Embed Size (px)
Citation preview

The Ohio State University
Efficient and Effective Sampling Methods for Aggregation Queries on
the Hidden Web
Fan WangGagan Agrawal
Presented By: Venu Satuluri

The Ohio State University 2
The Deep Web
• The definition of “the deep web” from Wikipedia
The deep Web refers to World Wide Web content that is not part of the surface web, which is indexed by standard search engines.
• Some Examples: Expedia, Priceline

The Ohio State University 3
The Deep Web is Huge and Informative• 500 times larger than the surface
web• 7500 terabytes of information (19
terabytes in the surface web)• 550 billion documents (1 billion in
the surface web)• More than 200,000 deep web
sites• Relevant to every domain:
scientific, e-commerce, market• 95 percent of the deep web is
publicly accessible (with access limitations)
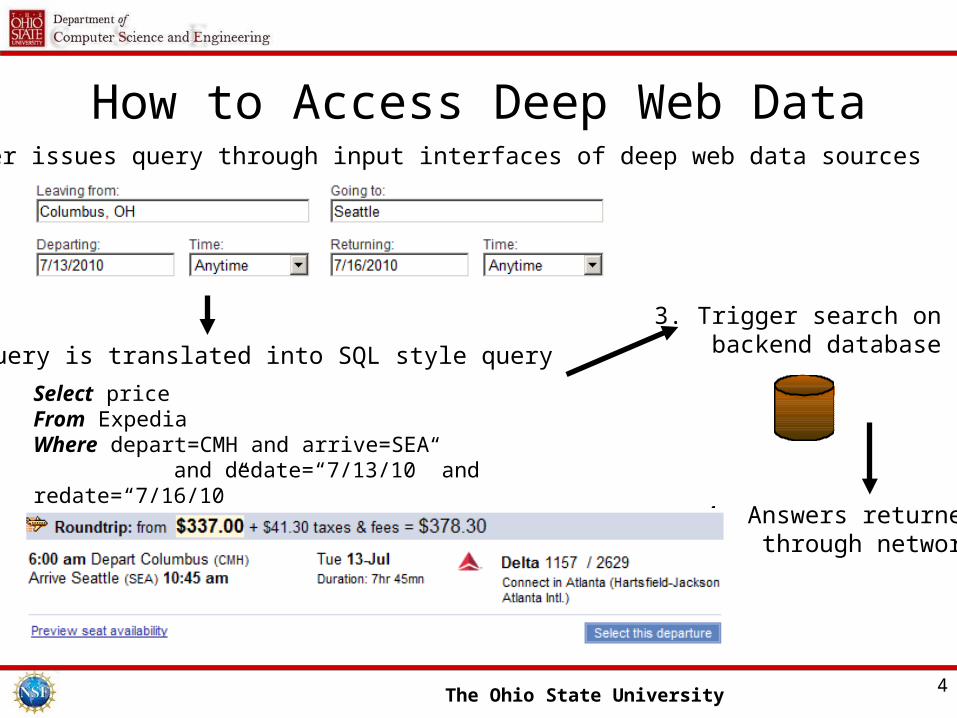
The Ohio State University 4
How to Access Deep Web Data1. A user issues query through input interfaces of deep web data sources
2. Query is translated into SQL style query
3. Trigger search on backend database
4. Answers returned through network
Select priceFrom ExpediaWhere depart=CMH and arrive=SEA and dedate=“7/13/10” and redate=“7/16/10”

The Ohio State University 5
High-level Goal
Develop a deep web search tool which could support online (real time)structured, and high level queries (semi)automatically

The Ohio State University 6
Challenges• Challenges for Integration
– Self-maintained and created– Heterogeneous, hidden and dynamically updated
metadata
• Challenges for Searching– Limited data access pattern– Data redundancy and data quality– Data source dependency
• Challenges for Performance– Network latency– Fault tolerance issue – …….

The Ohio State University 7
Specific Problem: Online Aggregation
• Aggregation queries requiring data enumeration
I want to know the average airfare from US to Europe across all major US airline flights in the next week
Select AVG(airfare)From AirTable ATWhere AT.depart=any US city and AT.arrive=any European city
Need Enumeration!!!
Relational DatabaseDeep Web Data Source
NYC, London
Boston, Paris
LA, Rome
AA: 500UA: 550
USAir: 450Delta: 400
UA: 600AA: 650
Where do you get these names?
How long can you wait?
What if the data is updated dynamically?

The Ohio State University 8
Initial Thoughts• Sampling: Approximate answers
• Simple random sampling (SRS)– Every data record has the same probability to
be selected
• Drawbacks of SRS– Bad performance on skewed data– High sampling cost to perform SRS on deep
web (Dasgupta et al, HDSampler)

The Ohio State University 9
We Want To Achieve• Handle data with (probably high) skew
– Top 20 IT companies account for 80% of the sales among all top 100 IT companies in 2005
– Hidden data (hard to gather statistical information)– Has skew or not? – Unknown data distribution– Pilot sample, how much can you trust your pilot
sample?
• Lower sampling cost for sampling deep web data

The Ohio State University 10
Our Contributions
• Two Sampling Algorithms– ANS (Adaptive Neighborhood Sampling): handling skewed
data, sample skew causing data easier
– TPS (Two Phase adaptive Sampling): lower sampling cost
• Performance– Accurate estimates without prior knowledge
– ANS and TPS outperform HDSampler by a factor of 4 on skewed data
– TPS has one-third of the sampling cost of HDSampler

The Ohio State University 11
Background Knowledge A survey on a type of rare monkey, which only lives in a small but
dangerous area in southern China Associated Samples

The Ohio State University 12
Why this is good and Can we use it?• Sample more rare but significant data records
– Good for handling with skewed data
• Associated samples have relatively low sampling cost– Cheaper than SRS with the same sample size
• Yes, we can use it! ~~ with modification– Much real world data has skew (IT company, household income)– Rare data often form clusters– Deep web data sources often return multiple records w.r.t. one
input sample

The Ohio State University 13
Drawbacks
• Performance depends on the initial sample• Initial sample is simple random sample• No cost limit explicitly considered
– What is the size of the initial sample?– How many associated samples should be added?

The Ohio State University 14
• Select a random sample– Stop random sampling if any of the two termination rules applies
• We have sampled k number of units of interest• We have reached the cost limit
– Take the sampled data record, add it to our sample
– If this data record is a unit of interest• Obtain its neighbors (neighborhood sampling)• For each data records obtained from neighborhood sampling
– Add it to our sample
– Perform recursive neighborhood sampling if necessary
– If neighborhoods are too large• Increase unit of interest threshold
– If neighborhoods are too small• Decrease unit of interest threshold
The ANS Sampling Algorithm
Aggressively sample skew causing data
Control sampling cost

The Ohio State University 15
ANS Example
• Estimate the total sale of IT companies in 2005
• Each point represents a company’s sale record
• Color shows the scale of the sale value, the darker, the higher
• Neighborhood of data records is defined according to some rules
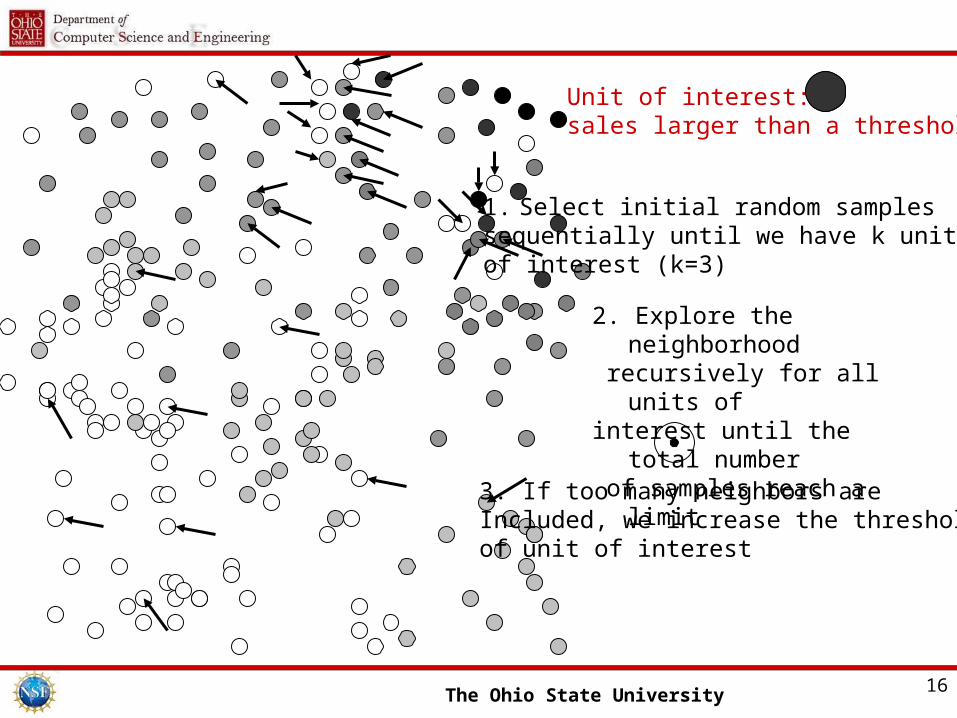
The Ohio State University 16
1. Select initial random samples sequentially until we have k units of interest (k=3)
Unit of interest: sales larger than a threshold
2. Explore the neighborhood recursively for all units of interest until the total number of samples reach a limit
3. If too many neighbors are Included, we increase the threshold of unit of interest

The Ohio State University 17
Estimators and Analysis for ANS• Estimator for AVG, fixed unit of interest threshold
Lemma 1: The above estimator is a biased estimator, when k is small, the bias is very small
• We also proposed estimator for variable unit of interest threshold using post-stratification
is the estimated average value from the hth stratum (all samples corresponding to one specific unit of interest threshold value)
β is the percentage of units ofInterest w.r.t. entire data setβ=(k-1)/(n-1)

The Ohio State University 18
Drawbacks of ANS
• Initial samples are simple random samples
• SRS: one input search only gets one sample from the output page
• High cost

The Ohio State University 19
The TPS Sampling Algorithm• Partition data set D into M sub-spaces
– According to combinations of input attribute values
• Random select m sub-spaces• Select a sample of size n1 from each of the m selected sub-spaces
– First phase sampling
– For one selected sub-space, if any such selected data record is a unit of interest, proceed
• Select a sample of size n2 from the corresponding sub-spaces– Second phase sampling
– Sub-spaces contains units of interest in the first sampling phase may give us more units of interests in the second sampling phase
Aggressively draw skewCausing data
Low sampling cost
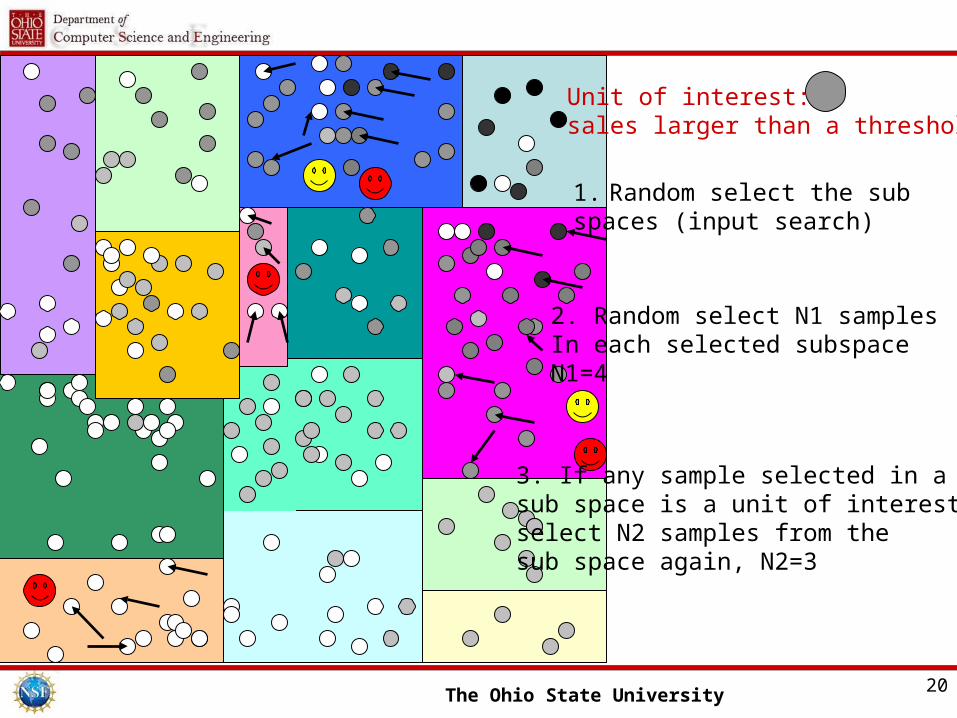
The Ohio State University 20
Unit of interest: sales larger than a threshold
1. Random select the subspaces (input search)
2. Random select N1 samplesIn each selected subspaceN1=4
3. If any sample selected in asub space is a unit of interest,select N2 samples from thesub space again, N2=3

The Ohio State University 21
Evaluation• Data sets
– Synthetic data sets: generated using MINITAB, varying data skew from 1 to 9
– US Census data: 2002 US economic census data on wholesale trade product lines listed by the kind of business (skew=8)
– Yahoo! Auto: prices of used Ford cars from 2000 to 2009 located within 50 miles of a zipcode (skew=0.7)
• Metrics– AER: Absolute Error Rate– Sampling cost: number of input samples needed
• Methods– ANS– TPS– SRS
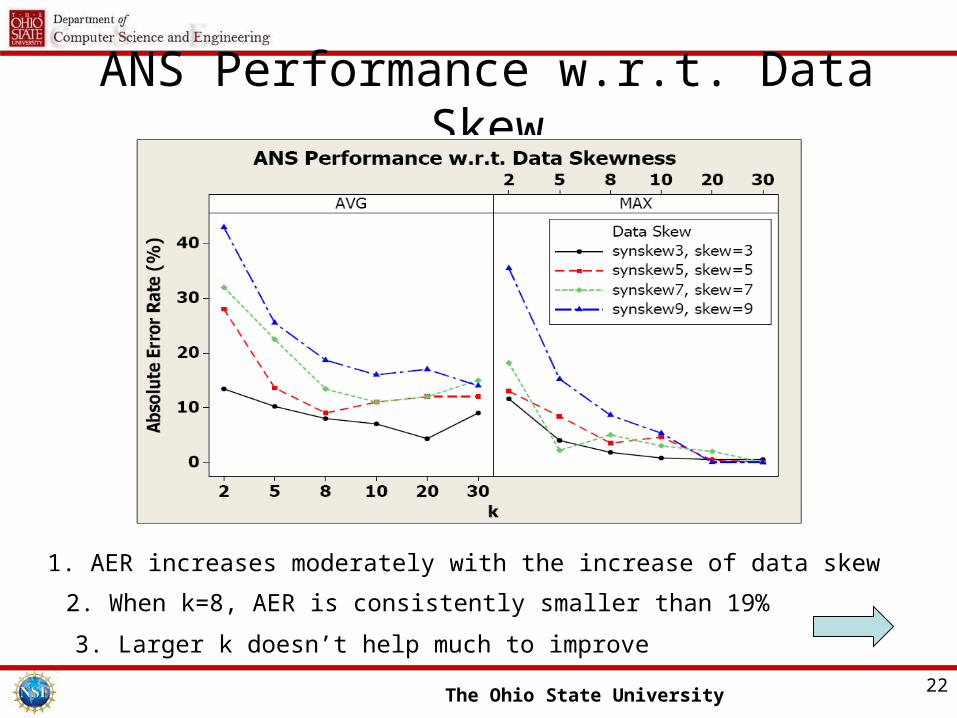
The Ohio State University 22
ANS Performance w.r.t. Data Skew
1. AER increases moderately with the increase of data skew
2. When k=8, AER is consistently smaller than 19%
3. Larger k doesn’t help much to improve
The Ohio State University 23
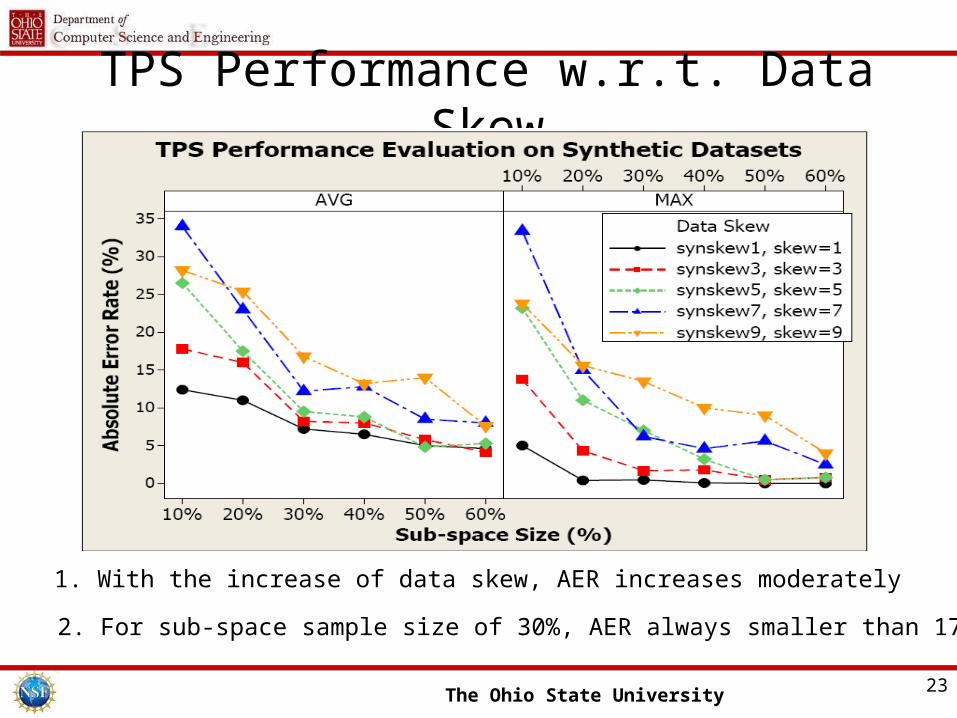
TPS Performance w.r.t. Data Skew
1. With the increase of data skew, AER increases moderately
2. For sub-space sample size of 30%, AER always smaller than 17%
The Ohio State University 24
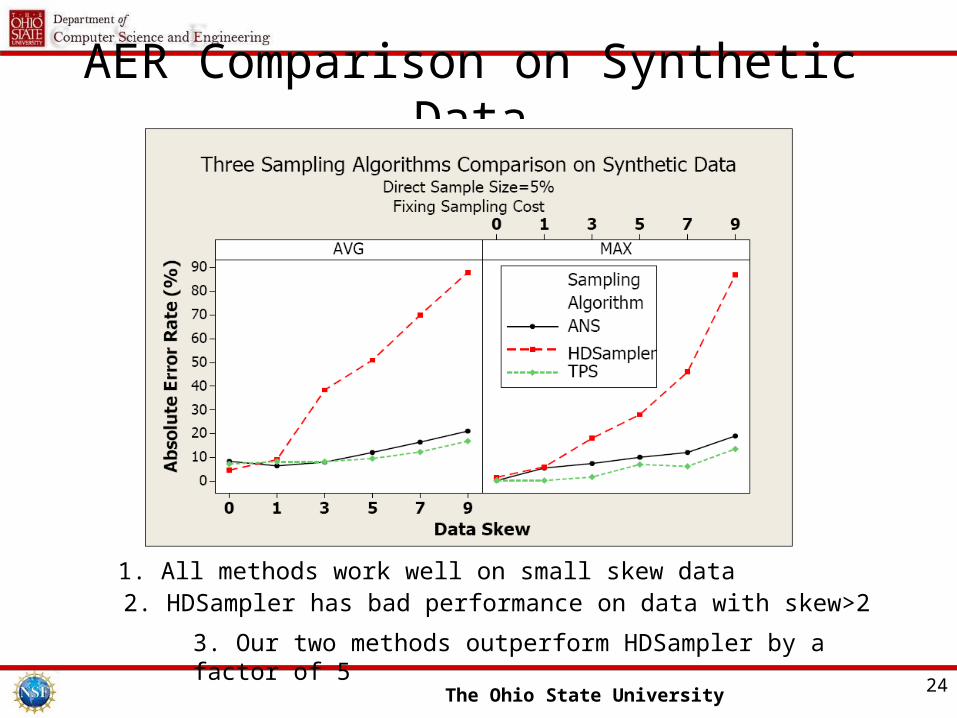
AER Comparison on Synthetic Data
1. All methods work well on small skew data2. HDSampler has bad performance on data with skew>2
3. Our two methods outperform HDSampler by a factor of 5
The Ohio State University 25
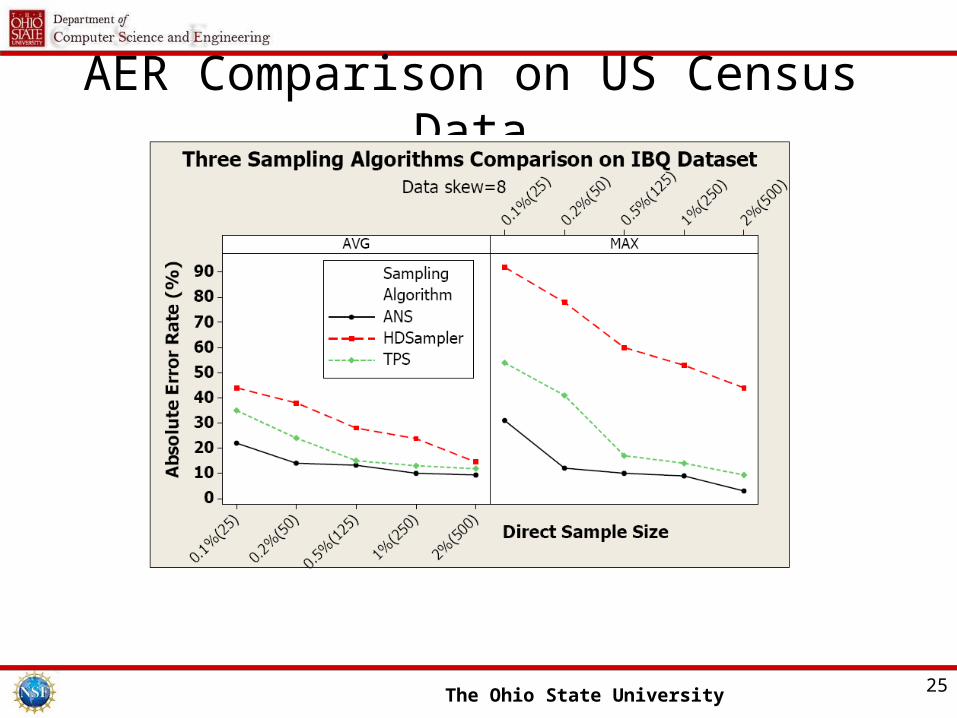
AER Comparison on US Census Data
The Ohio State University 26
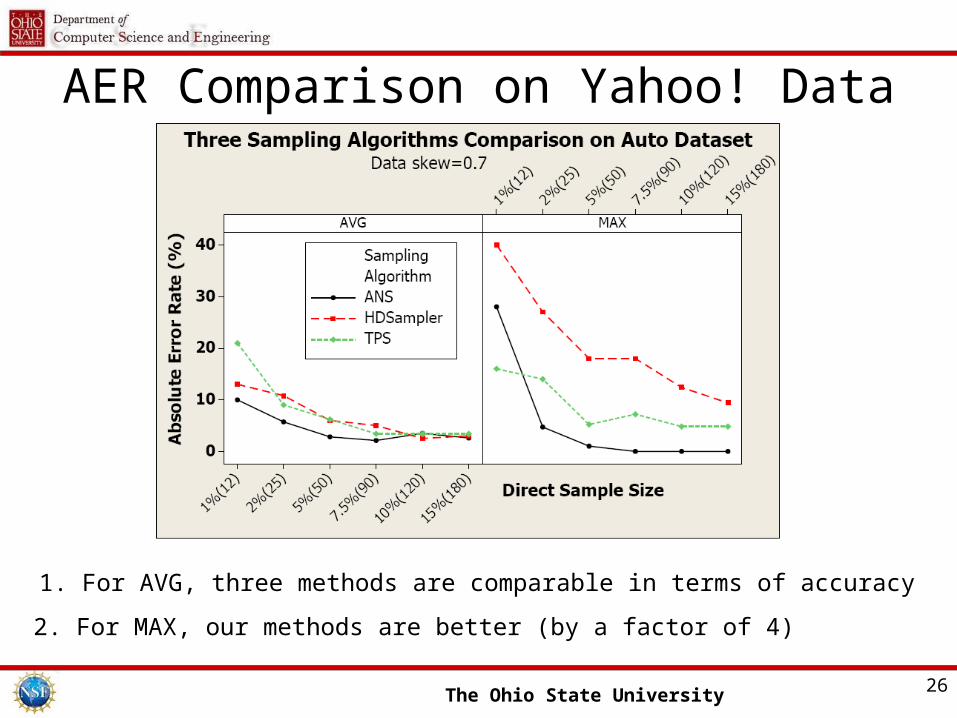
AER Comparison on Yahoo! Data
1. For AVG, three methods are comparable in terms of accuracy
2. For MAX, our methods are better (by a factor of 4)
The Ohio State University 27
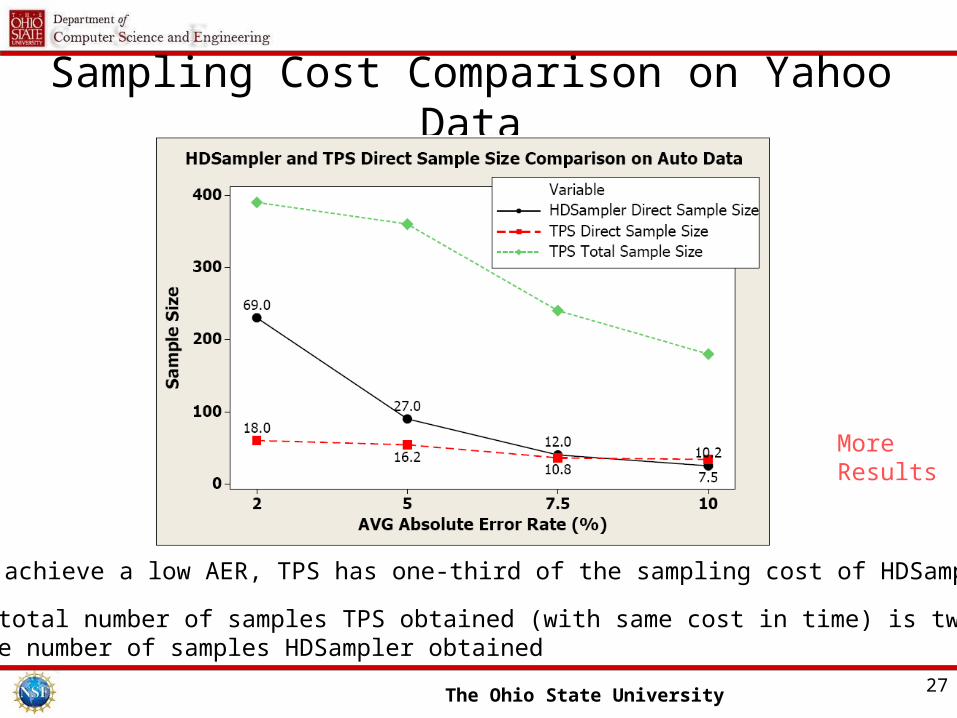
Sampling Cost Comparison on Yahoo Data
1. To achieve a low AER, TPS has one-third of the sampling cost of HDSampler
2. The total number of samples TPS obtained (with same cost in time) is twice the number of samples HDSampler obtained
More Results

The Ohio State University
Summary• Effective methods for sampling skewed
data on hidden data
• Outperform other methods
• Questions:– E-mail the authors!!
28





























