Embed Size (px)
Citation preview

The use of ontologies in The use of ontologies in Natural Language EngineeringNatural Language Engineering
Pattern Recognition & Artificial IntelligencePattern Recognition & Artificial Intelligence group group
Dept. of Computation and Information SystemDept. of Computation and Information System
Polytechnic University of Valencia, SpainPolytechnic University of Valencia, Spain
Paolo RossoPaolo Rosso
[email protected]@dsic.upv.es

Natural Language Engineering (NLE)Natural Language Engineering (NLE)
Ph.D. students:Ph.D. students:
Davide BuscaldiDavide Buscaldi
David Pinto David Pinto
Rafael GuzmánRafael Guzmán
Yassine BenajibaYassine Benajiba
(Natalia Ponomareva)(Natalia Ponomareva)
+ José Manuel Gómez+ José Manuel Gómez
On-going collaborations with:On-going collaborations with: INAOE (M. Montes), NPI (M. Alexandrov), INAOE (M. Montes), NPI (M. Alexandrov),
BUAP (H. Jiménez): MexicoBUAP (H. Jiménez): Mexico
University of San Luís (M. Errecalde): ArgentinaUniversity of San Luís (M. Errecalde): Argentina
University of Genova: ItalyUniversity of Genova: Italy

1.1. The WordNet ontologyThe WordNet ontology2.2. Conceptual Density for Word Sense DisambiguationConceptual Density for Word Sense Disambiguation3.3. Semantic (Geo) Information Retrieval and Text CategorizationSemantic (Geo) Information Retrieval and Text Categorization4.4. Semantic clusters of very short narrow-domain textsSemantic clusters of very short narrow-domain texts5.5. Lexical pattern extraction: mining the web with semantic infoLexical pattern extraction: mining the web with semantic info6.6. An ontology for Question Answering and vice versa: An ontology for Question Answering and vice versa:
OntotripleQAOntotripleQA7.7. Cluster analysis of transcribed spoken dialoguesCluster analysis of transcribed spoken dialogues8.8. The Clasitext ontology. Applications with ontologiesThe Clasitext ontology. Applications with ontologies
9.9. Semantic relatedness of conceptsSemantic relatedness of concepts10.10. Ontology matching: meta ontology or machine learning Ontology matching: meta ontology or machine learning
approach?approach?
11.11. The case study of biomedical ontologies: semantic relatedness The case study of biomedical ontologies: semantic relatedness of concepts of the different ontologiesof concepts of the different ontologies
12.12. Lab session: CALD, WordNet vs. Genia, GenOntology, MeSHLab session: CALD, WordNet vs. Genia, GenOntology, MeSH

1. The WordNet ontology1. The WordNet ontology
Basic lexical relations:
1. Synonymy
2. Polysemy: related meanings; e.g. bank, blood bank
3. Homonymy: not related meaning; e.g. bank (river) and bank (financial institution)
4. Hyponymy: sub-class (is-a relation), e.g. car is-a vehicle
5. Hypernymy: vice versa
6. Antonymy
7. Meronymy: part of (e.g. parts of a car)
8. Holonymy: vice versa (e.g. a car is_composed of)

1. The WordNet ontology1. The WordNet ontology
Dictionaries and thesaurus: are they enough?are they enough?
1.1. RogetRoget thesaurus thesaurus
2.2. LongmanLongman Dictionary of Contemporary English Dictionary of Contemporary English ((LODCELODCE))
3.3. CambridgeCambridge Advanced Learner’s Dictionary Advanced Learner’s Dictionary ((CALDCALD): ): http://dictionary.cambridge.org

1. The WordNet ontology1. The WordNet ontology We need an We need an ontology:
• word definitionword definition• examples of usage examples of usage • + lexical relations between words! + lexical relations between words!
The The WordNet (WN) ontology:WordNet (WN) ontology:• external lexical resource developed at Princeton external lexical resource developed at Princeton
University (G.A. Miller)University (G.A. Miller)• based on based on synsets synsets ((setset of of synsynonymonymss defining a lexical defining a lexical
conceptconcept))• not a poor ontology with only the not a poor ontology with only the is-ais-a relation (tree): relation (tree):
synsets are connected by various semantic relations synsets are connected by various semantic relations (graph)(graph)
• a a polysemic lexemepolysemic lexeme belongs to more synsets belongs to more synsets• no difference between no difference between polysemypolysemy and and homonymyhomonymy

1. The WordNet ontology1. The WordNet ontology
• lexical categorieslexical categories: : – (hierarchy) nouns(hierarchy) nouns– (3-level hierarchy) verbs(3-level hierarchy) verbs– adjective and adverbsadjective and adverbs
• language: language: EnglishEnglish
# nouns: # nouns: 114.648114.648 # synsets: # synsets: 79.68979.689
# verbs: # verbs: 11.306 11.306 13.50813.508
# adjectives: # adjectives: 21.436 21.436 18.56318.563
# adverbs: # adverbs: 4.669 4.669 3.6643.664
152.059152.059 115.424115.424
• fine fine granularitygranularity (version 2.0) : too much? (version 2.0) : too much? • mapping synsets onto the mapping synsets onto the WordNet DomainsWordNet Domains (IRST-Trento, (IRST-Trento,
B. Magnini)B. Magnini)

1. The WordNet ontology1. The WordNet ontology
Mapping of the WN synsets onto Mapping of the WN synsets onto WordNet DomainsWordNet Domains
(200 categories): the (200 categories): the FactotumFactotum category problem… category problem…

1. The WordNet ontology1. The WordNet ontology
lexical relationslexical relations between synsets ( between synsets (synonymysynonymy): ): • hypernymyhypernymy, , hyponymyhyponymy, , meronymymeronymy, , holonymyholonymy• entailmententailment (verbs): e.g. snore-> sleep (verbs): e.g. snore-> sleep• causecause (verbs): synset A causes synset B (verbs): synset A causes synset B
e.g. give – havee.g. give – have• pertainympertainym (adj-nouns) e.g. electrical – electricity (adj-nouns) e.g. electrical – electricity• attributeattribute (adj-nouns): e.g. small – size (adj-nouns): e.g. small – size• antonymantonym (adj): e.g. small - big (adj): e.g. small - big• similar sensesimilar sense (adj): e.g. far – distant (adj): e.g. far – distant• categorycategory: e.g. sample – statistics: e.g. sample – statistics• regionregion: e.g. French revolution – France: e.g. French revolution – France• useuse: e.g. gone - euphemism: e.g. gone - euphemism

1. The WordNet ontology1. The WordNet ontology
Access to WordNet (data base of lexical relations): Access to WordNet (data base of lexical relations):
a.a. library library functionsfunctions
b.b. on-lineon-line (browser): (browser): http://www.cogsci.princeton.edu/~wn/

1. The WordNet ontology1. The WordNet ontology
a.a.
Part Of Speech (POS): noun, verb, adj, adv
index fileindex file: : index.posindex.pos
e.g.e.g. plantplant n 4 5 @ n 4 5 @ #m %s %p 03138429 #m %s %p 03138429 0000886400008864 04539420 07480098 04539420 07480098
n: nounn: noun
4 senses4 senses
5 lexical relations: hypernymy, hyponymy, 5 lexical relations: hypernymy, hyponymy, mmember_of, ember_of, ssubstance_of, ubstance_of, ppart_of art_of
synset addressessynset addresses

1. The WordNet ontology1. The WordNet ontology
a.a.
data filedata file: : data.posdata.pos
e.g. e.g. 0000886400008864 n 03 plant 0 flora 0 plant_life 0 027 n 03 plant 0 flora 0 plant_life 0 027 @00002086 n 0000 … @00002086 n 0000 … 09463675 n 0000 | 09463675 n 0000 |
a living organism lacking the power of locomotiona living organism lacking the power of locomotion
n: nounn: noun
3: number de lexemes3: number de lexemes (0 separator) (0 separator)
27: number of lexical relations27: number of lexical relations

1. The WordNet ontology1. The WordNet ontology b.b. e.g. e.g. bassbass (noun): 8 senses (noun): 8 senses
1.1. bassbass -- (the lowest part of the musical range) -- (the lowest part of the musical range)2.2. bassbass, bass part -- (the lowest part in polyphonic , bass part -- (the lowest part in polyphonic
music)music)3.3. bassbass, basso -- (an adult male singer with the lowest , basso -- (an adult male singer with the lowest
voicevoice4.4. sea bass, sea bass, bassbass -- (the lean flesh of a saltwater fish of -- (the lean flesh of a saltwater fish of
the Serranidae family )the Serranidae family )5.5. freshwater bass, freshwater bass, bassbass -- (any of various North -- (any of various North
American freshwater fish with lean flesh (especially American freshwater fish with lean flesh (especially of the genus Micropterus))of the genus Micropterus))
6.6. bassbass, bass voice, basso -- (the lowest adult male , bass voice, basso -- (the lowest adult male singing voice)singing voice)
7.7. bassbass -- (the member with the lowest range of a family -- (the member with the lowest range of a family of musical instruments)of musical instruments)
8.8. bassbass -- (nontechnical name for any of numerous -- (nontechnical name for any of numerous edible marine and freshwater spiny-finned fishes)edible marine and freshwater spiny-finned fishes)

1. The WordNet ontology1. The WordNet ontology
classpathclasspath ( (is-ais-a relationship) of sense #7 of relationship) of sense #7 of bassbass
(the member with the lowest range of a family of(the member with the lowest range of a family of
musical instruments)musical instruments)
musical instrumentmusical instrument
instrumentinstrument
devicedevice
instrumentality, instrumentationinstrumentality, instrumentation
artifact, artefactartifact, artefact
object, physical objectobject, physical object
entityentity, something, something

1. The WordNet ontology1. The WordNet ontology
EuroWordNetEuroWordNet version (not available on-line) for version (not available on-line) for
different European languages:different European languages:• SpanishSpanish• FrenchFrench• GermanGerman• DutchDutch• CzechCzech• EstonianEstonian• ItalianItalian (CNR-Pisa) (CNR-Pisa)• ……
MultiWordNetMultiWordNet: : ItalianItalian (IRST-Trento, (IRST-Trento, B. MagniniB. Magnini))
1. The WordNet ontology1. The WordNet ontology

1.1. The WordNet ontologyThe WordNet ontology2.2. Conceptual Density for Word Sense DisambiguationConceptual Density for Word Sense Disambiguation3.3. Semantic (Geo) Information Retrieval and Text CategorizationSemantic (Geo) Information Retrieval and Text Categorization4.4. Semantic clusters of very short narrow-domain textsSemantic clusters of very short narrow-domain texts5.5. Lexical pattern extraction: mining the web with semantic infoLexical pattern extraction: mining the web with semantic info6.6. An ontology for Question Answering and vice versa: An ontology for Question Answering and vice versa:
OntotripleQAOntotripleQA7.7. Cluster analysis of transcribed spoken dialoguesCluster analysis of transcribed spoken dialogues8.8. The Clasitext ontology. Applications with ontologiesThe Clasitext ontology. Applications with ontologies
9.9. Semantic relatedness of concepts. Semantic relatedness of concepts. 10.10. Ontology matching: meta ontology or machine learning Ontology matching: meta ontology or machine learning
approach?approach?
11.11. The case study of biomedical ontologies: semantic relatedness The case study of biomedical ontologies: semantic relatedness of concepts of the different ontologiesof concepts of the different ontologies
12.12. Lab session: CALD, WordNet vs. Genia, GenOntology, MeSHLab session: CALD, WordNet vs. Genia, GenOntology, MeSH

2. Conceptual Density for WSD2. Conceptual Density for WSD • The problem of The problem of ambiguityambiguity: a : a wordword can have more can have more
than just one meaning (than just one meaning (polysemic)polysemic), i.e., it is , i.e., it is potentially ambiguouspotentially ambiguous
• A A wordword is is disambiguateddisambiguated along with a portion of the along with a portion of the text in which it is embedded (its text in which it is embedded (its contextcontext)...)...
e.g. This e.g. This bassbass has an incredible voice. has an incredible voice.(A fish does not sing...)(A fish does not sing...)
I would love to have a fried I would love to have a fried bassbass..(Cannibalism is banned...and frying the musical instrument (Cannibalism is banned...and frying the musical instrument does not seem a brilant idea either!)does not seem a brilant idea either!)
... and the use of a ... and the use of a lexical resourcelexical resource: a dictionary, a : a dictionary, a thesaurus or... an ontology!thesaurus or... an ontology!

2. Conceptual Density for WSD2. Conceptual Density for WSD • (Automatic) (Automatic) Word Sense Disambiguation (WSD)Word Sense Disambiguation (WSD)
consists in examining word tokens and specifying consists in examining word tokens and specifying exactly which sense of each word is being used, exactly which sense of each word is being used, taking into account the taking into account the contextcontext and using an and using an external external lexical resourcelexical resource
• Importance of WSD for Importance of WSD for NLE tasksNLE tasks::
– Text Categorizatione.g. Category_1: fish markets Category_2: opera
– Information Retrieval– Question Answering
e.g. Who is the most popular Italian bass singer?– Automatic Translation
e.g.Who is the bass singer who eats fried bass?

2. Conceptual Density for WSD2. Conceptual Density for WSD
• SensevalSenseval competition (last in 2004: Senseval-3; competition (last in 2004: Senseval-3; next in 2007: any taker?)next in 2007: any taker?)http://www.senseval.org
• main Senseval tasks:main Senseval tasks:
– All-Word Task (AWT): English, Basque…All-Word Task (AWT): English, Basque…– Lexical Sample Task: English, Italian, Spanish, Lexical Sample Task: English, Italian, Spanish,
Basque…Basque…– WordNet Gloss Disambiguation Task: EnglishWordNet Gloss Disambiguation Task: English

2. Conceptual Density for WSD2. Conceptual Density for WSD
Measures for Measures for evaluationevaluation::
• Precision: Precision: # of correctly disambiguated words / # of correctly disambiguated words / # disambiguated words# disambiguated words
• Recall: Recall: # of correctly disambiguated # of correctly disambiguated words / words / # words# words
• Coverage:Coverage: # of disambiguated words / # of disambiguated words / # words# words

2. Conceptual Density for WSD2. Conceptual Density for WSD WSD approaches:WSD approaches:
a.a. Corpus-basedCorpus-based– BayesBayes– Hidden Markov ModelHidden Markov Model– Super Vector MachineSuper Vector Machine– Maximum EntropyMaximum Entropy– Neural NetworksNeural Networks– Genetic Algorithm Genetic Algorithm
b.b. Knowledge-basedKnowledge-based– LeskLesk: # shared words between the : # shared words between the contextcontext and the i-th and the i-th
sense of the sense of the glossgloss (definition + examples) of the word to (definition + examples) of the word to disambiguatedisambiguate
– Conceptual DensityConceptual Density between the between the synsetssynsets of the of the wordword to to disambiguate and the words of the disambiguate and the words of the contextcontext
c.c. HybridHybrid

2. Conceptual Density for WSD2. Conceptual Density for WSD a.a. Corpora Corpora for corpus-based approaches:for corpus-based approaches:
• SemCorSemCor ( (SemSemantic Conantic Concorcordance) corpus:dance) corpus:– Brown corpus in SGML format Brown corpus in SGML format – syntactically (POS) and semantically (synsets) syntactically (POS) and semantically (synsets)
taggedtaggedhttp://www.cogsci.princeton.edu/~wn/
e.g. <wf cmd=done pos=NN lemma=muscle wnsn=1 e.g. <wf cmd=done pos=NN lemma=muscle wnsn=1 lexsn=1:08:00>lexsn=1:08:00>
• Corpora Corpora SensevalSenseval: :
Senseval-1, Senseval-2, Senseval-3Senseval-1, Senseval-2, Senseval-3http://www.senseval.org

2. Conceptual Density for WSD2. Conceptual Density for WSD
a. An example of a corpus-based approach: the Bayesian method
• a sliding window is used• a training phase is needed • a classifier is learnt

2. Conceptual Density for WSD2. Conceptual Density for WSD e.g.e.g. “Singer, electrical guitar and bass players
arrived at the concert and bla, bla, bla”
– word to disambiguate: bass– size of sliding window: 4– words transformed into its lemmas
guitar|n, and|cjc, player|n, arrive|v– stopwords not considered
electrical|adj, guitar|n, player|n, arrive|v– Noun Sense Disambiguation (for the sake of
clarity):
singer|n, guitar|n, player|n, concert|n

2. Conceptual Density for WSD2. Conceptual Density for WSD w=w=bassbass C=(C=(singersinger,,guitarguitar,,playerplayer,,concertconcert))
wwii i-th sense of w i-th sense of w
wwiiSSww S Sww : set of the senses of w : set of the senses of w
wwmaxmax = argmax P(w = argmax P(wii|C) = argmax P(C| w|C) = argmax P(C| wii) P(w) P(wii) / P(C)) / P(C)
= argmax P(w= argmax P(wii) ) P(c P(cjj| w| wii))
hp: P(C|whp: P(C|wii)) P(c P(cjj| w| wii))
SmoothingSmoothing techniques in order to avoid null techniques in order to avoid null
probabilitiesprobabilities

2. Conceptual Density for WSD2. Conceptual Density for WSD b. An example of a knowledge-based approach: b. An example of a knowledge-based approach:
the the Conceptual DensityConceptual Density method method
Basque Country University: Basque Country University: (Agirre and Rigau 96)(Agirre and Rigau 96)
improved version Polytechnic University Valencia: improved version Polytechnic University Valencia:
(Buscaldi and Rosso, (Buscaldi and Rosso, 04) 04)
ProblemProblem: not always a domain-specific corpus is: not always a domain-specific corpus is
availableavailable
AimAim: to use the : to use the knowledgeknowledge of an ontology to of an ontology to
disambiguatedisambiguate anyway anyway
2. Conceptual Density for WSD2. Conceptual Density for WSD
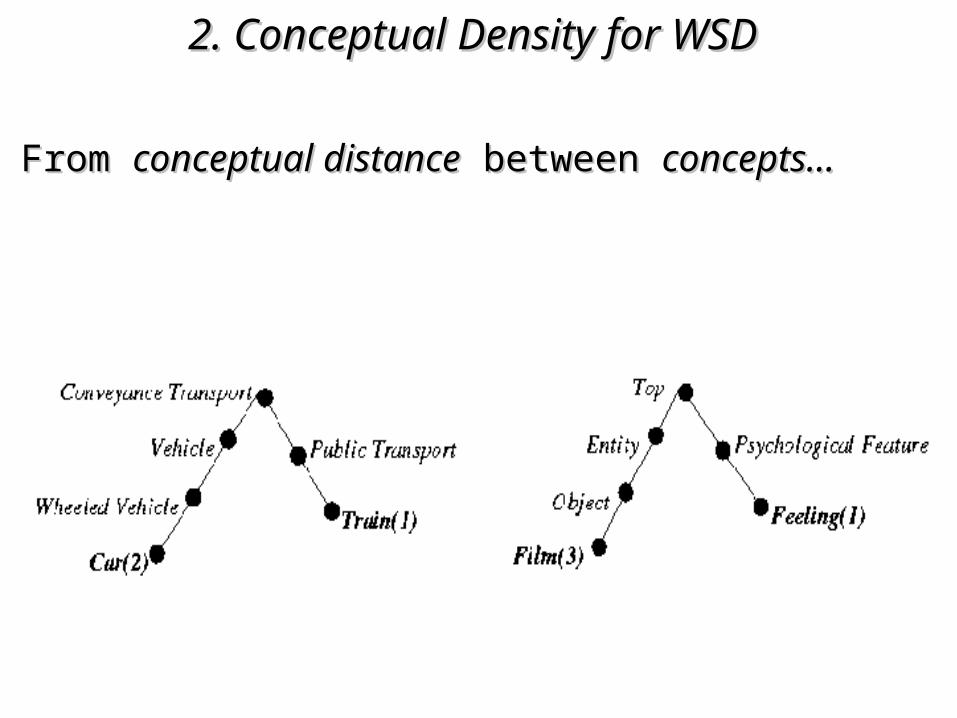
From From conceptual distanceconceptual distance between between concepts…concepts…
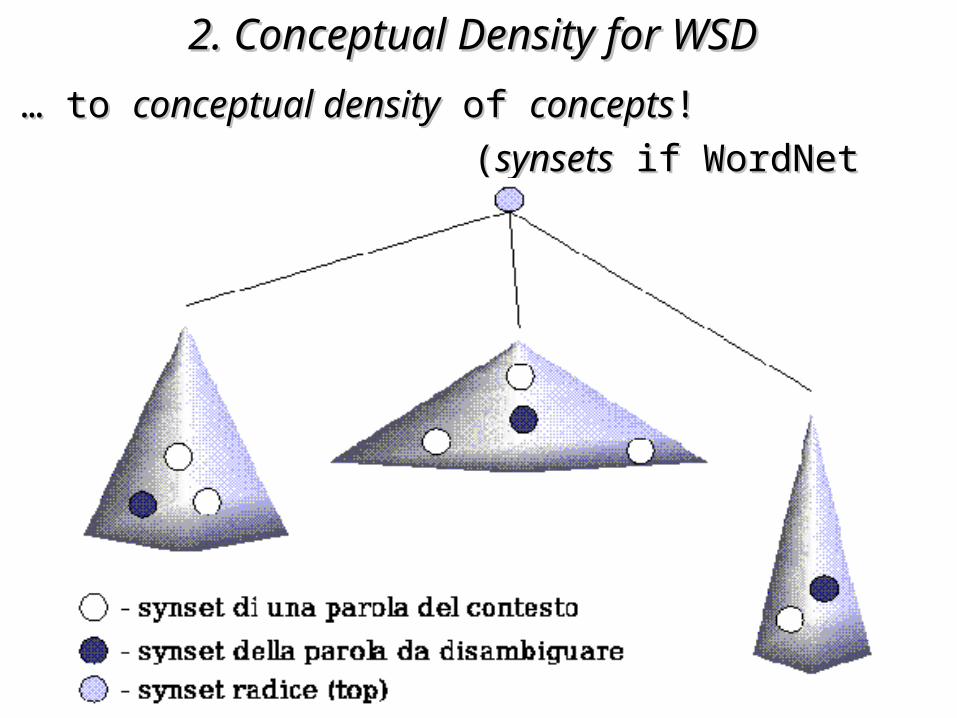
2. Conceptual Density for WSD2. Conceptual Density for WSD … … to to conceptual densityconceptual density of of conceptsconcepts!!
((synsetssynsets if WordNet if WordNet ontology)ontology)

2. Conceptual Density for WSD2. Conceptual Density for WSD the original approach (Agirre & Rigau):the original approach (Agirre & Rigau):
CD(c,m)=(CD(c,m)=(nhypnhypii) / descendant) / descendantcc descendant descendantcc = =nhypnhypii
c: concept (synset), at the top of the subhierarchyc: concept (synset), at the top of the subhierarchy
nhyp: # of hyponyms per nodenhyp: # of hyponyms per node
h: height of the subhierarchyh: height of the subhierarchy
m: marks (# of senses of the words to disambiguate)m: marks (# of senses of the words to disambiguate)
m-1m-1
i=0i=0 i=0i=0
h-1h-1
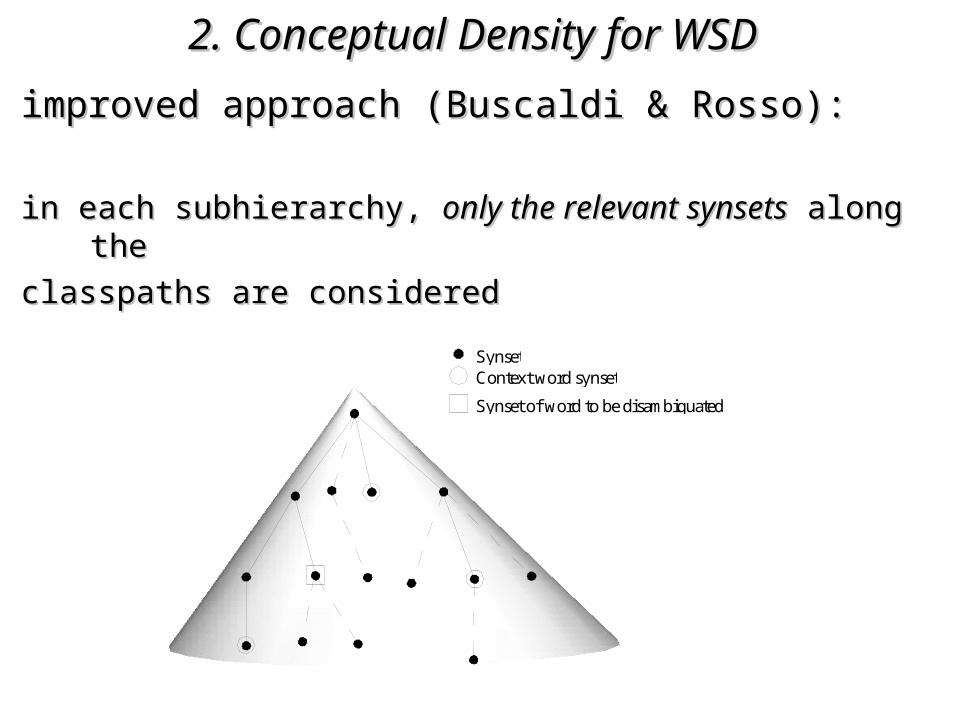
2. Conceptual Density for WSD2. Conceptual Density for WSD improved approach (Buscaldi & Rosso):improved approach (Buscaldi & Rosso):
in each subhierarchy, in each subhierarchy, only the relevant synsetsonly the relevant synsets along the along the
classpaths are consideredclasspaths are considered
SynsetContext word synset
Synset of word to be disambiguated

2. Conceptual Density for WSD2. Conceptual Density for WSD
e.g. Fulton_County_Grand_jury said e.g. Fulton_County_Grand_jury said FridayFriday an an investigationinvestigation of of AtlantaAtlanta's recent 's recent primary_electionprimary_election produced no produced no evidenceevidence that that any any irregularitiesirregularities took_place” took_place”
irregularityirregularity is the ( is the (root formroot form of the) noun to be disambiguated in of the) noun to be disambiguated in this case; it has 4 senses:this case; it has 4 senses:
1. Abnormality, irregularity - Behavior that breaches the rule 1. Abnormality, irregularity - Behavior that breaches the rule or etiquette or custom or moralityor etiquette or custom or morality2. Irregularity, unregularity - not characterized by a fixed 2. Irregularity, unregularity - not characterized by a fixed principle or rateprinciple or rate3. Irregularity (geometrical) - an asimmetry in space3. Irregularity (geometrical) - an asimmetry in space4. Constipation, irregularity (medical)4. Constipation, irregularity (medical)
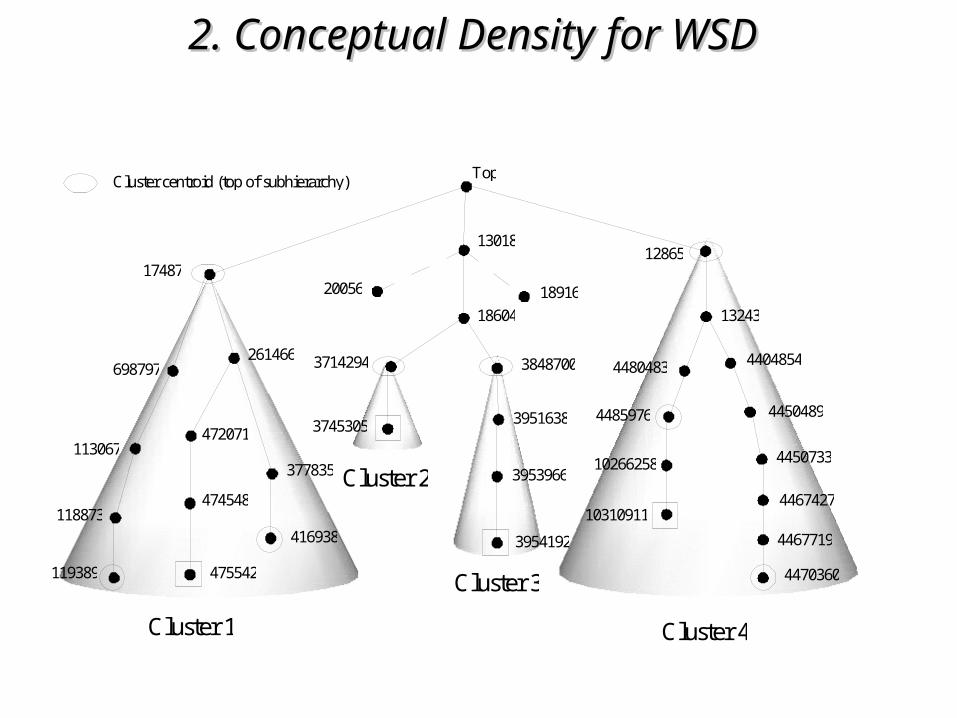
2. Conceptual Density for WSD2. Conceptual Density for WSD
Cluster centroid (top of subhierarchy)Top
17487
698797
113067
118873
119389
261466
377835
416938
472071
474548
475542
13018
1891620056
18604
38487003714294
3745305 3951638
3953966
3954192
12865
13243
4404854
4450489
4450733
4467427
4467719
4470360
4480483
4485976
10266258
10310911
Cluster 1
Cluster 2
Cluster 3
Cluster 4

2. Conceptual Density for WSD2. Conceptual Density for WSD
NounNoun Sense Disambiguation algorithm Sense Disambiguation algorithm
1.1. Select the Select the nounsnouns in the context in the context
““Brakes howled and a Brakes howled and a hornhorn blared furiously, but blared furiously, butthe the manman would have been hit if Phil hadn’t called would have been hit if Phil hadn’t calledout to him a out to him a secondsecond before” (Senseval-3) before” (Senseval-3)
2. 2. build subhierarchiesbuild subhierarchies3. 3. compute densitiescompute densities4. 4. assign the sense with highest CD to the nounassign the sense with highest CD to the noun
(when possible)(when possible)
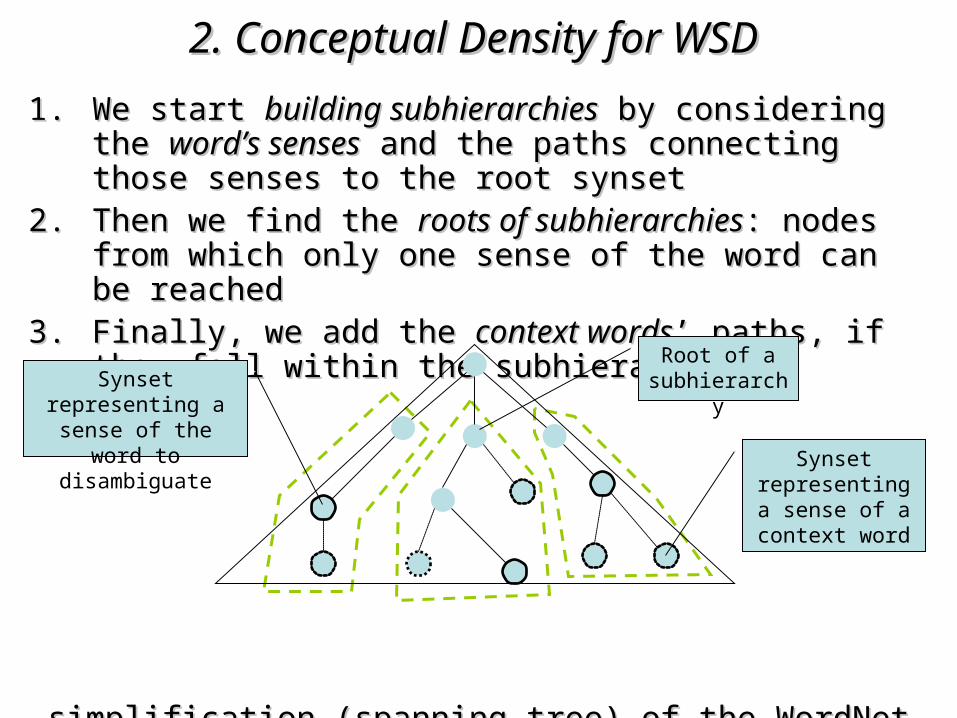
2. Conceptual Density for WSD2. Conceptual Density for WSD 1.1. We start We start building subhierarchiesbuilding subhierarchies by considering the by considering the word’s word’s
sensessenses and the paths connecting those senses to the root and the paths connecting those senses to the root synsetsynset
2.2. Then we find the Then we find the roots of subhierarchiesroots of subhierarchies: nodes from which : nodes from which only one sense of the word can be reached only one sense of the word can be reached
3.3. Finally, we add the Finally, we add the context wordscontext words’ paths, if they fall within ’ paths, if they fall within the subhierarchiesthe subhierarchies
simplification (spanning tree) of the WordNet (graph): simplification (spanning tree) of the WordNet (graph): only the only the is-ais-a relation is considered relation is considered
Synset representing a
sense of the word to disambiguate
Root of a subhierarchy
Synset representing a
sense of a context word

2. Conceptual Density for WSD2. Conceptual Density for WSD
MM: number of : number of relevant synsetsrelevant synsets falling in one of the falling in one of the subhierarchiessubhierarchies
hh: the : the heightheight of the of the subhierarchysubhierarchy
nhnh: total number of the : total number of the synsetssynsets in the in the subhierarchy subhierarchy
ff: : frequencyfrequency of the of the synsetsynset in WordNet (based on in WordNet (based on
SemCor)SemCor)
f
nh
MMfnhMCD
log
),,(
2. Conceptual Density for WSD2. Conceptual Density for WSD
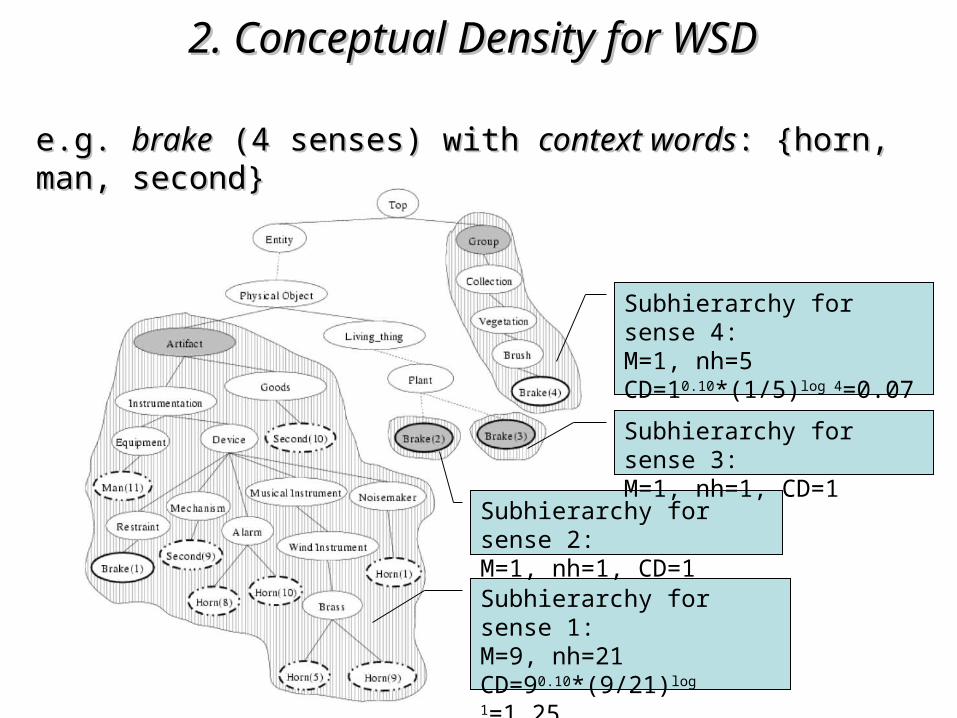
e.g. e.g. brakebrake (4 senses) with (4 senses) with context wordscontext words: {horn, man, : {horn, man, second}second}
Subhierarchy for sense 1:M=9, nh=21CD=90.10*(9/21)log 1=1.25
Subhierarchy for sense 2:M=1, nh=1, CD=1
Subhierarchy for sense 3:M=1, nh=1, CD=1
Subhierarchy for sense 4:M=1, nh=5CD=10.10*(1/5)log 4=0.07

2. Conceptual Density for WSD2. Conceptual Density for WSD
Adjective Adjective Sense Disambiguation: Sense Disambiguation:
Mutual Domain WeightsMutual Domain Weights
• no Conceptual Densityno Conceptual Density• WordNet Domains and (WordNet) frequencyWordNet Domains and (WordNet) frequency• context of only one word: the noun related to the adjective context of only one word: the noun related to the adjective
(e..g. academic (e..g. academic course)course)
for each sense of the adj and each sense the context noun
FactotumwDomcDomwDomif
FactotumwDomcDomwDomifif
cDomwDomif
cwMDW
fifif
fif
if
if
)()()(10
)()()(/1/1
)()(0
),(111

2. Conceptual Density for WSD2. Conceptual Density for WSD
Adjective Adjective Sense Disambiguation: Sense Disambiguation:
Mutual Domain WeightsMutual Domain Weights
additional MDWs taking into account adjs and nouns reacheable
with the lexical relations:
• similar sense (adj)similar sense (adj) e.g. far - distante.g. far - distant• antonym (adj)antonym (adj) e.g. small - bige.g. small - big• pertainym (adj-noun)pertainym (adj-noun) e.g. e.g. electrical - electricityelectrical - electricity• attribute (adj-noun)attribute (adj-noun) e.g. small - sizee.g. small - size

2. Conceptual Density for WSD2. Conceptual Density for WSD
Adjective Adjective Sense Disambiguation: Sense Disambiguation:
Mutual Domain WeightsMutual Domain Weights
c: context nounc: context noun
S: vector of synsets relatedS: vector of synsets related to the to the f-th sense of the adjectivef-th sense of the adjective
k:k: polysemic grade of cpolysemic grade of c ( (## senses of the context senses of the context
noun)noun)
z:z: ## not-null MDWsnot-null MDWs
SW (w f ,c,S)
MDW (w f ,c i) MDW (sm,c i)j0
S
i0
k
z

2. Conceptual Density for WSD2. Conceptual Density for WSD
Verb Verb andand Adverb Adverb Sense Disambiguation: Sense Disambiguation:
Mutual Domain WeightsMutual Domain Weights
• no CDno CD for for verbsverbs::– hyerarchy too shallow (only 3 levels)hyerarchy too shallow (only 3 levels)– usually only usually only one verb for sentenceone verb for sentence
• MDWs between the MDWs between the word senseword sense and the and the senses of senses of context wordscontext words
– verbs in verbs in AWTAWT: : nounnoun precedingpreceding and and followingfollowing the the verbverb
– other tasks: 4 words of any POSother tasks: 4 words of any POS• no MDWs from related synsetsno MDWs from related synsets

2. Conceptual Density for WSD2. Conceptual Density for WSD
Results over the SemCor Results over the SemCor nounsnouns::• Precision: Precision: 81.5%81.5%
baseline Most Frequent Sense (MFS): 75.5%baseline Most Frequent Sense (MFS): 75.5%• Recall: Recall: 59.9%59.9%
Results over the SemCor Results over the SemCor adjectivesadjectives::• Precision: Precision: 72.8% (baseline MFS: 79.4%)72.8% (baseline MFS: 79.4%)• Recall:Recall: 56.5%56.5%

2. Conceptual Density for WSD2. Conceptual Density for WSD
Advantages and drawbacks:Advantages and drawbacks:
• Pro:Pro:– fast, automaticfast, automatic– it distinguishes easy cases from difficult onesit distinguishes easy cases from difficult ones
• Contra:Contra:– low recalllow recall– higher mistake probability in difficult cases (when higher mistake probability in difficult cases (when
we try to add extra weights)we try to add extra weights)– lower precision when recall improveslower precision when recall improves

2. Conceptual Density for WSD2. Conceptual Density for WSD
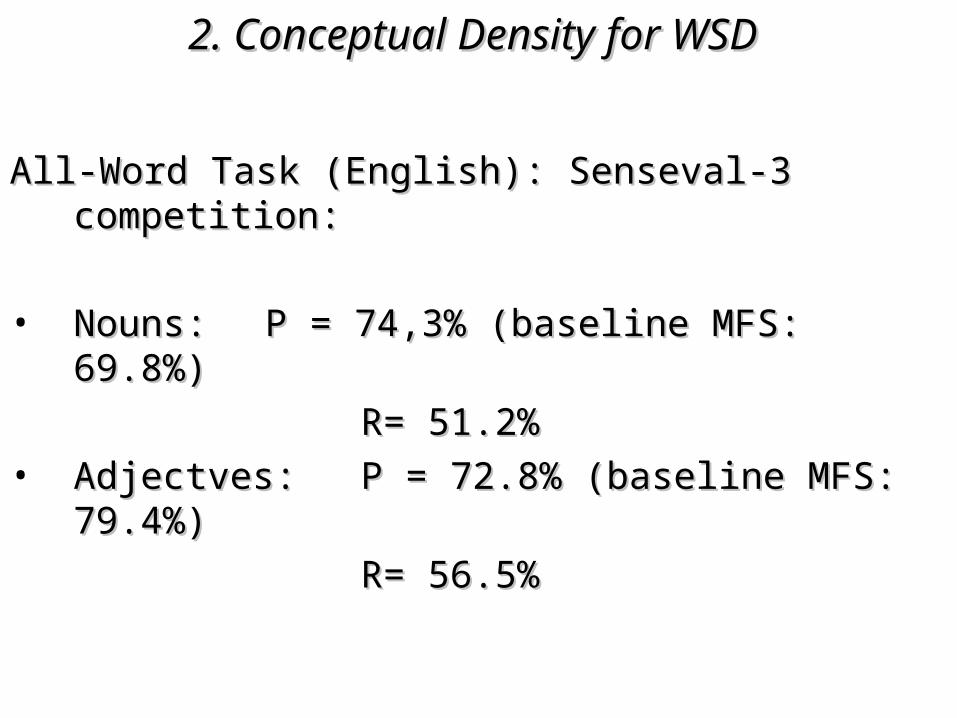
All-Word Task (English): All-Word Task (English): Senseval-3Senseval-3 competition: competition:
• Difficulty of AWT: Difficulty of AWT: inter-annotator (dis)agreement inter-annotator (dis)agreement 72.5%72.5%
• Best system (corpus-based): Best system (corpus-based): P=R= 65%P=R= 65%• CIAOSENSO (our system): CIAOSENSO (our system): P= 60%P= 60% R=48%R=48%• R2D2 (4-th best system): CIAOSENSO + other R2D2 (4-th best system): CIAOSENSO + other
corpus-based and knowledge-based systems corpus-based and knowledge-based systems
2. Conceptual Density for WSD2. Conceptual Density for WSD
All-Word Task (English): Senseval-3 competition:All-Word Task (English): Senseval-3 competition:
• Nouns: Nouns: P = 74,3% (baseline MFS: 69.8%)P = 74,3% (baseline MFS: 69.8%)
R= 51.2%R= 51.2%• Adjectves:Adjectves: P = 72.8% (baseline MFS: 79.4%)P = 72.8% (baseline MFS: 79.4%)
R= 56.5%R= 56.5%

2. Conceptual Density for WSD2. Conceptual Density for WSD
More Senseval-3 tasks:More Senseval-3 tasks:• Lexical Sample Lexical Sample Task: Task: hybridhybrid (partially supervised) (partially supervised)
system (the training corpus is used to system (the training corpus is used to change the change the ranking of sense frequency)ranking of sense frequency)
• Gloss Gloss Disambiguation Task:Disambiguation Task:
Additional weightsAdditional weights were added when the following were added when the following
relationshipsrelationships were found: were found:– Hypernyms and Hyponyms of the Hypernyms and Hyponyms of the headhead synset synset– Meronyms and HolonymsMeronyms and Holonyms– Pertainyms and AttributesPertainyms and Attributes– WordNet Domain correspondance with the head synset WordNet Domain correspondance with the head synset
(e.g. (e.g. Medicine Medicine for for bloodblood(2) in the definition of (2) in the definition of heartheart(1))(1))

2. Conceptual Density for WSD2. Conceptual Density for WSD Problem 1: Problem 1: low recalllow recall using the Conceptual Density using the Conceptual Density
Attempts to increase the recall (Attempts to increase the recall (nounsnouns) using:) using:
a. WordNet Domainsa. WordNet Domains
b. Density depth correctionb. Density depth correction
c. Specific context correctionc. Specific context correction
d. Context expansion with:d. Context expansion with:
I. The (definition part) of the I. The (definition part) of the glossgloss
II. The II. The global contextglobal context of the document of the document
e. e. GlossesGlosses of of CALD CALD (integrated into WN glosses)(integrated into WN glosses)
f. f. WebWeb as as lexical resource for WSDlexical resource for WSD
Problem 2: poor Problem 2: poor verbverb sense disambiguation sense disambiguation
Attempt using: Attempt using: Support Vector Machines (SVM)Support Vector Machines (SVM)

2. Conceptual Density for WSD2. Conceptual Density for WSD 1a. 1a. WordNet DomainWordNet Domain
Not of great help because of the Not of great help because of the FactotumFactotum category problem category problem
1b. 1b. Density depth correctionDensity depth correctionMore weight is given to a subhierarchy if placed in deeper More weight is given to a subhierarchy if placed in deeper
positions in the ontology:positions in the ontology:
1c. 1c. Specific context correctionSpecific context correctionMore weight is given to a subhierarchy if a context word sense is More weight is given to a subhierarchy if a context word sense is a hyponym (more specific sense) of a sense of the word to a hyponym (more specific sense) of a sense of the word to disambiguatedisambiguate
((small improvements of the recallsmall improvements of the recall but deterioration of the precision) but deterioration of the precision)
CD * (depth(subhierarchy) - avgdepth+1)CD * (depth(subhierarchy) - avgdepth+1)

2. Conceptual Density for WSD2. Conceptual Density for WSD
1d. 1d. Context expansionContext expansion
I. The (I. The (definitiondefinition part) of the (POS-tagged) part) of the (POS-tagged) glossgloss
II. The II. The Global ContextGlobal Context of the document of the documentExtraction of keywords in the document using Extraction of keywords in the document using frequencyfrequency and and
distributiondistribution: : great frequencygreat frequency and and standard deviationstandard deviation (Lee et al. 04) (Lee et al. 04)
PP RR CC
CIAOSENSOCIAOSENSO 74.3%74.3% 49.7%49.7% 66.9%66.9%
CIAOSENSO+GCCIAOSENSO+GC 73.4%73.4% 50.8%50.8% 69.2%69.2%

2. Conceptual Density for WSD2. Conceptual Density for WSD
1e. 1e. GlossesGlosses of of CALD CALD (integrated into WN glosses)(integrated into WN glosses)
• if more than the 40% of the if more than the 40% of the definition partdefinition part of the of the WN glossWN gloss is is found in one of the found in one of the CALD definition partsCALD definition parts of candidate glosses of candidate glosses (~ Lesk knowledge-based approach): (~ Lesk knowledge-based approach): the the sample partsample part of CALD is added to the WN gloss of CALD is added to the WN gloss
1) we search in the CALD Web pages for: 1) we search in the CALD Web pages for: coherencecoherence, …, …2) we calculate the matching % of the definition part2) we calculate the matching % of the definition part3) in case of 40% at least, we add its sample part 3) in case of 40% at least, we add its sample part
• e.g. WN sysnset: e.g. WN sysnset: coherencecoherence, , coherencycoherency, , cohesioncohesion, , cohesivenesscohesiveness (the state of cohering or sticking together) (the state of cohering or sticking together)

2. Conceptual Density for WSD2. Conceptual Density for WSD
1e. 1e. GlossesGlosses of of CALD CALD (integrated into WN glosses)(integrated into WN glosses)
• WN 2.0: 8195 samples + 7416 new CALD samplesWN 2.0: 8195 samples + 7416 new CALD samples• SemCor: with CALD samples P= 79.8% R= 59.76% SemCor: with CALD samples P= 79.8% R= 59.76%
(without(without P= 81.5% R= P= 81.5% R= 59.9%)59.9%)
• Senseval-3 (AWT corpus)Senseval-3 (AWT corpus)- without CALD samples:- without CALD samples: P= 74.3%P= 74.3%R=51.2%R=51.2%
- with:- with:
P R
GW 73.75% 52.14%
GWd 73.98% 51.81%
GWs 74.06% 52.03%

2. Conceptual Density for WSD2. Conceptual Density for WSD
1f. 1f. WebWeb as as lexical resource for WSDlexical resource for WSD
• knowledge acquisition bottleneck (sample size is knowledge acquisition bottleneck (sample size is too small) for WSDtoo small) for WSD
• Web redundancy to disambiguate Web redundancy to disambiguate nounsnouns using using modifier modifier adjectivesadjectives (web hits) (web hits)

2. Conceptual Density for WSD2. Conceptual Density for WSD
1f. 1f. WebWeb as as lexical resource for WSDlexical resource for WSD
Preliminary definitions:Preliminary definitions:
w w wordword
|w||w| senses senses
a a adjectiveadjective
nn synonyms synonyms ssikik of of wwkk
mm words words hhjkjk in the direct hypernym synset of in the direct hypernym synset of wwkk
ffSS(x,y) (x,y) : function returning the # of pages containing “: function returning the # of pages containing “x yx y” ”
(according to the search engine (according to the search engine SS))
ffSS(x) (x) : function returning the # of pages containing : function returning the # of pages containing xx

2. Conceptual Density for WSD2. Conceptual Density for WSD 1f. 1f. WebWeb as as lexical resource for WSDlexical resource for WSD
Web-based algorithm: Web-based algorithm: adjective-nounadjective-noun lexical patterns lexical patterns
1. 1. Select the adjective Select the adjective aa before before ww
2. 2. For each For each wwk k , synonym , synonym ssik ik , hypernym (or hyponym) , hypernym (or hyponym) hhjkjk
compute: compute: ffSS(a,s(a,sikik)) and and ffSS(a,h(a,hjkjk))
3. 3. Assign a weight to each Assign a weight to each wwkk (combining the results of 2.) (combining the results of 2.) using a given formula using a given formula FF
4. 4. Select the Select the wwkk with the highest weight with the highest weight

2. Conceptual Density for WSD2. Conceptual Density for WSD
1f. 1f. WebWeb as as lexical resource for WSDlexical resource for WSD
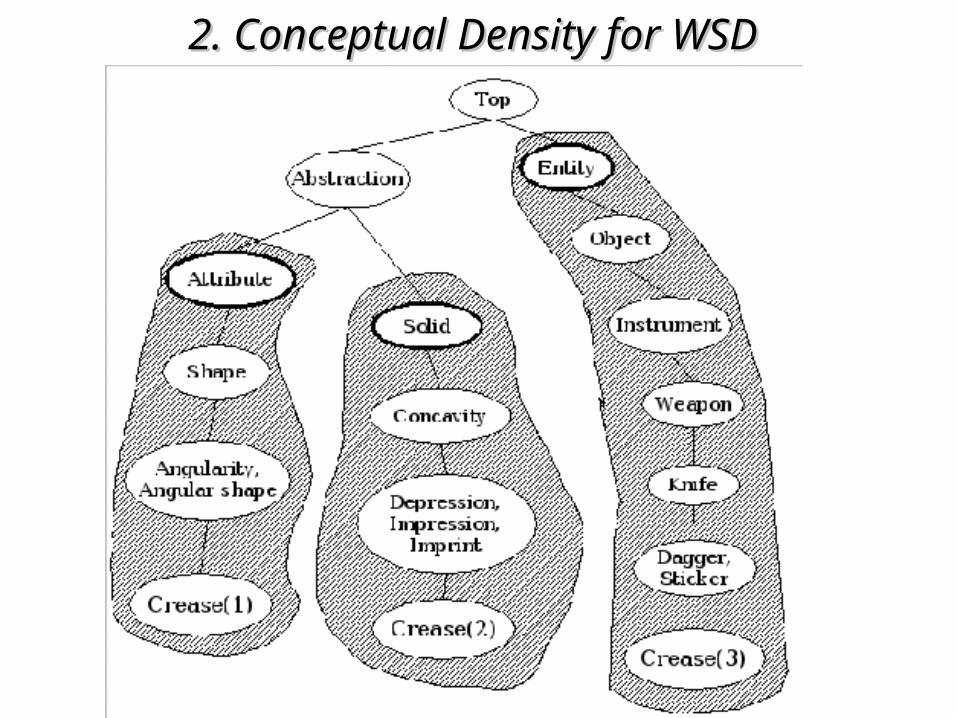
e. g. Senseval-3: e. g. Senseval-3: ““A A faint creasefaint crease appeared between the man’s eyebrows” appeared between the man’s eyebrows”
creasecrease11={fold, crease, bend,…}={fold, crease, bend,…}creasecrease22={wrinkle, crease, line,…}={wrinkle, crease, line,…}creasecrease33={kris, crease, creese}={kris, crease, creese}
hypernymshypernyms::hh11={angular shape, angularity}={angular shape, angularity}hh22={depression, impression, imprint}={depression, impression, imprint}hh33={dagger, sticker}={dagger, sticker}
2. Conceptual Density for WSD2. Conceptual Density for WSD

2. Conceptual Density for WSD2. Conceptual Density for WSD
1f. 1f. WebWeb as as lexical resource for WSDlexical resource for WSD
sense 1sense 1: :
(faint,fold), (faint,bend), …(faint,fold), (faint,bend), …
(faint, angular shape), (faint,angularity)(faint, angular shape), (faint,angularity)
sense 2sense 2: :
(faint,wrinkle), (faint,line), …(faint,wrinkle), (faint,line), …
(faint, depression), (faint,impression), (faint,imprint)(faint, depression), (faint,impression), (faint,imprint)
sense 3sense 3::
(faint, kris), (faint, creese)(faint, kris), (faint, creese)
(faint, dagger), (faint,sticker)(faint, dagger), (faint,sticker)

2. Conceptual Density for WSD2. Conceptual Density for WSD
1f. 1f. WebWeb as as lexical resource for WSDlexical resource for WSD
Some of the tested formulae, based on:Some of the tested formulae, based on:
• weight averageweight average::FFII: 1/2*( : 1/2*( f fSS(a,s(a,sikik) / n + ) / n + f fSS(a,h(a,hjkjk) / m)) / m)
FFIIII: F: FII with hyponyms with hyponyms
• weight maximumweight maximum::FFIIIIII: max ( f: max ( fSS(a,s(a,sikik) , f) , fSS(a,h(a,hjkjk) )) )
• similarity measuressimilarity measures::FFIVIV: max (f: max (fSS(a,s(a,sikik) log ( f) log ( fSS(a,s(a,sikik) /f) /fSS(s(sikik) ), f) ), fSS(a,h(a,hjkjk) log ( f) log ( fSS(a,h(a,hjkjk) )
/f/fSS(h(hjkjk) ))) ))
2. Conceptual Density for WSD2. Conceptual Density for WSD
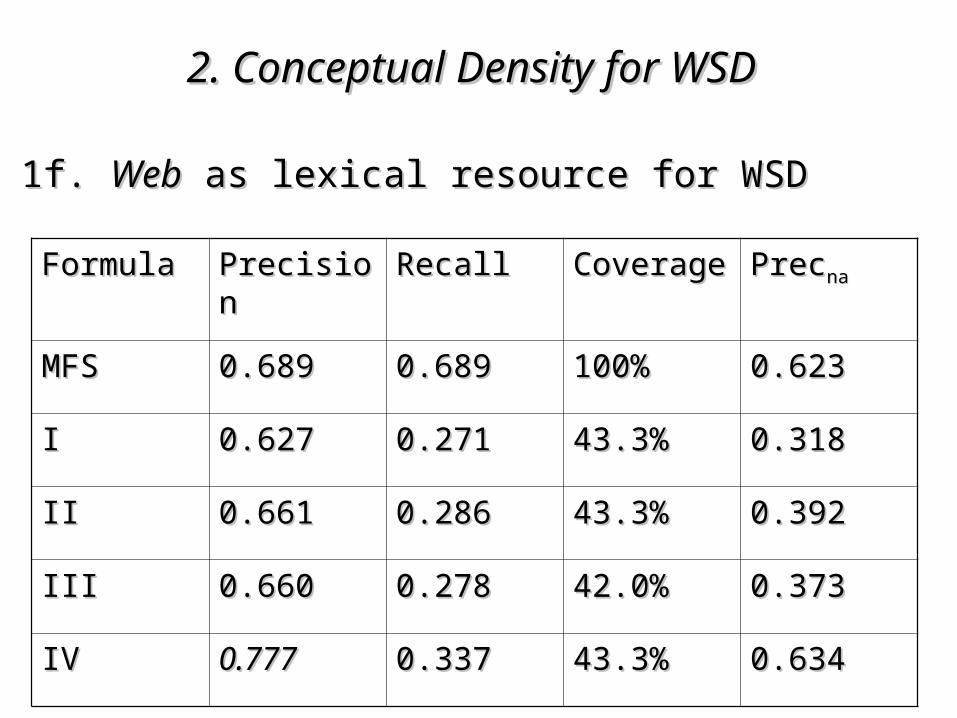
1f. 1f. WebWeb as as lexical resource for WSDlexical resource for WSD
FormulaFormula PrecisionPrecision RecallRecall CoverageCoverage PrecPrecnana
MFSMFS 0.6890.689 0.6890.689 100%100% 0.6230.623
II 0.6270.627 0.2710.271 43.3%43.3% 0.3180.318
IIII 0.6610.661 0.2860.286 43.3%43.3% 0.3920.392
IIIIII 0.6600.660 0.2780.278 42.0%42.0% 0.3730.373
IVIV 0.7770.777 0.3370.337 43.3%43.3% 0.6340.634

2. Conceptual Density for WSD2. Conceptual Density for WSD
1f. 1f. WebWeb as as lexical resource for WSDlexical resource for WSD
Search Engines (SE) comparison:Search Engines (SE) comparison:
• MSN, AltaVista + MSN, AltaVista + Lucene with the TREC-Lucene with the TREC-8 document collection8 document collection
• no significative no significative differences between the differences between the Web-based SEWeb-based SE
• Lucene (offline):Lucene (offline):– + precision, + precision,
- coverage- coverage– less dataless data but of but of
better qualitybetter quality

2. Conceptual Density for WSD2. Conceptual Density for WSD
1f. 1f. WebWeb as as lexical resource for WSDlexical resource for WSD
• in general in general better performancebetter performance in in precisionprecision (and (and recallrecall: 4% gain) of the : 4% gain) of the frequency-corrected formulaefrequency-corrected formulae (with probabilities over SemCor)(with probabilities over SemCor)
• importance of importance of polysemy of adjectivespolysemy of adjectives for nouns for nouns sense disambiguation: the sense disambiguation: the less polysemicless polysemic is the is the adjective, the higher is the probability of selecting adjective, the higher is the probability of selecting the right sensethe right sense
• same approach for the same approach for the disambiguation of adjectivesdisambiguation of adjectives (searching for (searching for ffSS(a(aik ik ,w),w)): ): poor precision 21.3%poor precision 21.3%

2. Conceptual Density for WSD2. Conceptual Density for WSD
1f. 1f. WebWeb as as lexical resource for WSDlexical resource for WSD
• in many cases just one in many cases just one adjective is not enoughadjective is not enough to to understand the meaning of a noun (e.g. pair still understand the meaning of a noun (e.g. pair still ambiguous: ambiguous: cold firecold fire cold passioncold passion): a greater ): a greater context should be taken into accountcontext should be taken into account
• better to better to integrateintegrate Web-based approaches and not Web-based approaches and not use them standaloneuse them standalone

2. Conceptual Density for WSD2. Conceptual Density for WSD 2. 2. Verb sense disambiguation with SVMVerb sense disambiguation with SVM
• Problems:Problems:– high polysemyhigh polysemy of verbs compared with the other categories of verbs compared with the other categories– lack of lexical resources providing lack of lexical resources providing relations between verbs relations between verbs
and nounsand nouns• Standard features:Standard features:
– Word FeatureWord Feature : the lexical form of each word : the lexical form of each word– Pos FeaturePos Feature : the Part-Of-Speech Tag of each word in the : the Part-Of-Speech Tag of each word in the
same windowsame window– Word.Pos featureWord.Pos feature : the concatenation of the previous : the concatenation of the previous
featuresfeaturese.g.:e.g.: Reid saw me looking at the iron bars.Reid saw me looking at the iron bars.
WF: WF: Reid, saw, me; at, the, ironReid, saw, me; at, the, ironPF: PF: NNP, VBD, PRP; IN, DT, NNNNP, VBD, PRP; IN, DT, NNWP: WP: Reid.NNP, saw.VBD, me.PRP; at.IN, the.DT, iron.NNReid.NNP, saw.VBD, me.PRP; at.IN, the.DT, iron.NN

2. Conceptual Density for WSD2. Conceptual Density for WSD
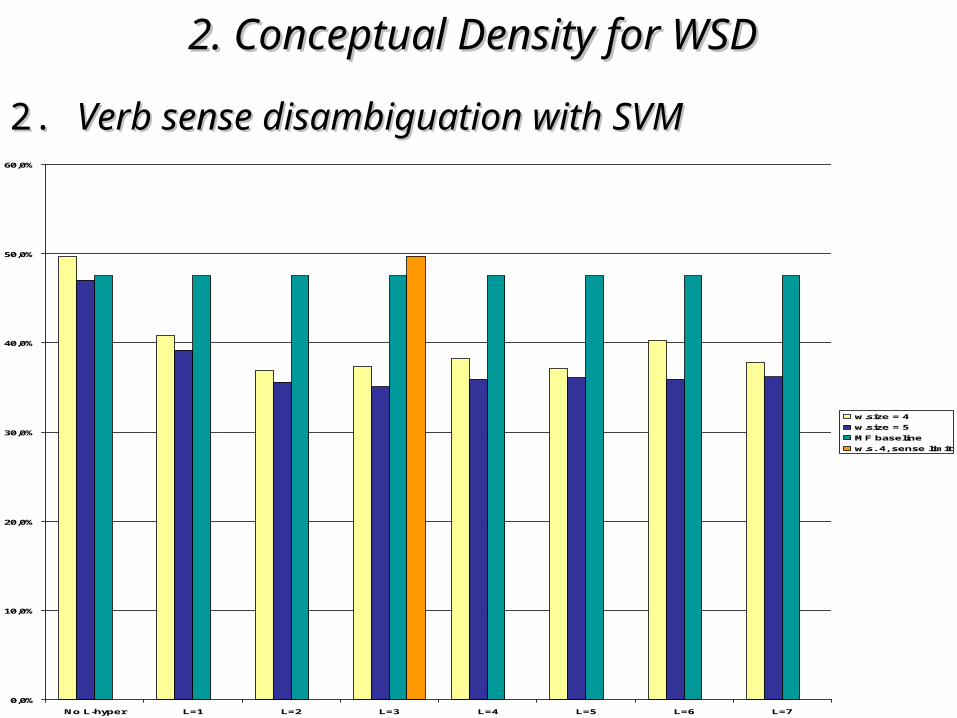
2. 2. Verb sense disambiguation with SVMVerb sense disambiguation with SVM
L-hypernymy feature:L-hypernymy feature:
the hyperonyms extracted from WordNet, for each noun the hyperonyms extracted from WordNet, for each noun in the context, at depth L, where L is the number of in the context, at depth L, where L is the number of levels to go up in the WordNet hierarchylevels to go up in the WordNet hierarchy
Sense 1: iron, Fe=> metallic element, metal => chemical element, element => substance, matter => entity
Sense 2: iron => golf club, golf-club, club => golf equipment => sports equipment => equipment => instrumentality ... => entity

2. Conceptual Density for WSD2. Conceptual Density for WSD
2. 2. Verb sense disambiguation with SVMVerb sense disambiguation with SVM
ExperimentsExperiments
• avg. # of training samples for each verb: 123.53avg. # of training samples for each verb: 123.53• avg. # of test samples for each verb: 61.81avg. # of test samples for each verb: 61.81
• implementation of SVM: SVM_light implementation of SVM: SVM_light ((http://svmlight.joachims.org/http://svmlight.joachims.org/) by Thorsten Joachims.) by Thorsten Joachims.
• a a modelmodel was built was built for every verbfor every verb of the corpus, using of the corpus, using the training set from the the training set from the Lexical Sample corpusLexical Sample corpus
• 1 ≤ L < 81 ≤ L < 8
2. Conceptual Density for WSD2. Conceptual Density for WSD
2. 2. Verb sense disambiguation with SVMVerb sense disambiguation with SVM
0,0%
10,0%
20,0%
30,0%
40,0%
50,0%
60,0%
No L-hyper L=1 L=2 L=3 L=4 L=5 L=6 L=7
w.size = 4
w.size = 5
MF baseline
w.s. 4, sense limit

2. Conceptual Density for WSD2. Conceptual Density for WSD
2. 2. Verb sense disambiguation with SVMVerb sense disambiguation with SVM
• WordNet-extracted features did not prove useful WordNet-extracted features did not prove useful
• better results could be achieved if better results could be achieved if only the only the hypernyms of the right sense of the context nounshypernyms of the right sense of the context nouns are considered: Noun Sense Disambiguation neededare considered: Noun Sense Disambiguation needed

1.1. The WordNet ontologyThe WordNet ontology2.2. Conceptual Density for Word Sense DisambiguationConceptual Density for Word Sense Disambiguation3.3. Semantic (Geo) Information Retrieval and Text Semantic (Geo) Information Retrieval and Text
CategorizationCategorization4.4. Semantic clusters of very short narrow-domain textsSemantic clusters of very short narrow-domain texts5.5. Lexical pattern extraction: mining the web with semantic infoLexical pattern extraction: mining the web with semantic info6.6. An ontology for Question Answering and vice versa: An ontology for Question Answering and vice versa:
OntotripleQAOntotripleQA7.7. Cluster analysis of transcribed spoken dialoguesCluster analysis of transcribed spoken dialogues8.8. The Clasitext ontology. Applications with ontologiesThe Clasitext ontology. Applications with ontologies
9.9. Semantic relatedness of concepts. Semantic relatedness of concepts. 10.10. Ontology matching: meta ontology or machine learning Ontology matching: meta ontology or machine learning
approach?approach?
11.11. The case study of biomedical ontologies: semantic The case study of biomedical ontologies: semantic relatedness of concepts of the different ontologiesrelatedness of concepts of the different ontologies
12.12. Lab session: CALD, WordNet vs. Genia, GenOntology, MeSHLab session: CALD, WordNet vs. Genia, GenOntology, MeSH

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC
Study of the impact of semantics in the tasks:Study of the impact of semantics in the tasks:
a.a. Retrieval of XML documents (not a NLE task)Retrieval of XML documents (not a NLE task)b.b. Information RetrievalInformation Retrievalc.c. Geo IRGeo IRd.d. Text CategorizationText Categorization

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC a.a. Retrieval of XML documents (not strictly a NLE task)Retrieval of XML documents (not strictly a NLE task)
• high dynamic nature of the Web + increased quantity high dynamic nature of the Web + increased quantity of of informationinformation represented as represented as XML documentsXML documents
• need for evaluating need for evaluating approximate queriesapproximate queries over XML over XML documents: documents: approximationapproximation = documents returned = documents returned even if even if not “completely” meeting the constraintsnot “completely” meeting the constraints the the query imposes query imposes
• returned documents ranked relying on a measure returned documents ranked relying on a measure evaluating the evaluating the similarity degreesimilarity degree

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC a.a. Retrieval of XML documents (not strictly a NLE task)Retrieval of XML documents (not strictly a NLE task)
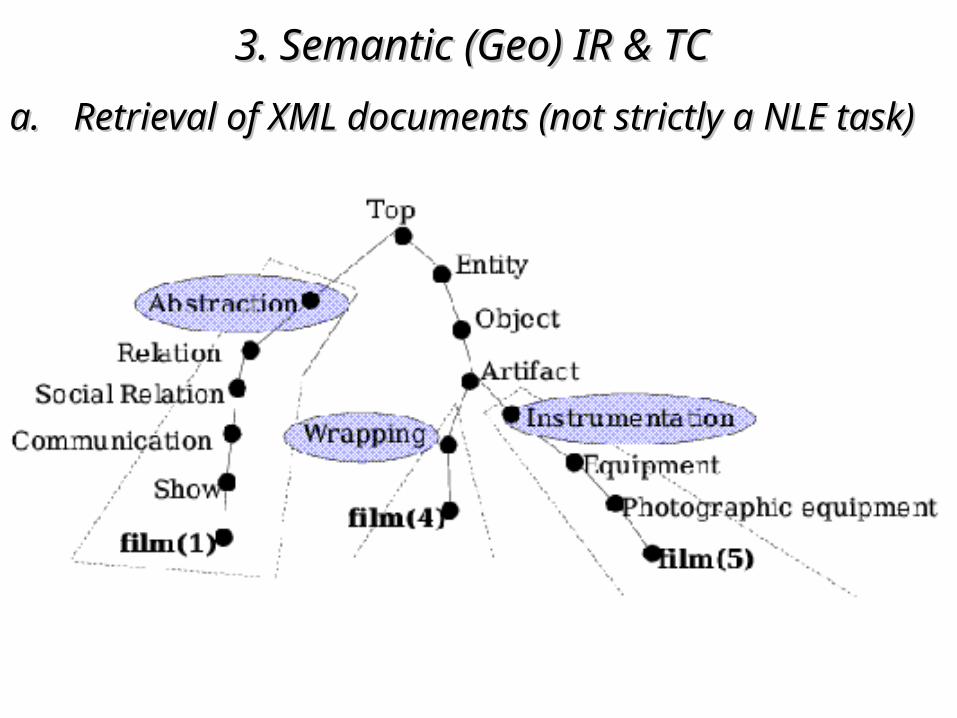
• tree representation of the query and a document (possible answer of the query)
• algorithm matching the two tree structures and returning the similarity degree
• vocabulary approximation: query tags query not “syntactically” matching document tags even if expressing the same concept
e.g. movie vs. film (but film NOT as photographic film)
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC a.a. Retrieval of XML documents (not strictly a NLE task)Retrieval of XML documents (not strictly a NLE task)
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC
a.a. Retrieval of XML documents (not strictly a NLE task)Retrieval of XML documents (not strictly a NLE task)

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC a.a. Retrieval of XML documents (not strictly a NLE task)Retrieval of XML documents (not strictly a NLE task)
• automatically assigning a automatically assigning a meaningmeaning to the to the query tagsquery tags• disambiguationdisambiguation of a of a query tagquery tag considering the considering the
neighbour tags (context): neighbour tags (context): father, children, brothersfather, children, brothers
e.g.1. query tag = e.g.1. query tag = filmfilm
a context with a context with directordirector helps to disambiguate helps to disambiguate filmfilm: :
(director, manager, managing director)(director, manager, managing director)
(stage director, director)(stage director, director)
(conductor, music director)(conductor, music director)
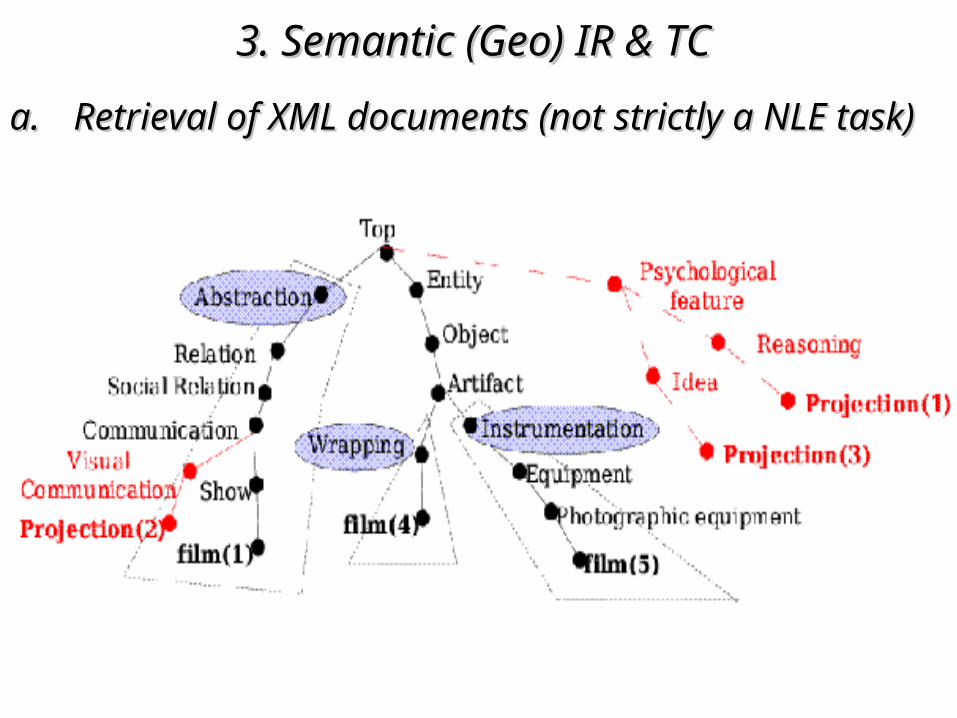
e.g.2. query tag = e.g.2. query tag = mapmap context tags = context tags = (water, mountain, sea)
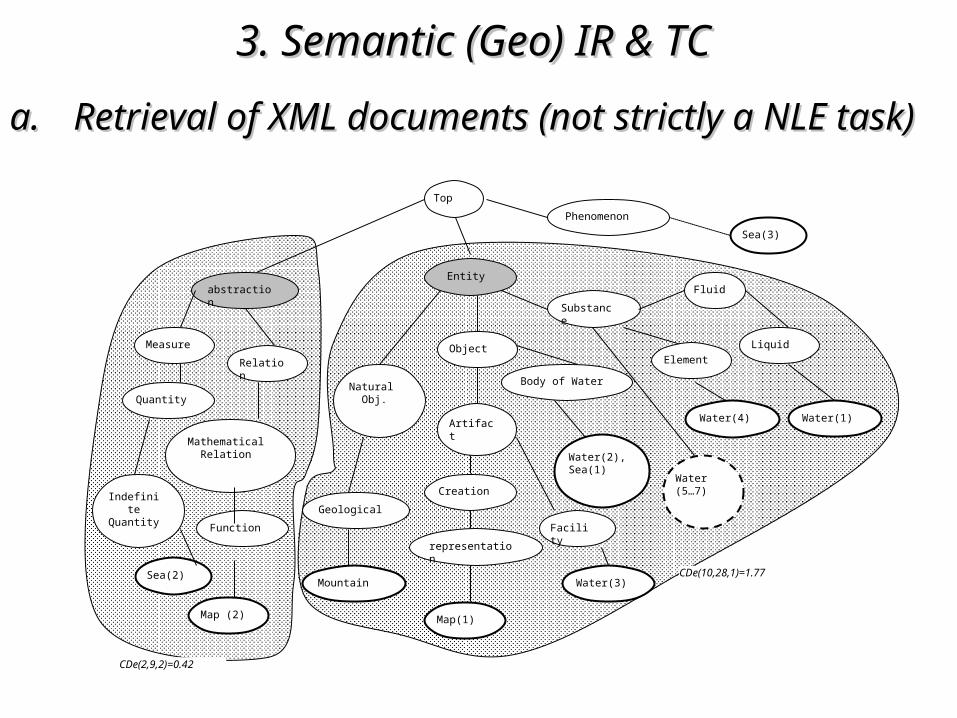
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC
a.a. Retrieval of XML documents (not strictly a NLE task)Retrieval of XML documents (not strictly a NLE task)
Top
Entity
Object
Artifact
Creation
representation
Map(1)
Body of Water
Water(2),Sea(1)
Liquid
Substance
Water(1)
Water(5…7)
Fluid
Water(3)
abstraction
Relation
Mathematical Relation
Function
Map (2)
Mountain
CDe(2,9,2)=0.42
CDe(10,28,1)=1.77
Facility
Water(4)
Sea(2)
Natural Obj.
Geological
Measure
Indefinite Quantity
Phenomenon
Quantity
Sea(3)
Element
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC a.a. Retrieval of XML documents (not strictly a NLE task)Retrieval of XML documents (not strictly a NLE task)
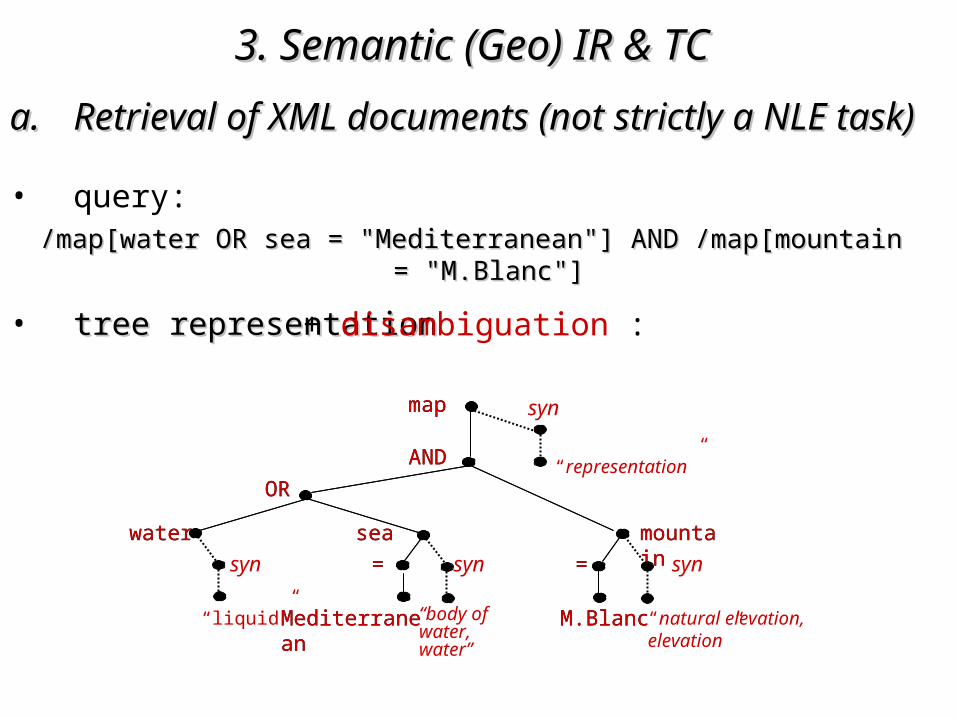
• query:
• tree representationtree representation
/map[water OR sea = "Mediterranean"] AND /map[mountain = "M.Blanc"]/map[water OR sea = "Mediterranean"] AND /map[mountain = "M.Blanc"]
AND
map
mountain
=
M.Blanc
water
=
sea
Mediterranean
OR
AND
map syn
mountain
syn=
M.Blanc “natural elevation, elevation”
“representation”
syn
“liquid”
water
syn=
sea
Mediterranean “body of water, water”
OR
+ disambiguation :
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC a.a. Retrieval of XML documents (not strictly a NLE task)Retrieval of XML documents (not strictly a NLE task)
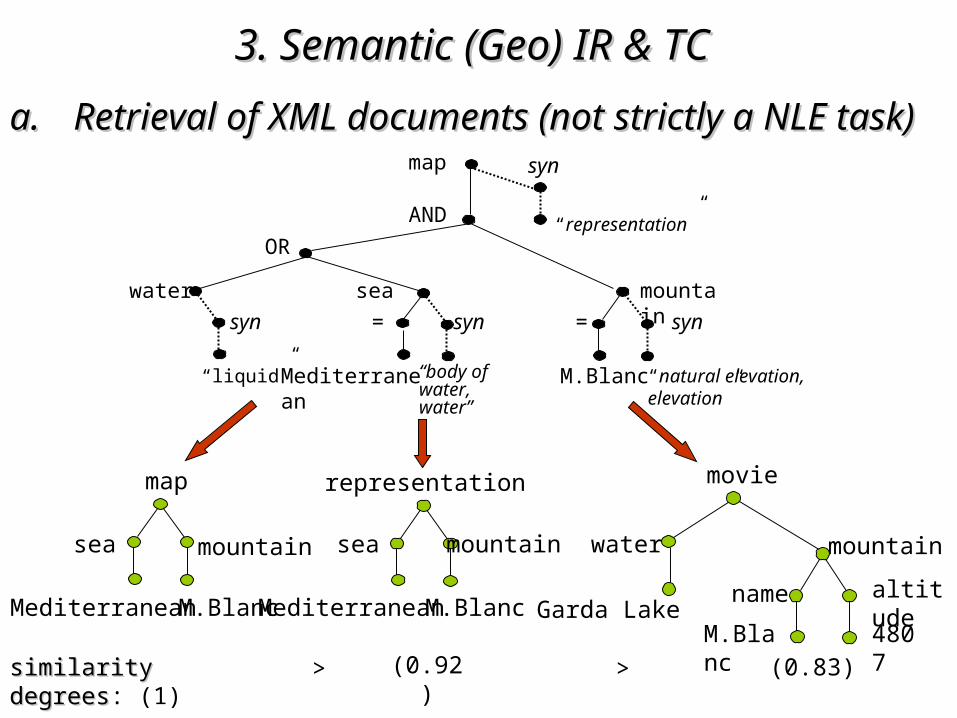
similarity degreessimilarity degrees: (1) (0.83)(0.92)> >
AND
map syn
mountain
syn=
M.Blanc “natural elevation, elevation”
“representation”
syn
“liquid”
water
syn=
sea
Mediterranean “body of water, water”
OR
map
sea mountain
M.BlancMediterranean
water
movie
mountain
name altitude
M.Blanc 4807Garda Lake
representation
sea mountain
M.BlancMediterranean
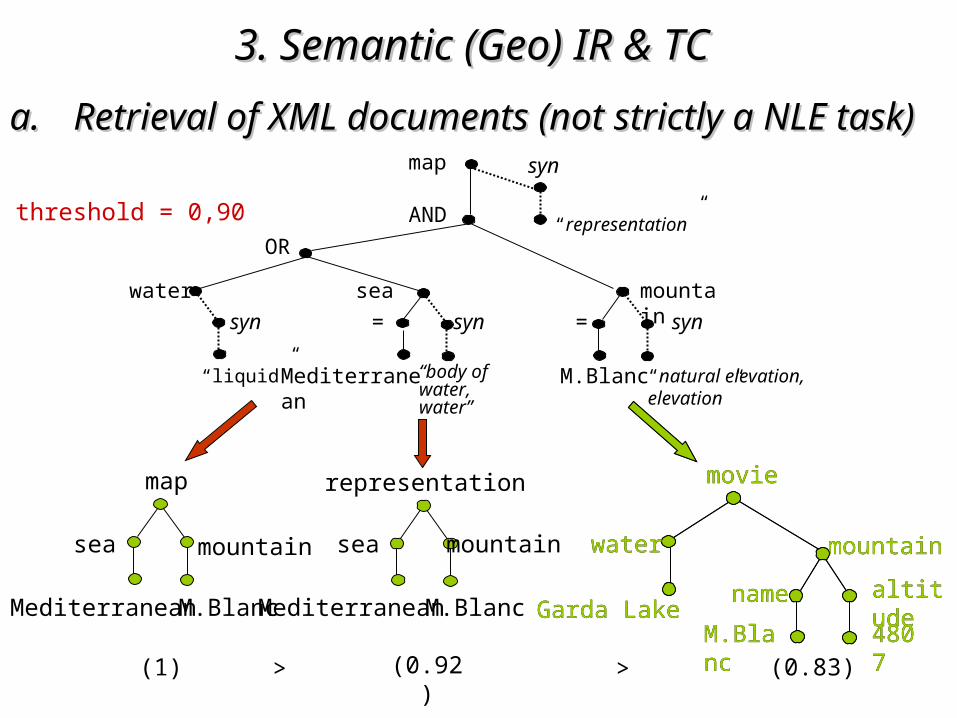
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC a.a. Retrieval of XML documents (not strictly a NLE task)Retrieval of XML documents (not strictly a NLE task)
AND
map syn
mountain
syn=
M.Blanc “natural elevation, elevation”
“representation”
map
sea mountain
M.Blanc
representation
sea mountain water
movie
mountain
name altitude
M.Blanc 4807
(1) (0.83)(0.92)> >
syn
“liquid”
water
syn=
sea
Mediterranean “body of water, water”
OR
Mediterranean M.Blanc Garda LakeMediterranean
threshold = 0,90
water
movie
mountain
name altitude
M.Blanc 4807Garda Lake

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC a.a. Retrieval of XML documents (not strictly a NLE task)Retrieval of XML documents (not strictly a NLE task)
(Mesiti, Guerrini, Buscaldi, Rosso, 03)(Mesiti, Guerrini, Buscaldi, Rosso, 03)• preliminary experiments: 30 Wepreliminary experiments: 30 Webb docs docs ( (~~ 600 distinct tags) 600 distinct tags)• NLE-oriented WordNet ontology not really well-suited for NLE-oriented WordNet ontology not really well-suited for
disambiguating XML docs: disambiguating XML docs: 30% of tags not30% of tags not contained in WN contained in WN– combination of nouns (e.g. combination of nouns (e.g. productListproductList, , clubnameclubname))– unintelligible abbreviations (e.g. unintelligible abbreviations (e.g. msrbmsrb, , cnamescnames))– verbsverbs– stoplist wordsstoplist words
• similar results with corpus-based (Bayes) and knowledge-similar results with corpus-based (Bayes) and knowledge-based (Conceptual Density) approachesbased (Conceptual Density) approaches
– 40% of the remaining tags were disambiguated correctly40% of the remaining tags were disambiguated correctly– CD approach fasterCD approach faster
• new relationships among tags should be considerednew relationships among tags should be considered
e.g.e.g. “is-used-in-the-context-of”“is-used-in-the-context-of”

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC a.a. Retrieval of XML documents (not strictly a NLE task)Retrieval of XML documents (not strictly a NLE task)
Gerhard WeikumGerhard Weikum “Efficient Top-k Queries for XML IR” “Efficient Top-k Queries for XML IR”Workshop “The Future of Web Search”Workshop “The Future of Web Search”Barcelona, May 19-20, 2006Barcelona, May 19-20, 2006
• Structure + Structure + contentcontent + semantics + semantics• Semantic searchSemantic search: semantic inference from the : semantic inference from the
gathered docsgathered docs• Relevance scoreRelevance score based on based on ontology similarity of ontology similarity of
concepts namesconcepts names• GlossesGlosses of WordNet of WordNet• ExpansionExpansion with with extracted infoextracted info (mutual info?) (mutual info?)• Towards a Towards a statistical Semantic Webstatistical Semantic Web

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC b. Information Retrievalb. Information Retrieval
Semantic indexing (with WordNet synsets):Semantic indexing (with WordNet synsets):
• if WSD with Precision >= 90% (Sanderson, 94)if WSD with Precision >= 90% (Sanderson, 94)• ““adding semantic indexing approach” (not an adding semantic indexing approach” (not an
“instead of” approach): query expansion (Krevetz, “instead of” approach): query expansion (Krevetz, 96)96)
e.g. “What financial institutions are found along the banks of the e.g. “What financial institutions are found along the banks of the
Nile?”Nile?” “(financial_institution OR 6003131/N) AND “(financial_institution OR 6003131/N) AND (bank OR 6800223/N) AND (Nile OR 6826174/N)”(bank OR 6800223/N) AND (Nile OR 6826174/N)”
• WSD with Precision >= 70% WSD with Precision >= 70% 29% increase of the 29% increase of the IR RecallIR Recall: experiments over SemCor (Gonzalo, 98): experiments over SemCor (Gonzalo, 98)

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC b. Information Retrievalb. Information Retrieval
Semantic IR experiments:Semantic IR experiments:
b1. b1. Latent Semantic Indexing (LSI) and k-meansLatent Semantic Indexing (LSI) and k-means (Jiménez, Vidal, Rosso, 03)(Jiménez, Vidal, Rosso, 03)
b2. b2. Conceptual clustersConceptual clusters using synonymy, using synonymy, hypernymy, hyponymy, meronymy lexical hypernymy, hyponymy, meronymy lexical relationships relationships (Kang et al. 04)(Kang et al. 04)……..
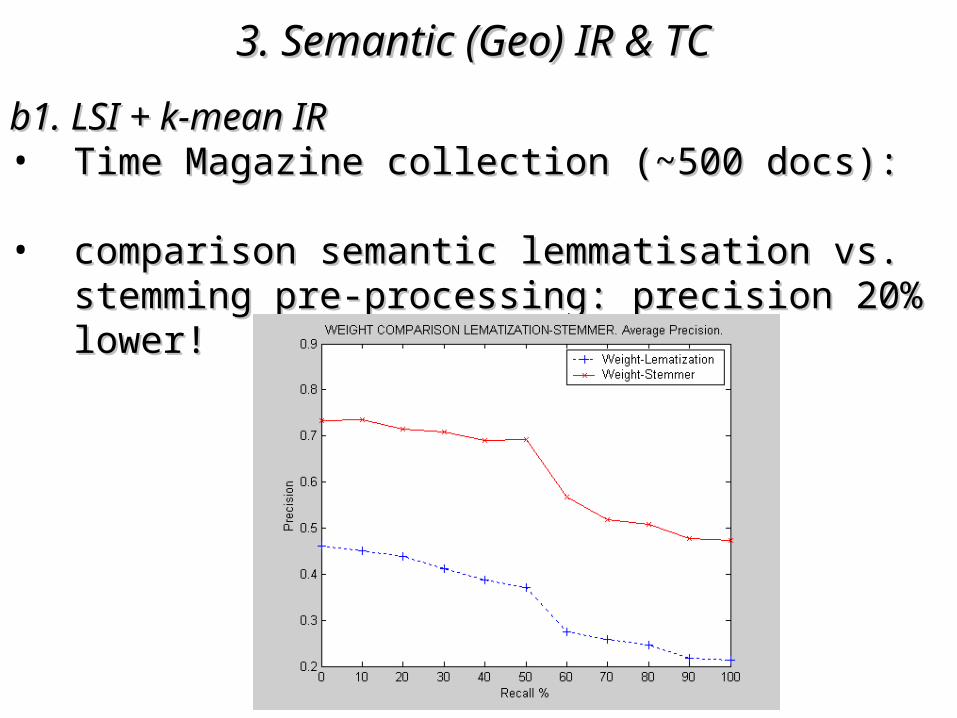
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC
b1. LSI + k-mean IRb1. LSI + k-mean IR• Time Magazine collection (~500 docs):Time Magazine collection (~500 docs): • comparison semantic lemmatisation vs. stemming comparison semantic lemmatisation vs. stemming
pre-processing: precision 20% lower!pre-processing: precision 20% lower!

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC b1. LSI + k-mean IRb1. LSI + k-mean IR
Why if (Gonzalo, 98) talks about an increase of recall in Why if (Gonzalo, 98) talks about an increase of recall in IR up to 29%?IR up to 29%?
Unfortunately, the error rate of state-of-the-art WSD Unfortunately, the error rate of state-of-the-art WSD systems is greater than 30%: 65% of precision (and systems is greater than 30%: 65% of precision (and recall) of best system in AWT of Senseval-3 recall) of best system in AWT of Senseval-3
Attempt in the future to include Attempt in the future to include semantic indexing semantic indexing only only for relevant words: for relevant words: selection of relevant wordsselection of relevant words first first

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC b2. IR with conceptual clustersb2. IR with conceptual clusters
• Aim: to consider the Aim: to consider the semantic importance semantic importance of the of the words and their concepts in a doc words and their concepts in a doc
• Conceptual clusters Conceptual clusters with k lexical relations with k lexical relations (“identity”, synonymy, hypernymy, hyponymy, (“identity”, synonymy, hypernymy, hyponymy, meronymy) with different weights meronymy) with different weights (Kang et al. 04)(Kang et al. 04)
weigh of word wweigh of word wii : : k_relations * weight_relation k_relations * weight_relationkk
weight of conceptual clusterweight of conceptual cluster ll: : i_w i_wwwii

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC b2. IR with conceptual clustersb2. IR with conceptual clusters
Conceptual cluster Conceptual cluster CCll is is representativerepresentative if its weight is if its weight is >= of the average of the weights of all the conceptual >= of the average of the weights of all the conceptual clustersclusters
w1 = 1*0.7+2*0.5=1.7
C1= 1.7+0.7+0.5+0.5=3.4
w1(1.7)
w2(0.7) w3(0.5)
w4(0.5)identity
synonymy
Cluster1 (3.4)

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC
b2. IR with conceptual clustersb2. IR with conceptual clusters““This This exerciseexercise routineroutine, developed by Steve, , developed by Steve, directordirector of rehabilitation at the of rehabilitation at the Centre for Centre for SpineSpine, and , and administratoradministrator of the Health Association, focuses on of the Health Association, focuses onthe right spots: It strengthens your the right spots: It strengthens your backback musclemuscle, abdominals, and obliques , abdominals, and obliques (the ab (the ab musclesmuscles that run from front to back along your lower ribs) and that run from front to back along your lower ribs) and stretches your legs and hips. Combine this stretches your legs and hips. Combine this practicepractice with three 30-minutes with three 30-minutes sessions of cardiovascular sessions of cardiovascular activityactivity such as such as joggingjogging, and you should be on , and you should be on your way to a healthier your way to a healthier backback””
back(0.7)
spine(0.5)
back(1.2)
C1(2.4)
muscle(0.7)
muscle(0.7)
C2(1.4)
director(0.3)
administrator(0.3)
C3(0.6)
exercise(0.6)
practice(0.3)
activity(1.2)
routine(0.3)
jogging(0.6)
C4(3.0)
The words The words practicepractice and and directordirector have the same weight, have the same weight, BUT practice is semantically more important:BUT practice is semantically more important:importance wimportance wii w.r.t. its representative w.r.t. its representative CCll
2
j
j
li
|C|C |w|

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC b2. IR with conceptual clustersb2. IR with conceptual clusters
Comparison with Comparison with TF*IDFTF*IDF (TREC-2 collection): (TREC-2 collection): • semantic indexessemantic indexes: words with a greater importance : words with a greater importance
than the average importance of all the wordsthan the average importance of all the words
• increaseincrease of the of the precisionprecision of 10% of 10%
• reductionreduction of the of the sizesize of the indexed terms of of the indexed terms of 80%80%!!

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC c. Geo IRc. Geo IR
Geo IR could be Geo IR could be ambiguousambiguous::
• (Geo I) R(Geo I) RRetrieval of information involving some kind of Retrieval of information involving some kind of spatial awarenessspatial awareness (Fred Gey @ (Fred Gey @ GeoCLEFGeoCLEF 2005) 2005)E.g. E.g. Find news about riots in France.Find news about riots in France.
• Geo (IR)Geo (IR)
Not a particular aspect of Spatial Information RetrievalNot a particular aspect of Spatial Information Retrieval
E.g. E.g. What is the river flowing through Paris?What is the river flowing through Paris?
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC c. Geo IRc. Geo IR
(Almost) The same (Almost) The same Geographical EntityGeographical Entity can be can be indicated in several indicated in several differentdifferent (and sometimes (and sometimes ambiguous) ambiguous) mannersmanners::
• United Kingdom of Great United Kingdom of Great Britain and Northern IrelandBritain and Northern Ireland• United Kingdom, UK, U.K. + United Kingdom, UK, U.K. + Northern IrelandNorthern Ireland• Great Britain, GB + Northern Great Britain, GB + Northern IrelandIreland• Reino Unido, Gran BretagnaReino Unido, Gran Bretagna• British IslesBritish Isles
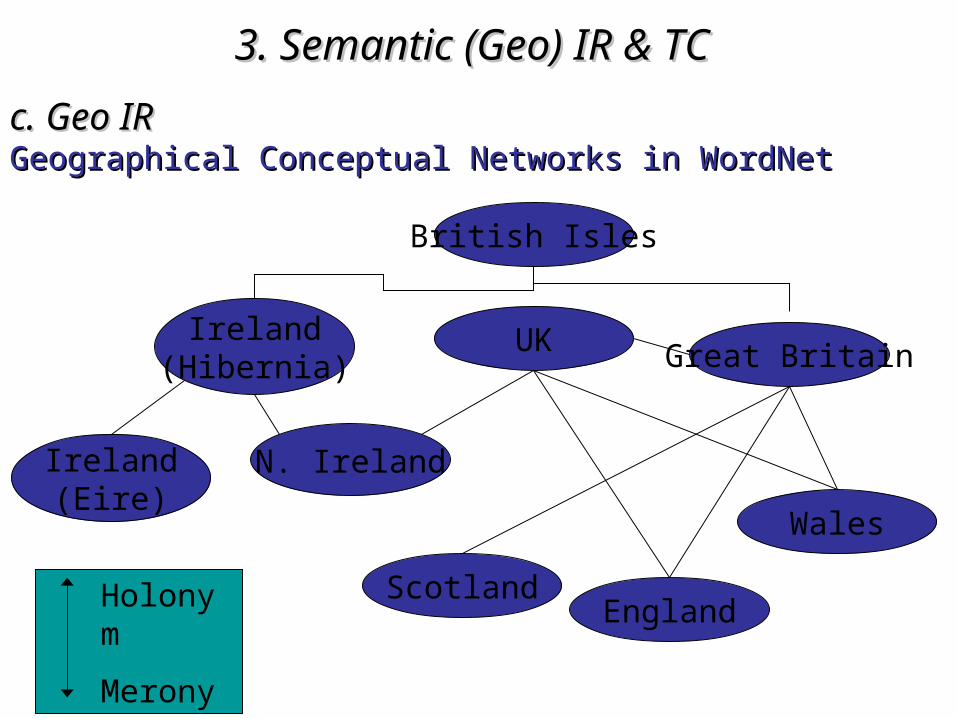
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC c. Geo IRc. Geo IRGeographical Conceptual Networks in WordNetGeographical Conceptual Networks in WordNet
N. Ireland
UK
EnglandScotland
Wales
British Isles
Great BritainIreland
(Hibernia)
Ireland(Eire)
Holonym
Meronym

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC c. Geo IRc. Geo IRExploiting WordNetExploiting WordNet
• Solving Solving synonymysynonymy::
E.g. synset corresponding to “E.g. synset corresponding to “U.K.U.K.”:”:
{United Kingdom, UK, U.K., Great Britain, GB, Britain, United {United Kingdom, UK, U.K., Great Britain, GB, Britain, United
Kingdom of Great Britain and Northern Ireland}Kingdom of Great Britain and Northern Ireland}• Finding Finding missing (geographical) informationmissing (geographical) information::
– MeronymyMeronymy (“has member/part” relationship) (“has member/part” relationship)– HolonymyHolonymy (“is member/part of”) (“is member/part of”)
Two Two solutions testedsolutions tested::• Query Expansion (QE)Query Expansion (QE)• Index Terms Expansion (ITE)Index Terms Expansion (ITE)

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC c. Geo IR: c. Geo IR: QEQE
Expand the geographical termsExpand the geographical terms of the query with of the query with
their their synonymssynonyms and ( and (somesome) ) meronymsmeronyms• geographical terms are identified through the geographical terms are identified through the
WordNet ontology: words having the WordNet ontology: words having the synsetsynset {region, {region, location}location} among their among their hypernymshypernyms
• MeronymsMeronyms containing the word “ containing the word “capitalcapital” in the ” in the definition (gloss)definition (gloss) or in the or in the meronym synsetmeronym synset itself itself

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC c. Geo IR: c. Geo IR: QEQE
e.g. e.g. Foreign minorities in GermanyForeign minorities in Germany• ““Germany” appears in the synset: {Germany, Germany” appears in the synset: {Germany,
Federal Republic of Germany, Deutschland, Federal Republic of Germany, Deutschland,
FRG}FRG}• The following meronyms contain the word “capital”:The following meronyms contain the word “capital”:
Berlin, german Berlin, german capitalcapital
Bonn (was the Bonn (was the capitalcapital of Germany between 1949 and 1989) of Germany between 1949 and 1989)
Munich, Muenchen (Munich, Muenchen (capitalcapital of Bavaria) of Bavaria)
Aachen, Aken, Aix-la-Chapelle (formerly Charlemagne Aachen, Aken, Aix-la-Chapelle (formerly Charlemagne northern northern capitalcapital))
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC c. Geo IR: c. Geo IR: ITEITE
• Find geographical termsFind geographical terms in the text collection: in the text collection:
openNLPopenNLP Named Entities detector ( Named Entities detector (http://opennlp.sourceforge.net))
• Put all their Put all their holonymsholonyms and and synonymssynonyms into a special into a special geo indexgeo index
Search Engine used: Lucene (Search Engine used: Lucene (http://lucene.jakarta.org))
• Label geographical termsLabel geographical terms in the in the queryquery with the with the geo geo search fieldsearch field::
e.g. “riots in France” -> text:riots geo:Francee.g. “riots in France” -> text:riots geo:France

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC c. Geo IR: c. Geo IR: ITEITE
““OnOn Sunday morningsSunday mornings, the, the covered market oppositecovered market opposite thethe stationstation in thein the leafy suburbleafy suburb ofof Aulnay-sous-BoisAulnay-sous-Bois -- barelybarely half an hour'shalf an hour's drivedrive fromfrom centralcentral ParisParis -- spills spills opulentlyopulently on to theon to the streetsstreets andand boulevardsboulevards.”.”
From WordNet:From WordNet:Paris, Paris, French capitalFrench capital, , capital of Francecapital of France, , city of lightcity of light
France, French RepublicFrance, French RepublicEuropeEurope
Northern hemisphereNorthern hemisphere
- To geographical index- To geographical index - To standard index- To standard index

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC c. Geo IRc. Geo IRExperiment setupExperiment setup
• GeoCLEF 2005 collection and queriesGeoCLEF 2005 collection and queries
Los Angeles Times 1994Los Angeles Times 1994
Glasgow Herald 1995Glasgow Herald 1995• Topic DescriptionTopic Description runs: runs:
e.g. TD from queries:e.g. TD from queries:
““Shark attacks near California and Australia”Shark attacks near California and Australia”
““Vegetable exporters of Europe”Vegetable exporters of Europe”
““Holidays in the Scottish Trossachs”Holidays in the Scottish Trossachs”• 1000 results returned for each query1000 results returned for each query
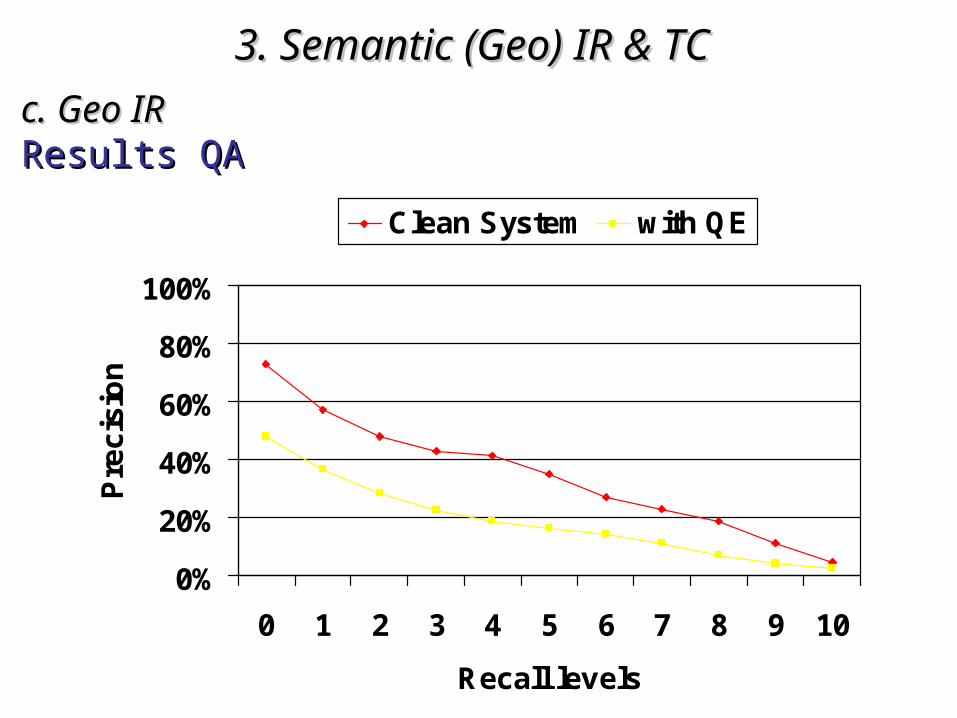
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC c. Geo IRc. Geo IRResults QAResults QA
0%
20%
40%
60%
80%
100%
0 1 2 3 4 5 6 7 8 9 10
Recall levels
Pre
cis
ion
Clean System with QE

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC c. Geo IRc. Geo IRResults QAResults QA
Why did it perform so bad? Two major errors:Why did it perform so bad? Two major errors:• Inconsistent expansionsInconsistent expansionse.g. e.g. “Sacramento” expanding “Sacramento” expanding CaliforniaCaliforniain the query: in the query: “Shark attacks in California”“Shark attacks in California”
• AmbiguityAmbiguitye.g. “Europe” in “Vegetable exporters of Europe”e.g. “Europe” in “Vegetable exporters of Europe”WordNet returns three senses forWordNet returns three senses for““Europe”:Europe”:
Europe as continentEurope as continentEurope as the European UnionEurope as the European UnionEurope as the set of nations on theEurope as the set of nations on theEuropean continentEuropean continent
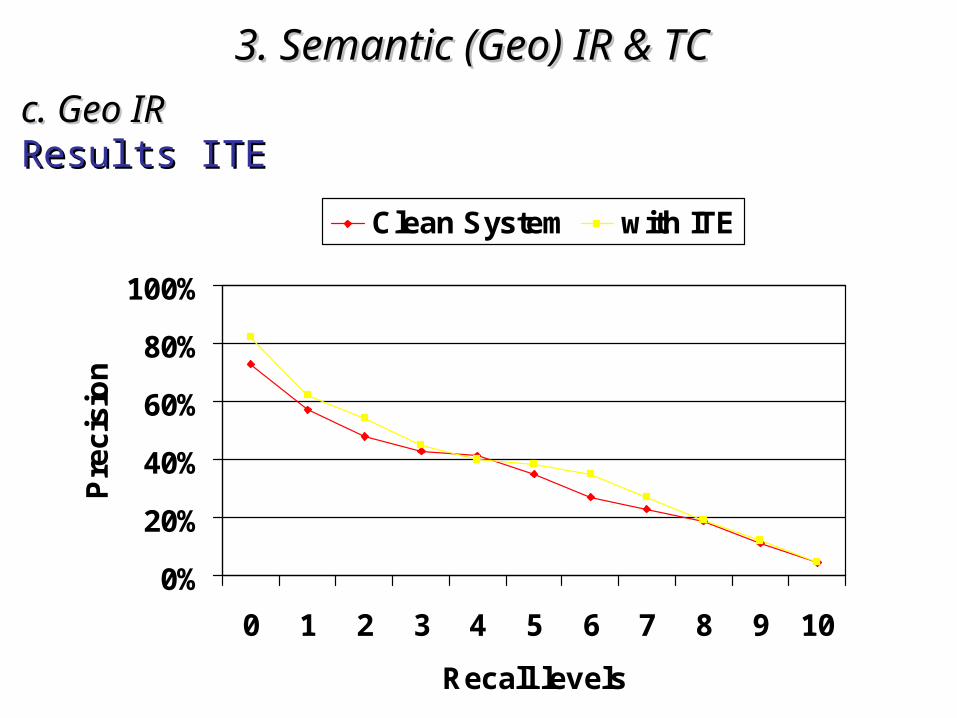
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC c. Geo IRc. Geo IRResults ITEResults ITE
0%
20%
40%
60%
80%
100%
0 1 2 3 4 5 6 7 8 9 10
Recall levels
Pre
cis
ion
Clean System with ITE

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC c. Geo IRc. Geo IRRemarksRemarks
• ITE better than QEITE better than QE– It seems to be It seems to be less sensitive to ambiguityless sensitive to ambiguity problems problems– However: it needs However: it needs NE recognition during the indexing NE recognition during the indexing
phase (not trivial)phase (not trivial)
• The The WordNet ontologyWordNet ontology cancan be used as a be used as a Geo IRGeo IR::– To be To be evaluated againstevaluated against a specialized resource like the a specialized resource like the
TGNTGN http://www.getty.edu/research/conducting_research/vocabularies/tgn/

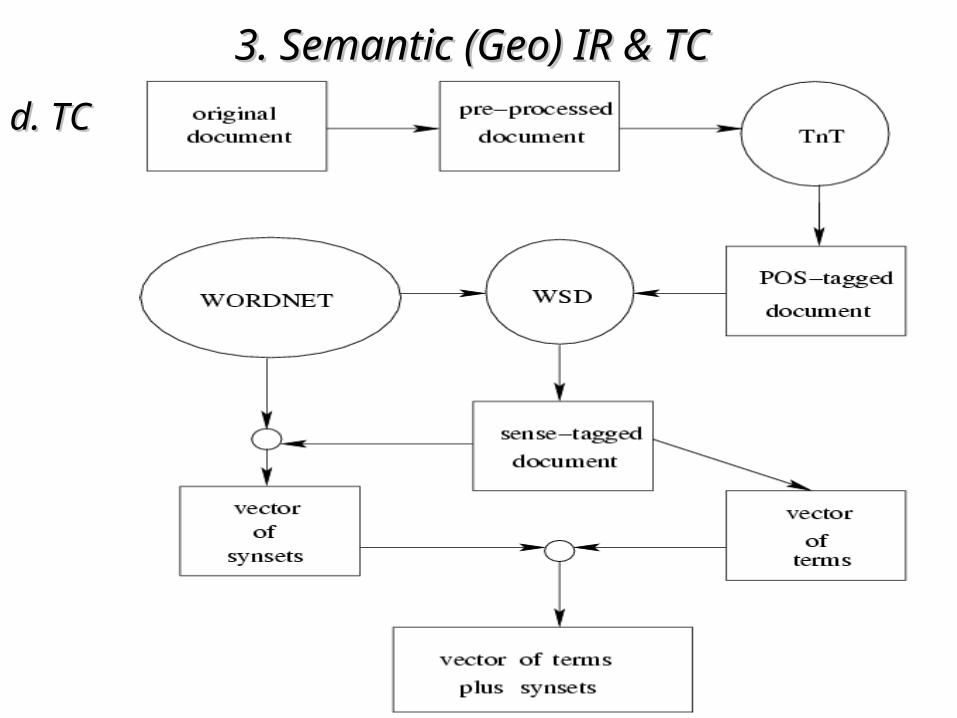
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC d. TCd. TC
• Text CategorisationText Categorisation: labelling natural language docs : labelling natural language docs with thematic categories from a predefined setwith thematic categories from a predefined set
• classifierclassifier learns from a training set the learns from a training set the correspondencecorrespondence between between docsdocs and and categoriescategories::
– the k-NN method finds its the k-NN method finds its kk Nearest Neighbours among Nearest Neighbours among the training docsthe training docs
– the the categoriescategories of the of the k neighboursk neighbours used to select the used to select the nearest categorynearest category for the test doc for the test doc

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC d. TCd. TC• Vector Space Model (Salton)Vector Space Model (Salton)• TF*IDF TF*IDF weighting schemeweighting scheme
• text codification: itext codification: ithth component of d: d component of d: d ii = =
n: nonen: none == n: nonen: none = = 1 n: none = n: none = 1
b: binary = b: binary = 0/1 t: t: c: cosinec: cosine
m = m =
a = a =
l = l =
NORMFIDFT idid ,,
idTF ,
)(maxmax
,
,
idi
id
TF
TFnorm
)(max5.05.0
,
,
idi
id
TF
TFnormavg
)log(1log ,idTF
)log(iDF
Ntfidf
iidid FIDFT 2
,,
1
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC d. TCd. TC

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC d. TCd. TC
• Hidden Markov Model corpus-based system WSD Hidden Markov Model corpus-based system WSD (Molina and Pla, 02)(Molina and Pla, 02)
• term selectionterm selection process process
– to to optimise the list of terms that identify the collectionoptimise the list of terms that identify the collection (optimisation focused to (optimisation focused to reduce the number of terms with reduce the number of terms with poor informationpoor information))
– Information GainInformation Gain (IG) method: IG measures the amount of (IG) method: IG measures the amount of information which contributes a term for the prediction of a information which contributes a term for the prediction of a category (as a function of its presence or absence in a category (as a function of its presence or absence in a given text)given text)

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC
d. TCd. TCExperiments on data sets (Ferretti, Errecalde, Rosso, 05):Experiments on data sets (Ferretti, Errecalde, Rosso, 05):
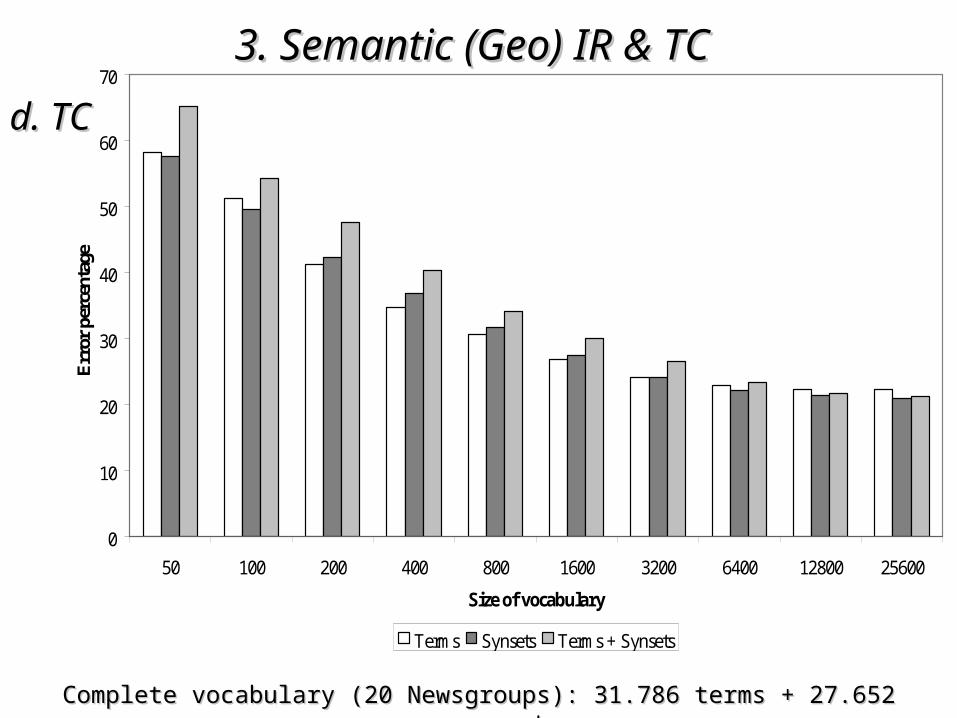
• 20 Newsgroup20 Newsgroup– ~20.000 news messages (sent in 1993) of ~20.000 news messages (sent in 1993) of 20 Usenet discussion groups20 Usenet discussion groups
((categoriescategories))– 1000 documents per category except for the soc.religion.christian 1000 documents per category except for the soc.religion.christian
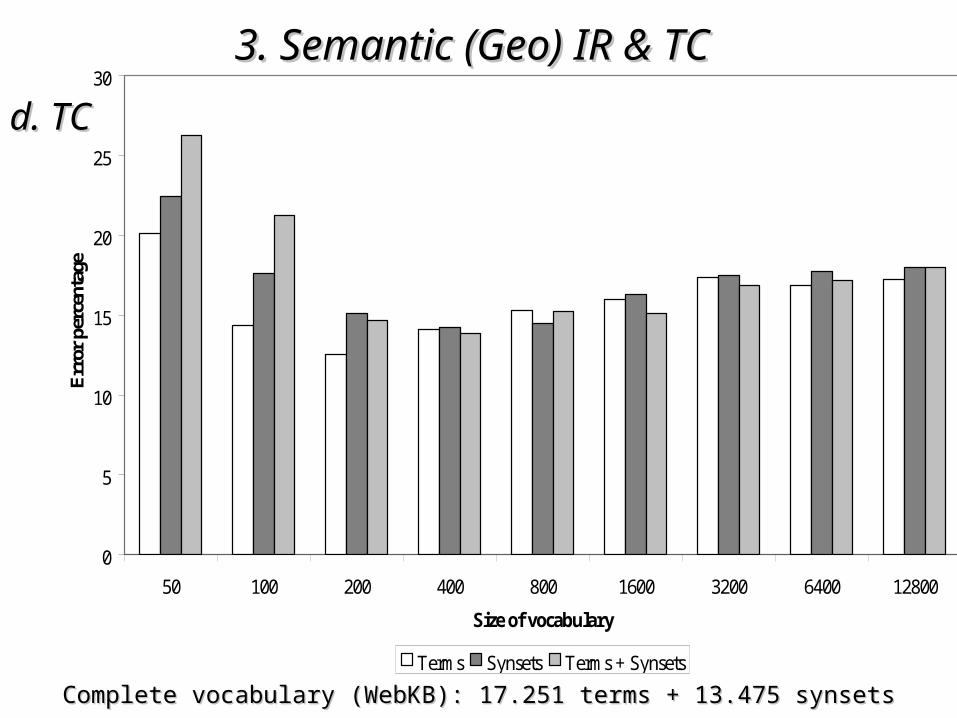
category that contains 997category that contains 997• WebKBWebKB
– ~5.000 ~5.000 Computer Science Web pages of universitiesComputer Science Web pages of universities (Cornell, Texas, (Cornell, Texas, Washington, Wisconsin and miscellaneous)Washington, Wisconsin and miscellaneous)
– pages divided into pages divided into 7 categories: student, faculty, staff, course, project, 7 categories: student, faculty, staff, course, project, department and otherdepartment and other
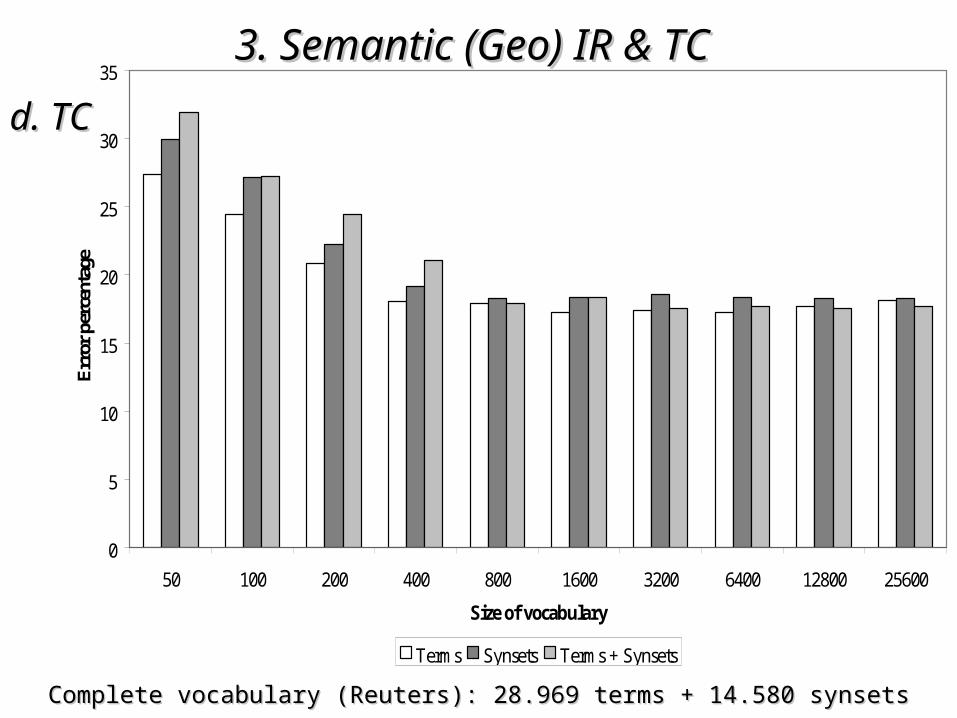
• Reuters-21578Reuters-21578– ~1.600 newswire docs distributed in 22 SGML format files~1.600 newswire docs distributed in 22 SGML format files– 5 different sets of 5 different sets of content related economic categoriescontent related economic categories
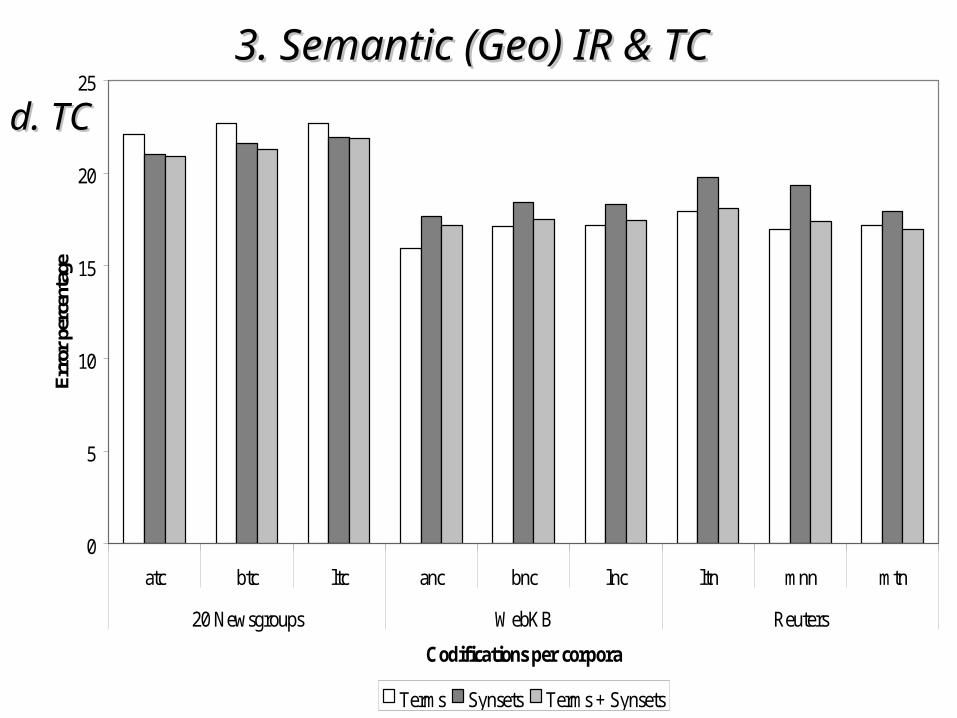
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC d. TCd. TC
0
5
10
15
20
25
atc btc ltc anc bnc lnc ltn mnn mtn
20 Newsgroups WebKB Reuters
Codifications per corpora
Err
or p
erce
ntag
e
Terms Synsets Terms + Synsets
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC d. TCd. TC
Complete vocabulary (20 Newsgroups): 31.786 terms + 27.652 synsetsComplete vocabulary (20 Newsgroups): 31.786 terms + 27.652 synsets
0
10
20
30
40
50
60
70
50 100 200 400 800 1600 3200 6400 12800 25600
Size of vocabulary
Err
or p
erce
ntag
e
Terms Synsets Terms + Synsets
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC d. TCd. TC
Complete vocabulary (WebKB): 17.251 terms + 13.475 synsetsComplete vocabulary (WebKB): 17.251 terms + 13.475 synsets
0
5
10
15
20
25
30
50 100 200 400 800 1600 3200 6400 12800
Size of vocabulary
Err
or p
erce
ntag
e
Terms Synsets Terms + Synsets
3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC d. TCd. TC
Complete vocabulary (Reuters): 28.969 terms + 14.580 synsetsComplete vocabulary (Reuters): 28.969 terms + 14.580 synsets
0
5
10
15
20
25
30
35
50 100 200 400 800 1600 3200 6400 12800 25600
Size of vocabulary
Err
or p
erce
ntag
e
Terms Synsets Terms + Synsets

3. Semantic (Geo)3. Semantic (Geo) IR & TC IR & TC d. TCd. TC
• the impact of the use of semantic information the impact of the use of semantic information depends on the particular characteristics of the depends on the particular characteristics of the corpuscorpus
• in corpora in corpora richer syntactically and semanticallyricher syntactically and semantically the the inclusion of semantic information allow a small inclusion of semantic information allow a small improvement improvement if vocabulariesif vocabularies with a sufficient number with a sufficient number of features are considered (of features are considered (50% of the original size50% of the original size))
• attempt in the future to include attempt in the future to include semantic indexing semantic indexing only for relevant words: only for relevant words: selection of relevant wordsselection of relevant words firstfirst

1.1. The WordNet ontologyThe WordNet ontology2.2. Conceptual Density for Word Sense DisambiguationConceptual Density for Word Sense Disambiguation3.3. Semantic (Geo) Information Retrieval and Text CategorizationSemantic (Geo) Information Retrieval and Text Categorization4.4. Semantic clusters of very short narrow-domain textsSemantic clusters of very short narrow-domain texts5.5. Lexical pattern extraction: mining the web with semantic infoLexical pattern extraction: mining the web with semantic info6.6. An ontology for Question Answering and vice versa: An ontology for Question Answering and vice versa:
OntotripleQAOntotripleQA7.7. Cluster analysis of transcribed spoken dialoguesCluster analysis of transcribed spoken dialogues8.8. The Clasitext ontology. Applications with ontologiesThe Clasitext ontology. Applications with ontologies
9.9. Semantic relatedness of conceptsSemantic relatedness of concepts10.10. Ontology matching: meta ontology or machine learning Ontology matching: meta ontology or machine learning
approach?approach?
11.11. The case study of biomedical ontologies: semantic relatedness The case study of biomedical ontologies: semantic relatedness of concepts of the different ontologiesof concepts of the different ontologies
12.12. Lab session: CALD, WordNet vs. Genia, GenOntology, MeSHLab session: CALD, WordNet vs. Genia, GenOntology, MeSH

4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts
ProblemsProblems• organization of text set =organization of text set =>> data structuringdata structuring• searching interesting texts =searching interesting texts =>> clustering based clustering based navigationnavigation
Typical situation Typical situation • free access to free access to full-text full-text scientific papers is limited to only their scientific papers is limited to only their
abstractsabstracts consisting of no more than several dozens of consisting of no more than several dozens of words words
• sometimes the set of sometimes the set of full-text full-text scientific papersscientific papers on a given on a given domaindomain areare not available not available is is absent absent at allat all and a library has and a library has only only abstractsabstracts
Typical opinionTypical opinionusual usual keyword-basedkeyword-based methods work well methods work well

4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts
Very short textsVery short texts• texts from texts from differentdifferent domains domains• texts from texts from narrow narrow domainsdomains SocietySociety SciencesSciences Physics Physics
CultureCulture PhysicsPhysics Nuclear physics Nuclear physics
EconomicsEconomics ChemistryChemistry Experimental physics Experimental physics
PoliticsPolitics BiologyBiology Optical physicsOptical physics
……………… …………………… ………………
NoNo intersection intersection WeakWeak intersection intersection StrongStrong intersection intersection
of vocabularies of vocabularies of vocabularies of vocabularies of vocabularies of vocabularies
Problem:Problem: the stronger the the stronger the vocabulary intersectionvocabulary intersection is, the more is, the more
unstableunstable results are results are

Very short textsVery short texts• news news and other and other self-containedself-contained• abstractsabstracts of full scientific texts or technical papers of full scientific texts or technical papers
AbstractsAbstracts explain the explain the goalsgoals of the research reported in the paper of the research reported in the paper (the problem), while (the problem), while paperspapers explain the explain the methodsmethods used to achieve used to achieve these goals (i.e., the algorithms)these goals (i.e., the algorithms)
Our goal is to shorten the gap between:Our goal is to shorten the gap between:1.1. Automatic Automatic abstractabstract clustering clustering vs. vs.
manual manual abstract abstract clusteringclustering2.2. Automatic Automatic abstractabstract clustering clustering vs. vs.
manual manual paperpaper clustering clustering
Problem:Problem: impreciseimprecise results when clustering abstracts results when clustering abstracts
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts

Very short texts Very short texts (50-100 words)(50-100 words)• absolute frequency of indexes are sometimesabsolute frequency of indexes are sometimes 3-4 generally 3-4 generally
0-20-2• onlyonly 5%-15% 5%-15% of the vocabulary is used in every text of the vocabulary is used in every text
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts

Traditional approach Traditional approach
1. Constructing word frequency list1. Constructing word frequency liststop-words are eliminated stop-words are eliminated
words having the same base meaning are joined (words having the same base meaning are joined (stemmingstemming))
2. Constructing text images 2. Constructing text images according to according to TFTF or or TF-IDF techniques TF-IDF techniques tftfi,ji,j = = ffi,ji,j / max / maxffi,ji,j idf idfii = Log ( = Log (N/nN/nii)) ii-th word, -th word, jj-th text-th text
3. Clustering 3. Clustering using theusing the cosine measure cosine measure From (2) :From (2) : highhigh randomness randomness in text imagesin text images
Results: Results: not such a big problem when texts are from different not such a big problem when texts are from different domains, but when they are narrow domain…domains, but when they are narrow domain…
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts

Struggling for stabilityStruggling for stability Using compensative effectUsing compensative effect• to join indexes (keywords) :to join indexes (keywords) : ((ww11 , w , w22 , ....w , ....wnn) => ) => WW11 = = ((ww11, w, w33, w, w1919), ), WW22 = = ((ww77, w, w1313, w, w2323),.. ),..
• to cluster abstracts in new index space (cluster coordinates):to cluster abstracts in new index space (cluster coordinates): ((WW11 , W , W22 ,.... ,....))
Selection of group of indexesSelection of group of indexes1. Use 1. Use synsetssynsets of an appropriate of an appropriate ontologyontology2. Use a 2. Use a thesaurusthesaurus of a given domain of a given domain
3. 3. ClusterCluster the words in the space of texts the words in the space of texts 4. Use the 4. Use the transition point techniquetransition point technique5. 5. Conceptual clusters Conceptual clusters (using WordNet synsets)(using WordNet synsets)
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts

Selection of group of indexesSelection of group of indexes
3.3. ClusterCluster the the wordswords in the space of texts: in the space of texts:
MajorClustMajorClust algorithm algorithm
Weighting indexesWeighting indexes WWkk = ∑ = ∑ ddi,j i,j / / NNkk, ,
kk is the number of the cluster is the number of the cluster
ii and and jj are the elements of this clusters ( are the elements of this clusters (ii ≠ ≠ jj) )
NNkk is the number of links in the cluster is the number of links in the cluster kk
(Alexandrov, Gelbukh, Rosso, 05)(Alexandrov, Gelbukh, Rosso, 05)
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts
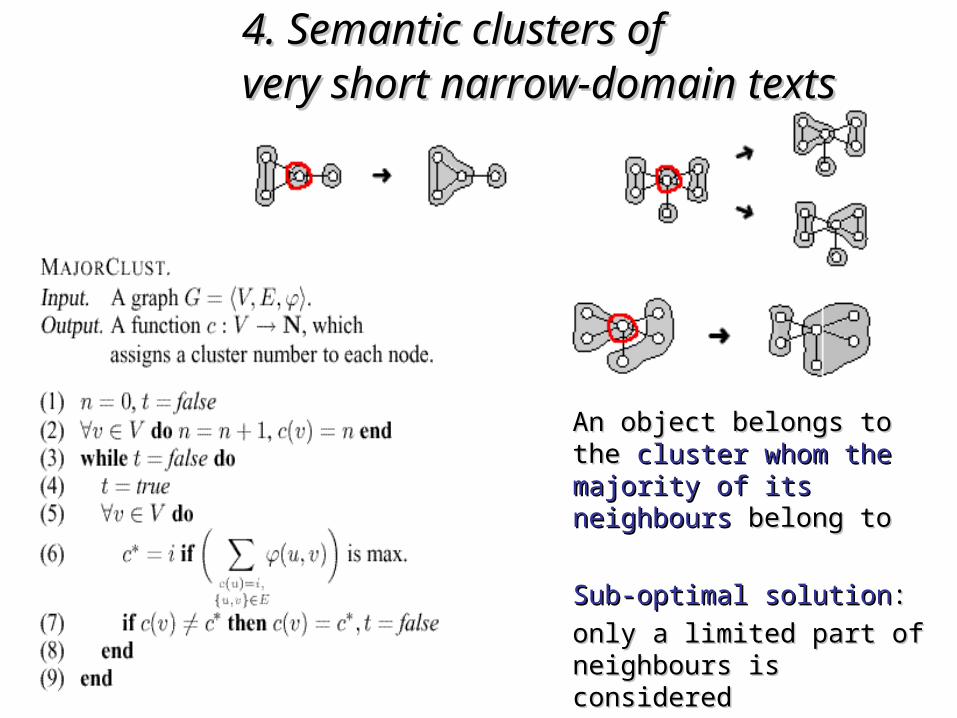
An object belongs to theAn object belongs to the cluster whom the majority of cluster whom the majority of its neighboursits neighbours belong to belong to
Sub-optimal solutionSub-optimal solution: :
only a limited part of only a limited part of neighbours is consideredneighbours is considered
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts

Struggling for precisionStruggling for precision Using a more adequate measureUsing a more adequate measure
cosine measurecosine measure CC1,21,2 = =
where where 1, 21, 2 are the numbers of texts are the numbers of texts
xxk,ik,i are the cluster coordinates are the cluster coordinates
Coordinate transformation:Coordinate transformation:
xxkiki = log (1 + = log (1 + ffk,ik,i) / log (1 + max( ) / log (1 + max( ffii))))
Aim:Aim: smoothing smoothing of high frequencies typical of high frequencies typical abstract wordsabstract words
(e.g. method, experiment, result etc.)(e.g. method, experiment, result etc.)
,
,
21
21
xx
xxk
kk
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts

Clustering indexesClustering indexesMajorClustMajorClust method: method: number of clusters is defined number of clusters is defined automaticallyautomatically
Clustering abstractsClustering abstracts• NNNN method method (hierarchy-based)(hierarchy-based)• K-meansK-means method method (example-based)(example-based)• MajorClustMajorClust method method (density-based)(density-based)
Abstracts Abstracts (preliminary results) improved using(preliminary results) improved using::• compensative effect compensative effect • logarithmic measurelogarithmic measure
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts

ExperimentsExperiments: : Clustering Clustering abstracts CICLingabstracts CICLing-2002-2002
Indexing: 390 keywordsIndexing: 390 keywords
Gold standard: Gold standard: 44 clusters (obtained also with MajorCluster): clusters (obtained also with MajorCluster):LinguisticLinguistic (semantics, syntax, morphology, parsing) (semantics, syntax, morphology, parsing)
AmbiguityAmbiguity (word sense disambiguation, anaphora, tagging, spelling) (word sense disambiguation, anaphora, tagging, spelling)
LexiconLexicon (lexicon and corpus, text generation) (lexicon and corpus, text generation)
Text processingText processing (information retrieval, summarization, text classification) (information retrieval, summarization, text classification)
Narrow domain:Narrow domain: e.g. Ve.g. V22 ∩ V ∩ V44 = 70% = 70%
Indexing log Scaling F-measure TF-IDF No 0.64 TF No 0.57 Grouping Yes 0.78 Grouping No 0.68
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts

F-measureF-measure = 2 P R / (P + R) = 2 P R / (P + R)
Digital library and Internet repositories should provide Digital library and Internet repositories should provide
open accessopen access both to both to abstractsabstracts and to and to document imagesdocument images
of full papersof full papers: this does not violate the copyright of authors! : this does not violate the copyright of authors!
(proposal by (proposal by Dr. MakagonovDr. Makagonov,, Mixteca University of Technology, Mexico)Mixteca University of Technology, Mexico)
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts

Selection of group of indexesSelection of group of indexes
4. Use the 4. Use the Transition Point Transition Point ((TPTP) technique) technique• based on the based on the Zip lawZip law of word frequency: of word frequency: mid-term frequency mid-term frequency
termsterms are closely related to the are closely related to the conceptual contentconceptual content of a of a documentdocument
– I1: # words of frequency equal to 1
– if very short texts: if very short texts: TP = the lowest frequency that is not repeatedTP = the lowest frequency that is not repeated
• mid-term frequency termsmid-term frequency terms + + mutual-information termsmutual-information terms (over the same collection)(over the same collection)
(Pinto, Jiménez, Rosso, 05)(Pinto, Jiménez, Rosso, 05)
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts
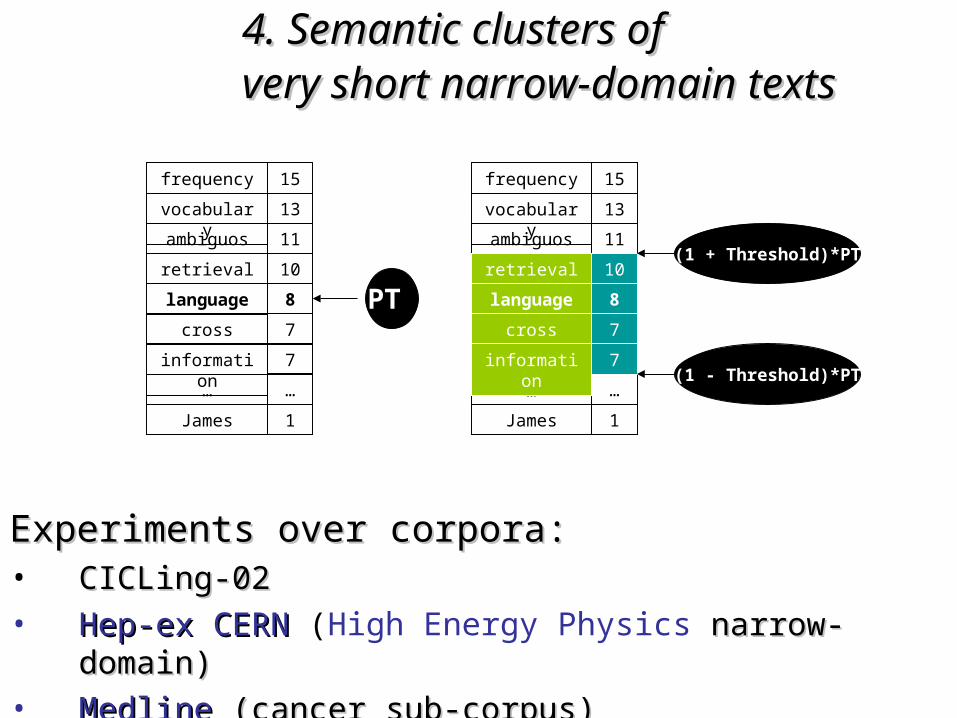
Experiments over corpora:Experiments over corpora:• CICLing-02CICLing-02• Hep-ex CERNHep-ex CERN (High Energy Physics narrow-domain)narrow-domain)• MedlineMedline (cancer sub-corpus) (cancer sub-corpus)
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts
15
13
11
10
8
7
…
1
7
frequency
vocabulary
ambiguos
retrieval
…
language
cross
James
information
PT
15
13
11
10
8
7
…
1
7
frequency
vocabulary
ambiguos
retrieval
…
language
cross
James
information
(1 + Threshold)*PT
(1 - Threshold)*PT

Term selection methodsTerm selection methods
• document frequencydocument frequency: : to a term t is assigned the weight to a term t is assigned the weight dfdftt
(# texts where t occurs)(# texts where t occurs)
• term strengthterm strength
where sim(Twhere sim(Tii, T, Tjj) ≤ β) ≤ β TTii, T, Tjj: :
textstexts• transition pointtransition point
where TPwhere TPvv: Transition Point value: Transition Point value
freq(t,T) of the term t in the text Tfreq(t,T) of the term t in the text T
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts
jiTtTtts jit with ),|(Pr
1),(1
),(
TtfreqTP
TtidtpV
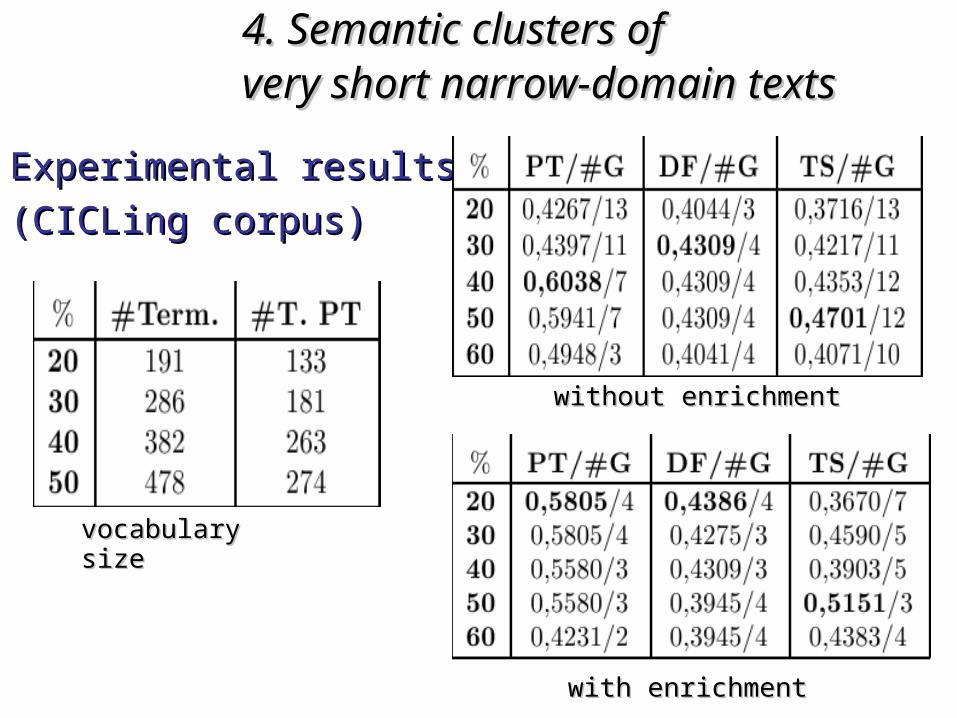
Experimental resultsExperimental results
(CICLing corpus)(CICLing corpus)
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts
without enrichmentwithout enrichment
with enrichmentwith enrichment
vocabulary sizevocabulary size
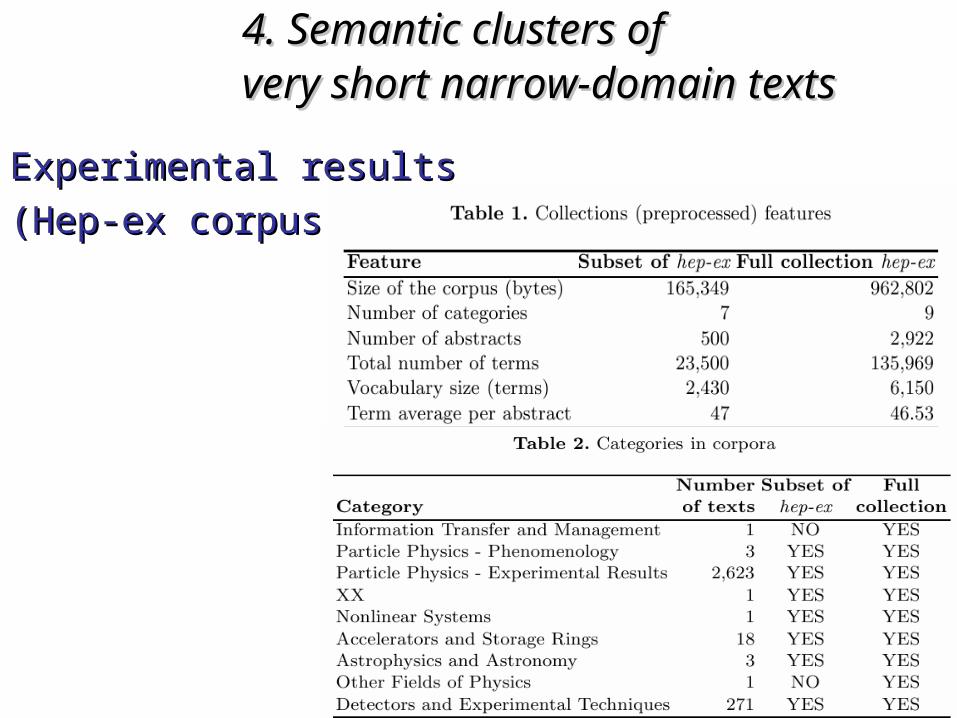
Experimental resultsExperimental results
(Hep-ex corpus)(Hep-ex corpus)
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts
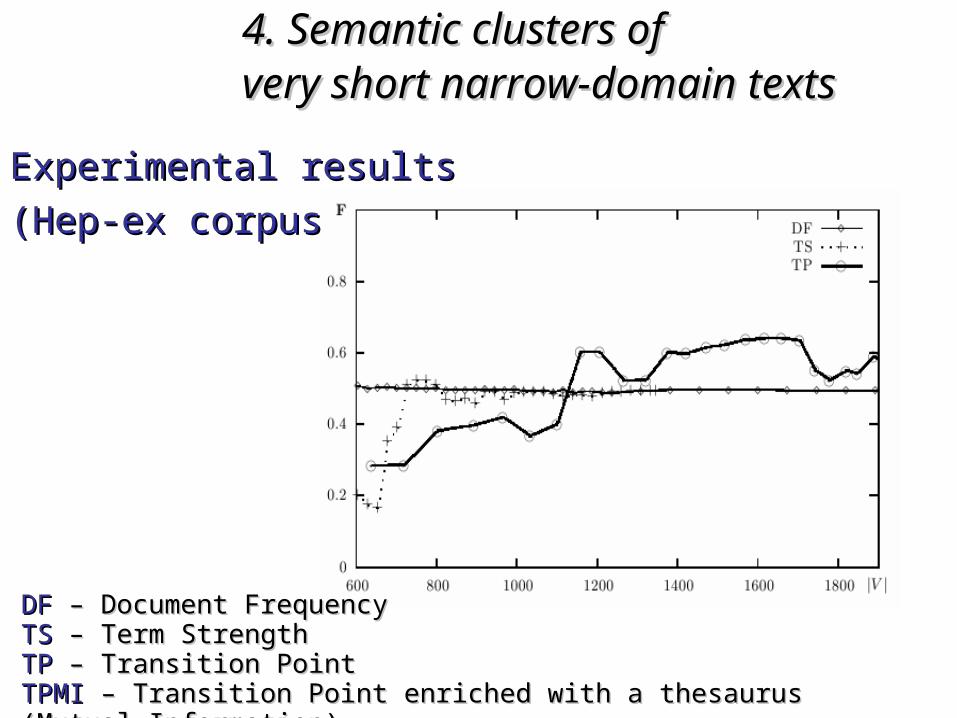
Experimental resultsExperimental results
(Hep-ex corpus)(Hep-ex corpus)
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts
DFDF – Document Frequency – Document FrequencyTSTS – Term Strength – Term StrengthTPTP – Transition Point – Transition PointTPMITPMI – Transition Point enriched with a thesaurus (Mutual Information) – Transition Point enriched with a thesaurus (Mutual Information)

Selection of group of indexes Selection of group of indexes “under construction”“under construction”
a.a. use the use the TP TP technique with technique with termsterms
+ + sense-taggingsense-tagging (with WordNet synsets) of (with WordNet synsets) of selected selected termsterms:: terms vs. synsets vs. terms + synsets terms vs. synsets vs. terms + synsets
b.b. use the use the TP TP technique withtechnique with synsets synsets
(sense-tag all terms first):(sense-tag all terms first):
terms terms (of a.) (of a.) vs. synsets vs. terms + synsetsvs. synsets vs. terms + synsets
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts

Selection of group of indexesSelection of group of indexes5. 5. Conceptual cluster Conceptual cluster (using WordNet synsets)(using WordNet synsets)
• Composed by Composed by two or more document nounstwo or more document nouns connected by connected by one or more relations (one or more relations (word-count identityword-count identity and and WordNet: WordNet: synonymy, hypernymy, meronymysynonymy, hypernymy, meronymy))see in see in 33. . IR with conceptual clustersIR with conceptual clusters
• Experiments Experiments (CICLing2002 corpus)(CICLing2002 corpus)
F-measure: 0.44 (poor results)F-measure: 0.44 (poor results)
• Further work: to investigate other Further work: to investigate other lexical relationslexical relations + their + their weightweight
4. Semantic clusters of 4. Semantic clusters of very short narrow-domain textsvery short narrow-domain texts

1.1. The WordNet ontologyThe WordNet ontology2.2. Conceptual Density for Word Sense DisambiguationConceptual Density for Word Sense Disambiguation3.3. Semantic (Geo) Information Retrieval and Text CategorizationSemantic (Geo) Information Retrieval and Text Categorization4.4. Semantic clusters of very short narrow-domain textsSemantic clusters of very short narrow-domain texts5.5. Lexical pattern extraction: mining the web with semantic Lexical pattern extraction: mining the web with semantic
informationinformation6.6. An ontology for Question Answering and vice versa: An ontology for Question Answering and vice versa:
OntotripleQAOntotripleQA7.7. Cluster analysis of transcribed spoken dialoguesCluster analysis of transcribed spoken dialogues8.8. The Clasitext ontology. Applications with ontologiesThe Clasitext ontology. Applications with ontologies
9.9. Semantic relatedness of conceptsSemantic relatedness of concepts10.10. Ontology matching: meta ontology or machine learning Ontology matching: meta ontology or machine learning
approach?approach?
11.11. The case study of biomedical ontologies: semantic relatedness The case study of biomedical ontologies: semantic relatedness of concepts of the different ontologiesof concepts of the different ontologies
12.12. Lab session: CALD, WordNet vs. Genia, GenOntology, MeSHLab session: CALD, WordNet vs. Genia, GenOntology, MeSH
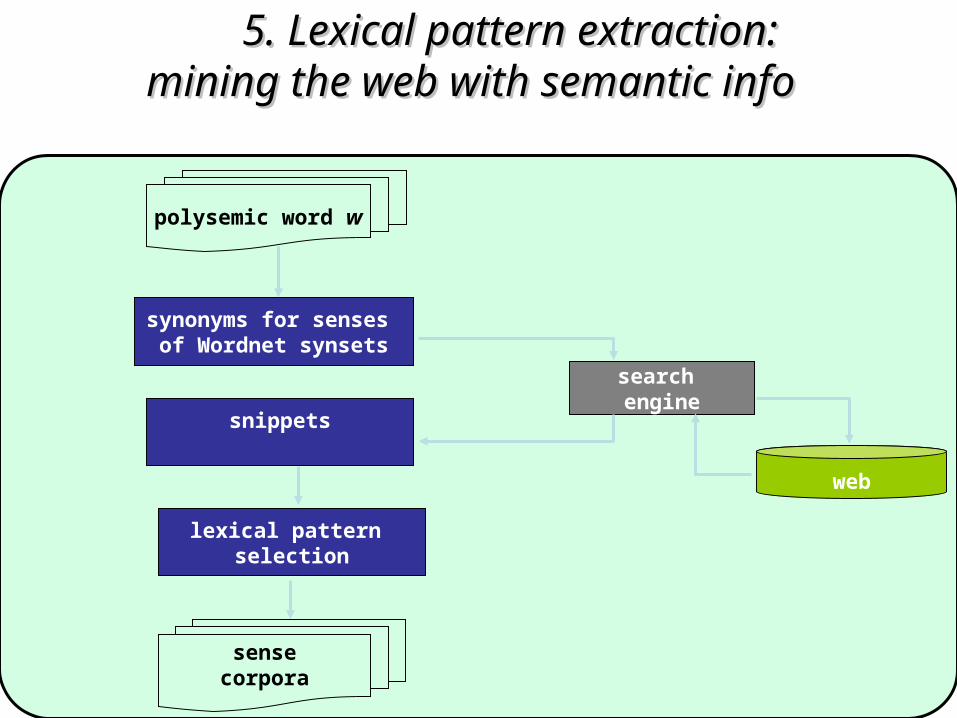
polysemic word w
sensecorpora
synonyms for senses of Wordnet synsets
snippets
lexical pattern selection
search engine
web
5. Lexical pattern extraction: 5. Lexical pattern extraction: mining the web with semantic infomining the web with semantic info

ff
S PP
1. 1. StrengthStrength of the lexical pattern P: of the lexical pattern P:
ffPP : frequency of : frequency of PP in the sense corpus in the sense corpus
ff : average frequency of all lexical patterns in the corpus : average frequency of all lexical patterns in the corpus
: standard deviation: standard deviation
2. 2. Internal dispersionInternal dispersion of the lexical pattern of the lexical pattern PP::Does PDoes P occur in the occur in the contextcontext of of allall the synonyms of a the synonyms of a sensesense of of ww ? ?Sense relevantSense relevant ! ! 3. 3. External dispersionExternal dispersion of the lexical pattern of the lexical pattern PP::Does PDoes P occur in just occur in just one sense corpusone sense corpus of of ww ? ?Sense relevant Sense relevant !!
5. Lexical pattern extraction: 5. Lexical pattern extraction: mining the web with semantic infomining the web with semantic info

5. Lexical pattern extraction: 5. Lexical pattern extraction: mining the web with semantic infomining the web with semantic info
Bootstrapping techniqueBootstrapping technique for corpora construction: for corpora construction:
• Categorization task (natural disaster corpus)Categorization task (natural disaster corpus)• Named Entity RecognitionNamed Entity Recognition• Word Sense DisambiguationWord Sense Disambiguation
(Guzmán, Montes, Rosso, 05)(Guzmán, Montes, Rosso, 05)

1.1. The WordNet ontologyThe WordNet ontology2.2. Conceptual Density for Word Sense DisambiguationConceptual Density for Word Sense Disambiguation3.3. Semantic (Geo) Information Retrieval and Text CategorizationSemantic (Geo) Information Retrieval and Text Categorization4.4. Semantic clusters of very short narrow-domain textsSemantic clusters of very short narrow-domain texts5.5. Lexical pattern extraction: mining the web with semantic infoLexical pattern extraction: mining the web with semantic info6.6. An ontology for Question Answering and vice versa: An ontology for Question Answering and vice versa:
OntotripleQAOntotripleQA7.7. Cluster analysis of transcribed spoken dialoguesCluster analysis of transcribed spoken dialogues8.8. The Clasitext ontology. Applications with ontologiesThe Clasitext ontology. Applications with ontologies
9.9. Semantic relatedness of conceptsSemantic relatedness of concepts10.10. Ontology matching: meta ontology or machine learning Ontology matching: meta ontology or machine learning
approach?approach?
11.11. The case study of biomedical ontologies: semantic relatedness The case study of biomedical ontologies: semantic relatedness of concepts of the different ontologiesof concepts of the different ontologies
12.12. Lab session: CALD, WordNet vs. Genia, GenOntology, MeSHLab session: CALD, WordNet vs. Genia, GenOntology, MeSH

• Text REtrieval (TREC)Text REtrieval (TREC) Collection: Collection: trec.nist.gov/• Cross-Language Evaluation Forum (CLEF) Cross-Language Evaluation Forum (CLEF) competition: competition:
www.clef-campaign.orgmain CLEF-05 tasks:main CLEF-05 tasks:
– Mono-, Bi- and Multilingual Document Retrieval on News Collections Mono-, Bi- and Multilingual Document Retrieval on News Collections (Ad-Hoc)(Ad-Hoc)
– Mono- and Cross-Language Information Retrieval on Structured Mono- and Cross-Language Information Retrieval on Structured Scientific DataScientific Data (Domain-Specific) (Domain-Specific)
– Interactive Cross-Language Information Retrieval (iCLEF)Interactive Cross-Language Information Retrieval (iCLEF) Multilingual Language Question Answering (Multilingual Language Question Answering (QA@CLEFQA@CLEF) ) – Cross-Language Retrieval in Image Collections (ImageCLEF)Cross-Language Retrieval in Image Collections (ImageCLEF)– Cross-Language Spoken Document Retrieval (CL-SR)Cross-Language Spoken Document Retrieval (CL-SR)– Multilingual Web Track (Multilingual Web Track (WebCLEFWebCLEF))– Cross-Language Geographical Retrieval (Cross-Language Geographical Retrieval (GeoCLEFGeoCLEF))
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA

e.g. CLEF-05 question: “Who is Silvio Berlusconi?”e.g. CLEF-05 question: “Who is Silvio Berlusconi?”
Answers:Answers:
Italian Prime Minister Italian Prime Minister (not valid anymore...)(not valid anymore...)
Italian PremierItalian Premier (not valid anymore...)(not valid anymore...)
Business TycoonBusiness Tycoon (still valid)(still valid)
Italy’s richest personItaly’s richest person (still valid) (still valid)
Leader of Forza ItaliaLeader of Forza Italia (still valid)(still valid)
Mediaset’s managing director Mediaset’s managing director (still valid)(still valid)
Milan’s presidentMilan’s president (still valid)(still valid)
... other possible answers could be added even if ... other possible answers could be added even if occurring with less redundancy in the document collection occurring with less redundancy in the document collection (or the Web)...(or the Web)...
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
3-level architecture3-level architecture::• Question Question Classification/Classification/AnalysisAnalysis• Block/Block/passagepassage/sentence based /sentence based Search Search
EngineEngine• Answer ExtractionAnswer Extraction
UPV UPV QUASARQUASAR system: a system: a Multilingual Multilingual QuQuestion estion AAnswering nswering SSystemystem based on a based on a Language-Language-Independent PIndependent Paassage ssage RRetrieval Engineetrieval Engine
6. An ontology for QA and vice 6. An ontology for QA and vice versa: versa: OntotripleQAOntotripleQA
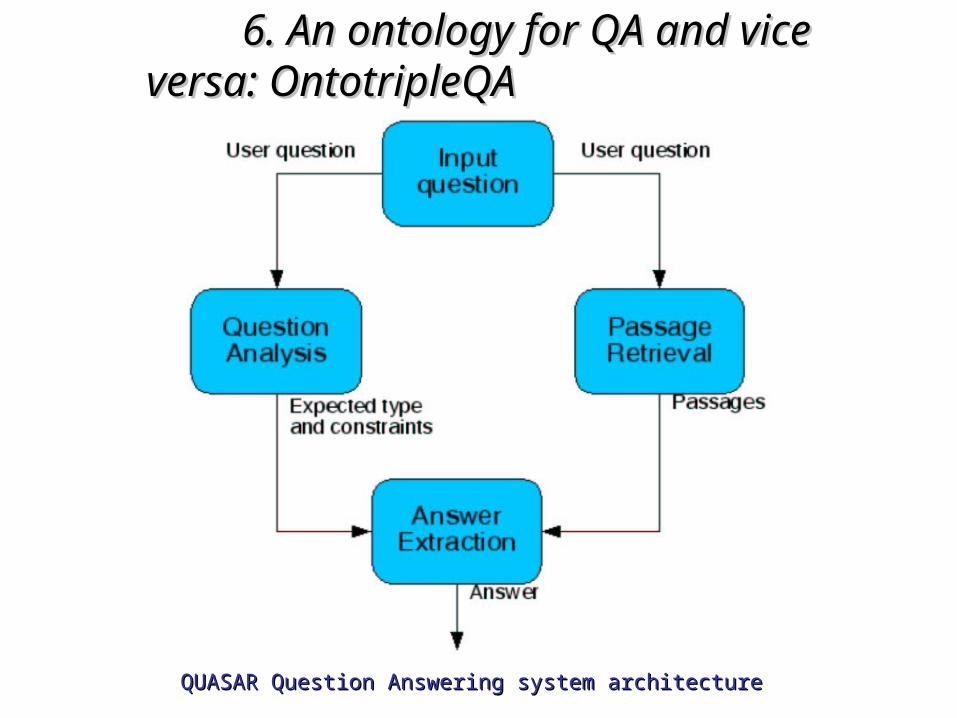
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
QUASAR Question Answering system architectureQUASAR Question Answering system architecture

Question AnalysisQuestion Analysis
Named Entity Recognition (NER)Named Entity Recognition (NER)
in the question and in the documentsin the question and in the documents
• to understand the to understand the rolerole of an of an entityentity: : minimum minimum contextcontext info extraction info extraction
• conceptual representationconceptual representation of documents of documents
(entities + contexts) with an (entities + contexts) with an ontologyontology
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA

QUASAR’s Question AnalysisQUASAR’s Question Analysis • mainly mainly pattern matchingpattern matching-based-based
– JAVA Regular Expressions (java.util.regex.*)JAVA Regular Expressions (java.util.regex.*)– patterns are stored in an XML filepatterns are stored in an XML file– 4 languages: Italiano, Español, English, Français4 languages: Italiano, Español, English, Français
• question are assigned the class related to the question are assigned the class related to the matching pattern matching pattern
(if a question matches with more than a pattern: (if a question matches with more than a pattern: the class related to the longest one is assigned)the class related to the longest one is assigned)
• 3-level ontology of 18 hierarchical classes 3-level ontology of 18 hierarchical classes (each class corresponds to a (each class corresponds to a strategy and/or set of strategy and/or set of patternspatterns used in the used in the Question Analysis moduleQuestion Analysis module))
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
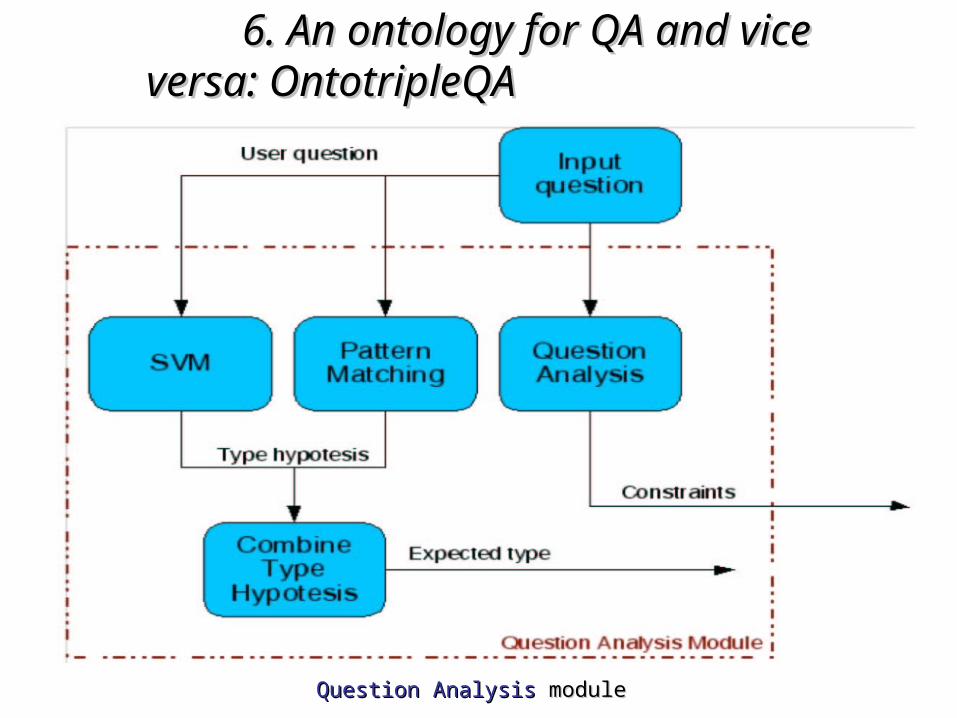
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
Question AnalysisQuestion Analysis module module

• 18 hierarchically grouped classes18 hierarchically grouped classes– roots: NAME;DEFINITION;DATE;QUANTITYroots: NAME;DEFINITION;DATE;QUANTITY
• Hybrid classification:Hybrid classification:– Combination of SVM + regular expressions for Combination of SVM + regular expressions for
Spanish and EnglishSpanish and English– Regular expressions for French and ItalianRegular expressions for French and Italian
• Extraction of “pivot” wordsExtraction of “pivot” words– Based on rulesBased on rulese.g. How many e.g. How many inhabitantsinhabitants were in were in SwedenSweden in in 19941994 ? ?
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
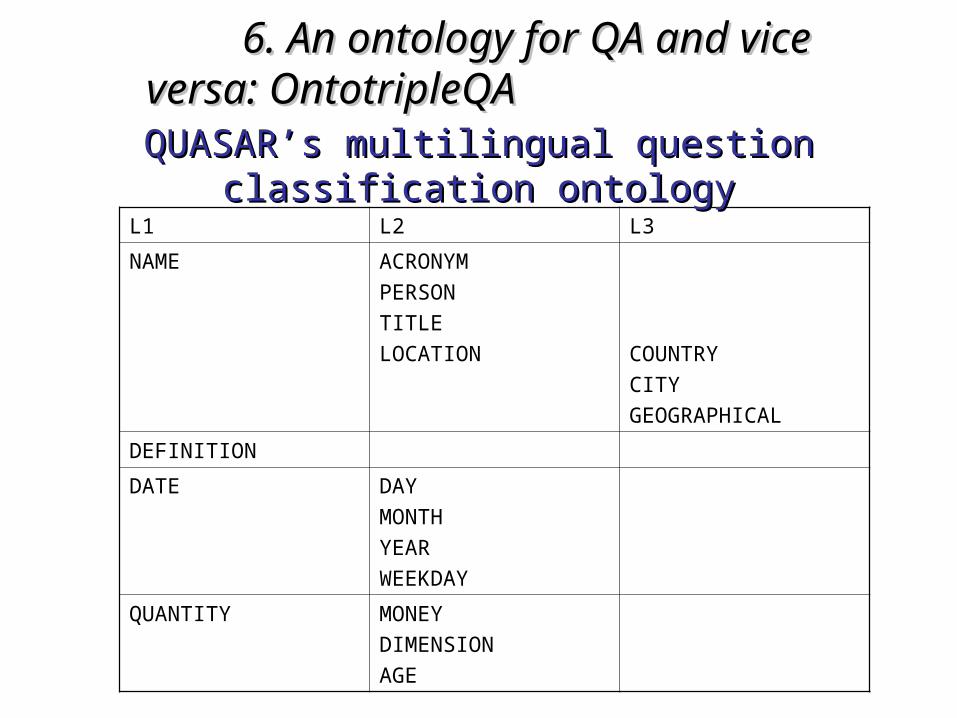
L1 L2 L3
NAME ACRONYM
PERSON
TITLE
LOCATION COUNTRY
CITY
GEOGRAPHICAL
DEFINITION
DATE DAY
MONTH
YEAR
WEEKDAY
QUANTITY MONEY
DIMENSION
AGE
QUASAR’s multilingual question classification ontologyQUASAR’s multilingual question classification ontology
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA

QUASAR’s ontology: pattern file sample (it)QUASAR’s ontology: pattern file sample (it)
<pattern class="DATE"><pattern class="DATE"><ptrtext>Quando .+</ptrtext><ptrtext>Quando .+</ptrtext><pattern class="YEAR"><pattern class="YEAR">
<ptrtext>(?i).*(che|quale) anno .+</ptrtext><ptrtext>(?i).*(che|quale) anno .+</ptrtext></pattern></pattern><pattern class="MONTH"><pattern class="MONTH">
<ptrtext>(?i).*(che|quale) mese .+</ptrtext><ptrtext>(?i).*(che|quale) mese .+</ptrtext></pattern></pattern><pattern class="DAY"><pattern class="DAY">
<ptrtext>(?i).*(che|quale) data .+</ptrtext><ptrtext>(?i).*(che|quale) data .+</ptrtext><ptrtext>(?i).*(che|quale) giorno .+</ptrtext><ptrtext>(?i).*(che|quale) giorno .+</ptrtext>
</pattern></pattern><pattern class="WEEKDAY"><pattern class="WEEKDAY">
<ptrtext>(?i).*(che|quale) giorno della settimana .+</ptrtext><ptrtext>(?i).*(che|quale) giorno della settimana .+</ptrtext></pattern></pattern>
</pattern></pattern>
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
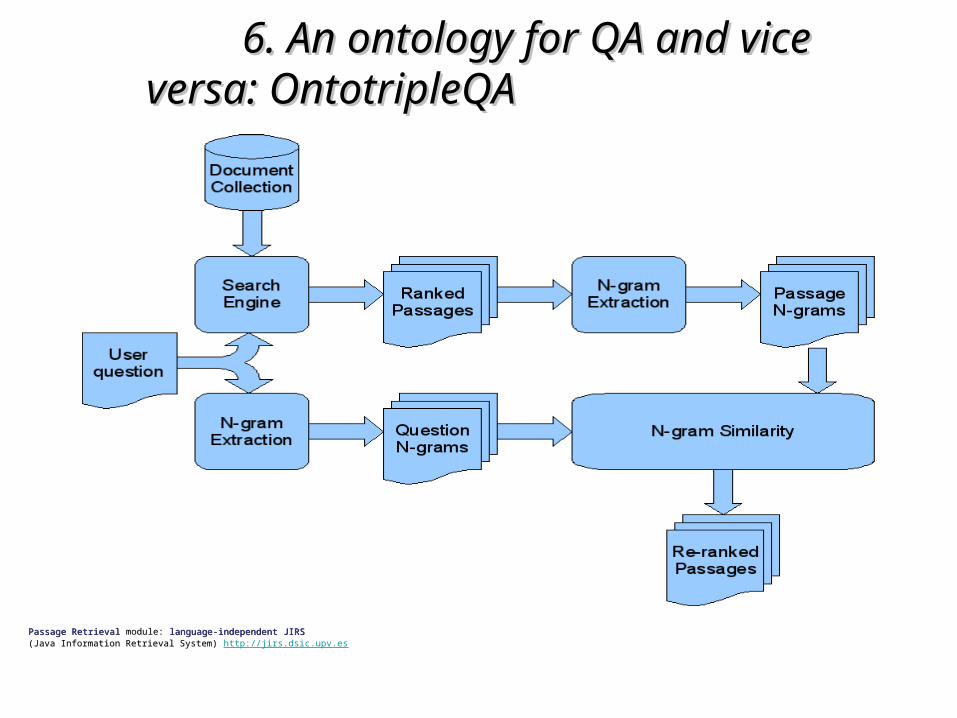
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
Passage RetrievalPassage Retrieval module: module: language-independentlanguage-independent JIRSJIRS (Java Information Retrieval System) (Java Information Retrieval System) http://jirs.dsic.upv.es
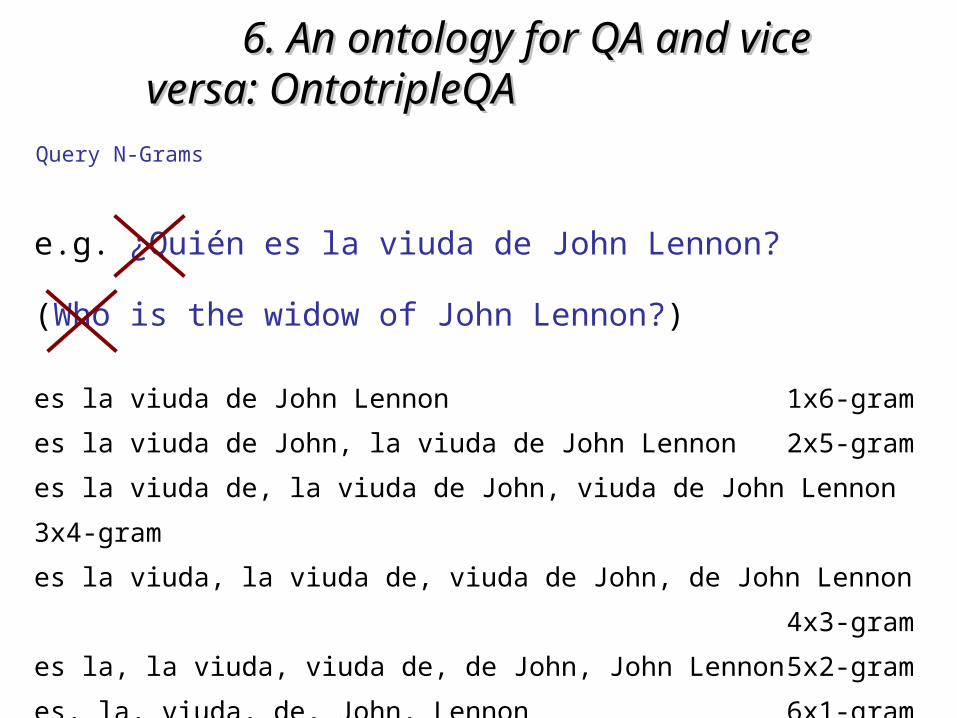
e.g. ¿Quién es la viuda de John Lennon?
(Who is the widow of John Lennon?)
es la viuda de John Lennon 1x6-gram
es la viuda de John, la viuda de John Lennon 2x5-gram
es la viuda de, la viuda de John, viuda de John Lennon 3x4-gram
es la viuda, la viuda de, viuda de John, de John Lennon 4x3-gram
es la, la viuda, viuda de, de John, John Lennon 5x2-gram
es, la, viuda, de, John, Lennon 6x1-gram
Query N-Grams
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA

Passage N-Grams
Both passagesBoth passages contain the most relevant words contain the most relevant words
((JohnJohn and and LennonLennon) but the ) but the passage 1passage 1 has one has one
5-gram5-gram whereas the whereas the passage 2passage 2 has two has two 2-grams2-grams
... inicio ... inicio de lade la carrera carrera de Johnde John fuera de fuera de los Beatles ... musicales que incluían a los Beatles ... musicales que incluían a John LennonJohn Lennon, Eric Clapton, Keith , Eric Clapton, Keith Richards ... .Richards ... .
La viuda de John LennonLa viuda de John Lennon 1 x 5-gram1 x 5-gram
... 4, 2004.-... 4, 2004.- La viuda de John Lennon La viuda de John Lennon, , Yoko Ono, se ha movilizado ... .Yoko Ono, se ha movilizado ... .
Passage 1Passage 1 Passage 2Passage 2
John LennonJohn Lennon 2 x 2-gram2 x 2-gramde lade la
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA

Term weightTerm weight
nnkk: # of passages in which t: # of passages in which tkk occurs occurs
NN: the total # of passages: the total # of passages
)ln(1
)ln(1
N
nw k
k
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA

L L ((LengthLength): # of ): # of words between words between xx and and xmax xmax ngramsngrams
otherwise
DxifxxdwDxh j
x
kk
j
0
),(),( max
||
1
... 4, 2004.- La viuda de John Lennon, Yoko Ono, se ha ... 4, 2004.- La viuda de John Lennon, Yoko Ono, se ha movilizado ... .movilizado ... .
Passage 1Passage 1
... inicio de la carrera de John fuera de los Beatles ... musicales que ... inicio de la carrera de John fuera de los Beatles ... musicales que incluían a John Lennon, Eric Clapton, Keith Richards ... .incluían a John Lennon, Eric Clapton, Keith Richards ... .
Passage 2Passage 2)1ln(1
1),( max L
xxd
Density Distance N-Gram ModelDensity Distance N-Gram Model
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA

Density Distance N-Gram ModelDensity Distance N-Gram Model
0.0610.061 0.0610.061 0.3890.389 0.0610.061 0.3590.359 0.3950.395¿Quién es la viuda de John Lennon?¿Quién es la viuda de John Lennon?es la viuda de John Lennones la viuda de John Lennon 1.3261.326
... 4, 2004.- ... 4, 2004.- La viuda de John LennonLa viuda de John Lennon, , Yoko Ono, se ha movilizado ... .Yoko Ono, se ha movilizado ... .
Passage 1Passage 1... inicio ... inicio de la de la carrera de John fuera de carrera de John fuera de los Beatles ... musicales que incluían a los Beatles ... musicales que incluían a John LennonJohn Lennon, Eric Clapton, Keith , Eric Clapton, Keith Richards ... .Richards ... .
Passage 2Passage 2
Passage 1Passage 1La viuda de John LennonLa viuda de John Lennon + 1.265+ 1.265
1.2651.265Passage 2Passage 2de lade la 0.122 x 0.2870.122 x 0.287John LennonJohn Lennon + 0,754+ 0,754
0.7890.789
0.9540.954
0.5950.595
d(x,xd(x,xmaxmax))
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA

Answer Extraction
Two philosophies:Two philosophies:
• Direct Direct searchsearch of the of the answeranswer, and later, search of, and later, search of
the the justificationjustification (QRISTAL, U.Amsterdam) (QRISTAL, U.Amsterdam)
• Direct Direct searchsearch of the of the passagepassage, with , with patternpattern
matchingmatching rules to obtain the answer (QUASAR, rules to obtain the answer (QUASAR,
INAOE, DFKI)INAOE, DFKI)
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
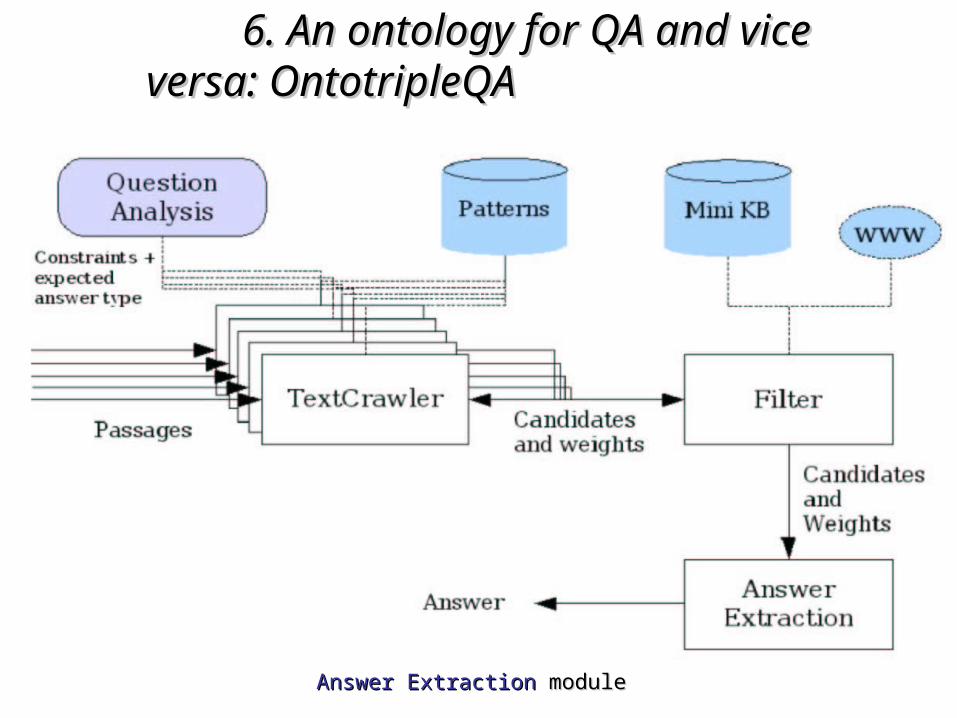
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
Answer ExtractionAnswer Extraction module module

QUASAR’s Answer ExtractionQUASAR’s Answer Extraction
Three sub-modules:Three sub-modules:TextcrawlerTextcrawler: selects the patterns that can match with the right : selects the patterns that can match with the right
answer (answer (candidatescandidates) in each of the passages and assigns ) in each of the passages and assigns a a weightweight depending on depending on distance from “pivot” wordsdistance from “pivot” words
FilterFilter: rejects patterns that cannot match with the right answer : rejects patterns that cannot match with the right answer (if it is the case, it asks for another candidate to the (if it is the case, it asks for another candidate to the Textcrawler: very useful for “location” questions)Textcrawler: very useful for “location” questions)
SelectorSelector: : selectsselects, from the candidates of every passage, the , from the candidates of every passage, the bestbest one. one.
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA

Selection strategiesSelection strategies
SVSV ( (Simple VotingSimple Voting): the most voted candidate is selected ): the most voted candidate is selected (NOUN questions)(NOUN questions)
WVWV ( (Weighted VotingWeighted Voting): the candidate with heaviest votes is ): the candidate with heaviest votes is selected (TIME, QUANTITY, DEFINITION and, if selected (TIME, QUANTITY, DEFINITION and, if ambiguity, for DV)ambiguity, for DV)
MWMW ( (Maximum WeightMaximum Weight): the candidate with maximum weight ): the candidate with maximum weight is selected (used only if there is ambiguity using WV)is selected (used only if there is ambiguity using WV)
DVDV ( (Double VotingDouble Voting): exactly like SV, but taking into account ): exactly like SV, but taking into account also the second best candidates of each passage (if also the second best candidates of each passage (if ambiguity with SV)ambiguity with SV)
TOPTOP: candidate returned by best passage is selected (only to : candidate returned by best passage is selected (only to compute the CWS)compute the CWS)
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
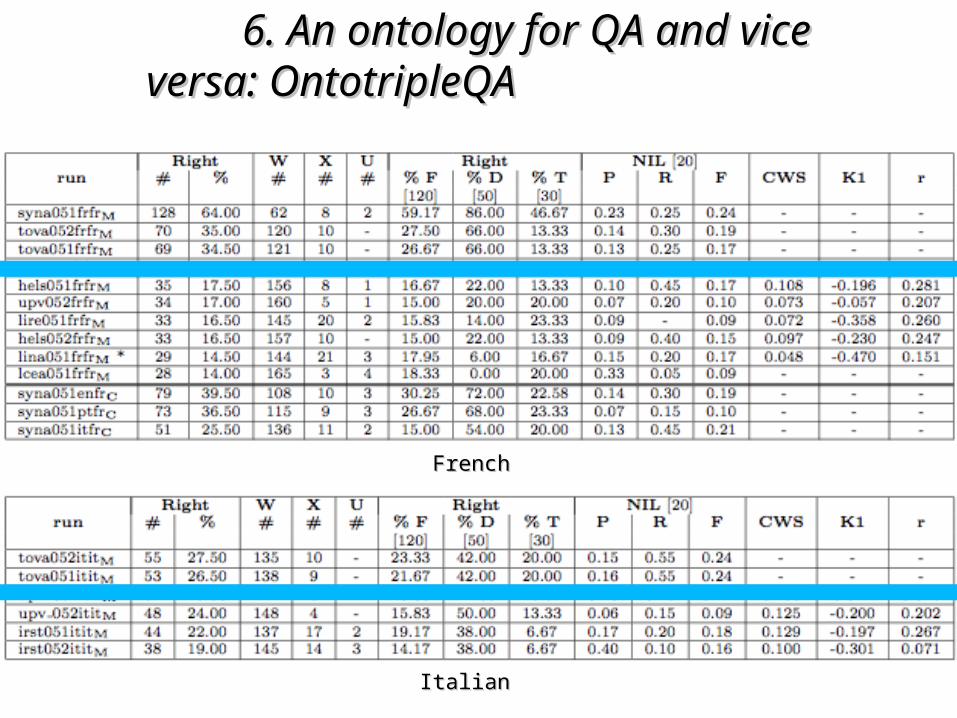
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
FrenchFrench
Italian Italian
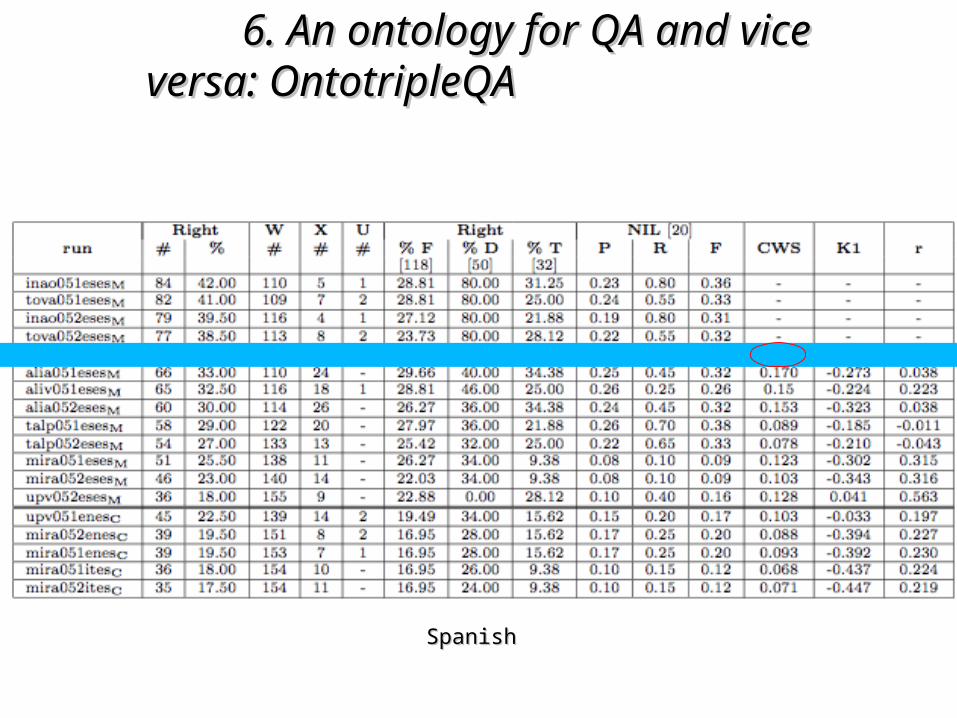
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
SpanishSpanish

Confiance Weighting Score (CWS)
In QUASAR the CWS is computed using the followingvariables:
– concordance: number of selection strategies giving the same answer divided by total number of strategies
– rarity: number of the returned passages divided by maximum number of passages that the JIRS PR module can return
– passage weight: weight of the selected passage
For the NIL answers, the CWS is:1-rarity if there are returned passages, 0 in other cases
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA

The The key-role of ontologykey-role of ontology in QA: in QA:
• best QA systems: best QA systems: – fr-fr: fr-fr: Synapse Synapse (64% - 2n(64% - 2ndd best: 35%...) best: 35%...)– pr-pr: pr-pr: PriberamPriberam (64.5% - 2 (64.5% - 2ndnd best: 25%...) best: 25%...)
• both QA systems based on the both QA systems based on the QRISTAL QRISTAL multilingual ontologymultilingual ontology (developed by the private (developed by the private research centre research centre Synapse Development ToulouseSynapse Development Toulouse) )
• Priberam QA system also: (“Priberam QA system also: (“headhead” of) ” of) question question expansion with synonyms expansion with synonyms
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA

• “diversified” search engine:– Index of definitions (INAOE, DFKI) – Index of answer type (QRISTAL)
• Classification:– used by QRISTAL, PRIBERAM and QUASAR– (mostly) based on patterns (regular expressions)– more classes, better results?
• 86 classes for PRIBERAM y QRISTAL• DFKI: 5 classes, INAOE: 3, QUASAR: 4
– deep analysis (syntax + semantics) of the question does not bring significative improvements
• use of “Pivot” words
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA

6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
Español -> Español42,00%
tova051eses 41,00%33,50%33,00%32,50%29,00%
mira051eses 25,50%
inao051eses
upv051esesalia051esesaliv051esestalp051eses
QAQA JIRS PR JIRS PR-based best systems @ -based best systems @ Spanish CLEF-Spanish CLEF-20052005 track track http://clef-qa.itc.it/2005/
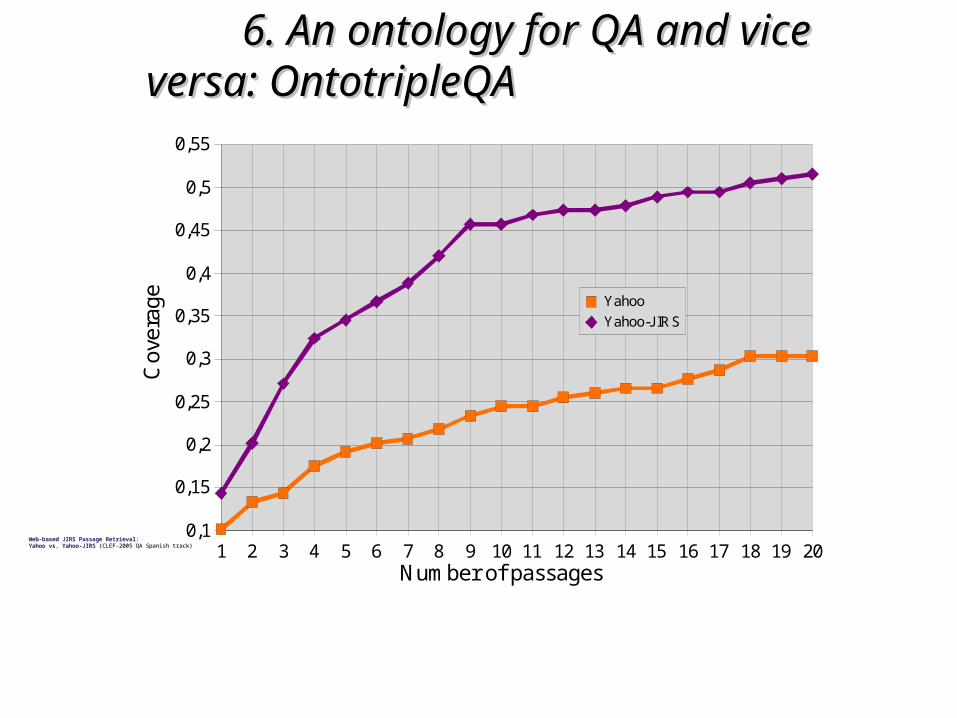
6. An ontology for QA and vice 6. An ontology for QA and vice versa: OntotripleQAversa: OntotripleQA
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 200,1
0,15
0,2
0,25
0,3
0,35
0,4
0,45
0,5
0,55
Yahoo
Yahoo-JIRS
Number of passages
Cov
erag
e
Web-based JIRS Passage RetrievalWeb-based JIRS Passage Retrieval: : Yahoo vs. Yahoo-JIRSYahoo vs. Yahoo-JIRS (CLEF-2005 QA Spanish track) (CLEF-2005 QA Spanish track)

OntotripleQAOntotripleQA: QA for ontology (Kim et al. 05): QA for ontology (Kim et al. 05)
• application of QA techniques to application of QA techniques to relation extractionrelation extraction• ontologyontology: : (class, relation, class)(class, relation, class)
e.g. e.g. (person, paint, painting)(person, paint, painting)
(person, is_member_of, group)(person, is_member_of, group)
• ontology instancesontology instances stored as stored as triplestriples::e.g. e.g. paint (Renoir Pierre-August, “The paint (Renoir Pierre-August, “The
umbrellas”)umbrellas”)
• triplestriples can be can be incompleteincomplete (one missing named entity) (one missing named entity) e.g.e.g. is_member_of (Renoir Pierre- is_member_of (Renoir Pierre-
August, ?)August, ?)
converted into a converted into a natural language questionnatural language question::e.g. e.g. Which group Renoir Pierre-August was member Which group Renoir Pierre-August was member
of?of?
search on the Web: answer = search on the Web: answer = impressionistimpressionist
6. An ontology for QA and 6. An ontology for QA and vice vice versaversa: OntotripleQA: OntotripleQA

1.1. The WordNet ontologyThe WordNet ontology2.2. Conceptual Density for Word Sense DisambiguationConceptual Density for Word Sense Disambiguation3.3. Semantic (Geo) Information Retrieval and Text CategorizationSemantic (Geo) Information Retrieval and Text Categorization4.4. Semantic clusters of very short narrow-domain textsSemantic clusters of very short narrow-domain texts5.5. Lexical pattern extraction: mining the web with semantic Lexical pattern extraction: mining the web with semantic
informationinformation6.6. An ontology for Question Answering and vice versa: An ontology for Question Answering and vice versa:
OntotripleQAOntotripleQA7.7. Cluster analysis of transcribed spoken dialoguesCluster analysis of transcribed spoken dialogues8.8. The Clasitext ontology. Applications with ontologiesThe Clasitext ontology. Applications with ontologies
9.9. Semantic relatedness of conceptsSemantic relatedness of concepts10.10. Ontology matching: via a meta ontology or a machine Ontology matching: via a meta ontology or a machine
learning approach?learning approach?11.11. The case study of biomedical ontologies: semantic The case study of biomedical ontologies: semantic
relatedness of concepts of the different ontologiesrelatedness of concepts of the different ontologies12.12. Lab session: CALD, WordNet vs. Genia, GenOntology, MeSHLab session: CALD, WordNet vs. Genia, GenOntology, MeSH

Spanish Railway ServiceSpanish Railway Service
Goal: Goal: Designing Designing automatic automatic dialogues systemsdialogues systems
Problem: Revealing the Problem: Revealing the typical typical scenariosscenarios of of
dialogdialog
Data: 100 realData: 100 real dialogues dialogues
Difficulties:Difficulties: Info is Info is fuzzyfuzzy Info is Info is absentabsent Info is in a Info is in a hidden formhidden form
(Alexandrov, Sanchís, Rosso, 05)(Alexandrov, Sanchís, Rosso, 05)
DIDI: Renfe customer service, good morning: Renfe customer service, good morningUSUS:: Good morningGood morningDIDI: May I help you?: May I help you?USUS:: Yes, please: I would like to know Yes, please: I would like to know
about a train from Valencia to about a train from Valencia to Barcelona.Barcelona.
DIDI: What day are you interested in?: What day are you interested in?USUS:: Next Thursday, in the afternoon. Next Thursday, in the afternoon.DIDI: Let’s see. <PAUSE> On Thursday : Let’s see. <PAUSE> On Thursday there is an EuroMed leaving at 3 P.M. there is an EuroMed leaving at 3 P.M.
and arriving in Barcelona at 6.45 P.M. and arriving in Barcelona at 6.45 P.M. USUS:: What about the next train? What about the next train? DIDI: It leaves at 8 P.M.: It leaves at 8 P.M.USUS:: Too late. Thank you. Bye. Too late. Thank you. Bye.
USUS = User = User DI DI = Directory Inquire Service = Directory Inquire Service Length = 25% like thisLength = 25% like this
7. 7. Cluster analysis of Cluster analysis of transcribed spoken dialoguestranscribed spoken dialogues

Spanish Railway ServiceSpanish Railway Service
Usual solution:Usual solution: ManualManual evaluation evaluation of person-to person of person-to person
dialogues based on dialogues based on lexical analysislexical analysis
Additional results of lexical analysis:Additional results of lexical analysis: Why citizens of Why citizens of TarragonaTarragona like to travel on like to travel on SundaySunday?? Why citizens of Why citizens of MadridMadrid like to like toask for ask for discountsdiscounts??
Example of solution:Example of solution: Hour of departure, discountsHour of departure, discounts Hour of departure, priceHour of departure, price Return ticketReturn ticket Type of trainType of train
7. 7. Cluster analysis of Cluster analysis of transcribed spoken dialoguestranscribed spoken dialogues

Type of parametersType of parameters Reflecting Reflecting transporttransport service service Reflecting Reflecting passengerpassenger behaviour behaviour
List of parametersList of parameters Town importance 0, 0.25,…1 Town importance 0, 0.25,…1
Urgency Urgency 0, 0.5, 10, 0.5, 1 Return ticket 1/0Return ticket 1/0 Time of departure Time of departure Time of departure (return) Time of departure (return) Wagon-lit 1/0Wagon-lit 1/0 Discounts Discounts 1/01/0 Length of talking Length of talking 0, 0.25,….10, 0.25,….1 Politeness Politeness 0, 0.25, 10, 0.25, 1
… …
DifficultiesDifficulties Information is Information is fuzzyfuzzy Information is Information is absentabsent Information is in a Information is in a hidden formhidden form
Nominal scalesNominal scales Time of departure: Time of departure: Indifference 1/0Indifference 1/0 Morning or day 1/0Morning or day 1/0 Evening or night 1/0Evening or night 1/0 =>=> [(1,0,0) , (0,1,0), (0,0,1)] [(1,0,0) , (0,1,0), (0,0,1)]
PresumptionPresumption For absent parameters For absent parameters it is used: it is used: - a value of - a value of indifferenceindifference - the - the cheapestcheapest and and simplestsimplest alternative alternative
7. 7. Cluster analysis of Cluster analysis of transcribed spoken dialoguestranscribed spoken dialogues

ProblemsProblems
• influence of influence of dominant parametersdominant parameters => => real real structurestructure will be will be hiddenhidden
• influence of influence of noisenoise =>=> real real structurestructure will be will be disfigureddisfigured
Parameter analysis Parameter analysis => => filtering parameters:filtering parameters:GroupsGroups of parameters of parameters
1. Significant value for 1. Significant value for 90%-95%90%-95% of objects of objects
2. Significant value for 2. Significant value for 5%-10%5%-10% of objects of objects
=>=> 3. Significant3. Significant value for value for more ~ 20%-30% more ~ 20%-30% of objectsof objects
RoleRole of parameters: of parameters:1. First group parameters are oriented to 1. First group parameters are oriented to uniformuniform object set: object set: eliminatedeliminated
2. Second group parameters oriented to very granulated object set (in 2. Second group parameters oriented to very granulated object set (in
subsystemssubsystems): ): eliminatedeliminated
7. 7. Cluster analysis of Cluster analysis of transcribed spoken dialoguestranscribed spoken dialogues
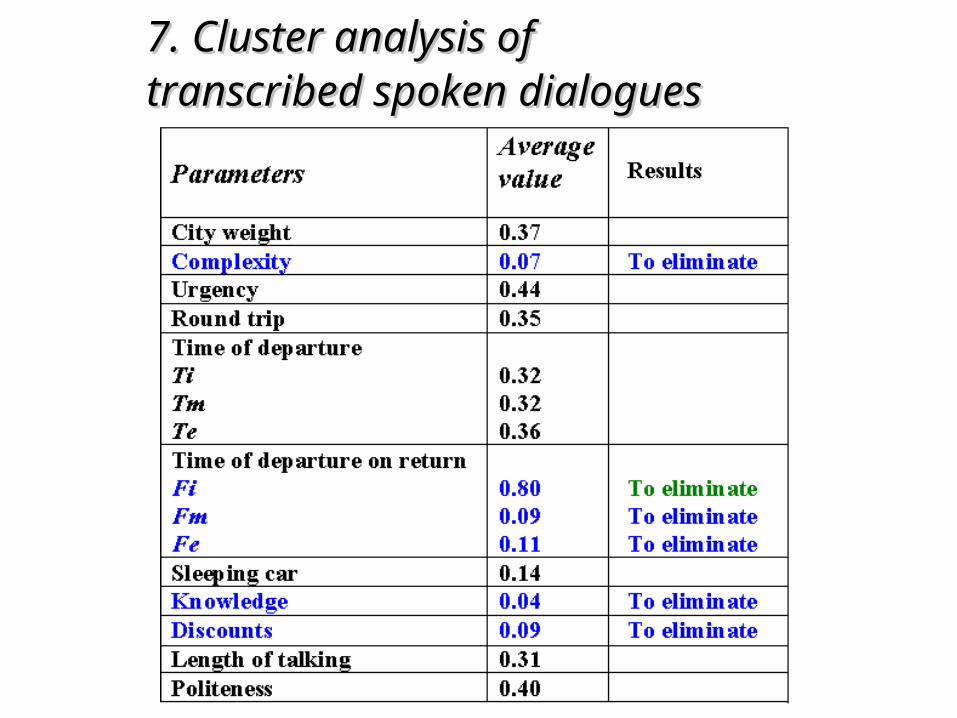
7. 7. Cluster analysis of Cluster analysis of transcribed spoken dialoguestranscribed spoken dialogues
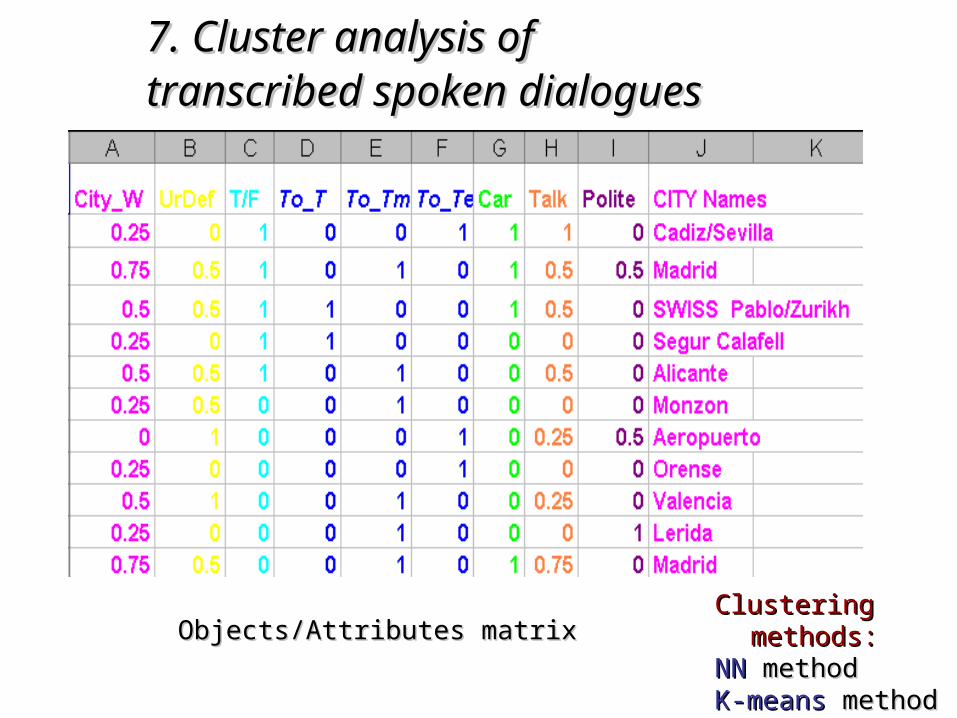
Objects/Attributes matrixObjects/Attributes matrixClustering methods:Clustering methods:NNNN method methodK-meansK-means method methodMajorClustMajorClust method method
7. 7. Cluster analysis of Cluster analysis of transcribed spoken dialoguestranscribed spoken dialogues

Some conclusions:Some conclusions:
• scenarios of dialogues may be determined by scenarios of dialogues may be determined by clustering clustering them in the them in the space of parametersspace of parameters defined by defined by an expertan expert
• importance of how to parameterize dialogues in order importance of how to parameterize dialogues in order to compensate to compensate incompleteness and fuzziness incompleteness and fuzziness of of source informationsource information
• procedure of procedure of weightingweighting dialogues and parameters dialogues and parameters allows to obtain information allows to obtain information useful useful for a user for a user
• the the MajorClust methodMajorClust method seems to be the one for seems to be the one for solving this kind of problemssolving this kind of problems
7. 7. Cluster analysis of Cluster analysis of transcribed spoken dialoguestranscribed spoken dialogues

Further workFurther work
RailwayOntoRailwayOnto (under construction), based on the (under construction), based on the
transcribed spoken dialogues: transcribed spoken dialogues:
• hierarchy of questionshierarchy of questions: by : by multilevel clustering of questionsmultilevel clustering of questions • typical typical chain of questionschain of questions
for:for:• a better a better cluster analysiscluster analysis• an an anticipationanticipation of the following of the following user’s question(s)user’s question(s)
((query recommendationquery recommendation))
7. 7. Cluster analysis of Cluster analysis of transcribed spoken dialoguestranscribed spoken dialogues

1.1. The WordNet ontologyThe WordNet ontology2.2. Conceptual Density for Word Sense DisambiguationConceptual Density for Word Sense Disambiguation3.3. Semantic (Geo) Information Retrieval and Text CategorizationSemantic (Geo) Information Retrieval and Text Categorization4.4. Semantic clusters of very short narrow-domain textsSemantic clusters of very short narrow-domain texts5.5. Lexical pattern extraction: mining the web with semantic infoLexical pattern extraction: mining the web with semantic info6.6. An ontology for Question Answering and vice versa: An ontology for Question Answering and vice versa:
OntotripleQAOntotripleQA7.7. Cluster analysis of transcribed spoken dialoguesCluster analysis of transcribed spoken dialogues8.8. The Clasitext ontology. Applications with ontologiesThe Clasitext ontology. Applications with ontologies
9.9. Semantic relatedness of conceptsSemantic relatedness of concepts10.10. Ontology matching: via a meta ontology or a machine Ontology matching: via a meta ontology or a machine
learning approach?learning approach?11.11. The case study of biomedical ontologies: semantic The case study of biomedical ontologies: semantic
relatedness of concepts of the different ontologiesrelatedness of concepts of the different ontologies12.12. Lab session: CALD, WordNet vs. Genia, GenOntology, MeSHLab session: CALD, WordNet vs. Genia, GenOntology, MeSH

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
The importance of analyzing and understanding docs to:The importance of analyzing and understanding docs to:• summarize themsummarize them• to compare two documents (w.r.t. a given topic)to compare two documents (w.r.t. a given topic)• to answer non trivial questions to answer non trivial questions
e.g.e.g.
Having Having read these textsread these texts::
Frogs live in waterFrogs live in water
Benito Juárez is buried in San Fernando cemeteryBenito Juárez is buried in San Fernando cemetery
Let us Let us answer these questionsanswer these questions::
Do frog get wet?Do frog get wet?
Where is the left big toe of Benito Juárez buried?Where is the left big toe of Benito Juárez buried?

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
The Spanish The Spanish CLASITEX ontologyCLASITEX ontology
(A. Guzmán, NPI, Mexico):(A. Guzmán, NPI, Mexico):tree-form conceptstree-form concepts::
e.g. a e.g. a conceptconcept denoting an denoting an objectobject
WEARABLE GARMENT (concept)WEARABLE GARMENT (concept)
SHOESHOE
sandalsandal
moccasinmoccasin
bootboot
SHIRTSHIRT
T-shirtT-shirt
long-sleeve shirtlong-sleeve shirt
PANTSPANTS

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
e.g.e.g. a a process (action, verbs)process (action, verbs)
MOVEMOVE CHANGE OF (X, Y) POSITION (of coordinates in Earth)CHANGE OF (X, Y) POSITION (of coordinates in Earth)
FloatFloatSwimSwimWalkWalk
runrunjumpjump
FlyFlysoarsoar
ROTATE (change orientation)ROTATE (change orientation)VIBRATEVIBRATECHANGE OF SIZECHANGE OF SIZE
INFLATE-EXPANDINFLATE-EXPANDCONTRACT-GET SMALLERCONTRACT-GET SMALLER
CHANGE OF HEALTHCHANGE OF HEALTHGET WELLGET WELLGET SICKGET SICKDIEDIE
CHANGE OF ECONOMIC STATUSCHANGE OF ECONOMIC STATUSGET POORGET POORGET RICHGET RICH

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
e.g.e.g. a a relationrelation RELATIVE OFRELATIVE OF
FATHER OFFATHER OF
SON OFSON OF
First son ofFirst son of
Preferred son ofPreferred son of
BROTHER OFBROTHER OF

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
Concept trees (CLASITEX)Concept trees (CLASITEX)::Spanish, English, FrenchSpanish, English, French

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
CLASITEX algorithmCLASITEX algorithm1. (BEGIN) Observe the 1. (BEGIN) Observe the sequence of four wordssequence of four words pointed at by the pointer. Do they pointed at by the pointer. Do they denote some denote some concept(s)concept(s)??
YesYes: increase by 1 the : increase by 1 the counterscounters of each of these concepts. Go to step (5). of each of these concepts. Go to step (5).NoNo: Go to next step (2).: Go to next step (2).
2. Observe the sequence of 2. Observe the sequence of three wordsthree words pointed at by the pointer. Do they denote some pointed at by the pointer. Do they denote some concept(s)concept(s)??
YesYes: increase by 1 the counters of each of these concepts. Go to step (5).: increase by 1 the counters of each of these concepts. Go to step (5).NoNo: Go to next step (3).: Go to next step (3).
3. Do same for the sequence of 3. Do same for the sequence of two wordstwo words. Go to step (5) or next step (4).. Go to step (5) or next step (4).4. Observe the 4. Observe the wordword pointed at. Does it denote some concept(s)? pointed at. Does it denote some concept(s)?
YesYes: increase by 1 the counters of each of these concepts. Go to step (5).: increase by 1 the counters of each of these concepts. Go to step (5).NoNo: Is it a word denoting no concept? That is, is it a meaningless word, according to : Is it a word denoting no concept? That is, is it a meaningless word, according to §3.4.1?§3.4.1?
YesYes: ignore it. Go to step (5) next.: ignore it. Go to step (5) next.NoNo: Print it as “I do not know what this word means, or if it is meaningless” : Print it as “I do not know what this word means, or if it is meaningless”
(One has to add these meanings, later, by hand, to the CLASITEX tree). Go to step (One has to add these meanings, later, by hand, to the CLASITEX tree). Go to step (5) next.(5) next.
5. Move the pointer to the right of the word(s) already analyzed. Repeat the operation or 5. Move the pointer to the right of the word(s) already analyzed. Repeat the operation or iteration: go to step (1) (BEGIN). When all text has been analyzed (we can no longer iteration: go to step (1) (BEGIN). When all text has been analyzed (we can no longer move the pointer to the right), report the most popular move the pointer to the right), report the most popular topicstopics as the themes of the as the themes of the docdoc..

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
Concept contributionConcept contribution in a text (CLASITEX): the in a text (CLASITEX): the “institutions”“institutions” concept concept
Concept representativityConcept representativity: : percentagepercentage of the of the wordswords related with it related with it

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
In In CLASITEXCLASITEX a a nodenode of the tree (a of the tree (a conceptconcept) is represented by a ) is represented by a
filefile containing containing single, double, triple or quadruple wordssingle, double, triple or quadruple words
e.g. the e.g. the 3-word sequence3-word sequence for the concept for the concept computadoracomputadora ( (computercomputer):):arquitectura de computadoras. base de datos. bases de datos. convertidor analogico digital. arquitectura de computadoras. base de datos. bases de datos. convertidor analogico digital.
convertidor digital analogico. convertidores analogico digital. convertidores analogico digitales.convertidor digital analogico. convertidores analogico digital. convertidores analogico digitales.
convertidores digital analogico. convertidores digital analogicos. editor de texto.convertidores digital analogico. convertidores digital analogicos. editor de texto.
editores de texto. estructura de computadoras. hoja de calculo. hojas de calculo.editores de texto. estructura de computadoras. hoja de calculo. hojas de calculo.
programa de computo. programa de graficacion. programas de computo. sistema de informacion.programa de computo. programa de graficacion. programas de computo. sistema de informacion.
sistemas de informacion.sistemas de informacion.
e.g. e.g. the the 2-word sequence2-word sequence for the concept for the concept utensilio-de-cocinautensilio-de-cocina ((kitchen-toolkitchen-tool):):bano maria. plato hondo. plato sopero. bano maria. plato hondo. plato sopero. plato tendido. vaso refresquero.plato tendido. vaso refresquero.
e.g. the sequence of e.g. the sequence of wordswords for the concept for the concept acto-jurídicoacto-jurídicoapelacion. audiencia. condena. condenada. condenadas. condenado. condenados. culpable. apelacion. audiencia. condena. condenada. condenadas. condenado. condenados. culpable.
delictuosa. delictuosas. delictuoso. delictuosos. delito. embargo. juicio. delictuosa. delictuosas. delictuoso. delictuosos. delito. embargo. juicio. procesado. procesado.
procesados. procesamiento. procesar. proceso. sentencia. sentenciado. sobresellar.procesados. procesamiento. procesar. proceso. sentencia. sentenciado. sobresellar.

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
Problem with Problem with short articlesshort articles: :
• histograms contain histograms contain fewer conceptsfewer concepts • less difference between the main and the secondary less difference between the main and the secondary
topicstopics (and noise…) (and noise…)
StemmingStemming or or lemmatizationlemmatization (or other techniques to (or other techniques to
group words: see part 4 of seminar) should be group words: see part 4 of seminar) should be
necessarynecessary

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
Ontology constructionOntology construction
• For an For an optimal ontology complexityoptimal ontology complexity : :– # # levelslevels– average # topics (nodes) in each level (average # topics (nodes) in each level (breadth of each breadth of each
levellevel))– conceptual densityconceptual density? Each part should not be too dense?? Each part should not be too dense?
• Method of Inductive Auto-Regulation of Models Method of Inductive Auto-Regulation of Models
((MIARMMIARM): mathematical model (): mathematical model (Ivakhnenko, 1980Ivakhnenko, 1980) to ) to
construct an ontology with optimal complexity (function construct an ontology with optimal complexity (function
of the above parameters)of the above parameters)

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
The level of the The level of the granularity of an ontologygranularity of an ontology depends on depends on
how generic is the NLE how generic is the NLE tasktask::
1.1. clustering of textsclustering of texts
2.2. definition of definition of main topics in a docmain topics in a doc• new knowledge discoveringnew knowledge discovering• noise filteringnoise filtering
3.3. domain trend analysisdomain trend analysis

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
1.1. clustering of textsclustering of texts
• a a similarity measuresimilarity measure is needed to calculate the similarity is needed to calculate the similarity between between two docstwo docs
• Domain DictionaryDomain Dictionary (DomD) words: (DomD) words: importance coefficientimportance coefficient (0..1](0..1] for the for the fuzzy relationfuzzy relation between between wordword and and DomDom; using:; using:
– an an expertexpert opinion opinion– statistical propertiesstatistical properties of keywords in docs of the domain: of keywords in docs of the domain:
p p ((wi wi | | DomDom)) normalized by normalized by max{max{pp((wjwj | | DomDom)})}– the keywords the keywords abstraction levelabstraction level: : domain-orienteddomain-oriented concept concept ontologyontology
e.g. e.g. m levelsm levels word: level jword: level j importance coefficient = j/mimportance coefficient = j/m
• just keywordsjust keywords, not all words, not all words
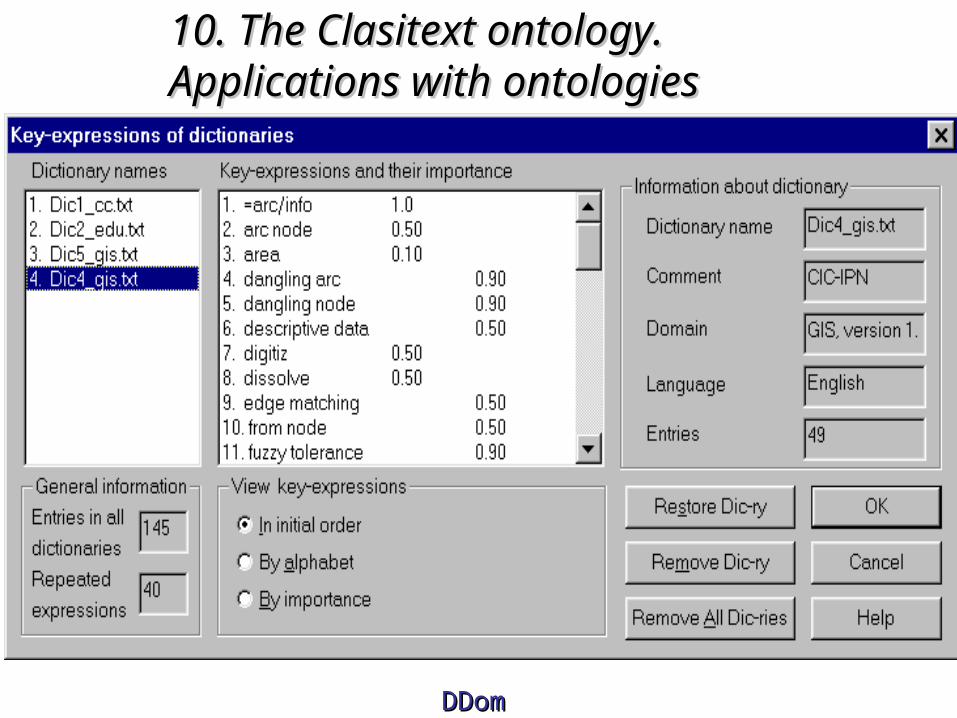
10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
DDomDDom

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
2. definition of 2. definition of main topics in a doc main topics in a doc (see previous example about “concept contribution” in a text)(see previous example about “concept contribution” in a text)
• QA systems: generalization by an ontology if there is no QA systems: generalization by an ontology if there is no answeranswere.g. How many cars are sold in Camogli?e.g. How many cars are sold in Camogli?
There isn’t any info, but in Genova are sold x carsThere isn’t any info, but in Genova are sold x cars
• docs summarizationdocs summarizationin the Mexican Senate: system developed by Gelbukh (NPI) based on in the Mexican Senate: system developed by Gelbukh (NPI) based on CLASITEX concepts treesCLASITEX concepts trees

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
2. definition of 2. definition of main topics in a doc main topics in a doc (see previous example about “concept contribution” in a text)(see previous example about “concept contribution” in a text)
• new knowledge discovering / extractionnew knowledge discovering / extraction::
if in a if in a texttext there are there are words relatedwords related with a certain subject and with a certain subject and their their conceptual densityconceptual density is greater than a certain threshold is greater than a certain threshold e.g. a e.g. a texttext with words about some with words about some diseasedisease, , treatmenttreatment, , hospitalhospital: :
text about text about medicinemedicine even without using the word medicine even without using the word medicine
• noise filteringnoise filteringwithout the without the support of one of its lower levelssupport of one of its lower levels, a topic has to be discarded , a topic has to be discarded as main theme as main theme
e.g. e.g. We cannot sell FIAT cars with the weather conditions of Egypt.We cannot sell FIAT cars with the weather conditions of Egypt.
in the analyzed text there is no other word related with weather in the analyzed text there is no other word related with weather (temperature, rain, sunshine, wind…) (temperature, rain, sunshine, wind…)
We cannot sell FIAT cars in Egypt.We cannot sell FIAT cars in Egypt.

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
3. 3. domain trend analysisdomain trend analysis (scientometrics)(scientometrics)
Analysis of a great number of publications of a certain domain per Analysis of a great number of publications of a certain domain per year: year: strengthen of some conceptsstrengthen of some concepts ( (some others notsome others not mentioned at mentioned at all)all)
e.g. Medicinee.g. Medicine
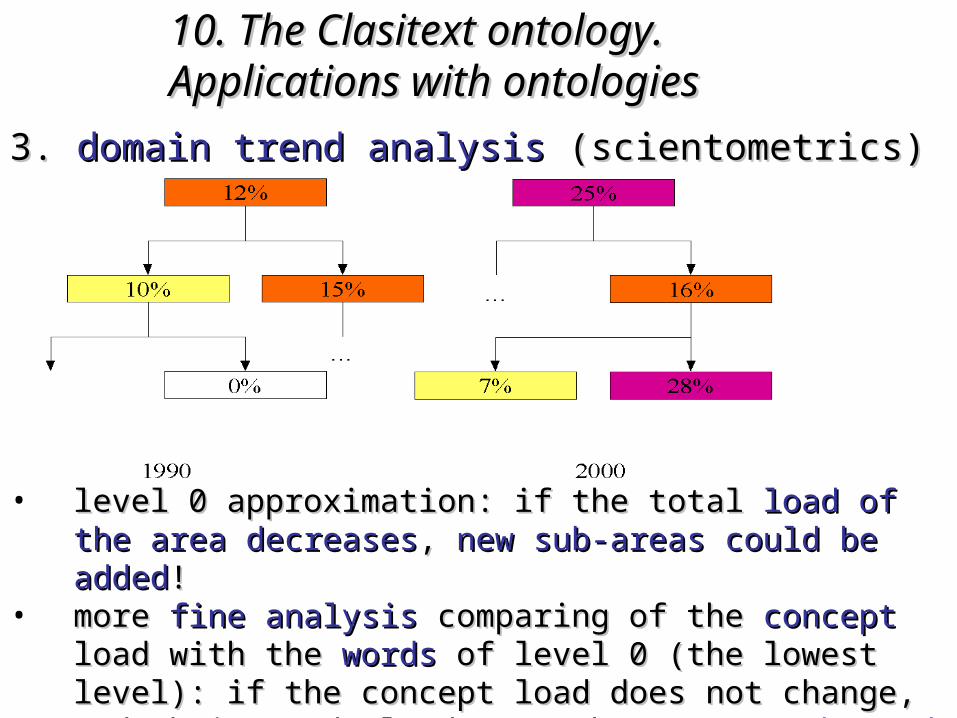
10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
3. 3. domain trend analysisdomain trend analysis (scientometrics) (scientometrics)
• level 0 approximation: if the total level 0 approximation: if the total load of the area decreasesload of the area decreases, , new sub-areas could be addednew sub-areas could be added!!
• more more fine analysisfine analysis comparing of the comparing of the conceptconcept load with the load with the wordswords of level 0 (the lowest level): if the concept load does of level 0 (the lowest level): if the concept load does not change, and their words load yes, the not change, and their words load yes, the concept changed concept changed its contentits content!!

10. The Clasitext ontology. 10. The Clasitext ontology. Applications with ontologies Applications with ontologies
3. 3. domain trend analysisdomain trend analysis (scientometrics) (scientometrics)
• trendtrend with with fixed conceptsfixed concepts: only : only redistributionredistribution of concept load of concept load
• DictionaryDomainDictionaryDomain approach approach (Makgonov, (Makgonov, Mixteca University of Technology, Mexico)Mixteca University of Technology, Mexico)
– keywordskeywords per per yearyear (not fixed along the years) (not fixed along the years)– clustering techniqueclustering technique to establish a to establish a stable set of domain stable set of domain
keywordskeywords to represent the to represent the trend of the domaintrend of the domain

1.1. The WordNet ontologyThe WordNet ontology2.2. Conceptual Density for Word Sense DisambiguationConceptual Density for Word Sense Disambiguation3.3. Semantic (Geo) Information Retrieval and Text CategorizationSemantic (Geo) Information Retrieval and Text Categorization4.4. Semantic clusters of very short narrow-domain textsSemantic clusters of very short narrow-domain texts5.5. Lexical pattern extraction: mining the web with semantic infoLexical pattern extraction: mining the web with semantic info6.6. An ontology for Question Answering and vice versa: An ontology for Question Answering and vice versa:
OntotripleQAOntotripleQA7.7. Cluster analysis of transcribed spoken dialoguesCluster analysis of transcribed spoken dialogues8.8. The Clasitext ontology. Applications with ontologiesThe Clasitext ontology. Applications with ontologies
9.9. Semantic relatedness of conceptsSemantic relatedness of concepts10.10. Ontology matching: meta ontology or machine learning Ontology matching: meta ontology or machine learning
approach?approach?
11.11. The case study of biomedical ontologies: semantic relatedness The case study of biomedical ontologies: semantic relatedness of concepts of the different ontologiesof concepts of the different ontologies
12.12. Lab session: CALD, WordNet vs. Genia, GenOntology, MeSHLab session: CALD, WordNet vs. Genia, GenOntology, MeSH

9. Semantic relatedness of concepts 9. Semantic relatedness of concepts

10. Ontology matching: 10. Ontology matching: meta ontology or machine learning approach?meta ontology or machine learning approach?
• Suggested Upper Merged Ontology Suggested Upper Merged Ontology ((SUMOSUMO))by IEEE Standard Upper Ontology Working Groupby IEEE Standard Upper Ontology Working Group
(e.g. mapping of WordNet)(e.g. mapping of WordNet) http://www.ontologyportal.org
• ResearchCycResearchCyc http://research.cyc.com/
open source version of the Cyc technology: the word open source version of the Cyc technology: the word largest and largest and most complete general knowledge basemost complete general knowledge base and and common sense reasoning enginecommon sense reasoning engine
• GLUE systemGLUE system employs machine learning techniques employs machine learning techniques to semi-automatically create semantic mappings (A. to semi-automatically create semantic mappings (A. Doan et al. 03)Doan et al. 03)

1.1. The WordNet ontologyThe WordNet ontology2.2. Conceptual Density for Word Sense DisambiguationConceptual Density for Word Sense Disambiguation3.3. Semantic (Geo) Information Retrieval and Text CategorizationSemantic (Geo) Information Retrieval and Text Categorization4.4. Semantic clusters of very short narrow-domain textsSemantic clusters of very short narrow-domain texts5.5. Lexical pattern extraction: mining the web with semantic infoLexical pattern extraction: mining the web with semantic info6.6. An ontology for Question Answering and vice versa: An ontology for Question Answering and vice versa:
OntotripleQAOntotripleQA7.7. Cluster analysis of transcribed spoken dialoguesCluster analysis of transcribed spoken dialogues8.8. The Clasitext ontology. Applications with ontologiesThe Clasitext ontology. Applications with ontologies
9.9. Semantic relatedness of conceptsSemantic relatedness of concepts10.10. Ontology matching: meta ontology or machine learning Ontology matching: meta ontology or machine learning
approach?approach?
11.11. The case study of biomedical ontologies: semantic The case study of biomedical ontologies: semantic relatedness of concepts of the different ontologiesrelatedness of concepts of the different ontologies
12.12. Lab session: CALD, WordNet vs. Genia, GenOntology, MeSHLab session: CALD, WordNet vs. Genia, GenOntology, MeSH

11. Biomedical ontologies: semantic relatedness 11. Biomedical ontologies: semantic relatedness of concepts of the different ontologiesof concepts of the different ontologies
• Genia ontologyGenia ontology (medline corpus) (medline corpus)
• GenOntologyGenOntology
• MeSHMeSH

11. Biomedical ontologies: semantic relatedness 11. Biomedical ontologies: semantic relatedness of concepts of the different ontologiesof concepts of the different ontologies
Genia ontologyGenia ontology ( (medline corpusmedline corpus))
<daml:<daml:ClassClass rdf:ID=" rdf:ID="sourcesource"></daml:Class>"></daml:Class>
<daml:Class rdf:ID="<daml:Class rdf:ID="naturalnatural"><rdfs:"><rdfs:subClassOfsubClassOf rdf:resource="#source"/></daml:Class>rdf:resource="#source"/></daml:Class>
<daml:Class rdf:ID="<daml:Class rdf:ID="organismorganism"><rdfs:subClassOf "><rdfs:subClassOf rdf:resource="#natural"/></daml:Class>rdf:resource="#natural"/></daml:Class>
<daml:Class rdf:ID="<daml:Class rdf:ID="multi_cellmulti_cell"><rdfs:subClassOf "><rdfs:subClassOf rdf:resource="#organism"/></daml:Class>rdf:resource="#organism"/></daml:Class>
<daml:Class rdf:ID="<daml:Class rdf:ID="mono_cellmono_cell"><rdfs:subClassOf "><rdfs:subClassOf rdf:resource="#organism"/></daml:Class>rdf:resource="#organism"/></daml:Class>
<daml:Class rdf:ID="<daml:Class rdf:ID="virusvirus"><rdfs:subClassOf "><rdfs:subClassOf rdf:resource="#organism"/></daml:Class>rdf:resource="#organism"/></daml:Class>
<daml:Class rdf:ID="<daml:Class rdf:ID="body_partbody_part"><rdfs:subClassOf "><rdfs:subClassOf rdf:resource="#natural"/></daml:Class>rdf:resource="#natural"/></daml:Class>
<daml:Class rdf:ID="<daml:Class rdf:ID="tissuetissue"><rdfs:subClassOf "><rdfs:subClassOf rdf:resource="#natural"/></daml:Class>rdf:resource="#natural"/></daml:Class>
<daml:Class rdf:ID="<daml:Class rdf:ID="cell_typecell_type"><rdfs:subClassOf "><rdfs:subClassOf rdf:resource="#natural"/></daml:Class>rdf:resource="#natural"/></daml:Class>
<daml:Class rdf:ID="<daml:Class rdf:ID="artificialartificial"><rdfs:subClassOf "><rdfs:subClassOf rdf:resource="#source"/></daml:Class>rdf:resource="#source"/></daml:Class>
<daml:Class rdf:ID="<daml:Class rdf:ID="cell_linecell_line"><rdfs:subClassOf "><rdfs:subClassOf rdf:resource="#artificial"/></daml:Class>rdf:resource="#artificial"/></daml:Class>
<daml:Class rdf:ID="<daml:Class rdf:ID="other_artificial_sourceother_artificial_source"><rdfs:subClassOf "><rdfs:subClassOf rdf:resource="#artificial"/></daml:Class>rdf:resource="#artificial"/></daml:Class>

11. Biomedical ontologies: semantic relatedness 11. Biomedical ontologies: semantic relatedness of concepts of the different ontologiesof concepts of the different ontologies
GenOntologyGenOntology
[[TermTerm]]
idid: GO:0000001: GO:0000001
namename: mitochondrion inheritance: mitochondrion inheritance
namespacenamespace: biological_process: biological_process
defdef: "The distribution of mitochondria, including the mitochondrial genome, into : "The distribution of mitochondria, including the mitochondrial genome, into daughter cells after mitosis or meiosis, mediated by interactions between daughter cells after mitosis or meiosis, mediated by interactions between mitochondria and the cytoskeleton." [GOC:mcc, PMID:10873824, mitochondria and the cytoskeleton." [GOC:mcc, PMID:10873824, PMID:11389764]PMID:11389764]
exact_exact_synonymsynonym: "mitochondrial inheritance" []: "mitochondrial inheritance" []
is_ais_a: GO:0048308 ! organelle inheritance: GO:0048308 ! organelle inheritance
is_a: GO:0048311 ! mitochondrion distributionis_a: GO:0048311 ! mitochondrion distribution
[Term][Term]
id: GO:0000002id: GO:0000002
name: mitochondrial genome maintenancename: mitochondrial genome maintenance
namespace: biological_processnamespace: biological_process
def: "The maintenance of the structure and integrity of the mitochondrial genome." def: "The maintenance of the structure and integrity of the mitochondrial genome." [GOC:ai][GOC:ai]
is_a: GO:0007005 ! mitochondrion organization and biogenesisis_a: GO:0007005 ! mitochondrion organization and biogenesis

11. Biomedical ontologies: semantic relatedness 11. Biomedical ontologies: semantic relatedness of concepts of the different ontologiesof concepts of the different ontologies
MeSHMeSH<<ConceptConcept PreferredConceptYN="N"> PreferredConceptYN="N">
<ConceptUI>M0353609</ConceptUI><ConceptUI>M0353609</ConceptUI>
<<ConceptNameConceptName>>
<String>A-23187</String><String>A-23187</String>
</ConceptName></ConceptName>
<ConceptUMLSUI>C0878412</ConceptUMLSUI><ConceptUMLSUI>C0878412</ConceptUMLSUI>
<RegistryNumber>0</RegistryNumber><RegistryNumber>0</RegistryNumber>
<SemanticTypeList><SemanticTypeList>
<SemanticType><SemanticType>
<SemanticTypeUI>T109</SemanticTypeUI><SemanticTypeUI>T109</SemanticTypeUI>
<<SemanticTypeNameSemanticTypeName>>Organic ChemicalOrganic Chemical</SemanticTypeName></SemanticTypeName>
</SemanticType></SemanticType>
<SemanticType><SemanticType>
<SemanticTypeUI>T195</SemanticTypeUI><SemanticTypeUI>T195</SemanticTypeUI>
<SemanticTypeName>Antibiotic</SemanticTypeName><SemanticTypeName>Antibiotic</SemanticTypeName>
</SemanticType></SemanticType>
</SemanticTypeList></SemanticTypeList>
<ConceptRelationList><ConceptRelationList>
<ConceptRelation RelationName="NRW"><ConceptRelation RelationName="NRW">
<Concept1UI>M0000001</Concept1UI><Concept1UI>M0000001</Concept1UI>
<Concept2UI>M0353609</Concept2UI><Concept2UI>M0353609</Concept2UI>
</ConceptRelation></ConceptRelation>
</ConceptRelationList></ConceptRelationList>
<TermList><TermList>
<Term ConceptPreferredTermYN="Y" IsPermutedTermYN="N" <Term ConceptPreferredTermYN="Y" IsPermutedTermYN="N" LexicalTag="LAB" PrintFlagYN="N" RecordPreferredTermYN="N">LexicalTag="LAB" PrintFlagYN="N" RecordPreferredTermYN="N">
<TermUI>T000001</TermUI><TermUI>T000001</TermUI>
<String>A-23187</String><String>A-23187</String>

1.1. The WordNet ontologyThe WordNet ontology2.2. Conceptual Density for Word Sense DisambiguationConceptual Density for Word Sense Disambiguation3.3. Semantic (Geo) Information Retrieval and Text CategorizationSemantic (Geo) Information Retrieval and Text Categorization4.4. Semantic clusters of very short narrow-domain textsSemantic clusters of very short narrow-domain texts5.5. Lexical pattern extraction: mining the web with semantic infoLexical pattern extraction: mining the web with semantic info6.6. An ontology for Question Answering and vice versa: An ontology for Question Answering and vice versa:
OntotripleQAOntotripleQA7.7. Cluster analysis of transcribed spoken dialoguesCluster analysis of transcribed spoken dialogues8.8. The Clasitext ontology. Applications with ontologiesThe Clasitext ontology. Applications with ontologies
9.9. Semantic relatedness of conceptsSemantic relatedness of concepts10.10. Ontology matching: meta ontology or machine learning Ontology matching: meta ontology or machine learning
approach?approach?
11.11. The case study of biomedical ontologies: semantic relatedness The case study of biomedical ontologies: semantic relatedness of concepts of the different ontologiesof concepts of the different ontologies
12.12. Lab session: CALD, WordNet vs. Genia, GenOntology, Lab session: CALD, WordNet vs. Genia, GenOntology, MeSHMeSH
12. Lab session: 12. Lab session: CALD, WordNet vs. CALD, WordNet vs. Genia, Genia,
GenOntology, MeSHGenOntology, MeSH
ThanksThanks
GrazieGrazie
GraciasGracias
Grasie (zeneize!)Grasie (zeneize!)





























