Embed Size (px)
Citation preview

Qualifying Examination
Frederico Guth
The Information Bottleneck Theoryof Deep Learning
Prof. Teófilo de Campos (supervisor)
UnB
Prof. John Shawe-Taylor
UCL
Prof. Moacir Antonelli Ponti
USP
Brasília, 13/07/2020.

Summary
1) Context/Problem
2) Research Objective
3) Literature Review: Background
4) Proposal
5) References
2

Fred in Theoryland ...
3

Fred in Theoryland ...
Vapnik
Valiant
CoLT SLT
“Unexplained”Phenomena
Information Bottleneck Theory
4

Fred in Theoryland ...
CoLT SLT
“Unexplained”Phenomena
Information Bottleneck TheoryInfo
rmatio
n Theo
ry
Shannon
Kolmogorov
ProbabilityTheory
Vapnik
Valiant
The Problem
5

The Problem
CoLT SLT
“Unexplained”Phenomena
Information Bottleneck TheoryInfo
rmatio
n Theo
ry
Shannon
Kolmogorov
ProbabilityTheory
Vapnik
Valiant
Epistemology
Hume
Feynman
AI History
6

Research Objective
To investigate the Information Bottleneck Theoryand to consolidate the literature into a
comprehensive digest.
• Which “unexplained” Deep Learning phenomena can
Information Bottleneck Theory address?
• What are the assumptions of this new theory?
• How does IBT compares to current Machine Learning Theory?
7

Research Objective
8

From Intelligence to Language
Intelligence is the ability to predict a course of actionto achieve success in specific goals.
9

From Language to Machine Learning Theory
Language
Logic ProbabilityTheory
i) Knowledge is a setof true or false statements
ii) unambiguousiii) consistentiv) minimal
Greeks
i ) Knowledge is a set of justified beliefs
ii) “common sense”iii) consistentiv) minimal
Babylonians
Machine LearningTheory
Epistemology
Axioms
The Language of Mathematics
The Language of Science
10

Machine Learning Theory
Machine Learning Theory deduces from Probability Theory
bounds for the behaviour of machine learning algorithms.
Learning problem setting:
Choose from the hypothesis space the one hypothesis that
best approximates the concept.
11

Critiques on Machine Learning Theory
- No assumption on P(X,Y)
- No notion of “time”
- i.i.d. sampling
- Vacuous bounds for DL
The case for a new narrative.
12
- DNN generalisation w/
hundred million params
- Flat minima
- Disentanglement
- Critical Learning Periods
- Superconvergence
“Unexplained” DL Phenomena

Information Bottleneck Theory
A deep neural network as a communication channel between the
input (the source) and the representation (the receiver).
Learning problem setting:
Find a representation T* that is a minimal sufficient statistic
of input X in relation to Y,
|H� | is the cardinality of the �-cover of the hypothesis space.Typically, it is assumed that |H� | ⇠
1�d ;
� is the con�dence margin;
m is the number of training samples, a.k.a. the sample com-plexity;
d is the Vapnik–Chervonenkis dimension of the hypothesisspace. In the case of neural networks it isO(|� |lo� |� |), where|� | is the number of parameters in the network.
The generalization error is bounded by a function of the hypothesisspace and the dataset sizes.
3.1 CriticismThe main criticism on the current state of Learning Theory in thecontext of DNNs are:
(1) the bounds are too loose and, therefore, not very valuable inpractice;
(2) it depends on the model (size of hypothesis space), not onlyon the problem;
(3) its preference for simpler algorithms (smaller hypothesisspace) does not explain the fact that larger and deeper DeepNeural Networks (DNNs) usually achieve better accuracyand generalization.
4 AN INFORMATION THEORY OF DEEPLEARNING
Tishby and Zaslavsky [20] propose a new Learning Theory of DeepLearning based on Shannon’s Information Theory. Therefore, it isimportant to establish some context.
Tasks can be easy or di�cult depending on how information isrepresented, a classical example is that it is much easier to calculateusing hindu-arabic numerals than with roman numerals. Thus, itis reasonable to think of supervised trained DNNs as performingrepresentation learning, where the last layer, the head, is typicallya softmax regression classi�er and all previous layers just learn toprovide a good representation for this last classi�er[11, Chapter15].
Another way is to think of the last layer as decoding a messagethat was encoded by the rest of the network (see �gure 2). In thisview, each layer can be seen as a single random variable, Ti , andthe network as the communication channel itself, p(T |X ), to whichall Shannon information properties apply.
4.1 Desiderata for representationsLet T denote a representation of X , that is optimal to the task Y ,meaning that T captures and exposes only the information from Xwhich is relevant to Y . Ideally, this representation should be [6]:
a statistic: a function T ⇠ p(T |X );
su�cient: I (Y ;T ) = I (Y ;X ), so there is no loss in relevant Y infor-mation;
minimal: I (T ;X ) is minimized, so that it retains as little of X aspossible. This means there is an encoding from X to T thatkeep only relevant information;
invariant: to the e�ect of nuisances N , where N ? Y ! I (N ;Y ) =0 ! I (T ;N ) = 0 means that if N does not have informationabout Y , there should not be information of N in the rep-resentation T , otherwise the classi�er could �t to spuriouscorrelations;
maximally disentangled: no information will be present in thecorrelations between components of T .
4.2 The Information BottleneckThe Information Bottleneck is a method for �nding minimal su�-cient statistics developed by Tishby et al. [19]:
T ⇤ = arg minT
I (T ;X )
s.t. I (T ;Y ) = I (X ;Y )(4)
Applying the lagrangian relaxation, we have:
T ⇤ = argminT
L
L = minq(T |X )
I (T ;X ) � � I (T ;Y ), � > 0 (IB)
where � is the Lagrange multiplier. Tishby and Zaslavsky [20] usedthe Information Bottleneck (IB) to formulate the deep learning goalas an information trade-o� between su�ciency and minimality,accuracy and generalization, prediction and compression.
4.3 Emerging Properties of DNNsIt is interesting to notice that it is possible to rewrite (AppendixA.1) the IB formulation as:
L = minq
Hp,q|{z}cross-entropy
(Y |T ) + � I (T ;X )| {z }regularizer
, � > 0 (IB Lagrangian)
and the cross-entropy, the most successful loss function for classi�-cation tasks, naturally emerges, as does a not usual regularizer in asecond term.
4.3.1 Invariance and minimality. Achille and Soatto [6] demon-strate that by using SGD there is in fact an implicit compressionof information, showing the regularizer is there, but implicit. Also,they show that by enforcing the minimization of the informationabout the input representation I (T ;X ), invariance and disentangle-ment naturally emerges as well, satisfying the desiderata(§4.1).
Source: Adapted from Achille [1].
Figure 3: Stacking layers improve generalization.
3
|H� | is the cardinality of the �-cover of the hypothesis space.Typically, it is assumed that |H� | ⇠
1�d ;
� is the con�dence margin;
m is the number of training samples, a.k.a. the sample com-plexity;
d is the Vapnik–Chervonenkis dimension of the hypothesisspace. In the case of neural networks it isO(|� |lo� |� |), where|� | is the number of parameters in the network.
The generalization error is bounded by a function of the hypothesisspace and the dataset sizes.
3.1 CriticismThe main criticism on the current state of Learning Theory in thecontext of DNNs are:
(1) the bounds are too loose and, therefore, not very valuable inpractice;
(2) it depends on the model (size of hypothesis space), not onlyon the problem;
(3) its preference for simpler algorithms (smaller hypothesisspace) does not explain the fact that larger and deeper DeepNeural Networks (DNNs) usually achieve better accuracyand generalization.
4 AN INFORMATION THEORY OF DEEPLEARNING
Tishby and Zaslavsky [20] propose a new Learning Theory of DeepLearning based on Shannon’s Information Theory. Therefore, it isimportant to establish some context.
Tasks can be easy or di�cult depending on how information isrepresented, a classical example is that it is much easier to calculateusing hindu-arabic numerals than with roman numerals. Thus, itis reasonable to think of supervised trained DNNs as performingrepresentation learning, where the last layer, the head, is typicallya softmax regression classi�er and all previous layers just learn toprovide a good representation for this last classi�er[11, Chapter15].
Another way is to think of the last layer as decoding a messagethat was encoded by the rest of the network (see �gure 2). In thisview, each layer can be seen as a single random variable, Ti , andthe network as the communication channel itself, p(T |X ), to whichall Shannon information properties apply.
4.1 Desiderata for representationsLet T denote a representation of X , that is optimal to the task Y ,meaning that T captures and exposes only the information from Xwhich is relevant to Y . Ideally, this representation should be [6]:
a statistic: a function T ⇠ p(T |X );
su�cient: I (Y ;T ) = I (Y ;X ), so there is no loss in relevant Y infor-mation;
minimal: I (T ;X ) is minimized, so that it retains as little of X aspossible. This means there is an encoding from X to T thatkeep only relevant information;
invariant: to the e�ect of nuisances N , where N ? Y ! I (N ;Y ) =0 ! I (T ;N ) = 0 means that if N does not have informationabout Y , there should not be information of N in the rep-resentation T , otherwise the classi�er could �t to spuriouscorrelations;
maximally disentangled: no information will be present in thecorrelations between components of T .
4.2 The Information BottleneckThe Information Bottleneck is a method for �nding minimal su�-cient statistics developed by Tishby et al. [19]:
T ⇤ = arg minT
I (T ;X )
s.t. I (T ;Y ) = I (X ;Y )(4)
Applying the lagrangian relaxation, we have:
T ⇤ = argminT
L
L = minq(T |X )
I (T ;X ) � � I (T ;Y ), � > 0 (IB)
where � is the Lagrange multiplier. Tishby and Zaslavsky [20] usedthe Information Bottleneck (IB) to formulate the deep learning goalas an information trade-o� between su�ciency and minimality,accuracy and generalization, prediction and compression.
4.3 Emerging Properties of DNNsIt is interesting to notice that it is possible to rewrite (AppendixA.1) the IB formulation as:
L = minq
Hp,q|{z}cross-entropy
(Y |T ) + � I (T ;X )| {z }regularizer
, � > 0 (IB Lagrangian)
and the cross-entropy, the most successful loss function for classi�-cation tasks, naturally emerges, as does a not usual regularizer in asecond term.
4.3.1 Invariance and minimality. Achille and Soatto [6] demon-strate that by using SGD there is in fact an implicit compressionof information, showing the regularizer is there, but implicit. Also,they show that by enforcing the minimization of the informationabout the input representation I (T ;X ), invariance and disentangle-ment naturally emerges as well, satisfying the desiderata(§4.1).
Source: Adapted from Achille [1].
Figure 3: Stacking layers improve generalization.
3
13

Machine Learning Theory vs. Information Bottleneck Theory
- Not DL specific
- generalisation: number of
params (data)
- Worse-case
Model-dependent
Distribution-independent
bounds
- DL specific
- generalisation: amount of
information
- Typical
Model-independent
Data-dependent
bounds
MLT IBT
14

From Language to Information Bottleneck Theory
Language
ProbabilityTheory
Machine LearningTheory
Information BottleneckTheory
InformationTheory
Intelligence
15

From Probability to Information Theory
* keeps consistency
Shannon’s self-information definition
“Information is what changes belief”
16
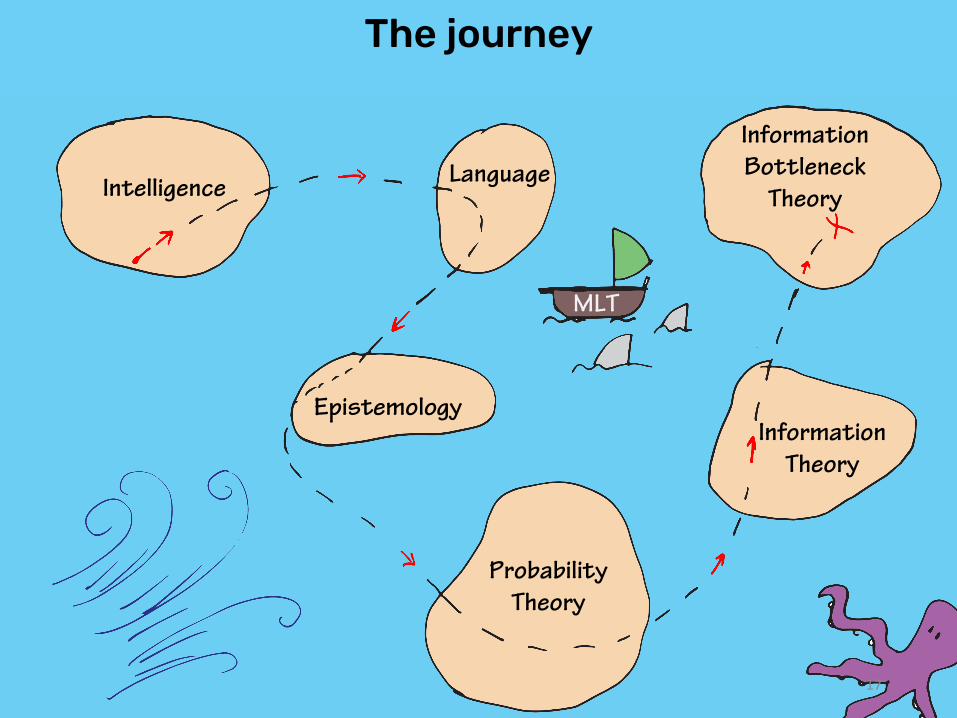
The journey5IF�1SPNJTF
Intelligence Language
Epistemology
ProbabilityTheory
InformationTheory
MLT
Information Bottleneck
Theory
17

Proposal
Structured review of 15 articles (CVPR, NeurIPS, ICLR, etc)
18

Proposal
Exploratory experiments
19

Proposal
Important deadlines in the next 4 mo:- AAAI, EACL, ICLR, CVPR
20

Proposal
For our research group
21

Proposal
IBT problem setting, MLT vs. IBT, explained phenomena
22

Proposal
23

Proposal
24

References (1)
(Cover):
John Shawe-Taylor and Omar Rivasplata. Statistical Learning Theory: A Hitchhiker’s Guide. Dec. 2018. [Online] url: https://youtube.videoken.com/embed/Bv5gzFZS5OI
Rodrigo F. Mello and Moacir Antonelli Ponti. Machine learning: a practical approach on the statistical learning theory. Springer, 2018.
Fred in Theoryland:
Jonathan Baxter. “A model of inductive bias learning”. In: Journal of artificial intelligence research 12 (2000), pp. 149–198.
L. G. Valiant. “A theory of the learnable”. In: Proceedings of the sixteenth annual ACM symposium on Theory of computing - 84. ACM Press, 1984. doi: 10.1145/800057.808710.
V. N. Vapnik. Statistical Learning Theory. Wiley-Interscience, 1998.
Ali Rahimi. Test-of-time award presentation (NeurIPS 2017). [Online] url: https://www.youtube.com/watch?v=Qi1Yry33TQE
25

References (2)
Naftali Tishby. Information Theory of Deep Learning. [Online; Published: 2017-10-16. Last Accessed: 2020-03-06]. Oct. 16, 2017. url: https://www.youtube.com/watch?v=FSfN2K3tnJU.
Jimmy Soni and Rob Goodman. A mind at play: how Claude Shannon invented the information age. Simon and Schuster, 2017.
Fred Guth. An Information Theoretical Transferability Metric. Tech. rep. UnB, June 2019. Fred Guth and Teofilo Emidio de Campos. Research Frontiers in Transfer Learning – a systematic and bibliometric review. 2019. arXiv: 1912.08812 [cs.DL].
The Problem:
David Hume. Tratado da natureza humana-2a Edica o. Editora UN-ESP, 2009. isbn: 97885-7139-901-3.
Richard Feynman. The Character of Physical Law. Modern Library, 1994. isbn: 0-679-60127-9.
From Intelligence to Language:
John G. Saxe. The blind men and the elephant. Enrich Spot Limited, 2016.
26

References (3)
From Language to Machine Learning Theory:
Alexander Terenin and David Draper. “Cox’s Theorem and the Jaynesian Interpretation of Probability”. In: (2015). arXiv: 1507.06597 [math.ST].
Damian Radoslaw Sowinski. “Complexity and stability for epistemic agents: The foundations and phenomenology of configurational Entropy”. PhD thesis. 2016.
Ariel Caticha. Lectures on Probability, Entropy, and Statistical- Physics. arXiv: 0808.0012 [physics.data-an].
Critiques on Machine Learning Theory:
Alessandro Achille, Matteo Rovere, and Stefano Soatto. Critical Learning Periods in Deep Neural Networks. 2017. arXiv: 1711.08856 [cs.LG].
Leslie N. Smith and Nicholay Topin. “Super-convergence: Very fast training of neural networks using large learning rates”. In: Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications. Vol. 11006. International Society for Optics and Photonics. 2019, p. 1100612.
Jeremy Howard and Sebastian Ruder. “Universal Language Model Fine-tuning for Text Classification”. In: ACL. Association for Computational Linguistics, 2018. url: http://arxiv.org/ abs/1801.06146.
27

References (4)
Jeremy Howard and Sebastian Ruder. “Universal Language Model Fine-tuning for Text Classification”. In: ACL. Association for Computational Linguistics, 2018. url: http://arxiv.org/ abs/1801.06146.
John R. Pierce. An Introduction to Information Theory: Symbols, Signals and Noise. Dover Publications. isbn: 0486240614.
Information Bottleneck Theory:
Ravid Shwartz-Ziv and Naftali Tishby. Representation Compression and Generalization in Deep Neural Networks. 2019. url: https: //openreview.net/forum?id=SkeL6sCqK7.
28





























