Embed Size (px)
Citation preview

The Lucene Search Engine
Kira Radinsky
Modified by Amit Gross to Lucene 4
Based on the material from: Thomas Paul and Steven J. Owens

What is Lucene?
• Doug Cutting’s grandmother’s middle name• A open source set of Java Classses– Search Engine/Document Classifier/Indexer– Developed by Doug Cutting (1996)
• Xerox/Apple/Excite/Nutch/Yahoo/Cloudera• Hadoop founder, Board of directors of the Apache Software
• Jakarta Apache Product. Strong open source community support.
• High-performance, full-featured text search engine library
• Easy to use yet powerful API

Use the Source, Luke• Document • Field
– Represents a section of a Document: name for the section + the actual data.
• Analyzer – Abstract class (to provide interface)– Document -> tokens (for later indexing)– StandardAnalyzer class.
• IndexWriter – Creates and maintains indexes.
• IndexSearcher – Searches through an index.
• QueryParser – Builds a parser that can search through an index.
• Query – Abstract class that contains the search criteria created by the QueryParser.
• TopDocs – Contains the top K Document objects found in a serach by an IndexSearcher,
and their scores.

Indexing a Document
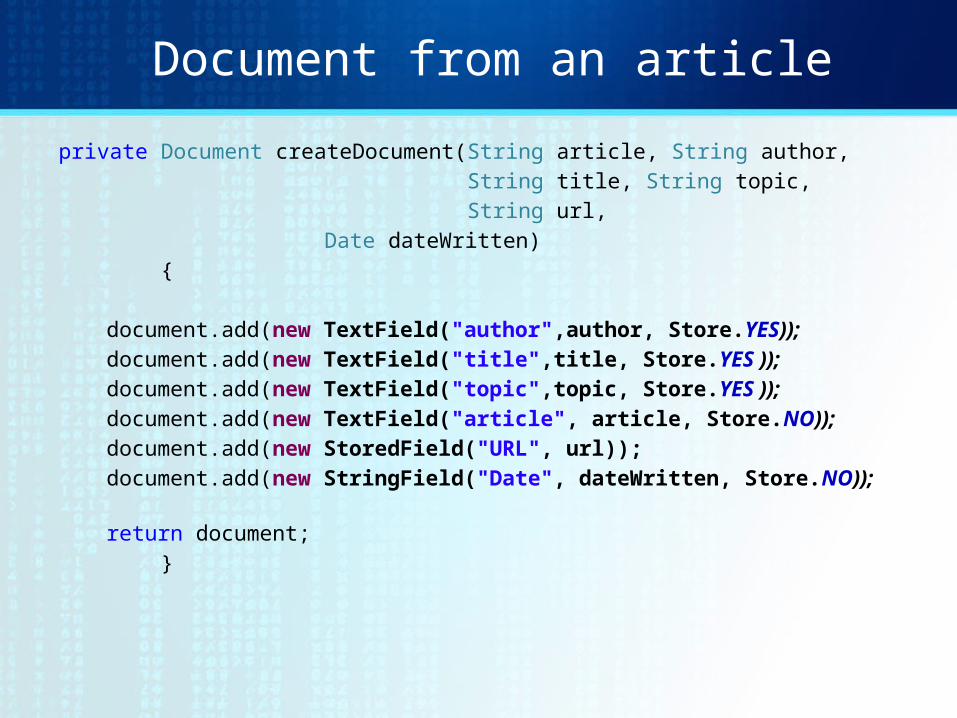
Document from an articleprivate Document createDocument(String article, String author, String title, String topic, String url,
Date dateWritten) {
document.add(new TextField("author",author, Store.YES));document.add(new TextField("title",title, Store.YES ));document.add(new TextField("topic",topic, Store.YES ));document.add(new TextField("article", article, Store.NO));document.add(new StoredField("URL", url));document.add(new StringField("Date", dateWritten,
Store.NO)); return document;
}
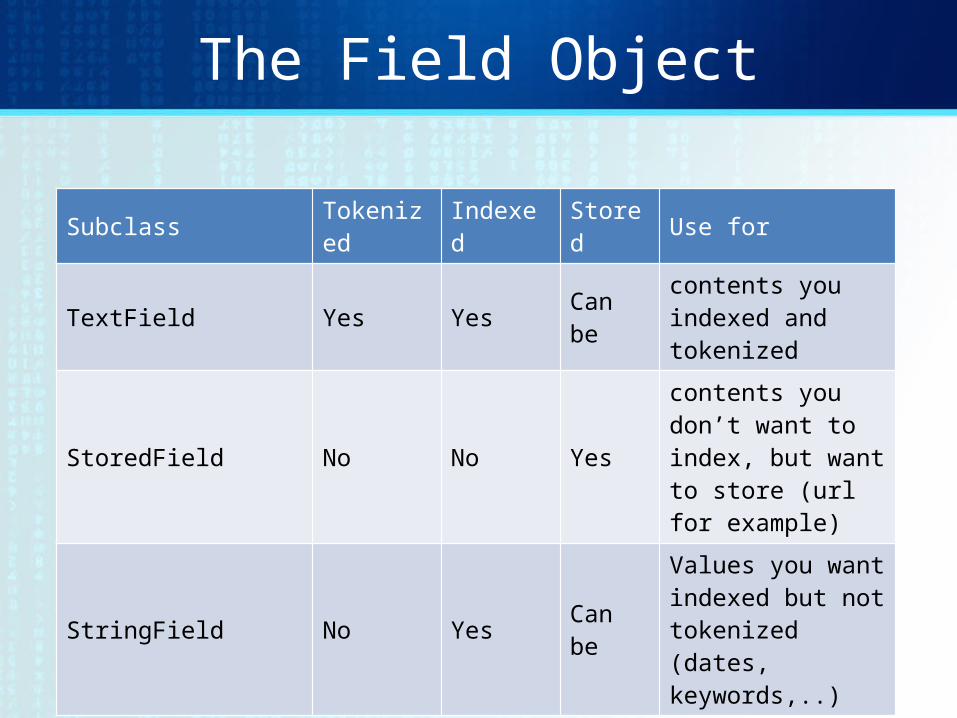
The Field Object
Subclass Tokenized Indexed Stored Use for
TextField Yes Yes Can be contents you indexed and tokenized
StoredField No No Yescontents you don’t want to index, but want to store (url for example)
StringField No Yes Can beValues you want indexed but not tokenized (dates, keywords,..)
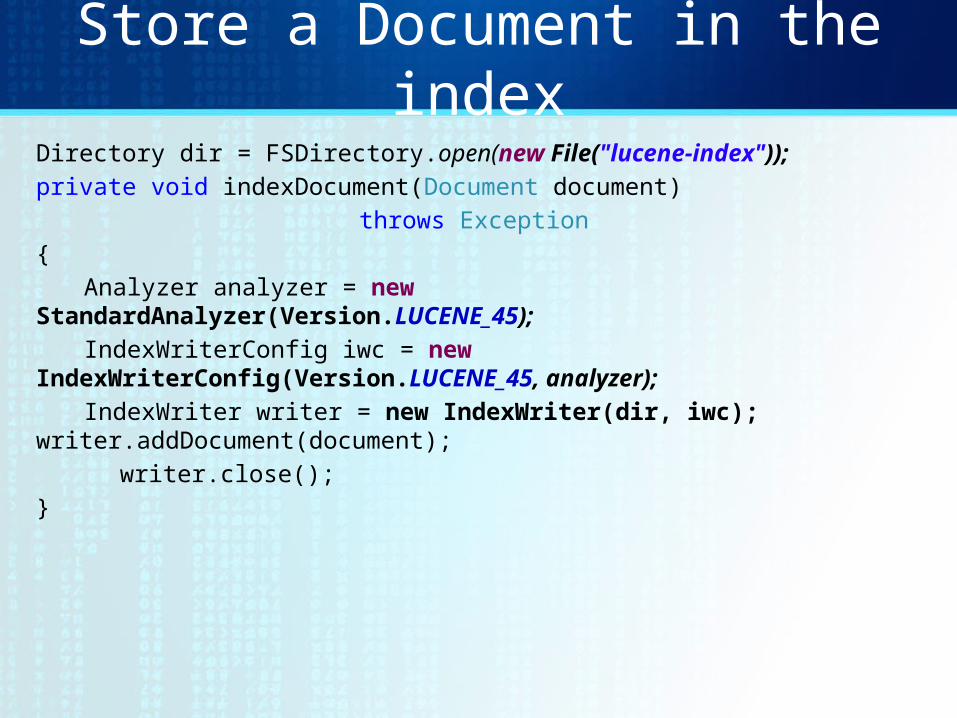
Store a Document in the indexDirectory dir = FSDirectory.open(new File("lucene-index"));private void indexDocument(Document document)
throws Exception {
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_45);
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_45, analyzer);
IndexWriter writer = new IndexWriter(dir, iwc); writer.addDocument(document);
writer.close();}

Analyzers and TokenizersSimpleAnalyzer SimpleAnalyzer seems to just use a Tokenizer that converts all
of the input to lower case.
StopAnalyzer StopAnalyzer includes the lower-case filter, and also has a filter that drops out any "stop words", words like articles (a, an, the, etc) that occur so commonly in english that they might as well be noise for searching purposes. StopAnalyzer comes with a set of stop words, but you can instantiate it with your own array of stop words.
StandardAnalyzer StandardAnalyzer does both lower-case and stop-word filtering, and in addition tries to do some basic clean-up of words, for example taking out apostrophes ( ' ) and removing periods from acronyms (i.e. "T.L.A." becomes "TLA").
Lucene Sandbox Here you can find analyzers in your own language

Adding to an Indexpublic void indexArticle(
String article, String author,String title, String topic,String url, Date dateWritten)
throws Exception { Document document = createDocument
(article, author, title, topic, url, dateWritten);
indexDocument(document);}

Searching the Index
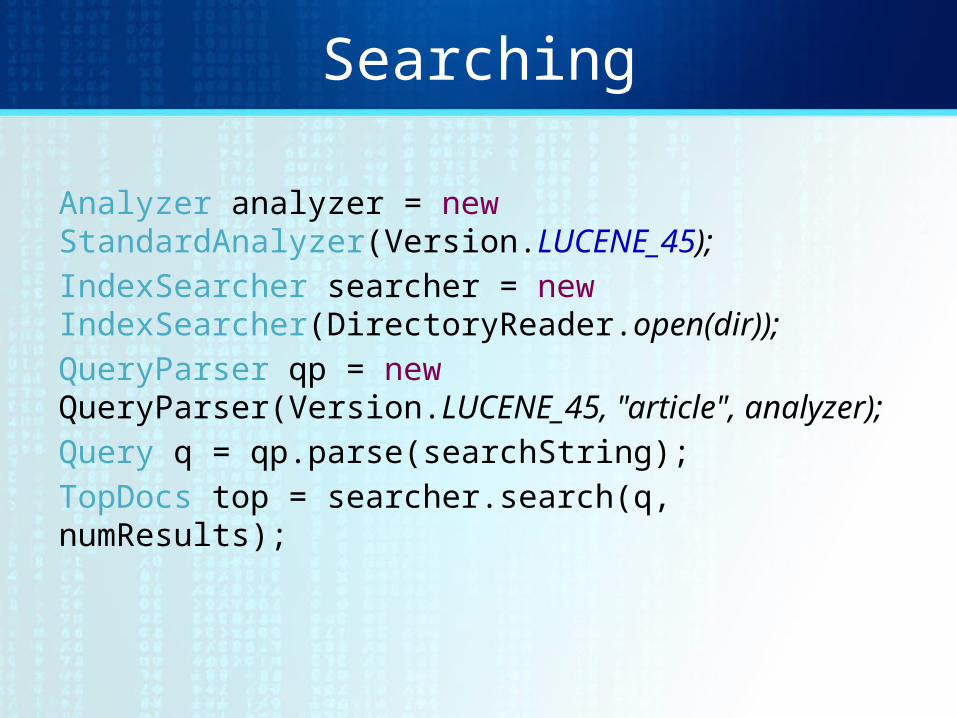
Searching
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_45);IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(dir));QueryParser qp = new QueryParser(Version.LUCENE_45, "article", analyzer);Query q = qp.parse(searchString);TopDocs top = searcher.search(q, numResults);
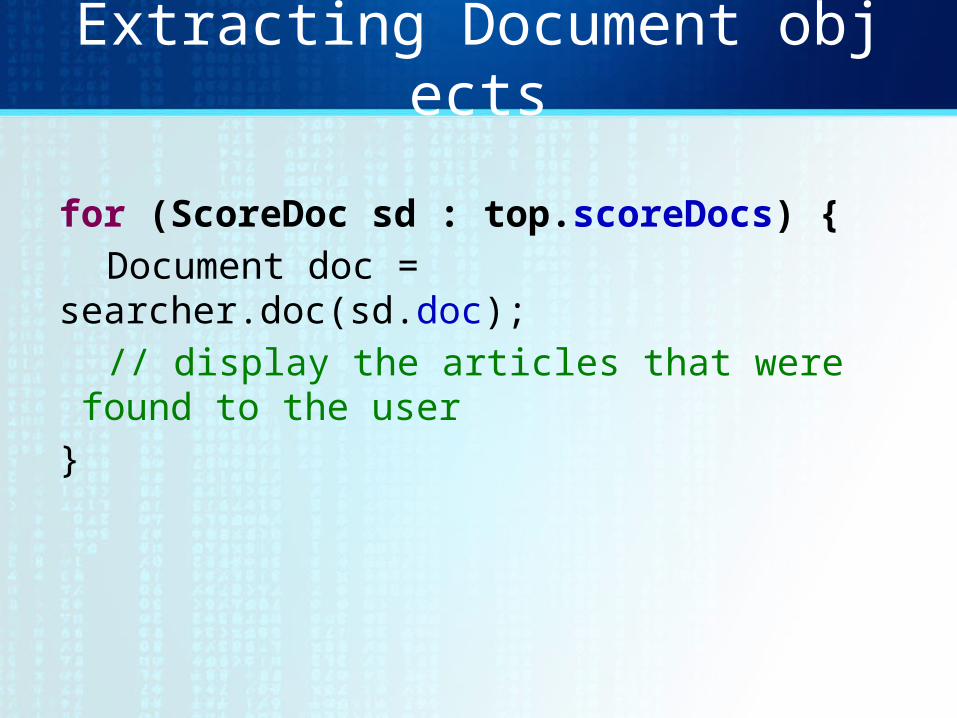
Extracting Document objects
for (ScoreDoc sd : top.scoreDocs) {Document doc =
searcher.doc(sd.doc); // display the articles that were
found to the user}

Search Criteria
Supports several searches: AND OR and NOT, fuzzy, proximity searches, wildcard searches, and range searches– author:Henry relativity AND "quantum physics“– "string theory" NOT Einstein– "Galileo Kepler"~5– author:Johnson date:[01/01/2004 TO 01/31/2004]

Thread Safety
• Indexing and searching are not only thread safe, but process safe. What this means is that:– Multiple index searchers can read the lucene index files
at the same time.– An index writer or reader can edit the lucene index files
while searches are ongoing– Multiple index writers or readers can try to edit the
lucene index files at the same time (it's important for the index writer/reader to be closed so it will release the file lock).
• The query parser is not thread safe, • The index writer however, is thread safe,

Luke
• Luke is a handy tool for development, that allows you to watch an already existing Lucene Index.
• http://code.google.com/p/luke/





























