Embed Size (px)
Citation preview

Scientific Programming 20 (2012) 129–150 129DOI 10.3233/SPR-2012-0342IOS Press
The Zoltan and Isorropia parallel toolkits forcombinatorial scientific computing:Partitioning, ordering and coloring
Erik G. Boman a, Ümit V. Çatalyürek b, Cédric Chevalier c and Karen D. Devine a,∗a Department of Scalable Algorithms, Sandia National Laboratories**, Albuquerque, NM, USAb Department of Biomedical Informatics and Department of Electrical and Computer Engineering, The Ohio StateUniversity, Columbus, OH, USAc Commissariat à l’Énergie Atomique et aux Énergies Alternatives, Direction des Applications Militaires, CEA,DAM, DIF, Arpajon, France
Abstract. Partitioning and load balancing are important problems in scientific computing that can be modeled as combinatorialproblems using graphs or hypergraphs. The Zoltan toolkit was developed primarily for partitioning and load balancing to supportdynamic parallel applications, but has expanded to support other problems in combinatorial scientific computing, includingmatrix ordering and graph coloring. Zoltan is based on abstract user interfaces and uses callback functions. To simplify the useand integration of Zoltan with other matrix-based frameworks, such as the ones in Trilinos, we developed Isorropia as a Trilinospackage, which supports most of Zoltan’s features via a matrix-based interface. In addition to providing an easy-to-use matrix-based interface to Zoltan, Isorropia also serves as a platform for additional matrix algorithms. In this paper, we give an overviewof the Zoltan and Isorropia toolkits, their design, capabilities and use. We also show how Zoltan and Isorropia enable large-scale,parallel scientific simulations, and describe current and future development in the next-generation package Zoltan2.
Keywords: Partitioning, load balancing, matrix ordering, fill-reducing ordering, graph coloring, parallel computing, combinatorialscientific computing
1. Introduction
The Zoltan project started in 1998 with the goal ofproviding a toolkit for partitioning and dynamic loadbalancing in dynamic applications [23]. Over the years,the scope of Zoltan has expanded to provide a collec-tion of utilities within the area of combinatorial scien-tific computing. The three main capabilities of Zoltanare now partitioning, ordering, and coloring. Having allthese capabilities in a single toolkit gives users a singleinterface to a wide range of capabilities. For example,
*Corresponding author: Karen D. Devine, Department of Scal-able Algorithms, Sandia National Laboratories, Albuquerque,NM 87185-1318, USA. E-mail: [email protected].
**Sandia National Laboratories is a multi-program laboratorymanaged and operated by Sandia Corporation, a wholly ownedsubsidiary of Lockheed Martin Corporation, for the US Depart-ment of Energy’s National Nuclear Security Administration undercontract DE-AC04-94AL85000. This work was supported by theNNSA’s ASC program and by the DOE Office of Science throughthe CSCAPES SciDAC Institute and ITAPS SciDAC Center.
the ShyLU hybrid solver [51] uses all the main capabil-ities. Partitioning is used to decompose a sparse matrixinto smaller submatrices that are loosely coupled. Ma-trix ordering is used to reorder the submatrices to min-imize fill. Coloring is used within a “probing” schemeto form a sparse approximation to the Schur comple-ment (see Section 2.4.2).
A key element of Zoltan’s design was the separa-tion of its data structures from the interfaces to sup-port a wide range of applications. Zoltan relies on asmall set of callback (query) functions that must be im-plemented by the user. When Zoltan was incorporatedinto the Trilinos solver framework [34], the need fora more “Trilinos-friendly” interface became clear. Thesolution was a new package called Isorropia. Isorropiais primarily a C++ layer on top of Zoltan that pro-vides matrix-based interfaces to Zoltan capabilities forTrilinos’ Epetra matrix/vector classes [35]. Isorropiaprovides the translation from a user’s Epetra matricesand vectors to the data model (e.g., graph, hypergraph,
1058-9244/12/$27.50 © 2012 – IOS Press and the authors. All rights reserved

130 E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing
coordinates) needed by Zoltan for partitioning, color-ing and ordering. While Zoltan’s more general inter-face supports a broad set of applications, applicationdevelopers using Epetra find Isorropia’s interface to bemuch simpler in terms of the amount and complexityof application code needed.
The main purpose of this paper is to give an up-to-date description of the Zoltan and Isorropia pack-ages. In Section 2, we give an overview of the capabil-ities and algorithms offered. In Section 3, we discussthe software design. Finally, in Section 4, we introduceZoltan2, the planned successor to both Zoltan and Isor-ropia.
2. Capabilities and algorithms
2.1. Partitioning and load-balancing
Partitioning and dynamic load balancing are keycomponents of scientific computations. Their goal isto divide applications’ data and work among processesin a way that minimizes the overall application ex-ecution time. The goal is most often achieved whenwork is distributed evenly to processes (eliminatingprocess idle time) while minimizing data dependenceand movement between processes. A partition is an as-signment of data and work to subsets called parts thatare mapped to processes. More precisely, given a set ofitems V , a k-way partition P = {V1, V2, . . . , Vk} as-signs members vi ∈ V with weight wi to k parts suchthat Vp ∩ Vq = ∅ for p �= q and
⋃kp=1 Vp = V . A par-
tition is said to be balanced if Wp � Wavg(1 + ε) forp = 1, 2, . . . , k, where part weight Wp =
∑vi ∈Vp
wi,
Wavg = 1k
∑vi∈V wi, and ε > 0 is a predetermined
maximum tolerable imbalance.Items vi ∈ V may depend on other vj for, say, com-
puting solution values at vi. A dependence that ex-tends between two or more parts requires communica-tion or data movement to satisfy the dependence. The“quality” of a partition is typically considered to be in-versely proportional to some measure of the costs tosatisfy inter-part dependence. Various cost measures(e.g., number of neighboring parts, number of depen-dences split between parts) can be used, but the mostcommon cost metric is the total volume of communi-cation between parts.
A common partitioning use-case arises in finite el-ement and volume methods used in structural anal-ysis and fluid dynamics simulations. In these meth-ods, mesh entities (elements, cells, mesh nodes) must
be distributed among processes. Each entity vi canhave an associated computational weight wi repre-senting, say, its number of degrees of freedom or thetime to perform computations on the entity. Mesh ad-jacencies define data dependence; for example, a meshnode’s solution values may be determined by integra-tions across its adjacent elements, or fluxes across anelement face may depend on solution values from ele-ments on both sides of the face. Thus, solutions of thepartitioning problem above distribute specified meshentities’ computational weight evenly across processeswhile attempting to minimize the cost of communi-cating data for relevant mesh adjacencies that extendacross two or more processes.
The partition used to distribute a mesh often inducesa partition on a related linear system Ax = b represent-ing the physics on the mesh. For example, each meshnode vi may correspond to a matrix row ai in A; so-lution values at vi are represented by vector entries xi.Non-zeros aij in the matrix represent a data depen-dence between mesh nodes vi and vj . Thus, a partitionof mesh nodes results in a row-based partition of thelinear system. In this case, the communication metric istaken to be the total amount of communication neededto perform a matrix–vector multiplication Ax.
Other parallel applications needing partitioning in-clude (but are certainly not limited to) particle meth-ods (e.g., for hydrodynamics or biological simula-tions), contact detection (e.g., for crash simulations),device-based electrical circuit simulations, circuit de-sign and layout, semantic analysis for term-documentdatabases, and graph analysis on networks. Character-istics of these applications and appropriate partition-ing strategies for them will be discussed in more detailbelow.
An application’s characteristics determine the parti-tioning strategy best-suited to the application. No sin-gle algorithm is best for all applications. Trade-offs be-tween partitioning strategies include geometric-baseddata locality versus connectivity-based data locality,static versus dynamic redistribution, and speed of par-titioning versus quality of the resulting partition. Forthis reason, we have included a suite of partitioning al-gorithms in Zoltan, each of which is accessible fromIsorropia as well. These algorithms range from fast,medium quality geometric partitioners to more expen-sive, higher quality graph and hypergraph-based meth-ods.
Geometric partitioning. Geometric methods parti-tion data based on their geometric locality. Items as-signed to the same part are physically close to each

E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing 131
other in space. This geometric locality makes geomet-ric methods ideal for particle-based applications andcontact detection algorithms. In particle methods, thevi are particles to be distributed to processes. Depen-dence arises, not between vi and other fixed vj , butrather between vi and all other particles within a cer-tain distance of vi. Thus, in addition to maintainingload balance, partitioners must maintain data localityof the particles within processes for efficient force cal-culations. Similarly, in contact detection, searches forcontact between entities are optimized when physicallyclose entities are assigned to the same process; parti-tioners must account for the geometric locality of en-tities to maintain efficient local search as the geometrydeforms. Geometric methods are also useful for appli-cations requiring frequent partitioning (e.g., adaptivemesh-based simulations), because they are fast and re-quire only coordinate information as input. However,because they do not explicitly model communication,they can produce partitions with only medium partitionquality.
Geometric methods in Zoltan include Recursive Co-ordinate Bisection, Recursive Inertial Bisection andHilbert Space-Filling Curve partitioning. RecursiveCoordinate Bisection (RCB) [2] was originally de-signed for adaptive mesh refinement methods, becauseit assigns parent and child elements to the same pro-cess, eliminating the need for communication betweenmesh levels. In RCB, the work of a problem is di-vided in two equally weighted halves using a cuttingplane orthogonal to a coordinate axis. Items are as-signed to sub-domains based on their geometric po-sition relative to the cutting plane. The resulting sub-domains are then recursively cut, until the number of
sub-domains equals the number of parts requested (seeFig. 1, left). (Although we have described the algo-rithm for k = 2m parts for some m, the Zoltan imple-mentation is applicable for all values of k.) RCB hasthe property that its resulting partitions are “incremen-tal”; that is, small changes in the input data result inonly small changes to the partition. This property canbe exploited to reduce data movement costs when fre-quent repartitioning is needed. Recursive Inertial Bi-section (RIB) [58,60] is a variant of RCB in whichcutting planes are chosen to be orthogonal to the prin-cipal axes of the geometry, rather than to the coordi-nate axes. Hilbert space-filling curve (HSFC) partition-ing [49,63] has been used for gravitational simulations,smoothed particle hydrodynamics, and adaptive finiteelement methods. In HSFC partitioning (Fig. 1, right),each item’s position along a Hilbert space-filling curveis computed based on its coordinate values. The re-sulting positions provide a one-dimensional orderingof the three-dimensional items in the domain, with theproperty that items that are close to each other in theone-dimensional ordering are also close to each otherin three-dimensional space. This one-dimensional or-dering is then cut into k equally weighted parts. LikeRCB, HSFC partitioning is fast and incremental, andcreates parts containing geometrically close items.
With the geometric partitioners in Zoltan, each pro-cess can inexpensively store information about the en-tire partition. By storing the cutting-plane locationsand directions used in RCB or RIB, or the cut positionsin HSFC partitioning, each process can know the re-gion of physical space assigned to every part; the to-tal storage is O(k) for k parts. Zoltan includes addi-tional functionality for querying this cut information
Fig. 1. Examples of Recursive Coordinate Bisection (RCB) (left) and Hilbert space-filling curve (HSFC) partitioning (right) in Zoltan. RCBrecursively cuts the domain into equally weighted halves. HSFC partitioning linearly orders elements according to their position alonga Hilbert space-filling curve (red), and cuts the curve equally among parts. (The colors are visible in the online version of the article;http://dx.doi.org/10.3233/SPR-2012-0342.)

132 E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing
Fig. 2. The graph (left) and hypergraph (right) models for connectivity-based partitioning. In the graph example, graph vertices (white) representmesh elements, while graph edges (blue) represent face adjacencies; element colors indicate part assignments. In the hypergraph, vertices (circles)are connected by hyperedges (squares); vertex colors indicate part assignments. (The colors are visible in the online version of the article;http://dx.doi.org/10.3233/SPR-2012-0342.)
to determine which part owns a given point in space,or which parts overlap a given bounding box in space.These functions (Zoltan_Point_PP_Assign andZoltan_Box_PP_Assign) are useful for globalsearches in contact detection where a process needsto know which other processes contain potential con-tacts with a given entity, based on the entity’s positionin space; local searches for contact can then be donewithin each of the processes with potential contacts.
Connectivity-based partitioning. Connectivity-based partitioning methods explicitly represent datadependence and use it to attempt to minimize com-munication and data movement costs. In connectivity-based methods, application data are represented by aweighted graph or hypergraph. Items to be partitionedare vertices. Pairwise or multiway data dependence isrepresented by graph or hypergraph edges, respectively(see Fig. 2). Any edge that has vertices in two or moreparts requires communication to satisfy the data de-pendence it represents. Thus, partitioning vertices intoequally weighted parts while minimizing the weight ofedges that are split among one or more parts providesa balanced work distribution with approximately min-imal total communication volume.
Graph partitioning [31] is perhaps the most well-known partitioning method. It has been applied exten-sively in finite element/volume applications and lin-ear algebra frameworks. In linear systems, for exam-ple, the structure of matrix A can be interpreted as theadjacency matrix of a graph, with non-zero entry aijrepresenting an edge from vi to vj . Since graph parti-tioners use an undirected model, the linear systems thatcan be represented are limited to square, structurallysymmetric matrices. For structurally non-symmetric
matrices, symmetrization via A + AT or AAT allowsgraph partitioners to be applied, but reduces the ac-curacy of the communication model. Zoltan includesinterfaces to two popular graph partitioning libraries:PT-Scotch [48] and ParMETIS [42]. It also has nativegraph-partitioning capabilities through its hypergraphpartitioner.
Hypergraph partitioning [14] improves the modelused in graph partitioning. In row-partitioning of a lin-ear system, for example, matrix rows are hypergraphvertices, and matrix columns are hypergraph edges(with non-zero column entries specifying which ver-tices are in the edges) [8]. There is no restriction thatthe matrix be square or structurally symmetric. Thus,hypergraphs can represent a much broader class ofproblems (e.g., term-document matrices, circuit net-works). While graph models must approximate multi-way data dependence by several pairwise edges, hy-pergraph models accurately represent multiway depen-dence within a single hyperedge. Thus, hypergraphmodels more accurately represent communication vol-ume for edges split by part boundaries, allowing hyper-graph partitioners to generate higher quality partitions.The main drawback of hypergraph partitions is thatthey often require more time to be generated than graphpartitions. Zoltan has a native parallel hypergraph par-titioner [24], as well as an interface to the serial hyper-graph partitioner PaToH [9].
Optimally balancing vertex weight while minimiz-ing the weight of split edges is an NP-hard optimiza-tion problem [26], but fast multilevel algorithms andsoftware produce good solutions in practice [7,9,24,32,42]. In multilevel algorithms, an input (hyper)graph isrepeatedly coarsened, with coarse vertices represent-

E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing 133
ing clusters of input vertices. The coarse (hyper)graphcan be partitioned easily. The coarse partition is thenprojected back to the finer (hyper)graphs, with localimprovements of the partition performed at each finerlevel. This approach produces very high quality par-titions for many applications, but is more expensivecomputationally than geometric methods.
Static versus dynamic partitioning. The amount ofchange in an applications’ computation over time de-termines whether static or dynamic partitioning shouldbe used. In applications such as traditional finite ele-ment methods, the mesh and the work associated witheach mesh entity do not change during the course of acomputation. Thus, a good static partition can be com-puted once at the beginning of a simulation and will re-main effective throughout a simulation. Because staticpartitioning is done only once, its cost can be amor-tized over the entire computation and, thus, more ex-pensive partitioners (e.g., graph and hypergraph parti-tioning) can be used to obtain higher quality partitions.Moreover, because data is moved only once to the newpartition, the partitioner does not have to minimize thecost of moving data from its old part assignment toits new one; that is, it does not have to account foran existing partition in computing the new one. All ofZoltan’s geometric, graph-based and hypergraph-basedmethods can be used for static partitioning.
Applications whose computational loads or data lo-cality vary during the course of a computation requiredynamic partitioning or load balancing. In h-adaptivefinite element methods, for example, the mesh is lo-cally refined or coarsened to satisfy accuracy con-straints, thus dynamically changing the amount ofwork per process and creating load imbalance. Geo-metric locality and load balance in particle methodsand crash simulations are often lost as particles moveand structures deform, respectively. Dynamic parti-tioning methods restore load balance and/or geomet-ric locality by redistributing data and work among pro-cesses. But since they are working with data that is al-ready distributed, dynamic partitioning methods mustattempt to also minimize the cost to move data fromthe existing partition to the new one. Some dynamicmethods (e.g., RCB, HSFC partitioning) achieve thisgoal implicitly; small changes in the data naturallyresult in only small changes to the partition. Otherdynamic methods (e.g., Zoltan’s hypergraph reparti-tioner, graph-based adaptive-refinement methods) ex-plicitly account for an existing distribution in com-puting the new distribution. Diffusive algorithms, forexample [56], in which work is shifted from heavily
loaded processors to more lightly loaded neighboringprocessors, provide one way to obtain incremental par-titions in connectivity-based models, but their qualitycan degrade over several invocations of the partitioningalgorithm; this approach is available in Zoltan throughits interfaces to ParMETIS’ adaptive-refinement graphalgorithms [42]. The approach used in Zoltan’s hyper-graph and native graph algorithms [12] connects eachvertex to its current process by an edge weighted by thecost of moving the vertex’s data to a new part; Zoltan’spartitioners then account for both data movement costsand data dependence costs in the new partition.
Additional partitioning functionality. Zoltan is thecontainer for all partitioning algorithms in Trilinos. Itincludes the algorithms described above, as well asrandom and block partitioning. Random partitioningsimply randomly assigns items to parts. Block parti-tioning assigns |V | items to parts in a linear fashion,with the first |V |/k items going to the first part, thenext |V |/k items going to the second part and so on.
Hierarchical partitioning strategies are also availablein Zoltan. These methods can be used to exploit user-provided information about the underlying machine ar-chitecture in heterogeneous parallel computers. For ex-ample, in a parallel machine with 10 nodes, where eachnode is a 16-core processor, users can choose to parti-tion first into 10 parts, and then further partition eachof those parts into 16 parts. Different partitioning algo-rithms can be applied at each level to attempt to mini-mize costs related to data movement at the level. Thishierarchical partitioning has shown benefit in someshared-memory clusters [61]; further experimentationfor multicore systems is underway.
Isorropia provides a Trilinos Epetra matrix-parti-tioning interface to Zoltan. It maps matrix data struc-tures (e.g., rows, non-zeros) to the partitioning models(e.g., vertices, edges) in Zoltan, provides access to allZoltan partitioners, and provides data redistribution ca-pabilities for Epetra matrices and vectors. The defaultEpetra partition is row-based; that is, entire rows of amatrix (along with corresponding vector entries) areassigned to parts. However, Isorropia provides moresophisticated partitions as well. For example, in two-dimensional matrix partitions, individual non-zeros ofthe matrix are assigned to parts, allowing greater flexi-bility to reduce total communication volume or numberof neighboring processes in matrix–vector multiplica-tion [11]. Two-dimensional matrix partitioning meth-ods available in Isorropia include fine-grained hyper-graph partitioning [11], Cartesian methods [11], andRCB partitioning of the (i, j) indices of the matrix non-zeros [22].

134 E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing
2.2. Ordering
The ordering of sparse data structures (graphs, ma-trices, meshes) is important to obtain good perfor-mance on modern architectures. In Zoltan/Isorropia,we have focused on two different goals: ordering ir-regular data for locality, and fill-reducing ordering forsparse matrix factorizations. The same interfaces andclasses are used for both types of ordering.
2.2.1. Locality-enhancing orderingsA very common kernel in scientific computing is
to loop over an irregular (unstructured) data structuresuch as a mesh or a sparse matrix. For example, insparse matrix–vector multiplication y = Ax, each non-zero entry in A has to be traversed. Mathematically, thevisit order does not matter because the result is invari-ant. However, the performance on a modern computeris highly dependent on the ordering since memory ac-cess is relatively slow compared to computation. Thegoal is thus to reorder the data such as to maximizelocality and reduce the number of cache misses. Thisis also known as loop permutation. Typically, the or-dering (permutation) is computed once but can be usedmany times.
In Zoltan/Isorropia, we provide two such orderings.One is based on space-filling curves, where items areordered in local memory according to their positionalong a space-filling curve through the items (Fig. 1).The other is the Reverse Cuthill–McKee (RCM) algo-rithm [20], which attempts to minimize the bandwidthof a sparse matrix. RCM is also often used to reordermatrices for iterative methods [25].
The typical use case is to use locality-enhancing or-dering on local data within a single compute node orcore. Thus, only a serial implementation is provided inZoltan/Isorropia.
2.2.2. Fill-reducing ordering of sparse matricesIn many scientific computing applications, it is nec-
essary to solve linear systems Ax = b. Either di-rect or iterative methods can be used. When A is ill-conditioned or no good preconditioner is known, directsolvers are preferred since iterative solvers will con-verge slowly or not at all. The work and memory re-quired to solve Ax = b depends on the fill in the factor-ization. A standard technique is therefore to permute(reorder) the matrix A such that one solves the equiv-alent system (PAQ)(QTx) = Pb, where P and Q arepermutation matrices. This reordering is usually per-formed as a preprocessing step, and depends only onthe non-zero structure, not on the numerical values. In
the symmetric positive definite case, a symmetric per-mutation is used to preserve symmetry and definite-ness, i.e., Q = P T. In the non-symmetric case, numer-ical pivoting is required for stability during the factor-ization phase. Generally, only a column permutation istherefore performed in the setup phase to reduce fill.
There are two broad categories of fill-reducing or-dering methods: minimum degree [62] and nested dis-section [29] methods. The minimum-degree class takesa local perspective and the algorithms are greedy. Thealgorithms are inherently sequential but fast to com-pute. The nested dissection methods, on the other hand,take a global perspective. Typically, recursive bisectionis used, which is suited for parallel processing. Nesteddissection methods usually give less fill for large prob-lems, and are better suited for parallel factorization. Inpractice, hybrid methods that combine nested dissec-tion with a local ordering are most effective.
Symmetric positive definite case. Most of the state-of-the-art symmetric ordering tools [10,16,33,40] arehybrid methods that combine multilevel (hyper)graphpartitioning for computing nested dissections with avariant of minimum degree for local ordering. Themain idea of nested dissection is as follows. Considera partitioning of vertices (V ) into three sets: V1, V2 andVS , such that the removal of VS , called a separator,decouples two parts V1 and V2. If we order the verticesof VS after the vertices of V1 and V2, i.e., if the elim-ination process starts with vertices of either V1 or V2,no fill will occur between the vertices of V1 and V2.Furthermore, the elimination process in V1 and V2 areindependent from each other and their elimination onlyincurs fill to themselves and VS . In the nested dissec-tion, the ordering of the vertices of V1 and V2 is simplycomputed by applying the same process recursively. Inthe hybrid methods, recursion is stopped when a partbecomes smaller than predetermined size, and mini-mum degree-based local ordering is used to order thevertices in that part.
Non-symmetric case. In non-symmetric direct solv-ers, partial pivoting is required for numerical stabilityand to avoid breakdown. Partial pivoting is usually per-formed by looking down a column for a large entry andthen swapping rows. This defines a row permutationbut it is determined during the numerical factorization.Therefore, fill-reducing ordering has focused on col-umn ordering. Consider A = PAQ. The column per-mutation Q can be computed in a preprocessing stepbased on the structure of A. Note that P is not knownat this point, so Q should reduce fill for any P .
There are two popular approaches to column order-ing. First, one can simply symmetrize A and compute

E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing 135
a nested dissection ordering for either A+AT or ATA.This is attractive because one can use the same algo-rithms and software as in the symmetric case. How-ever, ordering based on A + AT does not necessar-ily give good quality ordering for A. Ordering basedon ATA generally works better and has a theoreticalfoundation since the fill for LU factors of A is con-tained within the Cholesky factor of ATA. Unfortu-nately, ATA is often much denser than A and takestoo much memory to form explicitly. The second ap-proach is therefore to order the columns of A to re-duce fill in the Cholesky factor of ATA but withoutforming ATA. Several versions of minimum degreehave been adapted in this way; the most popular is CO-LAMD [21]. A limitation of COLAMD is that it is in-herently sequential and not suited for parallel compu-tations.
A third approach, the HUND method, was recentlyproposed in [30]. The idea is to use hypergraphs toperform a non-symmetric version of nested dissection,then switch to CCOLAMD on small subproblems. Hy-pergraph partitioning is used to obtain a singly bor-dered block diagonal (SBBD) form [1], see Fig. 3. It isshown in [30] that the fill in LU factorization is con-tained within the blocks in the SBBD form, even withpartial pivoting. Experiments with serial LU factor-ization show that HUND compares favorably to othermethods both in terms of fill and flops. Perhaps thegreatest advantage of HUND, though, is that it can bothbe computed in parallel and produces orderings wellsuited for parallel factorization.
The fill-reducing orderings are intended for solvinglarge systems, and thus must be computed in paral-lel. The focus in Zoltan is on nested-dissection meth-ods, since these generally work best on large problems.
Fig. 3. Sparse matrix reordered by the HUND algorithm. All fill inLU factorization is limited to the colored blocks. (Colors are vis-ible in the online version of the article; http://dx.doi.org/10.3233/SPR-2012-0342.)
Classic nested dissection for symmetric problems isprovided through interfaces to the third-party librariesScotch [16] and ParMETIS [41]. For non-symmetricproblems, Zoltan contains a native parallel implemen-tation of HUND. HUND can also be applied to sym-metric systems, but works best in the non-symmetriccase.
Isorropia provides the same capabilities as Zoltan,and in fact calls Zoltan. Zoltan and Isorropia do notprovide a sparse direct solver; rather, they should beused to compute a permutation vector before callinga direct solver. Isorropia provides the most convenientinterfaces for Trilinos solvers such as Amesos (Ame-sos2) [54], while Zoltan may be simpler to use for othersolvers.
2.3. Coloring
Graph coloring is an archetypal model in many sci-entific applications. Its applications vary from identify-ing concurrent computations, such as in iterative solu-tion of sparse linear systems [39], preconditioners [52],sparse tiling [59], and eigenvalue computation [45], toefficient computation of Jacobian and Hessian matrices[27], as well as channel assignment problems in radionetworks [43,44]. A distance-k coloring of a graph isan assignment of colors to vertices such that any twovertices connected by a path consisting of at most kedges receive different colors, and the goal of the as-sociated problem is to minimize the number of colorsused.
The distance-k coloring problem is formally definedas follows. Let G = (V , E) be a graph with |V | ver-tices and |E| edges. We call two distinct vertices inthe graph distance-k neighbors if a shortest path con-necting them consists of at most k edges. The setof distance-k neighbors of a vertex v is denoted byadjk(v); its cardinality, also called the degree-k of v,is denoted by δk(v). The degree of the vertex havingthe most neighbors is Δk = maxv δk(v). A distance-k coloring φ : V → N is a function that maps eachvertex of the graph to a color (represented by an inte-ger), such that two distance-k neighbor vertices havedifferent colors, i.e., ∀u ∈ adjk(v), φ(u) �= φ(v). With-out loss of generality, the number of colors used ismaxu∈V φ(u). The optimization problem at hand isto find a coloring with as few colors as possible. Indistance-1 coloring, the minimal number of colors agraph can be colored with is called the chromatic num-ber of the graph χ(G). The problem of finding χ(G) foran arbitrary graph G is known to be an NP-Complete

136 E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing
Fig. 4. A sample Jacobian matrix A and its compressed representation B. (Colors are visible in the online version of the article; http://dx.doi.org/10.3233/SPR-2012-0342.)
problem [46]; thus, finding optimal graph colorings forgeneral graphs is NP-Hard. Fortunately, simple heuris-tics often work well in practice.
Partial distance-2 coloring is another variant of col-oring that is used to identify a structurally orthogo-nal partition of a Jacobian matrix A [19]. Here struc-turally orthogonal means a partition of the columns ofA in which no two columns in a group share a non-zero at the same row index. This approach yields a seedmatrix S where the entries of A can be directly re-covered from the compressed representation B ≡ AS(see Fig. 4). In this problem, the structure of a Jaco-bian matrix A can be represented by the bipartite graphGb(A) = (V1, V2, E), where V1 is the row vertex set,V2 is the column vertex set, and (ri, cj) ∈ E when-ever the matrix entry aij is non-zero. A partitioning ofthe columns of the matrix A into groups consisting ofstructurally orthogonal columns is equivalent to a par-tial distance-2 coloring of the bipartite graph Gb(A) onthe vertex set V2 [27]. The coloring, also known as bi-partite coloring, is called “partial” distance-2 coloringbecause the row vertex set V1 is left uncolored.
In large scientific parallel applications, the compu-tational model (hence the graph) is already distributedonto the nodes of the parallel machine; therefore, col-oring needs to be performed in parallel. An alternative
approach, if the graph is sufficiently small, is to aggre-gate it on a single node and color it there sequentially.A better approach would be taking advantage of thepartitioning of the graph, and color the interior vertices(vertices for which all their distance-k neighbors arelocal) in parallel and then color the remaining (verticesthat have at least one non-local distance-j neighbor)sequentially, by aggregating the graph induced by themon a single processor. However, as shown in [4], onecan perform significantly better by using a distributedmemory coloring algorithm.
The distributed memory coloring frameworks fordistance-1 [4] and distance-2 [3] coloring have beenimplemented in Zoltan. The framework provides ef-ficient implementation for greedy graph coloring al-gorithms [17]. In greedy coloring, the vertices of thegraph are visited in some order and the smallest per-missible color at each iteration is assigned to the ver-tex. Choosing the smallest permissible color is knownas the First Fit strategy. This simple algorithm has twonice properties. First, for any vertex visit ordering, itproduces a coloring with at most 1 + Δk colors. Sec-ond, for some vertex-visit orderings it will produce anoptimal coloring [18]. Many heuristics for ordering thevertices have been proposed in the literature [18,27].Commonly known vertex orderings are Largest First,

E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing 137
Smallest Last, Saturation Degree, and Incidence De-gree orderings. We refer the reader to [27] for a suc-cinct summary of these ordering techniques, and toColPack [28] for a sequential implementation of var-ious coloring, ordering, matrix recovery and other sup-porting algorithms for Jacobian and Hessian computa-tions.
Zoltan provides a parallel coloring framework. Inthis framework, a coloring is constructed in multi-ple rounds. In each round, all the uncolored verticesare tentatively colored using the greedy coloring al-gorithm. This process may yield conflicts that can de-tected independently by each processor after coloring.When a conflict occurs, one of the vertices that are inconflict is marked for recoloring in the next round. Thevertex to be colored is chosen based on a random to-tal ordering generated beforehand to avoid load imbal-ance that may arise due to natural vertex numbering.The algorithm iterates until there are no more conflicts.
In order to reduce the number of conflicts at eachround, the coloring of the vertices is performed in su-persteps. In each superstep, each processor colors agiven number of its own vertices. Then it exchangesthe colors of the boundary vertices colored in that su-perstep, if any, with its neighbor processors. If car-ried out synchronously, this communication mecha-nism ensures that two vertices can be in a conflict onlyif they are colored in the same superstep. The size ofthe superstep becomes an important parameter sincea smaller size increases the number of messages ex-changed on the network while a larger size is likely toincrease the number of conflicts.
Coloring itself can be used to order vertices for re-coloring. Culberson [18] showed that in recoloring, ifthe vertices belonging to the same color class (i.e., thevertices of the same color) in a previous coloring arecolored consecutively, the number of colors will eitherdecrease or stay the same. Zoltan currently providesthree different heuristics to obtain new permutationsof color classes for recoloring of distance-1 coloring:Reverse order of colors [18], non-increasing numberof vertices, where the color classes are ordered in thenon-increasing order of their vertex counts, and non-decreasing number of vertices, where the color classesare ordered in the non-decreasing order of their vertexcounts.
There are five main parameters affecting the be-havior of the framework in Zoltan and all are tun-able by the user. These are superstep size, synchronousor asynchronous execution of supersteps, coloring or-der of the vertices, color selection strategy and recol-
oring (multiple passes of coloring). Several combina-tions of those were experimentally investigated to de-termine the best parameters for reducing the number ofcolors and the runtime. The studies [3,4,13,55] showthat there is no single combination that outperformsthe others both in terms of the number of colors andthe runtime. In general, the best runtime is achievedby a single pass of greedy coloring, coloring internalvertices first and using asynchronous communication,whereas the best number of colors is achieved by mul-tiple passes of recoloring using Smallest Last vertexvisit ordering and synchronous communication.
2.4. Utilities
While the focus of Zoltan and Isorropia is on com-binatorial algorithms, a few utilities related to andincluded in Zoltan and Isorropia functionality haveproven useful. Two examples are described below.
2.4.1. Distributed data directoriesDynamic applications often need to locate off-
processor information. After repartitioning, for exam-ple, a processor may need to rebuild ghost cells andlists of items to be communicated; it may know whichitems it needs, but may not know where they are lo-cated. After global ordering, data values such as thepermuted global numbering associated with items mayneed to be shared among processors.
To allow applications to locate off-processor data,Zoltan includes distributed data-directory utilitiesbased on a rendezvous algorithm [50]. Zoltan’s dis-tributed data directories have been used for updatingghost information and building communication mapsin finite element and particle simulations.
Each data directory is distributed evenly across pro-cesses in a predictable fashion (through either a lineardecomposition of the IDs or a hashing of IDs to pro-cesses). Within a process, directory entries are storedin hash tables to allow constant-time searches for spe-cific entries. Processes register their owned items’ IDsalong with their process number and desired user databy calling Zoltan_DD_Update. Other processescan obtain the process number and user data associ-ated with a given item by calling Zoltan_DD_Find,which, using the same distribution scheme, requeststhe information from the process holding the direc-tory entry. In this way, distributed data directories pro-vide memory efficient, constant time look-ups of off-process data. Total memory usage across all processesis proportional to the number of items. Distributing

138 E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing
the directory across processes avoids performance bot-tlenecks and memory limitations that would arise ifthe directory were stored on only one process. Usingpredictable, hash-based distribution and local-searchschemes allows constant-time access to the data.
2.4.2. ProbingA special feature in Isorropia (not included in
Zoltan) is the ability to perform probing on an op-erator. Often a linear operator is given only implic-itly, not explicitly as a matrix. In some situations, itis necessary to build an explicit matrix that representsor approximates the operator. The probing techniquewas first suggested by Chan and Matthews [15] to ap-proximate Schur complements in PDE solvers, but wasrestricted to banded approximations. An extension togeneral graphs was suggested in [57], where they usegraph coloring as a tool. The probing method in Isor-ropia is based on this approach.
The input to an Isoroppia::Prober is anEpetra_Operator and the sparsity pattern givenby a Epetra_CrsGraph, while the output is anEpetra_CrsMatrix that represents (approxi-mates) the operator by using the given sparsity pattern.The use of probing is best explained by an example.Suppose a user has a matrix-free numerical methodwhere the operator is given as a “black-box” but shewants to use an algebraic preconditioner (e.g., Ifpackor ML). Ifpack/ML needs a concrete sparse matrix, notan operator. A simple but inefficient way to solve thisproblem is to apply the desired operator to all the iden-tity vectors, ei, i = 1, . . . , n, where n is the dimen-sion of the operator. This would require n applicationsof the operator, which is usually too expensive to bepractical. However, if the user knows the sparsity pat-tern (or can estimate it), then he can use the prober toconstruct the desired matrix much more efficiently.
Internally, the prober applies the operator to a care-fully chosen set of vectors. To minimize the cost ofprobing, graph coloring is used to generate a mini-mal set of probing vectors. In fact, the probing vectorscorrespond to the seed matrix S as described in Sec-tion 2.3. Hence the main cost of the probing is to ap-ply the operator c times, where c is the number of col-ors. (This is analogous to Jacobian compression.) Typi-cally, c n so there is a substantial reduction of work.The coloring and reconstruction happen transparentlyto the user, and the coloring capabilities in Zoltan/Isor-ropia are leveraged.
3. Software design
The Trilinos packages Zoltan and Isorropia providecombinatorial algorithms to a wide range of applica-tions. Zoltan is the base package, containing the par-tititioning, ordering and coloring algorithms describedabove. It requires users to map their data into the par-ticular combinatorial model (e.g., graph, hypergraph,coordinates) to be used in partitioning, ordering andcoloring. For users of Trilinos’ Epetra [35], the mostwidely used matrix/vector classes in Trilinos, the Isor-ropia package performs this mapping from matricesto the combinatorial models and passes these modelsto Zoltan. Thus, the Isorropia interface is much sim-pler for Epetra users, and can provide richer algorithms(e.g., two-dimensional matrix partitioning) for matrix-based applications.
Both Zoltan and Isorropia assume an owner-com-putes model, where each process “owns” a distinctset of items and may optionally have copies of otherneeded items. Both can operate in serial; for paralleloperation, they rely on MPI [47] to perform interpro-cess message-passing communication. Zoltan is writ-ten in C and provides C, C++ and Fortran90 inter-faces; Isorropia’s Epetra-based interface is written inC++, with C++ and Python interfaces (through Trili-nos’ PyTrilinos package [53]). Details of Zoltan andIsorropia’s software design are below.
3.1. Zoltan
Zoltan is designed to provide parallel partitioning,coloring, and ordering to a wide range of parallel ap-plications. Zoltan uses a distributed-memory program-ming model with the Message-Passing Interface (MPI)library [47] performing interprocess communication.Although it is a Trilinos package, it does not depend onany other Trilinos package or data structure, and, in-deed, it can be built and used separately from Trilinos.Its callback-function user interface is “data-structureneutral” in that Zoltan users do not have to use a spe-cific data structure in their applications, nor do theyhave to build a specific data structure for Zoltan. Thisinterface has served well to support a variety of appli-cations, including finite element methods with adap-tive mesh refinement for multiphysics simulations, par-ticle methods for accelerator and biological simula-tions, crash simulations with contact detection, circuitsimulations, multigrid preconditioning, simulations ofemerging computer architectures, and peridynamicssimulations. Zoltan’s design and implementation en-

E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing 139
Table 1
Examples of large-scale partitioning performed by Zoltan
Partitioning Application Problem Number of Number of Architecture Source
algorithm size processes parts
Graph PHASTA 34M elements 16K 16K BG/P M. Zhou et al.,
computational RPI
fluid dynamics
Hypergraph PHASTA 1B elements 4096 160K Cray XT/5 M. Zhou et al.,
computational RPI
fluid dynamics
Hypergraph SPARTA load 800M zones 8192 262K Hera K. Lewis,
balancing toolkit AMD Quadcore LLNL
Geometric Pic3P particle 5B particles 24K 24K Cray XT/4 A. Candel,
(RCB) in cell SLAC
Geometric MPSalsa 208M mesh nodes 12K 12K Redstorm P. Lin,
(RCB) computational SNL
fluid dynamics
Geometric Trilinos/ML 24.6M rows; 24K 24K Redstorm J. Hu et al.,
(RCB) multigrid in 1.2B non-zeros SNL
shock physics
ables it to be used for large scale simulations, partition-ing for more than 200K processes; see Table 1 for someexamples. Zoltan’s design also supports research anddevelopment of new algorithms, such as its recentlydeveloped hypergraph and hierarchical partitioners.
In the set of applications that use Zoltan, data to beoperated on include (but are not limited to) mesh ele-ments and nodes, particles, matrix rows/columns/non-zeros, circuits, and agents. Rather than limit Zoltan’scapabilities to a specific type of data, we consider eachdata entity to be merely an item on which Zoltan oper-ates. Each item must have a globally unique identifier(ID) that can be represented as an array of unsignedintegers. Examples of single-integer global identifiersinclude global element numbers and global matrix rownumbers. Applications that do not support global num-bering can use, e.g., a two-integer tuple consisting ofthe process rank of the process that owns the entity anda local entity counter in the process. Zoltan uses theseglobal identifiers only to identify items; any uniquenaming scheme is acceptable. Zoltan also gives usersthe option of providing a local identifier (also an arrayof unsigned integers) for each item. These local identi-fiers allow applications to access data more directly incallback functions by avoiding a mapping from globalidentifiers to the local location of items. Examples ofuseful local identifiers include items’ indices in dataarrays and pointers to items’ locations in memory.
Zoltan uses a callback-function interface, throughwhich applications describe their data to Zoltan. Call-back functions are small functions written by the userthat access the user’s data structures and return neededdata to Zoltan. When applications invoke Zoltan’smethods, Zoltan calls these user-provided callbackfunctions to build the data structures (coordinates,graphs, hypergraphs, etc.) it needs for partitioning, col-oring and ordering. Figure 5 contains an example ofthe geometric callback functions for a simple particle-based simulation. Callback function num_geom re-turns the dimension of the problem domain, in thiscase, three for a three-dimensional problem. Call-back function geom_multi returns the coordinatesfor each on-process particle in arrays allocated byZoltan and provided to the application. Pointers tothese functions are registered with Zoltan through callsto Zoltan_Set_Fn. A complete example programusing these functions is included in the Appendix.
The set of callback functions used in Zoltan has beenkept quite small (see Table 2) and the same interfaceis used for partitioning, ordering, and coloring. More-over, users need to implement only those callbacks re-quired by the specific Zoltan capability they wish touse. At a minimum, users must provide callback func-tions that return the number of items owned by a pro-cess, and the unique global and optional local IDs forthose items. Other callback functions needed dependon the operations to be performed by Zoltan. Geomet-

140 E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing
1 / / / / / / / / / / / / / / / / / A p p l i c a t i o n d a t a f o r p a r t i c l e s i m u l a t i o n / / / / / / / / / / / /2 struct UserData {3 int numMyParticles;4 struct Particle {5 int id; / / u n i q u e g l o b a l name f o r p a r t i c l e6 double x, y, z; / / g e o m e t r i c c o o r d i n a t e s f o r p a r t i c l e7 / / . . . s o l u t i o n v a l u e s , e t c . . . .8 } *myParticles;9 };
1011 / / / / / / / / / / / / User−p r o v i d e d que ry f u n c t i o n s f o r c o o r d i n a t e s / / / / / / / / / / /12 / / Re tu rn d imens ion of problem .13 int num_geom(void *data, int *ierr)14 {15 return 3; / / 3D problem16 }1718 / / R e t u r n c o o r d i n a t e s f o r o b j e c t s r e q u e s t e d by Z o l t a n i n g l o b a l I D s a r r a y .19 void geom_multi(void *data, int nge, int nle, int numObj,20 ZOLTAN_ID_PTR globalIDs, ZOLTAN_ID_PTR localIDs,21 int dim, double *geomVec, int *ierr)22 {23 / / Ca s t d a t a p o i n t e r p r o v i d e d i n Z o l t a n _ S e t _ F n t o a p p l i c a t i o n d a t a t y p e .24 struct UserData *myData = (struct UserData *) data;2526 / / Copy c o o r d i n a t e s f o r p a r t i c l e g l o b a l I D [ i ] ( w i th l o c a l I D [ i ] )27 / / i n t o geomVec .28 int i, j = 0;29 for (i = 0; i < numObj; i++) {30 geomVec[j++] = myData->myParticles[localIDs[i]].x;31 if (dim > 1) geomVec[j++] = myData->myParticles[localIDs[i]].y;32 if (dim > 2) geomVec[j++] = myData->myParticles[localIDs[i]].z;33 }34 *ierr = ZOLTAN_OK;35 }
Fig. 5. Example of the geometric callback functions Zoltan_Num_Geom_Fn and Zoltan_Geom_Multi_Fn for simple particle-basedapplication. A full program using these callbacks is included in the Appendix.
ric partitioning and ordering methods, for example, re-quire two callback functions as in Fig. 5 to return thegeometric dimension of the data and each item’s ge-ometric coordinates. Graph-based partitioning, color-ing and ordering algorithms require graph-based call-backs that return information about edge connectivitybetween items. Hypergraph-based methods can use ei-ther graph-based callbacks (from which a hypergraphstructure is constructed) or hypergraph-based callbacksthat enable the full expressiveness of the hypergraphmodel to be used for, say, structurally non-symmetricproblems.
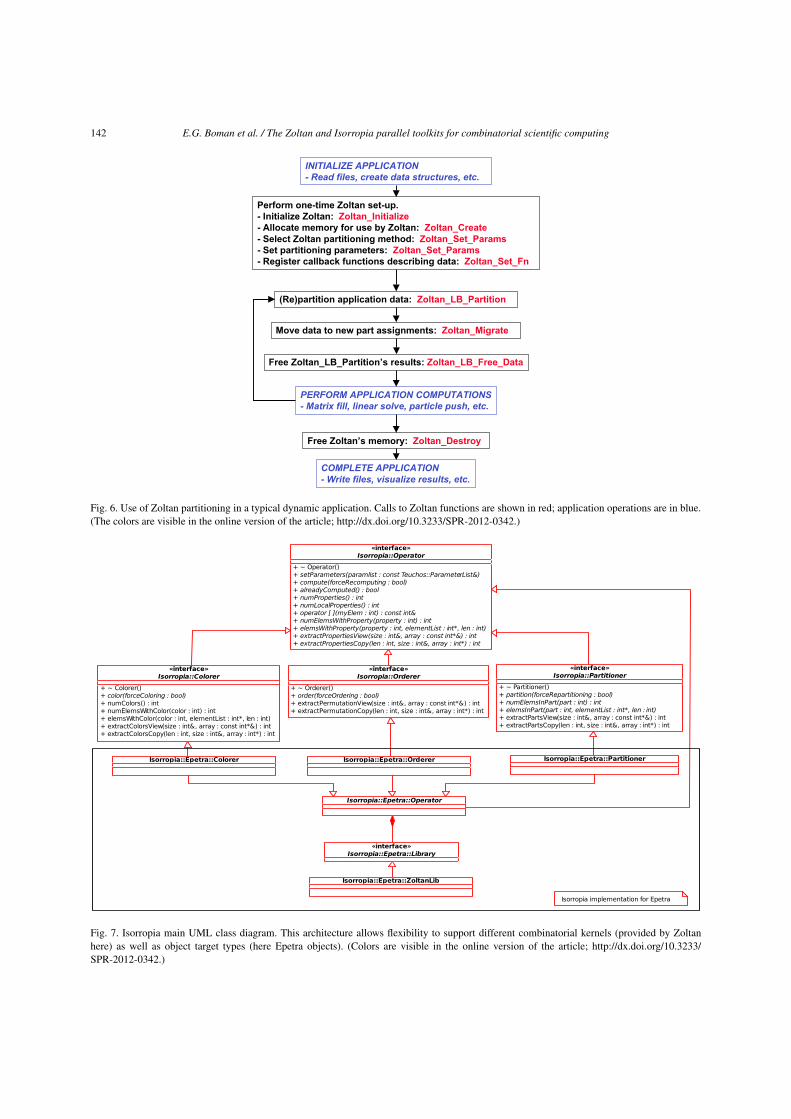
Figure 6 shows the basic use of Zoltan in an ap-plication needing dynamic load balancing. The appli-cation begins as usual, reading input files and creat-ing its data structures. Then it calls several Zoltan set-up functions. It initializes Zoltan by calling Zoltan_Initialize, which checks that MPI is initialized.
It also calls Zoltan_Create to allocate memoryfor Zoltan; a pointer to this memory is returned byZoltan_Create and must be passed to all otherZoltan functions. Next, by calling Zoltan_Set_Param, the application selects the partitioning methodit wishes to use and sets method-specific parameters.It registers pointers to callback functions through callsto Zoltan_Set_Fn. After the set-up is completed,the application computes a new partition by callingZoltan_LB_Partition and moves the data to itsnew part assignments by calling Zoltan_Migrate.After migration, Zoltan_LB_Free_Data frees thearrays returned by Zoltan_LB_Partition. Theapplication then proceeds with its computation usingthe newly balanced partition. Partitioning and compu-tation can occur in many iterations of the application,with part assignments changing to adjust for changes inthe computation. After the iterations are completed, the

E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing 141
Table 2
Zoltan callback functions and their return values
Callback Return values
All methods
ZOLTAN_NUM_OBJ_FN Number of items on processor
ZOLTAN_OBJ_LIST_FN List of global/local IDs and weights
Geometric partitioning and ordering
ZOLTAN_NUM_GEOM_FN Dimensionality of domain
ZOLTAN_GEOM_MULTI_FN Coordinates of items
Hypergraph partitioning
ZOLTAN_HG_SIZE_CS_FN Number of hyperedge pins
ZOLTAN_HG_CS_FN List of hyperedge pins
ZOLTAN_HG_SIZE_EDGE_WTS_FN Number of hyperedge weights
ZOLTAN_HG_EDGE_WTS_FN List of hyperedge weights
Graph/hypergraph partitioning, ordering, coloring
ZOLTAN_NUM_EDGE_MULTI_FN Number of graph edges
ZOLTAN_EDGE_LIST_MULTI_FN List of graph edges and weights
Data migration
ZOLTAN_PACK_OBJ_MULTI_FN Copy item data in a communication buffer
ZOLTAN_UNPACK_OBJ_MULTI_FN Copy item data inserted in data structure
Note: Applications need to implement only the callbacks required by the specific capa-bility (partitioning, coloring, ordering, migration) and methods (geometric, graph-based,hypergraph-based) the application is using.
application calls Zoltan_Destroy to free the mem-ory allocated in Zoltan_Create, and completes itsexecution by returning the results of the computation.
The basic set-up of Zoltan – initializing, allocatingmemory, setting parameters, and registering callbackfunctions, and freeing memory – is the same regardlessof whether one uses Zoltan for partitioning, orderingor coloring. Only the operations in the iteration loopwould change if ordering (Zoltan_Order) or color-ing (Zoltan_Color) were needed.
3.2. Isorropia
Isorropia was first designed to provide load-balanc-ing capabilities for Trilinos objects. It provided an easyand convenient way to perform partitioning and repar-titioning on Epetra objects. Isorropia can be viewedas an interface between Trilinos’ Epetra matrices andZoltan callbacks. Starting with Trilinos v9, Isorropiaprovides access to most Zoltan features related to ma-trices; therefore, it is possible for Trilinos users to par-tition, color or order Epetra_RowMatrix objectswithout having to write any specific Zoltan callbacks.Isorropia is designed to also extend Zoltan, by apply-ing higher level algorithms using Zoltan kernels.
As with most Trilinos packages, Isorropia is writtenin C++, and an effort has been made to obtain a con-
venient and robust interface for the user. Isorropia ca-pabilities are described by interfaces (abstract classes)for which an Epetra implementation is provided. How-ever, an implementation based on the templated ma-trix/vector classes in Tpetra [36] will use the same in-terface.
The interface by itself is divided in three mainclasses – Isorropia::Colorer, Isorropia::Orderer and Isorropia::Partitioner –which are designed to perform the associated task. Asall these tasks have similarities, they all inherit from aIsorropia::Operator class. It provides a stan-dard way to compute the task and also provides ac-cessors to the result. Indeed, coloring, ordering or par-titioning processes have almost identical signatures:they compute on a matrix (only the structure of thematrix is needed) and their result is an integer (color,number, part assignment) associated with every rowand/or column. Having Isorropia::Operator asa common ancestor provides a standard and coherentway to access results. In our case, the bracket operatoris the most natural way to access local results, but moreadvanced methods are also available.
Isorropia’s interface is implemented for Epetra ob-jects. An UML class diagram for the main classes ispresented Fig. 7.
142 E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing
Fig. 6. Use of Zoltan partitioning in a typical dynamic application. Calls to Zoltan functions are shown in red; application operations are in blue.(The colors are visible in the online version of the article; http://dx.doi.org/10.3233/SPR-2012-0342.)
Fig. 7. Isorropia main UML class diagram. This architecture allows flexibility to support different combinatorial kernels (provided by Zoltanhere) as well as object target types (here Epetra objects). (Colors are visible in the online version of the article; http://dx.doi.org/10.3233/SPR-2012-0342.)

E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing 143
While Isorropia::Operator is used to sharethe methods for defining problems or for accessingresults, its (partial) implementation Isorropia::Epetra::Operator is responsible for providingcode used to access data.
For Epetra matrices, we use only Zoltan for com-binatorial kernels; however, Zoltan calls are issuedthrough a specific class Isorropia::Epetra::ZoltanLib which provides an implementation ofthe Isorropia::Epetra::Library interface.Thus, using another combinatorial toolkit requiresmainly implementation of this library interface.
Another goal of Isorropia was to provide somehighly specialized solutions for combinatorial prob-lems on Trilinos objects. Thus, the architecture is de-signed to be more than a simple wrapper on Zoltan. Forexample, two-dimensional matrix partitioning in Isor-ropia is implemented as an extension of the partitionerclass.
The examples below show that Isorropia greatly re-duces the number of lines of source code for Epetrausers. First, given an Epetra sparse matrix, one can ob-tain a row partitioning in one line:
// crsmatrix is an Epetra_CrsMatrixIsorropia::Epetra::Partitioner
partitioner(crsmatrix);
By default, the constructor also performs the partition-ing. In more advanced use cases, the constructor justcreates the object and the partition() method isexplicitly called later:
// crsmatrix is an Epetra_CrsMatrixTeuchos::ParameterList params;params.set("PARTITIONING_METHOD","GRAPH"); // default is HYPERGRAPH
params.set("IMBALANCE_TOL", "1.03");// allow 3% imbalanceIsorropia::Epetra::Partitionerpartitioner(crsmatrix, params,
false);// do some other work ...partitioner.partition();
The result of the partitioning is stored in the Parti-tioner and can be accessed in several ways. A com-mon use case is to redistribute the distributed object ac-cording to the computed partition. This is easily done
using a redistributor:
// Assume partitioner wasconstructed as above
Isorropia::Epetra::Redistributorrd(partitioner);
// Redistribute the matrixnewmatrix =rd.redistribute(crsmatrix, true);
It is possible to reuse the redistributor to also distributevectors or another matrix.
Isorropia has its own parameters defined by aTeuchos::ParameterList with options namesthat are more relevant for an Epetra user. However, itis still possible to pass advanced parameters directly toZoltan.
To summarize, Isorropia provides solutions to com-binatorial problems such as partitioning, coloring orordering by an easy to use common interface whichcurrently deals with Epetra objects. Isorropia also pro-vides methods to apply these results so they can beused in complex Epetra-based codes with minimal ef-fort.
4. Next generation: Zoltan2
We have begun a refactoring of Zoltan and Isor-ropia, embodied in the new Trilinos package Zoltan2.Zoltan2 combines features of Isorropia and Zoltan ina uniform abstract interface. It will continue to sup-port a broad range of applications and provide themost commonly used features of Zoltan and Isorropia.It will also include new features and algorithms de-signed specifically for exascale computing, includingsupport for heterogeneous computers, multicore algo-rithms, and scalability to million-way parallelism. Thisrefactoring is motivated by a number of algorithmicand software engineering issues.
Zoltan2 enables future combinatorial algorithm re-search to better support exascale computing. As com-puter architectures evolve to include increasing het-erogeneity, new combinatorial algorithms are required.Zoltan was designed strictly for distributed memoryenvironments, but hybrid MPI+threads programmingmodels are becoming common in parallel comput-ers built from multicore processors. For applicationsusing hybrid programming models, partitioning withawareness of the underlying computing architectureand memory hierarchies can increase data locality for

144 E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing
efficient computation, and ordering algorithms anditerators can improve data access within multicore ar-chitectures. Within the combinatorial algorithms them-selves, adopting hybrid programming models canimprove the scalability of partitioning, coloring andordering. These features will be supported in Zoltan2through incorporation of architecture models and sys-tem information from systems such as the OVIS re-source analysis toolkit [5] and Portable Hardware Lo-cality toolkit (hwloc) [6], as well as node-level pro-gramming primitives from the Trilinos’ Kokkos nodepackage [37].
Zoltan2 exploits recent advances in compiler tech-nology and software design principles. Next-genera-tion packages in Trilinos (e.g., the Tpetra [36] ma-trix/vector classes and Belos [38] linear solvers) relyon templating to enable computations on large-scaleproblems (i.e., those with more than two billion (max-imum integer value on a 32-bit system) rows andnon-zeros). Global and local row/column numbers aretemplated separately to accommodate integers, long in-tegers, long long integers, etc. Scalar values are alsotemplated to allow reduced, increased, or mixed preci-sion computations. While Zoltan has been modified toallow more than two billion items to be partitioned, itdoes not yet support the full range of templating op-tions available in next-generation Trilinos packages.In addition to templated ordinal types, Zoltan2 allowstemplated types for global and local IDs, analogous tothe arbitrary IDs in Zoltan. Data types for weights arealso templated.
Zoltan2 also provides a more natural interface forapplication developers. At the time of Zoltan’s ini-tial design, C++ compilers were immature, particu-larly on massively parallel computers such as ASCIRed. Thus, while using an object-oriented design, theZoltan library is written in C. Isorropia simplifies useof Zoltan for applications with Epetra matrices, butother users must rely on the original C interface. Topreserve backward compatibility for long-time users,Zoltan’s interface is largely unchanged since its origi-nal design and can be improved by the user feedbackand lessons we have learned through many years ofZoltan use. In particular, Zoltan2 separates the user’sdata model from the data model used in Zoltan2’s al-gorithms, no longer requiring users to understand thedetails of graphs and hypergraphs to use partitioning,ordering and coloring algorithms.
Zoltan2 has an improved object-oriented designcompared to Zoltan; the improvements are enabled byclass hierarchies available in C++. We use a combina-
tion of templating and inheritance to abstract user datafrom the combinatorial model and algorithms. A high-level view of our design is shown in Fig. 8.
At the user level, users may provide parameterscontrolling the choice of combinatorial model and al-gorithms, and configuration options such as debug-ging levels and memory allocation routines. Users de-scribe their application data through InputAdapterobjects. Several types of InputAdapter objects –meshes, matrices, vectors, particles, networks – are de-fined to support different applications. These adaptersallow users to describe their data in its native for-mat, rather than mapping it to a particular model(e.g., graph, hypergraph) as in Zoltan. For exam-ple, the matrix InputAdapter has methods return-ing data about matrix rows and non-zeros; the meshInputAdapter describes the elements-node adja-cencies of a mesh. An InputAdapter also describeshow to redistribute data after partitioning or ordering.In the future, users will be able to provide descriptionsof the machine network and/or node architecture aswell. While a number of input classes are shown, manyare optional, allowing Zoltan2 to provide a novice in-terface suitable for the most common use cases (e.g.,TPetra matrix partitioning).
The user’s InputAdapter, parameters and con-figuration information are used to create a Problem,which may be a PartitioningProblem, Order-ingProblem, or ColoringProblem. As in Isor-ropia, the Problem manages the requested opera-tion (partitioning, ordering, coloring) and maintainsstate containing the result of the operation. Usingthe given input, the Problem creates an appropriateModel – the combinatorial representation of the in-put. This model describes how to use functions in theInputAdapter to build the representation neededfor an algorithm, bridging the separation between theapplication data and the data structures needed by acombinatorial algorithm. This model is then passed toan Algorithm that performs the requested opera-tion (partitioning, ordering, coloring); as in Zoltan andIsorropia, geometric, graph, and hypergraph-based al-gorithms will be supported. The Algorithm pop-ulates a Solution within the Problem. As withthe Problem class, the Solution class has specificsubclasses PartitioningSolution (containingimport and export lists and part maps), Ordering-Solution (containing permutations and iterators),and ColoringSolution (containing coloringmaps and iterators).

E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing 145
Fig. 8. High-level view of Zoltan2 design.
Initial release of Zoltan2 in Trilinos is scheduled for2012. It will support only a small subset of Zoltan/Isor-ropia capabilities initially, but anticipated future devel-opment will provide richer capabilities in future Trili-nos releases.
5. Conclusion and future work
We have described the design of two Trilinos pack-ages focused on combinatorial scientific computing:the Zoltan toolkit of partitioning, ordering and coloringalgorithms and the Isorropia toolkit of combinatorialalgorithms for Trilinos’ Epetra matrix/vector classes.These packages provide critical capabilities for a widerange of scientific computing applications, leading toimproved application performance through better loadbalancing, data locality, memory usage, and algorith-mic efficiency. We also introduced our next-generationpackage for combinatorial algorithms, Zoltan2, that
will support more robustly the needs of exascale com-puting and integrate more closely with other Trilinospackages.
Our future efforts focus on Zoltan2. In addition toimplementing the classes and algorithms that make upZoltan2’s base capability, we will pursue a numberof research directions. We will examine architecture-aware partitioning strategies, accounting for the un-derlying machine architecture and resource state inmaking partitioning decisions. We will support multi-core architectures through improved data layouts viaordering and partitioning. And we will begin imple-mentation of thread-enabled combinatorial algorithms.A greater amount of data can be made available toeach task via shared memory than via distributedmemory; we can exploit this fact in heuristic algo-rithms to make better decisions in partitioning, order-ing and coloring. As with Zoltan and Isorropia, wewill integrate and distribute Zoltan2 with the Trilinostoolkit.

146 E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing
Acknowledgements
Many people in addition to the authors have con-tributed to the design and software for the Zoltan andIsorropia toolkits: Doruk Bozdag, Jamal Faik, LuisGervasio, Robert Heaphy, Bruce Hendrickson, ArifKhan, Vitus Leung, William Mitchell, Siva Rajaman-ickam, Lee Ann Riesen, Chris Siefert, Matt St. John,Jim Teresco, Courtenay Vaughan, Alan Williams andMichael Wolf. In addition, the Zoltan and Isorropiateams benefit from technical support personnel inthe Trilinos framework: Roscoe Bartlett, Brent Per-schbacher and James Willenbring. This work waspartially supported by the US Department of En-ergy SciDAC Grant DE-FC02-06ER2775 and NSFGrants CNS-0643969, OCI-0904809 and OCI-0904802.
Appendix
Below is a complete example of a program usingZoltan for geometric partitioning in a simple particle-based application. The application’s data is stored ina simple structure User_Data, containing particles’unique IDs and their coordinates in space.
Four Zoltan query functions are needed to performgeometric partitioning. The Zoltan_Num_Obj_Fnnum_obj returns the number of particles ownedby the process. The Zoltan_Obj_List_Fn obj_list returns the global IDs of each of the particlesowned by the process, as well as local IDs that arethe indices into the local particles array data struc-ture. This example does not use particle weights butif it did, they would also be returned in this function.The Zoltan_Num_Geom_Fn num_geom returnsthe geometric dimension of the application’s domain –in this case, three. The Zoltan_Geom_Multi_Fngeom_multi returns the geometric coordinates of
each of the particles. The local IDs provided inobj_list are used here to quickly locate the coordi-nates for each requested particle.
In the main program, the application initializes MPIand its particle data. It creates a Zoltan_Structdata structure by calling Zoltan_Create. This datastructure contains state information needed by Zoltan;it is an input argument to subsequent Zoltan functioncalls. The program registers pointers to its callbackfunctions through calls to Zoltan_Set_Fn. It alsosets Zoltan parameters via Zoltan_Set_Param,in this case, selecting RCB to be the load-balancingmethod. It then calls Zoltan_LB_Partition tocompute a new partition. The return arguments ofZoltan_LB_Partition are lists of particles to beimported to the process from other processes, and par-ticles to be exported from the process to other pro-cesses. Both process ranks and part numbers are in-cluded in the import and export lists, to allow thenumber of parts to differ from the number of pro-cesses. These import and export lists are then in-put to a routine to actually move the particles to thenew partition. In the example, we assume the userhas provided his own function to perform the migra-tion. However, the Zoltan_Migrate function canbe used to move data. Zoltan_Migrate requiresadditional callback functions to specify the size ofthe particles to be moved, along with methods forloading particle data into communication buffers be-fore migration and unloading it into the applicationdata structures after migration. Since the import andexport lists are allocated by Zoltan, the user shoulduse Zoltan_LB_Free_Part to free the lists af-ter migration. At this point, the application has a bal-anced decomposition that maintains geometric localityof the particles, and it is ready to compute. It can usethis partition throughout its computation, or repartitionusing the same Zoltan_Struct and callbacks asneeded. When the application no longer needs to repar-tition, it deallocates its Zoltan_Struct by callingZoltan_Destroy.
1 #include " z o l t a n . h "23 / / / / / / / / / / / / / / / / / A p p l i c a t i o n d a t a f o r p a r t i c l e s i m u l a t i o n / / / / / / / / / / / /4 struct UserData {5 int numMyParticles;6 struct Particle {7 int id; / / u n i q u e g l o b a l name f o r p a r t i c l e8 double x, y, z; / / g e o m e t r i c c o o r d i n a t e s f o r p a r t i c l e9 / / . . . s o l u t i o n v a l u e s , e t c . . . .
10 } *myParticles;11 };

E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing 147
1213 / / / / / / / / / / / / / / / / / / User−p r o v i d e d que ry f u n c t i o n s f o r IDs / / / / / / / / / / / / / / /1415 / / R e t u r n number o f p a r t i c l e s on t h i s p r o c e s s .16 int num_obj(void *data, int *ierr)17 {18 / / Ca s t d a t a p o i n t e r p r o v i d e d i n Z o l t a n _ S e t _ F n t o a p p l i c a t i o n d a t a t y p e .19 struct UserData *myData = (struct UserData *) data;20 *ierr = ZOLTAN_OK;21 return myData->numMyParticles;22 }2324 / / R e t u r n g l o b a l and l o c a l i d s f o r p a r t i c l e s on t h i s p r o c e s s .25 / / No p a r t i c l e w e i g h t s used i n t h i s example .26 void obj_list(void *data, int nge, int nle,27 ZOLTAN_ID_PTR globalIDs, ZOLTAN_ID_PTR localIDs,28 int wgtDim, float *objWgts, int *ierr)29 {30 / / Ca s t d a t a p o i n t e r p r o v i d e d i n Z o l t a n _ S e t _ F n t o a p p l i c a t i o n d a t a t y p e .31 struct UserData *myData = (struct UserData *) data;3233 / / Copy g l o b a l ID f o r each p a r t i c l e i n t o g l o b a l I D s a r r a y .34 / / Pa s s l o c a l i n d e x i n t o p a r t i c l e a r r a y as t h e l o c a l I D .35 for (int i = 0; i < myData->numMyParticles; i++) {36 globalIDs[i] = myData->myParticles[i].id;37 localIDs[i] = i;38 }39 *ierr = ZOLTAN_OK;40 }4142 / / / / / / / / / / / / User−p r o v i d e d que ry f u n c t i o n s f o r c o o r d i n a t e s / / / / / / / / / / /43 / / Re tu rn d imens ion of problem .44 int num_geom(void *data, int *ierr)45 {46 return 3; / / 3D problem47 }4849 / / R e t u r n c o o r d i n a t e s f o r o b j e c t s r e q u e s t e d by Z o l t a n i n g l o b a l I D s a r r a y .50 void geom_multi(void *data, int nge, int nle, int numObj,51 ZOLTAN_ID_PTR globalIDs, ZOLTAN_ID_PTR localIDs,52 int dim, double *geomVec, int *ierr)53 {54 / / Ca s t d a t a p o i n t e r p r o v i d e d i n Z o l t a n _ S e t _ F n t o a p p l i c a t i o n d a t a t y p e .55 struct UserData *myData = (struct UserData *) data;5657 / / Copy c o o r d i n a t e s f o r p a r t i c l e g l o b a l I D [ i ] ( w i th l o c a l I D [ i ] )58 / / i n t o geomVec .59 int i, j = 0;60 for (i = 0; i < numObj; i++) {61 geomVec[j++] = myData->myParticles[localIDs[i]].x;62 if (dim > 1) geomVec[j++] = myData->myParticles[localIDs[i]].y;63 if (dim > 2) geomVec[j++] = myData->myParticles[localIDs[i]].z;64 }65 *ierr = ZOLTAN_OK;66 }6768 / / / / / / / / / / / / / / / / / / / / / / / / / / / Main program / / / / / / / / / / / / / / / / / / / / / / / /69 int main(int narg, char **arg)70 {71 / / User c r e a t e s and i n i t i a l i z e s h i s d a t a h e r e as a p p r o p r i a t e .72 MPI_Init(&narg, &arg);

148 E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing
73 struct UserData myData;74 user_initialize(&myData);7576 / / i n i t i a l i z e Z o l t a n and c r e a t e Z o l t a n d a t a s t r u c t u r e .77 float version;78 int ierr = Zoltan_Initialize(narg, arg, &version);79 struct Zoltan_Struct *zz = Zoltan_Create(MPI_COMM_WORLD);8081 / / r e g i s t e r Z o l t a n c a l l b a c k f u n c t i o n s .82 ierr = Zoltan_Set_Fn(zz, ZOLTAN_NUM_OBJ_FN_TYPE, (void (*)())num_obj, &myData);83 ierr = Zoltan_Set_Fn(zz, ZOLTAN_OBJ_LIST_FN_TYPE, (void (*)())obj_list, &myData);84 ierr = Zoltan_Set_Fn(zz, ZOLTAN_NUM_GEOM_FN_TYPE, (void (*)())num_geom, &myData);85 ierr = Zoltan_Set_Fn(zz, ZOLTAN_GEOM_MULTI_FN_TYPE, (void (*)())geom_multi, &myData);8687 / / s e t Z o l t a n p a r a m e t e r s : s e l e c t RCB p a r t i t i o n i n g88 ierr = Zoltan_Set_Param(zz, "LB_METHOD", "RCB");8990 / / a rgume n t s r e t u r n e d by Z o l t a n _ L B _ P a r t i t i o n ; a r r a y s a r e a l l o c a t e d by Z o l t a n .91 int anyChanges = 0;92 int ngid, nlid, numImport, numExport;93 ZOLTAN_ID_PTR importGIDs, importLIDs, exportGIDs, exportLIDs;94 int *importProc, *importPart, *exportProc, *exportPart;9596 / / c a l l Z o l t a n t o compute a new p a r t i t i o n .97 ierr = Zoltan_LB_Partition(zz, &anyChanges, &ngid, &nlid,98 &numImport, &importGIDs, &importLIDs, &importProc, &importPart,99 &numExport, &exportGIDs, &exportLIDs, &exportProc, &exportPart);
100101 / / m i g r a t e d a t a a s s p e c i f i e d by i m p o r t / e x p o r t l i s t s ;102 / / u s e r s can use Z o l t a n _ M i g r a t e i f d e s i r e d , b u t i t i s n o t r e q u i r e d .103 if (anyChanges)104 migrate(&myData, numImport, importGIDs, importLIDs, importProc, importPart,105 numExport, exportGIDs, exportLIDs, exportProc, exportPart);106107 / / f r e e d a t a a l l o c a t e d by Z o l t a n .108 Zoltan_LB_Free_Part(&importGIDs, &importLIDs, &importProc, &importPart);109 Zoltan_LB_Free_Part(&exportGIDs, &exportLIDs, &exportProc, &exportPart);110111 / / t h e Z o l t a n _ S t r u c t can be used f o r a d d i t i o n a l r e p a r t i t i o n i n g , b u t112 / / when i t i s no l o n g e r needed , i t s h o u l d be d e s t r o y e d .113 Zoltan_Destroy(&zz);114115 / / now t h e u s e r can compute wi th a b a l a n c e d p a r t i t i o n wi th g e o m e t r i c116 / / l o c a l i t y f o r t h e p a r t i c l e s .117 user_computation(&myData);118119 MPI_Finalize();120 }
References
[1] C. Aykanat, A. Pınar and Ü.V. Çatalyürek, Permuting sparserectangular matrices into block-diagonal form, SIAM J. Sci.Comput. 26(6) (2004), 1860–1879.
[2] M.J. Berger and S.H. Bokhari, A partitioning strategy fornonuniform problems on multiprocessors, IEEE Trans. Com-put. C-36(5) (1987), 570–580.
[3] D. Bozdag, Ü.V. Çatalyürek, A.H. Gebremedhin, F. Manne,E.G. Boman and F. Özgünner, Distributed-memory parallelalgorithms for distance-2 coloring and related problems inderivative computation, SIAM J. Sci.Comput. 32(4) (2010),2418–2446.
[4] D. Bozdag, A.H. Gebremedhin, F. Manne, E.G. Boman andÜ.V. Çatalyürek, A framework for scalable greedy coloringon distributed memory parallel computers, J. Parallel Distrib.Comput. 68(4) (2008), 515–535.

E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing 149
[5] J. Brandt, B. Debusschere, A. Gentile, J. Mayo, P. Pébay,D. Thompson and M. Wong, OVIS-2: a robust distributed ar-chitecture for scalable RAS, in: Proc. 4th Workshop on Sys-tem Management Techniques, Processes and Services at 22ndIEEE Int. Parallel and Distributed Processing Symposium, Mi-ami, FL, 2008.
[6] F. Broquedis, J. Clet-Ortega, S. Moreaud, N. Furmento,B. Goglin, G. Mercier, S. Thibault and R. Namyst, hwloc:a generic framework for managing hardware affinities in HPCapplications, in: Proc. 18th Euromicro Int. Conf. on Parallel,Distributed and Network-Based Computing, Pisa, 2010.
[7] T.N. Bui and C. Jones, A heuristic for reducing fill-in sparsematrix factorization, in: Proc. 6th SIAM Conf. Parallel Pro-cessing for Scientific Computing, SIAM, 1993, pp. 445–452.
[8] Ü.V. Çatalyürek and C. Aykanat, Hypergraph-partitioning-based decomposition for parallel sparse-matrix vector multipli-cation, IEEE Trans. Parallel Dist. Syst. 10(7) (1999), 673–693.
[9] Ü.V. Çatalyürek and C. Aykanat, PaToH: a multilevel hy-pergraph partitioning tool, Version 3.0, Bilkent University,Department of Computer Engineering, Ankara, PaToH isavailable at: http://bmi.osu.edu/~umit/software.htm, 1999.
[10] Ü.V. Çatalyürek, C. Aykanat and E. Kayaaslan, Hypergraphpartitioning-based fill-reducing ordering for symmetricmatrices, SIAM J. Sci. Comput. 33 (2011), 1996–2023.
[11] Ü.V. Çatalyürek, C. Aykanat and B. Uçar, On two-dimensionalsparse matrix partitioning: Models, methods and a recipe,SIAM J. Sci. Comput. 32(2) (2010), 656–683.
[12] Ü.V. Çatalyürek, E.G. Boman, K.D. Devine, D. Bozdag,R.T. Heaphy and L.A. Riesen, A repartitioning hypergraphmodel for dynamic load balancing, J. Parallel Distrib. Comput.69(8) (2009), 711–724.
[13] Ü.V. Çatalyürek, F. Dobrian, A. Gebremedhin, M. Halap-panavar and A. Pothen, Distributed-memory parallel algo-rithms for matching and coloring, in: Proc. Int. Symp. onParallel and Distributed Processing, Workshops and PhDForum, Workshop on Parallel Computing and Optimization,IEEE Press, 2011, pp. 1966–1975.
[14] Ü.V. Çatalyürek, B. Uçar and C. Aykanat, Hypergraph par-titioning, in: Encyclopedia of Parallel Computing, D. Padua,ed., Springer, 2011, pp. 871–881.
[15] T.F.C. Chan and T.P. Mathew, The interface probing techniquein domain decomposition, SIAM J. Matrix Anal. Appl. 13(1992), 212–238.
[16] C. Chevalier and F. Pellegrini, PT-SCOTCH: a tool for efficientparallel graph ordering, Parallel Comput. 34(6–8) (2008),318–331.
[17] T.F. Coleman and J.J. Moré, Estimation of sparse Jacobianmatrices and graph coloring problems, SIAM J. Numer. Anal.1(20) (1983), 187–209.
[18] J.C. Culberson, Iterated greedy graph coloring and the dif-ficulty landscape, Technical Report TR 92-07, University ofAlberta, June 1992.
[19] A.R. Curtis, M.J.D. Powell and J.K. Reid, On the estimationof sparse Jacobian matrices, J. Inst. Math. Appl. 13 (1974),117–119.
[20] E. Cuthill and J. McKee, Reducing the bandwidth of sparsesymmetric matrices, in: Proceedings of the 24th NationalConference, ACM, New York, NY, USA, 1969, pp. 157–172.
[21] T. Davis, J. Gilbert, S. Larimore and E. Ng, A column approx-imate minimum degree ordering algorithm, ACM Trans. Math.Software 30(3) (2004), 353–376.
[22] J. DeBlasio, K. Ewing, A. Lawrence and M. Leece, Exploringthe feasibility of 2D matrix partitioning, Technical report,Department of Computer Science, Harvey Mudd College,May 2011.
[23] K. Devine, E. Boman, R. Heaphy, B. Hendrickson andC. Vaughan, Zoltan data management services for paralleldynamic applications, Comput. Sci. Eng. 4(2) (2002), 90–97.
[24] K.D. Devine, E.G. Boman, R.T. Heaphy, R.H. Bisseling andÜ.V. Çatalyürek, Parallel hypergraph partitioning for scien-tific computing, in: Proc. 20th Int. Parallel and DistributedProcessing Symp., IEEE, 2006.
[25] I.S. Duff and G.A. Meurant, The effect of ordering onpreconditioned conjugate gradients, BIT 29 (1989), 635–657.
[26] M. Garey, D. Johnson and L. Stockmeyer, Some simplifiedNP-complete graph problems, Theoret. Comput. Sci. 1 (1976),237–267.
[27] A.H. Gebremedhin, F. Manne and A. Pothen, What color isyour Jacobian? Graph coloring for computing derivatives,SIAM Rev. 47(4) (2005), 629–705.
[28] A.H. Gebremedhin, D. Nguyen, M.M.A. Patwary andA. Pothen, ColPack: graph coloring software for sparsederivative matrix computation and beyond, ACM Trans. Math.Software (2012), to appear.
[29] J.A. George, Nested dissection of a regular finite elementmesh, SIAM J. Numer. Anal. 10 (1973), 345–363.
[30] L. Grigori, E. Boman, S. Donfack and T. Davis, Hypergraph-based unsymmetric nested dissection ordering for sparse LUfactorization, SIAM J. Sci. Comp. 32(6) (2010), 3426–3446.
[31] B. Hendrickson and T.G. Kolda, Graph partitioning models forparallel computing, Parallel Comput. 26 (2000), 1519–1534.
[32] B. Hendrickson and R. Leland, A multilevel algorithm forpartitioning graphs, in: Proc. Supercomputing’95, ACM, 1995.
[33] B. Hendrickson and E. Rothberg, Effective sparse matrixordering: just around the bend, in: Proc. 8th SIAM Conferenceon Parallel Processing for Scientific Computing, Atlanta, GA,1997.
[34] M. Heroux, R. Bartlett, V. Howle, R. Hoekstra, J. Hu, T. Kolda,R. Lehoucq, K. Long, R. Pawlowski, E. Phipps, A. Salinger,H. Thornquist, R. Tuminaro, J. Willenbring and A. Williams,An overview of Trilinos, Technical Report SAND2003-2927,Sandia National Laboratories, Albuquerque, NM, 2003.
[35] http://trilinos.sandia.gov/packages/epetra.[36] http://trilinos.sandia.gov/packages/tpetra.[37] http://trilinos.sandia.gov/packages/kokkos.[38] http://trilinos.sandia.gov/packages/belos.[39] M. Jones and P. Plassmann, Scalable iterative solution
of sparse linear systems, Parallel Comput. 20(5) (1994),753–773.
[40] G. Karypis and V. Kumar, METIS: unstructured graph parti-tioning and sparse matrix ordering system, Technical report,Department of Computer Science, University of Minnesota,1995, available at: http://www.cs.umn.edu/~karypis/metis.
[41] G. Karypis and V. Kumar, A fast and high quality multilevelscheme for partitioning irregular graphs, SIAM J. Sci. Comp.20(1) (1998), 359–392.
[42] G. Karypis, K. Schloegel and V. Kumar, ParMETIS: parallelgraph partitioning and sparse matrix ordering library, ver-sion 3.1, Technical report, Department of Computer Science,University of Minnesota, 2003, available at: http://www-users.cs.umn.edu/~karypis/metis/parmetis/download.html.

150 E.G. Boman et al. / The Zoltan and Isorropia parallel toolkits for combinatorial scientific computing
[43] S.O. Krumke, M. Marathe and S. Ravi, Models and approxi-mation algorithms for channel assignment in radio networks,Wireless Networks 7(6) (2001), 575–584.
[44] V.S.A. Kumar, M.V. Marathe, S. Parthasarathy and A. Srini-vasan, End-to-end packet-scheduling in wireless ad-hocnetworks, in: Proceedings of the 15th Annual ACM–SIAMSymp. on Discrete Algorithms, SIAM, 2004, pp. 1021–1030.
[45] F. Manne, A parallel algorithm for computing the extremaleigenvalues of very large sparse matrices, in: Proceedings ofPara, Lecture Notes in Computer Science, Vol. 1541, Springer,1998, pp. 332–336.
[46] D.W. Matula, A min–max theorem for graphs with applicationto graph coloring, SIAM Rev. 10 (1968), 481–482.
[47] Message Passing Interface Forum, MPI: a message-passinginterface standard, May 1994, available at: http://www.mpi-forum.org.
[48] F. Pellegrini, PT-SCOTCH 5.1 user’s guide, Technical report,LaBRI, September 2008.
[49] J.R. Pilkington and S.B. Baden, Partitioning with spacefillingcurves, CSE Technical Report CS94–349, Department ofComputer Science and Engineering, University of California,San Diego, CA, 1994.
[50] A. Pınar, Combinatorial algorithms in scientific computing,PhD thesis, University of Illinois at Urbana–Champaign, 2001.
[51] S. Rajamanickam, E.G. Boman and M.A. Heroux, ShyLU:a hybrid–hybrid solver for multicore platforms, in: Proc. of26th IEEE Int. Parallel and Distributed Processing Symp.,IEEE, 2012.
[52] Y. Saad, ILUM: a multi-elimination ILU preconditioner forgeneral sparse matrices, SIAM J. Sci. Comput. 17 (1996),830–847.
[53] M. Sala, W. Spotz and M. Heroux, PyTrilinos: high-performance distributed-memory solvers for Python, ACMTrans. Math. Software 34(2) (2008), 1–33.
[54] M. Sala, K.S. Stanley and M.A. Heroux, On the design ofinterfaces to sparse direct solvers, ACM Trans. Math. Software34(9) (2008), 1–22.
[55] A.E. Sarıyüce, E. Saule and Ü.V. Çatalyürek, Improvinggraph coloring on distributed-memory parallel computers, in:Proceedings of the 18th Annual International Conference onHigh Performance Computing, Bangalore, India, 2011.
[56] K. Schloegel, G. Karypis and V. Kumar, Multilevel diffusionalgorithms for repartitioning of adaptive meshes, J. ParallelDistrib. Comput. 47(2) (1997), 109–124.
[57] C. Siefert and E. de Sturler, Probing methods for saddle-pointproblems, Electr. Trans. Numer. Anal. 22 (2006), 163–183.
[58] H.D. Simon, Partitioning of unstructured problems for parallelprocessing, Comput. Syst. Eng. 2 (1991), 135–148.
[59] M.M. Strout, L. Carter, J. Ferrante, J. Freeman andB. Kreaseck, Combining performance aspects of irregularGauss–Seidel via sparse tiling, in: LCPC, W. Pugh andC.-W. Tseng, eds, Lecture Notes in Computer Science,Vol. 2481, Springer, 2002, pp. 90–110.
[60] V.E. Taylor and B. Nour-Omid, A study of the factorizationfill-in for a parallel implementation of the finite elementmethod, Int. J. Numer. Meth. Eng. 37 (1994), 3809–3823.
[61] J.D. Teresco, M.W. Beall, J.E. Flaherty and M.S. Shephard,A hierarchical partition model for adaptive finite elementcomputation, Comput. Methods Appl. Mech. Eng. 184 (2000),269–285.
[62] W.F. Tinney and J.W. Walker, Direct solution of sparse net-work equations by optimally ordered triangular factorization,Proc. IEEE 55 (1967), 1801–1809.
[63] M.S. Warren and J.K. Salmon, A parallel hashed oct-treen-body algorithm, in: Proc. Supercomputing’93, Portland,OR, 1993.

Submit your manuscripts athttp://www.hindawi.com
Computer Games Technology
International Journal of
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
Distributed Sensor Networks
International Journal of
Advances in
FuzzySystems
Hindawi Publishing Corporationhttp://www.hindawi.com
Volume 2014
International Journal of
ReconfigurableComputing
Hindawi Publishing Corporation http://www.hindawi.com Volume 2014
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
Applied Computational Intelligence and Soft Computing
Advances in
Artificial Intelligence
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
Advances inSoftware EngineeringHindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
Electrical and Computer Engineering
Journal of
Journal of
Computer Networks and Communications
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Advances in
Multimedia
International Journal of
Biomedical Imaging
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
ArtificialNeural Systems
Advances in
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
Computational Intelligence and Neuroscience
Industrial EngineeringJournal of
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
Modelling & Simulation in EngineeringHindawi Publishing Corporation http://www.hindawi.com Volume 2014
The Scientific World JournalHindawi Publishing Corporation http://www.hindawi.com Volume 2014
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014
Human-ComputerInteraction
Advances in
Computer EngineeringAdvances in
Hindawi Publishing Corporationhttp://www.hindawi.com Volume 2014





























