratischen ist die Menge der linearen Zeit-Frequenz Darstel-lungen, welche der Bedingung (2.4) sowie (2.5) oder (2.6) genugen, klein; sie bestehtgenau aus den Klassen der gefensterten Fouriertransformationen FT g
x und der Wave-lettransformationenWT h
x . Diese sind definiert durch:
FT gx (t, f) =
∫τx(τ)g(τ − t)e−i2πfτdτ =
⟨x(τ) , g(τ − t)ei2πfτ
⟩, (2.10)
WT hx (t, f) =
∫τx(τ)
√∣∣∣∣ ff0
∣∣∣∣h(f
f0(τ − t)
)dτ
=⟨x(τ) ,
√∣∣∣∣ ff0
∣∣∣∣h(f
f0(τ − t)
)⟩. (2.11)
Die Wavelettransformation wird auch haufig als Funktion des Skalierungsparametersa = f0/f definiert; wir wollen sie hier jedoch als Abbildung in die Zeit-FrequenzEbene betrachten.
Die gefensterte Fouriertransformation erfullt die Eigenschaft (2.5), die Transla-tionsinvarianz im Zeitraum ist dagegen nur mit der Einschrankung einer zusatzlichauftretenden Phase gegeben, vgl. (2.4):
x(t) = x(t− t0) ⇐⇒ F gx (t, f) = F g
x (t− t0, f)e−i2πft0 .
Da die gefensterte Fouriertransformation eines reellen Signals nicht reell ist3 und diePhasen meist keine auswertbaren Informationen enthalten (sie sind von den Anfangs-bedingungen abhangig), betrachtet man das Spektrogramm SP g
x (t, f) = |FT gx (t, f)|2
oder eine monotone Funktion hiervon. Das Spektrogramm laßt sich in der Form
SP gx (t, f) =
∫τ
∫νWx(τ, ν)Wg(τ − t, ν − f)dτdν (2.12)
3außer vielleicht fur isolierte Werte von t

12 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
schreiben und ist somit ein Element der Cohen Klasse, vgl. (2.8).Wg(τ, ν) bezeichnethierbei die Wigner-Ville Verteilung der Fensterfunktion g(τ).
DieWavelettransformation erfullt die Invarianzbedingungen (2.4) und (2.6). Auchwenn das Wavelet h(τ) reell gewahlt wird, geht man in in der Signalanalyse gerne zumeinfacher zu interpretierenden Skalogramm SKh
x(t, f) = |WT hx (t, f)|2 uber, welches
analog zum Spektrogramm die Darstellung
SKhx (t, f) =
∫τ
∫νWx(τ, ν)Wh
(f
f0(τ − t),
f0
fν
)dτdν (2.13)
besitzt und damit ein Element der affinen Klasse ist, vgl. (2.9). Wh(τ, ν) bezeichnetanalog die Wigner-Ville Verteilung des Wavelets h(τ).
Das Spektrogramm und das Skalogramm sind die wichtigsten Vertreter der Co-hen bzw. der affinen Klasse. Anhand dieser Beispiele laßt sich ein charakteristischerUnterschied zwischen der Cohen Klasse und der wichtigsten Teilmenge der affinenKlasse zeigen: Die Zeit-Frequenz Auflosungscharakteristik der ZFDs dieser Mengen;wir gehen hierauf im nachsten Abschnitt ein.
Aus (2.12) und (2.13) folgt, daß Spektrogramme und Skalogramme relativ starkgeglattete Wigner-Ville Verteilungen sind, da die Kerne Wg(τ, ν) und Wh(τ, ν) auf-grund der Zeit-Frequenz Unscharfe eine Mindestausdehnung in der Zeit-FrequenzEbene besitzen mussen, welche eine Obergrenze fur ihre mogliche Lokalisierung bildet.Es existieren Kernfunktionen, die abhangig von einem Parameter einen kontinuierli-chen Ubergang von (2.7) nach (2.12) bzw. von (2.7) zu (2.13) ermoglichen [33].
Wir wollen hier noch erwahnen, daß die Gleichungen (2.12) und (2.13), welcheSpektrogramme und Skalogramme in den Rahmen allgemeiner quadratischer Zeit-Frequenz Darstellungen stellen, relativ einfach hergeleitet werden konnen unter Ver-wendung der Eigenschaften (2.4)–(2.6) der Wigner-Ville Verteilung sowie den Unita-ritatsrelationen (2.3) und
⟨Wx ,Wy
⟩= |
⟨x , y
⟩|2.
Betrachten wir nun die Eigenschaften von gefensterten Fourier- und Wavelettrans-formationen genauer. Die Definition (2.10) kann als ein Ausdruck der Entwicklungs-koeffizienten von x(τ) bezuglich der kontinuierlichen Basis
gt,f(τ) = g(τ − t)ei2πfτ ; t, f ∈ R (2.14)
betrachtet werden, wobei gt,f(τ) durch eine Translation im Zeit- und anschließendim Frequenzraum aus einer zugrundeliegenden Fensterfunktion g0,0(τ) ≡ g(τ) hervor-geht4, siehe hierzu Abb. 2.1. Wir konnen hierbei annehmen, daß g0,0(τ) und g0,0(ν)im Zeit- bzw. Frequenzraum am Ursprung lokalisiert sind. Die Darstellung von x(τ)bezuglich der Basis (2.14) ergibt sich dann aus der Invertierung von (2.10):
x(τ) =1
‖g‖22
∫t
∫fFT g
x (t, f)g(τ − t)ei2πfτdtdf , (2.15)
4Translationen im Zeit- und Frequenzraum kommutieren nicht, das Resultat unterscheidet sich
um die Phase e−i2πft.

2.1. ZEIT-FREQUENZ DARSTELLUNGEN 13
)
|
Re(g
|h ||h
|g |^
f f0
τ τt
t τ
f
ν
f
ν
t,f
τ
t,f
τt
t
f
ν
t,f
f
ν
τ
νν
τ
0,0
0
τ0,fo|
(b)
(a)
)Re(g
νν
Re(h )t,fRe(h0,fo)
|g0,0
Abbildung 2.1: Die schematische Darstellung der Erzeugung der Basisfunktionen von
FT gx (t, f) und WT h
x (t, f): (a) gt,f geht durch eine Translation im Zeit- und anschließend
im Frequenzraum aus g0,0 hervor. (b) ht,f wird durch eine Translation im Zeitraum und
anschließende Skalierung aus h0,f0 erzeugt.
wobei Gl. (2.15) zumindest im Sinn der L2-Norm gilt. Ebenso laßt sich die Defini-tion (2.11) als ein Ausdruck der Entwicklungskoeffizienten von x(τ) bezuglich derkontinuierlichen Basis
ht,f(τ) =
√∣∣∣∣ ff0
∣∣∣∣h(f
f0(τ − t)
); t, f ∈ R (2.16)
auffassen, wobei ht,f (τ) durch Translation im Zeitraum und anschließende Skalierungmit dem Faktor f/f0 aus einem Mutterwavelet h0,f0(τ) ≡ h(τ) erzeugt wird, sieheAbb. 2.1. Die Entwicklung von x(τ) nach den Basisfunktionen (2.16) wird dann durch

14 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
die Invertierung von (2.11):
x(τ) =1Ch
∫t
∫fWT h
x (t, f)
√∣∣∣∣ ff0
∣∣∣∣h(f
f0(τ − t)
)dtdf (2.17)
mit der Normierungskonstanten Ch =∫f |f0/f | |h(f0/f)|2df = f0
∫a 1/|a| |h(a)|2da
gegeben. Gleichung (2.17) ist hierbei ebenfalls im Sinn der L2-Norm zu verstehen.Notwendige und in allen praktischen Fallen (d.h. fur ”hinreichend gut lokalisierte“Wavelets, siehe Abschnitt 2.1.3) auch hinreichende Bedingung fur die Existenz vonCh und damit die Invertierbarkeit der Wavelettransformation ist h(0) = 0, siehe [4].
Eine formal analoge Darstellung von gefensterten Fourier- und Wavelettransfor-mationen erhalten wir unter der (sinnvollen) Annahme, daß Wavelets Wellenpaketesind, durch die Schreibweise
h0,f0(τ) = h(τ)ei2πf0τ ,
wobei h(τ) und h(ν) im Ursprung von Zeit- bzw. Frequenzraum lokalisiert sein sollen.
(h(τ) ist somit kein Wavelet.) Damit ist
ht,f (τ) =
√∣∣∣∣ ff0
∣∣∣∣ h(f
f0(τ − t)
)ei2πf(τ−t) . (2.18)
Unter Verwendung von (2.3) lassen sich die Definitionen (2.10) und (2.11) auch alsAusdrucke der Entwicklungskoeffizienten von x(ν) bezuglich der kontinuierlichen Ba-sisfunktionen im Frequenzraum gt,f(ν) bzw. ht,f(ν) schreiben:
FT gx (t, f) =
⟨x(ν) , gt,f(ν)
⟩=
⟨x(ν) , g(ν − f)e−i2π(ν−f)t
⟩, (2.19)
WT hx (t, f) =
⟨x(ν) , ht,f(ν)
⟩=
⟨x(ν) ,
√∣∣∣∣f0
f
∣∣∣∣ h
(f0
f(ν − f)
)e−i2πνt
⟩. (2.20)
Betrachten wir nun FT gx und WT h
x als Funktionen von f , so haben (2.19) und(2.20) die Form eines Faltungsintegrals von x(ν) mit den Basisfunktionen gt,f(ν) bzw.ht,f(ν). Als Funktionen von t dagegen gesehen, sind die Gleichungen (2.19) und (2.20)Bandpaßtransformationen, da gt,f(ν) und ht,f(ν) im Frequenzraum an der Stelle flokalisiert sind und somit, spaltet man die Phase e−i2πνt fur die inverse Fouriertrans-formation ab, g(ν − f) und
√|f0/f | h(f0/f(ν − f)) Bandpaßfilter darstellen.
Da Falten und Filtern aquivalente Prozesse sind, die durch einander ausgedrucktwerden konnen, haben die Darstellungen (2.10) und (2.11) von FT g
x bzw. WT hx
naturlich analoge Interpretationen, die aber vielleicht nicht so offensichtlich sind.In diesem Sinn konnen (2.10) und (2.11) als Faltungen des Signals x(t) mit denBasisfunktionen (2.14) bzw. (2.18) wie auch als Bandpaßtransformationen mit denBandpaßfiltern g(τ − t), bzw.
√|f/f0| h(f/f0(τ − t)) aufgefaßt werden, wobei wir im
ersten Fall FT gx undWT h
x als Funktionen von t, im zweiten abhangig von f betrachtenwollen.

2.1. ZEIT-FREQUENZ DARSTELLUNGEN 15
ν
f
f
f
f 11
22
1
t ttt 121 2(b)(a)
τ τ
ν
∆f 1
∆ f2
∆f 1
∆f2
∆t2∆ t1∆t2∆t
Abbildung 2.2: Die schematische Darstellung der Zeit-Frequenz Auflosungscharakteristik
von FT gx (t, f) und WT h
x (t, f): Lokalisierung der Basisfunktionen gt,f (a) und ht,f (b) in
der Zeit-Frequenz Ebene.
2.1.3 Die Zeit-Frequenz Auflosungscharakteristik
Kommen wir nun zu der Auflosungscharakteristik von gefensterten Fourier- und Wa-velettransformationen. Die Bandbreite einer L2-Funktion x(τ) kann im Zeit- bzw.Frequenzraum definiert werden durch
∆t2 =
∫τ |x(τ)|
2τ2dτ∫τ |x(τ)|2dτ
sowie ∆f2 =
∫ν |x(ν)|
2ν2dν∫ν |x(ν)|2dν
. (2.21)
Wir nennen eine Funktion ”hinreichend gut lokalisiert“ in der Zeit-Frequenz Ebene,wenn sie ∆t2 <∞ und ∆f2 <∞ erfullt. Wir konnen annehmen, daß diese Eigenschaftfur alle Basisfunktionen gt,f und ht,f gegeben ist. Da FT g
x (t, f) und WT hx (t, f) Band-
paßtransformationen des Signals x(t) darstellen, wird die Zeit-Frequenz Auflosungvon x(t) durch die Lokalisierung von gt,f bzw. ht,f in der Zeit-Frequenz Ebene be-stimmt. Daß es sich hierbei immer um ein Abwagen zwischen Auflosen und Ausglattender Strukturen des Signals im Zeit- und Frequenzraum handelt, folgt aus der Zeit-Frequenz Unscharfe
∆t∆f ≥ 14π
, (2.22)
wobei die Gleichheitsbedingung genau fur Gaußverteilungen erfullt ist, siehe [2]. Inder Quantenmechanik wird (2.22) als Heisenbergsche Unscharferelation bezeichnet.Wir wollen die Zeit-Frequenz Unscharfe der Basisfunktionen gt,f und ht,f als ein(zumindest qualitatives) Maß dafur verwenden, wie gut sie in der der Zeit-FrequenzEbene lokalisiert sind. Dies ist damit ein Maß fur die Informationsauflosung der kor-respondierenden Zeit-Frequenz Darstellung.

16 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
0
(b) konstante relative Bandweite
(a) konstante Bandweite
ν7f 6f5f4f 3f2ff0
1
ν016f8f4f0f0
0
1
0
2f0 0
Abbildung 2.3: Der Frequenzraum wird von Wavelettransformationen logarithmisch uber-
deckt, d.h. in Oktaven eingeteilt (b), wahrend gefensterte Fouriertransformationen ihn
gleichformig uberdecken (a). Siehe hierzu auch Abb. 4.2
Die Bandbreite der Basisfunktionen gt,f hangt nicht von den Translationsfaktorent und f ab, d.h. es ist ∆t = const und ∆f = const. Dies folgt sofort durch Einsetzenvon gt,f(τ) und gt,f(ν) in (2.21). Dadurch ist die Auflosung eines Signals uberall in derZeit-Frequenz Ebene gleich; man spricht bei gefensterten Fouriertransformationen voneiner konstantenAuflosungscharakteristik. Anders im Fall der Wavelettransformation:Da hier die Basisfunktionen ht,f durch Skalierung aus einem Mutterwavelet h0,f0
hervorgehen, ist ihre Bandbreite ∆f proportional zur Grundfrequenz f , an der ht,f(ν)im Frequenzraum lokalisiert ist. Man erhalt aus (2.21)
∆ff
= const (2.23)
und damit auch ∆t ∼ 1/f . Die Auflosungscharakteristik von Wavelettransformatio-nen wird aus diesem Grund hyperbolisch genannt. In der Literatur wird WT h
x (t, f)auch als Zeit-Frequenz Darstellung mit ”konstanter relativer Bandweite“ bezeichnet[32]. In Abb. 2.2 ist die Auflosungscharakteristik von FT g
x (t, f) und WT hx (t, f) sowie
in Abb. 2.3 die Anordnung der Bandpaßfilter im Frequenzraum illustriert. Wave-lettransformationen teilen den Frequenzraum naturlich in Oktaven ein.
Das besondere Interesse an ZFDs mit hyperbolischer Zeit-Frequenz Auflosung be-ruht auf der Auflosungscharakteristik des menschlichen Gehors, die fur Frequenzen& 500Hz in guter Naherung die Form (2.23) hat [4, 32]. In der Schnecke im Innenohrfindet eine Dispersion der vom Mittelohr ubertragenen Schalldrucksignale statt mitder Charakteristik, daß die Frequenzauflosung der Schallsignale in etwa logarithmischerfolgt, also zu einer nach Oktaven gegliederten Wahrnehmung von Tonhohen fuhrt.

2.1. ZEIT-FREQUENZ DARSTELLUNGEN 17
Dies kann darauf zuruckgefuhrt werden, daß wichtige Gerausche in unserer Umwelt,wie vor allem die Sprache, sich aus niederfrequenten und langer andauernden sowiehochfrequenten und zeitlich kurzeren Komponenten zusammensetzen. Die musika-lischen Noten z.B. spiegeln die logarithmische Frequenzauflosung des menschlichenGehors wieder. Die Wahrnehmung stationarer Signale, d.h. die Empfindung der zeit-lichen Anderung eines Schallsignals, findet auf der Zeitskala ∆t & 200 ms statt undberuht im wesentlichen auf Anderungen von Tonhohe und Lautstarke [16].
Unsere Aufgabe in Kap. 4 ist die automatische Klassifikation von Schallsignalen,die durch menschliche Experten (prinzipiell) getrennt werden konnen. Der Ausgangs-punkt fur die Entwicklung eines hierauf angepaßten Merkmalsvektors ist aus diesemGrund eine (diskrete) Wavelettransformation.Wird dagegen die Analyse von Signalenbetrachtet, die fur das menschliche Gehor keine oder kaum Informationen enthalten,wie z.B. der Statorstrom von Induktionsmotoren in Kap. 3, so sind vermutlich an-dere Ansatze erfolgversprechender. Aufgrund der Quasiperiodizitat der Motorsignalebietet sich hier eine gefensterte Fouriertransformation als Ansatzpunkt an.
Zum Schluß dieses Abschnitts mochten wir den Weg wieder zuruck zu allgemei-neren Zeit-Frequenz Darstellungen finden. Aus der Translationsinvarianz in der Zeit-Frequenz Ebene (2.4), (2.5) folgt unmittelbar, daß alle ZFDs der Cohen Klasse einekonstante Zeit-Frequenz Auflosung haben. Die Menge der ZFDs mit einer hyperbo-lischen Auflosungscharakteristik bilden dagegen eine Teilmenge (die wichtigste aller-dings) der affinen Klasse. Dies ist klar, da der Schnitt von Cohen und affiner Klassenicht leer ist. Die hyperbolische Zeit-Frequenz Auflosung der Wavelettransformati-on folgt aus der Eigenschaft, daß der Skalierungsparameter f0/f der Basisfunktionenht,f umgekehrt proportional zur Grundfrequenz f ist, an der ht,f (ν) im Frequenzraumlokalisiert ist, die Skalierung also an eine Translation der Grundfrequenz gekoppeltist (2.20). Die Skalierungsinvarianz (2.6) ist hierfur nicht hinreichend, aber naturlichnotwendig.
Betrachtet man die Darstellungen (2.15) und (2.17) des Signals x(τ), so stellt sichdie Frage ob es auch abzahlbare Basen oder allgemeiner, abzahlbare und uberall inL2(R) dicht liegende Mengen von Funktionen des Typs (2.14) bzw. (2.16) gibt, wiesich aus den Abb. 2.2 und 2.3 vielleicht vermuten laßt. Die Antwort ist ja, und eineTheorie dieser sogenannten Rahmen (frames) findet sich z.B. in [4]. Wir wollen daraufnicht eingehen, aber noch bemerken, daß sich hierbei weitere interessante Unterschiedezwischen den Basisfunktionen (2.14) und (2.16) zeigen.

18 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
2.2 Diskrete Signaldarstellungen
Wahrend die mathematischen Konzepte der Signalverarbeitung vorwiegend in derSprache der Funktionalanalysis formuliert sind, hat man in allen praktischen Anwen-dungen nur endliche, diskret abgetastete Zeitreihen zur Verfugung. Die Umsetzungder Theorie kontinuierlicher Zeit-Frequenz Darstellungen in die Sprache der linea-ren Algebra fur die Anwendung auf Zeitreihen ist nicht nur ein technisches Problem;vielmehr muß beachtet werden, daß der Informationsgehalt kontinuierlicher Signaledurch die Diskretisierung mit einer endlichen Abtastrate wesentlich reduziert werdenkann und auch nur ein endlicher Ausschnitt des eigentlichen Signals bekannt ist. Da-mit stellt sich die Frage, inwiefern die Informationen kontinuierlicher Signale in einergemessenen Zeitreihe noch enthalten sind oder anders formuliert, wie gut laßt sichdas Signal aus der Zeitreihe rekonstruieren?
Diese Frage beantwortet das Shannonsche Samplingtheorem, auf das wir wegenseiner Bedeutung in der Zeitreihenanalyse in Abschnitt 2.2.1 eingehen. Allgemeinkann ein kontinuierliches Signal nicht vollstandig aus einer gemessenen Zeitreihe re-konstruiert werden. Damit stellt sich weiter die Frage, welche Informationen des Si-gnals aus einer endlichen Zeitreihe extrahiert werden konnen oder konkreter, mitwelcher Wahl der Fensterfunktion g(τ) oder des Waveletfilters h(ν) konnen aus derZeitreihe x(n∆τ); n = 1, · · · , N die moglichst hoch aufgelosten Zeit-Frequenz Dar-stellungen FT g
x (t, f) bzw.WT hx (t, f) des Signals x(τ) so gut wie moglich rekonstruiert
werden?Eine hohe Informationsauflosung von FT
gx (t, f) oder WT h
x (t, f) erfordert offen-sichtlich die gute Lokalisierung, d.h. eine kleine Zeit-Frequenz Unscharfe der Basis-funktionen g(τ) bzw. h(τ) in der Zeit-Frequenz Ebene (Abschnitt 2.1.3). Daruber-hinaus zeigt sich aber, daß es ebenso von der Wahl von g(τ) bzw. h(τ) abhangt,wie gut gefensterte Fourier- und Wavelettransformationen durch eine entsprechendediskrete Transformation approximiert werden konnen, oder anders ausgedruckt, wievollstandig sich FT g
x (t, f) oder WT hx (t, f) aus einer Zeitreihe rekonstruieren lassen.
In den Abschnitten 2.2.2 und 2.2.3 wird dieser Zusammenhang diskutiert.Da das Konzept der Skalierung auf diskrete Signale nicht unmittelbar ubertragbar
ist, lassen sich kontinuierliche Wavelettransformationen nur teilweise durch diskreteapproximieren. Daher muß die Definition einer diskreten Wavelettransformation vomkontinuierlichen Vorbild etwas abweichen. In Abschnitt 2.2.3 wird eine Moglichkeithierzu vorgestellt.
2.2.1 Das Shannonsche Samplingtheorem
Die Aussage des Shannonschen Samplingtheorems ist, daß L2-Funktionen, die imFrequenzraum einen kompakten Trager haben, aus einer (unendlichen) Zeitreihe voll-standig rekonstruiert werden konnen. Daruber hinaus kann der Informationsverlustabgeschatzt werden, der durch die Diskretisierung eines Signals mit einer endlichen

2.2. DISKRETE SIGNALDARSTELLUNGEN 19
Abtastrate entsteht, falls die Voraussetzungen des Satzes nicht erfullt sind. Damitbildet das Shannonsche Samplingtheorem den Verknupfungspunkt zwischen kontinu-ierlichen Signalen und Zeitreihen.
Betrachten wir zunachst Funktionen x(t) ∈ L2(R) mit kompaktem Trager imFrequenzraum, d.h. x(f) ≡ 0 fur f /∈ [−fc , fc]. Damit laßt sich x(f) in die Fourierreihe
x(f) =∑n∈Z
cne−i 2π
2fcnf (2.24)
entwickeln mit den Fourierkoeffizienten
cn =12fc
∫ fc
−fc
x(f)eiπfcnfdf
=12fc
∫ ∞
−∞x(f)ei
πfcnfdf =
12fc
x
(n
2fc
).
(2.25)
Es folgt, daß
x(t) =∫ ∞
−∞x(f)ei2πftdf =
∫ fc
−fc
(∑n
cne−i π
fcnf
)ei2πftdf
=∑n
cn
∫ fc
−fc
ei2πf
(t− n
2fc
)df =
∑n
x
(n
2fc
) sin(2πfc(t− n
2fc
))
2πfc(t− n
2fc
)=
∑n
x(n∆t)sin(2πfc(t− n∆t))
2πfc(t− n∆t).
(2.26)
Aufgrund der Vertauschung von Integration und Reihenentwicklung im Schritt vonder ersten zur zweiten Zeile setzen wir die gleichmaßige Konvergenz der Fourierreihe(2.24) voraus. Diese Bedingung ist gleichbedeutend mit
∑n |cn| <∞ und wird genau
fur stetige Funktionen x(f) erfullt. Die betragsmaßig maximale Frequenz fc, fur diex(f) = 0 sein kann, wird haufig als Nyquistfrequenz bezeichnet. Aus (2.26) folgt, daß∆t = 1/(2fc) das großte Abtastintervall im Zeitraum ist, welches ausreicht, um daskontinuierliche Signal x(t) durch die Zeitreihe x(n∆t); n ∈Z vollstandig, d.h. ohneInformationsverlust, zu rekonstruieren.
Die Reihenentwicklung (2.26) ist nicht eindeutig. Um dies zu sehen, betrachtenwir x(t) = x(t−τ). Da somit x(f) = x(f)e−i2πfτ ist, haben x(f) und x(f) den gleichenTrager. Damit existiert fur x(t) ebenfalls die Darstellung (2.26), woraus folgt:
x(t− τ) =∑n
x(n∆t− τ)sin(2πfc(t− n∆t))2πfc(t− n∆t)
=∑n
x(n∆t)sin(2πfc(t− τ − n∆t))
2πfc(t− τ − n∆t).
Somit kann das Signal x(t) aus jeder Zeitreihe x(n∆t+ τ); n ∈Z mit 0 ≤ τ < ∆tvollstandig rekonstruiert werden.

20 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
Betrachteten wir nun den Fall einer hoheren Samplingrate, d.h. ∆t < 1/(2fc). Indiesem Fall ist die Periode T = 2fc der Fourierreihe (2.24) großer als der Trager vonx(f), den wir als das Intervall [−λfc , λfc] mit λ < 1 annehmen. Wir betrachten nunstetige Funktionen φ(f) mit den Eigenschaften: φ(f) hat kompakten Trager auf demIntervall [−fc , fc] und φ(f) ≡ 1 fur −λfc ≤ f ≤ λfc. Damit folgt aus (2.26):
x(t) =∫ ∞
−∞x(f)ei2πftdf =
∫ fc
−fc
(∑n
cne−i π
fcnf
)φ(f)ei2πftdf
=∑n
x(n∆t)(
12fc
∫ fc
−fc
φ(f)ei2πf(t− n
2fc
)df
)=
∑n
x(n∆t)Φ(t− n∆t)
(2.27)
Aus (2.27) folgt, daß fur Zeitreihen, die mit einem Abtastintervall ∆t < 1/(2fc)gemessen werden, viele mogliche Funktionenreihen existieren, die gleichmaßig gegenx(t) konvergieren, falls x(t) stetig ist. Insbesondere lassen sich Reihen konstruieren,die schneller als (2.26) konvergieren [4].
Da ein zeitlich begrenztes Signal keinen kompakten Trager im Frequenzraum ha-ben kann, ist die vollstandige Charakterisierung eines kontinuierlichen Signals nurdurch eine unendliche Zeitreihe moglich. Daruber hinaus sind Signale mit beschrank-tem Frequenzband auch kein typischer Spezialfall. Wichtig in unserem Zusammen-hang ist es deshalb, den Informationsverlust zu studieren wenn die Samplingrate ∆tzu groß wird. In diesem Fall ist die Periode T = 2fc der Fourierreihe (2.24) kleinerals der Trager von x(f), der hier der Einfachheit halber als das Intervall [−λfc , λfc]mit λ > 1 angenommen werden soll. Damit folgt aus (2.25):
x( n
2fc
)=
∫ ∞
−∞x(f)ei
πfcnfdf =
∫ λfc
−λfc
x(f)eiπfcnfdf
=∫ fc
−fc
dfei π
fcnf [x(f) + x(f − 2fc) + x(f + 2fc) + x(f − 4fc)
+ x(f + 4fc) + · · ·+ x(f − 2kλfc) + x(f + 2kλfc)]
=∫ fc
−fc
x(f)ei πfcnfdf =
∫ ∞
−∞x(f)ei π
fcnfdf
= x( n
2fc
).
(2.28)
Bei der Umformung zwischen erster und zweiter Zeile haben wir ausgenutzt, daßeiπnf/fc die Periode 2fc hat. x(f) wird in der dritten Zeile durch den Ausdruck inden eckigen Klammern definiert, wobei die naturliche Zahl kλ durch die Bedingung2kλ − 1 < λ ≤ 2kλ + 1 gegeben ist.
Die Interpretation von (2.28) ist folgende: Wird eine Zeitreihe des Signals x(t)mit dem Abtastintervall ∆t gemessen, so erhalt man durch die Rekonstruktion nach

2.2. DISKRETE SIGNALDARSTELLUNGEN 21
-ff
fc
|x(f)|^
0 c
Abbildung 2.4: Illustration das Aliasing Effekts: x(f) wird stuckweise in das Intervall
[−fc , fc] hineingeschoben und addiert. Abbgebildet ist der Fall kλ = 1, siehe Gl. (2.28).
Gl. (2.26) anstatt x(t) die Funktion x(t), welche naturlich die gleichen Stutzstellen be-sitzt (x(n∆t) = x(n∆t)), im Frequenzraum aber das kompakte Intervall [−fc , fc] alsTrager hat. x(f) entsteht durch die Addition der stuckweise in das Intervall [−fc , fc]hineingeschobenen Funktion x(f), siehe Abb. 2.4. Diesen Informationsverlust von x(t)bezeichnet man als Aliasing Effekt5. Die Minimierung von Aliasing Effekten ist einwichtiger Aspekt bei der Umsetzung von Konzepten der kontinuierlichen Signalver-arbeitung in die Zeitreihenanalyse.
2.2.2 Diskrete gefensterte Fouriertransformationen
Wir wollen in diesem Abschnitt den Zusammenhang von kontinuierlichen und dis-kreten gefensterten Fouriertransformationen insbesondere mit Blick auf die Wahl derFensterfunktion genauer betrachten. Die diskrete Fouriertransformation einer Zeit-reihe xn; n = 1, · · · , N ist definiert durch
xk =1√N
N∑n=1
xn e−i2π k
Nn sowie xn =
1√N
N/2∑k=−N/2+1
xk ei2π k
Nn . (2.29)
Die diskrete Fouriertransformation ist unitar bezuglich des Standardskalarproduktsim CN . Aus (2.29) folgt, daß xk und xn periodisch im Frequenz- bzw. Zeitraummit der Periode N sind. Die Nyquistfrequenz ergibt sich aufgrund des Samplinginter-valls ∆t = 1 zu fc = 1/2; somit liegen die diskreten Frequenzen fk = k/N im Intervall(−1/2 , 1/2].
Sei nun xn; n = 1, · · · , LN die Zeitreihe eines kontinuierlichen Signalabschnittssowie gn = g(n∆t); n = 1, · · · , N eine diskrete Fensterfunktion, wobei g(t) kom-pakten Trager im Zeitraum hat und L,N ∈ N sind. Sei weiter gn; n = 1, · · · , LNdie Fortsetzung von gn mit Null auf das Intervall [1 , LN ]. Beachtet man noch die
5nach alias: lat. ein anderer

22 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
Konvention, gn an der StelleN/2 (statt am Ursprung) zu lokalisieren, so ergibt sichals diskretes Analogon zu (2.10) und (2.19):
FT gx (N/2 +m, j) =
1√LN
LN∑n=1
xn g(n−m) e−i2π j
LNn
=1√LN
LN/2∑k=−LN/2+1
xk g(k−j) ei2π k−j
LNm ,
(2.30)
wobei wir bei der Umformung die periodischen Randbedingungen mit der PeriodeLN ausgenutzt haben.
Fur die gegebene Zeitreihe eines endlichen Abschnitts des Signals x(t) soll nundie Fensterfunktion gn = g(n∆t); n = 1, · · · , N so gewahlt werden, daß die dis-krete gefensterte Fouriertransformation (2.30) das kontinuierliche Analogon (2.10)moglichst gut approximiert. Wegen der endlichen Lange der Zeitreihe nehmen wir an,daß g(t) kompakten Trager im Zeitraum hat. Da aus diesem Grund g(f) und somitauch die Faltung FT g
x (t, f) = (x∗g)(t, f) (Gl. (2.19)) kein beschranktes Frequenzbandhaben konnen, ist ein Aliasing Effekt unvermeidbar. Nach Abschnitt 2.2.1 ist dieserInformationsverlust jedoch um so kleiner, je besser g(f) bei einem gegebenen x(f)lokalisiert ist. Ein schnelles Abfallverhalten im Frequenzraum stellt sich damit alswichtiges Kriterium fur Fensterfunktionen heraus, sowohl fur die Minimierung vonAliasing Effekten als auch im Hinblick auf eine moglichst gute Informationsauflosungvon FT g
x (t, f).Minimale Zeit-Frequenz Unscharfe nehmen zwar genau Gauß-Verteilungen an,
jedoch haben sie weder im Zeit- noch im Frequenzraum kompakten Trager und konnendeshalb nicht durch eine endliche Zeitreihe (im Sinn von Gl. (2.26)) charakterisiertwerden. Die Diskretisierung des Produktes x(t)g(t−τ) mit einer endlichen Abtastrateergibt dann die Zeitreihe xn g(n−m); n = 1, · · · , LN.
Ein zweites Kriterium fur Fensterfunktionen ergibt sich aus den periodischenRandbedingungen der diskreten Fouriertransformation. Aus diesem Grund nahertsich die diskrete Fensterfunktion gn; n = 1, · · · , LN erst mit wachsendem L, d.h.mit großer werdender Periode von (2.30), der Zeitreihe g(n∆t); n ∈ Z im Sinnvon Gl. (2.26), d.h. der Fortsetzung von gn; n = 1, · · · , N mit Null bis ±∞, an.Ein Grenzubergang existiert im Rahmen der linearen Algebra naturlich nicht. Mitder Normierung ∆t = 1 in (2.26) nehmen fur wachsendes L entsprechend auch diediskreten Frequenzkomponenten
√LN gk; k = −LN/2 + 1, · · · , LN/2 zunehmend
weitere Punkte auf g(f), der alias-modifizierten kontinuierlichen Fouriertransforma-tion von g(t), an. Bereits angenommene Werte bleiben wegen
√L gLk = gk erhalten.
Diese Aussagen folgen aus dem Vergleich von √LN gk, wobei fk = k/(LN ) stetig
fortgesetzt wird, mit der Fourierreihe (2.24) von g(f):√LN gk =
LN∑n=1
gn e−i2π k
LNn
kLN
=fk → f−−−−−−−→
N∑n=1
gn e−i2πnf = g(f) , (2.31)

2.2. DISKRETE SIGNALDARSTELLUNGEN 23
0 16 32 48 64 80 96 112 128
Diskrete Frequenzen k
0
1
2
3
4A
mpl
itude
g1
g2−160 −128 −96 −64 −32 0 32 64 96 128 160
Stuetzstellen n
0
0.2
0.4
0.6
0.8
1
Am
plitu
de
g1g2
Abbildung 2.5: Die diskreten Fouriertransformationen von Rechteckfenster g1 und Hann-
Fenster g2 fur N = 256 und L = 1 (nur die Quadrate), L = 2 (Quadrate und gefullte
Kreise), L = 4 (zusatzlich die leeren Kreise) und L = 16 (die gepunktete bzw. durchge-
zogene Linie).
wobei wir verwenden, daß gn; n = 1, · · · , LN nur auf dem Intervall [1, N ] nichtverschwindet und fc = 1/2 ist. Die periodischen Randbedingungen von gn fuhrenzusammen mit dem Aliasing Effekt genau zur Abweichung von FT g
x (N/2+m, j) ge-genuber FT g
x (t, f) sofern das Fenster g(t) vollstandig innerhalb des bekannten Signal-ausschnitts liegt. Andernfalls machen sich auch die periodischen Randbedingungenvon xn; n = 1, · · · , LN bemerkbar. Da wir keine Annahmen uber die Fortsetzungder gegebenen Zeitreihe xn machen wollen, soll der Einfluß der periodischen Rand-bedingungen auf die Transformation (2.30) minimiert werden. Hierfur ist ebenfallsdie gute Lokalisierung der Fensterfunktion g(t) im Zeitraum erforderlich.
Wird ublicherweiseL = 1 in (2.30) gewahlt, so ist die Gute der Approximation vong(f) durch die diskreten Frequenzkomponenten √N gk; k = −N/2 + 1, · · · , N/2
vom Abfallverhalten von g(f) im Frequenzraum abhangig, da die Konvergenzge-schwindigkeit der trigonometrischen Interpolation (2.31) hierdurch bestimmt wird.Es zeigt sich, daß auch dafur ein schnelles Abfallen von g(f) gegen Null sinnvoll ist;dies wird in Abb. 2.5 illustriert. Zusammengenommen folgt damit die Bedingung dermoglichst guten Lokalisierung der Fensterfunktion g0,0 in der Zeit-Frequenz Ebene.
Wir wollen nun diese Kriterien fur die Wahl von Fensterfunktionen durch denVergleich des Rechteckfensters g1(t) und des Hann-Fensters g2(t) illustrieren. Hierbei

24 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
sind
g1(t) =
1 fur − N2 ≤ t ≤ N
2
0 sonstsowie (2.32)
g2(t) =
12(1 + cos
(2πtN
)) fur − N
2 ≤ t ≤ N2
0 sonst. (2.33)
Die kontinuierlichen Fouriertransformationen der Fenster sind
g1(f) =sin(πNf)
πfund (2.34)
g2(f) =sin(πNf)
2πf(N 2f2 − 1). (2.35)
In Abb. 2.5 sind die diskreten Fouriertransformationen von (2.32) und (2.33) furN = 256 und verschiedene Werte von L eingezeichnet. Insbesondere fur L = 1 un-terscheidet sich die diskrete Fouriertransformation des Rechteckfensters grundlegendvom kontinuierlichen Fall (2.34), wahrend das diskrete Hann-Fenster bereits eine gu-te Approximation von (2.35) ermoglicht. Bei dem Vergleich ist zu beachten, daß die(konventionelle) Normierung von diskreten und kontinuierlichen Fouriertransforma-tionen nicht kompatibel ist. Der Aliasing Effekt ist in Abb. 2.5 nicht zu erkennen; erist von der Anzahl der Stutzstellen N der Fenster abhangig und wirkt sich erst furkleinere Werte von N deutlich sichtbar aus. Bei diskreten Wavelettransformationenwird sich daher der Aliasing Effekt starker bemerkbar machen.
Zusammenfassend folgt, daß fur Fensterfunktionen mit endlicher Breite ein schnel-les Abfallverhalten im Frequenzraum sinnvoll ist sowohl fur die gute Lokalisierungdes Fensters in der Zeit-Frequenz Ebene, d.h. eine hohe Informationsauflosung vonFT g
x (t, f), als auch fur die Minimierung von Aliasing Effekten und den Einflussen derperiodischen Randbedingungen bei der Approximation von kontinuierlichen durch dis-krete gefensterte Fouriertransformationen. Ein geeignetes Fenster in diesem Sinn, daswir auch in Kap. 3 verwenden werden, ist das Hann-Fenster (2.33), weitere Moglich-keiten werden in [31] diskutiert. Hierzu soll noch bemerkt werden, daß die praktischenUnterschiede der verschiedenen in der Literatur vorgeschlagenen Fensterfunktioneneher gering sind.
2.2.3 Diskrete Wavelettransformationen
Bei dem Versuch, kontinuierliche Wavelettransformationen fur die Anwendung in derZeitreihenanalyse in eine diskrete Theorie umzusetzen, fallt zunachst auf, daß daszentrale Konzept der Skalierung auf diskrete Signale nicht ohne weiteres ubertragbarist, da die Skalierung einer Zeitreihe im allgemeinen mit einem Informationsverlustverbunden ist. Betrachten wir der Einfachheit halber die Skalierung der Zeitreihe

2.2. DISKRETE SIGNALDARSTELLUNGEN 25
xn; n = 1, · · · , N mit dem Faktor 2, so folgt dieser Informationsverlust aus
xn =√2x2n =
1√N/2
N/2∑k=−N/2+1
xk ei2π k
N2n
=1√N/2
N/4∑k=−N/4+1
[xk + x(k+N/2)] ei2π k
N/2n
=1√N/2
N/4∑k=−N/4+1
xk ei2π k
N/2n,
(2.36)
wobei wir ausnutzen, daß ei2πkn/(N/2) die Periode N/2 hat und bei der Definitionvon xk = xk + x(k+N/2); k = −N/4 + 1, · · · , N/4 die periodischen Randbeding-ungen von xk verwenden. Die Fouriertransformierte xk der skalierten Funktionxn; n = 1, · · · , N/2 wird somit durch eine Uberlagerung von xk analog zu (2.28)bestimmt. Wegen dieses diskreten Aliasing Effekts kann das ursprungliche Signal imallgemeinen nicht mehr durch eine inverse Transformation zuruckgewonnen werden.Dies ist nur fur den Spezialfall xk = xk ∀ k moglich, bei dem durch die Skalierung keinInformationsverlust entsteht. Aus diesem Grund definieren wir die inverse diskreteSkalierung durch eine trigonometrische Interpolation, indem das Nyquistintervall mitNull fortgesetzt wird.
Die Skalierung eines diskreten Signals hat den gleichen Effekt, als wenn das Ab-tastintervall ∆t beim Messen der Zeitreihe um den Skalierungsfaktor großer gewahltoder das kontinuierliche Signal mit dem gleichen Faktor skaliert worden ware. Be-trachtet man analog zu (2.36) die Skalierung von xk; k = −N/2 + 1, · · · , N/2,
xk = x2k ⇐⇒ xn =1√2(xn + x(n+N/2)) , (2.37)
so wird klar, daß die Skalierungen einer Zeitreihe im Zeit- und Frequenzraum nichtinvers zueinander sind, wie dies fur kontinuierliche Signale gilt. Hierdurch muß dieDefinition einer diskreten Wavelettransformation vom kontinuierlichen Vorbild ab-weichen.
Da Waveletfilter den Frequenzraum naturlich in Oktaven einteilen (Abb. 2.3), bie-tet sich die Moglichkeit einer rekursiven Definition der diskreten Wavelettransformati-on im Frequenzraum an: Im ersten Schritt wird das Signal in einen Hochpaß- und einenTiefpaß- gefilterten Anteil zerlegt, wobei die Trennfrequenz ft das Nyquistintervallhalbiert, d.h. ft = 1/2fc = 1/4. Der Filterprozeß wird fur das Tiefpaß- gefilterteSignal mit der Trennfrequenz ft = 1/4fc = 1/8 wiederholt; hierdurch entsteht einerstes Bandpaß- gefiltertes Signal und wiederum ein Tiefpaßanteil. Im n- ten Schrittder Rekursion liegt die Trennfrequenz von Hoch- und Tiefpaßfilter entsprechend beift = 2−nfc = 2−(n+1), bis schließlich beim Ereichen von ft = 1/N die Iteration ab-bricht. Diese Transformation zerlegt ein diskretes Signal in seine Bandpaß- gefilterten

26 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
Anteile, wobei eine Hochpaß- und eine Tiefpaß- gefilterte Komponente ubrig bleiben.Aufgrund des Skalierungsfaktors 2 wird ein Signal der Lange N , wobei N eine Potenzvon 2 sein muß, in die Matrix WT h
x (n, j) vom Format N × log2(N ) transformiert.Um die Skalierungseigenschaft dieser Transformation (naherungsweise) zu erhal-
ten, werden die Hoch- und Tiefpaßfilter hpk,j, tpk,j ; k = −N/2+1, · · · , N/2, wobeij = 1, log2(N ) − 1 ein Parameter ist, durch diskrete Skalierung im Frequenzraumsukzessiv auseinander erzeugt. Hierbei wird tpk,(j+1) durch die Fortsetzung vontp2k,j; k = −N/4+1, · · · , N/4mit Null auf dem Intervall [−N/2+1, N/2] definiert.Nach (2.36) und (2.37) ist damit im Zeitraum tpn,(j+1); n = 1, · · · , N die trigono-metrische Interpolation von (tpn,j+tp(n+N/2),j)/
√2; n = 1, · · · , N/2. Entsprechend
werden die Hochpaßfilter hpk,j im Frequenzraum skaliert, jedoch anschließend mit1 statt mit 0 fortgesetzt. Weiterhin fordern wir, daß (wegen der rekursiven Konstruk-tion der Filter) der Abfall des zugrundeliegenden Tiefpaßfilters tpk,1 von 1 auf 0innerhalb einer Oktave erfolgt, so daß die Eigenschaft
tpk,j tpk,j+1 = tpk,j+1 ∀ k ∈ [−N/2 + 1, N/2] ∀ j ∈ [1, log2(N )− 1] (2.38)
erfullt wird. Damit haben die Bandpaßfilter hk,j ; k = −N/2+ 1, · · · , N/2, d.h. diediskreten Waveletfilter nach Konstruktion die Form
hk,j = tpk,j−1hpk,j ; j = 2, · · · , log2(N )− 1 (2.39)
und gehen durch Skalierung sowie naherungsweise durch inverse Skalierung im Fre-quenzraum auseinander hervor, da sich diese Eigenschaft von den Tiefpaßfiltern uber-tragt.Weiterhin definieren wir hk,1 ≡ hpk,1 und hk,log2(N) ≡ tpk,(log2(N)−1) ∀ k um eineeinheitliche Notation zu erhalten.
Die so definierte diskrete Wavelettransformation ist unitar, d.h. es gilt
⟨x , y
⟩≡
N∑n=1
xnyn =log2(N)∑j=1
N∑n=1
WT hx (n, j)WT
hy (n, j)
≡⟨WT h
x ,WT hy
⟩,
(2.40)
falls die zugrundeliegenden Filter hpk,1 und tpk,1 die Bedingung
|hpk,1|2 + |tpk,1|2 = 1 ∀ k ∈ [−N/2 + 1, N/2] (2.41)
erfullen. Aus (2.41) folgt sofort |hpk,j|2 + |tpk,j |2 = 1 ∀ k, j und mit der Definition(2.39) der Waveletfilter die Relation
log2(N)∑j=1
|hk,j|2 = 1 ∀ k ∈ [−N/2 + 1, N/2] , (2.42)

2.2. DISKRETE SIGNALDARSTELLUNGEN 27
wobei der Hoch- und der Tiefpaßfilter eingeschlossen sind. Damit folgt (2.40) aus⟨x , y
⟩=
⟨x , y
⟩=
∑k
xk yk
=∑k
xkyk∑j
|hk,j|2 =∑j
∑k
(hk,jxk)(hk,j yk)
=∑j
∑k
WTh
x (k, j)WTh
y (k, j) =∑j
∑n
WT hx (n, j)WT
hy (n, j)
=⟨WT h
x ,WT hy
⟩.
(2.43)
Die Wavelettransformation WTh
x (k, j) wird durch die Multiplikation der Filter hk,jmit dem Signal im Frequenzraum definiert; die Fouriertransformation bezieht sichhierbei auf die Variable k. Diese Transformation ist nach Konstruktion auch dannunitar, wenn der rekursive Filterprozeß nicht bis zum Ende durchgefuhrt, sondernvorher abgebrochen wird. Es ist klar, daß wegen der Bedingung (2.38) auf diese Wei-se nur Waveletfilter mit beschranktem Frequenzband definiert werden konnen, einBeispiel hierfur ist (4.1). Andere (weniger anschauliche) Verfahren erlauben auch dieKonstruktion von Wavelets mit kompaktem Trager im Zeitraum, die es ermoglichen,die Filterprozesse durch die Multiplikation der Zeitreihe mit Bandmatrizen im Zeit-raum zu beschreiben [4].
Die diskrete WavelettransformationWT hx (n, j) kann durch einen Filterprozeß im
Frequenzraum oder alternativ als diskrete Faltung im Zeitraum definiert werden, wo-bei die Frequenzen fj; j = 1, · · · , log2(N ), an denen die diskreten Filter lokalisiertsind, als Parameterwerte betrachtet werden. Eine Approximation der kontinuierlichenWavelettransformation WT h
x (t, f) (2.11) durch WT hx (n, j) ist nur teilweise moglich,
da wegen der logarithmischen Uberdeckung des Frequenzraums durch die Filter hk,jWT h
x (n, j) nicht fur alle diskreten Frequenzen im Nyquistintervall definiert ist, sieheAbb. 2.6 und 4.2.
Um fur die gegebene Zeitreihe xn; n = 1, · · · , N eine moglichst gute Approxi-mation von WT h
x (t, f) an den Stellen fj zu erhalten, muß der Einfluß der endlichenSignallange, d.h. der periodischen Randbedingungen von xn auf WT h
x (n, j), sowieder Aliasing Effekt (2.37), der mit der Skalierung der diskreten Wavelets im Frequenz-raum verbunden ist, minimiert werden. Da die kontinuierlichen Waveletfilter ht,fj(ν)nach Konstruktion kompakten Trager im Frequenzraum haben, folgt dies auch fur dasgefilterte Signal x(ν)ht,fj(ν). Somit konnen die Funktionen ht,fj(τ) und die Faltun-gen WT h
x (t, fj) = (x∗h)(t, fj) (Gl. (2.11)) durch (unendliche) Zeitreihen vollstandigcharakterisiert werden. Jedoch laßt sich die Diskretisierung von WT h
x (t, fj) mit einerendlichen Abtastrate im allgemeinen nicht durch die diskrete Faltung der Zeitreihedes Signals xn; n ∈Zmit einer Zeitreihe der Wavelets hn,j; n ∈Z darstellen. Die
diskrete Faltung WTh
x (n, j) =∑∞
m=−∞ x(n−m)hm,j stellt hierfur eine Naherung dar,wobei der Informationsverlust (im Sinn des Shannonschen Sampelingtheorems) durch

28 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
(a)
jj
(b)
mn
Abbildung 2.6: Die Lokalisierung der Koeffizienten der diskreten Wavelettransformation
(a) und der diskreten gefensterten Fouriertransformation (b) eines Signals der Lange
N = 16 auf dem Zeit-Frequenz Gitter. (Die Randpunkte des Nyquistintervalls sind als
miteinander identifiziert zu betrachten.)
den Aliasing Effekt bestimmt wird, der mit der Diskretisierung von x(t) verbundenist. Nur im Spezialfall von Signalen mit kompaktem Trager im Frequenzraum (undeiner hinreichend großen Samplingrate) enthalten beide (unendlichen) Zeitreihen diegleiche Information.
Der Fehler, der durch die Trunkierung der Zeitreihen xn, hn,j; n ∈ Z entsteht,wird jedoch minimiert, wenn das Mutterwavelet h(τ) im Zeitraum optimal lokalisiertist, da hiermit sowohl der diskrete Aliasing Effekt (2.37) als auch der Einfluß derperiodischen Randbedingungen von xn; n = 1, · · · , N auf WT h
x (n, j) so klein wiemoglich bleiben. Wir wollen, wie erwahnt, keine Annahmen uber die Fortsetzungder Zeitreihe xn machen. Da die Waveletfilter kompakten Trager in Frequenzraumhaben, ergibt sich hieraus die Bedingung, daß das Mutterwavelet h0,f0 in der Zeit-Frequenz Ebene moglichst gut lokalisiert ist.
Da mit der Skalierung der Waveletfilter die Anzahl ihrer Stutzstellen im Frequenz-oder Zeitraum abnimmt, macht sich bei Wavelettransformationen der Aliasing Effektim allgemeinen (deutlich) starker als bei gefensterten Fouriertransformationen be-merkbar. Er ist das Maß dafur, wie gut sich diskrete Wavelets durch eine inverseSkalierung rekonstruieren lassen. Daneben bestimmt, wie bereits erwahnt, die Lo-kalisierung von h0,f0 auch die Informationsauflosung von WT h
x (t, f). Wir wollen andieser Stelle noch bemerken, daß bei der Konstruktion von diskreten Fourier- und Wa-velettransformationen, welche die entsprechenden kontinuierlichen Transformationenapproximieren, die Symmetrie zwischen Zeit- und Frequenzraum nur eingeschranktverwendet werden kann, da die Zeitreihe des kontinuierlichen Signals nur im Zeitraum(und nicht im Frequenzraum) vorliegt.

2.2. DISKRETE SIGNALDARSTELLUNGEN 29
Die soweit eingefuhrte diskrete Wavelettransformation bildet ein Signal der LangeN auf eine Matrix ab, die offensichtlich redundant ist. Inwiefern ist eine unitare Trans-formation in einen Vektor gleicher Dimension moglich? Betrachten wir den (ungunsti-gen) Spezialfall rechteckiger Filter im Frequenzraum, so folgt aus Abschnitt 2.2.1, daßaufgrund der Halbierung des Nyquistintervalls bei jedem Rekursionsschritt auch dieSamplingrate des Hochpaß- und des Tiefpaß- gefilterten Signals jeweils um den Fak-tor 2 reduziert werden kann ohne den Informationsgehalt zu andern. Ist somit jederFilterschritt mit dem Halbieren der Lange beider Teilsignale verbunden, so endet dieTransformation mit einem Vektor gleicher Dimension wie das Ausgangssignal.
Daß solche nicht redundanten Wavelettransformationen fur eine große Klasse vonFiltern, insbesondere auch fur Filter mit kompaktem Trager im Zeitraum, existie-ren, wird in der Multifrequenz-Analyse (multiresolution analysis) gezeigt, siehe [4].Tatsachlich wird in der Literatur unter dem Begriff der ”diskreten Wavelettransfor-mation“ auch meistens die Multifrequenz-Analyse verstanden. Der Ausgangspunkthierfur ist jedoch etwas anders als unserer und nicht durch Zeit-Frequenz Darstellun-gen motiviert. Wir wollen deshalb nicht naher hierauf eingehen, allerdings noch einewichtige Konsequenz der schrittweisen Verkleinerung der Samplingrate zeigen.
Hierzu betrachten wir in Abb. 2.6 die Lokalisierung der Koeffizienten einer dis-kreten Wavelettransformation und zum Vergleich einer diskreten gefensterten Fou-riertransformation auf einem Zeit-Frequenz Gitter (dem diskreten Analogon der Zeit-Frequenz Ebene). Wahrend die oben definierten Wavelettransformationen ein Signalder Lange N = 16 durch die Vereinigung der schwarz und weiß symbolisierten Ko-effizienten darstellen, sind es bei einer schrittweisen Verkleinerung der Samplingratenur die schwarzen. In diesem Fall geht offenbar die Translationsinvarianz im Zeitraumverloren. Diese wichtige Eigenschaft werden wir jedoch in Kap. 4 benotigen; sie wirdim ersten Fall nach Konstruktion erhalten.
Die Skalierungsinvarianz kann fur diskrete Wavelettransformationen naturlich nurnaherungsweise gegeben sein. Die Skalierung des Signals xn; n = 1, · · · , N wirdhierbei analog zur Skalierung der Waveletfilter definiert, d.h. die im Zeit- oder Fre-quenzraum skalierte Zeitreihe wird mit Null bis zur ursprunglichen Periode N fort-gesetzt.
Betrachten wir zum Vergleich noch einmal die diskrete gefensterte Fouriertrans-formation. Gl. (2.30) ist bis auf einen Phasenfaktor invariant gegenuber Translationenim Zeitraum, die ein Vielfaches des Abstands ∆m benachbarter Fensterfunktionen be-tragen (in Abb. 2.6 ist ∆m = 4). Das Verhaltnis von ∆m zur Breite N des Fenstersbestimmt gerade die Redundanz von FT
gx (N/2 +m, j). Fur ∆m = 1 wird die Inver-
tierung von (2.30) durch den zu Gl. (2.15) analogen Ausdruck gegeben. Die Transla-tionsinvarianz im Frequenzraum wird naturlich durch die Breite des Nyquistintervallsbeschrankt.

30 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
2.3 Statistische Merkmalsklassifikation
Wir wollen in diesem Abschnitt einen Schritt weiter gehen. Angenommen wir ha-ben im Hinblick auf eine gegebene Fragestellung geeignete Merkmalsvektoren auseinem Datensatz berechnet. Inwiefern erlauben diese Merkmale eine statistisch signi-fikante Klassifikation der Daten? Sind die Datensatze vorklassifiziert, so kann dieTrennungsleistung der extrahierten Merkmale durch den Vergleich der bekannten Vor-einteilung mit der statistischen Klassifikation der Merkmalsvektoren uberpruft wer-den. Der haufig recht kleine Umfang experimenteller Meßreihen erfordert allerdingsleistungsfahige statistische Methoden um eine signifikante Aussage zu ermoglichen.Zusatzlich kann bei experimentellen Daten die Schwierigkeit auftreten, daß die Vor-klassifikation nicht zuverlassig ist; dieses Problem wird uns in Kap. 4 begegnen. EineEinfuhrung in statistische Klassifikation und Mustererkennung findet sich z.B. in [10].
Zwei grundsatzliche Klassifikationsansatze sind moglich. Beim ersten wird dergesamte Datensatz mittels eines (Clusterbildungs-) Algorithmus in eine vorgegebeneoder offene Anzahl von Klassen eingeteilt. Diese Methode wird als unuberwachtesLernen (unsupervised learning) bezeichnet, da keine Informationen uber die zu erwar-tende Einteilung der Daten und eventuell die Anzahl der Klassen in den Algorithmuseingehen. Aus dem Abweichen der erhaltenen Einteilung von der Vorklassifikationkann auf die Trennungsleistung der getesteten Merkmale geschlossen werden.
Beim zweiten Verfahren werden die Daten in eine disjunkte Trainings- und Test-menge eingeteilt. Der Trainingssatz wird zur Entwicklung eines Klassifikators ver-wendet, der anschließend die Testdaten klassifiziert. Die Trainingsmenge kann hierbeiBeispiele aus allen oder nur aus einem Teil der Datenklassen enthalten, die durchdie Voreinteilung bekannt sind; eine entsprechende Anzahl von Klassen ”kennt“ derKlassifikator, nachdem er trainiert ist. Da Informationen uber die zu erwartende Ein-teilung der Datensatze zum Trainieren des Klassifikators verwendet werden, sprichtman entsprechend von uberwachtem Lernen (supervised learning). Diese Methode hatden Vorteil, eine praktische Anwendung zu erlauben, da nur der Trainingsdatensatzkomplett bekannt sein muß, die Testdaten aber in der Reihenfolge, in der sie erzeugtwerden, ”on-line“ klassifiziert werden konnen. Im Hinblick darauf haben wir in Kap. 3und 4 solche Verfahren gewahlt. Es ist naturlich zu erwarten, daß aufgrund der In-formationen, die in die Entwicklung des Klassifikators einfließen, diese Methode einbesseres Ergebnis im Sinn der Fragestellung erzielt als ein unuberwachter Lernprozeß.
Wir werden uns hier auf den Spezialfall des Zwei-Klassen Klassifikationsproblemsbeschranken, da in den spateren Anwendungen nur die Unterscheidung von Zeitreihenzwischen ”gut“ und ”fehlerhaft“ von Interesse sein wird.
2.3.1 Der Bayesche Klassifikator des kleinsten Fehlers
Betrachten wir die aus einem Datensatz berechneten Merkmalsvektoren als Realisie-rungen x einer (zeitunabhangigen) ZufallsvariablenX (oder genauer eines Zufallsvek-

2.3. STATISTISCHE MERKMALSKLASSIFIKATION 31
tors) mit den moglichen Ereignissen ω ∈ Ω1 ∪ Ω2 = Ω. Nach Voraussetzung lassensich die Merkmalsvektoren in die Klassen Ω1 und Ω2 einteilen. Siehe etwa [20] fureine Einfuhrung in die Begriffe der Statistik. Die Zuordnung der Elementarereignissex ∈ Ω zu einer der beiden Klassen erfolgt nach dem Kriterium
P (Ω1|x)Ω2
7Ω1
P (Ω2|x) , (2.44)
d.h. x wird Ω1 zugeordnet, wenn die bedingte Wahrscheinlichkeit fur das Vorliegenvon Ω1 unter der Voraussetzung, daß x eingetreten ist, großer als diejenige von Ω2 istund umgekehrt. Mit dem Bayeschen Satz
ρ(x∩ Ωi) = P (Ωi|x)ρX(x) = ρ(x|Ωi)P (Ωi) ; i = 1, 2
laßt sich das Klassifikationskriterium (2.44) umschreiben in
ρ(x|Ω1)P (Ω1)Ω2
7Ω1
ρ(x|Ω2)P (Ω2) , (2.45)
wobei ρ(x|Ωi) die bedingte Wahrscheinlichkeitsdichte fur das Eintreten von x unterder Voraussetzung des Vorliegens von Ωi ist; ρX(x) die Wahrscheinlichkeitsdichteder Zufallsvariablen X und P (Ωi) die Wahrscheinlichkeit fur das Vorliegen von Ωi
bezeichnet.Da die Klassifikationsregel (2.44) im allgemeinen keine perfekte Trennung der
Klassen Ω1 und Ω2 ermoglicht (Ω1 ∩ Ω2 = ∅), erhalt man die bedingte Wahrschein-lichkeit fur eine Fehlklassifikation von
R(x) = min[P (Ω1|x) , P (Ω2|x)] .
Der kleinstmogliche gesamte Klassifikationsfehler ε, auch der Bayesche Fehler ge-nannt, ergibt sich somit zu
ε = <R(x)> =∫
ΩR(x)ρX(x)dx
=∫
Ωmin[P (Ω1|x)ρX(x) , P (Ω2|x)ρX(x)]dx
=∫
Ωmin[ρ(x|Ω1)P (Ω1) , ρ(x|Ω2)P (Ω2)]dx
= P (Ω1)∫L2
ρ(x|Ω1)dx+ P (Ω2)∫L1
ρ(x|Ω2)dx .
(2.46)
Der Integrationsbereich L2 (L1) des Fehlerintegrals in der letzten Zeile uberdeckt denBereich von Ω, in dem x nach Gl. (2.45) der Klasse Ω2 (Ω1) zugeordnet wird; es istsomit Ω = L1∪L2 und L1∩L2 = ∅. Daß das Kriterium (2.44) den Klassifikationsfehlerminimiert, laßt sich anhand von Abb. 2.7 leicht verstehen. Jede Verschiebung derTrennungsgrenze wurde die Wahrscheinlichkeit fur Fehlklassifikationen erhohen.
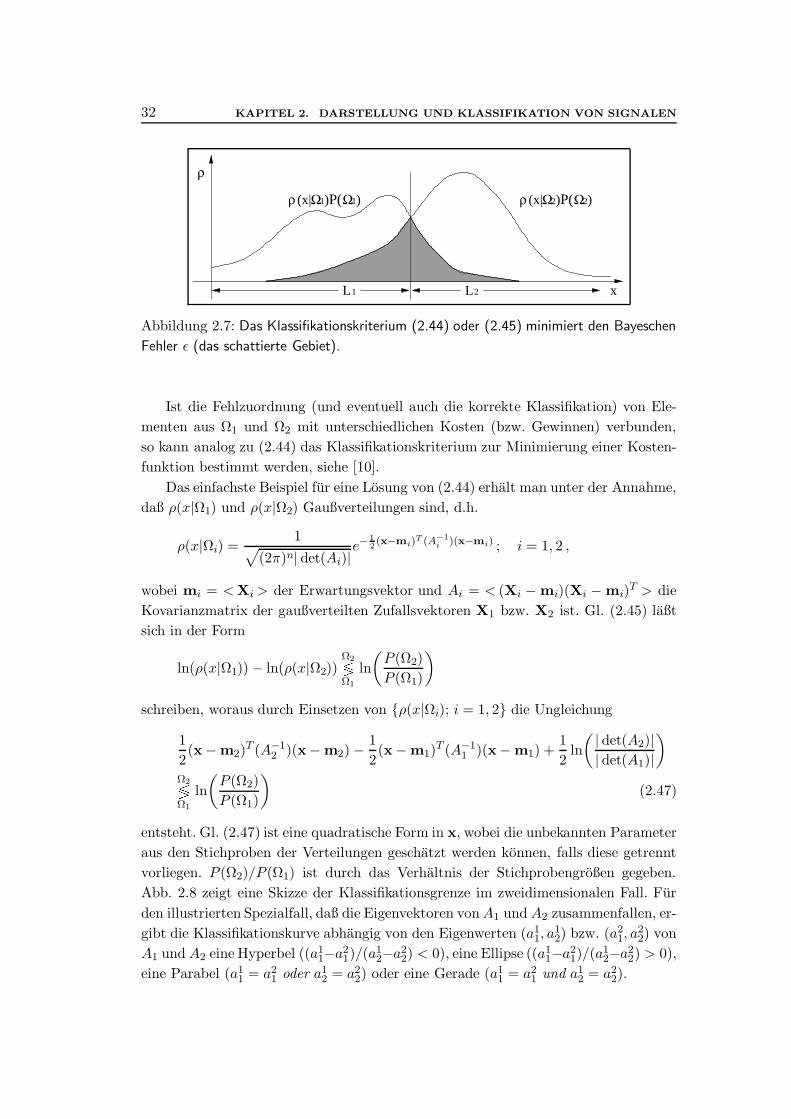
32 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
1L
Ω
L2
ρ
Ω1
x
)P( P()2Ω Ω2)1) (x|ρ(x|ρ
Abbildung 2.7: Das Klassifikationskriterium (2.44) oder (2.45) minimiert den Bayeschen
Fehler ε (das schattierte Gebiet).
Ist die Fehlzuordnung (und eventuell auch die korrekte Klassifikation) von Ele-menten aus Ω1 und Ω2 mit unterschiedlichen Kosten (bzw. Gewinnen) verbunden,so kann analog zu (2.44) das Klassifikationskriterium zur Minimierung einer Kosten-funktion bestimmt werden, siehe [10].
Das einfachste Beispiel fur eine Losung von (2.44) erhalt man unter der Annahme,daß ρ(x|Ω1) und ρ(x|Ω2) Gaußverteilungen sind, d.h.
ρ(x|Ωi) =1√
(2π)n| det(Ai)|e−
12(x−mi)
T (A−1i )(x−mi) ; i = 1, 2 ,
wobei mi = <Xi> der Erwartungsvektor und Ai = < (Xi −mi)(Xi −mi)T > dieKovarianzmatrix der gaußverteilten Zufallsvektoren X1 bzw. X2 ist. Gl. (2.45) laßtsich in der Form
ln(ρ(x|Ω1))− ln(ρ(x|Ω2))Ω2
7Ω1
ln(P (Ω2)P (Ω1)
)schreiben, woraus durch Einsetzen von ρ(x|Ωi); i = 1, 2 die Ungleichung
12(x−m2)T (A−1
2 )(x−m2)−12(x−m1)T (A−1
1 )(x−m1) +12ln
(| det(A2)|| det(A1)|
)Ω2
7Ω1
ln(P (Ω2)P (Ω1)
)(2.47)
entsteht. Gl. (2.47) ist eine quadratische Form in x, wobei die unbekannten Parameteraus den Stichproben der Verteilungen geschatzt werden konnen, falls diese getrenntvorliegen. P (Ω2)/P (Ω1) ist durch das Verhaltnis der Stichprobengroßen gegeben.Abb. 2.8 zeigt eine Skizze der Klassifikationsgrenze im zweidimensionalen Fall. Furden illustrierten Spezialfall, daß die Eigenvektoren vonA1 und A2 zusammenfallen, er-gibt die Klassifikationskurve abhangig von den Eigenwerten (a1
1, a12) bzw. (a
21, a
22) von
A1 und A2 eine Hyperbel ((a11−a2
1)/(a12−a2
2) < 0), eine Ellipse ((a11−a2
1)/(a12−a2
2) > 0),eine Parabel (a1
1 = a21 oder a
12 = a2
2) oder eine Gerade (a11 = a2
1 und a12 = a2
2).

2.3. STATISTISCHE MERKMALSKLASSIFIKATION 33
ρ (x )1Ω| P(Ω
x
1)
ρ (x | Ω2)P(Ω )21x
2
Abbildung 2.8: Die Klassifikationsgren-
ze (2.47) von zwei Gaußverteilungen nach
dem Kriterium (2.45). Fur den illustrier-
ten Spezialfall ist die Klassifikationskurve
eine Hyperbel.
2.3.2 Schatzen des Bayeschen Fehlers
Betrachten wir nun das allgemeine Problem, Bayesche Fehler zu schatzen. Hierzu mußder Bayesche Klassifikator, der nach Konstruktion den gesamten Klassifikationsfehlerε minimiert, aus dem Trainingsdatensatz geschatzt werden, um damit ε anhand derTestdaten schatzen zu konnen. Aufgrund ihrer Abhangigkeit von den Schatzern fur dieKlassifikatoren sind die Schatzer fur den Bayeschen Fehler im allgemeinen verzerrt.Es ist jedoch (bei einer hinreichenden Stichprobengroße) moglich, eine untere undobere Schranke fur den Bayeschen Fehler anzugeben.
Ein Schatzer ε fur den Bayeschen Fehler ε ist eine Funktion der unabhangigen undfur gleichen Index identischen ZufallsvariablenXT = X1
1 , · · · , XM11 , X1
2 , · · · , XM22 ,
deren Ereignisse die Testmenge ΩT1 ∪ ΩT2 bilden, wobei ΩTi ⊆ Ωi; i = 1, 2 ist,sowie eines Schatzers FK fur den Bayeschen Klassifikator FK(x); d.h.
ε = Fε(XT ; FK) . (2.48)
FK hangt implizit von den Zufallsvariablen YD = Y 11 , · · · , Y
K11 , Y 1
2 , · · · , YK22 ab,
deren Ereignisse die Trainingsmenge ΩD1 ∪ ΩD2 bilden, wobei ebenfalls ΩDi ⊆ Ωigilt. Unter der (einfachen) Realisierung der Zufallsvariablen ε versteht man die mitHilfe des geschatzenKlassifikators ermittelte Statistik der Fehlzuordnungen von Merk-malsvektoren aus der Testmenge. Diese Fehlerstatistik ist bezuglichXT , d.h. unter derVoraussetzung eines bekannten Klassifikators FK(x), erwartungstreu und konsistent.D.h., es gilt
<ε> = <Fε(XT ;FK(x)>XT= ε ,
wobei der Erwartungswert bezuglich den Wahrscheinlichkeitsdichten vonXT (d.h. derTestmenge) ρ(x|ΩTi)P (ΩTi); i = 1, 2 gebildet wird. Daruberhinaus konvergiert dieVarianz von ε als Funktion der Stichprobengroßen der Testmenge, M1 und M2, gegenNull. Hierdurch fallt der Schatzfehler von ε mit wachsender Große der Stichprobengegen Null hin ab.

34 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
Es folgt, daß der zweifache Erwartungswert von ε bezuglich der Wahrscheinlich-keitsdichten von XT und YD,
<<ε>> = <<Fε(XT ; FK)>YD>XT
,
den Bayeschen Fehler (2.46) ergibt, falls FK erwartungstreu ist, d.h. der Erwartungs-wert < FK > = <FK(x; g(YD))>YD
die Wahrscheinlichkeit fur Fehlklassifikationenminimiert, und wenn die Wahrscheinlichkeitsdichten von YD und XT ubereinstim-men. Eine Verzerrung des Schatzers FK setzt sich hingegen auf ε (2.48) fort.
Betrachten wir zunachst parametrische Schatzer fur Bayesche Klassifikatoren, wel-che die Form FK = FK(x; λ1, · · · , λL) haben, wobei λi; i = 1, · · · , L Schatzer furdie Parameter sind, durch die der Klassifikator
FK(x; λ1, · · · , λL)Ω2
7Ω1
P (ΩD2)P (ΩD1)
; x ∈ ΩT1 ∪ ΩT2
eindeutig bestimmt ist. Die Schatzer λi sind Funktionen der Zufallsvektoren YD
und wir wollen annehmen, daß sie konsistent sind. Eine Tailorentwicklung von FKbezuglich λ fuhrt auf
FK = FK(x;<λ1>, · · · , <λL>) +L∑i=1
∂FK(x;<λ>)∂λi
(λi− <λi>)
+12
L∑i=1
L∑j=1
∂2FK(x;<λ>)∂λi∂λj
(λi− <λi>)(λj − <λj>) + · · · .
Damit erhalt man den Erwartungswert und die Varianz von FK in fuhrender Ordnungvon λ:
<FK> = FK(x;<λ1>, · · · , <λL>)
+12
L∑i=1
L∑j=1
∂2FK(x;<λ>)∂λi∂λj
Cov(λi, λj) + · · · , (2.49)
Var(FK) =L∑i=1
L∑j=1
∂FK(x;<λ>)∂λi
∂FK(x;<λ>)∂λj
Cov(λi, λj) + · · · . (2.50)
Aus (2.49) folgt, daß Schatzer fur nichtlineare Klassifikatoren auch dann verzerrtsind, wenn die Schatzer λ1, · · · , λL erwartungstreu sind. Jedoch folgt aus der Kon-sistenz von λi; i = 1, · · · , L, daß die Verzerrung von FK als Funktion der Stichpro-bengroßen der Trainingsmengen K1, K2 gegen Null konvergiert, sofern auch moglicheVerzerrungen der Schatzer λi verschwinden. Damit folgt weiterhin aus (2.50) dieKonsistenz von FK . Aufgrund der Abhangigkeit der Schatzer ε von FK (2.48) bestim-men die Varianz und Verzerrung von FK die Verzerrung von ε. Diese Große ist nebender Varianz von ε das Maß fur den Schatzfehler von ε, d.h. fur die Abweichung dereinfachen Realisierung von ε vom Bayeschen Fehler (2.46).

2.3. STATISTISCHE MERKMALSKLASSIFIKATION 35
Gehen in FK keine Annahmen uber die Funktion der Wahrscheinlichkeitsdichtenρ(x|Ωi)P (Ωi); i = 1, 2 ein, so spricht man von einem nichtparametrischen Schatzer.Die Klassifikation der Testdaten erfolgt in diesem Fall durch das Schatzen der Dichtenρ(y|ΩD1) und ρ(y|ΩD2) der Trainingsmenge an den Stellen der Testvektoren x. DerBayesche Klassifikator hat nach (2.45) die allgemeine Form
FK(x) =ρ(x|ΩD1)ρ(x|ΩD2)
Ω2
7Ω1
P (ΩD2)P (ΩD1)
; x ∈ ΩT1 ∪ ΩT2 , (2.51)
wobei ρ(x|ΩDi); i = 1, 2 die Wahrscheinlichkeitsdichten ρ(y|ΩDi); i = 1, 2 an denStellen der Testvektoren x bezeichnen. ρ(x|ΩDi) kann durch ein Suchverfahren nachnachsten Nachbarn von x in der Trainingsstichprobe geschatzt werden. Die Schatzerρ(x|ΩDi) haben damit prinzipiell die Form
ρ(x|ΩDi) =k(x;YDi)Ni νi
oder ρ(x|ΩDi) =ki
Ni ν(x;YDi); i = 1, 2 ,
wobei k die Anzahl der Nachbarn und ν die Umgebungsgroße des Testvektors sowieNi den Umfang der Stichprobe aus ΩDi bezeichnet. Im linken Ausdruck wird bei derSuche die Umgebungsgroße, beim rechten hingegen die Anzahl der Nachbarn festge-halten. Die jeweils zu schatzende Große kann dann als von YD abhangige Zufalls-variable betrachtet werden. Verschiedene Schatzer fur lokale Dichten und die darausnach (2.51) konstruierten Schatzer fur Bayesche Klassifikatoren werden in [10] disku-tiert. Erwartungsgemaß ist die Verzerrung und Varianz nichtparametrischer Schatzerim allgemeinen (deutlich) großer als diejenige parametrischer, jedoch sind Annah-men uber die Funktionen ρ(x|Ωi)P (Ωi) haufig nicht moglich. Die oben diskutiertenFolgerungen fur den Schatzer ε sind aber qualitativ die gleichen.
2.3.3 Schranken des Bayeschen Fehlers: Die L- und die R- Statistik
In den meisten Fallen ist es nicht moglich, erwartungstreue Schatzer fur den Baye-schen Fehler zu konstruieren. Jedoch kann bei einer hinreichenden Stichprobengroßeeine untere und obere Schranke fur ε angegeben werden, da es von der Wahl derTrainings- und Testmengen abhangt, ob die Realisierung von ε zu einem großerenoder kleineren Klassifikationsfehler hin abweicht.
Zunachst ist klar, daß fur eine Minimierung des Schatzfehlers sowohl die Test- wieauch die Trainingsmenge moglichst groß gewahlt werden sollte. Simultan ermoglichtwird dies durch die Leave-one-out oder L- Statistik: Alle bis auf eine der N (un-abhangigen) Stichproben aus Ω1∪Ω2 werden zum Trainieren eines Klassifikators ver-wendet, mit welchem dann der ausgelassene Merkmalsvektor Ω1 oder Ω2 zugeordnetwird. Dieses Verfahren wird wiederholt, bis alle vorliegenden Daten klassifiziert sind.Damit enthalt die Testmenge am Ende alle N Stichproben und die Trainingsmen-gen jeweils N − 1. Die Unabhangigkeit von Trainings- und Testmenge bleibt denocherhalten, da diese Eigenschaft fur jeden einzelnen Test gilt und alle Testdurchlaufe

36 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN
unabhangig voneinander sind. Weiterhin entfallt die Schwierigkeit, eine Einteilungder Daten in eine Trainings- und Testmenge vornehmen zu mussen, was bei experi-mentellen Daten nicht unabhangig vom Ergebnis moglich sein muß.
Der Nachteil der L- Statistik ist, daß der Klassifikator auf allen N Trainingsmen-gen getrennt geschatzt werden muß. Wird statt dessen der Klassifikator nur einmal aufder gesamten Stichprobe geschatzt, so ist fur parametrische Schatzer nur eine relativkleine Abweichung zu erwarten, da lediglich ein Merkmalsvektor zu jeder Trainings-menge des L- Schatzers hinzugenommen wird. Im Fall nichtparametrischer Schatzerkonnen naturlich auch (unkontrollierbar) große Anderungen auftreten. Da Trainings-und Testmenge in diesem Fall nicht mehr unabhangig sind, spricht man von einerResubstitution oder R- Statistik. Fur einige einfache parametrische und nichtparame-trische Klassifikatoren, wie z.B. (2.47), kann der L- Schatzer fur den Bayeschen Fehleraus dem R- Schatzer berechnet werden; hierdurch reicht das einmalige Schatzen desKlassifikators fur die Erstellung beider Statistiken aus, siehe [10].
Die Varianz und die Verzerrung von FK sind das Maß fur die Uberanpassung desgeschatzten Klassifikators an die gegebene Stichprobe aus ΩD1 ∪ ΩD2. Die einfacheRealisierung von FK kann daher den Klassifikationsfehler der Testmenge ΩT1 ∪ ΩT2
nicht ideal minimieren. Sind Trainings- und Testmenge unabhangig, so ergibt die Rea-lisierung von ε einen (im allgemeinen) zu großen Schatzwert des Bayeschen Fehlers.Umgekehrt erfolgt im Fall der Abhangigkeit von Trainings- und Testmenge die Uber-anpassung des geschatzten Klassifikators an die Teststichprobe, wodurch die Realisie-rung von ε einen (im allgemeinen) zu kleinen Schatzwert fur ε liefert. Nach Konstruk-tion ist der aus der L- Statistik erhaltene Schatzwert des Bayeschen Fehlers immergroßer als der mit Hilfe der R- Statistik berechnete, jedoch mussen beide Schatzwertenicht notwendig eine obere bzw. untere Schranke von ε bilden.
Die Schatzwerte der L- und R- Statistik bilden eine (rigorose) obere bzw. unte-re Schranke fur den Bayeschen Fehler, falls die Varianz von ε (bezuglich XT ) hin-reichend klein ist, so daß die Uberanpassung des geschatzten Klassifikators an dieTrainingsstichprobe nicht durch Fluktuationen in der Statistik der Fehlzuordnungenuberkompensiert werden kann. Da die Schatzer ε konsistent sind, ist diese Eigenschaftbei einer hinreichenden Stichprobengroße gegeben. Da weiterhin die Trainings- undTestmengen maximal gewahlt sind, bilden die nach der L- und R- Methode erhaltenenSchatzwerte auch Schranken von ε mit kleinstmoglichem Fehler.
Wie stark die Ergebnisse der L- und R- Statistik tatsachlich vom Bayeschen Fehlerabweichen, ist neben dem Umfang des Datensatzes wesentlich von FK abhangig; je-doch lassen, wie bereits erwahnt, parametrische Schatzer allgemein eher kleine Abwei-chungen erwarten, wahrend bei nichtparametrischen Vorsicht geboten ist. In Kap. 4(und in modifizierter Form auch in Kap. 3) werden wir Schatzer konstruieren, in denenein Suchverfahren nach nachsten Nachbarn parametrisch optimiert wird. Wahrendwir aus praktischen Grunden die Parameter nur einmal auf dem gesamten Daten-satz durch die gezielte Minimierung des gesamten Klassifikationsfehlers schatzen, er-

2.3. STATISTISCHE MERKMALSKLASSIFIKATION 37
folgen die Nachbarschaftssuchen nach dem L- Verfahren mit jeweils unabhangigenTrainings- und Testmengen. Diese Mischform aus L- und R- Statistik bildet naturlichkeine rigorose Schranke fur ε mehr, jedoch ist es fur die statistische Klassifikation deraus experimentellen Zeitreihen berechneten Merkmalsvektoren unsere Absicht, mitvertretbarem Aufwand einen moglichst guten Schatzwert des Bayeschen Fehlers zuerhalten.

38 KAPITEL 2. DARSTELLUNG UND KLASSIFIKATION VON SIGNALEN

Kapitel 3
Fehlerfruherkennung bei
Induktionsmotoren
In diesem Kapitel wollen wir einen neuen Losungsansatz fur das Problem vorstel-len, den verschleiß- oder fehlerbedingten Ausfall von Induktionsmotoren (Asynchron-Drehstrommotoren) rechtzeitig vorherzusagen. Dieses Problem ist wegen des vielfalti-gen und weit verbreiteten Einsatzes von Induktionsmotoren in der Industrie von Inter-esse. Wesentlicher Teil der Problemstellung ist, daß die benotigte Uberwachungsdia-gnostik einfach, d.h. billig sein soll; die ublichen Verfahren der Maschinenuberwachungdurch mehrere Sensoren, welche alle relevanten Großen, wie Temperatur, Vibration,etc. getrennt kontrollieren, somit nicht in Frage kommen.
Eine einfach zugangliche Meßgroße bei Induktionsmotoren ist eine Phase des Sta-torstromes, die an der Stromzufuhrung abgenommen werden kann. Der Ausgangs-punkt unserer Untersuchungen war damit die Frage, inwiefern der Stromfluß durchden Stator die notwendigen Informationen fur die (statistisch signifikante) Unter-scheidung von guten und fehlerhaften Betriebszustanden des Motors enthalt und wiesie extrahiert werden konnen. Die grundlegende Idee dieser Arbeit und das daruberhinausgehende Ziel ist es, allgemein die aufwendige Diagnostik technischer Anlagenmittels einer Reihe spezifischer Meßinstrumente hin zu einer Uberwachung durch ein-fache Sensoren und einer dafur komplexen Signalverarbeitung zu verlagern, welcheaber auf den heutigen Rechnern relativ billig durchgefuhrt werden kann.
Zur Losung des hier untersuchten Problems fuhren wir die Methode der geometri-schen Signaltrennung im Merkmalsraum ein. Skalare Zeitreihen des Statorstromes vonInduktionsmotoren wurden uns von SCR (Siemens Corporate Research, Princeton,USA) zur Verfugung gestellt.
Der folgende Abschnitt gibt eine Einfuhrung in das Problem der Fehlererkennungbei Induktionsmotoren durch Analyse des Statorstromes. In Abschnitt 3.2 stellen wirunser Konzept der geometrischen Signaltrennung vor und wenden es in Abschnitt 3.3auf Daten an, die von vier 4-Pol Induktionsmotoren erzeugt wurden.
39

40 KAPITEL 3. FEHLERFRUHERKENNUNG BEI INDUKTIONSMOTOREN
3.1 Fehlererkennung durch Analyse des Statorstromes
Den unerwarteten verschleiß- oder fehlerbedingten Ausfall technischer Anlagen zuvermeiden ist ein altbekanntes Anliegen in der Industrie. Das Versagen eines Elek-tromotors in einer Fertigungsstraße oder Paketsortieranlage z.B. kann leicht Kostenverursachen, welche die des Motors bei weitem ubersteigen. Daher ist die Uberwa-chung und Diagnose technischer Anlagen seit langem ein wichtiger Bereich der elek-trotechnischen Forschung. Bei der Vielzahl moglicher Fehlerquellen und der relativenZuverlassigkeit der Systemkomponenten muß der Uberwachungsaufwand fur jede ein-zelne Maschine jedoch gering gehalten werden. So lohnt sich eine aufwendige Sensoriknur fur sehr große Induktionsmotoren, wahrend fur die weit verbreiteten Motorenmittlerer Leistung (≈10 – 100kW) nach gunstigeren Alternativen gesucht wird.
Eine Reihe von Veroffentlichungen [1, 5, 12, 23, 40, 35, 36, 41] beschaftigt sichseit ca. 1982 mit dem Problem, typische Fehler von Induktionsmotoren im Spek-trum des Statorstromes zu identifizieren. Hierbei wird versucht, haufigen Defekten,wie Lagerschaden, Unwuchten und Stabbruchen im Rotor (Kafiglaufer) charakteris-tische Frequenzen (Signaturen) im Spektrum des Statorstromes zuzuordnen, welchemoglicherweise wahrend des Betriebs detektiert werden konnen.
Der Rotor eines Asynchronmotors besteht aus Aluminiumstaben, in denen durchdas im Stator umlaufende Magnetfeld eine Spannung induziert wird. Aufgrund deshierdurch entstehenden Magnetfeldes dreht sich der Rotor nahezu mit der Frequenzdes umlaufenden Feldes mit. Die Drehfreqenz frm des Motors ist durch die Beziehung
frm = (1− s)fe
(p/2)
gegeben, wobei fe die Netzfrequenz, p die Anzahl der Pole des Stators und s denSchlupf bezeichnet. Der Schlupf entsteht, da der Rotor aufgrund der anliegenden Last(und der Reibung) in unregelmaßigen Abstanden eine viertel oder halbe Umdrehung(abhangig von der Anzahl der Pole) gegenuber dem umlaufenden Feld zuruckfallt.Der Schlupf hangt von der Große und dem Lastzustand des Motors ab und ist vonder Großenordnung s ≈ 0.01. Die Anzahl der Pole ist gewohnlich 2 oder 4.
Aus der Theorie der idealen Induktionsmaschine lassen sich die charakteristischenFrequenzen von Unwuchten (fuw) und Stabbruchen (fsb) sowie aus dem Aufbau vonKugellagern diejenige von Lagerschaden (f1
ls, f2ls) ableiten. Man erhalt:
fuw = fe
(1±m
(1− s
p/2
))= fe ±mfrm ; m = 1, 2, 3, · · · (3.1)
fsb = fe
(k
(1− s
p/2
)± s
)= kfrm ± sfe ; k/(p/2) = 1, 5, 7, 11, · · · (3.2)
f1ls ≈ 0.4nfrm , f2
ls ≈ 0.6nfrm , (3.3)
wobei in (3.3) n die Anzahl der Kugeln in den Kugellagern der Motorachse bezeich-net. In den zitierten Arbeiten wird (zum Teil durch den Vergleich mit anderen Me-

3.1. FEHLERERKENNUNG DURCH ANALYSE DES STATORSTROMES 41
thoden der Motoruberwachung) gezeigt, daß es prinzipiell moglich ist, diese Fehlerim Statorstromspektrum zu detektieren. Ein Uberblick uber verschiedene Uberwa-chungsverfahren bei Induktionsmotoren findet sich z.B. in [42].
Erwartungsgemaß wird der Statorstrom neben der Netzfrequenz durch Indukti-onseffekte, die von verschiedenen Großen verursacht werden, (unterschiedlich stark)beeinflußt. Dies sind
1. der Lastzustand des Motors, insbesondere im Fall oszillierender Lasten, wie siez.B. beim Antrieb von Kompressoren auftreten, da hierdurch Drehzahlschwan-kungen verursacht werden,
2. die Produktionstoleranzen des Motors, insbesondere Asymmetrien des Luftspal-tes zwischen Stator und Rotor und der Wicklungsverteilung des Stators,
3. die Umweltbedingungen wahrend des Betriebs, wie die Temperatur und Luft-feuchtigkeit, da hierdurch Toleranzen bzw. die Leitfahigkeit der Luft verandertwerden,
4. mogliche Defekte des Motors, wie Unwuchten, Lagerschaden, Stabbruche imRotor und Kurzschlusse im Stator.
Da der Einfluß sich entwickelnder Defekte auf den Statorstrom klein im Vergleichzu den anderen Großen ist, erfordert die zuverlassige Detektierung fehlerhafter Be-triebszustande eine aufwendige Signalanalyse; alleine die Uberwachung der charak-teristischen Frequenzen (3.1)–(3.3) im Spektrum des Statorstromes ermoglicht keineverlaßliche Kontrolle des Motors.
Ausgehend von den genannten Vorarbeiten werden in [8, 26, 38] verschiedeneDiagnosemethoden und in [9, 24, 30, 37] auf neuronalen Netzen basierende Algo-rithmen zur Uberwachung von Induktionsmotoren vorgeschlagen. Hierbei wird dieUberwachung der charakteristischen Frequenzen durch sogenannte Expertensysteme,d.h. empirische Regeln die auf Praxiserfahrung beruhen, erganzt [8, 9, 26, 30, 37] oderdas Spektrum des Statorstromes wird mit einer Datenbasis verglichen, die von ande-ren Motoren oder (und) numerisch simulierten idealen Induktionsmaschinen erzeugtwurde [9, 38]. Es zeigt sich aber, daß ein unuberwachter Lernprozeß Produktionstole-ranzen und sich andernde Lastzustande nicht von Motorfehlern unterscheiden kann,da deren Auswirkungen auf den Statorstrom um ca. ein bis zwei Großenordnungenkleiner als die der erstgenannten Einflusse sind, sofern die Defekte noch nicht zumunmittelbaren Versagen des Motors fuhren sollen.
Aus diesem Grund wird in [30, 37] das Konzept des Autoassoziators vorgeschla-gen, welches in weiteren anwendungsorientierten Arbeiten [24] ubernommen wird.Hierbei werden in einem Trainingszeitraum Meßreihen von allen wahrend des Be-triebs auftretenden Lastzustanden eines neuen (fehlerfreien) Motors aufgenommenund damit ein Uberwachungsalgorithmus trainiert. In der anschließenden Betriebs-

42 KAPITEL 3. FEHLERFRUHERKENNUNG BEI INDUKTIONSMOTOREN
Abbildung 3.1: Zeitreihen einer
Phase des (um die dominante
Netzfrequenz zu dampfen) vor-
gefilterten und verstarkten Sta-
torstromes: (a) konstante Last
bei halber Leistung, (b) mit
halber Netzfrequenz oszillieren-
de Last bei voller Leistung des
Motors. Die Zeitreihen uber-
decken vier Perioden der Netz-
spannung (ca. zwei Umdrehun-
gen des Motors).
0 16 32 48 64 80 96 112 128Stuetzstellen n
−15000
−10000
−5000
0
5000
10000
15000
Amplitude
(a)
0 16 32 48 64 80 96 112 128Stuetzstellen n
−15000
−10000
−5000
0
5000
10000
15000
Amplitude
(b)
phase konnen fur diesen Motor Abweichungen des aktuellen Statorstromes von derbekannten Datenbasis detektiert werden. In [24, 30, 37] ubernehmen neuronale Netzediese Uberwachungsaufgabe. Auch wenn die Idee des Autoassoziators die vielverspre-chendste fur die Motoruberwachung ist, die wir ebenfalls ubernehmen werden, bleibennoch zwei Probleme zu losen:
Zwar konnen wahrend der Trainingsphase Zeitreihen von allen Lastzustandendes Motors gemessen werden, jedoch ist es kaum moglich, alle Umweltbedingungenabzudecken, die wahrend des spateren Betriebs eintreten konnen. Die Temperaturdes Motors z.B. hat einen erheblichen Einfluß auf den Statorstrom, d.h. es ist eingroßer Unterschied, ob der Motor gerade eingeschaltet wurde oder schon langer lauft.Auch wenn man versuchen wird, alle typischen Betriebsbedingungen in die Trai-ningsdatenbasis aufzunehmen, bleibt es fur einen praxisgerechten Betrieb unerlaßlich,daß der Uberwachungsalgorithmus sich entwickelnde Defekte von Betriebszustandenunterscheiden kann, die sich nur durch außere Einflusse von allen bekannten Trai-ningszustanden unterscheiden. Dies laßt sich nicht alleine dadurch erreichen, daßder Schwellenwert fur das Ahnlichkeitsmaß im Merkmalsraum, mit dem Trainings-und Testdaten verglichen werden, hinreichend groß gewahlt wird, da die Auswir-kungen von Motorfehlern auf den Statorstrom von der gleichen Großenordnung wieUmwelteinflusse sind. Genauso konnen Umweltbedingungen nicht herausgefiltert wer-den, indem nur zeitlich bestandige Anderungen des Statorstromes, wie sie naturlich

3.1. FEHLERERKENNUNG DURCH ANALYSE DES STATORSTROMES 43
0 16 32 48 64 80 96 112 128Stuetzstellen n
−15000
−10000
−5000
0
5000
10000
15000
Amplitude
(a)
0 16 32 48 64 80 96 112 128Stuetzstellen n
−15000
−10000
−5000
0
5000
10000
15000
Amplitude
(b)
Abbildung 3.2: Zeitreihen der
gleichen Betriebszustande wie
in Abb. 3.1, wobei der Motor
eine Unwucht hat, die durch ei-
ne exzentrische Scheibe auf der
Motorachse erzeugt wird.
entstehende Defekte kennzeichnen, berucksichtigt werden.Ein weiteres in [35, 38] behandeltes Problem ist der Einfluß oszillierender Drehmo-
mente, wie sie z.B. beim Antrieb von Kompressoren auftreten. Erfolgt die Oszillationmit (mehrfacher) Drehfrequenz des Motors, so werden die gleichen charakteristischenFrequenzen fos im Statorstrom angeregt, wie sie fur Unwuchten und naherungswei-se auch fur Stabbruche typisch sind; man erhalt fos = fuw [35], vgl. (3.1) und (3.2).Oszillierende Lasten konnen diese Fehler daher leicht uberdecken. Abb. 3.1 zeigt Aus-schnitte aus zwei Zeitreihen, die von Motor 1 mit verschiedenen Lasten erzeugt wur-den. In Abb. 3.2 sind die gleichen Lastzustande des Motors mit einer Unwucht zusehen, die durch eine Exzenterscheibe auf der Motorachse erzeugt wurde. Es ist leichtzu erkennen, daß verschiedene Drehmomente des Motors zu einer qualitativen Ande-rung des Statorstromes fuhren, wahrend der Einfluß der Unwucht nicht unmittelbarsichtbar ist.
Wir wollen im nachsten Abschnitt das Konzept eines Autoassoziators vorstellen,welches nicht auf neuronalen Netzen basiert und auch keine empirischen (Experten-)Regeln oder technische Details des zu uberwachenden Motors verwendet, wie sie zurBerechnung der Signaturen (3.1)–(3.3) teilweise benotigt werden, da der Schlupf nichtgenau bekannt ist. Wir werden zeigen, daß mit diesem Ansatz das wichtige Problemunbekannter Umwelteinflusse wie auch jenes oszillierender Lastzustande zumindestteilweise behandelt werden kann.

44 KAPITEL 3. FEHLERFRUHERKENNUNG BEI INDUKTIONSMOTOREN
3.2 Geometrische Signaltrennung
Bevor wir die Einzelheiten erlautern, soll die generelle Idee der geometrischen Signal-trennung im Merkmalsraum vorgestellt werden. Wir nehmen an, daß eine einfacheMeßvorrichtung eine geeignete Zeitreihe der zu uberwachenden Maschine (hier desInduktionsmotors) liefert. Ausreichend lange Teilstucke der Signale werden in Merk-malsvektoren v in einem Merkmalsraum V transformiert. Die Komponenten von vkonnen beliebige statistische Schatzgroßen sein, die im Hinblick auf die Aufgabenstel-lung sinnvoll gewahlt sind. Hierfur gibt es keine allgemeingultigen Kriterien. Da derStatorstrom eines Induktionsmotors bei konstanten Betriebsbedingungen quasiperi-odisch ist (bei einem Schlupf s = 0 ware er periodisch), wahlen wir noch festzulegen-de Komponenten des gefensterten Fourierspektrums der Zeitreihen als Eintrage derMerkmalsvektoren.
Wahrend der Trainingsperiode wird ein Satz Merkmalsvektoren erzeugt, von de-nen angenommen werden kann, daß sie alle erlaubten Betriebszustande des intaktenMotors reprasentieren. Insbesondere mussen Beispiele von allen Lastzustanden da-rin enthalten sein. Diese Trainingsvektoren werden in Cluster eingeteilt und fur jedesCluster wird eine lokale Metrik im Merkmalsraum V definiert, welche den Abstand ei-nes Vektors zu dem spezifischen Cluster angibt. Die lokalen Metriken berucksichtigendie stark unterschiedliche Große und Ausdehnung der Cluster in den verschiedenenRaumrichtungen.
Wahrend der Uberwachungsphase werden die laufend berechneten Merkmalsvek-toren mit den Clustern in V verglichen. Zunachst wird der Abstand eines Testvektorszum nachstgelegenen Cluster im Merkmalsraum bestimmt und mit einem Schwel-lenwert verglichen. Dieses Uberwachungsverfahren reagiert sehr empfindlich auf sichandernde Betriebszustande des Motors bei einer gleichzeitigen statistischen Robust-heit. In Abschnitt 3.3.2 werden wir in einem out-of-sample Test zeigen, daß hiermitalle Testdaten eines Motors korrekt klassifiziert werden konnen.
Fur die Praxis ist dieses Resultat jedoch unzureichend, da, wie im letzten Ab-schnitt erlautert, bisher unbeobachtete Betriebszustande sowohl durch Motorfehlerwie durch Umwelteinflusse bedingt sein konnen. Da wir nicht annehmen konnen,daß alle wahrend des Betriebs eintretenden Umweltbedingungen in der Trainingsda-tenbasis enthalten sind, muß der Uberwachungsalgorithmus Defekte von sonstigenEinflussen trennen konnen. Die geometrische Methode bietet hierfur eine Losung:
Wir konstruieren zwei Typen von Merkmalsvektoren v1 und v2 in den RaumenV1 und V2 mit unterschiedlicher Dimension. Wahrend die Komponenten von v1 sogewahlt werden, daß sie Informationen uber Motordefekte enthalten, gehen in v2 fastausschließlich außere Einflusse ein. Daß solche Merkmalsraume V1 und V2 existieren,werden wir im Fall der Induktionsmotoren zeigen. In V1 gehen naturlich Informationenuber beides, Fehler und Umweltbedingungen (neben weiteren Einflussen) ein; dieserMerkmalsraum stimmt mit dem oben eingefuhrten Raum V uberein.

3.2. GEOMETRISCHE SIGNALTRENNUNG 45
Beide Typen von Merkmalsvektoren werden jetzt aus den Trainingsdaten berech-net und in Cluster eingeteilt, wobei nach Konstruktion je ein Cluster in V1 und V2 zu-einander korrespondieren. Die in der Uberwachungsphase erzeugten Testvektorpaare(v1, v2) werden mit den Clustern in V1 und V2 unabhangig voneinander verglichen.Im allgemeinen gibt es kein Paar zueinander korrespondierender Cluster, welche dieAbstande zu v1 und v2 simultan minimieren. Um den Testvektoren eindeutig einClusterpaar zuordnen zu konnen, muß deshalb die Summe ihrer geeignet gewichtetenAbstande in V1 und V2 minimiert werden.
Die in V2 beobachteten Abstande geben fast ausschließlich Abweichungen der Um-weltbedingungen von den Trainingsdaten wieder. Es existiert jedoch eine Korrelationzwischen v2 und den in v1 enthaltenen Umwelteinflussen, welche es erlaubt dieseStorungen naherungsweise herauszurechnen. Die so von Umwelteinflussen teilweisebereinigten Abstande in V1 werden wiederum mit einem Schwellenwert verglichen, derjetzt als Klassifikationskriterium zwischen guten und fehlerhaften Betriebszustandendes Motors dient. Weiterhin nutzen wir die Eigenschaft aus, daß entstehende Defektezeitlich bestandige Anderungen des Statorstromes hervorrufen; kurzzeitige Ereignis-se, die den Schwellenwert uberschreiten, wie z.B. Schwankungen der Netzspannung,konnen daher ignoriert werden.
Geometrische Signaltrennung ist mehr als das Messen von Abstanden in Merk-malsraumen, was lediglich skalare Großen sind. Als nachsten Schritt wird man daherversuchen eine Mannigfaltigkeit erlaubter Zustande im Merkmalsraum zu identifi-zieren, mit der die Testvektoren verglichen werden konnen. Diese Mannigfaltigkeitkonnte durch Cluster aus Trainingsvektoren, die ebenfalls zur Definition der loka-len Metriken dienen, naherungsweise trianguliert werden. Damit ware es moglich, diein den Trainingsdaten enthaltenen Informationen im Merkmalsraum zu inter- undextrapolieren. Nimmt man nun an, daß die Anzahl der effektiven Freiheitsgrade derUmweltbedingungen klein ist; vielleicht nur Temperatur und Luftfeuchtigkeit umfaßt,so ware die Mannigfaltigkeit der erlaubten Betriebszustande niedrigdimensional undwurde, falls sie nicht zu stark gefaltet ist, eine prazisere Trennung von Fehlern undUmwelt erlauben als der skalare Ansatz.
Allerdings erfordert die numerische Approximation von (nichtparametrischen)Mannigfaltigkeiten eine relativ große Datenmenge. Aufgrund des begrenzten Daten-umfangs, der uns von den Induktionsmotoren zur Verfugung steht, konnte dieserAnsatz nicht weiter verfolgt werden.
3.2.1 Vorprozessierung der Zeitreihen
Die uns von SCR zur Verfugung gestellten Zeitreihen sind bereits vorgefiltert undverstarkt, um die Amplitude der dominanten Netzfrequenz (um ca. 30dB) zu dampfen.Die Abtastrate der Zeitreihen wurde nach dem Filterprozeß auf 32 pro Periode derNetzfrequenz (60Hz) reduziert, siehe Abb. 3.1 und 3.2.

46 KAPITEL 3. FEHLERFRUHERKENNUNG BEI INDUKTIONSMOTOREN
Wir berechnen die Merkmalsvektoren aus Teilstucken der Zeitreihen der Lange5120 (= 2.67s Laufzeit des Motors). Zunachst werden gefensterte Fouriertransforma-tionen uber 512 Stutzstellen (16 Perioden der Netzfrequenz) mit zur Halfte uber-lappenden Fenstern berechnet und die Betragsquadrate uber das gesamte Teilstuckgemittelt, um statistische Fluktuationen zu dampfen. Wir verwenden das Hann- Fen-ster (2.33), welches bei der Wahl L = 1 (siehe Kap. 2.2.2) eine Breite von 3 Kanalenim diskreten Frequenzraum hat, siehe Abb. 2.5. Da aufgrund der Quasiperiodizitatder Zeitreihen ihre gefensterten Fouriertransformationen nur isolierte Spitzen enthal-ten, die genau in die beiden benachbarten Kanale hinein verbreitert werden, reicht esaus, nur jede zweite Frequenzkomponente zu berucksichtigen. Die hiermit verbundeneDampfung einiger Amplituden wird spater keine Rolle spielen.
Wir erhalten somit Vektoren mit 128 Spektralkomponenten, die wir wahrend derTrainingsperiode von allen Betriebszustanden des fehlerfreien Motors sammeln.
3.2.2 Auswahl und Clusterung der Merkmalsvektoren
Nachdem diese Trainingsmenge von Frequenzvektoren erzeugt ist, kommen wir zurAuswahl der Merkmalsvektoren, die fur jeden Motor individuell erfolgt. Wir verwen-den folgende Auswahlkriterien:
1. Da alle betrachteten Fehler periodisch mit der Drehfrequenz des Motors sind,enthalten die Komponenten der Netzfrequenz und ihre Harmonischen keine In-formationen uber den Zustand des Motors, jedoch gehen die Umweltbedingung-en in sie ein; diese Eigenschaft werden wir spater ausnutzen.
2. Wir betrachten alle Spektralkomponenten mit einem hinreichend hohen Signal-Rausch Verhaltnis als potentiell interessant fur die Fehlererkennung und erwar-ten, daß diese Menge ausreichend viele Frequenzen enthalt, die fur die Detektie-rung von Defekten geeignet sind. Die nicht fehlersensitiven Komponenten dieserMenge werden aufgrund ihres relativ kleinen Rauschanteils nur wenig storen-den Einfluß haben. Hierzu muß ein Maß zur Quantifizierung des Signal-RauschVerhaltnisses definiert werden. Die Amplituden der Spektralkomponenten allei-ne erachten wir nicht als wichtig, da sie im wesentlichen durch den Lastzustanddes Motors bestimmt werden.
3. Zusatzlich besteht die Moglichkeit, einige der physikalisch motivierten Signa-turen (3.1)–(3.3) zu berucksichtigen. Wir betrachten hier die Frequenzkompo-nenten fe ± frm, die durch Unwuchten des Motors angeregt werden und fur4-Pol Motoren bei der verwendeten Abtastrate unabhangig vom Schlupf in dieKanale 4 und 12 der Frequenzvektoren gefaltet werden. Auf diese Auswahlre-gel kann verzichtet werden, falls der Motor oszillierende Lasten antreibt, da indiesem Fall die betrachteten Frequenzen immer in der Menge der Spektralkom-ponenten mit hinreichend hohem Signal-Rausch Verhaltnis enthalten sind.

3.2. GEOMETRISCHE SIGNALTRENNUNG 47
Zur Definition eines Maßes fur das Signal-Rausch Verhaltnis der Spektralkomponen-ten teilen wir zunachst die 128-dimensionalen Frequenzvektoren in Cluster ein, diewir spater auch zur Definition der lokalen Metriken in den Merkmalsraumen V1 undV2 benotigen werden. Die Clustereinteilung erfolgt durch einen selbstorganisierendenClusterungsalgorithmus, der fur diese Aufgabe entwickelt wurde und Standardverfah-ren, wie z.B. [21] uberlegen ist:
Im ersten Schritt wird die Trainingsvektormenge in kleine Cluster eingeteilt, wel-che in einem zweiten Schritt geeignet zusammengefaßt werden. Der erste Vektor inder Reihenfolge, in der sie erzeugt wurden, bildet den Startpunkt des ersten Clusters.Falls sein Euklidischer Abstand zum zweiten Vektor in dieser Reihenfolge kleiner alsein Trennschwellenwert dsep ist, gehort auch er in dieses Cluster und der gemeinsa-me Schwerpunkt wird bestimmt. Der folgende Vektor kann entweder ebenfalls dazu-gehoren oder definiert, falls sein Abstand zum Schwerpunkt des Clusters großer alsdsep ist, ein weiteres Cluster. Im zweiten Fall wird angenommen, daß der Betriebszu-stand des Motors sich geandert hat und alle kommenden Vektoren werden nur nochmit dem zuletzt entstandenen Cluster verglichen bis wiederum ein neues gebildetwird. Wahrend dieses Prozesses entsteht eine relativ große Anzahl kleiner Cluster,deren Elemente einen kleinen Euklidischen Abstand zueinander haben.
Aus statistischen Grunden ist eine minimale Clustergroße erforderlich; wir wahlenals kleinstmogliche Anzahl von Vektoren 25 oder 50 abhangig von Große des Daten-satzes. Zunachst werden alle Cluster, deren Schwerpunktabstand kleiner als ein Ver-einigungsschwellenwert duni ist, zusammengelegt. Die Moglichkeit von Clusterkettenwird hierbei beachtet, d.h. wenn Cluster A in der Nahe von B und B nahe an Cliegt, C sich jedoch nicht in einer hinreichend kleinen Umgebung von A befindet, sowerden A, B und C vereinigt, um Eindeutigkeit zu erhalten. duni wird nun schrittwei-se erhoht und das Verfahren wiederholt, wobei jetzt allerdings Cluster, welche beidebereits die minimale Große erreicht haben, nicht vereinigt werden. Dies ist wichtig,da fur eine geeigneten Clusterung der Trainingsvektoren sowohl kleine und relativ na-he beieinander liegende wie auch sehr viel ausgedehntere Cluster entstehen mussen.Nachdem ein maximaler Wert von duni erreicht ist, werden alle Vektoren, die bis da-hin noch zu keinem Cluster minimaler Große gehoren, als Ausreißer betrachtet undaus der Trainingsmenge entfernt.
Es zeigt sich, daß Vektoren, die den gleichen Lastzustand und ahnliche Umwelt-bedingungen reprasentieren, in jeweils einem Cluster zusammengefaßt werden. Dawir als Abstandsmaß die Euklidische Norm verwenden, dominieren allerdings wenigegroße Spektralkomponenten, unter ihnen die Netzfrequenz und ihre Harmonischen,die Clustereinteilung. Die erzeugten Cluster sind nicht eindeutig, jedoch sollte die Feh-lererkennung mit jeder vernunftigen Einteilung der Trainingsvektoren funktionieren.Die Schwellenparameter werden durch die Euklidische Norm der Frequenzvektoren,d.h. den Verstarkungsfaktor des Statorstromes bestimmt. Damit ihre Wahl universalist, werden die Vektoren der Trainingsmenge auf die mittlere Amplitude 1 normiert.

48 KAPITEL 3. FEHLERFRUHERKENNUNG BEI INDUKTIONSMOTOREN
Fur jedes Cluster und jede Spektralkomponente definieren wir nun das Signal-Rausch Verhaltnis
ri,j =ci,jσi,j
; i = 1, · · · , 128 , (3.4)
wobei ci,j die i-te Komponente des Schwerpunktvektors von Cluster j und σi,j ein Maßfur die Ausdehnung dieses Clusters in der Raumrichtung i ist. Eine erste Moglichkeitσi,j zu definieren, bieten die Standardabweichungen der Cluster, jedoch wird damitdie unterschiedliche Form der Cluster zu wenig berucksichtigt. Daher stellt es sichals vorteilhaft heraus, auch den vierten Kumulanten der Verteilung der Vektoreneinzubeziehen. Die Wahrscheinlichkeitsdichte ρX(x) einer ZufallsvariablenX laßt sichdurch ihre Kumulanten κm; m = 1, 2, · · · vollstandig charakterisieren, falls dieseexistieren [20, 31]. Es gilt
ρX(x) =12π
∫exp
( ∞∑m=1
(−ik)mm!
κm
)eikxdk ,
wobei die fuhrenden Kumulanten gegeben sind durch
κ1 = <X> (Mittelwert)
κ2 = <X − <X>>2 = var(X) (Varianz)
κ3 = <X − <X>>3 (Schragheit)
κ4 = <X − <X>>4 − 3var2(X) (Kurtosis)... =
... .
(3.5)
Fur eine Gaußverteilung verschwinden alle Kumulanten von hoherer als zweiter Ord-nung. Daraus folgt die Relation
var(X) =√<X − <X>>4 − 2var2(X) .
Definiert man nun fur eine beliebige (1-dim.) Wahrscheinlichkeitsdichte die Große
σ =[max
(<X − <X>>4 − 2var2(X) ;
116
var2(X))]1/4
, (3.6)
so erhalt man ein Maß fur die raumliche Ausdehnung der Cluster, welches die Ab-weichung der Verteilung der Vektoren von einer Gaußverteilung in fuhrender geraderOrdnung berucksichtigt. Das Maximum unter der Wurzel garantiert ein positiv de-finites Argument. Das Maß σ reagiert auf statistische Fluktuationen deutlich emp-findlicher als die Standardabweichung; dies erweist sich fur die Quantifizierung vonSignal-Rausch Verhaltnissen als sinnvoll. Als Schatzer fur den vierten Kumulanteneiner Wahrscheinlichkeitsdichte verwenden wir den Ausdruck
κ4 =1
K − 1
K∑i=1
(Xi − Xi)4 − 3[
1K − 1
K∑i=1
(Xi − Xi)2]2
,

3.2. GEOMETRISCHE SIGNALTRENNUNG 49
wobei Xi; i = 1, · · · , K die Schatzer fur die Erwartungswerte von Xi ≡ X sind.Mit der Definition (3.6) fur die Großen σi,j (3.4) laßt sich das Signal-Rausch
Verhaltnis der Spektralkomponenten quantifizieren. Hierzu mitteln wir ri,j (3.4)uber alle Cluster, wobei der Signal-Rausch Vektor rj jedes Clusters auf 1 normiertwird, um alle Cluster gleich zu gewichten:
Ri =M∑j=1
ri,j√∑128k=1(rk,j)2
; i = 1, · · · , 128 , (3.7)
wobei M die Anzahl der Cluster bezeichnet. Die Menge Ri; i = 1, · · · , 128 ist vonder spezifischen Clustereinteilung der Trainingsvektoren naherungsweise unabhangigund definiert eine Reihenfolge der Spektralkomponenten entsprechend ihres Signal-Rausch Verhaltnisses.
Nun kann die Merkmalsauswahl vorgenommen werden. Als Eintrage der Vektorenv2 betrachten wir die Spektralkomponenten der Netzfrequenz und zwei ihrer Har-monischen, welche das großte Signal-Rausch Verhaltnis haben. Diese Wahl ist vomMotortyp, genauer der Windungsverteilung abhangig. Als Eintrage von v1 wahlenwir die 12 bis 14 Komponenten mit den hochsten Signal-Rausch Verhaltnissen, wobeijetzt alle Harmonischen der Netzfrequenz ausgeschlossen sind. Zusatzlich werden, wieerwahnt, die Komponenten 4 und 12 des Frequenzvektors berucksichtigt.
Die Auswahl der Merkmale hangt nicht nur vom spezifischen Motor, sondern auchvon den anliegenden Lasten ab. Fur unsere Motordaten zeigt sich, daß das Merk-malssuchverfahren bei allen Lastzustanden eine ausreichende Anzahl von Frequenzenfindet, die sensitiv auf die untersuchten Fehler reagieren. Eine Ausnahme bilden diecharakteristischen Frequenzen fe ± frm zur Detektierung von Unwuchten, die nurdann zuverlassig ausgewahlt werden, wenn der Motor eine mit (mehrfacher) Dreh-frequenz oszillierende Last treibt. Da hierdurch die gleichen Frequenzen wie im Falleiner Unwucht angeregt werden, haben diese Spektralkomponenten immer ein hinrei-chend hohes Signal-Rausch Verhaltnis. Naturlich kann, falls erforderlich, die Mengeder Merkmale um weitere physikalisch motivierte Signaturen erganzt werden.
Die ausgewahlten Spektralkomponenten sind im allgemeinen nicht diejenigen mitder großten Leistung; ihre Amplituden unterscheiden sich bis zu einem Faktor 104
voneinander, siehe Abb. 3.3 und 3.4. Umgekehrt enthalten manche Komponenten desFrequenzvektors mit wesentlich großerer spektraler Leistung fast nur Rauschen.
Fur unsere Motordaten wahlen wir als Dimension der Merkmalsraume V1 und V2
N1 = 14 – 16 sowie N2 = 3.
3.2.3 Die Struktur der Merkmalsraume
Kommen wir nun zur Konstruktion der Merkmalsraume V1 und V2. Die Abbildun-gen 3.3 und 3.4 zeigen Projektionen auf zwei Komponenten von v1 und v2. Diezugehorigen Daten wurden von Motor 4 bei konstanter (Abb. 3.3) sowie bei mit der
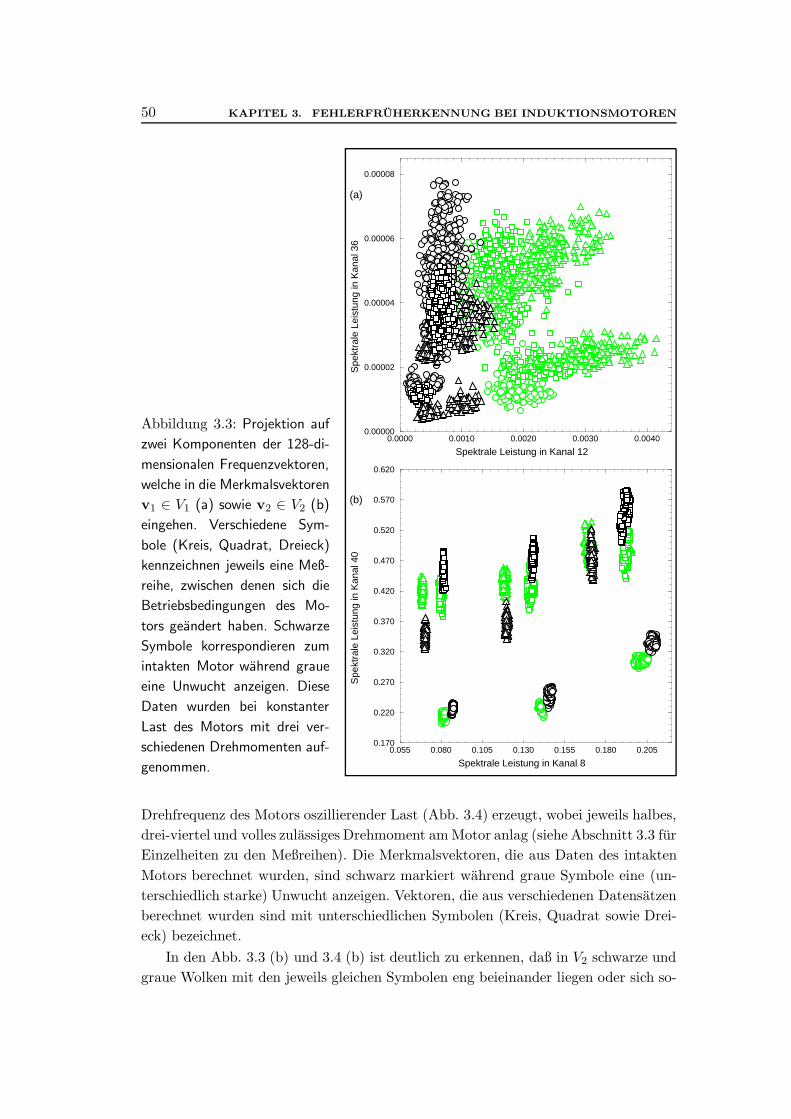
50 KAPITEL 3. FEHLERFRUHERKENNUNG BEI INDUKTIONSMOTOREN
Abbildung 3.3: Projektion auf
zwei Komponenten der 128-di-
mensionalen Frequenzvektoren,
welche in die Merkmalsvektoren
v1 ∈ V1 (a) sowie v2 ∈ V2 (b)
eingehen. Verschiedene Sym-
bole (Kreis, Quadrat, Dreieck)
kennzeichnen jeweils eine Meß-
reihe, zwischen denen sich die
Betriebsbedingungen des Mo-
tors geandert haben. Schwarze
Symbole korrespondieren zum
intakten Motor wahrend graue
eine Unwucht anzeigen. Diese
Daten wurden bei konstanter
Last des Motors mit drei ver-
schiedenen Drehmomenten auf-
genommen.
0.0000 0.0010 0.0020 0.0030 0.0040
Spektrale Leistung in Kanal 12
0.00000
0.00002
0.00004
0.00006
0.00008
Spe
ktra
le L
eist
ung
in K
anal
36
(a)
0.055 0.080 0.105 0.130 0.155 0.180 0.205
Spektrale Leistung in Kanal 8
0.170
0.220
0.270
0.320
0.370
0.420
0.470
0.520
0.570
0.620
Spe
ktra
le L
eist
ung
in K
anal
40
(b)
Drehfrequenz des Motors oszillierender Last (Abb. 3.4) erzeugt, wobei jeweils halbes,drei-viertel und volles zulassiges Drehmoment amMotor anlag (siehe Abschnitt 3.3 furEinzelheiten zu den Meßreihen). Die Merkmalsvektoren, die aus Daten des intaktenMotors berechnet wurden, sind schwarz markiert wahrend graue Symbole eine (un-terschiedlich starke) Unwucht anzeigen. Vektoren, die aus verschiedenen Datensatzenberechnet wurden sind mit unterschiedlichen Symbolen (Kreis, Quadrat sowie Drei-eck) bezeichnet.
In den Abb. 3.3 (b) und 3.4 (b) ist deutlich zu erkennen, daß in V2 schwarze undgraue Wolken mit den jeweils gleichen Symbolen eng beieinander liegen oder sich so-

3.2. GEOMETRISCHE SIGNALTRENNUNG 51
0.08 0.13 0.18 0.23 0.28 0.33
Spektrale Leistung in Kanal 12
0.00000
0.00010
0.00020
0.00030
0.00040
0.00050
Spe
ktra
le L
eist
ung
in K
anal
36
(a)
0.055 0.080 0.105 0.130 0.155 0.180 0.205
Spektrale Leistung in Kanal 8
0.180
0.230
0.280
0.330
0.380
0.430
0.480
0.530
0.580
Spe
ktra
le L
eist
ung
in K
anal
40
(b)
Abbildung 3.4: Projektion auf
die gleichen Komponenten von
v1 ∈ V1 (a) bzw. v2 ∈ V2 (b)
wie in Abb. 3.3. Die Zeitrei-
hen wurden bei mit der Dreh-
frequenz des Motors oszillieren-
der Last mit drei verschiedenen
Drehmomenten aufgenommen.
Die Symbole haben die gleiche
Bedeutung wie in Abb. 3.3.
gar uberdecken, was die Vermutung nahe legt, daß sie unter ahnlichen Bedingungen,d.h. innerhalb einer Meßreihe aufgenommen wurden, da in V2 keine Informationenuber Motorfehler eingehen, jedoch Umwelteinflusse und Lastzustande detektiert wer-den. Da Unwuchten durch das Aufstecken einer Exzenterscheibe auf die Motorachseschnell erzeugt werden konnen, ist es plausibel, daß diese Zeitreihen jeweils zu einerMeßreihe gehoren. Die Situation ist nicht so eindeutig in den Abb. 3.3 (a) und 3.4 (a),da in V1 eine Mischung aus Informationen uber Lastzustande, Umweltbedingungenund Defekte eingeht. Insbesondere zeigt sich in V1, anders als in V2, deutlich derUnterschied zwischen konstanten und oszillierenden Lasten.

52 KAPITEL 3. FEHLERFRUHERKENNUNG BEI INDUKTIONSMOTOREN
Die Frage der Fehler(fruh)erkennung bei Induktionsmotoren laßt sich nun wie folgtformulieren: Angenommen die Trainingsmenge umfaßt jeweils die Halfte der unterzwei (von drei) unterschiedlichen Betriebsbedingungen erzeugten Merkmalsvektoren(z.B. die schwarzen Kreise und schwarzen Quadrate), wahrend alle ubrigen Vektorenin der Testphase auftreten, in der keine zusatzlichen Informationen uber den Lastzu-stand des Motors verfugbar sind. Kann der Algorithmus dann zwischen Motorfehlern,welche durch graue Symbole gekennzeichnet sind, und den schwarz markierten erlaub-ten Betriebszustanden, die allerdings teilweise unter unbekannten Umwelteinflussenaufgenommen wurden (die schwarzen Dreiecke), statistisch signifikant unterscheiden?
Als nachsten Schritt zu einer Antwort definieren wir eine Metrik in V1 und V2,indem wir Konfidenzellipsoide an die im letzten Abschnitt erzeugten Cluster fitten.Hierzu betrachten wir eine Singularwertezerlegung der Cluster in V1 und V2: Seien dieSpalten der Matrix A die Merkmalsvektoren eines Clusters in seinem Schwerpunkt-system, d.h. A = ((vk,j − cj)k; k = 1, · · · , K), wobei cj den Schwerpunktvektor vonCluster j und K die Anzahl der darin enthaltenen Vektoren bezeichnet. Dann bil-den die Eigenvektoren von AA† eine Orthonormalbasis des Clusters, bezuglich deralle Kovarianzen der Verteilung der Vektoren verschwinden. Definiert man nun dieAusdehnung eines Clusters in diesen Koordinaten durch σi,j (3.6), so laßt sich derAbstand eines Vektors v zu dem Cluster im Merkmalsraum angeben:
d(v; j) =
√√√√ N∑i=1
v2i
σ2i,j
mit v = Rj(v− cj) , (3.8)
wobei Rj die Drehmatrix in das lokale Koordinatensystem von Cluster j und N dieDimension des Merkmalsraums bezeichnet.
Ca. 3% der Vektoren eines Clusters, welche die großten Abstande zum Schwer-punkt haben, werden nun entfernt; fur die ubrigen werden Rj und die Großen σi,jneu berechnet. Die so in V1 und V2 definierten Konfidenzellipsoide korrespondierennach Konstruktion paarweise zueinander.
Jetzt konnen die wahrend der Uberwachungsphase erzeugten Merkmalsvektorenmit allen Clustern in V1 und V2 verglichen und ihr minimaler Abstand bestimmtwerden. Damit kommen wir zur Berechnung der Umweltkorrekturen.
3.2.4 Berechnung von Umweltkorrekturen
Wir wollen nun die in den Merkmalsraumen V1 und V2 enthaltene Information kombi-nieren, um eine Umweltkorrektur fur die in V1 beobachteten Abstande zu berechnen.Zunachst mussen fur jedes Testvektorpaar (v1, v2) zwei zueinander korrespondieren-de Konfidenzellipsoide bestimmt werden, mit denen die Vektoren verglichen werdensollen. Diese Ellipsoide sollen einen moglichst ahnlichen Betriebszustand des Motorsreprasentieren, wie er gegenwartig vorliegt, jedoch ist daruber keine explizite Infor-mation verfugbar. Aufgrund moglicher unbekannter Umwelteinflusse ist das in V1

3.2. GEOMETRISCHE SIGNALTRENNUNG 53
0.0 10.0 20.0 30.0 40.0 50.0 60.0 70.0
d(v2)
0.0
10.0
20.0
30.0
40.0
50.0
60.0
70.0
80.0
d(v1)Abbildung 3.5: Die Abstande
d(v1) und d(v2) von Testvek-
torpaaren (v1, v2) gegeneinan-
der angetragen. Die Einheiten
sind dimensionslos. Schwarze
Symbole korrespondieren zum
intakten Motor, wahrend graue
eine Unwucht anzeigen. Die zu-
gehorigen Datensatze wurden
bei konstanten und oszillieren-
den Lasten mit verschiedenen
Drehmomenten erzeugt.
oder V2 am nachsten gelegene Cluster nicht unbedingt die beste Wahl. Tatsachlichgibt es im allgemeinen keine zwei zueinander korrespondierenden Ellipsoide, welchedie Abstande zu v1 und v2 simultan minimieren. Daher muß das Clusterpaar j, wel-ches bezuglich Lastzustand und Umweltbedingungen am besten mit dem gegebenenTestvektorpaar (v1, v2) ubereinstimmt, geschatzt werden. Die einfachste Moglichkeithierzu ist die Minimierung der gewichteten Summe
F (v1, v2; j) = d(v1; j) + αd(v2; j) (3.9)
bezuglich j. Die Wichtungskonstante α hangt von der Dimension von V1 und V2 abund ist von der Großenordnung α ≈ 1. Diese Wahl eines Clusterpaars berucksich-tigt unbekannte Umwelteinflusse durch die Mittelung der in V1 und V2 beobachtetenAbstande und definiert den Abstand eines Testvektors d(v) in seinem Merkmalsraumeindeutig.
In Abb. 3.5 sind die Abstande d(v1) und d(v2) einer großen Anzahl von Test-vektorpaaren gegeneinander angetragen. Wie vorher umfaßt die Trainingsmenge Bei-spiele aus zwei von drei Meßreihen: Kreise stehen fur ahnliche Umweltbedingungenvon Trainings- und Testmenge, wahrend Dreiecke voneinander abweichende Einflussekennzeichnen; schwarzen Symbole korrespondieren zu Daten des intakten Motors, wo-gegen graue eine Unwucht anzeigen. Naturlich sind d(v1) und d(v2) nicht korreliertin einem strengen Sinn, jedoch existiert die untere Schranke einer Korrelation, welchein Abb. 3.5 durch die ausgezogenen Linie verdeutlicht wird. Damit ist es moglich,

54 KAPITEL 3. FEHLERFRUHERKENNUNG BEI INDUKTIONSMOTOREN
die in d(v1) enthaltenen Umwelteinflusse teilweise herauszurechnen. Der in fuhrenderOrdnung korrigierte Abstand d(v1) wird gegeben durch
dkorr(v1, v2) = |d(v1)− βd(v2)− γ| , (3.10)
wobei β und γ von der Dimension der Merkmalsraume abhangige Konstanten sind,welche die geschatzte Koppelung von d(v1) und d(v2) festlegen. Das geschatzte Ver-haltnis von d(v1) und d(v2) fur N1 = 14 und N2 = 3 ist in Abb. 3.5 mit der gestri-chelten Linie eingezeichnet.
Zur Berechnung von dkorr mussen die Parameter α, β und γ geschatzt werden.Dies erfolgt durch die Minimierung des gesamten Klassifikationsfehlers der Motorda-ten in mehreren out-of-sample Tests mit unterschiedlich gewahlter Trainingsmenge.Jedoch werden aus praktischen Grunden die Parameter fur jeden Motor nur ein-mal auf dem gesamten Datensatz geschatzt; hierdurch ergibt sich eine Mischformaus in-sample und out-of-sample Test (siehe Kap. 2.3.3). Da die Minimierung desKlassifikationsfehlers fur verschiedene Trainingsmengen eine unterschiedliche Para-meterwahl erfordert, konnen α, β und γ nur Mittelwerte hiervon annehmen. UnserKriterium zum Schatzen dieser Parameter ist, daß sich fur alle Trainingsmengen dieFehlklassifikationsrate bei einer Variation der Parameter nur langsam andert, so daßwir annehmen konnen, uns in der Nahe des jeweiligen Minimums zu befinden.
Aus Gl. (3.10) folgt, daß die Empfindlichkeit des Fehlererkennungsalgorithmuskontinuierlich abnimmt, wenn die in V2 beobachteten Umweltbedingungen von allenaus der Trainingsperiode bekannten abweichen. Uberschreitet d(v2) einen Grenzwert,so muß die Fehleruberwachung abgeschaltet werden; dies kann z.B. bei Spannungs-schwankungen des Netzes passieren. Falls die Testvektoren in V2 fur langere Zeit nichtin der Nahe der Cluster liegen, muß vermutlich der Trainingsdatensatz erneuert wer-den; dies kann aufgrund von Alterungserscheinungen oder nach einer Reparatur desMotors erforderlich sein.
Man konnte aus Abb. 3.5 folgern, daß die moglichen Umweltkorrekturen relativklein sind. Aber Gl. (3.10) ist nur der zweite Schritt einer solchen Korrektur, dererste (und großere) besteht aus der richtigen Identifikation der Cluster, mit denen dieTestvektoren verglichen werden. Da Defekte des Motors keine kurzzeitigen Ereignissesind, sondern zu bestandigen Anderungen des Statorstromes fuhren, konnen wir alsEntscheidungskriterium bei der Fehlererkennung eine Klassifikationsstatistik verwen-den. Hier jedoch konnen bereits kleine Verbesserungen wesentlichen Einfluß auf dieSignifikanz haben, wie im nachsten Abschnitt deutlich werden wird.
3.3 Anwendungen und Ergebnisse
In diesem Abschnitt wollen wir Anwendungen unseres Fehlererkennungsalgorithmusauf Daten zeigen, die von vier 10PS 4-Pol Induktionsmotoren erzeugt wurden. DieDatensatze von Motor 1, 2 und 4 bestehen aus Zeitreihen der Lange 530.000 bis

3.3. ANWENDUNGEN UND ERGEBNISSE 55
Lastzustand Drehmoment
konstant halb und voll (max.)sinusformig mit der Drehfrequenz oszillierend halb und vollsinusformig mit doppelter Drehfrequenz oszillierend vollperiodisch mit der Drehfrequenz ein- und ausgeschaltet vollsinusformig mit 28Hz oszillierend halb und vollsinusformig mit 30Hz oszillierend vollperiodisch mit 30Hz ein- und ausgeschaltet voll
Tabelle 3.1: Lastzustande von Motor 1 und 2
Lastzustand Drehmoment
keine Lastkonstant halb, drei-viertel und vollsinusformig mit der Drehfrequenz oszillierend halb, drei-viertel und vollsinusformig mit halber Drehfrequenz oszillierend halb, drei-viertel und vollsinusformig mit doppelter Drehfrequenz oszillierend halb, drei-viertel und voll
Tabelle 3.2: Lastzustande von Motor 4
Datensatz von Zustande des Motors
Motor 1 intakt (ausgewuchtet), Unwucht, Loch im außeren Kugellager-ring, gebrochener Stab im Rotor
Motor 2 intakt, UnwuchtMotor 3 intakt, UnwuchtMotor 4 3×intakt, 4×Unwucht (vom Grad 1 bis 4), gebrochener Stab
im Rotor, 2×repariert (in Ordnung)
Tabelle 3.3: Datensatze von Motor 1 bis 4.
1.050.000 (= 4.6 – 9.1 min Laufzeit des Motors), die jeweils mit einer einzelnen Lastaufgenommen wurden. Alle untersuchten Lastzustande sind in Tabelle 3.1 und 3.2aufgefuhrt. Von Motor 3 liegen zwei Zeitreihen der Lange 10.400.000 vor, wobei dieLast des Motors zwischen 13 Lastzustanden zufallig wechselt. Die untersuchten De-fekte der Motoren sind in Tabelle 3.3 aufgelistet.
Die Betriebsbedingungen wahrend der Aufnahme der verschiedenen Meßreiheneines Motors weichen im allgemeinen voneinander ab. Die hierdurch bedingten Ein-flusse auf den Statorstrom sind von der gleichen Großenordnung (und sogar großer)wie die durch Defekte verursachten Anderungen. Sichtbar wird dies besonders furdie Daten von Motor 4: Die drei vom intakten Motor gemessenen Zeitreihensatzeunterscheiden sich deutlich voneinander. Auch wenn wir keine genauen Informatio-

56 KAPITEL 3. FEHLERFRUHERKENNUNG BEI INDUKTIONSMOTOREN
Abbildung 3.6: Motor 4: Wahr-
scheinlichkeit von Fehlklassifi-
kationen als die Funktion eines
Schwellenparameters λ. Durch-
gezogene Kurven: Falsche Zu-
ruckweisungen des guten Mo-
tors. Gebrochene Kurven: Fal-
sche Akzeptanzen des Motors
mit einer Unwucht (gestrichelt:
Grad 1, gepunktet: Grad 2, lang
gestrichelt: Grad 3, punkt-ge-
strichelt: Grad 4). (a) Training
unter Umweltbedingung 1 und
2, (b) Training unter Umwelt-
bedingung 2 und 3 in jeweils al-
len Lastzustanden.
0.0 10.0 20.0 30.0 40.0 50.0λ
0.0
0.2
0.4
0.6
0.8
1.0
P(F
ehle
r)
(a)
0.0 10.0 20.0 30.0 40.0 50.0λ
0.0
0.2
0.4
0.6
0.8
1.0
P(F
ehle
r)
(b)
nen daruber haben, liegt die Vermutung nahe, daß drei der vier Datensatze, die vondiesem Motor mit einer Unwucht vorliegen, innerhalb der jeweils gleichen Meßreihenwie die des intakten Motors aufgenommen wurden. Dieser Schluß laßt sich aus denAbb. 3.3 und 3.4 ziehen und erlaubt den Vergleich der Einwirkungen von Umwelt undFehlern auf den Statorstrom.
In den Abb. 3.6 bis 3.12, die im folgenden genauer diskutiert werden, ist auf dery- Achse der Anteil der Merkmalsvektoren einer Testmenge angetragen, deren Ab-stand dkorr (3.10) großer (bzw. kleiner) als der entlang der x- Achse aufgetrageneSchwellenwert λ ist, falls die Testdaten von einem intaken (fehlerhaften) Motor stam-men. D.h., fur Testdaten guter Motoren wird der Anteil der falschen Zuruckweisungen,fur die Signale defekter Motoren hingegen der Anteil falscher Akzeptanzen gegen λ
angetragen.
3.3.1 Signalklassifikation mit Umweltkorrekturen
Wir wahlen als Trainingsmenge fur Motor 4 jeweils eine Halfte der unter zwei von dreiUmweltbedingungen gemessenen Datensatze des guten Motors. Hierin sind Beispiele

3.3. ANWENDUNGEN UND ERGEBNISSE 57
0.0 10.0 20.0 30.0 40.0 50.0λ
0.0
0.2
0.4
0.6
0.8
1.0
P(F
ehle
r)
(a)
0.0 10.0 20.0 30.0 40.0 50.0λ
0.0
0.2
0.4
0.6
0.8
1.0
P(F
ehle
r)
(b)
Abbildung 3.7: Signalklassifi-
kation ohne Umweltkorrekturen
bei Motor 4: (a) Training un-
ter Umweltbedingung 1 und 2;
(b) Training unter Umweltbe-
dingung 2 und 3; vgl. Abb. 3.6.
Die Symbole entsprechen denen
in Abb. 3.6.
von allen Lastzustanden enthalten. Die ubrigen Zeitreihen bilden die Testmenge. Al-le Ergebnisse sind damit out-of-sample Tests (mit der erwahnten Einschrankung desSchatzens der Paramater α, β und γ), wobei keine Informationen uber die zu detek-tierenden Fehler zum Trainieren verwendet werden. Da die einzelnen Zeitreihen nichtexakt stationar sind, sondern (unterschiedlich starke) Parameterdrifts aufweisen, kanndas Testergebnis davon abhangen, ob der erste oder zweite Teil einer Zeitreihe zumTrainieren verwendet wird. Da keine dieser Moglichkeiten ausgezeichnet ist, mittelnwir jeweils uber beide. Die Zeitreihen der Trainingsmenge werden vor dem Start desAlgorithmus zu einer Datei verkettet.
Abb. 3.6 zeigt die Ergebnisse der Fehlererkennung bei Motor 4 fur Training undTest in allen Lastzustanden. Die unteren durchgezogenen Kurven bezeichnen diefalschen Zuruckweisungen der Testdaten des guten Motors, die unter ahnlichen Be-triebsbedingungen wie die Trainingsmenge aufgenommen wurden, wahrend die oberenzu den Testdaten korrespondieren, welche die unbekannten Umwelteinflusse reprasen-tieren. Die Trainingsmenge ist in Abb. 3.6 (a) und (b) unterschiedlich gewahlt. Es zeigtsich, daß der Statorstrom des Motors mit einer Unwucht vom Grad 2 – 4 signifikant

58 KAPITEL 3. FEHLERFRUHERKENNUNG BEI INDUKTIONSMOTOREN
Abbildung 3.8: Motor 4: (a)
Training und Test nur mit kon-
stanten Lasten unter Umwelt-
bedingung 2 und 3. (b) Trai-
ning und Test nur mit oszil-
lierenden Lasten (Drehfrequenz
des Motors) unter Umweltbe-
dingung 1 und 3. Die Symbole
sind in Abb. 3.6 erklart.
0.0 10.0 20.0 30.0 40.0 50.0λ
0.0
0.2
0.4
0.6
0.8
1.0
P(F
ehle
r)
(a)
0.0 10.0 20.0 30.0 40.0 50.0λ
0.0
0.2
0.4
0.6
0.8
1.0
P(F
ehle
r)
(b)
vom dem des intakten Motors unterschieden werden kann, auch wenn die Umweltbe-dingungen wahrend des Betriebs zum Teil unbekannt sind. Dies wird durch das Plus-Symbol verdeutlicht, welches in allen Abbildungen die Stelle (λ = 8.4, P = 0.325)markiert. Eine Unwucht vom Grad 1 stellt sich als zu klein zur Trennung heraus,doch wir kommen hierauf in Abb. 3.13 zuruck.
Da die Merkmalsauswahl jeweils auf der Trainingsmenge erfolgt, enthalten dieMerkmalsvektoren v1 bei verschiedener Wahl der Trainingsdaten im allgemeinen nichtdie gleichen Spektralkomponenten. Trotzdem zeigt sich fur unsere Motordaten, daßdas Merkmalssuchverfahren immer eine ausreichende Anzahl von Frequenzen findet,die sensitiv auf die untersuchten Fehler reagieren. Abb. 3.8 zeigt weitere Ergebnissevon Motor 4, wobei Training und Test (und damit die Merkmalsauswahl) getrenntnur fur konstante und nur fur mit der Drehfrequenz des Motors oszillierende Last-en erfolgt. Die statistische Signifikanz der Signaltrennung ist vergleichbar zu der inAbb. 3.6, wobei allerdings in Abb. 3.8 (b) der Schwellenwert λ fur das Ahnlichkeitsmaßim Merkmalsraum großer gewahlt werden muß. Der Grund hierfur sind Oszillationenim Datensatz 2, die in Abb. 3.4 (a) deutlich sichtbar sind (die schwarzen Dreiecke).
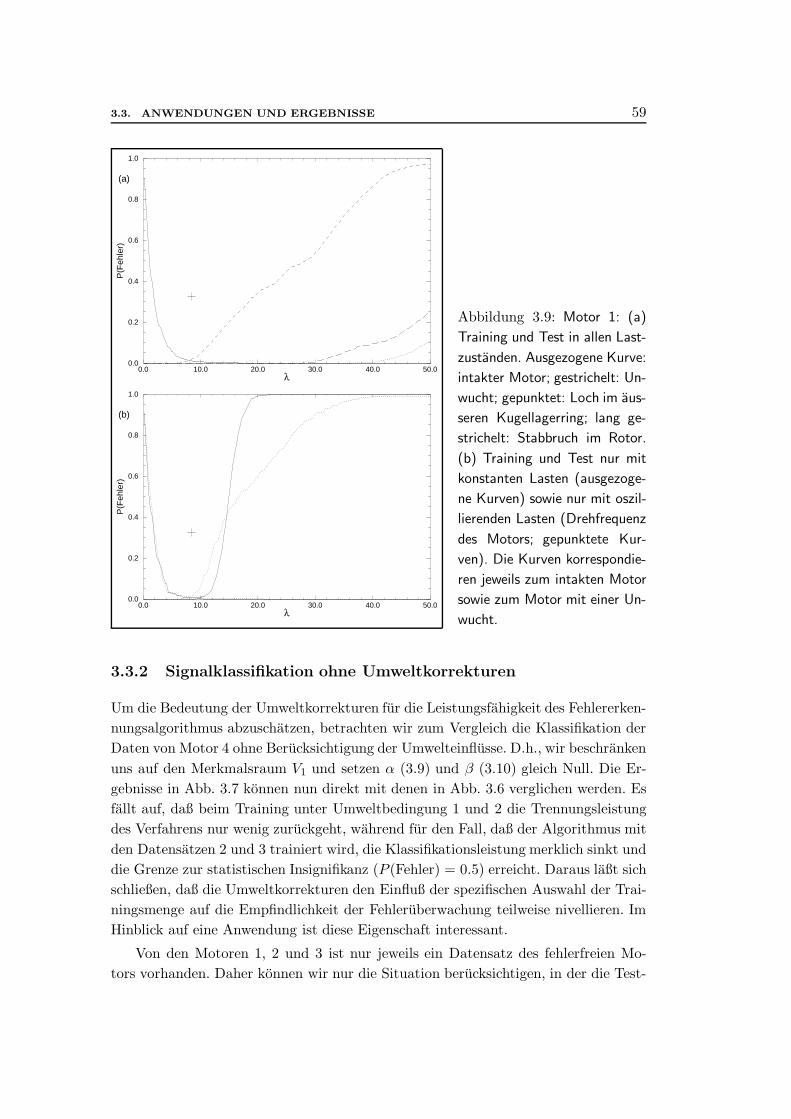
3.3. ANWENDUNGEN UND ERGEBNISSE 59
0.0 10.0 20.0 30.0 40.0 50.0λ
0.0
0.2
0.4
0.6
0.8
1.0
P(F
ehle
r)
(a)
0.0 10.0 20.0 30.0 40.0 50.0λ
0.0
0.2
0.4
0.6
0.8
1.0
P(F
ehle
r)
(b)
Abbildung 3.9: Motor 1: (a)
Training und Test in allen Last-
zustanden. Ausgezogene Kurve:
intakter Motor; gestrichelt: Un-
wucht; gepunktet: Loch im aus-
seren Kugellagerring; lang ge-
strichelt: Stabbruch im Rotor.
(b) Training und Test nur mit
konstanten Lasten (ausgezoge-
ne Kurven) sowie nur mit oszil-
lierenden Lasten (Drehfrequenz
des Motors; gepunktete Kur-
ven). Die Kurven korrespondie-
ren jeweils zum intakten Motor
sowie zum Motor mit einer Un-
wucht.
3.3.2 Signalklassifikation ohne Umweltkorrekturen
Um die Bedeutung der Umweltkorrekturen fur die Leistungsfahigkeit des Fehlererken-nungsalgorithmus abzuschatzen, betrachten wir zum Vergleich die Klassifikation derDaten von Motor 4 ohne Berucksichtigung der Umwelteinflusse. D.h., wir beschrankenuns auf den Merkmalsraum V1 und setzen α (3.9) und β (3.10) gleich Null. Die Er-gebnisse in Abb. 3.7 konnen nun direkt mit denen in Abb. 3.6 verglichen werden. Esfallt auf, daß beim Training unter Umweltbedingung 1 und 2 die Trennungsleistungdes Verfahrens nur wenig zuruckgeht, wahrend fur den Fall, daß der Algorithmus mitden Datensatzen 2 und 3 trainiert wird, die Klassifikationsleistung merklich sinkt unddie Grenze zur statistischen Insignifikanz (P (Fehler) = 0.5) erreicht. Daraus laßt sichschließen, daß die Umweltkorrekturen den Einfluß der spezifischen Auswahl der Trai-ningsmenge auf die Empfindlichkeit der Fehleruberwachung teilweise nivellieren. ImHinblick auf eine Anwendung ist diese Eigenschaft interessant.
Von den Motoren 1, 2 und 3 ist nur jeweils ein Datensatz des fehlerfreien Mo-tors vorhanden. Daher konnen wir nur die Situation berucksichtigen, in der die Test-

60 KAPITEL 3. FEHLERFRUHERKENNUNG BEI INDUKTIONSMOTOREN
Abbildung 3.10: Motor 2: Aus-
gezogene Kurven: Training und
Test in allen Lastzustanden; ge-
strichelt: nur konstante Lasten;
gepunktet: nur mit der Drehfre-
quenz des Motors oszillierende
Lasten. Die Kurven korrespon-
dieren jeweils zum intakten Mo-
tor sowie zum Motor mit einer
Unwucht.0.0 10.0 20.0 30.0 40.0 50.0
λ0.0
0.2
0.4
0.6
0.8
1.0
P(F
ehle
r)
zeitreihen unter ahnlichen Betriebsbedingungen wie die Trainingsdaten aufgenommenwurden. In diesem Fall sind keine Umweltkorrekturen erforderlich und es genugt denMerkmalsraum V1 zu betrachten. Wie zu erwarten, verbessert sich die Fehlererken-nungsrate fur die Signale von Motor 1, 2 und 3 deutlich, obwohl diese Motoren nichtalle vom gleichen Typ sind und die untersuchten Defekte sich teilweise unterscheiden.
In Abb. 3.9 sind die Ergebnisse der Fehlererkennung bei Motor 1 fur Trainingund Test in allen Lastzustanden sowie getrennt nur fur konstante und nur fur mit derDrehfrequenz des Motors oszillierende Lasten gezeigt. In den beiden letzten Fallenandern sich die Merkmalsvektoren aufgrund der Fehler ”Loch im außeren Kugellager-ring“ sowie ”Stabbruch im Rotor“ so stark, daß die Kurven der falschen Akzeptanzenin Abb. 3.9 (b) nicht mehr sichtbar sind. Abb. 3.10 und 3.11 schließlich zeigen dieErgebnisse von Motor 2 und 3.
Diese Resultate zeigen, daß die Methode der geometrischen Signaltrennung ver-schiedene Betriebszustande eines Motors leicht trennen und gleiche Zustande mit-
Abbildung 3.11: Motor 3: Aus-
gezogene Kurve: intakter Mo-
tor; gestrichelt: Unwucht.0.0 10.0 20.0 30.0 40.0 50.0
λ0.0
0.2
0.4
0.6
0.8
1.0
P(F
ehle
r)

3.3. ANWENDUNGEN UND ERGEBNISSE 61
0.0 20.0 40.0 60.0 80.0 100.0 120.0 140.0 160.0λ
0.0
0.2
0.4
0.6
0.8
1.0
P(F
ehle
r)
Abbildung 3.12: Motor 4: Aus-
gezogene und gestrichelte Kur-
ve rechts: Falsche Zuruckwei-
sungen des zerlegten und wie-
der montierten guten Motors.
Gepunktet: Stabbruch im Ro-
tor; vgl. Abb. 3.6 (a).
einander identifizieren kann. Fehlklassifikationen entstehen im wesentlichen aufgrundunbekannter Umwelteinflusse, die sich nur teilweise herausrechnen lassen.
3.3.3 Weitere Ergebnisse
Wir wollen uns weiter der Frage zuwenden, wie stark sich der Statorstrom andert,wenn der Motor gewartet oder repariert, also zerlegt und wieder zusammengebautwird. Abb. 3.12 stimmt mit Abb. 3.6 (a) uberein, wobei die Skala von λ großer ist undzusatzlich die falschen Zuruckweisungen der Testdaten des auseinander- und wiederzusammenmontierten guten Motors 4 eingezeichnet sind. Weiterhin sind die falschenAkzeptanzen des Motors mit einem Stabbruch im Rotor zu sehen. Aus Abb. 3.12geht deutlich hervor, daß das Zerlegen eines Motors die anschließende Erneuerung derTrainingsdaten erfordert. Aus im wesentlichen dem gleichen Grund, d.h. der Anderungvon Toleranzen, kann eine Trainingsmenge zur Fehlererkennung nur fur den Motorverwendet werden, von dem sie erzeugt wurde.
0.0 10.0 20.0 30.0 40.0 50.0λ
0.00
0.05
0.10
0.15
0.20
0.25
0.30
Pre
l(Feh
ler)
Abbildung 3.13: Motor 4: Re-
lative Wahrscheinlichkeit eines
Fehlers (3.11); vgl. Abb. 3.6.

62 KAPITEL 3. FEHLERFRUHERKENNUNG BEI INDUKTIONSMOTOREN
Dieser Punkt beleuchtet eine weiteres Problem: Wenn fur den Zweck der Erzeu-gung von Testdaten ein (kunstlicher) Defekt in einen Motor eingebaut wird, wozu esmeist erforderlich ist, ihn zu zerlegen, so kann alleine dieser Vorgang den Statorstromso stark verandern, daß die Fehlererkennung daraufhin immer anspricht. Lauft ein Mo-tor andererseits, bis sich ein Fehler durch Verschleiß von alleine einstellt, so werdenvermutlich Alterungseffekte lange vor dem Versagen des Motors Einfluß auf den Sta-torstrom nehmen und moglicherweise die Erneuerung der Trainingsdaten erfordern.Das Erzeugen von Unwuchten ist hingegen, wie schon erwahnt, unproblematisch. Ausdem Grund wird dieser Fehlertyp auch am haufigsten untersucht.
Wir wollen nun ein weiteres Mal die Eigenschaft ausnutzen, daß sich entwickelndeFehler zeitlich bestandige Anderungen des Statorstromes hervorrufen und kurzfristigeFluktuationen daher ignoriert werden konnen. Dies leitet uns, in Abb. 3.6 die folgendeGroße zu betrachten:
Prel(Fehler)(λ) = 1−max[P (falsche Zuruckweisungen)(λ)]
−max[P (falsche Akzptanzen)(λ)] ,(3.11)
wobei die Maxima uber alle korrespondierenden Kurven gebildet werden. Prel ist dieWahrscheinlichkeit einen guten Motors als gut zu identifizieren minus der Wahrschein-lichkeit einen Defekt nicht zu erkennen. Abbildung 3.13 zeigt Prel(λ) fur Motor 4: Dieausgezogene Kurve wurde aus Abb. 3.6 (a) und die gepunktete aus Abb. 3.6 (b)berechnet.
In Abb. 3.13 ist ersichtlich, daß es viele Moglichkeiten fur eine Wahl von λ in-nerhalb der Plateaus beider Kurven gibt. Fur alle Werte von λ in diesem Bereich istdie Wahrscheinlichkeit gute Motoren als gut zu erkennen mindestens 20% hoher alsdie Wahrscheinlichkeit einen Fehler zu ubersehen, wobei jetzt auch Unwuchten vomGrad 1 eingeschlossen sind, die wir in Abb. 3.6 noch nicht trennen konnten!
Bisher haben wir nur skalare Zeitreihen von einer Phase des Statorstromes unter-sucht. Jedoch ware der technische Aufwand, vektorwertige Zeitreihen aller drei Phasenzu messen und zu verarbeiten, nur unwesentlich hoher. Solche vektorwertigen Zeitrei-hen enthalten zusatzlich die Information uber Asymmetrien des Motors. Storungender Symmetrie werden durch Produktionstoleranzen, oszillierende Drehmomente so-wie typischerweise durch Motorfehler hervorgerufen, wobei die beiden ersten Effektewahrend der Trainingsphase erfaßt werden konnen. Da Umwelteinflusse aber keineAuswirkungen auf die Symmetrie des Motors erwarten lassen, entsteht hier eine wei-tere Moglichkeit, Motorfehler von unbeobachtbaren Umweltbedingungen zu trennen.Dieser Ansatz bietet in Kombination mit dem vorgestellten Verfahren der geometri-schen Signaltrennung im Merkmalsraum vermutlich weitere interssante Moglichkeitender Fehleruberwachung, jedoch liegen uns entsprechende Zeitreihen nicht vor.

Kapitel 4
Ein Merkmalsvektor zur
akustischen Guteprufung
Wahrend der Schwerpunkt des letzten Kapitels auf Methoden zur Auswahl und geo-metrischen Interpretation von Spektralkomponenten quasiperiodischer Signale lag,wollen wir uns in diesem Kapitel der Entwicklung eines Merkmalsvektors zuwendenfur den geeignete Merkmale nicht bereits aus der Struktur der Zeitreihen prinzipiellerkennbar sind. Dies wird man auch als den Normalfall ansehen konnen.
Sowohl bei der Qualitatskontrolle einer Vielzahl von Produkten wie auch bei derUberwachung von Fertigungsvorgangen werden haufig die emmitierten Gerausche vonmenschlichen Experten bewertet. Bei Maschinen (z.B. Motoren) oder Fertigungspro-zessen (z.B. Abspanvorgangen) sind dies meist deren Eigengerausche; im Fall vonGegenstanden, die keine Gerausche erzeugen, konnen Schwingungen kunstlich an-geregt werden, indem das zu prufende Produkt (z.B. ein Keramikteil) mit einemHammerchen angeschlagen wird. In allen Fallen enthalten die emmitierten Schallsi-gnale Informationen, die zur Unterscheidung von guten und fehlerhaften Produktenoder zur Erkennung unerlaubter Betriebszustande wesentlich beitragen konnen.
Da akustische Guteprufverfahren relativ einfach durchfuhrbar sind, besteht derWunsch nach einer Automatisierung nicht nur aus Kostengrunden, sondern wesent-lich auch, um Qualitatsprufungen objektivieren zu konnen, da menschliche Einschat-zungen haufig nicht reproduzierbar sind und großeren Schwankungen unterliegenkonnen. Die Schwierigkeit besteht darin, die Merkmale der Schallsignale, welche furdie Beurteilung des Produktes oder Herstellungsvorgangs relevant sind, zu extrahierensowie automatisch zu klassifizieren.
Wir untersuchen das spezielle Problem der automatischen Klassifikation von elek-trischen Schiebedachern in der Qualitatsendkontrolle.Hierzu wird das Schließgerausch,welches gewohnlich von einem Experten bewertet wird, mit einem Korperschallmikro-phon aufgenommen. Zeitreihen von als ”gut” sowie als ”fehlerhaft“ vorklassifiziertenSchiebedachern wurden uns von Carl Schenck AG, Darmstadt, zur Verfugung gestellt.
63

64 KAPITEL 4. EIN MERKMALSVEKTOR ZUR AKUSTISCHEN GUTEPRUFUNG
4.1 Darstellung und Klassifikation von Schallsignalen
Die Bedeutung der Qualitatskontrolle in einer zunehmend automatisierten Fertigunghat in den letzten Jahren stetig zugenommen. Die Forderung der Kunden nach gunsti-gen und zuverlassigen Produkten erfordert einerseits die sichere Einhaltung von Qua-litatsstandards wie auch aus Kostengrunden einen moglichst kleinen Produktions-ausschuß. Damit entsteht das Anliegen, die Qualitat eines Produktes oder bereitsdes Herstellungsvorgangs mit moglichst einfachen (d.h. billigen) Mitteln zuverlassigbeurteilen zu konnen.
Daß der Klang eines angeschlagenen Keramikelements (z.B. einer Porzellantasse)mogliche Risse verrat, ist schon langer bekannt; diese Methode wird z.B. bis heutezur Qualitatskontrolle von Dachziegeln verwendet [14]. Seit Beginn der 50er Jahrehat die Analyse von Schallsignalen fur die Guteprufung von Produkten und Ferti-gungssvorgangen (z.B. Abspan- und Umformprozesse, Laserschweißen) eine immen-se Entwicklung erfahren und ihren Platz neben traditionellen Verfahren gefunden[6]. Hierbei werden die von Maschinen, Herstellungsvorgangen oder kunstlich zumSchwingen angeregten Gegenstanden emmittierten Gerausche meist von menschli-chen Experten bewertet. Obwohl neben Kostengrunden insbesondere die Objekti-vierung von Qualitatskontrollen eine Automatisierung akustischer Guteprufverfahrenwunschenswert erscheinen laßt, hat es in diesem Bereich bisher nur langsame Fort-schritte gegeben. Die Grunde sind zum einen die Schwierigkeit, geeignete Merkmaleaus den Schallsignalen zu extrahieren, wofur keine allgemeine Losung bekannt ist,und zum anderen die haufig sehr große Variabilitat des Klangs von als ”gut“ bewerte-ten Pruflingen, was eine automatische Klassifikation schwierig macht. Ein verwandtesProblem ist uns bereits im letzten Kapitel als der Einfluß unbekannter Umweltbedin-gungen begegnet.
Trotzdem hat es fur eine Reihe speziell gestellter Probleme Losungsvorschlage imRahmen der Theorie der Zeit-Frequenz Darstellungen gegeben [7, 14, 15, 25]. In [7]wird gezeigt, daß aus den Luftschallsignalen, die wahrend des Laserschweißens vonStahlplatten aufgenommen werden, die Qualitat der Schweißnaht beurteilt werdenkann. Hierbei konnen aus der Leistung des Spektrogramms SP g
x (t, f) = |FT gx (t, f)|2
(2.10) der Schallsignale in einem geeigneten Frequenzband Ruckschlusse auf die Tiefeder Schweißnaht und mogliche Spalte zwischen den Platten gezogen werden. Ahnlicheelementare Methoden wurden bereits in [6] zur Uberwachung der Schneidwerkzeugebei Abspanprozessen, deren Zustand sich unmittelbar auf die Qualitat des Werkstucksauswirkt, vorgeschlagen.
In [25] werden Wignerspektren hoherer Ordnung, die als eine (nicht eindeuti-ge) Verallgemeinerung der Wigner-Ville Verteilung (2.7) definiert sind, zur Fehler-detektion bei rotierenden Maschinen und Getrieben untersucht. Es wird erwartet,daß sich mittels geeignet geglatteter1 Wignerspektren vierter Ordnung impulsartige
1durch Faltung mit einem Choi-Williams Kern, siehe Kap. 2.1.1

4.1. DARSTELLUNG UND KLASSIFIKATION VON SCHALLSIGNALEN 65
Signale besser detektieren lassen als mit Hilfe der quadratischen Wigner-Ville Ver-teilung, da hierdurch die Kurtosis (3.5) der Signale berucksichtigt wird. Weil dieInterpretation hochdimensionaler Zeit-Frequenz Darstellungen jedoch schwierig ist,bleibt unklar, inwiefern auch einfachere Ansatze zum gleichen Ziel fuhren.
In [14, 15] wird eine Automatisierung der Qualitatsendkontrolle bei kleinen Ge-triebemotoren sowie bei Dachziegeln, die durch ein Holzhammerchen zum Schwingenangeregt werden, untersucht. Die Schallsignale werden in Zeit-Frequenz DarstellungenCx(t, f) (2.8) der Cohen Klasse transformiert, wobei eine gaußformige KernfunktionΠ(t, f) ∼ e−(t/t0)
2e−(f/f0)
2gewahlt wird. Die Parameter t0, f0 werden hierbei auf ei-
ner Trainingsdatenmenge geschatzt. Dies geschieht durch die Definition eines MaßesmΠ(t0, f0) fur das Verhaltnis von Abstand zu Ausdehnung von zwei Signalklassen,z.B. von als ”gut“ und als ”fehlerhaft“ vorklassifizierten Schallsignalen, welches alsFunktion der Parameter t0, f0 auf den Trainingsdaten maximiert werden kann.
Auch wenn der Versuch gemacht wird, Darstellungen von Schallsignalen zu finden,die sich fur eine bestimmte Signalklasse automatisch optimieren lassen, ist klar, daßalle vorgeschlagenen Methoden fur spezielle Signaltypen und Fragestellungen kon-zipiert sind und sich (mit gutem Ergebnis) nur auf ahnliche Probleme ubertragenlassen. D.h., es kann automatisch nur ein lokales Optimum in der Menge aller mogli-chen Signaldarstellungen gefunden werden, welches vom globalen noch weit entferntliegen kann. Jedoch ist die Hoffnung nicht unberechtigt, daß die wachsende Sammlungvon speziellen Methoden zur Darstellung und Klassifikation von Schallsignalen auchfur vollig neue Problemstellungen Losungsansatze bieten kann, zumindest als einenersten Versuch. Die Idee hierbei ist eine Art ”Werkzeugkasten“ von Methoden zu-sammenzutragen, die geeignet kombiniert vielleicht weiter anwendbar sind als nur furdie spezielle Problemklasse, fur die sie entwickelt wurden. Einen Beitrag zu dieser
”Werkzeugsammlung“ zu bringen erscheint dann auch als losbare Aufgabe.Den Ausgangspunkt unserer Untersuchungen zur automatischen Klassifikation
der Korperschallsignale von elektrischen Schiebedachern bilden die folgenden Eigen-schaften der Zeitreihen, die mit einer Samplingrate von 10kH aufgenommen wurden:
1. Die Zeitreihen zeigen einen stochastischen Charakter, ein deterministischer An-teil laßt sich nicht erkennen. Wir testen dies durch den Vergleich der Zeitreihenmit Surrogatdaten. Die Surrogate werden mit der Methode der Phasenrando-misierung und anschließenden Anpassung von Verteilung und Spektrum derSurrogate an die Zeitreihe durch iteratives, wechselweises Skalieren der Vertei-lung und (Wiener-) Filtern des Spektrums erzeugt [22]. Als diskriminierendeStatistik verwenden wir den Mehrschritt- Vorhersagefehler durch Suche nachnachsten Nachbarn in einem rekonstruierten Phasenraum [22].
2. Die Information zur Klassifikation der Schiebedachdaten ist in dem mittleren,nahezu stationaren Teil der Zeitreihen enthalten, siehe Abb. 4.1. Diese Informa-tion wurde uns von Carl Schenck AG mitgeteilt. Als (zumindest qualitatives)

66 KAPITEL 4. EIN MERKMALSVEKTOR ZUR AKUSTISCHEN GUTEPRUFUNG
Abbildung 4.1: Zeitreihen der
Korperschallsignale des Schließ-
gerausches von zwei elektrischen
Schiebedachern. Die Sampling-
rate betragt 10kH. (a) In der
Qualitatsendkontrolle von einem
Prufer als”gut“ klassifiziertes
Produkt, (b) als”fehlerhaft“ be-
wertetes Produkt.
0 10000 20000 30000 40000 50000Stuetzstellen n
−20000
−15000
−10000
−5000
0
5000
10000
15000
20000
Amplitude
(a)
0 10000 20000 30000 40000 50000Stuetzstellen n
−25000
−20000
−15000
−10000
−5000
0
5000
10000
15000
20000
25000
Amplitude
(b)
Maß fur die Stationaritat der Zeitreihen verwenden wir die Ubereinstimmungder Koeffizienten eines AR(10)- Modells, welches an verschiedene Teilstucke derZeitreihen angefittet wird. Als Fitmethode benutzen wir die Minimierung derQuadrate der Einschritt- Vorhersagefehler [22]. Hierbei zeigt sich, daß der mitt-lere Teil der Zeitreihen ab einer Segmentlange von ca. 500, d.h. auf ZeitskalenT & 1/20s in guter Naherung als stationar angesehen werden kann.
3. Die fur die Fehlererkennung relevanten Informationen der Schallsignale konnenvom menschlichen Ohr, d.h. von Experten aufgelost werden. Da die tiefste wahr-nehmbare Frequenz ≈ 20Hz betragt, ist die Zeitskala zur Auflosung der klang-lichen Informationen T . 1/20s. Anderungen auf großeren Zeitskalen werdenals Signalsschwankungen wahrgenommen [16], die aber wegen der Stationaritatder Zeitreihen auf Zeitskalen T & 1/20s nicht auftreten.
Die Zeitreihen eines als ”gut“ und eines als ”fehlerhaft“ vorklassifizierten Schiebe-dachs sind in Abb. 4.1 gezeigt. Da die oben beschriebenen Eigenschaften vermutlichtypisch fur eine Reihe weiterer stationarer technischer Schallsignale sind, besteht dieHoffnung, daß der in diesem Kapitel vorgestellte Merkmalsvektor auch uber das spe-zielle hier untersuchte Problem hinaus anwendbar ist.

4.2. MERKMALE AUS WAVELET- RESTKLASSEN 67
4.2 Merkmale aus Wavelet- Restklassen
Wir wollen zunachst die Idee vorstellen, die der Entwicklung eines Merkmalsvek-tors zugrunde liegt, der auf Schallsignale mit den oben beschriebenen Eigenschaftenangepaßt ist. Die Eigenschaft, daß die Informationen zur Trennung von guten und feh-lerhaften Schiebedachern vom menschlichen Ohr aufgelost werden kann, leitet uns,die Zeit-Frequenz Auflosungscharakteristik des Gehors nachzuahmen. Allgemein istdie Analyse der psychoakustischen Eigenschaften von Gerauschen ein moglicher An-satzpunkt zur Merkmalsfindung [16]. Wir betrachten hiervon nur einen Aspekt, diefrequenzabhangige Auflosung von Schallsignalen durch das Gehor. Wie in Kap. 2.1.3erlautert, kann die fur Frequenzen & 500Hz in guter Naherung hyperbolische Auflo-sungscharakteristik durch eine Wavelettransformation approximiert werden.
Es ist klar, daß fur einen Prufer nur wenige Merkmale der Schallsignale fur dieBeurteilung eines Produktes von Bedeutung sind und viele weitere unabhangig da-von variieren konnen. Wir wollen jedoch nicht nach diesen Unterschieden, d.h. denSignaturen zwischen Wavelettransformationen von Schließgerauschen guter und feh-lerhafter Schiebedacher suchen. Statt dessen nehmen wir an, daß sich alle charakteris-tischen Merkmale der Zeitreihen, ob sie fur den Qualitatszustand zunachst bedeut-sam sind oder nicht, herausbilden werden, wenn uber statistische Fluktuationen undRauschanteile geeignet gemittelt werden kann. Enthalt ein Signal Informationen imoberen Frequenzbereich, wie es bei den Schiebedachdaten der Fall ist, so kann derRauschanteil nicht durch Tiefpaßfiltern abgetrennt werden.
Naturlich ist es nicht moglich uber eine Zeit-Frequenz Darstellung zu mitteln, dahierdurch die Informationen in dem Unterraum der Zeit-Frequenz Ebene, uber dengemittelt wurde, zerstort werden. Wir definieren daher eine Restklasse aus Wave-lettransformationen, aus denen wir Merkmalsvektoren konstruieren. Diese Großenerlauben einen Mittelungsprozeß im Zeitraum ohne die zeitaufgelosten Informationenzu verlieren. Wir zeigen zunachst anhand kunstlicher, verrauschter Signale, daß aufdiese Weise Merkmalsvektoren mit einem relativ hohen Signal-Rausch Verhaltnis kon-struiert werden konnen. Die Ergebnisse werden durch die anschließende Anwendungauf die Schiebedachdaten (qualitativ) bestatigt.
Im nachsten Schritt mussen die fur die Fehlererkennung relevanten Merkmale ausder Menge aller ”typischen“ Eigenschaften der Signale isoliert werden. Hierzu trainie-ren wir einen Klassifikationsalgorithmus mit Merkmalsvektoren, die aus Trainingsda-ten von guten und fehlerhaften Schiebedachern berechnet wurden. In der Trainings-menge sollten Beispiele aus allen Fehlerklassen enthalten sein. In der anschließendenKontrollphase werden die aus den Testdaten erzeugten Merkmalsvektoren mit denals ”gut“ sowie als ”fehlerhaft“ vorklassifizierten Trainingsvektoren in jeweils einerUmgebung der Testvektoren verglichen. Ist die Trainingsmenge hinreichend groß, soerwarten wir, daß die gemittelten Abstande eines Testvektors zu den am nachstengelegenen ”guten“ bzw. ”fehlerhaften“ Trainingsvektoren im wesentlichen die Merk-

68 KAPITEL 4. EIN MERKMALSVEKTOR ZUR AKUSTISCHEN GUTEPRUFUNG
0 32 64 96 128 160 192 224 256
Diskrete Frequenzen k
0
0.2
0.4
0.6
0.8
1
Am
plitu
de
Abbildung 4.2: Die Waveletfilter (Bandpaßfilter) hk,2, · · · , hk,5 (4.1) und (2.39) im
Frequenzraum (durchgezogene Linien), zusatzlich sind der Hoch- und der Tiefpaßfilter
hpk,1 bzw. tpk,5 gestrichelt eingezeichnet.
male der Zeitreihe reprasentieren, die fur die Qualitat des getesteten Schiebedachsvon Bedeutung sind. Die Klassifikation kann dann durch den Vergleich der Differenzder gewichteten Abstande mit einem Schwellenwert erfolgen.
4.2.1 Wavelettransformation der Zeitreihen
Wie im letzten Abschnitt erlautert, ist die relevante Zeitskala zur Auflosung derklanglichen Informationen der Schallsignale von den Schiebedachern T ≈ 1/20s. Wirberechnen daher diskrete Wavelettransformationen (wie in Kap. 2.2.3 dargestellt)uber alle Abschnitte der Lange N = 512 des mittleren Teils der Zeitreihen. Dieverwendeten Waveletfilter sollen die Eigenschaft haben, in der Zeit-Frequenz Ebenegut lokalisiert zu sein, d.h. eine kleine Zeit-Frequenz Unscharfe zu haben, sowie dieBedingungen (2.38) und (2.41) zu erfullen. Wir definieren damit die Hoch- und denTiefpaßfilter hpk,j , tpk,j; k = −N/2 + 1, · · · , N/2; j = 1, · · · , 5 durch
hpk,j =
0 fur 0 ≤
∣∣ kN
∣∣ < fj/√2√
12
(1 + sin
[π log2
(f−1j
∣∣ kN
∣∣ )])fur fj/
√2 ≤
∣∣ kN
∣∣ ≤ √2fj
1 fur√2fj <
∣∣ kN
∣∣ ≤ 12 ,
tpk,j =
1 fur 0 ≤
∣∣ kN
∣∣ < fj/√2√
12
(1− sin
[π log2
(f−1j
∣∣ kN
∣∣ )])fur fj/
√2 ≤
∣∣ kN
∣∣ ≤ √2fj
0 fur√2fj <
∣∣ kN
∣∣ ≤ 12 ,
(4.1)
wobei fj = 2−jfc = 2−(j+1) die Trennfrequenz der Filter hpk,j und tpk,j bezeich-net. Die Waveletfilter hk,j; k = −N/2 + 1, · · · , N/2; j = 1, · · · , 6 werden dann

4.2. MERKMALE AUS WAVELET- RESTKLASSEN 69
durch Gl. (2.39) definiert. Abb. 4.2 zeigt die Bandpaßfilter hk,2, · · · , hk,5 sowie denHoch- und Tiefpaßfilter hpk,1 ≡ hk,1 bzw. tpk,5 ≡ hk,6.
Durch Wavelettransformation mit den in Abb. 4.2 gezeigten Filtern erhalten wiraus jedem Zeitreihenabschnitt xn; n = 1, · · · , 512 eine MatrixWT h
x (n, j) vom For-mat 512×6, deren Spalten die Hochpaß-, Bandpaß- und Tiefpaß- gefilterten Kompo-nenten dieses Teilstucks der Zeitreihe enthalten. Von jeder Zeitreihe werden insgesamt40 Matrizen dieses Typs berechnet, uber die ein Mittel im Zeitraum gebildet werdensoll.
4.2.2 Definition der Wavelet- Restklassen
Wir wollen nun aus den Wavelettransformationen WT hx (n, j) ein Große definieren,
uber die im Zeitraum gemittelt werden kann. Da die Zeitreihen eine naherungsweisestationare Oszillation beschreiben, unterscheiden sich ihre Teilstucke im wesentlichendurch die Anfangsbedingungen, welche durch die Realisierung einer Zufallsvariablenbeschrieben werden konnen. Dies leitet uns, eine Große zu definieren, die keine Funk-tion der Anfangsbedingungen mehr ist: Die Menge (Restklasse) aller zyklischen Per-mutationen von WT h
x (n, j) in der Variablen n:
Rhx(j) := Pzyk
(WT h
x (n, j))| n = 1, · · · , N ; j = 1, · · · , log2(N ) . (4.2)
Fur die Definition der Große Rhx ist die Translationsinvarianz von WT h
x (n, j) im Zeit-raum erforderlich. Es gilt:
Pzyk(WT h
x (m, j))(n, j) =WT h
(Pzyk(x))(n, j) . (4.3)
Aus diesem Grund wird, wie in Kap. 2.2.3 erlautert, die Wavelettransformation einesVektors xn; n = 1, · · · , N durch eine (redundante) Matrix und nicht durch einenVektor gleicher Dimension dargestellt. Weiterhin ist klar, daß die Definition (4.2) vonder Anzahl der Spalten von WT h
x (n, j) unabhangig ist, die Zerlegung eines Signals inseine Bandpaß- gefilterten Anteile also nicht vollstandig zu sein braucht.
Auf der Menge Rhx laßt sich eine Metrik wie folgt definieren:
d(Rhx, R
hy) := min
n‖WT h
x − Pzyk(WT h
y (n, j))‖2 . (4.4)
Hierbei wird das Minimum des Abstands
‖WT hx −WT h
y ‖2 =√∑
n
∑j
(WT h
x (n, j)−WT hy (n, j)
)2
uber alle zyklischen Permutationen von WT hy (n, j) in der Variablen n gebildet. Es ist
zu zeigen, daß d(Rhx, R
hy) die Eigenschaften einer Metrik hat. Zunachst folgt aus der
Definition (4.4) sofort: d(Rhx, R
hy) = d(Rh
y , Rhx) ≥ 0 und d(Rh
x, Rhy) = 0 ⇐⇒ Rh
x = Rhy .

70 KAPITEL 4. EIN MERKMALSVEKTOR ZUR AKUSTISCHEN GUTEPRUFUNG
Die Dreiecksungleichung folgt schließlich aus der Abschatzung:
d(Rhx, R
hy) ≤ ‖WT h
x −WT hy ‖2
= ‖WT hx −WT h
z +WT hz −WT h
y ‖2
≤ ‖WT hx −WT h
z ‖2 + ‖WT hz −WT h
y ‖2 .
(4.5)
Diese Ungleichung gilt fur jede Wahl von WT hy und WT h
z unabhangig voneinander.Insbesondere konnen fur die gegebenen Signale xn, yn und zn die zyklischenPermutationen vonWT h
z (n, j) undWT hy (n, j) so gewahlt werden, daß ‖WT h
x−WT hz ‖2
und ‖WT hz − WT h
y ‖2 minimal werden. Damit steht in der letzten Zeile von (4.5):d(Rh
x, Rhy) ≤ d(Rh
x, Rhz) + d(Rh
z , Rhy).
Als nachsten Schritt definieren wir auf der Menge Rhx eine Addition durch:
Rhx ⊕Rh
y := Pzyk([WT h
x + Pmin
(WT h
y
)](n, j)
)| n = 1, · · · , N ; (4.6)
j = 1, · · · , log2(N ). Die zyklische Permutation Pmin
(WT h
y (m, j))wird hierbei durch
die Bedingung ‖WT hx −Pmin
(WT h
y (m, j))‖2 = min!, also durch die Minimumsbeding-
ung in der Definition der Metrik (4.4) bestimmt. Die Addition (4.6) ist kommutativaber aufgrund der Permutation Pmin nicht assoziativ. Aus (4.3) folgt die Abgeschlos-senheitsrelation
Rhx ⊕Rh
y = Rh(x+Pmin(y)) ∈ Rh
x ;
somit bildet die Menge Rhx | ⊕ einen Ring mit einer Metrik. Weiterhin gilt ∀ a ∈ R:
a(Rhx ⊕Rh
y
)= aRh
x ⊕ aRhy .
4.2.3 Konstruktion der Merkmalsvektoren
Wir wollen nun aus der Zeitreihe xn; n = 1, · · · , KN einen Merkmalsvektor kon-struieren, indem wir uber die Elemente Rh
xi; i = 1, · · · , K mitteln, die aus den K
Segmenten xin; n = 1, · · · , N berechnet werden (N muß hierbei eine Potenz von 2sein). Da die Addition (4.6) nicht assoziativ ist, muß die Summationsreihenfolge vonRh
xi festgelegt werden. Dies erfolgt durch einen Clusterungsalgorithmus:Zunachst definiert jedes Element ein eigenes Cluster mit dem ”Schwerpunktvek-
tor“ ci,1 = Rhxi . Der Index von ci,k gibt hierbei an, daß das Cluster i aus k Elementen
besteht. Im ersten Schritt werden die beiden Cluster mit dem kleinsten ”Schwer-punktabstand“ d(ci,1, cj,1) zusammengelegt, indem ein gemeinsamer ”Schwerpunkt“durch ci,2 = (ci,1 ⊕ cj,1)/2 definiert wird. Auf diese Weise werden in der Reihenfolgedes jeweils kleinsten Abstands d(ci,k, cj,l) alle Cluster sukzessiv vereinigt, wobei dergemeinsame ”Schwerpunkt“ von zwei Clustern durch ci,(k+l) = (kci,k ⊕ lcj,l)/(k + l)definiert wird. Dieser Prozeß endet mit dem Element c1,K, welches nun einen ”Schwer-punkt“ oder Mittelwert fur die Menge Rh
xi angibt. Die Eigenschaften der auf diese

4.2. MERKMALE AUS WAVELET- RESTKLASSEN 71
Weise konstruierten Merkmalsvektoren werden wir im im nachsten Abschnitt genaueruntersuchen.
Dieser Clusterungsalgorithmus ist nicht die einzige Moglichkeit, einen Mittelwertfur die Menge Rh
xi zu erhalten. DasWachstum der Cluster erfolgt bei dem Verfahrenvon mehreren ”Bildungskeimen“ aus, d.h. es entstehen im allgemeinen verschiedeneCluster mit mehreren Elementen, die am Ende vereinigt werden. Alternativ hierzukann man nur einen ”Bildungskeim“ zulassen, d.h. ausgehend vom ersten Clustermit zwei Elementen werden alle weiteren Ein-Elemente Cluster nur noch mit diesemgroßten Cluster in der Reihenfolge des jeweils kleinsten Abstands d(c1,k, cj,1) zum
”Schwerpunkt“ c1,k des Clusters vereinigt. Es stellt sich jedoch heraus, daß die aufdiese Weise konstruierten Merkmalsvektoren c1,K fur alle von uns untersuchten Daten(deutlich) schlechtere Eigenschaften als c1,K haben.
Wir erwarten, daß sich durch diesen Mittelungsprozeß die relevanten Informa-tionen im Zeitraum von WT h
x (n, j) herausbilden lassen, indem statistische Fluktua-tionen und Rauschanteile gedampft werden. Es reicht hierbei aus, nur diejenigenSignalkomponenten (d.h. Spalten) von WT h
x (n, j) zu berucksichtigen, welche rele-vante Zeitinformationen enthalten konnen. Dies sind der Hochpaß und die folgendenJ − 1 Bandpasse, wobei die Filterzahl J durch die Frequenz der Grundschwingungoder der langsamsten dominanten Modulation des Schallsignals bestimmt wird. DieFrequenzbander unterhalb dieser Grundfrequenz enthalten fast keine Zeitinformationmehr. Fur die Schallsignale der Schiebedacher ergibt sich J = 5 (Abb. 4.2).
Sei nun WTh
x (n, j) die Matrix, welche aus den ersten J Spalten von WT hx (n, j)
gebildet wird. Dann folgt aus (2.43):
‖WTh
x − WTh
y ‖22 =
∑k
(xk − yk)(xk − yk)J∑j=1
|hk,j|2
=∑k
(xk − yk)(xk − yk)|hpk,J |2
= ‖hpJ x− hpJ y ‖22 .
(4.7)
Im Schritt von der ersten zur zweiten Zeile haben wir die Eigenschaft (2.42) der Filter,d.h.
∑Jj=1 |hk,j|2 = 1− |tpk,J |2 = |hpk,J |2 ausgenutzt. Aus (4.7) folgt, daß d(Rh
x, Rhy)
(4.4) auch mit Hilfe der Hochpaß- gefilterten Signale hpk,J xk, hpk,J yk berechnetwerden kann. Damit muß nur ein eindimensionaler Vektor statt einer Matrix zyklischdurchpermutiert werden; fur die numerische Implementierung ist dieser Unterschiedbedeutsam.
4.2.4 Eigenschaften der Merkmalsvektoren
Wir wollen zunachst die Eigenschaften von aus Wavelet- Restklassen konstruiertenMerkmalsvektoren anhand kunstlicher, verrauschter Signale studieren. Hierzu be-trachten wir acht Sagezahnsignale, die sich durch ihre Flankensteilheit unterschei-

72 KAPITEL 4. EIN MERKMALSVEKTOR ZUR AKUSTISCHEN GUTEPRUFUNG
Abbildung 4.3: Sagezahnsigna-
le mit 15% weißem Rauschen.
Die (unverrauschten) Signale in
(a) und (b) sind paarweise sym-
metrisch zueinander.
0 45 90Stuetzstellen n
−2
−1
0
1
2
Am
plitu
de
(a)
(1)(2)
(3)(4)
0 45 90Stuetzstellen n
−2
−1
0
1
2
Am
plitu
de
(b)
(5) (6) (7) (8)
den, wobei je zwei der Signale symmetrisch zueinander sind, siehe Abb. 4.3. DieSagezahnsignale sind mit 15% weißem Rauschen uberlagert. Diese Signale haben mitden Schiebedachdaten die Eigenschaft gemeinsam, daß sie oberhalb einer Zeitskala Tstationar sind und sich alle Informationen, die fur die Klassifikation der Zeitreihenrelevant sind, unterhalb dieser Zeitskala befinden. Bei den einfachen Beispielsignalenin Abb. 4.3 ist T naturlich die Periode.
Wir wollen nun die Merkmalsvektoren c1,K mit der Standardmethode der Wahlvon Merkmalen aus Spektralkomponenten vergleichen. Hierzu berechnen wir gefen-sterte Fouriertransformationen der Sagezahnsignale uber 512 Stutzstellen mit zurHalfte uberlappenden Fenstern und mitteln die Betragsquadrate uber eine Signallangevon 30 ·512 = 15360. In Abb. 4.4 sind die paarweisen Euklidischen Abstande dieserMerkmalsvektoren mit gestrichelten Verbindungslinien angetragen.
Zum Vergleich berechnen wir die Merkmale ci1,K; i = 1, · · · , 8 der Signale, wo-bei K = 30 gewahlt wird. Die Wavelettransformationen WT h
xl(n, j); l = 1, · · · , Kuberdecken jeweils 512 Stutzstellen, damit ist die Lange der Zeitreihen ebenfalls15360. Es ist wichtig zu bemerken, daß die Periode von WT h
xl(n, j) kein Vielfaches(oder nahezu Vielfaches) der Periode der Sagezahnsignale T = 45 ist; dies konnte an-dernfalls die Ursache von Artefakten sein. Nach Konstruktion liegt die Frequenz derGrundschwingung der Signale f1 = 1/45 im Bereich des vierten Bandpaßes hk,5;
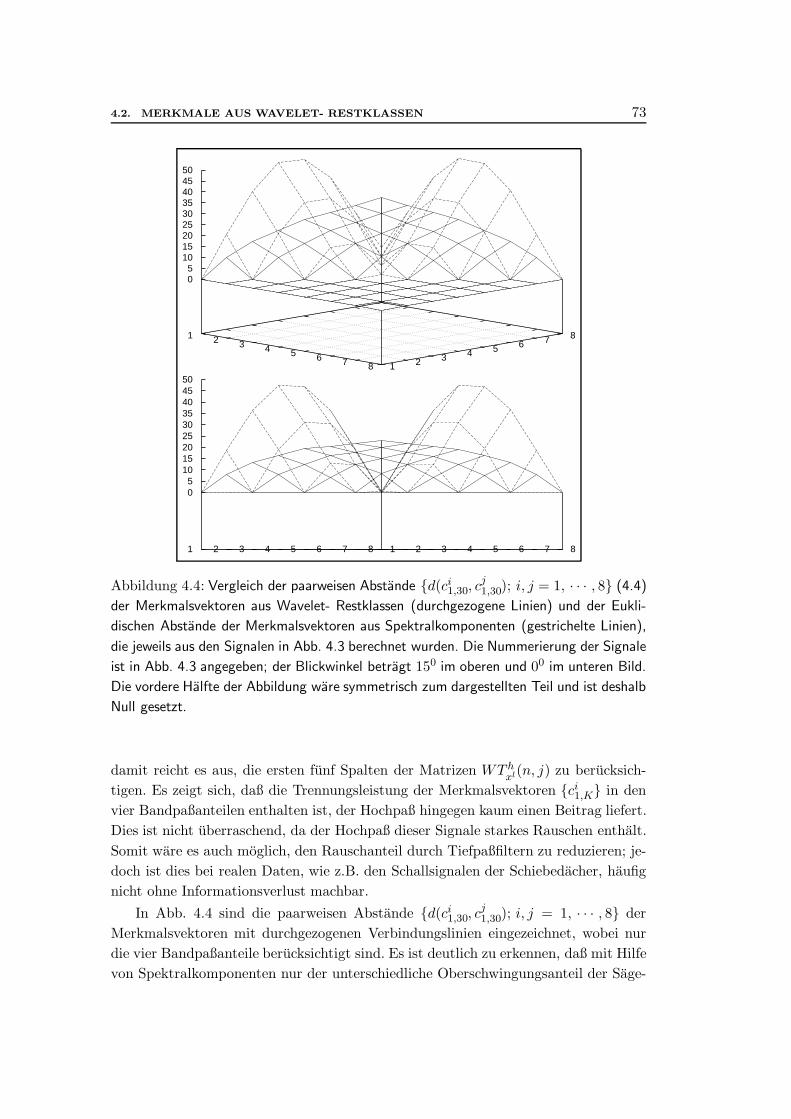
4.2. MERKMALE AUS WAVELET- RESTKLASSEN 73
1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8
05
101520253035404550
1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8
05
101520253035404550
Abbildung 4.4: Vergleich der paarweisen Abstande d(ci1,30, cj1,30); i, j = 1, · · · , 8 (4.4)
der Merkmalsvektoren aus Wavelet- Restklassen (durchgezogene Linien) und der Eukli-
dischen Abstande der Merkmalsvektoren aus Spektralkomponenten (gestrichelte Linien),
die jeweils aus den Signalen in Abb. 4.3 berechnet wurden. Die Nummerierung der Signale
ist in Abb. 4.3 angegeben; der Blickwinkel betragt 150 im oberen und 00 im unteren Bild.
Die vordere Halfte der Abbildung ware symmetrisch zum dargestellten Teil und ist deshalb
Null gesetzt.
damit reicht es aus, die ersten funf Spalten der Matrizen WT hxl(n, j) zu berucksich-
tigen. Es zeigt sich, daß die Trennungsleistung der Merkmalsvektoren ci1,K in denvier Bandpaßanteilen enthalten ist, der Hochpaß hingegen kaum einen Beitrag liefert.Dies ist nicht uberraschend, da der Hochpaß dieser Signale starkes Rauschen enthalt.Somit ware es auch moglich, den Rauschanteil durch Tiefpaßfiltern zu reduzieren; je-doch ist dies bei realen Daten, wie z.B. den Schallsignalen der Schiebedacher, haufignicht ohne Informationsverlust machbar.
In Abb. 4.4 sind die paarweisen Abstande d(ci1,30, cj1,30); i, j = 1, · · · , 8 der
Merkmalsvektoren mit durchgezogenen Verbindungslinien eingezeichnet, wobei nurdie vier Bandpaßanteile berucksichtigt sind. Es ist deutlich zu erkennen, daß mit Hilfevon Spektralkomponenten nur der unterschiedliche Oberschwingungsanteil der Sage-
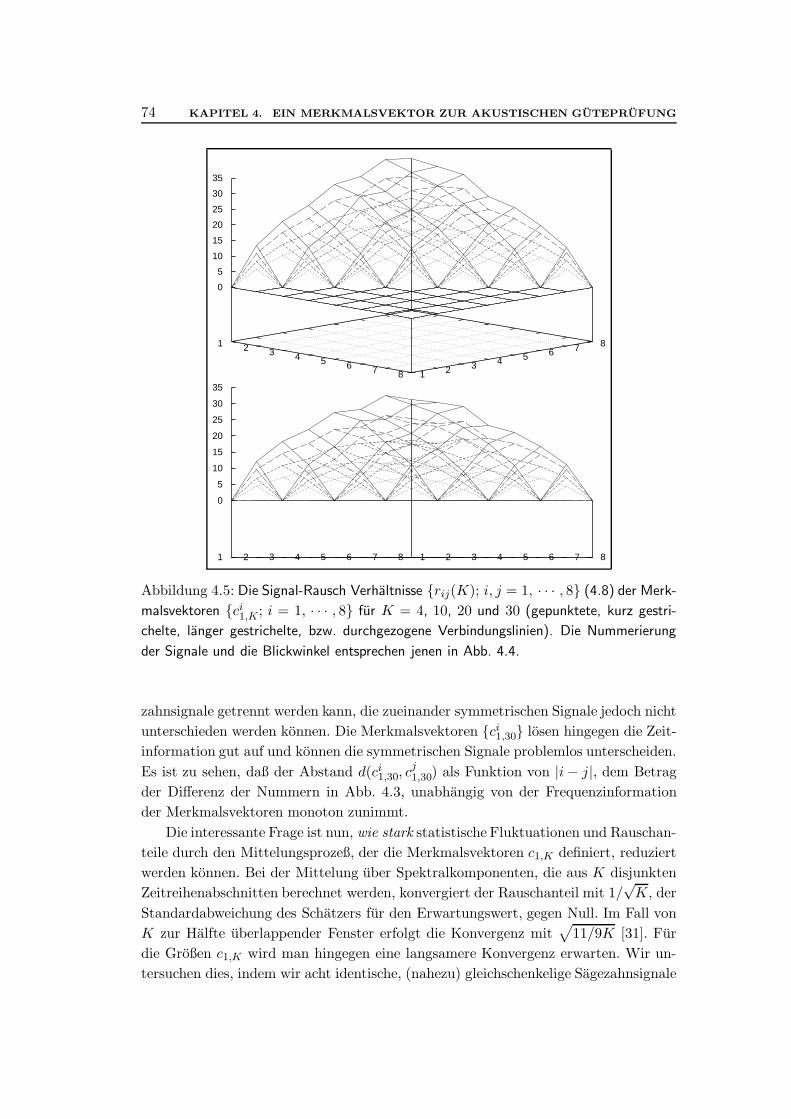
74 KAPITEL 4. EIN MERKMALSVEKTOR ZUR AKUSTISCHEN GUTEPRUFUNG
1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8
0
5
10
15
20
25
30
35
1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8
0
5
10
15
20
25
30
35
Abbildung 4.5: Die Signal-Rausch Verhaltnisse rij(K); i, j = 1, · · · , 8 (4.8) der Merk-
malsvektoren ci1,K; i = 1, · · · , 8 fur K = 4, 10, 20 und 30 (gepunktete, kurz gestri-
chelte, langer gestrichelte, bzw. durchgezogene Verbindungslinien). Die Nummerierung
der Signale und die Blickwinkel entsprechen jenen in Abb. 4.4.
zahnsignale getrennt werden kann, die zueinander symmetrischen Signale jedoch nichtunterschieden werden konnen. Die Merkmalsvektoren ci1,30 losen hingegen die Zeit-information gut auf und konnen die symmetrischen Signale problemlos unterscheiden.Es ist zu sehen, daß der Abstand d(ci1,30, c
j1,30) als Funktion von |i− j|, dem Betrag
der Differenz der Nummern in Abb. 4.3, unabhangig von der Frequenzinformationder Merkmalsvektoren monoton zunimmt.
Die interessante Frage ist nun, wie stark statistische Fluktuationen und Rauschan-teile durch den Mittelungsprozeß, der die Merkmalsvektoren c1,K definiert, reduziertwerden konnen. Bei der Mittelung uber Spektralkomponenten, die aus K disjunktenZeitreihenabschnitten berechnet werden, konvergiert der Rauschanteil mit 1/
√K, der
Standardabweichung des Schatzers fur den Erwartungswert, gegen Null. Im Fall vonK zur Halfte uberlappender Fenster erfolgt die Konvergenz mit
√11/9K [31]. Fur
die Großen c1,K wird man hingegen eine langsamere Konvergenz erwarten. Wir un-tersuchen dies, indem wir acht identische, (nahezu) gleichschenkelige Sagezahnsignale
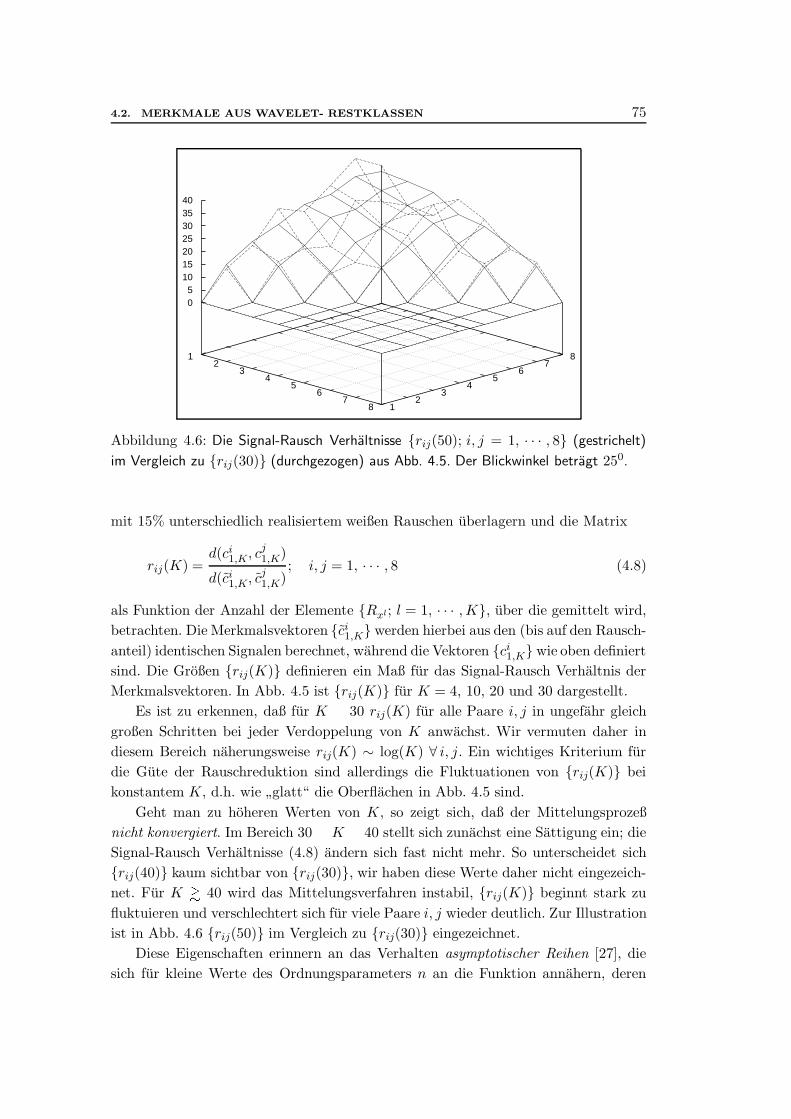
4.2. MERKMALE AUS WAVELET- RESTKLASSEN 75
12
34
56
78 1
23
45
67
8
05
10152025303540
Abbildung 4.6: Die Signal-Rausch Verhaltnisse rij(50); i, j = 1, · · · , 8 (gestrichelt)
im Vergleich zu rij(30) (durchgezogen) aus Abb. 4.5. Der Blickwinkel betragt 250.
mit 15% unterschiedlich realisiertem weißen Rauschen uberlagern und die Matrix
rij(K) =d(ci1,K, c
j1,K)
d(ci1,K, cj1,K)
; i, j = 1, · · · , 8 (4.8)
als Funktion der Anzahl der Elemente Rxl; l = 1, · · · , K, uber die gemittelt wird,betrachten. Die Merkmalsvektoren ci1,K werden hierbei aus den (bis auf den Rausch-anteil) identischen Signalen berechnet, wahrend die Vektoren ci1,K wie oben definiertsind. Die Großen rij(K) definieren ein Maß fur das Signal-Rausch Verhaltnis derMerkmalsvektoren. In Abb. 4.5 ist rij(K) fur K = 4, 10, 20 und 30 dargestellt.
Es ist zu erkennen, daß fur K . 30 rij(K) fur alle Paare i, j in ungefahr gleichgroßen Schritten bei jeder Verdoppelung von K anwachst. Wir vermuten daher indiesem Bereich naherungsweise rij(K) ∼ log(K) ∀ i, j. Ein wichtiges Kriterium furdie Gute der Rauschreduktion sind allerdings die Fluktuationen von rij(K) beikonstantem K, d.h. wie ”glatt“ die Oberflachen in Abb. 4.5 sind.
Geht man zu hoheren Werten von K, so zeigt sich, daß der Mittelungsprozeßnicht konvergiert. Im Bereich 30 . K . 40 stellt sich zunachst eine Sattigung ein; dieSignal-Rausch Verhaltnisse (4.8) andern sich fast nicht mehr. So unterscheidet sichrij(40) kaum sichtbar von rij(30), wir haben diese Werte daher nicht eingezeich-net. Fur K & 40 wird das Mittelungsverfahren instabil, rij(K) beginnt stark zufluktuieren und verschlechtert sich fur viele Paare i, j wieder deutlich. Zur Illustrationist in Abb. 4.6 rij(50) im Vergleich zu rij(30) eingezeichnet.
Diese Eigenschaften erinnern an das Verhalten asymptotischer Reihen [27], diesich fur kleine Werte des Ordnungsparameters n an die Funktion annahern, deren

76 KAPITEL 4. EIN MERKMALSVEKTOR ZUR AKUSTISCHEN GUTEPRUFUNG
Entwicklung sie darstellen, bei einem endlichen Wert nmax die beste Approximationerzielen und danach divergieren.
Ob uberhaupt, und wenn ja wie gut diese Rauschreduktion funktioniert, hangtstark vom Rauschanteil der Sagezahnsignale ab. Fur einen Rauschanteil < 15% erhal-ten wir entsprechend hohere Signal-Rausch Verhaltnisse (4.8), wahrend das Verfahrenbei einem zu großen Rauschanteil (in unserem Fall & 20%) versagt. Auch wenn wirdie Merkmalsvektoren c1,K nur anhand der einfachen Beispielsignale in Abb. 4.3 un-tersucht haben, werden wir einige der Eigenschaften bei den Merkmalsvektoren, diewir im nachsten Abschnitt aus den Schiebedachdaten berechnen, wiederfinden.
4.3 Akustische Qualitatskontrolle von Schiebedachern
In diesem Abschnitt wollen wir die Merkmalsvektoren c1,K auf die Klassifikationder Korperschallsignale von elektrischen Schiebedachern anwenden. Uns liegen ins-gesamt 108 Datensatze von 13 als ”gut“ und 14 als ”fehlerhaft“ vorklassifiziertenSchiebedachern vor, wobei von jedem Schiebedach je zwei Messungen in zwei ver-schiedenen Sensoranordnungen ausgefuhrt wurden.
Hierbei treten zwei Probleme auf: Erstens ist die Datenbasis fur eine statistischsignifikante Bestimmung der Trennungsleistung der Merkmalsvektoren zu klein. Da-ruberhinaus ist die Vorklassifikation der Datensatze auch nicht zuverlassig. Bei Nach-tests anhand der aufgenommenen Schallsignale ergaben sich einige Abweichungen vonden ursprunglichen Bewertungen der Prufer. Da wir aufgrund der kleinen Datenmengenicht die Moglichkeit haben, uns nur auf die Datensatze zuverlassig vorklassifizierterSchiebedacher zu beschranken, betrachten wir die folgende Fragestellung:
Angenommen ein Klassifikationalgorithmus wird mit Beispieldaten von als ”gut“und als ”fehlerhaft“ vorklassifizierten Schiebedachern trainiert. Wie gut kann dannin einem out-of-sample Test das Ergebnis der Vorklassifikation reproduziert werden?Wir nehmen hierbei an, daß nur die Bewertungen von Schiebedachern an der Grenzedes Toleranzbereichs unsicher sind und somit die Klassifikation der Testdaten nichtnach zufalligen antrainierten Kriterien erfolgt, sondern im wesentlichen aufgrund vonMerkmalen, die fur die Qualitat der Produkte von Bedeutung sind. Die Interpretati-on der Ergebnisse ist naturlich nur qualitativ moglich, indem die Trennungsleistungverschiedener Merkmalsvektoren verglichen wird.
4.3.1 Klassifikation der Merkmalsvektoren
Wir berechnen die Merkmale ci1,K ; i = 1, · · · , 108 der Schiebedacher jeweils ausdem mittleren Teil der Zeitreihen, wobei wir K = 20, 30 sowie 40 wahlen. Beidem Mittelungsprozeß werden, wie erwahnt, nur der Hochpaß und die vier fuhrendenBandpaße der Wavelettransformationen WT h
xl(n, j); l = 1, · · · , K berucksichtigt,da die ubrigen Signalkomponenten keine relevante Zeitinformation enthalten.

4.3. AKUSTISCHE QUALITATSKONTROLLE VON SCHIEBEDACHERN 77
Die Klassifiktion der Daten erfolgt in einer leave-one-out Statistik (Kap. 2.3.3)auf dem gesamten Datensatz, der in einer Sensoranordnung aufgenommen wurde. Davon jedem Schiebedach zwei Zeitreihen vorliegen, betrachten wir genauer eine leave-two-out Statistik, wobei die abhangigen Zeitreihen jeweils aus der Trainingsmengeentfernt werden.
Die Klassifikation eines Testvektors erfolgt durch den Vergleich mit den Trai-ningsvektoren von als ”gut“ sowie als ”fehlerhaft“ vorklassifizierten Schiebedachern,die sich jeweils in einer Umgebung (verschiedener Große) des Testvektors befinden.Zu den Vektoren in beiden Umgebungen wird ein gemittelter Abstand bestimmt unddie Differenz der gewichteten Abstande mit einem Schwellenwert verglichen.
Zunachst muß hierzu der Abstand eines Merkmalsvektors cT1,K zu einer MengeVektoren ci1,K; i = 1, · · · , L eindeutig definiert werden. Es ist naheliegend, denAbstand von cT1,K zu einem ”Schwerpunktvektor“ dieser Menge zu betrachten, wo-bei die erste Moglichkeit zur Definition eines ”Schwerpunkts“ CL der Clusterungsal-gorithmus bietet, den wir auch zur Konstruktion der Merkmalsvektoren (Abschnitt4.2.3) verwenden. Im Unterschied zu diesem Mittelungsverfahren existiert hier jedocheine naturliche Reihenfolge fur die Addition von ci1,K: Ihre Abstande zum Testvek-tor cT1,K. Damit laßt sich ein weiterer ”Schwerpunktvektor“ CL durch Summation vonci1,K in der Reihenfolge der Abstande d(cT1,K, c
i1,K), definieren, wobei mit den beiden
am nachsten zum Testvektor gelegenen Elementen begonnen wird. Die Konstrukti-on von CL erfolgt damit - im Unterschied zu CL - von einem ”Bildungskeim“ aus;diesen Unterschied haben wir bereits in Abschnitt 4.2.3 diskutiert. Damit ergibt sichals dritte Moglichkeit zur Definition eines ”Schwerpunkts“ CL der dort beschriebene
”Einkeim“- Clusterungsprozeß.Der Vergleich dieser drei Moglichkeiten fuhrt im Fall der Schiebedachdaten zu
dem interessanten Resultat, daß die Berechnung von ”Umgebungsschwerpunkten“nach den beiden ”Einkeim“- Clusterungsverfahren, CL und CL, zu ungefahr gleichenKlassifikationsergebnissen fuhrt, wahrend die Verwendung von CL (deutlich) schlech-tere Resultate liefert. Damit zeigt sich, daß zur Mittelung der Restklassen- ElementeRxl ; l = 1, · · · , K der ”Mehrkeim“- Clusterungsalgorithmus, fur die Definition von
”Umgebungsschwerpunkten“ hingegen ein ”Einkeim“- Verfahren offenbar besser ge-eignet ist. Bei der Addition von Trainingsvektoren in der Reihenfolge ihrer Abstandezum Testvektor entfallt zudem die Berechnung der Abstandsmatrizen; aus numeri-schen Grunden ist dieses Verfahren daher vorzuziehen.
Bei der Wahl der Trainingsmenge stellt es sich als sinnvoll heraus, Ausreißeraus der Stichprobe der als ”fehlerhaft“ vorklassifizierten Merkmalsvektoren nicht zuberucksichtigen um nur ”typische“ Fehler zu trainieren. Die Detektierung von Feh-lern, die zu starken Abweichungen der Schallsignale fuhren, stellt ohnehin kein Pro-blem dar. Hierzu berechnen wir die Abstande aller Trainingsvektoren von fehlerhaf-ten Schiebedachern zum jeweils korrespondierenden ”Schwerpunkt“ CL=26 derjenigenVektoren, welche die guten Produkte reprasentieren, und entfernen die n1 Elemente

78 KAPITEL 4. EIN MERKMALSVEKTOR ZUR AKUSTISCHEN GUTEPRUFUNG
mit den großten Abstanden. Aus der verbleibenden Trainingsmenge werden nun furjeden Testvektor cT1,K die n2 am nachsten gelegenen Elemente gesucht. Ebenso werdendie n3 als ”gut“ vorklassifizierten Trainingsvektoren mit den kleinsten Abstanden zucT1,K ermittelt und hieraus die Abstandsvektoren dg und df zu den Umgebungen der
”guten“ bzw. ”fehlerhaften“ Trainingsvektoren berechnet. Hierbei ist
dg,f = d([cT1,K]1, [Cg,fL ]1), · · · , d([cT1,K]J , [C
g,fL ]J ) . (4.9)
Die Metrik d([cT1,K]j, [Cg,fL ]j) (4.4) wird von jeweils einer Filterkomponente der Merk-
malsvektoren (d.h. einer Spalte von WT hx (n, j)) berechnet. Bei insgesamt J Filtern
erhalt man damit zwei J-dimensionale Vektoren. Hierdurch wird es moglich, die Fre-quenzbander der Signale individuell zu gewichten. Dies ist erforderlich, da sich sowohldie Defekte der Schiebedacher wie auch sonstige Einflusse in den verschiedenen Fre-quenzbandern der Schallsignale unterschiedlich stark bemerkbar machen und daherdie Abstande der Test- zu den Trainingsvektoren individuell fur die Komponenten derMerkmalsvektoren c1,K gewichtet werden mussen. Dies erfolgt durch die Definitioneines relativen Abstands, wobei
drel =⟨dg − αdf ,n
⟩mit ‖n‖2 = 1 (4.10)
ist. α bezeichnet hierbei eine vektorwertige Wichtungskonstante und n definiert denUnterraum, auf den der Abstandsvektor projeziert wird. Die Abstande drel der Test-vektoren konnen jetzt mit einem Schwellenwert verglichen werden.
Zur Berechnung von drel mussen die Konstanten α und n sowie die Umgebungs-großen n1, n2 und n3 geschatzt werden. Dies erfolgt durch die Minimierung des ge-samten Klassifikationsfehlers der leave-two-out Statistik. Da die Parameter aus prak-tischen Grunden auf dem gesamten Datensatz und nicht auf jeder Trainingsmengegetrennt geschatzt werden, ergibt sich allerdings eine Mischform aus L- und R- Sta-tistik (siehe Kap. 2.3.3), die keine rigorose Schranke fur den Bayeschen Fehler bildet.Jedoch fuhrt in unserem Fall die relativ große Zahl von Parametern vermutlich zueiner Uberanpassung des geschatzten Klassifikators an die Stichproben. Wir untersu-chen dies, indem wir die Merkmalsvektoren c1,20 aus verschiedenen Teilstucken derZeitreihen berechnen und die Parameter vergleichen, die sich jeweils durch die Mini-mierung des Klassifikationsfehlers ergeben. Wir nehmen daher an, daß die verwendeteStatistik den Bayeschen Fehler unterschatzt, jedoch ist hier der qualitative Vergleichverschiedener Merkmalsvektoren unser Ziel.
4.3.2 Ergebnisse
Wir wollen nun die Merkmalsvektoren c1,40 wiederum mit Merkmalen aus Spektral-komponenten vergleichen. Hierzu berechnen wir die gleichen Referenzvektoren wie inAbschnitt 4.2.4 uber eine Signallange von 40 · 512 = 20480. Die Klassifikation derMerkmalsvektoren aus Spektralkomponenten erfolgt analog zu dem oben beschriebe-

4.3. AKUSTISCHE QUALITATSKONTROLLE VON SCHIEBEDACHERN 79
−5 −4 −3 −2 −1 0 1 2 3λ
0
0.2
0.4
0.6
0.8
1
P(F
ehle
r)
(a)
−40 −30 −20 −10 0 10 20 30λ
0
0.2
0.4
0.6
0.8
1
P(F
ehle
r)
(b)Abbildung 4.7: Klassifikation
der Schiebedachsignale: Wahr-
scheinlichkeit von Fehlklassifi-
kationen (falsche Akzeptanzen
bzw. falsche Zuruckweisungen)
als die Funktion eines Schwel-
lenparameters λ. Durchgezoge-
ne Kurven: Sensoranordnung 1,
gestrichelte Kurven: Sensoran-
ordnung 2. (a) Merkmalsvektor
c1,40 aus Wavelet- Restklassen;
(b) Merkmalsvektor aus Spek-
tralkomponenten.
nen Verfahren, wobei die Abstande d1 und d2 der Testvektoren zu den Umgebungs-schwerpunkten der ”guten“ bzw. ”fehlerhaften“ Trainingsvektoren durch die Euklidi-sche Metrik bestimmt werden und der relative Abstand durch drel = d1 − αd2 miteiner skalaren Wichtungskonstante α definiert ist.
Zur Berechnung der Abstande drel (4.10) untersuchen wir zunachst, welche Filter-komponenten der Merkmalsvektoren c1,K Informationen zur Trennung der Schallsi-gnale von guten und fehlerhaften Schiebedacher beitragen, d.h. genauer, mit welcherKombination der Frequenzbander der Signale sich der kleinste Klassifikationsfehlererzielen laßt. Hierbei zeigt sich, daß der erste Bandpaß keinen Beitrag liefert. Zur Be-rechnung von drel verwenden wir daher nur den Hochpaß und die Bandpaße 2 – 4 derWavelettransformationen. Die gleiche Untersuchung fur die Merkmalsvektoren ausSpektralkomponenten zeigt hingegen, daß sich durch eine Auswahl von Frequenzban-dern keine Verbesserung der Klassifikationsleistung erzielen laßt.
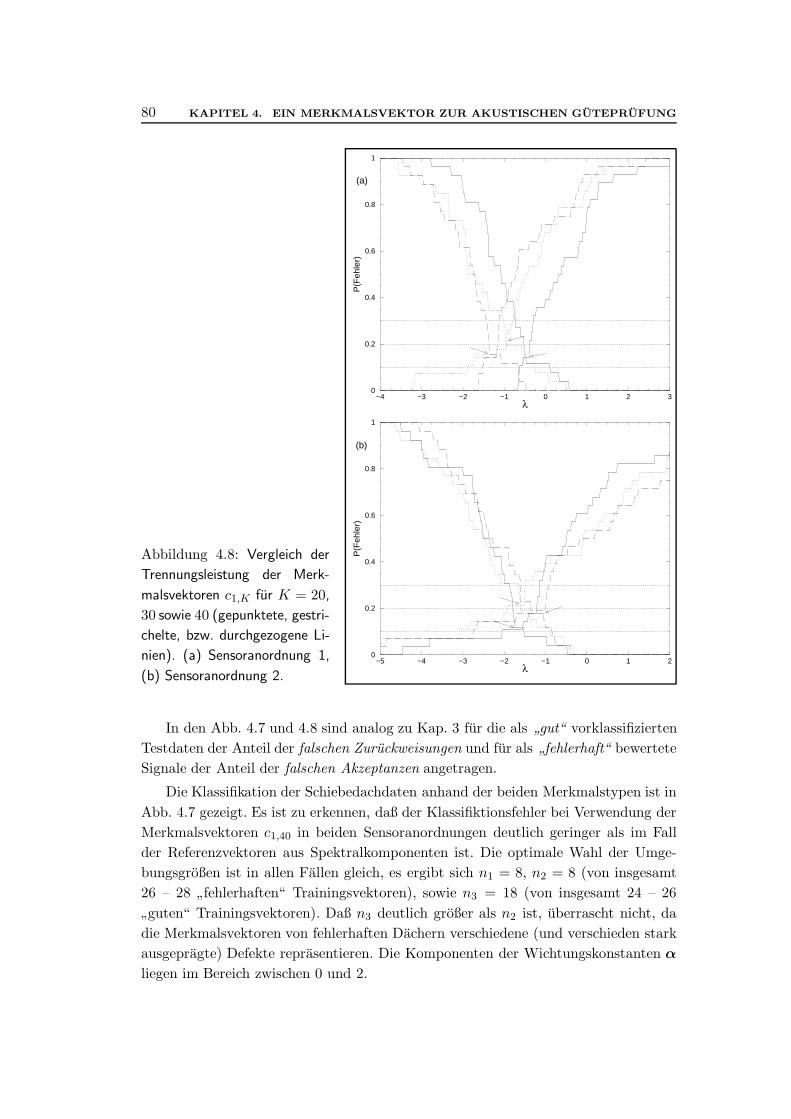
80 KAPITEL 4. EIN MERKMALSVEKTOR ZUR AKUSTISCHEN GUTEPRUFUNG
Abbildung 4.8: Vergleich der
Trennungsleistung der Merk-
malsvektoren c1,K fur K = 20,
30 sowie 40 (gepunktete, gestri-
chelte, bzw. durchgezogene Li-
nien). (a) Sensoranordnung 1,
(b) Sensoranordnung 2.
−4 −3 −2 −1 0 1 2 3λ
0
0.2
0.4
0.6
0.8
1
P(F
ehle
r)
(a)
−5 −4 −3 −2 −1 0 1 2λ
0
0.2
0.4
0.6
0.8
1
P(F
ehle
r)
(b)
In den Abb. 4.7 und 4.8 sind analog zu Kap. 3 fur die als ”gut“ vorklassifiziertenTestdaten der Anteil der falschen Zuruckweisungen und fur als ”fehlerhaft“ bewerteteSignale der Anteil der falschen Akzeptanzen angetragen.
Die Klassifikation der Schiebedachdaten anhand der beiden Merkmalstypen ist inAbb. 4.7 gezeigt. Es ist zu erkennen, daß der Klassifiktionsfehler bei Verwendung derMerkmalsvektoren c1,40 in beiden Sensoranordnungen deutlich geringer als im Fallder Referenzvektoren aus Spektralkomponenten ist. Die optimale Wahl der Umge-bungsgroßen ist in allen Fallen gleich, es ergibt sich n1 = 8, n2 = 8 (von insgesamt26 – 28 ”fehlerhaften“ Trainingsvektoren), sowie n3 = 18 (von insgesamt 24 – 26
”guten“ Trainingsvektoren). Daß n3 deutlich großer als n2 ist, uberrascht nicht, dadie Merkmalsvektoren von fehlerhaften Dachern verschiedene (und verschieden starkausgepragte) Defekte reprasentieren. Die Komponenten der Wichtungskonstanten α
liegen im Bereich zwischen 0 und 2.

4.3. AKUSTISCHE QUALITATSKONTROLLE VON SCHIEBEDACHERN 81
Zum Schluß wollen wir noch den Einfluß der Anzahl der Restklassen- ElementeRxl ; l = 1, · · · , K, uber die pro Zeitreihe gemittelt wird, auf die Klassifikationslei-stung der Merkmalsvektoren c1,K fur die Schiebedachdaten untersuchen. In Abb. 4.8sind die Klassifikationsergebnisse fur K = 20, 30 sowie 40 in beiden Sensoranordnun-gen gezeigt. Damit bestatigen sich (zumindest qualitativ) die Resultate, die wir imletzten Abschnitt fur die Sagezahnsignale gewonnen haben. Wahrend in Sensoranord-nung 1 die Trennungsleistung der Merkmalsvektoren c1,30 und c1,40 fast gleich ist, zeigtsich fur c1,20 eine sichtbare Verschlechterung. In Sensoranordung 2 wird hingegen nurbei Verwendung von c1,40 das beste Ergebnis erzielt, wahrend sich bei der Mittelungvon Rxl uber kurzere Zeitreihenabschnitte eine stetige Abnahme der Trennungslei-stung zeigt. Der Vergleich mit einem Merkmalsvektor, der aus einer großeren AnzahlRestklassen- Elemente berechnet wird, ist aufgrund der Gesamtlange der Zeitreihennicht moglich.
Als nachster Schritt ware der Vergleich mit Merkmalsvektoren interessant, die ausden Restklassen- Elementen anderer Zeit-Frequenz Darstellungen konstruiert sind.Betrachtet man Filter mit konstanter Breite im Frequenzraum statt der skaliertenFilter in Abb. 4.2, so erhalt man eine Zeit-Frequenz Darstellung mit konstanter statt,wie in unserem Fall, hyperbolischer Zeit-Frequenz Auflosung (Kap. 2.1.3). Hierauslassen sich Merkmalsvektoren in einer analogen Vorgehensweise konstruieren. DieserVergleich wurde die Uberprufung der psychoakustischen Uberlegungen ermoglichen,durch die unser Ansatz mit motiviert war, jedoch ist hierfur eine großere Daten-basis erforderlich, um statistisch signifikante Aussagen zu erhalten. Die prinzipielleAnwendbarkeit von Merkmalsvektoren aus Restklassen- Elementen zur Klassifikationstationarer Schallsignale konnte dennoch gezeigt werden.

82 KAPITEL 4. EIN MERKMALSVEKTOR ZUR AKUSTISCHEN GUTEPRUFUNG

Zusammenfassung
Das Ziel dieser Arbeit war die Entwicklung und Anwendung von Konzepten derZeitreihenanalyse auf technische Problemstellungen, die sich aus einem praxisbezoge-nen Umfeld heraus ergaben. Das Interesse an technischen Systemen entstand aus derIdee, Anwendungsmoglichkeiten der nichtlinearen Zeitreihenanalyse auf angewand-te Fragestellungen bei Systemen mit ”mittlerer Komplexitat“ zu untersuchen, d.h.bei Systemen, die nur eine begrenzte Anzahl (effektiver) Freiheitsgrade und eine be-grenzte Nichtstationaritat aufweisen. Fur solche Systeme scheint es mit dem heutigenWissensstand eher moglich, einen Losungsbeitrag im Sinn der praktischen Fragestel-lung zu leisten, als fur Systeme mit sehr hoher Komplexitat, wie z.B. physiologi-sche Systeme oder Volkswirtschaften. Durch Industriekontakte ergaben sich fur unszwei konkrete Projekte, die Fehlerfruherkennung bei Induktionsmotoren durch Ana-lyse des Statorstroms sowie die automatische Qualitatsendkontrolle von elektrischenSchiebedachern durch Klassifikation von Korperschallsignalen.
Aufgrund der Quasiperiodizitat des Statorstromes von Induktionsmotoren undden Eigenschaften idealer Induktionsmaschinen stellte es sich als sinnvoll heraus, ge-fensterte Fourierspektren des Statorstromes als Ausgangspunkt fur die Konstruk-tion von Merkmalsvektoren zu verwenden. Die Schallsignale des Schließgerauschesvon Schiebedachern zeigen ein stationar stochastisches Verhalten, wobei die fur dieFehlererkennung relevanten Informationen vom menschlichen Gehor, d.h. von Ex-perten aufgelost werden konnen. Hierauf beruhte unser Ansatz, die Zeit-FrequenzAuflosungscharakteristik des Ohrs nachzuahmen, was fur Frequenzen & 500Hz inguter Naherung durch eine Wavelettransformation moglich ist.
Damit zeigte sich, daß fur beide Probleme Zeit-Frequenz Darstellungen einengeeigneten Ausgangspunkt bilden. Der erste, theoretische Teil dieser Arbeit enthaltdaher einen Uberblick uber die recht allgemeinen linearen und quadratischen Zeit-Frequenz Darstellungen, wobei im Hinblick auf die Signalanalyse die Eigenschaftengefensterter Fourier- und Wavelettransformationen, insbesondere die Zeit-FrequenzAuflosungscharakteristik dieser Abbildungen, genauer diskutiert wurden. Da wir inallen Anwendungen nur endliche, diskret abgetastete Zeitreihen zur Verfugung ha-ben, wurde anschließend der genaue Zusammenhang zwischen kontinuierlichen unddiskreten gefensterten Fourier- und Wavelettransformationen dargestellt. Den Ver-knupfungspunkt hierfur bildet das Shannonsche Samplingtheorem. Unser Ziel war es,
83

84 ZUSAMMENFASSUNG
fur kontinuierliche Zeit-Frequenz Darstellungen dieses Typs mit einer hohen Informa-tionsauflosung moglichst gute diskrete Approximationen zu finden. Da das zentraleKonzept der Skalierung auf Zeitreihen nicht unmittelbar ubertragbar ist, mußte dieDefinition einer diskreten Wavelettransformation vom kontinuierlichen Vorbild et-was abweichen. Fur die Klassifikation der aus experimentellen Zeitreihen berechnetenMerkmalsvektoren wurden im letzten Abschnitt Schatzer fur den Bayeschen Fehlereiner Klassifikationsstatistik, d.h. fur den minimalen Klassifikationsfehler, der erzieltwerden kann, diskutiert.
In Kap. 3 stellten wir einen neuen Losungsansatz fur das Problem vor, denverschleiß- oder fehlerbedingten Ausfall von Induktionsmotoren durch Analyse desStatorstromes rechtzeitig vorherzusagen. Hierfur wurde das Konzept der geometri-schen Signaltrennung im Merkmalsraum eingefuhrt: Wahrend einer Trainingsperiodewerden Abschnitte der Zeitreihen eines fehlerfreien Motors in Merkmalsvektoren vtransformiert, deren Eintrage geeignete Spektralkomponenten des Statorstromes sind.Die Trainingsmenge muß hierbei alle erlaubten Betriebszustande des Motors reprasen-tieren. Diese Trainingsvektoren werden in Cluster eingeteilt und fur jedes Cluster wirdeine lokale Metrik im Merkmalsraum V definiert, die den Abstand eines Vektors zudem spezifischen Cluster angibt. Das uber alle Cluster gemittelte Verhaltnis der Kom-ponenten der Schwerpunktvektoren der Cluster zu ihren Ausdehnungen in den korres-pondierenden Raumrichtungen definiert das Maß fur das Signal-Rausch Verhaltnisder Spektralkomponenten, wobei die Ausdehnung der Cluster durch Kumulanten2. und 4. Ordnung beschrieben wird. Es zeigte sich, daß fur unsere Daten die Mengeder ca. 14 Spektralkomponenten mit den großten Signal-Rausch Verhaltnissen im-mer ausreichend viele Elemente enthalt, die sensitiv auf die untersuchten Motorfehlerreagieren. Dieses Kriterium legt die Eintrage der Merkmalsvektoren fest.
Wahrend der Uberwachungsphase kann nun der Abstand der laufend berechne-ten Merkmalsvektoren zum nachstgelegenen Cluster im Merkmalsraum bestimmt undmit einem Schwellenwert verglichen werden. Als Hauptproblem stellte sich die Un-terscheidung von Motorfehlern und unbekannten Umwelteinflussen heraus, da nichtalle wahrend des Betriebs eintretenden Umweltbedingungen in der Trainingsdaten-basis erfaßt werden konnen. Die geometrische Methode bietet hierfur eine Losung:Wir konstruierten zwei Typen von Merkmalsvektoren v1 und v2 in den Raumen V1
und V2 mit unterschiedlicher Dimension. Wahrend V1 eine Mischung aus Informatio-nen uber Lastzustande, Motorfehler und Umwelteinflusse enthalt, gehen in V2 nachKonstruktion keine Informationen uber Defekte ein. Da eine untere Schranke fur dieKorrelation zwischen den Vektoren v2 und den in v1 enthaltenen Umwelteinflussenexistiert, konnen diese Storungen teilweise herausgerechnet werden. Auch wenn die-se Korrektur relativ klein ist, ermoglichte sie fur unsere Motordaten die statistischsignifikante Trennung von Fehlern und unbekannten Umwelteinflussen. Wir zeigtendies durch die Klassifikation von Zeitreihen in out-of-sample Tests, die von vier 10PS4-Pol Induktionsmotoren erzeugt wurden.

ZUSAMMENFASSUNG 85
In Kap. 4 stellten wir einen neuen Merkmalsvektor fur akustische Guteprufungenvor. Hierzu wurden Merkmalsvektoren aus Wavelet- Restklassen konstruiert, welcheals die Menge der zyklischen Permutationen einer diskreten Wavelettransformati-on in der Zeitvariablen definiert sind. Da die Schallsignale in guter Naherung alsstationare Oszillationen betrachtet werden konnen, unterscheiden sich die aus ver-schiedenen Teilstucken einer Zeitreihe berechneten Wavelettransformationen im we-sentlichen durch ihre Anfangsbedingungen. Die Wavelet- Restklassen definieren eineGroße, welche von den Anfangsbedingungen unabhangig ist und uber die im Zeitraumgemittelt werden kann, ohne die zeitaufgelosten Informationen zu verlieren. Auf derMenge der Restklassen wurde eine Metrik und eine Addition definiert, welche dieserMenge die Struktur eines kommutativen aber nicht-assoziativen Rings mit einer Me-trik gibt. Die Additionsreihenfolge mehrerer Restklasse- Elemente wird durch einenClusterungsalgorithmus festgelegt, wobei wir verschiedene Clusterungsmoglichkeitendiskutiert haben.
Es zeigte sich, daß sich durch diesen Mittelungsprozeß die fur die Fehlererken-nung relevanten Informationen der Wavelettransformationen herausbilden lassen, in-dem statistische Fluktuationen und Rauschen gedampft werden. Die Eigenschaftender Merkmalsvektoren aus Wavelet- Restklassen, insbesondere die Konvergenz desRauschreduktionverfahrens wurden zunachst anhand verrauschter Sagezahnsignalestudiert. Die anschließende Anwendung auf die Korperschallsignale der Schiebedacherbestatigte (qualitativ) diese Ergebnisse. Die Klassifikation eines Testvektors erfolgtehierbei durch den Vergleich mit den Trainingsvektoren von als ”gut“ sowie als ”feh-lerhaft“ vorklassifizierten Schiebedachern, die sich jeweils in einer Umgebung (ver-schiedener Große) des Testvektors befinden. Obwohl der Umfang der Datenbasis furdie statistisch signifikante Bestimmung der Trennungsleistung der Merkmalsvekto-ren zu klein ist, konnte durch den Vergleich mit der Standardmethode der Wahl vonMerkmalen aus Spektralkomponenten dennoch die prinzipielle Anwendbarkeit vonMerkmalsvektoren aus Restklassen- Elementen zur Klassifiktion stationarer Schallsi-gnale gezeigt werden.
Zusammenfassend hat es sich gezeigt, daß die beiden in dieser Arbeit untersuchtenSignaltypen zu ”linear“ (quasiperiodisch bzw. stationar stochastisch) sind, um intrin-sisch nichtlineare Methoden erfolgreich anwenden zu konnen. Als optimal erwies sichhingegen die Kombination aus linearen Methoden, d.h. aus der Wahl von Merkmalenin der Zeit-Frequenz Ebene und darauf basierender Moglichkeiten zur Konstruktionvon Merkmalsvektoren, und geometrischen Trennungsverfahren, die durch die nicht-lineare Analyse motiviert sind. Auch wenn die nichtlineare Zeitreihenanalyse, d.h.genauer Verfahren, welche die deterministische Struktur eines Signals explizit ver-wenden, auf viele Probleme nicht direkt anwendbar ist, so liefert sie doch wichtigeImpulse fur die Weiterentwicklung von geometrisch motivierten Ideen zur Signaldar-stellung und -klassifikation. Eine weitere Anwendungsmoglichkeit von Konzepten dernichtlinearen Zeitreihenanalyse, auf die wir nicht eingegangen sind, ist die geometri-

86 ZUSAMMENFASSUNG
sche Trennung nichtstationarer Zeitreihen in stationare Teilstucke durch Einbettungin einen hochdimensionalen rekonstruierten Phasenraum. Hierfur wird keine determi-nistische Struktur des Signals benotigt.
Auch wenn die hier untersuchten Probleme (wie so haufig) spezieller Natur sind,hoffen wir doch, eine kleinen Beitrag zu der wachsenden Sammlung von Methodenzur Darstellung und Klassifikation (technischer) Signale gebracht zu haben. Die Kom-bination von Methoden aus einem solchen ”Werkzeugkasten“ kann vielleicht auch furweitere Problemstellungen Losungsmoglichkeiten bieten (zumindest als einen erstenAnsatz), als nur fur diejenigen, fur welche sie entwickelt wurden.

Literaturverzeichnis
[1] J. Cameron, W. Thomson und A. Dow, ”Vibration and current monitoring fordetecting airgap eccentricity in large induction motors“, IEE Proc., 133, B, 3,S. 155-163, Mai 1986.
[2] K. Chandrasekharan, Classical Fourier transforms, Springer, Heidelberg, Berlin,1989.
[3] L. Cohen, ”Generalized phase-space distribution functions“, J. Math. Phys.,7, 5, S. 781-786, 1966.
[4] I. Daubechies, Ten lectures on wavelets, Society for industrial and applied ma-thematics, Philadelphia, Pennsylvania, 1992.
[5] W. Deleroi, ”Der Stabbruch im Kafiglaufer eines Asynchronmotors, Teil 1: Be-schreibung mittels Uberlagerung eines Storfeldes“, Arch. fur Elektrotechnik, 67,S. 91-99, 1984.
[6] D. Dornfeld, ”Application of acoustic emission techniques in manufacturing“,NDT & E Int., 25, 6, S. 259-269, Dez. 1992.
[7] D. Farson, K. Hillsley, J. Sames und R. Young, ”Frequency-time characteristics ofair-borne signals from laser welds“, J. Laser Applicat., 8, 1, S. 33-42, Feb. 1996.
[8] F. Filippetti, M. Martelli, G. Franceschini und C. Tassoni, ”Development ofthe knowledge base of an expert system to diagnose electric faults of inductionmotors“, Conf. Rec. 27th Annu. IEEE Ind. Applicat. Soc. Meeting, Houston,USA, S. 92-99, Okt. 1992.
[9] F. Filippetti, G. Franceschini und C. Tassoni, ”Neural networks aided on-linediagnostics of induction motor rotor faults“, IEEE Trans. Ind. Applicat., 31, 4,S. 892-899, Juli 1995.
[10] K. Fukunaga, Introduction to statistical pattern recognition, Academic Press, SanDiego, London, 1990.
[11] M. Gutzwiller, Chaos in classical and quantum mechanics, Springer, Heidelberg,Berlin, New York, 1991.
87

88 LITERATURVERZEICHNIS
[12] C. Hargis, B. Gaydon und K. Kamash, ”The detection of rotor defects in induc-tion motors“, Int. Conf. Elec. Mach. – Design and Applicat., IEE Publication,213, S. 216-220, Juli 1982.
[13] C. Heitz, ”Optimum time-frequency representations for the classification anddetection of signals“, Applied Sig. Proces., 3, S. 124-143, 1995.
[14] C. Heitz, Optimierte Zeit-Frequenz Darstellung zur Klassifikation von Zeitreihen,Dissertation, Universitat Freiburg, 1996.
[15] C. Heitz und J. Timmer, ”Using optimized time-frequency representations foracoustic quality control of motors“, ACUSTICA, 83, S. 1-12, Nov. 1997.
[16] K. Heldmann, Wahrnehmung, gehorgerechte Analyse und Merkmalsextraktiontechnischer Signale, Fortschritt- Berichte VDI, VDI Verlag, Dusseldorf, 1994.
[17] F. Hlawatsch, ”Duality and classification of bilinear time-frequency signal repre-sentations“, IEEE Trans. Sig. Proces., 39, 7, S. 1564-1574, Juli 1991.
[18] F. Hlawatsch und G. Boudreaux-Bartels, ”Linear and quadratic time-frequencyrepresentations“, IEEE-SP Magazine, S. 21-67, April 1992.
[19] F. Hlawatsch und R. Urbanke, ”Bilinear time-frequency representations of si-gnals: The shift-scale invariant class“, IEEE Trans. Sig. Proces., 42, 2, S. 357,Feb. 1994.
[20] J. Honerkamp, Statistical physics, Springer, Heidelberg, Berlin, New York, 1998.
[21] IMSL STAT/LIBRARY: User’s Manual Fortran subroutines for statistical ana-lysis, Version 2.0, 1991.
[22] H. Kantz und T. Schreiber, Nonlinear time series analysis, Cambridge UniversityPress, Cambridge, UK, 1997.
[23] G. Kliman und J. Stein, ”Methods of motor current signature analysis“,Elec. Mach. Power Syst., 20, 5, S. 463-474, Sept. 1992.
[24] G. Kliman, W. Premerlani, B. Yazici, R. Koegl und J. Mazereeuw, ”Sensorless,online motor diagnostics“, Comp. Applicat. in Power, 10, 2, S. 39-43, April 1997.
[25] S. Lee und P. White, ”Higher-order time-frequency analysis and its applicationto fault detection in rotating machinery“,Mech. Syst. Sig. Proces., 11, 4, S. 637-650, Juli 1997.
[26] D. Leith und D. Rankin, ”Real time expert system for identifying rotorfaults and mechanical influences in induction motor phase current“, IEE 5thInt. Conf. Elec. Machines and Drives, London, S. 46-50, Sept. 1991.

LITERATURVERZEICHNIS 89
[27] A. Lichtenberg und M. Lieberman, Regular and chaotic dynamics, Springer, NewYork, Berlin, Heidelberg, 1992.
[28] W. Mecklenbraucker, Hrsg., The Wigner distribution – theory and applicationsin signal processing, North Holland Elsevier Science Publishers, 1992.
[29] M. Mehta, Random matrices, Academic Press, San Diego, 1991.
[30] T. Petsche, A. Marcantonio, C. Darken, S. Hanson, G. Kuhn und I. Santoso, ”Aneural network autoassociator for induction motor failure prediction“, Advan. inNeural Inform. Proces. Syst., 8, S. 924-930, Aug. 1996.
[31] W. Press, S. Teukolsky, W. Vetterling und B. Flannery, Numerical recipes, Cam-bridge University Press, Cambridge, UK, 1992.
[32] O. Rioul und M. Vetterli, ”Wavelets and signal processing“, IEEE-SP Magazine,S. 14-38, Okt. 1991.
[33] O. Rioul und P. Flandrin, ”Time-scale energy distributions: A general class ex-tending wavelet transforms“, IEEE Trans. Sig. Proces., 40, 7, S. 1746-1757,1992.
[34] T. Sauer, J. Yorke und M. Casdagli, ”Embedology“, J. Stat. Phys., 65, 3–4,S. 579-616, Nov. 1991.
[35] R. Schoen und T. Habetler, ”Effects of time-varying loads on rotor fault detectionin induction machines“, IEEE Trans. Ind. Applicat., 31, 4, S. 900-906, Juli 1995.
[36] R. Schoen, T. Habetler, F. Kamran und R. Bartheld, ”Motor bearing damagedetection using stator current monitoring“, IEEE Trans. Ind. Applicat., 31, 6,S. 1274-1279, Nov. 1995.
[37] R. Schoen, B. Lin, T. Habetler, J. Schlag und S. Farag, ”An unsupervised, on-line system for induction motor fault detection using stator current monitoring“,IEEE Trans. Ind. Applicat., 31, 6, S. 1280-1286, Nov. 1995.
[38] R. Schoen und T. Habetler, ”A new method of current-based condition mo-nitoring in induction machines operating under arbitrary load conditions“,Elec. Mach. Power Syst., 25, 2, S. 141-152, Feb. 1997.
[39] S. Smale, ”Differentiable dynamical systems“,Bull. Amer. Math. Soc., 73, S. 747-817, 1967.
[40] M. Steele, R. Ashen und L. Knight, ”An electrical method for condition monito-ring of motors“, Int. Conf. Elec. Mach. – Design and Applicat., IEE Publication,213, S. 231-235, Juli 1982.

90 LITERATURVERZEICHNIS
[41] P. Tavner, K. Arnim und C. Hargis, ”An electrical technique for monitoringinduction motor cages“, IEE Conf. Elec. Machines and Drives, IEE Publication,282, S. 43-46, 1987.
[42] O. Thorsen und M. Dalva, ”Methods of condition monitoring and fault diagnosisfor induction motors“, Europ. Trans. Elec. Power, 8, 5, S. 383-395, Sep. 1998.
[43] A. Valli, Failure detection through cross prediction error, Diplomarbeit, Univer-sitat Florenz, 1999.
[44] J. Ville, ”Theorie et applications de la notion de signal analytique“, Cables ettransmission, 2 A, S. 61-74, 1948.
[45] E. Wigner, ”On the quantum correction for the thermodynamic equilibrium“,Phys. Rev., 40, S. 749-759, 1932.
[46] R. Zoller, Methoden der nichtlinearen Dynamik zur Zustandsanalyse technischerSysteme, Dissertation, Technische Hochschule Darmstadt, 1997.

Danksagung
An dieser Stelle mochte ich allen herzlich danken, die zum Gelingen dieser Arbeitbeigetragen haben.
Meinen großen Dank mochte ich Priv. Doz. Dr. Holger Kantz fur die Moglichkeitaussprechen, diese Arbeit in seiner Arbeitsgruppe ”Nichtlineare Zeitreihenanalyse“am Max-Planck-Institut fur Physik komplexer Systeme in Dresden zu schreiben. Furdie kompetente Betreuung, viele Anregungen und das stetige Interesse an der Arbeit,bei der mir große Freiheit eingeraumt wurde, mochte ich besonders danken.
Mein Dank fur die vielfaltige Unterstutzung und das gute Arbeitsklima gilt al-len Mitgliedern dieser Gruppe, insbesondere Dr. Rainer Hegger und Dr. EckehardOlbrich, der am Projekt ”Fehlerfruherkennung mit nichtlinearer Zeitreihenanalyse“mitgearbeitet hat.
Fur die vielen auch nichtwissenschaftlichen Diskussionen geht ein spezieller Dankan meine Mitdoktoranden Lars Jaeger, Frank Schmuser und Stefan Blawid.
Fur die freundliche Kooperation und die uns zur Verfugung gestellten Datenmochte ich Dr. A. Jourjine und Dr. T. Petsche von Siemens Corporate Research,Princeton, USA, sowie Dr. R. Zoller von Carl Schenck AG, Darmstadt, danken.
Fur sein großes Engagement bei der Unterstutzung bei den haufigen Computer-und Softwareproblemen gilt mein großer Dank Hubert Scherrer.
Der Max-Planck-Gesellschaft danke ich fur das Doktoranden- Stipendium und dieexzellenten Arbeitsbedingungen, die mir hier zur Verfugung standen.
Zuletzt mein großes Dankeschon an Bettina Dannenmann, die die Enstehungszeitdieser Arbeit uber die große Entfernung nach Stuttgart hinweg begleitet hat.






























